- 投稿日:2019-12-22T09:54:07+09:00
tf.function内部の計算グラフ最適化処理について
TensorFlow2.0 Advent Calendar 2019 の22日目の記事になります。
本記事では、tf.functionでPythonプログラムからTensorFlowの計算グラフを構築するときに、TensorFlowが内部で行っている計算グラフの最適化処理とその最適化を制御する方法について紹介します。
なお本記事は、tf.functionの裏で行われていることを説明した記事であるため、tf.functionそのものの使い方に関しては、他の記事を参考にしてください。
TensorFlow2.0 Advent Calender 2019 でも、tf.functionに関する記事がいくつか投稿されています。
- tf.function の使い方について - https://qiita.com/Ryuichirou/items/66a75610c569a23ac493
- tf.functionの注意点とTracingについて - https://qiita.com/t_shimmura/items/1209d01f1e488c947cab
tf.function
@tf.functionでデコレートされた関数は、TensorFlowの計算グラフに変換されます。
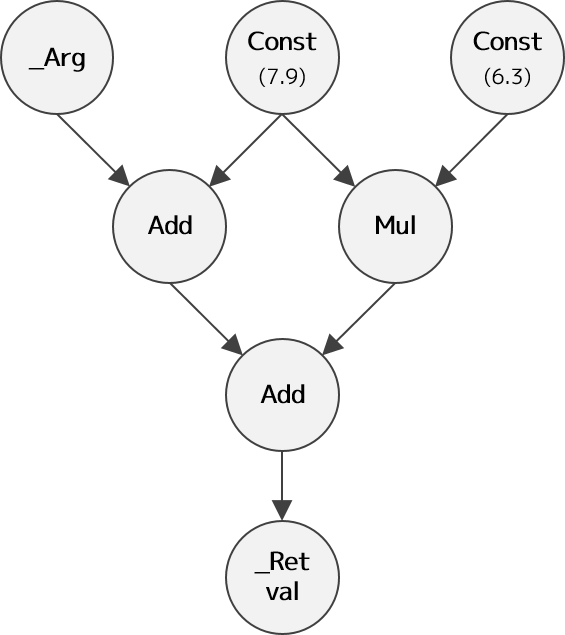
例えば、次のようなプログラムを考えてみます。import tensorflow as tf @tf.function def simple_func(arg): a = tf.constant(7.9) b = tf.constant(6.3) c = arg + a d = a * b ret = c + d return ret arg = tf.constant(8.9) print(simple_func(arg))
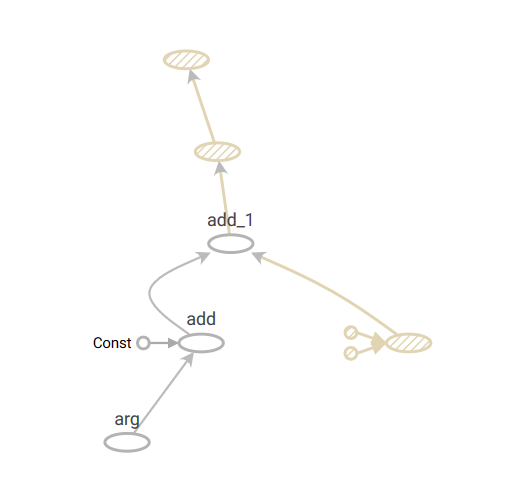
simple_func関数によって作成される計算グラフは、次のようになります。
計算グラフの最適化処理
tf.functionによって変換された計算グラフは、TensorFlowの内部(C++層)で最適化されます。
この最適化処理は、TensorFlow 1.xのデフォルトであったGraph Modeでも使われており、TensorFlow 1.xにて培われた計算グラフ最適化技術がtf.functionの中でも活用されています。TensorFlow 1.13を対象とした古い記事になりますが、TensorFlow内部で行われている計算グラフの最適化処理に興味のある方は、次の記事も参考にしてみてください。
なお、TensorFlow 2.0では、記事で紹介している最適化に加えて、Auto Mixed Precisionなどの最適化が新たに追加されています。
また別の機会に、最新の最適化処理について紹介したいと思います。
- TensorFlow内部構造解析 (4.4) 計算グラフ最適化処理1 Grappler
- TensorFlow内部構造解析 (4.6) 計算グラフ最適化処理2 GraphOptimizationPass
- TensorFlow内部構造解析 (4.7) 計算グラフ最適化処理3 GraphOptimizer
さて、先ほどの計算グラフに話を戻すと、tf.functionによって生成された計算グラフを最適化したあとの計算グラフは、以下のようになります。
生成された計算グラフを見ると、計算グラフ内のいくつかのノードが削除されていることがわかります。
ここで行われた最適化は、Constant Folding と呼ばれるもので、ノードの入力が全て定数値であるものを計算グラフ構築時に評価し、Constノードで置き換えます。
計算グラフを構築する時点で、評価できるところを事前に評価してしまうことで、計算グラフ全体としての処理時間を短縮できます。最適化された計算グラフを確認する
最適化された計算グラフは、TensorBoardを使って確認できます。
TensorBoard向けのSummaryデータを出力するためには、tf.functionによって構築された計算グラフを呼び出す前にtf.summary.trace_on()を呼んでおく必要があります。
なお、tf.summary.trace_on()の引数graphとprofilerにTrueを指定しないと、最適化された計算グラフが出力されない点に注意が必要です。
そして、確認したい計算グラフを実行したあとにtf.summary.trace_export()を呼ぶことで、最適化された計算グラフを出力できます。
最適化された計算グラフを、TensorBoard向けに出力するソースコードを次に示します。import tensorflow as tf @tf.function def simple_func(arg): a = tf.constant(7.9) b = tf.constant(6.3) c = arg + a d = a * b ret = c + d return ret # TensorBoard向けに、Summaryデータの収集を有効化する writer = tf.summary.create_file_writer("summary") # 引数graphとprofilerにTrueを指定することで、最適化された計算グラフを確認できる tf.summary.trace_on(graph=True, profiler=True) arg = tf.constant(8.9) print(simple_func(arg)) # 収集したSummaryデータを出力する with writer.as_default(): tf.summary.trace_export("summary", step=0, profiler_outdir="summary") # Summaryデータの収集を無効化する tf.summary.trace_off()プログラムを実行して出力されたTensorBoard向けのSummaryデータを、TensorBoardを使って読み込みます。
最初に、ユーザが定義したグラフを確認してみましょう。
TensorBoardの「GRAPHS」タブを選択した状態で、左側にあるラジオボックスから「Graph」を選択することで、ユーザが定義したグラフを表示できます。ユーザが定義したグラフは、
simple_func内で定義した計算グラフそのものになっています。
つづいて、最適化後の計算グラフを確認してみましょう。
TensorBoardの「GRAPHS」タブを選択した状態で、左側にあるラジオボックスから「Profile」を選択することで、最適化後の計算グラフを表示できます。最適化されたあとの計算グラフでは、1つのMulノードとその入力のConstantノードが網掛けされています。
網掛けされたノードは、TensorFlow内部で演算されなかったノードです。
TensorFlow内部で計算グラフが最適化された結果、これらの網掛けされたノードが演算されなくなったと考えられます。
このように、TensorBoardを利用することで、ユーザが定義した計算グラフと最適化後の計算グラフの違いを確認できます。
計算グラフの最適化処理を制御する
TensorFlowの内部で行われている計算グラフの最適化処理は、
tf.config.optimizer.set_experimental_options()を呼び出すことで、有効/無効を切りかえることができます。
なお、tf.config.optimizer.set_experimental_options()によって有効/無効を切りかえられる最適化処理は、Grapplerによって行われる最適化処理 のみです。
GraphOptimizationPass や GraphOptimizer による最適化は、必ず実行されてしまうことに注意してください。計算グラフの最適化処理について、有効/無効を切りかえるプログラムについて説明する前に、デフォルトの最適化の設定を確認してみましょう。
計算グラフの最適化に関する設定は、tf.config.optimizer.get_experimental.options()を呼び出すことで確認できます。import tensorflow as tf tf.config.optimizer.get_experimental_options()上記を実行すると、以下の結果が得られます。
{'disable_meta_optimizer': False, 'disable_model_pruning': False}
disable_meta_optimizerは、Grapplerによって行われる最適化処理 を無効化する設定で、デフォルトではFalseが指定されています。
このことから、デフォルトでGrapplerによる最適化処理が有効化されていることがわかります。
また、そのほかの最適化に関しては設定されていないため、それぞれ デフォルトの最適化設定 が適用されています。それでは実際に、最適化を有効化/無効化する例を挙げながら、その効果を確認していきたいと思います。
最適化「Debug Stripper」を無効化する
Debug Stripper は、デバッグ目的に使われるノード(Assertなど)を削除する最適化処理です。
Debug Stripperは、デフォルトで無効化されているため、tf.Assertによって追加されたAssertノードは削除されません。
このため、次に示すコードはtf.Assertで例外が発生します。import tensorflow as tf @tf.function def assert_func(): a = tf.constant(1.2) computation_graph = tf.Assert(tf.less_equal(a, 1.0), [a]) # 例外「InvalidArgumentError」が発生する return a print(assert_func())一方でDebug Stripperを有効化して実行すると、
tf.Assertによって追加されたAssertノードは削除され、上記で発生していた例外は発生しなくなります。import tensorflow as tf # 「Debug Stripper」を有効化する tf.config.optimizer.set_experimental_options({'debug_stripper': True}) @tf.function def assert_func(): a = tf.constant(1.2) computation_graph = tf.Assert(tf.less_equal(a, 1.0), [a]) # 例外は発生しない return a print(assert_func())デバッグ用途で追加したAssertなどは、テンソルデータを確認する必要があるなど処理に時間がかかるため、計算グラフの実行時間に影響を与えます。
デバッグが完了したあとは、デバッグ目的で追加したtf.Assertなどを1つ1つ削除するのもよいですが、ここで示した方法でDebug Stripperを有効化するだけで、デバッグ用途の演算がすべて削除されるため、ぜひ活用してみてはいかがでしょうか。Grapplerで行われる全ての計算グラフの最適化を無効化する
Grapplerで行われる全ての最適化処理は、
disable_meta_optimizerをTrueに設定することで無効化されると書きましたが、ここではその効果を確認してみたいと思います。最初に、デフォルトの最適化設定で最適化後の計算グラフを確認してみましょう。
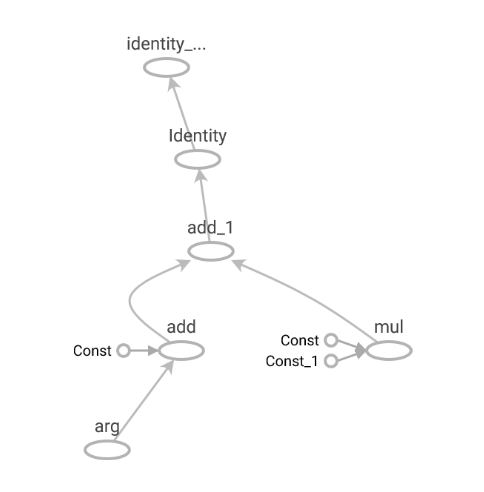
次に示すソースコードは、Transposeが連続した計算グラフを構築します。import tensorflow as tf import numpy as np @tf.function def optimized(arg): a = arg * 2 # 「Arithmetic Optimizer」により、削除される b = tf.transpose(a, perm=[1, 0]) ret = tf.transpose(b, perm=[1, 0]) return ret writer = tf.summary.create_file_writer("summary") tf.summary.trace_on(graph=True, profiler=True) arg = tf.constant(np.random.normal(size=(30, 40))) optimized(arg) with writer.as_default(): tf.summary.trace_export("summary", step=0, profiler_outdir="summary") tf.summary.trace_off()TensorBoardで最適化されたあとの計算グラフを確認すると、Transposeのノードが削除されていることが確認できます。
これは、Arithmetic Optimizer の RemoveIdentityTranspose によって互いに打ち消しあう転置のペアを削除したためです。
また、演算に影響を与えないIdentityノードも、最適化によって削除されていることがわかります。
続いて、
disable_meta_optimizerをTrueにした状態で同じ計算グラフを実行し、TensorBoardで最適化されたあとの計算グラフを確認してみましょう。import tensorflow as tf import numpy as np # Grapplerによって行われる、全ての計算グラフ最適化処理を無効化する tf.config.optimizer.set_experimental_options({'disable_meta_optimizer': True}) @tf.function def not_optimized(arg): a = arg * 2 b = tf.transpose(a, perm=[1, 0]) ret = tf.transpose(b, perm=[1, 0]) return ret writer = tf.summary.create_file_writer("summary") tf.summary.trace_on(graph=True, profiler=True) arg = tf.constant(np.random.normal(size=(30, 40))) not_optimized(arg) with writer.as_default(): tf.summary.trace_export("summary", step=0, profiler_outdir="summary") tf.summary.trace_off()最適化されたあとの計算グラフを見てみると、Transposeのノードがそのまま残っており、Arithmetic Optimizerが無効化されていることがわかります。
また、Identityノードが削除されていないことにも注目です。
まとめ
tf.functionによって構築された計算グラフが、TensorFlow内でどのように最適化されるかを紹介し、その最適化を制御する方法を説明しました。
最近でも新たな最適化が追加されるなど、計算グラフの最適化機能は継続して開発される見込みです。今後に期待しましょう。なお、本記事で紹介した内容は、英語版のドキュメントとして Pull Request を出し、先日無事にマージされました。
TensorFlowのドキュメントとして正式に公開されると思いますので、実際に計算グラフの最適化が動作していることを、Google Colab上で体験してもらえればと思います。
今回マージされたドキュメントは、いずれ 日本語訳も行ってTensorFlowのドキュメントにContributeしたい と考えていますので、ご期待ください。



- 投稿日:2019-12-22T08:06:07+09:00
スマホカメラで手のモーションを記録してUnityでピアノ演奏したかった
この記事は、 North Detail Advent Calendar 2019 の22日目の記事です
概要
やりたいこと
- ピアノ演奏中の手のモーションをスマホカメラで記録する
- Unityでアニメーションしてピアノ演奏する
技術的なこと
- google/mediapipeでハンドトラッキング用のiOSアプリをビルド
- iPhoneカメラで手のモーションを記録
- Blenderでアニメーション化 & ピアノオブジェクト作成
- Unityに取り込んで再生、指と鍵盤の当たり判定で音を鳴らす
成果物
※雑音が流れるのでご注意を
Unityでピアノを弾いてみたかった
— ヤマト (@yamatohkd) December 21, 2019
(雑音が流れますのでご注意を) pic.twitter.com/fVuHP9Xb0K
......はい(出落ち)作業環境
・MacBook Pro (Retina, 15-inch, Mid 2014) : Mojave 10.14.6
・iPhoneXs : iOS 13.2.2・Xcode : 11.3
・Blender : 2.79
・Unity : 2019.2.12今回はiPhoneのカメラを利用しますが、AndroidやPCのカメラでも同じことができるはず
※後述しますが、PCカメラ利用の場合はLinuxでGPUが利用できる環境推奨Google / MediaPipeでモーション記録用のアプリをビルド
MediaPipeってなぁに?
MediaPipe is a framework for building multimodal (eg. video, audio, any time series data) applied ML pipelines. With MediaPipe, a perception pipeline can be built as a graph of modular components, including, for instance, inference models (e.g., TensorFlow, TFLite) and media processing functions.
MediaPipeは、マルチモーダル(ビデオ、オーディオ、時系列データなど)を適用したMLパイプラインを構築するためのフレームワークです。 MediaPipeを使用すると、たとえばパイプラインモデル(TensorFlow、TFLiteなど)やメディア処理機能など、モジュラーコンポーネントのグラフとして認識パイプラインを構築できます。
......なるほど
(?)
どうやら機械学習パイプライン(画像処理→モデル推論→描画 など)の構築や、
それをグラフとして視覚化できるフレームワークらしいサンプルではTensorFlowやTensorFlow Liteなどを利用して、
顔認識や物体の識別、手のモーション取得(ハンドトラッキング)などができるLinux/Win/Macで実行したり、iOS/Android用にアプリをビルドしたりできる
MediaPipeをインストール
0. PCで実行したい人向け
モバイルアプリのビルドではなく、PCで直接実行したい人はLinux環境(OS Xは含まない)推奨です
2019/12/11現在、MediaPipeではデスクトップ用サンプルはLinuxのみGPUサポートが対応しています
(Win/MacでもCPU実行モードはあるのですが私の環境では即座にフリーズしました......)また、VMやdocker上のLinux環境ではホストGPUが使えないため、
MacならデュアルブートでOSインストールなどが必要です
(これを知らずにVirtualBoxのUbuntu上で作業していて土日まるまる潰しました......超頑張ればできないこともないとかなんとか?)1. 事前準備
インストールガイドページの
Installing on macOSを参考に進めていきます
- Homebrewをインストール
Xcodeと
Command Line ToolsをインストールPythonバージョンの確認
私の環境ではPython 2.7ではビルドが通らなかったため、下記サイトを参考にPython 3.7.5をインストールしました
参考:pyenvを使ってMacにPythonの環境を構築する"six"ライブラリをインストール
$ pip install --user future six2. MediaPipeリポジトリをクローン
$ git clone https://github.com/google/mediapipe.git $ cd mediapipe3. Bazelをインストール
二通りの方法がありますが、今回は
Option 1の方法でやります
※2019/12/11現在、MacではBazel 1.1.0より上のバージョンは対応していないため注意# Bazel 1.1.0より上のバージョンがインストールされている場合はアンインストール $ brew uninstall bazel # Install Bazel 1.1.0 $ brew install https://raw.githubusercontent.com/bazelbuild/homebrew-tap/f8a0fa981bcb1784a0d0823e14867b844e94fb3d/Formula/bazel.rb $ brew link bazel4. OpenCVとFFmpegをインストール
こちらも二通りあるので
Option 1の方法でインストール$ brew install opencv@35. Hello World desktop exampleを実行
$ export GLOG_logtostderr=1 $ bazel run --define MEDIAPIPE_DISABLE_GPU=1 \ mediapipe/examples/desktop/hello_world:hello_world # しばし待ったのち以下が表示されたらOK # Hello World! # Hello World! # Hello World! # Hello World! # Hello World! # Hello World! # Hello World! # Hello World! # Hello World! # Hello World!ここで私の環境ではPython2.7で以下のエラーが発生しました
同じ現象が起こった人は1. 事前準備を参考にPythonのバージョンを上げてみてくださいERROR: An error occurred during the fetch of repository 'local_config_git': Traceback (most recent call last):モバイルアプリのビルド
今回は両手のモーションを取得するモバイルアプリをビルドしたいので、以下のサンプルを利用します
Multi-Hand Tracking (GPU)※PCで直接実行したい場合は以下を利用してください
Multi-Hand Tracking on DesktopAndroidの場合
Androidの方が簡単にビルドできます
トラッキングには2Dと3Dモードの二通りあるので、3Dモードでビルドします$ bazel build -c opt --config=android_arm64 --define 3D=true mediapipe/examples/android/src/java/com/google/mediapipe/apps/multihandtrackinggpuかなり時間がかかるので待ちましょう
下記ディレクトリにapkファイルができるので実機にインストールすれば完了です!mediapipe/bazel-bin/mediapipe/examples/android/src/java/com/google/mediapipe/apps/multihandtrackinggpu/multihandtrackinggpu.apkiOSの場合
iOSの場合はこちらの設定がもうひと手間必要です
始めの方にあるXcodeやBazelのインストールは既に完了しているので不要です(しかもこちらの方法でBazelをインストールすると最新バージョンを取得して動かなくなるという罠。間違えてインストールしてしまった場合は前述の方法でv1.1.0に置き換えてください)
1. Provisioning Profileの用意
AppleDeveloperProgram加入者はデベロッパサイトでProvisioning Profileを作成してダウンロードしてください
そうでない方は以下のサイトなどを参考に作成してください
参考:[Xcode][iOS] 有料ライセンスなしでの実機インストール 全工程解説!Bundle Identifierを固有のものにしないとエラーが起きるので注意
どこかの誰かが使っているIDだとFailed to create provisioning profile.と怒られます
作成されたファイルは以下のpathにあります~/Library/MobileDevice/Provisioning Profiles/用意したファイルは
provisioning_profile.mobileprovisionにリネームして、
mediapipe/mediapipe/に配置します2. BUILDファイルの修正
mediapipe/mediapipe/examples/ios/multihandtrackinggpu/BUILD45行目のbundle_idを、
Provisioning Profileで設定したBundle Identifierに変更mediapipe/examples/ios/multihandtrackinggpu/BUILD:45bundle_id = "com.google.mediapipe.MultiHandTrackingGpu", ↓ bundle_id = "hoge.fuga.piyo",3. アプリのビルド
3Dモードでビルドします
$ bazel build -c opt --config=ios_arm64 --define 3D=true mediapipe/examples/ios/multihandtrackinggpu:MultiHandTrackingGpuApp長いのでしばらく待ちます
ビルドが完了すると下記ディレクトリにipaファイルができますbazel-bin/mediapipe/examples/ios/multihandtrackinggpu/4. 実機にインストール
Xcodeの
Window > Devices and Simulatorsから、
USB接続した実機デバイスを選択して、
画面下部の+ボタンからipaファイルをインストールすれば完了です!手の動きをトラッキング
ビルドしたアプリを動かしてみる
おお!両手の動きがリアルタイムで反映されていますね
このときのiPhoneのプロセス状態を、USB接続したMacの
コンソールアプリで確認してみましょう
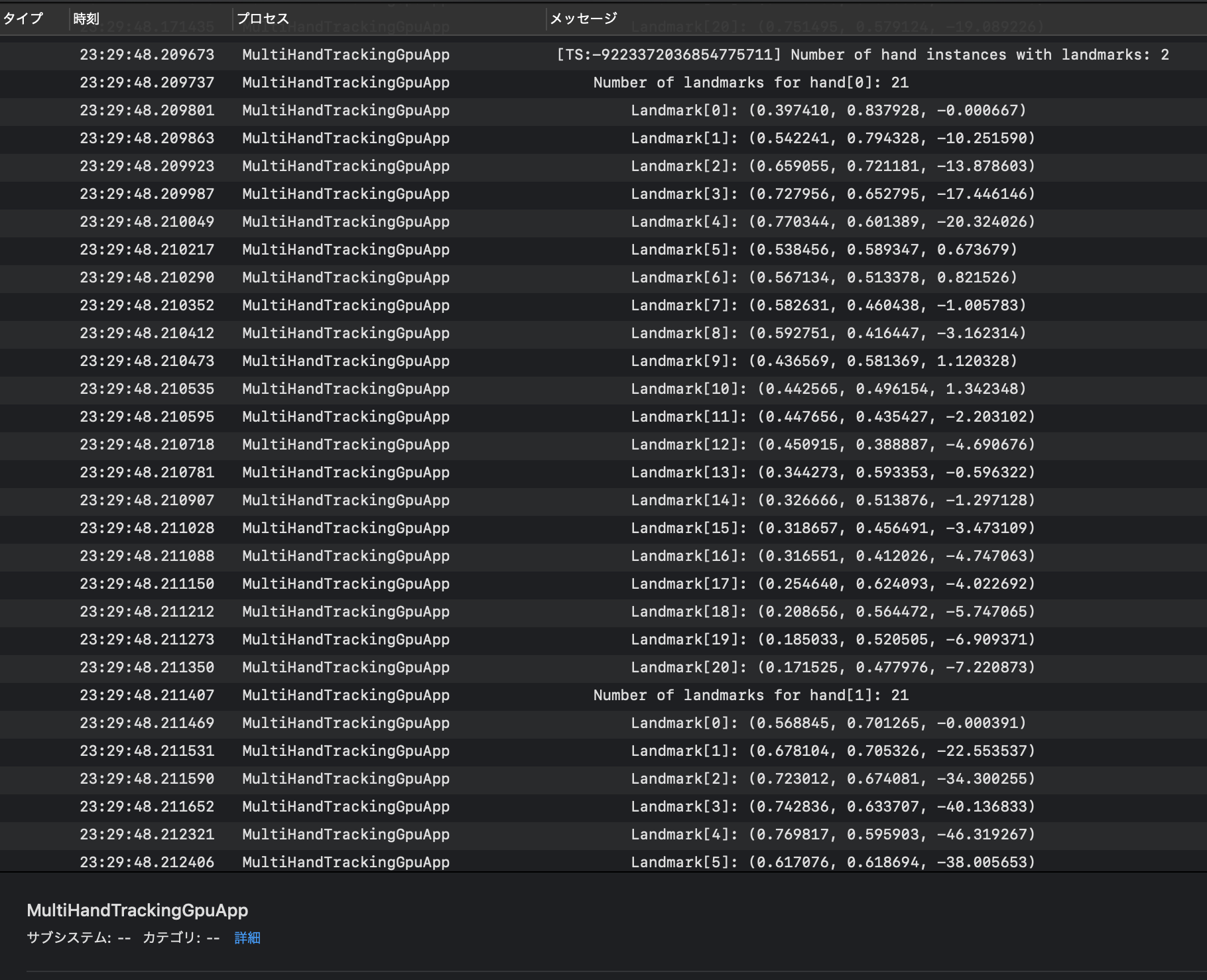
MultiHandTrackingGpuAppというプロセス名で何やらログが表示されています
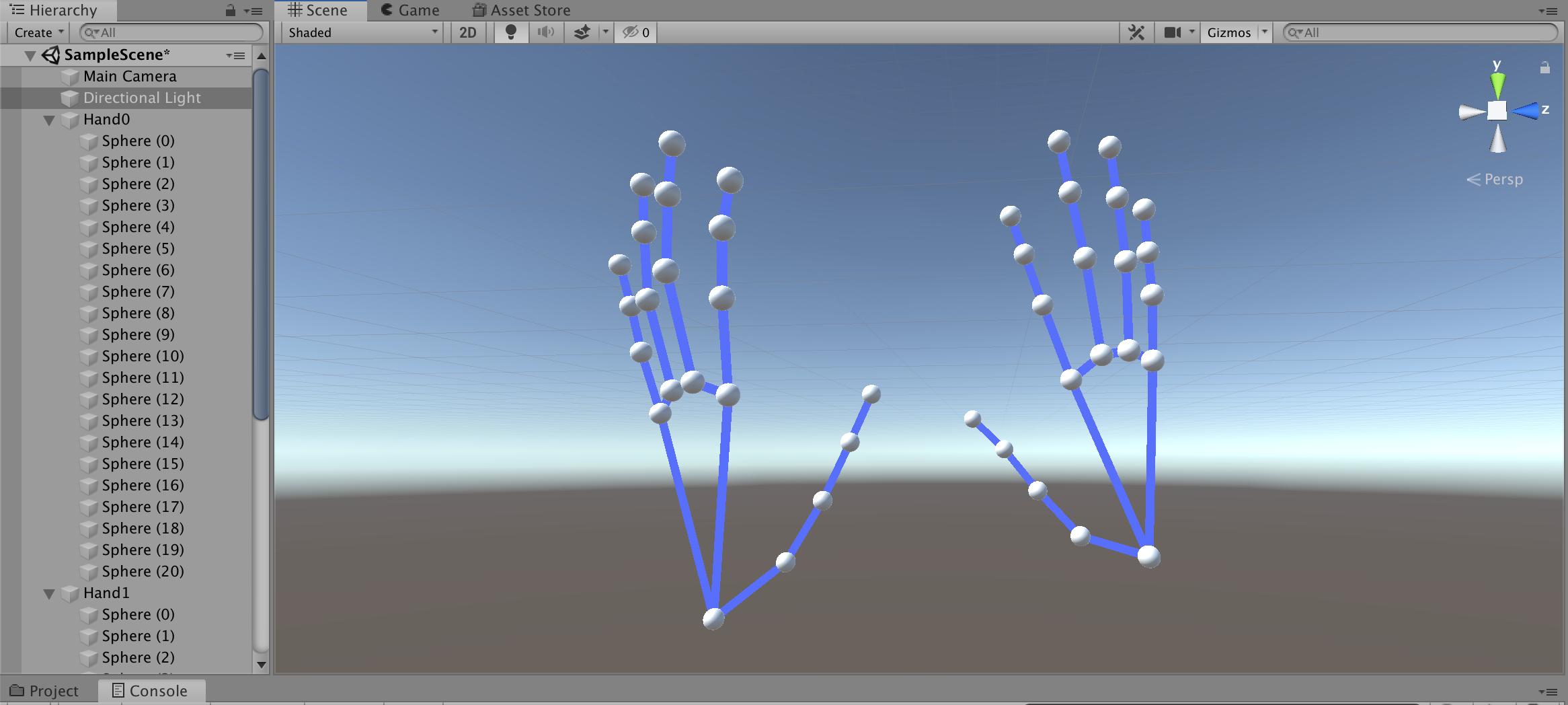
hand[0]とhand[1]の二つあり、それぞれ21個のLandmarkを持っています先程のgifの片手のポイントの数が21なので、その座標のようですね
それぞれの手のログは約0.05秒毎に表示されているようですちなみに、ログ出力のコードは下記ファイルに記述されていました
・mediapipe/mediapipe/examples/ios/multihandtrackinggpu/ViewController.mm : L177あたりフロントカメラではなく背面カメラを使用したい場合は、同ファイルの以下を変更してビルドし直すと可能です
mediapipe/mediapipe/examples/ios/multihandtrackinggpu/ViewController.mm// 100行目をYESからNOに _renderer.mirrored = NO; // 109行目を~Frontから~Backに _cameraSource.cameraPosition = AVCaptureDevicePositionBack;Unityで表示してみる
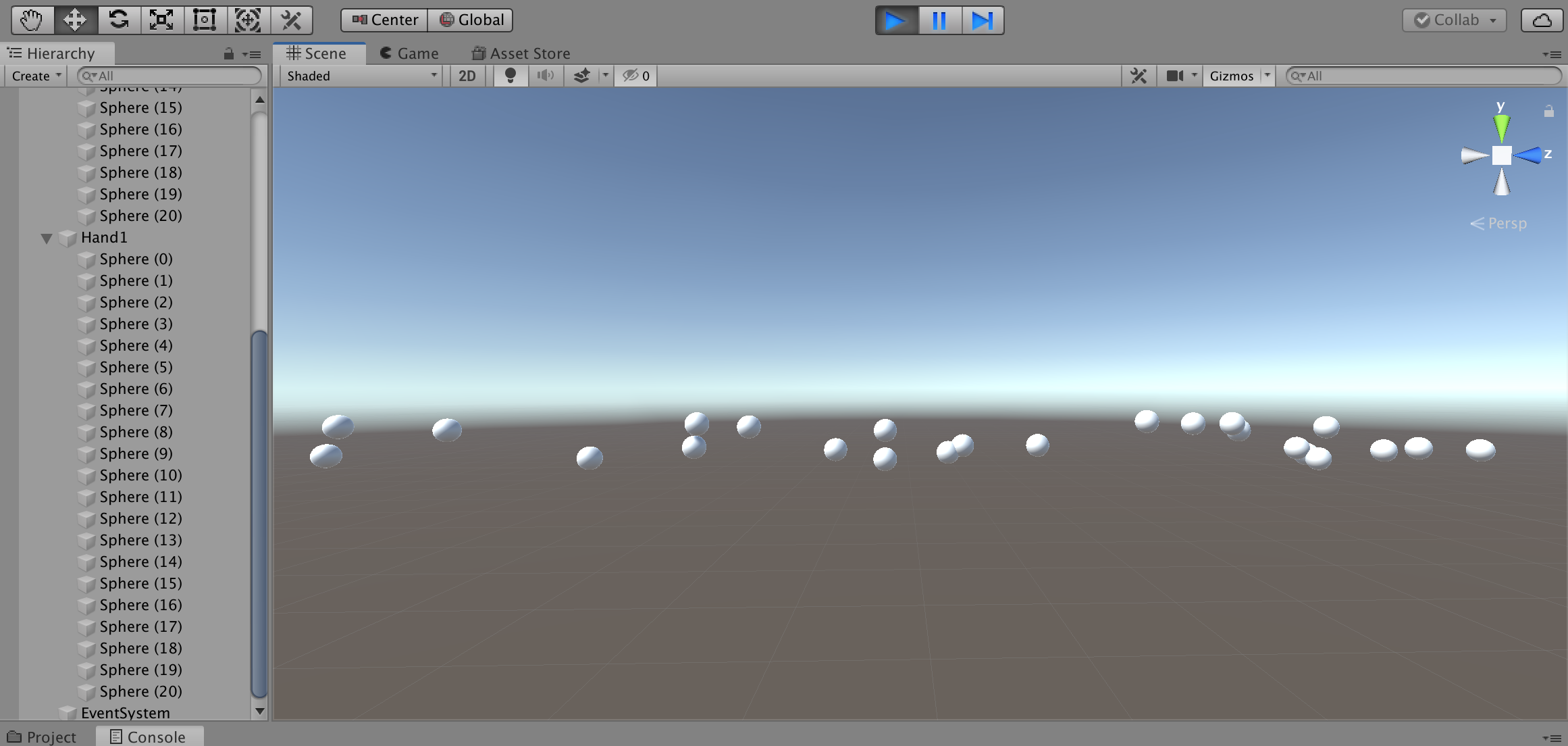
取得した座標をUnityの3D空間に浮かべてみます
なぁにこれぇ?ログをよくみるとz座標だけ数値が異様に大きいですね
倍率を変更してみます
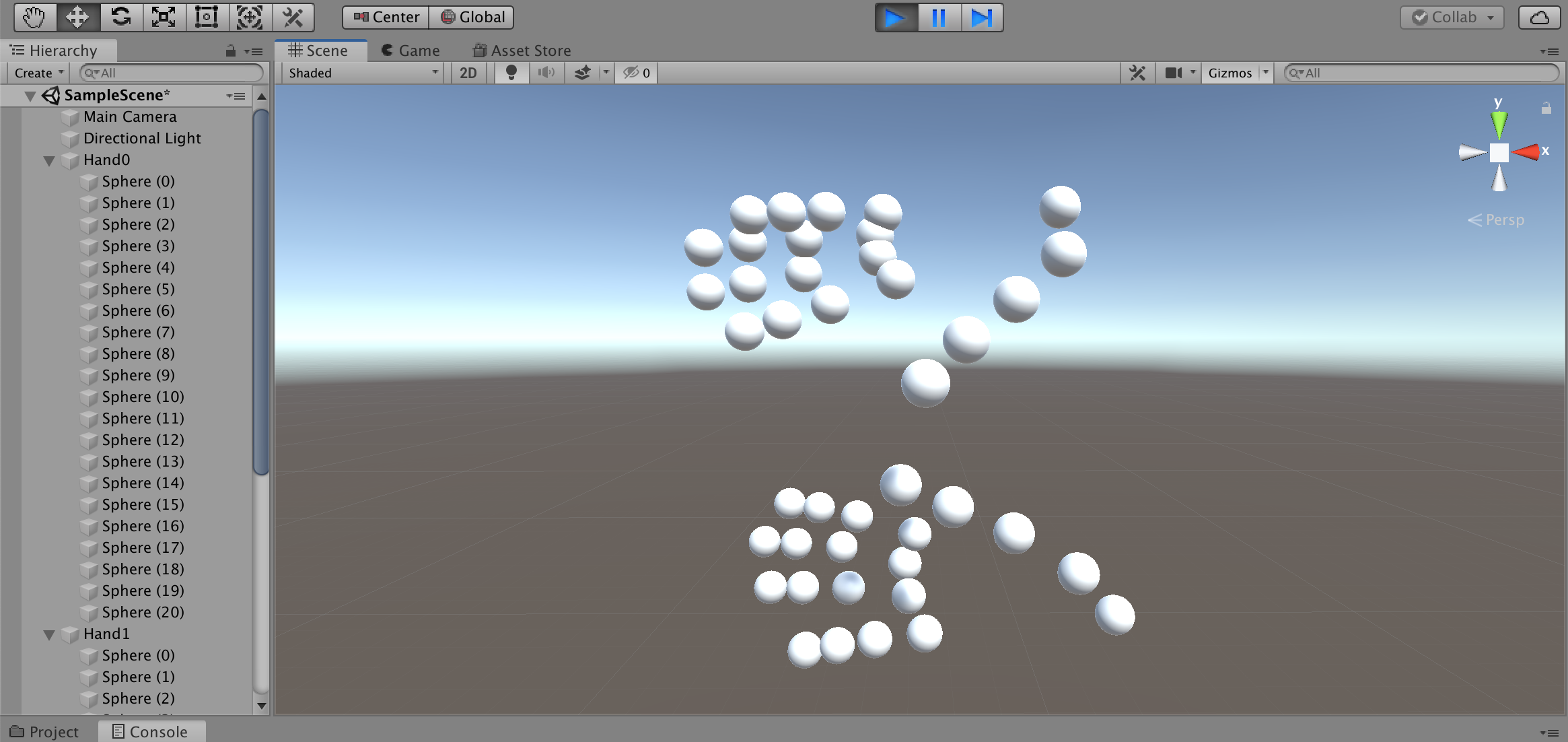
おっ!なんかそれっぽくなった!
向きと大きさを調整して線で繋いでみると・・・
完全に手だコレ! \\ ٩( 'ω' )و//あとはピアノを演奏しているところを撮影して座標を取得するだけです
Blenderでアニメーション化
Blenderとは?
- 3Dモデル作成、アニメーション作成、レンダリングなどができる
- 高機能・高品質、だけど高難度
- オープンソースで無料で使える
最近 v2.8がリリースされ、UIや操作方法が変わり直感的に操作できるようになりました
参考サイトはv2.7xの方が多く、古いプロジェクトをインポートすると壊れてしまう場合もあるため今回はv2.79を使用します「Blender アニメーション 作成」で検索すると、
手動でボーンを動かしてキーフレーム毎にポーズを設定する方法が主流のようです
参考:かんたんBlender講座 アニメーションの基本この方法は単純なアニメーションだとよいのですが、
ミリ秒単位で複雑な動きをさせる場合は骨が折れます(ボーンだけに)そのため今回はスクリプトで作成します
Pythonでスクリプト作成
BlenderではPythonスクリプトが実行できます
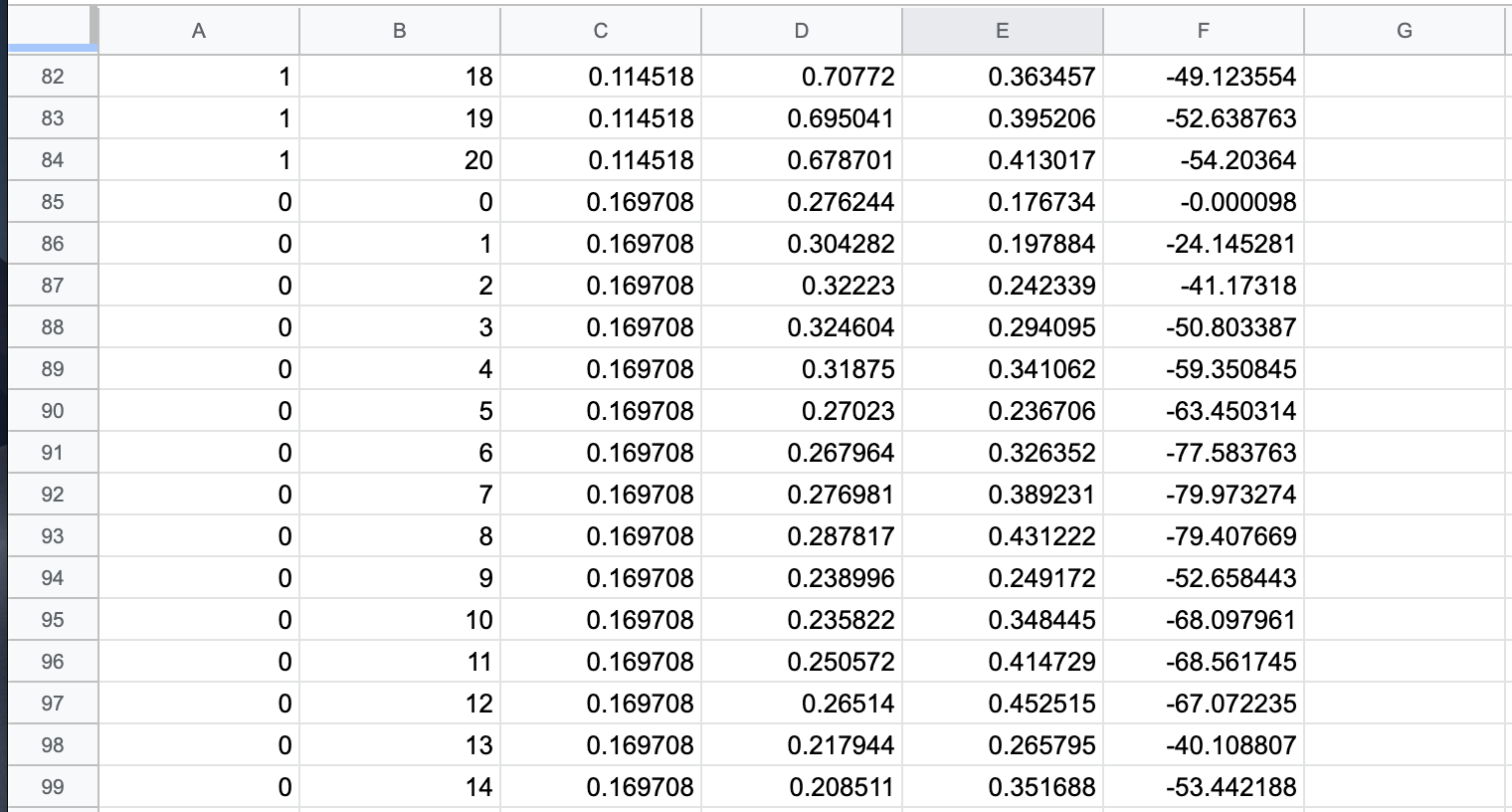
MediaPipeで取得した座標をCSVファイルにまとめて、スクリプトからアニメーション化します1. 座標CSVファイルの作成
こんな感じでCSVファイルを作成しました
左から以下の値となってます
- 手(0=左手、1=右手)
- Landmark
- 開始からの秒数
- x座標
- y座標
- z座標
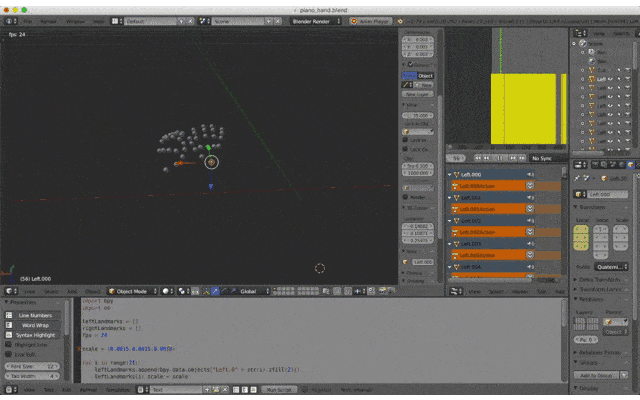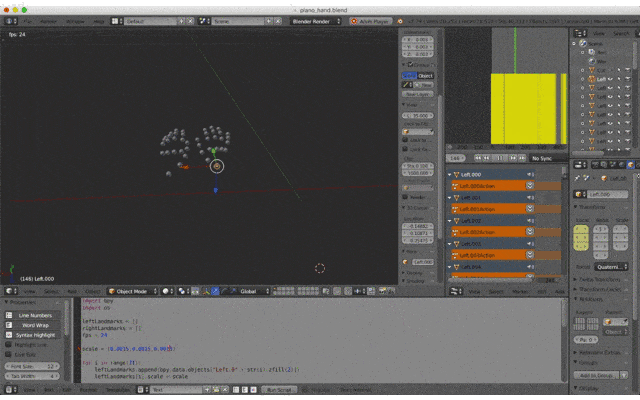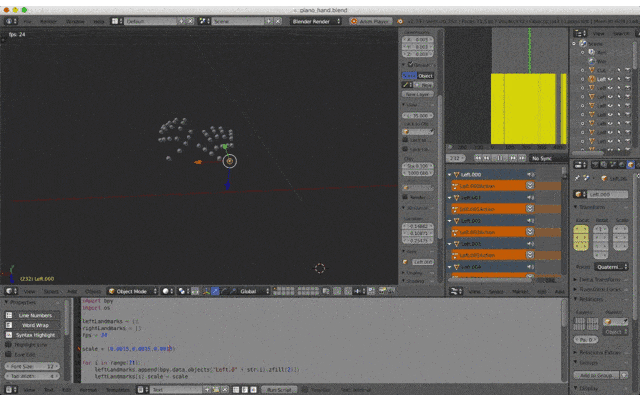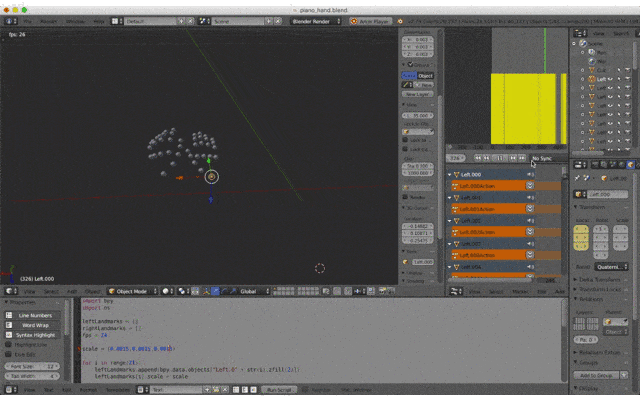
2. Landmarkオブジェクトの作成
以下のSphereオブジェクトを追加
これをLandmarkポイントとして動かします
- Left.000 ~ Left.020
- Right.000 ~ Right.020
3. スクリプトの作成
Pythonスクリプトはこんな感じ
投稿時間を過ぎてしまったので説明は省略...
(倍率とかfpsとか適当。。。)コメント追記しました
import bpy import os leftLandmarks = [] rightLandmarks = [] fps = 24 scale = (0.015,0.015,0.015) # Landmarkオブジェクトを割当 for i in range(21): leftLandmarks.append(bpy.data.objects["Left.0" + str(i).zfill(2)]) leftLandmarks[i].scale = scale for i in range(21): rightLandmarks.append(bpy.data.objects["Right.0" + str(i).zfill(2)]) rightLandmarks[i].scale = scale # csvのあるディレクトリ dirpath = "/Path/to/csv" filename = "animation.csv" filepath = os.path.join(dirpath, filename) # csvを一行ずつ処理 with open(filepath, mode='rt', encoding='utf-8') as f: for line in f: params = line.split(",") # 左手 or 右手 landmarks = leftLandmarks if params[0] == "0" else rightLandmarks # 座標を指定 landmarks[int(params[1])].location = (float(params[3]),float(params[4]),float(params[5])/512) # 指定した座標、フレームにキーフレームを設定 landmarks[int(params[1])].keyframe_insert(data_path="location", frame=int(float(params[2])*fps))4. スクリプトの実行
Editor Type「Text Editor」にスクリプトを貼り付けてRun Script!
5. Animationの再生
Editor Type「Timeline」から再生!
勝ったな
(フラグ)
6. オブジェクトのエクスポート
File > Export > FBXなどでエクスポートすれば完了!
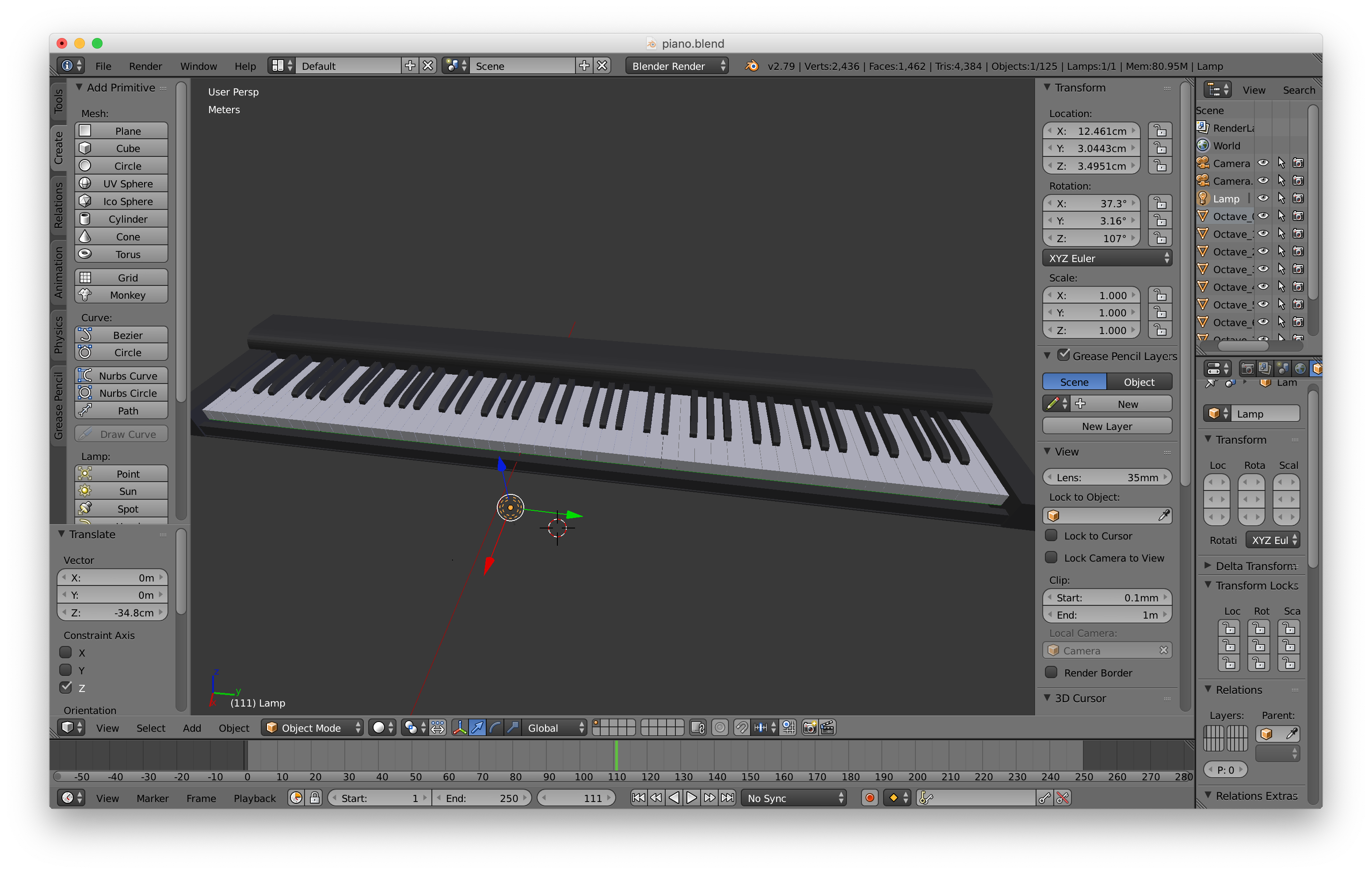
.blendファイルもUnityでそのまま読み込めますBlenderでピアノ作成
白鍵と黒鍵をCubeで並べていきます
アニメーションと合わせるので、実物の鍵盤と同じサイズ比を意識します
Unityに取り込んで再生
まずは用意した素材を取り込みます
- アニメーションを適用した3Dモデル
- ピアノオブジェクト
ピアノの設定
1. 音源Assetのインポート
ここにきて大誤算
ピアノの単音のフリー音源ってあまり無いんですね。。。自前の電子ピアノから音源を作成しました
コーラス音源であれば、以下のUnity Assetを無料で利用できます
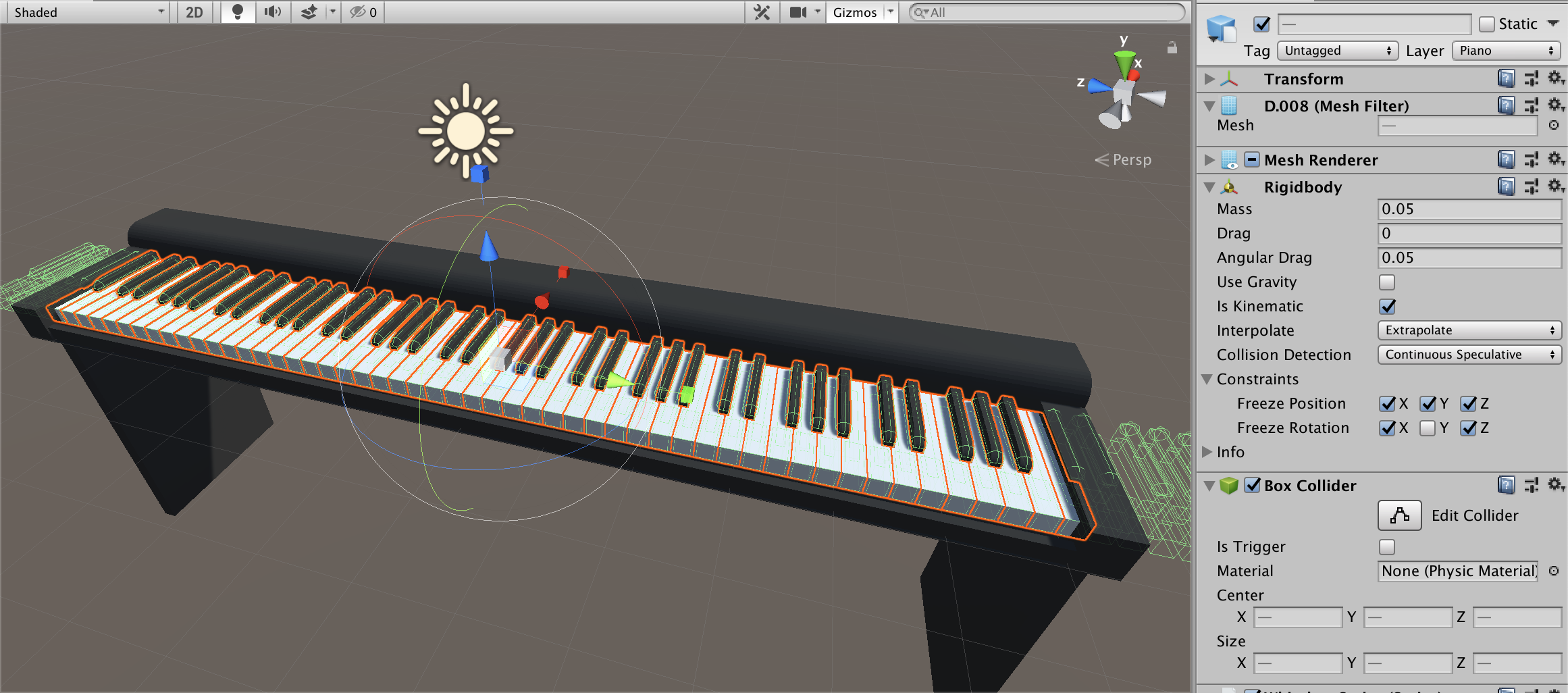
(同じ販売者から「グランドピアノ音源」も出品されているのですが$50もする・・・)2. 鍵盤の動きを設定
鍵盤は以下の条件で動かします
- 動きはy座標回転のみ(xyz位置とxz回転を制限)
- 指との衝突で回転
- 天井と床(鍵盤のみと衝突する)を作り、元の位置より上下しないようにする
鍵盤にはRigidbodyとBoxColliderで当たり判定を付与します
3. 打鍵すると音が鳴るよう設定
以下の条件で音が鳴るようにしました
- ハンドオブジェクトと当たり判定がある(OnCollisionStay関数)
- かつ鍵盤の角度が一定以下
アニメーションの設定
アニメーションコントローラの作成
3Dモデルに適用
サイズ比率の調整
手と鍵盤とのサイズ比を調整します
サイズ比や位置の調整用に別途アニメーションを作成しておくとよいかもしれません今回調整用のアニメーションも作成していたのですが、
手がドリルしていて使えませんでした。。。再生
雑音が流れました
まとめ
MediaPipe面白い技術ですね!
想像していたよりはきれいにアニメーションしてくれました
ちゃんと調整すればメロディーを奏でそうなムーブではある簡単な曲 → 複雑な曲というシナリオだったのですが思い通りにいかず
本当は3Dモデルにアニメーションさせたかったのですが、
時間も技術も足りませんでした。。。アプリのログからアニメーションを作成するという方法もスマートじゃないですね
Linuxで実行できたらもう少しやりようがあったかもしれません
MediaPipe開発者がUnityのサポートについて反応しているので今後に期待ですねまた先日、VRヘッドセットのOculus Questにハンドトラッキングが実装されました
Unity対応のSDKも今月中にリリースとのことなので、Oculus Questをお持ちの方は是非試してみてください
参考:「Oculus Quest」にハンドトラッキング機能実装。コントローラなしでメニューなどの操作が可能にちなみに演奏していた曲は「We Wish You a Merry Christmas」でした
よいクリスマスを✨

- 投稿日:2019-12-22T00:46:49+09:00
TensorFlowで安倍乙と石原さとみの顔認識をやってみた
はじめに
- ずっと前に、
TensorFlowでMNISTのチュートリアルをやりました。その後、何か関連アプリケーションを作りたかったが、時間がすぎました。- 今回、題材として
安倍乙さん、石原さとみさんが似ているとの話があり、識別をしてみるアプリケーションを作りました。- あくまで、遊びの範囲でしたが、一連の流れを理解出来たのは良かったです。
MNISTを元にしたので、その他の方々8人にも登場して頂きました。- アプリケーションは https://abe-or-ishihara.herokuapp.com/ です。
アプリケーション
- アプリケーションは、
TensorFlowDjangoOpenCVPillowHerokuS3等々を利用しています。
概要
- アプリケーションに至る一連の作業工程になります。結構色々やる事がありました。
- かなり辛かった箇所は、#4の顔画像の選別ですね。当初は、
MacのFinderで作業していましたが、辛すぎたので、Flaskの簡易管理アプリを作りました。
登場人物
- 安倍乙さん、石原さとみさんは、今回の顔認識の主役です。また、その他の方々は、私的に注目している方々です。ご了承下さい!
- 安倍乙
- 石原さとみ
- 大原優乃
- 小芝風花
- 川口春奈
- 森七菜
- 浜辺美波
- 清原果耶
- 福原遥
- 黒島結菜
記事一覧
- Google カスタム検索エンジンで画像リンクを取得する
- URLを記載したテキストファイルから画像をダウンロード
- OpenCV Haar Cascades で顔認識
- ダウンロード画像と顔画像の簡易管理アプリ
- 学習画像の水増し
- 学習に利用する画像のデータセットを作成する
- データセットのローダーの作成
- 学習モデルの作成、学習と推論
- FlaskとTensorFlowを利用した、顔画像の推論
- DjangoとTensorFlowを利用した、顔画像の推論
- HerokuとTensorFlowを利用した、顔画像の推論
おわりに
TensorFlow等を使った一連の流れを把握し、アプリケーションを作ってみました。- 正直、
Google Cloud AutoMLであっという間に終わる件だと思いつつ、意味があるんだろうか?と悩む事もありました。- なんか、私には遠い世界に思えたってのが、正直なところです。システムの下側、横側から機械学習等を支えて行ければと思います。


- 投稿日:2019-12-22T00:22:43+09:00
[LSTM文章生成]ml5jsを使う
Javascript Advent Calendar 2019 の24日目
LSTMってなんぞや
文章データを学習したmodelに対して、始まりの文字を与え、次に来る文字を推測させるというものです。
利用したライブラリー
ml5js
ml5
tensorflowのモデルを使用しjsで扱いやすくしてくれる。tensorflow
モデル生成に利用します。
tensorflow事前準備
インストールするもの
- Python
- tensorflowを動かすために必要
- Anaconda
- Pythonのディストリビューション。機械学習・科学計算で使うライブラリがまとまっている。Python本体もインストールされます。
- pip
- Pythonパッケージのインストールに利用する(TensorFlowはpipで入れます)
- nodejs
- ml5ライブラリーフロントエンド側を動かす為に利用する
私はAnacondaでPythonをインストールして、pipでTensorFlowをインストールしました。
環境
OS:windows 10
(ゲーミングPCです。負荷がそれなりにかかりそうと思いあえて。)トレーニング用セット
こちらをダウンロードします
training-charRNNgit clone https://github.com/ml5js/training-charRNN.gitデータを用意
後にも先にもここが一番大変な所なんですが、とりあえず動かせるようにする為、適当な文章データを用意しておきます。
日本語データを用意するのは文節等分ける作業が大変なので英語データにしましょう。日本語については後日まとめてみようと思っています。
ファイル名:input.txt
配置場所:training-lstm-master/[any_holder_name]/input.txtに文章を入力し保存します。
参考データ
フリーで使える英文の小説や物語が公開されています。試しに利用するのであれば、こちらから元となるデータを用意してみるだけでも良いかと思います。
Project Gutenbergトレーニングさせる
- AnacondaPromptを起動
- トレーニング用セットの、ディレクトリ配下に移動します。
cd training-lstm-master
- 作成したデータをトレーニングさせる
python train.py --data_path=./[any_holder_name]/input.txtこの後トレーニングが始まり、終わるとmodels/input/にファイルが生成されています。
生成されるファイル群
- embedding
- manifest.json
- rnnlm_multi_rnn_cell_cell_0_basic_lstm_cell_bias
- rnnlm_multi_rnn_cell_cell_0_basic_lstm_cell_kernel
- rnnlm_multi_rnn_cell_cell_1_basic_lstm_cell_bias
- rnnlm_multi_rnn_cell_cell_1_basic_lstm_cell_kernel
- rnnlm_softmax_b
- rnnlm_softmax_w
- Variable
- vocab.json
このファイル群を後で説明するml5-examplesで利用します。
エラーが起きたら
私は、tensorflow最新バージョンを入れていたのですが、怒られたんですよね。
(その時のエラー内容はすみませんが千の風になってしまいました。)仕方なく tensorflow 1.15.0 を入れました。
1系の関数に書き換えないといけず、train.pyの下記を修正しています。
# hide logs tf.logging.set_verbosity(tf.logging.ERROR)↓
# hide logs tf.compat.v1.logging.set_verbosity(tf.compat.v1.logging.ERROR)まだフロントエンドの話になっていないので、アドベント的にこれいいのかなと不安に襲われる・・
フロントエンド
やっとjavascriptの話にたどりつきました。
では先ほど作成したmodelを使ってみようと思います。ファイル群を移動
こちらをダウンロードします
ml5-examplesgit clone https://github.com/ml5js/ml5-examples.gitnodejsのpackageを利用しているのでいつものやつ
npm installファイル群を移動
先ほど生成したmodels/input/配下のファイル群を移動させる。
移動先
https://github.com/ml5js/ml5-examples/tree/release/p5js/CharRNN/CharRNN_Text/models/woolf※inputフォルダは文章に合わせたフォルダ名にすることをお勧めします。
例)
猫についての文章
ml5-examples-master/p5js/CharRNN/CharRNN_Text/models/cat占いについての文章
ml5-examples-master/p5js/CharRNN/CharRNN_Text/models/horoscopemodelを指定する
sketch.jsにmodelsの指定があるので、「woolf」の所を先程models配下に作成したフォルダ名にする。
charRNN = ml5.charRNN('./models/woolf/', modelReady);https://github.com/ml5js/ml5-examples/blob/release/p5js/CharRNN/CharRNN_Text/sketch.js#L24
local serverを立ち上げる
python 3系
python -m http.serverpython 2系
python -m SimpleHTTPServerhttp://localhost:8000/ を開くとディレクトリが見えると思います。
CharRNN Textを使う
pl5jsをクリック
CharRNNをクリック
CharRNN_Textをクリック
Generaterの画面にたどり着きます。
seed text: 最初に与える文字
length: 生成したい文字数
temperature: 重さ・深さ
seed text:happy
length:100
temperature:0.5で生成した文章happy and the other grown herself, 'I was than the bottle my to little sing how the poor comly up and gut
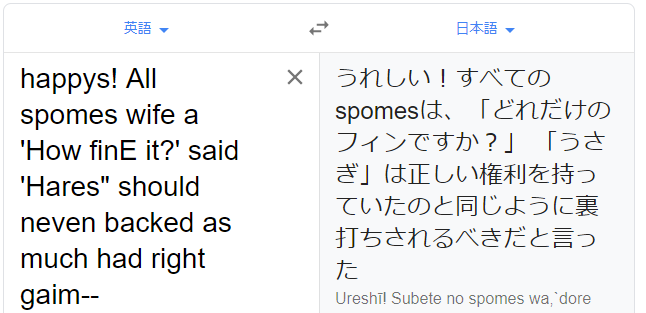
seed text:happy
length:100
temperature:1で生成した文章happys! All spomes wife a 'How finE it?' said 'Hares" should neven backed as much had right gaim--'
文章としては支離滅裂です。
さて私は何の文章をデータとしたでしょうか。
後者の生成した文章にヒントが載っています。ヒント「うさぎ」。
答え:Alice's Adventures in Wonderland
後者の文章はtemperatureを1にしたので、前者(temperature:0.5)に比べて、よりAlice's Adventures in Wonderlandっぽい文章となっているはずです。
確かに「うさぎ」とか「権利」とかの部分にそれっぽさが出ているような気がします。
ml5.CharRNNについてもっと調べていきたくなりました。
mecabを使い日本語の文章データを用意させれば日本語文章もいけるかも!という話をきいたので時間をみて、やってみようと思います。完全にjavascriptの話ではなくなる笑
参考記事