- 投稿日:2020-03-01T22:37:43+09:00
Version in "./docker-compose.yaml" is unsupported.と言われた
docker-composeのバージョンが古かったため、docker-compose upがエラーになってしまいました。
その際の対応をまとめていきます。起こったエラー
ERROR: Version in "./docker-compose.yml" is unsupported. You might be seeing this error because you're using the wrong Compose file version. Either specify a supported version ("2.0", "2.1", "3.0") and place your service definitions under the `services` key, or omit the `version` key and place your service definitions at the root of the file to use version 1. For more on the Compose file format versions, see https://docs.docker.com/compose/compose-file/やったこと
$ rm $(which docker-compose) $ curl -L https://github.com/docker/compose/releases/download/1.25.4/docker-compose-`uname -s`-`uname -m` > /usr/local/bin/docker-compose $ chmod +x /usr/local/bin/docker-composeまとめ
本来であれば、macの場合Docker for Macをインストールしたらdocker-composeが使えるのですが、他のバージョンを入れてしまったために起こったようです。
参照
https://stackoverflow.com/questions/30988566/how-do-i-uninstall-docker-compose
http://docs.docker.jp/compose/install.html
- 投稿日:2020-03-01T21:54:19+09:00
Kubernetes関連ツール調査(適宜追記)
Kubernetesを効果的に使うためのツール群をまとめる
Podのデバッグ
トラブルシューティング用のツールをインストール済みのcontainerを横付けすることで、本番側のPodにツールを入れずにトラブルシュートできる。
※使い方未確認brew install aylei/tap/kubectl-debug参考: https://github.com/aylei/kubectl-debug
下記のリストから個人的に使えるツール類をまとめる
http://dockerlabs.collabnix.com/kubernetes/kubetools/?utm_sq=ganrvzkv2k
- 投稿日:2020-03-01T21:23:46+09:00
Rails6でElasticsearchのキーワード検索実装ハンズオン
はじめに
本稿は、RailsとElasticsearchで検索機能をつくり色々試してみる - その1:サンプルアプリケーションの作成 を一部改変した内容でRailsとElasticsearchのキーワード機能を実装するハンズオン資料です。
※ 主な変更点
・ Ruby / Railsのバージョンは2020年の執筆時点でほぼ最新に変更 ・ Elasticsearch と PostgreSQL のみをDocker化 ・ Railsは通常通りのローカル環境で動かせるようにした違いがピンと来ない方もいらっしゃるかと思いますので補足しますとRails自体はDocker化しないことによってDockerの知見が少ない方でも学習上のデバッグや値の確認が容易に出来るようにしてあります。
このハンズオンで扱う技術
技術スタック バージョン Ruby 2.6.5 Ruby on Rails 6.0 Elasticsearch 6.5.4 PostgreSQL 12 Docker 19.03.5 このハンズオンを終えると出来るようになること
・ Railsアプリでミドルウェア(Elasticsearch / PostgreSQL)のみをDocker化すること ・ Elasticsearchによる簡単なキーワード検索機能の実装 ・ Elasticsearchでの簡単なテストをRSpecで書くこと
※ 完成リポジトリ
https://github.com/Shigeyuki-fukuda/elasticsearch_rails_sandbox前提環境
・ Macであること ・ Docker for Macがインストールされていること ・ rbenvなどのRubyの実行環境がローカルに出来ていることなるべくハマりどころは細かくメモしていこうと思いますので、
初心者の方も気軽にチャレンジしてみてください。目次
結構ボリューミーですが、少しずつやっていきましょう!
手順1:アプリの土台を作成 手順2:debug用のgemを追加 手順3:Docker関連ディレクトリとファイルの新規作成 手順4:Docker上のPostgreSQLとRailsが疎通するための設定を追加する 手順5:Docker上で動くPostgreSQLとRailsの疎通確認 手順6:Elasticsearchの起動確認 手順7:検索対象となるモデルの定義 手順8:サンプルデータの投入 手順9:コントローラー・ビュー・ルーティングの追加 手順10:スタイルの調整 手順11:Elasticsearch用のgemの追加 手順12:ElasticsearchをRailsアプリ上で動かせるようにする 手順13:Elasticsearchの動作確認 手順14:検索機能の追加 手順15:ページネーションの追加 手順16:RSpecのセットアップ 手順17:Elasticsearchのテストを追加Elasticsearchって何なの?
・ Elastic 社が開発しているオープンソースの全文検索エンジン ・ JSONフォーマットで柔軟にデータを格納出来るドキュメント指向データベース ・ 大量ドキュメントから目的の単語を含むドキュメントを高速に抽出出来るこれだけだとピンと来ない方もいると思うのですが、一旦今のところは
キーワード検索をMySQLやPostgreSQLなどのRDBよりも高速に行うことが出来るデータベースだと理解して先に進みましょう。手順1:アプリの土台を作成
DBはPostgreSQLを使用します!
$ rails new elasticsearch_rails_sandbox --database=postgresql --skip-bundle $ cd elasticsearch_rails_sandbox手順2:debug用のgemを追加
※ 不要なら飛ばしてOK
値の確認などを行いやすいようにdebug用途のgemを入れておきます。Gemfilegroup :development, :test do <中略> # 以下の3つを新規で追加 gem 'pry-rails' gem 'pry-byebug' gem 'pry-doc' end手順3:Docker関連ディレクトリとファイルの新規作成
まずappディレクトリと同階層にdockerディレクトリとdocker-compose.ymlというファイルを作ります。次にdockerディレクトリの中にelasticsearchディレクトリとpostgresqlディレクトリを作り、elasticsearchディレクトリの中にのみDockerfileという拡張子なしのファイルを作ります。
そして、以下に続く設定の通りにdocker-compose.ymlとDockerfileを編集します。ディレクトリ構成の確認
アプリ名のディレクトリ ├── app ├── docker │ ├── elasticsearch │ │ └── Dockerfile │ └── postgresql └── docker-compose.ymldocker-compose.ymlの設定
docker-compose.ymlversion: '3' services: postgresql: image: postgres:12 volumes: - ./docker/postgresql/data:/usr/local/var/postgres ports: - 127.0.0.1:5432:5432 environment: POSTGRES_USER: postgres POSTGRES_PASSWORD: mysecretpassword1234 PGDATA: /usr/local/var/postgres elasticsearch: build: context: . dockerfile: ./docker/elasticsearch/Dockerfile volumes: - ./docker/elasticsearch/data:/usr/share/elasticsearch/data ports: - 127.0.0.1:9200:9200 environment: - "ES_JAVA_OPTS=-Xms512m -Xmx512m" - "xpack.security.enabled=false" - "xpack.monitoring.enabled=false"docker/elasticsearch/Dockerfileの設定
- PostgreSQL は一旦、
docker/postgresqlディレクトリを作成するだけでOK
- Elasticseachは
docker/elasticsearch/DockerfileにDocker上で使うElasticseachのバージョンとインストールするプラグインを記載する(日本語の形態素解析用のプラグインを入れています)
docker/elasticsearch/DockerfileFROM docker.elastic.co/elasticsearch/elasticsearch:6.5.4 RUN bin/elasticsearch-plugin install analysis-kuromoji手順4:Docker上のPostgreSQLとRailsが疎通するための設定を追加する
config/database.ymldefault: &default adapter: postgresql port: 5432 username: postgres password: mysecretpassword1234 host: 127.0.0.1 encoding: unicode pool: 5 development: <<: *default database: elasticsearch_rails_sandbox_development test: <<: *default database: elasticsearch_rails_sandbox_test production: <<: *default database: elasticsearch_rails_sandbox_production username: elasticsearch_rails_sandbox password: <%= ENV['ELASTICSEARCH_RAILS_SANDBOX_DATABASE_PASSWORD'] %>
ハマりポイント解説
docker-compose.ymlに記載した内容とdatabase.ymlの内容で齟齬があるとRailsがDBに接続出来ないので注意
 config/database.ymlusername: postgres password: mysecretpassword1234
config/database.ymlusername: postgres password: mysecretpassword1234↑上記の部分と↓以下の
POSTGRES_USERとPOSTGRES_PASSWORDの部分が一致してる必要があります docker-compose.ymlversion: '3' services: postgresql: image: postgres:12 volumes: - ./docker/postgresql/data:/usr/local/var/postgres ports: - 127.0.0.1:5432:5432 environment: POSTGRES_USER: postgres POSTGRES_PASSWORD: mysecretpassword1234
docker-compose.ymlversion: '3' services: postgresql: image: postgres:12 volumes: - ./docker/postgresql/data:/usr/local/var/postgres ports: - 127.0.0.1:5432:5432 environment: POSTGRES_USER: postgres POSTGRES_PASSWORD: mysecretpassword1234手順5:Docker上で動くPostgreSQLとRailsの疎通確認
dockerコンテナを作成・バックグラウンド起動します
 # docker-compose.ymlと同じ階層で実行すること $ docker-compose up -d # 停止する場合は以下のコマンドを実行 $ docker-compose stop # プロセスを確認したい場合はdocker-compose psで確認出来る # statusがUpなら起動しているExitなら停止している $ docker-compose ps Name Command State Ports ----------------------------------------------------------------------------------------------------------------- elasticsearch_rails_sandbox_elastic /usr/local/bin/docker-entr ... Up 127.0.0.1:9200->9200/tcp, 9300/tcp search_1 elasticsearch_rails_sandbox_postgre docker-entrypoint.sh postgres Up 127.0.0.1:5432->5432/tcp sql_1
# docker-compose.ymlと同じ階層で実行すること $ docker-compose up -d # 停止する場合は以下のコマンドを実行 $ docker-compose stop # プロセスを確認したい場合はdocker-compose psで確認出来る # statusがUpなら起動しているExitなら停止している $ docker-compose ps Name Command State Ports ----------------------------------------------------------------------------------------------------------------- elasticsearch_rails_sandbox_elastic /usr/local/bin/docker-entr ... Up 127.0.0.1:9200->9200/tcp, 9300/tcp search_1 elasticsearch_rails_sandbox_postgre docker-entrypoint.sh postgres Up 127.0.0.1:5432->5432/tcp sql_1PostgreSQLとRailsの疎通確認
ローカルでDB作成コマンドを実行し、
localhost:3000にアクセスしてRailsの初期画面が表示出来たらOK。$ bundle exec rails db:create
手順6:Elasticsearchの起動確認
事前に
docker-compose up -dでバックグラウンドで動かしておきましょう!
curlで起動確認します。# docker-compose.ymlでElasticsearchに割り当てたポート番号をcurlする $ curl -XGET http://localhost:9200/ { "name" : "CBsfjEf", "cluster_name" : "docker-cluster", "cluster_uuid" : "2BT15kU2RsKTYbD-a6x74w", "version" : { "number" : "6.5.4", "build_flavor" : "default", "build_type" : "tar", "build_hash" : "d2ef93d", "build_date" : "2018-12-17T21:17:40.758843Z", "build_snapshot" : false, "lucene_version" : "7.5.0", "minimum_wire_compatibility_version" : "5.6.0", "minimum_index_compatibility_version" : "5.0.0" }, "tagline" : "You Know, for Search" }手順7:検索対象となるモデルの定義
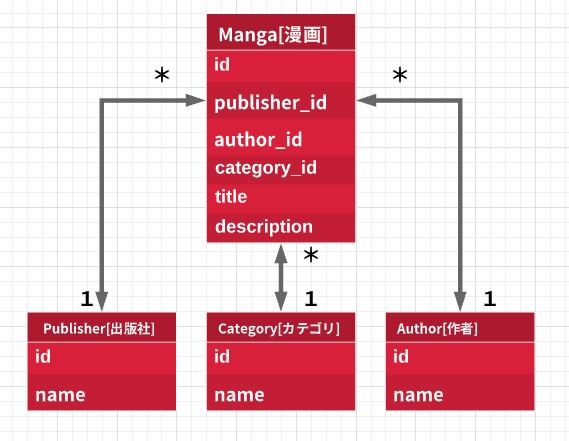
$ bin/rails g model author name:string $ bin/rails g model publisher name:string $ bin/rails g model category name:string $ bin/rails g model manga author:references publisher:references category:references title:string description:text手順8:サンプルデータの投入
以下はサンプルデータ投入用のseed.rbです。
db/seed.rb# This file should contain all the record creation needed to seed the database with its default values. # The data can then be loaded with the rails db:seed command (or created alongside the database with db:setup). # # Examples: # # movies = Movie.create([{ name: 'Star Wars' }, { name: 'Lord of the Rings' }]) # Character.create(name: 'Luke', movie: movies.first) # category ct1 = Category.create(name: 'バトル・アクション') ct2 = Category.create(name: 'ギャグ・コメディ') ct3 = Category.create(name: 'ファンタジー') ct4 = Category.create(name: 'スポーツ') ct5 = Category.create(name: 'ラブコメ') ct6 = Category.create(name: '恋愛') ct7 = Category.create(name: '異世界') ct8 = Category.create(name: '日常系') ct9 = Category.create(name: 'グルメ') ct10 = Category.create(name: 'ミステリー・サスペンス') ct11 = Category.create(name: 'ホラー') ct12 = Category.create(name: 'SF') ct13 = Category.create(name: 'ロボット') ct14 = Category.create(name: '歴史') ct15 = Category.create(name: '少女漫画') ct16 = Category.create(name: '戦争') ct17 = Category.create(name: '職業・ビジネス') ct18 = Category.create(name: 'お色気') ct19 = Category.create(name: '学園もの') # 出版社 pb1 = Publisher.create(name: '集英社') pb2 = Publisher.create(name: '講談社') pb3 = Publisher.create(name: '小学館') pb4 = Publisher.create(name: '芳文社') pb5 = Publisher.create(name: '双葉社') # 作者 at1 = Author.create(name: '原泰久') at2 = Author.create(name: '堀越耕平') at3 = Author.create(name: '清水茜') at4 = Author.create(name: '井上雄彦') at5 = Author.create(name: '吉田秋生') at6 = Author.create(name: '野田サトル') at7 = Author.create(name: 'あfろ') at8 = Author.create(name: '神尾葉子') at9 = Author.create(name: '冨樫義博') at10 = Author.create(name: '川上秦樹') at11 = Author.create(name: 'こうの史代') at12 = Author.create(name: '古舘春一') at13 = Author.create(name: '三田紀房') at14 = Author.create(name: '藤沢とおる') # 漫画 Manga.create(title: "キングダム", publisher: pb1, author: at1, category: ct14, description: "時は紀元前―。いまだ一度も統一されたことのない中国大陸は、500年の大戦争時代。苛烈な戦乱の世に生きる少年・信は、自らの腕で天下に名を成すことを目指す!!") Manga.create(title: "僕のヒーローアカデミア", publisher: pb1, author: at3, category: ct1, description: "多くの人間が“個性という力を持つ。だが、それは必ずしも正義の為の力ではない。しかし、避けられぬ悪が存在する様に、そこには必ず我らヒーローがいる! ん? 私が誰かって? HA‐HA‐HA‐HA‐HA! さぁ、始まるぞ少年! 君だけの夢に突き進め! “Plus Ultra!!") Manga.create(title: "はたらく細胞", publisher: pb2, author: at3, category: ct1, description: "人間1人あたりの細胞の数、およそ60兆個! そこには細胞の数だけ仕事(ドラマ)がある! ウイルスや細菌が体内に侵入した時、アレルギー反応が起こった時、ケガをした時などなど、白血球と赤血球を中心とした体内細胞の人知れぬ活躍を描いた「細胞擬人化漫画」の話題作、ついに登場!!肺炎球菌! スギ花粉症! インフルエンザ! すり傷! 次々とこの世界(体)を襲う脅威。その時、体の中ではどんな攻防が繰り広げられているのか!? 白血球、赤血球、血小板、B細胞、T細胞...etc.彼らは働く、24時間365日休みなく!") Manga.create(title: "スラムダンク SLAM DUNK 新装再編版", publisher: pb1, author: at4, category: ct4, description: '中学時代、50人の女の子にフラれた桜木花道。そんな男が、進学した湘北高校で赤木晴子に一目惚れ! 「バスケットは…お好きですか?」。この一言が、ワルで名高い花道の高校生活を変えることに!!') Manga.create(title: "BANANA FISH バナナフィッシュ 復刻版全巻BOX", publisher: pb3, author: at5, category: ct15, description: 'フラワーコミックスの黄色いカバーを完全再現!!吉田秋生の不朽の名作が復刻版BOXとなって登場しました。フラワーコミックスの黄色いカバーを完全再現したコミックスと、特典ポストカードをセットにした完全保存版。ポストカードはファン垂涎の、アッシュ・英二のイラストをセレクトしたここでしか手に入らないオリジナルです。') Manga.create(title: "ゴールデンカムイ", publisher: pb1, author: at6, category: ct1, description: '『不死身の杉元』日露戦争での鬼神の如き武功から、そう謳われた兵士は、ある目的の為に大金を欲し、かつてゴールドラッシュに沸いた北海道へ足を踏み入れる。そこにはアイヌが隠した莫大な埋蔵金への手掛かりが!? 立ち塞がる圧倒的な大自然と凶悪な死刑囚。そして、アイヌの少女、エゾ狼との出逢い。『黄金を巡る生存競争』開幕ッ!!!!') Manga.create(title: "ゆるキャン△", publisher: pb4, author: at7, category: ct8, description: '富士山が見える湖畔で、一人キャンプをする女の子、リン。一人自転車に乗り、富士山を見にきた女の子、なでしこ。二人でカップラーメンを食べて見た景色は…。読めばキャンプに行きたくなる。行かなくても行った気分になる。そんな新感覚キャンプマンガの登場です!') Manga.create(title: "花のち晴れ〜花男 Next Season〜", publisher: pb1, author: at8, category: ct6, description: '英徳学園からF4が卒業して2年…。F4のリーダー・道明寺司に憧れる神楽木晴は、「コレクト5」を結成し、学園の品格を保つため“庶民狩りを始めた!! 隠れ庶民として学園に通う江戸川音はバイト中に晴と遭遇し!?') Manga.create(title: "HUNTER×HUNTER ハンター×ハンター", publisher: pb1, author: at9, category: ct1, description: '父と同じハンターになるため、そして父に会うため、ゴンの旅が始まった。同じようにハンターになるため試験を受ける、レオリオ・クラピカ・キルアと共に、次々と難関を突破していくが…!?') Manga.create(title: "転生したらスライムだった件", publisher: pb2, author: at10, category: ct7, description: '通り魔に刺されて死んだと思ったら、異世界でスライムに転生しちゃってた!?相手の能力を奪う「捕食者」と世界の理を知る「大賢者」、2つのユニークスキルを武器に、スライムの大冒険が今始まる!異世界転生モノの名作を、原作者完全監修でコミカライズ!') Manga.create(title: "この世界の片隅に", publisher: pb5, author: at11, category: ct16, description: '平成の名作・ロングセラー「夕凪の街 桜の国」の第2弾ともいうべき本作。戦中の広島県の軍都、呉を舞台にした家族ドラマ。主人公、すずは広島市から呉へ嫁ぎ、新しい家族、新しい街、新しい世界に戸惑う。しかし、一日一日を確かに健気に生きていく…。') Manga.create(title: "スラムダンク SLAM DUNK", publisher: pb1, author: at4, category: ct4, description: '中学3年間で50人もの女性にフラれた高校1年の不良少年・桜木花道は背の高さと身体能力からバスケットボール部の主将の妹、赤木晴子にバスケット部への入部を薦められる。彼女に一目惚れした「初心者」花道は彼女目当てに入部するも、練習・試合を通じて徐々にバスケットの面白さに目覚めていき、才能を開花させながら、全国制覇を目指していくのであったが……。') Manga.create(title: "ハイキュー!!", publisher: pb1, author: at12, category: ct4, description: 'おれは飛べる!! バレーボールに魅せられ、中学最初で最後の公式戦に臨んだ日向翔陽。だが、「コート上の王様」と異名を取る天才選手・影山に惨敗してしまう。リベンジを誓い烏野高校バレー部の門を叩く日向だが!?') Manga.create(title: "インベスターZ", publisher: pb2, author: at13, category: ct17, description: '創立130年の超進学校・道塾学園に、トップで合格した財前孝史。入学式翌日に、財前に明かされた学園の秘密。各学年成績トップ6人のみが参加する「投資部」が存在するのだ。彼らの使命は3000億を運用し、年8%以上の利回りを生み出すこと。それゆえ日本最高基準の教育設備を誇る道塾学園は学費が無料だった!「この世で一番エキサイティングなゲーム、人間の血が最も沸き返る究極の勝負……それは金……投資だよ!」') Manga.create(title: "GTO", publisher: pb2, author: at14, category: ct19, description: "かつて最強の不良「鬼爆」の一人として湘南に君臨した鬼塚英吉は、辻堂高校を中退後、優羅志亜(ユーラシア)大学に替え玉試験で入学した。彼は持ち前の体力と度胸、純粋な一途さと若干の不純な動機で、教師を目指した。無茶苦茶だが、目先の理屈よりも「ものの道理」を通そうとする鬼塚の行為に東京吉祥学苑理事長の桜井良子が目を付け、ある事情を隠して中等部の教員として採用する。学園内に蔓延する不正義や生徒内に淀むイジメの問題、そして何より体面や体裁に振り回され、臭いものに蓋をして見て見ぬ振りをしてしまう大人たち、それを信じられなくなって屈折してしまった子どもたち。この学園には様々な問題が山積していたのである。桜井は、鬼塚が問題に真っ向からぶつかり、豪快な力技で解決してくれることに一縷の望みを託すようになる。")※
docker-compose up -dで事前にpostgresqlを起動した状態で行う点に注意
以下のコマンドからseedデータを投入します。$ bin/rails db:seed手順9:コントローラー・ビュー・ルーティングの追加
$ bin/rails g controller Mangas index --helper=false --assets=falseapp/controllers/mangas_controller.rbclass MangasController < ApplicationController def index @mangas = Manga.all end endconfig/routes.rbRails.application.routes.draw do root 'mangas#index' resources :mangas, only: %i(index) endapp/views/mangas/index.html.erb<h1>Mangas</h1> <table> <thead> <tr> <th>Aauthor</th> <th>Publisher</th> <th>Category</th> <th>Author</th> <th>Title</th> <th>Description</th> <th colspan="3"></th> </tr> </thead> <tbody> <% @mangas.each do |manga| %> <tr> <td><%= manga.author.name %></td> <td><%= manga.publisher.name %></td> <td><%= manga.category.name %></td> <td><%= manga.author.name %></td> <td><%= manga.title %></td> <td><%= manga.description %></td> </tr> <% end %> </tbody> </table>手順10:スタイルの調整
bulma-railsを追加してスタイルを調整します。
Gemfilegem "bulma-rails", "~> 0.7.2"Gemfileに追記出来たら、bundle installします。
$ bundle installcssをscssに変更します。
app/assets/stylesheets/application.scss/* * This is a manifest file that'll be compiled into application.css, which will include all the files * listed below. * * Any CSS and SCSS file within this directory, lib/assets/stylesheets, or any plugin's * vendor/assets/stylesheets directory can be referenced here using a relative path. * * You're free to add application-wide styles to this file and they'll appear at the bottom of the * compiled file so the styles you add here take precedence over styles defined in any other CSS/SCSS * files in this directory. Styles in this file should be added after the last require_* statement. * It is generally better to create a new file per style scope. * *= require ./manga *= require_tree . *= require_self */ // https://github.com/joshuajansen/bulma-rails @import "bulma";ここは手動で微調整します。
app/assets/stylesheets/manga.scss.table tr { td:nth-child(-n+3) { width:100px; } td:nth-child(4) { width:150px; } }ビューもbulmaを適用していきます。
app/views/mangas/index.html.erb<section class="hero is-info"> <div class="hero-body"> <div class="container"> <h1 class="title"> 漫画検索 </h1> </div> </div> </section> <div class="container" style="margin-top: 50px"> <table class="table is-striped is-hoverable"> <thead class="has-background-info"> <tr> <th class="has-text-white-bis">出版社</th> <th class="has-text-white-bis">ジャンル</th> <th class="has-text-white-bis">著者</th> <th class="has-text-white-bis">タイトル</th> <th class="has-text-white-bis">説明</th> </tr> </thead> <tbody> <% @mangas.each do |manga| %> <tr> <td><%= manga.publisher.name %></td> <td><%= manga.category.name %></td> <td><%= manga.author.name %></td> <td><%= manga.title %></td> <td><%= manga.description %></td> </tr> <% end %> </tbody> </table> </div>手順11:Elasticsearch用のgemの追加
※ Elasticsearchのメジャーバージョンとgemのメジャーバージョンは揃えないと動作しないので注意しましょう。
今回はElasticsearchが6.5.4なのでgemも6系を使います。Gemfilegem 'elasticsearch-rails', git: 'git://github.com/elastic/elasticsearch-rails.git', branch: '6.x' gem 'elasticsearch-model', git: 'git://github.com/elastic/elasticsearch-rails.git', branch: '6.x'*elasticsearch-rails
*elasticsearch-model
$ bundle install手順12:ElasticsearchをRailsアプリ上で動かせるようにする
configの設定
コメントにも書いていますが、host名は
docker-composeのservicesに設定した名前の「elasticsearch」ではなく「localhost」を指定しないとエラーになってしまったので、そこに留意してconfigを書いています。config/initializers/elasticsearch.rb# hostはdocker-composeのservicesに設定した名前「elasticsearch」ではなく「localhost」を指定しないとエラーになるので注意 # 参考:https://qiita.com/s_yasunaga/items/b0dac7f962c265158a34 config = { host: ENV['ELASTICSEARCH_HOST'] || "localhost", port: ENV['ELASTICSEARCH_PORT'] || "9200", user: ENV['ELASTICSEARCH_USER'] || "", password: ENV['ELASTICSEARCH_PASSWORD'] || "" } Elasticsearch::Model.client = Elasticsearch::Client.new(config)concernを追加
modelに検索モジュールをincludeします。
app/models/manga.rbclass Manga < ApplicationRecord include MangaSearch::Engine belongs_to :author belongs_to :publisher belongs_to :category end検索用モジュールは以下の通りです。
追って用語を補足します。app/models/concerns/manga_search/engine.rbmodule MangaSearch module Engine extend ActiveSupport::Concern included do include Elasticsearch::Model # ①index名 index_name "es_manga_#{Rails.env}" # ②mapping情報 settings do mappings dynamic: 'false' do indexes :id, type: 'integer' indexes :publisher, type: 'keyword' indexes :author, type: 'keyword' indexes :category, type: 'text', analyzer: 'kuromoji' indexes :title, type: 'text', analyzer: 'kuromoji' indexes :description, type: 'text', analyzer: 'kuromoji' end end # ③mappingの定義に合わせてindexするドキュメントの情報を生成する def as_indexed_json(*) attributes .symbolize_keys .slice(:id, :title, :description) .merge(publisher: publisher_name, author: author_name, category: category_name) end end def publisher_name publisher.name end def author_name author.name end def category_name category.name end class_methods do # ④indexを作成するメソッド def create_index! client = __elasticsearch__.client # すでにindexを作成済みの場合は削除する client.indices.delete index: self.index_name rescue nil # indexを作成する client.indices.create(index: self.index_name, body: { settings: self.settings.to_hash, mappings: self.mappings.to_hash }) end end end end*Elasticsearch関連用語の補足
※皆さんが普段使っているであろうRDBとの比較表
RDB Elasticsearch database index table type schema mapping column field record document 手順13:Elasticsearchの動作確認
- RailsコンソールからElasticsearchの疎通確認を行います。 (ここで接続が出来ていないと
Faraday::ConnectionFailedが発生します。)$ Manga.__elasticsearch__.client.cluster.health => {"cluster_name"=>"docker-cluster", "status"=>"yellow", "timed_out"=>false, "number_of_nodes"=>1, "number_of_data_nodes"=>1, "active_primary_shards"=>10, "active_shards"=>10, "relocating_shards"=>0, "initializing_shards"=>0, "unassigned_shards"=>10, "delayed_unassigned_shards"=>0, "number_of_pending_tasks"=>0, "number_of_in_flight_fetch"=>0, "task_max_waiting_in_queue_millis"=>0, "active_shards_percent_as_number"=>50.0}
- indexを作成します。
$ Manga.create_index! => {"acknowledged"=>true, "shards_acknowledged"=>true, "index"=>"es_manga_development"}
- importメソッドでmodelの情報を登録します。さっき追加したas_indexed_jsonの形式に変換してデータが登録されます。
$ Manga.__elasticsearch__.import Manga Load (12.7ms) SELECT "mangas".* FROM "mangas" ORDER BY "mangas"."id" ASC LIMIT $1 [["LIMIT", 1000]] Publisher Load (5.9ms) SELECT "publishers".* FROM "publishers" WHERE "publishers"."id" = $1 LIMIT $2 [["id", 1], ["LIMIT", 1]] Author Load (7.0ms) SELECT "authors".* FROM "authors" WHERE "authors"."id" = $1 LIMIT $2 [["id", 1], ["LIMIT", 1]] Category Load (7.2ms) SELECT "categories".* FROM "categories" WHERE "categories"."id" = $1 LIMIT $2 [["id", 14], ["LIMIT", 1]] Publisher Load (3.2ms) SELECT "publishers".* FROM "publishers" WHERE "publishers"."id" = $1 LIMIT $2 [["id", 1], ["LIMIT", 1]] Author Load (4.1ms) SELECT "authors".* FROM "authors" WHERE "authors"."id" = $1 LIMIT $2 [["id", 3], ["LIMIT", 1]] Category Load (3.7ms) SELECT "categories".* FROM "categories" WHERE "categories"."id" = $1 LIMIT $2 [["id", 1], ["LIMIT", 1]] Publisher Load (4.5ms) SELECT "publishers".* FROM "publishers" WHERE "publishers"."id" = $1 LIMIT $2 [["id", 2], ["LIMIT", 1]] Author Load (3.9ms) SELECT "authors".* FROM "authors" WHERE "authors"."id" = $1 LIMIT $2 [["id", 3], ["LIMIT", 1]] Category Load (3.3ms) SELECT "categories".* FROM "categories" WHERE "categories"."id" = $1 LIMIT $2 [["id", 1], ["LIMIT", 1]] Publisher Load (3.3ms) SELECT "publishers".* FROM "publishers" WHERE "publishers"."id" = $1 LIMIT $2 [["id", 1], ["LIMIT", 1]] Author Load (3.1ms) SELECT "authors".* FROM "authors" WHERE "authors"."id" = $1 LIMIT $2 [["id", 4], ["LIMIT", 1]] Category Load (2.6ms) SELECT "categories".* FROM "categories" WHERE "categories"."id" = $1 LIMIT $2 [["id", 4], ["LIMIT", 1]] Publisher Load (3.9ms) SELECT "publishers".* FROM "publishers" WHERE "publishers"."id" = $1 LIMIT $2 [["id", 3], ["LIMIT", 1]] Author Load (3.5ms) SELECT "authors".* FROM "authors" WHERE "authors"."id" = $1 LIMIT $2 [["id", 5], ["LIMIT", 1]] Category Load (4.2ms) SELECT "categories".* FROM "categories" WHERE "categories"."id" = $1 LIMIT $2 [["id", 15], ["LIMIT", 1]] Publisher Load (2.7ms) SELECT "publishers".* FROM "publishers" WHERE "publishers"."id" = $1 LIMIT $2 [["id", 1], ["LIMIT", 1]] Author Load (2.4ms) SELECT "authors".* FROM "authors" WHERE "authors"."id" = $1 LIMIT $2 [["id", 6], ["LIMIT", 1]] Category Load (2.6ms) SELECT "categories".* FROM "categories" WHERE "categories"."id" = $1 LIMIT $2 [["id", 1], ["LIMIT", 1]] Publisher Load (1.6ms) SELECT "publishers".* FROM "publishers" WHERE "publishers"."id" = $1 LIMIT $2 [["id", 4], ["LIMIT", 1]] Author Load (1.9ms) SELECT "authors".* FROM "authors" WHERE "authors"."id" = $1 LIMIT $2 [["id", 7], ["LIMIT", 1]] Category Load (1.8ms) SELECT "categories".* FROM "categories" WHERE "categories"."id" = $1 LIMIT $2 [["id", 8], ["LIMIT", 1]] Publisher Load (1.9ms) SELECT "publishers".* FROM "publishers" WHERE "publishers"."id" = $1 LIMIT $2 [["id", 1], ["LIMIT", 1]] Author Load (2.3ms) SELECT "authors".* FROM "authors" WHERE "authors"."id" = $1 LIMIT $2 [["id", 8], ["LIMIT", 1]] Category Load (2.7ms) SELECT "categories".* FROM "categories" WHERE "categories"."id" = $1 LIMIT $2 [["id", 6], ["LIMIT", 1]] Publisher Load (1.6ms) SELECT "publishers".* FROM "publishers" WHERE "publishers"."id" = $1 LIMIT $2 [["id", 1], ["LIMIT", 1]] Author Load (1.7ms) SELECT "authors".* FROM "authors" WHERE "authors"."id" = $1 LIMIT $2 [["id", 9], ["LIMIT", 1]] Category Load (1.9ms) SELECT "categories".* FROM "categories" WHERE "categories"."id" = $1 LIMIT $2 [["id", 1], ["LIMIT", 1]] Publisher Load (2.2ms) SELECT "publishers".* FROM "publishers" WHERE "publishers"."id" = $1 LIMIT $2 [["id", 2], ["LIMIT", 1]] Author Load (2.0ms) SELECT "authors".* FROM "authors" WHERE "authors"."id" = $1 LIMIT $2 [["id", 10], ["LIMIT", 1]] Category Load (1.8ms) SELECT "categories".* FROM "categories" WHERE "categories"."id" = $1 LIMIT $2 [["id", 7], ["LIMIT", 1]] Publisher Load (1.6ms) SELECT "publishers".* FROM "publishers" WHERE "publishers"."id" = $1 LIMIT $2 [["id", 5], ["LIMIT", 1]] Author Load (1.3ms) SELECT "authors".* FROM "authors" WHERE "authors"."id" = $1 LIMIT $2 [["id", 11], ["LIMIT", 1]] Category Load (2.0ms) SELECT "categories".* FROM "categories" WHERE "categories"."id" = $1 LIMIT $2 [["id", 16], ["LIMIT", 1]] Publisher Load (1.8ms) SELECT "publishers".* FROM "publishers" WHERE "publishers"."id" = $1 LIMIT $2 [["id", 1], ["LIMIT", 1]] Author Load (1.8ms) SELECT "authors".* FROM "authors" WHERE "authors"."id" = $1 LIMIT $2 [["id", 4], ["LIMIT", 1]] Category Load (2.0ms) SELECT "categories".* FROM "categories" WHERE "categories"."id" = $1 LIMIT $2 [["id", 4], ["LIMIT", 1]] Publisher Load (4.1ms) SELECT "publishers".* FROM "publishers" WHERE "publishers"."id" = $1 LIMIT $2 [["id", 1], ["LIMIT", 1]] Author Load (2.8ms) SELECT "authors".* FROM "authors" WHERE "authors"."id" = $1 LIMIT $2 [["id", 12], ["LIMIT", 1]] Category Load (1.7ms) SELECT "categories".* FROM "categories" WHERE "categories"."id" = $1 LIMIT $2 [["id", 4], ["LIMIT", 1]] Publisher Load (1.6ms) SELECT "publishers".* FROM "publishers" WHERE "publishers"."id" = $1 LIMIT $2 [["id", 2], ["LIMIT", 1]] Author Load (2.0ms) SELECT "authors".* FROM "authors" WHERE "authors"."id" = $1 LIMIT $2 [["id", 13], ["LIMIT", 1]] Category Load (1.8ms) SELECT "categories".* FROM "categories" WHERE "categories"."id" = $1 LIMIT $2 [["id", 17], ["LIMIT", 1]] Publisher Load (1.5ms) SELECT "publishers".* FROM "publishers" WHERE "publishers"."id" = $1 LIMIT $2 [["id", 2], ["LIMIT", 1]] Author Load (1.8ms) SELECT "authors".* FROM "authors" WHERE "authors"."id" = $1 LIMIT $2 [["id", 14], ["LIMIT", 1]] Category Load (1.6ms) SELECT "categories".* FROM "categories" WHERE "categories"."id" = $1 LIMIT $2 [["id", 19], ["LIMIT", 1]] => 0手順14:検索機能の追加
Elasticsearchの疎通確認が出来たので検索モジュールに検索メソッドを追加します。
検索モジュールに検索メソッドを追加
app/models/concerns/manga_search/engine.rb<中略> def search(query) elasticsearch__.search({ query: { multi_match: { fields: %w(publisher author category title description), type: 'cross_fields', query: query, operator: 'and' } } }) end実装を補足
multi_matchは複数のフィールドにまたがって検索したい場合に利用するオプションです。
fieldsでは検索対象のフィールドを指定しています。
typeでmulti_matchの検索タイプを指定していて、ここではcross_fieldsという複数のフィールドを結合して、一つのフィールドのように扱うタイプを指定しています。multi_match: { fields: %w(publisher author category title description), type: 'cross_fields',上記の実装の他にもどういったクエリの書き方があるのか詳しく調べたい場合は、公式ドキュメントのQuery DSLの部分を読んでみて下さい!
コントローラーの修正
- 検索メソッドをコントローラーに反映します。
app/controllers/mangas_controller.rbclass MangasController < ApplicationController def index @mangas = if query.present? Manga.search(query).records else Manga.all end end private def query @query ||= params[:query] end endビューの修正
- ヘッダーとテーブルの間に検索窓を追加します。
app/views/mangas/index.html.erb<section class="hero is-info"> <div class="hero-body"> <div class="container"> <h1 class="title"> 漫画検索 </h1> </div> </div> </section> ###### ここから下の検索窓の部分を追加 ##### <div class="container" style="margin-top: 30px"> <%= form_tag(mangas_path, method: :get, class: "field has-addons has-addons-centered") do %> <div class="control"> <%= text_field_tag :query, @query, class: "input", placeholder: "漫画を検索する" %> </div> <div class="control"> <%= submit_tag "検索", class: "button is-info" %> </div> <% end %> </div> <div class="container" style="margin-top: 50px"> <table class="table is-striped is-hoverable"> <thead class="has-background-info"> <tr> <th class="has-text-white-bis">出版社</th> <th class="has-text-white-bis">ジャンル</th> <th class="has-text-white-bis">著者</th> <th class="has-text-white-bis">タイトル</th> <th class="has-text-white-bis">説明</th> </tr> </thead> <tbody> <% @mangas.each do |manga| %> <tr> <td><%= manga.publisher.name %></td> <td><%= manga.category.name %></td> <td><%= manga.author.name %></td> <td><%= manga.title %></td> <td><%= manga.description %></td> </tr> <% end %> </tbody> </table> <%= paginate @mangas %> </div>手順15:ページネーションの追加
このままだと検索結果を全件表示することになってしまうので、ページネーションを追加していきます。
※ 注意点はこちらを参照
kaminariはElasticsearch関連のgemよりも上に追加するようにしましょう。Gemfilegem 'kaminari'kaminariをコントローラーに適用
変更点はElasticsearchや通常のDBへの検索両方に
pageとperで何ページ目を何件取るかを設定します。
通常APIを作る際はpageの方だけparams[:page]で取得して、per部分は任意の値を設定することが多いのかな?と思うので、今回はそういった実装になっています。app/controllers/mangas_controller.rbclass MangasController < ApplicationController def index @mangas = if query.present? Manga.search(query).page(page_number).per(5).records else Manga.page(page_number).per(5) end end private def query @query ||= params[:query] end def page_number [params[:page].to_i, 1].max end endkaminariのための日本語設定を追加
kaminariのページネーション部分を日本語表記にするための設定を追加します。
application.rbにconfig.i18n.default_locale = :jaを追加しましょう。config/application.rbmodule ElasticsearchRailsSandbox class Application < Rails::Application # Initialize configuration defaults for originally generated Rails version. config.load_defaults 6.0 <中略> config.i18n.default_locale = :ja end end新規で日本語設定ymlファイルを以下の通りの内容で作成します。
config/locales/ja.ymlja: views: pagination: first: "« 最初" last: "最後 »" previous: "‹ 前" next: "次 ›" truncate: "..."kaminariのためのビューの変更
kaminariのテンプレートを作成するコマンドを実行します。
$ bundle exec rails g kaminari:views default実行すると
app/views/kaminari以下にファイルが作成されるので、これらのファイルを修正していきます。kaminariについてはおまけ的な部分なので、以下に完成したビューを示すのみになりますので悪しからず
kaminari/_next_page.html.erb
app/views/kaminari/_next_page.html.erb<%# Link to the "Next" page - available local variables url: url to the next page current_page: a page object for the currently displayed page total_pages: total number of pages per_page: number of items to fetch per page remote: data-remote -%> <%= link_to_unless current_page.last?, t('views.pagination.next').html_safe, url, rel: 'next', remote: remote, class: 'pagination-next' %>kaminari/_page.html.erb
app/views/kaminari/_page.html.erb<%# Link showing page number - available local variables page: a page object for "this" page url: url to this page current_page: a page object for the currently displayed page total_pages: total number of pages per_page: number of items to fetch per page remote: data-remote -%> <li> <% if page.current? -%> <%= link_to page, '#', {remote: remote, rel: page.rel, class: "pagination-link is-current"} %> <% else -%> <%= link_to page, url, {remote: remote, rel: page.rel, class: "pagination-link"} %> <% end -%> </li>kaminari/_paginator.html.erb
app/views/kaminari/_paginator.html.erb<%# The container tag - available local variables current_page: a page object for the currently displayed page total_pages: total number of pages per_page: number of items to fetch per page remote: data-remote paginator: the paginator that renders the pagination tags inside -%> <%= paginator.render do -%> <nav class="pagination is-centered" role="navigation" aria-label="pager"> <%= prev_page_tag unless current_page.first? %> <% unless current_page.out_of_range? %> <%= next_page_tag unless current_page.last? %> <% end %> <ul class="pagination-list"> <% each_page do |page| -%> <% if page.left_outer? || page.right_outer? || page.inside_window? -%> <%= page_tag page %> <% elsif !page.was_truncated? -%> <%= gap_tag %> <% end -%> <% end -%> </ul> </nav> <% end -%>kaminari/_prev_page.html.erb
app/views/kaminari/_prev_page.html.erb<%# Link to the "Previous" page - available local variables url: url to the previous page current_page: a page object for the currently displayed page total_pages: total number of pages per_page: number of items to fetch per page remote: data-remote -%> <%= link_to_unless current_page.first?, t('views.pagination.previous').html_safe, url, rel: 'prev', remote: remote, class: 'pagination-previous' %>views/mangas/index.html.erb
<%= paginate @mangas %>を追加しています。app/views/mangas/index.html.erb<section class="hero is-info"> <div class="hero-body"> <div class="container"> <h1 class="title"> 漫画検索 </h1> </div> </div> </section> <div class="container" style="margin-top: 30px"> <%= form_tag(mangas_path, method: :get, class: "field has-addons has-addons-centered") do %> <div class="control"> <%= text_field_tag :query, @query, class: "input", placeholder: "漫画を検索する" %> </div> <div class="control"> <%= submit_tag "検索", class: "button is-info" %> </div> <% end %> </div> <div class="container" style="margin-top: 50px"> <table class="table is-striped is-hoverable"> <thead class="has-background-info"> <tr> <th class="has-text-white-bis">出版社</th> <th class="has-text-white-bis">ジャンル</th> <th class="has-text-white-bis">著者</th> <th class="has-text-white-bis">タイトル</th> <th class="has-text-white-bis">説明</th> </tr> </thead> <tbody> <% @mangas.each do |manga| %> <tr> <td><%= manga.publisher.name %></td> <td><%= manga.category.name %></td> <td><%= manga.author.name %></td> <td><%= manga.title %></td> <td><%= manga.description %></td> </tr> <% end %> </tbody> </table> <%= paginate @mangas %> </div>手順16:RSpecのセットアップ
RSpecに必要なGemの追加
※
'spring-commands-rspec'はRSpecをSpring経由で実行するためのgemです。
以下のgemを追加したらbundle installしましょう。Gemfilegroup :test do <中略> gem 'rspec-rails' gem 'spring-commands-rspec' gem 'factory_bot_rails' endRSpecの各種設定ファイルを生成するコマンドを実行
$ bundle exec rails generate rspec:install※生成されるファイル
.rspec spec/rails_helper.rb spec/spec_helper.rb.rspecの内容を修正
--colorは出力結果の色付け
--format documentationは specファイルのdescribeやitなどのコメント部分を結果と共に表示してくれるので、付けると視覚的にテスト結果が分かりやすくなるオプションです。.rspec--require spec_helper --color --format documentationRSpecをspringを経由して実行出来るようにセットアップ
以下のコマンドを実行します。
$ bundle exec spring binstub rspec生成されるファイルは以下の通りです。
bin/rspec#!/usr/bin/env ruby begin load File.expand_path('../spring', __FILE__) rescue LoadError => e raise unless e.message.include?('spring') end require 'bundler/setup' load Gem.bin_path('rspec-core', 'rspec')bin/spring#!/usr/bin/env ruby # This file loads Spring without using Bundler, in order to be fast. # It gets overwritten when you run the `spring binstub` command. unless defined?(Spring) require 'rubygems' require 'bundler' lockfile = Bundler::LockfileParser.new(Bundler.default_lockfile.read) spring = lockfile.specs.detect { |spec| spec.name == 'spring' } if spring Gem.use_paths Gem.dir, Bundler.bundle_path.to_s, *Gem.path gem 'spring', spring.version require 'spring/binstub' end endFactoryBotの各種ファイルを追加
spec/factories/author.rbFactoryBot.define do factory :author do sequence(:name) { |n| "TEST#{n}太郎" } end endspec/factories/category.rbFactoryBot.define do factory :category do name { %w(ラブコメ ファンタジー サスペンス バトル スポーツ サイコスリラー 日常系).sample } end endspec/factories/manga.rbFactoryBot.define do factory :manga do association :category, factory: :category association :author, factory: :author association :publisher, factory: :publisher sequence(:title) { |n| "TEST_PRODUCT#{n}" } sequence(:description) { |n| "TEST_DESCRIPTION#{n}" } end endspec/factories/publisher.rbFactoryBot.define do factory :publisher do sequence(:name) { |n| "TEST#{n}出版" } end endFactoryBotの名前空間を省略出来るようにする定義を追加
テストデータの呼び出しを
FactoryBot.create(:◯◯) → create(:◯◯)に簡略化出来る設定など細かい設定を以下の通りに追加しておきます。spec/rails_helper.rbRSpec.configure do |config| <中略> # テストデータの呼び出しをFactoryBot.create(:◯◯) → create(:◯◯)に簡略化 config.include FactoryBot::Syntax::Methods # springを使用してrspecを動かしているとfactoryで作成したデータが正しく読み込まれないことがあるので # 毎回全てのexample実行前にfactory_botを再読込させる config.before :all do FactoryBot.reload end end手順17:Elasticsearchのテストを追加
RSpecでElasticsearchのindexを作成するための設定
ElasticsearchをRSpec上でテストする際の設定をしていきます。
※テスト実行時にmetaデータを渡し、それがelasticsearchだった場合に該当リソースのindexを作成するように設定しています。spec/rails_helper.rbRSpec.configure do |config| <中略> # elasticsearchのテストの場合のみIndexを作成する config.before :each do |example| if example.metadata[:elasticsearch] && example.metadata[:model_name] # meta情報のモデル名の文字列をクラス定数に変換し、Elasticsearchのindexを作成する class_constant = example.metadata[:model_name].classify.constantize class_constant.create_index! end end endキーワード検索のテスト
spec/models/concerns/manga_search/engine_spec.rbrequire 'rails_helper' RSpec.describe MangaSearch::Engine, elasticsearch: true, model_name: "manga" do describe 'Manga.search' do describe '検索ワードにマッチする漫画の検索' do let!(:manga_1) do create(:manga, title: 'キングダム', description: '時は紀元前―。いまだ一度も統一...') end let!(:manga_2) do create(:manga, title: '僕のヒーローアカデミア', description: '多くの人間が“個性という力を持つ...') end let!(:manga_3) do create(:manga, title: 'はたらく細胞', description: '人間1人あたりの細胞の数、およそ60兆個...') end # 作成したデータをelasticsearchに登録する # refresh: true を追加することで登録したデータをすぐに検索できるようにする before { Manga.__elasticsearch__.import(refresh: true) } subject { Manga.search(query).records.pluck(:id) } context '検索ワードがタイトルにマッチする場合' do let(:query) { 'キングダム' } it '検索ワードにマッチする漫画を取得する' do is_expected.to include manga_1.id end end context '検索ワードが複数ある場合' do let(:query) { '人間 個性' } it '両方の検索ワードにマッチする漫画を取得する' do is_expected.to include manga_2.id end end context '検索ワードが本文にマッチする場合' do let(:query) { '60兆個' } it '検索ワードにマッチする漫画を取得する' do is_expected.to include manga_3.id end end end end endまとめ
以上でハンズオンのカリキュラムは終了になります。
駆け足ではありましたが、Dockerで環境を作って、Rails上でElasticsearchを試せるようになりました。
この後はサンプルアプリを自分なりに改造しつつ、デバッグしつつ、Elasticsearchの勉強用の教材として利用して頂ければ嬉しいです。
最後までお付き合い下さり、ありがとうございました
参考


- 投稿日:2020-03-01T19:40:47+09:00
GNU Prolog に UTF-8 サポートを追加した話
きっかけ
SWI-Prolog では Prolog コードに UTF-8 で記述することができます。
特に SWI-Prolog に不満があるわけではありませんが、GNU Prolog は WAM コードの出力とか面白い機能があります。また、異なる処理系上で同じソースコードを持っていって動かしてみたら挙動が違っていた、仕様を調べてみるとソースコードに不備が見つかった、などということもあります。
GNU Prolog でも UTF-8 が使えたら良いと思いました。
UTF-8 が使える GNU Prolog について
当方が UTF-8 サポートを追加した GNU Prolog を公開しています。
適当なディレクトリで以下のような git コマンドを実行するとソースコード一式をダウンロードできます。git clone https://github.com/tadashi9e/gprolog-utf8gprolog-utf8 というディレクトリができます。
元となっている GNU Prolog のソースコードと同じ手順でビルドできます。INSTALL ファイルにあるとおりですが、一応ビルド手順を書きます。
gprolog-utf8 のインストール手順
clone してきた gprolog-utf8 の下に src ディレクトリがあるので、そのディレクトリに移動します。
cd gprolog-utf8/srcautoconf, configure, make の順に実行してソースコードをコンパイルします(autoconf がない場合は別途インストールしてください)。
autoconf ./configure makeビルドできたらインストールします。
sudo make install-system install-links/usr/local/bin/gprolog として実行できるようになります。
インストール先を変えたい場合には INSTALL ファイルを参照し、configure に適当なオプションを付けると可能です。Docker でコンテナとして動かす
Docker で動かしたい、という人がいるかどうかわかりませんが、Dockerfile を書いてみました。
FROM alpine:3.11.3 RUN apk --update add autoconf git gcc libc-dev make && \ git clone https://github.com/tadashi9e/gprolog-utf8 && \ (cd gprolog-utf8/src && autoconf && ./configure && make && \ make install-system install-links) && \ rm -rf gprolog-utf8 ENV LANG ja_JP.UTF-8 ENV LANGUAGE ja_JP.UTF-8 ENV LC_ALL ja_JP.UTF-8調子に乗って Docker Hub に push してみました。以下のように pull して実行することもできます。
$ docker pull tadashi9e/gprolog-utf8 $ docker run -it tadashi9e/gprolog-utf8 /usr/local/bin/gprolog GNU Prolog 1.4.5 (64 bits) Compiled Mar 2 2020, 10:50:25 with gcc By Daniel Diaz Copyright (C) 1999-2015 Daniel Diaz | ?- atom_concat('東京', 'オリンピック', X). X = 東京オリンピック yes | ?-GNU Prolog への UTF-8 サポート追加のためにやったこと
あとから思い出して書いているので漏れがあるかもしれません。
組み込み述語への UTF-8 サポートの追加
アトムを扱う組み込み述語への UTF-8 サポートの追加。
atom_concat/3, get_char/1, get_char/2, get_code/1, get_code/2, get_key/1, get_key/2, get_key_no_echo/1, get_key_no_echo/2, peek_char/1 peek_char/2, peek_code/1, peek_code/2, unget_char/1 unget_char/2, unget_code/1, unget_code/2
ソースコード読み込み処理への UTF-8 サポートの追加
pl2wam, wam2ma が UTF-8 ソースコードを扱えるように修正。
コンソール処理への UTF-8 サポートの追加
コンソール(linedit) での UTF-8 入出力。
ヒストリ表示、カーソル移動は結構大変でした。UTF-8 文字が画面上でどのような幅として表示されるのかわからないので、一文字単位の前後移動は行頭から移動の度に表示しなおす、バックスペースやデリートの場合には一行まるごと削除して行頭から表示しなおす、というふうにエスケープシーケンス処理を再表示に書き換えています。
それでもヒストリ上の過去・未来への行き来を繰り返すとタイミング依存で表示がおかしくなることがありますが、実用上大きな問題ではないので放置しています。シングルトンチェックに関する変更
ワイドキャラクタ文字はすべて小文字扱いにしています。ワイドキャラクタ文字から始まる文字列はアトムとし、'_' にワイドキャラクタ文字が続く文字列は変数名として扱えばよいだろう、という判断です。
一方で GNU Prolog においては、'_' で始まる変数はシングルトンチェック対象外です。
しかし、変数名に日本語を使ったソースコードを書こうとすると、以下のように '_変数名' のような形式の変数を大量に書くことになります。
推論過程表示(_前提, _推論過程) :- 式一覧の表示(_前提), nl, 推論過程表示(_推論過程). 推論過程表示([]). 推論過程表示([_推論|_残りの推論]) :- _推論 =.. [ _推論ルール名, _前提, _結論, _次の式一覧], write('---------------- '), write(_推論ルール名), write(' ('), 式一覧の表示(_前提), write(' ⊢ '), 式一覧の表示(_結論), write(' )'), nl, 式一覧の表示(_次の式覧), nl, % ← うっかり一文字消してしまった! 推論過程表示(_残りの推論).シングルトンチェックの有無は動作に影響しないのでどうでもいいといえばどうでもいいことなのですが、Prolog ソースコードのタイポはバックトラックも絡んで非常にわかりにくい挙動を引き起こすことが多いのでシングルトンチェックがないのはつらいです。
GNU Prolog のパーサに手を入れて、'_' で始まる変数の場合であってもワイドキャラクタ文字が続く場合には特例としてシングルトンチェックするようにしてしまいました。
$ gprolog GNU Prolog 1.4.5 (64 bits) Compiled Mar 1 2020, 05:31:13 with gcc By Daniel Diaz Copyright (C) 1999-2015 Daniel Diaz | ?- [p]. compiling /tmp/p.pl for byte code... /tmp/p.pl:208-213: warning: singleton variables [_次の式一覧,_次の式覧] for 推論過程表示/1 /tmp/p.pl compiled, 321 lines read - 30396 bytes written, 14 ms (5 ms) yesSWI-Prolog も同様にシングルトンチェックが効くので、SWI-Prolog に寄せた、という言い方もできそうです。
$ swipl Welcome to SWI-Prolog (threaded, 64 bits, version 7.6.4) SWI-Prolog comes with ABSOLUTELY NO WARRANTY. This is free software. Please run ?- license. for legal details. For online help and background, visit http://www.swi-prolog.org For built-in help, use ?- help(Topic). or ?- apropos(Word). ?- [p]. Warning: /tmp/p.pl:208: Singleton variables: [_次の式一覧,_次の式覧] true.おまけ: Emacs の run-prolog で UTF-8 を扱う方法
SWI-Prolog をお使いの方にも役に立つ情報です。
SWI-Prolog はコンソール上で UTF-8 を出力すると微妙に表示が狂います(すみません。当方の環境だけなのかもしれません)。
emacs の run-prolog で実行すると SWI-Prolog でも UTF-8 を含んだ項をきれいに表示できます。
ただし、デフォルト設定で文字化けする場合には(~/.emacs.d/init.el などの)設定ファイルに以下のような記述をしておく必要があります。
(prefer-coding-system 'utf-8) (set-default-coding-systems 'utf-8) (set-terminal-coding-system 'utf-8) (set-keyboard-coding-system 'utf-8)また、run-prolog が SWI-Prolog を起動する場合で、GNU Prolog に切り替えたい場合には以下のように設定すれば可能です。
(setq prolog-program-name "/usr/local/bin/gprolog")


- 投稿日:2020-03-01T19:34:32+09:00
Dockerが動かない
dockerコマンドのほとんどが動かくなってしまった(sudoをつけるとたまにできることもあった)
errorの内容は、error during connect: Post http://host.docker.internal:2375/v1.39/auth: dial tcp: lookup host.docker.internal: no such host
host.docker.internalはdocker18.03.0から推奨になっているホストmacのdns名。そういや前にdockerから自分のPCにアクセスしようとした時に、
zshrcに$HOST=host.docker.internal的な設定をした気がする...その箇所を消すと治った。アンインする前に、docker周りの環境変数あたりをもう一度確認してみると時短になるかもしれません。しょうもない記事になってしまった。
- 投稿日:2020-03-01T17:44:31+09:00
dockerでOracle Database18cの開発環境構築してみた
dockerでOracle Database 12の開発環境構築
背景
とある調査を実施のためにlocalにOracle Databaseを構築してみました、という話です。
今回は、その備忘録です。開発環境
- Windows10
- Docker Desktop for Windows
- Oracle Database 18c (18.3.0) Express Edition (XE)
手順
oracle databeseの公式repositoryを取得
docker imageをbuildするためのscriptは、Oracleがgithub上で公開をしています。今回は、そのscriptを利用してdocker imageの作成を行います(手順は後述)。
cd ${projecty root}/build/docker/oracle/ git clone https://github.com/oracle/docker-images.gitoracle database本体の取得
oracle database 18c(18.3.0)にて公開されているバイナリを取得します。
downloadファイルを配置
cd ${projecty root}/build/docker/oracle/docker-images/OracleDatabase/SingleInstance/dockerfiles/18.3.0 cp ~/Download/linu.x64_180000_db_home.zip .docker imageのbuild
git cloneで取得したshell scriptにて、docker imageを作成します。
cd ${projecty root}/build/docker/oracle/docker-images/OracleDatabase/SingleInstance/dockerfiles sh biuldDockerImage.sh -v 18.3.0 -e以下のメッセージが出力されることを確認できれば、docker imageの作成を行います。
Oracle Database Docker Image for 'ee' version 18.4.0 is ready to be extended: --> oracle/database:18.4.0-ee Build completed in 928 seconds.ここで、以下のエラーが発生した場合は、docker imageを作成する際に実行するshell scriptの改行コードが
LFからCRLFに変更されている可能性があります。対象のshell scriptの改行コードをLFにします。MD5 for required packages to build this image did not match! Make sure to download missing files in folder 18.3.0.imageの出力確認
作成されたdocker imageを確認します。
docker images REPOSITORY TAG IMAGE ID CREATED SIZE oracle/database 18 3.0-ee c90d8241c96d 3 hours ago 5.98GB ...省略...docker-compose.ymlに構成の記述
version: '2' services: db: image: oracle/database:18.3.0-ee environment: ORACLE_SID: ORCL ORACLE_PDB: SAMPLE ORACLE_PWD: password ORACLE_CHARACTERSET: AL32UTF8 ORA_SDTZ: Japan ports: - "1521:1521" - "5500:5500" volumes: - ./build/docker/oracle/oradata:/opt/oracle/oradatadocker containerの起動
docker-composeコマンドでcontainerの起動をします。
なお、この処理には時間がかかります。(30分程度)docker-compose up -d起動が確認できれば、構築は完了です。

- 投稿日:2020-03-01T16:56:13+09:00
データ分析基盤構築入門 サンプルアプリエラー
データ分析基盤構築入門のサンプルアプリケーションを、Dockerで立ち上げる際にエラーが出て、うまく立ち上がらなかったので、色々ソリューションを試しました。
その中で、2020/3/1現在のソリューションを書きます。
エラー内容
$ docker-compose up --builddockerでelasticsearch fluentd goアプリケーションを立ち上げると、fluentdコンテナの立ち上げでエラーが出ます。
ソリューション
1.fluentdのtd-agent-gemのバージョンをあげる。
blog-sample/Dockerfile-fluentdの中身を以下のように変更します。FROM debian:jessie ENV DEBIAN_FRONTEND=noninteractive RUN apt-get -qq update && apt-get install --no-install-recommends -y curl ca-certificates sudo build-essential libcurl4-gnutls-dev RUN curl -L https://toolbelt.treasuredata.com/sh/install-debian-jessie-td-agent3.sh | sh RUN /usr/sbin/td-agent-gem install fluent-plugin-elasticsearch fluent-plugin-record-reformer EXPOSE 24224 CMD exec td-agent -c /fluentd/etc/$FLUENTD_CONF -p /fluentd/plugins $FLUENTD_OPT具体的には、4行目でインストールしているtd-agent-gemのバージョンを2 -> 3に変更します。
参考: td-agent2からtd-agent3へバージョンアップしました - Qiita
2. 1の対応をすると、全てのコンテナが立ち上がった。localhost:80にアクセスすると、マイグレーションされていないので、エラーが出る。
no such table: articlesgoアプリケーションコンテナに入ってあげてマイグレーション実行すると、さらにエラーが出ます。
go get github.com/rubenv/sql-migrate/... package math/bits: unrecognized import path "math/bits" (import path does not begin with hostname) Makefile:13: recipe for target '/go/bin/sql-migrate' failed make: *** [/go/bin/sql-migrate] Error 13.goのversionをあげる
1.8 -> 1.10に
go - Cannot find package math/bits - Stack Overflow
4.マイグレーションを実行すると、マイグレーション実行される
再びgoアプリケーションコンテナに入ってあげて、マイグレーションを実行してあげると、マイグレーションが正常に実行される。
go get github.com/rubenv/sql-migrate/... /go/bin/sql-migrate up -env=development Applied 2 migrations
- 投稿日:2020-03-01T16:25:48+09:00
【Rails】rails6 + docker + nuxt ssr で connect ECONNREFUSED ERROR socket hang up
rails + docker + nuxtでなにか作ろうとしていた際にハマった部分
時間があるときに詳細を書きたい。docker-compose.ymlversion: '3' services: db: image: mysql:8.0 environment: MYSQL_ROOT_PASSWORD: password ports: - '3306:3306' command: --default-authentication-plugin=mysql_native_password volumes: - mysql-data:/var/lib/mysql backend: build: ./backend/ command: bash -c "rm -f tmp/pids/server.pid && bundle install && bundle exec rails s -p 3000 -b '0.0.0.0'" volumes: - .:/app ports: - "3000:3000" depends_on: - db stdin_open: true tty: true command: bundle exec rails server -b 0.0.0.0 frontend: build: ./frontend/ command: npm run dev volumes: - .:/app ports: - 8080:3000 volumes: mysql-data: driver: localfrontend/pages/users/_id.vue<template> <h1>Hello, {{ id }}</h1> </template> <script> export default { asyncData ({ $axios, params }) { return $axios.$get(`http://localhost:3000/users/${params.id}`).then((res) => { return { id: res.id } }) } } </script>ブラウザからapi(http://localhost:3000/users/1) を叩くと
{ id: 1, email: "test@example.com", created_at: "2020-02-29T13:39:03.638Z", updated_at: "2020-02-29T13:39:12.055Z", url: "http://localhost:3000/users/1" }vueのfront(http://localhost:8080/users/1) からアクセスすると
frontend_1 | ERROR socket hang up frontend_1 | frontend_1 | at connResetException (internal/errors.js:604:14) frontend_1 | at Socket.socketOnEnd (_http_client.js:460:23) frontend_1 | at Socket.emit (events.js:323:22) frontend_1 | at Socket.EventEmitter.emit (domain.js:482:12) frontend_1 | at endReadableNT (_stream_readable.js:1204:12) frontend_1 | at processTicksAndRejections (internal/process/task_queues.js:84:21)以下に書き換える
frontend/pages/users/_id.vue<template> <h1>Hello, {{ id }}</h1> </template> <script> export default { asyncData ({ $axios, params }) { return $axios.$get(`http://backend:3000/users/${params.id}`).then((res) => { return { id: res.id } }) } } </script>Request failed with status code 403
railsを以下を追加
backend/config/environments/development.rbconfig.hosts << "backend"解決した。

- 投稿日:2020-03-01T16:02:02+09:00
AIきりたんをMacで動かしてみる
こんにちは、シンガーソングライティングSEのワタナベです。
AIきりたん、話題ですね。曲提供業のためにVOCALOID買おうかと思ってたので、ぜひ使いたい。
ただ、今のところ Windows か Linux でしか動かないんですよね。
なので、Mac 上で docker で動かしてみました。
簡単なのでDTM畑の非エンジニアもぜひ参考にしてみてね。dockerを入れる
https://qiita.com/kiyokiyo_kzsby/items/b46cfe1f1913891b05a9
こちらの記事の「Dockerのインストール」ってところまでやりましょう。NEUTRINOをダウンロードする
2020/3/1現在では、以下の手順が必要なようです。
1. まず本体をダウンロードする
https://n3utrino.work/501/
こちらで「Linux版」をダウンロードしてください。2. モデルファイルをダウンロードする
https://www.vector.co.jp/soft/dl/winnt/art/se520895.html
きりたんと謡子と両方使いたい場合は、こちらで「本体+歌声ライブラリ二種同梱版」をダウンロードしちゃうと手っ取り早いかと。
片方でいいときは適宜ダウンロードしてください。3. 解凍して適当なフォルダにコピー
先に、本体を解凍します。NEUTRINOフォルダの中を見ると、こんな感じのフォルダ構成になるかと思います。
この、modelフォルダの中に、後からダウンロードしたファイルを解凍してモデルファイルの中身を移動すればOK!
dockerイメージを作る
https://drive.google.com/open?id=1SkY38FD_lms4vEg2pAd3xFl-D54TFRjf
こちらからzipファイルをダウンロードして解凍し、NEUTRINOのフォルダにコピーしましょう。
こういうフォルダ構成になります。
いよいよAIきりたんに歌わせよう!
次に、build.command をダブルクリックして実行します。
こんな感じで環境構築がはじまって、
こんな感じで終わります。
これで準備完了!
このフォルダにコピーした、neutrino.command をダブルクリックしてみましょう。
ちょっと時間がかかりますが、無事実行が終わりました。output フォルダを覗いてみると・・・
おお、wavファイルができている!
あとは、色々な方が書かれているブログの、Run.batとかRun.shを「書き換える」という部分はそのままRun.shを書き換え、実行するときは neutrino.command を実行すれば、Mac上でもさくさく動くはずです。
それでは、また。







- 投稿日:2020-03-01T14:51:54+09:00
Raspberry Pi 4Bのdocker上でElastic Stack 7.6.0 を動かす
はじめに
以前からラズパイでElastic Stack(elasticsearch/kibana)を利用してますが、Raspberry Pi 4Bでメモリが飛躍的に多くなりました(RAM4GBモデル)。
メモリが多いと他にも色々動かしたくなりますが、そこで問題になるのがJavaとnode.jsのバージョン問題です。個人的にNode-REDも常用しているため、kibanaの要件だけでnode.jsのバージョン変更はできません。
ここでは、elasticsearchとkibanaのdockerイメージを作り、コンテナ仮想化技術でプロダクト間のバージョン問題を回避させた手順を記載しています。前提環境
- Raspberry Pi 4B RAM4GB
OS : Raspbian (buster)
Docker : 19.03.5dockerのインストール方法は公式にもありますし、別途調べてください。
Elasticsearchのイメージ作成
elasticの配布しているイメージはraspbianでは動作しません。アーキテクチャが違うので当然ですよね。
ラズパイではDockerfileを作り、イメージをビルドする必要があります。まず、作業用ディレクトリを作って、elasticsearch(Linux版)をダウンロードします。
$ mkdir /opt/elasticsearch $ cd /opt/elasticsearch $ wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.6.0-linux-x86_64.tar.gz自分用のDockerfileを作成します。
$ vi DockerfileDockerfileの内容は以下としています。
軽く説明すると、adoptopenjdkの公式イメージ(JDK13)をベースに、elasticsearchを構築しています。
kuromojiのプラグインもインストールしています。JVMのメモリは512MBです。FROM adoptopenjdk:13-jdk-hotspot COPY elasticsearch-7.6.0-linux-x86_64.tar.gz /opt RUN tar xzf /opt/elasticsearch-*.tar.gz -C /opt &&\ rm /opt/elasticsearch-*.tar.gz &&\ ln -s /opt/elasticsearch-* /opt/elasticsearch &&\ /opt/elasticsearch/bin/elasticsearch-plugin install analysis-kuromoji &&\ echo "network.host: 0.0.0.0" >> /opt/elasticsearch/config/elasticsearch.yml &&\ echo "discovery.type: single-node" >> /opt/elasticsearch/config/elasticsearch.yml &&\ echo "xpack.ml.enabled: false" >> /opt/elasticsearch/config/elasticsearch.yml &&\ perl -pi -e "s/Xms1g/Xms512m/" /opt/elasticsearch/config/jvm.options &&\ perl -pi -e "s/Xmx1g/Xmx512m/" /opt/elasticsearch/config/jvm.options ENV JAVA_HOME=/opt/java/openjdk CMD ["/opt/elasticsearch/bin/elasticsearch"]イメージをビルドします。タグ付けは自由にして良いと思います。
$ docker build -t rpi-elasticsearch:7.6.0 . Sending build context to Docker daemon 296.2MB Step 1/5 : FROM adoptopenjdk:13-jdk-hotspot 13-jdk-hotspot: Pulling from library/adoptopenjdk b9b5ae93466e: Pull complete 9e8983199234: Pull complete 1e76f87f706a: Pull complete b196ba84f492: Pull complete 22d5149f952e: Pull complete 23518038960e: Pull complete Digest: sha256:6774f80c4cd4f21a7bcf063453da70b77e17f251cf86a234fb608d943056daba Status: Downloaded newer image for adoptopenjdk:13-jdk-hotspot ---> ec294fa0b7ff Step 2/5 : COPY elasticsearch-7.6.0-linux-x86_64.tar.gz /opt ---> 180f95f02c67 Step 3/5 : RUN tar xzf /opt/elasticsearch-*.tar.gz -C /opt && rm /opt/elasticsearch-*.tar.gz && ln -s /opt/elasticsearch-* /opt/elasticsearch && /opt/elasticsearch/bin/elasticsearch-plugin install analysis-kuromoji && echo "network.host: 0.0.0.0" >> /opt/elasticsearch/config/elasticsearch.yml && echo "discovery.type: single-node" >> /opt/elasticsearch/config/elasticsearch.yml && echo "xpack.ml.enabled: false" >> /opt/elasticsearch/config/elasticsearch.yml && perl -pi -e "s/Xms1g/Xms512m/" /opt/elasticsearch/config/jvm.options && perl -pi -e "s/Xmx1g/Xmx512m/" /opt/elasticsearch/config/jvm.options ---> Running in 04614ec30c83 -> Installing analysis-kuromoji -> Downloading analysis-kuromoji from elastic [=================================================] 100% -> Installed analysis-kuromoji Removing intermediate container 04614ec30c83 ---> 9fe6e4aba987 Step 4/5 : ENV JAVA_HOME=/opt/java/openjdk ---> Running in e7ac29a6ba08 Removing intermediate container e7ac29a6ba08 ---> 3181a0333fce Step 5/5 : CMD ["/opt/elasticsearch/bin/elasticsearch"] ---> Running in 6e359a5a0d2c Removing intermediate container 6e359a5a0d2c ---> 5f154d40486e Successfully built 5f154d40486e Successfully tagged rpi-elasticsearch:7.6.0起動テストをします。
$ docker run --rm -it rpi-elasticsearch:7.6.0 OpenJDK Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release. [2020-03-01T03:40:15,773][WARN ][o.e.b.Natives ] [acfc53556bd0] unable to load JNA native support library, native methods will be disabled. : : [2020-03-01T03:41:52,371][INFO ][o.e.x.i.a.TransportPutLifecycleAction] [acfc53556bd0] adding index lifecycle policy [watch-history-ilm-policy] [2020-03-01T03:41:52,657][INFO ][o.e.x.i.a.TransportPutLifecycleAction] [acfc53556bd0] adding index lifecycle policy [slm-history-ilm-policy] [2020-03-01T03:41:52,984][INFO ][o.e.x.i.a.TransportPutLifecycleAction] [acfc53556bd0] adding index lifecycle policy [ilm-history-ilm-policy] [2020-03-01T03:41:53,859][INFO ][o.e.l.LicenseService ] [acfc53556bd0] license [62b59344-95fa-445c-919e-05d9cda77bfc] mode [basic] - valid [2020-03-01T03:41:53,863][INFO ][o.e.x.s.s.SecurityStatusChangeListener] [acfc53556bd0] Active license is now [BASIC]; Security is disabled若干警告が出ますが、問題なさそうなら[Ctrl]+[c]で終了させます。
Kibanaのイメージ作成
elasticsearch同様にディレクトリ作成後にkibanaをダウンロードします。
$ mkdir /opt/kibana $ cd /opt/kibana $ wget https://artifacts.elastic.co/downloads/kibana/kibana-7.6.0-linux-x86_64.tar.gz $ vi DockerfileDockerfileは以下の内容です。
軽く説明すると、node.jsの公式イメージ(10.18.0)をベースに、kibanaを構築しています。
Kibanaは日本語ロケール設定と接続先を「elasticsearch」というホスト名に変更しています。
もし、前項のelasticsearchコンテナの名前を「elasticsearch」以外にする際は変更が必要です。また、elasticsearchのコンテナもそうなのですが、コンテナ内ではrootユーザで起動させていますので、セキュリティ面を気にする場合は非rootユーザで起動できるようRUNスクリプトを見直してください。
FROM node:10.18.0 COPY kibana-7.6.0-linux-x86_64.tar.gz /opt RUN tar xzf /opt/kibana-*.tar.gz -C /opt &&\ rm /opt/kibana-*.tar.gz &&\ ln -s /opt/kibana-* /opt/kibana &&\ echo 'server.host: "0.0.0.0"' >> /opt/kibana/config/kibana.yml &&\ echo 'i18n.locale: "ja-JP"' >> /opt/kibana/config/kibana.yml &&\ echo 'elasticsearch.hosts: ["http://elasticsearch:9200"]' >> /opt/kibana/config/kibana.yml &&\ rm /opt/kibana/node/bin/node &&\ ln -sr `which node` /opt/kibana/node/bin/node ENV NODE_OPTIONS=--max-old-space-size=512 CMD ["/opt/kibana/bin/kibana","--allow-root"]kibanaのイメージをビルドします。
kibanaはファイル数が多いので、若干待たされますね。$ time docker build -t rpi-kibana:7.6.0 . Sending build context to Docker daemon 249.5MB Step 1/5 : FROM node:10.18.0 10.18.0: Pulling from library/node b531ae4a3925: Pull complete 22754f6fc5d5: Pull complete cb2155e4b345: Pull complete fad0ae228784: Pull complete a85007ed2d2e: Pull complete 107728f28858: Pull complete 8f80cc20793e: Pull complete 09183a419a5f: Pull complete 5d502ef30c0b: Pull complete Digest: sha256:49f77fd32e8e796f85581a8d2321c2a9f1b084e1f8b9baa02cb28bce49563ad5 Status: Downloaded newer image for node:10.18.0 ---> 0d771ddc5d69 Step 2/5 : COPY kibana-7.6.0-linux-x86_64.tar.gz /opt ---> 64fe78082d19 Step 3/5 : RUN tar xzf /opt/kibana-*.tar.gz -C /opt && rm /opt/kibana-*.tar.gz && ln -s /opt/kibana-* /opt/kibana && echo 'server.host: "0.0.0.0"' >> /opt/kibana/config/kibana.yml && echo 'i18n.locale: "ja-JP"' >> /opt/kibana/config/kibana.yml && echo 'elasticsearch.hosts: ["http://elasticsearch:9200"]' >> /opt/kibana/config/kibana.yml && rm /opt/kibana/node/bin/node && ln -sr `which node` /opt/kibana/node/bin/node ---> Running in ef24ee747be4 Removing intermediate container ef24ee747be4 ---> 5ee7f3f5dda0 Step 4/5 : ENV NODE_OPTIONS=--max-old-space-size=512 ---> Running in abc588273a14 Removing intermediate container abc588273a14 ---> dbc47aa1b62e Step 5/5 : CMD ["/opt/kibana/bin/kibana","--allow-root"] ---> Running in ef80e59468b0 Removing intermediate container ef80e59468b0 ---> eb092c8a307f Successfully built eb092c8a307f Successfully tagged rpi-kibana:7.6.0 real 4m37.608s user 0m0.966s sys 0m1.342skibanaの起動確認です。
$ docker run --rm -it rpi-kibana:7.6.0 log [04:31:04.224] [info][plugins-service] Plugin "case" is disabled. : : log [04:35:20.396] [warning][admin][elasticsearch] Unable to revive connection: http://elasticsearch:9200/ log [04:35:20.397] [warning][admin][elasticsearch] No living connectionselasticsearchに接続できない警告メッセージが続きますが、問題なさそうなら[Ctrl]+[c]で終了させます。
ElasticsearchとKibanaを起動する
dockerでは、コンテナ同士は同じ仮想ネットワークを利用する事で接続できるようになります。
docker-composeなどを使えば、設定ファイル1つで定義できますが、dockerコマンドの勉強も兼ねてコンテナ同士を連携させてみましょう。dockerにelasticというネットワークを作成します。
$ docker network create elastic先にホスト側にelasticsearchが使うdataディレクトリのマッピング先のディレクトリを作ります。
で、dockerのrunコマンドで、以下のようなオプションを使い起動させます。※説明は独自解釈
--rm : 終了時にコンテナを削除する
-d : バックグラウンド起動
--name : コンテナ名=ホスト名になる
--network : 接続するdockerネットワーク指定
-v : ホストとコンテナ内のボリュームマッピング
-p : ネットワークポートのマッピングオプションの詳細は調べてください。
$ mkdir /opt/elasticsearch/es-data $ docker run --rm -d --name elasticsearch --network elastic -v /opt/elasticsearch/es-data:/opt/elasticsearch/data -p 9200:9200 rpi-elasticsearch:7.6.0起動も確認しておきます。
$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES aca3cf3bc43a rpi-elasticsearch:7.6.0 "/opt/elasticsearch/…" 9 minutes ago Up 9 minutes 0.0.0.0:9200->9200/tcp elasticsearchkibanaの起動は以下のようにします。
$ docker run --rm -d --name kibana --network elastic -p 5601:5601 rpi-kibana:7.6.0こんな感じで起動が確認できます。
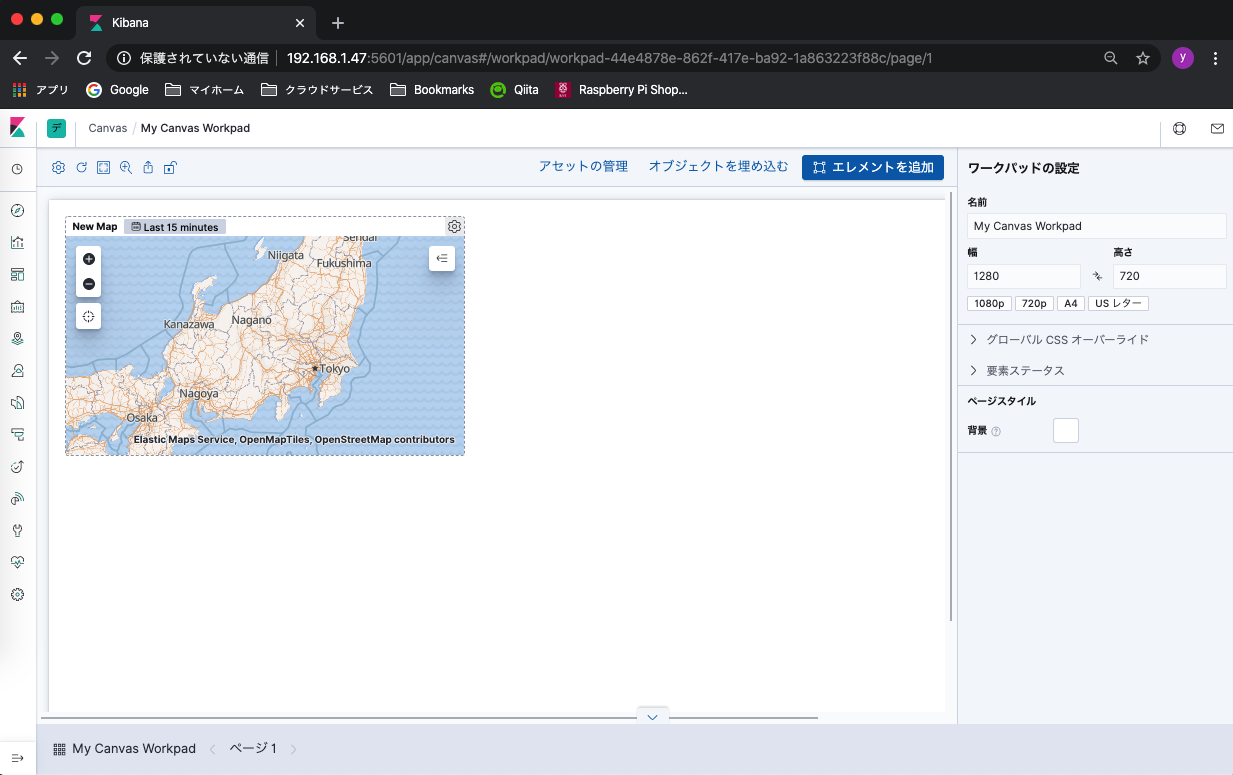
$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 11ea95981b71 rpi-kibana:7.6.0 "docker-entrypoint.s…" 7 minutes ago Up 7 minutes 0.0.0.0:5601->5601/tcp kibana aca3cf3bc43a rpi-elasticsearch:7.6.0 "/opt/elasticsearch/…" 37 minutes ago Up 37 minutes 0.0.0.0:9200->9200/tcp elasticsearchブラウザでも利用できる事が確認でき、お目当てのCanvasのMap埋め込みもできました!!
おわりに
7.6.0では以前のバージョンで問題となっていたkibanaのctagsやらnodegit絡みの問題が無くなって容易にDockerfileに落とし込めるようになっていました。elasticのエンジニアの方々はさすがです。
7.6.0では、データの時系列ソートなどの速度が向上されているとの事なので、できれば比較したいと思います。
あと、このイメージをkubernetes上でも使いたい!!←勉強しながら頑張ります。
- 投稿日:2020-03-01T14:39:09+09:00
Ubuntu上のDocker環境でWeChat/微信を使う
概要
WeChat/微信とは中国大陸で広く使われているLINEのようなチャットサービスです.WeChatはスマートフォン向けアプリの他に,PC環境においても使用でき,それらはWeb版とアプリ版に大別できます.しかし,Windows/MacOS向けにはアプリ版がありますが,Ubuntu等のLinux向けにはそのようなアプリはリリースされておりません.そのため,多くのLinuxユーザはWeb版を使用しています.ところが,人によってはWeb版にログインできないことがあります.1
本稿では,Ubuntu上でWeChatを使用するために,Wineを使用しWindow版アプリを使う方法について記述します.ただし,Wineのインストールは多少やっかいであるため,Dockerを用いてその環境を作ろうと思います.しかし,調べているうちに,そもそもWeChatをDockerで使えるようにしてくれているものを見つけましたので,それを使用することとしました.
真新しい情報はありませんが,この話題について日本語で書かれたものはあまりありませんので,必要な方の手助けになると幸いです.
環境
- HOST OS: Ubuntu 19.10 2
- Docker version 19.03.6, build 369ce74a3c
- docker-compose version 1.25.1, build a82fef07
以下では,すでにdocker, docker-composeは導入されているものとして進めます.
手順
Docker hub で公開されているimageをpullしてくる.
docker pull bestwu/wechat作成者のGithub上のレポジトリ にかかれている内容をコピペして,
docker-compose.ymlを作成.docker のコンテナを立ち上げる.
docker-compose -f docker-compose.yml upこれでWechatのGUIが起動されます.お疲れ様でした.
トラブルシューティング
基本的には以上の手順で終了のはずですが,環境によっては以下の問題が起こるかもしれません(起きました).
言語設定が中国語で読めない.
- 通常のWindows版WeChatと同様に設定画面から英語に変更できます.日本語は選べませんでした.
入力法を日本語に変えられない.
- この
docker-compose.ymlでは入力法フレームワークは fcitx となっています.私は ibus を使っていますので,次のように書き換えたらうまく行きました. 3- - QT_IM_MODULE=fcitx - - XMODIFIERS=@im=fcitx - - GTK_IM_MODULE=fcitx + - QT_IM_MODULE=ibus + - XMODIFIERS=@im=ibus + - GTK_IM_MODULE=ibus参考文献
WeChat on WINE
Wineのインストールが結構大変な感じがします.
- https://qiita.com/nanbuwks/items/bc6c3c171b7a3be981c9
- 日本語で書かれた,WeChatの使用のために様々な方法を試された記録です.
- https://puzy.site/2019/11/27/Wine-on-Ubuntu-19-10/
- Ubuntu 19.10でのWine + WeChatの使用手順.中国語.
ログインを試みても, "To protect your account, logging in to WeChat via the web has been suspended. Use WeChat for Windows or WeChat for Mac to log in on a computer. Download WeChat for Windows or Mac at http://wechat.com." というメッセージが表示され,ログインできない. ↩
Linuxであれば他の環境でも動作すると思います.実際,このdocker imageを提供してくれている方はFedoraを使用しているようです. ↩
- 投稿日:2020-03-01T14:34:04+09:00
CentOS7 Docker + Docker Compose 上で RestyaBoard を動かす
この記事に書かれている事
- CentOS7 + Docker + Docker-Compose が構成されてるサーバで
- Restyaboard を動かす
Docker/docker-compose がまだの場合 ここら辺 を参考にインストールしてください。
インストール方法の選択
トップページ下部の FAQ / Docs を選択して Restyaboard Docs に移動すると様々なインストール手順を確認できます。
代表的な物は
- shell script を使った Ubuntuへのインストール
- shell script を使った CentOSへのインストール
- DigitalOcean MarketPlace の利用
- Docker を使ったインストール
また、Install & Configure からメールアドレスを登録するとさらに多くの選択肢を提示してくれます。
今回は手軽に出来そうな Docker を使った手順でインストールしてみます。
Docker file を使ったインストール
参考URL)
Restyaboard Docs : Install Restyaboard through DockerDocker Compose用ファイルの作成
サンプルに以下の設定を追加しました。
- 自動起動設定
- postgresql のパスワード変更
- SMTPサーバの設定、後からできないからここで実施
- TOMEZONE設定
TIMEZONEは restyaboard/postgres の両方に設定してください。
最初、サンプルに TZ の記載がある restyaboard だけに設定してたら日時がずれて表示されてしまいました。[kichise@cent7 ~]$ sudo mkdir /usr/local/restyaboard [kichise@cent7 ~]$ cd /usr/local/restyaboard/ [kichise@cent7 ~]$ sudo vi docker-compose.yml version: '2' volumes: restyaboard_db: driver: local restyaboard_media: driver: local services: restyaboard: image: restyaplatform/restyaboard:dev restart: always <- 自動起動するように設定を追加 environment: POSTGRES_DB: restyaboard POSTGRES_HOST: postgres POSTGRES_PASSWORD: admin <- 複雑な文字列に変える、ここに書いてるからあまり意味ないか、、、 POSTGRES_USER: admin SMTP_DOMAIN: example.co.jp <- メールドメイン指定 SMTP_USERNAME: user <- SMTP認証用ユーザ名 SMTP_PASSWORD: pass <- SMTP認証用パスワード SMTP_SERVER: 192.168.1.23 <- メールサーバのhostname or IP SMTP_PORT: 25 <- メールサーバのport番号 TZ: Asia/Tokyo <- Etc/UTC から Asia/Tokyo に変更 volumes: - restyaboard_media:/usr/share/nginx/html/media ports: - "8081:80" postgres: image: postgres:9-alpine restart: always <- 自動起動するように設定を追加 environment: POSTGRES_DB: restyaboard POSTGRES_HOST: postgres POSTGRES_PASSWORD: admin <- 上で設定した POSTGRES_PASSWORD の値に合わせる POSTGRES_USER: admin TZ: Asia/Tokyo <- 行を追加 Asia/Tokyo に設定 volumes: - restyaboard_db:/var/lib/postgresql/data [kichise@cent7 restyaboard]$Docker-conpose 実行
意外なほどあっさりと完了します。
[kichise@cent7 restyaboard]$ docker-compose up -d Creating network "restyaboard_default" with the default driver Creating volume "restyaboard_restyaboard_db" with local driver Creating volume "restyaboard_restyaboard_media" with local driver Pulling restyaboard (restyaplatform/restyaboard:dev)... dev: Pulling from restyaplatform/restyaboard 146bd6a88618: Pull complete 81b609d94e65: Pull complete 80757a9e29b9: Pull complete 9e4c5c68ffd1: Pull complete e0361ee07b17: Pull complete 54eb2e7adc4c: Pull complete 150cccf7c0ae: Pull complete 4fddd0d459a2: Pull complete 3ec92c1c8a20: Pull complete 4c4993f48338: Pull complete 2ed94324b84a: Pull complete 5c2ae9783b23: Pull complete b3d663d234ea: Pull complete Digest: sha256:79fedfe8ec15c97eecaf74fc069d2ab93ac747f16ed841dc99132f2bf363812d Status: Downloaded newer image for restyaplatform/restyaboard:dev Pulling postgres (postgres:9-alpine)... 9-alpine: Pulling from library/postgres 4167d3e14976: Pull complete 153ce209e2ba: Pull complete b5e6278dc07d: Pull complete b4184112eeae: Pull complete 50634a031f77: Pull complete cf5601d968e8: Pull complete 1eaa021b2bed: Pull complete 2135b1524d0c: Pull complete 8bf70c06d10b: Pull complete Digest: sha256:50d91740bc52eb61226965af5fee0a2c4180d9828b4e89d43543537462602309 Status: Downloaded newer image for postgres:9-alpine Creating restyaboard_postgres_1 ... done Creating restyaboard_restyaboard_1 ... done [kichise@cent7 restyaboard]$初回ログイン・初期設定
最低限必要そうな設定項目
項目 設定値 備考 管理アカウント admin パスワード restya 早めに変更しましょう システム名 Restyaboard タブに表示されるサイト名が変わるくらい。Restyaboardを沢山立ち上げる時は一意の名前を付けましょう メールアドレス システムで利用する各種メールアドレスの設定 送信者、返信先、問い合わせ先 全部一緒でも良いかな。 言語 English 日本語が変なのでEnglishの方が良いと思います。 Site TIMEZONE Asis/Tokyo Default Language English 日本語が変なのでEnglishの方が良いと思います。v 0.6.8からはこの設定が有ってもクライアントのブラウザの言語設定が優先されます アカウント表示名 New Amin かっこ悪いから適当な名前に変えましょう ログイン画面
http://hostname or IP Address:8081/
初回ログイン時にRestyaboardを紹介する youtube の動画が流れます。
ログインの際パソコンのボリュームに注意してください。
システム言語切り替え画面
システム名/メールアドレスの設定画面
サイトのタイムゾーン/Defau言語の設定画面
管理者プロファイル設定画面
後は適当に使ってみる。
参考
インストール方法:Restyaboard Docs
インストール後の設定等:RestyaPlatform/board の github





- 投稿日:2020-03-01T11:43:34+09:00
[Docker]コンテナからローカルホストを指定する方法
127.0.0.1ではなくhost.docker.internalと指定する
- 投稿日:2020-03-01T11:07:09+09:00
ArgoのCronWorkflow解説(設定方法・手動実行の方法など)
はじめに
お疲れさまです!みなさん元気にワークフロー構築してますかー?
2/19についにArgo Workflow v2.5.0がリリースされまして1、CronWorkflowがGA版で使えるようになったので、使い方やオプションについて解説していきたいと思います。事前準備
- Kubernetesが利用可能であること
- Docker for desktopやminikubeでKubernetesが利用可能な状態にしておいてください。
Argoの準備
Argo CLIのインストール
argoの操作には
argoコマンドを使うので、あらかじめインストールしておいてください。
この記事で解説しているCronWorkflowの手動実行にはargo 2.5.2以上のCLIが必要なので、バージョンが古い人はargoコマンドをアップグレードしてください!# Mac $ brew install argoproj/tap/argo # アップグレードする人は brew upgrade argoしてください # Linux $ curl -sSL -o /usr/local/bin/argo https://github.com/argoproj/argo/releases/download/v2.5.2/argo-linux-amd64 $ chmod +x /usr/local/bin/argoArgoのインストール
今回はシンプルなWorkflowを実行するだけのつもりなので、minioとかworkflow-controller-configmapは準備せずにArgoのみインストールしてしまいます。
$ kubectl create ns argo $ kubectl apply -n argo -f https://raw.githubusercontent.com/argoproj/argo/v2.6.0/manifests/install.yamlCronWorkflowのマニフェスト
今回は本当にシンプルに、cowsayコマンドを定期実行するCronWorkflowを作成してみます。
CronWorkflowはWorkflow CRDとの互換性を保つため、Workflowで利用できる全てのオプションが利用可能な作りになっています。
今までWorkflowで定義していた項目はworkflowSpecの中に定義するフォーマットになっているので、既存のWorkflowを定期実行したいという人は、Workflowのspecの中身をCronWorkflowのworkflowSpecに登録すればそのままCron化が可能です。この記事ではWorkflowと共通のオプションには細かく説明せず、CronWorkflow特有のオプションについて解説したいと思います。
今回作成したマニフェストは以下の通りです。オプションについて順に見ていきましょう。apiVersion: argoproj.io/v1alpha1 kind: CronWorkflow metadata: name: cron-workflow-whalesay spec: schedule: "* * * * *" timezone: "Asia/Tokyo" # 複数のワークフローが同時にスケジュールされた場合の処理を決定するポリシー concurrencyPolicy: "Replace" # 本来の実行時刻を過ぎても実行したい場合のオプション startingDeadlineSeconds: 0 # 成功したワークフローの数。この設定だと4回以上成功すると古いworkflowの結果から削除されていく successfulJobsHistoryLimit: 3 # 失敗したワークフローの数。この設定だと2回以上失敗すると古いworkflowの結果から削除されていく failedJobsHistoryLimit: 1 workflowSpec: entrypoint: whalesay templates: - name: whalesay container: image: docker/whalesay command: [cowsay] args: ["hello cron workflow!!!!"]
- workflowSpecはArgoの通常のWorkflowと全く同じマニフェスト
- CronWorkflow独自の設定について説明する
- schedule
- timezone
- concurrencyPolicy
- 同じ種類のワークフローが同時にスケジュールされた場合の処理をどうするかを設定できる
- Allow: 全てのタスクを許可。つまり古いjobと新しいjobが並列動作する
- Replace: 新しいスケジュールを設定する前に古いものをすべて削除。つまり古いjobが残っていたらterminateされる
- Forbid: 古いjobが残っているうちは新しいjobは動かさない
- startingDeadlineSeconds
- concurrencyPolicyがForbidの時などに新しいjobが動けない状態が発生した場合に、本来の実行時刻を過ぎても実行したい場合数値を入力する
- 0だと本来の実行時刻を逃したjobは実行されない
- 60だと本来の実行予定時刻から60秒以内にWorkflowが実行可能な状態になれば実行される
- successfulJobsHistoryLimit
- failedJobsHistoryLimit
schedule
これはわかりやすいですね。cronと同じインターフェースで、workflowSpecで定義したjobをいつ実行するかを指定するオプションです。
timezone
これもわかりやすいですね。どのタイムゾーンの時刻に合わせてcronを実行するかを設定します。
みなさん大体"Asia/Tokyo"を指定することになるんじゃないでしょうか。concurrencyPolicy
これはちょっとわかりづらいかもしれないですね。
同じ種類のワークフローが同時にスケジュールされた場合の処理をどうするかを設定できるオプションです。
例えば、毎分実行している本来1分で終わるはずのworkflowがなんらかの理由で1分半かかってしまった、というシチュエーションで
- 1分後に起動される予定のworkflowを実行して良いのか?
- 実行する場合、先に起動していたworkflowはどのように取り扱うのか?を設定します。設定できるオプションは下記の通りです。
- Allow: 全てのタスクを許可。つまり古いjobと新しいjobが並列して実行される
- Replace: 新しいスケジュールを設定する前に古いものをすべて削除。古いjobが残っていた場合はterminateされる
- Forbid: 古いjobが残っているうちは新しいjobは動かさない
startingDeadlineSeconds
これもちょっとわかりづらいオプションですね。
例えばconcurrencyPolicyをForbidにしてworkflowが多重起動しない設定になっていた場合に、本来起動すべき時刻に実行できなかったworkflowをどのように扱うのか?を設定するためのオプションです。
デフォルトでは0となっており、本来実行する予定だった時刻に実行できなかったworkflowは実行されない設定になっています。ここの数値を60などにした場合、本来起動する予定だった時刻から60秒以内に実行可能な状態になると、後続のworkflowが直ちに実行されます。successfulJobsHistoryLimit
成功したJobの履歴を何回分保存しておくかの設定です。
例えば3と設定しておくと、成功したJobの実行結果が直近3回分だけ保存されて、古いものは適宜削除されるようになります。failedJobsHistoryLimit
失敗したJobの履歴を何回分保存しておくかの設定です。
例えば3と設定しておくと、失敗したJobの実行結果が直近3回分だけ保存されて、古いものは適宜削除されるようになります。CronWorkflowの登録/更新/削除方法
argo cronコマンドとkubectlコマンドを使う方法の両方があります。
argo cronコマンドはCronWorkflowを削除・更新できないのでkubectlコマンドを使っておくほうが無難だと思います(誰かargo cronコマンドを使うメリットを知っていたら教えてください)。また、細かい話ですがCronWorkflowによって実行されるJob用のPodはCronWorkflow CRDを作成したnamespaceで起動します。デフォルトで登録するとCronWorkflowはdefaultネームスペースに登録され、Cronで実行されるWorkflowもdefaultネームスペースで実行されるようになるため、適宜作成するネームスペースは変更するようにしましょう。
登録
argo cronコマンドとkubectl applyコマンドを使う方法の両方があります。$ argo cron create `マニフェストファイル` -n `ネームスペース` $ kubectl apply -f `マニフェストファイル` -n `ネームスペース`更新
kubectl applyコマンドを使います。$ kubectl apply -f `マニフェストファイル` -n `ネームスペース`削除
kubectl deleteコマンドを使います。$ kubectl delete -f `マニフェストファイル` -n `ネームスペース`CronWorkflowを手動実行する
開発・デバッグ時に地味に必須と言えるコマンドです。
基本的にはargo submitコマンドなんですが、実行するjobの指定方法が普通のWorkflowとちょっと違います。
手動で実行したいCronWorkflow CRDがapplyされている状態で --fromオプションを使って起動します。$ argo submit --from cronwf/`CronWorkflowの名前`以上です。それではみなさん良いワークフロー構築ライフを!
これを書いてる2/29にはv2.6.0がリリースされてるので遅きに失した感ありますけど ↩
- 投稿日:2020-03-01T00:04:31+09:00
GitHubActionsで定期実行と手動実行をやってみる
サクっと定期実行を動かしつつ、たまに任意のタイミングでもスクリプトを動かせる環境をGitHubActionsで作れないかなと試してみた記録。
GitHubActions以外の選択肢候補
下記は考えただけで、最後までうまく行くかまでは考えてない。
何で動かすか なんで選ばなかったか AWS EC2 外部APIを利用する際にVPCの構築とかめんどくさいし、稼働費がネック AWS Lambda 手動実行するのにコンソールにログイン必要? なぜGitHubActionsを選んだか
- githubのアカウントがあれば使える
- crontabのようなscheduleが使える
- repository_dispatchトリガーによりCurlで実行できる
作ったもの
現在時刻を記載したテキストファイルをAWS S3にアップロードする
(ネットワークの利用、環境変数の動作とかをみたかった)package main import ( "time" "os" "strings" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/credentials" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/s3/s3manager" ) func main() { currentTime := time.Now() creds := credentials.NewStaticCredentials(os.Getenv("MY_AWS_ACCESS_KEY_ID"), os.Getenv("MY_AWS_ACCESS_KEY_SECRET"), "") sess, _ := session.NewSession(&aws.Config{ Credentials: creds, Region: aws.String(os.Getenv("MY_AWS_REGION"))}, ) uploader := s3manager.NewUploader(sess) _, _ = uploader.Upload(&s3manager.UploadInput{ Bucket: aws.String(os.Getenv("MY_AWS_S3_BUCKET")), Key: aws.String("s3-put-object.txt"), Body: strings.NewReader(currentTime.Format("2006-01-02 15:04:05")), ContentType: aws.String("text/plain"), }) }name: UpdateS3Object on: schedule: - cron: '0 1 * * *' repository_dispatch: types: [build] jobs: execute: runs-on: ubuntu-latest steps: - uses: actions/checkout@v1 - name: build run: docker-compose run golang go build s3-put-object.go - name: execute env: MY_AWS_ACCESS_KEY_ID: ${{ secrets.MY_AWS_ACCESS_KEY_ID }} MY_AWS_ACCESS_KEY_SECRET: ${{ secrets.MY_AWS_ACCESS_KEY_SECRET }} MY_AWS_REGION: ${{ secrets.MY_AWS_REGION }} MY_AWS_S3_BUCKET: ${{ secrets.MY_AWS_S3_BUCKET }} run: ./golang/s3-put-object手動実行は
curl -X POST -H "Authorization: token #{Personal access token}" -H "Content-Type: application/json" -d '{"event_type":"build","client_payload":{}}' https://api.github.com/repos/:user/:repo/dispatches感想
docker-composeも使えたのでわりとなんでもできそう
手動実行をcurlで実現したが、slack botとかと連携させることもできそう
upload-artifact, download-artifactを使ってビルドと実行を分離すればもっときれいになりそう
秘匿情報の扱いも簡単(githubを全面的に信用している)この程度のスクリプトであれば、特になんの懸念もなくやりたいことができました。
今回のサンプルコードではAWSを使ったサンプルですが、定期実行自体にはAWSは関係なく、AWSアカウントの発行は不要です。
AWSやGCPの契約を必要とせずにgithubのアカウントだけでリモート環境に定期実行環境を構築できることはなかなか強みだなと思いました。