- 投稿日:2020-01-03T22:40:54+09:00
比較的早く Svelte を Amazon S3 上にホスティングする方法
The State of JavaScript 2019 にて突然出現した Svelte
比較的早く Svelte をセットアップする方法 に続いて、Amazon S3 に、
静的 website として hosting する方法をまとめてみました?
Build と deploy には、AWS Amplify を使用します
前提条件
- 比較的早く Svelte をセットアップする方法
- AWS account
1. リポジトリの作成
Push の準備として、AWS CodeCommit に repository を作成
接続のステップを参考に、適宜 setup を実施
2. Push
$ git init $ git add . $ git commit -m "1st commit" $ git add remote origin https://git-codecommit.${YOUR_REGION}.amazonaws.com/v1/repos/${YOUR_PROJECT_NAME} $ git push origin master
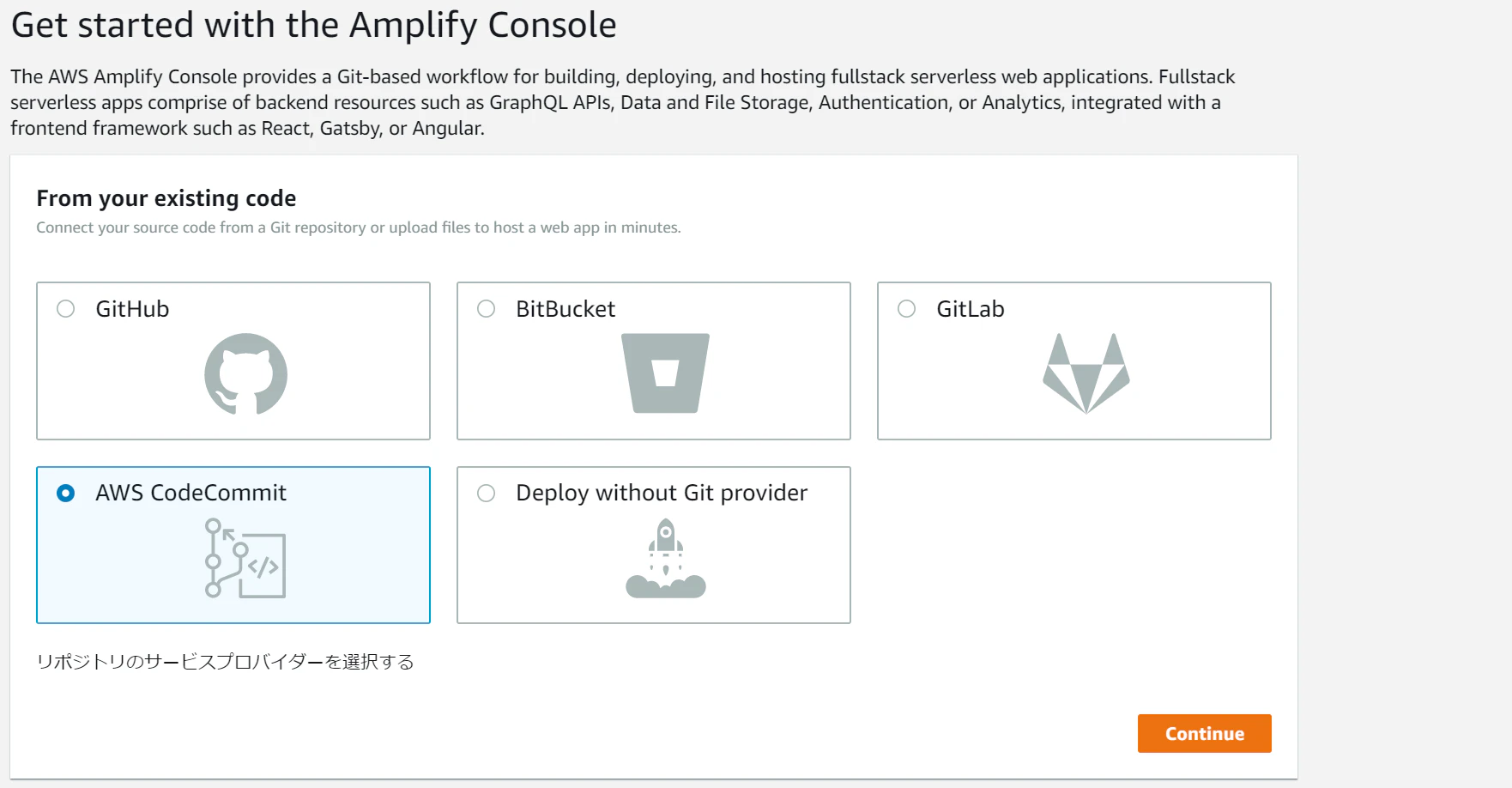
3. Build & deploy
Build & deploy の準備として、AWS Amplify に project を作成
Build command の baseDirectory を、
/から/publicに変更
Start
Complete
4. 確認
https://master.d1dar8nbyr7lfy.amplifyapp.com ( deleted )








- 投稿日:2020-01-03T19:22:50+09:00
4年ぶりにエンジニアに戻った人の話
こんにちは、Qiita初投稿です。
色々あって昨年末に4年間勤めていた外資系のゲーム会社でのプロデューサー業を辞めてエンジニアに戻りました。
前職ではエンジニアではなく、翻訳やアカウントマネージメント系の仕事などをやっていました。
エンジニアブログを書く前に、今回は元エンジニアが4年間経ってエンジニアに戻って世界が一変していた、浦島太郎のような話をしたいと思います。経歴:
2011年: 大手企業に新卒でエンジニア就職
秋入社というのもありまさかの新卒唯一の日本人、まわりは中国人とインド人ばっかり。入社一日目でエンジニア職人気なさすぎオワタと思う。まわりのエンジニアが毎月行われれていた深夜作業に駆り出されていくのを怯える毎日(結局一度もその作業をすることはなかったが)
2013年: ベンチャー企業へ転職
前職ではテスト業務しか触れず、いつの間にかポジションもQAエンジニアになってしまったのでエンジニアらしいことがしたいと一念発起して、当時黎明期だったモバイルアプリ業界へ転職。たまたま入社直後にアプリがヒットし、会社が急成長。カスタマーサポート担当→QAエンジニア→サーバーエンジニアと役割を変え、気づいたらエンジニアリードになっていった。
2015年: 外資系ゲーム会社へ転職
ヘッドハンティングで当時日本サーバーを建てようとしていた世界的人気のゲームを運営する会社へ入社。エンジニアではなく語学力+QA経験でLocalization QAを任される。そのうち、「君これもできるよね?」というノリでユーザーコミュニケーション担当をやっていたら、そちらが本業になりLocalizationチームから外れてMarketingチームへ異動。Abemaでテレビ番組のプロデューサーをやっていたら、半年で今度は当時のesports担当が外れたので急遽、責任者に就任。
2019年: 現在の会社へ
前職を8月末に辞表を出し11月末に退社(理由は色々あったので割愛)。就職先を決めていなかったので、「いい機会だし色んな業界の話を聞いてみよう」と多くの会社に面接に行っていたら現在の社長と意気投合、はれて4年ぶりにエンジニアに復職。
エンジニアに戻ってきて
前置きが長くなってしまいましたが、ここからが本題。まず転職時の感想ですが。
エンジニア職が好待遇に
昔はエンジニア職といえば3K(Kitsui, Kitanai, Kaerenai)のイメージが強かったです。実際「え、エンジニアなんてやってるんですか?」と大学時代の知り合いに言われたぐらいで、エンジニアなんてさっさとやめてマネージメントに入るのが勝ち組なんて影では言われていました。
正直直近の転職活動の時も、最初は「エンジニア戻るのはないなー」と思って、それでも経歴上エージェントから話が来るので渋々話を聞きにいっていたのですが。
…あれ?エンジニア職の待遇変わってね?
聞くと、今IT系エンジニアの求人倍率は10倍なんですね。昔は「私の代わりはいくらでもいるもの」という感じだったのですが、みんなどこへ行ってしまったのか…当然ながら給与も想像より上、同じように応募した翻訳やプロデューサー業よりも上でした。
技術の進歩
エンジニアに4年ぶりに戻るとあって、有給消化中はほぼ毎日10時間ぐらい今の技術を勉強に費やしていました。
完全にキャッチアップとはまだまだ遠いですが、思ったことを簡単に書くと、サーバーインフラ構築が簡単に
本当にこれ、当時(2013年ぐらい)だとAWSのEC2とS3とCloudFront使ってサーバーエンジニアが汗と涙で毎回デプロイしてたのに、DockerとEBS組み合わせたら何も考えずにサーバーが建てられる、しかもコンテナモデルだからデプロイが速い速い。あとサーバーレスアーキテクチャを使ったマイクロサービスとか、昔だったらEC2の別サーバーでバッチ処理させるしかなかったのに、凄い(求: 語彙力)
Javascriptって便利じゃない?
昔のJavascriptには何度泣かされたことか。しかしいざ、Vue.js触ってみて思ったのが「これ以外の言語で非同期処理って書けるの?」とまで思わされてしまうほど、Javascriptが使える言語になっていたのに驚き。
でも言語仕様はやっぱり好きじゃないPythonが主流言語に
これが地味に一番嬉しい。大学で時代を先取りしすぎた教授たちに「明日から課題はPythonで提出して」(当時はJavaで提出していた)と言われかれこれ10年以上Pythonを使っているのに、日本でPythonを使うのはスクリプト処理の時ぐらい。サーバーはRuby on Railsだったのも今は昔、若手のエンジニアから「RoR使ってるのは30代後半のおっさん」と言われ軽くショックを受けました。…ええそのせいもあって、弊社はDjangoでサーバー書いてます。
最後に
ここまでつらつらと書きました。エンジニアに戻ってまだ日も浅いのでまだまだわからないことが多いのですが、4年ぶりに戻ってきて思っていることは
エンジニアは雇うから、育てる職種に
エンジニアの待遇が良くなったという反面、優秀なエンジニアを採用するというのが本当に難しい時代になったと思います。反面、今までのような技術的なハードルは下がってきているので、きっちりと育てることのできるエンジニアをいかに採用し戦力としていくことが重要に思えます。エンジニアマーケットのグローバル化
Pythonなどの言語が主流言語として台頭してくる中で、多くのドキュメントなどのリソースは英語で書かれており、海外には多くのコミュニティも存在します。そのため、日本語だけだと最先端の技術を取り込んでいくための情報量に限りがあります。10年ぐらい前からも言われていることですが、エンジニアとして今優先すべきは英語での語学力だと思っています。合わせて、採用も日本人だけでなく海外の技術者を取り込んでいくことが重要なファクターとなると考えています。2をふまえて、今の会社でのエンジニア採用は「英語のみ可」に入社後に変更し、社内での英語の義務化を導入するか目下検討しています。1は会社のフェーズとして育てられる環境がないのでまだできていませんが、組織が安定してき次第取り掛かりたいと思っています。
ではでは
- 投稿日:2020-01-03T17:26:45+09:00
AWS+NodeJSでサーバレスな環境構築②
はじめに
前回の記事ではAPI Gateway+Lambda(NodeJS)を組み合わせてWEBページを表示するというアウトプットでした。今回はDynamoDBのテーブルと項目作成、Lambda関数で使うロールやインラインポリシーの設定を載せていきます。サーバレスに関しては個人的に興味があるとのと、次の案件で用いるからその予習になります。自身も初めてということもあり、表現がわかりにくいところもあるかもしれません。その場合は容赦無く、コメントで指摘していただければ幸いです。
※サーバレスに関してよくわからない方は、前回の記事をご覧いただければと思います。DynamoDBってなぁに?
簡単に言ってしまうと、AWSがマネージドサービスとして提供しているNoSQL(非リレーショナル)データベースになります。「値」とそれを取得するための「キー」だけを格納するというシンプルな機能を持った「Key-Valueストア」です。
一般的なユースケース
・ミリ秒単位のアクセスレイテンシーが求められる
・データの拡張性が求められる参考記事
・NoSQLとは
・DynamoDBをわかりやすく説明DynamoDBテーブルの作成
DynamoDBダッシュボード>テーブルの作成>テーブル名とプライマリキーだけ入力>作成ボタン
項目タブを選択>項目の作成>以下のように項目と値を追加
あとで使うので、DynamoDBテーブルのリソース名をコピー(黒枠部分)しておきます
IAMでロールの作成
IAMダッシュボードのロールを選択>ロール作成ボタン
Lambdaを選択>次のステップへ
AWSLambdaBasicExecutionRoleにチェック>次のステップへ
タグの追加 (オプション)そのまま>次のステップへ
ロール名の入力>作成ボタン
作成したロールでインラインポリシーの作成
ロール一覧から作成したロールを選択>概要画面でインラインポリシーの作成を選択
サービスをDynamoDBを選択>2つアクションを追加
⚠️ 下記ではGetItemとPutItemしか追加されませんが、DeleteItemとUpdateItemとScanも追加します。
リソースのARNを指定>追加
ポリシーの確認>ポリシー名>ポリシーの作成
最後に
次回はAPI Gateway(REST API)+Lambda(NodeJS)+DynamoDBの組み合わせで、DynamoDBのテーブルが更新されるようにしていきます。
















- 投稿日:2020-01-03T16:25:30+09:00
Amazon SageMaker リンク集(使い方で悩んだらここを見る!)
Amazon SageMaker の使い方で悩んだら
猫好きのみなさま、そうでないみなさま、こんにちは。
Amazon SageMaker 使ってますよね(使っていない場合もあります)。サクッと機械学習の開発環境を構築できたり、GPU マシンを使って分散学習できたり(Spot Instance も選択可能!)と、機械学習に関するあれこれに便利な Amazon SageMaker ですが、「SageMaker でこういうことできるの?」「これをやりたいとき、どうすれば良いの?」という状況になることもあると思います。
エンジニアの方は自己解決スキルが高い方が多いので、たいていググって正解にたどり着かれると思いますが、まれにググっても正解が見つからない、見つかるまでに時間がかかることもあると思います。そんなとき、この記事を思い出していただけるとお役に立つかもしれません。
具体的な使い方を知りたいとき:サンプルノートブック
AWS が SageMaker の サンプルノートブックを GitHub で公開 しているのをご存知でしょうか?
SageMaker の 開発者ガイド を読んで使い方を知るのもアリなのですが、こちらのサンプルノートブックから、ご自分のやりたいことに一番近そうなノートブックをベースに、それを改造していくと、やりたいことに最短距離で到達できることがあります。
2019年の AWS re:Invent で Amazon SageMaker Studio, Autopilot, Debugger, Experiments, Model Monitor などの新機能が発表されましたが、これらの機能を使うためのサンプルノートブックも用意されています。フォルダやノートブック名に機能名が入っているので、GitHub リポジトリ で機能名で検索いただくと所望のノートブックが見つかると思います。
どんな機能があるのかを俯瞰的に知りたいとき:開発者ガイド
サンプルノートブックを動かしてみて、他に便利な使い方はないかな?と思った場合は、こちらの 開発者ガイド を見ていただくと、サンプルノートブックには書かれていなかった他の方法や便利機能などを知ることができます。最新情報を知りたい場合は、言語設定を英語 にすると、日本語バージョンでは書かれていない情報が出てくることがあります。言語設定は、開発者ガイドの上のメニューから変更することができます。
API の使い方の詳細を知りたいとき:API リファレンス
サンプルノートブックで API のだいたいの使い方はわかったけど、他にはどんなオプションがあるの?などの詳細を知りたい場合は、API リファレンスを参照します。
Boto3 (AWS SDK for Python) の API について知りたい場合は こちら を、Amazon SageMaker Python SDK の API について知りたい場合は こちら を参照します。自分がどちらを使っているのかわからない!という方、ざっくり言うと、学習ジョブを立ち上げる際に create_training_job 関数を呼んでいれば AWS SDK for Python で、fit 関数を呼んでいれば Amazon SageMaker Python SDK を使っています。
その他の言語で SageMaker を使う場合は、以下を参照します。
- AWS Command Line Interface
- AWS SDK for .NET
- AWS SDK for C++
- AWS SDK for Go
- AWS SDK for Java
- AWS SDK for JavaScript
- AWS SDK for PHP V3
- AWS SDK for Ruby V2
謎のエラーがでたとき:Amazon SageMaker Discussion Forums
SageMaker をある程度使っていて、初めて遭遇したエラーが出たとき、Amazon SageMaker Discussion Forums でエラーメッセージで検索したり、機能や API 名で検索すると、ヒントが見つかるかもしれません。また、Forum で質問をすることで、解決策が見つかるかもしれません。
新しい機能を知りたいとき:AWS ブログ
新しい機能がリリースされると、AWS ブログ(日本語) や AWS ブログ(英語) で紹介されます。日本語の方にしかない記事や、英語の方にしかない記事もありますが、新しい機能の紹介だけでなく、SageMaker の便利な使い方の紹介の記事もあります。
まとめ
情報が散らばっていて、欲しい情報になかなかたどり着けないことがあるかもしれません。
そういうときに、この記事がお役に立てば幸いです。





- 投稿日:2020-01-03T13:02:46+09:00
Infrastructure as CodeのTips【Terraform/CDK/Cloudformation】
TL; DR
普段色々なツールを使ってインフラコード化を細々としています。
自分の中で少し溜まってきたので整理と備忘録も兼ねて書いていきます。Terraform
みんな大好きTerraformです。筆者も大好きです。
なんとなくで書けちゃうのがいいんですよね。とりあえずplan投げてエラー見て直してみたいな。
Terraformのおかげでエラー出ても焦らなくなりました。(initで出るとちょっと自分にムッとはしますがw)
多機能な分、追えていなかったり避けている機能がちょこちょこあったので使ってみるか〜くらいでやったのですがよかったものをピックアップしてます。for_each
名前から繰り返しの処理をするやつなんだろうな、と思いつつ
countで避けてきたfor_eachくん。
慣れてしまえば多用しそうになるやつです。
aws_subnetとかで使ってます。便利です。
resourceブロックでしか利用できないので注意です。count styleresource "aws_subnet" "public_subnet" { count = length(split(",",lookup(var.availability_zones,default))) // 2とかでもOK vpc_id = aws_vpc.service_vpc.id cidr_block = cidrsubnet(aws_vpc.service_vpc.cidr_block, 4, count.index) availability_zone = element(split(",", lookup(var.availability_zones, default)), count.index) map_public_ip_on_launch = true } variable "availability_zones" { default = "ap-northeast-1a,ap-northeast-1c" }for_each styleresource "aws_subnet" "public_subnet" { for_each = var.availability_zones vpc_id = aws_vpc.service_vpc.id cidr_block = cidrsubnet(aws_vpc.service_vpc.cidr_block, 4, each.value) availability_zone = each.key map_public_ip_on_launch = true } variable "availability_zones" { default = { "ap-northeast-1a" = 0 "ap-northeast-1c" = 1 } }こんな感じで違った書き方ができます。
なんとなくTerraformのFunctionsが苦手な筆者はこっちのがシンプルやんけ!と書けたときに小躍りしました。
リソースのインデックスもわかりやすいのでプラン結果やデプロイ中も見守りやすいのも理由です。plan result# module.service_vpc.aws_subnet.public_subnet["ap-northeast-1a"] will be created + resource "aws_subnet" "public_subnet" { + arn = (known after apply) + assign_ipv6_address_on_creation = false + availability_zone = "ap-northeast-1a" + availability_zone_id = (known after apply) + cidr_block = "192.168.0.0/20" + id = (known after apply) + ipv6_cidr_block = (known after apply) + ipv6_cidr_block_association_id = (known after apply) + map_public_ip_on_launch = true + owner_id = (known after apply) + tags = { + "ENV" = "sandbox" + "Name" = "terraform-sand-public-ap-northeast-1a" + "Service" = "terraform" } + vpc_id = (known after apply) } # module.service_vpc.aws_subnet.public_subnet["ap-northeast-1c"] will be created + resource "aws_subnet" "public_subnet" { + arn = (known after apply) + assign_ipv6_address_on_creation = false + availability_zone = "ap-northeast-1c" + availability_zone_id = (known after apply) + cidr_block = "192.168.16.0/20" + id = (known after apply) + ipv6_cidr_block = (known after apply) + ipv6_cidr_block_association_id = (known after apply) + map_public_ip_on_launch = true + owner_id = (known after apply) + tags = { + "ENV" = "sandbox" + "Name" = "terraform-sand-public-ap-northeast-1c" + "Service" = "terraform" } + vpc_id = (known after apply) }これらのリソースをアウトプットするときは少し工夫が必要で
for文で回してあげる必要があります。output.tfoutput "public_subnets" { value = [for subnet in aws_subnet.public_subnet : subnet.id] // 欲しいattributeは変数から取る } // NG例 output "public_subnets" { value = aws_subnet.public_subnet.*.id } output "public_subnets" { value = aws_subnet.public_subnet[*].id }dynamic block
複数設定可能な項目などは繰り返し書くのが面倒だったり、環境によって必要・不要が分かれていたりすることもあると思います。
そう言った部分を良きに計らってくれる優れものです。個人的には使いすぎはよくないとは思うのでaws_db_parameter_groupなんかはちょうどいいのかな?と思います。multiple writtenresource "aws_db_parameter_group" "mysql_56" { name = "${var.service_name}-${var.env}-${var.engine}-56" family = "mysql5.6" parameter { name = "character_set_server" value = "utf8" apply_method = "pending-reboot" } parameter { name = "character_set_client" value = "utf8" apply_method = "immediate" } parameter { name = "performance_schema" value = "1" apply_method = "pending-reboot" } }dynamic writtenresource "aws_db_parameter_group" "mysql_56" { name = "${var.service_name}-${var.env}-${var.engine}-56" family = "mysql5.6" dynamic "parameter" { for_each = var.db_params content { name = each.value.name value = each.value.value apply_method = each.value.apply_method } } variable db_params { default = { "server_character" = { name = "character_set_server" value = "utf8" apply_method = "pending-reboot" }, "client_character" = { name = "character_set_client" value = "utf8" apply_method = "immediate" }, "insight" = { name = "performance_schema" value = "1" apply_method = "pending-reboot" } } }いや、変数冗長じゃね?と思うかと思いますが、
moduleなどを利用して環境ごとに出し分けているとこういうcountとかが使えないものが出てきてつらみに陥ることがあるんです…。それがresource同じでmodule側だけ書き換えるみたいな運用ならまあ許容できるかなと思ってます。(そもそもそんな環境構成にするなよ、みたいなのはまた別のお話しです。)AWS CDK
最近は細々としたリソースをつくるときに利用したりしています。
ある程度まとまったリソース単位でStackとして利用できるので中々好きです!AWS公式ですし、Typescriptの型の恩恵受けまくりで書きやすいしエラーの発見も簡単です。
新しいリソースへの対応も早いので、ローンチされたばかりのサービスでもガンガン使えちゃいます!(AWS-SDK-JSとかからインポートして使う、が大体ですが。)cdk.json
cdk initすると自動で作成されるものですが、うまく使うと便利です!
以前IAMを管理している記事を書いたものをちょこちょことアップグレードしていて、今はcdk.jsonを使ってユーザーやロールの出し分けをしています。旧バージョンのユーザー作成の部分だけ抜き出しています。
ユーザーはベタがきでコードにそのまま書いています。old styleimport { Construct, Stack, StackProps } from '@aws-cdk/core'; import { Group, Policy, PolicyStatement, ManagedPolicy, User } from '@aws-cdk/aws-iam'; import AWS = require('aws-sdk'); const admins = 'testAdminGroup'; const adminUsers = [ 'demo01', ]; const developers = 'testDevGroup'; const devUsers = [ 'demo02', 'demo03' ]; export class IamUserStack extends Stack { constructor(scope: Construct, id: string, props?: StackProps) { super(scope, id, props); // Admin group const adminGroup = new Group(this, admins, { groupName: admins }); adminGroup.addManagedPolicy(adminPolicy); adminGroup.attachInlinePolicy(commonPolicy); // Developer group const devGroup = new Group(this, developers, { groupName: developers }); devGroup.addManagedPolicy(powerUserPolicy); devGroup.attachInlinePolicy(devPolicy); devGroup.attachInlinePolicy(commonPolicy); // Create users adminUsers.forEach(adminUser => { new User(this, adminUser, { userName: adminUser, groups: [adminGroup], }); }); devUsers.forEach(devUser => { new User(this, devUser, { userName: devUser, groups: [devGroup] }); }); } }
cdk.jsonを利用しているパターンはこちら。
5-14行目でcdk.jsonをcontextとして利用できるように呼び出しています。using cdk.jsonimport { Aws, Construct, Stack, StackProps, App, CfnOutput, Fn, Arn } from '@aws-cdk/core'; import { Group, Policy, PolicyStatement, ManagedPolicy, User } from '@aws-cdk/aws-iam'; import AWS = require('aws-sdk'); const app = new App(); const stage: any = app.node.tryGetContext("stage") // Admin Users Configure const admins: string = 'adminGroup'; const adminUsers = app.node.tryGetContext(stage).adminUsers // contextとしてユーザーをcdk.jsonから呼び出している。 // Develop Users Configure const developers: string = 'devGroup'; const devUsers = app.node.tryGetContext(stage).devUsers export class IamUserStack extends Stack { /** @returns the ARN of the IAM User */ public readonly userArn: string; constructor(scope: Construct, id: string, props?: StackProps) { super(scope, id, props); // Admin group const adminGroup = new Group(this, admins, { groupName: admins }); adminGroup.addManagedPolicy(adminPolicy); adminGroup.attachInlinePolicy(commonPolicy); // Developer group const devGroup = new Group(this, developers, { groupName: developers }); devGroup.addManagedPolicy(powerUserPolicy); devGroup.attachInlinePolicy(devPolicy); devGroup.attachInlinePolicy(commonPolicy); // Create Admin users adminUsers.forEach((adminUser: string) => { const adminUserName = new User(this, adminUser, { userName: adminUser, groups: [adminGroup] }); new CfnOutput(this, `${adminUserName}`, { value: adminUserName.userArn, description: `${stage} environment admin user arn`, exportName: `${stage}AdminUsersArn` }); }) // Create Develop users devUsers.forEach((devUser: string) => { const devUserName = new User(this, devUser, { userName: devUser, groups: [devGroup] }); new CfnOutput(this, `${devUserName}`, { value: devUserName.userArn, description: `${stage} environment develop user arn`, exportName: `${stage}DevUsersArn` }); }) } }cdk.json{ "context": { "division": "hogehoge", "prj": "fugafuga", "dev": { "adminUsers": [ "demo01" ], "devUsers": [ "demo02", "demo03" ] }, "stg": { "adminUsers": [ "circleci", "github" ], "devUsers": [ "jenkins" ] }, "prd": { "adminUsers": [ "circleci", "github" ], "devUsers": [ "jenkins" ] } }, "app": "npx ts-node bin/iam_user.ts" }こんな感じのファイル構成をしています。
divisionやprjはタグ付けなどに利用していますので、特に環境ごとの配下にしていません。
これらをデプロイするときはcdk deploy -c stage=devと言った感じで出し分けています。
本当は環境ではなくアカウントナンバーにしてstackの中でアカウントナンバーを取得してからcontextを注入したかったのですが、その前にcdk.jsonが読み込まれてしまうため実現できませんでした。
今は一旦これでいいかな、という感じで落ち着いています。Cloudformation
AWSの初期からある(たしか…)インフラコード化の走りみたいな存在ですね。
正直あんまり使ってこなかったのですが、AWS CDKの利用に伴い色々と理解が必要だったので使っています。
yaml形式自体なので可読性は高いと思うのですが、リソース名や独自の関数など覚えることいっぱいです。
まあ時間をみつけてゆるゆるとやっている感じです。ユーザーデーターが使える
完全にシェルこねこねと思っていたのですが、Cloudformationに普通に書けました。
userdata templateResources: BastionLaunchTemplate: Type: AWS::EC2::LaunchTemplate Properties: LaunchTemplateName: bastion-launch-template LaunchTemplateData: UserData: Fn::Base64: !Sub - | #!/bin/bash # timezone timedatectl set-timezone "Asia/Tokyo" # time sync yum -y remove ntp yum -y install chrony echo '#Add TimeSync' >> /etc/chrony.conf echo 'server 169.254.169.123 prefer iburst' >> /etc/chrony.conf systemctl start chrony systemctl enable chrony共通
リソース名の命名規則は最初から揃えて、変数なり
Parameterなりで使いまわせるようにしましょう。
ベタがき、不揃いは後々つらくなってきます…。terraformvariable "Name" { default = "hoge" } variable "Service" { default = "fuga" } variable "Env" { default = "hogefuga" } resource "hogehoge" "fugafuga" { /////////////省略///////////// tags = { Name = "${var.service_name}-${var.env}-fugahoge" Service = var.service_name Env = var.env } }cdk.json{ "context": { "Name": "hoge", "Service": "fuga", "Env": "hogefuga" } }CloudformationParameters: Name: Description: resource name. Type: String Default: hoge Service: Description: service name. Type: String Default: fuga Env: Description: environment name. Type: String Default: hogefuga ############################## Tags: - Key: "Name" Value: !Ref Name - Key: "Service" Value: !Ref Service - Key: "Env" Value: !Ref Envおまけ
どうでもいいけどなんでQiitaのコードブロックから
HCLを消してしまったのでしょう…。
Terraformのコードか見づらいじゃないの…布教できない…。
- 投稿日:2020-01-03T12:13:00+09:00
AWS trusted adviser による制限監視
AWS Limit Monitorを使う
https://dev.classmethod.jp/cloud/aws/aws-answers-try-aws-limit-monitor/実行している流れ
1. CloudWatch Events作成。定期的にMaster Lambda Functionを呼び出す。
2. Master Lambda Function は、指定したAWSアカウント単位で Child Lambda Function を起動します。複数のAWSアカウントに対応
3. Child Lambda Function は、AWSアカウント単位で Trusted Advisor、および Trusted Advisor で管理されていないEC2インスタンス全体の上限数、CloudFormation Stack の上限数、DynamoDB の各種キャパシティユニットをチェック
4. サービス制限値の80%以上利用しているリソースがある場合、SNSをキック
5. ユーザーはアラートメールを受信
- 投稿日:2020-01-03T11:38:17+09:00
CodeBuild のリンク
参考
https://docs.aws.amazon.com/ja_jp/codebuild/latest/userguide/how-to-create-pipeline.html
https://aws.amazon.com/jp/blogs/news/create-multiple-builds-from-the-same-source-using-different-aws-codebuild-build-specification-files/
https://docs.aws.amazon.com/ja_jp/codebuild/latest/userguide/getting-started.html
- 投稿日:2020-01-03T10:56:47+09:00
【AWS】Elastic BeanstalkでLinux 用 Windows サブシステムを使用せずにLaravelアプリケーションをデプロイする
Elastic BeanstalkでLinux 用 Windows サブシステムを使用せずにLaravelアプリケーションをデプロイ方法です。
本手順では、代わりに、フリーの圧縮・解凍ソフトを使用しています。環境
- PHP:バージョン7.3(Elastic Beanstalk)
- Laravel:バージョン6.9.0
- OS:Windows10(ローカル)
手順
Elastic Beanstalk への Laravel アプリケーションのデプロイ | aws
に従って実施します。
タイトルの件を以下に、補足事項としてまとめます。補足事項
手順では、Linux 用 Windows サブシステムを使用するとありますが、以下の通り実行すればインストール不要です。
1. Laravelプロジェクトの作成
ローカル環境でコマンドプロンプトを起動して、任意のパスでコマンドを実行し、Laravelプロジェクト作成します。
こちらは、手順と同じコマンドで大丈夫です。
※今回は、プロジェクト名を「testLaravelApp」としました。> composer create-project --prefer-dist laravel/laravel testLaravelApp2. zipファイルの作成
1で作成したプロジェクトを圧縮します。
Windowsにおいては、デフォルトではzipコマンドを実行できないため、GUIベースで圧縮します。
私はフリーの圧縮・解凍ソフト7-Zipを使用しました。注意点
圧縮実行時には、以下の点に気をつけてください。
1. デプロイしたいプロジェクト直下で圧縮する
公式の手順(コマンド)からもわかる通り、デプロイしたいプロジェクト直下で圧縮作業を実施します。
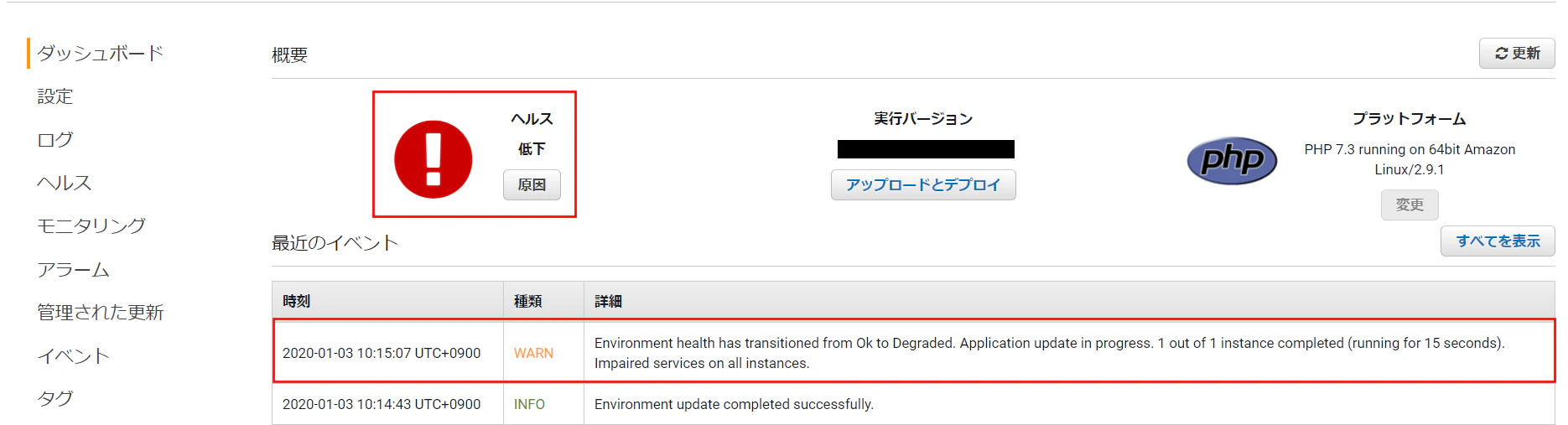
プロジェクトをそのまま圧縮してデプロイすると以下のようなエラーが出てしまい、ページへのアクセスもできないので要注意!ダッシュボード
ヘルス
調べたところ、対象プロジェクトをそのまま圧縮すると余計なディレクトリが含まれてしまうから、とのこと。
【参考】
Following services are not running: proxy @ AWS — after Laravel re-config | stack overflow2. vendorは対象外とする
公式の手順にも記載ありますが、念のため。
上記1, 2を考慮しての7-Zipでの圧縮は以下の通りとなります。
そうすると、同フォルダ内に対象のLaravelプロジェクトと同じ名称のzipファイルができるので、それをアップロード・デプロイすればOK!
オマケの注意点
こちらも公式手順に記載ありですが、ドキュメントのルートを
/public
とするのを忘れずに☆
無事、デプロイ→ページ表示できました!
ダッシュボード
ページ
参考






- 投稿日:2020-01-03T10:33:06+09:00
AWS CodePipeline QAリンク
引用元
一部、理解のために自分の表現に変更
https://aws.amazon.com/jp/codepipeline/faqs/Q: パイプラインとは何ですか?
パイプラインとは、ソフトウェアの変更がリリースプロセスをどのように通過するかを明確にするワークフロー構造です。ワークフローをステージとアクションのシーケンスで定義できます。
[追記]同一のアクションを開発環境、本番環境のように異なる環境に渡すための仕組みと理解Q: リビジョンとは何ですか?
リビジョンとは、パイプラインのために定義されたソースロケーションに加えられた変更です。ソースコード、ビルドアウトプット、設定、データなどが対象となります。パイプラインには複数のリビジョンを同時に通過させることができます。
Q: ステージとは何ですか?
ステージとは、1 つまたは複数のアクションのグループです。パイプラインには 2 つ以上のステージを設定できます。
Q: アクションとは何ですか?
アクションとは、リビジョンに対して実行されるタスクです。パイプラインのアクションは、ステージ設定の定義に従い、指定された順番で直列的または並列的に実行されます。詳細は、 Edit a Pipeline および Action Structure Requirements in AWS CodePipeline を参照してください。
Q: アーティファクトとは何ですか?
アクションが実行される場合、1 つまたは一連のファイルが対象となります。これらの対象となるファイルがアーティファクトと呼ばれています。アーティファクトはパイプラインのその後のアクションでも対象となる場合があります。例えば、ソースアクションが、ソースアーティファクトとしてコードの最新バージョンを出力し、ビルドアクションがそのアーティファクトを読み込みます。コンパイル後、ビルドアクションはビルドアウトプットを別のアーティファクトとしてアップロードし、その後のデプロイアクションでそのアーティファクトが読み込まれます。
Q: AWS CodePipeline のイベントに関する通知やアラートを受け取るにはどうすればよいですか?
パイプラインに影響を与えるイベントに関する通知を作成することができます。通知は Amazon SNS 通知という形で送信されます。各通知には、ステータスメッセージに加えて、その通知が生成される原因となったイベントが存在するリソースへのリンクも含まれます。通知に追加費用はかかりませんが、Amazon SNS など、通知に利用される他の AWS のサービスの料金が課金される場合があります。
- 投稿日:2020-01-03T10:30:25+09:00
AppSyncをフロントエンドとバックエンドで利用する
AppSyncをフロントエンドとバックエンドで利用する
この記事はサーバーレスWebアプリ Mosaicを開発して得た知見を振り返り定着させるためのハンズオン記事の1つです。
以下を見てからこの記事をみるといい感じです。
イントロダクション
アップロードした画像や処理された画像のデータ管理や、クライアント側とのデータ受け渡しのために、AppSyncというAPIを利用します。AppSyncのデータソースにはDynamoDBが使われます。
AppSyncはAmplify CLIでもセットアップ可能なのですが、DynanoDBのパーティションキーやソートキーの指定ができないようだったので、Amplify CLIは使いません。AWSコンソールでDynamoDBとAppSyncを構築します。
フロントエンドのVueからはAmplifyを利用してSubscription、バックエンドのLambda(Python)からはHTTPでリクエストします。コンテンツ
AppSyncのセットアップ
Amplify CLIでAppSyncのセットアップはできるのですが、DynamoDBのパーティションキーやソートキーの指定ができないようなんですよね。実はできるのかもしれませんが、やり方わかりませんでした。知ってる人がいたら教えて下さい。
ということで、コマンドラインに比べると若干手間ですが、AWSコンソールで作っていきましょう。DynamoDB テーブルの作成
AppSyncのデータソースとするDynamoDBを先に作成しておきます。
AWSコンソール > DynamoDB > テーブルの作成
以下の設定でテーブルを作成します。
テーブル名 : sample_appsync_table
パーティションキー : group (文字列)
ソートキー : path (文字列)
AppSync APIの作成
DynamoDBが作れたら、続いてAppSyncを作成します。
AWSコンソール > AppSync > APIを作成Step1 : ご利用開始にあたって
「DynamoDBテーブルをインポートする」を選択して「開始」ボタン押下。
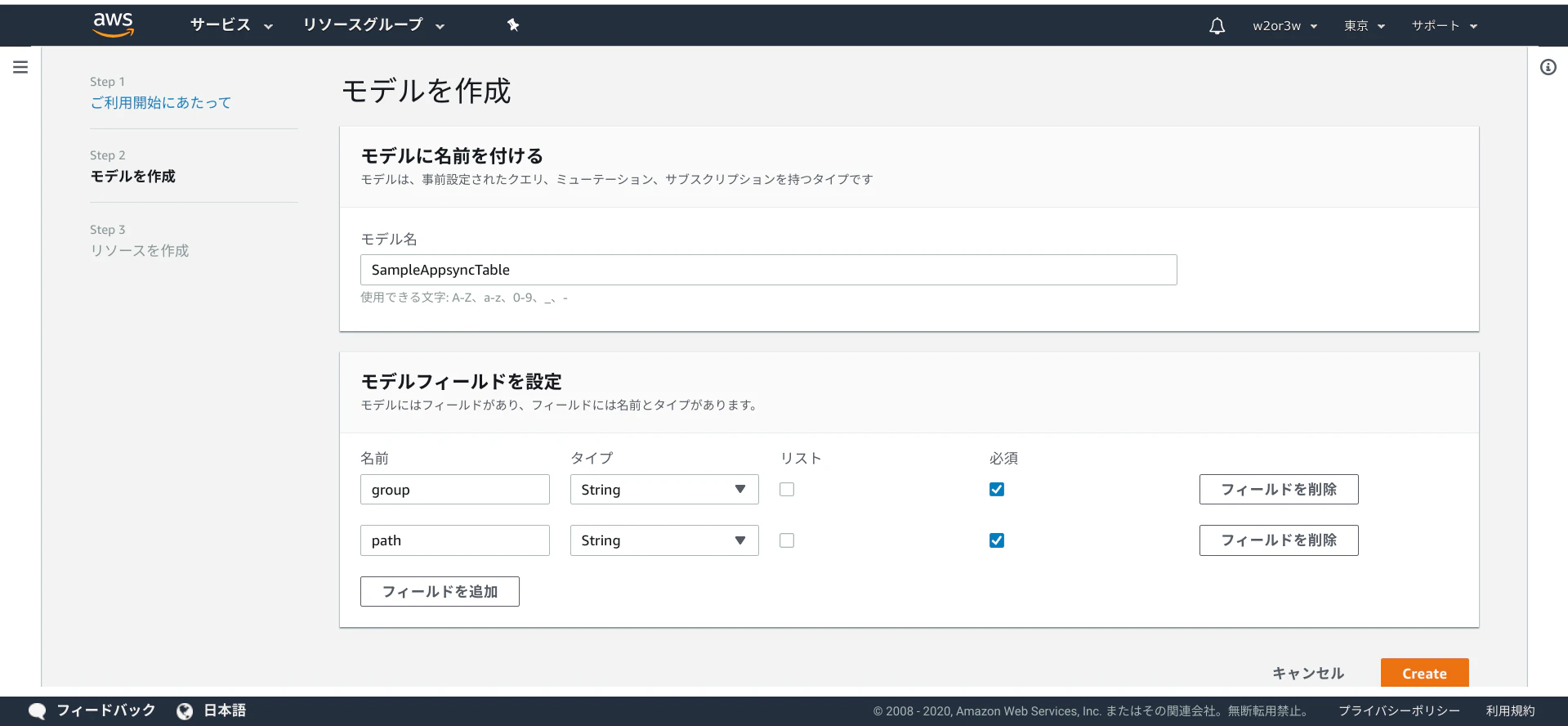
Step2 : モデルを作成
先ほど作成したテーブル(sample_appsync_table)を選択。
「既存のロールを作成または使用する」では「New role」を選択。
「インポート」ボタンを押下。
そのまま「Create」ボタンを押下。
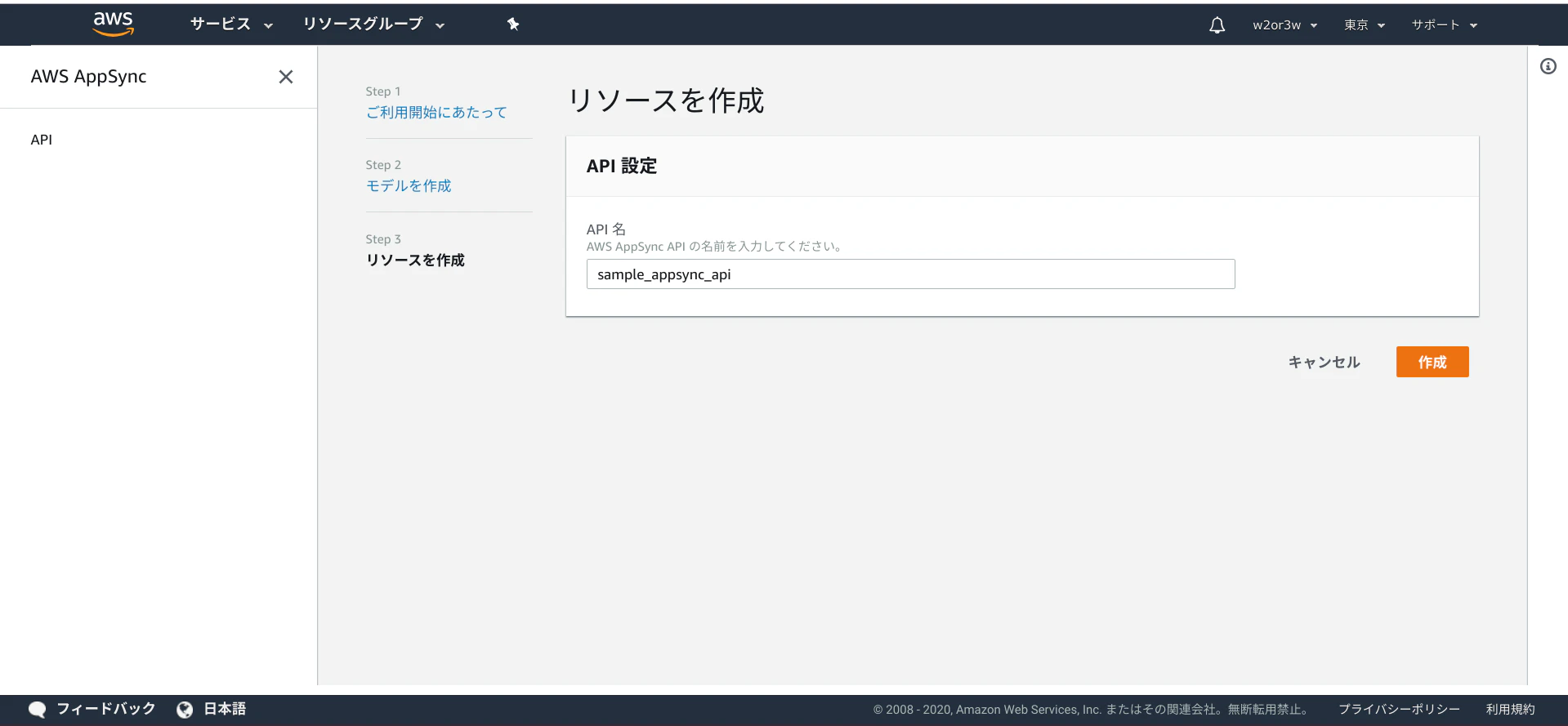
Step3 : リソースを作成
API名を設定して「作成」ボタンを押下。
schema.jsonの入手
AWSコンソール > AppSync > sample_appsync_table > スキーマ メニューから
schema.jsonをダウンロードします。このファイルはWebアプリで利用します。
認証情報の入手
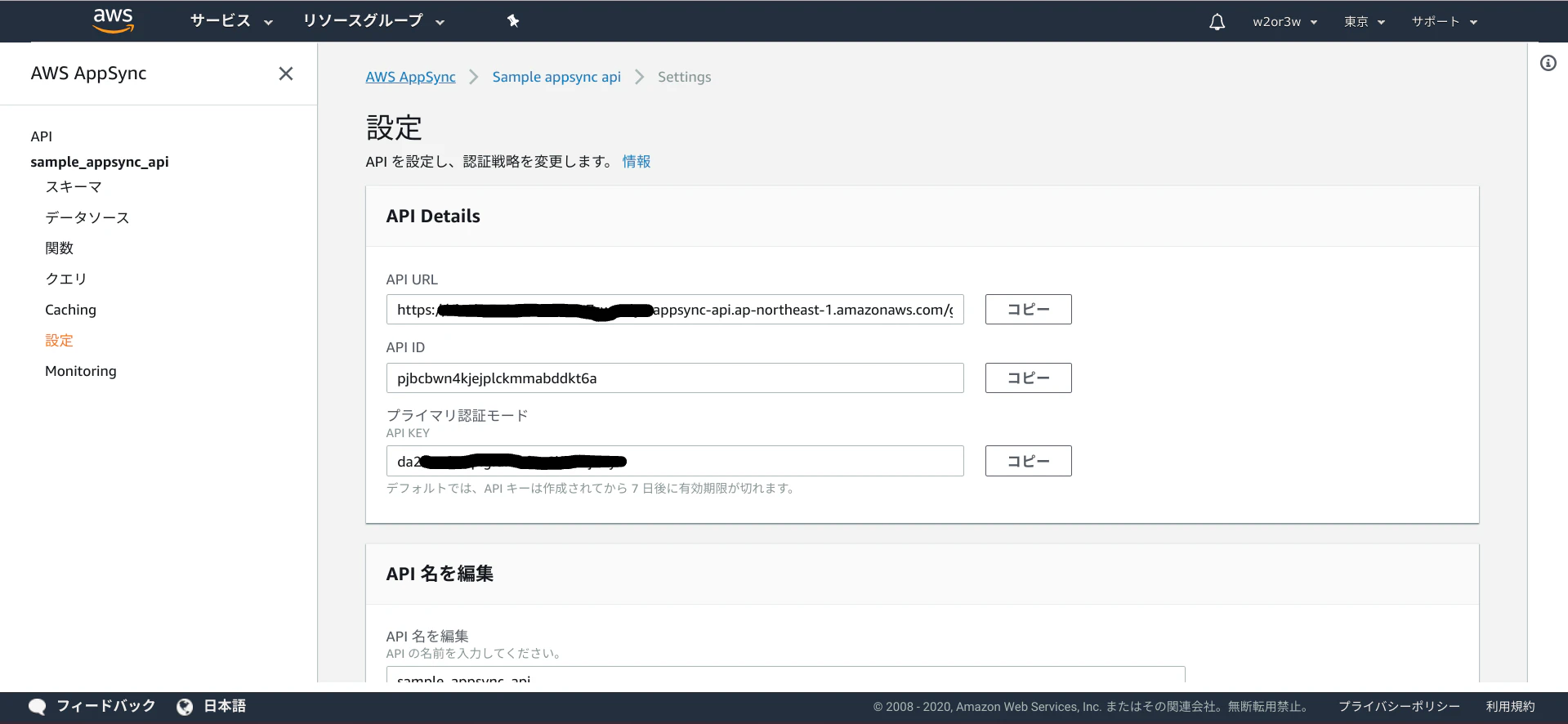
AWSコンソール > AppSync > sample_appsync_table > 設定 メニューから
API DetailのAPI URLやAPI KEYの情報を確認します。この情報はアプリで利用します。
認証モードは「APIキー」のままとします。APIキーの有効期限はデフォルト7日となっていますが、編集することで最大365日まで伸ばすことができます。
認証モードをStorageのようにCognitoユーザーとして利用する方法については別記事にしようと思っています。フロントエンド(VueのWebアプリ)でSubscription
AppSyncのセットアップが完了したら、続いてWebアプリを更新してゆきます。
graphql定義ファイルの追加
src/graphqlフォルダを作成し、3つのファイルを追加します。
src/graphql/schema.json
先ほどダウンロードしたファイルをそのままプロジェクトに追加します。src/graphql/queries.jsexport const listSampleAppsyncTables = `query listSampleAppsyncTables($group: String) { listSampleAppsyncTables( limit: 1000000 filter: { group: {eq:$group} } ) { items { group path } } } `;パーティションキーのgroupを指定して、レコード一覧を取得するためのqueryです。
これは謎なのですが、limitの指定をしてあげないとデータを取ってこれないんですよ。graphqlではなくてAppSyncの仕様だと思うのですが、、どうなんでしょうか。1000000と適当に大きな数字を指定してますが、正直微妙すぎますよね。もっと良い書き方を知っている人がいたら是非教えて下さい。src/graphql/subscriptions.jsexport const onCreateSampleAppsyncTable = `subscription OnCreateSampleAppsyncTable($group: String) { onCreateSampleAppsyncTable(group : $group) { group path } } `;パーティションキーのgroupを指定して、レコードが挿入されたらその情報とともに通知してもらうためのsubscriptionです。
「レコードが挿入されたら」と書きましたが、DynamoDBに直接レコードを挿入してもダメで、AppSyncのcreateによって挿入される必要があります。aws-exports.jsにAppSync情報を追記
src/aws-exports.jsにAppSyncにアクセスする際に必要となる情報を追記します。src/aws-exports.jsconst awsmobile = { "aws_project_region": "ap-northeast-1", "aws_cognito_identity_pool_id": "ap-northeast-1:********-****-****-****-************", "aws_cognito_region": "ap-northeast-1", "aws_user_pools_id": "ap-northeast-1_*********", "aws_user_pools_web_client_id": "**************************", "oauth": {}, "aws_user_files_s3_bucket": "sample-vue-project-bucket-work", "aws_user_files_s3_bucket_region": "ap-northeast-1", "aws_appsync_graphqlEndpoint": "https://**************************.appsync-api.ap-northeast-1.amazonaws.com/graphql", "aws_appsync_region": "ap-northeast-1", "aws_appsync_authenticationType": "API_KEY", "aws_appsync_apiKey": "da2-**************************" }; export default awsmobile;このファイルに書かれている情報は大切な情報なので、漏洩しないよう、取り扱いに注意してください。
Webアプリの実装
Homeで画像を選択してアップロードしたら、ページ遷移した先でアップロードされた画像やモノクロ処理された画像の情報をリストするような実装を施します。
Listというページを追加します。そのためのルーター設定。
src/router.jsimport Vue from 'vue'; import Router from 'vue-router'; import Home from './views/Home.vue'; import About from './views/About.vue'; import List from './views/List.vue'; Vue.use(Router); export default new Router({ routes: [ { path: '/', name: 'home', component: Home, }, { path: '/about', name: 'about', component: About, }, { path: '/list', name: 'list', component: List, }, ] });Listページのビュー
src/views/List.vue<template> <List /> </template> <script> import List from '../components/List' export default { components: { List } } </script>Listページのコンポーネント
src/components/List.vue<template> <v-container> <p>リスト</p> <router-link to="/" >link to Home</router-link> <hr> <v-list> <v-list-item v-for="data in this.dataList" :key="data.path"> <v-list-item-content> <a :href="data.image" target=”_blank”> <v-list-item-title v-text="data.path"></v-list-item-title> </a> </v-list-item-content> <v-list-item-avatar> <v-img :src="data.image"></v-img> </v-list-item-avatar> </v-list-item> </v-list> </v-container> </template> <script> import { API, graphqlOperation, Storage } from 'aws-amplify'; import { listSampleAppsyncTables } from "../graphql/queries"; import { onCreateSampleAppsyncTable } from "../graphql/subscriptions"; const dataExpireSeconds = (30 * 60); export default { name: 'List', data: () => ({ group: null, dataList: [], }), mounted: async function() { this.getList(); }, methods:{ async getList() { this.group = this.$route.query.group; console.log("group : " + this.group); if(!this.group){ return; } let apiResult = await API.graphql(graphqlOperation(listSampleAppsyncTables, { group : this.group })); let listAll = apiResult.data.listSampleAppsyncTables.items; for(let data of listAll) { let tmp = { path : data.path, image : "" }; let list = [...this.dataList, tmp]; this.dataList = list; console.log("path : " + data.path); Storage.get(data.path.replace('public/', ''), { expires: dataExpireSeconds }).then(result => { tmp.image = result; console.log("image : " + result); }).catch(err => console.log(err)); } API.graphql( graphqlOperation(onCreateSampleAppsyncTable, { group : this.group } ) ).subscribe({ next: (eventData) => { let data = eventData.value.data.onCreateSampleAppsyncTable; let tmp = { path : data.path, image : "" }; let list = [...this.dataList, tmp]; this.dataList = list; console.log("path : " + data.path); Storage.get(data.path.replace('public/', ''), { expires: dataExpireSeconds }).then(result => { tmp.image = result; console.log("image : " + result); }).catch(err => console.log(err)); } }); }, } } </script>クエリパラメータでgroupを取得します。
画面表示前のmountedで、groupを指定してレコードデータを取得したり、挿入イベント受信時にレコードデータを取得したりしています。
取得したレコードデータはdataListというメンバ変数配列で保持し、画面にv-listで並べて表示します。
v-listでは、レコードデータのpathと画像を表示しています。画像はStrageで有効期限(30分)付きアドレスをgetしてそれでアクセスしています。src/components/Home.vue<template> <v-container> <p>ホーム</p> <router-link to="about" >link to About</router-link> <hr> <v-btn @click="selectFile"> SELECT A FILE !! </v-btn> <input style="display: none" ref="input" type="file" @change="uploadSelectedFile()"> </v-container> </template> <script> import Vue from 'vue' import { Auth, Storage } from 'aws-amplify'; export default { name: 'Home', data: () => ({ loginid: "sample-vue-project-user", loginpw: "sample-vue-project-user", }), mounted: async function() { this.login(); }, methods:{ login() { console.log("login."); Auth.signIn(this.loginid, this.loginpw) .then((data) => { if(data.challengeName == "NEW_PASSWORD_REQUIRED"){ console.log("new password required."); data.completeNewPasswordChallenge(this.loginpw, {}, { onSuccess(result) { console.log("onSuccess"); console.log(result); }, onFailure(err) { console.log("onFailure"); console.log(err); } } ); } console.log("login successfully."); }).catch((err) => { console.log("login failed."); console.log(err); }); }, selectFile() { if(this.$refs.input != undefined){ this.$refs.input.click(); } }, uploadSelectedFile() { let file = this.$refs.input.files[0]; if(file == undefined){ return; } console.log(file); let dt = new Date(); let dirName = this.getDirString(dt); let filePath = dirName + "/" + file.name; Storage.put(filePath, file).then(result => { console.log(result); }).catch(err => console.log(err)); this.$router.push({ path: 'list', query: { group: dirName }}); }, getDirString(date){ let random = date.getTime() + Math.floor(100000 * Math.random()); random = Math.random() * random; random = Math.floor(random).toString(16); return "" + ("00" + date.getUTCFullYear()).slice(-2) + ("00" + (date.getMonth() + 1)).slice(-2) + ("00" + date.getUTCDate()).slice(-2) + ("00" + date.getUTCHours()).slice(-2) + ("00" + date.getUTCMinutes()).slice(-2) + ("00" + date.getUTCSeconds()).slice(-2) + "-" + random; }, } } </script>uploadSelectedFileで、ファイルをアップロードした後にListページへ遷移させます。その際、groupというクエリパラメータを付けています。
これでフロントエンド(Webアプリ)の改修は完了ですが、動作確認はバックエンド側が済んでからとします。
バックエンド (LambdaのPython)から叩く
Webアプリからアップロードされたファイルや、Lambdaで生成してアップロードしたモノクロ画像のパス(S3のKey)を、AppSync経由でレコード挿入する実装を施します。
gqlをインストールします。
pip3 install gql -t .
lambda_function.pyを以下のように更新します。lambda_function.py# coding: UTF-8 import boto3 import os from urllib.parse import unquote_plus import numpy as np import cv2 import logging logger = logging.getLogger() logger.setLevel(logging.INFO) s3 = boto3.client("s3") from gql import gql, Client from gql.transport.requests import RequestsHTTPTransport ENDPOINT = "https://**************************.appsync-api.ap-northeast-1.amazonaws.com/graphql" API_KEY = "da2-**************************" _headers = { "Content-Type": "application/graphql", "x-api-key": API_KEY, } _transport = RequestsHTTPTransport( headers = _headers, url = ENDPOINT, use_json = True, ) _client = Client( transport = _transport, fetch_schema_from_transport = True, ) def lambda_handler(event, context): bucket = event['Records'][0]['s3']['bucket']['name'] key = unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8') logger.info("Function Start (deploy from S3) : Bucket={0}, Key={1}" .format(bucket, key)) fileName = os.path.basename(key) dirPath = os.path.dirname(key) dirName = os.path.basename(dirPath) orgFilePath = u'/tmp/' + fileName processedFilePath = u'/tmp/processed-' + fileName if (key.startswith("public/processed/")): logger.info("not start with public") return apiCreateTable(dirName, key) keyOut = key.replace("public", "public/processed", 1) logger.info("Output local path = {0}".format(processedFilePath)) try: s3.download_file(Bucket=bucket, Key=key, Filename=orgFilePath) orgImage = cv2.imread(orgFilePath) grayImage = cv2.cvtColor(orgImage, cv2.COLOR_RGB2GRAY) cv2.imwrite(processedFilePath, grayImage) s3.upload_file(Filename=processedFilePath, Bucket=bucket, Key=keyOut) apiCreateTable(dirName, keyOut) logger.info("Function Completed : processed key = {0}".format(keyOut)) except Exception as e: print(e) raise e finally: if os.path.exists(orgFilePath): os.remove(orgFilePath) if os.path.exists(processedFilePath): os.remove(processedFilePath) def apiCreateTable(group, path): logger.info("group={0}, path={1}".format(group, path)) try: query = gql(""" mutation create {{ createSampleAppsyncTable(input:{{ group: \"{0}\" path: \"{1}\" }}){{ group path }} }} """.format(group, path)) _client.execute(query) except Exception as e: print(e)
ENDPOINTとAPI_KEYは、AppSyncに先ほど作成したAPI設定を参照してください。
zip圧縮してS3にアップロードしてLambdaにデプロイしてください。動作確認
Webアプリを実行して画像をアップロードすると、LambdaからAppSyncが叩かれて、それを検出してWebアプリ側でリストされます。クエリパラメータ付きのURLを直接叩いても、AppSyncからリストを取得してリストするようにしています。
Webアプリ(Vue)のプロジェクトは以下においておきます。
https://github.com/ww2or3ww/sample_vue_project/tree/work5Lambdaのプロジェクトは以下においておきます。
https://github.com/ww2or3ww/sample_lambda_py_project/tree/work3あとがき
JAWS UG 浜松に参加して初めて声に出して質問した話題がこのあたりでした。
AmplifyのAPIってDynamoDBのパーティションキーとかソートキー指定できないんですかねぇ?
DynamoDBってキー設定無しで使うことってあんまり無いですよねぇ?
WebSocketって詳しく知らないですけどロングポーリングみたいなものですかねぇ?
ドキドキしながら発言したのを覚えています。ところでネットワークって難しいですよね。ネットワークエンジニアを名乗れる人、尊敬します。
MQTT over WebSocketとか言われても正直良くわからないです。誰か分かりやすく教えて下さい、、。AppSyncのサンプルって、Amplify CLIとセットで語られることが多いからか、フロントエンドからの利用ばかりですよね。チャットアプリしかり、TODOアプリしかり。DynamoDBも全件スキャンですし。
DynamoDBってレコードの数が増えていきがちというか、そういう用途で利用されがちだと思っていて、そういった意味では全件スキャンは良くないですよね。






- 投稿日:2020-01-03T10:20:19+09:00
React/Next.jsアプリケーションを作成し、AWS EC2を使って本番環境にデプロイするまで
対象
- Next.js 等、Node.js で動かすアプリをローカル環境で作成することはできるが、それを本番環境で動かす方法と仕組みがわからない人
- Heroku や Zeit Now を使うと簡単にリリースできるが、その仕組がさっぱりわかっていない人
この記事の存在意義
初心者が掲題のことをやろうと思ったときに、全体感を把握できる記事が見当たらなかったので、こういう記事があっても良いかなと思った。
流れ
以下のような手順で進める。
1. ローカル環境で動く Next.js を用いたサンプルアプリの作成
2. EC2 インスタンスの作成
3. EC2 インスタンス上でのサンプルアプリの起動&接続1. ローカル環境で動く Next.js を用いたサンプルアプリの作成
- 事前に npm をインストール
npm install -g npm
↓の公式チュートリアルの Getting Started の部分を進める。
それ用の GitHub リポジトリを用意して、package.json と pages ディレクトリ は remote に push しておく。
2. EC2 インスタンスの作成
公式に従ってやっていく。
自分の環境から ssh できるようにしておき、かつ http 通信はできるようにしておく。3. EC2 インスタンス上でのサンプルアプリの起動&接続
3.1 外部アクセスをローカルホストにつなげるようにする
外部からアクセスがあったときに、そのアクセスをサンプルアプリが受け取って結果を返さなければならない。
しかしここまでのところ、localhost:3000 でアプリケーションを起動することしかできていない
そこで、「外部からのアクセスを受けたらそれをローカルホストにつなげるような仕組みを用意する」ことにする。nginx を使ってそれを実現する。すなわち、「nginx をリバースプロキシとして用い、ポート80へのアクセスをlocalhostの3000ポートに振り向ける」ようにする。
- ssh で EC2 インスタンスに入る。
ssh -i <key.pem> <public ip address>
- nginx の install
sudo su - root yum update -y yum install nginx -y↑これを実行すると、nginx の install 時に Amazon Linux 2だとエラーになる。
Loaded plugins: extras_suggestions, langpacks, priorities, update-motd No package nginx available. Error: Nothing to do nginx is available in Amazon Linux Extra topics "nginx1.12" and "nginx1" To use, run # sudo amazon-linux-extras install :topic: Learn more at https://aws.amazon.com/amazon-linux-2/faqs/#Amazon_Linux_Extrasエラーメッセージの指示に従う。
sudo amazon-linux-extras install nginx1.12
- nginx の起動
sudo systemctl start nginx.serviceこの時点で、ブラウザからアクセスすると以下のような状態になっているはず。
- nginx の設定変更(リバースプロキシの設定)
# 〜省略〜 http { # 〜省略〜 server { # 〜省略〜 location / { # 以下の行を追加 proxy_pass http://localhost:3000; } # 〜省略〜 } }この1行を追加することにより、ローカルホストの port:3000 に向けることができるようになる。ただし、nginx の設定を反映させるために nginx を再起動させることを忘れてはならない。
- nginx の再起動
sudo systemctl restart nginxこの時点で、ブラウザからアクセスすると以下のような状態になっているはず。
これはまだサンプルアプリを起動しておらず、振り向けた先から応答が返ってこないから。
3.2 サンプルアプリの起動
- ssh で EC2 インスタンスに入る(既に入っていればそのままでOK)。
ssh -i <key.pem> <public ip address>
- git の install
sudo yum -y install git vim ~/.ssh/id_rsa # 自分のローカルのものをコピーしてくる chmod 400 ~/.ssh/id_rsa git clone https://github.com/<your sample app repository>
- npm/node の install(公式のダウンロード方法はこちら)
sudo su - root curl -sL https://rpm.nodesource.com/setup_13.x | bash - yum install -y nodejs
- 確認
$ npm -v 6.13.4 $ node -v v13.5.0
- アプリケーションのビルド
cd <your repository> npm install npm run build
- アプリケーションの実行
npm run startブラウザから見てみると、以下のように適切に表示されているはず!
まとめ
個人開発の際、なるべく早めに本番環境へのデプロイができることを確認しておくと、(不慣れな方は特に)不確実性を(そして心理的不安を)大きく減らすことができるかと思います。
まだ問題の切り分けを行いやすい最初のうちにこそ、本番環境でのデプロイを一度試してみることをおすすめします。



- 投稿日:2020-01-03T08:44:31+09:00
GCP・AWS・Heroku の最低価格帯インスタンスの料金比較(2020年1月版)
はじめに
規模の小さい Web アプリケーション(CPU 1 コア・メモリ 1 GB 弱のサーバ 1 台で動作可能)を
動かすための環境として GCP・AWS・Heroku を検討したので、
各サービスごとの最低価格帯の料金をまとめてみました。(料金は 2020年1月3日現在のもの。)
Azure は今まで全く触ったことがないので検討に入れておらず…すみません…料金比較表
主なサービスを月間料金の昇順でソートしてみました。
Service Instance (v)CPU RAM(GB) 時間料金(USD) 月間料金(USD) 月間料金概算 Region Heroku free ?1 0.5 $0 2 0円 US AWS t3a.nano 2 0.5 $0.0061 $4.392 480円 東京 GCP f1-micro 1 0.6 $0.0092 $4.70 520円 東京 AWS t3.nano 2 0.5 $0.0068 $4.896 540円 東京 AWS t2.nano 1 0.5 $0.0076 $5.472 600円 東京 Heroku Hobby ?1 0.5 $7 770円 US AWS t3a.micro 2 1.0 $0.0122 $8.784 960円 東京 AWS t3.micro 2 1.0 $0.0136 $9.792 1070円 東京 AWS t2.micro 1 1.0 $0.0152 $10.944 1200円 東京 GCP g1-micro 1 1.70 $0.0322 $16.45 1800円 東京 AWS t3a.small 2 2.0 $0.0245 $17.568 1920円 東京 AWS t3.small 2 2.0 $0.0272 $19.584 2140円 東京 AWS t2.small 1 2.0 $0.0304 $21.888 2400円 東京 GCP n1マシンタイプ 1 1.0 $0.0460 3 $23.5249 4 2600円 東京 GCP n1-standard-1 1 3.75 $0.0610 $31.17 3500円 東京 Heroku Standard 1x ?1 0.5 $25 2750円 US Heroku Standard 2x ?1 1.0 $50 5500円 US GAE F1,B1 1 0.25 $0.07 $50.4 5600円 東京 注意事項・補足
- 月間料金概算は、1ドル約110円として概算
- 各料金は、各サービスの下記公式ページから抜粋
- AWS の月間料金は、1時間料金 * 24 * 30 として算出
- GCP の月間料金は、GCP の料金表より抜粋
- 一定時間以上使用すると継続利用割引(最大 30 %)が適用される
- 無料枠
- GAE の Standard Environment では 1 日あたり 28 インスタンス時間の無料枠がある
- GCE では 1 インスタンス
- f1-micro、ただしリージョンは、オレゴン(us-west1)、アイオワ(us-central1)、サウスカロライナ(us-east1) に限られる
- AWS は、無期限での無料利用枠は AWS Lambda のみ
- 12ヶ月間限定では、750 時間 / 月の t2.micro (Linux、RHEL、または SLES) インスタンスが含まれる
- AWS の「東京」は
アジアパシフィック(東京)、GCP の東京は東京(asia-northeast1)- Heroku の US は North Virginia にあるらしい。公式ページ で Region を調べる方法の記載がある。
- AWS の t3 と t3a の違いは、下記引用の通り、CPU が若干異なるだけとのこと。
T3a インスタンスは T3 インスタンスのバリアントであり、全コアターボのクロック速度が最大 2.5 GHz の AMD EPYC プロセッサを搭載しています。T3a インスタンスは、使用中に一時的なスパイクが生じる中程度の CPU 使用率を持つアプリケーション向けの Amazon EC2 コンピューティング環境で、10% のコスト削減を目指すお客様にとっての新たな選択肢となります。
個人的な所感
Heroku はとても安いので、GCP の GAE も安いのではと思っていたところ
GCE に比較して全く安くないということがわかりました。
確かに、GAE はマシン自体の管理が必要ないという点で GCE と比較して
運用側のコストが抑えられるものの、Docker コンテナ等でサービスを運用するのであれば
GCE が最適かなーと思いました。AWS は相変わらず安いですが、色々考えてプラットフォームは一つに絞りたいし、
GCP がいいかなーと考えています。[参考] Heroku の各タイプの特徴
- Free
- スリープ状態への移行あり
- カスタムドメインは使用可
- プロセスタイプ数 〜2
- Hobby
- スリープ状態への移行なし
- 高度なアプリケーション用に複数の WORKER を使用可
- 10分毎のメトリクス
- プロセスタイプ数 〜10
- Standard
- 手動スケール
- 閾値によるアラート
Heroku 上の CPU コア数は非公表。ただし StackOverflow には、調べた結果 4 コアまたは 8 コアだったという情報がある。 ↩
1アカウントあたり合計 1000時間 / 月まで無料 ↩
(\$0.040618 / vCPU hour) + ($0.005419 / GB hour) として算出 ↩
(\$20.755798 / vCPU month) + ($2.769109 / GB month) として算出 ↩
- 投稿日:2020-01-03T05:47:27+09:00
AWS認定デベロッパーアソシエイト合格と、勉強方法と使ったサイトの感想
はじめに
- 2019年12月にAWS認定デベロッパーアソシエイトに合格しました。(886/1000点)
- 合格までの勉強方法と利用したサイト(有料)について記事にしようと思います。
- 前回受験したソリューションアーキテクト合格の記事はこちらになります。
バックグラウンド
- 業務アプリメインのSIer、AWSは仕事でほぼ関わっていません。
- アーキテクト取得のキッカケでAWSにハマり、インフラ知識はほんの少しだけ。
- ブラックベルトの記事は日頃少しずつ読んでいます。
勉強方法
以下の順番で勉強していきました。最短ルートではないと思いますが、オススメ出来るものをピックアップしていこうと思います。
AWS 認定デベロッパー アソシエイト模擬試験問題集(3回分195問:全5回分準備中)
- 日本語の模擬試験。Udemyのお得期間に購入しました。
- いきなりですが、模擬試験を解くところから始めました。
- 時間を止めたり、途中から開始もできますのでゆっくり進み回答を確認していきます。
- 公式ドキュメントに記載されている「試験範囲が具体的にイメージできる」これをゴールとしました。
- 3回分の試験をやり切ったころには、理解度が不足しているサービス名が列挙されているはずです。
実際に動かして確認する
- AWS環境を用意し模擬試験で頻出していた理解度不足の箇所を組んでみました。以下、私が試した一部、一例です。
- ポイントはサービスをいくつか組み合わせることです。サービス単体の動作確認ではどうしても試験とは乖離してしまいます。
- Lambda
- コンソールでコードを書き、Lambdaを単体で動作させる
- バージョンとエイリアスをいじくり倒す
- ZipしてCLIからアップロードしてみる
- CloudWatchで成功ログと失敗ログを確認する
- X-Rayと連携する
- 定期イベントとしてCloudWatchからトリガーしてみる
- DynamoDBと連携してみる(テーブル操作、IAMロールを体験)
- API Gatewayと連携する
- ECS
- サンプルを動かしてみる(まとめて記事にしてみた)
- Elastic Beanstack
- 一通り簡単に動かしてみる(まとめて記事にしてみた)
- Codeシリーズ
- 一通り動かしてみる
- 可能ならECRの連携も試してみる
AWS Certified Developer - Associate 2020
- Udemyの教材。試験対策の動画(英語)
- 5時間ほどありますが、日本語字幕を使って1週間で消化しました。
- 1.25倍速でも問題なく進めます。ちょっとしたテストもついています。
- 模擬試験と実機での検証を済ませてからの視聴している為、復習と理解が浅い箇所を探す作業でした。
- 最短ルートで合格を目指すのであればカットしても良いと思います。
- 勉強後、英語文章の読むスピードがレベルアップしていたという想定外の副産物がありました(個人的にはとても嬉しくって寄り道だとしてもやって良かったです)
WHIZLABS
- AWS試験問題が充実しているサービスです(最終テストと合わせて模擬試験6つあります)
- Google、Facebook、LinkdInどれかのAAUTHでアカウント登録簡単
- AWSで検索してHITしたものをPayPalでかんたん決済
- ほぼ常時半額セールやってて10ドル程度でお手頃、すごくオススメです!
- 英語できなくてもブラウザの翻訳機能ですべて解決!
- 右クリック禁止はブラウザによってはアドオンで解除可能です。(リンクは貼りません)
さいごに
- 最終的にUdemy、WHIZLABS合わせて65問ある模擬試験9種類を繰り返し解いたのが効きました。
- 日本語の対策本がない不安感は、2つのサイトで模擬試験を行うことで確実に補えます。セールを狙って購入しましょう。もし英語が苦手でも翻訳機能で余裕で乗り切れます。
- 見たことのない問題が出ると実機で動かした事を思い出して回答すると解けました。動かすことは大事です。
アーキテクトと重複するサービスもデベロッパー用に復習が必要です。おろそかにしない方がよいです。(私はおろそかにしました。失点の主な要因はこれでした。)
この記事が今後受験する皆様にとって、少しでもお役に立つことができれば幸いです。








- 投稿日:2020-01-03T02:33:36+09:00
AWSでCycleGANを実行してみる
AWSを使ってみたい
しばらくGoogle Colabを使っていたけど、ディープラーニング以外のところでつまずくことが多かった。AWSを一応使ってもいいので、使ってみようと思います。
本当はPyCharmでリモート開発?をやりたいけど、とりあえずターミナルから触れるように頑張るCycleGANとは
GANは敵対的生成ネットワークのこと。生成モデルと識別モデルを用意して、偽物を作ってそれを判別する。これらを交互に学習を進めることで精度が高くなる。
CycleGANはそれの応用で、Cycleなので循環させるのがポイント。ペアになっていない2種類の学習用データ(ex. 紅葉と緑葉)を使って、元データと変換後のデータから元データを復元したものとの損失を小さくしていく。説明が難しいから無理CycleGANの使い方は親切に書いてある
論文はこちら
GitHubにコードは上がっている。いろんなフレームワーク(?)で用意してくれていて、なんかずっとPytorchを触っているのでそれを使います。
GitHubのリンクREADMEの前にやること
AWSの準備
アカウント作るとかは覚えてないので省き
- AWSマネジメントコンソールにログイン
- ここからログイン
- インスタンスを立てる
- サービス > コンピューティング > EC2 > 実行中のインスタンス > インスタンスを作成
- Deep Learning で検索して出てきた良さそうなやつを選択。ubuntuにした
- インスタンスタイプは、無料じゃないけどGPUのp2.xleargeを選択。確認と作成
- セキュリティグループはよくわからないけどlaunch-wizard-32にしてる、わかんない
- ストレージをでかくしとく。100とか150とか適当
- キーペアの確認。既存のがあればそれを使う、なければ新しく作る。このpemというのがしぬほど大切らしい
- そこにターミナルで入る
- pemのいるディレクトリでssh
sudo ssh -i n_nagata2.pem ubuntu@ec2-なんとか(パブリックDNS名)
ec2-うにゃららは、実行中のインスタンスのとこからコピーしてくる。READMEを読む
Pytorchや必要なライブラリを入れる
- READMEをよく読むとcondaユーザ用のスクリプトが用意されている。
- これです
- なんかデフォでcondaになっている感じがした
gitからコードとかいろいろクローンする
git clone https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix cd pytorch-CycleGAN-and-pix2pixCycleGANを回す
あとは書いてあるままに…
データセットをダウンロードして
bash ./datasets/download_cyclegan_dataset.sh maps学習させて
#!./scripts/train_cyclegan.sh python train.py --dataroot ./datasets/maps --name maps_cyclegan --model cycle_ganテストして
#!./scripts/test_cyclegan.sh python test.py --dataroot ./datasets/maps --name maps_cyclegan --model cycle_ganこれは例としてmapというデータセットを使っているから、航空写真と地図とを変換できるやつができるんじゃないかな
- 投稿日:2020-01-03T01:02:57+09:00
aws DR クラウド構成例
multi-azはdrにならない?
https://aws.koiwaclub.com/forums/topic/multi-az%E3%81%AFdr%E3%81%AB%E3%81%AA%E3%82%89%E3%81%AA%E3%81%84%EF%BC%9F/ディザスタリカバリを考慮したクラウド構成例
https://aws.amazon.com/jp/cdp/cdp-dr/AWS資格試験問題に対応するためにも下記は全部読んだ方がいいかも
https://aws.amazon.com/jp/cdp/
- 投稿日:2020-01-03T00:57:09+09:00
Locustの分散負荷テスト環境をAWS Fargateを使って簡単に用意してやる
概要
この記事では、負荷テストツールLocustで分散負荷テスト環境を構築するに当たって私が使っている方法をまとめます。
構築はAWS Fargateを使って、設定をできるだけ少なくしました。
AWSの操作にはTerraformを使って、構築・破棄を繰り返しできるようにしています。背景
これまでやっていた負荷テスト
負荷テストはどのようにして実行しているでしょうか?
私はこれまで簡単なものはApacheBenchで行い、
ログインを含むシナリオが必要なものはシェルスクリプトでコードを書いて実行していました。しかし、ApacheBenchは静的なWebサイトなどで使うには良いのですが、Webアプリのテストとなると機能が足りないと感じていました。
シェルスクリプトを使えば何でもできる反面、テストの作成に時間がかかりがちで、メンテナンスもしずらくなっていました。Locustを使った負荷テスト
そんなときに、Locustというツールを知りました。
まだ使い始めて一ヶ月ほどですが、満足できそうな予感がしています。
(ツールの特徴については公式をはじめ多数情報があるので、割愛します)今回紹介する方法の良い点
Locustは気に入ったので、これから何度も使うつもりなのですが、毎回Locustサーバーを立てるのは面倒です。
使わないサーバーを停止状態で放置するのもリソースが無駄になって良くないと思います。
そこでFargateとTerraformも使い、使いたいときに立ち上げてすぐに破棄できるようにコード化しました。
Locustを使うことで
- テストスクリプトが見やすくなる(と思う)
- イベントやタスクの重み付けで、リアルなユーザーを想定したシナリオでテストできる
- 分散クラスターの構築に対応していて、テストのスケールアウトに対応できる
Fargateを使うことで
- 多数のコンテナをサーバーの台数やスペックを気にせずに立ち上げられる
Terraformを使うことで
- 使いたくなったときにコマンド一発で環境が立ち上がり、コマンド一発でネットワーク設定もろとも破棄できる
構築手順
実際に環境を構築する方法です。
攻撃スクリプトコンテナを用意する
攻撃スクリプトは事前に用意して、コンテナに入れてイメージリポジトリにpushしておきます。
コンテナ内には複数種類のスクリプトを入れておいて、Terraformの変数でどのスクリプトを実行するか切り替えられるようにしています。実業務では、攻撃スクリプトコンテナはプライベートなECRリポジトリに置いていますが、今回はgithubとDockerHubでサンプルを作っています。
github: https://github.com/neilli-sable/locust_scripts
dokcerhub: https://hub.docker.com/repository/docker/neilli/locust_scriptsTerraformから環境を構築する
このリポジトリに置いたコードから、攻撃スクリプトコンテナを起動して構築します。
https://github.com/neilli-sable/locust_fargate設定内容について
「ネットワーク設定する -> ECSのクラスタを作る -> クラスタの上でLocustコンテナを動かす」というような内容になっています。
細かい部分はコードをご確認いただきたいですが、いくつか設定のポイントになった箇所を書いておきます。接続情報と変数
variable.tf.defaultにプロバイダーと変数設定のサンプルがあります。
variable.tfとリネームして、設定値を変更することで構築するLocustクラスタのスペック変更などができます。接続情報として、providerに名前付きプロファイル名と、regionを指定しておきます。
provider "aws" { profile = "my-profile" region = "ap-northeast-1" }変数は以下の種類を用意しました。
- general_name
- AWSのリソース名やタグ付けに使うための文字列を指定します
- slave_count
- LocustのSlaveサーバーの数を指定します
- fargate_cpu
- LocustコンテナのCPUスペックを指定します
- fargate_memory
- Locustコンテナのメモリ量を指定します
- locust_container
- Locustの攻撃スクリプトを入れたコンテナのURLを指定します
- locust_script_path
- 使用する攻撃スクリプトのファイルパスを指定します
開放するポート
Masterサーバーは3つのポートを開放します。
- 8089
- WebブラウザからUIにアクセスするためのポート
- 5557/5558
- Slaveサーバーからの通信を受けるためのポート
5557と5558はSlaveサーバー向けのセキュリティグループからのみアクセス可にしておきます。
8089は今回アクセス制限していませんが、必要に応じてIP制限などを設定すると良いと思います。一方、Slaveサーバーはポート開放は必要ありません。
セキュリティグループからingressは削除し、egressだけ設定して、外部からの接続はできないようにしておきます。MasterサーバーのプライベートDNS
SlaveはMasterに通信しないといけないですが、コンテナは起動するまでIPアドレスが割り当たっていないため、単純なIPアドレスの指定は使えません。
なのでECSのサービスディスカバリ機能を使って、プライベートDNSを設定します。vpc.tfにある、この以下の部分です。
# Service Discovery resource "aws_service_discovery_private_dns_namespace" "locust_internal" { name = "locust.internal" description = var.general_name vpc = aws_vpc.vpc.id } resource "aws_service_discovery_service" "master" { name = "master" dns_config { namespace_id = aws_service_discovery_private_dns_namespace.locust_internal.id dns_records { ttl = 10 type = "A" } routing_policy = "MULTIVALUE" } health_check_custom_config { failure_threshold = 1 } }そうすることで、タスク定義で
master.locust.internalというプライベートDNSアドレスを解決できます。container_definitions = <<DEFINITION [ { "cpu": ${var.fargate_cpu}, "essential": true, "image": "${var.locust_container}", "memoryReservation": ${var.fargate_memory}, "name": "locust", "command": ["locust", "-f", "${var.locust_script}", "--slave", "--master-host=master.locust.internal"] } ] DEFINITIONTerraformの実行
terraformディレクトリが実行用のディレクトリなので、移動します。cd ./locust_fargate/terraform「接続情報と変数」の項目でも書きましたが、variable.tfを作成して、接続情報などを設定します。
初回のみ、initコマンドを使います。
terraform init一度 init すれば、以後はapplyコマンドで環境構築できます。
terraform apply負荷テストを実行する
UIへのアクセス
terraform applyの結果、成功すればURLを出力するようにしています。
こんな感じに。Outputs: endpoint = access to here (wait a minute): http://locust-fargate-application-xxxxxxxxx.ap-northeast-1.elb.amazonaws.com
terraform applyが終わってしばらくしてからURLにアクセスすると、LocustのUIが表示されます。
変数で設定した数のSlave数になっていることが確認できるはずです。しばらくしてからと書きましたが、
terraform applyの完了からサーバーが実際に起動完了するまでにタイムラグがあります。起動する前にURLにアクセスすると503エラーとなるので数分程度待たないといけません。
いつまでも503が続く場合は、エラーなどが原因でタスク自体が停止している可能性があります。Locustを使う
UIに接続できれば、普通にLocustを使うことができます。
「Number of users to simulate」「Hatch rate」「Host」を入力して、テストを開始してください。
Hostに「http://」から入力しないといけないのをいつも間違えるのは私だけでしょうか。お片付け
テストを実行してデータの回収などを完了したら、AWS上に作成したリソースを破棄します。
terraform destroyこれでキレイサッパリなはずなので、気軽に破棄してお金が掛からない状態にしておきます。
またテストしたくなったら、terraform applyからやり直すだけです。感想
これまでの負荷テストだと、始めるまでがちょっとした仕事量になってしまい、実行がおろそかになっていたように思います。
もっと気軽にテストをしていきたいものです。参考文献など
- AWS FargateとTerraformで最強&簡単なインフラ環境を目指す
- TerraformからFargateを操作する際の導入
- MQTTの負荷テストもバッチリ!!Locustを活用した分散負荷テスト環境の構築
- Locust+ECS の組み合わせの事例
- ECSのサービスディスカバリーが東京にやってきて、コンテナ間通信の実装が簡単になりました!
- ECSのサービスディスカバリー概要
- Amazon Web Services負荷試験入門 (書籍)
- 負荷試験全般の参考図書
- 投稿日:2020-01-03T00:22:02+09:00
CloudFrontでmulti originをするときにハマったところ
概要
年末で暇だったので、個人サービスの画像配信部分をCloudFront経由で早くしてやろうと思い、見事にハマった出来事についての備忘録です。
ちゃんと調べずに自分でトライアンドエラーをしているので、かなりグダグダした内容になっています。ご了承ください
TL;DR
内容がグダグダなので、何にハマったか知りたい人はこれだけ見て退散することをオススメします
- BehaviorのPath PatternがOriginに渡るときにIgnoreされると思っていた
- Path Patternは正規表現なのでIgnoreされずにOriginに届く
- 例:
- Path Pattern(
image/*)を持つmulti-origin(image-bucket)なCloudFrontに対してリクエストを送るhttps://www.app.com/image/full/sample1.pngがOriginに届く時には、s3://image-bucket/full/sample1.pngになると思っていた- 実際にOriginに届くリクエストは
s3://image-bucket/image/full/sample1.png- ErrorになったBehaviorはスキップされて次にマッチするBehaviorに行く(っぽい)
やったこと
前提条件
個人サービスはSPAでS3にアップロードしたものを、CloudFrontで配信していましたので、既にDistributionが一つあり、カスタムドメインも設定されていました。
画像はSPAのS3 Bucketとは別のBucketに保管されており、S3のWeb Hosting機能を使って配信をしていました。
この部分をCloudFrontでCacheさせて高速化を図るというのが、今回やりたいことでした。別のDistributionを作成しても良かったのですが、設定を作り直すのも面倒だし、別ドメインだとCORSやDNS Lookupなど余計なものを気にしないといけない
し面倒だなと思ったので、multi-originでやってみることに。CloudFrontでmulti-origin
CloudFrontにはmulti-origin機能が既に備えられており、それの通りに作成するだけ...、のハズでした。
これの設定方法については色々な記事で紹介されていました。
(何故かほとんどの記事で扱っていたのが、S3とELBのmulti origin)やることは以下の3つです。
- 既存のDistributionにoriginを追加
- Behaviorを追加し、path patternで任意のpathのときに追加したoriginに向くようにする
- CloudFrontに設定がDeployされるのを待つ
コンソールからDistributionを作成するときは一つのoriginとBehaviorしか設定できませんが、Distribution作成後追加できるようになります。
大体どの記事を見ても画像付きでこの説明がされていたのですが、自分はなぜかうまくいきませんでした。
1. 既存のDistributionにoriginを追加
画像がSPAとは別のBucketで保管していましたので、originを作成します。
Origin Pathについては、リクエストが来たときにPrefixでoriginに追加されるPathになります。
例えばSingle Originで上のような設定とリクエストをしていた場合、CloudFrontは
s3://sample-image-bucket/thumbnail/sample1.pngからObjectをGetします。Origin: `image-bucket.s3.amazonaws.com` Origin Path: `/thumbnail` Request: `https://img.app.com/sample1.png`今回の画像のBucketは以下のようなディレクトリ構造になっていたので、Origin Pathは設定していません。
image-bucket L full L ~.png L thumbnail L ~.png2. Behaviorを追加し、path patternで任意のpathのときに追加したoriginに向くようにする
BehaviorはEdgeロケーションのCacheの振る舞いを設定します。
Behaviorは複数設定することが可能で、Path Patternを設定することによって、複数のBefaviorに振り分けることが可能です。
コンソールからCloudFrontを作成し際には、DefaultのBehaviorだけ設定されています。ここに画像配信用のBehaviorを作成します。
Path Patternは正規表現で表します。今回は画像配信部分でしたので、
image/*に設定しています。
これで、https://cdn.app.com/image/full/~.pngにリクエストが来れば、画像を返してくれるはずでした...。3. CloudFrontに設定がDeployされるのを待つ
待つだけです。だいたい10〜15分くらいでDeployされます。
起こったこと
何故かDefaultのBehaviorにルーティングされ、SPAのエラー画面が表示されます (404 Not found)。
CloudFrontの設定が良くないのかと思い色々調べてみました。1. CloudFrontのログを出してみる
CloudFrontはDistributionの設定でログをS3に出力することができます。
これが設定されてなかったので、ログを有効化しデプロイされるのを待ちます。デプロイされた後に、該当画像にアクセスしてみます。
するとログが出力されたのですが、CloudFrontのログは基本的にアクセスログしか残らないので、Errorが発生したかどうかはわかるのですが、エラーメッセージまでは見ることができませんでした。
https://docs.aws.amazon.com/ja_jp/AmazonCloudFront/latest/DeveloperGuide/AccessLogs.html#BasicDistributionFileFormatとにかく、該当画像にアクセスした際にBehaviorのPath Patternの割り振りは動いているようでした。
権限的な問題かと思いましたが、既にWeb HostingでPublicになっているバケットでしたので、ありえませんでした。2. 別のDistributionで画像BucketをDefaultのBehaviorのOriginにしてみる
最初の決意がゆらいで別のDistoributionでも良いかなと思い始めてきたので、新しくDistributionを作成し、DefaultのBehaviorを画像BucketのOriginに設定してみました。
すると、問題なくアクセスできました
つまり、権限的な問題でもなくBehaviorの問題では無いことがわかりました。ついでに、新しく作成したDistributionにSPAのOriginも設定してみます。
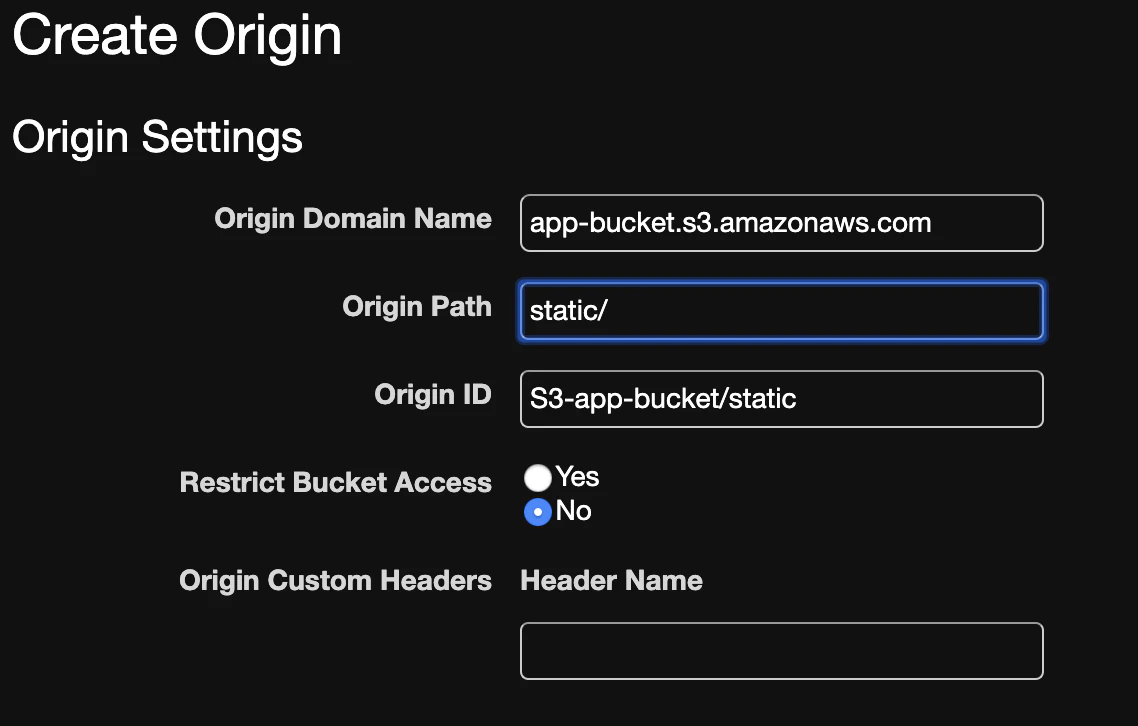
そのときに、Origin Pathのテストがしたくなったので、Origin Pathをstatic/にしてみました。
BehaviorのPath Patternは
app/*です。
それでもアクセスできませんでしたが、エラーの内容は変わりました。
どうやら、DefaultのBehaviorである画像Bucketの方にリクエストがいっているようです。
予定では、static/以下のjsファイルが取得できる予定でした。Origin Pathの設定が悪かった可能性もあったので、Origin Pathの設定を削除してみました。
それでも接続できません。どうやらOrigin Pathの設定ではないようです。手詰まり感が出てきたので、一旦Path Patternを
static/*にしてみました。
すると、アクセスできるようになりました!原因
つらつらとトライアンドエラーしてきた内容を書いていきましたが、ようやく原因がわかりました。
BehaviorのPath Patternで設定したPathにマッチしたPathはOriginに送られる際に無視されるわけではなく、Path PatternのPathも含めてOriginに送られるのでした。前提条件を整理すると以下のような感じでした。
// CloudFrontの設定 - Origin: `image-bucket.s3.amazonaws.com` - Behavior Path Pattern: `image/*` - Request: `https://www.app.com/image/full/sample1.png`// S3のBucket構造 image-bucket L full L ~.png thumbnail L ~.pngこの場合、画像Bucketに対するCloudFrontのリクエストは
s3://image-bucket/image/full/sample1.pngに飛んでいた訳です。
image-bucketにはimage/をPrefixに持つObjectは無いためCloudFrontはエラーを返し、DefaultのBehaviorであるSPAのOriginにリクエストが飛んでいたということです。
そして、SPAでは/imageというルーティングは存在しないため404 Not Foundが発生していたのです。まとめ
ということで、画像のBucketに
image/というPrefixをつけるようにすることで、無事multi-originで画像配信が実現できました。てっきりBehaviorのPath PatternはOriginに到達するときにIgnoreされているという思い込みが自分の中のハマりポイントでした。
しかし、ネタが割れてしまえば当たり前のことで、Path Patternは正規表現だし、元々Single-Originで配信したいObjectの種類に応じてCacheのパターン(Behavior)を変えたいときに使われていたと思われるので、そりゃそうだよなとなった。大体思い通りに行かずにハマるときは自分の勘違いが招いていることが多い気がする...。