- 投稿日:2020-03-01T23:47:21+09:00
time-windowを使ってみた
はじめに
みなさま,はじめまして.
株式会社オプティマインドにて,GISエンジニアをしている@tkmbnです.
Qiitaへの初投稿です.概要
時間枠(日時の組み合わせ,開始日時〜終了日時)のあれやこれをしてくれるライブラリtime-windowの使い方を解説します.
複雑な時間枠をスッキリまとめてくれたりします!←このライブラリを使って一番やりたいこと.
なぜ書いたか
DBから時間枠つきのデータを取得する際に,時間枠に重なりがあればまとめてほしいという依頼がありました.
どうにかこうにか自力で実装しようとしたんですが,混乱しだして,「なんか良いツールないかなぁ...」と探していたところ上記のライブラリに出会いました.
readmeとか読んでみたんですが,あまり詳細に書かれていないため,自分への覚書も含め,記事にしました.まるまる解説!というわけではないので,あしからず...
本題
インストール方法
pip install time-window具体的な使い方
最初の方は,readmeの日本語訳的なものと思ってください笑
TimeWindow オブジェクト
作り方
2020年03月01日12:00:00から2020年03月01日15:00:00のTimeWindowを作りたいときは...from datetime import datetime from time_window import TimeWindow t1 = datetime(2020, 3, 1, 12, 00, 00) t2 = datetime(2020, 3, 1, 15, 00, 00) tw1 = TimewWindow(t1, t2) tw1 -> TimeWindow(datetime.datetime(2020, 3, 1, 12, 0), datetime.datetime(2020, 3, 1, 15, 0))このとき,時間枠は,
[t1, t2)になることに注意!また,timedeltaでも作成可能です.
from datetime import datetime, timedelta from time_window import TimeWindow t1 = datetime(2020, 3, 1, 12, 00, 00) delta = timedelta(hours=3) tw2 = TimeWindow.from_timedelta(t1, delta) tw2 -> TimeWindow(datetime.datetime(2020, 3, 1, 12, 0), datetime.datetime(2020, 3, 1, 15, 0))同じ結果が得られました.
delta, middle
時間枠の差分を知りたいときは,
tw1.delta -> datetime.timedelta(0, 10800)時間枠の中間の時点を知りたいときは,
tw1.middle -> datetime.datetime(2020, 3, 1, 13, 30)overlaps
tw = TimeWindow(datetime(2020, 3, 1, 12, 0), datetime(2020, 3, 1, 15, 0)) tw2 = TimeWindow(datetime(2020, 3, 1, 13, 0), datetime(2020, 3, 1, 18, 0)) tw.overlaps(tw2) -> True重なっていれば,True, そうでなければ,False.
contains(readme未掲載)
tw = TimeWindow(datetime(2020, 3, 1, 12, 0), datetime(2020, 3, 1, 15, 0)) tw4 = TimeWindow(datetime(2020, 3, 1, 13, 0), datetime(2020, 3, 1, 14, 0)) tw.contains(tw4) -> True含まれていれば,True, そうでなければ,False.
contiguous
tw = TimeWindow(datetime(2020, 3, 1, 12, 0), datetime(2020, 3, 1, 15, 0)) tw3 = TimeWindow(datetime(2020, 3, 1, 15, 0), datetime(2020, 3, 1, 18, 0)) tw.contiguous(tw3) -> [TimeWindow(datetime.datetime(2020, 3, 1, 12, 0), datetime.datetime(2020, 3, 1, 15, 0)), TimeWindow(datetime.datetime(2020, 3, 1, 15, 0), datetime.datetime(2020, 3, 1, 18, 0))]接している場合は,TimeWindowのリストが,接していない場合は,Falseが返ってくる.
set型みたいな事もできる
積集合
tw = TimeWindow(datetime(2020, 3, 1, 12, 0), datetime(2020, 3, 1, 15, 0)) tw2 = TimeWindow(datetime(2020, 3, 1, 13, 0), datetime(2020, 3, 1, 18, 0)) tw.intersection(tw2) -> TimeWindow(datetime.datetime(2020, 3, 1, 13, 0), datetime.datetime(2020, 3, 1, 15, 0))和集合
tw.union(tw2) -> TimeWindow(datetime.datetime(2020, 3, 1, 12, 0), datetime.datetime(2020, 3, 1, 18, 0))TimeWindowsCollection オブジェクト (readme未掲載)
作り方
from datetime import datetime, timedelta from time_window import TimeWindow, TimeWindowsCollection tw = TimeWindow(datetime(2020, 3, 1, 13, 0), datetime(2020, 3, 1, 18, 0)) tw2 = TimeWindow(datetime(2020, 3, 1, 12, 0), datetime(2020, 3, 1, 15, 0)) twc = TimeWindowsCollection([tw, tw2]) twc -> [TimeWindow(datetime.datetime(2020, 3, 1, 13, 0), datetime.datetime(2020, 3, 1, 18, 0)), TimeWindow(datetime.datetime(2020, 3, 1, 12, 0), datetime.datetime(2020, 3, 1, 15, 0))] ##開始時刻で並べ替えたい! twc.time_windows_sorted_by_since -> [TimeWindow(datetime.datetime(2020, 3, 1, 12, 0), datetime.datetime(2020, 3, 1, 15, 0)), TimeWindow(datetime.datetime(2020, 3, 1, 13, 0), datetime.datetime(2020, 3, 1, 18, 0))]複数の時間枠をまとめたい
これで自分のやりたいことは,完璧にできました.
tw = TimeWindow(datetime(2020, 3, 1, 13, 0), datetime(2020, 3, 1, 18, 0)) tw2 = TimeWindow(datetime(2020, 3, 1, 12, 0), datetime(2020, 3, 1, 15, 0)) tw3 = TimeWindow(datetime(2020, 3, 1, 19, 0), datetime(2020, 3, 1, 21, 0)) twc = TimeWindowsCollection([tw, tw2, tw3]) twc -> [TimeWindow(datetime.datetime(2020, 3, 1, 13, 0), datetime.datetime(2020, 3, 1, 18, 0)), TimeWindow(datetime.datetime(2020, 3, 1, 12, 0), datetime.datetime(2020, 3, 1, 15, 0)), TimeWindow(datetime.datetime(2020, 3, 1, 19, 0), datetime.datetime(2020, 3, 1, 21, 0))] twc.compressed() -> [TimeWindow(datetime.datetime(2020, 3, 1, 12, 0), datetime.datetime(2020, 3, 1, 18, 0)), TimeWindow(datetime.datetime(2020, 3, 1, 19, 0), datetime.datetime(2020, 3, 1, 21, 0))]重なり合っている時間枠はまとまり,重なっていないものは別の時間枠となっています.
しかし,落とし穴がありました.
普通にインデックス指定して,TimeWindowを取り出そうとしたところ,twc.compressed()[0] -> Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'TimeWindowsCollection' object does not support indexing返ってくる形見ると,普通のリストなんですが,どうやら違うみたいです...
TimeWindowsCollectionオブジェクトをTimeWindowのリストに戻してやる必要があるので,twc.compressed().time_windows -> [TimeWindow(datetime.datetime(2020, 3, 1, 12, 0), datetime.datetime(2020, 3, 1, 18, 0)), TimeWindow(datetime.datetime(2020, 3, 1, 19, 0), datetime.datetime(2020, 3, 1, 21, 0))] twc.compressed().time_windows[0] TimeWindow(datetime.datetime(2020, 3, 1, 12, 0), datetime.datetime(2020, 3, 1, 18, 0))無事取り出せることができました!!
参考文献
最後に
最後まで読んでいただきありがとうございます!
なにか疑問点,間違っている点,等ございましたら,コメントお願いいたします.



- 投稿日:2020-03-01T23:45:56+09:00
プログラミングスクール卒業後3ヶ月たった所感
2019年10月に最近youtubeでよく広告を見る某プログラミングスクールに通い、11月より機械学習エンジニア・データサイエンティストとして現職につきました。
卒業後3ヶ月経った今、スクールで学んだことで役立ったこと、今大変なことなどをつらつらと書いていきたいと思います。経歴
2015年4月 食品会社の研究・開発職として4年間務める
2019年7月 プログラミングスクール学習開始
2019年10月 プログラミングスクール卒業
2019年11月 機械学習エンジニア・データサイエンティストとして転職スキルセット
言語の使用状況
スクール 転職後 HTML ○ ○ CSS ○ ○ JavaScript ○ ○ SQL ○ △ Linux ○ ○ Ruby ○ - Python - ○ フレームワークの使用状況
スクール 転職後 SCSS ○ ○ jQuery ○ △ Vue - ○ Ruby on Rails ○ - Flask - ○ Django - ○ インフラ等
スクール 転職後 Git/Github ○ ○ Nginx ○ - EC2(AWS) ○ ○ S3(AWS) ○ ○ スクールについて
役立ったこと
- HTML/CSS/JavaScript/Linuxについて基礎が学べ、今でもシステムを作成する際に役立っている
- Ruby→Pythonに言語が変わったがどちらも動的型付けなため、基礎的な文法を学ぶことへの学習コストはかからなかった
- EC2およびS3の作成・運用の基礎が学べ、現職ではシステムのデプロイは全てAWSを用いているため、すんなり業務に入ることができた
- 現職では頻繁には使用しないが、Gitを利用した複数人の開発の経験は業務の随所で役立つ
- メンターへの質問シートの書き方を守ることで、先輩エンジニアなどに質問する際に、何が問題で・どこで詰まっているのかが明確に伝えられ、回答を頂きやすい
役立たなかったこと
基本的には学んだことはある程度役立つと思いますが、下記点は仕方ないと考えていました。
- スクールでRubyを学んだが、現職では全く使用しないこと(機械学習案件を志望していたため、仕方ないと割り切ってはいました)
転職前にやるべきだったこと
- 簡単でもいいので、新しい職場で使用するであろう言語で簡易的なシステムやアプリをデプロイまで持っていく
理由
コードの書き方や、フレームワークを予め触っておいて、素早く職場に馴染めるようにもっと努力をすべきと思いました。
- AWSのサービスをより理解しておく
理由
最近のサービスのデプロイのほとんどはAWSを利用していると思います。無料枠内で学ぶのもいいですが、実際には有料で数万円数十万円をかけてシステムを運用します。そのため少しの金額でも身銭を切って、ドメインの取り方を学んだり、アクセスの分散方法を学ぶなど、AWSというサービスを少しでも多く理解しておいた方がよかったと思いました。
- 綺麗なコードを書く意識をつける・練習する
理由
シンプルにレビュアーが大変なのと、あとで改修する際に自分でもわからなくなってしまうので、綺麗なコードを意識することは非常に大事です。(作者はめっちゃ冗長に書きすぎて、最初はレビューの時間が非常にかかってしまいました)
今大変なこと
- 想像以上にJavaScriptを多用するため、様々な機能を覚える必要がある
- 基本的に少人数でシステムを作成したり、データ分析を行うため分からない部分が多く、仕事が止まりやすい
他にもいろいろ大変なこともあるのですが、結論としては悩んだらわかりそうな人に聞く!!これが仕事をうまく進める方法だと思います。私自身人に聞くということが苦手で、どうしても1人でやろうとしがちだったのでした。しかし、先輩エンジニアに聞いたら数分で解決してくれたり、アドバイスしてくれるため、1時間もかけて調べるよりも、わかる人に聞いた方が100%早いです!!
- 投稿日:2020-03-01T23:34:51+09:00
[整理用]Python開発環境
整理がてら自分のPython開発環境のメモ
用途
- Deep learning / 画像処理の開発
- リモートセンシング
方針
- なるべく楽に導入
- 管理は最低限出来れば良い
- コードを楽に書ける
- 補完やフォーマットなど
OS: Ubuntu 18.04
- ライブラリなどの導入がWindowsに比べて楽
- 最近はそうでもないけど、Ubuntuじゃないと動かないものもあったので
環境管理: Anaconda
- 機械学習で必要なのが一通りインストールされる + 最低限の環境管理が出来るため
- 主なライブラリは以下
- numpyとかAnacondaについてくるのは省く
- geopandasはないとやってられない
# Deep learning用 pytorch torchvision tensorboard # 画像処理用 opencv # リモートセンシング用 gdal qgis geopandasエディタ: VSCode
- Extensionの充実
- Remote Development
- リモートサーバ上(GPUサーバ)で開発しているため
- Extensionがリモート先でも使えるのがよい
- ms-python
- Microsoft公式Extension
- イライラしない程度に補完してくれる
- Bracket Pair Colorizer
- 対応する括弧の色付け
- LinterやFormatterの設定が楽
- notebookファイル編集が出来る
Linter: Flake8
- 厳しすぎず緩すぎずといった感じ
max-line-length = 120, max-complexity = 10で使用Formatter: yapf
- Format後の感じが一番しっくり来たので
- Flake8と同じく
column_limit = 120で使用おわりに
- albumentationsとか便利系も今後は入れていきたい
- 他に良さげなものがあれば教えていただけるとありがたいです
- 投稿日:2020-03-01T23:21:39+09:00
elasticsearch_dsl 覚書
環境
Python3.8.2
elasticsearch-dsl 7.1Elasticsearch側は面倒だったので、Python上でクエリのみ確認。
A, Q
test = A("terms", field="hoge") print(test.to_dict()) print(type(test)) test2 = Q("terms", field="huge") print(test2.to_dict()) print(type(test2)){'terms': {'field': 'hoge'}} <class 'elasticsearch_dsl.aggs.Terms'> {'terms': {'field': 'huge'}} <class 'elasticsearch_dsl.query.Terms'>Agg Array
array_test = [A("terms", field="key_" +str(i)) for i in range(5)] search = Search() for i in range(5): search.aggs.bucket("array_" + str(i), array_test[i]) print(search.to_dict()){'aggs': { 'array_0': {'terms': {'field': 'key_0'}}, 'array_1': {'terms': {'field': 'key_1'}}, 'array_2': {'terms': {'field': 'key_2'}}, 'array_3': {'terms': {'field': 'key_3'}}, 'array_4': {'terms': {'field': 'key_4'}} }}Aggs Array ネストをつけたい
array_test = [A("terms", field="key_" +str(i)) for i in range(5)] search = Search() X = search.aggs.bucket("array_0", array_test[0]) for i in range(1, 5): X = X.bucket("array_" + str(i), array_test[i]) print(search.to_dict()){'aggs': {'array_0': { 'terms': {'field': 'key_0'}, 'aggs': {'array_1': { 'terms': {'field': 'key_1'}, 'aggs': {'array_2': { 'terms': {'field': 'key_2'}, 'aggs': {'array_3': { 'terms': {'field': 'key_3'}, 'aggs': {'array_4': { 'terms': {'field': 'key_4'} }} }} }} }} }}}
- 投稿日:2020-03-01T23:16:47+09:00
Python Windows実行ファイル実行時に陥った罠
PythonのWindows実行ファイル作成時に陥った罠
Pythonを用いてWindowsの実行ファイルを作成した際に、コマンドライン引数を用いて処理を行たかったが、その際に陥った罠について備忘として記録する。
コマンドライン引数
コマンドライン引数を用いたhelloworld
hello.pyimport sys str1 = sys.argv[1] print(str1)
python test.py helloworld
>>> helloworldpyinstallerを使って実行ファイル化
pyinstaller hello.py --onefilehello.exeの実行
IndexError: list index out of range
原因は、コマンドラインを使用しないため、リストが作成できなかった。解決方法
Input関数を使用
hello.pystr1 = input("please put something") print(str1)hello.pyの実行
>>>please put something
helloworld結論
試行錯誤した結果、sysを用いてコマンドライン引数を取得することができなかったため、Input関数を使用することとした結果、うまく行った。
もし、Windowsの実行ファイルにて、コマンドライン引数を使用する方法をご存知の方がいらっしゃいましたら、是非ご教示いただければと存じます。
- 投稿日:2020-03-01T23:12:37+09:00
pythonでのcsvファイル読み書きの際の文字コード ~windows環境ver~
本稿の投稿経緯
python初心者の私が、csvファイルの読み書きの際のエンコードにたまにエラーに躓くので、その内容のまとめをメモしたもの。同じく初心者向けの記事になります。なお、環境はwindows環境になります。
エラー
csvファイルの読み書きの際に、よく引っかかるエラーについて
書き込み時のエラー
エラー内容UnicodeEncodeError: 'shift_jis' codec can't encode character '\u9ad9' in position 14: illegal multibyte sequenceshift-jisでエンコードできない文字があるよってことですね。ファイル書き込みの際にファイルの文字コードと書き込み文字の文字コードの不一致で発生します。
ちなみにコードの指定箇所はここなど。
コード例with open(filepath, 'w', newline='', encoding='shift-jis') as f読み込み時のエラー
エラー内容UnicodeDecodeError: 'shift_jis' codec can't decode byte 0xee in position 0shift-jisででコードできない文字があるよってことですね。ファイル読み込みの際にファイルの文字コードとファイルの読み込みで指定した文字コードの不一致で発生します。(もしくは、ファイルの読み込み時に指定した文字コードで読めない文字がファイルに書き込まれている。)
ちなみにコードの指定箇所はここなど。
コード例data = pd.read_csv(filepath, encoding = 'shift-jis')正しい文字コードの指定は?
ファイル作成、書き込み、読み込みの一連の動作をpython上でする場合は、以下の横軸通りに指定しておけば、エラーは発生しないはずです。
(ファイルの文字コードの意味は、書き込み時に指定した文字コードによって作成されるcsvの文字コードを表しています)
書き込み時の文字コード ファイルの文字コード 読み込み時の文字コード UTF-8 UTF-8 UTF-8 cp932 ansi cp932 shift-jis ansi shift-jis cp932もshift-jisもファイルだとansiだけどどっちつかうの?
cp932とshift-jisの違いは、例えば髙(はしごだか)や﨑(たてさき)といった、環境依存文字が取り扱いできるかどうかの違いが一番の差かと思います。できるのがcp932になります。なので、例えば、他システムからansiのcsvファイルが連携されてくる時は、shift-jisではなく、cp392で取り込む想定にしておくほうが吉ということです。
- 投稿日:2020-03-01T23:11:42+09:00
AtCoder Beginner Contest 157 参戦記
AtCoder Beginner Contest 157 参戦記
ABC157A - Duplex Printing
1分で突破. 書くだけ.
N = int(input()) print((N + 1) // 2)ABC157B - Bingo
7分半で突破. 書くだけ……ではあるけど、エレガントに書こうと思えばどう書けばいいんですかね……. 特にビンゴ判定のところ.
A = [list(map(int, input().split())) for _ in range(3)] N = int(input()) for _ in range(N): b = int(input()) for y in range(3): for x in range(3): if A[y][x] == b: A[y][x] = -1 for y in range(3): f = True for x in range(3): if A[y][x] != -1: f = False if f: print('Yes') exit() for x in range(3): f = True for y in range(3): if A[y][x] != -1: f = False if f: print('Yes') exit() f = True for x in range(3): if A[x][x] != -1: f = False if f: print('Yes') exit() f = True for x in range(3): if A[2 - x][x] != -1: f = False if f: print('Yes') exit() print('No')ABC157C - Guess The Number
20分で突破. WA4. やー、これは酷い. N = 1 のときは先頭桁が0を取れることを見落としてボッコボコになった. それを除けば解くのは難しくなく、配列で決まった桁を管理し、決まらなかった桁には最小になる数字を割り付ければいいだけである.
N, M = map(int, input().split()) t = [-1] * N for _ in range(M): s, c = map(int, input().split()) s -= 1 if t[s] != -1 and t[s] != c: print(-1) exit() t[s] = c if N != 1: if t[0] == 0: print(-1) exit() if t[0] == -1: t[0] = 1 for i in range(1, N): if t[i] == -1: t[i] = 0 else: if t[0] == -1: t[0] = 0 print(''.join(map(str, t)))ABC157D - Friend Suggestions
25分くらいで突破? Eに寄り道したので正確には分からず. 友達候補は友達の友達クラスタの大きさから以下を引いたもの.
- 自分の数(= 1)
- 友達の数
- 友達の友達クラスタにいるブロックした人の数
友達の友達クラスタの大きさはサイズ付き UnionFind で簡単に求まる.
from sys import setrecursionlimit def find(parent, i): t = parent[i] if t < 0: return i t = find(parent, t) parent[i] = t return t def unite(parent, i, j): i = find(parent, i) j = find(parent, j) if i == j: return parent[j] += parent[i] parent[i] = j setrecursionlimit(10 ** 5) N, M, K = map(int, input().split()) AB = [list(map(int, input().split())) for _ in range(M)] CD = [list(map(int, input().split())) for _ in range(K)] parent = [-1] * N friends = [[] for _ in range(N)] for A, B in AB: unite(parent, A - 1, B - 1) friends[A-1].append(B-1) friends[B-1].append(A-1) blocks = [[] for _ in range(N)] for C, D in CD: blocks[C-1].append(D-1) blocks[D-1].append(C-1) result = [] for i in range(N): p = find(parent, i) t = -parent[p] - 1 t -= len(friends[i]) for b in blocks[i]: if p == find(parent, b): t -= 1 result.append(t) print(*result)ABC157E - Simple String Queries
敗退. セグ木とsetで行けるかなあと思ったけど TLE. 遅延セグ木で行けるかなあと思って、ちゃんと調べてる暇がなかったので Dirty 管理すればいいのかなと適当に書いたけど、性能改善しても TLE 消えず. PyPy は更に性能改善してくれたけどやっぱり足りず.
- 投稿日:2020-03-01T23:07:18+09:00
【Udemy Python3入門+応用】 19.リストのコピー
※この記事はUdemyの
「現役シリコンバレーエンジニアが教えるPython3入門+応用+アメリカのシリコンバレー流コードスタイル」
の講座を受講した上での、自分用の授業ノートです。
講師の酒井潤さんから許可をいただいた上で公開しています。■リストを代入した場合の挙動
list_copyx = [1, 2, 3, 4, 5] y = x y[0] = 100 print('x = ', x) print('y = ', y)resultx = [100, 2, 3, 4, 5] y = [100, 2, 3, 4, 5]
xをいじっただけなのに、yにまで変更が及んでしまう。list_copyx = [1, 2, 3, 4, 5] y = x.copy() y[0] = 100 print('x = ', x) print('y = ', y)resultx = [1, 2, 3, 4, 5] y = [100, 2, 3, 4, 5]
xの代わりにx.copy()とすることで、
「xそのもの」ではなく「xのコピー」をyに代入することができる。
■なぜ影響が及んだのか
◆別のid
id_differentX = 20 Y = X Y = 5 print('X = ', X) print('Y = ', Y) print('id of X =', id(X)) print('id of Y =', id(Y))resultX = 20 Y = 5 id of X = 4364961520 id of Y = 4364961040リストではなく、数値で同様にしてみると、
Yを書き換えてもXには影響が出ない。
id()を使って、XとYのidをみてみると、それぞれ別のidとなっていることが確認できる。◆同じid
id_sameX = ['a', 'b'] Y = X Y[0] = 'p' print('X = ', X) print('Y = ', Y) print('id of X =', id(X)) print('id of Y =', id(Y))resultX = ['p', 'b'] Y = ['p', 'b'] id of X = 4450177504 id of Y = 4450177504リストでは
Yの書き換えにより、Xにも影響が出ている。
この場合idをみてみると、XもYも同じidをさしていることがわかる。id_sameX = ['a', 'b'] Y = X.copy() Y[0] = 'p' print('X = ', X) print('Y = ', Y) print('id of X =', id(X)) print('id of Y =', id(Y))resultX = ['a', 'b'] Y = ['p', 'b'] id of X = 4359291360 id of Y = 4359293920
.copy()により回避した場合は、
XとYのidが異なっていることがわかる。
- 投稿日:2020-03-01T23:02:18+09:00
【初心者】Python、FlaskとHerokuで、ニャンコつぶやきフォームを作った。
FlaskとHerokuを使って、簡単な投稿フォームを作った。
(1)アウトプットイメージ
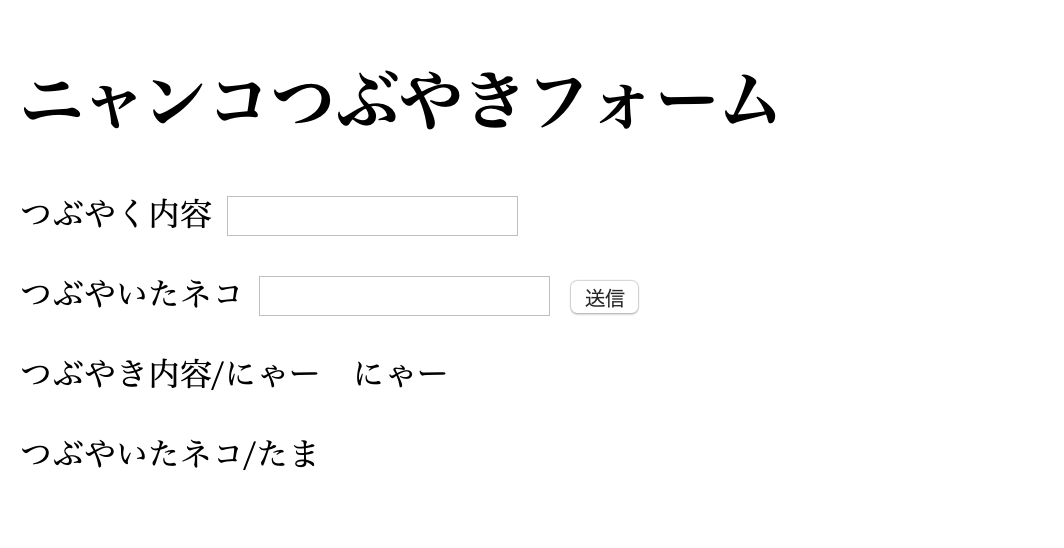
以下のような簡単な投稿フォームを作成することをゴールとした。
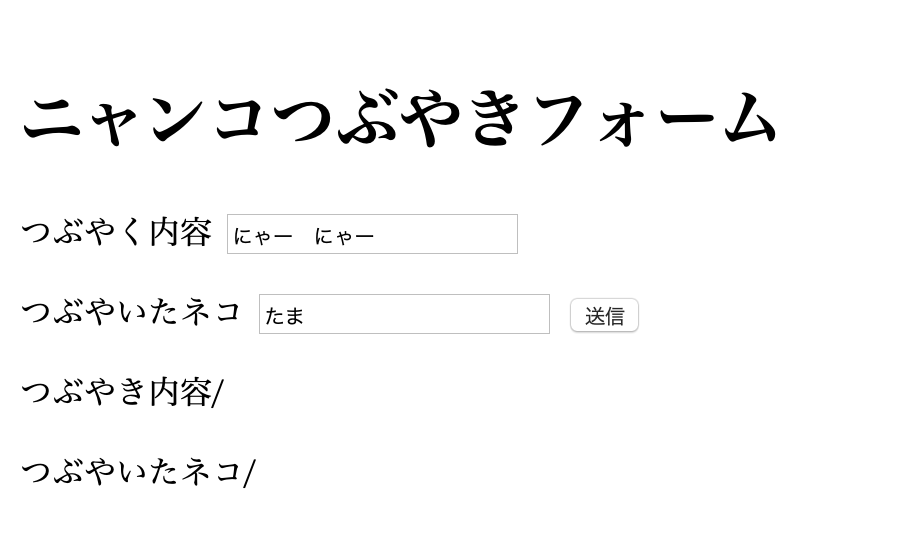
つぶやく内容に”にゃー にゃー”、つぶやいたネコに”たま”を入力し、送信ボタンを押すと、
こんな感じで投稿される。(2)仮想環境を設定
desktopに、my_formというディレクトリを作成、ディレクトリに移動して仮想環境を設定。仮想環境を起動する。
python3 -m venv .source bin/activate(3)必要なフレームワークと、WEBサーバーをインストール
flaskとgunicornをインストール。
pip install flaskpip install gnicorn(4)必要なディレクトリとファイル(.py .html)を準備
my_formディレクトリ内にform.pyを作成、
また、my_formディレクトリ内にtemplatesディレクトリと(templatesディレクトリ内に)index.html、layout.htmlを作成する。(4)form.pyを記述
以下を記述する。
form.pyfrom flask import Flask,request,render_template app = Flask(__name__) @app.route("/") def show(): return render_template("index.html") @app.route("/result",methods=["POST"]) def result(): article = request.form["article"] name = request.form["name"] return render_template("index.html",article=article,name=name)render_templateをインポートすることで、Jinja2を使う環境を整えた。Jinja2テンプレートエンジンにより、htmlのテンプレートを呼び出す(ここでは、index.html)。
まず、@app.route("/")の処理であるが、Jinja2でindex.htmlを呼び出す。
具体的には、return render_template("index.html" 〜)とする。
次に、@app.route("/result",method=["POST"])の処理であるが、reuestをインポートすることで、呼び出したhtml側でフォームに入力したデータを取り出すことできる。
例えば、articleについては、article = request.form["article"]とすることで、index.html側でフォームに入力した内容を(index.html側のフォームname属性は、"article"を設定したものと想定)取り出すことができる。
なお、methodsは、index.html側のフォームをPOSTメソッドで今回は送信するので、[POST]とした。GETメソッドによる送信は後述する。article = request.form["article"]取り出したarticleと、nameの内容を再度return render_templateとして、index.htmlに返す。その際に、引数articleと、nameのそれぞれに値を代入。
return render_template("index.html",article=article,name=name)methodsはPOSTとする
@app.route("/result",methods=["POST"])(5)layout.htmlを記述
テンプレート部分が増えても共通部分のメンテナンスが容易になるよう共通のhtmlを作成しておく。
layout.html<!DOCTYPE html> <html lang="ja"> <head> <meta charset="utf-8"> <title>Nyanco Form</title> <style>body {padding: 10px;}</style> </head> <body> {% block content %} {% endblock %} </body> </html>以下の部分に個別の内容(index.html)をはめ込むことができる。
{% block content %}(6)index.htmlを記述
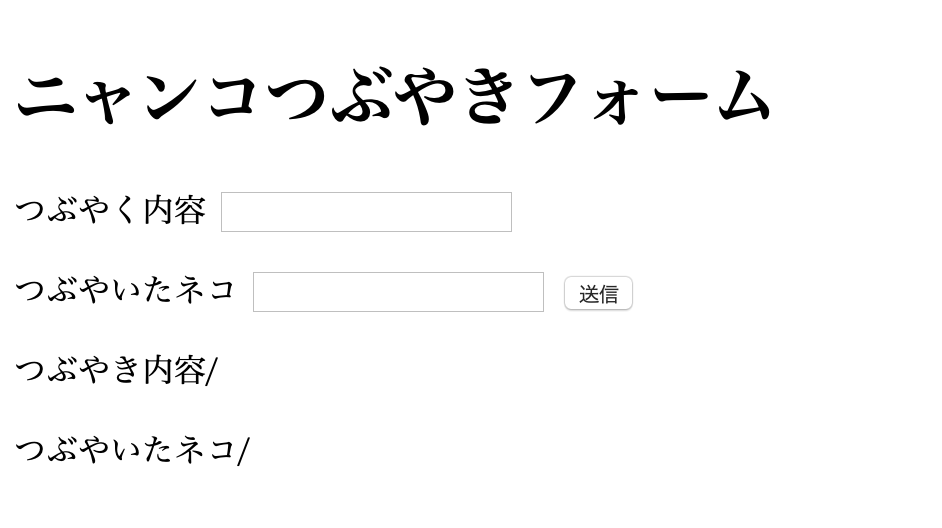
index.html{% extends "layout.html" %} {% block content %} <h1> ニャンコつぶやきフォーム </h1> <form action="/result" method="post"> <label for="article">つぶやく内容</label> <input type="text" name="article"> <p></p> <label for="name">つぶやいたネコ</label> <input type="text" name="name"> <button type="submit">送信</button> </form> <p></p> <p>つぶやき内容/{{ article }}</p> <p>つぶやいたネコ/{{ name }}</p> {% endblock %}layout.htmlの部分位に{% block content %}から、{% endblock %}までの内容をはめ込む処理をしている。
inputのname属性は"article"とした。<input type="text" name="article">送信先アドレスは、/result、フォームに入力した内容はPOSTメソッドで送信する。
<form action="/result" method="post">(7)ローカル環境で起動してみる
以下のようにflaskを起動してみる。
FLASK_APP=form.py flask run* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)と出るので、ブラウザに http://〜の部分を貼り付けると、
と出ていれば成功。(8)POSTメソッド、GETメソッドの違いについて
なお、今回はPOSTメソッドを使用したが、GETメソッドの場合も備忘しておく。
POSTメソッドの場合、フォームを送信すると、
となり、ブラウザのアドレスを見ると、
となっている。
一方で、GETメソッドによる方法をとるのであれば、form.pyと、index.htmlを以下のように修正し、form.pyfrom flask import Flask,request,render_template app = Flask(__name__) @app.route("/") def show(): return render_template("index.html") @app.route("/result",methods=["GET"]) def result(): article = request.args.get("article") name = request.args.get("name") return render_template("index.html",article=article,name=name)index.html{% extends "layout.html" %} {% block content %} <h1> ニャンコつぶやきフォーム </h1> <form action="/result" method="get"> <label for="article">つぶやく内容</label> <input type="text" name="article"> <p></p> <label for="name">つぶやいたネコ</label> <input type="text" name="name"> <button type="submit">送信</button> </form> <p></p> <p>つぶやき内容/{{ article }}</p> <p>つぶやいたネコ/{{ name }}</p> {% endblock %}送信してブラウザのアドレスを見ると、
GETメソッドでは、送信するデータをアドレスの末尾に付け加える仕様となっている。したがって、どんなデータか他の人に見られてしまうので、例えば検索等のアプリに使われる。パスワード等を入力するようなフォームには使わないようにする必要がある。(9)Herokuにデプロイ
Herokuへのデプロイ詳細は以下の記事に書いた通りなので、エッセンスのみとし、詳細説明を省く。
https://qiita.com/nooonchi/items/a7ea7c7a12c56ab8e901Herokuにログインし、Heroku上にアプリを作成
heroku loginアプリ名はcat-formとした。
Heroku create cat-formディレクトリmy_formを初期化して、
git initHerokuとローカル環境を紐つけて、
heroku git:remote -a cat-formディレクトリmy_formにrequirements.txtを作成して、
pip freeze > requirements.txtディレクトリmy_formにProckfileを作成し、以下を入力。
この時、gの前はブランク一つ必要、また、:appの前のformは、form.pyのformという意味なので注意が必要。web: gunicorn form:app --log-file -addして、
git add .今回は、the-firstという名前でcommitして、
git commit -m'the-first'Herokuにpushする。
git push heroku master最後に、
heroku openすれば完成。
(10)おわりに
今後は、これを発展させ、掲示板にチャレンジしたい。




- 投稿日:2020-03-01T23:02:18+09:00
【初心者】Python、FlaskとHerokuで、ニャンコつぶやきフォームを作った
FlaskとHerokuを使って、簡単な投稿フォームを作った。
(1)アウトプットイメージ
以下のような簡単な投稿フォームを作成することをゴールとした。
つぶやく内容に”にゃー にゃー”、つぶやいたネコに”たま”を入力し、送信ボタンを押すと、
こんな感じで投稿される。(2)仮想環境を設定
desktopに、my_formというディレクトリを作成、ディレクトリに移動して仮想環境を設定。仮想環境を起動する。
python3 -m venv .source bin/activate(3)必要なフレームワークと、WEBサーバーをインストール
flaskとgunicornをインストール。
pip install flaskpip install gnicorn(4)必要なディレクトリとファイル(.py .html)を準備
my_formディレクトリ内にform.pyを作成、
また、my_formディレクトリ内にtemplatesディレクトリと(templatesディレクトリ内に)index.html、layout.htmlを作成する。(4)form.pyを記述
以下を記述する。
form.pyfrom flask import Flask,request,render_template app = Flask(__name__) @app.route("/") def show(): return render_template("index.html") @app.route("/result",methods=["POST"]) def result(): article = request.form["article"] name = request.form["name"] return render_template("index.html",article=article,name=name)render_templateをインポートすることで、Jinja2を使う環境を整えた。Jinja2テンプレートエンジンにより、htmlのテンプレートを呼び出す(ここでは、index.html)。
まず、@app.route("/")の処理であるが、Jinja2でindex.htmlを呼び出す。
具体的には、return render_template("index.html" 〜)とする。
次に、@app.route("/result",method=["POST"])の処理であるが、reuestをインポートすることで、呼び出したhtml側でフォームに入力したデータを取り出すことできる。
例えば、articleについては、article = request.form["article"]とすることで、index.html側でフォームに入力した内容を(index.html側のフォームname属性は、"article"を設定したものと想定)取り出すことができる。
なお、methodsは、index.html側のフォームをPOSTメソッドで今回は送信するので、[POST]とした。GETメソッドによる送信は後述する。article = request.form["article"]取り出したarticleと、nameの内容を再度return render_templateとして、index.htmlに返す。その際に、引数articleと、nameのそれぞれに値を代入。
return render_template("index.html",article=article,name=name)methodsはPOSTとする
@app.route("/result",methods=["POST"])(5)layout.htmlを記述
テンプレート部分が増えても共通部分のメンテナンスが容易になるよう共通のhtmlを作成しておく。
layout.html<!DOCTYPE html> <html lang="ja"> <head> <meta charset="utf-8"> <title>Nyanco Form</title> <style>body {padding: 10px;}</style> </head> <body> {% block content %} {% endblock %} </body> </html>以下の部分に個別の内容(index.html)をはめ込むことができる。
{% block content %}(6)index.htmlを記述
index.html{% extends "layout.html" %} {% block content %} <h1> ニャンコつぶやきフォーム </h1> <form action="/result" method="post"> <label for="article">つぶやく内容</label> <input type="text" name="article"> <p></p> <label for="name">つぶやいたネコ</label> <input type="text" name="name"> <button type="submit">送信</button> </form> <p></p> <p>つぶやき内容/{{ article }}</p> <p>つぶやいたネコ/{{ name }}</p> {% endblock %}layout.htmlの部分位に{% block content %}から、{% endblock %}までの内容をはめ込む処理をしている。
inputのname属性は"article"とした。<input type="text" name="article">送信先アドレスは、/result、フォームに入力した内容はPOSTメソッドで送信する。
<form action="/result" method="post">(7)ローカル環境で起動してみる
以下のようにflaskを起動してみる。
FLASK_APP=form.py flask run* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)と出るので、ブラウザに http://〜の部分を貼り付けると、
と出ていれば成功。(8)POSTメソッド、GETメソッドの違いについて
なお、今回はPOSTメソッドを使用したが、GETメソッドの場合も備忘しておく。
POSTメソッドの場合、フォームを送信すると、
となり、ブラウザのアドレスを見ると、
となっている。
一方で、GETメソッドによる方法をとるのであれば、form.pyと、index.htmlを以下のように修正し、form.pyfrom flask import Flask,request,render_template app = Flask(__name__) @app.route("/") def show(): return render_template("index.html") @app.route("/result",methods=["GET"]) def result(): article = request.args.get("article") name = request.args.get("name") return render_template("index.html",article=article,name=name)index.html{% extends "layout.html" %} {% block content %} <h1> ニャンコつぶやきフォーム </h1> <form action="/result" method="get"> <label for="article">つぶやく内容</label> <input type="text" name="article"> <p></p> <label for="name">つぶやいたネコ</label> <input type="text" name="name"> <button type="submit">送信</button> </form> <p></p> <p>つぶやき内容/{{ article }}</p> <p>つぶやいたネコ/{{ name }}</p> {% endblock %}送信してブラウザのアドレスを見ると、
GETメソッドでは、送信するデータをアドレスの末尾に付け加える仕様となっている。したがって、どんなデータか他の人に見られてしまうので、例えば検索等のアプリに使われる。パスワード等を入力するようなフォームには使わないようにする必要がある。(9)Herokuにデプロイ
Herokuへのデプロイ詳細は以下の記事に書いた通りなので、エッセンスのみとし、詳細説明を省く。
https://qiita.com/nooonchi/items/a7ea7c7a12c56ab8e901Herokuにログインし、Heroku上にアプリを作成
heroku loginアプリ名はcat-formとした。
Heroku create cat-formディレクトリmy_formを初期化して、
git initHerokuとローカル環境を紐つけて、
heroku git:remote -a cat-formディレクトリmy_formにrequirements.txtを作成して、
pip freeze > requirements.txtディレクトリmy_formにProckfileを作成し、以下を入力。
この時、gの前はブランク一つ必要、また、:appの前のformは、form.pyのformという意味なので注意が必要。web: gunicorn form:app --log-file -addして、
git add .今回は、the-firstという名前でcommitして、
git commit -m'the-first'Herokuにpushする。
git push heroku master最後に、
heroku openすれば完成。
(10)おわりに
今後は、これを発展させ、掲示板にチャレンジしたい。
- 投稿日:2020-03-01T22:57:58+09:00
ハイパーパラメータチューニングってなに。
はじめに
ハイパーパラメータチューニングはモデルの精度を向上させるために用いられる手法です.
scikit-learn でモデルを作り、パラメータを設定しないと適当な複雑さで設定されます.ハイパーパラメータってなに。
学習の前に指定し、学習の方法や速度、モデルの複雑さを定めるパラメータのことです.
手法(種類)
- 手動
- グリッドサーチ
- ランダムサーチ
出典:http://www.jmlr.org/papers/volume13/bergstra12a/bergstra12a.pdfグリッドサーチ
各パラメータに対して候補を決め、それらの組み合わせを全て試す方法です. 全て試すのでパラメータ候補を多くはできません.
ランダムサーチ
各パラメータに対して候補を決め、ランダムなパラメータの組み合わせをn回繰り返す方法です. 全て試さないのでよりよいパラメータの組み合わせを探索できないかもしれません.
パラメータの組み合わせ
import numpy as np params_list01 = [1, 3, 5, 7] params_list02 = [1, 2, 3, 4, 5] # グリッドサーチ grid_search_params = [] for p1 in params_list01: for p2 in params_list02: grid_search_params.append(p1, p2) # append(): リストの末尾に要素を追加する # ランダムサーチ random_search_params = [] count = 10 for i in range(count): p1 = np.random.choice(params_list01) # random.choice(): 配列の中身をランダムに取得する p2 = np.random.choice(params_list02) random_search_params.append(p1, p2)scikit-learn
from sklearn.model_selection import GridSearchCV, RandomizedSearchCV params = { "max_depth": [2, 4, 6, 8, None], "n_estimators": [50,100,200,300,400,500], "max_features": range(1, 11), "min_samples_split": range(2, 11), "min_samples_leaf": range(1, 11) } # グリッドサーチ gscv = GridSearchCV(RandomForestRegressor(), params, cv=3, n_jobs=-1, verbose=1) gscv.fit(X_train_valid, y_train_valid) print("Best score: {}".format(gscv.best_score_)) print("Best parameters: {}".format(gscv.best_params_)) # ランダムサーチ rscv = RandomizedSearchCV(RandomForestRegressor(), params, cv=3, n_iter=10, n_jobs=-1, verbose=1) rscv.fit(X_train_valid, y_train_valid) print("Best score: {}".format(rscv.best_score_)) print("Best parameters: {}".format(rscv.best_params_))おわりに
いったいどれを採用したら良いのー??というときはランダムサーチをします. 効率よく良いパラメータの組み合わせがみつかるようです.
参考

- 投稿日:2020-03-01T22:55:01+09:00
類似画像解析のための近似最近傍探索(初心者向け)(1)
類似画像について書き残したいが、まずはK-NN法の説明から。
K-NN法
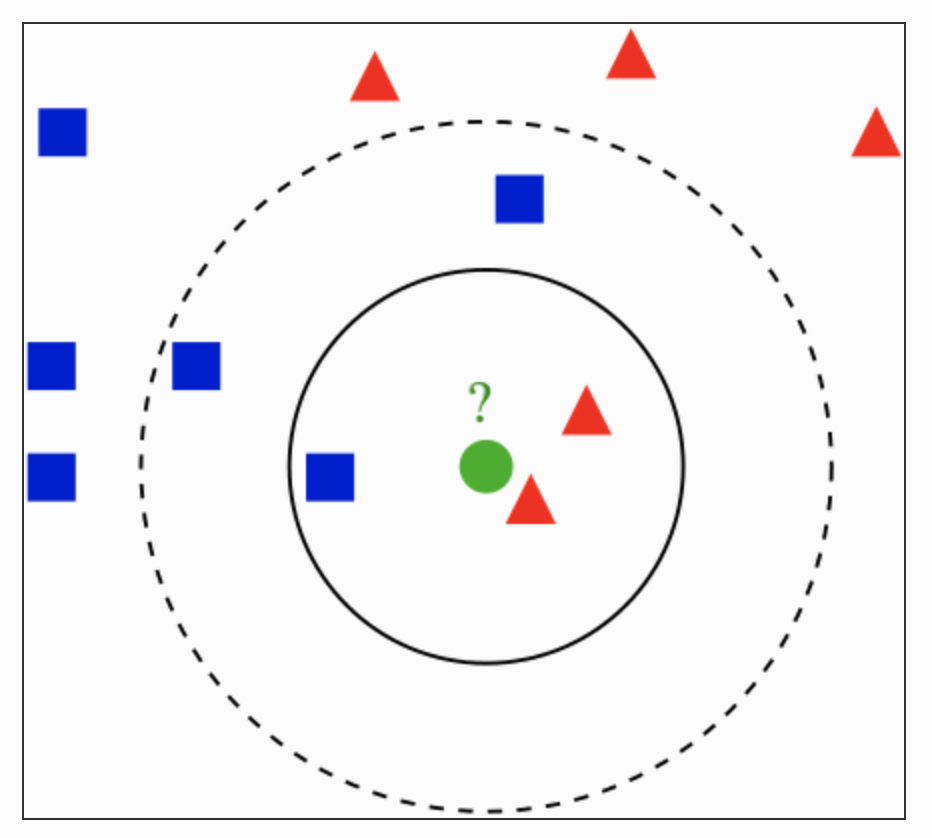
あるデータから近いデータk個のデータから識別していく。
数が多いものデータのクラスと同じクラスと判断していく。
ex)
k=3の場合、四角1個と三角2個のため、三角のグループとみなす。
k=5の場合、四角3個と三角2個のため、四角のグループとみなす。
どのkをとるかによって、解はバラバラなので適切なkを見つける必要がある。
crossvalidationを使い、k毎の汎化誤差を求めて、最小のものを最適なkとする。
汎化誤差(=テストデータによる実績との誤差)
これらを全てk毎の計算をするのは、画像によるベクトル変換をした時膨大な処理時間となる。
そこで、近似最近傍検索。近似最近傍検索
最近傍が遠くても、許容して採用する。
d(q,x) <= (1+ε)d(q,x*)
d(q,x) が近似解までの距離
d(q,x*)が最近傍までの距離近似解は、最良優良探索で決める
最良優良探索は、何らかの規則に従って次に探索する最も望ましいノードを選択するようにした探索アルゴリズム。
次回、近似最近傍探索を実際に使ってみたいと思う。
参考

- 投稿日:2020-03-01T22:23:25+09:00
【Udemy Python3入門+応用】 18.リストのメソッド
※この記事はUdemyの
「現役シリコンバレーエンジニアが教えるPython3入門+応用+アメリカのシリコンバレー流コードスタイル」
の講座を受講した上での、自分用の授業ノートです。
講師の酒井潤さんから許可をいただいた上で公開しています。■リストのメソッド
◆
.index().indexr = [1, 2, 3, 4, 5, 1, 2, 3] print(r.index(3))result2
.index()を使うことで、指定した要素のインデックスを調べることができる。
この場合、先頭から探してくれるので、インデックスが2と返ってきている(1番目の「3」を検出している)。.indexr = [1, 2, 3, 4, 5, 1, 2, 3] print(r.index(3, 3))result7
.index(3, 3)の
最初の3は「『3』を探してくれ」というように、検索する要素を指定しており、
後ろの3は「インデックス『3』以降から探してくれ」というように、検索範囲を指定している。◆
.count().countr = [1, 2, 3, 4, 5, 1, 2, 3] print(r.count(3))result2「『3』が何個あるか数えておくれ」という意味。
◆if文
ifr = [1, 2, 3, 4, 5, 1, 2, 3] if 5 in r: print('exist')resultexistIf '5' exists in r, print "exist."
という意味。
if文については後の授業で扱う。◆数字順に並べる
sort_and_reverser = [1, 2, 3, 4, 5, 1, 2, 3] r.sort() print(r) r.sort(reverse=True) print(r) r.reverse() print(r)result[1, 1, 2, 2, 3, 3, 4, 5] [5, 4, 3, 3, 2, 2, 1, 1] [1, 1, 2, 2, 3, 3, 4, 5]
.sort()を用いることで、数字の小さい順にリストの要素を並べ替えできる。
.sort(reverse=True)とすると、逆順にできる。
.reverse()というメソッドも用意されているので、それでもOK。◆
.split()と.join()split_and_joins = 'My name is Tony.' to_split = s.split(' ') print(to_split) x = ' '.join(to_split) print(x)result['My', 'name', 'is', 'Tony.'] My name is Tony.
.split(' ')によって、
「(スペース)で文字列をバラバラにして、それを要素にしてリストを作ってくれ」
ということができる。
逆に、' '.join()を使うことで、
「(スペース)を要素間に挟んで、要素を結合して文字列にしてくれ」
ということができる。◆help
helphelp(list)resultclass list(object) | list(iterable=(), /) | | Built-in mutable sequence. | | If no argument is given, the constructor creates a new empty list. | The argument must be an iterable if specified. | | Methods defined here: | | __add__(self, value, /) | Return self+value. | | __contains__(self, key, /) | Return key in self. | | __delitem__(self, key, /) | Delete self[key]. | | __eq__(self, value, /) | Return self==value. | | __ge__(self, value, /) | Return self>=value. | | __getattribute__(self, name, /) | Return getattr(self, name). | | __getitem__(...) | x.__getitem__(y) <==> x[y] | | __gt__(self, value, /) | Return self>value. | | __iadd__(self, value, /) | Implement self+=value. | | __imul__(self, value, /) | Implement self*=value. | | __init__(self, /, *args, **kwargs) | Initialize self. See help(type(self)) for accurate signature. | | __iter__(self, /) | Implement iter(self). | | __le__(self, value, /) | Return self<=value. | | __len__(self, /) | Return len(self). | | __lt__(self, value, /) | Return self<value. | | __mul__(self, value, /) | Return self*value. | | __ne__(self, value, /) | Return self!=value. | | __repr__(self, /) | Return repr(self). | | __reversed__(self, /) | Return a reverse iterator over the list. | | __rmul__(self, value, /) | Return value*self. | | __setitem__(self, key, value, /) | Set self[key] to value. | | __sizeof__(self, /) | Return the size of the list in memory, in bytes. | | append(self, object, /) | Append object to the end of the list. | | clear(self, /) | Remove all items from list. | | copy(self, /) | Return a shallow copy of the list. | | count(self, value, /) | Return number of occurrences of value. | | extend(self, iterable, /) | Extend list by appending elements from the iterable. | | index(self, value, start=0, stop=9223372036854775807, /) | Return first index of value. | | Raises ValueError if the value is not present. | | insert(self, index, object, /) | Insert object before index. | | pop(self, index=-1, /) | Remove and return item at index (default last). | | Raises IndexError if list is empty or index is out of range. | | remove(self, value, /) | Remove first occurrence of value. | | Raises ValueError if the value is not present. | | reverse(self, /) | Reverse *IN PLACE*. | | sort(self, /, *, key=None, reverse=False) | Stable sort *IN PLACE*. | | ---------------------------------------------------------------------- | Static methods defined here: | | __new__(*args, **kwargs) from builtins.type | Create and return a new object. See help(type) for accurate signature. | | ---------------------------------------------------------------------- | Data and other attributes defined here: | | __hash__ = Nonehelpでメソッドの使い方を呼び出すこともできる。
- 投稿日:2020-03-01T21:57:59+09:00
pythonのpikaで色々なrabbimqの機能を使用する
はじめに
前回のpythonでrabbimqを扱うではRabbitMqで単純なメッセージのやり取りを行いましたが、RabbitMqは色々な機能があるため今回はその色々な機能と使用方法をまとめます。
環境
- python:3.6.5
- イメージ:rabbitmq:3-management
キューの確認設定
標準のpikaの設定ではRabbitMq内に送受信したいキューが存在しないときは自動的にキューを作成しますが、自動的にキューを作成せずにエラーしたい場合があります。その場合は、チャンネルの
queue_declare()関数のpassive引数にTrueを与えるとキューがないときはエラーします。シチュエーション例
プロデューサー側で全てのキューを管理して、コンシューマー側では純粋に接続のみ許したいときなど。
passiveをtrueにしたプロデューサー
前回の例として作成したプロデューサーの
channel.queue_declare()にpassive=Trueを追加しているだけです。キューが存在すればそのまま接続できますが、キューが存在しなければpika.exceptions.ChannelClosedByBrokerがエクセプションとして上がってきます。client_main.pyimport pika pika_param = pika.ConnectionParameters('localhost') connection = pika.BlockingConnection(pika_param) channel = connection.channel() try: channel.queue_declare(queue='hello', passive=True) except pika.exceptions.ChannelClosedByBroker as ex: print(ex) exit(1) channel.basic_publish(exchange='', routing_key='hello', body='Hello World!') connection.close()キューチェックの実行
ソースができたため、実行してみます。エクセプションが発生しました。発生したエクセプションを表示するとhelloのキューがないということがわかります。
PS C:\Users\xxxx\program\python\pika> python .\client_main.py (404, "NOT_FOUND - no queue 'hello' in vhost '/'")コネクションの排他設定
標準のpikaの設定では無条件にコネクションを受け付けますが、他のコネクションを受け付けないように排他制御をかけることができます。その場合は、チャンネルの
queue_declare()関数のexclusive引数にTrueを与えると他にコネクションが接続しているときはエラーするため、排他のチェックに利用できます。コネクションをクローズすればまた別のコネクションを接続することができます。シチュエーション例
コンシューマー側でメッセージを用意してRabbitMqに送るまでは、他のコンシューマからメッセージの受け付けをしたくないときなど。
コネクションの排他設定を有効にしたプロデューサー
channel.queue_declare()にexclusive=Trueを追加しているだけです。今回は、一度接続してからコネクションをクローズせずに新しくコネクションを作って接続しています。後から来たコネクションに対してはpika.exceptions.ChannelClosedByBrokerがエクセプションとして上がってきます。client_main.pyimport pika pika_param = pika.ConnectionParameters('localhost') connection = pika.BlockingConnection(pika_param) channel = connection.channel() channel.queue_declare(queue='hello', exclusive=True) channel.basic_publish(exchange='', routing_key='hello', body='Hello World!') channel.close() connection = pika.BlockingConnection(pika_param) channel = connection.channel() try: channel.queue_declare(queue='hello') except pika.exceptions.ChannelClosedByBroker as ex: print('other connection access fail') exit(1) channel.basic_publish(exchange='', routing_key='hello', body='Hello World!') channel.close()
channel.close()の下にconnection.close()を入れると正常に終了します。コネクションの排他の実行
ソースができたため、実行してみます。2つめのキュー接続時にエクセプションが発生しました。発生したエクセプションを表示するとhelloにアクセスロックがかかっていることがわかります。
PS C:\Users\xxxx\program\python\pika> python .\client_main.py other connection access fail (405, "RESOURCE_LOCKED - cannot obtain exclusive access to locked queue 'hello' in vhost '/'. It could be originally declared on another connection or the exclusive property value does not match that of the original declaration.")チャンネルの上限設定
標準のpikaの設定では無条件にチャンネルを作成できますが、チェンネルの上限を設定することができます。その場合は、pikaの
pika.ConnectionParameters()関数のchannel_max引数に上限値を与えると上限を設定することができます。上限を超えるチャンネルを作成しようとするとエラーを発生させます。シチュエーション例
RabbitMqのサーバが潤沢ではないため、チャンネル生成数を加減するときなど
チャンネルの上限設定を有効にしたプロデューサー
pika.ConnectionParameters()にchannel_max=2を追加しているだけです。今回は、上限値を2にしているので無意味に3つのチャンネルを作成しています。その結果、3つめのチェンネルに対しては作成できずにpika.exceptions.ConnectionClosedByBrokerがエクセプションとして上がってきます。client_main.pyimport pika pika_param = pika.ConnectionParameters('localhost', channel_max=2) connection = pika.BlockingConnection(pika_param) channel = connection.channel(1) channel = connection.channel(2) try: channel = connection.channel(3) except pika.exceptions.ConnectionClosedByBroker as ex: print('channel crate error') print(ex)チャンネルの上限の実行
ソースができたため、実行してみます。3つめのチャンネル作成時にエクセプションが発生しました。発生したエクセプションを表示するとチャンネル上限が2であることがわかります。
PS C:\Users\xxxx\program\python\pika> python .\client_main.py channel crate error (530, 'NOT_ALLOWED - number of channels opened (2) has reached the negotiated channel_max (2)')リトライの設定
pikaの接続に失敗したときにリトライする回数を設定することができます。その場合は、pikaの
pika.ConnectionParameters()関数のconnection_attempts引数にリトライ回数を与えると回数を設定することができます。シチュエーション例
RabbitMqのサーバへのネットワークが不安定の場合など
リトライの設定を有効にしたプロデューサー
pika.ConnectionParameters()にconnection_attempts=2を追加しているだけです。今回は、リトライをしているのがわかるようにpikaのログを出すようにして、RabbitMqを落としています。上のlogger.xxx系はpika内のログを出すための設定です。client_main.pyimport pika import datetime import logging logger = logging.getLogger('pika') logger.setLevel(logging.ERROR) logger.addHandler(logging.StreamHandler()) pika_param = pika.ConnectionParameters('localhost', connection_attempts=2) try: print('start connect {}'.format(datetime.datetime.now())) connection = pika.BlockingConnection(pika_param) except pika.exceptions.AMQPConnectionError as ex: print('connect error {}'.format(datetime.datetime.now())) print(ex)リトライの実行
ソースができたため、実行してみます。ログが大量に出て分かり難いですが同じようなエラーが4回(2回エラー×設定値リトライ(2回))出ています。
PS C:\Users\xxxx\program\python\pika> python .\client_main.py start connect 2020-03-01 21:46:18.549268 Socket failed to connect: <socket.socket fd=936, family=AddressFamily.AF_INET6, type=SocketKind.SOCK_STREAM, proto=6, laddr=('::', 38520, 0, 0)>; error=10061 (Unknown error) TCP Connection attempt failed: ConnectionRefusedError(10061, 'Unknown error'); dest=(<AddressFamily.AF_INET6: 23>, <SocketKind.SOCK_STREAM: 1>, 6, '', ('::1', 5672, 0, 0)) AMQPConnector - reporting failure: AMQPConnectorSocketConnectError: ConnectionRefusedError(10061, 'Unknown error') Socket failed to connect: <socket.socket fd=936, family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM, proto=6, laddr=('0.0.0.0', 38524)>; error=10061 (Unknown error) TCP Connection attempt failed: ConnectionRefusedError(10061, 'Unknown error'); dest=(<AddressFamily.AF_INET: 2>, <SocketKind.SOCK_STREAM: 1>, 6, '', ('127.0.0.1', 5672)) AMQPConnector - reporting failure: AMQPConnectorSocketConnectError: ConnectionRefusedError(10061, 'Unknown error') Socket failed to connect: <socket.socket fd=812, family=AddressFamily.AF_INET6, type=SocketKind.SOCK_STREAM, proto=6, laddr=('::', 38533, 0, 0)>; error=10061 (Unknown error) TCP Connection attempt failed: ConnectionRefusedError(10061, 'Unknown error'); dest=(<AddressFamily.AF_INET6: 23>, <SocketKind.SOCK_STREAM: 1>, 6, '', ('::1', 5672, 0, 0)) AMQPConnector - reporting failure: AMQPConnectorSocketConnectError: ConnectionRefusedError(10061, 'Unknown error') Socket failed to connect: <socket.socket fd=812, family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM, proto=6, laddr=('0.0.0.0', 38535)>; error=10061 (Unknown error) TCP Connection attempt failed: ConnectionRefusedError(10061, 'Unknown error'); dest=(<AddressFamily.AF_INET: 2>, <SocketKind.SOCK_STREAM: 1>, 6, '', ('127.0.0.1', 5672)) AMQPConnector - reporting failure: AMQPConnectorSocketConnectError: ConnectionRefusedError(10061, 'Unknown error') AMQP connection workflow failed: AMQPConnectionWorkflowFailed: 4 exceptions in all; last exception - AMQPConnectorSocketConnectError: ConnectionRefusedError(10061, 'Unknown error'); first exception - AMQPConnectorSocketConnectError: ConnectionRefusedError(10061, 'Unknown error'). AMQPConnectionWorkflow - reporting failure: AMQPConnectionWorkflowFailed: 4 exceptions in all; last exception - AMQPConnectorSocketConnectError: ConnectionRefusedError(10061, 'Unknown error'); first exception - AMQPConnectorSocketConnectError: ConnectionRefusedError(10061, 'Unknown error') Connection workflow failed: AMQPConnectionWorkflowFailed: 4 exceptions in all; last exception - AMQPConnectorSocketConnectError: ConnectionRefusedError(10061, 'Unknown error'); first exception - AMQPConnectorSocketConnectError: ConnectionRefusedError(10061, 'Unknown error') Error in _create_connection(). Traceback (most recent call last): File "C:\Users\minkl\AppData\Local\Programs\Python\Python36-32\lib\site-packages\pika\adapters\blocking_connection.py", line 450, in _create_connection raise self._reap_last_connection_workflow_error(error) pika.exceptions.AMQPConnectionError connect error 2020-03-01 21:46:28.665843おわりに
良く使いそうなRabbitMqの機能を使用してみました。必要な機能は一通りあると思いますが、どの設定がキューなのかコネクションなのかチャンネルなのかを理解して使用しないと混乱しそうに感じました。
- 投稿日:2020-03-01T21:52:55+09:00
確率積分(Ito integral)を算出してみた
■ 確率積分として以下のような方式があります
Riemann sum
式)
$ \sum_{j=0}^{N-1} h(t_j) (t_{j+1}-t_j) $Ito integral.
伊藤清(Kiyoshi Ito)によって拡張された確率過程の方式
式)
$ \sum_{j=0}^{N-1}h(t_j) (W(t_{j+1})-W(t_j)) $.
<=> $ \int_0^{T} h(t)dW(t) $.Stratonovich integrals
式)
$\sum_{j=0}^{N-1}h\big(\frac{t_j+t_{j+1}}{2}\big)(W(t_{j+1})-W(t_j))$Ito integralの計算
$h(t)\equiv W(t)$の時、Ito integralは、
\begin{align*} \sum_{j=0}^{N-1} W(t_j) (W(t_{j+1})-W(t_j)) \\ &=\sum_{j=0}^{N-1} ({W(t_{j+1})}^2 - {W(t_{j+1})}^2 + 2 W(t_j) W(t_{j+1}) - {W(t_j)}^2 - {W(t_j)}^2) \\ &= \frac{1}{2} \sum_{j=0}^{N-1} ({W(t_{j+1})}^2 - {W(t_j)}^2 - (W(t_{j+1}) - W(t_j))^2 )\\ &= \frac{1}{2} (W(T)^2 - W(0)^2) - \frac{1}{2} \sum_{j=0}^{N-1} (W(t_{j+1}) - W(t_j))^2 \end{align*}$\sum_{j=0}^{N-1} (W(t_{j+1}) - W(t_j))^2$はWiener Processの分散に等しく、$T$とおけるため、上記の式は、
$$\sum_{j=0}^{N-1} (W(t_{j+1}) - W(t_j))^2=\frac{1}{2}(W(T)^2-T)$$と表現できる。Ito integralを算出してみる。
N=10000; M=1; T = 1.0 dt = T / N; t = np.arange(0.0,1.0, dt); dW = np.sqrt(dt)*randn(N,M); # (N, M)行列 W = np.cumsum(dW,axis=0); e = np.array([[0]]) W_=np.concatenate((e,W[:-1]), axis=0) # 初期値に0をおく W(0)として。 ito = np.dot(W_.T,dW) # (10000, 1).T * (10000, 1) => (1, 1) np.abs(ito - 0.5*(W[-1]**2 - T) )[0][0] ## output ## 0.00414652405737参考記事
- Desmond J. Higham "An Algorithmic Introduction to Numerical Simulation of Stochastic Differential Equations"
- Wikipedia「伊藤清」 https://ja.wikipedia.org/wiki/%E4%BC%8A%E8%97%A4%E6%B8%85
- Learning SDEs in Python https://www.quantopian.com/posts/learning-sdes-in-python
- 投稿日:2020-03-01T21:33:18+09:00
【Udemy Python3入門+応用】 17.リストの操作
※この記事はUdemyの
「現役シリコンバレーエンジニアが教えるPython3入門+応用+アメリカのシリコンバレー流コードスタイル」
の講座を受講した上での、自分用の授業ノートです。
講師の酒井潤さんから許可をいただいた上で公開しています。■リストの操作
◆リストの要素を置換する
>>> s = ['a', 'b', 'c', 'd', 'e', 'f', 'g'] >>> s[0] = 'A' >>> s ['A', 'b', 'c', 'd', 'e', 'f', 'g'] >>> s[2:5] = ['C', 'D', 'E'] >>> s ['A', 'b', 'C', 'D', 'E', 'f', 'g']リスト内のインデックスやスライスを指定して、直接文字列を代入することができる。
◆
.append()と.insert()>>> n = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] >>> n [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] >>> n.append(100) >>> n [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 100] >>> n.insert(0, 200) >>> n [200, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 100]
.appendにより、リスト内の最後に文字列が付け加えられる。
.insertを用いると、任意のインデックスを指定し、その場所に文字列を挿入できる。◆
.pop()>>> n = [200, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 300] >>> n [200, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 300] >>> n.pop(0) 200 >>> n [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 300] >>> n.pop() 300 >>> n [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
.pop()でインデックスを指定すると、その要素が抽出される。
抽出された要素はリストからなくなる。
インデックスを指定しない場合は、最後の要素が抽出される。◆リストの要素を消去する(空のリストで置換する)
>>> s = ['a', 'b', 'c', 'd', 'e', 'f', 'g'] >>> s[2:5] = [] >>> s ['a', 'b', 'f', 'g']指定した部分を空のリストに置換してやることで、要素を消去できる。
◆リストの要素を消去する(
delを用いる)>>> n = [1, 2, 3, 4, 5] >>> n [1, 2, 3, 4, 5] >>> del n[0] >>> n [2, 3, 4, 5] >>> del n >>> n Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'n' is not definedインデックスを指定したものを
delで消去できる。
うっかりインデックスを指定せずにnにdelをかけた場合、n自体が抹消されるため注意。◆リストの要素を消去する(
.remove()を用いる)>>> n = [1, 2, 3, 4, 5] >>> n [1, 2, 3, 4, 5] >>> n.remove(2) >>> n [1, 3, 4, 5] >>> n.remove(4) >>> n [1, 3, 5] >>> n.remove(6) Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: list.remove(x): x not in list
.remove()を用いると、要素を直接指定して消去することができる。
このときリスト内に存在しない要素を指定するとエラーとなる。◆リストに別のリストの要素を追加する
>>> a = [1, 2, 3] >>> b = [4, 5, 6] >>> x = a + b >>> x [1, 2, 3, 4, 5, 6]これは前にやった通り。
>>> a = [1, 2, 3] >>> b = [4, 5, 6] >>> a += b >>> a [1, 2, 3, 4, 5, 6]
+=により、bのリスト内の要素がaのリストに付け加えられる。>>> x = [1, 2, 3] >>> y = [4, 5, 6] >>> x.extend(y) >>> x [1, 2, 3, 4, 5, 6]
.extend()というメソッドを使う方法もある。
- 投稿日:2020-03-01T21:23:13+09:00
時系列予測のためのLSTM(1)(初心者向け)
今回は、LSTMについて。
時系列などの規則性がある現象についての予測問題はアプローチとして有効かもしれない。
自分の理解のためのアウトプットなので、一旦は参考サイトをほぼトレースしている。LSTM(Long Short-Term Memory)
ひとことでいうと、短期記憶で長期期間で活用して学習を進める。特徴がある。
LSTMの部分を図式化すると、以下になる。
htでの計算で、前の出力結果ht-1とXtを使い求める。htはht+1を求めるために使われるイメージ。
それぞれ、
・OutputGate
・Forget Gate
・Input Gate
・活性化関数部分
・Memory Cell
で成り立っているOutputGate
以下の矢印赤い部分。
Xtに対しての線形変換Wo、htに対しての線形変換Ro、バイアスBoを使い
Ot=σ(WoXt+Roht−1+Bo)
という計算が行われる。
ニューラルネットワークと同様の計算式。
Forget Gate
OutputGateと同様、
Wf、Rf、Bfのパラメータがあり
ft=σ(WfXt+Rfht−1+Bf)
という計算が行われる。
Input Gate
同様に、
it=σ(WiXt+Riht−1+Bi)
という計算が行われる。
活性化関数部分
Zt=tanh(WzXt+Rzht−1+Bz)
活性化関数部分の計算式。
Memory Cell付近の計算
①Forget Gate側
ft=σ(WfXt+Rfht−1+Bf)とセル点線からのアウトプットCt-1により
Ct−1 ⊗ ft というアウトプット。
⊗ は要素ごとの積
②Input Gate側
it=σ(WiXt+Riht−1+Bi)とZt=tanh(WzXt+Rzht−1+Bz)により、
it ⊗ Zt というアウトプット。
③Cellの手前
①でのCt−1 ⊗ ft と②での it ⊗ Zt により
Ct = Ct−1 ⊗ ft + it ⊗ Zt
という計算が行われる。
④出力付近
Memory Cell部分 Ct = it ⊗ Zt + Ct−1 ⊗ ft
OutputGate部分 Ot = σ(WoXt+Roht−1+Bo)
を使い
ht = Ot ⊗ tanh(Ct)
が行われる。
LSTMのポイント
Ct = Ct−1 ⊗ ft + it ⊗ Zt
Ct−1 ⊗ ft Forget Gate部分で、Ct-1は過去の情報のパラメータをどれくらい反映するかを調整している。
it ⊗ Zt Input部分で、得られた入力値 it をどれだけ反映するか、を Zt 活性化関数により調整している。参考









- 投稿日:2020-03-01T20:25:33+09:00
【Udemy Python3入門+応用】 16.リスト型
※この記事はUdemyの
「現役シリコンバレーエンジニアが教えるPython3入門+応用+アメリカのシリコンバレー流コードスタイル」
の講座を受講した上での、自分用の授業ノートです。
講師の酒井潤さんから許可をいただいた上で公開しています。■リスト型
◆リストの使い方
>>> l = [1, 20, 4, 50, 2, 17, 80] >>> type(l) <class 'list'>このように、リストを使うことができる。
>>> l [1, 20, 4, 50, 2, 17, 80] >>> l[0] 1 >>> l[1] 20 >>> l[-1] 80 >>> l[0:2] [1, 20] >>> l[:2] [1, 20] >>> l[2:] [4, 50, 2, 17, 80] >>> l[:] [1, 20, 4, 50, 2, 17, 80]リストに対しては、インデックスやスライスも使える。
■リストに
len()を使う>>> len(l) 7リストに対して
len()を用いると、リストに含まれるデータの個数が返る。
■文字列をリストに変換する
>>> letters = list('abcdefg') >>> letters ['a', 'b', 'c', 'd', 'e', 'f', 'g']あまり使いみちはないらしいが…
■リストからの抽出
◆1つとばしで抽出する
>>> n = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] >>> n[::2] [1, 3, 5, 7, 9]
[::2]とすることで、1つとばしに抽出できる。◆反対順にする
>>> n[::-1] [10, 9, 8, 7, 6, 5, 4, 3, 2, 1]
[::-1]とすることで、並び順を逆にして出力することができる。
■リストの中にリストを入れる
◆リストの中にリストを入れる
>>> a = ['a', 'b', 'c'] >>> n = [1, 2, 3] >>> x = [a, n] >>> x [['a', 'b', 'c'], [1, 2, 3]]◆インデックスはどうなる?
>>> x[0] ['a', 'b', 'c'] >>> x[1] [1, 2, 3]この状態では、含まれているリストにインデックスがふられる。
◆要素になっているリストの中でのインデックス
>>> x[0][1] 'b'
[0][1]とすることにより、[0]の中での[1]を指定できる。
- 投稿日:2020-03-01T20:17:25+09:00
にじさんじで学ぶPythonプログラミング入門【カルロスピノ氏リスペクト】
こんにちは。タケシです。
インフラエンジニアとして働きながら、スキルの幅を広げるためにプログラミングを学んでいます。Progateなどの教材で学習するだけでは興味がそそられず、いかにもお勉強って感じでやる気が出なかったのですが、初学者でも楽しく無料でプログラミングが学べそうな動画を先日見つけました。
ホロライブで学ぶPython入門~15分でYoutubeの情報取得までやる編~この動画では投稿主のカルロスピノ氏が、プログラミング初心者向けにPythonでYoutubeの動画情報取得をする方法を解説しています。
ブラウザ(Chrome)でPythonのコードを実行するので面倒な環境構築も不要ですし、お金もかかりません。
この記事ではカルロスピノ氏の動画を見た視聴者(私)が、動画内で紹介されている内容を実行した結果を交えつつPythonを使ってできることを紹介していきます。
この記事はこのような人向けに書いています。
・プログラミングをこれから学びたい初心者
・Pythonを学びたいけど既存の教材はとっつきにくい人
・Pythonを学びたいけどスクールに通うお金がない人
・Youtubeで情報収集するアプリを開発したい人この記事を読むとできるようになること
・Pythonのコードを無料で実行できる環境が用意できる
・Pythonの簡単なプログラミングができるようになる
・推しのYoutuber/VTuberの情報収集ができるようになるブラウザ(Chrome)でPythonプログラムを実行するための環境構築
詳しい手順はカルロスピノ氏の動画内で解説されていますが、補足も兼ねてこの記事でも手順を紹介していきます。
Google Colaboratoryにアクセスする
Googleがクラウド上でPythonのプログラムを実行できる環境を無料で提供しています。
それがGoogle Colaboratoryです。以下のURLからアクセスしましょう。https://colab.research.google.com/notebooks/welcome.ipynb
Google Colaboratoryにアクセスするとこのような画面が表示されるので左上の「ファイル」タブをクリックします。
「ノートブックを新規作成」をクリックしましょう。
※カルロスピノ氏の動画では、ノートブックの新規作成をする項目が「Python3の新しいノートブック」「Python2の新しいノートブック」になっていましたが、私がGoogle Colaboratoryにアクセスしたときには項目が「ノートブックを新規作成」に変わっていました。
ノートブックが新規作成されると、コードが実行できる箱(セル)が表示されます。
箱(セル)内にコードを書いたのち、左端の●ボタンをクリックすると実行されます。※セルは「+コード」タブをクリックすると追加可能。
必要な外部ライブラリの用意
カルロスピノ氏の当該動画内では、Youtubeの動画情報収集を手軽に行えるRDFを使用しています。
そのRDFで動画情報を取得する上でfeedparserという外部ライブラリを使用しているので、そのインストールとインポートを事前に行っておきましょう。
feedparserのインストール
新しいセルで
pip install feedparserと入力し、実行するとGoogle Colaboratoryの環境にfeedparserがインストールされます。Collecting feedparser Downloading https://files.pythonhosted.org/packages/91/d8/7d37fec71ff7c9dbcdd80d2b48bcdd86d6af502156fc93846fb0102cb2c4/feedparser-5.2.1.tar.bz2 (192kB) |████████████████████████████████| 194kB 2.8MB/s Building wheels for collected packages: feedparser Building wheel for feedparser (setup.py) ... done Created wheel for feedparser: filename=feedparser-5.2.1-cp36-none-any.whl size=44940 sha256=e16ce8a47aa3d1c3dd0fe4b042ecf27cdc731a2f20e05d2885cd6de37f4a268f Stored in directory: /root/.cache/pip/wheels/8c/69/b7/f52763c41c5471df57703a0ef718a32a5e81ee35dcf6d4f97f Successfully built feedparser Installing collected packages: feedparser Successfully installed feedparser-5.2.1このような実行結果が表示されていれば成功です。
feedparserのインポート
続いて新しいセルで
import feedparserと入力し実行しましょう。何も表示されなければ成功です。
これで任意のYoutubeチャンネルで公開されている動画の情報が収集できます。
RDFで収集できる情報
RDFで収集できる情報の一覧は、以下のコードを実行することで確認することができます。
※チャンネルIDの部分は任意のYoutuber/VTuberのチャンネルIDに置き換えてください。
rdf_url = "https://www.youtube.com/feeds/videos.xml?channel_id=チャンネルID" document = feedparser.parse(rdf_url) for entry in document.entries: print(entry)ちなみに、RDFによって私がいくつかのYoutubeチャンネルで情報収集した結果、以下のことがわかりました。
- 情報収集できるのは最新の動画15件分程度
- 公開後に非公開とした動画の情報は収集不可
- 動画の評価、コメント、スパチャの金額、同時接続数等は収集できない
Youtube RDFでにじさんじライバーの動画情報収集をしてみよう
カルロスピノ氏がほぼ日刊ホロライブというチャンネルでホロライブの切り抜き動画をUPされていますので、私はにじさんじライバーの動画情報を収集してみます。
Pythonで書いたプログラムによる基本的な情報収集方法は、カルロスピノ氏が動画内で解説されているので、ここではカルロスピノ氏のプログラムにアレンジを加えるやり方を紹介しましょう。
各ライバーのArk配信のタイトル・再生数を収集
にじさんじライバーの配信(アーカイブ)の中でも、任意のゲームタイトルの実況のみを表示する方法を紹介します。
ここでは例としてArkというゲームの実況をしていた配信(アーカイブ)のタイトル・再生数を表示してみます。
rdf_url = "https://www.youtube.com/feeds/videos.xml?channel_id=チャンネルID" document = feedparser.parse(rdf_url) for entry in document.entries: if "ARK" in entry["title"] or "Ark" in entry["title"] or "アーク" in entry["title"]: print(entry["title"]+" 再生数:"+entry["media_statistics"]["views"]) print(entry["author"])上記のコード内のチャンネルIDの部分を、任意のライバーのチャンネルIDに変更してください。
チャンネルIDは、各ライバーのチャンネルにアクセスしたときに表示されるURLの末尾になります。
なお、ゲームタイトルは各ライバーによって表記ゆれがある(ARK,Ark,アークなど)ので、orで表記ゆれに対応しています。
本間ひまわり氏のチャンネルURL https://www.youtube.com/channel/UC0g1AE0DOjBYnLhkgoRWN1w一例ですが、本間ひまわり氏のチャンネルIDは
UC0g1AE0DOjBYnLhkgoRWN1wになります。#8【ARK】?捕獲よ~ん?【本間ひまわり/にじさんじ】 再生数:82420 #7【ARK】?おそらのおうさまテイムする?【本間ひまわり/叶/にじさんじ】 再生数:111207 #6【ARK】海中生物捕獲大作戦~モサほし~【本間ひまわり】 再生数:100238 #5【ARK】どうくつたんけん!!!【本間ひまわり】 再生数:111546 #4【ARK】筋肉痛バキバキザウルス【本間ひまわり】 再生数:156699 #3【ARK】38万人おめでとう!38の何かしちゃうよ~ん^^【本間ひまわり】 再生数:185975 本間ひまわり - Himawari Honma -このようにARKの配信(アーカイブ)のタイトル・再生数が表示できます。
夜王国のスプラ配信のタイトル・再生数を収集
先ほどのコードではライバー1人1人の配信(アーカイブ)情報しか収集できません。
そこで、ライバーのユニット単位で特定の配信に関する情報収集をしたいときのコードを紹介します。
例として、夜王国それぞれのスプラトゥーン配信のタイトル・再生数を収集してみましょう。
night_kingdom = ["UC6wvdADTJ88OfIbJYIpAaDA", "UCuvk5PilcvDECU7dDZhQiEw", "UC1QgXt46-GEvtNjEC1paHnw"] for channel_id in night_kingdom: rdf_url = "https://www.youtube.com/feeds/videos.xml?channel_id=" + channel_id document = feedparser.parse(rdf_url) for entry in document.entries: if "スプラ" in entry["title"]: print(entry["title"]+" 再生数:"+entry["media_statistics"]["views"]) print(entry["author"]+"\n")night_kingdomという配列に要素として不破氏、白雪氏、グウェル氏のチャンネルIDが入っています。
【スプラトゥーン2】ありがとうございました【にじさんじ】 再生数:64893 【#にじさんじスプラ杯】スプラが大好きです。今度は嘘じゃないっす【にじさんじ】 再生数:101978 【スプラトゥーン2】最後の練習...見てるか谷沢...【にじさんじ】 再生数:56815 【スプラトゥーン2】イカ杯メンツで前夜祭だあああああああああ【にじさんじ】 再生数:49194 【スプラトゥーン2】何故だが涙がこぼれる...今日は最後の練習だ【にじさんじ】 再生数:117751 【スプラトゥーン2】深夜1時!?いいから練習だぁ!!!!!!【にじさんじ】 再生数:56281 【スプラトゥーン2】夜王国で戦争!?いいから脳死だぁ!!!!!!【にじさんじ】 再生数:52810 【スプラトゥーン2】大会までもう時間ないってマジ??【にじさんじ】 再生数:64277 【スプラトゥーン2】俺の回線なんか重いよ【にじさんじ】 再生数:54743 【スプラトゥーン2】プラべでイカ杯の全ステ全ルールで遊ぶぞ!!【にじさんじ】 再生数:52664 【スプラトゥーン2】エスコート??俺が姫になるんだよ!!!!!【にじさんじ】 再生数:71476 【スプラトゥーン2】後輩ちゃんと地獄のリグマが始まります【にじさんじ】 再生数:64756 【スプラトゥーン2】ぜっっっっったいに脳死しないガチマッチ【にじさんじ】 再生数:55901 不破 湊 / Fuwa Minato【にじさんじ】 【#にじさんじスプラ杯】大会本番!!意外に強いらCチーム【白雪 巴/にじさんじ】 再生数:22140 【スプラトゥーン2】試合目前!!白雪ボム強化意識【白雪 巴/にじさんじ】 再生数:12360 【スプラトゥーン2】意外に強いらしいチームCの本番前日練習【白雪 巴/にじさんじ】 再生数:9868 【スプラトゥーン2】夜王国で銃撃訓練【白雪 巴/にじさんじ】 再生数:13229 【スプラトゥーン2】深夜の͡͡コソ練。ランク20いくまで耐久【白雪 巴/にじさんじ】 再生数:21462 【スプラトゥーン2】お姉さんとイカプレイしない?【白雪 巴/にじさんじ】 再生数:13949 白雪 巴/Shirayuki Tomoe【にじさんじ】 【Splatoon2】 #にじさんじスプラ杯 本戦【黛灰/夜見れな/フミ/グウェル・オス・ガール】 再生数:14572 【Splatoon2】ガチ練習試合 GチームとIチーム #にじさんじスプラ杯【黛灰/夜見れな/フミ/グウェル・オス・ガール/イブラヒム/フレン・E・ルスタリオ/鷹宮リオン/天宮こころ】 再生数:17937 【Splatoon 2】夜王国スプラ【不破湊/白雪巴/グウェル・オス・ガール/にじさんじ】 再生数:16813 【Splatoon 2】#にじさんじスプラ杯 Gチーム練習会【フミ/黛灰/夜見れな/グウェル・オス・ガール/にじさんじ】 再生数:71870 グウェル・オス・ガール / Gwelu Os Gar 【にじさんじ】コードを実行した結果、夜王国のチャンネルでそれぞれ行われたスプラトゥーン配信のタイトル・再生数が収集できました。
グウェル氏のアーカイブのサムネイルを収集しダウンロード
カルロスピノ氏の動画内では、アーカイブのサムネイルを一括保存する方法が紹介されています。
そこで解説されているコードに対するコメントで
for文でインデックスを取りたいならenumerate関数を使うといいですよ。
とありましたので、enumerate関数を使った一括保存のコードを書いてみました。
※下記コードを実行する前に
import requestsを実行する必要があります。for index, entry in enumerate(document.entries): url = entry["media_thumbnail"][0]["url"] response = requests.get(url) image = response.content file_name = "Gwelu"+str(index)+".jpg" with open(file_name, "wb") as image_file: image_file.write(image)
グウェル氏の直近のアーカイブ15件分のサムネイルをクラウド上に保存できました。
Pythonでできるようになること
Google Colaboratory + RDFでは出来ることも限られていますが、Pythonでのプログラミングによってカルロス氏作成のopipi.netで公開されているグラフやTwitter Botの作成ができるようになるとのこと。
今後、Youtube APIの使い方講座なども動画として投稿されるそうなので、気になった方はチャンネル登録しておくといいでしょう。






- 投稿日:2020-03-01T19:51:15+09:00
【Udemy Python3入門+応用】 14.文字の代入 15.f-strings
※この記事はUdemyの
「現役シリコンバレーエンジニアが教えるPython3入門+応用+アメリカのシリコンバレー流コードスタイル」
の講座を受講した上での、自分用の授業ノートです。
講師の酒井潤さんから許可をいただいた上で公開しています。■文字の代入
◆
{}と.format()>>> 'A is {}.' .format('a') 'A is a.' >>> 'A is {}.' .format('test') 'A is test.'
{}の部分に.format()で指定した文字列が代入される。◆どこに代入するかを指定する
>>> 'My name is {} {}.' .format('Tony', 'Stark') 'My name is Tony Stark.' >>> 'My name is {0} {1}.' .format('Tony', 'Stark') 'My name is Tony Stark.' >>> 'My name is {0} {1}. Watashi ha {1} {0} desu.' .format('Tony', 'Stark') 'My name is Tony Stark. Watashi ha Stark Tony desu.'
{}が複数ある場合、前から順に代入される。
インデックスを指定してやると、そのインデックスに相当する文字列が代入される。◆変数を用いて指定する
>>>Watashi ha {family} {name} desu.' .format(name = 'Tony', family = 'Stark') Watashi ha Stark Tony desu.'◆他の型のものはstr型に変換されて代入される
>>> type('1') <class 'str'> >>> type(1) <class 'int'>>>> '{}, {}, {}, Go!' .format('1', '2', '3') '1, 2, 3, Go!' >>> '{}, {}, {}, Go!' .format(1, 2, 3) '1, 2, 3, Go!'
1はint型であるが、str型に変換されて代入される。
■f-strings
Python 3.6から、f-stringsが以下のように使えるようになった。
f-stringsa = 'a' print(f'a is {a}') x, y, z = 1, 2, 3 print(f'a is {x}, {y}, {z}') print(f'a is {z}, {y}, {x}') name = 'Tony' family = 'Stark' print(f'My name is {name} {family}. Watashi ha {family} {name} desu.')resulta is a a is 1, 2, 3 a is 3, 2, 1 My name is Tony Stark. Watashi ha Stark Tony desu.
- 投稿日:2020-03-01T19:21:24+09:00
【Udemy Python3入門+応用】 13.文字のメソッド
※この記事はUdemyの
「現役シリコンバレーエンジニアが教えるPython3入門+応用+アメリカのシリコンバレー流コードスタイル」
の講座を受講した上での、自分用の授業ノートです。
講師の酒井潤さんから許可をいただいた上で公開しています。■文字のメソッド
◆
.startswith.startswiths = 'My name is Mike. Hi, Mike.' print(s) is_start = s.startswith('My') print(is_start) is_start = s.startswith('You') print(is_start)resultMy name is Mike. Hi, Mike. True False
.startswithでは「指定した文字(列)で始まっているかどうか?」を調べることができる。◆
.findと.rfind.find_and_.rfinds = 'My name is Mike. Hi, Mike.' print(s) print(s.find('Mike')) print(s.rfind('Mike'))resultMy name is Mike. Hi, Mike. 11 21
.findで、「指定した文字(列)が何番目か?」を調べることができる。
今回 'Mike' は文中に2回登場しているが、.findでは最初に登場した 'Mike' の位置を調べている。
.rfindでは後ろから探すことなる。
今回では2回目に登場した 'Mike' の位置を調べている。M y n a m e i s M i k e . H i , M i k e . 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25インデックスを書いてみるとこんな感じ。
◆
.count.counts = 'My name is Mike. Hi, Mike.' print(s) print(s.count('Mike'))resultMy name is Mike. Hi, Mike. 2
.countで、文中に 'Mike' が登場した回数を調べている。◆
.capitalizeと.title.capitalizes = 'My name is Mike. Hi, Mike.' print(s) print(s.capitalize()) print(s.title()) print(s.upper()) print(s.lower())resultMy name is Mike. Hi, Mike. My name is mike. hi, mike. My Name Is Mike. Hi, Mike. MY NAME IS MIKE. HI, MIKE. my name is mike. hi, mike.
.capitalizeを使うと、文の先頭の文字だけ大文字となり、残りはすべて小文字となる。
.titleを使うと、各単語の頭文字が大文字になる。
.upperでは全ての文字が大文字になる。
.lowerでは全ての文字が小文字になる。◆
.replace.replaces = 'My name is Mike. Hi, Mike.' print(s) print(s.replace('Mike', 'Nancy'))resultMy name is Mike. Hi, Mike. My name is Nancy. Hi, Nancy.
.replaceで、指定した文字列を任意の文字列に入れ替えることができる。
- 投稿日:2020-03-01T19:20:01+09:00
FlaskでPostgreSQLと連携した読書記録簿を作った
はじめに
土日で勉強がてら、ちょっとした読書記録簿を作りました。
画面はこちら。
機能としては、読んだ本を登録することと、登録された本のリストを見ることくらいです。
ソースコード
ソースコードは以下の通りです。htmlは見たままなので割愛します。
app.pyfrom flask import Flask, render_template,url_for,request,redirect from sqlalchemy import create_engine import pandas import psycopg2 ''' 参考にしたサイト https://tanuhack.com/pandas-postgres-readto/ ''' # PostgreSQLの接続情報 connection_config = { 'user': 'user', 'password': 'password', 'host': 'localhost', 'port': '5432', 'database': 'mydb' } # psycopg2を使ったDB接続 connection = psycopg2.connect(**connection_config) # dfの作成 df = pandas.read_sql(sql='SELECT * FROM books;', con=connection) header = ['id','書籍名','著者','読了日','評価'] record = df.values.tolist() # DataFrameのインデックスを含まない全レコードの2次元配列のリスト app = Flask(__name__) @app.route('/') def index(): #indexを読み込むたびにDBからのSELECT文更新 df = pandas.read_sql(sql='SELECT * FROM books;', con=connection) record = df.values.tolist() return render_template('index.html', header=header, record=record) @app.route('/result', methods=['GET','POST']) def addition(): if request.method == "POST": # レコード数再取得が必要 df = pandas.read_sql(sql='SELECT * FROM books;', con=connection) record = df.values.tolist() # POSTの内容を元にINSERT文の値取得、idは現在のレコード数+1 book_id = len(record)+1 res1 = request.form['書籍名'] res2 = request.form['著者'] res3 = request.form['読了日'] res4 = request.form['評価'] dict1={'id':[book_id],'name':[res1],'writer':[res2],'read_day':[res3],'rank':[res4]} # DBに飛ばすにはSQLAlchemy必要 engine = create_engine('postgresql://{user}:{password}@{host}:{port}/{database}'.format(**connection_config)) df = pandas.DataFrame(data=dict1) df.to_sql('books', con=engine, if_exists='append', index=False) return redirect(url_for('index')) ## おまじない if __name__ == "__main__": app.run(debug=True)概要としては、PostgreSQLに読んだ本のテーブルがあり、SELECT文でDataFrameとして取得した内容をリスト化し、render_templateでindex.htmlに送って「あなたが読んだ本」として表示させます。
そして、読んだ本の登録は入力フォームに情報を入力し、登録ボタンを押すことでPOSTメソッドとして処理されます。idは最新の番号を自動で割り振り、他は入力フォームから取得し、1行の辞書型のデータを作ります。
最後に、辞書型のデータをDataFrameに変換し、df.to_sqlでDBにINSERT文を飛ばせばデータが追加されます。課題
・デプロイできなかった
herokuを使おうとしたんですが、デプロイしたものがうまく起動せずに断念しました。
原因ははっきりしていないのですが、生の環境でやったのが影響していそうだったので、virtualenvを使うべきだったと思います。・機能不足
ご覧の通り、データを追加する機能しかありません。登録情報を修正したり、消したかったらコマンドプロンプトで直接DBを見に行かなければいけません。今後に向けて
とりあえず、最低限やりたかったDBとウェブページの連携(DBからの取得とDBへの追記)はできたので及第点にしちゃいます。
次は読書記録簿をリメイクするのか別のものを作るか決めていませんが、virtualenvをつかい、少しずつherokuにデプロイする、という作成スタイルでやりたいと思います。

- 投稿日:2020-03-01T19:16:16+09:00
回帰と二値分類の評価指標についてのメモランダム
タスクごとの評価指標についてあまりに忘れるので、最低限覚えておきたいことをまとめる。
この記事では、回帰と二値分類の主な評価指標を扱う。
参考文献: Kaggle本1. 準備
1-1. 環境
記事中のコードは、Windows-10, Python 3.7.3で動作を確認した。
import platform print(platform.platform()) print(platform.python_version())1-2. データセット
回帰、二値分類用データセットを、sklearn.datasetsから読み込む。
from sklearn import datasets import numpy as np import pandas as pd # 回帰用データセット boston = datasets.load_boston() boston_X = pd.DataFrame(boston.data, columns=boston.feature_names) boston_y = pd.Series(boston.target) # 二値分類用データセット cancer = datasets.load_breast_cancer() cancer_X = pd.DataFrame(cancer.data, columns=cancer.feature_names) cancer_y = pd.Series(cancer.target)1-3. モデリング
評価指標を得るため、テキトウにモデリングし、予測値を出力する。
本当に評価指標を得るためだけなので、EDAも特徴量作成もバリデーションすらしていない。罪悪感が凄い。from sklearn.linear_model import LinearRegression, LogisticRegression # 回帰 slr = LinearRegression() slr.fit(boston_X, boston_y) boston_y_pred = slr.predict(boston_X) # 二値分類 lr = LogisticRegression(solver='liblinear') lr.fit(cancer_X, cancer_y) cancer_y_pred = lr.predict(cancer_X) cancer_y_pred_prob = lr.predict_proba(cancer_X)[:, 1]2. 回帰タスクの評価指標
RMSE (Root Mean Squared Error: 平均平方二乗誤差)
$$
\mathrm{RMSE}=\displaystyle\sqrt{\dfrac{1}{N}\sum_{i=1}^N(y_i-\hat{y}_i)^2}
$$
予測値がどれだけ真の値から外れているのか直感的に把握できるので、実務でもよく使っている。
メジャーな評価指標なのに、sklearnはMSEしかサポートしていない。np.sqrtしてから返してくれればいいのに。from sklearn.metrics import mean_squared_error rmse = np.sqrt(mean_squared_error(boston_y, boston_y_pred)) print(rmse)4.679191295697281
MAE (Mean Absolute Error)
$$
\mathrm{MAE}=\dfrac{1}{N}\displaystyle\sum_{i=1}^N|y_i-\hat{y}_i|
$$
隣のチームがこれを評価指標にしていた。私は使ったことがない。
RMSEと比べて、外れ値の影響が少ない。RMSEが平均なら、MAEは中央値というイメージ。from sklearn.metrics import mean_absolute_error mae = mean_absolute_error(boston_y, boston_y_pred) print(mae)3.2708628109003115
決定係数
R^2=1-\dfrac{\sum_{i=1}^N(y_i-\hat{y}_i)^2}{\sum_{i=1}^N(y_i-\bar{y})^2}1に近づくほど精度が高いという、まさに文系のためにあるような指標。
そのため昔は大好きだったが、一度実務で痛い目を見てからあまり信用しなくなった。
決定係数は分母が分散なので、データのバラツキが大きければテキトウなモデルでも割と高く出る。
参考程度に見て、実際の当たり具合はRMSEで判断した方が無難。from sklearn.metrics import r2_score r2 = r2_score(boston_y, boston_y_pred) print(r2)0.7406426641094095
3. 二値分類タスクの評価指標
二値分類タスクは、正例か負例かの分類結果を予測値とする場合と、正例である確率を予測値とする場合があるので、分けて扱う。
3-1. 分類結果を予測値とする場合
混同行列 (confusion matrix)
- TP (True Positive, 真陽性): 予測値を正例として、その予測が正しい場合
- TN (True Negative, 真陰性): 予測値を負例として、その予測が正しい場合
- FP (False Positive, 偽陽性): 予測値を正例として、その予測が誤りの場合
- FN (False Negative, 偽陰性): 予測値を負例として、その予測が誤りの場合
ただの集計だが、なんだかんだで一番大切ではないだろうか。
例えば、100人に1人しか感染しないウイルスが流行したので、検査を行ったとする。
このとき、とにかく全員を陰性としてしまえば、その精度は一見99%に見えてしまう……みたいなトリックに惑わされないよう、混同行列はしっかり覚えておく必要がある。
なのに、いっつもTPだのFNだのワケが分からなくなる。from sklearn.metrics import confusion_matrix cm = confusion_matrix(cancer_y, cancer_y_pred) tn, fp, fn, tp = cm.flatten() print(cm)[[198 14]
[ 9 348]]accuracy (正答率)
$$
accuracy = \frac{TP+TN}{TP+TN+FP+FN}
$$error rate (誤答率)
$$
error \; rate = 1-accuracy
$$
先程の例で言えば、全員を陰性とした場合の正答率は0.99となってしまう。
二値分類タスクの場合、まずデータが不均衡かどうかを見なければ何も始まらないことがよく分かる。from sklearn.metrics import accuracy_score accuracy = accuracy_score(cancer_y, cancer_y_pred) print(accuracy)0.9595782073813708
precision (適合率)
$$
precision = \frac{TP}{TP+FP}
$$recall (再現率)
$$
recall = \frac{TP}{TP+FN}
$$
precisionは正例と予測したもののうち真の値も正例の割合、recallは真の値が正例のもののうちどの程度を正例と予測したかの割合。
両者はトレードオフの関係にある。precisionは誤検知の割合で、recallは見逃しの割合なので、目的に応じてどちらを重視するか決める。
先程のウイルス検査の例などはrecallを重視するだろうし、マーケティングの文脈ならprecisionが重要になってくるだろう。from sklearn.metrics import precision_score, recall_score precision = precision_score(cancer_y, cancer_y_pred) recall = recall_score(cancer_y, cancer_y_pred) print(precision) print(recall)0.9613259668508287
0.9747899159663865F1-score
$$
F_1 = \dfrac{2}{\dfrac{1}{recall}+\dfrac{1}{precision}}
$$Fβ-score
$$
F_\beta = \dfrac{(1+\beta^2)}{\dfrac{\beta^2}{recall}+\dfrac{1}{precision}}
$$
F1-scoreはprecisionとrecallの調和平均、Fβ-scoreはそれをrecallをどれだけ重視するかを表す係数βで調整した指標。
バランスを取っているので使い勝手が良さそうだが、なにぶん実務で使ったことがないのでイメージが湧かない。from sklearn.metrics import f1_score, fbeta_score f1 = f1_score(cancer_y, cancer_y_pred) fbeta = fbeta_score(cancer_y, cancer_y_pred, beta=0.5) print(f1) print(fbeta)0.968011126564673
0.96398891966759MCC (Matthews Correlation Coefficient)
$$
MCC = \dfrac{TP \times TN - FP \times FN}{\sqrt{(TP+FP)(TP+FN)(TN+FP)(TN+FN)}}
$$
寡聞にして聞いたことがない。
-1から1の値をとり、1のときに完璧な予測を、0のときにランダムな予測を、-1のときは完全に反対の予測を行っていると解釈するらしい。
不均衡なデータでも適切に評価しやすいとのことで、是非使えるようになりたい。from sklearn.metrics import matthews_corrcoef mcc = matthews_corrcoef(cancer_y, cancer_y_pred) print(mcc)0.9132886202215396
3-2. 確率を予測値とする場合
AUC (Area Under the ROC Curve)
横軸に偽陽性率、縦軸に真陽性率をプロットしたROC曲線の、下部の面積。
左から順に予測値が高いレコードを並べ、実際に正例なら上に、負例なら横に進むプロットと考えればいい。
そのため、完全な予測のときROC直線は左上の天井に跳ね上がり、AUCは1となる。ランダムな予測なら対角線上をなぞる。
有名なGini係数はGini = 2AUC - 1と表されるため、AUCと線形。import japanize_matplotlib import matplotlib.pyplot as plt from sklearn.metrics import roc_auc_score, roc_curve %matplotlib inline auc = roc_auc_score(cancer_y, cancer_y_pred_prob) print(auc) fpr, tpr, thresholds = roc_curve(cancer_y, cancer_y_pred_prob) plt.plot(fpr, tpr, label='AUC={:.2f}'.format(auc)) plt.legend() plt.xlabel('偽陽性率') plt.ylabel('真陽性率') plt.title('ROC曲線') plt.show()0.9946488029173934
logloss
$$
logloss = -\frac{1}{N} \sum_{i=1}^N(y_i {\log} p_i+(1-y_i){\log}(1-p_i))
$$
これもAUCと並んで有名。cross entropyとも呼ばれる。
真の値を予測している確率の対数をとり、符号を反転させているので低い方がいい(らしい)
正例である確率を低く見積もったのに正例である場合や、高く見積もったのに負例だった場合にペナルティを与える発想になっている。from sklearn.metrics import log_loss logloss = log_loss(cancer_y, cancer_y_pred_prob) print(logloss)0.09214591499092101
多クラス分類やレコメンデーションは実務経験がなく、ただ写経するだけになりそうだったので次の機会に譲る。
いつか書けるようになりたい。

- 投稿日:2020-03-01T18:50:16+09:00
【Udemy Python3入門+応用】 12.文字列のインデックスとスライス
※この記事はUdemyの
「現役シリコンバレーエンジニアが教えるPython3入門+応用+アメリカのシリコンバレー流コードスタイル」
の講座を受講した上での、自分用の授業ノートです。
講師の酒井潤さんから許可をいただいた上で公開しています。■インデックス
◆インデックスの使い方
indexword = 'python' print(word[0]) print(word[1]) print(word[2]) print(word[3]) print(word[4]) print(word[5])resultp y t h o n変数に文字列を代入したとき、その文字列の任意の文字を指定できる。
Pythonにおいて、「1番目の文字」のインデックスは「0」であることに注意。◆インデックスのエラー
indexword = 'python' print(word[100])resultprint(word[100]) IndexError: string index out of rangeこのとき、文字列の範囲を超えたインデックスを指定するとエラーとなる。
◆インデックスの「ー」
indexword = 'python' print(word[-1]) print(word[-2]) print(word[-3])resultn o h
[-1]などは先頭の文字([0])から更に左にいき、最後の文字に回るようにカウントされる。
よって、[-1]は最後の文字を表すインデックスとなる。
■スライス
◆スライスの使い方
sliceword = 'python' print(word[0:2])resultpy
[:]により、始点と終点を指定し、その間の数を指定することができる。|p|y|t|h|o|n| 0 1 2 3 4 5 6インデックスは実際は文字と文字の間を表しており、このように考えるとわかりやすい。
(0と2の間は「py」となる。)◆省略
sliceword = 'python' print(word[:2]) print(word[2:]) print(word[:])resultpy thon python始点を省略すると「最初から」になり、
終点を省略すると「最後まで」になる。
始点も終点も省略した場合は、文字列全体を指定することになる。
■文字列の任意の文字だけを入れ替える
◆「python」→「jython」
change_letterword = 'python' word = 'j' + word[1:] print(word)resultjython
■文字数をカウントする
count_lettersword = 'python' n = len(word) print(n)result6文字列の"length"を
len()を用いてカウントすることができる。
- 投稿日:2020-03-01T18:35:11+09:00
お絵かきで Python を学ぶ(タートルグラフィックス)
タートルグラフィックスとは
教育用プログラミング言語の「LOGO」を元に画面上の亀をプログラミングで操作して図として描画するといったものです。
1960 年代に開発され、プログラムの結果を視覚ですぐに確認できることから、子供向けのプログラミング学習に用いられることもあります。環境
- PyCharm
- Python3
タートルグラフィックスに触れる(対話型シェル)
まずは対話型シェルを用いて簡単にタートルグラフィックスに触れてみようと思います。
PyCharm のターミナル画面を開いて、
Pythonと入力します。$ Pythonこれで対話型シェルになったので、
turtleを import します。>>> import turtleつぎに
turtle.forward(100)と入力します。>>> turtle.forward(100)すると以下のようにグラフィックが立ち上がります。
これは矢印が前に 100 回進んだということを表しています。
矢印の向きを下に向けたい場合には
turtle.right(90)として 右に 90 度曲げます。>>> turtle.right(90)
この状態で再度
turtle.forward(100)入力すると下に進みます。>>> turtle.forward(100)
先頭の矢印の形が味気ないと感じる場合には
shape.()で変更できます。
今回は亀に変更させてみたいと思います。>>> turtle.shape('turtle')
color()でこの亀の色を変更させることも可能です。>>> turtle.color('red')
この亀を隠したい場合には
hideturtle()を使用します。>>> turtle.hideturtle()
隠した亀を再び表示させたい場合には
showturtle()と入力します。>>> turtle.showturtle()
直線以外にも円を描くこともできます。
>>> turtle.circle(100)
今、赤い線で描かれていますがこの線の色を変更させたい場合には
pencolor()を使用します。同時に角度を少し変更させて進ませてみます。
>>> turtle.pencolor('blue') >>> turtle.right(45) >>> turtle.forward(100)
後ろに進むことも可能であり、
backward()を使用します。>>> turtle.backward(200)
一番最初の位置に戻りたい場合には
home()を使用します。>>> turtle.home()
すべてクリアにしたい場合には
clear()を使用します。>>> turtle.clear()
終了させるときには最後に
done()と入力します。>>> turtle.done()ファイルを作成して実行させる
上記ではターミナルから対話型シェルで実行させたが、ここからは
適当な名前の Python ファイルを作成してファイルから実行させてみます。ファイル上に以下の前進させるだけの簡単な処理を記述して実行させてみます。
import turtle turtle.forward(100)すると一瞬だけ表示されてすぐに消えてしまうことが確認できると思います。
ずっと表示するには最後の行にすべての処理が完了しましたと表す、done()を
記述してあげます。import turtle turtle.forward(100) turtle.done()
これでしっかりと表示されることが確認できると思います。
四角形
Python の for ループ使用して四角形を出力させてみます。
考え方としてはturtle.forward(100)の前進を 4 回繰り返し、
一度前進が完了したら 90 度に曲がる処理を加えるといったものである。import turtle turtle.color('red', 'yellow') turtle.begin_fill() for _ in range(4): turtle.forward(100) turtle.right(90) turtle.end_fill() turtle.done()ファイル形式では処理の内容を
turtle.begin_fill()とturtle.end_fill()で
括ってあげます。実行してあげると線が赤で中が黄色の四角形が表示されます。
星形
星形のプログラムですが、四角形のプログラムと構成がほとんど一緒になります。
変更箇所としては前進する回数が 5 回になるのと角度が360 / 5 * 2になります。import turtle turtle.color('red', 'yellow') turtle.begin_fill() for _ in range(5): turtle.forward(100) turtle.right(360 / 5 * 2) turtle.end_fill() turtle.done()
星を三回作成させ、一度進むたびに前進する距離を少しずつ増やしてみる。
import turtle turtle.color('red', 'yellow') turtle.begin_fill() for i in range(5 * 3): turtle.forward(100 + i * 10) turtle.right(360 / 5 * 2) turtle.end_fill() turtle.done()すると以下のように綺麗な図形ができる。
このようにループの処理を色々としてあげると違った形になり楽しむことができる。
三角形
三角形も同様に三回前進して、一度前進したあとに角度を変えるといった処理になります。
import turtle turtle.color('red', 'yellow') turtle.begin_fill() for i in range(3): turtle.forward(100) turtle.left(360 / 3) turtle.end_fill() turtle.done()実行してみると三角形が表示されます。
星形でも行ったように一度前進したあとの角度を少しずらしてあげるとどうなるか見てみます。
import turtle turtle.begin_fill() for i in range(200): turtle.forward(200) turtle.left(360 / 3 + 10) turtle.end_fill() turtle.done()このように星型の時と同様に綺麗な図形になります。
おわり
ざっくりでしたが以上が扱い方の説明になります。
このタートルグラフィックスを使用することで自分のプログラミングが
簡単に可視化できるため子供はもちろん大人も楽しんでプログラミングを学習することができると思います。最後に以下のような木を作成することも可能です。
import turtle as t foo = t.Turtle() foo.left(90) foo.speed(10) def draw(l): if(l<10): return else: foo.forward(l) foo.left(30) draw(3*l/4) foo.right(60) draw(3*l/4) foo.left(30) foo.backward(l) draw(100)








- 投稿日:2020-03-01T18:33:53+09:00
はじめてのDjango起動
■環境
windows10
Pycharm Community 2019.3
Python3.7■前提条件
Djangoプロジェクト、アプリケーション作成していることを前提。以下参照
■Djangoの起動
プロジェクトのディレクトリに移動して、runserver
C:\python_project\venv_python_dev\Private_Diary_project>python manage.py runserverブラウザで http://127.0.0.1:8000/
つながりました!
ターミナルで、「 CTL+C 」 でWebサーバ停止
以上


- 投稿日:2020-03-01T18:28:28+09:00
気象データをもとに「天気図っぽい前線」を機械学習で描いてみる(5)
気象データをもとに「天気図っぽい前線」を機械学習で描いてみる(5)機械学習編 Automatic Front Detection in Weather Data
1. 「天気図っぽい前線」の学習
1.1 「天気図っぽい前線」とは?
天気図の前線は、防災的な観点からか、日本に影響のあるような部分を中心に解析されているようです。
他の国の天気図を見ると、日本の天気図では描かれないような前線が登場してたりします。
例えば下記のコラムではヨーロッパの気象図に登場する前線についての記載があります。
衛星でも見えない、「隠れた」前線の話これらから言えるのは、前線解析は必ずしも一意に決まるものでなく、機関ごとの流儀や意図がありそうということです。ということは、私が試みている機械学習による前線描画は、気象データから日本の天気図っぽい前線を描画させるもの、と言えるでしょう。
学習精度をどんどん高めて気象庁のような日本の天気図っぽい前線解析を完璧に描画できるようになると、気象実況解析のエキスパートシステムとなるものかもしれません。永澤義嗣氏が著された気象予報と防災ー予報官の道(中公新書)には、「天気図を三千枚書いて一人前」という記載があります。今回学習に使用しているデータはおよそ2000枚です。Deep Learning予報官として、一人前というにはまだ努力不足です。
ところで、この機械学習は天気図を生成しているものの、天気予報をしているものではありません。
天気予報は現在から将来を予測するもので、前線描画は現在から現在のデータへの変換です。2. 機械学習の流れ
2.1 何をやるのか?
CNNによって画像から画像を生成するものです。生成画像のピクセルごとに赤・青・白どの色になるべきか、確率を計算させて確率の高かった色をピクセルにセットするという手法です。
この手法は下記を参考にしています。
Exascale Deep Learning for Climate Analytics
Thorsten Kurth, Sean Treichler, Joshua Romero, Mayur Mudigonda, Nathan Luehr, Everett Phillips, Ankur Mahesh, Michael Matheson, Jack Deslippe, Massimiliano Fatica, Prabhat, Michael Houston
arXiv:1810.01993 [cs.DC]2018年にテキサス州ダラスで開催されたSC18というスパコン分野の国際学会において、ACM Gordon Bell Prizeを受賞した論文です。私は幸いにも、SC18へ出張していて受賞講演を聴講する機会に恵まれ、公私混同しながらとても感慨深かった思い出があります。
2.2 機械学習の流れ
ニューラルネットワークによる機械学習の流れをまとめます。
(1) 入力画像を作る
気象データをダウンロードして可視化する。
6種類のカラー画像を用意しました(第2回)(2) 教師画像を作る
「速報天気図」から色をもとに前線要素だけを抜き出した画像を作る(第3回)
教師画像を増やすために白黒天気図のカラー化なんてのもやりました(第4回)(3) CNNのあれこれ
・入力データ:並べ替え
CNNの入力は、6種類の入力画像(channel数は3)をconcatenateした18channelのテンソルになります。
CNNのミニバッチの中に、近接した時間のデータばかりになると学習時に偏ってしまうので、入力データと教師画像の組を時間的にランダムに並べ替えておきます。・入力データ:one-hotベクトル
CNNは各ピクセルが赤、青、白のそれぞれに該当する確率を計算するように作成するので、RGBである教師画像については、正解が1、その他が0となった配列に変換しておきます。つまり、白なら(1,0,0)、赤なら(0,1,0)、青なら(0,0,1)というデータを作ります。・出力データ
例えばCNNはあるピクセルの値としては、例えば(0.1, 0.7, 0.2)を出力します。この場合はこのピクセルは赤だ、として絵を作ります。・ニューラルネットワーク
CNNはU-Netを意識した分岐経路を有するものを作成します。・ロス関数
categorical_cross_entropyを用います。これにより赤、青、白の確率を計算します。(4) 学習させる!
いよいよCNNを学習させます。
今回、2017年1月から2019年10月まで、各日から2枚(6時UTCと18時UTCのデータ)を使用して学習させています。教師データは赤、青、白のいずれかが1になっているone-hotベクトルですから学習が進むにつれて前線要素のカラーを再現できるようになっていきます。私のMac miniは数日の間、触れないくらいの高温になります。
Mac miniのうち、最もCPUを酷使されている個体のひとつではないかと思っており、CPU冥利に尽きるというものでしょう。(5) 予測させる!(初見データに前線を描かせる)
学習が収束したところで、学習済ネットワークを使って、初見データの前線を描画します。今回は初見データとして2019年11月から2020年1月までのデータに前線を描画させました。3. 何はともあれ結果
3.1 学習データ
学習データの一例です。
速報天気図の前線ととほぼ同じような位置に該当する前線要素が生成できるまで収束しているように見えます。左上から右へ、
出力結果:生成した前線要素(地上気圧の可視化画像へ重ね合わせたもの)
教師画像:速報天気図
入力:相当温位850hPa
入力:気温・気圧・風(地上)左下から右へ、
入力:気温・高度・風(850hPa)
入力:湿数(700hPa)
入力:鉛直流(700hPa)
入力:気温・高度・風(500hPa)
3.2 生成データ(初見データ)
3.1で、2017年1月から2019年10月のデータによって学習させたネットワークを使って、前線生成させました。
うまく生成できている例
日本の東の海上に低気圧があり、寒冷前線が南西に延びています。
ニューラルネットワークでもこの寒冷前線を生成できています。また、温暖前線も途切れながらも生成されています。
かなりダメな例
速報天気図では、千島列島近海の低気圧から南西に寒冷前線が延びています。また、北緯30度線にほぼ沿って停滞前線が解析されています。
これに対して、ニューラルネットワークではどちらの前線もほぼ生成できていません。
どのデータが寄与しているのか?
パッとデータを眺めていると、入力データのうち、850hPaの相当温位で、等値線が混み合っている領域に前線が引かれているようです。ダメな例では混み合い具合が少し弱いようにも見えますがどうでしょう?
今回のCNNのフィルタサイズは3x3です。もう少し大きなフィルタを使ってみるか、画像を縮小してみるということも手かもしれません。
さて、2020年1月分の前線生成結果です。こんな感じのデータが生成されるんです、というだけのアニメです。
3.3 学習の進行状況
LossおよびAccuracyの遷移です。このデータを取り直すために再度学習させた800エポックまでの状況です。
200エポックごとに学習を止めて再スタートさせているのですが、その際に入力画像のランダム化(後述)を行うことで学習対象のデータが一部入れ替わったりするので、一度LossやAccuracyが悪くなります。
先ほどのうまく生成できた例についての生成画像の変化です。
左から、200、400、600、800エポック学習時点のパラメタでの生成画像、最終的に1500エポック以上
実行したときの生成画像。
前線を描くべき場所に前線を引くこと自体は早期にできるようになり、前線記号(山型のマークなど)の精度が上がってきているように見えます。
ダメな例の方です。
ん?学習が浅い方のパラメタで生成した方がまだマシだったかもしれない?
学習時間ですが、私のMac miniで1エポックで580秒前後でした。これでマル4日くらい実行し続けでした。
GPUを持っていたりするともっと先まで実行する気になるのかなあ。3.4 ところで・・・
まだ前線がくっきり間違えずにできるところまで来ていませんが、データ例を増やして計算リソースを増やせば、かなり良いところまでいけるのではないか、という感触です。
それではこれは何かの役に立つのか?
前線解析は気象庁で実施している結果を入手できることができますので、プロにお任せした方がお得です。意味があるとすると、数値予報結果や気候計算結果に自動的に前線を描く、ということでしょうか?
例えば上記は2020年2月18日12時UTCを初期値としたGSMの予報計算結果に対して前線を描いたものです。予想天気図は24時間後、48時間後という間隔での発表ですので、GSMの6時間ごとの結果に対して前線を描く、ということを行っています。
4. TL;DR CNNのあれこれ
以下はCNN本体の説明と、多少ハマった部分のTipsです。
4.1 入力データ
4.1.1 入力画像・教師画像の組をランダムに並べ替える
入力画像と教師画像は、読み込んだ直後には日付順に並んでいます。
このまま学習させると、ミニバッチの各回は時間的に近接した気象状況となってしまうことが想定されるので、異なる気象状況が混じったバッチとするために、リストをランダムにソートします。randomize.py# i_datalist_train 年月日時順に並んだn_datalist個の入力用気象画像データ # t_datalist_train 年月日時順に並んだn_datalist個の教師画像データ # 0からn_datalist-1までの数列からランダムにn_datalistのインデックスを生成して # ループ処理する for c_list in random.sample(range(n_datalist), n_datalist ): t_datalist_train.append(t_datalist[c_list]) # 並び替え済教師画像リスト i_datalist_train.append(i_datalist[c_list]) # 並び替え済入力画像リスト4.1.2 前線画像のone-hot化
前回までで作成した教師画像用の前線要素画像は、各ピクセルが赤、青、白のいずれかとなっています。
ほとんどの面積を占めるのバックグラウンドが白色、寒冷前線と高気圧記号が青色、温暖前線と閉塞前線および低気圧記号が赤色です。
CNNにより画像を生成して教師画像との間でcategorical_cross_entropyによる誤差関数を計算しますので、この前線要素画像データをone-hotベクトル化しておきます。to_categoricalというnumpyのメソッドを利用するために、RGB配列をいったん0,1,2のいずれかをとる配列に変換します。その後にto_categoricalを用いてone-hotベクトルに変換します。そのあたりを実行しているのが下記のソースです。one-hot.py# t_img 読み込んだ前線画像ファイル # img_size t_imgの画像サイズ t_data = np.empty((img_size[1],img_size[0])) # t_data one-hot化するために0,1,2の3値化するための配列を用意 # ピクセル毎に赤は1, 青は2, それ以外は0 とセットする for x in range(img_size[1]): for y in range(img_size[0]): r,g,b = t_img.getpixel((y,x)) # r g bにそれぞれRGB値を格納する if(r>g+20): if(r>b+20): t_data[x,y]=1 # 赤色ピクセル else: if(b>g+20): t_data[x,y]=2 # 青色ピクセル else: t_data[x,y]=0 # 白色ピクセル else: if(b>r+20): if(b>g+20): t_data[x,y]=2 # 青色ピクセル else: t_data[x,y]=0 # 白色ピクセル else: t_data[x,y]=0 # 白色ピクセル # t_data から、3要素のone-hot vector配列 T_data に変換 T_data = np_utils.to_categorical(t_data[:,:],3)4.2 出力データ
予測させた出力データから、最も確率が大きいものを採用して3色画像に変換します。
データを出力すると下記のように、ひとつの値が大きくなっています。その値に該当する色をピクセルに配置します。w_array (256, 256, 3) [[[9.99969959e-01 1.26371087e-05 1.73822737e-05] [1.00000000e+00 8.79307649e-09 8.33461922e-09] [1.00000000e+00 1.22459204e-12 8.95228910e-16] ... [9.99985695e-01 6.48013793e-06 7.86928376e-06] [9.99960303e-01 8.51386540e-06 3.12020056e-05] [9.99833941e-01 2.61777150e-05 1.39806682e-04]] [[9.99999881e-01 8.55169304e-08 1.83308195e-08] [1.00000000e+00 9.66997732e-11 1.11044485e-12] [1.00000000e+00 4.26908814e-16 1.04265986e-22] ...ピクセルへの色配置のためのソースです。
w_arrayは、(R,G,B)の確率値ベクトルが緯度x経度に並んでいます。これをもとに、画像データmask1を作成します。rasterize.py# w_array 予測させた出力データのNd_array配列の1画面分が格納されている s_img = array_to_img(w_array[:,:,:].reshape(i_dmlat,i_dmlon,3)) # s_img 画像化したデータ new_img_size = [w_array.shape[1], w_array.shape[0]] mask1 = Image.new('RGB', new_img_size) # mask1 出力するための配列 for x in range(new_img_size[1]): for y in range(new_img_size[0]): # w_arrayの第3要素をw1/r1/b1に格納する w1 = w_array[x,y,0] r1 = w_array[x,y,1] b1 = w_array[x,y,2] if(r1>w1): if(r1>b1): # r1>w1, r1>b1 r,g,b=255,0,0 # r1が最大の場合はRGBとして赤色をセット else: # r1=<w1 if(b1>w1): # r1=<w1<b1 r,g,b=0,0,255 # b1 が最大の場合はRGBとして青色をセット else: # r1=<w1, b1=<w1 r,g,b=255,255,255 # w1 が最大の場合はRGBとして白色をセット else: # w1>=r1 if(b1>r1): if(b1>w1): # b1>w1>r1 r,g,b=0,0,255 # b1 が最大の場合はRGBとして青色をセット else: # w1>=b1>r1 r,g,b=255,255,255 # w1 が最大の場合はRGBとして白色をセット else: # w1>=r1 w>=b1 r,g,b=255,255,255 # w1 が最大の場合はRGBとして白色をセット mask1.putpixel((y,x),(r,g,b)) # RBGの値をmask1にセット4.3 ニューラルネットワーク(Convolutional Neural Network)
4.3.1 ネットワーク構造
CNNの構造は、U-Netのような分岐を持たせているもので自作です。
入力が18x256x256のテンソル、出力が3x256x256のテンソルです。
画像サイズはConv2Dのstride=(2,2)パラメタの指定により半分になっていき、最終的に120x16x16になります。
通常のU-Netでは、画像サイズを半分にする際にチャネル数を倍にするのですが、今回はメモリ量の都合で、きれいに倍にはしていません。
4.3.2 Kerasによるネットワーク定義
ネットワーク定義部分のPython-Kerasのソースは下記です。
Kerasのネットワークの定義のやり方としては、Functional APIを用いて各レイヤの出力を次レイヤまたは先の方の結合部分に繋いでいくものです。
cnv2dtra = concatenate([cnv2dtra , cnv2d14 ], axis=1)
などの部分が,cnv2dtraに分岐しきたcnv2d14を第1要素(チャンネル)で結合させている部分です。cnn.py#- Neural Network Definition num_hidden1 = 18 num_hidden2 = 32 num_hidden3 = 48 num_hidden3a = 72 num_hidden3b = 120 num_hidden4 = 128 num_hidden5 = 16 num_hidden6 = 16 num_itter = int(_num_itter) # 学習回数 #--- seting Neural Network using Keras in_ch = 18 # 入力画像 RGB x 6種類 のチャンネル数 cnn_input = Input(shape=(in_ch, i_dmlat, i_dmlon)) # i_dmlat, i_dmlon 画像の緯度方向、経度方向の画素数 # 1st hidden layer cnv2d1 = Conv2D(num_hidden1, data_format='channels_first', kernel_size=(3,3), dilation_rate=(3,3), activation='relu', padding='same')(cnn_input) cnv2d2 = Conv2D(num_hidden1, data_format='channels_first', kernel_size=(3,3), dilation_rate=(3,3), activation='relu', padding='same')(cnv2d1) cnv2d4 = Conv2D(num_hidden1, data_format='channels_first', strides=(2,2) , kernel_size=(3,3), activation='relu', padding='same')(cnv2d2) # 2nd hidden layer cnv2d5 = Conv2D(num_hidden2, data_format='channels_first', kernel_size=(3,3), dilation_rate=(3,3), activation='relu', padding='same')(cnv2d4) cnv2d6 = Conv2D(num_hidden2, data_format='channels_first', kernel_size=(3,3), dilation_rate=(3,3), activation='relu', padding='same')(cnv2d5) cnv2d8 = Conv2D(num_hidden2, data_format='channels_first', strides=(2,2) , kernel_size=(3,3), activation='relu', padding='same')(cnv2d6) # 3rd hidden layer cnv2d9 = Conv2D(num_hidden3, data_format='channels_first', kernel_size=(3,3), activation='relu', padding='same')(cnv2d8) cnv2d10 = Conv2D(num_hidden3, data_format='channels_first', kernel_size=(3,3), activation='relu', padding='same')(cnv2d9) cnv2d12 = Conv2D(num_hidden3, data_format='channels_first', strides=(2,2) , kernel_size=(3,3), activation='relu', padding='same')(cnv2d10) # 4th hidden layer cnv2d13 = Conv2D(num_hidden3a, data_format='channels_first', kernel_size=(3,3), activation='relu', padding='same')(cnv2d12) cnv2d14 = Conv2D(num_hidden3a, data_format='channels_first', kernel_size=(3,3), activation='relu', padding='same')(cnv2d13) cnv2d16 = Conv2D(num_hidden3a, data_format='channels_first', strides=(2,2) , kernel_size=(3,3), activation='relu', padding='same')(cnv2d14) cnv2d17 = Conv2D(num_hidden3b, data_format='channels_first', kernel_size=(3,3), activation='relu', padding='same')(cnv2d16) cnv2d19 = Conv2D(num_hidden3b, data_format='channels_first', kernel_size=(3,3), activation='relu', padding='same')(cnv2d17) #--- decode start cnv2dtra = Conv2DTranspose(num_hidden3a, data_format='channels_first', kernel_size=(3,3), strides=(2,2), activation='relu', padding='same')(cnv2d19) cnv2dtra = concatenate([cnv2dtra , cnv2d14 ], axis=1) # 分岐結合 cnv2dtrb = Conv2D(num_hidden3a, data_format='channels_first', kernel_size=(3,3), activation='relu', padding='same')(cnv2dtra) cnv2dtr1 = Conv2DTranspose(num_hidden3, data_format='channels_first', kernel_size=(3,3), strides=(2,2), activation='relu', padding='same')(cnv2dtrb) cnv2dtr1 = concatenate([cnv2dtr1 , cnv2d10 ], axis=1) # 分岐結合 cnv2dtr2 = Conv2D(num_hidden3, data_format='channels_first', kernel_size=(3,3), activation='relu', padding='same')(cnv2dtr1) cnv2dtr4 = Conv2DTranspose(num_hidden2, data_format='channels_first', kernel_size=(3,3), strides=(2,2), activation='relu', padding='same')(cnv2dtr2) cnv2dtr4 = concatenate([cnv2dtr4, cnv2d6], axis=1) # 分岐結合 cnv2dtr5 = Conv2D(num_hidden2, data_format='channels_first', kernel_size=(3,3), activation='relu', padding='same')(cnv2dtr4) cnv2dtr7 = Conv2DTranspose(num_hidden1, data_format='channels_first', kernel_size=(3,3), strides=(2,2), activation='relu', padding='same')(cnv2dtr5) cnv2dtr7 = concatenate([cnv2dtr7, cnv2d2], axis=1) # 分岐結合 cnv2dtr8 = Conv2D(num_hidden1, data_format='channels_first', kernel_size=(3,3), activation='relu', padding='same')(cnv2dtr7) cnv2dtr9 = Conv2D(num_hidden1, data_format='channels_first', kernel_size=(3,3), activation='relu', padding='same')(cnv2dtr8) cnv2dtr10 = Conv2D(3, data_format='channels_first', kernel_size=(1,1), activation=softMaxAxis , padding='same')(cnv2dtr8) # 最終的に1枚の3値の画像にする NN_1 = Model( input=cnn_input , output=cnv2dtr10 ) # 入力はcnn_inputで最後のcnv2dtr10を出力としてネットワークを構築 NN_1.compile(optimizer='adam', loss='categorical_crossentropy' , metrics=['accuracy']) # ロス関数 categorical_crossentropy4.4 最終層のsoftmax
最終層では、各ピクセルについて赤青白をsoftmaxで計算します。
標準のsoftmaxでは配列の一部を指定することができないので、softMaxAxisという関数を定義しています。
この方法は
Stack Over flow:"How to specify the axis when using the softmax activation in a Keras layer?"
を参考にしています。softMaxAxis.pydef softMaxAxis(x): return softmax(x,axis=1)このとき、モデルを保存して再読み込みさせるときに、カスタムオブジェクトの名前を教えてあげる必要があるようです。
load_modelNN_1 = load_model( paramfile , custom_objects={'softMaxAxis': softMaxAxis })4.5 生成画像と等圧線図の重ね合わせ
ImageMagickを利用します。
convert -compose multiplyが重ね合わせを行うコマンドです。
-gravity center -geometry +0+0により2つの画像の中心を縦横のオフセット無しで合わせることを指定します。Image_Overlay.sh# m_file 生成した前線画像(PNG) # s_file 等圧線図(PNG) composite -gravity center -geometry +0+0 -compose multiply ${m_file} ${s_file} out.png5.まとめ
気象データ可視化画像を認識して、「日本気象庁の解析するような前線画像」を生成するニューラルネットワークを作成し、前線の自動描画をやってみました。
この手法は前線描画に限らず、地図上にプロットされる何らかのデータで気象と関連するものであれば有効なのではないかと思っています。
一方で、当たりハズレの評価が結構難しい気がします。機械的にピクセル値のズレを見ても違う気がしますし、前線という形を捉えていることの評価をどうするか。気象予報士試験のように、人が採点するのが案外正しいかもしれません。現在、MSMの気象データから合成レーダの画像を生成するということに取り組んでいて、それについては正解データとの評価も検討しております。
こちらも近日公開しようかと思っています。今回Qiita初投稿でしたが、5回にわたって長文を投稿してしまいした。
読んで頂いた皆様どうもありがとうございました。
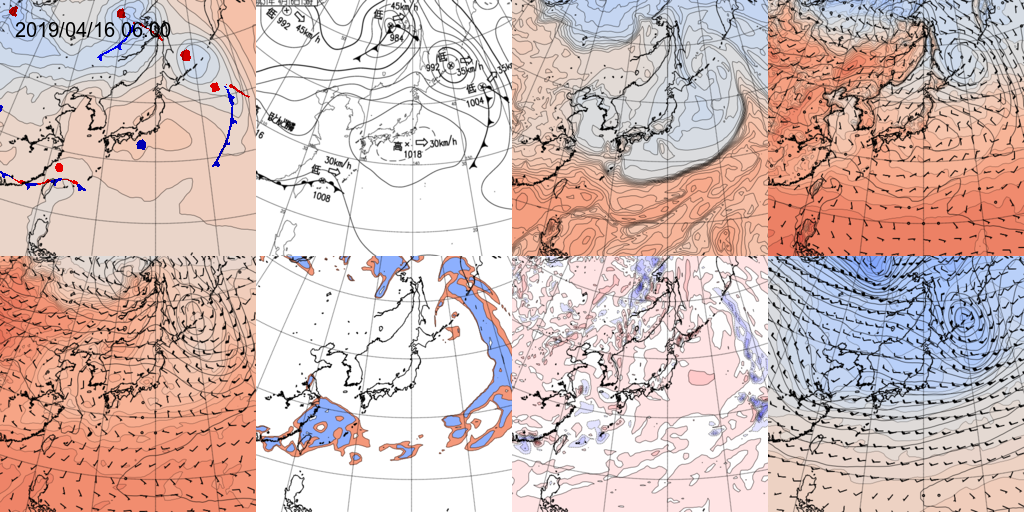
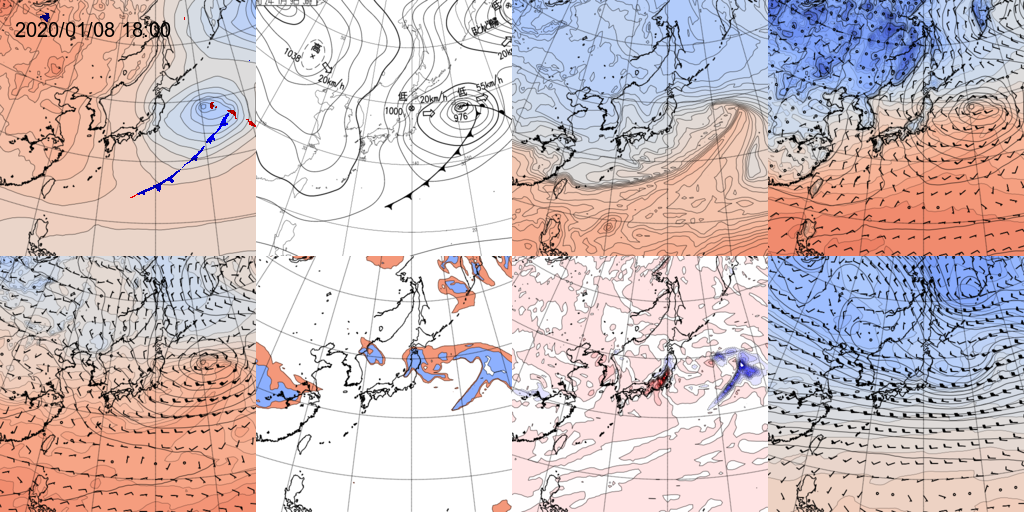
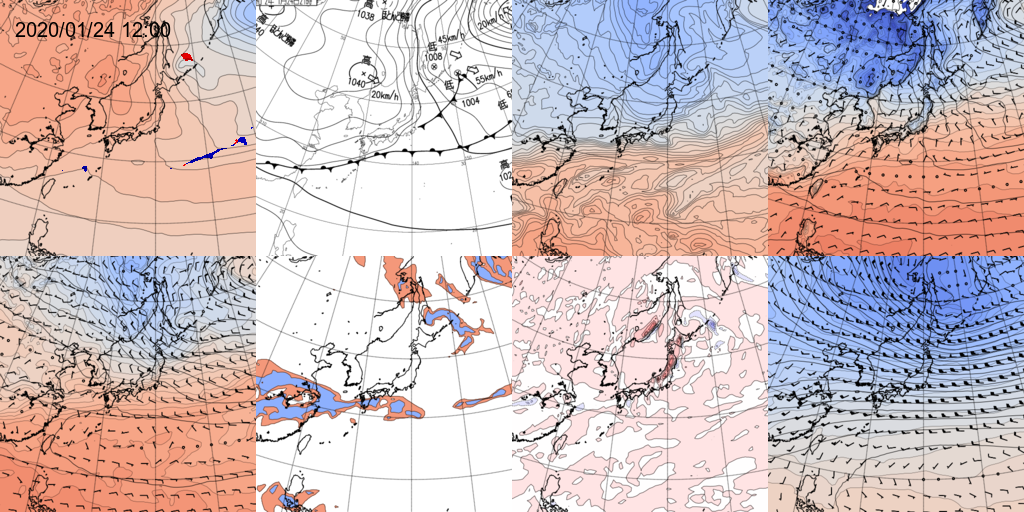
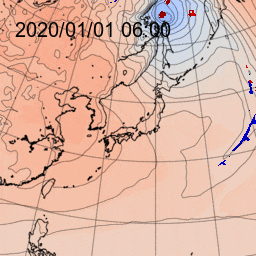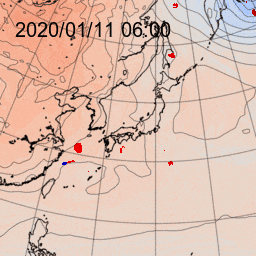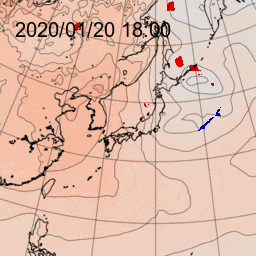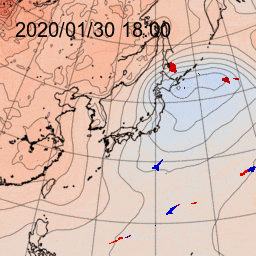




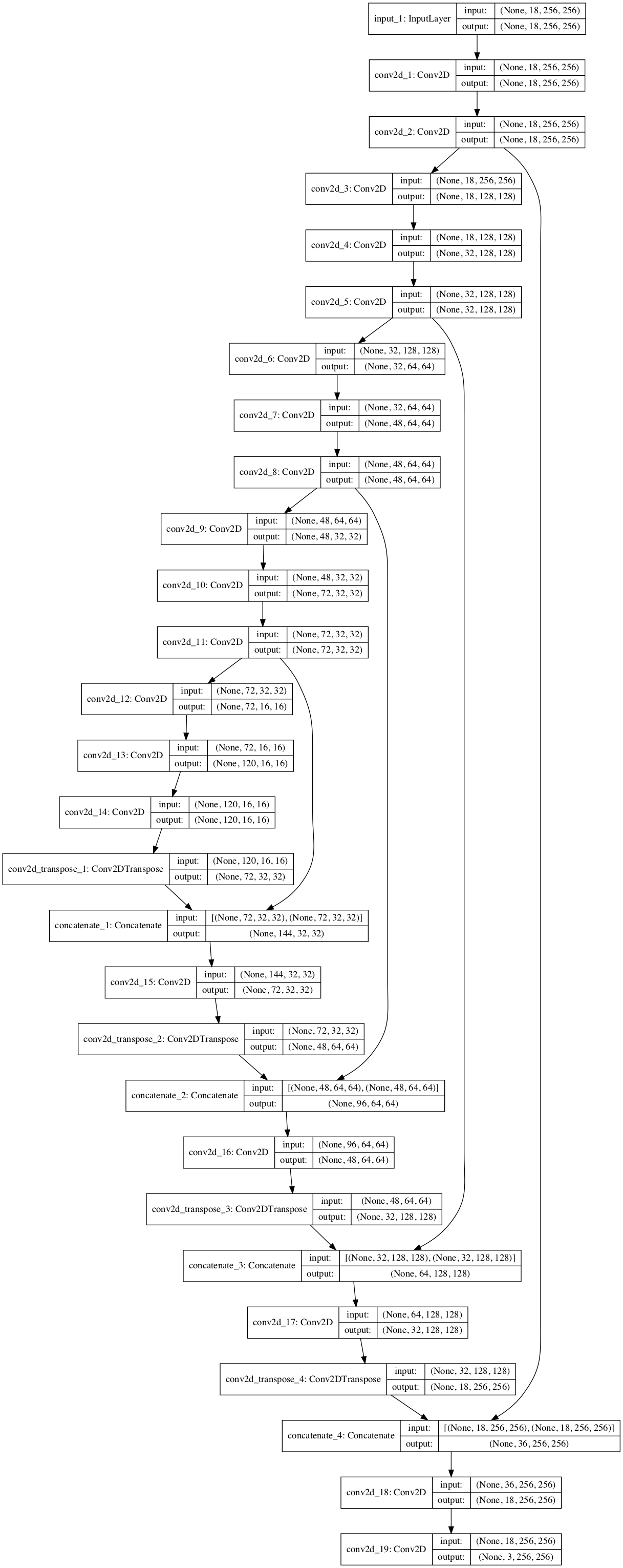
- 投稿日:2020-03-01T18:19:42+09:00
POJ 2386 python DFS
POJ2386 LakeCounting をpythonで
DFS(深さ優先探索)を学習中。
蟻本だけでは分からなかったので備忘録として。
.replace('.','0').replace('W','1')はしなくてもよい。2386.pyn,m=map(int,input().split()) a=[list(map(int,list(input().replace('.','0').replace('W','1')))) for i in range(n)] def dfs(x,y): a[x][y]=0 for dx in [-1,0,1]: for dy in [-1,0,1]: nx=x+dx ny=y+dy if 0<=nx<n and 0<=ny<m and a[nx][ny]==1: dfs(nx,ny) cnt=0 for i in range(n): for j in range(m): if a[i][j]==1: dfs(i,j) cnt+=1 print(cnt)
- 投稿日:2020-03-01T18:19:42+09:00
POJ 2386 をpythonで解く
POJ2386 LakeCounting をpythonで解く
DFS(深さ優先探索)を学習中。
蟻本だけでは分からなかったので備忘録として。
.replace('.','0').replace('W','1')はしなくてもよい。2386.pyn,m=map(int,input().split()) a=[list(map(int,list(input().replace('.','0').replace('W','1')))) for i in range(n)] def dfs(x,y): a[x][y]=0 for dx in [-1,0,1]: for dy in [-1,0,1]: nx=x+dx ny=y+dy if 0<=nx<n and 0<=ny<m and a[nx][ny]==1: dfs(nx,ny) cnt=0 for i in range(n): for j in range(m): if a[i][j]==1: dfs(i,j) cnt+=1 print(cnt)
- 投稿日:2020-03-01T18:08:39+09:00
【Udemy Python3入門+応用】 11.文字列
※この記事はUdemyの
「現役シリコンバレーエンジニアが教えるPython3入門+応用+アメリカのシリコンバレー流コードスタイル」
の講座を受講した上での、自分用の授業ノートです。
講師の酒井潤さんから許可をいただいた上で公開しています。■基本の文字列
print_standardprint('hello') print("hello")resulthello hello
print()内で文字列を指定する場合は、''でも""でもよい。
■文字列内に「'」がある場合
◆
""で括るprint_'print("I don't know.")resultI don't know.
""で括った場合は、きちんと出力される。◆
''で括るとエラーになるprint_'print('I don't know.')resultprint('I don't know.') ^ SyntaxError: invalid syntax
''で括った場合、文字列中の「'」が括りの終わりと判定されてしまい、エラーとなってしまう。◆
\を使ってエラーを回避するprint_'print('I don\'t know.')resultI don't know.文字列中の
'の前に\を入れてやることで、括りとしての判定を回避できる。print_'print('say "I don\'t know."') print("say \"I don't know.\"")resultsay "I don't know." say "I don't know."応用。
■文字列内に「\n」がある場合
◆改行の
\nprint_\nprint('Hello. \nHow are you?')resultHello. How are you?
\nが「改行」となるのは以前扱った。◆誤って
\nと判定されるprint_\nprint('C:\name\name')resultC: ame ame「C:\name\name」を表示させたかったのに、
\nの部分が改行判定されてしまった。◆
rを用いた判定回避print_\nprint(r'C:\name\name')resultC:\name\nameその際は、"raw"の頭文字である
rを文字列の先頭につけることで、文字列をそのままprintすることができる。
■改行
new_lineprint(""" line1 line2 line3 """)resultline1 line2 line3上のように
""" """を用いることで、\nを使って一行で記述せずとも、見やすいコードが書ける。new_lineprint('#######') print(""" line1 line2 line3 """) print('#######')result####### line1 line2 line3 #######ただし、この書き方だと文字列の上下に空白行が挿入されることになる。
new_lineprint('#######') print("""\ line1 line2 line3\ """) print('#######')result####### line1 line2 line3 #######
\をこのように入れてあげることで、「次に書くコードは次の行から始めてね」という意味になる。
■演算子を用いる
◆文字列と演算子
operatorprint('Hi.' * 3 + 'Mike.') print('Py' + 'thon') print('Py''thon')resultHi.Hi.Hi.Mike. Python Python文字列に対し、演算子を組み合わせることもできる。
単純に文字列同士を接続する場合、+を記述しなくても接続してprintされる。◆変数と文字列の並列
operatorprefix = ('Py') print(prefix'thon')resultprint(prefix'thon') ^ SyntaxError: invalid syntaxただし、変数に文字列を代入した場合は
+を省略することはできない。operatorprefix = ('Py') print(prefix + 'thon')resultPython
+できちんと接続することができた。◆
+の省略が好まれる場合operatorprint('aaaaaaaaaaaaaaaaaaaaaaaaaaa' 'bbbbbbbbbbbbbbbbbbbbbbbbbbb')resultaaaaaaaaaaaaaaaaaaaaaaaaaaabbbbbbbbbbbbbbbbbbbbbbbbbbb長い文字列をつなげて表示させる場合は、このように記述するとコードが見やすくなる。
(1行で書くと画面サイズに収まりきらない場合があったりして見にくい。)