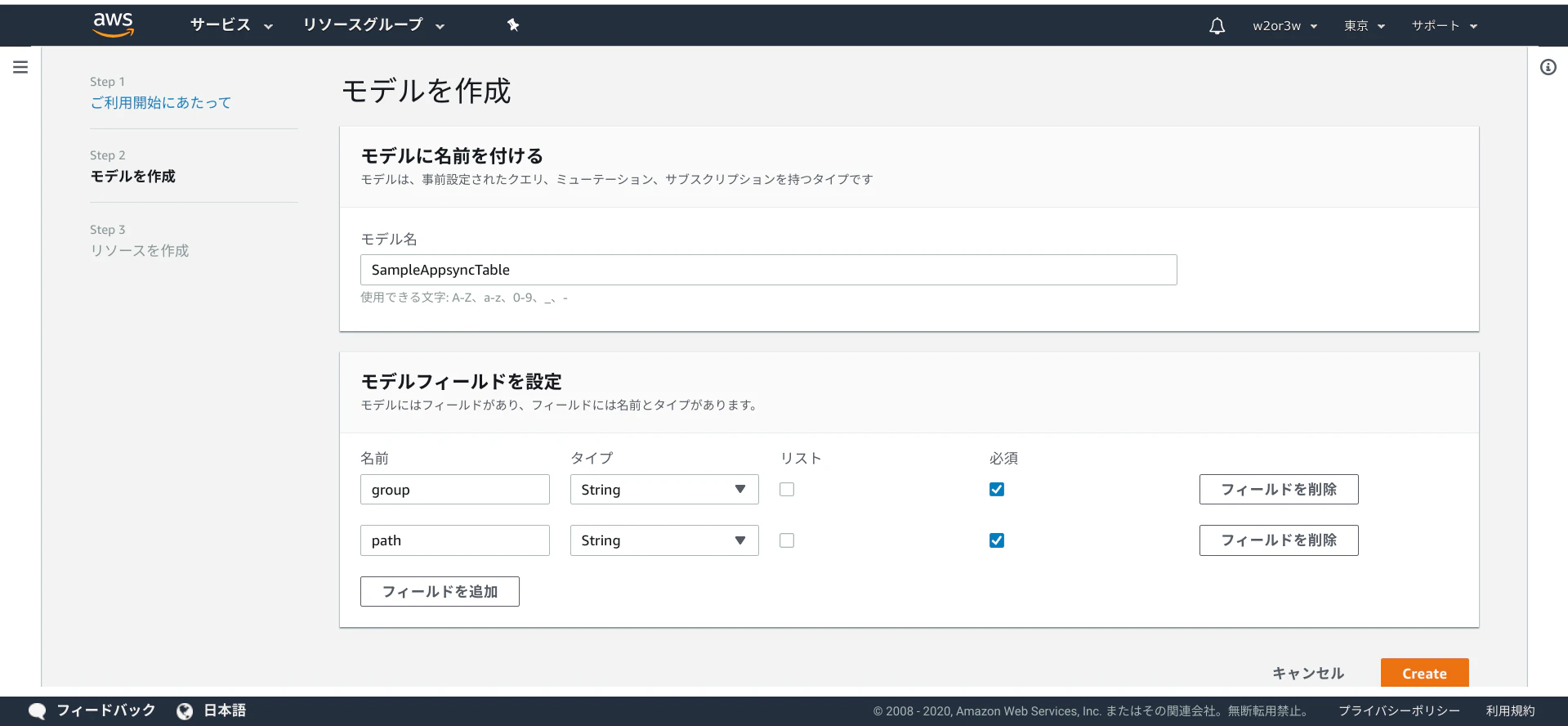
- 投稿日:2020-01-03T23:25:39+09:00
pythonでMongoDB入門するときの設定
データ解析用によく使われているデータベースMongoDBの設定方法を記録しています。
ダウンロード
ダウンロードリンク → https://www.mongodb.com/download-center/community
インストールの設定
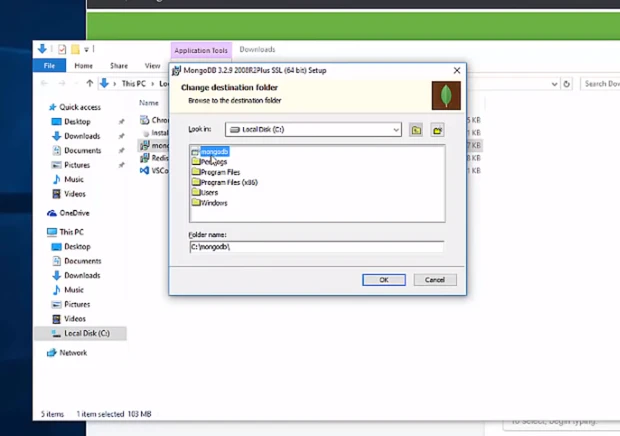
パスの設定は
C:\mongodbに設定(C:\Program Filesではない)インストールは
CompleteではなくCustomに設定、Cドライブの下に新しいフォルダーを作る。↓
インストールは約5分かかる。
インストールができたら、
C:\mongodb\dataフォルダーを作っておいてください。
サーバーを起動する方法
cd C:\mongodb\binでダイレクトリーを移動し、
(これからよく使う方はC:\mongodb\binを環境係数に登録してもいいかもしれません)データぱすの登録としてサーバーを起動する:
mongod.exe --dbpath C:\mongodb\data以下の画面が出れば成功
よく失敗してしまう理由は
C:\mongodb\dataが作成されないからなどにあると思います。
GUIでMongoDB の中身を確認する
MongoDB GUI の接続先は
mongodb://localhost:27017/に設定する。(サーバーが立ち上げないとと当然エラーが発生)(
mongodb://は必要、Port番号27017はデフォルトの設定)
接続ができたら、データベーステーブルの画面が出れば成功。
(初めて起動するときはなにもないはずなので参考までにしてください)
Python で試す
Qiita : pythonでMongoDBを操作するはとてもわかりやすいので確認してみてください。
毎回Pythonで接続する前に、必ずサーバーを立ち上げておいてください。
参考
YouTube-MongoDB In 30 Minutes
https://www.youtube.com/watch?v=pWbMrx5rVBEQiita - pythonでMongoDB入門しようhttps://qiita.com/Syoitu/items/db192385a4b2e4884ed5#%E3%83%A9%E3%82%A4%E3%83%96%E3%83%A9%E3%83%AA%E3%81%AE%E3%82%A4%E3%83%B3%E3%82%B9%E3%83%88%E3%83%BC%E3%83%AB



- 投稿日:2020-01-03T23:06:32+09:00
【Python】matplotlibで「ONEPIECE」億越えキャラの懸賞金を可視化してみた。
概要
ロジャーや白ひげの親父などの懸賞金が公開され、海賊王を目指すルフィー君と大海賊たちの差はどれだけ離れているのか気になり、matplotlibの練習を兼ねて可視化してみることにしました。
環境
・Python 3.8.0
・windows10
・Jupyter Notebook参考資料
・ドラゴンボールの戦闘力とmatplotlibで対数を勉強
・【2019年最新版】「ワンピース」懸賞金ランキング!ついにロジャーの懸賞金が発覚
大まかな流れ
- 懸賞金が・キャラ名を取得(スクレイピング)
- 可視化する(matplotlib)
1. 懸賞金が・キャラ名を取得(スクレイピング)
こちらの記事から、ワンピースの懸賞金を取得しました。
スクレイピングの流れは以下の通り。
1. 全キャラ懸賞金取得
2. 全キャラ名を取得
3. 億越えキャラのみ、キャラ名・懸賞金を取得scraping_onepiece.pyimport requests from bs4 import BeautifulSoup import pandas as pd import re import time list_df = pd.DataFrame(columns=['キャラ', '懸賞金']) url = 'https://ciatr.jp/topics/311415' response = requests.get(url) soup = BeautifulSoup(response.text, 'lxml') # 全キャラ懸賞金を取得 bounty_tags = soup.find_all('div', class_='component ArticleComponentHead') bounty_tags = soup.find_all('h3') # h3要素に含まれる['作品情報', '記事情報', 'ciatrについて']は無視 bounty_tags = [tag.text for tag in bounty_tags if tag.text not in ['作品情報', '記事情報', 'ciatrについて']] # 1秒待機 time.sleep(1) # キャラ名取得 name_tags = soup.find_all('div', class_='component ArticleComponentHead scroll-margin') name_tags = [tag.text for tag in name_tags if tag.text not in ['『ONE PIECE』に登場する並み居る強豪たちの懸賞金額が知りたい!', '懸賞金不明な大物はまだいる!最高額はまだまだ更新されそう']] # {キャラ名: 懸賞金}とするため辞書作成 master_table = dict() for bounty_tag, name_tag in zip(bounty_tags, name_tags): # 正規表現で余計な文字削除 bounty = re.sub(r'[懸賞金元ベリー以上]', '', bounty_tag) # 懸賞金が億超してないキャラは除外 if '億' in bounty: #以降、懸賞金をmatplotlibで使うので整数化する oku_ind = bounty.find("億") man_ind = bounty.find("万") oku = bounty[:oku_ind] if bounty[oku_ind + 1:man_ind] != '': man = bounty[oku_ind + 1:man_ind] else: man = 0 bounty = int(oku) * 100000000 + int(man) * 10000 name = re.sub(r'[【】0-9位]', '', name_tag) # 辞書に追加 master_table[name] = bounty for name, bounty in master_table.items(): tmp_se = pd.DataFrame([name, bounty], index=list_df.columns).T list_df = list_df.append(tmp_se) print(list_df) # csv保存 list_df.to_csv('onepiece.csv', mode = 'a', encoding='cp932')2. 可視化する(matplotlib)
malplotlib_onepiece.ipynb#Jupyter Notebook上にグラフを描画する際に指定する記述 %matplotlib inlineimport matplotlib.pyplot as plt import pandas as pdplt.rcParams["font.family"] = "IPAexGothic"フォントエラーはこちらを参考にしました。
matplotlibの日本語文字化けを解消する(Windows編)
df_file = pd.read_csv('onepiece.csv', encoding='cp932')df_name = df_file['キャラ'].tolist() df_bounty = df_file['懸賞金'].tolist()d = [] for name, bounty in zip(df_name, df_bounty): data = [name, bounty] d.append(data)#懸賞金降順 name = list(reversed([x[0] for x in d])) bounty = list(reversed([x[1] for x in d]))#図全体のサイズ plt.figure(figsize=(12, len(d)/2)) #横棒グラフ plt.barh(name, bounty) #グラフ全体のタイトル plt.title('ワンピース懸賞金ランキング') #xラベルのタイトル plt.xlabel('懸賞金(億)') #x軸(懸賞金)のスケールを設定 plt.xscale('log') plt.show()
可視化してみると、四皇の強さ半端じゃないですね。まだ、未公開のドラゴンやレイリー師匠の懸賞金が楽しみです。個人的な意見なんですが、ドラゴンの懸賞金は世界政府を直接倒そうとしている組織のボスですから50億はいってほしいです。
おわりに
今回はワンピースの億越キャラの可視化を目的にスクレイピング、malplotlibを学びました。スクレイピングで文字列の漢数字を算用数字に変換する作業が難しく時間がかかりました。
次回は、教師なし学習のクラスタリングや感情分析を学びたいと思います。長くなりましたが、ここまで読んでくださりありがとうございます。誤っている箇所がございましたら、コメントでご指摘頂けると大変嬉しいです。

- 投稿日:2020-01-03T22:16:11+09:00
[前処理編] ロイター通信のデータセットを用いて、ニュースをトピックに分類するモデル(MLP)をkerasで作る(TensorFlow 2系)
概要
kerasを使ったテキスト分類を試し、記事にまとめます。
データセットはtensorflowに内蔵されたロイター通信のデータセットです(英語のテキストデータ)。Keras MLPの文章カテゴリー分類を理解する というブログ記事を参考に、一度取り組んだことがあります。
今回はドキュメントを引きつつ手を動かしており、理解を深める目的でこの記事をアウトプットします。
構築したモデルは、非常にシンプルなMLPです。分量が長くなったので2つに分けます:
- 本記事で扱うこと
- データセットについて
- 前処理について
- 次の記事で扱うこと
- モデルの学習について
- モデルの性能評価について
動作環境
$ sw_vers ProductName: Mac OS X ProductVersion: 10.14.6 BuildVersion: 18G103 $ python -V # venvモジュールによる仮想環境を利用 Python 3.7.3 $ pip list # 主要なものを抜粋 ipython 7.11.0 matplotlib 3.1.2 numpy 1.18.0 pip 19.3.1 scikit-learn 0.22.1 scipy 1.4.1 tensorflow 2.0.0データセット
読み込み
tensorflow.keras.datasets.reuters.load_data(ドキュメント)で読み込むことができます。
test_split引数のデフォルト値が0.2のため、学習用8割、テスト用2割に分かれて読み込まれます。
※初回実行時は、データがダウンロードされます。In [1]: from tensorflow.keras.datasets import reuters In [2]: (x_train, y_train), (x_test, y_test) = reuters.load_data() In [3]: len(y_train), len(y_test) Out[3]: (8982, 2246) # 合計 11228 件ラベルを見る
ラベルはニュースのトピックを表すそうです。
試しにラベルを1つ見てみましょう。In [4]: y_train[1000] Out[4]: 19数値で表されています(※それぞれがどんなトピックなのかまでは調べきれていません)。
学習用とテスト用のデータ全体で何種類のラベルがあるか確認します。
numpy.ndarrayのy_trainとy_testをリストに変換して、collections.Counter(ドキュメント)に渡します。In [5]: from collections import Counter In [8]: counter = Counter(list(y_train) + list(y_test)) In [9]: len(counter) Out[9]: 46全部で46のトピックがありました。
トピックごとに何件あるか確認します。
In [10]: for i in range(46): ...: print(f'{i}: {counter[i]},') ...: 0: 67, 1: 537, 2: 94, 3: 3972, 4: 2423, 5: 22, 6: 62, 7: 19, 8: 177, 9: 126, 10: 154, 11: 473, 12: 62, 13: 209, 14: 28, 15: 29, 16: 543, 17: 51, 18: 86, 19: 682, 20: 339, 21: 127, 22: 22, 23: 53, 24: 81, 25: 123, 26: 32, 27: 19, 28: 58, 29: 23, 30: 57, 31: 52, 32: 42, 33: 16, 34: 57, 35: 16, 36: 60, 37: 21, 38: 22, 39: 29, 40: 46, 41: 38, 42: 16, 43: 27, 44: 17, 45: 19,3と4のトピックが図抜けて多く、約57%を占めます。
トピックに含まれる記事の数に偏りがありますが、今回は46クラスへの分類という問題設定で進めます。ニュースのテキストを見る
ニュースも1つ見てみましょう。
In [12]: x_train[1000] Out[12]: [1, 437, 495, 1237, 55, 9070, : 12]整数からなるリストが表示されました。
今回のデータセットの場合、単語が数値に変換されています。
元のテキストを確認してみます。まず、単語と数値の対応表は、
tensorflow.keras.datasets.reuters.get_word_index(ドキュメント)で取得できます。
※初回実行時は、データがダウンロードされます。In [16]: word_index = reuters.get_word_index() In [17]: len(word_index) Out[17]: 30979 In [18]: word_index Out[18]: {'mdbl': 10996, 'fawc': 16260, 'degussa': 12089, 'woods': 8803, 'hanging': 13796, 'localized': 20672, : 'hebei': 9407, ...} In [19]: for word, index in word_index.items(): ...: if index in [0, 1, 2]: ...: print(word, index) ...: the 1 of 2 In [20]: for word, index in word_index.items(): ...: if index in [30978, 30979, 30980]: ...: print(word, index) ...: jung 30978 northerly 30979
word_indexは単語に対する数値の辞書です。
この対応を逆にして数値に対する単語の辞書を用意すればよさそうです。
ここで、x_trainとx_testに使われた整数は、word_indexの整数とずれていることに対応する必要があります。ずれる理由は
load_dataの3つの引数にあります。1. 開始を表す数値:
start_char=1The start of a sequence will be marked with this character. Set to 1 because 0 is usually the padding character.
x_trainとx_testの中で1は開始を表します。
0がpadding character(埋め草文字。余白を埋めるための文字)に使われるため、1がデフォルト値となっているそうです。2. 対応しない語を表す数値:
oov_char=2words that were cut out because of the num_words or skip_top limit will be replaced with this character.
num_wordsやskip_top引数によって、使う単語の範囲を区切ることで、対応しない語がoov_charに置き換えられます。
今のx_trainやx_testを取得する際、これらの引数を指定していないため、oov_charは現時点では無関係です。
(load_dataのドキュメントを見ると、oovはout of vocabularyの略のようです)3. 単語に対応する数値の最初の値:
index_from=3index actual words with this index and higher.
数値のうち、0, 1, 2が意味を持っているため、単語の対応がずれるわけです。
index_from引数によりx_trainやx_testはword_indexの0が3に該当するという対応1で読み込まれています。ニュースを単語の並びとして見るために、数値のズレを考慮して、
数値: 単語という辞書を作ります。In [22]: index_word_map = { ...: index + 3: word for word, index in word_index.items() ...: } ...: index_word_map[0] = "[padding]" ...: index_word_map[1] = "[start]" ...: index_word_map[2] = "[oov]" In [23]: len(index_word_map) Out[23]: 30982この辞書を使うことで
x_train,x_testの整数の並びから文章を復元することができました。In [24]: for index in x_train[1000]: ...: print(index_word_map[index], end = " ") ...: [start] german banking authorities are weighing rules for banks' off balance sheet activities in an attempt to cope with the growing volume of sophisticated capital market instruments banking sources said interest rate and currency swaps and ...前処理
テキストの前処理
整数で表されたニュース記事の長さはまちまちです。
In [31]: for x in x_train[998:1003]: ...: print(len(x)) ...: 133 51 626 17 442そこで長さが揃うように変換して前処理します。
今回は、各ニュース記事を、ニュース記事全体に登場する頻度の上位1000語が含まれるか否かで表します。例えば、上位1000語の中に「currency」という単語があり、対応する整数は500とします。
各記事を0か1の並びで表すとき、currencyという語を含む記事は、インデックス500に1が来ます。
currencyという語を含まない記事は、インデックス500が0です。
これが他の語にも当てはまります。この変換により、
- ニュース記事の長さが1000に揃います
- ニュース記事は1000個の0または1の並びで表されます
load_dataメソッドのnum_words引数2に1000を渡して、登場する頻度の上位1000語でx_train,x_testを表すように変換します。In [32]: (x_train, y_train), (x_test, y_test) = reuters.load_data(num_words=1000) ...: In [33]: len(y_train), len(y_test) Out[33]: (8982, 2246)
num_wordsを登場頻度の上位1000語としたので、そこに含まれない語はoov_char(整数では2)としてx_train,x_testで表されます。In [34]: for index in x_train[1000]: ...: print(index_word_map[index], end = " ") ...: [start] german banking [oov] are [oov] [oov] for [oov] off balance [oov] [oov] in an [oov] to [oov] with the growing volume of [oov] capital market [oov] banking sources said interest rate and currency [oov] and ...この段階ではニュース記事の長さはまだ揃っていません。
上位1000語がニュース記事に含まれるか否かを表すために、tensorflow.keras.preprocessing.text.Tokenizer(ドキュメント)を使います。
Tokenizerの初期化でnum_words引数に1000を渡します。
Tokenizerを使った処理でnum_words-1の語が考慮されます。num_words: the maximum number of words to keep, based
on word frequency. Only the most commonnum_words-1words will
be kept.In [37]: from tensorflow.keras.preprocessing.text import Tokenizer In [42]: tokenizer = Tokenizer(1000)
load_dataで上位1000語を取り出しているので、x_train,x_testに含まれる整数の最大は999です3。In [71]: max_index = 0 In [72]: for x in list(x_train)+list(x_test): ...: now_max = max(x) ...: if now_max > max_index: ...: max_index = now_max ...: In [73]: max_index Out[73]: 999
sequences_to_matrixメソッド(ドキュメント)で、x_train,x_testをそれぞれ変換します。In [36]: x_train.shape, x_test.shape Out[36]: ((8982,), (2246,)) In [76]: x_train = tokenizer.sequences_to_matrix(x_train, "binary") In [77]: x_test = tokenizer.sequences_to_matrix(x_test, "binary") In [78]: x_train.shape, x_test.shape Out[78]: ((8982, 1000), (2246, 1000))全てのニュース記事が長さが1000で表されました。
sequences_to_matrixのドキュメントによると、a sequence is a list of integer word indices
すなわち、sequenceとは「単語を表す整数のリスト(意訳)」なので、
x_train,x_testはまさしくsequenceです。第2引数の指定ですが、
"binany"の場合は各語が存在するかしないかの0/1で表されます。
他に、"count", "tfidf", "freq"を指定できるそうです。変換されたニュース記事を試しに1つ見てみると
In [58]: x_train[1000] Out[58]: array([0., 1., 1., 0., 1., 1., 1., 1., 1., 1., 1., 0., 1., 1., 0., 0., 1., ...と0/1で表現されています。
index_word_mapの中で0(埋め草文字にあたる)や、3(もともと0の語がないので、3というキーがない)はどのニュースにも登場しないので0です。
1([start])や2([oov])、4(the)、5(of)などはx_train[1000]に登場するので1となっています。テキストの前処理は以上です。
ラベルの前処理
ラベル(ニュースのトピック)は0〜45のいずれかですが、これをone-hot表現に変換します。
(one-hot表現とする理由は、ラベル同士に大小関係を持たせないようにするため)
tensorflow.keras.utils.to_categorical(ドキュメント)を使います。In [80]: y_train.shape, y_test.shape Out[80]: ((8982,), (2246,)) In [81]: from tensorflow import keras In [85]: number_of_classes = len(counter) In [86]: y_train = keras.utils.to_categorical(y_train, number_of_classes) In [88]: y_test = keras.utils.to_categorical(y_test, number_of_classes) In [89]: y_train.shape, y_test.shape Out[89]: ((8982, 46), (2246, 46))ラベルをインデックスと見立てて、ラベルのインデックスだけ1、他は0という形式に変換されます。
y_train[1000]は19でしたが、y_train[1000][19]が1、他は0となるように変換されています。In [90]: y_train[1000] Out[90]: array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.], dtype=float32)前処理は以上です。
本記事のまとめ
- データセットについて
- ロイター通信のニュースのトピック分類データ(多クラス分類)
- ラベルは46クラスあり、含まれるニュースの件数に偏りがある
- ニュースは整数のリストで表されている。単語の並びへ復元して元のニュースを確認できる
- 前処理について
- テキストを固定長の0/1の並びに変換(登場頻度上位1000語のそれぞれが含まれるか否か)
- ラベルをone-hot表現に変換
本記事は[モデル構築編](近日公開)に続きます。
- 投稿日:2020-01-03T21:19:47+09:00
ROSに依存しないROSと連携できるPythonパッケージの作り方
Pythonをぶっ壊〜〜〜す。
どうもこんにちは、「Pythonの被害から国民を守る党」党首を自称しております片岡です。
Pythonは嫌いで嫌いで正直一生書きたくないのですが、なんやかんやで書く羽目になりますよね。
ポストPythonなスクリプト言語よ早く生まれてPythonを滅ぼしておくれ・・・・・
と嘆いたところでPythonの快進撃は現状止まる気配がないのでうまいこと付き合っていかないといけません
ホントは明日にでも消えてほしいけど
まあPythonの中にも一部捨てたもんじゃない部分もあってそのおいしいとこだけはちゃんと活用していこうよということですね。
今回は普段良く使うROS1/ROS2においてPythonをなんとかうまく使っていく方法を紹介したいと思います。ROS1におけるPython
ROS1にはPythonクライアントであるrospyがあります。
rospyの内部実装を追ってみるとSubscriberのオブジェクト作った瞬間からspinしなくても実はコールバックが回ってる、
spinは単にrospy.ok()みたいなことしてspinしてるだけとか怪しげな実装がコアライブラリに散見されます。大丈夫なんかコレ。。。
シリアライズされたrosメッセージをやり取りするので比較的すくないオーバーヘッドで他のROSノードと通信できます。
Pythonはスクリプト言語なのでビルドしないにもかかわらずビルドシステムにcatkinを使用し、しばしばrosdepによってpipに依存関係が崩壊します。
なお基本的にPython2のためrospyで実装したコードは今後技術的負債になる可能性は高いと思われます。
またROS1 -> ROS2の変換に関してはほぼリビルドになるのでそこも将来的に苦労が約束されていますROS2におけるPython
ROS2にはPythonクライアントであるrclpyがあります。
シリアライズされたrosメッセージをやり取りするので比較的すくないオーバーヘッドで他のROSノードと通信できます。
ちなみに、現状rclpyのパッケージを作るのは結構一苦労(ros2 pkg createするとC++向けパッケージが作られるため手動でいろいろ追記しないといけない)です。
Pythonはスクリプト言語なのでビルドしないにもかかわらずビルドシステムにcolconを使用し、しばしばrosdepによってpipに依存関係が崩壊します。なんとかならんのか・・・・
これらの手段を見て僕が思ったのは・・・・
なんだこの新手の罰ゲームは・・・・という印象ですね。
数年前の僕はこれらのことにPythonの記法から生まれる性質(長いコードを書くと可読性が低い、コンパイルがないのでテストできっちり網羅しない限り最低限のチェックすらままならない)
を鑑みてROSノードを書く時はPythonを完全排除するという考えにいたりました。
一応ある程度の成果は出て、いろいろ使いやすいROSノードが生み出せたかなと思います。
まあでもしかし、ツール系のものを整備するにはそうも行ってられません。
C++でweb APIとか叩くのほんとめんどい、となるとそういうことに強いPythonが選択肢として上がってきます。
うーんでも上記の理由でrospy等はできれば使いたくない、さらにあわよくばpipによる環境破壊を避けるため
Pythonのvenvとか依存解決ツールとかも使って効率的に開発したい・・・・・
あわよくばROS1/ROS2で入る破壊的変更でコードの書き直しが発生するのは嫌だ・・・・
となると理想形の手法はこういうことになります・・・・「PythonとROS1/2の間で通信はできるが、パッケージ自体はROSに依存しないパッケージをつくる」
んなもんできるんか??
できるんだなコレが・・・・
ということでサンプルのパッケージを作ってみました。
依存解決ツールにはpipenvを使用しました。
pipenvはpip+venvをパッケージングしたツールでパッケージごとに仮想環境を作って依存解決をかんたんにやってくれます。
詳しくはこちらの記事を参照ください
以下のコマンドをターミナルに入力します。mkdir roslibpy_example cd roslibpy_example pipenv installすると以下のような出力が得られます。
Creating a virtualenv for this project... Pipfile: /home/masaya/lib/roslibpy_example/Pipfile Using /usr/bin/python (2.7.15+) to create virtualenv... ⠏ Creating virtual environment...Already using interpreter /usr/bin/python New python executable in /home/masaya/.local/share/virtualenvs/roslibpy_example-mGuxztlN/bin/python Installing setuptools, pip, wheel... done. ✔ Successfully created virtual environment! Virtualenv location: /home/masaya/.local/share/virtualenvs/roslibpy_example-mGuxztlN Creating a Pipfile for this project... Pipfile.lock not found, creating... Locking [dev-packages] dependencies... Locking [packages] dependencies... Updated Pipfile.lock (dfae9f)! Installing dependencies from Pipfile.lock (dfae9f)... ? ▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉ 0/0 — 00:00:00 To activate this project's virtualenv, run pipenv shell. Alternatively, run a command inside the virtualenv with pipenv run.これでROSとの依存が切れたPythonパッケージが作れました。
ではこのパッケージの依存にROSとの通信を担当するroslibpyパッケージを追加しましょう。
以下のコマンドをターミナルで実行すると仮想環境にroslibpyがインストールされます。pipenv install roslibpyすると以下のような表示が現れインストールが完了します。
Installing roslibpy... Adding roslibpy to Pipfile's [packages]... ✔ Installation Succeeded Pipfile.lock (134db9) out of date, updating to (dfae9f)... Locking [dev-packages] dependencies... Locking [packages] dependencies... ✔ Success! Updated Pipfile.lock (134db9)! Installing dependencies from Pipfile.lock (134db9)... ? ▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉ 18/18 — 00:00:01 To activate this project's virtualenv, run pipenv shell. Alternatively, run a command inside the virtualenv with pipenv run.roslibpyはrosbridge protocolによってROS1/ROS2と通信を行います。
rosbridge protocolはROSのメッセージをjson文字列にしてwebsockやその他の手法で投げつけるプロトコルです。
詳しくはこちらの記事を参考にしてください。あとはこの記事のようにroslibpyをimportしたスクリプトを作って実行するだけです。
ROSライクにかけるのでとてもかんたんですね。# -*- coding:utf8 -*- import time from roslibpy import Message, Ros, Topic def main(): # roscoreを実行しているサーバーへ接続 ros_client = Ros('192.168.1.104', 9090) # Publishするtopicを指定 publisher = Topic(ros_client, '/turtle1/cmd_vel', 'geometry_msgs/Twist') def start_sending(): while True: if not ros_client.is_connected: break # 送信するTwistメッセージの内容 publisher.publish(Message({ 'linear': { 'x': 2.0, 'y': 0, 'z': 0 }, 'angular': { 'x': 0, 'y': 0, 'z': 1.8 } })) time.sleep(0.1) publisher.unadvertise() # Publish開始 ros_client.on_ready(start_sending, run_in_thread=True) ros_client.run_forever() if __name__ == '__main__': main()出典:https://symfoware.blog.fc2.com/blog-entry-2288.html
最後に、setup.py等を書いたらパッケージの完成です。
いろんな人がつかえるようにPypyとかに登録しちゃいましょう。まとめ
以上のようなやり方を取るとROS1/2両方に対応できてROSに依存のないROSと通信できるPythonパッケージを作ることが可能です。
最後にこのやり方に対して来るであろう「大きいメッセージをこの方法でやり取りたらレイテンシがやばいでしょ」というツッコミに対して一言。
パフォーマンス気にするならおとなしくPythonをやめましょう。
Pythonをぶっ壊〜〜〜す。
- 投稿日:2020-01-03T20:11:49+09:00
「効果検証入門」をPythonで書いた
TL;DR
- 書籍「効果検証入門 正しい比較のための因果推論/計量経済学の基礎」のRソースコードを、Pythonで(ほぼ)再現しました
- https://github.com/nekoumei/cibook-python
- 本記事では、主にRではライブラリどーん!で済むけどPythonではそうはいかない部分の解説をします
書籍の紹介
https://www.amazon.co.jp/dp/B0834JN23Y
上記Amazonに目次が載っているのでそれを見るのが早い気がしますが。。
とても良い本です。正確な意思決定を行うためにどうやってバイアスを取り除くか?に焦点を当てて種々の因果推論の手法(傾向スコア/DiD/RDDなど)をRソースコードによる実装とともに紹介されています。
全体を通して、現実問題の効果検証に因果推論を活用するにはどうすればいいか?という観点で書かれており、非常に実用的だなーと感じました。Pythonで書きました
https://github.com/nekoumei/cibook-python
大元の公開されているRソースコード(https://github.com/ghmagazine/cibook )と対応する形で、Jupyter Notebookを作成しました。
また、本Python実装にあたって、グラフの可視化ライブラリは一部を除いてplotly.expressを使用しています。
GithubのNotebookレンダリングではplotlyのグラフは表示できないので、オンラインで確認したい場合はREADMEに記載しているGithub Pagesをご確認ください。(images配下のhtmlを表示しています)
plotly.expressに関しては、日本語だと下記記事がとても参考になります。
令和時代のPython作図ライブラリのデファクトスタンダードPlotlyExpressの基本的な描き方まとめPythonで書くうえでの主要なポイント
回帰分析
statsmodelsのOLSおよびWLSを利用しています。
(ch2_regression.ipynbより抜粋)
## バイアスのあるデータでの重回帰 y = biased_df.spend # R lmではカテゴリ変数は自動的にダミー変数化されているのでそれを再現 X = pd.get_dummies(biased_df[['treatment', 'recency', 'channel', 'history']], columns=['channel'], drop_first=True) X = sm.add_constant(X) results = sm.OLS(y, X).fit() nonrct_mreg_coef = results.summary().tables[1] nonrct_mreg_coefここで、Rのlm関数との違いが2つあります。
①lmではカテゴリカル変数のダミー変数化を自動で行っているようです。sm.OLSでは自動でできないのでpd.get_dummies()を利用しています。
②lmではバイアス項が自動で追加されます。こちらも手動で追加します。(参考:統計: Python と R で重回帰分析してみる)RData形式のデータセットの読込
実装内で利用されているデータセットの中には、experimentdatarのようにRパッケージとして公開されていたり、RData形式で公開されているデータセットがあります。
これらをPythonのみで読み込む方法はないです。(あったら教えてください)
コメント欄にて、upuraさんにご教示いただきました!
https://qiita.com/nekoumei/items/648726e89d05cba6f432#comment-0ea9751e3f01b27b0adb
.rdaファイルは、rdataというパッケージで、Rなしで読み込みが可能です。
(ch2_voucher.ipynbより抜粋)parsed = rdata.parser.parse_file('../data/vouchers.rda') converted = rdata.conversion.convert(parsed) vouchers = converted['vouchers']rpy2経由でRを使ってデータを読込、pandas DataFrameへの変換を行う場合は下記のとおりです。
(ch2_voucher.ipynbより抜粋)from rpy2.robjects import r, pandas2ri from rpy2.robjects.packages import importr pandas2ri.activate() experimentdatar = importr('experimentdatar') vouchers = r['vouchers']ch2_voucher.ipynbに記載しているとおり、Rパッケージのインストール等は事前にRの対話環境で行っています。
また、ch3_lalonde.ipynbにて使用するデータセットは.dtaファイルです。
こちらは、pandasのread_stata()によって読み込むことができます。
(ch3_lalonde.ipynbより抜粋)cps1_data = pd.read_stata('https://users.nber.org/~rdehejia/data/cps_controls.dta') cps3_data = pd.read_stata('https://users.nber.org/~rdehejia/data/cps_controls3.dta') nswdw_data = pd.read_stata('https://users.nber.org/~rdehejia/data/nsw_dw.dta')傾向スコアマッチング(最近傍マッチング)
傾向スコアマッチングのマッチング手法はいくつかありますが、書籍ではMatchItの最近傍マッチングを使っているようです。
Pythonにはちょうどいいライブラリはなさそうだったので愚直に実装しています。
(ch3_pscore.ipynbより抜粋)def get_matched_dfs_using_propensity_score(X, y, random_state=0): # 傾向スコアを計算する ps_model = LogisticRegression(solver='lbfgs', random_state=random_state).fit(X, y) ps_score = ps_model.predict_proba(X)[:, 1] all_df = pd.DataFrame({'treatment': y, 'ps_score': ps_score}) treatments = all_df.treatment.unique() if len(treatments) != 2: print('2群のマッチングしかできません。2群は必ず[0, 1]で表現してください。') raise ValueError # treatment == 1をgroup1, treatment == 0をgroup2とする。group1にマッチするgroup2を抽出するのでATTの推定になるはず group1_df = all_df[all_df.treatment==1].copy() group1_indices = group1_df.index group1_df = group1_df.reset_index(drop=True) group2_df = all_df[all_df.treatment==0].copy() group2_indices = group2_df.index group2_df = group2_df.reset_index(drop=True) # 全体の傾向スコアの標準偏差 * 0.2をしきい値とする threshold = all_df.ps_score.std() * 0.2 matched_group1_dfs = [] matched_group2_dfs = [] _group1_df = group1_df.copy() _group2_df = group2_df.copy() while True: # NearestNeighborsで最近傍点1点を見つけ、マッチングする neigh = NearestNeighbors(n_neighbors=1) neigh.fit(_group1_df.ps_score.values.reshape(-1, 1)) distances, indices = neigh.kneighbors(_group2_df.ps_score.values.reshape(-1, 1)) # 重複点を削除する distance_df = pd.DataFrame({'distance': distances.reshape(-1), 'indices': indices.reshape(-1)}) distance_df.index = _group2_df.index distance_df = distance_df.drop_duplicates(subset='indices') # しきい値を超えたレコードを削除する distance_df = distance_df[distance_df.distance < threshold] if len(distance_df) == 0: break # マッチングしたレコードを抽出、削除する group1_matched_indices = _group1_df.iloc[distance_df['indices']].index.tolist() group2_matched_indices = distance_df.index matched_group1_dfs.append(_group1_df.loc[group1_matched_indices]) matched_group2_dfs.append(_group2_df.loc[group2_matched_indices]) _group1_df = _group1_df.drop(group1_matched_indices) _group2_df = _group2_df.drop(group2_matched_indices) # マッチしたレコードを返す group1_df.index = group1_indices group2_df.index = group2_indices matched_df = pd.concat([ group1_df.iloc[pd.concat(matched_group1_dfs).index], group2_df.iloc[pd.concat(matched_group2_dfs).index] ]).sort_index() matched_indices = matched_df.index return X.loc[matched_indices], y.loc[matched_indices]treatment群の1点と最も傾向スコアが近いcontrol群1点をマッチングさせる、を反復しています。その際、距離がstdの0.2倍に収まるペアのみ抽出するようしきい値を設けています。
このあたりの詳細は傾向スコアの概念とその実践が詳しかったです。
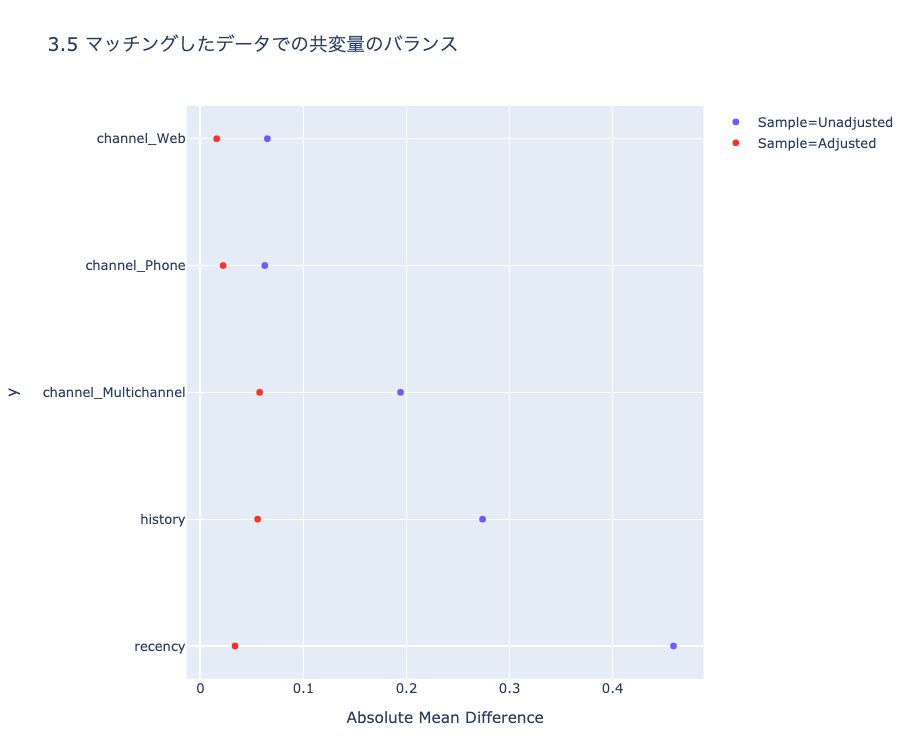
ch3_pscore.ipynbにてMatchItによるマッチング結果との比較をしていますが、完全に一致はしていません。結論が変わらない且つ共変量のバランスも良い感じ(下記参照)のため概ね良しとしています。
こちらも、Rのcobalt love.plot()のような便利ライブラリはないので自力で可視化しています。
(images/ch3_plot1.htmlより)
逆確率重み付き推定(IPW)
IPWは実装がシンプルなのがいいところですね。
こちらもWeightItと比較していますが、概ね正しそうです。
(ch3_pscore.ipynbより抜粋)def get_ipw(X, y, random_state=0): # 傾向スコアを計算する ps_model = LogisticRegression(solver='lbfgs', random_state=random_state).fit(X, y) ps_score = ps_model.predict_proba(X)[:, 1] all_df = pd.DataFrame({'treatment': y, 'ps_score': ps_score}) treatments = all_df.treatment.unique() if len(treatments) != 2: print('2群のマッチングしかできません。2群は必ず[0, 1]で表現してください。') raise ValueError # treatment == 1をgroup1, treatment == 0をgroup2とする。 group1_df = all_df[all_df.treatment==1].copy() group2_df = all_df[all_df.treatment==0].copy() group1_df['weight'] = 1 / group1_df.ps_score group2_df['weight'] = 1 / (1 - group2_df.ps_score) weights = pd.concat([group1_df, group2_df]).sort_index()['weight'].values return weightsCausalImpact
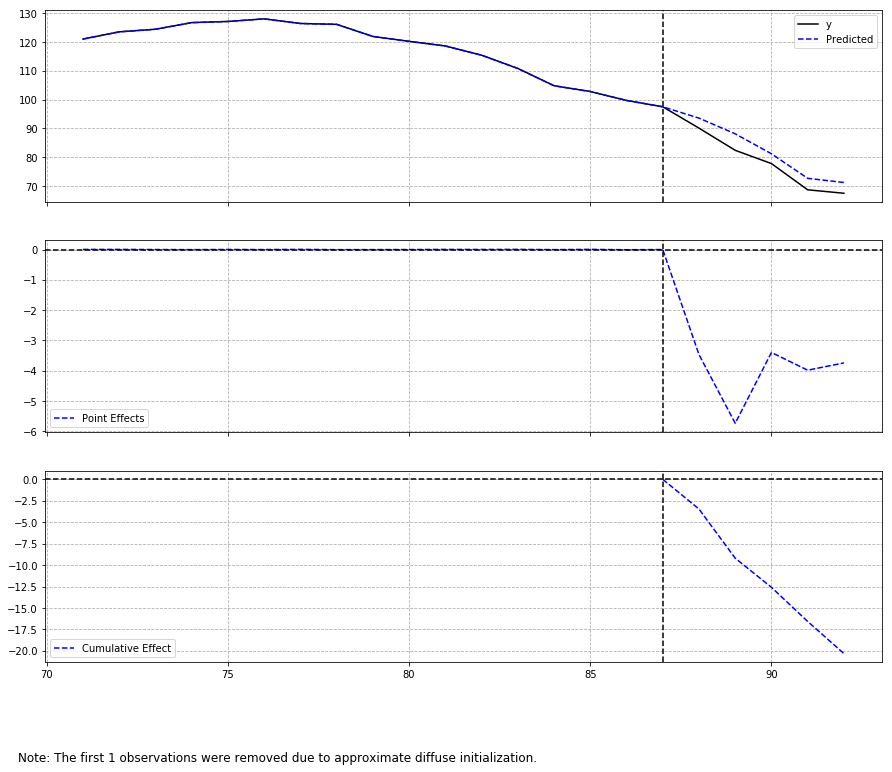
ch4_did.ipynbに記載しているとおり、下記2つのライブラリを使い、比較しています。
- dafiti/causalinpact: https://github.com/dafiti/causalimpact
- tcassou/causal_impact: https://github.com/tcassou/causal_impact
outputがキレイなのでいつもはdafitiのcausalimpactを使っているんですが、推定結果が書籍(Rの本家causalimpact)に近いのはtcassouのcausal_impactでした。
両者とも、statsmodelsの状態空間モデルで推定してるみたいですが、、ちょっと実装の違いはよくわからなかったです。誰か教えて下さい。。
どちらも、R実装と比較して推定誤差がめちゃめちゃ小さくなってるんですよね。共変量が多いのがあまりよくないのかもしれない。dafiti/causalimpactのplot
tcassou/causal_impactのplot
回帰不連続デザイン(RDD)
Rだとrddtoolsでサクっと実行できますが、Pythonだとそうはいかないです。
まず、rddtoolsのrdd_reg_lmで使われている回帰式を確認します。
(参考:https://cran.r-project.org/web/packages/rddtools/rddtools.pdf P23)Y = α + τD + β_1(X-c)+ β_2D(X-c) + ε余談ですが、私はてっきりRDDって、cut-off値の左と右でそれぞれ回帰モデルつくって、cut-off値での推定値の差分を取るんだと思ってたんですが、1つの回帰式で表すんですね。意味的には同じなのかな。
ここで、DはXがcut-off値以降なら1, 以前なら0の値を持つバイナリ変数です。Dのcoefが効果量として確認したい値です。
また、cはcut-off値です。
以上を踏まえて、実装します。実装にあたってはrddtoolsのソースコードも参照しています。(https://github.com/MatthieuStigler/RDDtools/blob/master/RDDtools/R/model.matrix.RDD.R )
(ch5_rdd.ipynbより抜粋)class RDDRegression: # Rパッケージrddtoolsのrdd_reg_lmを再現する # 参考:https://cran.r-project.org/web/packages/rddtools/rddtools.pdf P23 def __init__(self, cut_point, degree=4): self.cut_point = cut_point self.degree = degree def _preprocess(self, X): X = X - threshold_value X_poly = PolynomialFeatures(degree=self.degree, include_bias=False).fit_transform(X) D_df = X.applymap(lambda x: 1 if x >= 0 else 0) X = pd.DataFrame(X_poly, columns=[f'X^{i+1}' for i in range(X_poly.shape[1])]) X['D'] = D_df for i in range(X_poly.shape[1]): X[f'D_X^{i+1}'] = X_poly[:, i] * X['D'] return X def fit(self, X, y): X = X.copy() X = self._preprocess(X) self.X = X self.y = y X = sm.add_constant(X) self.model = sm.OLS(y, X) self.results = self.model.fit() coef = self.results.summary().tables[1] self.coef = pd.read_html(coef.as_html(), header=0, index_col=0)[0] def predict(self, X): X = self._preprocess(X) X = sm.add_constant(X) return self.model.predict(self.results.params, X)多項式回帰を行うための前処理として、scikit-learnのPolynomialFeaturesを利用しています。
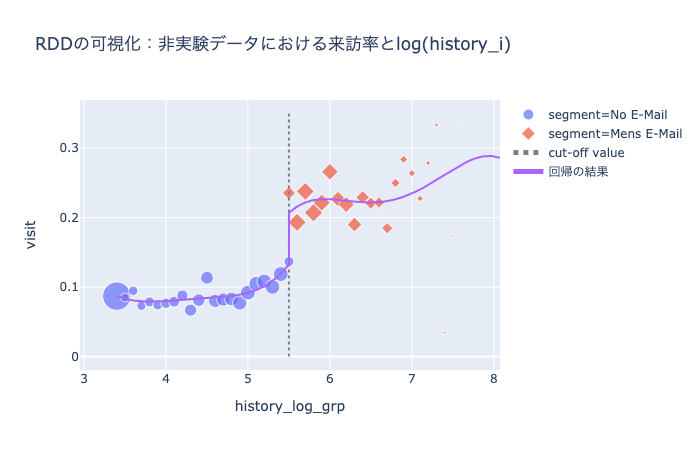
(images/ch5_plot2_3.htmlより)
良いかんじに推定できました。Notebookを見ていただければわかりますが、効果量の推定も書籍とほぼ一致しています。よかった。nonparametric RDD (RDestimate)
できませんでした、、、冒頭の「Pythonで(ほぼ)再現しました」のほぼの部分です。
RDestimateでは、Imbens and Kalyanaraman(2012) Optimal Bandwidth Choice for the Regression Discontinuity Estimator の手法を用いて、最適なバンド幅を選択するんですが、そのバンド幅の推定がどうやってるのかよくわかんなかったです。
ch5_rdd.ipynbでは、雑にバンド幅を変えたときのMSEが最適なバンド幅を見つけるように実装してみましたが、あまりうまく行っているように見えないです。
(ch5_plot4.htmlより)
うーんってかんじですね。純粋にバンド幅を狭めて推定するとバンド幅外は予測できなくなるのはそれはそうな気がするんですが、実際どうやるんですかね。
あるいは、cut-off近傍の推定にだけ興味があるからあまり気にしなくていいのかな。おわりに
理解や実装が間違っていたり、なんかおかしいところとかがあったらぜひ教えてほしいです。



- 投稿日:2020-01-03T19:55:36+09:00
Pytorchで自作の活性化関数をかく(hard sigmoid)
ChainerからPytorchへの移植
研究でDeep Learningをしているのですが、先日Chainerのアップデートが終わりを迎えるのを知り、開発元と同様Pytorchにフレームワークを変更することになりました。
手始めに今あるChainerのプログラムからPytorchに移植することにしました。基本的には関数の名前などを変えるだけでよかったんですが、途中でPytorchにHardSigmoidがないことに気づきました。
ということで自分で作っちゃおうということです。実際にかいてみた
...といっても、公式リファレンスに書いてあるのでほぼその通りにやっただけです。
--> https://pytorch.org/docs/master/autograd.htmlclass MyHardSigmoid(torch.autograd.Function): @staticmethod def forward(ctx, i): ctx.save_for_backward(i) result = (0.2 * i + 0.5).clamp(min=0.0, max=1.0) return result @staticmethod def backward(ctx, grad_output): grad_input = grad_output.clone() result, = ctx.saved_tensors grad_input *= 0.2 grad_input[result < -2.5] = 0 grad_input[result > -2.5] = 0 return grad_input@staticmethodを書かないとwarningが出てきます。
公式のものは、指数関数になっていますが、これをhard sigmoidに変えていきます。まずforward()には、順伝搬をかきます。
hard sigmoid()は以下のような式になるのでそうなるように書きました。h(x) = \left\{ \begin{array}{ll} 0 & (x \lt -2.5) \\ 0.2x + 0.5 & (-2.5 \leq x \leq 2.5) \\ 1 & (2.5 \lt x) \end{array} \right.次にbackward()で、これは逆伝搬を書きます。
微分係数は以下のようになります。\frac{\partial h(x)}{\partial x} = \left\{ \begin{array}{ll} 0 & (x \lt -2.5) \\ 0.2 & (-2.5 \leq x \leq 2.5) \\ 0 & (2.5 \lt x) \end{array} \right.そして最後にこれをモデルに適用させます。(モデルの中身は適当です。)
model.pyimport torch.nn as nn import torch.nn.functional as F class Model(nn.Module): def __init__(self): super(Model, self).__init__() self.conv1 = nn.Conv2d(1, 20, 5) self.conv2 = nn.Conv2d(20, 20, 5) def forward(self, x): x = F.relu(self.conv1(x)) hard_sigmoid = MyHardSigmoid.apply return hard_sigmoid(self.conv2(x))これでバッチリ!!...なはず
- 投稿日:2020-01-03T19:34:04+09:00
ゼロから作るDeep Learningで素人がつまずいたことメモ:4章
はじめに
ふと思い立って勉強を始めた「ゼロから作るDeep LearningーーPythonで学ぶディープラーニングの理論と実装」の4章で私がつまずいたことのメモです。
実行環境はmacOS Mojave + Anaconda 2019.10です。詳細はこのメモの1章をご参照ください。
4章 ニューラルネットワークの学習
この章はニューラルネットワークの学習についての説明です。
4.1 データから学習する
通常は人が規則性を導き出してアルゴリズムを考え、それをプログラムに書いてコンピューターに実行させます。このアルゴリズムを考える作業自体もコンピューターにやらせてしまおうというのが、機械学習やニューラルネットワーク、ディープラーニングです。
この本では、処理したいデータに対して、事前に人が考えた特徴量の抽出(ベクトル化など)が必要なものを「機械学習」、さらにその「機械学習」に特徴量の抽出まで任せて生データをそのまま渡せるようにしたものを「ニューラルネットワーク(ディープラーニング)」と定義しています。この定義はやや乱暴な感じもしますが、言葉の使い分けにはあまり興味がないので気にせず先に進みます。
訓練データ、テストデータ、過学習などについて解説されていますが、特につまずく部分はありませんでした。
4.2 損失関数
損失関数として良く使われる2乗和誤差と交差エントロピー誤差の解説、そして訓練データの一部を使って学習するミニバッチ学習の解説です。ここも特につまずく部分はありませんでした。訓練データを全数使っても良さそうですが時間がかかって非効率ということですね。いわゆる標本調査みたいなことなのかと思います。
また、損失関数の代わりに認識精度を使うことができない理由として、認識精度は結果の微小な変化で反応せず不連続に変化するためうまく学習できないと解説されています。最初はピンと来ないかも知れませんが、次の微分の説明が終わると腹落ちするかと思います。
4.3 数値微分
微分の解説です。実装時の丸め誤差の説明は実用的でありがたいです。「微分」とか「偏微分」とか言葉を聞くと難しそうに思えてしまいますが、ちょっと値を変化させたら結果はどう変わるか?というだけなので、特に高校数学のおさらいとかはしなくても前に進めます。
ちなみに微分で出てくる $ \partial $ という記号はWikipedia曰くデルとかディーとかパーシャル・ディーとかラウンド・ディーとか読むそうです。
それにしても、Pythonは引数に関数が簡単に渡せていいですね。私のプログラマー現役時代はC/C++メインだったのですが、関数ポインタの表記がホント分かりにくくて嫌いでした
4.4 勾配
すべての変数の偏微分をベクトルにしたものが勾配です。これ自体は難しくはありません。
NumPy配列で小数を出力する時に値を丸めて表示してくれるのは見やすくていいですね。
>>> import numpy as np >>> a = np.array([1.00000000123, 2.99999999987]) >>> a array([1., 3.])でも勝手に丸められると困ることもあるし、どんな仕様なんだろうと調べて見たら、表示方法を設定する機能がありました。
numpy.set_printoptionsで、小数の表示方法や、要素数が多い場合の省略方法などを変更できます。例えばprecisionで小数点以下の桁数を大きく指定すると、きちんと丸められずに表示されます。>>> np.set_printoptions(precision=12) >>> a array([1.00000000123, 2.99999999987])これは便利!
4.4.1 勾配法
文中で「勾配降下法(gradient descent method)」という言葉が出てきますが、これは、以前勉強した時の教材では「最急降下法」と訳されていたものでした。
あと、学習率を示す $ \eta $という記号が出てきますが、これはギリシャ文字でイータと読みます(以前勉強した時は読み方を覚えていたのですが、すっかり忘れていてググりました
)。
4.4.2 ニューラルネットワークに対する勾配
numerical_gradient(f, x)を使って勾配を求めるのですが、このfに渡す関数がdef f(W): return net.loss(x, t)となっていて、あれ?この関数は引数
Wを使っていない?と少し混乱しましたが、「4.4 勾配」のところで実装したnumerical_gradient(f, x)の関数の形をそのまま使おうとしているためで、引数Wはダミーとのこと。確かにsimpleNetクラスは自身で重みWを保持しているので、損失関数simpleNet.lossに重みWを渡す必要はありません。ダミーがあると分かりにくいので、私は引数なしで実装してみることにしました。あとここで、
numerical_gradientを多次元配列でも大丈夫な形に修正しておく必要があります。4.5 学習アルゴリズムの実装
ここからは、これまでに学んだ内容を使って、実際に確率的勾配降下法(SGD)を実装します。
まず、必要な関数を寄せ集めた
functions.pyです。functions.py# coding: utf-8 import numpy as np def sigmoid(x): """シグモイド関数 本の実装ではオーバーフローしてしまうため、以下のサイトを参考に修正。 http://www.kamishima.net/mlmpyja/lr/sigmoid.html Args: x (numpy.ndarray): 入力 Returns: numpy.ndarray: 出力 """ # xをオーバーフローしない範囲に補正 sigmoid_range = 34.538776394910684 x2 = np.maximum(np.minimum(x, sigmoid_range), -sigmoid_range) # シグモイド関数 return 1 / (1 + np.exp(-x2)) def softmax(x): """ソフトマックス関数 Args: x (numpy.ndarray): 入力 Returns: numpy.ndarray: 出力 """ # バッチ処理の場合xは(バッチの数, 10)の2次元配列になる。 # この場合、ブロードキャストを使ってうまく画像ごとに計算する必要がある。 # ここでは1次元でも2次元でも共通化できるようnp.max()やnp.sum()はaxis=-1で算出し、 # そのままブロードキャストできるようkeepdims=Trueで次元を維持する。 c = np.max(x, axis=-1, keepdims=True) exp_a = np.exp(x - c) # オーバーフロー対策 sum_exp_a = np.sum(exp_a, axis=-1, keepdims=True) y = exp_a / sum_exp_a return y def numerical_gradient(f, x): """勾配の算出 Args: f (function): 損失関数 x (numpy.ndarray): 勾配を調べたい重みパラメーターの配列 Returns: numpy.ndarray: 勾配 """ h = 1e-4 grad = np.zeros_like(x) # np.nditerで多次元配列の要素を列挙 it = np.nditer(x, flags=['multi_index']) while not it.finished: idx = it.multi_index # it.multi_indexは列挙中の要素番号 tmp_val = x[idx] # 元の値を保存 # f(x + h)の算出 x[idx] = tmp_val + h fxh1 = f() # f(x - h)の算出 x[idx] = tmp_val - h fxh2 = f() # 勾配を算出 grad[idx] = (fxh1 - fxh2) / (2 * h) x[idx] = tmp_val # 値を戻す it.iternext() return grad def cross_entropy_error(y, t): """交差エントロピー誤差の算出 Args: y (numpy.ndarray): ニューラルネットワークの出力 t (numpy.ndarray): 正解のラベル Returns: float: 交差エントロピー誤差 """ # データ1つ場合は形状を整形 if y.ndim == 1: t = t.reshape(1, t.size) y = y.reshape(1, y.size) # 誤差を算出してバッチ数で正規化 batch_size = y.shape[0] return -np.sum(t * np.log(y + 1e-7)) / batch_size def sigmoid_grad(x): """5章で学ぶ関数。誤差逆伝播法を使う際に必要。 """ return (1.0 - sigmoid(x)) * sigmoid(x)
softmaxは、ゼロから作るDeep Learningで素人がつまずいたことメモ:3章で直したものをさらにスッキリさせてみました。この本のGitHubリポジトリのissueにあったsoftmax関数のコード改善案 #45を参考にしています。
numerical_gradientは前述のように、引数fで渡す関数の引数をなくしました。また、多次元配列に対応させるため、numpy.nditerでループしています。なお、本のコードではnumpy.nditerを使う際にop_flags=['readwrite']を指定していますが、xにアクセスするためのインデックスをmulti_indexで取り出しているだけで、イテレータにより列挙させたオブジェクトを更新している訳ではないのでop_flagsは省略(op_flags=['readonly']になる)しました。詳細は英語ですがIterating Over Arrays#Modifying Array Valuesを参照してください。最後の関数
sigmoid_gradは5章で学ぶものなのですが、処理時間短縮のために必要なので(後述)、本の通り実装しています。続いて2層ニューラルネットワークを実装した
two_layer_net.pyです。two_layer_net.py# coding: utf-8 from functions import sigmoid, softmax, numerical_gradient, \ cross_entropy_error, sigmoid_grad import numpy as np class TwoLayerNet: def __init__(self, input_size, hidden_size, output_size, weight_init_std=0.01): """2層のニューラルネットワーク Args: input_size (int): 入力層のニューロンの数 hidden_size (int): 隠れ層のニューロンの数 output_size (int): 出力層のニューロンの数 weight_init_std (float, optional): 重みの初期値の調整パラメーター。デフォルトは0.01。 """ # 重みの初期化 self.params = {} self.params['W1'] = weight_init_std * \ np.random.randn(input_size, hidden_size) self.params['b1'] = np.zeros(hidden_size) self.params['W2'] = weight_init_std * \ np.random.randn(hidden_size, output_size) self.params['b2'] = np.zeros(output_size) def predict(self, x): """ニューラルネットワークによる推論 Args: x (numpy.ndarray): ニューラルネットワークへの入力 Returns: numpy.ndarray: ニューラルネットワークの出力 """ # パラメーター取り出し W1, W2 = self.params['W1'], self.params['W2'] b1, b2 = self.params['b1'], self.params['b2'] # ニューラルネットワークの計算(forward) a1 = np.dot(x, W1) + b1 z1 = sigmoid(a1) a2 = np.dot(z1, W2) + b2 y = softmax(a2) return y def loss(self, x, t): """損失関数の値算出 Args: x (numpy.ndarray): ニューラルネットワークへの入力 t (numpy.ndarray): 正解のラベル Returns: float: 損失関数の値 """ # 推論 y = self.predict(x) # 交差エントロピー誤差の算出 loss = cross_entropy_error(y, t) return loss def accuracy(self, x, t): """認識精度算出 Args: x (numpy.ndarray): ニューラルネットワークへの入力 t (numpy.ndarray): 正解のラベル Returns: float: 認識精度 """ y = self.predict(x) y = np.argmax(y, axis=1) t = np.argmax(t, axis=1) accuracy = np.sum(y == t) / x.shape[0] return accuracy def numerical_gradient(self, x, t): """重みパラメーターに対する勾配の算出 Args: x (numpy.ndarray): ニューラルネットワークへの入力 t (numpy.ndarray): 正解のラベル Returns: dictionary: 勾配を格納した辞書 """ grads = {} grads['W1'] = \ numerical_gradient(lambda: self.loss(x, t), self.params['W1']) grads['b1'] = \ numerical_gradient(lambda: self.loss(x, t), self.params['b1']) grads['W2'] = \ numerical_gradient(lambda: self.loss(x, t), self.params['W2']) grads['b2'] = \ numerical_gradient(lambda: self.loss(x, t), self.params['b2']) return grads def gradient(self, x, t): """5章で学ぶ関数。誤差逆伝播法の実装 """ W1, W2 = self.params['W1'], self.params['W2'] b1, b2 = self.params['b1'], self.params['b2'] grads = {} batch_num = x.shape[0] # forward a1 = np.dot(x, W1) + b1 z1 = sigmoid(a1) a2 = np.dot(z1, W2) + b2 y = softmax(a2) # backward dy = (y - t) / batch_num grads['W2'] = np.dot(z1.T, dy) grads['b2'] = np.sum(dy, axis=0) dz1 = np.dot(dy, W2.T) da1 = sigmoid_grad(a1) * dz1 grads['W1'] = np.dot(x.T, da1) grads['b1'] = np.sum(da1, axis=0) return gradsほとんど本のコードと同じです。最後の
gradientは5章で学ぶものなのですが、処理時間短縮のために必要なので(後述)、本の通り実装しています。最後にミニバッチ学習の実装です。
mnist.py# coding: utf-8 import numpy as np import matplotlib.pylab as plt import os import sys from two_layer_net import TwoLayerNet sys.path.append(os.pardir) # パスに親ディレクトリ追加 from dataset.mnist import load_mnist # MNISTの訓練データとテストデータ読み込み (x_train, t_train), (x_test, t_test) = \ load_mnist(normalize=True, one_hot_label=True) # ハイパーパラメーター設定 iters_num = 10000 # 更新回数 batch_size = 100 # バッチサイズ learning_rate = 0.1 # 学習率 # 結果の記録リスト train_loss_list = [] # 損失関数の値の推移 train_acc_list = [] # 訓練データに対する認識精度 test_acc_list = [] # テストデータに対する認識精度 train_size = x_train.shape[0] # 訓練データのサイズ iter_per_epoch = max(train_size / batch_size, 1) # 1エポック当たりの繰り返し数 # 2層のニューラルワーク生成 network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10) # 学習開始 for i in range(iters_num): # ミニバッチ生成 batch_mask = np.random.choice(train_size, batch_size, replace=False) x_batch = x_train[batch_mask] t_batch = t_train[batch_mask] # 勾配の計算 # grad = network.numerical_gradient(x_batch, t_batch) 遅いので誤差逆伝搬法で…… grad = network.gradient(x_batch, t_batch) # 重みパラメーター更新 for key in ('W1', 'b1', 'W2', 'b2'): network.params[key] -= learning_rate * grad[key] # 損失関数の値算出 loss = network.loss(x_batch, t_batch) train_loss_list.append(loss) # 1エポックごとに認識精度算出 if i % iter_per_epoch == 0: train_acc = network.accuracy(x_train, t_train) test_acc = network.accuracy(x_test, t_test) train_acc_list.append(train_acc) test_acc_list.append(test_acc) # 経過表示 print(f"[更新数]{i: >4} [損失関数の値]{loss:.4f} " f"[訓練データの認識精度]{train_acc:.4f} [テストデータの認識精度]{test_acc:.4f}") # 損失関数の値の推移を描画 x = np.arange(len(train_loss_list)) plt.plot(x, train_loss_list, label='loss') plt.xlabel("iteration") plt.ylabel("loss") plt.xlim(left=0) plt.ylim(bottom=0) plt.show() # 訓練データとテストデータの認識精度の推移を描画 x2 = np.arange(len(train_acc_list)) plt.plot(x2, train_acc_list, label='train acc') plt.plot(x2, test_acc_list, label='test acc', linestyle='--') plt.xlabel("epochs") plt.ylabel("accuracy") plt.xlim(left=0) plt.ylim(0, 1.0) plt.legend(loc='lower right') plt.show()本のコードでは、ミニバッチ生成の際に使っている
numpy.random.choiceの引数にreplace=Falseの指定がありませんが、これだと同じ要素を重複して取り出してしまうことがありそうなので指定してみました。勾配の算出は、本来は
TwoLayerNet.numerical_gradientを使って数値微分でやるのですが、処理速度が遅くて手元の環境では1日かかっても10,000回の更新が終わらなそうです。そのため本のアドバイスに従い、5章で学ぶ誤差伝搬法を実装したTwoLayerNet.gradientを使いました。最後に損失関数の値の推移と、訓練データ・テストデータの認識精度の推移をグラフで表示しています。
以下、実行結果です。
[更新数] 0 [損失関数の値]2.2882 [訓練データの認識精度]0.1044 [テストデータの認識精度]0.1028 [更新数] 600 [損失関数の値]0.8353 [訓練データの認識精度]0.7753 [テストデータの認識精度]0.7818 [更新数]1200 [損失関数の値]0.4573 [訓練データの認識精度]0.8744 [テストデータの認識精度]0.8778 [更新数]1800 [損失関数の値]0.4273 [訓練データの認識精度]0.8972 [テストデータの認識精度]0.9010 [更新数]2400 [損失関数の値]0.3654 [訓練データの認識精度]0.9076 [テストデータの認識精度]0.9098 [更新数]3000 [損失関数の値]0.2816 [訓練データの認識精度]0.9142 [テストデータの認識精度]0.9146 [更新数]3600 [損失関数の値]0.3238 [訓練データの認識精度]0.9195 [テストデータの認識精度]0.9218 [更新数]4200 [損失関数の値]0.2017 [訓練データの認識精度]0.9231 [テストデータの認識精度]0.9253 [更新数]4800 [損失関数の値]0.1910 [訓練データの認識精度]0.9266 [テストデータの認識精度]0.9289 [更新数]5400 [損失関数の値]0.1528 [訓練データの認識精度]0.9306 [テストデータの認識精度]0.9320 [更新数]6000 [損失関数の値]0.1827 [訓練データの認識精度]0.9338 [テストデータの認識精度]0.9347 [更新数]6600 [損失関数の値]0.1208 [訓練データの認識精度]0.9362 [テストデータの認識精度]0.9375 [更新数]7200 [損失関数の値]0.1665 [訓練データの認識精度]0.9391 [テストデータの認識精度]0.9377 [更新数]7800 [損失関数の値]0.1787 [訓練データの認識精度]0.9409 [テストデータの認識精度]0.9413 [更新数]8400 [損失関数の値]0.1564 [訓練データの認識精度]0.9431 [テストデータの認識精度]0.9429 [更新数]9000 [損失関数の値]0.2361 [訓練データの認識精度]0.9449 [テストデータの認識精度]0.9437 [更新数]9600 [損失関数の値]0.2183 [訓練データの認識精度]0.9456 [テストデータの認識精度]0.9448
結果を見ると、すでに認識精度が94.5%くらいになっていて、3章で用意されていた学習済みパラメーターの認識精度を超えていました。
4.6 まとめ
4章は本として読むだけなら良いのかも知れませんが、実装しながら進めると結構大変でした。
(ソフトマックス関数と数値微分の関数を多次元配列に対応させる部分の解説は欲しかったなぁ……)この章は以上です。誤りなどありましたら、ご指摘いただけますとうれしいです。


- 投稿日:2020-01-03T18:55:20+09:00
デザインパターンについて勉強してみた(個人的メモ)その5(Compositeパターン、Decoratorパターン、Visitorパターン)
はじめに
この記事は個人的な勉強メモです。inputしたものはoutputしなくてはという強迫観念に駆られて記事を書いています。
あわよくば詳しい人に誤りの指摘やアドバイスを頂ければいいなという思いを込めてQiitaの記事にしています。エンジニアとして社会人生活を送っていますが、デザインパターンについてちゃんと学んだことがなかったので勉強してみました。
ここに記載している内容は
https://github.com/ck-fm0211/notes_desigh_pattern
にuploadしています。過去ログ
デザインパターンについて勉強してみた(個人的メモ)その1
デザインパターンについて勉強してみた(個人的メモ)その2
デザインパターンについて勉強してみた(個人的メモ)その3
デザインパターンについて勉強してみた(個人的メモ)その4Compositeパターン
- Composite パターンは、「容器と中身を同一視する」ことで、再帰的な構造の取り扱いを容易にするもの
- 例:ファイルシステム
- あるフォルダ以下のファイルやフォルダをすべて削除したい場合など、それがファイルなのかフォルダなのかを意識せずに、同じように削除できたほうが都合が良い
実際に使ってみる
題材
- サンプルケースでは、ディレクトリとファイルを考える。
- Composite パターンを意識せずに、ファイルとディレクトリを表すクラスを作成してみる。
class File: def __init__(self, name): self._name = name def remove(self): print("{}を削除しました".format(self._name))
- ディレクトリを表す、Directory クラスは、List オブジェクトとして、配下のディレクトリとファイルのオブジェクトを管理し、remove メソッドが呼ばれた場合には、list に保持しているオブジェクトをすべて削除してから、自らを削除するものとする
class Directory: def __init__(self, name): self._name = name self._list = [] def add(self, arg): self._list.append(arg) def remove(self): itr = iter(self._list) i = 0 while next(itr, None) is not None: obj = self._list[i] if isinstance(obj, File): obj.remove() elif isinstance(obj, Directory): obj.remove() else: print("削除できません") i += 1 print("{}を削除しました".format(self._name)) if __name__ == "__main__": file1 = File("file1") file2 = File("file2") file3 = File("file3") file4 = File("file4") dir1 = Directory("dir1") dir1.add(file1) dir2 = Directory("dir2") dir2.add(file2) dir2.add(file3) dir1.add(dir2) dir1.add(file4) dir1.remove()
- ここまでは問題ない。ここに「ディレクトリには、ディレクトリとファイルだけでなくシンボリックリンクも入るようにしたい」という要求が出てくると面倒になる
- Composite パターンでは、容器の中身と入れ物を同一視する。同一視するために、容器と中身が共通のインタフェースを実装するようにする。
- File と Directory が共通のインタフェース DirectoryEntry を実装するようにする
class DirectoryEntry(metaclass=ABCMeta): @abstractmethod def remove(self): pass
- DirectoryEntry インタフェースでは、remove メソッドのみを定義する
- これを実装する形でFileクラス、Directoryクラスを実装する。
class File(DirectoryEntry): def __init__(self, name): self._name = name def remove(self): print("{}を削除しました".format(self._name)) class Directory(DirectoryEntry): def __init__(self, name): self._name = name self._list = [] def add(self, entry: DirectoryEntry): self._list.append(entry) def remove(self): itr = iter(self._list) i = 0 while next(itr, None) is not None: obj = self._list[i] obj.remove() i += 1 print("{}を削除しました".format(self._name))
- Directory クラス、File クラスを共に DirectoryEntry クラスを実装するクラスとすることで、 Directory クラスの remove メソッド内では、実態が File クラスのインスタンスであるのか、Directory クラスのインスタンスであるのかを気にせず、どちらも DirectoryEntry オブジェクトとして扱うことができるようになっている。
- このように Composite パターンを利用していることで、SymbolicLink クラスを追加する必要が生じた場合も、 柔軟に対応できる。
- DirectoryEntry インタフェースを 実装するように、SymbolicLink クラスを実装すればよい。
class SymbolicLink(DirectoryEntry): def __init__(self, name): self._name = name def remove(self): print("{}を削除しました".format(self._name))Compositeパターンのまとめ
Decoratorパターン
- Decorator パターンでは、飾り枠と中身を同一視することで、より柔軟な機能拡張方法を提供する。
- Decoratorパターンは機能を一つひとつかぶせていくイメージ。ある機能を持ったDecorationをコアとなるものにかぶせていくイメージである。
実際に使ってみる
題材
- アイスクリーム屋では、自由にトッピングを選べるようになっている。客は、トッピングしなくても良いし、複数のトッピングを重ねて選択することもできる。
- アイスクリーム共通のインタフェースとして、以下のインタフェースを定義する。
class Icecream(metaclass=ABCMeta): @abstractmethod def get_name(self): pass @abstractmethod def how_sweet(self): pass
- これらのインタフェースを持つクラスとしては、バニラアイスクリームクラス、抹茶アイスクリームクラスなどが以下のように提供されている。
class VanillaIcecream(Icecream): def get_name(self): return "バニラアイスクリーム" def how_sweet(self): return "バニラ味" class GreenTeaIcecream(Icecream): def get_name(self): return "抹茶アイスクリーム" def how_sweet(self): return "抹茶味"
- これらのアイスクリームインタフェース実装クラスにトッピングをしていくことを考える。
- トッピングとしては、カシューナッツ、スライスアーモンドを考えてみる。
- カシューナッツがトッピングされたバニラアイスクリームや、スライスアーモンドがトッピングされたバニラアイスクリームが要求される。
- ここでは、トッピングを乗せることで、名前(getName メソッドの返り値)が変わり、味(howSweet() メソッドの返り値) は変わらないことにする。
- このような要求を満たすために、カシューナッツがトッピングされたバニラアイスクリームを表現するために、カシューナッツバニラアイスクリームクラスを作成する方法が考えられる。
class CashewNutsVanillaIcecream(Icecream): def get_name(self): return "カシューナッツバニラアイスクリーム"
- このような「継承を利用した機能の追加」は、非常に固定的なものとなってしまう。
- 例えば、カシューナッツを乗せた抹茶アイスクリームを表すインスタンスが欲しい場合は、抹茶アイスクリーム継承クラスが必要となる。
- Decorator パターンは、このように、様々な機能追加を柔軟に行いたい場合に威力を発揮する。
- Decorator パターンを利用した設計では、拡張機能部分のみを持たせた別クラスを用意し、 そのクラスのインスタンス変数に、拡張対象となるインスタンスを持たせ、 拡張対象と同じインタフェースを実装させる。
class CashewNutsToppingIcecream(Icecream): def __init__(self, ice: Icecream): self._ice = ice def get_name(self): name = "カシューナッツ" name += self._ice.get_name() return name def how_sweet(self): return self._ice.how_sweet()
- CashewNutsToppingIcecream クラスは、カシューナッツがトッピングされたアイスクリームを表すクラス。
- このクラスは、Icecream インタフェースを実装し、その getName() メソッドでは、自身が持つインスタンス変数 ice(Icecream インスタンス) の getName() で得られる値に「カシューナッツ」という文字列を付加した値を返り値として返す。また、howSweet() メソッドでは、インスタンス変数 ice の howSweet() メソッドの返り値をそのまま返している。
- このような設計とすることで、以下のように、カシューナッツがトッピングされたバニラアイスクリームも、カシューナッツがトッピングされた抹茶アイスクリームも、 スライスアーモンドがトッピングされたバニラアイスや、スライスアーモンドと、カシューナッツの両方がトッピングされたバニラアイスクリームなど、多様な組合せでのトッピングが可能になる。
ice1 = CashewNutsToppingIcecream(VanillaIcecream()) # カシューナッツトッピングのバニラアイス ice2 = CashewNutsToppingIcecream(GreenTeaIcecream()) # カシューナッツトッピングの抹茶アイスDecoratorパターンのまとめ
Visitorパターン
- Visitor パターンでは、「処理」を訪問者である Visitor オブジェクトに記述することで、処理の追加を簡単にする。
- 処理対象となる、Acceptor オブジェクトは、Visitor オブジェクトを受け入れる accept(Visitor visitor)メソッドを実装している必要ある。
- 例
- 家の「水道工事」を行ってもらう場合、「水道工事業者」を家に呼んで、「よろしくお願いします。」と言って、後は全てお任せする。
- そのほかにも、電気工事業者を呼ぶことも、リフォーム業者を呼ぶこともある。
- これらの訪問者に対して、あなたは、「では、よろしく」と言って、ほとんどの作業をお任せする
- お任せの仕方に多少の違いがあるかもしれないが、最終的には、全てを業者にお任せすることになる。
- もし、新しいサービスを提供する業者が現れたときにも、各家庭は、なんら態度を変える必要が無く、その業者を呼んで、「よろしくお願いします。」というだけで、その新しいサービスを受けることができる。
- Visitor パターンでは、このように、受け入れる側に処理を追加することなく、処理を追加することができるパターン。
実際に使ってみる
題材
- 家庭訪問を例に考える。
- 各家庭では、先生であろうと、近所のおばちゃんであろうと、訪問者が訪れると、知らない人でなければ、「いらっしゃい」と言って受け入れる。
- この際、各家庭を Acceptor 、先生を Visitor として、Visitor パターンに当てはめて考えてみる。
- Visitor パターンでは、Visitor は、訪問対象となる、家庭を訪問する。訪問された家庭は、「ようこそいらっしゃいました」と先生を受けいれる。
- このとき、新人だろうがベテランだろうが、先生を受け入れる側は変化がない。
# -*- coding:utf-8 -*- from abc import ABCMeta, abstractmethod # 先生クラス class Teacher(metaclass=ABCMeta): def __init__(self, students): self._students = students @abstractmethod def visit(self, student_home): getattr(self, 'visit_' + student_home.__class__.__name__.lower())(student_home) @abstractmethod def get_student_list(self): return self._students # 新人先生クラス class RookieTeacher(Teacher): def __init__(self, students): super().__init__(students) def visit(self, student_home): print("先生:こんにちは") super().visit(student_home) @staticmethod def visit_tanaka(tanaka): tanaka.praised_child() @staticmethod def visit_suzuki(suzuki): suzuki.reproved_child() def get_student_list(self): return self._students # 家庭クラス class Home(metaclass=ABCMeta): @staticmethod def praised_child(): pass @staticmethod def reproved_child(): pass # 受け入れインタフェース class TeacherAcceptor(metaclass=ABCMeta): def accept(self, teacher: Teacher): pass # 鈴木さんの家庭 class Suzuki(Home, TeacherAcceptor): @staticmethod def praised_child(): print("スズキ母:あら、先生ったらご冗談を") @staticmethod def reproved_child(): print("スズキ母:うちの子に限ってそんなことは・・・。") def accept(self, teacher: Teacher): teacher.visit(self.__class__) # 田中さんの家庭 class Tanaka(Home, TeacherAcceptor): @staticmethod def praised_child(): print("タナカ母:あらあら、先生ったらご冗談を") @staticmethod def reproved_child(): print("タナカ母:まさか、うちの子に限ってそんなことは・・・。") def accept(self, teacher: Teacher): teacher.visit(self.__class__) if __name__ == "__main__": rt = RookieTeacher(["suzuki", "tanaka"]) rt.visit(Suzuki()) rt.visit(Tanaka())
- 各家庭のacceptメソッドが先生(visitor)のvisitメソッドを呼び出すことで、共通の処理を実現している
Visitorパターンのまとめ
所感
- もっといい例がある気がする・・・



- 投稿日:2020-01-03T18:53:07+09:00
pipenv on WSLでwindowsのpythonが呼ばれてしまう問題
状況
少し前まで、WSL(ubuntu18.04LTS)上でpipenvを使っていて、
WSL上のpythonが呼ばれていて全く問題なかったのに、しばらくWSL使っていなかったら気づいたら表題の状況になっていた。windows側のアップデートやらなんやらしていたので何が原因かはわからない。
方法
アプリと機能>アプリ実行エイリアスでpythonをオフにする
蛇足
pipenvを入れればいいとか、pyenvを入れればいいとか混乱したので、一回全部消して下記に落ち着いた。1
pyenv install
$ git clone https://github.com/pyenv/pyenv.git ~/.pyenv $ echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bashrc $ echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bashrc $ echo 'eval "$(pyenv init -)"' >> ~/.bashrc $ source ~/.bashrcお好みのpython
$ pyenv install 3.8.1 $ python -V Python 3.8.1pipenv install
$ pip list Package Version ---------- ------- pip 19.2.3 setuptools 41.2.0 WARNING: You are using pip version 19.2.3, however version 19.3.1 is available. You should consider upgrading via the 'pip install --upgrade pip' command. $ pip install --upgrade pip $ pip install pipenv $ pip list Package Version ---------------- ---------- certifi 2019.11.28 pip 19.3.1 pipenv 2018.11.26 setuptools 41.2.0 virtualenv 16.7.9 virtualenv-clone 0.5.3pipenvの環境作成
プロジェクトのディレクトリで
pipenv installでほしいバージョンを指定すると
pyenvですでにインストールしていない場合、インストールするか聞いてくる。$ cd your_project $ pipenv install --python 3.7 Warning: Python 3.7 was not found on your system… Would you like us to install CPython 3.7.6 with pyenv? [Y/n]:yPipfileとPipfile.lockが生成されている。
$ pipenv shell (your_project) $ python -V Python 3.7.6 (your_project) $ pyenv versions system 3.7.6 * 3.8.1 (set by PYENV_VERSION environment variable)無事イケそうです。
参考
https://qiita.com/mashita1023/items/10239f5621ef2fc8acb9
https://qiita.com/foewhoew32f320/items/bfa90ae1003e45cefe33
https://github.com/pypa/pipenv/issues/3488
https://github.com/pyenv/pyenv/tree/4e0ba2f47d97acd1284439cff57af059ce376b9d#installation
ちゃんと消えてるかはしりません ↩

- 投稿日:2020-01-03T18:20:02+09:00
Talking Head Anime from a Single Image でバ美肉してみる.
はじめに
みなさん Vtuber 好きですか?
バ美肉したくありませんか?私はしたいです.
しかし私には 3D モデリングの技術も, 絵を描く技術もありません.ならば技術のある人に依頼すればいいじゃないか.
- 2D モデル 数万円 !
- 3D モデル 数十万円 !!
技術もありませんが, お金はもっとありません.
安心してください.
人類の技術の進歩によって, 技術とお金, 両方なくても バ美肉できます.これがバ美肉ですか pic.twitter.com/zNFuW3xV5U
— ナス科ナス属トマト (@tomato08131491) January 2, 2020Talking Head Anime from a Single Image
Google Japan のソフトウェアエンジニアである Pramook Khungurn によって開発された, 1枚の正面を向いているキャラクターの画像から顔アニメーションを自動生成する技術です.
Talking Head Anime from a Single Image
ご想像の通り, ディープラーニングです.
学習データとして
MikuMikuDanceネットワークアーキテクチャとして
Pumarola et al.'s algorithm
Zhou et al.'s view synthesis algorithmが利用されています.
この技術によってこんなことや,
こんなことや
— ナス科ナス属トマト (@tomato08131491) January 3, 2020
一枚のキャラクター画像だけで簡単な顔アニメーションを制作するシステムを作ってみました【日本語版】 https://t.co/Nv5pz9HmoQ @YouTubeさんからこんなことができます.
こんなことが
— ナス科ナス属トマト (@tomato08131491) January 3, 2020
Talking Head Anime from a Single Image https://t.co/LsWaguCG3t @YouTubeさんから準備 applications
このリンクからリポジトリをクローン.
このリンクからダウンロードして解凍,
combiner.pt,face_morpher.pt,two_algo_face_rotator.pt
上記3つのモデルをdataディレクトリに保存.このリンクから
shape_predictor_68_face_landmarks.dat.bz2をダウンロードして解凍,dataディレクトリに保存.
talking-head-anime-demo-masterは以下のような構成になります.+ data + illust - placeholder.txt - waifu_00_256.png - waifu_01_256.png - waifu_02_256.png - waifu_03_256.png - waifu_04_256.png - combiner.pt - face_morpher.pt - placeholder.txt - shape_predictor_68_face_landmarks.dat - two_algo_face_rotator.pt準備 python
別の記事で後日解説
実際に動かしてみる
ディレクトリを
talking-head-anime-demo-masterに変更.
- 手動で動かす場合は,
python app/manual_poser.pyを実行.- 顔をトラッキングして動かす場合はwebカメラなどを用意して,
python app/puppeteer.pyを実行.
Load Image ...で画像を選択.
- 手動で動かす場合は, バーをいろいろ動かしてみると目を閉じたり, 頭を動かしたりできる.
- 顔をトラッキングして動かす場合は, 自分の頭を動かしたり, 瞬きしたりするとそれに合わせてキャラクターも動いてくれる.
あとは自由に遊ぼう!
まとめ
今回, 自分がバ美肉するのにかかった費用は, WEBカメラ
logicool C270N HD WEBCAMの購入代金である
¥2010だけです. このWEBカメラでさえスマホアプリで代用可能なので, もはやバ美肉するのに金銭的ハードルはないに等しいでしょう.プログラムを少し変えることによってアニメーション画像の表示だけにもできるので, それも後日解説したいと思っています.
それではみなさん Let's バ美肉 !
- 投稿日:2020-01-03T18:02:50+09:00
Nクイーン問題をPyQUBOのSAで解いてみる
年末年始の時間を利用してPyQUBOの理解を深めるためにNクイーン問題をやってみました。
PyQUBOは、アニーリングマシンを使う上で、とても便利なQUBO作成ツールだと思います。
「n個のうちmだけを1にする問題をPyQUBOを使ってアニーリングマシンで解く」
https://qiita.com/morimorijap/items/196e7fc86ecff927bf40
などでも使っていますが、改めて、Nクイーン問題をPyQUBOを使って解いてみようと思います。Nクイーン問題とは、Wikipediaの8クイーンは、マスが8x8個で8クイーン https://ja.wikipedia.org/wiki/エイト・クイーン
に対して、マスがNxN個の問題を言います。クイーンの動きは、上下左右斜めの8方向に、遮る物がない限り進めるので、マスの列、行、斜めにクイーンがいないように配置する問題となります。
これをアニーリング マシンで解くためにコスト関数の形式にすると、N-Queen問題のハミルトニアン、 列column、行row、斜めdiagonal
$$H = \sum_{col}\left(\sum_{i \in col} x_i - 1\right)^2
+ \sum_{row}\left(\sum_{i \in row} x_i - 1\right)^2
+ \sum_{diag} \left((\sum_{i \in diag}
x_i ) (\sum_{i \in diag} x_i - 1 )\right)$$となります。
斜めのコスト関数の表現が異なりますが、東北大学のT-Waveの記事になる「N-クイーン問題 をD-Waveマシンで解く」https://qard.is.tohoku.ac.jp/T-Wave/?p=884
も参考になります。4x4の場合は、
のようなマスの表現を考え、PyQUBOで0,1のQUBO形式 Binary(q[0]) のようなArrayを表現します。
from pyqubo import Array, Placeholder, solve_qubo, Sum from pprint import pprint import numpy as npまずは、PyQUBO など必要なものをインポートします。
4x4のマスを作るとします。# N-Queenのマスの数 N = 4 #pyQUBOで0、1の変数をNxN正方マス分つくる q = Array.create('q', (N*N), 'BINARY') q_shape = np.reshape(q,(N,N)) print(q_shape)そうすると、
[[Binary(q[0]) Binary(q[1]) Binary(q[2]) Binary(q[3])]
[Binary(q[4]) Binary(q[5]) Binary(q[6]) Binary(q[7])]
[Binary(q[8]) Binary(q[9]) Binary(q[10]) Binary(q[11])]
[Binary(q[12]) Binary(q[13]) Binary(q[14]) Binary(q[15])]]このようにPyQUBOのBinaryを4x4配列の形式に作成することができます。
行の部分は、数式で以下のようになっていますので、$$\sum_{row}\left(\sum_{i \in row} x_i - 1\right)^2 $$
これをPyQUBOで表すと、行ごとスライスしてそのまま足し2乗し、最後に合計するように表せます。
#行 row_const = 0.0 for row in range(N): row_const += (sum(i for i in q_shape[row, :]) -1)**2また、列もどうように以下のように表せます。
$$ \sum_{col}\left(\sum_{i \in col} x_i - 1\right)^2 $$
#列 col_const = 0.0 for col in range(N): col_const += (sum(i for i in q_shape[:, col]) -1)**2となります。
そして、問題の斜めの表現ですが、
$$\sum_{diag} \left((\sum_{i \in diag}
x_i ) (\sum_{i \in diag} x_i - 1 )\right)$$をPyQUBOで表すことになりますが、Numpyの変換を利用し、「\」「/」の2つに分けて記述することができます。(もっといい方法をご存知の方は教えてください)
#斜め # \の方 diag_const = 0.0 xi = 0.0 xi_1 = 0.0 for k in range(-N+1,N): xi += (sum(i for i in np.diag(q_shape,k=k))) xi_1 += (sum(i for i in np.diag(q_shape,k=k))) -1 diag_const += xi * xi_1と
#斜め # /の方のために入れ替えて, \ をする。 diag_const_f = 0.0 xi = 0.0 xi_1 = 0.0 for k in range(-N+1,N): xi += (sum(i for i in np.diag(np.fliplr(q_shape),k=k))) xi_1 += (sum(i for i in np.diag(np.fliplr(q_shape),k=k))) -1 diag_const_f += xi * xi_1となります。
これを全て足すとことで、エネルギー関数のハミルトニアンを表現することができます。
また、パラメータ調整のためにPyQUBOのPlaceholderを使いalpha,beta,gammaをつけておきます。# エネルギー (ハミルトニアン) を構築 alpha = Placeholder("alpha") beta = Placeholder("beta") gamma = Placeholder("gamma") #パラメータ feed_dict = {'alpha': 1.0, 'beta': 1.0, 'gamma': 1.0} H = alpha * col_const + beta * row_const + gamma *(diag_const + diag_const_f)次にQUBOへ変換をします。
#QUBOのコンパイル model = H.compile() qubo, offset = model.to_qubo(feed_dict=feed_dict) pprint(qubo)だけで、QUBOを作ってくれます。
{('q[0]', 'q[0]'): -11.0,
('q[0]', 'q[10]'): 6.0,
('q[0]', 'q[11]'): 4.0,
('q[0]', 'q[12]'): 2.0,
('q[0]', 'q[13]'): 6.0,
('q[0]', 'q[14]'): 6.0,
('q[0]', 'q[15]'): 6.0,
('q[0]', 'q[1]'): 6.0,
('q[0]', 'q[2]'): 4.0,・・・長いので、途中省略・・・
('q[8]', 'q[8]'): -19.0,
('q[8]', 'q[9]'): 14.0,
('q[9]', 'q[9]'): -21.0}です。 これをそのまま、PyQUBOのSAで計算することができます。
# PyQUBOのSAで計算 solution = solve_qubo(qubo) # pyQUBOのSAで計算結果のデコード decoded_solution, broken, energy = model.decode_solution(solution, vartype="BINARY", feed_dict=feed_dict) pprint(solution)結果は、
{'q[0]': 0,
'q[10]': 0,
'q[11]': 0,
'q[12]': 0,
'q[13]': 0,
'q[14]': 1,
'q[15]': 0,
'q[1]': 1,
'q[2]': 0,
'q[3]': 0,
'q[4]': 0,
'q[5]': 0,
'q[6]': 0,
'q[7]': 1,
'q[8]': 1,
'q[9]': 0}
となり、一応条件は満たしていますが、13にQueenが入ってもいいので、パラメータの調整などが必要な感じがします。
追記:斜めの一番角が抜けていましたので、最適解が出てなかったようです。
今回はちゃんと解が出るようになりました。番外:
レゴのハリーポッターのアドベントカレンダー2019についていたチェス盤で実験(笑)
PyQUBOについては、公式ドキュメント参考になります。
https://pyqubo.readthedocs.io/以上。
追記:
2020/1/3 9:20pm
斜めの条件が間違っていたので編集しました。



- 投稿日:2020-01-03T18:00:01+09:00
Python(及び型が明示されていない言語)が糞だと思う点
注意:型に詳しくない為用語など間違っている可能性があります。まさかり投げてください。
ソースリーディングをしていて以下のようなコードに出くわした時
class BaseRequestHandler: """Base class for request handler classes. This class is instantiated for each request to be handled. The constructor sets the instance variables request, client_address and server, and then calls the handle() method. To implement a specific service, all you need to do is to derive a class which defines a handle() method. The handle() method can find the request as self.request, the client address as self.client_address, and the server (in case it needs access to per-server information) as self.server. Since a separate instance is created for each request, the handle() method can define other arbitrary instance variables. """ def __init__(self, request, client_address, server): self.request = request self.client_address = client_address self.server = server self.setup() try: self.handle() finally: self.finish()request, client_address, serverってなんやねんってなる。
このコードを書いた人はある特定の型のオブジェクトがここに突っ込まれることを想定していると思う。でも型が明示されていない為それが何なのか分からない。呼び出す側を探してそれが何なのか確認しなきゃならない。
コードを書いている人の脳内にある型の情報がソースコード上では省略されているからこんなことになる。
- 投稿日:2020-01-03T17:43:26+09:00
Apache Beam (Dataflow) 実践入門【Python】
はじめに
本記事は、Apache Beam Documentation の内容を翻訳したものをベースとしています。
Apache Beam Python SDK でバッチ処理が可能なプログラムを実装し、Cloud Dataflow で実行する手順や方法をまとめています。また、Apache Beam の基本概念やテストなどについても少し触れています。
Beam SDK
Beam SDK は、Java, Python, Go の中から選択することができ、以下のような分散処理の仕組みを単純化する機能を提供しています。
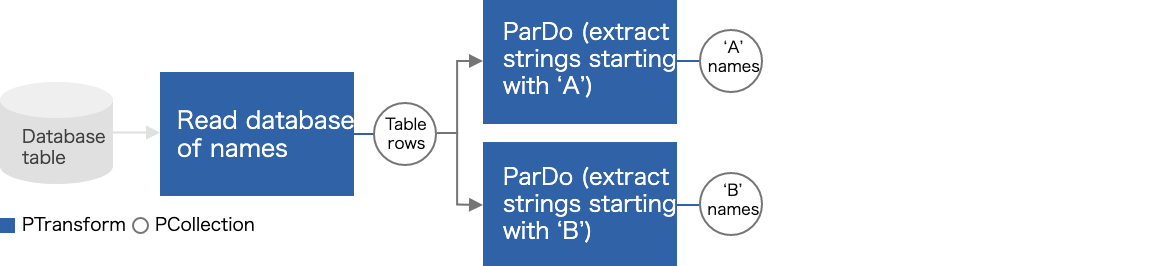
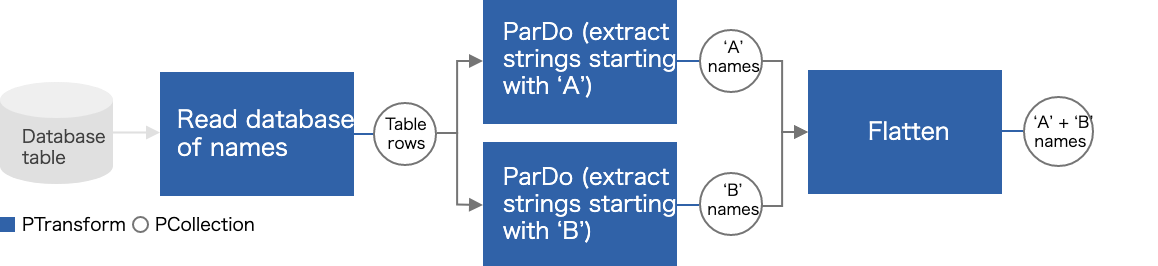
- Pipeline:処理タスク全体(パイプライン)をカプセル化します。処理タスクには、入力データの読み取り、変換処理、および出力データの書き込み等が含まれます。
- PCollection:分散処理対象のデータセットを表すオブジェクトです。通常は、外部のデータソースからデータを読み取り、PCollectionを作成しますが、インメモリから作成することも可能です。
- PTransform:データ変換処理の機能を提供します。すべてのPTransformは、1つ以上のPCollectionを入力として受け取り、そのPCollectionの要素に対して何らかの処理を実行して、0個以上のPCollectionを出力します。
- I/O Transform:様々な外部ストレージシステム(GCS や BigQuery など)で、データの読み書きができる機能を提供しています。
実行環境
Beam SDK によって作成されたプログラムは、以下のような分散データ処理システム上で実行することができます。Apache Beam では、この実行環境のことをランナーと呼んでいます。
- DirectRunner: ローカルマシン上(テストを行う際などに使う)
- SparkRunner: Apache Spark
- DataflowRunner: Google Cloud Dataflow
- その他はこちらを参照
処理フローの例
一般的な(単純な)Beam プログラムは以下のように動作します。
- Pipeline オブジェクトを作成し、実行オプションを設定します。
- Read Transform を使用して外部ストレージシステムまたはインメモリからデータを読み込み、 PCollectionを作成します。
- 各 PCollection に PTransform を適用します。PTransformは、PCollection内の要素を様々なロジックで変換処理することが可能です。
- Write Transform を適用して、PTransform によって変換された PCollection を外部ソースに書き込みます。
この処理フローの場合、以下のような単純なパイプラインになります。
パイプラインの実装
上記のパイプラインを、実際に Python で実装してみます。
- Python バージョン:2系で
2.7以上 または 3系で3.5以上- Beam バージョン:
2.15.*Beam SDK のインストール
追加パッケージを特に必要としない場合は、次のコマンドでインストールします。
pip install apache-beam今回は、Dataflow(GCP) 上で実行することを想定しているため、GCPの追加パッケージもインストールしておきます。
pip install apache-beam[gcp]完成コード
こちらは完成形のコードになります。以下で各々について説明していきます。
pipeline.pyimport apache_beam as beam from apache_beam.options.pipeline_options import PipelineOptions from apache_beam.options.pipeline_options import StandardOptions class MyOptions(PipelineOptions): """カスタムオプション.""" @classmethod def _add_argparse_args(cls, parser): parser.add_argument( '--input', default='./input.txt', help='Input path for the pipeline') parser.add_argument( '--output', default='./output.txt', help='Output path for the pipeline') class ComputeWordLength(beam.DoFn): """文字数を求める変換処理.""" def __init__(self): pass def process(self, element): yield len(element) def run(): options = MyOptions() # options.view_as(StandardOptions).runner = 'DirectRunner' p = beam.Pipeline(options=options) (p | 'ReadFromText' >> beam.io.ReadFromText(options.input) # I/O Transform を適用して、オプションで指定したパスにデータを読み込む | 'ComputeWordLength' >> beam.ParDo(ComputeWordLength()) # Transform を適用 | 'WriteToText' >> beam.io.WriteToText(options.output)) # I/O Transformを適用して、オプションで指定したパスにデータを書き込む p.run() if __name__ == '__main__': run()Pipeline
Pipeline オブジェクトは、データ処理タスクのすべてをカプセル化します。Beam プログラムは通常、PCollection の作成と PTransform の適用のために、まずは Pipeline オブジェクトを作成します。
Pipeline の作成
Beam プログラムを使用するには、最初に Beam SDK の Pipeline のインスタンスを(通常 main 関数内に)作成する必要があります。そして、Pipeline を作成するときには実行オプションを設定します。
次のコードは、Pipeline のインスタンスを作成する例です。
import apache_beam as beam from apache_beam.options.pipeline_options import PipelineOptions p = beam.Pipeline(options=PipelineOptions())PipelineOptions の設定
PipelineOptions を使用して、パイプラインを実行するランナーや、選択したランナーに必要な固有のオプションなどを付与することができます。例として、プロジェクトIDやファイルの格納場所などの情報が含まれる可能性があります。
import apache_beam as beam from apache_beam.options.pipeline_options import PipelineOptions p = beam.Pipeline(options=PipelineOptions())選択したランナーに必要な固有のオプションを設定するには、プログラム上で行う方法と、コマンドライン引数から行う方法の2通りがありますが、その例は、後述の Dataflow で説明します。
カスタムオプションを追加する
標準の PipelineOptions に加えてカスタムオプションを追加できます。次の例では、入力先と出力先のパスを指定するオプションを追加しています。カスタムオプションでは、ユーザーがコマンドライン引数から
--helpを渡したときに表示される説明やデフォルト値を指定することもできます。PipelineOptions を継承することで、カスタムオプションを作成することができます。
class MyOptions(PipelineOptions): """カスタムオプション.""" @classmethod def _add_argparse_args(cls, parser): parser.add_argument( '--input', # オプション名 default='./input.txt', # デフォルト値 help='Input path for the pipeline') # 説明 parser.add_argument( '--output', default='./output.txt', help='Output path for the pipeline')作成したオプションは次のように渡します。
p = beam.Pipeline(options=MyOptions())カスタムオプションにデフォルト値以外の値を設定するには、コマンドライン引数から次のように値を渡します。
--input=value --output==valuePCollection
PCollection は、分散処理対象のデータセットを表すオブジェクトです。Beam のパイプラインで、PTransform は入力と出力として PCollection を使用します。そのため、パイプラインでデータを処理したい場合は、PCollection を作成する必要があります。
Pipeline オブジェクトを作成したら、まず何らかの形で少なくとも1つの PCollection を作成する必要があります。
PCollection の作成
I/O Transform を使用して外部ソースからデータを読み取るか、インメモリから PCollection を作成します。後者は主にテストやデバッグする際に役立ちます。
外部ソースから PCollection を作成する
外部ソースから PCollection を作成するには、I/O Transform を使用します。データを読み取るためには、各 I/O Transform が提供する Read Transform を Pipeline オブジェクトに適用します。
PCollection を作成するために Read Transform を Pipeline に適用する方法は次のとおりです。
lines = p | 'ReadFromText' >> beam.io.ReadFromText('gs://some/input-data.txt')インメモリから PCollection を作成する
インメモリから PCollection を作成するには、Create Transform を使用します。
lines = (p | 'ReadFromInMemory' >> beam.Create(['To be, or not to be: that is the question: ', 'Whether \'tis nobler in the mind to suffer ', 'The slings and arrows of outrageous fortune, ', 'Or to take arms against a sea of troubles, ']))PTransform
PTransformは、一般的な処理フレームワークを提供します。PTransform は、入力の PCollection の各要素に適用されます。
Beam SDK は、PCollection に適用できる様々な PTransform を提供しています。これには、ParDo や Combine などの汎用な Core transforms や、1つ以上の Core transforms を組み合わせた Composite transforms が含まれます。様々な PTransform が提供されていますので、こちらなどを参照してみてください。
PTransform の適用
Beam SDK の各 PTransform には、パイプ演算子
|が提供されているので、そのメソッドを入力のPCollection に適用することで PTransform を適用することができます。[Output PCollection] = [Input PCollection] | [PTransform]次のように PTransform を連鎖してパイプラインを作成することもできます。
[Output PCollection] = ([Initial Input PCollection] | [First PTransform] | [Second PTransform] | [Third PTransform])このパイプラインは、今回の実装例と同じフローなので、このような形状のパイプラインになります。
PTransform は、入力の PCollection には変更を加えずに、新しい PCollection を作成します。PTransform によって入力の PCollection に変更が加わることはありません。 PCollection は定義上不変です。そのため、同じ PCollection に複数の PTransform を適用して PCollection を分岐させることもできます。
[Output PCollection] = [Initial Input PCollection] [Output PCollection A] = [Output PCollection] | [Transform A] [Output PCollection B] = [Output PCollection] | [Transform B]このパイプラインの形状は、次のようになります。
I/O Transform
パイプラインを作成するときは、多くの場合、ファイルやデータベースなどの外部ソースからデータを読み取る必要があります。同様に、パイプラインからデータを外部ストレージシステムに出力することもできます。
Beam SDKは、一般的なデータストレージタイプに対して I/O Transform を提供しています。サポートされていないデータストレージの読み書きを行いたい場合は、独自の I/O Transform を実装する必要があります。
データの読み込み
Read Transform は、外部ソースからの読み取りデータを PCollection に変換します。パイプラインを構築している間はいつでも Read Transform を使用できますが、一般的には最初に実行します。
lines = pipeline | beam.io.ReadFromText('gs://some/input-data.txt')データの書き込み
Write Transform は、PCollection 内のデータを外部データソースに書き込みます。パイプラインの結果を出力するには、ほとんどの場合、パイプラインの最後で Write Transform を使用します。
output | beam.io.WriteToText('gs://some/output-data')複数ファイルからの読み込み
多くの Read Transform は、glob 演算子にマッチする複数の入力ファイルからの読み込みをサポートしています。 次の例では、glob 演算子 (*) を使用して、指定された場所に接頭辞「input-」と接尾辞「.csv」があるすべての一致する入力ファイルを読み取ります。
lines = p | 'ReadFromText' >> beam.io.ReadFromText('path/to/input-*.csv')複数ファイルへの書き込み
Write Transform はデフォルトで複数のファイルに書き込みます。その際、ファイル名がすべての出力ファイルの接頭辞として使用されます。
次の例では、複数ファイルを1つのロケーションに書き込みます。各ファイルには、接頭辞「numbers」、および接尾辞「.csv」が付与されます。
output | 'WriteToText' >> beam.io.WriteToText('/path/to/numbers', file_name_suffix='.csv')パイプラインの実行
それでは、完成コードを使用してパイプラインを実行してみます。実行環境として、ローカルと Cloud Dataflow それぞれで実行します。
入力には次のような文字列が含まれるテキストファイルを用意します。
input.txtgood morning. good afternoon. good evening.ローカルで実行
ローカルでパイプラインを実行するには、PipelineOptions にランナーとして
DirectRunnerを設定しますが、特に細かい設定がない限りは、ランナーを明示的に指定する必要はありません。次のコマンドをコマンドラインから実行します。入力先と出力先のパスは環境によって書き換えてください。
python pipeline.py --input=./input.txt --output=./output.txt今回の実装例は、単語の文字数を数えるパイプラインですので、次のような結果が出力されます。
また、beam.io.WriteToTextはデフォルトでファイル名の接尾に00000-of-00001という文字列を付与して複数のファイルに分散して書き込みます。1つのファイルに書き込みたい場合は、shard_name_template引数を空にすることで可能です。output.txt-00000-of-0000113 15 13Cloud Dataflow で実行
Cloud Dataflow は、GCP (Google Cloud Platfom) で提供されている、ストリームモードまたはバッチモードでデータ処理を行うフルマネージドサービスです。利用者はサーバなどインフラの運用を気にすることなく、実質無制限の容量を従量課金制で使用して、膨大な量のデータ処理を行うことができます。
Cloud Dataflow でパイプラインを実行すると、GCP プロジェクトで Compute Engine リソースと Cloud Storage リソースを使用するジョブが作成されます。Cloud Dataflow を利用するには、GCP で Dataflow API をオンにしてください。
Cloud Dataflow で完成コードを実行するには少しの修正が必要です。次のように修正します。
pipeline.pyimport apache_beam as beam from apache_beam.options.pipeline_options import GoogleCloudOptions from apache_beam.options.pipeline_options import PipelineOptions from apache_beam.options.pipeline_options import StandardOptions from apache_beam.options.pipeline_options import WorkerOptions GCP_PROJECT_ID = 'my-project-id' GCS_BUCKET_NAME = 'gs://my-bucket-name' JOB_NAME = 'compute-word-length' class MyOptions(PipelineOptions): """カスタムオプション.""" @classmethod def _add_argparse_args(cls, parser): parser.add_argument( '--input', default='{}/input.txt'.format(GCS_BUCKET_NAME), # GCS に input.txt を置く help='Input for the pipeline') parser.add_argument( '--output', default='{}/output.txt'.format(GCS_BUCKET_NAME), # GCS に出力する help='Output for the pipeline') class ComputeWordLength(beam.DoFn): """文字数を求める変換処理.""" def __init__(self): pass def process(self, element): yield len(element) def run(): options = MyOptions() # GCP オプション google_cloud_options = options.view_as(GoogleCloudOptions) google_cloud_options.project = GCP_PROJECT_ID # プロジェクトID google_cloud_options.job_name = JOB_NAME # 任意のジョブ名 google_cloud_options.staging_location = '{}/binaries'.format(GCS_BUCKET_NAME) # ファイルをステージングするための GCS パス google_cloud_options.temp_location = '{}/temp'.format(GCS_BUCKET_NAME) # 一時ファイルの GCS パス # ワーカーオプション options.view_as(WorkerOptions).autoscaling_algorithm = 'THROUGHPUT_BASED' # 自動スケーリングを有効化する # 標準オプション options.view_as(StandardOptions).runner = 'DataflowRunner' # Dataflow ランナーを指定 p = beam.Pipeline(options=options) (p | 'ReadFromText' >> beam.io.ReadFromText(options.input) | 'ComputeWordLength' >> beam.ParDo(ComputeWordLength()) | 'WriteToText' >> beam.io.WriteToText(options.output, shard_name_template="")) p.run() # p.run().wait_until_finish() # パイプラインの完了までブロックする if __name__ == '__main__': run()そのほかの Dataflow のオプションについてはこちらを参照してください。
ストリーミング実行するには、streamingオプションをtrueにする必要があります。こちらも、同様のコマンドで実行できます。
python pipeline.py --input=gs://my-project-id/input.txt --output=gs://my-project-id/output.txtGCP から Dataflow サービスにアクセスするとパイプラインをモニタリングできます。UI はこのようになり、指定したパスに結果が出力されます。
こうした Dataflow のバッチ処理を定期実行したい場合などは、Dataflow テンプレートを利用すると便利です。詳しくは、こちらを参照してみてください。
パイプラインのテスト
多くの場合、パイプラインを Dataflow などのリモート実行をデバッグするよりも、ローカルで単体テストする方がデバッグにかかる時間と労力を大幅に節約できます。
依存関係の解決のために以下をインストールする必要があります。
pip install noseパイプラインをテストするには、
TestPipelineオブジェクトを用います。入力は外部ソースから読み取る代わりに、apache_beam.Createを用いてインメモリから PCollection を作成します。出力結果をassert_thatで比較します。test_pipeline.pyfrom unittest import TestCase import apache_beam as beam from apache_beam.testing.test_pipeline import TestPipeline from apache_beam.testing.util import assert_that, equal_to from src.pipeline import ComputeWordLength class PipelineTest(TestCase): def test_pipeline(self): expected = [ 13, 15, 13 ] inputs = [ 'good morning.', 'good afternoon.', 'good evening.' ] with TestPipeline() as p: actual = (p | beam.Create(inputs) | beam.ParDo(ComputeWordLength())) assert_that(actual, equal_to(expected))パイプラインの設計
上記で、既にシンプルなパイプラインと、分岐するパイプラインを作成する場合の設計(処理フロー)について簡単に説明しました。ここでは、その他の一般的なパイプラインの設計について紹介します。
複数の PCollection を生成する PTransform を持つパイプライン
Apache Beam の Additional outputs という機能を使って実現できます。
class ExtractWord(beam.DoFn): def process(element): if element.startswith('A'): yield pvalue.TaggedOutput('a', element) # タグ名をつける(先頭が'A'の要素だったら'a') elif element.startswith('B'): yield pvalue.TaggedOutput('b', element) # タグ名をつける(先頭が'B'の要素だったら'b') mixed_col = db_row_col | beam.ParDo(ExtractWord()).with_outputs()) mixed_col.a | beam.ParDo(...) # .タグ名でアクセスできる mixed_col.b | beam.ParDo(...)PCollection を結合する PTransform を持つパイプライン
Flattenを用いることで実現できます。col_list = (a_col, b_col) | beam.Flatten()複数の入力ソースを持つパイプライン
それぞれの入力ソースから PCollection を作成し、
CoGroupByKeyなどで Join することができます。user_address = p | beam.io.ReadFromText(...) user_order = p | beam.io.ReadFromText(...) joined_col = (user_address, user_order) | beam.CoGroupByKey() joined_col | beam.ParDo(...)その他の便利機能
Composite transforms
Composite transforms は、複数の PTransform (ParDo, Combine, GroupByKey...) を組み合わせたものです。複数の PTransform を入れ子構造にすることで、コードがよりモジュール化されて理解しやすくなります。
実装例
Composite transforms を実装するには、PTransform クラスを継承し、expand メソッドをオーバーライドする必要があります。
"""文章の単語数を数えるパイプライン.""" import apache_beam as beam from apache_beam.options.pipeline_options import PipelineOptions class ComputeWordCount(beam.PTransform): """単語数を数える Composite transforms.""" def __init__(self): pass def expand(self, pcoll): return (pcoll | 'SplitWithHalfSpace' >> beam.Map(lambda element: element.split(' ')) | 'ComputeArraySize' >> beam.Map(lambda element: len(element))) def run(): p = beam.Pipeline(options=PipelineOptions()) inputs = ['There is no time like the present.', 'Time is money.'] (p | 'Create' >> beam.Create(inputs) | 'ComputeWordCount' >> ComputeWordCount() | 'WriteToText' >> beam.io.WriteToText('出力先のパス')) p.run() if __name__ == '__main__': run()output7 3Side inputs
Side inputs は、通常の入力(主入力)の PCollection に加えて、追加の入力(副入力)を PTransform に渡すことができる機能です。
実装例
"""全体の平均以上の長さを持つ文字列の長さを出力するパイプライン.""" import apache_beam as beam from apache_beam.options.pipeline_options import PipelineOptions from apache_beam import pvalue class FilterBelowMeanLengthFn(beam.DoFn): """平均以下の文字数を持つ文字列をフィルタリングする.""" def __init__(self): pass # mean_word_length は副入力 def process(self, element, mean_word_length): if element >= mean_word_length: yield element def run(): p = beam.Pipeline(options=PipelineOptions()) inputs = ["good morning.", "good afternoon.", "good evening."] # 主入力 word_lengths = (p | 'Create' >> beam.Create(inputs) | 'ComputeWordLength' >> beam.Map(lambda element: len(element))) # 副入力 mean_word_length = word_lengths | 'ComputeMeanWordLength' >> beam.CombineGlobally(beam.combiners.MeanCombineFn()) (word_lengths | 'FilterBelowMeanLength' >> beam.ParDo(FilterBelowMeanLengthFn(), pvalue.AsSingleton(mean_word_length)) # 副入力を引数に取る DoFn を適用する ParDo の第2引数に副入力を挿入する(pvalue.~ は渡したいデータ型によって異なる) | 'write to text' >> beam.io.WriteToText('出力先のパス')) p.run().wait_until_finish() if __name__ == '__main__': run()「good morning.」, 「good afternoon.」, 「good evening.」の文字数はそれぞれ「13」, 「15」, 「13」で、その平均は13.67ほどなので、次のような出力になります。
output15パイプラインの中で何が起きているか?
「パイプラインの中で何が起きているか」について少し記述しています。
シリアライズと通信
パイプラインの分散処理において最もコストの高い操作の1つは、マシン間で要素をシリアライズして通信を行うことです。Apache Beam のランナーは、マシン間で通信を行うなどの理由で PCollection の要素をシリアライズします。次のような手法を用いて、Transform と次のステップの Transform との間で要素の通信を行います。
- 要素をシリアライズしてワーカーにルーティングする
- 要素をシリアライズして複数のワーカーに再分配する
- Side inputs を使用する場合は、 要素をシリアライズしてすべてのワーカーにブロードキャストする必要がある
- Transform と次のステップの Transform が同じワーカーで実行されている場合は、要素の通信をインメモリを使って行う(シリアライズしないことで通信コストを下げることができる)
同梱と永続化
Apache Beam は、embarassingly parallel 問題に焦点を当てています。Apache Beam は、要素を並列で処理することを重要視しているので、PCollection の各要素にシーケンス番号を割り当てるなどの動作を表現するのが苦手です。このようなアルゴリズムはスケーラビリティの問題を抱える可能性がはるかに高いためです。
すべての要素を並列に処理することにもいくつかの欠点があります。例えば、要素を出力先に書き込む場合です。出力処理において、すべての要素を並列にバッチ処理することは不可能です。
そのため、Apache Beam のランナーは、すべての要素を同時に処理するのではなく、PCollection の要素を同梱して処理します。ストリーミング処理の場合は、小さな単位で同梱して処理する傾向があり、バッチ処理の場合は、より大きな単位で同梱して処理する傾向があります。
並列処理
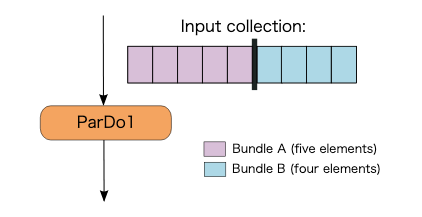
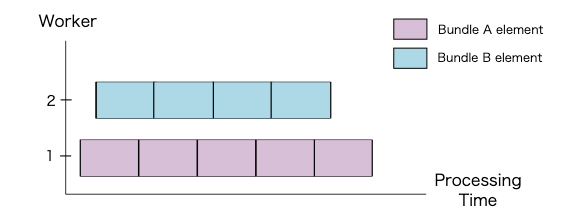
Transform 内の並列処理
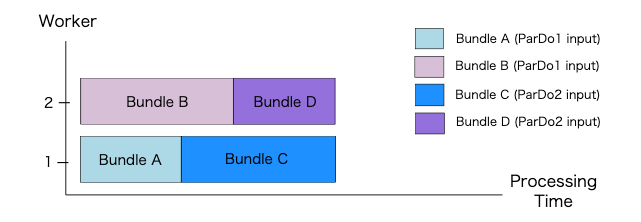
単一の ParDo を実行する場合、Apache Beam のランナーは、PCollection の要素を2つに分割・同梱(Bundle)することがあります。
ParDoが実行されると、ワーカーは、次に示すように2つのBundleを並列で処理します。
単一の要素は分割できないため、Transform の最大並列処理は PCollection の要素数によって異なります。今回の場合の最大並列処理数は図から見て 9 です。
※ 単一の要素を複数の Bundle に分割できる機能(Splittable ParDo)が開発中らしい
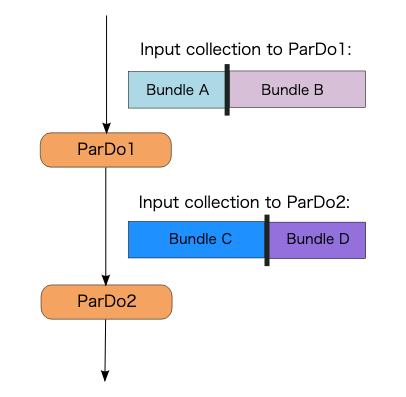
Transform 間の並列処理
ParDo は従属並列になることがあります。例えば、次のように ParDo1 の出力を同じワーカーで処理する必要がある場合、ParDo1 と ParDo2 は従属並列になります。
Worker1 では、Bundle A の要素に対して ParDo1 が実行され、Bundle C になります。次に、Bundle C の要素に対して ParDo2 が実行されます。同様に、Worker2 では、Bundle B の要素に対して ParDo1 が実行され、Bundle D になります。そして、Bundle D の要素に対して ParDo2 が実行されます。
このように ParDo を実行することで、Apache Beam のランナーは、ワーカー間で要素を再配布することを回避できます。そして、これにより通信コストを節約できます。ただし、最大並列処理数は、従属並列の最初の ParDo の最大並列処理数に依存するようになります。
障害発生時の挙動
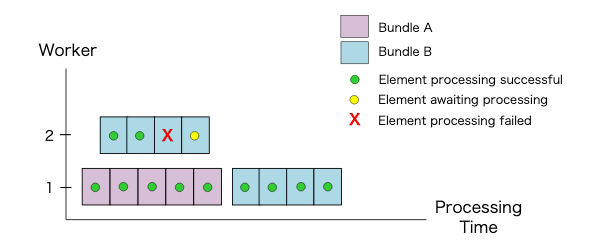
Transform 内の障害発生時の挙動
Bundle 内の要素に対する処理が失敗すると Bundle 全体が失敗してしまいます。そのため、処理を再試行する必要があります(そうしないとパイプライン全体が失敗します)。
次の例では、Worker1 が Bundle A の5つの要素すべてを正常に処理します。Worker2 は Bundle B の4つの要素を処理しますが、Bundle B の最初の2つの要素は正常に処理され、3番目の要素は処理が失敗します。
その後、Apache Beam のランナーが Bundle B のすべての要素を再試行し、2回目で処理が正常に完了しています。図のように、再試行は必ずしも元の処理の試行と同じ Worker で発生するわけではありません。
Transform 間の障害発生時の挙動
ParDo1 の処理後、ParDo2 内の要素を処理できなかった場合、これら2つの Transform は同時に失敗したことになります。
次の例では、Worker2 は Bundle B のすべての要素に対して ParDo1 を正常に実行します。しかし、Bundle D の要素を処理できないため、ParDo2 は失敗します。
その結果、Apache Beam のランナーは ParDo2 の出力を破棄して再び処理を実行する必要があります。その際には、ParDo1 の Bundle も破棄されなければならず、Bundle のすべての要素は再試行されなければいけません。
まとめ
本記事では、Apache Beam Documentation の内容をもとに学習した内容を記述してみました。
間違っている点などあればご指摘ください!





- 投稿日:2020-01-03T17:27:55+09:00
[FastAPI] Python製のASGI Web フレームワーク FastAPIに入門する
FastAPI
PythonのWeb frameworkで、Flaskのようなマイクロフレームワークにあたります。
パフォーマンスの高さ、書きやすさ、本番運用を強く意識した設計、モダンな機能などが強みです。FastAPIはStarletteの肩に乗る形で書かれており、非同期処理が扱いやすいです。
特に、以下の様な特徴があります。
- ASGI
- websocketのサポート
- GraphQLのサポート
- バックグラウンドプロセスが扱いやすい
- python type hintによる自動ドキュメント生成 (Swagger UI)
- pydanticをベースとしたdata validation
率直に言って、responderに非常に似ています。(でた時期も近いですし、responderもStarletteがベースなので)
ですが、下の2つはFastAPIの方がよっぽど使いやすく設計されています。
以下の観点から総合的に見てFastAPIの方が本番運用向けだけだと思います。(個人的にはサクッと自由に書くならresponderの方が使いやすいと思います)
- ドキュメントが丁寧 (DBとの連携、認証、https化なども紹介されている)
- 自動ドキュメント生成機能が手厚いのでフロントエンドの開発者との連携が向上しそう
- 本番運用のためのdocker imageまである
また、いくつかのPythonのframeworkとのパフォーマンスを比較しましたが、FastAPIは確かにパフォーマンスが高いと言えそうでした。(参考: PythonのWeb frameworkのパフォーマンス比較 (Django, Flask, responder, FastAPI, japronto))
本記事の目的
FastAPIのありがたみを感じようとすると公式tutorialが適切かと思います。内容が充実しているのですごくわかりやすいです。しかし、その反面、使い始めるだけのために参照するのは少し量的に重いです。
そこで、必要最低限でFastAPIを使えるようになるための内容にまとめ直して紹介したいと思います。また、本記事は、以下を想定して書いています。
- pythonの何らかのmicroframeworkの基本的な記法が分かる
- 基本的なpythonの型ヒント (mypy) の記法が分かる
ここで紹介する内容に相当するコード例をこちらにまとめています。Swaggerだけさわってみたいなどの場合にご利用下さい。
目次
- intro
- requestの扱い
- responseの扱い
- error handling & status code管理
- background process
- unittest
- deployment
- その他 (CORS問題への対処、認証)
intro
install FastAPI
fastapiとそのASGI serverとなるuvicornをinstallします。
$ pip install fastapi uvicornintro code
GETするとjsonで
{"text": "hello world!"}が返ってくるAPIをたててみます。intro.pyfrom fastapi import FastAPI app = FastAPI() @app.get('/') # methodとendpointの指定 async def hello(): return {"text": "hello world!"}Pythonのmicroframeworkの中でも簡潔に書けるほうだと思います。
run server
以下でサーバーが起動します。(--reloadとするとファイルの変更の度にサーバーが更新されるので開発時には便利です)
intro:appの部分はfile名:FastAPI()のインスタンス名です。適宜置き換えて下さい。$ uvicorn intro:app --reload自動生成ドキュメント(Swagger UI)を確認
http://127.0.0.1:8000/docs にアクセスします。すると、Swagger UIが開きます。ここでAPIを叩くことができます。
また後述の方法でrequestとresponseのスキーマを確認したりできるようになります。FastAPIの大きな強みの一つがこのドキュメントが自動生成される点です。普通に開発していれば勝手にドキュメントが生成されていきます。
requestの扱い
以下の項目を扱います。
- GET method:
- path parameterの取得
- query parameterの取得
- validation
- POST method:
- request bodyの取得
- validation
GET method
path parameter & query parameterの取得
parameterの取得はparameter名を引数に入れるだけで実現できます。
一旦、
- endpointに
/{param}のように宣言したparameter名はpath parameter- それ以外はquery parameterを指す
という理解をして下さい。また、引数の順番は関係ありません。そして、デフォルト値を宣言するか否かで引数に入っているparameterがGET時に入っていない場合の処理がかわります。
- not required: デフォルト値を宣言すると、parameterがきていない場合にはデフォルト値が使われる
- required: 一方、デフォルト値を宣言していないparameterがこないときは
{"detail": "Not Found"}を返すそして、引数は以下の様にpythonの型ヒントをつけるのがFastAPIの特徴です。
@app.get('/get/{path}') async def path_and_query_params( path: str, query: int, default_none: Optional[str] = None): return {"text": f"hello, {path}, {query} and {default_none}"}こうすることで、parameterの取得時に、pythonの型ヒントを考慮してFastAPIが、
- 変換: データを指定した型に変換した状態で引数に入る
- 検証: 指定した型に変換できない場合は、
{"detail": "Not Found"}を返す- 自動ドキュメント生成: swagger UIに型情報を追記
を行います。実際にSwaggerを確認すると、以下の様にparameterの型情報が確認できます。
validation
上記に加えて以下のQuery, Pathを使うと多少高度なことができます。Queryはquery parameter用で、Pathはpath parameter用です。
from fastapi import Query, Path以下の様に使用します。QueryとPathの引数は基本的に同じものが使えて、
- 第一引数はデフォルト値を指定。デフォルト値なし (required)にしたい場合は、
...を渡す- alias: parameter名を指定します。引数名とparameter名を別にしたい時に使います。pythonの命名規則に反している場合用です
- その他: 文字長、正規表現、値の範囲を指定して受け取る値を制限できます
@app.get('/validation/{path}') async def validation( string: str = Query(None, min_length=2, max_length=5, regex=r'[a-c]+.'), integer: int = Query(..., gt=1, le=3), # required alias_query: str = Query('default', alias='alias-query'), path: int = Path(10)): return {"string": string, "integer": integer, "alias-query": alias_query, "path": path}Swaggerから制限内容も確認できます。APIが叩けるので、色々と値を変えてみて正しくvalidationがなされているか確認してみて下さい。
POST method
request bodyの取得
基本形
post dataの受け取り方を説明します。まず、基本は以下の様に、
pydantic.BaseModelを継承した上で、attributesに型ヒントをつけたクラスを別途用意し、それをrequest bodyの型として引数で型ヒントをつければよいです。from pydantic import BaseModel from typing import Optional, List class Data(BaseModel): """request data用の型ヒントがされたクラス""" string: str default_none: Optional[int] = None lists: List[int] @app.post('/post') async def declare_request_body(data: Data): return {"text": f"hello, {data.string}, {data.default_none}, {data.lists}"}ここで、上記のコードは、以下のようなjsonがpostされてくる想定です。
requestBody{ "string": "string", "default_none": 0, "lists": [1, 2] }もしもfieldが足りなければstatus code 422が返ります。(余分なfieldが入っている場合は正常に動いているようです)
また、ここまでの処理を行うと、想定しているrequest bodyのデータ構造がSwagger UIから確認できるようになっています。
embed request body
先程の例と少しかわって以下の様なデータ構造の場合のための記法を説明します。
requestBody{ "data": { "string": "string", "default_none": 0, "lists": [1, 2] } }このような構造の場合は、Data classは先程のと同じものを使います。
fastapi.Bodyを使うことで構造だけかえることができます。fastapi.BodyはGET methodのvalidationで紹介したpydantic.Queryの仲間です。同じく第一引数はデフォルト値です。pydantic.Queryなどにはなかったembedという引数を利用します。以下の微小な変更で構造の変更が実現できます。from fastapi import Body @app.post('/post/embed') async def declare_embedded_request_body(data: Data = Body(..., embed=True)): return {"text": f"hello, {data.string}, {data.default_none}, {data.lists}"}nested request body
次は、以下のようにリストや辞書がネストした構造の扱いを説明します。
subDataの構造は先程のembed request bodyの形ですが、異なる書き方を紹介します。{ "subData": { "strings": "string", "integer": 0 }, "subDataList": [ {"strings": "string0", "integer": 0}, {"strings": "string1", "integer": 1}, {"strings": "string2", "integer": 2} ] }pythonの型ヒントであればネスト構造の型宣言は多くの場合、すごく大雑把にしかできません。(もし、大雑把でいいならば、以下のsubDataListは
List[Any]とかList[Dict[str, Any]などの型をつけるだけで十分です)
一方、FastAPI (というかpydantic) だとネストした複雑な構造でも対応できます。
以下の様にネスト構造に沿って忠実にサブクラスを定義して型ヒントをつけていけばいいです。class subDict(BaseModel): strings: str integer: int class NestedData(BaseModel): subData: subDict subDataList: List[subDict] @app.post('/post/nested') async def declare_nested_request_body(data: NestedData): return {"text": f"hello, {data.subData}, {data.subDataList}"}validation
GET methodとやること、できることはほぼ同じです。違いと言えば、
fastapi.Queryなどではなく、pydantic.Fieldを使用する点です。しかし引数は差異がないです。
nested request bodyで使用した各クラスにpydantic.Fieldを導入しただけです。また、fastapi.Queryなどでも使えますが、引数exampleを利用しています。この引数に渡したデータがSwagger上からAPIを叩くときのデフォルト値になります。from pydantic import Field class ValidatedSubData(BaseModel): strings: str = Field(None, min_length=2, max_length=5, regex=r'[a-b]+.') integer: int = Field(..., gt=1, le=3) # required class ValidatedNestedData(BaseModel): subData: ValidatedSubData = Field(..., example={"strings": "aaa", "integer": 2}) subDataList: List[ValidatedSubData] = Field(...) @app.post('/validation') async def validation(data: ValidatedNestedData): return {"text": f"hello, {data.subData}, {data.subDataList}"}responseの扱い
responseにもrequest bodyで定義したようなクラスを定義してvalidationを行うことができます。
基本形
response_modelに渡すと、デフォルトで、
- returnした辞書について、attributesに一致する名前が存在しないkeyは破棄される
- returnした辞書には含まれないが、attributesにはデフォルト値がある場合はその値が補填される
ここで、以下のように書くと、returnしている辞書のうち
integerは捨てられ、auxが補われてjsonを返します。 (非常にシンプルな例を挙げていますが、ネストしていたり、少し複雑なvalidationが必要な場合は「requestの扱い」で挙げたような型ヒントについての記法をそのまま流用すればよいです)class ItemOut(BaseModel): strings: str aux: int = 1 text: str @app.get('/', response_model=ItemOut) async def response(strings: str, integer: int): return {"text": "hello world!", "strings": strings, "integer": integer}この段階でSwaggerからresponse dataのschemaが確認できるようになります。
派生形
response_modelの利用はいくつかのオプションがあります。
# 辞書に存在しない場合にresponse_modelのattributesのデフォルト値を"いれない" @app.get('/unset', response_model=ItemOut, response_model_exclude_unset=True) async def response_exclude_unset(strings: str, integer: int): return {"text": "hello world!", "strings": strings, "integer": integer} # response_modelの"strings", "aux"を無視 -> "text"のみ返す @app.get('/exclude', response_model=ItemOut, response_model_exclude={"strings", "aux"}) async def response_exclude(strings: str, integer: int): return {"text": "hello world!", "strings": strings, "integer": integer} # response_modelの"text"のみ考慮する -> "text"のみ返す @app.get('/include', response_model=ItemOut, response_model_include={"text"}) async def response_include(strings: str, integer: int): return {"text": "hello world!", "strings": strings, "integer": integer}error handling & status code管理
status code管理は3段階あります。
- defaultのstatus codeを宣言: decoratorで宣言する
- error handlingで400番台を返す: 適切な場所で
fastapi.HTTPExceptionをraiseする- 柔軟にstatus code変更してreturnする: starletteを直接さわる
- 引数に
starlette.responses.Responseを型としたものを追加response.status_codeを書き換えると出力のstatus codeを変更できる- 通常通り返したいdataをreturnする
from fastapi import HTTPException from starlette.responses import Response from starlette.status import HTTP_201_CREATED @app.get('/status', status_code=200) # default status code指定 async def response_status_code(integer: int, response: Response): if integer > 5: # error handling raise HTTPException(status_code=404, detail="this is error messages") elif integer == 1: # set manually response.status_code = HTTP_201_CREATED return {"text": "hello world, created!"} else: # default status code return {"text": "hello world!"}background process
background processを用いれば、重い処理が完了する前にレスポンスだけ返すことができます。
WSGI (Djangoなど) 系だとこの処理は結構たいへんです。しかし、StarletteベースのASGIだとこの処理が非常に簡潔に扱えます。手順は、
1.fastapi.BackgroundTasksを型とする引数を宣言
2..add_taskでタスクを投げる何が起きているのかこれだけでは予想もつかないですが、記述自体は簡単と言えるレベルかと思います。
重い処理の例として、受け取ったpath parameter秒だけスリープし、その後にprintするようなbackground processを実行してみます。
from fastapi import BackgroundTasks from time import sleep from datetime import datetime def time_bomb(count: int): sleep(count) print(f'bomb!!! {datetime.utcnow()}') @app.get('/{count}') async def back(count: int, background_tasks: BackgroundTasks): background_tasks.add_task(time_bomb, count) return {"text": "finish"} # time_bombの終了を待たずにレスポンスを返す結果は、次の順序で処理されています
1. Response headersのdate=17時37分14秒
2. printに出力されたdate=17時37分25秒なので、ちゃんとバックグラウンドで処理されていそうです。
unittest
StarletteのTestClientというのが優秀で、unittestのために簡単にapiを叩けます。
今回は、tutorial通りに、pytestでunittestを行ってみます。install
$ pip install requests pytestdirectory配置
├── intro.py └── tests ├── __init__.py └── test_intro.pyここで、以下のunittestを行うことにします。
intro.pyfrom fastapi import FastAPI from pydantic import BaseModel from typing import Optional, List app = FastAPI() @app.get('/') async def hello(): return {"text": "hello world!"} class Data(BaseModel): string: str default_none: Optional[int] = None lists: List[int] @app.post('/post') async def declare_request_body(data: Data): return {"text": f"hello, {data.string}, {data.default_none}, {data.lists}"}unittest
以下の様に
starlette.testclient.TestClientで簡単にGETとPOSTが叩けて、レスポンスのassertができるというのが売りです。test_intro.pyfrom starlette.testclient import TestClient from intro import app # get and assign app to create test client client = TestClient(app) def test_read_hello(): response = client.get("/") assert response.status_code == 200 assert response.json() == {"text": "hello world!"} def test_read_declare_request_body(): response = client.post( "/post", json={ "string": "foo", "lists": [1, 2], } ) assert response.status_code == 200 assert response.json() == { "text": "hello, foo, None, [1, 2]", }pytest実行
$ pytest ========================= test session starts ========================= platform darwin -- Python 3.6.8, pytest-5.3.2, py-1.8.1, pluggy-0.13.1 rootdir: ***/***/*** collected 1 items tests/test_intro.py . [100%] ========================== 1 passed in 0.44s ==========================deployment
以下のような選択肢があります。シンプルなアプリケーションなので、インフラで困るようなことは少ないと思います。
- pip installができて、uvicornさえ起動できればローカルと同じ用に動く
- Docker image (Official): パフォーマンスのチューニングがされているそうです。何より公式なので信頼感があります。
基本的にdockerが使える場合は後者、それ以外に (PaaSでサクッとAPIたてるなど)の場合は前者の方法がいいと思います。
具体的なことに関しては、特にFastAPI特有の処理はなく、その他のmicroframeworkと何らかわりない手続きなので今回は省きます。
参考:その他 (CORS問題への対処、認証)
他にtutorialとして書くまでもないけれども頻出の設定や、コンテキストに強く依存する事柄のリファレンスをまとめます。
- CORS (Cross-Origin Resource Sharing)問題への対処: frontendがbackendと別サーバーにいるときに発生する問題です
- 認証: OAuth2とHTTPベーシック認証の例が載っています。認証に関してもドキュメントが自動生成されます
まとめ
以上でミニマムのtutorialは終了です。
これで一通りのAPIサーバーの開発 -> deploymentまでできるようになると思います。今回扱った内容に加えて、databaseとの連携、htmlのレンダリング、websocket、GraphQLなどを扱いたい場合はそれに関連するチャプターだけ参照すれば十分だと思います。
とにかく自動でSwaggerが生成されるのが便利なので自分で手を動かしながら試してみていただきたいです!
最後に、本記事の内容とはほぼ関係ないですが、FastAPIの公式ドキュメントで一番おもしろかったチャプターを紹介します。開発の経緯と他のframeworkとの差別化点が挙げられています。
Refs
補足
手前味噌ですが、以前responderでもSchema定義 -> swagger生成をやってみたんですが、記述量が全く違いました。(FastAPIはSwaggerのためだけの記述は一つもないので) こちらの記事を見て頂けると、如何にFastAPIがすごいか逆にわかって頂けると思います。

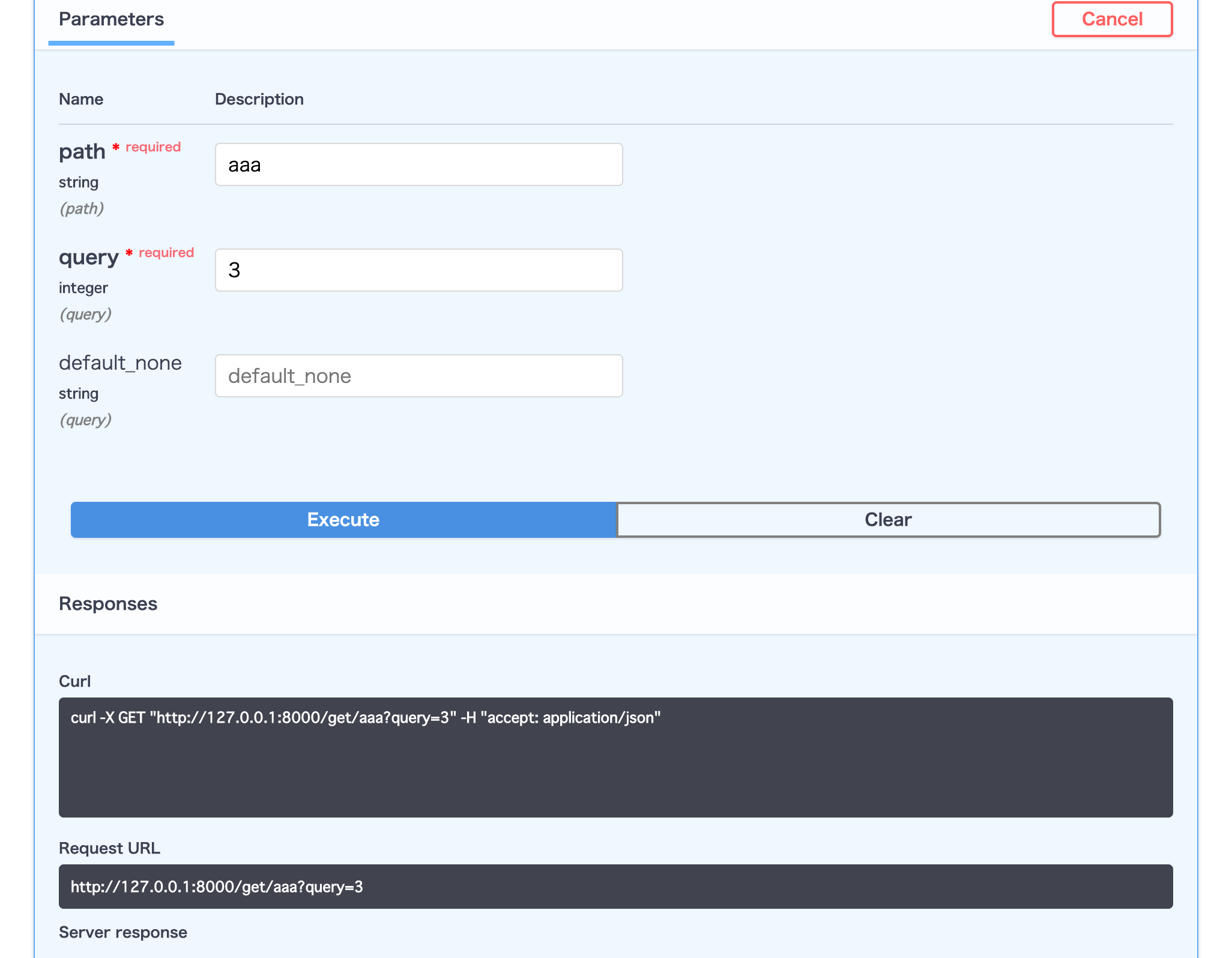
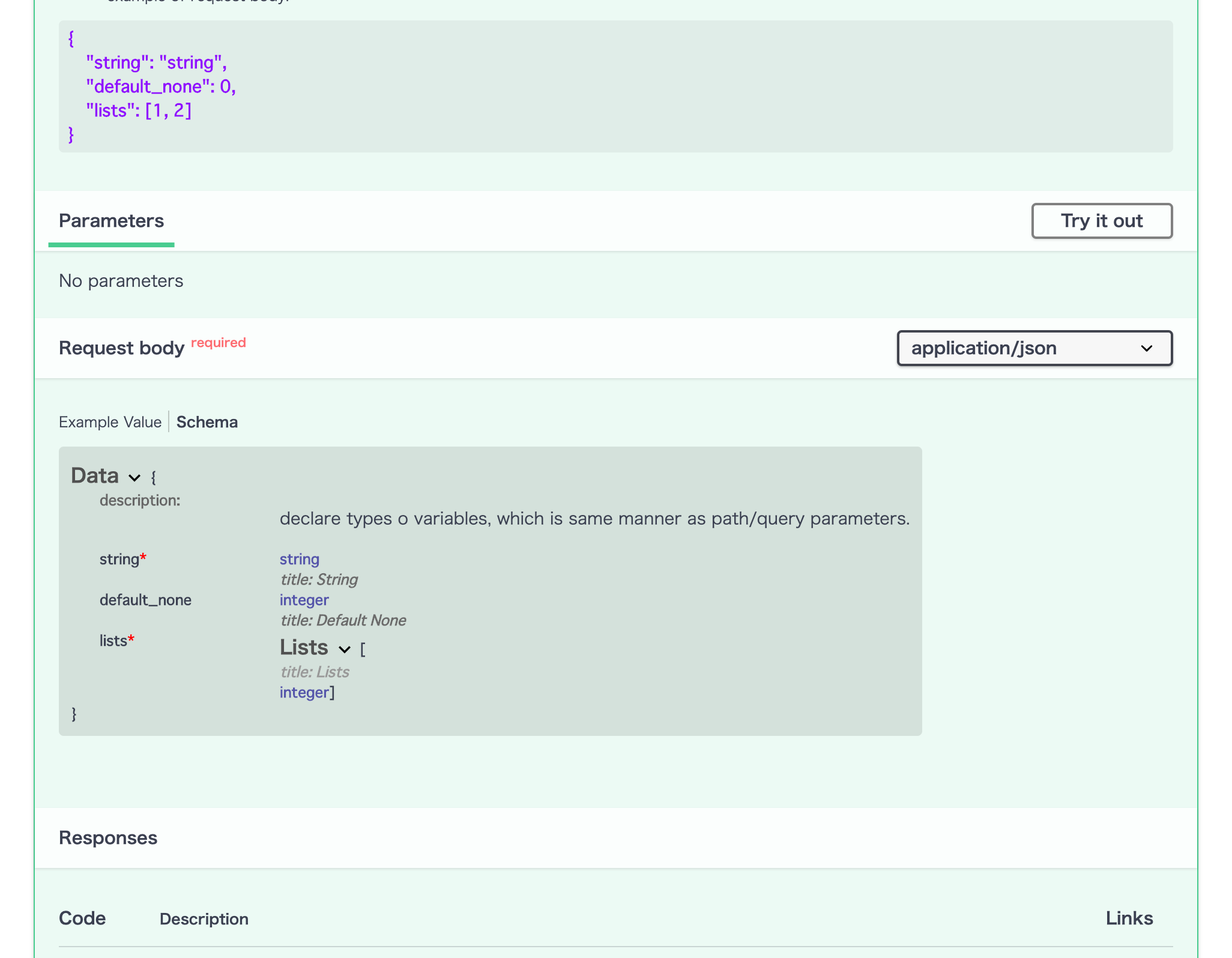
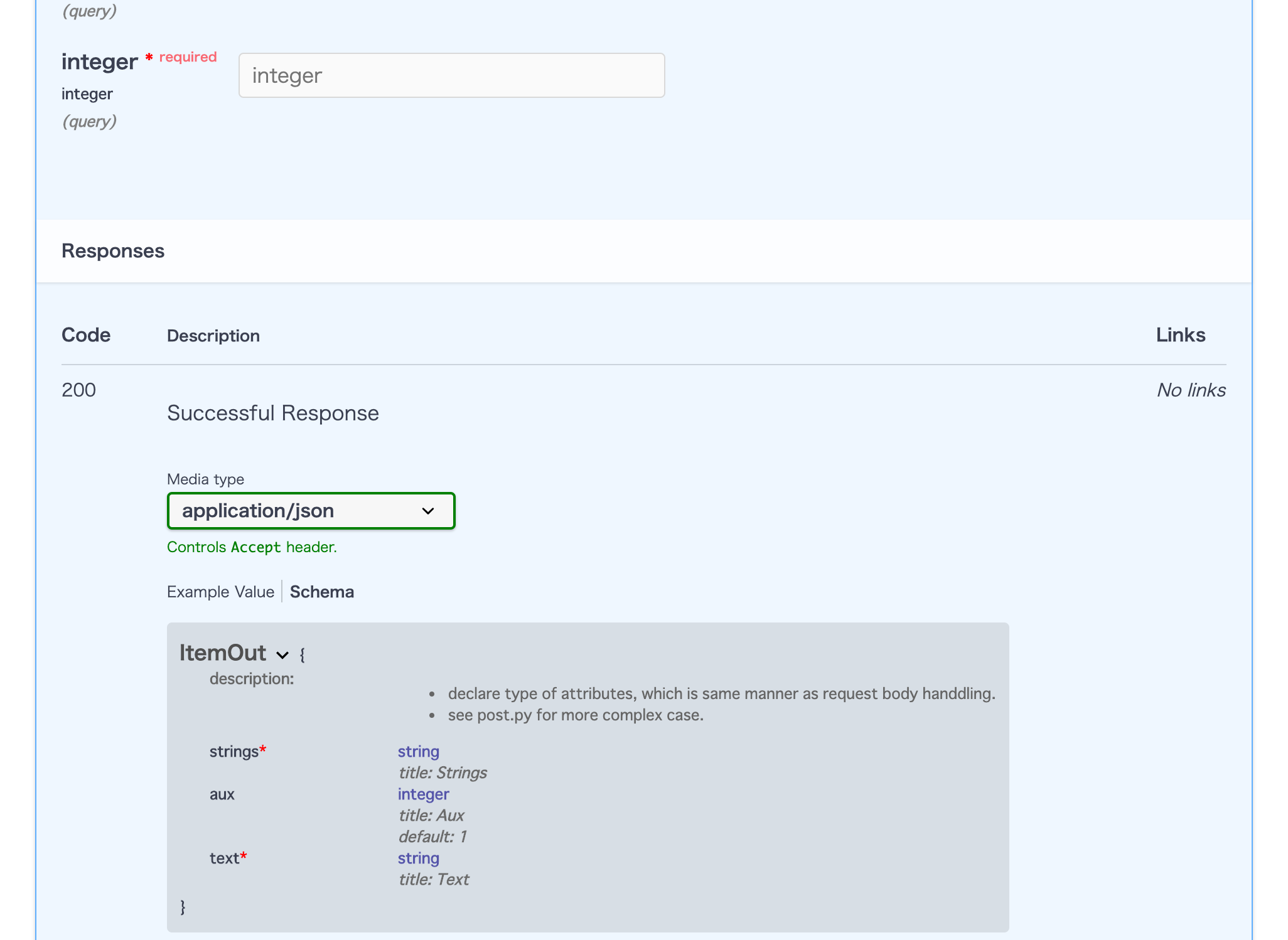
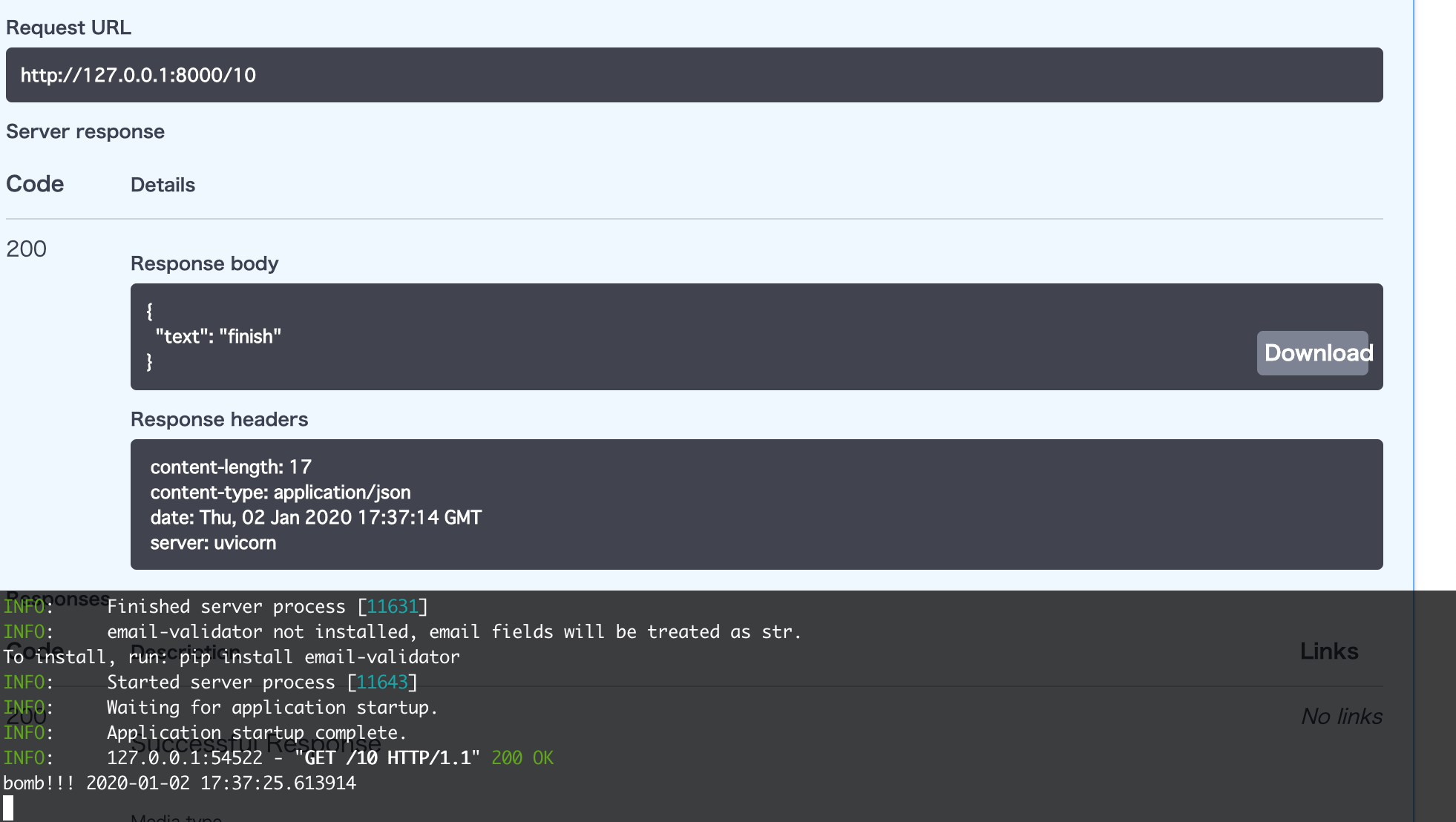
- 投稿日:2020-01-03T16:03:30+09:00
TensorFlow2 + Keras による画像分類に挑戦8 ~最適化アルゴリズムと損失関数を選択する~
はじめに
TensorFlow2 + Keras を利用した画像分類(Google Colaboratory 環境)についての勉強メモ(第8弾)です。題材は、ド定番である手書き数字画像(MNIST)の分類です。
- TensorFlow2 + Keras による画像分類に挑戦 シリーズ
前回は、TF公式HPの「初心者のための TensorFlow 2.0 入門」で取り上げられているニューラルネットワークモデルについて、それを構成する各層(Dense層、Dropout層、Flatten層)と活性化関数(ReLU関数、Softmax関数)の観点から、その概要を理解しました。
今回は、チュートリアルのプログラムの
model.compileのところ(最適化アルゴリズムや損失関数の設定)について、理解していきたいと思います。model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])また、同じ構成のニューラルネットモデルであっても、学習に用いる最適化アルゴリズムの違いにより正解率(accuracy)や損失関数値(loss)、収束速度、計算時間が大きく変わることを実験により確認します。そこでは、次のようなグラフを作成していきます。
モデルのコンパイル
model.compile(...)についてTF公式HPの「初心者のための TensorFlow 2.0 入門」のチュートリアルプログラムのでは、
tf.keras.models.Sequential(...)によって、ニューラルネットの層構成を定義したあと、それをトレーニングする前に、compile(optimizer=..., loss=..., metrics=...)というプロセスをはさんでいます。
model.compile()のリファレンスはこちらを参照このプロセスでは、ニューラルネットモデルのトレーニング(重みパラメータの最適化)で、評価指標として使用する損失関数(誤差関数、目的関数、Loss Function)の設定や、最適化アルゴリズム(勾配法、Optimizer)の設定しています。
また、metrics は、トレーニングのログとして誤差関数(loss)以外に出力する項目を指示するもので、トレーニングそのものに何らかの影響を与える設定ではないようです(いまいち自信なし)。
以下、これらについて詳しく見ていきます。
最適化アルゴリズム(Optimizer)の選択
compileのoptimizer=引数では、トレーニングに使用する最適化アルゴリズム(勾配法、Optimizer)を選択します。ここで、選択可能な Optimizer は、こちらのリファレンス から一覧をみることができます。2020/01/03 の時点では、次の Optimizer が利用できます。なお、「深層学習の最適化アルゴリズム」を参考にアルゴリズムが発表された年も併記しています。
SGDFtrlAdagrad:2011年RMSprop:2012年Adadelta:2012年Adam:2014年Adamax:2015年Nadam:2016年上記の
xxxを使ってoptimizer='xxxx'のように文字列で指定することも、optimizer=tf.optimizers.Adam()のように指定して与えることも可能です(両者で微妙に大文字小文字が違ったりするので注意、詳細はリファレンスで確認)。チュートリアルでも採用されているように、まずは
Adamから試してみるのがよいのかもしれません。無論、扱う問題やNNモデルの構造や規模により、最適な Optimizer は変わるので、より良いトレーニングをさせるためには、色々と手法を変えて試すことが要求されます。あとで、MNISTについて、最適化アルゴリズムを変えてトレーニングする実験を行ないます。
損失関数(loss)の選択
深層学習におけるトレーニングとは、最適化問題の求解と同義です。最適化問題で言うところの目的関数が「損失関数(最小化)」、決定変数が「ニューラルネットのパラメータ(重みやバイアス)」になります。
損失関数は、「NNモデルによる予測値」と「正解値」を入力として、その差異を定量化して出力する関数です。トレーニングでは、この損失関数の出力値を最小化するようにパラメータ(重みやバイアス)の調整が進みます。
MNISTのような多クラス分類問題では、通常、その損失関数として「交差エントロピー誤差(Cross Entropy Error)」という尺度を計算するものが使われます。よって、チュートリアルでも
loss='sparse_categorical_crossentropy'のように交差エントロピー誤差を計算するように設定されています。なお、選択可能な損失関数は、こちら から一覧を見ることができます。なお、交差エントロピー誤差の計算に関しては、
sparse_categorical_crossentropyとcategorical_crossentropyの2つがありますが、違いは以下の通りです。
sparse_categorical_crossentropyは、MNISTのように多クラス分類問題の正解データ(ラベル)をカテゴリ番号で与えている場合に使います。正解が「0」「4」「2」のとき、[2,7,5]のように与えている場合。categorical_crossentropyは、多クラス分類問題の正解データ(ラベル)を、one-hot表現(one-hotベクトル)で与えている場合に使います。正解が「0」「4」「2」のとき、[[1,0,0,0,0,0,0,0,0,0],[0,0,0,0,1,0,0,0,0,0],[0,0,1,0,0,0,0,0,0,0]]のように与えている場合。仮に、カテゴリが4個だったとして、正解データが $[0,1,0,0]$、予測データが $[0.1,0.6,0.2,0.1]$ だったとすれば、交差エントロピー誤差 $\mathrm{CE}$ は次のように計算できます。
\begin{align} \mathrm{CE} &= - ( 0\times \log_{\,e} 0.1 + 1\times \log_{\,e} 0.6 + 0\times \log_{\,e} 0.2 + 0\times \log_{\,e} 0.1 ) \\ & = -\log_{\,e} 0.6 \\ & = 0.51083 \end{align}テストデータが複数ある場合は、平均をとればOKです。ところで、正解データは、$0$ または $1$ に限られるので、複数のテストデータ($1,2,\cdots,n$)の平均交差エントロピー誤差は、シンプルに次のように計算できます。
$$ \mathrm{CE} = -\frac{1}{n} \sum_{i=1}^{n} \log_{\ e} p_{i} $$
なお、$f(x) = - \log_{\ e} x $ について、$0.0 < x \le 1.0$ でプロットすると、次のようになります。
正解データと予測データが一致していれば、$-\log_{\ e}1.0=0.0$ で、CE誤差はゼロとなります。なお、$\log_{\ e}0.0=-\infty $ なのでプログラムで計算する際には工夫が必要です。
手動で交差エントロピー誤差(loss)を計算
チュートリアルのプログラムを実行すると、
model.evaluate(x_test, y_test, verbose=2)のログとして次のように loss を出力してくれます。10000/10000 - 0s - loss: 0.0734 - accuracy: 0.9775
これを自分で計算してみます。
交差エントロピー誤差を計算import numpy as np import math s_test = model.predict(x_test) # 学習済みモデルで予測 # 交差エントロピー誤差(Cross Entropy Error) ce = 0 n = len(y_test) for i in range(0,n) : ce = ce - math.log(s_test[i,y_test[i]]) ce = ce/n print(f'CE(手計算) = {ce} ')実行結果は以下のようになりました。
CE(手計算) = 0.07341307844041595
これは、
evaluate(...)で出力されたloss: 0.0734に一致します。最適化アルゴリズムを変えて学習、結果の比較
現時点で、TF+Keras で選択可能な8つの最適化アルゴリズム(
SGD、Ftrl、Adagrad、RMSprop、Adadelta、Adam、Adamax、Nadam)で、MNISTをターゲット学習、評価を行ないました。Epochs数=100 として、トレーニングプロセスのEpoch毎に、トレーニングデータ
x_trainに対する正答率(accuracy)と損失関数値(loss)、テストデータx_testに対する正答率(val_accuracy)と損失関数値(val_loss)を取得してプロットしました。先に結果を表示します。
正答率(accuracy)
Y軸の範囲を拡大します。
汎化性能を考慮したテストデータに対する結果として、AdaMax(2015) が非常に優れています。SGDは、非常に時間がかかりますが、最終的には AdaMax(2015) と同じ程度の正答率が得らるモデルになっています。
損失関数値(loss)
Y軸の範囲を拡大します。
RMSprop(2012)では、過学習を起していることが確認できます。最終的には SGD が最も優れたスコアになっています。
計算時間
Google Colab.環境で実行したとき、Epochs=100 に要した時間です。
(最適化手法については、完全にブラックボックスとして扱っているので下手なことは言えませんが・・・)どうも「AdaMax」が良さそうです。
プログラム
上記のグラフを求めるために使ったプログラムです。
データの計算と取得import time import pickle import tensorflow as tf tf.keras.backend.clear_session() # セッションクリア # (1) データセットの準備 mnist = tf.keras.datasets.mnist (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train, x_test = x_train / 255.0, x_test / 255.0 # (2) NNモデルの構築 model = tf.keras.models.Sequential() model.add( tf.keras.layers.Flatten(input_shape=(28, 28)) ) model.add( tf.keras.layers.Dense(128, activation=tf.nn.relu) ) model.add( tf.keras.layers.Dropout(0.2) ) model.add( tf.keras.layers.Dense(10, activation=tf.nn.softmax) ) # (3) NNモデルの学習設定・学習・評価 epochs = 100 prm = [ dict(label='SGD', optm='SGD') , dict(label='FTRL', optm='Ftrl') , dict(label='AdaGrad(2012)', optm='Adagrad') , dict(label='RMSprop(2012)', optm='RMSprop') , dict(label='AdaDelta(2012)', optm='Adadelta'), dict(label='Adam(2014)', optm='Adam') , dict(label='AdaMax(2015)', optm='Adamax') , dict(label='NAdam(2016)', optm='Nadam') ] for p in prm : print(f"■ 最適化アルゴリズム {p['label']}") t = time.time() model.compile(optimizer=p['optm'], loss='sparse_categorical_crossentropy', metrics=['accuracy']) h = model.fit(x_train, y_train, validation_data=(x_test,y_test), epochs=epochs) p['log'] = h.history p['time'] = time.time() - t p['epochs'] = epochs results = prm # 結果の保存 path = 'optimizer-1.pickle' with open(path,mode='wb') as f : pickle.dump(results,f)データの可視化import numpy as np import matplotlib.pyplot as plt title = dict( ) title['accuracy'] = 'Accuracy (TarinData)' title['val_accuracy'] = 'Accuracy (TestData)' title['loss'] = 'Loss (TarinData)' title['val_loss'] = 'Loss (TestData)' # 正答率 fig, ax = plt.subplots(nrows=1, ncols=2, sharey='row', figsize=(10,3), dpi=120) plt.subplots_adjust(wspace=0.03) for i, v in enumerate(['accuracy','val_accuracy']) : for r in results : ax[i].plot( range(1,r['epochs']+1),r['log'][v],label=r['label']) ax[i].set_xlim(1,r['epochs']) ax[i].set_ylim( 0.97,1.00 ) # ■■■要調整■■■ ax[i].set_title( title[v] ) ax[i].tick_params(which='both', direction='in') ax[i].grid(True) ax[1].legend(bbox_to_anchor=(1.02, 1), loc='upper left', borderaxespad=0) plt.show() # 損失関数値 fig, ax = plt.subplots(nrows=1, ncols=2, sharey='row', figsize=(10,3), dpi=120) plt.subplots_adjust(wspace=0.03) for i, v in enumerate(['loss','val_loss']) : for r in results : ax[i].plot( range(1,r['epochs']+1),r['log'][v],label=r['label']) ax[i].set_xlim(1,r['epochs']) ax[i].set_ylim( 0.0, 0.3 ) # ■■■要調整■■■ ax[i].set_title( title[v] ) ax[i].tick_params(which='both', direction='in') ax[i].grid(True) ax[1].legend(bbox_to_anchor=(1.02, 1), loc='upper left', borderaxespad=0) plt.show() # 時間 labels = list() times = list() for r in results : labels.append(r['label']) times.append(r['time']) plt.figure(dpi=120,figsize=(6,3)) plt.bar(labels,times) plt.ylabel('Time (sec)') plt.xticks(rotation=-90) plt.gca().set_axisbelow(True) plt.grid(axis='y') plt.show()次回
- 未定
おまけ
-log_xのグラフ作成import numpy as np import matplotlib.pyplot as plt import matplotlib.ticker as tk import matplotlib.patheffects as pe plt.rcParams['mathtext.fontset'] = 'cm' # 数式用フォント yt_style = lambda x, pos=None : f'{x:.1f}' x = np.linspace(0.001, 1, 1000) y = -np.log(x) plt.figure(dpi=120,figsize=(5,3)) plt.plot(x,y,lw=2) plt.xlim(0,1) plt.ylim(0,6) plt.gca().yaxis.set_major_formatter(tk.FuncFormatter(yt_style)) plt.xlabel('$x$',fontsize=15) plt.grid() plt.ylabel('$f\,(x)$',fontsize=15) t = plt.text(0.95,5, r'$f\,(x)=-\log_{\,e}\,x$', fontsize=18, ha='right',va='center') t.set_path_effects([pe.Stroke(linewidth=9, foreground='white'), pe.Normal()])

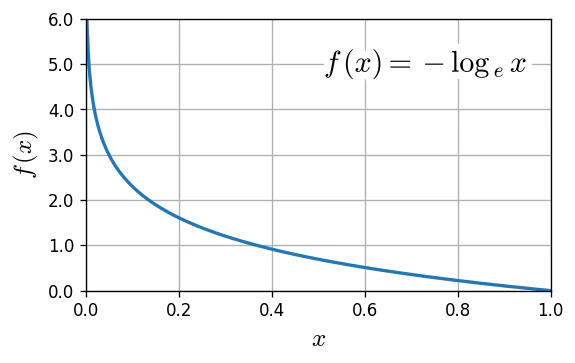




- 投稿日:2020-01-03T16:02:45+09:00
[NNabla]構築済みネットワークの中間層を削除する方法
はじめに
qiitaへの2回目の投稿です。(article2)
前回に引き続き、私がnnablaを使っていた中で「こういう情報がqiitaとかにあったらよかったのに」と思いながらなんとか気合いでnnablaのreferenceとdir()(pythonの標準関数。引数のメンバ変数・関数を返してくれる)で見つけてきたことについてまとめます。1. 要件
・OS: macOS Catalina (バージョン 10.15.1)
・python: 3.5.4
・nnabla: 1.3.02. ネットワークの構築
サンプルのネットワークを下記で定義します。(ここまでは前回同様)
article2_rewire_on.pyimport nnabla as nn import nnabla.functions as F # [define network] x = nn.Variable() y = F.add_scalar(x, 0.5) # <-- (1)とおく y = F.mul_scalar(y, -2)単純に $y=(x+0.5)\times2$ という形になってます。
この時、変数yは上の式の結果をもつ変数となっていて、途中の計算であるF.add_scalar(x, 0.5)の結果を(1)と呼びます。3. 中間層を削除
前述の(1)を削除し、単に$y=x\times2$とする方法を説明します。
これは、nnablaのreferenceにあったnnabla.Variableのメンバ変数rewire_onを使用します。これはreferenceにも(比較的)わかりやすい説明があります。下記で実践しました。article2_rewire_on.pyh1 = y.parent.inputs[0] # = (1) x.rewire_on(h1)動作確認は下記で行いました。
article2_rewire_on.py# [check func for visit] def get_func_name(f): print(f.name) print('--- before ---') y.visit(get_func_name) print('') # [rewire_on] h1 = y.parent.inputs[0] # = (1) x.rewire_on(h1) print('--- after ---') y.visit(get_func_name) print('')出力
--- before --- AddScalar MulScalar --- after --- MulScalarmemo
- まず(1)を上記の
h1として取得しました。これについての詳細な説明は前回を参照してください。x.rewire_on(h1)でh1が消えます。正確には、計算グラフ上でh1がxで置き換えられるようです。記述はコードから自明ですが、[新たな変数].rewire_on([上書きする変数])となります。- 確認方法として、前回使用した
visitを用いて、get_func_name(f)によって全レイヤーのレイヤー名を表示させています。その結果、rewire_onの後で(1)の計算をしているAddScalarが消えていることから、所望の動作が確認できました。4. 次回予告(?)
rewire_onを使用すれば、中間層を削除するだけでなく、新たなレイヤーを挟み込みこともできます。これもなんとか自分でできるようになりましたが、「qiitaとかに誰か書いといて欲しかった」と思ったので次回にでも書いてみようかと思います。
- 投稿日:2020-01-03T15:58:37+09:00
【2020年1月】令和だし本格的にVSCodeのRemote Containerで、爆速の"開発コンテナ"始めよう
VSCode の Remote Conainer で"開発環境+プロジェクト全部入りのコンテナ"から開発をスタートダッシュをキメませんかッ!?
開発でVS Code の Remote Conainer使っていますか?単に既存のコンテナに入るだけなら Remote SSH でも構いませんが、"ローカル開発環境の一部"として、いやむしろローカルの開発環境=Remote Containerとして、ビンビンにRemote Container使っていきましょう。令和だし!
(すでに2年だけどね・・・?)特にMacを使っていると最初からPythonやらPHPやらRubyやらが入ってしまっているので開発環境があるのですが、これらは割とmacOSのエコシステムに組み込まれているので不要にパッケージの追加削除、できないのですよ。
brewとか意外とあっさり壊れますしね・・・。特にバージョンアップなんてもってのほかです。全然、余裕でおかしくなります。
そんなわけでMacに入っているPythonやRubyでプログラミングをバリバリしていると・・・ふと、後戻りできない状況になったりするわけです。
そんなことにならないためにも、"Remote Containerでの開発"に入門しましょう~!"Dev Container" 機能のご紹介
Remote Container の本家サイトと本家Githubで"Try a dev container"と言う項目とリポジトリがあるの、ご存知でしょうか?
"dev container"は開発環境入りコンテナが付属したプロジェクトのサンプルで、以下の各言語向けにdev-containerのサンプルが用意されています。
- Node.js, Javascript
- Python
- Go
- Java
- .Net Core
- PHP
- Rust
- C++
例えば、node.js、Javascript用のサンプルは以下のようなツリーになっております。
% git clone https://github.com/Microsoft/vscode-remote-try-node nodejs-dev-sample % cd nodejs-dev-sample % tree -a -I ".git" . ├── .devcontainer │ ├── Dockerfile │ └── devcontainer.json ├── .eslintrc.json ├── .gitattributes ├── .gitignore ├── .vscode │ └── launch.json ├── LICENSE ├── README.md ├── package.json ├── server.js └── yarn.lock
treeコマンドで.gitだけ除外して全て表示すると上記のようになります。
ここで気になるのが・・・.devcontainerですよね?!
中身のDockerfileとdevcontainer.jsonは以下のようになっております。#------------------------------------------------------------------------------------------------------------- # Copyright (c) Microsoft Corporation. All rights reserved. # Licensed under the MIT License. See https://go.microsoft.com/fwlink/?linkid=2090316 for license information. #------------------------------------------------------------------------------------------------------------- FROM node:10 # The node image includes a non-root user with sudo access. Use the "remoteUser" # property in devcontainer.json to use it. On Linux, the container user's GID/UIDs # will be updated to match your local UID/GID (when using the dockerFile property). # See https://aka.ms/vscode-remote/containers/non-root-user for details. ARG USERNAME=node ARG USER_UID=1000 ARG USER_GID=$USER_UID # Avoid warnings by switching to noninteractive ENV DEBIAN_FRONTEND=noninteractive # Configure apt and install packages RUN apt-get update \ && apt-get -y install --no-install-recommends apt-utils dialog 2>&1 \ # # Verify git and needed tools are installed && apt-get -y install git iproute2 procps \ # # Remove outdated yarn from /opt and install via package # so it can be easily updated via apt-get upgrade yarn && rm -rf /opt/yarn-* \ && rm -f /usr/local/bin/yarn \ && rm -f /usr/local/bin/yarnpkg \ && apt-get install -y curl apt-transport-https lsb-release \ && curl -sS https://dl.yarnpkg.com/$(lsb_release -is | tr '[:upper:]' '[:lower:]')/pubkey.gpg | apt-key add - 2>/dev/null \ && echo "deb https://dl.yarnpkg.com/$(lsb_release -is | tr '[:upper:]' '[:lower:]')/ stable main" | tee /etc/apt/sources.list.d/yarn.list \ && apt-get update \ && apt-get -y install --no-install-recommends yarn \ # # Install eslint globally && npm install -g eslint \ # # [Optional] Update a non-root user to UID/GID if needed. && if [ "$USER_GID" != "1000" ] || [ "$USER_UID" != "1000" ]; then \ groupmod --gid $USER_GID $USERNAME \ && usermod --uid $USER_UID --gid $USER_GID $USERNAME \ && chown -R $USER_UID:$USER_GID /home/$USERNAME; \ fi \ # [Optional] Add add sudo support for non-root user && apt-get install -y sudo \ && echo node ALL=\(root\) NOPASSWD:ALL > /etc/sudoers.d/$USERNAME \ && chmod 0440 /etc/sudoers.d/$USERNAME \ # # Clean up && apt-get autoremove -y \ && apt-get clean -y \ && rm -rf /var/lib/apt/lists/* # Switch back to dialog for any ad-hoc use of apt-get ENV DEBIAN_FRONTEND=dialog上記の解説は後に回して、続いて
devcontainer.jsonの中身は・・・devcontainer.json{ "name": "Node.js Sample", "dockerFile": "Dockerfile", // Use 'appPort' to create a container with published ports. If the port isn't working, be sure // your server accepts connections from all interfaces (0.0.0.0 or '*'), not just localhost. "appPort": [3000], // Comment out the next line to run as root instead. "remoteUser": "node", // Use 'settings' to set *default* container specific settings.json values on container create. // You can edit these settings after create using File > Preferences > Settings > Remote. "settings": { "terminal.integrated.shell.linux": "/bin/bash" }, // Specifies a command that should be run after the container has been created. "postCreateCommand": "yarn install", // Add the IDs of extensions you want installed when the container is created in the array below. "extensions": [ "dbaeumer.vscode-eslint" ] }と、コンテナの設定とvscodeのsettings.jsonの混ざったような形式のファイルとなっております。
この設定がなんなのかはだいたい、想像がつくかと思いますが、このフォルダをVSCodeで開くと何が起こるのでしょうか…試してみましょう!
その前に、Dockerデーモンが立ち上がってない方は事前にDockerデーモンを立ち上げてください。WindowsやMacの方はDocker for Desktopを起動しておいてください。Dockerが起動したらVSCodeを立ち上げて
nodejs-dev-sampleを開いてみます。
すると・・・
dev container configurationが見つかったからコンテナで開くか?と言う問い合わせが出ました!
そしてReopen in Containerをクリックすると・・・
しばらく時間が経って…開きました!左下のステータスバーがグリーンに変わってRemote接続中であることと、"Dev Container: Node.js Sample"の文字が眩しいですね!
そうなんです。.devcontainerフォルダとdevcontainer.jsonの設定と然るべきDockerfileが揃っていればプロジェクトフォルダ内のファイルを丸ごとマウントしたコンテナの自動生成とプロジェクトをVSCodeで開くのを勝手にやってくれるのです!また、ここでのDockerfileの特筆するべき点はdockerに問題の"root"ユーザー問題を宜しく解決してくれている点です。
"コンテナの中で開発する"のは聞こえはいいですが、大抵のイメージはそのまま実行するとユーザーが"root"になってしまうのが多いので、コンテナの中で更新されるファイルのオーナーが"root"になってしまってウザい問題がありました。自前でDockerfile書けばなんとでもなるのですがいちいち書いてられないし、いちいちDockerfile書くくらいなら開発環境汚れても別にいいじゃん会社のPCだし、みたいなことになってますよね!?
このDockerfileでは丁寧にそこのところをサポートしてくれているので、rootユーザー問題が無事に解決されています。ついでにコンテナの管理も VSCode からできるので…
このようにどのプロジェクトでどのコンテナ使っているかは、VSCodeから管理できます。
特にDockerではどのフォルダのDockerfileで立ち上げたコンテナかがわからない(と言うかイメージを作ってコンテナ起動するのでどこのフォルダのDockerfileで作成したイメージかどうかは本来は関係ないハズ)のでこれは便利です。どうやって使うのか?
まずは本家リポジトリのご紹介をしておきましょう。
リポジトリ名からどの言語向けのサンプルプロジェクトかわかると思います。
- microsoft/vscode-remote-try-python
- microsoft/vscode-remote-try-node
- microsoft/vscode-remote-try-go
- microsoft/vscode-remote-try-java
- microsoft/vscode-remote-try-cpp
- microsoft/vscode-remote-try-dotnetcore
- microsoft/vscode-remote-try-rust
- microsoft/vscode-remote-try-php
実際には
.devcontainerフォルダとdevcontainer.jsonの設定と使用されるDockerfileの3つが揃っていれば自動的にやってくれますので、これらのファイルのみを本家リポジトリからコピペで作成するのもアリです。
とは言え毎度コピペするのも面倒なので、以下のように手順を整えてしまいましょう。1. 雛形としてクローン
上記のリポジトリを以下のように"プロジェクトの名前"でクローンしてきます。
$ git clone https://github.com/microsoft/vscode-remote-try-php my-first-phpリポジトリ名の後ろの引数が作成されるフォルダ名で、別名でクローンするのが第1のミソです。
2. 履歴の削除と再作成
当然、cloneしたばかりでは本家リポジトリのコミット履歴を全て含んでおります。
このまま再利用しても全然、良いのですが・・・大抵の場合は気になるでしょう。
そこで.git以下をざっくり削除します。$ rm -rf .gitこれで過去のコミット履歴は綺麗さっぱり忘れました。
ついでに不要なファイルは削除しておきましょう。
なんなら.devcontainer以外は不要です。.vscodeはお好みにお任せいたします。で、お掃除が完了したところで新規のリポジトリとして初期化します。
$ git init ...これで新たな開発コンテナプロジェクトとして第一歩が始まりました!
3. Dockerfile のカスタマイズ
実際の案件ではDBやAngular、Aws、Firebase、AzureなどのCLIなどなどなどを入れる必要があったりするのでDockerfileがそのまま使えることはほぼないです。
よってDockerfileに予め必要なツールをインストールするコマンドを入れておきます。Dockerfileの記述に関してはここでは割愛させていただきます。。。
4. devcontainer.json のカスタマイズ
devcontainer.jsonではプロジェクト名や転送するポート、必要なVSCodeのプラグインなどの設定ができ、とても重要なファイルです。
設定値のリストは以下の箇所にあります。サンプルリポジトリの中で使われている設定をいくつか抜き出してみますと・・・
- settings … これはコンテナの中で使用される VSCodeのsetting.jsonの設定値となります。
- appPort … 転送するポートです
- postCreateCommand … コンテナ作成後に実行されるコマンド
- extensions … リモート側にインストールされるVSCodeプラグイン
あたりが重要なカスタマイズするポイントでしょうか。
また、リファレンスによると
docker-compose.ymlも利用可能な模様です。これらを設定後に、VSCodeからフォルダを開けば、即座に開発環境込みのプロジェクトのスタートです!
まとめ
VScode Remoteコンテナの機能の入門編を書いてみるにあたって、公式ドキュメントを見直しましたが…ボリュームが半端ないですね。
これをどこまで深堀りするべきか悩みましたが、入門編ということでほとんど触れないようにいたしました(笑)
本文中に飛び飛びでリンクを貼っていますが、Remote Containerの公式ヘルプは驚愕の1ページです。これだけで本書けそうなボリュームですよ・・・
というところで、今回はここまでといたします!
- 投稿日:2020-01-03T15:49:51+09:00
GoのS3 ListObjectsはPythonより20秒遅いのか?問題
はじめに
S3から大量Objectをダウンロードする場合、Objectサイズに関わらず中々速度が出ないですよね。
Pythonで書いている時も、concurrent.futuresなどで頑張ってたのですが、もしかしてGoroutineで出来るのでは?と思い、Golangデビューしてみました。やろうと思ったこと
- ListObjectV2を用いて、S3の特定Prefix配下のKeyをすべて取得
- 取得したKeyをGoroutineでいい感じにダウンロード
実際起こったこと
- ListObject部分を試しに書いてみたが、はっきり言って遅い。
- なんならPythonで書いた方が早い気が?
ん?API叩くだけなので同じ速度。だったらまだ納得は出来るが、スクリプト言語よりGoの方が遅いというのはちょっと気になる。
予定を急遽変更して、本件を少し検証してみました。ソースコード
Go版
main.gopackage main import ( "fmt" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/s3" "os" ) func main() { bucket := os.Getenv("BUCKET") prefix := os.Getenv("PREFIX") region := os.Getenv("REGION") sess := session.Must(session.NewSession()) svc := s3.New(sess, &aws.Config{ Region: ®ion, }) params := &s3.ListObjectsV2Input{ Bucket: &bucket, Prefix: &prefix, } fmt.Println("Start:") err := svc.ListObjectsV2Pages(params, func(p *s3.ListObjectsV2Output, last bool) (shouldContinue bool) { for _, obj := range p.Contents { fmt.Println(*obj.Key) } return true }) fmt.Println("End:") if err != nil { fmt.Println(err.Error()) return } }Python版
こちらもサクッと書いてみる。
Goと条件を合わせる為、低レベルクライアントで。main.py#!/usr/bin/env python # -*- coding: utf-8 -*- import os import boto3 bucket = os.environ["BUCKET"] prefix = os.environ["PREFIX"] region = os.environ["REGION"] # r = boto3.resource('s3').Bucket(bucket).objects.filter(Prefix=prefix) # [print(r.key) for r in r] # 普段は上記の様に取得するが、Golangへ寄せるため下記のコードにて測定 s3_client = boto3.client('s3', region) contents = [] next_token = '' while True: if next_token == '': response = s3_client.list_objects_v2(Bucket=bucket, Prefix=prefix) else: response = s3_client.list_objects_v2(Bucket=bucket, Prefix=prefix, ContinuationToken=next_token) contents.extend(response['Contents']) if 'NextContinuationToken' in response: next_token = response['NextContinuationToken'] else: break [print(r["Key"]) for r in contents]環境
サーバ等
- 基本的にCloud9 on EC2(t2.micro)で実行。
ビルド・デプロイ等
- 環境を汚したくない&面倒なので、全部Dockerで構築。
$ docker-compose up -d --build
- ちなみに構築資材は下記を参照。
DockerfileFROM golang:1.13.5-stretch as build RUN go get \ github.com/aws/aws-sdk-go/aws \ github.com/aws/aws-sdk-go/aws/session \ github.com/aws/aws-sdk-go/service/s3 COPY . /work WORKDIR /work RUN CGO_ENABLED=0 GOOS=linux GOARCH=amd64 go build -o main main.go FROM python:3.7.6-stretch as release RUN pip install boto3 COPY --from=build /work/main /usr/local/bin/main COPY --from=build /work/main.py /usr/local/bin/main.py WORKDIR /usr/local/bin/docker-compose.ymlversion: '3' services: app: build: context: . container_name: "app" tty: True environment: BUCKET: <Bucket> PREFIX: test/ REGION: ap-northeast-1S3バケット
東京リージョンにバケットを一つ作って、以下のツールで1000件程度作成。
#/bin/bash Bucket=<Bucket> Prefix="test" # テストファイル作成 dd if=/dev/zero of=testobj bs=1 count=30 # マスタファイルのコピー aws s3 cp testobj s3://${Bucket}/${Prefix}/testobj # マスタファイルを複製 for i in $(seq 0 9); do for k in $(seq 0 99); do aws s3 cp s3://${Bucket}/${Prefix}/testobj s3://${Bucket}/${Prefix}/${i}/${k}/${i}_${k}.obj done done測定
測定結果(1000 Object)
- Go
$ time docker-compose exec app ./main ~略~ real 0m21.888s user 0m0.580s sys 0m0.107s
- Python
$ time docker-compose exec app ./main.py ~略~ real 0m2.671s user 0m0.577s sys 0m0.104sGoがPythonより10倍遅い。なんでや!
Object数を増やしてみる
- もうすこしobjectを増やしてみましょう。とりあえず10000件あたりで。
#差分のみ for i in $(seq 0 99); do for k in $(seq 0 99); do
- ちなみにアップロード完了までに3、4時間かかりました。ツールはちゃんと作っとけばよかったね…
再測定結果(10000 Object)
- Go
$ time docker-compose exec app ./main ~略~ real 0m23.276s user 0m0.617s sys 0m0.128s
- Python
$ time docker-compose exec app ./main.py ~略~ real 0m5.973s user 0m0.576s sys 0m0.114s今回は4倍程度の差。
というよりObject数によらず18秒ほど差が出ている様子。うーむ。終わりに
- ライブラリの設定起因か、言語仕様の理解不足な気もしているので、もう少し情報を漁ってみたい。
- そもそもの目的であるGoroutineでの並列ダウンロード処理の効率が良ければ20秒程度は誤差な気もするので、残りも実装してみます。
気になるところ
- よく見るとuser, sysは同じ程度なのでS3でI/O周りが怪しい。
- goのコードを雑にprintデバッグしたところ("Start:", "End:")、list objectが処理時間の大半を占めている様子。もしやboto3とはS3設定のデフォルト値が異なるのだろうか。
- 同じコンテナで動かしてるので、T系インスタンスのCPUクレジット問題やNW帯域の差も関係ないと思うが……
- 前者はm5.largeに代えても解決しなかったので関係なさげ。
- 投稿日:2020-01-03T15:00:25+09:00
【小ネタ】Jupyterでmatplotlibのグラフを一括で保存する方法
はじめに
matplotlibのグラフを1つ1つfigsaveしないで、一括で保存する方法についてです。
JupyterをMarkdownで保存するだけです。グラフの保存形式はpngになります。方法
- Jupyterをmarkdownで保存する。"File" -> "Export Notebook As..." -> "Export Notebook to Markdown"
- zipで保存されるので解凍する。
結果
保存されたグラフは、同じpng形式でもmatplotlibのsavefig("*.png")を使ったものと違うものになります。
figsave("a.png")
Markdownで保存
白背景でブラウザから見ただけではわからないので、茶色の背景にグラフを貼ったものを掲示します。
figsave("a.png")
Markdownで保存
figsaveでも同じように透過させたい場合は、fig.patch.set_alpha(0)とすれば良いそうです。




- 投稿日:2020-01-03T14:52:15+09:00
[python]取得したTwitterタイムラインをMeCabで形態素に分解する
目的
Twitterのタイムラインが、txtファイルになっています。
一つのフォルダに、複数ユーザーのタイムラインが格納してあります。
これらのファイルを、MeCabを用いて全て形態素解析するのが今回のゴールです。背景・準備
タイムラインの取得
タイムラインの取得は、次の記事のように行いました。
[python]複数ユーザーのTwitterタイムラインを取得するMeCabの準備
形態素解析のために、形態素解析エンジン'MeCab'を使用します。macで使用する方法について、
mecabインストール手順
を参考にさせていただきました。実装
フォルダ内のファイル名一覧をpythonのリストに取得
ファイル名リストからタイムラインのリストを作成する関数
形態素解析の関数
フォルダ内の全ファイルを形態素解析する
1. フォルダ内のファイル名一覧をリストに取得
ファイル'timelines'に、操作したい全てのtxtファイルが入っています。
これらのファイル名(文字列)をリスト'file_names'に格納します。import glob file_names=[] files = glob.glob("./timelines/*") for file in files: file_names.append(file)取得したfile_namesは、次のような形をしています。
['./timelines/20191210_user0_***.txt',..,'./timelines/20191210_user199_***.txt']2. ファイル名リストからタイムラインのリストを作成する関数
timelines.pydef timelines(file_list): timelines=[] for file in file_list: text=open(file).read() open(file).close() timelines.append([text]) return timelines3. 形態素解析の関数
形態素解析の関数を定義します。
関数の引数は文字列、返り値は形態素解析結果のリストです。mecab_list.pyimport MeCab def mecab_list(text): tagger = MeCab.Tagger("-Ochasen") tagger.parse('') node = tagger.parseToNode(text) mecab_output = [] while node: word = node.surface wclass = node.feature.split(',') if wclass[0] != u'BOS/EOS': if wclass[6] == None: mecab_output.append([word,wclass[0],wclass[1],wclass[2],""]) else: mecab_output.append([word,wclass[0],wclass[1],wclass[2],wclass[6]]) node = node.next return mecab_output'mecab_list'関数の動作を確認しましょう。
print(mecab_list('昨日飼いはじめたネコはよく食べる。')) ''' 結果 [['昨日', '名詞', '副詞可能', '*', '昨日'], ['飼い', '動詞', '自立', '*', '飼う'], ['はじめ', '動詞', '非自立', '*', 'はじめる'], ['た', '助動詞', '*', '*', 'た'], ['ネコ', '名詞', '一般', '*', 'ネコ'], ['は', '助詞', '係助詞', '*', 'は'], ['よく', '副詞', '一般', '*', 'よく'], ['食べる', '動詞', '自立', '*', '食べる'], ['。', '記号', '句点', '*', '。']]問題ないようです。
4. フォルダ内の全ファイルを形態素解析する
mecab_results_list=[] the_timelines=timelines(file_names) for the_timeline in the_timelines: mecab_result=[] for twt in the_timeline: mecab_result.append(mecab_list(twt)) mecab_results_list.append(mecab_result)print(mecab_results_list) #結果 [[[['w', '記号', 'アルファベット', '*', 'w'], ['まだ', '副詞', '助詞類接続', '*', 'まだ'], ['亜', '名詞', '固有名詞', '地域', '亜'], ['種', '名詞', '接尾', '一般', '種'], ['?', '記号', '一般', '*', '?'], ['が', '助詞', '格助詞', '一般', 'が'],..,]]]]求める結果が得られました。
環境
macOS Catalina
Jupyter notebook
- 投稿日:2020-01-03T14:21:34+09:00
【小ネタ】JupyterをPDFに変換する簡単な方法
はじめに
自分で書いたJupyter notebookをHTMLで保存して、iPhoneで閲覧したところ、Texで書いた数式がうまく表示されませんでした。そこでPDFで保存しようと思ったら、日本語を含んでいると標準のPDF出力は使えないようでした。
もちろんその解決方法は色々とありますが、ちょっと大変です。
Qiita:日本語のJupyter NotebookをPDFとしてダウンロードする
Qiita:Jupyter notebookからpdfに変換する[mac]解決策
レイアウトが若干崩れる問題はありますが、手っ取り早いのはJupyterをHTMLでエクスポートして、ブラウザから印刷でPDFに変換する方法です。Google Chromeを使った手順を以下に示します。
"File" -> "Export Notebook As..." -> "Export Notebook to HTML"でJupyterをHTMLで保存する。
ブラウザでそのHTMLファイルを開く。印刷をクリックする。
送信先を"PDFに保存"に変更して、"保存"をクリック。
結果
日本語やTexもちゃんと表示されます。
まとめ
いかがでしたか



- 投稿日:2020-01-03T14:04:18+09:00
CatBoostのインストール方法【2020年1月時点】
CatBoost のインストール方法 ※2020.1.3時点
CatBoostの公式サイトを見れば載っていますが、英語で書かれているので日本語版としてQiitaに載せておきます。
※初学者の方でそもそもAnaconda Promptの場所がわからないという方は下記を参考にしてください。
XGBoostの簡単なインストール方法 (2019年7月時点)手順1 : 下記コードをAnaconda Promptで実行
conda config --add channels conda-forge手順2 : 上記実行後、下記コードをAnaconda Promptで実行
conda install catboost※途中でこのままインストールを続けるか[y/n]と聞かれるので y と入力してEnter
手順3 : 数分待つとインストール完了
あとはコードで
import catboostすればCatBoostが使える。
詳しい使い方は下記の公式ドキュメントを参考に。参考文献
- 投稿日:2020-01-03T14:03:52+09:00
質問です。rasberry pi 3 model3 にprotocolbuffersをmakeできない。
ラズベリーパイで画像認識をするために、Qiitaの投稿などをもとに”protocolbuffers”をインストールしています。” ./configure”でエラーが出てしまいます。その後"make”しようとしていますが、”make: *** ターゲットが指定されておらず, makefile も見つかりません. 中止.”となり、前に進むことが出来ません。
どなたか、解決方法を教えて頂けないでしょうか?
投稿元:https://qiita.com/kobayuta/items/59c7b84caf8994071357以下エラーコード:
$ cd protobuf-3.7.1
$ ./configure
checking whether to enable maintainer-specific portions of Makefiles... yes
checking build system type... armv7l-unknown-linux-gnueabihf
checking host system type... armv7l-unknown-linux-gnueabihf
checking target system type... armv7l-unknown-linux-gnueabihf
checking for a BSD-compatible install... /usr/bin/install -c
checking whether build environment is sane... yes
checking for a thread-safe mkdir -p... /bin/mkdir -p
checking for gawk... no
checking for mawk... mawk
checking whether make sets $(MAKE)... yes
checking whether make supports nested variables... yes
checking whether UID '1000' is supported by ustar format... yes
checking whether GID '1000' is supported by ustar format... yes
checking how to create a ustar tar archive... gnutar
checking for gcc... no
checking for cc... no
checking for cl.exe... no
configure: error: in/home/pi/protobuf-3.7.1':config.log' for more details
configure: error: no acceptable C compiler found in $PATH
See
$ make
make: *** ターゲットが指定されておらず, makefile も見つかりません. 中止.
$
- 投稿日:2020-01-03T14:03:52+09:00
質問です。rasberry pi 3 modelB にprotocolbuffersをmakeできない。
ラズベリーパイで画像認識をするために、Qiitaの投稿などをもとに”protocolbuffers”をインストールしています。” ./configure”でエラーが出てしまいます。その後"make”しようとしていますが、”make: *** ターゲットが指定されておらず, makefile も見つかりません. 中止.”となり、前に進むことが出来ません。
どなたか、解決方法を教えて頂けないでしょうか?
投稿元:https://qiita.com/kobayuta/items/59c7b84caf8994071357以下エラーコード:
$ cd protobuf-3.7.1
$ ./configure
checking whether to enable maintainer-specific portions of Makefiles... yes
checking build system type... armv7l-unknown-linux-gnueabihf
checking host system type... armv7l-unknown-linux-gnueabihf
checking target system type... armv7l-unknown-linux-gnueabihf
checking for a BSD-compatible install... /usr/bin/install -c
checking whether build environment is sane... yes
checking for a thread-safe mkdir -p... /bin/mkdir -p
checking for gawk... no
checking for mawk... mawk
checking whether make sets $(MAKE)... yes
checking whether make supports nested variables... yes
checking whether UID '1000' is supported by ustar format... yes
checking whether GID '1000' is supported by ustar format... yes
checking how to create a ustar tar archive... gnutar
checking for gcc... no
checking for cc... no
checking for cl.exe... no
configure: error: in/home/pi/protobuf-3.7.1':config.log' for more details
configure: error: no acceptable C compiler found in $PATH
See
$ make
make: *** ターゲットが指定されておらず, makefile も見つかりません. 中止.
$
- 投稿日:2020-01-03T12:41:58+09:00
GitLab CIでflake8とpytestを実行
この記事で取り扱うこと
- GitLabのパイプラインで
flake8とpytestを実行する- 上記の実行タイミングをmerge request提出時に変更する
この記事を書いたきっかけ
静的解析やフォーマッターの利用、テストコードを書くことはソフトウェアの品質を担保する手段として有用なのは頭ではわかっていますが、なかなかそれをチームでの開発に導入することに難しさ(というか単純にどうすればいいんだろうという気持ち)を感じていました。
普段の業務でGitLabを使っていることもあり、色々調べるうちに難しいことはおいておいて簡単な仕組みならすぐに作れるんじゃないかと思い、簡単にまとめてみました。
GitLabの登録さえすればFreeプランで実行可能なのですぐに試すことはできると思います。
実行環境
- GitLab.com(クラウドサービスの方です)
- GitLab Shared Runner
1. 環境構築およびFlake8によるチェックの実施
1-1.リポジトリをGitLabに作成する
一連の作業を実施するためのリポジトリをGitLabに作ります。プライベートで大丈夫です。
1-2. gitlab-ymlの追加およびPUSH
ステージ分けの概念もない極めてシンプルなものです。
Python3のイメージを引っ張ってきて、flake8をsrcディレクトリは以下のコードに対して実行します。image: python:3 before_script: - pip install flake8 test: script: - flake8 src/PUSH後にCI/CDを確認してみると、パイプラインが稼働し、flake8による解析が実行されていることが確認できました。
2. Testの追加
flake8の実行は上記で終わったので、次にpytestによるテストの実行をやってみます。
2-1. テストの作成およびローカルでの実行
以下のようにtest用のファイルを分けたディレクトリ構成でテストコードを作ってみます。
. ├── __init__.py ├── poetry.lock ├── pyproject.toml ├── src │ └── main.py │ └── __init__.py ├── tests # 追加 │ └── test_main.py # 追加 │ └── __init__.py # 追加 └── venvテストコードの中身は以下の通りです。
内容は今回あまり気にしていないので、かなり適当です。import sys, os current_path = os.path.dirname(os.path.abspath(__file__)) sys.path.insert(0, current_path + '/../') from src import main def test_add(): result = main.add(3, 5) expected = 8 assert result == expected def test_substract(): result = main.substract(10, 5) expected = 5 assert result == expected def test_multiply(): result = main.multiply(4, 5) expected = 20 assert result == expected作成したテストをローカルで実行して全てパスすることが確認できました。
$ pytest tests ======================== test session starts ======================== platform darwin -- Python 3.7.6, pytest-5.3.2, py-1.8.1, pluggy-0.13.1 collected 3 items tests/test_main.py ... [100%] ========================= 3 passed in 0.01s =========================2-2. カバレッジの計測
pytest-covを使ってカバレッジの計測もやってみます。
$ pytest --cov=src tests/ ======================== test session starts ======================== ... collected 3 items tests/test_main.py ... [100%] ---------- coverage: platform darwin, python 3.7.6-final-0 ----------- Name Stmts Miss Cover ------------------------------------- src/__init__.py 0 0 100% src/main.py 6 0 100% ------------------------------------- TOTAL 6 0 100% ========================= 3 passed in 0.03s =========================これだけだとつまらないので、main.pyに新しいコードを追加して意図的にカバレッジを下げてみます。
- 追加したコード
... def divide(x, y): return x / y
- pytest-covの出力結果
% pytest --cov=src tests/ ============================================ test session starts ============================================ ... collected 3 items tests/test_main.py ... [100%] ---------- coverage: platform darwin, python 3.7.6-final-0 ----------- Name Stmts Miss Cover ------------------------------------- src/__init__.py 0 0 100% src/main.py 8 1 88% ------------------------------------- TOTAL 8 1 88% ============================================= 3 passed in 0.03s =============================================2-3. GitLab CI/CDでの実行
yamlファイルに新しくpytest-covの実行を追加してPUSHします。
image: python:3 before_script: - pip install flake8 pytest pytest-cov test: script: - flake8 src/ - pytest --cov=src tests/コードをPUSHしてパイプラインの実行結果を確認すると、以下の通り新しく追加したコードでflake8によるチェックに引っかかったためパイプラインがとまりました。
再度コードを修正してPUSHします。
今度は正常に終了しました。
2-4. パイプラインにカバレッジの表示を追加
カバレッジを計測してもいちいちJOBのログを見に行かなければいけないので、
GitLabの機能を使ってカバレッジを表示するように対応します。具体的にはGitLabの設定ページよりテストカバレッジ解析の機能を使います。
正規表現を使ってログからカバレッジ率を表示する機能みたいですが、pytest-covの場合は例の中にあるのでそのままコピペして保存します。
コードを再度Pushしてみると以下の通りカバレッジ率が表示されていることが確認できました。
3. パイプラインの実行タイミングを変更
今はmasterに直接PUSH→パイプラインの実行という流れになっていますが、
実際の開発ではマージリクエスト等でレビューを挟むことが多いと思います。なので、マージリクエストの提出時にパイプラインを実行して、flake8による解析とpytestによるテストが通った場合のみレビュー、マージという流れを構築してみたいと思います。
3-1. yamlの修正
新しいブランチを切って以下の通りyamlファイルの内容を修正します。
修正点はonlyでmerge_requestを指定するだけです。詳細はGitLabのページより以下を参照ください。
Pipelines for Merge Requestsimage: python:3 before_script: - pip install flake8 pytest pytest-cov test: script: - flake8 src/ - pytest --cov=src tests/ only: - merge_requestsプッシュしたら、まずこれまでと違いパイプラインが稼働していないことを確認します。
3-2. merge requestの実行
新しく切ったブランチからmasterへのマージリクエストを提出します。
マージリクエスト提出後(パイプライン稼働中)
以下の通りパイプラインが稼働していることが確認できました。
通常では表示されない「パイプラインが成功したときにマージ」というボタンが見えます。
マージリクエスト提出後(パイプライン稼働後)
パイプライン稼働中から表示が変わってパイプラインの実行結果(成功)とカバレッジが出力されています。
3-3. マージリクエストの実行(失敗編)
意図的に失敗するテストケースを追加して新しいコミットをPUSHしてみます。
以下の通り、新規マージリクエストだけでなく、追加でのコミットでもパイプラインが稼働することが確認できました。
パイプラインの稼働後は以下の通りに表示が変更されました。
現在の設定(デフォルト)ではパイプラインの稼働が失敗してもマージが可能です。
GitLabではマージはパイプラインが成功したときのみ可能という設定が可能みたいなので、
「Pipelines must succeed」にチェックを入れて設定を保存します。
すると以下の通り、マージが不可能になりました。
運用をどうするかはプロジェクト次第だと思いますが、静的解析とテストに通過したコードのみマージされるという決まりがあれば品質を担保しやすいのではないでしょうか。














- 投稿日:2020-01-03T11:42:12+09:00
[NNabla]構築済みネットワークの中間層の出力(variable)を取得する方法
はじめに
これは私のqiita初投稿です。(article1)
sonyが公開したDeep Learning用ライブラリnnablaについての記事です。私がnnablaを使っていた中で「こういう情報がqiitaとかにあったらよかったのに」と思いながらなんとか気合いでnnablaのreferenceとdir()(pythonの標準関数。引数のメンバ変数・関数を返してくれる)で見つけてきたことについてまとめます。1. 要件
・OS: macOS Catalina (バージョン 10.15.1)
・python: 3.5.4
・nnabla: 1.3.02. ネットワークの構築
サンプルのネットワークを下記で定義します。
article1_make_network.pyimport nnabla as nn import nnabla.functions as F # [define network] x = nn.Variable() y = F.add_scalar(x, 0.5) # <-- (1)とおく y = F.mul_scalar(y, -2)単純に $y=(x+0.5)\times2$ という形になってます。
この時、変数yは上の式の結果をもつ変数となっていて、途中の計算であるF.add_scalar(x, 0.5)の結果を(1)と呼びます。(1)は最後の行でyが上書きされて見えなくなってます。この時の(1)の変数取得方法を解説します。3. 中間層の変数の取得(簡易版)
nnabla referenceによると、yには
parentというメンバ変数があり、名前とリファレンスの説明からしてyを出力したレイヤーを取得できるようです。また、parentは何を持っているかdir(y.parent)でみると、inputs、outputsというメンバ変数がありました。これらを用いれば、前述程度の浅いネットワークであれば下記によって(1)の出力を得られます。article1_make_network.py# [get middle variable] h1 = y.parent.inputs[0]動作確認は下記で行いました。
article1_make_network.py# [set value & forward] x.d.fill(0) y.forward() print('y.d = {}'.format(y.d)) print('h1.d = {}'.format(h1.d))出力
y.d = -1.0 h1.d = 0.5memo
y.parent.inputsでyを出力したレイヤーの入力変数(variable)をlistとして取得できます。F.mul_scalarは入力変数を1つしかとらないので上記の記述で(1)の出力を取得できます。(scalarはレイヤーのパラメータという扱い(convolutionでいうstrideなどと同じ)で、ネットワーク上の変数ではないのでカウントされません。)レイヤーがconvolutionの時は、inputs[1]でweight,inputs[2]でbiasとなっていました。- さらに入力に近いレイヤーの出力を取得したい場合は、次のように取得できます。
h = y.parent.inputs[0].parent.inputs[0]....しかし、これでは多くのレイヤーを持つネットワークについて中間層を取得する際は現実的ではないため、下記で私のよく使用する一般的な方法を紹介します。4. 中間層の変数の取得(一般)
nnabla.Variableのreferenceを見ると、ある関数funcを与え、レイヤーを順方向にnnabla._function.Function型のオブジェクトfを引数としてなんか処理func(f)をしてくれそうなvisitというメンバ関数があります(元の文は下記に記載)。これを使用すれば前述のように各レイヤーの出力を取得できます。
(先ほどはnnabla.function.Functionで、visitで扱われるのがnnabla._function.Functionで若干違う気もしましたが、やってみるとう所望の動作をしました。)visit(self, f)
Visit functions recursively in forward order.Parameters: f (function) – Function object which takes nnabla._function.Function object as an argument.
下記が具体的なコードになります。
単に関数を定義してvisitに入力するだけではその関数内でしか取得した変数を保持してくれないので、classにしてメンバ関数__call__(self, f)を実行してメンバ変数self.middle_vars_dictに保持させていく形にしています。article1_make_network.pyfrom collections import OrderedDict class get_middle_variables: def __init__(self): self.middle_vars_dict = OrderedDict() self.middle_layer_count_dict = OrderedDict() def __call__(self, f): if f.name in self.middle_layer_count_dict: self.middle_layer_count_dict[f.name] += 1 else: self.middle_layer_count_dict[f.name] = 1 key = f.name + '_{}'.format(self.middle_layer_count_dict[f.name]) self.middle_vars_dict[key] = f.outputs[0] GET_MIDDLE_VARIABLES_CLASS = get_middle_variables() y.visit(GET_MIDDLE_VARIABLES_CLASS) middle_vars = GET_MIDDLE_VARIABLES_CLASS.middle_vars_dict動作確認は下記で行いました。
article1_make_network.pyfor key in middle_vars: print('{} : {}, .d = {}'.format(key, middle_vars[key], middle_vars[key].d))出力
AddScalar_1 : <Variable((), need_grad=False) at 0x119fe41d8>, .d = 0.5 MulScalar_1 : <Variable((), need_grad=False) at 0x119fe4188>, .d = -1.0memo
y.visit(GET_MIDDLE_VARIABLES_CLASS)の部分で、中間層の変数を集めてきてます。- 今回visitに与えているのはクラスですが、関数のようにしてクラスを呼び出す(class(引数)の形)と、そのクラス内の
__call__と定義されたメンバ関数が呼ばれます。f.nameでそのレイヤー名を取得できるようです。- 同じ名前のレイヤーを複数使用してしまうと、単に
f.nameをkeyにして保存していたら上書きされてしまうので、同じレイヤーでも何番目のレイヤーなのか区別できるようにself.middle_layer_count_dictでレイヤーの番号を数えて覚えておく形にしました。(今回のケースではレイヤーの被りがないので、なくても問題ないです。)
- 投稿日:2020-01-03T10:58:19+09:00
Django Rest Framework で RESTful な APIを作成する
概要
この記事は初心者の自分がRESTful なAPIとswiftでiPhone向けのクーポン配信サービスを開発した手順を順番に記事にしています。技術要素を1つずつ調べながら実装したため、とても遠回りな実装となっています。
前回のSwiftのTableViewCellを使ってTableViewを自由にカスタマイズで、データベースで管理するクーポン情報をAPIを通してアプリが取得し、リスト形式で表示するところまで作成しました。
次はこのAPIをRESTfulなAPIに改造します。改造にあたりコードを大幅に変更するため、一旦GETで全てのクーポン情報をレスポンスするだけのAPIを実装し、その後にリクエストに応じたクーポン情報をレスポンスするよう修正を加えていきます。
参考
- Django REST Framework の使い方メモ
- Django REST Frameworkを使って爆速でAPIを実装する
- 【Django入門】REST FrameworkでAPIを作ってみよう
- 適当に作る python Djnago REST frameworkで作る初めてのAPI
- よく使うcurlコマンドのオプション
環境
Mac OS 10.15
VSCode 1.39.2
pipenv 2018.11.26
Python 3.7.4
Django 2.2.6手順
- Django Rest Framework をインストールする
- Django Rest Framework を取り込む
- Serializerを定義する
- View.pyを改造する
- URL_patternを定義する
- curl コマンドを使って動作確認をする
Django Rest Framework をインストールする
自分はpipenvでpythonのプロジェクト(仮想環境)を作っているので、そこに django rest framework をインストールします。pipenvのシェルに入り、インストールのコマンドを実行します。
$ pipenv shell #シェルに入る $ pipenv install djangorestframework # インストール実行インストール中のターミナル...
インストール完了後にPipfileの中を見ると、
[packages]にdjangorestframeworkが追加されています。[[source]] name = "pypi" url = "https://pypi.org/simple" verify_ssl = true [dev-packages] [packages] django = "*" djangorestframework = "*" [requires] python_version = "3.7"Django Rest Framework を取り込む
プロジェクト名のディレクトリ配下の
setting.pyのINSTALLED_APPS = {に インストールしたrest_frameworkを追加するだけです。INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'coupon', 'rest_framework', # 追加 ]これで Django Rest Framework を使う準備が完了しました。
Serializerを定義する
Rest Framework を使うには Serializer というモジュールが必要です。アプリのディレクトリ配下に自分で Serializer のファイルを作り実装します。
下記のように実装しました。
coupon/serializer.pyfrom rest_framework import serializers # Django Rest Frameworkをインポート from .models import Coupon # models.py のcouponクラスをインポート class CouponSerializer(serializers.ModelSerializer): class Meta: model = Coupon # 扱う対象のモデル名を設定する fields = '__all__'上のコードで、
fieldsはレスポンスしたいモデルフィールド(ここではクーポン情報)を指定します。特に指定せず全ての項目をレスポンスする場合は'__all__'とします。View.pyを改造する
views.pyを Django Rest Framework を使った場合に合わせて改造します。
- rest_framework の viewsets と filters をインポート
- 上で定義した serializer の CouponSerializer をインポート
- 全てのクーポン情報をレスポンスする queryset に変更
- rest_framework を使うと データをjson 形式にしたり dump したり、HTTPでレスポンスする処理は自動でやってくれるようなので、それらの不要になった処理を削除
- 上で定義した serializer.pyのCouponSerializer を呼ぶ。
コードは下記のようになります。非常にシンプルになりました。
views.pyfrom django.shortcuts import render from .models import Coupon from rest_framework import viewsets, filters from .serializer import CouponSerializer class CouponViewSet(viewsets.ModelViewSet): queryset = Coupon.objects.all() # 全てのデータを取得 serializer_class = CouponSerializerURL_patternを定義する
ami_coupon_api/urls.pyと、coupon/urls.pyを編集します。実感としてはcoupon/urls.pyから編集した方が良さそうです。
coupon/urls.pyの編集内容は下記の通りです。
- rest_framework の routers をインポート
- views.py で定義した、CouponViewSet をインポート
- router を定義して、
router.registerに URLとそのURLがリクエストされた時に呼び出すview.pyのクラス(ここでは CouponViewSet)を紐付ける。coupon/urls.pyfrom django.urls import path from . import views from rest_framework import routers from .views import CouponViewSet router = routers.DefaultRouter() router.register(r'coupons', CouponViewSet)上記で、
r’coupons’の‘coupons’の部分が リクエストURLの後ろに付きます。
ami_coupon_api/urls.pyの編集内容は下記の通りです。
django.conf.urlsの url と include をインポートcoupon/urls.pyで定義した router を coupon_routerとしてインポート- urlpatternsにURLと呼び出し先を定義
- URLが
admin/の場合は、django の コンソールへ進むように設定api/の場合は、router で設定したオブジェクトへ進むように設定ami_coupon_api/urls.pyfrom django.contrib import admin from django.urls import path,include from django.conf.urls import url, include from coupon.urls import router as coupon_router urlpatterns = [ url(r'^admin/', admin.site.urls), url(r'^api/', include(coupon_router.urls)), ]curl コマンドを使って動作確認をする
新しいターミナルを開いて GET、POST、PUT のリクエストを試してみます。リクエストの書き方は下記の通りです。-X はHTTPメソッド(GET、POST、PUT など)を指定するためのオプションです。なお、GETとPOST は指定しなくても実行可能でした。
$ curl -X [HTTPメソッド] [URL] [リクエストパラメータ]GETを試します。リクエストパラメータは付けていません。
$ curl -X GET http://127.0.0.1:8000/api/coupons/こんなjsonが返ってきました。
[{"id":1,"code":"0001","benefit":"お会計から1,000円割引","explanation":"5,000円以上ご利用のお客様限定。他クーポンとの併用不可。","store":"全店","start":"2019-10-01","deadline":"2019-12-31","status":true},{"id":2,"code":"0002","benefit":"お会計を10%オフ!","explanation":"他クーポンとの併用不可","store":"有楽町店","start":"2019-10-01","deadline":"2019-12-31","status":true},{"id":3,"code":"0003","benefit":"【ハロウィン限定】仮装して来店すると30%オフ","explanation":"全身の50%以上を仮装されているお客様限定(判断はスタッフの感覚とさせて頂きます)。他クーポンとの併用不可","store":"神田店","start":"2019-10-31","deadline":"2019-10-31","status":true},{"id":4,"code":"0004","benefit":"【9月限定】お月見団子サービス","explanation":"ご希望のお客様に月見団子をプレゼント! 他クーポンとの併用可能です!","store":"全店","start":"2019-09-01","deadline":"2019-09-30","status":true},{"id":5,"code":"0005","benefit":"【雨の日限定】お会計から15%オフ","explanation":"クーポンが配信された時だけ利用可能です。他クーポンとの併用不可","store":"全店","start":"2019-10-01","deadline":"2019-12-31","status":false},{"id":6,"code":"0006","benefit":"【日曜日限定】乾杯テキーラサービス","explanation":"テキーラを人数分サービスします。他クーポンとの併用可。","store":"神田店","start":"2019-11-03","deadline":"2019-12-01","status":true}]
POSTを試します。
curl -X POST http://127.0.0.1:8000/api/coupons/ -d "code=0007" -d "benefit=お会計から19%引き" -d "explanation=12月29日~12月31日限定。 " -d "store=神田店" -d "start=2019-12-29" -d "deadline=2019-12-31" -d "status=true"上手くいくとPOSTしたデータがjsonで返って来ます。
{"id":7,"code":"0007","benefit":"お会計から19%引き","explanation":"12月29日~12月31日限定。","store":"神田店","start":"2019-12-29","deadline":"2019-12-31","status":true}
PUTを試します。
PUTの時はHTTPメソッドを指定する必要があります。それより重要なのは、URLにテーブルのプライマリキーを指定する必要があります。couponモデルでは”id”がプライマリキーになっているので、URLの末尾に上書きしたいデータのid(ここでは 7 )を指定します。curl -X PUT http://127.0.0.1:8000/api/coupons/7/ -d "code=0007" -d "benefit=お会計から19%引き" -d "explanation=12月29日~12月31日限定。他のクーポンとの併用不可 " -d "store=神田店" -d "start=2019-12-29" -d "deadline=2019-12-31" -d "status=true"上手くいくと上書きされたデータがjsonで返って来ます。
{"id":7,"code":"0007","benefit":"お会計から19%引き","explanation":"12月29日~12月31日限定。他のクーポンとの併用不可","store":"神田店","start":"2019-12-29","deadline":"2019-12-31","status":true}
DELETEを試します。
先ほどPOSTしたリクエストをもう一度実行し、id=8のクーポンを作ります。GETリクエストかDjangoサーバのコンソールでid=8のクーポンが追加されたことを確認してください。次に、下記のリクエストでid=8のクーポンを削除します。PUTと同様に削除対象のクーポンのプライマリキーの指定が必要です。
curl -X DELETE http://127.0.0.1:8000/api/coupons/8/上手くいくと何も返って来ません。
GETリクエストかDjangoサーバのコンソールでid=8のクーポンが削除されたことを確認してください。ここまでで基本的なRest Framework が出来ました。ここから 条件に合うクーポンのみをGETするためのフィルタや認証機能を追加していきます。
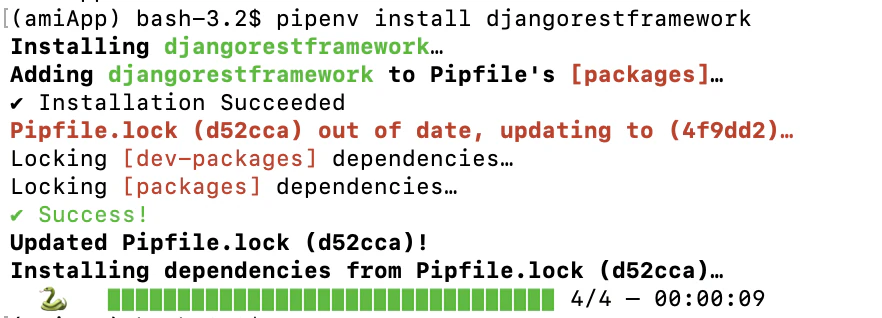
- 投稿日:2020-01-03T10:45:09+09:00
APIの仕組みが分かる・使いこなせる人材になれる記事(Pythonコード付き)
はじめに
プログラミングを勉強していて、APIってなんだ?と感じた経験はないでしょうか。
「そもそもAPIを使って何ができるの?」
「どうやって使うの?」こういった悩みを解決するには どのAPIにも共通する仕組み を理解すると良いです。
具体的なPythonのコードまで紹介するので、読み終わる頃にはAPIの使い方が身に付いているはずです。章構成は以下の通りです。
- APIとは(APIを使うメリット)
- APIを理解する
- APIサービスの例
- Pythonコードサンプル
※※SNS でも色々な情報を発信しているので、記事を読んで良いなと感じて頂けたら
Twitterアカウント「Saku731」 もフォロー頂けると嬉しいです。※※APIとは(APIを使うメリット)
APIは「Application Programming Interface」の略です。
直訳すると以下の様になります。
- アプリケーション(Application)を
- プログラミング(Programming)を使って
- 繋ぐ(Interface)
※Applicationは「Webサービス」「システム」といった意味です。
もう少し深ぼりすると、APIが必要とされる最大の利点は
『自分が作ったWebサービスに、他の人が作った便利な機能を借りてくる』
これに尽きると考えています。つまり、自分で苦労してゼロから開発する必要が無くなるのです。
例えばECサイトを開発する際、皆さんはどちらを選ぶでしょうか?
- 自分でクレジット決済機能を作る
- カード会社が提供しているクレジット決済APIを使う
このように「自分で作らない」という選択肢がAPIの最大メリットです。
APIを理解する
APIの利点が分かったところで、その仕組みを理解して行きましょう。
大きく分けて3つの知識が必要となります。
- 1)Webの仕組み
- 2)HTTPリクエスト
- 3)HTTPレスポンス
1)Webの仕組み
普段から何気なく使っているインターネットはWebのおかげで成り立っています。
Webは『インターネット上で文章や画像など、あらゆる種類のデータを送る仕組み』です。なので、APIで他の人が作ったWebサービスを借りてくるには当然ながらWebの理解が必要です。
Webを理解するためには以下3つを押さえましょう。
- HTTP(Hyper Text Transfer Protocol)
- URL(正確にはURI)
- ハイパーテキスト(HTMLなど)
文章で整理するとこういった具合です。
Webとは、、
『HTTPという通信の約束に従って』
『URLで指定する場所(サーバー)を』
『ハイパーテキスト(情報)をやり取りする』ための仕組み。Webを詳しく理解するためには何冊も本を読まないといけないですが、
「URLで指定したサーバーと情報のやり取りを行う技術」だと理解すれば十分です。このWeb技術を使用して自分のWebサービスと他の人が作ったWebサービス(サーバー)の間で
簡単に情報のやり取りを実現する仕組みがAPIなのです。そして、具体的にAPIを使いこなすには、Webが採用しているHTTP(通信上の約束事)を使用する必要があります。「相手へ情報を送信するHTTPリクエスト」と「相手から情報を受け取るHTTPレスポンス」の2種類があるので以降で理解して行きましょう。
2)HTTPリクエスト
まず自分から相手にデータを送信するHTTPリクエストです。
API経由で他の人が作ったWebサービスに「機能を使わせて下さい」といったリクエストを投げる処理です。WebサービスごとにAPIの使い方が異なって見えるのですが共通する基礎があります。
どんなAPIを使うときでも共通して以下の情報を用意すれば良いです。
- Webサービスに接続するための情報(サービス登録時に手に入る)
- API エンドポイント(サービスに接続するためのURL)
- API キー(接続に必要なパスワード)
- Webサービスに送信する情報(APIの仕様書で確認できる)
- メソッド(主にPOSTかGET)
- クエリパラメータ(使用するAPI・サービスの種類など詳細を指定)
- ヘッダー(データの種類や、API キーなどの認証情報を入力 ※POSTメソッドで指定する)
- ボディ(APIと送受信したい情報を入力。※POSTメソッドで指定する)
これらの大項目はどんなAPIでも共通なのですが、細かな内容で違いが出てきます。
各サービスが公開している「API仕様書」で必要な内容を確認しましょう。
※慣れるまではQiitaに投稿されているサービス利用手順を読むのが1番おススメです。各地の天気を取得できるAPIを使用するとしたら、こういった具合に情報整理されます。
POST・GETどちらを使用すべきかはAPI仕様書に書いてあるので、最初は意識しなくても大丈夫です。
※違いを詳しく知りたい方は 【こちら】 を参照ください。天気予報API(POSTメソッドの場合)
- Webサービスに接続するための情報
- API エンドポイント:https:/world_weather.com/api ※架空のURLです
- API キー:aaabbbccc
- Webサービスに送信する情報
- メソッド:POST
- クエリパラメータ:service=Weatyer(使用するサービスを指定)
- ヘッダー:application/json(データの種類)
- ボディ:date=today, area=Tokyo(送受信したい情報を入力)
プログラムのサンプルとしては以下の様になります。
※実在しないAPIなので実行してもエラーになります。# ライブラリのインポート import requests import json # APIに接続するための情報 API_Endpoint = https:/world_weather.com/api API_Key = aaabbbccc # APIに送信する情報 headers = {'Content-Type': 'application/json', 'key':API_Key} body = {date='today', area=Tokyo} # API接続の実行 result = requests.post(API_Endpoint, data=json.dumps(body), headers=headers)天気予報API (GETメソッドの場合)
- Webサービスに接続するための情報
- API エンドポイント:https:/world_weather.com/api
- API キー:aaabbbccc
- Webサービスに送信する情報
- メソッド:GET
- クエリパラメータ:service=Weatyer, date=today, area=Tokyo
(GETメソッドでは全てクエリパラメータに納めます)GETメソッドについてはサービスにもよりますが以下の様な書き方が一般的です。
①原則:エンドポイント(URL)にすべての情報を含める
こちらの記述方法はPOSTに似ていますが、裏側では「①原則」と同じ形で送信されるので結果は同じです。
# ライブラリのインポート import requests import json # APIに接続するための情報(「?」の後ろに「&」で条件を繋いでいく) API_Endpoint = https:/world_weather.com/api?Key=aaabbbccc&date='today'&area='Tokyo' # API接続の実行 result = requests.get(API_Endpoint)②
requestsモジュールの機能:POSTみたいに情報を切り分ける# ライブラリのインポート import requests import json # APIに接続するための情報 API_Endpoint = https:/world_weather.com/api API_Key = aaabbbccc # APIに送信する情報 params = {'key':API_Key, date='today', area=Tokyo} # API接続の実行 result = requests.post(API_Endpoint, data=json.dumps(body), params=params)3)HTTPレスポンス
API経由でWebサービスにHTTPリクエストを送ると、HTTPレスポンスという『返事』が送られてきます。
この『返事』を自分のWebサービス上で表示させることで、自分で1から開発する手間が省けます。例えば、、
『リクエスト:天気を教えてください。今日, 日本, 東京』
『レスポンス:晴れのち曇りです』
APIサービスの例
ここまででAPIの概要を理解したので、実際に利用できる無料のAPIサービスを使用してみましょう。
使用するAPIのサービス概要
Livedoor天気情報サービス Weather Hacks を使ってみます。
無料で日本全国142ヵ所の天気予報を「今日・明日・明後日」まで取得する事が出来ます。http://weather.livedoor.com/weather_hacks/webservice
API仕様書を見てみる
上記リンクをクリックしてAPI仕様書を見てみましょう。
サービスによって項目数・名称は異なりますが、おおむね確認すべき順番は以下の通りです。
- API エンドポイントは?
- API Keyの取得方法は?
- POSTかGETか?
- クエリパラメータは?
- ヘッダ・ボディで送信すべき情報は?
順番に整理して行きましょう。今回は無料サービスということもあって非常にシンプルです。
API エンドポイントは?
http://weather.livedoor.com/forecast/webservice/json/v1
※エンドポイントはURL/URI といった名称で記載されていることがあります。API Keyの取得方法は?
特に記述がないので、認証不要(API Key不要)で利用できるサービスのようです。POSTかGETか?
このサービスではGETメソッド を使用します。今回の様に仕様書を一見してもメソッドが明記されていないケースでは以下のように判別します。
- 「エンドポイント(URL)+クエリパラメータ」の形で使用する記述がある場合:GETの場合が多い
- それ以外:POSTの場合が多い
クエリパラメータは?
天気予報を取得したい地域(city)を指定すれば良いようです。
サンプルで書いてある「久留米:400040」を使用してみましょう。ヘッダ・ボディで送信すべき情報は?
GETメソッドを使用するのでヘッダ・ボディは用意する必要ありません。Pythonコードサンプル
リクエストに必要な情報が分かったのでPythonを使ってAPIを使ってみましょう。
APIリクエストの送信
コードをコピペしてそのまま実行して頂ければ大丈夫です。
# APIリクエストに必要なライブラリ import requests # URL+クエリパラメータ url = 'http://weather.livedoor.com/forecast/webservice/json/v1?city=400040' # APIリクエストを送信 result = requests.get(url).json()戻ってきた結果を
print()で表示するととても判読が難しい表示になります。
このままでは使用できないのでJSONデータの使用方法を理解する必要があります。print(tenki_data)
APIレスポンスのJSONデータ確認
APIから戻ってきたデータは JSON形式 であることが多いです。詳細な説明は割愛しますが、コードの
requests.get(url).json()に含まれる.json()の部分でJSON形式から辞書型に変換した上で使用する事が一般的です。辞書型をどの様に使用すると良いのかはAPI仕様書に書いてあります。
http://weather.livedoor.com/weather_hacks/webservice
まず、辞書型で
titleを指定すると「タイトル・見出し」が取得できると書いてあります。print('タイトル:', tenki_data['title'])
続いて、
forecastsを指定すると「予報日ごとの天気予報」が取得できる様です。
JSON形式に特有の少し複雑な手順が必要なので、一緒に流れを押さえて行きましょう。print(tenki_data['forecasts'])
まず、
forecastsを指定すると最初・最後が[]で囲われているリスト型が表示されました。
ここは取得したいデータに応じて『今日:[0]、明日:[1]、明後日[2]』といったように指定すれば良いと予想ができます。# 「今日」のデータを指定 print(tenki_data['forecasts'][0])
だいぶスッキリしましたね。ここまで来たら目的に応じて好きなデータを取ってくれば良いので、今回は「予報日:
dataLabel、天気:telop」を表示させてみましょう。# 予報日 print('予報日:', tenki_data['forecasts'][0]['dateLabel']) # 天気 print('天気:', tenki_data['forecasts'][0]['telop'])
このようにしてAPI仕様書チェック~リクエスト~レスポンスの一連手順が流れて行きます。
他にも色々な情報が取得できるので、ご自身で色々と試されてみて下さい。さいごに
APIはサービスによって使用方法がバラバラである点が非常に困りものです。
しかし、今回ご紹介した以下をベースに考えていけば、ほとんどのAPIを使いこなすことが可能です。APIを使用するために必要な情報
- Webサービスに接続するための情報(サービス登録時に手に入る)
- API エンドポイント(サービスに接続するためのURL)
- API キー(接続に必要なパスワード)
- Webサービスに送信する情報(API仕様書で確認できる。))
- メソッド(主にPOSTかGET)
- クエリパラメータ(使用するAPI・サービスの種類など詳細を指定)
- ヘッダー(データの種類や、API キーなどの認証情報を入力 ※POSTメソッドで指定する)
- ボディ(APIと送受信したい情報を入力。※POSTメソッドで指定する)
確認の手順
- API エンドポイントは?
- API Keyの取得方法は?
- POSTかGETか?
- クエリパラメータは?
- ヘッダ・ボディで送信すべき情報は?
以上で「APIの仕組み・使いこなす方法」は終了です。
皆さん開発に役立つ情報になれば幸いです。SNS でも色々な情報を発信しているので、記事を読んで良いなと感じて頂けたら
Twitterアカウント「Saku731」 もフォロー頂けると嬉しいです。










- 投稿日:2020-01-03T10:40:04+09:00
pythonで画像をパワポ資料に自動で貼り付ける +α
はじめに
パワポのスライド1枚に1枚ずつ画像を貼り付けていって作業手順書にする、みたいなのありますよね。超絶単純作業なのになかなか時間かかるやつ。
単純な繰り返し作業なので、ネット上に転がっていたコードを用いて自動化したいと思います。目標実装機能
少なくとも必ず実装したい機能
スライド1枚につき1枚の画像が貼り付けられたパワポの資料を自動で作成すること。
願わくば
- 表紙の追加
- テキストボックスの追加
- 画像を貼り付けないスライドの挿入
自動作成したいスライド
私の好きな某アニメの登場人物紹介スライドを作成したいと思っています。
構成は、
表紙→画像→キャラ説明→画像→キャラ説明→…(以下、画像とキャラ説明を交互に)
としています。
今回作成したコードを用いて自動作成したスライドは、最後にご紹介します。環境
python3.7.2
Windows10コード
ppt.pyimport pptx from pptx.util import Inches from pptx import Presentation from glob import glob ppt = Presentation() width = ppt.slide_width height = ppt.slide_height #使用するスライドの種類 title_slide_layout = ppt.slide_layouts[0] #Title Slideの作成 bullet_slide_layout = ppt.slide_layouts[1] #Title and Contentの作成 blank_slide_layout = ppt.slide_layouts[6] #Blankの作成 #Title Slide slide = ppt.slides.add_slide(title_slide_layout) title = slide.shapes.title subtitle = slide.placeholders[1] title.text = "○○ Description" subtitle.text = "kokoro pyonpyon" #画像をBlankに張り付ける準備 fnms = glob('figures/*.JPG') tx_left = tx_top = tx_width = tx_height = Inches(1) i = 1 for fnm in fnms: #画像をBlankに張る slide_picture = ppt.slides.add_slide(blank_slide_layout) pic = slide_picture.shapes.add_picture(fnm, width/4,height/2, width/2, height/2) #ついでに空きスペースにテキストボックスを挿入する txBox = slide_picture.shapes.add_textbox(tx_left, tx_top, tx_width*15, tx_height) tB = txBox.text_frame tB.text = "Name: " #Title and Contentの作成 slide_description = ppt.slides.add_slide(bullet_slide_layout) shapes = slide_description.shapes title_shape = shapes.title body_shape = shapes.placeholders[1] #Title and Contentにタイトルとテキストを書き込む title_shape.text = 'Character description ' + str(i) tf = body_shape.text_frame tf.text = 'She works at ' i += 1 ppt.save('figure.pptx')解説
importするライブラリ
pptx
パワーポイントのファイル(.pptx)を作成、アップデートするPythonライブラリ。
典型的な用途として、データベースからパワーポイント資料をカスタマイズした状態で作成したり、webアプリ上のリンクをクリックすることでダウンロードできるようにしたりすることが挙げられる。業務管理システム上の情報をまとめた、エンジニアリングステータスレポートを報告可能な形式で自動作成させることもできる。プレゼンテーションのライブラリーを一括でアップデートしたり、いちいち取り組むのは飽き飽きするような、一枚か二枚のスライドの作成を自動で行ったりすることもある。(この資料の一部を直訳。)
まあこれを簡単にわかっていれば事足ります。多分。
各コマンドの簡単な意味は、コードの中でコメントしています。このコードを用いてできたスライド
細かい部分はスライドごとに手動で入力しましょう。
大半の部分は自動で作成されているので、かなり省力化されているはずです。おまけ
ライブラリのインストールの仕方。
$ pip install numpyみたいな。なんとなくnumpyにしました。
参考資料



- 投稿日:2020-01-03T10:30:25+09:00
AppSyncをフロントエンドとバックエンドで利用する
AppSyncをフロントエンドとバックエンドで利用する
この記事はサーバーレスWebアプリ Mosaicを開発して得た知見を振り返り定着させるためのハンズオン記事の1つです。
以下を見てからこの記事をみるといい感じです。
イントロダクション
アップロードした画像や処理された画像のデータ管理や、クライアント側とのデータ受け渡しのために、AppSyncというAPIを利用します。AppSyncのデータソースにはDynamoDBが使われます。
AppSyncはAmplify CLIでもセットアップ可能なのですが、DynanoDBのパーティションキーやソートキーの指定ができないようだったので、Amplify CLIは使いません。AWSコンソールでDynamoDBとAppSyncを構築します。
フロントエンドのVueからはAmplifyを利用してSubscription、バックエンドのLambda(Python)からはHTTPでリクエストします。コンテンツ
AppSyncのセットアップ
Amplify CLIでAppSyncのセットアップはできるのですが、DynamoDBのパーティションキーやソートキーの指定ができないようなんですよね。実はできるのかもしれませんが、やり方わかりませんでした。知ってる人がいたら教えて下さい。
ということで、コマンドラインに比べると若干手間ですが、AWSコンソールで作っていきましょう。DynamoDB テーブルの作成
AppSyncのデータソースとするDynamoDBを先に作成しておきます。
AWSコンソール > DynamoDB > テーブルの作成
以下の設定でテーブルを作成します。
テーブル名 : sample_appsync_table
パーティションキー : group (文字列)
ソートキー : path (文字列)
AppSync APIの作成
DynamoDBが作れたら、続いてAppSyncを作成します。
AWSコンソール > AppSync > APIを作成Step1 : ご利用開始にあたって
「DynamoDBテーブルをインポートする」を選択して「開始」ボタン押下。
Step2 : モデルを作成
先ほど作成したテーブル(sample_appsync_table)を選択。
「既存のロールを作成または使用する」では「New role」を選択。
「インポート」ボタンを押下。
そのまま「Create」ボタンを押下。
Step3 : リソースを作成
API名を設定して「作成」ボタンを押下。
schema.jsonの入手
AWSコンソール > AppSync > sample_appsync_table > スキーマ メニューから
schema.jsonをダウンロードします。このファイルはWebアプリで利用します。
認証情報の入手
AWSコンソール > AppSync > sample_appsync_table > 設定 メニューから
API DetailのAPI URLやAPI KEYの情報を確認します。この情報はアプリで利用します。
認証モードは「APIキー」のままとします。APIキーの有効期限はデフォルト7日となっていますが、編集することで最大365日まで伸ばすことができます。
認証モードをStorageのようにCognitoユーザーとして利用する方法については別記事にしようと思っています。フロントエンド(VueのWebアプリ)でSubscription
AppSyncのセットアップが完了したら、続いてWebアプリを更新してゆきます。
graphql定義ファイルの追加
src/graphqlフォルダを作成し、3つのファイルを追加します。
src/graphql/schema.json
先ほどダウンロードしたファイルをそのままプロジェクトに追加します。src/graphql/queries.jsexport const listSampleAppsyncTables = `query listSampleAppsyncTables($group: String) { listSampleAppsyncTables( limit: 1000000 filter: { group: {eq:$group} } ) { items { group path } } } `;パーティションキーのgroupを指定して、レコード一覧を取得するためのqueryです。
これは謎なのですが、limitの指定をしてあげないとデータを取ってこれないんですよ。graphqlではなくてAppSyncの仕様だと思うのですが、、どうなんでしょうか。1000000と適当に大きな数字を指定してますが、正直微妙すぎますよね。もっと良い書き方を知っている人がいたら是非教えて下さい。src/graphql/subscriptions.jsexport const onCreateSampleAppsyncTable = `subscription OnCreateSampleAppsyncTable($group: String) { onCreateSampleAppsyncTable(group : $group) { group path } } `;パーティションキーのgroupを指定して、レコードが挿入されたらその情報とともに通知してもらうためのsubscriptionです。
「レコードが挿入されたら」と書きましたが、DynamoDBに直接レコードを挿入してもダメで、AppSyncのcreateによって挿入される必要があります。aws-exports.jsにAppSync情報を追記
src/aws-exports.jsにAppSyncにアクセスする際に必要となる情報を追記します。src/aws-exports.jsconst awsmobile = { "aws_project_region": "ap-northeast-1", "aws_cognito_identity_pool_id": "ap-northeast-1:********-****-****-****-************", "aws_cognito_region": "ap-northeast-1", "aws_user_pools_id": "ap-northeast-1_*********", "aws_user_pools_web_client_id": "**************************", "oauth": {}, "aws_user_files_s3_bucket": "sample-vue-project-bucket-work", "aws_user_files_s3_bucket_region": "ap-northeast-1", "aws_appsync_graphqlEndpoint": "https://**************************.appsync-api.ap-northeast-1.amazonaws.com/graphql", "aws_appsync_region": "ap-northeast-1", "aws_appsync_authenticationType": "API_KEY", "aws_appsync_apiKey": "da2-**************************" }; export default awsmobile;このファイルに書かれている情報は大切な情報なので、漏洩しないよう、取り扱いに注意してください。
Webアプリの実装
Homeで画像を選択してアップロードしたら、ページ遷移した先でアップロードされた画像やモノクロ処理された画像の情報をリストするような実装を施します。
Listというページを追加します。そのためのルーター設定。
src/router.jsimport Vue from 'vue'; import Router from 'vue-router'; import Home from './views/Home.vue'; import About from './views/About.vue'; import List from './views/List.vue'; Vue.use(Router); export default new Router({ routes: [ { path: '/', name: 'home', component: Home, }, { path: '/about', name: 'about', component: About, }, { path: '/list', name: 'list', component: List, }, ] });Listページのビュー
src/views/List.vue<template> <List /> </template> <script> import List from '../components/List' export default { components: { List } } </script>Listページのコンポーネント
src/components/List.vue<template> <v-container> <p>リスト</p> <router-link to="/" >link to Home</router-link> <hr> <v-list> <v-list-item v-for="data in this.dataList" :key="data.path"> <v-list-item-content> <a :href="data.image" target=”_blank”> <v-list-item-title v-text="data.path"></v-list-item-title> </a> </v-list-item-content> <v-list-item-avatar> <v-img :src="data.image"></v-img> </v-list-item-avatar> </v-list-item> </v-list> </v-container> </template> <script> import { API, graphqlOperation, Storage } from 'aws-amplify'; import { listSampleAppsyncTables } from "../graphql/queries"; import { onCreateSampleAppsyncTable } from "../graphql/subscriptions"; const dataExpireSeconds = (30 * 60); export default { name: 'List', data: () => ({ group: null, dataList: [], }), mounted: async function() { this.getList(); }, methods:{ async getList() { this.group = this.$route.query.group; console.log("group : " + this.group); if(!this.group){ return; } let apiResult = await API.graphql(graphqlOperation(listSampleAppsyncTables, { group : this.group })); let listAll = apiResult.data.listSampleAppsyncTables.items; for(let data of listAll) { let tmp = { path : data.path, image : "" }; let list = [...this.dataList, tmp]; this.dataList = list; console.log("path : " + data.path); Storage.get(data.path.replace('public/', ''), { expires: dataExpireSeconds }).then(result => { tmp.image = result; console.log("image : " + result); }).catch(err => console.log(err)); } API.graphql( graphqlOperation(onCreateSampleAppsyncTable, { group : this.group } ) ).subscribe({ next: (eventData) => { let data = eventData.value.data.onCreateSampleAppsyncTable; let tmp = { path : data.path, image : "" }; let list = [...this.dataList, tmp]; this.dataList = list; console.log("path : " + data.path); Storage.get(data.path.replace('public/', ''), { expires: dataExpireSeconds }).then(result => { tmp.image = result; console.log("image : " + result); }).catch(err => console.log(err)); } }); }, } } </script>クエリパラメータでgroupを取得します。
画面表示前のmountedで、groupを指定してレコードデータを取得したり、挿入イベント受信時にレコードデータを取得したりしています。
取得したレコードデータはdataListというメンバ変数配列で保持し、画面にv-listで並べて表示します。
v-listでは、レコードデータのpathと画像を表示しています。画像はStrageで有効期限(30分)付きアドレスをgetしてそれでアクセスしています。src/components/Home.vue<template> <v-container> <p>ホーム</p> <router-link to="about" >link to About</router-link> <hr> <v-btn @click="selectFile"> SELECT A FILE !! </v-btn> <input style="display: none" ref="input" type="file" @change="uploadSelectedFile()"> </v-container> </template> <script> import Vue from 'vue' import { Auth, Storage } from 'aws-amplify'; export default { name: 'Home', data: () => ({ loginid: "sample-vue-project-user", loginpw: "sample-vue-project-user", }), mounted: async function() { this.login(); }, methods:{ login() { console.log("login."); Auth.signIn(this.loginid, this.loginpw) .then((data) => { if(data.challengeName == "NEW_PASSWORD_REQUIRED"){ console.log("new password required."); data.completeNewPasswordChallenge(this.loginpw, {}, { onSuccess(result) { console.log("onSuccess"); console.log(result); }, onFailure(err) { console.log("onFailure"); console.log(err); } } ); } console.log("login successfully."); }).catch((err) => { console.log("login failed."); console.log(err); }); }, selectFile() { if(this.$refs.input != undefined){ this.$refs.input.click(); } }, uploadSelectedFile() { let file = this.$refs.input.files[0]; if(file == undefined){ return; } console.log(file); let dt = new Date(); let dirName = this.getDirString(dt); let filePath = dirName + "/" + file.name; Storage.put(filePath, file).then(result => { console.log(result); }).catch(err => console.log(err)); this.$router.push({ path: 'list', query: { group: dirName }}); }, getDirString(date){ let random = date.getTime() + Math.floor(100000 * Math.random()); random = Math.random() * random; random = Math.floor(random).toString(16); return "" + ("00" + date.getUTCFullYear()).slice(-2) + ("00" + (date.getMonth() + 1)).slice(-2) + ("00" + date.getUTCDate()).slice(-2) + ("00" + date.getUTCHours()).slice(-2) + ("00" + date.getUTCMinutes()).slice(-2) + ("00" + date.getUTCSeconds()).slice(-2) + "-" + random; }, } } </script>uploadSelectedFileで、ファイルをアップロードした後にListページへ遷移させます。その際、groupというクエリパラメータを付けています。
これでフロントエンド(Webアプリ)の改修は完了ですが、動作確認はバックエンド側が済んでからとします。
バックエンド (LambdaのPython)から叩く
Webアプリからアップロードされたファイルや、Lambdaで生成してアップロードしたモノクロ画像のパス(S3のKey)を、AppSync経由でレコード挿入する実装を施します。
gqlをインストールします。
pip3 install gql -t .
lambda_function.pyを以下のように更新します。lambda_function.py# coding: UTF-8 import boto3 import os from urllib.parse import unquote_plus import numpy as np import cv2 import logging logger = logging.getLogger() logger.setLevel(logging.INFO) s3 = boto3.client("s3") from gql import gql, Client from gql.transport.requests import RequestsHTTPTransport ENDPOINT = "https://**************************.appsync-api.ap-northeast-1.amazonaws.com/graphql" API_KEY = "da2-**************************" _headers = { "Content-Type": "application/graphql", "x-api-key": API_KEY, } _transport = RequestsHTTPTransport( headers = _headers, url = ENDPOINT, use_json = True, ) _client = Client( transport = _transport, fetch_schema_from_transport = True, ) def lambda_handler(event, context): bucket = event['Records'][0]['s3']['bucket']['name'] key = unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8') logger.info("Function Start (deploy from S3) : Bucket={0}, Key={1}" .format(bucket, key)) fileName = os.path.basename(key) dirPath = os.path.dirname(key) dirName = os.path.basename(dirPath) orgFilePath = u'/tmp/' + fileName processedFilePath = u'/tmp/processed-' + fileName if (key.startswith("public/processed/")): logger.info("not start with public") return apiCreateTable(dirName, key) keyOut = key.replace("public", "public/processed", 1) logger.info("Output local path = {0}".format(processedFilePath)) try: s3.download_file(Bucket=bucket, Key=key, Filename=orgFilePath) orgImage = cv2.imread(orgFilePath) grayImage = cv2.cvtColor(orgImage, cv2.COLOR_RGB2GRAY) cv2.imwrite(processedFilePath, grayImage) s3.upload_file(Filename=processedFilePath, Bucket=bucket, Key=keyOut) apiCreateTable(dirName, keyOut) logger.info("Function Completed : processed key = {0}".format(keyOut)) except Exception as e: print(e) raise e finally: if os.path.exists(orgFilePath): os.remove(orgFilePath) if os.path.exists(processedFilePath): os.remove(processedFilePath) def apiCreateTable(group, path): logger.info("group={0}, path={1}".format(group, path)) try: query = gql(""" mutation create {{ createSampleAppsyncTable(input:{{ group: \"{0}\" path: \"{1}\" }}){{ group path }} }} """.format(group, path)) _client.execute(query) except Exception as e: print(e)
ENDPOINTとAPI_KEYは、AppSyncに先ほど作成したAPI設定を参照してください。
zip圧縮してS3にアップロードしてLambdaにデプロイしてください。動作確認
Webアプリを実行して画像をアップロードすると、LambdaからAppSyncが叩かれて、それを検出してWebアプリ側でリストされます。クエリパラメータ付きのURLを直接叩いても、AppSyncからリストを取得してリストするようにしています。
Webアプリ(Vue)のプロジェクトは以下においておきます。
https://github.com/ww2or3ww/sample_vue_project/tree/work5Lambdaのプロジェクトは以下においておきます。
https://github.com/ww2or3ww/sample_lambda_py_project/tree/work3あとがき
JAWS UG 浜松に参加して初めて声に出して質問した話題がこのあたりでした。
AmplifyのAPIってDynamoDBのパーティションキーとかソートキー指定できないんですかねぇ?
DynamoDBってキー設定無しで使うことってあんまり無いですよねぇ?
WebSocketって詳しく知らないですけどロングポーリングみたいなものですかねぇ?
ドキドキしながら発言したのを覚えています。ところでネットワークって難しいですよね。ネットワークエンジニアを名乗れる人、尊敬します。
MQTT over WebSocketとか言われても正直良くわからないです。誰か分かりやすく教えて下さい、、。AppSyncのサンプルって、Amplify CLIとセットで語られることが多いからか、フロントエンドからの利用ばかりですよね。チャットアプリしかり、TODOアプリしかり。DynamoDBも全件スキャンですし。
DynamoDBってレコードの数が増えていきがちというか、そういう用途で利用されがちだと思っていて、そういった意味では全件スキャンは良くないですよね。