- 投稿日:2020-04-14T23:58:25+09:00
Google Colaboratoryでバグに悩まされずにcartopyを使う
Python(pandasやNumPy)でデータサイエンスをしたい場合、描画ライブラリとしてはmatplotlibを使うのが現在のデファクトスタンダードで、地理空間データや地図の描画にはcartopyを使うのがよいです。そのcartopyですが、Googleクラウド上のJupyter notebookであるGoogle Colaboratoryで使おうとすると、2020-04現在は、公式の方法ではバグで悩まされ、実質的に使えません。回避策とその説明をこちらにまとめてみました。
結論
以下のどちらかでインストールしましょう。
パターン1
!grep '^deb ' /etc/apt/sources.list | \ sed 's/^deb /deb-src /g' | \ tee /etc/apt/sources.list.d/deb-src.list !apt-get -qq update !apt-get -qq build-dep python3-cartopy !pip uninstall -y shapely !pip install --no-binary cartopy cartopy==0.17.0パターン2
!grep '^deb ' /etc/apt/sources.list | \ sed 's/^deb /deb-src /g' | \ tee /etc/apt/sources.list.d/deb-src.list !apt-get update !apt-get -qq build-dep python3-cartopy !apt-get -qq remove python-shapely python3-shapely !pip install --no-binary shapely shapely --force !pip install --no-binary cartopy cartopy==0.17.0公式の方法だとバグで悩む
Google Colaboratory公式のノートブックにもcartopyのインストール方法は書かれており、下記のように、OSのパッケージングシステムaptを使ってできることになっています。
!apt-get -qq install python-cartopy python3-cartopy import cartopyしかし、こうしてインストールしたcartopyにはバグがあり、次のような簡単なコードで落ちます。
問題1:
gridlines()がエラーになる
gridlines()でエラーになるので、グリッドが引けません。サンプルコード:
import cartopy.crs as ccrs import matplotlib.pyplot as plt ax = plt.axes(projection=ccrs.PlateCarree()) ax.gridlines() ax.coastlines()エラー:
--------------------------------------------------------------------------- ValueError Traceback (most recent call last) <ipython-input-4-3e1ebed7d096> in <module>() 3 4 ax = plt.axes(projection=ccrs.PlateCarree()) ----> 5 ax.gridlines() 6 ax.coastlines() 4 frames /usr/local/lib/python3.6/dist-packages/matplotlib/ticker.py in _validate_steps(steps) 2108 steps = np.asarray(steps) 2109 if np.any(np.diff(steps) <= 0) or steps[-1] > 10 or steps[0] < 1: -> 2110 raise ValueError('steps argument must be an increasing sequence ' 2111 'of numbers between 1 and 10 inclusive') 2112 if steps[0] != 1: ValueError: steps argument must be an increasing sequence of numbers between 1 and 10 inclusive問題2:
coastlines()で落ちる
coastlines()を用いた海岸線の描画が、次のようなランタイムログとともに、「不明な理由により、セッションがクラッシュしました」となります。サンプルコード:
import cartopy.crs as ccrs import matplotlib.pyplot as plt ax = plt.axes(projection=ccrs.PlateCarree()) ax.coastlines()エラーログ(ランタイムログ):
Apr 14, 2020, 6:18:57 PM WARNING warn("IPython.utils.traitlets has moved to a top-level traitlets package.") Apr 14, 2020, 6:18:57 PM WARNING /usr/local/lib/python3.6/dist-packages/IPython/utils/traitlets.py:5: UserWarning: IPython.utils.traitlets has moved to a top-level traitlets package. Apr 14, 2020, 6:18:57 PM WARNING WARNING:root:kernel e5263554-c566-4983-aea5-418e4cb6441a restarted Apr 14, 2020, 6:18:57 PM INFO KernelRestarter: restarting kernel (1/5), keep random ports Apr 14, 2020, 6:18:54 PM WARNING python3: geos_ts_c.cpp:3991: int GEOSCoordSeq_getSize_r(GEOSContextHandle_t, const geos::geom::CoordinateSequence*, unsigned int*): Assertion `0 != cs' failed.それぞれの問題の原因
問題1
問題1の原因は、インストールされているcartopyがv0.14.2と古いことです。cartopyのIssue #1374などでも報告されていますが、バグ自体はPR #773で修正され、2018年2月のv0.16.0以降は直っています。
ちなみに、v0.14.2は2016年4月にリリースされたバージョンで、そのように古いものがインストールされてしまうのは、OSがUbuntu 18.04.3 LTSであるためです。LTSとあるとおりlong-term support(長期サポート)されているバージョンで、最初のリリースの18.04は2018年4月にリリースされています。長期サポート版なので長期間安心して使えるのですが、マイナーなソフトウェアだったりまだ安定していないソフトウェアだったりすると、バグが入ったバージョンがパッケージ化されてずっと使われることになってしまうのは少し難点です(パッケージ情報参照)。
In [1]: cartopy.__version__ Out[1]: '0.14.2' In [2]: !cat /etc/os-release Out[2]: NAME="Ubuntu" VERSION="18.04.3 LTS (Bionic Beaver)" ID=ubuntu ID_LIKE=debian PRETTY_NAME="Ubuntu 18.04.3 LTS" VERSION_ID="18.04" HOME_URL="https://www.ubuntu.com/" SUPPORT_URL="https://help.ubuntu.com/" BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/" PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy" VERSION_CODENAME=bionic UBUNTU_CODENAME=bionic問題2
問題2は、cartopyとcartopyが使っているShapelyが、異なるバージョンのGEOSを使っており、非互換が発生しているためです。cartopyのIssue #871やIssue #1490として報告されており、Issue #805で根本的な対応が議論されていますが、まだ解決していません。
DebianやUbuntuにおいては、ライブラリパッケージのバージョンが上がればそれに依存するパッケージはリビルドされるため、異なるバージョンのライブラリにリンクされることはないはずです。実際、aptでcartopyを入れると、下記のとおり、OS提供のdebパッケージ版Shapely 1.6.4が、それにリンクされたcartopyと一緒に入ります。そのShapelyが使われれば問題は起きません。
冒頭の
apt-get installで入るdebパッケージたち:python-pkg-resources (39.0.1-2 Ubuntu:18.04/bionic [all]) python-pyshp (1.2.12+ds-1 Ubuntu:18.04/bionic [all]) python-shapely (1.6.4-1 Ubuntu:18.04/bionic [amd64]) python-six (1.11.0-2 Ubuntu:18.04/bionic [all]) python-cartopy (0.14.2+dfsg1-2build3 Ubuntu:18.04/bionic [amd64]) python3-pkg-resources (39.0.1-2 Ubuntu:18.04/bionic [all]) python3-pyshp (1.2.12+ds-1 Ubuntu:18.04/bionic [all]) python3-shapely (1.6.4-1 Ubuntu:18.04/bionic [amd64]) python3-six (1.11.0-2 Ubuntu:18.04/bionic [all]) python3-cartopy (0.14.2+dfsg1-2build3 Ubuntu:18.04/bionic [amd64])しかし、実は下記のとおり、Google Colaboratoryには最初からpipでShapelyの最新版v1.7.0が入ってしまっているようです。
In [3]: !pip list | grep Shapely Out[3]: Shapely 1.7.0この状態で単純にimportすると、cartopyはaptのもの、Shapelyはpipのものが使われます。これが非互換の原因です。面倒くさいですね。
In [4]: import shapely shapely.__version__ Out[4]: '1.7.0'余談:問題2だけなら実は対応策は簡単
問題2についてはpipとaptの併用が悪さをしているので、こちらだけなら実は簡単です。冒頭の
apt-get installの前か後に下記を実行してあげれば、Shapelyはaptで入れたもの(deb版)が使われるからです(pip uninstall前にimport cartopyしてしまうと、その中でimport shapelyされてしまうので注意)。!pip uninstall -y shapely対応策
原因が上記であることから、対応策の方針は下記のようになります。
- cartopy v0.16.0以降(できれば最新版v0.17.0)を入れる
- 同じGEOSにリンクされたShapelyとcartopyを使う
具体的には、こうします。
- pipで入れたShapelyは削除する
- ShapelyがリンクされているGEOSを用いて、cartopy最新版をpipでソースからビルドして入れる
apt-get build-dep
ソースから入れる際には、GEOSなどの依存ライブラリが入っていないといけません。1つ1つ入れるのは面倒なので、今回は
apt-get build-depを使います。
apt-get build-depは、指定したdebパッケージのソースパッケージをビルドするのに必要なdebパッケージをインストールしてくれるコマンドです。今回だと、cartopy v0.17.0のビルドに必要な環境を、cartopy v0.14.2のdebパッケージのソースパッケージのビルド情報に基づいて整えることになります。当然ながらv0.14.2とv0.17.0とで依存関係に変化がある場合はこれだとうまくいきませんが、大きな変化がなければ大丈夫でしょう(実際、今回はこれでうまくいきました)。aptのsources.listの編集
では早速
apt-get build-depを、と行きたいところですが、いきなり走らせてもエラーになります。In [5]: !apt-get build-dep cartopy Out[5]: Reading package lists... Done E: Unable to find a source package for cartopy
apt-get build-depで使うソースパッケージ情報は、aptのパッケージ取得元設定である/etc/apt/sources.list(および/etc/apt/sources.list.d/*)では、デフォルトではコメントアウトされているからです。In [6]: !grep deb /etc/apt/sources.list Out[6]: deb http://archive.ubuntu.com/ubuntu/ bionic main restricted # deb-src http://archive.ubuntu.com/ubuntu/ bionic main restricted deb http://archive.ubuntu.com/ubuntu/ bionic-updates main restricted # deb-src http://archive.ubuntu.com/ubuntu/ bionic-updates main restricted deb http://archive.ubuntu.com/ubuntu/ bionic universe # deb-src http://archive.ubuntu.com/ubuntu/ bionic universe deb http://archive.ubuntu.com/ubuntu/ bionic-updates universe # deb-src http://archive.ubuntu.com/ubuntu/ bionic-updates universe deb http://archive.ubuntu.com/ubuntu/ bionic multiverse # deb-src http://archive.ubuntu.com/ubuntu/ bionic multiverse deb http://archive.ubuntu.com/ubuntu/ bionic-updates multiverse # deb-src http://archive.ubuntu.com/ubuntu/ bionic-updates multiverse deb http://archive.ubuntu.com/ubuntu/ bionic-backports main restricted universe multiverse # deb-src http://archive.ubuntu.com/ubuntu/ bionic-backports main restricted universe multiverse # deb http://archive.canonical.com/ubuntu bionic partner # deb-src http://archive.canonical.com/ubuntu bionic partner deb http://security.ubuntu.com/ubuntu/ bionic-security main restricted # deb-src http://security.ubuntu.com/ubuntu/ bionic-security main restricted deb http://security.ubuntu.com/ubuntu/ bionic-security universe # deb-src http://security.ubuntu.com/ubuntu/ bionic-security universe deb http://security.ubuntu.com/ubuntu/ bionic-security multiverse # deb-src http://security.ubuntu.com/ubuntu/ bionic-security multiverse deb https://cloud.r-project.org/bin/linux/ubuntu bionic-cran35/原因はそれだけなので、単に
debで始まる行をdeb-srcに置換したファイルを用意してやり、apt-get updateでパッケージ情報を更新してあげるだけで解決できます。In [7]: !grep '^deb ' /etc/apt/sources.list | \ sed 's/^deb /deb-src /g' | \ tee /etc/apt/sources.list.d/deb-src.list !apt-get -qq updateこれで前述の
apt-get build-depも通るようになります。インストール
あとは、
pip install --no-binaryを用いて、バイナリパッケージを使わずビルドするようにすれば冒頭で書いた手順になります。aptのShapelyで問題ない場合とGoogle Colaboratoryに元々入っていた最新版を使いたい場合の両方があると思いますので、2パターン示します。どのShapelyを使いたいかによって変えるとよいでしょう。パターン1:aptのdebパッケージ版Shapely (v1.6.4) を使う場合
!grep '^deb ' /etc/apt/sources.list | \ sed 's/^deb /deb-src /g' | \ tee /etc/apt/sources.list.d/deb-src.list !apt-get -qq update !apt-get -qq build-dep python3-cartopy !pip uninstall -y shapely !pip install --no-binary cartopy cartopy==0.17.0パターン2:最新版のShapely (v1.7.0) をソースから入れて使う場合
!grep '^deb ' /etc/apt/sources.list | \ sed 's/^deb /deb-src /g' | \ tee /etc/apt/sources.list.d/deb-src.list !apt-get update !apt-get -qq build-dep python3-cartopy !apt-get -qq remove python-shapely python3-shapely !pip install --no-binary shapely shapely --force !pip install --no-binary cartopy cartopy==0.17.0動作確認
問題1と2のPythonプログラムはどちらも問題なく動きます。下記のように、公式ギャラリーのwavesもきちんと動きます。
import matplotlib.pyplot as plt import numpy as np import cartopy.crs as ccrs def sample_data(shape=(73, 145)): """Return ``lons``, ``lats`` and ``data`` of some fake data.""" nlats, nlons = shape lats = np.linspace(-np.pi / 2, np.pi / 2, nlats) lons = np.linspace(0, 2 * np.pi, nlons) lons, lats = np.meshgrid(lons, lats) wave = 0.75 * (np.sin(2 * lats) ** 8) * np.cos(4 * lons) mean = 0.5 * np.cos(2 * lats) * ((np.sin(2 * lats)) ** 2 + 2) lats = np.rad2deg(lats) lons = np.rad2deg(lons) data = wave + mean return lons, lats, data def main(): fig = plt.figure(figsize=(10, 5)) ax = fig.add_subplot(1, 1, 1, projection=ccrs.Mollweide()) lons, lats, data = sample_data() ax.contourf(lons, lats, data, transform=ccrs.PlateCarree(), cmap='nipy_spectral') ax.coastlines() ax.set_global() plt.show() main()
追記(2020-04-15):初期状態に戻す
インストールではOSのファイルシステムの中身(状態)が変わりますので、インストールを試行錯誤する場合、初期状態に戻せるやり方を知っておいたほうがよいでしょう。下記の方法でリセットできます。
- 「ランタイム」メニューから「ランタイムを出荷時設定にリセット」を選択
「ランタイムを再起動」だと、コードの実行状態は初期状態(何もメモリに載っていない状態)になりますが、ファイルシステムは変化したままです。

- 投稿日:2020-04-14T23:56:49+09:00
Windowsでpythonを実行してもMicrosoft Storeが開いてしまう時の対処法
はじめに
会社で使用しているwindowsにpythonをインストールしたところ、
powershellなどでpythonコマンドを実行しても、Microsoft StoreのPythonページが開いてしまうという問題に遭遇しました。
この問題は、python.orgのインストーラを使用して、インストールの途中で「Pathに追加」オプションを選んだ場合は発生しないようです。
ただ、選択せずにインストールしてしまった場合、正しい手順を踏まないとpythonコマンドを使えないので、備忘録として残しておきます。手順
pythonのインストール自体は終わっている前提です。
1. python実行ファイルのpathを確認する
スタートボタン横の検索窓から、「python」と入力し、表示されたpythonのコマンドラインアプリの選択肢から、「ファイルの場所を開く」を選択します。
ファイルエクスプローラが開き、pythonがインストールされた場所が表示されるので、インストールされた場所のパスをコピーします。2. 環境変数にpathを追加する
[参考 : 環境変数PATHを設定する]などを参考に環境変数にpathを追加してください。
3. アプリ実行エイリアスからpythonを見つけてオフにする
スタートボタン横の検索窓から、「アプリ実行エイリアス」と入力し、表示された「アプリ実行エイリアスの管理」を選択します。
「アプリ実行エイリアスの管理」に表示された、python.exeとpython3.exeの項目をOFFにします。参考
- 投稿日:2020-04-14T23:37:07+09:00
最近サイバーパンク風グラフ流行っていません?
まずはどんなグラフか?
その特徴は
* ネオンカラーを使う。
* 基本線の前後に透明度の低い線を引いて、ボケ感を出す。
* 透明度の低い面装飾を追加して、ボケ感を追加する。
* 使用するフォントをサイバーっぽい物を使用する。投稿のキッカケ
- matplotlib公式サイトにmatplotblogがあるのは、皆さんご存知でした?
- このサイトの最新の投稿がMatplotlib Cyberpunk Styleで上記のグラフの作成について解説しています。(2020/03/27 投稿)
- NHKスペシャル▽新型コロナウイルス瀬戸際の攻防〜感染拡大阻止(2020/4/11 PM9:00-PM10:04)でもサイバーパンク風グラフが使用されていました。(2020/4/11放送)
[引用:NHKスペシャル:NHKプラス再配信から]
- R界隈でもサイバーパンク風グラフパッケージがリリースされています。(リリース日:2020/04/02)
- 立て続けにこのようなグラフイメージを見るにつけ、この状況なので「見えない敵」に準えてサイバー感のあるグラフニーズがあるようです。
レシピ
- まず基本的なプロットを描く
- ダーク系の背景を設定する
- カラーをネオン色系に設定する
- ネオン管のようにグロー感を出す(透明度の低い線を基本線の前後に引く)
- サイバー感を強めるため、面領域を透明度の低いネオンカラーで塗りつぶす
公式ブログの投稿には、全コードが記載されていますので参考にしてください。
自分的にカスタマイズ
- このサイバーパンク風にアニメーションを加えたらどんな感じ?
import numpy as np import matplotlib.pyplot as plt import matplotlib.animation as animation # from IPython.display import HTML fig = plt.figure(figsize=(8, 4.5), dpi=144) ax = fig.add_subplot(111) plt.style.use("dark_background") for param in ['text.color', 'axes.labelcolor', 'xtick.color', 'ytick.color']: plt.rcParams[param] = '0.9' # very light grey for param in ['figure.facecolor', 'axes.facecolor', 'savefig.facecolor']: plt.rcParams[param] = '#212946' # bluish dark grey colors = [ '#08F7FE', # teal/cyan '#FE53BB', # pink '#F5D300', # yellow '#00ff41', # matrix green ] n_shades = 10 diff_linewidth = 1.05 alpha_value = 0.3 / n_shades ims = [] def plot(data): plt.cla() rand = np.random.randint(1,8,(50,)) for n in range(1, n_shades+1): # 基本線の前後にアルファ値の低い線を描画する im = plt.plot(rand, color=colors[3], linewidth=2+(diff_linewidth*n), alpha=alpha_value) # 基本線を描画する im2 = plt.plot(rand, color=colors[3], marker='o', markersize=3) # 線以下を描画する im3 = ax.fill_between(x=np.arange(50), y1=rand, y2=[0]*len(rand), color=colors[3], alpha=0.03) ims.append(im) ims.append(im2) ims.append(im3) ani = animation.FuncAnimation(fig, plot, interval=50) ax.grid(color='#2A3459') ax.set_xlim([ax.get_xlim()[0] - 0.2, ax.get_xlim()[1] + 0.2]) # to not have the markers cut off ax.set_ylim(0) # グラフ枠を消去 ax.spines["top"].set_linewidth(0) ax.spines["right"].set_linewidth(0) ax.spines["left"].set_linewidth(0) ax.spines["bottom"].set_linewidth(0) ani.save('./cyberpunk.mp4', writer='ffmpeg', fps=15) plt.show()改良点:(公式ブログの骨格を残して、アニメしただけです)
* 基準線の前後にアルファ値の低い線を描く。
* 基本線を描く。
* 面領域を塗りつぶす。
* それをimsに追加して、それをFuncAnimationで実行する。
* なぜかグラブ領域の枠が表示されるので非表示設定をしました。
* 作成したgif画像がQiita.comには上げられなかったのでmp4形式で作成
* その結果グラフ領域の背景が白くに変更されたため、styleをコメントアウトして以下の動画となりました。
まとめ
- 「全然、サイバーぽっく無いじゃん!」というコメントはスルーで、、、
- サイバーパンク風は意外と簡単に実装できる。
- 「見えない敵と戦う」この状況に、ならではのニーズがあると思いました。



- 投稿日:2020-04-14T23:36:42+09:00
Anacondaで日本語OCR環境を作る(tesseract+pyocr)
概要
AnacondaだけでOCR環境を構築する
ぶっちゃけ難しいことは分からないのでとにかく簡単な方法を模索環境
Windows10
Anaconda
Python 3.6
Spyder 4.1.2tesseractとpyocrについて
調べたら、PythonでOCRするならtesseract+pyocrのやり方がありそうなので、
この方法を試してみることにしましたtesseract
現在Googleが開発しているOCR(光学文字認識)のエンジンとのこと
v4.0以降では機械学習のLSTMベースになっていることから、
認識率を考えると最新バージョンが良さそうpyocr
Python用のOCRツールラッパーとのこと
tesseractにも対応参考
Anacondaだけで環境を構築して、Python+OCRをやってみる
https://qiita.com/anzanshi/items/9ee94affecd74be33159参考にしましたが、環境違いからかちょっとハマってしまいました
tesseractのインストール
いろいろやり方はありそうですが、今回はAnacondaでインストールします
conda-forgeリポジトリにtesseractが置いてありました
https://anaconda.org/conda-forge/tesseract素直にインストール(2020/4/14現在はv4.1.1)
conda install -c conda-forge tesseractpyocrのインストール
こちらはbrianjmcguirkというあまり見ないリポジトリ…?
こちらも素直にインストールします(こちらは現在v0.5)
conda install -c brianjmcguirk pyocr公式ページのコードを実行してみる
上記記事を参考に、公式ページのコードで確認する
from PIL import Image import sys import pyocr import pyocr.builders tools = pyocr.get_available_tools() if len(tools) == 0: print("No OCR tool found") sys.exit(1) # The tools are returned in the recommended order of usage tool = tools[0] print("Will use tool '%s'" % (tool.get_name())) # Ex: Will use tool 'libtesseract' langs = tool.get_available_languages() print("Available languages: %s" % ", ".join(langs)) lang = langs[0] print("Will use lang '%s'" % (lang)) # Ex: Will use lang 'fra' # Note that languages are NOT sorted in any way. Please refer # to the system locale settings for the default language # to use.と、実行結果は
実行結果Will use tool 'Tesseract (sh)' Available languages: eng, osd Will use lang 'eng'となります。
書いてある通り、英語だけで日本語はまだOCRできません。日本語OCR環境作成
さて、日本語のOCRができるようにします
学習済データのダウンロード
ここからjpn.traineddataをダウンロードします
昔と場所が変わっているようで探すのに少し苦労しました。
https://github.com/tesseract-ocr/tessdoc/blob/master/Data-Files.mdversionによってデータが異なるため注意!(一回間違えた…)
適切な場所に置く
ここもちょっと厄介…
私の環境の場合は
/Anaconda3/envs/(環境名)/Library/bin/tessdata
配下に置くと読み込むことができました
(すでにeng.traineddata、osd.traineddataがあります)(環境名)配下にもtessdataディレクトリがありますが、
こちらは読みに行かない模様再実行
再度公式ページのコードを実行
実行結果Will use tool 'Tesseract (sh)' Available languages: eng, jpn, osd Will use lang 'eng'ちゃんと「jpn」も追加されました
次は日本語を読み取らせてみます↓テスト用の画像
txt = tool.image_to_string( Image.open('test.png'), lang="jpn", builder=pyocr.builders.TextBuilder(tesseract_layout=6) ) print( txt )実行結果raise TesseractError(status, errors) pyocr.error.TesseractError: (1, b"Error, unknown command line argument '-psm'\r\n")予期しないエラーが発生…
これも似たようなエラーが出た方の記事が参考になりました
https://xkage.com/python-ocr.htmltesseract.pyとbuilders.py
の「-psm」を「--psm」と書き換えたらいけました再再度実行
txt = tool.image_to_string( Image.open('test.png'), lang="jpn", builder=pyocr.builders.TextBuilder(tesseract_layout=6) ) print( txt )実行結果て す と テ ス トできた!
まとめ
Anacondaでも環境作れますが思ったより情報が少ないので結構ハマりました
さてOCR使ってガンガン遊ぼうと思います

- 投稿日:2020-04-14T22:57:08+09:00
Python,AI関連の英単語でなくて「英文法」を覚えよう。。。
目的
Pythonとか、AIとかの関連で、英語を目にすることは多いが、英語力が低すぎて損をしている。英語をマスターするために、英単語でなくて、英文法を理解する(覚える)。
大半は、自分が理解してなくて、ちょっと、損をした、時間をロスったと思うもの
を記載する。
極一部、自分は、なんかの関連で既に知っていたが、普通、知らないのでは?というのも入れる。とりあえず、当面、
ちょっと、読み間違える可能性のある
- マニュアル
- エラーメッセージ
などを対象にしてみる。
英文法
現在分詞の後置修飾
現在分詞は、前から修飾するのを最初に勉強するから、後ろから修飾するのに、慣れていないのでは?
例文1
sys.executableの説明文
(出典: 出典1 参照)String giving the full file pathname of the Python interpreter program running the caller
後ろから修飾2か所。
フルパスを与える文字列
呼び元を実行するプログラム※文法が理解できてないと、文字、単語が躍る。。。。で、勝手な意味を頭の中で勝手に構成してしまう。
念のため、Google(翻訳)にご賛同いただくため、訳してみてもらう。(適当に文章に変更して。)結果は、以下。
"sys.executable" is a string giving the full file pathname of the Python interpreter program running the caller. 「sys.executable」は、呼び出し元を実行しているPythonインタープリタープログラムの完全なファイルパス名を示す文字列です。 出典
出典1
Python Pocket Reference, 5th Edition
Python In Your Pocket
By Mark Lutz
Publisher: O'Reilly Mediaまとめ
この記事の構成は、いきあたりばったりとします。
- 投稿日:2020-04-14T22:30:59+09:00
Pythonの応用: Numpyその2: 2重配列
2重配列
2重配列は、数学で言う「行列」として扱えます。
例えばnp.array([リスト, リスト, リスト...])と書くと
2重の配列データ(ndarray型)が作られます。数学に倣って、多重配列の階層を「次元」と呼ぶことがあります。2重配列は、2次元配列といった具合です。
行列数の確認
nparrayの配列は
shapeというメンバー変数を持っています。
nparray配列.shape #これを書くと、配列の要素数が記録されています。例えば2行3列の行列に相当する2重配列なら
ndarray配列.shapeは(2, 3)という値です。import numpy as np arr = np.array([[1,2,3],[4,5,6]]) print(arr) print(arr.shape) # 出力 [[1 2 3] [4 5 6]] # 行と列の数は下記のように、行がリスト数、列が要素数となってます (2, 3)行列の調整
配列の形状(shape)は、
ndarray配列.reshape()というメソッドで変更できます。
2つの引数a、bを使って
ndarray配列.reshape(a,b)と記述すると、返り値としてa行b列の行列に相当する配列データが得られます。
この時、要素の総数とreshapeメソッドの引数は対応していないといけません。
引数に-1を使うと、ほかの引数から適切な値を推測して変形します。import numpy as np arrA = np.array([1,2,3,4,5,6]) print(arrA) arrB = arrA.reshape(2,3) print(arrB) arrC = arrA.reshape(-1,2) print(arrC) # 出力 # arrA [1 2 3 4 5 6] # arrB: 引数より行列の数を調整 [[1 2 3] [4 5 6]] # arrC: -1の引数から、2という列の引数より調整 [[1 2] [3 4] [5 6]]インデックス参照とスライス
2次元配列の場合、インデックスを1つしか指定しない場合、任意の行を配列で取得できます。
arr = np.array([[1, 2 ,3], [4, 5, 6]]) print(arr[1]) # 出力結果 [4 5 6]個々の要素つまりスカラー値にたどり着くには、インデックスを2つ指定する必要があります。
つまり、arr[1][2]またはarr[1, 2]のようにアクセスします。arr[1][2]はarr[1]で取り出した配列の3番目の要素にアクセスしており
arr[1, 2]では2次元配列の軸をそれぞれ指定して同じ要素にアクセスしています。arr = np.array([[1, 2 ,3], [4, 5, 6]]) print(arr[1][2]) print(arr[1,2]) # 出力結果 6 62次元配列を参照する時にスライスを利用することも可能です。
arr = np.array([[1, 2 ,3], [4, 5, 6]]) print(arr[1,1:]) # 出力結果 [5 6] # :で要素以降や以前の要素を取り出します。axis
2次元配列からはaxisという概念が重要になってきます。
axisとは座標軸のようなものです。
NumPyの関数の引数としてaxisを設定できる場面が多々あります。2次元配列の場合、以下の図のようにaxisが設定されています。
列ごとに処理を行う軸がaxis = 0で
行ごとに処理を行う軸がaxis = 1
ということになります。
例えば、ndarray配列のsum()メソッドを考えてみましょう。
ndarray.sum()で 要素を足し合わせる ことができます。mport numpy as np arr = np.array([[1, 2 ,3], [4, 5, 6]]) print(arr.sum()) # sum()の引数に何も指定しない場合は、合計値がスカラー(整数や小数など)となり print(arr.sum(axis=0)) # axis=0を指定した場合は縦に足し算が行われて要素が3つの1次元配列に print(arr.sum(axis=1)) # axis=1を指定した場合は横に足し算が行われて要素が2つの1次元配列になることが分かります。 # 出力結果 21 [5 7 9] [ 6 15] # axis=0 で要素(インデックス番号ごと) # axis=1 で1次リストごとファンシーインデックス参照
インデックス参照にインデックスの配列を用いる方法のことです。
ndarray配列からある特定の順序で行を抽出するには
その順番を示す配列をインデックス参照として渡します。[[]] # ファンシーインデックス参照には2重括弧を用います。arr = np.array([[1, 2], [3, 4], [5, 6], [7, 8]]) # 3行目、2行目、0行目の順に行の要素を抽出し、新しい要素を作成します。 # インデックス番号は0から始まります。 print(arr[[3, 2, 0]]) # 出力結果 [[7 8] [5 6] [1 2]]転置行列
行列では、行と列を入れ替えることを転置と言います。
ndarray配列を転置するにはnp.transpose()これを用いる方法と
.Tを用いる方法の2通りがあります
import numpy as np arr = np.arange(10).reshape(2, 5) # 変数arrを転置させ出力 print(arr.T) # 又は print(arr.transpose()) # 出力 [[0 5] [1 6] [2 7] [3 8] [4 9]]ソート
いくつかソートする方法があり、どれも用途が異なります。
sort()
ndarray配列もリスト型と同様にsort()でソートすることが可能です。
2次元配列の場合、0を引数にすると列単位で要素がソートされます
import numpy as np arr = np.array([[15, 5, 200], [2, 100, 60], [100, 50, 8]]) print(arr) arr.sort(axis=0) # ここで列に指定している。 print(arr) # 出力結果 [[ 15 5 200] [ 2 100 60] [100 50 8]] [[ 2 5 8] [ 15 50 60] [100 100 200]]1を引数にすると行単位で要素がソートされます。
import numpy as np arr = np.array([[15, 5, 200], [2, 100, 60], [100, 50, 8]]) print(arr) arr.sort(1) # axis無しで1を指定で行単位で指定 print(arr) # 出力結果 [[ 15 5 200] [ 2 100 60] [100 50 8]] [[ 5 15 200] [ 2 60 100] [ 8 50 100]]np.sort()
np.sort()を使ってもソートができます。ただし、使い方が違うので注意が必要です。
データを保存したarrのメソッドである
arr.sort() # arrのデータを並び替えます。一方
np.sort(arr) # arrは変わらず、データを並び替えた別の配列が作られます。np.sort()はを使う場合、新しく作った変数を代入しないと並び替えたデータが使えません。
import numpy as np arrA = np.array([[15, 5, 200], [2, 100, 60], [100, 50, 8]]) arrB = np.sort(arrA) print(arrA) # 並び替える前の配列 print(arrB) # 並び替えた後の配列 # sortメソッド(arr.sort())を使って似たようなコードを書くと、挙動が全く変わります。 import numpy as np arrA = np.array([[15, 5, 200], [2, 100, 60], [100, 50, 8]]) arrB = arrA.sort() print(arrA) # 並び替えた後の配列 print(arrB) # None # np.をつけることで、新たに配列が作成されるとことになります。np.sort()はを使う場合、新しく作った変数を代入しないと並び替えたデータが使えません。
NumPyは大量のデータを扱うことを想定した設計がされており、一部のメソッドにNoneを返すといった、Pythonモジュールとしては珍しい設計を採用しています。
argsort()メソッド: 「配列インデックス」を返す。
機械学習でよく使われるメソッドには
argsort() # これもあります。argsort()メソッドはソート後の「配列インデックス」を返します。
import numpy as np arr = np.array([15, 30, 5]) arr.argsort() # 実行すると以下のような結果が得られます。 # 出力結果 [2 0 1]arr.sort()すると、[5 15 30]となるので
もとの配列で「2番目」にあった要素「5」が0番目
もとの配列で「0番目」にあった要素「15」が1番目
もとの配列で「1番目」にあった要素「30」が2番目の要素になります。そのため、[15, 30, 5]を.argsort()すると
順に「2番目、0番目、1番目」の要素になるということで、 [2 0 1]と値が返されるのです。行列計算
行列計算を行う関数には
np.dot(a,b) # 2つの行列の行列積を返すnp.linalg.norm(a) # ノルムを返す行列の積を計算すると、行列の中にある行ベクトルと列ベクトルとの内積を要素とする行列が新たに作り出されます
ノルム
ノルムとは、ベクトルの長さを返すもので
要素の二乗値を足し合わせてルートを被せたものです。
統計関数
統計関数とはndarray配列全体、もしくは特定の軸を中心とした数学的な処理を行う関数
またはメソッドです。np.argmax() # 要素の最大値のインデックス番号 np.argmin() # 要素の最小値のインデックス番号さらにこれらの関数は
np.average() # 平均このaverageを除き、
ndarray配列に適用する
ndarray.mean() ndarray.max()などのようにオブジェクトそのものに対するメソッドも用意されています。
統計で扱われる物として
np.std() #標準偏差 np.var() #分散などあります。
np.sum() # これでaxisで指定することにより # どの軸を中心に処理するかを決めることができたように np.mean() mean() # これらなどでも同じように軸を指定できます。np.argmax() argmax() np.argmin() argmin() # これらのメソッドの場合は # axisで指定された軸ごとに最大または最小値のインデックスを返します。ブロードキャスト
サイズの違うndarray配列同士の演算時に
ブロードキャストという処理が自動で行われます。ブロードキャストは、2つのndarray配列同士の演算時に
サイズの小さい配列の行と列を自動で大きい配列に合わせます。2つの配列の行数が一致しないときは
行の少ない方が多い方の行数に合わせて、足りない分を既存の行からコピーします。列数が一致しない場合も同様の処理を行います。
どのような配列でもブロードキャストができるわけではありませんが
下図のようにすべての要素に同じ処理をする時などはブロードキャストが可能になります。
x = np.arange(6).reshape(2, 3) print(x + 1) # 出力結果 [[1 2 3] [4 5 6]]




- 投稿日:2020-04-14T22:29:33+09:00
Altairのすすめ!Pythonによるデータの可視化
この記事について
Pythonのデータ可視化ライブラリー、Altairの紹介です。日本語の情報が少ないので布教用に記事にします。英語に抵抗がない方は公式ページを見るのが一番わかりやすいと思います。
インストール
pipコマンドで簡単にインストールできます。vega_datasetsはこの後使うので一緒にインストールしましょう。pip install altair vega_datasets私はGoogle Colaboratoryを使いましたが、インストールなしで最初から使えました。
事前準備
以下でライブラリとデータセットを読み込んでください。
import altair as alt from vega_datasets import data iris = data.iris()AltairはPandasとの連携が得意で、
irisはPandasのDataFrameです。基本的な可視化
以下はJupyterなどで直接可視化する想定のコードです。htmlで出力したい場合は末尾に
.save("filename.html")を足してください。.interactive()はなくても大丈夫ですが、書くとグラフを動かせるようになります。この記事に貼るのは普通の画像なので、ぐりぐり動かしたい方はこちらでどうぞ。例①散布図
x軸とy軸の値を以下のように指定します。コメントのような
alt.X()という書き方もできて、複雑な可視化の際はこちらを使います。alt.Chart(iris).mark_point().encode( x="sepalLength", # alt.X("sepalLength"), y="sepalWidth", # alt.Y("sepalWidth"), color="species" ).interactive()例②棒グラフ
average()でspeciesごとに平均をとっているのがポイントです。平均以外にも様々な操作ができて、一覧はここで確認できます。alt.Chart(iris).mark_bar().encode( x="average(sepalLength)", # alt.X("sepalLength", aggregate="average"), y="species", # alt.Y("species"), ).interactive()要領はこんな感じです。
make_xxxxxの部分をmake_lineとすれば折れ線グラフなんかも簡単に書けます。困ったときは公式ページのギャラリーから類似したグラフを探せば大体解決します。TIPS(加筆するかも)
マウスオーバーで情報表示
tooltip引数で指定した情報がマウスオーバーで表示されます。alt.Chart(iris).mark_point().encode( x="sepalLength", y="sepalWidth", color="species", tooltip=["sepalLength", "sepalWidth", "petalLength", "petalWidth", "species"] ).interactive()軸を0から書きたくない
量的なデータは基本的に0を含んで可視化されます。上のグラフは0を含まないよう
zero=Falseで明示しています。alt.Chart(iris).mark_point().encode( alt.X("sepalLength", scale=alt.Scale(zero=False)), alt.Y("sepalWidth", scale=alt.Scale(zero=False)), color="species" ).interactive()データ型の指定
名義尺度が整数になっていることはよくありますよね。そのときは
species_int:Nのように名義尺度であることを明示します。ちなみに順序尺度は:O、量的データなら:Qです。詳細は公式ドキュメントのここに記載があります。# 整数値に変換 (setosa: 0, versicolor: 1, virginica: 2) iris["species_int"] = [["setosa", "versicolor", "virginica"].index(x) for x in iris["species"]] # 正しい例 alt.Chart(iris).mark_point().encode( x="sepalLength", y="sepalWidth", color="species_int:N" ).interactive()ちなみに
:Nを付けないと以下のようになります。
MaxRowError対応
5000行超えると怒られます。ここの情報を参考に以下を実行。
alt.data_transformers.disable_max_rows()最後に
シンプルに記述できて探索的な分析には便利です。欠点があるとすると、htmlの出力は簡単ですがpngの出力がやや大変そうでした。参考になれば!






- 投稿日:2020-04-14T21:30:50+09:00
pipを直で使うのは非推奨っぽい?
エラーメッセージが出てました。
いつものように、新規に建てたインスタンスに
python3-pipをインストールした後、pipを使おうとするとエラーメッセージが出ました。$ pip3 install pip WARNING: pip is being invoked by an old script wrapper. This will fail in a future version of pip. Please see https://github.com/pypa/pip/issues/5599 for advice on fixing the underlying issue. To avoid this problem you can invoke Python with '-m pip' instead of running pip directly."please see"と書いてあるリンクを見てみると、pipのアップグレード後に色々と問題が発生してるみたいです。
--userをつけてインストールした方が、不具合が発生しにくくなるとか色々ありつつも、一番確実な方法はpython -m pipでインストールすることみたいです。私はいつもpipは最新版にしてから使うので、いつものように
--upgradeしてみます。$ python3 -m pip install --upgrade pip Collecting pip Cache entry deserialization failed, entry ignored Using cached https://files.pythonhosted.org/packages/54/0c/d01aa759fdc501a58f431eb594a17495f15b88da142ce14b5845662c13f3/pip-20.0.2-py2.py3-none-any.whl Installing collected packages: pip Successfully installed pip-20.0.2正常に、最新版へのバージョンアップができました。
$ python3 -m pip --version pip 20.0.2 from /home/ubuntu/.local/lib/python3.6/site-packages/pip (python 3.6)今後はこの方法で使おうかなと思います。
補足
pipが Python に付属するのは 3.4 以降です。
https://docs.python.org/ja/3.6/installing/index.htmlそのため、python3.4より前の場合は上記の方法は使えません。今までどおりpipをインストールして使いましょう。
- 投稿日:2020-04-14T21:16:58+09:00
0埋めされていない年月日を、正規表現でdatetime型に変換
pythonのdatetimeには、文字列型をdatetime型に変換する関数
strptime()があるが、0埋めされていない文字列は変換できない。
(2020/04/03は変換できるけど2020/4/3はできない)その簡単な代替方法があったのでメモ。
全角が含まれる場合は、何らかの方法で全角を半角にしてから実行。
方法はいろいろあるのでお好みのものを。コード
strptime()の代わりに、datetimeのコンストラクタを用いる。
https://docs.python.org/ja/3/library/datetime.html#datetime.datetimeclass datetime.datetime(year, month, day, hour=0, minute=0, second=0, microsecond=0, tzinfo=None, *, fold=0)
import datetime import re # 文字列に含まれる数字のリストを取得 l = re.findall(r"\d+", text) # 文字列のリストを数値のリストにする l = [int(s) for s in l] # datetime型のコンストラクタで、日時を指定(リストを展開して渡す) date = datetime.datetime(*l)サンプル
import datetime import re text = "2020/4/2" l = re.findall(r"\d+", text) # l : ["2020", "4", "2"] l = [int(s) for s in l] # l : [2020, 4, 2] date = datetime.datetime(*l) # date = datetime.datetime(2020, 4, 2)おまけ
和暦 to 西暦の変換にも使えるかも
("元年"に対応させる必要はあり)import datetime import re text = "令和2年4月3日" diff = 0 if text[:2]=="令和": diff = 2018 else: # hoge pass l = re.findall(r"\d+", text) l = [int(s) for s in l] l[0] += diff date = datetime.datetime(*l)
- 投稿日:2020-04-14T21:11:53+09:00
Discord ボットを24時間起動します。
何が必要
- Repl.itのアカウント
必要なのはこれだけです。
ステップ1
"+new repl"をクリックします。
ステップ2
新しいreplを作成します。
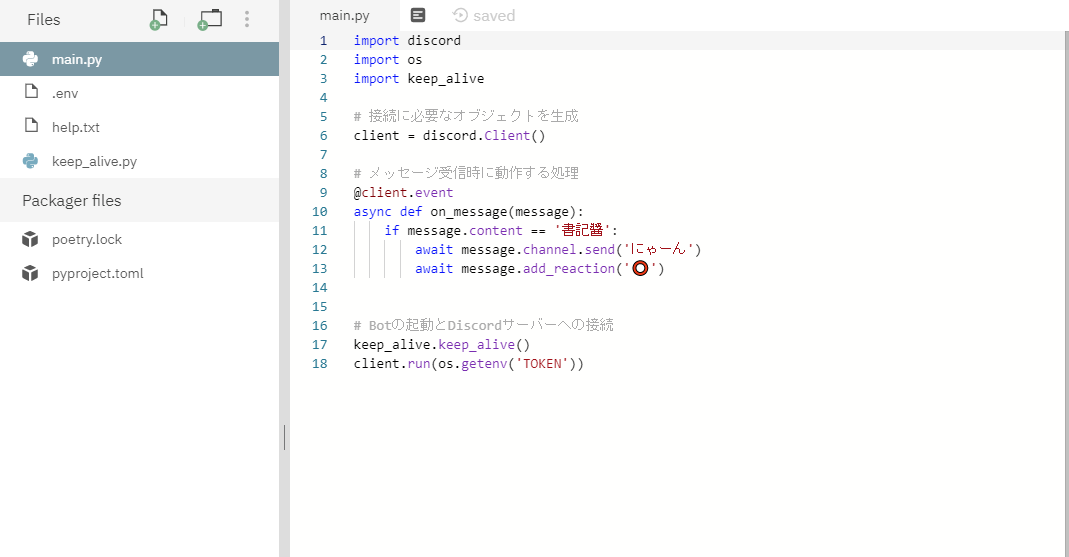
ステップ3
"main.py"を作成します。
# 最初はこれが必要です。 import os import keep_alive # client.runの前はこれが必要です。 keep_alive.keep_alive() # そしてclient.runはこのようです。 client.run(os.getenv('TOKEN'))import discord import os import keep_alive # 接続に必要なオブジェクトを生成 client = discord.Client() # メッセージ受信時に動作する処理 @client.event async def on_message(message): if message.content == '書記醬': await message.channel.send('にゃーん') await message.add_reaction('⭕') # Botの起動とDiscordサーバーへの接続 keep_alive.keep_alive() client.run(os.getenv('TOKEN'))ステップ4
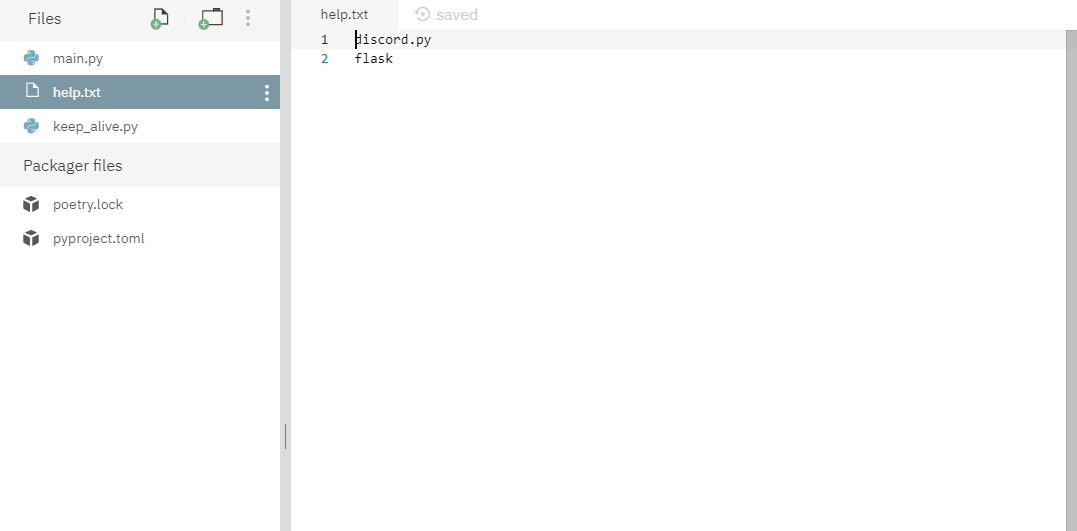
"help.txt"を作成します。
discord.py flaskステップ5
"keep_alive.py"を作成します。
from flask import Flask from threading import Thread app = Flask('') @app.route('/') def main(): return 'Bot is aLive!' def run(): app.run(host="0.0.0.0", port=8080) def keep_alive(): server = Thread(target=run) server.start()ステップ6
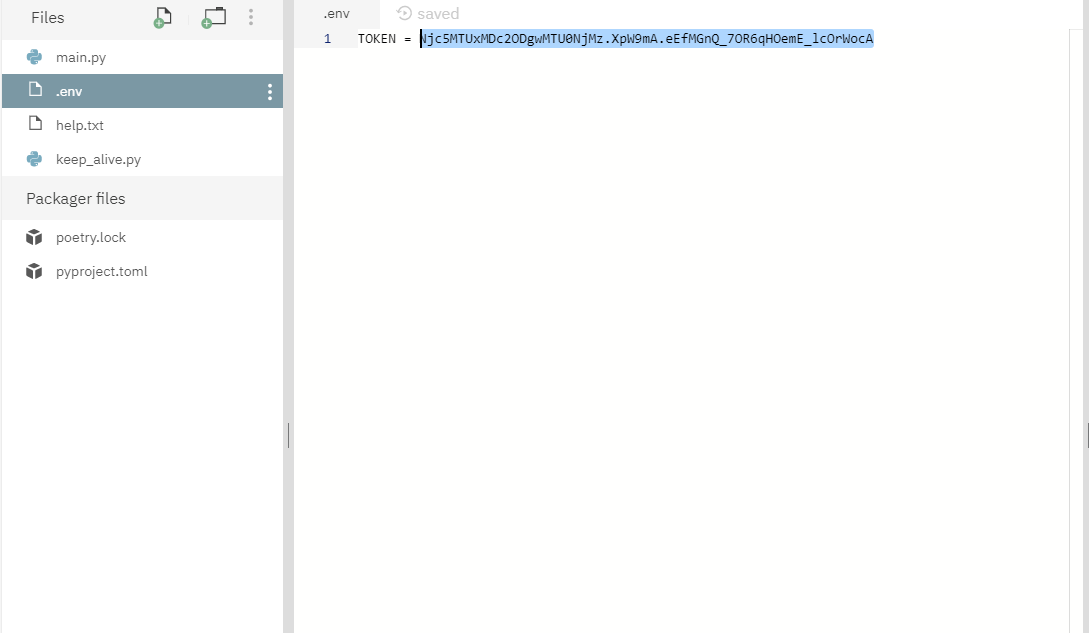
".env"を作成します。
".env"を作成しなければならない原因は
Repl.it は、Starterという無料プランでは、プライベートにすることが出来ず、誰でも見れる状態になるので Discord Token は、.envファイルに書けば誰でも見れる状態になりません。 ---by 7yultukuri7さん
TOKEN = XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXステップ7
最後は"run"をクリックします。
その他
"poetry.lock"と"pyproject.toml"は自動的に生成します。


- 投稿日:2020-04-14T21:01:22+09:00
書庫の湿度と温度の記録を採るためにやったこと
国立国会図書館の温湿度管理のページ には次のような説明が書かれています。
==========
国立国会図書館の書庫では、温度と湿度を制御できる空調機を設置しており、書庫内の温湿度をこまめにチェックし、「書庫内で人が作業できる温度」「65%以下の湿度」を目指し、1年間を通じて、また1日の中でも、温湿度を急激に変動させないことを目指しています。また、閲覧室との温湿度差ができるかぎり小さくなるようにも心がけています。
==========また、温度が高いほど飽和水蒸気量が大きくなるため湿度を制御するためには温度を最適に調節する必要があることも記載されています。
湿度が65%を越えたらアラートを出すしかけを作りたいのですが、その前に私の環境での1時間ごとの湿度と温度を、ついでに気圧の記録を採り続けてみようと考えました。
そのためにやったことを書き残しておきます。
用意したもの
Raspberry Pi Zero W ピンヘッダを別途購入してはんだ付けしました。
Raspberry Pi Zero用赤外線+環境センサ「RPZ-IR-Sensor」Rev2.0(端子実装済+外付けセンサ)OS
Debian GNU/Linux
Linux raspberrypi 4.19.97+ #1294 Thu Jan 30 13:10:54 GMT 2020 armv6l[Rasperry Pi の設定] - [インターフェース] で I2C を有効にしておきます。
組み立て
①Raspberry Pi Zero W
②電源供給
③マウス、キーボードへ
④ディスプレイへ
⑤Raspberry Pi Zero用赤外線+環境センサ
⑥温度・湿度・気圧センサ
⑦端子実装済+外付けセンサ の温度・湿度・気圧センサ
⑧赤外線通信端子(今回は使用しません)
⑨光(照度)センサ(今回は使用しません)
注:⑥はRaspberry Pi Zero の発熱も感知してしまうため、⑦の計測値を用います。
用意されたサンプルプログラム
https://www.indoorcorgielec.com/products/rpz-ir-sensor/
のサンプルプログラム rzp-sensor.zip を解凍してをそのまま使いました。
readme.txt の最後にログ出力の方法が記載されています。
サンプルプログラムのテスト
$ python3 rpz_sensor.py BME280 0x76 Temp : 19.9C Pressure : 1006.0hPa Humidity : 38.6% BME280 0x77 Temp : 23.0C Pressure : 1005.6hPa Humidity : 35.0% TSL2572 Lux : 176.3luxBME280 0x76 は組み立て⑦の計測値です。
BME280 0x77 は組み立て⑥の計測値です。⑦より3℃ほど高いのは、RaspberryPy Zero の発熱による影響とみられます。⑦よりも温度が高いため湿度の値が低めになってしまっています。
TSL2572 は組み立て⑨の計測値です。シェルスクリプトを作ってでログ出力のテスト
do.sh
#!/bin/sh date +"%Y/%m/%d %T" cd rpz-sensor/python3 python3 ./rpz_sensor.py -l ./log/logfile.csvシェルスクリプトを実行可能モードにします。
$ chmod +x do.sh実行してみます。
$ rpz-sensor/do.sh 2020/04/14 18:37:07 BME280 0x76 Temp : 21.9C Pressure : 1008.8hPa Humidity : 45.7% BME280 0x77 Temp : 22.7C Pressure : 1008.4hPa Humidity : 44.8% TSL2572 Lux : 170.7luxログが出力されています。
$ cat logfile.csv Time,Temp ch1,Temp ch2,Pressure ch1,Pressure ch2,Humidity ch1,Humidity ch2,Lux 2020/04/14 18:37,21.9,22.7,1008.8,1008.4,45.7,44.8,170.7定期実行の設定
$ crontab -eエディターが起動するので、毎時ゼロ分に計測してログを出力するように設定します。
# m h dom mon dow command 00 * * * * rpz-sensor/do.sh設定が有効となるように、cronを再起動します。
$ sudo /etc/init.d/cron restart数時間後に確認したところ、シナリオ通りにログが出力されていました。
cat logfile.csv Time,Temp ch1,Temp ch2,Pressure ch1,Pressure ch2,Humidity ch1,Humidity ch2,Lux 2020/04/14 18:37,21.9,22.7,1008.8,1008.4,45.7,44.8,170.7 2020/04/14 19:00,21.6,22.8,1009.6,1009.2,47.5,45.7,15.6 2020/04/14 20:00,18.7,22.4,1010.8,1010.3,60.6,50.2,87.9 2020/04/14 21:00,18.7,22.3,1011.3,1010.9,57.5,48.3,88.9ディレクトリ構成
次のような構成でやってみました。
pi@raspberrypi:/home $ ls pi pi@raspberrypi:/home $ cd pi pi@raspberrypi:~ $ ls Desktop Downloads Music Public Videos Documents MagPi Pictures Templates rpz-sensor pi@raspberrypi:~ $ cd rpz-sensor pi@raspberrypi:~/rpz-sensor $ ls do.sh python3 readme.txt pi@raspberrypi:~/rpz-sensor $ cd python3 pi@raspberrypi:~/rpz-sensor/python3 $ ls __pycache__ bme280i2c.py log rpz_sensor.py tsl2561.py tsl2572.py pi@raspberrypi:~/rpz-sensor/python3 $ cd log pi@raspberrypi:~/rpz-sensor/python3/log $ ls logfile.csv参考図書
このあとやりたいこと
・ログデータをもとにしたグラフ表示の自動化
・一定の湿度以上になったときにLINE Bot へアラート





- 投稿日:2020-04-14T19:36:49+09:00
Flaskのアクセスログをカスタマイズする
やりたいこと
以下のようなFlask(version 1.1.2)のプログラムを作成し
from flask import Flask app = Flask(__name__) @app.route("/") def hello(): return "Hello World!" if __name__ == "__main__": app.run(host='0.0.0.0')実行してアクセスすると以下のようなログが出ますが、
127.0.0.1 - - [14/Apr/2020 19:13:43] "\x1b[37mGET / HTTP/1.1\x1b[0m" 200 -このアクセスログは(私にとって)不要な文字列が入っている上、本文のメッセージに色がついていて、扱いにくいです。
なので、このログをカスタマイズする方法を説明します。
カスタマイズ方法
結論からいうと、Flaskが内部で利用しているWerkzeug (version 1.0.1) という名前のloggerが上記のログを出力しているため、以下のようにWerkzeugのloggerを取得してカスタマイズします。
例1)ログのレベルをERRORに変更する
from flask import Flask import logging # ロガーの取得 werkzeug_logger = logging.getLogger("werkzeug") # レベルの変更 werkzeug_logger.setLevel(logging.ERROR) app = Flask(__name__) @app.route("/") def hello(): return "Hello World!" if __name__ == "__main__": app.run(host='0.0.0.0', port=4001)例2)出力する文字列の変更
デフォルトでは
(IPアドレス) - - [(日時)] (メッセージ(色付き))というフォーマットで出力されますが、以下の例では、(メッセージ)の部分を色無しで出力しています。from flask import Flask import logging from werkzeug.serving import WSGIRequestHandler from werkzeug.urls import uri_to_iri werkzeug_logger = logging.getLogger("werkzeug") def custom_log_request(self, code="-", size="-"): try: path = uri_to_iri(self.path) msg = "%s %s %s" % (self.command, path, self.request_version) except AttributeError: msg = self.requestline code = str(code) werkzeug_logger.info('"%s" %s %s' % (msg, code, size)) # 関数の置き換え WSGIRequestHandler.log_request = custom_log_request app = Flask(__name__) @app.route("/") def hello(): return "Hello World!" if __name__ == "__main__": app.run(host='0.0.0.0')出力されるログは以下のように色がなくシンプル
"GET / HTTP/1.1" 200 -なぜこの方法でいいのか?
Flaskは内部でwerkzeugというパッケージを利用しています。
そのため、Flaskでは2つのloggerが登場します。
一つはlogging.getLogger("app.flask")で取得できるFlaskが使うlogger,
もう一つはlogging.getLogger("werkzeug")で取得できるwerkzeugが使うloggerです。上記のログはwerkzeugのソースコードの↓の場所で出力しています。
https://github.com/pallets/werkzeug/blob/1.0.x/src/werkzeug/serving.py#L406
なのでこの関数を置き換えてあげることで、カスタマイズ可能になります。
app.flaskのloggerをいくらいじってもこのログは消えないのでだいぶハマりました(笑)
- 投稿日:2020-04-14T19:13:38+09:00
(Python) ABC162-D 考察ログと解法
ABC162 に(バーチャル)参加しました。
D問題が面白かったので初めての解説記事を書きます!
綺麗な解説ではなく、その時思ったことを垂れ流すように書いてみました。
なお解いている様子は YouTube に動画があります。
問題
入力を受け取りながら問題文を理解する
脳死でやれることをやりながら問題を読む。まずは入力を受け取ろう。
n = int(input()) s = input()文中の2つの条件は、つまりこういうことか。
- 文字列 $S$ から、
R,G,Bを一つずつ取り出す。- ただし、 $i, j, k$ が等間隔に並ぶのはだめ。 $(i, j, k) = (1, 2, 3), (3, 5, 7)$ など。
愚直を書きながら考察する
困ったら愚直。手を動かしながら考えよう。
$i < j < k$となる組み合わせを全探索して、条件に一致したら
ansを加算する。ans = 0 for i in range(n-2): for j in range(i+1, n-1): for k in range(j+1, n): if s[i]!=s[j] and s[j]!=s[k] and s[i]!=s[k]: if j-i != k-j: ans += 1 print(ans)これは明らかに $O(N^3)$ 。ループ回数減らせるかな?
2つ決めたら残り1つは自動で決まる
3重ループを見たら、 Otoshidama を連想した。
2重ループにできるかな。こんな処理ができれば$O(N^2)$でいけるか?
for i in range(n-2): for j in range(i+1, n-1): if s[i] == s[j]: continue c = "(s[i],s[j]と異なる、(R,G,B)のどれか)" ans += "s[j+1:n] の中の c の個数" # ただし、i,j,kが等間隔に並ぶ位置は不適なので1減らす if j+(j-i)<n and s[j+(j-i)] == c: ans -= 1累積和3本
「"区間中の個数" は累積和!(素振り)」ということで、累積和でしょう。
ここまでくればあとは累積和を作るだけ。ruisekiR = [0] * (n+1) ruisekiG = [0] * (n+1) ruisekiB = [0] * (n+1) for i,c in enumerate(s): ruisekiR[i+1] = ruisekiR[i] + ( 1 if c == "R" else 0) ruisekiG[i+1] = ruisekiG[i] + ( 1 if c == "G" else 0) ruisekiB[i+1] = ruisekiB[i] + ( 1 if c == "B" else 0)これを作っておけば、
s[j+1:n] の中の c の個数は$O(1)$で求まる。# c = (s[i],s[j]と異なる、(R,G,B)のどれか) c = "R" if "R" in (s[i], s[j]): c = "G" if "G" in (s[i], s[j]): c = "B" # ans += (s[j+1:n] の中の c の個数) if c == "R": ans += (ruisekiR[n] - ruisekiR[j]) if c == "G": ans += (ruisekiG[n] - ruisekiG[j]) if c == "B": ans += (ruisekiB[n] - ruisekiB[j])なんか汚いけどコンテストなので気にしない。
これでAC!ソース全体
n = int(input()) s = input() ruisekiR = [0] * (n+1) ruisekiG = [0] * (n+1) ruisekiB = [0] * (n+1) for i,c in enumerate(s): ruisekiR[i+1] = ruisekiR[i] + ( 1 if c == "R" else 0) ruisekiG[i+1] = ruisekiG[i] + ( 1 if c == "G" else 0) ruisekiB[i+1] = ruisekiB[i] + ( 1 if c == "B" else 0) ans = 0 for i in range(n-2): for j in range(i+1, n-1): if s[i] == s[j]: continue c = "R" if "R" in (s[i], s[j]): c = "G" if "G" in (s[i], s[j]): c = "B" if c == "R": ans += (ruisekiR[n] - ruisekiR[j]) if c == "G": ans += (ruisekiG[n] - ruisekiG[j]) if c == "B": ans += (ruisekiB[n] - ruisekiB[j]) if j+(j-i)<n and s[j+(j-i)] == c: ans -= 1 print(ans)


- 投稿日:2020-04-14T19:12:09+09:00
レラティブストレングス投資の月次シグナルを判定するpythonコード
私のブログでレラティブストレングス投資の月次シグナルを更新していますが、今まではデータ取得とエクセルでの計算を手作業でやっていました。
この度、月次シグナルを判定するpythonコードを書きました。なにぶんpython歴数か月の初心者なので、見苦しいコードかもしれませんがご容赦ください。私が確認した限りでは、正しく動いているようです。
1. データのスクレイピング
[Monthly_check]RS_signal.ipynbimport numpy as np import pandas as pd from datetime import datetime import urllib.request #SMTAMウェブサイトから投信データcsvを取得して保存。 #スクレイピングを最小限に抑えるため、一度スクレイピングしたらcsvファイルとして保存。 #JE:日本株、EE:新興国株、IE:先進国株、JB:日本債券、EB:新興国債券、IB:先進国債券、IR:先進国リート、JR:日本リート url_list = {'JE':'https://www.smtam.jp/chart_data/140833/140833.csv', 'EE':'https://www.smtam.jp/chart_data/140841/140841.csv', 'IE':'https://www.smtam.jp/chart_data/140834/140834.csv', 'JB':'https://www.smtam.jp/chart_data/140835/140835.csv', 'EB':'https://www.smtam.jp/chart_data/140842/140842.csv', 'IB':'https://www.smtam.jp/chart_data/140836/140836.csv', 'IR':'https://www.smtam.jp/chart_data/140838/140838.csv', 'JR':'https://www.smtam.jp/chart_data/140837/140837.csv'} for key in url_list: url = url_list[key] title = "{0}.csv".format(key) urllib.request.urlretrieve(url,title)2. シグナル判定
[Monthly_check]RS_signal.ipynb#全ファンドの累積基準価額をひとつにまとめたデータを作成 assets = ['JE','EE','IE','JB','EB','IB','JR','IR'] df_all = pd.DataFrame() for asset in assets: asset_file = "{0}.csv".format(asset) df = pd.read_csv(asset_file, skiprows = [0], names = ['date','nav', 'div', 'aum'], parse_dates = True, index_col = 0) df['div'] = pd.to_numeric(df['div'],errors='coerce') df['div'] = df['div'].fillna(0) df['cum_nav'] = (df['nav'] + df['div']) / df['nav'].shift(1) df[asset] = df['cum_nav'].cumprod() df_all[asset] = df[asset] #日次データを月次データに変換してシグナル判定 dfm = df_all.resample('M').ffill() dfm = dfm[dfm.index < datetime.now()] calc = pd.DataFrame(columns = ['JE','EE','IE','JB','EB','IB','JR','IR']) calc.loc['asset class'] = ['日本株','新興国株','先進国株','日本債券','新興国債券', '先進国債券','日本リート','先進国リート'] calc.loc['3 months'] = (dfm.iloc[-1] / dfm.iloc[-4] -1)*100 calc.loc['6 months'] = (dfm.iloc[-1] / dfm.iloc[-7] -1)*100 calc.loc['12 months'] = (dfm.iloc[-1] / dfm.iloc[-13] -1)*100 calc.loc['mean'] = (calc.loc['3 months']+calc.loc['6 months']+calc.loc['12 months'])/3 calc.loc['rank'] = calc.loc['mean'].rank(ascending = False).astype(int) calc.loc['latest nav'] = dfm.iloc[-1] calc.loc['12ma NAV'] = dfm.iloc[-12:].mean() calc.loc['Buy/Sell'] = np.where(calc.loc['latest nav'] > calc.loc['12ma NAV'], 'Buy', 'Sell') #月次シグナル判定結果を表示 date = dfm.index.max() print(str(date.year) + '年' + str(date.month) + '月末のシグナルは以下の通りとなりました。') calc.T.set_index('rank')[['asset class', 'Buy/Sell']].sort_index()実行するとJupyter Notebook上に、以下のように表示される(はずです)。
3. ブログに反映
上記シグナルを反映したブログ記事はこちらです。
↓
【レラティブストレングス投資月次シグナル解説(2020年3月末基準)】4. おわりに
月次シグナルエクセル更新手作業の、数十年分の時間をかけてやっと完成ました。
費用対効果を出すには数十年使わなければなりません。シグナル判定するくだりのコードがいかにも素人臭いです。上達したら改善したいと思います。

- 投稿日:2020-04-14T19:00:02+09:00
100日後にエンジニアになるキミ - 25日目 - Python - Python言語の基礎2
今日もPython言語の続きです
前回はこちら
100日後にエンジニアになるキミ - 24日目 - Python - Python言語の基礎1
インデックス
インデックスとはプログラム上で何番目?というのを表す数字です。
インデックスを用いることでプログラムでは様々なことが行えます。
インデックスの表記
[]四角カッコで囲みその中に数値を入力する[5]文字のインデックスの例
print('はじめの一歩'[5])歩
文字列は複数の文字からなるデータなので
インデックス番号の文字を取り出すことができる。インデックスの数え方
インデックスは
0から始まるので文字列の最初の文字を取りたい場合インデックスは
0
2番目を取りたい場合インデックスは1になる
n番目のインデックス値はn-1
1つズレるので注意最後の文字を指定する場合は
-1で指定でき
マイナスを付けると末尾から数えることができる。# 最初 print('あいうえお'[0]) # 2番目 print('あいうえお'[1]) # 最後 print('あいうえお'[-1]) # 最後から数えて3番目 print('あいうえお'[-3])あ
い
お
うまた
存在しないインデックス値を指定するとエラーになります。print('あいうえお'[7])IndexError Traceback (most recent call last)
in ()
----> 1 print('あいうえお'[7])
IndexError: string index out of range
IndexErrorはインデックス値が範囲外の場合に起こるエラーのことで
index out of rangeとは
インデックス値が存在しない値を参照している意味です。インデックスは必ず存在する値を指定してあげないといけません。
スライス
Pythonではインデックスを使って
範囲指定でデータを取り出すことができる機能があり
「スライス」と呼んでいます。スライスの書き方:
[n:m]n番目からm番目まで
[n:]n番目以降
[:n]n番目まで
[n:m:o]n番目からm番目までo個とばして# 3番目から5番目 print('あいうえおかき'[2:5]) # 2番目以降 print('あいうえおかき'[1:]) # 3番目まで print('あいうえおかき'[:3]) # 最初から最後の1つ手前まで print('あいうえおかき'[0:-1]) # 最初から最後の1つ手前までで1つ飛ばして print('あいうえおかき'[0:-1:2])うえお
いうえおかき
あいう
あいうえおか
あうお変数
プログラムでは入力されたデータを使い回す機能があります。
それが変数という概念です。変数を用いることで入力したデータを再利用できるようになります。
変数の宣言と値の代入
変数名 = 値
=は代入を表す演算子(代入演算子)
=の左側に右側を代入する。a = 12345 b = 23456個数が合えば複数同時に宣言と代入が行える。
a,b,c = 4,5,6 d,e,f = '10','20','30'変数名に使用できる文字
a - zのアルファベット(大文字と小文字)
0 - 9までの数字
_(アンダースコア)変数名は自分で考えて付けるものなのでなんでも良いですが
中に格納するデータがどんなものかを考えて名称をつけるのが良いでしょうこの講義ではアンダーバーで
2つ以上の英単語を用いることを推奨します。# 例: magic_spell_name attack_pointなお変数名は
予約語や組み込み関数名に該当するものでなければ
なんでも付けることができます。
予約語などについては次項で変数の使い方
宣言した後は、その変数を入力すれば使うことができます。
# 変数 a に 数値の12345 を代入する a = 12345 # 変数 b に 数値の23456 を代入する b = 23456 # 変数 a と b を足した結果を出力する print(a + b)35801
# 変数c にa + b の結果を代入する c = a+b # 結果 print(c)35801
同じ変数名に値を代入すると上書きされます。
# 変数 a に数値の123を代入 a = 123 print(a) # 変数 a に数値の234を代入 a = 234 print(a)123
234a,b = 12345,23456 print(a) print(b) # a + b の結果を再度 a に代入する(上書き) a = a+b print(a)12345
23456
35801プログラムではデータの形も重要です。文字と数値は一緒に計算できません。
a = '文字' b = 1 print(a + b)TypeError Traceback (most recent call last)
in ()
1 a = '文字'
2 b = 1
----> 3 print(a + b)
TypeError: Can't convert 'int' object to str implicitly
TypeError: 変数 a と b のデータの形が違うので
計算できない(変換できない)という意味合いのエラーです。数値の型と文字の型ではデータの形が違うため一緒にすることができません。
データの形の確認
type関数を使って変数のデータ型を確認する
type(変数名)# 変数aとcは数値、bは文字列を代入 a,b,c = 1 , '3' , 4 print(type(a)) print(type(b)) print(type(c))
<class 'int'>
<class 'str'>
<class 'int'>
intは整数の型
strは文字列の型を表す言葉です。変数に格納したもののことを「オブジェクト」と呼んだりもします。
変数=データの型=オブジェクト
という関係性になるので、呼び方や概念を覚えておきましょう。予約語
予約語というのはプログラム内であらかじめ使われてしまっている
言葉のことで、プログラムの中では特別な意味を持つ言葉になります。予約語一覧
# 予約語の一覧を出す __import__('keyword').kwlistFalse None True and as assert break class continue def del elif else except finally for from global if import in is lambda nonlocal not or pass raise return try while with yieldPythonの予約語はこれだけあります。
この予約語は変数名や関数名などに用いることはできません。
jupyter notebook上で予約語を使うと
緑色に表示が変わるので、気付けるかと思います。for in with
組み込み関数一覧
# 組み込み関数を表示する dir(__builtins__)ArithmeticError AssertionError AttributeError BaseException BlockingIOError BrokenPipeError BufferError BytesWarning ChildProcessError ConnectionAbortedError ConnectionError ConnectionRefusedError ConnectionResetError DeprecationWarning EOFError Ellipsis EnvironmentError Exception False FileExistsError FileNotFoundError FloatingPointError FutureWarning GeneratorExit IOError ImportError ImportWarning IndentationError IndexError InterruptedError IsADirectoryError KeyError KeyboardInterrupt LookupError MemoryError NameError None NotADirectoryError NotImplemented NotImplementedError OSError OverflowError PendingDeprecationWarning PermissionError ProcessLookupError RecursionError ReferenceError ResourceWarning RuntimeError RuntimeWarning StopAsyncIteration StopIteration SyntaxError SyntaxWarning SystemError SystemExit TabError TimeoutError True TypeError UnboundLocalError UnicodeDecodeError UnicodeEncodeError UnicodeError UnicodeTranslateError UnicodeWarning UserWarning ValueError Warning ZeroDivisionError __IPYTHON__ __build_class__ __debug__ __doc__ __import__ __loader__ __name__ __package__ __spec__ abs all any ascii bin bool bytearray bytes callable chr classmethod compile complex copyright credits delattr dict dir divmod dreload enumerate eval exec filter float format frozenset get_ipython getattr globals hasattr hash help hex id input int isinstance issubclass iter len license list locals map max memoryview min next object oct open ord pow print property range repr reversed round set setattr slice sorted staticmethod str sum super tuple type vars zipこれを変数名に用いてしまうと、その関数の機能を
変数で上書きしてしまいその関数が使えなくなってしまいます。間違えて使用してしまったらノートッブックを再起動しましょう。
変数名の宣言は英単語2個以上にすることで
こういった問題を回避することができたりするので推奨します。# 例: magic_spell_name attack_pointデータ型
プログラム言語で取り扱うデータにはデータの型があり
書き方などが決まっています。
変数などで取扱う際も、データの型に合わせて書く必要があります。Pythonのデータ型を調べる方法
type関数を用いる
type(データ型)整数型
整数値を取扱うための型で
int型とも言います(integer の略)
四則計算を行うことができるデータ型です。num = 1234 print(type(num))プログラムでは通常の数値を書くと10進法で解釈されますが
その他に2,8,16進法を用いることができます。数値の前に以下をつける
0b2進法
0o8進法
0x16進法# 2進法 num = 0b11000100 print(num) # 8 進法 num = 0o777 print(num) # 16進法 num = 0xffff print(num)196
511
6553510進法は0から9まで数えて10までいくと1つ桁が繰り上がります。
2進法は0 , 1 で2つ数えて繰り上がり、
8進法は0から7まで行ったら繰り上がり
16進法は0から9までいったら次は英語のabcdefまでいくと
繰り上がるというものです。小数型
整数型は小数点を取り扱えませんが
小数型は小数点も取扱うことができます。
浮動小数点型、float型ともいいます。num = 1.234 print(type(num))
<class 'float'>指数表記も使えます。
指数表記は英文字の
eをつけ数値でn乗を表します。
e3は10の3乗を表し-を付けると逆に-n乗になります。# 1.2の10の3乗 num = 1.2e3 print(type(num)) print(num) # 1.2の10の -3乗 num = 1.2e-3 print(num)
1200.0
0.0012同じ数値でも、整数型と小数型では違う形なので注意が必要です。
小数型と整数型の計算結果は小数型になります。# 整数割る整数 print(10/4) # 整数割る整数(余りなし) print(10//4) # 整数割る小数 print(10//4.0) # 小数割る小数 print(12.3/4.0)2.5
2
2.0
3.075論理型
真偽値を取扱うための型で
booleanを略してbool型とも言います。
TrueかFalseどちらかの値が入る型です。answer = True print(answer) print(type(answer))True
<class 'bool'>計算の判定結果はbool型になります。
==を用いると==の左側と右側が等しいかどうかを判定できます。1==2False
等しいかどうかを判定した場合、正しければ
True
正しくなければFalseという結果になります。文字列型
文字列を取扱うための型で
string型とも言います。
文字列(str)は"ダブルクォート
または'シングルクォートで囲む必要があります。# 文字列型 print(type('12345')) # こちらは数値 print(type(12345))
<class 'str'>
<class 'int'>数字をそのまま書くと整数型、もしくは小数点型になるので
文字列として扱いたい場合は'などが必要です。文字と数値の変換
文字列を整数型に直す場合は
int('数字')整数型や小数型を文字列に直す場合は
str(数値)# 文字列を整数型に a = '12345' # 文字を数値に変換したので計算できるようになる print(int(a) + 12345)24690
# 小数点を文字列に変換 b = 2.5 # 数値を文字列に変換したので文字列として加えられる print('江頭' + str(b) + '分')江頭2.5分
byte型
バイト列として扱いたい文字列の"..."や'...'
の前にbまたはBを記述して、バイト列(bytes)であることを示すと
byte型になります。byte_st = b'0123456789abcdef' print(byte_st) print(type(byte_st))b'0123456789abcdef'
<class 'bytes'>
bがついていたら byte型で文字列型とは別物になります。まとめ
Python言語に関わらず、プログラム言語には様々なデータ型が存在します。
プログラムはデータを取扱うのでデータの型に合わせて書く必要があります。プログラムでは変数を用いてデータの使い回しをしていきます。
変数の取り扱い方をデータ型と一緒に押さえておきましょう。複数のデータが格納されるデータ型は
インデックスを用いて値を取り出すスライス機能が使えるので
取り扱い方を押さえておきましょう。インデックスは様々なところで多用されるので
早めに覚えておく必要があります。君がエンジニアになるまであと75日
作者の情報
乙pyのHP:
http://www.otupy.net/Youtube:
https://www.youtube.com/channel/UCaT7xpeq8n1G_HcJKKSOXMwTwitter:
https://twitter.com/otupython





- 投稿日:2020-04-14T18:26:04+09:00
スクレイピング入門
スクレイピング
ちょっと原始的な手法
Webページの特定箇所を抽出する場合
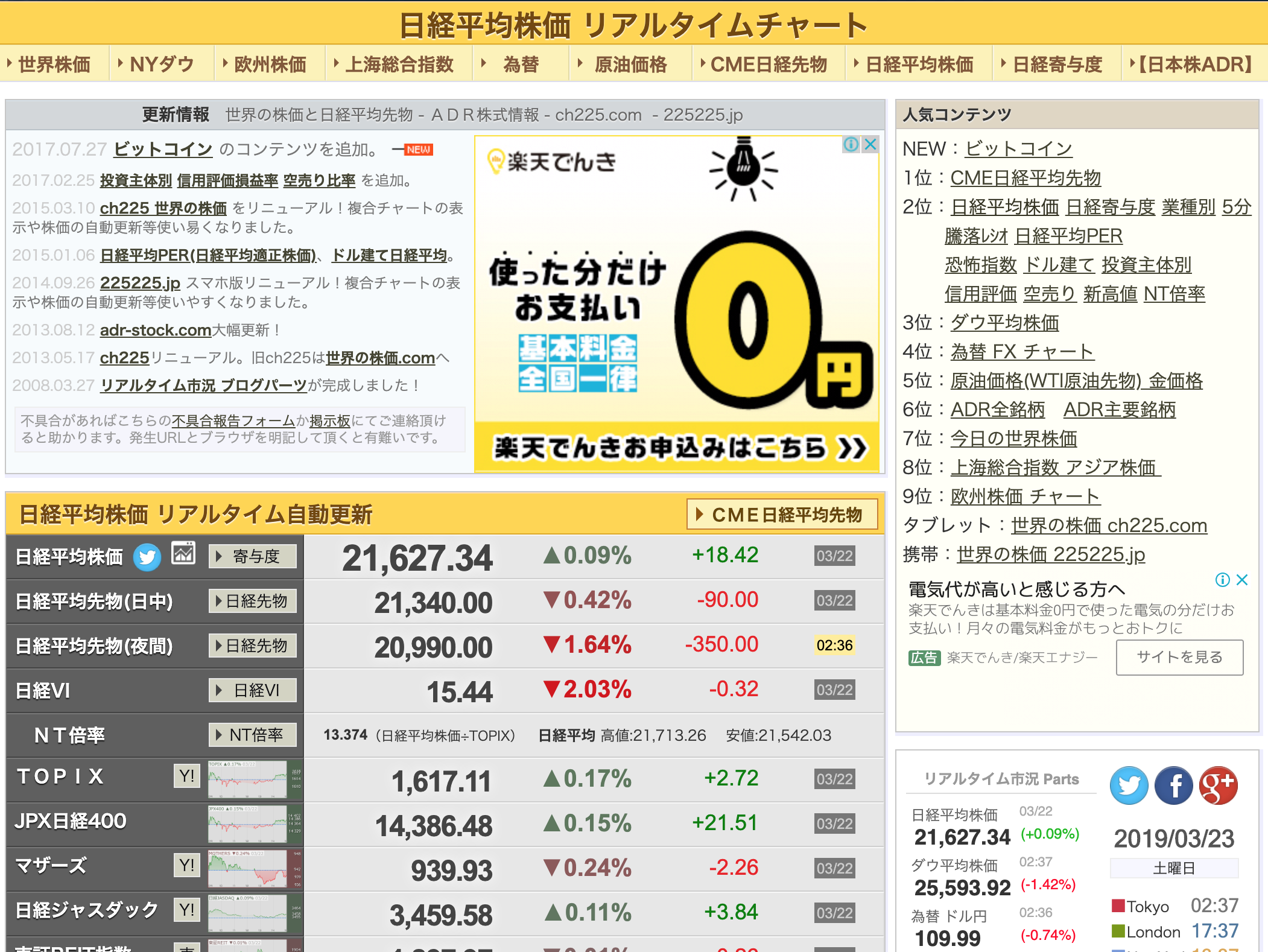
Python3import requests import json r = requests.get('https://nikkei225jp.com/chart/') text = r.text #htmlオブジェクトを返す date = text.split('<div class=wtimeT>')[1].split('</div>')[0] nikkei = text.split('<div class=if_cur>')[1].split('</div>')[0].replace(',','') dau = text.split('<div class=if_cur>')[2].split('</div>')[0].replace(',','') kawase = text.split('<div class=if_cur>')[3].split('</div>')[0].replace(',','') print('今日は',date,'です') print ('日経株価は ',nikkei, '円です') print ('ダウ平均株価は', dau, '円です') print ('為替ドルは', kawase,'円です') a=open('shares.csv','w') a.write('日時,日経平均株価,ダウ平均株価,為替ドル\n') a.write(date+','+nikkei+','+dau+','+kawase+'\n') a.close()結果(コマンドライン)今日は 2019/03/23 です 日経株価は 21627.34 円です ダウ平均株価は 25502.32 円です 為替ドルは 109.93 円ですこんなかんじにprintされてたと思う
結果(shares.csv)日時,日経平均株価,ダウ平均株価,為替ドル 2019/03/23,21627.34,25502.32,109.93こんなかんじのファイルができてるから確認したよね.
プログラムが何をやったのかというと
この日経株価サイトの
日時,日経平均株価,ダウ平均,為替ドル
といった情報を抽出・print・保存しました
引用:https://nikkei225jp.com/chart/このページの
ここの部分の情報を抽出してますWeb Scrapingにも Beautiful Soup だったり Selenium 使った便利なやり方があるけど
今回は requests のみの原始的なやり方を採用〜
流れとしては
r = requests.get('スクレイピングしたいページのURL')で返されたたレスポンス(ページ情報)が変数rに格納されて
text = r.textで返ってきたレスポンスrのボディ(HTML本体)をtextとしてテキスト形式でゲッチュ
例えば日経平均株価である21,627.34
を抽出したければ
上図のように抽出したい情報を選択して
「検証」または「ページのソースを表示」で検索にかけると<div class="if_cur">21,627.34</div><img width="674" alt="スクリーンショット 2020-04-14 18.27.54.png" src="https://qiita-image-store.s3.ap-northeast-1.amazonaws.com/0/377231/64fddc0e-29c5-8d2a-09ee-bb3656fc0895.png">このようにif_curというクラスでサンドイッチ状態なんで
nikkei = text.split('<div class=if_cur>')[1].split('</div>')[0].replace(',','')この一行でnikkeiとして中身を抽出してるかんじ.
例2)日時の抽出例
.replace(',','')はカンマ(,)を取り除いてるだけ.
数字のとこにあるカンマが邪魔だから.(あとでint型に変換して演算をしたい場合カンマが残ってるとint型に変換できない)ダウ平均, 為替ドル, 時刻 も同じやり方です
一番原始的だけどわりといろんなパターンに対応できるやり方.
スマートな手法
今度はさっきの日経平均株価ページ内に存在するリンク(URL)を全部抽出
今回はさっきのように一個ずつ抽出するコード描いてたらキリがないから
とりあえずaタグ(URLのあるタグ)を全部抽出して配列に格納してくパターン
Beautiful Soupはこれで
$ pip install beautifulsoup4さっきのコードにaタグ取得コードを追加しただけです
import requests import json from bs4 import BeautifulSoup r = requests.get('https://nikkei225jp.com/chart/') text = r.text date = text.split('<div class=wtimeT>')[1].split('</div>')[0] nikkei = text.split('<div class=if_cur>')[1].split('</div>')[0].replace(',','') dau = text.split('<div class=if_cur>')[2].split('</div>')[0].replace(',','') kawase = text.split('<div class=if_cur>')[3].split('</div>')[0].replace(',','') print('今日は',date,'です') print ('日経株価は ',nikkei, '円です') print ('ダウ平均株価は', dau, '円です') print ('為替ドルは', kawase,'円です') a=open('shares.csv','w') a.write('日時,日経平均株価,ダウ平均株価,為替ドル\n') a.write(date+','+nikkei+','+dau+','+kawase+'\n') a.close() #ここから下が追加分 soup = BeautifulSoup(r.text , "html.parser") for a in soup.find_all('a'): if 'http' in str(a): #今回は http ついてる aタグのみに限定 #print(a.text) # aタグの中身(タイトル) print(a.attrs['href']) #URL結果(コマンドライン)今日は 2019/03/23 です 日経株価は 21627.34 円です ダウ平均株価は 25502.32 円です 為替ドルは 109.93 円です http://xn--u9jt60g57a227ciso.com/ http://quote.jpx.co.jp/jpx/template/quote.cgi?F=tmp/real_index&QCODE=155 http://klug-fx.jp/holiday/ https://jp.investing.com/holiday-calendar/ https://db.225225.jp/ https://nikkei225jp.com/chart/ https://nikkei225jp.com/nasdaq/ https://nikkei225jp.com/fx/ https://ch225.com/ https://225225.jp/ https://nikkei225jp.com/cme/ https://adr-stock.com/ http://fx.minkabu.jp/indicators/calendar http://jp.reuters.com/investing/news/economic http://www3.nhk.or.jp/news/html/20190323/k10011858101000.html http://moneyzine.jp/article/detail/215915 http://feeds.reuters.com/~r/reuters/JPBusinessNews/~3/19cDqM88PGE/graphics-frb-idJPKCN1R30VK http://feeds.reuters.com/~r/reuters/JPBusinessNews/~3/wqkbZgbeMMA/asia-companies-outlook-analysis-idJPKCN1R30Y2 http://www.asahi.com/articles/ASM3D3S9TM3DULFA00N.html?ref=rss http://diamond.jp/articles/-/197806 http://www.asahi.com/articles/ASM3R1SPZM3RUHBI003.html?ref=rss https://zai.diamond.jp/list/fxnews/detail?id=312805&utm_source=zaifxrss&utm_medium=rss&utm_term=zaifxnews&utm_campaign=zaifxrss https://zai.diamond.jp/list/fxnews/detail?id=312804&utm_source=zaifxrss&utm_medium=rss&utm_term=zaifxnews&utm_campaign=zaifxrss https://zai.diamond.jp/list/fxnews/detail?id=312803&utm_source=zaifxrss&utm_medium=rss&utm_term=zaifxnews&utm_campaign=zaifxrss https://zai.diamond.jp/list/fxnews/detail?id=312802&utm_source=zaifxrss&utm_medium=rss&utm_term=zaifxnews&utm_campaign=zaifxrss https://zai.diamond.jp/list/fxnews/detail?id=312801&utm_source=zaifxrss&utm_medium=rss&utm_term=zaifxnews&utm_campaign=zaifxrss http://www3.nhk.or.jp/news/html/20190322/k10011857501000.html http://diamond.jp/articles/-/197800 http://feeds.reuters.com/~r/reuters/JPMarketNews/~3/k7hVYUD0Rlw/usa-trump-russia-idJPL3N21949Q http://feeds.reuters.com/~r/reuters/JPBusinessNews/~3/7SX2E12xQqA/ny-market-summary-0322-idJPKCN1R32TP https://www.nikkei.com/article/DGXLASM7IAA05_T20C19A3000000/ http://feeds.reuters.com/~r/reuters/JPCompanyNews/~3/vP8IyPxDb_w/EU-HUAWEI-TECH--idJPL3N21946T http://feeds.reuters.com/~r/reuters/JPBusinessNews/~3/dhPXy0bfxg8/ny-stx-us-idJPKCN1R32SJ http://feeds.reuters.com/~r/reuters/JPBusinessNews/~3/f5sMkCorXO8/ny-forex-idJPKCN1R32SB http://feeds.reuters.com/~r/reuters/JPMarketNews/~3/fYZ-Sat0U3Y/ny-markets-summary-idJPL3N2194BF http://feeds.reuters.com/~r/reuters/JPCompanyNews/~3/unMMYgBSv38/ny-stx-us-idJPL3N21946R http://feeds.reuters.com/~r/reuters/JPCompanyNews/~3/FIxyRRMByHY/pinterest-ipo-idJPL3N21949V https://zai.diamond.jp/list/fxnews/detail?id=312800&utm_source=zaifxrss&utm_medium=rss&utm_term=zaifxnews&utm_campaign=zaifxrss https://www.nikkei.com/article/DGXLASH2ICE01_T20C19A3000000/ http://www.traders.co.jp/foreign_stocks/market_s.asp#today http://www.gaitame.com/market/yosoku.html http://market.fisco.co.jp/update/index.jsp http://www.traderswebfx.jp/news/default.aspx?ID=7#newslist http://kabuyoho.ifis.co.jp/ http://www.tokyoipo.com/top/iposche/index.php?j_e=J http://klug-fx.jp/holiday/ https://jp.investing.com/holiday-calendar/ http://world.honda.com/worldclock/ https://news.yahoo.co.jp/search?p=%E6%97%A5%E7%B5%8C%E5%B9%B3%E5%9D%87&ei=utf-8&fr=news_sw https://www.google.co.jp/search?hl=ja&gl=jp&tbm=nws&authuser=0&q=%E6%97%A5%E7%B5%8C%E5%B9%B3%E5%9D%87&oq=%E6%97%A5%E7%B5%8C%E5%B9%B3%E5%9D%87&gs_l=news-cc.1.0.43j43i53.2284.2284.0.5545.1.1.0.0.0.0.56.56.1.1.0...0.0...1ac.1.oMorwBF68ss#q=%E6%97%A5%E7%B5%8C%E5%B9%B3%E5%9D%87&hl=ja&gl=jp&authuser=0&tbm=nws&tbs=sbd:1 http://chart.fisco.co.jp/fisco/cgi-bin/index.cgi http://chart.fisco.co.jp/fisco/cgi-bin/index.cgi https://www.dukascopy.jp/ページ内のリンクとってこれてるのがわかると思う.
#print(a.text) # aタグの中身(タイトル)部分のコメントアウトとればaタグのタイトルもとってこれるよ〜
今日は 2019/03/23 です 日経株価は 21627.34 円です ダウ平均株価は 25502.32 円です 為替ドルは 109.93 円です 世界の株価.com http://xn--u9jt60g57a227ciso.com/ 東 http://quote.jpx.co.jp/jpx/template/quote.cgi?F=tmp/real_index&QCODE=155 [Klug] http://klug-fx.jp/holiday/ [Investing] https://jp.investing.com/holiday-calendar/ リアルタイム市況 Parts https://db.225225.jp/ 日経平均株価 https://nikkei225jp.com/chart/ ダウ平均株価 https://nikkei225jp.com/nasdaq/ 為替 ドル円 https://nikkei225jp.com/fx/ 世界株価 https://ch225.com/ 携帯 https://225225.jp/ CME https://nikkei225jp.com/cme/ ADR https://adr-stock.com/ みんなの為替 http://fx.minkabu.jp/indicators/calendar ロイター http://jp.reuters.com/investing/news/economic 外国人材受け入れ拡大で生活支援サービス強化の動き http://www3.nhk.or.jp/news/html/20190323/k10011858101000.html 銀行の預金、149か月連続で前年同月上回る マイナス金利導入後、銀行の収益環 … http://moneyzine.jp/article/detail/215915 アングル:FRBのハト派転換、米家計にもたらす好影響 http://feeds.reuters.com/~r/reuters/JPBusinessNews/~3/19cDqM88PGE/graphics-frb-idJPKCN1R30VK 焦点:アジア企業の設備投資、中国減速で3年ぶりに減少へ http://feeds.reuters.com/~r/reuters/JPBusinessNews/~3/wqkbZgbeMMA/asia-companies-outlook-analysis-idJPKCN1R30Y2 原発支援へ補助制度案 経産省、2020年度創設めざす http://www.asahi.com/articles/ASM3D3S9TM3DULFA00N.html?ref=rss 22日のNY市場は大幅下落 - 最新株式ニュース http://diamond.jp/articles/-/197806 NYダウ大幅反落、460ドル安 世界経済の減速懸念 http://www.asahi.com/articles/ASM3R1SPZM3RUHBI003.html?ref=rss 続伸、株安や債券高からリスク回避的な資金が流入 https://zai.diamond.jp/list/fxnews/detail?id=312805&utm_source=zaifxrss&utm_medium=rss&utm_term=zaifxnews&utm_campaign=zaifxrss NY金先物は続伸、株安や債券高からリスク回避的な資金が流入 https://zai.diamond.jp/list/fxnews/detail?id=312804&utm_source=zaifxrss&utm_medium=rss&utm_term=zaifxnews&utm_campaign=zaifxrss NY原油先物は続落、世界経済の悪化が深刻化するとの懸念 https://zai.diamond.jp/list/fxnews/detail?id=312803&utm_source=zaifxrss&utm_medium=rss&utm_term=zaifxnews&utm_campaign=zaifxrss NY市場動向(取引終了):ダウ460.19ドル安(速報)、原油先物0.94ドル安 https://zai.diamond.jp/list/fxnews/detail?id=312802&utm_source=zaifxrss&utm_medium=rss&utm_term=zaifxnews&utm_campaign=zaifxrss 世界各国通貨に対する円:対ドル0.81%高、対ユーロ1.43%高 https://zai.diamond.jp/list/fxnews/detail?id=312801&utm_source=zaifxrss&utm_medium=rss&utm_term=zaifxnews&utm_campaign=zaifxrss 外国人材 新在留資格取得へテキスト作成 外食企業の業界団体 http://www3.nhk.or.jp/news/html/20190322/k10011857501000.html ECBはデジタル通貨発行の意思なし=メルシュ理事【フィスコ・ビットコインニュ … http://diamond.jp/articles/-/197800 UPDATE 1-米特別検察官、ロシア疑惑の捜査報告書提出 これ以上の起訴提言せず http://feeds.reuters.com/~r/reuters/JPMarketNews/~3/k7hVYUD0Rlw/usa-trump-russia-idJPL3N21949Q NY市場サマリー(22日) http://feeds.reuters.com/~r/reuters/JPBusinessNews/~3/7SX2E12xQqA/ny-market-summary-0322-idJPKCN1R32TP NY円、反発 1ドル=109円90銭?110円00銭で終了、一時1カ月ぶり円高 https://www.nikkei.com/article/DGXLASM7IAA05_T20C19A3000000/ 再送-EXCLUSIVE-欧州委、5Gからファーウェイ排除せず データ共有提言へ=関 … http://feeds.reuters.com/~r/reuters/JPCompanyNews/~3/vP8IyPxDb_w/EU-HUAWEI-TECH--idJPL3N21946T 米国株式市場が急反落、世界景気低迷不安強まる http://feeds.reuters.com/~r/reuters/JPBusinessNews/~3/dhPXy0bfxg8/ny-stx-us-idJPKCN1R32SJ ドルが対円で下落、米長短金利逆転で景気懸念高まる=NY市場 http://feeds.reuters.com/~r/reuters/JPBusinessNews/~3/f5sMkCorXO8/ny-forex-idJPKCN1R32SB NY市場サマリー(22日) http://feeds.reuters.com/~r/reuters/JPMarketNews/~3/fYZ-Sat0U3Y/ny-markets-summary-idJPL3N2194BF 米国株式市場=急反落、世界景気低迷不安強まる http://feeds.reuters.com/~r/reuters/JPCompanyNews/~3/unMMYgBSv38/ny-stx-us-idJPL3N21946R UPDATE 1-米画像共有ピンタレストがIPO申請、1億ドル規模か http://feeds.reuters.com/~r/reuters/JPCompanyNews/~3/FIxyRRMByHY/pinterest-ipo-idJPL3N21949V NYマーケットダイジェスト・22日 株大幅安・ユーロ安・リラ急落 https://zai.diamond.jp/list/fxnews/detail?id=312800&utm_source=zaifxrss&utm_medium=rss&utm_term=zaifxnews&utm_campaign=zaifxrss シカゴ日本株先物概況・22日 https://www.nikkei.com/article/DGXLASH2ICE01_T20C19A3000000/ スケジュール http://www.traders.co.jp/foreign_stocks/market_s.asp#today 経済指標予定 http://www.gaitame.com/market/yosoku.html 強弱材料・留意事項 http://market.fisco.co.jp/update/index.jsp 要人発言 http://www.traderswebfx.jp/news/default.aspx?ID=7#newslist 決算スケジュール http://kabuyoho.ifis.co.jp/ IPOスケジュール http://www.tokyoipo.com/top/iposche/index.php?j_e=J 市場休日 http://klug-fx.jp/holiday/ 市場休日 https://jp.investing.com/holiday-calendar/ 世界時計 http://world.honda.com/worldclock/ Yahoo!News「日経平均」 https://news.yahoo.co.jp/search?p=%E6%97%A5%E7%B5%8C%E5%B9%B3%E5%9D%87&ei=utf-8&fr=news_sw Google News「日経平均」 https://www.google.co.jp/search?hl=ja&gl=jp&tbm=nws&authuser=0&q=%E6%97%A5%E7%B5%8C%E5%B9%B3%E5%9D%87&oq=%E6%97%A5%E7%B5%8C%E5%B9%B3%E5%9D%87&gs_l=news-cc.1.0.43j43i53.2284.2284.0.5545.1.1.0.0.0.0.56.56.1.1.0...0.0...1ac.1.oMorwBF68ss#q=%E6%97%A5%E7%B5%8C%E5%B9%B3%E5%9D%87&hl=ja&gl=jp&authuser=0&tbm=nws&tbs=sbd:1 FISCO http://chart.fisco.co.jp/fisco/cgi-bin/index.cgi http://chart.fisco.co.jp/fisco/cgi-bin/index.cgi https://www.dukascopy.jp/こんなかんじでURLとタイトル部分を抽出したよね.
中にはhttpのリンク部分はあるけどリンクタイトルがないなんて場合もあるよ.


- 投稿日:2020-04-14T18:23:38+09:00
TypeError: __init__() got an unexpected keyword argument 'status'の対処方法
はじめに
firebaseをpythonで使用する際、
エラー内容TypeError: __init__() got an unexpected keyword argument 'status'上記エラーに遭遇したため、解決方法を記録として残しておきます。
解決方法
下記コマンドは以下の通りです。
解決方法pip uninstall requests pip install requests==2.23.0 pip install firebase_admin上記コマンドで解決できました。
2.23.0のところはrequestsの最新バージョンを指定してください。今回参考にしたGitHubの記事です。
より詳細に記載がりますので、よろしければご参照ください。
https://github.com/firebase/firebase-admin-python/issues/262ご参考になれば幸いです。
- 投稿日:2020-04-14T18:17:11+09:00
Numpyの基本操作をJupyter Labで書いてみた。
この記事はかめ(@usdatascientist)さんのブログ(https://datawokagaku.com/python_for_ds_summary/ ) に書かれているNumpyの基本操作を実際にJupyter Labを用いてコーディングしてみた、という記事です。
NumPyの基本操作まとめ
Array
import numpy as np #numpyをnpとしてインポートnp.array([1,2,3,4]) #arrayのリストarray([1, 2, 3, 4])python_list = (1,2,3,4) #Pythonのリストpython_list(1, 2, 3, 4)np.array([[1,2,3], [4,5,6],[7,8,9]]) #arrayの入れ子のリストarray([[1, 2, 3], [4, 5, 6], [7, 8, 9]])[[1,2,3], [4,5,6],[7,8,9]] #Pythonの入れ子のリスト[[1, 2, 3], [4, 5, 6], [7, 8, 9]]Arrayの計算
arr1 = np.array([[1,2,3], [4,5,6],[7,8,9]]) arr2 = np.array([[1,2,3], [4,5,6],[7,8,9]])arr1array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])arr2array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])arr1 + arr2array([[ 2, 4, 6], [ 8, 10, 12], [14, 16, 18]])arr1 - arr2array([[0, 0, 0], [0, 0, 0], [0, 0, 0]])arr1 * arr2array([[ 1, 4, 9], [16, 25, 36], [49, 64, 81]])arr1 / arr2array([[1., 1., 1.], [1., 1., 1.], [1., 1., 1.]])#arrayの足りない要素は[1,2,3]で自動的に補完される。(Broadcasting) arr3= np.array([[1,2,3]]) arr4 = np.array([[1,2,3], [4,5,6],[7,8,9]])arr3 + arr4array([[ 2, 4, 6], [ 5, 7, 9], [ 8, 10, 12]])arr3 - arr4array([[ 0, 0, 0], [-3, -3, -3], [-6, -6, -6]])arr = np.array([[1,2,3], [4,5,6],[7,8,9]])#arrayの行列のサイズを調べる arr.shape(3, 3)Indexing
indexは0から始まり、0-1番目の値まで取ってくることができる。
ndarray = np.array([[1,2], [3,4],[5,6]]) ndarrayarray([[1, 2], [3, 4], [5, 6]])ndarray[1][0]3ndarray[1,0]3Slicing
slicingは[N:M]のとき「N以上M未満」の要素を取ってくる。
arr = np.array([[1,2,3,4], [2,4,6,4], [3,5,7,4], [3,5,7,4]])arrarray([[1, 2, 3, 4], [2, 4, 6, 4], [3, 5, 7, 4], [3, 5, 7, 4]])arr[0:4, 2:4]array([[3, 4], [6, 4], [7, 4], [7, 4]])arr[:,2:] #全ての行の2列以降の要素を全て取ってくる。array([[3, 4], [6, 4], [7, 4], [7, 4]])arr = np.array([1,2,3,4,2,4,6,4,5,7,4,5,7,4])arr[1:6:2] #2つ飛びでslicingarray([2, 4, 4])様々なArray
np.arange[(start,)stop(,step)]
np.arange(0,5,2) #[start, stop, step] #0~5を2で区切った値のリストarray([0, 2, 4])np.arange(5) # start stepは省略可能。省略した場合デフォルトでそれぞれ0と1が入る。array([0, 1, 2, 3, 4])np.arange(0,5,0.1) #stepは0.1刻みも可能array([0. , 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1. , 1.1, 1.2, 1.3, 1.4, 1.5, 1.6, 1.7, 1.8, 1.9, 2. , 2.1, 2.2, 2.3, 2.4, 2.5, 2.6, 2.7, 2.8, 2.9, 3. , 3.1, 3.2, 3.3, 3.4, 3.5, 3.6, 3.7, 3.8, 3.9, 4. , 4.1, 4.2, 4.3, 4.4, 4.5, 4.6, 4.7, 4.8, 4.9])np.linspace(start, stop, num=50)
np.linspace(1, 2, 20) #1~2を20等分するarray([1. , 1.05263158, 1.10526316, 1.15789474, 1.21052632, 1.26315789, 1.31578947, 1.36842105, 1.42105263, 1.47368421, 1.52631579, 1.57894737, 1.63157895, 1.68421053, 1.73684211, 1.78947368, 1.84210526, 1.89473684, 1.94736842, 2. ]).copy()
arr_copy = arr.copy()arr_copyarray([0, 1, 2, 3, 4])ndarray = np.arange(0, 5) ndarray_copy = ndarray.copy() print('original array is {}'.format(id(arr))) print('copied array is {}'.format(id(arr))) #copyしたものはコピー元とは別のオブジェクトoriginal array is 140571396284208 copied array is 140571396284208ndarray[:] = 100 print('original array:\n', ndarray) #copyしないと元のarrayが更新される print('copied array:\n', ndarray_copy) #copyすると元のarrayが更新されないoriginal array: [100 100 100 100 100] copied array: [0 1 2 3 4]def add_world(hello): hello += ' world' return hello h_str = 'hello' h_list = ['h', 'e', 'l', 'l', 'o'] output_str = add_world(h_str) output_list = add_world(h_list) print('output_str: {}'.format(output_str)) #Stringは値渡しなので直接変更する print('output_list: {}'.format(output_list)) #listは参照渡しなので直接変更しない print('h_str: {}'.format(h_str)) print('h_list: {}'.format(h_list))output_str: hello world output_list: ['h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd'] h_str: hello h_list: ['h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd']def change_hundred(array): array[0] = 100 #copyしないと元のarrayが更新される return array def change_hundred_copy(array): array_copy = array.copy() #copyすると元のarrayが更新されない array_copy[0] = 100 return array_copy array_1 = np.arange(0, 4) array_2 = np.arange(0,4) output_array = change_hundred(array_1) output_array_copy = change_hundred_copy(array_2) print('original_array_1/n', array_1) print('original_array2/n', array_2)original_array_1/n [100 1 2 3] original_array2/n [0 1 2 3]np.zeros(shape)
shape = (2,3,5) #零行列 zeros = np.zeros(shape) print(zeros)[[[0. 0. 0. 0. 0.] [0. 0. 0. 0. 0.] [0. 0. 0. 0. 0.]] [[0. 0. 0. 0. 0.] [0. 0. 0. 0. 0.] [0. 0. 0. 0. 0.]]]np.ones(shape)
shape = (2,3,5) ones_array_1 = np.ones(shape) ones_array_2 = np.ones(4) print(ones_array_1) print(ones_array_2)[[[1. 1. 1. 1. 1.] [1. 1. 1. 1. 1.] [1. 1. 1. 1. 1.]] [[1. 1. 1. 1. 1.] [1. 1. 1. 1. 1.] [1. 1. 1. 1. 1.]]] [1. 1. 1. 1.]np.eye(N)
np.eye(3) #N * Nの単位行列。対角成分が全て1となる。array([[1., 0., 0.], [0., 1., 0.], [0., 0., 1.]])np.random.rand()
random_float = np.random.rand() # 0~1からランダムな数を返す。 random_1d = np.random.rand(3) random_2d = np.random.rand(3, 4) print('random_float:{}'.format(random_float)) print('random_1d:{}'.format(random_1d)) print('random_2d:{}'.format(random_2d))random_float:0.48703321814513356/n random_1d:[0.27824053 0.60682459 0.22001138] random_2d:[[0.52285782 0.87272074 0.03123286 0.7921472 ] [0.80209903 0.26478273 0.91139303 0.63077037] [0.72151924 0.91234378 0.69355857 0.9969298 ]]np.random.randn()
random_float = np.random.randn() #標準正規分布0〜1から値が返される。 random_1d = np.random.randn(3) random_2d = np.random.randn(3, 4) print('random_float:{}'.format(random_float)) print('random_1d:{}'.format(random_1d)) print('random_2d:{}'.format(random_2d))random_float:-0.013248078417389888 random_1d:[-1.11606544 -0.24693187 0.17212059] random_2d:[[-0.85896581 0.53993487 0.09458454 1.3505381 ] [-1.83510873 0.09966918 -0.22293729 0.58218476] [ 0.37403933 0.83349568 0.73407002 -0.32979339]]np.random.randint(low[,high][,size])
np.random.randint(10, 50, size=(2,4,3)) #low以上high未満のintegerからランダムに、指定したsizeのndarrayを返す。 今回は2次元の4行3列。array([[[30, 14, 11], [33, 24, 48], [15, 43, 41], [18, 26, 49]], [[18, 22, 16], [15, 10, 43], [43, 48, 10], [42, 29, 10]]]).reshape(shape)
array = np.arange(0, 10) print('array:{}'.format(array)) new_shape = (2, 5) reshaped_array = array.reshape(new_shape) print('reshaped array:{}'.format(reshaped_array)) print("reshaped array's is {}".format(reshaped_array.reshape)) print('original array is NOT changed:{}'.format(array))array:[0 1 2 3 4 5 6 7 8 9] reshaped array:[[0 1 2 3 4] [5 6 7 8 9]] reshaped array's is <built-in method reshape of numpy.ndarray object at 0x7fd9420d8030> original array is NOT changed:[0 1 2 3 4 5 6 7 8 9]要素の統計量を求める
normal_dist_mat = np.random.randn(5,5) print(normal_dist_mat)[[-1.51861663 -2.09873943 -0.99761607 0.95395101 -0.04577882] [-0.81944941 0.54339984 0.45265577 -2.56369775 -1.8300719 ] [ 0.63372482 -0.35763135 0.31683655 1.44185989 -1.2110421 ] [-1.56200024 1.17061544 1.35721624 -0.46023814 0.3496441 ] [ 1.09102475 -0.47551934 -0.75747612 0.34564251 1.62400795]].max() 最大値
print('max is') print(normal_dist_mat.max())max is 1.6240079549859363.argmax() 最大値のindexを求める。
print('argmax is') print(normal_dist_mat.argmax())argmax is 24.flatten()[] index=9に格納された値を一列にする。
normal_dist_mat.flatten()[9]-1.83007190063398.min() 最小値
print('min is') print(normal_dist_mat.min())min is -2.5636977453276137.argmin() 最小値のindexを求める。
print('argmin is') print(normal_dist_mat.argmin())argmax is 8.mean() 平均値
print('mean is') print(normal_dist_mat.mean())mean is -0.1766919366579146np.median(ndarray) 中央値
print('median is') print(np.median(normal_dist_mat))median is -0.04577882007895756.std() 標準偏差
print('standard deviation is') print(normal_dist_mat.std())standard deviation is 1.1634432893009636print(normal_dist_mat.std()) #上記の関数は全てnp.関数名(ndarray)で呼ぶことも可能1.1634432893009636print(normal_dist_mat) #特定の行,列での統計量を求めたい場合は引数axisを指定。 print('axis=0 > {}'.format(normal_dist_mat.max(axis=0))) #axis=0を指定すると各列の統計量, print('axis=1 > {}'.format(normal_dist_mat.max(axis=1))) #axis=1を指定すると各行の統計量を返す。[[-1.51861663 -2.09873943 -0.99761607 0.95395101 -0.04577882] [-0.81944941 0.54339984 0.45265577 -2.56369775 -1.8300719 ] [ 0.63372482 -0.35763135 0.31683655 1.44185989 -1.2110421 ] [-1.56200024 1.17061544 1.35721624 -0.46023814 0.3496441 ] [ 1.09102475 -0.47551934 -0.75747612 0.34564251 1.62400795]] axis=0 > [1.09102475 1.17061544 1.35721624 1.44185989 1.62400795] axis=1 > [0.95395101 0.54339984 1.44185989 1.35721624 1.62400795]数学で使う関数
np.exp(ndarray)
ndarray = np.linspace(-3,3,10) expndarray = np.exp(ndarray) print(ndarray) print(expndarray)[-3. -2.33333333 -1.66666667 -1. -0.33333333 0.33333333 1. 1.66666667 2.33333333 3. ] [ 0.04978707 0.09697197 0.1888756 0.36787944 0.71653131 1.39561243 2.71828183 5.29449005 10.3122585 20.08553692]np.log(nd.array)
ndarray = np.linspace(-3,3,10) logndarray = np.log(ndarray) print(ndarray) print(logndarray) #負の値は対数を取れないのでnan。[-3. -2.33333333 -1.66666667 -1. -0.33333333 0.33333333 1. 1.66666667 2.33333333 3. ] [ nan nan nan nan nan -1.09861229 0. 0.51082562 0.84729786 1.09861229] /opt/anaconda3/lib/python3.7/site-packages/ipykernel_launcher.py:2: RuntimeWarning: invalid value encountered in logprint(logndarray[0]) print('nan ==None? {}'.format(logndarray[0] is None))nan nan ==None? Falsenp.isnan(logndarray[0])Truenp.e
print(np.e) print(np.log(np.e))2.718281828459045 1.0ndarrayのshape操作
ndarray = np.array([[1,2,3], [4,5,6], [7,8,9]]) print('array is :{}'.format(ndarray)) print("ndarray's shape is :{}".format(ndarray.shape)) #次元の数をrankという。array is :[[1 2 3] [4 5 6] [7 8 9]] ndarray's shape is :(3, 3)np.expand_dims(nd.array, axis)
expanded_ndarray = np.expand_dims(ndarray, axis=0) #次元の追加 expanded_ndarray.shape(1, 3, 3)np.squeeze(ndarray)
squeezed_ndarray = np.squeeze(expanded_ndarray) #shapeの次元を1つなくす。 squeezed_ndarray.shape(3, 3).flatten()
flatten_array = ndarray.flatten() #1列にする print('flatten_array is :{}'.format(flatten_array)) print('ndarray is :{}'.format(ndarray))flatten_array is :[1 2 3 4 5 6 7 8 9] ndarray is :[[1 2 3] [4 5 6] [7 8 9]]Numpy Arrayを保存、読み込む
np.save('ファイルパス', ndarray)
ndarray = np.array([ [1,2,3,4], [10,20,30,40], [100,200,300,400] ]) np.save('saved_numpy', ndarray)np.load('ファイルパス')
loaded_numpy = np.load('saved_numpy.npy') loaded_numpyarray([[ 1, 2, 3, 4], [ 10, 20, 30, 40], [100, 200, 300, 400]])
- 投稿日:2020-04-14T18:17:10+09:00
Pythonで毎日AtCoder #36
はじめに
前回
今日は頭が動かなかったので、1問しか解いてません。#36
考えたこと
全ての要素の対してcountしているとTLEします。
countは使えないので、sortした後に隣り合う要素同士を比較していって要素の数を数えます。
要素の種類$set(a)$が$k$よりも多い場合は、$set(a)$から小さい順にansに足していきます。n, k = map(int,input().split()) a = list(map(int,input().split())) a.sort() count = [] c = 1 for i in range(n-1): if a[i] != a[i+1]: count.append(c) c = 1 else: c += 1 if i == n - 2: count.append(c) l = len(count) #print(a) #print(count) c = 0 if l <= k: print(0) else: count.sort() for i in range(l): l -= 1 c += count[i] if l <= k: print(c) quit()まとめ
countは遅い。(おそらく$O(N)$)。ではまた。
- 投稿日:2020-04-14T18:09:53+09:00
Pythonの応用 Numpyその1 1次元配列
前の投稿が量があるので分けることにしました。
こちらでは1次元配列について投稿します。
ndarrayクラス
NumPyには配列を高速に扱うためのndarrayクラスが用意されています
ndarray配列を生成する方法はいくつかあります。
np.array(リスト)
import numpy as np np.array([1,2,3]) # 出力結果 array([1, 2, 3])np.arange(X)
等間隔に増減させた値の要素をX個作成してくれます。
import numpy as np np.arange(4) # 出力結果 array([0, 1, 2, 3])各次元のndarrayクラス
ndarrayクラスは
1次元の場合はベクトル
2次元の場合は行列
3次元以上はテンソルと呼ばれます。1次元、2次元、3次元のnp.arrayの例は以下のようになります
# ベクトル(1次元のndarrayクラス) array_1d = np.array([1,2,3,4,5,6,7,8])# 行列(2次元のndarrayクラス) array_2d = np.array([[1,2,3,4],[5,6,7,8]])# テンソル(3次元のndarrayクラス) array_3d = np.array([[[1,2],[3,4]],[[5,6],[7,8]]])1次元配列の計算
リストでは、要素ごとの計算を行うためにはループさせて
要素を一つずつ取り出して足し算を行う必要がありましたが
ndarray配列ではループさせる必要はありません。
ndarray配列同士の算術演算では、同じ位置にある要素同士が計算されますNumPyを使わない実行例 storages = [1, 2, 3, 4] new_storages = [] for n in storages: n += n new_storages.append(n) print(new_storages) # 出力結果 [2, 4, 6, 8] NumPyを使う実行例 import numpy as np storages = np.array([1, 2, 3, 4]) storages += storages print(storages) # 出力結果 [2 4 6 8] # 単純に同じインデックスの位置で計算されてゆくのが味噌です。インデックス参照とスライス
NumPyでもインデックス参照やスライスをすることができます。
スライスの値を変更したいときは
arr[start:end] = # 変更したい値と表記します。なお、
arr[start:end]# この時、startから(end-1)までのリストが作成されることに注意してくださいarr = np.arange(10) print(arr) # 出力結果 [0 1 2 3 4 5 6 7 8 9] arr = np.arange(10) arr[0:3] = 1 print(arr) # 出力結果 [1 1 1 3 4 5 6 7 8 9]ndarray配列の注意点
ndarray配列はPythonのリストと同じように
代入先の変数の値を変更すると元のndarray配列の値も変更されます。そのため、ndarray配列をコピーして別の変数として扱いたい場合は
コピーしたい配列.copy( ) # このメソッドを使用します。viewとcopy
Pythonのリストとndarray配列の相違点は
ndarray配列のスライスは配列のコピーではなくviewであることです。viewはもとの配列と同じデータを参照しています。
つまりndarray配列のスライスの変更は、オリジナルのndarray配列を変更するということです。スライスをコピーとして扱いたい場合にはarr[:].copy()を使用します
ブールインデックス参照
論理値(True/False)の配列を用いて要素を取り出す方法のことです。
arr[ndarrayの論理値の配列]と記述すると
論理値配列のTrueに該当する箇所の要素のndarray配列を作成して返します。arr = np.array([2, 4, 6, 7]) print(arr[np.array([True, True, True, False])]) # 出力結果 [2 4 6]これを応用すると、ndarray配列の要素を抽出することができます。 下記のコードは、3で割った時の余りが1の要素をTrueとして返し、3で割った時の余りの要素を出力しています。
arr = np.array([2, 4, 6, 7]) print(arr[arr % 3 == 1]) # 出力結果 [4 7]例としてはこちら
import numpy as np arr = np.array([2, 3, 4, 5, 6, 7]) # 変数arrの各要素が2で割り切れるかどうかを示す真偽値の配列を出力してください print(arr%2 == 0) # 出力結果 [ True False True False True False] # 変数arr各要素のうち2で割り切れる要素の配列を出力してください print(arr[arr%2 == 0]) # 出力結果 [2 4 6]ユニバーサル関数
ndarray配列の各要素に対して演算した結果を返す関数のことです。
要素ごとの計算なので多次元配列でも用いることができます。
ユニバーサル関数には引数が1つのものと2つのものがあります引数が1つの関数
np.abs() # 要素の絶対値を返すnp.exp() # 要素の ? (自然対数の底)のべき乗を返すnp.sqrt() # 要素の平方根を返す引数が2つの関数
要素同士の和を返すnp.add()
要素同士の差を返すnp.subtract()
要素同士の最大値を格納した配列を返すnp.maximum() など集合関数
Numpyの集合関数は数学の集合演算を行う関数のことで、1次元配列のみを対象としています。
代表的な関数は、以下の通りです。
注意事項
- これらはソートした結果を返すので注意してください。
- 各集合には最後に1dが付属されてるのを注意してください。
np.unique() # 配列要素から重複を取り除きソートした結果を返すnp.union1d(x, y) # (和集合)配列xとyのうち少なくとも一方に存在する要素を取り出しソートするnp.intersect1d(x, y)# (積集合)配列xとyのうち共通する要素を取り出しソートするnp.setdiff1d(x, y) # (差集合)配列xと配列yに共通する要素を配列xから取り除きソートする など乱数
NumPyはnp.randomモジュールで乱数を生成することができます。
代表的な関数は以下の通りです。
np.random.rand() # 0以上1未満の一様乱数を生成する # ()の中に指定した整数の個数分の乱数を生成します。np.random.randint(x, y, z) # x以上y未満の整数をz個生成する # x以上y未満の整数を生成することに注意しましょう。 # さらに、zに(2,3)のように引数を指定すると、 2×3 の行列を生成することができます。np.random.normal() # ガウス分布に従う乱数を生成するなどがあります。
以下が実装例です。
import numpy as np # randint()をnp.randomと記述しなくてもいいようにimportしてください from numpy.random import randint # 乱数を一定のルールで作るように設定(正誤判定用) np.random.seed(2) # 変数arr_randintに各要素が1以上11以内の整数の行列(6 × 2)を代入してください arr_randint = randint(1,11,(6,2)) print(arr_randint) # 変数arr_randomに0以上1未満の一様乱数を3つ代入してください arr_random =rand(3) print(arr_random) [[9 9] [7 3] [9 8] [3 2] [6 5] [5 6]] [0.68302599 0.49856117 0.58679698]コードの省略
通常これらの関数を用いる時
np.random.randint()のように記述しますが、毎回np.randomを記述するのは手間なだけでなく
コードも読み難くなります。そこでインポートする際にfrom numpy.random import randintと最初に記述しておくとrandint()のみで用いることができるようになります。
これは他の関数も同様で
「from モジュール名 import そのモジュールの中にある関数名」とすることでモジュール内の関数を直接インポートするので、モジュール名を記述する必要がなくなります。
- 投稿日:2020-04-14T18:09:53+09:00
Pythonの応用: Numpyその1: 1次元配列
前の投稿が量があるので分けることにしました。
こちらでは1次元配列について投稿します。
ndarrayクラス
NumPyには配列を高速に扱うためのndarrayクラスが用意されています
ndarray配列を生成する方法はいくつかあります。
np.array(リスト)
import numpy as np np.array([1,2,3]) # 出力結果 array([1, 2, 3])np.arange(X)
等間隔に増減させた値の要素をX個作成してくれます。
import numpy as np np.arange(4) # 出力結果 array([0, 1, 2, 3])各次元のndarrayクラス
ndarrayクラスは
1次元の場合はベクトル
2次元の場合は行列
3次元以上はテンソルと呼ばれます。1次元、2次元、3次元のnp.arrayの例は以下のようになります
# ベクトル(1次元のndarrayクラス) array_1d = np.array([1,2,3,4,5,6,7,8])# 行列(2次元のndarrayクラス) array_2d = np.array([[1,2,3,4],[5,6,7,8]])# テンソル(3次元のndarrayクラス) array_3d = np.array([[[1,2],[3,4]],[[5,6],[7,8]]])1次元配列の計算
リストでは、要素ごとの計算を行うためにはループさせて
要素を一つずつ取り出して足し算を行う必要がありましたが
ndarray配列ではループさせる必要はありません。
ndarray配列同士の算術演算では、同じ位置にある要素同士が計算されますNumPyを使わない実行例 storages = [1, 2, 3, 4] new_storages = [] for n in storages: n += n new_storages.append(n) print(new_storages) # 出力結果 [2, 4, 6, 8] NumPyを使う実行例 import numpy as np storages = np.array([1, 2, 3, 4]) storages += storages print(storages) # 出力結果 [2 4 6 8] # 単純に同じインデックスの位置で計算されてゆくのが味噌です。インデックス参照とスライス
NumPyでもインデックス参照やスライスをすることができます。
スライスの値を変更したいときは
arr[start:end] = # 変更したい値と表記します。なお、
arr[start:end]# この時、startから(end-1)までのリストが作成されることに注意してくださいarr = np.arange(10) print(arr) # 出力結果 [0 1 2 3 4 5 6 7 8 9] arr = np.arange(10) arr[0:3] = 1 print(arr) # 出力結果 [1 1 1 3 4 5 6 7 8 9]ndarray配列の注意点
ndarray配列はPythonのリストと同じように
代入先の変数の値を変更すると元のndarray配列の値も変更されます。そのため、ndarray配列をコピーして別の変数として扱いたい場合は
コピーしたい配列.copy( ) # このメソッドを使用します。viewとcopy
Pythonのリストとndarray配列の相違点は
ndarray配列のスライスは配列のコピーではなくviewであることです。viewはもとの配列と同じデータを参照しています。
つまりndarray配列のスライスの変更は、オリジナルのndarray配列を変更するということです。スライスをコピーとして扱いたい場合にはarr[:].copy()を使用します
ブールインデックス参照
論理値(True/False)の配列を用いて要素を取り出す方法のことです。
arr[ndarrayの論理値の配列]と記述すると
論理値配列のTrueに該当する箇所の要素のndarray配列を作成して返します。arr = np.array([2, 4, 6, 7]) print(arr[np.array([True, True, True, False])]) # 出力結果 [2 4 6]これを応用すると、ndarray配列の要素を抽出することができます。 下記のコードは、3で割った時の余りが1の要素をTrueとして返し、3で割った時の余りの要素を出力しています。
arr = np.array([2, 4, 6, 7]) print(arr[arr % 3 == 1]) # 出力結果 [4 7]例としてはこちら
import numpy as np arr = np.array([2, 3, 4, 5, 6, 7]) # 変数arrの各要素が2で割り切れるかどうかを示す真偽値の配列を出力してください print(arr%2 == 0) # 出力結果 [ True False True False True False] # 変数arr各要素のうち2で割り切れる要素の配列を出力してください print(arr[arr%2 == 0]) # 出力結果 [2 4 6]ユニバーサル関数
ndarray配列の各要素に対して演算した結果を返す関数のことです。
要素ごとの計算なので多次元配列でも用いることができます。
ユニバーサル関数には引数が1つのものと2つのものがあります引数が1つの関数
np.abs() # 要素の絶対値を返すnp.exp() # 要素の ? (自然対数の底)のべき乗を返すnp.sqrt() # 要素の平方根を返す引数が2つの関数
要素同士の和を返すnp.add()
要素同士の差を返すnp.subtract()
要素同士の最大値を格納した配列を返すnp.maximum() など集合関数
Numpyの集合関数は数学の集合演算を行う関数のことで、1次元配列のみを対象としています。
代表的な関数は、以下の通りです。
注意事項
- これらはソートした結果を返すので注意してください。
- 各集合には最後に1dが付属されてるのを注意してください。
np.unique() # 配列要素から重複を取り除きソートした結果を返すnp.union1d(x, y) # (和集合)配列xとyのうち少なくとも一方に存在する要素を取り出しソートするnp.intersect1d(x, y)# (積集合)配列xとyのうち共通する要素を取り出しソートするnp.setdiff1d(x, y) # (差集合)配列xと配列yに共通する要素を配列xから取り除きソートする など乱数
NumPyはnp.randomモジュールで乱数を生成することができます。
代表的な関数は以下の通りです。
np.random.rand() # 0以上1未満の一様乱数を生成する # ()の中に指定した整数の個数分の乱数を生成します。np.random.randint(x, y, z) # x以上y未満の整数をz個生成する # x以上y未満の整数を生成することに注意しましょう。 # さらに、zに(2,3)のように引数を指定すると、 2×3 の行列を生成することができます。np.random.normal() # ガウス分布に従う乱数を生成するなどがあります。
以下が実装例です。
import numpy as np # randint()をnp.randomと記述しなくてもいいようにimportしてください from numpy.random import randint # 乱数を一定のルールで作るように設定(正誤判定用) np.random.seed(2) # 変数arr_randintに各要素が1以上11以内の整数の行列(6 × 2)を代入してください arr_randint = randint(1,11,(6,2)) print(arr_randint) # 変数arr_randomに0以上1未満の一様乱数を3つ代入してください arr_random =rand(3) print(arr_random) [[9 9] [7 3] [9 8] [3 2] [6 5] [5 6]] [0.68302599 0.49856117 0.58679698]コードの省略
通常これらの関数を用いる時
np.random.randint()のように記述しますが、毎回np.randomを記述するのは手間なだけでなく
コードも読み難くなります。そこでインポートする際にfrom numpy.random import randintと最初に記述しておくとrandint()のみで用いることができるようになります。
これは他の関数も同様で
「from モジュール名 import そのモジュールの中にある関数名」とすることでモジュール内の関数を直接インポートするので、モジュール名を記述する必要がなくなります。
- 投稿日:2020-04-14T17:54:06+09:00
ポアソン分布間のKLダイバージェンスのメモ
ポアソン分布に従う2つの確率分布のKLダイバージェンスの計算をメモとしてまとめました。
前提
2つの確率分布$p, q$はパラメータ$\lambda_p, \lambda_q$をそれぞれ持つポアソン分布に従っている。
$p$の確率密度関数は以下のように定義する。$$p(x) = e^{-\lambda_p} \frac{\lambda_p^x}{x!}$$
また離散確率分布のKLダイバージェンスは以下のようになる。
$$D_{KL}(p, q) = \sum_{x=0}^{\infty} p(x) \log \frac{p(x)}{q(x)}$$
計算式
\begin{equation*}\begin{split}D_{KL}(p,q) &= \sum_{x=0}^{\infty} p(x) \log \frac{p(x)}{q(x)} \\&=\sum_{x=0}^{\infty} e^{-\lambda_p} \frac{\lambda_p^x}{x!} \cdot \log \frac{e^{-\lambda_p} \frac{\lambda_p^x}{x!}}{e^{-\lambda_q} \frac{\lambda_q^x}{x!}} \\&=\sum_{x=0}^{\infty} e^{-\lambda_p} \frac{\lambda_p^x}{x!} \cdot ( \log e^{-\lambda_p} \frac{\lambda_p^x}{x!} - \log e^{-\lambda_q} \frac{\lambda_q^x}{x!} )\\&=\sum_{x=0}^{\infty} e^{-\lambda_p} \frac{\lambda_p^x}{x!} \cdot (-\lambda_p +\log \frac{\lambda_p^x}{x!} +\lambda_q - \log \frac{\lambda_q^x}{x!} )\\&=\sum_{x=0}^{\infty} e^{-\lambda_p} \frac{\lambda_p^x}{x!} \cdot (\lambda_q -\lambda_p +\log \frac{\lambda_p^x}{x!} \frac{x!}{\lambda_q^x} )\\&=\sum_{x=0}^{\infty} e^{-\lambda_p} \frac{\lambda_p^x}{x!} \cdot (\lambda_q -\lambda_p +\log \frac{\lambda_p^x}{\lambda_q^x} )\\&=\sum_{x=0}^{\infty} e^{-\lambda_p} \frac{\lambda_p^x}{x!} \cdot (\lambda_q -\lambda_p) + \sum_{x=0}^{\infty} e^{-\lambda_p} \frac{\lambda_p^x}{x!} \cdot \log \frac{\lambda_p^x}{\lambda_q^x} \\&=\lambda_q -\lambda_p + \sum_{x=0}^{\infty} e^{-\lambda_p} \frac{\lambda_p^x}{x!} \cdot x \log \frac{\lambda_p}{\lambda_q} \\&=\lambda_q -\lambda_p + \sum_{x=0}^{\infty} e^{-\lambda_p} \frac{\lambda_p^{x-1}}{(x-1)!} \lambda_p \cdot \log \frac{\lambda_p}{\lambda_q}\\&=\lambda_q -\lambda_p + \sum_{t=0}^{\infty} e^{-\lambda_p} \frac{\lambda_p^{t}}{t!} \lambda_p \cdot \log \frac{\lambda_p}{\lambda_q} &\mbox{$t=x-1$とする}\\&=\lambda_q -\lambda_p + e^{-\lambda_p} e^{\lambda_p} \lambda_p \cdot \log \frac{\lambda_p}{\lambda_q} \\&=\lambda_q -\lambda_p + \lambda_p \cdot \log \frac{\lambda_p}{\lambda_q}\\\end{split}\end{equation*}検証
scipyのpmf, entropyを利用したKLダイバージェンスの計算と上の数式での結果が等しくなるかどうか試した。
import numpy as np from scipy.stats import poisson, entropy x = np.linspace(0, 100, 101) # パラメータλをalphaとして定義 alpha_p = 1 alpha_q = 5 p = poisson.pmf(x, alpha_p) q = poisson.pmf(x, alpha_q) kl = entropy(p, q) # 上の式に基づいた計算 kl_alpha = alpha_q - alpha_p + alpha_p * np.log(alpha_p / alpha_q) print("entropy関数を利用したKLダイバージェンス:", kl) print("alphaを利用したKLダイバージェンス:", kl_alpha)出力結果
entropy関数を利用したKLダイバージェンス: 2.3905620875658995 alphaを利用したKLダイバージェンス: 2.3905620875658995
- 投稿日:2020-04-14T17:49:35+09:00
汎用的に使えるPythonプロジェクトのテンプレートを作成しました
Pythonをよく使うのですが、毎回毎回同じようなコードを叩いて環境を構築していました。
これがかなり時間かかる&使う部分は同じなので、汎用目的に使えるプロジェクトテンプレートとしてリポジトリを公開しました。
https://github.com/odrum428/python_setup目的
Pythonプロジェクトを始めるときに、CIやドキュメント周りなど、いつも同じようなコマンド入力して作ってました。
Pipenv使ってプロジェクト初期化して、CI定義して、テストとlint入れて、Sphinxでドキュメント化みたいな感じです。
これらを整えるのに毎回そこそこ時間がかかっていたので、どんなPythonプロジェクトでも使える構成を目指してプロジェクトのテンプレートを作成しました。
分析、アプリ、モデル生成でも一応対応可能に作ってあります。
構成概要
パッケージ
パッケージや環境諸々管理にはpipenvを使用しています。
これら管理ツールについては以下の記事がまとまっているので、参照されるといいかと思います。
Pythonのパッケージ周りのベストプラクティスを理解する現状ではpipenvを使い、諸々の設定管理をsetup.pyとsetup.cfgで行うのが最適だと思います。
使ってみた感じ、かなり管理や構築は楽になりました。今回作成したプロジェクトで使っているパッケージ等をまとめました。
- isort
- flake8
- Sphinx
- pytest
- sphinx-rtd-theme
基本のlint系として、パッケージのimportなどを整える
isortとコードスタイルを整えるflake8を導入しました。
これ以外にもyapfなどもありますが、標準であるPEP8を採用し、とりまわりのいいflake8にしました。こちらはエラー箇所のコードが表示
されるように設定を行っています。テストにはpytestを採用しました。
正直pythonのテストはpytestを使っておけば、まず問題ないと思います。標準のunittestよりもpytestの方ができることも多いし、取り回しも良いです。また、このテンプレートでは、Sphinxを用いたドキュメント生成を行っています。
ドキュメントはtestsフォルダ内で定義されたテストコードやdocstringから生成されます。
テストケースのみからドキュメントを生成することで、積極的にテストケースが書かれ、かつドキュメントも充実していくことを目指しています。
ドキュメントのテーマには sphinx-rtd-themeを使用しています。CI
Circle CIを用いたCIも導入しています。
コードのスタイルを保つためにisortとflake8によるLintを実行し、pytestを用いてテストコードを実行します。
複数バージョンのテスト実行を可能にするtoxやテストをランダムにするpytest-randomlyなどは汎用的には使用しないので除外しています。また、これらに加え、ドキュメントの自動更新も実装しました。
testsフォルダに更新があった場合は、CIでドキュメントを更新してGitのコミットまでを行うようにしています。is_docs_update: steps: - run: name: check tests folder is updated command: | if [[ ! $(git diff --diff-filter=d --name-only HEAD | grep tests/ ) = '' ]]; then echo "build and deploy" else echo "no need docs update" circleci step halt fi - run: name: make rst file command: | pipenv run sphinx-apidoc -f -o docs/ tests/ - run: name: make html command: | pipenv run sphinx-build -a ./docs ./docs/public - run: name: git push command: | git config --global user.email oxkeita@gmail.com git config --global user.name odrum428 git add -A git commit -m 'updating docs [skip ci]' git push origin HEADファイル構成
以下にファイル構成を示します。
├ .circleci/ ├ .envrc ├ .github/ ├ .gitignore ├ docs/ │ ├ Makefile │ ├ conf.py │ ├ index.rst │ ├ make.bat │ ├ modules.rst │ ├ public/ │ └ tests.rst │ ├ src/ ├ tests/ ├ LICENSE ├ Pipfile ├ Pipfile.lock ├ README.md ├ setup.cfg └ setup.py簡単にソースとテスト、ドキュメントに構成を分けました。
アプリコード、機械学習、分析コードなどはすべて
src内で、それぞれいい感じに管理。それと同じファイル構成でテストコードを書く。
テストコードからドキュメントが生成される。みたいなイメージです。ここから用途に合わせて、拡張させていけばよいと考えています。
パッケージや諸々の設定はsetup.cfgで行います。
こうすることでかなりコードが簡素化でき、以下のように書くことができます。setup.pyfrom setuptools import setup setup()設定の実質的な中身はsetup.cfg内で設定します。
[metadata] name = sample-package version = '1.0' auther = Keita Mizushima auther_email = oxkeita@gmail.com description = sample repogitory of python description-file = file: README.md url = http://example.com license = MIT license_file = LICENSE [options] install_requires= packages = find: [flake8] show_source = True max-line-length=120 max-complexity=15使い方
シンプルにこのリポジトリをベースに新しいプロジェクトを登録するだけです。
1.GitHubのリポジトリを作成する。今回は
new_projectというリポジトリを作成しました。
- このリポジトリを元に、新しいプロジェクトを開始する
git clone git@github.com:odrum428/python_setup.git new_poject cd new_project git remote set-url origin git@github.com:user_name/new_project.git git push origin masterこれでこのリポジトリを引き継いだまま、新しいプロジェクトが作成できた。
3 pipenvをinstallする。
pip install pipenvおまけですが、direnvを使うと仮想環境間を自動で切り替えてくれるので、おすすめです!
いちいち環境をactivateする必要がなくなります。
https://github.com/direnv/direnvまとめ
今後も環境が変わるたびにアップデートしていこうと思っているので、構成に困ったら使ってみてください。
また、リポジトリへのPRやまさかりもいただけると嬉しいです。

- 投稿日:2020-04-14T16:42:29+09:00
Pythonの基本文法をJupyter Labで書く。
Pythonの基本文法
3+363-2 4*5 6/2 7%2 #最後に実行された行の返り値のみ1type(1)inttype(1.0)floattype(3.14)floattype('string')str'hello'[2]'l''hello'[1:3]'el''hello{}'.format('world')'helloworld'print('{one}{two}'.format(one='hello', two='world'))helloworldList
list_out = [1,2,'three'] list_out[1, 2, 'three']list_in = ['one', 'two', 3]
list_out.append(list_in)
print(list_out)list_out[1]2list_out[3][1]'two'list_out = [1,2,'three']Dictionary
dict = {'key1':'value1', 'key2':2}dict['key1']'value1'dict = {'key1':[1,2,'value1']}dict['key1'][2]'value1'dict = {'key_out':{'key_in':'value_in'}}dict['key_out']{'key_in': 'value_in'}dict = {'key1':'value2', 'key2':2} dict['key3'] = 'new_value'dict{'key1': 'value2', 'key2': 2, 'key3': 'new_value'}Tuples
list1 = [1,2,3,4,5] tuple1 = (1,2,3,4,5,6)list1[1, 2, 3, 4, 5]tuple1(1, 2, 3, 4, 5, 6)list1[1] = 10 #listは変更可list1[1, 10, 3, 4, 5]tuple1[1] = 10 #tupleは変更不可--------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-38-df5023792f06> in <module> ----> 1 tuple1[1] = 10 #tupleは変更不可 TypeError: 'tuple' object does not support item assignment関数
result_list=[] #頻出 for i in range(0,4): result_list.append(i*10)result_list[0, 10, 20, 30][i*10 for i in range(0,4)][0, 10, 20, 30]i=0 while i<5: print('{} is less than 10'.format(i)) i+=10 is less than 10 1 is less than 10 2 is less than 10 3 is less than 10 4 is less than 10lambda関数
def function_name (param1, param2): print('Do something for {} and {}.format(param1, param2)') return 'param1' + 'and' + 'param2'param1 = 'something1' param2 = 'something2' output = function_name(param1, param2)Do something for {} and {}.format(param1, param2)def get_filename (path): return path.split('/')[-1]get_filename('/home/school/pet/corona')'corona'lambda path: path.split('/')[-1]<function __main__.<lambda>(path)>x = lambda path: path.split('/')[-1]x('/home/school/pet/corona')'corona'
- 投稿日:2020-04-14T16:06:48+09:00
【最新手法】Pan-Matrix Profileによる時系列データの可視化と頻出パターンの抽出
概要
次のような時系列データがあります。
上図のような時系列データに対して、Pan-Matrix Profileは次のようになります。
下部のヒートマップがPan-Matrix Profileで、横軸が時間、縦軸が部分時系列の長さになります。★で示す頂点(?)を参照することで、時系列に内在する頻出パターンの出現位置(横軸)とその長さ(縦軸)が一目で分かります。Pan-Matrix Profileとは
前回、時系列データ解析の革新的技術としてMatrixProfileについて紹介しました。Pan-Matrix Profile(PMP)は、簡潔に言えばMatrixProfileの部分時系列長$m$をある範囲で全て調べ、行列としたものです。
先ほどの画像の例を見てみましょう。
Pan-Matrix Profileの行列の各要素が何を意味するのか説明します。例として、(504,80)の要素を考えます。先ほど述べた通り、この行列は横軸が時間、縦軸が部分時系列の長さを表します。まず、時系列の504点目~504+80点目の部分時系列(上側の図の青色の部分時系列の左の方)について、その部分時系列と最も似ている、同じ長さの部分時系列(上図、青色、右の方)との距離を計算します。ここで、距離の尺度はZ-正規化ユークリッド距離を用います。今、その距離の値が0.95なので、(504,80)の要素には0.95が入ります。
さて、この行列を力任せ探索で作ろうとすれば実に$O(n^4)$(ただし$n$は時系列長)とかいう計算時間がかかる訳ですが、文献[1]では様々な高速化テクニックにより$O(n^2r)$(ただし$r$は部分時系列長の候補数)まで削減されます。
Pan-MatrixProfile用ライブラリ"matrixprofile"
matrixprofile用のライブラリはたくさんあって迷ってしまいますが、今回はmatrixprofileという名のPython用ライブラリを使います。そのまんまですね。
pip install matrixprofile実装例①:人工データへの適用
まずは、ライブラリに標準でついてくるいくつかの時系列データを合成された人工データで実装してみましょう。
from matplotlib import pyplot as plt import numpy as np import matrixprofile as mp #データの読み込み dataset = mp.datasets.load('motifs-discords-small') X = dataset['data'] #データの可視化 plt.figure(figsize=(18.0, 6.0)) plt.plot(np.arange(len(X)), X, color="k") plt.xlim(0, len(X)) plt.title('Synthetic Time Series')
Pan-Matrix Profileを作成し、可視化するコードは次のようになります。
#Pan-Matrix Profileおよびその他の解析 profile, figures = mp.analyze(X) #PMP表示 figures[0]
mp.analyze(X)で簡単にPMPが作成出来ます。profile内にはPMPの行列の他、PMP作成時に必要な各部分時系列に対する最近傍部分時系列のインデックスの行列(PMPI)、MotifやDiscord等の解析情報やその他もろもろが入っています。そして、
figuresには解析を可視化した画像が入っており、mp.analyze(X)の実行時点で表示が実行されますが、figures[0]でPMPの部分のみを表示することが出来ます。実装例②:ミトコンドリアのDNA配列への適用
続いて実データへ適用してみましょう。元論文[1]で紹介されていたミトコンドリアのDNA配列へ適用します。(こちらは厳密には時系列ではないですが…。)
データはこちらからmat形式のものが入手できます。
#データの読み込みその2 import scipy.io as sio dataset = sio.loadmat('termite_DNA_circular_shift') X = dataset['t2'].reshape((-1,)) #データの可視化 plt.figure(figsize=(18.0, 6.0)) plt.plot(np.arange(len(X)), X, color="k") plt.xlim(0, len(X)) plt.title('Mitochondrial DNA Sequence')
Pan-Matrix Profileを作成してみましょう。今回は数分かかります。#Pan-Matrix Profileおよびその他の解析その2 profile, figures = mp.analyze(X) #PMP表示その2 figures[0]
PMPが無駄に大きいような気がしますね。実は、mp.analyzeには閾値パラメータthresholdがあり、そちらを調整することで部分時系列長上限値の探索範囲を調整出来ます。パラメータフリーの文言はどこ行ったって思いますが、まぁ部分時系列長$m$ほど敏感ではないらしいです。実装例③:眼電図(EOG)への適用
こちらも元論文[1]にて用いられていたEOGのデータです。
#データの読み込み3 dataset = sio.loadmat('eog_multiple_scale_example') X = dataset['testdata'].reshape((-1,)) #データの可視化 plt.figure(figsize=(18.0, 6.0)) plt.plot(np.arange(len(X)), X, color="k") plt.xlim(0, len(X)) plt.title('EOG')
デフォルトのままで可視化すると以下のようになります。#Pan-Matrix Profileおよびその他の解析その3 profile, figures = mp.analyze(X) #PMP表示その3 figures[0]
さて、今回は非常に縦幅の小さなPMPとなりました。拡大して、適当にMotifを取り出してみます。
さて、一番長いMotifでこんな形です。元論文で紹介されていたこのデータのMotifはもっと長かったはずです。一体何が問題なのでしょうか。
まず、
matrixprofileライブラリの可視化部分のコードを覗いてみると、PMPにおける距離が1以上のものは全て1で埋められています。つまり、PMPの画像において、黄色い部分は全て1です。こんなことしちゃってよいのでしょか。直観的に、部分時系列間の距離は、部分時系列長が長くなれば長くなるほど大きくなる傾向にあるように考えられます。つまり、この方法では長いMotifを取り出すことが出来ません。
ちなみに、元論文によると、(理解出来ているか自信がないのですが)Top-k個のMotifを取り出す方法はPMPの値が小さいものを取り出しているっぽいです。
matrixprofileライブラリのMotif抽出コードもそのようになっています。これでは、短いMotifほど過大に評価されると思うのですが・・・。まとめ
という訳で、今回は時系列データ解析の最新手法Pan-Matrix Profileの紹介でした。どうも疑問の残る終わり方となってしまいましたが、そのうちこの疑問解決に取り組んでみたいと思います。
参考文献とか
- [1]Madrid et. al. Matrix Profile XX: Finding and Visualizing Time Series Motifs of All Lengths using the Matrix Profile. IEEE Big Knowledge 2019.
- UCRのMatrixProfileサイト:https://www.cs.ucr.edu/~eamonn/MatrixProfile.html
- PMPのライブラリ:https://matrixprofile.docs.matrixprofile.org/installation/Linux_Installation.html
- データセット:https://sites.google.com/view/pan-matrix-profile/datasets?authuser=0









- 投稿日:2020-04-14T15:48:06+09:00
リストのループ内で要素の書き換え(Python)
こんにちは。
Python で、リストのループ内で、下記のようにw = [-1]では、元のリストを書き換えませんが、w[0] = -1では書き換えます。alist = [[0], [0], [0]] for w in alist: w = [-1] print(alist) # ==> [[0], [0], [0]] for w in alist: w[0] = -1 print(alist) # ==> [[-1], [-1], [-1]]$ python3 -V Python 3.7.7
- 投稿日:2020-04-14T14:07:37+09:00
AtCoder Beginner Contest 116 過去問復習
所要時間
感想
D問題のWAが取れずコンテスト後に二時間くらい時間を費やしてWAをとる羽目になりました。しかも、考え方はあっていて間違っているのは一行だけでした。辛かったです。しかも、くだらないミスだったのでしっかり反省してこれを次に生かしたいと思います。
A問題
直角を挟む辺の積を2で割ります。
answerA.pya,b,_=map(int,input().split()) print(a*b//2)B問題
問題を言い換えれば二回目に出てくるときのインデックスを出力すれば良いので、setで数字を管理しておきsetにすでに入っている数字が出てきた時のインデックスを出力してbreakしていけば良いです。
answerB.pyx=set() s=int(input()) ans=0 while True: ans+=1 if s in x: print(ans) break x.add(s) if s%2==0: s=s//2 else: s=3*s+1C問題
個人的にはめちゃくちゃ難しかったです。
水やりして花の高さを高くするのではなく、逆に最終的な花の高さから下げて全ての花の高さを0にするとして考えました。
また、この際、0以外の数字が連続している部分について最小の数を選んでその数の分だけ選んだ部分の数字を減らす操作を繰り返すので、0以外の数字が連続している部分の左端と右端のインデックスをとってくる必要があります((1)と(2)がそれに相当します。)。また、(2)で最小の数を選ぶ操作も同時に行っているので、(3)でその最小の数で高さを減らしています。以上を行って全ての花の高さを0にするまでにどれだけ花の高さを下げたかを合計することで問題を解くことができます。answerC.pyn=int(input()) h=list(map(int,input().split())) ans=0 while True: l,m=-1,-1 #(1) for i in range(n): if h[i]!=0: l=i break if l==-1: break if l==n-1: ans+=h[l] break r=l #(2) for i in range(l,n): if h[i]==0: break else: r=i if m==-1: m=h[i] else: m=min(m,h[i]) #(3) for i in range(l,r+1): h[i]-=m ans+=m print(ans)D問題
まず初めはネタの種類を固定して考えようとしましたが、その種類を決定するために有効な手段があると思えなかったのですぐに却下しました。ここで、同じ種類のネタを食べるなら美味しさ基礎ポイントが高いものを選んだ方が良いと思ったので、まず美味しさ基礎ポイントの大きい順に並べてK番目までのネタを選択すると考えました。ここで、K個のネタより美味しさ基礎ポイントの低いネタを選択しながら満足ポイントを高めるには、種類を増やして種類ボーナスポイントを高める必要があります。また、種類ボーナスを高めるようなネタは、今までにとっていない種類のネタの中で最も美味しさ基礎ポイントが高いものになります。さらに、種類ボーナスを高めるようなネタを一つ選ぶ時に除くネタについては種類ボーナスポイントを下げてはいけないので、二つ以上ネタが存在する種類のネタで最も美味しさ基礎ポイントが低いものになります。また、それまでにどの種類のネタをいくつとったかを記録する必要があるので、klという辞書に保存してあります。
よって、これらを素直に実装すれば良いのですが、実装が若干面倒でした。そのため、ネタを除いた後に次のネタを走査するためにnow変数を-1するのを忘れてしまい、チェックするのに二時間程度かかりました。また、そのチェックはバチャコンの後に行ったのですが、バチャコン中はnowを保存せずに毎回0~k-1のインデックスを全て走査していたので遅くなってしまいました。計算量の感覚的に怪しいと思ったらすぐにプログラムをより良くするのを怠らないようにしたいです。
また、他の方が読まれる際にコードが読みにくいと思ったのでコメントアウトでかなりメモを残しておきました。コードのコメントアウトも参考にしてみてください。answerD.pyn,k=map(int,input().split()) #tdは大きさ順に並んでいる td=sorted([list(map(int,input().split())) for i in range(n)],reverse=True,key=lambda x:x[1]) #以下は美味しさ基礎ポイントが高いk番目までのものを選んだ際の満足ポイントを求めるコード ans=0 kl=dict() for i in range(k): ans+=td[i][1] if td[i][0] in kl: kl[td[i][0]]+=1 else: kl[td[i][0]]=1 l=len(kl) ans+=(l**2) ans_=ans #以下は種類ボーナスポイントを高めるネタを選ぶ際のコード now=k-1 #除くことのできるネタは0~nowまでのインデックスで探す for i in range(k,n): #種類ボーナスポイントを高めるネタはk~n-1までのインデックスで順に探す if td[i][0] not in kl: #今までに選択していないネタの場合 while now>=0: #除くことのできるネタが存在するか(now<0の場合は走査し終わっているので終了) if kl[td[now][0]]>1: #二つ以上ネタが存在する種類のネタしか除けない mi=td[now] #除くネタの種類および美味しさ基礎ポイントをメモする kl[mi[0]]-=1 #その種類のネタの個数を一つ減らす now-=1 #除いた次のネタから走査する break now-=1 #ネタが一つしか存在しない種類の場合は次を走査する if now==-1: #走査し終わっている場合 break else: ans=ans+2*l+1-mi[1]+td[i][1] #種類ボーナスポイントを高めた場合の満足ポイントをメモ(更新) kl[td[i][0]]=1 #そのネタの種類を記録する ans_=max(ans,ans_)#満足ポイントが上回っている場合は更新 l+=1 #ネタの種類を一つ分増やす(lenでいちいち取得するのは遅いと思ったので) print(ans_)

- 投稿日:2020-04-14T13:52:31+09:00
Pythonで仮想環境を作ろう!
Pythonの機能で、仮想環境を作成することができやす。
仮想環境で開発するメリットとして
メリット・プロジェクトごとにまっさらな環境を作ることができる(わかりやすい。) ・Pythonのパッケージやバージョンを使い分けれる。 (このバージョンでないとできないといった問題も解決するかも…) ・不必要なライブラリ等に干渉されない。私が仮想環境を作成してみた感想としては、非常にシンプルになり、わかりやすかったです。作成方法も簡単ですので、作ってみます
作成方法
コマンドプロンプトを開いて、カレントディレクトリで作りたい場所に行く。
作りたい場所のディレクトリで下記のコードを実行しやす。仮想環境作成virtualenv かそうかんきょうこれだけで、「かそうかんきょう」という名の仮想環境ができます。
もしも、pyhtonのバージョンを指定したいときは、
仮想環境作成(Pythonバージョン指定)virtualenv -p python3.7 かそうかんきょうバージョンを指定することも可能。
使用方法
仮想環境を使用するときに「有効化(activate)」。
使い終わったら「無効化(deactivate)」をします。有効化C:\かそうかんきょう>Scripts\\activate無効化C:\かそうかんきょう>Scripts\\deactivate大まかな流れとしては、
仮想環境を作る→有効化→プログラムの実行やライブラリのインストール
→最後に無効化→何かするときは再度有効化
といった流れ。いらなくなったら、環境(かそうかんきょうのフォルダ)ごと削除してください。
- 投稿日:2020-04-14T13:47:59+09:00
PythonGUIによる簡易営業ツール作成:社員番号検索(ラジオボタン)
PythonGUIによる簡易営業ツール作成:社員番号検索(ラジオボタン)
以前投稿したものをラジオボタン方式にして変更しました。社員数が少ない場合はこちらの方が良さそう。Spyder(python3.7)を使ってます。
#ラジオボタンで社員番号検索 import tkinter as tk root = tk.Tk() root.geometry('300x150') root.title('社員') radioValue = tk.IntVar() #textには社員名、valueには社員番号入力 rdioOne = tk.Radiobutton(root, text='田中', variable=radioValue, value=101) rdioTwo = tk.Radiobutton(root, text='鈴木', variable=radioValue, value=202) rdioThree = tk.Radiobutton(root, text='野村', variable=radioValue, value=303) rdioOne.grid(column=0, row=0) rdioTwo.grid(column=0, row=1) rdioThree.grid(column=0, row=2) #社員番号表示方法 labelValue = tk.Label(root, textvariable=radioValue) labelValue.grid(column=2, row=0, sticky="E", padx=40) root.mainloop()
- 投稿日:2020-04-14T13:11:55+09:00
見えないものを見る、家庭でできる流体可視化 BOS法
はじめに
透明な気体は肉眼では見えません。それでも見たいときがあります。
そこで役立つのがシュリーレン法やシャドウグラフ法といった流体可視化技術です。
今回は家庭にあるものでこの流体可視化に試みます。
用意するものは基本的にはカメラだけです。参考文献
こちらを参考に実験しました。
詳細な理論などはこちらを読むことをおすすめします。
BOS法に基づく密度勾配の可視化法の改良流体可視化技術の紹介
シュリーレン法
夏場に見る陽炎、ライターのガスなど、密度勾配が大きければ肉眼でも何かが見えることがあります。
シャドウグラフ法はこれらが肉眼で見えるのと同じ原理で可視化します。
この手法の感度を更に上げる方法としてシュリーレン法があります。
NOBBY TECH シュリーレン装置この光学系はこのような構成になっています。
点光源から放たれた光はレンズによって一点に集まります。実際には焦点はある程度の広がりを持っています。この光を半分くらい遮るようにナイフエッジを設置します。
光路上に密度勾配(密度のむら)があると、光は屈折し一点に集まらなくなります。ナイフエッジ側に屈折すれば遮られてセンサー上の像は暗くなり、反対に屈折すれば明るくなります。このようにして密度勾配を明るさの情報として記録することができます。この方法は感度が高く、綺麗な写真が撮れますが家庭で再現するのは少し大変です。
何が大変かというと、まず準備しなくてはいけないものが多い点です。
- 点光源(ピンホールで遮って点光源を作ります。穴の直径は小さければ小さいほど焦点のスポット径が小さくなり感度が上がります。一方光量も減っていきます。輝度の高い水銀灯のような光源が望ましいです)
- レンズ(平行光である必要ないので最低1個)
- ナイフエッジ
- カメラ
次に光学系の設置の難しさです。光軸を合わせるのに骨が折れます。
特にナイフエッジは正確に焦点の位置にある必要があります。微動ステージがあればいいですが、なければそれなりに工夫が要ります。SPBOS法(Stripe-patterned Background Oriented Schlieren)
シュリーレン法と同じように密度勾配を可視化できる手法がこのBOS法です。
これにはナイフエッジが要りません。光学系も非常に簡素です。
背景だけの画像と密度勾配のある写真の2枚を撮影し、その差から密度勾配を計算します。
背景にランダムパターンを使用したBOS法もありますが、そちらはPIVのように相互相関を計算してずれを求めるのでプログラムが面倒になります。
今回はプログラムも簡単になる縞模様を利用したSPBOS法でやります。実験
準備するもの
- 縞模様のスクリーン
- カメラ
- 測りたいもの
今回使用したものは以下の通りです。
- iphone8
- D5100, AF-S DX NIKKOR 55-300mm f/4.5-5.6G ED VR
- モノタロウのエアダスター
スクリーンはスマホでもプリンターで紙に印刷しても良いと思います。
カメラはRAWで保存できるものが望ましいです。
D5100のビット深度は14bit(16383階調)ありますが、jpgで保存するとディスプレイの階調に合わせて8bit(255階調)しかありません。
それとガンマ補正が効いているので、リニアに戻すと更に悪くなります。
三脚もあれば良いですが、床に置くのでも良いと思います。シャッターを押すときはカメラがぶれないように気をつけます。撮影
今回はこのように設置しました。焦点距離300mm、露光時間1/60、F値20、ISO感度400です。
カメラのピントはスクリーンに合わせます。
スクリーンと測定物の距離に気をつける必要があります。
近すぎると感度がでません。
仮に、スクリーンのすぐ近くに密度勾配があって光が曲がったとしても、その曲がった光は曲がらなかったときと同じ位置に結像してしまいます。
反対に遠すぎると測定物がボケます。F値を上げて被写界深度を深くして対応します。背景用の画像は以下のプログラムで作成しました。
import numpy as np # ディスプレイ ppi = 326 # 1inch(25.4mm)あたりのピクセル数 x_pix = 750 # 横解像度 y_pix = 1334 #縦解像度 pix_per_mm = ppi / 25.4 x_mm = x_pix / pix_per_mm y_mm = y_pix / pix_per_mm lam = 1.0 # mm def sin_img(direction="x",bit=8): if direction == "x": x = np.linspace(0.0,x_mm,x_pix) sin = np.sin(2.0*np.pi*x/lam) img = np.tile(sin,(y_pix,1)).T img = 0.5 * (img + 1.0) * (2**bit-1.0) elif direction == "y": y = np.linspace(0.0,y_mm,y_pix) sin = np.np.sin(2.0*np.pi*y/lam) img = np.tile(sin,(x_pix,1)) img = 0.5 * (img + 1.0) * (2**bit-1.0) if bit == 8: img = img.astype(np.uint8) elif bit == 16: img = img.astype(np.uint16) else: print("bit数は8か16") return img撮影した背景
測定物あり
解析
まずは解析に使用したプログラムを貼ります。
RAW画像はrawpyを使用して現像します。ガンマ補正のないリニアスケールの輝度値を使用します。
import rawpy import numpy as np from scipy import signal import matplotlib.pyplot as plt import cv2 from pathlib import Path def postproccesing(path): raw = rawpy.imread(str(path)) return raw.postprocess(gamma=[1.0,1.0], no_auto_bright=True, output_color=rawpy.ColorSpace.raw, use_camera_wb=True, use_auto_wb=False, output_bps=16, no_auto_scale=True ) ref_path = Path("data/ref2.NEF") jet_path = Path("data/jet2.NEF") ref_img = postproccesing(ref_path) jet_img = postproccesing(jet_path) ref_gray = ref_img[:,:,1] #グレイスケール jet_gray = jet_img[:,:,1]可視化は差分を取り、空間の微分をかけるだけです。
差分を取ることで密度勾配によって屈折した部分がわかります。
同じ方向に光が曲がったにしても、背景の模様によって暗くなる側か明るくなる側になるため、勾配を掛け算する必要があります。bos = (jet_gray-ref_gray) * np.gradient(0.5*(jet_gray+ref_gray))[1]ローパスフィルタをかけます。
適当に見た目を見ながら帯域を決めます。def fft_lpf(img,r): #周波数空間マスク mask = np.zeros_like(img) X,Y = np.meshgrid(np.arange(img.shape[1])-img.shape[1]/2.0,np.arange(img.shape[0])-img.shape[0]/2.0) mask[np.sqrt(X**2 + Y**2) < r] = 1.0 #FFT fft_img = np.fft.fftshift(np.fft.fft2(img)) fft_img *= mask return np.abs(np.fft.fft2(np.fft.fftshift(fft_img)))ローパスフィルタをかけたら画像を保存して終了です。
ノイズが多いですが、しっかりジェットが可視化できています。
もう少し工夫すればノイズは減らせそうです。まとめ
家庭にあるものだけで、それなりに流体可視化ができることを示しました。
ぜひ試してみてください。






