- 投稿日:2020-08-24T23:58:16+09:00
Spotifyのランキング特徴【8/17〜8/23】
Spotify APIを使ったランキング分析【8/17〜8/23】
今週の動きを見ていきましょう!
「香水」「夜に駆ける」強すぎ
相変わらず首位はYOASOBIの「夜に駆ける」。すごいですね。
トップソングにあるから聴いちゃう→聴かれるからランキングに居続ける、という好循環が最強。夜に駆ける
一瞬下がっている日は米津玄師の「Kanden」が1位を取った8/5のみ!香水
YOASOBIの1日以外にも動きはありましたが、安定して2位をキープ。後を追う米津玄師
3位は米津玄師の「Kanden」が3位をキープしています。
米津玄師「Kanden」
今週の注目は?
じわじわとランキングをあげているのがあいみょんの「裸の心」。これがこんご順位をあげていくのか、下がっていくのか注目です!
あいみょん「裸の心」
まとめ
ランキングの予測をしてみると、少し伸びるようだけど、、どうなることやら??
では、また!





- 投稿日:2020-08-24T23:44:44+09:00
データ分析コンペで使う思考停止初手LightGBM
はじめに
最近KaggleやSignateなどのデータ分析コンペにはまっており、いくつかのコンペに少しづつ参加しながら日々勉強中。
毎回はじめにデータに向き合う前に、コンペの難易度やデータの傾向を知るために行っているLightGBMのテンプレートがあるので、それを公開します。もっとこうした方がいいとかあったら教えてください!
環境
- Ubuntu18.04
- Python3.8.0
- 利用したデータはKaggleのTitanic
Titanic: Machine Learning from Disaster | Kaggle全体像
データの読み込み
データの読み込みと必要なライブラリのインポートを行う。学習データをよく確認しずに始めると、意外にデータ量が膨大だった、、、みたいなことがあるのでデータ数量くらいは確認しておく。
from datetime import datetime import numpy as np import matplotlib.pyplot as plt import os from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelEncoder # データの読み込み train_df = pd.read_csv("./train.csv") test_df = pd.read_csv("./test.csv") print(train_df.shape, test_df.shape)(891, 12) (418, 11)特徴量加工
はじめにデータを眺める
train_dfPassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked 0 1 0 3 Braund, Mr. Owen Harris male 22.0 1 0 A/5 21171 7.2500 NaN S 1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1 0 PC 17599 71.2833 C85 C 2 3 1 3 Heikkinen, Miss. Laina female 26.0 0 0 STON/O2. 3101282 7.9250 NaN S 3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35.0 1 0 113803 53.1000 C123 S 4 5 0 3 Allen, Mr. William Henry male 35.0 0 0 373450 8.0500 NaN S 5 6 0 3 Moran, Mr. James male NaN 0 0 330877 8.4583 NaN Q 6 7 0 1 McCarthy, Mr. Timothy J male 54.0 0 0 17463 51.8625 E46 S 7 8 0 3 Palsson, Master. Gosta Leonard male 2.0 3 1 349909 21.0750 NaN S 8 9 1 3 Johnson, Mrs. Oscar W (Elisabeth Vilhelmina Berg) female 27.0 0 2 347742 11.1333 NaN S 9 10 1 2 Nasser, Mrs. Nicholas (Adele Achem) female 14.0 1 0 237736 30.0708 NaN C 10 11 1 3 Sandstrom, Miss. Marguerite Rut female 4.0 1 1 PP 9549 16.7000 G6 S 11 12 1 1 Bonnell, Miss. Elizabeth female 58.0 0 0 113783 26.5500 C103 S 12 13 0 3 Saundercock, Mr. William Henry male 20.0 0 0 A/5. 2151 8.0500 NaN S 13 14 0 3 Andersson, Mr. Anders Johan male 39.0 1 5 347082 31.2750 NaN S 14 15 0 3 Vestrom, Miss. Hulda Amanda Adolfina female 14.0 0どんなコンペでもデータを見るのは大事。
今回の目的変数がSuvived、PassengerIdとNameはユニークな特徴量なので使わないなど、最低限のデータの確認を行う。説明変数と目的変数に分割
説明変数と目的変数に分割を行う。
train_x, train_y = train_df.drop("Survived", axis=1), train_df["Survived"]特徴量加工
特徴量加工も行うが最低限。以下の3つ観点でしか行わない。
- null埋め
- 質的変数->量的変数(ラベルエンコーディング)
- 不要カラムの削除(
PassengerIdとName)def label_encording(data_col): ''' ラベルエンコーディング data_col : 対象のデータフレームの1つの列 ''' le = LabelEncoder() le = le.fit(data_col) #ラベルを整数に変換 data_col = le.transform(data_col) return data_col def preprocess(df): ''' 前処理を行う df : padnas.Dataframe 対象のデータフレーム ''' df = df.drop("PassengerId", axis=1) df = df.drop("Name", axis=1) # 質的変数を数値に変換 for column_name in df: if df[column_name][0].dtypes == object: # 欠損値に関してはNULLを代入する df[column_name] = df[column_name].fillna("NULL") df[column_name] = label_encording(df[column_name]) elif df[column_name][0].dtypes == ( "int64" or "float64") : # 欠損値に関しては-999を代入する df[column_name] = df[column_name].fillna(-999) return dfラベルエンコーディングを行う際に、学習データとテストデータでラベルの対応関係が崩れるとよくないので、学習データとテストデータを同時に特徴量加工をかける。
all_x = pd.concat([train_x, test_df]) preprocessed_all_x = preprocess(all_x) # 前処理を行なったデータを,学習データとテストデータに再分割 preprocessed_train_x, preprocessed_test_x = preprocessed_all_x[:train_x.shape[0]], preprocessed_all_x[train_x.shape[0]:] print(preprocessed_train_x.head(5))モデル作成
LightGBMを学習するクラスを作成する。細かいパラメータの説明は以下の公式サイトを参照。
* Parameters — LightGBM 3.0.0 documentation
objectiveやmetricsは学習データやコンペに応じて変更する。# LightGBM import lightgbm as lgb class lightGBM: def __init__(self, params=None): self.model = None if params is not None: self.params = params else: self.params = {'objective':'binary', 'seed': 0, 'verbose':10, 'boosting_type': 'gbdt', 'metrics':'auc', 'reg_alpha': 0.0, 'reg_lambda': 0.0, 'learning_rate':0.01, 'drop_rate':0.5 } self.num_round = 20000 self.early_stopping_rounds = self.num_round/100 def fit(self, tr_x, tr_y, va_x, va_y): self.target_columms = tr_x.columns print(self.target_columms) # データセットを変換 lgb_train = lgb.Dataset(tr_x, tr_y) lgb_eval = lgb.Dataset(va_x, va_y) self.model = lgb.train(self.params, lgb_train, num_boost_round=self.num_round, early_stopping_rounds=self.early_stopping_rounds, valid_names=['train', 'valid'], valid_sets=[lgb_train, lgb_eval], verbose_eval=self.num_round/100 ) return self.model def predict(self, x): data = lgb.Dataset(x) pred = self.model.predict(x, num_iteration=self.model.best_iteration) return pred def get_feature_importance(self, target_columms=None): ''' 特徴量の出力 ''' if target_columms is not None: self.target_columms = target_columms feature_imp = pd.DataFrame(sorted(zip(self.model.feature_importance(), self.target_columms)), columns=['Value','Feature']) return feature_imp学習器の定義
def model_learning(model, x, y): ''' モデルの学習を行う。 ''' tr_x, va_x, tr_y, va_y = train_test_split(x, train_y, test_size=0.2, random_state=0) return model.fit(tr_x, tr_y, va_x, va_y)モデルをクラスで定義しておき学習器に渡す構成にすることで、異なるモデルを利用する時にソースコードの変更を最小限にすることができる。
例えばXGBoostを使いたい時、以下のように書き換えることですぐに学習するモデルを差し替えることができる。
class XGBoost: def __init__(self, params=None): # 初期化処理~~~ def fit(self, tr_x, tr_y, va_x, va_y): # 学習の処理~~~ def predict(self, x): # 評価の処理~~~ xgboost_model = XGBoost() model_learning(xgboost_model, preprocessed_train_x, train_y)学習
lightgbm_model = lightGBM() model_learning(lightgbm_model, preprocessed_train_x, train_y)Index(['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'], dtype='object') Training until validation scores don't improve for 200.0 rounds Early stopping, best iteration is: [172] train's auc: 0.945026 valid's auc: 0.915613学習が完了!すぐに終わった。
特徴量の重要度の評価
LightGBMでは学習した特徴量の内、どれをよく使ったかを確認することができる。これにより次のステップでおこなうEDAのヒントを得ることができる。
なんとなくAgeやTicket、Fareが上位にあることから、年齢とか座席の位置が重要そうだなあ、AgeとSurvivedの相関見るか、などなんとなく次やることが見えてくる。lightgbm_model.get_feature_importance()Value Feature 0 32 Parch 1 58 SibSp 2 158 Embarked 3 165 Cabin 4 172 Sex 5 206 Pclass 6 1218 Fare 7 1261 Ticket 8 1398 Age評価&提出ファイル作成
モデルの評価。出力結果は確率であるが、今回は
0,1のどちらでなければならないので、それに合わせて整形する。# テスト用のモデルの評価 proba_ = lightgbm_model.predict(preprocessed_test_x) proba = list(map(lambda x: 0 if x < 0.5 else 1, proba_))予測値を提出データに合わせて整形する。何気にここが一番詰まりやすい....
# テストデータの作成 submit_df = pd.DataFrame({"Survived": proba}) submit_df.index.name = "PassengerId" submit_df.index = submit_df.index + len(train_df) + 1ファイル名は
submit_{%Y-%m-%d-%H%M%S}形式で保存する。
そうすることで不意の上書きを防ぐことができるし、ファイル名を毎回考えなくていいので地味に便利。# 保存 save_folder = "results" if not os.path.exists(save_folder): os.makedirs(save_folder) submit_df.to_csv("{}/submit_{}.csv".format(save_folder, datetime.now().strftime("%Y-%m-%d-%H%M%S")),index=True)終わりに
この結果を提出したところPublicScoreが
0.77033で6610位/20114人だった。(2020/08/25時点)
とりあえず回してみてコンペの難易度や感覚を掴む、という目的では悪くないテンプレートかと思う。EDAが甘いなあと毎回思うので今後はEDAをもっとしっかりやっていきたところ。
- 投稿日:2020-08-24T23:38:42+09:00
python 文字列のスライス
はじめに
この記事を書く理由は、競プロを始めてスライスを使う場面が多く、頭の中が混雑してきたので簡単にまとめようと思ったことがきっかけです。単なるスライスのメモです。
プログラムコード
数字の文字列です。数字の文字列にした理由は、出力結果がわかりやすいと思ったからです。
s = "12345" print(s[-1]) # 末尾 5 # 出力結果 print(s[:-1]) # 末尾を削除 1234 print(s[0]) # 先頭 1 print(s[0:]) # 先頭から最後まで 12345 print(s[1:]) # 1番目から最後まで 2345 start = "6" + s[1:] print(start) # 先頭を削除して、6を先頭に追加 62345 end = s[:-1] + "6" print(end) # 末尾を削除して、6を末尾に追加 12346
- 投稿日:2020-08-24T23:21:49+09:00
Geolonia 住所データを使って不審者MAPをサクッと作ってみた
この記事について
箇条書きにすると、以下のモチベーションで本件に取り組みました。
- Geolonia 住所データ というものが公開されたので、これを使って何かしてみたかった
- ほぼ同時期に不審者情報サイトを見つけたので、これだ!と即決
- selenium を使ったスクレイピングをしてみたかった
- beautifulsoupしか利用経験がなかったのです
成果物
このような物ができました。
https://suzukidaisuke.gitlab.io/fushinsha_map/
大島てるの不審者情報バージョンみたいなものですね。
比べちゃ失礼なほど完成度低いけど。
※ gitlab pages というものを初めて使いました。こんな機能が有ったんですね。どうやって作ったか
コードを gitlab にアップしたので、これを読めばわかります。
https://gitlab.com/suzukidaisuke/fushinsha_map一応書くと
- 日本不審者情報センターから 2020年8月 東京都の不審者情報をスクレイピング
東京は基本的に以下のようなタイトルになっているので、正規表現で住所部分を取得
(東京)西東京市田無町3丁目で公然わいせつ 8月24日昼過ぎ
取得した住所と Geolonia 住所データを結合して、緯度経度を得る
folium ライブラリを使って、地図上に不審者情報をマッピング
感想など
- サクッとつくった割にはいい感じのものができたように思う。
- git の notebook みればサクッと加減がわかると思います。
- もっと作り込むこと(全国版にするとか、サーバ立てるとか)も出来そう
- だけど一旦ここでお終いの予定
- 住所が「○○丁目」まであれば簡単にこの位のものは作れる。
- selenium は簡単・便利。でも beautifulsoup のほうが早いかな?
- 気づかずサイズが大きいファイルを git にアップしてしまった。こういうの使えばいいのかしら。
https://docs.gitlab.com/ee/topics/git/lfs/最後に
不審者には気をつけましょう。
- 投稿日:2020-08-24T22:53:32+09:00
犬ですが何か?GETリクエストとクエリパラメータの巻
URLクエリパラメータを受け取る
こんにちワン!柴犬のぽん太です。今日は公園でボール遊びをしていたらボールを顔面に受けてしまってかなり恥ずかしかったです。
さて、タイトル通り、URLクエリパラメータを受け取って表示してみたいと思います。
http://example.com/wan/?type=shiba&name=Ponta
と書いてあったら{type:shiba},{name:Ponta}({キー:値}の組み合わせです)というデータとして受け取ります。(venv_dog) Ponta@shiba_app # cat wan/views.py from django.http import HttpResponse def index(request): if 'name' in request.GET: name = request.GET['name'] res = "名前は" + name + "です。" else: res = "" if 'dogtype' in request.GET: dogtype = request.GET['dogtype'] res = res + "犬種は" + dogtype + "です。" if len(res) == 0: res = "Wan!名前(name)と犬種(dogtype)を教えてね!" return HttpResponse(res) (venv_dog) Ponta@shiba_app #うまくできたかな?
パラメータあるとき
ないとき
うまくいったワン!
じゃあまたね!バイバイ!


- 投稿日:2020-08-24T22:42:34+09:00
python使うなら絶対に使いたい2つのドキュメント生成ツール
python、djangoを本格的に勉強し始めて3ヶ月の自分からみて、これは便利だ!!!と思ったドキュメント生成ツールを2つ紹介します!
各ツールの概要 → djangoでの適用方法の順で記載しています。検索してもよく上位に記載されている内容ですが、djangoでの適用例として参考いただければ幸いです。
sphinxを使ったdocstringのドキュメンテーション
Sphinxは知的で美しいドキュメントを簡単に作れるようにするツールです。Georg Brandlによって開発され、BSDライセンスのもとで公開されています。
このツールはもともと、Python のドキュメンテーション用に作られました、今では幅広い言語のプロジェクトでドキュメント作成を容易にするツールとして利用されています。(by 公式サイト)自分が知ったきっかけはRead the docsというオープンソースコミュニティのためのドキュメントホスティングサービスです。ちなみに、このサービスもDjangoで作られているそうです。
Sphinxでは reStructuredText と呼ばれるマークアップを利用する必要がありますが
sphinx-apidocというコマンドでrstソースを自動生成することができます。
rstに変換する元の文章はdocstringを使用します。sphinx設定ファイルのconf.pyで記載されているsphinx.ext.autodocさんが元ディレクトリ下のdocstringを探してくれるようです。つまりは、
python docstring -> rst -> html
の変換をsphinxが全部やってくれるということです!圧倒的感謝!!作成手順
早速django projectのドキュメントを作成していきましょう!
※事前にpython projectにdocstringを書いておく必要があります。
さっきから出てくるdocstringって何・・?って方はこちらの記事おすすめです → - Google docstring 入門ターミナルで以下のコマンドを実行します。
# ライブラリとテーマインストール pip install sphinx sphinx-rtd-theme # ドキュメント出力先作成 mkdir docs # django project rootを指定してrst作成 sphinx-apidoc -fF -o ./docs ./path/to/django_project_root # change directory cd docs # conf.pyの調整(内容別途書いています!) vi conf.py # html作成 make html
- conf.py
追記部分のみ記載しています。
追記位置は# -- hogehoge --------を参考にしてみてください。conf.py# -- Path setup -------------------------------------------------------------- # django projectへのパスとsettingsを指定 import os import sys sys.path.insert(0, os.path.abspath('path/to/django_project_root')) import django os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'config.settings') django.setup() # -- General configuration --------------------------------------------------- extensions = [ 'sphinx.ext.autodoc', 'sphinx.ext.viewcode', 'sphinx.ext.todo', 'sphinx.ext.napoleon', # google, numpy styleのdocstring対応 ] language = 'ja' # あいあむじゃぱにーず # -- Options for HTML output ------------------------------------------------- html_theme = 'sphinx_rtd_theme' # Read the Docsの見た目指定あくまでも自動生成するだけなのですが、かなり完成度が高いです!
自動出力したrstを整えたい向けのにはこの記事が参考になりました → study sphinx
自分もrstで記述したリンク先が、django projectで使っているディレクトリ名とconflictしたため、rstを一部修正しました(・_・)coverageを使ったカバレッジレポート
お次はカバレッジレポートの生成です!完成イメージは → コチラ
使用するツールはpytest、coverageの2つです!
公式: pytestpytest は、より良いプログラムを書くのに役立つ、成熟したフル機能の Python テストツールです。
pytest フレームワークを使用すると、小規模なテストを簡単に書くことができますが、アプリケーションやライブラリの複雑な機能テストをサポートするために拡張することができます。(by 公式)pythonのテストフレームワークの1つです。
python標準のunittestというテストフレームワークがありますが、個人的にはpytestの方が比較演算子が直感的に書きやすいのが好みです。
公式: coverageCoverage.pyはPythonプログラムのコードカバレッジを測定するツールです。プログラムを監視し、コードのどの部分が実行されたかを記録し、ソースを分析して、実行された可能性があったが実行されなかったコードを特定します。
カバレッジの測定は通常、テストの有効性を評価するために使用されます。コードのどの部分がテストによって実行されていて、どの部分が実行されていないかを示すことができます。(by 公式)テストしたコードの網羅性を確認するのに役立ちます。100%にすると満足感がありますが、まだまだ確認することはあるので要注意です。
coverageの機能の1つにreportのhtmlの出力の機能があります。
- テストした箇所がわかりやすい
- ドキュメント作成の手間を削減できる
と一石二鳥です!ぜひ使ってみてください!
作成手順
それでは、Django projectにおけるpytest,coverageの設定とレポートの出力を行っていきましょう!
ターミナルで以下のコマンドを実行します。
# ライブラリをインストール pip install pytest-django coverage # change directory(django projectのディレクトリ) cd django_project_path # pytest.iniの調整(内容別途書いています!) vi pytest.ini # p.coveragercの調整(内容別途書いています!) vi .coveragerc # coverageの取得 coverage run -m pytest # coverage reportの確認 coverage report -m # coverage htmlの出力 coverage html
- pytest.ini
今回は最低限の設定にしました。公式pytest-djangoも分量少なくわかりやすいのでチェックしてみてください。
pytest.ini[pytest] addopts = --ds=config.settings # django settingsを指定 python_files = tests.py test_*.py # テストコードを指定
- .coveragerc
coverageコマンドのrun、report、htmlのオプションを定義するファイルです。
こちらも公式coverageのオプション説明が分量もすくなくわかりやすいです。html出力の他にxml、json出力も可能です。.coveragerc[run] source=. # django project rootを指定 omit= */migrations/* # 対象外にしたいファイル、ディレクトリを記載 */tests/* */htmlcov/* [report] omit= */migrations/* */tests/* [html] directory = htmlcov # htmlcovというディレクトリにhtmlを出力します※htmlカバレッジも取りたい場合は
pip install django-coverage-pluginを実行し以下を追記してください。.coveragerc[run] plugins = django_coverage_plugin参考:Djangoメモ(26) : coverage.pyでカバレッジ(網羅率)を計測
こちらも簡単操作で、見やすいドキュメントが自動生成できます!
コマンドで行う場合はcoverage report -mで網羅できていない行番号を確認したり、pytest -vでテストの詳細を表示したりするのがわかりやすいです。最後に
少ない手間でドキュメントを作成できるので、使うのが許されるのであれば仕事効率も捗るのではないでしょうか。
今回はdjangoを例に上げましたが、djangoではなくても利用できるのでぜひ使ってみてください。
他にもおすすめのドキュメント自動作成ツールがありましたらコメントいただけると幸いです。お読みいただきありがとうございました。



- 投稿日:2020-08-24T22:42:34+09:00
python書くなら絶対に使いたい2つのドキュメント生成ツール
python、djangoを本格的に勉強し始めて3ヶ月の自分からみて、これは便利だ!!!と思ったドキュメント生成ツールを2つ紹介します!
各ツールの概要 → djangoでの適用方法の順で記載しています。検索してもよく上位に記載されている内容ですが、djangoでの適用例として参考いただければ幸いです。
sphinxを使ったdocstringのドキュメンテーション
Sphinxは知的で美しいドキュメントを簡単に作れるようにするツールです。Georg Brandlによって開発され、BSDライセンスのもとで公開されています。
このツールはもともと、Python のドキュメンテーション用に作られました、今では幅広い言語のプロジェクトでドキュメント作成を容易にするツールとして利用されています。(by 公式サイト)自分が知ったきっかけはRead the docsというオープンソースコミュニティのためのドキュメントホスティングサービスです。ちなみに、このサービスもDjangoで作られているそうです。
Sphinxでは reStructuredText と呼ばれるマークアップを利用する必要がありますが
sphinx-apidocというコマンドでrstソースを自動生成することができます。
rstに変換する元の文章はdocstringを使用します。sphinx設定ファイルのconf.pyで記載されているsphinx.ext.autodocさんが元ディレクトリ下のdocstringを探してくれるようです。つまりは、
python docstring -> rst -> html
の変換をsphinxが全部やってくれるということです!圧倒的感謝!!作成手順
早速django projectのドキュメントを作成していきましょう!
※事前にpython projectにdocstringを書いておく必要があります。
さっきから出てくるdocstringって何・・?って方はこちらの記事おすすめです → - Google docstring 入門ターミナルで以下のコマンドを実行します。
# ライブラリとテーマインストール pip install sphinx sphinx-rtd-theme # ドキュメント出力先作成 mkdir docs # django project rootを指定してrst作成 sphinx-apidoc -fF -o ./docs ./path/to/django_project_root # change directory cd docs # conf.pyの調整(内容別途書いています!) vi conf.py # html作成 make html
- conf.py
追記部分のみ記載しています。
追記位置は# -- hogehoge --------を参考にしてみてください。conf.py# -- Path setup -------------------------------------------------------------- # django projectへのパスとsettingsを指定 import os import sys sys.path.insert(0, os.path.abspath('path/to/django_project_root')) import django os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'config.settings') django.setup() # -- General configuration --------------------------------------------------- extensions = [ 'sphinx.ext.autodoc', 'sphinx.ext.viewcode', 'sphinx.ext.todo', 'sphinx.ext.napoleon', # google, numpy styleのdocstring対応 ] language = 'ja' # あいあむじゃぱにーず # -- Options for HTML output ------------------------------------------------- html_theme = 'sphinx_rtd_theme' # Read the Docsの見た目指定あくまでも自動生成するだけなのですが、かなり完成度が高いです!
自動出力したrstを整えたい向けのにはこの記事が参考になりました → study sphinx
自分もrstで記述したリンク先が、django projectで使っているディレクトリ名とconflictしたため、rstを一部修正しました(・_・)coverageを使ったカバレッジレポート
お次はカバレッジレポートの生成です!完成イメージは → コチラ
使用するツールはpytest、coverageの2つです!
公式: pytestpytest は、より良いプログラムを書くのに役立つ、成熟したフル機能の Python テストツールです。
pytest フレームワークを使用すると、小規模なテストを簡単に書くことができますが、アプリケーションやライブラリの複雑な機能テストをサポートするために拡張することができます。(by 公式)pythonのテストフレームワークの1つです。
python標準のunittestというテストフレームワークがありますが、個人的にはpytestの方が比較演算子が直感的に書きやすいのが好みです。
公式: coverageCoverage.pyはPythonプログラムのコードカバレッジを測定するツールです。プログラムを監視し、コードのどの部分が実行されたかを記録し、ソースを分析して、実行された可能性があったが実行されなかったコードを特定します。
カバレッジの測定は通常、テストの有効性を評価するために使用されます。コードのどの部分がテストによって実行されていて、どの部分が実行されていないかを示すことができます。(by 公式)テストしたコードの網羅性を確認するのに役立ちます。100%にすると満足感がありますが、まだまだ確認することはあるので要注意です。
coverageの機能の1つにreportのhtmlの出力の機能があります。
- テストした箇所がわかりやすい
- ドキュメント作成の手間を削減できる
と一石二鳥です!ぜひ使ってみてください!
作成手順
それでは、Django projectにおけるpytest,coverageの設定とレポートの出力を行っていきましょう!
ターミナルで以下のコマンドを実行します。
# ライブラリをインストール pip install pytest-django coverage # change directory(django projectのディレクトリ) cd django_project_path # pytest.iniの調整(内容別途書いています!) vi pytest.ini # p.coveragercの調整(内容別途書いています!) vi .coveragerc # coverageの取得 coverage run -m pytest # coverage reportの確認 coverage report -m # coverage htmlの出力 coverage html
- pytest.ini
今回は最低限の設定にしました。公式pytest-djangoも分量少なくわかりやすいのでチェックしてみてください。
pytest.ini[pytest] addopts = --ds=config.settings # django settingsを指定 python_files = tests.py test_*.py # テストコードを指定
- .coveragerc
coverageコマンドのrun、report、htmlのオプションを定義するファイルです。
こちらも公式coverageのオプション説明が分量もすくなくわかりやすいです。html出力の他にxml、json出力も可能です。.coveragerc[run] source=. # django project rootを指定 omit= */migrations/* # 対象外にしたいファイル、ディレクトリを記載 */tests/* */htmlcov/* [report] omit= */migrations/* */tests/* [html] directory = htmlcov # htmlcovというディレクトリにhtmlを出力します※htmlカバレッジも取りたい場合は
pip install django-coverage-pluginを実行し以下を追記してください。.coveragerc[run] plugins = django_coverage_plugin参考:Djangoメモ(26) : coverage.pyでカバレッジ(網羅率)を計測
こちらも簡単操作で、見やすいドキュメントが自動生成できます!
コマンドで行う場合はcoverage report -mで網羅できていない行番号を確認したり、pytest -vでテストの詳細を表示したりするのがわかりやすいです。最後に
少ない手間でドキュメントを作成できるので、使うのが許されるのであれば仕事効率も捗るのではないでしょうか。
今回はdjangoを例に上げましたが、djangoではなくても利用できるのでぜひ使ってみてください。
他にもおすすめのドキュメント自動作成ツールがありましたらコメントいただけると幸いです。お読みいただきありがとうございました。
- 投稿日:2020-08-24T22:31:41+09:00
【データサイエンティスト入門】記述統計と単回帰分析♬
昨夜で、【データサイエンティスト入門】科学計算、データ加工、グラフ描画ライブラリの使い方の基礎までまとめました。今夜からいよいよそれらを使って本題に入っていきます。今夜は記述統計と単回帰分析をまとめます。本書に乗った解説を補足することとします。
【注意】
「東京大学のデータサイエンティスト育成講座」を読んで、ちょっと疑問を持ったところや有用だと感じた部分をまとめて行こうと思う。
したがって、あらすじはまんまになると思うが内容は本書とは関係ないと思って読んでいただきたい。Chapter 3 記述統計と単回帰分析
Chapter 3-1 統計解析の種類
3-1-1 記述統計と推論統計
統計解析の手法は、記述統計と推論統計に分かれる。
3-1-1-1 記述統計
「集めたデータの特徴をつかんだり分かり易く整理したり見やすくしたりする方法。平均、標準偏差などを計算してデータの特徴を計算したり、データを分類したり、図やグラフを用いて表現したりするのが、記述統計です。」
3-1-1-2 推論統計
「部分的なデータしかないものから、確率分布に基いたモデルを用いて精密な解析をし、全体を推論して統計を求めるのが推論統計の考え方です。」
「過去のデータから未来予測するときにも使われます。この章では、推論統計の基礎である単回帰分析について説明します。より複雑な推論統計については、次の4章で扱います。」3-1-2 ライブラリのインポート
import numpy as np import scipy as sp import pandas as pd from pandas import Series, DataFrame import matplotlib as mpl import seaborn as sns import matplotlib.pyplot as plt sns.set() from sklearn import linear_model$ sudo pip3 install scikit-learn以下のとおり、Rasipi4でも使えそうです。
$ python3 Python 3.7.3 (default, Jul 25 2020, 13:03:44) [GCC 8.3.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> from sklearn import linear_model >>>一応、python3-sklearn-docが見つかりませんでしたがDebian/Ubuntuの以下でもインストール出来たようです。
$ sudo apt-get install python3-sklearn python3-sklearn-lib※検証は以下単回帰分析のとき問題でるかを見ていきます
Chapter 3-2 データの読込と対話
...省略
3-2-1-5
以下のサイトから、以下のプログラムでデータstudent.zipを取得します。
https://archive.ics.uci.edu/ml/machine-learning-databases/00356/student.zipimport requests, zipfile from io import StringIO import io url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/00356/student.zip' r = requests.get(url, stream = True) z = zipfile.ZipFile(io.BytesIO(r.content)) z.extractall()以下の4つのファイルが展開されました。
student.txt
student-mat.csv
student-merge.R
student-pcr.csv3-2-2 データ読み込みと確認
上記importにつなげて、以下を実行
student_data_math = pd.read_csv('./chap3/student-mat.csv') print(student_data_math.head())データが ;区切りを確認できる。
school;sex;age;address;famsize;Pstatus;Medu;Fedu;Mjob;Fjob;reason;guardian;traveltime;studytime;failures;schoolsup;famsup;paid;activities;nursery;higher;internet;romantic;famrel;freetime;goout;Dalc;Walc;health;absences;G1;G2;G3 0 GP;"F";18;"U";"GT3";"A";4;4;"at_home";"teacher... 1 GP;"F";17;"U";"GT3";"T";1;1;"at_home";"other";... 2 GP;"F";15;"U";"LE3";"T";1;1;"at_home";"other";... 3 GP;"F";15;"U";"GT3";"T";4;2;"health";"services... 4 GP;"F";16;"U";"GT3";"T";3;3;"other";"other";"h...読込を ;に変更して再読み込み。
student_data_math = pd.read_csv('./chap3/student-mat.csv', sep =';') print(student_data_math.head())綺麗に見えた。
school sex age address famsize Pstatus Medu Fedu ... goout Dalc Walc health absences G1 G2 G3 0 GP F 18 U GT3 A 4 4 ... 4 1 1 3 6 5 6 6 1 GP F 17 U GT3 T 1 1 ... 3 1 1 3 4 5 5 6 2 GP F 15 U LE3 T 1 1 ... 2 2 3 3 10 7 8 10 3 GP F 15 U GT3 T 4 2 ... 2 1 1 5 2 15 14 15 4 GP F 16 U GT3 T 3 3 ... 2 1 2 5 4 6 10 10 [5 rows x 33 columns]3-2-3 データの性質を確認する
print(student_data_math.info())<class 'pandas.core.frame.DataFrame'> RangeIndex: 395 entries, 0 to 394 Data columns (total 33 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 school 395 non-null object 1 sex 395 non-null object 2 age 395 non-null int64 3 address 395 non-null object 4 famsize 395 non-null object 5 Pstatus 395 non-null object 6 Medu 395 non-null int64 7 Fedu 395 non-null int64 8 Mjob 395 non-null object 9 Fjob 395 non-null object 10 reason 395 non-null object 11 guardian 395 non-null object 12 traveltime 395 non-null int64 13 studytime 395 non-null int64 14 failures 395 non-null int64 15 schoolsup 395 non-null object 16 famsup 395 non-null object 17 paid 395 non-null object 18 activities 395 non-null object 19 nursery 395 non-null object 20 higher 395 non-null object 21 internet 395 non-null object 22 romantic 395 non-null object 23 famrel 395 non-null int64 24 freetime 395 non-null int64 25 goout 395 non-null int64 26 Dalc 395 non-null int64 27 Walc 395 non-null int64 28 health 395 non-null int64 29 absences 395 non-null int64 30 G1 395 non-null int64 31 G2 395 non-null int64 32 G3 395 non-null int64 dtypes: int64(16), object(17) memory usage: 102.0+ KBcat student.txtして、中身を見るとこのデータは以下のような内容だそうです。
※本書では翻訳されています$ cat student.txt # Attributes for both student-mat.csv (Math course) and student-por.csv (Portuguese language course) datasets: 1 school - student's school (binary: "GP" - Gabriel Pereira or "MS" - Mousinho da Silveira) 2 sex - student's sex (binary: "F" - female or "M" - male) 3 age - student's age (numeric: from 15 to 22) 4 address - student's home address type (binary: "U" - urban or "R" - rural) 5 famsize - family size (binary: "LE3" - less or equal to 3 or "GT3" - greater than 3) 6 Pstatus - parent's cohabitation status (binary: "T" - living together or "A" - apart) 7 Medu - mother's education (numeric: 0 - none, 1 - primary education (4th grade), 2 – 5th to 9th grade, 3 – secondary education or 4 – higher education) 8 Fedu - father's education (numeric: 0 - none, 1 - primary education (4th grade), 2 – 5th to 9th grade, 3 – secondary education or 4 – higher education) 9 Mjob - mother's job (nominal: "teacher", "health" care related, civil "services" (e.g. administrative or police), "at_home" or "other") 10 Fjob - father's job (nominal: "teacher", "health" care related, civil "services" (e.g. administrative or police), "at_home" or "other") 11 reason - reason to choose this school (nominal: close to "home", school "reputation", "course" preference or "other") 12 guardian - student's guardian (nominal: "mother", "father" or "other") 13 traveltime - home to school travel time (numeric: 1 - <15 min., 2 - 15 to 30 min., 3 - 30 min. to 1 hour, or 4 - >1 hour) 14 studytime - weekly study time (numeric: 1 - <2 hours, 2 - 2 to 5 hours, 3 - 5 to 10 hours, or 4 - >10 hours) 15 failures - number of past class failures (numeric: n if 1<=n<3, else 4) 16 schoolsup - extra educational support (binary: yes or no) 17 famsup - family educational support (binary: yes or no) 18 paid - extra paid classes within the course subject (Math or Portuguese) (binary: yes or no) 19 activities - extra-curricular activities (binary: yes or no) 20 nursery - attended nursery school (binary: yes or no) 21 higher - wants to take higher education (binary: yes or no) 22 internet - Internet access at home (binary: yes or no) 23 romantic - with a romantic relationship (binary: yes or no) 24 famrel - quality of family relationships (numeric: from 1 - very bad to 5 - excellent) 25 freetime - free time after school (numeric: from 1 - very low to 5 - very high) 26 goout - going out with friends (numeric: from 1 - very low to 5 - very high) 27 Dalc - workday alcohol consumption (numeric: from 1 - very low to 5 - very high) 28 Walc - weekend alcohol consumption (numeric: from 1 - very low to 5 - very high) 29 health - current health status (numeric: from 1 - very bad to 5 - very good) 30 absences - number of school absences (numeric: from 0 to 93) # these grades are related with the course subject, Math or Portuguese: 31 G1 - first period grade (numeric: from 0 to 20) 31 G2 - second period grade (numeric: from 0 to 20) 32 G3 - final grade (numeric: from 0 to 20, output target) Additional note: there are several (382) students that belong to both datasets . These students can be identified by searching for identical attributes that characterize each student, as shown in the annexed R file.3-2-4 量的データと質的データ
・量的データ
四則演算を適用可能な連続値で表現されるデータであり、比率に意味がある。例;人数、金額など
・質的データ
四則演算を適用不可能な不連続のデータであり、状態を表現するために利用される。
例;順位、カテゴリなど性別は質的データ
print(student_data_math['sex'].head()) 0 F 1 F 2 F 3 F 4 F Name: sex, dtype: object欠席数は量的データ
print(student_data_math['absences'].head()) 0 6 1 4 2 10 3 2 4 4 Name: absences, dtype: int643-2-4-2 軸別に平均値を求める
print(student_data_math.groupby('sex')['age'].mean()) sex F 16.730769 M 16.657754 Name: age, dtype: float64女性の方が勉強する。
print(student_data_math.groupby('sex')['studytime'].mean()) sex F 2.278846 M 1.764706 Name: studytime, dtype: float64記述統計
3-3-1 ヒストグラム
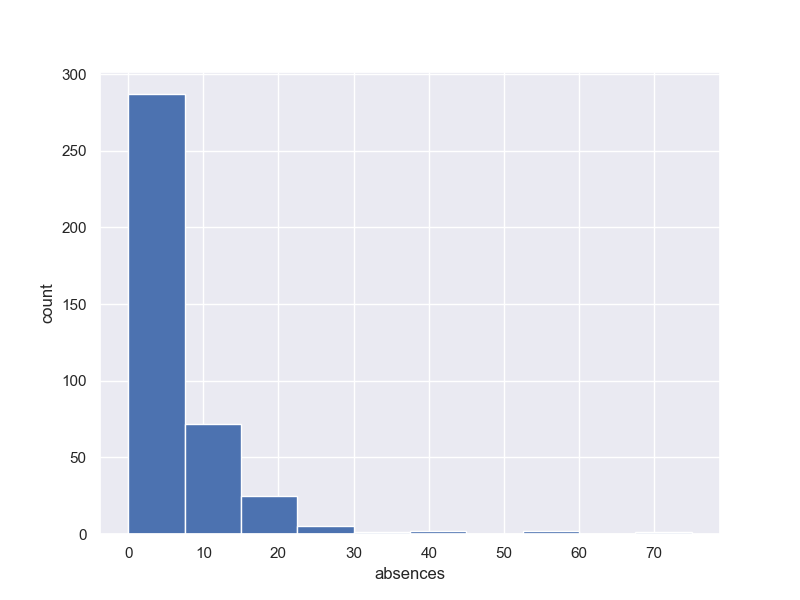
fig, (ax1) = plt.subplots(1, 1, figsize=(8,6)) y1 = student_data_math['absences'] ax1.hist(y1, bins = 10, range =(0.0,max(y1))) ax1.set_ylabel('count') ax1.set_xlabel('absences') plt.grid(True) plt.show()
3-3-2 平均値、中央値、最頻値
print('平均値{}'.format(student_data_math['absences'].mean())) print('中央値{}'.format(student_data_math['absences'].median())) print('最頻値{}'.format(student_data_math['absences'].mode())) 平均値5.708860759493671 中央値4.0 最頻値0 0 dtype: int64図で検証するために、上記を図を拡大して記入します。
※横軸0.5修正しています。fig, (ax1) = plt.subplots(1, 1, figsize=(8,6)) y1 = student_data_math['absences'] ax1.hist(y1, bins = 30, range =(0.0,30)) #,max(y1) x0 = student_data_math['absences'].mean() ax1.plot(x0+0.5, 70, 'red', marker = 'o',markersize=10,label ='mean') x0 = student_data_math['absences'].median() ax1.plot(x0+0.5, 70, 'blue', marker = 'o',markersize=10,label ='median') x0 = student_data_math['absences'].mode() ax1.plot(x0+0.5, 70, 'black', marker = 'o',markersize=10,label ='mode') ax1.legend() ax1.set_ylabel('count') ax1.set_xlabel('absences') plt.grid(True) plt.show()
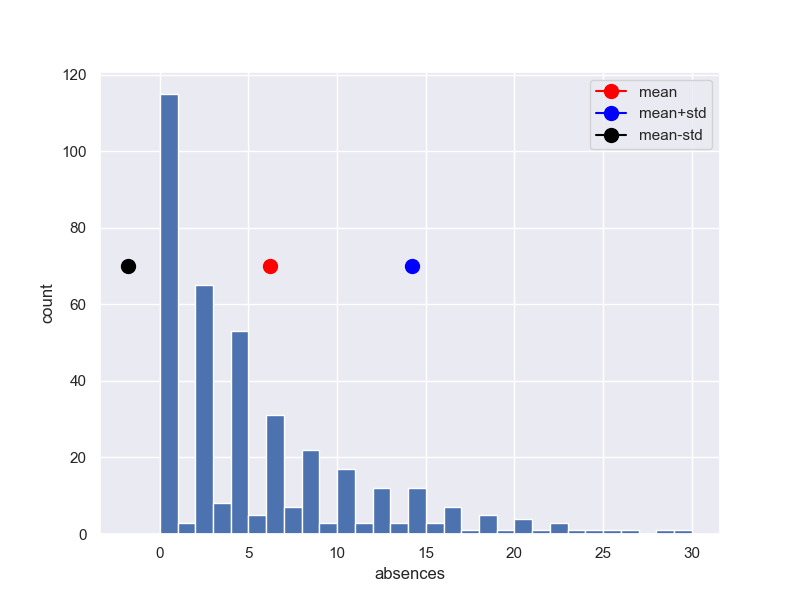
3-3-3 分散と標準偏差
定義式
分散$σ^2$σ^2 = \frac{1}{n}\Sigma_{i=1}^{n}(x_i-\bar{x})^2標準偏差$σ$
std(standered deviation)σ = \sqrt{\frac{1}{n}\Sigma_{i=1}^{n}(x_i-\bar{x})^2}print('分散{}'.format(student_data_math['absences'].var(ddof=0))) print('標準偏差{}'.format(student_data_math['absences'].std(ddof = 0))) print('標準偏差{}'.format(np.sqrt(student_data_math['absences'].var()))) 分散63.887389841371565 標準偏差7.99295876640006 標準偏差8.00309568710818平均±標準偏差をプロットする。
fig, (ax1) = plt.subplots(1, 1, figsize=(8,6)) y1 = student_data_math['absences'] ax1.hist(y1, bins = 30, range =(0.0,30)) #,max(y1) x0 = student_data_math['absences'].mean() ax1.plot(x0+0.5, 70, 'red', marker = 'o',markersize=10,label ='mean') x1 = student_data_math['absences'].std(ddof=0) ax1.plot(x0+x1+0.5, 70, 'blue', marker = 'o',markersize=10,label ='mean+std') ax1.plot(x0-x1+0.5, 70, 'black', marker = 'o',markersize=10,label ='mean-std') ax1.legend() ax1.set_ylabel('count') ax1.set_xlabel('absences') plt.grid(True) plt.show()
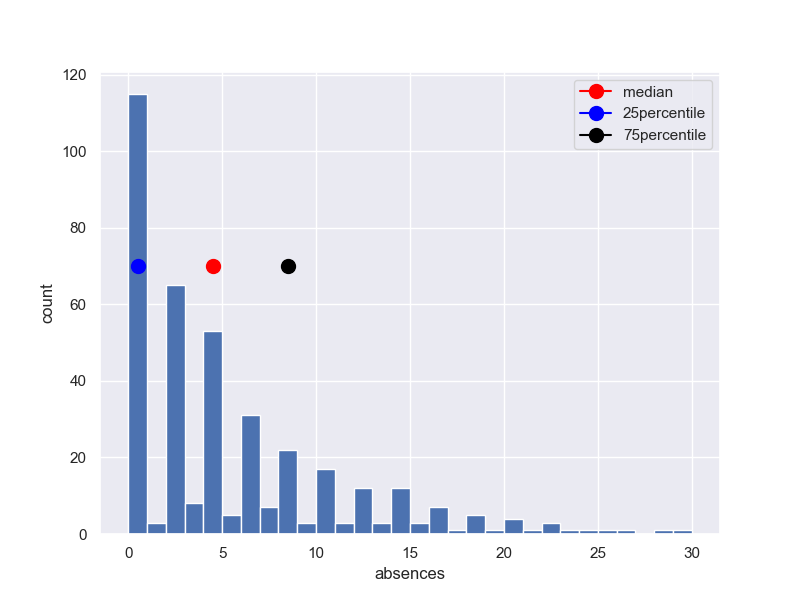
3-3-4 要約統計量とパーセンタイル値
パーセンタイル値は全体数を100とした時の順位
25番目を25パーセンタイル、第一四分位点
75番目を75パーセンタイル、第三四分位点
50パーセンタイル値、中央値print('要約統計量', student_data_math['absences'].describe()) 要約統計量 count 395.000000 mean 5.708861 std 8.003096 min 0.000000 25% 0.000000 50% 4.000000 75% 8.000000 max 75.000000 Name: absences, dtype: float64四分位範囲を求める
25パーセンタイル;describe(4)
75パーセンタイル:describe(6)
差;describe(6)-describe(4)
print('75-25パーセンタイル',student_data_math['absences'].describe()[6]-student_data_math['absences'].describe()[4])
75-25パーセンタイル 8.0fig, (ax1) = plt.subplots(1, 1, figsize=(8,6)) y1 = student_data_math['absences'] ax1.hist(y1, bins = 30, range =(0.0,30)) #,max(y1) x0 = student_data_math['absences'].median() ax1.plot(x0+0.5, 70, 'red', marker = 'o',markersize=10,label ='median') x1 = student_data_math['absences'].describe()[4] ax1.plot(x1+0.5, 70, 'blue', marker = 'o',markersize=10,label ='25percentile') x1 = student_data_math['absences'].describe()[6] ax1.plot(x1+0.5, 70, 'black', marker = 'o',markersize=10,label ='75percentile') ax1.legend() ax1.set_ylabel('count') ax1.set_xlabel('absences') plt.grid(True) plt.show()
3-3-4-2 全列のdescribe()
print('全列要約統計量', student_data_math.describe()) 全列要約統計量 age Medu Fedu traveltime ... absences G1 G2 G3 count 395.000000 395.000000 395.000000 395.000000 ... 395.000000 395.000000 395.000000 395.000000 mean 16.696203 2.749367 2.521519 1.448101 ... 5.708861 10.908861 10.713924 10.415190 std 1.276043 1.094735 1.088201 0.697505 ... 8.003096 3.319195 3.761505 4.581443 min 15.000000 0.000000 0.000000 1.000000 ... 0.000000 3.000000 0.000000 0.000000 25% 16.000000 2.000000 2.000000 1.000000 ... 0.000000 8.000000 9.000000 8.000000 50% 17.000000 3.000000 2.000000 1.000000 ... 4.000000 11.000000 11.000000 11.000000 75% 18.000000 4.000000 3.000000 2.000000 ... 8.000000 13.000000 13.000000 14.000000 max 22.000000 4.000000 4.000000 4.000000 ... 75.000000 19.000000 19.000000 20.000000 [8 rows x 16 columns]3-3-5 箱ひげ図
箱ひげ図は、(最小値,第1四分位点,中央値,第3四分位点,最大値)で以下のように箱とひげで表す手法。
fig, (ax1,ax2) = plt.subplots(2, 1, figsize=(8,2*4)) y1 = student_data_math['G1'] ax1.hist(y1, bins = 30, range =(0.0,max(y1))) #,max(y1) x0 = student_data_math['G1'].median() ax1.plot(x0+0.5, 60, 'red', marker = 'o',markersize=10,label ='median') x1 = student_data_math['G1'].describe()[4] ax1.plot(x1+0.5, 60, 'blue', marker = 'o',markersize=10,label ='25percentile') x1 = student_data_math['G1'].describe()[6] ax1.plot(x1+0.5, 60, 'black', marker = 'o',markersize=10,label ='75percentile') ax2.boxplot(y1) ax2.set_xlabel('G1') ax2.set_ylabel('count') ax1.legend() ax1.set_ylabel('count') ax1.set_xlabel('G1') plt.grid(True) plt.show()
fig, (ax1) = plt.subplots(1, 1, figsize=(8,6)) y1 = [student_data_math['G1'],student_data_math['G2'],student_data_math['G3'],student_data_math['absences']] ax1.boxplot(y1,labels=['G1', 'G2', 'G3', 'absences']) ax1.set_xlabel('category') ax1.set_ylabel('count') ax1.legend() ax1.set_ylabel('count') ax1.set_xlabel('category') plt.grid(True) plt.show()
3-3-6 変動係数
変動係数CVとは、標準偏差σ/平均値$\bar{x}$
変動係数は、スケールに依存せず、散らばり具合が分かる。print(student_data_math.std()/student_data_math.mean()) age 0.076427 Medu 0.398177 Fedu 0.431565 traveltime 0.481668 studytime 0.412313 failures 2.225319 famrel 0.227330 freetime 0.308725 goout 0.358098 Dalc 0.601441 Walc 0.562121 health 0.391147 absences 1.401873 G1 0.304266 G2 0.351086 G3 0.439881 dtype: float643-3-7 散布図と相関係数
fig, (ax1) = plt.subplots(1, 1, figsize=(8,6)) x = student_data_math['G1'] y = student_data_math['G3'] ax1.plot(x,y, 'o') ax1.set_xlabel('G1-grade') ax1.set_ylabel('G3-grade') ax1.legend() plt.grid(True) plt.show()G1-Gradeの高かった人は、G3-Gradeも高い。
ただし、G3-Gradeが0の人が数人出ている。これは、異常値だが、理由はいろいろちゅさして、除外するかどうか決めようという議論がされている。
そこで、G3-Gradeが0の人の出席日数はどうなのということで、以下の相関図を描いて見る。fig, (ax1) = plt.subplots(1, 1, figsize=(8,6)) x = student_data_math['G3'] y = student_data_math['absences'] ax1.plot(x,y, 'o') ax1.set_xlabel('G3-grade') ax1.set_ylabel('absences') ax1.legend() plt.grid(True) plt.show()結果は、G3-Gradeが0の人は欠席0という結果。なんかおかしい。実は、途中でやめてノーカウントなのではとか想像できる。
さらに、G1-Gradeと欠席数で相関取ると、以下の通り
そもそも、G2-Gradeの時点で数名が0Gradeになっている。
そして、G2-GradeとG3-Gradeの相関見ても、何人かは0Gradeに転落しており、そういう人も段々増えていることが分かる。そして、落伍者は点数の低めの人の中から出ているようだ。
だから、一つのグラフで結論を急ぐよりも、いろいろデータを分析することも大切だと言える。
3-3-7-1 共分散
定義式は、以下の通り
S_{xy}=\frac{1}{n}\Sigma_{i=1}^{n}(x_i-\bar{x})(y_i-\bar{y})すなわち、対角項は上で定義した分散になります。
では、非対角項は何を意味するのでしょう。
参考によれば、$x$と$y$が本来線形な関係があるとすると、最小二乗法で導かれる直線の方程式は以下となる。
【参考】
線形回帰分析・最小二乗法とは 共分散・相関係数の意味y=\frac{S_{xy}}{\sigma^2_{x}}x + \bar y−\frac{S_{xy}}{\sigma^2_x}\bar x \\ 変形すると、\\ \frac{y-\bar y}{\sigma_y}=\frac{S_{xy}}{\sigma_x\sigma_y}\frac{x-\bar x}{\sigma_x}すなわち、標準偏差と平均値で規格化した一次方程式の傾きは以下の式となります。
r_{xy}=\frac{S_{xy}}{\sigma_x\sigma_y}すなわち、共分散を標準偏差で規格化した値になり、これがいわゆる相関係数$r_{xy}$の定義式です。
3-3-7-2 相関係数
ここでは、共分散と相関係数を求めます。
共分散は、非対角項、対角項はG1,G3の分散です。print(np.cov(student_data_math['G1'],student_data_math['G3'])) [[11.01705327 12.18768232] [12.18768232 20.9896164 ]]相関係数は、前が相関係数、第二項はp値です。
※p値については後ろの章で取り上げる予定print(sp.stats.pearsonr(student_data_math['G1'],student_data_math['G3'])) (0.801467932017414, 9.001430312277865e-90)相関行列は、以下で求められます。
print(np.corrcoef(student_data_math['G1'],student_data_math['G3'])) [[1. 0.80146793] [0.80146793 1. ]]3-3-8 すべての変数のヒストグラムや散布図を描く
Dalc;平日のアルコール摂取量
Walc;週末のアルコール摂取量
とG1,G3の得点に相関はあるか、散布図を描いて見る。
結果;無さそうg = sns.pairplot(student_data_math[['Dalc','Walc','G1','G3']]) g.savefig('seaborn_pairplot_g.png')
【参考】
Python, pandas, seabornでペアプロット図(散布図行列)を作成
WalcとG3得点の相関無しprint(np.corrcoef(student_data_math['Walc'],student_data_math['G3'])) [[ 1. -0.05193932] [-0.05193932 1. ]]グループ毎のバラツキ無し
print(student_data_math.groupby('Walc')['G3'].mean()) Walc 1 10.735099 2 10.082353 3 10.725000 4 9.686275 5 10.142857 Name: G3, dtype: float64練習問題3-1
age Medu Fedu traveltime ... absences G1 G2 G3 count 649.000000 649.000000 649.000000 649.000000 ... 649.000000 649.000000 649.000000 649.000000 mean 16.744222 2.514638 2.306626 1.568567 ... 3.659476 11.399076 11.570108 11.906009 std 1.218138 1.134552 1.099931 0.748660 ... 4.640759 2.745265 2.913639 3.230656 min 15.000000 0.000000 0.000000 1.000000 ... 0.000000 0.000000 0.000000 0.000000 25% 16.000000 2.000000 1.000000 1.000000 ... 0.000000 10.000000 10.000000 10.000000 50% 17.000000 2.000000 2.000000 1.000000 ... 2.000000 11.000000 11.000000 12.000000 75% 18.000000 4.000000 3.000000 2.000000 ... 6.000000 13.000000 13.000000 14.000000 max 22.000000 4.000000 4.000000 4.000000 ... 32.000000 19.000000 19.000000 19.000000練習問題3-2
df =student_data_math.merge(student_data_por,left_on=['school','sex','age','address','famsize','Pstatus','Medu','Fedu','Mjob','Fjob','reason','nursery','internet'], right_on=['school','sex','age','address','famsize','Pstatus','Medu','Fedu','Mjob','Fjob','reason','nursery','internet'], suffixes=('_math', '_por')) print(df.head()) school sex age address famsize Pstatus ... Walc_por health_por absences_por G1_por G2_por G3_por 0 GP F 18 U GT3 A ... 1 3 4 0 11 11 1 GP F 17 U GT3 T ... 1 3 2 9 11 11 2 GP F 15 U LE3 T ... 3 3 6 12 13 12 3 GP F 15 U GT3 T ... 1 5 0 14 14 14 4 GP F 16 U GT3 T ... 2 5 0 11 13 13 [5 rows x 53 columns]練習問題3-3
gm = sns.pairplot(df[['G1_math','G3_math','G1_por','G3_por']]) gm.savefig('seaborn_pairplot_gm.png')mathどうし、porどうしの相関が高そう
mathよりporの方が分散は小さそう
以下の結果からも裏付けられる。print(np.corrcoef(df['G1_math'],df['G3_math'])) [[1. 0.8051287] [0.8051287 1. ]] print(np.corrcoef(df['G3_math'],df['G3_por'])) [[1. 0.48034936] [0.48034936 1. ]] print(np.cov(df['G1_math'],df['G3_math'])) [[11.2169202 12.63919693] [12.63919693 21.9702354 ]] print(np.cov(df['G3_math'],df['G3_por'])) [[21.9702354 6.63169394] [ 6.63169394 8.67560567]]Chapter 3-4 単回帰分析
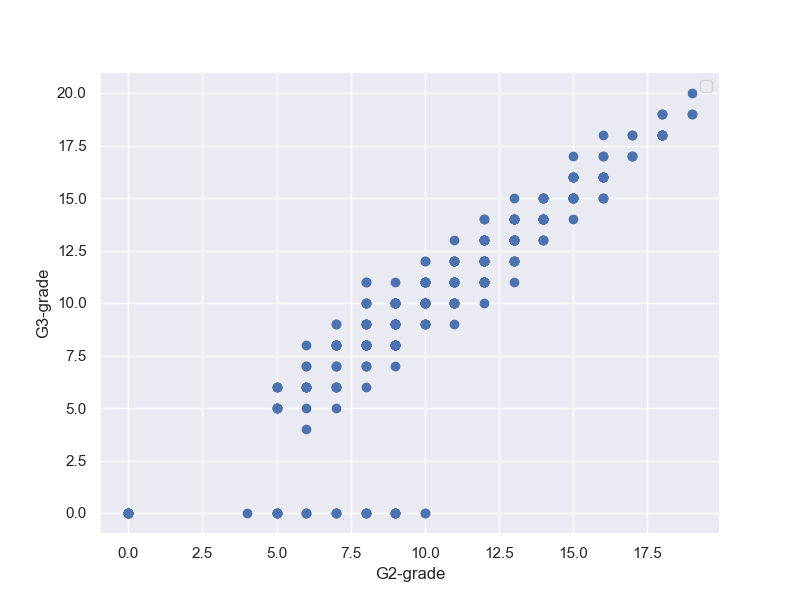
「記述統計の次は、回帰分析の基礎を学びましょう。」
「回帰分析とは、数値を予測する分析です。...上の学生のデータについて、グラフ化しました。この散布図から、G1とG3には関係がありそうだというのは分かります。」fig, (ax1) = plt.subplots(1, 1, figsize=(8,6)) ax1.plot(student_data_math['G1'],student_data_math['G3'],'o') ax1.set_xlabel('G1_Grade') ax1.set_ylabel('G3_Grade') ax1.grid(True) plt.show()
「回帰問題では、与えられたデータから関係式を仮定して、データに最も当てはまる係数を求めて行きます。具体的にはあらかじめわかっているG1の成績をもとに、G3の成績を予測します。つまり、目的となる変数G3(目的変数という)があり、それを説明する変数G1(説明変数という)を使って予測します。回帰分析では、説明変数が1つのものと、複数のものがあり、前者を単回帰、後者を重回帰分析と言います。この章では単回帰分析の説明をします。」
※若干意訳しています3-4-1 線形単回帰分析
「ここでは単回帰分析の内、アウトプットとインプットが線形の関係が成り立つことを前提とした線形単回帰という手法で回帰問題を解く方法を説明します。」
import pandas as pd from sklearn import linear_model reg = linear_model.LinearRegression() student_data_math = pd.read_csv('./chap3/student-mat.csv', sep =';') x = student_data_math.loc[:,['G1']].values y = student_data_math['G3'].values reg.fit(x,y) print('回帰係数;',reg.coef_) print('切片;',reg.intercept_) 回帰係数; [1.10625609] 切片; -1.6528038288004616fig, (ax1) = plt.subplots(1, 1, figsize=(8,6)) ax1.plot(student_data_math['G1'],student_data_math['G3'],'o') ax1.plot(x,reg.predict(x)) ax1.set_xlabel('G1_Grade') ax1.set_ylabel('G3_Grade') ax1.grid(True) plt.show()
3-4-2 決定係数
R^2 = 1- \frac{\Sigma_{i=1}^{n}(y_i-f(x_i))^2}{\Sigma_{i=1}^{n}(y_i-\bar y)^2}上式は、決定係数と呼ばれ、$R^2=1$が最大値であり、1に近ければ近いほど良いモデルになります。
print('決定係数;',reg.score(x,y)) 決定係数; 0.64235084605227総合問題3-2-1 Lorenz Curve
df0 = student_data_math[student_data_math['sex'].isin(['M'])] df = df0.sort_values(by=['G1']) df['Ct']=np.arange(1,len(df)+1) x = df['Ct'] print(x) y = df['G1'].cumsum() print(y) fig, (ax1) = plt.subplots(1, 1, figsize=(8,6)) ax1.plot(x/max(x),y/max(y)) ax1.set_xlabel('peoples') ax1.set_ylabel('G1_Grade.cumsum') ax1.grid(True) plt.show() 248 1 144 2 164 3 161 4 153 5 ... 113 183 129 184 245 185 42 186 47 187 Name: Ct, Length: 187, dtype: int32 248 3 144 8 164 13 161 18 153 23 ... 113 2026 129 2044 245 2062 42 2081 47 2100 Name: G1, Length: 187, dtype: int64M
F
参考
M;G1 vs peaples
F;G1 vs peaples















- 投稿日:2020-08-24T22:00:14+09:00
japanese-addressesを使ったジオコーディング
はじめに
「Geolonia 住所データ | japanese-addresses」で住所データと代表点の緯度経度が公開されました。
参考: 無料で使える「住所マスターデータ」公開、表記統一や緯度経度への変換に活用可能 - INTERNET Watch
このデータを使って、住所⇔緯度経度変換のコマンドを作ったので紹介します。
Python3.8が必要です。インストール&設定
まず、上記サイトで「ダウンロード」からCSV(latest.csv)をダウンロードしてください。ダウンロードしたパスを「
/path/to/latest.csv」とします。
下記コマンドを実行してください。pip install simple-geocoding python -c '__import__("simple_geocoding").Geocoding("/path/to/latest.csv")'2つ目のコマンドでCSVから「住所リスト、KDTree、住所をキーとした緯度経度の辞書」を作成してインストール先にpickleで保存しています。
使い方
住所→緯度経度
simple-geocoding 東京都千代田区丸の内一丁目 >>> (35.68156, 139.767201)引数が1つのときは、住所とみなして、緯度経度に変換します。
これは、単純に住所をキーにした緯度経度を返しています。
なお、単純化のため同一の住所に対して複数の緯度経度が存在しても1つだけ返しています。緯度経度→住所
simple-geocoding 35.68156 139.7672 >>> 東京都千代田区丸の内一丁目引数が2つのときは、緯度と経度とみなして、住所に変換します。
これは、KD-Treeで最寄りの登録地点を求めています。補足
KD-Treeというデータ構造を使うことで、不均一に存在する地点を効率よく管理できます。
また、PythonではKD-Treeがscipyに含まれているので、簡単に利用できます。
- 投稿日:2020-08-24T21:21:22+09:00
DjangoでError: That port is already in use.が出たら
完全に備忘録です。
ポートを解放したいとき
ps aux | grep -i manage下記が表示される
ユーザ名 778 0.0 0.1 4349020 4252 ?? S 31May20 0:39.16 /System/Library/CoreServices/RemoteManagement/SSMenuAgent.app/Contents/MacOS/SSMenuAgent ユーザ名 775 0.0 0.0 4333584 1012 ?? S 31May20 0:02.50 /System/Library/CoreServices/backgroundtaskmanagementagent ユーザ名 771 0.0 0.0 4337392 1720 ?? S 31May20 0:24.40 /System/Library/CoreServices/RemoteManagement/ARDAgent.app/Contents/MacOS/ARDAgent ユーザ名 85298 0.0 0.0 4268040 788 s002 S+ 9:15PM 0:00.00 grep -i managekillしたいPIDを選択
kill -9 85298
- 投稿日:2020-08-24T21:12:37+09:00
slackのbotを作成する
インターンの業務で、既存のAPIを叩いて情報をひっぱってくる予定だったが、どうもそのAPIを今後使わない方向でいるということで、今slackで勤怠管理とか色々やってるからそこで一緒に個人情報も入力できたら楽だよねってことで、slackのbotを作ることになった。
まずは、pythonでやるかjavaScriptでやるか比較してみる。flask
以下のurlを参考に実装した。
https://qiita.com/sh-tatsuno/items/55cd5f9e78b212fb57c2なんかslackclientのバージョンでimportするモジュールの名前が違うみたいだから注意。
import slack slack_client = slack.WebClient(SLACK_BOT_TOKEN)普通のflaskの処理でslackのbotを簡単に実現できた。
- 投稿日:2020-08-24T21:00:00+09:00
データサイエンス100本ノック解説(P041~060)
1. はじめに
前回に引き続き、データサイエンス100本ノックの解説を行う。
データサイエンス100本ノック解説(P001~020)
データサイエンス100本ノック解説(P021~040)導入についてはこちらの記事を参考に進めてください(※ MacでDockerを扱います)
基本的には解答の解説ですが別解についても記述しています。
※徐々に難易度が上がってきています。2. 解説編
P-041: レシート明細データフレーム(df_receipt)の売上金額(amount)を日付(sales_ymd)ごとに集計し、前日からの売上金額増減を計算せよ。なお、計算結果は10件表示すればよい。
P-041# 売上金額(amount)を日付(sales_ymd)ごとに集計(groupbyメソッド) # reset_index()でインデックスを振り直す。 df_sales_amount_by_date = df_receipt[['sales_ymd', 'amount']].groupby('sales_ymd').sum().reset_index() # 比較用に売上金額(amount)を日付(sales_ymd)のコピーを下に1行移動したものを結合する。 # concat([df1, df2], axis=1)で横方向に結合。shift()で1行下に移動 df_sales_amount_by_date = pd.concat([df_sales_amount_by_date, df_sales_amount_by_date.shift()], axis=1) # カラム名を変更する df_sales_amount_by_date.columns = ['sales_ymd','amount','lag_ymd','lag_amount'] # 売上金額増減(diff_amount)を追加する df_sales_amount_by_date['diff_amount'] = df_sales_amount_by_date['amount'] - df_sales_amount_by_date['lag_amount'] df_sales_amount_by_date.head(10)
参考: pandas.DataFrame, Seriesを連結するconcat
参考: pandasでデータを行・列(縦・横)方向にずらすshiftP-042: レシート明細データフレーム(df_receipt)の売上金額(amount)を日付(sales_ymd)ごとに集計し、各日付のデータに対し、1日前、2日前、3日前のデータを結合せよ。結果は10件表示すればよい。
P-042# (縦持ちのケース) # 売上金額(amount)を日付(sales_ymd)ごとに集計(groupby) df_sales_amount_by_date = df_receipt[['sales_ymd', 'amount']].groupby('sales_ymd').sum().reset_index() # for文で繰り返す。range(1, 4)>>>1, 2, 3がiに入る。 for i in range(1, 4): # i==1のときは横方向に結合。shiftで1行下に移動(1日前) if i == 1: df_lag = pd.concat([df_sales_amount_by_date, df_sales_amount_by_date.shift()], axis=1) # iが1以外の場合、データフレームに追加する。 else: df_lag = df_lag.append(pd.concat([df_sales_amount_by_date, df_sales_amount_by_date.shift(i)], axis=1)) # カラム名を変更する df_lag.columns = ['sales_ymd', 'amount', 'lag_sales_ymd', 'lag_amount'] # 欠損値NaNを除外(dropna())し、ソートする(sort_values)。 df_lag.dropna().sort_values('sales_ymd').head(10)P-042# 横持ちのケース # 売上金額(amount)を日付(sales_ymd)ごとに集計(groupby) df_sales_amount_by_date = df_receipt[['sales_ymd', 'amount']].groupby('sales_ymd').sum().reset_index() # for文で繰り返す。range(1, 4)>>>1, 2, 3がiに入る。 for i in range(1, 4): # iが1の時、横方向に連結したdf_lagを作成する。 if i == 1: df_lag = pd.concat([df_sales_amount_by_date, df_sales_amount_by_date.shift(1)], axis=1) # iが1以外の場合、すでにdf_lagが作成されているのでdf_lagと連結させる。 else: df_lag = pd.concat([df_lag, df_sales_amount_by_date.shift(i)], axis=1) # カラム名を変更する df_lag.columns = ['sales_ymd', 'amount', 'lag1_sales_ymd', 'lag1_amount', 'lag2_sales_ymd', 'lag2_amount', 'lag3_sales_ymd', 'lag3_amount'] # 欠損値NaNを除外(dropna())し、ソートする(sort_values)。 df_lag.dropna().sort_values('sales_ymd').head(10)参考: pandasで欠損値NaNを除外(削除)・置換(穴埋め)・抽出
P-043: レシート明細データフレーム(df_receipt)と顧客データフレーム(df_customer)を結合し、性別(gender)と年代(ageから計算)ごとに売上金額(amount)を合計した売上サマリデータフレーム(df_sales_summary)を作成せよ。性別は0が男性、1が女性、9が不明を表すものとする。
ただし、項目構成は年代、女性の売上金額、男性の売上金額、性別不明の売上金額の4項目とすること(縦に年代、横に性別のクロス集計)。また、年代は10歳ごとの階級とすること。
P-043# レシート明細データフレーム(df_receipt)と顧客データフレーム(df_customer)を結合 # merge(df1, df2, on='キー名', how='inner') df_tmp = pd.merge(df_receipt, df_customer, on='customer_id', how='inner') # 年代を10歳ごとの階級にする。 # math.floor: 小数点以下を切り捨て。ex) 22の場合 22/10 * 10 = 2(2.2の切り捨て) *10 = 20 df_tmp['era'] = df_tmp['age'].apply(lambda x: math.floor(x/10)*10) # ピボットテーブルを作成(pivot_table()関数)詳細は下記 df_sales_summary = pd.pivot_table(df_tmp, index='era', columns='gender_cd', values='amount', aggfunc='sum').reset_index() # カラム名を変更する df_sales_summary.columns = ['era', 'male', 'female', 'unknown'] df_sales_summarypivot_table()関数
・data(第一引数): 参照するデータフレーム
・index: 行名を指定
・columns: 列名を指定
・values: 参照しているデータフレームの列名を指定すると、その列に対する結果のみが算出
・aggfunc: 結果の値の算出方法を指定
参考: pandasのピボットテーブルでカテゴリ毎の統計量などを算出P-044: 前設問で作成した売上サマリデータフレーム(df_sales_summary)は性別の売上を横持ちさせたものであった。このデータフレームから性別を縦持ちさせ、年代、性別コード、売上金額の3項目に変換せよ。ただし、性別コードは男性を'00'、女性を'01'、不明を'99'とする。
P-044# set_indexで既存の列をインデックスindex(行名、行ラベル)に割り当てる # stack()で列から行へピボット。 # replace()で文字列を置換する # rename()メソッドで任意の行名・列名を変更する df_sales_summary.set_index('era').stack().reset_index().replace( {'female': '01', 'male': '00', 'unknown': '99'}).rename( columns={'level_1': 'gender_cd', 0: 'amount'})参考: pandas.DataFrameの列をインデックス(行名)に割り当てるset_index
参考: pandasでstack, unstack, pivotを使ってデータを整形
参考: Pythonで文字列を置換(replace, translate, re.sub, re.subn)
参考: pandas.DataFrameの行名・列名の変更P-045: 顧客データフレーム(df_customer)の生年月日(birth_day)は日付型(Date)でデータを保有している。これをYYYYMMDD形式の文字列に変換し、顧客ID(customer_id)とともに抽出せよ。データは10件を抽出すれば良い。
P-045# 顧客ID(customer_id)とYYYYMMDD形式の文字列に変換した生年月日(birth_day)を結合する。 # concat([df1, df2], axis=1)で横方向に結合する。 # pd.to_datetimeで文字列をdatetime64[ns]型に変換する。 # dt.strftime()で列を一括で任意のフォーマットの文字列に変換する。 pd.concat([df_customer['customer_id'], pd.to_datetime(df_customer['birth_day']) \ .dt.strftime('%Y/%m/%d')], axis=1).head(10)参考: pandasで日付・時間の列を処理(文字列変換、年月日抽出など)
P-046: 顧客データフレーム(df_customer)の申し込み日(application_date)はYYYYMMDD形式の文字列型でデータを保有している。これを日付型(dateやdatetime)に変換し、顧客ID(customer_id)とともに抽出せよ。データは10件を抽出すれば良い。
P-046# 顧客ID(customer_id)と日付型(dateやdatetime)に変換した申し込み日(application_date)を結合する # P-045を参考 pd.concat([df_customer['customer_id'], pd.to_datetime(df_customer['application_date'])], axis=1).head(10)参考: pandasで日付・時間の列を処理(文字列変換、年月日抽出など)
P-047: レシート明細データフレーム(df_receipt)の売上日(sales_ymd)はYYYYMMDD形式の数値型でデータを保有している。これを日付型(dateやdatetime)に変換し、レシート番号(receipt_no)、レシートサブ番号(receipt_sub_no)とともに抽出せよ。データは10件を抽出すれば良い。
P-047# 売上日(sales_ymd)をto_datetime()で日付型に変換する # pandas.concat()で横方向に結合する # astype()メソッドで文字列str型に変換すると、標準的な書式で文字列に変換する pd.concat([df_receipt[['receipt_no', 'receipt_sub_no']], pd.to_datetime(df_receipt['sales_ymd'].astype('str'))],axis=1).head(10) # (別解) pd.concat([df_receipt[['receipt_no', 'receipt_sub_no'], pd.to_datetime(df_receipt['sales_ymd']).dt.strftime('%Y-%m-%d')]], axis=1).head(10)参考: pandasで日付・時間の列を処理(文字列変換、年月日抽出など)
P-048: レシート明細データフレーム(df_receipt)の売上エポック秒(sales_epoch)は数値型のUNIX秒でデータを保有している。これを日付型(dateやdatetime)に変換し、レシート番号(receipt_no)、レシートサブ番号(receipt_sub_no)とともに抽出せよ。データは10件を抽出すれば良い。
P-048# pd.concat()を用いての売上エポック秒(sales_epoch)のデータフレームとレシート番号(receipt_no)、レシートサブ番号(receipt_sub_noを結合 # 売上エポック秒(sales_epoch)を日付型に変換する(to_datetime(df, unit='s')で変換) pd.concat([df_receipt[['receipt_no', 'receipt_sub_no']], pd.to_datetime(df_receipt['sales_epoch'].astype(int), unit='s')], axis=1).head(10)参考: Pandasで時間や日付データに変換するto_datetime関数の使い方
P-049: レシート明細データフレーム(df_receipt)の売上エポック秒(sales_epoch)を日付型(timestamp型)に変換し、"年"だけ取り出してレシート番号(receipt_no)、レシートサブ番号(receipt_sub_no)とともに抽出せよ。データは10件を抽出すれば良い。
P-049# 売上エポック秒(sales_epoch)を日付型(timestamp型)に変換 # "年"だけ取り出す(dt.year) pd.concat([df_receipt[['receipt_no', 'receipt_sub_no']], pd.to_datetime(df_receipt['sales_epoch'], unit='s').dt.year], axis=1).head(10)参考: Pandasで時間や日付データに変換するto_datetime関数の使い方
P-050: レシート明細データフレーム(df_receipt)の売上エポック秒(sales_epoch)を日付型(timestamp型)に変換し、"月"だけ取り出してレシート番号(receipt_no)、レシートサブ番号(receipt_sub_no)とともに抽出せよ。なお、"月"は0埋め2桁で取り出すこと。データは10件を抽出すれば良い。
P-050# 売上エポック秒(sales_epoch)を日付型に変換(to_datetime(, unit='s')) # "月"だけ取り出す(0埋め2桁で取り出すためstrftime('%m')) # pd.concatでデータフレームを結合する pd.concat([df_receipt[['receipt_no', 'receipt_sub_no']], pd.to_datetime(df_receipt['sales_epoch'], unit='s') \ .dt.strftime('%m')], axis=1).head(10)P-051: レシート明細データフレーム(df_receipt)の売上エポック秒(sales_epoch)を日付型(timestamp型)に変換し、"日"だけ取り出してレシート番号(receipt_no)、レシートサブ番号(receipt_sub_no)とともに抽出せよ。なお、"日"は0埋め2桁で取り出すこと。データは10件を抽出すれば良い。
P-051# 売上エポック秒(sales_epoch)を日付型に変換(to_datetime(, unit='s')) # 日だけを抜き出す(dt.strftime('%d')) # pd.concat()で結合 pd.concat([df_receipt[['receipt_no', 'receipt_sub_no']], pd.to_datetime(df_receipt['sales_epoch'], unit='s') \ .dt.strftime('%d')], axis=1).head(10)P-052: レシート明細データフレーム(df_receipt)の売上金額(amount)を顧客ID(customer_id)ごとに合計の上、売上金額合計に対して2000円以下を0、2000円超を1に2値化し、顧客ID、売上金額合計とともに10件表示せよ。ただし、顧客IDが"Z"から始まるのものは非会員を表すため、除外して計算すること。
P-052# lambdaを使った場合 # 顧客IDが"Z"から始まるのものを除外する(queryで探し、notで以外、str.startswith('Z')) df_sales_amount = df_receipt.query('not customer_id.str.startswith("Z")', engine='python') # 顧客ID(customer_id)ごとにグループ分けする。売上金額(amount)を合計(sum) df_sales_amount = df_sales_amount[['customer_id', 'amount']].groupby('customer_id').sum().reset_index() # 2000円以下を0、2000円超を1に2値化(apply(lambda)で指定の列に1行ずつ条件を適用する) df_sales_amount['sales_flg'] = df_sales_amount['amount'].apply(lambda x: 1 if x>2000 else 0) df_sales_amount.head(10) # (別解: np.where) df_sales_amount = df_receipt.query('not customer_id.str.startswith("Z")', engine='python') df_sales_amount = df_sales_amount[['customer_id', 'amount']].groupby('customer_id').sum().reset_index() # np.where(条件式, x(真の場合), y(偽の場合)) df_sales_amount['sales_flg'] = np.where(df_sales_amount['amount']>2000, 1, 0) df_sales_amount.head(10) # (別解) df_sales_amount = df_receipt[~df_receipt['customer_id'].str.startswith('Z')].groupby('customer_id').amount.sum().reset_index() df_sales_amount.loc[df_sales_amount['amount']<=2000, 'threshold'] = 0 df_sales_amount.loc[df_sales_amount['amount']>2000, 'threshold'] = 1 df_sales_amount.head(10)参考:pandasで指定の列に1行ずつ関数を適用するapply+lambdaの使い方
P-053: 顧客データフレーム(df_customer)の郵便番号(postal_cd)に対し、東京(先頭3桁が100〜209のもの)を1、それ以外のものを0に2値化せよ。さらにレシート明細データフレーム(df_receipt)と結合し、全期間において買い物実績のある顧客数を、作成した2値ごとにカウントせよ。
P-053# 郵便番号(postal_cd)を2値化する(東京:1, その他:0) df_tmp = df_customer[['customer_id', 'postal_cd']].copy() df_tmp['postal_flg'] = df_tmp['postal_cd'].apply(lambda x: 1 if 100 <= int(x[0:3]) <=209 else 0) # レシート明細データフレーム(df_receipt)と結合(pd.merge(df1, df2, on='キー', how='inner')) # ユニークな要素の個数(重複のない個数)をcustomer_idごとに算出(pandas.DataFrame.nunique()) pd.merge(df_tmp, df_receipt, on='customer_id', how='inner') \ .groupby('postal_flg').agg({'customer_id': 'nunique'}) # (別解) np.whereの使い方はP-052を参考 df_tmp = df_customer[['customer_id', 'postal_cd']].copy() df_tmp['postal_flg'] = np.where(df_tmp['postal_cd'].str[0:3].astype(int) .between(100, 209), 1, 0) pd.merge(df_tmp, df_receipt, how='inner', on='customer_id'). \ groupby('postal_flg').agg({'customer_id':'nunique'})P-054: 顧客データデータフレーム(df_customer)の住所(address)は、埼玉県、千葉県、東京都、神奈川県のいずれかとなっている。都道府県毎にコード値を作成し、顧客ID、住所とともに抽出せよ。値は埼玉県を11、千葉県を12、東京都を13、神奈川県を14とすること。結果は10件表示させれば良い。
P-054# 住所(address)の都道府県部分を抽出し、それぞれ値をつける # map()の引数に辞書dict({key: value})を指定すると、keyと一致する要素がvalueに置き換えられる。 pd.concat([df_customer[['customer_id', 'address']], df_customer['address'].str[0:3] \ .map({'埼玉県': '11', '千葉県': '12', '東京都': '13', '神奈川': '14'})], axis=1).head(10)参考: pandas.Seriesのmapメソッドで列の要素を置換
P-055: レシート明細データフレーム(df_receipt)の売上金額(amount)を顧客ID(customer_id)ごとに合計し、その合計金額の四分位点を求めよ。その上で、顧客ごとの売上金額合計に対して以下の基準でカテゴリ値を作成し、顧客ID、売上金額と合計ともに表示せよ。カテゴリ値は上から順に1〜4とする。結果は10件表示させれば良い。
P-055# 顧客ID(customer_id)ごとにグループ分け(groupby)し、売上金額(amount)を合計する(sum) df_sales_amount = df_receipt[['customer_id', 'amount']].groupby('customer_id').sum().reset_index() # 売上金額(amount)ごとに四分位点を求める。(25パーセンタイル: 25pct, 50パーセンタイル: 50pct, 75パーセンタイル: 75pct) pct25 = np.quantile(df_sales_amount['amount'], 0.25) pct50 = np.quantile(df_sales_amount['amount'], 0.5) pct75 = np.quantile(df_sales_amount['amount'], 0.75) # カテゴリ値の関数を作成し、適用する def pct_group(x): if x < pct25: return 1 elif pct25 <= x < pct50: return 2 elif pct50 <= x < pct75: return 3 elif pct75 <= x: return 4 # applyを用いてpct_groupを各行に適用する df_sales_amount['pct_group'] = df_sales_amount['amount'].apply(lambda x: pct_group(x)) df_sales_amount参考: pandasのcut, qcut関数でビニング処理(ビン分割)
P-056: 顧客データフレーム(df_customer)の年齢(age)をもとに10歳刻みで年代を算出し、顧客ID(customer_id)、生年月日(birth_day)とともに抽出せよ。ただし、60歳以上は全て60歳代とすること。年代を表すカテゴリ名は任意とする。先頭10件を表示させればよい。
P-056# 年齢(age)を10歳刻みで年代を算出 # math.floorで切り捨て。min(, 60)で60以上が出力されない。 df_customer_era = pd.concat([df_customer[['customer_id', 'birth_day']], df_customer['age'].apply(lambda x: math.floor(x / 10) * 10, 60)], axis=1) df_customer_era.head(10) # (別解) # 年齢(age)を(10代未満、10代、20代、30代、40代、50代、60代以上)で分ける。(flg_age) def age_group(x): if x < 10: return '10代未満' elif 10 <= x <20: return '10代' elif 20 <= x < 30: return '20代' elif 30 <= x < 40: return '30代' elif 40 <= x < 50: return '40代' elif 50 <= x < 60: return '50代' elif 60 <= x: return '60代以上' df_customer['flg_age'] = df_customer['age'].apply(lambda x: age_group(int(x))) # 顧客ID(customer_id)、生年月日(birth_day)とともに抽出 df_customer[['customer_id', 'birth_day', 'flg_age']].head(10)P-057: 前問題の抽出結果と性別(gender)を組み合わせ、新たに性別×年代の組み合わせを表すカテゴリデータを作成せよ。組み合わせを表すカテゴリの値は任意とする。先頭10件を表示させればよい。
P-057# カテゴリーデータ(性別x年代)'gender_era'を作成する # ageはint型なのでastype(str)で変換する df_customer_era['gender_era'] = df_customer['gender_cd'] + df_customer_era['age'].astype(str) df_customer_era.head(10)P-058: 顧客データフレーム(df_customer)の性別コード(gender_cd)をダミー変数化し、顧客ID(customer_id)とともに抽出せよ。結果は10件表示させれば良い。
P-058# 性別コード(gender_cd)をダミー変数化する(get_dummies) # 引数columnsにダミー化したい列の列名をリストで指定 pd.get_dummies(df_customer[['customer_id', 'gender_cd']], columns=['gender_cd'])参考: pandasでカテゴリ変数をダミー変数に変換(get_dummies)
P-059: レシート明細データフレーム(df_receipt)の売上金額(amount)を顧客ID(customer_id)ごとに合計し、合計した売上金額を平均0、標準偏差1に標準化して顧客ID、売上金額合計とともに表示せよ。標準化に使用する標準偏差は、不偏標準偏差と標本標準偏差のどちらでも良いものとする。ただし、顧客IDが"Z"から始まるのものは非会員を表すため、除外して計算すること。結果は10件表示させれば良い。
P-059# 顧客IDが"Z"から始まるのものを除外し、顧客ID(customer_id)ごとに売上金額(amount)を合計する df_sales_amount = df_receipt.query("not customer_id.str.startswith('Z')", engine='python') \ .groupby('customer_id').agg({'amount': 'sum'}).reset_index() # 売り上げ金額を標準化する df_sales_amount['amount_ss'] = preprocessing.scale(df_sales_amount['amount']) df_sales_amount.head(10) # (別解) # コード例2(fitを行うことで、別のデータでも同じの平均・標準偏差で標準化を行える) df_sales_amount = df_receipt.query('not customer_id.str.startswith("Z")', engine='python'). \ groupby('customer_id').agg({'amount':'sum'}).reset_index() scaler = preprocessing.StandardScaler() scaler.fit(df_sales_amount[['amount']]) df_sales_amount['amount_ss'] = scaler.transform(df_sales_amount[['amount']]) df_sales_amount.head(10)参考: Pythonで正規化・標準化(リスト、NumPy配列、pandas.DataFrame)
P-060: レシート明細データフレーム(df_receipt)の売上金額(amount)を顧客ID(customer_id)ごとに合計し、合計した売上金額を最小値0、最大値1に正規化して顧客ID、売上金額合計とともに表示せよ。ただし、顧客IDが"Z"から始まるのものは非会員を表すため、除外して計算すること。結果は10件表示させれば良い。
P-060# 売上金額(amount)を顧客ID(customer_id)ごとに合計 df_sales_amount = df_receipt.query("not customer_id.str.startswith('Z')", engine='python') \ .groupby('customer_id').agg({'amount': 'sum'}).reset_index() df_sales_amount # 売上金額を最小値0、最大値1に正規化(preprocessing.minmax_scale) df_sales_amount['amount_mm'] = preprocessing.minmax_scale(df_sales_amount['amount']) df_sales_amount.head(10) # (別解) # コード例2(fitを行うことで、別のデータでも同じの平均・標準偏差で標準化を行える) df_sales_amount = df_receipt.query('not customer_id.str.startswith("Z")', engine='python'). \ groupby('customer_id').agg({'amount':'sum'}).reset_index() scaler = preprocessing.MinMaxScaler() scaler.fit(df_sales_amount[['amount']]) df_sales_amount['amount_mm'] = scaler.transform(df_sales_amount[['amount']]) df_sales_amount.head(10)参考: Pythonで正規化・標準化(リスト、NumPy配列、pandas.DataFrame)
3. 参考文献
データサイエンス100本ノック
Macでデータサイエンス100本ノックを動かす方法4. 所感
40以降難易度が上がった。写経でもいいので何が書かれているか言語化する。

- 投稿日:2020-08-24T20:57:25+09:00
【競プロ初心者向け】Pythonで競技プログラミングを始める上で覚えるべき3つの入力方法
2020年8月22日に競技プログラミングにPythonでデビューを果たしました。
参加したのは、日本で競技プログラミングといえばまっさきに思い浮かぶAtCoderです。新しく学び始めたPythonをようと、実際にはその前に会員登録して、始める準備万端でした。
過去問を解いた時に??ってなってしまい、心の物置部屋にそっとAtCoderに登録したことをおいてきていました。なぜ競技プログラミングに取り組めなかったのか?
その理由はシンプルです。
そもそもPythonでの標準入力の部分で躓いたからorz
もちろんそれまでにPythonの入門書も読破していたので、入力方法についてもinput使えばいいことはわかっていました。
しかし、inputに関する理解が圧倒的に足りていませんでした。Python入門書で扱うinputといえば
inputっていえば、Python入門書で環境セットアップ後の1,2章のところで登場します。
サンプルコードは控えますが、だいたいこんなアウトプットになるサンプルコードが掲載されています。$:テキストを入力してね!:○○ $:こんにちは!○○その後の章に進んでも、inputの様々な使い方を学ぶよりも、他の内容についての勉強にいきがちです。
その結果、inputについてわかっても、理解にまでは至っていなかったです。
それを競技プログラミングにチャレンジして思い知らされました。
あっという間に頭がフリーズし、AtCoderのタブを閉じてしまいました・・・過去問を解いて分かった覚えるべき3つのinputの使い方
そんな中、きちんとコードを書く機会を増やしたことで、再び競技プログラミングに挑もうという意欲が湧いてきたので、AtCoderに再度舞い戻ってきました。
「今回は俺わからなくても、フリーズせずにググろうと思うんだ」
という決意の元、入力の方法からしっかり調べてみたところ、A,B問題はクリアできるようになりました。
C問題は、計算量O(N^2)に苦戦し、制限時間をオーバー「TLE」の壁に苦しみます…そんな中、自分が躓いて投げ出してしまった導入部分の「標準入力」は主に以下の3つに集約されることが判明しました。
1つの整数を入力
a = int(input())1行で入力する整数が1個のパターンです。2020年8月22日のAtCoder Beginner Contest 176のB問題がこのパターンでした。
ただ、1つの整数だけを入力するというケースは少なく、基本的に後述する2つのパターンと組み合わせて出題されるケースが多いです。複数個の整数を入力
a,b,c = map(int,input().split())入力する整数の数が増えて、複数個になるパターンです。AtCoder Beginner Contest 176のA問題がこのパターンでした。
1行で整数を複数入力する際には、スペースで区切るため、分割できるようにsplit()が組み込まれています。リストとして整数を入力
A = list(map(int,input().split()))入力する数が決まっていない場合に、入力した整数をリストに格納します。AtCoder Beginner Contest 176のC問題が1個の整数入力と、リストによる整数入力を組み合わせた形でした。
この3つの入力方法を覚えれば、競技プログラミングの最初のつまづきポイントである標準入力を回避することができます。
もちろん、他にも色々な入力形式がありますが、あまり追求すると、頭がオーバーヒートします。
覚えられないと高らかに宣言することも大切です。まとめ・終わりに
競技プログラミングで最初のつまづき「標準入力」は以下の3つで回避
# 1つの整数を入力 a = int(input()) # 複数個の整数を入力 a,b,c = map(int,input().split()) # リストとして整数を入力 A = list(map(int,input().split()))A問題、B問題が解けると競技プログラミングへの意欲が湧いてきます!
- 投稿日:2020-08-24T20:39:05+09:00
【Lambda】import requests が使えるようにする【python】
やること
↓これを実行したら
↓こうなってほしい
↓しかし、こうなってしまう
{ "errorMessage": "Unable to import module 'lambda_function': No module named 'requests'", "errorType": "Runtime.ImportModuleError" }手順概要
- requests が動くようにLayerファイル(zip)を作る
- LambdaにLayerファイルをアップロードする
- Layerを使って関数を作る
Layerファイルを作ります
クライアントで作業します。
pipが動くようにして、外部モジュールを入れたものをzipしてaws管理コンソールから入れるだけ例えば、amazon linux2で作業する場合は…
mkdir python/ cd python yum -y install gcc gcc-c++ kernel-devel python-devel libxslt-devel libffi-devel openssl-devel yum -y install python-pip pip install -t ./ requests cd python cd .. zip -r Layer.zip python/zipをLambdaに登録します
AWS管理コンソールで作業します。
「レイヤーの作成」で、先ほど作ったLayer.zipファイルを入れれば終わりです。関数の準備
Layersを選択して
「レイヤーの追加」押下で先ほど作ったレイヤーが出てきますので、選択。
関数の作成
lambda_function.pyimport requests def lambda_handler(event, context): # テストサイトにGETを投げてみる response = requests.get('https://httpbin.org/get', params={'foo': 'bar'}) return response.json()実行結果{ "args": { "foo": "bar" }, "headers": { "Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Host": "httpbin.org", "User-Agent": "python-requests/2.24.0", "X-Amzn-Trace-Id": "Root=1-5f43a5ad-a04c8100f8c999999e8e2e" }, "origin": "913.931.998.950", "url": "https://httpbin.org/get?foo=bar" }






- 投稿日:2020-08-24T20:24:15+09:00
逆ガンマ関数をpythonで実装してみた
導入
Pythonで逆ガンマ関数からサンプリングを行いたいのに、scipyに実装されているinvgamma1はなぜか片方のパラメータがいじれない仕様になっていたので(次の節で出てくる関数のパラメータβがβ=1で固定:理由を知っている人がいたら教えてください)、練習(pythonとQiitaへの投稿の両方)がてら作ってみました(備忘録込み)。
逆ガンマ関数とは
逆ガンマ関数とは、以下の形で表される連続な確率分布です。
f(x,α,β) = \frac{β^α}{Γ(α)}x^{-α-1}e^{\frac{-β}{x}} (x>0)\\ (ただし Γ(α) = \int_{0}^{∞}x^{α-1}e^{-x}dx で表されるガンマ関数)scipyのinvgammaがなんでβ=1で固定なのかよく分かりませんが(自分の分野以外のことはたいして知らない...)、私はMCMC(マルコフ連鎖モンテカルロ法)で正規分布の分散の事前分布に使用する時に、β=1以外も使いたいので今回この記事を書きました。MCMCを詳しく知りたい方は@pynomiさんの記事2を見るといいと思います。
実際に書いてみた
from scipy import stats from scipy.special import gamma import numpy as np ###逆ガンマ分布の確率密度関数### class invgamma(stats.rv_continuous): def _pdf(self, x,alpha,beta): px = (beta**alpha)/gamma(alpha)*x**(-alpha-1)*np.exp(-beta/x) return px ###逆ガンマ関数からサンプリング### invgamma = invgamma(name="invgamma", a=0.0) sample_from_invgamma = invgamma.rvs(size=1, alpha = 1, beta = 1.0)こんな感じ。
(OS:Windows10, Python3.7, 開発環境:Spyderで動作確認済み、β=1として乱数を固定したとき、scipyのinvgammaとサンプリングの値が一致したので、多分あってると思います。)引用
この記事とコードを書くに当たって、@physics303さんの記事3も参考にしました。ありがとうございます。
- 投稿日:2020-08-24T20:13:12+09:00
Matplotlib備忘録
概要
Matplotlibで覚えておきたいことをメモ
(神記事ありました、こちらで全て済むかも笑)タスク
1. 折れ線グラフ
方法
1で扱うサンプル
head head head sample1 sample2 sample3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 10 20 30 10 20 30 10 20 30 10 20 30 10 20 30 10 20 30 10 20 30 10 20 30 10 20 30 10 20 30 10 20 30 10 20 30 100 200 300 100 200 300 100 200 300 100 200 300 100 200 300 100 200 300 100 200 300 100 200 300 100 200 300 100 200 300 100 200 300 100 200 300 100 200 300 1. 折れ線グラフ
import matplotlib as mpl import matplotlib.pyplot as plt df = pd.read_csv("./matplotlib1.csv") name="sample1" x = df.index y = df[name] plt.figure(figsize=(6, 4), dpi=72, tight_layout=True) plt.title('タイトル') plt.tick_params(bottom=False) plt.plot(x, y, label=name) plt.ylabel("value") plt.xlabel("index") plt.legend(loc="upper left",bbox_to_anchor=(1, 1)) plt.grid()出力!
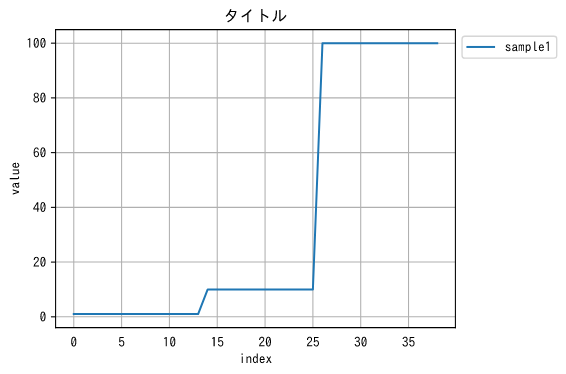
- 投稿日:2020-08-24T19:52:45+09:00
[Python]gspread-formattingで行の固定+一行おきに色付け
目的
自動でスプレッドシートを見易くするためにgspreadを用いて行の固定と色付けをしたい。
サンプルシート
こちらのシートを使用。
コード
import gspread from gspread_formatting import * from oauth2client.service_account import ServiceAccountCredentials from pydrive.auth import GoogleAuth from pydrive.drive import GoogleDrive import os # 数値からアルファベットを求める def num2alpha(num): if num<=26: return chr(64+num) elif num%26==0: return num2alpha(num//26-1)+chr(90) else: return num2alpha(num//26)+chr(64+num%26) """ スプレッドシート内フォーマット設定 """ # ヘッダー行 header_fmt = cellFormat( backgroundColor=color(1, 0.7, 0.3), textFormat=textFormat(bold=True, foregroundColor=color(0, 0, 0)), horizontalAlignment='CENTER' ) # データ行 data_fmt = cellFormat( backgroundColor=color(1, 0.9, 0.7) ) """ スプレッドシート編集 """ # 自身が格納されているパス abs_path = f'{os.path.dirname(os.path.abspath(__file__))}\\' # GoogleAPI scope = ['https://spreadsheets.google.com/feeds', 'https://www.googleapis.com/auth/drive'] # 認証用キー json_keyfile_path = f'{abs_path}credentials.json' # サービスアカウントキーを読み込む credentials = ServiceAccountCredentials.from_json_keyfile_name(json_keyfile_path, scope) # pydrive用にOAuth認証を行う gauth = GoogleAuth() gauth.credentials = credentials drive = GoogleDrive(gauth) # スプレッドシート格納フォルダ folder_id = 'フォルダID' # スプレッドシート格納フォルダ内のファイル一覧取得 file_list = drive.ListFile({'q': "'%s' in parents and trashed=false" % folder_id}).GetList() # ファイル一覧からファイル名のみを抽出 title_list = [file['title'] for file in file_list] # gspread用に認証 gc = gspread.authorize(credentials) # スプレッドシートID sheet_id = [file['id'] for file in file_list if file['title'] == 'test'] sheet_id = sheet_id[0] # ワークブックを開く workbook = gc.open_by_key(sheet_id) # ワークシートを開く worksheet = workbook.worksheet('シート1') # 入力されている最終列を取得 last_column_num = len(list(worksheet.row_values(1))) # 最終列を数値→アルファベットへ変換 last_column_alp = num2alpha(last_column_num) # フィルタをかける worksheet.set_basic_filter(name=(f'A:{last_column_alp}')) # 一行目を固定する worksheet.freeze(rows=1) # ヘッダー行の色付け+太字+中央揃え format_cell_range(worksheet, f'A1:{last_column_alp}1', header_fmt) # 入力されているデータの最終行取得 last_row_num = len(list(worksheet.col_values(1))) # データ行を一行おきに色付け for row in range(2, last_row_num + 1, 2): format_cell_range(worksheet, f'A{row}:{last_column_alp}{row}', data_fmt)実行結果
コードの説明
順を追って説明します。
フォーマット設定
""" スプレッドシート内フォーマット設定 """ # ヘッダー行 header_fmt = cellFormat( backgroundColor=color(1, 0.7, 0.3), textFormat=textFormat(bold=True, foregroundColor=color(0, 0, 0)), horizontalAlignment='CENTER' ) # データ行 data_fmt = cellFormat( backgroundColor=color(1, 0.9, 0.7) )フォーマット設定部分。
backgroundColorで色を設定。
(R,G,Bを0~1の数値で任意に設定する)
textFormatで太文字、文字色を設定。
horizontalAlignmentで文字位置を設定。参考リンクは下記。
PythonでGoogleSpreadSheetのセルにコメントを付加したり色や枠線をつけるGoogleドライブへアクセス~フィルタをかける
筆者が投稿した過去記事を参照してください。
[Python]gspreadでスプレッドシートにフィルタをかける一行目を固定
# 一行目を固定する worksheet.freeze(rows=1)rowsで任意の行数を指定してあげれば好きな箇所で固定出来ます。
ヘッダー行の色付け+太字+中央揃え
# ヘッダー行の色付け+太字+中央揃え format_cell_range(worksheet, f'A1:{last_column_alp}1', header_fmt)引数は(編集したいワークシート、セルの範囲(A1~C1)、フォーマット)です。
データ行を一行おきに色付け
# 入力されているデータの最終行取得 last_row_num = len(list(worksheet.col_values(1))) # データ行を一行おきに色付け for row in range(2, last_row_num + 1, 2): format_cell_range(worksheet, f'A{row}:{last_column_alp}{row}', data_fmt)データ入力行の最終行を取得
↓
二行目から一行おきに最終行までループで色付けという処理の流れ。
これで一行おきに色付けが出来ました。
リクエスト制限を考慮する
先程のサンプルでは行数が少ないので上記コードで問題ないですが、行数が増えるとスプレッドシートのリクエスト制限に引っ掛かってエラーで落ちます。
(100 秒あたりのリクエスト数100件等の制限があります)この制限に引っ掛からないように改修します。
改修前のコードはこのように一行ずつ選択→色付け→一行選択...という処理。
改修後はこのように一括選択→色付けという処理に変更。
これでリクエスト回数を減らすというわけです。コード
#リストへデータ部分の色付け範囲とフォーマットをタプル型で格納 ranges = [(f'A{row}:{last_column_alp}{row}', data_fmt) for row in range(2, last_row_num + 1, 2)] print(ranges) #作成したリストの先頭にヘッダー部分のフォーマットを格納 ranges.insert(0, (f'A1:{last_column_alp}1', header_fmt)) print(ranges) #一括で色付け format_cell_ranges(worksheet, ranges)実行結果[('A2:C2', <CellFormat backgroundColor=(red=1;green=0.9;blue=0.7)>), ('A4:C4', <CellFormat backgroundColor=(red=1;green=0.9;blue=0.7)>)] [('A1:C1', <CellFormat backgroundColor=(red=1;green=0.7;blue=0.3);horizontalAlignment=CENTER;textFormat=(foregroundColor=(red=0;green=0;blue=0);bold=True)>), ('A2:C2', <CellFormat backgroundColor=(red=1;green=0.9;blue=0.7)>), ('A4:C4', <CellFormat backgroundColor=(red=1;green=0.9;blue=0.7)>)]リストへ色付けしたい範囲を全て格納
↓
一括で色付けという処理です。
(実行結果部分でrangesの中身を表示させているので参考にして下さい)先程と違ってformat_cell_rangesというモジュールを使用しています。
公式サンプル
fmt = cellFormat( backgroundColor=color(1, 0.9, 0.9), textFormat=textFormat(bold=True, foregroundColor=color(1, 0, 1)), horizontalAlignment='CENTER' ) fmt2 = cellFormat( backgroundColor=color(0.9, 0.9, 0.9), horizontalAlignment='RIGHT' ) format_cell_ranges(worksheet, [('A1:J1', fmt), ('K1:K200', fmt2)])このようにリスト内にタプルで範囲とフォーマットを格納することによって一括処理が出来るようになっています。
これで制限に引っ掛かる事無く行固定+一行おきに色付けが可能!
公式リンク



- 投稿日:2020-08-24T19:00:32+09:00
Web-WF Python Tornado その3(Openpyexcelの紹介)
はじめに
webServer APIServerとして、かんたん・すぐれている(と思っている)Tornadoを何回かにわけて紹介したいと思います
Web-WF Python Tornado その1
Web-WF Python Tornado その2
Web-WF Python Tornado その3 (この記事対象
フルスタックエンジニア、フロントエンジニア、Pythonが好きな人、その1・その2を読んだ人、Excelでなにか資料を出力する必要に迫られた人
Python3.6以上、tornadoがインストールされている
ゴール
今回はちょっと趣向をかえてアプリケーションにあると便利なモジュールの紹介
(Openpyxl)Openpyxlとは
pythonからExcelファイルを読み書き編集できるモジュール
集計結果をExcelでレポート出力したり、逆にExcelのデータをインポートするのに便利です
今回は請求書を出力するサンプルを作成します
公式はこちらインストール
Openpyxlのインストールはpipのみ
$ pip install openpyxlexcelテンプレートの準備
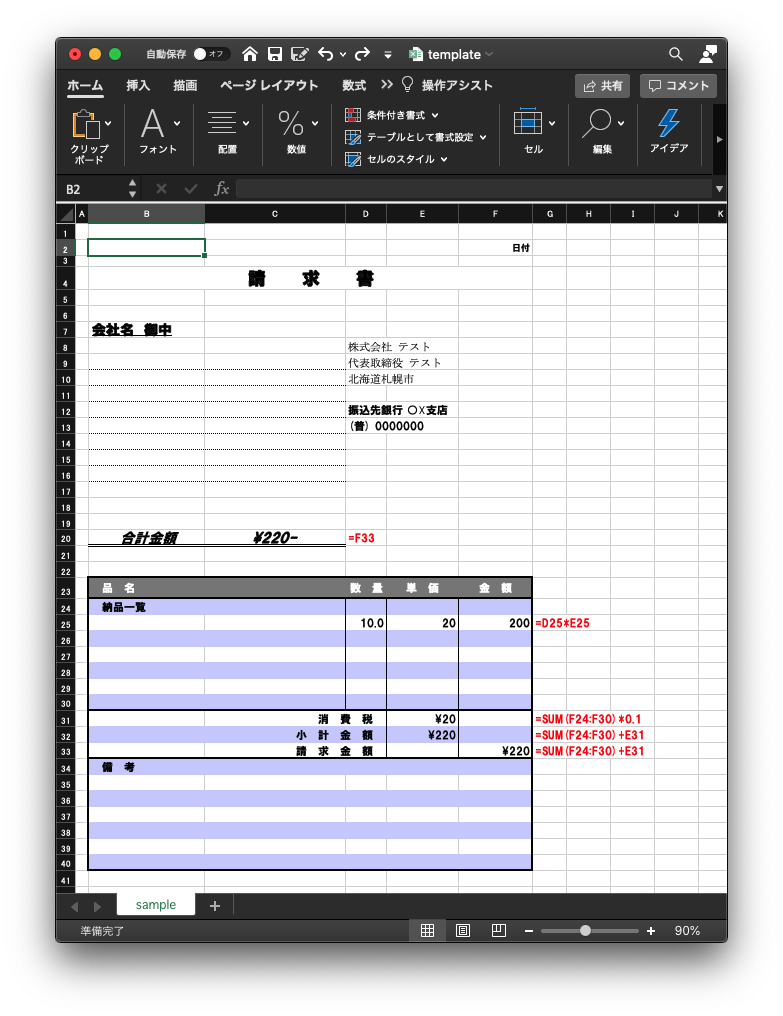
以下のようなテンプレートを準備しておきます
(赤字の部分はマクロのサンプル)
ソースコード
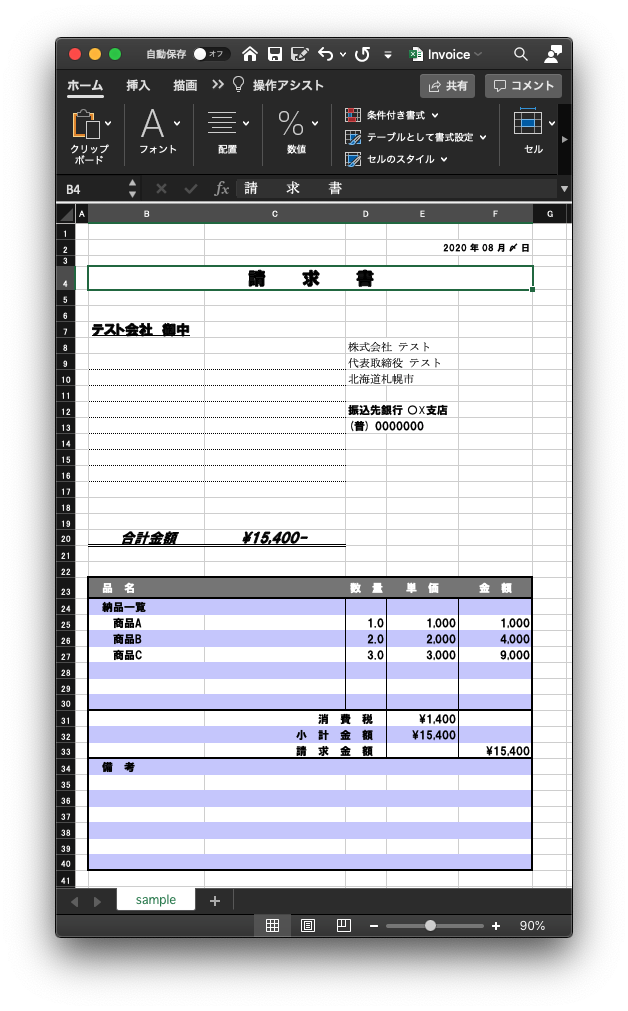
その1やその2で紹介したソースに以下のソースを追加しておきます
main.pyimport os import datetime import openpyxl as px from openpyxl.writer.excel import save_virtual_workbook class prtInvoice(tornado.web.RequestHandler): def get(self): # 請求書のtemplateをLoad wb = px.load_workbook(BASE_DIR+u'/template.xlsx') ws = wb.active # 印刷範囲を指定 ws.page_setup.fitToWidth = 1 ws.page_setup.fitToHeight = 0 ws.sheet_properties.pageSetUpPr.fitToPage = True # こんなmodelを準備(実際にはDBなどから model = { 'companyName': 'テスト会社', 'items': [ {'itemName': '商品A', 'price': 1000, 'quantity': 1}, {'itemName': '商品B', 'price': 2000, 'quantity': 2}, {'itemName': '商品C', 'price': 3000, 'quantity': 3} ] } # 今日の日付をセット # F2はセルのExcelのセル dt_now = datetime.datetime.now() ws['F2'] = dt_now.strftime("%Y 年 %m 月 〆 日") # 会社名をセット ws['B7'] = '{0} 御中'.format(model['companyName']) for i, item in enumerate(model['items']): # 商品名をセット ws['B'+str(i+25)] = ' {0}'.format(item['itemName']) # 数量をセット ws['D'+str(i+25)] = item['quantity'] # 単価をセット ws['E'+str(i+25)] = item['price'] # Excel形式でダウンロード self.set_header('Cache-Control', 'no-store, no-cache, must-revalidate, max-age=0') self.set_header( 'Content-Type', 'application/vnd.openxmlformats-officedocument.spreadsheetml.sheet') fileName = "Invoice.xlsx" self.set_header('Content-Disposition', "attachment; filename=\"{}\"".format(fileName)) self.write(save_virtual_workbook(wb)) def make_app(): return tornado.web.Application( [ (r"/html", htmlHandler), (r"/json", jsonHandler), (r"/excel", prtInvoice), ], debug=True, )ws['B7'] = 'Hello'こんなふうに、Excelのセルにデータをセットしたり、読み込んだりできるのがこのモジュールの特徴となります
実行&閲覧
以下のようにURLを直接指定することでExcelファイルをダウンロードすることができます
(クライアントのダウンロードフォルダに直接保存される)
ダウンロードしたExcelファイルを開くと
はい、なんとかそれっぽいデータが表示できました
- 投稿日:2020-08-24T17:20:30+09:00
[Python]gspreadでスプレッドシートにフィルタをかける
目的
gspreadを用いてスプレッドシートにフィルタをかけたい。
公式リファレンス以外に手順が載っていない(自分調べ)ので紹介。サンプルシート
このシートを使います。
コード
import gspread from oauth2client.service_account import ServiceAccountCredentials from pydrive.auth import GoogleAuth from pydrive.drive import GoogleDrive import os # 数値からアルファベットを求める def num2alpha(num): if num<=26: return chr(64+num) elif num%26==0: return num2alpha(num//26-1)+chr(90) else: return num2alpha(num//26)+chr(64+num%26) # 自身が格納されているパス abs_path = f'{os.path.dirname(os.path.abspath(__file__))}\\' # GoogleAPI scope = ['https://spreadsheets.google.com/feeds', 'https://www.googleapis.com/auth/drive'] # 認証用キー json_keyfile_path = f'{abs_path}credentials.json' # サービスアカウントキーを読み込む credentials = ServiceAccountCredentials.from_json_keyfile_name(json_keyfile_path, scope) # pydrive用にOAuth認証を行う gauth = GoogleAuth() gauth.credentials = credentials drive = GoogleDrive(gauth) # スプレッドシート格納フォルダ folder_id = 'フォルダID' # スプレッドシート格納フォルダ内のファイル一覧取得 file_list = drive.ListFile({'q': "'%s' in parents and trashed=false" % folder_id}).GetList() # ファイル一覧からファイル名のみを抽出 title_list = [file['title'] for file in file_list] # gspread用に認証 gc = gspread.authorize(credentials) # スプレッドシートID sheet_id = [file['id'] for file in file_list if file['title'] == 'test'] sheet_id = sheet_id[0] # ワークブックを開く workbook = gc.open_by_key(sheet_id) # ワークシートを開く worksheet = workbook.worksheet('シート1') # 入力されている最終列を取得 last_column_num = len(list(worksheet.row_values(1))) print(f'last_column_num:{last_column_num}') # 最終列を数値→アルファベットへ変換 last_column_alp = num2alpha(last_column_num) print(f'last_column_alp:{last_column_alp}') # フィルタをかける worksheet.set_basic_filter(name=(f'A:{last_column_alp}'))実行結果last_column_num:3 last_column_alp:C
コードの説明
順を追って説明していきます。
ワークブックの展開
# 自身が格納されているパス abs_path = f'{os.path.dirname(os.path.abspath(__file__))}\\' # GoogleAPI scope = ['https://spreadsheets.google.com/feeds', 'https://www.googleapis.com/auth/drive'] # 認証用キー json_keyfile_path = f'{abs_path}credentials.json' # サービスアカウントキーを読み込む credentials = ServiceAccountCredentials.from_json_keyfile_name(json_keyfile_path, scope) # pydrive用にOAuth認証を行う gauth = GoogleAuth() gauth.credentials = credentials drive = GoogleDrive(gauth) # スプレッドシート格納フォルダ folder_id = 'フォルダID' # スプレッドシート格納フォルダ内のファイル一覧取得 file_list = drive.ListFile({'q': "'%s' in parents and trashed=false" % folder_id}).GetList() # ファイル一覧からファイル名のみを抽出 title_list = [file['title'] for file in file_list] # gspread用に認証 gc = gspread.authorize(credentials) # スプレッドシートID sheet_id = [file['id'] for file in file_list if file['title'] == 'test'] sheet_id = sheet_id[0] # ワークブックを開く workbook = gc.open_by_key(sheet_id)まず、この部分で
認証用キーの指定
↓
Googleドライブへアクセス
↓
スプレッドシート格納フォルダを指定
↓
ファイル名(スプレッドシート名)を指定してワークブックを開くという処理を行っています。
詳細は下記の記事を参考にして下さい。
pythonでGoogle Driveの任意のフォルダにスプレッドシートを作成・編集する
PythonでGoogleスプレッドシートを編集フィルタをかける
ここから本題のフィルタ部分です。
# ワークシートを開く worksheet = workbook.worksheet('シート1')まずはワークシートを展開します。
今回は「シート1」という名称なのでシート1と指定します。# 入力されている最終列を取得 last_column_num = len(list(worksheet.row_values(1))) print(f'last_column_num:{last_column_num}')次に対象のワークシートに入力されているデータの最終列を取得します。
実行結果last_column_num:3先程貼ったシートを見て頂ければわかりますが3列目なので上手く取得出来ていますね。
ただ、このままではフィルタをかける事が出来ないので「3列目」をアルファベット形式に変換する必要があります。
(数値でも試しましたが上手く動作しなかったのでライブラリの仕様だと思われます)# 数値からアルファベットを求める def num2alpha(num): if num<=26: return chr(64+num) elif num%26==0: return num2alpha(num//26-1)+chr(90) else: return num2alpha(num//26)+chr(64+num%26) # 最終列を数値→アルファベットへ変換 last_column_alp = num2alpha(last_column_num) print(f'last_column_alp:{last_column_alp}')実行結果last_column_alp:C3→Cへ上手く変換出来ました。
変換用の関数は下記の記事の物を使用させて頂きました。
Pythonで数値とアルファベットを何桁でも相互変換する方法そして最後にフィルタをかけます。
# フィルタをかける worksheet.set_basic_filter(name=(f'A:{last_column_alp}'))これで完成です。
「開始列:終了列」という形式で指定すれば任意の列にフィルタがかかります。
今回のケースではA~C列にフィルタをかけたいので上記のような指定となります。
リファレンス


- 投稿日:2020-08-24T17:16:59+09:00
【Python】cachetoolsを利用した処理の高速化
- キャッシュを利用した処理の高速化が、pythonでも可能かどうかを調査。
- 結果、cachetoolsというライブラリを利用して容易に利用できることが判明。
- そこで今回はライブラリの概要と処理の記述例を記載。
- ※この内容では、概要や結果イメージ・基本記述を扱うため、詳細内容はドキュメントを参考。
概要
- cachetoolsとは、キャッシュを利用した高速化処理(メモ化)をまとめたコレクションライブラリ。
- 特徴は以下。
- 少ない記述で、多くのキャッシュアルゴリズムを扱うことができる。
- 拡張可能で、用途や環境に合わせて適切な仕組みへ変更することが可能。
- データはRAMに保存される。
- Github : cachetools
結果
- 以下の2枚の比較画像のように、少ない記述で容易に重たい処理を高速化することが可能。
環境
- Google Colaboratory
インストール
- 以下のコマンドで、cachetoolsライブラリをインストールする。
pip install cachetools記述例
※この内容では、概要や結果イメージ・基本記述を扱うため、詳細内容はドキュメントを参考。
基本
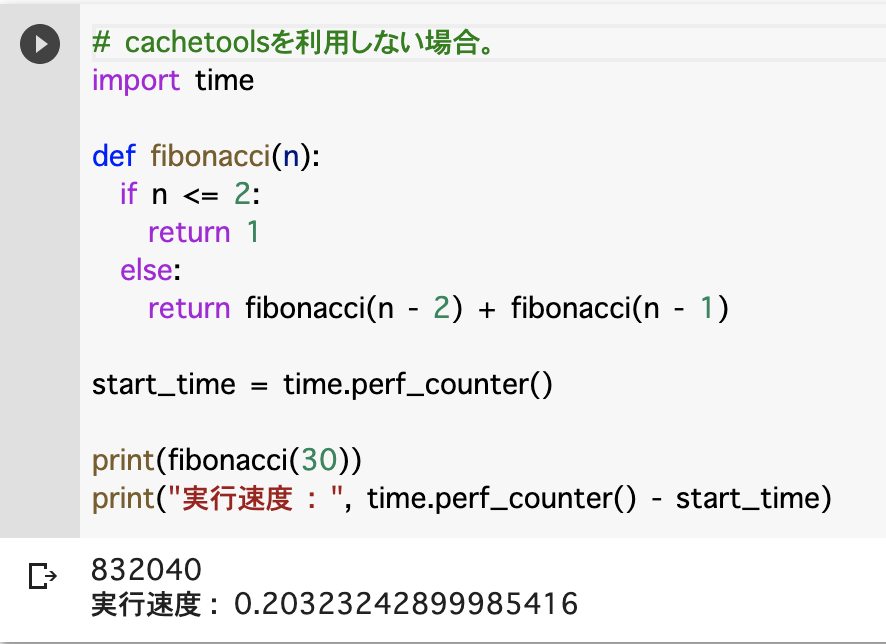
- 標準(オプション指定無し)のキャッシュ処理を利用する場合。
# ライブラリの読み込み from cachetools import cached # キャッシュ有効化 @cached(cache ={}) def fibonacci(n): if n <= 2: return 1 else: return fibonacci(n - 2) + fibonacci(n - 1) print(fibonacci(30))各オプション
- 以下利用できるキャッシュ処理の種類は下記。
名前 内容 TTLCache キャッシュの存続可能時間指定。
存続可能時間を超えたものにはアクセス不可。
最も使用頻度の低いアイテムから破棄される。LFUCache 最小使用頻度。アイテム取得頻度を計測して、最も頻繁に使用されていないものから破棄 LRUCache 最長未使用頻度。最も長く使用されていないものから破棄 RRCache ランダム。アイテムをランダムに選択して、そこから破棄
- 以下、記述例
# ライブラリの読み込み from cachetools import cached, LFUCache, TTLCache, RRCache @cached(cache=LFUCache(maxsize=10)) # 最大保持数 def get_all_item: # 処理 @cached(cache=TTLCache(maxsize=10, ttl=300)) # 最大保持数と存続可能時間 def get_user_item: # 処理 @cached(cache=RRCache(maxsize=10, choice=min)) # 最大保持数と任意の要素を返す代替関数 def get_random: # 処理。cache.choiceで指定関数(min)の呼び出し可能。参考

- 投稿日:2020-08-24T16:58:39+09:00
便利! AtCoder で競技プログラミングをするときに重宝する AtCoder Tools のご紹介
はじめに
AtCoder の問題を解くとき、みなさんはどのようにプログラミングしていますか? 基本的にはローカル環境のエディタでプログラムを書いて提出することになるかと思います。
問題を解いていると、こういった要望が出てきます。
- 一通りできた! 問題文に載っている入力値でテストしたい!
- 1 つめの入力値は正しかったけど 2 つめ、3 つめはどうだろう? 一つずつチェックするのはめんどくさい……
- プログラム完成したから提出しよう! CLI からそのまま提出したい!
こんな要望を満たしてくれる CLI ツールが AtCoder Tools です。この記事ではインストールから基本的な使いかたまでを紹介します。
長い説明は良いからはやく使いたいんだけど?
了。最低限の使いかただけ説明します。
# インストール $ pip install atcoder-tools # 入出力値の一括ダウンロードとテンプレートからコードを生成 ## abs はコンテスト ID ## --workspace でダウンロードするパスを指定 ## --lang で自動生成するコードの言語を指定 ## --without-login でログインせずにダウンロード $ atcoder-tools gen abs --workspace=path/to/atcoder-workspace/ --lang=python --without-login # 複数の入力値に対してまとめてテストを実行 $ cd path/to/program-location $ atcoder-tools test # プログラムの提出 $ atcoder-tools submit環境
環境 バージョン インストール元 AtCoder Tools 1.1.7.1 pipenv (pip) pipenv 2020.8.13 pip pip 20.1.1 (python 3.8) pyenv Python 3.8.5 pyenv pyenv 1.2.20-3-g58c776a1 anyenv anyenv 1.1.1 Homebrew Homebrew 2.4.9 n/a macOS 10.15.6 n/a インストール方法
AtCoder Tools は Python で作られているツールです。pip を使ってインストールすることができます。Homebrew からインストールしたいところですがフォーミュラが用意されていないので今のところは pip を使ったインストール方法しかありません。
$ pip install atcoder-toolsまたは
Pipfile[[source]] url = 'https://pypi.python.org/simple' verify_ssl = true name = 'pypi' [requires] python_version = '3.8' [packages] atcoder-tools = '*'$ pip install pipenv # pipenv が未インストールの場合 $ pipenv install --system
注意点
AtCoder Tools は Python 3.5 以降でのみ動作が保証されているようです。そのため、インストールする際は pip 3 系 (Python 3 系) を使用する必要があります。
必要に応じて
pipをpip3やpip3.8などに置き換える必要があります。以下のコマンドを実行して Python 3 系であることを事前に確認してください。# 結果が Python 2 系だった場合は pip3 などを使用しましょう $ pip --version pip 20.1.1 from /Users/noraworld/.anyenv/envs/pyenv/versions/3.8.5/lib/python3.8/site-packages/pip (python 3.8)また、インストール後はシェルを再起動する必要があるかもしれません。
$ exec -l $SHELL入出力値を一括ダウンロードしたいとき
問題文に掲載されている入出力値をコピーしてファイルにペーストして……、とやっても良いですが、問題を解くごとに毎回やるのは面倒です。
AtCoder Tools を使えば以下のコマンドでコンテストの全問題の全入出力値を一括でダウンロードすることができます。
たとえば、AtCoder に登録したらまず最初にやるべきと言われている AtCoder Beginners Selection の問題全 11 問の全入出力値をダウンロードするには以下のコマンドを実行します。
$ atcoder-tools gen abs --workspace=path/to/atcoder-workspace/ --lang=python --without-loginすると
path/to/atcoder-workspace/以下にこのようにダウンロードされます。
ディレクトリツリー (クリックで展開)
. ├── ABC049C │ ├── in_1.txt │ ├── in_2.txt │ ├── in_3.txt │ ├── main.py │ ├── metadata.json │ ├── out_1.txt │ ├── out_2.txt │ └── out_3.txt ├── ABC081A │ ├── in_1.txt │ ├── in_2.txt │ ├── main.py │ ├── metadata.json │ ├── out_1.txt │ └── out_2.txt ├── ABC081B │ ├── in_1.txt │ ├── in_2.txt │ ├── in_3.txt │ ├── main.py │ ├── metadata.json │ ├── out_1.txt │ ├── out_2.txt │ └── out_3.txt ├── ABC083B │ ├── in_1.txt │ ├── in_2.txt │ ├── in_3.txt │ ├── main.py │ ├── metadata.json │ ├── out_1.txt │ ├── out_2.txt │ └── out_3.txt ├── ABC085B │ ├── in_1.txt │ ├── in_2.txt │ ├── in_3.txt │ ├── main.py │ ├── metadata.json │ ├── out_1.txt │ ├── out_2.txt │ └── out_3.txt ├── ABC085C │ ├── in_1.txt │ ├── in_2.txt │ ├── in_3.txt │ ├── in_4.txt │ ├── main.py │ ├── metadata.json │ ├── out_1.txt │ ├── out_2.txt │ ├── out_3.txt │ └── out_4.txt ├── ABC086A │ ├── in_1.txt │ ├── in_2.txt │ ├── main.py │ ├── metadata.json │ ├── out_1.txt │ └── out_2.txt ├── ABC086C │ ├── in_1.txt │ ├── in_2.txt │ ├── in_3.txt │ ├── main.py │ ├── metadata.json │ ├── out_1.txt │ ├── out_2.txt │ └── out_3.txt ├── ABC087B │ ├── in_1.txt │ ├── in_2.txt │ ├── in_3.txt │ ├── main.py │ ├── metadata.json │ ├── out_1.txt │ ├── out_2.txt │ └── out_3.txt ├── ABC088B │ ├── in_1.txt │ ├── in_2.txt │ ├── in_3.txt │ ├── main.py │ ├── metadata.json │ ├── out_1.txt │ ├── out_2.txt │ └── out_3.txt └── PracticeA ├── in_1.txt ├── in_2.txt ├── main.py ├── metadata.json ├── out_1.txt └── out_2.txt
in_*.txtというファイルが入力値、out_*.txtというのが出力値です。main.pyはテンプレートから自動生成されたコードです。
引数についての解説
genサブコマンドを使用します。続く
absはコンテスト名 (コンテスト ID) です。https://atcoder.jp/contests/<CONTEST_ID>の<CONTEST_ID>の部分です。
--workspaceオプションでダウンロードするパスを指定します。
--langでプログラミング言語を指定します。ここで指定した言語のテンプレートからコード (入力フォーマットなどを解析しているらしい) が自動生成されます。対応している言語は ここ をご覧ください。ぼくの大好きな Ruby はまだ対応していないみたい。残念!
--without-loginをつけるとログインせずにダウンロードすることができます。つけないと ID とパスワードを求められます。ログインしなくてもダウンロードできる場合はつけておくと楽でしょう。まとめるとこんな感じ。
引数 説明 省略時のデフォルト値 genサブコマンド名 (省略不可) absコンテスト ID (省略不可) --workspaceダウンロードするパス ~/atcoder-workspace--lang自動生成されるテンプレートコードの言語 cpp(C++)--without-loginログインせずに使用する nil(ログインを要求される)"gen コマンドの --without-login をデフォルトにしたい #99" という issue が上がっているのでもしかしたら今後のバージョンで
--without-loginがデフォルトになるかもしれません。毎回オプション指定するのめんどくさい……
--workspaceや--langなどのオプションを毎回指定するのはめんどくさいと思います。AtCoder Tools では、
~/.atcodertools.tomlに設定を書くことができ、オプションを省略することができます。~/.atcodertools.toml[codestyle] workspace_dir='~/Workspace/competitive_programming/atcoder/' lang='python' [etc] download_without_login=true
--workspaceで指定するパスを[codestyle]のworkspace_dirに、--langで指定する言語を[codestyle]のlangに設定します。
[etc]にdownload_without_login=trueを設定すれば--without-loginを省略できるのかなと思ったのですが、省略できませんでした (ログインを要求されてしまいました)。使いかたが間違っているのか、あるいはバグなのかもしれません。複数の入出力値でまとめてテストを行いたいとき
さて、入出力値は一通り揃いました。入力値をプログラムに与えて出力された結果と、正しい出力値を見比べる、ということをしたくなります。
AtCoder Tools を使わずに愚直にやるとこうなると思います。
$ cat in_1.txt | python main.py # 出力結果が表示される $ cat out_1.txt # 先ほどの出力結果と同じか見比べる $ cat in_2.txt | python main.py # 2 つめのテストケースについても同様に $ cat out_2.txt # 同じ結果がチェック $ cat in_3.txt | python main.py # 3 つめも $ cat out_3.txt # チェック # ... 以下同様……めんどくさいですよね。
AtCoder Tools を使えばコマンド一つでまとめてチェックできます。
$ cd path/to/program-location # プログラムと入出力ファイルがあるディレクトリに移動 $ atcoder-tools test # in_1.txt ... PASSED 163 ms # in_2.txt ... PASSED 136 ms # in_3.txt ... PASSED 130 ms Passed all test cases!!!とても便利ですね!
実行可能ファイルであれば非対応言語でも OK!
このコマンドでテストされるプログラムは実行権限のあるファイルです。
つまり、プログラムに shebang を設定して実行権限を与えれば、AtCoder Tools で対応していない言語 (たとえば Ruby) のプログラムでもテストできます!
main.rb#!/usr/bin/env ruby # ↑ 1 行目に shebang をつけて # プログラムを書く# 実行権限を与える $ chmod +x main.rb言語が対応しているかどうかというのはあくまでテンプレートから生成されるコードのことであり、テストを実行する言語には特に制限がないようですね。
オプションについて
カレントディレクトリ以外のディレクトリからテストを実行したい場合は
--dirオプションをつけることで対応できます。また、プログラム (実行権限のあるファイル) は自動検出されますが、ファイルが複数ある場合は自動的にどれかが選ばれます。複数プログラムがある場合に特定のプログラムを指定したい場合は
--execオプションをつければ良さそうな気がしますが、自分の環境ではFileNotFoundErrorが発生してうまくいきませんでした。プログラムを CLI から提出したいとき
これに関してはまだ自分も使っていないので勘で書いています。間違っていたらすみません
さて、テストも通り、いよいよ提出! プログラムをコピペして提出しても良いですが、AtCoder Tools にはプログラム提出機能が実装されています。これを使えば CLI から簡単にプログラムを提出することができます。
$ atcoder-tools submitこれだけです。
おそらく (というか
submitコマンドに関しては確実に) ログインが必要だと思うので ID とパスワードを要求されたら AtCoder の ID とパスワードを入力します。もっと詳しいことが知りたい!
README をご覧ください。日本語で書かれているので英語苦手な方でも大丈夫です。
さいごに
自分はまだ AtCoder (競プロ) 歴 2 日1なんですが、このツールは絶対あったほうが便利だとすぐにわかったので速攻でインストールしました。
自分は今のところ Ruby で問題を解いているのでコード生成が Ruby に対応していなかったり、ところどころオプションや設定が使えなかったりなどの問題はありますが、これらも徐々に改善されていくでしょう。
(ちなみに Ruby に対応する PR を送ろうと思ったのですが、Python 初心者 & ライブラリの contribute 経験がほぼないので挫折しました……w)。
- 投稿日:2020-08-24T14:58:18+09:00
学習用データの水増し【ImageDateGenerator】
学習用データの水増し【ImageDateGenerator】
from keras.preprocessing.image import load_img,img_to_array,ImageDataGenerator, array_to_img # import matplotlib.pyplot as plt from keras_preprocessing.image import list_pictures import os from PIL import Image # ---- 分類するクラス --- # classes = ["犬","猫","鳥"] # ---- 画像の大きさを設定 ---- # img_width, img_height = 1600, 1200 # ---- ディレクトリ定義 ---- # DATA_DIR = [""] * len(classes) SAVE_DIR = [""] * len(classes) for i in range(len(classes)): DATA_DIR[i] = 'input/' + classes[i] SAVE_DIR[i] = os.path.join('output/', classes[i]) # 生成画像の保存先ディレクトリ if not os.path.exists(SAVE_DIR[i]): os.makedirs(SAVE_DIR[i]) # 画像をロード(PIL形式画像) # img = load_img(IMAGE_FILE) # 貼り付け # plt.imshow(img) # 表示 # plt.show() # 回転:-15~15 # 上下平行移動:-0.8~1.2割の移動 # 左右平行移動:-0.8~1.2割の移動 # せん断:-5度~5度でせん断 # 拡大縮小:0.8~1.2割で拡大縮小 # 明度変更:-5.0~5.0の範囲で画素値に値を足す # 各画素値に値を足す:0.3~1.0の範囲で値を変更する datagen = ImageDataGenerator( rotation_range=15, height_shift_range=0.2, width_shift_range=0.2, shear_range=5, zoom_range=0.2, channel_shift_range=5, brightness_range=[0.3, 1.0] ) for i in range(len(classes)): for picture in list_pictures(DATA_DIR[i]): img = img_to_array(load_img(picture, target_size=(img_height, img_width))) # numpyの配列に変換 x = img_to_array(img) # 4次元配列に変換 # x = np.expand_dims(x, axis=0) x = x.reshape((1,) + x.shape) # print(x.shape) g = datagen.flow(x, batch_size=1, save_to_dir=SAVE_DIR[i], save_prefix='out', save_format='jpg') for j in range(3): batches = g.next() # (1,縦サイズ, 横サイズ, チャンネル数) # print(batches.shape) # 画像として表示するため、4次元から3次元データにし、配列から画像にする。 gen_img = array_to_img(batches[0]) # plt.subplot(8, 8, i + 1) # plt.imshow(gen_img) # plt.axis('off')
- 投稿日:2020-08-24T14:35:52+09:00
「時系列分析と状態空間モデルの基礎」(隼本)をpystanで実装してみた
やったこと
- 「時系列分析と状態空間モデルの基礎 RとStanで学ぶ理論と実装」のstanの章のコードをpystanを用いて実装した
この記事の対象者
- 時系列分析を知りたくて隼本を読んだけどpythonしかわからない!pythonで書いてくれ!という人
はじめに
時系列分析の入門書で調べると必ず出てくるのが「時系列分析と状態空間モデルの基礎 RとStanで学ぶ理論と実装」,いわゆる隼本です。
この本では,「ARモデル,MAモデルといった時系列分析」,「ガウス線形状態空間モデル」「ベイズ推定による状態空間モデル」について非常に噛み砕いて説明されています。
本の中で使用されているのはR言語とstan言語であり,pythonしか使えない筆者のような人間にとってはそれが少し痛手です。しかし,pythonでもstanを使用することも可能なので,本で紹介されていることと同じことが実装可能です。
そこで実際にpythonを用いて,隼本のstanによるベイズ推定を実装したので紹介します。実装はgoogle colabを用いて行っています。google colabではpystanがimportするのみで使用可能です。つまり初期設定がいりません,非常に便利です。
コードはこちらから。
https://github.com/nakanakana12/hayabusa-bon実装結果
コードはgithubを参照していただくとして,ここでは簡単に結果のみを紹介します。
Stanによるローカルレベルモデルの推定
ローカルレベルモデル(ランダムウォークにノイズが加わったもの)の状態空間を推定した結果が下記になります。
青が状態,オレンジが観測値です。stanを用いて推定した状態の95%区間が青網になります。本のグラフと比べると正しく実装できていそうです。
応用:複雑な観察方程式を持つモデル
次の章では,もう少し複雑な方程式をモデリングしています。
青線が観測値,オレンジ線が過程誤差がない場合の値になります。こちらも正しく実装できています。
まとめ
- 隼本のstan部分をpythonを用いて実装した。
- 本の結果と比較して正しく実装できていそうなことを確認した。
少しでも皆さんの役に立てれば幸いです。
参考サイト

- 投稿日:2020-08-24T14:09:31+09:00
Pythonのinput関数活用の備忘録メモ
筆者がPythonを勉強する為に読んだ書籍入門 Python3では、なぜか標準入力関数の解説が掲載されていませんでした。
ただ、使ってみると大変便利な関数なので活用方法を備忘録として残しておこうと思います。
最も基本的な使い方
最も基本的な利用方法は以下の通りです。実行すると標準入力(通常はキーボード)からの入力待ち状態となります。変数xに代入したい内容を入力し、最後にReturnを入力すると入力内容がxに代入されます。
入力例>>> x = input() 5 >>> print(x) 5入力を促すメッセージを表示
入力を促すメッセージを表示させることも可能です。表示させたい内容をinput関数の引数として渡します。
入力例>>> x = input("数値を入力: ") 数値を入力: 2 >>> print(x) 2整数として取り出す
まずはinput関数の戻り値の型を見てみます。文字列型(str)と出力されます。
>>> x = input() 2 >>> print(type(x)) <class 'str'>整数として取り出す場合はint関数(浮動小数点の場合float)を用いてキャストします。
入力例>>> x = int(input()) 2 >>> print(type(x)) <class 'int'>複数の値を一度に入力
基本は文字列
複数の値を一度に標準入力から入力したい場合は多々あります。複数の値をスペース区切りで入力した場合以下の様に変数に代入されます。
入力例>>> x = input() 2 3 4 >>> print(x) 2 3 4文字列を分解して複数の値の取り出し
これは複数の値をスペースで連結した文字列として代入されています。故に以下の様に内包表記を用いれば複数の値が一度に取り出せます。(int関数でキャストし、整数型として取り出しています。)
入力例>>> x, y, z = (int(x) for x in input().split()) 2 3 4 >>> print(x, y, z) 2 3 4 >>> print(type(x), type(y), type(z)) <class 'int'> <class 'int'> <class 'int'>リストに変換
以下の様にするとリストとして代入できます。
入力例>>> x = input().split() 2 3 4 >>> print(x) ['2', '3', '4']この場合、文字列のリストになってしまいます。整数値のリストとする為に、リスト内包表記を用います。
入力例>>> x = [int(x) for x in input().split()] 2 3 4 >>> x [2, 3, 4]if文との組み合わせ
enumerate文とif文を追加すると取り出す値の個数を制御出来ます。
入力例>>> x = [int(x) for i, x in enumerate(input().split()) if i < 3] 1 2 3 >>> print(x) [1, 2, 3] >>> x = [int(x) for i, x in enumerate(input().split()) if i < 3] 1 2 3 4 >>> print(x) [1, 2, 3]
- 投稿日:2020-08-24T13:40:35+09:00
入力した値の約数を調べる
- 投稿日:2020-08-24T13:40:35+09:00
pythonで入力した値の約数を調べる
- 投稿日:2020-08-24T12:58:58+09:00
[tensorflow , keras , mnist] mnistのデータから各ラベルごとにn枚ずつ取り出し10*n枚のデータを作成する
前置き
なぜわざわざデータ量を少なく取りたいのか
- データ量が少ない場合にも良い精度が出るモデルを考えたいため
- 各ラベルごとに偏りをなくしたいため
コード
github
mnistのロードを行う(x_train, y_train), (x_test, y_test) = mnist.load_data()y_trainをpandasのdataframeに一度格納し、そこからdataframeを分割、indexを取り出す。という流れでn=100で取り出します。
#各label100枚ずつ足りだすためのコード、pandasを用いて行う df = pd.DataFrame(columns=["label"]) df["label"] = y_train.reshape([-1]) list_0 = df.loc[df.label==0].sample(n=100)#n=100でsampling list_1 = df.loc[df.label==1].sample(n=100) list_2 = df.loc[df.label==2].sample(n=100) list_3 = df.loc[df.label==3].sample(n=100) list_4 = df.loc[df.label==4].sample(n=100) list_5 = df.loc[df.label==5].sample(n=100) list_6 = df.loc[df.label==6].sample(n=100) list_7 = df.loc[df.label==7].sample(n=100) list_8 = df.loc[df.label==8].sample(n=100) list_9 = df.loc[df.label==9].sample(n=100) label_list = pd.concat([list_0,list_1,list_2,list_3,list_4,list_5,list_6,list_7,list_8, list_9]) label_list = label_list.sort_index() label_idx = label_list.index.values train_label = label_list.label.values """ x_trainからlabel用のdataframe.indexを取り出すことでlabelに対応したデータを取り出す。 """ x_train = x_train[label_idx] y_train= train_label x_train = x_train / 255 x_test = x_test / 255これで各ラベル100枚ごとにサンプリングできました。
- 投稿日:2020-08-24T12:49:25+09:00
pythonでflickrから画像データをスクレイピングする方法
Flickrの利用方法
Flickr APIよりkeyを取得する
まずFlickrのページへいきRequest an API Keyをクリックする。ここでFlickrのアカウントを作成していない場合は作成しログインしておく。
左側が無償(非商法)、右側が有償(商法)用なので、赤線で囲んであるAPPLY FOR A NON-COMMERICIAL KEYを選択する。
するとアプリケーションの登録画面が表示されるのでアプリケーションに使用する名前と使用用途を記載し、SUBMITをクリックする。
登録後、key と Secret が取得できるのでメモ帳などに控えておく。
Flickr APIから画像を取得するプログラムを作成する
以下のコマンドよりFlickrのモジュールをインストールする。
pip install flickrapi
プログラム実行前に、取得した画像を保存するフォルダを作成する。
download.pyfrom flickrapi import FlickrAPI from urllib.request import urlretrieve from pprint import pprint import os,time,sys key = "取得したkey" secret = "取得したSecret" wait_time = 1 # コマンドラインの引数の1番目の値を取得。以下の場合は[cat]を取得 # python download.py cat animalname = sys.argv[1] savedir = "./"+animalname # format:受け取るデータ(jsonで受け取る) flickr = FlickrAPI(key, secret, format='parsed-json') """ text : 検索キーワード per_page : 取得したいデータの件数 media : 検索するデータの種類 sort : データの並び safe_seach : UIコンテンツの表示有無 extras : 取得したいオプションの値(url_q 画像のアドレス情報) """ result = flickr.photos.search( text = animalname, per_page = 400, media = 'photos', sort = 'relevance', safe_seach = 1, extras = 'url_q, licence' ) # 結果 photos = result['photos'] pprint(photos)上記のプログラムを実行し、成功すると以下の表示がされる。
{'farm': 5, 'height_q': 150, 'id': '4375810205', 'isfamily': 0, 'isfriend': 0, 'ispublic': 1, 'owner': '47750313@N07', 'secret': '8d0a7d24a1', 'server': '4008', 'title': 'cat', 'url_q': 'https://live.staticflickr.com/4008/4375810205_8d0a7d24a1_q.jpg', 'width_q': 150}, {'farm': 1, 'height_q': 150, 'id': '27083352608', 'isfamily': 0, 'isfriend': 0, 'ispublic': 1, 'owner': '144380504@N04', 'secret': 'd1cd159107', 'server': '811', 'title': 'cat', 'url_q': 'https://live.staticflickr.com/811/27083352608_d1cd159107_q.jpg', 'width_q': 150}],'url_q'に登録されているURLを取得し、urllibを使用して画像データを取得する。
さきほどのプログラムに画像データを取得するプログラムを追加する。
for i,photo in enumerate(photos['photo']): url_q = photo['url_q'] filepath = savedir + '/' + photo['id'] + '.jpg' # 重複したファイルが存在する場合スキップする。 if os.path.exists(filepath):continue # 画像データをダウンロードする urlretrieve(url_q, filepath) # サーバーに負荷がかからないよう、1秒待機する time.sleep(wait_time)「cat」を引数にプログラム実行後、猫の画像がFlickrから取得できた。



- 投稿日:2020-08-24T12:14:15+09:00
nginx-unitのdocker版でflaskやるとちょっと大変だった
パッケージのnginx-unitは前回の通り問題なく使えたが、dockerの方ではなかなかうまく動かず手こずった。
公式にもあまり書いてないことが多かったので、書いておく。dockerイメージ
公式doc↓
https://unit.nginx.org/howto/docker/#running-apps-in-containerized-unit
最初にapt叩くので、apt叩いたあとのイメージ作っててもいいかも。
(エラー出まくったときaptで待ちまくるのが面倒だったので…)FROM nginx/unit:1.19.0-python3.7 RUN apt-get update && apt-get install -y python3-pip \ && rm -rf /var/lib/apt/lists/*だけにしといて、build with name(適当な名前にしておく)
docker build -t nginx-unit-python .flaskを動かそうとした
flask自体はVisual Studioでつくってくれるサンプルを使う。
githubはこちら
https://github.com/microsoft/python-sample-vs-learning-flask(実際はapp.pyから動くように少々変更している)
nginx-unit用のconfig.json
これはdocker版でも必要なので、作成
config.json{ "listeners":{ "*:8000":{ "pass":"applications/webapp" } }, "applications":{ "webapp":{ "type":"python 3", "path":"/www/", "module":"app" } } }で、アプリイメージ用のdockerfile
FROM nginx-unit-python:latest COPY requirements.txt /config/requirements.txt RUN pip3 install --no-cache-dir -r /config/requirements.txt \ && rm -rf /var/lib/apt/lists/* COPY ./config /docker-entrypoint.d/ # config.json を入れる COPY --chown=nobody:nogroup webapp/ /www/ # chown重要 EXPOSE 8000イメージは上で作成したローカルのイメージを使っている。
もちろん一回イメージを作らなくて、そのままaptコマンド入れても大丈夫。一応公式のコマンドに寄せて、copyしていく。(公式はbindオプションで入れてるけど)
requirements.txtを/configに入れて、pip
config.jsonは/docker-entrypoint.d/に入れる重要だったこと
webapp/にflaskが入っていて、これを/wwwに入れるのだが、そのままだと
テンプレート読み出しなどのときにpremission deniedと出てきて、動かない。2020/08/21 13:45:42 [alert] 19#19 Python failed to import module "views" Traceback (most recent call last): File "<frozen importlib._bootstrap>", line 983, in _find_and_load File "<frozen importlib._bootstrap>", line 967, in _find_and_load_unlocked File "<frozen importlib._bootstrap>", line 677, in _load_unlocked File "<frozen importlib._bootstrap_external>", line 724, in exec_module File "<frozen importlib._bootstrap_external>", line 859, in get_code File "<frozen importlib._bootstrap_external>", line 916, in get_data PermissionError: [Errno 13] Permission denied: '/www/views.py'こんな感じ。(テンプレートでも同じpermission deniedと言われる)
dockerコンテナ内は基本rootで動いてるものとばっかり思ってたので、ここでかなりハマった。
いろいろアプリの場所変えたりしてもだめ。
仕方なく思い、コンテナ内に入って、/www以下を777に変えたらちゃんと動いた。コンテナ内ユーザー調査
これはいったい?と思ったので、どんなプロセスがコンテナ内で動いているのか調査する。
(なお、コンテナ内でのps auxコマンドは使えません)
docker container top [container id]
で見るとUID PID PPID C STIME TTY TIME CMD root 27891 27874 0 13:50 ? 00:00:00 unit: main v1.19.0 [unitd --no-daemon --control unix:/var/run/control.unit.sock] nobody 27947 27891 0 13:50 ? 00:00:00 unit: controller nobody 27948 27891 0 13:50 ? 00:00:00 unit: router nobody 27949 27891 0 13:50 ? 00:00:00 unit: "webapp" application↑こんな感じだった。
で、よく見るとunitの本体はnobodyで動いているようだ。
あとnobodyのグループも確認。コンテナ内に入って、
# groups nobody→nogroupと返ってくる。なので、copyのときに--chownオプションをつける。
(最初はdockerfileにchmodなり、chownを入れないとだめなのかな、と思ったけどオプションができたらしい)
https://ken5scal.hatenablog.com/entry/2017/10/13/DockerfileのADD/COPYに--chownオプションができた
↑参考にしました。ありがとうございます。これでやっと問題なく動くようになった。大変
思ったこと
情報が少ないものは使うのがつらい。特にlatestバージョンについての情報が少ないものは…
急がば回れ、ということでスタンダードなuWSGIなどを使え、ということなのか…
- 投稿日:2020-08-24T12:02:29+09:00
Prometheusを使用してPythonアプリケーションを監視する4つの方法を紹介
はじめに
Prometheusはもともとマルチプロセスではなくシングルプロセスマルチスレッドアプリケーション用に設計されていたにもかかわらず、現在Pythonアプリケーションを監視するための人気のツールになりつつあります。
PrometheusはSoundcloud環境で開発され、GoogleのBorgmonに触発されました。 元の環境では、Borgmonはサービス検出の単純な方法に依存しており、クラスターで実行されているすべてのジョブを簡単に見つけることができます。
Prometheusはこれらの前提を継承するため、1つのターゲットが単一のマルチスレッドプロセスであると想定しています。 Prometheusのクライアントライブラリは、メトリックが共有アドレススペースで実行されている複数の実行スレッドのさまざまなライブラリおよびサブシステムからのものであるという前提で話を進めていきます。
開始するには、MetricFireの無料トライアルにサインアップしてください。このトライアルでは、プラットフォームでPrometheusの使用をすぐに開始でき、この記事から学んだことを実践することができます。
PrometheusをPython WSGIアプリケーションに統合する際の問題
WSGIアプリケーションサーバーでPythonアプリを実行すると、問題が発生し始めます。 WSGIアプリケーションでは、リクエストは単一のプロセスではなく、多くの異なるワーカーに割り当てられます。 これらの各ワーカーは、複数のプロセスを使用して展開されることにより、マルチプロセスアプリケーションになります。
この種のアプリケーションがPrometheusにエクスポートされると、Prometheusはスクレイプ要求に応答する複数の異なるワーカーを取得します。 ワーカーはそれぞれ、知っている価値観で対応するため、Prometheusはカウンターメトリックをスクレイピングして100として返し、それが200として返された直後に返すことができます。各ワーカーは独自の値をエクスポートしているため、カウンターメトリックはジョブ全体ではなくランダムな情報を測定します。
これらの問題を処理するために、以下の4つのソリューションがあります。
1. すべてのワーカーノードを合計する
各メトリックに一意のラベルを付けると、それらすべてを一度にクエリでき、ジョブ全体を効率的にクエリできます。 たとえば、各ワーカーにworker_nameなどのラベルを付けると、次のようなクエリを記述できます。
sum by (instance, http_status) (sum without (worker_name) (rate(request_count[5m])))これにより、1つのジョブのすべてのワーカーノードが一度に集約されます。 ただし、これの問題点は、あなたが所持するメトリックの数が急増してしまうことです。
2. マルチプロセスモード
このメソッドは、私たちMetricFireがオススメする方法です。 この方法では、gunicornアプリケーションサーバー上のマルチプロセスアプリを処理するPrometheus Pythonクライアントを使用し、Prometheusで独自のアプリケーションを監視します。
MetricFireでPythonクライアントを使用して独自のサービスを監視する方法に関しては、Prometheusを使ってPython Webアプリの監視の記事を確認してみてください。 その記事では、Prometheusを使用してPython Webアプリを監視する各手順を説明しています。
3. Django Prometheusクライアント
このメソッドは、各ワーカーを完全に別個のターゲットとして指定します。 Django Prometheusクライアントは、各ワーカーが独自のポートを介してPrometheusのスクレイプリクエストをリッスンするように設定します。
4. StatsDエクスポーター
この方法は、Prometheusがアプリケーションを直接こする必要があるという概念を拒否します。 代わりに、アプリからローカルで実行されているStatsDインスタンスにメトリックをエクスポートし、アプリケーションの代わりにStatsDインスタンスを取得するようにPrometheusを設定します。 これにより、各カウンターが何をカウントするかをより詳細に制御できます。
まとめ
マルチプロセスアプリケーションをPrometheusでネイティブに監視することはできませんが、これらの4つのソリューションは優れた回避策です。 これにより、ITリソースとAPMの両方に対して、Prometheusを企業全体の主要な監視ツールとして使用できます。
Prometheusを使用してPythonアプリを監視する方法の詳細については、Pythonベースのエクスポーターに関する記事と、Kubernetesを使用したPython APIの開発とデプロイに関するシリーズをご覧ください。
Prometheusを試して、この記事から学んだことを実践するには、MetricFireの無料トライアルをチェックしてください。 私たちのプラットフォームで直接Prometheusを使用して、セットアップなしでメトリックを監視を開始できます。 また、デモを予約して直接お問い合わせください。お客様の会社の監視ニーズについて、いつでも喜んでお話を伺います。
それでは、またの記事で!
