- 投稿日:2020-01-07T23:24:45+09:00
気付いたらAWSの無料枠が終了していた!(無料枠からスポットインスタンスへの移行)
要約
AWSのEC2無料枠が終わったことに気づいたので、使用料金を下げるためにスポットインスタンスに移行した話です。
いまさらの二番煎じ感ありますが、、、起きたこと
- AWSの無料枠の範囲内でWordpressを運用していたつもりが、ある日突然50円/日くらい課金されていることに気づく。
- AWSのインスタンスの無料使用枠が12ヶ月間限定だということを失念しており、無料期間が終わっていた模様。
やったこと
- そのまま運用すると、1500円/月。自己満足のブログには高い。
- EC2インスタンスをスポットインスタンスに移行することで、400円/月(想定)あたりまで料金を下げた
ポイント
- インスタンスの移行は本当に一瞬で終わる。すごい。
そもそもAWS無料枠とは?スポットインスタンスとは?
AWS無料枠
AWS のプラットフォーム、製品、サービスを無料で実際に体験できます。
上記の通り、AWSのサービスの一部を無料で使用できる、ということです。
私はてっきり、条件さえ気をつけていれば、無限に無料で使えるものと思い、Amazonさんすごいなぁ、とか思っていたのですが...オファーの種類
60 を超える製品から選んで、無料利用枠で実際に AWS に構築してください。ご使用の製品によって、3 種類の無料オファーがご利用いただけます。
無期限無料
これらの無料利用枠に有効期限はなく、AWSのお客様すべてが利用可能
12か月間無料
AWSへの最初のサインアップ日から12か月間無料で利用可能
トライアル
さまざまなソフトウェアソリューションが、短期間の無料トラアイルとして利用可能しっかり記載されている通り、全てが無料なわけではなく、一部はAWSへの最初のサインアップ日から12か月間無料で利用可能なんですね。
ちなみに、Wordpress運用のために使用していたEC2はというと...コンピューティング
無料利用枠
12 か月間無料
Amazon EC2
750 時間はい、1年間でした。いつの間にか1年経ってたんですね。。ブログを作ったり消したり繰り返していたこともあり、全く気づきませんでした。
スポットインスタンスとは
参考:AWS公式 Amazon EC2 スポットインスタンス
耐障害性を備えたワークロードを最大 90% OFF で実行
上記の通り、通常のインスタンスよりも安く使えます。
すごくざっくりとした説明ですが
- その時々の需要によって使用料金が決まる(通常は安くなる)
- 最大支払う料金を決めておくことで、予想外に高い使用料金で使用することを防げる
- その代わり、設定しておいた最大料金を上回る料金になった時、インスタンスが停止してしまう
という感じです。
最大支払う料金を上げておけば止まりにくくはなりますが、100%止まらない、というものにはできません。
個人運用レベルで、サービスレベルを気にしないならこっちを選んでおけば良いと考えています。通常インスタンスからスポットインスタンスへの移行手順
バックアップ(AMI)の作成
まずは既存のインスタンスのバックアップを作成します。
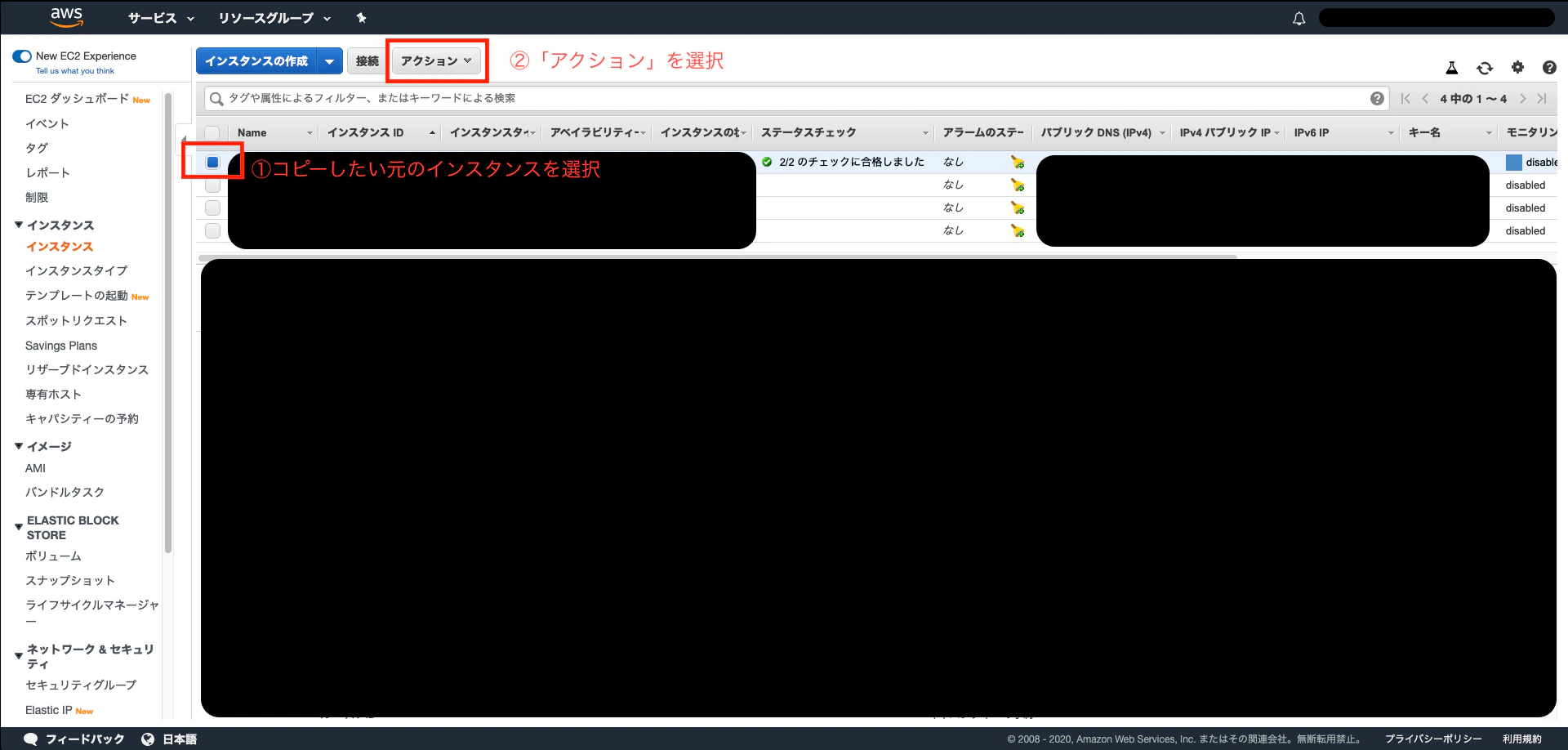
⓪AWSコンソールの「インスタンス」から
①コピーしたい、元のインスタンスを選択します
②「アクション」を選択します
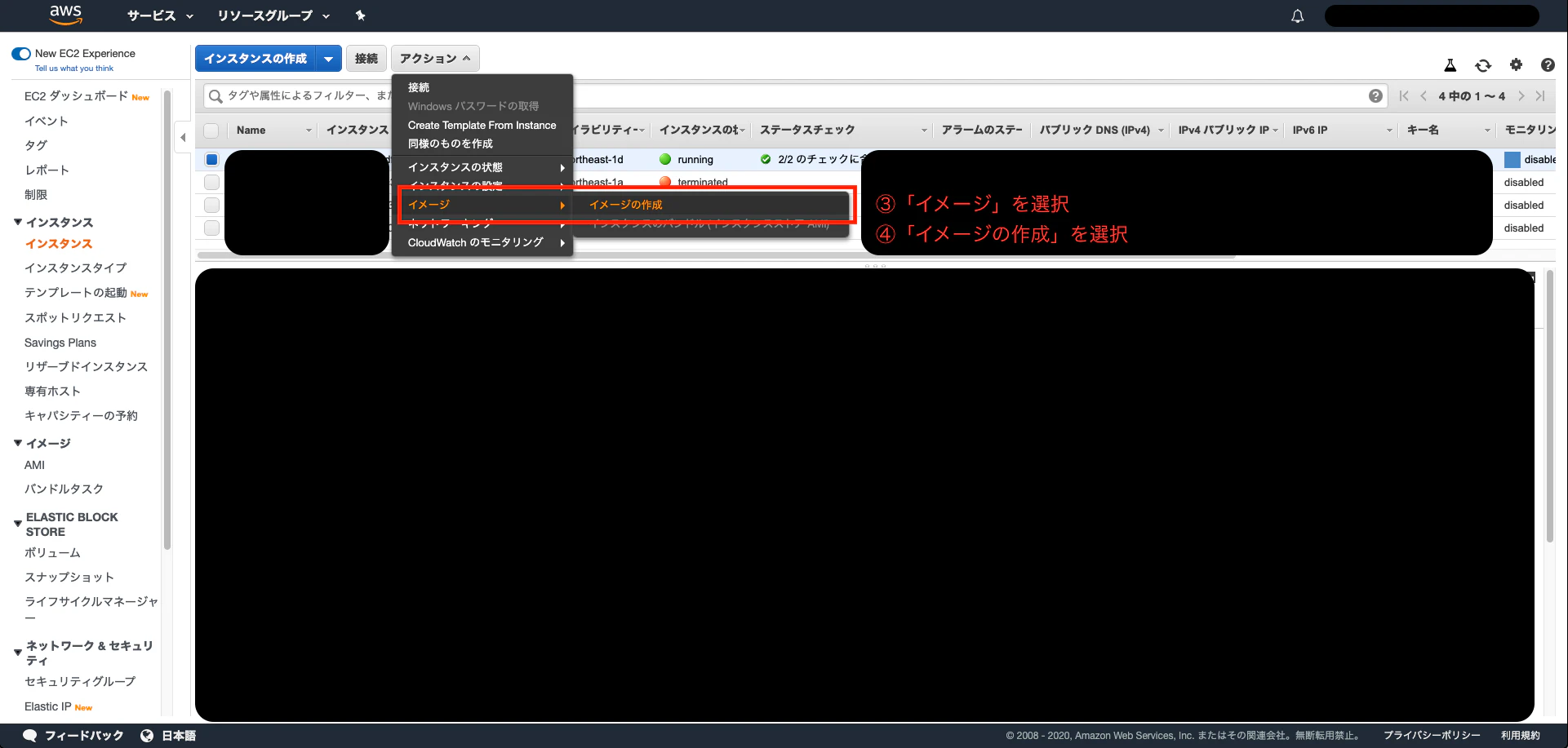
③「イメージ」を選択します
④「イメージの作成」を選択します
⑤イメージ名などを適当に設定します
⑥「イメージの作成」を選択します
イメージからスポットインスタンスの作成
先程のバックアップから、スポットインスタンスを立ち上げます。
⑦メニューの「AMI」を選択します
⑧先程作成したイメージを選択します
⑨「アクション」を選択します
⑩「スポットリクエスト」を選択します
ここから先は、通常のインスタンス作成とほとんど変わりません。
まずはインスタンスタイプを選択します。
以前のものと同じものを選んでもいいですが、無料枠対象の「t2.micro」よりも「t3a.micro」の方が安くて高性能です。
もっと性能を落としてもいいなら、「t3a.nano」でもいいでしょう。
次にインスタンス詳細の設定を行います。
ここで、使用料金として払っていい額の上限を設定しておけます。
「最高価格」の欄を記載しておけば、その額以上になったときにはインスタンスを停止させることができます。
以降は、通常のインスタンス作成と変わらないので割愛させていただきます。
まとめ
上記の手順で、AWSの無料枠EC2インスタンスから、低価格なスポットインスタンスへの移行ができました。
ほんの15分程度で完了してしまうので、やはりそこら辺はAWSすごいなぁと感じるところですね。





- 投稿日:2020-01-07T23:24:45+09:00
気付いたらAWS EC2の無料枠が終了していた!(無料枠からスポットインスタンスへの移行)
要約
AWSのEC2無料枠が終わったことに気づいたので、使用料金を下げるためにスポットインスタンスに移行した話です。
いまさらの二番煎じ感ありますが、、、起きたこと
- AWSの無料枠の範囲内でWordpressを運用していたつもりが、ある日突然50円/日くらい課金されていることに気づく。
- AWSのインスタンスの無料使用枠が12ヶ月間限定だということを失念しており、無料期間が終わっていた模様。
やったこと
- そのまま運用すると、1500円/月。自己満足のブログには高い。
- EC2インスタンスをスポットインスタンスに移行することで、400円/月(想定)あたりまで料金を下げた
ポイント
- インスタンスの移行は本当に一瞬で終わる。すごい。
そもそもAWS無料枠とは?スポットインスタンスとは?
AWS無料枠
AWS のプラットフォーム、製品、サービスを無料で実際に体験できます。
上記の通り、AWSのサービスの一部を無料で使用できる、ということです。
私はてっきり、条件さえ気をつけていれば、無限に無料で使えるものと思い、Amazonさんすごいなぁ、とか思っていたのですが...オファーの種類
60 を超える製品から選んで、無料利用枠で実際に AWS に構築してください。ご使用の製品によって、3 種類の無料オファーがご利用いただけます。
無期限無料
これらの無料利用枠に有効期限はなく、AWSのお客様すべてが利用可能
12か月間無料
AWSへの最初のサインアップ日から12か月間無料で利用可能
トライアル
さまざまなソフトウェアソリューションが、短期間の無料トラアイルとして利用可能しっかり記載されている通り、全てが無料なわけではなく、一部はAWSへの最初のサインアップ日から12か月間無料で利用可能なんですね。
ちなみに、Wordpress運用のために使用していたEC2はというと...コンピューティング
無料利用枠
12 か月間無料
Amazon EC2
750 時間はい、1年間でした。いつの間にか1年経ってたんですね。。ブログを作ったり消したり繰り返していたこともあり、全く気づきませんでした。
スポットインスタンスとは
参考:AWS公式 Amazon EC2 スポットインスタンス
耐障害性を備えたワークロードを最大 90% OFF で実行
上記の通り、通常のインスタンスよりも安く使えます。
すごくざっくりとした説明ですが
- その時々の需要によって使用料金が決まる(通常は安くなる)
- 最大支払う料金を決めておくことで、予想外に高い使用料金で使用することを防げる
- その代わり、設定しておいた最大料金を上回る料金になった時、インスタンスが停止してしまう
という感じです。
最大支払う料金を上げておけば止まりにくくはなりますが、100%止まらない、というものにはできません。
個人運用レベルで、サービスレベルを気にしないならこっちを選んでおけば良いと考えています。通常インスタンスからスポットインスタンスへの移行手順
バックアップ(AMI)の作成
まずは既存のインスタンスのバックアップを作成します。
⓪AWSコンソールの「インスタンス」から
①コピーしたい、元のインスタンスを選択します
②「アクション」を選択します
③「イメージ」を選択します
④「イメージの作成」を選択します
⑤イメージ名などを適当に設定します
⑥「イメージの作成」を選択します
イメージからスポットインスタンスの作成
先程のバックアップから、スポットインスタンスを立ち上げます。
⑦メニューの「AMI」を選択します
⑧先程作成したイメージを選択します
⑨「アクション」を選択します
⑩「スポットリクエスト」を選択します
ここから先は、通常のインスタンス作成とほとんど変わりません。
まずはインスタンスタイプを選択します。
以前のものと同じものを選んでもいいですが、無料枠対象の「t2.micro」よりも「t3a.micro」の方が安くて高性能です。
もっと性能を落としてもいいなら、「t3a.nano」でもいいでしょう。
次にインスタンス詳細の設定を行います。
ここで、使用料金として払っていい額の上限を設定しておけます。
「最高価格」の欄を記載しておけば、その額以上になったときにはインスタンスを停止させることができます。
以降は、通常のインスタンス作成と変わらないので割愛させていただきます。
まとめ
上記の手順で、AWSの無料枠EC2インスタンスから、低価格なスポットインスタンスへの移行ができました。
ほんの15分程度で完了してしまうので、やはりそこら辺はAWSすごいなぁと感じるところですね。
- 投稿日:2020-01-07T23:10:02+09:00
Elasticsearch Service 6.8 に取り込んだログ(INDEX)を Curator で削除するメモ(Lambda Python 3.8 版)
Curator による取り込みログ(INDEX)削除の Elasticsearch Service 6.8 / Lambda Python 3.8 対応化メモを残しておきます。
旧記事:
手順
1. IAM Role の確認/作成
ログ取り込みで IAM Role は作成されてるはずですが、なければ作成します。
- IAM Role の作成(以前の ALB/CLB 取り込みメモより)
2. AWS Lambda ファンクションの作成
Lambda にアップロードする .zip ファイルの作成(Amazon Linux 2 上で)
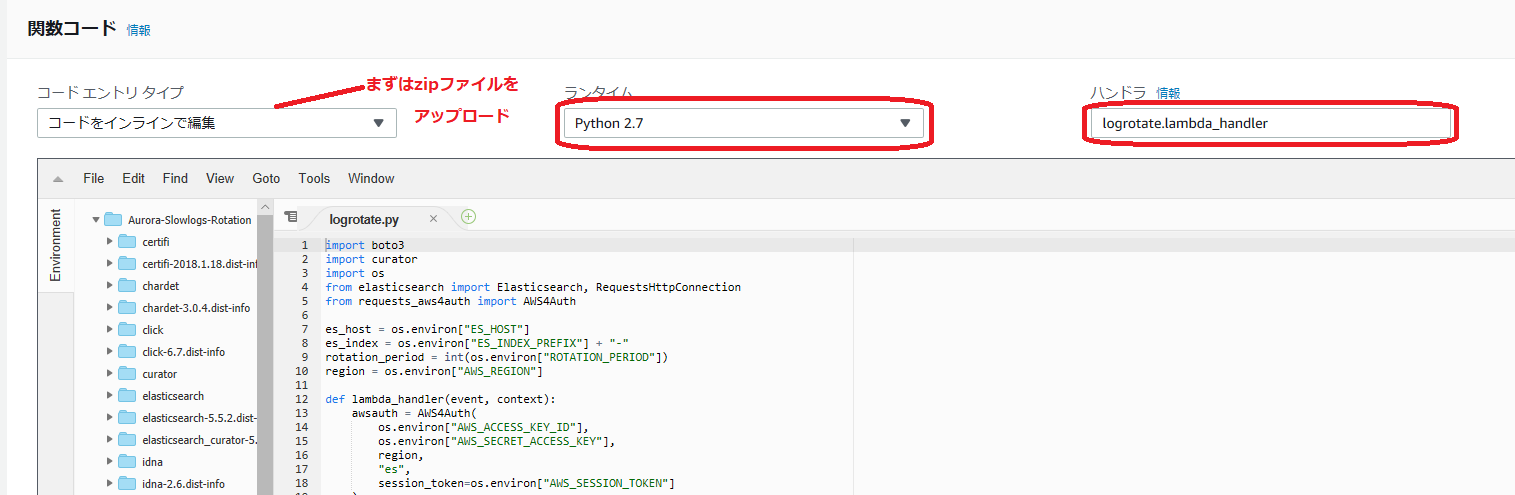
Lambda用アップロードファイル.zip化$ . dev/bin/activate (dev) $ mkdir logrotate (dev) $ cd logrotate/ (dev) $ pip install elasticsearch-curator requests_aws4auth -t ./ (省略) (dev) $ rm -rf *.dist-info (dev) $ vi logrotate.py (ここで「logrotate.py」のコードを入力) (dev) $ zip -r ../logrotate.ziplogrotate.pyimport boto3 import curator import os from elasticsearch import Elasticsearch, RequestsHttpConnection from requests_aws4auth import AWS4Auth es_host = os.environ["ES_HOST"] es_index = os.environ["ES_INDEX_PREFIX"] + "-" rotation_period = int(os.environ["ROTATION_PERIOD"]) region = os.environ["AWS_REGION"] def lambda_handler(event, context): awsauth = AWS4Auth( os.environ["AWS_ACCESS_KEY_ID"], os.environ["AWS_SECRET_ACCESS_KEY"], region, "es", session_token=os.environ["AWS_SESSION_TOKEN"] ) es = Elasticsearch( hosts=[{"host": es_host, "port": 443}], http_auth=awsauth, use_ssl=True, verify_certs=True, connection_class=RequestsHttpConnection ) runCurator(es) def runCurator(es): ilo = curator.IndexList(es) ilo.filter_by_regex(kind="prefix", value=es_index) ilo.filter_by_age(source="name", direction="older", timestring="%Y%m%d", unit="days", unit_count=rotation_period) delete_indices = curator.DeleteIndices(ilo) delete_indices.do_action()※Python コード自体は変わりませんが、.zip ファイルの作成方法が変わっています。
Lambda ファンクションの作成
ここから先は旧記事と同じ手順です。
先ほどの .zip ファイルをアップロードする形で作成します。
ランタイムは Python 3.8、ハンドラはlogrotate.lambda_handlerを指定します。※elasticsearch-curator の容量が大きくなった関係で、↑のスクリーンショットの頃とは違い、Python のコードは表示されない可能性が高いです。
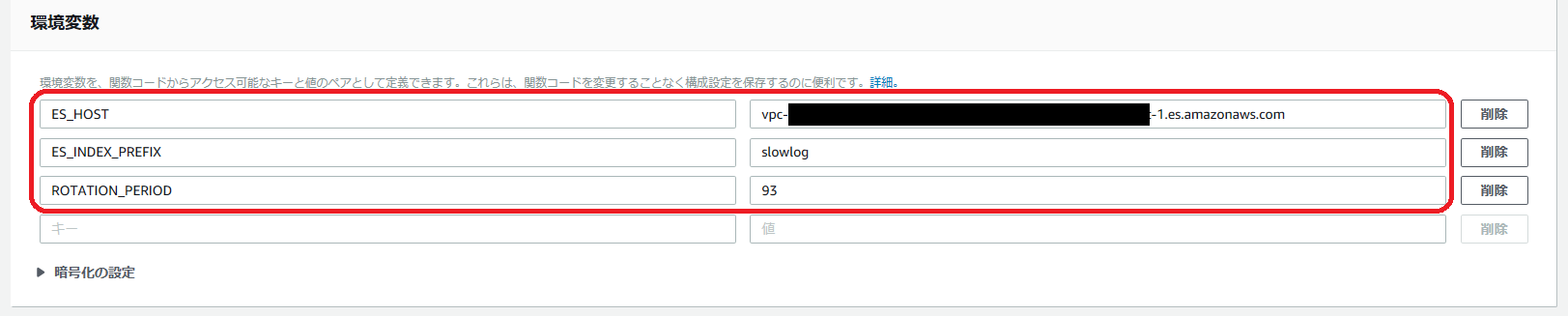
- 環境変数
ES_INDEX_PREFIXで削除対象のログ(INDEX)のプレフィックス、ROTATION_PERIODで削除するまでの期間(日数)を指定します。
- トリガー
「CloudWatch Events」で cron 式を使って、00:00 UTC を過ぎたあたりの時刻に、毎日実行するよう指定すると良いでしょう(画面は省略)。
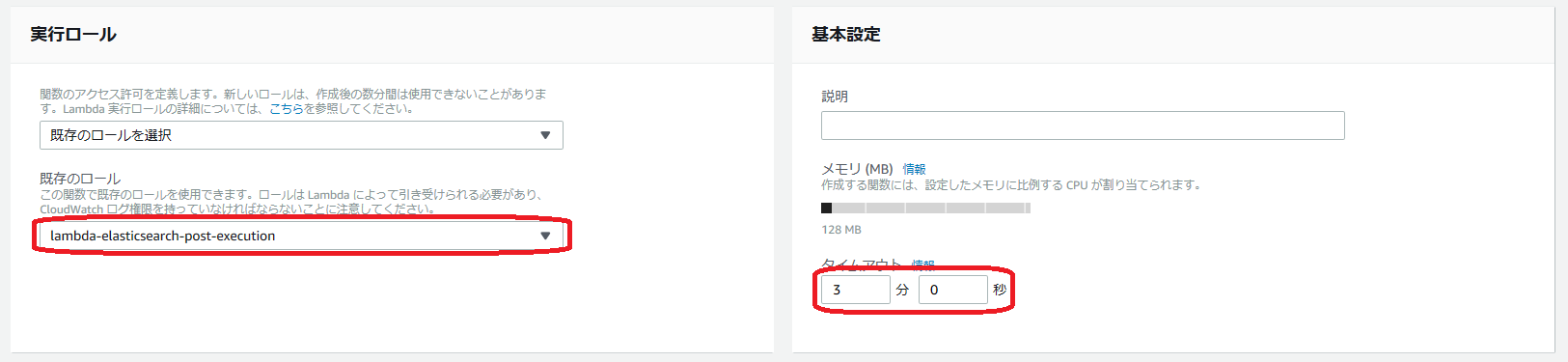
- 実行ロール
最初に確認/作成したものを使います。タイムアウトの時間も延長しておきます。
- ネットワーク
環境に合わせます。VPC を使う場合は、ALB の元記事を参考にしてください。
※実行時、まだ削除対象のログ(INDEX)がない場合はエラーが発生しますが、異常ではありません。
- 投稿日:2020-01-07T22:22:44+09:00
AWS+NodeJSでサーバレスな環境構築⑤
はじめに
前回ではAPI Gateway(REST API)+Lambda(NodeJS)+DynamoDBの組み合わせてCRUDを作りました。今回はS3+Lambda+DynamoDBを組み合わせていきます。S3をトリガー(S3バケットにJsonファイルがアップロードされた段階)にし、Lambda(NodeJS)で取得したJson形式のデータをDynamoDBテーブルに保存します。
表現等がわかりにくければ、容赦無くご指摘いただければ幸いです。
※サーバレスでピンとこない方はこちらをご覧ください。DynamoDBを作成
DynamoDBダッシュボード>テーブルの作成
概要タブのARNはインラインポリシー作成時に使いますので、コピーしときます
IAMでロールとインラインポリシーの作成
IAMダッシュボード>ロール>ロールの作成
AWSサービス>Lambda>次のステップ
AWSLambdaExecute選択>次のステップ
次のステップ
ロール名入力>ロールの作成
インラインポリシーの作成はここを参考にしてください。
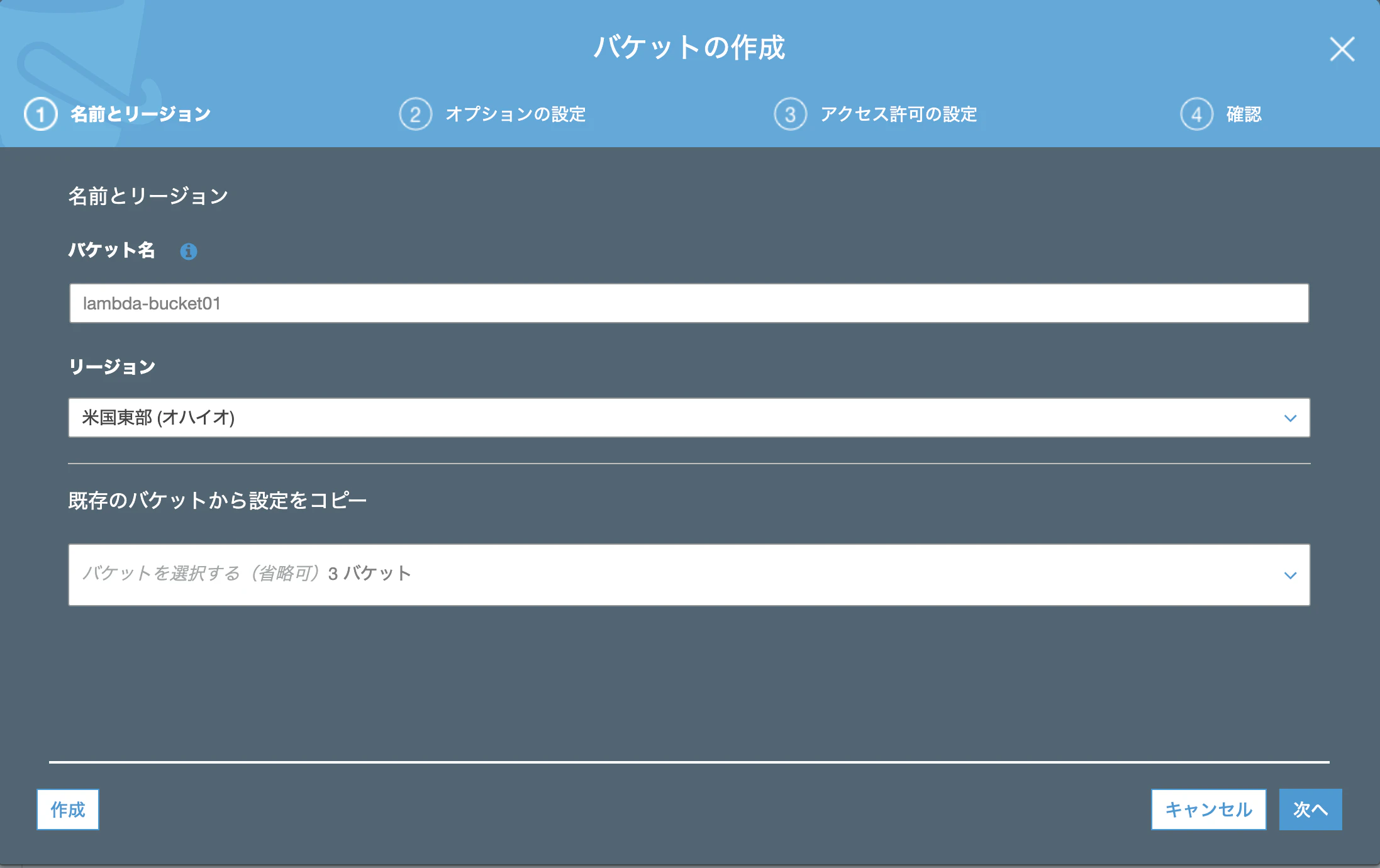
ちなみに今回はDynamoDBテーブルに書込みをするだけなので、アクション(権限)はPutItemだけでOKです。S3バケットの作成
S3ダッシュボード>バケットを作成する>バケット名を入力>作成
Lambda関数の作成と設定
- Lambdaダッシュボード>関数の作成
関数名入力>既存ロール選択(上記で作成したロール)
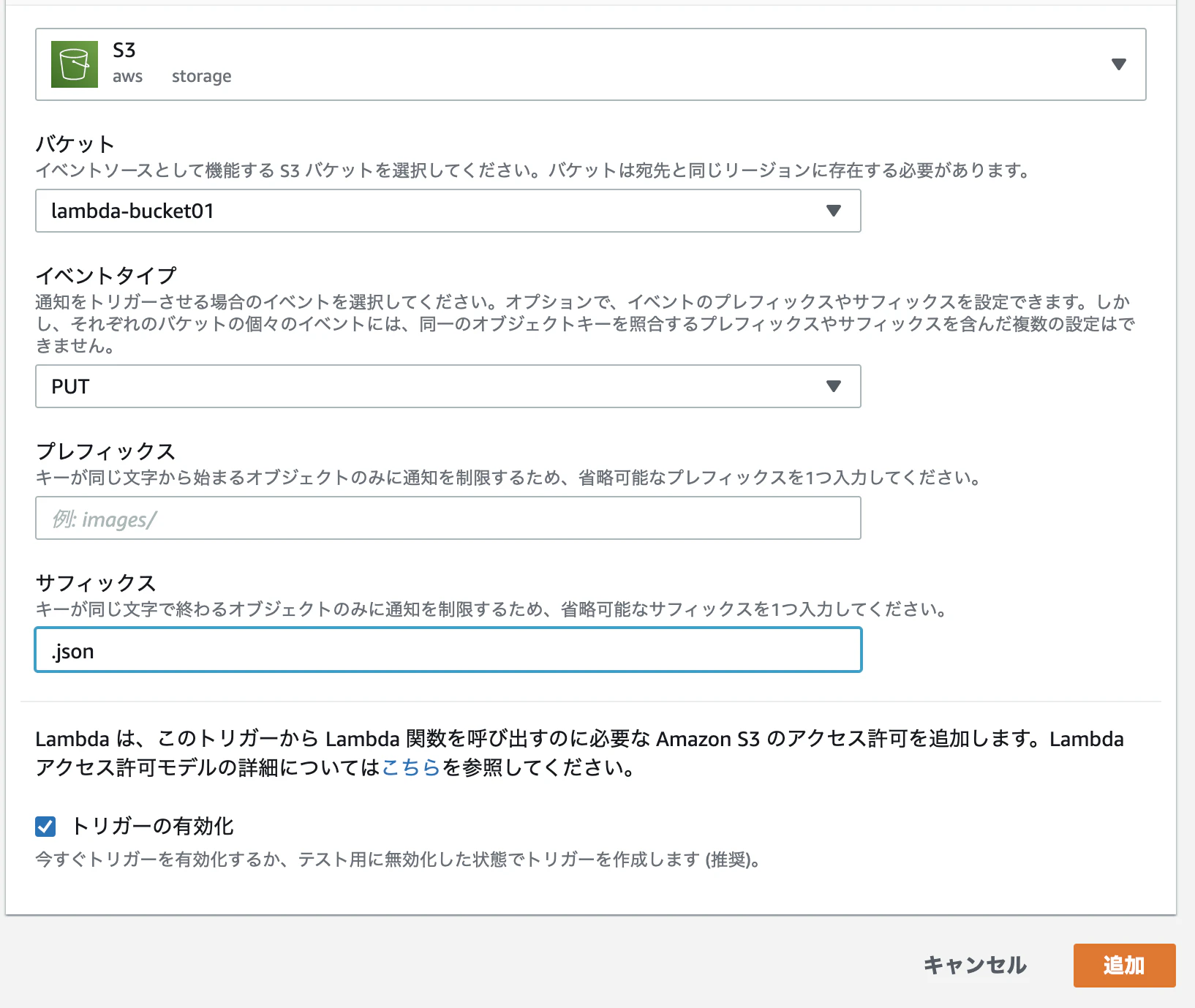
トリガーを追加>S3選択>バケット名選択(上記で作成したやつ)
イベントタイプ選択>サフィックス入力>追加
ソースindedx.jsconst AWS = require('aws-sdk'); const s3 = new AWS.S3(); const documentClient = new AWS.DynamoDB.DocumentClient(); exports.handler = async (event) => { const { name } = event.Records[0].s3.bucket; const { key } = event.Records[0].s3.object; const getObjectParams = { Bucket: name, Key: key }; try { const s3Data = await s3.getObject(getObjectParams).promise(); const usersStr = s3Data.Body.toString(); const usersJSON = JSON.parse(usersStr); console.log(`Jsonファイル取得結果 ::: ${usersStr}`); //取得した文のJson結果をDynamoDBテーブルに追加する await Promise.all(usersJSON.map(async user => { const { id, firstname, lastname } = user; const putParams = { TableName: "JsonDataFromS3", Item: { id: id, firstname: firstname, lastname: lastname } }; await documentClient.put(putParams).promise(); })); } catch(err) { console.log(err); } };結果の確認
S3ダッシュボード>今回使うバケットを選択>ファイル追加>アップロード
使用したJson内容JsonDataFromS3.json[ { "id": "5ac6be6b-8064-4159-9de6-89178a9f8a54", "firstname": "Matt", "lastname":"Hansen" }, { "id": "4b912da3-66aa-45c1-a87f-9f79a256e570", "firstname": "Brad", "lastname":"Lunsford" }, { "id": "8ef0c795-42d4-439d-962e-75afe957e069", "firstname": "Jeremy", "lastname":"Kane" } ]DynamoDBテーブルの中身がS3にアップロードしたJsonファイル通りの内容になっていることを確認
最後に
次はサーバレスでRESTful ウェブサービスを作っていきたいと思っています。
Lambda(NodeJS)+API GateWay+DynamoDB+Cognitoを組み合わせる予定です。






- 投稿日:2020-01-07T22:20:16+09:00
Lambda+API GatewayのレスポンスをJSONとしてパース出来ない
はじめに
「内閣府の祝日CSVをLambda上でJSON形式に加工して、API Gateway経由で使えるようにする」というプログラムを考えたのですが、API GatewayのレスポンスがJSONとして正しくパース出来ないことが分かりました。
Lambda上で動いているRubyプログラムは単体のスクリプトとして問題なく動作することを既に確認していましたが、原因が分かるまで少し時間がかかったので、その記録をまとめてみました。
使用した環境
- Lambda(Ruby)
- API Gateway
正しく動作しなかったコード
JSON.pretty_generateやJSON.generate、JSON.dumpなどでシリアライズした結果を返すと、API Gatewayを通して取得したレスポンスの前後に不要なダブルクォート(")が付いてしまい、JSONとしてパース出来ませんでした。
- その後にさらに調べてみると、API Gatewayを通さずにLambda単体の状態でもレスポンスの前後に不要なダブルクォートが付いていたため、この現象がAPI Gatewayによるものではないと分かりました。
lambda_function.rbrequire 'json' require 'open-uri' def lambda_handler(event:, context:) csv = OpenURI.open_uri('https://www8.cao.go.jp/chosei/shukujitsu/syukujitsu.csv') {|io| io.read } csv = csv.force_encoding("sjis") array = [] csv.split(/\r\n|\r|\n/).each_with_index {|row, i| next if (i==0) # ヘッダ行は読み飛ばす buffs = row.split(",") hash = {"date": buffs[0], "name": buffs[1]} array.push(hash) } return JSON.pretty_generate(array) # この行をJSON.generate()やJSON.dump()に変えても結果は変わらず... end出力結果の例"[\n {\n \"date\": \"1955/1/1\",\n \"name\": \"元日\"\n },...,\n {\n \"date\": \"2020/11/23\",\n \"name\": \"勤労感謝の日\"\n }\n]"正しく動作したコード
- こちらのページに書かれているように、シリアライズせずにオブジェクトをそのまま返す形にコードを直したところ、正しいJSONをレスポンスとして受け取れるようになりました。
- どうやら、 「Lambdaの関数の戻り値として文字列のJSONを指定すると、JSONとして二重にシリアライズされてしまう」 ことが今回の問題の原因のようです。
lambda_function.rbrequire 'json' require 'open-uri' def lambda_handler(event:, context:) csv = OpenURI.open_uri('https://www8.cao.go.jp/chosei/shukujitsu/syukujitsu.csv') {|io| io.read } csv = csv.force_encoding("sjis") array = [] csv.split(/\r\n|\r|\n/).each_with_index {|row, i| next if (i==0) # ヘッダ行は読み飛ばす buffs = row.split(",") hash = {"date": buffs[0], "name": buffs[1]} array.push(hash) } return array # ArrayやHashなどのオブジェクトをそのまま返せばOK! end出力結果の例[{"date":"1955/1/1","name":"元日"},...,{"date":"2020/11/23","name":"勤労感謝の日"}]まとめ
- ある程度調べたところでLambdaの仕様による現象だと分かっていたものの、中々解決策が見つからずに苦労しました。
- 上記の仕様について、AWS公式ページのどこかに記載されているのかもしれませんが、大事な事なのでもう少し分かりやすく書いて欲しかったです。
- もしかしたら私が気付かなかっただけで、どこかに明記されていたのかもしれません。
- あるいは私がLambda初心者で知らなかっただけで、暗黙知だったのかもしれませんが...
- 投稿日:2020-01-07T20:54:50+09:00
AWSでのデプロイ手順①ネットワーク環境設定
初心者には難関である、AWSを使用したデプロイ手順を書いてみます
AWSはUIもよく変化するので、
現在のもの(2019/10)で書いています※アカウントがない人はまず新規で申し込みしておいてください
今回内容
STEP1 ネットワーク環境設定
1.VPCの作成
2.サブネットの作成
3.インターネットゲートウェイの作成
4.ルートテーブルの作成
5.サブネットとの紐付け
6.セキュリティグループの作成STEP2 EC2の設定
1.EC2にてインスタンスの作成
2.Elastic IPの割り当て
3.インスタンスにSSHでログイン次回内容
STEP3以降
AWSでデプロイするまでの手順②サーバー(EC2インスタンス)環境設定※ここでいうサーバーとはAWS EC2インスタンス (Amazon Linux) のこととする
STEP1 ネットワーク環境設定
1.VPCの作成
https://aws.amazon.com/
Amazon Web Servicesでサインインしますヘッダーにあるリージョンを東京に設定し、
「VPC」を検索し「VPC」にいきます
サイドメニューのVPCより[VPCの作成]を押下します
作成画面になるので
今回は下のように設定し、[作成]を押下します・ネームタグ :testVPC ・IPv4 CIDRブロック:10.0.0.0/16 ・IPv4 CIDRブロック:ブロックなし ・テナンシー :デフォルト
2.サブネットの作成
サイドメニューのサブネットより[サブネットの作成]を押下します
作成画面になるので
下のように設定し、[作成]を押下します・ネームタグ:testSubnet ・VPC:先ほど作成したものを選択 ・アベイラビリティゾーン:ap-northeast-1a ・CIDRブロック:10.0.0.0/24
3.インターネットゲートウェイの作成
サイドメニューのインターネットゲートウェイより
[インターネットゲートウェイの作成]を押下します
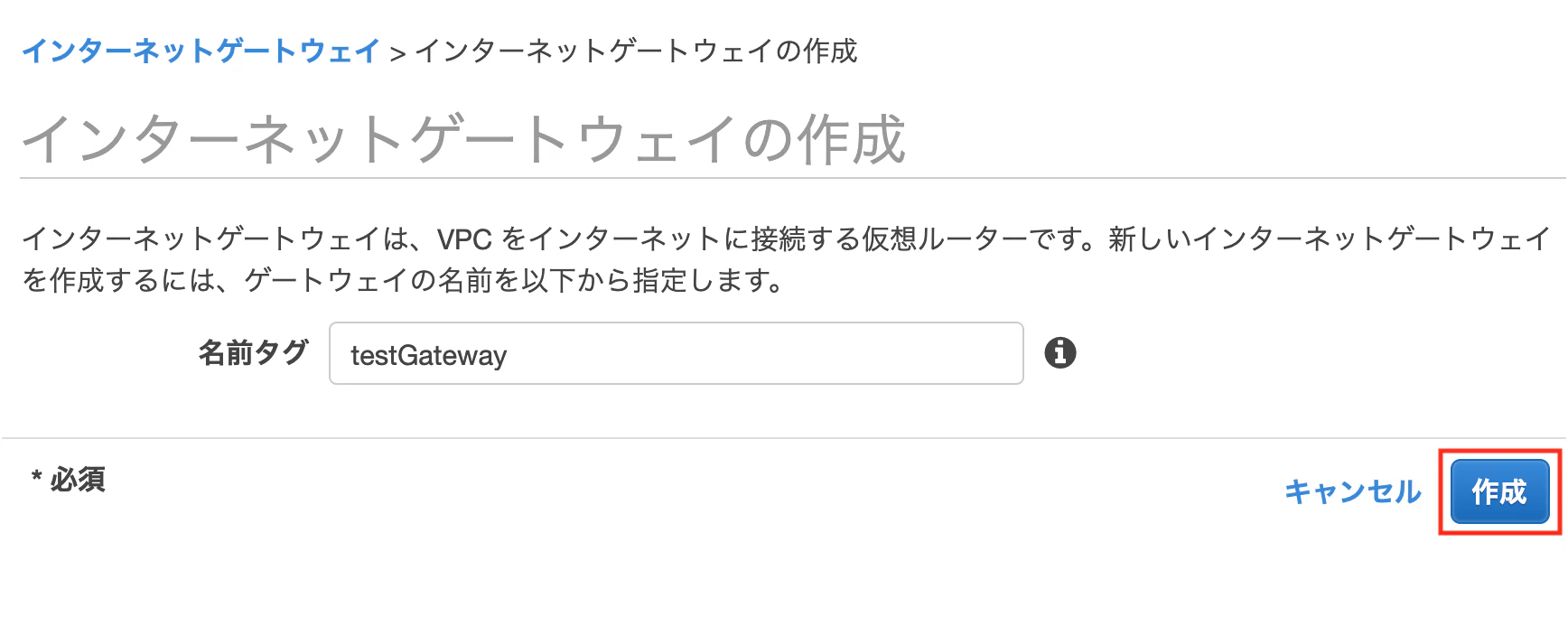
作成画面になるので
下のように設定し、[作成]を押下します名前タグ:testGateway
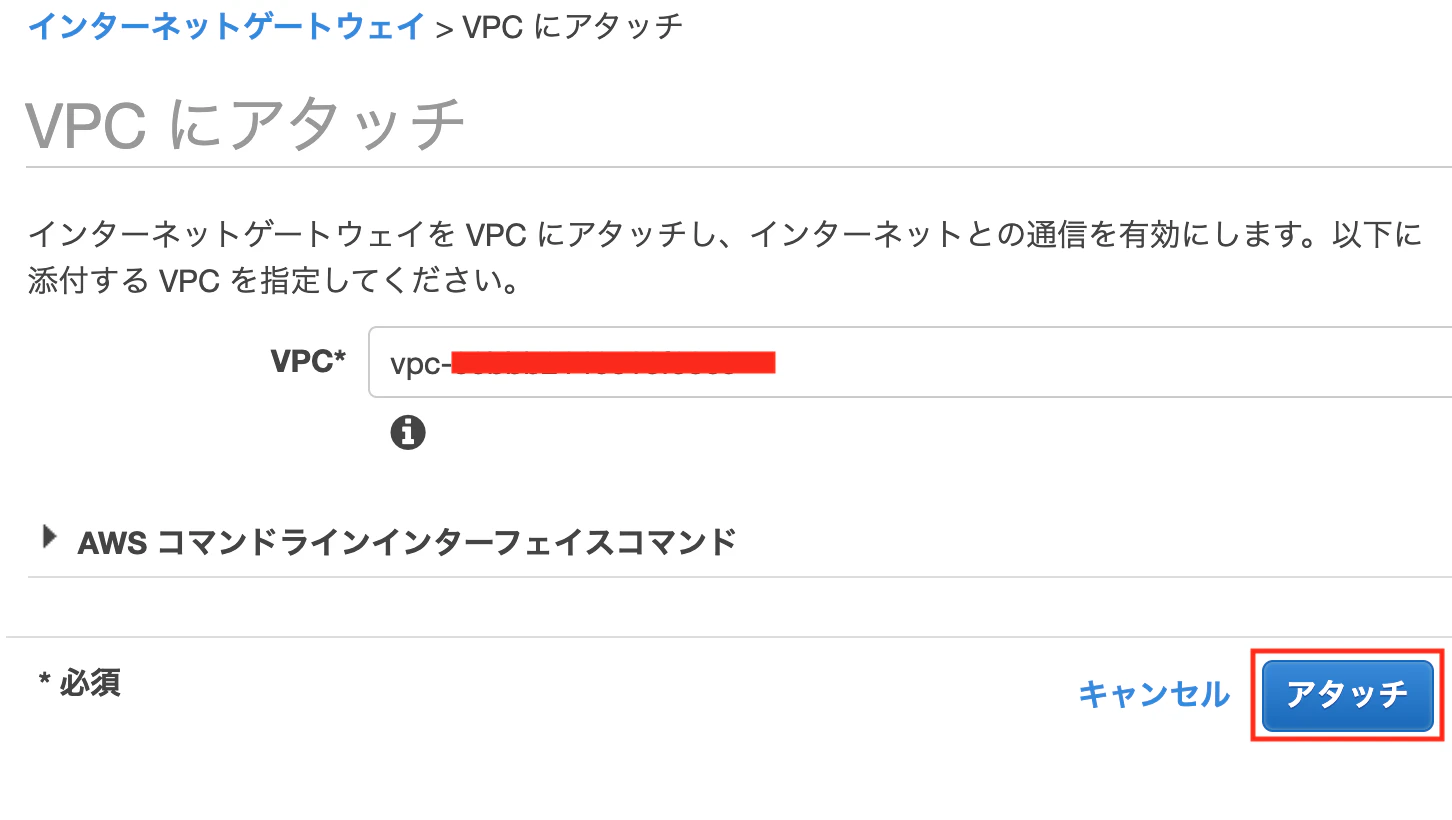
[アクション]を押下し、[VPCにアタッチ]を押下します
下のように設定し、[アタッチ]を押下する
VPC:先ほど作成したものを選択
4.ルートテーブルの作成
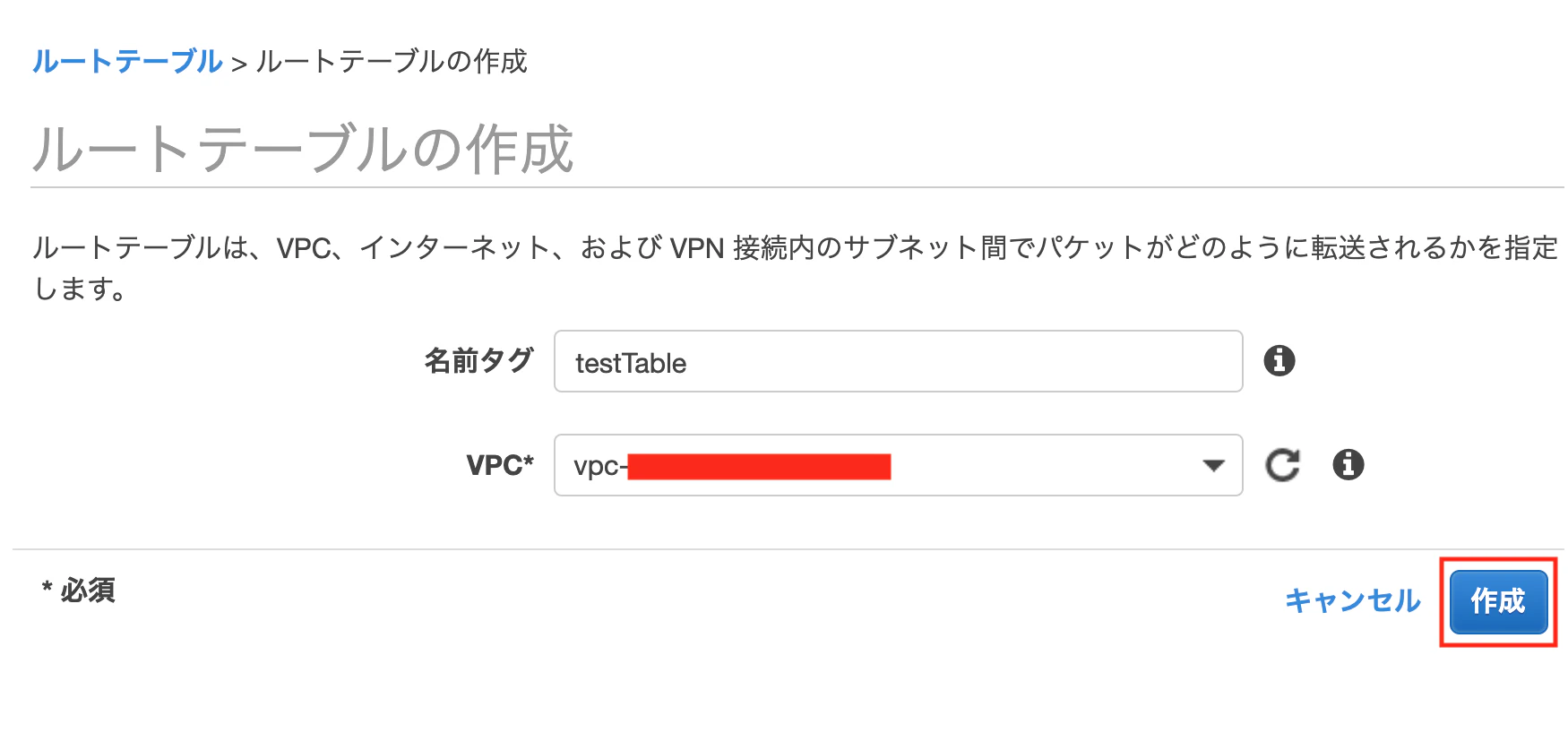
サイドメニューのルートテーブルより[ルートテーブルの作成]を押下
作成画面になるので
下のように設定し、[作成]を押下します名前タグ:testTable VPC:先ほど作成したものを選択
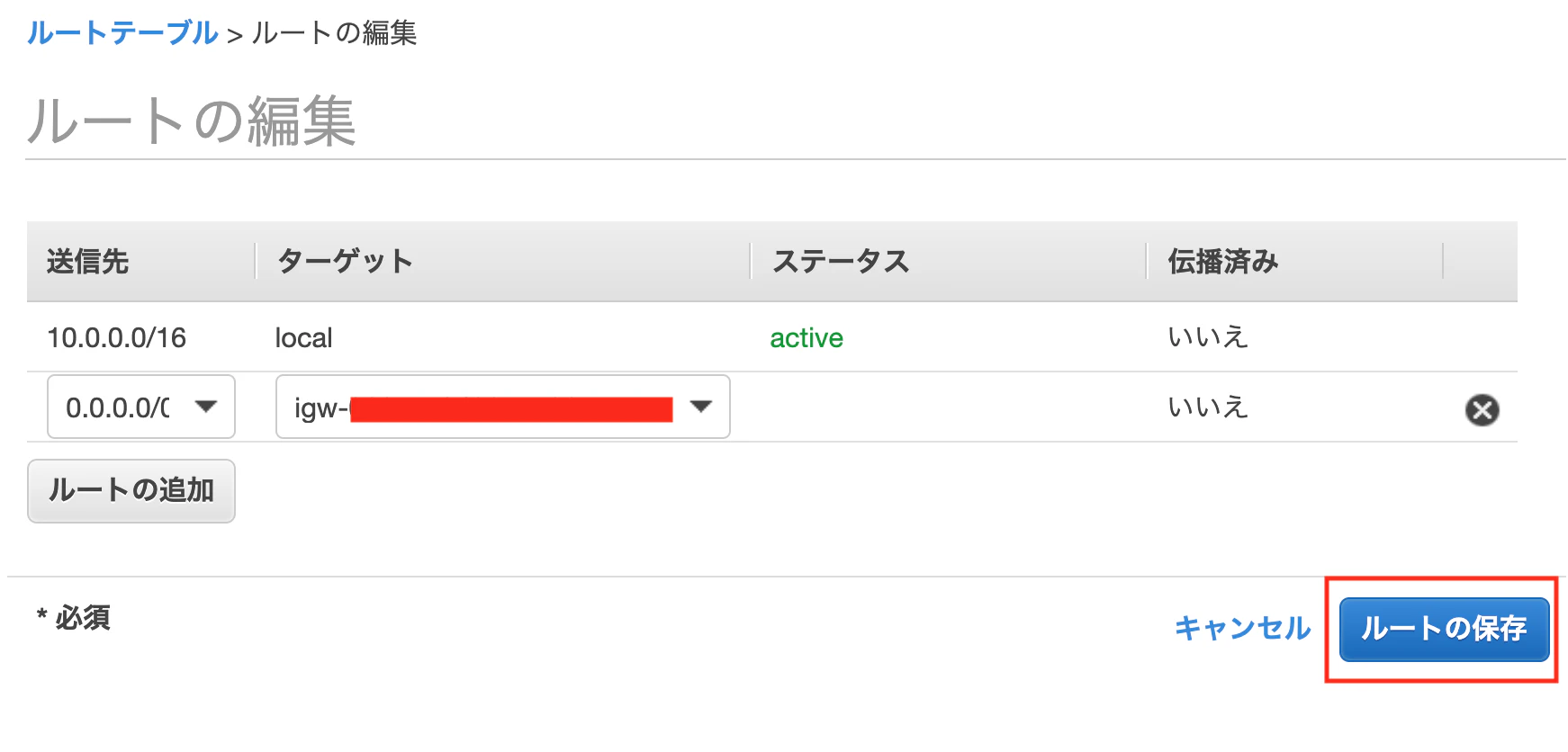
作成したルートテーブルを選択した状態で、
下のタブ「ルート」>「ルートの編集」を押下、[ルートの追加]を押下
下のように設定し[ルールの保存]を押下します
送信先:0.0.0.0/0 ターゲット:Internet Gatewayを選択し、先ほど作成したゲートウェイIDを選択
5.サブネットとの紐付け
→左側の「サブネット」を選択します →関連付けを変更するサブネットを選択します →画面下のルートテーブルを選択します →[ルートテーブルの関連付けの編集]を押下します
→先ほど作成したルートテーブルIDを選択します →[保存]を押下します
6.セキュリティグループの作成
サイドメニューの
セキュリティ>セキュリティグループより>[セキュリティグループの作成]を押下します
下のように設定し、[作成]を押下する
セキュリティグループ名:testSecurityGroup 説明:そのセキュリティグループの説明 VPC:先ほど作成したものを選択
画面下のインバウンドのルールの[ルールの編集]を押下し、[ルールの追加]を押下、
下のように設定し、[ルールの保存]を押下するタイプ:SSH ソース:マイIP
STEP2 EC2の設定
AWSでDBを利用したい場合、
・EC2にてインスタンスの作成 ・RDSを利用する ※ ただRDSを使用すると料金が掛かるので、 使用しない場合はサーバーに直接データベースを作成してください。この2種類の方法があります。
今回は
EC2にてインスタンスの作成(サーバーに直接データベースを作成)
をメインに行なっていきます1.EC2にてインスタンスの作成
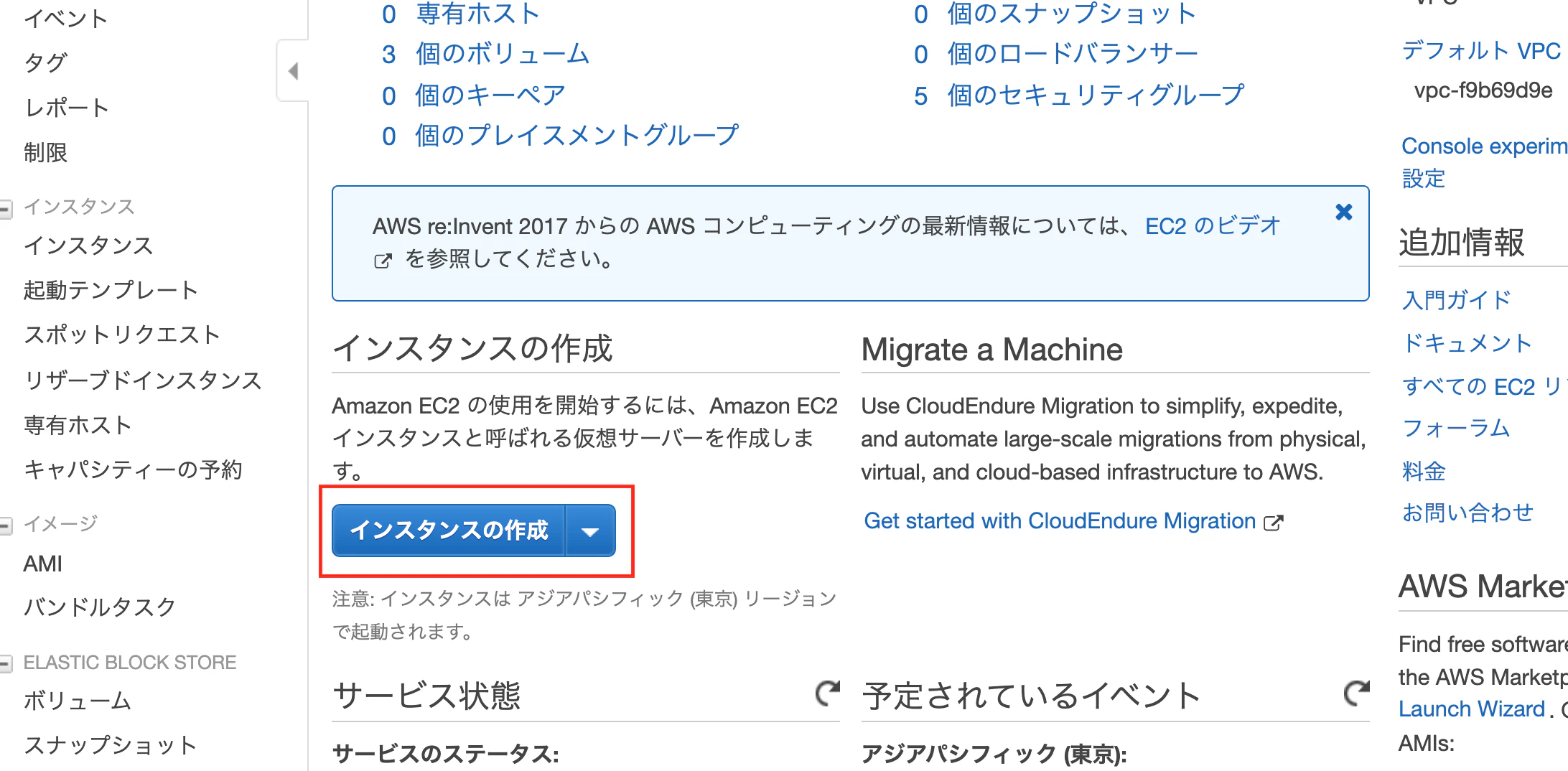
AWS マネジメントコンソールにて"EC2"を検索しアクセスする
サイドメニューのインスタンスより[インスタンスの作成]を押下する
今回はこちらをクリックします
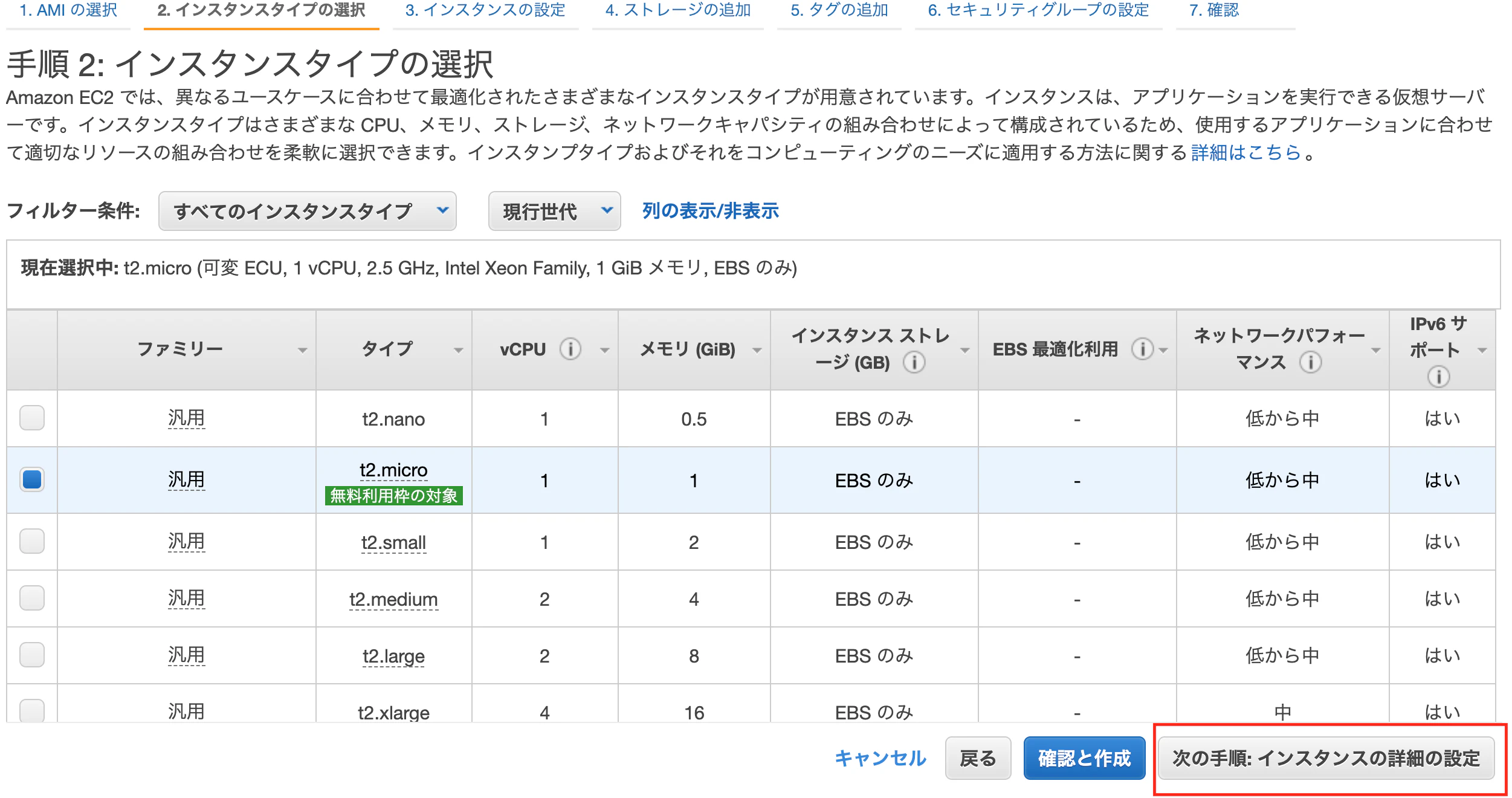
[次の手順: インスタンスの詳細の設定]をクリックする
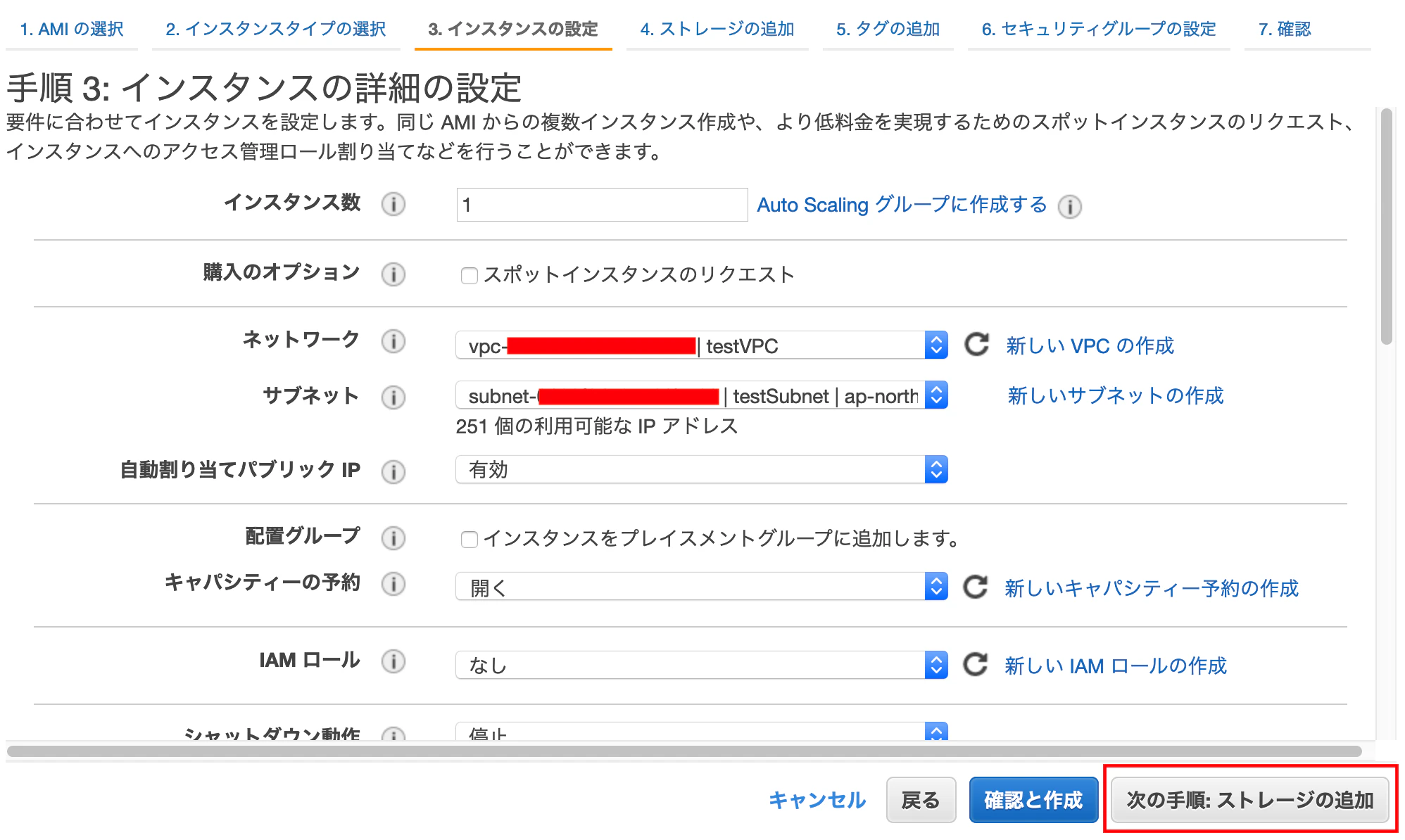
下を設定し,[次の手順: ストレージの追加]を押下する
ネットワーク:先ほど作成したVPCを選択 サブネット:先ほど作成したサブネットを選択 自動割り当てパブリック IP:有効 他はデフォルトのまま
デフォルトのままで,[次の手順: タグの追加]を押下する
タグを追加する
[タグの追加]を押下する
キー:Name 値:testInstanceで[次の手順: セキュリティグループの設定]を押下する
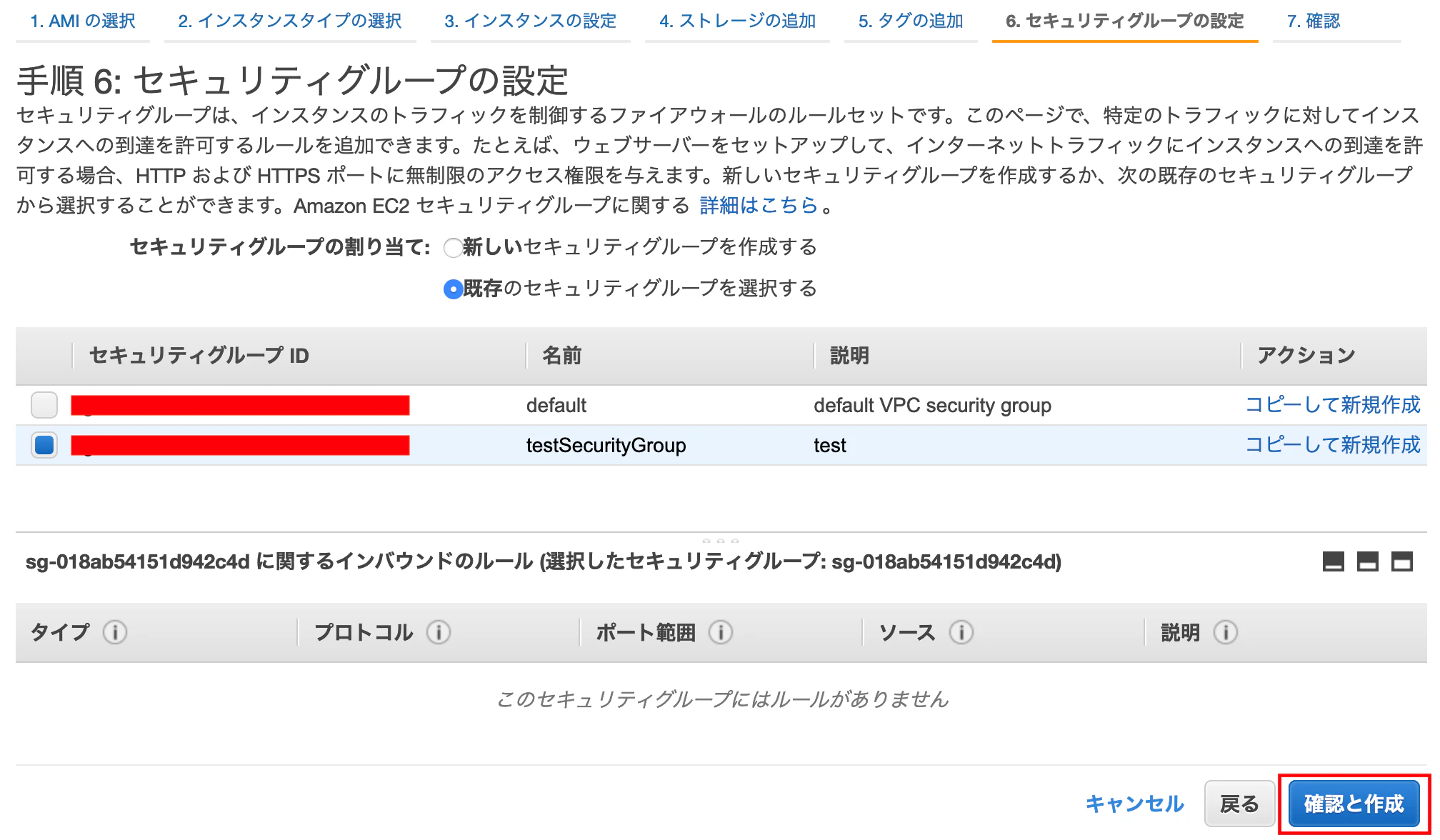
セキュリティグループの設定する
セキュリティグループの割り当て:既存を
選択し、先ほど作成したセキュリティグループを選択し、
[確認と作成]を押下する
一覧画面にて、
最後に[起動]を押下します下ような表示になり、
新しいキーペアを作成を選択、
キーペア名を入力し、
[キーペアのダウンロード]を押下します
(一度作成されたファイルは再度ダウンロードができなくなるので注意)
ダウンロードしたら[インスタンスの作成]を押下します
しばらくするとインスタンスが作成されます!!
2.Elastic IPの割り当て
サイドメニューの
ネットワーク&セキュリティ>
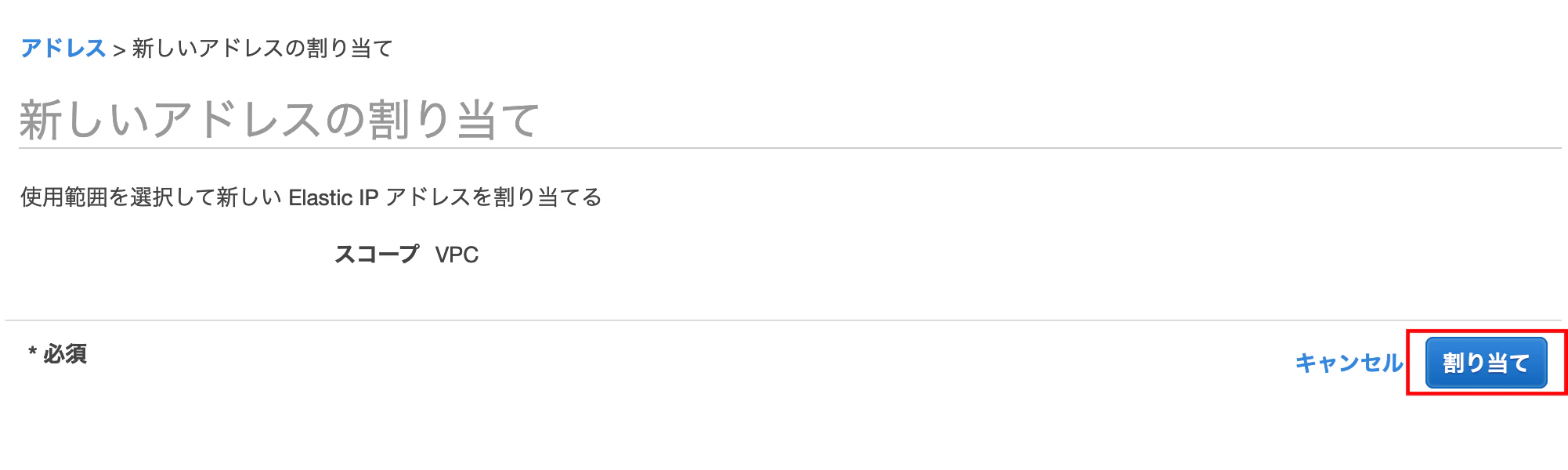
Elastic IP[新しいアドレスの割り当て]を押下する
[割り当て]を押下します
[閉じる]で戻り
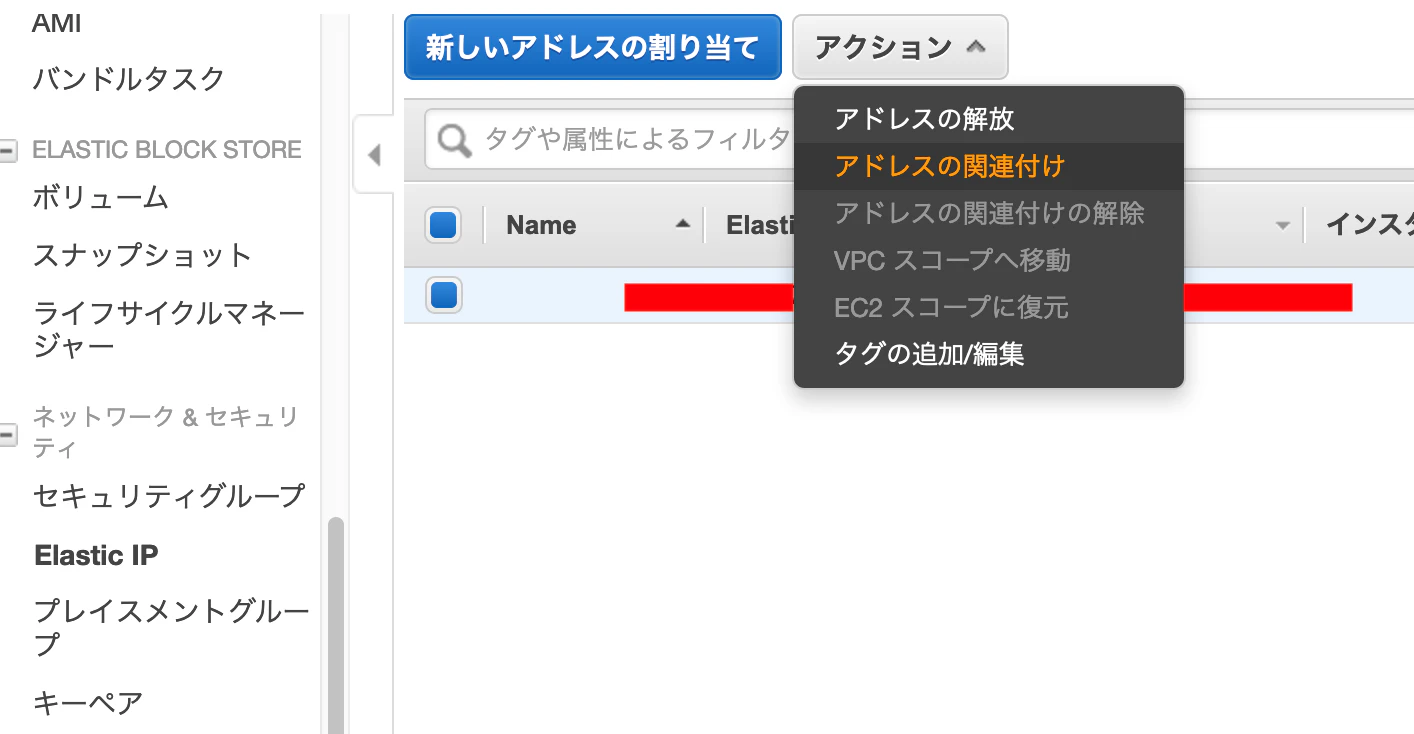
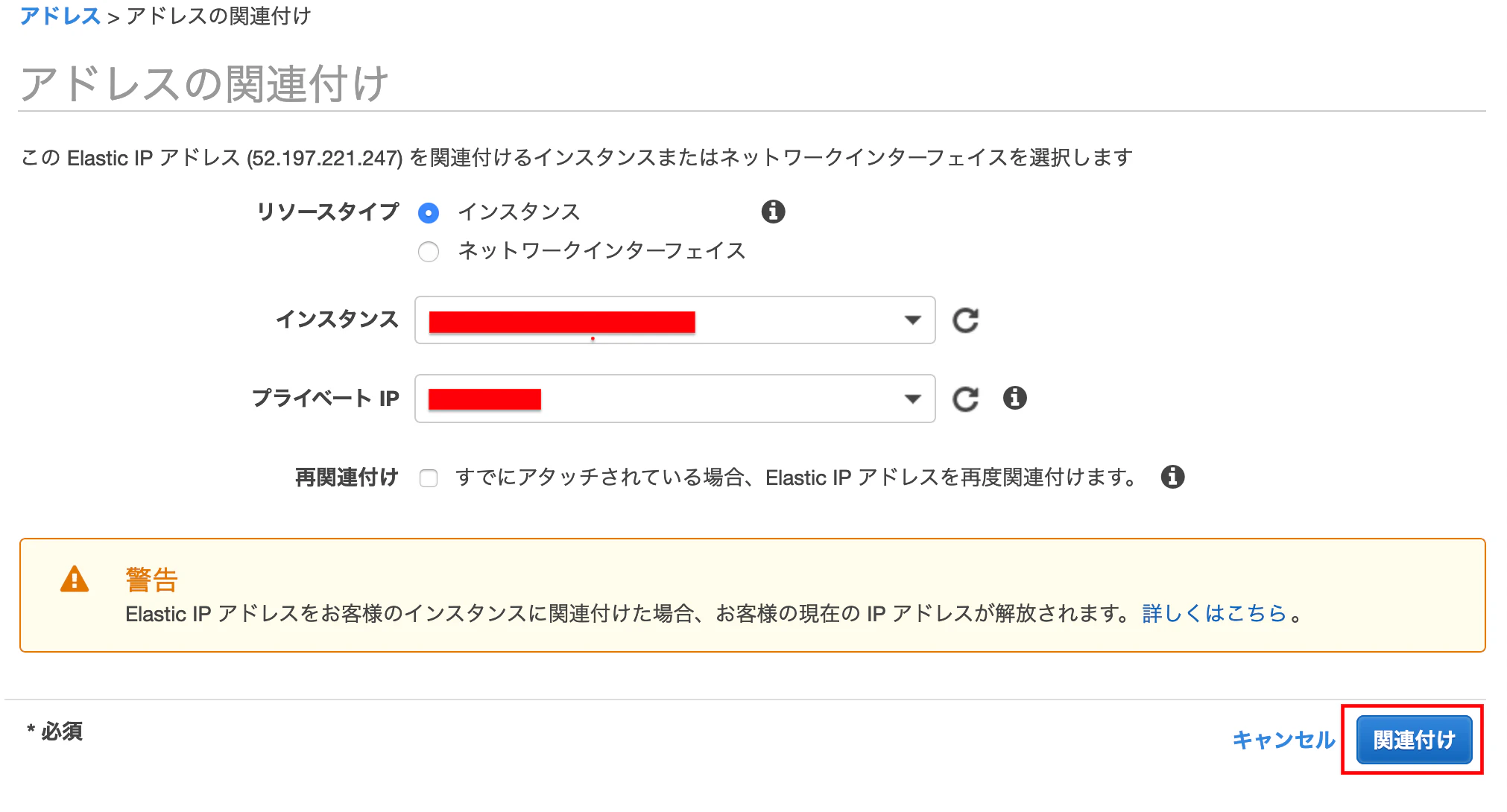
[アクション]>アドレスの関連付けを押下します
インスタンスを先ほど作成したものを選択し、[関連付け]を押下する
3.インスタンスにSSHでログイン
各種インストール
python
$ brew install pythonpip(pythonのパッケージ管理システム)
$ easy_install pipawscli(awsをPCのコンソール上から扱うためのもの)
$ pip install awscliできない場合はこちら
https://docs.aws.amazon.com/ja_jp/cli/latest/userguide/install-macos.htmlec2-userでインスタンスにログインする
AWSでは、
EC2インスタンスにログインできるユーザーとして、
デフォルトでec2-userという名のユーザーが用意されています
こちらではまずec2-userでログインしますターミナルで以下を入れていきます
(※testKey.pemは、先ほどSTEP2でダウンロードしたキーです)$ mv Downloads/testKey.pem .ssh/ (#作成した公開鍵をsshフォルダに移動) $ cd .ssh/ (#ディレクトリをsshに移動) $ chmod 600 testKey.pem (#公開鍵に600番で定義されたアクセス権を付与する) $ ssh -i testKey.pem ec2-user@(@以降のURLは、作成したEC2インスタンスと紐付けたElastic IPを使用してください。) (#公開鍵を利用してec2-userとしてログイン) 例: ($ ssh -i testKey.pem ec2-user@13.112.140.56)yes/noを聞かれるので
yesでEnterを押下
無事にログインできました!!!
※
ssh port 22 Operation timed out
エラーになる場合はこちら
https://qiita.com/yokoto/items/338bd80262d9eefb152ehttps://qiita.com/minicoopers0716/items/cac50f29ef79a03f1d8d
ユーザー作成(EC2上での操作)
上記方法でインスタンスにログインしている状態で
[ec2-user|~]$ sudo adduser testuser (#新規ユーザー名の登録) [ec2-user|~]$ sudo passwd testuser (#新規ユーザー名のパスワード登録) パスワードを登録します
vimでユーザーに権限を追加する記述する$ sudo visudovimモードになります
## Allows people in group wheel to run all commands # %wheel ALL=(ALL) ALL ## Same thing without a password # %wheel ALL=(ALL) NOPASSWD: ALL ## Allows members of the users group to mount and unmount the ## cdrom as root # %users ALL=/sbin/mount /mnt/cdrom, /sbin/umount /mnt/cdrom ## Allows members of the users group to shutdown this system # %users localhost=/sbin/shutdown -h now検索モードにし下の
"wheel"を探します
(キーボードで"/wheel"を入力し押下、"N"を押下すると次にいけます)## Same thing without a password # %wheel ALL=(ALL) NOPASSWD: ALLキーボードの「i」を押下し、編集モードで
# %wheel ALL=(ALL) NOPASSWD: ALL
のコメントアウトを外します## Same thing without a password %wheel ALL=(ALL) NOPASSWD: ALLさらに
その下に、作成したユーザーに権限を追加する記述 testuser ALL=(ALL) ALL を追加する## Allow root to run any commands anywhere root ALL=(ALL) ALL testuser ALL=(ALL) ALLキーボードの「esc」を押下します
「:wq」を入力しEnterで保存しますこちらでユーザーの切り替えを行ってください。
[ec2-user|~]$ sudo su - testuser (#ユーザー名の切り替え) [testuser@ ~]無事に[ec2-user|がtestuser(作成したユーザー名)と切り替わればOKです。
exitを二回いれて
で一度ログアウトする追加ユーザ用キーペアを作成
こちらはローカルでの作業です
$ cd .ssh [.ssh]$ ssh-keygen -t rsa (#公開鍵を作成) ----------------------------- Enter file in which to save the key (): (#ここでファイルの名前を記述して、エンターを押す) test_key_rsa Enter passphrase (empty for no passphrase): (#何もせずそのままエンター) Enter same passphrase again: (#何もせずそのままエンター) ----------------------------- [.ssh]$ ls #「test_key_rsa」と「test_key_rsa.pub」が生成されたことを確認 [.ssh]$ vi config (#VIMを起動し、設定ファイルを編集する) ----------------------------- キーボードの「i」を押下し、編集モードで # 以下を追記 Host test_key_rsa Hostname 前出のElastic IP (#自分の設定に合わせて) Port 22 User testuser (#先ほどのユーザー名) IdentityFile ~/.ssh/test_key_rsa (#秘密鍵の設定) * ()部分は削除する。 ----------------------------- キーボードの「esc」を押下します 「:wq」で保存します [.ssh]$ cat test_key_rsa.pub (#鍵の中身をターミナル上に出力) ★ ssh-rsa~~~~localまでをコピーしておくサーバー側作業
続いてサーバーでの作業です
ec2-userでログインします$ cd .ssh $ ssh -i testKey.pem ec2-user@(@以降のURLは、作成したEC2インスタンスと紐付けたElastic IPを使用してください。) [ec2-user|~]$ sudo su - testuser [testuser@ ~]$ mkdir .ssh [testuser@ ~]$ chmod 700 .ssh [testuser@ ~]$ cd .ssh [testuser@ |.ssh~]$ vi authorized_keys (vimがオープンするので、「i」を押し、 先ほど ★ で、コピーしたssh-rsaをペーストする) キーボードの「esc」を押下します 「:wq」で保存します [testuser@ |.ssh~]$ chmod 600 authorized_keys $ exit もう一度 $ exit ログアウト[~]$ ssh test_key_rsaログインできれば、無事ユーザー設定は終了です。
なお、時間が経つとローカルからログインできなくなることがあるので、その場合は、 セキュリティグループ>インバウンド>編集で SSHのソースで マイIPを選択し[保存]すると繋がるようになります


















- 投稿日:2020-01-07T19:34:32+09:00
#Ruby + #AWS S3 / publish presigned url ( temporary access URL ) / example codes
Code
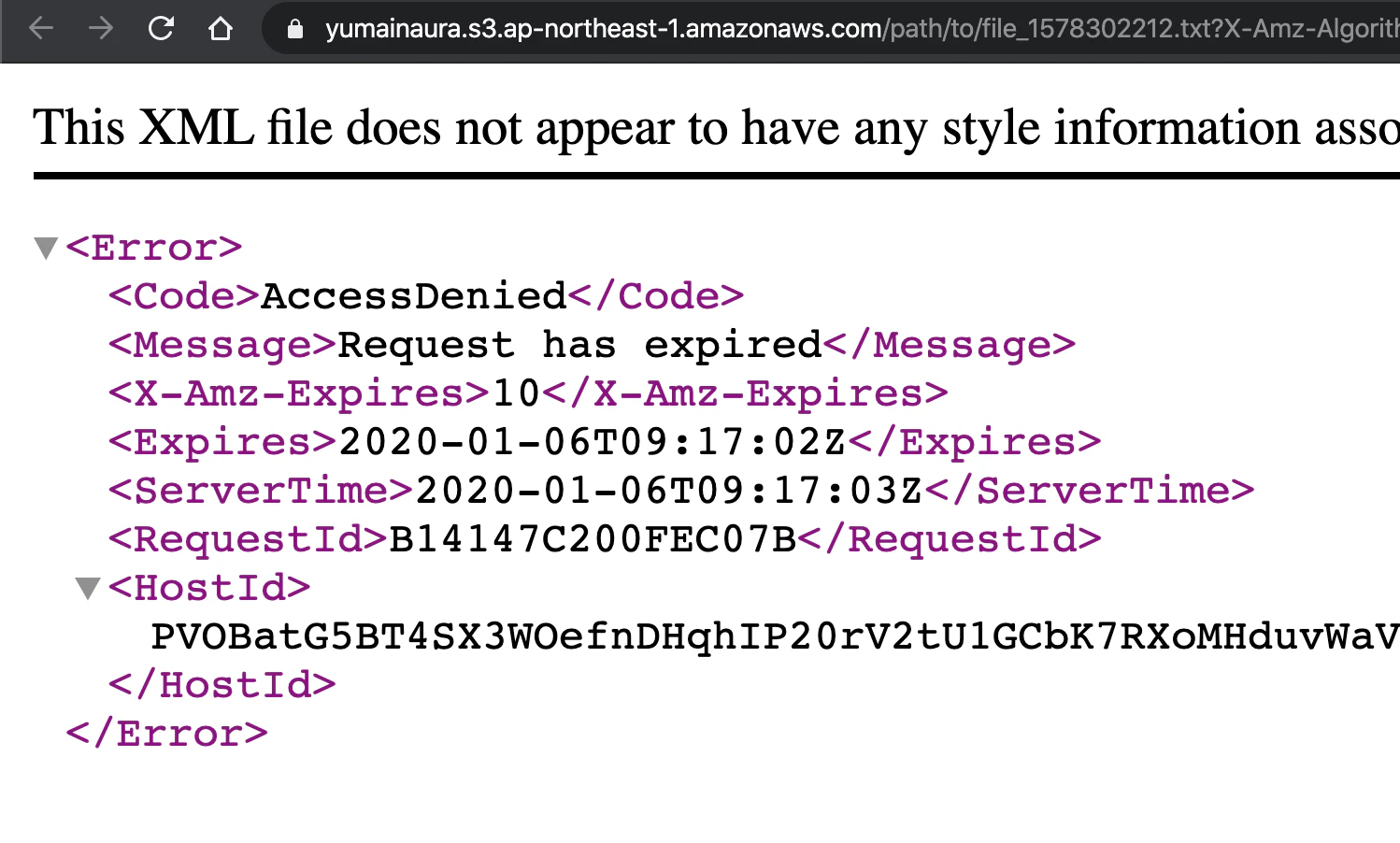
# https://www.rubydoc.info/github/aws/aws-sdk-ruby/Aws%2FS3%2FObject:presigned_url require 'aws-sdk-s3' credentials = Aws::Credentials.new(ENV['AWS_ACCESS_KEY_ID'], ENV['AWS_SECRET_ACCESS_KEY']) s3_resource = Aws::S3::Resource::new(region: ENV['AWS_REGION'], credentials: credentials) # e.g ap-northeast-1 # If no bucket then create # s3_bucket.create s3_bucket = s3_resource.bucket(ENV['AWS_BUCKET']) # <Aws::S3::Bucket:0x00007fd7145b34f0 @arn=nil, @client=#<Aws::S3::Client>, @data=nil, @name="yumainaura", @waiter_block_warned=false> object = s3_bucket.object("path/to/file_#{Time.now.to_i}.txt") # #<Aws::S3::Object:0x00007fd7139fb8b0 # @bucket_name="yumainaura", # @client=#<Aws::S3::Client>, # @data=nil, # @key="path/to/file_1578302095.txt", # @waiter_block_warned=false> object.put(body: 'ABC') presigned_url = object.presigned_url(:get, expires_in: 10) # => "https://yumainaura.s3.ap-northeast-1.amazonaws.com/path/to/file_1578302095.txt?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4INFFTNLCQ6PIZOP%2F20200106%2Fap-northeast-1%2Fs3%2Faws4_request&X-Amz-Date=20200106T091516Z&X-Amz-Expires=10&X-Amz-SignedHeaders=host&X-Amz-Signature=f413cb0d564b69422f58b988cd2cbe39f4ca6b52e7a5e2975d1e22094706d3a0" p presigned_urlBrowser
access to text file
10 seconds later
Original by Github issue

- 投稿日:2020-01-07T19:34:31+09:00
#Ruby + #AWS S3 / パブリックに一時アクセス可能な「resigned URL」を発行するコード例
Ref
【AWS S3】S3 Presigned URLの仕組みを調べてみた - Qiita
https://qiita.com/tmiki/items/87697d3d3d5330c6fc08Code
# https://www.rubydoc.info/github/aws/aws-sdk-ruby/Aws%2FS3%2FObject:presigned_url require 'aws-sdk-s3' credentials = Aws::Credentials.new(ENV['AWS_ACCESS_KEY_ID'], ENV['AWS_SECRET_ACCESS_KEY']) s3_resource = Aws::S3::Resource::new(region: ENV['AWS_REGION'], credentials: credentials) # e.g ap-northeast-1 # If no bucket then create # s3_bucket.create s3_bucket = s3_resource.bucket(ENV['AWS_BUCKET']) # <Aws::S3::Bucket:0x00007fd7145b34f0 @arn=nil, @client=#<Aws::S3::Client>, @data=nil, @name="yumainaura", @waiter_block_warned=false> object = s3_bucket.object("path/to/file_#{Time.now.to_i}.txt") # #<Aws::S3::Object:0x00007fd7139fb8b0 # @bucket_name="yumainaura", # @client=#<Aws::S3::Client>, # @data=nil, # @key="path/to/file_1578302095.txt", # @waiter_block_warned=false> object.put(body: 'ABC') presigned_url = object.presigned_url(:get, expires_in: 10) # => "https://yumainaura.s3.ap-northeast-1.amazonaws.com/path/to/file_1578302095.txt?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4INFFTNLCQ6PIZOP%2F20200106%2Fap-northeast-1%2Fs3%2Faws4_request&X-Amz-Date=20200106T091516Z&X-Amz-Expires=10&X-Amz-SignedHeaders=host&X-Amz-Signature=f413cb0d564b69422f58b988cd2cbe39f4ca6b52e7a5e2975d1e22094706d3a0" p presigned_urlBrowser
access to text file
10 seconds later
Original by Github issue
- 投稿日:2020-01-07T19:34:27+09:00
[AWS] EC2からRDS(MySQL)へ接続する方法
参考記事
Amazon RDS編~EC2インスタンスからDBインスタンスへの接続~
EC2からデータベースの中身をみるには
- EC2へssh接続する
- 接続するコマンドを入力する
- 設定したパスワードを入力する
のたった三つの手順です。
接続するコマンドとは
こちらです
mysql -h エンドポイント -P 3306 -u ユーザー名 -p データベース名各パラメータの確認方法
エンドポイント
- AWSへログイン
- サービスから「RDS」を選択
- "データベース"から接続したいデータベースを選択
- 【接続とセキュリティ欄】にてエンドポイントを確認
ユーザー名
1~3まではエンドポイントと同じ
4. 【設定】にてユーザー名を確認データベース名
エンドポイントやユーザー名を確認した際のデータベース名です
以上です
qiita初投稿でした。至らない点があると思いますが、ご指摘いただけたらと思います。
また、この記事がどなたかのお役に立てれば幸いです。
- 投稿日:2020-01-07T16:13:48+09:00
aws cliでセキュリティグループにICMPのルールを追加するときのPortの意味
aws cliでセキュリティグループにICMPのルールを追加するとき、
FromPort、ToPortには0、65535でも指定しておけば良いのかなと思ったらエラーになった。$ aws ec2 authorize-security-group-ingress --group-id sg-xxxxxxxx --ip-permissions IpProtocol=icmp,FromPort=0,ToPort=65535,IpRanges='[{CidrIp=999.999.999.999/32,Description="Example"}]' An error occurred (InvalidParameterValue) when calling the AuthorizeSecurityGroupIngress operation: ICMP code (65535) out of range0、0にしたらエラーにはならなかったけど、プロトコルが
エコー応答として登録された。プロトコルはすべてで登録したい。調べてみたところ、ICMPのルールを追加するときの
FromPort、ToPortにはICMP codeを指定するらしい。authorize-security-group-ingress — AWS CLI 1.16.311 Command Reference
0はエコー応答なのね。
Internet Control Message Protocol - Wikipedia
すべてを指定したい時は−1を指定すれば良いようなので、FromPort、ToPortに−1を指定したら、プロトコル:すべてで無事登録された。$ aws ec2 authorize-security-group-ingress --group-id sg-xxxxxxxx --ip-permissions IpProtocol=icmp,FromPort=-1,ToPort=-1,IpRanges='[{CidrIp=999.999.999.999/32,Description="Example"}]'大量のIP許可設定とかやる時はCLIがやっぱり便利。
- 投稿日:2020-01-07T16:00:38+09:00
ecs-cliでHelloWorldしてみた
背景
あるバッチ処理をクラウド上で定期実行させたかった。
色々調べてた所、ECS-Fargateで定期実行が出来るみたい。
とりあえず雰囲気掴むためにHelloWorldしてみた。チュートリアル
公式チュートリアル: Amazon ECS CLI を使用して Fargate タスクのクラスターを作成する
手順
1. config編集
$ ecs-cli configure --cluster hello-world --default-launch-type FARGATE --region ap-northeast-1 --config-name hello-world $ cat ~/.ecs/config version: v1 default: ecs-cli-test-config clusters: hello-world: cluster: hello-world region: ap-northeast-1 default_launch_type: FARGATE2. credential編集
$ export AWS_ACCESS_KEY_ID=xxxxxxxxx $ export AWS_SECRET_ACCESS_KEY=xxxxxx上記を実行した状態で、
$ ecs-cli configure profile --profile-name ecs-profile --access-key $AWS_ACCESS_KEY_ID --secret-key $AWS_SECRET_ACCESS_KEY $ cat ~/.ecs/credentials version: v1 default: ecs-profile ecs_profiles: ecs-profile: aws_access_key_id: 【AWS_ACCESS_KEY】 aws_secret_access_key: 【AWS_SECRET_KEY】3. クラスター作成
$ ecs-cli up --cluster-config hello-world --ecs-profile ecs-profile --force INFO[0001] Created cluster cluster=hello-world region=ap-northeast-1 INFO[0002] Waiting for your cluster resources to be created... INFO[0003] Cloudformation stack status stackStatus=CREATE_IN_PROGRESS INFO[0064] Cloudformation stack status stackStatus=ROLLBACK_FAILED INFO[0125] Cloudformation stack status stackStatus=ROLLBACK_FAILED INFO[0186] Cloudformation stack status stackStatus=ROLLBACK_FAILED→ CloudFormationの作成途中で止まっている模様
AWSコンソール上、
CloudFormation > スタック > amazon-ecs-cli-setup-hello-world
にてエラー内容を確認イベントで各種権限が足りないよとのエラーが表示
ex. CloudFormationでのエラーの一部
↓
IAM編集(権限追加)ec2:DeleteVpc ec2:DescribeVpcs ec2:CreateInternetGateway ec2:DescribeInternetGateways ec2:ModifyVpcAttribute ec2:DeleteInternetGateway ec2:DescribeAvailabilityZones ec2:DescribeAccountAttributes ec2:DescribeSubnets ec2:CreateRouteTable ec2:CreateSubnet ec2:AttachInternetGateway ec2:DeleteSubnet ec2:DeleteRouteTable ec2:DetachInternetGateway ec2:CreateRoute ec2:AssociateRouteTable ec2:DeleteRoute cloudformation:DescribeStackResources↓
$ ecs-cli up --cluster-config hello-world --ecs-profile ecs-profile --force INFO[0001] Created cluster cluster=hello-world region=ap-northeast-1 INFO[0002] Waiting for your CloudFormation stack resources to be deleted... INFO[0002] Cloudformation stack status stackStatus=DELETE_IN_PROGRESS INFO[0034] Waiting for your cluster resources to be created... INFO[0035] Cloudformation stack status stackStatus=CREATE_IN_PROGRESS INFO[0096] Cloudformation stack status stackStatus=CREATE_IN_PROGRESS VPC created: 【VPC_ID】 Subnet created: 【SUBNET_ID_A】 Subnet created: 【SUBNET_ID_B】 Cluster creation succeeded.4. 作成したVPCのセキュリティグループIDを取得
$ aws2 ec2 describe-security-groups --filters Name=vpc-id,Values=【VPC_ID】 --region ap-northeast-1 An error occurred (UnauthorizedOperation) when calling the DescribeSecurityGroups operation: You are not authorized to perform this operation.権限(ec2:DescribeSecurityGroups)が必要なので注意
5. docker-compose.yml/ecs-params.yml を用意する
ecs-params.ymlversion: 1 task_definition: task_execution_role: ecsTaskExecutionRole ecs_network_mode: awsvpc task_size: mem_limit: 0.5GB cpu_limit: 256 run_params: network_configuration: awsvpc_configuration: subnets: "【SUBNET_ID_A】" "【SUBNET_ID_B】" security_groups: "【SECURITY_GROUP_ID】" assign_public_ip: ENABLEDdocker-compose.ymlhello_world: cpu_shares: 135 mem_limit: 131072000 image: hello-world log_driver: awslogs log_opt: awslogs-group: "tutorial" awslogs-region: "ap-northeast-1" awslogs-stream-prefix: "hello-world"6. 5で作成したファイルを元にデプロイ
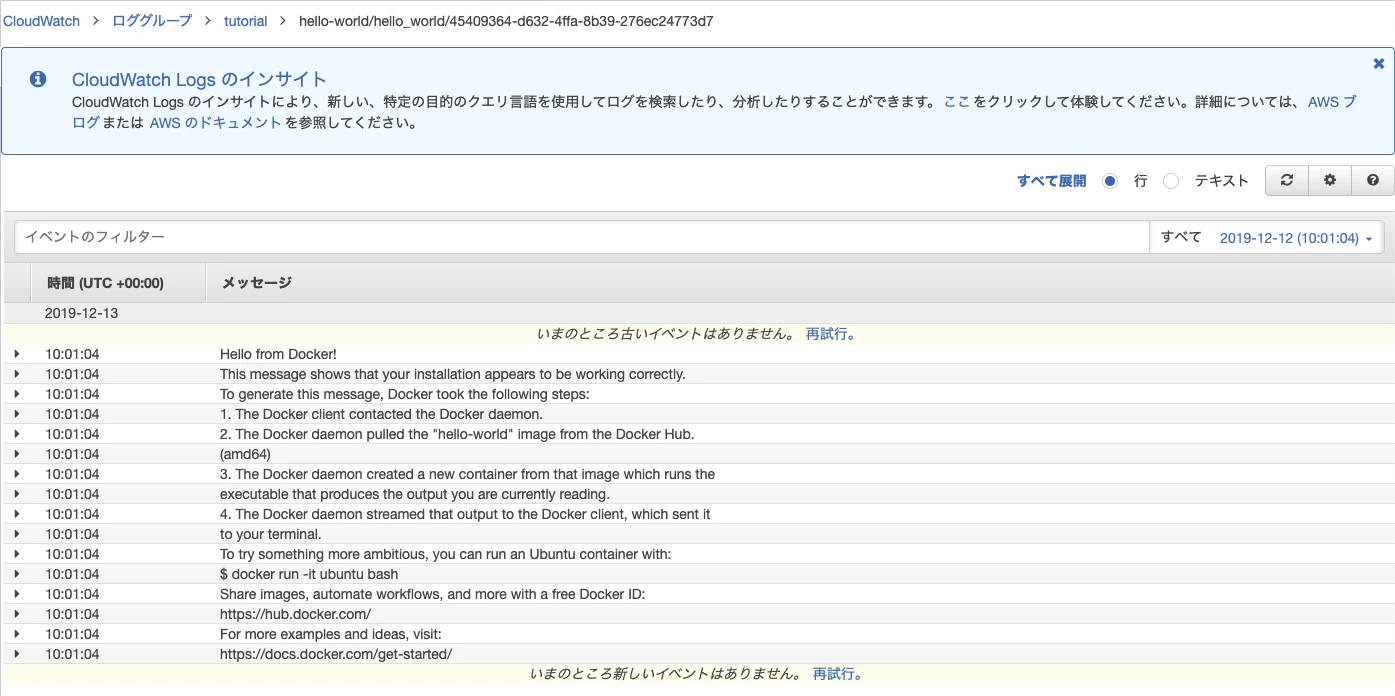
# カレントディレクトリにあるファイルを自動で参照 $ ecs-cli compose up # ファイルを指定する場合 $ ecs-cli compose -f docker-compose.yml --ecs-params ecs-params.yml up7. CloudWatchLogsを確認
docker-compose.ymlにlogの設定をawslogsに設定しているので、CloudWatchLogsにログが流れているはず。
AWSコンソール上で、
CloudWatch > ロググループ > tutorial > hello-world/hello_world/45409364-d632-4ffa-8b39-276ec24773d7
よしよし、想定通り!!
まとめ
あとは、ECRに実行したいバッチ処理のイメージ載せて、タスク定義とタスク作って、スケジュール組むだけ。
割とすんなりいく印象。もう少しいじってみたいと思います。

- 投稿日:2020-01-07T14:50:53+09:00
STOPPEDになってから1時間以上経過したECSタスクの起動ログを確認する
TL;DR
CloudTrailイベント履歴から、RunTask APIの実行結果を参照します。
概要
ECSのコンソールで確認できるECSのタスク実行結果は、1時間以内のものに限られています
(それ以上昔の実行結果の表示は保証されない)
夜間のバッチ処理が失敗していたときなど、すぐに気がつけなかったときは困ります。CloudTrailから証跡を確認しましょう。手順
基本的にCluodTrailの公式ドキュメントに沿う形で進めます。
https://docs.aws.amazon.com/ja_jp/awscloudtrail/latest/userguide/view-cloudtrail-events-console.html
CloudTrailのコンソールを開きます。
https://ap-northeast-1.console.aws.amazon.com/cloudtrail/homeイベント名
RunTaskで絞り込みます。
目当てのイベントを見つけたら
イベントの表示でAPIの実行結果を参照します。
以上です。

- 投稿日:2020-01-07T11:16:35+09:00
New – Amazon Comprehend Medical Adds Ontology Linking 和訳してみた
はじめに
Danilo Poccia 氏が2019年12月16日に投稿した「New – Amazon Comprehend Medical Adds Ontology Linking」の記事を翻訳し、まとめてみました。
■本記事 URL
New – Amazon Comprehend Medical Adds Ontology LinkingAmazon Comprehend
Amazon Comprehend とは
Amazon Comprehend は自然言語処理サービス(NLP)で、機械学習を用いて非構造化された文章の中から洞察を見つけるサービスです。本サービスは機械学習の知識が無くとも利用でき、そしてユーザ自身でカスタマイズすることが可能です。
※当サービスは東京リージョンでは利用できませんのでご注意ください(2020年1月6日現在)そして昨年、AWS では医学用語にも対応できるよう Amazon Comprehend Medical という新サービスを紹介しました。こちらのサービスを用いることで、機械学習を利用して関連する医学情報を非構造化テキストから抜き出すことが、より簡単になります。Amazon Comprehend Medical を使用すれば、医療情報を素早く、そして正確に集めることができます。
オントロジー
オントロジーはドメインの宣言型モデルを提供し、そしてそのドメインに内在する関係性や属性といったコンセプトを定義し、表しています。
通常は知識ベースで表され、知識の使用、あるいは共有の必要があるアプリで利用が可能です。健康情報学的には、オントロジーは健康関連ドメインのフォーマルな記述です。Amazon Comprehend Medical でサポートされているオントロジーは以下の2つです。
- 病状をエンティティとして識別する
- 診断、重症度、解剖学的区別などの関連情報を、エンティティの属性としてリンクする
- 薬物をエンティティとして識別する
- 用量、頻度、強度、投与経路などの属性を、エンティティにリンクする
それぞれのオントロジーに対して、Comprehend Medical はランク付けされた潜在的マッチングリストを出します。ユーザは信頼度スコアを通じて、どのマッチングが意味が通じるかを判断したり、また、より深く検討するために何が必要なのかを判断することができます。
オントロジーのリンクの利用
オントロジーのリンクがどの様なものか、試して見ます。 Comprehend Medical コンソール上で利用することができます。
非構造化された医者のメモを、Input に入力します。
はじめに、Comprehend Medical で既に利用可能な機能を使用して、医療や保護された健康情報(PHI)エンティティを検出します。
認識されたエンティティの中には、症状や薬品なども認識されていました。薬品はジェネリック、あるいはブランドとして認識されているので、これらのエンティティをより具体的なコンセプトと結びつけましょう。
新しい機能を使用し、これらのエンティティを 医薬品の RxNorm コンセプトとリンクさせます。
テキストでは、医薬品について触れている部分だけが検出されました。回答の詳細には、より多くの情報が載っています。詳しく見てみましょう
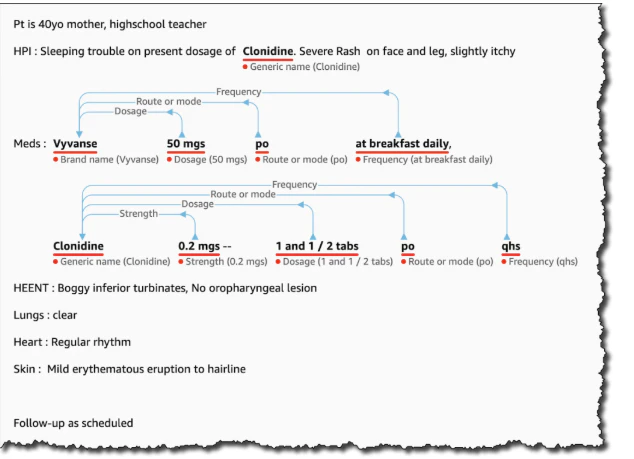
- 最初に登場した “Clonidine” は RxNorm オントロジーの一般的な概念と結びついてます
- 2回目に登場した “Clonidine” は具体的な投与量と結びつきいており、RxNorm オントロジーの投与量を含むより規範的な形式とリンクしてますICD-10-CM コンセプトを使用したメディカルコンディションを見るために、先程とは異なるインプットを入力します。
症状や診察といった、特定のコンセプトと検出されたエンティティをリンクさせます。
予想通り、症状や診察などはエンティティとして検出されました。詳細な結果では、それらのエンティティは ICD-10-CM オントロジーのメディカルコンディションとリンクされていました。例えば、入力テキストにある2つの主な症状はトップの結果であり、オントロジーの特定の概念はComprehend Medicalによって推測され、それぞれ独自のスコアがついています。
おわりに
Amazon Comprehend Medical はAWS CLI 、AWS SDK 、そしてコンソール上から利用することができ、従量課金となっております。医療分野で AWS の利用を考えている方は、この機会に是非このサービスを利用してみてください。





- 投稿日:2020-01-07T10:30:38+09:00
今年できるようになったこと・来年の目標
はじめに
Qiitaに投稿をはじめてまだ間もないですが、せっかくの年末年始なので今年できるようになったことと来年の目標を書いていこうと思います。
簡単に自己紹介
とある会社でIT部門に配属され、2020年1月現在新卒2年目です。
大学までスポーツに明け暮れ、文系大学で心理学を専攻し、イギリス留学で英語に目覚め、なんだかんだあってプログラムを書いています。
プログラミング自体はもともと興味があり、初めてのHello world はプログラミングのオンラインスクールに通い始めた20歳の夏でした(照)
当時はhtml/css/JS/phpを基礎の基礎レベルで書いており、教材通りに書いただけで俺はなんでも作れるという謎の全能感に支配されていたのですが、入社してからボコボコにされて日々勉強に追われています。現在は社会人としてオンライン行動データのアクセスログ計測サービスの開発に携わっております。
今年できるようになったこと
自身が触ってみて身についたと感じるものをサービス/言語ごとに超簡単にまとめていきます。
真面目に書きます。AWS
AWSはかなり多くの種類のサービスを触りました。
業務でもメインで扱っているクラウドサービスで勉強の重要度もかなり高いです。【取得した資格】
・AWS Certified Cloud Practitioner(English)Cloud Front
・CloudFrontの基本的な仕組み
・EdgeLocation、キャッシングによるレイテンシーの低減
・Distributionの設定、ログとS3バケットとの連携
・Behaviourによるリクエストの振り分けCloud Watch
・CloudWatchの基本的な仕組み、メリット
・ダッシュボードの作成、参照、設定等
・アラームの設定
・アラームからスケーリングやSNSとの連携Route53
・AWSのDNSサービスとしてのRoute53
・各種レコードの概要
・AレコードにはELBも設定可能
・Route53で設定可能なルーティングポリシーと各種ポリシーのメリット/デメリット
・ブルーグリーンデプロイメントEC2
・インスタンスのセットアップ(AMI/インスタンスタイプ/VPC/サブネット/AvailavilityZone/セキュリティグループ)
ELB/ALB
・health checkによるインスタンスの健康管理
・リクエスト分配、ポート管理
・ターゲットグループの設定AutoScaling
・起動設定の各種設定項目の理解
・スケーリングポリシー(条件、台数、AMI、インスタンスキャパシティ)S3
・S3の仕組みの基本的な理解
・グローバルアクセスとリージョンの設定
・webサイトホスティングによる静的コンテンツへのリクエスト・レスポンス
・AWS CLIからの基本的操作(コピー、削除、アップロード、ダウンロード)
・ファイルのバージョン管理(バージョニング)
・IPアドレス、IAMによるアクセス制限
・バケットイベント(putイベントのみ)
・料金管理/最適化Athena
・基本的なクエリ操作(select, create table, CTAS, insert, drop table, alter table)
・パーティションの設定
・AWS CLIからの操作
・料金管理RDS
・RDSのメリット(スケーリングやセットアップの手軽さ、他AWSサービスとの連携)
・基本的なクエリ操作
・インスタンスサイズ(まだちょっと怪しい)
・VPC/サブネット/AZSystems Manager
・対象インスタンスの選択からコマンドの実行
・コマンドが途中でエラーになってもSUCCESSで終了することがある(なんとかしてくれ)ECS
・タスク定義の各種設定
・ECRのリポジトリ指定
・クラスターの設定/サービスの管理/タスクのモニタリング
・ドレイニングECR
・基本的なリポジトリ操作
・imageタグの作成プッシュまでCode Commit
・code commitでの基本的なバージョン管理の仕組み理解
・基本操作(add/commit/push)Secrets Manager
・Secrets Managerを使用するメリット
・キーの設定方法
・APIによるキーやキー情報の取得※別記事を書いてます!
AWS Secrets Managerを使おう!Trusted Advisor
・料金や仕様状況ダッシュボードの見方
Jenkins
・CIツールとは Jenkinsのメリットとは
・Jenkinsの基本的な仕組みの理解
・JenkinsCLIからの操作(job一覧取得/job作成/ビルド/jobの削除)
・Jenkinsのディレクトリ構成、jobの設定ファイル等の操作
・crontab(jobの定期実行周りで覚えたのでここに書きます。)※別記事を書いてます!
JenkinsJobの情報を取得する扱っている言語
php
自分が一番メインで書いている言語になります。
バージョンが5.6だなんて言えない・・・・基本的処理
・フレームワーク Laravel/CakePHP(EOL来てますが・・・)の基本文法理解
・DB操作(MySQL)
・s3、Athena操作shell script
最近はphpより書いている気がします。
最初は大嫌いでしたが半年くらい付き合っていたら好きになっちゃいました。・基本的処理
・DB処理(MySQL)
・Linuxコマンド各種python
ほとんど触ってないですしフレームワークもよくわかりません。
でも一応触ったので。。。その他
・ApacheJmeter
・OWASP ZAP
・cookieのsamesite属性周り
・ITP周りの規制関連の話
などなど・・・来年の目標
僕は正直売り上げを生むサービスを作るよりも考える方に快感を覚える性格なので、エンジニアリングのスキルは勿論のばしつつ、上流工程や企画にも積極的に参加していけたらと考えております。
ここでは一旦技術面の目標のみ書いておきます。資格
・AWS Certified Solutions Architect Associate
AWSの知識は本当に持っていて損はないどころか、もっと知識を付けないと会社で運営しているサービスにも追い付けないのでこれは必須にします。英語でとります。・AWS Certified SysOps Administrator Associate
上流工程に関わっていくにはベストプラクティスの提示や料金の最適化も検討できるようになる必要があるのでこの資格も狙っていきたいです。英語です。Seleniumを覚える!
業務ではブラウザ操作を行うテストが多く、単純な操作も多いので是非自動化したいと考えています。
まだ全く触っていないので具体的に何ができるかなど詳細は分かっていませんが、絶対キャッチしておきたいと思っています。Tableauを覚える!
業務等で使用する機会は今のところありませんが、BIツールについてしっかり知っておきたいので空き時間に触っていこうと思います。
まとめ
想像より時間がかかりましたが、自分の知識がどれほど身についているか、どこがまだわからないのかなどがはっきりするため、知識の棚卸は大切だと感じました。
今年中にしっかりと上記の目標を達成できるように空き時間を有効に使っていこうと思います!
- 投稿日:2020-01-07T10:25:45+09:00
M5StackでAmazon FreeRTOSを使用する6(OTA編)
はじめに
Amazon FreeRTOSのデバイス管理、次はOTAを試してみましょう。AWS S3に新しいファームウェアを置いてデバイスに配布することができます。
AWSのドキュメント Amazon FreeRTOS 無線による更新 の流れに沿って作業を行います。
前提条件
無線による更新(OTA)の前提条件として次のものがあります
1.更新を保存する Amazon S3 バケットを作成する.
新しいファームウェアを格納する場所を作成します。バージョニングを有効にする必要があります。
2.OTA 更新サービスロールの作成.
OTA 更新ジョブを実行する権限です。OTA 用のロールを作成して「AmazonFreeRTOSOTAUpdate」ポリシーをアタッチします。
「AWSIoTThingsRegistration 」のほうは一緒に割り当てられました。3.OTA ユーザーポリシーの作成.
AWS IoTコンソールから配布する人の権限。(おすすめできませんが、ルートアカウントでテストする場合はスキップ可能)
4.コード署名証明書の作成.
ファームウェアへの署名用。
OpenSSL、AWS CLI がインストールされた環境で、Espressif ESP32 のコード署名証明書の作成 を実行します。5.Code Signing for AWS IoT を使用している場合は、Code Signing for AWS IoT へのアクセスの許可.
AWS IoTコンソールから配布するファームに署名する人の権限(おすすめできませんが、ルートアカウントでテストする場合はスキップ可能)
6.OTA ライブラリで Amazon FreeRTOS をダウンロードする.
アプリケーション作成用。すでにサンプルアプリケーションを作成している場合は不要。
アプリケーション
前回 作成したファームウェアのバージョン、接続時刻をシャドウに送信するアプリケーションにOTAを追加します。
ネットワーク、MQTTに接続してOTA_AgentInitを呼び出します。void vRunOTAUpdateDemo( IotMqttConnection_t mqttConnection, const IotNetworkInterface_t * pNetworkInterface, void * pNetworkCredentialInfo ) { // IotMqttConnectInfo_t xConnectInfo = IOT_MQTT_CONNECT_INFO_INITIALIZER; OTA_State_t eState; OTA_ConnectionContext_t xOTAConnectionCtx = { 0 }; configPRINTF( ( "OTA demo version %u.%u.%u\r\n", xAppFirmwareVersion.u.x.ucMajor, xAppFirmwareVersion.u.x.ucMinor, xAppFirmwareVersion.u.x.usBuild ) ); configPRINTF( ( "Creating MQTT Client...\r\n" ) ); xOTAConnectionCtx.pvControlClient = mqttConnection; xOTAConnectionCtx.pxNetworkInterface = ( void * ) pNetworkInterface; xOTAConnectionCtx.pvNetworkCredentials = pNetworkCredentialInfo; OTA_AgentInit( ( void * ) ( &xOTAConnectionCtx ), ( const uint8_t * ) ( clientcredentialIOT_THING_NAME ), App_OTACompleteCallback, ( TickType_t ) ~1 ); while( ( eState = OTA_GetAgentState() ) != eOTA_AgentState_Stopped ) { /* Wait forever for OTA traffic but allow other tasks to run and output statistics only once per second. */ vTaskDelay( myappONE_SECOND_DELAY_IN_TICKS ); configPRINTF( ( "State: %s Received: %u Queued: %u Processed: %u Dropped: %u\r\n", pcStateStr[ eState ], OTA_GetPacketsReceived(), OTA_GetPacketsQueued(), OTA_GetPacketsProcessed(), OTA_GetPacketsDropped() ) ); } }Espressif ESP32 にファームウェアの初期バージョンをインストールする の通り、無線による更新の前提条件 で生成した SHA-256/ECDSA PEM 形式のコード署名証明書(サンプル通りであれば、ecdsasigner.crt の内容)を demos/include/aws_ota_codesigner_certificate.h にコピーします。これは、次の方法でフォーマットする必要があります。
static const char signingcredentialSIGNING_CERTIFICATE_PEM[] = "-----BEGIN CERTIFICATE-----\n" ...base64 data...\n" -----END CERTIFICATE-----\n";ビルドできたら、フラッシュします。
Espressif ESP32 にファームウェアの初期バージョンをインストールする のように、ネットワークに接続し、shadowを更新した後に、OTA待ちになります。
アプリケーションのバージョンアップ
1.demos/include/aws_application_version.h を開き、APP_VERSION_BUILD トークン値を増やします。今回の例では0.9.2 → 0.9.3になります。
2.アプリケーションをビルドします。
3.ファームウェアをS3にアップロードします。サンプルであれば、build/freertos-ex.bin ファイルをアップロードします。
OTA 更新の作成 (AWS IoT コンソール)
AWS IoT コンソールから、対象デバイスの指定、更新するファイル(ファームウェア)の選択、署名を指定して、更新ジョブを作成します。
まだジョブがない場合はこんな画面。すでにジョブがある場合は右上にボタンが表示されます。
Amazon FreeRTOS 無線通信経由 (OTA) の更新ジョブの作成
更新するデバイスを選択
今回はプロトコルにMQTTを選択、新しいファームウェアイメージに署名します、を選択
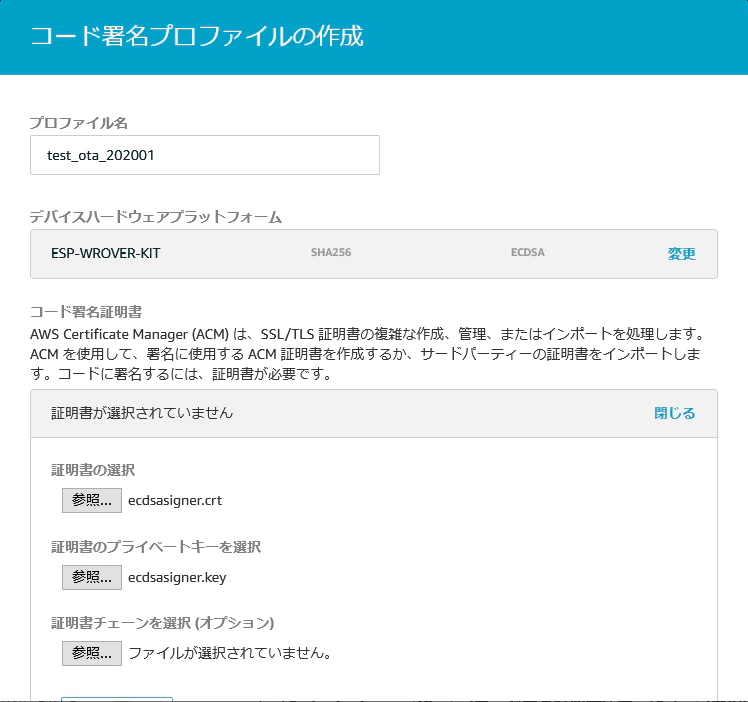
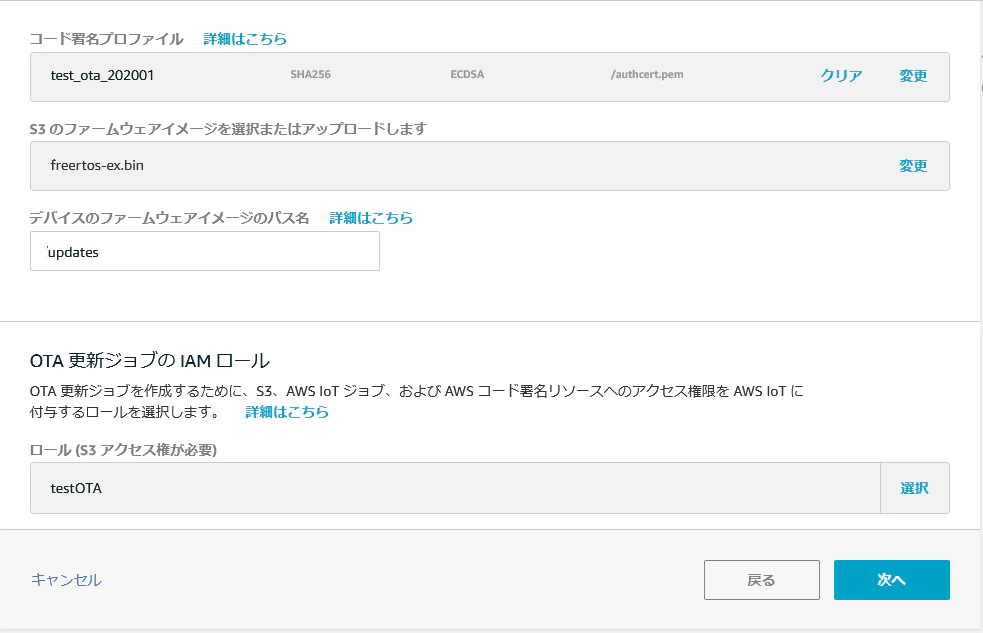
コード署名プロファイルを作成します。作成済の証明書、鍵を指定します。テストでは、aws_ota_codesigner_certificate.h が使用されるため、デバイスのコード署名証明書のパス名は、指定した値は実行時に無視されます。
S3 のファームウェアイメージを選択します。デバイスのファームウェアイメージのパス名はupdatesとしました。(このパス名でダウンロードされる???)
ジョブを実行すると、次のようなログが表示されて更新が始まり、終了するとデバイスが再起動されます。
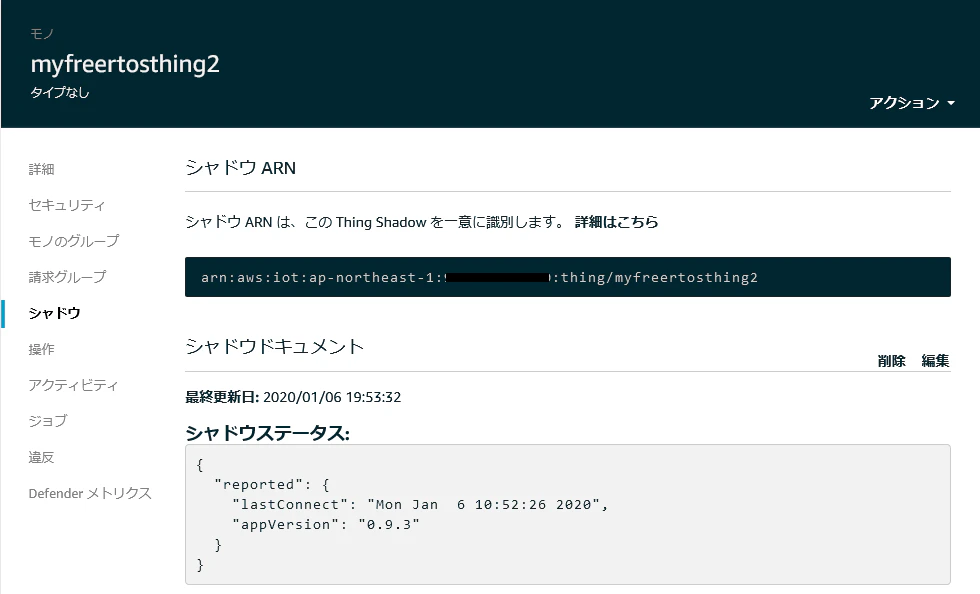
109 7334 [iot_thread] OTA demo version 0.9.2 110 7334 [iot_thread] Creating MQTT Client... 111 7335 [iot_thread] [OTA_AgentInit_internal] OTA Task is Ready. 112 7335 [OTA Agent Task] [prvOTAAgentTask] Called handler. Current State [Ready] Event [Start] New state [RequestingJob] 113 7335 [OTA Agent Task] [INFO ][MQTT][73350] (MQTT connection 0x3ffe1edc) SUBSCRIBE operation scheduled. 114 7335 [OTA Agent Task] [INFO ][MQTT][73350] (MQTT connection 0x3ffe1edc, SUBSCRIBE operation 0x3ffe895c) Waiting for operation completion. 115 7341 [OTA Agent Task] [INFO ][MQTT][73410] (MQTT connection 0x3ffe1edc, SUBSCRIBE operation 0x3ffe895c) Wait complete with result SUCCESS. 116 7341 [OTA Agent Task] [prvSubscribeToJobNotificationTopics] OK: $aws/things/myfreertosthing2/jobs/$next/get/accepted 117 7341 [OTA Agent Task] [INFO ][MQTT][73410] (MQTT connection 0x3ffe1edc) SUBSCRIBE operation scheduled. 118 7341 [OTA Agent Task] [INFO ][MQTT][73410] (MQTT connection 0x3ffe1edc, SUBSCRIBE operation 0x3ffe8c18) Waiting for operation completion. 119 7346 [OTA Agent Task] [INFO ][MQTT][73460] (MQTT connection 0x3ffe1edc, SUBSCRIBE operation 0x3ffe8c18) Wait complete with result SUCCESS. 120 7346 [OTA Agent Task] [prvSubscribeToJobNotificationTopics] OK: $aws/things/myfreertosthing2/jobs/notify-next 121 7346 [OTA Agent Task] [prvRequestJob_Mqtt] Request #0 122 7348 [OTA Agent Task] [INFO ][MQTT][73460] (MQTT connection 0x3ffe1edc) MQTT PUBLISH operation queued. 123 7348 [OTA Agent Task] [INFO ][MQTT][73480] (MQTT connection 0x3ffe1edc, PUBLISH operation 0x3ffe895c) Waiting for operation completion. 124 7351 [OTA Agent Task] [INFO ][MQTT][73510] (MQTT connection 0x3ffe1edc, PUBLISH operation 0x3ffe895c) Wait complete with result SUCCESS. 125 7351 [OTA Agent Task] [prvOTAAgentTask] Called handler. Current State [RequestingJob] Event [RequestJobDocument] New state [WaitingForJob] 126 7352 [OTA Agent Task] [prvParseJobDoc] Size of OTA_FileContext_t [64] 127 7353 [OTA Agent Task] [prvParseJSONbyModel] Extracted parameter [ clientToken: 0:myfreertosthing2 ] 128 7353 [OTA Agent Task] [prvParseJSONbyModel] parameter not present: execution 129 7353 [OTA Agent Task] [prvParseJSONbyModel] parameter not present: jobId 130 7353 [OTA Agent Task] [prvParseJSONbyModel] parameter not present: jobDocument 131 7353 [OTA Agent Task] [prvParseJSONbyModel] parameter not present: afr_ota 132 7353 [OTA Agent Task] [prvParseJSONbyModel] parameter not present: protocols 133 7353 [OTA Agent Task] [prvParseJSONbyModel] parameter not present: files 134 7353 [OTA Agent Task] [prvParseJSONbyModel] parameter not present: filepath 135 7353 [OTA Agent Task] [prvParseJSONbyModel] parameter not present: filesize 136 7353 [OTA Agent Task] [prvParseJSONbyModel] parameter not present: fileid 137 7353 [OTA Agent Task] [prvParseJSONbyModel] parameter not present: certfile 138 7353 [OTA Agent Task] [prvParseJSONbyModel] parameter not present: sig-sha256-ecdsa 139 7353 [OTA Agent Task] [prvDefaultCustomJobCallback] Received Custom Job inside OTA Agent which is not supported. 140 7353 [OTA Agent Task] [prvParseJobDoc] Ignoring job without ID. 141 7354 [OTA Agent Task] [prvOTA_Close] Context->0x0x3fff8c40 I (73859) ota_pal: prvPAL_SetPlatformImageState, 4 W (73959) ota_pal: Set image as aborted! I (73969) esp_ota_ops: aws_esp_ota_get_boot_flags: 1 I (73979) esp_ota_ops: [0] aflags/seq:0x2/0x1, pflags/seq:0xffffffff/0x0 W (73979) ota_pal: Image not in self test mode 2 I (73989) esp_ota_ops: aws_esp_ota_get_boot_flags: 1 I (73989) esp_ota_ops: [0] aflags/seq:0x2/0x1, pflags/seq:0xffffffff/0x0 142 7368 [OTA Agent Task] [prvOTAAgentTask] Handler failed. Current State [WaitingForJob] Event [ReceivedJobDocument] Error Code [603979776] 143 7435 [iot_thread] State: Ready Received: 1 Queued: 0 Processed: 0 Dropped: 0 144 7535 [iot_thread] State: WaitingForJob Received: 1 Queued: 0 Processed: 0 Dropped: 0 145 7635 [iot_thread] State: WaitingForJob Received: 1 Queued: 0 Processed: 0 Dropped: 0 146 7735 [iot_thread] State: WaitingForJob Received: 1 Queued: 0 Processed: 0 Dropped: 0 147 7835 [iot_thread] State: WaitingForJob Received: 1 Queued: 0 Processed: 0 Dropped: 0 148 7935 [iot_thread] State: WaitingForJob Received: 1 Queued: 0 Processed: 0 Dropped: 0 149 8035 [iot_thread] State: WaitingForJob Received: 1 Queued: 0 Processed: 0 Dropped: 0 150 8135 [iot_thread] State: WaitingForJob Received: 1 Queued: 0 Processed: 0 Dropped: 0 151 8235 [iot_thread] State: WaitingForJob Received: 1 Queued: 0 Processed: 0 Dropped: 0 152 8335 [iot_thread] State: WaitingForJob Received: 1 Queued: 0 Processed: 0 Dropped: 0 153 8435 [iot_thread] State: WaitingForJob Received: 1 Queued: 0 Processed: 0 Dropped: 0 154 8535 [iot_thread] State: WaitingForJob Received: 1 Queued: 0 Processed: 0 Dropped: 0 155 8635 [iot_thread] State: WaitingForJob Received: 1 Queued: 0 Processed: 0 Dropped: 0 156 8735 [iot_thread] State: WaitingForJob Received: 1 Queued: 0 Processed: 0 Dropped: 0 157 8835 [iot_thread] State: WaitingForJob Received: 1 Queued: 0 Processed: 0 Dropped: 0 158 8935 [iot_thread] State: WaitingForJob Received: 1 Queued: 0 Processed: 0 Dropped: 0 159 8941 [OTA Agent Task] [prvParseJobDoc] Size of OTA_FileContext_t [64] 160 8941 [OTA Agent Task] [prvParseJSONbyModel] Extracted parameter [ jobId: AFR_OTA-20200106_4 ] 161 8941 [OTA Agent Task] [prvParseJSONbyModel] Extracted parameter [ protocols: ["MQTT"] ] 162 8941 [OTA Agent Task] [prvParseJSONbyModel] Extracted parameter [ streamname: AFR_OTA-c30cb685-9965-47e0-9da2-36ec32d4a205 ] 163 8941 [OTA Agent Task] [prvParseJSONbyModel] Extracted parameter [ filepath: updates ] 164 8941 [OTA Agent Task] [prvParseJSONbyModel] Extracted parameter [ filesize: 1011632 ] 165 8941 [OTA Agent Task] [prvParseJSONbyModel] Extracted parameter [ fileid: 0 ] 166 8942 [OTA Agent Task] [prvParseJSONbyModel] Extracted parameter [ certfile: aws_ota_codesigner_certificate.h ] 167 8942 [OTA Agent Task] [prvParseJSONbyModel] Extracted parameter [ sig-sha256-ecdsa: MEQCIHCs4rIMpRX9/y+AWApczDaCvd5w... ] 168 8942 [OTA Agent Task] [prvParseJobDoc] Job was accepted. Attempting to start transfer. I (89739) ota_pal: prvPAL_GetPlatformImageState I (89819) esp_ota_ops: aws_esp_ota_get_boot_flags: 1 I (89819) esp_ota_ops: [0] aflags/seq:0x2/0x1, pflags/seq:0xffffffff/0x0 I (89829) ota_pal: Writing to partition subtype 17 at offset 0x1a0000 169 9049 [iot_thread] State: WaitingForJob Received: 2 Queued: 0 Processed: 0 Dropped: 0 170 9164 [iot_thread] State: WaitingForJob Received: 2 Queued: 0 Processed: 0 Dropped: 0 171 9278 [iot_thread] State: WaitingForJob Received: 2 Queued: 0 Processed: 0 Dropped: 0 I (93829) ota_pal: aws_esp_ota_begin succeeded 172 9351 [OTA Agent Task] [prvSetDataInterface] Data interface is set to MQTT. 173 9351 [OTA Agent Task] [prvProcessJobHandler] Setting OTA data inerface. 174 9351 [OTA Agent Task] [prvOTAAgentTask] Called handler. Current State [WaitingForJob] Event [ReceivedJobDocument] New state [CreatingFile] 175 9351 [OTA Agent Task] [INFO ][MQTT][93510] (MQTT connection 0x3ffe1edc) SUBSCRIBE operation scheduled. 176 9351 [OTA Agent Task] [INFO ][MQTT][93510] (MQTT connection 0x3ffe1edc, SUBSCRIBE operation 0x3fff3dc4) Waiting for operation completion. 177 9355 [OTA Agent Task] [INFO ][MQTT][93550] (MQTT connection 0x3ffe1edc, SUBSCRIBE operation 0x3fff3dc4) Wait complete with result SUCCESS. 178 9355 [OTA Agent Task] [prvInitFileTransfer_Mqtt] OK: $aws/things/myfreertosthing2/streams/AFR_OTA-c30cb685-9965-47e0-9da2-36ec32d4a205/data/cbor 179 9355 [OTA Agent Task] [prvOTAAgentTask] Called handler. Current State [CreatingFile] Event [CreateFile] New state [RequestingFileBlock] 180 9357 [OTA Agent Task] [INFO ][MQTT][93570] (MQTT connection 0x3ffe1edc) MQTT PUBLISH operation queued. 181 9357 [OTA Agent Task] [prvRequestFileBlock_Mqtt] OK: $aws/things/myfreertosthing2/streams/AFR_OTA-c30cb685-9965-47e0-9da2-36ec32d4a205/get/cbor 182 9357 [OTA Agent Task] [prvOTAAgentTask] Called handler. Current State [RequestingFileBlock] Event [RequestFileBlock] New state [WaitingForFileBlock] 183 9378 [iot_thread] State: WaitingForJob Received: 2 Queued: 0 Processed: 0 Dropped: 0 184 9396 [OTA Agent Task] [prvIngestDataBlock] Received file block 3, size 4096 185 9397 [OTA Agent Task] [prvIngestDataBlock] Remaining: 246 186 9397 [OTA Agent Task] [prvOTAAgentTask] Called handler. Current State [WaitingForFileBlock] Event [ReceivedFileBlock] New state [WaitingForFileBlock] 187 9404 [OTA Agent Task] [prvIngestDataBlock] Received file block 0, size 4096 188 9405 [OTA Agent Task] [prvIngestDataBlock] Remaining: 245 189 9405 [OTA Agent Task] [prvOTAAgentTask] Called handler. Current State [WaitingForFileBlock] Event [ReceivedFileBlock] New state [WaitingForFileBlock] 190 9410 [OTA Agent Task] [prvIngestDataBlock] Received file block 2, size 4096 191 9410 [OTA Agent Task] [prvIngestDataBlock] Remaining: 244 192 9410 [OTA Agent Task] [prvOTAAgentTask] Called handler. Current State [WaitingForFileBlock] Event [ReceivedFileBlock] New state [WaitingForFileBlock] 193 9417 [OTA Agent Task] [prvIngestDataBlock] Received file block 1, size 4096 194 9418 [OTA Agent Task] [prvIngestDataBlock] Remaining: 243 195 9418 [OTA Agent Task] [prvOTAAgentTask] Called handler. Current State [WaitingForFileBlock] Event [ReceivedFileBlock] New state [WaitingForFileBlock] 196 9425 [OTA Agent Task] [prvIngestDataBlock] Received file block 6, size 4096 197 9426 [OTA Agent Task] [prvIngestDataBlock] Remaining: 242 198 9426 [OTA Agent Task] [prvOTAAgentTask] Called handler. Current State [WaitingForFileBlock] Event [ReceivedFileBlock] New state [WaitingForFileBlock] 199 9431 [OTA Agent Task] [prvIngestDataBlock] Received file block 4, size 4096 200 9432 [OTA Agent Task] [prvIngestDataBlock] Remaining: 241 201 9432 [OTA Agent Task] [prvOTAAgentTask] Called handler. Current State [WaitingForFileBlock] Event [ReceivedFileBlock] New state [WaitingForFileBlock] 202 9438 [OTA Agent Task] [prvIngestDataBlock] Received file block 7, size 4096 203 9439 [OTA Agent Task] [prvIngestDataBlock] Remaining: 240シャドウでも、ファームウェアのバージョンが更新されています。
取得した時刻や、ファームウェアのバージョンでシャドウを更新します。サンプルソースとビルド
サンプルソースは こちら を参照してください。
ビルドは、
git clone https://github.com/fukuen/m5stack-freertos-ota --recursiveダウンロードしたディレクトリーに移動して、アプリケーションをビルドします。
cd m5stack-freertos-tft cmake -DCMAKE_TOOLCHAIN_FILE=amazon-freertos/tools/cmake/toolchains/xtensa-esp32.cmake -GNinja -S . -B build cd build ninjaメモ
第1回 Amazon FreeRTOSインストール
第2回 Lチカ
第3回 TFT
第4回 SDカード
第5回 AWS Shadows



- 投稿日:2020-01-07T08:55:49+09:00
[Redash] Redashの別AWS VPC環境への移行手順
[Redash] Redashの別AWS VPC環境への移行手順
目的
AWS VPC上に本家AMIから構築したRedashを別VPC上に移行する手順の共有、および移行時発生したトラブルについての対処法の記録
背景
AWS上に本家のAMIから構築したRedashだが、都合により別VPC上へリプレイスする必要がでた。
参照するデータソースについても新VPC上のものへ変更になるが、そこらへんは後から何とでもなるだろうと考え、
巷に溢れるバックアップ/レストア手順を元に移行作業を実施した。しかし、移行後RedashのUIへアクセスすると既存のデータソースを参照できないどころか、新規データソースも作成できない問題が発生した。
環境/名称
- Redash
Redash Version: 8.0.0+b32245 (a16f551e)
Redash AMI: ami-060741a96307668be
- 移行元環境名称
Item Name VPC src_vpc Redash Instance i-src-redash DataSource DB Host srcdb.example.ap-northeast-1.rds.amazonaws.com DataSource DB migration_db_a DataSource DB migration_db_b
- 移行先環境名称
Item Name VPC dst_vpc Redash Instance i-dst-redash DataSource DB Host dstdb.example.ap-northeast-1.rds.amazonaws.com DataSource DB migration_db_a DataSource DB migration_db_b 移行手順
移行データの取得
RedashのDBのdump
何はともあれ移行データの取得
$ cid=$(sudo docker ps -qf "name=redash_postgres_1") $ docker exec -t ${cid} pg_dumpall -c -U postgres | gzip > redash_dump.sql.gzdumpのS3 upload
移行先インスタンスからデータを取得できるようにS3にデータアップロード
移行データ受け渡し用のS3 bucketを用意
AWS Web Consoleからredash-migrationという名でS3 bucketを用意しておく
i-src-redashに対しIAM RoleのS3 Full Accessを付与
AWSのWeb Consoleを利用して権限を付与する
i-src-redashへaws cliのインストール
python-pipではなくpython3-pip$ sudo apt install python3-pip $ sudo pip3 install awscli動作確認でS3 bucket(redash-migration)が参照できることを確認
$ aws s3 ls移行データのS3アップロード
$ aws s3 cp redash_dump.sql.gz s3://redash-migration/ $ aws s3 ls s3://redash-migration/ →ファイルがアップロードされたことを確認新規Redashサーバ(i-dst-redash)の構築
@hujuu さんの AWSにRedashを設置 を参考に本家AMIを利用してRedashを立ち上げ。
移行データのレストア
dst_vpc上のi-dst-redashにsrc_vpc上のi-src-redashから取得した移行用データをレストアする
移行データをS3からダウンロード
i-dst-redashに対しIAM RoleのS3 Full Accessを付与(Read Only Accessのみでもよい)
AWSのWeb Consoleを利用して権限を付与する
i-dst-redashへaws cliのインストール
$ sudo apt install python3-pip $ sudo pip3 install awscli動作確認でS3 bucket(redash-migration)が参照できることを確認
$ aws s3 ls移行データをS3からダウンロード
$ aws s3 cp s3://redash-migration/redash_dump.sql.gz ./ $ ls -l →ファイルがダウンロードされたことを確認
移行データのレストア
起動しているredashコンテナの停止
$ sudo docker-compose --file /opt/redash/docker-compose.yml down --remove-orphansPostgreSQLコンテナのみ起動
$ sudo docker-compose --file /opt/redash/docker-compose.yml up --detach postgres $ cid=$(sudo docker ps -qf "name=redash_postgres_1")
- 移行データをPostgreSQLコンテナへ展開
$ sudo docker container cp redash_dump.sql.gz ${cid}:/usr/local/redash_dump.sql.gz $ sudo docker container exec ${cid} /bin/bash -c 'psql -c "drop database if exists postgres" -U postgres template1' $ sudo docker container exec ${cid} /bin/bash -c 'psql -c "create database postgres" -U postgres template1' $ sudo docker container exec ${cid} /bin/bash -c 'zcat /usr/local/redash_dump.sql.gz | psql -U postgres -d postgres'
- PostgreSQLコンテナを停止し、Redash全体を起動
$ sudo docker-compose --file /opt/redash/docker-compose.yml down --remove-orphans $ sudo docker-compose --file /opt/redash/docker-compose.yml up --detachRedashへの接続確認
i-dst-redashのPublic IPを確認しブラウザでアクセスすると、Redashのログイン画面が表示されるので、i-src-redashで利用していたアカウントとパスワードでログインできることを確認する。
正常動作が確認できない場合は以下を再度確認する。
- AWS上のセキュリティグループ
- AWS上のネットワークACL
- AWS上のルーティングテーブル(インターネットGWへのルートは適切か)
ログインすると、Dashboardのデータなどが表示されるが、ドリルダウンしてもデータは参照できない。
なぜなら、データソースのDataSource DB Hostが変更になっているため。また、ここでデータソースを変更しようとSettings > Data Sources へアクセスしても、以下のエラーが出力され新規データソースの追加もできない状態となる
Sorry, we couldn't find anything.データソースの復旧
一旦、既存のデータソース情報をDBから削除すると新規にデータソースを追加できるようになる。
そのため、以下の流れでデータソースを復旧させる。(1). 既存データソース情報の確認
(2). データソース削除
(3). Web/UIからデータソースの作成
(4). 新規データソースとqueryが参照するデータソースの紐づけ
既存データソース情報の確認
PostgreSQLへpsqlを利用しログイン
$ cid=$(sudo docker ps -qf "name=redash_postgres_1") $ sudo docker container exec -it ${cid} /bin/bash →PostgreSQLコンテナへログインしたことを確認 # psql -U postgres postgres既存の data_sources, data_source_groups テーブルのデータを確認
data_sources の id が query テーブルで参照されている。
「(4).新規データソースとqueryが参照するデータソースの紐づけ」作業で必要となるので必ずメモっておく# select * from data_sources; id | org_id | name | type | encrypted_options | queue_name | scheduled_queue_name | created_at ----+--------+----------------+-----------+---------------------+------------+----------------------+------------------------------- 1 | 1 | migration_db_a | rds_mysql | \x67413d3d(snippet) | queries | scheduled_queries | 2019-11-27 02:20:13.635035+00 2 | 1 | migration_db_b | rds_mysql | \x67415f42(snippet) | queries | scheduled_queries | 2019-11-28 04:07:50.333332+00 (2 rows) postgres=# select * from data_source_groups; id | data_source_id | group_id | view_only ----+----------------+----------+----------- 1 | 1 | 2 | t 2 | 1 | 1 | f 3 | 2 | 2 | f 4 | 2 | 1 | f (4 rows)データソース削除
data_sourcesのレコードは他のテーブルのレコードと依存関係(FOREIGN KEY CONSTRAINT)があるので、そのまま削除するとエラーになる。
一旦、DISABLE TRIGGERで依存を切ってから削除する。
DISABLEした依存関係の復旧は「(4). 新規データソースとqueryが参照するデータソースの紐づけ」の中で実施する。# delete from data_source_groups; DELETE 4 # delete from data_sources; ERROR: update or delete on table "data_sources" violates foreign key constraint "queries_data_source_id_fkey" on table "queries" # ALTER TABLE data_sources DISABLE TRIGGER ALL; ALTER TABLE # delete from data_sources; DELETE 2Web/UIからデータソースの作成
i-src-redashに設定したときと同様にRedashのWeb/UIから
dstdb.example.ap-northeast-1.rds.amazonaws.com上のmigration_db_a,migration_db_bをデータソースとして登録する。正常にデータソースにconnectできない場合は以下を確認する
- AWS上のセキュリティグループ
- AWS上のネットワークACL
- AWS上のルーティングテーブル
- DBのアカウント設定(特にアクセス元ホストのIPが変更になっているのでその点をチェック)
新規データソースとqueryが参照するデータソースの紐づけ
新規データソースの data_sources, data_source_group テーブル上のレコードを確認
# select * from data_sources; id | org_id | name | type | encrypted_options | queue_name | scheduled_queue_name | created_at ----+--------+----------------+-----------+---------------------+------------+----------------------+------------------------------- 3 | 1 | migration_db_a | rds_mysql | \x67413d3d(snippet) | queries | scheduled_queries | 2020-01-06 07:31:34.455437+00 4 | 1 | migration_db_b | rds_mysql | \x67415f42(snippet) | queries | scheduled_queries | 2020-01-06 07:33:56.520092+00 (2 rows) # select * from data_source_groups; id | data_source_id | group_id | view_only ----+----------------+----------+----------- 5 | 3 | 2 | f 6 | 4 | 2 | fdata_sourcesのidと、data_source_groupsのid, data_source_idを修正する
「(1). 既存データソース情報の確認」で確認したものに合わせるよう、修正する
# update data_sources set id = 1 where id = 3; UPDATE 1 # update data_sources set id = 2 where id = 4; UPDATE 1 # select * from data_sources; id | org_id | name | type | encrypted_options | queue_name | scheduled_queue_name | created_at ----+--------+----------------+-----------+---------------------+------------+----------------------+------------------------------- 1 | 1 | migration_db_a | rds_mysql | \x67413d3d(snippet) | queries | scheduled_queries | 2020-01-06 07:31:34.455437+00 2 | 1 | migration_db_b | rds_mysql | \x67415f42(snippet) | queries | scheduled_queries | 2020-01-06 07:33:56.520092+00 (2 rows) # update data_source_groups set id = 1, data_source_id = 1 where id = 5; UPDATE 1 # update data_source_groups set id = 3, data_source_id = 2 where id = 6; UPDATE 1 # select * from data_source_groups; id | data_source_id | group_id | view_only ----+----------------+----------+----------- 1 | 1 | 2 | f 3 | 2 | 2 | f (2 rows) # insert into data_source_groups (id, data_source_id, group_id, view_only) values (2, 1, 1, true); INSERT 0 1 # insert into data_source_groups (id, data_source_id, group_id, view_only) values (4, 2, 1, true); INSERT 0 1 # select * from data_source_groups; id | data_source_id | group_id | view_only ----+----------------+----------+----------- 1 | 1 | 2 | f 3 | 2 | 2 | f 2 | 1 | 1 | t 4 | 2 | 1 | t (4 rows)DISABLEしたdata_sourcesテーブルの依存関係を復元する
# ALTER TABLE data_sources ENABLE TRIGGER ALL; ALTER TABLERedashの動作確認
データソースが参照できるようになり、queryの結果が確認できることをRedashのWeb/UIから確認する
- 投稿日:2020-01-07T08:49:19+09:00
npm run serveの速度改善
npm run serveが遅い
Vue.jsで書いたプログラムを確認しようとした時に、
npm run serveをしますが、動作が遅いし、他のブラウジングも同時に遅くなってしまう現象が発生しました。原因
ESETなどのセキュリティソフトが影響しているみたい。
回避方法
Vue.jsのプロジェクトルートに、vue.config.jsというファイルを作成し、配置する。中身はこんな感じ。
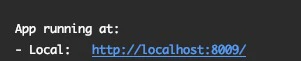
module.exports = { devServer: { port: 8009, }, };これで
npm run serveすると、
指定した通り、8009ポートで立ち上げている。
参考サイト
https://blog.kobasato.net/entry/vue-cli-yarn-serve-npm-run-serve-issue/
- 投稿日:2020-01-07T00:06:38+09:00
[AWS S3ファイルアップロード] Error retrieving credentials from the instance profile metadata server.
こちらのQiita記事を参考に、LaravelでAWS S3へ画像をアップロードする機能を実装しようとしていたら、以下のエラーが発生しました。
Aws\Exception\CredentialsException
Error retrieving credentials from the instance profile metadata server. (cURL error 7: (see https://curl.haxx.se/libcurl/c/libcurl-errors.html))
こちらのstackoverflowの回答の通り、以下のコマンドを叩いたら解決しました!!
$ php artisan config:clear日本語での解説がなかったので、こちらでシェアします〜!!
