- 投稿日:2020-01-07T23:29:53+09:00
【Python】JSONファイルに登録されたWebサイトのページを一括表示するツールを作成したこと&引っ掛かったところについて
1.この記事について
きっかけ
ECサイトや作品投稿サイトなどで同じ検索タグのページを一気に開くGUI型のツールが欲しかった。
※chromeなどではブックマークでフォルダにまとめて入れて一挙に開くことは可能だが、
変更したり追加したりするのはjsonとかのほうが手早いし、そのためにブックマークの編集を頑張るのもめんどくさかった。
あとはTkinter実装の再練習も含めて。※スクレイピングは用いていません(今後連携することも考えていますが...)。
※したがってseleniumも用いていません。
※最新のツールとソースコードはGitHubに上げてます(後述)
2.やりたいこと
・(jsonクラスは以前に作ったものを改良&共通部品化)
・Tkinterのコンボボックスのハンドリングクラスを実装&共通部品化
・mainメソッドでGUIを設定し、データを読み取り、GUIで選択されたwebページを開く3.使用したツール・環境
・Windows10
・Python 3.7.0
・開発はPycharm4.作成したコードと解説
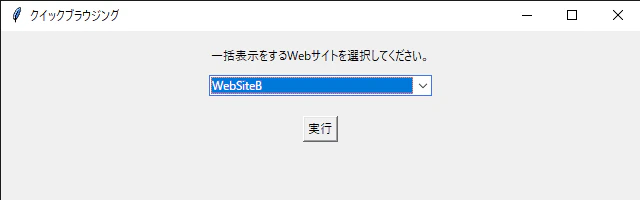
外観
GUIはこんな感じ。
Jsonファイル
webSiteDetails.json{ "WebSiteA": { "OnlyOpenPage": true, "PageSet": [ "http://foobar.com", "http://foobar.com", "http://foobar.com", "http://foobar.com", "http://foobar.com", "http://foobar.com", "http://foobar.com", "http://foobar.com", "http://foobar.com" ] }, "WebSiteB": { "OnlyOpenPage": true, "PageSet": [ "http://foobar.com", "http://foobar.com" ] }, "WebSiteC": { "OnlyOpenPage": true, "PageSet": [ "http://foobar.com", "http://foobar.com", "http://foobar.com", "http://foobar.com" ] }, "WebSiteD": { "OnlyOpenPage": true, "PageSet": [ "http://foobar.com", "http://foobar.com", "http://foobar.com", "http://foobar.com" ] }, "WebSiteE": { "OnlyOpenPage": true, "PageSet": [ "http://foobar.com", "http://foobar.com", "http://foobar.com" ] } }「OnlyOpenPage」プロパティを付与したのは、
今後スクレイピング機能実装も視野に入れた場合に
ただ開くだけ、と
スクレイピング処理付与、の
区別を付けたかったから。Jsonハンドリングクラス
JsonHandler.pyimport json class JsonHandler: def __init__(self, jsonPath): # jsonファイル読み込み self.file = open(jsonPath, 'r', encoding="utf-8_sig") self.jsonData = json.load(self.file) # 一次ネストのjsonデータ取得 def getParam_OneNest(self, args): return self.jsonData[args] # 一次ネストのjsonデータ一覧取得 def getAll_OneNest(self): # list = [] # for d in self.jsonData.keys(): # list.append(d) list = [d for d in self.jsonData.keys()] return list # 二次ネストのjsonデータ取得 def getParam_TwoNest(self, args1, args2): return self.jsonData[args1][args2] def __del__(self): # ファイル閉じる self.file.close()以前作成したもの(※)を少し変えた。
一次ネストのデータのみをまとめて取得する必要があったため。
[※:https://qiita.com/dede-20191130/items/65b0f4c3c2b5c7f97546]list = [d for d in self.jsonData.keys()]ここはリスト内包形式。
Tkinterコンボボックスのハンドリングクラス
TkHandler_Combo_1.pyimport tkinter as tk import tkinter.ttk as ttk class TkHandler_Combo_1: """GUIの共通部品。コンボボックスを作成""" def __init__(self, rootTitle='タイトル', rootGeometry='640x480'): # ルートフレームの作成 self.root = tk.Tk() self.root.title(rootTitle) # rootウィンドウの大きさを引数の値に self.root.geometry(rootGeometry) # クローズイベント設定 self.root.protocol("WM_DELETE_WINDOW", self.onClosing) self.frame = None self.label = None self.combo = None self.button = None self.isDestroyed = False def createFrame(self): # フレームの作成 self.frame = ttk.Frame(self.root, width=self.root.winfo_width() - 20, height=self.root.winfo_height() - 20, padding=10) self.frame.pack() def createLabel(self, myText="選択してください"): # ラベルの作成 self.label = ttk.Label(self.frame, text=myText, padding=(5, 5)) self.label.pack() def createCombo(self, myWidth=None, myState='readonly', myValue=None, ): # widthの設定 myWidth = myWidth or self.frame.winfo_width() - 20 # コンボボックスの作成 self.combo = ttk.Combobox(self.frame, width=myWidth, state=myState) self.combo["values"] = myValue # デフォルトの値を(index=0)に設定 self.combo.current(0) # コンボボックスの配置 self.combo.pack(padx=5, pady=5, fill=tk.X) def createButton(self, myText="実行", myFunc=None): """引数に関数をとる""" # 関数の設定 myFunc = myFunc or (lambda: self.dummy()) # ボタンの作成 self.button = tk.Button(text=myText, command=lambda: myFunc(self.combo.get())) # ※↑↑最初はこのように実装していた # if myFunc: # self.button = tk.Button(text=myText, command=lambda: myFunc(self.combo.get())) # else: # self.button = tk.Button(text=myText, command=lambda: self.dummy()) # ボタンの配置 self.button.pack(padx=5, pady=5, ) def dummy(self, arg=''): pass def mainLoop(self): self.root.mainloop() def onClosing(self): self.root.destroy() self.isDestroyed = True def __del__(self): if not self.isDestroyed: self.root.destroy()解説
# クローズイベント設定 self.root.protocol("WM_DELETE_WINDOW", self.onClosing)実行ボタンを押さずにウィンドウを閉じたときに呼ばれるメソッドを設定する構文。
onClosingで閉じる前にフレームを消しておいて、
デストラクタ(_del_関数)が動作するときにエラーが起きないようにする。def createCombo(self, myWidth=None, myState='readonly', myValue=None, ): # widthの設定 myWidth = myWidth or self.frame.winfo_width() - 20myWidthに対しての引数の指定があればその値を持ち続けるし、
もしデフォルト引数Noneのままならば、フレームのwidth値よりも20小さくする値が入る。orの使い方についてはこちらの記事を参考にさせていただきました。
https://blog.pyq.jp/entry/python_kaiketsu_181016なぜ直接デフォルト引数に「self.frame.winfo_width() - 20」をいれなかったかというと、
自分自身のクラスが持つフィールドのメンバを引数に取れないようだ。
もし可能な方法があるとご存知の方がいたら教えてほしいです。引っ掛かったところ:関数を引数にとる(高階関数)ときの動作
def createButton(self, myText="実行", myFunc=None): """引数に関数をとる""" # 関数の設定 myFunc = myFunc or (lambda: self.dummy()) # ボタンの作成 self.button = tk.Button(text=myText, command=lambda: myFunc(self.combo.get())) # ※↑↑最初はこのように実装していた # if myFunc: # self.button = tk.Button(text=myText, command=lambda: myFunc(self.combo.get())) # else: # self.button = tk.Button(text=myText, command=lambda: self.dummy())Tkinterのボタンオブジェクトは押下されたときのイベントとして
command引数に関数を代入するようになっている。そのため、createButtonメソッドを呼ばれた時点で
呼び出し側に関数を用意しておかないといけない。しかし、共通部品化するにあたり、
関数を特に定めないときのためにデフォルト引数を用意しておきたかった。デフォルト引数の定め方をどうするか?
最初はこうしてみた。
def createButton(self, myText="実行", myFunc=lambda: pass):これは動作しなかった。
引数にlambda関数を設定するのは難しいらしい。そこで、クラス内にダミーメソッドdummyを定義し
それを代入する方針で行こうとした。ここで、上述したように「自分自身のクラスが持つフィールドのメンバを引数に取れない」ので、
次のように書いた。def createButton(self, myText="実行", myFunc=None): """引数に関数をとる""" # if myFunc: # self.button = tk.Button(text=myText, command=lambda: myFunc(self.combo.get())) # else: # self.button = tk.Button(text=myText, command=lambda: self.dummy())これでも良かったけど、ちょっと冗長だし
二回もbuttonフィールドを定義する式を記述するのはメンテの苦労も二倍。よって、次のように書き直した。
def createButton(self, myText="実行", myFunc=None): """引数に関数をとる""" # 関数の設定 myFunc = myFunc or (lambda: self.dummy()) # ボタンの作成 self.button = tk.Button(text=myText, command=lambda: myFunc(self.combo.get()))Mainメソッド
QuickBrowsing.pyimport os import subprocess import sys # モジュール検索パスを再設定 # ダブルクリックによる起動にも対応できるようにする sys.path.append(os.getenv("HOMEDRIVE") + os.getenv("HOMEPATH") + r"\PycharmProjects\CreateToolAndTest") from Commons.JsonHandler import JsonHandler from Commons.TkHandler_Combo_1 import TkHandler_Combo_1 import webbrowser from time import sleep # global jsonHandler = None siteList = None tkHandler = None siteName = None def Main(): global jsonHandler global siteList global tkHandler global siteName # 項目取得 jsonHandler = JsonHandler( r'C:\Users\dede2\PycharmProjects\CreateToolAndTest\Tool_Python/QuickBrowsing/webSiteDetails.json') siteList = jsonHandler.getAll_OneNest() # フォーム表示 tkHandler = TkHandler_Combo_1('クイックブラウジング', '640x200') tkHandler.createFrame() tkHandler.createLabel('一括表示をするWebサイトを選択してください。') tkHandler.createCombo(myValue=siteList) tkHandler.createButton(myFunc=getSiteName) tkHandler.mainLoop() # サイトが設定されていなければ正常終了 # webページが登録されていなければ正常終了 if siteName == None or not jsonHandler.getParam_TwoNest(siteName, 'OnlyOpenPage'): exit(0) # webサイトを順番に開く subprocess.Popen("start chrome /new-tab www.google.com --new-window", shell=True) sleep(1) browser = webbrowser.get(r'"' + os.getenv(r'ProgramFiles(x86)') + \ r'\Google\Chrome\Application\chrome.exe" %s') for url in jsonHandler.getParam_TwoNest(siteName, 'PageSet'): browser.open(url) def getSiteName(argName=''): global tkHandler global siteName tkHandler.onClosing() siteName = argName if __name__ == '__main__': Main()解説
siteList = jsonHandler.getAll_OneNest() 省略 tkHandler.createCombo(myValue=siteList)jsonから、サイト名の見出しだけ取得して
ドロップダウンリストの項目とする。tkHandler.createButton(myFunc=getSiteName) 省略 def getSiteName(argName=''): global tkHandler global siteName tkHandler.onClosing() siteName = argNameGUIのボタン押下したら、
グローバル変数に値を入れて、保持するようにしている。引っ掛かったところ:新しいウィンドウでchromeを開く方法
調べたら、webbrowserモジュールのopen_newメソッドで
新しいウィンドウで開けるとの記載が。しかし、動かしてみたらそうはいかず、
もともとあったウィンドウに新しいタブとして開かれてしまう。理由
どうやら、このような仕様らしい。
https://docs.python.org/ja/3/library/webbrowser.htmlwebbrowser.open_new(url)
可能であれば、デフォルトブラウザの新しいウィンドウで url を開きますが、そうでない場合はブラウザのただ1つのウィンドウで url を開きます。webbrowser.open_new_tab(url)
可能であれば、デフォルトブラウザの新しいページ(「タブ」)で url を開きますが、そうでない場合は open_new() と同様に振る舞います。もともとchromeが開かれていたらそのウィンドウのタブとして
開いてしまうと予想。対策
# webサイトを順番に開く subprocess.Popen("start chrome /new-tab www.google.com --new-window", shell=True) sleep(1) browser = webbrowser.get(r'"' + os.getenv(r'ProgramFiles(x86)') + \ r'\Google\Chrome\Application\chrome.exe" %s') for url in jsonHandler.getParam_TwoNest(siteName, 'PageSet'): browser.open(url)subprocess.Popen関数で新しいウィンドウでchromeブラウザを開き、
一秒待機したあと、
そのウィンドウに選択したサイトの全ページをまとめて開くことにした。seleniumを使えば...
もっとエレガントに実装できるかもしれない。
5.終わりに
最新のツールとソースコードはこちらに上げています。↓
https://github.com/dede-20191130/CreateToolAndTest/tree/master/Tool_Python/QuickBrowsingなにか補足がありましたらコメントください。
- 投稿日:2020-01-07T22:49:52+09:00
論文の実装(特許文書からのブートストラップ手法を用いた課題・効果表現対の抽出)-途中
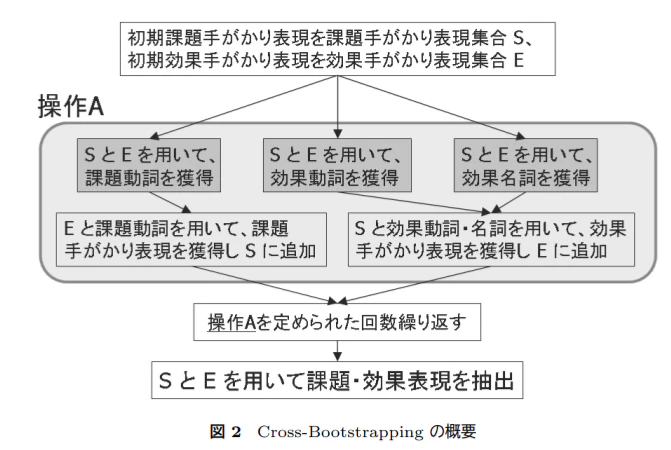
1.概要
・前回の論文の内容を踏まえスクリプトに落とし込んでみた。(が途中で力尽き停滞中)
・未完成だが、クロスブートストラップ手法は体験できた。
・やたら似た感じの関数や配列ばっかになってしまったのでクラスなどをうまく使えばもっと簡潔に書けるのでは。
・頭がこんがらがってきて辛い。2.環境
Google Colaboratory
3.詳細
事項
実装するに当たり論文を何回も読み直したところ、関数とかリストがたくさん必要なことを発見し苦しむ。
下記のような感じで読み流すだけなら「ふーん」で通れるが、いざ書くときは頭を悩ませ中。
4.工夫したところ
リスト名
⇒似たような名前の集合をクロスさせながら処理を進めるので、名前で大混乱にならないようにするのは大事なのが分かった。名前のとおり頭の中で各表現がクロスして混乱してしまう。
表現 リスト名 備考 課題手掛かり表現 list_S_tgkr あらゆる表現更新に使う 効果手掛かり表現 list_E_tgkr 効果動詞の更新等に使う 課題表現(候補) list_S 最終的にほしいもの 効果表現(候補) list_E 最終的にほしいもの 効果動詞 list_E_VERB 効果手がかり表現の更新等に使う 効果名詞 list_E_NOUN 効果手がかり表現の更新等に使う 「こと型」効果手がかり表現 list_E_tgkr_NOUN 効果名詞の更新等に使う 「動詞型」効果手がかり表現 list_E_tgkr_VERB 課題動詞抽出に使う プログラムを書くと、前に抽出した表現を使って
(初期課題手掛かり表現+初期効果手がかり表現から)課題動詞の更新⇒課題手掛かり表現の更新⇒効果動詞の更新⇒「こと」型効果手がかり表現⇒効果名詞の更新⇒「動詞型」効果手がかり表現の更新⇒最初に戻る
を繰り返し、
⇒課題・効果表現の抽出
最後つなげる、という流れが良く理解できました。係り受け解析器
・論文ではMecab+CabochaだがColaboratoryにCabochaを入れるのが大変そうだったので、どうにかならないかと見たら、ちょうどGoogle Natural Language APIに係り受け解析があったので、それを使わせてもらうことに。便利!
def extract_Dependency(text): response = lservice.documents().analyzeSyntax( body={ 'document': { 'type': 'PLAIN_TEXT', 'content': text, 'language': 'ja' }, }).execute() counter = 0 dep =[] #係り受け関係の抽出 word_list =[] for token in response['tokens']: moto = token['text']['content'] moto_num = counter moto_depend = token['dependencyEdge']['headTokenIndex'] moto_pos = token['partOfSpeech']['tag'] saki = response['tokens'][moto_depend]['text']['content'] saki_depend = response['tokens'][moto_depend]['dependencyEdge']['headTokenIndex'] saki_pos = response['tokens'][moto_depend]['partOfSpeech']['tag'] dep.append(moto+'('+ moto_pos+')_'+saki+'('+saki_pos +')') counter+=1 return dep4.苦しんでいるところ
クロスブートストラップの部分。
沢山関数を作らないといけないが、似ているけど引数や中の処理が微妙に違う。
現状下記みたいな関数を作ることになっているがややこしくなってきてしまった。
さらにこれから、課題/効果手がかり表現と、それによって獲得した表現の共起確率によるエントロピーを計算するための関数(これも各計算式がかなり似てるが微妙に違う)を作らないといけないのでそれも混乱しそう。このデータの持たせ方も検討しないといけない。
整理してみると課題手掛かり表現が重要なのが分かったので良かったですが。
これはきっとクラスなどを使えばもっと簡潔になると思われるので再構成しないと。def Update_S(text,deps,wordlist,list_S_tgkr,list_S):~~ def Update_S_tgkr(text,deps,wordlist,list_S,list_E_tgkr,list_S_tgkr):~~ def Update_E_VERB(text,deps,wordlist,list_S_tgkr,list_E_tgkr,list_E_VERB):~~ def Update_E_tgkr(text,deps,wordlist,list_S_tgkr,list_E_VERB,list_E_tgkr):~~ def Update_E_NOUN(text,deps,wordlist,list_S_tgkr,list_E_tgkr_VERB,list_E_NOUN):~~ def Update_E_tgkr_VERB(text,deps,wordlist,list_S_tgkr,list_E_NOUN,list_E_tgkr_VERB):~~ Def Update_E_tgkr_NOUN理想
ほんとうは
"移載装置は、旋回により収容部材を搬送することができるため、位相装置を小型化することができ、洗浄システムの据付けに必要な設置スペースを少なくすることができる。" "光量が最小となる再帰性反射体からの反射光が、光学的開口面に略垂直に入射されるようにしたので、光量が最小となる反射光を効率良く受光でき、検出精度の向上を図れる。" "この態様によれば、複数の資産情報が記憶された複数の第1サーバにわたって複数の匿名資産情報を受信し、それらを1又は複数の識別子と関連付けて記憶することで、様々な資産情報を、第三者に提供可能な匿名加工した状態で記憶することができ、資産情報の活用を円滑化することができる。"のような文章に
初期課題手がかり表現=「ことができ」 初期効果手がかり表現=「ことができる」を入れると、最終的に課題と効果の表現(論文では「課題表現候補」「効果表現候補」)を自動的に抽出してほしいが)
list_S=["位相装置を小型化する","光量が最小となる反射光を効率良く受光する","様々な資産情報を、第三者に提供可能な匿名加工した状態で記憶する"] list_E=["洗浄システムの据付けに必要な設置スペースを少なくすることができる。","検出精度の向上を図れる。","資産情報の活用を円滑化する。"]というように抽出してほしいが、
現実
途中段階でも上記プログラムを事項してみると、
list_S=['を小型化する', 'が記憶された複数の第1サーバにわたって複数の匿名資産情報を受信し、それらを1又は複数の識別子と関連付けて記憶することで、様々な資産情報を、第三者に提供可能な匿名加工した状態で記憶する'] list_E=['ため位相装置を小型化する洗浄システムの据付けに必要な設置スペースを少なくする', '洗浄システムの据付けに必要な設置スペースを少なくする', '検出精度の向上を']っていう感じで理想どおりいかず。
「直前の名詞」「直前の格助詞」のような文章の中の表現の切り取り
正規表現と係り受けの組み合わせで何とかしないといけないけど上記のColabを見てもらうとおり、うまく抽出できない。
しかし、ぜひ完成させて使いたい。
夢の課題解決手段マップの自動生成につながるので楽しみ。
関連するものとして色々ありました。
特許文章を対象とした因果関係抽出に基づく発明の新規用途探索
同じ効果を持つ複数技術を同定するための知識抽出
特許マップ作成のための文書処理技術

- 投稿日:2020-01-07T22:34:42+09:00
LINE BOT で ウェブページの更新監視する
tl;dr
- 完全に個人用であれば、かんたんに LINE の Bot を作成することができました。
- Broadcast(友達登録した全員に送信)であれば サーバーも不要で動かせます。
- また、ngrokなどを活用することで、特定少数のグループに投稿することもサーバー不要で可能でした
はじめに
- 限定商品の販売ページのようにウェブページを定期的に確認しに行きたいときがあると思います。
- ここでは Python で 定期的な更新監視と LINE BOT による通知をするコードを書いてみました。
流れ
- LINE Developers に登録
- Channel access token を手に入れる
- LINE 上で bot と友だちになる
- line/line-bot-sdk-python を使ってLINE BOTを書く
- psf/requests-html を使って更新監視コードを書く
- なお、特定ユーザーや特定グループに投稿したいなら投稿先を示すIdを手に入れる必要があります。
- Webhook で BOTに対するイベントを受ける必要があるのでWebサーバーが必要です
- もし準備が難しい場合は ngrok などを使えば とりあえず必要十分です。
説明
LINE Developers に登録
- LINE Developers - Messaging API を利用するには
- 公式を見るのが一番ですね。UIが少し変わってたりするようなので留意ください
- ログインにはLINEのIDが必要です。チャネルの作成まで行なってください。
- なお、作成するチャネルは Messaging API channelです。
チャネル選択 Channel access token を手に入れる
- チャネル作成後 Messaging API タブ から Issue(申請) をして
Channel access token (long-lived)を取得します。
channel access token 友達登録する
- channel access token を取得した この画面上部のQR コードを読み取って LINE で友だちになってください。
line/line-bot-sdk-python を使ってコードを書く
- LINE が公式で python 用に SDK を公開しているのでこれを使います。
SDKをインストール
$ pip install line-bot-sdk友達全員と、先程取得したグループ宛にそれぞれ投稿してみます
- broadcast が 友達登録全員に対しての送信になります。
from linebot import LineBotApi from linebot.models import TextSendMessage access_token = 'XXXXXXXXXXXXXXX' line_bot_api = LineBotApi(access_token) line_bot_api.broadcast(TextSendMessage(text='友達全員にBroadcast'))動作確認
- 以下のように「友達全員にBroadcast」というメッセージが BOT から送られてきているはずです。
- うまく行かない場合はaccess_token, 友達登録等見直してみてください。
メッセージ例 4. psf/requests-html を使って更新監視コードを書く
- Webページの監視をするためには、表示内容を解釈する必要があります。
- ここでは psf/requests-html を使ってみます。
インストール
$ pip install requests-html使い方
説明
- 例として 以下のようなページ の 商品が注文できるかどうかを見てみます。
- このWebページでは 注文できるかどうか以下のように表現されています。
- 「ご注文できない商品」の場所が「在庫あり」などに変化するので、これを見張れば良さそうです。
<div class="status-text"> <div class="status-heading"> <span class="status">ご注文できない商品*</span> </div> <div class="status-note"> <p> </p> </div><!-- /div#status-note --> </div>スクレイピングしてみる
- 以下のように Webページにアクセスしたあと
from requests_html import HTMLSession session = HTMLSession() r = session.get('https://XXXXXXXXXXXXX/') # <---- ここにアクセスしたいURLを入力
- r.html.find() を利用して 要素を絞り込むことができます。
from requests_html import HTMLSession session = HTMLSession() r = session.get('hxxps://XXXXXXXXXXXXX/') # <---- ここにアクセスしたいURLを入力 r.html.find('div.status-heading span.status')[0].text # <----- ご注文できない商品*
- うまく 文字列を得られたので あとはこれで条件判定してあげれば良さそうです。
LINEの通知部分と組み合わせてみる
- 品切れを示す文字列が 消えたら 通知を送るようにしてみます。
# -*- coding:utf-8 -*- from linebot import LineBotApi from linebot.models import TextSendMessage from requests_html import HTMLSession ACCESS_TOKEN = 'XXXXXXXXXXX' TARGET_URL = 'hxxps://XXXXXXXXXXXXX/rb/16057071/' STATUS_CSS_SELECTOR = 'div.status-heading span.status' NG_STATUS = 'ご注文できない商品' def get_status(): session = HTMLSession() r = session.get(TARGET_URL) return r.html.find(STATUS_CSS_SELECTOR)[0].text def broadcast_to_friends(message): line_bot_api = LineBotApi(ACCESS_TOKEN) line_bot_api.broadcast(TextSendMessage(text=message)) if not NG_STATUS in get_status(): broadcast_to_friends("商品が購入できます:" + TARGET_URL)
- 実行すると以下のようにメッセージが送られてきました。
メッセージ例 特定ユーザーや特定グループに投稿したいとき
- broadcast ではなく push message になります。
- これを送信するためには group などを特定するIDが必要です。
- IDは BOTに対する操作が行われたときに webhook で LINE から送られてくるので、その準備をします。
webhook を受け取る
- ngrok と Python で 単に webhook を受け取ってみる などを参考に webhook を受け取れる環境を整えてください。
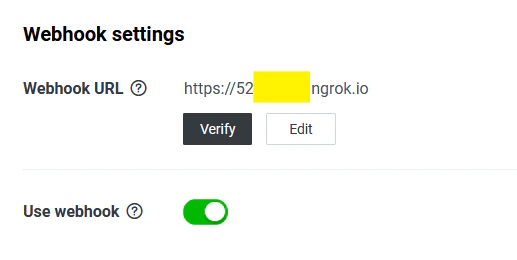
- 準備ができたらそのURLを Messaging API タブの Webhook URL に入力
- Verify を押して success となったら Use Webhook にチェックを入れておきます。
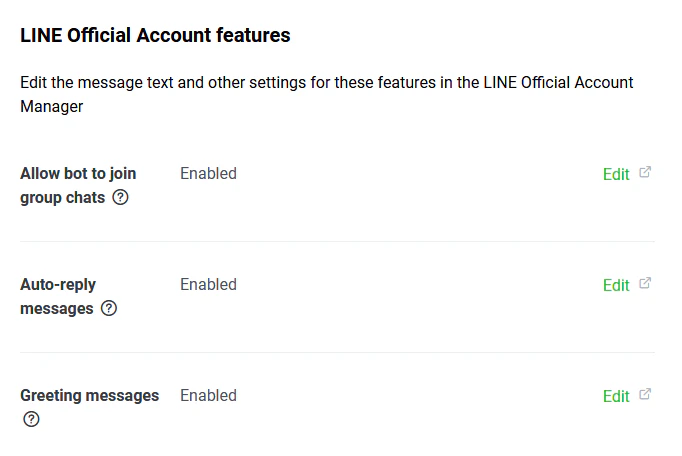
設定例 グループにBOTを入れて group_id を得る
- 次に、 Messaging API タブの
Allow bot to join group chatsの設定を Enabled にします。
設定例
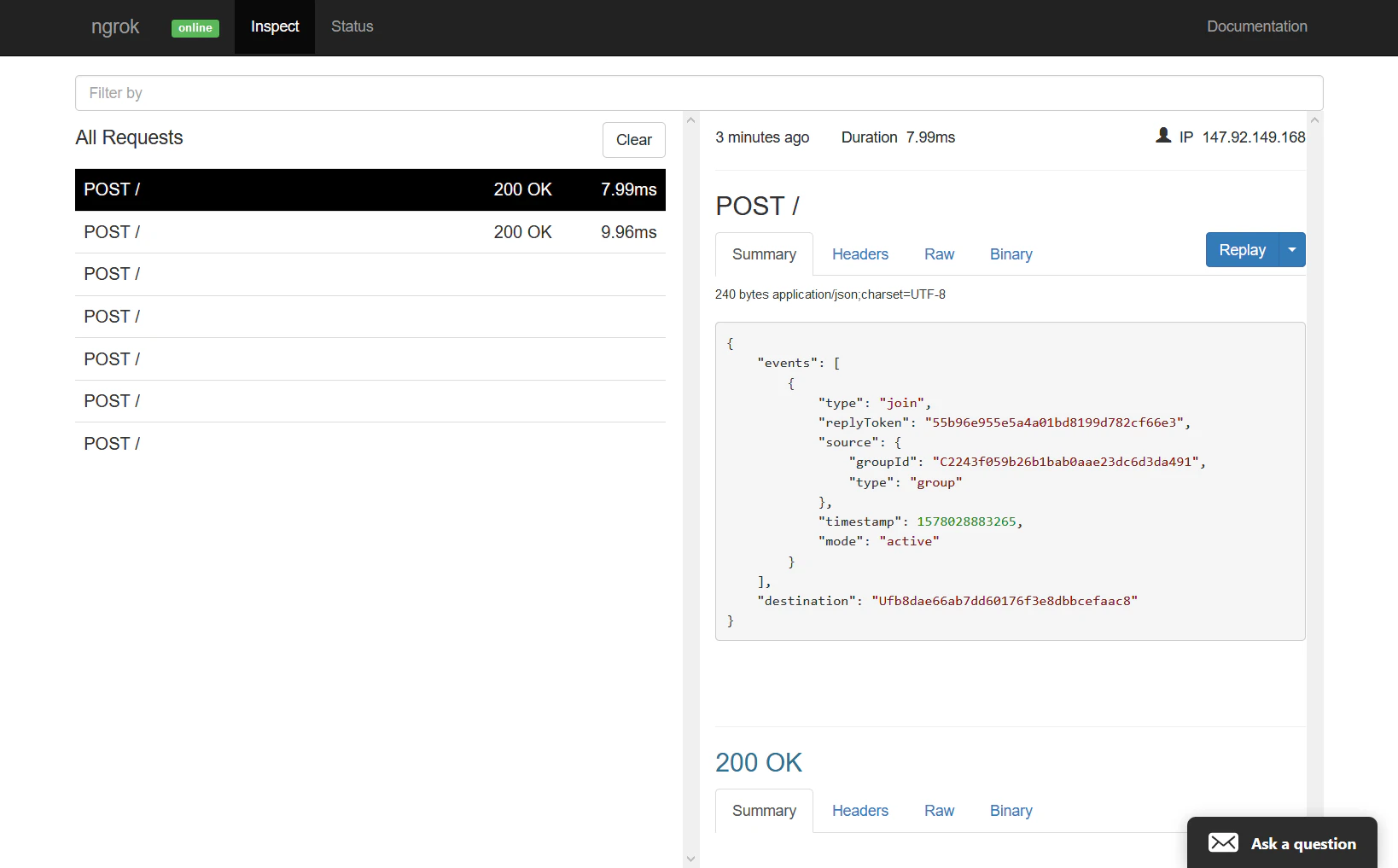
- その状態で 適当なグループに この LINE BOTを入れると webhook が飛んできます。
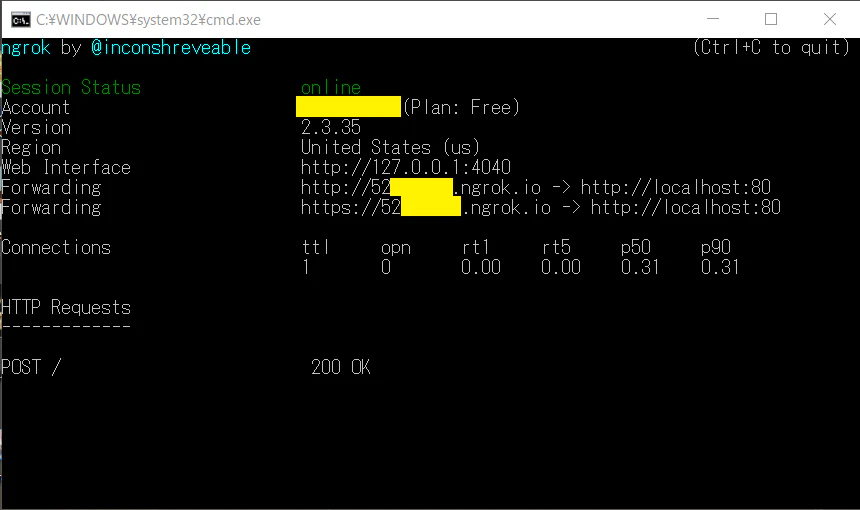
- ngrok には リクエストを確認できる画面があるので、以下のように確認できます。
- 必要なのは events[0].source.groupId だけです。
ngrokのinspect画面で確認している例 broadcast ではなく push_message へ
- groupId が取得できたら
broadcastではなくpush_messageにします。- このとき第一引数に id を与えてください。
-line_bot_api.broadcast(TextSendMessage(text='友達全員にBroadcast')) +line_bot_api.push_message(group_id, TextSendMessage(text='ある個人にpush message'))最後に
- あとはタスクスケジューラや cron などで定期的に実行するようにすれば完成です。
- なお、このように機械的にwebページへアクセスすることは場合によってはアクセス先のサーバーに負荷をかけることにつながるため、実際に運用する場合は 下記ページを一読することをおすすめします。
- http://librahack.jp/
- https://vaaaaaanquish.hatenablog.com/entry/2017/12/01/064227



- 投稿日:2020-01-07T22:24:18+09:00
ngrok と Python で 単に webhook を受け取ってみる
tl;dr
- botの作成などに webhookにより送られてくるtoken が必要な場合がある
- webhook には外部に公開するサーバーが必要であるが、極力かんたんに webhook を受け取ってみる
- 単に listen するだけでなく、 200 OK を返すだけのサーバーなどは Python を使えば簡単に作ることができた
題材
- LINE の Messaging API の Webhook を題材にします。
- これは、JSON形式のデータが POST で送信されます。
- 今回は LINE 側へ Webhook が受信できると申告できるよう 200 OK を返します。
流れ
- Python で 何を受けても 200 OK を返すようなサーバーを作る
- ngrok で 外部からのアクセスを受け取れる環境を作る
- ngrok に付属している Inspectツールで 受け取った Webhookの中身を見てみる
Python で 何を受けても 200 OK を返すようなサーバーを作る
GETやPOSTに応じて振る舞いを変更したいので、 http.server の BaseHTTPRequestHandler を使います。
今回は 80 port で listen し, POST を受け取ったら とりあえず 200 OK だけを返すようにします。
import http.server import socketserver import json class MyHandler(http.server.BaseHTTPRequestHandler): def do_POST(self): self.send_response(200) self.end_headers() with socketserver.TCPServer(("", 80), MyHandler) as httpd: httpd.serve_forever()
- 作成したら実行しておいてください。
serving at port 80と表示されていればOKです。ngrok で 外部からのアクセスを受け取れる環境を作る
- ngrok は ローカルホストを かんたんに インターネットに公開することができるサービスです。
- サインアップしたら 以下のような 画面になるのでガイドに従っていきましょう
Guide
- コマンドプロンプトで authtoken の登録や http tunnel の起動をしても良いですが、batファイルを使っても便利です。
- ダウンロードした zip を展開すると ngrok.exe があります。
- 同じ場所に 以下のような内容の ファイルを作成します。
auth.batngrok authtoken 1UFVG5sdtzGXXXXXXXXX80listen.batngrok http 80
- それぞれ ダブルクリックで実行してください。
- auth.bat は一瞬で閉じます。
- 80listen.bat は 以下のようになるはずです。
ngrok
- このウインドウで表示されている Forwarding 欄の ngrok.io で終わるアドレスが、あなたのアドレスです。
ngrok に付属している Inspectツールで 受け取った Webhookの中身を見てみる
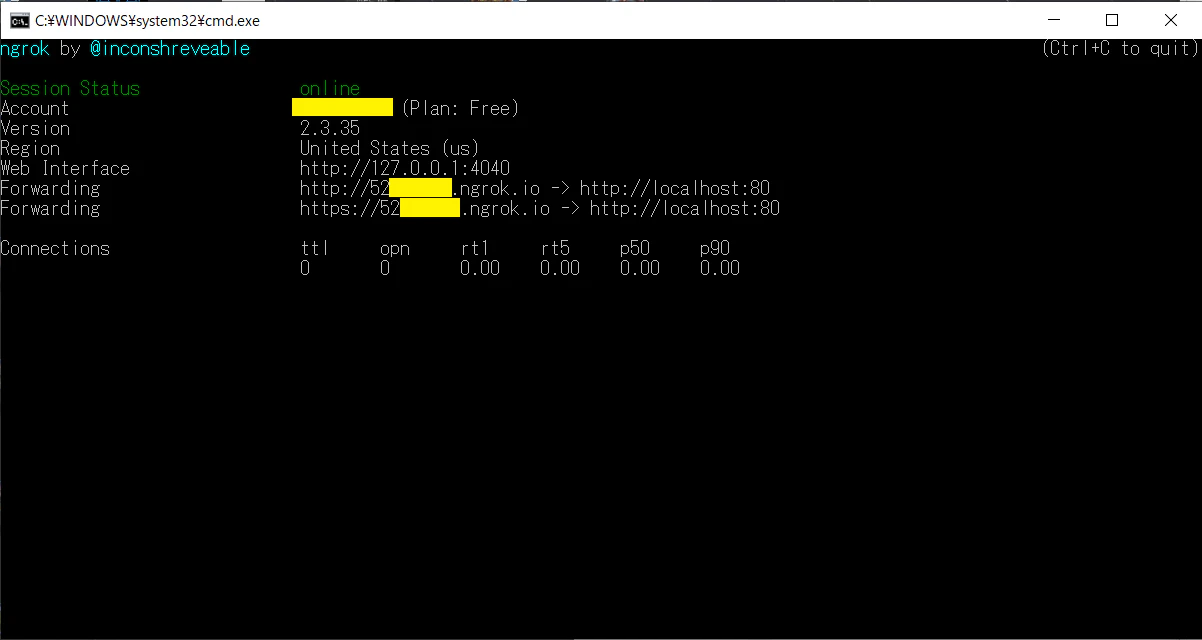
- 試しに 外部からこの ngrok.io のアドレスへ POSTすると
- ngrok の画面 では / へ POST が来たことが表示され
ngrok
python 製のサーバーの画面では リクエストの中身が表示されます。
ブラウザで http://localhost:4040/inspect/http へアクセスするとよりわかりやすく見ることができます。
inspect画面例

- 投稿日:2020-01-07T22:10:42+09:00
VueとFlaskでITイベント情報を地図表示するウェブアプリを作った�
はじめに
ネットサーフィンをしていると、ITイベントポータルサイトのconnpassがイベント情報を提供するWebAPIを配信している事を知り、開催地などを地図上で表示するアプリがあれば便利なのではないかと思い制作、年始の3日間を生贄に捧げ完成。
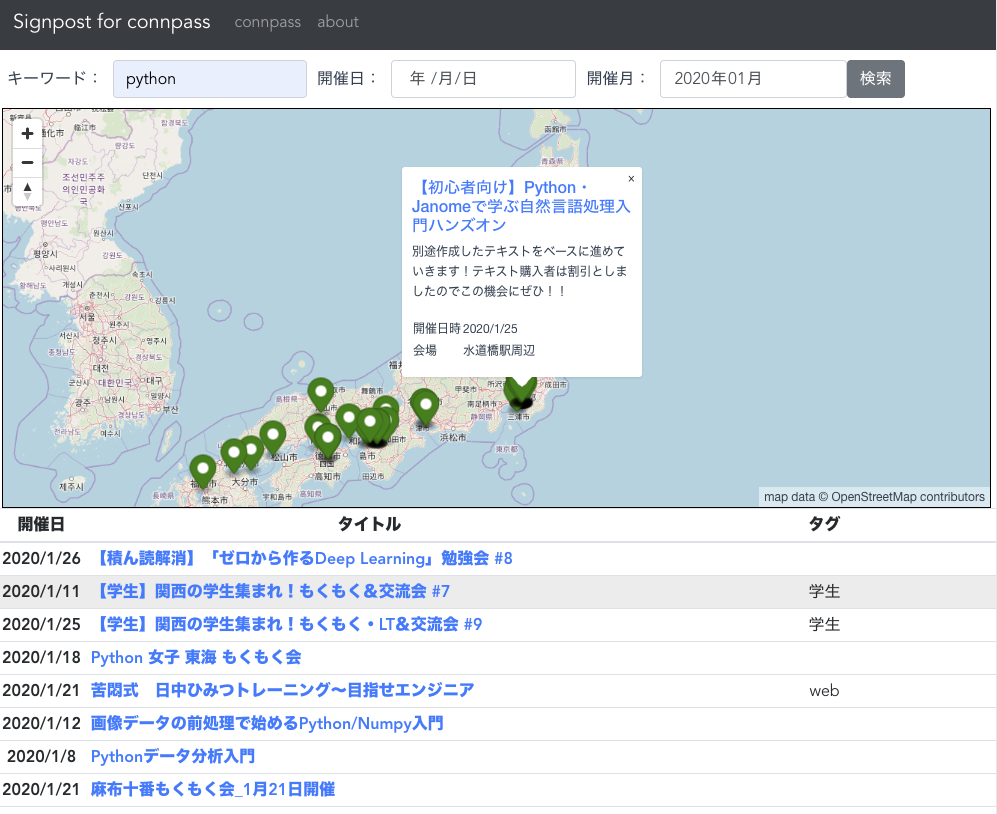
成果物
いわゆるSPAアプリケーションで、非同期通信で得たレスポンスを動的に地図表示します。
フレームワーク・ライブラリと選定理由
- Flask:後述
- Vue.js (Vue CLI):勉強中であるため、Reactよりしっくり来るため
- Mapbox Gl JS (+VueMapbox):多数の地物を表示するため動作パフォーマンスを重視した
- BootstrapVue:神
- OpenStreetMap(背景地図):国土地理院の基本地図よりも建物名などが見やすいから
各種ポイント
CORS制限
CORSとは、オリジン間リソース共有(Cross-Origin Resource Sharing)のこと。
簡単には、「許可を得ていない他人のウェブサイトのデータを非同期通信で持ってくるのはダメよ」、と理解している。
今回のケースでは、connpassAPIのレスポンスは、CORS制限のためフロント側で取得する事が出来ない。一度自らのサーバで受けておけばCORS制限には引っかからない。という訳で、当初はfirebaseのhostingやfunctionで対応しようと考えていたが、connpassAPIにアクセスしレスポンスを受け取るサーバをFlaskで構築する事とした。Flaskはとてもシンプルなので、今回のようになんでも良いからサーバが必要な場合に最適だと思うし、個人的に好きだから採用。FlaskとVue.jsの環境構築
Vue.jsはnode.jsと組み合わせて使う事が多いと思います。色々調べた結果、Flaskと共存して開発出来る構成に至りました。
ルートにPythonスクリプトやherokuサーバ用ファイルを配置し、フロント側はvueディレクトリに納めてあります。以下のとおり設定する事で、Flaskは、vue/distをtemplateフォルダとして参照するようになります。
from flask import Flask, render_template, request, jsonify, make_response, send_file, redirect, url_for app = Flask(__name__, static_folder='./vue/dist/static', template_folder='./vue/dist') #以下ルーティング…APIサーバの構築
connpassAPIの仕様に沿ってアクセスし、得たレスポンスをフロントへ返すAPIサーバを以下のようにつくりました。
import urllib.request, urllib.parse import json @app.route('/api/') def getApi(): keyword_or = request.args.get('keyword_or') ym = request.args.get('ym') ymd = request.args.get('ymd') owner_nickname = request.args.get('owner_nickname') start = request.args.get('start') order = request.args.get('order') count = request.args.get('count') all_params = { "keyword_or": keyword_or, "ym":ym, "ymd":ymd, "owner_nickname":owner_nickname, "start":start, "order":order, "count":100 } params = {} #値がNoneとなっている要素はパラメータから削除する for key in all_params: if all_params[key] != None: params[key] = all_params[key] p = urllib.parse.urlencode(params) url = "https://connpass.com/api/v1/event/?" + p with urllib.request.urlopen(url) as res: html = res.read().decode().replace(r"\n","") jsonData = json.loads(html) return jsonify(jsonData)connpassAPIと同じパラメータを受け、そのままconnpassAPIに投げ、レスポンスをデコードし、jsonとして返しています。完全なる中継サーバという事です。
参考サイト
Vue.js(vue-cli)とFlaskを使って簡易アプリを作成する【後半 - サーバーサイド編】
BootstrapVue
VueMapbox
- 投稿日:2020-01-07T22:09:09+09:00
【統計検定2級・準1級】Pythonで回帰分析実習(2)
はじめに
【統計検定2級・準1級】Pythonで回帰分析実習(1) - Qiita の続きです。
今回は、独立変数(説明変数)が2個以上ある重回帰分析をPythonを使って実際に試し、統計的な解釈を考えます。今回もnumpyやpandasなどのライブラリを使って計算部分は数式をもとに自分で書いていきます。参考書
長谷川勝也『ゼロからはじめてよくわかる多変量解析』 技術評論社 (2004) Chapter 2
理論的な部分の参考としては以下も参照しています。
東京大学教養学部統計学教室『統計学入門 (基礎統計学Ⅰ)』 東京大学出版会 (1991) 第13章題材
前回使ったJRの路線データでできればよかったのですが、独立変数を集めてくるのが大変そうだったので、今回は別のデータを使うことにしました。
統計局ホームページ/日本の統計 2019-第2章 人口・世帯以下の都道府県ごとのデータを組み合わせ、CSV形式に加工して使用します。
- 2-2 都道府県別人口と人口増減率
- 2-13 都道府県別昼間人口と自宅外就業・通学者数
- 2-14 都道府県別転出入者数
- 2-16 都道府県別出生・死亡数と婚姻・離婚件数
(2020/01/07) 人口と人口性比の列のみ、行が1つずれていましたので修正しました。
都道府県,人口,人口性比,人口増減率,昼夜間人口比率,転入超過数,出生率,死亡率,自然増減率,婚姻率,離婚率 北海道,5320,89.1,-0.455,99.945,-6569,6.4,11.8,-5.4,4.5,1.92 青森,1278,88.6,-0.965,99.849,-6075,6.3,13.8,-7.5,4.0,1.64 : : 沖縄,1626,88.5,0.582,99.968,-1112,11.3,8.4,3.0,5.7,2.44
- 人口(単位:千人)は平成29年の推計人口です。
- 人口増減率は ((平成27年の人口/平成22年の人口)^(1/5) - 1)×100 で計算した、1年当たりの平均増減率とします(元のデータの数値ではありません)。
これを前回と同様、文字コードをUTF-8として population.csv というファイル名で保存することとします。
実習
以下、Python 3.6.8で動作確認しています。
データ入力
import numpy as np import pandas as pd df = pd.read_csv("population.csv") print(df) # 取り込んだデータの内容を確認多変数の回帰分析 (2-3節)
このデータを使って、独立変数が2個以上の場合の回帰分析、つまり「重回帰分析」を考えてみましょう。
独立変数と従属変数の組み合わせは色々考えられるのですが、まずは手法を確認するという意味で、分かりやすい関係が出そうなで試してみましょう。
出生率を $x_1$、死亡率を $x_2$、人口増減率を $y$ として、$y = \beta_0 + \beta_1 x_1 + \beta_2 x_2$ という回帰モデルを考えます。1変数の場合と同じで、各データ点の残差(従属変数の観測値(実現値)と理論値(予測値)との差)の二乗和を最小とするように偏回帰係数 $\beta_0, \beta_1, \beta_2$ の値を定めます。
各データ点(観測値) $(x_1^{(1)}, x_2^{(1)}, y^{(1)}), ..., (x_1^{(n)}, x_2^{(n)}, y^{(n)})$ について、従属変数の理論値を $\hat{y}^{(i)} = \beta_0 + \beta_1 x_1^{(i)} + \beta_2 x_2^{(i)}$ とすると、残差の二乗和 $L$ は\begin{align} L &= \sum_{i=1}^n (y^{(i)} - \hat{y}^{(i)})^2 \\ &= \sum_{i=1}^n (y^{(i)} - \beta_0 - \beta_1 x_1^{(i)} - \beta_2 x_2^{(i)})^2 \end{align}となります。$\beta_0, \beta_1, \beta_2$ についてそれぞれ偏微分係数を0とおいたときの解を推定値 $\hat\beta_0, \hat\beta_1, \hat\beta_2$ とすると
\begin{align} \hat{\boldsymbol{\beta}} &= (\boldsymbol{X}^\top \boldsymbol{X})^{-1} \boldsymbol{X}^\top \boldsymbol{y} \end{align}が得られます($^\top$は行列・ベクトルの転置を表すものとします)。ただし
\begin{align} \hat{\boldsymbol{\beta}} &= (\hat\beta_0, \hat\beta_1, \hat\beta_2)^\top \\ \boldsymbol{X} &= \begin{pmatrix} 1 & x_1^{(1)} & x_2^{(1)} \\ \vdots & \vdots & \vdots \\ 1 & x_1^{(n)} & x_2^{(n)} \\ \end{pmatrix} \\ \boldsymbol{y} &= (y^{(1)}, ..., y^{(n)})^\top \end{align}で、$\boldsymbol{X}^\top \boldsymbol{X}$は逆行列を持つものとします。
この結果を用いて、偏回帰係数を計算してみるとn = len(df) X = np.c_[np.ones(n), df[["出生率", "死亡率"]].values] y = df["人口増減率"] b = np.linalg.inv(X.T.dot(X)).dot(X.T).dot(y) print(b) # Output: [ 1.00978055 0.10175178 -0.18246347]よって、人口増減率の理論値 $\hat{y}$ の回帰式として $\hat{y} = 1.010 + 0.102 x_1 - 0.182 x_2$ が得られます。
- 人口1000人当たり出生率が1増加すると、1年当たりの人口増減率は0.102ポイント増加する。
- 人口1000人当たり死亡率が1増加すると、1年当たりの人口増減率は0.182ポイント減少する。
1変数の場合と同様に決定係数を求めてみると
TSS = ((y - y.mean()) ** 2).sum() # 全変動 ESS = ((X.dot(b) - y.mean()) ** 2).sum() # 回帰変動 RSS = ((y - X.dot(b)) ** 2).sum() # 残差変動 R_2 = ESS / TSS # 決定係数 print(R_2) # 0.9014307808651625となり、約0.901と求められました。
この値が大きいのか小さいのか。後で他の独立変数を取った場合も試してみますので、値を比較してみてください。偏回帰係数の計算式の導出
前述の参考書では詳細がすっ飛ばされているのですが、偏回帰係数 $\beta_0, \beta_1, \beta_2$ の計算式の導出をしてみます。普通に偏微分して連立方程式として解いても求められるはずですが、独立変数1個でも面倒だった式変形がますます面倒になるので、「ベクトルの微分」を使って見通しよく整理しましょう。
ここでは、一般化して独立変数の数を $p$ とし、偏回帰係数 $\beta_0, \beta_1, ..., \beta_p$ の計算式を求めます。
\begin{align} \boldsymbol{\beta} &= (\beta_0, \beta_1, ..., \beta_p)^\top \\ \boldsymbol{x}^{(i)} &= (1, x_1^{(i)}, ..., x_p^{(i)})^\top \\ \boldsymbol{X} &= (\boldsymbol{x}^{(1)}, ..., \boldsymbol{x}^{(n)})^\top = \begin{pmatrix} 1 & x_1^{(1)} & \cdots & x_p^{(1)} \\ \vdots & \vdots & & \vdots \\ 1 & x_1^{(n)} & \cdots & x_p^{(n)} \\ \end{pmatrix} \\ \boldsymbol{y} &= (y^{(1)}, ..., y^{(n)})^\top \\ \epsilon^{(i)} &= y^{(i)} - \hat{y}^{(i)} = y^{(i)} - (\beta_0 + \beta_1 x_1^{(i)} + ... + \beta_p x_p^{(i)} ) \\ &= y^{(i)} - \boldsymbol{\beta}^\top \boldsymbol{x}^{(i)} \\ \boldsymbol{\epsilon} &= (\epsilon^{(1)}, ..., \epsilon^{(n)})^\top \\ &= \boldsymbol{y} - \boldsymbol{X} \boldsymbol{\beta}\\ \end{align}とします。式を簡単にするため、$\boldsymbol{x}^{(i)}$ に定数項に相当する成分を1次元加えていることに注意してください。
また零ベクトル(すべての成分が0のベクトル)を $\boldsymbol{0}$ と書くことにします。$\beta_0, \beta_1, ..., \beta_p$ についてそれぞれ偏微分係数を0とおくことは、$\frac{\partial L}{\partial \boldsymbol{\beta}} = \boldsymbol{0}$ とおくことと同じです。上記ページの公式を適宜用いて$\boldsymbol{\beta}$を求めます。以下の内容の式変形を少し丁寧に書いたものになります。
統計学入門−第7章 | 我楽多頓陳館>雑学の部屋>雑学コーナー\begin{align} L &= \sum_{i=1}^n (\epsilon^{(i)})^2 = \boldsymbol{\epsilon}^\top \boldsymbol{\epsilon} \\ &= (\boldsymbol{y} - \boldsymbol{X} \boldsymbol{\beta})^\top (\boldsymbol{y} - \boldsymbol{X} \boldsymbol{\beta}) \\ &= \boldsymbol{y}^\top \boldsymbol{y} - \boldsymbol{y}^\top (\boldsymbol{X} \boldsymbol{\beta}) - (\boldsymbol{X} \boldsymbol{\beta})^\top \boldsymbol{y} + \boldsymbol{\beta}^\top \boldsymbol{X}^\top \boldsymbol{X} \boldsymbol{\beta} \\ &= \boldsymbol{y}^\top \boldsymbol{y} - 2 \boldsymbol{y}^\top \boldsymbol{X} \boldsymbol{\beta} + \boldsymbol{\beta}^\top \boldsymbol{X}^\top \boldsymbol{X} \boldsymbol{\beta} \\ \frac{\partial L}{\partial \boldsymbol{\beta}} &= \frac{\partial}{\partial \boldsymbol{\beta}} \boldsymbol{y}^\top \boldsymbol{y} - 2 \frac{\partial}{\partial \boldsymbol{\beta}}(\boldsymbol{y}^\top \boldsymbol{X}) \boldsymbol{\beta} + \frac{\partial}{\partial \boldsymbol{\beta}}\boldsymbol{\beta}^\top (\boldsymbol{X}^\top \boldsymbol{X}) \boldsymbol{\beta} \\ &= -2 (\boldsymbol{y}^\top \boldsymbol{X})^\top + (\boldsymbol{X}^\top \boldsymbol{X} + (\boldsymbol{X}^\top \boldsymbol{X})^\top) \boldsymbol{\beta} \\ &= -2 \boldsymbol{X}^\top \boldsymbol{y} + 2\boldsymbol{X}^\top \boldsymbol{X}\boldsymbol{\beta} \end{align}よって、$\boldsymbol{X}^\top \boldsymbol{X}$に逆行列が存在するとき、$\frac{\partial L}{\partial \boldsymbol{\beta}} = \boldsymbol{0}$ の解を推定値 $\hat{\boldsymbol{\beta}}$ とすると
\begin{align} \hat{\boldsymbol{\beta}} &= (\boldsymbol{X}^\top \boldsymbol{X})^{-1} \boldsymbol{X}^\top \boldsymbol{y} \end{align}が得られます。
回帰分析の統計的理論(2-4節)
回帰式を得ることはできましたが、次は「得られた回帰式がどれだけ信頼できるか」を統計的に考えましょう。
ここまで統計学というより線形代数学の話ばかりでしたので。今までは、従属変数の観測値から最適な回帰式を1つ求めるという考え方をとっていました。
ここで、従属変数をある確率分布に従う確率変数と考えるとどうなるでしょう。つまり、独立変数$\boldsymbol{X}$の値が同じであっても、何度も観測を行えば毎回異なる観測値$\boldsymbol{y}$が得られると考えます。このとき、前述の式で得られる偏回帰係数 $\hat{\boldsymbol{\beta}}$ も観測ごとに変わる確率変数となります。真の偏回帰係数の値を我々は知ることができませんが、偏回帰係数の従う確率分布を考えることはできます。このあたりの考え方は統計検定2級範囲の母平均の区間推定(真の母平均を知ることはできず、母平均の確率分布を求める)などと同じです。例えば、実際に回帰式を求めたときに、回帰式で重要な役割を果たしている独立変数と、ほとんど影響しない独立変数があるかもしれません。仮に $\beta_j = 0$ であるならば、対応する独立変数 $x_j$ は従属変数の値に何の影響もありません。そこで、観測値から回帰式を得たときに、帰無仮説 $\beta_j = 0$、対立仮説 $\beta_j \neq 0$ を立て、帰無仮説が棄却されれば、その独立変数はその回帰式で確かに従属変数を説明している、と考えることができます。そのためには、観測値から得られた $\hat{\beta_j}$ の確率分布を考える必要が出てきます。
ここでは、各データの誤差 $\epsilon^{(i)}$ が互いに独立に平均0, 分散$\sigma^2$の正規分布に従うと仮定します。すると
- (確率変数としての)$y^{(i)}$ は互いに独立に平均$\hat{y}^{(i)}$, 分散$\sigma^2$の正規分布に従う
- $\hat{\boldsymbol{\beta}} = (\boldsymbol{X}^\top \boldsymbol{X})^{-1} \boldsymbol{X}^\top \boldsymbol{y}$ より、$\hat\beta_j$ は $y^{(1)}, ..., y^{(n)}$ の線形和になり、やはり正規分布に従う
ということがいえます。
この $\hat{\boldsymbol{\beta}}$ の平均は、真の偏回帰係数 $\boldsymbol{\beta}$ に一致します(証明は後述)。
また、$S_{ij}$ を $(\boldsymbol{X}^\top \boldsymbol{X})^{-1}$ の$(i,j)$成分と定める(ただし、$\beta_j$の番号付けに合わせて左上を(0,0)成分とします)と、各 $\hat{\beta_j}$ の分散は $\sigma^2 S_{jj}$ となります(証明は後述)。
よって、$\hat{\beta_j}$ を平均0、分散1に標準化したZ_j = \frac{\hat{\beta_j} - \beta_j}{\sqrt{\sigma^2 S_{jj}}}は標準正規分布に従うことになりますが、例によって誤差分散 $\sigma^2$ の値を知ることはできません。実際には観測値から推定するしかありませんが、不偏推定量にするには分母をデータの数から(独立変数+1)を引いた値とします。独立変数の個数を$p$とすると
s^2 = \frac{\sum_{i=1}^n (y^{(i)} - \hat{y}^{(i)})^2}{N-p-1}が $\sigma^2$ の不偏推定量となり、これを誤差分散の推定値とします。$s^2$ で $\sigma^2$ を置き換えた
t_j = \frac{\hat{\beta_j} - \beta_j}{\sqrt{s^2 S_{jj}}}は、自由度 $n-p-1$ の $t$分布に従います。
これが$t$分布に従う理由は、以下の「t統計量 (10.4)」とほぼ同じです。
【統計検定2級】正規母集団に対する仮説検定に出てくる確率分布まとめ - Qiitaよって、$\beta_j = 0$ といえるかどうかを検定するときには、
t_j = \frac{\hat{\beta_j} - 0}{\sqrt{s^2 S_{jj}}} = \frac{\hat{\beta_j}}{\sqrt{(y^{(i)} - \sum_{i=1}^n y^{(i)})^2 S_{jj} / (N-p-1)}}の値を計算して、求めた値を自由度$n-p-1$の$t$分布表から探して$P$値を求めます。$t$値の絶対値が大きいほど$P$値は小さくなり、その独立変数が意味を持っているということになります。
また、先程求めた誤差分散の推定値 $s^2$ は、回帰式で表現しきれない部分を表すわけですので、これが(相対的に)小さいほうが(大雑把には)良い回帰式といえるでしょう。
前置きが長くなりましたが、いよいよ実践。
先程のデータで、2つの独立変数に対応する偏回帰係数について、帰無仮説 $\beta_j = 0$ に対する$t$統計量と$P$値を計算してみましょう。試験で$P$値を求めるときは$t$分布表を用いますが、ここではscipy.statsモジュールで計算してしまいます。from scipy import stats p = X.shape[1] - 1 # 独立変数の個数 S = np.linalg.inv(X.T.dot(X)) # (X^T X) の逆行列 s_2 = ((y - X.dot(b)) ** 2).sum() / (n - p - 1) # 誤差分散の推定値 t = b / np.sqrt(s_2 * S.diagonal()) # t統計量 P = (1 - stats.t.cdf(np.abs(t), n - p - 1)) * 2 # P値 print(s_2) # 0.015396963025934803 print(t) # [ 3.273055 3.94856867 -13.93114362] print(P) # [0.00207535 0.00028009 0. ]統計検定2級ではRの出力結果を読み取らせる問題が必ず1問は出てきますが、その出力はこういう計算で得られているのですね。
この結果を見ると、有意水準5%で $\beta_1 = 0, \beta_2 = 0$ はいずれも棄却されます。そして、出生率より死亡率のほうがよく効いている、と読み取れます。
一方、$s^2 = 0.0154$ より人口増減率 [%] の標準誤差は $s = 0.124$ と推定されるのですが、この結果がよいのかどうか、比較対象がないのでなんともいえませんね。偏回帰係数の平均の導出
以下、ベクトルの期待値は各成分の期待値を並べたベクトルと思って読んでください。
各データの誤差 $\epsilon^{(i)}$ の平均を0とすると\begin{align} {\rm E}[\hat{\boldsymbol{\beta}}] &= {\rm E}[(\boldsymbol{X}^\top \boldsymbol{X})^{-1} \boldsymbol{X}^\top \boldsymbol{y}] \\ &= (\boldsymbol{X}^\top \boldsymbol{X})^{-1} \boldsymbol{X}^\top {\rm E}[\boldsymbol{y}] \\ &= (\boldsymbol{X}^\top \boldsymbol{X})^{-1} \boldsymbol{X}^\top {\rm E}[\boldsymbol{X} \boldsymbol{\beta} + \boldsymbol{\epsilon}] \\ &= (\boldsymbol{X}^\top \boldsymbol{X})^{-1} \boldsymbol{X}^\top \boldsymbol{X} \boldsymbol{\beta} \\ &= \boldsymbol{\beta} \end{align}このように、偏回帰係数の平均は真の偏回帰係数 $\boldsymbol{\beta}$ と一致します(不偏推定量)。
偏回帰係数を推定する方法は最小二乗法以外にも色々考えられますが、不偏推定量が得られることは最小二乗法の大きなメリットといえます。偏回帰係数の分散の導出
このページを参考に、表記を合わせて途中計算を補完しました。
2.4節 偏回帰係数とその検定 | データ解析/基礎と応用以下、${\rm V}[\hat{\boldsymbol{\beta}}]$ と書けば、分散共分散行列を表すこととします。つまり、$(i, j)$成分が、$\hat{\beta_i}, \hat{\beta_j}$の共分散($(i, j)$成分は$\hat{\beta_i}$の分散。ただし、$\beta_j$の番号付けに合わせて左上を(0,0)成分とします)であるような行列です。
\begin{align} \hat{\boldsymbol{\beta}} &= (\boldsymbol{X}^\top \boldsymbol{X})^{-1} \boldsymbol{X}^\top \boldsymbol{y} \\ &= (\boldsymbol{X}^\top \boldsymbol{X})^{-1} \boldsymbol{X}^\top (\boldsymbol{\epsilon} + \boldsymbol{X} \boldsymbol{\beta}) \\ &= (\boldsymbol{X}^\top \boldsymbol{X})^{-1} \boldsymbol{X}^\top \boldsymbol{\epsilon} + (\boldsymbol{X}^\top \boldsymbol{X})^{-1} \boldsymbol{X}^\top \boldsymbol{X} \boldsymbol{\beta} \\ &= (\boldsymbol{X}^\top \boldsymbol{X})^{-1} \boldsymbol{X}^\top \boldsymbol{\epsilon} + \boldsymbol{\beta} \end{align}となることを用いて
\begin{align} {\rm V}[\hat{\boldsymbol{\beta}}] &= {\rm E}[(\hat{\boldsymbol{\beta}} - {\rm E}[\hat{\boldsymbol{\beta}}])(\hat{\boldsymbol{\beta}} - {\rm E}[\hat{\boldsymbol{\beta}}])^\top] \\ &= {\rm E}[(\hat{\boldsymbol{\beta}} - \boldsymbol{\beta})(\hat{\boldsymbol{\beta}} - \boldsymbol{\beta})^\top] \\ &= {\rm E}[((\boldsymbol{X}^\top \boldsymbol{X})^{-1} \boldsymbol{X}^\top \boldsymbol{\epsilon})((\boldsymbol{X}^\top \boldsymbol{X})^{-1} \boldsymbol{X}^\top \boldsymbol{\epsilon})^\top] \\ &= {\rm E}[(\boldsymbol{X}^\top \boldsymbol{X})^{-1} \boldsymbol{X}^\top \boldsymbol{\epsilon} \boldsymbol{\epsilon}^\top \boldsymbol{X} ((\boldsymbol{X}^\top \boldsymbol{X})^{-1})^\top] \\ &= {\rm E}[(\boldsymbol{X}^\top \boldsymbol{X})^{-1} \boldsymbol{X}^\top \boldsymbol{\epsilon} \boldsymbol{\epsilon}^\top \boldsymbol{X} (\boldsymbol{X}^\top \boldsymbol{X})^{-1}] \\ &= (\boldsymbol{X}^\top \boldsymbol{X})^{-1} \boldsymbol{X}^\top {\rm E}[\boldsymbol{\epsilon} \boldsymbol{\epsilon}^\top] \boldsymbol{X} (\boldsymbol{X}^\top \boldsymbol{X})^{-1} \\ &= (\boldsymbol{X}^\top \boldsymbol{X})^{-1} \boldsymbol{X}^\top (\sigma^2 \boldsymbol{I}) \boldsymbol{X} (\boldsymbol{X}^\top \boldsymbol{X})^{-1} \\ &= \sigma^2 (\boldsymbol{X}^\top \boldsymbol{X})^{-1} \\ \end{align}と整理できます($\boldsymbol{I}$は単位行列)。ここで $S_{ij}$ を $(\boldsymbol{X}^\top \boldsymbol{X})^{-1}$ の$(i,j)$成分と定義すれば、各 $\hat{\beta_j}$ の分散は $\sigma^2 S_{jj}$ とわかります。
回帰式の検討 (2-6節)
さて、今まで人口増減率を推定するために、独立変数として出生率と死亡率の2つを用いました。ここでは、この独立変数で本当によいのか、他の独立変数の組み合わせのほうがよいということはないか、を検討します。もしかすると、出生率・死亡率以外にも人口増減率に影響を及ぼす要素があるかもしれませんよね。
仮に人口増減率(と、名義尺度である都道府県名)以外の変数から独立変数を任意に2個選ぶとした場合、どのような組み合わせがよいのでしょうか?
import itertools y = df["人口増減率"] vars = [x for x in df.columns if x not in ["都道府県", "人口増減率"]] for exp_vars in itertools.combinations(vars, 2): # 2つの独立変数を選ぶ X = np.c_[np.ones(n), df[list(exp_vars)].values] b = np.linalg.inv(X.T.dot(X)).dot(X.T).dot(y) # 偏回帰係数を計算する TSS = ((y - y.mean()) ** 2).sum() # 全変動 ESS = ((X.dot(b) - y.mean()) ** 2).sum() # 回帰変動 R_2 = ESS / TSS # 決定係数 p = X.shape[1] - 1 # 独立変数の個数 S = np.linalg.inv(X.T.dot(X)) # (X^T X) の逆行列 s_2 = ((y - X.dot(b)) ** 2).sum() / (n - p - 1) # 誤差分散の推定値 t = b / np.sqrt(s_2 * S.diagonal()) # t統計量 P = (1 - stats.t.cdf(np.abs(t), n - p - 1)) * 2 # P値 print("独立変数: ", exp_vars) print("偏回帰係数: ", b) print("決定係数: ", R_2) print("t統計量: ", t) print("P値: ", P) print("誤差分散の推定値:", s_2) print()すべての結果を出力すると長すぎるので、決定係数が0.9以上の組み合わせに対する出力を抜粋すると以下のようになります。
(2020/01/07) データ修正に伴い結果を差し替えました。独立変数: ('人口', '自然増減率') 偏回帰係数: [1.35396495e-01 2.92466698e-05 1.38354513e-01] 決定係数: 0.9202813093155153 t統計量: [ 2.50498414 4.06232118 16.12219163] P値: [0.01602233 0.00019698 0. ] 誤差分散の推定値: 0.012452424232620031 独立変数: ('転入超過数', '自然増減率') 偏回帰係数: [2.36387964e-01 6.30652813e-06 1.43339245e-01] 決定係数: 0.9235317925311585 t統計量: [ 6.24974791 4.36740999 18.56543006] P値: [1.44848286e-07 7.53394644e-05 0.00000000e+00] 誤差分散の推定値: 0.011944683881961054 独立変数: ('出生率', '死亡率') 偏回帰係数: [ 1.00978055 0.10175178 -0.18246347] 決定係数: 0.9014307808651792 t統計量: [ 3.273055 3.94856867 -13.93114362] P値: [0.00207535 0.00028009 0. ] 誤差分散の推定値: 0.015396963025934803 独立変数: ('出生率', '自然増減率') 偏回帰係数: [ 1.02915847 -0.08316346 0.18254551] 決定係数: 0.9030150527461578 t統計量: [ 3.35453348 -2.39398938 14.07003206] P値: [0.00164462 0.02099475 0. ] 誤差分散の推定値: 0.01514949250939055 独立変数: ('死亡率', '自然増減率') 偏回帰係数: [ 1.00487249 -0.08024897 0.10178654] 決定係数: 0.902445538157104 t統計量: [ 3.30081126 -2.33256484 4.02629601] P値: [0.00191782 0.02430887 0.0002203 ] 誤差分散の推定値: 0.01523845329397937 独立変数: ('自然増減率', '婚姻率') 偏回帰係数: [-0.56327258 0.12603311 0.16092148] 決定係数: 0.9001397075218234 t統計量: [-1.3456451 7.29460315 2.0734612 ] P値: [1.85310560e-01 4.23937485e-09 4.40154160e-02] 誤差分散の推定値: 0.015598634589388555この中だと、転入超過数と自然増減率の組み合わせが、決定係数が大きく、誤差分散の推定値も小さいのでよいですかね?しかし、転入超過数は割合ではなく実数なので、元の人口によって自然増減率への影響は変わるはずです。ここは、代わりに人口で割ったものを転入超過率とでも呼んで独立変数とすべきでしょう。
df["転入超過率"] = df["転入超過数"] / (df["人口"] * 1000) * 100 n = len(df) exp_vars = ("転入超過率", "自然増減率") y = df["人口増減率"] X = np.c_[np.ones(n), df[exp_vars].values] b = np.linalg.inv(X.T.dot(X)).dot(X.T).dot(y) TSS = ((y - y.mean()) ** 2).sum() # 全変動 ESS = ((X.dot(b) - y.mean()) ** 2).sum() # 回帰変動 R_2 = ESS / TSS # 決定係数 p = X.shape[1] - 1 # 独立変数の個数 S = np.linalg.inv(X.T.dot(X)) # (X^T X) の逆行列 s_2 = ((y - X.dot(b)) ** 2).sum() / (n - p - 1) # 誤差分散の推定値 t = b / np.sqrt(s_2 * S.diagonal()) # t統計量 P = (1 - stats.t.cdf(np.abs(t), n - p - 1)) * 2 # P値 print("独立変数: ", exp_vars) print("偏回帰係数: ", b) print("決定係数: ", R_2) print("t統計量: ", t) print("P値: ", P) print("誤差分散の推定値:", s_2) print()独立変数: ('転入超過率', '自然増減率') 偏回帰係数: [0.20976966 0.75632976 0.10990394] 決定係数: 0.9580723972439072 t統計量: [ 7.50186534 8.42827532 14.31096232] P値: [2.11598050e-09 9.87150361e-11 0.00000000e+00] 誤差分散の推定値: 0.006549283387531298転入超過数をそのまま使う場合と比較すると、決定係数も誤差分散の推定値も良くなっています。
転入超過率と自然増減率は、ともに人口を増やす効果があると考えられるので、対応する偏回帰係数が確かに正の値になっていることに注意しましょう。独立変数を3個使うとどうでしょうか?
for exp_vars in itertools.combinations(vars, 3): # 3つの独立変数を選ぶ X = np.c_[np.ones(n), df[list(exp_vars)].values] b = np.linalg.inv(X.T.dot(X)).dot(X.T).dot(y) # 偏回帰係数を計算する TSS = ((y - y.mean()) ** 2).sum() # 全変動 ESS = ((X.dot(b) - y.mean()) ** 2).sum() # 回帰変動 R_2 = ESS / TSS # 決定係数 p = X.shape[1] - 1 # 独立変数の個数 S = np.linalg.inv(X.T.dot(X)) # (X^T X) の逆行列 s_2 = ((y - X.dot(b)) ** 2).sum() / (n - p - 1) # 誤差分散の推定値 t = b / np.sqrt(s_2 * S.diagonal()) # t統計量 P = (1 - stats.t.cdf(np.abs(t), n - p - 1)) * 2 # P値 print("独立変数: ", exp_vars) print("偏回帰係数: ", b) print("決定係数: ", R_2) print("t統計量: ", t) print("P値: ", P) print("誤差分散の推定値:", s_2) print()例えばこういう組み合わせが見つかります。(これが一番よいというわけではありません。結果の解釈がしやすい一例です)
独立変数: ('自然増減率', '婚姻率', '離婚率') 偏回帰係数: [-0.30054533 0.12984192 0.19858489 -0.25130329] 決定係数: 0.9109243128862279 t統計量: [-0.72219064 7.82613187 2.61426129 -2.28169067] P値: [4.74086687e-01 8.36975600e-10 1.22779282e-02 2.75178580e-02] 誤差分散の推定値: 0.014237611977607154自然増減率と婚姻率が高いほど人口は増え、離婚率が高いほど人口は減ります。納得できそうな結果ですね。偏回帰係数は(定数項を除き)3つとも5%有意です。
一方で、あまり良くない例も見ていきましょう。独立変数: ('出生率', '死亡率', '自然増減率') 偏回帰係数: [ 1.03883742 -0.2559058 0.17133451 0.35353742] 決定係数: 0.9034996234109349 t統計量: [ 3.3482056 -0.68534239 0.4646739 0.96013752] P値: [0.00169918 0.49680614 0.6445094 0.34235404] 誤差分散の推定値: 0.015424353851135318出生率が上がると人口が減り、死亡率が上がると人口が増えるという奇妙な結果になっています。
これは、「自然増減率 = 出生率 - 死亡率」という独立変数間の関係があるからでして、多重共線性というやっかいな問題を引き起こします。
多重共線性とは何? Weblio辞書変数選択を行わない場合には,独立変数相互間に相関の高いものは含めないほうがよい。
もし,それらの中に独立でないものが含まれていると( 例えば変数 A,B とその合計値 C = A + B が共に含まれていると )分析は失敗する。
場合によっては,各独立変数と従属変数との相関係数の符号と,偏回帰係数の符号が一致しない場合が生ずる。(中略)このようなことが起きるのは,独立変数間に相関の高いものが混ざっていることが原因である( ある変数で予測しすぎた部分を別の変数で打消しているような場合がある )。しかし,このようなことは因果関係を考える上では不都合なので,符号が一致しない独立変数を除いた重回帰式を探索するとよいであろう。多重共線性が起きているかどうかは、ある程度は検出しようがあるでしょうが、「出生率が高いほど人口が増えないとおかしい」といった話を機械はなかなか分かりません。「符号が一致しない独立変数を除いた重回帰式」って実は結構難しいような。最終的な結果の解釈は、人間がちゃんと考える必要があるところです。
ということで
長かった回帰分析、とりあえず終わり。
次回はChapter 3「主成分分析」の予定です。
人口1,000人あたりの出生数・死亡数 ↩
- 投稿日:2020-01-07T21:55:15+09:00
【StyleGAN入門】まゆゆもアニメも微笑んだ♬
表題のとおりです。
今回は以下の参考のとおりに自前学習したまゆゆとアニメ顔が微笑んでくれるかやってみました。
【参考】
StyleGanで福沢諭吉を混ぜてみる結論からいうと以下のような笑顔画像が得られ成功しました♬
癒されますね♬やったこと
・自前の画像を学習する
・笑顔画像を生成し、動画を作成する
・アニメ顔画像もやってみる・自前の画像を学習する
まゆゆは、前回と同じというか前回のnpyデータを利用しました。
一方、アニメ顔画像は同じようにalignしようとしましたが、顔の作りが違いすぎてalignできませんでした。
しかし、アニメ顔画像についても同様に学習しました。
その結果、学習は出来たようで、以下の画像が出力できるnpyが取得できました。
1 2 当然のように、これらの画像を利用してMixingもやってみました。
しかし、。。。結果は以下のとおり、
Mixing in projected latent space どうも写像潜在空間は人間どもに汚されてしまっているようです
この傾向は、人の顔とMixingしても同様な感じです。
その絵は今回は貼らずに置きます。・笑顔画像を生成し、動画を作成する
原理は、簡単に書くと以下のとおりです。
latent_vector = np.load('./latent/mayuyu.npy') coeff = [-1,-0.8,-0.6,-0.4,-0.2, 0,0.2,0.4,0.6,0.8, 1] direction = np.load('ffhq_dataset/latent_directions/smile.npy') new_latent_vector[:8] = (latent_vector + coeff*direction)[:8] smile_image = generate_image(new_latent_vector)この新しいnew_latent_vectorで、smile画像生成します。
ということで、以下のようなコードになります。
コードは以下に置きました。
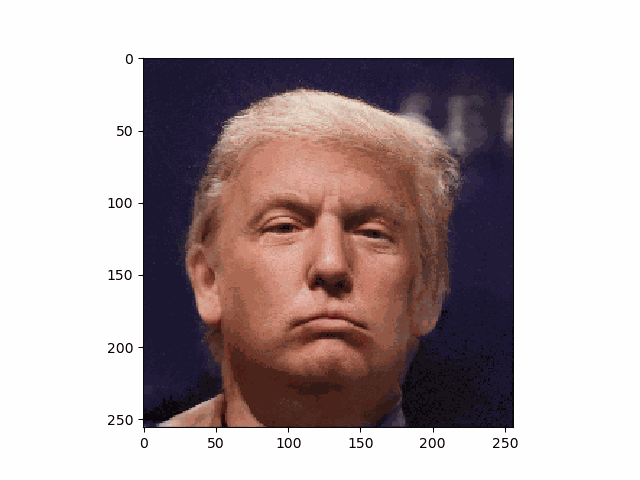
StyleGAN/mayuyu_smile.pyimport os import pickle import numpy as np import PIL.Image import dnnlib import dnnlib.tflib as tflib import config import sys from PIL import Image, ImageDraw from encoder.generator_model import Generator import matplotlib.pyplot as plt tflib.init_tf() fpath = './weight_files/tensorflow/karras2019stylegan-ffhq-1024x1024.pkl' with open(fpath, mode='rb') as f: generator_network, discriminator_network, Gs_network = pickle.load(f) generator = Generator(Gs_network, batch_size=1, randomize_noise=False) def generate_image(latent_vector): latent_vector = latent_vector.reshape((1, 18, 512)) generator.set_dlatents(latent_vector) img_array = generator.generate_images()[0] img = PIL.Image.fromarray(img_array, 'RGB') return img.resize((256, 256)) def move_and_show(latent_vector, direction, coeffs): for i, coeff in enumerate(coeffs): new_latent_vector = latent_vector.copy() new_latent_vector[:8] = (latent_vector + coeff*direction)[:8] plt.imshow(generate_image(new_latent_vector)) plt.pause(1) plt.savefig("./results/example{}.png".format(i)) plt.close() mayuyu = np.load('./latent/mayuyu.npy') smile_direction = np.load('ffhq_dataset/latent_directions/smile.npy') move_and_show(mayuyu, smile_direction, [-1,-0.8,-0.6,-0.4,-0.2, 0,0.2,0.4,0.6,0.8, 1]) s=22 images = [] for i in range(0,11,1): im = Image.open(config.result_dir+'/example'+str(i)+'.png') im =im.resize(size=(640,480), resample=Image.NEAREST) images.append(im) for i in range(10,0,-1): im = Image.open(config.result_dir+'/example'+str(i)+'.png') im =im.resize(size=(640, 480), resample=Image.NEAREST) images.append(im) images[0].save(config.result_dir+'/mayuyu_smile{}.gif'.format(11), save_all=True, append_images=images[1:s], duration=100*2, loop=0)こうして、トランプさんも笑顔です。
・アニメ顔画像もやってみる
上記のとおり、アニメ顔画像はnpyは生成出来たのでこれを使って、笑顔に挑戦です。
結果は以下のとおり、まあ笑ってる。。。かな
。。。しかし、問題は口が、。。。らしいものしかないってことですねまとめ
・アニメ画像の学習をやってみた
・自前学習の「まゆゆもアニメも微笑んだ」に挑戦してみた・だいたい出来たが、もう少し口のあるアニメ画像でやってみようと思う
・アニメ画像のいわゆるTrainingをやってみよう
・そもそもsmile.npyと同じように動作用のnpyを作成したい



- 投稿日:2020-01-07T21:32:33+09:00
Pythonで日付から曜日を取得する際に`locale.Error: unsupported locale setting`が出た
Pythonで日付から曜日を取得したい
以下のようなイメージ
2019-01-07 00:00:00⇒火曜日実行環境
- Windows10 Pro
- Python 3.7.4
やったこと
こちらの記事を参考になりそうだったので、ほぼコピペして実行。
Pythonで日付から曜日や月を文字列(日本語や英語など)で取得localeモジュールでロケールを変更すれば取得できるらしい。
time_test.pyimport datetime import locale dt = datetime.datetime(2018, 1, 1) print(dt) # 2018-01-01 00:00:00 print(dt.strftime('%A, %a, %B, %b')) # Monday, Mon, January, Jan locale.setlocale(locale.LC_TIME, 'ja_JP.UTF-8') print(locale.getlocale(locale.LC_TIME)) # ('ja_JP', 'UTF-8') print(dt.strftime('%A, %a, %B, %b')) # 月曜日, 月, 1月, 1上記のような参考コードがあったので実行したところエラーに…
2018-01-01 00:00:00 Monday, Mon, January, Jan Traceback (most recent call last): File ".\time_test.py", line 11, in <module> locale.setlocale(locale.LC_TIME, 'ja_JP.UTF-8') File "C:\Users\XXXXX\AppData\Local\Programs\Python\Python37\lib\locale.py", line 604, in setlocale return _setlocale(category, locale) locale.Error: unsupported locale setting
locale.Error: unsupported locale settingとあるのでsetlocaleで指定する言語と地域が間違ってる感じがする。エラー対応
setlocaleで渡す引数をちゃんと確認してみる。
locale --- Pythonドキュメント
まずは以下のようなコードを書けと書いてある。import locale locale.setlocale(locale.LC_ALL, '')
locale.setlocale(locale.LC_TIME, 'ja_JP.UTF-8')の部分を上記の書き方に変更してみると…time_test.pyimport datetime import locale dt = datetime.datetime(2018, 1, 1) print(dt) # 2018-01-01 00:00:00 print(dt.strftime('%A, %a, %B, %b')) # Monday, Mon, January, Jan #locale.setlocale(locale.LC_TIME, 'ja-JP') locale.setlocale(locale.LC_ALL, '') print(locale.getlocale(locale.LC_TIME)) print(dt.strftime('%A, %a, %B, %b')) # 月曜日, 月, 1月, 1出力結果
2018-01-01 00:00:00 Monday, Mon, January, Jan ('Japanese_Japan', '932') 月曜日, 月, 1月, 1取得したい曜日が表示できました。
print(locale.getlocale(locale.LC_TIME))で出力結果が('Japanese_Japan', '932')となっているので、原因はja_JPで指定していたことだろうと推測。
locale.setlocale(locale.LC_ALL, '')を
locale.setlocale(locale.LC_TIME, 'Japanese_Japan.UTF-8')に変更しても日本語の結果が得られそうだったので実行。('Japanese_Japan', 'utf8') 月曜日, 月, 1月, 1想定通りの結果が取得できました。
- 投稿日:2020-01-07T20:47:58+09:00
gitのbranch名,tag名をpythonで取得する
はじめに
機械学習系でmodelと中間生成ファイル,精度などの結果を同時に管理したいとき,Githubでbranchを切ってコードを管理するだけでなく,S3などのストレージを用いて管理したい欲が深いです。
既存のツール
既存のツールで同様の課題を解決したかったら,mlflowを使うのが良さそうです.
ただ,mlflowでversion管理するにせよ,flaskなどで自作管理アプリを開発するにせよ,gitのbranch名とS3のobject名は統一した方がいいという気持ちがありました.
また,過去に切ったreleaseタグにcheckoutして当時の推定値を再現したい欲もあります.
ということで現在のbranchと,remoteのreleaseタグを全取得するPythonコードを書きました.
import subprocess import pandas as pd def get_current_branch(repository_dir='./') -> str: '''現在のbranch名を取得 Args: repository_dir(str): リポジトリのあるディレクトリ Return: str ''' cmd = "cd %s && git rev-parse --abbrev-ref HEAD" % repository_dir proc = subprocess.Popen(cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE) proc.wait() stdout_data = proc.stdout.read() # stderr_data = proc.stderr.read() current_branch = stdout_data.decode('utf-8').replace('\n','') return current_branch def get_remote_tags(repository_dir='./') -> pd.core.frame.DataFrame: '''リモートのタグを取得する Args: repository_dir(str): リポジトリのあるディレクトリ Returns: pd.core.frame.DataFrame ''' cmd = "cd %s && git ls-remote --tags" % repository_dir proc = subprocess.Popen(cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE) proc.wait() stdout_data = proc.stdout.read() # stderr_data = proc.stderr.read() tag_df = pd.DataFrame([r.split('\t') for r in stdout_data.decode('utf-8').split('\n')], columns=['hash', 'tag_name']) return tag_df.dropna(how='any')
- 投稿日:2020-01-07T20:40:50+09:00
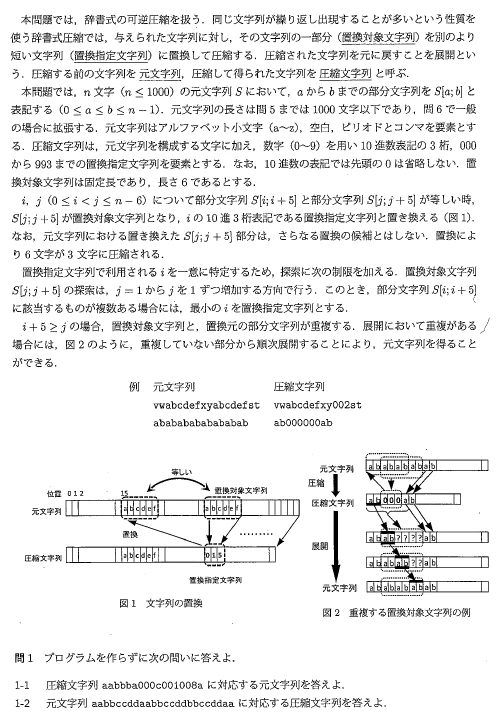
東京大学大学院情報理工学系研究科 創造情報学専攻 2011年度夏 プログラミング試験
20011年度夏の院試の解答例です
※記載の内容は筆者が個人的に解いたものであり、正答を保証するものではなく、また東京大学及び本試験内容の提供に関わる組織とは無関係です。出題テーマ
- 正規表現
問題文
※ 東京大学側から指摘があった場合は問題文を削除いたします。
(1)
1-1
aabbbaaabbbacabbbaabbbacaa
1-2
aabbccdd000dd002aa
(2)
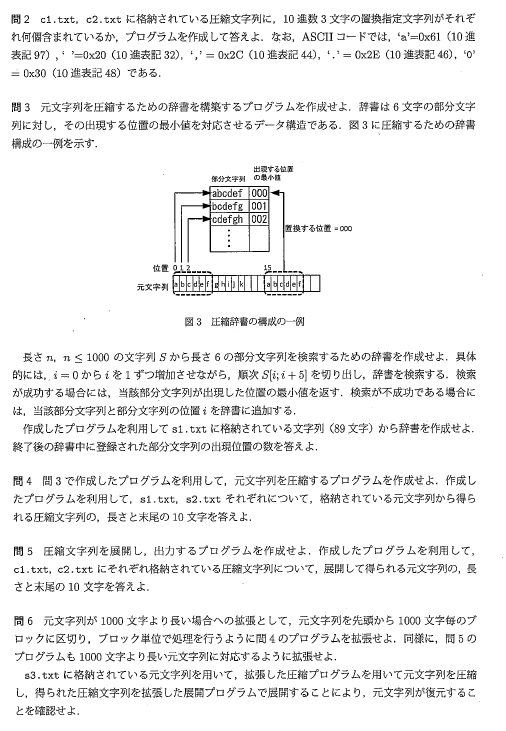
import re def get_row_text(file_path): with open(file_path, 'r') as f: return f.read() def get_compressions(text): return re.findall(r'[0-9]{3}', text) def solve2(file_path): row_text = get_row_text(file_path) compressions = get_compressions(row_text) print(len(compressions))(3)
def get_row_text(file_path): with open(file_path, 'r') as f: return f.read() def make_dic(text): n = len(text) dic = {} key_set = set([]) for i in range(n - 5): si = text[i:i+6] if not(si in key_set): str_num = str(i) str_num = '0' * (3 - len(str_num)) + str_num dic[si] = str_num key_set.add(si) return dic def solve3(file_path): row_text = get_row_text(file_path) dic = make_dic(row_text) print(dic)(4)
def get_row_text(file_path): with open(file_path, 'r') as f: return f.read() def compress_text(text): text_array = list(text) dic = make_dic(text) key_set = set(dic.keys()) n = len(text) j = 0 memo = [] while j < n - 5: sj = text[j:j+6] if sj in key_set: v = dic[sj] int_v = int(v) if int_v == j: j += 1 continue tmp = ['9', '9', '9'] tmp.extend(list(v)) text_array[j:j+6] = tmp j += 6 else: j += 1 return ''.join(text_array).replace('999', '') def solve4(file_path): row_text = get_row_text(file_path) compressed_text = compress_text(row_text) print(compressed_text)(5)
def get_row_text(file_path): with open(file_path, 'r') as f: return f.read() def get_content(text): size = len(text) ret = '' ret += (text * ((6+size-1)//size)) return ret[:6] def decode(compressed_text): text = compressed_text codes = re.findall(r'[0-9]{3}', compressed_text) for code in codes: m = re.search(code, text) i = int(code) j = m.span()[0] tmp = min(6, j - i) rep = get_content(text[i:i+tmp]) text = text[:j] + rep + text[j+3:] return text def solve5(file_path): compressed_text = get_row_text(file_path) text = decode(compressed_text) print('size: {0}, last10: {1}'.format(len(text), text[-10:]))(6)
import re def get_row_text(file_path): with open(file_path, 'r') as f: return f.read() def get_compressions(text): return re.findall(r'[0-9]{3}', text) def make_dic(text): n = len(text) dic = {} key_set = set([]) for i in range(n - 5): si = text[i:i+6] if not(si in key_set): str_num = str(i) str_num = '0' * (3 - len(str_num)) + str_num dic[si] = str_num key_set.add(si) return dic def compress_text(text): text_array = list(text) dic = make_dic(text) key_set = set(dic.keys()) n = len(text) j = 0 memo = [] while j < n - 5: sj = text[j:j+6] if sj in key_set: v = dic[sj] int_v = int(v) if int_v == j: j += 1 continue tmp = ['9', '9', '9'] tmp.extend(list(v)) text_array[j:j+6] = tmp j += 6 else: j += 1 return ''.join(text_array).replace('999', '') def compress_text_mt1000(text): block_nums = 0 rest_num = len(text) text_block = [] while rest_num > 0: if rest_num >= 1000: text_block.append(text[block_nums*1000:(block_nums+1)*1000]) block_nums += 1 rest_num -= 1000 else: text_block.append(text[block_nums*1000:]) block_nums += 1 rest_num -= 1000 compressed_text_block = [] for text in text_block: compressed_text_block.append(compress_text(text)) return ''.join(compressed_text_block) def get_content(text): size = len(text) ret = '' ret += (text * ((6+size-1)//size)) return ret[:6] def decode(compressed_text): text = compressed_text codes = re.findall(r'[0-9]{3}', compressed_text) for code in codes: m = re.search(code, text) i = int(code) j = m.span()[0] tmp = min(6, j - i) rep = get_content(text[i:i+tmp]) text = text[:j] + rep + text[j+3:] return text def decode_mt1000(compressed_text): decode_text_size = 0 s = 0 i = 0 compressed_text_blocks = [] while i < len(compressed_text): ch = compressed_text[i] if ch.isnumeric(): decode_text_size += 6 i += 3 else: decode_text_size += 1 i += 1 if decode_text_size % 1000 == 0 or i == len(compressed_text): compressed_text_blocks.append(compressed_text[s:i]) s = i ret = '' for compressed_text in compressed_text_blocks: ret += decode(compressed_text) return ret def solve6(file_path): row_text = get_row_text(file_path) compressed_text = compress_text_mt1000(row_text) text = decode_mt1000(compressed_text) print(text)感想
- 今まで避けてきたけどさすがに正規表現使いました笑。
- 後は特にすごく難しい部分はないと思います。ただ、文字列を切りはりしているので計算量はちょっと微妙なところはあると思います。
- 投稿日:2020-01-07T20:12:10+09:00
MacOS(Catallina)でpython環境構築
初めてのMacでプログラミング始めるぞーと思ったらさっそく環境構築で詰まったのでメモとして
環境
- MacOS Catallina 10.15.2
- zsh 5.7.1
詰まった原因
だいたいzshのせい
Catallinaから標準のシェルがbashからzshに変わったためテキトーに検索してきた記事に添うとパスが通らないといった不具合が出る
シェルの設定ファイル名に違いがあり、bashを使っている記事を参考にするのであれば
.bash_profile→.zprofile.bashrc→.zshrcと置き換える必要がある
python環境構築
Macには標準で古いバージョンのpython(2系)が入っている
2系は最新のバージョンpython(3系)のと書き方が異なるため切り替えたほうがよい
今回はpyenv(パイエンブ)というツールでpythonのバージョンを切り替えるpyenvのインストール
以下のコマンドをシェルで実行する
brewがインストールされていない場合は先にbrewをインストールbrew install pyenvインストール後、パスを通すために
.zshrcに以下を転記
.zshrcがない場合は作る.zshrcexport PYENV_ROOT="$HOME/.pyenv" export PATH="$PYENV_ROOT/bin:$PATH" if command -v pyenv 1>/dev/null 2>&1; then eval "$(pyenv init -)" fi ~保存して
.zshrcを再読み込みする以下のコマンドを実行source ~/.zshrcこれでインストールは完了、
pyenv --versionを実行してパスが通っていることを確認pyenvでpythonをインストール
以下のコマンドを実行するとpyenvでインストールできるpythonのバージョンが一覧表示される
pyenv install --listそこから使いたいバージョンを選んでインストール
今回は3.8.0を選択pyenv install 3.8.0インストールが終わったら下記のコマンドで標準のpythonを切り替える
2つめのは今いるディレクトリにのみ切り替えを適応するコマンドpyenv python global 3.8.0 pyenv python local 3.8.0切り替え後、
python --versionでpythonのバージョンを確認
任意のバージョンに変わっていたら成功参考リンク
- 投稿日:2020-01-07T18:47:39+09:00
AtCoder AGC 041 C - Domino Quality の全探索でハマった
概要
- N=7,Quality=3の時のドミノの置き方の探索にかなり時間がかかった
- $2^{49}\fallingdotseq 10^{15} $の探索を実装するときは、うまく枝を刈る必要がある
- PythonはC++よりも条件によっては20倍以上遅い
pythonでN=7,Quality=3の場合の置き方の探索をした時
(0,0)からドミノを置いて試していく。試す順番は
1.縦向き
2.横向き
3.置かないこれで適した配置1つを見つけるのに 約740[s] かかった。
findPattern.pyimport sys import numpy as np import datetime sys.setrecursionlimit(10 ** 7) def cntQuality(N, grids, num, axis): q = 0 if axis == 0: g = grids[num, :] else: g = grids[:, num] last = -1 for i in range(N): d = g[i] if last == d or d == 0: continue q += 1 last = d return q def dfs(N, grids, pos, num, q): x = pos // N y = pos % N if y == 0 and x != 0: qx = cntQuality(N, grids, x-1, 0) if qx != q: return False # end grids if x == N and y == 0: # valid for i in range(N): qy = cntQuality(N, grids, i, 1) if qy != q: return False return grids # not yet pos += 1 # put vertical if y < N-1 and grids[x][y] == 0 and grids[x][y+1] == 0: v_num = num + 1 # v_grids = copy.copy(grids) grids[x][y] = v_num grids[x][y+1] = v_num g = dfs(N, grids, pos, v_num, q) if g is not False: return g grids[x][y] = 0 grids[x][y+1] = 0 # put horizontal if x < N-1 and grids[x][y] == 0 and grids[x+1][y] == 0: h_num = num + 1 # h_grids = copy.copy(grids) grids[x][y] = h_num grids[x+1][y] = h_num g = dfs(N, grids, pos, h_num, q) if g is not False: return g grids[x][y] = 0 grids[x+1][y] = 0 # dont put domino g = dfs(N, grids, pos, num, q) if g is not False: return g return False start = datetime.datetime.now() print("start", start) N = 7 q = 3 grids = np.zeros((N, N)) g = dfs(N, grids, 0, 0, q) end = datetime.datetime.now() print("end", end) print(g)実行結果.txtstart 2020-01-07 18:13:18.477510 end 2020-01-07 18:22:35.768316 [[ 1. 1. 2. 2. 3. 3. 0.] [ 4. 4. 5. 5. 6. 0. 0.] [ 7. 7. 0. 0. 6. 8. 8.] [ 0. 0. 9. 10. 0. 0. 11.] [ 0. 0. 9. 10. 0. 0. 11.] [ 0. 0. 0. 0. 12. 13. 14.] [ 0. 0. 0. 0. 12. 13. 14.]]なんで740[s]もかかったのか?
探索する順番が悪かった模様。
1.横向き
2.縦向き
3.置かないで探索した場合、1[s]以内で配置が見つかった。
おそらくこの探索順の場合、合致する枝が近くにあるのだろう。PythonとC++でいくつかパターンを試してみた
※手元で一度しか試してないので、ブレがあると思います
探索順 Python C++ 横->縦->なし 100[ms] 5[ms] 縦->横->なし 740[s] 17[s] なし->横->縦 430[ms] 10[ms] 結論
- うまく枝刈りできないと、探索順によってはかなり時間の差が生まれる
- このくらいのオーダーだとPythonよりC++を使った方が良さそう
- 投稿日:2020-01-07T18:25:00+09:00
【新年】すべてのプログラマの皆様へ新年のご挨拶【ちょっとした小ネタ】
ただの小ネタです。今年はまだ簡単です。
手元で、さくっと動作確認できた言語だけになっています。
ちなみに、BOMは入っていません。C#とか
byte[] utf8Bytes = { 0xe4, 0xbb, 0x8a, 0xe5, 0xb9, 0xb4, 0xe3, 0x82, 0x82, 0x31, 0xe5, 0xb9, 0xb4, 0xe3, 0x81, 0x8a, 0xe4, 0xba, 0x92, 0xe3, 0x81, 0x84, 0xe3, 0x81, 0xab, 0xe3, 0x80, 0x81, 0xe6, 0x99, 0x82, 0xe3, 0x81, 0xab, 0xe3, 0x81, 0xaf, 0xe8, 0x8b, 0xa6, 0xe3, 0x81, 0x97, 0xe3, 0x81, 0xbf, 0xe3, 0x81, 0xaa, 0xe3, 0x81, 0x8c, 0xe3, 0x82, 0x89, 0xe3, 0x82, 0x82, 0xe3, 0x80, 0x81, 0xe6, 0xa5, 0xbd, 0xe3, 0x81, 0x97, 0xe3, 0x82, 0x93, 0xe3, 0x81, 0xa7, 0xe3, 0x82, 0xb3, 0xe3, 0x83, 0xbc, 0xe3, 0x83, 0x87, 0xe3, 0x82, 0xa3, 0xe3, 0x83, 0xb3, 0xe3, 0x82, 0xb0, 0xe3, 0x81, 0x97, 0xe3, 0x81, 0xbe, 0xe3, 0x81, 0x97, 0xe3, 0x82, 0x87, 0xe3, 0x81, 0x86, 0xef, 0xbc, 0x81 };Javaとか
byte[] utf8Bytes = { (byte)0xe4, (byte)0xbb, (byte)0x8a, (byte)0xe5, (byte)0xb9, (byte)0xb4, (byte)0xe3, (byte)0x82, (byte)0x82, (byte)0x31, (byte)0xe5, (byte)0xb9, (byte)0xb4, (byte)0xe3, (byte)0x81, (byte)0x8a, (byte)0xe4, (byte)0xba, (byte)0x92, (byte)0xe3, (byte)0x81, (byte)0x84, (byte)0xe3, (byte)0x81, (byte)0xab, (byte)0xe3, (byte)0x80, (byte)0x81, (byte)0xe6, (byte)0x99, (byte)0x82, (byte)0xe3, (byte)0x81, (byte)0xab, (byte)0xe3, (byte)0x81, (byte)0xaf, (byte)0xe8, (byte)0x8b, (byte)0xa6, (byte)0xe3, (byte)0x81, (byte)0x97, (byte)0xe3, (byte)0x81, (byte)0xbf, (byte)0xe3, (byte)0x81, (byte)0xaa, (byte)0xe3, (byte)0x81, (byte)0x8c, (byte)0xe3, (byte)0x82, (byte)0x89, (byte)0xe3, (byte)0x82, (byte)0x82, (byte)0xe3, (byte)0x80, (byte)0x81, (byte)0xe6, (byte)0xa5, (byte)0xbd, (byte)0xe3, (byte)0x81, (byte)0x97, (byte)0xe3, (byte)0x82, (byte)0x93, (byte)0xe3, (byte)0x81, (byte)0xa7, (byte)0xe3, (byte)0x82, (byte)0xb3, (byte)0xe3, (byte)0x83, (byte)0xbc, (byte)0xe3, (byte)0x83, (byte)0x87, (byte)0xe3, (byte)0x82, (byte)0xa3, (byte)0xe3, (byte)0x83, (byte)0xb3, (byte)0xe3, (byte)0x82, (byte)0xb0, (byte)0xe3, (byte)0x81, (byte)0x97, (byte)0xe3, (byte)0x81, (byte)0xbe, (byte)0xe3, (byte)0x81, (byte)0x97, (byte)0xe3, (byte)0x82, (byte)0x87, (byte)0xe3, (byte)0x81, (byte)0x86, (byte)0xef, (byte)0xbc, (byte)0x81 };C/C++とか
const char utf8Bytes[] = { (char)0xe4, (char)0xbb, (char)0x8a, (char)0xe5, (char)0xb9, (char)0xb4, (char)0xe3, (char)0x82, (char)0x82, (char)0x31, (char)0xe5, (char)0xb9, (char)0xb4, (char)0xe3, (char)0x81, (char)0x8a, (char)0xe4, (char)0xba, (char)0x92, (char)0xe3, (char)0x81, (char)0x84, (char)0xe3, (char)0x81, (char)0xab, (char)0xe3, (char)0x80, (char)0x81, (char)0xe6, (char)0x99, (char)0x82, (char)0xe3, (char)0x81, (char)0xab, (char)0xe3, (char)0x81, (char)0xaf, (char)0xe8, (char)0x8b, (char)0xa6, (char)0xe3, (char)0x81, (char)0x97, (char)0xe3, (char)0x81, (char)0xbf, (char)0xe3, (char)0x81, (char)0xaa, (char)0xe3, (char)0x81, (char)0x8c, (char)0xe3, (char)0x82, (char)0x89, (char)0xe3, (char)0x82, (char)0x82, (char)0xe3, (char)0x80, (char)0x81, (char)0xe6, (char)0xa5, (char)0xbd, (char)0xe3, (char)0x81, (char)0x97, (char)0xe3, (char)0x82, (char)0x93, (char)0xe3, (char)0x81, (char)0xa7, (char)0xe3, (char)0x82, (char)0xb3, (char)0xe3, (char)0x83, (char)0xbc, (char)0xe3, (char)0x83, (char)0x87, (char)0xe3, (char)0x82, (char)0xa3, (char)0xe3, (char)0x83, (char)0xb3, (char)0xe3, (char)0x82, (char)0xb0, (char)0xe3, (char)0x81, (char)0x97, (char)0xe3, (char)0x81, (char)0xbe, (char)0xe3, (char)0x81, (char)0x97, (char)0xe3, (char)0x82, (char)0x87, (char)0xe3, (char)0x81, (char)0x86, (char)0xef, (char)0xbc, (char)0x81 };Pythonとか
utf8_bytes = [ 0xe4, 0xbb, 0x8a, 0xe5, 0xb9, 0xb4, 0xe3, 0x82, 0x82, 0x31, 0xe5, 0xb9, 0xb4, 0xe3, 0x81, 0x8a, 0xe4, 0xba, 0x92, 0xe3, 0x81, 0x84, 0xe3, 0x81, 0xab, 0xe3, 0x80, 0x81, 0xe6, 0x99, 0x82, 0xe3, 0x81, 0xab, 0xe3, 0x81, 0xaf, 0xe8, 0x8b, 0xa6, 0xe3, 0x81, 0x97, 0xe3, 0x81, 0xbf, 0xe3, 0x81, 0xaa, 0xe3, 0x81, 0x8c, 0xe3, 0x82, 0x89, 0xe3, 0x82, 0x82, 0xe3, 0x80, 0x81, 0xe6, 0xa5, 0xbd, 0xe3, 0x81, 0x97, 0xe3, 0x82, 0x93, 0xe3, 0x81, 0xa7, 0xe3, 0x82, 0xb3, 0xe3, 0x83, 0xbc, 0xe3, 0x83, 0x87, 0xe3, 0x82, 0xa3, 0xe3, 0x83, 0xb3, 0xe3, 0x82, 0xb0, 0xe3, 0x81, 0x97, 0xe3, 0x81, 0xbe, 0xe3, 0x81, 0x97, 0xe3, 0x82, 0x87, 0xe3, 0x81, 0x86, 0xef, 0xbc, 0x81 ]
- 投稿日:2020-01-07T17:13:25+09:00
PythonでExcelファイルを開く、そして日本地図に色を塗る
- PythonでExcelファイルを開く
- Pythonで日本地図に色を塗る
この2つをここでは取り扱います。 Google Colaboratory 上で動きます。
日本地図に色を塗る
ライブラリ japanmap のインストール
!pip install japanmap必要なライブラリのインポート
from japanmap import pref_names,pref_code,picture都道府県の名前
print(pref_names)['_', '北海道', '青森県', '岩手県', '宮城県', '秋田県', '山形県', '福島県', '茨城県', '栃木県', '群馬県', '埼玉県', '千葉県', '東京都', '神奈川県', '新潟県', '富山県', '石川県', '福井県', '山梨県', '長野県', '岐阜県', '静岡県', '愛知県', '三重県', '滋賀県', '京都府', '大阪府', '兵庫県', '奈良県', '和歌山県', '鳥取県', '島根県', '岡山県', '広島県', '山口県', '徳島県', '香川県', '愛媛県', '高知県', '福岡県', '佐賀県', '長崎県', '熊本県', '大分県', '宮崎県', '鹿児島県', '沖縄県']都道府県コード
pref_code('東京都')13白地図の描画
%matplotlib inline import matplotlib.pyplot as plt from pylab import rcParams rcParams['figure.figsize'] = 6, 6 plt.imshow(picture())
指定した都道府県の色ぬり
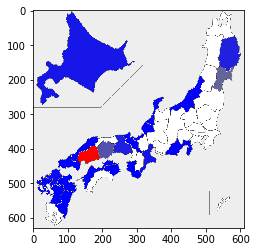
plt.imshow(picture({'鳥取':'red','佐賀':(0,255,0)}))
Excelファイルを開く
題材として、 帝国書院 様のホームページで公開している都道府県別統計データをエクセルファイル化したものを用いました。
ダウンロード
urllib はダウンロード用のライブラリですが、 Google Colab 上で使うと、Google Colab 上にアップロードすることになります。Google Colabでは、セッションが終わるとアップロードしたファイルは消えてしまうので、そのときは再度アップロードしましょう。
# urllibによるダウンロード import urllib.request url = "エクセルファイルが置いてあるURL" urllib.request.urlretrieve(url, 'Teikoku-Shoin-Japan.xlsx')Excel を開く
PythonでExcelファイルを開く方法は、私が把握している限り2つほどあります。
import pandas as pd excel = pd.read_excel('Teikoku-Shoin-Japan.xlsx') # こっちの方法だとうまくいかないかもimport pandas as pd excel = pd.ExcelFile('Teikoku-Shoin-Japan.xlsx') # こっちのほうがうまくいく気がするExcel は csv などと違い、複数のシートから成っています。
for s in enumerate(excel.sheet_names): print(s) # シートの名前と番号を列挙(0, '面積\u3000〔2017年〕') (1, '人口\u3000〔2018年〕') (2, '人口密度\u3000〔2018年〕') (3, '人口増加率\u3000〔2010~2015年〕') (4, '老年(65歳以上)人口率\u3000〔2018年〕') (5, '産業別人口割合(2015年)') (6, '平均寿命(女)\u3000〔2015年〕') (7, '平均寿命(男)\u3000〔2015年〕') (8, '耕地面積〔2017年〕') (9, '耕地率\u3000〔2017年〕') (10, '森林率・人工林率〔2017年〕') (11, '小麦の生産\u3000〔2018年〕') (12, '米の生産\u3000〔2017年〕') (13, 'さつまいもの生産\u3000〔2017年〕') (14, 'じゃがいもの生産\u3000〔2017年〕') (15, '大豆の生産\u3000〔2017年〕') (16, '落花生の生産\u3000〔2017年〕') (17, 'キャベツの生産\u3000〔2017年〕') (18, 'きゅうりの生産\u3000〔2017年〕') (19, 'すいかの生産\u3000〔2017年〕') (20, 'だいこんの生産\u3000〔2017年〕') (21, 'なたねの生産〔2017年〕') (22, 'にんじんの生産\u3000〔2017年〕') (23, 'ねぎの生産\u3000〔2017年〕') (24, 'はくさいの生産\u3000〔2017年〕') (25, 'ピーマンの生産\u3000〔2017年〕') (26, 'ほうれん草の生産\u3000〔2017年〕') (27, '茶(荒茶)の生産\u3000〔2017年〕') (28, 'いちごの生産\u3000〔2017年〕') (29, 'うめの生産\u3000〔2017年〕') (30, 'メロンの生産\u3000〔2017年〕') (31, '柿の生産\u3000〔2017年〕') (32, 'さくらんぼの生産\u3000〔2017年〕') (33, 'みかんの生産\u3000〔2017年〕') (34, 'ももの生産\u3000〔2017年〕') (35, 'りんごの生産\u3000〔2017年〕') (36, '菊の出荷量 〔2017年〕') (37, 'パンジーの出荷量 〔2017年〕') (38, '洋ラン類(切り花)の出荷量\u3000〔2017年〕') (39, 'ブロイラーの飼養羽数\u3000〔2018年〕') (40, '豚の飼養頭数\u3000〔2018年〕') (41, '肉牛の飼養頭数\u3000〔2018年〕') (42, '乳牛の飼養頭数\u3000〔2018年〕') (43, 'まゆの生産 〔2017年〕') (44, '農業産出額\u3000〔2017年〕') (45, '米の産出額\u3000〔2017年〕') (46, '麦類の産出額\u3000〔2017年〕') (47, '豆類の産出額\u3000〔2017年〕') (48, 'いも類の産出額\u3000〔2017年〕') (49, '野菜の産出額\u3000〔2017年〕') (50, '果実の産出額\u3000〔2017年〕') (51, '花きの産出額\u3000〔2017年〕') (52, '工芸農作物の産出額\u3000〔2017年〕') (53, '畜産の産出額\u3000〔2017年〕') (54, '漁業生産量(漁業・養殖業)〔2016年〕') (55, 'いかの漁獲量\u3000〔2016年〕') (56, 'かつおの漁獲量\u3000〔2016年〕') (57, 'さんまの漁獲量\u3000〔2016年〕') (58, 'まいわしの漁獲量\u3000〔2016年〕') (59, 'まぐろの漁獲量\u3000〔2016年〕') (60, 'かきの養殖\u3000〔2016年〕') (61, 'ほたてがいの養殖\u3000〔2016年〕') (62, 'わかめの養殖\u3000〔2016年〕') (63, '素材(原木)の生産\u3000〔2016年〕') (64, '工業出荷額\u3000〔2016年〕') (65, '果実酒の生産 〔2016年〕') (66, '焼ちゅうの生産 〔2016年〕') (67, '清酒(濁酒を含む)の生産\u3000〔2016年〕') (68, 'ビールの生産\u3000〔2016年〕') (69, '石油・石炭製品の生産 〔2016年〕') (70, '半導体の生産\u3000〔2016年〕') (71, '産業用ロボットの生産\u3000〔2016年〕') (72, '自動車(二輪自動車を含む)の生産\u3000〔2016年〕') (73, '繊維の生産\u3000〔2016年〕') (74, '鉄鋼の生産\u3000〔2016年〕') (75, '集積回路の生産\u3000〔2016年〕') (76, '1人あたりの県民所得\u3000〔2015年〕') (77, '1人あたりの都市公園面積\u3000〔2017年3月末〕') (78, '1人あたりの電力需要量\u3000〔2015年〕') (79, '1日1人あたりのごみ排出量\u3000〔2016年〕') (80, '下水道の普及率\u3000〔2018年〕') (81, '1世帯あたりの乗用車台数\u3000〔2018年〕') (82, '小売業年間販売額\u30002015年') (83, '公害苦情件数\u3000〔2017年〕')適当なシートを選択してみます
sheet_index = 2 print(excel.sheet_names[sheet_index]) sheet = excel.parse(excel.sheet_names[sheet_index], header=None) # 2枚目のシートの中身を pandas 形式にする人口密度 〔2018年〕sheet.head() # データの形を確認する
0 1 2 0 出典:平成30年住民基本台帳人口・世帯数表、平成29年全国都道府県市区町村別面積調 NaN NaN 1 県コード 県名 (人/km2) 2 1 北海道 64 3 2 青森 136 4 3 岩手 83 データの加工
sheet.iloc[2:49, [0, 2]] # 必要部分を抜き出す
0 2 2 1 64 3 2 136 4 3 83 5 4 317 ... ... ... 46 45 144 47 46 180 48 47 645 sheet.iloc[2:49, [0, 2]].values # pandas 形式を numpy 形式に変換するarray([[1, 64], [2, 136], [3, 83], [4, 317], [5, 87], ..., [46, 180], [47, 645]], dtype=object)Excelのデータで日本地図に色を塗る
データの加工
values = sheet.iloc[2:49, [0, 2]].values色の塗り方の指定
以下のコードは、
- 最大値は赤色
- 最大値の半分の値は黄色
- ゼロは青色
- データなしは白色
のカラーコードを出力します。
import numpy as np def color_scale(value, max_value): try: v = value / max_value if v >= 1.0: return (255, 0, 0) elif v <= 0: return (0, 0, 255) elif v > 0.5: red = 1 green = int(255 * (2 - 2 * v)) blue = 0 return (red, green, blue) else: red = int(255 * 2 * v) green = int(255 * 2 * v) blue = int(255 * (1 - 2 * v)) return (red, green, blue) except: return (255, 255, 255)使用例はこんな感じ。
for v in [0.0, 0.2, 0.5, 0.7, 1.0, "string"]: print(v, color_scale(v, 1))0.0 (0, 0, 255) 0.2 (102, 102, 153) 0.5 (255, 255, 0) 0.7 (1, 153, 0) 1.0 (255, 0, 0) string (255, 255, 255)最大値を求めます
max_value = np.max([a for a in values[:, 1] if not isinstance(a, str)])都道府県ごとにカラーを決めます
data ={} for code, value in zip(values[:, 0], values[:, 1]): data[code] = color_scale(value, max_value)日本地図に色を塗ります
%matplotlib inline import matplotlib.pyplot as plt from pylab import rcParams print(excel.sheet_names[sheet_index]) plt.imshow(picture(data))人口密度 〔2018年〕
まとめ
別のデータで塗るとこんな感じ。データがない場所はしっかり白になってます。
sheet_index = 60 print(excel.sheet_names[sheet_index]) sheet = excel.parse(excel.sheet_names[sheet_index], header=None) values = sheet.iloc[2:49, [0, 2]].values max_value = np.max([a for a in values[:, 1] if not isinstance(a, str)]) data ={} for code, value in zip(values[:, 0], values[:, 1]): data[code] = color_scale(value, max_value) plt.imshow(picture(data))かきの養殖 〔2016年〕


- 投稿日:2020-01-07T17:11:21+09:00
GNSSのおもひで(継続は力なり?
記事をご覧くださりありがとうございます。
どうも、びりどらです。
メンタルが壊れて昨年10月に会社を退職して、
ほうれん草を植えたり、カメを買い始めたり
謎のチャレンジをしている変人です。
びりどら(ひとり)はみんなのために...
※専門家ではないので、内容に不備があるかもしれません、ご了承ください。取り扱う内容
(1)ヒートショック危険お知らせ装置/(ラジオ体操)圧電ブザー演奏装置の開発
(2)OpenCvを用いてホウレンソウの成長把握/OpenCVを用いてマクロ(陸ガメ)の生態把握
(3)GPSの猛勉強・GPS便利ツールなどを作る←ココ
(4)アルゴリズムのお勉強
(5)PHPフレームワークのお勉強
(-) メンタルの療養本題
今回は、特に新たにチャレンジしたことを乗せる記事ではありません。
pythonを用いてGPS座標から二点間の距離を出して検証したい方、向けの記事です。
DEG形式の時系列GPSデータから球面三角法を使って、二点間の距離(m単位)を出したい人にとって幸せになれるプログラムについてです
具体的実行方法は、下記スクリプトをご覧くださいな。
特に苦労したのは、どうしても入ってしまうBOM文字を除外する部分(今となってはBOMなし保存すればいいだけの話ですが?...DistanceBetweenTwoPoints.py#DistanceBetweenTwoPoints : create by Biridora! # -*- coding: utf-8 -*- #●二地点の緯度経度の距離を計算して表示するプログラム● #---------------------------------------------------- #実行の仕方 #python DistanceBetweenTwoPoints.py filename.csv #第一引数:このスクリプトの名前 #第二引数:読み込む緯度経度ファイル名を指定 #「filename.csv」には以下の形式のファイルを用意する #緯度A,経度A,緯度B,経度B #緯度C,経度C,緯度D,経度D # ・ # ・ # ・ #---------------------------------------------------- import math import sys import csv #球面三角法により、大円距離(メートル)を求める def distance(lat1,lng1,lat2,lng2): #緯度経度をラジアンに変換 rlat1 = lat1 * math.pi / 180 rlng1 = lng1 * math.pi / 180 rlat2 = lat2 * math.pi / 180 rlng2 = lng2 * math.pi / 180 #2点の中心角(ラジアン)を求める a = math.sin(rlat1) * math.sin(rlat2) + math.cos(rlat1) * math.cos(rlat2) * math.cos(rlng1 - rlng2) rr = math.acos(a) #地球赤道半径(メートル) earth_radius = 6378140 #2点間の距離(メートル) distance = earth_radius * rr return distance; def main(): args = sys.argv print "------------------------------------------------------------------" with open(args[1], 'r') as csvfile: csv_reader = csv.reader(csvfile,delimiter=',',quotechar='"') for row in csv_reader: row[0] = row[0].replace('\xef\xbb\xbf', '') print "latA:"+ row[0] + " lngA:" + row[1] print "latB:"+ row[2] + " lngB:" + row[3] print "" print str(distance(float(row[0]),float(row[1]),float(row[2]),float(row[3])))+" m" print "------------------------------------------------------------------" # main関数呼び出し if __name__ == "__main__": main()最後に
僕自身、メンタル療養しながら、ホウレンソウ植えたり、お世話になった友人に技術共有をしたり
今年はやること多いです。
この記事をご覧になった方、
GNSSに関しては楽しいので、また何かしら、お役に立てるものを共有したいと考えています。
それでは✋
- 投稿日:2020-01-07T17:06:38+09:00
raspberry piでpythonを用いてグーグルスプレッドシートにアクセスする(自分用)
目的
raspberry piでpythonを用いてグーグルスプレッドシートにアクセスするまでの覚え書きを記します
準備
・↓google spread sheet に書き込み・読み取りをする準備まで
https://qiita.com/akabei/items/0eac37cb852ad476c6b9raspberry piで準備するコード
呼ばれる側
test.pyimport sys sys.path.append('/usr/lib/python3/dist-packages') import gspread from oauth2client.service_account import ServiceAccountCredentials def main(): scope = ['https://spreadsheets.google.com/feeds','https://www.googleapis.com/auth/drive'] credentials = ServiceAccountCredentials.from_json_keyfile_name('/home/pi/Downloads/xxxxxxxxxxx.json', scope) gc = gspread.authorize(credentials) wks = gc.open('gspreadサンプル').sheet1 wks.update_acell('A1', 'Hello World!') print(wks.acell('A1')) if __name__ == "__main__": main()呼ぶ側
yobu.pyimport test test.main()問題
LANの異なる環境(自宅のLANと研究室のLAN)で以下のような問題が現れた.
raise HttpAccessTokenRefreshError(error_msg, status=resp.status) oauth2client.client.HttpAccessTokenRefreshError: invalid_grant: Invalid JWT: Token must be a short-lived token (60 minutes) and in a reasonable timeframe. Check your iat and exp values and use a clock with skew to account for clock differences between systems.これはOSの内部時刻が現在時刻と同期されてないことに起因する問題だった.
sudo date --set='2020/01/07 16:54'このように手動で時刻を合わせることで解決した
参考文献
・https://qiita.com/AAkira/items/22719cbbd41b26dbd0d1
・https://hombre-nuevo.com/microcomputer/raspberrypi/raspberrypi0044/
・https://www.xn--tckk6a9dufrb.com/raspberry-piraspbian%E3%81%AEntp%E3%82%B5%E3%83%BC%E3%83%90%E8%A8%AD%E5%AE%9A/
- 投稿日:2020-01-07T16:23:35+09:00
AtCoder Beginner Contest 060 過去問復習
所要時間
A問題
前と後ろを比較
answerA.pya,b,c=input().split() if a[-1]==b[0] and b[-1]==c[0]: print("YES") else: print("NO")answerA_better.pya,b,c=input().split() print("YES" if a[-1]==b[0] and b[-1]==c[0] else "NO")B問題
頭の中がバグっていて10分くらい考えてしまった。
answerB.pyimport fractions a,b,c=map(int,input().split()) d=fractions.gcd(a,b) if c%d==0: print("YES") else: print("NO")answerB_better.pyimport fractions a,b,c=map(int,input().split()) d=fractions.gcd(a,b) print("YES" if c%d==0 else "NO")C問題
Bで頭がバグったまま考えたのでさらにバグりそうになった。
こういう問題は前から貪欲に(?)数えていけばいいけど、それぞれの人が来た後にどうなっているかを正確に把握するのが大事、その時の時間と答えとして求める時間は別なので二つ変数を用意しておく。
ある人が来た時点でお湯が出ているかどうかで場合分けすれば良い。answerC.pyt=0 N,T=map(int,input().split()) nt=[int(i) for i in input().split()] ans=0 for i in range(N): if nt[i]>t: ans+=T else: ans+=(T-(t-nt[i])) t=nt[i]+T print(ans)D問題
シンプルなナップザック→DPチャンスという短絡的な思考をしました。頭が悪すぎます。
制約を見たら最大の重さが$10^9$以上になり得るのでDPで間に合うわけがありません。
よく問題を睨むと、nが極めて小さい($O(n^3)$でも余裕)なのと、重さが四通りしかないことがわかります。
つまり、同じ重さのものがいくつもあるはずなので、同じ重さの物について価値の高いものから順に選んでいくのが良いことがわかります。
さらに、n<=100よりそれぞれの重さのものをいくつ選ぶかを考えて四重ループを回しても$25^4<10^6$程度にしかならないので余裕で間に合います。(この計算量の感覚が重要)
ただし、累積和を先に考えてそれぞれの重さのものの合計をO(1)で得られるようにしておく必要があります。(C++なら累積和を考えなくても間に合いそうです。)
これを愚直に実装したものがanswerD1.pyのコードになります。
流石に可読性の低いコードであったので書き直したのがanswerD2.pyのコードになります。(四重ループを三重ループにもしています。)
しかし、書き直したもののまだ改善の余地があるので後半のforループでbreakを多用したのがanswerD3.pyになります。
ここで最速のコードにしようと努力して最終的にanswerD4.pyのようなコードにしましたが(最初のソートの部分などをかなり工夫しました。)、32msまでしかいかず26msの最速の方には届きませんでした。(コードを改善するのに二時間かけてます。きつかった。)answerD1.pyn,w=map(int,input().split()) wv=[list(map(int,input().split())) for i in range(n)] wv.sort(key=lambda x:-x[1]) wv.sort(key=lambda x:x[0]) w0=wv[0][0] x=[[0],[0],[0],[0]] for i in range(n): if wv[i][0]==w0: k=wv[i][1]+x[0][-1] l=len(x[0]) if l*w0<=w:x[0].append(k) elif wv[i][0]==w0+1: k=wv[i][1]+x[1][-1] l=len(x[1]) if l*(w0+1)<=w:x[1].append(k) elif wv[i][0]==w0+2: k=wv[i][1]+x[2][-1] l=len(x[2]) if l*(w0+2)<=w:x[2].append(k) else: k=wv[i][1]+x[3][-1] l=len(x[3]) if l*(w0+3)<=w:x[3].append(k) #print(x) ma=0 for i in range(len(x[0])): for j in range(len(x[1])): for k in range(len(x[2])): for l in range(len(x[3])): ma_sub=0 if i*w0+j*(w0+1)+k*(w0+2)+l*(w0+3)<=w: ma_sub+=x[0][i] ma_sub+=x[1][j] ma_sub+=x[2][k] ma_sub+=x[3][l] ma=max(ma,ma_sub) print(ma)answerD2.pyn,w=map(int,input().split()) wv=[list(map(int,input().split())) for i in range(n)] wv.sort(key=lambda x:-x[1])#reverse wv.sort(key=lambda x:x[0]) w0=wv[0][0] x=[[0],[0],[0],[0]] for i in range(n): z=wv[i][0]-w0 k=wv[i][1]+x[z][-1] l=len(x[z]) if l*wv[i][0]<=w: x[z].append(k) ma=0 l3=len(x[3]) l2=len(x[2]) l1=len(x[1]) for i in range(l3): for j in range(l2): for k in range(l1): d=w-(i*(w0+3)+j*(w0+2)+k*(w0+1)) if d>=0: ma_sub=x[3][i]+x[2][j]+x[1][k]+x[0][min(d//w0,len(x[0])-1)] ma=max(ma,ma_sub) print(ma)answerD3.pyn,w=map(int,input().split()) wv=[tuple(map(int,input().split())) for i in range(n)] wv.sort(key=lambda x:-x[1])#reverse wv.sort(key=lambda x:x[0]) w0=wv[0][0] x=[[0],[0],[0],[0]] for i in range(n): z=wv[i][0]-w0 k=wv[i][1]+x[z][-1] l=len(x[z]) if l*wv[i][0]<=w: x[z].append(k) #print(x) #print(w0) ma=0 l3=len(x[3]) l2=len(x[2]) l1=len(x[1]) l0=len(x[0]) for i in range(l3): for j in range(l2): d=w-i*(w0+3)-j*(w0+2) if d>=0: for k in range(l1): d=w-i*(w0+3)-j*(w0+2)-k*(w0+1) if d>=0: ma=max(ma,x[3][i]+x[2][j]+x[1][k]+x[0][min(d//w0,l0-1)]) else: break else: break print(ma)answerD4.pyn,w=map(int,input().split()) w_sub,v_sub=map(int,input().split()) w0=w_sub inf=1000000001 x=[[inf,v_sub],[inf],[inf],[inf]] for i in range(n-1): w_sub,v_sub=map(int,input().split()) z=w_sub-w0 x[z].append(v_sub) for i in range(4): x[i].sort(key=lambda x:-x) x[i][0]=0 l_sub=len(x[i]) for j in range(1,l_sub): x[i][j]+=x[i][j-1] ma=0 l3=len(x[3]) l2=len(x[2]) l1=len(x[1]) l0=len(x[0]) for i in range(l3): for j in range(l2): d=w-i*(w0+3)-j*(w0+2) if d>=0: for k in range(l1): d=w-i*(w0+3)-j*(w0+2)-k*(w0+1) if d>=0: ma=max(ma,x[3][i]+x[2][j]+x[1][k]+x[0][min(d//w0,l0-1)]) else: break else: break print(ma)

- 投稿日:2020-01-07T15:56:32+09:00
OpenCV で保存する時にエラーが出た
はじめに
学習メモです。
問題発生
OpenCVを使い始めたばかりの頃、
#ファイル読み込み img = cv2.imread('./img.jpg') ###処理### #ファイル出力 cv2.imwrite('./output', img)とすると、ファイル出力時に以下のエラーが出ました。
cv2.error: OpenCV(4.1.1) C:\projects\opencv-python\opencv\modules\imgcodecs\src\ loadsave.cpp:662: error: (-2:Unspecified error) could not find a writer for the specified extension in function 'cv::imwrite_'解決
出力時に拡張子を付け忘れていたのが原因だったようです。
#ファイル出力 cv2.imwrite('./output.jpg', img)と、拡張子を付けると無事出力できました。
ちなみに、出力は以下の形式に対応しているようです。
jpg, jpeg, jpe, jp2, png, webp, bmp, pbm, pgm, ppm, pxm, pnm, sr, ras, tiff, tif, exr, hdr, pic, dibおわりに
気づいてしまえば笑ってしまうような問題でしたが、発生した時はけっこう悩みました。
特に簡単な見落としこそ無くせるように精進していきたいです。ご覧いただきありがとうございました。
参考URL
http://blog.livedoor.jp/airyglyph0000/archives/3969423.html
http://lang.sist.chukyo-u.ac.jp/classes/OpenCV/py_tutorials/py_gui/py_image_display/py_image_display.html
- 投稿日:2020-01-07T15:21:49+09:00
No module named 'distutils.util'でget-pip.pyで使えない
解決
sudo apt-get install python3-distutils
- 投稿日:2020-01-07T14:41:05+09:00
VSCodeで自作モジュールimport時のエラー表示(unresolved import 'hoge')が消えない
はじめに
VSCodeでの開発時(Python3)、実行ファイルと同階層に配置している自作モジュールのimportエラーがどうしても解消できず、地味~にハマったので対策を共有。結論を先に書くと、単なるオートコンプリートの設定漏れでした。。。
環境設定
- Windows10(64bit)
- Visual Studio Code 1.41.1
- Python 3.7.3(64bit)
発生事象
- 実行ファイルと同階層に配置した自作クラスをimport時、「unresolved import」エラーが消えない
- 表示上はエラーが出ているが、プログラムを実行すると問題なく動作する

対策
ワークスペースの設定(settings.json)に「python.autoComplete.extraPaths」を追加、
自作モジュールがあるフォルダのPathを記述すればOK。今回の例は以下のとおり。settings.json{ "python.autoComplete.extraPaths": ["./src/get_tweet_data"] }参考記事
- 投稿日:2020-01-07T14:25:10+09:00
GCPのコンピューティングサービスの比較【サーバレスに使いたい】
概要
去年GCPを利用していて、最終的にCloud Runに行き着いた理由を示します。ここで挙げるGCPのサービスは以下の通りです。
- GAE(Google App Engine)
- GCE(Google Compute Engine)
- Cloud Functions
- Cloud Run
前提条件は以下の通り。
- アプリケーションとして管理
- 料金は安く
- サーバレス
- Pythonを使用
ここでの観点は「実装のしやすさ」「料金の安さ」「管理のしやすさ」です。ここでの管理のしやすさとは、「アプリケーションとしての管理のしやすさ」としています。結論から述べると、この観点においてCloud Runが良いのかなと思っています。Beta版であることを気にしないのであれば、これで十分だと思います(2020年1月7日現在)。
また、GKEをここで出してないのは私がコンテナ技術に疎いのと、先にCloud Runを触ったからです(ちなみにCloud Runもコンテナサービスです。私は一応以前に勉強していたので、そこそこ振り返って実装できました。ただ、初学者でも基本的にはマニュアルやブログを参考にすればそこまで実装が難しくありません)。
比較
先に比較表を載せます。完全個人的な印象です。
サービス名 GAE GCE Cloud Function Cloud Run 実装しやすさ △ × 〇 △ 料金の安さ × × 〇 〇 管理のしやすさ 〇 × △ 〇 実装のしやすさ
ここでは、「必須知識量の多さ」で比較しています。この場合、Cloud Function以外はソースコード以外に設定ファイル等が必要になります。GAEはインスタンスの発行条件、GCEはそもそもレンタルサーバ、Cloud Runはコンテナサービスなので、ソースコードのみのCloud Functionsと比べるとやや必要知識が多くなりがちです。
料金の安さ
そのままGCPの料金表を見た感じです。
GAEおよびGCEは動作時間で課金されます。GAEは発行されるインスタンス数および時間で課金されるため、設定を間違えるとパケ死のような状態になります。
Cloud FunctionsおよびCloud Runはアクセス数で課金されます。ここで、厳密にいえばCloud RunもCPUなどの使用時間で課金されますが、GAEよりも安いという記事がいくつか出ています。管理のしやすさ
これは簡単に言うと、管理時のフォルダ構成の明瞭さや設定ファイルの少なさです。Cloud Functionsは「関数一つにつき一ファイル」必要になるため、共通的に使用する自作ライブラリがあるとファイル構造が複雑化し始めます。GAEおよびCloud Runでは少なく済ませようと思えばファイルは2~3つ程度になる上、一般的なワークスペースの構造を保ちやすいです。GCEはレンタルサーバなので、こういう意味では論外ですかね。
こうしてみるとCloud FunctionsとCloud Runだとあんまり違いがないように見えますが、私の場合はコンテナについての知識が少しだけあったので、実装しやすさがあまりデメリットにならないため、Cloud Runの方を採用しています。ですが、少しマニュアルにexampleがあるので、Cloud Runで「△」にしているのも僅差のような裁定だと考えています。Cloud Functionsの真価はどちらかというと「GCPのサービスにイベント処理を追加する」という意味な気がするので、この記事で言うところの「アプリケーションとして」という観点では分が悪いように思います。
おわりに
ここで、以上のような比較をしていますが、結局のところどういう風に利用したいかによって選択すると良いと思っています。今回「サーバレス」という設定が選定の幅を狭めています。今までのオンプレをクラウド化などの用途であれば素直にGCEを使うと良かったりします。
- 投稿日:2020-01-07T13:50:32+09:00
Goの内部パッケージ関係をコミットごとに可視化する
使用したプログラム: bxcodec/go-clean-arch概要
- Goの内部パッケージの関係が複雑なプログラムは理解するのが大変
- 可視化したい
- せっかくだからコミットごとに可視化してアニメーションにしてみる
準備
コード
やったこと
- コミットログを取得
- コミットごとにコマンドを実行
- Goの内部パッケージ関係をdotファリルに出力し、gifを作成
- コミットごとのgifのサイズを揃えて、アニメーションを作成
1. コミットログを取得
git log --pretty=onelineで取得できる。
pythonでかくとres = subprocess.check_output(["git", "-C", path_dir, "log", "--pretty=oneline"])コミットのハッシュ値だけを取得したい(ハッシュ値+コメントになっている)。空白で区切って一番最初のハッシュ値だけを取得してリストにした。
2. コミットごとにコマンド実行
コミットごとにresetしてコマンドを実行した(reset以外にいい方法がある??)。
for commit in log_list: subprocess.call(["git", "-C", path_dir, "reset", "--hard", commit]) | command(path_dir)コマンドを実行するときはプログラムのあるディレクトリのパスを使用する。
3. Goの内部パッケージ関係をdotファリルに出力し、gifを作成
3.1. dotファイル作成
ここが一番難しい。
parser というとても便利なパッケージがあり、ファイル内でimportしているパッケージを取得してくれる。これをファイルごとからパッケージごとにまとめれば良い。困ったこと
- ファイルごと --> パッケージごと
parserはファイルのパッケージ名も取得してくれるが、別のディレクトリに同じパッケージ名があると区別できない。ディレクトリを保存したが、もっと簡単な方法がありそう- 外部パッケージの区別
内部パッケージ(自分で作ったもの)だけを対象にしたかったがどうやって区別すればいいか??「githubってあれば外部」みたいにしたが、あまりいい方法ではなさそう。3.2. dotファイルからgifファイル作成
graphvizを使用する。
dot -T gif sample.dot -o sample.gif4. コミットごとのgifのサイズを揃えて、アニメーションを作成
4.1. gifのサイズを揃える
アニメーションにするときファイルごとのサイズが違うと大きいサイズは切れてしまう。
mogrify -resize (width)x(height)! *.gif
指定するサイズはいい感じのを選ぶ。4.2. アニメーション作成
ImageMagickを使用する。
convert -delay 5 -loop 0 *.gif animation.gif参考にしたサイト
- Gitディレクトリ外からgitコマンドを実行する
- Pythonでsubprocessを使ってコマンドを実行する方法
- package parser
- 画像の拡大・縮小
- アニメーションGIF ImageMagick編
- st34-satoshi/for-each-commit
- st34-satoshi/call-graph
これから
コミットごとにグラフの表示位置がバラバラになってしまいアニメーションにしたとき見にくい。どうにか揃えたい。

- 投稿日:2020-01-07T12:22:44+09:00
【異常検知】深層距離学習の最新手法を使ってみる
以前に、深層距離学習を使い「画像の異常検知」を行いました。
その後、深層距離学習の最新手法「AdaCos」が登場しました。本稿では、AdaCosを「異常検知」に適用し簡単なベンチマークを行いたいと思います。
コード全体はこちら※こちらはPythonデータ分析勉強会#15の発表資料です。
結論から
AdaCosを異常検知に適用することで、以下が分かりました。
- 精度はArcFaceと同等
- パラメータのチューニングが不要になるのがありがたい
AdaCos
AdaCosは深層距離学習の最新手法といいながら、2020年1月現在、論文掲載後、半年以上も
経っています。しかし、私が知る範囲では「純粋な深層距離学習」の枠では、未だに
SOTAだと思われます。AdaCosとは、ArcFaceなどを主体にした手法であり、ArcFaceなどで用いられるパラメータを
自動的に決める手法です。ArcFaceはパラメータの選択次第で精度が劇的に変わるため、
パラメータのチューニングが非常にシビアでした。しかし、AdaCosを導入して自動的に
パラメータを決められるおかげで、このチューニング作業から解放されます。さらに、精度も上がることが確認されており、作業能率と精度が向上することから非常に
有用性の高い手法です。詳しくは、以下の記事を参考にしてください。AdaCos: Adaptively Scaling Cosine Logits for Effectively Learning Deep Face Representationsを読んだ
制約
AdaCosには、FixedとDynamicの二種類があります。
本稿で用いる手法は「Fixed AdaCos」とします。また、AdaCosはクラス数が3以上のときのみ適用できます。
これは自己教師あり学習を適用する際に、ネックになってきますが、そこの考察は
次回の記事で行います。今回行う実験はクラス数が9のため、ここは問題になりません。実験
以前に行った実験と同じ条件で実験を行います。
AdaCosのコード自体はArceFaceのものとほぼ同じです。
ただ、パラメータの与え方をAdaCos流に変更しています。コード全体はこちら
条件
- AdaCosのepochは10、最適化手法はAdam
- バッチサイズは128
- ベースモデルはMobileNet V2(学習済モデルを使用、つまり転移学習)
- 10回試行してAUCを算出
- データはFashion-MNISTとcifar-10を使用
<Fashion-MNIST>
データの内訳は以下のとおりです。
正常は「スニーカー」、異常は「ブーツ」。
個数 クラス数 備考 学習用リファレンスデータ 8000 8 スニーカーとブーツを除く 学習用正常データ 1000 1 スニーカー テストデータ(正常) 1000 1 スニーカー テストデータ(異常) 1000 1 ブーツ ※学習用リファレンスデータとは、学習用正常データと見比べるためのデータです。
<cifar-10>
データの内訳は以下のとおりです。
正常は「鹿」、異常は「馬」。
個数 クラス数 備考 学習用リファレンスデータ 8000 8 鹿と馬を除く 学習用正常データ 1000 1 鹿 テストデータ(正常) 1000 1 鹿 テストデータ(異常) 1000 1 馬 Fashion-MNISTの結果
「L2-SoftmaxLoss」と「ArcFace」は前回の実験結果を掲載しています。
「AdaCos」の結果が今回の実験結果です。「AdaCos」の中央値はArcFaceとほぼ同じAUCになりました。
やはり、パラメータチューニングが不要になっているのはありがたいです。
CIFAR-10の結果
「L2-SoftmaxLoss」と「ArcFace」は前回の実験結果を掲載しています。
「AdaCos」の結果が今回の実験結果です。Fashin-MNISTと同様に、「AdaCos」の中央値はArcFaceとほぼ同じAUCになっています。
まとめ
- AdaCosを異常検知に適用すると、ArcFaceと同等の精度が出た
- しかも、「パラメータのチューニングが不要」でありがたい
- そもそも、異常検知の性能評価では、異常データが非常に少ない状況が考えられ、その状況下でパラメータチューニング用のデータを捻出しなければならない状況が避けられると思うと、非常に有用性の高い手法と思われる。
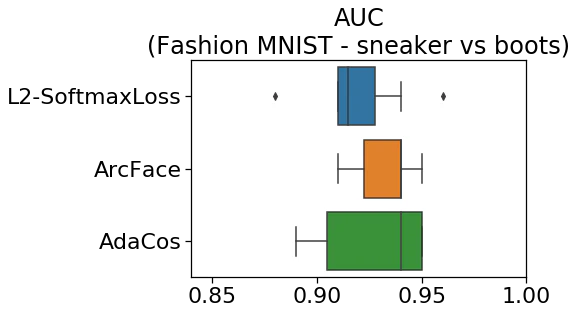

- 投稿日:2020-01-07T11:22:47+09:00
[Hyperledger Iroha]Python SDKの使い方メモ
記事の内容
Hyperledger IrohaのPython SDKを使って、
・Assetの作成
・Assetの送信
・ブロック情報の取得
を行ってみます。前提
・irohaの公式ガイドに従って環境構築が出来ていること
・Python3が使える環境であること参考
Iroha Python Libraryドキュメント
https://iroha.readthedocs.io/en/latest/develop/libraries/python.htmlこのページのExample CodeはAssetの送信から書かれているので、事前にAssetの作成をしておかないと動きません。
そのコードもこの記事ではPythonを使ってやってみます。Assetの作成
CreateAsset.pyfrom iroha import Iroha, IrohaCrypto, IrohaGrpc net = IrohaGrpc('Host IP Address:50051') iroha = Iroha('admin@test') admin_priv_key = 'Admin Private Key' # 一行前に指定したアカウントのPrivate Key # Transactionの作成 create_asset_tx = iroha.transaction( [iroha.command( 'CreateAsset', # Assetの作成 asset_name = 'samplecoin', domain_id = 'test', precision = 10 ), iroha.command( 'AddAssetQuantity', # Assetの初期保有量の設定 asset_id = 'samplecoin#test', amount = '100000000' )] ) # Transactionへ署名 IrohaCrypto.sign_transaction(create_asset_tx, admin_priv_key) # Transactionの送信 net.send_tx(create_asset_tx) # 結果の確認 for status in net.tx_status_stream(create_asset_tx): print(status)このコードでは、「admin@test」アカウントでAssetの作成を行い、「admin@test」アカウントが保有するAssetの量を設定しています。
処理の流れはTransactionの作成→署名→送信→結果の確認という流れになっています。
正常に実行されれば以下の結果になると思います。
('ENOUGH_SIGNATURES_COLLECTED', 9, 0) ('STATEFUL_VALIDATION_SUCCESS', 3, 0) ('COMMITTED', 5, 0)irohaコンテナの「/tmp/block_store」ディレクトリ配下にブロックが追加されています。
{ "blockV1": { "payload": { "transactions": [ { "payload": { "reducedPayload": { "commands": [ { "createAsset": { "assetName": "samplecoin", "domainId": "test", "precision": 10 } }, { "addAssetQuantity": { "assetId": "samplecoin#test", "amount": "100000000" } } ], "creatorAccountId": "admin@test", "createdTime": "1578361629026", "quorum": 1 } }, "signatures": [ { "publicKey": "313a07e6384776ed95447710d15e59148473ccfc052a681317a72a69f2a49910", "signature": "a414d71e6b2022a81d375d2a367827800a072b465ace7e919c23336b572e5c7511854c2abcff08736d6a687e261a21e1121180f561b8e18729a0fdeaffbbc401" } ] } ], "height": "2", "prevBlockHash": "9debdb1a70db2cede2222427b849f6bf7ab20845da7c3db1837c0df25ec1c61a", "createdTime": "1578361629022" }, "signatures": [ { "publicKey": "bddd58404d1315e0eb27902c5d7c8eb0602c16238f005773df406bc191308929", "signature": "20a900f3587ccdadcb128a6d597cd0406e90882cbc9b12017c938d4f0c4a4cd6bd6cd09b674289c5146f1026bfdfc33a922a6cb925429db29e49605ffc392c09" } ] } }Assetの送信
ここのコードは上述の参考に記載した公式ドキュメントに書かれてあるコードのままです。
TransferAsset.pyfrom iroha import Iroha, IrohaCrypto, IrohaGrpc net = IrohaGrpc('Host IP Address:50051') iroha = Iroha('admin@test') admin_priv_key = 'Admin Private Key' # 一行前に指定したアカウントのPrivate Key # Transactionの作成 transfer_asset_tx = iroha.transaction( [iroha.command( 'TransferAsset', src_account_id='admin@test', dest_account_id='test@test', asset_id='samplecoin#test', description='test', amount='10000' )] ) # Transactionの署名 IrohaCrypto.sign_transaction(transfer_asset_tx, admin_priv_key) # Transactionの送信 net.send_tx(transfer_asset_tx) # 結果の確認 for status in net.tx_status_stream(transfer_asset_tx): print(status)送信元アカウント(src_account_id)、送信先アカウント(dest_account_id)、アセットID(asset_name # domain_id)を環境に合わせて修正します。
正常に実行されれば以下の結果になると思います。
('ENOUGH_SIGNATURES_COLLECTED', 9, 0) ('STATEFUL_VALIDATION_SUCCESS', 3, 0) ('COMMITTED', 5, 0)irohaコンテナの「/tmp/block_store」ディレクトリ配下にブロックが追加されています。
{ "blockV1": { "payload": { "transactions": [ { "payload": { "reducedPayload": { "commands": [ { "transferAsset": { "srcAccountId": "admin@test", "destAccountId": "test@test", "assetId": "samplecoin#test", "description": "test", "amount": "10000" } } ], "creatorAccountId": "admin@test", "createdTime": "1578362174344", "quorum": 1 } }, "signatures": [ { "publicKey": "313a07e6384776ed95447710d15e59148473ccfc052a681317a72a69f2a49910", "signature": "7bf5bec8110cbe618b05cd3bf8b69d0eb1e6e2eb4f3efcc41d0573b8e3638bc220b49c251c0f3238bb753d85d4b7a3e032f420f5c0e4f0e8fe18a72c9ec0800e" } ] } ], "height": "3", "prevBlockHash": "ac0f2ad5cdbea3c6cd8eb0e4e1b7679b595a9c26ddda1acc75a5ff031abf9c91", "createdTime": "1578362175915" }, "signatures": [ { "publicKey": "bddd58404d1315e0eb27902c5d7c8eb0602c16238f005773df406bc191308929", "signature": "507a96cbb0ac99fada62cf36097204fc166a4635b70e68b9c87d007300ca0f7b231f4787cc9fe8751cc640a9cf2b7c161cc0bedb31e606363d4c18256268660f" } ] } }Block情報の取得
Block情報の取得はこれまでと少しコードが変わります。
GetBlock.pyfrom iroha import Iroha, IrohaCrypto, IrohaGrpc net = IrohaGrpc('Host IP Address:50051') iroha = Iroha('admin@test') admin_priv_key = 'Admin Private Key' # 一行前に指定したアカウントのPrivate Key # Queryの作成 get_block_query = iroha.query( 'GetBlock', height = 3 # 取得するBlock Height(番号)を指定する ) # Queryへ署名 IrohaCrypto.sign_query(get_block_query, admin_priv_key) # Queryの送信 response = net.send_query(get_block_query) # Responseの出力 print(response)やってることはQueryの作成→署名→送信→結果の確認なのでTransactionの送信と変わりません。
少し使うFunctionが変わってきます。実行結果
query_hash: "eb7035cdde49e26f2271b7991933a5eb8321f1a3176014a73f53a1c86d91b8bc" block_response { block { block_v1 { payload { transactions { payload { reduced_payload { commands { transfer_asset { src_account_id: "admin@test" dest_account_id: "test@test" asset_id: "samplecoin#test" description: "test" amount: "10000" } } creator_account_id: "admin@test" created_time: 1578362174344 quorum: 1 } } signatures { public_key: "313a07e6384776ed95447710d15e59148473ccfc052a681317a72a69f2a49910" signature: "7bf5bec8110cbe618b05cd3bf8b69d0eb1e6e2eb4f3efcc41d0573b8e3638bc220b49c251c0f3238bb753d85d4b7a3e032f420f5c0e4f0e8fe18a72c9ec0800e" } } height: 3 prev_block_hash: "ac0f2ad5cdbea3c6cd8eb0e4e1b7679b595a9c26ddda1acc75a5ff031abf9c91" created_time: 1578362175915 } signatures { public_key: "bddd58404d1315e0eb27902c5d7c8eb0602c16238f005773df406bc191308929" signature: "507a96cbb0ac99fada62cf36097204fc166a4635b70e68b9c87d007300ca0f7b231f4787cc9fe8751cc640a9cf2b7c161cc0bedb31e606363d4c18256268660f" } } } }Block Height(番号)が3の情報を取得できました。
ドキュメントを読んでる限りだと、最新のBlockを取得する、最新のBlock Height(番号)を取得するというライブラリは用意されてなさそうです。
上記のコードでqueryの「height」を指定すると必須項目未入力でエラーになりました。感想
IrohaのJava SDKを使ってみるという記事も書きましたが、Python初心者の私でも断然Pythonの方が楽に使えました。
コマンドの組み立て方も公式ドキュメントのAPIページに詳細が書かれているので割と分かり易いです。公式ドキュメント
https://iroha.readthedocs.io/en/latest/develop/api.html
- 投稿日:2020-01-07T09:44:56+09:00
PyTorchで学ぶGraph Convolutional Networks
PyTorchで学ぶGraph Convolutional Networks
この記事では近年グラフ構造をうまくベクトル化(埋め込み)できるニューラルネットワークとして、急速に注目されているGCNとGCNを簡単に使用できるライブラリPyTorch Geometricについて説明する。応用分野は生物学から、渋滞予測、レコメンダーシステムまで幅広い。
本記事はGCN生みの親のブログ記事とPyTorch Geometricの公式チュートリアルをかなり参考にしております。読んで少しでも何か学べたと思えたら 「いいね」 や 「コメント」 をもらえるとこれからの励みになります!よろしくお願いします!
1. Graph Convolutional Networksとは?
1.1 そもそもグラフとは?
ノードとエッジで定義される。折れ線グラフやヒストグラムといった類のグラフではないことに注意。具体例では、Facebookの友達関係(人がノードで友人関係がエッジ)や酵素の構造(原子がノードで結合関係がエッジ)など。(ここでは重みなし無向グラフとします。)
それぞれがそれぞれの特性を持つ。
またグラフは数学的に行列で表すことができ、このGCNでは隣接行列と特徴行列の2つを用いる。
- 隣接行列: ノードとノードの結合関係を表す行列
- 特徴行列: 各ノードの特徴ベクトルを表す行列
先ほどの図の例を隣接行列と特徴行列で表すと以下になる。
オレンジ色の文字が各ノードを表す。例えば、隣接行列において1行目の3列目はノードaとノードcが接続されているため1が入っている。特徴行列は $x_1, x_2$ がそれぞれ特徴を示している。
1.2 GCNとは?
1.2.1 概要
GCN(=Graph Neural Networks)とはグラフ構造をしっかりと加味しながら、各ノードを数値化(ベクトル化、埋め込み)するために作られたニューラルネットワーク。
GCNのゴールは 各ノードを構造を加味して数値化する というところにある。
ここで、構造を加味しながらというのはつまり いま注目しているノード(数値化したいノード)がどういったノードとくっついているかを加味しながら 数値化していくと言える。
具体的にノードcについて考えると以下の図。
同様に他のノードに対しても色付けを行うと以下の図。
これを全ノードに対して行う。
GCNは一言で言えば、あるノードの隣接たちを見て埋め込むネットワーク と言える。GCNは2種類の行列を入力とし、1つの行列を出力する。
- 入力
- 隣接行列 $\mathbf{A} \in \mathbb{R}^{n\times n}$ : どのノードとどのノードが繋がっているかを表す行列。
- 特徴行列 $\mathbf{F}_{in} \in \mathbb{R}^{n\times |F|}$: 各ノードの特徴ベクトルを表す行列。
- 出力
- 潜在行列 $\mathbf{H}_{out} \in \mathbb{R}^{n\times |H|}$: 各ノードの潜在表現ベクトルを表す行列。(GCNによる変換済)
1.2.2 数式
早速だが、GCNを数式で表すと以下になる。
$$
\mathbf{H}^{(l+1)} = f(\mathbf{H}^{(l)}, \mathbf{A})
$$
ただし、$H^{(0)}=X$ である。これでGCN自体の定義は終わりなのだが、ちょっと意味がわからないので具体例で見てみる。
ここで活性化関数をReLUとした1層のGCNを例にとってみる。先ほどのGCNの図を再掲する。ここで活性化関数はReLUが使われていると仮定している。
これを数式で表すと、
$$
f(H^{(0)}, A) = f(X, A) = \mathrm{ReLU}(AX\cdot W)
$$となる。$W$ は通常のニューラルネットワークと同じく、重みである。 $A, X$ はそれぞれ隣接行列および特徴行列(入力)である。ここで $AX$の意味について考えてみよう 。
これは実際にAXを計算してみるとわかるのでやってみる。
再び以下のグラフを使う。
$AX$ を計算してみる。以下の図で隣接行列が1となっているところだけ色付けした。
たとえば、ノードcの計算結果を見てみると、隣接しているaとbの元々の特徴量を足し合わせた得られていることがわかる。
このことから、$AX$ つまり 隣接行列 $\times$ 特徴行列はあるノードと繋がっているノードたちの特徴量を足し算したもの であることがわかる。$AX$によって周りのノードたちを考慮した特徴量を獲得でき、あとはそれに通常のニューラルネットワークのように重み$W$を掛け算し、非線形の活性化関数 $\mathrm{ReLU}$ を適用しているだけである。現時点である程度強いのだが、実は問題点が2つある。その2つを解決したものこそが一般的に使われているGCNである。それでは問題点とその解決方法を見ていこう。
1.2.3 問題点と解決方法
1. 自身ノードの情報が入っていない。(近傍ノードの情報のみ)
2. $AX$ の行列の乗算のせいで 各ノードごとにスケールが大きく異なってしまう。この2つの問題点を解決する方法はいたって簡単。
1. 隣接行列$A$に単位行列$I$を足して $\hat{A}=A+I$ とすることで自身ノードの情報も加える。ここで$I$とは対角成分が1でそれ以外0の行列のこと。
2. 隣接行列 $\hat{A}$ を $\hat{D}^{-\frac{1}{2}}\hat{A}\hat{D}^{-\frac{1}{2}}$ として正規化。つまり各行の合計値を1としている。ここで、$\hat{D}$ は $\hat{A}$ の次数行列。次数行列とは、対角成分が各ノードの次数でそれ以外0の行列のこと。こうして最終的なGCNの式は以下の式となる。
$$
f(H^{(0)}, A) = \mathrm{ReLU}(\hat{D}^{-\frac{1}{2}}\hat{A}\hat{D}^{-\frac{1}{2}}X\cdot W)
$$1.3 GCNの例
上の式で実現されたGCNを使って、複雑ネットワーク界隈のMNIST的存在である空手クラブネットワーク(Zachary (1977))の各ノードをベクトル空間に埋め込んでみる。まずは元々のネットワークは以下の図。ノードが空手クラブの部員、エッジが友人関係を示している。
Image Credit: Kipf, T. et al. (2017)
同一色は同一クラスターを表しており、4つのクラスターがあることがわかる。これを3層GCNを使って各ノードを二次元空間に埋め込んだ結果が以下。同じクラスター同士は近く、異なるクラスター同士は遠くに埋め込まれており、うまくいっている ことがわかる。
Image Credit: Kipf, T. et al. (2017)
1.4 なぜGCNがうまくいくのか。
ここは主題であるPyTorch Geometricから離れてしまうので、詳しくは参考文献を当たって欲しいが簡単にだけ説明すると、GCNは、Weisfeiler-Lehmanアルゴリズムに①パラメータを持たせ、②微分可能性を追加した特殊ケースと捉えることができるため うまくいっていると考えられる。
(Weisfeiler-Lehmanアルゴリズムではノードの潜在表現は $\mathrm{hash}(AX)$ という任意のハッシュ関数を用いて獲得するが、GCNでは $\mathrm{ReLU}(\hat{D}^{-\frac{1}{2}}\hat{A}\hat{D}^{-\frac{1}{2}}X\cdot W)$ というパラメトリックでかつ微分可能な関数を用いていると考えられる。)
2. GCNを使ってみよう
PyTorch Geometric(PyG)で実際にGCNに触れてみる。PyGのチュートリアルを順にやっていく。
ノートブックを日本語のコメント豊富にこちらのGithubにあげましたのでお手元で実行しながらお読みいただければ、より理解が深まるかと思います。ここでは インストール と実際に GCNレイヤーを使う ところのみ紹介。より詳しいデータの準備などはGithub先のノートブックを参照してください。
2.1 PyGのインストール
pytorchのバージョンが1.2.0以上であることを確かめてください。pytorchが入っていなければ
$ pip install torchでインストールしましょう。
$ python -c "import torch; print(torch.__version__)" >>> 1.2.0続いてPyTorch Geometricをインストールしてみましょう。
$ pip install --verbose --no-cache-dir torch-scatter $ pip install --verbose --no-cache-dir torch-sparse $ pip install --verbose --no-cache-dir torch-cluster $ pip install --verbose --no-cache-dir torch-spline-conv (optional) $ pip install torch-geometric2.2 グラフデータ
PyGにベンチマーク的なデータセットは用意されているので、今回は 論文の被引用ネットワークを示すCoraデータセット を使う。Coraは2708もの論文を含み、それぞれの論文が7つのクラスに分けられている。このデータセットを使って、各ノード(論文)のカテゴリを予測 する。
from torch_geometric.datasets import Planetoid dataset = Planetoid(root='/tmp/Cora', name='Cora')2.3 GCNレイヤーを使ってみる。
基本的にPyTorchと同じ記法なので、PyTorchを触ったことある方なら特に問題はないかもしれない。PyTorchがわからない場合は公式チュートリアル(英語)がわかりやすい。
NetクラスにNNの構造とforwardメソッドを記入。その中で単純に
GCNConvを呼び出すだけ。import torch import torch.nn.functional as F from torch_geometric.nn import GCNConv class Net(torch.nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = GCNConv(dataset.num_node_features, 16) self.conv2 = GCNConv(16, dataset.num_classes) def forward(self, data): x, edge_index = data.x, data.edge_index x = self.conv1(x, edge_index) x = F.relu(x) x = F.dropout(x, training=self.training) x = self.conv2(x, edge_index) return F.log_softmax(x, dim=1)2.4 GCNの学習
学習はPyTorchといたって同じだが、念のため丁寧に触れておく。
学習の時の手順は以下の5つをエポック回だけ繰り返す。つまり、
1. 勾配初期化
2. 予測値
3. 損失
4. バックプロップ
5. 更新で、コードで書けば、
1.optimizer.zero_grad()
2.output=model(input)
3.loss=Loss(output, target)
4.loss.backward()
5.optimizer.step()device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model = Net().to(device) data = dataset[0].to(device) optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4) model.train() #モデルを訓練モードにする。 for epoch in range(200): optimizer.zero_grad() out = model(data) loss = F.nll_loss(out[data.train_mask], data.y[data.train_mask]) loss.backward() optimizer.step()これにて学習が完成する。
2.5 評価
model.eval() #モデルを評価モードにする。 _, pred = model(data).max(dim=1) correct = float(pred[data.test_mask].eq(data.y[data.test_mask]).sum().item()) acc = correct / data.test_mask.sum().item() print('Acc: {:.4f}' .format(acc)) >>> Accuracy: 0.8150これで評価までできた。
このような簡単なネットワークでもノードのクラスをうまく推測できていることがわかる。もっと詳しくはノートブックをご参照ください。
3. まとめと所感
GCNの簡単な説明とPyTorch Geometricの簡単な使い方について紹介した。
さらなる可能性を秘めているであろうGCNについてこれからも注目していきたい。読んで少しでも何か学べたと思えたら 「いいね」 や 「コメント」 をもらえるとこれからの励みになります!よろしくお願いします!
4. 参考
Kipf, T. et al. "Semi-Supervised Classification with Graph Convolutional Networks" (2017)
(論文) 現在広く使われるGCNの原型となる論文.PyTorch Geometric Documentation
(英語)PyTorch Geometricの公式ドキュメントGRAPH CONVOLUTIONAL NETWORKS
(英語) GCN生みの親のブログ記事。とてつもなく参考にしています。半教師あり学習_Semi-Supervised Learning (Vol.20)
半教師あり学習についてわかりやすくまとめてくれている。
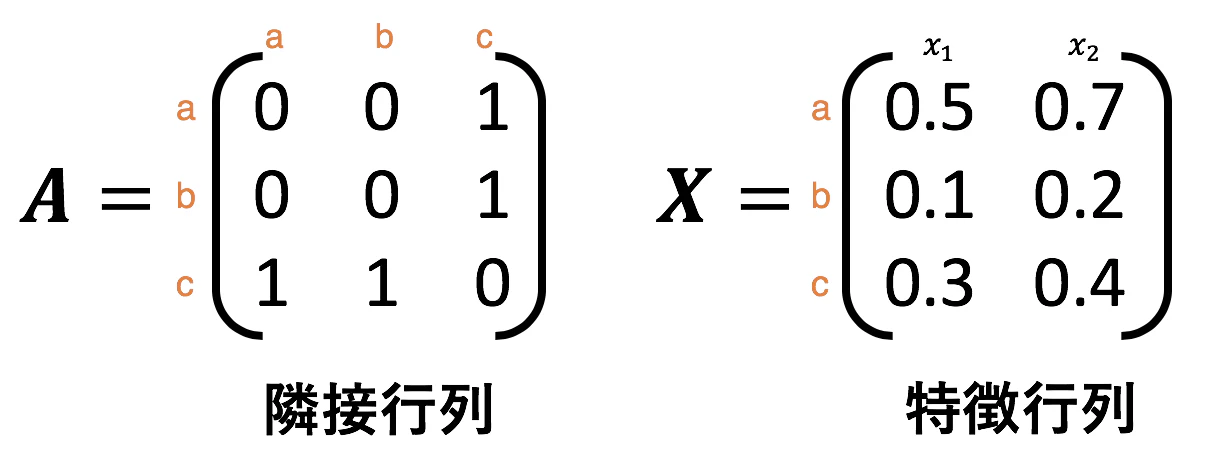

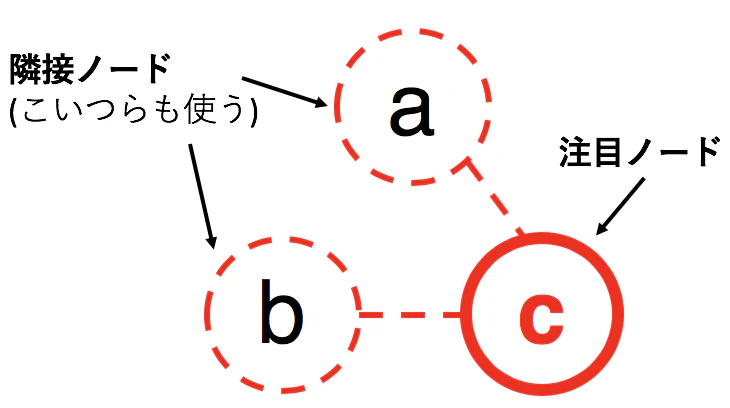
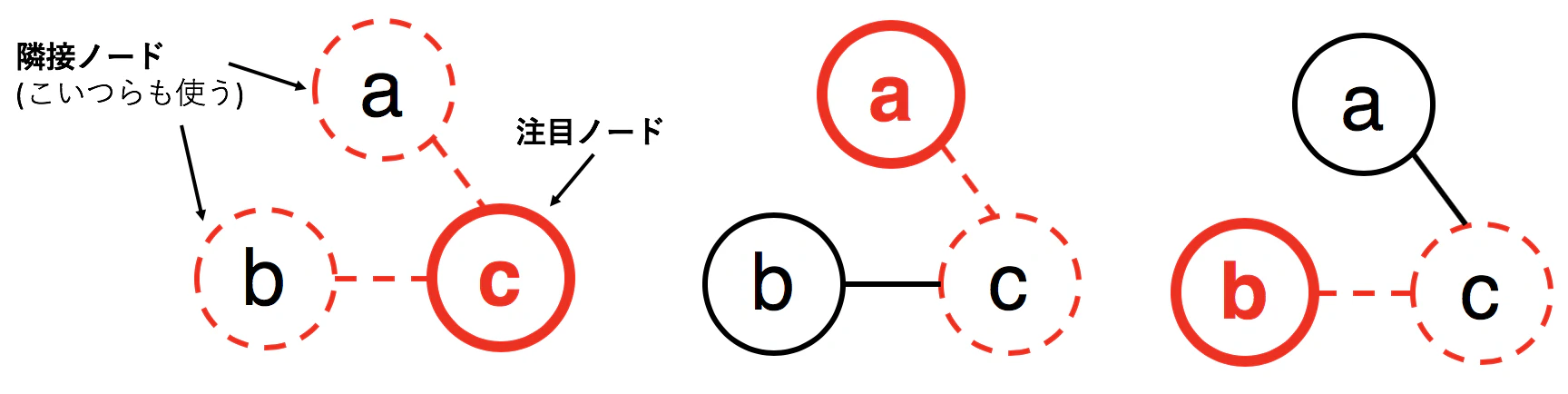
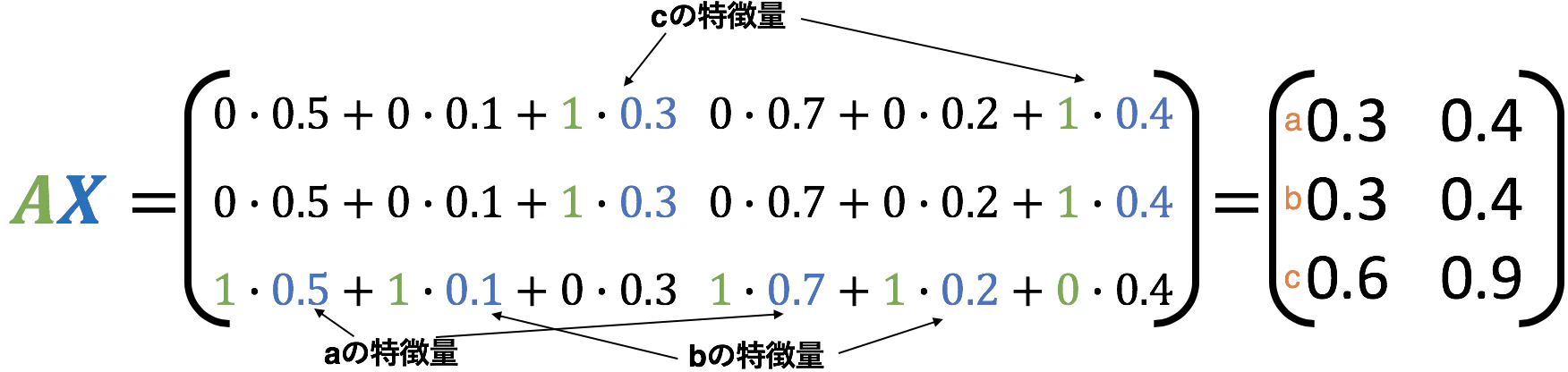

- 投稿日:2020-01-07T09:33:57+09:00
pythonで九九表を表示する方法
pythonで九九表を表示する方法
pythonの学習の為に九九表を作成しました。
コードは下記の通りです。
main.pydef multiplicationTable(): for a in range(1,10): for b in range(1,10): ans = str(a * b) result = ans.rjust(4) print(result,end=" ") print('') if __name__ == "__main__": multiplicationTable()rjsutメソッドでインデントを揃えています。
terminal1 2 3 4 5 6 7 8 9 2 4 6 8 10 12 14 16 18 3 6 9 12 15 18 21 24 27 4 8 12 16 20 24 28 32 36 5 10 15 20 25 30 35 40 45 6 12 18 24 30 36 42 48 54 7 14 21 28 35 42 49 56 63 8 16 24 32 40 48 56 64 72 9 18 27 36 45 54 63 72 81
- 投稿日:2020-01-07T02:22:02+09:00
M5Stick VをuPyLoaderで動かす時のメモ
概要
M5Stick Vにファイルを入れるやり方を調べたのでメモとして書きます。
行う処理は、今回は簡単に「Hello World」と文字列を出力させていきます。
こちらのリンクの回と同じ処理です。↓
M5Stick Vで「Hello World」を出力するまでの最短ステップ(リンク)準備
使用するPC: MacBook Air
M5Stick V本体
USB Type-CケーブルuPyLoaderをダウンロード
こちらのGithubのリンクからダウンロードします↓
GithubのリンクmacOSの方は0.1.3が最新です。
M5Stick Vと接続する。
USB Type-Cケーブルを使いPC本体と接続します。
次に上でインストールしたuPyLoaderを起動します。
左側がローカルのフォルダ、右側がリモートで繋いでいる先のフォルダです。
M5Stick Vをコネクトしていきます。コネクトする際の注意!
uPyLoaderとM5Stick Vをコネクトする際は、M5Stick V本体のボタンAを長押ししながらコネクトボタンを押します。
そうすることで、M5Stick Vの起動時に行われるbootファイルの実行を回避することができます。
こちらエラーみたいに見えますが、接続成功した時にでるポップアップだそうです。
こちらの情報は、Switch ScienseのM5Stick V購入ページにも記載されています。ファイルを転送する前に
接続したら、ファイルを転送していくのですが、その前に環境を整えます。
Fileからinit trasfer filesを実行します。
すると、右側のM5Stick Vのフォルダに「__download.py」と「__upload.py」というファイルが転送されているかと思います。これで準備完了です。お好きなコードエディタで、
「helloworld.py」などと適当なフォルダ名でファイルを作りましたら、それをuPyLoaderの左側の画面で選択していきます。。ちなみに、今回のファイル(helloworld.py)の中身は以下のようなコードです。
import lcd lcd.init() lcd.draw_string(100, 100, "hello world", lcd.RED, lcd.BLACK)
このように選択しましたら、「Transfer」というボタンを押します。
分かりにくいですが、画面の下の方にあります。
これで、ファイルを転送できたかと思います。そして、実行していきます。
こちらの「Execute」ボタンで実行することができます。
このような画面が確認できるかと思います。
おまけ
また、uPyLoader上で転送したファイルを編集することもできます。
ファイルを選択し、もう一度クリックすると編集画面が開きます。
こちらが編集画面になります。



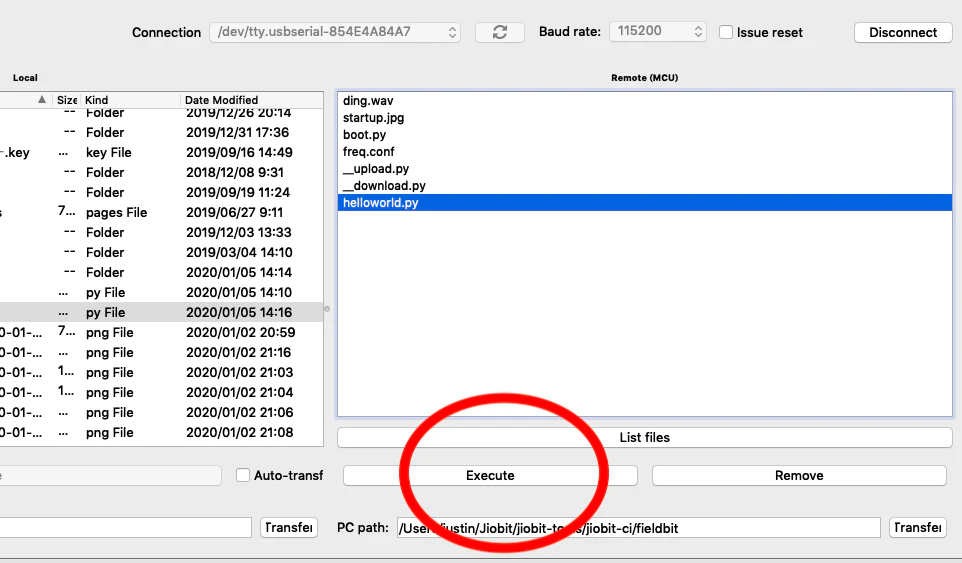

- 投稿日:2020-01-07T01:35:14+09:00
"素人銀行員"が1週間でPython 3 エンジニア認定基礎試験に合格した方法
Python3エンジニア認定基礎試験について、Qiitaにはエンジニアの方が「簡単だぜ」というトーンでマウントした記事が多いと感じたので、非エンジニアの方に役に立てばと思い書きました
プログラミング初心者が試験の合格だけを目的に「成功談」「失敗談」を簡潔に書きます
私のスペック
・プログラミングを普段しない銀行員
・新入社員研修で、COBOLを3か月ほど学んだが挫折。以後、触らず。試験結果
・750点/1000点(合格点700点:合格率7~8割)
・勉強期間は、年末年始の7日×3時間理想の勉強方法
0)Pythonのインストール(私はjupyter notebookをインストールしました)【0.5h】
1)試験範囲の確認【0.1h】
試験概要や出題問題数に目を通しましょう
https://www.pythonic-exam.com/exam/basic2)Webで超基礎を学習(WEB INTO DIVE)【5h】
必ず、手を動かしながらPythonで色々なパターンを実行しながら進めるのが重要です
https://exam.diveintocode.jp/exam3)模擬試験+復習【5h】
早い段階で模擬試験を一回解くのが重要です。やらなくて良いことが何かここで抑えましょう。
https://exam.diveintocode.jp/exam〇、×どちらも内容が理解できるまで、以下のサイト等を参考に復習しまくりましょう。
https://qiita.com/Lily0727K/items/87304160e09aff5e8a184)Pythonチュートリアル流し読み【5h】
いきなり読むと嫌気がさすので、概要が纏めてある以下リンクを読みます
https://qiita.com/R1ck29/items/17f8bcf70feb2c3d516cいよいよチュートリアルを一読しますが、すべての理解は不要です。
模擬試験で出た内容が書いてある箇所の前後をチェックしていく感覚で十分です5)Pythonチュートリアル復習&模擬試験2回目【5h】
チュートリアルの重点ポイントを出題数と重ね絞ります。
1,2,3,4,5,8,10,12,14章がコスパが良いので、ここを中心に勉強します模擬試験2回目を受験し、復習をして対策完了です!!
私がしてしまった勉強方法(失敗談含む)
1)Pythonチュートリアルから読む
難しすぎて最初の2ページで本棚行き。"素人は絶対に最初に手を出さないでください!!"
2)Pythonスタートブック(辻真吾 著)
初心者向けの名著ですが、範囲が広すぎて試験対策には不向き。
「8章関数を作る」で難しく挫折・・・
ただ、プログラミング初心者が「クラスって何?」とかの感触を掴みたいということであれば、1章~3章だけ勉強するのはあり。
試験中に思ったこと
・問題のイマイチ良く分からなくても、選択肢から消去法で結構絞れる(明らかに違う回答が混在)
・7割程度、模擬試験と類似の問題(まるっきり同じ問題はなしなので、内容の理解は必要)
・時間は余る、見直し込みでも30分あれば十分(試験時間は60分)(余談)私がこれから目指すこと
・ビジネス目線で、AI/人工知能の案件企画・組織作りを実施しています。中身も知らないと、伸びしろに限界があると感じているので以下の勉強を継続したいと思います。
2019年度4Q:「udemy 実践Pythonデータサイエンス」「kaggle参加」「AWS関連の資格」
2020年度:「ディープラーニングE検定」
Facebook友達申請、フォロー
https://www.facebook.com/profile.php?id=100003256287953
人口知能×金融事業のコミュニティ(主催)のフォロー よろしくお願いします
- 投稿日:2020-01-07T00:56:10+09:00
【Python】ヘロンの公式の関数化と面積の最大値の算出
三角形の3辺をx, y, zと定義し、x + y + z = L(定数)とする。Lを一定にしたとき、三角形の面積を最大にする三角形がどんなものか答えよ。
という課題が学校から出されました。
本来ならこれを数学的に解くことが必要となりますが、私はこの問題を見た瞬間。
「プログラムで証明した方が自明でわかりやすくないか」
そう考えました。
なので今回はPythonでヘロンの公式の関数を作成し、whileループによって証明しようと考えました。ヘロンの公式
面積 = \sqrt{s(s-x)(s-y)(s-z)}\\ s= \frac{x+y+z}{2}まずはヘロンの公式を関数化していきます。
ヘロンの公式の関数化
def heron(a, b, c): x, y, z = float(a), float(b), float(c) s = (x + y + z) / 2 if x+y>z and y+z>x and z+x>y: return (s * (s - x) * (s - y) * (s - z)) ** 0.5 #ヘロンの公式 else: return 0 if __name__ == '__main__': x = input('xの値 : ') y = input('yの値 : ') z = input('zの値 : ') print(heron(x, y, z))これでヘロンの公式を関数化することができました。
if文では、三角形が成り立つ場合と成り立たない場合で条件分岐しています。
成り立つ場合はヘロンの公式の計算結果を返し、成り立たない場合は0を返すようにしています。
input文を関数に入れても良いのですが、引数として代入した方がマルチに対応できると感じたので入れませんでした。
~~ # 面積の最大値の算出
3辺の長さの合計Lを一定にした時の面積が最大となる三角形の形は何か。
ということを考えるにあたって、人間がまず考えるのは総当たりですよね。
しかしこの膨大な計算を人間がするのは不可能ではないですがとてつもなく困難です。
ならどうするか。コンピュータにやらせれば良い。という考えに至るわけです。
ソースコード
import random def heron(a, b, c): # ヘロンの公式 x, y, z = float(a), float(b), float(c) s = (x + y + z) / 2 if x+y>z and y+z>x and z+x>y: return (s * (s - x) * (s - y) * (s - z)) ** 0.5 else: return 0 if __name__ == '__main__': s = 0 i = 0 while i < 20000000: x = random.randint(1, 120) #変更可能 y = random.randint(1, 120) #変更可能 z = random.randint(1, 120) #変更可能 if (x+y+z) == 120.0: #辺の合計が120 if heron(x, y, z) > s: s = heron(x, y, z) print('x={}, y={}, z={}で面積s={}'.format(x, y, z, s)) else: continue i += 1 else: i += 1
ここでは乱数を使用する為に、ライブラリ関数のrandomをインポートしてきます。
今回は3辺の長さの合計を120に設定しています。なぜ120なのかは後に説明します。
randint(a, b)
randint()ではa以上b以下の整数の乱数を返します。
実数値の乱数を使いたい時は,uniform(a, b)を使用します。
1~120の整数の乱数を3種類返すので、単純計算で120の3乗の1728000回ループしなければなりません。
念のため今回は200万回ループしています。
最大値が更新されるたびに出力する様にしており、最後に出力されたものがこの三角形の面積の最大値となっています。 ~~結果
結果を先に言うと、正三角形が最大値をとります。
3辺の長さの合計を120にしたのも、x=40, y=40, z=40という結果を期待していたからです。
実際にソースコードを実行しても同じ結果が得られるはずです。
値を変えてみても、「(3辺の長さの合計)/ 3」が成り立つならば、x=y=zとなるはずです。