- 投稿日:2020-01-01T23:53:11+09:00
TensorFlow2 + Keras による画像分類に挑戦7 ~層タイプ・活性化関数について理解する~
はじめに
Google Colaboratory 環境で TensorFlow2 + Keras を利用した画像分類を勉強した際のメモ(第7弾)です。題材は、ド定番である手書き数字画像(MNIST)の分類です。
前回は、自分で用意した画像について、TF公式HPの「初心者のための TensorFlow 2.0 入門」で紹介されていたモデルで予測(分類)を行ないました。
今回は、そのニューラルネットワークモデルの構成してる層のタイプ(
Dense、Dropout、Flatten)と、活性化関数について勉強してみました。
モデルの記述方法
以下のコードは「初心者のための TensorFlow 2.0 入門」からのコピペです。
NNモデルの構築(記述1)model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28)), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dropout(0.2), tf.keras.layers.Dense(10, activation='softmax') ])上記のコードでは活性化関数を指定するキーワード引数の
activationを文字列で指定していますが、次のように直接的に関数を与えて指定することもできます。NNモデルの構築(記述2)model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28)), tf.keras.layers.Dense(128, activation=tf.nn.relu), # 変更 tf.keras.layers.Dropout(0.2), tf.keras.layers.Dense(10, activation=tf.nn.softmax) # 変更 ])また、ここでは、ニューラルネットの層構成情報を
Sequential(...)の引数としてリスト型で与えていますが、次のようにadd(...)を使って層をひとつずつ追加していくこともできます。NNモデルの構築(記述3)model = tf.keras.models.Sequential() # (0) model.add( tf.keras.layers.Flatten(input_shape=(28, 28)) ) # (1) model.add( tf.keras.layers.Dense(128, activation=tf.nn.relu) ) # (2) model.add( tf.keras.layers.Dropout(0.2) ) # (3) model.add( tf.keras.layers.Dense(10, activation=tf.nn.softmax) ) # (4)モデルの概要を表示
上記のように層を設定したNNモデルは
summary()で、その概要を確認することができます。モデルの概要確認model.summary()実行結果Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= flatten (Flatten) (None, 784) 0 _________________________________________________________________ dense (Dense) (None, 128) 100480 _________________________________________________________________ dropout (Dropout) (None, 128) 0 _________________________________________________________________ dense_1 (Dense) (None, 10) 1290 ================================================================= Total params: 101,770 Trainable params: 101,770 Non-trainable params: 0 _________________________________________________________________表は上から下に向かって、入力層、中間層(隠れ層)、・・・、出力層となります。
表内の左端の値は「層の名前」になります。
add()の際にname=を省略していると自動的に付与されるもので、モデルを構築するたびにflatten_1、flatten_2のように番号がついていきます。左から2番目の
( )の値は「層のタイプ」になります。ここではFlatten、Dense、Dropoutの3タイプが登場します。この解説は次のセクションで。項目「Output Shape」のタプルの2個目の数値は、当該層のニューロン数(=当該層からの出力数)になります。
(None, 128)であれば、その層には 128個のニューロン(ノード)が存在するということです。つづいて、項目「Param」は、パラメータ(当該層の入力に係る重みとバイアス)の総数になります。
例えば、第2層「dense (Dense) 」の $100480$ は、第1層の出力数 $784$ と 第2層のノード数 $128$ を掛けた数だけの重みのパラメータ、第2層ノード数 $128$ 個のバイアス をあわせた全パラメータ数にになります。つまり、 $784\times 128 + 128=100480$ です。これらパラメータの最適値を求めるための操作がトレーニング(訓練・学習)になります。
表の最後には、Total params(総パラメータ数)、Trainable params(トレーニングにより求められるパラメータ)、Non-trainable params(トレーニングでは求めないパラメータ)の数が記載されています。
各層の役割・動作・意味
Flatten層
手書き数字文字の1枚のイメージは 28 $\times$28 pixel であり、大きさが (28,28) の numpy.ndarray 型、つまり2次元配列です。Flatten層では、これを平坦化して 1次元配列的に直しています。よって、その出力数は、
model.summary()で確認したように $28\times 28=784$ となります。プログラムでは、次のようにしてモデルにFlatten層を追加しています。
model.add( tf.keras.layers.Flatten(input_shape=(28, 28)) ) # (1)
input_shape引数には、x_train[*].shapeと一致させて(28, 28)を指定しています。もし、32 $\times$32 pixel の画像を入力とするならばinput_shape=(32, 32)のようにします。リファレンスはこちら。Dense層
前層と当該層のあいだを全結合(密結合)した全結合層を意味します。ニューラルネットワークを構成する標準的な層となります。
プログラムでは、次のようにしてモデルにDense層を追加しています。
中間層としての全結合層model.add( tf.keras.layers.Dense(128, activation=tf.nn.relu) ) # (2)出力層としての全結合層model.add( tf.keras.layers.Dense(10, activation=tf.nn.softmax) ) # (4)1個目の引数には、その層を構成するノード数(ニューロン数)を与えます。上記の (2) のように中間層として設定する全結合層のノード数をいくつにするか?はモデルの性能を左右する要素になります(ユーザが勘なり試行錯誤で設定するハイパーパラメータになります)。なお、ノード数が多ければ高性能なモデルになるというわけではないです(少なくともノードが増えると、それだけパラメータ数が増えるので計算量が大きくなり学習に時間がかかります)。
一方で、多クラス分類問題を扱っている場合、出力層として設定する全結合層のノード数は、分類したいクラス数と一致させる必要があります。MNISTの場合は、0~9までの数字の分類、つまり 10クラス分類問題なので、ここでは
10を設定する必要があります。また、
activation引数には、活性化関数を与えます。ここでは、ReLU関数(tf.nn.relu)とSoftMax関数(tf.nn.softmax)が使われていますが、その詳細は次のセクションで解説します。なお、activation=を省略した場合は、活性化関数は適用されず、計算された値がそのまま出力される仕様です)。リファレンスはこちら。Dropout層
モデルをトレーニングする際に(ノード単位で)指定された確率に応じて前層から次層への出力を遮断する働きをします(前層の対応ノードを確率に応じて不活性/ドロップさせるとも表現されます)。この層を設けることで過学習という状況になりづらくなるようです。
これについては、「【ニューラルネットワーク】Dropout(ドロップアウト)についてまとめる」の解説が、とても分かりやすかったです。
プログラムでは、次のようにしてモデルにDropout層を追加しています。
model.add( tf.keras.layers.Dropout(0.2) ) # (3)引数には、不活性させたいノード割合を 0.0 から 1.0 の範囲で指定します。これを 0.0 に設定すると、実質的にDropout層が存在しないのと同じになります。また、1.0 に設定するとネットワークが Dropout層で完全遮断されるので、一切の学習が機能しません(実際には、
ValueError: rate must be a scalar tensor or a float in the range [0, 1), got 1というエラーが発生します)。なお、不活性されるノードは、指定した確率に応じてランダムに選択されます。よって、このDropout層をもうけていると、トレーニング毎に学習済みモデルが(わずかに)変化します。そのため、Dense層のノード数と正解率の関係など、他のハイパーパラメータの影響を調べるときなどは、
seed=1のように引数を与え、ランダムシードを固定します(ただし、トレーニングのほうでランダム要素があると、ここを固定しても実行毎に生成される学習済みモデルが変化します)。リファレンスはこちら。
活性化関数
活性化関数を適用しない場合、第2層の1個目のノード出力 $y_1$ は次のように計算されます($x_i$は前層の $i$ 番目ノードの出力、$w_{i1}$ は重み、$b_{1}$ はバイアス)。
$$ y_1 = b_1 + \sum_{i=1}^{784} x_{i}w_{i1} $$
一方、活性化関数 $f$ を適用すると、その $y_1$ は次のようになります。
$$ y_1 = f ( b_1 + \sum_{i=1}^{784} x_{i}w_{i1} ) $$
ニューラルネットで使用される活性化関数は、様々なものがありますが、大きくは中間層でよく使われるもの、問題タイプに応じて出力層で使われるものに分けられます。
中間層では、ReLU関数やシグモイド関数が利用されます。また、多クラス分類問題の出力層では、その性質からSoftnMax関数が、2クラス分類問題ではシグモイド関数が使用されます。
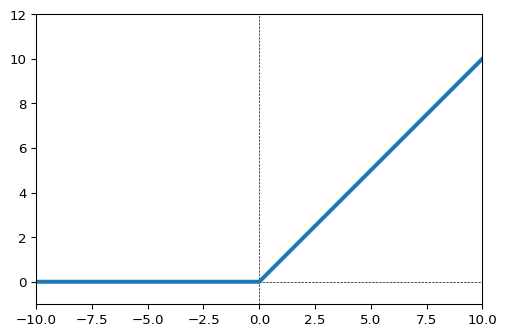
ReLU関数
中間層において最も一般に用いられる活性化関数らしいです。入力が0未満の場合は出力は0、入力が0以上のときは、入力をそのまま出力します。
tf.nn.relu()。リファレンスはこちら。
ReLU関数import numpy as np import matplotlib.pyplot as plt import tensorflow as tf xmin, xmax = -10,10 x = np.linspace(xmin, xmax,1000) y = tf.nn.relu(x) # ReLU関数 # グラフで形状を確認 plt.figure(dpi=96) plt.plot(x,y,lw=3) plt.xlim(xmin, xmax) plt.ylim(-1, 12) plt.hlines([0],*(plt.xlim()),ls='--',lw=0.5) plt.vlines([0],*(plt.ylim()),ls='--',lw=0.5)ReLU関数の亜種に「Leaky Relu関数」「Parametric ReLU関数」などがあるようです。
SoftMax関数
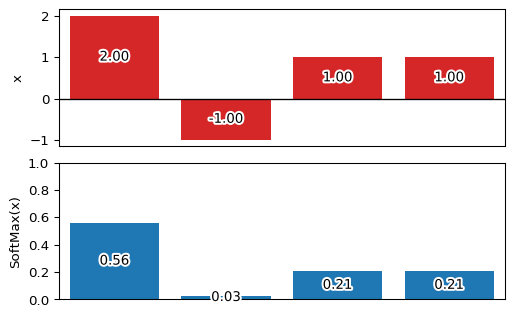
一般に、多クラス分類問題の出力層で使用されます。入力に関わらず出力は 0.0 ~ 1.0 の範囲をとり、出力の総和が 1.0 となるのが特徴です。
tf.nn.softmax()。リファレンスはこちら。例えば、次のように
[2, -1, 1, 1]という入力に対してSoftMax関数を適用すると、[0.56, 0.03, 0.21, 0.21]といった出力(要素の総和は 1.0)を得ることができます。
ReLU関数import numpy as np import matplotlib.pyplot as plt import matplotlib.patheffects as pe import tensorflow as tf x = np.array( [2, -1, 1, 1], dtype=np.float64 ) fx = tf.nn.softmax(x) fx = fx.numpy() # 'numpy.ndarray'で内容取得 np.set_printoptions(precision=2) print(f'fx = {fx}') print(f'fx.sum() = {fx.sum():.2f}') fig, ax = plt.subplots(nrows=2, ncols=1, dpi=96) plt.subplots_adjust(hspace=0.12) ep = (pe.Stroke(linewidth=3, foreground='white'),pe.Normal()) tp = dict(horizontalalignment='center',verticalalignment='center') ax[0].bar( np.arange(0,len(x)), x, fc='tab:red' ) ax[1].bar( np.arange(0,len(fx)), fx ) ax[1].set_ylim(0,1) for i, p in enumerate([x,fx]) : ax[i].tick_params(axis='x', which='both', bottom=False, labelbottom=False) ax[i].set_xlim(-0.5,len(p)-0.5) for j, v in enumerate(p): t = ax[i].text(j, v/2, f'{v:.2f}',**tp) t.set_path_effects(ep) ax[0].hlines([0],*(plt.xlim()),lw=1) ax[0].set_ylabel('x') ax[1].set_ylabel('SoftMax(x)')次回
未定
- 投稿日:2020-01-01T23:49:44+09:00
(番外編)Raspberry Piでcm精度のRTK-GPS~2019年のあゆみ
はじめに
この記事は私が2019年に苦闘した記録ですが技術的に有用な情報はあまりないのであしからず。
ここまでの歩み(2018年)
最初の記事に書いたようにUblox-M8Pを手にし初めてRTKをしたのが2年前。4ヶ月ぐらいかけて直進ガイダンスを作り春の田植作業に使用。有用性を感じてQittaに投稿したのが6月。秋の農繁期を終えて11月にFOSS4Gという地図好きの集まりがあると知り東京までいって刺激を受けてくる。(この頃からTwitter始める)
ボタン一つでAB基準線を呼び出したり自分の使いたい機能を付けて満足しつつあるときに、
AgOpenGPS (以下AOG)というソフトをカナダの農家が作成してオープンソースで公開していることを知る。自作でモーターを取り付け自動操舵までやってる!!2019年1月~3月
自作ガイダンスでトラクター作業をしつつ 帽子にLEDを付けてみたり , 傾斜補正をつけてみたり しているが自動操舵の方は手つかず。
巷ではF9Pを手にした方の報告が上がるようになり指をくわえてみている。4月~5月
春の農繁期。自作の他にAOGも併用して使い方がだんだんわかってくる。セクションコントロール や、GPSでお絵かきなど。
忙しさの勢いでF9Pを一つだけ買うがまだ2周波の威力を試せず6月~8月
F9Pの使い方を覚えたり,
自分用のNtripCasterを立ち上げたり
時間ができ、またAOGのフォーラムを読んでいると自動操舵用のPCBの設計まで公開していた。
そのなかからESP32,IMU,モータードライバ,A/Dコンバータ、Ethernet,リレー,F9Pコネクタ…全部乗せの基板のガーバーデータが公開されているのを知る当時fusionpcbで基板製造+部品実装5枚で実装代無料のキャンペーンが行われていたこともあり、無謀にも初のPCBで表面実装部品点数120以上/枚を発注
9月~10月
結局発注から到着するまで一月半かかり秋の農繁期に入ってしまったので基板は手つかずのまま。
コンバインにガイダンスをつけて使ってみたら中割作業に役立った。
また降水予測機能を付けて助かったり騙されたり
台風で稲刈りが出来ない日に試しにコンバインの自動操舵を付けてみたら意外にスムーズに動いた!11月~12月
稲刈りも終わりいよいよトラクタの自動操舵に手を付ける。
ざっくりとAOGの仕組みを説明すると1. GPS受信機からNMEAを受信(AOGからRTCMを送信する機能もあり)
2. AutosteerPCBからRoll,Headingを受信
3. AOG本体はWindowsPC上で動くC#で書かれていて、ステアリングの目標角を計算しAutosteerPCBに送信。
4. AutosteerPCB上のAruduinoまたはESP32 で受け取った目標角(steerAngleSetPoint)と、ポテンショメータとA/Dコンバータで計測した前輪の操舵角(steerAngleActual)の差がゼロになるようにPID制御(実際はP制御のみ)でモータードライバのPWM値を決めハンドルに取り付けたDCモーターを回す。1.2.4.を一つのESP32 で動かそうとマルチコアだとか非同期UDP通信とか(AsyncUDP)とか、入門書には書いてないようなものを訳も分からずコピペで動かそうとする。一瞬うごいた気がしたが安定には程遠く数十秒で再起動を繰り返し原因がつかめず。
それはひとまず置いおいて、並行してモーター取り付けのハードウェアにも取り掛かる。とりあえず置いてみただけでは強度的にも精度的にも使い物にならないので海外のサイトを参考に探していたら、ドイツのフォーラムで3Dプリンタ用のギア図面を公開している人がいる!
3DCADソフトFusion360の基本的な使い方を覚えて(つくづくフリーソフトが好きだな)3万以下の3DプリンターEnder-3 Proを購入。
ABS樹脂の層割れや反りなど初心者の失敗を一通り経験したあと、PETG樹脂で ハードは結構うまく出来上がった!そして現時点。AOG-ESP(wifi_UDP)の通信部のエラーがまだ未解決。ならばと自作ラズパイとESPにUSB接続で動かせないか、と考えてみたがこれも制御アルゴリズムを一から勉強しないと難しそう。
もうひとつの手はせっかく作ったESPの基板を諦めてAruduinoではじめから作り直す。こちらはAOGの作者本人が作ったのでスケッチも改変せずにそのままで動くはず(?)
さて2020年には完成するでしょうか? ... to be continued
- 投稿日:2020-01-01T23:46:22+09:00
コピペで試せる!Pythonのnetworkxでかっこいいネットワーク図を描いてみよう
冬休みはかっこいいネットワーク図が描けるnetworkxでネットワーク図を描いてみよう
みなさまはいい冬休みを過ごしていますか?わが社は28から5日までお休みをいただき本当にネズミに感謝している日々です。
でも技術者はこういった時こそマック難民をして自己の技術を研鑽させるべきだと思います。
今日はnetworkxというネットワーク図が描けるライブラリを紹介します。
- 今回のワークの所要時間:10分程度
- 用意するもの
- Python 3.x
- jupyterhub(pandasとmatplotlibをインストールしておいてください)
インストール
(venv)$pip install networkxまずはデータをpandasでデータをロードします
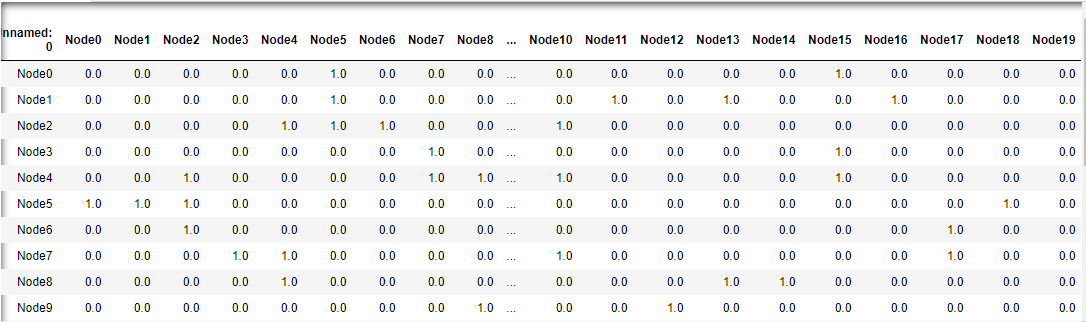
import pandas as pd df_links = pd.read_csv('https://microlearning.site/pydata/ch8/links.csv') df_links.head(20)以下のような表がロードされていることを確認してください。関係があるネットワーク同士は1になっています。
いよいよネットワーク図を描画
ネットワーク図の描画は以下です。
import networkx as nx import matplotlib.pyplot as plt G = nx.Graph() NUM = len(df_links.index) for i in range(1,NUM+1): node_no = df_links.columns[i].strip("Node")#「Node」の文字を除去 G.add_node(str(node_no)) for i in range(NUM): for j in range(NUM): if df_links.iloc[i][j] == 1: G.add_edge(str(i),str(j)) nx.draw_networkx(G,nide_color="k",edge_color="k",font_color="w") plt.show()何をしているかざっくりと説明させていただくと、まずノードを追加して
表のノード同士が1になっている部分(関係している部分)を線で結んでいます。すると、以下のようなネットワーク図が表示されます(毎回表示は異なります)
各ノードと関係が濃い番号が中心に来ています。(4や5など)
お疲れさまでした。実行するたびに形が異なります。試してみてください。
更新履歴
- 2020/1/1 新規作成

- 投稿日:2020-01-01T23:42:02+09:00
Raspberry pi初期設定(自分用)
背景と概要
通常Raspberry Pi(以下RPi) をセットアップするとき、SDカードにイメージを焼き込んだあと、HDMIディスプレイとUSBキーボードを RPi に直接接続して色々と設定します。しかしいちいちディスプレイとかキーボードに繋ぐのめちゃくちゃ面倒くさいかつ自分の覚書きのためにこの記事を書きます
環境
・Windows10
・raspberry pi 3 model B
・有線LAN1.OSのイメージ作成
OSダウンロード
・https://www.raspberrypi.org/downloads/raspbian/SDカードフォーマット
・https://www.sdcard.org/downloads/formatter/eula_windows/index.htmlSDカードにOSイメージを書き込み
・https://www.balena.io/etcher/2.設定
最上位に"ssh"という名前の空フォルダを作成
(これでRPiを起動したときにsshの自動起動ができる)RPiを有線LANに繋いで起動する
tera termから以下を打ち込んでssh接続
ホスト名 :raspberrypi.local
ユーザー名:pi
パスワード:raspberry3.Wi-fi設定
以下のコードを打ち込んで手順に従ってSSIDとパスワードを入れつ
rasbian$ sudo raspi-config4.固定ipアドレス設定
$ sudo nano /etc/dhcpcd.conf以下のコードを末尾に追記
interface wlan0 static ip_address=192.168.1.221/24 static routers=192.168.1.1 static domain_name_servers=192.168.1.1あとはtera termでipアドレス=192.168.1.221としてsshでつなげばよろしい
参考文献
https://qiita.com/eup42/items/58bf6c336d325eba3ee2
https://qiita.com/mym/items/468d2cdb30d756b6df24
http://www.fml.org/home/fukachan/ja/linux.share.network.debian.html
https://qiita.com/yuppejp/items/413b32d14d58c10e192c
https://physical-computing-lab.net/raspberry-pi/raspberry-pi-3-%E3%81%AE%E7%84%A1%E7%B7%9Alan%E3%81%AB%E5%9B%BA%E5%AE%9Aip%E3%82%A2%E3%83%89%E3%83%AC%E3%82%B9%E3%82%92%E8%A8%AD%E5%AE%9A%E3%81%99%E3%82%8B.html
- 投稿日:2020-01-01T22:50:03+09:00
Vue.js+Flaskの環境構築備忘録〜Anaconda3を添えて〜
はじめに
私が愛用しているFlaskでVueを使いたくなったので環境構築手順をメモしておきます。
自分用の走り書きです。登場人物
- Vue.js(Vue CLI)
- Flask
- Anaconda3
手順
conda仮想環境の作成
Anaconda3で必要なライブラリをインストールした仮想環境を作る。
僕は大概、conda環境の中身にscriptsという開発フォルダを作成しています。
なので、その中にflaskフォルダとvueフォルダを作成します。flask環境構築
from flask import Flask, render_template, request, jsonify, make_response, send_file app = Flask(__name__, static_folder='../vue/dist/static', template_folder='../vue/dist') @app.route('/') def index(): return render_template('index.html') if __name__ == "__main__": app.run()template_folderとstatic_folderでvueのビルドフォルダを指定しておく。
vueアプリケーション作成とビルド設定
vueフォルダにアプリケーションを作成します。
僕はvue uiでサクッと作成します。
vueフォルダ直下にvue.config.jsという設定ファイルを作成し、以下のとおりにします。module.exports = { assetsDir: 'static', };.jsファイルやらを全てdist/staticフォルダに保存するという設定です。
完成
vueでビルド後にflaskサーバを起動すれば、vueアプリケーションが読み込まれます。
- 投稿日:2020-01-01T22:14:41+09:00
なぜ分類問題の目的関数には交差エントロピーが使われるのか
分類問題とは
分類問題とは,データをいくつかのカテゴリに分類するもので,機械学習の代表的な方法の一つです。
購買サイトを例にとってみましょう。
ユーザの購買情報からそのユーザが新商品を買うか買わないかを予測します。
2つのカテゴリ(クラス)に分類することを2値分類と呼びます。2クラスより多い分類予測については、多クラス分類と呼ばれます。
画像に写っている物の判断(画像認識)も多クラス分類問題の1つです。
猫の画像をもとにして、それが猫であると判断するのも分類問題ということですね。交差エントロピー
2つの確率分布
P(x): 正解データ分布 \\ Q(x): 予測モデル分布に対して、交差エントロピーは以下で定義されます。
L = - \sum_{x} P(x) \log{Q(x)}2つの確率分布が似ている分布であるほど、交差エントロピーは小さくなります。
この関数の性質を利用して、機械学習(とくに分類問題)においては目的関数として採用されることが多いです。本記事では、なぜ目的関数に交差エントロピーが採用されることが多いのか数学的に考察してみます。
交差エントロピーについての詳しい説明は以下が参考になりました。
http://cookie-box.hatenablog.com/entry/2017/05/07/121607二項分布(ベルヌーイ分布)
分類問題を考察する上で、最も簡単な確率分布である二項分布を例にとります。
P(x_1) = p \;\;\; P(x_2) = 1 - p \\ Q(x_1) = q \;\;\; Q(x_2) = 1 - q \\
箱に赤と白の2色の玉が入っていて、赤を引く確率が
P(赤) = p白を引く確率が
P(白) = 1 - pと考えるとわかりやすいですね。
玉が合計10個入っていて、赤が2個、白が8個であるならP(赤) = 0.2 \quad P(白) = 0.8ということです。
さて、このとき目的関数は
\begin{align} L &= - \sum_{x} P(x) \log{Q(x)} \\ &= - p \log{q} - (1-p) \log{(1-q)} \end{align}と展開できます。
以下のようなシンプルなニューラルネットワークを考えてみましょう。最終的に確率分布 $q$ を求めたいというシナリオを想定してください。先ほどの例をあげると、箱の中身が全くわからないけれど、いくつかの入力データを使用して赤色の玉を引く確率分布をモデルとして構築して結果を予測しようというわけです。
y = \sum_{i} x_i w_i \\ \\ q(y) = \frac{1}{1+e^{-y}} : シグモイド関数ここで $x_i$を入力、$w_i$を重み、$y$を途中の値、$q$を出力としています。
活性化関数には最も代表的なシグモイド関数を採用しました。ニューラルネットワークの訓練
目的関数の値を最小にするようなパラメータの値を求めることで、ニューラルネットワークを訓練します。 最適化アルゴリズムの一つである勾配降下法 (gradient descent) を使用します。
w \leftarrow w - \eta \frac{\partial L}{\partial w}勾配降下法では学習率×目的関数の勾配を繰りかえし計算し、目的関数の最小値をとる重みを求める手法です。
このあたりの詳しい説明は以下の Chainer Tutorial が非常にわかりやすいです。
https://tutorials.chainer.org/ja/13_Basics_of_Neural_Networks.htmlさっそく目的関数を微分していきましょう。
\frac{\partial L }{\partial w_i} = \frac{\partial y}{\partial w_i} \frac{\partial q }{\partial y}\frac{\partial L }{\partial q}1つ目の微分は
\frac{\partial y}{\partial w_i} = \frac{\partial}{\partial w_i} \sum_i x_i w_i = x_i2つ目の微分は
\begin{align} \frac{\partial q }{\partial y} &= \frac{\partial}{\partial y} \frac{1}{1+e^{-y}} \\ &= \frac{\partial u}{\partial y}\frac{\partial}{\partial u} \frac{1}{u} \\ &= -e^{-y} (-u^{-2}) \\ &= \frac{e^{-y}}{1+e^{-y}}\frac{1}{1+e^{-y}} \\ &= \bigl( \frac{1+e^{-y}}{1+e^{-y}} - \frac{1}{1+e^{-y}} \bigr) \frac{1}{1+e^{-y}} \\ &= \bigl( 1-q(y) \bigr) q(y) \end{align}3つ目の微分は
\begin{align} \frac{\partial L}{\partial q} &= \frac{\partial}{\partial q} \{ - p \log{q} - (1-p) \log{(1-q)} \} \\ &= - \frac{p}{q} + \frac{1-p}{1-q} \end{align}と計算できるので
\frac{\partial L }{\partial w_i} = x_i (1-q) q \bigl( - \frac{p}{q} + \frac{1-p}{1-q} \bigr) = x_i (q-p)つまり
p = qであるとき、目的関数は最小値をとります。
これはいいかえれば正解データの分布と予測モデルの分布が完全に一致することを意味していますね。まぁ当たり前のことを言っているだけです。
実際に箱の中には赤が8個、白が2個入っていて
赤が80%, 白が20%の確率でしょうと予測しているということです。分類問題に適用する
さて、分類問題としてもう少しバリエーションを増やしてみましょう。たとえば分類問題ではカテゴリーを 0, 1 で表現することができます。
りんご: [1, 0, 0] ごりら: [0, 1, 0] らっぱ: [0, 0, 1]もう少し汎化していえば
x が所属するクラスの正解が、
t=[t_1, t_2 …t_K]^Tというベクトルで与えられているとします。 ただし、このベクトルは $t_k \; (k=1,2,…,K)$ のいずれか 1 つだけが 1 であり、それ以外は 0 であるようなベクトルであるとします。 これをワンホットベクトル(1-hot vector)と呼びます。
このように分類問題を定義できるようになったので、目的関数は以下のようになります。
L = - \sum_x P(x) \log{ Q(x) } = - \log{ Q(x) }$Q(x)$ は学習データが教師データと同じになる確率を表しています。
プロットしてみましょう。
勾配降下法では、学習率×目的関数の勾配を繰りかえし計算することで目的関数を最小とする重み $w_i$ を求めるのでした。学習率が極端に高い、あるいは目的関数の勾配が大きければ学習効率が良さそうです。計算のステップ数も少なくなります。
$0 < Q(x) < 1$ に対して、目的関数 $L$ は $Q(x) = 0$ 近傍で急激に減少することがわかります。
このことから教師データと学習結果が違いすぎる場合、1 Stepあたりの減少量が大きいと解釈できます。
分類問題では交差エントロピーを目的関数に選ぶと、計算効率が良いのですね。実際に Chainer や Pytorch などのライブラリを使っていると忘れてしまいがちですが
基礎的な理論を忘れないように振り返るのも良いですね。勉強になりました。参考
https://mathwords.net/kousaentropy
https://water2litter.net/rum/post/ai_loss_function/
http://yaju3d.hatenablog.jp/entry/2018/11/30/225841
https://avinton.com/academy/classification-regression/





- 投稿日:2020-01-01T21:38:28+09:00
Pythonを超初心者がまとめてみよう
はじめに
あけましておめでとうございます。python初めて2か月がたとうとしておりました。せっかくなので、学んだことを外に出しておこうかなと思いまして、これから毎日Pythonまとめていこうと思います。
Pythonってなに?
1. プログラミング言語のひとつ
Pythonはプログラミング言語のひとつ。プログラミング言語っていうのは、パソコンにこれやってあれやってっていろいろ命令することができる言葉のこと。
HTMLCSS、Ruby、Swiftなど。英語、日本語、中国語みたいに外国語がたくさんあるように、プログラミング言語もたくさんある。● HTMLとCSSは文字とか画像を画面に表示できます。いわゆるWebページの見えている部分が作れます。
● Rubyはアプリが簡単に作れます
● SwiftはIphoneのアプリがさらに簡単に作れます
こうした言語のひとつにPythonがいます。
2. 何ができるの
アプリも作れます。エクセルもいじれます。AIが作れます。などやれることがとっても多いのがPythonの特徴。
なかでも、最近Pythonの人気が上がっているのがAIが作れるから。
AI=人工知能。
「OK!google」「Hey,Siri」みたいな声でいろいろやってくれる機械が当たり前になったのも、音声を機械が認識する力がめちゃくちゃ高くなったから。すごーーくわかりやすくいうとこの認識している力のことをAIっていう。
もちろんもっと広義な意味だから、そのうちまとめます。まなびかた
前出の通り、言語なので使いながら学ぶのが一番。ただ、英語などのような語学と違うのはしゃべらなくていいってこと。つまり、わからなければカンニングし放題。やったね
1. 書き方を知る
プログラミングを始めるとき、エディタ(プログラミング言語を記入する黒板みたいなところ)に、命令を打ち込んでパソコンの画面に「Hello world!」と表示させる練習をします。
print("Hello world")と入力すると
パソコンが
Hello world!と返してくれます。多分初心者はだからなんじゃいってなると思うんですが、これは言語学習で言えば声の出し方を教えている段階なので、気にせずマネしときましょう。
「()内に書かれた文字や値を表示して!」ってprintと書くことで命令しています。この命令って考え方ができると個人的に一歩成長。
2. めちゃくちゃ基本の概念を知る
「あいうえお」って文字じゃないですか。
「1,2,3,4」って数字じゃないですか。何を当たり前のことをって思うと思います。でも、プログラミングはこの二つはしっかり分けなきゃあかんのです。
具体的にはさっきの
print("Hello World!"")を
print(Hello World!)って書いちゃうと
SyntaxError: invalid syntaxってエラーが帰ってきて、PCはゆうことを聞いてくれません。
違い分かりますか??
下は「""」がないんです。この「""」は、この中に書いてるのは文字だよってPCに教える合図です。
だから書かないと拗ねてエラーを返してきます。几帳面なんですね。ちなみに数字は
print(4)って感じで「""」書かなくてOKです。文字じゃないんで。てか、数字として使うならかいちゃだめ、絶対。
4ちゃんとやれば上のように帰ってきます。
ほかにも最低限
● 演算のしかた
● 変数の意味
● 型
● If文
● for文
● 関数(これはあとででもいいかも)は覚えないと多分だめだと思います。
こんな感じで、やりだせば当たり前になる概念をつかんでいくのが最初のステップです。ここはProgateっていうサイトで勉強できるのでチャチャっとやっちゃいましょ。
繰り返しいいますが、いくらカンニングし放題でもここがわからないとカンニングの仕方も謎になっちゃいますよ~3. なにかつくってみる
王道です。プログラミングは何かを作るための言葉なので、基本がわかったら何か作っちゃいましょう。
この辺はまた後日まとめていきますねおわり
ちょっと駆け足でしたが、入門の入門くらいでまとめてみました。
明日も頑張ります
- 投稿日:2020-01-01T20:48:33+09:00
デザインパターンについて勉強してみた(個人的メモ)その3(AbstractFactoryパターン、Bridgeパターン、Strategyパターン)
はじめに
この記事は個人的な勉強メモです。inputしたものはoutputしなくてはという強迫観念に駆られて記事を書いています。
あわよくば詳しい人に誤りの指摘やアドバイスを頂ければいいなという思いを込めてQiitaの記事にしています。エンジニアとして社会人生活を送っていますが、デザインパターンについてちゃんと学んだことがなかったので勉強してみました。
ここに記載している内容は
https://github.com/ck-fm0211/notes_desigh_pattern
にuploadしています。過去ログ
デザインパターンについて勉強してみた(個人的メモ)その1
デザインパターンについて勉強してみた(個人的メモ)その2
デザインパターンについて勉強してみた(個人的メモ)その3AbstractFactoryパターン
- インスタンスの生成を専門に行うクラスを用意することで、整合性を必要とされる一連のオブジェクト群を間違いなく生成するためのパターン
- 例
- 「車」を作成するプログラムを考える
- 「車」オブジェクトである変数 car にタイヤとハンドルを追加してみる
car.add_tire(CarTire()); car.add_handle(CarHandle());
- プログラマのミスで異なるタイヤ(自転車のタイヤ)を渡してしまうこともあるかもしれない
car.add_tire(BicycleTire()); car.add_handle(CarHandle());
- 利用すべきではないオブジェクトを利用してしまうことはあり得る
- このようなとき、車を作成するために必要な一連のオブジェクトを作成することを一手に引き受ける工場クラスを用意し、タイヤやハンドルといったオブジェクトを生成するときは、この工場クラスを利用してオブジェクトの生成を行うようにすることで、先ほどのような間違いが起こることを回避することができる
- この工場クラスを変更することで、利用する一連のオブジェクトをごっそり変更することもできるようになる。
実際に使ってみる
題材
- 「鍋」を作ることを考える
- 構成要素
- スープ
- メインの具(たんぱく質)
- 野菜
- その他の具
- 鍋物をあらわす HotPot クラスは以下のように定義されているものとする
# -*- coding:utf-8 -*- class HotPot: pot = None soup = None protein = None vegetables = [] other_ingredients = [] @staticmethod def hot_pot(pot): HotPot.pot = pot @staticmethod def add_soup(soup): HotPot.soup = soup @staticmethod def add_main(protein): HotPot.protein = protein @staticmethod def add_vegitables(vegitables): HotPot.vegetables = vegitables @staticmethod def add_other_ingredients(other_ingredients): HotPot.other_ingredients = other_ingredients
- 鍋を作る工程を抽象化した Factory クラスを用意する
class Factory(metaclass=ABCMeta): @abstractmethod def get_soup(self): pass @abstractmethod def get_main(self): pass @abstractmethod def get_vegetables(self): pass @abstractmethod def get_other_ingredients(self): pass
- これを継承したMizutaki(水炊き)Factoryクラスを用意し、これをもとに水炊きをつくる。
class MizutakiFactory(Factory): def get_soup(self): return "torigara" def get_main(self): return "chicken" def get_vegetables(self): return ["hakusai", "ninjin", "negi"] def get_other_ingredients(self): return ["tofu"] class Sample: @staticmethod def main(): hp = HotPot() mf = MizutakiFactory() hp.add_soup(mf.get_main()) hp.add_main(mf.get_main()) hp.add_vegitables(mf.get_vegetables()) hp.add_other_ingredients(mf.get_other_ingredients())
- 引数に与えられた文字列によって、実際に利用する Factory クラスを選択して生成する
class Sample: @staticmethod def create_factory(s): if s == "キムチ鍋": return KimuchiFactory() elif s == "すき焼き": return SukiyakiFactory() else: return MizutakiFactory() @staticmethod def main(arg): hp = HotPot() fc = create_factory(arg) hp.add_soup(fc.get_main()) hp.add_main(fc.get_main()) hp.add_vegitables(fc.get_vegetables()) hp.add_other_ingredients(fc.get_other_ingredients())
- main メソッドの中では、Factory メソッドの実際の型を知ることなく処理が進んでいる。すなわち、抽象的な Factory クラスを利用して処理を進めていっている。
- 「利用するオブジェクト群をごそっと入れ替える」という要求に応えることができる
Builderパターンのまとめ
Bridgeパターン
- 機能と実装を分離して、それぞれを独立に拡張することができるようになる
- 例
- ある methodA というメソッドを持つクラス MyClassA は、methodA メソッドの実装が異なる MyClassASub1、MyClassASub2 という2つのクラスによって継承されているとする
- MyClassA にmethodB というメソッドを追加するために、MyClassB クラスという MyClassA を継承するクラスを作成したとする
- MyClassB でも、MyClassASub1、MyClassASub2 で実装している methodA と同じ実装を利用したい場合、MyClassB クラスを継承する MyClassBSub1、MyClassBSub2 といったクラスを作成する必要がある ← めんどい
- 規模が大きくなると面倒さが倍々ゲームになる
実際に使ってみる
題材
- ソート機能を持つ抽象クラスSorter と、この Sorter クラスで定義されている抽象メソッドである sort(Object obj[]) メソッドを実装するクラス (QuickSorter クラス、BubbleSorter クラス) について考える
- Sorter クラス、QuickSorter クラス、BubbleSorter クラスのコードはそれぞれ以下のようになっている。ソート部分の実装に関しては、ここでは重要でないため省略する。
# -*- coding:utf-8 -*- from abc import ABCMeta, abstractmethod class Sorter(metaclass=ABCMeta) @abstractmethod def sort(self, obj): pass class QuickSorter(Sorter): def sort(self, obj): # クイックソート pass class BubbleSorter(Sorter): def sort(self, obj): # バブルソート pass
- Sorterクラスにソートにかかった時間を表示する機能を持つ timer_sorter メソッドを追加したい
from datetime import datetime class TimerSorter(metaclass=ABCMeta, Sorter): @abstractmethod def time_sorter(self, obj): start = datetime.now() Sorter.sort(obj) end = datetime.now() print("time:" + str((end - start)))
- このままだと、TimerSorterクラスに実装を与えられない
- 実装するためにはQuickSorter/BubbleSorter相当のクラスを用意する必要がある
- Bridgeパターンで考える。実装の変更が考えられるメソッドに関しては、実装用のクラス階層に委譲するように設計する。
- 実装用のクラス階層:ここでは sort メソッドの実装を与えるクラス階層として、SortImple クラスを親とするクラス階層を考える
class SortImple(metaclass=ABCMeta): @abstractmethod def sort(self, obj): pass class Sorter: si = SortImple() @staticmethod def sorter(si): Sorter.si = si def sort(self, obj): Sorter.si.sort(obj) class QuickSorterImple(SortImple): def sort(self, obj): # クイックソート pass class BubbleSorterImple(SortImple): def sort(self, obj): # バブルソート pass
- こうすることで機能を追加するために、Sorter クラスを拡張して作成した新しいクラスでも、すでに存在する実装部分を利用することができるようになる。例えば、Sorter クラスを拡張する TimerSorter クラスを作成する場合には、以下のようになる。
from datetime import datetime class TimerSorter(metaclass=ABCMeta, Sorter): def __init__(self, sort_impl): super(sort_impl) @abstractmethod def time_sorter(self, obj): start = datetime.now() Sorter.sort(obj) end = datetime.now() print("time:" + str((end - start)))
- 機能を拡張するためのクラス階層と、実装を拡張するためのクラス階層を分けておくことで、実装階層クラスと機能拡張クラスを好みの組み合わせで利用することができるようになる
- 今回の例では、Sorter クラスと SortImple クラスが機能拡張クラス階層と実装拡張クラス階層を橋渡しする役目を果たしている
Builderパターンのまとめ
Strategyパターン
- 普通にプログラミングしていると、メソッドの中に溶け込んだ形でアルゴリズムを実装してしまうことがある
- if 文などで分岐させることでアルゴリズムを変更するなど
- Strategy パターンでは、戦略の部分を意識して別クラスとして作成するようにする
- 戦略x部分を別クラスとして作成しておき、戦略を変更したい場合には、利用する戦略クラスを変更するという方法で対応する
- Strategy パターンを利用することで、メソッドの中に溶け込んだ形のアルゴリズムより柔軟でメンテナンスしやすい設計となる
実際に使ってみる
題材
- 状況に応じてアルゴリズムを変えなければならないことは多々ある。例えばゲームのプログラムでは、難易度の設定によって、その戦略アルゴリズムを変えるなど。
- ここでは簡単に、大小の比較を行うアルゴリズムを考えてみる。
- まずは、人間を表す Human クラスを作成する。Human クラスは、名前、身長、体重、年齢の4つのパラメータを持つものとする。
# -*- coding:utf-8 -*- from abc import ABCMeta, abstractmethod class Human: def __init__(self, name, height, weight, age): self.name = name self.height = height self.weight = weight self.age = age
- ここで、2つのHuman インスタンスが与えられた場合に、それらの大小を比較する SampleClass というクラスを考える。
class SampleClass: @staticmethod def compare(h1: Human, h2: Human) -> int: if h1.age > h2.age: return 1 elif h1.age == h2.age: return 0 else: return -1
- ここでは年齢を比較してその結果を返すことだけしか考えていない
- しかし、Human オブジェクトには複数のパラメータがあり、Human を比較する方法はいくつか考えられる
- 比較結果は、どのパラメータをどのように利用するかにより異なってしまう。
- 例えば、単純に年齢で比較する場合と、身長で比較する場合では異なる結果となる
- そこで、比較するパラメータを指定できるようなプログラムとすることを考える。
class SampleClass2: type = -1 COMPARE_AGE = 1 COMPARE_HEIGHT = 2 COMPARE_WEIGHT = 3 def __init__(self, type): SampleClass2.type = type @staticmethod def compare(h1: Human, h2: Human) -> int: if SampleClass2.type == SampleClass2.COMPARE_AGE: if h1.age > h2.age: return 1 elif h1.age == h2.age: return 0 else: return -1 elif SampleClass2.type == SampleClass2.COMPARE_HEIGHT: if h1.height > h2.height: return 1 elif h1.height == h2.height: return 0 else: return -1 # ・・・
- 煩雑なコードになってしまう。Strategy パターンでは、状況に応じて、変更する必要のあるアルゴリズムの部分を、意識的に別クラスとして分離することで、アルゴリズムの修正、追加等の見通しを良くする。
- まずは、比較アルゴリズム部分をクラスとして分離する。例えば、年齢を比較するための、AgeComparatorクラスを作成する。
class AgeComparator: @staticmethod def compare(h1: Human, h2: Human) -> int: if h1.age > h2.age: return 1 elif h1.age == h2.age: return 0 else: return -1
- 比較アルゴリズム部分を分離し、実際の比較処理は、AgeComparator に委譲できるようにしておく。
class MyClass: @staticmethod def compare(h1: Human, h2: Human) -> int: return AgeComparator.compare(h1, h2)
- これだけではメリットはなく、 Strategy パターンにもなっていない。Strategy パターンでは、分離したアルゴリズム部分が共通のインタフェースを持つようにすることが求められる。
- すなわち、アルゴリズムとして分離された複数のクラスが共通のインタフェースを持つ必要がある。
- サンプルケースでは、年齢を比較する AgeComparator クラス以外にも、身長を比較するための HeightComparatorクラス、体重を比較するための WeightComparatorクラスなどが考えられる。
- これらの比較アルゴリズムを表すクラスに共通のインタフェースを持たせる。
- ここでは、Comparator インタフェースを定義してみます。
class Comparator(metaclass=ABCMeta): @staticmethod @abstractmethod def compare(h1: Human, h2: Human) -> int: pass class AgeComparator(Comparator): @staticmethod def compare(h1: Human, h2: Human) -> int: if h1.age > h2.age: return 1 elif h1.age == h2.age: return 0 else: return -1 class HeightComparator(Comparator): @staticmethod def compare(h1: Human, h2: Human) -> int: if h1.height > h2.height: return 1 elif h1.height == h2.height: return 0 else: return -1
- こうすることでSampleClassは以下のように書き換えられる
class SampleClass: def __init__(self, comp: Comparator): self._comp = comp def compare(self, h1: Human, h2: Human) -> int: return self._comp.compare(h1, h2)Strategyパターンのまとめ



- 投稿日:2020-01-01T20:48:33+09:00
デザインパターンについて勉強してみた(個人的メモ)その4(AbstractFactoryパターン、Bridgeパターン、Strategyパターン)
はじめに
この記事は個人的な勉強メモです。inputしたものはoutputしなくてはという強迫観念に駆られて記事を書いています。
あわよくば詳しい人に誤りの指摘やアドバイスを頂ければいいなという思いを込めてQiitaの記事にしています。エンジニアとして社会人生活を送っていますが、デザインパターンについてちゃんと学んだことがなかったので勉強してみました。
ここに記載している内容は
https://github.com/ck-fm0211/notes_desigh_pattern
にuploadしています。過去ログ
デザインパターンについて勉強してみた(個人的メモ)その1
デザインパターンについて勉強してみた(個人的メモ)その2
デザインパターンについて勉強してみた(個人的メモ)その3AbstractFactoryパターン
- インスタンスの生成を専門に行うクラスを用意することで、整合性を必要とされる一連のオブジェクト群を間違いなく生成するためのパターン
- 例
- 「車」を作成するプログラムを考える
- 「車」オブジェクトである変数 car にタイヤとハンドルを追加してみる
car.add_tire(CarTire()); car.add_handle(CarHandle());
- プログラマのミスで異なるタイヤ(自転車のタイヤ)を渡してしまうこともあるかもしれない
car.add_tire(BicycleTire()); car.add_handle(CarHandle());
- 利用すべきではないオブジェクトを利用してしまうことはあり得る
- このようなとき、車を作成するために必要な一連のオブジェクトを作成することを一手に引き受ける工場クラスを用意し、タイヤやハンドルといったオブジェクトを生成するときは、この工場クラスを利用してオブジェクトの生成を行うようにすることで、先ほどのような間違いが起こることを回避することができる
- この工場クラスを変更することで、利用する一連のオブジェクトをごっそり変更することもできるようになる。
実際に使ってみる
題材
- 「鍋」を作ることを考える
- 構成要素
- スープ
- メインの具(たんぱく質)
- 野菜
- その他の具
- 鍋物をあらわす HotPot クラスは以下のように定義されているものとする
# -*- coding:utf-8 -*- class HotPot: pot = None soup = None protein = None vegetables = [] other_ingredients = [] @staticmethod def hot_pot(pot): HotPot.pot = pot @staticmethod def add_soup(soup): HotPot.soup = soup @staticmethod def add_main(protein): HotPot.protein = protein @staticmethod def add_vegitables(vegitables): HotPot.vegetables = vegitables @staticmethod def add_other_ingredients(other_ingredients): HotPot.other_ingredients = other_ingredients
- 鍋を作る工程を抽象化した Factory クラスを用意する
class Factory(metaclass=ABCMeta): @abstractmethod def get_soup(self): pass @abstractmethod def get_main(self): pass @abstractmethod def get_vegetables(self): pass @abstractmethod def get_other_ingredients(self): pass
- これを継承したMizutaki(水炊き)Factoryクラスを用意し、これをもとに水炊きをつくる。
class MizutakiFactory(Factory): def get_soup(self): return "torigara" def get_main(self): return "chicken" def get_vegetables(self): return ["hakusai", "ninjin", "negi"] def get_other_ingredients(self): return ["tofu"] class Sample: @staticmethod def main(): hp = HotPot() mf = MizutakiFactory() hp.add_soup(mf.get_main()) hp.add_main(mf.get_main()) hp.add_vegitables(mf.get_vegetables()) hp.add_other_ingredients(mf.get_other_ingredients())
- 引数に与えられた文字列によって、実際に利用する Factory クラスを選択して生成する
class Sample: @staticmethod def create_factory(s): if s == "キムチ鍋": return KimuchiFactory() elif s == "すき焼き": return SukiyakiFactory() else: return MizutakiFactory() @staticmethod def main(arg): hp = HotPot() fc = create_factory(arg) hp.add_soup(fc.get_main()) hp.add_main(fc.get_main()) hp.add_vegitables(fc.get_vegetables()) hp.add_other_ingredients(fc.get_other_ingredients())
- main メソッドの中では、Factory メソッドの実際の型を知ることなく処理が進んでいる。すなわち、抽象的な Factory クラスを利用して処理を進めていっている。
- 「利用するオブジェクト群をごそっと入れ替える」という要求に応えることができる
Builderパターンのまとめ
Bridgeパターン
- 機能と実装を分離して、それぞれを独立に拡張することができるようになる
- 例
- ある methodA というメソッドを持つクラス MyClassA は、methodA メソッドの実装が異なる MyClassASub1、MyClassASub2 という2つのクラスによって継承されているとする
- MyClassA にmethodB というメソッドを追加するために、MyClassB クラスという MyClassA を継承するクラスを作成したとする
- MyClassB でも、MyClassASub1、MyClassASub2 で実装している methodA と同じ実装を利用したい場合、MyClassB クラスを継承する MyClassBSub1、MyClassBSub2 といったクラスを作成する必要がある ← めんどい
- 規模が大きくなると面倒さが倍々ゲームになる
実際に使ってみる
題材
- ソート機能を持つ抽象クラスSorter と、この Sorter クラスで定義されている抽象メソッドである sort(Object obj[]) メソッドを実装するクラス (QuickSorter クラス、BubbleSorter クラス) について考える
- Sorter クラス、QuickSorter クラス、BubbleSorter クラスのコードはそれぞれ以下のようになっている。ソート部分の実装に関しては、ここでは重要でないため省略する。
# -*- coding:utf-8 -*- from abc import ABCMeta, abstractmethod class Sorter(metaclass=ABCMeta) @abstractmethod def sort(self, obj): pass class QuickSorter(Sorter): def sort(self, obj): # クイックソート pass class BubbleSorter(Sorter): def sort(self, obj): # バブルソート pass
- Sorterクラスにソートにかかった時間を表示する機能を持つ timer_sorter メソッドを追加したい
from datetime import datetime class TimerSorter(metaclass=ABCMeta, Sorter): @abstractmethod def time_sorter(self, obj): start = datetime.now() Sorter.sort(obj) end = datetime.now() print("time:" + str((end - start)))
- このままだと、TimerSorterクラスに実装を与えられない
- 実装するためにはQuickSorter/BubbleSorter相当のクラスを用意する必要がある
- Bridgeパターンで考える。実装の変更が考えられるメソッドに関しては、実装用のクラス階層に委譲するように設計する。
- 実装用のクラス階層:ここでは sort メソッドの実装を与えるクラス階層として、SortImple クラスを親とするクラス階層を考える
class SortImple(metaclass=ABCMeta): @abstractmethod def sort(self, obj): pass class Sorter: si = SortImple() @staticmethod def sorter(si): Sorter.si = si def sort(self, obj): Sorter.si.sort(obj) class QuickSorterImple(SortImple): def sort(self, obj): # クイックソート pass class BubbleSorterImple(SortImple): def sort(self, obj): # バブルソート pass
- こうすることで機能を追加するために、Sorter クラスを拡張して作成した新しいクラスでも、すでに存在する実装部分を利用することができるようになる。例えば、Sorter クラスを拡張する TimerSorter クラスを作成する場合には、以下のようになる。
from datetime import datetime class TimerSorter(metaclass=ABCMeta, Sorter): def __init__(self, sort_impl): super(sort_impl) @abstractmethod def time_sorter(self, obj): start = datetime.now() Sorter.sort(obj) end = datetime.now() print("time:" + str((end - start)))
- 機能を拡張するためのクラス階層と、実装を拡張するためのクラス階層を分けておくことで、実装階層クラスと機能拡張クラスを好みの組み合わせで利用することができるようになる
- 今回の例では、Sorter クラスと SortImple クラスが機能拡張クラス階層と実装拡張クラス階層を橋渡しする役目を果たしている
Builderパターンのまとめ
Strategyパターン
- 普通にプログラミングしていると、メソッドの中に溶け込んだ形でアルゴリズムを実装してしまうことがある
- if 文などで分岐させることでアルゴリズムを変更するなど
- Strategy パターンでは、戦略の部分を意識して別クラスとして作成するようにする
- 戦略x部分を別クラスとして作成しておき、戦略を変更したい場合には、利用する戦略クラスを変更するという方法で対応する
- Strategy パターンを利用することで、メソッドの中に溶け込んだ形のアルゴリズムより柔軟でメンテナンスしやすい設計となる
実際に使ってみる
題材
- 状況に応じてアルゴリズムを変えなければならないことは多々ある。例えばゲームのプログラムでは、難易度の設定によって、その戦略アルゴリズムを変えるなど。
- ここでは簡単に、大小の比較を行うアルゴリズムを考えてみる。
- まずは、人間を表す Human クラスを作成する。Human クラスは、名前、身長、体重、年齢の4つのパラメータを持つものとする。
# -*- coding:utf-8 -*- from abc import ABCMeta, abstractmethod class Human: def __init__(self, name, height, weight, age): self.name = name self.height = height self.weight = weight self.age = age
- ここで、2つのHuman インスタンスが与えられた場合に、それらの大小を比較する SampleClass というクラスを考える。
class SampleClass: @staticmethod def compare(h1: Human, h2: Human) -> int: if h1.age > h2.age: return 1 elif h1.age == h2.age: return 0 else: return -1
- ここでは年齢を比較してその結果を返すことだけしか考えていない
- しかし、Human オブジェクトには複数のパラメータがあり、Human を比較する方法はいくつか考えられる
- 比較結果は、どのパラメータをどのように利用するかにより異なってしまう。
- 例えば、単純に年齢で比較する場合と、身長で比較する場合では異なる結果となる
- そこで、比較するパラメータを指定できるようなプログラムとすることを考える。
class SampleClass2: type = -1 COMPARE_AGE = 1 COMPARE_HEIGHT = 2 COMPARE_WEIGHT = 3 def __init__(self, type): SampleClass2.type = type @staticmethod def compare(h1: Human, h2: Human) -> int: if SampleClass2.type == SampleClass2.COMPARE_AGE: if h1.age > h2.age: return 1 elif h1.age == h2.age: return 0 else: return -1 elif SampleClass2.type == SampleClass2.COMPARE_HEIGHT: if h1.height > h2.height: return 1 elif h1.height == h2.height: return 0 else: return -1 # ・・・
- 煩雑なコードになってしまう。Strategy パターンでは、状況に応じて、変更する必要のあるアルゴリズムの部分を、意識的に別クラスとして分離することで、アルゴリズムの修正、追加等の見通しを良くする。
- まずは、比較アルゴリズム部分をクラスとして分離する。例えば、年齢を比較するための、AgeComparatorクラスを作成する。
class AgeComparator: @staticmethod def compare(h1: Human, h2: Human) -> int: if h1.age > h2.age: return 1 elif h1.age == h2.age: return 0 else: return -1
- 比較アルゴリズム部分を分離し、実際の比較処理は、AgeComparator に委譲できるようにしておく。
class MyClass: @staticmethod def compare(h1: Human, h2: Human) -> int: return AgeComparator.compare(h1, h2)
- これだけではメリットはなく、 Strategy パターンにもなっていない。Strategy パターンでは、分離したアルゴリズム部分が共通のインタフェースを持つようにすることが求められる。
- すなわち、アルゴリズムとして分離された複数のクラスが共通のインタフェースを持つ必要がある。
- サンプルケースでは、年齢を比較する AgeComparator クラス以外にも、身長を比較するための HeightComparatorクラス、体重を比較するための WeightComparatorクラスなどが考えられる。
- これらの比較アルゴリズムを表すクラスに共通のインタフェースを持たせる。
- ここでは、Comparator インタフェースを定義してみます。
class Comparator(metaclass=ABCMeta): @staticmethod @abstractmethod def compare(h1: Human, h2: Human) -> int: pass class AgeComparator(Comparator): @staticmethod def compare(h1: Human, h2: Human) -> int: if h1.age > h2.age: return 1 elif h1.age == h2.age: return 0 else: return -1 class HeightComparator(Comparator): @staticmethod def compare(h1: Human, h2: Human) -> int: if h1.height > h2.height: return 1 elif h1.height == h2.height: return 0 else: return -1
- こうすることでSampleClassは以下のように書き換えられる
class SampleClass: def __init__(self, comp: Comparator): self._comp = comp def compare(self, h1: Human, h2: Human) -> int: return self._comp.compare(h1, h2)Strategyパターンのまとめ
- 投稿日:2020-01-01T20:43:22+09:00
Happy new year 2020!
2020年も、#CiscoSE #DevNet #DevNetExpress #Catalyst #CiscoIOS 共々、どうぞよろしくお願い致します!
Guestshell
Cat9300-1#sh version | i 16.12 Cisco IOS XE Software, Version 16.12.01 Cisco IOS Software [Gibraltar], Catalyst L3 Switch Software (CAT9K_IOSXE), Version 16.12.1, RELEASE SOFTWARE (fc4) BOOTLDR: System Bootstrap, Version 16.12.1r, RELEASE SOFTWARE (P) * 1 41 C9300-24P 16.12.1 CAT9K_IOSXE INSTALL Cat9300-1# Cat9300-1#guestshell [guestshell@guestshell ~]$ ls | grep print2020 print2020.py [guestshell@guestshell ~]$ pwd /home/guestshell [guestshell@guestshell ~]$コード
print2020.pyimport sys from termcolor import cprint from pyfiglet import figlet_format cprint(figlet_format('Happy New Year 2020!'), 'white', 'on_magenta') cprint(figlet_format('#CiscoSE #DevNet'), 'white', 'on_blue')実行例
Cat9300-1#guestshell run python print2020.py _ _ _ _ __ __ | | | | __ _ _ __ _ __ _ _ | \ | | _____ __ \ \ / /__ __ _ _ __ | |_| |/ _` | '_ \| '_ \| | | | | \| |/ _ \ \ /\ / / \ V / _ \/ _` | '__| | _ | (_| | |_) | |_) | |_| | | |\ | __/\ V V / | | __/ (_| | | |_| |_|\__,_| .__/| .__/ \__, | |_| \_|\___| \_/\_/ |_|\___|\__,_|_| |_| |_| |___/ ____ ___ ____ ___ _ |___ \ / _ \___ \ / _ \| | __) | | | |__) | | | | | / __/| |_| / __/| |_| |_| |_____|\___/_____|\___/(_) _ _ ____ _ ____ _____ _| || |_ / ___(_)___ ___ ___/ ___|| ____| |_ .. _| | | / __|/ __/ _ \___ \| _| |_ _| |___| \__ \ (_| (_) |__) | |___ |_||_| \____|_|___/\___\___/____/|_____| _ _ ____ _ _ _ _| || |_| _ \ _____ _| \ | | ___| |_ |_ .. _| | | |/ _ \ \ / / \| |/ _ \ __| |_ _| |_| | __/\ V /| |\ | __/ |_ |_||_| |____/ \___| \_/ |_| \_|\___|\__| Cat9300-1#実行例(キャプチャ)

- 投稿日:2020-01-01T20:41:55+09:00
ROS講座108 ROSでDatabase(mongo)を使う
環境
この記事は以下の環境で動いています。
項目 値 CPU Core i5-8250U Ubuntu 16.04 ROS Kinetic python 2.7.12 mongodb 2.6.10 インストールについてはROS講座02 インストールを参照してください。
またこの記事のプログラムはgithubにアップロードされています。ROS講座11 gitリポジトリを参照してください。概要
ROSでは情報は基本的にrosbagに保存しますがこれは後から人間が見返すデバッグログ的な物であり、実行時に再利用するデータベース的になデータは各ノードが保存するか自前でファイルをwrite, readするしかありません。ここで出てくるものがDataBaseで、ROSではmongodbというDataBaseとつながるパッケージが公開されています。
mongodbの構成
mongodbは
database -> collection -> documentという構成をしています。
- documentは実際のデータの実態で、excelでの1行に当たります。
- collectionはdocumentを複数まとめたもの
- batabaseはcollectionを複数まとめたもの
インストール
mongodb_storeのインストールsudo apt install ros-kinetic-mongodb-storemongodb_storeで書き込みをしてみる
DataBaseの実行
起動時にデータベースのファイルを置くディレクトリを決めます。空のディレクトリを作成します。存在しないディレクトリを指定するとエラーになります。
mongodb_storeの実行mkdir /tmp/test_db roslaunch mongodb_store mongodb_store.launch db_path:=/tmp/test_db port:=27017書き込みノードの実行
web_lecture/scripts/mongo_pose_write.py#!/usr/bin/env python # -*- coding: utf-8 -*- import rospy from mongodb_store.message_store import MessageStoreProxy from geometry_msgs.msg import Pose, Point, Quaternion if __name__ == '__main__': rospy.init_node("mongo_pose_write") msg_store = MessageStoreProxy(database="srs", collection="pose1") p = Pose(Point(0, 1, 2), Quaternion(0, 0, 0, 1)) try: p_id = msg_store.insert_named("named_pose", p) p_id = msg_store.insert(p) except rospy.ServiceException, e: print "Service call failed: %s"%e
MessageStoreProxy(database="srs", collection="pose1")で書き込みをするためのオブジェクトを生成します。ここでdatabas名とcollection名を指定します。msg_store.insert_named("named_pose", p)でデータを書き込みます。書き込みノードの実行rosrun web_lecture mongo_pose_write.py読み込みノードの実行
web_lecture/scripts/mongo_pose_read.py#!/usr/bin/env python # -*- coding: utf-8 -*- import rospy import mongodb_store_msgs.srv as dc_srv import mongodb_store.util as dc_util from mongodb_store.message_store import MessageStoreProxy from geometry_msgs.msg import Pose, Point, Quaternion import StringIO if __name__ == '__main__': rospy.init_node("mongo_pose_write") msg_store = MessageStoreProxy(database="srs", collection="pose1") try: for item in msg_store.query(Pose._type): print item[0].position except rospy.ServiceException, e: print "Service call failed: %s"%e
msg_store.query(Pose._type)でデータベースの中からpose型のデータを抽出してきます。もと詳しくクエリを入れることもできます。- 結果はリストで帰ってきます。要素の中の0番目はROSのメッセージ型になっています。1番目にはメタ情報が入っています。
読み込みノードの実行rosrun web_lecture mongo_pose_read.py実行結果x: 0.0 y: 1.0 z: 2.0 x: 0.0 y: 1.0 z: 2.0mongoでデータを読む
ROSのインターフェースではなく直接databaseを読むこともできます。
mongoとコマンドを起動するとmongoのコンソールにつながります。
show dbsでdatabaseの一覧を見れます。use {database名}でそのdatabaseを使用します。show collectionsでcollectionの一覧を見れます。db.{collection名}.find()でそのcollectionの中のデータの全体を見れます。目次ページへのリンク
- 投稿日:2020-01-01T19:37:05+09:00
AtCoder Beginner Contest 063 過去問復習
初めて解いた過去問
所要時間
A問題
三項演算子で書いたら文字数少ないので早く打てるようになった
answerA.pya,b=map(int,input().split()) print(a+b if a+b<10 else "error")B問題
被りがあるかどうかはset、三項演算子ここでも利用した
answerB.pys=list(input()) t=list(set(s)) print("yes" if len(s)==len(t) else "no")C問題
10の倍数かどうかで場合分け、10の倍数しかない時は和は必ず10の倍数なので0を出力、10の倍数でないものがある場合はとりあえず全部足して10の倍数なら10の倍数でないもので一番小さいものを引けば良いだけ。
answerC.pyn=int(input()) a=[] b=[] for i in range(n): s=int(input()) if s%10==0: a.append(s) else: b.append(s) b.sort() if len(b)==0: print(0) else: if sum(b)%10==0: print(sum(a)+sum(b[1:])) else: print(sum(a)+sum(b))D問題
直近のAGC041のB問題がかなり似た問題でした(典型??)。
まず、爆発を愚直に繰り返すのは計算量的に間に合わないのは必至なので、$X$回の爆発を繰り返した場合にどうなるかを考えました。ここで、$X$回の爆発について$i$番目の魔物を中心とした爆発が$m_i$回起こると仮定します。この時、$i$番目の魔物の体力は$h_i-m_i \times A-(X-m_i) \times B=h_i-X \times B-m_i \times (A-B)$であり、これが任意の1<=$i$<=Nについて0以下となればN体の全魔物を倒すことができます。したがって、$(h_i-X \times B)/(A-B)$を切り上げたものがそれぞれの魔物を倒すのに必要なその魔物を中心とした爆発の回数になります。この回数をそれぞれの魔物で計算して足し合わせた値が$X$以下であればx回の爆発により全魔物を消し去ることができると言えます。
また、$X$はたかだか$10^9$であることは制約から明らかかつある$X$を境に全魔物を消し去れるかが分かれるのは明らかなので、二分探索によりその値を求めていくことができます。
以上よりO(n)の定数倍(10倍程度)で求めらることがわかりました。answerD.pyimport math n,a,b=map(int,input().split()) h=[int(input()) for i in range(n)] def explode(x): global n c=0 for i in range(n): if h[i]-x*b>0: c+=math.ceil((h[i]-x*b)/(a-b)) return c<=x l,r=1,10**9 while l+1<r: k=(l+r)//2 if explode(k): r=k else: l=k print(l if explode(l) else r)

- 投稿日:2020-01-01T19:08:32+09:00
ニューラルネットワークを使ってカルロス・ゴーンとMr.ビーンを識別する
はじめに
日産自動車の元会長、カルロス・ゴーン氏が保釈条件を破ってレバノンに渡航したニュースが話題です。
ずっと前から、思っていたのですが、Mr.ビーンと似てますよね・・・
左:カルロス・ゴーン
右:Mr.ビーン(Rowan Atkinson)年末年始で休みだったので、ちょっとした分類器をニューラルネットワークを使って作ってみました。
ググれば2人の画像はたくさん出てくるのでCNNでも良かったのですが、
今回は別のアプローチとして、顔のランドマークの位置を元に分類を行いたいと思います。コーディングは雑です、予めご了承ください。
GitHubにソースコードと使った画像データをあげてます。
face_identification環境
- Ubuntu 16.04
- Python 2.7
- Keras 1.14.0
- OpenCV 3.4.2
処理の流れ
- OpenCVのcascadeを使って顔検出
- 検出した顔の領域を元に、dlibを使って68点のランドマークを推定
- 68点の位置を分類器に入力
- 出力が0ならカルロス、1ならMr.ビーン
データセットの作成
カルロスとビーンの顔写真をそれぞれ10枚ずつ用意します。
20枚だけだと心許ないので、それぞれの画像をリサイズして水増しします。顔認識にはopencvのcascade、ランドマーク推定にはdlibを使います。
※ランドマーク推定はこちらの記事を参考にさせていただきました。(PythonでOpenCVの顔認識を試してみた)dataset_generator.py#!/usr/bin/env python #coding:utf-8 import cv2 import dlib import numpy as np cascade_path = "~/face_identification/model/haarcascade_frontalface_alt.xml" cascade = cv2.CascadeClassifier(cascade_path) model_path = "~/face_identification/model/shape_predictor_68_face_landmarks.dat" predictor = dlib.shape_predictor(model_path) detector = dlib.get_frontal_face_detector() image_file_dir = "~/face_identification/images/carlos/" #image_file_dir = "~/face_identification/images/rowan/" save_file_path = "~/face_identification/dataset/carlos.csv" #save_file_path = "~/face_identification/dataset/rowan.csv" face_landmarks = [] for n in range(10): #image_file_name = "carlos"+str(n)+".jpeg" image_file_name = "rowan"+str(n)+".jpeg" raw_img = cv2.imread(image_file_dir+image_file_name) original_width, original_height = raw_img.shape[:2] multiple_list = [0.5, 0.75, 1.0, 1.25, 1.5, 1.75, 2.0] for m in multiple_list: size = (int(original_height*m), int(original_width*m)) img = cv2.resize(raw_img, size) gray_img = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY) faces = cascade.detectMultiScale(gray_img) if len(faces) != 0: for(x, y, width, height) in faces: cv2.rectangle(img, (x, y), (x+width, y+height), (0, 0, 255), 1) rects = detector(gray_img, 1) landmarks = [] for rect in rects: landmarks.append(np.array([[p.x, p.y] for p in predictor(gray_img, rect).parts()])) for landmark in landmarks: face_landmark = [] for i in range(len(landmark)): cv2.drawMarker(img, (landmark[i][0], landmark[i][1]), (21, 255, 12)) #座標の位置を正規化 landmark_x = (landmark[i][0]-x)*100.00/width landmark_y = (landmark[i][1]-y)*100.00/height face_landmark.append(landmark_x) face_landmark.append(landmark_y) face_landmarks.append(np.array(face_landmark).flatten()) cv2.imshow("viewer", img) key = cv2.waitKey(100) print "finish" np_dataset = np.array(face_landmarks) np.savetxt(save_file_path, np_dataset)カルロスとゴーン、それぞれの顔のランドマークをcsvファイルに出力します。
(dataset_generator.pyのコメントアウトの部分を入れ替えて2回実行してください。)
顔のランドマークは68点取れます。
各点のx,y座標を順に配列に格納しています(したがってひとつの顔から取れる値は68×2=136個)
また、顔のサイズによって座標の値が大きく変わるので、正規化しています。
ココらへんの理解はまだ微妙です。(いい方法があれば教えてください)ネットワークの構成
Kerasでシンプルなfeed forward型のニューラルネットワークを作ります。
中間層が3つの簡単な構成です。network_model.py#!/usr/bin/env python #coding:utf-8 from keras.models import Sequential from keras.layers import Activation, Dense, Dropout class DNNModel(): def __init__(self): self.model = Sequential() self.model.add(Dense(1024, input_dim=136)) self.model.add(Activation('relu')) self.model.add(Dropout(0.1)) self.model.add(Dense(512)) self.model.add(Activation('relu')) self.model.add(Dropout(0.1)) self.model.add(Dense(256)) self.model.add(Activation('relu')) self.model.add(Dropout(0.1)) self.model.add(Dense(2))#正解ラベルの数に合わせる self.model.add(Activation('softmax'))学習
train.py#!/usr/bin/env python #coding:utf-8 import numpy as np import keras from network_model import DNNModel from keras.optimizers import RMSprop, SGD, Adam from keras.utils import to_categorical from keras.utils import np_utils carlos_data_path = "~/face_identification/dataset/carlos.csv" rowan_data_path = "~/face_identification/dataset/rowan.csv" weight_file_path = "~/face_identification/model/weight.hdf5" landmarks = [] labels = [] with open(carlos_data_path, "r") as f: carlos_lines = f.read().split("\n") f.close() with open(rowan_data_path, "r") as f: rowan_lines = f.read().split("\n") f.close() for i in range(len(carlos_lines)-1): carlos_line = carlos_lines[i].split(" ") landmarks.append(np.array(carlos_line).flatten()) labels.append(0) #カルロスは0 for i in range(len(rowan_lines)-1): rowan_line = rowan_lines[i].split(" ") landmarks.append(np.array(rowan_line).flatten()) labels.append(1) #Mr.ビーンは1 landmarks = np.asarray(landmarks).astype("float32") labels = np_utils.to_categorical(labels, 2) model = DNNModel().model model.summary() model.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.0001), metrics=['accuracy']) history = model.fit(landmarks, labels, batch_size=64, epochs=3000) model.save_weights(weight_file_path) print "model was saved."学習は5分もかからずに終わると思います。
結果
正解
正解
正解
正解
失敗
カルロスは顔検出に失敗。
Mr.ビーンは分類に失敗。
失敗test.py#!/usr/bin/env python #coding:utf-8 import cv2 import dlib import numpy as np import tensorflow as tf from network_model import DNNModel cascade_path = "~/face_identification/model/haarcascade_frontalface_alt.xml" cascade = cv2.CascadeClassifier(cascade_path) model_path = "~/face_identification/model/shape_predictor_68_face_landmarks.dat" predictor = dlib.shape_predictor(model_path) detector = dlib.get_frontal_face_detector() trained_model_path = "~/face_identification/model/weight.hdf5" model = DNNModel().model model.load_weights(trained_model_path) graph = tf.get_default_graph() test_image_path = "~/face_identification/images/test.jpeg" result_image_path = "~/face_identification/images/result.jpeg" img = cv2.imread(test_image_path) gray_img = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY) faces = cascade.detectMultiScale(gray_img, minSize=(30, 30)) if len(faces) != 0: for(x, y, width, height) in faces: cv2.rectangle(img, (x, y), (x+width, y+height), (0, 0, 255), 1) rects = detector(gray_img, 1) landmarks = [] for rect in rects: landmarks.append(np.array([[p.x, p.y] for p in predictor(gray_img, rect).parts()])) for landmark in landmarks: input_data = [] face_landmark = [] for i in range(len(landmark)): landmark_x = (landmark[i][0]-x)*100.00/width landmark_y = (landmark[i][1]-y)*100.00/height face_landmark.append(landmark_x) face_landmark.append(landmark_y) face_landmark = np.array(face_landmark).flatten() input_data.append(face_landmark) with graph.as_default(): pred = model.predict(np.array(input_data)) result_idx = np.argmax(pred[0]) if result_idx == 0: text = "Carlos:" + str(pred[0][result_idx]) else: text = "Rowan:" + str(pred[0][result_idx]) #文字の書き込み cv2.putText(img, text, (x, y), cv2.FONT_HERSHEY_SIMPLEX, 0.5,(0,0,255)) #cv2.imshow("viewer", img) cv2.imwrite(result_image_path, img)終わりに
カルロス・ゴーンは手強い。








- 投稿日:2020-01-01T19:04:54+09:00
SSIDとパスワードを生成し、QRコードにして Slack にぶん投げる。
ゲスト用無線 LAN の SSID とパスワードの更新作業を自動化したい
ゲスト用無線 LAN 設定の更新作業が面倒なため、この作業を自動化しようと思います。
できること
- スクリプトを実行すると Slack へ 無線 LAN の設定情報が載った QR コードが発行される
- slack に発行された QR コードを iPhone や Android 端末で読み取ると無線 LAN の接続を提案する
画像で言うなら、これができるようにします。
仕組みの概要
- SSIDとパスワードを生成する
- 生成された情報をQRコードの画像にする
- SSIDとパスワードの情報を画像にする
- 上記の内容を Slack にぶん投げる
環境
- CentOS Linux release 7.7.1908 (Core)
- Python 3.6.8
実装
使ってみる
Slack の設定(Tokenが取得できればOK)
slack で app を選択し bot を追加する
bot に名前を設定する
bot に対する Token を取得する(このトークンは後で設定します)
python のコードに設定
rice_cooker.py(8行目~13行目)# Please Write Your Wi-Fi Setting & Slack Token & Font Path CONPANY_NAME = 'GUEST' ENCRYPTION_METHOD = 'WPA' SLACK_TOKEN = '' SLACK_CHANNEL = 'freewifi-dev' FONT_PATH = '/usr/share/fonts/dejavu/DejaVuSans.ttf'下記の項目を入力します。
- 設定項目
- CONPANY_NAME = 'SSID の先頭の文字列を入力します'
- ENCRYPTION_METHOD = '無線 LAN の暗号化方式を入力します'
- SLACK_TOKEN = 'QRコードを投下する Slack に投下するためのトークンを入力します'
- SLACK_CHANNEL = 'QRコードを投下する Slack のチャンネルを指定します'
- FONT_PATH = 'CentOS 上にあるフォントの位置を指定します'
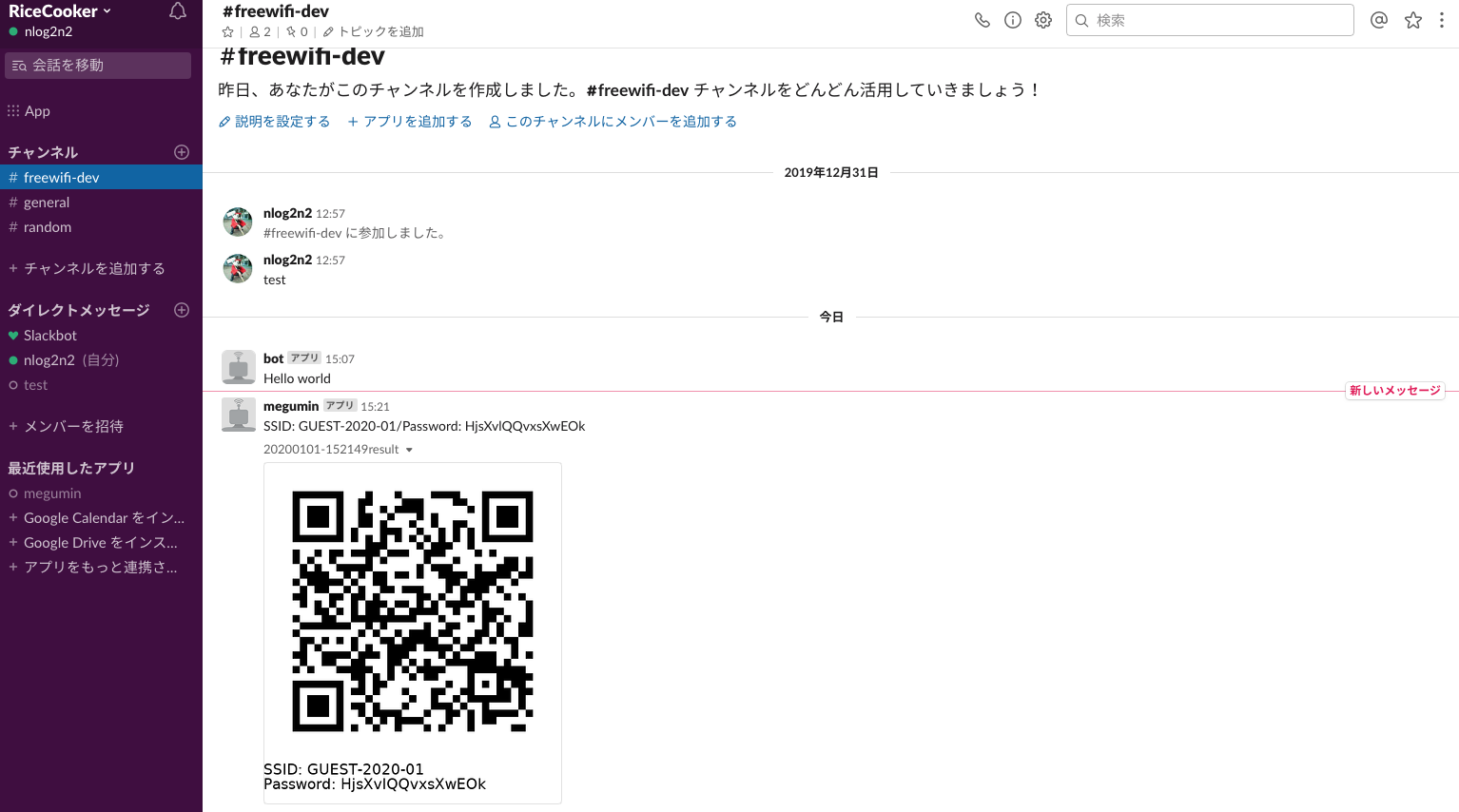
Slack へ QR コードの投下と確認
python3 rice_cooker.py で実行する
slack で QR コード、SSID、パスワードを確認する
iOS から Wi-Fi 接続
iPhone を立ち上げて、 QR コードを読み取る
ネットワークに接続することを促されるので、接続をタップする
無線 LAN に接続されていることを確認する
無事、接続されました!
ネットワーク設定自動化について
本来は、この処理の後に、 SSH で AP に接続し、無線 LAN の設定(SSID,Password)を追加および削除するコードが入っていました。
Ansible か Netmiko で実装しようかと思いましたが、使っていた無線 LAN の端末が Aruba製品 で、それらが使えず Python の expect で対応しました。
モチベーションが残っていれば expect でのネットワーク設定自動化についても書いていこうかと思います。ハマる点
- Pillow の Image.width は正しく処理されないことがあり、 Image.size[0] に処理を入れ替えてお茶を濁しました。
参考
- パスワード作成の参考
- QR コードの発行
- 画像の生成、結合
- slack への通知機能








- 投稿日:2020-01-01T18:14:22+09:00
【Python】Tkinterによる複数ウィンドウの作成
はじめに
こんにちは。
この記事ではTkinterを用いた複数のウィンドウを作るためのソースが分かる記事となっています。
よろしくお願いします。環境
- Windows 10 home
- Python 3.7.1
ソースコード
こちらが完成したソースコードになります。
ぜひ実行してみてください。main.pyimport tkinter as tk class Application(tk.Frame): def __init__(self,master): super().__init__(master) self.pack() master.geometry("300x300") master.title("ベースウィンドウ") self.window = [] self.user = [] self.button = tk.Button(master,text="ウィンドウ作成",command=self.buttonClick,width=10) self.button.place(x=110, y=150) self.button.config(fg="black", bg="skyblue") def buttonClick(self): self.window.append(tk.Toplevel()) self.user.append(User(self.window[len(self.window)-1],len(self.window))) class User(tk.Frame): def __init__(self,master,num): super().__init__(master) self.pack() self.num = num master.geometry("300x300") master.title(str(self.num)+"つ目に作成されたウィンドウ") self.button = tk.Button(master,text="コンソール上での確認",command=self.buttonClick,width=20) self.button.place(x=70, y=150) self.button.config(fg="black", bg="pink") def buttonClick(self): print("こちらは"+str(self.num)+"つ目に作成されたウィンドウです。") def main(): win = tk.Tk() app = Application(win) app.mainloop() if __name__ == '__main__': main()実際の動作
このプログラムを実行してみると、まずベースウィンドウが表示されます。
次に、ベースウィンドウにあるボタンをクリックすると、新たなウィンドウが作成され、表示されます。
作られたウィンドウにあるボタンをクリックするとコンソール上に、このウィンドウが何個目に作成されたのかを表示してくれます。ベースウィンドウにあるボタンをクリックすれば、いくつでも新たなウィンドウを作成することができますので、ぜひ試してみてください。
ここまで読んでいただき、ありがとうございました。
- 投稿日:2020-01-01T17:48:06+09:00
ubuntu16.04をインストールしたPCにrealsenseD435を接続してpythonでデプス動画を保存する
目的
ubuntu16.04をインストールしたPCにrealsenseD435を接続してpythonでデプス動画を保存した際の備忘録です
準備
ubuntu16.04をインストールしたPC
realsenseD435pyrealsense2インストール
pip install pyrealsense2コード
動画を保存する:record.py
保存した動画を再生する:play.py
保存した動画を連番画像にする:save.pyrecord.pyimport pyrealsense2 as rs import numpy as np import cv2 import time # Configure depth and color streams config = rs.config() config.enable_stream(rs.stream.infrared, 1, 640, 480, rs.format.y8, 30) config.enable_stream(rs.stream.depth, 640, 480, rs.format.z16, 30) config.enable_stream(rs.stream.color, 640, 480, rs.format.bgr8, 30) config.enable_record_to_file('d435data.bag') # Start streaming pipeline = rs.pipeline() pipeline.start(config) start = time.time() frame_no = 1 try: while True: # Wait for a coherent pair of frames: depth and color frames = pipeline.wait_for_frames() color_frame = frames.get_color_frame() depth_frame = frames.get_depth_frame() ir_frame = frames.get_infrared_frame() fps = frame_no / (time.time() - start) print(fps) frame_no = frame_no+1 if not ir_frame or not color_frame : ir_image = np.asanyarray(ir_frame .get_data()) depth_image = np.asanyarray(depth_color_frame.get_data()) color_image = np.asanyarray(color_frame.get_data()) finally: pipeline.stop()play.py#!/usr/bin/env python # -*- coding: utf-8 -*- import pyrealsense2 as rs import numpy as np import cv2 # ストリーム(Color/Depth/Infrared)の設定 config = rs.config() # ↓ ここでファイル名設定 config.enable_device_from_file('d435data.bag') #config.enable_device_from_file('./20191229.bag') config.enable_stream(rs.stream.color, 640, 480, rs.format.bgr8, 30) config.enable_stream(rs.stream.depth, 640, 480, rs.format.z16, 30) config.enable_stream(rs.stream.infrared, 1, 640, 480, rs.format.y8, 30) # ストリーミング開始 pipeline = rs.pipeline() profile = pipeline.start(config) try: while True: # フレーム待ち(Color & Depth) frames = pipeline.wait_for_frames() ir_frame = frames.get_infrared_frame() depth_frame = frames.get_depth_frame() color_frame = frames.get_color_frame() if not depth_frame or not color_frame or not ir_frame : continue # Convert images to numpy arrays ir_image = np.asanyarray(ir_frame .get_data()) depth_color_frame = rs.colorizer().colorize(depth_frame) depth_image = np.asanyarray(depth_color_frame.get_data()) color_image = np.asanyarray(color_frame.get_data()) # Show images cv2.namedWindow('ir_image', cv2.WINDOW_AUTOSIZE) cv2.imshow('ir_image', ir_image) cv2.namedWindow('color_image', cv2.WINDOW_AUTOSIZE) cv2.imshow('color_image', color_image) cv2.namedWindow('depth_image', cv2.WINDOW_AUTOSIZE) cv2.imshow('depth_image', depth_image) cv2.waitKey(1) finally: # Stop streaming pipeline.stop()save.py#!/usr/bin/env python # -*- coding: utf-8 -*- import pyrealsense2 as rs import numpy as np import cv2 # ストリーム(Color/Depth/Infrared)の設定 config = rs.config() # ↓ ここでファイル名設定 config.enable_device_from_file('d435data.bag') #config.enable_device_from_file('./20191229.bag') config.enable_stream(rs.stream.color, 640, 480, rs.format.bgr8, 30) config.enable_stream(rs.stream.depth, 640, 480, rs.format.z16, 30) config.enable_stream(rs.stream.infrared, 1, 640, 480, rs.format.y8, 30) # ストリーミング開始 pipeline = rs.pipeline() profile = pipeline.start(config) try: count = 0 while True: count_padded = '%05d' % count count += 1 # フレーム待ち(Color & Depth) frames = pipeline.wait_for_frames() ir_frame = frames.get_infrared_frame() depth_frame = frames.get_depth_frame() color_frame = frames.get_color_frame() if not depth_frame or not color_frame or not ir_frame : continue # Convert images to numpy arrays ir_image = np.asanyarray(ir_frame .get_data()) depth_color_frame = rs.colorizer().colorize(depth_frame) depth_image = np.asanyarray(depth_color_frame.get_data()) color_image = np.asanyarray(color_frame.get_data()) write_file_name_color = "color_" + count_padded + ".jpg" cv2.imwrite(write_file_name_color, color_image) write_file_name_depth = "depth_" + count_padded + ".jpg" cv2.imwrite(write_file_name_depth, depth_image) # Show images cv2.namedWindow('ir_image', cv2.WINDOW_AUTOSIZE) cv2.imshow('ir_image', ir_image) cv2.namedWindow('color_image', cv2.WINDOW_AUTOSIZE) cv2.imshow('color_image', color_image) cv2.namedWindow('depth_image', cv2.WINDOW_AUTOSIZE) cv2.imshow('depth_image', depth_image) cv2.waitKey(1) finally: # Stop streaming pipeline.stop()その他
保存した画像を動画に変換するにはffmpegで連番画像から動画生成 / 動画から連番画像を生成 ~コマ落ちを防ぐには~を参照すれば良さそうです。
CodingError対策
python2.7系で実行していますが、それ以上だとエラーが出るかもしれません。。
参考
IntelのRealsense D435を動かす
IntelのRealsense D435で録画と出力
Pythonではじめる3Dセンシング!!
ffmpegで連番画像から動画生成 / 動画から連番画像を生成 ~コマ落ちを防ぐには~
- 投稿日:2020-01-01T17:35:16+09:00
Python3で配列をクイックソートする
はじめに
皆さん2020年あけましておめでとうございます。ryuichi69と申します。
本日もアルゴリズムの練習のアウトプット、説明の練習がてらこの文章を書きました。正直分かりやすく書くのが大変で、説明の分かりにくい部分、要件漏れ等がありましたらご連絡下さい。クイックソート
概要
まずソートとは、配列の要素を昇順または降順に並び替える事を言います。
ソートの方法は何種類もありますが、そのうちクイックソートとは、配列の基準値を起点として、それより大きいものの配列、小さいものの配列に小分けにしていって行ってソートしていく手法です。
クイックソートの例
例えば配列a=[5,6,3,1,8]があり、これを昇順にクイックソートする事を考えます。さらに配列内の中央値を基準値とします。
ここで配列aの要素の中央値は3ですね。この3を境目に3より小さい要素を下の青、3より大きい要素を下の黄色のように、半分に2分割していきます。さらに下の図の2回目の分割のように、再帰的に配列を半分に分割していき、配列の要素数が1つになった時点で再帰を打ち切ります。最後に1つの配列に統合して完成です。
ここで実装の手順をまとめると、
実装の手順
- 配列a[i]の要素eの中央値m(基準値)を探します。
- 分割後の配列の要素数が1個になったら、再帰を打ち切る処理を書く(再帰の停止条件)。
- 配列の各要素elementごとに。a[i] < mの場合はelementを配列left、a[i] > mの場合はelementを配列rightに値を格納します。
- 配列left、配列rightに対し上記1~2を再帰的に実行します。
例題
nを自然数、iを0≦i≦(n-1)を満たす整数とする。このときクイックソートにより、n個の要素を持つ配列a[i]を昇順にソートせよ。
制約
- 1≦n≦10
- 1≦a[i]≦10
入力
a = [7,3,10,5,9,1,6,4,8,2]
出力
[1,2,3,4,5,6,7,8,9,10]
プログラム
ソースコードは、@suecharoさんの「ソートアルゴリズムと Python での実装 - Qiita」のクイックソートのものベースとしています。配列を2つに分けてソートする点が分からなかったので、カンニングさせて頂きました。
quickSort.pyimport os import statistics def quickSort(arr): # 配列のメジアンより小さい要素を集めた配列 left = [] # 配列のメジアンより大きい要素を集めた配列 right = [] # 再帰の停止条件 # 再帰的に配列を分割した後の、要素数が1以下になったら停止する if len(arr) <= 1: return arr # 配列の中央値(メジアン)を取得する median = int(statistics.median(arr)) # 配列内に含まれる中央値の個数を数えるための変数 medianFlg = 0 for element in arr: # 配列の要素(element)が中央値より小さいので、 # 配列leftに値を格納する if element < median: left.append(element) # 配列の要素(element)が中央値より大きいので、 # 配列rightに値を格納する elif element > median: right.append(element) else: # elementが配列の中央値の場合は、 # 返り値に加える中央値の個数分だけ、フラグに+1し続ける medianFlg += 1 # 配列がどのように分割されているかを確かめたい場合は、 # このタイミングでprintで確認すると良い # print(left) # print(right) # 配列left、配列right毎に再帰を行い # 配列を小さな配列に区切る left = quickSort(left) right = quickSort(right) # 配列left、中央値の[median]、配列rightを結合したものを返す return left + [median] * medianFlg + right # テスト用 if __name__ == "__main__": print(quickSort([7,3,10,5,9,1,6,4,8,2]))

- 投稿日:2020-01-01T17:18:47+09:00
AtCoder Beginner Contest 064 過去問復習
すでに解いたことのある過去問、二回目
所要時間
A問題
4で割り切れるかは下2桁でOK
answerA.pyr,g,b=map(int,input().split()) if (10*g+1*b)%4==0: print("YES") else: print("NO")三項演算子も利用すると
answerA_better.pyr,g,b=map(int,input().split()) print("YES" if (10*g+1*b)%4==0 else "NO")B問題
最小の座標→最大の座標が当然最小
answerB.pyn=input() a=[int(i) for i in input().split()] print(max(a)-min(a))C問題
前に書いた時よりもシンプルにかけていて良い。
普通に配列で前から順に対応するものを書いていけば良い。
ただし、全て3200以上の場合は最小が1になるのでそこだけ注意answerC.pyx=[0]*9 n=int(input()) a=[int(i) for i in input().split()] for i in range(n): for j in range(8): if a[i]<400*(j+1): x[j]=1 break else: x[8]+=1 if x[:-1].count(1)!=0: print(x[:-1].count(1),end=" ") else: print(1,end=" ") print(x[:-1].count(1)+x[-1])D問題
初めて解いた時は本当に難しいと感じた。要するに"("と")"の組が組として存在すれば良い。"("と")"の組が組として存在するには"("の個数が常に")"より多く、"("と")"の数が同じになる必要がある。入れ子になって〜とか考え始めると逆に複雑になってしまう。このようにカッコの個数が整合性取れているようにするにはスタック的な考えをするようにすれば良い!!スタック的な考えをする場合はスタックにわざわざ詰めなくても+1と-1でチェックすることでOK(その数がstackの大きさに対応する。)
answerD.pyn=int(input()) s=input() if s[0]=="(": c=1 d=1 else: c=-1 d=-1 for i in range(1,n): if s[i]=="(": d+=1 else: d-=1 c=min(c,d) if c<0: s="("*(-c)+s print(s+")"*(s.count("(")-s.count(")")))

- 投稿日:2020-01-01T16:36:29+09:00
【StyleGAN入門】「ある男性の生涯」で遊んでみた♬
はっきり言ってExampleを利用するだけで、よく流れている動画(男性⇒女性とかの変換)はすぐ再現出来、やってみるとほんとに凄い。
今回は、その一番の入り口だけやってみての紹介記事です。
参考は以下のとおりです。
【参考】
①StyleGANを使ってみた
②StyleGanで福沢諭吉を混ぜてみる
③Puzer/stylegan-encoder
④NVlabs/stylegan
現在、styleGAN2も出ているようですが、まずはStyleGANの最初の一歩をやってみて、実感を持ちたいと思います。
その結果、ほぼ1日で以下の動画が作成できたので、気になったところを記事にしておきます。
※老人~幼児~老人に変化するものも作成しましたが、$512^2$でも10MB超えてしまいましたやったこと
・環境
・pretrained_example.pyを動かす
・潜在空間を動かす
・Gifアニメーション・環境
先日Pytorchをインストールした関係でKeras-gpu環境が壊れているので、ゼロからインストールしました。
マシン;1060ベース
OS;Windows10
基本は、以前の記事のとおりです。
ただし、Chainerなどはインストールしません。
環境構築終わったところで、Tensorflowにエラーがでました。
ということで、以下の参考のとおりTensorflow=1.13.1に入れ替えをしています。
入れ替えた後、うまく動かないので再起動を実施しています。
【参考】
⑤Anacondaのconda installでビルドを指定する方法
これで安定して動いてくれました。
エビデンスは以下のとおり(...の部分にワーニングが出ていますが今回は影響ないので削除しています)(keras-gpu) C:\Users\user\stylegan-encoder-master>python Python 3.6.9 |Anaconda, Inc.| (default, Jul 30 2019, 14:00:49) [MSC v.1915 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> import tensorflow as tf ... >>> print(tf.__version__) 1.13.1・pretrained_example.pyを動かす
これを動かすには、参考①と同様、コード内ではWeightsがダウンロードできませんでした。
そこで、以下の参考⑦からダウンロードしてそれをTensorflow版を参考①と同様に配置しています。
参考⑥は面白そうですが、まだまだ理解するのは大変なので次回に後回しします。
【参考】
⑥StyleGANを遊び尽くせ!! ~追加学習不要の画像編集~
⑦pacifinapacific/StyleGAN_LatentEditorということで、最初のコードは以下のとおりです。
pretrained_example.py# Copyright (c) 2019, NVIDIA CORPORATION. All rights reserved. # # This work is licensed under the Creative Commons Attribution-NonCommercial # 4.0 International License. To view a copy of this license, visit # http://creativecommons.org/licenses/by-nc/4.0/ or send a letter to # Creative Commons, PO Box 1866, Mountain View, CA 94042, USA. """Minimal script for generating an image using pre-trained StyleGAN generator.""" import os import pickle import numpy as np import PIL.Image import dnnlib import dnnlib.tflib as tflib import config def main(): # Initialize TensorFlow. tflib.init_tf() # Load pre-trained network. #url = 'https://drive.google.com/uc?id=1MEGjdvVpUsu1jB4zrXZN7Y4kBBOzizDQ' # karras2019stylegan-ffhq-1024x1024.pkl #with dnnlib.util.open_url(url, cache_dir=config.cache_dir) as f: # _G, _D, Gs = pickle.load(f) fpath = './weight_files/tensorflow/karras2019stylegan-ffhq-1024x1024.pkl' with open(fpath, mode='rb') as f: _G, _D, Gs = pickle.load(f) # _G = Instantaneous snapshot of the generator. Mainly useful for resuming a previous training run. # _D = Instantaneous snapshot of the discriminator. Mainly useful for resuming a previous training run. # Gs = Long-term average of the generator. Yields higher-quality results than the instantaneous snapshot. # Print network details. Gs.print_layers() # Pick latent vector. rnd = np.random.RandomState(5) latents = rnd.randn(1, Gs.input_shape[1]) # Generate image. fmt = dict(func=tflib.convert_images_to_uint8, nchw_to_nhwc=True) images = Gs.run(latents, None, truncation_psi=0.7, randomize_noise=True, output_transform=fmt) # Save image. os.makedirs(config.result_dir, exist_ok=True) png_filename = os.path.join(config.result_dir, 'example.png') PIL.Image.fromarray(images[0], 'RGB').save(png_filename) if __name__ == "__main__": main()このコードの肝は、以下でGenerator Gsの入力初期値として同サイズの乱数を与えて、
latents = rnd.randn(1, Gs.input_shape[1])
それを使って以下で画像に変換している部分です。
images = Gs.run(latents, None, truncation_psi=0.7, randomize_noise=True, output_transform=fmt)
【参考】
⑧Numpyによる乱数生成まとめ
このコードで以下が出力しました。
・潜在空間を動かす
次は何をするかと言えば、上記のlatentsの乱数を変更して出力してみたいところです。
ということで、以下のコードでやってみました。(主要な部分のみ記載すると)def main(): # Initialize TensorFlow. tflib.init_tf() fpath = './weight_files/tensorflow/karras2019stylegan-ffhq-1024x1024.pkl' with open(fpath, mode='rb') as f: _G, _D, Gs = pickle.load(f) # Print network details. Gs.print_layers() # Pick latent vector. rnd = np.random.RandomState(5) #5 latents1 = rnd.randn(1, Gs.input_shape[1]) latents2 = rnd.randn(1, Gs.input_shape[1]) for i in range(1,101,4): latents = i/100*latents1+(1-i/100)*latents2 # Generate image. fmt = dict(func=tflib.convert_images_to_uint8, nchw_to_nhwc=True) images = Gs.run(latents, None, truncation_psi=0.7, randomize_noise=True, output_transform=fmt) # Save image. os.makedirs(config.result_dir, exist_ok=True) png_filename = os.path.join(config.result_dir, 'example{}.png'.format(i)) PIL.Image.fromarray(images[0], 'RGB').save(png_filename)すなわち、乱数ではあるが連続するlatents1 latents2を計算してその間をパラメータを変更して描画してみるということです。
この操作で見事に女性から男性1そして男性2に滑らかに変更していく様子が出力します。
ここでは、さらにもう一歩潜在空間を彷徨う方法を考えました。
すなわち、以下のコードで当該部分を置き換えます。
これで、潜在空間の一部ですがどんな画像が隠れているか見えると思います。# Pick latent vector. rnd = np.random.RandomState(6) #5 for i in range(1,101,4): latents = rnd.randn(1, Gs.input_shape[1])以下が得られました。
こうなると、やはりこの画像の中の任意の人を選んでその遷移を見たくなります。
ということで、一番変化の大きそうなexample73の男性とexample69の子供の絵をやってみました。たまたま隣り合っていますが…
コードは以下になります。# Pick latent vector. rnd = np.random.RandomState(6) #5 latents_=[] a=17 b=18 for i in range(1,101,4): latents = rnd.randn(1, Gs.input_shape[1]) latents_.append(latents) for j in range(25): latents_mean=j/25*latents_[a]+(1-j/25)*latents_[b] # Generate image. fmt = dict(func=tflib.convert_images_to_uint8, nchw_to_nhwc=True) images = Gs.run(latents_mean, None, truncation_psi=0.7, randomize_noise=True, output_transform=fmt) # Save image. os.makedirs(config.result_dir, exist_ok=True) png_filename = os.path.join(config.result_dir, 'example{}.png'.format(j)) PIL.Image.fromarray(images[0], 'RGB').save(png_filename)出力結果は以下のように期待以上の結果がでました。
子供がほんとにおじさんに成長したような絵が出ているのがある意味不思議です。・Gifアニメーション
最後にみんながやっているようにGifアニメーションにしたいと思います。
それには以下のコードを最後に置けばgifが保存されます。
※ここでは最初から最後まで行ったところで逆回しして最初に戻るようにしていますs=50 images = [] for i in range(25): im = Image.open(config.result_dir+'/example'+str(i)+'.png') im =im.resize(size=(512, 512), resample=Image.NEAREST) images.append(im) for i in range(24,0,-1): im = Image.open(config.result_dir+'/example'+str(i)+'.png') im =im.resize(size=(512, 512), resample=Image.NEAREST) images.append(im) images[0].save(config.result_dir+'/example{}_{}.gif'.format(a,b), save_all=True, append_images=images[1:s], duration=100*2, loop=0)以下の結果は、掲載サイズの関係でsize=(256, 256)に変更しています。
また、6の2値間補間を除いてs=25で出力しています。
※冒頭のGifアニメは$512^2$です。
実際$1024^2$だとほんとに美しい絵が出力して驚くばかりです
乱数$seed$ 2値間補間 部分空間 6 5 まとめ
・環境構築が出来れば動かせると思う
・素晴らしい画像補間ができる・このアプリだけでも応用はいろいろ考えられるので自前画像でやってみようと思う
・さらに発展的にいわゆる動画に挑戦したいと思う









- 投稿日:2020-01-01T16:28:30+09:00
ゼロから作るDeepLearning3 フレームワーク編の感想をかく
年末2、3日かけて、現在公開レビュー中のゼロから作るDeepLearning❸ フレームワーク編(ゼロD31)をやってみました。個人的には、無印以上に良本だった気がするので、どこが魅力だったのか、どういう人が読むとハッピーなのかを書ければと思います。
内容と感想
Numpyを用いたスクラッチ実装を通して、最近のフレームワーク(PyTorchやChainer)をコードレベルで理解する内容でした。フレームワーク編というだけあって、DLだけでなく、効率的なコードの書き方や、フレームワークの根幹であるDefine-by-runの設計思想などにもフォーカスされていました。
一通りやってみて、感じたこと、得られたことがいくつかありました。順番はテキトウです。
- Backpropの重要性
無印以上に何度も出てきた気がします。全部で5ステージ(章)ありましたが、そのうち2ステージがBackpropに関するものでした。
具体的には、基本的な微分とBackpropから、自動微分(AutoGrad)や高階微分、ニュートン法の説明、実装など無印では扱われていない新しい部分が結構ありました。まさしく、No Backprop, No Deep Learningなんだろうなと感覚的に思いました。
- Define-by-runとDefine-and-runの違い
この説明が一番最初ではなく、ある程度読み進めた後に出てきたのが印象的でした。ノードやinput, creator, outputなどの説明の後にがあったので、両者の違いをスムーズに理解できる構成になっているなと思いました。
- フレームワーク(とりわけPyTorch)への入りがスムーズになる
それを目的にしているから、そりゃそうですが、本書を読むとかなり意識されていることがわかります。PyTorchを触れたことがない場合、これは大きいのではないかなと思います。
一例として、PyTorchの学習時に以下のようなコードを書くと思います。本書では赤線部に該当するコードが背後でどのように動いているのかを実装レベルでカバーしていました。
今春に出版されるPyTorch公式本も読めるようになっていたので読んでみましたが、あくまで使い方の説明に留まっていた印象でした。その点で本書はユニークであり、著者が言うようにほとんど類書がないと思いました。2
- Python自体の知識
Pythonの特殊メソッドを使用する場面が度々あり、個人的には普段あまりみないメソッドも使われていました( __ rmul__など)。
また、x * w + b で使われている演算子(+や*など)には使用条件がある話や、演算量が膨大になってくるため、どのようにメモリ管理を行うのかなどにも触れていました。
- 高揚感
PyTorchなどのフレームワークを使ったことがある場合に限りますが、本書が後半になるにつれ、段々と見覚えのあるコードに近づいてきます。なんとなく理解していたPyTorch一行一行の背景が繋がっていく高揚感が個人的にありました。
例えるなら、普段電車で行く目的地に徒歩で辿りついて、脳内のマップが拡張される感覚です(この道がここに繋がっていたのか、の方がイメージとして近いかもです)。
ゼロDシリーズ内での位置付けを考える
本書はあくまでフレームワークがメインテーマなので、前半は細かいメソッド(transposeなど)の実装やメモリ管理手法などにも紙面が割かれていました。
ただ、本書後半になってくると、フレームワークの土台が固まり、Optimizer、Loss、CNN、LSTMなどの実装に話が移っていきます。無印と内容の似る部分がそこそこ出てくるため、numpyやPythonの使い方がある程度わかっていれば、ゼロD3から初めてもそこまで問題ないかなというのが個人的な印象です。
自然言語(NLP)に関してはノータッチでしたが、時系列分析と言う文脈でRNN、LSTMが紹介されていました。そのため、NLP自体をがっつり知りたい場合はゼロD2になります。
どういう人が読むとハッピーなのか考える
本書の特徴は、DL自体の説明だけでなく、"コードを通じてフレームワークそのものの成り立ちを理解する"だと思います。今までの書籍は、"DL自体の説明+Numpy実装" or "DL自体の説明+フレームワークの使い方"のどちらかを提供するものが多かった印象です(自身の少ないサンプルなので実態はそうではないかもしれないですが)。
私自身が陥ったケースとして、DL、Numpy、フレームワークがざっくりとわかり、フレームワーク単体で動かす分にはそこまで問題ないが、実際の理解との間に隔たりがありました(橋渡しができていない状態)。
そのため、PyTorchを使ったことがある方にとって本書は、Numpy or 数式とPyTorch間の結びつきを強める価値を提供しているのではないかと思います。
一方、DLに興味はあるがフレームワークを使用したことがない方にとって本書は、スムーズにフレームワークに移行するtransition的な価値を提供していると思います。
おわりに
実用性関係なく、ブラックボックスを1つ1つ解き明かすこと、また既知のもの同士に関係性を見つけて両者を繋げる面白さがありました。まだ理解が十分でないこともあり、何周かしたいと思える一冊でした。
1 / 13まで公開レビューしているようなので、レビューしつつ読んでみると面白いかもしれません。
略称がわかってないです。ゼロD、ゼロDeep、ゼロつくどれなんでしょう。 ↩
fast.aiのDeep Learning from the Foundationsが立ち位置としては近いかなと思います。こちらはPyTorchを用いてfastai libraryを実装するという内容です。ゼロD3より圧倒的に難しく、カバー範囲は広いです。 ↩



- 投稿日:2020-01-01T15:55:00+09:00
Zshでanacondaの仮想環境を使う(不具合対応)
概要
pyenvでインストールしたanacondaのJupyter Notebookをzshで使う(不具合対応)に続き,ZshでJupyter Notebookを使うための試行錯誤を備忘録としてまとめておく.
不具合状況
$ conda info -eで仮想環境が確認できるにも関わらず,$ conda activate <仮想環境名>でアクティベートできない環境
Mac OS Mojave
方法
1. 仮想環境の実行をトライする
Terminal$ conda activate <仮想環境名>返ってきたエラーメッセージ
TerminalCommandNotFoundError: Your shell has not been properly configured to use 'conda activate'. To initialize your shell, run $ conda init <SHELL_NAME> Currently supported shells are: - bash - fish - tcsh - xonsh - zsh - powershell See 'conda init --help' for more information and options. IMPORTANT: You may need to close and restart your shell after running 'conda init'.2. イニシャライズ
Terminal$ conda init <SHELL_NAME> ※今回は”zsh”3.シェルの再起動
Terminal$ exec $SHELL -l余談. シェル再起動後の対応
シェルを再起動したら,プロンプトが
(base) <ユーザー名>%となっていた.Pythonのベース環境内に入ってしまっているようだったので$ conda deactivateで仮想環境を終了.参考にさせていただいたサイト
- 投稿日:2020-01-01T15:52:39+09:00
単回帰モデルを通してベイズ推定の流れとPystanの使い方を学ぶ
はじめに
RとStanではじめる ベイズ統計モデリングによるデータ分析入門を読みました。わかりやすく、詰まることなく読みすすめることができました。おすすめです。
さらに理解を深めるために、本の内容をなぞって試したいと思います。こちらの書籍ではRとstanを使用していますが、ここではPythonとPystanを使います。
この投稿の大まかな内容は次の通りです。
1. ベイズの定理
2. MCMC法
3. Pystanの使い方
4. 単回帰モデル単回帰モデルという単純なモデルを通して、ベイズ推定の流れとPystanの使い方を学びます。
0. モジュール
ここで予め必要になるモジュールをインポートしておきます。
import numpy as np import matplotlib.pyplot as plt import pystan import arviz plt.rcParams["font.family"] = "Times New Roman" #全体のフォントを設定 plt.rcParams["xtick.direction"] = "in" #x軸の目盛線を内向きへ plt.rcParams["ytick.direction"] = "in" #y軸の目盛線を内向きへ plt.rcParams["xtick.minor.visible"] = True #x軸補助目盛りの追加 plt.rcParams["ytick.minor.visible"] = True #y軸補助目盛りの追加 plt.rcParams["xtick.major.width"] = 1.5 #x軸主目盛り線の線幅 plt.rcParams["ytick.major.width"] = 1.5 #y軸主目盛り線の線幅 plt.rcParams["xtick.minor.width"] = 1.0 #x軸補助目盛り線の線幅 plt.rcParams["ytick.minor.width"] = 1.0 #y軸補助目盛り線の線幅 plt.rcParams["xtick.major.size"] = 10 #x軸主目盛り線の長さ plt.rcParams["ytick.major.size"] = 10 #y軸主目盛り線の長さ plt.rcParams["xtick.minor.size"] = 5 #x軸補助目盛り線の長さ plt.rcParams["ytick.minor.size"] = 5 #y軸補助目盛り線の長さ plt.rcParams["font.size"] = 14 #フォントの大きさ plt.rcParams["axes.linewidth"] = 1.5 #囲みの太さ1. ベイズの定理
ベイズ推定は、ベイズの定理が基礎になっています。
p(\theta|x)=p(\theta) \frac{p(x|\theta)}{\int p(x|\theta)p(\theta)d\theta}ここで$\theta$はパラメータ、$p(\theta)$は事前分布、$p(x|\theta)$は$\theta$であるときの$x$の条件付き確率(尤度)、$p(\theta|x)$は事後分布です。
日本語で書くと、このようになります。(事後分布) = (事前分布) \times \frac{(尤度)}{(周辺尤度)}また、周辺尤度は事後分布の積分値を1にする正規化定数です。従って、周辺尤度の項を省略して以下の関係が成り立ちます。
(事後分布) \propto (事前分布) \times (尤度)1.1 例
ある正規分布に従う確率変数$x$を例に、平均値をベイズ推定することを考えます。標準偏差は1であるとわかっているとします。その正規分布の確率密度関数は以下のようになります。
\begin{align} p(x|\mu, \sigma=1) &= \frac{1}{\sqrt{2\pi\sigma^2}}\exp{\left(-\frac{(x-\mu)^2}{2\sigma^2}\right)} \\ &= \frac{1}{\sqrt{2\pi}}\exp{\left(-\frac{(x-\mu)^2}{2}\right)} \end{align}np.random.seed(seed=1) #乱数の種 mu = 5.0 #平均 s = 1.0 #標準偏差 N = 10 #個数 x = np.random.normal(mu,s,N)print(x)array([6.62434536, 4.38824359, 4.47182825, 3.92703138, 5.86540763, 2.6984613 , 6.74481176, 4.2387931 , 5.3190391 , 4.75062962])上記のデータが得られる確率(尤度)を求めます。データは$D$とします。それぞれのデータを得る事象は独立であるため、1つ1つのデータが得られる確率をかけ合わせます。
f(D|\mu) = \prod_{i=0}^{N-1} \frac{1}{\sqrt{2\pi}}\exp{\left(-\frac{(x_i-\mu)^2}{2}\right)}書籍にはありませんが、上の関数を可視化してみます。ここで尤度関数の最大値を取って平均は5だと決める(点推定)のを最尤法と言うそうですね。
mu_ = np.linspace(-5.0,15.0,1000) f_D = 1.0 for x_ in x: f_D *= 1.0/np.sqrt(2.0*np.pi) * np.exp(-(x_-mu_)**2 / 2.0) #尤度関数 fig,axes = plt.subplots(figsize=(8,6)) axes.plot(mu_,np.log(f_D)) axes.set_xlabel(r"$\mu$") axes.set_ylabel(r"$log (f(D|\mu))$")
ベイズ推定の話に戻って、事前分布を決めます。パラメータである$\mu$について前もって知識がないときは、根拠不十分の原則に従って、とりあえず広い分布を考えます。今回は分散10000で平均0の正規分布にします。
$$f(\mu) = \frac{1}{\sqrt{20000\pi}}\exp{\left(-\frac{(x-\mu)^2}{20000}\right)}$$
パラメータ$\mu$の事後分布の確率密度関数$f(\mu|D)$は、$(事前分布) \times (尤度)$に比例するのでした。
$$\begin{eqnarray}f(\mu|D) &\propto& f(\mu) f(D|\mu) \
&=& \left[ \frac{1}{\sqrt{20000\pi}}\exp{\left(-\frac{\mu^2}{20000}\right)} \right]
\left[ \prod_{i=0}^{N-1} \frac{1}{\sqrt{2\pi}}\exp{\left(-\frac{(x_i-\mu)^2}{2}\right)} \right]
\end{eqnarray}$$ベイズ推定では、事後分布が複雑で積分が難しいことがあります。せっかく事後分布の確率密度関数を得ても、積分できなければ、例えば平均値が4から6の間にある確率などが求められません。そのような場合に活躍するのがMCMC法というわけです。今回の例ではパラメータが1つなので、MCMC法ではなく$\mu$について分割して事後分布の様子を見てみます。
f_mu = 1.0/np.sqrt(20000.0*np.pi) * np.exp(-mu_**2.0 / 20000) #事前分布 f_mu_poster = f_mu * f_D #(事前分布)×(尤度) f_mu_poster /= np.sum(f_mu_poster) #積分値を1にする fig,axes = plt.subplots(figsize=(8,6)) axes.plot(mu_,f_mu,label="Prior distribution") axes.plot(mu_,f_mu_poster,label="Posterior distribution") axes.legend(loc="best")
事前分布は裾の広い分布でしたが、ベイズ更新された事後分布では裾が狭くなっています。最尤法で得られたように、事後分布の期待値は5にあるように見えます。
2. MCMC法
MCMC法とは、マルコフ連鎖モンテカルロ法の略です。ある時点の値が1つ前の時点の影響だけを受けるマルコフ連鎖を利用した乱数生成手法です。ベイズ推定では、パラメータの事後分布に従う乱数をMCMC法で生成し、積分の代わりに利用します。例えば事後分布の期待値を求めようと思えば、乱数たちの平均を計算すれば求まります。
2.1 メトロポリス・ヘイスティングス法(MH法)
ある確率分布に従う乱数を発生させるアルゴリズムについて説明します。簡単のため、推定するパラメータは1つだけとします。
1. 乱数の初期値$\hat{\theta}$を適当に決める。
2. 平均0、分散$\sigma^2$の正規分布に従う乱数を生成する。
3. それの乱数と初期値$\hat{\theta}$の和を計算する。これを$\theta^{suggest}$とする。
4. $\hat{\theta}$と$\theta^{suggest}$の確率密度の比を計算する。
5. 確率密度の比が1より大きければ$\theta^{suggest}$を採用、1以下ならその値を確率として、採用または不採用にする。採用された乱数を初期値として、何度も繰り返します。確率密度が高いところほど乱数が採用されやすくなるので、確率分布に従いそうな感じがします。
1.1の例を再び用いて、事後分布に従う乱数を上記の方法で生成してみます。np.random.seed(seed=1) #乱数の種 def posterior_dist(mu): #事後分布 #(事前分布)×(尤度) return 1.0/np.sqrt(20000.0*np.pi) * np.exp(-mu**2.0 / 20000) \ * np.prod(1.0/np.sqrt(2.0*np.pi) * np.exp(-(x-mu)**2 / 2.0)) def MH_method(N,s): rand_list = [] #採用した乱数 theta = 1.0 #1. 初期値を適当に決める for i in range(N): rand = np.random.normal(0.0,s) #2. 平均0、標準偏差sの正規分布に従う乱数を生成する suggest = theta + rand #3. dens_rate = posterior_dist(suggest) / posterior_dist(theta) #4. 確率密度の比 # 5. if dens_rate >= 1.0 or np.random.rand() < dens_rate: theta = suggest rand_list.append(theta) return rand_list手順2で発生させる乱数の標準偏差を1として、1から5の手順を50000回繰り返します。
rand_list = MH_method(50000,1.0)len(rand_list) / 500000.3619乱数が採用される確率を受容率と言います。今回は36.2%でした。
fig,axes = plt.subplots(figsize=(8,6)) axes.plot(rand_list)
このようなグラフをトレースプロットと呼びます。始めの何点かは初期値の影響を受けて非定常になっています。ここでは始めの1000点を捨ててヒストグラムを描きます。
fig,axes = plt.subplots(figsize=(8,6)) axes.hist(rand_list[1000:],30)
いい感じの結果が得られました。
次に手順2で発生させる乱数の標準偏差を0.01にして同じことを繰り返します。rand_list = MH_method(50000,0.01) len(rand_list) / 500000.98898受容率が98.9%と大きくなりました。
fig,axes = plt.subplots(figsize=(8,6)) axes.plot(rand_list)
始めの10000点を捨ててヒストグラムを描画します。
fig,axes = plt.subplots(figsize=(8,6)) axes.hist(rand_list[10000:],30)
ご覧のように、MH法は手順2で使用する乱数の分散によって結果が変わってしまいます。この問題を解決するためのアルゴリズムとしてハミルトニアン・モンテカルロ法などがあります。Stanは色々と賢いアルゴリズムが実装されているので、その恩恵に与ります。
3. Pystanの使い方
Stanコードは、dataブロック、parametersブロック、modelブロックが必要です。dataブロックは使用するデータの情報、parametersブロックは推定したいパラメータたち、modelブロックは事前分布や尤度を記述します。generated quantitiesブロックは推定したパラメータを使って乱数を生成したりできます。記述方法はStanコード中のコメントに書きました。
stan_code = """ data { int N; // サンプルサイズ vector[N] x; // データ } parameters { real mu; // 平均 real<lower=0> sigma; // 標準偏差 <lower=0>は、0以上の値しか取らないという指定 } model { // 平均mu、標準偏差sigmaの正規分布 x ~ normal(mu, sigma); // "~"記号は、左辺が右辺の分布に従うことを表す } generated quantities{ // 事後予測分布を得る vector[N] pred; // Pythonと違って、添字は1から始まる for (i in 1:N) { pred[i] = normal_rng(mu, sigma); } } """Stanコードをコンパイルします。
sm = pystan.StanModel(model_code=stan_code) #stanコードのコンパイル使用するデータをまとめます。上記Stanコードのdataブロックで宣言した変数名と対応させます。
#データをまとめる stan_data = {"N":len(x), "x":x}MCMCを実行する前に、samplingメソッドの引数について説明します。
1. 繰り返し数 iter : 生成される乱数の数。何も指定しないとデフォルト2000になります。収束が悪いときは大きな値にすることがあります。
2. バーンイン期間 warmup : 2.1のトレースプロットのように、始めは初期値の影響を受けます。その影響を避けるため、warmupで指定した点数分を捨てます。
3. 間引き thin : thin個に1個の乱数を採用します。MCMC法はマルコフ連鎖を利用しているため、1時点前の影響を受け、自己相関性を持ちます。この影響を低減します。
4. チェーン chains : 収束の評価のため、初期値を変えてchains回MCMCによる乱数生成を行います。それぞれの試行の結果が同じようであれば、収束したと判断することができます。MCMCの実行をします。
#MCMCの実行 mcmc_normal = sm.sampling( data = stan_data, iter = 2000, warmup = 1000, chains = 4, thin = 1, seed = 1 )その結果を表示します。使用したデータは、平均5、標準偏差1の正規分布に従う乱数でした。muが平均、sigmaが標準偏差を表します。
結果の表の各項目について説明します。
1. mean : 事後分布の期待値
2. se_mean : 事後分布の期待値を有効なサンプル数の平方根で割った値1
3. sd : 事後分布の標準偏差
4. 2.5% - 97.5% : ベイズ信用区間。事後分布に従う乱数を小さい順に並べて、2.5%地点から97.5%地点に該当する値を調べます。この差を取れば、95%ベイズ信用区間(信頼区間)を得ることができます。
5. n_eff : 採用された乱数の個数
6. Rhat : 同一チェーン内での乱数の分散の平均値と異なるチェーンを含めたすべての乱数の分散の比を表します。chainsが3以上のとき、Rhatが1.1より小さくなるのが目安らしいです。
7. lp__ : 対数事後確率2mcmc_normalInference for Stan model: anon_model_710b192b75c183bf7f98ae89c1ad472d. 4 chains, each with iter=2000; warmup=1000; thin=1; post-warmup draws per chain=1000, total post-warmup draws=4000. mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat mu 4.9 0.01 0.47 4.0 4.61 4.89 5.18 5.87 1542 1.0 sigma 1.46 0.01 0.43 0.89 1.17 1.38 1.66 2.58 1564 1.0 pred[1] 4.85 0.03 1.58 1.77 3.88 4.86 5.83 8.0 3618 1.0 pred[2] 4.9 0.03 1.62 1.66 3.93 4.9 5.89 8.11 3673 1.0 pred[3] 4.87 0.03 1.6 1.69 3.86 4.85 5.86 8.14 3388 1.0 pred[4] 4.86 0.03 1.57 1.69 3.89 4.87 5.81 7.97 3790 1.0 pred[5] 4.88 0.03 1.6 1.67 3.89 4.89 5.89 7.98 3569 1.0 pred[6] 4.86 0.03 1.61 1.56 3.94 4.87 5.81 8.01 3805 1.0 pred[7] 4.89 0.03 1.6 1.7 3.9 4.88 5.86 8.09 3802 1.0 pred[8] 4.88 0.03 1.61 1.62 3.87 4.88 5.9 8.12 3210 1.0 pred[9] 4.87 0.03 1.6 1.69 3.86 4.87 5.85 8.1 3845 1.0 pred[10] 4.91 0.03 1.63 1.73 3.91 4.88 5.9 8.3 3438 1.0 lp__ -7.63 0.03 1.08 -10.48 -8.03 -7.29 -6.85 -6.57 1159 1.0 Samples were drawn using NUTS at Wed Jan 1 14:32:42 2020. For each parameter, n_eff is a crude measure of effective sample size, and Rhat is the potential scale reduction factor on split chains (at convergence, Rhat=1).fit.plot()としたところ、WARNINGがでたのでそれに従います。
WARNING:pystan:Deprecation warning. PyStan plotting deprecated, use ArviZ library (Python 3.5+). pip install arviz; arviz.plot_trace(fit))簡単にトレースプロットや事後分布の確認ができます。
arviz.plot_trace(mcmc_normal)
MCMCサンプルを直接いじって何かしたいときや、グラフをもっとこだわりたいときはextractで取り出せます。デフォルトではpermuted=Trueで、順番が混ぜられた乱数が返ってきます。トレースプロットは時系列であってほしいので、この引数はFalseにしておきます。また、inc_warmupはバーンイン期間を含めるか否かです。それとfit["変数名"]でもバーンイン期間を除いた乱数は得られました。
mcmc_extract = mcmc_normal.extract(permuted=False, inc_warmup=True)mcmc_extract.shape(2000, 4, 13)次元を確認すると、(iter,chains,パラメータの数)になっています。先程のグラフの数は12なのに13次元目がありますが、プロットして確認したところlp__のようです。
4. 単回帰分析
ここまでのまとめとして、単回帰分析をベイズ推定で行います。$y$を応答変数、$x$を説明変数とします。$y$は、傾き$a$と切片$b$を用いて平均$\mu=ax + b$、標準偏差$\sigma^2$の正規分布に従うとします。
\begin{align} \mu &= ax + b \\ y &\sim \mathcal{N}(\mu,\sigma^2) \end{align}他の単回帰分析の説明でよく見られる表記も示します。
\begin{align} y &= ax + b + \varepsilon \\ \varepsilon &\sim \mathcal{N}(0,\sigma^2) \end{align}上2式はどちらも同じです。最初に示した式のほうがStanコードを書くのに便利です。
今回の例では$y$が得られる過程を決めて、そこから値をサンプリングしてベイズ推定するという流れですが、実際のデータでは、データが得られる過程を考えて、ベイズ推定をして結果を見て、モデルを修正する試行錯誤をします。4.1 データの確認
まずは、使用するデータを作成します。
np.random.seed(seed=1) #乱数の種 a,b = 3.0,1.0 #傾きと切片 sig = 2.0 #標準偏差 x = 10.0* np.random.rand(100) y = a*x + b + np.random.normal(0.0,sig,100)プロットして確認します。合わせて最小二乗法による線形回帰も表示します。
a_lsm,b_lsm = np.polyfit(x,y,1) #最小二乗法で線形回帰 (2.936985017531063, 1.473914508297817)fig,axes = plt.subplots(figsize=(8,6)) axes.scatter(x,y) axes.plot(np.linspace(0.0,10.0,100),a_lsm*np.linspace(0.0,10.0,100)+b_lsm) axes.set_xlabel("x") axes.set_ylabel("y")
4.2 データ生成過程の考察とStanコードの作成
データを作成した過程をすっかり忘れたとして、グラフを見て$y$と$x$は比例関係にありそうだと考えます。ばらつきは正規分布に従っていると仮定して、Stanコードを書きます。
stan_code = """ data { int N; // サンプルサイズ vector[N] x; // データ vector[N] y; // データ int N_pred; // 予測対象のサンプルサイズ vector[N_pred] x_pred; // 予測対象のデータ } parameters { real a; // 傾き real b; // 切片 real<lower=0> sigma; // 標準偏差 <lower=0>は、0以上の値しか取らないという指定 } transformed parameters { vector[N] mu = a*x + b; } model { // b ~ normal(0, 1000) 事前分布の指定 // 平均mu、標準偏差sigmaの正規分布 y ~ normal(mu, sigma); // "~"記号は、左辺が右辺の分布に従うことを表す } generated quantities { vector[N_pred] y_pred; for (i in 1:N_pred) { y_pred[i] = normal_rng(a*x_pred[i]+b, sigma); } } """新たに登場したtransformed parametersブロックはparametersブロックで宣言した変数を使って新しい変数を作成できます。今回は単純な式なのであまり差がありませんが、複雑な式であればこうすると見通しが良くなります。また、事前分布を指定するときはコメントアウトしてあるmodelブロックの"b ~ normal(0, 1000)"のように書きます。
4.3 MCMCの実行
Stanコードをコンパイルし、MCMCを実行します。
sm = pystan.StanModel(model_code=stan_code) #stanコードのコンパイルx_pred = np.linspace(0.0,11.0,200) stan_data = {"N":len(x), "x":x, "y":y, "N_pred":200, "x_pred":x_pred}#MCMCの実行 mcmc_linear = sm.sampling( data = stan_data, iter = 4000, warmup = 1000, chains = 4, thin = 1, seed = 1 )4.4 結果の確認
print(mcmc_linear)Inference for Stan model: anon_model_28ac7b1919f5bf2d52d395ee71856f88. 4 chains, each with iter=4000; warmup=1000; thin=1; post-warmup draws per chain=3000, total post-warmup draws=12000. mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat a 2.94 9.0e-4 0.06 2.82 2.89 2.94 2.98 3.06 4705 1.0 b 1.47 5.1e-3 0.35 0.79 1.24 1.47 1.71 2.16 4799 1.0 sigma 1.83 1.7e-3 0.13 1.59 1.74 1.82 1.92 2.12 6199 1.0 mu[1] 13.72 1.8e-3 0.19 13.35 13.59 13.72 13.85 14.09 10634 1.0 mu[2] 22.63 2.2e-3 0.24 22.16 22.47 22.63 22.78 23.1 11443 1.0 Samples were drawn using NUTS at Wed Jan 1 15:07:22 2020. For each parameter, n_eff is a crude measure of effective sample size, and Rhat is the potential scale reduction factor on split chains (at convergence, Rhat=1).とても長い出力なので省略してあります。Rhatを見ると収束は問題なさそうです。事後予測分布から95%信用区間を図示します。
reg_95 = np.quantile(mcmc_linear["y_pred"],axis=0,q=[0.025,0.975]) #事後予測分布 fig,axes = plt.subplots(figsize=(8,6)) axes.scatter(x,y,label="Data",c="k") axes.plot(x_pred,np.average(mcmc_linear["y_pred"],axis=0),label="Expected value") axes.fill_between(x_pred,reg_95[0],reg_95[1],alpha=0.1,label="95%") axes.legend(loc="best") axes.set_xlabel("x") axes.set_ylabel("y")
概ね良さそうです。
まとめ
単回帰モデルのベイズ推定を通して、ベイズ推定の流れとStanの使い方を学びました。もう一度ベイズ推定の流れを記録しておきます。
1. データの確認 : グラフにプロットするなどして、データの構造を掴みます。
2. データ生成過程の考察とStanコードの作成 : データの構造を数式化してStanコードを書きます。
3. MCMCの実行 : MCMCを実行して、事後分布を得ます。
4. 結果の確認 : 結果を確認して、繰り返しモデルの修正を行います。今回は単純なモデルを使用しましたが、次回は状態空間モデルなどのより汎用的なモデルで試したいと思います。




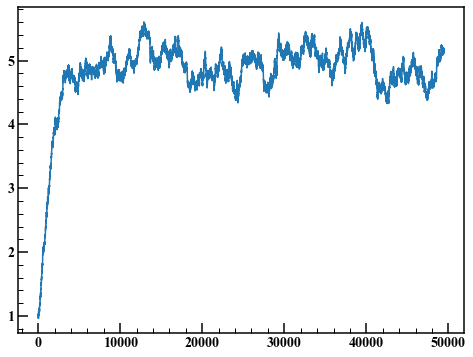
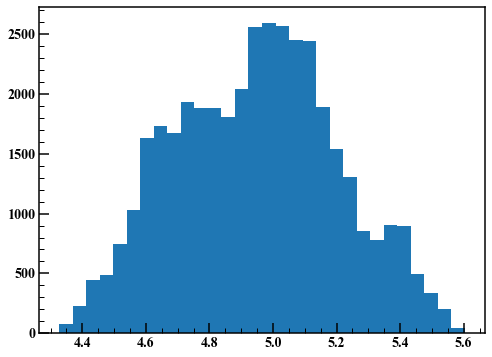


- 投稿日:2020-01-01T14:41:02+09:00
眺めて覚えるGo言語 その8 PythonからGO言語を呼ぶ
今回は、PythonからGO言語を呼んでpythonの弱点である速度向上させるアプローチです。
Pythonを語ったとき「コンパイラ」ではない。で炎上しました。
javaでも「コンパイラ」ではないし、C#もコンパイラではないのです。
中間言語に変換して実行するのは、スピード遅いし、第一電池がすぐ減るのです。
GOは、本物っぽいコンパイラーです。
pythonから見ると計算部分を高速化できる可能性があります。
フィボナッチ数を参考にしました。
- 1つがいの兎は、産まれて2か月後から毎月1つがいずつの兎を産む。
- 兎が死ぬことはない。
- この条件のもとで、産まれたばかりの1つがいの兎は1年の間に何つがいの兎になるか?
fib_go.pyfrom ctypes import * lib = cdll.LoadLibrary("./fib.so") for i in range(40): print ("fib %d %d" %(i, lib.fib(i)))lib.fib(i)で下記の関数呼ぶだけ。
fib.gopackage main import "C" //export fib func fib(n int) int { if n <= 1 { return n } return fib(n-1) + fib(n-2) } func main() {}Goで書いた関数をコンパイルする。
> go build -o fib.so -buildmode=c-shared fib.go実行する
>python fib_go.py fib 0 0 fib 1 1 fib 2 1 fib 3 2 fib 4 3 fib 5 5 fib 6 8 fib 7 13 fib 8 21 fib 9 34 fib 10 55 fib 11 89 fib 12 144 fib 13 233 fib 14 377 fib 15 610 fib 16 987 fib 17 1597 fib 18 2584 fib 19 4181 fib 20 6765 fib 21 10946 fib 22 17711 fib 23 28657 fib 24 46368 fib 25 75025 fib 26 121393 fib 27 196418 fib 28 317811 fib 29 514229 fib 30 832040 fib 31 1346269 fib 32 2178309 fib 33 3524578 fib 34 5702887 fib 35 9227465 fib 36 14930352 fib 37 24157817 fib 38 39088169 fib 39 63245986 fib 40 10233415510倍以上速くなる。
- 投稿日:2020-01-01T14:30:38+09:00
【Python】JSONファイルのデータを元にOutlook新規メールを作成するツールを作成したことと、引っ掛かった部分について
1.この記事について
主目的は、
日次メール作成作業や月次定期メールなど
定型的な作業を効率化したかったこと。第二の目的は、
Pythonにおけるjsonファイルの扱いや
Outlookの連携を学習したかった。
(率直なところOutlookをいじるだけなら
Excelにデータを載せてVBAで作成するのが
一番正着なんではないかと思うけど)※ツールとソースコードはGithubに上げてます(後述)
2.やりたいこと
・jsonファイルの項目を考える
・jsonファイルをハンドリングするクラス作成
・Office Outlookをハンドリングするクラス作成
・上記クラスを連携してメール作成するmainメソッドの開発3.使用したツール・環境
・Windows10
・Python 3.7.0
・office2016
・その他下記コードに記載のライブラリ各種4.作成したコードと解説
クラス図
pycharmで作成したクラス図はこのようになる。
jsonファイルの中身
要件としては、
・フォーマット(テキストメールかHTMLメールかリッチテキストか)
・差出人
・送り先(複数指定可)
・CC(複数指定可)
・BCC(複数指定可)
・件名
・本文
・添付ファイル
を設定できるものが望ましかったため、
このようになった。mailSetting.json{ "mailFormat": 3, "senderAddress": "foo@gmail.com", "receiverAddressSet": ["bar@Test.jp","bar2@Test.jp","bar3@Test.jp"], "CC_AddressSet": ["bar@Test.jp","bar4@Test.jp"], "BCC_AddressSet": ["bar@Test.jp","bar5@Test.jp"], "title":"あいうえお", "attachedFileFolderPath": "C:\\Users\\UserName\\Test", "body": "〇〇様\n\nお疲れさまです。〇〇です。\n\n〇〇を送付します。\n\n以上。\n" }mailFormatは1~3の数字から選び、
それぞれが[テキストメールかHTMLメールかリッチテキストか]に該当しているようだ。jsonハンドリングクラス
JsonHandler.pyimport json class JsonHandler: def __init__(self, jsonPath): # jsonファイル読み込み self.file = open(jsonPath, 'r', encoding="utf-8_sig") self.jsonData = json.load(self.file) # 一次ネストのjsonデータ取得 def getParam_OneNest(self, args): return self.jsonData[args] def __del__(self): # ファイル閉じる self.file.close()引っ掛かった点①:エンコーディングについて
ファイル取込の際のエンコードの方法を検索しましたが、
こちらの記事を参考にさせていただいた。
WindowsでCP932(Shift-JIS)エンコード以外のファイルを開くのに苦労した話 - QiitaどうやらBOMの処理のためにencoding="utf-8_sig"という方法を採用する必要があるようだ。
outlookハンドリングクラス
OutlookHandler.pyimport glob import os import win32com.client class OutlookHandler: def __init__(self): self.outlook = win32com.client.Dispatch("Outlook.Application") self.newMail = None def create(self): self.newMail = self.outlook.CreateItem(0) def setting(self, argMailformat, argSenderaddress, argReceiveraddressset, argCc_Addressset, argBcc_Addressset, argTitle, argAttachedfilefolderpath, argBody): # ///メールアイテムに情報設定 self.newMail.BodyFormat = argMailformat try: self.newMail._oleobj_.Invoke(*(64209, 0, 8, 0, self.outlook.Session.Accounts(argSenderaddress))) except: pass self.newMail.To = argReceiveraddressset self.newMail.cc = argCc_Addressset self.newMail.Bcc = argBcc_Addressset self.newMail.Subject = argTitle # 本文に署名を付与(Outlook起動時のみ) try: self.newMail.Body = argBody \ + os.linesep \ + self.newMail.GetInspector.WordEditor.Bookmarks('_MailAutoSig').Range.Text except: self.newMail.Body = argBody # 添付ファイル取得 if os.path.isdir(argAttachedfilefolderpath): for file in glob.glob(argAttachedfilefolderpath + '\\*'): if os.path.isfile(file): self.newMail.Attachments.Add(file) def display(self): self.newMail.Display(False) def release(self): self.newMail = None self.outlook = None引っ掛かった点②:差出人メールアドレス設定について
こんなへんてこなやり方をしている。
self.newMail._oleobj_.Invoke(*(64209, 0, 8, 0, self.outlook.Session.Accounts(argSenderaddress)))VBAの場合に定石だった
「SentOnBehalfOfName」フィールドがなぜか使えなかった(outlook側の設定の問題かもしれないけど)。
調べたらこんな記事がヒットしたため、それを採用。
https://stackoverflow.com/questions/35908212/python-win32com-outlook-2013-sendusingaccount-return-exceptionただしこの方法は、jsonで設定したアドレスがoutlookにユーザーのアドレスとして登録されていることが前提。
もし登録されていなかったら例外が発生するのでtrycatchで処理している。
SentOnBehalfOfNameのように登録していないものでも使えるというわけではない。
そのため、改良の余地はある。
(デフォルトのアドレスしか使わない場合は特に問題もない)引っ掛かった点③:本文に署名を乗せる方法について
self.newMail.Body = argBody \ + os.linesep \ + self.newMail.GetInspector.WordEditor.Bookmarks('_MailAutoSig').Range.Text # 本文に署名を付与このようにWordEditor.Bookmarksのフィールドを使用した方法だと、
「※outlookアプリケーション起動時にしか署名が付与されない」という大きな問題がある。
もし起動していない状態でmainメソッドを実行したら例外が発生する。そのため、今回はtrycatchで処理して、
もし起動してないなら署名は諦めることにしている。これも改良の余地がある部分だけど、仕方ない(outlook起動処理はそれはそれでけっこうめんどくさいので)。
mainメソッド
OutloookMailCreater.pyimport datetime import sys # モジュール検索パスを再設定 # ダブルクリックによる起動にも対応できるようにする sys.path.append(r"C:\Users\UserName\PycharmProjects\CreateToolAndTest") import os import tkinter from tkinter import messagebox from PrivateTool.OutlookMailCreater.JsonHandler import JsonHandler from PrivateTool.OutlookMailCreater.OutlookHandler import OutlookHandler import traceback if __name__ == '__main__': try: # messageウィンドウの準備 root = tkinter.Tk() root.withdraw() root.attributes("-topmost", True) # outlook起動 outlookHandler = OutlookHandler() outlookHandler.create() # jsonファイル操作オブジェクト jsonHandler = JsonHandler(os.path.join(os.path.dirname(os.path.abspath(__file__)), 'mailSetting.json')) # jsonから値を取得しリストに格納 settingList = [jsonHandler.getParam_OneNest('mailFormat'), ] settingList.append(jsonHandler.getParam_OneNest('senderAddress')) tempSet = jsonHandler.getParam_OneNest('receiverAddressSet') settingList.append('; '.join(tempSet)) tempSet = jsonHandler.getParam_OneNest('CC_AddressSet') settingList.append('; '.join(tempSet)) tempSet = jsonHandler.getParam_OneNest('BCC_AddressSet') settingList.append('; '.join(tempSet)) settingList.append(jsonHandler.getParam_OneNest('title')) settingList.append(jsonHandler.getParam_OneNest('attachedFileFolderPath')) settingList.append(jsonHandler.getParam_OneNest('body')) # ◆◆◆リストデータになにか処理を加える場合はここに記述◆◆◆ # myDate = datetime.date.today() # if myDate.day < 16: # myDate -= datetime.timedelta(days=15) # settingList[5] = settingList[5].replace('$date', myDate.strftime('%Y%m')) # ◆◆◆◆◆◆ # outlookの新規メールアイテム作成 outlookHandler.setting(*settingList) # メールアイテムの表示 outlookHandler.display() outlookHandler.release() # アナウンス messagebox.showinfo("", "正常終了") except: print("Error", messagebox.showinfo("Error", "エラー発生")) traceback.print_exc() finally: pass引っ掛かった点④:messageウィンドウを最前面に出す方法について
次のように設定してあげればいいらしい。
root.attributes("-topmost", True)5.終わりに
ツールとソースコードはこちら↓
CreateToolAndTest/Tool_Python/OutlookMailCreater at master · dede-20191130/CreateToolAndTestなにか補足がありましたらコメントください。

- 投稿日:2020-01-01T14:08:23+09:00
非正規分布をrobust Z-scoreで標準化する
正規化・標準化には、min-max normalizationとZ-score Normalization(Standardization)がよく使われています。今回、robust Z-scoreを試して、上記の正規化と比較してみました。
min-max normalization
min-max normalizationとは、データが最小値0・最大値1になるようにする方法で、以下の式で正規化します。
x' = \frac{x-min(x)}{max(x)-min(x)}pythonでは、
sklearn.preprocessingのminmax_scaleかMinMaxScalerで計算できます。
この正規化は、データの分布が一様分布であることを前提としています。Z-score Normalization(Standardization)
Z-score Normalizationとは、データが平均0・分散1になるようにする方法で、以下の式で正規化します。この値をZ-scoreといいます。μ は平均、σ は標準偏差を表しています。
x' = \frac{x-\mu}{\sigma}pythonでは、
sklearn.preprocessingのscaleかStandardScalerで計算できます。
この正規化は、データの分布が正規分布であることを前提としています。一様分布でも正規分布でもないときはどうするのか?
実際のデータでは一様分布でも正規分布でもないことが多かったので、どうしたらよいのか調べていたところ、以下の記事でrobust Z-scoreを見つけました。
ロバストzスコア:中央値と四分位数で,非正規分布,外れ値を含む標準化
(メモ)ロバストzスコアを用いた異常値の除外以下で、Pythonで試してみました。
robust Z-scoreの実装
robust Z-scoreについての詳細は上記の記事を読んでいただければと思います。以下では、簡略に説明して実装します。
Z-scoreは正規分布を前提としていますが、これを非正規分布にあてはめるために、まず、平均 μを中央値 、標準偏差 σ を四分位範囲(IQR)に置き換えます。
x' = \frac{x-median(x)}{IQR}この式は
sklearn.preprocessingのrobust_scaleかRobustScalerで計算できます。さらに、これを標準正規分布に対応できるものにします。IQRを標準正規分布に対応させたものを正規化四分位範囲(NIQR)といい、IQRをF(0.75) - F(0.25) = 1.3489で割ったものとなります。(F(x)は累積分布関数の逆関数)
NIQR = \frac{IQR}{0.13489}先ほどの式の分母をIQRからNIQRに置き換えたものが、robust Z-scoreになります。
robust Z score = \frac{x-median(x)}{NIQR}以上のことを踏まえて実装すると、以下のような関数となります。
def robust_z(x): from sklearn.preprocessing import robust_scale from scipy.stats import norm coefficient = norm.ppf(0.75)-norm.ppf(0.25) robust_z_score = robust_scale(x)*coefficient return robust_z_score3つの正規化の比較
これまでに出てきた3つの正規化を比較したいと思います。
まず、データを用意します。一様分布でも正規分布でもないデータがほしいので、一様分布と正規分布を結合したデータを用意しました。import numpy as np import matplotlib.pyplot as plt import pandas as pd from scipy.stats import chisquare, shapiro, norm from sklearn.preprocessing import minmax_scale, scale, robust_scale np.random.seed(2020) # 一様分布と正規分布を結合したデータ。 data = np.concatenate((np.random.uniform(low=5.0, high=10.0, size=100), np.random.normal(loc=5.0, scale=1.0, size=100))) # ヒストグラムを作画。 fig, axes = plt.subplots() axes.hist(data) axes.set_title("Histogram of data") fig.show()
このデータが一様分布でないことと正規分布でないことを検定で確かめます。
一様性はカイ2乗検定、正規性は(シャピロ–ウィルク検定)で確かめました。# 度数分布を計算する。 hist_data, _ = np.histogram(data, bins="auto") # 一様性検定(カイ2乗検定) _, chisquare_p = chisquare(hist_data) print("一様性検定(カイ2乗検定)のp値 : {}".format(chisquare_p)) # 正規性検定(シャピロ–ウィルク検定) _, shapiro_p = shapiro(data) print("正規性検定(シャピロ–ウィルク検定)のp値 : {}".format(shapiro_p))結果は以下の通りです。どちらもP値が0.05より小さいので、一様分布でも正規分布でもないといえそうです。
一様性検定(カイ2乗検定)のp値 : 3.8086163670115985e-09 正規性検定(シャピロ–ウィルク検定)のp値 : 8.850588528730441e-06このデータでmin-max normalization、Z-score、robust Z-scoreを計算し、比較してみます。
# 各方法で正規化を行い、データフレームに入れる。 score_df = pd.DataFrame(data=np.array([minmax_scale(data), scale(data), robust_z(data)]).T, columns=["min-max", "Z-score", "robust Z-score"]) # グラフを作成 fig, axs = plt.subplots(ncols=3, constrained_layout=True) # x軸の幅の設定 xrange = {"min-max":(0,1), "Z-score":(-2.5,2.5), "robust Z-score":(-2.5,2.5)} # 各ヒストグラムの作画 for i, score_name in enumerate(score_df.columns): axs[i].hist(score_df[score_name]) axs[i].set_title(score_name) axs[i].set_xlim(xrange[score_name]) fig.show()結果が以下の図です。あまり違いがありません。データの分布次第では違いが出てくるのかもしれません。
外れ値があるデータで比較する
そもそもrobust Z-scoreの"robust"は、外れ値に対してrobust(頑健)であるという意味です。robust Z-scoreは外れ値検出にも利用されています。
そこで、データに外れ値を入れて比較したいと思います。比較しやすいように、極端で多数の外れ値を入れてみます。# 外れ値(一様分布)をデータに結合する。 outier = np.concatenate((data, np.random.uniform(low=19.0, high=20.0, size=15))) # 各方法で正規化を行い、データフレームに入れる。 outlier_df = pd.DataFrame(data=np.array([minmax_scale(outier), scale(outier), robust_z(outier)]).T, columns=["min-max", "Z-score", "robust Z-score"]) # 外れ値なしと外れ値ありのデータフレームを結合。 concat_df = pd.concat([score_df, outlier_df], axis=1, keys=['without outlier', 'with outlier']) # グラフを作成 fig, axs = plt.subplots(nrows=2, ncols=3, constrained_layout=True) # x軸の幅の設定 xrange = {"min-max":(0, 1), "Z-score":(-6.5, 6.5), "robust Z-score":(-6.5, 6.5)} # ヒストグラムの作画 for i, (data_name, score_name) in enumerate(concat_df.columns): row, col = divmod(i, 3) axs[row, col].hist(concat_df[(data_name, score_name)]) axs[row, col].set_xlim(xrange[score_name]) title = "\n".join([data_name, score_name]) axs[row, col].set_title(title) plt.show()結果が以下の図です。上が外れ値なし、下が外れ値ありの場合です。
min-max normalizationは、外れ値に非常に影響を受けています。Z-scoreも外れ値の影響を受け、外れ値なしの場合と大きく異なっています。robust Z-scoreが最も外れ値の影響が少なく、外れ値なしの場合と比較的似ています。
最後に
robust Z-scoreは、データが正規分布のときはZ-scoreと同じ結果となるので、迷ったらrobust Z-scoreを使おうと考えています。特に、外れ値も使いたい場合にはrobust Z-scoreが有効であると感じました。

- 投稿日:2020-01-01T13:47:57+09:00
AtCoder Grand Contest 041 復習
先日あったAGC041の復習をしたいと思います。
今回の成績
初めて二完できたので自分に及第点は上げれると思っていますが、C問題は発想を少し転換すればいいだけだったので、三完したかったというのが今回のAGCの感想です。
A問題
比較的すぐ解法を思いついたのですが、早とちりして明らかに間違っている解法を提出したのと、C++のコードとしてPythonのコードを提出しまったので2WAを吐きました。
まず、一番わかりやすいのは卓Aと卓Bの距離が偶数である場合です。この場合はそれぞれの卓にいる卓球選手がお互いに卓の距離を2ずつ縮めていけばよく、距離を2で割ったものを出力します。
次に、卓Aと卓Bの距離が奇数である場合を考える必要があります。その場合、端(卓1or卓N)まで行ってそこに一つのラウンドでとどまることで二人のいる卓の距離を偶数にすることができます。この際、端の近い方を考える必要があるので、以下のコードのc,dの二つでminの方を出力すれば良いです。(この辺の式を適当にコーディングしたらWAになりました。)
この問題で重要なのは、遷移の際の状態を分類することです。この問題では卓1で勝利する場合と卓Nで敗北する場合でのみ他の卓に移らないことがわかります。また、両者が共に近づく場合が明らかに最小になり、そのような場合はその距離が偶数になり、端にいる場合は偶奇が変化するということも考察するのは容易です。answerA.pyx=[] n,a,b=map(int,input().split()) if (b-a)%2==0: print((b-a)//2) else: c=(a-1)+(b-a+1)//2 d=(n-b)+(b-a+1)//2 print(min(c,d))B問題
とりあえず降順に人を並べます。この時、A1~Apの問題はP問がコンテストに採用されることから無条件に採用することができます。ここで、そのP個の問題のうちの一番点の低いApの問題に変えてそれよりも小さい問題を選ぶことができればその問題はコンテストに採用することができます。
v<=pの場合はA1~Ap-1とAj(j>=p+1)に投票し続け、AjがApを超えることができれば良いとわかります。
それに対し、v>pの場合はAj(j>=p+1)についてA1~Ap-1、Ajに全員のジャッジが投票してもまだ票が余っており、AjがApを超えることができれば良いだけでは判断できないことがわかります(Apに票が入った場合はAjを超えてしまう可能性があるので)。ここで、ジャッジの残りの票の選び方を考えた時、Ak(k>j+1)にも投票してもAjを超えることにも気づかねばなりません。
つまり、A1~Ap-1、Aj~Anに投票し(この時点で、投票した問題の点数は+mされている)、ジャッジの残りの票をAp~Aj-1に入れても、Ajが任意のlについてAl(p<=l<=j-1)以上であればAjをコンテストに採用することができると言えます。また、ジャッジの残りの票をApがAjを超えないよう最大限投票した時に、Ap~Aj-1がAjに等しくなることがわかります(この時、Ap~Aj-1は元のAjよりも大きいのでそれぞれに最大限投票してもmを超えないことが保証されます。)。
また、降順に並んでおり、あるAjを境にコンテストに採用できなくなるので、そのようなAjは二分探索で探すことができます。
adopt関数の中を一応説明すると、まず、A1~Ap-1はそもそも考慮する必要がないのでa[p-1:]としてスライスして考えています。bはAx+p+1(xは0インデックスで考えてます。)に最大限投票した場合の値、bがAp以上にならない場合は採用できないのでFalseをreturn(1)、alはジャッジ全員の投票数の合計(ただし、A1~Ap-1、Ax+p+1~Anは投票するのでその分はすでに引いておきます。)で、alが0以下の場合はジャッジ全員の票を使いきっているのでTrueをreturn(2)、sはAp~Ax+pをAx+p+1(b)にするのに必要な票数を表し、alがsを超えてしまったらFalse、超えなければTrueをreturnします。answerB.pyn,m,v,p=map(int,input().split()) a=[int(i) for i in input().split()] a.sort(reverse=True) a=a[p-1:] le=len(a) l,r=0,le-1 def adopt(x): global a,n,m,v,p b=a[x]+m #(1) if b<a[0]: return False al=v*m al-=(n-x)*m #(2) if al<=0: return True s=x*b-sum(a[:x]) #(3) if al>s: return False else: return True while l+1<r: k=(l+r)//2 if adopt(k): l=k else: r=k if adopt(r): print(p+r) else: print(p+l)コンテスト後にshortestとfastest両方狙いに行ったコード↓(大して短くも早くもない中途半端なコードになった。)
answerB_better.pyn,m,v,p=map(int,input().split()) a=sorted(list(map(int, input().split())),reverse=True)[p-1:] l,r=0,n-p while l+1<r: k=(l+r)//2 b=a[k]+m if b<a[0] or (v-(n-k))*m>(k*b-sum(a[:k])): r=k else: l=k b=a[r]+m print(p+l if(b<a[0] or (v-(n-r))*m>(r*b-sum(a[:r]))) else p+r)C問題
コンテスト中には解けませんでした。コンテスト中の考察により縦長にドミノを置いた場合と横長にドミノを置いた場合の数を均等にする必要があり、均等にした場合はクオリティを3にすることで条件を満たすドミノの配置が作れることがわかりました(n=2,3の場合は除く)。
ここで対称性を考えてドミノを配置していったところnが3の倍数では対角線にそって順に縦横にドミノを配置することでクオリティ1のドミノの配置を見つけることができました。しかし、nが3の倍数ではないときは対称性の高い配置を見つけることができませんでした(ここで別の方法を考えるべき。)。
そこで、大きい数のものは分割するとうまくいくことが多いので、この問題でもそのようにして考えます。i行目からj行目かつi列目からj列目の部分正方行列に注目して考えると、この正方行列以外のi行目からj行目とi列目からj列目の部分が0であれば部分正方行列のクオリティがi行目からj行目およびi列目からj列目になることがわかります。したがって、そのような部分正方行列で構成すれば良いことがわかります。先ほどのクオリティが3である行列を考えると、4次以上の正方行列では見つかりそうな雰囲気を感じます。ここからは頑張ってそのような正方行列を探していくことになります。
解答の方法を見ると、3,4,5,6,7次の正方行列を見つけ、mod4で場合分けをして正方行列の対角線に順に正方行列を配置していけば良いです。(上から数えると4次,4次,4次,…,(4or5or6or7)次と並びます。)僕は、nが3の倍数の時は簡単な配置があることを利用してmod6で場合分けをしましたが、3,4,5,6,7,8次の正方行列を見つける必要があるので解答の方法がおそらく一番簡単な方法になると思われます。answerC.pyn=int(input()) if n==2: print(-1) else: x=[] if n%3==0: for i in range(n//3): x.append("."*(3*i)+"a"+"."*(n-3*i-1)) x.append("."*(3*i)+"a"+"."*(n-3*i-1)) x.append("."*(3*i)+".aa"+"."*(n-3*i-3)) elif n%6==1: for i in range(n//6-1): x.append("."*(6*i)+".a.b.c"+"."*(n-6*i-6)) x.append("."*(6*i)+".a.b.c"+"."*(n-6*i-6)) x.append("."*(6*i)+"ddg.ll"+"."*(n-6*i-6)) x.append("."*(6*i)+"e.g.kk"+"."*(n-6*i-6)) x.append("."*(6*i)+"e.hhj."+"."*(n-6*i-6)) x.append("."*(6*i)+"ffiij."+"."*(n-6*i-6)) x.append("."*(n-7)+".aab.c.") x.append("."*(n-7)+"d..b.c.") x.append("."*(n-7)+"d..eeff") x.append("."*(n-7)+"g..mm.l") x.append("."*(n-7)+"gnn...l") x.append("."*(n-7)+"h...kkj") x.append("."*(n-7)+"hii...j") elif n%6==2: for i in range(n//6-1): x.append("."*(6*i)+".a.b.c"+"."*(n-6*i-6)) x.append("."*(6*i)+".a.b.c"+"."*(n-6*i-6)) x.append("."*(6*i)+"ddg.ll"+"."*(n-6*i-6)) x.append("."*(6*i)+"e.g.kk"+"."*(n-6*i-6)) x.append("."*(6*i)+"e.hhj."+"."*(n-6*i-6)) x.append("."*(6*i)+"ffiij."+"."*(n-6*i-6)) x.append("."*(n-8)+".a.bb.cc") x.append("."*(n-8)+".a...m.j") x.append("."*(n-8)+"..pp.m.j") x.append("."*(n-8)+"hh..i.o.") x.append("."*(n-8)+"gg..i.o.") x.append("."*(n-8)+"..n.ll.k") x.append("."*(n-8)+"f.n....k") x.append("."*(n-8)+"f.dd.ee.") elif n%6==4: for i in range(n//6): x.append("."*(6*i)+".a.b.c"+"."*(n-6*i-6)) x.append("."*(6*i)+".a.b.c"+"."*(n-6*i-6)) x.append("."*(6*i)+"ddg.ll"+"."*(n-6*i-6)) x.append("."*(6*i)+"e.g.kk"+"."*(n-6*i-6)) x.append("."*(6*i)+"e.hhj."+"."*(n-6*i-6)) x.append("."*(6*i)+"ffiij."+"."*(n-6*i-6)) x.append("."*(n-4)+"aacb") x.append("."*(n-4)+"ffcb") x.append("."*(n-4)+"hgdd") x.append("."*(n-4)+"hgee") else: for i in range(n//6): x.append("."*(6*i)+".a.b.c"+"."*(n-6*i-6)) x.append("."*(6*i)+".a.b.c"+"."*(n-6*i-6)) x.append("."*(6*i)+"ddg.ll"+"."*(n-6*i-6)) x.append("."*(6*i)+"e.g.kk"+"."*(n-6*i-6)) x.append("."*(6*i)+"e.hhj."+"."*(n-6*i-6)) x.append("."*(6*i)+"ffiij."+"."*(n-6*i-6)) x.append("."*(n-5)+"aabbc") x.append("."*(n-5)+"g.h.c") x.append("."*(n-5)+"gjh..") x.append("."*(n-5)+"dj.ii") x.append("."*(n-5)+"deeff") for i in range(n): print("".join(x[i]))D問題以降
まだ解くべきレベルではないかなと感じたので、次にやる時にチャレンジしたいと思います。

- 投稿日:2020-01-01T13:17:36+09:00
KaggleのTitanicでscikit-learnの全モデルを試す(kaggle⑤)
はじめに
初めてKaggle(カグル)のコンペに参加してみたお話です。
前回の「KaggleのTitanicでモデルを選別する」では、いくつかのモデルを評価してスコアを少し上げることができました。
今回は scikit-learn の全モデルを試してみたいと思います。目次
1.結果
2.scikit-learnの全モデルについて
3.交差検証
4.全モデルを交差検証で評価する
5.パラメータチューニング
6.Kaggleに提出する
7.まとめ履歴
1.結果
結果から言うと、さらにスコアが少しあがり「0.78947」になりました。
上位25%(2019/12/30現在)という結果です。
提出までの流れを見ていきたいと思います。2.scikit-learnの全モデルについて
scikit-learnの全モデルは「all_estimators」で取得することができます。
取得するときに「type_filter」のパラメータで以下の4つから絞り込みを行うことができます。
「classifier / regressor / cluster / transformer」
今回は分類問題ですので「classifier 」でフィルターします。from sklearn.utils.testing import all_estimators all_estimators(type_filter="classifier")3.交差検証
上で取得したモデルに対して「交差検証」で検証を行ってみましょう。
今回は「K-分割交差検証」を行います。
K-分割交差検証は、まずトレーニングデータをK個に分割します。そして、そのうちの1つをテストデータとし、残った K − 1 個をトレーニングデータとします。
K − 1 個のトレーニングデータで学習し、残ったテストデータで評価します。
これを k 回繰り返し、得られた k 回の結果(score)を平均してモデルを評価する方法です。
scikit-learnに、K-分割交差検証のクラスが用意されています。
「KFold」と「cross_validate」です。from sklearn.model_selection import KFold from sklearn.model_selection import cross_validate kf = KFold(n_splits=3, shuffle=True, random_state=1) scores = cross_validate(model, x_train, y_train, cv=kf, scoring=['accuracy'])KFoldの「n_splits」で何分割するかを指定します。
cross_validateでトレーニングデータとKFold、およびscoringの方法を指定します。
cross_validateの戻り値には、scoringで指定した評価が返却されます。返却値はn_splitsで分割した分だけ配列で返却されます。4.全モデルを交差検証で評価する
それでは、全モデルをK-分割交差検証で評価してみたいと思います。
コードは以下です。「準備」のコードは今までと同じです。準備import numpy import pandas ############################## # データ前処理 # 必要な項目を抽出する # Data preprocessing # Extract necessary items ############################## # train.csvを読み込む # Load train.csv df = pandas.read_csv('/kaggle/input/titanic/train.csv') df = df[['Survived', 'Pclass', 'Sex', 'Fare']]準備from sklearn.preprocessing import LabelEncoder ############################## # データ前処理 # ラベル(名称)を数値化する # Data preprocessing # Digitize labels ############################## #df = pandas.get_dummies(df) encoder_sex = LabelEncoder() df['Sex'] = encoder_sex.fit_transform(df['Sex'].values)準備from sklearn.preprocessing import StandardScaler ############################## # データ前処理 # 数値を標準化する # Data preprocessing # Standardize numbers ############################## # 標準化 standard = StandardScaler() df_std = pandas.DataFrame(standard.fit_transform(df[['Pclass', 'Fare']]), columns=['Pclass', 'Fare']) df['Pclass'] = df_std['Pclass'] df['Fare'] = df_std['Fare']K-分割交差検証import sys from sklearn.model_selection import KFold from sklearn.model_selection import cross_validate from sklearn.utils.testing import all_estimators ############################## # 全モデルでK-分割交差検証を行う # K-fold cross-validation with all estimators. ############################## x_train = df.drop(columns='Survived').values y_train = df[['Survived']].values y_train = numpy.ravel(y_train) kf = KFold(n_splits=3, shuffle=True, random_state=1) writer = open('./all_estimators_classifier.txt', 'w', encoding="utf-8") writer.write('name\taccuracy\n') for (name,Estimator) in all_estimators(type_filter="classifier"): try: model = Estimator() if 'score' not in dir(model): continue; scores = cross_validate(model, x_train, y_train, cv=kf, scoring=['accuracy']) accuracy = scores['test_accuracy'].mean() writer.write(name + "\t" + str(accuracy) + '\n') except: print(sys.exc_info()) print(name) pass writer.close()「all_estimators(type_filter="classifier")」で分類問題のモデルを取得し、ループしています。
「if 'score' not in dir(model):」でscoreを持っているモデルのみを対象にしています。
「cross_validate」で交差検証を評価します。パラメータに上で指定した「KFold」を指定します。
モデル名と評価の値を「all_estimators_classifier.txt」というファイル名に出力します。実行してみます。
処理が完了すると「all_estimators_classifier.txt」が出力されます。
中身を見てみましょう。
モデル名が30個ほど出力されています。
「accuracy」が大きい順に10個のモデルをピックアップすると以下になりました。
name accuracy ExtraTreeClassifier 0.82155 GradientBoostingClassifier 0.82043 HistGradientBoostingClassifier 0.81706 DecisionTreeClassifier 0.81481 ExtraTreesClassifier 0.81481 RandomForestClassifier 0.80920 GaussianProcessClassifier 0.80471 MLPClassifier 0.80471 KNeighborsClassifier 0.80022 LabelPropagation 0.80022 前回の「RandomForestClassifier」より正解率が高いモデルが5つあります。
5.パラメータチューニング
上位5つのモデルをそれぞれグリッドサーチでパラメータを確認してみます。
以下になりました。
モデル パラメータ ExtraTreeClassifier criterion='gini', min_samples_leaf=10, min_samples_split=2, splitter='random' GradientBoostingClassifier learning_rate=0.2, loss='deviance', min_samples_leaf=10, min_samples_split=0.5, n_estimators=500 HistGradientBoostingClassifier learning_rate=0.05, max_iter=50, max_leaf_nodes=10, min_samples_leaf=2 DecisionTreeClassifier criterion='entropy', min_samples_split=2, min_samples_leaf=1 ExtraTreesClassifier n_estimators=25, criterion='gini', min_samples_split=10, min_samples_leaf=2, bootstrap=True 6.Kaggleに提出
それぞれのモデルでKaggleに提出してみます。
パラメータはグリッドサーチで調べたパラメータにします。
スコアは以下になりました。
モデル score ExtraTreeClassifier 0.78947 GradientBoostingClassifier 0.75598 HistGradientBoostingClassifier 0.77990 DecisionTreeClassifier 0.77511 ExtraTreesClassifier 0.78468 ExtraTreeClassifier が一番良いscoreになり「0.78947」という結果になりました。
7.まとめ
scikit-learn の全モデルを交差検証で評価しました。
今回の入力データの場合は、ExtraTreeClassifierが最もスコアが良く
「0.78947」という結果になりました。
次回は、データを目視で確認して見たいと思います。
生データを確認することで、スクリーニングなどにより、さらに入力データの精度を上げられるか調べてみたいと思います。参考
最適なモデル選びall_estimators()
Python: scikit-learn の cross_validate() 関数で独自の評価指標を計算する
sklearnの交差検証の種類とその動作履歴
2020/01/01 初版公開
- 投稿日:2020-01-01T11:35:28+09:00
CentOS7+Apache2.4+Python3.6でとりあえず動かす
捨ててもいいCentOSでとにかく動かしたいとき。
python3はvirtualenvでインストールした方が良い。
Versions
CentOS
CentOS Linux release 7.6.1810 (Core)HTTPD
httpd-develもインストールする。httpd-tools-2.4.6-90.el7.centos.x86_64 httpd-2.4.6-90.el7.centos.x86_64 httpd-devel-2.4.6-90.el7.centos.x86_64PYTHON
yum install python3で入れるPython 3.6.8ポイント
mod_wsgiはyumでインストールしない。
- python27のものが入ってしまう。
pip3 install mod_wsgiでインストールする- これをインストールするときに
gccが必要になる。yum install httpd httpd-devel python3 python3-devel gcc -y pip3 install mod_wsgi
- HTTPDのconf
LoadModuleで、上でインストールした物を指定する。これがApacheが動かすPythonのバージョンとなる。python-pathはsite-packagesまで含めたPathを指定する- 親玉confに
Listen 8080をちゃんと指定しておく[root@ryo httpd]# cat /etc/httpd/conf.d/userdir.conf <VirtualHost *:8080> ServerName example.com LoadModule wsgi_module /usr/local/lib64/python3.6/site-packages/mod_wsgi/server/mod_wsgi-py36.cpython-36m-x86_64-linux-gnu.so WSGIDaemonProcess ml user=vagrant group=vagrant threads=5 python-path=/usr/local/lib64/python3.6/site-packages WSGIScriptAlias / /opt/tryml/ryo/wsgi.wsgi <Directory /opt/tryml/ryo/> WSGIProcessGroup ml Order deny,allow Allow from all Require all granted </Directory> </VirtualHost>
- wsgiのファイルを作る
import sys, os sys.path.insert(0, os.path.dirname(__file__)) from sebserver import app as application参考
- 投稿日:2020-01-01T10:43:48+09:00
JSON形式でレスポンスをするwebAPIを作成する
概要
この記事は初心者がRest fullなAPIとswiftでiPhone向けのクーポン配信サービスを開発する手順を順番に記事にしています。
前回の Djangoのテンプレート機能を使ってみるで作ったコードを改造して、JSON形式でレスポンスするようにします。Django Rest Frameworkという便利なフレームワークが存在しますが、まずは仕組みを理解するのを目的に Django Rest Framework 等は使わずに書いてみます。参考
環境
Mac OS 10.15
VSCode 1.39.2
pipenv 2018.11.26
Python 3.7.4
Django 2.2.6手順
- views.pyを修正
- 動作確認
views.pyを修正
データをjson形式に変換するためにjsonのモジュールをインポートします。
コードにimport jsonを追加します。
json.dumpsを使って、構造体をインプットにしてjson形式の文字列を作成するプログラムを追加します。構造体を作るコードは元のコードのparams = { }の部分をそのまま流用します。json形式の文字列を作るコードを追加します。引数として構造体データの
paramsを渡しています。
json_str = json.dumps(params, ensure_ascii=False, indent=2)戻り値は、
HttpResponseメソッドで単純にJson形式の文字列を返すだけです。
return HttpResponse(json_str)修正後の
views.pyはこちらです。views.pyfrom django.shortcuts import render from django.http import HttpResponse import json #追加した def coupon(request): if 'coupon_code' in request.GET: coupon_code = request.GET['coupon_code'] if coupon_code == '0001': benefit = '1000円引きクーポン!' deadline = '2019/10/31' message = '' elif coupon_code == '0002': benefit = '10%引きクーポン!' deadline = '2019/11/30' message = '' else: benefit = 'NA' deadline = 'NA' message = '利用可能なクーポンが見つかりません' params = { 'coupon_code':coupon_code, 'coupon_benefits':benefit, 'coupon_deadline':deadline, 'message':message, } #json形式の文字列を生成 json_str = json.dumps(params, ensure_ascii=False, indent=2) return HttpResponse(json_str)動作確認
コードを保存してdjangoのサーバを起動します。
ターミナルからcurlコマンドで
http://127.0.0.1:8000/coupon/?coupon_code=0001にアクセスすると、jsonで値が取得出来ています。
次はブラウザで
http://127.0.0.1:8000/coupon/?coupon_code=0001にアクセスすると、json形式のデータが表示されました。
以上です。


- 投稿日:2020-01-01T10:43:48+09:00
【Python/Django】JSON形式でレスポンスをするwebAPIを作成する
概要
この記事は初心者の自分がRest fullなAPIとswiftでiPhone向けのクーポン配信サービスを開発した手順を順番に記事にしています。技術要素を1つずつ調べながら実装したため、とても遠回りな実装となっています。
前回の Djangoのテンプレート機能を使ってみるで作ったコードを改造して、JSON形式でレスポンスするようにします。Django Rest Frameworkという便利なフレームワークが存在しますが、まずは仕組みを理解するのを目的に Django Rest Framework 等は使わずに書いてみます。
参考
環境
Mac OS 10.15
VSCode 1.39.2
pipenv 2018.11.26
Python 3.7.4
Django 2.2.6手順
- views.pyを修正
- 動作確認
views.pyを修正
データをjson形式に変換するためにjsonのモジュールをインポートします。
コードにimport jsonを追加します。
json.dumpsを使って、構造体をインプットにしてjson形式の文字列を作成するプログラムを追加します。構造体を作るコードは元のコードのparams = { }の部分をそのまま流用します。json形式の文字列を作るコードを追加します。引数として構造体データの
paramsを渡しています。
json_str = json.dumps(params, ensure_ascii=False, indent=2)戻り値は、
HttpResponseメソッドで単純にJson形式の文字列を返すだけです。
return HttpResponse(json_str)修正後の
views.pyはこちらです。views.pyfrom django.shortcuts import render from django.http import HttpResponse import json #追加した def coupon(request): if 'coupon_code' in request.GET: coupon_code = request.GET['coupon_code'] if coupon_code == '0001': benefit = '1000円引きクーポン!' deadline = '2019/10/31' message = '' elif coupon_code == '0002': benefit = '10%引きクーポン!' deadline = '2019/11/30' message = '' else: benefit = 'NA' deadline = 'NA' message = '利用可能なクーポンが見つかりません' params = { 'coupon_code':coupon_code, 'coupon_benefits':benefit, 'coupon_deadline':deadline, 'message':message, } #json形式の文字列を生成 json_str = json.dumps(params, ensure_ascii=False, indent=2) return HttpResponse(json_str)動作確認
コードを保存してdjangoのサーバを起動します。
ターミナルからcurlコマンドで
http://127.0.0.1:8000/coupon/?coupon_code=0001にアクセスすると、jsonで値が取得出来ています。
次はブラウザで
http://127.0.0.1:8000/coupon/?coupon_code=0001にアクセスすると、json形式のデータが表示されました。
以上です。