- 投稿日:2020-08-02T22:54:46+09:00
No such file or directory @ rb_sysopen - /Users/○○/Gemfile.lock (Errno::ENOENT)で苦しんだ
railsコマンドを打とうとすると
$ rails ○○ Traceback (most recent call last): 4: from bin/rails:3:in `<main>` 3: from bin/rails:3:in `load` 2: from /Users/user/[プロジェクト名]/bin/spring:10:in `<top(required)>` 1: from /Users/user/[プロジェクト名]/bin/spring:10:in `read` /Users/user/[プロジェクト名]/bin/spring:10:in `read`: No such file or directory @ rb_sysopen - /Users/user/[プロジェクト名]/Gemfile.lock(Errno::ENOENT)こんなエラーが出てしまい号泣。
原因
railsコマンドでは、gemのバージョンも確認工程に含まれるため
Gemfile.lockの中身が参照される。
ただ今回、参照されるべきGemfile.lockがない状態なのでエラーが出てしまっている状況。対処法
Gemfile.lockはgemfileのバージョンを記録しておくもので、bundle installコマンドによって自動的に生成されるため、bundle installを実行する必要がある。早速、アプリディレクトリ上にて
bundle installを実行↓$ pwd /Users/○○/アプリ名 $ bundle installその後、再度railsコマンドを入力してみる。
すると、無事にrailsコマンドが効く状態になってるはず!まとめ
かなり初歩的な内容かもですが、自分は過去にこのエラーで相当時間を取られました...
同じエラーで苦しむ人が減れば幸いです!
- 投稿日:2020-08-02T22:15:09+09:00
Dockerを使ったRails開発でブラウザテストが実行できない
概要
・RSpecでCapybaraを使ったブラウザテストを実装する際にエラー
RSpecの学習をしている際にテストを実行すると下記のエラーが発生しました。
解決するのに結構時間がかかりました。Selenium::WebDriver::Error::UnknownError: unknown error: Chrome failed to start: exited abnormally. (unknown error: DevToolsActivePort file doesn't exist) (The process started from chrome location /usr/bin/google-chrome is no longer running, so ChromeDriver is assuming that Chrome has crashed.)spec-helper.rbCapybara.register_driver :selenium_chrome_headless do |app| browser_options = ::Selenium::WebDriver::Chrome::Options.new() browser_options.args << '--headless' browser_options.args << '--no-sandbox' browser_options.args << '--disable-gpu' Capybara::Selenium::Driver.new(app, browser: :chrome, options: browser_options) end解決方法
Dockerfileにchrome driverをインストールする記述を追加したところ上手くテストが実行されました。
追記分
DockerfileRUN CHROME_DRIVER_VERSION=`curl -sS chromedriver.storage.googleapis.com/LATEST_RELEASE` && \ wget -N http://chromedriver.storage.googleapis.com/$CHROME_DRIVER_VERSION/chromedriver_linux64.zip -P ~/ && \ unzip ~/chromedriver_linux64.zip -d ~/ && \ rm ~/chromedriver_linux64.zip && \ chown root:root ~/chromedriver && \ chmod 755 ~/chromedriver && \ mv ~/chromedriver /usr/local/bin/chromedriver && \ sh -c 'wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.pub | apt-key add -' && \ sh -c 'echo "deb [arch=amd64] http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google-chrome.list' && \ apt-get update && apt-get install -y google-chrome-stable動作確認済みDockerfile↓
DockerfileFROM ruby:2.5 RUN apt-get update && apt-get install -y \ build-essential \ libpq-dev \ node.js \ yarn # Rspecで使うchormedriverをインストール RUN CHROME_DRIVER_VERSION=`curl -sS chromedriver.storage.googleapis.com/LATEST_RELEASE` && \ wget -N http://chromedriver.storage.googleapis.com/$CHROME_DRIVER_VERSION/chromedriver_linux64.zip -P ~/ && \ unzip ~/chromedriver_linux64.zip -d ~/ && \ rm ~/chromedriver_linux64.zip && \ chown root:root ~/chromedriver && \ chmod 755 ~/chromedriver && \ mv ~/chromedriver /usr/local/bin/chromedriver && \ sh -c 'wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.pub | apt-key add -' && \ sh -c 'echo "deb [arch=amd64] http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google-chrome.list' && \ apt-get update && apt-get install -y google-chrome-stable # 作業ディレクトリに移動(無ければ自動で作成) WORKDIR /app #build context内のGemfileとGemfile.lockをコピー COPY Gemfile Gemfile.lock /app/ #Gemをインストール RUN bundle installDockerfileを編集しているので
$docker-compose build再度コンテナを起動してテストを実行するとうまくテストが実行されました。
- 投稿日:2020-08-02T20:47:54+09:00
rails開発の条件分岐のあれこれ
rails開発の条件分岐のあれこれ
rails でのwebアプリケーション開発であるといい記述をまとめてみました!
投稿に対して投稿者のみ編集・削除ができるようにしたい!
rails でSNSのようなアプリケーションを作るとき,投稿に対してユーザー誰もが編集したり
削除できるとダメですよね!
そんなとき便利なのが下の条件分岐です!devise(Gem)をインストールしていうることを前提とします
post.rbbelongs_to :useruser.rbhas_many :postsroute.rbresources :post, only: [:show]post_controller.rbdef show @film = Post.find(params[:id]) endshow.html.erb<% if @post.user_id == current_user.id %> #追記 <%= link_to "編集する", edit_post_path(@post.id) %> <%= link_to "削除する", post_path, method: :delete %> <% end %> #追記このように編集・削除の部分を条件分岐で
もし,投稿者のidがログイン中のユーザーidと一致したら
の意味を持つ,<% if @post.user_id == current_user.id %> でかこんであげるといいでしょう!ログインしている人としていない人で記述を変えたい!
例えばこのようなことはないでしょうか?
ログイン前には,ヘッダーに新規登録・ログインのリンクを
ログイン後には,マイページやログアウトのリンクを
実装したい!
こんな時に便利なのが下の条件分岐です!devise(Gem)をインストールしていうることを前提とします
今回,bootstrapを使用したナビゲーションバーを使用しています
bootstrapはこちらlayout/application.html.erb<% if user_signed_in? %> <nav class="navbar fixed-top navbar-expand-lg navbar-light"> <a class="navbar-brand" href="/">ホーム</a> <div class="collapse navbar-collapse" id="navbarSupportedContent"> <ul class="navbar-nav mr-auto"> <li class="nav-item"> <a class="nav-link" href="/post/new" style="color: white;">投稿する<span class="sr-only">(current)</span></a> </li> <li class="nav-item"> <a class="nav-link" href="/users/<%= current_user.id %>">マイページ</a> </li> <li class="nav-item" > <%= link_to 'ログアウト', destroy_user_session_path, data: { confirm: "ログアウトしますか?" }, method: :delete, class:"nav-link"%> </li> </ul> </div> </nav> <% else %> <nav class="navbar fixed-top navbar-expand-lg navbar-light"> <a class="navbar-brand" href="/home">トップ</a> <button class="navbar-toggler" type="button" data-toggle="collapse" data-target="#navbarSupportedContent" aria-controls="navbarSupportedContent" aria-expanded="false" aria-label="Toggle navigation"> <span class="navbar-toggler-icon"></span> </button> <div class="collapse navbar-collapse" id="navbarSupportedContent"> <ul class="navbar-nav mr-auto"> <li class="nav-item"> <a class="nav-link" href="/users/sign_up" style="color: white;">新規登録</a> </li> <li class="nav-item"> <a class="nav-link" href="/users/sign_in" style="color: white;">ログイン</a> </li> </ul> </div> </nav> <% end %><% if user_signed_in? %>の部分が重要です!
これは,「もしユーザーがログインしていたら」という条件分岐なのです!
<% else %>(そうでなければ→「ログインしていなかったら」)との組み合わせでさらなる力を発揮します!画像投稿でnilのエラーを吐いてしまう
**cloudinaryを使った画像投稿を実装できていることとします
今回は画像投稿を例に出していますがその他にも,nilのときどうしよう..という場合にこれが使えます!
db/migrate/OOOOOOOOOOOOOO_add_image_to_posts.rbdef change add_column :posts, :image, :string endpost_controller.rbdef show @film = Post.find(params[:id]) endshow.html.erb<% if @post.image.present? %> <%= image_tag @post.image_url, :size =>'150x150', class: "img_fluid rounded-circle" %> <% end %><% レコード.カラム.present? %>の部分が大事です!
これによってnilではなく存在していれば表示される条件分岐となります![補足]
画像サイズを正方形にして,bootstrapによって画像をTwitterのプロフィール画像のように丸くしています最後に
ここまで3つの個人的によく使用する条件分岐をについて記述してみました!
間違い等ございましたら指摘してください!条件分岐(if)文はプログラミングの中でも共通で大事なものです!
実際に手を動かして理解してみましょう!
- 投稿日:2020-08-02T20:37:33+09:00
A server is already running(rails sのプロセスが切れない)をさっさと解決する
サーバーを起動しようとすると以下がでるときの対処法を数種類まとめました!
どれかで解決できる(はず)。❯ rails s => Booting Puma => Rails 5.0.7.2 application starting in development on http://localhost:3000 => Run `rails server -h` for more startup options A server is already running. Check プロジェクト名/tmp/pids/server.pid. Exiting何種類もあるため、上手くいかないときは順番に試してみるコトをおすすめします。
まず確認すること
たまに
Mac標準のターミナルでサーバー起動状態&VSCodeなどのテキストエディタ上のターミナルでサーバー起動しようとしている方がいるので、
まずは別のターミナルで既にサーバーを動かしていないかを確認しましょう!パターン①
railsのプロセスを削除する$ rails s => Booting Puma => Rails 5.0.7.2 application starting in development on http://localhost:3000 => Run `rails server -h` for more startup options A server is already running. Check プロジェクト名/tmp/pids/server.pid. Exiting $ ps aux | grep rails user 28321 s001 S+ 0:00.00 grep rails $ kill -9 28321 $ rails s → 解決パターン②
ポート番号3000番のプロセスを削除する$ lsof -wni tcp:3000 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME ruby 28295 user 21u IPv4 0x77d8a30cabb79cc9 0t0 TCP 127.0.0.1:hbci (LISTEN) ruby 28295 user 22u IPv6 0x77d8a30cac93f9f9 0t0 TCP [::1]:hbci (LISTEN) # 「COMMAND」に「ruby」と書いてある行のPIDをコピーして処理を停止(今回は28295) $ kill -9 28295 $ rails s → 解決パターン③
サーバー起動の際に使用するIDを削除する$ rm /tmp/pids/server.pid $ rails s → 解決このファイルの場所は
[アプリ名]/tmp/pids/server.pidに入っているので、パスを指定して削除します。
本来、サーバーを終了するとこのファイルは削除されますが、残ったままでエラーになっている可能性があるみたい。
※server.pidはサーバー起動や終了で勝手に作られたり削除されたりするので、普段は気にしなくて良いです。まとめ
頻繁に出てきた
kill -9 ○○はLinuxコマンドの一つで、プロセスを終了するためのものです。
個人的には、パターン②ですんなりプロセスを終了出来ることが多い気がします。サーバーの立ち上げで足止めをくらうと萎えるので、さくっと解決してください!
- 投稿日:2020-08-02T19:04:41+09:00
RailsでOpenWeatherMapから天気予報を取得する
初めに
Qitta初投稿です!
初心者なので至らぬ点も多いかと思いますが、暖かくコメント頂けると嬉しいです!概要
- 無料のapiを提供しているOpenWeatherMapのapiを叩くことで、全国各地の天気予報を取得する。
- HTTPリクエストはhttpclientを使用し、rake taskにすることで定期的に叩けるように実装する。
開発環境
ruby: 2.7.1
rails: 6.0.3.2手順
- API KEYの取得
- 取得したい都市のCITY IDを取得
- Cityテーブルの作成・保存
- HTTPリクエストの実装
- WeatherForecastテーブルの作成・保存
1. API KEYの取得
OpenWeatherMapのホームページにアクセスし、Sign inからCreate an accountでアカウントを作成しましょう。送られてくるメールから有効化するとAPI KEYが送られてきます。
これを環境変数なり
credentialsなりに保存しておきます。今回はcredentialsを利用していきます。
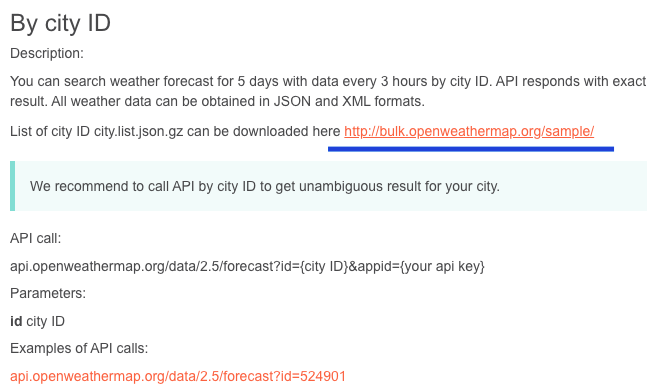
credentialsに関してはこちらの方の記事がとても参考になります。EDITOR=vi bin/rails credentials:editcredentials.yml.encopen_weahter: appid: <API_KEY> uri: https://samples.openweathermap.org/data/2.5/forecastなお、今回は3時間毎の天気を取得しようと思うので、APIドキュメントを参考にリクエストを送るURIを取得しています。
無料枠でも取得できる天気の種類は豊富にあるようです!APIドキュメントを色々と探してみると面白いです。
2. CITY IDの取得
APIドキュメントから
city.list.jsonをダウンロードします。このファイルから、取得したい都市のCITY IDを取得していきます。中身一部抜粋です。
ちなみにlonは経度、latは緯度を指します。city.list.json{ "id": 1850147, "name": "Tokyo", "state": "", "country": "JP", "coord": { "lon": 139.691711, "lat": 35.689499 } },私はこのid取得を泣く泣く手作業でしました...
同じ名前の都市でも経緯度が違うものが混じっているので注意が必要です!エクセルやmacならnumbersなどにリストアップしてCSVに変換すると良いと思います!
ちなみに私が作成したCSVはこんな感じです。一部カラムを削ってます。db/csv/cities.csv札幌,2128295 青森,2130658 盛岡,2111834 仙台,2111149 秋田,2113126 山形,2110556 福島,2112923 水戸,2111901 宇都宮,1849053 前橋,1857843 さいたま,6940394 千葉,2113015 東京,1850147 横浜,1848354 新潟,1855431 富山,1849876 金沢,1860243 福井,1863983 山梨,1848649 長野,1856215 岐阜,1863640 静岡,1851715 名古屋,1856057 津,1849796 大津,1853574 京都,1857910 大阪,1853909 神戸,1859171 奈良,1855612 和歌山,1926004 鳥取,1849890 松江,1857550 岡山,1854383 広島,1862415 山口,1848689 徳島,1850158 高松,1851100 松山,1926099 高知,1859146 福岡,1863967 佐賀,1853303 長崎,1856177 熊本,1858421 大分,1854487 宮崎,1856717 鹿児島,1860827 那覇,18560353. Cityテーブルの作成・保存
seeds.rbかtaskにコードを書いて、データベースに保存していきます。今回はlib/tasks以下に実装しました。CITY IDはカラム名をlocation_idとして保存しています。import_csv.rakedesc 'Import cities' task cities: [:environment] do list = [] CSV.foreach('db/csv/cities.csv') do |row| list << { name: row[0], location_id: row[1], } end puts 'start creating cities' begin City.create!(list) puts 'completed!' rescue ActiveModel::UnknownAttributeError puts 'raised error: unknown attributes' end endCSV.foreachメソッドで先ほど作成した
cities.csvを一行ずつ読み込みます。row[0]で1列目の都市名、row[1]で2列目のCITY IDが取得できるので、ハッシュの配列を作成してCity.create!でデータベースに保存しています。4. HTTPリクエストの実装
レスポンスの解析
HTTPリクエストを実装する前に、まずは、レスポンスのJSONファイルを解析していきます。
APIドキュメントに各項目について詳しく説明が書かれているので、それを参考に欲しいデータのキーを取得していきます。
1つのCityに関するリクエストは以下のようなJSON形式で返ってきます。
(curlコマンドや、VScodeをお使いの方はREST Client等で試してみると良いと思います。)example_resopnse.json{ "cod": "200", "message": 0, "cnt": 40, "list": [ { "dt": 1578409200, "main": { "temp": 284.92, "feels_like": 281.38, "temp_min": 283.58, "temp_max": 284.92, "pressure": 1020, "sea_level": 1020, "grnd_level": 1016, "humidity": 90, "temp_kf": 1.34 }, "weather": [ { "id": 804, "main": "Clouds", "description": "overcast clouds", "icon": "04d" } ], "clouds": { "all": 100 }, "wind": { "speed": 5.19, "deg": 211 }, "sys": { "pod": "d" }, "dt_txt": "2020-01-07 15:00:00" },今回は以下の項目を使ってテーブルを作成しています。
- list
- main
- feels_like: 体感気温
- temp_max: 最高気温
- temp_min: 最低気温
- weather
- id: 天気ID
- rain
- 3h: 降水量
降水がある場合のみ、
rainがlistに追加されます。なお、天気IDはこちらを参考にしてください。OpenWeatherMapでは、IDによって天気を分類しています。
descriptionから天気を取得することも可能です。しかし種類が多いため、今回の実装ではデータベースには天気IDを保存しておき、メソッドで天気を割り振るようにしています。HTTPリクエストの実装
まずは、httpclientをGemfileに追加し、
bundle installします。gem 'httpclient', '~> 2.8', '>= 2.8.3'次に
lib/api/open_weather_map/request.rbを作成します。
ここまで深くする必要はないかなと思ったのですが、このapiに関して他のクラスを実装したり、他のapiクラスを実装することを考慮してこのようなファイル配置にしました。lib以下はデフォルトではtask以外読み込まれないので、
config/application.rbに、以下の設定が必要です。eager_load_pathsなので本番環境も大丈夫です。config/application.rbconfig.paths.add 'lib', eager_load: trueおいおいこれはあかんやろ、っていう箇所があればご指摘頂けるととても嬉しいです。ファイルの配置が今回の実装で最も悩みました...
リクエストを保存するWeatherForecastテーブル↓
WeatherForecast temp_max float temp_min float temp_feel float weather_id int rainfall float date datetime aquired_at datetime 以下が実装したRequestクラスです。
request.rbmodule Api module OpenWeatherMap class Request attr_accessor :query def initialize(location_id) @query = { id: location_id, units: 'metric', appid: Rails.application.credentials.open_weather[:appid], } end def request client = HTTPClient.new request = client.get(Rails.application.credentials.open_weather[:uri], query) # 戻り値は3時間ごとのデータ5日分 JSON.parse(request.body) end def self.attributes_for(attrs) rainfall = attrs['rain']['3h'] if attrs['rain'] date = attrs['dt_txt'].in_time_zone('UTC').in_time_zone { temp_max: attrs['main']['temp_max'], temp_min: attrs['main']['temp_min'], temp_feel: attrs['main']['feels_like'], weather_id: attrs['weather'][0]['id'], rainfall: rainfall, date: date, aquired_at: Time.current, } end end end end
initializeでクエリストリングを設定しています。今回のリクエストで必要なクエリストリングは、CITY IDを示すlocation_idとAPI KEY, そして気温の表示を摂氏表示に変更するためにunits: 'metric'を加えています。返ってきたリクエストをデータベースに保存できる形に直すために
attributes_forメソッドをクラスメソッドにしています。注意が必要なのは、降水量と予報日付です。
- 降水量は、降水がない場合は項目が存在しません。なのである場合のみ取得するように条件分岐しています。
- 予報日付に関しては、タイムゾーンに注意が必要です。OpenWeatherMapのタイムゾーンはUTCなので、JTCに変換してから保存しています。
タイムゾーンの扱いについてはこちらの記事が参考になります。
5. WeatherForecastテーブルの作成・保存
rake taskの作成
データベースへの保存・更新は定期的に実行したいので
rake taskに書いていきます。
と言っても、先ほどのRequestクラスでほぼメソッドを書いたので、後はそれを使うだけです。open_weather_api.rakenamespace :open_weather_api do desc 'Requests and save in database' task weather_forecasts: :environment do City.all.each do |city| open_weather = Api::OpenWeatherMap::Request.new(city.location_id) # リクエスト上限:60回/min response = open_weather.request # 3時間ごとのデータ2日分を保存 16.times do |i| params = Api::OpenWeatherMap::Request.attributes_for(response['list'][i]) if weather_forecast = WeatherForecast.where(city: city, date: params[:date]).presence weather_forecast[0].update!(params) else city.weather_forecasts.create!(params) end end end puts 'completed!' end end今回は、3時間毎のデータを2日分ずつデータベースに保存、更新する仕様にしました。
ポイントはリクエスト上限と、データの作成なのか更新なのかという点です。
- リクエスト上限は無料プランでは60calls/minです。登録している都市が60を超える場合は、分けてリスエストを送る必要があります。今回は47なので問題ありません。
presenceメソッドはpresent?メソッドを呼び出して、trueだった場合はレシーバー自身を返すメソッドです。同じ都市の同時刻に関する予報がすでにデータベースに存在する場合はupdate!を、存在しない場合はcreate!を呼び出しています。最後に
保存した
weather_idに対応する天気のアイコンを用意すると天気予報らしい見た目になると思います!
cronや、herokuならheroku schedularなどで定期的にapiを叩くようにしておくと良いかと思います!こんな感じで表示でしました!
長々とした文章を読んで頂きありがとうございました!
参考
https://openweathermap.org/api
https://qiita.com/yoshito410kam/items/26c3c6e519d4990ed739

- 投稿日:2020-08-02T19:04:32+09:00
スタートアップである弊社が全員ほぼ未経験でRoRをScalaに移行した理由、その効果と苦労点
この記事を書くに至った経緯
僕が代表をしている株式会社KOSKAでは製造業の原価管理をIoTで自動化するGenkanというサービスを提供しております。
そんな弊社では半年前、バックエンドをRoRからScalaに移行したのですが、その効果が思ったよりだいぶ大きく、いずれこの効果を共有したいなーと思っていました。
弊社ではスタートアップで全員ほぼ未経験状態のScalaを採用するという挑戦をした結果、「Scalaを書きたい」というレベルの高い人材をかなりの確率で捕まえられるようになり、開発がものすごい加速した上に堅牢になったのでそのうちスタートアップでScalaを採用するメリットを記事にする予定。 https://t.co/uqZ5YWs6Ru
— ソネケン (@sonken625) January 9, 2020そんな折、このようなツイートをしたところ予想外にいいねRTが多く、思っていたよりだいぶ興味ある人が多いことがわかったので早く書かないといけないと感じて書き始めました・・・が、書きたいことがおおくて全く進まない
そして半年後、あまりにも僕が書かないので弊社CPOが以下の記事を書きました。
0からScalaを本番導入して感じたこと・考えたこと - Qiitaここで結構色々書いてくれてるのですが、当時の詳しい状況や、CEOとして考えていたこと等を僕も書いておこうと思い公開します。
結果だけ知りたい人は最後にまとめておきますので最初の方は飛ばしてください。スタートアップでRoRやPHPのようなスクリプト言語系を移行しようか迷っている人、などを考えている人の参考になれば幸いです。
当時の状況
2019年7月時点まで、弊社のGenkanはフロントエンドがTypeScript×React、バックエンドはRoRで作られていた。2018年11月に起業したので人数は少なく、2019年3月くらいまでは実質僕とCPOの2人でバックエンドフロントエンドをほぼ全て作る必要があったため、2人が一番慣れている構成にしていた。
PMF前でもあったので仕様変更が激しく、とりあえず動くならなんでもいいという状況であったため負債のたまり方も尋常ではなかった。
いわゆる普通のWEBサービスと少し差があったのは、弊社のサービスはIoTデータを自動で分析し、原価で分析するというものでセンサーから送られてくるタイムスタンプをかなり色々な複雑な計算によって分析結果を出さなければならなかった。とはいえ四則演算の領域なのでアプリケーションだけの計算でどうにかなるだろうと見積もり、RoRで基本計算も行うような形にしていた。
IoTデータとはいえセンサー側で計算もしており、4秒に1回ほどのデータが飛ぶだけなのでNoSQLに頼るほどのものでもないという考え方でRDBMSにタイムスタンプデータを貯め、SQLとRailsのモデル層で計算し、フロントにJSONを返す流れでおこなっていた。
ただ実際これが意外と複雑で、SQLである程度行えば計算部分は多少マシにはなるがRoRでSQLを柔軟に構築するタスクに躊躇していたのと、アプリケーションの方がアルゴリズムを変えるのが(自分たちの慣れの問題で)早かったために、アプリケーションコードでほとんどのアルゴリズムを構築していた。
その結果、RoR側での複雑性はどんどん増していった。対処法としてサービス層作成、モジュール化、Trailblazer使ってDDDのレイヤードアーキテクチャの真似事をするなど頑張ってリファクタし続けていたが、7月になるころにはサーバーの機能を追加するのにも影響範囲を考えながら行う必要が出てきたために機能追加がだんだん遅くなってしまっていた。
また、会社的にはトライアルが増え始め、最初は運用は完全手動でやるしかなかったためにCTO、CPO、僕で半田付けしたり、センサーのアルゴリズム書き換えたりハードウェアスタートアップによくある多大な苦労がどんどん増えていた。
また弊社のエンジニアの人材的な側面での環境を整理すると
- CTOはハードウェア担当。ソフトウェアもできるがモダンな開発が得意というほどでもない。
- CPOはソフトウェア担当。フロントもサーバーも行うがRoRでのバックエンド作成を最後の方ほとんど一人で行っていた。
CEOである僕もソフトウェアをガンガン開発していた。バックエンドもフロントエンドもできるがフロントエンドの方が得意なためフロントエンドメインと、インフラ(AWSでECSを使って基本コンテナで運用している。)を担当した。
これは少し特殊なカルチャーであり自慢でもあるのだが、弊社は創業時からエンジニア経験ゼロの文系学生を教育しモダンな開発ができるレベルまで育てており、2020年現在ではそうやって育てたエンジニアがすでに5人ほどいる。1年程度しか経っていないが全員React×TypeScriptはできるし、特に初期からいた2人(@unirt,@Ki-da)はScalaサーバーをメインエンジニアとしてガンガン開発していたりHadoop&Sparkでの分散プラットフォーム分析環境を構築、開発していたりと経験1年のエンジニアとしてはあり得ないレベルまで育っている。そこまでにするのに相当な教育コストをかけているが、弊社の大事にしていることは「エンジニアが成長できる環境」をつくることであり、エンジニアが成長できるなら多少コストがかかっても組織としては強くなると考える文化が形成されていた。
意思決定
課題
8月になった際にこのままだとまずいが、どう対処を取るかという会議を行った。弊社の状況を整理すると
- 機能追加がどんどん遅くなっている。アーキテクチャを再検討していく必要がありそう
- トライアルにかかるコストを減らしていかないとどう考えてもリソースが足りない。スケールさせる上でも必須なことは間違いない
- エンジニアが成長できる環境を作りたい。それは難しい言語やフレームワークを使わなくても達成はできるのでアーキテクチャ採用に直接は関係しないが、やはりエンジニアの意識に影響するような環境を作れるのであれば技術の難しさは関係ない。
- 一方でシード期のスタートアップに時間はそこまで残されていない。実はこの時すでに資金調達が迫っていた。とはいえ現在のシステムを全て移行するなら3ヶ月程度を見込まないといけないと考えられる。ここはCEOである僕がもし再設計や再実装を行うのであればそのメリットを投資家に伝え、社内でも全員が正しい意思決定であると納得するまで議論することがCEOの責任でもあると考えていた。
このような条件のもと議論し、どのように対処していくのが一番最適かを全員で考えた。
決定事項
まず最初に決まったのは
- 少なくともトライアルにかかるコストを削減するために、ハードウェアやセンサー解析アルゴリズムをある程度自動化する社内システムを作る。
- その社内システムは現在のシステムとは独立して動かす。
ということだった。(現在そのシステムはGKAssistantという名で、ハードウェア内のアルゴリズムを自動で書き換えたり管理できたりするシステムとして狙い通り動いている。)
これはトライアルのコストを削減するためには必須であったし、ハードウェア管理コストが減れば減るほど機能追加が加速できるのもあり明らかなメリットがあったためすぐに決まった。
Genkanの改修戦略
続いてGenkanのリファクタについて議論した。この時の選択肢は
- RoRでアーキテクチャを作り直す(Trailblazerというライブラリである程度作っていたが、さらに改造していく)
- RubyではあるがDDDに向いていたHanamiを試す
- 別言語にする
というものであった。
単純に他の言語やフレームワークがやりたい!で意思決定しても仕方ない。僕はそこにメリットがあるのかのロジックを詰めることに重きを置いていた。(ちなみにCPOはやりたいがメインだった見たいですが、それはそれでいいカルチャーだと僕は思います。技術は手段だからなんでもいいみたいな考え方は技術が好きな人が多かった弊社だとあまり合いませんでした。)
まずHanamiを試すという選択肢はすぐに消えた。
そこまでしてRubyにこだわる必要を感じられなかった上に、その当時DDDもそこまで知見がなく、そもそも今回のシステムの問題がDDDで解決するのかも不明だった。(実際結局現在はCQRSを採用しているのでリードが複雑な部分は解消しなかったかもしれない)実質的にはRoRに留めるか、別言語にするかの二択であった
RoRに留めるメリット
- (別言語に変えるよりは)工数がかからない。これにつきる。
- (別言語よりは)現在の問題に対する打ち手がいくらか思いつく。別に言語を変えなくても解決する可能性はある。
別言語にするメリット
- 静的型付け言語に変えることができる。(TypeScriptでフロントエンドを書いていたため、サーバーでも静的型付け言語を使いたかった)
アーキテクチャの選択肢が言語に縛られないためより最適な構成を作れる可能性がある。
エンジニアのモチベーションを高めることができる。弊社のエンジニアは成長できることにインセンティブを感じる人間が上記の理由で多かった。そのためエンジニアのモチベーションを大幅に上がる可能性があった。
このような部分で議論を繰り返し、結局は別言語を採用することになった。
決め手となったのは上記のメリットもあったのだが、実はもう一つ自分たちで考えた仮説があった。スタートアップの言語選択の採用への影響
どこのスタートアップでもそうだと思うのだが、エンジニアの採用の難易度は非常に高い。特にtoCアプリの場合プロダクトの魅力などで参加してくれるエンジニアもいるが、toBのSaaSプロダクトなどはそもそもその分野のことを知っているエンジニアの方が少ないためプロダクトの魅力が特に最初の時点では非常に伝わりづらい。(例えば弊社のサービスは「IoTで工場の原価管理を自動化し、工場の方々が簡単に分析できるようにする」といったサービスだが、工場と原価管理に関わったことがないとピンとこないと思う。)
そのためスタートアップならではの働き方だったりをアピールすることになるのだが、だいたいスタートアップでやれることはみんな一緒になるのでどこも似たような形になる。さらにいうならそういう施策はシード期のベンチャーよりシリーズA以降のベンチャーの方がよっぽど強い。同じ条件なら既にでかくなっている企業に入りたいと思うのは合理的だとも思う。そうなるとシード期のスタートアップでエンジニアが働く理由は
1. 超レベルの高いエンジニアがいる
2. 給料
3. プロダクトの技術スタックが自分がやりたい方向などが主要因になる。僕が他のスタートアップで働いていた時もだいたいそのような軸であって、決してお菓子が食べ放題でフリーアドレスだからではない。
そこで上の3つを達成しようと思った時に、1は運ゲーであり、超ハイレベルエンジニアが興味持ってくれるかどうかによる。うちのエンジニアもレベルは高いが流石に超有名OSSのコミッターとかはいない。そういうのがシード期にいるスタートアップの方が珍しいと思う。
2も弊社は結構頑張っているつもりだが、シリーズAを超えたスタートアップに勝つのは非常に難しいだろう。同じ水準を出すことは可能だが差が出るほどではない。
となるとシード期のスタートアップはどこにいってもエンジニア側からすると似たような部分だけになってくる。あとはもはや合う合わないの世界である。
そこで3をある程度狙っていくのも戦略の一つではないかと考えた。
僕がもし採用される側なら選ぶ要因の一番大きいのは言語や技術スタックだし、そういう人材はスキルもかなり高いことが多い。そこで僕らが採用したのはScalaであった。Scalaの採用理由
選択肢はGoとKotlinとScalaであった。バックエンドでの実績が多く、現状の課題を解決する可能性がある言語を選んだ結果である。
様々な議論があった。CPOもここで書いている。
0からScalaを本番導入して感じたこと・考えたこと - QiitaCPOは割と楽しそうだからというところしか書いていないが、(ここも重要なポイント)実際はScalaにした理由がいくつかある。
DDDがやりやすい言語と聞いていた。
もともとRailsのコードがある程度めんどくさい分析をコードで行なっていたというのもあり、今後管理系の機能も追加されていくことがわかっていたので、DDDをはじめとしたいい感じのアーキテクチャを使いたかった。Scalaという言語はDDDにおいてかなり優秀であるという噂を聞いていたのでうまくいく可能性も大きいのではと予想した。金融系やTwitterでの採用実績から大規模分散処理に強そうという予想
弊社はIoTデータを分析するサービスなので、サービス規模の割には処理量が多い。今後スケールしてきたときに分析バッチなどをどのように回すのか等を考えた場合、Scalaなら外さないだろうと考えた。採用として強い。
GoやKotlinも悪くないのだが、実際今スタートアップだとかなりの割合でGo,TypeScript, Kotlin等のモダン言語で開発が行われている。
ちょうど僕らの投資元がとてもいい資料を作ってくれたので見てみると、pythonやrubyなどは圧倒的だが、かなりGoとかKotlinもいる。
スタートアップ開発環境マップ(約40社)by Coral Capital - Google スプレッドシート
上で書いてある採用を考えたとして、Go言語使えるからという理由だけなら選択肢がたくさん存在する。Scala言語は見ればわかるのだがその難易度や情報の少なさとの関連上そもそも実務で行うことが意外と難しい。なので「Scalaを実務で使ってみたい」というレベルが高いし成長意欲が高いエンジニアが採用できる可能性が高いのではという理由であった。現在の状況
かくしてScala採用を行い、すでに1年過ぎた。
結論からいうと正解でしかなかった。 どういうメリットがあったか上げていく。管理系のシステムをとても効率よく作ることができた。
現在は全てのバックエンドがScalaで動いている。
アーキテクチャはDDD×CQSっぽいReadとWriteをコードベースで分けたものを採用している。
このアーキテクチャで一番良かったのは管理系の仕組みを作った時で、弊社のように原価計算をやるときには原価情報の管理がかなり複雑な条件を持つ(工場の工程や機械は時系列で変化しうるのでバージョン管理みたいなものが必要)
しかし管理系のシステムを実装したとき、ほとんど問題がなく設計し実装まで全員で取り組め、1ヶ月程度でほとんど完成した。
Scala×DDDの破壊力を知ることができた部分であった。採用活動が本当に一瞬でおわった。
調達直後に採用を始め、とりあえず3人程度増やしたいと考えた。
1ヶ月採用活動して、結果
- Scalaやりたがってたフロントエンドエンジニア
- Scalaやりたがってたバックエンドエンジニア
- Scalaを実務で行なっていた金融系のエンジニア
- Scalaをやりたがっていたフロントエンドエンジニア
- Scalaをやりたがっていたインフラ系エンジニア
と技術力が尋常じゃないメンバーをすぐに採用することができた。かれらが弊社に貢献してくれた部分はとても大きく、組織が明らかに大きく成長していった。
ちなみに採用活動中に行なったのは、CEOである僕が面接中にひたすらScalaって言語で開発するのが本当に楽しいって話しをし続けただけである。本当に素晴らしい言語である。
Scala採用したときによく言われたのが「Scalaってできる人が少ないしできる人はすごく単価高いから採用難しいんじゃ?」だった。
これは確かに事実。Scalaを使っているような企業に所属するエンジニアを採用するのはなかなか難しい。
だが、今まで他の言語をやっていて、Scalaをやってみたいエンジニアも同じくらいハイレベルなことが多い。そういう人材は普通に1、2ヶ月以内にある程度Scalaをマスターし、開発に参加し、今までの持ってた経験等で組織を大きく成長させてくれた。つまり、Scalaを採用し、少しキャッチアップに時間を割くだけで、結局強力な人材を速攻で採用しているのと変わらなくなっている。
Rubyで3ヶ月以上採用活動してもあまりいい人材が見つかっていないスタートアップを様々みてきたが、採用に関しては人材がたくさんいるRubyやPHPよりも人材がそこまでいないがみんながやりたがるScalaの方が優位であると感じた。分析システムにSparkをすぐに採用することができた。
SparkというHadoopを使う仕組みがある。これはScalaで動いており、ものすごくScalaと相性がいい。(Pythonでもうごくので別にScala限定ではない。)
今弊社の分析バッチ処理は全てSparkで行われており、IoTデータがスケールしたとしてもほとんど同じ仕組みで継続できる。
Scalaを採用したことでこのSpark採用に全く抵抗がなかったのは大きくメリットであった。他にも弊社CPOが書いた記事にある定性的なメリットもすごく大きかったので参考にしていただければ。
結論:スタートアップでScalaを採用できるのか&意味はあるのか?
結論からいうとできるし、採用やチームのモチベーション、開発スピードにものすごいプラスの影響を与える。
特に「Scalaをやりたいという優秀なエンジニア」を採用できるというメリットが会社としてここまで影響があるとは思わなかった。エンジニア採用はスタートアップにとって大きな課題であるため、このメリットだけでもScalaを選択肢にいれてもいいと考えている。ただ、いきなりシステムを置き換えるのはお勧めしない。一番いいのはとりあえず別の機能や小さいサービスを別サーバーで作り、それをScalaで作る方がいいであろう。
Scalaは慣れてしまえばメリットが大きいのだが、RubyやPHP,Python等でサービス作ることに慣れていると本当に混乱する。そこに慣れるまでにおそらく3ヶ月はかかると考えていい。
さらに情報が全くないので、これが正解なんだろうかという疑問を常時持っている状態になる。個人的にはCTOなどチームの中でも技術力が高いメンバーが1人か2人で探索していくのがいいだろう。(弊社では僕とCPOがハードウェアを管理する仕組みをScalaで作ることでScala開発を探索していきました。)
苦労はしないのか?
導入が大変じゃないのかといえば、結構大変である。
Scalaを採用したら5ヶ月くらいは色々苦労すると思う。
ただ、弊社の場合それ以降の開発の速度が尋常じゃ無くなった。
優秀な人が組織を成長させてくれたし、成功体験が多くなり、開発が楽しいのでみんな熱中して開発するみたいな素晴らしいサイクルが生まれた。その結果弊社では次から次へと機能開発が進みCEOである僕はほとんど開発に参加しなくても問題ないようになっていった。
もし検討している人がいたら勇気を持って採用してほしい。
あと多分苦労するところは同じなので困ったらなんか連絡くだされば答えられることであればなんでも答えます。DMでも飛ばしてください最後に、今後Scalaを採用するに当たってめちゃくちゃ引っかかるところをだいたい解決策も書いた記事を書きました。
RoRやLaravelなどのフレームワークを使ってきた人がScalaを導入した時に引っかかる点とその解決策
RoR等を使った開発に慣れているがScalaが初めてと言う人は参考になるかなと思います。
Scalaは本当にいい言語ですし、メリットも大きいのでスタートアップのCTOなどは、ぜひ検討してみてください。
- 投稿日:2020-08-02T18:04:56+09:00
Rubyでクラスの継承を書く
親クラスで定義したメソッドを他の新規クラスで継承して使用する方法を書いていきます。
書き方は以下の通りです。
class 子クラス名 < 親クラス名
end
まずは、親クラスの例をみてみましょう。
class Mos
def eat
puts "食べる"
enddef drink
puts "飲む"
enddef take_out
puts "持ち帰り"
end
end次に継承した子クラスの例をみてみましょう。
class Mcdo < Mos # クラスの継承
def smile
puts "笑顔無料"
end
end親クラスのメソッドは、継承した他のクラスでも使用できます。
メソッド名 Mos(親クラス) Mcdo(子クラス) eat ◯ ◯ drink ◯ ◯ take_out ◯ ◯ smile × ◯ 上記の図をみてみると、親クラスのメソッドに記述したeat、drink、take_outを
子クラスに継承できていることがわかります。しかし、子クラスMcdoのメソッドであるsmileは親クラスのMos
には継承されていません。つまり
class 子クラス名 < 親クラス名
end
のように記述することで親クラスのメソッドを他のクラスで継承させながら、新たなメソッドを
付け加えることができます。
- 投稿日:2020-08-02T17:25:07+09:00
[rails]画像の投稿方法
画像投稿方法
画像の投稿方法はこんな感じの手順です。
・refileをgemfileに追加
・image_idカラムを追加
・attachmentメソッドを追加する
・Strong Parametersにimage_idを追加する
・viewファイルにf.attachment_fieldを埋め込む1.refileをgemfileに追加
refileの役割
・画像を簡単に組み込むことができる。
・サムネイルを生成できる。
・ファイルのアップロード先を設定できる。refile-mini-magickは画像をサイズを変更するためのgemです。
# 画像投稿用gem gem "refile", require: "refile/rails", github: 'manfe/refile' # 画像加工用(サイズ調整など)gem gem "refile-mini_magick"bundle installは忘れずに。
$ bundle install2.image_idカラムを追加
Userテーブルにimage_idカラムを追加します。
$ rails g migration AddImageIdToUsers image_id:stringこれも忘れてはいけません。
$ rails db:migrateでデータベースに反映。$ rails db:migrate3.attachmentメソッドを追加する
Refileを使うには、attachmentメソッドをモデルに追加する必要があります。
attachmentメソッドとは、refileが指定のカラムにアクセスするために必要です。
これによりDBに存在する画像を取得したりアップロードが可能となります。
カラム名はimage_idですが、ここでは_idは不要です。app/models/user.rbclass User < ApplicationRecord attachment :image end4.Strong Parametersにimage_idを追加する
class UserController < ApplicationController #省略 private def list_params params.require(:user).permit(:name, :email, :image) end end5.viewファイルにf.attachment_fieldを埋め込む
次に画像を投稿するページに以下の通り、記述します。
<%= f.attachment_field :image %>
- 投稿日:2020-08-02T12:36:56+09:00
rubyで世界のナベアツさんのネタを実装してテストを書く
なぜやろうと思ったか
- rspecで単体テストを書いてみたかった
- 単純なプログラムがよかった
- 世界のナベアツさんのネタがシンプルかつ無駄がなく面白いから
- 思いついたから
- やりたかったから
仕様
- 最初に「これから面白いことつまりオモローなことをします」という
- 1から40まで数を数える
- 3がつく数字のときアホになる
- 3の倍数のときアホになる
- 5の倍数のとき犬になる(3と5の倍数なら犬になる)
- 最後に「オモロー」という
まず、実装
omoro.rbTSUJO_KAO_MOJI = "( ・`ω・´)" # 通常 AHO_KAO_MOJI = "ʅ( ՞ਊ՞)ʃ≡" # アホのつもり DOG_KAO_MOJI = "∪・ω・∪" # イッヌのつもり puts 'これから面白いことつまりオモローなことをします' (1..40).each do |figure| sleep 0.5 if figure % 5 == 0 puts figure.to_s + DOG_KAO_MOJI next end if figure % 3 == 0 puts figure.to_s + AHO_KAO_MOJI next end if /3/ =~ figure.to_s puts figure.to_s + AHO_KAO_MOJI next end puts figure.to_s + TSUJO_KAO_MOJI end puts 'オモロー'
ruby omoro.rbで実行1( ・`ω・´) 2( ・`ω・´) 3ʅ( ՞ਊ՞)ʃ≡ 4( ・`ω・´) 5∪・ω・∪ 6ʅ( ՞ਊ՞)ʃ≡ 7( ・`ω・´) 8( ・`ω・´) 9ʅ( ՞ਊ՞)ʃ≡ 10∪・ω・∪ 11( ・`ω・´) 12ʅ( ՞ਊ՞)ʃ≡ 13ʅ( ՞ਊ՞)ʃ≡ 14( ・`ω・´) 15∪・ω・∪ 16( ・`ω・´) 17( ・`ω・´) 18ʅ( ՞ਊ՞)ʃ≡ 19( ・`ω・´) 20∪・ω・∪ 21ʅ( ՞ਊ՞)ʃ≡ 22( ・`ω・´) 23ʅ( ՞ਊ՞)ʃ≡ 24ʅ( ՞ਊ՞)ʃ≡ 25∪・ω・∪ 26( ・`ω・´) 27ʅ( ՞ਊ՞)ʃ≡ 28( ・`ω・´) 29( ・`ω・´) 30∪・ω・∪ 31ʅ( ՞ਊ՞)ʃ≡ 32ʅ( ՞ਊ՞)ʃ≡ 33ʅ( ՞ਊ՞)ʃ≡ 34ʅ( ՞ਊ՞)ʃ≡ 35∪・ω・∪ 36ʅ( ՞ਊ՞)ʃ≡ 37ʅ( ՞ਊ՞)ʃ≡ 38ʅ( ՞ਊ՞)ʃ≡ 39ʅ( ՞ਊ՞)ʃ≡ 40∪・ω・∪ オモローできた。
ただこれだとメソッドがなく全部の処理が一緒で単体テストが書けない。
メソッドを責務ごとに分けた。omoro_class.rbclass Omoro TSUKAMI = "これから面白いことつまりオモローなことをします" OCHI = "オモロー" TSUJO_KAO_MOJI = "( ・`ω・´)" AHO_KAO_MOJI = "ʅ( ՞ਊ՞)ʃ≡" DOG_KAO_MOJI = "∪・ω・∪" # ネタ def main(max_kazu = 40) speak(TSUKAMI) (1..max_kazu).each do |figure| sleep 1 kao_moji = verification(figure) serif = make_serif(figure, kao_moji) speak(serif) end speak(OCHI) end # セリフを作る def make_serif(figure, kao_moji) figure.to_s + kao_moji end # 判断する def verification(figure) if figure % 5 == 0 return DOG_KAO_MOJI end if figure % 3 == 0 || /3/ =~ figure.to_s return AHO_KAO_MOJI end TSUJO_KAO_MOJI end # 話す def speak(serif) puts serif end end omoro = Omoro.new omoro.main(40)オモロークラスができました。
余談ですが、mainメソッドに任意の数を渡すことで数えるマックスの数字を動的に変えられます。
400と入れると300-399までアホか犬になります。
人力だと大変ですが、プログラムで書くと簡単です。テストを書きます。
勉強中です。
letがよくわからないので使っていません。
もし、優しいマサカリをお持ちの方は、コメントでexampleを書いてください。omoro_spec.rbrequire 'rspec' require_relative '../omoro_class' RSpec.describe Omoro do TSUJO_KAO_MOJI = "( ・`ω・´)" AHO_KAO_MOJI = "ʅ( ՞ਊ՞)ʃ≡" DOG_KAO_MOJI = "∪・ω・∪" it '数字(1)+顔文字(( ・`ω・´))のセリフを生成すること' do expect(Omoro.new.make_serif(1, TSUJO_KAO_MOJI)).to eq '1( ・`ω・´)' end it '数字(3)+顔文字(3ʅ( ՞ਊ՞)ʃ≡)のセリフを生成すること' do expect(Omoro.new.make_serif(3, AHO_KAO_MOJI)).to eq '3ʅ( ՞ਊ՞)ʃ≡' end it 'イッヌ' do expect(Omoro.new.make_serif(5, DOG_KAO_MOJI)).to eq '5∪・ω・∪' end it '3がつく' do expect(Omoro.new.make_serif(33, 'ʅ( ՞ਊ՞)ʃ≡')).to eq '33ʅ( ՞ਊ՞)ʃ≡' end it 'verification' do omoro = Omoro.new (1..40).each do |figure| if figure % 5 == 0 expect(omoro.verification(figure)).to eq DOG_KAO_MOJI elsif figure % 3 == 0 || /3/ =~ figure.to_s expect(omoro.verification(figure)).to eq AHO_KAO_MOJI else expect(omoro.verification(figure)).to eq TSUJO_KAO_MOJI end end end it 'main' do omoro = Omoro.new expect { omoro.main(5) }.to output( "これから面白いことつまりオモローなことをします\n1( ・`ω・´)\n2( ・`ω・´)\n3ʅ( ՞ਊ՞)ʃ≡\n4( ・`ω・´)\n5∪・ω・∪\nオモロー\n").to_stdout end end個人的にverificationメソッドとmainメソッドは改良できそうな気がしますが、やり方がわかりませんでした。
参考文献
- 投稿日:2020-08-02T11:21:45+09:00
Rubyでシステムコマンドの実行
Rubyを書いてる時にスクリプト内で、システムコマンドを実行したくなったので調べてみました。
Kernel#system
最も、シンプルな書き方です。
system("ls") # => true標準出力にコマンドの実行結果が返却されます。
メソッドの戻り値は以下の通り
trueコマンド成功時falseコマンド失敗時nilコマンドがない時Kernel#`
コマンドの実行結果を戻り値で欲しい時に使います。
`ls` # => "Applications\nLibrary\nSystem\nUsers\nVolumes\nbin\ncores\ndev\netc\nhome\nopt\nprivate\nsbin\ntmp\nusr\nvar\n"戻り値は文字列型で返ってくるみたいですね。
%x||というエイリアスもあるみたいです。参考
- 投稿日:2020-08-02T09:58:35+09:00
【Rails】一意性を保つバリデーションの実装
一意性バリデーションの実装に必要なタスク
- アプリ側に記述(uniqueness: true)
- データベース側に記述(unique: true)
アプリ側に記述
models/user.rbvalidates :email, uniqueness: trueデータベース側に記述
$ rails g migration add_column_to_usersadd_column_to_users.rbdef change add_index :users, :email, unique: true end$ rails db:migrateテーブルのカラムに一意性を持たせるには、インデックスの作成も必要になる。
理由は、全てのデータを検索することで、過去のデータと重複しているか確認できるため。
- 投稿日:2020-08-02T08:14:43+09:00
オリジナルのアプリを完成させるまでの解説
環境
macOS 10.15.5
Rails 5.2.4.2
Docker 19.03.12概要
オリジナルアプリの概要はCRUDのシステムを意識した簡易的なメモアプリの開発です。
簡易的なアプリと言っても実用性には欠かないよう注意を払いました。行数が増えてもレイアウト崩れが起きないように実装し、文字数制限や空白の項目が新規作成されないようにも設定しました。Dockerを用いてフレームワークはRailsを使用しました。そしてHerokuにより公開をしています。
オリジナル性について
HTMLに関してはclass名などは学習サイトをヒントに用いて、デザインは外観は学習サイトをヒントにしましたが実装は全て自走で行いました。
Railsの機能の実装に関して事前に学習サイトを何度も繰り返し行い、CRUDの機能を頭に入れてから今回の作成を行いました。そのため短いコードなどはなるべくサイトなどを参考にせず、自分で覚えた内容で実装し、コマンド操作は基本的に全て頭に入れた内容のみで行いました。サイトについて
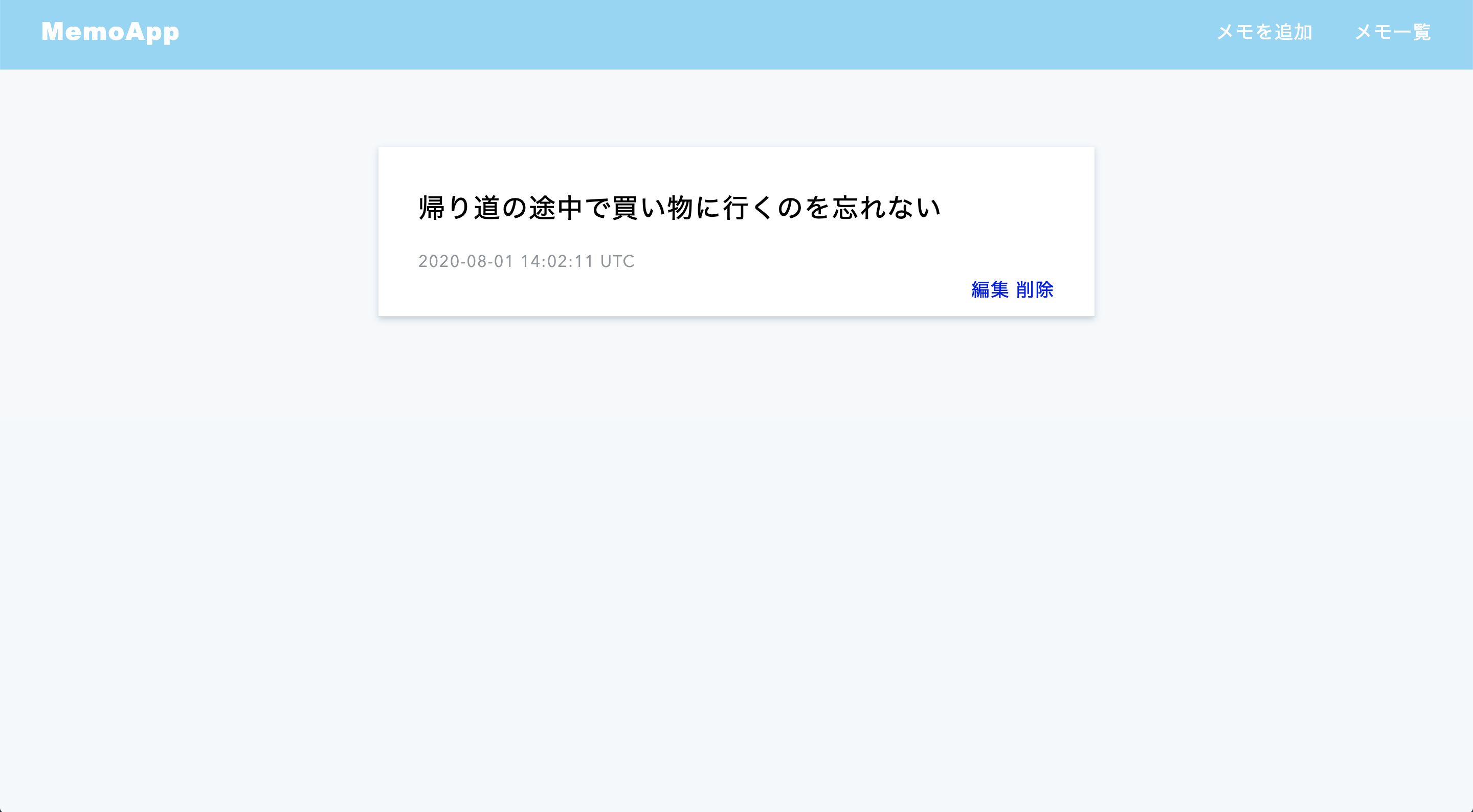
一覧ページをトップページとして定めメモの項目が個々の詳細が表示できるようにリンク指定をしています。その際に新規投稿された項目が最上部に移動するように実装しました。lists_controller.rbclass ListsController < ApplicationController def index @lists = List.all.order(created_at: :desc) end新規作成ページ
新規作成ページでは空白の内容と141文字以上の内容が実行されないように設定しています。list.rbclass List < ApplicationRecord validates :content, {presence: true, length: {maximum: 140}} end詳細ページ
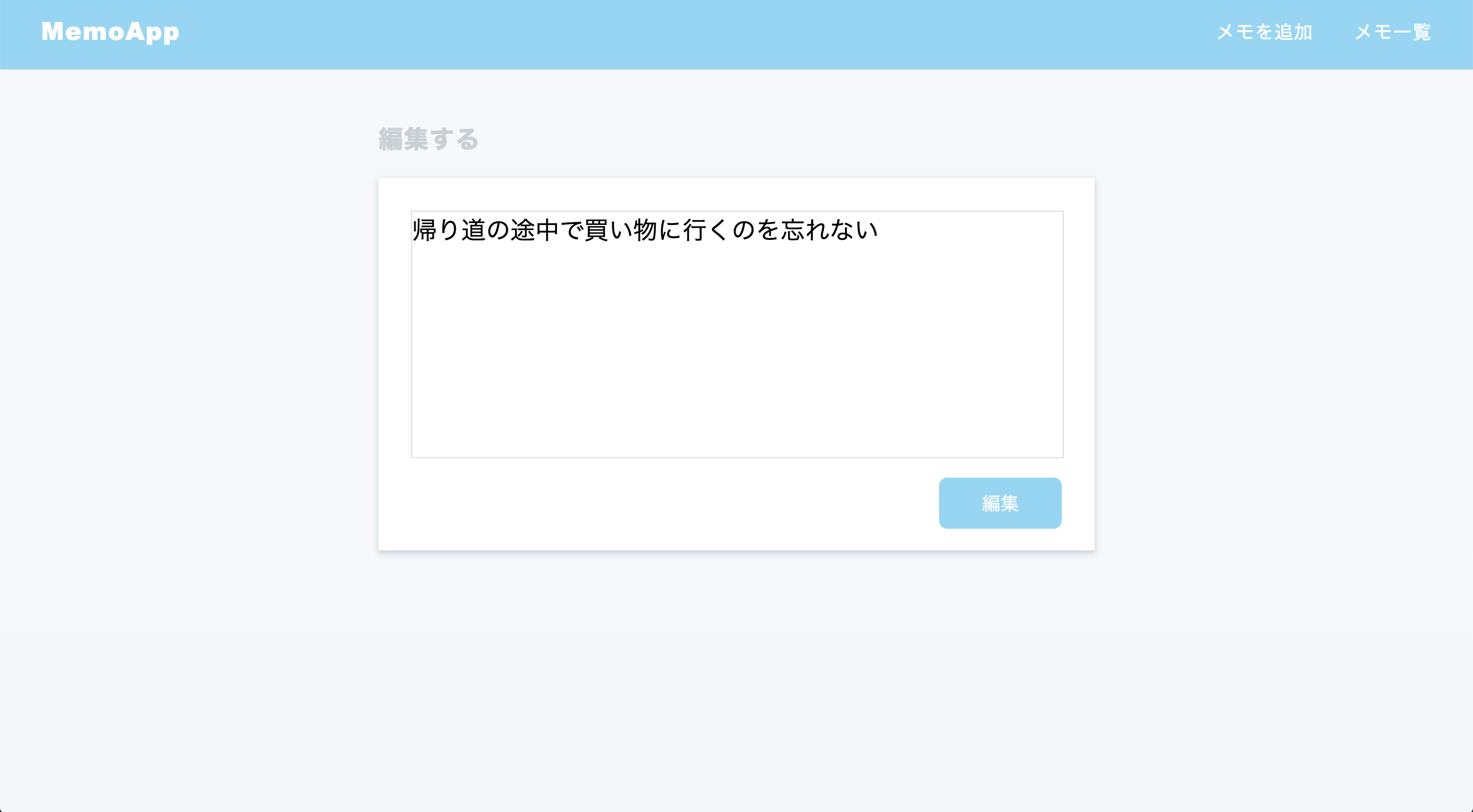
メモ一覧の個々の項目のリンクから移動すると個々の詳細ページが閲覧できます。そこから「編集」と「削除」を実行することができます。編集ページ
編集ページではページを開いたときに編集前の内容が表示されるように実装しています。edit.html.erb<div class="form-bady"> <textarea name="content"><%= @list.content %></textarea> <input type="submit" value="編集"> </div>lists_controller.rbdef edit @list = List.find_by(id: params[:id]) endオリジナルアプリを作るにあたり意識したこと
わたしは自走できるエンジニアとしてスキルを身に付けたい!という思いからどんなやり方がそんなエンジニアに近づける方法なのか良く自問自答をします。今回このシンプルなメモアプリを作成しようと考えたのはRailsのCRUDの機能やMVCは完璧に落とし込もうと考えたのでこのシンプルさにまとめてみました。
今後はログイン機能やユーザーごとのアクセス権限を設けたページの作成などの機能を有したアプリの作成などにも取り組みたいです!
- 投稿日:2020-08-02T07:14:25+09:00
カリー化チートシート
拙作『不動点コンビネータを用いた無名再帰関数の実行まとめ』の補足説明として書き始めたところ,カリー化関数を記述・利用するための独立したチートシートとした方が少なくとも約1名(自分自身)には役立ちそうだったので,新しく記事にした.なお,カリー化してくれる関数の定義ではないことに注意.複数言語にわたっている都合上,各言語に精通している方々のツッコミ歓迎.
記法のみの一覧は次の通り.なお,
fは関数,aは引数を指す.
言語 各引数の戻り値 各引数の指定 備考 Haskell \->による無名関数(・・・(f a) a)・・・a自動的にカリー化 Scheme lambdaによる無名関数(・・・((f a) a)・・・a)Python 関数内部で定義した関数 f(a)(a)・・・(a)無名関数も使用可 Ruby ->を用いた無名関数f.(a).(a)・・・.(a)またはf[a][a]・・・[a]カリー化メソッドあり JavaScript =>やfunctionを用いた無名関数f(a)(a)・・・(a)Scala =>を用いた無名関数f(a)(a)・・・(a)カリー化メソッドあり,強い型付け Perl subを用いた無名サブルーチンf(a)->(a)・・・->(a)$f->(a)・・・の場合ありGo言語 funcを用いた無名関数f(a)(a)・・・(a)強い型付け PHP functionとuseを用いた無名関数f(a)(a)・・・(a)7.4より fnと=>を用いた無名関数が利用可Haskell(GHC)
Haskellでは,複数引数で定義しても自動的にカリー化される.カリー化関数の引数指定は
(・・・(関数 引数) 引数)・・・引数である.Prelude> func x y z = if x > 0 then y else z Prelude> func (-100) 0 (-1) -1 Prelude> ((func (-100)) 0) (-1) -1
\および->を用いた無名関数を戻り値にして実現する方法は次の通り.ただし,この場合でも引数の複数指定が可能.Prelude> func = \x -> \y -> \z -> if x > 0 then y else z Prelude> ((func (-100)) 0) (-1) -1 Prelude> func (-100) 0 (-1) -1 Prelude> func = \x y z -> if x > 0 then y else z Prelude> ((func (-100)) 0) (-1) -1 Prelude> func (-100) 0 (-1) -1Scheme(Gauche)
lambdaを用いた無名関数を戻り値にして実現する.カリー化関数の引数指定は(・・・((関数 引数) 引数)・・・引数)である.gosh> (define (func x y z) (if (> x 0) y z)) func gosh> (func -100 0 -1) -1 gosh> (define func (lambda (x) (lambda (y) (lambda (z) (if (> x 0) y z))))) func gosh> (((func -100) 0) -1) -1Python(Python3,Python2)
lambdaを用いた無名関数を用いることもできるが,無名関数を直接変数に代入するのがPEP8非推奨ということもあり,関数内部で定義した関数を戻り値にする方法が一般的である.カリー化関数の引数指定は関数(引数)(引数)・・・(引数)である.>>> def func(x, y, z): return y if x > 0 else z ... >>> func(-100, 0, -1) -1 >>> def func(x): ... def func(y): ... def func(z): return y if x > 0 else z ... return func ... return func ... >>> func(-100)(0)(-1) -1 >>> func = lambda x: lambda y: lambda z: y if x > 0 else z # PEP8非推奨 >>> func(-100)(0)(-1) -1Ruby(CRuby,JRuby)
Rubyでは,カリー化するメソッド
curryが用意されている.ただし,複数引数の無名関数を->によって一度定義してからcurryを適用する.カリー化関数の引数指定は関数.(引数).(引数)・・・.(引数)または関数[引数][引数]・・・[引数]である.def func1(x,y,z) x > 0 ? y : z end p func1(-100,0,-1) # => -1 func2 = -> x,y,z { x > 0 ? y : z } p func2.curry.(-100).(0).(-1) # => -1 p func2.curry[-100][0][-1] # => -1
->のみを用いた無名関数によって実現する方法は次の通り.func3 = -> x { -> y { -> z { x > 0 ? y : z } } } p func3.(-100).(0).(-1) # => -1 p func3[-100][0][-1] # => -1JavaScript(Node.js)
=>やfunctionを用いた無名関数を戻り値にする方法で実現する.カリー化関数の引数指定は関数(引数)(引数)・・・(引数)である.function func1(x,y,z) { return x > 0 ? y : z } console.log(func1(-100,0,-1)) // => -1 func2 = x => y => z => x > 0 ? y : z console.log(func2(-100)(0)(-1)) // => -1 function func3(x) { return function (y) { return function (z) { return x > 0 ? y : z } } } console.log(func3(-100)(0)(-1)) // => -1Scala(Scala 2.11 + Java VM 12)
Scalaでは,カリー化するメソッド
curriedが用意されている.ただし,複数引数の無名関数を=>によって一度定義してからcurriedを適用する.カリー化関数の引数指定は関数(引数)(引数)・・・(引数)である.scala> def func(x: Int, y: Int, z: Int): Int = if (x > 0) y else z func: (x: Int, y: Int, z: Int)Int scala> func(-100,0,-1) res0: Int = -1 scala> val func = (x: Int, y: Int, z: Int) => if (x > 0) y else z func: (Int, Int, Int) => Int = <function3> scala> val func_curried = func.curried func_curried: Int => (Int => (Int => Int)) = <function1> scala> func_curried(-100)(0)(-1) res1: Int = -1
=>のみを用いた無名関数によって実現する方法は次の通り.強い型付け言語であるため,関数全体の型の推移を明示する必要がある.scala> val func: Int => (Int => (Int => Int)) = (x: Int) => (y: Int) => (z: Int) => if (x > 0) y else z func: Int => (Int => (Int => Int)) = <function1> scala> func(-100)(0)(-1) res2: Int = -1Perl(perl 5)
subを用いた無名関数(サブルーチン)を戻り値にして実現する.カリー化関数の引数指定は関数(引数)->(引数)・・・->(引数)である.なお,関数本体の名前も無名関数とした場合は$関数->(引数)->(引数)・・・->(引数)である.sub func { my ($x,$y,$z) = @_; $x > 0 ? $y : $z; }; print func(-100,0,-1), "\n"; # => -1 sub func_curried { my $x = shift; return sub { my $y = shift; return sub { my $z = shift; return $x > 0 ? $y : $z; }; }; }; print func_curried(-100)->(0)->(-1), "\n"; # => -1 my $func_curried2 = sub { my $x = shift; return sub { my $y = shift; return sub { my $z = shift; return $x > 0 ? $y : $z; }; }; }; print $func_curried2->(-100)->(0)->(-1), "\n"; # => -1Go言語(gc)
funcを用いた無名関数を戻り値にして実現する.カリー化関数の引数指定は関数(引数)(引数)・・・(引数)である.なお,強い型付け言語であるため,扱う引数が増えるほど,各引数の関数の戻り値に対する型付け記述が増えていく.package main import "fmt" func func1 (x, y, z int) int { if x > 0 { return y } else { return z } } func func2 (x int) func(int) func(int) int { return func(y int) func(int) int { return func(z int) int { if x > 0 { return y } else { return z } } } } func main() { fmt.Println(func1(-100,0,-1)) // => -1 fmt.Println(func2(-100)(0)(-1)) // => -1 }PHP(PHP 7.3,PHP 7.4)
PHP7.3までは,
functionとuseを用いた無名関数を戻り値にする方法で実現する.カリー化関数の引数指定は関数(引数)(引数)・・・(引数)である.<?php function func1($x,$y,$z) { return ($x > 0) ? $y : $z; } echo func1(-100,0,-1) . PHP_EOL; // => -1 function func2($x) { return function($y) use ($x) { return function($z) use ($x,$y) { return ($x > 0) ? $y : $z; }; }; } echo func2(-100)(0)(-1) . PHP_EOL; // => -1PHP 7.4からは,
fnと=>を用いた無名関数が利用可能.function func2($x) { return fn($y) => fn($z) => ($x > 0) ? $y : $z; } echo func2(-100)(0)(-1) . PHP_EOL; // => -1備考
カリー化の概要
カリー化とは,高階関数の機能を利用して,複数の引数を指定する関数を,ひとつの引数のみを指定する関数の繰り返しに変換することである.処理記述の共有が可能な『部分適用』の手段として有名であるが,あくまで利用例のひとつである.カリー化自体の特徴は,ラムダ計算などの数学的な理論を適用しやすいことに加え,引数を再帰的に受け取る汎用的な関数を定義したり,引数ごとに値の適用を調節したり,データ構造を要素ごとに受け取ったりすることで,より簡潔で柔軟なプログラミングが可能となることである.
なお,下記のPythonの例のように,今回の記述方法を用いることで,複数引数をもつ既存の関数のカリー化も容易に行える.ただし,複数引数をもつ既存の関数をカリー化関数に変換してくれる関数やマクロは作成できない.理由は,既存関数の引数の数が不定であり,任意の数の無名関数や内部関数を(クロージャ機能を含めて)生成できないためである.RubyやScalaのカリー化メソッドは個別に型定義された複数引数をもつ無名関数から変換しており,Haskellは言語仕様としてカリー化関数のみを扱っている(関数定義を行った時点で,型をもつ引数ごとのカリー化関数となる).
Pythonでのカリー化関数利用例
>>> def func(y): ... def func(z): ... def func(w): ... def func(x): return y if x > 0 else z if x < 0 else w ... return func ... return func ... return func ... >>> func1 = func('positive')('negative') >>> func2 = func1('zero') >>> func2(1) 'positive' >>> func2(-1) 'negative' >>> func2(0) 'zero' >>> func2 = func1('ゼロ') >>> func2(0) 'ゼロ' >>> T = (3, -2, 0, 1, -7) >>> dict(zip(T, map(func2, T))) {3: 'positive', -2: 'negative', 0: 'ゼロ', 1: 'positive', -7: 'negative'} >>> def recur(f, t): return f if not t else recur(f(t[0]), t[1:]) ... >>> dict(zip(T, map(recur(func, ('正', '負', 'ゼロ')), T))) {3: '正', -2: '負', 0: 'ゼロ', 1: '正', -7: '負'} >>> def is_t(t): ... def r(v): return isinstance(v, t) ... return r ... >>> T = 10, "hoge", 20.4, False, "hage" >>> tuple(map(is_t(str), T)) (False, True, False, False, True) >>> tuple(map(is_t(int), T)) (True, False, False, True, False)(同様の内容をSchemeで記述したものはこちら)
変更履歴
- 2020-08-03:カリー化の概要説明部分を修正(コメントより)
- 2020-08-03:Rubyのカリー化関数を追加(コメントより)
- 2020-08-03:PHP 7.4を追加(コメントより)
- 2020-08-02:PHPを追加
- 2020-08-02:記法のみの一覧を追加
- 2020-08-02:Go言語を追加
- 2020-08-02:初版公開(Haskell,Scheme,Python,Ruby,JavaScript,Scala,Perl,Python利用例)
- 投稿日:2020-08-02T06:00:17+09:00
railsで動画を投稿する
今回、初投稿させていただきます。
少し、見にくかったりしてもご了承お願いします。今回は、railsで動画アップロード機能の備忘録となっております。
個人的にFFmpegを使用した動画アップロードが分かりにくかったので、なるべく分かりやすく説明できればと思います。環境
Ruby 2.6.5
Rails 6.0.3.2早速取り掛かっていく
ターミナルrails new RailsAppターミナルでRailsAppを作ります。
Gemfilegem 'carrierwave' gem 'mini_magick'Gemfileに追記
ターミナルrails bundle installターミナルでbundle installします。
ターミナルrails g uploader video rails g scaffold post video:stringターミナルでuploaderとscaffoldを作成
ターミナルrails db:migrate忘れずにマイグレーション
app/models/post.rbmount_uploader :video, VideoUploaderpost.rbに追記
app/uploaders/video_uploader.rbdef extension_whitelist %w(jpg jpeg gif png MOV wmv mp4) end38行目からコメントを外して、追記
views/posts/_form.html.erb<div class="field"> <%= form.label :video %> <%= form.file_field :video, :accept => 'video/*' %> </div>text.fieldになっていると思うので、file.fieldに書き換える。
app/views/posts/show.html.erb<p> <%= link_to @post.video_url.to_s do %> <%= video_tag(@post.video.to_s) %> <% end %> </p><%= @post.video %>になっていると思うので書き換えます。
<%= link_to @post.video_url.to_s do %>を書かないと動画をクリックしても再生されません。ありがとうございました
動画アップロードに悪戦苦闘したので、皆さんが簡単にできたら幸いです。
- 投稿日:2020-08-02T00:01:11+09:00
【今日の積み上げ#1】cloud9上でon railsするまで
結果
こちらの記事
(https://skillhub.jp/courses/134/lessons/785)
を元に、cloud9上でrailsサーバーを動かし、「Yay! You’re on Rails!」の画面を拝むまで完了しました。事前知識として、Progateのrails学習コースⅠを受講済み。
が、こんな簡単な手順でも躓きポイントがあったため備忘録として本記事を作成します。
手順
- Cloud9の環境作成
- Railsのインストール
- ディレクトリの作成、及び操作フォルダの移動
- yarn、webpackerのインストール
- railsのサーバー起動、停止
エラーの内容
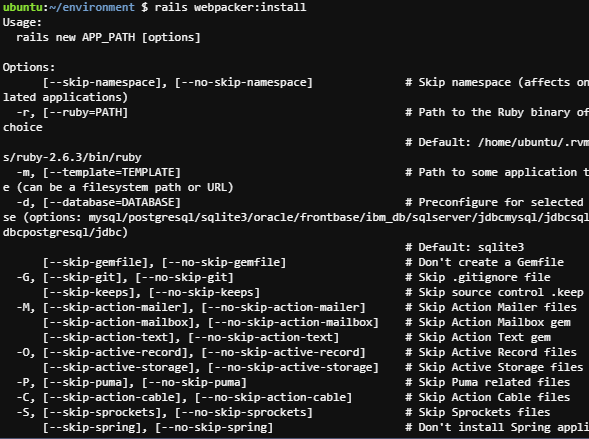
結論から言うと、yarnとwebpackerのインストールが上手くいかず、何度も何度もエラーを吐いて、「良く分からないから環境作成からやり直す」というようなことを繰り返してしまいました。
この画像のエラーの他にも、コマンドミスや誤字脱字もあり頭を抱えました。
原因
操作ディレクトリが間違っていました(=yarnとwebpackerのインストール先が間違っていた)。
参考のサイトでは、ディレクトリの作成→ディレクトリの移動を特に説明なくさらっと流していたため重要なこととは考えず、なんとなく「インストールするならhomeディレクトリにすれば間違いないべ!!」と謎の確信を持って作業を行っていたためエラーを吐いていた模様。
疑問と反省
インストールする場所が変わっていたとしても、windowsで言うところの環境変数のようなパスを渡してやれば無理やりでも作業を継続することができるのだろうか?
とにかく環境の構築はもう少し考えてからやった方がいいみたいでした。
ポートフォリオの作成を急ぐあまりどうも作業の精細を欠いた所があったことに、振り返って初めて気付きました。以上