- 投稿日:2020-08-24T20:45:05+09:00
EC2でPlantUML Server
EC2へのMavenインストール
sudo wget https://repos.fedorapeople.org/repos/dchen/apache-maven/epel-apache-maven.repo -O /etc/yum.repos.d/epel-apache-maven.repo sudo yum install -y apache-maven sudo sed -i s/\$releasever/6/g /etc/yum.repos.d/epel-apache-maven.repo sudo yum install -y apache-mavenJavaのインストール
sudo amazon-linux-extras enable corretto8 sudo yum install java-1.8.0-amazon-corretto-devel sudo /usr/sbin/alternatives --config java sudo /usr/sbin/alternatives --config javacPlantUML serverのインストール、起動
git clone https://github.com/plantuml/plantuml-server.git cd plantuml-server/ mvn jetty:run
- 投稿日:2020-08-24T20:20:55+09:00
[AWS CDK] Private Subnetで運用するBatchコンピューティング環境(EC2タイプ)を構築した
概要
CDKを用いて,AWS Batchのコンピューティング環境(EC2起動タイプ)を,インターネットとの通信経路を持たないVPCで起動する方法をまとめました.
Batchのコンピューティング環境は,ECSクラスタとして作成されます.なので,ECSクラスタが展開できるVPC環境を準備してあげればOKです.
なぜそんなことをしたのか?
Batchで高負荷な計算処理(シミュレーション)を行う環境1を構築していたのですが,セキュリティ上の理由から,「インターネット経由の通信が存在しない環境でで」との要件があったためです.
検証環境
- CDK 1.59.0, Typesccript
- 東京リージョン (ap-northeast-1) 2
VPC Endpointを設置する
NAT GatewayやInternet Gateway等との通信経路が一切ないSubnetを選択しても,コンピューティング環境の作成自体は正常に終了します(してしまいます).
しかし,この状態では,ECSのコントロールプレーンやECRリポジトリとの通信もできず,コンピューティング環境を利用することができません.
そこで,必要なプライベート通信経路を確保するため,VPC Endpointを設置します.
必要なVPC Endpointは,下記のとおりです.
ECS コントロールプレーンとの通信経路
3つのInterface endpointが必要です(公式ドキュメントはこちら).
- com.amazonaws.ap-northeast-1.ecs-agent
- com.amazonaws.ap-northeast-1.ecs-telemetry
- com.amazonaws.ap-northeast-1.ecs
ECR リポジトリとの通信経路
2つのInterface endpointとS3 gateway endpointが必要です(公式ドキュメントはこちら).
- com.amazonaws.ap-northeast-1.ecr.dkr
- com.amazonaws.ap-northeast-1.ecr.api
- com.amazonaws.ap-northeast-1.s3
(用途によって) CloudWatch Logsとの通信経路
CloudWatch Logsへログを流したい場合には,追加で下記のInterface endpointも設置してください(公式ドキュメントはこちら).
- com.amazonaws.ap-northeast-1.logs
CDKで実装する
それでは,上述の環境をCDKで構築していきたいと思います.
Importするモジュール
import ec2 = require('@aws-cdk/aws-ec2'); import batch = require('@aws-cdk/aws-batch');VPC
まずは,VPCを作成します.今回は,インターネットとの通信経路を持たないVPCを作成するので,
VPCコンストラクタに,下記のように引数を与えます.const vpc = new ec2.Vpc(this, 'vpc', { cidr: "10.0.0.0/16", // ここは環境に応じて変更してください maxAzs: 3, // EC2を分散配置する際の,最大AZ数を指定する subnetConfiguration: [{ cidrMask: 18, // ここは環境に応じて変更してください name: 'for-batch-compute-env', subnetType: ec2.SubnetType.ISOLATED, // ISOLATEDを指定する }] });subnetTypeに
ISOLATEDを指定することがポイントです.こうすると,NAT Gatewayを設置しないVPCを構築できます.(他に
PRIVATEやPUBLICを指定できますが,これらはNAT Gatewayを設置する構成となります.)Security Group, Subnet Selection
次にEC2用のセキュリティグループを設定します.今回は,同一VPC内のみの通信を許可しました.
const securityGroup = new ec2.SecurityGroup( this, 'batch-compute-env-sg', { vpc: vpc, allowAllOutbound: true, description: `For batch compute environment.`, securityGroupName: `for-batch-compute-environment` }); securityGroup.addIngressRule( ec2.Peer.ipv4(vpc.vpcCidrBlock), ec2.Port.allTraffic(), `Allow inside security group` );後ほど用いる,サブネット選択の変数も定義しておきます.
const subnetSelection: ec2.SubnetSelection = { subnetType: ec2.SubnetType.ISOLATED, onePerAz: true };VPC Endpoint
VPCを作成したら,必要なVPC endpointを設置していきます.CDKでは,専用のコンストラクタがあるので,VPC endpoint設置も簡単です.
S3向けのendpointのみgateway endpointでコンストラクタが違うので注意してください.
// Create VPC Endpoints for ECS new ec2.InterfaceVpcEndpoint( this, `vpce-ecs-agent`, { service: ec2.InterfaceVpcEndpointAwsService.ECS_AGENT, open: true, privateDnsEnabled: true, vpc: vpc, subnets: { subnetType: ec2.SubnetType.ISOLATED }, securityGroups: [securityGroup] }); new ec2.InterfaceVpcEndpoint( this, `vpce-ecs-telemetry`, { service: ec2.InterfaceVpcEndpointAwsService.ECS_TELEMETRY, open: true, privateDnsEnabled: true, vpc: vpc, subnets: { subnetType: ec2.SubnetType.ISOLATED }, securityGroups: [securityGroup] }); new ec2.InterfaceVpcEndpoint( this, `vpce-ecs`, { service: ec2.InterfaceVpcEndpointAwsService.ECS, open: true, privateDnsEnabled: true, vpc: vpc, subnets: { subnetType: ec2.SubnetType.ISOLATED }, securityGroups: [securityGroup] }); // Create VPC Endpoints for ECR new ec2.InterfaceVpcEndpoint( this, `vpce-ecr-docker`, { service: ec2.InterfaceVpcEndpointAwsService.ECR_DOCKER, open: true, privateDnsEnabled: true, vpc: vpc, subnets: { subnetType: ec2.SubnetType.ISOLATED }, securityGroups: [securityGroup] }); new ec2.InterfaceVpcEndpoint( this, `vpce-ecr`, { service: ec2.InterfaceVpcEndpointAwsService.ECR, open: true, privateDnsEnabled: true, vpc: vpc, subnets: { subnetType: ec2.SubnetType.ISOLATED }, securityGroups: [securityGroup] }); new ec2.GatewayVpcEndpoint( this, `vpce-s3`, { service: ec2.GatewayVpcEndpointAwsService.S3, vpc: vpc, subnets: [subnetSelection], });Batch Computing環境
VPCの準備ができたらBatchコンピューティング環境を作成していきます.
const computeEnv = new batch.ComputeEnvironment(this, 'cluster', { computeEnvironmentName: `my-batch-cluster`, enabled: true, managed: true, computeResources: { type: batch.ComputeResourceType.ON_DEMAND, // spotインスタンスを使いたいときはSPOTを指定 // type: batch.ComputeResourceType.SPOT, instanceTypes: [new ec2.InstanceType("t3small")], // インスタンスタイプ vpc: vpc, // 先ほど作成したVPC vpcSubnets: subnetSelection, // Isolated subnetを指定 securityGroups: [securityGroup], // インスタンスのセキュリティグループを指定 minvCpus: 0, // min VCPU数を指定 desiredvCpus: 0, // desired VCPU数を指定 (minとmaxの間の値) maxvCpus: 4, // max VCPU数を指定 // 特定のAMIを指定したい場合はAMI IDの変数も与えます. // image: new ec2.GenericLinuxImage({ 'ap-northeast-1': "AMI-ID" }), } });注意点
- VPCエンドポイントは,利用状況に関わらず立てておくだけで料金が発生します.ECSクラスタ(EC2タイプ)では,最低6つのエンドポイントが必要で,そこそこの金額になります.お試しする際は,終わったら全てのリソースを削除することをお忘れなく!
- 本番で運用する際には,コストに見合うかの判断が大切ですね.状況によっては,セキュリティを担保する他の方法を検討したほうが良さそうです.
- EFSなど他のサービスも使用したい場合は,それぞれに対応したエンドポイント設置などの対応が必要です.
参考
Fargate起動タイプでは,必要なエンドポイントを減らせるようです.詳しくは,こちらのウェブサイトをご参照ください(分かりやすくまとまっており,私も助かりました).
ソースコード
- 投稿日:2020-08-24T19:28:51+09:00
Amazon S3, Route53, CloudFront を利用して SSL化した LP をホスティングする方法
まえがき
本記事では、Amazon S3, Route53, CloudFront を利用して SSL化した LP をホスティングする方法についてご紹介します。
実際に、最近この方法で LP を公開したので、備忘録も兼ねて以下に大まかな流れを記載します。⓪ AWS の 利用
・まず、AWS にて、アカウントを作成します。
・アカウント情報, 連絡先情報, お支払い情報 を登録して、SMS等でのアカウント認証を行います。
・その後、サポートプランの選択を済ませれば、アカウント作成完了。AWSコンソールにログインできる様になります。① S3 に LP をデプロイする
・まず、サービス の ストレージ から S3 を選択します。
・S3 にて、 バケットを作成する を選択し、バケット名(プロジェクト名, ドメイン名等)、
リージョン(アジアパシフィック(東京)) を入力します。
・作成した バケット に LP の ディレクトリ をデプロイします。
・アクセス権限 から ブロックパブリックアクセス をオフにします。
・プロパティ から Static website hosting の ウェブサイトをホストする を選択し、
インデックスドキュメント を設定します。
・エンドポイント (http://[バケット名].s3-website-[region].amazonaws.com/~) からアクセスできればデプロイ完了です。② Route53 にて ネームサーバー の設定を行う
・まず、サービス の ネットワーキングとコンテンツ配信 から Route53 を選択します。
・ホストゾーン から、ホストゾーンの作成を選択し、ドメイン名 を入力します。
・作成した ホストゾーン の NSレコード に割り当てられた、 4つの ネームサーバー をコピーします。
・ドメインを取得したサイトの管理画面から、対象ドメインのネームサーバー設定を、上記のネームサーバ情報に変更すれば完了です。③ Certificate Manager にて SSL の設定を行う
・まず、サービス の セキュリティ、ID、およびコンプライアンス から Certificate Manager を選択します。
・証明書のプロビジョニング を選択し、パブリック証明書のリクエスト を選択します。
・CloudFront との兼ね合いにより、画面右上のリージョンを「米国東部 (バージニア北部)」に変更します。
・ドメイン名を追加し、DNSの検証 を選択後、任意でタグを入力し、確定とリクエスト を選択します。
・検証保留中の証明書のリクエストが作成されるので、詳細から Route53でのレコードの作成 を選択します。
・検証が進行するので、状況欄が 発行済み になれば完了です。④ CloudFront にて SSL の設定を行う
・まず、サービス の ネットワーキングとコンテンツ配信 から CloudFront を選択します。
・Create Distribution を選択し、Web の Get Started を選択します。
・Origin Domain Name に S3 の バケット名 を入力します。
・Viewew Protocol Policy にて Redirect HTTP to HTTPS を選択します。
・SSL Certificate にて Certificate Manager にて作成した証明書を選択します。
・Alternate Domain Name にて ドメイン名 を入力します。
・Default Root Object にて S3 の インデックスドキュメント を入力します。
・設定内容を保存するとデプロイが始まるので、Status欄 が Deployed になれば完了です。⑤ Route53 にて Aレコード の追加設定を行う
・まず、対象ホストゾーン から レコードを作成 を選択し、タイプ(Aレコード)、エイリアス(はい)、エイリアス先(CloudFrontディストリビューションから選択)という内容で作成します。
・指定ドメインでアクセスできればデプロイ完了です。⑥ CloudFront にて ポリシー の設定を行う
・まず、対象Distribution の Origins and Origin Groups から、表示されている S3 Origin の編集を選択し、Restrict Bucket Access(Yes)、 Origin Access Identity(Create a New Identity)、 Grant Read Permissions on Bucket(Yes, Update Bucket Policy) という内容で更新します。
・S3 の 対象バケット の バケットポリシー にて、ステートメントが追加されていれば完了です。⑦ CloudFront にて キャッシュ の管理を行う
・まず、対象Distribution から Create Invalidation を選択し、 Object Paths にて 削除したいオブジェクトのキャッシュ を入力します。(全選択の場合は、
/*と入力)
・Invalidate を選択すると、キャッシュ削除が始まるので、Status欄 が Completed になれば完了です。まとめ
今回、社内のプロジェクトで急遽 LP を制作する流れになったため、ホスティングの方法等いろいろ悩んだのですが、初の S3 でのデプロイにもかかわらず、思っていたよりスムーズ(約1~2時間)だったので、軽く感動しました。
もし、LP をアップロードすることがあれば、参考にしていただければ幸いです。-次回 (8/31)
「GAOGAO 社内 OOUI WorkShop 体験記」参考文献
この記事は以下の情報を参考にして執筆しました。
- 投稿日:2020-08-24T14:43:58+09:00
AWS Redshift Spectrumとviewの組み合わせのアクセス権限を調べる
公式ドキュメントにわかりやすい説明が見つからなかったので、実際にRedshiftを動かして試した結果をまとめました。試した結果なので、違ってたらごめんなさい。
図の中の3つのライン
- 通常のRedshift内のtableにviewを通してアクセス(PostgreSQLでも同様)
- Redshift Spectrumの外部スキーマのtableに直接アクセス
- Redshift Spectrumの外部スキーマのtableにviewを通してアクセス
1. 通常のRedshift内のtableにviewを通してアクセス(PostgreSQLでも同様)
まず、DB userはviewへのSELECT権限が必要です。viewを作成したオーナーであればSELECT権限があります。viewを作成したのが別のDB userの場合は、オーナーを変更するかGRANTする必要があります。
次に、viewのオーナーはtableへのSELECT権限が必要です。tableを作成したオーナーであればSELECT権限があります。tableを作成したのが別のDB userの場合は、オーナーを変更するかGRANTする必要があります。
これらの条件を満たせば、DB userはtableへのSELECT権限を持っていなくても、viewを通すことでtableにあるデータにアクセスできます。
これはPostgreSQLでも同じです。
2. Redshift Spectrumの外部スキーマのtableに直接アクセス
DB userはSpectrumの外部スキーマのUSAGE権限が必要です。外部スキーマを作成したオーナーであればUSAGE権限があります。外部スキーマを作成したのが別のDB userの場合は、オーナーを変更するかGRANTする必要があります。
3. Redshift Spectrumの外部スキーマのtableにviewを通してアクセス
まず、DB userはviewへのSELECT権限が必要です。viewを作成したオーナーであればSELECT権限があります。viewを作成したのが別のDB userの場合は、オーナーを変更するかGRANTする必要があります。
次に、viewを参照するDB userは外部スキーマのUSAGE権限が必要です。外部スキーマを作成したオーナーであればUSAGE権限があります。外部スキーマを作成したのが別のDB userの場合は、オーナーを変更するかGRANTする必要があります。
1と2の事実からすると、3のケースでは、外部スキーマのUSAGE権限が必要なのはviewのオーナーだと思ったのですが、viewのオーナーは関係なくて、viewを参照するDB userが直接外部スキーマへの権限を必要とするようなんです。
そうなのか。。。

- 投稿日:2020-08-24T12:44:03+09:00
PDCAサイクルとOODAループを併用する方法
今回の記事では、PDCAサイクルとOODAループの違いについて解説し、併用する方法について紹介したいと思う。
インターネット上の記事では、OODAループとPDCAサイクルを比較する論調が目立つがその考えは誤りである。
PDCAサイクルは計画、実行、チェック、改善のループを回すことによって、全体的なパフォーマンス向上を目的としている。
OODAループは、観察、判断、意識決定、手段のループを行うことで、人間が変化が激しい現実の世界に適応する思考のプロセスをモデル化し、良い判断を行うことを目的としている。
PDCAサイクルやOODAループは人間が無意識に行っている思考のプロセスを客観化、モデル化したものである。
そのため、PDCAサイクルとOODAループは人間の思考プロセスで無意識的に併用している。PDCAサイクルとは
PDCAサイクルは戦略レベルの思考である。
1920年代において「戦略」について明確な定義を行ったのは、ロシア帝国時代とソビエト時代の将軍であるアレクサンドル・スヴェチンである。
スヴェチンが定義した「戦略」の定義は以下の内容となっている。
戦争の準備と作戦のグループ化を組み合わせて、軍が戦争によって提唱した目標を達成する技術そして、1980年代で最も適切に戦略について解説した著書「戦略論の原点」を発表したアメリカ海軍の将軍であるジョセフ・カルドウェル・ワイリーは「戦略」を以下のように定義している。
戦略とは「何かしらの目標を達成するための一つの「行動計画」であり、その目標を達成するために手段が組み合わさってシステムと一体となった、一つの「ねらい」である」戦略家であるアレクサンドル・スヴェチンとジョセフ・カルドウェル・ワイリーは戦略を目標を達成するための行動計画と定義している。
PDCAサイクルとは、戦略のパフォーマンスを検証、改善することによって、よりよい戦略を作り出すフィードバックループを構築するためのモデルと定義すること的確である。OODAループとは
OODAループとは、アメリカの航空戦略家であるジョンボイドが朝鮮戦争の航空戦、ナチスの電撃戦を研究し、変化に適応する人間の意識決定のスピードが勝敗が分けたと結論づけた。
人間の意識決定のプロセスを可視化したのが以下のOODAループである。
観察(Observe)- 情勢への適応(Orient)- 意思決定(Decide)- 行動(Act)通常の人間の認知範囲は作戦レベルに対応していると考えられている。
そして、この思考の上位に戦略レベルが下位に戦術レベルが存在している。
現場レベルの作業に従事している人間は、変化が激しい情勢に柔軟に対応しなければならない。
OODAループとは、人間が現実の世界に対応するために思考パターンをモデル化したものである。
そのため、OODAループとは作戦レベル、戦術レベルの思考パターンと考えられる。戦略レベルの行動のフェーズについて
スヴェチンは「戦略」の行動を以下のフェーズごとに分類した
1.計画フェーズ・・・目標を達成するめの行動計画を立てるフェーズ。
2.開発フェーズ・・・目標を達成するめの手段を開発するためのフェーズ。新しいアイディアの作成、アイディアに基づく手段の作成、手段を運用する人の教育、もの or サービスの作成などが該当
3.配置フェーズ・・・開発フェーズで作成したオブジェクトを配置するフェーズ。オブジェクトの管理 or 保存、人材の配置、ものの運搬経路の設定、通信経路の設定などが該当
4.運用フェーズ・・・配置フェーズで作成したオブジェクトを作戦レベルで運用するフェーズ。開発フェーズで作られたアイディアを組み合わせ、目標を達成する。
PDCAサイクルは戦略のプロセスを検証、評価、改善し、次の戦略へフィードバックすることを目的としている。PDCAサイクルとOODAループの併用
PDCAサイクルとOODAループの併用を図式化したのが以下の画像である、
戦略レベルで作成した行動計画がPDCAサイクルによってフィードバックされ、次の戦略の行動計画へ繋がり、OODAループが変化が激しい変化に適応していくためのサイクルだと理解することができる。
PDCAサイクルとOODAループを比較した際に違和感が発生するのは、比較している行動モデルの階層が一致しないためである。まとめ
PDCAサイクルとOODAループはモデルを提供することによって、人間に共通した認識を提供してくれる。
しかし、具体的な手段までは定義していないため、PDCAサイクルとOODAループを適用するためには、組織に合致した手段、チェック方法を独自に考えなければならない。
PDCAサイクルとOODAループを適切に運用できないケースとは、組織がPDCAサイクルとOODAループに合致した手段を用意できないことが原因だと思われる。

- 投稿日:2020-08-24T12:40:57+09:00
Amazon Chime SDKでスライドをバーチャル背景に設定する
この記事はこちらでも紹介しています。
https://cloud.flect.co.jp/entry/2020/08/24/123607前回は、Amazon Chime SDKでビデオセッションの上限(16セッション)を超えて映像配信する実験をご紹介しました。
https://qiita.com/wok/items/683561486c7b79c25edc今回もAmazon Chime SDKについて、最近他のビデオ会議ツール等で話題になっていた機能を実現する方法をご紹介したいと思います。
今回ご紹介するのは、パワーポイントなどのスライドをバーチャル背景にする方法です。
最初に大きな話題になったのは、mmhmmでしたね。その後、Zoomでも同様の機能がリリースされました。リモートで行うプレゼンに臨場感が出て良いと思います。これをAmazon Chime SDKを用いて実現する方法をご紹介します。
Amazon Chime SDK(js)を使うので、特にソフトウェアをインストールすることなく使えちゃいます!!
また、スライド以外にも、画面共有可能なウィンドウをすべて背景にすることができます。
なので、例えばエディタとスピーカーを表示しながらライブコーディング、なんてことも出来たりします。実際の動作イメージはこちらです。
Amazon Chime SDKでカメラの映像を送信する方法
以前、バーチャル背景の記事でもご説明した内容ですが、チュートリアルやサンプルなどではカメラの映像を送信する際の一般的な方法としてカメラデバイスのIDを登録する方法が紹介されています。しかし、実は同一のメソッドでMediaStreamを登録することもできるようになっています。
つまり、実はAmazon Chime SDKではMediaStreamさえ取得できれば、何でもシェアできるという柔軟な設計になっているのです。
たとえば、HTMLCanvasElementからはMediaStreamが取得できます。このため、HTMLCanvasElementになにか描画して、それを配信することが出来ます。
上述の記事では、これを利用してバーチャル背景は実現しました。
今回も、これを利用してスライドをバーチャル背景にします。スライドの画像取得
バーチャル背景では、カメラの映像をBodyPixを用いて人物の領域と背景の領域を識別し、背景部分を指定された背景画像の映像に置き換えてHTMLCanvasElementに描画していました。
今回は、この背景画像を、パワーポイントなどのアプリケーションのウィンドウから取得します。下記のようにを呼び出すことで、アプリケーションの映像をMediaStreamとして取得できます。これをHTMLVideoElementのソースに設定した後に、カメラ映像と同じサイズのHTMLCanvasElementにフレームを描画します。そして、カメラの映像のフレームごとに、このHTMLCanvasElementのイメージをキャプチャして背景画像として用います。navigator.mediaDevices.getDisplayMedia().then(media => { ... })処理の流れを纏めると次のようになります。図中上部は前述の通常のバーチャル背景の処理の流れです。図中下部が今回の処理です。赤字部分が変更点となります。
バーチャルフォアグランドもやってみた。
ここまでの説明で、Amazon Chime SDKでは、様々な加工をした映像を配信できることがおわかりになるかと思います。
例えば、下図は人物を線画にしたり、Asciiアートにしたりしてみたものです。
バーチャル背景(バックグラウンド)ではらぬ、バーチャルフォアグラウンドといったところでしょうか。
このように、Amazon Chime SDKでは、カメラの映像配信用にMediaStreamを受け付けることで、さまざまな拡張が可能になっています。楽しいですね。
デモ
今回ご紹介したものと同等のロジックを組み込んだサイトを用意しました。
https://flect-lab-web.s3-us-west-2.amazonaws.com/001_virtual_background/index.html
npmパッケージ
また、簡単に使えるようにnpmパッケージも作ってみました。
https://www.npmjs.com/package/local-video-effector
FLECT Amazon Chime Meeting
また、ビデオ会議の新機能のテストベッドとしてビデオ会議室システムを作成しており、リポジトリを公開しています。
今回ご紹介した機能も、こちらに実装されていますので、興味があればアクセスしてみてください。https://github.com/FLECT-DEV-TEAM/FLECT_Amazon_Chime_Meeting
最後に
今回は、Amazon Chime SDKでスライドをバーチャル背景に設定する方法をご紹介しました。
また、この方法は、画面共有可能なアプリケーションであれば何でも背景に設定することができます。
このため、例えばライブコーディングを配信してみるなど、様々な活用の仕方が考えられると思いますので、是非お試しください。次回は、またAmazon Chimeで遊ぶか、以前紹介したマルチバーコードリーダの技術的な内容をご紹介するかをしようと思ってます。
では。




- 投稿日:2020-08-24T12:15:49+09:00
【IAM】IAMとは
IAMとは
AWS Identity and Access Manegement の略
AWSのサービスを利用するための権限を管理し、各サービスへのアクセスを制御する仕組み主要トピック
- ユーザー
- グループ
- ポリシー
- ロール
ユーザー
1. ルートユーザー
AWSアカウント作成時に作られるアカウント
全てのAWSサービスとリソースを使用できる権限を有する
※ 基本的に、日常的なタスクには使用しない2. IAMユーザー
IAMポリシー内でAWSサービスを使用出来るユーザー
※ 基本操作はIAMユーザーアカウントで行う
- 1アカウント5,000ユーザーまで作成可能
- 1ユーザー10グループまで所属可能
グループ
IAMユーザーをグルーピングし、権限管理を容易にする仕組み
- 1アカウント300グループまで作成可能
ポリシー
どのAWSリソースにどのサービスのどのような操作を許可/拒否するかを定義するもの
JSON形式で記述1. 管理ポリシー
AWS管理ポリシー:AWSが作成・管理するポリシー
カスタム管理ポリシー:AWSアカウントで作成・管理するポリシー2. インラインポリシー
1つのプリンシパルエンティティ(ユーザー、グループ、またはロール)に埋め込まれた固有ポリシー
JSONに記述する設定内容
key value Effect Allow / Deny Action 対象のAWSサービス Resource 対象のAWSリソース Condition アクセス制御が有効となる条件 ポリシー適用
ユーザーベースのポリシー適用:IAMユーザー、IAMグループ、IAMロールにアタッチ
リソースベースのポリシー適用:AWSリソースにアタッチロール
AWSサービスやIAMユーザーの役割を定義し、アクセス権限を管理する概念
1. AWSサービスロール
付与先がAWSリソースであるロールのこと
AWSリソースがIAMロールの内容に応じて別のAWSリソースにアクセスする際には、AWS STK(Security Token Service)から一時的なアクセスキーを取得し、利用する
→ アクセスキーとシークレットキーのペアは不要2. クロスアカウントアクセス用ロール
AWSアカウントをまたいだAWSサービスへのアクセスを一時的に許可するためのロール
3. AWSの外部ユーザー用ロール
IDフェデレーションという仕組みを利用し、AWS外のユーザーIDに対してAWSアカウント内のAWSリソースへのアクセスを許可出来る
※ IDフェデレーション:複数のシステムやサービスをまたがってIDを利用できるようにする認証連携機能
- 投稿日:2020-08-24T11:57:49+09:00
初めてLambdaとAPI Gatewayを触ってみる(まずは動かすお勉強)
こんにちは、端くれ駆け出しエンジニアの@Occhiii623です
これから実装予定のサービスで使うことになるであろう、AWSサービスであるLambda(ラムダ)とAPI Gatewayをまず触ってどんなものなのか知ろうとなりました。
そこで、この記事は私自身のアウトプットがいち目的ですが、自分のようなAWS超初心者で
「文字だけ読んでもわからんっ!とりあえず動かしてみたい!」
という方の参考になれば幸いです。
Qiita初投稿なので、お見苦しい点ご容赦くださいちなみに私はAWSのEC2ぐらいしか使ったことのない超初心者です。
そもそもLambdaって何?
Amazon公式ページによると・・・
AWS Lambda はサーバーをプロビジョニングしたり管理する必要なくコードを実行できるコンピューティングサービスです。 AWS Lambda は必要時にのみてコードを実行し、1 日あたり数個のリクエストから 1 秒あたり数千のリクエストまで自動的にスケーリングします。使用したコンピューティング時間に対してのみお支払いいただきます。
これだけじゃピンとこなかったんですが、要はコードが実行される時だけコンテナを作って、サーバー稼働させるというように、常にサーバーが稼働しているわけではないんですよね。プログラムが実行される時だけ稼働します。
なので、Lambdaを利用するメリットとしては・・・
- AWSのような使う分だけのコストがかかる従量課金の料金体系だと、常にサーバーを稼働させているEC2のインスタンスよりも費用が安くなる。
- サーバーの構築や保守などの管理はAWSがやってくれ、利用者はサーバーの管理が一切不要になる(サーバー管理レス=サーバーレス)ため、メンテナンスを行う人的リソースも抑えられる(人件費もかなりお高いですからね)
とてもわかりやすくLambdaについて解説してくれている動画がありました。
【Schoo】AWS Lambdaを活用したサーバレス実践 -第1回- | 大澤 文孝 先生ここの動画でも解説されているように、デメリットもあって
どれだけアクセスがあるかによって料金が変わってくるので、コスト見積もりがしにくいです。それでもAWSの他サービスと連携できるメリットもあって、利用する恩恵の方が大きいと感じました。
Lambraを動かしてみよう
実際私がやってみた以下手順を追っていきたいと思います。
- 簡単なLambra関数を作ってみる
- Amazon API Gatewayと連携させてブラウザからLambda関数を呼び出してみる
簡単なLambra関数を作ってみる
コンソールから、サービス→Lambdaを選択して開きます。
そうすると、下記のような画面になります。
すでに作ってあるやつがありますが、右上の
関数の作成を押します。
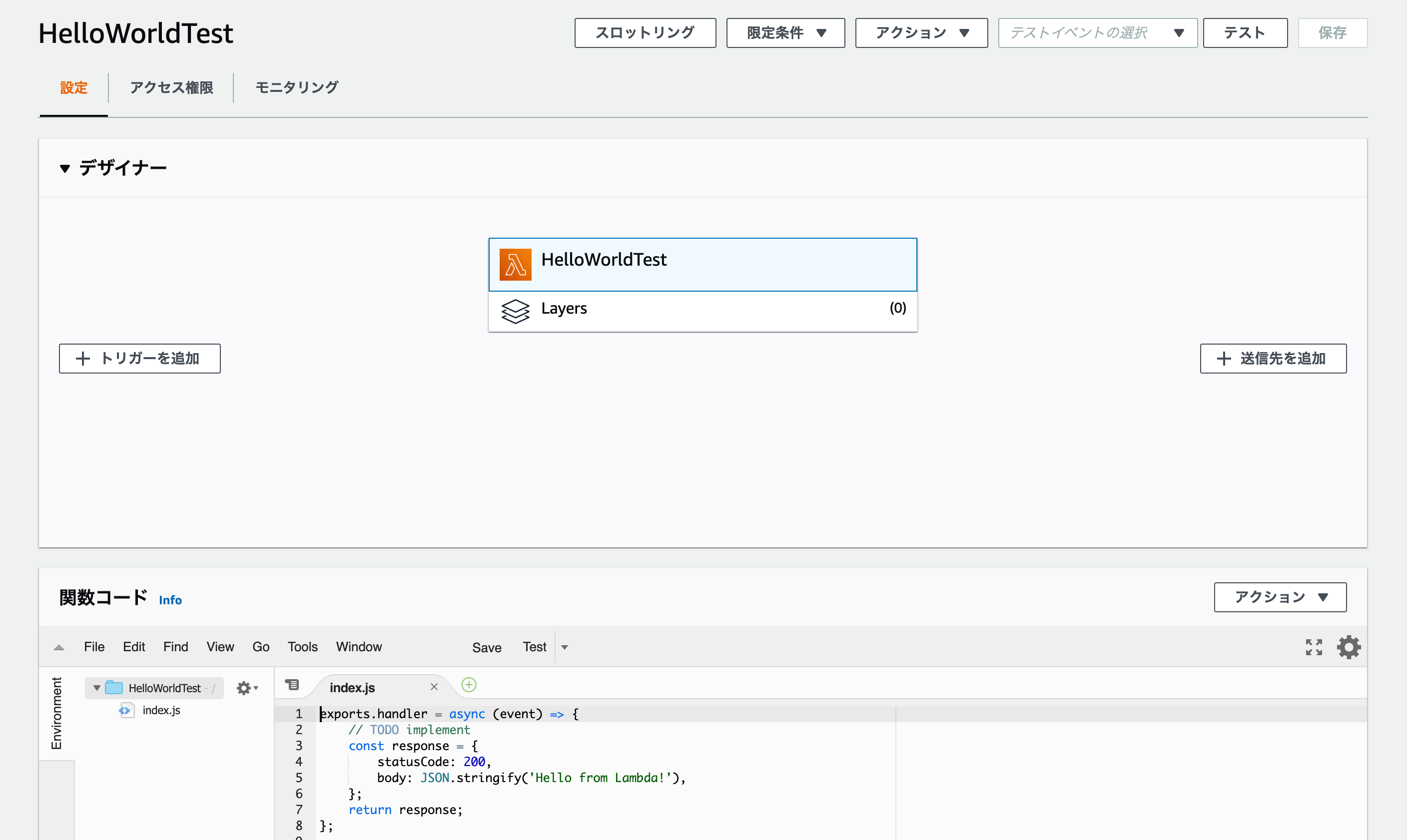
関数の作成画面になるので、左の一から作成を選択して下の基本的な情報を入力します。関数名は、今回は「HelloWorldTest」とでもしておきます。
言語をいくつか選択できますが、今回はNode.jsを選択します。
アクセス権限については、既存のものを選択するか新しく作ることもできます。今回はテスト動作だけなので、「基本的な Lambda アクセス権限で新しいロールを作成」で進めます。右下の
関数の作成を押すとこんな画面になります。
関数コードというところに、すでに
Hello Worldを出力するプログラムが書いてあります。
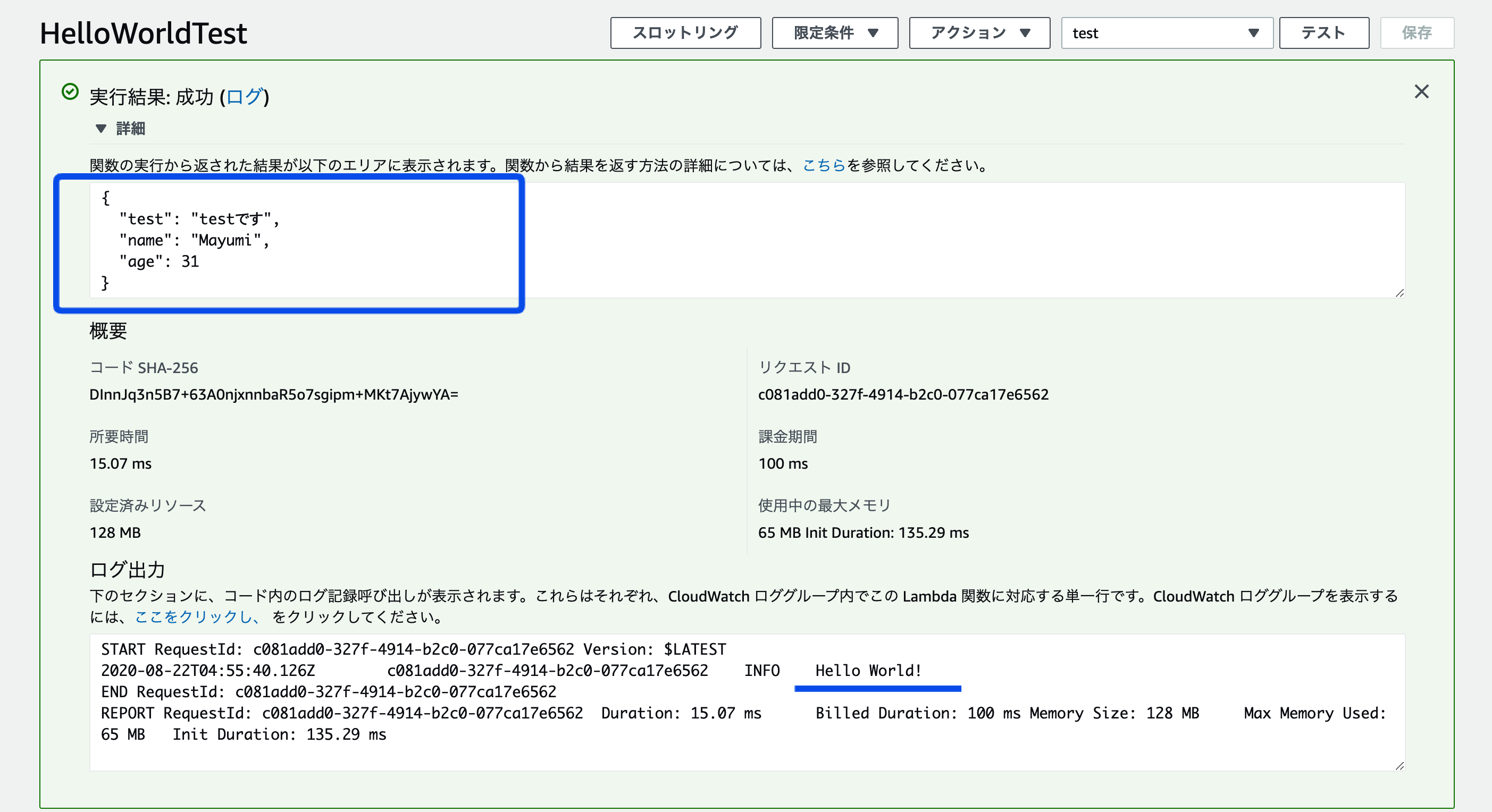
右上のテストというボタンをクリックして、適当な名前をつけて保存→再度テストのボタンをクリックするとプログラムが無事成功した表示とともに、コードを実行後の結果が出てきました。# 実行結果 { "statusCode": 200, "body": "\"Hello from Lambda!\"" }すでに書いてあるコードをコンソール上で編集することもできるのですが、あえてローカルでコードを作成し、ファイルをzip化して読み込んでみます。
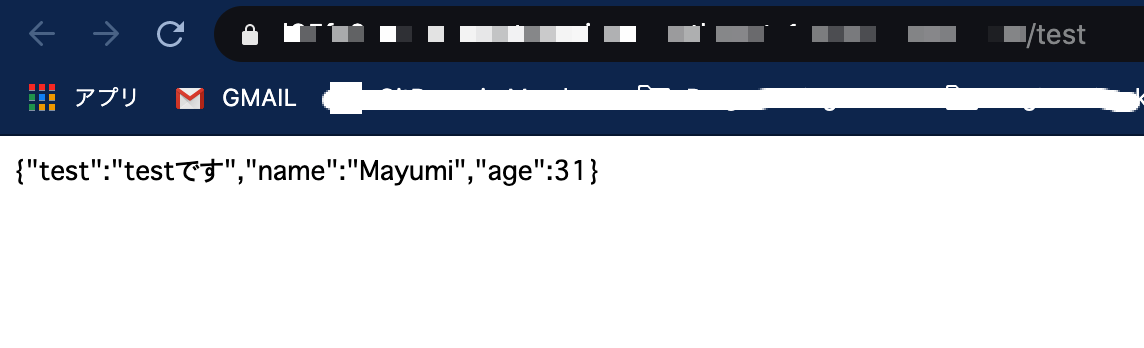
簡単なコードを書きました。
Hello World!をコンソール上で出すだけのメソッドと、戻り値としてaaaの中身を返すコードを作りました。index.jsexports.handler = async (event) => { // 冒頭のexports~は、JSでいうimportと同じように // Lambraで以下コードを読み込むために必要なLambda関数内のメソッド function hoge() { console.log("Hello World!"); }; const aaa = { test: "testです", name: "Mayumi", age: 31, } hoge(); return aaa; };できたら、zip化します。
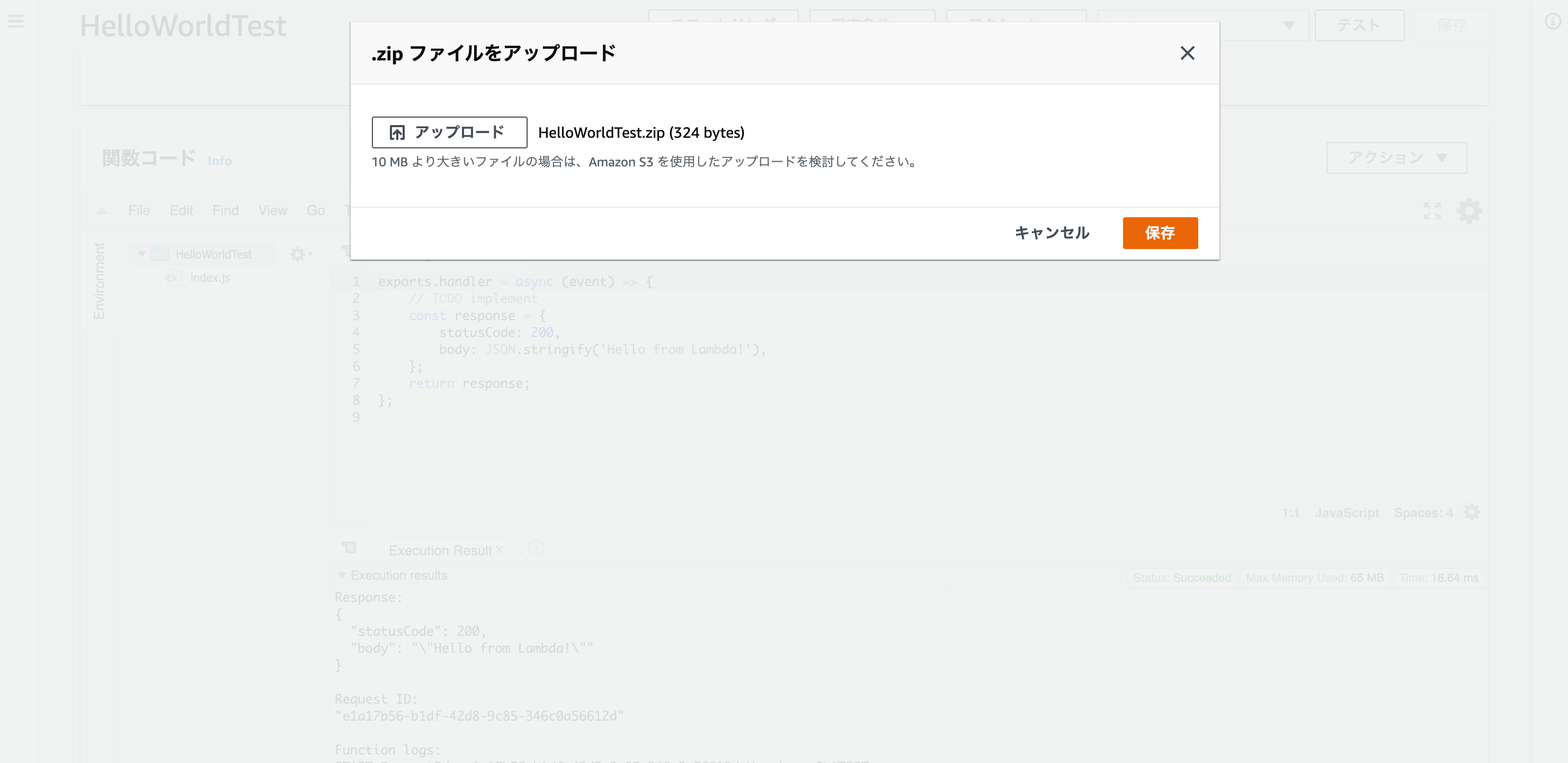
$ zip HelloWorldTest(←zipファイル名は適当) index.jszipファイルができたら、コンソール上で読み込みます。
読み込めたら、index.jsの中身が変わってアップロードした内容に変わっていると思います。
右上のテストを実行すると、、、
無事動きました^^Amazon API Gatewayと連携させてブラウザからLambda関数を呼び出してみる
最初はHTTP APIで作ったAPIをトリガーにやったのですが、この記事ではREST APIでやってみます。
▼こちらを参考にしました
AWS Lambdaで簡単なREST APIを作ってみたAPIとは???ってところからわからずでしたが・・・^^;
わかりやすく教わったのでまたそれは別記事でまとめたいと思います!HTTP APIとREST APIの違いについては、こちらの記事がわかりやすかったです。
0からREST APIについて調べてみた▼では手順
Lambda画面の+トリガーを追加からでも設定はできるのですがサービス検索からAPI Gatewayに飛んで新しいAPIを作成します。
右下のAPIの作成ボタンを押します。
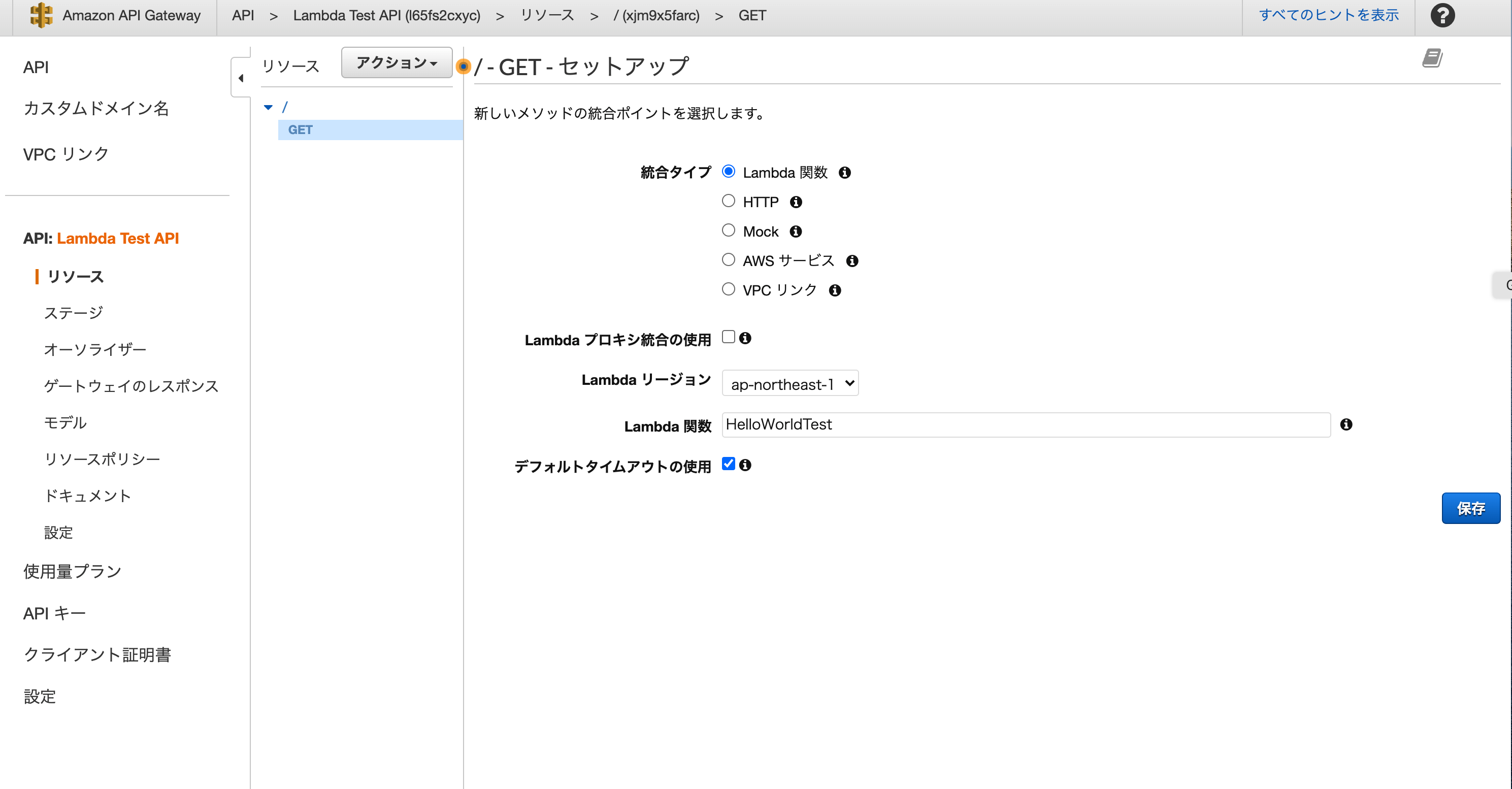
そうすると下のようなページになるので、プルダウンのアクションから今回は特にデータを登録したり、更新したりするわけではないので、GETを選択します。
Lambda関数は、先ほど作ったものを選択して保存します。
保存ボタンを押すと、Lambra関数にアクセスする権限を与えますかといった表示されるので「はい」を押します。
※でないと、権限がなくAPI GatewayからLambra関数にアクセスできません。
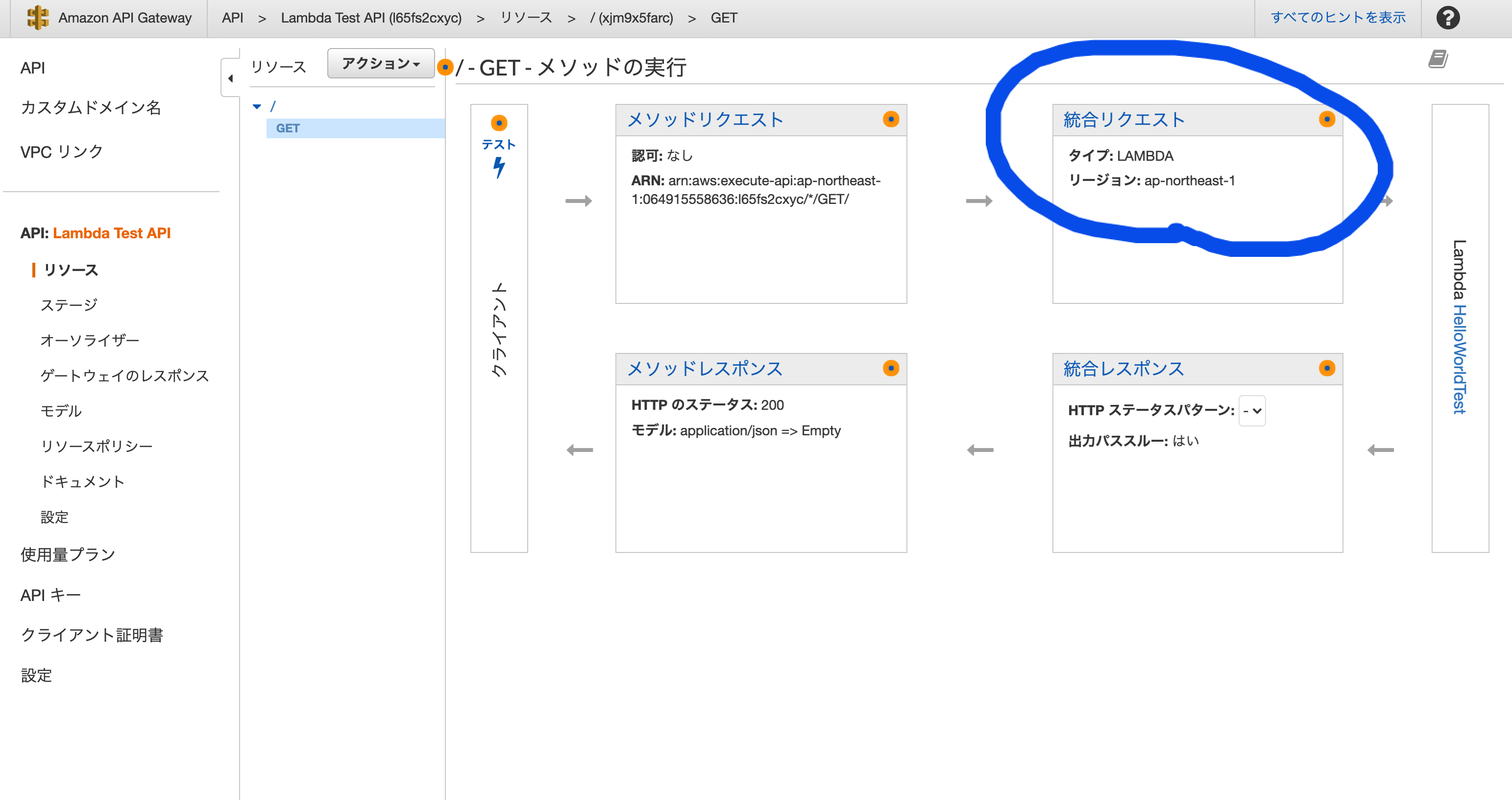
このままだとエンドポイントがない状態みたいなので、統合リクエストから細かい設定をします。
(参考記事どおりに行いました)そしたら、最後にプルダウンの
アクションから、APIのデプロイを選択して新しいステージを作成。
URLが発行されたら、アクセスしてみます!
Lambda関数の呼び出しができました!
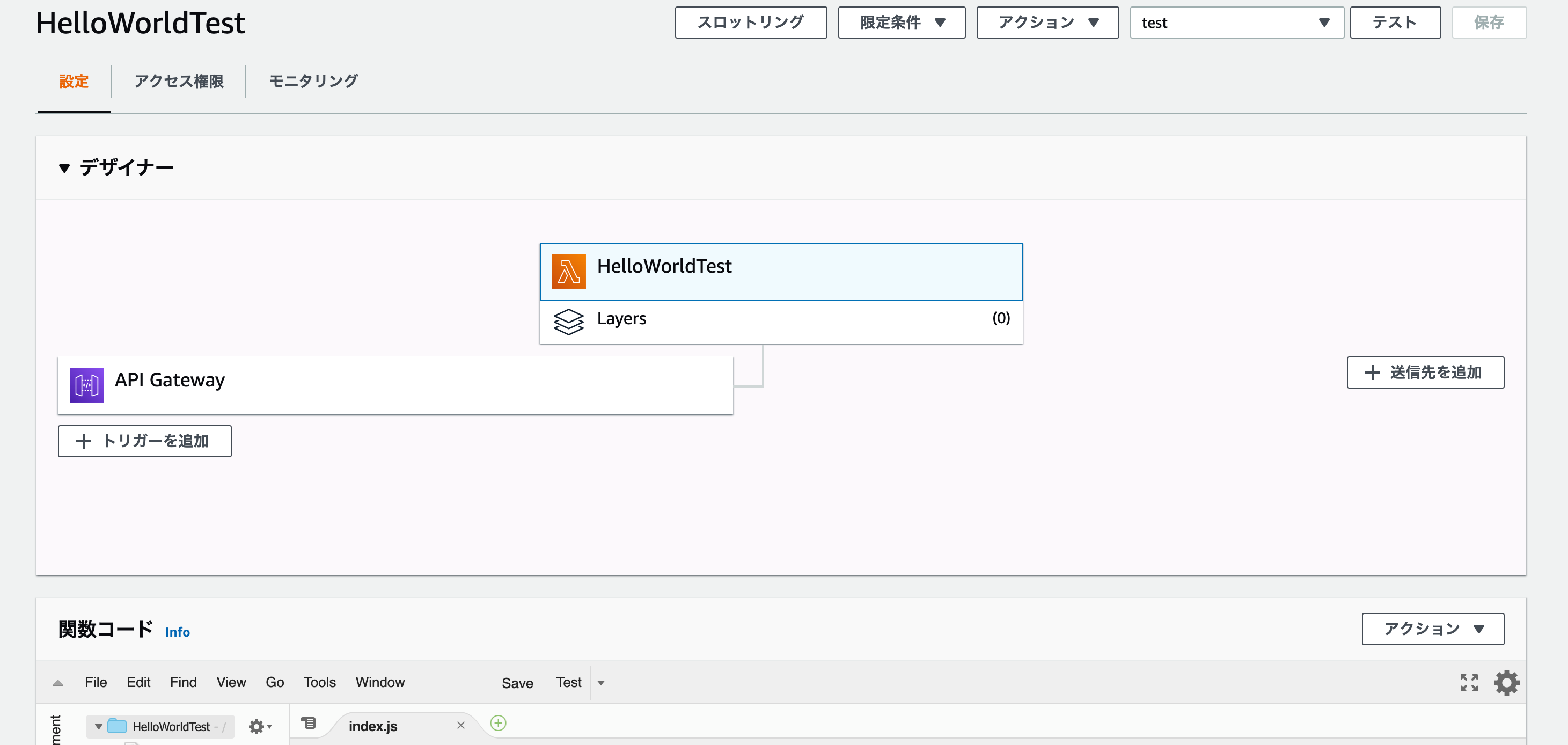
Lambdaの画面に戻ると、API Gatewayがトリガーとして設定されていることが再確認できます。
これで、基本の「き」な操作ができました!複数のJSファイルをwebpackで1つにしてLambra関数で動かしてみる
次のステップとして「複数のJSファイルをwebpackで1つのファイルにしてLambra関数で動かす」ってこともやりました。
普通のアプリケーションであれば、一つのリポジトリで管理して、起動時に実行環境でコードをまとめて読み込むってことをしますが、lamnda関数を使う場合にはアプリケーションの機能ごとに実行環境が分かれるので、コードごとにリポジトリを分けるような管理になる難しさがあるようです。そこで、このwebpackの出番だ!というわけです。
webpackとは?
JSファイルをまとめる、高機能モジュールバンドラーです。(知らなかった)
モジュールは、一つひとつのJSファイルのことを指していてそれをバンドル(=まとめる)するのがwebpackです。webpackを使ってファイルを一つにすることでどんないいことがあるのか?
- ブラウザからリクエストが飛んだ時に複数のファイルだと接続する分時間がかかるが、これを一つにすることで読み込み速度が早くなる
- 一つにまとめる時にes6やVue.js, TypeScript等で書かれたJSファイルをトランスパイルしてブラウザで実行可能なJavaScriptファイルへと変換してくれる(トランスパイルは、別言語を共通語にしてくれるようなものです)
なんだかとてもスグレものです。
導入にするには、Node.jsのバージョン13以上が必要です。
(それ12以下であれば、バージョンを更新してください)
私の場合、Ubuntu環境で行っています。▼導入手順
1.まずローカルにディレクトリを作り、そこにJSファイルを2つ作成します。(例) myProjectフォルダ ├─index.js └─service.js二つのファイルの中身を書いてしまいます。
webpackビルド時に読み込むファイルは、このindex.jsにするので別ファイルのservice.jsをimportで読み込むようにします。index.jsimport { aaa } from "./service.js" // service.jsの変数を、ここで変数hogeに代入 const hoge = aaa exports.handler = async (event) => { //Lambda関数内でイベント処理するのに必要なメソッドを書いておきます console.log(hoge); return hoge; };service.jsexport const aaa = { test: "testです", name: "ohnishi", age: 28, }このまま実行しても、
importとexportという書き方はNode.jsに対応していないのでうまく動作しません。そこを、webpackでトランスパイルすることで実行できるようになるため、あえてこのままにしておきます。2.できたらフォルダに移動
$ cd /Users/myName/Document/myProject3.
packege.jsonファイルを生成します。
-yをつけているのは、作成時に聞かれる質問をスキップするためです。$ npm init -yそうすると、ディレクトリ内に
packege.jsonというファイルができていると思います。package.jsonとは?
package.jsonファイルは、Node.jsベースのJavaScriptアプリ開発において、npmでパッケージ(各種フレームワークやライブラリ)を管理するために使われる構成ファイル。
私はRuby on Railsを触っていたので、それになぞると・・・
- npm = RailsでいうGem(ジェム)
- package.json = RailsでいうGemfile
こんな感じに関連づけられたら、腹落ちしました。
世の中には、ライブラリという便利な道具箱がたくさんあるので、それをnpmで管理して、自分のアプリケーションに入れるライブラリを管理するのにpackage.jsonがあるという感じです。話が脱線しましたが、package.jsonが生成できたらwebpackをインストールします。
4.アプリケーションのディレクトリ上で以下コマンドを実行します。
npm i -D webpack webpack-cliこれで、webpackを使う準備ができました!
webpack.config.jswebpackを利用するためにはwebpack.config.jsというファイルに設定を記述する必要があります。
5.webpack.config.jsというファイルを作成して、中身のコードを書いていきます。
書く項目はある程度決まっているようなのですが、なかなか難しいため今回は最低限動かすための内容を書きます。webpack.config.jsconst path = require('path') const webpack = require('webpack') module.exports = { mode: "development", //今回は開発モードで記述 entry: { index: path.join(__dirname, 'index.js') //webpackビルド時に読み込むファイルを記述します。 //entry項目では、/myProject/index.jsを読み込んでねという設定をしています。 }, output: { path: path.join(__dirname, 'dist'), filename: 'index.js' //output項目では、webpackビルド時に出力するファイル名と作成フォルダ名を指定しています。 //今回は、distという名前のフォルダ内に、index.jsというファイルを作成します。 }, target: 'node', //'node'として、Node.jsのような環境で使用するためにコンパイルするようwebpackに指示します module: { rules: [ { test: /.js$/, //拡張子を.jsで設定しています loader: 'babel-loader' //.jsと設定したファイルをbabel-loaderで読み込む設定をしています } ] } }6.
babel-loaderがないと、webpackビルド時にエラーが出てしまうのでインストールします。$ npm i --save-dev @babel/core @babel/polyfill @babel/preset-env babel-loader7.まだこのままだと「buildなんてコマンドはないよ」と怒られてしまうので、今度は
package.jsonにタスクを設定します。package.json{ "name": "myProject", "version": "1.0.0", "description": "", "main": "index.js", "scripts": { "test": "echo \"Error: no test specified\" && exit 1", "build": "webpack" →追記箇所 }, "keywords": [], "author": "", "license": "ISC", "devDependencies": { "@babel/core": "^7.11.4", "@babel/polyfill": "^7.10.4", "@babel/preset-env": "^7.11.0", "babel-loader": "^8.1.0", "webpack": "^4.44.1", "webpack-cli": "^3.3.12" } }8.インストールできたら、webpackを実行します。
$ npm run startそうすると、distフォルダが作成されて中に
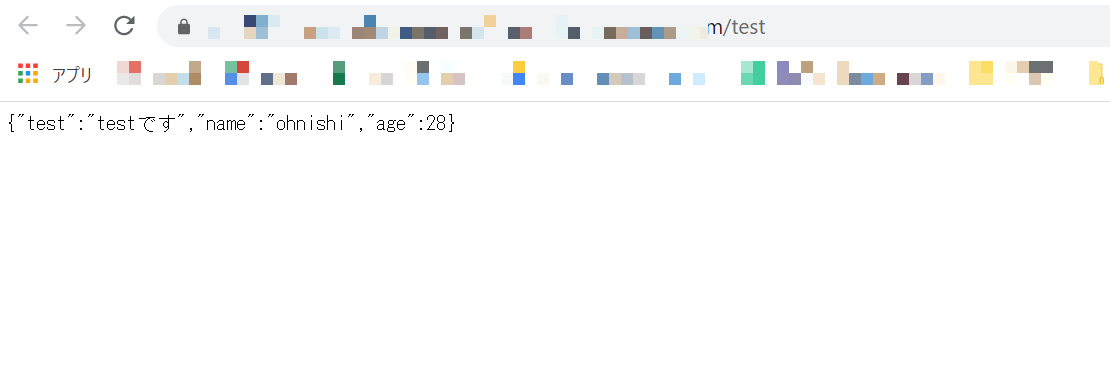
index.jsというファイルができていると思います。それをLambdaで読み込めるように、zip化します。9.AWSのコンソールでLambda画面を開いて、生成したzipファイルを読み込みます。
読み込めたら、右上のテストから実行してみると無事実行されたことが確認できると思います。
すでに上に記述した手順を同じように踏んでREST APIも設定してLambra関数を呼び出してみます。
呼び出せてます!
複数のJSファイルを作成⇒webpack⇒Lambda関数として読み込み⇒API GatewayでブラウザからLambda関数を呼び出す
以上の一連の流れを確認することができました。
Lambdaの何もわからない状態から、なんとなくこんな風に動くんだなというイメージをつけることができたので、一つのアプリケーションを実際作る時の実践的な使い方までを知れたらまた自身の備忘録としてまとめたいと思います
参考URL
webpack.config.js の書き方をしっかり理解しよう - Qiita
最新版で学ぶwebpack 4入門 - JavaScriptのモジュールバンドラ






- 投稿日:2020-08-24T11:12:54+09:00
Redashのデータソースを作成する
前回の記事でAWSのRDSにデータをインポートしてデータの準備が出来ましたので、今回はRedashにログインしてデータソースを作成してみたいと思います。
Redashへのログイン
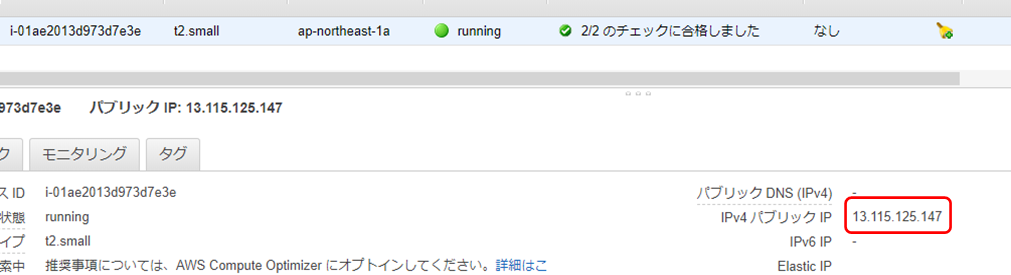
① 最初にAWSのEC2インスタンスとRDSが起動されていることを確認します。
起動されていない場合は、起動しておいてください。
② EC2インスタンスのパブリックIPアドレスをコピーします。
③ コピーしたIPアドレスをブラウザのURLに入力します。
④ Redashの初期設定画面が表示されますので、各項目を入力し、「セットアップ」ボタンを押下します。
⑤ 以下の画面が表示され、ログイン完了です。
データソース(Amazon RDS)作成
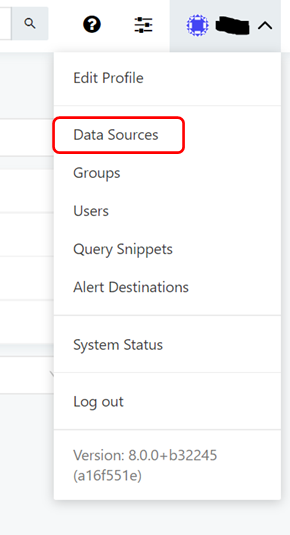
① ツールバー右の「v」を選択し、表示されたリストから「Data Sources」を選択します。
② 設定画面が表示されますので、「+ New Data Source」ボタンを押下します。
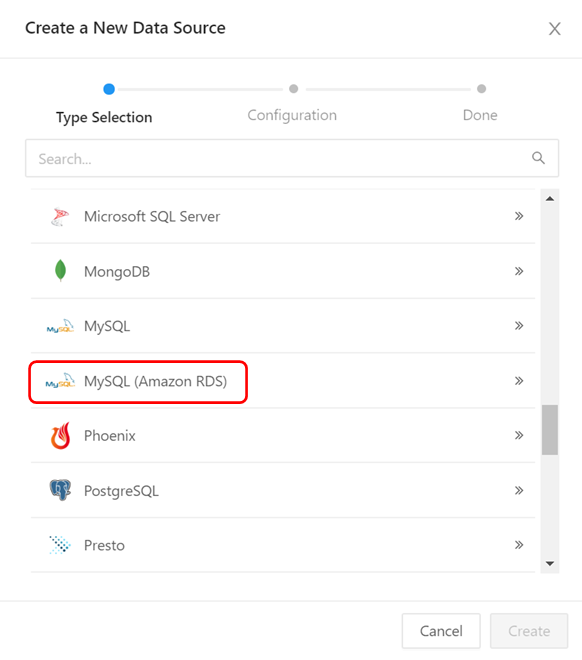
③ データソースを選択するサブウインドウが表示されますので、ここでは「MySQL (Amazon RDS)」を選択します。選択したら「Create」ボタンを押下します。
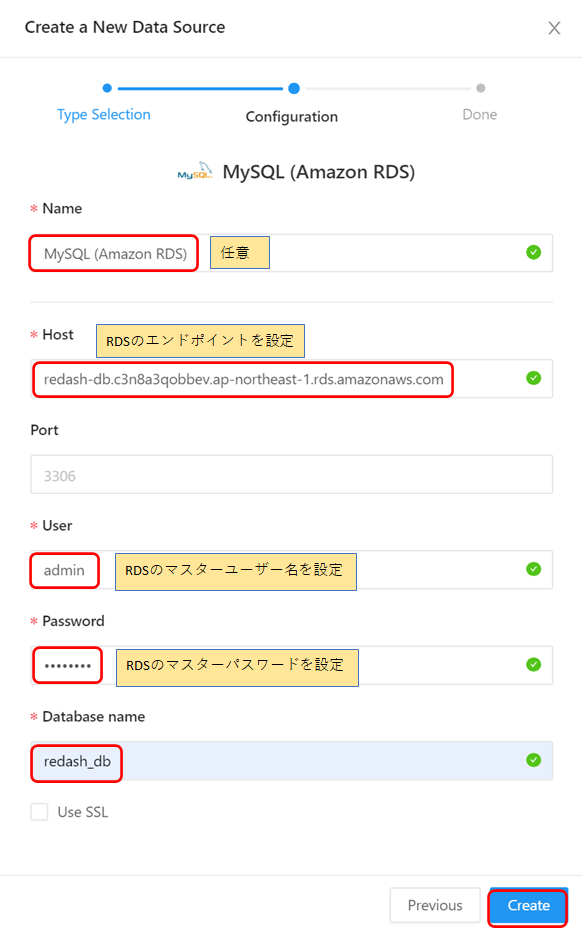
④ データソースの接続情報を入力し、データソースの作成を行います。
⑤ 接続テストを行い、成功と表示されたら「保存」ボタンを押下します。
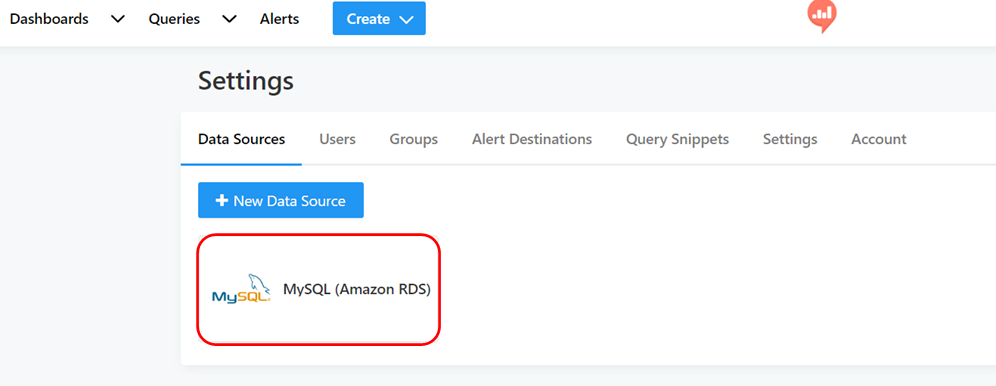
⑥ Data Sourcesタブにデータソースが作成されました。
以上で、データソース(Amazon RDS)の作成は終了です。



- 投稿日:2020-08-24T01:33:41+09:00
AWS CLI(命令的)とTerraform, CloudFormation(宣言的)の違い
AWS CLIにてターミナルから、AWSリソースの作成をすることや、IaC(Infrastructure as Code)のTerraformやCloudFormationでAWSリソースをコード化することはもはや今の時代普通となってきてはいるが、今回はこれらの技術を触り始めたばかりの人にこの両者の違いを命令的、宣言的な言葉から説明しようと思います。
両者の違い
「EC2インスタンスを1つ作る」を例に取る。
AWS CLI (命令的) は How を指定する。
EC2インスタンスを1つ作るとなったら: -VPC作って〜 -AZ作って〜 -サブネット作って〜 -インスタンスタイプはこれを指定して〜 etc...命令的では、EC2インスタンスを1つ作るためには何から用意して、どのようになどのlow level=Howの指定をする。
Terraform, CloudFormation (宣言的) はWhatを指定する。
EC2インスタンスを1つ欲しい!宣言的は最終的なDesired State=What,欲しい物を指定する。
そのため、TerraformではHCL(HashiCorp Configuration Language),CloudFormationではYAML形式で宣言的に最終の状態Whatを定義し、それを達成するためのHowを抽象化する。
つまり、ある目標に対して命令形では具体的に1つずつアプローチしていき、宣言的では飛び級をして一気に目標まで到達するようなイメージです(笑)
- 投稿日:2020-08-24T01:12:02+09:00
Amplify + AppSync + React + Typescriptで簡単アプリ作成【完成】
概要
前回の記事の続きを書いていきます。
前回の記事をみたい人はこちらクライアントからAPIを呼び出す
プロジェクト内でAppSyncを仕様するために, 提供されているライブラリを使用していきます。
$ yarn add aws-amplify aws-amplify-reactpackage.jsonを確認してインストールがされたことを確認してください。
確認できたら早速、エントリーポイントであるindex.tsxにインポートしましょう。import './index.css'; import Amplify from 'aws-amplify'; // <--- ライブラリインポート import React from 'react'; import ReactDOM from 'react-dom'; import App from './App'; import config from './aws-exports'; // <--- 追加 import * as serviceWorker from './serviceWorker'; // バックエンドの情報をAmplifyに渡してあげる Amplify.configure(config); ReactDOM.render( <React.StrictMode> <App /> </React.StrictMode>, document.getElementById('root') ); serviceWorker.unregister();一覧表示
最初の一歩として、一覧表示のAPIとつなぎ込んでみましょう。
import './App.css'; import { API, graphqlOperation } from 'aws-amplify'; import React, { useEffect, useState } from 'react'; import { listTodos } from './graphql/queries'; type Todo = { id: string; name: string; description: string | null; createdAt: string; updatedAt: string; }; const App: React.FC = () => { // Todoリスト const [posts, setPosts] = useState<Todo[]>([]); useEffect(() => { (async () => { // Todoの一覧取得 const result = await API.graphql(graphqlOperation(listTodos)); // graphqlOperationの内容によって戻り値が変わるのと、objectで特に型の指定もできないで型ガード入れてキャストしている if ("data" in result && result.data) { const posts = result.data as ListTodosQuery; if (posts.listTodos) { console.log(posts.listTodos); setPosts(posts.listTodos.items as Todo[]); } } })(); }, []); return ( <div className="App"> </div> ); }; export default App;まだamplifyで連携しているDB(DynamoDB)にデータがないので、空の配列が取得できると思います。
デベロッパーツールのコンソールを確認してみてください。
確認ができたら接続はできているかと思います。登録
一覧表示してもデータがなければ意味がないので、新規追加APIともつなぎ込みます。
import './App.css'; import { API, graphqlOperation } from 'aws-amplify'; import React, { useEffect, useState } from 'react'; import { ListTodosQuery, OnCreateTodoSubscription } from './api'; import { createTodo } from './graphql/mutations'; import { listTodos } from './graphql/queries'; type Todo = { id: string; name: string; description: string | null; createdAt: string; updatedAt: string; }; const App: React.FC = () => { // Todoリスト const [posts, setPosts] = useState<Todo[]>([]); // Todo名 const [name, setName] = useState(""); // Todo内容 const [description, setDescription] = useState(""); useEffect(() => { (async () => { // Todoの一覧取得APIを呼ぶ const result = await API.graphql(graphqlOperation(listTodos)); if ("data" in result && result.data) { const posts = result.data as ListTodosQuery; if (posts.listTodos) { setPosts(posts.listTodos.items as Todo[]); } } })(); }, []); // Todoを新規追加 const addTodo = async () => { if (!name || !description) { return; } // パラメタ const createTodoInput = { name, description, }; try { // Todoの新規追加APIを呼ぶ await API.graphql( graphqlOperation(createTodo, { input: createTodoInput }) ); } catch (error) { console.log(error); } }; // Todo名の入力値をstateにセットする const handleChangeName = (e: React.ChangeEvent<HTMLInputElement>) => { setName(e.target.value); }; // Todo内容の入力値をstateにセットする const handleChangeDescription = (e: React.ChangeEvent<HTMLInputElement>) => { setDescription(e.target.value); }; return ( <div className="App"> <div> Todo名 <input value={name} onChange={handleChangeName} /> </div> <div> Todo内容 <input value={description} onChange={handleChangeDescription} /> </div> <button onClick={addTodo}>Todo追加</button> </div> ); }; export default App;実際にフォームからTodoを追加してみましょう。
追加したらDynamoDBにレコードが追加されていることを確認してください。そこまでできたら、あとは追加したTodoをリアルタイムで表示したいですよね。
サブスクリプション(購読)
Todoの追加をトリガーにリアルタイムで画面を更新した内容で描画するようにしてみます。
import './App.css'; import { API, graphqlOperation } from 'aws-amplify'; import React, { useEffect, useState } from 'react'; import { ListTodosQuery, OnCreateTodoSubscription } from './api'; import { createTodo } from './graphql/mutations'; import { listTodos } from './graphql/queries'; import { onCreateTodo } from './graphql/subscriptions'; type PostSubscriptionEvent = { value: { data: OnCreateTodoSubscription } }; type Todo = { id: string; name: string; description: string | null; createdAt: string; updatedAt: string; }; const App: React.FC = () => { // Todoリスト const [posts, setPosts] = useState<Todo[]>([]); // Todo名 const [name, setName] = useState(""); // Todo内容 const [description, setDescription] = useState(""); useEffect(() => { (async () => { // Todoの一覧取得APIを呼ぶ const result = await API.graphql(graphqlOperation(listTodos)); if ("data" in result && result.data) { const posts = result.data as ListTodosQuery; if (posts.listTodos) { setPosts(posts.listTodos.items as Todo[]); } } // 新規追加イベントの購読 const client = API.graphql(graphqlOperation(onCreateTodo)); if ("subscribe" in client) { client.subscribe({ next: ({ value: { data } }: PostSubscriptionEvent) => { if (data.onCreateTodo) { const post: Todo = data.onCreateTodo; setPosts((prev) => [...prev, post]); } }, }); } })(); }, []); // Todoを新規追加 const addTodo = async () => { if (!name || !description) { return; } // パラメタ const createTodoInput = { name, description, }; try { // Todoの新規追加APIを呼ぶ await API.graphql( graphqlOperation(createTodo, { input: createTodoInput }) ); } catch (error) { console.log(error); } }; // Todo名の入力値をstateにセットする const handleChangeName = (e: React.ChangeEvent<HTMLInputElement>) => { setName(e.target.value); }; // Todo内容の入力値をstateにセットする const handleChangeDescription = (e: React.ChangeEvent<HTMLInputElement>) => { setDescription(e.target.value); }; return ( <div className="App"> <div> Todo名 <input value={name} onChange={handleChangeName} /> </div> <div> Todo内容 <input value={description} onChange={handleChangeDescription} /> </div> <button onClick={addTodo}>追加</button> <div> {posts.map((data) => { return ( <div key={data.id}> <h4>{data.name}</h4> <p>{data.description}</p> </div> ); })} </div> </div> ); }; export default App;追加アクションの監視を実装しました。
マウント時に一覧取得、新規追加の購読を行い、Todoが追加されると新規で追加したTodoが表示している一覧に追加され表示される流れです。
実際にアプリケーションを起動して試してみてください。最後に
記事だけでみると一見難しそうな感じはしていましたが、いざ触ってみるとこんな簡単にGraphQLのAPIが作れてしまうのは驚きました。
今回はDynamoDBがメインで連携していましたが、他にもlambdaやcognitoとも連携ができるので時間あるときに試してみようかなと思います。