- 投稿日:2020-08-02T22:54:46+09:00
No such file or directory @ rb_sysopen - /Users/○○/Gemfile.lock (Errno::ENOENT)で苦しんだ
railsコマンドを打とうとすると
$ rails ○○ Traceback (most recent call last): 4: from bin/rails:3:in `<main>` 3: from bin/rails:3:in `load` 2: from /Users/user/[プロジェクト名]/bin/spring:10:in `<top(required)>` 1: from /Users/user/[プロジェクト名]/bin/spring:10:in `read` /Users/user/[プロジェクト名]/bin/spring:10:in `read`: No such file or directory @ rb_sysopen - /Users/user/[プロジェクト名]/Gemfile.lock(Errno::ENOENT)こんなエラーが出てしまい号泣。
原因
railsコマンドでは、gemのバージョンも確認工程に含まれるため
Gemfile.lockの中身が参照される。
ただ今回、参照されるべきGemfile.lockがない状態なのでエラーが出てしまっている状況。対処法
Gemfile.lockはgemfileのバージョンを記録しておくもので、bundle installコマンドによって自動的に生成されるため、bundle installを実行する必要がある。早速、アプリディレクトリ上にて
bundle installを実行↓$ pwd /Users/○○/アプリ名 $ bundle installその後、再度railsコマンドを入力してみる。
すると、無事にrailsコマンドが効く状態になってるはず!まとめ
かなり初歩的な内容かもですが、自分は過去にこのエラーで相当時間を取られました...
同じエラーで苦しむ人が減れば幸いです!
- 投稿日:2020-08-02T22:38:56+09:00
【Rails】 APIキーやDBのパスワードをcredential.ymlに記述する
※自分用メモです。
1.credentials.yml.encに隠したい情報を記述する
まずcredentials.yml.encを編集します。
コマンドdocker-compose run -e EDITOR=vim web rails credentials:editDockerを使用している場合
vimをインストールしていないとエラーが出るのでインストールしておきましょう。DockerfileRUN apt-get install -y vimcredentials.yml.encdb: password: XXXXXXX api_key: google: XXXXXX2.呼び出し方法
database.yml
database.ymlpassword: <%= Rails.application.credentials.db[:password]%>~.erb
~~html.erb<script src="https://maps.googleapis.com/maps/api/js?key=<%= Rails.application.credentials.api_key[:google]%&callback=initMap" async defer></script>補足
.gitignoreでmaster.keyが記述されているか確認しておきましょう。
gitignoreにはgithubにpushしないファイルを設定するファイルになります。
master.keyはデフォルトで.gitignoreに記述されていますが、念のため確認します。
- 投稿日:2020-08-02T22:15:09+09:00
Dockerを使ったRails開発でブラウザテストが実行できない
概要
・RSpecでCapybaraを使ったブラウザテストを実装する際にエラー
RSpecの学習をしている際にテストを実行すると下記のエラーが発生しました。
解決するのに結構時間がかかりました。Selenium::WebDriver::Error::UnknownError: unknown error: Chrome failed to start: exited abnormally. (unknown error: DevToolsActivePort file doesn't exist) (The process started from chrome location /usr/bin/google-chrome is no longer running, so ChromeDriver is assuming that Chrome has crashed.)spec-helper.rbCapybara.register_driver :selenium_chrome_headless do |app| browser_options = ::Selenium::WebDriver::Chrome::Options.new() browser_options.args << '--headless' browser_options.args << '--no-sandbox' browser_options.args << '--disable-gpu' Capybara::Selenium::Driver.new(app, browser: :chrome, options: browser_options) end解決方法
Dockerfileにchrome driverをインストールする記述を追加したところ上手くテストが実行されました。
追記分
DockerfileRUN CHROME_DRIVER_VERSION=`curl -sS chromedriver.storage.googleapis.com/LATEST_RELEASE` && \ wget -N http://chromedriver.storage.googleapis.com/$CHROME_DRIVER_VERSION/chromedriver_linux64.zip -P ~/ && \ unzip ~/chromedriver_linux64.zip -d ~/ && \ rm ~/chromedriver_linux64.zip && \ chown root:root ~/chromedriver && \ chmod 755 ~/chromedriver && \ mv ~/chromedriver /usr/local/bin/chromedriver && \ sh -c 'wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.pub | apt-key add -' && \ sh -c 'echo "deb [arch=amd64] http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google-chrome.list' && \ apt-get update && apt-get install -y google-chrome-stable動作確認済みDockerfile↓
DockerfileFROM ruby:2.5 RUN apt-get update && apt-get install -y \ build-essential \ libpq-dev \ node.js \ yarn # Rspecで使うchormedriverをインストール RUN CHROME_DRIVER_VERSION=`curl -sS chromedriver.storage.googleapis.com/LATEST_RELEASE` && \ wget -N http://chromedriver.storage.googleapis.com/$CHROME_DRIVER_VERSION/chromedriver_linux64.zip -P ~/ && \ unzip ~/chromedriver_linux64.zip -d ~/ && \ rm ~/chromedriver_linux64.zip && \ chown root:root ~/chromedriver && \ chmod 755 ~/chromedriver && \ mv ~/chromedriver /usr/local/bin/chromedriver && \ sh -c 'wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.pub | apt-key add -' && \ sh -c 'echo "deb [arch=amd64] http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google-chrome.list' && \ apt-get update && apt-get install -y google-chrome-stable # 作業ディレクトリに移動(無ければ自動で作成) WORKDIR /app #build context内のGemfileとGemfile.lockをコピー COPY Gemfile Gemfile.lock /app/ #Gemをインストール RUN bundle installDockerfileを編集しているので
$docker-compose build再度コンテナを起動してテストを実行するとうまくテストが実行されました。
- 投稿日:2020-08-02T20:47:54+09:00
rails開発の条件分岐のあれこれ
rails開発の条件分岐のあれこれ
rails でのwebアプリケーション開発であるといい記述をまとめてみました!
投稿に対して投稿者のみ編集・削除ができるようにしたい!
rails でSNSのようなアプリケーションを作るとき,投稿に対してユーザー誰もが編集したり
削除できるとダメですよね!
そんなとき便利なのが下の条件分岐です!devise(Gem)をインストールしていうることを前提とします
post.rbbelongs_to :useruser.rbhas_many :postsroute.rbresources :post, only: [:show]post_controller.rbdef show @film = Post.find(params[:id]) endshow.html.erb<% if @post.user_id == current_user.id %> #追記 <%= link_to "編集する", edit_post_path(@post.id) %> <%= link_to "削除する", post_path, method: :delete %> <% end %> #追記このように編集・削除の部分を条件分岐で
もし,投稿者のidがログイン中のユーザーidと一致したら
の意味を持つ,<% if @post.user_id == current_user.id %> でかこんであげるといいでしょう!ログインしている人としていない人で記述を変えたい!
例えばこのようなことはないでしょうか?
ログイン前には,ヘッダーに新規登録・ログインのリンクを
ログイン後には,マイページやログアウトのリンクを
実装したい!
こんな時に便利なのが下の条件分岐です!devise(Gem)をインストールしていうることを前提とします
今回,bootstrapを使用したナビゲーションバーを使用しています
bootstrapはこちらlayout/application.html.erb<% if user_signed_in? %> <nav class="navbar fixed-top navbar-expand-lg navbar-light"> <a class="navbar-brand" href="/">ホーム</a> <div class="collapse navbar-collapse" id="navbarSupportedContent"> <ul class="navbar-nav mr-auto"> <li class="nav-item"> <a class="nav-link" href="/post/new" style="color: white;">投稿する<span class="sr-only">(current)</span></a> </li> <li class="nav-item"> <a class="nav-link" href="/users/<%= current_user.id %>">マイページ</a> </li> <li class="nav-item" > <%= link_to 'ログアウト', destroy_user_session_path, data: { confirm: "ログアウトしますか?" }, method: :delete, class:"nav-link"%> </li> </ul> </div> </nav> <% else %> <nav class="navbar fixed-top navbar-expand-lg navbar-light"> <a class="navbar-brand" href="/home">トップ</a> <button class="navbar-toggler" type="button" data-toggle="collapse" data-target="#navbarSupportedContent" aria-controls="navbarSupportedContent" aria-expanded="false" aria-label="Toggle navigation"> <span class="navbar-toggler-icon"></span> </button> <div class="collapse navbar-collapse" id="navbarSupportedContent"> <ul class="navbar-nav mr-auto"> <li class="nav-item"> <a class="nav-link" href="/users/sign_up" style="color: white;">新規登録</a> </li> <li class="nav-item"> <a class="nav-link" href="/users/sign_in" style="color: white;">ログイン</a> </li> </ul> </div> </nav> <% end %><% if user_signed_in? %>の部分が重要です!
これは,「もしユーザーがログインしていたら」という条件分岐なのです!
<% else %>(そうでなければ→「ログインしていなかったら」)との組み合わせでさらなる力を発揮します!画像投稿でnilのエラーを吐いてしまう
**cloudinaryを使った画像投稿を実装できていることとします
今回は画像投稿を例に出していますがその他にも,nilのときどうしよう..という場合にこれが使えます!
db/migrate/OOOOOOOOOOOOOO_add_image_to_posts.rbdef change add_column :posts, :image, :string endpost_controller.rbdef show @film = Post.find(params[:id]) endshow.html.erb<% if @post.image.present? %> <%= image_tag @post.image_url, :size =>'150x150', class: "img_fluid rounded-circle" %> <% end %><% レコード.カラム.present? %>の部分が大事です!
これによってnilではなく存在していれば表示される条件分岐となります![補足]
画像サイズを正方形にして,bootstrapによって画像をTwitterのプロフィール画像のように丸くしています最後に
ここまで3つの個人的によく使用する条件分岐をについて記述してみました!
間違い等ございましたら指摘してください!条件分岐(if)文はプログラミングの中でも共通で大事なものです!
実際に手を動かして理解してみましょう!
- 投稿日:2020-08-02T20:37:33+09:00
A server is already running(rails sのプロセスが切れない)をさっさと解決する
サーバーを起動しようとすると以下がでるときの対処法を数種類まとめました!
どれかで解決できる(はず)。❯ rails s => Booting Puma => Rails 5.0.7.2 application starting in development on http://localhost:3000 => Run `rails server -h` for more startup options A server is already running. Check プロジェクト名/tmp/pids/server.pid. Exiting何種類もあるため、上手くいかないときは順番に試してみるコトをおすすめします。
まず確認すること
たまに
Mac標準のターミナルでサーバー起動状態&VSCodeなどのテキストエディタ上のターミナルでサーバー起動しようとしている方がいるので、
まずは別のターミナルで既にサーバーを動かしていないかを確認しましょう!パターン①
railsのプロセスを削除する$ rails s => Booting Puma => Rails 5.0.7.2 application starting in development on http://localhost:3000 => Run `rails server -h` for more startup options A server is already running. Check プロジェクト名/tmp/pids/server.pid. Exiting $ ps aux | grep rails user 28321 s001 S+ 0:00.00 grep rails $ kill -9 28321 $ rails s → 解決パターン②
ポート番号3000番のプロセスを削除する$ lsof -wni tcp:3000 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME ruby 28295 user 21u IPv4 0x77d8a30cabb79cc9 0t0 TCP 127.0.0.1:hbci (LISTEN) ruby 28295 user 22u IPv6 0x77d8a30cac93f9f9 0t0 TCP [::1]:hbci (LISTEN) # 「COMMAND」に「ruby」と書いてある行のPIDをコピーして処理を停止(今回は28295) $ kill -9 28295 $ rails s → 解決パターン③
サーバー起動の際に使用するIDを削除する$ rm /tmp/pids/server.pid $ rails s → 解決このファイルの場所は
[アプリ名]/tmp/pids/server.pidに入っているので、パスを指定して削除します。
本来、サーバーを終了するとこのファイルは削除されますが、残ったままでエラーになっている可能性があるみたい。
※server.pidはサーバー起動や終了で勝手に作られたり削除されたりするので、普段は気にしなくて良いです。まとめ
頻繁に出てきた
kill -9 ○○はLinuxコマンドの一つで、プロセスを終了するためのものです。
個人的には、パターン②ですんなりプロセスを終了出来ることが多い気がします。サーバーの立ち上げで足止めをくらうと萎えるので、さくっと解決してください!
- 投稿日:2020-08-02T19:04:41+09:00
RailsでOpenWeatherMapから天気予報を取得する
初めに
Qitta初投稿です!
初心者なので至らぬ点も多いかと思いますが、暖かくコメント頂けると嬉しいです!概要
- 無料のapiを提供しているOpenWeatherMapのapiを叩くことで、全国各地の天気予報を取得する。
- HTTPリクエストはhttpclientを使用し、rake taskにすることで定期的に叩けるように実装する。
開発環境
ruby: 2.7.1
rails: 6.0.3.2手順
- API KEYの取得
- 取得したい都市のCITY IDを取得
- Cityテーブルの作成・保存
- HTTPリクエストの実装
- WeatherForecastテーブルの作成・保存
1. API KEYの取得
OpenWeatherMapのホームページにアクセスし、Sign inからCreate an accountでアカウントを作成しましょう。送られてくるメールから有効化するとAPI KEYが送られてきます。
これを環境変数なり
credentialsなりに保存しておきます。今回はcredentialsを利用していきます。
credentialsに関してはこちらの方の記事がとても参考になります。EDITOR=vi bin/rails credentials:editcredentials.yml.encopen_weahter: appid: <API_KEY> uri: https://samples.openweathermap.org/data/2.5/forecastなお、今回は3時間毎の天気を取得しようと思うので、APIドキュメントを参考にリクエストを送るURIを取得しています。
無料枠でも取得できる天気の種類は豊富にあるようです!APIドキュメントを色々と探してみると面白いです。
2. CITY IDの取得
APIドキュメントから
city.list.jsonをダウンロードします。このファイルから、取得したい都市のCITY IDを取得していきます。中身一部抜粋です。
ちなみにlonは経度、latは緯度を指します。city.list.json{ "id": 1850147, "name": "Tokyo", "state": "", "country": "JP", "coord": { "lon": 139.691711, "lat": 35.689499 } },私はこのid取得を泣く泣く手作業でしました...
同じ名前の都市でも経緯度が違うものが混じっているので注意が必要です!エクセルやmacならnumbersなどにリストアップしてCSVに変換すると良いと思います!
ちなみに私が作成したCSVはこんな感じです。一部カラムを削ってます。db/csv/cities.csv札幌,2128295 青森,2130658 盛岡,2111834 仙台,2111149 秋田,2113126 山形,2110556 福島,2112923 水戸,2111901 宇都宮,1849053 前橋,1857843 さいたま,6940394 千葉,2113015 東京,1850147 横浜,1848354 新潟,1855431 富山,1849876 金沢,1860243 福井,1863983 山梨,1848649 長野,1856215 岐阜,1863640 静岡,1851715 名古屋,1856057 津,1849796 大津,1853574 京都,1857910 大阪,1853909 神戸,1859171 奈良,1855612 和歌山,1926004 鳥取,1849890 松江,1857550 岡山,1854383 広島,1862415 山口,1848689 徳島,1850158 高松,1851100 松山,1926099 高知,1859146 福岡,1863967 佐賀,1853303 長崎,1856177 熊本,1858421 大分,1854487 宮崎,1856717 鹿児島,1860827 那覇,18560353. Cityテーブルの作成・保存
seeds.rbかtaskにコードを書いて、データベースに保存していきます。今回はlib/tasks以下に実装しました。CITY IDはカラム名をlocation_idとして保存しています。import_csv.rakedesc 'Import cities' task cities: [:environment] do list = [] CSV.foreach('db/csv/cities.csv') do |row| list << { name: row[0], location_id: row[1], } end puts 'start creating cities' begin City.create!(list) puts 'completed!' rescue ActiveModel::UnknownAttributeError puts 'raised error: unknown attributes' end endCSV.foreachメソッドで先ほど作成した
cities.csvを一行ずつ読み込みます。row[0]で1列目の都市名、row[1]で2列目のCITY IDが取得できるので、ハッシュの配列を作成してCity.create!でデータベースに保存しています。4. HTTPリクエストの実装
レスポンスの解析
HTTPリクエストを実装する前に、まずは、レスポンスのJSONファイルを解析していきます。
APIドキュメントに各項目について詳しく説明が書かれているので、それを参考に欲しいデータのキーを取得していきます。
1つのCityに関するリクエストは以下のようなJSON形式で返ってきます。
(curlコマンドや、VScodeをお使いの方はREST Client等で試してみると良いと思います。)example_resopnse.json{ "cod": "200", "message": 0, "cnt": 40, "list": [ { "dt": 1578409200, "main": { "temp": 284.92, "feels_like": 281.38, "temp_min": 283.58, "temp_max": 284.92, "pressure": 1020, "sea_level": 1020, "grnd_level": 1016, "humidity": 90, "temp_kf": 1.34 }, "weather": [ { "id": 804, "main": "Clouds", "description": "overcast clouds", "icon": "04d" } ], "clouds": { "all": 100 }, "wind": { "speed": 5.19, "deg": 211 }, "sys": { "pod": "d" }, "dt_txt": "2020-01-07 15:00:00" },今回は以下の項目を使ってテーブルを作成しています。
- list
- main
- feels_like: 体感気温
- temp_max: 最高気温
- temp_min: 最低気温
- weather
- id: 天気ID
- rain
- 3h: 降水量
降水がある場合のみ、
rainがlistに追加されます。なお、天気IDはこちらを参考にしてください。OpenWeatherMapでは、IDによって天気を分類しています。
descriptionから天気を取得することも可能です。しかし種類が多いため、今回の実装ではデータベースには天気IDを保存しておき、メソッドで天気を割り振るようにしています。HTTPリクエストの実装
まずは、httpclientをGemfileに追加し、
bundle installします。gem 'httpclient', '~> 2.8', '>= 2.8.3'次に
lib/api/open_weather_map/request.rbを作成します。
ここまで深くする必要はないかなと思ったのですが、このapiに関して他のクラスを実装したり、他のapiクラスを実装することを考慮してこのようなファイル配置にしました。lib以下はデフォルトではtask以外読み込まれないので、
config/application.rbに、以下の設定が必要です。eager_load_pathsなので本番環境も大丈夫です。config/application.rbconfig.paths.add 'lib', eager_load: trueおいおいこれはあかんやろ、っていう箇所があればご指摘頂けるととても嬉しいです。ファイルの配置が今回の実装で最も悩みました...
リクエストを保存するWeatherForecastテーブル↓
WeatherForecast temp_max float temp_min float temp_feel float weather_id int rainfall float date datetime aquired_at datetime 以下が実装したRequestクラスです。
request.rbmodule Api module OpenWeatherMap class Request attr_accessor :query def initialize(location_id) @query = { id: location_id, units: 'metric', appid: Rails.application.credentials.open_weather[:appid], } end def request client = HTTPClient.new request = client.get(Rails.application.credentials.open_weather[:uri], query) # 戻り値は3時間ごとのデータ5日分 JSON.parse(request.body) end def self.attributes_for(attrs) rainfall = attrs['rain']['3h'] if attrs['rain'] date = attrs['dt_txt'].in_time_zone('UTC').in_time_zone { temp_max: attrs['main']['temp_max'], temp_min: attrs['main']['temp_min'], temp_feel: attrs['main']['feels_like'], weather_id: attrs['weather'][0]['id'], rainfall: rainfall, date: date, aquired_at: Time.current, } end end end end
initializeでクエリストリングを設定しています。今回のリクエストで必要なクエリストリングは、CITY IDを示すlocation_idとAPI KEY, そして気温の表示を摂氏表示に変更するためにunits: 'metric'を加えています。返ってきたリクエストをデータベースに保存できる形に直すために
attributes_forメソッドをクラスメソッドにしています。注意が必要なのは、降水量と予報日付です。
- 降水量は、降水がない場合は項目が存在しません。なのである場合のみ取得するように条件分岐しています。
- 予報日付に関しては、タイムゾーンに注意が必要です。OpenWeatherMapのタイムゾーンはUTCなので、JTCに変換してから保存しています。
タイムゾーンの扱いについてはこちらの記事が参考になります。
5. WeatherForecastテーブルの作成・保存
rake taskの作成
データベースへの保存・更新は定期的に実行したいので
rake taskに書いていきます。
と言っても、先ほどのRequestクラスでほぼメソッドを書いたので、後はそれを使うだけです。open_weather_api.rakenamespace :open_weather_api do desc 'Requests and save in database' task weather_forecasts: :environment do City.all.each do |city| open_weather = Api::OpenWeatherMap::Request.new(city.location_id) # リクエスト上限:60回/min response = open_weather.request # 3時間ごとのデータ2日分を保存 16.times do |i| params = Api::OpenWeatherMap::Request.attributes_for(response['list'][i]) if weather_forecast = WeatherForecast.where(city: city, date: params[:date]).presence weather_forecast[0].update!(params) else city.weather_forecasts.create!(params) end end end puts 'completed!' end end今回は、3時間毎のデータを2日分ずつデータベースに保存、更新する仕様にしました。
ポイントはリクエスト上限と、データの作成なのか更新なのかという点です。
- リクエスト上限は無料プランでは60calls/minです。登録している都市が60を超える場合は、分けてリスエストを送る必要があります。今回は47なので問題ありません。
presenceメソッドはpresent?メソッドを呼び出して、trueだった場合はレシーバー自身を返すメソッドです。同じ都市の同時刻に関する予報がすでにデータベースに存在する場合はupdate!を、存在しない場合はcreate!を呼び出しています。最後に
保存した
weather_idに対応する天気のアイコンを用意すると天気予報らしい見た目になると思います!
cronや、herokuならheroku schedularなどで定期的にapiを叩くようにしておくと良いかと思います!こんな感じで表示でしました!
長々とした文章を読んで頂きありがとうございました!
参考
https://openweathermap.org/api
https://qiita.com/yoshito410kam/items/26c3c6e519d4990ed739

- 投稿日:2020-08-02T18:20:54+09:00
Route53でドメインを登録した際にNginxのページが表示されてしまう時の対処
経緯
・Railsのアプリケーションは既にAWSへデプロイ済み
・せっかくならIPアドレスのままではなく、独自ドメインで表示したい!行ったこと
1.お名前.comでドメインを購入。
2.Route53でホストゾーンを作成し、ネームサーバーをお名前.comからRoute53へ変更。
3.レコードセットを作成し、ドメインに紐づくIPアドレスを登録起こった問題
AWSのコンソール、レジストラ側の設定が全て完了して、いざ取得したドメインで自分のサイトが開ける。と思ったが、Nginxのページが出てしまいアプリケーションへアクセス出来ない。
対処
・Nginxの設定で新しいドメインのURLを明記する
EC2へログインして、
[ec2-user@ip-xxxx ~]$ sudo vim /etc/nginx/conf.d/rails.confrails.confupstream app_server { server unix:/var/www/<アプリケーション名>/tmp/sockets/unicorn.sock; } server { listen 80; # ここのElasticIPとなっている箇所を、 server_name xxx.xxx.xx.xx; # 取得したURLへ変更する server_name <取得したドメインのアドレス>; client_max_body_size 2g; root /var/www/<アプリケーション名>/public; location ^~ /assets/ { gzip_static on; expires max; add_header Cache-Control public; } try_files $uri/index.html $uri @unicorn; location @unicorn { proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; proxy_pass http://app_server; } error_page 500 502 503 504 /500.html; }最後にNginxを起動させて設定ファイルの変更を読み込ませる
[ec2-user@ip-xxxx ~]$ sudo systemctl start nginx [ec2-user@ip-xxxx ~]$ sudo systemctl reload nginxあとは、Capistranoを走らせるついでにUnicornを再起動したら、無事に自分のアプリケーションが開けました!
- 投稿日:2020-08-02T18:11:30+09:00
jquery.raty rails導入
はじめに
- Golf GearのReviewサイトを作成中。
- Reviewの評価を星で表示する。
- 公式サイトはなぜかアクセスできないので、githubや画像をそれぞれ拾ってきて、表示できるようにする。

jquery.raty.jsファイルとstar画像を配置
- jquery.raty.js (https://github.com/wbotelhos/raty/blob/master/lib/jquery.raty.js) 上記記述をコピーし、
jquery.raty.jsというFile名で、app/assets/javascripts下に配置。- DOWNLOADからFileをダウンロードし、imgフォルダから、
star-on.png,star-off.png,star-half.pngをapp/assets/images下に配置。(https://www.alpinestyle.co.il/media/vendor/jquery.raty-1.4.3/)
application.jsでrequireする。app/assets/javascripts/application.js//= require jquery.raty.jsReview評価数を星に置き換える
app/views/reviews/_review.html.erb<div class="review-rating" data-score="<%= review.rating %>"></div> <p><%= review.comment %></p>app/views/gears/show.html.erb<%# 末尾に記載 %> <script> $('.review-rating').raty({ readOnly: true, score: function() { return $(this).attr('data-score'); }, path: '/assets/' }); </script>
- 今回、
_review.html.erbでdata-scoreを読み込み、render @gear.reviewsで呼び出しているので、gears/show.html.erbにjquery発火イベントを記載。Review投稿Formにstarで評価する
app/views/reviews/_form.html.erb<%= simple_form_for ([@gear, @gear.reviews.build]) do |f| %> <div id="rating-form"> <label>Rating</label> </div> <%= f.input :comment %> <%= f.button :submit %> <% end %> <script> $('#rating-form').raty({ path: '/assets/', scoreName: 'review[rating]' }); </script>https://gyazo.com/56bec592eeb6da5f719aa162dc26feed
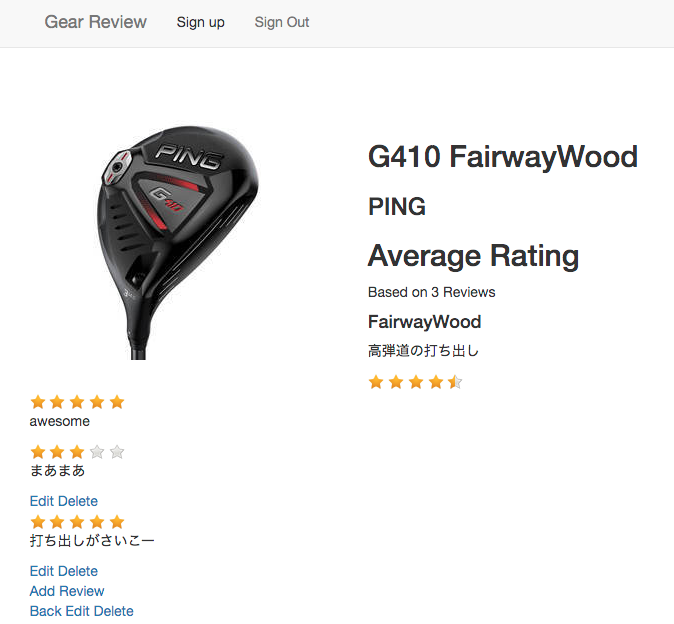
投稿Reviewの平均を表示
app/controllers/gears_controller.rbdef show if @gear.reviews.blank? @average_review = 0 else @average_review = @gear.reviews.average(:rating).round(2) end end # @average_reviewのインスタンス変数を設定app/views/gears/show.html.erb<div class="col-sm-8"> <h2><%= @gear.name %></h2> <h3><%= @gear.maker.name %></h3> <h2>Average Rating</h2> <div class="average-review-rating" data-score=<%= @average_review %>> <span>Based on <%= @gear.reviews.count %> Reviews</span> <h4><%= @gear.club.name %></h4> <p><%= @gear.description %></p> </div> <%# data-scoreに先ほど設定した@average_reviewのインスタンス変数を当てる。 %> <script> $('.average-review-rating').raty({ readOnly: true, path: '/assets/', score: function() { return $(this).attr('data-score') } }); </script> <%# jquery発火条件記載 %>
- 投稿日:2020-08-02T17:44:28+09:00
ファイル保存先をS3に設定後、RailsアプリをHerokuにpushすると失敗するエラーについて
エラー発生の経緯
本番環境でファイルを投稿後、1日程経つとファイルが表示されなくなる問題が発生していたため、HerokuへデプロイしていたRailsアプリを更新し、ファイルアップロード先をAWS S3に変更しました。
ローカル環境では適用に成功しましたが、
git push heroku masterコマンドで本番環境に適用しようとするとエラーが発生しました。エラー内容
ターミナルCaused by: ArgumentError: key must be 16 bytes結論
以下のコマンドで環境変数を設定するとエラーが解消されました。
heroku config:set RAILS_MASTER_KEY=`cat config/master.key`原因
元々下記のようなエラーが出ており、解消のために
heroku config:set RAILS_MASTER_KEY=`rake secret`
と言うコマンドで環境変数を設定していました。ターミナル-----> Preparing app for Rails asset pipeline Running: rake assets:precompile Missing encryption key to decrypt file with. Ask your team for your master key and write it to /tmp/build_6edee55a_/config/master.key or put it in the ENV['RAILS_MASTER_KEY']. ! ! Precompiling assets failed. ! ! Push rejected, failed to compile Ruby app. ! Push failed
`rake secret`は secret.yml を使っている場合のコマンドであり、credentials.yml.enc (Rails5.2以降) を使っている場合はRAILS_MASTER_KEYには`cat config/master.key`と設定する必要がありました。参考:Ask your team for your master key and put it in ENV[“RAILS_MASTER_KEY”] on heroku deploy
解決までに行ったこと
エラー解消方法に気づく直前まで、最後の方で出力されていた以下のようなエラーに注目していました。
出力されている通りPrecompiling assets failed、Push rejected、failed to compile Ruby、Push rejectedといったワードで検索してエラー解消に奮闘していましたが、解決しませんでした。ターミナルremote: /tmp/build_0a1646cf/vendor/bundle/ruby/2.5.0/gems/sprockets-rails-3.2.1/lib/sprockets/rails/task.rb:62:in `block (2 levels) in define' remote: Tasks: TOP => environment remote: (See full trace by running task with --trace) remote: remote: ! remote: ! Precompiling assets failed. remote: ! remote: ! Push rejected, failed to compile Ruby app. remote: remote: ! Push failed remote: Verifying deploy... remote: remote: ! Push rejected to (アプリ名). remote: To https://git.heroku.com/(アプリ名).git ! [remote rejected] master -> master (pre-receive hook declined) error: failed to push some refs to 'https://git.heroku.com/(アプリ名).git'エラー解消に繋がらなかった作業
1. heroku git push先を再設定
herokuのリモートリポジトリをセット
git remote set-url heroku https://git.heroku.com/(アプリ名).git
heroku git push先確認
git remote -v
2. config/application.rbの設定変更
config/application.rb のconfig.assets.initialize_on_precompile = trueをconfig.assets.initialize_on_precompile = falseに変更
参考 RailsでアプリをHerokuにあげる時のエラー各種
Herokuにpushしたらprecompile assets faild.が。pushできたと思ったらApplication Errorが。解決するまで。
3. assets:precompileの設定変更
RAILS_ENV=production bundle exec rake assets:precompile
参考 Herokuにデプロイしたときの「Precompiling assets failed.」エラーについて
5. Herokuを消して、作り直し
Herokuのアプリ管理画面の Settings → Delete app からアプリを削除
git remote rm herokuでremoteにあるherokuを削除
heroku create (アプリ名)でアプリを作り直す ※アプリ名は元と同じ
git push heroku masterでデプロイ
参考 herokuにデプロイできない
6. 通常にデプロイできていた部分までrevertして再デプロイ
GitHub Desktop の History でコミットを1つずつ右クリックして Revert this Commit
7. 強制プッシュでデプロイ
git push heroku --force master学んだこと
・ログは上の方もしっかり読む(最後の方のログに惑わされない)
・エラー発生直前に行った作業から原因を推測する(関係の薄いファイルはいじり過ぎない)
・credentials.yml.enc、config/master.key、 環境変数の仕組みを理解することが重要
・herokuはアプリを消すと再度同じURLでアプリ作成、デプロイできる
・Git で管理されないファイルを変更したりして環境変数が関わるエラーが発生した際は revert や 再デプロイしても本番環境のエラーは直らない特に
Precompiling assets failedといったエラーに関する情報は沢山ありますが、原因は様々なため、エラー内容をしっかり見ることが非常に大切だと実感しました。※最後の方のエラーばかり見て解決に何時間もかかっていましたが
「ArgumentError: key must be 16 bytes」がエラーの本体だと気づいた後、30分もかからずに解決しました!
- 投稿日:2020-08-02T17:25:07+09:00
[rails]画像の投稿方法
画像投稿方法
画像の投稿方法はこんな感じの手順です。
・refileをgemfileに追加
・image_idカラムを追加
・attachmentメソッドを追加する
・Strong Parametersにimage_idを追加する
・viewファイルにf.attachment_fieldを埋め込む1.refileをgemfileに追加
refileの役割
・画像を簡単に組み込むことができる。
・サムネイルを生成できる。
・ファイルのアップロード先を設定できる。refile-mini-magickは画像をサイズを変更するためのgemです。
# 画像投稿用gem gem "refile", require: "refile/rails", github: 'manfe/refile' # 画像加工用(サイズ調整など)gem gem "refile-mini_magick"bundle installは忘れずに。
$ bundle install2.image_idカラムを追加
Userテーブルにimage_idカラムを追加します。
$ rails g migration AddImageIdToUsers image_id:stringこれも忘れてはいけません。
$ rails db:migrateでデータベースに反映。$ rails db:migrate3.attachmentメソッドを追加する
Refileを使うには、attachmentメソッドをモデルに追加する必要があります。
attachmentメソッドとは、refileが指定のカラムにアクセスするために必要です。
これによりDBに存在する画像を取得したりアップロードが可能となります。
カラム名はimage_idですが、ここでは_idは不要です。app/models/user.rbclass User < ApplicationRecord attachment :image end4.Strong Parametersにimage_idを追加する
class UserController < ApplicationController #省略 private def list_params params.require(:user).permit(:name, :email, :image) end end5.viewファイルにf.attachment_fieldを埋め込む
次に画像を投稿するページに以下の通り、記述します。
<%= f.attachment_field :image %>
- 投稿日:2020-08-02T16:16:59+09:00
rails 本番環境のエラーをブラウザで表示する方法
結論
下記を変更するだけで本番環境でもブラウザ上でエラーを表示することが可能である。
//config/enviroments/production.rb config.consider_all_requests_local = false 変更前 config.consider_all_requests_local = true 変更後注意点
本番環境の詳細なエラー内容がユーザに見えてしまうのはよくないので、
エラー原因が特定できれば元に戻すのが良いかと思います。開発環境ではエラーが存在する場合、ブラウザ上で表示してくれる。
しかし、本番環境ではproduction.rbのログを見たり、unicornやnginxのエラーログを見るくらいしか知らなかった。
- 投稿日:2020-08-02T15:39:39+09:00
[Rails] Serviceクラスの設計で悩んだこと
RailsでServiceクラスの設計について考えたことを、まとめておきます。
(まだ最適解には至ってないです)会員登録機能を作る
分かりやすいように例として、よくあるユーザの会員登録機能を実装してみます。
パスワードの暗号化、認証urlの発行、認証メールの送信など、Controllerに全て書くとfatになってしまいそうです。こういう処理の流れは1つの処理の流れとしてどこかにまとめて書いた方が良さそうです。Serviceクラスの役割とは
自分の中でServiceクラスの役割として、
- ロジックの集約
- Controllerの肥大化を防ぐ
- ユースケースを表現する
があると思っています。会員登録はユースケースとして捉えることができるので、Serviceクラスに当てはまりました。
いざ設計
では、具体的に設計を考えてみます。まず、漠然と呼び出しのイメージを考えてみます。
registration_controller.rbclass RegistrationController < ApplicationController def create SignUpService.sign_up(email, password, confirm_password) if # 成功したかの判定 redirect_to user_confirm_path else render 'new' end end end大まかですが呼び出し側は、メソッド1発呼び出して全ての処理ができるといいなと考えました。
次にSerivice側です。
こっちの設計にとても悩みました。moduleにしてみる
moduleとclassの違いは、インスタンス化できるかどうかです。
処理の塊にしたかっただけなので、インスタンス化する必要はなさそうだと判断し、まずはmoduleに決めました。sign_up_service.rbmodule SignUpService def sign_up(email, password, confirm_password) validate_params(email, password, confirm_password) user_create(email, password) send_confirmation_mail(email) end private def validate_params(email, password, cofirm_password); end def user_create(email, password); end def send_confirmation_mail(email); end endこんな感じでsign_upメソッドを呼び出すと順々に処理がされるようなイメージになりました。
外からはsign_upメソッドしか見えないので、使い方が分かりやすくて良さそうです。moduleでの問題点
いざ上記の設計で作っていくと、「状態を持たせたく」なってきました。
例えば、処理が成功したかどうか、エラーメッセージなどです。
moduleでも実現できそうですが、classにしてnewしてインスタンス変数に処理結果を持たせた方がシンプルでいいのではないかと思い始めました。やっぱclassにしてみる
やっぱclassで大枠を作ってみました。
sign_up_serviceclass SignUpService attr_reader :success, :error_messages def initialize(email, password, confirm_password) # インスタンス変数へ代入 end def sign_up return unless validate_params user_create send_confirmation_mail end private def validate_params if @password != @confirm_password error_messages.push('パスワードが一致しません') success = false return false else ... end end def user_create; end def send_confirmation_mail; end end
@successや@error_messagesなどのインスタンス変数を持たせ、処理が終わるとそれぞれ結果を代入します。registration_controller.rbclass RegistrationController < ApplicationController def create sign_up_service = SignUpService.new(email, password, confirm_password) sign_up_service.sign_up if sign_up_service.success redirect_to user_confirm_path else @error_messages = sing_up_service.error_messages render 'new' end end end呼び出し側では、インスタンスを作成しsign_upメソッドを呼び出した後に、インスタンス変数の中身を取り出すことで処理結果が分かります。使い勝手は良さそうです。
ただ、インスタンス変数への代入が複数箇所に及ぶのが気になるところではあります。また、SignUpServiceでsign_upメソッドを呼び出すのもなんだかなという気がします。結果
いろんな記事を参考にしつつ、色々迷いがありましたが自分の中でこの形に落ち着きました。
(具体的な処理は省略しています)sign_up_serviceclass SignUpService attr_reader :success, :error_messages def initialize(email, password, confirm_password) @email = email ... # 省略 @error_messages = [] end def call return unless validate_params user_create send_confirmation_mail end private def validate_params if @password != @confirm_password error_messages.push('パスワードが一致しません') success = false return false else ... end end def user_create; end def send_confirmation_mail; end endregistration_controller.rbclass RegistrationController < ApplicationController def create sign_up_service = SignUpService.new(email, password, confirm_password) sign_up_service.call if sign_up_service.success redirect_to user_confirm_path else @error_messages = sing_up_service.error_messages render 'new' end end endまとめるとこのようになります。
Serviceクラス
- classにする
- 外から見えるのはcallメソッドのみにする
- attr_readerで状態を持たせる
- 処理結果をインスタンス変数に格納するようにする
呼び出し側
- インスタンス化する
- インスタンスに対してcallメソッドを呼び出す
- インスタンスの属性を見て処理をする
処理結果をインスタンス越しに取得できるのが便利になりました。
課題
課題点として
- 呼び出しがnewしてcallしてと冗長
- class内でインスタンス変数に代入する処理が散らばっている(代入し忘れや予期せぬ上書きなどが起こりそう)
があげられそうです。まだまだ改善の余地がありそうです。
もっと調べて固めていきたいです。
- 投稿日:2020-08-02T11:56:15+09:00
Docker 入門 1項目ずつ理解する
まず使い方を理解する
流れ
1.プロジェクト用のフォルダを作成
2.その中に手動でファイルを作成
2-1.【docker-compose.yml】を作成 & 貼り付け
2-2.【Dockerfile】を作成 & 貼り付け
2-3.【Gemfile】を作成 & gem 'rails' を記述
2-4.【Gemefile.lock】を作成(Gemfile.lockは空のまま何もしない。)
3.rails newを実行する
4.コンテナの作成 docker-compose build
5.database.ymlの編集
6.dbの作成 rake db:create
7.コンテナサーバーの起動 docker-compose up実際にやってみる。
操作1.2に関しては、追記予定です。
いったん、ここは飛ばして、Dockerfileについて、進めてくださいrails new(手順3)
コマンド$ docker-compose run --rm app rails new . --force --database=mysql --skip-bundleコンテナを作成(手順4)
$ docker-compose builddatabase.ymlを編集(手順5)
database.ymldefault: &default adapter: mysql2 encoding: utf8 pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> username: root - password: #passwordを追加 - host: localhost #dbに変更 + password: password + host: dbdatabase.ymlの変更後default: &default adapter: mysql2 encoding: utf8 pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> username: root password: password socket: /tmp/mysql.sock host: dbコマンドの理解
コンテナの作成
$ docker-compose build
buildは建てるの意味なので、コンテナを作成します。
Dockerfileの記述を変更した際などもdocker-compose buildで更新します。コンテナの起動
$ docker-compose upRuby on Railsでは
$ rails sでアプリを起動していましたが、dockerでは$docker-compose upでアプリを起動します。なぜというと、$docker-compose upを実行すると、後述するdocker-compose.ymlに記述した$rails sが実行されるためです。つまり、結果的にどちらも$ rails sを実行しているだけなのです。メリットは何か
どの言語でも
docker-compose upだけで起動ができます。これにより、自分が知らない言語でもアプリを起動できます。例えば、面接官がRubyやRuby on Railsを知らない場合、起動コマンドは当然知りません。しかし、あなたがdocker-compose.ymlに起動コマンドを記述すれば、
docker-compose upを実行するだけで面接官でもアプリを起動できます。だから、Dockerはとても親切なのです。コンテナの停止・再起動
コンテナの停止$ docker-compose stopコンテナの停止は
stopです。upの逆であるdownではありません。
インストールしたgemやパッケージを反映させるには、一度アプリを再起動しなければなりません。
その際に$docker-compose stopを実行して、アプリを停止させます。その後、$ docker-compose upを実行し、再度起動します。コンテナの再起動$ docker-compose restartいちいち、
stopとupをやるのが面倒な場合は、$ docker-compose restartでコンテナが再起動します。なので、基本的にgemインストール後は$ docker-compose restartを実行します。コンテナの削除
$ docker-compose downコンテナを削除します。
-vで後述するvolumes(バックアップデータ)も削除されます。
コンテナが削除されますので、基本的に利用しません。Dockerfileを理解する
Dockerの使い方がわかったところで、Dockerfileでよく使う項目を学習していきます。
公式ページで詳しく記載されているのは、下記になります。
Dockerfileの辞書はこちら。
自分が知りたい項目があれば、一度確認すると良いでしょう。では、一緒にみていきましょう。
FROM
FROMではインストールしたいrubyのバーションを指定します。
実際にrubyをインストールするには、複数のコマンドを実行しなければならないが、それらをセットにしたimageを利用して、1行でrubをインストールする。例えば、rubyのをインストールしたい場合、
dockerfileFROM rubyと記述するだけ、rubyの環境構築ができる。
さらに、rubyのバージョンを2.5.1と指定したい場合は、dockerfileFROM ruby:2.5.1と記述してバーションを指定する。
Dockerではimageのバージョンのことをtagと呼びます。基本的な下記の公式になります。
DockerfileFROM image:tag(バージョン) #imageはrubyやphpなどの言語などを指定する。基本的に
imageはrubyやphpなどの言語やmysqlなどを指定しますが、imageを自作することも可能です。imageをカスタマイズして自作すれば、より簡略して環境構築ができます。会社で用意されたimageを利用して開発することもあるようです。今回はruby:2.5.1を利用したいので、下記の記述で進めていきます。
DockerfileFROM ruby:2.5.1RUN
RUNでは実行したいコマンドを記述します。RUNFROM ruby:2.5.1 RUN 実行したいコマンドNode.jsやyarnなど必要なものをインストールしたり、bundle installなどコンテナをbuildした際に実行させたいコマンドを記述します。
DockerfileFROM ruby:2.5.1 ## ディレクトリ(ファルダ)を作成する。 RUN mkdir /webapp ## bundle installでgemを反映させる(build直後)。ターミナルでやる場合, $ docker-compose run web bundle installのようにします(後述します)。 RUN bundle install ## 必要なものをインストール RUN apt-get update -qq && \ apt-get install -y build-essential \ libpq-dev \ git \ vim ##yarnのインストール RUN apt-get update && apt-get install -y curl apt-transport-https wget && \ curl -sS https://dl.yarnpkg.com/debian/pubkey.gpg | apt-key add - && \ echo "deb https://dl.yarnpkg.com/debian/ stable main" | tee /etc/apt/sources.list.d/yarn.list && \ apt-get update && apt-get install -y yarn ##Nodejsをバージョン指定してインストール RUN curl -sL https://deb.nodesource.com/setup_12.x | bash - && \ apt-get install nodejs
apt-getはLinuxコマンドです。macでは利用できませんが、Dockerのコンテナ上では利用できます。ENV
DockerfileENV 変数 値 # $変数で利用可能例えば、フォルダ
app_nameを作成し、これを変数APPと定義したい場合、DockerfileのENV例FROM ruby:2.5.1 RUN mkdir /app_name ENV APP /app_nameと記述する。
これで、APP = app_nameと定義される。定義した変数を利用したい場合、
$マークをつける。
今回の例だとAPPを利用するには、$APPと記述する。DockerfileのENV例FROM ruby:2.5.1 RUN mkdir /app_name ENV APP /app_name WORKDIR $APP # 変数 APPを指定しているWORKDIR
DockerfileFROM ruby:2.5.1 RUN mkdir /app_name ENV APP /app_name WORKDIR $APPワーキングディレクトリを定義する。
ワーキングディレクトリとは、作業用フォルダを意味する。
つまりWORKDIRでは、アプリ開発するフォルダを指定します。
Dockerなしだと$rails new アプリ名でワーキングディレクトリを作成&指定されていたが、Dockerでは、RUN mkdir /フォルダ名でフォルダを作成し、それをWORKDIR /フォルダ名で指定する必要があります。WORKDIRの公式リファレンス
そもそもワーキングディレクトリとは?作業用フォルダ = カレントディレクトリ = .
カレントディレクトリ(英語: current directory、現行ディレクトリ。つまり現在開いているフォルダ)とは、現在の位置であるディレクトリ(フォルダ)のことである。作業フォルダ(ワーキングディレクトリ)とも呼ばれることがある。ADD
DockerfileADD [追加したいもの] → [追加したい場所]
左にあるファイルを右の場所に追加する。フォルダ内にファイルを追加したい場合は、
フォルダ名/と記述する。
ファイルを上書きさせたい場合は、フォルダ名/ファイル名と記述する。testファイルをDirフォルダに入れる場合ADD test Dir/testの内容をDirフォルダのtestに上書きADD test Dir/testRailsでよく使う例WORKDIR /webapp ## はじめに記述したGemfile → Dockerの作業用ディレクトリに追加 ADD ./Gemfile /webapp/Gemfile ## はじめに記述したGemfile.lock → Dockerの作業用ディレクトリに追加 ADD ./Gemfile.lock /webapp/Gemfile.lock使うことはないが、知識として知っておきたいこと。
条件を指定して取り込むADD hom* /mydir/ # "hom" で始まる全てのファイルを追加 ADD hom?.txt /mydir/ # ? は1文字だけ一致します。例: "home.txt"その他は辞書で調べてね
Dockerfileの辞書はこちら。
COPYとADDの違い実例
Dockerfile(ruby)FROM ruby:2.5.1 #ruby 2.5.1のimageを利用 # RUNはコマンド実行を意味する。必要なものをインストール RUN apt-get update -qq && \ apt-get install -y build-essential \ libpq-dev \ git \ vim #yarnのインストール RUN apt-get update && apt-get install -y curl apt-transport-https wget && \ curl -sS https://dl.yarnpkg.com/debian/pubkey.gpg | apt-key add - && \ echo "deb https://dl.yarnpkg.com/debian/ stable main" | tee /etc/apt/sources.list.d/yarn.list && \ apt-get update && apt-get install -y yarn #Nodejsをバージョン指定してインストール RUN curl -sL https://deb.nodesource.com/setup_12.x | bash - && \ apt-get install nodejs #Dockerでアプリ開発をするディレクトリを作成する。 RUN mkdir /webapp #作成したディレクトリを作業用のディレクトリに指定する。 WORKDIR /webapp #値は1でなくても何でも良いです。dockerfileとかだとDontWarnにしてる例が多いです。 ENV APT_KEY_DONT_WARN_ON_DANGEROUS_USAGE=DontWarn #GemfileとGemfile.lockを追加 ADD ./Gemfile /webapp/Gemfile ADD ./Gemfile.lock /webapp/Gemfile.lock #bundlerをインストール(途中からDockerを導入したため、bundlerを一致させないとエラーが発生するため) RUN gem install bundler -v 2.1.4 #gemをインストールするために、bundle install RUN bundle install #現在のディレクトリ に /webappの内容を追加 ADD . /webapp #puma.rb用のsocketsを作成 RUN mkdir -p tmp/socketsよく使う内容を把握しておけば、意味は理解できるはず。
docker-compose.ymlを理解する
docker-compose.ymlの辞書はこちら。
読み込みdocker-compose.yml → Dockerfileversion
まずdocker-composeのバージョンを指定します。
どんなバージョンがあるかを知りたい方はこちらdocker-compose.yml#version:3のdocker-composeを利用 version: "3"services
db用, アプリ用などに分ける
docker-compose.ymlversion: "3" services: db: #dbに関することを書く #この例だとdbにしているが、名前は自由 app: #appのことを書く #この例だとappにしているが、名前は自由(よくある例:web) nginx: #本番環境で公開するために必要なnginxについて書く ##この例だとnginxにしているが、名前は自由(よくある例:web)コマンドの実行
サービスを分けることによって、コマンドをdbに対してのコマンドなのか、appに対してのコマンドなのか使い分けることができる。
コマンドの公式$ docker-compose run サービス名 コマンド
runは実行するの意味があるので、docker-compose.ymlのサービス名に対してコマンドをrun(実行)の意味になるdbに対してコマンド実行したい場合、
docker-compose.ymlversion: "3" services: db: #ここに対して対して、コマンドを実行したい app: nginx:サービスがdbなので
dbに関するコマンド処理を実行$ docker-compose run db コマンドとなる。
runは実行するの意味があるので、docker-compose.ymlのdbに対してコマンドをrun(実行)の意味になる具体例:dbにコマンド処理(mysql)$ docker-compose run db mysql -u [ユーザー名] -p続いて、appに対してコマンド処理をしたい場合
docker-compose.ymlversion: "3" services: db: app: #ここに対して対して、コマンドを実行したい nginx:サービス名がappなので、
appに対してコマンド実行$ docker-compose run app コマンドとなります。
runは実行するの意味があるので、docker-compose.ymlのappに対してコマンドをrun(実行)の意味になる例:appにコマンド処理#appに対してコマンド実行したい(imageがrubyなので、railsに関するコマンドはここ) $ docker-compose run app bundle install $ docker-compose run app rake db:create $ docker-compose run app rake db:migrate #今回のdocker-compose.ymlがappにしているだけで、もしも[web]としていたら、下記になる $ docker-compose run web bundle install $ docker-compose run web rake db:create $ docker-compose run web rake db:migrate特にコマンドはないですが、nginxに対してコマンド処理をしたい場合
docker-compose.ymlversion: "3" services: db: app: nginx: #ここに対して対して、コマンドを実行したいnginxに対してコマンド$ docker-compose run nginx [コマンド]
runは実行するの意味があるので、docker-compose.ymlのnginxに対してコマンドをrun(実行)の意味になるbuild: 読み込むDockerfileを指定する
先ほど記述した
dbやappといったservicesごとに、どのDockerfileを読み込むのか指定する必要がある。
build:を記述して、どのDockerfileを読み込むのか指定します。context: Dockerfileを持つフォルダを指定する
フォルダを指定してDockerfileを読み込む場合は、
build:下のcontext:にパスを記述します。
では例をみていきましょう。ワーキングディレクトリ直下にある場合
/webapp(アプリ名) ├── docker-compose.yml ├── Dockerfile (これを指定したい) ├── Gemfile └── Gemfile.lockカレントディレクトリである
webappフォルダ内にDockerfileがあります。
カレントディレクトリのパスは.なので、下記のように指定します。docker-compose.ymlversion: "3" services: app: build: context: . #カレントディレクトリ上のDockerfileを読み込むこれでサービス
appはカレントディレクトリにあるDockerfileを読み込みます。
デフォルトでDockerfileを読み込む設定になっているので、ファイル名は指定しなくて大丈夫です。contextを省略した場合version: "3" services: app: #webapp / Dockerfile #直下にあるので build: . #appはカレントディレクトリ(.)にあるDockerfileを使うよくある例として、
build: .とcontext:を省略している例があります。
やっていることは同じなので、context:を理解すれば大丈夫です。では、さらに例をみて理解を深めましょう。
フォルダの中にDockerfileがある場合
/webapp ├── containers │ └── nginx │ ├── Dockerfile (nginx用:ここを指定したい) │ └── nginx.conf ├── docker-compose.yml ├── Gemfile └── Gemfile.lockこの例では、
webapp/containers/nginxフォルダ内のDockerfileを利用したいので、containers/nginxを指定します。docker-compose.ymlversion: "3" services: nginx: build: context: containers/nginx #nginフォルダ内のDockerfileを使うDockerfileが不要な場合(imageだけで十分)
下記のように、imageしかDockerfileに記述する必要がない場合、
Dockerfile(mysql用)FROM mysql:mysql:5.6.47わざわざDockerfileを作成せずに、直接docker-compose.ymlにimageを記述すればよい。
Dockerfileなし/webapp ├── docker-compose.yml ├── Gemfile └── Gemfile.lockサービス
dbはimage: mysql:5.6.47を利用したい場合、docker-compose.ymlversion: "3" services: db: image: mysql:5.6.47 #imageを直接指定応用:サービスごとにDockerfile(複数)を使い分ける
これまで学んだことを組み合わせて、
サービスapp用のDockerfile(image: ruby)と
サービスnginx用のDockerfile(image: nginx)を使い分けましょう。
サービスdbはimageを直接指定します。フォルダの階層/webapp ├── containers │ └── nginx │ ├── Dockerfile (nginx用) │ └── nginx.conf ├── docker-compose.yml ├── Dockerfile (app用) ├── Gemfile └── Gemfile.lock下記のdocker-composeのdbに対して、image: を指定している。
このように、Dockerfileを作成しなくてもimageを指定することが可能docker-compose.ymlversion: "3" services: db: image: mysql:5.6.47 app: build: . nginx: build: context: containers/nginxdockerfile:ファイル名がDockerfileではない場合
デフォルトでは、
context:で指定したフォルダ内のDockerfileを見つけてbuildします。
ここでは、ファイル名がDockerfileではない場合を解説します。例えば、nginx用のDockerfileを
Dockerfile-nginxというファイルだった場合
dockerfile:を記述してDockerfileとして読み込みたいファイルを指定します。
公式リファレンスdocker-compose.ymlversion: "3" services: db: image: mysql:5.6.47 app: build: . nginx: build: context: containers/nginx dockerfile: Dockerfile-nginx #フィル名を指定するdepends_on:
サービスとサービスを紐付ける
ここまで学んだ、下記だとdb, app, nginxが繋がっていません。
docker-compose.ymlversion: "3" services: db: image: mysql:5.6.47 app: build: . nginx: build: context: containers/nginx今回は、それぞれのサービスを紐づけます。
dbとappを紐付ける
app単体だと,dbのデータを保持できないので、紐付けます。
docker-compose.ymlversion: "3" services: db: image: mysql:5.6.47 app: build: . depends_on: #依存する - db #dbを紐付けこれにより、
appを起動するとdbも起動させます。
app系のコマンド実行する際は、DBの情報が必要になるので、appにdbを紐付けています。
ターミナルコマンドを見て、より理解を深めましょう。appに対するコマンド$ docker-compose run app rails g model message上記のコマンドを実行すると
dbが起動している箇所Starting web-share_db_1 ... done # dbが起動していると表示されており、appのコマンド実行前に
dbが起動しているとわかります。appとnginxを紐付ける
docker-compose.ymlversion: "3" services: db: image: mysql:5.6.47 app: build: . depends_on: #依存する - db #dbと紐付け nginx: build: context: containers/nginx depends_on: #依存する - app #appと紐付けnginxを起動すると、
appも起動する。appが起動するので、dbも起動します。
db ← app ← nginxでは、
$ docker-compse up実行時に、の動作をみましょう。
上記の写真をみてみると$ docker-compose up Starting web-share_db_1 ... done #dbが起動 Starting web-share_app_1 ... done #appが起動 Starting web-share_nginx_1 ... done #nginxが起動 #紐付けされる Attaching to web-share_db_1, web-share_app_1, web-share_nginx_1それぞれのサービスが起動し、Attachingで紐づいていることがわかる。
Nginxとappを紐付ける理由
Nginxを利用していない場合、
localhost:3000というように:3000をurlに含めないとサイトを見れません。example.comの場合、
example.com:3000でなければサイトにアクセスできない。Nginxでアプリを起動すると80ポートで起動するので、
localhostだけでサイトを見れます。:3000のようなポート番号を指定する必要はありません。example.comの場合、
example.comでアクセスできる。ポート番号なしにアクセスできるようにするために、
nginxにappを紐付けています。複数のサービスを紐付ける
複数のサービスの紐付けたい場合があると思います。
その際は下記のdocker-compose.ymlのように記述しますdocker-compose.ymlversion: "3.8" services: web: build: . depends_on: - db - redis redis: image: redis db: image: postgres上記の例では、サービス
webは、redisとdbの二つの依存関係を同時に保有しています。
このように複数のサービスと紐付けることも可能です。volumes: (バックアップ)
volumes:でデータのバックアップを作成し、別のコンテナでもデータを使い回します。
これをしておかないと、Dockerfileを更新して$ docker-compose buildし直す際に、DBの情報が消えます。新品のiPhoneには、何もデータがないように
新しく作成したコンテナは、前のコンテナの情報は入っていません。buildするたびにDBの情報を作り直すのは、非常にめんどくさいので、バックアップを作成しておき、それをコンテナに使いまわします。
そのバックアップをvolumeと呼びます。volumeの必要性
現実の例
新しいPCを購入した = 前のPCのデータは当然ない
なので、前のPCで作成したバックアップデータを新しいPCに入れる。Dockerをbuildし直した(コンテナを作り直す)
新しいコンテナ = 前のコンテナのデータは当然ない
バックアップデータであるvolumeを新しいコンテナに紐付けるvolumesを記述する
docker-compose.ymlversion: "3" services: db: app: nginx: volumes: #ここにvolumeをセットする。 #volumeの名前は自由 mysql_data: gem_data: public-data: tmp-data: log-data:サービスとvolumesを紐付ける
dbのvolume名を
mysql_dataとして場合、docker-compose.ymlversion: "3" services: db: volumes: - mysql_data: #使用するvolumeを指定 volumes: mysql_data: #これを紐付けmysqlを利用するに当たって、決まった階層があるので、それを指定します。
docker-compose.ymlversion: "3" services: db: volumes: - mysql_data:/var/lib/mysql # mysqlは読み込み場所が決まっているので(/var/lib/mysql)、 # 保存する階層を指定している volumes: mysql_data: #これを紐付けこれでbuildしてコンテナを作り直してもmysqlのデータは保持される。
appのgemをvolumesで保持する。
$docker-compose builddocker-compose.ymlversion: "3" services: db: volumes: - mysql_data:/var/lib/mysql app: volumes: - gem_data:/usr/local/bundle nginx: volumes: mysql_data: gem_data: #これをappに紐付ける実例
docker-composeversion: "3" services: db: image: mysql:5.6.47 volumes: - mysql_data:/var/lib/mysql app: build: context: . volumes: - .:/webapp - public-data:/webapp/public - tmp-data:/webapp/tmp - log-data:/webapp/log - gem_data:/usr/local/bundle depends_on: - db nginx: build: context: containers/nginx volumes: - public-data:/webapp/public - tmp-data:/webapp/tmp depends_on: - app volumes: mysql_data: gem_data: public-data: tmp-data: log-data:command: docker-compose up時のコマンド
command:は$docker-compose up時のコマンドを処理します。基本的にはサーバー起動関連のコマンドを記述します。
rails sで起動version: '3' services: web: build: . command: bundle exec rails s -p 3000 -b '0.0.0.0'"pumaで起動version: "3" services: app: build: context: . command: bundle exec puma -C config/puma.rb volumes:unicornで起動version: "3" services: app: build: context: . command: bundle exec unicorn_rails -c config/unicorn.rb volumes:rails s(邪魔なファイルを削除)version: '3' services: web: build: . command: bash -c "rm -f tmp/pids/server.pid && bundle exec rails s -p 3000 -b '0.0.0.0'"この
command:により、$docker-compose up時に$rails sなどを実行されて、アプリが起動される。portを指定する
ポートを指定したい場合は下記
port:を利用します。docker-compose.ymlversion: '3' services: db: image: mysql:5.7 environment: MYSQL_ROOT_PASSWORD: 'password' ports: - "4306:3306" volumes: - mysql_data:/var/lib/mysql web: build: . command: bash -c "rm -f tmp/pids/server.pid && bundle exec rails s -p 3000 -b '0.0.0.0'" volumes: - .:/app_name # volumeを使用してbundle installしてきたものを永続化 - gem_data:/usr/local/bundle ports: - "3000:3000" depends_on: - db volumes: mysql_data: gem_data:environment: 環境変数
環境変数を指定してbuildしたいとき、どのようにすればよいのか解説していきます。
mysqlの例
mysqlの環境変数を定義version: "3" services: db: image: mysql:5.6.47 environment: MYSQL_ROOT_PASSWORD: password MYSQL_DATABASE: root上記の例でbuildすると、usernameとpasswordが反映されます。
database.ymldefault: &default adapter: mysql2 encoding: utf8 pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> username: root #反映 password: password #反映本番環境で実行したい場合
docker-compose.ymlversion: "3" services: app: build: context: . command: bash -c "rm -f tmp/pids/server.pid && bundle exec puma -C config/puma.rb" environment: RAILS_ENV: production #本番環境で$docker-compose up。指定なしの場合、developmentで実行envファイルを利用して、値を隠したい場合
env_fileオプションを利用して、envファイルを読み込みます。envファイルが複数の場合env_file: - ./common.env - ./apps/web.env - /opt/runtime_opts.envenvファイルが1つの場合env_file: .envこれで、envファイルを読み込む方法がわかりました。
では、どのように.envファイルで環境変数を定義すれば良いのか?
確認していきましょう!mysqlの環境変数を定義version: "3" services: db: image: mysql:5.6.47 environment: MYSQL_ROOT_PASSWORD: password #隠したい MYSQL_DATABASE: root #隠したいenvファイルを用意して、環境変数を定義
.envMYSQL_ROOT_PASSWORD=password MYSQL_DATABASE=rootでは、これを読み込みます
docker-compose.ymlversion: "3" services: db: image: mysql:5.6.47 env_file: .env environment: MYSQL_ROOT_PASSWORD: password #隠したい MYSQL_DATABASE: root #隠したい
env_file:で読み込んだので、environment:は不要になりました。
なので、environmet:を削除しますdocker-compose.ymlversion: "3" services: db: image: mysql:5.6.47 env_file: .envだいぶスッキリしましたね!
注意事項は
env_fileよりも、environment:の方が優先されます。たとえば
.envMYSQL_ROOT_PASSWORD=pass12345 MYSQL_DATABASE=mysql_userdocker-compose.ymlversion: "3" services: db: image: mysql:5.6.47 env_file: .env environment: MYSQL_ROOT_PASSWORD: password #優先=上書き MYSQL_DATABASE: root #優先=上書き上記のような場合は、
environmentの内容に上書きされます。docker-compose.ymlで環境変数を定義しない場合
environment:を利用しなくても、実行可能です。
環境変数をdocker-compose.ymlで定義しない場合、
docker-compose run -e 環境変数=値 サービス名で実行可能です。言うまでもなく、オプション-eはenvironmentのeです。例$ docker-compose run -e RAILS_ENV=production app bundle install $ docker-compose run -e RAILS_ENV=production app rake db:create $ docker-compose run -e RAILS_ENV=production app rake db:migrate $ docker-compose run -e RAILS_ENV=production web bundle install $ docker-compose run -e RAILS_ENV=production web rake db:create $ docker-compose run -e RAILS_ENV=production web rake db:migrateじゃあ、なぜdocker-compose.yml上で定義しなければいけないのか?
それは$docker-compose up には、環境変数を指定するオプションが無いからです。
$ docker-compose up -e RAILS_ENV=production > -bash: $: command not found本番環境と開発環境で切り分ける場合
方法は2つ
方法1:環境変数を本番環境、開発環境で違うようにする。
docker-compose.ymlを本番環境(EC2)上で編集し、環境変数を定義する
開発環境のdocker-compose.ymlversion: "3" services: app: build: context: . command: bash -c "rm -f tmp/pids/server.pid && bundle exec puma -C config/puma.rb"本番環境のdocker-compose.ymlversion: "3" services: app: build: context: . command: bash -c "rm -f tmp/pids/server.pid && bundle exec puma -C config/puma.rb" environment: #EC2上でvimを使って追記 RAILS_ENV: production #EC2上でvimを使って追記env_fileでもよいでしょう
本番環境のdocker-compose.ymlversion: "3" services: app: build: context: . command: bash -c "rm -f tmp/pids/server.pid && bundle exec puma -C config/puma.rb" env_file: .env #EC2上でvimを使って追記.envRAILS_ENV=production方法2
docker-compose.ymlを2つ作成し、開発環境用、本番環境用に使いわける。
docker-compose -f ファイル名 upというように、-fオプションを利用して、別のdocker-compose.ymlを指定することが可能です。参考:本番環境での Compose の利用 | Docker ドキュメント
例えば、
開発環境用
docker-compose.ymlと本番環境用docker-compose-production.ymlを用意した場合、基本的に読み込まれるのは
docker-compose.ymlです。
名前が異なるのでdocker-compose-production.ymlは読み込まれません。
しかし、-fオプションを利用して、読み込むファイルを指定すれば、docker-compose-production.ymlでも読み込みされます。通常はdocker-compose.ymlで実行$ docker-compose updocker-compose-production.ymlで実行$ docker-compose -f docker-compose-production.yml up他にも
docker-compose.ymlに本番環境設定だけを追加したい場合、$ docker-compose -f docker-compose.yml -f docker-compose.production.yml up上記のように
-fオプションを二つ利用して、合算させることも可能です。
ただし、コマンドは少しが長くなりますけどね。実例
docker-compose.ymlversion: "3" services: db: image: mysql:5.6.47 environment: MYSQL_ROOT_PASSWORD: password MYSQL_DATABASE: root ports: - "4306:3306" volumes: - mysql_data:/var/lib/mysql app: build: context: . command: bash -c "rm -f tmp/pids/server.pid && bundle exec puma -C config/puma.rb" volumes: - .:/webapp - public-data:/webapp/public - tmp-data:/webapp/tmp - log-data:/webapp/log - gem_data:/usr/local/bundle depends_on: - db tty: true stdin_open: true nginx: build: context: containers/nginx volumes: - public-data:/webapp/public - tmp-data:/webapp/tmp ports: - 80:80 depends_on: - app volumes: mysql_data: gem_data: public-data: tmp-data: log-data:実際に試みる2
docker-compose.ymlversion: "3" services: db: image: mysql:5.6.47 environment: MYSQL_ROOT_PASSWORD: password MYSQL_DATABASE: root ports: - "4306:3306" volumes: - mysql_data:/var/lib/mysql app: build: context: . command: bash -c "rm -f tmp/pids/server.pid && bundle exec puma -C config/puma.rb" volumes: - .:/webapp - public-data:/webapp/public - tmp-data:/webapp/tmp - log-data:/webapp/log - gem_data:/usr/local/bundle depends_on: - db tty: true stdin_open: true nginx: build: context: containers/nginx volumes: - public-data:/webapp/public - tmp-data:/webapp/tmp ports: - 80:80 depends_on: - app volumes: mysql_data: gem_data: public-data: tmp-data: log-data:Dockerfile(app用)FROM ruby:2.5.1 RUN apt-get update -qq && \ apt-get install -y build-essential \ libpq-dev \ git \ vim #yarnのインストール RUN apt-get update && apt-get install -y curl apt-transport-https wget && \ curl -sS https://dl.yarnpkg.com/debian/pubkey.gpg | apt-key add - && \ echo "deb https://dl.yarnpkg.com/debian/ stable main" | tee /etc/apt/sources.list.d/yarn.list && \ apt-get update && apt-get install -y yarn #Nodejsをバージョン指定してインストール RUN curl -sL https://deb.nodesource.com/setup_12.x | bash - && \ apt-get install nodejs RUN mkdir /webapp WORKDIR /webapp ENV APT_KEY_DONT_WARN_ON_DANGEROUS_USAGE=DontWarn ADD ./Gemfile /webapp/Gemfile ADD ./Gemfile.lock /webapp/Gemfile.lock RUN gem install bundler -v 2.1.4 RUN bundle install ADD . /webapp RUN mkdir -p tmp/socketscontainers/nginx/Dockerfile(nginx用)FROM nginx:1.15.8 RUN rm -f /etc/nginx/conf.d/* ADD nginx.conf /etc/nginx/conf.d/webapp.conf CMD /usr/sbin/nginx -g 'daemon off;' -c /etc/nginx/nginx.confnginx.confupstream webapp { server unix:///webapp/tmp/sockets/puma.sock; } server { listen 80; server_name example.com [or 192.168.xx.xx [or localhost]]; access_log /var/log/nginx/access.log; error_log /var/log/nginx/error.log; root /webapp/public; client_max_body_size 100m; error_page 404 /404.html; error_page 505 502 503 504 /500.html; try_files $uri/index.html $uri @webapp; keepalive_timeout 5; location @webapp { proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_pass http://webapp; } }puma.rb# Puma can serve each request in a thread from an internal thread pool. # The `threads` method setting takes two numbers: a minimum and maximum. # Any libraries that use thread pools should be configured to match # the maximum value specified for Puma. Default is set to 5 threads for minimum # and maximum; this matches the default thread size of Active Record. # threads_count = ENV.fetch("RAILS_MAX_THREADS") { 5 } threads threads_count, threads_count # Specifies the `port` that Puma will listen on to receive requests; default is 3000. # port ENV.fetch("PORT") { 3000 } # Specifies the `environment` that Puma will run in. # environment ENV.fetch("RAILS_ENV") { "development" } # Specifies the `pidfile` that Puma will use. pidfile ENV.fetch("PIDFILE") { "tmp/pids/server.pid" } # Specifies the number of `workers` to boot in clustered mode. # Workers are forked webserver processes. If using threads and workers together # the concurrency of the application would be max `threads` * `workers`. # Workers do not work on JRuby or Windows (both of which do not support # processes). # # workers ENV.fetch("WEB_CONCURRENCY") { 2 } # Use the `preload_app!` method when specifying a `workers` number. # This directive tells Puma to first boot the application and load code # before forking the application. This takes advantage of Copy On Write # process behavior so workers use less memory. # # preload_app! # Allow puma to be restarted by `rails restart` command. plugin :tmp_restart app_root = File.expand_path("../..", __FILE__) bind "unix://#{app_root}/tmp/sockets/puma.sock" stdout_redirect "#{app_root}/log/puma.stdout.log", "#{app_root}/log/puma.stderr.log", truenginxの設定について
ここでは、nginxの詳細設定は解説しませんが、参考になるリンクを貼っておきます。
Nginx設定のまとめ
この記事を辞書代わりに使うと理解が早まるでしょう。upstream
docker-compose.ymlversion: "3" services: app: build: context: . command: bundle exec puma -C config/puma.rbdocker-compose.ymlの
command:において、bundle exec puma -C config/puma.rbが実行されいている。これはpumaによって起動するコマンドだが、その設定は
-Cオプションによりconfig/puma.rbファイルより読み込まれる。puma.rbでpuma.sockを作成する
puma.rbbind "unix://#{app_root}/tmp/sockets/puma.sock"
puma.sockは、Nginxとソケット通信をする際に必要になるファイルです。puma.rbで作成したpuma.sockをnginx.confに読み込む
upstreamでsocketを指定します。nginx.confupstream webapp { server unix:///webapp/tmp/sockets/puma.sock; }proxy_pass
upstreamをproxy_passで指定する。nginx.confupstream puma { server unix:///usr/local/var/work/app-name/tmp/sockets/puma.sock; } server { location @puma { proxy_pass http://puma; #ここ proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; } }例えば、upstreamがwebappだった場合
nginx.confupstream webapp { server unix:///webapp/tmp/sockets/puma.sock; } server { location @webapp { proxy_pass http://webapp; } }listen 80
nginx.confupstream webapp { server unix:///webapp/tmp/sockets/puma.sock; } server { listen 80; location @webapp { proxy_pass http://webapp; } }
listen 80;でport:80を指定している。TCP 20 : FTP (データ)
TCP 21 : FTP (制御)
TCP 22 : SSH
TCP 23 : Telnet
TCP 25 : SMTP
UDP 53 : DNS
UDP 67 : DHCP(サーバ)
UDP 68 : DHCP(クライアント)
TCP 80 : HTTP
TCP 110 : POP3
UDP 123 : NTP
TCP 443 : HTTPS
WELL KNOWN PORT NUMBERS 0~1023特定のIPアドレス上で公開されているサーバ上で、HTTPというプロトコルにそったアプリケーション、Apacheなどが80番ポートで、クライアントとの通信を待機し、要求に応じてWebページの情報を送信するといった流れだ。
一般的にport:80を指定する。
location
server_name
** localhostを指定する場合 **
nginx.confupstream webapp { server unix:///webapp/tmp/sockets/puma.sock; } server { listen 80; server_name localhost; }server_nameは指定のドメインの場合に対象となります。
このケースではhttp://localhost:80の場合に適用されます。** IPアドレスを指定する場合 **
nginx.confupstream webapp { server unix:///webapp/tmp/sockets/puma.sock; } server { listen 80; server_name 192.168.11.11; }このケースでは、IPアドレスを指定しています。
http://192.168.11.11:80** ドメインを指定する場合 **
nginx.confupstream webapp { server unix:///webapp/tmp/sockets/puma.sock; } server { listen 80; server_name example.com; }このケースでは、ドメインを指定しています。
http://example.com:80** 複数合わせる場合 **
nginx.confupstream webapp { server unix:///webapp/tmp/sockets/puma.sock; } server { server_tokens off; listen 80; server_name example.com [or 192.168.xx.xx [or localhost]]; }proxy_set_header
nginx.confupstream webapp { server unix:///webapp/tmp/sockets/puma.sock; } server { server_tokens off; listen 80; server_name example.com [or 192.168.xx.xx [or localhost]]; location @webapp { proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_pass http://webapp; } }基本的に
proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host;としか利用しません。
X-Real-IPこれもHTTPヘッダの一つ。ロードバランサやプロキシを経由する時に送信元を判別するために利用。アプリケーション層の情報。
X-Forwarded-Forと同じような値だけど、複数の可能性があるX-Forwarded-Forと違って1つ。
X-Forwarded-ForHTTPヘッダの一つ。ロードバランサやプロキシを経由する時に送信元を判別するために利用。アプリケーション層の情報。
詳しくはこちらの記事をみてください
https://christina04.hatenablog.com/entry/2016/10/25/190000try_files
try_files $uri $uri.html $uri/index.html @webapp;指定のファイルが存在するかを左から探しに行きます。
例えばhttp://***/hogeでアクセスした場合はhoge.html、hoge/index.html、location @webapp {}の順番に探します。次の例をみてみましょう。
nginx.confupstream webapp { server unix:///webapp/tmp/sockets/puma.sock; } server { listen 80; server_name example.com [or 192.168.xx.xx [or localhost]]; try_files $uri/index.html $uri @webapp; location @webapp { proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_pass http://webapp; } }
locationで定義した@webappをtry_filesで読み込みさせています。try_files $uri/index.html $uri @webapp;全体
nginx.confupstream webapp { server unix:///webapp/tmp/sockets/puma.sock; } server { listen 80; server_name example.com [or 192.168.xx.xx [or localhost]]; access_log /var/log/nginx/access.log; error_log /var/log/nginx/error.log; root /webapp/public; client_max_body_size 100m; error_page 404 /404.html; error_page 505 502 503 504 /500.html; try_files $uri/index.html $uri @webapp; keepalive_timeout 5; location @webapp { proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_pass http://webapp; } }

- 投稿日:2020-08-02T10:33:33+09:00
Rails testで「 FATAL: Listen error: unable to monitor directories for changes.」のエラー
前提
Rails 6.0.3
ruby 2.6.3本題
$rails testのコマンドを実行した時に以下のエラーが発生。
$ rails test FATAL: Listen error: unable to monitor directories for changes. Visit https://github.com/guard/listen/wiki/Increasing-the-amount-of-inotify-watchers for info on how to fix this.1つのユーザIDに対して生成できるinotifyのインスタンスの数の上限に達してしまったようなことが書かれている?のではないかと思いました。
エラー内容に書いている通り、Githubを確認しコマンドを入力し解決。解決方法
ユーザーインスタンスを確認。
$ cat /proc/sys/fs/inotify/max_user_instancesinotifyのインスタンス上限を変更。
$ echo fs.inotify.max_user_watches=524288 | sudo tee -a /etc/sysctl.conf設定を反映。
$ sudo sysctl -p再びコマンド実行。
$ rails test
- 投稿日:2020-08-02T09:58:35+09:00
【Rails】一意性を保つバリデーションの実装
一意性バリデーションの実装に必要なタスク
- アプリ側に記述(uniqueness: true)
- データベース側に記述(unique: true)
アプリ側に記述
models/user.rbvalidates :email, uniqueness: trueデータベース側に記述
$ rails g migration add_column_to_usersadd_column_to_users.rbdef change add_index :users, :email, unique: true end$ rails db:migrateテーブルのカラムに一意性を持たせるには、インデックスの作成も必要になる。
理由は、全てのデータを検索することで、過去のデータと重複しているか確認できるため。
- 投稿日:2020-08-02T08:14:43+09:00
オリジナルのアプリを完成させるまでの解説
環境
macOS 10.15.5
Rails 5.2.4.2
Docker 19.03.12概要
オリジナルアプリの概要はCRUDのシステムを意識した簡易的なメモアプリの開発です。
簡易的なアプリと言っても実用性には欠かないよう注意を払いました。行数が増えてもレイアウト崩れが起きないように実装し、文字数制限や空白の項目が新規作成されないようにも設定しました。Dockerを用いてフレームワークはRailsを使用しました。そしてHerokuにより公開をしています。
オリジナル性について
HTMLに関してはclass名などは学習サイトをヒントに用いて、デザインは外観は学習サイトをヒントにしましたが実装は全て自走で行いました。
Railsの機能の実装に関して事前に学習サイトを何度も繰り返し行い、CRUDの機能を頭に入れてから今回の作成を行いました。そのため短いコードなどはなるべくサイトなどを参考にせず、自分で覚えた内容で実装し、コマンド操作は基本的に全て頭に入れた内容のみで行いました。サイトについて
一覧ページをトップページとして定めメモの項目が個々の詳細が表示できるようにリンク指定をしています。その際に新規投稿された項目が最上部に移動するように実装しました。lists_controller.rbclass ListsController < ApplicationController def index @lists = List.all.order(created_at: :desc) end新規作成ページ
新規作成ページでは空白の内容と141文字以上の内容が実行されないように設定しています。list.rbclass List < ApplicationRecord validates :content, {presence: true, length: {maximum: 140}} end詳細ページ
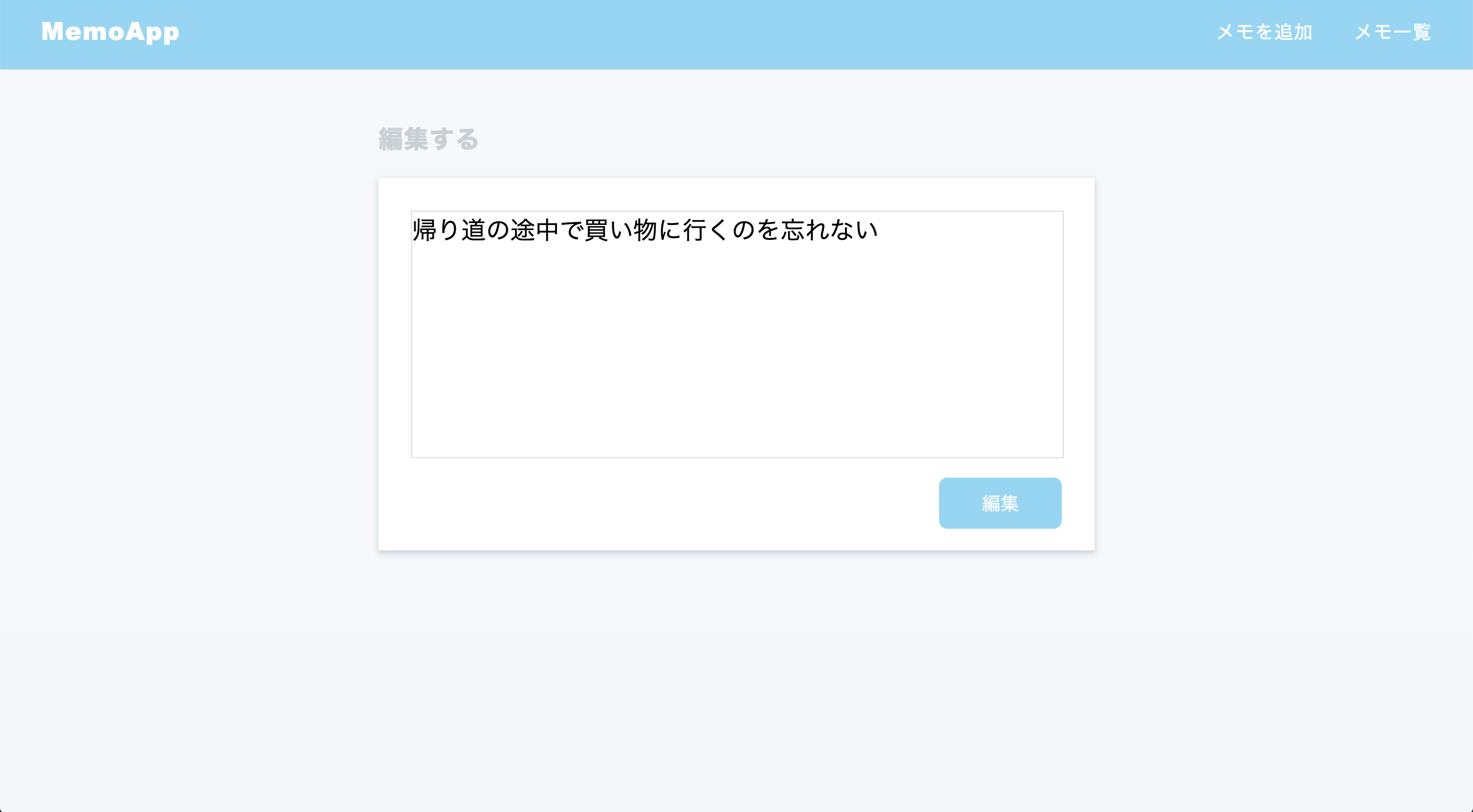
メモ一覧の個々の項目のリンクから移動すると個々の詳細ページが閲覧できます。そこから「編集」と「削除」を実行することができます。編集ページ
編集ページではページを開いたときに編集前の内容が表示されるように実装しています。edit.html.erb<div class="form-bady"> <textarea name="content"><%= @list.content %></textarea> <input type="submit" value="編集"> </div>lists_controller.rbdef edit @list = List.find_by(id: params[:id]) endオリジナルアプリを作るにあたり意識したこと
わたしは自走できるエンジニアとしてスキルを身に付けたい!という思いからどんなやり方がそんなエンジニアに近づける方法なのか良く自問自答をします。今回このシンプルなメモアプリを作成しようと考えたのはRailsのCRUDの機能やMVCは完璧に落とし込もうと考えたのでこのシンプルさにまとめてみました。
今後はログイン機能やユーザーごとのアクセス権限を設けたページの作成などの機能を有したアプリの作成などにも取り組みたいです!
- 投稿日:2020-08-02T06:00:17+09:00
railsで動画を投稿する
今回、初投稿させていただきます。
少し、見にくかったりしてもご了承お願いします。今回は、railsで動画アップロード機能の備忘録となっております。
個人的にFFmpegを使用した動画アップロードが分かりにくかったので、なるべく分かりやすく説明できればと思います。環境
Ruby 2.6.5
Rails 6.0.3.2早速取り掛かっていく
ターミナルrails new RailsAppターミナルでRailsAppを作ります。
Gemfilegem 'carrierwave' gem 'mini_magick'Gemfileに追記
ターミナルrails bundle installターミナルでbundle installします。
ターミナルrails g uploader video rails g scaffold post video:stringターミナルでuploaderとscaffoldを作成
ターミナルrails db:migrate忘れずにマイグレーション
app/models/post.rbmount_uploader :video, VideoUploaderpost.rbに追記
app/uploaders/video_uploader.rbdef extension_whitelist %w(jpg jpeg gif png MOV wmv mp4) end38行目からコメントを外して、追記
views/posts/_form.html.erb<div class="field"> <%= form.label :video %> <%= form.file_field :video, :accept => 'video/*' %> </div>text.fieldになっていると思うので、file.fieldに書き換える。
app/views/posts/show.html.erb<p> <%= link_to @post.video_url.to_s do %> <%= video_tag(@post.video.to_s) %> <% end %> </p><%= @post.video %>になっていると思うので書き換えます。
<%= link_to @post.video_url.to_s do %>を書かないと動画をクリックしても再生されません。ありがとうございました
動画アップロードに悪戦苦闘したので、皆さんが簡単にできたら幸いです。
- 投稿日:2020-08-02T02:55:32+09:00
has_manyとbelongs_toの使い方
プログラミングの勉強日記
2020年8月2日 Progate Lv.226
has_manyとbelongs_toの使い分けに戸惑った。has_manyのときに複数形にするのを忘れてしまい、うまく実行されなかったので、has_manyとbelongs_toについてまとめる。関連付け(アソシエーション)とは
2つのテーブルを関連付けさせること。テーブル間の関係をモデル上の関係として操作する仕組み。
テーブル同士の関係には「1:1」「1:多」「多:多」の3つの関係が存在する。今回は「1:1」「1:多」の関係を表すときに使うhas_manyとbelongs_toについてまとめる今回は、UserテーブルのidをPostテーブルと関連付けをして、誰の投稿かわかるようする。
has_manyとは
has_manyは「1:多」の関連付けを表し、〇〇が複数の〇〇を所有しているという関係を表す時に使う。関連付けをすることによって、データをまとめて扱えるようになるので、より効率的にデータベースを操作することができる。models/user.rbclass User < ApplicationRecord has_many :posts end
has_manyを使うときは複数形にするbelongs_toとは
belongs_toは「1:1」の関連付けを表し、〇〇が◯◯に従属するという関係を表す時に使う。models/post.rbclass Post < ApplicationRecord belongs_to :user end
belongs_toを使うときは単数形にする