- 投稿日:2020-03-01T23:45:56+09:00
プログラミングスクール卒業後3ヶ月たった所感
2019年10月に最近youtubeでよく広告を見る某プログラミングスクールに通い、11月より機械学習エンジニア・データサイエンティストとして現職につきました。
卒業後3ヶ月経った今、スクールで学んだことで役立ったこと、今大変なことなどをつらつらと書いていきたいと思います。経歴
2015年4月 食品会社の研究・開発職として4年間務める
2019年7月 プログラミングスクール学習開始
2019年10月 プログラミングスクール卒業
2019年11月 機械学習エンジニア・データサイエンティストとして転職スキルセット
言語の使用状況
スクール 転職後 HTML ○ ○ CSS ○ ○ JavaScript ○ ○ SQL ○ △ Linux ○ ○ Ruby ○ - Python - ○ フレームワークの使用状況
スクール 転職後 SCSS ○ ○ jQuery ○ △ Vue - ○ Ruby on Rails ○ - Flask - ○ Django - ○ インフラ等
スクール 転職後 Git/Github ○ ○ Nginx ○ - EC2(AWS) ○ ○ S3(AWS) ○ ○ スクールについて
役立ったこと
- HTML/CSS/JavaScript/Linuxについて基礎が学べ、今でもシステムを作成する際に役立っている
- Ruby→Pythonに言語が変わったがどちらも動的型付けなため、基礎的な文法を学ぶことへの学習コストはかからなかった
- EC2およびS3の作成・運用の基礎が学べ、現職ではシステムのデプロイは全てAWSを用いているため、すんなり業務に入ることができた
- 現職では頻繁には使用しないが、Gitを利用した複数人の開発の経験は業務の随所で役立つ
- メンターへの質問シートの書き方を守ることで、先輩エンジニアなどに質問する際に、何が問題で・どこで詰まっているのかが明確に伝えられ、回答を頂きやすい
役立たなかったこと
基本的には学んだことはある程度役立つと思いますが、下記点は仕方ないと考えていました。
- スクールでRubyを学んだが、現職では全く使用しないこと(機械学習案件を志望していたため、仕方ないと割り切ってはいました)
転職前にやるべきだったこと
- 簡単でもいいので、新しい職場で使用するであろう言語で簡易的なシステムやアプリをデプロイまで持っていく
理由
コードの書き方や、フレームワークを予め触っておいて、素早く職場に馴染めるようにもっと努力をすべきと思いました。
- AWSのサービスをより理解しておく
理由
最近のサービスのデプロイのほとんどはAWSを利用していると思います。無料枠内で学ぶのもいいですが、実際には有料で数万円数十万円をかけてシステムを運用します。そのため少しの金額でも身銭を切って、ドメインの取り方を学んだり、アクセスの分散方法を学ぶなど、AWSというサービスを少しでも多く理解しておいた方がよかったと思いました。
- 綺麗なコードを書く意識をつける・練習する
理由
シンプルにレビュアーが大変なのと、あとで改修する際に自分でもわからなくなってしまうので、綺麗なコードを意識することは非常に大事です。(作者はめっちゃ冗長に書きすぎて、最初はレビューの時間が非常にかかってしまいました)
今大変なこと
- 想像以上にJavaScriptを多用するため、様々な機能を覚える必要がある
- 基本的に少人数でシステムを作成したり、データ分析を行うため分からない部分が多く、仕事が止まりやすい
他にもいろいろ大変なこともあるのですが、結論としては悩んだらわかりそうな人に聞く!!これが仕事をうまく進める方法だと思います。私自身人に聞くということが苦手で、どうしても1人でやろうとしがちだったのでした。しかし、先輩エンジニアに聞いたら数分で解決してくれたり、アドバイスしてくれるため、1時間もかけて調べるよりも、わかる人に聞いた方が100%早いです!!
- 投稿日:2020-03-01T23:35:51+09:00
AWS Amplify フレームワークの使い方Part10〜Storage編〜
はじめに
AmplifyはS3を画像などのストレージとしての利用も簡単にできます。
設定の流れ
amplifyにstorageを追加
いつものコマンドを叩いて、設定を開始します。
$ amplify add storageサービスの選択
画像ファイルの保存に使用するため
Contetntを選択。? Please select from one of the below mentioned services Content (Images, audio, video, e名前の設定
Storage管理におけるプロジェクト名とバケット名を設定。
Please provide a friendly name for your resource that will be used to label this catego ry in the project: <プロジェクト名> ? Please provide bucket name: <バケット名>権限設定
認証ユーザーと未認証ユーザーのCRUD設定を行います。今回は認証ユーザーはCRUDがすべてでき、未認証ユーザーはreadだけできるように設定しています。
? Who should have access: Auth and guest users ? What kind of access do you want for Authenticated users? create/update, read, delete ? What kind of access do you want for Guest users? readPush
さぁ、これで準備は完了です。
$ amplify push使い方
基本的な使い方はいたってシンプルなので簡単に解説していきます。
保存レベル
保存には3段階のレベルがあり、public・protected・privateの3パターンがあります。
- public
全体に公開されます。- protected
自身とidentityIdを知っている人に公開されます。- private
全体には非公開で自身のみが取得できます。import { Storage } from 'aws-amplify';Put
保存のレベルによって、Putの方法が若干変わります。返り値に、保存先のURLは含まれていません。
// public await Storage.put( 'test.png', // ファイル名 file // アップロードするファイル ) // protected await Storage.put('test.png', file, { level: 'protected', // レベルの宣言 contentType: 'image/png' // file形式 } ) // private await Storage.put('test.png', file, { level: 'private', // レベルの宣言 contentType: 'image/png' // file形式 } )Get
基本的には以下のようになります。どこまでどのように権限が効いているのか明確に調べていません。次で解説しますが、このidentityIdが曲者でした。
// public const iconURL = await Storage.get('test.png') // protected(自身のファイルにアクセス) const iconURL = await Storage.get('test.png', { level: 'protected' }) // protected(他者のファイルにアクセス) const iconURL = await Storage.get('test.png', { level: 'private', identityId: identityId // cognitoで管理されるユーザーIDに紐づく一意なID } ) // public const iconURL = await Storage.get('test.png', { level: 'private' })Remove
こちらも検証はしていませんが、基本的に以下のようになります。publicは他ユーザーがUPした画像もremoveできました。
// public const iconURL = await Storage. remove('test.png') // protected const iconURL = await Storage. remove('test.png', { level: 'protected' }) // public const iconURL = await Storage. remove('test.png', { level: 'private' })ハマリポイント
以下はprotectedで画像ファイルを保存した場合のハマリポイントです。
一定時間が経つとファイルが取得できなくなる
getして取得したURLにはtokenがついており、一定時間が経つと画像ファイルを取得できなくなります。
このURLを保存しておけば、わざわざidentityIdなんて知らなくてもicon画像取得し放題だ!、と思ったもののしばらくすると取得できなくなるのでややハマりました。
これにより、identityIdと向き合うことになります。protectedの場合、identityIdがわからないと取得できない
identityIdは各ユーザーに振られているuserIdとは別のcognitoさんが管理しているIDです。(ソーシャルログインをしてユーザープールにデータが作成されない人や未承認ユーザーを管理するためのもの?的なイメージ)
そんなあまり身近ではないidentityIdを使わずに、簡単に取得できる方法はないか?、と各方面で議論されているようですが、現状はまだ未実装のようです。
ただ、githubのissueでだいぶ議論されているようなので、そのうちひっそりと実装されている可能性はあるので、要チェックです。identityIdをどうやって取得したらいいかわからない
これハマりました。全然調べても出てこないんです。見つけたら案外簡単でした。
const currentCredentials = await Auth.currentCredentials() const identityId = currentCredentials.identityIdおわりに
サクッと実装できたと思っていたら、全然そんなことなくて時間がかかりましたが、わかったらなんてことのない内容です。これ以上の掘り下げは行っていませんが、公式ドキュメントを見る限りでは、まだまだ細かい機能があるようですので、引き続き調査していければと思います。
参考
- 投稿日:2020-03-01T23:16:30+09:00
Amazon Linux2でyumできない時に疑うべきこと
結論
VPCエンドポイントのポリシーの設定を疑いましょう。
事象
EC2(Amazon Linux2)で、
yum updateが通らなかった。$ sudo yum update Loaded plugins: extras_suggestions, langpacks, priorities, update-motd Could not retrieve mirrorlist http://amazonlinux.us-east-1.amazonaws.com/2/core/latest/x86_64/mirror.list error was 14: HTTP Error 403 - Forbidden One of the configured repositories failed (Unknown), and yum doesn't have enough cached data to continue. At this point the only safe thing yum can do is fail. There are a few ways to work "fix" this: 1. Contact the upstream for the repository and get them to fix the problem. 2. Reconfigure the baseurl/etc. for the repository, to point to a working upstream. This is most often useful if you are using a newer distribution release than is supported by the repository (and the packages for the previous distribution release still work). 3. Run the command with the repository temporarily disabled yum --disablerepo=<repoid> ... 4. Disable the repository permanently, so yum won't use it by default. Yum will then just ignore the repository until you permanently enable it again or use --enablerepo for temporary usage: yum-config-manager --disable <repoid> or subscription-manager repos --disable=<repoid> 5. Configure the failing repository to be skipped, if it is unavailable. Note that yum will try to contact the repo. when it runs most commands, so will have to try and fail each time (and thus. yum will be be much slower). If it is a very temporary problem though, this is often a nice compromise: yum-config-manager --save --setopt=<repoid>.skip_if_unavailable=true Cannot find a valid baseurl for repo: amzn2-core/2/x86_64原因と対処法
Amazon Linux2のyumリポジトリにアクセスできていないためエラーが起きています。
Amazon LinuxおよびAmazon Linux2のyumリポジトリは、S3に存在します。
EC2インスタンスが所属しているVPCのエンドポイントが、
S3のyumリポジトリにアクセスできるようにポリシーを設定します。VPCエンドポイントのポリシーの変更方法
[EC2] -> [インスタンス]とアクセスし、yumできないインスタンスを選択します。
[説明]タブの中に「VPC ID」があるので、クリックします。
遷移先で左の一覧から[エンドポイント]を選びます。
EC2が所属するVPCをクリックし、下の欄の[ポリシー]を選択します。
[ポリシーの編集]ボタンからポリシーを変更できます。
Amazon Linux2の場合
大事なのは、Resources の中に
"arn:aws:s3:::amazonlinux.*.amazonaws.com/*"が入っていることです。
以下に設定例を示しますが、おそらくこの例通りにはなっていないと思います。
Resources の中に"arn:aws:s3:::amazonlinux.*.amazonaws.com/*"を追記して保存することをオススメします。追記した行がResourceの中で最終行でないときは、末尾に,(コンマ)をつけ忘れないようにしましょう。
{ "Statement": [ { "Sid": "AmazonLinux2AMIRepositoryAccess", "Principal": "*", "Action": [ "s3:GetObject" ], "Effect": "Allow", "Resource": [ "arn:aws:s3:::amazonlinux.*.amazonaws.com/*" ] } ] }Amazon Linux の場合(参考)
こちらは、以下の2つのリソースへアクセスできる必要があります。
"arn:aws:s3:::packages.*.amazonaws.com/*""arn:aws:s3:::repo.*.amazonaws.com/*"こちらもAmazon Linux2の場合と同様、Resourceの中に以上の2つを追記しましょう。
以下は設定例です。{ "Statement": [ { "Sid": "AmazonLinuxAMIRepositoryAccess", "Principal": "*", "Action": [ "s3:GetObject" ], "Effect": "Allow", "Resource": [ "arn:aws:s3:::packages.*.amazonaws.com/*", "arn:aws:s3:::repo.*.amazonaws.com/*" ] } ] }結果
無事にyumが通りました。
$ sudo yum update Loaded plugins: extras_suggestions, langpacks, priorities, update-motd amzn2-core | 2.4 kB 00:00:00 Resolving Dependencies --> Running transaction check ---> Package binutils.x86_64 0:2.29.1-29.amzn2 will be updated ---> Package binutils.x86_64 0:2.29.1-30.amzn2 will be an update ---> Package dyninst.x86_64 0:9.3.1-1.amzn2.0.2 will be updated ---> Package dyninst.x86_64 0:9.3.1-3.amzn2 will be an update (以下略)参考


- 投稿日:2020-03-01T22:30:37+09:00
AWS サーバー構築手順(ネットワーク編)
勉強したことを忘れないようにメモ
概要
AWSの第一段階の勉強として基本的なWEBサーバーをAWSを使用して構築してみた。
ネットワーク構築から各サーバーの立ち上げをまとめる
やった流れ
・ネットワーク設定
・ユーザー設定(IAM)
・EC2インスタンス作成
・CloudWatchでの料金ログチェック
・CloudTrailでのアクションログチェック
・ストレージ設定(EBS,S3)詳細
◆ネットワーク設定
・CloudWatchでの料金ログチェック
・CloudTrailでのアクションログチェック
・公開用サーバーと非公開用サーバーの立ち上げ
・各サーバーにIPアドレスを設定◆ユーザー設定(IAM)
・AWSではルートユーザーのログインは推奨されていないので、Admin権限を持つユーザーを新規作成
◆EC2インスタンス作成
・使用するOSのスペックによって値段が変動する
・Elastic IPで固定IPの指定が可能。EC2の稼働に応じて料金発生
・セキュリティグループ設定(簡単に言えばファイアウォール)◆ストレージ設定(S3)
・CloudTrailのログデータをS3に格納。
・S3は無制限のストレージ・高耐久
1か月のストレージ料金・リクエスト料金・データ転送料金発生まとめ
掘り下げるときりがないのでこの辺で。。。
可用性重視の設計が一般的(AZを2か国運用)
VPCは一度設定すると変更不可のためIPアドレスが溢れないように設定するのが大事。AWSマネジメントコンソール関係の記事は個人情報怖いのでスクショ少なめです。
WEBサーバーとDBサーバーを構築してなんかWEBサイトでも載せてみようかと思います。
- 投稿日:2020-03-01T21:59:17+09:00
【AWS】プライベートサブネット3分クッキング(ハンズオン)
はじめに
先日、プライベートサブネットとパブリックサブネットの違いをまとめた記事を書きました。
【AWS】パブリックサブネットとプライベートサブネットの違いとは
じゃあ実際、どう作んのよって話を今回紹介したいと思います。
せっかくなのでハンズオン形式で、画像と合わせて説明していきます。また今回作成するプライベートサブネットには、NATゲートウェイをアタッチします。
NATゲートウェイをアタッチせずともプライベートサブネットと呼べるのですが、せっかくなので作っていこうと思います。レシピ
私が思いつく限りでは、3通りあると思います。
- マネジメントコンソールで作成
awscli(コマンド)で作成CloudFormationで作成今回は1のレシピで解説していきます。
前提条件
- AWSのアカウントを持っている
1. サブネット作成
AWSマネジメントコンソールにアクセスします。
サービス一覧からVPCを選びます。
VPCのページには、VPCだけでなくネットワーク関連のものがずらっと左のメニューに並んでいます。
この中から「サブネット」を選択します。
「サブネット」を選択したらサブネットの設定画面に遷移します。
そこで「サブネットの作成」を選択しましょう。サブネット設定画面では以下の4項目を設定します。
- サブネットの名前タグ
- 所属させるVPC
- 所属させるAZ(アベイラビリティゾーン)
- IPv4 CIDR ブロック(Classless Inter-Domain Routing)
CIDRブロックの設定方法について
サブネットのCIDRブロックは、以下の条件のものを設定する必要があります。
- VPCのCIDRブロックに内包されるブロック
- VPC内で既に使用されていないブロック
1. VPCのCIDRブロックに内包されるブロックを満たすためには、
VPCのxxx.xxx.xxx.xxx/yyのyy(サブネットマスク)の数字より大きいzz(サブネットマスク)にする必要があります。
例えばVPCが172.31.0.0/16の場合、
サブネットは172.31.0.0/20を設定します。
(172.31.0.0/18や172.31.0.0/24)でも良いと思います。
2. VPC内で既に使用されていないブロックを満たすためには、
やり方が正しいのかわかりませんが、とにかく入れてみて作れるか試せば良いと思います。
既に使われていれば下の画像のように表示されるので、数字を少し変えて再度作成する流れになります。
私の場合、
172.31.0.0/20からスタートして、
172.31.16.0/20172.31.32.0/20172.31.48.0/20もダメで、
172.31.64.0/20に落ち着きました。他のサブネットで使用されてました。2. NATゲートウェイ作成
次にNATゲートウェイを作成します。
ルートテーブルと同様に左のメニューから遷移できます。
- NATゲートウェイを設置するサブネット(パブリックサブネットを選択します)
- NATゲートウェイに割り当てるElastic IP(固定IP)
NATゲートウェイは、先ほど作成したプライベートサブネットではなく、デフォルトなどで作成されているパブリックサブネットに設置しましょう。
Elastic IPは「新しいEIPの作成」ボタンで一発で作成してくれます。
上記2つの設定が終わったら「NATゲートウェイの作成」を実行します。
作成後の画面から「ルートテーブルの編集」を選択して次のステップに進みます。
3. ルートテーブルの作成
次にプライベートサブネット用のルートテーブルを作成します。
VPCダッシュボードの左のメニューからでも遷移できます。
- ルートテーブルの名前
- 所属させるVPC
を設定したら作成します。
作成後の画面から、作成したルートテーブルの詳細に飛びましょう。
作成したルートテーブルを選択した状態で、
画面下に表示される詳細情報の「ルート」タブ > 「ルートの編集」を選択します。
「ルートの追加」を選択して、ルートを一つ作成します。
- 送信先(
0.0.0.0/0)- ターゲット(NATゲートウェイ→作成したNATゲートウェイを選択)
全ての通信をNATゲートウェイに流す設定をしています。
NATゲートウェイの選択ではIDから選択しなければなりません。。(面倒)
設定が終わったら「ルートの保存」を実行します。
4. サブネットにルートテーブルを関連付ける
最後に、プライベートサブネットにルートテーブルを関連付けます。
サブネットを作成したままだと、デフォルトのルートテーブルが関連付けられているため、手動で関連付けしてあげる必要があります。
そのままルートテーブルの詳細情報から「サブネットの関連付け」 > 「サブネットの関連付けの編集」を選択します。
初期ではどのサブネットも関連付けされていないと思うので、ここでプライベートサブネットを選択して「保存」を実行します。
(プライベートサブネットの名前で検索をかけています。
これで、プライベートサブネットの作成が完了しました。
参考











- 投稿日:2020-03-01T21:36:25+09:00
Lambda入門#5 Lambdaと連携したAPI Gatewayのバージョン管理
さぁ、今日もlambdaを触っていきます!
参考URL
クラウドメソッドさんの記事を参考にしてやってます。
APIゲートウェイのバージョン管理(lambda連携)
https://dev.classmethod.jp/cloud/aws/version-management-with-api-gateway-and-lambda/前回までのおさらい lambdaのエイリアス設定
最初の状態ではAPIゲートウェイに紐づいている
$LATESTの結果が返ってきます。
では、実際に紐づけを行う前に$LATESTがどのようになっていて、エイリアスでprodステージとdevステージとの違いが分かるように整理しておきます。そこでちょっと、おさらいなのですが、lambdaのエイリアスとバージョン管理の方法にも触れておきます。
1.lambdaでバージョンを作成
2.エイリアスの作成
どちらも、lambda上のGUIから操作して簡単に作成可能でした。
ちなみに削除する際は「エイリアス」→「バージョン」の順で設定を削除します。
※逆に操作しようとするとエラーが発生します。ではこれを応用して、APIゲートウェイのバックエンドで動作させるlambdaの関数を本番と開発で分け、かつ、そのバージョン管理も行えるようにしてみようっていうのが、記事の主旨になります。
でちなみにいろいろと操作してたので、4版までバージョン発行を行ってしまったので、少し表示に違和感がありますが、↓のような感じでエイリアスを用意しておきます。
どちらのlambda関数ともに単にバージョンと数字を返すだけの単純な関数が設定されています。
前回の記事にも記載しましたが、prodは固定で変更することはできず、以下の通り、「バージョン1」の値を返します。
一方、devのほうは「バージョン2」の値を返します。
それから、APIゲートウェイのほうも設定を用意しておきます。
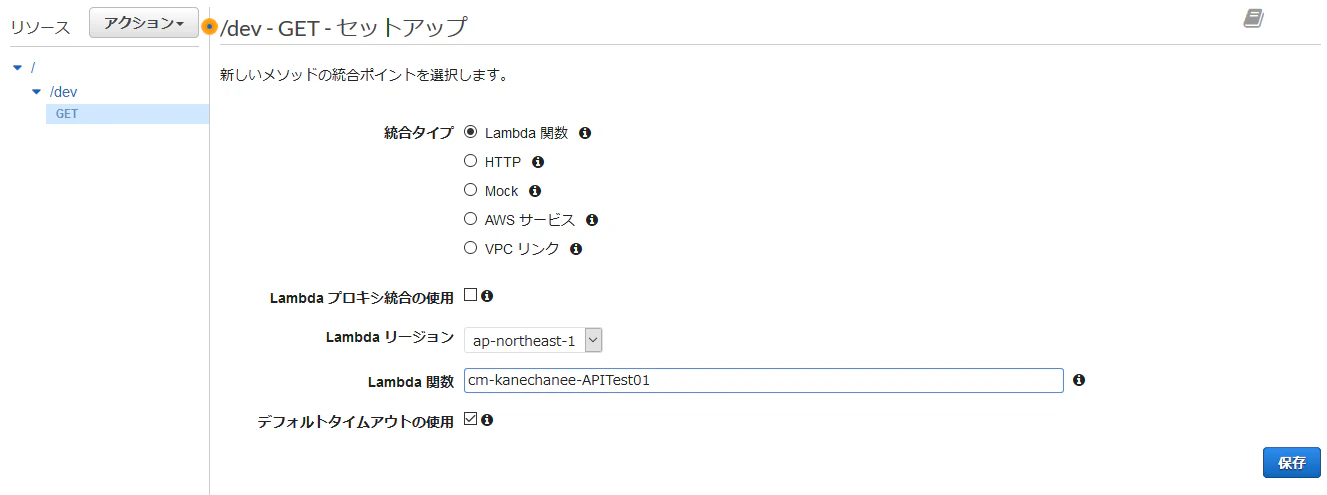
まず、リソースは分かりやすく「dev」としておきます。
次にメソッドはGetの定義を用意しておきます。
メソッドを用意したら、デプロイしていきましょう!
今回はテストなので、APIキーは流用で構成しておきます。
スロットリングとかクォータの設定がないのは、前回の記事を踏襲しています。
APIゲートウェイとlambdaのエイリアス設定を連携する
まずはAPIゲートウェイ側の設定を変更していきます。
作成したAPIゲートウェイの[統合リクエスト]をクリックします。
そこで[Lambda関数]に入力している関数名の末尾に以下の変数を追加して保存します。追加変数:${stageVariables.alias}
保存すると以下のようにAWSCLIのコマンドが発行されるので、コマンドを控えておきます。
AWSCLIのコマンドaws lambda add-permission --function-name "arn:aws:lambda:*******:${stageVariables.alias}" --source-arn "arn:aws:execute-api:*******:*******:kcgilegeu5/*/GET/dev" --principal apigateway.amazonaws.com --statement-id ******* --action lambda:InvokeFunctionただ、このコマンドを実際に実行する際には「dev」と「prod」でlambdaのエイリアスが分かれますので、
"arn:aws:lambda:*******:${stageVariables.alias}"の:${stageVariables.alias}をdevとprodに変更して2回実行する必要があります。実際に実行してみると以下のような感じでコマンドが戻ってくると思います。
実行結果{ "Statement": "{\"Sid\":\"******\",\"Effect\":\"Allow\",\"Principal\":{\"Service\":\"apigateway.amazonaws.com\"},\"Action\":\"lambda:InvokeFunction\",\"Resource\":\"arn:aws:lambda:******:******:function:cm-kanechanee-APITest01:dev\",\"Condition\":{\"ArnLike\":{\"AWS:SourceArn\":\"arn:aws:execute-api:******:******:kcgilegeu5/*/GET/dev\"}}}" }次にprodのステージ設定をまだ作成していないので、作成します。
ステージの作成はステージの設定からではなく、デプロイから行います。
デプロイが終わったら、ステージ変数を追加していきます。
クラスメソッドさんの記事にも記載されていますが、ステージ変数はあの[統合リクエスト]の画面で追加した変数名として、利用することができます。つまり、今回のケースではlambdaで作成したエイリアスを指定できるということになりますね。ステージ変数はステージごとに異なる値を設定でき、${stageVariables.xxxxx}で利用することができます。
この状態でprodのエンドポイントに対して、curlでアクセスしてみると
prodエンドポイントへのアクセスcurl https://*********/prod/test01 -H 'x-api-key:******'アクセス結果"version1"lambdaで設定しているエイリアスの通り、prodエイリアスで設定している"version1"の出力を返しました。
この時点ではまだ、devエイリアスには何も紐づけていないので、試しに新しいバージョンを作成して紐づけてみます。ではlambda側で新しいバージョンを作成してみます。
新しいバージョンは"version2"を出力するという内容にします。
この状態でlambda側のエイリアスdevをこの新しく作成したバージョン2と紐づけておきます。lambdaのエイリアスとバージョンの紐づけを変更する場合、[バージョンとエイリアスの切り替え]から[エイリアス:dev]を選択します。
そこからエイリアスの設定画面に移って、画面下のほうに存在する[バージョン]のプルダウンメニューからエイリアス:devと紐づけるバージョンを選択します。
次に、実験として、この時点でlambda側の
$LATESTの内容を"version3"に変えてみます。
この時点ではまだ、lambdaのdevとAPIゲートウェイのdevステージは紐づいていないので、仮に$LATESTを変更したらAPIゲートウェイのエンドポイントをたたいた出力結果は"version3"が返ってくるはずです。
※つまり、devはlambdaとは連携しない構成となっているはず。では試しに、変えてみましょう!
さぁ変えてみましたよ。これでdevのエンドポイントへアクセスしてみるとどうなるのでしょうか?
devエンドポイントへのアクセスcurl https://*********/dev/test01 -H 'x-api-key:******'アクセス結果"version3"ちゃんと、"version3"が返ってきました!
ちなみにprodステージに反映させたデプロイの設定をdevステージにも同様に反映させることが可能です。
APIゲートウェイの[ステージ]でdevステージを選択し、[デプロイ履歴]を選択すると、prodステージで反映したデプロイの履歴が残っているので、選んだ状態で[デプロイの変更]をクリックし、devステージへ適用します。
↓のように✔の位置が変わればOKです!
あとはprodと同様にステージ変数でdevと設定してあげれば、lambdaのdevエイリアスと紐づけることができます。
この状態でアクセスすると結果は先ほど、lambdaでdevエイリアスに紐づけた"version2"の結果が返ってくるはずです。
devエンドポイントへのアクセスcurl https://*********/dev/test01 -H 'x-api-key:******'アクセス結果"version2"最初、この記事を読んだときはややこしかったのですが、実際に触ってみると覚えることができました。
やっぱり、こういった技術は触れて覚えていくことが一番大事ですね。明日もまた、別のlambdaの勉強記事をアップしたいと思います。



























- 投稿日:2020-03-01T21:33:30+09:00
コロナウイルス対応のため、学習コンテンツの無料開放にひと肌脱いだ話。
0.まえおき
新型コロナウイルスによる、学校の休校を受け、
教育業界において、コンテンツの無料開放などが流行っています。そんなさなか、とある老舗の参考書出版会社さまから、
コンテンツ無料解放をしたいと相談を受けたのが金曜日の夜。。。すばらしい社会貢献!
ひと肌脱ぐことになり、私の休日(ほぼ徹夜)は消え去りました。
(えぇ、もちろん私も無償奉仕です。)
1.要件/状況
・PDFの書籍データがある
・誰にでも見せたいけど、ダウンロードとか印刷をされてしまっては困る。
(過度には誰にも見せたくない、、、)
・サーバとか何もないという、本当にゼロからのスタートです;;
2.実現方法概要
1.PDF(URL)の保護
PDF自体のDRMとかもあるのかもしれないですが、Adobeが絡むはずなので、(あまり詳しくないです)
AWSの署名付きURLで期限付きのURLを発行して、URLの流出やクローラに対応。2.PDFのDLや印刷を禁止する
ブラウザでのPDF閲覧ではなく、独自Viewer(PDF.js)を採用し、DF閲覧時の機能を制限する。3.時間もないためにサーバレスで実装
静的コンテンツであれば、関連するシステム上に配置可能とのことで、
それ以外については、AWSを多用しまくります。4.致し方ないこと
・それなりにITの知識がある人にはどうしてもPDFデータはDLされちゃう。
・画面キャプチャなど、OSによる機能は防げない。
3.という事で、全体のシーケンス
もっと、いい案がないのか、、、と思いつつも時間がないので、即実装です。
①AWS API Gateway
・GETリクエストで、閲覧したい書籍のパラメータを受ける。
・APIについては、IP制限が使えないため(IP固定なのか不明・・・)、アクセス元ドメインでのリファラー制限を実施。
(リファラー詐称をされない限り、APIは実行不可)③AWS Lamda
・受け取った書籍情報について、S3上のPDFに対し署名付きURLを発行する。
・そのままURLを返却してしまうと通常のブラウザで見えてしまうので、
署名付きURLを付与したViewerのURLへリダイレクトさせる。③PDF.js
・パラメータにある署名付きURLのデータをPDF.jsが読み込む。
(この際、PDF.jsのパラメータを見て、ヨシヨシ!という感の鋭い人には、PDFそのもののアクセスができちゃう。
ただ、URLがすごく長いのでぱっと見わからないかも。)④公開領域フォルダ
・DLや印刷機能を禁止したカスタマイズ版のPDF.jsを配置します。⑤PDFの書籍データ
・署名付きURLでしかアクセスできないようにします。
・Viewerからアクセスされるので特定ドメインのCORS設定も行います。
4.各々の詳細
①②AWSのLambdaコードです。(node.js v12.Xです)
ポイントは、Lambda プロキシ統合利用でのCORS設定と、
302リダイレクトのあたりでしょうか。APIGatewayとLambdaについては、前回の記事も参考ください。
AWS APIGateway + Lambda プロキシ統合 の利用でCORS設定にはまった話署名付きURLの発行と302リダイレクトconst https = require('https'); const AWS_ACCESSKEY_ID = process.env.AWS_ACCESSKEY_ID; const AWS_SECRET_ACCESSKEY = process.env.AWS_SECRET_ACCESSKEY; const PDF_BASE_URL = process.env.PDF_BASE_URL; const PDF_BUCKET = process.env.PDF_BUCKET; const PDF_EXPIRES = parseInt(process.env.PDF_EXPIRES,10); let AWS = require('aws-sdk'); AWS.config.update({accessKeyId: AWS_ACCESSKEY_ID, secretAccessKey: AWS_SECRET_ACCESSKEY,region:"ap-northeast-1"}); let s3 = new AWS.S3({signatureVersion:'v4'}); exports.handler = async function (event, context, callback) { const done = (err, res) => callback(null, { statusCode: err ? '400' : '302', body: res, headers: { "Access-Control-Allow-Origin": "*", //Lambdaプロキシ統合の場合は自前でCORS設定。 "Location": res //302リダイレクトのために独自設定 } }); switch (event.httpMethod) { case 'GET': const book = event['queryStringParameters']['book']; const page = event['queryStringParameters']['page']; let presignedURL = await createPresignedURL(PDF_BUCKET,book+"/"+page+".pdf"); let return_url = PDF_BASE_URL+"?file="+encodeURIComponent(presignedURL); console.log('createPresignedURL :' + return_url); done(null,return_url); break; default: done(new Error(`Unsupported method "${event.httpMethod}"`)); } }; /** * 対象のURLに対して署名を行い、公開用のURLを発行します。 */ async function createPresignedURL(inBucket,pdffilename){ const s3params = { Bucket: inBucket, Key: pdffilename, Expires: PDF_EXPIRES }; console.log('createPresignedURL:', JSON.stringify(s3params)); try { let signed_url = await s3.getSignedUrl('getObject', s3params); return signed_url; } catch (err) { console.log("Err:"+err); return err; } }また、API GateWay側にはリダイレクト設定が必要です。
あとは、APIGateWayのリソースポリシー設定を行います。
APIGateway全般なんですが、設定などを変えた後、「APIのデプロイ」を忘れがちです。。。
リソースポリシー{ "Version": "2012-10-17", "Id": "policy example", "Statement": [ { "Effect": "Allow", "Principal": "*", "Action": "execute-api:Invoke", "Resource": "arn:aws:execute-api:Hogehoge/*", "Condition": { "StringLike": { "aws:Referer": [ "https://foobar/*" ] } } } ] }
③PDF.js(pdfjs-2.2.228)の修正
・PDF.jsについては、DLボタンの禁止
・印刷の禁止
・縦スクロールを見やすい横スクロールに
・HOSTED_VIEWER_ORIGINSの設定
などを実施しています。viewer.css/* ツールバーのボタン類を削除 */ #sidebarToggle, #openFile, #viewBookmark, #print, #download, #secondaryOpenFile, #secondaryViewBookmark, #secondaryDownload, #secondaryPrint, #secondaryToolbarToggle { display: none !important; } /* ブラウザ印刷時のデータ削除 */ @media print{ body{ display: none; } }viewer.js(13900行目あたり)function getDefaultPreferences() { if (!defaultPreferences) { defaultPreferences = Promise.resolve({ "cursorToolOnLoad": 0, "defaultZoomValue": "", "disablePageLabels": false, "enablePrintAutoRotate": false, "enableWebGL": false, "eventBusDispatchToDOM": false, "externalLinkTarget": 0, "historyUpdateUrl": false, "pdfBugEnabled": false, "renderer": "canvas", "renderInteractiveForms": false, "sidebarViewOnLoad": -1, "scrollModeOnLoad": 1, //ここのデフォルトを-1⇒1に変更 "spreadModeOnLoad": -1, "textLayerMode": 1, "useOnlyCssZoom": false, "viewOnLoad": 0, "disableAutoFetch": false, "disableFontFace": false, "disableRange": false, "disableStream": false }); }
④公開領域バケットの設定
(割愛)
公開領域といえども、無駄なアクセスを避けるため、
気持ち程度にリファラー設定。
バケットポリシー{ "Version": "2012-10-17", "Id": "policyexample", "Statement": [ { "Effect": "Allow", "Principal": "*", "Action": "s3:GetObject", "Resource": "arn:aws:s3:::hogehoge/*", "Condition": { "StringLike": { "aws:Referer": [ "https://foo.bar/*" ] } } } ] }
⑤非公開領域バケットの設定
(割愛)
Viewerから呼び出されるために、CORS設定が必要になります。
CORSの設定<?xml version="1.0" encoding="UTF-8"?> <CORSConfiguration xmlns="http://s3.amazonaws.com/doc/2006-03-01/"> <CORSRule> <AllowedOrigin>https://hogehohogehoge</AllowedOrigin> <AllowedMethod>GET</AllowedMethod> <AllowedMethod>POST</AllowedMethod> <MaxAgeSeconds>3000</MaxAgeSeconds> <ExposeHeader>ETag</ExposeHeader> <ExposeHeader>Accept-Ranges</ExposeHeader> <ExposeHeader>Content-Encoding</ExposeHeader> <ExposeHeader>Content-Length</ExposeHeader> <ExposeHeader>Content-Range</ExposeHeader> <AllowedHeader>*</AllowedHeader> </CORSRule> </CORSConfiguration>
5.あとがき
サービスサイトから、GETパラメータを渡すことで、無事にPDFの表示ができています。
不用意にコピーされたくない、PDFをWeb上で公開する方法の1案ではないでしょうか。作成しましたサイトですが、
公開可能でしたら、後日ご紹介したいと思います。
(フロント側については、もう一人のエンジニアの方と実装&ブラッシュアップ中です)なんだかんだ、時間を要したのは、PDFの加工(原本はGB単位)だったりしました。。。
(PDFを命名ルールを付けながらリネーム、分割、圧縮、結合、ディレクトリへの配置。)







- 投稿日:2020-03-01T21:31:57+09:00
【初心者向け】AWS EC2デプロイ時にでるエラーを解決する
自作したアプリケーションをAWS上にデプロイする際に、いくつかエラーが出てつまづいたので、どうやって解決したかをまとめ的な感じでつらつらと書いていきます。
各エラーの内容にはそこまで踏み込まず、解決するという部分にフォーカスしてます。なお、デプロイ時は、下記のQiita記事を参考に行いました。
題の通り、世界一丁寧でした。。。誠に有難うございます。。。世界一丁寧なAWS解説。EC2を利用して、RailsアプリをAWSにあげるまで
環境
macOS:10.14.6
Ruby:2.5.7
Rails:5.2.4.1①ssh: connect to host [作成したEC2のElasticIP] port 22: Operation timed out
これは、EC2インスタンスにsshログインした時に出たエラー。
$ ssh -i [app名].pem ec2-user@[作成したEC2のElasticIP] ssh: connect to host [作成したEC2のElasticIP] port 22: Operation timed out解決方法
1.AWSコンソールに入り、AWSのサービスからEC2を選択
2.左のメニューバーからセキュリティグループを選択
3.インバウンドを選択
4.編集
5.タイプ:SSH、ソース:マイIPのルールを追加
6.保存これでsshログインできるようになります。
ちなみに自分のIPアドレスはwi-fi環境により異なったりするので注意が必要です。②ERROR: Ruby install aborted due to missing extensions
これは、EC2インスタンスにrubyをインストールする際に出たエラー。
$ rbenv install -v 2.5.7 ~ #省略 ~ BUILD FAILED (Amazon Linux AMI 2018.03 using ruby-build 20200224) Inspect or clean up the working tree at /tmp/ruby-build.20200229053400.25770.gpU4NA Results logged to /tmp/ruby-build.20200229053400.25770.log Last 10 log lines: installing capi-docs: /home/irikawa/.rbenv/versions/2.5.7/share/doc/ruby The Ruby readline extension was not compiled. ERROR: Ruby install aborted due to missing extensions Try running `yum install -y readline-devel` to fetch missing dependencies.解決方法
これはエラー文に書かれている以下のコマンドを実行し、
$ sudo yum install -y readline-develその後、rubyをインストール
$ rbenv install -v 2.5.7 ~ #省略 ~ Installed ruby-2.5.7 to /home/user/.rbenv/versions/2.5.7無事入りました。
③EC2インスタンスにmaster.keyを作成する
これは特別エラーが出たわけではないのですが、考え方の整理として。
rails5.2以上では、rails newをしたタイミングで、「credentials.yml.enc」と「master.key」が生成されます。
それぞれの役割は、超ざっくり説明すると、「credentials.yml.enc」が鍵穴で、「master.key」が鍵という位置付けになり、「credentials.yml.enc」を複合する際には「master.key」が必要になるとのこと。ローカル環境で開発している段階では特別意識しなくても良いのですが、EC2にあげるタイミングで.gitignoreに書かれている「master.key」はEC2側には渡ってくれません。
なので、以下の方法でEC2側に「master.key」を手動で作成してあげる必要があります。
まずはローカル環境でmaster.keyの中身をコピーします。
以下のコマンドを打って出てくる英数字の暗号みたいなものをコピーする。local.~/myapp$ vi config/master.key次にEC2側にmaster.keyを以下のコマンドで作成し、先程コピーしたものをペーストします。
server.[user|myapp]$ vim config/master.key保存して終了。これでOKです。
④bundle install時、mysqlが入らないエラー:Gem::Ext::BuildError: ERROR: Failed to build gem native extension.
EC2インスタンス内でbundle install時に以下のエラー。主要部分のみ抜粋してます。
server.[user|myapp]$ bundle install ~ #省略 ~ Gem::Ext::BuildError: ERROR: Failed to build gem native extension. ----- mysql client is missing. You may need to 'sudo apt-get install libmariadb-dev', 'sudo apt-get install libmysqlclient-dev' or 'sudo yum install mysql-devel', and try again. ----- An error occurred while installing mysql2 (0.5.3), and Bundler cannot continue. Make sure that `gem install mysql2 -v '0.5.3' --source 'https://rubygems.org/'` succeeds before bundling.mysqlクライアントがないというエラーみたいですね。
エラー文に書いている以下のコマンドを実行。
server.[user|myapp]$ sudo yum install mysql-develその後、bundle installしたら無事mysqlが入りました。
一旦、以上になります。
今後随時更新していきます。
- 投稿日:2020-03-01T20:20:27+09:00
【初心者のためのポートフォリオ作成】 Rails6 + MySQL + AWS + Capistrano + Circle CI ①アプリ作成〜githubへのpushまで
はじめに
未経験からのWEBエンジニアへの転職を目指し、railsでポートフォリオを作成しました。
今回はその復習を兼ねて、アプリ作成〜デプロイ、さらにCapistranoとCircle CIを使ったCI/CDまでの流れを記事にしたいと思います。アプリケーションの中身は一旦置いておいて、上記過程を把握することを目的としています。
ただ、それなりに詳しく書いていきたいと思うので、アプリケーションの作り込み以外の部分は、参考にしていただいて問題ないかと思います。
また、エラーが出れば都度参考記事とともに対応策も記述していきますので、これからポートフォリオ作成を始める初学者の方の参考になればと思います。
本記事は第1回目として、
rails newからgithubへのpushまでを説明していきます。使用技術
- Rails 6
- MySQL
- Rspec(テスト)
- Capistrano
- Circle CI
- AWS(VPC,EC2,ALB,RDS,S3,Route53,ACM)
アーキテクチャ
最終的には、以下のような構成をイメージしています。
(私のポートフォリオの構成図をそのまま転用していますが、今回ひとまずdockerには触れません。余力があればそちらもいずれ・・・)
アプリ作成(MySQL)
今回はデータベースにMySQLを使います。
とは言っても難しいことはなく、以下のようにrails new アプリ名 -d mysqlとすればOKです。
(MySQLを自分のPCにインストールする部分で苦戦した記憶がありますが、そこは一旦割愛させていただきます。)$ rails new test_app -d mysqlエラー発生
早速ですが、サーバー起動しちゃいます。
$ rails s => Booting Puma => Rails 6.0.2.1 application starting in development => Run `rails server --help` for more startup options Exiting Traceback (most recent call last): 77: from bin/rails:3:in `<main>' 76: from bin/rails:3:in `load' (省略) Webpacker configuration file not found /Users/ユーザー名/test_app/config/webpacker.yml. Please run rails webpacker:install Error: No such file or directory @ rb_sysopen - /Users/beppuyuusuke/test_app/config/webpacker.yml (RuntimeError)なにやらエラーが発生しました。
Please run rails webpacker:installとのことなので、$ rails webpacker:installが、、、またもやエラー・・・
sh: node: command not found sh: nodejs: command not found Node.js not installed. Please download and install Node.js https://nodejs.org/en/download/そういえば、
rails newした時も、同じエラーメッセージが出てスルーしてました。Node.jsのインストール
Node.jsのインストールが必要とのことなので、以下の記事を参考にインストールを進めていきます。
https://qiita.com/kyosuke5_20/items/c5f68fc9d89b84c0df09$ brew install nodebrew (省略) zsh completions have been installed to: /usr/local/share/zsh/site-functions ==> Summary ? /usr/local/Cellar/nodebrew/1.0.1: 8 files, 38.6KB, built in 7 seconds $ mkdir -p ~/.nodebrew/src #ディレクトリを作成 $ nodebrew install-binary stable #安定版をインストール Fetching: https://nodejs.org/dist/v12.16.1/node-v12.16.1-darwin-x64.tar.gz ######################################################################### 100.0% Installed successfully
Installed successfullyと出たので、インストールは成功したっぽいです。これだけではダメで、有効化の手順が必要なようです。
nodebrew lsでインストールされたバージョンを確認すると、$ nodebrew ls v12.16.1 current: none
current: none
つまり、無効な状態ということで、以下コマンドを実行して有効化します。$ nodebrew use v12.16.1 use v12.16.1改めて確認すると、
nodebrew ls v12.16.1 current: v12.16.1有効化されました。
最後に環境パスを通します。$ echo 'export PATH=$HOME/.nodebrew/current/bin:$PATH' >> ~/.bash_profileターミナルの再起動をして、再度
rails webpacker:installを実行します。$ rails webpacker:install Yarn not installed. Please download and install Yarn from https://yarnpkg.com/lang/en/docs/install/あれ?またエラー??
今度はYarnがインストールされてない、ですか・・・。Yarnのインストール
これまでRails5を使っていましたが、Rails6だとつまづくみたいです。
以下の記事を見つけたので、こちらを参考に(というか、そのまま真似して)対応していきます。
https://qiita.com/NaokiIshimura/items/8203f74f8dfd5f6b87a0$ brew install yarn #インストール ==> Installing dependencies for yarn: icu4c and node ==> Installing yarn dependency: icu4c (省略) ==> node Bash completion has been installed to: /usr/local/etc/bash_completion.d $ yarn -v #バージョン確認 1.22.0 $ yarn install yarn install v1.22.0 info No lockfile found. [1/4] ? Resolving packages... [2/4] ? Fetching packages... [3/4] ? Linking dependencies... [4/4] ? Building fresh packages... success Saved lockfile. ✨ Done in 0.91s.特に深く考えず、
brew install yarn→yarn -v→yarn install
を実行すればOKです。ようやく、rails webpacker:installを実行
$ rails webpacker:install create config/webpacker.yml Copying webpack core config create config/webpack create config/webpack/development.js create config/webpack/environment.j (省略) ✨ Done in 7.98s. Webpacker successfully installed ? ?クラッカーとケーキでお祝いされました。
ここまで長かった・・・(参考記事のコピペですけど)改めて rails sでサーバー起動
$ rails s => Booting Puma => Rails 6.0.2.1 application starting in development => Run `rails server --help` for more startup options Puma starting in single mode... * Version 4.3.3 (ruby 2.6.0-p0), codename: Mysterious Traveller * Min threads: 5, max threads: 5 * Environment: development * Listening on tcp://127.0.0.1:3000 * Listening on tcp://[::1]:3000 Use Ctrl-C to stop
http://localhost:3000/にアクセスしてみると
またエラーかい!
datebaseがないって言われてますね。
これはすっかり忘れてました。rails:db createでデータベース作成
一旦、
Ctr-Cでサーバーを停止して、データベースを作成→再度サーバーを起動します。$ rails db:create Created database 'test_app_development' Created database 'test_app_test' $ rails s => Booting Puma => Rails 6.0.2.1 application starting in development => Run `rails server --help` for more startup options Puma starting in single mode... * Version 4.3.3 (ruby 2.6.0-p0), codename: Mysterious Traveller * Min threads: 5, max threads: 5 * Environment: development * Listening on tcp://127.0.0.1:3000 * Listening on tcp://[::1]:3000 Use Ctrl-C to stop無事におなじみのページが表示されました。
エラー続きで少し長くなりましたが、これでアプリケーション側の準備はOKです。
エラーが出た時は焦らず、はいはいって感じでエラーメッセージをコピペしてググればなんとかなります。
というか、学習を進めていくうちに自然とそうなっていくので、めげずに頑張りましょう!githubへのpush
さて、一息つきたいところですがもう少しです。
ここで一度、githubにpushしておきましょう。
https://github.com/私もまだまだ初学者なので個人的&漠然としたイメージですが、githubへのpush=セーブするみたいなことだと考えています。
railsチュートリアルでのその辺は解説されていたので、まだの方は一度ざっと学習することをお勧めします。
(私は基本コピペ&わからない部分はスルーして、約2週間で1回通ったきりです。)githubの活用は、後半のデプロイ以降の手順にも必須ですので、早めに使って慣れておきましょう。
新規リポジトリ作成
では、順番に説明していきます。
一旦ターミナルから離れて、ブラウザ上のgit hubページでの操作となります。ここでは割愛しますが、登録がまだの方は以下の記事が参考になるかと思います。
https://techacademy.jp/magazine/6235そのまま上記記事を参考にして進めていただいても結構ですが(そっちの方がわかりやすいかも)、リポジトリの作成から説明していきます。
こんな感じの画面ですが、とりあえず
Repository nameにお好みの名前を入力して、Create repositoryボタンを押します。
Repository nameはなんでもOKですが、混乱を避けるためにrails new時に指定したアプリ名を使うのが一般的です。早速pushする
Create repositoryボタンを押すと、以下のような画面に進みます。
...or create a new ...(省略)の手順に従い、ターミナルに戻って上から順番にコマンドを実行します。$ echo "# test_app" >> README.md $ git init Reinitialized existing Git repository in /Users/ユーザー名/test_app/.git/ $ git add README.me $ git commit -m "first commit" [master (root-commit) 02bc84e] first commit 1 file changed, 25 insertions(+) create mode 100644 README.md $ git remote add origin git@github.com:vppysk/test_app.git $ git push -u origin master Counting objects: 3, done. Delta compression using up to 4 threads. Compressing objects: 100% (2/2), done. Writing objects: 100% (3/3), 458 bytes | 458.00 KiB/s, done. Total 3 (delta 0), reused 0 (delta 0) To github:vppysk/test_app.git * [new branch] master -> master Branch 'master' set up to track remote branch 'master' from 'origin'.
ブラウザに戻って確認すると、
first commitが反映され、READMEが表示されていますね。私の場合、すでに他アプリでgithubを使用していたためスムーズでしたが、初めての方だとgitのインストール等が必要になるかと思います。
一応参考記事を載せておきますが、そんなに難しいことはないかと。
https://qiita.com/folivora/items/763d06b26bafd573a456まとめ
さて、これで一通りの手順は完了して、アプリ開発の準備が整いました。
私と違うところでエラーが出ることもあるかと思いますが、慌てずエラーメッセージを読み、ググる習慣をつければ大丈夫です。
英語がわからない場合は、迷わずグーグル翻訳に頼りましょう。もちろん、コメントで質問していただいても結構ですので、頑張っていきましょう。
(上級者の方は逆にアドバイスいただけると嬉しいです)次回の第2回目は簡単な機能の実装と、Rspecを導入したテスト駆動開発(といっても初心者ですけど)について説明したいと思います。
それでは、またお会いしましょう!






- 投稿日:2020-03-01T20:20:27+09:00
【初心者のためのポートフォリオ作成】 Rails6 + MySQL + AWS + Capistrano + Circle CI ①アプリ作成〜サーバー起動まで
はじめに
未経験からのWEBエンジニアへの転職を目指し、railsでポートフォリオを作成しました。
今回はその復習を兼ねて、アプリ作成〜デプロイ、さらにCapistranoとCircle CIを使ったCI/CDまでの流れを記事にしたいと思います。アプリケーションの中身は一旦置いておいて、上記過程を把握することを目的としています。
ただ、それなりに詳しく書いていきたいと思うので、アプリケーションの作り込み以外の部分は、参考にしていただいて問題ないかと思います。
また、エラーが出れば都度参考記事とともに対応策も記述していきますので、これからポートフォリオ作成を始める初学者の方の参考になればと思います。
本記事は第1回目として、
rails newからサーバー起動までを説明していきます。使用技術
- Rails 6
- MySQL
- Rspec(テスト)
- Capistrano
- Circle CI
- AWS(VPC,EC2,ALB,RDS,S3,Route53,ACM)
アーキテクチャ
最終的には、以下のような構成をイメージしています。
(私のポートフォリオの構成図をそのまま転用していますが、今回ひとまずdockerには触れません。余力があればそちらもいずれ・・・)
アプリ作成(MySQL)
今回はデータベースにMySQLを使います。
とは言っても難しいことはなく、以下のようにrails new アプリ名 -d mysqlとすればOKです。
(MySQLを自分のPCにインストールする部分で苦戦した記憶がありますが、そこは一旦割愛させていただきます。)$ rails new test_app -d mysqlエラー発生
早速ですが、サーバー起動しちゃいます。
$ rails s => Booting Puma => Rails 6.0.2.1 application starting in development => Run `rails server --help` for more startup options Exiting Traceback (most recent call last): 77: from bin/rails:3:in `<main>' 76: from bin/rails:3:in `load' (省略) Webpacker configuration file not found /Users/XXXXX/test_app/config/webpacker.yml. Please run rails webpacker:install Error: No such file or directory @ rb_sysopen - /Users/beppuyuusuke/test_app/config/webpacker.yml (RuntimeError)なにやらエラーが発生しました。
Please run rails webpacker:installとのことなので、$ rails webpacker:installが、、、またもやエラー・・・
sh: node: command not found sh: nodejs: command not found Node.js not installed. Please download and install Node.js https://nodejs.org/en/download/そういえば、
rails newした時も、同じエラーメッセージが出てスルーしてました。Node.jsのインストール
Node.jsのインストールが必要とのことなので、以下の記事を参考にインストールを進めていきます。
https://qiita.com/kyosuke5_20/items/c5f68fc9d89b84c0df09$ brew install nodebrew (省略) zsh completions have been installed to: /usr/local/share/zsh/site-functions ==> Summary ? /usr/local/Cellar/nodebrew/1.0.1: 8 files, 38.6KB, built in 7 seconds $ mkdir -p ~/.nodebrew/src #ディレクトリを作成 $ nodebrew install-binary stable #安定版をインストール Fetching: https://nodejs.org/dist/v12.16.1/node-v12.16.1-darwin-x64.tar.gz ######################################################################### 100.0% Installed successfully
Installed successfullyと出たので、インストールは成功したっぽいです。これだけではダメで、有効化の手順が必要なようです。
nodebrew lsでインストールされたバージョンを確認すると、$ nodebrew ls v12.16.1 current: none
current: none
つまり、無効な状態ということで、以下コマンドを実行して有効化します。$ nodebrew use v12.16.1 use v12.16.1改めて確認すると、
nodebrew ls v12.16.1 current: v12.16.1有効化されました。
最後に環境パスを通します。$ echo 'export PATH=$HOME/.nodebrew/current/bin:$PATH' >> ~/.bash_profileターミナルの再起動をして、再度
rails webpacker:installを実行します。$ rails webpacker:install Yarn not installed. Please download and install Yarn from https://yarnpkg.com/lang/en/docs/install/あれ?またエラー??
今度はYarnがインストールされてない、ですか・・・。Yarnのインストール
これまでRails5を使っていましたが、Rails6だとつまづくみたいです。
以下の記事を見つけたので、こちらを参考に(というか、そのまま真似して)対応していきます。
https://qiita.com/NaokiIshimura/items/8203f74f8dfd5f6b87a0$ brew install yarn #インストール ==> Installing dependencies for yarn: icu4c and node ==> Installing yarn dependency: icu4c (省略) ==> node Bash completion has been installed to: /usr/local/etc/bash_completion.d $ yarn -v #バージョン確認 1.22.0 $ yarn install yarn install v1.22.0 info No lockfile found. [1/4] ? Resolving packages... [2/4] ? Fetching packages... [3/4] ? Linking dependencies... [4/4] ? Building fresh packages... success Saved lockfile. ✨ Done in 0.91s.特に深く考えず、
brew install yarn→yarn -v→yarn install
を実行すればOKです。ようやく、rails webpacker:installを実行
$ rails webpacker:install create config/webpacker.yml Copying webpack core config create config/webpack create config/webpack/development.js create config/webpack/environment.j (省略) ✨ Done in 7.98s. Webpacker successfully installed ? ?クラッカーとケーキでお祝いされました。
ここまで長かった・・・(参考記事のコピペですけど)改めて rails sでサーバー起動
$ rails s => Booting Puma => Rails 6.0.2.1 application starting in development => Run `rails server --help` for more startup options Puma starting in single mode... * Version 4.3.3 (ruby 2.6.0-p0), codename: Mysterious Traveller * Min threads: 5, max threads: 5 * Environment: development * Listening on tcp://127.0.0.1:3000 * Listening on tcp://[::1]:3000 Use Ctrl-C to stop
http://localhost:3000/にアクセスしてみると
またエラーかい!
datebaseがないって言われてますね。
これはすっかり忘れてました。rails:db createでデータベース作成
一旦、
Ctr-Cでサーバーを停止して、データベースを作成→再度サーバーを起動します。$ rails db:create Created database 'test_app_development' Created database 'test_app_test' $ rails s => Booting Puma => Rails 6.0.2.1 application starting in development => Run `rails server --help` for more startup options Puma starting in single mode... * Version 4.3.3 (ruby 2.6.0-p0), codename: Mysterious Traveller * Min threads: 5, max threads: 5 * Environment: development * Listening on tcp://127.0.0.1:3000 * Listening on tcp://[::1]:3000 Use Ctrl-C to stop無事におなじみのページが表示されました。
お疲れ様でした!
エラー続きで少し長くなりましたが、これでアプリケーションを作る準備が整いました。エラーが出た時は焦らず、はいはいって感じでエラーメッセージをコピペしてググればなんとかなります。
というか、学習を進めていくうちに自然とそうなっていくので、めげずに頑張りましょう!次回も基本的な内容ですが、githubへのpushを解説していきたいと思います。
- 投稿日:2020-03-01T18:34:57+09:00
【AWS】【SAA対策】DynamoDB
DynamoDB
サービス概要
高速で予測可能なパフォーマンスとシームレスなスケーラビリティのフルマネージド型の NoSQL データベースサービス。
特徴
- 分散データベースの運用とスケーリングに伴う管理作業(ハードウェアのプロビジョニング、設定と構成、レプリケーション、ソフトウェアのパッチ適用、クラスタースケーリングなど)を自分で行う必要がなくなる。
- 十分な数のサーバー間でデータとトラフィックを自動的に分散し、一貫した高速なパフォーマンスを維持。
- 保管時の暗号化。
- 任意の量のデータを保存および取得できるデータベーステーブルを作成し、任意のレベルのリクエストトラフィックを処理。
- ポイントインタイムリカバリを使用すれば、過去 35 日間の任意の時点にテーブルを復元可能。
- Key-Valueストア=「値」とそれを取得するための「キー」だけを格納するというシンプルな構造。
- DynamoDB Acceleration
- 可用性が高くフルマネージドなDynamoDB用 インメモリキャッシ。1秒あたり100万回単位のリクエストに数ミリ秒の応答時間で処理が可能。DynamoDBに格納されたデータの読み込み回数を減らすことができるため、読み込みスループットが向上。
類似サービスとの比較
RDS DynamoDB Redshift ElastiCache 概要 ・リレーショナルデータベース。
・主なDBエンジンをサポート、ツールがそのまま使えるため、オンプレからの移行に便利。
・データベースソフトウェアのパッチは自動パッチが可能。・NoSQL データベースサービス。
・結果整合性
・write直後のreadでは整合性が取れない場合あり。
・「強い整合性」オプションを指定すると性能は落ちる。
・レコードのサイズに上限あり。
・リージョンサービスでありプライベートネットワークからはNAT経由でアクセスする必要あり。・データウェアハウスタイプ
・スケーラブル
・高パフォーマンス・メモリーキャッシュタイプ
・Memcached:Key-Value Store形式のメインメモリキャッシュ。マルチノートのキャッシュクラスタ。
・Redis:Memcached:Key-Value Store形式のメインメモリキャッシュ。場所 AZ サービス(VPC内に配置) リージョン AZ サービス AZ サービス(VPC内に配置) バックアップ スケージュールで1日1回取得可能(手動可)※ただし、バックアップ中はI/O停止、止めたくない場合はマルチAZ利用する必要あり - - (memcached)バックアップ機能はなし(Redis)Snapshotによる永続化 ユースケース OS以下レイヤの管理不要、高可用性な、既存データベースの利用など 大量のオンライントランザクション処理など 大容量データの分析など DBの負荷低減用のメモリキャッシュ ★NoSQLとRDBMS
NoSQL RDBMS 特性 ・Basically Available(基本利用可能)
・Soft-state(柔軟な状態)
・Eventual Consistency(結果整合性)・Atomicity(原子性)
・Consistency(一貫性)
・Isolation(独立性)
・Durability(永続性)処理 トランザクション処理にあたり、データの更新においては、古いデータが存在する時間を許容。 トランザクション処理にあたり、即時に一貫したデータの整合性を保証し、処理が途中で失敗した場合は、ロールバックし、処理がなかったことになる。 スケールアウト スキーマを固定しないシンプル構造のため、水平的に分散スケールアウトが可能 整合性をもってデータを更新するため、水平的に分散スケールアウトするのが困難。 ベストプラクティス
- DynamoDBストリームを有効にすると、作成したLambda関数にストリームARNを関連させることができる。Lambdaがストリームをポーリングすることで、新しいレコードを検出し、Lambda関数を呼び出す。
- DynamoDBのテーブルは、パーティションキー全体でアクティビティが均一になるアプリケーション設計をする。テーブルはスキーマを持たないため、開発の自由度があがる。また、キーバリューの構造はキーをもとにして、データを分散格納できるため、水平にスケールが可能。
- DynamoDBでThlottlingExceptionとLimitExceedExceptionのエラーが返されたときは、アプリケーションでリクエストを再試行することで解決できる。
- フルマネージドによる高い拡張性、データへの1桁ミリ秒のレイテンシー、マルチリージョン/マルチマスターの高い信頼性を実現するNoSQLDBはDynamoDB。
- DynamoDBは、データベースとして、JSONドキュメントの保存、インデックスの可用性、Auto Scalingが必要な場合にも適している。
- DynamoDBでは結果整合性に基づく処理をするため、多くのトラフィックを処理可能だが、一方それらの読み込みを可能にするため、古いデータの読み込みが発生してしまう。DynamoDBの読み込みオペレーションのオプションのConsistReadパラメータをTrueにすることで強力な整合性のある読み込みを可能とし、回避できる。
- DynamoDBに一時的なアクセス集中がある場合、以下の手段により、対応が可能。
- SQSメッセージからDynamoDBに書き込みをするように連携
- DynamoDBに対してAutoScalingを適用
- 新規テーブル作成の際、Read,Writeに対して、プロビジョニングスループットを指定する。
- クロスリージョンレプリケーションが可能なテーブルを作成することにより、グローバルユーザー向けにスケールしたアプリケーションの構築やDR対策に利用できる。
- キャパシティユニットを適切に設定することでコストを抑えることができる。
- 投稿日:2020-03-01T18:29:20+09:00
プログラミングを学んで2ヶ月半でAWS認定ソリューションアーキテクト-アソシエイト-を取得したので勉強法をまとめてみる
はじめに
プログラミング未経験からスクールに入学し、2ヶ月半後の卒業するくらいのタイミングでAWSのソリューションアーキテクトアソシエートを取得しました。
勉強期間は2週間フルコミットしました。
取得しようと思った理由は①AWSを触ってみて楽しかったから、②取得できたら就活の時に自走能力アピールできるかなと思ったからです。最近勉強法などを聞かれることが多いので簡単にまとめておこうと思います。
※こちらは2020年3月1日受験時点での内容となります。ご了承ください。
※また、試験内容は2020年3月23日以降バージョンが変わりますのでご注意ください。筆者の前提知識レベル
- 基本情報技術者試験 取得済み
- ポートフォリオ作成時にAWSサービス使用経験あり(IAM, EC2, S3, RDS, ELB, CloudFront, Route53, ACM)
試験について
試験についての情報はたくさんあるので詳細は割愛しますが、テストセンターに行って受験します。
オンラインで申し込んでテストセンターさえ空いてればすぐにでも受験できます。
僕は申し込んでから5日後くらいに受験しました。
試験料は15000円(税別)です、高いですね。笑試験内容について
AWSのソリューションアーキテクトアソシエート(以下、SAA)の位置付けや概略については以下のリンクがとても参考になりました。
https://qiita.com/fukubaka0825/items/238225f9e4c1962bc00c一応簡単に説明しておきますと、Well-Architected Frameworkで提唱されている5つの設計原則に沿った設計ができるかどうかを試す試験です。
分野 比率 1. 信頼性 34% 2. パフォーマンス効率 24% 3. セキュリティ 26% 4. コスト最適化 10% 5. 運用上の優秀性 6% *ちなみに2020年3月23日以降は以下のようになります。
運用上の優秀性が無くなる他、信頼性の比率が下がってセキュリティとコスト最適化の比率が上がってますね。
分野 比率 1. 信頼性 30% 2. パフォーマンス効率 24% 3. セキュリティ 28% 4. コスト最適化 18% 要するにアプリケーションを開発する各ケースにおいて、満たしたいパフォーマンスレベルやセキュリティを担保できて、かつコスト最適なアーキテクチャ設計をするためにはどういうサービスをどの設定で組み合わせて使えばいいかを問われる試験です。
勉強法について
肝心の勉強法についてですが、まずSAAの試験は範囲がとても広いです。
なので多くのサービスについて何ができるサービスなのかを知る必要があります。僕はポートフォリオ作成時にいくつかサービスを使ってたのでいきなり試験勉強から入りました。
SAA対策本ではないですが、AWSのサービスを地図的に理解するには以下の本がわかりやすいそうです。
試験は受けないけど、AWSの各種サービスについてざっくり知りたいという人にもオススメです。図解即戦力 Amazon Web Servicesのしくみと技術がこれ1冊でしっかりわかる教科書
使った教材
僕が実際に使った教材は以下です。
インプット編
① これだけでOK! AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座(初心者向け22時間完全コース)
有名なのでご存知の方も多いと思います。
ハンズオン形式で実際に手を動かしながら学ぶことができます。
ただ22時間と長いです。。。僕は途中で飽きてやめてしまいました。笑
僕は動画教材が基本的に合わないのですが、動画教材が好きな方にはオススメです!
模試が2回分ついてくるのも嬉しい。② 徹底攻略 AWS認定 ソリューションアーキテクト – アソシエイト教科書 徹底攻略シリーズ
通称黒本と言われているものです。
各種サービスについての概要がわかりやすく書いてあります。
わりと試験に特化した記述という印象でした。③ AWS認定資格試験テキスト AWS認定 ソリューションアーキテクト-アソシエイト
オレンジの本。
個人的にはこの本が一番オススメです!
内容が充実してますし、後々辞書的にも使えそうだなと思いました。④ 一夜漬け AWS認定ソリューションアーキテクト アソシエイト 直前対策テキスト
最も試験に特化した本です。
資格取得という目的であればオススメですが、実用的な知識を身に付けたいということであれば③の本の方がオススメです。アウトプット編
⑤ AWS SAA 公式模擬試験
公式サイトが出している模擬試験で2000円で受けれますが、問題数が25問と少なめです。(本番は65問)
本番より簡単な問題なので、あくまでも本番の形式を知りたいという人向け。
オススメする人が多いですが、個人的には受けなくてもよかったかなと思います。⑥ AWS 認定ソリューションアーキテクト アソシエイト模擬試験問題集(5回分325問)
Udemyの模試です。5回分もあるのが嬉しい。そして何より本番と同等かそれ以上に難しい問題が多い。
参考書にも問題はついてきますが、わりと簡単な問題が多めです。
この模試は難しいですが、ぜひチャレンジすることをオススメします。
難しくて心折れそうになりますが、これが理解できるようになれば合格の可能性はだいぶ高まるのではないかと思います。実際に勉強した順番としては
1. まずは過去問を見てどういう問題形式でどういう難易度かを知る
2. Udemy(①)を見て途中までやるが飽きて挫折する笑
3. 黒本(②)を読む
4. オレンジの本(③)を読む
5. 公式模擬試験(⑤)を受ける
6. Udemyの模試(⑥)を受ける
7. 全然できなくて絶望して一夜漬けの本(④)を読む笑
8. 模試の復習をして本番という感じです。
本でインプットする場合は最低2冊やることをオススメします。1冊じゃ網羅しきれません。
例えば黒本(②)はベストプラクティスの5つの原則に基づいた章構成になっており、オレンジの本(③)は各サービスごとの章構成になっているので違う視点から学べてとてもよかったです。そしてインプットをできるだけ早めに終わらせてさっさと模試を受けるのがオススメです。
どれだけインプットを頑張ってもできない問題が多々あるので、実際に問題を受ける中で慣れていくのが一番効率がいいと思います。
できなかった部分を各参考書やUdemyで復習するのがいいと思います。最後は模試をひたすら復習してました。
こんな感じで2週間フルコミットしたら合格できました。
おわりに
試験合格に特化するのであれば参考書と模試をやりまくれば十分合格できると思います。
実際にサービスを使えるレベルを目指すのであれば、やはりハンズオンなどで実際に自分でサービスを使ってみるのが一番いいでしょう。僕は無事合格はできたものの、最後の方は試験合格のための勉強になっていた感が否めず、各サービスをきちんと理解して使いこなせるかと言われると怪しいです。
この辺は反省を生かしながら徐々に使いこなせるようになっていきたいと思います。
- 投稿日:2020-03-01T18:29:16+09:00
【AWS】【SAA対策】Route53
Route53
サービス概要
可用性と拡張性に優れたDNSウェブサービス。
ドメイン登録、DNSルーティング、ヘルスチェックの3つの主要な機能を任意の組み合わせで実行可能。特徴
- ドメイン名の登録
- 新しいドメイン名(URL が http://example.com であれば、example.com という部分)を取得する場合は、ドメイン名を Amazon Route 53 に登録可能。既存のドメインの登録を他のレジストラから Route 53 に移管することも、逆に、Route 53 に登録したドメインの登録を別のレジストラに移管することも可能。
- ドメインのリソースへのインターネットトラフィックのルーティング
- ホストゾーンの作成(パブリックホスト/プライベートホスト)
- リソースの正常性のチェック
- Route 53 ヘルスチェックでは、ウェブサーバーや E メールサーバーなどのリソースの正常性を監視します。必要に応じて、リソースが使用不可になったら通知を受け取るように、ヘルスチェックに対して Amazon CloudWatch アラームを設定可能
- A,CNAME,MX,NS等の代表的なレコードタイプはサポート。
- エイリアスレコード:Amazon CloudFront ディストリビューションやAmazon S3バケットなどの AWSリソースにトラフィックをルーティングするためにAmazon Route 53で作成できるレコードタイプ。CNAMEと同様な扱いを受ける。実態はAレコード。
- CNAMEは他のレコードとの共存ができないため、Zone Apexに設定できないが、エイリアスレコードの実態はAレコードのため、Zone Apexに設定できる。
- エイリアスレコードはAWS内で利用する限られたDNS名に対してのみ指定可能。(CloudFront distribution, ELB, static website設定をしたS3バケット, 他のRoute 53リソースレコードセット)
種類やタイプ
ルーティングポリシー
ルーティング シンプルルーティングポリシー ドメインで特定の機能を実行する単一のリソース (example.com ウェブサイトにコンテンツを提供するウェブサーバーなど) にインターネットトラフィックをルーティング フェイルオーバールーティングポリシー アクティブ/パッシブフェイルオーバーを構成する場合に使用 位置情報ルーティングポリシー ユーザーの場所に基づいてインターネットトラフィックをリソースにルーティング 地理的近接性ルーティングポリシー リソースの場所に基づいてトラフィックをルーティングし、必要に応じてトラフィックをある場所のリソースから別の場所のリソースに移動する レイテンシールーティングポリシー 複数の場所にリソースがあり、レイテンシーが最も小さいリソースにトラフィックをルーティングする 複数値回答ルーティングポリシー ランダムに選ばれた最大 8 つの正常なレコードを使用して Route 53 が DNS クエリに応答する場合に使用 加重ルーティングポリシー 指定した比率で複数のリソースにトラフィックをルーティング レコードタイプ
CNAMEレコード ALIESレコード リダイレクト先 DNSクエリを任意の DNSレコードにリダイレクト。
A や AAAA などのレコードタイプに関係なく、レコード名に対する DNS クエリをリダイレクト選択したAWSリソースにのみクエリをリダイレクト。
エイリアスレコードの名前 (acme.example.com など) とエイリアスレコードのタイプ (A や AAAA など) が DNS クエリの名前とタイプと一致した場合にだけ DNS クエリに応答。ドメイン名そのものへのマッピング 不可 可能(Zone Apexを利用) Zone Apex 不可(Zone ApexにはNSレコードが必要なため。) 可能(AWS リソースにトラフィックをルーティング) パフォーマンス 良い CNAMEより良い ベストプラクティス
- ブルーグリーンデプロイメントは、稼働システムと準備システムで本番系のトラフィックを切り替える方法で、重み付けで段階的移行が可能になる加重ルーティングが適切。
- 複数リソースにDNSクエリのレスポンスを分散して返答する場合は複数値回答ルーティングを利用し、正常なリソースの値のみを戻すことができる。
- Route53のヘルスチェックはインターネット経由でアクセスできるエンドポイントに使用可能なため、オンプレミスからクラウド環境へのDNSフェイルオーバーとして、利用可能。
- エイリアスレコードを利用すると、DNSクエリに対して、AWSサービスのエンドポイントのIPアドレスを直接返すため、レスポンスがはやくなる。
- サーバーごとに性能の偏りがある場合は、加重ルーティングで性能ごとに分配して振り分けができる。
- 自動フェールオーバーのルーティングではCNAMEを利用する。
- 投稿日:2020-03-01T18:28:49+09:00
【AWS】【SAA対策】EBS
EBS(Elastic Block Store)
サービス概要
EC2 インスタンスで使用するためのブロックレベルのストレージボリュームを提供。
ボリュームは、デバイスとしてインスタンスにマウントが可能で、同じインスタンスに複数のボリュームをマウント可能。これらのボリューム上にファイルシステムを構築も可能。
EBSは、データにすばやくアクセスする必要があり、長期永続性が必要な場合に推奨。特徴
- EBS ボリュームは、特定のAZで作成され、そのAZ内のインスタンスにアタッチ可能。
- AZの外部でボリュームを使用するには、スナップショットを作成し(S3へ保存)、そのスナップショットをその外部リージョン内の新しいボリュームに復元する。
- EBS には、ボリュームタイプとして 汎用 SSD (gp2)、プロビジョンド IOPS SSD (io1)、スループット最適化 HDD (st1)、および Cold HDD (sc1) が用意されている。
- 暗号化は EC2 インスタンスをホストするサーバーで行われ、EC2 インスタンスから EBS ストレージに転送されるデータが暗号化される。
- 汎用 SSD (gp2) ボリューム=さまざまなワークロードに対応できるコスト効率の高いストレージとして使用可能。レイテンシーは 1 桁台のミリ秒であり、長時間 3,000 IOPS にバースト可能。(I/O クレジットおよびバーストパフォーマンス)
- プロビジョンド IOPS SSD (io1) ボリューム=ランダムアクセス I/O スループットにおけるストレージパフォーマンスと整合性が重要な、I/O 集約型ワークロード (特にデータベースワークロード) のニーズを満たすように設計。ボリュームの作成時に一定の IOPS レートを指定可能。
- スループット最適化 HDD (st1) ボリューム=IOPS ではなくスループットでパフォーマンスを示す、低コストの磁気ストレージに使用可能。ボリュームのベースラインスループット (ボリュームのスループットクレジットが蓄積されるレート) は、ボリュームサイズによって決まる。(スループットクレジットとバーストパフォーマンス)
- Cold HDD (sc1) ボリュームは、IOPS ではなくスループットでパフォーマンスを示す、低コストの磁気ストレージに使用可能。
種類やタイプ
ボリュームタイプ
汎用 SSD (gp2) プロビジョンド IOPS SSD (io1) スループット最適化 HDD (st1) Cold HDD (sc1) 説明 さまざまなワークロードに適した、価格とパフォーマンスのバランスが取れているSSD ミッションクリティカルな低レイテンシーまたは高スループットワークロードに適した、最高パフォーマンスのSSD 高スループットを必要とするアクセス頻度の高いワークロード向けの低コストのHDD アクセス頻度の低いワークロード用に設計された低コストのHDD ユースケース ・ほとんどのワークロード
・システムブートボリューム
・仮想デスクトップ
・開発/テスト環境・持続的なIOPSパフォーマンス、またはボリュームあたり 16,000 IOPSまたは250 MiB/秒以上のスループットを必要とする重要なビジネスアプリケーション
・大規模なデータベースワークロード・低コストで安定した高速スループットを必要とするストリーミングワークロード
・ビッグデータ
・データウェアハウス
・ログ処理
・ブートボリュームには使用できないアクセス頻度の低い大量データ用のスループット指向ストレージ低いストレージ
・コストが重視されるシナリオ
・ブートボリュームには使用できないボリュームサイズ 1GiB - 16TiB 4 GiB~16 TiB 500 GiB~16 TiB 500 GiB~16 TiB ボリュームあたりの最大 IOPS 16,000 (16 KiB I/O) 64,000 (16 KiB I/O) † 500 (1 MiB I/O) 250 (1 MiB I/O) ボリュームあたりの最大 スループット MiB/秒 * 1,000 MiB/秒 † 500 MiB/秒 250 MiB/秒 類似サービスとの比較
S3 EBS EFS Glacier 概要 オブジェクトストレージ、安価で高信頼性のストレージ、インターネットからもアクセス可能 ブロックレベルのファイルストレージ、EC2のローカルストレージ 共有ファイルストレージ 低価格、長期保管ストレージ 場所 リージョン AZ リージョン リージョン 自動複製 複数AZ AZ内3か所 複数AZ 暗号化 設定する必要あり。SSE-S3/KMS/C。 ボリューム作成時に暗号化。既存ボリュームの暗号化不可。(使用中ボリュームを暗号化=スナップショットを取得し、新規に暗号化ボリュームを作成し、リストア。 保管中、転送中のデータを暗号化。暗号化のキーはKMSにて管理可。 AES-256で自動で暗号化 ベストプラクティス
- EBSのBCP(事業継続計画)対策としては、EBSボリュームのスナップショットを作成し、そのスナップショットを別リージョンでも利用する。別AZ/別リージョンのインスタンスにコピーをする際は、一度スナップショットをS3へ保存し、別AZ/別リージョンへ展開する。
- EC2とEBSを利用してDBを構築する場合、読み取りと書き取り性能を考慮して、EBSボリュームはプロビジョンドIOPS SSDにする。
- EBSのポイントインタイムスナップショットでは、増分バックアップにより、初期スナップショットからの差分のみを取得するため、ストレージコストを最小限にできる。
- EBSのボリュームタイプの選択で、ボリュームサイズが100GBなど小さい場合、gp2(汎用SSD)を利用したほうがコストを抑えられる。
- SSD:小さく煩雑な読み書き。1GB~16TB(io1は4GB~16TB)。料金は単位あたりHDDの倍くらい。
- HDD:大きなストリーミングデータ用。500GB~16TB。単位当たりでは安い。(が、初期が500GBのため、~200GBくらいまではSSDの方が安くなる。)
- スループットが最大500MB/秒必要なストレージでは、するプット最適化HDDが費用対効果が高い。
- Data Lifecycle Managerを使用すると、EBSスナップショットをスケジュールし、保持ポリシーに従い古いスナップショットを削除できる。Data Lifecycle Managerはスナップショットの作成、保持、削除を自動化できる。
- AMIはEBSのスナップショットを含んでいるため、障害時に備えるのはAMIのコピーのみで可能。
- 最も回復性が高く、1つのボリュームが故障してもすぐにデータ利用がしたい場合、RAID1構成で2つ以上のEBSボリューム間でミラーリングをとれば、回復性の高いデータ冗長構成にできる。
- 投稿日:2020-03-01T18:28:18+09:00
【AWS】【SAA対策】Redshift
Redshift
サービス概要
エンタープライズレベル、ペタバイト規模、フルマネージド型のデータウェアハウスサービス。
超並列処理、列指向データストレージ、および非常に効率的で対象を限定したデータ圧縮エンコードスキームの組み合わせによって、効率的なストレージと最善のクエリパフォーマンスを実現。
シンプルで費用対効果の高いサービスを実現し、既存のビジネスインテリジェンスツールを使用して、すべてのデータを効率的に分析可能。特徴
- ビジネスインテリジェンス (BI)、レポート、データ、分析ツールなど、多くの種類のアプリケーションとのクライアント接続をサポート。
類似サービスとの比較
*比較対象としてDynamoDBも記載されることが多いが、NoSQLDBのため、今回は省きます。
Redshift RDS 概要 ・データウェアハウスタイプ/スケーラブル/高パフォーマンス。
・OLAP(複雑で分析的な問い合わせに回答)・インスタンスでありVPC内に配置可能。
・MySQL、Oracle、Microsoft SQL Server、PostgreSQL、MariaDB、Amazon Auroraをサポート。現行のツールがそのまま使えるため、オンプレからの移行が比較的容易。
・データベースソフトウェアのパッチは自動パッチが可能。ユースケース 大容量データ分析。列指向DB。リレーショナルデータベース リレーショナルデータベース。メタデータ分析。比較的、汎用的に利用可能 ベストプラクティス
- 列指向データベースは水平スケーリングが可能なため、低コストの分散クラスターを使用し、スケールアウトすることで、高い費用対効果でスループットを向上できる。ペタバイトクラスの構造化データウェアハウスとしてビッグデータ分析処理に最適。
- Redshiftは暗号化されたSSL接続を使用して、スナップショットをS3に保存可能。EBS同様、増分スナップショットを自動作成し、このスナップショットからクラスターを復元可能。このバックアップは残ってしまうため、保持期間を指定または削除が推奨される。
- プライマリクラスターがダウンした場合、すぐに利用できるようにするにはクロスリージョンスナップショットを利用する。(自動的に他リージョンへコピーされるよう設定)
- S3に蓄積したデータをRedshiftと連携する場合で、VPCのプライベートサブネット内でのデータ利用に限定したいという要件がある場合、
- Redshift拡張VPCルーティングの設定する
- S3にVPCエンドポイントからアクセスする
- 投稿日:2020-03-01T18:27:44+09:00
【AWS】【SAA対策】S3
S3(Simple Storage Service)
サービス概要
スケーラビリティ、データ可用性、セキュリティ、およびパフォーマンスを提供する、容量無制限のオブジェクトストレージサービス。
データを整理して、細かく調整されたアクセス制御を設定できる。
99.999999999% (9 x 11) の耐久性を実現するように設計。特徴
- 複数のシステムにまたがる S3 オブジェクトをすべて自動的に作成して保存しており、99.999999999% (9 x 11) のデータ耐久性を実現するように設計。
- データアクセスレベルをサポートする S3 ストレージクラスにデータを保存することで、コスト削減。
- S3 ストレージクラス分析=アクセスパターンに基づき、低コストのストレージクラスに移動する必要のあるデータを検出し、S3 ライフサイクルポリシーを設定して転送を実行。
- S3 Intelligent-Tiering=アクセスパターンが変化するデータか、パターンが不明なデータを格納することもできる。これにより、オブジェクトはアクセスパターンの変化に応じて階層化されるため、コストは自動的に抑えられる。
- Block Public Access=バケットレベルまたはアカウントレベルで、すべてのオブジェクトへのパブリックアクセスをブロックできる
- S3 Access Points=共有データセットを使用するアプリケーションに個別のアクセス許可を付与できるため、データアクセスの管理が容易になる。
- Amazon Athena を使用して標準のSQL式でS3データを照会し、Amazon Redshift Spectrumを使用してAWSデータウェアハウスおよびS3リソース全体に格納されているデータを分析可能。
- データ転送による課金はS3からの送信のみで、アップロードなど受信は無料。*同一リージョン内通信はすべて無料。
- リクエスト数による課金は、GETとPUTは料金が発生する。(GET<PUT)。DELETEは無料。
- 署名付きURL
- 署名付きURLの作成者がそのオブジェクトへのアクセス許可を持っている場合、署名付きURLを使用して、URL で識別されるオブジェクトにアクセスすることができる。
- ユーザー/顧客が特定のオブジェクトをバケットにアップロードできるようにする必要があるが、AWS セキュリティ認証情報またはアクセス許可を持つことを求めない場合に有用。
- 署名付き URL を作成するときは、セキュリティ認証情報を提供し、次にバケット名、オブジェクトキー、HTTP メソッド (オブジェクトのアップロードの PUT)、および有効期限の日時を指定する。
- AWS SDK for Java または AWS SDK for .NET のプログラムを使用して、署名付き URL を生成可能。AWS Explorer を使用して、コードを記述せずに署名付きオブジェクト URL を生成することも可能。
種類やタイプ
ストレージクラス
ストレージクラス データ格納料金 データ読み取りの即時性 主な用途 ユースケース 標準 最初の50TB\$0.023/GB。次の450TB \$0.022/GB、500TB~ $0.021/GB 即時 アクセス頻度の高いデータ コンテンツ配信、ビッグデータ分析など、幅広いユースケース 標準-IA $0.0125/GB 即時 アクセス頻度は低いが、必要時にすぐにアクセスが必要なデータの長期保存 データのバックアップ等 Intelligent-Tiering 高頻度層:標準と同様。低頻度:標準-IAと同様 即時 アクセスパターンが予測不能または変化し、必要時にすぐにアクセスが必要なデータの長期保存 アクセスパターンが予測できないコンテンツ配信など 1ゾーン-IA $0.01/GB 即時 アクセス頻度が低く、クリティカルではないデータの長期保存 サムネイル画像、データのセカンダリバックアップ等 Glacier $0.004/GB 数分から数時間 アクセス頻度が非常に低く、必要時にすぐにアクセスが基本不要なデータの長期保存 長期アーカイブ(緊急性の高いアクセスあり) Glacier Deep Archive $0.00099/GB 12時間以内 アクセス頻度が非常に低く、必要時にすぐにアクセスが不要なデータの長期保存 長期アーカイブ(緊急性の高いアクセスなし) 類似サービスとの比較
S3 EBS EFS Glacier 概要 オブジェクトストレージ、安価で高信頼性のストレージ、インターネットからもアクセス可能 ブロックレベルのファイルストレージ、EC2のローカルストレージ 共有ファイルストレージ 低価格、長期保管ストレージ 場所 リージョン AZ リージョン リージョン 自動複製 複数AZ AZ内3か所 複数AZ 暗号化 設定する必要あり。SSE-S3/KMS/C。 ボリューム作成時に暗号化。既存ボリュームの暗号化不可。(使用中ボリュームを暗号化=スナップショットを取得し、新規に暗号化ボリュームを作成し、リストア。 保管中、転送中のデータを暗号化。暗号化のキーはKMSにて管理可。 AES-256で自動で暗号化 ベストプラクティス
- S3バケットのクロスリージョンレプリケーションにより、リージョン全体に及ぶ大規模災害に対して、データを保護できる。(基本的にはリージョン外コピーはしない。)
- S3は大量ストレージ容量、コスト効率、拡張性、耐久性に優れている。
- オンプレミスでストレージが不足した際に、AWS Storage Gatewayを利用し、低レイテンシアクセスでS3と接続できる。
- クロスオリジンリソース共有(CORS)は別のドメインにあるリソースとの通信の設定。これを利用し、クライアントのウェブアプリケーションから別ドメインにあるS3リソースに対するアクセスを選択的に許可できる。
- S3の読み書きリクエスト性能の向上にはプレフィックスに日付順の名前を使用する。(以前のガイドラインではオブジェクトプレフィックスをランダム化し、各オブジェクト名の日付の前にハッシュキーをつける。)
- S3 API利用時のセキュリティ強化にはAPI認証情報を保存するのではなく、利用アプリケーションにIAMロールを割り当てる。
- S3バケットのオブジェクトを誤って削除しないように、MFA削除/バージョニング/IAMロールの有効化をすることができる。
- S3の暗号化には3つがある。
- SSE-S3:デフォルト暗号化設定可。
- SSE-KMS:デフォルト暗号化設定可。証跡管理可能。
- SSE-C3:ユーザによる暗号化キー管理。独自のキー設定可能。
- S3のオブジェクトをライフサイクル全体にわたり、コスト効率よく保存するためには、S3バケットのライフサイクルポリシーを使用し、ファイルをGlacierに転送する。
- S3ストレージクラスの中で、即時に取り出せるが、煩雑なアクセスはなく、高可用性と費用対効果の高い要件を満たすのは標準-IA。1ゾーン-IAはさらに低コストだが、可用性の面で標準-IAに劣る。
- 署名付きURLは通常AWSへのアクセスを許可しない場合に、期間限定的にアクセス許可をする際に利用する。
- 標準-IAは低頻度アクセス用だが、すぐに読み込みが可能かつ安価なため、重要なデータの保存にも適している。
- S3バケットのイベント機能を利用することで、Lambda関数と連携が可能となる。(ex.S3バケットにファイルがアップロードされたらイベント通知が発行され、Lambda関数を呼び出し、DynamoDBへデータ書き込み等)
- 読み/書きトラフィックに対して、アクセスパフォーマンスを最大化する際、以前はプレフィックスの文字列をランダムにするといった対策があったが、現在はデフォルトの設定のままで問題はない。
- Glacierのデータ最低保持期間は90日間のため、30日だけの保管の場合やかつ低頻度アクセスといった場合、GlacierよりS3 標準-IAのほうがコスト効率は良い。
参考例
用語
- PUTメソッド:リソースの更新、リソースの作成
- GETメソッド:リソースの取得
- DELETEメソッド:リソースの削除
- 投稿日:2020-03-01T18:25:23+09:00
【AWS】【SAA対策】RDS
RDS(Relational Database Service)
サービス概要
リレーショナルデータベースを簡単にセットアップ、運用、スケーリングできるウェブサービス。
費用対効果に優れた拡張機能を備え、一般的なデータベース管理タスクを管理。特徴
- サーバーを購入するときは、CPU、メモリ、ストレージ、IOPS をすべて一緒にまとめて入手可能。
- バックアップ、ソフトウェアパッチ、自動的な障害検出、および復旧を管理。
- 自動バックアップ実行可能。または、手動で独自のバックアップスナップショットを作成可能。これらのバックアップを使用してデータベースを復元可能。
- プライマリインスタンスと同期しているセカンダリインスタンスがあると、問題が発生したときにセカンダリインスタンスにフェイルオーバーできるため、高可用性を実現できる。
- MySQL、MariaDB、PostgreSQL、Oracle、Microsoft SQL Server など既に使い慣れたデータベース製品を使用可能。
- IAMを使用してユーザーとアクセス許可を定義すると、RDSデータベースにアクセスできるユーザーを制御可能。また、VPCに配置すると、データベースを保護できる。
- DBインスタンス
- クラウド内の独立したデータベース環境。
- DB インスタンスには、ユーザーが作成した複数のデータベースを含めることができる。
- MySQL、MariaDB、PostgreSQL、Oracle、および Microsoft SQL Serverが実行可能。
- ストレージには、マグネティック、汎用 (SSD)、Provisioned IOPS (PIOPS) の 3 タイプがある。
- 汎用SSDはボリュームサイズによって、ボリュームのベースパフォーマンスレベルや I/O クレジットを取得する速さが決まる。
- マルチAZ配置=複数AZのDBインスタンスを実行可能。AmazonによりセカンダリスタンバイDBインスタンスが別AZで自動的にプロビジョニングされる。
- プライマリDBインスタンスは、同期的にAZ間でセカンダリインスタンスにレプリケートされる。データの冗長性およびフェイルオーバーサポートを提供し、I/Oフリーズを排除して、システムのバックアップの際のレイテンシーのスパイクを最小限に抑える。
- セキュリティグループにより、DB インスタンスへのアクセスを制御する。制御するには、アクセスを許可する IP アドレスの範囲または Amazon EC2 インスタンスを指定。
種類やタイプ
ストレージタイプ
レイテンシー ユースケース 汎用 (SSD) ベースラインI/Oパフォーマンスは1GiB あたり3IOPS。ボリュームが大きいほどパフォーマンスが向上する。 さまざまなワークロードで最適。 マグネティック 下位互換性としてサポートされているストレージ。 利用にはいくつかの制限が設けられており、非推奨。 Provisioned IOPS (PIOPS) DB インスタンスの作成時に、IOPS レートとボリュームのサイズを指定。 高速で一貫した I/O 性能を必要とする本稼働アプリケーション。 類似サービスとの比較
RDS DynamoDB Redshift ElastiCache 概要 ・リレーショナルデータベース。
・主なDBエンジンをサポート、ツールがそのまま使えるため、オンプレからの移行に便利。
・データベースソフトウェアのパッチは自動パッチが可能。・NoSQL データベースサービス。
・結果整合性
・write直後のreadでは整合性が取れない場合あり。
・「強い整合性」オプションを指定すると性能は落ちる。
・レコードのサイズに上限あり。
・リージョンサービスでありプライベートネットワークからはNAT経由でアクセスする必要あり。・データウェアハウスタイプ
・スケーラブル
・高パフォーマンス・メモリーキャッシュタイプ
・Memcached:Key-Value Store形式のメインメモリキャッシュ。マルチノートのキャッシュクラスタ。
・Redis:Memcached:Key-Value Store形式のメインメモリキャッシュ。場所 AZ サービス(VPC内に配置) リージョン AZ サービス AZ サービス(VPC内に配置) バックアップ スケージュールで1日1回取得可能(手動可)※ただし、バックアップ中はI/O停止、止めたくない場合はマルチAZ利用する必要あり - - (memcached)バックアップ機能はなし(Redis)Snapshotによる永続化 ユースケース OS以下レイヤの管理不要、高可用性な、既存データベースの利用など 大量のオンライントランザクション処理など 大容量データの分析など DBの負荷低減用のメモリキャッシュ ベストプラクティス
- RDSリードレプリカ(非同期レプリケーション)を利用することで以下の効果を期待できる。
- DBインスタンスの読み取り頻度の高いDBのワークロードを緩和することで、全体の読み込みスループットを向上させる。
- 必要に応じてスタンドアロンDBに昇格させ、マスターDBのバックアップとして使用できる。
- リードレプリカを使用して、マスターDBやスタンバイDBへ影響することなく、レポート生成をできる。
- データベース作成時にRDSの暗号化オプションを有効化することで、インスタンスとスナップショットを暗号化できる。暗号化には「データ保存時の暗号化」と「通信アクセスの暗号化」()がある。
- メモリ、CPU、ストレージの使用状況をモニタリングする。Amazon CloudWatchで通知するように設定し、システムのパフォーマンスと可用性を維持する。
- 自動バックアップを有効にし、1 日のうちで書き込み IOPS が低くなる時間帯にバックアップが実行されるようにバックアップウィンドウを設定する。
- 読み取りリクエストの増加によるRDSインスタンスの負荷を抑えるには下記の方法などがある。
- RDSリードレプリカの作成
- RDSインスタンスのタイプを高性能なものにする。
参考例
用語
- 投稿日:2020-03-01T17:56:54+09:00
AWS AmplifyのAPI認証はどれがいいのか?
はじめに
Amplify add apiをすると、API認証の種類を選ぶことができる。
設定できるオプションの特徴をまとめる。比較
API Key
一番手軽。テスト用。
必ず指定した日にちごとに再設定しなければならない。
-1を指定すると自動更新されるとの記事を見かけたが、自分の環境では更新されなかった。Cognito User Pools
本番にも使える。基本はこれにしておけば間違いない。
ユーザごとのアクセス制御である。Amplifyのユーザー認証と組み合わせて、ログインしたユーザに対してアクセスできるリソースを指定して用いる。IAM
未認証ユーザにも使える。公開APIにしたいときにおすすめ。
ロールベースのアクセス制御である。Amplifyの場合、デフォルトだと、authRole, unAuthRoleが生成されるので、それぞれ認証ユーザ、未認証ユーザにアクセスさせたいリソースを指定して用いる。OIDC Auth
外部の認証を使いたいときに使う。
上記3認証方式と組み合わせて使うと良い。おまけ
UserPoolとIAMのユースケースの違いは、Amazon公式にまとまっている。
https://aws.amazon.com/jp/premiumsupport/knowledge-center/cognito-user-pools-identity-pools/
- 投稿日:2020-03-01T17:56:14+09:00
AWS Well-Architected Framework「信頼性」
信頼性の柱の5つの設計原則をざっくりまとめてみたいと思います。
この内容はnoteのほうで投稿したものと同じ内容になります。
「③信頼性」1, 復旧手順をテストする
障害のシュミレーションをし、復旧手順が適切であるか、検証しましょう。オンプレミス環境でも復旧手順の検証をできるといいのですが、手順が適切でなかった場合、壊れて使えなくなったシステムを再構築するのは多くの時間や費用がかかるので、復旧手順の検証はリスクがあります。一方クラウド環境では、再構築にかかるコストが抑えられるため、障害のシュミレーションが容易にできるようになりました。それにより、実際に障害が起きる前に適切な復旧手順を用意しておくことができます。また自動化ツールを使い、シュミレーションを自動化することもできます。
2, 障害から自動的に復旧する
復旧手順を自動化しましょう。システムの使用状況をモニタリングし、障害発生時に自動で通知・対処・修正することができます。
3, 水平方向にスケールしてシステム全体の可用性を高める
リソースを冗長化し、疎結合なシステム構成にしましょう。単一障害点(ここで障害が発生するとシステム全体に影響を与えてしまう、という点)を無くすことが重要です。
4, キャパシティーを予測しない
リソースを適宜追加・削除し、需要と使用率を最適化しましょう。オンプレミス環境では、初めに予測したリソースの使用率より実際の使用率が上回り、需要に応えられなくなって障害が発生するケースが一般的でした。しかしクラウド環境では、使用率をモニタリングし、リソースを最適化することができます。
5, オートメーションで変更を管理する
モニタリングし、需要の変化に応じたリソースの追加・削除を自動化しましょう。変更履歴は自動的にログに記録されます。
- 投稿日:2020-03-01T17:51:37+09:00
AWS日記①
AWSの利用の動機
- 無料利用枠がある
- 機械学習・深層学習のサービスを利用できる
- Lambdaを利用してサーバレスなWEBサービスを作成できる
AWSのアカウント登録
AWSの「無料サインアップ」をクリックし、以下の項目を入力・選択していく
- E メールアドレス
- パスワード
- AWS アカウント名
- アカウントの種類
- パーソナル
- フルネーム
- 電話番号
- 国/地域
- アドレス
- 市区町村
- 都道府県または地域
- 郵便番号
- クレジット/デビットカード番号
- 有効期限日
- カード保有者の氏名
- 請求先住所
- 検証コードをどのように受け取りますか?
- 国またはリージョンコード
- 携帯電話番号
- セキュリティチェック
アカウント登録が完了すれば「AWS マネジメントコンソール」に入れるようになります
終わりに
住所・クレカ・スマホ(電話番号)を持っていればAWSのアカウントを作成できます
無料利用枠だけ使用したい場合でもクレカ情報の入力を求められます
- 投稿日:2020-03-01T17:44:41+09:00
【AWS】【SAA対策】EC2
EC2(Elastic Compute Cloud)
サービス概要
EC2はAWSで最も重要といっても過言ではないサービス。
クラウド上でサイズが変更できるコンピューティングキャパシティーを提供する。
EC2を利用することで、必要な数の仮想サーバーを起動し、セキュリティ/ネットワークの設定、ストレージの管理を実施できる。特徴
- 仮想コンピューティング環境をインスタンスという単位で管理。
- AMIと呼ばれる、OSおよびソフトウェアを事前に設定したテンプレートを既存(標準/AWS Marketplace)の物から利用あるいは、自作可能。
- インスタンスタイプ=CPU、メモリ、ストレージ、ネットワーキングキャパシティーの構成
- インスタンスストアボリューム=インスタンスを停止/終了すると一時データが削除されるボリューム
- EBS=永続的ストレージボリューム。インスタンスにアタッチすることで利用。
- セキュリティグループ=プロトコル、ポート、ソースIP範囲で指定できるファイアウォール
- Elastic IPアドレス=動的クラウドコンピューティング用の静的なIPv4アドレス
- オンデマンドインスタンス=従量課金。リザーブドインスタンス=前払いで値引き(1~3年)。スポットインスタンス=未使用のEC2インスタンスをリクエストしてコスト削減。
種類やタイプ
インスタンスファミリー
特徴 ユースケース 汎用 T2,T3=負荷が少ないときに「CPUクレジット」を貯め、突発的に負荷が高まったときに貯めてたCPUクレジットを消する「バースト」機能。 「ある時間だけ負荷が集中する」といった傾向が見えているWebサイト(T2,T3)。その他、バランス重視のサイト コンピューティング最適 高パフォーマンスプロセッサの恩恵を受けるコンピューティングバウンドなアプリケーションに最適 バッチ処理ワークロード、メディアトランスコード、高性能ウェブサーバーなどコンピューティング負荷の高いアプリケーション メモリ最適 メモリ内の大きいデータセットを処理するワークロードに対して高速なパフォーマンスを実現する 高パフォーマンスデータベース、リアルタイムのビッグデータ分析、およびその他エンタープライズアプリケーションなどのメモリ集約型アプリケーション 高速コンピューティング ハードウェアアクセラレーター (コプロセッサ) を使用して、浮動小数点計算、グラフィックス処理、データパターン照合などの機能を、CPU で実行中のソフトウェアよりも効率的に実行 機械学習/深層学習、ハイパフォーマンスコンピューティング (HPC) ストレージ最適化 ローカルストレージの大規模データセットに対する高いシーケンシャル読み取りおよび書き込みアクセスを必要とするワークロード用に設計されている。ストレージ最適化インスタンスは、数万 IOPS もの低レイテンシーなランダム I/O オペレーションをアプリケーションに提供するように最適化されている NoSQL データベース (例:. Cassandra、MongoDB、Redis)、インメモリデータベース (例: Aerospike)、スケールアウトトランザクションデータベース、データウェアハウジング、Elasticsearch、分析ワークロード 購入タイプ
オンデマンドインスタンス リザーブドインスタンス スポットインスタンス 概要 一般的な従量課金制のインスタンス。 1 年あるいは 3 年のコミットメントで購入することができる。オンデマンドインスタンスの料金と比べて Amazon EC2 コストの大幅な割引を受けられる。 使用料金を入札して安値で使用。入札できないと起動中のインスタンスが停止する。新規の場合はインスタンスが起動できない。 価格 起動するインスタンスに対して秒単位でお支払い 支払方法 ・すべて前払い : 期間の開始時に全額が支払われ、使用時間数に関係なく、残りの期間にその他のコストや追加時間課金は生じません。
・一部前払い : 料金の一部を前払いする必要があり、期間内の残りの時間は、リザーブドインスタンス が使用されたどうかにかかわらず、割引された時間料金で請求されます。
・前払いなし : リザーブドインスタンス が使用されたどうかにかかわらず、期間内のすべての時間は割引時間料金での請求となります。前払い料金は必要ではありません。
リザーブドインスタンス の前払い額を高く設定するほど、より多くの費用を節約できる。ユースケース 短期間、不規則なワークロードがあり中断できないアプリケーション 長期使用が確定しており、リソースの需要が固定している。 後回し可能な処理を行う場合など。 用途 開発、テスト環境など 本番環境、長期稼働が確定したシステム 突然停止、稼働延滞が起きても問題ないシステム *1 時間 につき USD 単位で一定の使用量を守り、割引を得る、Savings plansもある。
リザーブドインスタンスの購入クラス
スタンダード コンバーティブル 概要 最大の割引を提供するが、変更のみを行うことができる スタンダード リザーブドインスタンス より金額が高いが、異なるインスタンス属性を使用する別のコンバーティブル リザーブドインスタンス と交換できる。 ベストプラクティス
- Dedicated Hostは完全に専用で利用できる物理サーバーのため、ソフトウェアライセンスの条項で物理コアなどを制限しているときに有用。
- プレイスメントグループ=EC2インスタンスの配置方法の戦略。クラスター(単一AZ内インスタンスグループ化)、パーティション(論理パーティション分散)、スプレッド(電源隔離ネットワーク配置グループ)の3つがある。
- ハイバネーション機能により、インスタンスを休止し、セットアップ状態で再開できる。
- EC2の災害復旧ソリューションとしてインスタンスのAMI作成、別リージョンへのコピー。
- インスタンスにタグを追加し、IAMポリシーでタグへのアクセス定義をし、アクセス制御。
- 常時稼働しているインスタンスが複数ある場合、リザーブドインスタンスを使うことでコスト削減。
- 処理時間がかかるが、途中でアプリケーションが中断してもよい場合、スポットインスタンスを選択することで、費用対効果が高くなる。
- 高負荷による処理性能に限界が発生した場合、AutoScalingによる拡張は一時的なもののため、コストを抑えたい場合はスポットインスタンスを利用する。(長期的な対応には不向き)
- EC2インスタンス間の通信がうまくできない場合、セキュリティグループの通信許可がされているかを確認する。
- EC2インスタンスのAMIを別リージョンにコピーすることで、リージョンによる障害発生時に低コストでEC2インスタンスの復元が可能。(定期的に実施することが推奨。)*EBSのスナップショットのみではEBS内のデータのみのため、インスタンスの設定などはコピーできない。
- リザーブドインスタンスは1年または3年のため、期限切れの前にPJが終了したり、現在の容量が不要な場合にはマーケットプレイスで販売することでコスト削減できる。
参考例
用語
- 投稿日:2020-03-01T17:06:45+09:00
Cognito認証されているAppSyncをIAM認証で後ろから叩く
Cognito認証されているAppSyncをIAM認証で後ろから叩く
はじめに
以前、サーバーレスWebアプリハンズオン記事として「AppSyncをフロントエンドとバックエンドで利用する」を投稿しました。
ここでは認証モードとして当然のように「API Key」を利用していました。
このAPI Keyでの認証、初学者がまず使ってみる場合や簡易的なプロトタイプとして利用する分には良いのですが、安全性や有効期限が最大365日という更新の手間のことを考えると、なるべく他の認証モードを採用すべきです。
その鍵、見えてますよ、、。
365日後に鍵の更新、絶対忘れますよ、、。AppSyncの認証モードの種類
AppSyncはAPI Key以外に以下の認証モードをサポートしています。
- AWS Identity and Access Management (IAM)
- Amazon Cognito ユーザープール
- OpenID Connect
IAMとは
AWSリソースへアクセスできる範囲やアクセス方法を制御するための仕組みです。Cognitoユーザープールとは
アプリユーザー管理(サインアップやサインイン状態)を提供する仕組みです。OpenID Connectとは
使ったことがないため良く知らないです、、。
(Cognitoと同じように、ログインして発行されたトークンを利用して認証する感じ?)複数の認証モードを組み合わせて使う
AppSyncは2019年5月に複数の認証モードをサポートしました。
https://aws.amazon.com/jp/about-aws/whats-new/2019/05/aws-appsync-now-supports-configuring-multiple-authorization-type/これにより、フロントエンド(クライアントサイド)はCognitoで、バックエンド(サーバーサイド)はIAMで認証するということができるようになりました。
IAM認証を追加して、Lambda(Python)で叩く
Amplifyを利用することで、Cognito認証を効かせたAppSyncの構築と、それをフロントエンド(Webアプリ)から利用する実装については、サクッと実現できるようになりました。
この記事ではそこからさらに、
バックエンドで利用するための認証プロバイダーとしてIAMを追加し、
Lambda(Python)から実際に叩く(APIをコールする)ところについて書きたいと思います。追加の認証プロバイダーにIAMを追加する
AWSコンソール > AWS AppSync > 目的のAPIを選択 > 設定
下の方に「追加の認証プロバイダー」という項目があるので、Newボタンを押下。
「追加の認証プロバイダーを設定する」ポップアップ画面の認証モードコンボボックスから、「AWS Identify and Access Management(IAM)」を選択して「送信」ボタンを押下。
設定の「追加の認証プロバイダー」に「AWS Identify and Access Management(IAM)」が追加されているのを確認し、最下にある「保存」ボタンを押下。(※忘れずに!)
スキーマに認証モードを指定する
複数の認証モードを利用する場合、スキーマへの追記が必要です。
どの認証モードで何ができるのか、Query、Mutation、Subscriptionなどのルート型や、その中にユーザー定義した関数フィールドやオブジェクト型ごとに細かく指定することができます。
(※input(入力型)には指定できません。)デフォルトでは何も指定されておらず、その場合はプライマリ認証モードのみ許可されている状態ということになり、追加した認証モードは許可されていません。
以下のマーキングをすることで認証モードを指定できます。
@aws_api_key
フィールドが API_KEY で承認されることを指定します。@aws_iam
フィールドが AWS_IAM で承認されることを指定します。@aws_oidc
フィールドが OPENID_CONNECT で承認されることを指定します。@aws_cognito_user_pools
フィールドが AMAZON_COGNITO_USER_POOLS で承認されることを指 定します。詳細はこちらの開発者ガイドをどうぞ。(というかここに全て書いてある)
https://docs.aws.amazon.com/ja_jp/appsync/latest/devguide/appsync-dg%20.pdfAWSコンソール > AWS AppSync > 目的のAPIを選択 > スキーマ
ここでgraphqlのスキーマを編集した後、「スキーマを保存」ボタンを押下してください。
一部ですが、編集前(Before.graphql)と編集後(After.graphql)のスキーマの例を載せておきます。
Before.graphqltype Mutation { createSampleAppsyncTable(input: CreateSampleAppsyncTableInput!): SampleAppsyncTable updateSampleAppsyncTable(input: UpdateSampleAppsyncTableInput!): SampleAppsyncTable deleteSampleAppsyncTable(input: DeleteSampleAppsyncTableInput!): SampleAppsyncTable } type Query { getSampleAppsyncTable(group: String!, path: String!): SampleAppsyncTable listSampleAppsyncTables(filter: TableSampleAppsyncTableFilterInput, limit: Int, nextToken: String): SampleAppsyncTableConnection } type SampleAppsyncTable { group: String! path: String! }After.graphqltype Mutation { createSampleAppsyncTable(input: CreateSampleAppsyncTableInput!): SampleAppsyncTable @aws_cognito_user_pools @aws_iam updateSampleAppsyncTable(input: UpdateSampleAppsyncTableInput!): SampleAppsyncTable @aws_iam deleteSampleAppsyncTable(input: DeleteSampleAppsyncTableInput!): SampleAppsyncTable } type Query @aws_cognito_user_pools { getSampleAppsyncTable(group: String!, path: String!): SampleAppsyncTable listSampleAppsyncTables(filter: TableSampleAppsyncTableFilterInput, limit: Int, nextToken: String): SampleAppsyncTableConnection } type SampleAppsyncTable @aws_cognito_user_pools @aws_iam { group: String! path: String! }この例では、以下のように指定しています。
Mutation.create : CognitoとIAM
Mutation.update : IAMのみ
Mutation.delete : Cognitoのみ(指定なし=プライマリ)
Query : getもlistもCognitoのみここまで書いて思いましたが、プライマリ認証はCognitoではなくIAMにして、クライアント側で必要なものだけCognito許可を与えるような設計が良さそうですね。
Lambda(Python)で叩く
IAM認証許可を与えたAppSyncを、LambdaのPythonで叩くための実装です。
sample_graphql_with_iam.pyimport requests from requests_aws4auth import AWS4Auth AWS_REGION = os.environ["AWS_REGION"] AWS_ACCESS_KEY_ID = os.environ["AWS_ACCESS_KEY_ID"] AWS_SECRET_ACCESS_KEY = os.environ["AWS_SECRET_ACCESS_KEY"] AWS_SESSION_TOKEN = os.environ["AWS_SESSION_TOKEN"] ENDPOINT = "https://{0}.{1}.{2}.amazonaws.com/{3}".format("xxxxxxxxxxxxxxxxxxxxxx", "appsync-api", AWS_REGION, "graphql") AUTH = AWS4Auth(AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY, AWS_REGION, 'appsync', session_token=AWS_SESSION_TOKEN) def apiCreateTable(group, path): try: body_json = {"query": """ mutation create {{ createSampleAppsyncTable(input:{{ group: \"{0}\" path: \"{1}\" }}){{ group path }} }} """.format(group, path) } body = json.dumps(body_json) response = requests.request("POST", ENDPOINT, auth=AUTH, data=body, headers={}) except Exception as e: logger.exception(e) raise eIAMロールへポリシーの追加
実行するLambdaのIAMロールへ、AppSyncのポリシーを加えます。
AWSAppSyncAdministratorをアタッチしてあげればOKです。
(※ 本当はAppSync全体ではなく目的のAPIのみ許可するようにインラインポリシーを書いてあげたほうがいいのだと思いますが、書き方が分かりません。誰か教えて下さい!)あとがき
前から叩いて良し、後ろから叩いて良し。
後ろから叩かれるのを前で待たせておくとイケてる感じになります。(※Subscriptionの話)
前も後ろもCognitoじゃ退屈っていうんで、後ろはIAMにしてるんですよ。(※認証の話)っていう話をJAWS UG浜松のある方(Amplifyおじさん)とした結果、この記事を書くに思い至りました。
昨年末のLTではこのようなイラストで表現しましたね。
(後ろから叩かれるのを前で監視して待ってるイメージ)様々な用途に活用できそうで開発のし甲斐がある、そんなAppSyncを今後ますます攻略してゆきたいですね!






- 投稿日:2020-03-01T16:56:50+09:00
サーバーについて
はじめに
しばらく期間が空いておりました。
アプリ作成に取り掛かっており、とても楽しんでおりました。その分outputが疎かに・・・ではデプロイに取りかかる前に、学んだことをoutput致します。
もうすでにご存知の方、省略の仕方等ご存知でしたら、ご教授願います。サーバーについて
サーバーの種類
- サーバー(Server)とは「何か(モノやサービスなど)を提供する人」という意味。
- サーバーという呼び方をするものには、2種類ある。
- ハードウェア:ソフトウェアを格納する倉庫
- ソフトウェア: Webサーバーなど(Webブラウザからコンテンツを閲覧できる状態にしてくれているモノ)
今回学習したのはソフトウェアのサーバーですので、それについてoutputします。
サーバーの意味
- サイトの情報を持ったコンピューターを サーバー と呼ぶ。
- 仮に自身のアプリケーションを世界中に公開したい場合、サーバを用意しWebアプリケーションをそこに設置する必要がある。
サーバーに関する用語
- サーバー(server): Webで情報を公開しているコンピューターのこと
- クライアント(client): サーバーから情報を受信して利用するコンピューターやソフトウェアのこと
- デプロイ(deploy): サーバー上にアプリケーションを配置し、Web上に展開する
- クラウドコンピューティング: ソフトウェアやハードウェアの利用権などをネットワーク越しに提供する技術
デプロイするまでのステップ
- アプリケーションを開発する
- アプリケーションをデプロイするためのサーバーを用意する
- アプリケーションをデプロイする
AWSについて
- AWS は、2つめのステップのサーバーの用意において必要となる。
- AWSとはAmazon Web Servisesの略(クラウドコンピューティングサービス の総称)
- 代表的なサービス
- Amazon EC2(仮想サーバ)
- Amazon S3(クラウドストレージ)
- Amazon RDS(データベース)など
さいごに
日々勉強中ですので、随時更新します。
皆様の復習にご活用頂けますと幸いです。
- 投稿日:2020-03-01T14:24:48+09:00
wordpressをはじめる。
wordpressをはじめる。
wordpressをはじめるにあたり調べると色々なはじめ方があるある!
その中から今回はawsのLightsailを使用しはじめました。
その前に今回の目標は、
①wordpressをインストールする
②wordpressの初期設定を行う
③テーマを設定する
④プラグインを追加する
⑤投稿を公開する
としました。では、awsからLightsailに入り、インスタンスの作成。
選択肢の中にwordpressがあるのでチョイス!
その他設定をしスタート!今後、テーマの設定や色々いじいじして行こうと思ってますので、その都度投稿できる様にして行こう。
- 投稿日:2020-03-01T13:19:30+09:00
EC2 + RDS + Capistrano + unicorn + nginxでrailsアプリを自動デプロイする【後半】
いよいよ本題であるCapistranoを使用したデプロイについて解説していきます。
EC2の事前準備
最初に準備としてEC2内に必要なものをインストールしていきます。
1. rbenv, git,環境変数の設定
[sample_user@ip-10-0-0-79 ~] $ sudo yum -y install git [sample_user@ip-10-0-0-79 ~] $ git clone https://github.com/sstephenson/rbenv.git ~/.rbenv #rbenv [sample_user@ip-10-0-0-79 ~] $ git clone https://github.com/sstephenson/ruby-build.git ~/.rbenv/plugins/ruby-build #ruby-build [sample_user@ip-10-0-0-79 ~] $ sudo vim .bash_profile ----------------------------- export PATH="$HOME/.rbenv/bin:$PATH" eval "$(rbenv init -)" #この2行を追加してpathを通します ----------------------------- [sample_user@ip-10-0-0-79 ~] $source ~/.bash_profile #設定の反映 [sample_user@ip-10-0-0-79 ~] $ rbenv -v #pathが通ったかを確認環境変数
[sample_user@ip-10-0-0-79 ~] $ sudo vim .bashrc #環境変数の設定 ------------------------------- export sample_variable="sample_sample_sample" #アプリ内で環境変数を使用している方はここで設定 ------------------------------- [sample_user@ip-10-0-0-79 ~] $ source ~/.bashrc #設定の反映2. Ruby(version 2.6.3)
[sample_user@ip-10-0-0-79 ~] $ sudo yum install -y gcc [sample_user@ip-10-0-0-79 ~] $ sudo yum install -y openssl-devel readline-devel zlib-devel [sample_user@ip-10-0-0-79 ~] $ rbenv install 2.6.3 #ruby2.6.3をインストール3. bundler
[sample_user@ip-10-0-0-79 ~] $ rbenv exec gem install bundler [sample_user@ip-10-0-0-79 ~] $ rbenv rehash4. mysql
[sample_user@ip-10-0-0-79 ~] $ sudo yum install mysql mysql-server mysql-devel5. sqlite
[sample_user@ip-10-0-0-79 ~] $ sudo yum install sqlite-devel6. node.js
[sample_user@ip-10-0-0-79 ~] $ sudo amazon-linux-extras install epelデプロイ先の作成
Capistranoはgit cloneを通してコードをコピーするため、デプロイ先のディレクトリを作成します。
[sample_user@ip-10-0-0-79 ~] $ sudo mdkir /var/www [sample_user@ip-10-0-0-79 var] $ sudo chmod 777 www [sample_user@ip-10-0-0-79 var] $ cd www [sample_user@ip-10-0-0-79 www] $ mkdir sample_app [sample_user@ip-10-0-0-79 www] $ cd sample_app [sample_user@ip-10-0-0-79 sample_app] $ rbenv local 2.6.3 #バージョンを設定Git HubのSSh設定
前半でlocalからserverへSSH接続した時と同様に、server側からGit HubへSSH接続ができるよう設定を行います。
[sample_user@ip-10-0-0-79 ~]$ cd .ssh [sample_user@ip-10-0-0-79 .ssh]$ ssh-keygen -t rsa Enter file in which to save the key (/home/sample_user/.ssh/id_rsa): sample_git_rsa #sample_git_rsaという名前で鍵を生成 [sample_user@ip-10-0-0-79 .ssh]$ ls authorized_keys sample_git_rsa sample_git_rsa.pub [sample_user@ip-10-0-0-79 .ssh]$ cat sample_git_rsa.pub #中身をコピーSettings→SSH and GPG keysでNew SSH keyでkeyを新規作成し中身を貼り付ける。
次は設定ファイルを作成。
[sample_user@ip-10-0-0-79 .ssh] $ vim config ------------------------------------------- Host github Hostname github.com User git IdentityFile ~/.ssh/sample_git_rsa (#先ほど作成した秘密鍵のpath) -------------------------------------------最後にserverからGitHubへSSh接続ができているかを確認
[sample_user@ip-10-0-0-79 .ssh] $ sudo chmod 600 config [sample_user@ip-10-0-0-79 .ssh] $ ssh -T github #成功 Permanently added the RSA host key for IP address '140.82.114.3' to the list of known hosts. Hi ichihara-development-github! You've successfully authenticated, but GitHub does not provide shell access.Nginx
今回はWebサーバーにnginx、アプリケーションサーバーにunicornを使用するのでEC2側でNginxの設定を行います。
Webサーバーとアプリケーションサーバーに関してはこちらの記事が参考になるため、ご一読下さい。
なぜrailsの本番環境ではUnicorn,Nginxを使うのか? ~ Rack,Unicorn,Nginxの連携について ~【Ruby On Railsでwebサービス運営】
Nginx
[sample_user@ip-10-0-0-79 ~] $ sudo yum install nginx #nginxをインストール [sample_user@ip-10-0-0-79 ~] $ cd /etc/nginx/conf.d/ [sample_user@ip-10-0-0-79 conf.d] $ sudo vim sample_app.conf #nginxはデフォルト設定で.confファイルを読み込みます -------------------------------------------- #以下を追加 upstream unicorn { server unix:/tmp/unicorn.sock; } server { listen 80; server_name 〇.〇.〇.〇(Elastic IP); access_log /var/log/nginx/sample_access.log; error_log /var/log/nginx/sample_error.log; #エラーログの保存先を指定 location / { proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_pass http://unicorn; } } --------------------------------------------local
それではCapistranoをlocalにインストールし、デプロイの準備を行いましょう。
Gemfile#以下を追加 gem 'mysql2' platforms :ruby do gem 'unicorn' end group :development do gem 'capistrano' gem 'capistrano-bundler' gem 'capistrano-rails' gem 'capistrano-rbenv' gem 'capistrano3-unicorn' end ------------------------------------------ $ bundle installsample_app$ bundle exec cap install mkdir -p config/deploy create config/deploy.rb create config/deploy/staging.rb create config/deploy/production.rb mkdir -p lib/capistrano/tasks create Capfile Capifiedbundle exec cap installを実行するとCapistanoの設定ファイルが自動生成されます。
1. Capfileの設定
Capfilerequire 'capistrano/setup' require 'capistrano/deploy' require 'capistrano/rbenv' require 'capistrano/bundler' require 'capistrano/rails/assets' require 'capistrano/rails/migrations' require 'capistrano3/unicorn'capistranoを使用できるように読み込みます。
2. config/deploy.rbの設定
config/deploy.rblock '3.12.0' set :application, 'sample_app' #アプリ名を記載 set :repo_url, 'github:ichihara-development-github/sample_app.git' #cloneを行うリモートリポジトリを記載 #ただし、configファイルでgithub.com→githubとして置き換えられているので注意 set :rbenv_type, :user set :rbenv_ruby, '2.6.3' set :rbenv_prefix, "RBENV_ROOT=#{fetch(:rbenv_path)} RBENV_VERSION=#{fetch(:rbenv_ruby)} #{fetch(:rbenv_path)}/bin/rbenv exec" set :rbenv_map_bins, %w{rake gem bundle ruby rails} set :rbenv_roles, :all set :log_level, :warn set :linked_files, fetch(:linked_files, []).push('config/database.yml', 'config/secrets.yml') set :linked_dirs, fetch(:linked_dirs, []).push('log', 'tmp/pids', 'tmp/cache', 'tmp/sockets', 'vendor/bundle', 'public/system') set :keep_releases, 3 set :unicorn_pid, "#{shared_path}/tmp/pids/unicorn.pid" set :unicorn_config_path, -> { File.join(current_path, "config", "unicorn.rb") } namespace :deploy do after :restart, :clear_cache do on roles(:web), in: :groups, limit: 3, wait: 10 do end end end after 'deploy:publishing', 'deploy:restart' namespace :deploy do task :restart do invoke 'unicorn:restart' end end3. config/deploy/production.rbの設定
config/deploy/production.rbserver "〇.〇.〇.〇", user: "sample_user", roles: %w{app db web} #serverのIPと、ログイン可能なuser名を記載してください set :ssh_options, { keys: %w(~/.ssh/sample_app_key_rsa), #秘密キーのpathを記載 forward_agent: true, auth_methods: %w(publickey), port: 22 }4. unicornの設定(local側)
config配下にunicron.rbを作成します。
config/unicorn.rbAPP_PATH = "#{File.dirname(__FILE__)}/.." unless defined?(APP_PATH) RAILS_ROOT = "#{File.dirname(__FILE__)}/.." unless defined?(RAILS_ROOT) RAILS_ENV = ENV['RAILS_ENV'] || 'development' worker_processes 3 listen "/tmp/unicorn.sock" pid "tmp/pids/unicorn.pid" preload_app true timeout 60 working_directory APP_PATH # logのpath stderr_path "#{RAILS_ROOT}/log/unicorn_error.log" stdout_path "#{RAILS_ROOT}/log/unicorn_access.log" if GC.respond_to?(:copy_on_write_friendly=) GC.copy_on_write_friendly = true end before_exec do |server| ENV['BUNDLE_GEMFILE'] = APP_PATH + "/Gemfile" end before_fork do |server, worker| defined?(ActiveRecord::Base) and ActiveRecord::Base.connection.disconnect! old_pid = "#{ server.config[:pid] }.oldbin" unless old_pid == server.pid begin Process.kill :QUIT, File.read(old_pid).to_i rescue Errno::ENOENT, Errno::ESRCH end end end after_fork do |server, worker| defined?(ActiveRecord::Base) and ActiveRecord::Base.establish_connection end最後にここまでの内容をGitHubに反映しておきましょう。
$ git add . $ git commit -m "first_commit" $ git push origin masterデプロイ!
これでようやくデプロイに必要な設定が終了しました!
いやー長かった…というわけで早速デプロイができる状態なのかをチェックしていきます。
(sample_app)$ bundle exec cap production deploy:checkすると順々に処理が走っていき、以下のようなエラーが発生すると思います。
00:10 deploy:check:linked_dirs 01 mkdir -p /var/www/sample_app/shared/log /var/www/sample… ✔ 01 sample_user@3.21.59.95 0.675s 00:10 deploy:check:make_linked_dirs 01 mkdir -p /var/www/sample_app/shared/config ✔ 01 sample_user@3.21.59.95 0.554s 00:12 deploy:check:linked_files ERROR linked file /var/www/sample_app/shared/config/databa…これは/sample_app/shared/config配下にdatabase.ymlが存在しませんというエラーです。
実はCapistranoのdeployコマンドを実行するとサーバー側のディレクトリの構造が少しだけ変化し、新たにsharedというディレクトリが生成されます。
/var/www/sample_app[sample_user@ip-10-0-0-79 sample_app] $ ls releases sharedそのためshared配下にdatabase.ymlを作成、編集していきます。
/var/www/sample_app/shared/config[sample_user@ip-10-0-0-79 config] $ vim database.yml ----------------------------------- default: &default adapter: sqlite3 pool: 5 timeout: 5000 development: <<: *default database: db/development.sqlite3 # Warning: The database defined as "test" will be erased and # re-generated from your development database when you run "rake". # Do not set this db to the same as development or production. test: <<: *default database: db/test.sqlite3 production: adapter: mysql2 pool: 5 database: sample_app_db #RDSに設定したデータベース名 host: database-1.ckbaeqyxwuvr.us-east-2.rds.amazonaws.com #エンドポイント username: sample_user #RDSに設定したuser名 password: password #RDSに設定したパスワード -----------------------------------
localにあるdatabase.ymlにproduction環境のみ変更を加えました。
新たにRDSの情報を記載することで、RDSをデータベースとして使用することが可能です。さらにこちらの内容をlocalにもコピーしておきましょう。この状態でdeploy:checkを実行すると、同様にsecrets.ymlがないといったエラーも発生してしますので、事前に作成します。
/var/www/sample_app/shared/config[sample_user@ip-10-0-0-79 config] $ vim secrets.yml ------------------------------------------------- development: secret_key_base: bf8daa05189f332e986f7fcb26bbb25c9c34da0257b9994931dd0f5265e325f3a84c9630b1e264b96c8e28276ab7bc41a9c6761b8b2befeb1bd53bbcb53afb59 test: secret_key_base: 0c1f0d49d25f201c31378d38eb12cf87f4684f321ed0f2b1b66f704c6daf77690f487c77ab6347d1ddf5bfc3c258048be5ca34e406c0d4de34599305623f699d # Do not keep production secrets in the unencrypted secrets file. # Instead, either read values from the environment. # Or, use `bin/rails secrets:setup` to configure encrypted secrets # and move the `production:` environment over there. production: secret_key_base: <%= ENV["SECRET_KEY_BASE"] %> -------------------------------------------------これでlocalに戻り、もう一度deploy:checkを実行すると、今度はエラーがなく処理が終わるはずです。以下のコマンドで本デプロイを行って下さい。
sample_app$ bundle exec cap production deploy以下のようにエラーが出なればデプロイ完了です。
01:27 deploy:cleanup Keeping 3 of 33 deployed releases on 3.21.59.95 01 rm -rf /var/www/sample_app/releases/20200227082245 /var/www/sample_app/releases/20200227082547 /var/www/ … ✔ 01 sample_user@3.21.59.95 0.899s 01:31 deploy:log_revision 01 echo "Branch master (at 803b41a3fe36f77c2682d9f740f4dbd45047b08d) deployed as release 20200228055144 by … ✔ 01 sample_user@3.21.59.95 0.826sそして最後の仕上げにsecret_key_baseを生成してsecrets.ymlに張り付けましょう。
デプロイ自体にエラーは出ていませんが実はこの状態でアクセスしてもページが表示されません。
そのためunicornのエラーログを確認してみると…
current/unicorn_error.log[sample_user@ip-10-0-0-79 ~] $ cat /var/www/sample_app/current/log/unicorn_error.log I, [2020-02-28T05:52:58.354411 #23838] INFO -- : worker=2 ready I, [2020-02-28T05:52:58.420071 #23777] INFO -- : reaped #<Process::Status: pid 23780 exit 0> worker=0 I, [2020-02-28T05:52:58.420171 #23777] INFO -- : reaped #<Process::Status: pid 23781 exit 0> worker=1 I, [2020-02-28T05:52:58.420211 #23777] INFO -- : reaped #<Process::Status: pid 23782 exit 0> worker=2 I, [2020-02-28T05:52:58.420260 #23777] INFO -- : master complete E, [2020-02-28T06:05:54.876223 #23838] ERROR -- : app error: Missing `secret_key_base` for 'production' environment, set this value in `config/secrets.yml` (RuntimeError)とsecret_key_baseがないとのエラーが発生しているのが分かります。
(currentディレクトリはCapistranoのデプロイによってデプロイ先の配下に新しく生成されるディレクトリで、ここにGitt Hubからコードがcloneされます。)
なので[sample_user@ip-10-0-0-79 ~] $ cd /var/www/sample_app [sample_user@ip-10-0-0-79 current] $ bundle exec rake secret 81734ede2dfc8644523baabe7b8614081c53c43580feb5f9f23140d946040d22dfe2324756eedd7d103057718fc28587e7b57619f7eb077f57054a [sample_user@ip-10-0-0-79 current] $ vim secrets.yml ---------------------------------------------- # Do not keep production secrets in the unencrypted secrets file. # Instead, either read values from the environment. # Or, use `bin/rails secrets:setup` to configure encrypted secrets # and move the `production:` environment over there. production: secret_key_base: 81734ede2dfc8644523baabe7b8614081c53c43580feb5f9f23140d946040d22dfe2324756eedd7d103057718fc28587e7b57619f7eb077f57054a ---------------------------------------------- [sample_user@ip-10-0-0-79 ~] $ exit #local $ bundle exec cap production deploy # 再度デプロイ一度デプロイが成功すると後は変更があった時に
git push → cap production deploy を実行するだけでデプロイ先に内容が反映されるのでデプロイ作業が大幅に楽になります。それではサーバーにアクセスしてみて、作ったAPPが存在するかを確認してみてください。
あったぁ!
日本語登録も大丈夫です。
とはいっても自分はここでエラーを吐き出しまくって全然前に進めなったため、その時の対処法を別の記事にまとめました(泣)
デプロイが上手くいかなかった方はこちらを参考にしてみてください。
Capistranoで何回やってもデプロイできないときの対処法
まとめ
初めてAWSを利用したサーバー構築と自動デプロイを行ったのですが結構つまづくポイントが多く時間を費やしてしまったため、これを機にAWSやサーバー、データベースといったWebの基礎をもう一度学び直そうと思います。
長くなってしましましたがお読みいただきありがとうございました。
参考記事
こちらの記事を参考にデプロイと記事を書かせていただきました。ありがとうございました。




- 投稿日:2020-03-01T13:10:51+09:00
AWS Deep Learning AMI でJupyter Notebookを開く
AWS Deep Learning AMI
AWS Deep Learning AMI(DLAMI)は、AWS EC2サービスで機械学習に適したインスタンスをかんたんに作成できるというものです。
GPUを搭載しているほか、condaや各種フレームワークもはじめから入っており、ML/DLのセットアップが非常にやりやすくなっています。
同様のサービスに「SageMaker」もありますが、こちらのほうが割安だと思います。1.インスタンスの作成
AWS EC2で「インスタンスの作成」をクリック
AMI検索窓で「Deep Learning AMI」を入力
Ubuntu系、Amazon Linux、Microsoft Windows Serverの3つがあります。
ここでは、「Deep Learning AMI (Ubuntu 16.04) Version 26.0」を選択しますステップ2の「インスタンスタイプの選択」でも、複数のGPUインスタンスがありますが、ここでは安価な「p2.xlarge」を選択します。
他は特に設定をしないので、「確認と作成」を押下して、インスタンスを作成します。
ちなみにこの構成では料金は、「1.542USD/時間」となっていました。2.インスタンスの設定
後々、ローカルクライアント側からJupyter Notebookにアクセスできるよう、インスタンスの8888ポートを開けておきます。
作成したインスタンス>「説明」タブ>セキュリティグループのリンクをクリックし、セキュリティグループの詳細画面を開きます。
さらに「インバウンド」タブ>「編集」で「タイプ:カスタムTCPルール/ポート:8888」のルールを追加します。
3.インスタンスへの接続
インスタンスを起動後、Teratermなどでインスタンスに接続します。
(ユーザー名は「ubuntu」です)
Deep Learning AMIを起動すると、下記の様に表示され、このインスタンスで起動可能なフレームワークとその起動コマンドの一覧が表示されています。
赤枠にはTensorFlowの仮想環境の起動コマンドが記載されていますので、
TensorFlowを起動するには下記を入力すればOKです。$ source activate tensorflow_p364.Jupyter Notebookの設定
Jupyter にはパスワードユーティリティがあるので、こちらを利用します。
後ほどブラウザからアクセスする際、パスワード認証がされるようになります。$ jupyter notebook passwordと入力し、パスワードを設定します。
次にコンフィグファイルを設定します。
$ nano ~/.jupyter/jupyter_notebook_config.py下記の行を加えておきます。
c.NotebookApp.ip = '*' #外部からのアクセスを許可する c.NotebookApp.open_browser = False #自動でウィンドウを開かないようにする c.NotebookApp.port = 8888 #ポート指定さらに、自己署名 SSL 証明書を作成を作成しておきます。
$ cd ~ $ mkdir ssl $ cd ssl $ openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout mykey.key -out mycert.pem5.Jupyter Notebookの起動
先に作成した証明書を利用しつつ、notebookを起動します。
$ jupyter notebook --certfile=~/ssl/mycert.pem --keyfile ~/ssl/mykey.key
クライアントPCのブラウザで、
https://[インスタンスのグローバルIPアドレス]:8888/
と入力すると、パスワードを求められた後、notebookを起動できます。







- 投稿日:2020-03-01T12:15:07+09:00
【AWS SAM】sam local invokeの「invalid ELF header」をなんとかする
環境
- MacOSX
- SAM CLI, version 0.41.0
- python3.8
下記内容は
sam initで作成されたものそのまま使用しています。
違いはrequirements.txtの内容のみです。現象
以下のような状態でpip installをして
sam local invokeをすると invalid ELF headerが発生する。$ cat sam-app/hello_world/requirements.txt requests pysftp $ pip install -r requirements.txt -t ./ $ sam local invoke Invoking app.lambda_handler (python3.8) (中略) {"errorType":"Runtime.ImportModuleError","errorMessage":"Unable to import module 'app': /var/task/bcrypt/_bcrypt.abi3.so: invalid ELF header"}これについてはモジュールに含まれているバイナリファイルがAmazonLinux2ではないための環境要因とのこと。
Error in AWS Lambda: invalid ELF header #117
https://github.com/Cyan4973/xxHash/issues/117AmazonLinux2内で実行する、もしくはそこで実行したものを持ってくれば一応は解決すると言う感じっぽい。
ただそのためにEC2を立ち上げるのはやはり面倒な上に(と言うかお金もかかるし)、
記事投稿時点でAnazonLinuxの標準のPythoはPython2なのでその辺もなんとかする必要があり手間が大きい解決
sam buildを行なって実行すればLambda(AmazonLinux2?)用の環境に作られたライブラリがインストールされる。$ sam build Building resource 'HelloWorldFunction' Running PythonPipBuilder:ResolveDependencies Running PythonPipBuilder:CopySource Build Succeeded (中略) $ sam local invoke Invoking app.lambda_handler (python3.8) (中略) {"statusCode":200,"body":"{\"message\": \"hello world\"}"}ただし、buildをした場合は、作成される
.aws-sam/buildの方のコードが実行されるので、
毎回buildが必要となりインタプリタ系の言語のお手軽さが失われてしまう。なので、
.aws-sam/buildにinstallされたモジュールを現在開発しているディレクトリに移動し.aws-sam/buildを削除する。
こうすることで毎回buildする必要がなくbuild前の元の方のコードが実行することができる。$ ls .aws-sam/build/HelloWorldFunction/ PyNaCl-1.3.0.dist-info certifi-2019.11.28.dist-info idna-2.9.dist-info requests (以下省略) $ cp .aws-sam/build/HelloWorldFunction/ ./hello_world/ $ sam local invoke Invoking app.lambda_handler (python3.8) (中略) {"statusCode":200,"body":"{\"message\": \"hello world\"}"}(未解決)サブディレクトリにモジュールを配置したい
上記の方法ではbuild時にinstallされるモジュールは指定場所直下になるみたいです。
なのでcpの際にはモジュール以外の自分の書いたソースコードも含まれています(上記では取り除いてませんが)
これについてはまだ現時点で解決にたどり着けていません。
.aws-sam/build/から持ってくる際は.libディレクトリを作成してそこにコピー、
以下を記載することでlib配下のモジュールを取ってこれるのでこれで開発中は多少ごちゃごちゃ感がなくなると思います。sys.path.append("./lib/")
- 投稿日:2020-03-01T11:42:38+09:00
[AWS]アクセス権限を管理する方法
2020年2月15日現在の内容です。
構成イメージ
用語説明
IAM(Identity and Access Management)
AWSサービスを利用するユーザー権限を管理するサービス
概要
- AWSサービスをセキュアに操作するために、認証・認可の仕組みを提供する
- 各AWSサービスに対して別々のアクセス権限をユーザー毎に付与できる
- IAMの利用は無料
- ポリシー
- アクセス許可の定義
- ユーザー
- 個々のアカウントのユーザー
- グループ
- IAMユーザーの集合(複数のユーザーにアクセス許可を付与する作業を簡素化できる)
- ロール
- 一時的にアクセスを許可したアカウントを発行(EC2やLambdaなどのAWSリソースに権限を付与するために使用)
IAMのベストプラクティス
- 個々人にIAMユーザーを作成する
- ユーザーはグループに所属させてグループに権限を割り当てる
- 権限は最小限にする
- EC2インスタンスから実行するアプリケーションはロールを使用する
- 定期的に不要な認証情報を削除する
IAMポリシーの作成
AWSコンソールからIAMを検索し、クリック
サイドバーからポリシーをクリック
「ポリシーの作成」をクリック
以下の通り設定
「さらにアクセス許可を追加する」をクリック
同様に以下の通り設定し、「ポリシーの確認」をクリック
名前、説明に任意名を入力
設定内容を確認し、「ポリシーの作成」をクリック
ポリシーが作成されていることを確認
同様に、「ポリシーの作成」をクリック
以下の通り設定し、「ポリシーの確認」をクリック
名前、説明に任意名を入力
設定内容を確認し、「ポリシーの作成」をクリック
ポリシーが作成されていることを確認
IAMグループの作成
サイドバーからグループをクリック
「新しいグループの作成」をクリック
任意のグループ名を入力し、「次のステップ」をクリック
作成したDeveloperPolicyを選択し、「次のステップ」をクリック
設定内容を確認し、「グループの作成」をクリック
グループが作成されていることを確認
同様に、「新しいグループの作成」をクリック
任意のグループ名を入力し、「次のステップ」をクリック
作成したDirectorPolicyを選択し、「次のステップ」をクリック
設定内容を確認し、「グループの作成」をクリック
グループが作成されていることを確認
IAMユーザーの作成
サイドバーからユーザーをクリック
「ユーザーを追加」をクリック
以下の通り設定し、「次のステップ」をクリック
ユーザー名:任意名
アクセスの種類:「AWS マネジメントコンソールへのアクセス」
ユーザーをグループに追加 → 作成したDeveloperグループをチェックし、「次のステップ」をクリック
タグは設定せず、「次のステップ」をクリック
設定内容を確認し、「ユーザーの作成」をクリック
Eメールの送信及びCSVのダウンロードを行っておく
ユーザーが作成されていることを確認
同様に、「ユーザーを追加」をクリック
以下の通り設定し、「次のステップ」をクリック
ユーザー名:任意名
アクセスの種類:「AWS マネジメントコンソールへのアクセス」
ユーザーをグループに追加 → 作成したDirectorグループをチェックし、「次のステップ」をクリック
タグは設定せず、「次のステップ」をクリック
設定内容を確認し、「ユーザーの作成」をクリック
Eメールの送信及びCSVのダウンロードを行っておく
ユーザーが作成されていることを確認
IAMロールの作成
サイドバーからロールをクリック
「ロールの作成」をクリック
AWSサービス → EC2をチェックし、「次のステップ」をクリック
AmazonS3FullAccessをチェックし、「次のステップ」をクリック
タグは設定せず、「次のステップ」をクリック
任意のロール名を入力し、「ロールの作成」をクリック
ロールが作成されていることを確認
IAMロールのアタッチ
EC2に移動
インスタンス → アクション → インスタンスの設定 → IAMロールの割り当て/置換をクリック
作成したロールを選択し、「適用」をクリック
ロールが適用されていることを確認
EC2インスタンスにログイン
ssh -i test-ssh-key.pem ec2-user@18.179.167.73S3にアクセスできることを確認
[ec2-user@ip-10-0-10-10 ~]$ aws s3 ls 2020-02-02 08:45:43 test-aws-wp参考















































- 投稿日:2020-03-01T11:15:48+09:00
[AWS]システムを監視する方法
2020年2月11日現在の内容です。
構成イメージ
用語説明
システム監視
システムを正常な状態に保てるよう、稼働状況やリソースを監視すること
目的
- すぐに障害発生を確認できるようにする
- 復旧にすぐに取りかかれるようにする
内容
- 正常な状態を監視項目 + 正常な結果の形で定義する
- 正常な状態でなくなった際の対応方法を監視項目ごとに定義する
- 正常な状態であることを継続的に確認する
- 正常な状態でなくなった場合に通知を行い、すぐ正常な状態に復旧させる
監視の種類
死活監視
- 正常にシステムが動作していることを確認
メトリクス監視
- パフォーマンスを定量的に確認
- 指標を決め、指標が閾値以上・以下となっていることを確認
監視をする際のポイント
- システムや利用状況は変動するので、足りない監視を都度追加していく
- 項目が多すぎると、監視疲れする
- 最初は基本的な項目で問題ない
- CPU,メモリ,ディスク,ネットワークの使用率・枯渇
- これらの情報を確認できれば、障害がいつ・どこで発生したものか特定できる
CloudWatch
AWSサービスの監視やモニタリングができる監視サービス
概要
- AWSサービスのメトリクス(リソースの状況)を監視する
- メトリクスに対して閾値を登録し、その条件を満たしたら通知する(アラーム発生)
Amazon SNS(Simple Notification Service)
AWSサービスが提供している通知サービス
Topicを作成することで、Publisher(EC2,CloudWatchなど)がメッセージを送信し、Subscriber(Email,SMSなど)が通知を受信するための通信チャネルとして機能するCloudWatchのアラームを作成
AWSコンソールからCloudWatchを検索し、クリック
サイドバーから「アラーム」をクリック
「アラームの作成」をクリック
「メトリクスの作成」をクリック
「EC2」をクリック
「インスタンス別メトリクス」をクリック
「CPUUtilization」にチェックを入れ、「メトリクスの選択」をクリック
以下の通り設定し、「次へ」をクリック
「新しいトピックの作成」にチェックを入れ、以下の通り設定し、「トピックの作成」をクリック
トピック名:任意名
Eメールエンドポイント:通知先のメールアドレス
通知の送信先が作成したトピックになっていることを確認し、「次へ」をクリック
以下の通り設定し、「次へ」をクリック
アラーム名,アラームの説明:任意名
設定内容に問題がないことを確認し、「アラームの作成」をクリック
アラームが作成されていることを確認
注:トピックで設定したメールアドレスに認証メールが届いているので、認証を済ませておく
作成したトピックはSNSで確認できる
アラームの確認
EC2インスタンスにログイン
ssh -i test-ssh-key.pem ec2-user@18.179.167.73CPUに負荷をかける
[ec2-user@ip-10-0-10-10 ~]$ yes > /dev/null & [1] 20407 [ec2-user@ip-10-0-10-10 ~]$ yes > /dev/null & [2] 20408 [ec2-user@ip-10-0-10-10 ~]$ yes > /dev/null & [3] 20409 [ec2-user@ip-10-0-10-10 ~]$ yes > /dev/null & [4] 20410 [ec2-user@ip-10-0-10-10 ~]$ yes > /dev/null & [5] 20411一定時間経過後、CloudWatchがアラーム状態になり、メールで通知されることを確認
おまけ(CPUの解放)
プロセスの確認
[ec2-user@ip-10-0-10-10 ~]$ ps aux | grep yes ec2-user 20407 19.3 0.0 114636 760 pts/0 R 13:10 2:09 yes ec2-user 20408 19.2 0.0 114636 724 pts/0 R 13:10 2:07 yes ec2-user 20409 19.2 0.0 114636 724 pts/0 R 13:10 2:07 yes ec2-user 20410 19.1 0.0 114636 748 pts/0 R 13:10 2:06 yes ec2-user 20411 19.1 0.0 114636 748 pts/0 R 13:10 2:06 yes ec2-user 20467 0.0 0.0 119436 944 pts/0 S+ 13:21 0:00 grep --color=auto yesプロセスの削除
kill -9 20407
kill -9 20408
kill -9 20409
kill -9 20410
kill -9 20411参考




















- 投稿日:2020-03-01T09:22:09+09:00
【AWS】AWS ソリューションアーキテクトアソシエイトに合格した勉強法
はじめに
仕事で1年くらい前からAWSの環境のシステム保守運用をするようになりました。
それに伴いAWSの資格の取得を目指すようになりました。
2019年11月ごろから本格的に勉強を始め、2020年1月25日に合格しました。試験結果
ギリギリ合格しました!勉強したこと
これだけでOK! AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座(初心者向け22時間完全コース)
https://www.udemy.com/course/aws-associate/
上記のudemyのコースを一通り自分のAWS環境を使って行いました。udemyのコースは頻繁に値下げしており、私は1800円くらいで購入しました。
手を動かしながらやるのでAWSの主要機能の理解が進みました。徹底攻略 AWS認定 ソリューションアーキテクト – アソシエイト教科書
udemyのコースが終わった後一通りやりました。間違えた箇所は何度かやり直しました。
AWSの模擬試験
https://aws.amazon.com/jp/certification/certified-solutions-architect-associate/
AWSの模擬試験を2回受けました。1回2000円でした。
解答は出なく最後にスコアのみ表示されます。1回目が50%くらいで、2回目が84%でした。
問題をスクリーンショット取りながら受験するのが、受験後に問題の見直しができるのでおすすめです。最後に
AWSの資格に合格できたのは自信になりました。
次はソリューションアーキテクトプロフェッショナルの合格を目指してがんばります!

