- 投稿日:2020-04-14T21:38:44+09:00
プロジェクトをMavenでビルドできない時の対応方法
- 環境
- CentOS Linux release 7.6.1810 (Core)
- Apache Maven 3.2.5
- Java1.8.0_242 と Java1.6.0_41
事象1 : Unknown host static.appfuse.org
$ mvn install -Dmaven.test.skip=true ...省略... [ERROR] Failed to execute goal on project ... Could not transfer artifact jsonic:jsonic:pom:1.2.0 from/to appfuse (http://static.appfuse.org/repository): static.appfuse.org: Name or service not known: Unknown host static.appfuse.org: Name or service not known -> [Help 1] [ERROR] [ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch. [ERROR] Re-run Maven using the -X switch to enable full debug logging. [ERROR] [ERROR] For more information about the errors and possible solutions, please read the following articles: [ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/DependencyResolutionException原因 : リポジトリがもうない
http://static.appfuse.org/repositoryはなくなったようだ・・・あったことも知らなかったけど対応方法 : pom.xmlのリポジトリ設定を削除する
pom.xml<?xml version="1.0" encoding="UTF-8"?> ...省略... <repositories> ...↓削除↓... <repository> <id>appfuse</id> <url>http://static.appfuse.org/repository</url> </repository> ...↑削除↑... <repository> <id>central</id> <url>http://repo1.maven.org/maven2</url> </repository> ...省略...事象2 : Return code is: 501, ReasonPhrase: HTTPS Required.
事象1のエラーで
-eオプションを知った。To see the full stack trace of the errors, re-run Maven with the -e switch.
$ mvn install -Dmaven.test.skip=true -e ...省略... Caused by: org.apache.maven.wagon.TransferFailedException: Failed to transfer file: http://repo1.maven.org/maven2/junit/junit/4.7/junit-4.7.pom. Return code is: 501, ReasonPhrase: HTTPS Required. at org.apache.maven.wagon.providers.http.AbstractHttpClientWagon.resourceExists(AbstractHttpClientWagon.java:740) at org.apache.maven.wagon.providers.http.AbstractHttpClientWagon.resourceExists(AbstractHttpClientWagon.java:696) at org.eclipse.aether.transport.wagon.WagonTransporter$PeekTaskRunner.run(WagonTransporter.java:518) at org.eclipse.aether.transport.wagon.WagonTransporter.execute(WagonTransporter.java:427) at org.eclipse.aether.transport.wagon.WagonTransporter.peek(WagonTransporter.java:398) at org.eclipse.aether.connector.basic.BasicRepositoryConnector$PeekTaskRunner.runTask(BasicRepositoryConnector.java:376) at org.eclipse.aether.connector.basic.BasicRepositoryConnector$TaskRunner.run(BasicRepositoryConnector.java:350) ... 40 more [ERROR] [ERROR] Re-run Maven using the -X switch to enable full debug logging. [ERROR] [ERROR] For more information about the errors and possible solutions, please read the following articles: [ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/DependencyResolutionException原因 :
repo.maven.apache.org/maven2/ではHTTPが使えなくなったからCentral 501 HTTPS Required – Sonatype Support
対応 : pom.xmlのリポジトリ設定をHTTPSに変更する
pom.xml<?xml version="1.0" encoding="UTF-8"?> ...省略... <repositories> <repository> <id>central</id> <url>https://repo1.maven.org/maven2</url> </repository> ...省略...事象3 : SSLException: Received fatal alert: protocol_version
$ mvn install -Dmaven.test.skip=true -e Caused by: javax.net.ssl.SSLException: Received fatal alert: protocol_version at sun.security.ssl.Alerts.getSSLException(Alerts.java:208) at sun.security.ssl.Alerts.getSSLException(Alerts.java:154) at sun.security.ssl.SSLSocketImpl.recvAlert(SSLSocketImpl.java:1902) at sun.security.ssl.SSLSocketImpl.readRecord(SSLSocketImpl.java:1074) at sun.security.ssl.SSLSocketImpl.performInitialHandshake(SSLSocketImpl.java:1320) at sun.security.ssl.SSLSocketImpl.startHandshake(SSLSocketImpl.java:1347) at sun.security.ssl.SSLSocketImpl.startHandshake(SSLSocketImpl.java:1331) at org.apache.maven.wagon.providers.http.httpclient.conn.ssl.SSLConnectionSocketFactory.createLayeredSocket(SSLConnectionSocketFactory.java:275) at org.apache.maven.wagon.providers.http.httpclient.conn.ssl.SSLConnectionSocketFactory.connectSocket(SSLConnectionSocketFactory.java:254) at org.apache.maven.wagon.providers.http.httpclient.impl.conn.HttpClientConnectionOperator.connect(HttpClientConnectionOperator.java:123) at org.apache.maven.wagon.providers.http.httpclient.impl.conn.PoolingHttpClientConnectionManager.connect(PoolingHttpClientConnectionManager.java:318) at org.apache.maven.wagon.providers.http.httpclient.impl.execchain.MainClientExec.establishRoute(MainClientExec.java:363) at org.apache.maven.wagon.providers.http.httpclient.impl.execchain.MainClientExec.execute(MainClientExec.java:219) at org.apache.maven.wagon.providers.http.httpclient.impl.execchain.ProtocolExec.execute(ProtocolExec.java:195) at org.apache.maven.wagon.providers.http.httpclient.impl.execchain.RetryExec.execute(RetryExec.java:86) at org.apache.maven.wagon.providers.http.httpclient.impl.execchain.RedirectExec.execute(RedirectExec.java:108) at org.apache.maven.wagon.providers.http.httpclient.impl.client.InternalHttpClient.doExecute(InternalHttpClient.java:184) at org.apache.maven.wagon.providers.http.httpclient.impl.client.CloseableHttpClient.execute(CloseableHttpClient.java:82) at org.apache.maven.wagon.providers.http.AbstractHttpClientWagon.execute(AbstractHttpClientWagon.java:848) at org.apache.maven.wagon.providers.http.AbstractHttpClientWagon.resourceExists(AbstractHttpClientWagon.java:708) ... 46 more [ERROR] [ERROR] Re-run Maven using the -X switch to enable full debug logging. [ERROR] [ERROR] For more information about the errors and possible solutions, please read the following articles: [ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/DependencyResolutionException原因 :
repo.maven.apache.org/maven2/ではTLSv1.0とTLSv1.1は使えないからJDK8はデフォルトでTLSv1.2になるらしいが・・・プロジェクトはJDK6だからTLS v1.1になってしまったのかしら?
Diagnosing TLS, SSL, and HTTPS | Oracle Java Platform Group, Product Management Blog対応方法 :
-Dhttps.protocols=TLSv1.2を指定するJava7 環境で maven が失敗する (Received fatal alert: protocol_version) - Qiita
$ mvn install -Dmaven.test.skip=true -e -Dhttps.protocols=TLSv1.2 ...省略... [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------ [INFO] Total time: 0.980 s [INFO] Finished at: 2020-04-14T21:34:21+09:00 [INFO] Final Memory: 22M/962M [INFO] ------------------------------------------------------------------------事象4 : Could not transfer artifact jsonic:jsonic:pom:1.2.0 from/to central
$ mvn install -Dmaven.test.skip=true -e ...省略... Caused by: org.eclipse.aether.transfer.ArtifactTransferException: Could not transfer artifact jsonic:jsonic:pom:1.2.0 from/to central (https://repo1.maven.org/maven2): Received fatal alert: protocol_version at org.eclipse.aether.connector.basic.ArtifactTransportListener.transferFailed(ArtifactTransportListener.java:43) at org.eclipse.aether.connector.basic.BasicRepositoryConnector$TaskRunner.run(BasicRepositoryConnector.java:355) at org.eclipse.aether.util.concurrency.RunnableErrorForwarder$1.run(RunnableErrorForwarder.java:67) at org.eclipse.aether.connector.basic.BasicRepositoryConnector$DirectExecutor.execute(BasicRepositoryConnector.java:581) at org.eclipse.aether.connector.basic.BasicRepositoryConnector.get(BasicRepositoryConnector.java:249) at org.eclipse.aether.internal.impl.DefaultArtifactResolver.performDownloads(DefaultArtifactResolver.java:520) at org.eclipse.aether.internal.impl.DefaultArtifactResolver.resolve(DefaultArtifactResolver.java:421) ... 35 more Caused by: org.apache.maven.wagon.TransferFailedException: Received fatal alert: protocol_version at org.apache.maven.wagon.providers.http.AbstractHttpClientWagon.fillInputData(AbstractHttpClientWagon.java:1085) at org.apache.maven.wagon.providers.http.AbstractHttpClientWagon.fillInputData(AbstractHttpClientWagon.java:977) at org.apache.maven.wagon.StreamWagon.getInputStream(StreamWagon.java:116) at org.apache.maven.wagon.StreamWagon.getIfNewer(StreamWagon.java:88) at org.apache.maven.wagon.StreamWagon.get(StreamWagon.java:61) at org.eclipse.aether.transport.wagon.WagonTransporter$GetTaskRunner.run(WagonTransporter.java:560) at org.eclipse.aether.transport.wagon.WagonTransporter.execute(WagonTransporter.java:427) at org.eclipse.aether.transport.wagon.WagonTransporter.get(WagonTransporter.java:404) at org.eclipse.aether.connector.basic.BasicRepositoryConnector$GetTaskRunner.runTask(BasicRepositoryConnector.java:447) at org.eclipse.aether.connector.basic.BasicRepositoryConnector$TaskRunner.run(BasicRepositoryConnector.java:350) ... 40 more Caused by: javax.net.ssl.SSLException: Received fatal alert: protocol_version ...省略...原因1 : もうCentralポジトリにgroupIdが
jsonicのjsonicはないMaven Repository: Search/Browse/Exploreで検索すると・・・ない
pom.xml<dependency> <groupId>jsonic</groupId> <artifactId>jsonic</artifactId> <version>1.2.0</version> </dependency>対応 : 違うgroupIdとversionの
jsonicにするセントラルリポジトリにはjsonicのバージョン1.2.0がなかったのでバージョンも上げる
pom.xml<dependency> <groupId>net.arnx</groupId> <artifactId>jsonic</artifactId> <version>1.2.7</version> </dependency>原因2 :
.m2ディレクトリの持ち主が自分じゃないから原因と対応方法は Dockerで作った環境のMavenで/home/path/.m2/repository/x.pom.part.lock (Permission denied)となった時の対応方法 - Qiita
事象5 : Fatal error compiling: 1.8は無効なターゲット・リリースです
maven-compiler-pluginでJava1.8を指定したら怒られた。$ mvn install -Dmaven.test.skip=true ...省略... [ERROR] Failed to execute goal org.apache.maven.plugins:maven-compiler-plugin:3.1:compile (default-compile) on project プロジェクト: Fatal error compiling: 1.8は無効なターゲット・リリースです -> [Help 1] [ERROR] [ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch. [ERROR] Re-run Maven using the -X switch to enable full debug logging. [ERROR] [ERROR] For more information about the errors and possible solutions, please read the following articles: [ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/MojoExecutionExceptionpom.xml<plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.1</version> <configuration> <encoding>UTF-8</encoding> <source>1.8</source> <target>1.8</target> </configuration> </plugin>原因 : 現在のJavaとMavenで使っているJavaのバージョンが違うから
参考 : Maven に JDK 1.8 を認識させる - blog.kymmt.com
Mavenは、JAVA_HOMEがあるとJavaを使うそうです。# Mavenが使っているのはJava1.6 $ mvn -v ...省略... Java version: 1.6.0_41, vendor: Sun Microsystems Inc. Java home: /usr/lib/jvm/java-1.6.0-openjdk-1.6.0.41.x86_64/jre ...省略... # JAVA_HOMEもJava1.6 $ printenv JAVA_HOME /usr/lib/jvm/java-1.6.0-openjdk.x86_64 # 使っているのはJava1.8 $ java -version openjdk version "1.8.0_242" OpenJDK Runtime Environment (build 1.8.0_242-b08) OpenJDK 64-Bit Server VM (build 25.242-b08, mixed mode)対応 : JAVA_HOMEを削除してMavenが使うJavaのバージョンを変更する
削除しないでJAVA_HOMEを変更する手段もある。
# JAVA_HOMEを削除して、 $ unset JAVA_HOME # .bash_profile のJAVA_HOME設定をコメントアウトして $ vi ~/.bash_profile cat ~/.bash_profile ...省略... #JAVA_HOME=/usr/lib/jvm/java-1.6.0-openjdk.x86_64 #export JAVA_HOME # 反映すると $ source ~/.bash_profile [1]+ Done exec ibus-daemon -dx # JAVA_HOMEがなくなり、 $ printenv JAVA_HOME $ # Mavenが使うJavaが、Java1.8になる $ mvn -v ...省略... Java version: 1.8.0_242, vendor: Oracle Corporation Java home: /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.242.b08-0.el7_7.x86_64/jre ...省略... # そうするとエラーが解消する $ mvn install -Dmaven.test.skip=true ...省略... [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------ [INFO] Total time: 2.202 s [INFO] Finished at: 2020-04-15T11:33:39+09:00 [INFO] Final Memory: 18M/749M [INFO] ------------------------------------------------------------------------事象6 : was cached in the local repository, resolution will not be reattempted until the update interval of local has elapsed or updates are forced
$ mvn install -Dmaven.test.skip=true -e ...省略... Caused by: org.eclipse.aether.transfer.ArtifactNotFoundException: Failure to find ... was cached in the local repository, resolution will not be reattempted until the update interval of local has elapsed or updates are forced at org.eclipse.aether.internal.impl.DefaultUpdateCheckManager.newException(DefaultUpdateCheckManager.java:231) at org.eclipse.aether.internal.impl.DefaultUpdateCheckManager.checkArtifact(DefaultUpdateCheckManager.java:206) at org.eclipse.aether.internal.impl.DefaultArtifactResolver.gatherDownloads(DefaultArtifactResolver.java:585) at org.eclipse.aether.internal.impl.DefaultArtifactResolver.performDownloads(DefaultArtifactResolver.java:503) at org.eclipse.aether.internal.impl.DefaultArtifactResolver.resolve(DefaultArtifactResolver.java:421) ... 40 more [ERROR] [ERROR] Re-run Maven using the -X switch to enable full debug logging. [ERROR] [ERROR] For more information about the errors and possible solutions, please read the following articles: [ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/DependencyResolutionException原因1 : キャッシュ?
[Eclipse]pom.xmlで余計なキャッシュのせいでエラーが発生 | ntの備忘録
対応方法 :
.m2/repository/org/apache/mavenディレクトリを削除する$ rm -rf ~/.m2/repository/org/apache/maven原因2 : 依存関係にあるプロジェクトのjarがないから
$ mvn install -Dmaven.test.skip=true -e ...省略... Caused by: org.eclipse.aether.resolution.ArtifactDescriptorException: Failed to read artifact descriptor for jp.co.hoge:hoge-framework-fuga:jar:3.0.0 at org.apache.maven.repository.internal.DefaultArtifactDescriptorReader.loadPom(DefaultArtifactDescriptorReader.java:337) at org.apache.maven.repository.internal.DefaultArtifactDescriptorReader.readArtifactDescriptor(DefaultArtifactDescriptorReader.java:217) at org.eclipse.aether.internal.impl.DefaultDependencyCollector.resolveCachedArtifactDescriptor(DefaultDependencyCollector.java:525) ...省略... Caused by: org.eclipse.aether.transfer.ArtifactNotFoundException: Failure to find ...was cached in the local repository, resolution will not be reattempted until the update interval of local has elapsed or updates are forced at org.eclipse.aether.internal.impl.DefaultUpdateCheckManager.newException(DefaultUpdateCheckManager.java:231) at org.eclipse.aether.internal.impl.DefaultUpdateCheckManager.checkArtifact(DefaultUpdateCheckManager.java:206) at org.eclipse.aether.internal.impl.DefaultArtifactResolver.gatherDownloads(DefaultArtifactResolver.java:585) at org.eclipse.aether.internal.impl.DefaultArtifactResolver.performDownloads(DefaultArtifactResolver.java:503) at org.eclipse.aether.internal.impl.DefaultArtifactResolver.resolve(DefaultArtifactResolver.java:421) ... 40 more [ERROR] [ERROR] Re-run Maven using the -X switch to enable full debug logging. [ERROR] [ERROR] For more information about the errors and possible solutions, please read the following articles: [ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/DependencyResolutionException対応方法 : 依存関係にあるプロジェクトのjarを作ってからやり直す
STS(eclipse)からmavenビルドでjarファイルを作ろうとしたらエラーになった話 | ヰ刀のおもちゃ箱
今回の場合は、依存関係にある
hoge-framework-fugaプロジェクトのjarを作ってからやり直す原因3 : リポジトリがないかURLが古い
Eclipseで、プロジェクトを選択 > [Maven] > [Update Project...]したらErrorになった時のこと
[Problems]タブのエラーFailure to transfer javax.resource:connector:jar:1.0 from http://maven.ow2.org/maven2/ was cached in the local repository, resolution will not be reattempted until the update interval of ow2.org has elapsed or updates are forced. Original error: Could not transfer artifact javax.resource:connector:jar:1.0 from/to ow2.org (http://maven.ow2.org/maven2/): Cannot access http://maven.ow2.org/maven2/ with type legacy using the available connector factories: AetherRepositoryConnectorFactory, BasicRepositoryConnectorFactory ...省略... Failure to transfer javax.resource:connector:jar:1.0 from http://download.java.net/maven/2/ was cached in the local repository, resolution will not be reattempted until the update interval of java.net has elapsed or updates are forced. Original error: Could not transfer artifact javax.resource:connector:jar:1.0 from/to java.net (http://download.java.net/maven/2/): Cannot access http://download.java.net/maven/2/ with type legacy using the available connector factories: AetherRepositoryConnectorFactory, BasicRepositoryConnectorFactory ...省略...対応方法 : リポジトリの設定を修正する
- エラーになっている
http://maven.ow2.org/maven2/はブラウザでアクセスするとhttps://repository.ow2.org/nexus/content/repositories/ow2-legacy/へリダイレクトされるのでリダイレクトされたURLへ変更する- エラーになっている
http://download.java.net/maven/2/はブラウザでアクセスするとWe're sorry, the page you requested was not found.となるので削除する- プロジェクトを選択 > [Maven] > [Update Project...]を再度実行
変更前のpom.xml↓削除↓ <repository> <id>java.net</id> <url>http://download.java.net/maven/2/</url> </repository> ↑削除↑ <repository> <id>ow2.org</id> ↓URL変更↓ <url>http://maven.ow2.org/maven2/</url> </repository>事象7 : Mavenリポジトリにない独自のjarを指定したらCould not find artifact jp.co.hoge.fuga:hoge-fuga-project:pom
Mavenリポジトリにない独自のjarを指定したら、その親プロジェクトのpomがないと言われた・・・
$ mvn install -Dmaven.test.skip=true -e Caused by: org.eclipse.aether.transfer.ArtifactNotFoundException: Could not find artifact jp.co.hoge.fuga:hoge-fuga-project:pom:2.0.0 in local (file:/home/fuga/hoge-fuga-project/hoge-framework-core/../repo) at org.eclipse.aether.connector.basic.ArtifactTransportListener.transferFailed(ArtifactTransportListener.java:39) at org.eclipse.aether.connector.basic.BasicRepositoryConnector$TaskRunner.run(BasicRepositoryConnector.java:355) at org.eclipse.aether.util.concurrency.RunnableErrorForwarder$1.run(RunnableErrorForwarder.java:67) at org.eclipse.aether.connector.basic.BasicRepositoryConnector$DirectExecutor.execute(BasicRepositoryConnector.java:581) at org.eclipse.aether.connector.basic.BasicRepositoryConnector.get(BasicRepositoryConnector.java:249) at org.eclipse.aether.internal.impl.DefaultArtifactResolver.performDownloads(DefaultArtifactResolver.java:520) at org.eclipse.aether.internal.impl.DefaultArtifactResolver.resolve(DefaultArtifactResolver.java:421) ... 40 more [ERROR] [ERROR] Re-run Maven using the -X switch to enable full debug logging. [ERROR] [ERROR] For more information about the errors and possible solutions, please read the following articles: [ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/DependencyResolutionException原因 : 不明
以下サイトの「ローカルリポジトリにインストールする方法その1」みたいなことをやっている。
Mavenリポジトリにないライブラリをpom.xmlで指定する方法 - grep Tips *対応方法 : pomがないと言われたプロジェクトのpom.xmlをコピーした
Could not find artifact jp.co.hoge.fuga:hoge-fuga-project:pom:2.0.0と言われたので
{ユーザホーム}/.m2/repository/jp/co/hoge/fuga/hoge-fuga-project/pom/2.0.0/ディレクトリ配下に
プロジェクトのpomをhoge-fuga-project-2.0.0.pom(.xmlは不要)にリネームしてコピーしてしのいだ。
ちゃんとした原因と対応方法を知りたい。


- 投稿日:2020-04-14T18:00:38+09:00
JerseyでHttpServletRequestなどのコンテキスト情報を得る
Jersey+SpringFrameworkでRESTFulAPIを実装していて、以下の情報が必要になりました。
- HttpServletRequest
- HttpServletResponse
その方法を調べたので覚え書き。
環境など
ツールなど バージョンなど MacbookPro macOS Mojave 10.14.5 IntelliJ IDEA Ultimate 2019.3.3 Java AdoptOpenJDK 11 apache maven 3.6.3 Jersey 2.30.1 JUnit 5.6.0 Tomcat apache-tomcat-8.5.51 Postman 7.19.1 Spring Framework 5.2.4-RELEASE 取得方法
@Contextをつけてメンバー変数に宣言するだけ。@Service @Path("/my") class MyResourceApi{ @Context HttpServletRequest httpServletRequest; @Context HttpServletResponse httpServletResponse; }これ以外のコンテキスト関係の情報は、どれも同じようにして取得可能かと思われます。
もうちょっと詳しく
これは、Jerseyのそのものの機能というより、Jerseyがversion2から組み込んでいるHK2というアノテーションベースでのDI機能のおかげのようです。
詳しくはこちらで。
HK2
https://javaee.github.io/hk2/introduction.htmlJersey2に組み込まれてるDI機能(HK2)を試す
https://qiita.com/opengl-8080/items/9bdc98aa5269512bd70e
- 投稿日:2020-04-14T17:47:51+09:00
[Android] レビューダイアログ表示
レビューダイアログ表示
ライブラリ導入
1. implementation 'com.vorlonsoft:androidrate:1.2.5-SNAPSHOT'
2. Gradle Syncしてライブラリを入れる
ライブラリ使う
1. 使いたいクラスでインポートする
import com.vorlonsoft.android.rate.*
2. レビューダイアロ作成する
AppRate.with(this)3. ライブラリ動作をコンフィグレーションする
.setStoreType(StoreType.GOOGLEPLAY) .setTimeToWait(Time.DAY, 10) .setLaunchTimes(3) .setRemindTimeToWait(Time.DAY,20) .setRemindLaunchesNumber(5) .setSelectedAppLaunches(1) .setShowLaterButton(true) .setVersionCodeCheck(false) .setVersionNameCheck(false) .setDebug(false) .setCancelable(false) .setTitle(R.string.new_rate_dialog_title) .setTextLater(R.string.new_rate_dialog_later) .setMessage(R.string.new_rate_dialog_message) .setTextNever(R.string.new_rate_dialog_never) .setTextRateNow(R.string.new_rate_dialog_ok) .monitor()
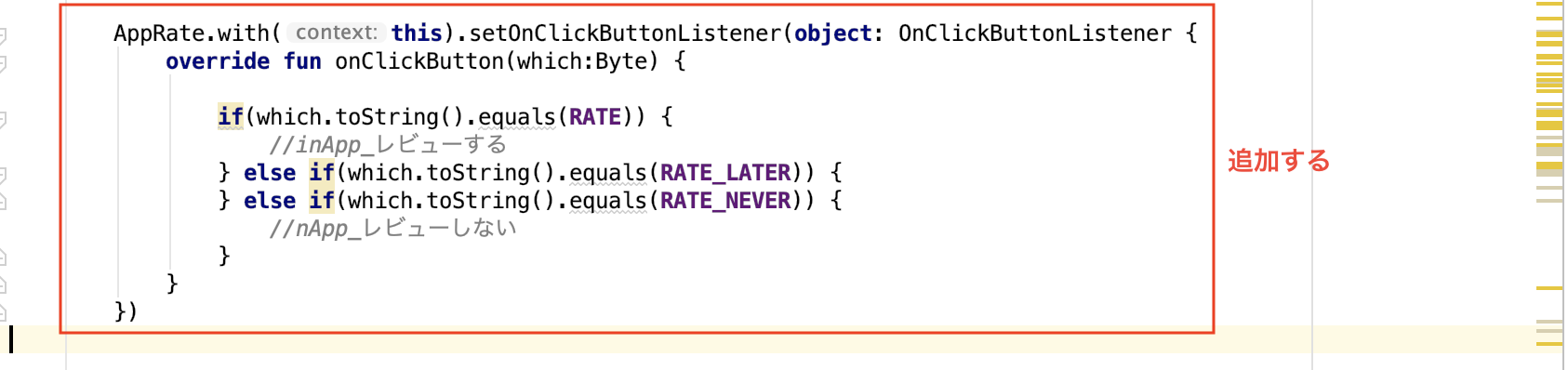
4. ダイアログのボタンクリックイベント追加
AppRate.with(this).setOnClickButtonListener(object: OnClickButtonListener { override fun onClickButton(which:Byte) { if(which.toString().equals(RATE)) { //inApp_レビューする } else if(which.toString().equals(RATE_LATER)) { } else if(which.toString().equals(RATE_NEVER)) { //nApp_レビューしない } } })
5. コンフィグレーションしたのを設定する
if (AppRate.with(this).getStoreType() == StoreType.GOOGLEPLAY) { // Checks that current app store type from library options is StoreType.GOOGLEPLAY if (GoogleApiAvailability.getInstance().isGooglePlayServicesAvailable(this) != ConnectionResult.SERVICE_MISSING) { // Checks that Google Play is available AppRate.showRateDialogIfMeetsConditions(this) // Shows the Rate Dialog when conditions are met } } else { AppRate.showRateDialogIfMeetsConditions(this) // Shows the Rate Dialog when conditions are met }




- 投稿日:2020-04-14T15:50:19+09:00
フィールドに改行文字を含むCSVのパース
手段のために目的を探す。
ある時、図書館で出会った「ふつうのコンパイラを作ってみよう」という本の影響で、javaCCを使ったパーサを作ってみたいなぁ、と思っていたところ、
「jp1baseのイベントDBをダンプしたCSVファイルって、ダブルクォートで囲まれたフィールドに改行やカンマが含まれているので、Excelに貼ったりするのが大変だよなぁ。」
という事で、早速パーサを作ってみることにしました。
やること
フィールドデータとしてカンマや改行を含むCSVデータをExcelで読み込み易い形に変換して標準出力する。
やり方
大まかな流れ
- CSVデータをパースして配列データにする。
- 1行分のデータを読み込んだら整形して出力する。
- 上記をjavaで実現する。
CSVデータの定義
- カンマ区切りのデータ
- ダブルクォーテーション(")で囲まれたフィールドにはカンマや改行を含む。
- また、ダブルクォーテーションで囲まれたフィールド内でダブルクォーテーションそのものを表す場合は、バックスラッシュ(¥)でエスケープする。
出力形式
- 各フィールドをカンマ区切りで出力
- 各フィールドはダブルクォーテーションでくくって出力
- 各フィールドデータ内のダブルクォーテーションと改行文字はスペースに置き換える。
環境
- OS JDKが対応しているOSならどこでも大丈夫です。(自宅のMacで作ったものが、職場のRHEL6サーバとWindow10でそのまま動きました。)
JDK
この記事はJDK1.6の環境で動作確認しています。
なお、2020年4月現在、公式サイトによれば100%pureなJavaなのでRuntimeへの依存はありませんとのこと。JavaCC
6.0を利用しました。
セットアップ方法はこちらの記事を参考にしていただければと思います。
参考記事スキャナの定義
まず始めにスキャナを定義します。
スキャナとは、字句解析を担う部分で、文字列の羅列から意味のある字句(TOKEN)を生成するものです。
スキャナ定義は".jj"という拡張子のテキストファイルに記述します。
以降、今回私が作成したスキャナ定義です。CSVParser.jj// 空白文字を無視するためSKIPの定義です。 // スキップした文字からはTOKENを生成しません。 // ここではスペースとタブを無視してもらいます。 SKIP : { " " | "\t" } // ダブルクォーテーションで囲まれた文字列をうまく読むための定義 // MOREディレクティブを使って、 // ダブルクォーテーションを見つけたら、"IN_DOUBLE_QUOTE"というモードに移行せい! // と、指示します。 MORE : { "\"" : IN_DOUBLE_QUOTE } // ダブルクォーテーション読み込み中のルールです。 // IN_DOUBLE_QUOTEモードの場合 // 1. バックスラッシュ以外の文字がきたら続けて次の文字を読みなさい。 // 2. バックスラッシュの次に何かしら文字がきたら、さらに次の文字を読みなさい。 // と指示しています。(2のルールにより、バックスラッシュに続いたダブルクォーテーションをただの文字として読み込んでくれます。 <IN_DOUBLE_QUOTE> MORE: { < ~["\\"] > | < "\\" ~[] > } // 次はダブルコーテーションから抜けるための定義 // IN_DOUBLE_QUOTEモード内で // 単独のダブルクォーテーションが現れたら、DQFIELDというトークンを生成し、 // デフォルトモード(DEFAULT)に戻れ!と指示しています。 // "DQFIELD"というのは勝手に決めた名前です。 // ついでにIN_DOUBLE_QUOTEというのも勝手に決めた名前です。 <IN_DOUBLE_QUOTE> TOKEN: { <DQFIELD : "\""> : DEFAULT } // デフォルトモードでは // カンマ,ダブルクォーテーション, 改行文字を含まない文字の羅列をSTDFIELDトークンとして定義しました。 // また、カンマを<SEPARATOR>トークンとします。 // さらに、行の終端を表す文字として"\n"または"\r"の連続を<EOL>トークンとしてまとめて扱うようにします。 TOKEN : { <STDFIELD : (~["\"", ",", "\r", "\n"])+ > | <SEPARATOR : "," > | <EOL : (["\r", "\n"])+ > }パーサの定義
パーサとは、スキャナが生成したTOKENの羅列を解析して、必要なお仕事を行うものです。
ここでは、1行分のCSVデータを配列にして返すことを目指します。
まずは、CSVデータの定義をしていきます。CSVデータの定義
CSVデータとは各データ(フィールドと呼んでます)がカンマ区切りで並んだ行(レコード)がズラーっと繰り返されているものですね。
CSVデータイメージフィールド1-1,フィールド1-2,フィールド1-3,・・・・ フィールド2-1,フィールド2-2,フィールド2-3,・・・・ :まずは、この構造をパーサで表現していきます。
最初にフィールドの定義。
ちなみに、パーサ定義もスキャナ定義と同じファイルに記述しました。
(CSV程度ならそんなに大きくならないので。)CSVParser.jj(フィールドの定義)String field() : { } { ( <DQFIELD> | <STDFIELD> ) } ///// 解説 ////// // 戻り値: データを文字列データとして生成したいので、戻り値の型はStringにしてます。 // 名前: あとで分かりやすいように"filed"という名前にしました。 // 内容: ダブルクォーテーションで囲まれた文字列(DQFIELD)または、普通の文字列(STDFIELD)である。 // と、定義しています。続いて1行分のデータ(ここではレコードと呼ぶことにしました)の定義です。
jp1EventParser.jj(レコードの定義)// SEPARATORで区切られたフィールドの0個以上連続しているものとして定義しました。 // フィールドの配列ってことで、List<String>として定義しています。 List<String> record() : { } { // まずフィールドがあって field() // 後ろにSEPARATOR区切りでフィールドが0個以上続く(=無い場合もある。) // なお、いきなりカンマが来る場合には対応していません。 ( <SEPARATOR> (field())? )* }最後にCSVファイル全体の定義です。
CSVParser.jj(CSVファイルの定義)// csvContents()(CSVの中身ってことで)は // レコードが複数行並んだものだとおっしゃっています。 // 一行ごとに標準出力してしまい、何も返すつもりは無いのでvoidにしました。 void csvContents() : { } { ( record() <EOL> )+ <EOF> }そしてパーサに肉付け。
CSVファイルの構造を定義したところで、次はその構造を読み込んだら何をさせるか?
という具体的な処理を書いて行きます。
実際に書いたコードがこちら。CSVParser.jj(パーサ定義に実処理を書き加えたもの。)// 恐ろしく見た目が変わって見えますが、基本的には()の中に処理を書き足しているだけです。 // フィールドの定義 String field() : { String data = ""; // 読み込んだ文字列を格納するための変数(空文字列で初期化しておく。) Token fieldToken; // 読み込んだトークンを格納する変数 } { ( // DQFIELDを読んだら、そのイメージ(実際の文字列)を変数dataに格納。 fieldToken = <DQFIELD> { data = fieldToken.image; } // または、STDIELDを読んだら、そのイメージ(実際の文字列)を、やっぱり変数dataに格納。 | fieldToken = <STDFIELD> { data = fieldToken.image; } ) { // DQFILEDもしくはSTDFIELDを一つ読み込んだら、変数dataの値を返す。 return data; } } // レコードの定義 List<String> record() : { List<String> fieldList = new ArrayList<String>(); String fieldData; } { // まずフィールドがあって fieldData = field(){ // 1個目のフィールドを配列に追加 fieldList.add(fieldData); } // 後ろにSEPARATOR区切りでフィールドが0個以上続く(=無い場合もある。) // なお、いきなりカンマが来る場合には対応していません。 ( <SEPARATOR> (fieldData = field(){ // SEPARATOR区切りで後ろのデータを見つけたら、配列にさらに追加していく。 fieldList.add(fieldData); })? )* { // 一行分読んだらそこまでできた配列を返します。 return fieldList; } } // CSVファイル全体の定義 void csvContents() : { List<String> csvRecord; // 一行分のデータを格納する変数 } { ( csvRecord = record(){ // 一行読んだら標準出力に出力します。 // ここのwriterってのは自作のクラスです。(あとで出てきます。) CSVWriter.writeLine(csvRecord); } <EOL> )+ <EOF> }CSVファイルの中身を変換して出力
パーサの書き方としてはここまでですが、せっかくなので実際に動かせるところまで持っていきます。
まず、さっき出てきた文字列配列をカンマ区切りでダブルクォーテーションでくくって出力してくれるCSVWriterクラスを定義。CSVWriter.javaimport java.util.List; public class CSVWriter { public static void writeLine(List<String> record) { String line = ""; String comma = ""; for ( String field : record ) { // 各フィールドの文字列をカンマ区切りで連結。 line = line + comma + "\"" + sanitizeString(field) + "\""; // 昔からカンマ区切りのレコード作るときはこんな風に最初だけ空文字列が連結されるようにしてるんですが、他にいい方法あったら知りたい。 comma = ","; } System.out.println(line); } private static sanitaizeString(String input){ // 適当ですみません。 // 改行文字とダブルクォーテーションを消すのです。 return input.replace("\n", " ").replace("\r", " ").replace("\"", ""); } }次にCSVParser.jjを完成形に。
CSVParser.jj// このへんおまじないです。 options { // DEBUG_PARSER=true; UNICODE_INPUT=true; } // パーサクラスの定義(javaのコード)はこのPARSER_BEGIN〜PARSER_ENDの間に記述します。 PARSER_BEGIN(CSVParser) import java.util.List; import java.util.ArrayList; import java.util.HashMap; import java.io.InputStream; import java.io.FileInputStream; public class CSVParser { public void parseCSV() { try { csvContents(); } catch(Exception ex) { System.out.println("ParseError occured: " + ex.toString()); } } } PARSER_END(CSVParser) // ここからスキャナの定義(コメントは割愛。) SKIP : { " " | "\t" } MORE : { "\"" : IN_DOUBLE_QUOTE | "'" : IN_SINGLE_QUOTE } <IN_DOUBLE_QUOTE> MORE: { < ~["\"", "\\"] > | < "\\" ~[] > | < "\"" "\"" > } <IN_SINGLE_QUOTE> MORE: { < ~["'", "\\"] > | < "\\" ~[] > | < "'" "'" > } <IN_DOUBLE_QUOTE> TOKEN: { <DQSTR : "\""> : DEFAULT } TOKEN : { <STDFIELD : (~["\"", ",", "\r", "\n" ])+ > | <SEPERATOR : "," > | <EOL : (["\r", "\n"])+ > } // ここからパーサの定義(コメントは割愛。) void csvContents() : { List<String> csvRecord; } { ( csvRecord = record() { CSVWriter.writeLine(csvRecord); } <EOL> )+ <EOF> } List<String> record() : { List<String> fieldList = new ArrayList<String>(); String fieldData; } { fieldData = field() { fieldList.add(fieldData); } ( <SEPERATOR> (fieldData = field(){ fieldList.add(fieldData); })? )* { return fieldList; } } String field() : { String data = ""; Token fieldToken; } { ( fieldToken = <DQSTR> { data = fieldToken.image; } | fieldToken = <STDFIELD> { data = fieldToken.image; } ) { return data; } }最後、mainエントリポイントが必要ですよね。
すっごい適当ですが。。。一応呼び出しのサンプルになるので。CSVConv.javaimport java.io.InputStream; import java.io.FileInputStream; public class CSVConv { public static void main(String[] args) { if ( args.length != 1 ) { return; } // 引数をそのまま渡すのは悪い方法だと、後輩に散々教えながら。これ。。 try(InputStream csvReader = new FileInputStream(args[0])) { // こんなInputStreamをもらうコンストラクタを定義した覚えは無いですね。 // javaCCが勝手に作ってくれるのでご心配なく。 CSVParser parser = new CSVParser(csvReader, "utf8"); // 実際にファイルをパースさせます。 // 読んだ行を勝手に標準出力させてるのでこんな書き方です。 parser.parseCSV(); } catch(Exception ex) { System.out.println("Error occured: " + ex.toString()); } } }コンパイルの仕方など
一応コンパイルの手順を書いておきます。
shell# javaCCを実行 => CSVParser.jjを読んでCSVParser.javaを作ってくれます。 javacc CSVParser.jj # そしたら、これでまとめてコンパイル。 javac CSVConv.javaで、お試しCSVファイル作成(こういう改行が含まれた意地悪なデータありますよね。)
hoge.csvabc,"def ghi",jkl,"mno,pqr" stu,vwx,yzそれでは、実行!!
shelljava CSVConv hoge.csv # こんな出力が得られるはず。 # "abc","def ghi","jkl", "mno,pqr" # "stu","vwx","yz"長々と書いてしまいましたが、「こういうデータ、テキストで渡されると困るよね?」を解決する手段の一つとして使えるかな?と思い、記事にしてみました。
- 投稿日:2020-04-14T12:17:21+09:00
parquet-tools が java.lang.ExceptionInInitializerError するので java8 で動くようにした話
概要
parquetの確認用に
parquet-toolsをインストールしたのですが、今どきの環境だと java8 より高いバージョンが入ってしまって動かないと思うので、 java8 をいれて使えるようにしました。事象
とりあえずどんなインストールしたらエラー出るのか
% brew install parquet-tools% parquet-tools meta ファイルパス java.lang.ExceptionInInitializerError軽くググると java8 じゃないと動かないよとのこと
% java -version openjdk version "14" 2020-03-17 OpenJDK Runtime Environment (build 14+36-1461) OpenJDK 64-Bit Server VM (build 14+36-1461, mixed mode, sharing)対応
java8 をインストールして、実行時にjavaのバージョンを切り替えるようにしようううう
% brew tap homebrew/cask-versions % brew cask install adoptopenjdk8 % /usr/libexec/java_home -v "1.8" /Library/Java/JavaVirtualMachines/adoptopenjdk-8.jdk/Contents/Home % export JAVA_HOME=`/usr/libexec/java_home -v "1.8"` % PATH=${JAVA_HOME}/bin:${PATH} % parquet-tools meta ファイルパス file: file:ファイルパス creator: parquet-mr file schema: hive_schema -------------------------------------------------------------------------------- hoge: OPTIONAL BINARY O:UTF8 R:0 D:1 … row group 1: RC:87 TS:4687 OFFSET:4 -------------------------------------------------------------------------------- hoge: BINARY SNAPPY DO:0 FPO:4 SZ:1281/3193/2.49 VC:87 ENC:BIT_PACKED,PLAIN,RLE ST:[no stats for this column] …めでたしめでたし
- 投稿日:2020-04-14T12:13:55+09:00
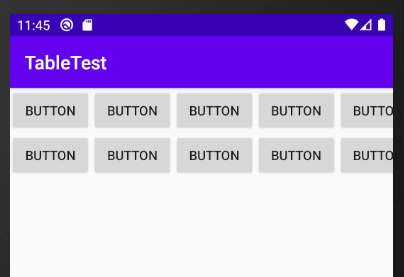
TableLayoutでボタンを画面いっぱいに表示する
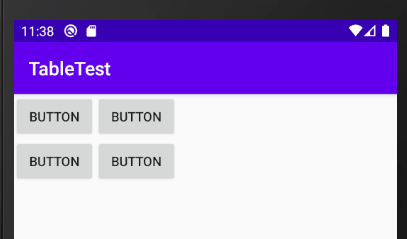
横幅を画面いっぱいに広げたい
↓このボタンを横幅いっぱいに広げたい。
元となるコード
activity_main.xml<?xml version="1.0" encoding="utf-8"?> <TableLayout xmlns:android="http://schemas.android.com/apk/res/android" android:layout_width="match_parent" android:layout_height="match_parent"> <TableRow android:layout_width="match_parent" android:layout_height="match_parent"> <Button android:id="@+id/button2" android:layout_width="match_parent" android:layout_height="match_parent" android:text="Button" /> <Button android:id="@+id/button" android:layout_width="match_parent" android:layout_height="match_parent" android:text="Button" /> </TableRow> <TableRow android:layout_width="0dp" android:layout_height="match_parent"> <Button android:id="@+id/button4" android:layout_width="match_parent" android:layout_height="match_parent" android:text="Button" /> <Button android:id="@+id/button3" android:layout_width="match_parent" android:layout_height="match_parent" android:text="Button" /> </TableRow> </TableLayout>stretchColumns
android:stretchColumns="列番号"を設定する。
activity_main.xml<TableLayout xmlns:android="http://schemas.android.com/apk/res/android" android:layout_width="match_parent" android:layout_height="match_parent" android:stretchColumns="0,1">
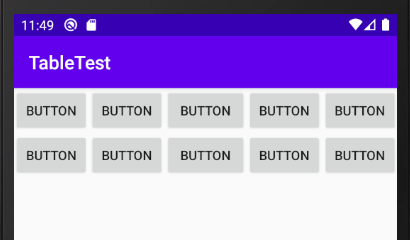
綺麗に広がりました。横幅を画面内に収めたい
今度はボタンが画面幅からはみ出てしまった場合。
shrinkColumns
android:shrinkColumns="列番号"を設定する。
activity_main.xml<TableLayout xmlns:android="http://schemas.android.com/apk/res/android" android:layout_width="match_parent" android:layout_height="match_parent" android:shrinkColumns="0,1,2,3,4">
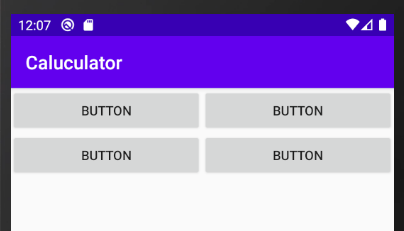
収まりました。縦幅を画面いっぱいに広げたい
TableRowにweight="1"を設定します。
activity_main.xml<TableRow android:layout_width="match_parent" android:layout_height="match_parent" android:layout_weight="1">
縦横を画面にいっぱいに広げたい
shrinkColumnsとweight="1"を設定します。
activity_main.xml<TableLayout xmlns:android="http://schemas.android.com/apk/res/android" android:layout_width="match_parent" android:layout_height="match_parent" android:shrinkColumns="0,1,3,4"> <TableRow android:layout_width="match_parent" android:layout_height="match_parent" android:layout_weight="1">


- 投稿日:2020-04-14T12:03:36+09:00
[Java] Arrays.sort よりも速いsortを書く
Javaで競技プログラミングをしているのですが,Javaの標準ライブラリに用意されている primitive type の配列をソートを行う関数Arrays.sortの最悪計算量が $O(N^2)$ だと聞き, さすがにそれはまずいということで自前のソート関数を実装しました ( ただし, primitive でない場合は最悪 $O(N\log N)$ のMerge Sort が使われているようです. 安定ソートであることしか保証されていないのでこれも変更される可能性があります ) .( 追記 2020/04/14 15:27 )
Java 14 では以下の通り最悪計算量が $O(N\log N)$ となるよう修正されているようです. ただ, 競プロで Java 14 が使えるようになるにはまだまだ時間がかかりそうなので, 自作ソートは持っていても良さそうです.
Java 14のArrays.sort(int[]) より引用The sorting algorithm is a Dual-Pivot Quicksort by Vladimir Yaroslavskiy, Jon Bentley, and Joshua Bloch. This algorithm offers O(n log(n)) performance on all data sets, and is typically faster than traditional (one-pivot) Quicksort implementations.
( 追記終わり )
また, どうせ書くなら
Arrays.sortに勝ちたくなったので, 高速化の工夫を施した複数パターンのソートアルゴリズムを実装してその速度を比較しました.今回実装・計測したのは, 以下の3種類のソートアルゴリズムで, これらを
Arrays.sortと戦わせます.
- Merge Sort ( 再帰, 愚直な実装 )
- Merge Sort ( 再帰 ) + Insertion Sort
- Merge Sort ( 非再帰 ) + Insertion Sort
- Radix Sort ( 基数ソート )
テストに用いた配列サイズは $N=10^5, 10^6, 10^7$ であり, 複数回の実行時間の平均値を測定した. 実行時間の関係上, $N=10^5$ では $1000$ 回, $10^6$ では $100$ 回, $10^7$ では $10$ 回分しか計測出来ていません. テストケースは
java.util.RandomのnextInt()およびnextLong()を使用して生成し, 入力による差をなくす為, 生成した配列をコピーして同じ内容の配列に対して各ソートを実行・計測しました.
Arrays.sortの特長としてソート済みの配列に対する処理が爆速であることが知られていますが, 非本質的な気がしたので今回はランダムケースでの勝利を目指しました.Merge Sort (再帰版) + Insertion Sort
Merge Sort は, 簡単に説明すると以下のようなアルゴリズムです. 詳細な説明は既に多くの方が分かりやすく書かれているので省略します.
Step 1. 配列を前半部分と後半部分に分ける.
Step 2. 配列の前半部分と後半部分を再帰的呼び出しでソートする.
Step 3. ソートされた前半部分と後半部分を上手く Merge して全体をソートする.このアルゴリズムの計算量ですが, 配列のサイズを $N$ として漸化式を立てると $O(N\log N)$ になることが分かります. 比較に基づくソートの計算量の下限は $O(N\log N)$ であることが知られており, オーダー上は高速であるということになります.
しかし, 実際にこのアルゴリズムを書いて動かしてみると, 以下のように
Arrays.sortには到底及ばない速度となりました. なお, この Merge Sort の実装は, 後に示す再帰版の Merge Sort + Insertion Sort のコードから Insertion Sort の部分を消して終了条件を足すだけでほとんど同じなので省略します.
int配列のソート $N=10^5$ $N=10^6$ $N=10^7$ Arrays.sort ( 標準ライブラリ ) 5.979 73.396 891.750 MergeSort ( 再帰 ) 9.373 117.921 1238.865 原因の1つとして挙げられるのが, 配列を小さく分割した時の挙動です. 一般的に, オーダーを改善すればその分計算やデータの持ち方が複雑になるため, 小さなサイズではそのオーバーヘッドがオーダー上の優位性を上回ることがあります. Merge Sortに関して言えば, サイズが小さい場合にはオーダー上では劣るInsertion Sort ( 挿入ソート, 計算量は $O(N^2)$ ) の方が速くなります.
そこで, 配列サイズに対して境界値を設定し, その境界値以下のサイズの配列が渡された場合には Insertion Sort を実行するように Merge Sort を書き換えます. この書き換えを施したコードを以下に示します. なお, 以下のコードでは範囲は全て半開区間として扱います.
RecursionalMergeSort.java// Merge Sort から Insertion Sort に切り替える境界値 private static final int INSERTION_SORT_THRESHOLD = 60; // 外から見える関数 public static final void sort(int[] a, int from, int to) { sort(a, from, to, new int[a.length >> 1]); } // Merge Sort + Insertion Sort の処理本体 // workは前半部分と後半部分をMergeする際に元の配列を退避するための作業領域. // workはメモリ使用量を節約するために使い回す. private static final void sort(int[] a, int begin, int end, int[] work) { // 与えられた配列の長さが境界値以下なら挿入ソートを実行 if (end - begin <= INSERTION_SORT_THRESHOLD) { insertionSort(a, begin, end); return; } // 配列の真ん中となる添字. // >> 1 は 2 で割ることを表している. int mid = (begin + end) >> 1; // 配列の前半分を再帰的にソートする. sort(a, begin, mid, work); // 配列の後半分を再帰的にソートする. sort(a, mid, end, work); // 前半分の配列長 int len = mid - begin; // 作業領域に配列の前半部分をコピーしておく. // 配列のコピーはfor文で回すよりもSystem.arraycopyの方が高速に動作する System.arraycopy(a, begin, work, 0, len); // i は格納先の添字. // wiはwork(=配列の前半分)のどの添字を見ているかを表す. // tiは配列の後半分のどの添字を見ているかを表す. // 配列の後半部分の添字はmidから始まる. for (int i = begin, wi = 0, ti = mid;; i++) { if (ti == end) { // 後半分を全て見終わっていれば, 作業領域に残っている要素をコピー System.arraycopy(work, wi, a, i, len - wi); // もうMergeすべき要素は残っていないのでループを抜ける break; } else if (work[wi] > a[ti]) { // 前半分で今見ている要素と後半分で今見ている要素を比較. // 小さい方を格納し, 添字を後ろにずらす. a[i] = a[ti++]; } else { // 上と同様. a[i] = work[wi++]; // 前半分を見終われば, 後半分の残りの要素は既に配列に入っている if (wi == len) { break; } } } } // 配列サイズが小さいときに呼び出されるInsertion Sort. private static final void insertionSort(int[] a, int from, int to) { // 配列aが from <= x < iの範囲で昇順に並んでいる時に, // a[i]がどこに挿入すべきなのかを要素を後ろにずらしながら探す. for (int i = from + 1; i < to; i++) { // 挿入する値 int tmp = a[i]; // a[i-1]以上なら探索する必要は無い if (a[i - 1] > tmp) { // 挿入先の添字 int j = i; // 初めの1回は必ずwhileの条件文を満たすのでdo-whil do { // 要素を1つ後ろにずらす. a[j] = a[j - 1]; // 挿入先はもっと前 j--; // 「先頭に到達」or「a[i]以下の要素を発見」で抜ける } while (j > from && a[j - 1] > tmp); // a[i]を挿入すべき場所に入れる. a[j] = tmp; } } }比較結果は以下のようになりました. ( 単位はミリ秒, 同じテストデータを使用 )
int配列のソート $N=10^5$ $N=10^6$ $N=10^7$ Arrays.sort ( 標準ライブラリ ) 5.979 73.396 891.750 MergeSort ( 再帰 ) 9.373 117.921 1238.865 MergeSort ( 再帰 ) + Insertion Sort 6.557 82.228 991.833 まだ
Arrays.sortには及びませんが, 実用上耐えうる速度まで高速化されています. ただし, 今回の目標はArrays.sortよりも速いソートを実装することなので, もっと高速化します.遅さの原因としては再帰呼び出しが考えられます. 再帰呼び出しは
forやwhileに書き換えると速度が向上すると言われています. そこで, 次は再帰を用いないMerge Sortを実装します.Merge Sort (非再帰) + Insertion Sort
再帰版の Merge Sort では, 上から下に ( 大きい方から小さい方に ) 降りていくイメージ ( =トップダウン ) での実装でしたが, 非再帰版では逆向き ( =ボトムアップ ) の実装をします. つまり, まず小さいサイズに配列を分解し, その配列たちをソートします. このソート済みの部分列をブロック ( block ) と呼ぶことにします. その後, このブロックを先程の実装と同じ要領で 2 つずつ Merge して大きくしていくことで, 最終的には列全体をソートします. 以下にその実装を載せますが, 再帰版と共通するコードやコメントは適宜省略しています.
NonRecursionalMergeSort.java// 非再帰なので, 作業領域の配列は内部で生成する(引数に渡さなくてよい). public static final void sort(int[] a, int begin, int end) { // まず初めに, 小さなブロック毎にInsertion Sortを行う. // 今回, ブロックの最小単位として前の実装で定義した境界値を用いる // i はブロックの先頭の添字 for (int i = begin;;) { // j はブロックの終端の添字(ただし, 半開区間なので j は含まれない) int j = i + INSERTION_SORT_THRESHOLD; // 配列長がブロックの大きさで割り切れるとは限らない. // なので, ブロックの幅が十分に取れるかを判定. if (j < end) {// 十分な幅を取れた場合 // Insertion Sortを実行 insertionSort(a, i, j); } else {// 十分な幅が取れなかった場合(=配列の端に到達した場合) // i から端までInsertion Sortを実行. insertionSort(a, i, end); // 端に到達したのでループを抜ける. break; } // 次のブロックの始点は j. (i, jは半開区間だったことに注意) i = j; } // ソートすべき配列の範囲の長さ. int len = end - begin; // 作業領域. 先程と同様, 配列の前半部分を退避するのに用いる. // ブロック分割では端数が出るため境界が真ん中とは限らない. // 従って, 確保すべき領域は広くなる. int[] work = new int[len]; // blockはブロックの大きさ. Mergeする度に大きさは2倍になるので, // 更新式はblock <<= 1 とする. for (int block = INSERTION_SORT_THRESHOLD; block <= len; block <<= 1) { // blockを2つずつMergeするので, block 2つ分の大きさを計算しておく. int twoBlocks = block << 1; // from は Mergeする2つのブロックのうち1つ目の先頭を指す添字. // 従って, 更新式ではブロック2つ分の大きさを加算する. // max は from の取れる最大の値(-1). // 端数が区間1つ以下の長さしかなければMergeする必要は無いので, // max = end - blockとしてブロック1つ分の長さを引いている. for (int from = begin, max = end - block; from < max; from += twoBlocks) { // 2つのblockの境界(2つ目のブロックの先頭を指す). int mid = from + block; // 2つ目のブロックの終端. 区間の端に注意してminを取る. int to = Math.min(from + twoBlocks, end); // 2つのブロックのmergeは再帰版と同様なので説明は省略. System.arraycopy(a, begin, work, 0, block); for (int i = from, wi = 0, ti = mid;; i++) { if (ti == to) { System.arraycopy(work, wi, a, i, block - wi); break; } else if (work[wi] > a[ti]) { a[i] = a[ti++]; } else { a[i] = work[wi++]; if (wi == block) { break; } } } } } } // insertionSort メソッドは再帰版と同様なので省略.比較結果は以下のようになりました.
int配列のソート $N=10^5$ $N=10^6$ $N=10^7$ Arrays.sort ( 標準ライブラリ ) 5.979 73.396 891.750 MergeSort ( 再帰 ) 9.373 117.921 1238.865 MergeSort ( 再帰 ) + Insertion Sort 6.557 82.228 991.833 MergeSort ( 非再帰 ) + Insertion Sort 3.926 43.144 477.579 非再帰に書き換えただけでかなり高速化できたようです.
Arrays.sortに勝っています.しかし, 実は
intやlongを要素として持つ配列をソートするのであれば更に高速なアルゴリズムが存在します.Radix Sort ( 基数ソート )
ここでは, Radix Sort ( 基数ソート ) なるアルゴリズムを実装します. Radix Sort の計算量は, 位取り記法 ( 例えば$10$進数表記など ) の語長を $k$ として, なんと $O(k\ast N)$ です.
Radix Sortは "比較による" ソートアルゴリズムではありません. どういうことかと言うと, Radix Sort では, 要素が何らかの位取り記法で表すことが出来る場合に, 直接比較をせずともそれぞれの位の値に着目するだけでソートすることが出来ます.
intやlongは bit 列で表され, この bit 列は位取り記法に他なりません. 従って,intやlongからなる列は Radix Sort によりソートされます. 以下で示す実装を見れば, ソートアルゴリズムなのに配列の 2 要素の比較は一切存在しないことが見て取れると思います.具体的には, bit 長を k として, 以下のような k Step からなるのアルゴリズムになります. 各 Step を $O(N)$ で行うことで, 全体$O(k\ast N)$ が達成できます.
Step 1. 最下位 bit が 0 である要素を入れる bucket と, 1 である要素を入れる bucket を用意し, 数列の要素を格納する.
Step 2. 最下位から 2 番目の bit に対して Step 1 と同様の操作を行う. ただし, 同じ bucket に入る任意の 2 要素に関して, 格納される順番は手順 1 での bucket の順番を崩さないようなものでなければならない.
Step i. 最下位から i 番目の bit に対して同様に並び替える.
Step k. 最下位から k 番目の bit に対して同様に並び替える.Step 2 の「ただし, ...」が分かりにくいと思うので, 例を挙げて流れを追うことにします. 以下では, a = [010, 011, 100, 101, 000] を上の手順に従ってソートします. 語長は 3 なので以下のStep 1~3でソートが完了することになります.
Step 1.
a = [010, 011, 100, 101, 000] -> bucket = [[010, 100, 000], [011, 101]] とする. これを a に戻して, a = [010, 100, 000, 011, 101]と更新.Step 2.
a = [010, 100, 000, 011, 101] -> bucket = [[100, 000, 101], [010, 011]] とする. これを a に戻して, a = [010, 100, 000, 011, 101]と更新. この時, bucket 0に入れる[100, 000, 101]は, 処理前の a と同じ順番に入れている. bucket 1でも同様.Step 3.
a = [100, 000, 101, 010, 011] -> bucket = [[000,010、011], [100, 101]] とし, これを a に戻して, a = [000,010、011, 100, 101]と更新. a は確かにソートされている.以上が Radix Sort の大まかな流れとなるが, 1 つ大きな問題があります. それは, 負数の扱いです.
Javaなど多くの言語では負の整数を 2 の補数表現を用いて表しており, そのため上のアルゴリズムをそのまま適用すると最上位 bit が 1 である負の数が正の数よりも大きいとして並べ替えられてしまいます ( 言い換えると,unsignedとみなした場合でのソートが行われる ) . また,signedでの負数の大小関係とunsignedでの大小関係はちょうど逆となっています. そこで, 次のような手順を踏むことで正しいソート列が得ることを考えます.Step 1. (
unsignedとして ) 降順に Radix Sort を行う.
Step 2.unsignedでの降順に並べ替えられているので, 前に負の数, 後に正の数が固まっている. また,signedとして大小関係を見ると, 負の数, 正の数はそれぞれ降順に並んでいる. そこで, 負数列だけを反転し, さらに正数列だけを反転すれば,signedでのソート列が得られる.これで負の数にも対応した Radix Sort が書けるようになりました. ただし, これから示す実装では, 語長を短くする為に 1 bitではなく 8 bitをまとめて一つの位として見ています. つまり, $2^8=256$ 進数での位取り記法を用いてRadix Sortを行っています.
RadixSort.java// bucket のサイズ. private static final int BUCKET_SIZE = 256; // intは32bitなので, 256進数における語長は 32 / 8 = 4. private static final int INT_RECURSION = 4; // 下位8bit(256進数での一桁)を抽出するためのマスク private static final int MASK = 0xff; // 外から見える関数 public static final void sort(int[] a, int from, int to) { sort(a, from, to, 0, new int[to - from]); } // メモリ節約のためにbucketは1次元配列で表現. // l は今 Step l であることを表す. (ただし, 0-indexed で l = 0, 1, 2, 3) private static final void sort(int[] a, final int from, final int to, final int l, final int[] bucket) { // 右シフトをしてからmaskをするので, その右シフト量を計算しておく. final int shift = l << 3; // 各bucketに入る個数を管理. // 各bucketの始点が欲しいので累積和で持つ. final int[] cnt = new int[BUCKET_SIZE + 1]; // 各bucketに何個置いたかを管理する. final int[] put = new int[BUCKET_SIZE]; for (int i = from; i < to; i++) { // a[i] >>> shift で所望の8bitを最下位に移動させる. // (a[i] >>> shift) & MASK でどのbucketに入るかが求まる. // ただし, あとで累積するので添字は1つずらしておく. cnt[((a[i] >>> shift) & MASK) + 1]++; } // 累積を取ると, cnt[i] にはi個目のbucketの始点が格納される. for (int i = 0; i < BUCKET_SIZE; i++) { cnt[i + 1] += cnt[i]; } for (int i = from; i < to; i++) { // 先程と同様にしてどのbucketに入るかを計算. int bi = (a[i] >>> shift) & MASK; // bi個目のbucketに格納. // 既に置いたものを上書きしないよう, put[bi]を増やす bucket[cnt[bi] + put[bi]++] = a[i]; } // 降順にソートしたいので, bucketを逆順に走査 // idx は配列 a 上で次に格納すべき場所の添字を表す. for (int i = BUCKET_SIZE - 1, idx = from; i >= 0; i--) { // i個目のbucketの始点 int begin = cnt[i]; // i個目のbucketのサイズ. cntが累積和であることを用いて計算. int len = cnt[i + 1] - begin; // bucketの内容を元の配列にコピーして戻す. System.arraycopy(bucket, begin, a, idx, len); // 次格納すべき場所は len だけ先にある idx += len; } // 次の Step は Step l + 1. final int nxtL = l + 1; // まだ位が残っているか if (nxtL < INT_RECURSION) { // 次のStepへ. bucketは再利用 sort(a, from, to, nxtL, bucket); // i = 0でここに到達しているならば, unsignedでの降順ソートが終了している if (l == 0) { // 使い回す変数. int lft, rgt; // 前半に負数, 後半に正数があるので境界を二分探索. // 負数の数を求める. O(log N). lft = from - 1; rgt = to; while (rgt - lft > 1) { int mid = (lft + rgt) >> 1; if (a[mid] < 0) { lft = mid; } else { rgt = mid; } } // 負数の数がrgtの値になっている. final int negative = rgt; // 配列aの部分列[from:negative-1](閉区間)をreverseする. // この区間には負数が降順に並んでいる. lft = from; rgt = negative - 1; while (rgt > lft) { int tmp = a[lft]; a[lft] = a[rgt]; a[rgt] = tmp; lft++; rgt--; } // 配列aの部分列[negative:to-1](閉区間)をreverseする. // この区間には正数が降順に並んでいる. lft = negative; rgt = to - 1; while (rgt > lft) { int tmp = a[lft]; a[lft] = a[rgt]; a[rgt] = tmp; lft++; rgt--; } } } }比較結果は以下のようになりました.
int配列のソート $N=10^5$ $N=10^6$ $N=10^7$ Arrays.sort ( 標準ライブラリ ) 5.979 73.396 891.750 MergeSort ( 再帰 ) 9.373 117.921 1238.865 MergeSort ( 再帰 ) + Insertion Sort 6.557 82.228 991.833 MergeSort ( 非再帰 ) + Insertion Sort 3.926 43.144 477.579 RadixSort 1.000 11.124 133.713 圧倒的勝利です. ただ, 少し注意しないといけないのは, オーダーが語長に比例するため
long配列のソートではその分だけ多くの時間がかかるということです. 実際にlong配列で計測すると以下のように Radix Sort のパフォーマンスが低下している結果が得られました.
long配列のソート $N=10^5$ $N=10^6$ $N=10^7$ Arrays.sort ( 標準ライブラリ ) 6.300 67.841 751.904 MergeSort ( 再帰 ) 9.110 111.099 1340.971 MergeSort ( 再帰 ) + Insertion Sort 6.594 76.131 922.294 MergeSort ( 非再帰 ) + Insertion Sort 4.108 43.538 484.530 RadixSort 2.684 29.359 339.683 それでもこの中では圧倒的最速ですね.
まとめ
Arrays.sortに見事勝利することが出来たのではないでしょうか. Radix Sort は騙されたような気がしないこともないですが, Merge Sort でも勝てたので大満足です.
- 投稿日:2020-04-14T10:26:37+09:00
【Java初心者】コマンドライン引数って…わからんなぁ~
コマンドラインで~,コマンドラインの引数の数が~,
みたいな課題出されても、『意味わからん!』となるあつぎです。
なのでググって調べてみた!Let's Google it!Q.1 コマンドライン引数とは?
結論:プログラムを起動した際に一番最初に渡される情報
いちいちコードを書かなくてもファイルの情報を勝手に持ってきてくれるから便利との評判です。
ざっくり説明すると、コマンドライン引数に最も多く設定されるのはファイルの情報で、別に文字や数値でもOKだそうです。設定するときに必要なデータが入っているフォルダのパスを指定してあげればフォルダの中身の情報が取得できるそう。
Q.2 コマンドライン引数の情報はどこに渡されるの?
結論: mainメソッドの引数部分
public class sample{ public static void main(String[] args){ } //String[] argsの部分 }javaの仮想マシン(VM)から最初に呼び出されるのは、"public static void main(String[] args)"と決まっているらしくString型の配列で受け取っています。
ちなみに変数名だけは別に"args"じゃなくても良いそうな。
Q.3 mainメソッドは他の場所から引数の値を受け取れないの?
結論:mainメソッドの引数はコマンドライン引数専用である
mainメソッドプログラムの中で一番最初に呼ばれるため、下のようにメソッドで引数を渡すことができないのです。だからコマンドライン引数で情報を渡してあげる必要があるそうな。
public class sample{ public static void main(String[] args){ hello("こんにちは","柿崎"); } public void hello(String a, String b){ System.out.println(a + "," + b + "さん") //結果:こんにちは,柿崎さん } }知らないと意外と困る場面多そうですね。
僕も気を付けます。
では、またの
- 投稿日:2020-04-14T10:04:12+09:00
Javaにおける円周率【Mathクラス】 ~Mathクラスってなんぞ?~
円周率はMathクラスのPI使ってね?
こういわれても頭の中は『?』なあつぎです?
なのでGoogle先生お願いします。なんでもしますかr
◆そもそもMathクラスとは
Math クラスは、指数関数、対数関数、平方根、および三角関数といった基本的な数値処理を実行するためのメソッドを含んでいます。はい、なんのこっちゃですよね。
なので、こんな種類があるよーって参考記事があったので記載させていただきます?♂️
【結論:円周率はこれでOK】
この記事読んでる方は、さっさと答えを知りたい!という人だと思うので、さっさと結論から書きます。
public class sample { public static void main(String[] args) { double x = Math.PI; //Javaにおける円周率 System.out.println(x); } }
※ちょい補足
【PI】
円周率πに最も近いdouble値、3.141592653589793です。では、またの
- 投稿日:2020-04-14T10:04:12+09:00
【Java初心者】Javaにおける円周率【Mathクラス】 ~Mathクラスってなんぞ?~
円周率はMathクラスのPI使ってね?
こういわれても頭の中は『?』なあつぎです?
なのでGoogle先生お願いします。なんでもしますかr
◆そもそもMathクラスとは
Math クラスは、指数関数、対数関数、平方根、および三角関数といった基本的な数値処理を実行するためのメソッドを含んでいます。はい、なんのこっちゃですよね。
なので、こんな種類があるよーって参考記事があったので記載させていただきます?♂️
【結論:円周率はこれでOK】
この記事読んでる方は、さっさと答えを知りたい!という人だと思うので、さっさと結論から書きます。
public class sample { public static void main(String[] args) { double x = Math.PI; //Javaにおける円周率 System.out.println(x); } }
※ちょい補足
【PI】
円周率πに最も近いdouble値、3.141592653589793です。では、またの
- 投稿日:2020-04-14T09:43:11+09:00
文字列から数値への変換 ~IntegerクラスのparseIntメソッドとは何ぞや?~
こんにちは、あつぎです!
IntegerクラスのparseIntメソッドとは?
と質問され、「未経験にわかるかいっ!」と思ったのでメモしておきます。
これをスパッと答えられる経験者は回れ右してお帰り下さい。◆文字列から数値への変換
数値形式の文字列を数値そのものに変換する方法があるそうです。
その1つが、『parsexxxメソッドを使用する』とのこと。◆parsexxxメソッドを使用する
この方法は、各ラッパークラスで用意されているparsexxxメソッドを使う方法です。xxxの部分はラッパークラス毎に異なりそれぞれ次のようなメソッドが用意されています。
Byteクラス: static byte parseByte(String s) Shortクラス: static short parseShort(String s) Integerクラス: static int parseInt(String s) Longクラス: static long parseLong(String s) Floatクラス: static float parseFloat(String s) Doubleクラス: static double parseDouble(String s)◆使用例:parsexxxメソッド
たとえば、Integerクラスで用意されているparseIntメソッドは、引数に指定された文字列を整数の値として解析しint型の値として返すそうです。実際には次のように記述します。
String str = "124"; int i = Integer.parseInt(str);
なお、整数でない数値の文字列をparseIntメソッドを使って変換しようとしたり、そもそも数値形式でない文字列を変換しようとすると、コンパイルエラーとはなりませんが実行時に
「java.lang.NumberFormatException: For input string」というエラーが発生します。
例えば次のような場合です。
String str = "124.567"; int i = Integer.parseInt(str);
また、範囲を超えた数値の文字列を変換しようとすると、コンパイルエラーになりませんが実行時に
「java.lang.NumberFormatException: Value out of range」というエラーが発生します。
例えば次のような場合です。
String str = "198667234"; byte b = Byte.parseByte(str);いずれの場合もコンパイル時にはエラーとなりませんので注意して下さい。
◆サンプル
class JSample5_1{ public static void main(String args[]){ String str1 = "124"; int i = Integer.parseInt(str1); System.out.println(i); //124 } }以上です。
ではまたの。
- 投稿日:2020-04-14T09:43:11+09:00
【Java初心者】文字列から数値への変換 ~IntegerクラスのparseIntメソッドとは何ぞや?~
こんにちは、あつぎです!
※円の面積の問題の追記アリIntegerクラスのparseIntメソッドとは?
と質問され、「未経験にわかるかいっ!」と思ったのでメモしておきます。
これをスパッと答えられる経験者は回れ右してお帰り下さい。◆文字列から数値への変換
数値形式の文字列を数値そのものに変換する方法があるそうです。
その1つが、『parsexxxメソッドを使用する』とのこと。◆parsexxxメソッドを使用する
この方法は、各ラッパークラスで用意されているparsexxxメソッドを使う方法です。xxxの部分はラッパークラス毎に異なりそれぞれ次のようなメソッドが用意されています。
Byteクラス: static byte parseByte(String s) Shortクラス: static short parseShort(String s) Integerクラス: static int parseInt(String s) Longクラス: static long parseLong(String s) Floatクラス: static float parseFloat(String s) Doubleクラス: static double parseDouble(String s)◆使用例:parsexxxメソッド
たとえば、Integerクラスで用意されているparseIntメソッドは、引数に指定された文字列を整数の値として解析しint型の値として返すそうです。実際には次のように記述します。
String str = "124"; int i = Integer.parseInt(str);
なお、整数でない数値の文字列をparseIntメソッドを使って変換しようとしたり、そもそも数値形式でない文字列を変換しようとすると、コンパイルエラーとはなりませんが実行時に
「java.lang.NumberFormatException: For input string」というエラーが発生します。
例えば次のような場合です。
String str = "124.567"; int i = Integer.parseInt(str);
また、範囲を超えた数値の文字列を変換しようとすると、コンパイルエラーになりませんが実行時に
「java.lang.NumberFormatException: Value out of range」というエラーが発生します。
例えば次のような場合です。
String str = "198667234"; byte b = Byte.parseByte(str);いずれの場合もコンパイル時にはエラーとなりませんので注意して下さい。
◆サンプル
class JSample5_1{ public static void main(String args[]){ String str1 = "124"; int i = Integer.parseInt(str1); System.out.println(i); //124 } }以上です。
ではまたの。
- 投稿日:2020-04-14T09:37:05+09:00
ラッパークラスとはなんぞ? ~Javaでこれは知っておこう~
ラッパークラスとはなんぞやと思い、まとめてみました。
◆ラッパークラスとは?
javaでは基本データ型として、byte, short, long, integer, float, char, double, booleanが規定されています。これらをプリミティブ型というそうです。
プリミティブ型はオブジェクトではないので、それ自身のメソッドを持っていません。
ところがオブジェクトを使ってゆくと、これらの基本型を操作しなければならない局面が出てきます。そのためプリミティブ型をオブジェクトとして操作するクラスが各種定義されています。 これらはプリミティブ型を包み込むという意味でラッパークラスといいます。
あんまりわかりませんね。情報系の学部卒ならスッと頭に入るのでしょうか?
絵にするとわかりやすい?
◆プリミティブ型の種類によっていくつかあるそうな
ラッパークラスは下の表で示されるように、プリミティブ型の種類によっていくつかの種類があります。オブジェクトですので、それぞれ固有のプリミティ値を持ち、それを操作するメソッドを持っています。
プリミティブ型 ラッパークラス byte Byte short Short int Integer long Long char Character float Float double Double boolean Boolean 使い方は色々ありますが1例として、数字の文字列 "123" "123.45" はそのままでは計算ができませんが、ラッパークラスで数字に変換することによって数値計算することができるそうな。
基本データ型はNULLデータは代入できません。オブジェクト型ならNULLが代入できます。
頭が大文字になっているのが特徴ですね?

- 投稿日:2020-04-14T09:37:05+09:00
【Java初心者】ラッパークラスとはなんぞ? ~Javaでこれは知っておこう~
ラッパークラスとはなんぞやと思い、まとめてみました。
◆ラッパークラスとは?
javaでは基本データ型として、byte, short, long, integer, float, char, double, booleanが規定されています。これらをプリミティブ型というそうです。
プリミティブ型はオブジェクトではないので、それ自身のメソッドを持っていません。
ところがオブジェクトを使ってゆくと、これらの基本型を操作しなければならない局面が出てきます。そのためプリミティブ型をオブジェクトとして操作するクラスが各種定義されています。 これらはプリミティブ型を包み込むという意味でラッパークラスといいます。
あんまりわかりませんね。情報系の学部卒ならスッと頭に入るのでしょうか?
絵にするとわかりやすい?
◆プリミティブ型の種類によっていくつかあるそうな
ラッパークラスは下の表で示されるように、プリミティブ型の種類によっていくつかの種類があります。オブジェクトですので、それぞれ固有のプリミティ値を持ち、それを操作するメソッドを持っています。
プリミティブ型 ラッパークラス byte Byte short Short int Integer long Long char Character float Float double Double boolean Boolean 使い方は色々ありますが1例として、数字の文字列 "123" "123.45" はそのままでは計算ができませんが、ラッパークラスで数字に変換することによって数値計算することができるそうな。
基本データ型はNULLデータは代入できません。オブジェクト型ならNULLが代入できます。
頭が大文字になっているのが特徴ですね?