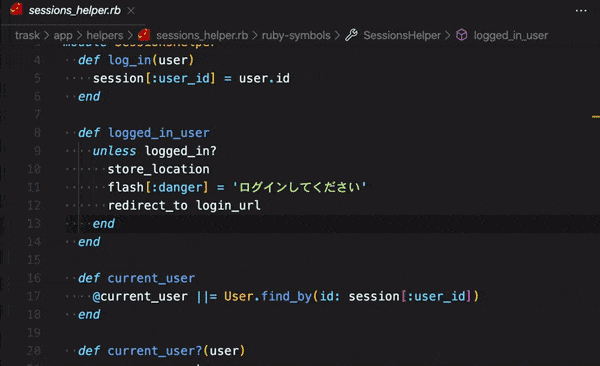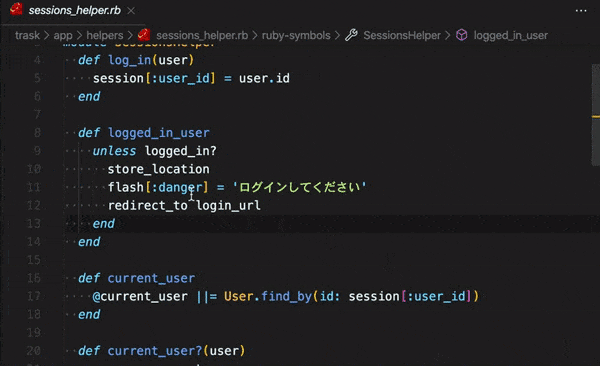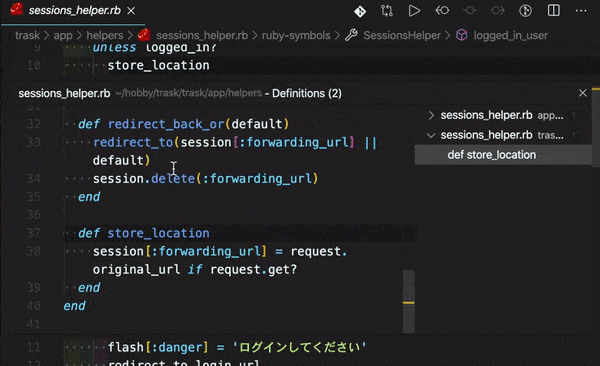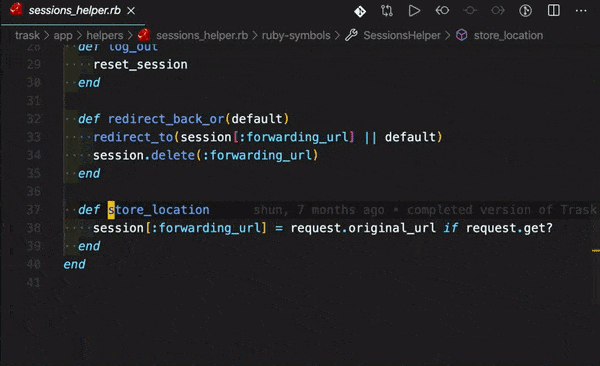
「ActiveRecord::AssociationNotFoundError in Tweet#index」エラー向けの記事になります。
エラー勉強会の復習した時に、疑問に思ったのでアウトプットしてみました。
Associationと出てる時点で、DBの問題であると考える事ができますが、今回は掘り下げてみたいと思います。
②ERROR: Ruby install aborted due to missing extensions
これは、EC2インスタンスにrubyをインストールする際に出たエラー。
$ rbenv install -v 2.5.7
~
#省略
~
BUILD FAILED (Amazon Linux AMI 2018.03 using ruby-build 20200224)
Inspect or clean up the working tree at /tmp/ruby-build.20200229053400.25770.gpU4NA
Results logged to /tmp/ruby-build.20200229053400.25770.log
Last 10 log lines:
installing capi-docs: /home/irikawa/.rbenv/versions/2.5.7/share/doc/ruby
The Ruby readline extension was not compiled.
ERROR: Ruby install aborted due to missing extensions
Try running `yum install -y readline-devel` to fetch missing dependencies.
④bundle install時、mysqlが入らないエラー:Gem::Ext::BuildError: ERROR: Failed to build gem native extension.
EC2インスタンス内でbundle install時に以下のエラー。主要部分のみ抜粋してます。
server.
[user|myapp]$ bundle install
~
#省略
~
Gem::Ext::BuildError: ERROR: Failed to build gem native extension.
-----
mysql client is missing. You may need to 'sudo apt-get install libmariadb-dev', 'sudo apt-get install libmysqlclient-dev' or 'sudo yum install mysql-devel',
and try again.
-----
An error occurred while installing mysql2 (0.5.3), and Bundler cannot continue.
Make sure that `gem install mysql2 -v '0.5.3' --source 'https://rubygems.org/'` succeeds before bundling.
classAddStatusToCatalogs<ActiveRecord::Migration[5.1]defupexecute<<-SQL
CREATE TYPE catalog_status AS ENUM ('published', 'unpublished', 'not_set');
SQLadd_column:catalogs,:status,:catalog_statusenddefdownremove_column:catalogs,:statusexecute<<-SQL
DROP TYPE catalog_status;
SQLendend
> Catalog.order
ArgumentError: You tried to define an enum named "order" on
the model "Catalog", but this will generate a class method
"first", which is already defined by Active Record.
> Catalog.order
ArgumentError (You tried to define an enum named "order" on the
model "Catalog", but this will generate an instance method
"none?", which is already defined by another enum.)
rails g migration add_status_to_catalogs status:catalog_status
マイグレーションファイルの編集
classAddStatusToCatalogs<ActiveRecord::Migration[5.1]defupexecute<<-SQL
CREATE TYPE catalog_status AS ENUM ('published', 'unpublished', 'not_set');
SQLadd_column:catalogs,:status,:catalog_statusadd_index:catalogs,:statusenddefdownremove_column:catalogs,:statusexecute<<-SQL
DROP TYPE catalog_status;
SQLendend
Value Object の作成
classCatalogStatusSTATUSES=%w(published unpublished not_set).freezedefinitialize(status)@status=statusend# what you need hereend
# aws:
# access_key_id: 123
# secret_access_key: 345
# Used as the base secret for all MessageVerifiers in Rails, including the one protecting cookies.
secret_key_base: *******************************************************
aws:
access_key_id: ***
secret_access_key: ***
# Used as the base secret for all MessageVerifiers in Rails, including the one protecting cookies.
secret_key_base: *******************************************************
frontend_1 | ERROR socket hang up
frontend_1 |
frontend_1 | at connResetException (internal/errors.js:604:14)
frontend_1 | at Socket.socketOnEnd (_http_client.js:460:23)
frontend_1 | at Socket.emit (events.js:323:22)
frontend_1 | at Socket.EventEmitter.emit (domain.js:482:12)
frontend_1 | at endReadableNT (_stream_readable.js:1204:12)
frontend_1 | at processTicksAndRejections (internal/process/task_queues.js:84:21)