- 投稿日:2020-03-01T23:25:21+09:00
レシーバがnilかもしれないときの単純なメソッドの書き方
概要
下記のような単純なメソッドがあります。
def user_name user.name end上記メソッド内に登場する
userという変数には、
nameというメソッドを実行できるオブジェクトが格納されていると仮定します。上記メソッド内の
userがnilかもしれない場合は、NoMethodErrorが発生する可能性があります。
なので、 nilの場合の処理 を書く必要があります。どのように書くのが1番読みやすいか悩んでいた時に4人の方に相談したのですが、
メソッドの内容によって、どれを読みやすいと思うかが変わる結果になりました。同じような単純なメソッドだけど結果が変わってくるのが面白く思ったので、その時の結果を記事にします。
- 注意
- この場合はこの書き方が絶対いい!!ということを主張する記事ではないです。
- そもそも上記のような単純なメソッドの場合は、わざわざメソッドを書かずに他の方法が使えるケースも多いと思いますが、今回はその辺りには踏み込まないです。
ケース1: メソッドで処理さえできればいい時
下記のような条件のメソッドの場合は、どのように書くのが読みやすいでしょうか。
メソッドの条件
- メソッドの名前は
delete_user!- メソッド内では変数
userが使える- メソッド内の変数
userがnilではない場合は、userをレシーバーとしてdestroy!メソッドを実行する- メソッドの戻り値は利用しないので気にしなくていい
考えられるバターン
下記の2パターンを作成してみました。
パターン1: 早期リターン
def delete_user! return unless user user.destroy! end「やることないならとにかく早期リターンやろ」という考えを元に作成しました。
パターン2:
&.を使うdef delete_user! user&.destroy! end「1行で書けるんやから
&.を使うべきやろ」という考えを元に作成しました。相談の結果
4人とも、 「パターン2:
&.を使う」 が読みやすいとのことでした。やはり、ここまで単純だとわざわざ早期リターンしてメソッド内を3行にするより、
1行で書けるメリットの方が大きく感じられるようでした。ケース2: メソッドの戻り値が必要な時
下記のような条件のメソッドの場合は、どのように書くのが読みやすいでしょうか。
メソッドの条件
- メソッドの名前は
user_name- メソッド内では変数
userが使えるuserがnilではない場合は、userをレシーバーとしてnameメソッドを実行する- メソッドの戻り値を、呼び出し元で利用する
userがnilの場合は、'no name'という文字列を返却する考えられるバターン
下記の2パターンを作成してみました。
(早期リターンは、ケース1で評判が悪かったので最初から選択肢に入れませんでした)
パターン1: 三項演算子
def user_name user ? user.name : 'no name' end「三項演算子がパッと見で読みやすいかな〜」と思って作成しました。
パターン2:
&.を使うdef user_name user&.name || 'no name' endケース1では全員が読みやすいと考えた
&.を使った書き方です。
三項演算子を使うより短く書けます。
三項演算子が好きではない人向けに作成しました。個人的には、今回の場合は
||を書く必要があるので、
ちょっとパッと見では読みづらい気がしました。結果
投票結果は2対2に割れました。
「うーんどうしたものか。好みの問題かな・・・」と思っていると、
「早期リターンを使った書き方がよいのでは?」との提案をいただきました。def user_name return 'no name' unless user user.name end確かに・・・1番分かりやすい気がする・・・!!
ケース1では不評だった早期リターンが、今回は1番読みやすい気がします。今回のケースの場合は早期リターンを使うと、
「userがnilの場合は'no name'を返却する」
というのが1番パッと見で伝わりやすいし、メソッドの意図が伝わりやすい感じがします。メソッドの戻り値が重要なときは、こちらの書き方を採用しようと思いました。
おわりに
Railsは、いろいろ自由な書き方が出来る分、書き方にこだわったり悩んだりする必要が多いと思います。
今回考えた内容は「好みの問題」で片付けられてしまうことも多いですが、
人にも聞いてみると、「こういうとき、1番読みやすいのはこれじゃないか」という傾向が見えてきて面白かったです。一緒に考えてくれた4名のみなさんありがとうございました
- 投稿日:2020-03-01T23:25:21+09:00
nilで場合分けの必要がある単純なメソッドの書き方
概要
下記のような単純なメソッドがあります。
def user_name user.name end上記メソッド内に登場する
userは、 「Userオブジェクトまたはnilを返却するメソッド」だと仮定してください。
Userオブジェクトにはnameというメソッドが実行できます。
nilの可能性があるので、NoMethodErrorが発生する可能性があります。
なので、 nilの場合の処理 を書く必要があります。どのように書くのが1番読みやすいか悩んでいた時に4人の方に相談したのですが、
メソッドの内容によって、どれを読みやすいと思うかが変わる結果になりました。同じような単純なメソッドだけど結果が変わってくるのが面白く思ったので、その時の結果を記事にします。
- 注意
- この場合はこの書き方が絶対いい!!ということを主張する記事ではないです。
- そもそも上記のような単純なメソッドの場合は、わざわざメソッドを書かずに他の方法が使えるケースも多いと思いますが、今回はその辺りには踏み込まないです。
ケース1: メソッドで処理さえできればいい時
下記のような条件のメソッドの場合は、どのように書くのが読みやすいでしょうか。
メソッドの条件
- メソッドの名前は
delete_user!- メソッド内では変数
userが使える- メソッド内の変数
userがnilではない場合は、userをレシーバーとしてdestroy!メソッドを実行する- メソッドの戻り値は利用しないので気にしなくていい
考えられるパターン
下記の2パターンを作成してみました。
パターン1: 早期リターン
def delete_user! return unless user user.destroy! end「やることないならとにかく早期リターンやろ」という考えを元に作成しました。
パターン2:
&.を使うdef delete_user! user&.destroy! end「1行で書けるんやから
&.を使うべきやろ」という考えを元に作成しました。相談の結果
4人とも、 「パターン2:
&.を使う」 が読みやすいとのことでした。やはり、ここまで単純だとわざわざ早期リターンしてメソッド内を3行にするより、
1行で書けるメリットの方が大きく感じられるようでした。ケース2: メソッドの戻り値が必要な時
下記のような条件のメソッドの場合は、どのように書くのが読みやすいでしょうか。
メソッドの条件
- メソッドの名前は
user_name- メソッド内では変数
userが使えるuserがnilではない場合は、userをレシーバーとしてnameメソッドを実行する- メソッドの戻り値を、呼び出し元で利用する
userがnilの場合は、'no name'という文字列を返す考えられるパターン
下記の2パターンを作成してみました。
(早期リターンは、ケース1で評判が悪かったので最初から選択肢に入れませんでしたパターン1: 三項演算子
def user_name user ? user.name : 'no name' end「三項演算子がパッと見で読みやすいかな〜」と思って作成しました。
パターン2:
&.を使うdef user_name user&.name || 'no name' endケース1では全員が読みやすいと考えた
&.を使った書き方です。
三項演算子を使うより短く書けます。
三項演算子が好きではない人向けに作成しました。個人的には、今回の場合は
||を書く必要があるので、
ちょっとパッと見では読みづらい気がしました。結果
投票結果は2対2に割れました。
「うーんどうしたものか。好みの問題かな・・・」と思っていると、
「早期リターンを使った書き方がよいのでは?」との提案をいただきました。def user_name return 'no name' unless user user.name end確かに・・・1番分かりやすい気がする・・・!!
ケース1では不評だった早期リターンが、今回は1番読みやすい気がします。今回のケースの場合は早期リターンを使うと、
「userがnilの場合は'no name'を返す」
というのが1番パッと見で伝わりやすいし、メソッドの意図が伝わりやすい感じがします。メソッドの戻り値が重要なときは、こちらの書き方を採用しようと思いました。
おわりに
Railsは、いろいろ自由な書き方が出来る分、書き方にこだわったり悩んだりする必要が多いと思います。
今回考えた内容は「好みの問題」で片付けられてしまうことも多いですが、
人にも聞いてみると、「こういうとき、1番読みやすいのはこれじゃないか」という傾向が見えてきて面白かったです。一緒に考えてくれた4名のみなさんありがとうございました
- 投稿日:2020-03-01T23:12:12+09:00
gonを使ってJavaScriptでRailsの環境変数を使用する
概要
Railsアプリケーションを作成時、
dotenv-railsを使って.envファイルに環境変数を書き込んだのですが
JSファイルではそのまま使用することができず、gonというGemを使用するとJSと連携ができるとのことだったので備忘録としてまとめてみます。(間違いや改善点があればご教示いただけますと幸いです!)
Gemをインストール
Gemfile.gem 'dotenv-rails' gem 'gon'bundle installを実行
.envファイルを作成
appファイル直下に作成して、環境変数を記述します
MY_PRIVATE_KEY = '************'Rails側の呼び出し
(JSファイルのみでの使用であればなくてOK)
def new my_private_key = ENV["MY_PRIVATE_KEY"] endJSファイルへの連携
def new gon.my_private_key = ENV['MY_PRIVATE_KEY'] endJSファイルでの表記
var mykey = gon.my_private_key;これで環境変数が取ってこれます!
.envを.gitignoreに追記
/.envこれで安全に環境変数を扱えますね。
gonは便利と聞いたのでもっと理解を深めていきたいです!
間違いがあればご指摘くださいm(__)m
以上となります、ありがとうございました。
- 投稿日:2020-03-01T22:12:13+09:00
何でbelongs_to :userになるか?(忘備録)
はじめに
「ActiveRecord::AssociationNotFoundError in Tweet#index」エラー向けの記事になります。
エラー勉強会の復習した時に、疑問に思ったのでアウトプットしてみました。
Associationと出てる時点で、DBの問題であると考える事ができますが、今回は掘り下げてみたいと思います。
エラーの意味
エラーの通りで、tweet_controllerのindexアクションでAssociationが見つからないエラーです。
Associationとは
DBに構築されているテーブルの関連付ける事を指しています。
今回は、下図のようなAssciationを組んでいる時に起こるエラーとなります。
まずは、tweet_controllerのindexアクションをみてみます。
app/controllers/tweet_controller.rb
記述に問題はありませんが、SQLを読み込むincludeメソッドにエラーが起きている事が分かります。
:userはUserモデルの事を指しているので、 Userモデルを見てみます。app/models/user.rb
記述に問題はなさそうです。
has_manyの復習すると、 has_many モデル名(複数) という記述をします。
userはtweetとcommentの1対多の関係になります。そうすると、他のtweetモデルかcommentモデルに問題があると考えます。
app/models/tweet.rb
app/models/comment.rb
)
ようやくエラー元を見つけました。 belongs_to :usersが悪さをしていました。
belongs_to モデル名(単数) と定義されます。
ここで :users ⇨ :user に直すとエラーが解消されます。tweetモデルとuserモデルが、associationができていなかった為にエラーが出てたようです。
参照文献:railsガイド





- 投稿日:2020-03-01T22:00:45+09:00
Rails探検録 ActiveSupport 編: TimeZone
【概要】
最近、ライブラリを読むのが楽しくて、今まで敬遠していた Rails のソースコードを読み始めたので、記録していく。全部のメソッドは書いてないよ。
- 環境
- Ruby 2.7.0
- Rails 6.0.2
- 参考: 学習情報 URL
※ 例文の実行環境は既存のRailsプロジェクト
bashgem install timecop rails c # `rails c`起動後, timecop を読み込む( ディレクトリは,`gem which timecop`で検索 ) require "/usr/local/bundle/gems/timecop-0.9.1/lib/timecop.rb" # zone を指定 Time.zone = "Asia/Tokyo" => "Asia/Tokyo" # 本記事における現在時刻を`2020年3月1日12:00`に固定 time_for_freeze = Time.local(2020, 3, 1, 12) Timecop.freeze time_for_freeze【本文】
□ Time Class と Date Class 拡張
time = Time.now => 2020-03-01 12:00:00 +0900 time.class => Time after_time = time.in_time_zone => Sun, 01 Mar 2020 12:00:00 JST +09:00 after_time.class => ActiveSupport::TimeWithZone # 引数で他都市の TimeZone を指定可能 after_time = time.in_time_zone("London") => Sun, 01 Mar 2020 03:00:00 GMT +00:00
- ↑ Time と Date インスタンスを TimeWithZone クラスに変換する。
□ Time Class 拡張
Time.zone => #<ActiveSupport::TimeZone:0x0000563071f03910 @name="Asia/Tokyo", @tzinfo=#<TZInfo::DataTimezone: Asia/Tokyo>, @utc_offset=nil>
- ↑ 設定された zone を元に TimeZone インスタンスを生成する。
Time.zone = "Sapporo" => "Sapporo" Time.zone => #<ActiveSupport::TimeZone:0x0000563071fd3958 @name="Sapporo", @tzinfo=#<TZInfo::DataTimezone: Asia/Tokyo>, @utc_offset=nil>
- ↑ 設定可能な TimeZone に変更する。
Time.use_zone("London") do Time.zone.now end => Sun, 01 Mar 2020 03:00:00 GMT +00:00
- ↑ ブロック内で指定した TimeZone による処理が可能となる。
- ↑ 処理後は、元の TimeZone に戻る。
Time.find_zone!("London") => #<ActiveSupport::TimeZone:0x00005630705df1f0 @name="London", @tzinfo=#<TZInfo::DataTimezone: Europe/London>, @utc_offset=nil> Time.find_zone("Naboo") => nil
- ↑ Rails 内の定数で定義された都市の TimeZone を表示する。
- ↑ 存在しなかったら例外起こすけど、
!を外したら nil を返す。□ TimeZone Class
■ Class Methods
ActiveSupport::TimeZone::MAPPING => {"International Date Line West"=>"Etc/GMT+12", "Midway Island"=>"Pacific/Midway", "American Samoa"=>"Pacific/Pago_Pago", # 省略... "Osaka"=> "Asia/Tokyo", "Sapporo"=> "Asia/Tokyo", "Tokyo"=> "Asia/Tokyo", # 省略... }
- ↑ Rails で定義可能な TimeZone を確認できる。
- ↑ 定数だが便宜上、ここに記載した( 他の Class Method 紹介してないや... )
■ Instance Methods
Time.zone =~ "Tokyo" => true Time.zone =~ "Sapporo" => false
- ↑ 設定された都市を比較できる。
Time.zone.to_s => "(GMT+09:00) Tokyo"
- ↑ 現在の zone と utc のオフセット及び設定された都市を表示する。
Time.zone.local(2020, 1, 1, 11, 11, 11) => Wed, 01 Jan 2020 11:11:11 JST +09:00 Time.zone.local(2020) => Wed, 01 Jan 2020 00:00:00 JST +09:00
- ↑
Time.utcを元に TimeWithZone に変換している。f = Time.utc(2020, 3, 1, 12, 00, 00).to_f => 1583064000.0 Time.zone.at(f) => Sun, 01 Mar 2020 21:00:00 JST +09:00 # ナノ秒まで指定可能 Time.zone.at(f, 123456.789).nsec => 123456789
- ↑
Time.atを元に TimeWithZone Class に変換する。Time.zone.iso8601("2020-03-01T12:00:00+09:00") => Sun, 01 Mar 2020 12:00:00 JST +09:00
- ↑ ISO8601 形式の文字列を TimeWithZone Class に変換する。
- ↑
Time#iso8601の TimeWithZone 版Time.zone.rfc3339("2020-03-01T12:00:00.123456789+09:00") => Sun, 01 Mar 2020 12:00:00 JST +09:00
- ↑ RFC3339 形式の文字列を TimeWithZone Class に変換する。
- ↑
Time#rfc3339の TimeWithZone 版Time.zone.parse("20200202111111") => Sun, 02 Feb 2020 11:11:11 JST +09:00 Time.zone.parse("20200202") => Sun, 02 Feb 2020 00:00:00 JST +09:00 Time.zone.parse("2020-02-02 11:11:11") => Sun, 02 Feb 2020 11:11:11 JST +09:00 Time.zone.parse("2020-02-02") => Sun, 02 Feb 2020 00:00:00 JST +09:00 Time.zone.parse("2020-02") => ArgumentError: argument out of range
- ↑ 引数の文字列をDate._parseで変換するため、少なくとも月日が必要となる。
Time.zone.strptime("2020-03-01 11:11:11", "%Y-%m-%d %H:%M:%S") => Sun, 01 Mar 2020 11:11:11 JST +09:00 Time.zone.strptime("11:::11:::11", "%H:::%M:::%S") => Sun, 01 Mar 2020 11:11:11 JST +09:00 Time.zone.strptime("Mar.1 2020", "%b.%d %Y") => Sun, 01 Mar 2020 00:00:00 JST +09:00
- ↑ 第一引数に任意の文字列、第二引数にフォーマットを指定することで、フォーマットを元に文字列を TimeWithZone に変換する。
- ↑ 引数の文字列をDateTime._parseで変換している。
- ? メソッド名は String Parse Time の略 ?
Time.zone.today => Sun, 01 Mar 2020 Time.zone.tomorrow => Mon, 02 Mar 2020 Time.zone.yesterday => Sat, 29 Feb 2020
- ↑
Time.zone.tzinfoを使用して、Date Class に変換する。Time.zone.local_to_utc(Time.parse("2020-03-01 12:00")) => 2020-03-01 03:00:00 UTC Time.zone.utc_to_local(Time.parse("2020-03-01 12:00")) => 2020-03-01 21:00:00 UTC
- ↑ UTC の Time Class に変換する。
# utc = Time.zone.local_to_utc(Time.parse("2020-03-01 12:00")) Time.zone.period_for_utc(utc) => #<TZInfo::TimezonePeriod: #<TZInfo::TimezoneTransitionDefinition: #<TZInfo::TimeOrDateTime: -577962000>,#<TZInfo::TimezoneOffset: 32400,0,JST>>,nil> Time.zone.period_for_local(Time.zone.now) => #<TZInfo::TimezonePeriod: #<TZInfo::TimezoneTransitionDefinition: #<TZInfo::TimeOrDateTime: -577962000>,#<TZInfo::TimezoneOffset: 32400,0,JST>>,nil>
- ↑ TimeWithZone Instance が
TZInfo::TimezoneClass も使用可能にする。
- 投稿日:2020-03-01T21:31:57+09:00
【初心者向け】AWS EC2デプロイ時にでるエラーを解決する
自作したアプリケーションをAWS上にデプロイする際に、いくつかエラーが出てつまづいたので、どうやって解決したかをまとめ的な感じでつらつらと書いていきます。
各エラーの内容にはそこまで踏み込まず、解決するという部分にフォーカスしてます。なお、デプロイ時は、下記のQiita記事を参考に行いました。
題の通り、世界一丁寧でした。。。誠に有難うございます。。。世界一丁寧なAWS解説。EC2を利用して、RailsアプリをAWSにあげるまで
環境
macOS:10.14.6
Ruby:2.5.7
Rails:5.2.4.1①ssh: connect to host [作成したEC2のElasticIP] port 22: Operation timed out
これは、EC2インスタンスにsshログインした時に出たエラー。
$ ssh -i [app名].pem ec2-user@[作成したEC2のElasticIP] ssh: connect to host [作成したEC2のElasticIP] port 22: Operation timed out解決方法
1.AWSコンソールに入り、AWSのサービスからEC2を選択
2.左のメニューバーからセキュリティグループを選択
3.インバウンドを選択
4.編集
5.タイプ:SSH、ソース:マイIPのルールを追加
6.保存これでsshログインできるようになります。
ちなみに自分のIPアドレスはwi-fi環境により異なったりするので注意が必要です。②ERROR: Ruby install aborted due to missing extensions
これは、EC2インスタンスにrubyをインストールする際に出たエラー。
$ rbenv install -v 2.5.7 ~ #省略 ~ BUILD FAILED (Amazon Linux AMI 2018.03 using ruby-build 20200224) Inspect or clean up the working tree at /tmp/ruby-build.20200229053400.25770.gpU4NA Results logged to /tmp/ruby-build.20200229053400.25770.log Last 10 log lines: installing capi-docs: /home/irikawa/.rbenv/versions/2.5.7/share/doc/ruby The Ruby readline extension was not compiled. ERROR: Ruby install aborted due to missing extensions Try running `yum install -y readline-devel` to fetch missing dependencies.解決方法
これはエラー文に書かれている以下のコマンドを実行し、
$ sudo yum install -y readline-develその後、rubyをインストール
$ rbenv install -v 2.5.7 ~ #省略 ~ Installed ruby-2.5.7 to /home/user/.rbenv/versions/2.5.7無事入りました。
③EC2インスタンスにmaster.keyを作成する
これは特別エラーが出たわけではないのですが、考え方の整理として。
rails5.2以上では、rails newをしたタイミングで、「credentials.yml.enc」と「master.key」が生成されます。
それぞれの役割は、超ざっくり説明すると、「credentials.yml.enc」が鍵穴で、「master.key」が鍵という位置付けになり、「credentials.yml.enc」を複合する際には「master.key」が必要になるとのこと。ローカル環境で開発している段階では特別意識しなくても良いのですが、EC2にあげるタイミングで.gitignoreに書かれている「master.key」はEC2側には渡ってくれません。
なので、以下の方法でEC2側に「master.key」を手動で作成してあげる必要があります。
まずはローカル環境でmaster.keyの中身をコピーします。
以下のコマンドを打って出てくる英数字の暗号みたいなものをコピーする。local.~/myapp$ vi config/master.key次にEC2側にmaster.keyを以下のコマンドで作成し、先程コピーしたものをペーストします。
server.[user|myapp]$ vim config/master.key保存して終了。これでOKです。
④bundle install時、mysqlが入らないエラー:Gem::Ext::BuildError: ERROR: Failed to build gem native extension.
EC2インスタンス内でbundle install時に以下のエラー。主要部分のみ抜粋してます。
server.[user|myapp]$ bundle install ~ #省略 ~ Gem::Ext::BuildError: ERROR: Failed to build gem native extension. ----- mysql client is missing. You may need to 'sudo apt-get install libmariadb-dev', 'sudo apt-get install libmysqlclient-dev' or 'sudo yum install mysql-devel', and try again. ----- An error occurred while installing mysql2 (0.5.3), and Bundler cannot continue. Make sure that `gem install mysql2 -v '0.5.3' --source 'https://rubygems.org/'` succeeds before bundling.mysqlクライアントがないというエラーみたいですね。
エラー文に書いている以下のコマンドを実行。
server.[user|myapp]$ sudo yum install mysql-develその後、bundle installしたら無事mysqlが入りました。
一旦、以上になります。
今後随時更新していきます。
- 投稿日:2020-03-01T21:23:46+09:00
Rails6でElasticsearchのキーワード検索実装ハンズオン
はじめに
本稿は、RailsとElasticsearchで検索機能をつくり色々試してみる - その1:サンプルアプリケーションの作成 を一部改変した内容でRailsとElasticsearchのキーワード機能を実装するハンズオン資料です。
※ 主な変更点
・ Ruby / Railsのバージョンは2020年の執筆時点でほぼ最新に変更 ・ Elasticsearch と PostgreSQL のみをDocker化 ・ Railsは通常通りのローカル環境で動かせるようにした違いがピンと来ない方もいらっしゃるかと思いますので補足しますとRails自体はDocker化しないことによってDockerの知見が少ない方でも学習上のデバッグや値の確認が容易に出来るようにしてあります。
このハンズオンで扱う技術
技術スタック バージョン Ruby 2.6.5 Ruby on Rails 6.0 Elasticsearch 6.5.4 PostgreSQL 12 Docker 19.03.5 このハンズオンを終えると出来るようになること
・ Railsアプリでミドルウェア(Elasticsearch / PostgreSQL)のみをDocker化すること ・ Elasticsearchによる簡単なキーワード検索機能の実装 ・ Elasticsearchでの簡単なテストをRSpecで書くこと
※ 完成リポジトリ
https://github.com/Shigeyuki-fukuda/elasticsearch_rails_sandbox前提環境
・ Macであること ・ Docker for Macがインストールされていること ・ rbenvなどのRubyの実行環境がローカルに出来ていることなるべくハマりどころは細かくメモしていこうと思いますので、
初心者の方も気軽にチャレンジしてみてください。目次
結構ボリューミーですが、少しずつやっていきましょう!
手順1:アプリの土台を作成 手順2:debug用のgemを追加 手順3:Docker関連ディレクトリとファイルの新規作成 手順4:Docker上のPostgreSQLとRailsが疎通するための設定を追加する 手順5:Docker上で動くPostgreSQLとRailsの疎通確認 手順6:Elasticsearchの起動確認 手順7:検索対象となるモデルの定義 手順8:サンプルデータの投入 手順9:コントローラー・ビュー・ルーティングの追加 手順10:スタイルの調整 手順11:Elasticsearch用のgemの追加 手順12:ElasticsearchをRailsアプリ上で動かせるようにする 手順13:Elasticsearchの動作確認 手順14:検索機能の追加 手順15:ページネーションの追加 手順16:RSpecのセットアップ 手順17:Elasticsearchのテストを追加Elasticsearchって何なの?
・ Elastic 社が開発しているオープンソースの全文検索エンジン ・ JSONフォーマットで柔軟にデータを格納出来るドキュメント指向データベース ・ 大量ドキュメントから目的の単語を含むドキュメントを高速に抽出出来るこれだけだとピンと来ない方もいると思うのですが、一旦今のところは
キーワード検索をMySQLやPostgreSQLなどのRDBよりも高速に行うことが出来るデータベースだと理解して先に進みましょう。手順1:アプリの土台を作成
DBはPostgreSQLを使用します!
$ rails new elasticsearch_rails_sandbox --database=postgresql --skip-bundle $ cd elasticsearch_rails_sandbox手順2:debug用のgemを追加
※ 不要なら飛ばしてOK
値の確認などを行いやすいようにdebug用途のgemを入れておきます。Gemfilegroup :development, :test do <中略> # 以下の3つを新規で追加 gem 'pry-rails' gem 'pry-byebug' gem 'pry-doc' end手順3:Docker関連ディレクトリとファイルの新規作成
まずappディレクトリと同階層にdockerディレクトリとdocker-compose.ymlというファイルを作ります。次にdockerディレクトリの中にelasticsearchディレクトリとpostgresqlディレクトリを作り、elasticsearchディレクトリの中にのみDockerfileという拡張子なしのファイルを作ります。
そして、以下に続く設定の通りにdocker-compose.ymlとDockerfileを編集します。ディレクトリ構成の確認
アプリ名のディレクトリ ├── app ├── docker │ ├── elasticsearch │ │ └── Dockerfile │ └── postgresql └── docker-compose.ymldocker-compose.ymlの設定
docker-compose.ymlversion: '3' services: postgresql: image: postgres:12 volumes: - ./docker/postgresql/data:/usr/local/var/postgres ports: - 127.0.0.1:5432:5432 environment: POSTGRES_USER: postgres POSTGRES_PASSWORD: mysecretpassword1234 PGDATA: /usr/local/var/postgres elasticsearch: build: context: . dockerfile: ./docker/elasticsearch/Dockerfile volumes: - ./docker/elasticsearch/data:/usr/share/elasticsearch/data ports: - 127.0.0.1:9200:9200 environment: - "ES_JAVA_OPTS=-Xms512m -Xmx512m" - "xpack.security.enabled=false" - "xpack.monitoring.enabled=false"docker/elasticsearch/Dockerfileの設定
- PostgreSQL は一旦、
docker/postgresqlディレクトリを作成するだけでOK
- Elasticseachは
docker/elasticsearch/DockerfileにDocker上で使うElasticseachのバージョンとインストールするプラグインを記載する(日本語の形態素解析用のプラグインを入れています)
docker/elasticsearch/DockerfileFROM docker.elastic.co/elasticsearch/elasticsearch:6.5.4 RUN bin/elasticsearch-plugin install analysis-kuromoji手順4:Docker上のPostgreSQLとRailsが疎通するための設定を追加する
config/database.ymldefault: &default adapter: postgresql port: 5432 username: postgres password: mysecretpassword1234 host: 127.0.0.1 encoding: unicode pool: 5 development: <<: *default database: elasticsearch_rails_sandbox_development test: <<: *default database: elasticsearch_rails_sandbox_test production: <<: *default database: elasticsearch_rails_sandbox_production username: elasticsearch_rails_sandbox password: <%= ENV['ELASTICSEARCH_RAILS_SANDBOX_DATABASE_PASSWORD'] %>
ハマりポイント解説
docker-compose.ymlに記載した内容とdatabase.ymlの内容で齟齬があるとRailsがDBに接続出来ないので注意
 config/database.ymlusername: postgres password: mysecretpassword1234
config/database.ymlusername: postgres password: mysecretpassword1234↑上記の部分と↓以下の
POSTGRES_USERとPOSTGRES_PASSWORDの部分が一致してる必要があります docker-compose.ymlversion: '3' services: postgresql: image: postgres:12 volumes: - ./docker/postgresql/data:/usr/local/var/postgres ports: - 127.0.0.1:5432:5432 environment: POSTGRES_USER: postgres POSTGRES_PASSWORD: mysecretpassword1234
docker-compose.ymlversion: '3' services: postgresql: image: postgres:12 volumes: - ./docker/postgresql/data:/usr/local/var/postgres ports: - 127.0.0.1:5432:5432 environment: POSTGRES_USER: postgres POSTGRES_PASSWORD: mysecretpassword1234手順5:Docker上で動くPostgreSQLとRailsの疎通確認
dockerコンテナを作成・バックグラウンド起動します
 # docker-compose.ymlと同じ階層で実行すること $ docker-compose up -d # 停止する場合は以下のコマンドを実行 $ docker-compose stop # プロセスを確認したい場合はdocker-compose psで確認出来る # statusがUpなら起動しているExitなら停止している $ docker-compose ps Name Command State Ports ----------------------------------------------------------------------------------------------------------------- elasticsearch_rails_sandbox_elastic /usr/local/bin/docker-entr ... Up 127.0.0.1:9200->9200/tcp, 9300/tcp search_1 elasticsearch_rails_sandbox_postgre docker-entrypoint.sh postgres Up 127.0.0.1:5432->5432/tcp sql_1
# docker-compose.ymlと同じ階層で実行すること $ docker-compose up -d # 停止する場合は以下のコマンドを実行 $ docker-compose stop # プロセスを確認したい場合はdocker-compose psで確認出来る # statusがUpなら起動しているExitなら停止している $ docker-compose ps Name Command State Ports ----------------------------------------------------------------------------------------------------------------- elasticsearch_rails_sandbox_elastic /usr/local/bin/docker-entr ... Up 127.0.0.1:9200->9200/tcp, 9300/tcp search_1 elasticsearch_rails_sandbox_postgre docker-entrypoint.sh postgres Up 127.0.0.1:5432->5432/tcp sql_1PostgreSQLとRailsの疎通確認
ローカルでDB作成コマンドを実行し、
localhost:3000にアクセスしてRailsの初期画面が表示出来たらOK。$ bundle exec rails db:create
手順6:Elasticsearchの起動確認
事前に
docker-compose up -dでバックグラウンドで動かしておきましょう!
curlで起動確認します。# docker-compose.ymlでElasticsearchに割り当てたポート番号をcurlする $ curl -XGET http://localhost:9200/ { "name" : "CBsfjEf", "cluster_name" : "docker-cluster", "cluster_uuid" : "2BT15kU2RsKTYbD-a6x74w", "version" : { "number" : "6.5.4", "build_flavor" : "default", "build_type" : "tar", "build_hash" : "d2ef93d", "build_date" : "2018-12-17T21:17:40.758843Z", "build_snapshot" : false, "lucene_version" : "7.5.0", "minimum_wire_compatibility_version" : "5.6.0", "minimum_index_compatibility_version" : "5.0.0" }, "tagline" : "You Know, for Search" }手順7:検索対象となるモデルの定義
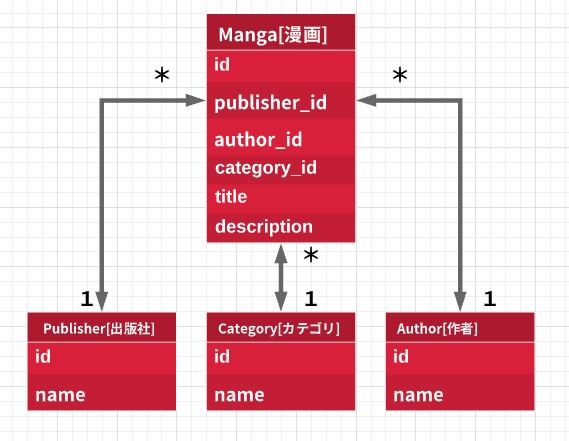
$ bin/rails g model author name:string $ bin/rails g model publisher name:string $ bin/rails g model category name:string $ bin/rails g model manga author:references publisher:references category:references title:string description:text手順8:サンプルデータの投入
以下はサンプルデータ投入用のseed.rbです。
db/seed.rb# This file should contain all the record creation needed to seed the database with its default values. # The data can then be loaded with the rails db:seed command (or created alongside the database with db:setup). # # Examples: # # movies = Movie.create([{ name: 'Star Wars' }, { name: 'Lord of the Rings' }]) # Character.create(name: 'Luke', movie: movies.first) # category ct1 = Category.create(name: 'バトル・アクション') ct2 = Category.create(name: 'ギャグ・コメディ') ct3 = Category.create(name: 'ファンタジー') ct4 = Category.create(name: 'スポーツ') ct5 = Category.create(name: 'ラブコメ') ct6 = Category.create(name: '恋愛') ct7 = Category.create(name: '異世界') ct8 = Category.create(name: '日常系') ct9 = Category.create(name: 'グルメ') ct10 = Category.create(name: 'ミステリー・サスペンス') ct11 = Category.create(name: 'ホラー') ct12 = Category.create(name: 'SF') ct13 = Category.create(name: 'ロボット') ct14 = Category.create(name: '歴史') ct15 = Category.create(name: '少女漫画') ct16 = Category.create(name: '戦争') ct17 = Category.create(name: '職業・ビジネス') ct18 = Category.create(name: 'お色気') ct19 = Category.create(name: '学園もの') # 出版社 pb1 = Publisher.create(name: '集英社') pb2 = Publisher.create(name: '講談社') pb3 = Publisher.create(name: '小学館') pb4 = Publisher.create(name: '芳文社') pb5 = Publisher.create(name: '双葉社') # 作者 at1 = Author.create(name: '原泰久') at2 = Author.create(name: '堀越耕平') at3 = Author.create(name: '清水茜') at4 = Author.create(name: '井上雄彦') at5 = Author.create(name: '吉田秋生') at6 = Author.create(name: '野田サトル') at7 = Author.create(name: 'あfろ') at8 = Author.create(name: '神尾葉子') at9 = Author.create(name: '冨樫義博') at10 = Author.create(name: '川上秦樹') at11 = Author.create(name: 'こうの史代') at12 = Author.create(name: '古舘春一') at13 = Author.create(name: '三田紀房') at14 = Author.create(name: '藤沢とおる') # 漫画 Manga.create(title: "キングダム", publisher: pb1, author: at1, category: ct14, description: "時は紀元前―。いまだ一度も統一されたことのない中国大陸は、500年の大戦争時代。苛烈な戦乱の世に生きる少年・信は、自らの腕で天下に名を成すことを目指す!!") Manga.create(title: "僕のヒーローアカデミア", publisher: pb1, author: at3, category: ct1, description: "多くの人間が“個性という力を持つ。だが、それは必ずしも正義の為の力ではない。しかし、避けられぬ悪が存在する様に、そこには必ず我らヒーローがいる! ん? 私が誰かって? HA‐HA‐HA‐HA‐HA! さぁ、始まるぞ少年! 君だけの夢に突き進め! “Plus Ultra!!") Manga.create(title: "はたらく細胞", publisher: pb2, author: at3, category: ct1, description: "人間1人あたりの細胞の数、およそ60兆個! そこには細胞の数だけ仕事(ドラマ)がある! ウイルスや細菌が体内に侵入した時、アレルギー反応が起こった時、ケガをした時などなど、白血球と赤血球を中心とした体内細胞の人知れぬ活躍を描いた「細胞擬人化漫画」の話題作、ついに登場!!肺炎球菌! スギ花粉症! インフルエンザ! すり傷! 次々とこの世界(体)を襲う脅威。その時、体の中ではどんな攻防が繰り広げられているのか!? 白血球、赤血球、血小板、B細胞、T細胞...etc.彼らは働く、24時間365日休みなく!") Manga.create(title: "スラムダンク SLAM DUNK 新装再編版", publisher: pb1, author: at4, category: ct4, description: '中学時代、50人の女の子にフラれた桜木花道。そんな男が、進学した湘北高校で赤木晴子に一目惚れ! 「バスケットは…お好きですか?」。この一言が、ワルで名高い花道の高校生活を変えることに!!') Manga.create(title: "BANANA FISH バナナフィッシュ 復刻版全巻BOX", publisher: pb3, author: at5, category: ct15, description: 'フラワーコミックスの黄色いカバーを完全再現!!吉田秋生の不朽の名作が復刻版BOXとなって登場しました。フラワーコミックスの黄色いカバーを完全再現したコミックスと、特典ポストカードをセットにした完全保存版。ポストカードはファン垂涎の、アッシュ・英二のイラストをセレクトしたここでしか手に入らないオリジナルです。') Manga.create(title: "ゴールデンカムイ", publisher: pb1, author: at6, category: ct1, description: '『不死身の杉元』日露戦争での鬼神の如き武功から、そう謳われた兵士は、ある目的の為に大金を欲し、かつてゴールドラッシュに沸いた北海道へ足を踏み入れる。そこにはアイヌが隠した莫大な埋蔵金への手掛かりが!? 立ち塞がる圧倒的な大自然と凶悪な死刑囚。そして、アイヌの少女、エゾ狼との出逢い。『黄金を巡る生存競争』開幕ッ!!!!') Manga.create(title: "ゆるキャン△", publisher: pb4, author: at7, category: ct8, description: '富士山が見える湖畔で、一人キャンプをする女の子、リン。一人自転車に乗り、富士山を見にきた女の子、なでしこ。二人でカップラーメンを食べて見た景色は…。読めばキャンプに行きたくなる。行かなくても行った気分になる。そんな新感覚キャンプマンガの登場です!') Manga.create(title: "花のち晴れ〜花男 Next Season〜", publisher: pb1, author: at8, category: ct6, description: '英徳学園からF4が卒業して2年…。F4のリーダー・道明寺司に憧れる神楽木晴は、「コレクト5」を結成し、学園の品格を保つため“庶民狩りを始めた!! 隠れ庶民として学園に通う江戸川音はバイト中に晴と遭遇し!?') Manga.create(title: "HUNTER×HUNTER ハンター×ハンター", publisher: pb1, author: at9, category: ct1, description: '父と同じハンターになるため、そして父に会うため、ゴンの旅が始まった。同じようにハンターになるため試験を受ける、レオリオ・クラピカ・キルアと共に、次々と難関を突破していくが…!?') Manga.create(title: "転生したらスライムだった件", publisher: pb2, author: at10, category: ct7, description: '通り魔に刺されて死んだと思ったら、異世界でスライムに転生しちゃってた!?相手の能力を奪う「捕食者」と世界の理を知る「大賢者」、2つのユニークスキルを武器に、スライムの大冒険が今始まる!異世界転生モノの名作を、原作者完全監修でコミカライズ!') Manga.create(title: "この世界の片隅に", publisher: pb5, author: at11, category: ct16, description: '平成の名作・ロングセラー「夕凪の街 桜の国」の第2弾ともいうべき本作。戦中の広島県の軍都、呉を舞台にした家族ドラマ。主人公、すずは広島市から呉へ嫁ぎ、新しい家族、新しい街、新しい世界に戸惑う。しかし、一日一日を確かに健気に生きていく…。') Manga.create(title: "スラムダンク SLAM DUNK", publisher: pb1, author: at4, category: ct4, description: '中学3年間で50人もの女性にフラれた高校1年の不良少年・桜木花道は背の高さと身体能力からバスケットボール部の主将の妹、赤木晴子にバスケット部への入部を薦められる。彼女に一目惚れした「初心者」花道は彼女目当てに入部するも、練習・試合を通じて徐々にバスケットの面白さに目覚めていき、才能を開花させながら、全国制覇を目指していくのであったが……。') Manga.create(title: "ハイキュー!!", publisher: pb1, author: at12, category: ct4, description: 'おれは飛べる!! バレーボールに魅せられ、中学最初で最後の公式戦に臨んだ日向翔陽。だが、「コート上の王様」と異名を取る天才選手・影山に惨敗してしまう。リベンジを誓い烏野高校バレー部の門を叩く日向だが!?') Manga.create(title: "インベスターZ", publisher: pb2, author: at13, category: ct17, description: '創立130年の超進学校・道塾学園に、トップで合格した財前孝史。入学式翌日に、財前に明かされた学園の秘密。各学年成績トップ6人のみが参加する「投資部」が存在するのだ。彼らの使命は3000億を運用し、年8%以上の利回りを生み出すこと。それゆえ日本最高基準の教育設備を誇る道塾学園は学費が無料だった!「この世で一番エキサイティングなゲーム、人間の血が最も沸き返る究極の勝負……それは金……投資だよ!」') Manga.create(title: "GTO", publisher: pb2, author: at14, category: ct19, description: "かつて最強の不良「鬼爆」の一人として湘南に君臨した鬼塚英吉は、辻堂高校を中退後、優羅志亜(ユーラシア)大学に替え玉試験で入学した。彼は持ち前の体力と度胸、純粋な一途さと若干の不純な動機で、教師を目指した。無茶苦茶だが、目先の理屈よりも「ものの道理」を通そうとする鬼塚の行為に東京吉祥学苑理事長の桜井良子が目を付け、ある事情を隠して中等部の教員として採用する。学園内に蔓延する不正義や生徒内に淀むイジメの問題、そして何より体面や体裁に振り回され、臭いものに蓋をして見て見ぬ振りをしてしまう大人たち、それを信じられなくなって屈折してしまった子どもたち。この学園には様々な問題が山積していたのである。桜井は、鬼塚が問題に真っ向からぶつかり、豪快な力技で解決してくれることに一縷の望みを託すようになる。")※
docker-compose up -dで事前にpostgresqlを起動した状態で行う点に注意
以下のコマンドからseedデータを投入します。$ bin/rails db:seed手順9:コントローラー・ビュー・ルーティングの追加
$ bin/rails g controller Mangas index --helper=false --assets=falseapp/controllers/mangas_controller.rbclass MangasController < ApplicationController def index @mangas = Manga.all end endconfig/routes.rbRails.application.routes.draw do root 'mangas#index' resources :mangas, only: %i(index) endapp/views/mangas/index.html.erb<h1>Mangas</h1> <table> <thead> <tr> <th>Aauthor</th> <th>Publisher</th> <th>Category</th> <th>Author</th> <th>Title</th> <th>Description</th> <th colspan="3"></th> </tr> </thead> <tbody> <% @mangas.each do |manga| %> <tr> <td><%= manga.author.name %></td> <td><%= manga.publisher.name %></td> <td><%= manga.category.name %></td> <td><%= manga.author.name %></td> <td><%= manga.title %></td> <td><%= manga.description %></td> </tr> <% end %> </tbody> </table>手順10:スタイルの調整
bulma-railsを追加してスタイルを調整します。
Gemfilegem "bulma-rails", "~> 0.7.2"Gemfileに追記出来たら、bundle installします。
$ bundle installcssをscssに変更します。
app/assets/stylesheets/application.scss/* * This is a manifest file that'll be compiled into application.css, which will include all the files * listed below. * * Any CSS and SCSS file within this directory, lib/assets/stylesheets, or any plugin's * vendor/assets/stylesheets directory can be referenced here using a relative path. * * You're free to add application-wide styles to this file and they'll appear at the bottom of the * compiled file so the styles you add here take precedence over styles defined in any other CSS/SCSS * files in this directory. Styles in this file should be added after the last require_* statement. * It is generally better to create a new file per style scope. * *= require ./manga *= require_tree . *= require_self */ // https://github.com/joshuajansen/bulma-rails @import "bulma";ここは手動で微調整します。
app/assets/stylesheets/manga.scss.table tr { td:nth-child(-n+3) { width:100px; } td:nth-child(4) { width:150px; } }ビューもbulmaを適用していきます。
app/views/mangas/index.html.erb<section class="hero is-info"> <div class="hero-body"> <div class="container"> <h1 class="title"> 漫画検索 </h1> </div> </div> </section> <div class="container" style="margin-top: 50px"> <table class="table is-striped is-hoverable"> <thead class="has-background-info"> <tr> <th class="has-text-white-bis">出版社</th> <th class="has-text-white-bis">ジャンル</th> <th class="has-text-white-bis">著者</th> <th class="has-text-white-bis">タイトル</th> <th class="has-text-white-bis">説明</th> </tr> </thead> <tbody> <% @mangas.each do |manga| %> <tr> <td><%= manga.publisher.name %></td> <td><%= manga.category.name %></td> <td><%= manga.author.name %></td> <td><%= manga.title %></td> <td><%= manga.description %></td> </tr> <% end %> </tbody> </table> </div>手順11:Elasticsearch用のgemの追加
※ Elasticsearchのメジャーバージョンとgemのメジャーバージョンは揃えないと動作しないので注意しましょう。
今回はElasticsearchが6.5.4なのでgemも6系を使います。Gemfilegem 'elasticsearch-rails', git: 'git://github.com/elastic/elasticsearch-rails.git', branch: '6.x' gem 'elasticsearch-model', git: 'git://github.com/elastic/elasticsearch-rails.git', branch: '6.x'*elasticsearch-rails
*elasticsearch-model
$ bundle install手順12:ElasticsearchをRailsアプリ上で動かせるようにする
configの設定
コメントにも書いていますが、host名は
docker-composeのservicesに設定した名前の「elasticsearch」ではなく「localhost」を指定しないとエラーになってしまったので、そこに留意してconfigを書いています。config/initializers/elasticsearch.rb# hostはdocker-composeのservicesに設定した名前「elasticsearch」ではなく「localhost」を指定しないとエラーになるので注意 # 参考:https://qiita.com/s_yasunaga/items/b0dac7f962c265158a34 config = { host: ENV['ELASTICSEARCH_HOST'] || "localhost", port: ENV['ELASTICSEARCH_PORT'] || "9200", user: ENV['ELASTICSEARCH_USER'] || "", password: ENV['ELASTICSEARCH_PASSWORD'] || "" } Elasticsearch::Model.client = Elasticsearch::Client.new(config)concernを追加
modelに検索モジュールをincludeします。
app/models/manga.rbclass Manga < ApplicationRecord include MangaSearch::Engine belongs_to :author belongs_to :publisher belongs_to :category end検索用モジュールは以下の通りです。
追って用語を補足します。app/models/concerns/manga_search/engine.rbmodule MangaSearch module Engine extend ActiveSupport::Concern included do include Elasticsearch::Model # ①index名 index_name "es_manga_#{Rails.env}" # ②mapping情報 settings do mappings dynamic: 'false' do indexes :id, type: 'integer' indexes :publisher, type: 'keyword' indexes :author, type: 'keyword' indexes :category, type: 'text', analyzer: 'kuromoji' indexes :title, type: 'text', analyzer: 'kuromoji' indexes :description, type: 'text', analyzer: 'kuromoji' end end # ③mappingの定義に合わせてindexするドキュメントの情報を生成する def as_indexed_json(*) attributes .symbolize_keys .slice(:id, :title, :description) .merge(publisher: publisher_name, author: author_name, category: category_name) end end def publisher_name publisher.name end def author_name author.name end def category_name category.name end class_methods do # ④indexを作成するメソッド def create_index! client = __elasticsearch__.client # すでにindexを作成済みの場合は削除する client.indices.delete index: self.index_name rescue nil # indexを作成する client.indices.create(index: self.index_name, body: { settings: self.settings.to_hash, mappings: self.mappings.to_hash }) end end end end*Elasticsearch関連用語の補足
※皆さんが普段使っているであろうRDBとの比較表
RDB Elasticsearch database index table type schema mapping column field record document 手順13:Elasticsearchの動作確認
- RailsコンソールからElasticsearchの疎通確認を行います。 (ここで接続が出来ていないと
Faraday::ConnectionFailedが発生します。)$ Manga.__elasticsearch__.client.cluster.health => {"cluster_name"=>"docker-cluster", "status"=>"yellow", "timed_out"=>false, "number_of_nodes"=>1, "number_of_data_nodes"=>1, "active_primary_shards"=>10, "active_shards"=>10, "relocating_shards"=>0, "initializing_shards"=>0, "unassigned_shards"=>10, "delayed_unassigned_shards"=>0, "number_of_pending_tasks"=>0, "number_of_in_flight_fetch"=>0, "task_max_waiting_in_queue_millis"=>0, "active_shards_percent_as_number"=>50.0}
- indexを作成します。
$ Manga.create_index! => {"acknowledged"=>true, "shards_acknowledged"=>true, "index"=>"es_manga_development"}
- importメソッドでmodelの情報を登録します。さっき追加したas_indexed_jsonの形式に変換してデータが登録されます。
$ Manga.__elasticsearch__.import Manga Load (12.7ms) SELECT "mangas".* FROM "mangas" ORDER BY "mangas"."id" ASC LIMIT $1 [["LIMIT", 1000]] Publisher Load (5.9ms) SELECT "publishers".* FROM "publishers" WHERE "publishers"."id" = $1 LIMIT $2 [["id", 1], ["LIMIT", 1]] Author Load (7.0ms) SELECT "authors".* FROM "authors" WHERE "authors"."id" = $1 LIMIT $2 [["id", 1], ["LIMIT", 1]] Category Load (7.2ms) SELECT "categories".* FROM "categories" WHERE "categories"."id" = $1 LIMIT $2 [["id", 14], ["LIMIT", 1]] Publisher Load (3.2ms) SELECT "publishers".* FROM "publishers" WHERE "publishers"."id" = $1 LIMIT $2 [["id", 1], ["LIMIT", 1]] Author Load (4.1ms) SELECT "authors".* FROM "authors" WHERE "authors"."id" = $1 LIMIT $2 [["id", 3], ["LIMIT", 1]] Category Load (3.7ms) SELECT "categories".* FROM "categories" WHERE "categories"."id" = $1 LIMIT $2 [["id", 1], ["LIMIT", 1]] Publisher Load (4.5ms) SELECT "publishers".* FROM "publishers" WHERE "publishers"."id" = $1 LIMIT $2 [["id", 2], ["LIMIT", 1]] Author Load (3.9ms) SELECT "authors".* FROM "authors" WHERE "authors"."id" = $1 LIMIT $2 [["id", 3], ["LIMIT", 1]] Category Load (3.3ms) SELECT "categories".* FROM "categories" WHERE "categories"."id" = $1 LIMIT $2 [["id", 1], ["LIMIT", 1]] Publisher Load (3.3ms) SELECT "publishers".* FROM "publishers" WHERE "publishers"."id" = $1 LIMIT $2 [["id", 1], ["LIMIT", 1]] Author Load (3.1ms) SELECT "authors".* FROM "authors" WHERE "authors"."id" = $1 LIMIT $2 [["id", 4], ["LIMIT", 1]] Category Load (2.6ms) SELECT "categories".* FROM "categories" WHERE "categories"."id" = $1 LIMIT $2 [["id", 4], ["LIMIT", 1]] Publisher Load (3.9ms) SELECT "publishers".* FROM "publishers" WHERE "publishers"."id" = $1 LIMIT $2 [["id", 3], ["LIMIT", 1]] Author Load (3.5ms) SELECT "authors".* FROM "authors" WHERE "authors"."id" = $1 LIMIT $2 [["id", 5], ["LIMIT", 1]] Category Load (4.2ms) SELECT "categories".* FROM "categories" WHERE "categories"."id" = $1 LIMIT $2 [["id", 15], ["LIMIT", 1]] Publisher Load (2.7ms) SELECT "publishers".* FROM "publishers" WHERE "publishers"."id" = $1 LIMIT $2 [["id", 1], ["LIMIT", 1]] Author Load (2.4ms) SELECT "authors".* FROM "authors" WHERE "authors"."id" = $1 LIMIT $2 [["id", 6], ["LIMIT", 1]] Category Load (2.6ms) SELECT "categories".* FROM "categories" WHERE "categories"."id" = $1 LIMIT $2 [["id", 1], ["LIMIT", 1]] Publisher Load (1.6ms) SELECT "publishers".* FROM "publishers" WHERE "publishers"."id" = $1 LIMIT $2 [["id", 4], ["LIMIT", 1]] Author Load (1.9ms) SELECT "authors".* FROM "authors" WHERE "authors"."id" = $1 LIMIT $2 [["id", 7], ["LIMIT", 1]] Category Load (1.8ms) SELECT "categories".* FROM "categories" WHERE "categories"."id" = $1 LIMIT $2 [["id", 8], ["LIMIT", 1]] Publisher Load (1.9ms) SELECT "publishers".* FROM "publishers" WHERE "publishers"."id" = $1 LIMIT $2 [["id", 1], ["LIMIT", 1]] Author Load (2.3ms) SELECT "authors".* FROM "authors" WHERE "authors"."id" = $1 LIMIT $2 [["id", 8], ["LIMIT", 1]] Category Load (2.7ms) SELECT "categories".* FROM "categories" WHERE "categories"."id" = $1 LIMIT $2 [["id", 6], ["LIMIT", 1]] Publisher Load (1.6ms) SELECT "publishers".* FROM "publishers" WHERE "publishers"."id" = $1 LIMIT $2 [["id", 1], ["LIMIT", 1]] Author Load (1.7ms) SELECT "authors".* FROM "authors" WHERE "authors"."id" = $1 LIMIT $2 [["id", 9], ["LIMIT", 1]] Category Load (1.9ms) SELECT "categories".* FROM "categories" WHERE "categories"."id" = $1 LIMIT $2 [["id", 1], ["LIMIT", 1]] Publisher Load (2.2ms) SELECT "publishers".* FROM "publishers" WHERE "publishers"."id" = $1 LIMIT $2 [["id", 2], ["LIMIT", 1]] Author Load (2.0ms) SELECT "authors".* FROM "authors" WHERE "authors"."id" = $1 LIMIT $2 [["id", 10], ["LIMIT", 1]] Category Load (1.8ms) SELECT "categories".* FROM "categories" WHERE "categories"."id" = $1 LIMIT $2 [["id", 7], ["LIMIT", 1]] Publisher Load (1.6ms) SELECT "publishers".* FROM "publishers" WHERE "publishers"."id" = $1 LIMIT $2 [["id", 5], ["LIMIT", 1]] Author Load (1.3ms) SELECT "authors".* FROM "authors" WHERE "authors"."id" = $1 LIMIT $2 [["id", 11], ["LIMIT", 1]] Category Load (2.0ms) SELECT "categories".* FROM "categories" WHERE "categories"."id" = $1 LIMIT $2 [["id", 16], ["LIMIT", 1]] Publisher Load (1.8ms) SELECT "publishers".* FROM "publishers" WHERE "publishers"."id" = $1 LIMIT $2 [["id", 1], ["LIMIT", 1]] Author Load (1.8ms) SELECT "authors".* FROM "authors" WHERE "authors"."id" = $1 LIMIT $2 [["id", 4], ["LIMIT", 1]] Category Load (2.0ms) SELECT "categories".* FROM "categories" WHERE "categories"."id" = $1 LIMIT $2 [["id", 4], ["LIMIT", 1]] Publisher Load (4.1ms) SELECT "publishers".* FROM "publishers" WHERE "publishers"."id" = $1 LIMIT $2 [["id", 1], ["LIMIT", 1]] Author Load (2.8ms) SELECT "authors".* FROM "authors" WHERE "authors"."id" = $1 LIMIT $2 [["id", 12], ["LIMIT", 1]] Category Load (1.7ms) SELECT "categories".* FROM "categories" WHERE "categories"."id" = $1 LIMIT $2 [["id", 4], ["LIMIT", 1]] Publisher Load (1.6ms) SELECT "publishers".* FROM "publishers" WHERE "publishers"."id" = $1 LIMIT $2 [["id", 2], ["LIMIT", 1]] Author Load (2.0ms) SELECT "authors".* FROM "authors" WHERE "authors"."id" = $1 LIMIT $2 [["id", 13], ["LIMIT", 1]] Category Load (1.8ms) SELECT "categories".* FROM "categories" WHERE "categories"."id" = $1 LIMIT $2 [["id", 17], ["LIMIT", 1]] Publisher Load (1.5ms) SELECT "publishers".* FROM "publishers" WHERE "publishers"."id" = $1 LIMIT $2 [["id", 2], ["LIMIT", 1]] Author Load (1.8ms) SELECT "authors".* FROM "authors" WHERE "authors"."id" = $1 LIMIT $2 [["id", 14], ["LIMIT", 1]] Category Load (1.6ms) SELECT "categories".* FROM "categories" WHERE "categories"."id" = $1 LIMIT $2 [["id", 19], ["LIMIT", 1]] => 0手順14:検索機能の追加
Elasticsearchの疎通確認が出来たので検索モジュールに検索メソッドを追加します。
検索モジュールに検索メソッドを追加
app/models/concerns/manga_search/engine.rb<中略> def search(query) elasticsearch__.search({ query: { multi_match: { fields: %w(publisher author category title description), type: 'cross_fields', query: query, operator: 'and' } } }) end実装を補足
multi_matchは複数のフィールドにまたがって検索したい場合に利用するオプションです。
fieldsでは検索対象のフィールドを指定しています。
typeでmulti_matchの検索タイプを指定していて、ここではcross_fieldsという複数のフィールドを結合して、一つのフィールドのように扱うタイプを指定しています。multi_match: { fields: %w(publisher author category title description), type: 'cross_fields',上記の実装の他にもどういったクエリの書き方があるのか詳しく調べたい場合は、公式ドキュメントのQuery DSLの部分を読んでみて下さい!
コントローラーの修正
- 検索メソッドをコントローラーに反映します。
app/controllers/mangas_controller.rbclass MangasController < ApplicationController def index @mangas = if query.present? Manga.search(query).records else Manga.all end end private def query @query ||= params[:query] end endビューの修正
- ヘッダーとテーブルの間に検索窓を追加します。
app/views/mangas/index.html.erb<section class="hero is-info"> <div class="hero-body"> <div class="container"> <h1 class="title"> 漫画検索 </h1> </div> </div> </section> ###### ここから下の検索窓の部分を追加 ##### <div class="container" style="margin-top: 30px"> <%= form_tag(mangas_path, method: :get, class: "field has-addons has-addons-centered") do %> <div class="control"> <%= text_field_tag :query, @query, class: "input", placeholder: "漫画を検索する" %> </div> <div class="control"> <%= submit_tag "検索", class: "button is-info" %> </div> <% end %> </div> <div class="container" style="margin-top: 50px"> <table class="table is-striped is-hoverable"> <thead class="has-background-info"> <tr> <th class="has-text-white-bis">出版社</th> <th class="has-text-white-bis">ジャンル</th> <th class="has-text-white-bis">著者</th> <th class="has-text-white-bis">タイトル</th> <th class="has-text-white-bis">説明</th> </tr> </thead> <tbody> <% @mangas.each do |manga| %> <tr> <td><%= manga.publisher.name %></td> <td><%= manga.category.name %></td> <td><%= manga.author.name %></td> <td><%= manga.title %></td> <td><%= manga.description %></td> </tr> <% end %> </tbody> </table> <%= paginate @mangas %> </div>手順15:ページネーションの追加
このままだと検索結果を全件表示することになってしまうので、ページネーションを追加していきます。
※ 注意点はこちらを参照
kaminariはElasticsearch関連のgemよりも上に追加するようにしましょう。Gemfilegem 'kaminari'kaminariをコントローラーに適用
変更点はElasticsearchや通常のDBへの検索両方に
pageとperで何ページ目を何件取るかを設定します。
通常APIを作る際はpageの方だけparams[:page]で取得して、per部分は任意の値を設定することが多いのかな?と思うので、今回はそういった実装になっています。app/controllers/mangas_controller.rbclass MangasController < ApplicationController def index @mangas = if query.present? Manga.search(query).page(page_number).per(5).records else Manga.page(page_number).per(5) end end private def query @query ||= params[:query] end def page_number [params[:page].to_i, 1].max end endkaminariのための日本語設定を追加
kaminariのページネーション部分を日本語表記にするための設定を追加します。
application.rbにconfig.i18n.default_locale = :jaを追加しましょう。config/application.rbmodule ElasticsearchRailsSandbox class Application < Rails::Application # Initialize configuration defaults for originally generated Rails version. config.load_defaults 6.0 <中略> config.i18n.default_locale = :ja end end新規で日本語設定ymlファイルを以下の通りの内容で作成します。
config/locales/ja.ymlja: views: pagination: first: "« 最初" last: "最後 »" previous: "‹ 前" next: "次 ›" truncate: "..."kaminariのためのビューの変更
kaminariのテンプレートを作成するコマンドを実行します。
$ bundle exec rails g kaminari:views default実行すると
app/views/kaminari以下にファイルが作成されるので、これらのファイルを修正していきます。kaminariについてはおまけ的な部分なので、以下に完成したビューを示すのみになりますので悪しからず
kaminari/_next_page.html.erb
app/views/kaminari/_next_page.html.erb<%# Link to the "Next" page - available local variables url: url to the next page current_page: a page object for the currently displayed page total_pages: total number of pages per_page: number of items to fetch per page remote: data-remote -%> <%= link_to_unless current_page.last?, t('views.pagination.next').html_safe, url, rel: 'next', remote: remote, class: 'pagination-next' %>kaminari/_page.html.erb
app/views/kaminari/_page.html.erb<%# Link showing page number - available local variables page: a page object for "this" page url: url to this page current_page: a page object for the currently displayed page total_pages: total number of pages per_page: number of items to fetch per page remote: data-remote -%> <li> <% if page.current? -%> <%= link_to page, '#', {remote: remote, rel: page.rel, class: "pagination-link is-current"} %> <% else -%> <%= link_to page, url, {remote: remote, rel: page.rel, class: "pagination-link"} %> <% end -%> </li>kaminari/_paginator.html.erb
app/views/kaminari/_paginator.html.erb<%# The container tag - available local variables current_page: a page object for the currently displayed page total_pages: total number of pages per_page: number of items to fetch per page remote: data-remote paginator: the paginator that renders the pagination tags inside -%> <%= paginator.render do -%> <nav class="pagination is-centered" role="navigation" aria-label="pager"> <%= prev_page_tag unless current_page.first? %> <% unless current_page.out_of_range? %> <%= next_page_tag unless current_page.last? %> <% end %> <ul class="pagination-list"> <% each_page do |page| -%> <% if page.left_outer? || page.right_outer? || page.inside_window? -%> <%= page_tag page %> <% elsif !page.was_truncated? -%> <%= gap_tag %> <% end -%> <% end -%> </ul> </nav> <% end -%>kaminari/_prev_page.html.erb
app/views/kaminari/_prev_page.html.erb<%# Link to the "Previous" page - available local variables url: url to the previous page current_page: a page object for the currently displayed page total_pages: total number of pages per_page: number of items to fetch per page remote: data-remote -%> <%= link_to_unless current_page.first?, t('views.pagination.previous').html_safe, url, rel: 'prev', remote: remote, class: 'pagination-previous' %>views/mangas/index.html.erb
<%= paginate @mangas %>を追加しています。app/views/mangas/index.html.erb<section class="hero is-info"> <div class="hero-body"> <div class="container"> <h1 class="title"> 漫画検索 </h1> </div> </div> </section> <div class="container" style="margin-top: 30px"> <%= form_tag(mangas_path, method: :get, class: "field has-addons has-addons-centered") do %> <div class="control"> <%= text_field_tag :query, @query, class: "input", placeholder: "漫画を検索する" %> </div> <div class="control"> <%= submit_tag "検索", class: "button is-info" %> </div> <% end %> </div> <div class="container" style="margin-top: 50px"> <table class="table is-striped is-hoverable"> <thead class="has-background-info"> <tr> <th class="has-text-white-bis">出版社</th> <th class="has-text-white-bis">ジャンル</th> <th class="has-text-white-bis">著者</th> <th class="has-text-white-bis">タイトル</th> <th class="has-text-white-bis">説明</th> </tr> </thead> <tbody> <% @mangas.each do |manga| %> <tr> <td><%= manga.publisher.name %></td> <td><%= manga.category.name %></td> <td><%= manga.author.name %></td> <td><%= manga.title %></td> <td><%= manga.description %></td> </tr> <% end %> </tbody> </table> <%= paginate @mangas %> </div>手順16:RSpecのセットアップ
RSpecに必要なGemの追加
※
'spring-commands-rspec'はRSpecをSpring経由で実行するためのgemです。
以下のgemを追加したらbundle installしましょう。Gemfilegroup :test do <中略> gem 'rspec-rails' gem 'spring-commands-rspec' gem 'factory_bot_rails' endRSpecの各種設定ファイルを生成するコマンドを実行
$ bundle exec rails generate rspec:install※生成されるファイル
.rspec spec/rails_helper.rb spec/spec_helper.rb.rspecの内容を修正
--colorは出力結果の色付け
--format documentationは specファイルのdescribeやitなどのコメント部分を結果と共に表示してくれるので、付けると視覚的にテスト結果が分かりやすくなるオプションです。.rspec--require spec_helper --color --format documentationRSpecをspringを経由して実行出来るようにセットアップ
以下のコマンドを実行します。
$ bundle exec spring binstub rspec生成されるファイルは以下の通りです。
bin/rspec#!/usr/bin/env ruby begin load File.expand_path('../spring', __FILE__) rescue LoadError => e raise unless e.message.include?('spring') end require 'bundler/setup' load Gem.bin_path('rspec-core', 'rspec')bin/spring#!/usr/bin/env ruby # This file loads Spring without using Bundler, in order to be fast. # It gets overwritten when you run the `spring binstub` command. unless defined?(Spring) require 'rubygems' require 'bundler' lockfile = Bundler::LockfileParser.new(Bundler.default_lockfile.read) spring = lockfile.specs.detect { |spec| spec.name == 'spring' } if spring Gem.use_paths Gem.dir, Bundler.bundle_path.to_s, *Gem.path gem 'spring', spring.version require 'spring/binstub' end endFactoryBotの各種ファイルを追加
spec/factories/author.rbFactoryBot.define do factory :author do sequence(:name) { |n| "TEST#{n}太郎" } end endspec/factories/category.rbFactoryBot.define do factory :category do name { %w(ラブコメ ファンタジー サスペンス バトル スポーツ サイコスリラー 日常系).sample } end endspec/factories/manga.rbFactoryBot.define do factory :manga do association :category, factory: :category association :author, factory: :author association :publisher, factory: :publisher sequence(:title) { |n| "TEST_PRODUCT#{n}" } sequence(:description) { |n| "TEST_DESCRIPTION#{n}" } end endspec/factories/publisher.rbFactoryBot.define do factory :publisher do sequence(:name) { |n| "TEST#{n}出版" } end endFactoryBotの名前空間を省略出来るようにする定義を追加
テストデータの呼び出しを
FactoryBot.create(:◯◯) → create(:◯◯)に簡略化出来る設定など細かい設定を以下の通りに追加しておきます。spec/rails_helper.rbRSpec.configure do |config| <中略> # テストデータの呼び出しをFactoryBot.create(:◯◯) → create(:◯◯)に簡略化 config.include FactoryBot::Syntax::Methods # springを使用してrspecを動かしているとfactoryで作成したデータが正しく読み込まれないことがあるので # 毎回全てのexample実行前にfactory_botを再読込させる config.before :all do FactoryBot.reload end end手順17:Elasticsearchのテストを追加
RSpecでElasticsearchのindexを作成するための設定
ElasticsearchをRSpec上でテストする際の設定をしていきます。
※テスト実行時にmetaデータを渡し、それがelasticsearchだった場合に該当リソースのindexを作成するように設定しています。spec/rails_helper.rbRSpec.configure do |config| <中略> # elasticsearchのテストの場合のみIndexを作成する config.before :each do |example| if example.metadata[:elasticsearch] && example.metadata[:model_name] # meta情報のモデル名の文字列をクラス定数に変換し、Elasticsearchのindexを作成する class_constant = example.metadata[:model_name].classify.constantize class_constant.create_index! end end endキーワード検索のテスト
spec/models/concerns/manga_search/engine_spec.rbrequire 'rails_helper' RSpec.describe MangaSearch::Engine, elasticsearch: true, model_name: "manga" do describe 'Manga.search' do describe '検索ワードにマッチする漫画の検索' do let!(:manga_1) do create(:manga, title: 'キングダム', description: '時は紀元前―。いまだ一度も統一...') end let!(:manga_2) do create(:manga, title: '僕のヒーローアカデミア', description: '多くの人間が“個性という力を持つ...') end let!(:manga_3) do create(:manga, title: 'はたらく細胞', description: '人間1人あたりの細胞の数、およそ60兆個...') end # 作成したデータをelasticsearchに登録する # refresh: true を追加することで登録したデータをすぐに検索できるようにする before { Manga.__elasticsearch__.import(refresh: true) } subject { Manga.search(query).records.pluck(:id) } context '検索ワードがタイトルにマッチする場合' do let(:query) { 'キングダム' } it '検索ワードにマッチする漫画を取得する' do is_expected.to include manga_1.id end end context '検索ワードが複数ある場合' do let(:query) { '人間 個性' } it '両方の検索ワードにマッチする漫画を取得する' do is_expected.to include manga_2.id end end context '検索ワードが本文にマッチする場合' do let(:query) { '60兆個' } it '検索ワードにマッチする漫画を取得する' do is_expected.to include manga_3.id end end end end endまとめ
以上でハンズオンのカリキュラムは終了になります。
駆け足ではありましたが、Dockerで環境を作って、Rails上でElasticsearchを試せるようになりました。
この後はサンプルアプリを自分なりに改造しつつ、デバッグしつつ、Elasticsearchの勉強用の教材として利用して頂ければ嬉しいです。
最後までお付き合い下さり、ありがとうございました
参考


- 投稿日:2020-03-01T21:19:17+09:00
特定パスのファイルをまとめて require するワンライナー
1. はじめに
はじめに結論!
Dir.glob(Rails.root.join('lib', 'tasks', 'module', '*')).each(&method(:require))2. そもそも
Array#mapなどに、ブロックではなく、&:メソッド名を渡すショートハンドは、Ruby に慣れた方なら割と使っているかもしれませんこういうやつirb(main):001:0> [1, 2, 3].map(&:to_s) => ["1", "2", "3"]ところで、この配列の要素を、レシーバー側ではなく、引数側に取りたい場合は、
#methodメソッドを用いて以下のような書き方ができますこんな感じirb(main):002:0> [1, 2, 3].map(&2.method(:eql?)) => [false, true, false]ただこの書き方は、ややテクニカル過ぎてかえってコードが読みづらくなるため、あまり使うことはないだろうと思っていました
3. 何があったのか
ところが、仕事が4つも5つもある、妙に多機能な rake task スクリプトを書かされる悲しい事件が起きたとき
4. まとめ
#requireならレシーバーも省略できてややスッキリ書けますし、記述するのはファイルの冒頭なので、お決まりの書き方的な感じで、他のコーダーにも受け入れてもらいやすいかもしれません
みなさんもぜひ使ってみてくださいね

これらのショートハンドが動作する仕組みについては、以下の記事が詳しいです
参考: &演算子と、procと、Object#method について理解しなおす
- 投稿日:2020-03-01T20:36:14+09:00
【Rails】5ステップでイケてる enum を作る(翻訳)
※ この記事は Ruby on Rails - How to Create Perfect Enum in 5 Steps を許可をとって翻訳したものです。日本語で読みやすいように一部意訳しております。
はじめに
エンジニアの皆さんなら客先からの仕様変更なんてものは日常茶飯事でしょう。度々来る仕様変更に対して柔軟に対応できるモデルを設計する必要があります。大抵のモデルはその属性を表すカラムを持っているでしょう。例えば宅配モデルなら「通常配送」「お急ぎ便」「時間指定」などの属性を持つことが想定されます。このような属性を定義する方法の一つが列挙型、すなわち enum です。
Rails では4.1以降で enum をサポートしています。
この記事は下記のような構成になっています。
- 基本的な使い方 ー
ActiveRecord::Enumを出来るだけ簡単に導入する- 5ステップで enum を改善する
- 5ステップ全部載せ
わかりやすくするために実際の例を用いていきます。ここでは作品モデル
Artworksとそれを収録するカタログモデルCatalogsを考えます。また、Catalogsが持つ属性の中でも以下の4つを扱うことにしてみます。
state: ["incoming", "in_progress", "finished"]auction_type: ["traditional", "live", "internet"]status: ["published", "unpublished", "not_set"]localization: ["home", "foreign", "none"]基本的な使い方
既存のモデルに enum を追加するのは簡単です。まず最初にマイグレーションファイルを作成します。Rails では enum を用いるのに integer 型のカラムを定義します。
rails g migration add_status_to_catalogs status:integerclass AddStatusToCatalogs < ActiveRecord::Migration[5.1] def change add_column :catalogs, :status, :integer end endモデルに enum を宣言します。
class Catalog < ActiveRecord::Base enum status: [:published, :unpublished, :not_set] endそして、マイグレーションを実行しましょう。これで便利な追加メソッドをたくさん使えるようになりました。
例えば、次のようにして現在のステータスをチェックすることができます。
catalog.published? # false属性の値の変更は次のようにします。
catalog.status = "published" # published catalog.published! # published値が published のカタログ一覧は次のようにすれば取得できます。
Catalog.published全てのメソッドを見るには ActiveRecord::Enum を参照してください。
以上の方法は非常にシンプルで便利ですが、プロジェクトが進むといくつかの問題に直面するでしょう。備えあれば憂いなし、いくつかの準備をすることでメンテナンス性の高い enum を作ることができます。
5ステップで enum を改善する
STEP1 enum を配列ではなくハッシュで定義する
enum を配列で定義すると、DBで保持される整数値は、配列の順番に依存します。
class Catalog < ActiveRecord::Base enum localization: [:home, :foreign, :none] end0 -> home 1 -> foreign 2 -> noneこの方法は柔軟性が全くありません。例えば、 "foreign" が "America" と "Asia" に分割された時、古い値を削除して新しい値を追加する必要があります。しかし、このケースでは "foreign" を削除すると "foreign" に割り当てられていた整数値 1 が他の属性に割り当てられ、過去の紐付けとの食い違いが発生してしまいます。
ハッシュで定義することでこの問題を回避することができます。
class Catalog < ActiveRecord::Base enum localization: { home: 0, foreign: 1, none: 2 } endこの方法なら宣言の順番に依存することなく整数値を割り当てることができるため、属性の削除や追加が可能になります。
STEP2 ActiveRecord::Enum と PostgreSQL enum を紐付ける
rails 側で属性と整数値を紐付けた enum を定義した時、DB側が保持するのは整数値のみです。当然、整数値自体は意味を持たない値なのでDB上の値を見ても「1」が何を指しているのかは分かりません。
rails consoleで次のように where メソッドを使うとエラーになってしまいます。> Catalog.where.not(“state = ?”, “finished”) ActiveRecord::StatementInvalid: PG::InvalidTextRepresentation: ERROR: invalid input syntax for integer: "finished"このエラーはDB側では "finished" という値ではなく整数値を保持しているために起こってしまいます。
ActiveRecordを介さない SQL クエリを実行するときにも同様の問題が発生します。単純にDBに保存されている情報を見ようとしただけでも、どの整数値がどの属性に対応するかを逐一確認する必要があるため、非常に手間がかかります。このように、整数型の enum を用いることで情報が失われてしまうことを理解しておく必要があります。
さらに、データの安全性に関する問題もあります。例えば、DB側では整数値であれば insert 可能ですので、enum で宣言した値以外の値が insert されてしまうことも起こり得ます。この問題は
PostgreSQL enumによりデータベースレベルで制約を設けることで解決可能です。どの程度の信頼性を確保するかは設計者自身が決める必要があります。PostgreSQL は Ruby on Rail のプロダクトで標準的に使用されているデータベースです。
PostgreSQLはテーブルの中で属性値を扱うのに適しています。それでは、早速実装してみましょう。
rails g migration add_status_to_catalogs status:catalog_statusデータ型を変更する時、 "status" のような命名はおすすめできません。近い将来別の "status" という属性が必要になる可能性が大いにあるからです。
次は、マイグレーションファイルを編集します。マイグレーションファイルは基本的に可逆的で SQL を実行できる必要があります。
class AddStatusToCatalogs < ActiveRecord::Migration[5.1] def up execute <<-SQL CREATE TYPE catalog_status AS ENUM ('published', 'unpublished', 'not_set'); SQL add_column :catalogs, :status, :catalog_status end def down remove_column :catalogs, :status execute <<-SQL DROP TYPE catalog_status; SQL end endenum の宣言部分は前回のものに少し変更が必要です。
class Catalog < ActiveRecord::Base enum status: { published: "published", unpublished: "unpublished", not_set: "not_set" } endSTEP3 index を enum で定義した属性に追加する
この変更はシンプルなものです。enum 属性はモデル内の特定のオブジェクトを抽出するときによく使われます。例えば、カタログモデルの中で "published" のものと そうでないものをリスト化する時などです。このようなフィルタリングの処理は非常に頻繁に行われるので index を追加しておくことはパフォーマンスの工場に繋がります。
次のようにマイグレーションファイルを修正しましょう。
class Catalog < ActiveRecord::Base enum status: { published: "published", unpublished: "unpublished", not_set: "not_set" } endSTEP4 prefix または suffix オプションを使う
今一度
Catalogモデルを見てみましょう。
state: ["incoming", "in_progress", "finished"]auction_type: ["traditional", "live", "internet"]status: ["published", "unpublished", "not_set"]localization: ["home", "foreign", "none"]prefix または suffix は次のようにして enum に追加します。
class Catalog < ActiveRecord::Base enum status: { published: "published", unpublished: "unpublished", not_set: "not_set" }, _prefix: :status enum auction_type: { traditional: "traditional", live: "live", internet: "internet" }, _suffix: true endなぜこれが役立つのでしょうか。
Catalogモデルを見てみると、4つの enum と 12 の属性値を持っていることが分かります。すなわち、12のスコープを持つことになり、直感的には非常に分かりづらいものになっています。Catalog.not_set Catalog.live Catalog.unpublished Catalog.in_progress上記のメソッドがどんな値が返すかすぐ答えるためには、全ての enum 属性をを常に覚えておく必要があります。とても大変なことです。
Catalog.status_not_set Catalog.live_auction_type Catalog.status_unpublished Catalog.state_in_progressだいぶ分かりやすくなりました。
ここでもう一つ
Catalogに enum を加えることになったとしましょう。グローバルカタログ内の各カタログの順序に関する情報を保持する enum です。一部のカタログの順序は指定されていない場合があります。最も重要なのは、どのカタログが最初でどれが最後かが分かることです。次のように作成します。class Catalog < ActiveRecord::Base enum order: { first: "first", last: "last", other: "other", none: "none" } endでは、
rails consoleで作成した enum をチェックしてみましょう。> Catalog.order ArgumentError: You tried to define an enum named "order" on the model "Catalog", but this will generate a class method "first", which is already defined by Active Record."first" は既に ActiveRecord で定義されているというエラーが表示されました。そこで次のように修正します。
class Catalog < ActiveRecord::Base enum order: { first_catalog: "first_catalog", last_catalog: "last_catalog", other: "other", none: "none" } end再度チェックしてみます。
> Catalog.order ArgumentError (You tried to define an enum named "order" on the model "Catalog", but this will generate an instance method "none?", which is already defined by another enum.)先程と違うエラーです。"none" が別の enum で使われていることを指摘されています。
prefix または suffixs オプションはこの問題を解決するのに最適です。"first" "last" のような属性値自体はシンプルなまま残すことができます。また、スコープは直感的で分かりやすいものとなります。変更後のコードは次のようになります。
class Catalog < ActiveRecord::Base enum order: { first: "first", last: "last", other: "other", none: "none" }, _prefix: :order endSTEP5 enum を Value Object として切り出す
次のような状態の場合は enum 属性をValue Object として切り出すことを推奨します。
- enum 属性が2つ以上のモデルで使われている場合
- enum 属性がモデルを複雑にする特定のロジックを持っている場合
それでは例を用いて説明します。我々のプロジェクトではアートワークを販売するオークションハウスを全国に配置しています。ポーランドは voivodeships(日本で言うところの県)と呼ばれる16の地域に分かれています。各
AuctionHouseモデルはVoivodeship属性を含むAddressモデルを持っています。なんらかの理由で下記のメソッドを実装することになったとします。
- 北部のオークションハウスをリスト化するメソッド
- 人口の多いいくつかの県のオークションハウスをリスト化するメソッド
これらのメソッドを
Addressモデルに実装すると、モデルが肥大化してしまいます。そこで、別のクラスに切り出すことで再利用可能かつよりクリーンな状態を実現します。class Voivodeship VOIVODESHIPS = %w(dolnoslaskie kujawsko-pomorskie lubelskie lubuskie lodzkie malopolskie mazowieckie opolskie podkarpackie podlaskie pomorskie slaskie swietokrzyskie warminsko-mazurskie wielkopolskie zachodnio-pomorskie).freeze NORTHERN_VOIVODESHIPS = %w(warminsko-mazurskie pomorskie zachodnio-pomorskie podlaskie).freeze MOST_POPULAR_VOIVODESHIPS = %w(dolnoslaskie mazowieckie slaskie malopolskie).freeze def initialize(voivodeship) @voivodeship = voivodeship end def northern? NORTHERN_VOIVODESHIPS.include? @voivodeship end def popular? MOST_POPULAR_VOIVODESHIPS.include? @voivodeship end def eql?(other) to_s.eql?(other.to_s) end def to_s @voivodeship.to_s end end次に
Addressモデルから切り出したVoivodeshipを呼び出す部分を記述します。array_to_enum_hashは配列で定義された enum をハッシュに変換するメソッドです。class Address < ApplicationRecord enum voivodeship: array_to_enum_hash(Voivodeship::VOIVODESHIPS), _sufix: true def voivodeship @voivodeship ||= Voivodeship.new(read_attribute(:voivodeship)) end endこれで
Voivodeshipsに関連するロジック全体が単一のクラスにカプセル化されました。必要に応じて拡張可能で、Addressが肥大化することもありません。voivodeships 属性を取得したいときは、
Voivodeshipsクラスが返されます。これはまさに Value Object です。※Value Object はデザインパターンの一つです。こちら等が参考になります。
voivodeship_a = Address.first.voivodeship # #<Voivodeship:0x000000000651eef0 @voivodeship="pomorskie"> voivodeship_b = Address.second.voivodeship # #<Voivodeship:0x00000000064e9cf0 @voivodeship="pomorskie"> voivodeship_c = Address.third.voivodeship # #<Voivodeship:0x000000000641ef00 @voivodeship="lodzkie">voivodeship_a と voivodeship_b は同じ voivodeship の値を持っていますが、オブジェクトとしてはイコールではありません。幸いなことに、我々が作ったメソッドは値が等しいかをチェックすることができます。
voivodeship_a.eql? voivodeship_b # true voivodeship_a.eql? voivodeship_c # falseさらに、先程定義したメソッドを使用して次のように記述できるのも非常に強力なメリットです。
voivodeship_a.northern? # true voivodeship_a.popular? # false voivodeship_c.northern? # false voivodeship_c.popular? # false5ステップ全部載せ
ここまで5ステップに渡って enum の改善方法を示してきました。それでは、ここまでの振り返りとして、これら全てを実装した究極の enum を作っていきましょう。例として、
Catalogモデルのstatus属性を考えます。マイグレーションファイルの作成
rails g migration add_status_to_catalogs status:catalog_statusマイグレーションファイルの編集
class AddStatusToCatalogs < ActiveRecord::Migration[5.1] def up execute <<-SQL CREATE TYPE catalog_status AS ENUM ('published', 'unpublished', 'not_set'); SQL add_column :catalogs, :status, :catalog_status add_index :catalogs, :status end def down remove_column :catalogs, :status execute <<-SQL DROP TYPE catalog_status; SQL end endValue Object の作成
class CatalogStatus STATUSES = %w(published unpublished not_set).freeze def initialize(status) @status = status end # what you need here endCatalog モデルと enum の定義
class Catalog enum status: array_to_enum_hash(CatalogStatus::STATUSES), _sufix: true def status @status ||= CatalogStatus.new(read_attribute(:status)) end end結論
以上がイケてる enum を作る5つのステップです。
これら全てが必要になることもあるし、一部だけ使うこともあります。自分のプロジェクトのニーズに合わせて調整してください。
最後に、この記事が誰かの訳に立つことを願っています。より良い改善方法があればコメントをよろしくお願いします。
この記事について
冒頭でも述べたとおり、下記を翻訳したものです。
Ruby on Rails - How to Create Perfect Enum in 5 Steps著者に掲載の許可を取って公開しています。
enum 以外にもマイグレーションの可逆性、Value Objectによるリファクタリングなど、多くの学びがある非常に良質な内容だと感じました。また、日本語で同様の情報を見つけることができなかったので自分で翻訳してみました。より良い改善方法があればこちらでもコメントしてもらえると助かります。
最後までご覧いただきありがとうございました。
- 投稿日:2020-03-01T20:04:20+09:00
REST APIがエラー発生時に返すべきJSONの形(+Railsでの実装方法)
はじめに
- RailsのAPIでエラー処理ってどうすればいいんだろう?
- どんなJSONを返せばいいんだろう?
筆者が関わっている企業でよくこのように悩んでる人を見かけるので、自分の経験を基に記事にまとめてみました。
返すべきJSONの形
ぶっちゃけ、企業によってまちまちですし、「これが絶対正解だ!」と言えるものはありません。
いろんな企業のAPIがどのような形のレスポンスを返しているか知りたければ、WebAPIでエラーをどう表現すべき?15のサービスを調査してみたという記事が非常に参考になります。
ただ、上記の記事にも書いてありますが、2016年に出たRFC7807が、「こういう形でいいんじゃね!?」っていう標準となるようなJSONの形を提案してくれています。RFC7807が提案する形
詳しくはRFCの方を参照していただければと思いますが、具体例を書くとこんな感じです。
{ "type": "https://your-api-url.com/problems/article-not-found", "title": "お探しの記事は見つかりませんでした", "status": 404, "detail": "IDが999の記事は見つかりませんでした。URLが正しいかご確認ください。", "instance": "/articles/999" }
フィールド名 必須 簡単な説明(詳しくはRFCを参照) type ✔︎ エラーの種類を識別するURI。URIに遷移すると、エラーのドキュメンテーションが返されることが望ましい。 title エラーを説明する短い文章。typeと1:1の関係(i18nは除く)。 status httpステータスコード detail titleの長いバージョン。より詳細な説明のための文章。 instance エラーの原因となったリソースのインスタンスを識別するURI。 また、上記以外にも必要に応じてフィールドを追加することも可能。
RFC7807に準拠した最低限の形
では、実際に
type,title,status,detail,instanceは全て必要かと言われたら、そんなことはありません。
以下は、筆者の個人的な意見になりますが、各フィールドの必要性を判断したものです。
type: 必須だしエラーの種類を識別するエラーコード的な役割も果たしてくれるので必要title: ユーザーに表示するエラーメッセージとして使えるので必要status: レスポンスのボディになくてもヘッダーを見ればわかるので不要detail,instance: あっても使う機会は少なそう(規模にもよるかもしれない)ので不要まとめると「とりあえず
typeとtitleさえあれば困らないかな」という感じです。
なので、ミニマムな形としては以下で十分だと思います。{ "type": "https://your-api-url.com/problems/article-not-found", "title": "お探しの記事は見つかりませんでした" }
typeは相対ぱすでも良いので、以下のような形でも大丈夫です。{ "type": "/problems/article-not-found", "title": "お探しの記事は見つかりませんでした" }さらに、「内部でしか使わないからAPIのエラーコードのドキュメンテーションをわざわざURLでアクセスするようにしないよ!」っていう方も多いと思うので、その場合は(RFC7807の仕様からは外れてしまいますが)以下のような形でも良いと思います。
{ "type": "article-not-found", "title": "お探しの記事は見つかりませんでした" }異論は認めます。ぜひコメントを投げてください!
Railsにおける実装方法
さて、JSONの形が決まったところで、次はRailsで実装する方法を考えます。
実装方法1. 返すJSONベタがき
これはスケールしないのであまりおすすめしませんが、すごく小規模なアプリケーション、使い捨てのアプリケーション、なんらかの制約でとりあえず早くリリースしなければいけない場合などはありかなと思います。
class HogesController before_action :authenticate! def show # ログインしてないと見れない情報を返す end private # こういう共通で使いそうなメソッドは実際には親コントローラーやconcernに定義されてそうだが、 # 今回は簡単にするためにprivate methodとして定義する def authenticate! @user = # 認証するコード return if @user render json: { type: '/problems/authentication_required', title: 'ログインしてください' }, status: 401, content_type: 'application/problem+json' end end全てのコントローラーに継承される親コントローラーに、このようにJSONをとりあえずベタがきで書いて返します。
親コントローラーがない場合は、各コントローラーにincludeされるモジュールでも良いと思います。実装方法2. エラーごとにクラスを定義し、SerializerでJSONを組み立てる
1. エラーの親クラスを作成
まず、
ApiExceptions::BaseExceptionと言う、エラークラスの親を作成します。# app/models/api_exceptions/base_exception.rb module ApiExceptions class BaseException < StandardError attr_reader :status_code, :type, :title def initialize raise NotImplementedError end end end2. 個別のエラークラスを作成
次に、個別のエラークラスを作成します。
# 例) 認証エラー # app/models/api_exceptions/authentication_required.rb module ApiExceptions class AuthenticationRequired < BaseException def initialize @status_code = 401 # Unauthorized @type = '/problems/authentication_required' @title = 'ログインしたください' end end end3. 例外のSerializerを作成
エラークラスをJSONに変換する
ApiExceptionSerializerを作成します。
今回の例では、ActiveModel::Serializerを使っていますが、他のSerializerでも同じことを実現できるはずです。# app/serializers/api_exception_serializer.rb class ApiExceptionSerializer < ActiveModel::Serializer attributes :type, :title end4. 親コントローラーで
ApiExceptionをrescueする# app/controllers/base_controller.rb class BaseController < ActionController::API rescue_from ApiException, with: :render_api_exception private def render_api_exception(exception) render json: exception, serializer: ApiExceptionSerializer, status: exception.status_code, content_type: 'application/problem+json' end end5. 各コントローラーで
raiseするclass HogesController < BaseController before_action :authenticate! def show # ログインしてないと見れない情報を返す end private def authenticate! @user = # 認証するコード raise ApiExceptions::AuthenticationRequired unless @user # 認証なしでアクセスすると以下のJSONが返される # { # "type": "/problems/authentication_required", # "title": "ログインしてください" # } end endこのアプローチの何が嬉しいか
実装方法1.と比べると、
- 各コントローラーで書くのはエラーを
raiseするコードのみなので、コントローラーをスリムに保てる- エラーの種類に対応するクラスを
app/models/api_exceptions配下に必ず作成しなければいけないので、どんなエラーの種類があるのかわかりやすい=ドキュメンテーションになる。- JSONを生成する責務をコントローラーからSerializerに移せるので責務がいい感じに別れる
content_type: 'application/problem+json'のような共通で返す必要があるJSONは一箇所に定義すれば済むまとめ
- エラーで返すJSONはRFC7807に準拠するのが無難
- 最低限、エラーの種類を表す
typeと、エラー内容の説明をするtitleは入れよう- その他は必要に応じて追加すれば良い
- エラーの種類ごとにクラスを定義するといい感じに書ける
- 投稿日:2020-03-01T19:49:35+09:00
RailsにMySQLを導入する
Railsアプリを作っていて、DBは何にしよう?
MySQLかな(使い慣れているし)と思い、導入することにしました。MySQLのインストール
Homebrewを使ってインストールします
$ brew update $ brew install mysqlバージョン確認(接続前)$ mysql --version mysql Ver 8.0.19 for osx10.14 on x86_64 (Homebrew)バージョン確認(接続後)mysql> select version(); +-----------+ | version() | +-----------+ | 8.0.19 | +-----------+ 1 row in set (0.00 sec)MySQL起動
インストールが成功したら起動してみましょう
MySQL起動、接続$ mysql.server start $ mysql -u rootセキュリティ設定
接続できたらセキュリティ設定を行います
セキュリティ設定$ mysql_secure_installation下記4つの項目を聞かれます。
1.rootのパスワードの変更
まずは、rootユーザーのパシワード変更です。
パスワードの変更VALIDATE PASSWORD PLUGIN can be used to test passwords and improve security. It checks the strength of password and allows the users to set only those passwords which are secure enough. Would you like to setup VALIDATE PASSWORD plugin? Press y|Y for Yes, any other key for No: yパスワードの強度は3種類あるようです。
パスワードの変更There are three levels of password validation policy: LOW Length >= 8 MEDIUM Length >= 8, numeric, mixed case, and special characters STRONG Length >= 8, numeric, mixed case, special characters and dictionary file Please enter 0 = LOW, 1 = MEDIUM and 2 = STRONG: 2・LOW:8文字以上
・MEDIUM:8文字以上 + 数字・アルファベットの大文字と小文字・特殊文字を含む
・STRONG:8文字以上 + 数字・アルファベットの大文字と小文字・特殊文字を含む + 辞書ファイルでのチェックご自身にあったものを選んで変更してください
2.匿名ユーザの削除
匿名ユーザーを削除するか聞かれるので、削除します
anonymousユーザーの削除By default, a MySQL installation has an anonymous user, allowing anyone to log into MySQL without having to have a user account created for them. This is intended only for testing, and to make the installation go a bit smoother. You should remove them before moving into a production environment. Remove anonymous users? (Press y|Y for Yes, any other key for No) : y3.リモートからのrootユーザでのログイン禁止
リモートから root ユーザでログインできるかの設定を求められます。
yを入力してログインできないようにします。リモートからのrootユーザでのログイン禁止By default, a MySQL installation has an anonymous user, allowing anyone to log into MySQL without having to have a user account created for them. This is intended only for testing, and to make the installation go a bit smoother. You should remove them before moving into a production environment. Remove anonymous users? (Press y|Y for Yes, any other key for No) : y4.testデータベースの削除
最後にデフォルトで作成されている
testという名前のデータベースを削除するか聞かれるので、yを入力します。リモートからのrootユーザでのログイン禁止By default, MySQL comes with a database named 'test' that anyone can access. This is also intended only for testing, and should be removed before moving into a production environment. Remove test database and access to it? (Press y|Y for Yes, any other key for No) : yこれで、データベースと権限が削除されます。
ここまでで、セキュリティ設定が完了しました。MySQLへ接続し新しいユーザーの作成
基本的にローカル開発でrootユーザーは使いたくないので、新しいユーザーを作成します。
先ほど設定した新しいrootユーザーのパスワードでログインし、作成します。ユーザー作成mysql> create user 'local-user'@'localhost' identified by '○○○○○○(設定したいパスワード)'; Query OK, 0 rows affected (0.06 sec)ユーザー確認mysql> select User,Host from mysql.user; +------------------+-----------+ | User | Host | +------------------+-----------+ | local-user | localhost | | mysql.infoschema | localhost | | mysql.session | localhost | | mysql.sys | localhost | | root | localhost | +------------------+-----------+ 5 rows in set (0.00 sec)権限設定mysql> grant all on *.* to 'local-user'@'localhost'; Query OK, 0 rows affected (0.06 sec)Railsに導入
ここまでMySQLの設定が完了したら、Railsで使えるように設定します。
新規で作る場合は、下記コマンドでMySQLを使うように設定できます。プロジェクト作成$ rails new アプリケーション名 --database=mysql
config/database.ymlを確認すると以下のようになっています。database.ymldefault: &default adapter: mysql2 encoding: utf8 pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> username: root password: host: localhost development: <<: *default database: アプリケーション名_development test: <<: *default database: アプリケーション名_test production: <<: *default database: アプリケーション名_production username: アプリケーション名 password: <%= ENV['アプリケーション名_DATABASE_PASSWORD'] %>そして、
GemFileを修正します。(既存プロジェクトに組み込む場合はここからです)
下記を追加、もしくはsqlLiteがある場合はそれを削除してください。GemFilegem mysql2
bundle installを実行します。database.ymldevelopment: adapter: mysql2 encoding: utf8 database: <%= ENV['DATABASE_NAME'] %> pool: 5 username: <%= ENV['DATABASE_USER'] %> password: <%= ENV['DATABASE_PASSWORD'] %> host: <%= ENV['DATABASE_HOST'] %>上記のように環境変数を使えるようになるので、パスワード等が外部に漏れずにすみます。
環境変数は
.envファイルを作成し、記入します。
※.envファイルは.ignoreに設定しないと公開する可能性があるので注意してください!.env作成vi .env.envDATABASE_PASSWORD = '設定したパスワードを記入' DATABASE_USER = '作成したMySQLユーザー名を記入' DATABASE_HOST = 'localhostなど(MySQLのユーザーを確認)'ここまで完了したら、
$ rails db:createでDBを作成します。
完了したら、MySQLが使えるようになっているはずです。【補足】
Sequel Proを使いたい場合は、下記コマンドでインストールできます。
Sequel ProとはDBを管理するGUIツールです。SequelProのインストール$ brew cask install sequel-proまた、
Sequel Proでログインできない場合があります。
下記のようなエラーが発生したら、認証プラグインを変更してください。
Authentication plugin 'caching_sha2_password' cannot be loaded: dlopen(/usr/local/lib/plugin/caching_sha2_password.so, 2): image not foundpluginの確認mysql> SELECT host, user, plugin FROM mysql.user; +-----------+------------------+-----------------------+ | host | user | plugin | +-----------+------------------+-----------------------+ | localhost | local-user | caching_sha2_password | +-----------+------------------+-----------------------+ 5 rows in set (0.03 sec)認証プラグインの変更mysql> ALTER USER 'local-user'@"localhost" IDENTIFIED WITH mysql_native_password BY '{password}';公式によると、MySQL8.0からデフォルトの認証プラグインが
caching_sha2_passwordに変更されたようです。(以前はmysql_native_password)ただ、
Sequel Pro等のツールはまだ新しい認証プラグインに対応していない場合があるようです。
なので、mysql_native_passwordに戻す必要があるようです。参照
- 投稿日:2020-03-01T19:32:59+09:00
bootstrap4導入
注意点 gemfileに記入するgemを
bootstrapにする。bootstrap-sassはbootstrap2,3に対応していたらしいこれにより、.scssファイルの
@import bootstrap-sprocketsを削除する。
また次のようなエラーが出るので、gemfilegem 'sqlite3', '~> 1.3.6'としてsqliteのバージョンを管理する。
gem変更の際は一度railsを再起動しなければgemが更新されないことを忘れずに
- 投稿日:2020-03-01T19:03:21+09:00
chartkickに計算したデータを渡す
chartkickに計算したデータを渡す
参考にした記事
https://qiita.com/withelmo/items/1eb02f784eea414fc723
グラフを作ってくれるgem chartkick に同じハッシュ形式のデータ同士を計算して渡したかった。
ハッシュに対してmergeを使うことで解決しました。こんな感じのデータと
@group_month_income_sum = current_user.accounts.where(income_check: true).group_by_month(:date).sum(:income) @group_month_income_sum => {Wed, 01 Jan 2020=>2917931, Sat, 01 Feb 2020=>996911, Sun, 01 Mar 2020=>1078732, Wed, 01 Apr 2020=>891573, Fri, 01 May 2020=>345790, Mon, 01 Jun 2020=>979213, Wed, 01 Jul 2020=>62281, Sat, 01 Aug 2020=>1660182, Tue, 01 Sep 2020=>155942, Thu, 01 Oct 2020=>64652, Sun, 01 Nov 2020=>926668, Tue, 01 Dec 2020=>895074}こんな感じのデータ(keyは同じだけどvalueの中の数字が違う)を計算してchartkickに渡したかった。
@group_month_spend_sum = current_user.accounts.where(spend_check: true).group_by_month(:date).sum(:spend) @group_month_spend_sum => {Wed, 01 Jan 2020=>323982, Sat, 01 Feb 2020=>685464, Sun, 01 Mar 2020=>47592, Wed, 01 Apr 2020=>1693776, Fri, 01 May 2020=>465287, Mon, 01 Jun 2020=>1445360, Wed, 01 Jul 2020=>1288774, Sat, 01 Aug 2020=>1804126, Tue, 01 Sep 2020=>1200592, Thu, 01 Oct 2020=>1660155, Sun, 01 Nov 2020=>727937, Tue, 01 Dec 2020=>287939}mergeメソッドをつかって解決しました。
@group_month_total = @group_month_income_sum.merge(@group_month_spend_sum){|k, v1, v2| v1 - v2} @group_month_total => {Wed, 01 Jan 2020=>2593949, Sat, 01 Feb 2020=>311447, Sun, 01 Mar 2020=>1031140, Wed, 01 Apr 2020=>-802203, Fri, 01 May 2020=>-119497, Mon, 01 Jun 2020=>-466147, Wed, 01 Jul 2020=>-1226493, Sat, 01 Aug 2020=>-143944, Tue, 01 Sep 2020=>-1044650, Thu, 01 Oct 2020=>-1595503, Sun, 01 Nov 2020=>198731, Tue, 01 Dec 2020=>607135}chartkickのコード
<%= line_chart [ { name: "収入", data: @group_month_income_sum, curve: false }, { name: "支出", data: @group_month_spend_sum, curve: false }, { name: "収支", data: @group_month_total, curve: false } ], colors: ["blue", "red", "green"], thousands: ",", messages: {empty: "データが登録されていません"} %>実際のグラフ

- 投稿日:2020-03-01T18:21:28+09:00
Rails 5.2~ credentials.yml.enc/master.key の扱いについて(備忘録)
credentials.yml.enc / master.keyとは何か
Rails 5.2 ~ からはsecret.ymlが廃止され、credentials.yml.enc / master.keyが導入されました。credentials.ymlはmaster.keyによって暗号化、復号化されます。secret.ymlは暗号化されておりませんでしたので、セキュリティ的にはより強固なものとなったようです。
特徴
- Rails 5.2 ~
- credentials.yml.encはmaster.keyとペアであり、master.keyによって暗号化されている。
- credentials.yml.enc, master.key共にデフォルトでgitignoreに追加されている。
編集及び取得方法
編集方法
$ cd [アプリケーションのディレクトリ] $ sudo EDITOR=vim bin/rails credentials:edit初めてこのコマンドを叩くとcredentials.yml.encとmaster.keyのペアが自動生成されます。
編集コマンドを叩いて次のような画面が出てきたらOK# aws: # access_key_id: 123 # secret_access_key: 345 # Used as the base secret for all MessageVerifiers in Rails, including the one protecting cookies. secret_key_base: *******************************************************ここにAWSやその他のサービスを使う際に必要となるaccess_key_id, secret_access_keyの情報を入力する。
aws: access_key_id: *** secret_access_key: *** # Used as the base secret for all MessageVerifiers in Rails, including the one protecting cookies. secret_key_base: *******************************************************取得方法
credentials.yml.encに書き込んだ情報はmaster.keyによって復号化され取得されます。その際の取り出し方について。
Rails.application.credentials.***例 AWSの場合
Rails.application.credentials.aws[:access_key_id] # アクセスキーID Rails.application.credentials.aws[:secret_access_key] # シークレットアクセスキー実際に取得できるか試してみる
credentials.yml.encに入力した情報の取得が成功しているかを判定する際に非常に便利なコマンドがあります。
$ rails c $ [1] pry(main) > Rails.application.credentials.aws $ => { :access_key_id=>"123", :secret_access_key=>"456" }このように表示されていればOK!
チーム開発におけるcredentials.yml.encとmaster.keyの扱いについて
チーム開発においては、master.keyを信頼できる開発メンバーにファイル共有ソフト等を用いて共有します。credentials.yml.encは本番環境にデプロイしてもmaster.keyによって暗号化されているため問題ありません。
本番環境ではmaster.keyを絶対にアップロードしないで下さい。本番環境でのmaster.keyの値を取得方法
本番環境にはmaster.keyは当然アップロードすることは出来ません。代わりに環境変数に設定してcredentials.yml.encを復号化します。
$ cd ~ #本番環境 $ sudo vim /etc/environment #環境変数の設定環境変数は必ず、RAILS_MASTER_KEYとして設定して下さい。
また、デフォルトでcredentials.yml.encはgitignoreに追加されてしまっているので、この記述をコメントアウトします。.gitignore # config/credentials.yml.enc config/master.key #マスターキーは絶対にgit addしない。
- 投稿日:2020-03-01T18:18:58+09:00
Railsで既存のテーブルのカラムを追加・編集・削除する方法
今回は「users」というモデルのカラムを色々いじくりたいとします
マイグレーションファイルを作成
rails generate EditColumndbディレクトリ配下にできたマイグレーションファイルをいじっていきます
「name」カラムを追加するとき
20200301090906_edit_column.rbclass EditColumn < ActiveRecord::Migration[5.2] def change add_column :users, :name, :string end end既存の「age」カラムを「nenrei」に変更するとき
20200301090906_edit_column.rbclass EditColumn < ActiveRecord::Migration[5.2] def change rename_column :users, :age, :nenrei end end既存の「age」カラムを削除
20200301090906_edit_column.rbclass EditColumn < ActiveRecord::Migration[5.2] def change remove_column :users, :age, :string end end
- 投稿日:2020-03-01T17:31:56+09:00
Railsとrubyの感嘆符!は意味が違う件について
はじめに
rubyのメソッドに対して使う!と、Railsのメソッドに対して使う!では、意味が異なるので簡単にまとめてみました。めちゃくちゃ簡潔に言うと...
●
rubyの場合
注意喚起。今からオブジェクトに対して何らかの変化を加えますよ〜とういう合図。
例:uniq! reverse!●
Railsの場合
メソッドを実行した結果の返却値がnilの場合に例外を発生させる。
例:save! update!● rubyの場合
hoge = [1,2,2,3,3] hoge.uniq! #たまに見かけるこれ!●
uniqとuniq!何が違うの?
uniq配列から重複した要素を取り除いた新しい配列を返す。
uniq!削除を破壊的に行い元の配列をの値を操作する。hoge = [1,2,2,3,3] hoge.uniq p hoge #-> [1,2,2,3,3] hoge.uniq! p hoge #-> [1,2,3]●まとめると...
!は配列を破壊的に操作すると言う注意喚起を意味しています。(慣習的に!は注意喚起に使われることが多い様です。)
!をつけることで、配列そのものに変更を加えています。● Railsの場合
def update @hoge = Hoge.find(params[:id]) @hoge.save! #よく見かけるこれ! end●
saveとsave!何が違うの?
saveレコードの保存に失敗 → nilを返す
save!レコードの保存に失敗 → 例外を発生させる●まとめると...
!はメソッドの処理が失敗した場合に、例外処理を行います。番外編
● 例外処理とは
例えば、「入力された2つの数を足し合わせて結果を返す」コードがあるとき、利用者が入力欄に「あ」と書き入れると数値の足し算の処理は実行不可能となる。
このようなプログラムが通常の処理では想定していない事態や事象を「例外」(exception)と呼び、例外が生じた時の対応を記述したコードを例外処理という。つまり、何らかの予期せぬエラーが発生した際に、別の処理を行うこと。
- 投稿日:2020-03-01T17:03:30+09:00
CSVファイルを作成してrails db:seedで大量のデータを投入する
栄養価を意識したレシピ投稿サイトを作っています
大量の食材を一つ一つデータに投入するのは面倒です
そこで食品成分表2015のデータを使って(そこらへんにあります)、
自分の使いたいデータを抽出してcsvファイルにまとめてrails db:seed で一気にデータを入れます僕のPCはMacbookなのでGoogleスプレッドシートを使います
手順
- 使いたいデータをgoogleスプレッドシートに入れます
2.左上の「ファイル」→「ダウンロード」→「カンマ区切りの値(.csv、現在のシート)」でcsvファイルを保存
3.保存したファイルをrailsのdb/csvのなかに保存
4.db/seedsrbに書き込み
db/seeds.rbrequire "csv" CSV.foreach('CSVファイルのパス',headers: true) do |row| モデル名.create( カラム名: row['csvファイルの列'], 〜 〜 ) end5.rails db:migrate → rails db:seedでデータ呼び込み
以上
初めてcsvファイルを触りましたが思ってたよりカンタンに導入できましたいつものことですが、もし間違ってたらご指摘いただけると助かります
- 投稿日:2020-03-01T16:31:07+09:00
Rails+Reactアプリを1つのdynoでデプロイする
railsAPIモードとReactで記事投稿アプリを作りました。API側とクライアント側を別々にHerokuにデプロイすると、SPAとは思えないほどアプリの動きが重くなったので、1つのdynoでデプロイし直した時のことをメモします。
参考になった記事
A Rock Solid, Modern Web Stack—Rails 5 API + ActiveAdmin + Create React App on Heroku | Heroku
ReactJS + Ruby on Rails API + Heroku App - Medium
React + RailsのアプリをHerokuで動かす方法 - Qiitaはじめに
ディレクトリ構成
project ┝ app ┝ bin ┝ config ┝ db ┝ front <--reactのディレクトリ ┝ lib ┝ log ┝ public ┝ storage ┝ test ┝ tmp ┗ vendorアプリ名をprojectとしています
ディレクトリ構成はrailsアプリの中にreactアプリがあるという状態です
アプリのルートディレクトリにGemfileがないと後々buildpackを用いてデプロイする時にエラーが出るのでこのような構成にしました
参考:Heroku:Buildpackエラーでハマった.envファイル生成
開発環境でのAPI側のURLを.envファイルに書きます
frontディレクトリ下で.envファイルを作成し、以下を記述しますproject/front/.envREACT_APP_SERVER_URL=http://localhost:3001URLを取得する時は
process.env.REACT_APP_SERVER_URLで取得できます
axiosでHTTP通信する場合は以下のように書けますproject/front/Component/UserIndex.jsaxios .get(`${process.env.REACT_APP_SERVER_URL}/api/users`, headers)Foremanの導入
Foremanは複数のプロセスをまとめて管理できるツールです
APIとクライアント側を一つのコマンドで動かせるので便利です
Gemfileに以下を記述し、bundle install --path vendor/bundleしますproject/Gemfilegem 'foreman'次にProcfile.devを作成し、以下を記述します
project/Procfile.devfrontend: exec /usr/bin/env PORT=3000 sh -c 'cd front && yarn start' backend: exec /usr/bin/env PORT=3001 sh -c 'bundle exec rails s'ここで
foreman start -f Procfile.devを実行し、http://localhost:3000にアクセスすると確認できますただ、
lib/tasks下にstart.rakeファイルを作成し、以下を記述すると、rake startとコマンドに打つだけでブラウザで確認できますproject/lib/tasks/start.rakenamespace :start do desc 'Start dev server' task :development do exec 'foreman start -f Procfile.dev' end desc 'Start production server' task :production do exec 'NPM_CONFIG_PRODUCTION=true yarn heroku-postbuild && foreman start' end end task :start => 'start:development'また、
rake start:productionコマンドでデプロイ前にローカルで簡単に本番環境のテストを行うことができるように記述していますHerokuにデプロイ
package.json作成
まず、projectディレクトリ下にpackage.jsonファイルを
npm initコマンドで作成しますproject/package.json{ "name": "project", "version": "1.0.0", "description": "You can post articles using this application.", "main": "index.js", "scripts": { "build": "cd front && npm install && npm run build && cd ..", "deploy": "cp -a front/build/. public/", "heroku-postbuild": "npm run build && npm run deploy && echo 'Client built!'" } }Herokuは
heroku-postbuildに定義されていることを実行します。ここでは、frontディレクトリでnpm install, npm run buildを実行し、front/buildの内容をpublic/にコピーしますHerokuアプリ作成
heroku create アプリ名でHerokuアプリを生成します
そして、Herokuのbuildpackを追加します$ heroku buildpacks:add heroku/nodejs --index 1 $ heroku buildpacks:add heroku/ruby --index 2
heroku buildpacksで確認して、以下のような順番になっていればOKです=== project Buildpack URLs 1. heroku/nodejs 2. heroku/rubyProcfile作成
次にProcfileを作成し、Herokuがrailsアプリを起動するためのコマンドを記述します
project/Procfileweb: bundle exec rails sProcfileを作成したため、ここで
rake start:productionコマンドによりローカルで本番環境のテストを行うことができます本番環境用のエンドポイント設定
Reactアプリが本番環境でのAPI側のURLを参照できるように.env.productionファイルを作成します
project/front/.env.productionREACT_APP_SERVER_URL=https://project.herokuapp.comまた、クライアント側からのアクセスを許可するため、cors.rbのoriginに追記します
project/config/initializers/cors.rborigins 'http://localhost:3000', 'https://project.herokuapp.com/api'本番環境では、APIは
https://project.herokuapp.com/api/で、クライアント側はhttps://project.herokuapp.com/で起動するようになっています.gitignoreに追記
次に.gitignoreに以下を追記します
project/.gitignore/public /vendor/bundlePostgre.SQLを使用するための設定
本番環境のDBにPostgre.SQLを使用するための設定を行います
Gemfileに以下を追記し、bundle install --without productionを実行しますproject/Gemfilegroup :production do gem 'pg', '>= 0.18', '< 2.0' end次にdatabase.ymlを以下のように書き換えます
project/config/database.ymlproduction: adapter: postgresql encoding: unicode pool: 5 database: project_production username: project password: <%= ENV['PROJECT_DATABASE_PASSWORD'] %>デプロイ
これでデプロイする準備が整いました
Herokuにpushしてくださいgit add . git commit -m 'ready for first push to heroku' git push heroku master
heroku run rails db:migrateして終了ですReact Routerを使っている場合
React Routerを機能させるために以下の設定をします
fallback_index_htmlメソッド定義
ApplicationControllerにfallback_index_htmlメソッドを追加します
project/app/controllers/application_controller.rbclass ApplicationController < ActionController::Base def fallback_index_html render :file => 'public/index.html' end endApplicationControllerがActionController::APIを継承している場合はhtmlファイルを返すことができないため、以下のように追記します
project/app/controllers/application_controller.rbclass ApplicationController < ActionController::API include ActionController::MimeResponds def fallback_index_html respond_to do |format| format.html { render body: Rails.root.join('public/index.html').read } end end endroute.rbでfallback_index_html
そして、routes.rbにも以下を追記します
railsのルーティングについて書いている部分より下に追記してください
ここでfallback_index_htmlメソッドによりpublic/index.htmlが返されるため、React Routerを参照することができますproject/config/routes.rbRails.application.routes.draw do get '*path', to: "application#fallback_index_html", constraints: ->(request) do !request.xhr? && request.format.html? end endこれでpushすると、React Routerによるルーティングが反映されると思います
Herokuにデプロイするまでの手順は以上です最後に
参考にしたサイトを見ながらでも結構エラーで詰まるところがあり、デプロイするまでに時間がかかりました。しかし、APIとクライアントを別々でデプロイするよりもアプリの動きは軽くなったのでよかったです。
この記事について間違っているとこなどあればご指摘いただけると嬉しいです。
- 投稿日:2020-03-01T16:25:48+09:00
【Rails】rails6 + docker + nuxt ssr で connect ECONNREFUSED ERROR socket hang up
rails + docker + nuxtでなにか作ろうとしていた際にハマった部分
時間があるときに詳細を書きたい。docker-compose.ymlversion: '3' services: db: image: mysql:8.0 environment: MYSQL_ROOT_PASSWORD: password ports: - '3306:3306' command: --default-authentication-plugin=mysql_native_password volumes: - mysql-data:/var/lib/mysql backend: build: ./backend/ command: bash -c "rm -f tmp/pids/server.pid && bundle install && bundle exec rails s -p 3000 -b '0.0.0.0'" volumes: - .:/app ports: - "3000:3000" depends_on: - db stdin_open: true tty: true command: bundle exec rails server -b 0.0.0.0 frontend: build: ./frontend/ command: npm run dev volumes: - .:/app ports: - 8080:3000 volumes: mysql-data: driver: localfrontend/pages/users/_id.vue<template> <h1>Hello, {{ id }}</h1> </template> <script> export default { asyncData ({ $axios, params }) { return $axios.$get(`http://localhost:3000/users/${params.id}`).then((res) => { return { id: res.id } }) } } </script>ブラウザからapi(http://localhost:3000/users/1) を叩くと
{ id: 1, email: "test@example.com", created_at: "2020-02-29T13:39:03.638Z", updated_at: "2020-02-29T13:39:12.055Z", url: "http://localhost:3000/users/1" }vueのfront(http://localhost:8080/users/1) からアクセスすると
frontend_1 | ERROR socket hang up frontend_1 | frontend_1 | at connResetException (internal/errors.js:604:14) frontend_1 | at Socket.socketOnEnd (_http_client.js:460:23) frontend_1 | at Socket.emit (events.js:323:22) frontend_1 | at Socket.EventEmitter.emit (domain.js:482:12) frontend_1 | at endReadableNT (_stream_readable.js:1204:12) frontend_1 | at processTicksAndRejections (internal/process/task_queues.js:84:21)以下に書き換える
frontend/pages/users/_id.vue<template> <h1>Hello, {{ id }}</h1> </template> <script> export default { asyncData ({ $axios, params }) { return $axios.$get(`http://backend:3000/users/${params.id}`).then((res) => { return { id: res.id } }) } } </script>Request failed with status code 403
railsを以下を追加
backend/config/environments/development.rbconfig.hosts << "backend"解決した。

- 投稿日:2020-03-01T15:28:41+09:00
form_with [Rails 5.1から新規導入されたformヘルパー]
概要
Rails 5.1から導入されたform_with
これはrailsでは非推奨のヘルパーとなったform_for,form_tagの代わりに新たに実装されたformヘルパーです。
今回はform_withの使い方についてまとめていこうと思います。
拙い記事でツッコミどころが多々あると思いますが、よろしくお願いします。
form_for&form_tagとは?
Formbuilderオブジェクトのformブロックを引数にした入力フォームのヘルパー。
Rails 5.1では非推奨機能になり、今後廃止される可能性のあるヘルパーメソッド。
<%= form_for @sample do |f| %> <%= f.label :name %> <%= f.text_field :name %> <%= end %>form_forとform_tagの違いは入力フォームをモデルと関連付けるか付けないか
form_forは入力フォームに@sampleという具合にインスタンス変数が指定されている。
一方でform_tagは<%= form_tag(sample_path) do |f| %> <%= f.label :name %> <%= f.text_field :name %> <%= end %>モデルとは関連付けない形でformブロックを生成している。
二つの使い分けとしては、
form_forは投稿フォームなどのモデルと関連づけたデータの送信。
form_tagは検索フォームなどのモデルと関連しないデータの送信。これが一般的だと思います。
form_forとform_tagにはURLオプションとHTMLオプションが存在している。
URLオプション
formに設定したいアクションや送信先がある場合に設定する。
HTMLオプション
formなどにclassなどの要素を追加したい場合に設定する。
form_withとは
fprm_withとはrails 5.1から新しく追加されたヘルパーメソッド。
form_forとform_tagが廃止予定になる代わりに新しく追加された。
form_withの構文
<%= form_with(model: sample, remote: true) do |f| %> <%= f.label :name %> <%= f.text_field :name %> <%= end %><%= form_with(url: sample_path, remote: true) do |f| %> <%= f.label :name %> <%= f.text_field :name %> <%= end %>form_withはform_forとform_tagと違い、モデルを指定する場合と指定しない場合の二通りで実装できる。
また、form_withではデフォルトでremote: tureになっており、特にオプションを設定しなくともajaxでの
データ送信を行える。form_withのオプション
オプション 説明文 :url 送信先のURLを指定する :method HTTPリクエストの指定を行なう (POST/GETなど) :format データ形式の指定 (JSON/XMLなど) :scope inputフィールドにプレフィックスの追加を行なう :namescope form要素に一意のIDを追加する場合に使用 :model form要素と関連づけるモデルの指定 :authenticity_token 認証用のトークンを送信する場合に使用 :local リモート送信を行なわない設定。ページが遷移する送信設定にする場合に使用 :skip_enforcing_utf8 utf-8を消す場合に使用 :builder Formbuilderオブジェクトで定義した独自formコントロールを設定する場合に使用 :id formのidを指定する場合に使用 :class formのclassを指定する場合に使用 まとめ
form_forとform_tagは廃止される可能性が高いため,
form_withを使用した方がよろしいのではと思います。
- 投稿日:2020-03-01T14:55:14+09:00
renderでビューを出す時の注意点
- 投稿日:2020-03-01T14:27:51+09:00
空のデータが登録できないようにするために
空のデータが登録できないようにするには
空のデータが登録できないようにするにはバリデーションを使います。
バリデーション
バリデーションとはデータを登録する際、一定の制約をかけること
空のデータが登録できないようにする
すでに登録されている文字列を登録できないようにする(メールアドレスの登録など)
文字数制限をかける(パスワードなど)
などがあります。app/models/XXXXX.rbclass Post < ApplicationRecord validates :title, :comment, presence: true end上記のように記述すれば空白、同じ文字列を投稿をした際は、空のデータや、すでに登録がされているデータがある場合は登録ができないようになりました。
- 投稿日:2020-03-01T14:10:52+09:00
リダイレクト処理の仕方
リダイレクト
リダイレクトとは受け取ったパスとは別のパスへ転送すること
アクションに処理を持たせて実行し、パスのビューを返すのではなく別のパスにユーザーをredirect_toメソッドで転送させることができるredirect_to メソッド
コントローラーで処理が終わった後に、別ページへリダイレクトさせること
redirect_to "リダイレクト先のパス"【例】root_pathに飛ばしたい場合(仮にmodel名をpostとする)
app/controllers/posts_controller.rbdef create Post.create(post_params) redirect_to root_path end_pathを付けることにより、ルートパスを指定しました
ルートパスに対応するアクションはindexなので投稿後(createはデータの投稿を行うリクエストに対応して動くアクション)はトップページへ遷移します
- 投稿日:2020-03-01T14:08:52+09:00
【RSpec】PATCHリクエストで躓いた変数の更新やパラメーターの付与
概要
- PATCHリクエストのテストで詰まった以下の2点についてのメモです。
- ストロングパラメーターをpassするようにパラメーターを付与する方法
- オブジェクトの更新をテストする方法
前提
- 詳しい話はわからずに解決した方法を書いているため、間違いやツッコミがありましたらコメントをいただけると助かります。
ストロングパラメーターをpassするようにパラメーターを付与する方法
it '名前が更新される' do user = create(:user, name: 'hoge') patch user_path(user, user: { name: 'new_hoge' }) # このように書くとストロングパラメーターに許可された形でパラメーターを送れる expect(user.name).to eq 'new_hoge' endしかし、これではuser.nameは
hogeのままであるため、テストはfailしてしまいます。原因は、
userはあくまで変数であり、DBの方でuser.nameに変更があったとしても変数userには変更が反映されていないためです。オブジェクトの更新をテストする方法
先ほどのテストがfailしてしまう原因は
userはあくまで変数であり、DBの方でuser.nameに変更があったとしても
変数userには変更が反映されていないためです。そのため、変数userに変更を反映する必要があります。
その時に使えたのがreloadでした。
具体的には以下のように追記することでテストがpassすることができました it '名前が更新される' do user = create(:user, name: 'hoge') patch user_path(user, user: { name: 'new_hoge' }) user.reload # 追記 expect(user.name).to eq 'new_hoge' end
it '名前が更新される' do user = create(:user, name: 'hoge') patch user_path(user, user: { name: 'new_hoge' }) user.reload # 追記 expect(user.name).to eq 'new_hoge' end感想
PATCHリクエストを書くだけでも学ぶことが多いですね。
ストロングパラメーターの復習にもなって学びが多い挫折でした。
- 投稿日:2020-03-01T10:17:34+09:00
Rspec_Gem調査メモ
開発環境
- Ruby 2.5.3
- Rails 5.2.2
spec-rails
rspec-railsデフォルトのテストフレームワークであるMinitestのドロップイン代替として、RSpecテストフレームワークをRuby on Railsにもたらします。RSpecでは、テストはアプリケーションコードを検証する単なるスクリプトではありません。また、仕様(または仕様、略して)です。アプリケーションがどのように動作するかについての詳細な説明を、わかりやすい英語で表現します。
group :test, :development do gem 'rspec-rails', '~> 3.8' endfactory_bot_rails
テストデータの作成
group :development, :test do gem 'factory_bot_rails' endCapybara(記述済)
Webアプリケーションの受け入れテストフレームワーク
capybara ドキュメントcapybara APIドキュメント
group :test do gem 'capybara', '>= 2.15' endcapybara-screenshot
Capybaraシナリオが失敗したときにスクリーンショットを自動的に保存する
group :test do gem 'capybara-screenshot' endlaunchy
A helper for launching cross-platform applications in a fire and forget manner
Rubyで外部アプリケーションを起動できる(現在、ブラウザの起動のみがサポートされています。)
group :test do gem 'launchy' endselenium-webdriver(記述済)
ブラウザー自動化フレームワークとエコシステム
group :test do gem 'selenium-webdriver' endwebdrivers(記述済)
サポートされているすべてのWebドライバーのインストールと更新により、Seleniumテストをより簡単に実行できます。
gem 'chromedriver-helper'のサポートが終了し、その後継として作成された
group :test do gem 'webdrivers', , '~> 4.0' endrubocop-rspec
RSpecファイルのコードスタイルチェック。RuboCopコードスタイルの強制およびリンティングツールのプラグイン。
group :development, :test do gem 'rubocop-rspec', require: false enddatabase_cleaner
データベースをクリーニングするための戦略。テストのためにクリーンな状態を確保するために使用できます。
テスト後に作成されたデータを削除する
group :test do gem 'database_cleaner-active_record' endsimplecov
SimpleCovは、Ruby用のコードカバレッジ分析ツールです。
Rubyのビルトインカバレッジライブラリを使用してコードカバレッジデータを収集しますが、クリーンなAPIを提供して結果をフィルター処理、グループ化、マージ、フォーマット、表示することにより、結果の処理をはるかに容易にします。わずか数行のコードでセットアップします。
SimpleCov / Coverageトラックはルビーコードをカバーしており、erb、slim、hamlなどの一般的なテンプレートソリューションのカバレッジの収集はサポートされていません。
SimpleCovの公式フォーマッターは、simplecov-htmlという別のgemとしてパッケージ化されていますが、SimpleCovを起動すると自動的にインストールおよび構成されます。興味があれば、GitHubでも見つけることができます。
ほとんどの場合、すべてのタイプのテスト、Cucumber機能などを含むプロジェクトの全体的なカバレッジ結果が必要になります。SimpleCovは、レポートを生成するときに結果をキャッシュおよびマージして自動的に処理します。これにより、空白のスポットのより良い全体像が得られます。
group :test, :development do gem 'simplecov', require: false endteaspoon-jasmine
RailsのJavascriptテストランナー。Selenium、BrowserStack、またはPhantomJSを使用します。
group :development, :test do gem "teaspoon-jasmine" endguard-rspec
ファイル監視して変更されたときに仕様を自動的かつインテリジェントに起動できます。
group :development, :test do gem 'guard-rspec', require: false endFaker
名前、住所、電話番号などの偽データを生成するためのライブラリ。
group :test do gem 'faker', :git => 'https://github.com/faker-ruby/faker.git', :branch => 'master' endrails-controller-testing
このgemはassigns、コントローラーテストとassert_template コントローラーおよび統合テストの両方を再現します。
rails-controller-testing APIドキュメント
group :test do gem 'rails-controller-testing' endparallel_tests
Speedup Test :: Unit + RSpec + Cucumber + Spinach(複数のCPUコアで並列実行)
ParallelTestsは、テストを(行数またはランタイムごとに)偶数のグループに分割し、各グループを独自のデータベースを使用して単一プロセスで実行します。
group :test, :development do gem 'parallel_tests' endShoulda Matchers
Shoulda Matchersは、RSpecおよびMinitest互換のワンライナーを提供して、手作業で記述した場合、はるかに長く、複雑で、エラーが発生しやすい一般的なRails機能をテストします。
group :test do gem 'shoulda-matchers' endrspec-sidekiq
マッチャーとヘルパーのコレクションを介したSidekiqジョブの簡単なテスト
group :test do gem 'rspec-sidekiq' endtimecop
「タイムトラベル」および「タイムフリーズ」機能を提供するgem。時間依存コードのテストが非常に簡単です。Time.now、Date.today、DateTime.nowを1回の呼び出しでモックする統一されたメソッドを提供します。
group :test do gem "timecop" endtest-prof
TestProfは、テストスイートのパフォーマンスを分析するためのさまざまなツールのコレクションです。
group :test do gem "test-prof" endrspec-retry
失敗したテストを再実行する
group :test do gem "rspec-retry" endpundit-matchers
Pundit認証ポリシーをテストするためのRSpecマッチャーのセット
group :test do gem 'pundit-matchers', '~> 1.6.0' end
- 投稿日:2020-03-01T10:17:34+09:00
RSpec_Gem調査メモ
開発環境
- Ruby 2.5.3
- Rails 5.2.2
spec-rails
rspec-railsデフォルトのテストフレームワークであるMinitestのドロップイン代替として、RSpecテストフレームワークをRuby on Railsにもたらします。RSpecでは、テストはアプリケーションコードを検証する単なるスクリプトではありません。また、仕様(または仕様、略して)です。アプリケーションがどのように動作するかについての詳細な説明を、わかりやすい英語で表現します。
group :test, :development do gem 'rspec-rails', '~> 3.8' endfactory_bot_rails
テストデータの作成
group :development, :test do gem 'factory_bot_rails' endCapybara(記述済)
Webアプリケーションの受け入れテストフレームワーク
capybara ドキュメントcapybara APIドキュメント
group :test do gem 'capybara', '>= 2.15' endcapybara-screenshot
Capybaraシナリオが失敗したときにスクリーンショットを自動的に保存する
group :test do gem 'capybara-screenshot' endlaunchy
A helper for launching cross-platform applications in a fire and forget manner
Rubyで外部アプリケーションを起動できる(現在、ブラウザの起動のみがサポートされています。)
group :test do gem 'launchy' endselenium-webdriver(記述済)
ブラウザー自動化フレームワークとエコシステム
group :test do gem 'selenium-webdriver' endwebdrivers(記述済)
サポートされているすべてのWebドライバーのインストールと更新により、Seleniumテストをより簡単に実行できます。
gem 'chromedriver-helper'のサポートが終了し、その後継として作成された
group :test do gem 'webdrivers', , '~> 4.0' endrubocop-rspec
RSpecファイルのコードスタイルチェック。RuboCopコードスタイルの強制およびリンティングツールのプラグイン。
group :development, :test do gem 'rubocop-rspec', require: false enddatabase_cleaner
データベースをクリーニングするための戦略。テストのためにクリーンな状態を確保するために使用できます。
テスト後に作成されたデータを削除する
group :test do gem 'database_cleaner-active_record' endsimplecov
SimpleCovは、Ruby用のコードカバレッジ分析ツールです。
Rubyのビルトインカバレッジライブラリを使用してコードカバレッジデータを収集しますが、クリーンなAPIを提供して結果をフィルター処理、グループ化、マージ、フォーマット、表示することにより、結果の処理をはるかに容易にします。わずか数行のコードでセットアップします。
SimpleCov / Coverageトラックはルビーコードをカバーしており、erb、slim、hamlなどの一般的なテンプレートソリューションのカバレッジの収集はサポートされていません。
SimpleCovの公式フォーマッターは、simplecov-htmlという別のgemとしてパッケージ化されていますが、SimpleCovを起動すると自動的にインストールおよび構成されます。興味があれば、GitHubでも見つけることができます。
ほとんどの場合、すべてのタイプのテスト、Cucumber機能などを含むプロジェクトの全体的なカバレッジ結果が必要になります。SimpleCovは、レポートを生成するときに結果をキャッシュおよびマージして自動的に処理します。これにより、空白のスポットのより良い全体像が得られます。
group :test, :development do gem 'simplecov', require: false endteaspoon-jasmine
RailsのJavascriptテストランナー。Selenium、BrowserStack、またはPhantomJSを使用します。
group :development, :test do gem "teaspoon-jasmine" endguard-rspec
ファイル監視して変更されたときに仕様を自動的かつインテリジェントに起動できます。
group :development, :test do gem 'guard-rspec', require: false endFaker
名前、住所、電話番号などの偽データを生成するためのライブラリ。
group :test do gem 'faker', :git => 'https://github.com/faker-ruby/faker.git', :branch => 'master' endrails-controller-testing
このgemはassigns、コントローラーテストとassert_template コントローラーおよび統合テストの両方を再現します。
rails-controller-testing APIドキュメント
group :test do gem 'rails-controller-testing' endparallel_tests
Speedup Test :: Unit + RSpec + Cucumber + Spinach(複数のCPUコアで並列実行)
ParallelTestsは、テストを(行数またはランタイムごとに)偶数のグループに分割し、各グループを独自のデータベースを使用して単一プロセスで実行します。
group :test, :development do gem 'parallel_tests' endShoulda Matchers
Shoulda Matchersは、RSpecおよびMinitest互換のワンライナーを提供して、手作業で記述した場合、はるかに長く、複雑で、エラーが発生しやすい一般的なRails機能をテストします。
group :test do gem 'shoulda-matchers' endrspec-sidekiq
マッチャーとヘルパーのコレクションを介したSidekiqジョブの簡単なテスト
group :test do gem 'rspec-sidekiq' endtimecop
「タイムトラベル」および「タイムフリーズ」機能を提供するgem。時間依存コードのテストが非常に簡単です。Time.now、Date.today、DateTime.nowを1回の呼び出しでモックする統一されたメソッドを提供します。
group :test do gem "timecop" endtest-prof
TestProfは、テストスイートのパフォーマンスを分析するためのさまざまなツールのコレクションです。
group :test do gem "test-prof" endrspec-retry
失敗したテストを再実行する
group :test do gem "rspec-retry" endpundit-matchers
Pundit認証ポリシーをテストするためのRSpecマッチャーのセット
group :test do gem 'pundit-matchers', '~> 1.6.0' end
- 投稿日:2020-03-01T09:27:01+09:00
nokogiriのインストールに詰まった
昔作っていたRailsアプリを久しぶりに開いてリファクタしようと思ったときのことの備忘録です。
rails sで/Users/***/Desktop/Ruby/***_app/vendor/bundle/ruby/2.5.0/gems/bootsnap-1.4.4/lib/bootsnap/load_path_cache/core_ext/kernel_require.rb:22:in `require': cannot load such file -- /Users/***/Desktop/Ruby/***_app/vendor/bundle/ruby/2.5.0/gems/nokogiri-1.10.3/lib/nokogiri/nokogiri.bundle (LoadError)なんか色々試してエラーが変わった
gem installしたときに Permission denied @ rb_sysopen
こちら(Permission denied @ rb_sysopen )
まさに環境も全く同じだったので
最後のコマンドrbenv install 2.5.1をうった
gem uninstall nokogiriでnokogiriが入っていないことを確認
bundle install失敗
この記事通りにやって見た(nokogiriのインストールに失敗する問題)
brew install --force libxml2 brew link libxml2Warning: Refusing to link macOS-provided software: libxml2 If you need to have libxml2 first in your PATH run: echo 'export PATH="/usr/local/opt/libxml2/bin:$PATH"' >> ~/.zshrc For compilers to find libxml2 you may need to set: export LDFLAGS="-L/usr/local/opt/libxml2/lib" export CPPFLAGS="-I/usr/local/opt/libxml2/include" For pkg-config to find libxml2 you may need to set: export PKG_CONFIG_PATH="/usr/local/opt/libxml2/lib/pkgconfig"やっぱ権限ないって言われる
ERROR: While executing gem ... (Errno::EACCES) Permission denied @ rb_sysopen - /Users/***/.rbenv/gems/2.5.0/gems/nokogiri-1.10.8/LICENSE-DEPENDENCIES.mdライセンス...?
なんか昔メールでgithubからnokogiriの件でなんか来てた気がする。。確認
まじか...バージョン変えてみよう
gem 'nokogiri', '~> 1.10.1' ↓ gem "nokogiri", ">= 1.10.8"bundle installYou have requested: nokogiri >= 1.10.8 The bundle currently has nokogiri locked at 1.10.3. Try running `bundle update nokogiri` If you are updating multiple gems in your Gemfile at once, try passing them all to `bundle update`bundle update
bundle instaillはとおった!rails sCould not find 'nokogiri' (>= 1.6) among 1151 total gem(s) (Gem::MissingSpecError) Checked in 'GEM_PATH=/Users/***/.gem/ruby/2.5.0:/Users/***/.rbenv/gems/2.5.0', execute `gem env` for more informationん。。一回ギブ
次の日
とりあえずgemの更新だけをgitにあげよう。。。(herokuにも自動push)
なんかherokuからおこられて
###### WARNING: This buildpack was created as a stop-gap measure to allow running applications with Bundler 2 on Heroku. Heroku now supports Bundler 2 directly: https://devcenter.heroku.com/changelog-items/1563 Please discontinue use of this buildpack and instead directly use the `heroku/ruby` buildpack. To remove this buildpack use the `heroku buildpacks` command to list your existing buildpacks. If you only have one buildpack listed you can run: ``` heroku buildpacks:set heroku/ruby ``` If you have multiple buildpacks, you'll need to add the buildpack to the correct location using `heroku buildpacks:add heroku/ruby -i <correct index>` and then remove this buildpack via: ``` heroku buildpacks:remove https://github.com/bundler/heroku-buildpack-bundler2 ```コマンドを打って見た。
githubにきてたgemの更新のプルリクが全部closeされ、よくわからないけど
rails sできるようになっていた...わからん。。

- 投稿日:2020-03-01T04:36:54+09:00
mLabを使用してMongoDBの書き込み時に"MongoError: This MongoDB deployment does not support retryable writes"のエラー
概要
MongoDBをクラウド上で提供しているmLab MongoDBというサービスがあるのですが、データの書き込みを行った時に、
MongoError: This MongoDB deployment does not support retryable writesのエラーが発生したので、対応方法をメモします。原因
このStack Overflowの記事によると、mLabではMongoDBの接続設定
retryWritesオプションが使用できないので、falseにする必要があるとのこと。
retryWritesオプションは書き込みのエラー発生時に、DB側で自動的にretryしてくれる機能で、公式のマニュアルによると、MongoDB4.2のドライバーだとデフォルトでtrueになるみたいです。接続時の設定
以下はRailsのMongoidを使用した際の、
retryWritesオプションをfalseにする設定です。なお、設定ファイルmongoid.ymlの詳細については、mongoid-configurationを参照ください。mongoid.ymlproduction: clients: default: database: heroku_test hosts: - test111111.mlab.com:51180 options: user: "test_user" password: "test_password" retry_writes: false options:
- 投稿日:2020-03-01T03:40:55+09:00
Railsで綺麗に\nを<br>に変換する方法
準備
まず、Stringクラスを拡張します。ファイルの置き場所はお作法です。
/lib/ext/string.rbclass String def to_br ERB::Util.h(self).gsub(/\R/, "<br>") end end先ほどのstring.rbを初期化時に読み込みます
/config/initializers/extension.rbrequire 'ext/string'これで準備完了です。
使い方
あとは任意のhtmlファイルにて、
hoge.html.erb<%== hoge_str.to_br %>または、
hoge.html.slim== hoge_str.to_brなどで綺麗に<br>へ変換することができます。
- 投稿日:2020-03-01T02:46:08+09:00
railsをversion指定してアプリ作成する方法
railsをversion(5.2.4.1)指定してアプリ制作したかったのでその方法をば…
まずは現在のversionを確認
現在のrailsのversionを確認するコマンド
ターミナル$ rails -v現在のversion
Rails 6.0.2.1version(5.2.4.1)を指定してインストールするコマンド
ターミナル$ gem install rails:5.2.4.1「/Library/Ruby/Gems/2.6.0ディレクトリに対する書き込み権限がありません。」と言われる
ERROR: While executing gem ... (Gem::FilePermissionError) You don't have write permissions for the /Library/Ruby/Gems/2.6.0 directory.
sudoを付けて再びコマンド入力$ sudo gem install rails:5.2.4.1MacBookのpassを入力
(入力中passはターミナルに表示されないので、入力が終わったらそのままエンターキーでOK)
ターミナルPassword:インストール完了
(上記の様な"権限がない系のエラー"が出た時は頭にsudoを付けたらだいたい解決する説)Successfully installed rails-5.2.4.1 Parsing documentation for rails-5.2.4.1 Done installing documentation for rails after 0 seconds 1 gem installed現在のversionを確認する
$ rails -v最新versionのまま…
Rails 6.0.2.1気を取り直して、方法を変えてみる
versionを指定して新しいアプリを作るコマンド
$ rails _5.2.4.1_new ○○○○(アプリ名)問題なさそう…?
(省略) * * Bundle complete! 14 Gemfile dependencies, 64 gems now installed. Use `bundle info [gemname]` to see where a bundled gem is installed. run bundle exec spring binstub --all * bin/rake: Spring inserted * bin/rails: Spring inserted再びversion確認
$ rails -v最新のまま…orz
Rails 6.0.2.1ググったら
どうやら作ったアプリに入ってからversion確認してみると良さげらしい作ったアプリに移動するコマンド
$ cd ○○○○(アプリ名)↓ユーザーの後ろにアプリ名がくっついて表示されていればOK
○○○○(アプリ名) $version確認
○○○○(アプリ名) $ rails -v成功!!
Rails 5.2.4.1