- 投稿日:2020-08-24T19:48:43+09:00
ポインタとは何か、初心者目線で解説してみた
業務でGO言語を扱うことになり、必死に勉強していたのですが、
ポインタが最初はなかなか理解できずに苦労しました。今回はそんなポインタとはなんぞやという方に向けて解説していきたいと思います。
※自分もまだまだ未熟なため、一部不適切な部分があるかもしれませんが、ご了承ください。
ポインタを理解するために抑えておくべき用語
・メモリ
・アドレス
・値渡し一応、さらっと用語について解説します。
メモリとアドレス
メモリはデータを一時的に保存する場所ですね。
メモリに変数が格納され、変数に値が格納されています。
つまり、 メモリ<変数<値(文字列とか数値)という構造になります。メモリは広大な野原だと思ってください。
その野原に変数という名の箱がたくさん置かれています。
多すぎて、どれが何の箱なのかわかりません。
なので、箱ごとに住所をつけて管理をします。その住所がアドレスです。
main.goa := "asfd" fmt.Println(&a) // 0xc00008e1e0実際のアドレスはこのように文字と数字の羅列(16進数)で表されています。
値渡し
値渡しは関数の呼び出し方の方法の一つです。
重要なのは、引数に指定した値のコピーが関数内部で使用されるということです。main.gofunc printValue(a string) { a := "fuga" fmt.Println(a) } value := "hoge" printValue(value) // 出力結果 "fuga" fmt.Println(value) // 出力結果 "hoge"値渡しは値をコピーして渡しているだけなので、
関数内で引数の値を書き換えても、呼び出し元で指定した引数(value)の値は変わりません。いよいよポインタの説明に入ります。
ポインタとは何か
ポインタとは実際のアドレスを指定したデータ型。及び、変数のことです
ポインタ型は「*変数名」とすることで生成することができます
実際にコードを見ながら解説していきます。
main.gofunc printValue(a *string) { //valueの値を直接書き換えている *a = "fuga" fmt.Println(*a) } func main() { value := "hoge" fmt.Println(value) //出力結果 hoge printValue(&value) //出力結果 fuga fmt.Println(value) //出力結果 fuga }「&変数名」でアドレスを参照することができて、「*変数名」は値を参照することができます。
値渡しは値のコピーで元の変数の中身を書き換えることはできない。
ポインタ渡しは実際の値を書き換える。これが値渡しとポインタ渡しの違いになります。
- 投稿日:2020-08-24T19:05:36+09:00
Go + VSCode 再入門
概要
半年ほど前に Go の勉強を始めたのだが、何かと忙しく今日まで期間が空いてしまった。暇ができたので久しぶりに VSCode を開いたものの、PC 交換時に移行を怠ってしまい、再び環境構築から Hello, world までやり直したのでその備忘録。今回は Mac での作業だが、Windows でも大差ない気がする。
前提条件
- macOS High Sierra 10.13.6
- bash 3.2.57(1)-release
- Homebrew 2.4.13
- VSCode 1.48.1
インストール
Homebrew 経由でインストール。
brew install goバージョンは記事の執筆時点で
1.15。go version go version go1.15 darwin/amd64一応 Windows でもパッケージマネージャの Scoop 経由でインストールが可能。
PATH 関連
GOPATH
ソースコードや実行ファイル、コンパイル済みのパッケージファイルなどを保存するためのディレクトリを指定する。デフォルトでは
$HOME/goとなってるので、特にこだわりがなければそのままホーム直下を指定。echo 'export GOPATH=$HOME/go' >> ~/.bash_profileGOROOT
SDK のディレクトリを指定する。Homebrew でインストールした場合は
brew upgradeでのバージョン更新が反映されないため、エイリアスへのパスを指定する。echo 'export GOROOT=/usr/local/opt/go/libexec' >> ~/.bash_profileVSCode
拡張機能
Marketplace から拡張機能をインストールする。以前は Microsoft のリポジトリで管理されていたが、Go のプロジェクトへ移行されたらしい。『Go』で検索すれば恐らく 1 番上に表示されるはず。
ツール群
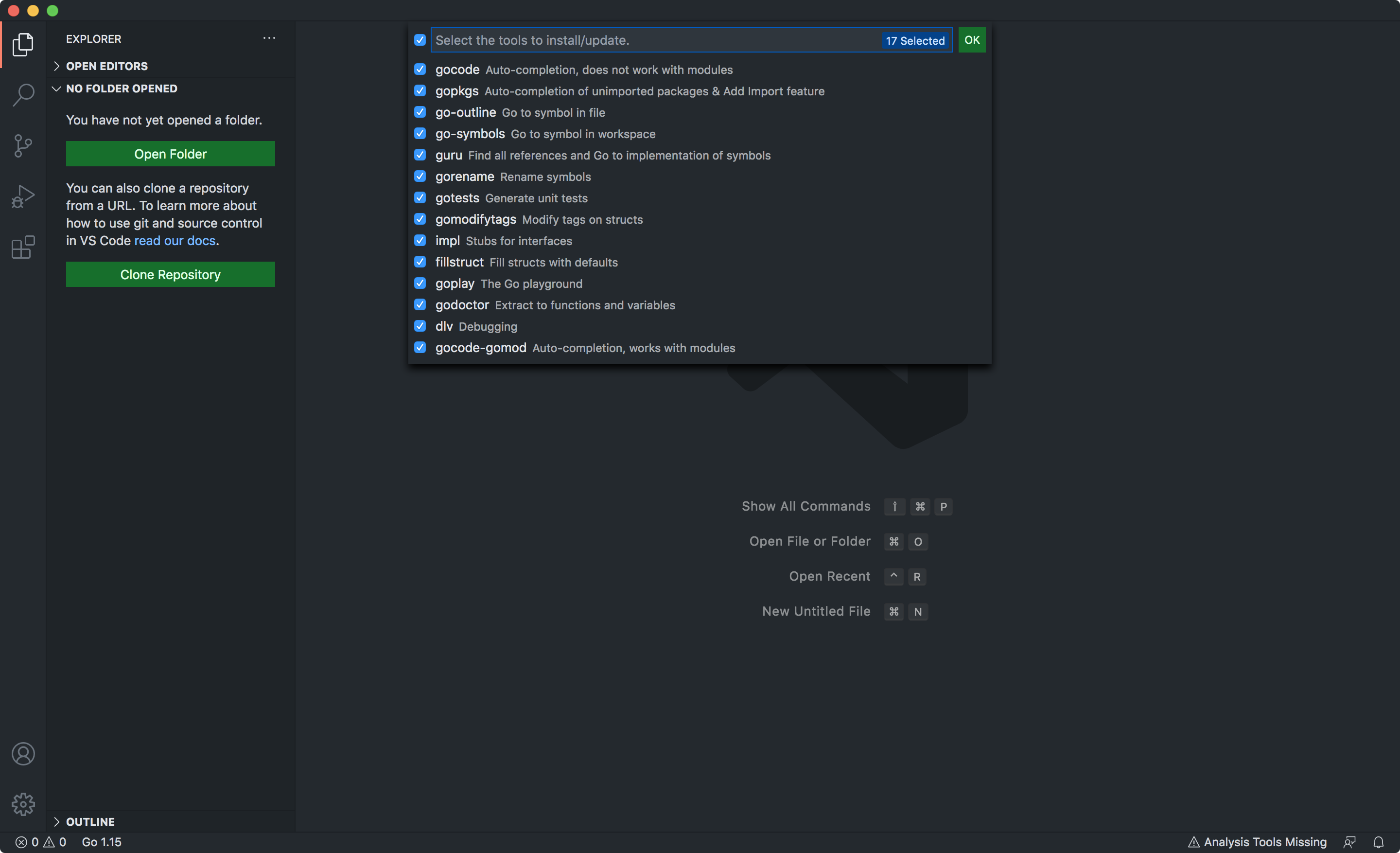
拡張機能のインストール後
⌘+⇧+Pでコマンドパレットを呼び出し、開発に必要なツール群をインストールする。Go: Install/Update Toolsツールは個別に選択が可能だが、取り敢えず全てにチェックして OK を押し、インストールを完了させる。
Hello World
動作確認のためにお決まりのアレをやる。
mkdir -p $GOPATH/src/golang/hello cd $GOPATH/src/golang/hello touch hello.goGOPATH 配下で新規にプロジェクトを作成。パスは適当になんかいい感じにしとけ。
hello.goという名前の空ファイルを生成したら、VSCode でコーディングしていく。package main import "fmt" func main() { fmt.Println("Hello, world.") }
⌃+⇧+^でターミナルを呼び出して実行。go run hello.go Hello, world. // 実行結果問題なく Hello, world 出来れば一先ず環境構築は終了。
gopls
概要
gopls (pronounced: "go please") is the official language server for the Go language.
ざっくり言えば IDE で必要なコード補完や定義へのジャンプ、フォーマットなどをまるっと提供する機能のこと。Microsoft が定義した Language Server Protocol (LSP) に沿って実装されている。gopls は Go 公式の Language Server。現段階でサポートされるのは以下の通り。
- Autocompletion(コードの自動補完)
- Jump to definition(定義へのジャンプ)
- Signature help(ヒントの表示)
- Hover(カーソル位置の情報の表示)
- Document symbols(シンボル一覧の表示)
- References(参照へのジャンプ)
- Rename(命名変更)
導入
ここに書いてある内容を
settings.jsonに追加する。"go.useLanguageServer": true, "[go]": { "editor.formatOnSave": true, "editor.codeActionsOnSave": { "source.organizeImports": true, }, "editor.snippetSuggestions": "none", }, "[go.mod]": { "editor.formatOnSave": true, "editor.codeActionsOnSave": { "source.organizeImports": true, }, }, "gopls": { "usePlaceholders": true, "staticcheck": false, }保存するとインストールを促す通知が表示されるので、『Install』をクリックすれば OK。
参考


- 投稿日:2020-08-24T19:05:36+09:00
Go 再入門 - VSCode で環境構築
概要
半年ほど前から Go 言語の勉強を始めたのだが、何かと忙しく放置気味になってしまった。余裕ができたので久しぶりに VSCode を開いたものの、PC 交換時に環境移行を怠ってしまい、再び環境構築から Hello, world までやり直したのでその備忘録。今回は Mac での作業だが、Windows でもパスなどを随時読み替えれば OK。
前提条件
- macOS High Sierra 10.13.6
- bash 3.2.57(1)-release
- Homebrew 2.4.13
- VSCode 1.48.1
インストール
Homebrew 経由でインストール。
brew install goバージョンは記事の執筆時点で
1.15。go version go version go1.15 darwin/amd64一応 Windows でもパッケージマネージャの Scoop 経由でインストールが可能。
PATH 関連
GOPATH
ソースコードや実行ファイル、コンパイル済みのパッケージファイルなどを保存するためのディレクトリを指定する。デフォルトでは
$HOME/goとなってるので、特にこだわりがなければそのままホーム直下を指定。echo 'export GOPATH=$HOME/go' >> ~/.bash_profileGOROOT
SDK のディレクトリを指定する。Homebrew でインストールした場合は
brew upgradeでのバージョン更新が反映されないため、エイリアスへのパスを指定する。echo 'export GOROOT=/usr/local/opt/go/libexec' >> ~/.bash_profileVSCode
拡張機能
Marketplace から拡張機能をインストールする。以前は Microsoft のリポジトリで管理されていたが、Go のプロジェクトへ移行されたらしい。『Go』で検索すれば恐らく 1 番上に表示されるはず。
ツール群
拡張機能のインストール後
⌘+⇧+Pでコマンドパレットを呼び出し、開発に必要なツール群をインストールする。Go: Install/Update Toolsツールは個別に選択が可能だが、取り敢えず全てにチェックして OK を押し、インストールを完了させる。
Hello, world
動作確認のためにお決まりのアレをやる。
mkdir -p $GOPATH/src/golang/hello cd $GOPATH/src/golang/hello touch hello.goGOPATH 配下で新規にプロジェクトを作成。パスは適当。GitHub 上でパッケージを公開することから
github.com/username/repositoryにすることが多い。hello.goという名前の空ファイルを生成したら、VSCode でコーディングしていく。package main import "fmt" func main() { fmt.Println("Hello, world") }
⌃+⇧+^でターミナルを呼び出して実行。go run hello.go Hello, world // 実行結果問題なく Hello, world 出来れば一先ず環境構築は終了。
gopls
機能
gopls (pronounced: "go please") is the official language server for the Go language.
ざっくり言えば IDE で必要なコード補完や定義へのジャンプ、フォーマットなどをまるっと提供する機能のこと。Microsoft が定義した Language Server Protocol (LSP) に沿って実装されている。gopls は Go 公式の Language Server。現段階でサポートされるのは以下の通り。
- Autocompletion (コードの自動補完)
- Jump to definition (定義へのジャンプ)
- Signature help (ヒントの表示)
- Hover (カーソル位置の情報の表示)
- Document symbols (シンボル一覧の表示)
- References (参照へのジャンプ)
- Rename (命名変更)
導入
ここに書いてある内容を
settings.jsonに追加する。"go.useLanguageServer": true, "[go]": { "editor.formatOnSave": true, "editor.codeActionsOnSave": { "source.organizeImports": true, }, "editor.snippetSuggestions": "none", }, "[go.mod]": { "editor.formatOnSave": true, "editor.codeActionsOnSave": { "source.organizeImports": true, }, }, "gopls": { "usePlaceholders": true, "staticcheck": false, }保存するとインストールを促す通知が表示されるので、『Install』をクリックすれば OK。
参考
- 投稿日:2020-08-24T17:53:30+09:00
AWS API Gateway がリクエストヘッダーを小文字にしてしまう時の解決策 (golang)
ここ最近業務で API Gateway + Lambda を使った開発を行っており、API Gateway の振る舞いで注意しなければならない点を見つけたので、解決方法も添えて記事にしたいと思います。開発言語は Go言語です
AWS API Gateway がリクエストヘッダーを小文字にしてしまう
- 今回使用するサンプルプログラムです
package main import ( "errors" "fmt" "log" "github.com/aws/aws-lambda-go/events" "github.com/aws/aws-lambda-go/lambda" "github.com/aws/aws-lambda-go/lambdacontext" ) type ( request = events.APIGatewayProxyRequest response = events.APIGatewayProxyResponse ) // handler handles AWS Lambda execution. func handler(ctx context.Context, r request) (response, error) { if _, ok := lambdacontext.FromContext(ctx); !ok { return response{StatusCode: http.StatusBadRequest}, errors.New("not invoked from aws lambda") } log.Print(r.Headers) accept, _ := r.Headers["Accept"] // 実際は accept としないと取得できない if == strings.Contains(accept, "application/json") { return response{StatusCode: http.StatusOK, Body:"{}"}, nil } return response{StatusCode: http.StatusOK, Body: fmt.Sprintf("It Works! path=%s", r.Path)}, nil } func main() { lambda.Start(handler) }サンプルプログラムでは Accept ヘッダーが application/json だった場合に空の json を返します。
今回の一例ですが、下記のようなリクエストを送信したとします。
curl -X GET -H "Accept:application/json" https://hogehogeこれが API Gateway を通って Lambda 側にきた時には Accept → accept になっていて、
r.Headers["Accept"]では取得できません。
そもそもRFCの定義では、リクエストヘッダーは小文字大文字を区別しないとなっています。
「とりあえず全部小文字に変換しておくから、アプリケーション側で取得する時は小文字で取得してね」という事なのでしょうかね?大文字、小文字の区別なく取得できるようにするには
全て小文字で書かなければならないのはとてもモヤモヤします。この問題に対して有効な解決策が、Lambda の SDK 開発の PR の議論のなかにありました。
vents.APIGatewayProxyRequest の header を net/http の header に置き換えてしまうというやり方です。
net/http の Header は CanonicalHeaderKey() を用いて正規化されるので、AcceptでもacceptでもACCEPTでも問題ありません。headers := http.Header{} for header, values := range r.MultiValueHeaders { for _, value := range values { headers.Add(header, value) } } headers.Get("Accept")golang で Lambda 開発を行う方は是非参考にしてください。
- 投稿日:2020-08-24T17:36:32+09:00
ノート投稿型サービスをGoで作った話
概要
こんにちは。今回は1年弱ほどかけて5人の学生で開発したサービスの、サーバーサイドについてお話させていただきます。
サービスの内容
学生をターゲットにした、大学の講義ノートのシェアリングサービスeeNotesを開発しました。大学の講義のノートや、試験前に作るまとめノートを作成、シェアすることができます。ノートは大学や授業名、ノートの内容から検索することができます。気になったノートは「いいね」できる他、フレーズを保存して、自分のノートに簡単に引用することができます。
チームメンバー
チームメンバーはこんな感じです。役割分担は一応得意な分野で分かれていましたが、役割を超えてタスクを共有することが多かったです。
サーバー
フロント
インフラ
サーバーサイドの実装の話
私が主に担当したのはサーバーサイドでした。特に奇を衒ったことはしていないですが、実装の一例として紹介します。
Golang
この開発はTreasureというインターンから派生したこともあり、コードはインターンで用意していただいたベースプログラムを流用しました。そのため、特に理由があってGolangにした訳ではないのですが、パフォーマンスや並列処理の観点から、他の案件でもGolangを使うことが多いです。今回はechoなどのフレームワークは使用していません。
構成
サーバーのディレクトリ構成はこのようになっています。
├── controller ├── customerror ├── db ├── dbutil ├── firebase ├── httputil ├── middleware ├── model ├── repository ├── service ├── go.mod ├── go.sum └── server.go
server.go
サーバーの立ち上げ、ミドルウェアの設定、ルーティングを行っています。middleware
認証を行っています。今回はFirebase Authenticationを使用しており、クライアントから送られてくるヘッダーのトークンで認証を行い、contexにユーザー情報を保存し、適宜contenxから引き出すようにしています。controller
サーバーのビジネスロジックを記述しています。エンドポイントが/users/{user_id}の、あるユーザーを取得するメソッドは以下のように記述します。パスパラメーターのuser_idをmuxを使って取り出しています。controller/user.gofunc (u *User) Show(w http.ResponseWriter, r *http.Request) (int, interface{}, error) { vars := mux.Vars(r) uid, ok := vars["user_id"] if !ok { return http.StatusBadRequest, nil, &httputil.HTTPError{Message: "invalid path parameter"} } user, _ := httputil.GetUserFromContext(r.Context()) userService := service.NewUser(u.db, u.authClient) userDetail, err := userService.FindUserDetail(uid, user) if err != nil && err == sql.ErrNoRows { return http.StatusNotFound, nil, err } else if err != nil { return http.StatusInternalServerError, nil, err } return http.StatusOK, userDetail, nil }
service
複数のリソースを操作する時や、トランザクションを必要とするドメインロジックを記述しています。
service/user.gofunc (u *User) FindUserDetail(id string, user *model.User) (*model.UserResponse, error) { userDetail, err := repository.FindUserByUserID(u.db, id) if err != nil { return nil, err } // 認証ユーザーが対象ユーザーをフォローしているかを確認 isFollow := false if user != nil { follow := &model.Follow{ FollowingID: user.ID, FollowedID: userDetail.ID, } isFollow, _ = repository.ExistsFollow(u.db, follow) } userDetailResponse := &model.UserResponse{ ID: userDetail.ID, DisplayName: userDetail.DisplayName, Icon: userDetail.Icon, DepartmentName: userDetail.DepartmentName, UniversityID: userDetail.UniversityID, UniversityName: userDetail.UniversityName, UniversitySlug: userDetail.UniversitySlug, Profile: userDetail.Profile, IsFollow: isFollow, } return userDetailResponse, nil }
repository
DBの操作を記述しています。sqlxを使って、DBからのレスポンスを構造体にマップしています。
repository/user.gofunc FindUserByUserID(db *sqlx.DB, uid string) (*model.UserResponse, error) { var u model.UserResponse if err := db.Get(&u, ` SELECT u.account_name, u.display_name, u.icon, d.name AS department_name, uni.id AS university_id, uni.slug AS university_slug, uni.name AS university_name, u.profile FROM users AS u INNER JOIN departments AS d ON u.department_id = d.id INNER JOIN universities AS uni ON d.university_id = uni.id WHERE u.account_name = ?; `, uid); err != nil { return nil, err } return &u, nil }
model
リクエストやレスポンス、DBの構造体を定義しています。型の後ろの
dbタグはsqlxが構造体にマップする時に使用する、構造体のフィールドが対応するDBのカラム名を明示的に表しています。jsonタグは構造体をクライアントにjsonとして返すときに使用するフィールド名を定義しています。model/user.gotype UserResponse struct { ID string `db:"account_name" json:"id"` DisplayName string `db:"display_name" json:"display_name"` Icon string `db:"icon" json:"icon"` DepartmentName string `db:"department_name" json:"department_name"` UniversityID int64 `db:"university_id" json:"university_id"` UniversityName string `db:"university_name" json:"university_name"` UniversitySlug string `db:"university_slug" json:"university_slug"` Profile *string `db:"profile" json:"profile"` IsFollow bool `json:"is_follow"` }工夫した点
サービスを開発する中で工夫した点や、使ってよかったものなどは以下の通りです。
エラーハンドリング
Goのエラーハンドリングに関しては、個人的にベストプラクティスが確立されていないと思っています。今回はGo標準のerrorsを使い、予めエラーの型を定義しておき、それを上位層に返し、上位層でハンドリングを行いました。例えば、講義ノートを投稿したり、更新する際に、講義が行われた大学の名前がDBで見つからなかった時に、Bad Requestを返すことにします。まず、
universityというリソースが見つからなかった時のエラー型を定義します。customerror/db.gopackage customerror import ( "errors" ) var NotFoundUniversity = errors.New("not found university")使い方としては、domain層で、想定するエラー(ここでは
universityが見つからない)が起きた時、定義したエラーを返します。service/note.gouniv, err := repository.FindUniversityByName(n.db, reqParam.UniversityName) if err != nil || univ == nil { return customerror.NotFoundUniversity }controllerのようなserviceやrepositoryを呼び出している上位層では、エラーにカスタムエラーが含まれているかを確認し、含まれていたらそれにあったレスポンスをクライアントに返します。
controller/note.goif errors.Is(err, customerror.NotFoundUniversity) { return http.StatusBadRequest, err, nil }ここで、
errors.Isを使っているのは、他のerrがwrapされていても判定することができるからです。具体的には以下のようなコードになります。(PlayGroundで試せます。)package main import ( "fmt" "github.com/pkg/errors" ) func main() { NotFoundUniversity := errors.New("not found university") err := NotFoundUniversity wrapErr := errors.Wrap(err, "other error") fmt.Println("err: ", errors.Is(err, NotFoundUniversity)) // err: true fmt.Println("wrapErr: ", errors.Is(wrapErr, NotFoundUniversity)) // wrapErr: true }
errorsはerrをWrapすることができます。繰り返しWrapされていても、errors.Isは、第一引数のエラーに第二引数のエラーがWrapされているか、またはそれ自体だったらtrueを返します。そのため、repositoryやserviceなどのdomain層で、エラーをWrapし、handler層では関心のあるエラー型のみハンドリングするということが可能になります。このような方針を取っているのは、domain層はクライアントにどのようなエラー(NotFound, BadRequest, ...)を返すかを知るべきではないからです。
上の例では、domain層は「大学というリソースが見つからない」という意味を持つ
NotFoundUniversityというエラーを返しています。例えば大学の情報を取得するような、大学に関するエンドポイントであれば、handlerは404 NotFoundを返します。しかし、講義ノートを投稿するような、大学がメタデータになっているエンドポイントであれば、handlerは400 BadRequestを返すべきです。Elasticsearch
サービスに検索機能を作るにあたり、Elasticsearchを導入しました。検索が強い以外の、Elasticsearchを導入してよかった点とイマイチだった点は以下の通りです。
よかった点
スキーマレスである
開発している中で、データの構造が変わることや、検索に使うフィールドが増えることが多くありました。そういう時に、RDBであればmigrarionファイルを作るなど、スキーマを変更する必要がありますが、Elasticsearchは基本的にはスキーマがないので、雑に格納するデータ構造を変えられて、スムーズに開発ができました。
プライマリーDBから切り離して考えられる
厳密に言えばElasticsearchの利点ではないのですが、Elasticsearchを検索用として割り切って使うことで、プライマリーDB(今回はMySQL)の管理が楽になりました。
例えば、今回のノートを投稿してもらうサービスの中で、ノートの内容をバージョンごとに保存しておく機能があり、更新するごとにノートの内容が保存されたレコードがDBに1つ増える仕様になっています。プライマリーDBで検索をしようとすると、検索対象は一番新しいバージョンのレコードに対してのみになり、これを実現するためには最新バージョンであることを示すフラグを追加するなどの対応が必要になります。ノートを更新した際には、更新する前まで最新だったバージョンのレコードを探し、最新フラグをfalseにする作業が増え、最新バージョンのレコードを探すためのロジックも必要になり、考えなければいけないことが増大します。イマイチだった点
index内に違うスキーマのドキュメントがあるとエラーになる
(スキーマレスであることを良い点で挙げておきながら、何言ってるのというツッコミが飛んできそうですが、)
スキーマレスなので、雑にスキーマを変えたドキュメントをインデックスに突っ込もうとすると、たまに怒られて入りません。これは、フィールドを追加したor削除した時などには起きないのですが、フィールドの型を変えた時に起こります。検索の時に、違う型のフィールドを持つドキュメントは走査できないからだと考えられます。例えば以下のようなドキュメントは同じインデックスには入れられません。スキーマ変更前
{ "name": "Sato", "type": 1, }スキーマ変更後
{ "name": "Sato", "type": "admin", }
トランザクションが貼れないので、RDBとの不整合が起きる場面がある
これもElasticsearchの欠点というより、NoSQLの問題なのですが、トランザクションを貼ることができないので、途中で処理が失敗しても簡単にロールバックするということができません。なので、複数リソースを編集&削除するような、トランザクションを貼りたい場面でElasticsearchも操作する場合、トランザクションの最後や、トランザクションが終わった後に実行する必要があります。
ロールバックがうまくいっているように見える例
- Transaction start - RDB処理A - RDB処理B - Elasticsearch処理A - Transaction end3つの処理がTransactionの中で行われるとします。もし仮に最後の
Elasticsearch処理Aで失敗しても、この3つの処理はトランザクションの中で行われているので、ロールバックすることができます。(厳密にはRDB処理AとRDB処理Bしかロールバックしていません。)ロールバックがうまくいかない例
- Transaction start - RDB処理A - RDB処理B - Elasticsearch処理A - Elasticsearch処理B - Transaction endしかし、複数のElasticsearchの処理をトランザクションの中で行い、
Elasticsearch処理Bで失敗した場合、トランザクションが正しく貼れているRDBの処理であるRDB処理AとRDB処理Bはロールバックできますが、トランザクションをサポートしていないElasticsearch処理Aはロールバックすることができません。上のロールバックがうまくいっているように見える例も、Elasticsearch処理Aの中で破壊的な処理が既に行われていれば、それはロールバックすることはできません。このように、Elasticsearchはトランザクションがサポートされていないため、プライマリーDBとの不整合が起こる可能性があり、工夫が必要だと感じました。
Stoplight(OpenAPI)でAPI仕様を残す
フロントとサーバーで役割分担をしていたので、フロントの開発メンバーにサーバーの仕様を予め伝えることで、開発の手が止まらないように工夫しました。最初にOpenAPIで仕様を全部書き、その後にコードを書き始めるという開発プロセスだったので、仕様書の自動生成などは行いませんでした。
当初はswaggerをローカルで立ち上げて、SwaggerUIで仕様書を確認していたのですが、立ち上げるのが面倒だったので、stoplightを導入しました。
Stoplight StdioはSwagger UIのように仕様書を確認 & リクエスト実行だけでなく、GUIでAPI仕様書を編集、任意のブランチにコミットができます。もちろん、表示する仕様書のブランチも変更することができます。Stoplight導入で、個人的にはサーバーの開発スピードをあげることができたと感じています。導入前と導入後の仕様書を編集する手順は以下の通りです。
導入前
- ローカルでswaggerを立ち上げる
- 任意のエディターでyamlを編集する
- ブラウザで仕様書を確認
- (良い感じになるまで2,3を繰り返す)
- 任意のツールでgit add & git commit & git push
導入後
- Stoplight Stdioにアクセスする
- 仕様書をGUIで編集
- ブラウザからコミット&プッシュ
もちろん手順も少なくなっているのですが、一番大きいのはyamlを直接編集する必要がなくなった事です。yamlを直接編集していたときは、インデントのずれやtypo一つでエラーになり、無駄なデバックの時間が生まれていました。
まとめ
今回はGoを使って開発を行った時のお話でした。他のチームメンバーが色んな視点から記事を書いているので、是非そちらもご覧になってください!