- 投稿日:2020-08-24T23:32:50+09:00
【Railsチュートリアル 4章】Rails風味のRuby
引数のデフォルト値
メソッドを呼び出した時に指定した引数は、メソッド側で先頭から順に代入されていきます。
この時、代入するオブジェクトが無かった場合(呼び出し側で指定した引数の数が、メソッド定義側で指定した引数よりも少なかった場合)、
デフォルト値が設定されていればその値が代わりに代入されます。def printHello(msg="No msg", name="No name") print(msg + "," + name + "¥n") end printHello("こんにちは", "佐藤") #=>こんにちには,佐藤 printHello("お元気ですか") #=> お元気ですか,No name printHello() #=> No msg, No namedef printHello(msg="No msg", name="No name") print(Kconv.tosjis(msg + "," + name + "¥n")) endカスタムヘルパー
Railsのビューでは膨大な数の組み込み関数が使えるが、それだけでなく、新しく作成することもできる。
単なるRubyのコードを書くのであれば、モジュールを作成するたびに明示的に読み込んで使うのが普通。
Railsでは自動的にヘルパーモジュールを読み込んでくれるので、
include行をわざわざ書く必要がない。app/helpers/application_helper.rbmodule ApplicationHelper # ページごとの完全なタイトルを返します。 def full_title(page_title = '') base_title = "Ruby on Rails Tutorial Sample App" if page_title.empty? base_title else page_title + " | " + base_title end end endapp/views/layouts/application.html.erb<!DOCTYPE html> <html> <head> <title><%= full_title(yield(:title)) %></title> <!-- full_tileメソッドの使用ができている --> <%= csrf_meta_tags %> <%= csp_meta_tag %> <%= stylesheet_link_tag 'application', media: 'all', 'data-turbolinks-track': 'reload' %> <%= javascript_pack_tag 'application', 'data-turbolinks-track': 'reload' %> </head> <body> <%= yield %> </body> </html>
- 投稿日:2020-08-24T23:32:30+09:00
【Railsチュートリアル 3章】リファクタリング
DRYなコードを書く
同じコードを書く事はRubyの「DRY」(Don’t Repeat Yourself: 繰り返すべからず)という原則に反する。
provideメソッド
文字列とラベルを与えて、関連付ける
<% provide :ラベル, 'タイトル' %>yieldメソッドを用いて呼び出す
<%= yield(:ラベル) %>application.html.erbのレイアウト
下のコード内にあるyieldは
例えば/static_pages/homeにアクセスすると
home.html.erbの内容がhtmlに変換され、<%= yield %>の位置に挿入される。:application.html.erb <!DOCTYPE html> <html> <head> <title><%= yield(:title) %> | Ruby on Rails Tutorial Sample App</title> <%= csrf_meta_tags %> <%= csp_meta_tag %> <%= stylesheet_link_tag 'application', media: 'all', 'data-turbolinks-track': 'reload' %> <%= javascript_pack_tag 'application', 'data-turbolinks-track': 'reload' %> </head> <body> <%= yield %> </body> </html>
- 投稿日:2020-08-24T23:29:54+09:00
operator does not exist: timestamp without time zone ~~ unknownというエラーの対処
環境
・Rails 6.0.3.2
・mysql Ver 14.14 Distrib 5.6.47
・osx10.15
・herokuへデプロイあらすじ
railsでWebアプリを作成しherokuへデプロイするときにエラーが発生した。
heroku log でエラーを確認すると以下のような表示を発見
operator does not exist: timestamp without time zone ~~ unknownエラー文は初めはよくわからなかったがtimestampとはカラムの型なので型のところで何かエラーが起こっていることがわかりさらに調べて見ました。
そうするとDBの検索の条件文に問題点があることが判明。
もうすこし詳しくいうと、データの作成日時で検索をかけていたロジックが以下みたいに文字列(string型)で検索していたため問題が発生。where('created_at: LIKE(?)', "%%-%%-%%") #左記は問題のコード原因
原因は端的にいえばherokuのDBは『PostgreSQL』であり自分の環境(MySQL)と異なっていたことです。
『MySQL』ではtimestamp型のカラムをstring型で検索しても自動で変換してくれる(寛容)みたいです。
『PostgreSQL』ではSQL文を厳密にしないと動作しないみたいです。(厳しい・・・)対策
xxx.in_time_zone.というメソッドを使うことで解決しました!
例えば自分の場合は月単位でデータを取りたくて2020年8月のデータを取得したい場合(以下)search_time = "2020-08-01" (モデル名).where(created_at: search_time.in_time_zone.all_month)とすることでうまくtimestamp型でデータ検索ができるので『PostgreSQL』でもうまく動きました!
また記述も少なくなりスッキリしました!
最後のall_monthをall_dayなどに変更可能でかなり使えます!詳しくはリンクがあるのでそちらがとてもわかりやすく書いてあります!参照
エラー文について
・https://nobuneko.com/blog/archives/2010/05/postgresql83operator_does_not.html
TimeクラスとDateTimeクラスについて
・https://qiita.com/jnchito/items/cae89ee43c30f5d6fa2c
- 投稿日:2020-08-24T22:08:51+09:00
rails g controller コマンドで作成されるファイルを制限
開発環境
rails 6.0.3
(Minitestを使用していないプロジェクトを想定しています)説明
rails g controller <コントローラー名> <アクション名>
を実行すると、controllerとview以外に、特に必要のないファイルが作成される。これを回避するために、
railsプロジェクト内に、次のファイルを作成すれば,
controllerとview以外のファイルが作成されないようになる。config/initializers/generators.rbRails.application.config.generators do |g| g.assets false g.helper false g.skip_routes true end上記ファイルの作成が面倒なときは、
rails g controllerコマンドを実行時に下記3つのオプションを追加して実行する。ターミナルrails g controller <コントローラー名> <アクション名> --no-assets --no-helper --skip-routes
上記によって、下記のメリットがある。
・app/assets/配下にstylesheetsのファイルが作成されない。
・app/helpers/配下にhelperファイルが作成されない。
・config/routes.rbにルーティングが追加されない。
- 投稿日:2020-08-24T21:59:36+09:00
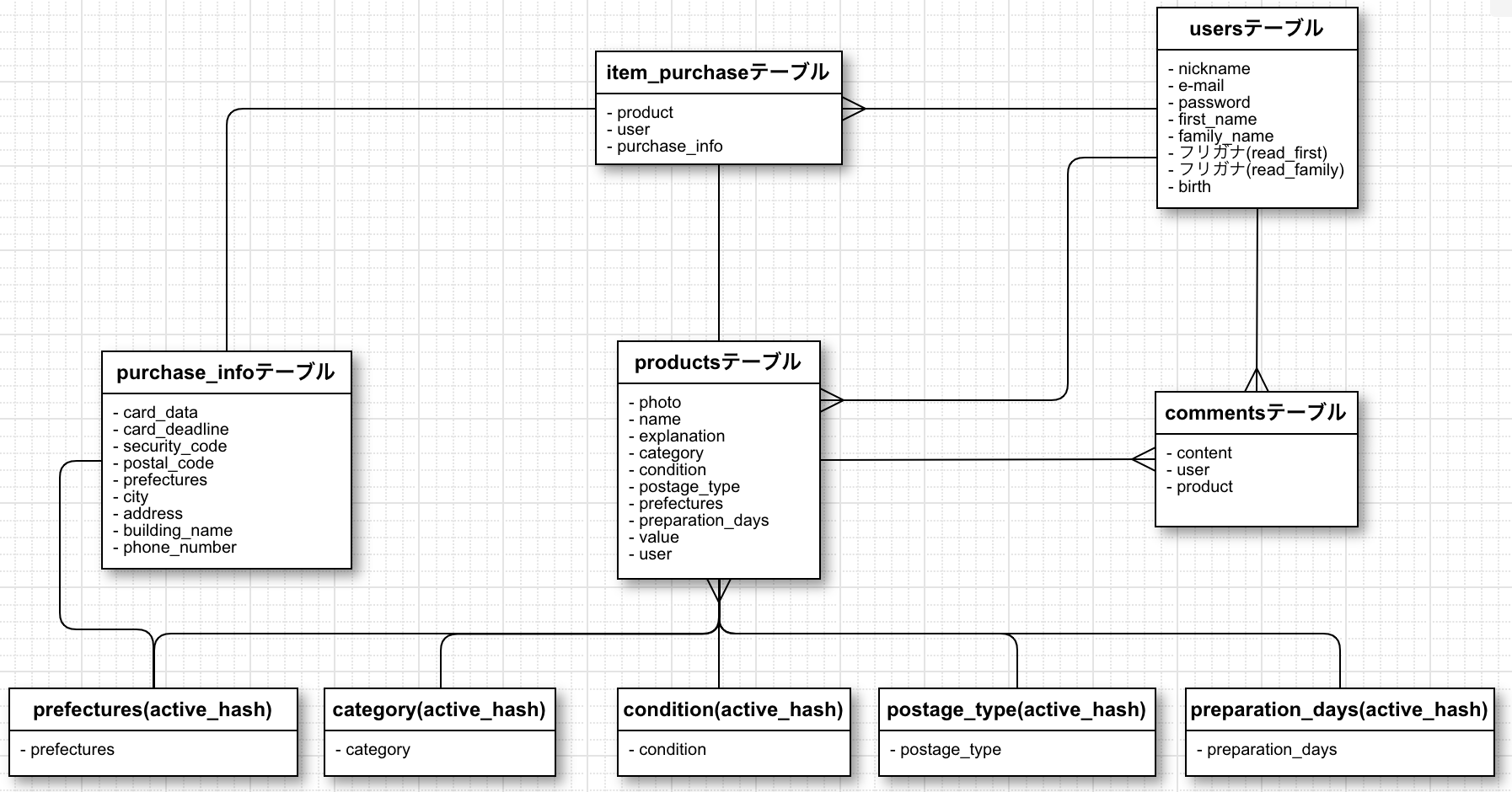
テーブル設計(Active Hashを利用する)
概要
今回は、フリマアプリのクローンサイトを作る上でテーブル設計をしていきました。
初めて自作で作るのでテーブル設計のクオリティはまだまだですが、とりあえずアウトプットということで見逃してください、、、ER図
このようになりました。
ポイントとしては、既存のデータから選択させるような箇所はActive Hashを用いてファイルを用意しておくことです。
商品のコンディションや、購入時の届け先の都道府県など、、、
都道府県を表すprefectures(active_hash)テーブルに関しては発送元と届け先で二箇所利用しています。Active Hashの使い方
インストール
Gemfileに以下を記載してbundle installする。
Gemfilegem 'active_hash'あとはActive Hash用のモデルを作成します。
⚠︎ターミナルでのコマンドで作らず、ActiveHash::Baseを継承したモデルを自作すること⚠︎ファイル記述
例として、カテゴリーのファイルをあげておきます。
app/models/category.rbclass Category < ActiveHash::Base self.data = [ {id: 1, name: '---'},{id: 2, name: 'レディース'},{id: 3, name: 'メンズ'},{id: 4, name: 'ベビー・キッズ'},{id: 5, name: 'インテリア・住まい・小物'},{id: 6, name: '本・音楽・ゲーム'},{id: 7, name: 'おもちゃ・ホビー・グッズ'},{id: 8, name: '家電・スマホ・カメラ'},{id: 9, name: 'スポーツ・レジャー'},{id: 10, name: 'ハンドメイド'},{id: 11, name: 'その他'} ]README
また、今回設計したテーブル、アソシエーションのREADMEは次のようになりました。
README.md# テーブル設計 ## users テーブル | Column | Type | Options | | ----------- | ------ | ----------- | | nickname | string | null: false | | email | string | null: false | | password | string | null: false | | first_name | string | null: false | | family_name | string | null: false | | read_first | string | null: false | | read_family | string | null: false | | birth | date | null: false | ### Association - has_many :products - has_many :item_purchases - has_many :comments ## products テーブル | Column | Type | Options | | ------------------- | ---------- | ----------- | | photo | text | null: false | | name | string | null: false | | explanation | text | null: false | | category | integer | null: false | | condition | integer | null: false | | postage_type | integer | null: false | | prefectures | integer | null: false | | preparation_days | integer | null: false | | value | integar | null: false | | user | references | null: false | ### Association - belongs_to :user - has_one :item_purchase - has_many :comments - belongs_to_active_hash :category - belongs_to_active_hash :condition - belongs_to_active_hash :postage_type - belongs_to_active_hash :prefectures - belongs_to_active_hash :preparation_days - belongs_to :seller, class_name: "User" ## item_purchases テーブル | Column | Type | Options | | ------------- | ------- | ------------------------------ | | product | integer | null: false, foreign_key: true | | user | integer | null: false, foreign_key: true | | purchase_info | integer | null: false, foreign_key: true | ### Association - belongs_to :user - belongs_to :product - belongs_to :purchase_info ## comments テーブル | Column | Type | Options | | ------- | ---------- | ------------------------------ | | content | string | null: false | | user | integer | null: false, foreign_key: true | | product | integer | null: false, foreign_key: true | ### Association - belongs_to :product - belongs_to :user ## purchase_info テーブル | Column | Type | Options | | ------------- | ---------- | ------------------------------ | | postal_code | string | null: false | | prefectures | integer | null: false, foreign_key: true | | city | string | null: false | | address | string | null: false | | building_name | string | | | phone_number | string | null: false | | item_purchase | integer | null: false, foreign_key: true | ### Association - has_one_active_hash :prefectures - has_one :item_purchaseここでは、has_oneとbelongs_toの従属関係に注意しましょう。
外部キーが必要な場合はbelongs_toでアソシエーションが組まれていることが必要です。
最後に少しだけ感想ですが、初めての自力実装はめちゃくちゃ時間がかかりますが、楽しくてしかたなかったです。ただ、今日これをやるだけでも10時間ほどかかってしまったので挫折しないように頑張ります、、、
- 投稿日:2020-08-24T21:46:58+09:00
(´-`).。oO(標準出力の『Hello』をお手軽に探したい。
Ruby初心者です。
今日は「Hello World」を出力するだけのrakeタスクを作りました。
# rake hoge:hello "Hello World"結果に「Hello」が含まれていることを確認するテストを書いてて、簡潔に文字列指定で探せる方法があれば良いと思ったのですが。。。
コード
hoge_spec.rbrequire 'rails_helper' require 'rake' RSpec.describe 'Hoge', type: :task do # 中略 describe 'rake hoge:hello' do let(:task) { 'hoge:hello' } context '標準出力のHelloを探せ' do it '標準出力でHello #1 outputマッチャーの引数に文字列' do # ※理想型。ただし完全一致しないので失敗する。。。 expect{ @rake[task].invoke() }.to output('Hello').to_stdout end it '標準出力でHello #2 outputマッチャーの引数に正規表現' do # ※うまくいくけど正規表現のマッチ使いにくい。。。 expect{ @rake[task].invoke() }.to output(/Hello/).to_stdout end it '標準出力でHello #3 includeで部分一致' do # ※うまくいくけどコードが長い。。。 $stdout = StringIO.new @rake[task].invoke() output_text = $stdout.string $stdout = STDOUT expect(output_text).to include 'Hello' end end end end実行結果
・・・文字列指定(#1)でできたら良いなと思ってたのですがエラー。
目的を実現するには正規表現(#2)にするか標準出力を変数に代入する(#3)しか方法が見つからず。。。
何か良い方法がないものかと思ってます。


- 投稿日:2020-08-24T19:33:34+09:00
OAuth 2.0、scopeのフォーマットどうする?
※ OAuth 2.0の規程に則って「認可サーバーを作成する」側の話です。
OAuth 2.0では、
scopeというパラメーターでアクセス範囲を表します。クライアントは scope リクエストパラメーターを用いて要求するアクセス範囲を明示することができる.
同様に, 認可サーバーは発行されたアクセストークンの範囲をクライアントに通知するために scope レスポンスパラメーターを使用する.このscopeですが、どんな形式にするかは実装者に委ねられています。RFCが定めている制約といえば下記くらいのものです。
- 大文字と小文字は区別する
- スペースは使えない(複数のscopeをスペース区切りで表すため)
- scopeを省略しても良いことにしても良い(デフォルト値を定義する)
めっちゃ自由ですね。自由すぎてどんな形式にするのが良いかちょっと悩みます。
ref. https://openid-foundation-japan.github.io/rfc6749.ja.html#scope
他社事例を見てみる
悩んだときは先人の様子を伺います。
GitHub OAuth Apps
Scope一覧
- (no scope)
- repo
- repo:status
- repo_deployment
- public_repo
- repo:invite
- security_events
- admin:repo_hook
- write:repo_hook
- read:repo_hook
- admin:org
- write:org
- read:org
- admin:public_key
- write:public_key
- read:public_key
- admin:org_hook
- gist
- notifications
- user
- read:user
- user:email
- user:follow
- delete_repo
- write:discussion
- read:discussion
- write:packages
- read:packages
- delete:packages
- admin:gpg_key
- write:gpg_key
- read:gpg_key
- workflow
特徴
- コロン(
:)区切りになっている。write:discussionやread:discussionのように、「権限:リソース」の形をしているものが散見される。その視点で見ると、「権限」にあたるものはread,write,admin,deleteの4つ。- scopeなし(空欄)でパブリックな情報へのread only権限が与えられる。
「権限:リソース」のフォーマット良さそう。
YouTube Data API
Scope一覧
- https://www.googleapis.com/auth/youtube
- https://www.googleapis.com/auth/youtube.readonly
- https://www.googleapis.com/auth/youtube.upload
- https://www.googleapis.com/auth/youtubepartner-channel-audit
特徴
- URLの形をしている。
- URLを叩くと、
text/plainでscope名が返ってくる。- scopeなし(空欄)はサポートされていない。
URLを内部でどのように使っているのか気になる。httpでアクセスしたりするのかな。
LINE Social API
Scope一覧
- profile
- profile%20openid
- profile%20openid%20email
- openid
- openid%20email
ref. https://developers.line.biz/ja/docs/line-login/integrate-line-login/#scopes
特徴
- あらかじめ空白文字(
%20)で区切られた状態で列挙されている。例えば- scopeなし(空欄)はサポートされていない。
scopeはなし。
OAuth 1.0aでの認可がまだ主流のようで、OAuth 2.0ではClient Credentials Grantでのpublicな情報へのアクセスしかサポートしていないため、scopeでアクセス範囲を決める必要がないのだろう。ref. https://developer.twitter.com/en/docs/authentication/api-reference/token
ぼくのかんがえたさいきょうのscope
先人たちのscopeを見てみましたが、(Twitterを除いて)三者三様でした。
リソースサーバーがどんなAPIを提供するのかに依ってscopeのフォーマットも変わると思いますが、ここではRESTfulなAPIへの認可を考えることにします。という前置きをしといて、ぼくのかんがえたさいきょうのscopeはこれだっ!!!
read:リソース名write:リソース名理由
このscopeの前提となる思想は下記2つです。
- 最小権限の原則に則って必要最低限の権限のみを認可できるように、scopeのアクセス範囲はなるべく小さくしたい。
- scope名を見ただけでアクセス範囲が分かるような明快なものが良い。
この思想をもとに、下記のように考えました。
- RESTの「リソース」という概念を利用して、リソース単位で切ると、明快で小さく権限を分けられるだろう。
- リソースに対してなんでもできるというアクセス範囲はまだ大きい。
- 読み出しと書き込みの権限は分けたいので、リソースをさらにreadとwriteの2つの権限に分けると良いだろう。
- read/writeはLINUXのファイルパーミッションでも登場するので、馴染み深く明快だろう。
- HTTP動詞で言うなら、GETをread、POST, UPDATE, DELETEをwriteとすれば良いので、明快だろう。
- HTTP動詞(GET, POST, PUT, DELETE)や、Railsのcontrollerのアクション名など、より細かい権限分離も考えたが、リソースの新規作成ができるclientには、作成したリソースの更新・削除する権限も与えたいという考えで、read/writeという分け方にした。
オマケ 〜Railsの場合〜
「リソース名」は単数形にしても複数形にしても良いですが、Railsでは
controller_nameでコントローラー名(基本的にリソースの複数形)が取れるので、私はこれを利用するために複数形にしました。# こんなアクセスのとき... http://hoge.jp/articles controller_name # => “articles” # こんなのが取れる!これを利用すれば、scopeの検証は2つのメソッドのみで事足ります。controller concernなどに書くと良いと思います。
def required_read_scope scope_name = "read:#{controller_name}" render_unauthorized unless current_access_token.scopes.include?(scope_name) end def required_write_scope scope_name = "write:#{controller_name}" render_unauthorized unless current_access_token.scopes.include?(scope_name) endあとはこのメソッドを各controllerのbefore_actionで、指定したアクションの前に呼び出すだけです。
class ArticlesController < ApplicationController before_action :required_read_scope, only: %i[index show] before_action :required_write_scope, only: %i[create update destroy] ... endOAuth 2.0の他の仕様で迷ったら
私がOAuth 2.0の自由な仕様で迷ったときに、各社の仕様をこちらにまとめました。他の仕様で迷っているときは、もしかしたら参考になるかもしれません。
https://qiita.com/murs313/items/078025d671e937a09285
- 投稿日:2020-08-24T19:33:34+09:00
OAuth 2.0のscopeのフォーマットどうする?
※ OAuth 2.0の規程に則って「認可サーバーを作成する」側の話です。
OAuth 2.0では、
scopeというパラメーターでアクセス範囲を表します。クライアントは scope リクエストパラメーターを用いて要求するアクセス範囲を明示することができる.
同様に, 認可サーバーは発行されたアクセストークンの範囲をクライアントに通知するために scope レスポンスパラメーターを使用する.このscopeですが、どんな形式にするかは実装者に委ねられています。RFCが定めている制約といえば下記くらいのものです。
- 大文字と小文字は区別する
- スペースは使えない(複数のscopeをスペース区切りで表すため)
- scopeを省略しても良いことにしても良い(デフォルト値を定義する)
めっちゃ自由ですね。自由すぎてどんな形式にするのが良いかちょっと悩みます。
ref. https://openid-foundation-japan.github.io/rfc6749.ja.html#scope
他社事例を見てみる
悩んだときは先人の様子を伺います。
GitHub OAuth Apps
Scope一覧
- (no scope)
- repo
- repo:status
- repo_deployment
- public_repo
- repo:invite
- security_events
- admin:repo_hook
- write:repo_hook
- read:repo_hook
- admin:org
- write:org
- read:org
- admin:public_key
- write:public_key
- read:public_key
- admin:org_hook
- gist
- notifications
- user
- read:user
- user:email
- user:follow
- delete_repo
- write:discussion
- read:discussion
- write:packages
- read:packages
- delete:packages
- admin:gpg_key
- write:gpg_key
- read:gpg_key
- workflow
特徴
- コロン(
:)区切りになっている。write:discussionやread:discussionのように、「権限:リソース」の形をしているものが散見される。その視点で見ると、「権限」にあたるものはread,write,admin,deleteの4つ。- scopeなし(空欄)でパブリックな情報へのread only権限が与えられる。
「権限:リソース」のフォーマット良さそう。
YouTube Data API
Scope一覧
- https://www.googleapis.com/auth/youtube
- https://www.googleapis.com/auth/youtube.readonly
- https://www.googleapis.com/auth/youtube.upload
- https://www.googleapis.com/auth/youtubepartner-channel-audit
特徴
- URLの形をしている。
- URLを叩くと、
text/plainでscope名が返ってくる。- scopeなし(空欄)はサポートされていない。
URLを内部でどのように使っているのか気になる。httpでアクセスしたりするのかな。
LINE Social API
Scope一覧
- profile
- profile%20openid
- profile%20openid%20email
- openid
- openid%20email
ref. https://developers.line.biz/ja/docs/line-login/integrate-line-login/#scopes
特徴
- あらかじめ空白文字(
%20)で区切られた状態で列挙されている。例えば- scopeなし(空欄)はサポートされていない。
scopeはなし。
OAuth 1.0aでの認可がまだ主流のようで、OAuth 2.0ではClient Credentials Grantでのpublicな情報へのアクセスしかサポートしていないため、scopeでアクセス範囲を決める必要がないのだろう。ref. https://developer.twitter.com/en/docs/authentication/api-reference/token
ぼくのかんがえたさいきょうのscope
先人たちのscopeを見てみましたが、(Twitterを除いて)三者三様でした。
リソースサーバーがどんなAPIを提供するのかに依ってscopeのフォーマットも変わると思いますが、ここではRESTfulなAPIへの認可を考えることにします。
という前置きをしといて、ぼくのかんがえたさいきょうのscopeはこれだっ!!!
read:リソース名write:リソース名理由
このscopeの前提となる思想は下記2つです。
- 最小権限の原則に則って必要最低限の権限のみを認可できるように、scopeのアクセス範囲はなるべく小さくしたい。
- scope名を見ただけでアクセス範囲が分かるような明快なものが良い。
この思想をもとに、下記のように考えました。
- RESTの「リソース」という概念を利用して、リソース単位で切ると、明快で小さく権限を分けられるだろう。
- リソースに対してなんでもできるというアクセス範囲はまだ大きい。
- 読み出しと書き込みの権限は分けたいので、リソースをさらにreadとwriteの2つの権限に分けると良いだろう。
- read/writeはLINUXのファイルパーミッションでも登場するので、馴染み深く明快だろう(executeはないけど)。
- HTTP動詞で言うなら、GETをread、POST, UPDATE, DELETEをwriteとすれば良いので、明快だろう。
- HTTP動詞(GET, POST, PUT, DELETE)や、Railsのcontrollerのアクション名など、より細かい権限分離も考えたが、リソースの新規作成ができるclientには、作成したリソースの更新・削除する権限も与えたいという考えで、read/writeという分け方にした。
オマケ 〜Railsの場合〜
「リソース名」は単数形にしても複数形にしても良いですが、Railsでは
controller_nameでコントローラー名(基本的にリソースの複数形)が取れ、私はこれを利用するために複数形にしました。# こんなアクセスのとき... http://hoge.jp/articles controller_name # => “articles” # こんなのが取れる!これを利用すれば、scopeの検証は2つのメソッドのみで事足ります。controller concernなどに書くと良いと思います。
def required_read_scope scope_name = "read:#{controller_name}" render_unauthorized unless current_access_token.scopes.include?(scope_name) end def required_write_scope scope_name = "write:#{controller_name}" render_unauthorized unless current_access_token.scopes.include?(scope_name) endあとはこのメソッドを各controllerのbefore_actionで、指定したアクションの前に呼び出すだけです。
class ArticlesController < ApplicationController before_action :required_read_scope, only: %i[index show] before_action :required_write_scope, only: %i[create update destroy] ... endOAuth 2.0の他の仕様で迷ったら
私がOAuth 2.0の自由な仕様で迷ったときに、各社の仕様をこちらにまとめました。他の仕様で迷っているときは、もしかしたら参考になるかもしれません。
https://qiita.com/murs313/items/078025d671e937a09285
- 投稿日:2020-08-24T19:33:34+09:00
OAuth 2.0、ぼくのかんがえたさいきょうのscope
※ OAuth 2.0の規程に則って「認可サーバーを作成する」側の話です。
OAuth 2.0では、
scopeというパラメーターでアクセス範囲を表します。クライアントは scope リクエストパラメーターを用いて要求するアクセス範囲を明示することができる.
同様に, 認可サーバーは発行されたアクセストークンの範囲をクライアントに通知するために scope レスポンスパラメーターを使用する.このscopeですが、どんな形式にするかは実装者に委ねられています。RFCが定めている制約といえば下記くらいのものです。
- 大文字と小文字は区別する
- スペースは使えない(複数のscopeをスペース区切りで表すため)
- scopeを省略しても良いことにしても良い(その場合デフォルト値を定義する)
ref. https://openid-foundation-japan.github.io/rfc6749.ja.html#scope
めっちゃ自由。自由すぎてどんな形式にするのが良いかちょっと悩みます。
この記事では他社事例を見た後、ぼくのかんがえたさいきょうのscopeを提示します。他社事例を見てみる
悩んだときは先人の様子を伺います。
GitHub OAuth Apps
Scope一覧
- (no scope)
- repo
- repo:status
- repo_deployment
- public_repo
- repo:invite
- security_events
- admin:repo_hook
- write:repo_hook
- read:repo_hook
- admin:org
- write:org
- read:org
- admin:public_key
- write:public_key
- read:public_key
- admin:org_hook
- gist
- notifications
- user
- read:user
- user:email
- user:follow
- delete_repo
- write:discussion
- read:discussion
- write:packages
- read:packages
- delete:packages
- admin:gpg_key
- write:gpg_key
- read:gpg_key
- workflow
特徴
- コロン(
:)区切りになっている。write:discussionやread:discussionのように、「権限:リソース」の形をしているものが散見される。その視点で見ると、「権限」にあたるものはread,write,admin,deleteの4つ。- scopeなし(空欄)でパブリックな情報へのread only権限が与えられる。
「権限:リソース」のフォーマット良さそう。
YouTube Data API
Scope一覧
- https://www.googleapis.com/auth/youtube
- https://www.googleapis.com/auth/youtube.readonly
- https://www.googleapis.com/auth/youtube.upload
- https://www.googleapis.com/auth/youtubepartner-channel-audit
特徴
- URLの形をしている。
- URLを叩くと、
text/plainでscope名が返ってくる。- scopeなし(空欄)はサポートされていない。
URLを内部でどのように使っているのか気になる。httpでアクセスしたりするのかな。
LINE Social API
Scope一覧
- profile
- profile%20openid
- profile%20openid%20email
- openid
- openid%20email
ref. https://developers.line.biz/ja/docs/line-login/integrate-line-login/#scopes
特徴
- あらかじめ空白文字(
%20)で区切られた状態で列挙されている。例えば- scopeなし(空欄)はサポートされていない。
scopeはなし。
OAuth 1.0aでの認可がまだ主流のようで、OAuth 2.0ではClient Credentials Grantでのpublicな情報へのアクセスしかサポートしていないため、scopeでアクセス範囲を決める必要がないのだろう。ref. https://developer.twitter.com/en/docs/authentication/api-reference/token
ぼくのかんがえたさいきょうのscope
先人たちのscopeを見てみましたが、(Twitterを除いて)三者三様でした。
リソースサーバーがどんなAPIを提供するのかに依ってscopeのフォーマットも変わると思いますが、ここではRESTfulなAPIへの認可を考えることにします。
さて、本題のぼくのかんがえたさいきょうのscopeは、これだっ!!!
read:リソース名write:リソース名理由
このscopeの前提となる思想は下記2つです。
- 最小権限の原則に則って必要最低限の権限のみを認可できるように、scopeのアクセス範囲はなるべく小さくしたい。
- scope名を見ただけでアクセス範囲が分かるような明快なものが良い。
この思想をもとに、下記のように考えました。
- RESTの「リソース」という概念を利用して、リソース単位で切ると、明快で小さく権限を分けられるだろう。
- リソースに対してなんでもできてしまう権限は大きいので、リソースに対する動作でさらに権限を分ける必要がある。下記の理由で1つのリソースに対しreadとwriteの2つの権限に分けることにした。
- HTTP動詞で言うなら、GETをread、POST, UPDATE, DELETEをwriteとすれば良いので、明快だろう。
- HTTP動詞(GET, POST, PUT, DELETE)や、Railsのcontrollerのアクション名など、より細かい権限分離も考えたが、リソースの新規作成ができるclientには、作成したリソースの更新・削除する権限も与えたいという考えで、readとwriteという分け方にした。
- readとwriteはLINUXのファイルパーミッションでも登場するので、馴染み深く明快だろう(executeは使わないけど)。
オマケ 〜Railsの場合〜
「リソース名」は単数形にしても複数形にしても良いですが、Railsでは
controller_nameでコントローラー名(基本的にリソースの複数形)が取れ、私はこれを利用するために複数形にしました。# こんなアクセスのとき... http://hoge.jp/articles controller_name # => “articles” # こんなのが取れる!これを利用すれば、scopeの検証は2つのメソッドのみで事足ります。controller concernなどに書くと良いと思います。
def required_read_scope scope_name = "read:#{controller_name}" render_unauthorized unless current_access_token.scopes.include?(scope_name) end def required_write_scope scope_name = "write:#{controller_name}" render_unauthorized unless current_access_token.scopes.include?(scope_name) endあとはこのメソッドを各controllerのbefore_actionで、指定したアクションの前に呼び出すだけです。
class ArticlesController < ApplicationController before_action :required_read_scope, only: %i[index show] before_action :required_write_scope, only: %i[create update destroy] ... endOAuth 2.0の他の仕様で迷ったら
私がOAuth 2.0の自由な仕様で迷ったときに、各社の仕様をこちらにまとめました。他の仕様で迷っているときは、もしかしたら参考になるかもしれません。
https://qiita.com/murs313/items/078025d671e937a09285
- 投稿日:2020-08-24T18:35:03+09:00
実装するにあたり、テストを記述したのち、処理をコーディングする
背景
現場でのあるあるですが、普段は以下の流れで開発を進めることが多いと思います。
(1)設計→(2)処理のコーディング→(3)テストのコーディング→(4)単体テストなど…しかし、Railsチュートリアルでは、
(1)設計→(2)テストのコーディング→(3)処理のコーディング…
という流れで解説されていました。自分も少し勉強になったので、記事として掲載しようと思います。環境
項目 内容 OS aws #35-Ubuntu SMP(Cloud9) Ruby ruby 2.6.3p62 (2019-04-16 revision 67580) Ruby On Rails Rails 6.0.3 対応
以下は、ルーティング、コントローラが設定されているアプリに、新たにabout(概要)ページを追加する場合、テストソースからコーディングする例です。
config/route.rbRails.application.routes.draw do get 'static_pages/home' get 'static_pages/help' root 'static_pages#home' ※概要ページのルーティングはまだ設定されていません。 endapp/controller/static_pages_controller.rbclass StaticPagesController < ApplicationController def home end def help end ※概要ページのアクションはまだ設定されていません。 end手順1)ここで、新たに追加するページに対するテストを予め記述しておきます。
test/static_pages_controller_test.rbrequire 'test_helper' class StaticPagesControllerTest < ActionDispatch::IntegrationTest 1 2 test "should get home" do 3 get static_pages_home_url 4 assert_response :success 5 end 6 7 test "should get help" do 8 get static_pages_help_url 9 assert_response :success 10 end 11 12 ※~~~~ ここから想定で概要ページのテストを記入する。~~~~ 13 test "should get about" do 14 get static_pages_about_url 15 assert_response :success 16 end end手順2)テストを実行してみる(1回目=まだ処理を記述していないのでエラーになる)
$rails test Error: StaticPagesControllerTest#test_should_get_about: NameError: undefined local variable or method `static_pages_about_url' .. Finished in 2.157942s, 1.3902 runs/s, 0.9268 assertions/s. 3 runs, 2 assertions, 0 failures, 1 errors, 0 skipsエラーが出てしまいました。
手順3)上記から、パスが通っていないので、ルーティングを見直します。
config/route.rbRails.application.routes.draw do get 'static_pages/home' get 'static_pages/help' get 'static_pages/about' ←ここを追加した☆ root 'static_pages#home' end手順4)テストを実行する(2回目=想定ではエラーになる)
$ rails test Error: StaticPagesControllerTest#test_should_get_about: AbstractController::ActionNotFound: The action 'about' could not be found for StaticPagesController… 3 runs, 2 assertions, 0 failures, 1 errors, 0 skipsまたエラーが出てしまいました。
手順5)上記エラーから、アクションが原因なのでコントローラを見直します。
app/controller/static_pages_controller.rbclass StaticPagesController < ApplicationController def home end def help end def about ←ここを追加した☆ end end手順6)さらにテストを実行してみる(3回目=どうなるか…)
$ rails test Error: StaticPagesControllerTest#test_should_get_about: ActionController::MissingExactTemplate: StaticPagesController#about is missing a template for request formats: .. 3 runs, 2 assertions, 0 failures, 1 errors, 0 skipsまたエラーが出てしまいました。次はまた文言が違うようです…
手順7)上記エラーから、テンプレートが原因のようなのでビューを追加します。
touch app/views/static_pages/about.html.erb手順8)テストを実行する(4回目=正常テストパス)
$ rails test ... 3 runs, 3 assertions, 0 failures, 0 errors, 0上手くいきました…基本中の基本ですが、リファクタリングを含めておさえておくべき内容だと感じました。
参考文献
- 投稿日:2020-08-24T17:00:22+09:00
【Rails】Semantic UIを使って動的にフラッシュメッセージを表示する方法
Semantic UI
BootstrapのフレームワークであるSemantic UIを使って、Railsに動的なフラッシュメッセージを導入する方法を以下に記しておきます。
Railsを使ったSemantic UIの導入方法は、以下の記事を参考にしてみてください。
class属性を動的に設定するためのヘルパーを作成
app/helpers/application_helper.rbmodule ApplicationHelper def flash_class(level) case level when "success" then "ui success message" when "danger" then "ui error message" end end endフラッシュメッセージ用のパーシャルを作成
上記で作った
flash_class(level)メソッドを使用。app/views/shared/_flash_message.html.slim- flash.each do |message_type, message| div class="#{flash_class(message_type)} closable" i class="close icon" = messageJavaScriptの導入
フラッシュメッセージの右上の×ボタンを押すと、フラッシュメッセージが消えるようにjsの記述をしておく。
app/javascript/packs/flash_message.js$(function () { $(".closable .close.icon").on("click", () => { $('.closable').fadeOut("slow"); }); });エントリポイントである
app/javascript/packs/application.jsに、app/javascript/packs/flash_message.jsを読み込んでおく。app/javascript/packs/application.jsrequire("packs/flash_message")パーシャルをレンダリングする。
== render "shared/flash_message"でオッケーですね。app/views/layouts/application.html.slimdoctype html html head title = page_title(yield(:title)) = csrf_meta_tags = csp_meta_tag = stylesheet_pack_tag "application", media: "all", "data-turbolinks-track": "reload" = javascript_pack_tag 'application', 'data-turbolinks-track': 'reload' body == render 'shared/header' == render "shared/flash_message" == yield == render 'shared/footer'各コントローラで、
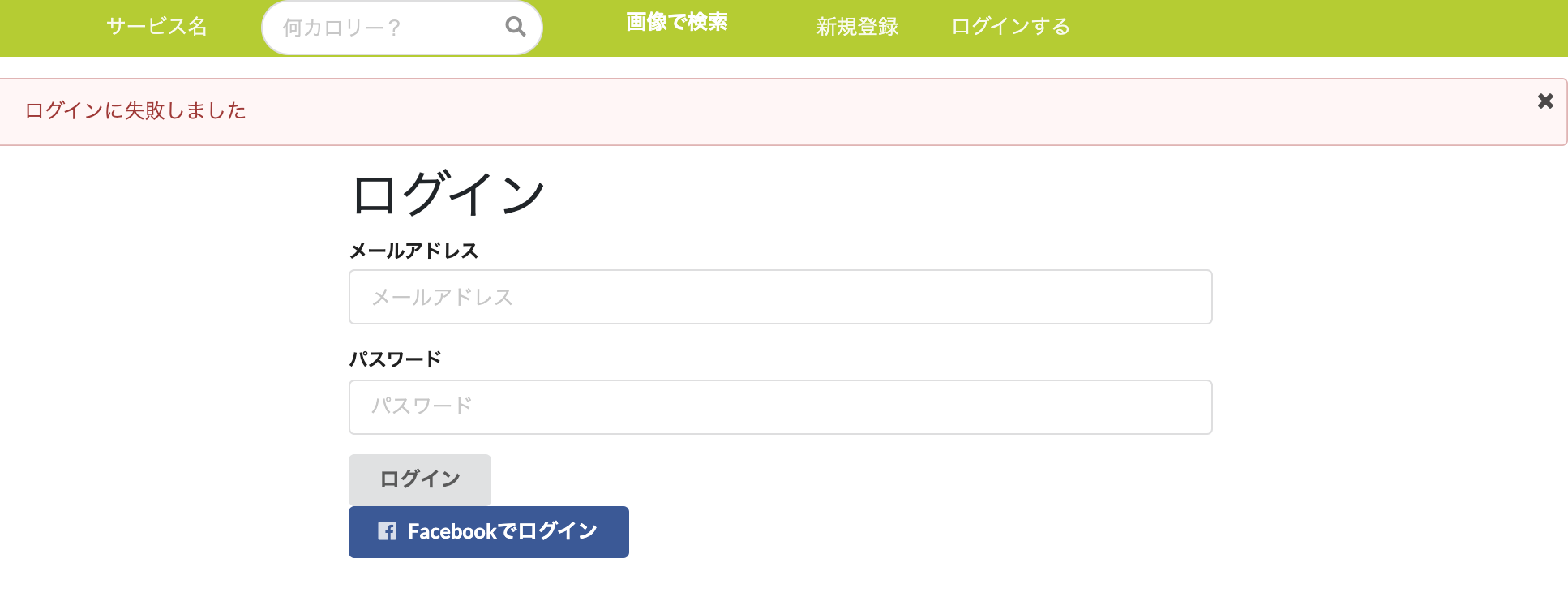
flash_class(level)メソッドに渡すキーとバリューをセットする。app/controllers/user_sessions_controller.rbclass UserSessionsController < ApplicationController skip_before_action :require_login, only: %i[new create] def new; end def create @user = login(params[:email], params[:password]) if @user redirect_back_or_to root_path, success: 'ログインに成功しました' else flash.now[:danger] = 'ログインに失敗しました' render action: 'new' end endブラウザで確認
記述は以上です。
最後にブラウザで挙動を確認します!レイアウトは気にしないでください?
ログイン成功時
ログイン失敗時
×ボタンを押すとフラッシュメッセージが消える。


- 投稿日:2020-08-24T15:43:27+09:00
[Rails]rails db:migrateを実行した際に発生したエラー
状況説明
ターミナル.$ rails db:migrate上記のコードを実行した際に下記エラーが発生。
ターミナル.== 20200823050614 DeviseCreateUsers: migrating ================================ -- create_table(:users) rails aborted! StandardError: An error has occurred, all later migrations canceled: Mysql2::Error: Table 'users' already exists: CREATE TABLE `users` (`id` bigint NOT NULL AUTO_INCREMENT PRIMARY KEY, `nickname` varchar(255) NOT NULL, `email` varchar(255) DEFAULT '' NOT NULL, `pass` varchar(255) NOT NULL, `confirmation_pass` varchar(255) DEFAULT '' NOT NULL, `family_name` varchar(255) NOT NULL, `family_name_kana` varchar(255) NOT NULL, `first_name` varchar(255) NOT NULL, `first_name_kana` varchar(255) NOT NULL, `birth_year` int NOT NULL, `birth_month` int NOT NULL, `birth_day` int NOT NULL, `icon` varchar(255), `reset_password_token` varchar(255), `reset_password_sent_at` datetime, `remember_created_at` datetime, `created_at` datetime NOT NULL, `updated_at` datetime NOT NULL) /Users/sasakiken/projects/furima_app/db/migrate/20200823050614_devise_create_users.rb:5:in `change' /Users/sasakiken/projects/furima_app/bin/rails:9:in `<top (required)>' /Users/sasakiken/projects/furima_app/bin/spring:15:in `<top (required)>' bin/rails:3:in `load' bin/rails:3:in `<main>' Caused by: ActiveRecord::StatementInvalid: Mysql2::Error: Table 'users' already exists: CREATE TABLE `users` (`id` bigint NOT NULL AUTO_INCREMENT PRIMARY KEY, `nickname` varchar(255) NOT NULL, `email` varchar(255) DEFAULT '' NOT NULL, `pass` varchar(255) NOT NULL, `confirmation_pass` varchar(255) DEFAULT '' NOT NULL, `family_name` varchar(255) NOT NULL, `family_name_kana` varchar(255) NOT NULL, `first_name` varchar(255) NOT NULL, `first_name_kana` varchar(255) NOT NULL, `birth_year` int NOT NULL, `birth_month` int NOT NULL, `birth_day` int NOT NULL, `icon` varchar(255), `reset_password_token` varchar(255), `reset_password_sent_at` datetime, `remember_created_at` datetime, `created_at` datetime NOT NULL, `updated_at` datetime NOT NULL) /Users/sasakiken/projects/furima_app/db/migrate/20200823050614_devise_create_users.rb:5:in `change' /Users/sasakiken/projects/furima_app/bin/rails:9:in `<top (required)>' /Users/sasakiken/projects/furima_app/bin/spring:15:in `<top (required)>' bin/rails:3:in `load' bin/rails:3:in `<main>' Caused by: Mysql2::Error: Table 'users' already exists /Users/sasakiken/projects/furima_app/db/migrate/20200823050614_devise_create_users.rb:5:in `change' /Users/sasakiken/projects/furima_app/bin/rails:9:in `<top (required)>' /Users/sasakiken/projects/furima_app/bin/spring:15:in `<top (required)>' bin/rails:3:in `load' bin/rails:3:in `<main>' Tasks: TOP => db:migrate (See full trace by running task with --trace)エラー内容
Table 'users' already exists: CREATE TABLEusers``の箇所を翻訳すると、usersテーブルは既に存在しますと言った内容。作成した覚えはないが、存在していると言うことなので下記コードで一度確認。
ターミナル.$ rails db:migrate:statusすると以下のように...
ターミナル.database: furima_app_development Status Migration ID Migration Name -------------------------------------------------- up 000 ********** NO FILE ********** down 20200823050614 Devise create usersどうやら
up 000 ********** NO FILE **********が悪さをしていたようですね。エラー原因
マイグレーションファイルをコマンドで削除せずに、手動で削除したことが原因のようで、マイグレーションファイルの操作は必ずコマンドで行わなければならないと言うことでした...。(初歩的だけど一度はやってしまいがち?)
エラー対処法
ステータスがupとなっているところをdownにしなければいけないので、そのためのマイグレーションファイルをdb/migrate配下に作成。
NO FILEとなっているマイグレーションIDのファイルが必要なので、
000_dummy.rbとし、以下のようにコード記述。db/migrate/000_dummy.rbclass Dummy < ActiveRecord::Migration[5.2] def change end endこの状態でもう一度、
rails db:migrate:statusを実行すると、以下のように作成したマイグレーションファイルが確認できる。ターミナル.database: furima_app_development Status Migration ID Migration Name -------------------------------------------------- up 000 Dummy down 20200823050614 Devise create users続いて、次のコマンドでdownにします。(マイグレーションIDはご自身のものを指定)
ターミナル.$ rails db:migrate:down VERSION=000再び
rails db:migrate:statusを実行すると、downに変更されているはずですので、後はDummyファイルを削除すれば解決!改めて
rails db:migrateを実行すればテーブルを作成できると思います。最後に
今回の発信で50記事達成!
この調子で継続していきますので今後も宜しくお願いします。
- 投稿日:2020-08-24T14:35:17+09:00
rails実行時のエラー”warning: already initialized constant FileUtils::VERSION”
初めてみた内容だったので、備忘録として記録します
概要
rails sを実行すると以下の様な文が出る様になった↓rbenv/versions/2.6.0/lib/ruby/2.6.0/fileutils/version.rb:4: warning: already initialized constant FileUtils::VERSION rbenv/versions/2.6.0/lib/ruby/gems/2.6.0/gems/fileutils-1.4.1/lib/fileutils.rb:105: warning: previous definition of VERSION was here /Users.rbenv/versions/2.6.0/lib/ruby/2.6.0/fileutils.rb:1267: warning: already initialized constant FileUtils::Entry_::S_IF_DOOR rbenv/versions/2.6.0/lib/ruby/gems/2.6.0/gems/fileutils-1.4.1/lib/fileutils.rb:1284: warning: previous definition of S_IF_DOOR was here rbenv/versions/2.6.0/lib/ruby/2.6.0/fileutils.rb:1540: warning: already initialized constant FileUtils::Entry_::DIRECTORY_TERM rbenv/versions/2.6.0/lib/ruby/gems/2.6.0/gems/fileutils-1.4.1/lib/fileutils.rb:1568: warning: previous definition of DIRECTORY_TERM was here rbenv/versions/2.6.0/lib/ruby/2.6.0/fileutils.rb:1595: warning: already initialized constant FileUtils::OPT_TABLE rbenv/versions/2.6.0/lib/ruby/gems/2.6.0/gems/fileutils-1.4.1/lib/fileutils.rb:1626: warning: previous definition of OPT_TABLE was here rbenv/versions/2.6.0/lib/ruby/2.6.0/fileutils.rb:1649: warning: already initialized constant FileUtils::LOW_METHODS rbenv/versions/2.6.0/lib/ruby/gems/2.6.0/gems/fileutils-1.4.1/lib/fileutils.rb:1685: warning: previous definition of LOW_METHODS was here rbenv/versions/2.6.0/lib/ruby/2.6.0/fileutils.rb:1656: warning: already initialized constant FileUtils::METHODS rbenv/versions/2.6.0/lib/ruby/gems/2.6.0/gems/fileutils-1.4.1/lib/fileutils.rb:1692: warning: previous definition of METHODS was here原因
調べてみると、fileutilsgを複数回読み込むエラーのよう
解決策
gem uninstall fileutilsgem update --defaultこれでエラーが消えました!
- 投稿日:2020-08-24T14:22:36+09:00
[Rails]Faradayのミドルウェアを使ってみる
Faradayのミドルウェアを使ってみたので簡単にまとめます。
Faradayとは?
rubyで書かれたHTTPクライアントライブラリであり、
これを利用してRailsプロジェクトから外部APIにアクセスすることができます。Faradayのミドルウェアとは?
Faradayにはリクエストやレスポンス処理についてカスタマイズできるミドルウェアがあります。
RequestミドルウェアとResponseミドルウェアの2つがあり、これを利用することによってリクエスト時の認証情報を付与したり、通信についてログに書き出すことができます。シンボルを使って以下のように使うことができます。
api_client.rbFaraday.new(url: 'https://test.com') do |builder| # ミドルウェアを使用する builder.request :url_encoded builder.response :logger, Config.logger if Config.enable_logger endRequestミドルウェアについて
Requestミドルウェアはリクエスト送信前にリクエストの詳細を設定することができます。
ここでは2つのミドルウェアを紹介します。
認証ミドルウェアはAuthorizationヘッダーの設定ができ、
UrlEncodedミドルウェアはキーと値のペアのハッシュをURLエンコードされたリクエスト本文に変換することができます。使用例
api_client.rb# 認証ミドルウェア builder.request :basic_auth, "username", "password" builder.request : authorization :Basic, "aut_key" # UrlEncodedミドルウェア builder.request :url_encodedResponseミドルウェアについて
responseミドルウェアはレスポンスを受け取る際にレスポンスの詳細を設定することができます。
ここではLoggerミドルウェアを紹介します。
Loggerミドルウェアを使うと、リクエストとレスポンスの本文およびヘッダーをログに出力することができます。
またフィルター機能もあり、正規表現を利用して機密情報をフィルタリングすることができます。使用例
api_client.rb# Loggerミドルウェア builder.response :logger # フィルター builder.response :logger do | logger | logger.filter(/(password=)(\w+)/, '\1[REMOVED]') endfaraday_middlewareを使うとさらに便利!
faraday_middlewareというgemをいれると使えるミドルウェアがさらに増えます。
例えば、ParseJsonクラスを使って、parser_optionsとcontent_typeを指定すればハッシュキーをシンボルにしてJSONパースすることもできます。
使用例
api_client.rbbuilder.response :json, parser_options: { symbolize_names: true }, content_type: 'application/json'参考ドキュメント
https://lostisland.github.io/faraday/
https://lostisland.github.io/faraday/middleware/list
- 投稿日:2020-08-24T14:22:36+09:00
[Rails]Faradyのミドルウェアを使ってみる
Faradyのミドルウェアを使ってみたので簡単にまとめます。
Faradyとは?
rubyで書かれたHTTPクライアントライブラリであり、
これを利用してRailsプロジェクトから外部APIにアクセスすることができます。Faradyのミドルウェアとは?
Faradayにはリクエストやレスポンス処理についてカスタマイズできるミドルウェアがあります。
RequestミドルウェアとResponseミドルウェアの2つがあり、これを利用することによってリクエスト時の認証情報を付与したり、通信についてログに書き出すことができます。シンボルを使って以下のように使うことができます。
api_client.rbFaraday.new(url: 'https://test.com') do |builder| # ミドルウェアを使用する builder.request :url_encoded builder.response :logger, Config.logger if Config.enable_logger endRequestミドルウェアについて
Requestミドルウェアはリクエスト送信前にリクエストの詳細を設定することができます。
ここでは2つのミドルウェアを紹介します。
認証ミドルウェアはAuthorizationヘッダーの設定ができ、
UrlEncodedミドルウェアはキーと値のペアのハッシュをURLエンコードされたリクエスト本文に変換することができます。使用例
api_client.rb# 認証ミドルウェア builder.request :basic_auth, "username", "password" builder.request : authorization :Basic, "aut_key" # UrlEncodedミドルウェア builder.request :url_encodedResponseミドルウェアについて
responseミドルウェアはレスポンスを受け取る際にレスポンスの詳細を設定することができます。
ここではLoggerミドルウェアを紹介します。
Loggerミドルウェアを使うと、リクエストとレスポンスの本文およびヘッダーをログに出力することができます。
またフィルター機能もあり、正規表現を利用して機密情報をフィルタリングすることができます。使用例
api_client.rb# Loggerミドルウェア builder.response :logger # フィルター builder.response :logger do | logger | logger.filter(/(password=)(\w+)/, '\1[REMOVED]') endfaraday_middlewareを使うとさらに便利!
faraday_middlewareというgemをいれると使えるミドルウェアがさらに増えます。
例えば、ParseJsonクラスを使って、parser_optionsとcontent_typeを指定すればハッシュキーをシンボルにしてJSONパースすることもできます。
使用例
api_client.rbbuilder.response :json, parser_options: { symbolize_names: true }, content_type: 'application/json'参考ドキュメント
https://lostisland.github.io/faraday/
https://lostisland.github.io/faraday/middleware/list
- 投稿日:2020-08-24T11:25:53+09:00
PG::UniqueViolation: ERROR: duplicate key value violates unique constraintエラーの解決
PGデータベースにデータをインポートの後など、このエラーが発生する場合があります。
PG::UniqueViolation: ERROR: duplicate key value violates unique constraint "<sample_tables>_pkey"原因
データインポートなどの場合、PostgreSQLが指定したカラムの最大値を取ってくれず、別に保存してある最大値になってしまいます。
解決
Railsコンソールで以下のコードを実行すれば治ります。
ActiveRecord::Base.connection.tables.each do |t| ActiveRecord::Base.connection.reset_pk_sequence!(t) end
- 投稿日:2020-08-24T10:50:38+09:00
rails イメージ画像表示の仕方
アウトプット用に記述しました。
rails のアプリケーションサービスを1から作っています。間違いがあればご指摘お願いします。
今回はアプリケーションサービスにアクセスした際のトップ画面にイメージ画像をフルスクリーンで表示させる方法を記録します。image_tagメソッドの定義
<%= image_tag "画像の名前", class:"クラス名" %><%= image_tag "top-img.jpg", class:"pict" %>表示するファイルの置き場所はapp/assets/imagesフォルダとpublicフォルダの2つが用意されています。
今回私はダウンロードしてきた画像をapp/assets/imagesフォルダに入れました。
リロードすると、
このままだとサイズ指定できていないので、意図しないサイズで表示させてしまうので
<%= image_tag "top-img.jpg", size: '100x200' %>とサイズ指定を直接できます。
ですが、私は今回フルスクリーンにしたり、色々なCSSを当てたかったのでclass指定しました。
.pict{ height: 100vh; width: 100vw; background-size: cover; background-repeat: no-repeat; background-position: top center; display: flex; flex-direction: column; align-items: flex-start; justify-content: center; }すると、
トップページにアクセスした時にこのフルスクリーンのサイズで表示されます。
上の空白部分にアプリケーション名やログイン画面を作っていきたいと思います。
※そのほかにリセットCSSなどもやらないといけないですが、
stylesheetsの配下にreset.cssファイルを作り、ファイル内は『reset.css』でコピペして持ってきました。
これからたくさんのアプリケーション作っていく際に自分のreset.cssをカスタマイズできたらいいなと思っています。



- 投稿日:2020-08-24T10:34:36+09:00
Rails でherokuデプロイ時にPrecompiling assets failedが出た
環境
Rails 5.2
Ruby 2.6フロント側ではvue+vuex+vue-routerを使用
症状
herokuにプッシュしようとしたら、
Precompiling assets failedのメッセージが出て、デプロイが失敗する。ログの上のほうには
Field 'browser' doesn't contain a valid alias configuration
のメッセージあり。原因
パッケージの依存関係に問題あり?
package.json
{ "name": "mapApp", "private": true, "dependencies": { "@rails/webpacker": "5.1.1", "axios": "^0.20.0", "google-maps-api-loader": "^1.1.1", "leader-line-vue": "^2.1.1", "vue": "^2.6.11", "vue-loader": "^15.9.2", "vue-router": "^3.4.3", "vue-template-compiler": "^2.6.11", "vuex": "^3.5.1" }, "devDependencies": { "webpack-dev-server": "^3.11.0" } }解決方法
片っ端からパッケージのアンインストールとインストールをしたら、デプロイできました。
(npmとyarnを共存させると良くないと思ったので、インストール時にはyarnを使ってます)npm uninstall vuex yarn add vuex //vuexだけでなくvue-routerや他のパッケージにも同じ操作Precompiling assets failedの原因は、scssとcss起因のものなど色々あるそうですが、
とりあえず今回はこれで解決できました
- 投稿日:2020-08-24T09:34:12+09:00
ソースコードを読むための技術(チートシート)
1 概要
聞くところによると業務の8割がソースコードを読む時間らしい。しかし、8割という規模感の割には世間でソースコードの読み方についての議論が活発にされている印象はない上に、体系的かつ順序立てたソースコードの読み方をまとめたWebサイトや書籍も少ない。疑問に思いながらもそれなりに長いことデバッガーを使った読み方・リーダブルコードの内容・Web記事を参照にしてソースコードを読んでいた。
しかし、ソースコードリーディングの方法についての情報がメモアプリ内で散らかってしまい、いつまで経ってもソースコードリーディングの技術が体系的に身についていないと感じた。そのため、本稿では本・Web記事・YouTubeなど媒体を問わず、様々な文献からソースコードを効率的に読む方法をチートシートにしてまとめた。チートシートにする目的は「見返して反復し長期記憶化しやすいようにするため」と「ソースコードリーディングについての知識を体系的にまとめ、情報を一元化することで情報の取り出しを容易にするため」である。また、本稿で想定している言語は私に馴染みのあるRubyとする。
2 コードリーディングにおける階層
コードリーディングには以下の階層があるとのこと。
それぞれ通し番号を以下のように設定する。
- ソースコードとして書かれている各行
- 基本文法
- ライブラリ・フレームワーク
- 設計パターン、データ構造・アルゴリズム、パラダイム・原理原則
- IDE(開発ツール)、デバッガ(デバッグツール)、実行環境
- チームルール
- 業務知識・業務要件・非機能要件(実現したいこと)
この「コードリーディングという行為を構成する知識群」という画像における読解は、通し番号でいうと1→7に。詳細から全体へ向かって読むことをコードリーディングと呼称している。
しかし、これはある程度プログラムを把握し終えた時の読解方法であり、エラーやプロジェクト参画1日目などの場合は7→5→6→4→3→2→1(筆者はこの順番で読みますが、スタイルは自由です)のように全体から詳細に向かって読むのがプログラムを把握するのには向いているのではないかと考える。したがって本稿では、エラーやプロジェクト参画1日目にソースコードを読む場合を想定した順序で記載していく。
余談だが「コードリーディングという行為を構成する知識群」はソースコードを読むという方法を階層化し分類している点で優秀な図だと思う。
それでは次稿からソースコードを読むための技術を詳説していく。
3 目的の設定
読むプログラムが決まった。さてどうするか。なんの方針もなくただ ただ mainから読んでいってもコードが言おうとしていることは理解できないだろう。まずコードを読む目的を明確に決め、それにだけ 集中するようにする。全てを読まなければいけないときでも、パスを分けて部分ごとに読む。(*1)
先述の画像における⑦業務知識・業務要件・非機能要件(実現したいこと)がこれにあたる。「エラーを解決するため」「プロジェクトの理解のため」などが該当し、具体的には「NoMethodErrorになったので解決したい」や「いいね機能を実装したい」などが目的として設定される。
ちなみに筆者は、早く目的を達成するために日頃から業務や自主勉強を通して得た知識を、機能要件・非機能要件に分けてチートシート形式で蓄えている。検索機能を作りたい!()と思った時には機能要件のこれを参照にするし、カラムを変更したい!と思った時には非機能要件のこれを参照にする。一度ハマったエラーなどもチートシート形式で保存をしておくと、同じエラーに遭遇した際に二度手間にならずにURLを参照できる。これは心理的安定にも繋がる。
また筆者は、とりあえずのメモ帳としてはiOS純正のメモ帳やInkDropを使ってチートシートを作成し、外部にアウトプットする時はブログやQiitaなどを使っている。OSSなど読んでよさそうだと思ったソースコードはGitHubに逐一蓄えておくと再利用が可能なのでとてもよい。
4 動的解析
大雑把に言って解析手法は静的な手法と動的な手法に分類できる。 静的な手法とは、ソースコードそれ自体を読むこと。 動的な手法とは、デバッガなどを使って実行時の動きを追うことだ。
基本的に解析は動的解析から始めるのがよい。 静的解析とは、多かれ少なかれ、プログラムの動作を予想することである。 対して動的解析で見るのは事実である。 まず事実を見ておいたほうが方向付けがしやすいし、間違いも減る。 最適化する前にプロファイルを取れ、というのと似ているだろうか。 事件解決はまず現場から、というのでもよい。(*1)らしい。よって、動的手法から解説していく。
また、本稿では「エラーを解決することを目的」として動的解析を行っているが、「プロジェクトの理解が目的」でも同様にしてソースコードを動的解析する。「エラーが起きたら〜」部分を「プロジェクトで気になるソースコードが見つかったら」と適宜、変換してしてほしい。
4.1 デバッガーを使う
Webプログラミングというのはクライアントがパラメーター付きのリクエストを送り、それをサーバーサイドで加工しクライアントにレスポンスするものだと考えている。時にはパラメーターの値を参照にデータベースから値を持ってきて、サーバーサイドで加工しクライアントにレスポンスすることもある。つまり、Webプログラミングはバケツリレー大会であり駅伝大会である。バケツの水やタスキが変数になっただけなのだ。そして、エラーは変数の値が予想と違ったり、大会のルールがロジカルではないなどの原因で発生する。
そのバケツリレーの流れの中でどの地点がエラーになったのかを分析するのがデバッガーである。先述の「1 目的の設定」で決めた目的に合致するエラーの箇所をブラウザ・URL・バックトレースから判別し、プロジェクトファイルから該当のフォルダとファイルを、付与された名前を駆使して類推・探索する。それによってそれっぽいファイル名・関数名・変数名・型名・メンバ名を特定し、特定地点にデバッガーを挿し込んで変数の流れを把握する。
静的な文字情報として脳内で認識していたプログラムをデバッガーを使用することで、一気に動的な風景として脳内で認識することができる。個人的には80年前の写真が突如動画になって動き始めるた時の感動に近いものを感じる。プログラムをイメージで把握することで右脳や空間知覚を使用することができる。記憶容量の大きい右脳に処理の流れをストックできるので、空いた左脳でソースコードの分析ができる。
デバッガーは、IDEであればEclipseやJetBrain系IDEに予め内蔵されているものを使う。そうでない場合はRubyであればbyebugやpryなどのサードパーティ製のライブラリを使うといいだろう。
4.2 ソースコードの処理の流れを日本語や図でメモに記載する
4.1ではバックトレースを読んだりデバッガーを使用し、ソースコードの処理の流れを把握した。処理の流れを把握したらその次は把握した内容を日本語や図でメモなどに記載することをする。
なぜ「ソースコードの処理の流れを日本語に置き換えメモをする」のか。理由は2つある。
1つ目は「ソースコードは抽象的だから」だ。
ソースコードを解読するということは抽象概念を具象概念に落とし込むことであると考えている。天才や業務経験の長いエンジニアであれば抽象を抽象のまま理解しそれを活用することができるが、プログラミングに関して私は凡人であり業務経験も少ない。そのため、抽象概念を具象概念に落とし込み日本語でメモをすることは業務効率、学習、思考の外部記憶装置の面で重要なファクターだと考えている。故に「ソースコードの処理の流れを日本語に置き換えメモをする」ことは重要である。
2つ目は「ソースコードは英語で記載されているから」だ。
まず我々は日本人だ。24時間日本語を使っている。日本語で記載されているものは0秒で理解できるしイメージ理解が容易である。しかし、残念なことにソースコードは英語で記載されている。母国語ではない英語には馴染みがない。英語でGiraffeと言われてもすぐに理解はできないが、日本語でキリンと言われれば0秒で動物のキリンが頭の中にイメージできる。つまり、英語で記載されている単語の意味は0秒で理解できないし、増してやイメージ記憶は日本語に比べて難解だということだ。そのため、英語で書かれた抽象的なソースコードの流れを具体的に日本語や図でメモに記載することは、業務を早くするという面で重要なファクターを持つ。
仮にソースコードを英語のまま理解したいのであれば、英語を英語で理解する習慣を意識的に作り、英語脳を養うことが必要であると考える。しかし、恐らく英語脳習得にはかなりの時間がかかると見ている。ライティングは特に。またプログラミングやマーケティングなど学ぶことも多いため、英語ばかりにリソースを割けないというのも実情だ。そのため、取り急ぎ英語で記載されたプログラムを日本語に変換し、処理の流れを順次メモし整理することは、重要なことであると考える。
以上の理由から、ソースコードの処理の流れを日本語や図で記載することは重要であると考えた。実は3つ目に「処理の流れを俯瞰で理解できる点」というものを用意していたが、詳細の文章をどう書けばいいかわからなくなったため記載を省きました。
4.3 エラー箇所の挙動を確認
4.1でエラーの箇所を、4.2で処理の流れ全体を把握することができた。
デバッグは「ある処理(行)のときに・データ状態はこうなっているはず」という仮説検証の行為だと考えている。
エラーの箇所がなぜ動かないのかはエラーメッセージを読めば大体のあたりがつくが、中にはなぜ動かないのか分からない時がある。そういう時は以下の手法を用いることでエラーを解決できる。3.3ではプロを目指す人のためのRuby入門の11章を参考にさせて頂いた。名著なのでRuby経験者なら一度は耳にしたことがあると思うが、「コードリーディングという行為を構成する知識群」の②基本文法を抑えるという意味で重要なので、気になった方は読んでみまSHOW TIME。
4.3.1 自分で解決する
①エラーメッセージを読む
エラーメッセージをコピペしてググれば大抵の問題は解決する。
②バックトレースを読む
バックトレースとは、大雑把にいうと「メソッドの呼び出し状況を表したデータ」でメソッドがどこから呼び出されたかを調べることができる。railsでいえばApplication Traceを使う。
③ログを調べる
Railsなどのフレームワークにはログを出力するものがあるらしい。
④プログラムの途中経過を確認する
概要
自分の推測と実際の処理動作が正しいのかどうか。変数の推測と実際のズレはどこにあるのかを調べたい。
方法
1. printデバッグやloggerデバッグをし変数を確認
2. メソッドチェーンにtapを仕込み、変数を確認
3. ByebugやIDE標準のデバッガーでブレークポイントを打ち、変数を確認⑤インタラクティブに試す。
メソッドの挙動が自分の想定していたものと違ったり、ライブラリの挙動を調べたりしたい時に行う。
方法
1. irbで簡単なコードを動かす
2. フレームワーク由来のエラーであればscaffoldでエラー箇所を再現する。⑥ライブラリのコードを読む
外部ライブラリの挙動がどうなっているかを知りたい時や、バージョンアップ等で外部ライブラリ自体が動かない原因になっていることがある場合、ライブラリのコードまで降りる必要がある。Rubyはスクリプト言語なので、実行に必要なライブラリはRubyのコードとして手元に存在しているはずである。あとはプロジェクトからライブラリの場所を探すためにMethodクラスのsource_locationメソッドを使うことで調べることができる。なお、戻り値がnilの場合(C言語で実装されているケース)は、Rubyの標準ライブラリのメソッドであることが多い。
また、ライブラリのソースコードはソースコードとして優秀であることが多いので、書き方を学んでGitHubなどに蓄えておくと再利用可能で技術力も向上する。
⑦テストコードを書く
メリット
1. デバッグにかける時間を節約できる
2. これまで作ったプログラムのロジックが壊れていないことを保証するドキュメントの代わりにできる
3. 自身の思考の認知外にある予期せぬエラーを事前に対策できる方法
各言語のテストフレームワークを参照。
⑧パソコンの前から離れる
トイレに行く、飲み物を買いに行く、散歩をする、運動をする、昼寝する、ご飯を食べる、お風呂に入る、早めに寝る。
ことにより、視界がひらけてくるため数時間悩んでいた問題が解決することがある。
4.3.2 他人を頼る
①社内&公式ドキュメント
どちらも1次情報なので正確かつ確実に問題を解決できるものだと考える。
②ネットの情報を参考にする
Qiitaや個人ブログを参照にする。
③issueを検索
issueトラッキングサービスなるものが存在するらしい(初めて知った)。全文英語でよく分からないのが玉に瑕だが、公式のissueなのでエラー解決の選択肢として頭の片隅に置いておくと、困った際に正確かつ確実に問題を解決できるものだと考える。
④誰かに聞く(職場の人、teratail)
個人的には、ある程度の時間調べて悩んで分からなかったらそこが現時点での自分の限界なので、要点をまとめた上で人に聞くことをしたいと思っている。しかし、苦い顔をされることも多いため抵抗がある方法でもある。
5 静的解析
5.1 ドキュメントを読む
そもそもソースコードを読まない
ソースコード読んだら負けかなと思っています。
リファレンスマニュアル、ドキュメント
設計関連の文書・資料
自然言語で書かれた素晴らしいものがたくさんあるはずなので、まずはそちらを読みましょう。そういったものがあまり頼れないとき、そういったもので解決しないときは、しょうがないのでコードを読みます。それでもコメントや識別子の命名を重視して、まずはできるだけ意味的に解釈してみます。
コメント皆無、変数名適当……というケースでは、仕方ありません。他にどうしようもないので、コードロジックを見ていきましょう。
読むのは面倒くさいので、できればやりたくないことの筆頭です。できるだけやらないで済ませる方法を考えます。
初心者だと読解力不足で捗らないということも多々あるでしょうし、よほどの必要性に迫られていなければ「コード読むのは、もう少し上達してからでいいよ」なのでは。
前任者がドキュメントを残しているはずなので、それを読む。
https://teratail.com/questions/147782これも前項と似ていて、まず仕様を知っておこうということ。 また内部構造を解説したドキュメントが付いていたらそれもぜひ見ておきたい。 「HACKING」「TOUR」などという名前のファイルがあったら要チェック。
「コードリーディングという行為を構成する知識群」における⑥チームルールにあたるものだ。
せっかく前任者が工数をかけて自然言語や図でドキュメントを残しているので、あるならドキュメントを先に読解するのがいい。5.2 構造、設計の理解
「コードリーディングという行為を構成する知識群」における④設計パターン、データ構造・アルゴリズム、パラダイム・原理原則にあたるものだ。
5.2.1 ディレクトリ構造を読む
どういう方針でディレクトリが分割されているのか見る。 そのプログラムがどういう作りになっているのか、 どういうパートがあるのか、概要を把握する。 それぞれのモジュールがどういう関係にあるのか確かめる。
5.2.2 ファイル構成を読む
ファイルの中に入っている関数(名)も合わせて見ながら、 どういう方針でファイルが分割されているのか見る。 ファイル名は衰えないコメントのようなものであり、注目すべきである。
また関数名の名前付けルールについてもあたりをつけておきたい。 C のプログラムなら extern 関数にはたいていプリフィクスを 使っているはずで、これは関数の種類を見分けるのに使える。また オブジェクト指向式のプログラムだと関数の所属情報がプリフィクスに 入っていることがあり、貴重な情報になる。(例: rb_str_push)
5.2.3 関数同士の呼び出し関係を把握する
関数名の次に重要な情報。 特に関数の数が多い場合はこれが重要である。 このへんはツールを活用したい。 図にしてくれるツールがあればそれが一番いいが、 なければ特に重要な部分だけでいいので自分で図を書いておくといい。 図に凝る必要はないので、裏紙にざっと描けば十分だろう。
ちなみにこのこの呼び出しの関係を図にしたもののことを コールグラフ (call graph) と言うことがある。 ソースコードに書いてある呼び出し関係を そのまま図にしたのが静的なコールグラフ (static call graph) で、 実際に動作させたときに呼び出した関数だけを書いた図が 動的なコールグラフ (dynamic call graph) である。
ただ、検索した感じでは、日本語の文章だと「コールグラフ」 は暗黙のうちに dynamic call graph を指し、 static call graph は「関数呼び出し関係」と言うことが多いようだ。 だが static と dynamic で対になっているほうがわかりやすいので 筆者は動的コールグラフ・静的コールグラフと呼ぶことにしている。
コールグラフはJavaをやっていた頃にEclipseの機能の1つとしてみた気がします。「Ruby コールグラフ」や「vscode コールグラフ」で調べても出てこない上にあまり詳しく内容を把握していないので、とりあえず頭の片隅に置いておきます。知りたい人は検索してみてください。
5.2.4 デザインパターン
デザインパターンとは「オブジェクト指向において、よく使われる設計をパターン化したもの」「何度も遭遇する似たような問題に関する解法」である。デザインパターンを知っておくことでソースコードを読み書きする際に以下のメリットを享受できる。
メリット
1. プログラムの再利用性が高い
2. 効率的に品質の高い構造を作れる
3. 可読性が高い故に保守性に優れる
4. デザインパターンを知っていれば設計の意図が読めるようになるので、引継ぎする際に保守しやすくなる
5. 転じてデザインパターンを知ることで開発者同士の意思疎通がスムーズになる凡人の凡人による凡人のためのデザインパターン第一幕 Public
5.2.5 アルゴリズムとデータ構造
プログラムなんて、データ構造がどうなっているのか分かれば もう半分勝ったようなものだ。コードを書くときも、 コードに逐一コメントを付けるよりデータ構造 (だけ) を 解説するほうがはるかに役に立つ。 (と、何かの本に書いてあったんだけど、なんだっけ?)
※ 追記:『プログラム書法』だった。以下、同書の p.168 より引用する。 「プログラムに解説をつけるための、もっとも効果的な方法の一つは、 単にデータの割り付けかたをくわしく説明する、というものである。 おもな変数について、その値としてはどんなものが可能かを示し、 それが変って行くようすを説明すれば、それだけでプログラムの解説は、 ずいぶん進んだといってよい。」
ちなみにこの本の原書は 1974 年に出版されている。※ 追記2:『Cプログラミング診断室』でも似たようなコメントを発見した。 以下、同書の p.78 より引用する。 「フローチャートは禁止しましょう。フローチャートは、 制御の流れを「もろ」に書けてしまうのでよくありません。 プログラムは、データを処理するためにあり、データの違いによって 制御の流れが変更されます。あくまでも、データが主体です。 変数、引数などのデータをどう定義するかで、プログラムの組みやすさは 大幅に改良されます。データ構造がどうなっているかの図のほうが、 フローチャートよりはるかに役立ちます。データの意味だけは、 しっかり書きましょう。」
閑話休題。 C でデータ構造を作るならもちろん struct か union を使うはずだ。 そういう重要構造はヘッダファイルで定義されていることが多い。 もちろん内部構造は .c で定義されることもあるし動的に構築される データ構造もあるので、最終的には関数を読んでいかないとわからない。 それでもまずはヘッダファイルを読むべきだろう。ヘッダファイルを 読むときにもやはりファイル名は重要である。例えば言語処理系で frame.h というファイルがあったら、たぶんスタックフレームの定義だ。
データ構造を予測する時は構造体メンバに注目する。構造体の定義中に next というポインタがあればリンクリストだろうと想像できる。 同様に、parent・children・sibling と言った要素があれば十中八九 ツリーだ。
アルゴリズムとデータ構造を実務で使用した経験がないため、これらをどう使うかはよくわかっていない。どうやらビックデータ分析を行う際に多用されるらしい。文献等は以下を読むと理解が深まると考えられる。
STEP1
STEP2
AtCoder:競技プログラミングコンテストを開催する国内最大のサイト
これら以外に何かおすすめがあったら教えてください!
5.3 ソースコードの意味を理解する
5.3.1 単語単位で読む
ソースコードに出現する単語はファイル・関数(メソッド)・型(クラス)・変数・メンバ変数・予約語のどれを指しているのか。どんな書き方をしているかを知る。
① ファイル
Railsなどのフレームワークなら命名規則が存在する。ファイル名でそれがソフトウェアにおいてどんな役割を担っているかをある程度類推できる。
② 関数(メソッド)の種類
標準ライブラリ産のメソッド(使用頻度が高いのでRuby,Railsなどに元々備わっているクラスやそれに付随するメソッド。殿堂入り)
外部ライブラリ産のメソッド(gem)
自作ライブラリ産のメソッド(helper,model,application)
メソッドのオプション
③ 型の種類
integer,string,arrayなど
オブジェクト志向プログラミングでは、型をクラスと呼び、クラスを自身で作成して使うことができる。
オブジェクト志向プログラミングの用語
クラス、オブジェクト、インスタンス、レシーバ、メソッド、メッセージ、状態(ステート)、属性(アトリビュート、プロパティ)
④変数(インスタンス)
変数、メンバ変数、インスタンス変数、クラスインスタンス変数
https://qiita.com/mogulla3/items/cd4d6e188c34c6819709
⑤名前空間を用いたクラスの差別化
クラス名の予期せぬ衝突を防ぐのが目的。
⑥予約語や識別子
「順次処理」「条件分岐」「繰り返し」のような構造を表した単語。
# rubyにおける予約語や識別子 BEGIN class ensure nil self when END def false not super while alias defined? for or then yield and do if redo true __LINE__ begin else in rescue undef __FILE__ break elsif module retry unless __ENCODING__ case end next return until⑦略語の調査
わかりにくい略語があればリストアップしておいて早めに調べる。 例えば「GC」と書いてあった場合、それが garbage collection なのか graphic context なのかでずいぶん話が違ってしまう。 英語だと単語の頭文字をとるとか、母音をなくすとかが多い。 特に対象プログラムの分野で有名な略語は問答無用で使われるので あらかじめチェックしておく。
筆者の記憶にある中から一つ例を挙げよう。 とある Lisp 処理系で、 プログラム全体で「blt」というプリフィクスが使われているのだが、 これが何を表しているのかわからなくて困ったことがある。 これは実は built-in function (組み込み関数) のことであった。 わかってみると単純なことだが、これがわかるのとわからないのでは ずいぶん難易度が違う。
らしい。確かにJavaの案件で略語を見た気がする。分からない場合は
- 詳しい人に聞く
- ドキュメントを調べる
- 検索する
のいずれかの戦略を取る必要があるだろう。
また、自分で変数などをコーディングする際はリーダブルコードを参照にするといい。
5.3.2 どのような目的で設計されたコードなのかを読む
RASISとは、コンピュータシステムに関する評価指標の一つで、「信頼性」「可用性」「保守性」「保全性」「安全性」の5項目をアクロニム(頭文字語)によって表現したもののことである。
業務でWebサービス開発をする際に気をつけたいこと(新卒向け)を基に作成しました。RASISに関しては明るくないため、詳細を知りたい場合は参照元から。
①Reliability(信頼性)
システム障害への強さ「壊れにくさ」システムの故障しにくさを表します。
- 例外設計
- デプロイ/ロールバックの手順を完璧にする
- 死活監視/障害検知をする
- ログファイルを適切に扱う
- バックアップを取る
②Availability(可用性)
必要なタイミングで要求サービスが利用可「サービスが利用できる」度合い。システムが継続して稼働できる能力。
- 単一障害点をなくす
③Serviceability(保守性)(拡張性)
「シンプルなシステム」を志向する。シンプルだと内容の把握やアップデートが簡単。
- テストコード
- リーダブルコードの命名規則に沿った変数名
- バージョン管理
- ドキュメントを残す
- 障害情報をログに残す
- 開発環境を簡単に作る
④Integrity(保全性)
データの一貫性や整合性をさす。データベースのデータについて言及される事が多い。Railsであればモデル層やDBで制約をかけたりする。
- トランザクション制御
トランザクションとは?【13分でわかるDBトランザクション処理】データベース入門講座#4
- DBの制約
「SQLアンチパターン」を避けるためのチェックリスト①(DB論理設計編)
- モデル設計
データモデルの設計とベストプラクティス(第2部) - Talend
モデル設計を適当にやるとどうなるのか - SlideShare
ドメイン駆動設計をわかりやすく - ドメインのモデル設計を手を動かしながら学ぼう
⑤Security(機密性)(安全性)
情報が流出しないようにする。
- SSL化
- パスワードのハッシュ化
- フレームワークの機能を使う
- ストロングパラメーターの設定
- プレースホルダーの設定
5.3.3 歴史を読む
GitHubのコミットログを参照する。開発者の意図がわかるのと、完成モジュールに関わるソースコードがどれなのかが分かりやすい。
6 ちょっと変更して動作させてみる
これは「この段階でやる」という類のものではなくて手法の一つである。 人間の頭というのは不思議なもので、できるだけ身体のいろんな場所を 使いながらやったことは記憶に残りやすい。パソコンのキーボードより 原稿用紙のほうがいい、という人が少なからずいるのは、単なる懐古趣味ではなく そういうことも関係しているのではないかと思う。
そういうわけで、単にモニタで読むというのは非常に身体に残りにくいので、 書き換えながら読む。そうするとわりと早く身体がコードに馴染んでくることが 多い。気にくわない名前やコードがあったら書き換える。わかりずらい略語は メモるだけでなく省略しない語に置換してしまってもよい。
ただし、当然のことだが書き換えるときはオリジナルのソースは別に残し、 途中で辻褄が合わないと思ったら元のソースを見て確認すること。でないと 自分の単純ミスで何時間も悩む羽目になる。
書き換えて動かす
前項と似ているが、こちらは実際にプログラムを動かしてみる。例えば 動作のわかりにくいところでパラメータやコードをちょっとだけ変えて 動かしてみる。そうすると当然動きが変わるから、コードがどういう意味 なのか類推できる。これまた言うまでもないが、オリジナルのバイナリは残しておいて 同じことを両方にやってみるべきである。
変更させて動作確認する行為は、私の経験上プログラミングスキルを高めることができるものだと考えており、特に初心者におすすめである。しかし、変更を元に戻せなくてエラーになって焦ってしまい、エラーが怖いから試さなくなってしまい成長機会を逃すというのを経験している。なので、命綱として変更を取り消すやり方について下記に記していく。
6.1 Git上で作業した内容を取り消す
DBのマイグレーションやファイルなどの作成も消せるので便利
git checkout . git clean -df .6.2 irbなどのインタラクティブな機能で試す
ライブラリやメソッドがどう動いているかを仮説検証できる
rails c --sandbox7 ソースコードを楽しく読みたい(ゲーム感覚で取り組みたい)
- 記録を付ける
- 興味を持っている分野のソースコードを読む
- 良いソースコードを読む
- 仕事でも役立つソースコードを読む
- ちょっと変更して動作させてみる
- バグがないか探してみる
プログラマーが教える、ソースコードを読むための4つの方法!
【新人なるプログラマーへ】ソースコードを読みましょう (2/2)8 終わりに
さしあたってはこれくらいです。なお、外部からのコメントや、自身の成長度合いによってこの文章は随時更新していくつもりです。

- 投稿日:2020-08-24T09:11:11+09:00
[Rails] webpackerでCSSを読み込みたい
railsのver.6以上を使うなら
asset pipelineではなくwebpackerでCSSを読み込みたいと思い、実装したのでメモです。ディレクトリ構成
webpacker のREADME.mdより。
app/javascript: └── packs: # only webpack entry files here └── application.js └── application.css手順
rails newは完了しているものとします。
rails6より下のversion使ってる人はwebpackerもインストールしましょう。新規フォルダ・ファイル作成
↑のディレクトリ構成に従う。
app/javascript/packsにapplication.cssファイルを作成エントリーポイント
エントリーポイントは packs/application.js なので、application.cssファイルをimport。
packs/application.jsimport "packs/application.css";application.html.erbを編集
views/layouts/application.html.erb に以下を記述。
おそらくデフォルトだとstylesheets_link_tagになっているので、そこをstylesheets_pack_tagに変更すればいいかと。<%= javascript_pack_tag 'application' %> <%= stylesheet_pack_tag 'application' %>CSSを書く
あとはCSSを書くのみです。
次はReact、Vue.jsあたりも導入してみたい。今回は手順だけをメモした感じなので、もう少し詳しく中身を知りたい人は↓が参考になると思われます。
参考
Rails 6+Webpacker開発環境をJS強者ががっつりセットアップしてみた(翻訳)
webpackerでcssとimagesを参照したい
webpacker でページごとにスタイルを分ける
- 投稿日:2020-08-24T03:55:30+09:00
お気に入り機能のajax化
備忘録です!!
ajax化とは
ajaxとは、Asynchronous JavaScript + XML の略で、非同期通信と呼ばれる通信方法のことを指します。
クライアントとサーバー間の通信においては、通常、同期通信と呼ばれる方法が用いられ、一瞬画面が白くなった後、画面が切り替わるような通信は、全てこの同期通信です。
同期通信では、
クライアント → サーバーを呼び出す → サーバー側で処理が行われる →(クライアント側では、処理を待っている)
→ クライアントに結果を返す
非同期では、
クライアント → サーバーを呼び出す → サーバー側で処理が行われる →(クライアント側では、処理を待たずに他の操作ができる)
→ クライアントに結果を返す
同期通信では、サーバーにリクエストを送るとページ全体の情報を返すように処理され、サーバーかの応答があるまでその結果を待機し、結果を受け取った後に画面全体を切り替える処理を行うのです。
非同期通信では、一部の情報しか返さないように処理され、ユーザーに処理待ちの時間を与えずに、裏では随時通信が行われています。今回は、ajax化を用いて、お気に入りボタンを押した時に、画面が切り替わることなく、ボタンの色だけが変化するようにしていきます。
remote: true
Railsにおいてajax通信を実装する場合、主に二つの方法があります。
remote: trueを指定する方法
JSファイルに任意のタイミングでajax処理を発火させるように記述を施す方法
今回は、より手軽に実装できるremote: trueを使用する方法で実装してきます。_bookmark.html.erb<%= link_to board_bookmarks_path(board.id), id: "js-bookmark-button-for-board-#{board.id}", remote: true, method: :post do %> <%= icon 'far', 'star' %> <% end %>_unbookmark.html.erb<%= link_to board_bookmarks_path(board.id), id: "js-bookmark-button-for-board-#{board.id}", remote: true, method: :delete do %> <%= icon 'fas', 'star' %> <% end %>お気に入りボタンをremote: trueして、ajax化しました。
ajax化していない場合、呼び出しの際、HTMLリクエストを送信します。
ターミナル# お気に入りボタンクリック時に下記のように表示 Processing by BookmarksController#create as HTML今回のように、ajax化すると、JSリクエストを送信します。
ターミナル# お気に入りボタンクリック時に下記のように表示 Processing by BookmarksController#create as JSお気に入りボタンをクリックすると、アクションを経由し、create.js.erbやdestroy.js.erbファイルに向かいます。
bookmarkコントローラーを修正
bookmarks_controllerbefore_action :set_board, only: %i[create destroy] def create @bookmark = current_user.bookmarks.build(board_id: params[:board_id]) @bookmark.save end def destroy current_user.bookmarks.find_by(board_id: params[:board_id]).destroy! end private def set_board @board = Board.find(params[:board_id]) endcreate.js.erbとdestroy.js.erbの作成
ajax化したので、bookmarkコントローラーは、create.js.erbとdestroy.js.erb
に向かいます。bookmarks/create.js.erb$("#js-bookmark-button-for-board-<%= @board.id %>").replaceWith("<%= escape_javascript(render 'boards/unbookmark', {board: @board}) %>");bookmarks/destroy.js,erb$('#js-bookmark-button-for-board-<%= @board.id %>').replaceWith("<%= escape_javascript(render 'boards/bookmark', {board: @board}) %>");以上のように設定します。
bookmarks/create.js.erbでは、
お気に入りボタン(js-bookmark-button-for-board-<%= @board.id %>)を、クリックすると、boards/unbookmarkを呼び出しますよということを設定しています。以上で設定完了です。
- 投稿日:2020-08-24T02:26:49+09:00
【railsチュートリアル 3章】テスト関連
コントローラを作成した際にできるデフォルトのテスト
getはHomeページやHelpページがいわゆる「GET」リクエストを受け付ける普通のWebページであるということを示す。
「response:success」は、実際にはHTTPのステータスコード(ここでは200 OK)を表す。つまり
「GETリクエストをhomeアクションに対して送信すれば、リクエストに対するレスポンスは成功になるはず」
static_pages_controller_test.rbrequire 'test_helper' class StaticPagesControllerTest < ActionDispatch::IntegrationTest test "should get home" do get static_pages_home_url assert_response :success end test "should get help" do get static_pages_help_url assert_response :success end endルートの追加
ルートにstatic_pages/aboutを追加下とすると、/static_pages/aboutというURLに対してGETリクエストが来たら、StaticPagesコントローラのaboutアクションに渡すようRailsに指示している。この結果、自動的に次のようなヘルパーが使えるようになる。
static_pages_about_url
routes.rbRails.application.routes.draw do get 'static_pages/home' get 'static_pages/help' get 'static_pages/about' #←この行を追加 root 'application#hello' endassert_selectメソッド
特定のHTMLタグが存在するかどうかをテストする。
assert_select "title", "Home | Ruby on Rails Tutorial Sample App" # <title>タグに「Home | Ruby on Rails Tutorial Sample App」という文字列があるかどうかをチェックしている。setpuメソッド
各テストが実行される直前で実行されるメソッド
def setup @base_title = "Ruby on Rails Tutorial Sample App" end