- 投稿日:2019-12-22T23:51:21+09:00
【AWS SAM】 DynamoDB+Lambda+APIGatewayでAPIを作る
内容
DynamoDBのデータを取ってくるAPIを、AWS SAMで構築してみる
要するに、こんな感じのテーブルから、、、
group(Hash) name(Range) group1 name1 group1 name2 group2 name3 こんな感じに取ってこれるようにしたい。
curl https://hogehoge/Prod/dynamo-api/v1/?group=group1&name=name1 { "result": [ { "name": "group1", "group": "name1" } ] }環境
- macOS Mojave -10.14
- python3.7.4
- sam 0.38.0
目次
- アプリケーションの環境構築
- template.yamlを書く
- 実行スクリプトを書く
- デプロイ
- 検証
1. アプリケーションの環境構築
構築は前回の【AWS SAM】Python版入門 を参考にしてください。
(Pipenvを使ったAWS SAMアプリケーションの初期化手順です。)2. template.yamlを書く
リソース
今回作成するリソースは以下です
- Table(DynamoDB)
- Lambda用Role(IAM)
- Lambda
リソース定義
では、上記リソースを作成するtemplate.yamlを書いていきましょう。
template.yamlAWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31 Description: > dynamo-api Sample SAM Template for dynamo-api # Lambdaのタイムアウト設定 Globals: Function: Timeout: 60 # テーブル名、関数名などの定義 Parameters: DynamoAPIFunctionName: Type: String Default: dynamo-api DynamoTableName: Type: String Default: DynamoApiTable # リソースの定義 Resources DynamoTable: Type: AWS::DynamoDB::Table Properties: TableName: !Ref DynamoTableName # HashキーとRangeキーの定義(カラム名と型) AttributeDefinitions: - AttributeName: group AttributeType: S - AttributeName: name AttributeType: S KeySchema: - AttributeName: group KeyType: HASH - AttributeName: name KeyType: RANGE # 料金モード指定(PAY_PER_REQUESTは従量課金) BillingMode: PAY_PER_REQUEST DynamoAPIFunctionRole: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Principal: Service: - 'lambda.amazonaws.com' Action: - 'sts:AssumeRole' ManagedPolicyArns: - 'arn:aws:iam::aws:policy/CloudWatchLogsFullAccess' # DynamoDBテーブルへの読み取り許可(こうすると、今回作成するテーブルの読み取りのみを許可できます) Policies: - PolicyName: 'DynamoApiTablePolicy' PolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Action: - dynamodb:Get* - dynamodb:Query Resource: !GetAtt DynamoTable.Arn DynamoAPIFunction: Type: AWS::Serverless::Function Properties: FunctionName: !Ref DynamoAPIFunctionName Role: !GetAtt DynamoAPIFunctionRole.Arn # app.pyがあるディレクトリパス CodeUri: dynamo-api/ # ハンドラーのパス(むやみに変更するとミスしやすい、、、そっとしておくのが吉) Handler: app.lambda_handler Runtime: python3.7 # APIGatewayの設定(SAM独特の記述) Events: DynamoApi: Type: Api Properties: Path: /dynamo-api/v1/ Method: get # Outputsに指定したパラメータは、他のtemplateへデータを渡したりするのが本来の役目ですが # 今回はデプロイ完了時にAPIのエンドポイントを出力するために使っています。 Outputs: DynamoApi: Description: "API Gateway endpoint URL for Prod stage for Dynamo API function" Value: !Sub "https://${ServerlessRestApi}.execute-api.${AWS::Region}.amazonaws.com/Prod/dynamo-api/v1/"LambdaやAPIGatewayの設定なんかは、ほとんど雛形と同じなので楽に書けます。
3. 実行スクリプトを書く
ライブラリのインストール
まずは、必要なライブラリをインストールします。
$ pipenv install requests boto3APIの処理を書く
次に、実際にDynamoテーブルからデータを取ってくる処理を作っていきます。
GETパラメータに指定されたgroupとnameでDynamoテーブルを検索、その値を返す
という単純な仕組みです。
nameは前方一ができるようにしてみました。app.pyimport json import json import boto3 from boto3.dynamodb.conditions import Key from http import HTTPStatus as status DYNAMODB_TABLE_NAME = 'DynamoApiTable' def lambda_handler(event, context): table = boto3.resource('dynamodb').Table(DYNAMODB_TABLE_NAME) params = event.get('queryStringParameters') results = dynamo_search(table, params) if results is None: return { "statusCode": status.BAD_REQUEST, "body": json.dumps({ "error": "Bad Request" }, ensure_ascii=False), } return { "statusCode": status.OK, "body": json.dumps({ "results": results }, ensure_ascii=False), } def dynamo_search(table, params): if params.get('group'): keyConditionExpression = Key('group').eq(params.get('group')) if params.get('name'): keyConditionExpression &= Key('name').begins_with(params.get('name')) return table.query( KeyConditionExpression=keyConditionExpression).get('Items', []) return None4. デプロイ
(余談) Pipfile to requirements.txt
Pipfileからrequirements.txtに変換したい、、、
そんな時はこのコマンドで変換可能です。
(boto3もLambdaに最初から用意されてるし、あまり使い所ないかも。。)
$ pipenv lock -r > requirements.txt今回は、デフォルトの
requirements.txtのままで大丈夫ですビルド
$ sam buildBuilding resource 'DynamoAPIFunction' Running PythonPipBuilder:ResolveDependencies Running PythonPipBuilder:CopySource Build Succeeded Built Artifacts : .aws-sam/build Built Template : .aws-sam/build/template.yaml Commands you can use next ========================= [*] Invoke Function: sam local invoke [*] Deploy: sam deploy --guidedデプロイ
~/.aws/credentialsで設定を分けている方は、--profile オプションを付けてください。
--guidedオプションは初回のみでOKです。(samconfig.tomlに設定が保存されるので)$ sam deploy --guidedStack dynamo-api-stack outputs: ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- OutputKey-Description OutputValue ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- DynamoApi - API Gateway endpoint URL for Prod stage for Dynamo API function https://hogehoge/Prod/dynamo-api/v1/ -----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------エンドポイントもちゃんと出力されてますね〜
5.検証
Dynamoにデータを登録
今回は(も)、推しのグループ名と名前を登録しました。
group(Hash) name(Range) ハニーストラップ 周防パトラ ハニーストラップ 堰代ミコ ホロライブ 白上フブキ ... ... APIを叩いてみる
出力されたエンドポイントにリクエストを送ってみます。見にくいので
jqで整形しましょう。
(curl面倒だよって人はブラウザで)
まずは
group(Hashキー)指定です。$ curl https://hogehoge/Prod/dynamo-api/v1/ \ --get \ --data-urlencode 'group=ハニーストラップ' | jq{ "results": [ { "name": "周防パトラ", "group": "ハニーストラップ" }, { "name": "堰代ミコ", "group": "ハニーストラップ" }, { "name": "島村シャルロット", "group": "ハニーストラップ" }, { "name": "西園寺メアリ", "group": "ハニーストラップ" } ] }取れました
もちろん、前方一致で
name(Rangeキー)も検索できます。$ curl https://hogehoge/Prod/dynamo-api/v1/ \ --get \ --data-urlencode 'group=ハニーストラップ' \ --data-urlencode 'name=周防' | jq{ "results": [ { "name": "周防パトラ", "group": "ハニーストラップ" } ] }取れました!完璧です!
終わりに
今回は、単純なAPIを作ってみました。次回は
pytestでテストをしてみようと思います。
最後まで読んでいただきありがとうございました!前回
- 投稿日:2019-12-22T23:43:55+09:00
[AWS] VPCでネットワーク構築3
[AWS] VPCでネットワーク構築1
[AWS] VPCでネットワーク構築2
の続きプライベートサブネットを作って、DBサーバを配置するまで
1.プライベートサブネットを作る
・リージョンが東京になっていることを確認
・VPCに作成済みのVPCを選択
・アベイラビリティゾーンに作成済みパブリックサブネットのアベイラビリティゾーンを選択(サブネット > パブリックサブネットを選択 > 説明タグで確認できる)2.インスタンスを作成する
・パブリックサブネットに作成したEC2インスタンスのときと同じ流れ
・ネットワークに作成済みのVPCを選択
・サブネットに1で作成したプライベートサブネットを選択
・自動割り当てパブリックIPにはネットワークに接続させないため「無効化」を選択
・プライマリIPは10.0.2.10にしてみる3.サーバ名をつける
4.セキュリティグループを設定する
・セキュリティグループ名に「DB-SG」と入力する
・今回はDBサーバでMySQLを使用するため、ルールを追加する
・送信元は任意の場所にしておく5.作成済みのWEBサーバを踏み台にしてDBサーバにログインする
・キーをsshで転送する(画像はwindowsの場合の例、teraTerm > ファイル > SSH SCPから送信)[ec2-user@ip-10-0-1-10 ~]$ ssh -i my-key.pem ec2-user@10.0.2.10 The authenticity of host '10.0.2.10 (10.0.2.10)' can't be established. Warning: Permanently added '10.0.2.10' (ECDSA) to the list of known hosts. __| __|_ ) _| ( / Amazon Linux AMI ___|\___|___| https://aws.amazon.com/amazon-linux-ami/2018.03-release-notes/ [ec2-user@ip-10-0-2-10 ~]$ hostname ip-10-0-2-10・配置したキーを使用してssh接続する
6.プライベートサブネットに配置したサーバにMySQLをインストールする
プライベートサブネットはインターネットに接続できないため、yumなどのコマンドでインストールできない
NAT(Network Address Translation)という仕組みを使ってインストールしてく
- VPC > NATゲートウェイ > NATゲートウェイの作成
・パブリックサブネットを選択し、新しいEIPの作成をクリック
7.デフォルトゲートウェイにNATゲートウェイを設定する
・VPC > ルートテーブル > メインが「はい」になっているルートテーブルを選択 > ルートの追加
・送信先にはデフォルトゲートウェイを表す0.0.0.0/0を、ターゲットには作成したNATゲートウェイを選択する8.MySQLをインストール
[ec2-user@ip-10-0-2-10 ~]$ sudo yum -y install mysql-server sudo service mysqld start [ec2-user@ip-10-0-2-10 ~]$ mysqladmin -u root password New password: Confirm new password:
AWS無料枠を超えてしまうのでNATゲートウェイは使い終わったら削除しちゃいます
これで今回作成しようとした環境は完成です!






- 投稿日:2019-12-22T23:27:03+09:00
riot.jsでAmazon S3使う際にリロードすると403が出てしまう時にすべきこと
はじめに
どうもです。
Riot.jsを利用して作成したコンテンツをAmazon S3で配信する際に、404エラーが想定通り処理されなかったので対応した内容を書きます。Riot.jsアドベントカレンダー2019の5日目、@nekijakさんの記事を見ながらふんふんとルーティングについて学び、最高にわかりやすかったです。ありがとうございます。
その後、じゃーいつも使ってるS3に乗っけてみるかと漫然と乗っけたところうまく行かなかったのでじゃあこれを書こうと思った次第です。参考にさせていただいた記事
- Riot.js v4対応 Router - Qiita (件の@nekijakさんの記事)
問題点
例えば、一度
/helloにアクセスし、そのままブラウザでリロードした場合に、デフォルトではスクショのように403エラーが返ります。直接的な原因は「hello」に対応するオブジェクトがないという事に対し、S3側から403エラーが返ってきていることです。根本的には色々とすべきことはありそうですが、ここではまずちゃんと 対応するオブジェクトがない場合404エラーが返るように修正する必要がある という問題認識だとします。
解決方法
CloudFrontを利用して、コンテンツを配置したバケットに対して設定を行います。403エラーの場合に404エラーを返すようにした上で、所定のエラーページを表示されるようにします。
Distributionの作成
- CloudFrontで「Create Distribution」を選択します。
- delivery methodとしてWebかRTMPか聞かれるので「Web」を選択します(ちなみにRTMPはCFとS3で動画ストリームを配信するやつです)
- Originの設定画面に移るので「Origin Domain Name」にコンテンツを配置したバケットのパスを入力します。めっちゃ項目ありますが、他はデフォルトのままでOKです。
- 余談ですがここでComment欄にも入力することをオススメします。また内容はこのDistributionを作った日付や目的にするのがオススメです。なぜなら、空欄のままだと後からなんで作ったのかわからなくなりがちだからです。

Error Pagesの設定
Distributionが作成されたら、「Error Pages」の設定タブを開きます
「Error Pages」の設定タブで「Create Custom Error Response」を選択します
設定画面に移るので、次の項目をそれぞれ設定します。
Key Value HTTP Error Code 403:Forbidden Customize Error Response Yes(これを選択すると、下のパスやエラーコードの入力欄が展開されます) Response Page Path エラーページのコンテンツのパス HTTP Response Code 404: Not Found 設定が完了したら、StatusがDeployedになるまで待ちます。
Distributionの設定が反映されるまでは、結構時間がかかります。私の実績としては今回のような設定で毎回20-30分くらいかかりました。
▼
結果
404.htmlの画面が表示されます。
また、存在しないオブジェクトへのURLを指定した場合にも404.htmlの画面が表示されます(404として処理されます)
さいごに
404エラー以外にも同様にエラーをハンドリングできます。
Riot.jsっていうかAWSの話になってしまったんですが、同じ問題にあたった方の参考になれば幸いです。やっぱAWS面倒くさいって思います?でも、なれればかゆいところに手が届くクラウドサービスなので僕は好きです。
Riot.jsもAWS使ってやっていこう。






- 投稿日:2019-12-22T22:25:22+09:00
AWS上にCentOSでrocket chatを構築してみる
EC2でインスタンスを立てる
- AMI:CentOS 7 (x86_64) - with Updates HVM
- タイプ:t2.micro
- セキュリティグループ:22,80,3000
必要な依存パッケージをインストール
- Rocket.Chat 1.0.2
- OS:CentOS 7.6
- Mongodb 4.0.9
- NodeJS 8.11.4
# sudo yum -y check-update # cat << EOF | sudo tee -a /etc/yum.repos.d/mongodb-org-4.0.repo [mongodb-org-4.0] name=MongoDB Repository baseurl=https://repo.mongodb.org/yum/redhat/7/mongodb-org/4.0/x86_64/ gpgcheck=1 enabled=1 gpgkey=https://www.mongodb.org/static/pgp/server-4.0.asc EOF ※catからEOFまで全て入力 # sudo yum install -y curl && curl -sL https://rpm.nodesource.com/setup_8.x | sudo bash - # sudo yum install -y gcc-c++ make mongodb-org nodejs # sudo yum install -y epel-release && sudo yum install -y GraphicsMagick # sudo npm install -g inherits n && sudo n 8.11.4Rocket.Chatサービスを構成
# sudo useradd -M rocketchat && sudo usermod -L rocketchat # sudo chown -R rocketchat:rocketchat /opt/Rocket.Chat # cat << EOF |sudo tee -a /lib/systemd/system/rocketchat.service [Unit] Description=The Rocket.Chat server After=network.target remote-fs.target nss-lookup.target nginx.target mongod.target [Service] ExecStart=/usr/local/bin/node /opt/Rocket.Chat/main.js StandardOutput=syslog StandardError=syslog SyslogIdentifier=rocketchat User=rocketchat Environment=MONGO_URL=mongodb://localhost:27017/rocketchat?replicaSet=rs01 MONGO_OPLOG_URL=mongodb://localhost:27017/local?replicaSet=rs01 ########################################### ROOT_URL=http://"パブリックDNSを入力":3000/ ########################################### PORT=3000 [Install] WantedBy=multi-user.target EOF ※catからEOFまで全て入力rocket.chatにログイン & アカウント登録
ログインするためのアカウント情報を登録
- ユーザ名
- メールアドレス
- パスワード

ログイン完了
使用感はSlackと遜色無いかと思います。
備考
得に難しい事はしていませんが、今まで情報発信をしていなかったので、これからOUTPUTを出すための
切っ掛けになればと投稿してみました。これから頑張って行こうと思います。

- 投稿日:2019-12-22T22:13:08+09:00
[AWS] EKSでFargateが使えるようになったらしいので試してみた
はじめに
少し前に開催されたre:Inventで
「EKS(Elastic Kubernetes Service) 上のPodをFargateで実行できるようになった」
と発表されました。
https://aws.amazon.com/jp/blogs/news/amazon-eks-on-aws-fargate-now-generally-available/ということで試してみました。
先にまとめ
- ワーカーノード無し (コントロールプレーン + Fargateのみ) でPodが実行可能
EKS + Fargate 構築
ちなみに、以下の内容は基本的に公式を簡略化したものですので、実際にやる場合は公式をご覧ください。
1. eksctlでクラスタを作成
今回は東京リージョンでクラスタを作成していきます。
EKS + Fargate に対応していないリージョンだとエラーになります。
(2019年12月現在 東京リージョンを含む4つのリージョンしか対応していません)eksctl create cluster --name my-cluster --version 1.14 --fargate --region ap-northeast-1
--fargateを指定することでFargateプロファイルなるものが作成され、PodをFargateで実行できるようになります。
なおこのとき、実行するIAMユーザーにeks:CreateFargateProfile等の権限が無いとエラーになります。
その後の削除等も含めるとeks:*FargateProfile*の権限を付けた方が良いかと思います。2. 作成したクラスタにPodをデプロイ
普通にkubectlで作成するだけで、自動的にFargateで実行されます。
特にEKS/Fargate用の設定等は必要ありません。(Dockerイメージの取得元をECRにする等はあるかもですが)kubectl apply -f deployment.yaml3. デプロイしたPodがRunningになるのを待つ
今回
replicas: 2の Deployment で試しましたが、
1つのPodは30秒くらいでContainerCreatingになったのに対して
もう1つは80秒くらいまでPendingのままでした。
このあたりはFargateの機嫌次第だと思われます。というわけで、ワーカーノードを追加することなくFargateでPodが実行できました。
その他
Fargateで稼働しているPodに対してALBを設定しようとしたのですが
alb-ingress-controller 内でエラーとなりうまくいきませんでした。
また別途調査しようと思います…
- 投稿日:2019-12-22T21:57:27+09:00
ほぼオンプレしか触ったことがないインフラエンジニアがAWS SAAを取得するまで
はじめに
ほぼインフラしか触ったことがないインフラエンジニアでしたが、
一か月半くらいの勉強で合格出来ましたので備忘録がてらメモです。
同じようにオンプレの経験しかない方の参考になれればいいと思います私のスキルセット
業界3年(最初の会社で取ったCCNAが失効した。。。)
Linuxなんとなく操作できる(LPICレベル3はもってる)
IAサーバならなんとなく構築できる
OSの動作とかコンピュータアーキテクチャがなんとなくわかる
ラッキングとか物理作業もなんとなくできるAWSの勉強を始めた直後ぐらいにAWSの案件にぶち込まれたので
AWSの業務経験としては1か月くらいです。(右も左もわからんのにTerraformな感じでした)勉強方法
参考書を読む
以下の本を2周読みました。
この1冊で合格! AWS認定ソリューションアーキテクト - アソシエイト テキスト&問題集
AWS認定資格試験テキスト AWS認定 ソリューションアーキテクト-アソシエイト
Amazon Web Services 業務システム設計・移行ガイド以下の本も買いましたが、上記で分からなかった部分だけ読みました
Amazon Web Servicesインフラサービス活用大全 システム構築/自動化、データストア、高信頼化 (impress top gear
Black Belt を読み漁る
動画はあまり見てません、、、1時間ぐらいかかってしまうので
AWS各サービスのよくある質問を読み漁る
※一番大事だったかもしれません。一次情報なので
そもそもベンダー試験なので公式ドキュメントを暗記すれば解けるはず試験結果
788点で合格でした。
結構ひっかけというか単純に暗記してるだけだと間違えるような問題が結構ありましたので、
暗記でなく、実際の構成例とかも見ないと厳しいかもしれません。最後に
オンプレの設計構築経験があるサーバエンジニアであれば
1か月くらいの実務期間とそれに並行して勉強すれば問題なく合格できるレベル感だと思います。
- 投稿日:2019-12-22T21:52:44+09:00
【AWS】Route53で取得したドメインをElastic IPとひもづける方法。
Route53を使用して取得したドメインを、ElasticIPと紐付けてアクセスできるようにする方法を記事にしました。
前提条件
・AWSでアカウントを登録済み。
・ElasticIPを使用してデプロイがすんでいる。
・Route53をドメインを取得するが、課金に抵抗がない(例えば.comのドメインの場合、年間12$かかります)無料でドメインを取得する方法もあるそうですが、エラーにはまる可能性があると聞いたので、今回はRoute53を使用して取得したドメインをElasticIPとひもづけることでAWS上で完結させます。
ドメインを取得するメリットをこちらの通りです。
・Twitterの自己紹介にURLを載せることができる(ElasticIPだと入力がはじかれました)
・番号よりドメインの方が見栄えがよい。
・アドレスを利用者に覚えてもらいやすくなる。まずはAWSのコンソールにアクセスします。
1.Route53のダッシュボードに移動
Route53をのページにアクセスします。
2.ドメインの取得画面へ移動します。
記事にしたのは登録後の為、便宜上私の登録済みのドメインが画面に表示されていますが、ご了承ください。ドメインの登録は初めてかと思うので、左上のドメインの登録ボタンを押します。
3.ドメイン名の選択
自分の好きなドメイン名を入力してチェックボタンを押します。
使用が不可能の場合は下の写真のように使用不可のボタンが出ますが、まだ使用済みのドメインでなければ利用可能と出ます。ドメインは.comを選ぶのが一般的なようなので、特に理由がなければ.comのドメインを選択しておきましょう。少しでも安く済ませたければ.netのドメインでも大丈夫です。
4.購入する
入力したドメインが取得可能であれば、右側のカートを入れるボタンが押せるようになるので、そちらを押しましょう。
カートに入れるボタンを押すと、右側に小計が表示されます。
金額と取得するドメイン名に間違いないかを確認したら、下にスクロールして続行ボタンを押します。
5.連絡先の詳細を記入。
連絡先の詳細を上から順番に記入します。
登録後に記事にしたため、画面による説明がないことをご了承ください。
不安な場合は、こちらのサイトをご参照ください。
https://qiita.com/ymzk-jp/items/ae115ed6d0fd2d383cec6.確認と購入。
購入内容を確認します。
よければ同意するにチェックを押して、購入を確定させます。7.ドメインの登録に成功できたかを確認。
ドメインの登録に成功すると、ステータスのところにドメインの登録に成功と出ます。
自分の場合ですが、ドメインの登録が成功と出るまで半日ほどかかりました。
また、メールアドレスに購入確認の通知がくるかと思うので、確認しておきましょう。
DNSに登録
お疲れ様でした!
登録しただけでは、ElasitcIPとひもづけができないので、今度は紐付けをします。1.ホストゾーン
左側のホストゾーンをクリックして選びましょう。
取得したドメインのホストゾーンは既に作成済みになっているかと思いますので、水色の文字で表示されている自分のドメイン名をクリックしましょう。
2.レコードセットの作成。
レコードセットの作成の青いボタンを押すと右側にタブが表示されます。
名前は空欄。タイプはそのままA-IPv4アドレスのままで大丈夫です。
値の入力欄にElasticIPを入れてください。画面の下にある例が参考になります。
うまく行かない場合はこちらの記事が参考になるかもしれません。
https://qiita.com/ymzk-jp/items/ae115ed6d0fd2d383cec独自ドメインにアクセスできるようにする
取得したドメインをアクセスするとこのような画面がおそらく出るかと思います。
この画面が出ていればAWS上での登録はうまくいっているかと思うので、nginxの設定が
できればうまくいくかと思います。あともう少しです。
ここから先は我流になりますので、うまくいかない可能性もあるかと思いますがご了承ください。
アプリのフォルダを開いて
config/deploy/production.rbを選択する。server '11.111.111.111'
このようにElasticIPのアドレスが設定されているかと思いますが、先ほど取得したドメインに書き換えます。続いてnginxの設定。
まずは. ssh/に移動してEC2のサーバーを立ち上げます。|[ec2-user@ip-111-11-11-111 ~]$ sudo vim /etc/nginx/conf.d/rails.conf|
このようにコマンドを打ち込んで、設定を変更します。
server {
# このプログラムが接続を受け付けるポート番号
listen 80;
# 接続を受け付けるリクエストURL ここに書いていないURLではアクセスできない
server_name 11.111.111.111;画面上でiボタンを押して、server_nameの右側の横に
server_name 11.111.111.111 取得したドメイン;
といった形で空欄を一つ開けてドメイン名をうちます。
打ち込み終わったら、ESCボタンを押した後、:wqとして設定を終了させます。忘れずにnginxの設定を反映させましょう。
[ec2-user@ip-111-11-11-111 ~]$ cd /var/lib
[ec2-user@ip-111-11-11-111 lib]$ sudo chmod -R 775 nginxnginxを再起動して設定ファイルを読み込ませます。
[ec2-user@ip-172-31-25-189 lib]$ cd ~
[ec2-user@ip-172-31-25-189 ~]$ sudo service nginx restartこれで設定が完了したかと思います。
ドメインとElasticIPの両方でアクセスできるか確認してみましょう。
取得したドメイン及びIPアドレスでアクセスできれば無事成功です。
お疲れ様でした。これでTwitterの自己紹介にもURLを載せれるようになりました。
ドメイン取得はお金がかかりますが、アドレスを覚えてもらいやすくなるなどメリットが大きいので、
チャレンジしてみる価値はあるかと思います。無料でドメインを取得してAWSのIPと紐付けする方法もあります。
参考になる記事もいくつかありますので、気になるようでしたら
チャレンジしてみるのもありかもしれません。








- 投稿日:2019-12-22T20:11:37+09:00
Amazon Linux 2 初期設定 & Rails5.2 + Capistrano3.11で自動デプロイ
はじめに
EC2にRails環境を構築、Capistranoで自動デプロイするための初期設定を紹介していきます。
主に個人開発やテスト環境で扱う最低限の設定のみ記載します。
コピペで大体できるはず、、!環境
OS : Amazon Linux 2
Webサーバー : Nginx
アプリケーションサーバー : puma
メールサーバー : postfix
DB : RDS(MySQL)前提
macOS
AWSにてEC2、RDSを構築済みEC2に接続
ローカルPCのターミナル."sudo ssh -i [keyペアファイル] ec2-user@[パブリックIP]" #確認が出るので "yes" #PCのパスワードを要求されるので、入力。初期設定
- yumをアップデート
SSH接続したEC2インスタンス内.yumをまとめてアップデート $ sudo yum update -y $ sudo yum install -y yum-cron EPELを有効化 # sudo amazon-linux-extras install epel セキュリティのみ自動でパッチがあたるようにcronの設定ファイルを変更します。 $ vi /etc/yum/yum-cron.conf 変更点 update_cmd = security apply_updates = yes email_to = [任意] 設定したら起動及び再起動自動の自動実行を設定 $ systemctl start yum-cron $ systemctl enable yum-cron
- タイムゾーンを日本時間に変更します。
タイムゾーンをJSTに設定 $ sudo ln -sf /usr/share/zoneinfo/Asia/Tokyo /etc/localtime タイムゾーンがJSTに変更されたか確認 $date /etc/sysconfig/clockの設定変更を変更 $ sudo vi /etc/sysconfig/clock/etc/sysconfig/clock.以下の内容を変更 ZONE="Asia/Tokyo" UTC= true
- EC2インスタンスを再起動し、全てのプロセスが新しいタイムゾーンを設定を利用するようにします。
SSH接続したEC2インスタンス内.$ sudo rebootユーザー追加
セキュリティ強化のため、ec2-userのアカウント名をそのまま使うのではなく、
ec2-userを停止にして、新しいユーザでログインできるようにします。SSH接続したEC2インスタンス内.新規ユーザー作成 $ sudo adduser my-user wheelグループに追加 $ sudo usermod -G wheel my-user sudo権限を付与 $ sudo visudoviが開くので、行末に「my-user ALL=(ALL) NOPASSWD: ALL」を追加
visudo.my-user ALL=(ALL) NOPASSWD: ALL:wqで保存
ec2-userのauthorized_keysをmy-userの.sshディレクトリにコピーし、適切なパーミッションを設定します。
SSH接続したEC2インスタンス内.$ sudo rsync -a ~/.ssh/authorized_keys ~my-user/.ssh/ $ sudo chown -R my-user:my-user ~my-user/.ssh $ sudo chmod 700 ~my-user/.ssh/ $ sudo chmod 600 ~my-user/.ssh/**SSH接続設定
EC2のシークレットキーをローカルPCの以下に配置
/Users/[ユーザー]/.ssh/***.pemローカルPCのターミナル..sshディレクトリに移動 cd .ssh シークレットキーを持っている他のユーザーもログインできるように権限を変更 $ chmod 600 ***.pem 権限が変更されているか確認 $ ls -al -rw------- になっていればOK configに接続設定を記載 $ vi configローカルにショートカットを作成
/.ssh/config.Host [ホスト名] HostName [パブリックIP] Port 22 User my-user IdentityFile ~/.ssh/***.pem:wqで保存
my-userで接続できるか確認します。
ローカルPCのターミナル.$ ssh [ホスト名]接続できたら、rootになれるか確認
SSH接続したEC2インスタンス内.$ sudo su -SSHのセキュリティ設定
rootとec2-userでのSSHを禁止する
SSH接続したEC2インスタンス内.$ sudo vi /etc/ssh/sshd_config/etc/ssh/sshd_config.以下を追加 #ec2-userでのログインを禁止 DenyUsers ec2-user #暗号化アルゴリズムの指定 Ciphers aes128-ctr,aes192-ctr,aes256-ctr #鍵付きハッシュのアルゴリズム MACs hmac-sha2-256,hmac-sha2-512 以下を変更 AuthorizedKeysFile .ssh/authorized_keys PermitRootLogin no:wqで保存
SSH接続したEC2インスタンス内.設定を反映 $ service sshd reloadRVMとRubyをインストール
SSH接続したEC2インスタンス内.Rootに変更 $ sudo su - RVMをインストール # gpg --keyserver hkp://keys.gnupg.net --recv-keys 409B6B1796C275462A1703113804BB82D39DC0E3 # curl -sSL https://get.rvm.io | bash Rubyのインストールに必要なライブラリをインストール # yum install -y gcc-c++ patch readline readline-devel zlib zlib-devel libyaml-devel libffi-devel openssl-devel make bzip2 autoconf automake libtool bison iconv-devel wget libxml2 libxml2-devel libxslt libxslt-devel # yum install -y bzip2-devel lcms-devel libjpeg-devel libX11-devel libXt-devel libtiff-devel ghostscript-devel libXext-devel libpng-devel ImageMagickを使うのでインストール(任意) # yum install -y ImageMagick ImageMagick-devel RVMを有効にするために一旦ログアウトし、もう一度SSH接続してrootになります。 Rubyをインストール 今回は2.3.8を使用 # rvm install 2.3 # rvm use 2.3.8 # ruby -v bundllerをcapistranoが使うのでインストール # gem install bundlerMySQLをインストール
SSH接続したEC2インスタンス内.mariaDB削除 $ sudo yum remove mariadb-libs $ sudo rm -rf /var/lib/mysql mysqlインストール $ sudo yum install mysql Amazon RDSヘ接続 $ mysql -h {ENDPOINT} -P 3306 -u {Username} –p パスワードが要求されるので、RDSで設定したパスワードを入力posfixのインストール
SSH接続したEC2インスタンス内.# yum install postfix 設定ファイルを変更 # vi /etc/postfix/main.cf 適宜各要素を以下のように変更 inet_interfaces = all mydestination = $myhostname, localhost.$mydomain, localhost, $mydomain home_mailbox = Maildir/ smtpd_banner = $myhostname ESMTP unknown allow_min_user = yes 自動起動設定 # systemctl enable postfix # systemctl start postfixNginxをインストール
SSH接続したEC2インスタンス内.# yum -y install nginx NginxでSSL通信する場合は鍵を配置 # vi /etc/nginx/conf.d/server.key サーバー証明書、中間証明書を配置 # vi /etc/nginx/conf.d/server_geotrustca.crt 自動起動設定 # systemctl start nginx # systemctl enable nginx 設定ファイルの文法チェック # nginx -tredisのインストール
SSH接続したEC2インスタンス内.$ rpm -ivh http://rpms.famillecollet.com/enterprise/remi-release-7.rpm $ yum install --enablerepo=epel,remi redis $ systemctl enable redis $ systemctl start redisRailsディレクトリとShared内ファイルの作成
Capistranoのディレクトリ構成に合わせます。
SSH接続したEC2インスタンス内.sharedディレクトリを作成 mkdir -p /usr/local/rails/[デプロイするアプリ名]/shared/ mkdir -p /usr/local/rails/[デプロイするアプリ名]/shared/public/assets/ mkdir -p /usr/local/rails/[デプロイするアプリ名]/shared/config ※Webpackerを使う場合、アセットパイプラインでエラーが出る場合は空ファイルを配置 touch /usr/local/rails/[デプロイするアプリ名]/shared/public/assets/.manifest.json touch /usr/local/rails/[デプロイするアプリ名]/shared/public/assets/.sprockets-manifest.json secret_key_baseを.envで管理(デモ環境なのでmaster.keyは使わない) vi /usr/local/rails/[デプロイするアプリ名]/shared/.envRuntimeErrorになるので、rake secretで生成した文字列を貼り付けます。
bundle exec rake secret ff9906beb21fd77ca11aa433d42b7caa720f37641a27bf1617e67894a4fca2c64526af874d1ef1cfac4372cabdf18127110b31bb766c46ef35dbab62736b04e3shared/.envSECRET_KEY_BASE: ff9906beb21fd77ca11aa433d42b7caa720f37641a27bf1617e67894a4fca2c64526af874d1ef1cfac4372cabdf18127110b31bb766c46ef35dbab62736b04e3SSH接続したEC2インスタンス内.ファイルの所有者を変更 chown -R my-user:my-user /usr/local/rails※AWS認証情報を扱う場合は参考にしてください(CLI設定がおすすめ)
https://dev.classmethod.jp/cloud/aws/how-to-configure-aws-cli/node.jsとyarnを使う場合はインストール
SSH接続したEC2インスタンス内.node.jsのインストール $ curl --silent --location https://rpm.nodesource.com/setup_8.x | sudo bash - sudo yum install nodejs yarnのインストール $ curl --silent --location https://dl.yarnpkg.com/rpm/yarn.repo | sudo tee /etc/yum.repos.d/yarn.repo $ sudo rpm --import https://dl.yarnpkg.com/rpm/pubkey.gpg $ sudo yum install yarnCapistranoでのデプロイ
参考にさせていただきました。
https://qiita.com/ea54595/items/12ab7b3a8213b35cca10pumaの設定のみ追記しました。
config/deploy.rb#Capistranoのバージョンを固定 lock '3.11.0' #アプリケーション名 set :application, "[アプリ名]" #レポジトリURL set :repo_url, "ssh://git@github.com:****/[アプリ名].git" #gitでバージョン管理方法 set :scm, :git #対象ブランチ masterに固定 set :branch, 'master' #デプロイ先ディレクトリ フルパスで指定 set :deploy_to, "/usr/local/rails/[アプリ名]" #sharedに入るものを指定 set :linked_dirs, %w{bin log tmp/pids tmp/cache tmp/sockets bundle public/system public/assets public/uploads} #rvmのパス set :default_env, { rvm_bin_path: '~/.rvm/bin' } # sudo に必要 set :pty, true #5回分のreleasesを保持する set :keep_releases, 5 #puma設定 set :puma_threds, [4, 16] set :puma_workers, 0 set :puma_bind, "unix://#{shared_path}/tmp/sockets/#{fetch(:application)}-puma.sock" set :puma_state, "#{shared_path}/tmp/pids/puma.state" set :puma_pid, "#{shared_path}/tmp/pids/puma.pid" set :puma_access_log, "#{release_path}/log/puma.error.log" set :puma_error_log, "#{release_path}/log/puma.access.log" set :puma_preload_app, true set :puma_worker_timeout, nil set :puma_init_active_record, true SSHKit.config.command_map[:rake] = 'bundle exec rake' namespace :deploy do #puma再起動タスク desc "Restart Application" task :restart do on roles(:app), in: :sequence, wait: 5 do invoke 'puma:restart' end end after :finishing, 'deploy:cleanup' endおまけ logのローテーション
SSH接続したEC2インスタンス内.$ sudo vi /etc/logrotate.d/[アプリ名]/etc/logrotate.d/[アプリ名]/usr/local/rails/[アプリ名]/shared/log/*.log { daily #ログを毎日ローテーションする missingok #ログファイルが存在しなくてもエラーを出さずに処理を続行 rotate 10 #10世代分古いログを残す dateext #日次ローテート+日付文字列 compress #ローテーションしたログをgzipで圧縮 sharedscripts #複数指定したログファイルに対し、postrotateで記述したコマンドを実行 su my-user my-user #rotateするユーザを指定 postrotate puma_pid=/usr/local/rails/[アプリ名]/shared/tmp/pids/puma.pid test -e $puma_pid && kill -USR2 $(cat $puma_pid) || true endscript }SSH接続したEC2インスタンス内.エラーが出ていないか確認 $ logrotate -d /etc/logrotate.d/[アプリ名]
- 投稿日:2019-12-22T19:17:54+09:00
ただのWebエンジニアがaws認定の機械学習専門知識に合格した話
本日(2019/12/22)、受かってきました。
今年の6月にAWS 認定 機械学習 – 専門知識 サンプル問題 日本語訳なんて記事を書いてますが、ちょうどここがスタートで半年ちょいかかってますね。。
これで9冠目なんだけど、これまでで一番苦労してるかも。というか2回落ちてますねん。。なお、本記事ではしがないWebエンジニアがどうやって合格までたどり着けたのかを書いていきます。
me
- アソシエイト、プロは取得済。専門知識もいくつか
- しがないWebエンジニア(インフラ寄り)
- 業務ではまったく機械学習系やってない
- awsは使っている
- aws歴2年ちょい
- 数字嫌い
aws認定 機械学習の対象(推奨)
・AWS クラウドでの ML/深層学習ワークロードの開発、設計、実行における、1~2 年の経験
・基本的な ML アルゴリズムの基となる考えを表現する能力
・基本的なハイパーパラメータ最適化の実践経験
・ML および深層学習フレームワークの使用経験
・モデルトレーニングのベストプラクティスを実行する能力
・デプロイと運用のベストプラクティスを実行する能力https://aws.amazon.com/jp/certification/certified-machine-learning-specialty/
やべえ、どれも満たしてない。。
aws認定機械学習の受験履歴
模試 2019.10.04
70%くらい2019.10.14
不合格
スコア 646/7502019.10.31
不合格
スコア 730/7502019.12.22
合格
スコア ?/750
(スコアは後日)最初の試験までにやったこと
まず、ここに到るまでやったことですが、
機械学習ぜんぜんわかってなかったので本をいくつか流し読みしました。・マンガでわかる機械学習
マンガでもわからない機械学習でした。。
確か、伊豆に鯛食いに言った時の電車の中で読んだなー。
理解度はともかく、マンガなのでさらっと読めました。
実際に機械学習を用いるケースなんかもわかりやすい。
基礎の方はけっこう掴める。・人工知能プログラミングのための数学がわかる本
数学の本。昔の消費税の税率ぐらいには理解できたと思う。
役にたったのは実践編以降かなー。自然言語処理とかモデルうんぬんとか。数式はぜんぜんわかりません。。・仕事ではじめる機械学習
オライリーのアルマジロ本。
これはaws認定っていう目的には不向きな気がする。
「機械学習とかビジネスでどう活かしたらええねん」って思ってる人向けかも。
機械学習しなくて良い方法を考えるってプロセスが盛り込まれてたりする。・やさしく学ぶ 機械学習を理解するための数学のきほん
ぜんぜんやさしくない。
アヤノ&ミオと一緒に学ぶ〜.. みたいなサブタイトルもついてて一見やさしそうなんだけど、よくわかんない数式が山ほど出てくるのにこの二人がスイスイといていってしまう。。
もっとやさしい本はないものか。ただ、pythonのソースが出てきたあたりからは少し入ってきた。・つくりながら学ぶ! 深層強化学習 ~PyTorchによる実践プログラミング~
プログラミングがテーマの方が入ってきやすいのかと思って今度はこれ。
実際にコード打ってみたりしなかったので雰囲気だけなんだけど、実践的な部分が少し理解できたきがする。
迷路とかMINISTとかチュートリアル的なのがいくつかある感じ。いざ、業務でってなったら参考にできそう。それ以外だと、kaggleでタイタニックをしてみたりとか、sagemakerでタイタニックしてみたりとか、aws personalizeつかってみたりとか、実際にサービスを触ってみたりしてました。
・kaggle
・SageMakerでタイタニックしてみる
・Amazon Personalizeでレコメンドしてみる話そのほかには勉強会を少々。やってみて覚えてくタイプです。
模試 2019.10.04
ちょっと腕試しに模試を受けてみました。
結果は70%ちょっとくらいで合格ライン?
そんならちょっと本番受けてみときますか、ってなる。
ただ、模試の方が難易度低かったような気がするなー。80%くらい取らないと安心できないかもしれん。1回目 2019.10.14
やったこととしては、
- サンプル問題を解く
- 模試の問題をキャプチャしてたのでそれを解く
- 模試で引っかかったワードを調べてみる
- sagemakerのblackbelt見る
くらいだったかな。正直一回落ちてもいいかなって心持ちで受けました。
が・・
スコア 646/750
というのは予想に反して悪い。。テスト自体は半分くらいの時間でさっくりと終わって、「ぼちぼと解けたか」って感触だったのになー。
敗因としてはテストを想定した準備をほとんどやってなかった事。
まあ、一回やって傾向つかもうって部分もあったんですけどね。2回目 2019.10.31
やったこと
- udemy
通勤時とかお昼休みに問題をちょくちょくといてました。やってたのはコレ。
https://www.udemy.com/course/aws-machine-learning-practice-exam/
問題は全部で75問と少ないですが。
他にもやったんだけど回答の解説がなかったりとかでいまいちだったりして返品しちゃった。
ちなみにudemyは値引きがないと購入しません。
当日にもガツっと解いておく。そして結果は・・
スコア 730/750
惜しいな。。あと3問くらいかな。感触は悪くなかったんだが。。
3回目 2019.12.22
さてもうちょっと点数を上げるだけだ。
しかし、11/1に会社を移り、生活のリズムもかわりでぜんぜん学ぶ時間を作れない。。
結局、試験の前日から頑張り始めました。やったこと
- udemy
- 前回の復習
- 1講座追加
間が開いちゃったので前回の問題を復習しておく。解いて見ると合格ギリギリラインにまで退化してました。。
そしてめぼしい講座を一つ追加。
https://www.udemy.com/course/aws-certified-machine-learning-specialty-full-practice-exams/なんか新しめの事も多くて、試験に直結するかは微妙だけど、知らない事もけっこう出てくるし、いちいち調べてると理解度が高まってる感じはした。
そんなわけで、前日夜に3hくらい、当日AMに3hくらいで一夜漬けをし、見事合格にこぎつけました!
結果はまだでないので結果出たらまた更新します。最後に
- 混同行列大事
- sagemakerはしっかりさわっておくべし
- ストリームとかリアルタイムなやつ大事
- glueとかathena周りも
- 当然ながらアルゴリズムも
- transcribeとかその関連も
- object2vecとか、関連性を求めるやつの違いを覚えておく
ざっくり書くとこんな感じ。機械学習、知らない人にとってはかなり範囲が広いなー。
しかしですよ。取るなら今って気もしますねん。今年のre:inventで機械学習系のが主役だったりもしたわけで、あと半年もしたら問題がガラッと変わってたりして?
- 投稿日:2019-12-22T19:14:57+09:00
Serverless Framework で SPA 環境を構築してみる(with Lambda@Edge & API Gateway)
はじめに
最近ある案件で Serverless Framework (以下、SF)を触る機会があり、いろいろ試行錯誤したので、せっかくなのでブログにしてみました。
今回はAWSにおけるSPAとして割とメジャーな構成 (CloudFront + S3 + API Gateway) をSFでつくりつつ、その過程でちょっとハマったところについても最後に記載しています。
なお、今回はSFに焦点を当てており、Lambda関数や静的コンテンツ自体の実装については言及していません。
また、SFを含む各種ツールやプロダクトの紹介およびインストール方法などは割愛しています。注意点など
IAM
今回、 IAM は administration 権限で sls コマンドなど実行していますので、
例えば本番環境で継続的にデプロイする場合など適切なポリシーを設定してください。
参考: https://serverless.com/framework/docs/providers/aws/guide/iam/SFバージョン
Framework Core: 1.57.0 Plugin: 3.2.3 SDK: 2.2.1 Components Core: 1.1.2 Components CLI: 1.4.0構成
ClodFrontでリクエストを受け取り、パスベースで S3 または API GW にリクエストを振り分けます。
ということで今回作成する構成は以下の通りです。
- S3 (SF デプロイ用バケット。us-east-1) - S3 (SF デプロイ用バケット。ap-northeast-1) - S3 (コンテンツ配信。CloudFront のオリジンの一つ。ap-northeast-1) - API Gateway + Lambda (CloudFront のオリジンの一つ) - CloudFront (Path ベースで API Gateway と S3 に振り分ける) - Lambda@Edge (レスポンスにヘッダを付与する)
ここで、3つのS3バケットはあらかじめ作成しています。
デプロイ用のバケットは使い回しが可能なので、実質的に新規作成するのはコンテンツ配信用のバケットのみです。
また、コンテンツ配信用のS3は Static website hosting としてすでに外部公開の設定が完了しているものとします。API Gateway + Lambda と S3 アップロード
API Gateway + Lambda の作成
まずは、API Gateway と Lambda を作成します。
serverless.ymlservice: sample-api-lambda provider: name: aws runtime: nodejs12.x stage: ${opt:stage, 'develop'} region: ap-northeast-1 deploymentBucket: name: "deploymentBucket-ap-northeast-1" functions: sample: name: sample-lambda runtime: nodejs12.x handler: handler.hello role: "arn:aws:iam::xxxxx:role/service-role/xxxxx" events: - http: GET api resources: Outputs: ApiGwDomain: Description: "API Gateway Domain" Value: Fn::Join: - "." - - Ref: ApiGatewayRestApi - "execute-api" - ${self:provider.region} - "amazonaws.com" Export: Name: ApiGwDomainここで、
handler.jsは サンプル をそのまま利用することにします。
また、 API Gateway のドメインを CloudFront 側で参照したいので Outputs として定義しています。S3 アップロード
CloudFront で配信するために S3へのコンテンツアップロードも前述の serverless.yml に組み込んでおきます。
(ここは必須の設定ではないので、手動で実行しても大丈夫です。)今回は
serverless-s3-syncplugin を利用します。以下を serverless.yml に追記します。plugins: - serverless-s3-sync custom: s3Sync: - bucketName: sample-s3-orin localDir: assets/local の assets ディレクトリには
index.htmlを配置しておきます。
(内容はS3 bucket originとしておきます。)CloudFront + Lambda@Edge と Invalidation
CloudFront + Lambda@Edge の作成
次に CloudFront 側の設定です。
前述の API Gateway + Lambda の serverless.yml とは分割して作成します。serverless.ymlservice: sample-cloudfront provider: name: aws runtime: nodejs10.x stage: ${opt:stage, 'develop'} region: us-east-1 deploymentBucket: name: "deploymentBucket-us-east-1" functions: sampleLambdaEdge: handler: sample.handler events: - cloudFront: eventType: viewer-response origin: DomainName: sample-s3-orin.s3-website-ap-northeast-1.amazonaws.com CustomOriginConfig: OriginProtocolPolicy: match-viewer - cloudFront: eventType: viewer-response pathPattern: /api origin: DomainName: ${cf.ap-northeast-1:sample-api-lambda-${self:provider.stage}.ApiGwDomain} OriginPath: /${self:provider.stage} CustomOriginConfig: OriginProtocolPolicy: match-viewerここでは、
- Region を
us-east-1にしています。- API Gateway の DomainName を
cf.REGION:stackName.outputKeyで動的に取得しています。- sample.js は SF の サンプル を利用しています。
余談ですが、CloudFormation のシンタックス も利用可能なので、CloudFront を単体で作成する(Lambda@Edge を利用しない)ことも可能です。(が、この場合は SF 使わなくてもいいかもしれませんね。)
Invalidation の設定
CloudFront のデプロイ後、Invalidation が自動的に実行されるように Invalidation の設定も組み込んでおきます。
(ここは必須の設定ではないので、手動で実行しても大丈夫です。)今回は
serverless-cloudfront-invalidateplugin を利用します。
以下を CloudFront の serverless.yml に追記します。plugins: - serverless-cloudfront-invalidate custom: cloudfrontInvalidate: distributionIdKey: 'CDNDistributionId' items: - '/index.html'デプロイ
それでは、上記で作成したものをデプロイしていきます。
ここでディレクトリ構成は以下のようにしています。events/ ├── api-gateway │ ├── assets │ │ └── index.html │ ├── handler.js │ └── serverless.yml └── cloudfront ├── sample.js └── serverless.ymlまずは、API Gateway+Lambda をデプロイします。
$ cd events/api-gateway/ $ sls deploy -v
ApiGwDomain: xxxxx.execute-api.ap-northeast-1.amazonaws.comS3 Sync: Synced.が出力されていれば成功です。次に、CloudFront をデプロイしていきます。
$ cd events/cloudfront/ $ sls deploy -v
CloudFrontDistributionDomainName: xxx.cloudfront.netCloudfrontInvalidate: Invalidation startedが出力されていれば成功です。
動作確認
デプロイが無事完了したら、
CloudFrontDistributionDomainNameで出力された CloudFront のURLにアクセスして確認します。# S3 オリジン $ curl https://xxx.cloudfront.net/ S3 bucket origin # API GW オリジン $ curl https://xxx.cloudfront.net/api {"message":"Hello World!"}よさそうですね。(もちろん、 Sampleでは
x-serverless-timeヘッダを Lambda@Edge で付与するようになっているので、これも確認ができました。)ハマったところ
いくつかあるのですが、ここでは2つほど挙げておきます。
リージョンの指定
当初、CloudFront の serverless.yml を記述する際に、 region を
ap-northeast-1としていました。
これによって、デプロイ時に 2 つのエラーに遭遇しました。- Could not locate deployment bucket. Error: Deployment bucket is not in the same region as the lambda function - CloudFront associated functions have to be deployed to the us-east-1 region.まー言われてみれば当然なのですが、デプロイ用の S3 バケットは同一リージョンに存在する必要があるのと、
Lambda@Edge は 2019年12月現在us-east-1でしか利用できないことが原因です。従って、
API Gateway + LambdaとCloudfront + Lambda@Edgeの serverless.yml を分割し、
各リージョンでデプロイ用バケット作成することで対応しました。CloudFormation のリージョンをまたがるクロススタックの参照
CloudFormation はリージョンをまたがったクロススタック参照ができません。従って、SFも同様に
ap-northeast-1で作成したスタックはus-east-1では参照できないとばかり思い込んでいました。今回だと API Gateway のドメインなのでそうそう変更になるようなこともないですが、例えば、検証目的で作ったり壊したりをやっていると、都度書き出すのはちょっと不便だな...とも思っていました。が、ドキュメントを読み返してたら、ありましたありました。(ちゃんと読みましょう、自分。。。)
別リージョンの outputKey 参照方法(cf.REGION:stackName.outputKeyの部分)これで API Gateway + Lambda 側のスタックが変更になっても、CloudFront 側で追従してくれるようになります。複数リージョンで作成する場合、とても便利ですね。
さいごに
ということで、Serverless Framework を使って、CloudFront, S3, API Gateway を作成してみました。
そこは間違っているとか、もっとこうした方がいいよなど、ご指摘やご意見お待ちしております。

- 投稿日:2019-12-22T17:43:41+09:00
サーバーレスアセンブリ
みんな大好きLambda
今年の re:Invent では RDS Proxy という個人的神アップデートも発表されて、
ますますサーバーレスしやすくなってきましたね!
(Provisioned Concurrency もな!)そんな Lambda ですが、現在サポートされているランタイムは以下です。
- Node.js
- Python
- Ruby
- Java
- Go
- .NET
もちろんこれ以外の言語でも使いたい人はたくさんいますよね。
そんなときはカスタムランタイムです。
カスタム AWS Lambda ランタイム
去年(2018)の re:Invent で発表された機能ですね。
New for AWS Lambda – Use Any Programming Language and Share Common Components
bootstrapという実行可能ファイルにパッケージできれば、
どんな言語でも Lambda 上で動かすことができます。見た感じそんなに難しくなさそうだったので自分でも何か作ってみることにしました。
カスタムランタイムの例
- カスタムランタイムを使ってLambdaでAWSCLIを動かす
- AWS Lambda 新機能 Custom Runtime を作ってみた
- AWS LambdaのCustom RuntimeでサーバーレスDartしてみた
- AWS LambdaのCustom RuntimeでRustを実行してみた #reinvent
有名どころの言語はあらかた先人たちが試していて、
車輪の再発明するのもあれだな...と思っていたところ、ふと、
「あれ、アセンブリない......」
ということに気づきました。
かわいそう。
作ってあげないと。アセンブる
まずソースコードから書きます。
シンプルに Hello world を。app.asmsection .data message: db "早めのパブロン", 10 length: equ $ - message section .text global _start _start: mov rax, 1 mov rdi, 1 mov rsi, message mov rdx, length syscall mov rax, 60 xor rdi, rdi syscall同じものを Ruby で書くとこうです。
app.rbprint("早めのパブロン")?♂️
ざっくり解説すると、
まず1バイトの容量を確保して変数を初期化。
10は ASCII コードの改行を表す。message: db "早めのパブロン", 10出力するサイズも明示する必要がある。
文字列長を計算しているのがここ。
$がその行の先頭アドレスを表しているので、
そこから文字列の先頭アドレスを引けば自動的に文字列長が求められるのだとか。length: equ $ - message
raxレジスタに格納している1はwriteシステムコールの番号を表している。
システムコールの一覧はausyscall --dumpで見れる。
コマンドが入ってなかったらauditとかauditdとかインストールする。mov rax, 1
rdiレジスタの1は出力先でstdoutを表す。mov rdi, 1文字列と文字列長を指定して
syscallで呼び出す。mov rsi, message mov rdx, lengthこれは
exit 0と等価。mov rax, 60 xor rdi, rdi syscall一つだけ気になったこととして、 32ビットのレジスタである
eaxにすると動きませんでした。
正確にいうと、 amazonlinux:2018.03 ベースの Docker コンテナ上では動くのに、
Lambda に載せるとなぜか SIGSEGV を投げてくる。
これは...ソースコードができたのでこれをコンパイルして実行可能ファイルにします。
最終 Lambda に載せるので Amazon Linux ベースの Dockerを実行環境として使います。DockerfileFROM amazonlinux:2018.03 RUN yum update -y && yum install -y wget tar gzip gcc make perl RUN cd /tmp \ && wget https://www.nasm.us/pub/nasm/releasebuilds/2.14.02/nasm-2.14.02.tar.gz \ && tar xvfz nasm-2.14.02.tar.gz \ && cd nasm-2.14.02 \ && ./configure --prefix=/usr/local/nasm/2_14_02 \ && make \ && make install \ && ln -s /usr/local/nasm/2_14_02/bin/nasm /usr/local/bin/ ENV APP_HOME /usr/src/assemmbly_on_aws_lambda RUN mkdir -p $APP_HOME WORKDIR $APP_HOME ADD . $APP_HOME RUN nasm -f elf64 $APP_HOME/src/app.asm -o $APP_HOME/src/app.o RUN ld $APP_HOME/src/app.o -o $APP_HOME/bin/appアセンブラには NASM を使います。
yum でインストールできる。
nasmでオブジェクトファイルを作り、ldでリンクして実行可能形式に変換します。これで実行。
./bin/app 早めのパブロン簡単ですね!!
Bootstrap
Lambdaでカスタムランタイムを動かすには、
bootstrapというファイルを作成する必要があります。
難しいことは考えずにチュートリアルのをコピペしてきてちょろっと修正します。bootstrap#!/bin/sh set -euo pipefail while true do HEADERS="$(mktemp)" EVENT_DATA=$(curl -sS -LD "$HEADERS" -X GET "http://${AWS_LAMBDA_RUNTIME_API}/2018-06-01/runtime/invocation/next") REQUEST_ID=$(grep -Fi Lambda-Runtime-Aws-Request-Id "$HEADERS" | tr -d '[:space:]' | cut -d: -f2) EXEC="$LAMBDA_TASK_ROOT/$(echo "$_HANDLER" | cut -d . -f 1)" RESPONSE=$(echo "$EVENT_DATA" | $EXEC) curl -X POST "http://${AWS_LAMBDA_RUNTIME_API}/2018-06-01/runtime/invocation/$REQUEST_ID/response" -d "$RESPONSE" done
EVENT_DATAが 引数に渡されるeventを取得してきている部分です。
カスタムランタイム用に、APIのエンドポイントが用意されています。取得したイベントデータは、実行するプログラムに渡すのと、
最後に結果を返すエンドポイントのパスにリクエストIDを含める必要があるのでそれに使います。
$LAMBDA_TASK_ROOTは関数にアップロードしたファイルが置かれる場所です。
見たら/var/taskでした。
$_HANDLERはハンドラのファイル名+関数名です。
デフォルトで lambda_function.lambda_handler になってるやつですね。今回は実行可能ファイルを直接呼び出すため、
bin/appと設定しています。他にもエラーハンドリングを実装しないといけないんですが、最低限これで動くので省略します。
最後に、ファイルに実行権限をつけます。
Lambda がこいつを呼び出せるようにchmod 755 bootstrapします。関数の作成
普段は CloudFormation 原理主義者ですが、
zipアップロードが面倒なのでマネジメントコンソールから作ります。ランタイムには、「ユーザー独自のブートストラップを提供する」を選択します。
英語だとprovidedって言うらしいですね。
先ほどの
bootstrapと実行可能ファイルを zip でポンして、
ハンドラにbin/appを指定します。
テストして動作確認。
終わり
ということで、 Lambda でアセンブリ動くよ。
サーバーレスアセンブリ
Blue-Pix/nasm_on_aws_lambda




- 投稿日:2019-12-22T17:43:41+09:00
サーバーレスアセンブリ?
みんな大好きLambda
今年の re:Invent では RDS Proxy という個人的神アップデートも発表されて、
ますますサーバーレスしやすくなってきましたね!
(Provisioned Concurrency もな!)そんな Lambda ですが、現在サポートされているランタイムは以下です。
- Node.js
- Python
- Ruby
- Java
- Go
- .NET
もちろんこれ以外の言語でも使いたい人はたくさんいますよね。
そんなときはカスタムランタイムです。
カスタム AWS Lambda ランタイム
去年(2018)の re:Invent で発表された機能ですね。
New for AWS Lambda – Use Any Programming Language and Share Common Components
bootstrapという実行可能ファイルにパッケージできれば、
どんな言語でも Lambda 上で動かすことができます。見た感じそんなに難しくなさそうだったので自分でも何か作ってみることにしました。
カスタムランタイムの例
- カスタムランタイムを使ってLambdaでAWSCLIを動かす
- AWS Lambda 新機能 Custom Runtime を作ってみた
- AWS LambdaのCustom RuntimeでサーバーレスDartしてみた
- AWS LambdaのCustom RuntimeでRustを実行してみた #reinvent
有名どころの言語はあらかた先人たちが試していて、
車輪の再発明するのもあれだな...と思っていたところ、ふと、
「あれ、アセンブリない......」
ということに気づきました。
かわいそう。
作ってあげないと。アセンブる
まずソースコードから書きます。
シンプルに Hello world を。app.asmsection .data message: db "早めのパブロン", 10 length: equ $ - message section .text global _start _start: mov rax, 1 mov rdi, 1 mov rsi, message mov rdx, length syscall mov rax, 60 xor rdi, rdi syscall同じものを Ruby で書くとこうです。
app.rbputs "早めのパブロン"?♂️
ざっくり解説すると、
まず1バイトの容量を確保して変数を初期化。
10は ASCII コードの改行を表す。message: db "早めのパブロン", 10出力するサイズも明示する必要がある。
文字列長を計算しているのがここ。
$がその行の先頭アドレスを表しているので、
そこから文字列の先頭アドレスを引けば自動的に文字列長が求められるのだとか。length: equ $ - message
raxレジスタに格納している1はwriteシステムコールの番号を表している。
システムコールの一覧はausyscall --dumpで見れる。
コマンドが入ってなかったらauditとかauditdとかインストールする。mov rax, 1
rdiレジスタの1は出力先でstdoutを表す。mov rdi, 1文字列と文字列長を指定して
syscallで呼び出す。mov rsi, message mov rdx, lengthこれは
exit 0と等価。mov rax, 60 xor rdi, rdi syscall一つだけ気になったこととして、 32ビットのレジスタである
eaxにすると動きませんでした。
正確にいうと、 amazonlinux:2018.03 ベースの Docker コンテナ上では動くのに、
Lambda に載せるとなぜか SIGSEGV を投げてくる。
これは...ソースコードができたのでこれをコンパイルして実行可能ファイルにします。
最終 Lambda に載せるので Amazon Linux ベースの Dockerを実行環境として使います。DockerfileFROM amazonlinux:2018.03 RUN yum update -y && yum install -y wget tar gzip gcc make perl RUN cd /tmp \ && wget https://www.nasm.us/pub/nasm/releasebuilds/2.14.02/nasm-2.14.02.tar.gz \ && tar xvfz nasm-2.14.02.tar.gz \ && cd nasm-2.14.02 \ && ./configure --prefix=/usr/local/nasm/2_14_02 \ && make \ && make install \ && ln -s /usr/local/nasm/2_14_02/bin/nasm /usr/local/bin/ ENV APP_HOME /usr/src/assemmbly_on_aws_lambda RUN mkdir -p $APP_HOME WORKDIR $APP_HOME ADD . $APP_HOME RUN nasm -f elf64 $APP_HOME/src/app.asm -o $APP_HOME/src/app.o RUN ld $APP_HOME/src/app.o -o $APP_HOME/bin/appアセンブラには NASM を使います。
yum でインストールできる。
nasmでオブジェクトファイルを作り、ldでリンクして実行可能形式に変換します。これで実行。
./bin/app 早めのパブロン簡単ですね!!
Bootstrap
Lambdaでカスタムランタイムを動かすには、
bootstrapというファイルを作成する必要があります。
難しいことは考えずにチュートリアルのをコピペしてきてちょろっと修正します。bootstrap#!/bin/sh set -euo pipefail while true do HEADERS="$(mktemp)" EVENT_DATA=$(curl -sS -LD "$HEADERS" -X GET "http://${AWS_LAMBDA_RUNTIME_API}/2018-06-01/runtime/invocation/next") REQUEST_ID=$(grep -Fi Lambda-Runtime-Aws-Request-Id "$HEADERS" | tr -d '[:space:]' | cut -d: -f2) EXEC="$LAMBDA_TASK_ROOT/$(echo "$_HANDLER" | cut -d . -f 1)" RESPONSE=$(echo "$EVENT_DATA" | $EXEC) curl -X POST "http://${AWS_LAMBDA_RUNTIME_API}/2018-06-01/runtime/invocation/$REQUEST_ID/response" -d "$RESPONSE" done
EVENT_DATAが 引数に渡されるeventを取得してきている部分です。
カスタムランタイム用に、APIのエンドポイントが用意されています。取得したイベントデータは、実行するプログラムに渡すのと、
最後に結果を返すエンドポイントのパスにリクエストIDを含める必要があるのでそれに使います。
$LAMBDA_TASK_ROOTは関数にアップロードしたファイルが置かれる場所です。
見たら/var/taskでした。
$_HANDLERはハンドラのファイル名+関数名です。
デフォルトで lambda_function.lambda_handler になってるやつですね。今回は実行可能ファイルを直接呼び出すため、
bin/appと設定しています。他にもエラーハンドリングを実装しないといけないんですが、最低限これで動くので省略します。
最後に、ファイルに実行権限をつけます。
Lambda がこいつを呼び出せるようにchmod 755 bootstrapします。関数の作成
普段は CloudFormation 原理主義者ですが、
zipアップロードが面倒なのでマネジメントコンソールから作ります。ランタイムには、「ユーザー独自のブートストラップを提供する」を選択します。
英語だとprovidedって言うらしいですね。
先ほどの
bootstrapと実行可能ファイルを zip でポンして、
ハンドラにbin/appを指定します。
テストして動作確認。
終わり
ということで、 Lambda でアセンブリ動くよ。
サーバーレスアセンブリ
Blue-Pix/nasm_on_aws_lambda
- 投稿日:2019-12-22T17:43:02+09:00
Amazon ElastiCache Rails設定
AWS側の設定
https://qiita.com/leomaro7/items/f031cfdd7d12d5d5ccc5
https://lab.sonicmoov.com/development/aws/elasticache/Rails側の設定
config/environments/staging.rbconfig.session_store :redis_store, { servers: { host: '[プライマリエンドポイント]', port: 6379, db: 0, namespace: 'sessions' }, expire_after: 60.minutes }config/initializers/sidekiq.rbSidekiq.configure_server do |config| case Rails.env when 'staging' then redis_conn = proc { Redis.new(host: 'プライマリエンドポイント', port: 6379, db: 2) } config.redis = ConnectionPool.new(size: 27, &redis_conn) else config.redis = { url: 'redis://127.0.0.1:6379' } end end Sidekiq.configure_client do |config| case Rails.env when 'staging' then redis_conn = proc { Redis.new(host: 'プライマリエンドポイント', port: 6379, db: 2) } config.redis = ConnectionPool.new(size: 27, &redis_conn) else config.redis = { url: 'redis://127.0.0.1:6379' } end end
- 投稿日:2019-12-22T17:43:02+09:00
【Amazon ElastiCache】 Rails設定
AWS側の設定
参考
https://qiita.com/leomaro7/items/f031cfdd7d12d5d5ccc5
https://lab.sonicmoov.com/development/aws/elasticache/Rails側の設定
config/environments/staging.rbconfig.session_store :redis_store, { servers: { host: '[プライマリエンドポイント]', port: 6379, db: 0, namespace: 'sessions' }, expire_after: 60.minutes }config/initializers/sidekiq.rbSidekiq.configure_server do |config| case Rails.env when 'staging' then redis_conn = proc { Redis.new(host: 'プライマリエンドポイント', port: 6379, db: 2) } config.redis = ConnectionPool.new(size: 27, &redis_conn) else config.redis = { url: 'redis://127.0.0.1:6379' } end end Sidekiq.configure_client do |config| case Rails.env when 'staging' then redis_conn = proc { Redis.new(host: 'プライマリエンドポイント', port: 6379, db: 2) } config.redis = ConnectionPool.new(size: 27, &redis_conn) else config.redis = { url: 'redis://127.0.0.1:6379' } end end
- 投稿日:2019-12-22T17:18:18+09:00
インフラ設計時に気をつけていること(基本編)
古木です。
この記事はiRidge Advent Calendar 2019 22日目の記事です。
今まで、AWSでのインフラ設計・構築をやってきましたが、ある程度パターン化されてきておりサービス運営を考えた際に、インフラ設計の基本に立ち返って必ず意識する点を初心に返ってお話したいと思います。
設計時に意識している指標
RASIS というシステム評価指標があります。
5つの項目(信頼性(Reliability)、可用性(Availability)、保守性(Serviceability)、完全性(Integrity)、機密性(Security))の頭文字を取っています。
2008年に発売されたサーバー/インフラを支える技術という私の好きな本でも、この辺りの概念が記載されており(ただし、RASISという用語は出てきません)、サーバー/インフラでの用語から、今は広義に解釈されるようになってきている印象があります(個人的な意見ですが)。各指標を達成するために意識している一例
1.信頼性(Reliability)障害のおきにくさ
指標:平均故障間隔 Mean Time Between Failures=MTBF が使われるA. 事前把握などが可能な障害監視
- 通常の監視に加えてAWSだと料金やメンテナンス情報などの外部要因も監視した方が良いです。
B. CI/CD(Continuous Delivery)を意識した構築
- (障害は、リリース作業時に起きる確率が高いという統計をどこかで読んだことがあります。)継続的なインテグレーションや人に依存しない継続的なデリバリーが必要です。
C. テスト計画およびテスト手法
- 単一の自動テストでプログラムバグは防げても、仕様バグやサービス障害を防げないケースがあります。
- 私の会社ではアプリ開発を主としてますので、アプリからの自動テストおよび内部結合テスト・外部結合テスト・受入テストなどその時の改修ボリュームなどに応じて、スケジュールを勘案し、実施していく必要があります。
D. 本番同等環境でのテスト(環境に対する設計)
- 開発環境などデータ状態が本番を想定できていないとテストをして問題ないけど、本番で起きちゃいましたが発生します。事前に本番同等環境を用意するなどの計画を立て、実施する必要があります。
2.可用性(Availability)サービスの止まりにくさ
指標: 稼働率 MTBF ÷ (MTBF + MTTR)A. 単一障害点(single point of failure、SPOF)をなくすように設計
- AWSを使う上で、単一障害点は発生しにくいですが、漏れやすい部分でいうと、
- アベイラビリティーゾーンがちゃんと分かれているか
- バッチ処理や外部連携処理などでリカバリ・リトライが可能(冪等性を意識している)かなどがあると思います。
B. 負荷に耐えられる設計
- 負荷対策は深い話になるので、今回は割愛しますが、サイジングに基づく負荷試験の実施やAutoScalingなど拡張性を持たせた設計が必要になります。
3.保守性(Serviceability)障害復旧のしやすさ
指標:平均修理時間 Mean Time To Repair、MTTR が使われる
A. コーディング規約やコメントルールや開発設計手法などが周知されている
- 同じプロジェクトでも、箇所によってコードの書きっぷりが全く異なることがあります。
- 一人での対応には限界があるので、チームでサポートもしくは引き継げる状況を作っておくことも大事だと思います。
B. 障害対応におけるフローや既知のものなどが共有、周知されているか
- プロジェクトをまたいで、過去にあった障害などがドキュメント化され共有されていると気がつきやすいです。障害時対応には一時対応や恒久対応などありますので復旧を優先すべきかの判断をしてから対応を心がけるなども必要になってくると思います。
C. エラーログの設計
- 共通のフォーマットになっていたり、見やすい内容になっているだけで障害調査の対応は格段に早くなります。いつ、どこで、誰に対して、どういったことが起こっているのかがわかることが重要です。
- だいたいこの辺りの整備はあと回しになりがちですが、はじめに共通functionを通してもらうなどのルールを作ってしまった方が後々、キレイにいきます。
4.完全性(Integrity)データの保証および一貫性
A. サービスのニーズを把握する
- 一貫性というとRDBMSを私は想像してしまいますが、サービスによって一貫性の捉え方も変わってくると思います。atomic なトランザクション管理をしないといけないケースと、トランザクションが途中で失敗した場合でも、イニシャルから再処理することで一貫性が保てるケースもあるかと思いますので、その考慮が必要です。
B. 排他制御を意識する
- トランザクション管理は意識できても、排他制御が漏れるケースがあります。特に座席予約やポイント付与などがそれにあたるかと思います。データにロックをかけるもしくはメッセージングサービス(キュー)などを利用し、二重処理をしないように意識する必要があります。
C. テーブル設計はレビューしてもらう
- 後々、直しが効かない大事なところですので、設計コストをかけるべきです。また、誰かに見てもらうことで盲点に気がつく事が多いです。
5.機密性(Security)許可されたユーザーしか情報を閲覧出来ない、第三者に漏洩しない
A. 暗号化する、ハッシュ化する
- SSLなどの通信暗号化およびAPI通信時の認証フローなどが重要になってくると思います。OAuth2のように期限付きの認証アルゴリズムの検討および、暗号化やハッシュ化アルゴリズムに関しては単純に使うとそのアルゴリズムの脆弱性が露呈すると終わりますので、より機密性が求められるものは、独自情報を付加した方が良いです。
B. ログイン時の2段階認証やパズル認証などの検討
- 総当たりでパスワードが漏洩するケースもありますので、パズル認証や2段階認証は効果的です。
C. システム管理者や管理PCのデータ管理を徹底する
- 人的な漏洩もあるので、サーバーの操作履歴を取る、AWSでの操作履歴(AWS CloudTrailなど)を導入すると良いです。
設計時によくあるライトなやり取り
この辺りも指標などに照らし合わせながら、ちゃんと考えていきたいところ
1.信頼性(Reliability): 障害を減らして欲しい
- (回答)クロスチェックします。
2.可用性(Availability): 性能面は大丈夫?
- (回答)AWSですぐに拡張出来るんで大丈夫です。
3.保守性(Serviceability): 対応が遅いんだけど?
- (回答)すぐ反応出来るように待機します。
4.完全性(Integrity): ...
- (回答)(聞かれないので説明しない・考えない)
5.機密性(Security): セキュリティは大丈夫?
- (回答)AWSを使っているので大丈夫です。
参考記事
・Wikipedia - RASIS -
・業務でWebサービス開発をする際に気をつけたいこと(新卒向け) - Qiita
- 投稿日:2019-12-22T17:02:42+09:00
Lambda + CloudWatch + DynamoDB + LINE Notifyでリマインダーを作る
はじめに
DynamoDBのキャッチアップのついでに、リマインダーを作りたかったので作ってみた。
今回は時間があまりなかったので、備忘録みたいな感じ。(まだ完成していない)構成としては以下のような感じ。
本当は、Androidアプリを作って、プッシュ通知までもって行きたかったが時間がないので後日。
通知の部分は、簡単にできるLineNotifyを使ってLineで通知をするようにした。DynamoDBを立てる
- IAMにて、ユーザーにAmazonDynamoDBFullAccessの権限をつける
- DynamoDBのトップページにてテーブル作成を押す
- テーブル名とパーティーションキー名(今回はDate)を入力する。
- できたDynamoDBの構成は以下の通り
- テーブル…データのコレクション。
- 項目 …各テーブルには0以上の項目がある。
- 属性 …各項目は1つ以上の属性でできている。
- 項目の作成ボタンから指定のテーブルの項目とデータが設定できる 今回の構成
- remainder_id: Number ID
- color: String 表示カラー(6進数)
- contents: String 内容
- Date: String 日付(format: 2019-12-22)
- time: String 時間(format: 00:00)
- type: Number カテゴリー
DynamoDB開発者ガイド:https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/Introduction.html
Lambdaで関数を作成する
Lambdaには3つ関数を作る予定。
- Regist Remainder: リマインダーを登録する
- Put Remainder: 前日にリマインダーをCloudWatchに登録する
- Push Remainder: リマインダーを通知する注意点1: 関数内でDynamoDBを接続する際は、roleの設定を忘れない
参考→ LambdaからDynamoDB見るときの権限:https://qiita.com/hellscare/items/d80c9ff0290966eb0cf8
注意点2: パーティションキーとソートキーの関係を理解しないとデータをうまく取れない。
参考→ DynamoDBでPythonを使って試してみた:https://qiita.com/estaro/items/b329deafdfef790aa355RegistRemainder関数
※あとで作る
PutRemainder関数
※これまだうまくできていません。。
import json import boto3 import datetime from boto3.dynamodb.conditions import Key cloudwatch = boto3.resource('cloudwatch') dynamodb = boto3.resource('dynamodb') remainder_table = dynamodb.Table('Remainder') def lambda_handler(event, context): # get tomorrow schedule from DB response= remainder_table.query( KeyConditionExpression=Key('Date').eq(str(datetime.date.today())) ) print('Get Tommorow Data: ', response) if len(response['Items']) > 0: for data in response['Items']: print('GET Items: ', data) # リマインド時間取得 remaind_date = datetime.datetime.strptime(str(data['Date'])+ " " + str(data['time']), '%Y-%m-%d %H:%M') print('Set Date: ', remaind_date.datetime) print('Set Remaind Id', data['remaind_id']) # Put an event response = cloudwatch.put_events( Entries=[ { 'Time': remaind_date.datetime, 'Resources': [ ‘ARN(Your AmazonResourceName)', ], 'Detail': {"remaind_id": data['remaind_id']} } ] ) print(response['Entries']) return { 'statusCode': 200, 'body': json.dumps('Hello from Lambda!') }このLambda関数は毎日0時に起動するようにCloudWatchで設定。
起動すると、今日のRemainderの時間をDynamoDBから探し出して、CloudWatchEventに登録する。PushRemainder関数
import json import boto3 import datetime from boto3.dynamodb.conditions import Key import requests dynamodb = boto3.resource('dynamodb') def lambda_handler(event, context): print('START lambda_handler: getParam ->', event) print('TODAY IS: ', str(datetime.date.today())) remainder_table = dynamodb.Table('Remainder') table_response= remainder_table.query( KeyConditionExpression=Key('Date').eq(str(datetime.date.today())) & Key('remaind_id').eq(event['remaind_id']) ) print('>>>>>>Get Data: ', table_response) if len(table_response['Items']) > 0: for remaind_data in table_response['Items']: header = {'Authorization':'Bearer <access token>'} param = {'message': remaind_data['contents']} response = requests.post('https://notify-api.line.me/api/notify', headers=header, data=param,) print('>>>>>SEND: ', remaind_data['contents']) print('>>>>>>POST Response: ', response) return { 'statusCode': 200, 'body': json.dumps('Remaind Finish!') }CloudWatchEventに登録されて、指定の時間になると引数が渡されて実行される関数。
実行されたら、
今日の日付と、引数で渡されたremaider_idを元にDynamoDBから検索。
取得したリマインダーデータをLineNotifyを使ってLineに通知をする。<LineNotifyに接続する>
公式Document: https://notify-bot.line.me/doc/ja/
※LineNotifyにリクエストを送る必要があるので、Lambdaにrequestsライブラリ等の外部モジュールを設定する
注意点: zipをアップロードするとき、lambda_function.pyのデータが消える可能性があるので注意!!!!!!
→requestsモジュールのインストール:https://qiita.com/SHASE03/items/16fd31d3698f207b42c9※Notifyのアクセストークン取得はPCサイトからしかできないので注意
→トークンの発行方法:https://qiita.com/iitenkida7/items/576a8226ba6584864d95結論
こんな感じ。
画像とかも表示できると思うので、おいおい追加していきます。
終わりに
随時、進捗があったら更新します!
年末までには完成させたらいいなと思います!


- 投稿日:2019-12-22T16:55:33+09:00
【AWS S3 + EC2 + CarrierWave + Fog】RailsからS3へ画像アップロード手順
はじめに
Ruby on Rails 5.2からAWS S3へ画像をアップロードをするため、CarrierWave+fogを使って実装を進めました。
対象
EC2構築、デプロイ経験のある方
EC2へ画像をアップロードしていた方
はじめてS3を利用する方AWSの設定
S3作成
S3 バケットを作成する方法
https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/user-guide/create-bucket.html
- 東京リージョン
- バージョニング有効
- Static website hosting有効
- パブリックアクセスをすべてブロック
バケットポリシー{ "Statement": [ { "Effect": "Allow", "Principal": "*", "Action": "s3:*", "Resource": [ "arn:aws:s3:::[バケット名]", "arn:aws:s3:::[バケット名]/*" ], "Condition": { "StringEquals": { "aws:SourceIp": "[EC2のパブリックIP]" } } } ] }VPCエンドポイントの設定
EC2とS3の間でファイルの転送を行います。
VPCのダッシュボードを開き、 エンドポイント の作成ボタンをクリックします。
宛先の選択をします。 AWS services と com.amazonaws.ap-northeast-1.s3 にチェックを入れます。
通信したいEC2インスタンスが置かれているVPC と そのサブネットに当てられているルートテーブル を選択します。
カスタムポリシーの設定
カスタムポリシーの例{ "Statement": [ { "Effect": "Allow", "Principal": "*", "Action": "s3:*", "Resource": [ "arn:aws:s3:::[バケット名]", "arn:aws:s3:::[バケット名]/*" ] } ] }作成が完了すると、ダッシュボードにエンドポイントが表示されます。
紐付けたサブネットのルートテーブルを確認すると、エンドポイントを介したS3への経路が追加されています。AWS CLIを使ってS3へデータを送信テスト
EC2へ接続 $ ssh -i [keyペアファイル] ec2-user@[パブリックIP] テストファイルを転送 $ touch test.txt $ aws s3 mv test.txt s3://YOUR_S3_BUCKET/uploads s3バケットが閲覧できるか確認 $ aws s3 ls s3://YOUR_S3_BUCKET/ --recursiveAmazon Linux 2の設定
ImageMagickを導入
$ yum install -y ImageMagick ImageMagick-develアクセスキーとシークレットアクセスキーの設定
aws configure コマンドが、AWS CLI のインストールをセットアップするための最も簡単な方法です。
詳しくは
https://docs.aws.amazon.com/ja_jp/cli/latest/userguide/cli-chap-configure.html
https://dev.classmethod.jp/cloud/aws/how-to-configure-aws-cli/$ aws configure AWS Access Key ID [None]: AKIAXXXXXXXXXXXXXXXX AWS Secret Access Key [None]: 5my9xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx Default region name [None]: ap-northeast-1 Default output format [None]:設定の確認
$ aws configure listRailsの設定
Gemの設定
Gemfilegem 'carrierwave' gem 'rmagick' gem 'fog-aws'ImageUploaderの設定
$ rails g uploader Image/uploaders/image_uploader.rbclass ImageUploader < CarrierWave::Uploader::Base # 画像サイズを取得するためにRMagick使用 include CarrierWave::RMagick # developmentとtest以外はS3を使用 if Rails.env.development? || Rails.env.test? storage :file else storage :fog end # 画像ごとに保存するディレクトリを変える def store_dir "uploads/#{model.class.to_s.underscore}/#{model.id}/#{mounted_as}" end # 許可する画像の拡張子 def extension_whitelist %w(jpg jpeg gif png) end # ファイル名を書き換える def filename "#{Time.zone.now.strftime('%Y%m%d%H%M%S')}.#{file.extension}" if original_filename end endCarrierWaveの設定
/config/initializers/carrierwave.rb# CarrierWaveの設定呼び出し require 'carrierwave/storage/abstract' require 'carrierwave/storage/file' require 'carrierwave/storage/fog' # 画像名に日本語が使えるようにする CarrierWave::SanitizedFile.sanitize_regexp = /[^[:word:]\.\-\+]/ # 保存先の分岐 CarrierWave.configure do |config| # 本番環境はS3に保存 if Rails.env.production? config.storage = :fog config.fog_provider = 'fog/aws' config.fog_directory = '[S3のバケット名]' config.asset_host = 'https://s3-ap-northeast-1.amazonaws.com/[S3のバケット名]' # iam_profile config.fog_credentials = { provider: 'AWS', # credentialsで管理する場合 aws_access_key_id: Rails.application.credentials.aws[:access_key_id], aws_secret_access_key: Rails.application.credentials.aws[:secret_access_key], # 環境変数で管理する場合 # aws_access_key_id: ENV["AWS_ACCESS_KEY_ID"], # aws_secret_access_key: ENV["AWS_SECRET_ACCESS_KEY"], region: 'ap-northeast-1' #東京リージョン } # キャッシュをS3に保存 # config.cache_storage = :fog else # 開発環境はlocalに保存 config.storage :file config.enable_processing = false if Rails.env.test? #test:処理をスキップ end endアップローダーの使い方
作成したUploaderをModelに紐付けます。Userモデルのimageカラムに紐付ける例
User.rbclass User < ApplicationRecord mount_uploader :image, ImageUploader end



- 投稿日:2019-12-22T16:51:36+09:00
実際に本番導入してみて分かった!ツラさから考える最強のMLデータパイプライン
ランサーズ AdventCalendar 22日目担当の @odrum428 です。
10 ~ 11月にかけてSage Maker上に構築した機械学習モデルを本番導入までをやりました。
そこからいろいろ実運用でのつらさが見えてきたので問題点の共有と
その一部を解決するためにMLデータマートを考えてみたという記事です。MLOps周りをやっている方や取り組もうとしている方、特徴量管理、データの知見管理に悩んでいる方向けの記事です!
9月ごろにAIチームの立ち上げを行いました?
今までも機械学習を使った機能開発はありましたが、会社としてやっていき?な機運だったのでチームとしてが立ち上がる運びとなりました。
チームについての詳細は以下の記事に書いたので、読んでもらえると嬉しいです!
AIチームの立ち上げとこれから既存の機械学習機能は僕がちょこちょこ作ったものや、数年前に作られていたものだったので
過去機械学習周りをやっていた人はすでにいなくなっており、実際に手を動かすのは僕一人という状況でした。最初のうちは手探り状態で、何が失敗かわからず、見えている領域も狭いので、とりあえず小さく運用してみて感覚と知見を得ることを目的にしました。
めでたく施策も決定し(ここの詰めが中途半端で痛い目見るのはまた別の話...)、どうやって導入するかを考え始めました。
サービス導入ににあたってのアーキテクチャ要件は以下を設定しました。
- *既存環境がAWSに寄っていたので、AWS上に構築する
- 一人での開発なので、なるべく意識することを減らしたい
- Jupyter Notebookでいい感じにデータ分析&モデリングできる
- なるべく身軽なアーキテクチャで本番導入したい
- コストはちょっとかかってもしゃーなし
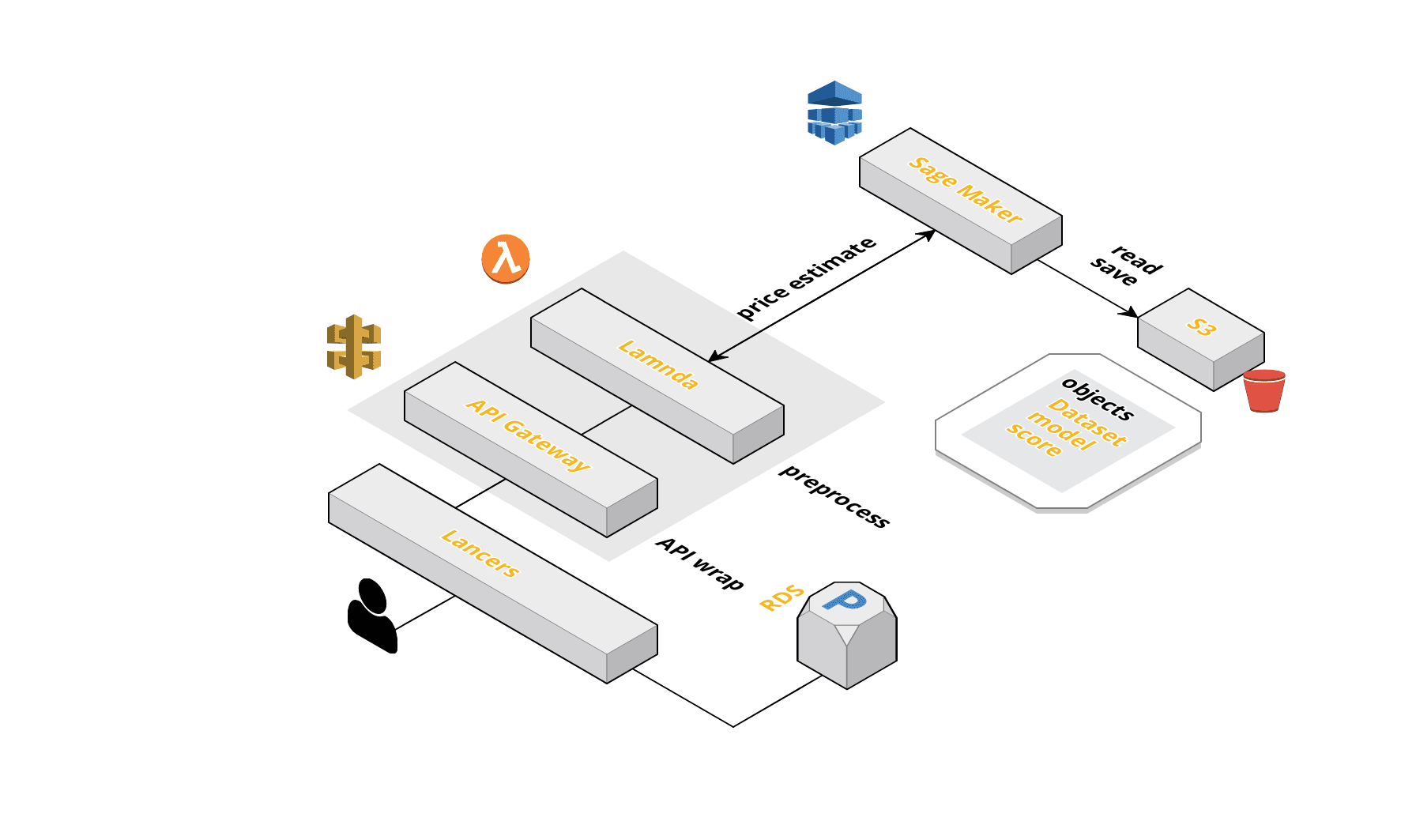
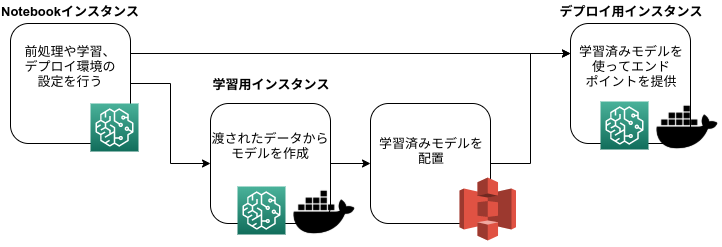
こんな感じのをつくりました
上記を満たすのがSage Maker+Lambda+API Gatewayの構成でした。
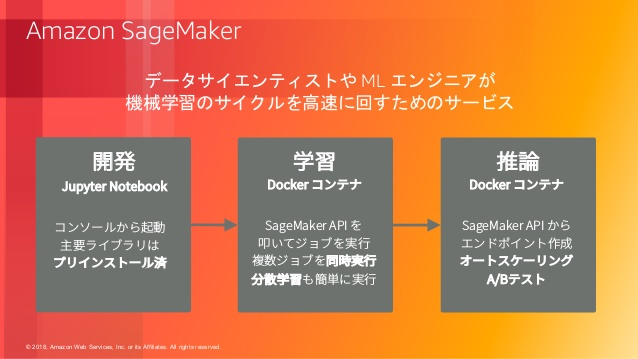
Sage MakerはAWSが提供するマネージドのML開発サービスです。
対応している範囲も広く、Juptyter Notebookを使ったデータ分析や、学習用コンテナの提供、作成したモデルのデプロイまでを一貫して行うことができるイカしたサービスです。
参考 : Amazon SageMaker を中心とした持続的な ML システムこのサービスは今回の要件にベストマッチしてました。ありがとうAmazonさん?。
Sage Makerを使うことでデータ分析や推論用エンドポイントの提供までを簡単に行うことができます。
あとは作成したエンドポイントを導入したいサービス側からSage Makerのエンドポイントを呼び出してやれば、推論を実行できます。ただ、それだけではうまく動作せず、入力データをデータセット形式に加工する必要があります。
サービスと推論用エンドポイント間での依存関係を少なくしたかったので、Lambdaを使ってこれを実装しました。エンドポイントがどこからでも叩けるのはちょっとまずいのでLambdaの前にAPI Gatewayを配置しました。
これによってエンドポイントのIP制限やデータ形式の制御などを行うことができます。
またこのような構成にしておくことでLambdaやSage Makerのエンドポイントを変更したい場合は、自由に置き換えることができます。やってわかったツラみポイント
一ヶ月半ほどでサービスへの導入が完了したのですが、当初の目的どおりやってみないとわからないツラさがいろいろ出てきました。
データを手動で持ってこないといけない
弊社ではありがたいことにいい感じのDHWが以下のような構成で構築されていました。
参考 : ランサーズの分析基盤(capybara)と運用について紹介Sage MakerはS3に配置されたデータセットをデータソースとして参照することが出来ます。
Sage MakerのJuptyter Notebook上でモデル開発を行うには、Big Queryに構築されているDWHからS3に持ってくる必要がありました。少し頑張れば、Big Queryのデータをいい感じに持ってこれるような機能を作ることは出来ます。
しかし、そもそも作るのが面倒なのとスピードを早くする目的から一旦手動でのデータ転送を選択しました。
目的のデータセットを抽出するクエリをRedashで書いて、CSVでダウンロードしてS3に配置するみたいなことをやってました。データ分析や特徴量解析やっているときに、別のデータ要素が欲しくなったら、Redashのクエリを書き直して、手動でS3に配置する必要がありました。これが結構めんどくさかったです。
ここからちゃんと自動でデータセットが更新される仕組みと直接データにアクセスできる環境が必要だと思いました。
テストができない
Sage Makerはデータの前処理から学習、デプロイまでを行うことができて非常に便利です。
しかし、僕は単一のJupyter Notebookですべての処理を行っていました。ただやはり、記述されているコードにテストがないのはすごく不安です。
pytest-ipynbなどをJupyter Notebookでテストを行うこともできましたが、一時しのぎにしかならず、本質的じゃないと思ったのでやめました。ここから前処理部分などのテストをちゃんと行うようにしたいと思いました。
レビューしにくい
上記の通り、単一のJupyter Notebookに前処理からデプロイまでを書いていたので、かなりレビューがしにくかったと思います。
(レビューして頂いた各位ありがとうございました)import部分でさえこんな感じです。
{ "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "import os\n", "import sys\n", "import math\n", "import numpy as np\n", "import boto3\n", "import pandas as pd\n", "import matplotlib.pyplot as plt\n", "import numpy as np \n", "from io import StringIO\n", "import seaborn as sns\n", "import sagemaker\n", "from pytz import timezone\n", "from datetime import datetime\n", "\n", "sagemaker_session = sagemaker.Session()\n", "\n", "%matplotlib inline" ] },一応Python形式でもExportしていましたが、大きい単一ファイルだったので可読性は低かったです。
またSage Makerは以下のような複数のコンテナ環境でモデルのデプロイまでを行います。
このような一連の流れから、学習用コンテナの設定部分やデプロイ周りの設定もNotebookで行いました。
これには使用するDocker Imageの指定やインスタンスタイプの設定、インスタンスに渡すハイパーパラメータの設定などが含まれます。
この部分の記述はSage Maker特有の知識が含まれ、レビューするのにも勉強する必要がありました。ここから小さいスクリプトの集合で処理や設定を定義したいと思いました。
データや特徴量の知見が貯まらない
単一のJupyter Notebookではデータの知見がその中に閉じてしまい、なぜその特徴量を使ったのかを体系的に共有できないと感じました。
なんでそのデータを使ったのか、なぜそのような特徴量変換を行ったのか、その分析で使わなかったデータはどういう傾向があるのかなどが失われてしまっていました。
なるべくコメントを残すようにしましたが、それでもどうしてもわからなくなってしまいます。きちんとドキュメントを書けばいいのではと思いましたが、そういうドキュメントは往々にして手が行き届かなくなっていくと思っています。
ここからなるべくコードに近いところでドキュメントを管理し、レビューを通すようにすればいいのではと思いました。
MLデータパイプラインを作ろう
上記の問題を解決するためにアーキテクチャの改善を行うことにしました。
まずは一番ツラさが存在するデータ取得部分と前処理部分の改善を行うことにします。
どういう風に直していくかを考えてみます。
データ取得部分の問題は、モデリングまでの環境(学習済みモデルを作成する部分まで)をGCPに変更することにします。
こうすることでDWHが構築されているBig Queryから直接データをとってこれるようにします。
GCPにはAI PlatformというML開発サービスが存在するので、これを使うことにしました。前処理部分の問題は前処理ををスクリプトとして切り出し、それを使ってデータを特徴量に加工するデータパイプラインを構築することにしました。スクリプトとして切り出すことで、それぞれに対してちゃんとテストを書くことができるようになります。
また、それぞれに対してDoc Stringにデータの知見をきちんと書き、それをShpinxを使って静的ページとして公開することで知見が共有できるようになると思いました。
あとは個別に前処理したデータをBig Query上に戻し、MLデータマートとして扱うことで次回モデリング時にそこからデータ使うことができるので、無駄な計算を行う必要もなくなります。データパイプラインを使って定期的に処理を実行させるようにすることで、特徴量の更新を行うことができます。
まとめると、上記の問題を解決するためにはBig Query上にMLデータマートを作ってやればデータ取得から前処理までの問題は解決することができ、さらに大きなメリットが発生することがわかりました。
データマートなどの説明はゆずたそさんの記事が詳しいので以下に貼っておきます。
データ基盤の3分類と進化的データモデリング #DPCT / 20190213MLデータマートの構築にあたって、アーキテクチャの構成には以下の要件を設定しました。
- ワークフローのDAGを柔軟にかけること
- モデルが増えても対応できるようにする
- アドホックな処理に耐えられるようにする
- コストをなるべくかけないようにしたい
- 社内に知見があるようなツール
- スケジュールリングを簡単に行うことができる
- エラーハンドリングを簡単に行うことができる
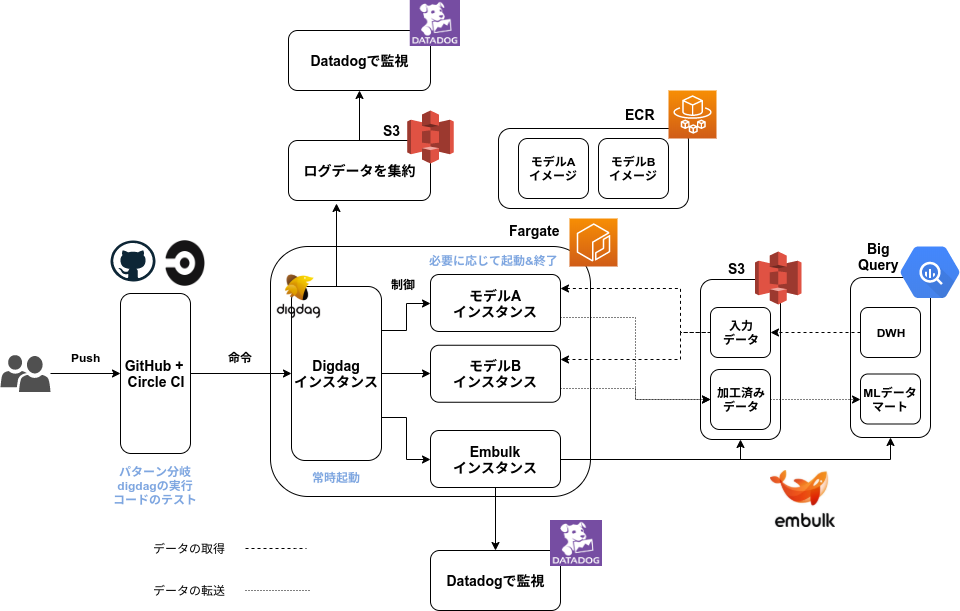
最終的にはこうなりました
様々なツールを検討・比較しましたが、最終的にはDigdag+Embulk+Fargateの構成 になりました。
命令部分について
ワークフローやスクリプトの更新をCircle CIで監視し、更新内容によって実行するワークフローの分岐を行います。
その命令はFargate内で常時起動しているDigdagに渡されます。
このインスタンスはワークフローの実行だけを担うので、比較的サイズの小さいインスタンスで実行させることができます。実行させる処理の制御やDAG構築、インスタンスの起動&終了、GUIからの再実行、エラー時のリトライ処理などをこのDigdagが担保します。
処理部分について
CircleCIからの命令を常時起動のDigdagが受けて、API経由でFargateインスタンスを立ち上げます。
これらはモデルごとにDockerイメージをECRに登録しておき、それをベースに構築されます。
データ加工を行うインスタンスは処理だけに役割を絞ることで、粗結合な仕組みにすることができます。
行う処理内容から比較的大きなサイズのインスタンスを指定してやります。データ転送部分について
今回の構成ではBig Query ~ S3間のデータ転送部分をEmbulkコンテナに切り出しています。データ
こうすることで各モデルのワーカーインスタンスは処理だけに特化させることができるようになり、コンテナ内部での依存関係とイメージサイズをなるべく小さくすることができます。各モデルのワーカーコンテナについてはS3のデータを用いて処理を行い、加工が終わったものをS3に戻すようなフローを組んでいます。すべてのデータ加工が完了したら、S3の加工済みデータをEmbulkコンテナがBig Queryに格納することでデータマートにデータが溜まっていきます。
監視部分について
監視はDatadogを使って行います。
Datadogにデータの加工処理で発生する負荷のモニタリングや、エラー検知、ログの可視化などを任せます。
Fargateから直接参照させることできないので、Digdagの実行ログをS3に吐き出し、それをS3に参照させます。
各モデルのワーカーインスタンスはCPUやメモリの負荷についてもDatadogを使って監視することにします。コスト部分について
この構成だと、比較的重い処理も必要最低限のコストで実行することができます。
常時起動なのは比較的サイズの小さいDigdagだけで、必要に応じて各モデルのワーカーインスタンスを適切なサイズで起動させます。処理が終わればdigdagインスタンスが終了命令を出してくれるので大きなサイズのインスタンスを使用しても、コストがかからないような設計になっています。この仕組みだと機械学習モデルごとにDocker imageを定義してやればいくらでも拡張することができます。
まだまだ見えてない部分は多いですが、上記の問題は解消されるようなアーキテクチャになっています。MLデータマートの使用ワークフロー
上記を使用したモデリングのワークフローを示します。
- DWHからデータを持ってきてGCP上でデータ分析やモデリングを行う
MLデータマート部分
2. 必要な変換や処理が決まったら、それを個別のスクリプトに分解する
3. スクリプトをDigdagのタスクに落とし込む
4. スクリプトのテストと解説を書く
5. GitHubにPush
6. CircleCIで実行するワークフローを指定
7. Digdagがデータ変換処理を行なってMLデータマートに格納
MLデータマート部分終了
- モデリング部分のコードはデータとMLデータマートから呼び出すように修正
- モデル作成 & デプロイ
- サービスとMLエンドポイントの前処理は定義したタスクを使ってストリーム処理
- Doc StringをSphinxを使って静的なページにする+どこかでホスティング
- Digdagが定期的にデータマートを最新の状態に更新
- MLデータマートの特徴量を使って次のモデルを開発
Q&A (&Q)
Q. なんでデータパイプラインをAWS上に構築したの?無駄じゃない?
A. 既存との繋げ込みと運用実績からAWS上に構築しました
最初はCGPのCloud Composer+Dataflowを使って構築しようとしていました。
GCP Composer&Dataflowの構成やData Fusionを使った構成、GCP上にDigdag+embulkでパイプラインを作るなどいろいろな構成を考えました。どの構成も運用経験がなく、問題の発生予想が不透明だったのとそれなりに複雑なので覚えないといけないこと一杯で会社的にちょっときつかったです。どれも採用には一歩足りず、既存でDHWへのデータ転送をdigdag+embulkでやっていたり、チームにAWS運用の知見が溜まっていたのでAWS上での構築を選択しました。
Q. なんでEmbulkコンテナ切り出したの?
A. 機械学習モデルをなるべくシンプルにしたかったから。
このイメージは学習環境やデプロイ環境にも使うので、余計な部分が増えてボリュームが大きくなるのが嫌でした。
またdigdagのアップデートやプラグインを追加したいときに、個別に分散していると移行作業が面倒になると予想しました。
まとめて置くことでバージョンアップ等が楽になり、プラグインも一括管理できます。Q. 前処理部もデータパイプラインで定義したスクリプト使いたい。
この記事を読んでいるみなさんへの質問です。
サービス ~ エンドポイント間に存在する前処理部分(Sage Maker時代の運用例だとLambda)って今回作ったMLデータマートと全く同じ処理をするんですよ。同じこと二度かくのは面倒だし、ダサいのでこれも同じスクリプトを使っていい感じに処理できるようにしたいと思っています。
バッチ処理は上記の構成で満たしているので、ストリーム処理をいい感じにできるようにしたいです。
僕が考えているのは、Lambdaを使って実現する方法です。
Digdagで定義されているスクリプトをいい感じにPythonパッケージにして(どうやればいいのかはよくわからん)、Zip形式で固めたものをLambda Layerに定義してやります。
このパッケージをLambdaで呼び出して、前処理を定義してやればよいのではと思っています。が、ベストではないので、もしよければ、アドバイスもらえると嬉しいです。
まとめ
以上、見えている範囲で僕が考えた最強のMLデータマートの話でした。
今回改善できた部分はデータ取得 ~ 前処理部分だけなので、次はモデルのデプロイ周りやA/Bテスト環境を整えようと思います。Sage Makerは個人的にとても良いツールだと思っているので、そこからエッセンスを学びつつ、開発できたらと思います。※ヴァイオレット・エヴァーガーデン見ながらこの記事を書いたのですが、良すぎて全く手が進みませんでした?。今年見た中で一番良かった作品でした。みなさんも見てみてください。

- 投稿日:2019-12-22T16:28:17+09:00
Web開発勉強のためWordpressでポートフォリオサイトを開設するまで③〜XAMPPローカル環境構築失敗編〜
XAMPPでローカル環境を構築できたといったな。あれは嘘だ。
いや、嘘ではないんですけど、うまくいったのはインストールまででした。
講座の動画に従って投稿や固定ページの更新をしたところ、
「更新に失敗しました。 エラーメッセージ: 返答が正しい JSON レスポンスではありません。」
というエラーメッセージが表示され、なにもできない状態でした。いまだにデータ交換をテキストやらCSVでやっている仕事ですので、XMLはおろかJSONとは、みたいな状態で、ググってもいまいち解決方法がピンとこない・・・
UdemyのQ&Aを覗いても同様の質問がなかったため、思いきって自ら質問してみました。
すると、すぐに先生自ら回答をくださいました!php.iniのmax_execution_timeをデフォルト設定から300に変更して、Apacheを再起動してみてください。
とのこと。ちなみにこの日は有給予定だったので平日朝の7時ぐらいに書きこみました。
先生ヒマなのかしら。
というわけで、php.iniを探してパラメーターを上書き。
念のためPCも再起動しましたが・・・残念ながら改善せず。
どうするかなあと悩みましたが、この時点でもうローカル環境は諦めるつもりでした。
Railsチュートリアルやろうとした時のAWSアカウント、まだ無料枠残ってるからそれ使って環境構築すればええやん、と。
程度にもよりますが、初心者向けの講座もろもろいじって無料枠超えても1000円は取られないらしいので、今後のAWSの勉強も兼ねてAWSで環境構築することにしました。というわけで、先生にはうまくいかなかったことと、AWSで環境構築する旨をお伝えしました。
先生からも、XAMPP とWordPressのいずれが原因かどうか切り分けるために、AWSやVPSなどでApacheやNginxで試してみるのがよいと思います。
とのご回答が。
めんどくさくなったんですね、わかります。ちなみに先生からlogsフォルダにエラーログ出てない?と聞かれたんですが、残念ながらエラーログは見当たりませんでした。
これでAWSの環境構築を試してうまくいかなかったら、いよいよMAC買うしかないな、と思いました。そんな背水の覚悟で臨んだAWSのWordpress環境構築ですが、下記のサイトを参考にしました。
・https://skillhub.jp/blogs/197結論から言うと、ようやくうまくいきました。
ターミナルの開き方とかAWSの操作面で不安がありましたが、それほど難しくないと思います。
投稿や固定ページの更新も問題なくオーケー。
ようやくスタートラインに立てたかなという感じです。
次回からは、サイトを作っていく中でつまづいた点などを書いていきたいと思います。
- 投稿日:2019-12-22T15:34:38+09:00
帰宅時に人を認識してGoogle Homeに「おかえり」と言わせる(Sesami×AWS Rekognition)
はじめに
- UL Systems Advent Calendar 2019 の12/25の記事になります。
「スマートホーム」が益々定着していますね。
先日、Amazon、Apple、Googleがスマートホーム機器接続の統一規格に向けて提携し、更に注目を集めているようです。
自宅でも、Google Homeを中心に電灯、テレビ、エアコン、空気清浄機、鍵等、色々操作するようにしています。但し、Google Homeの欠点として、能動的に動作しない(話しかけないと始まらない)という点があります。
家に着いたら、存在を認識して、
・「テレビでこんな面白い番組やっていますよ、見ますか?」とか
・「お風呂を入れておきますね」とか
勝手に対話や行動を始めてくれたらいいなぁ、と思いました。
そこで、その入口となるスクリプトを紹介します。ゴール
- 今回は、以下の3点を実装し、「帰宅時に人を認識してGoogle Homeに「おかえり」と言わせる」ことをゴールとします。
- 家に帰ってきたことをSesami解錠にて感知する(画像処理量軽減も兼ねて)
- 家に入った人をAWS Rekognitionにて認証させる(セキュリティ対策も兼ねて)
- 認証結果が正しければ、Google Homeに話しかけさせる
前提・準備
物理的なものとして、以下が無いと始められません。
- Sesami
- Google Home
- カメラ付きのPC
※将来的なことを考えて、私はRaspberryPiとそれに繋げられるカメラ(「5MP OV5647」という製品を使用)を用いて環境を整えました。Pythonで実装します。
- AWS、Google Home、カメラ、画像処理、音声処理のライブラリが充実しているので採用しています。
各種APIを使いたいため、以下のアカウントを準備してください。
実装:1. 家に帰ってきたことをSesami解錠にて感知する
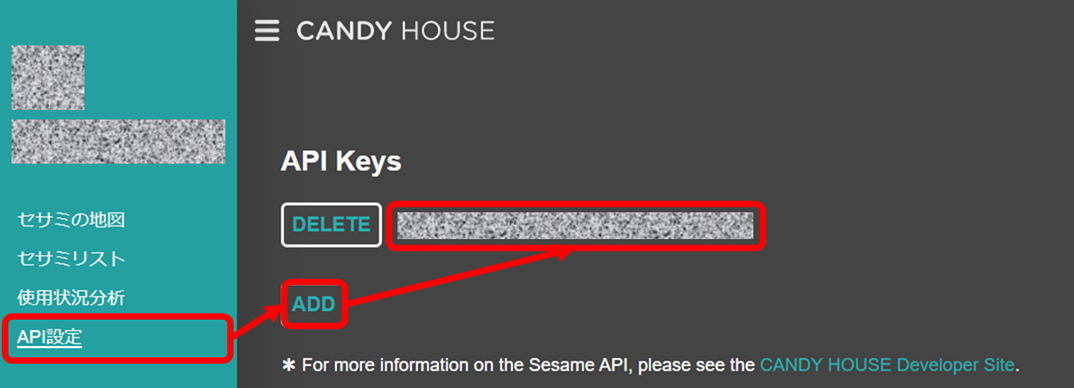
1-1. CANDY HOUSEにアクセスして、API Keyを取得します。
1-2. 念の為、API Keyで正常に動くかを検証します。curl -H "Authorization: [Your API Key]" https://api.candyhouse.co/public/sesames1-3. 無事動くことを検証できたら、「解錠を検知するスレッドクラス」を作成します。
sesami.py#!/usr/bin/env python # -*- coding: utf-8 -*- import os,json,logging,requests,threading,time from datetime import datetime logger = logging.getLogger() # Sesami API情報 API_URL = 'https://api.candyhouse.co/public' API_KEY = '[Your API Key]' # 解錠を検知する周期(秒) WAITTIME = 5 # 解錠を検知する時間(開始、終了) ACTIVETIMES = [ ('0000','0200'), ('1800','2400'), # 夕方18時から深夜2時まで検知 ] # Sesamiの解錠を検知するスレッドクラス class SesamiEventHandler(threading.Thread) : devices = None # Sesami解錠状態を検知するクラスメソッド @classmethod def get_devices(cls) : # 認証しているSesami情報一覧を取得 if cls.devices is None : res = requests.get( '%s/sesames' % (API_URL), headers={ 'Authorization' : API_KEY } ) logger.debug('got sesamis : %s' % (res.text)) cls.devices = json.loads(res.text) # Sesami解錠状態を検知するクラスメソッド @classmethod def is_open(cls) : cls.get_devices() # 認証しているSesamiの中で解錠状態になっているものがあればTrueを返す # 一つもなければ、Falseを返す for v in cls.devices : device_id = v.get('device_id') res = requests.get( '%s/sesame/%s' % (API_URL,device_id), headers={ 'Authorization' : API_KEY } ) logger.debug('got sesami condition(%s) : %s' % (device_id,res.text)) if json.loads(res.text).get('locked',True) == False : return True return False # Sesamiにコマンドを送信するクラスメソッド @classmethod def send_command(cls,command) : cls.get_devices() # 認証しているSesamiにコマンドを送信する for v in cls.devices : device_id = v.get('device_id') res = requests.post( '%s/sesame/%s' % (API_URL,device_id), json.dumps({ 'command' : command }), headers={ 'Authorization' : API_KEY, 'Content-Type' : 'application/json' } ) logger.debug('send sesami command (%s, %s) : %s' % (device_id,command,res.text)) # Sesami施錠メソッド @classmethod def lock(cls) : cls.send_command('lock') # Sesami解錠メソッド @classmethod def unlock(cls) : cls.send_command('unlock') # Sesami状態の強制取得メソッド @classmethod def sync(cls) : cls.send_command('sync') # コンストラクタ def __init__(self,listener=None) : threading.Thread.__init__(self) self.enable = True self.listeners = [] self.waittime = WAITTIME self.actives = ACTIVETIMES self.add_listener(listener) # スレッドの停止メソッド def stop(self) : self.enable = False # 検知リスナーの追加メソッド def add_listener(self,listener) : if listener is not None : self.listeners.append(listener) # スレッド処理メソッド def run(self) : # 有効な間は繰り返し処理 while self.enable : # 現在時間が有効時間内で、且つ解錠状態であれば # 検知リスナーを順次実行する logger.debug('checking sesami...') t = datetime.now().strftime('%H%m') for start,end in self.actives : if start <= t and t <= end and self.is_open() : for lsn in self.listeners : lsn() time.sleep(self.waittime)テストコードはこんな感じで。鍵を開けたときに「Opened!」と出ることを確認。
test_sesami.py#!/usr/bin/env python # -*- coding: utf-8 -*- import sys,time from sesami import SesamiEventHandler try : # Sesamiハンドラスレッドの生成、検知開始 th = SesamiEventHandler(lambda : print('Opened!')) th.start() time.sleep(10) SesamiEventHandler.unlock() time.sleep(10) SesamiEventHandler.lock() time.sleep(10) finally : # 終わったら、Sesamiハンドラスレッドの停止して終了 th.stop() th.join() sys.exit(1)実装:2. 家に入った人をAWS Rekognitionにて認証させる
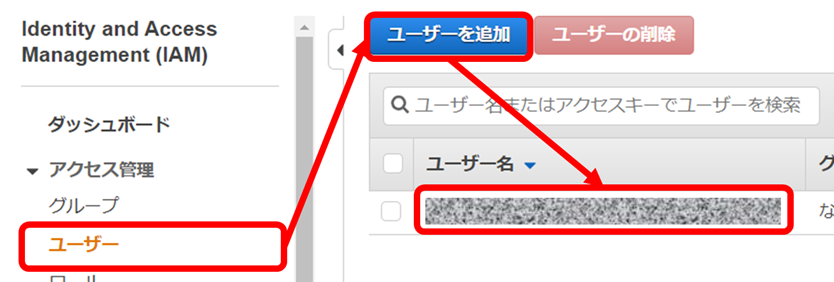
2-1. AWS IAMにて、API利用のためのユーザーを用意します。
2-2. 用意したユーザーに、「AmazonRekognitionFullAccess」のアクセス権限を付与します。
2-3. 更にユーザーの、アクセスキーを作成します。
2-4. 用意したアクセスキーを使えるよう、ローカル側に認証ファイルを保存しておきます。
~/.aws/config[default] output = json region = [Your Region]~/.aws/credentials[default] aws_access_key_id = [AWS Access Key] aws_secret_access_key = [AWS Secret Access Key]2-5. 顔認証をする「AWS Rekognitionクライアント」を作成します。
rekognition.py#!/usr/bin/env python # -*- coding: utf-8 -*- import os,json,codecs,logging,boto3,cv2 logger = logging.getLogger() WORKDIR = os.path.dirname(os.path.abspath(__file__)) # AWSセッティング COLLECTION_ID = 'MyFaces' # 顔コレクションID THRESHOLD = 97.5 # 顔の一致具合(97.5%以下は対象としない) MAX_FACES = 3 # 一度に分析する最大人数(3名まで) FACEIDSDUMP = os.path.join(WORKDIR ,'faceids.json') # 顔認証IDの保管ファイル名 # AWS Rekognitionサービスクライアント class AWSRekognitionClient(object) : camera = None # カメラ操作オブジェクトの生成 @classmethod def open_camera(cls) : try : cls.camera = cv2.VideoCapture(0) except : pass # カメラ操作オブジェクトの開放 @classmethod def close_camera(cls) : try : cls.camera.release() except : pass @classmethod def read_image(cls,path) : # 画像があれば、データを取得 # 画像がなければ、カメラから撮影 try : with open(path,'rb') as fp : buf = fp.read() except : _, buf = cls.camera.read() _, buf = cv2.imencode('.png',buf) buf = buf.tobytes() return buf # コンストラクタ def __init__(self) : self.open_camera() self.client = boto3.client('rekognition') self.faceids = [] # 顔認証IDの保管ファイルが既にあれば、初回に読み込み if os.path.exists(FACEIDSDUMP) : try : with codecs.open(FACEIDSDUMP,'rb','utf-8') as fp : self.faceids = json.load(fp) except : pass # コレクションIDの生成 def create_colleciton(self) : self.client.create_collection(CollectionId=COLLECTION_ID) # コレクションIDの削除 def delete_collection(self) : self.client.delete_collection(CollectionId=COLLECTION_ID) self.faceids = [] if os.path.exists(FACEIDSDUMP) : os.remove(FACEIDSDUMP) # 画像から顔認証IDを生成し、保管する def regist_faceid(self,src_path=None) : logger.info('regist faceid : image = %s' % (src_path if src_path is not None else '(camera picture)')) # 画像をアップロードして、顔認証IDを取得 buf = self.read_image(src_path) res = self.client.index_faces( CollectionId = COLLECTION_ID, Image = { 'Bytes' : buf } ) # 顔認証IDリストに追加(退避用ファイルにも保管) self.faceids.extend(res.get('FaceRecords',[])) logger.debug('registed : %s' % (json.dumps(self.faceids,indent=4,ensure_ascii=False))) with codecs.open(FACEIDSDUMP,'wb','utf-8') as fp : fp.write(json.dumps(self.faceids,indent=4,ensure_ascii=False)) logger.info('faceids = %s' % (json.dumps(self.faceids))) # 画像から合致する顔認証IDを取得する def is_match_faceid(self,src_path=None) : logger.info('check faceid : image = %s' % (src_path if src_path is not None else '(camera picture)')) # 画像をアップロードして、顔認証IDを検索 buf = self.read_image(src_path) res = self.client.search_faces_by_image( CollectionId = COLLECTION_ID, Image = { 'Bytes' : buf }, FaceMatchThreshold = THRESHOLD, MaxFaces = MAX_FACES ) logger.debug('got faceids : %s' % (json.dumps(res,indent=4,ensure_ascii=False))) # 念の為、FaceIDが一致しているか確認 fids = [id.get('Face',{}).get('FaceId') for id in self.faceids] for r in res.get('FaceMatches',[]) : fid = r.get('Face',{}).get('FaceId') if fid in fids : return True return Falseテストコードはこんな感じで。自分の顔写真を1度撮影・登録した上で、2度目の自分の顔写真は「True」で、他人の顔写真「otherface.jpg」は「False」で返ってくることを確認。
test_rekognition.py#!/usr/bin/env python # -*- coding: utf-8 -*- from rekognition import AWSRekognitionClient # クライアントの生成 client = AWSRekognitionClient() # 初回にコレクションIDを削除して、作り直し try : client.delete_collection() except : pass client.create_colleciton() # 自分の顔写真1枚撮影・登録 client.regist_faceid() # 2度目の自分の顔写真を検証(True) print(client.is_match_faceid()) # 他人の顔写真を検証(Falseが返ってくる) print(client.is_match_faceid('otherface.jpg'))実装:3. 認証結果が正しければ、Google Homeに話しかけさせる
3-1. 1、2で作成したスクリプトを組み合わせて、解錠を検知したら、顔認証して、Google Homeに「おかえり」と言わせるスクリプトを作成します。
homeservice.py#!/usr/bin/env python # -*- coding: utf-8 -*- import sys,os,json,logging,time,pychromecast from bottle import route, run as brun, static_file from sesami import SesamiEventHandler from rekognition import AWSRekognitionClient logger = logging.getLogger() REKOGNITION_TIME = 60 # 鍵を開けてから顔認証する最大時間(一旦60秒) VOICEDIR = 'voices' # 音声ファイル管理ディレクトリ CHROMECAST_IP = '[Your Google Home IP Address]' # Google Home IPアドレス BOTTLE_HOST = '[Your Machine IP Address]' # ローカルPC IPアドレス(Bottle用) BOTTLE_PORT = '[Your Port]' # Bottleポート WELCOME_VOICE = 'welcome_back.mp3' # 音声ファイル名 WORKDIR = os.path.dirname(os.path.abspath(__file__)) # 音声ファイルが無ければ事前に作成 voicedir = os.path.join(WORKDIR,VOICEDIR) if not os.path.exists(voicedir) : os.makedirs(voicedir) voicepath = os.path.join(WORKDIR,VOICEDIR,WELCOME_VOICE) if not os.path.exists(voicepath) : from gtts import gTTS tts = gTTS(text='おかえりなさい',lang='ja') tts.save(voicepath) # Bottleリクエスト処理(音声ファイルのレスポンス) @route('/%s/<file_path:path>' % (VOICEDIR)) def get_talk_path(file_path) : return static_file(file_path, root=os.path.join(WORKDIR,VOICEDIR)) # 顔認証処理 is_rekognition = False def rekognize_face() : # 二重起動防止の為の排他処理 global is_rekognition try : if is_rekognition : return is_rekognition = True # Google Homeを取得 cast = pychromecast.Chromecast(CHROMECAST_IP) cast.wait() # 顔認証クライアントの準備 client = AWSRekognitionClient() cnt = 0 while cnt < REKOGNITION_TIME : # 顔認証が一致したら、Google Homeに音声を流す # 終わったら、施錠をする if client.is_match_faceid() : url = 'http://%s:%s/%s/%s' % (BOTTLE_HOST,BOTTLE_PORT,VOICEDIR,WELCOME_VOICE) cast.media_controller.play_media(url,'audio/%s' % (WELCOME_VOICE.split('.')[-1])) cast.media_controller.block_until_active() SesamiEventHandler.lock() client.close_camera() time.sleep(30) break cnt += 1 time.sleep(1) except Exception as e : exc_type, exc_obj, tb = sys.exc_info() lineno = tb.tb_lineno logger.error('happend error : %s,%s,%s' % (exc_type, exc_obj, lineno)) finally : is_rekognition = False try : client.close_camera() except : pass # メイン処理 def main() : th = None try : # Sesamiイベントハンドラを起動 # イベントリスナーとして顔認証処理を追加 th = SesamiEventHandler(rekognize_face) th.start() brun(host=BOTTLE_HOST,port=BOTTLE_PORT) finally : th.stop() th.join() sys.exit(1) if __name__=='__main__' : import logging.config logging.config.fileConfig(os.path.join(WORKDIR,'logging.conf')) main()実行の結果、帰宅して部屋に入ると、「おかえりなさい」と言ってくれました。よしよし。
おわりに
- 上記を色々いじって、我が家に着くと、「おかえり」と言ってくれるだけでなく、電灯とテレビ、エアコン等を自動的に点けたりしてくれます。
今後、規格統一化が図られると、もっと家電と結びつけやすくなると思います。そうなれば生活はより便利になるでしょうね。
ではでは。


- 投稿日:2019-12-22T15:30:55+09:00
AWS DeepComporser について
はじめに
この記事は株式会社ナレッジコミュニケーションが運営する Amazon AI by ナレコム Advent Calendar 2019 の21日目の記事です。
今回の re:Invent で発表された DeepComposer についてご紹介します。
AWS 機械学習スキル学習のインターフェイス
機械学習モデルの学習ツールとして、DeepLens、DeepRacer、DeepComposer の三種がラインナップされたことになります。
左上がDeepLens、右上がDeepRacer。
そして下が今回の re:Invent で発表された DeepComposer
DeepLens
DeepLens は昨今社会実装が進んでいるコンピュータービジョンのモデルを搭載可能なビデオカメラです。
- 深層学習モデルに対応したビデオカメラ
- 2017年の AWS re:Invent で発表
- クラウドで深層学習モデルの学習、ローカルのカメラにモデルを搭載
- オブジェクトの検出、行動認識、顔認識、頭部姿勢の検出など、撮影した動画の分析や処理が可能
- 実機の価格は 249 ドル
DeepRacer
DeepRacer は誤解を恐れずにいえば強化学習を学ぶための最先端ラジコン。実機の値段もさることながら、モデルの学習にかなりの計算資源を要します。継続的に学習できる方は限られるのではないでしょうか?
- 強化学習のモデルを搭載できる自走型のレーシングカー
- 2018年の AWS re:Invent で発表
- 高度な機械学習テクニックである強化学習モデルのトレーニング方法を楽しみながら学習
- 世界各地でリーグ開催中。2019年11月には新モデル AWS DeepRacer Evo 発表
- 実機の価格は 399ドル
DeepComposer
DeepComposer は Generative AI を楽しみながら学べる、機械学習を搭載した世界初のキーボードです。
- 敵対的生成ネットワーク(GAN)モデルのトレーニングと最適化を通して、オリジナルの音楽を作曲
- 2019年の AWS re:Invent で発表
- 物理的なキーボードだけではなく、仮想キーボードを用いて、どこでも作曲・学習可能
- 実機の価格は 99 ドル
DeepComposer、なにができる?
もう少し DeepComposer について見ていきましょう
無料利用枠 (12か月間)でできること
無料枠の範囲内で、事前にトレーニングされたモデルを活用でき、以下が実行可能です。
AWS クラウド上の仮想キーボードであれば、すぐにでも使えます。
- 音楽のジャンル (ロックやポップなど) のサンプルモデルを用いることで、コード記述不要でモデル構築可能
- キーボードを使ってメロディを入力すると、AWS DeepComposer はクラウドで機械学習の推論を実行し、4 つのパートの伴奏を生成
- 音源に対し、ポップ、ロック、ジャズなど編曲が可能
無料トライアル (3か月間) でできること
無料利用枠に加えて、30 日間の AWS DeepComposer 無料試用版を利用できます。
- 最大 4 つのモデルのトレーニングと、それらのモデルを使用した新しい音楽作品の生成を最大 40 回まで実行
- Amazon SageMaker を用いて、独自のGANアーキテクチャを構築可能。
- 手元の DAW (デジタルで音声の編集や編曲などできるシステム)を使用して、楽曲のカスタム可能
- Amazon.com で AWS DeepComposer キーボードを購入すると、さらに 3 か月間の無料試用期間が追加
- Generative AI Talent Show (気になりますね!)に提出する楽曲の作成
まとめ
DeepComposer は、DeepLens、DeepRacerに比べて、要する知識レベル・コストともに学習のハードルがかなり下がっている印象を受けました。今が旬の差の Generative AI (また別の記事でご紹介しようと思います) について学習できるのもポイントです。
そもそも音楽はパーソナルなものなので、アウトプットそのものに優劣をつける性質自体が希薄です。個人学習との親和性も高そうですし、モデルの派生系、例えば特定のアーティストの楽曲傾向をシュミレートするモデルや、特定ジャンル(デスメタルとかエレクトロニカとか)のモデルを作る人が出てくると面白そうです。
一刻も早く実機を触ってみたいですね。仮想キーボードであればすぐにでも使用可能なので、休暇中に遊んでみるのも良いのではないでしょうか。


- 投稿日:2019-12-22T15:10:21+09:00
Web開発勉強のためWordpressでポートフォリオサイトを開設するまで②〜MAMPローカル環境構築失敗編〜
Wordpressの講座で、ローカルで使用環境を構築するための案内をしていたので、動画に沿って環境構築をしていきました。
PCは動画ではMacを使って案内していましたが、当方Windowsでの環境構築となります。
ちなみに使用PCのスペックは、
・Windows10 HOME バージョン1909
・CPU Cerelon(R) N4000CPU 1.10GHz 1.10GHz
・メモリ 4GB
・ストレージ HDD1TB
です。(ムダにHDD1TBなのがツッコミどころですw)まずMAMPをインストールするよう案内されました。
・https://www.mamp.info/
LAMPをもじったオープンソースで、Webサーバーの環境構築が簡単にできるソフトです。
WindowsだからWAMPだよなーと思いつつ無事にインストールまで完了。動画の案内通り、MAMPのフォルダ内にあるhtdocs内にダウンロードしたWordpress一式を移動。
MAMPを起動させ、ブラウザが起動したのでパスにWordpressのフォルダ名を指定。
この時点でインストール画面が表示されるはずなのですが・・・うまくいかない。
ネットを調べていたところ、wp-config.phpをパスに指定すればオーケーとのことだったのでその通りに操作。
(参考サイト:MAMP・Wordpressセットアップの詳細な手順はこちらのサイトで丁寧に解説されています。)
・https://bazubu.com/how-to-insall-wp-in-mamp-23798.html
無事にセットアップ画面が表示されたので、データベースを作成。
Wordpressのセットアップ手順に従い、データベース名やサイト名を入力。
無事にダッシュボード画面が開きました!わーぱちぱちぱち!え、ローカル環境構築失敗してないじゃないかって?
そう、タイトル詐欺です。ここまでは。
とりあえずその日はそこまでで操作を終え、翌日にMAMPを起動したところ・・・あれ?Apacheに緑のランプがつかないぞ?
まあいいかと気にせずWordpressを開こうとするもエラーに。そりゃそうだ。
ネットで調べていたらポート番号が別のアプリケーションと被ってダメなことがあるらしい。
ならばとポート番号をいろいろ変更するも・・・やはりApacheのグリーンライトは点灯せず。
うーむ、困ったなあ・・・と思っていたところ、そういえばUdemyには講座ごとにQ&Aが存在していたことを思い出す。
Q&Aを眺めていたところ、同様の質問が何件か。やはりけっこうある現象なのね。
講師の先生が自ら原因を探っていくも、最終的にはXAMPPを使っては?という回答に大半が落ち着いている。めんどくさくなったんですね、わかります。ということで、自分もXAMPPをインストールしました。
・https://www.apachefriends.org/jp/index.html
インストール手順は下記のサイトを参考にしました。
・https://bazubu.com/xampp-wordpress-23795.htmlMAMPよりボタンとか項目が多いので戸惑うかもしれませんが、基本の流れは一緒なのですんなりインストールできました。
念のためPCを再起動しても問題ないか確認したところ、無事にWordpressのダッシュボード画面を開くことができました!というわけで、MAMPでうまくいかなかった皆様、その時はXAMPPをインストールしましょう!
- 投稿日:2019-12-22T13:16:08+09:00
【AWSハンズオン】Nuxt + Golang構成のWebアプリをAWSへデプロイしよう!
みなさん、こんにちは!
学生サーバサイドエンジニアのくろちゃんです。今日はAWSを題材に、自分で作ったWebアプリケーションをデプロイできるようになることを目指して記事を書かせていただきます!
この記事を最後まで読むことで、下記のようなことができるようになります!
- 自分のWebアプリケーションを公開できるようになる
- AWSの下記のサービスを使えるようになる
- VPC
- EC2
ぜひ最後まで一緒に手を動かしながら楽しんでいってくださいね?
なお、この記事はCA Tech Dojo/Challenge/JOB Advent Calendar 2019(22日目)の記事になります!
前日の@yawn_yawn_yawn_さんのUbuntu + nginx + LetsEncryptでSSL/TLSを設定するからバトンを引き継いでお送りしています。まだ見てないよって方はそちらも合わせてどうぞ!
では、早速ハンズオン始めていきましょう〜!!
前提条件これらはできることを前提として話を進めていきますのでご了承ください。
※なお、本ハンズオンはOS Xを対象ユーザとして定めていますので、Windowsその他OSを使用している皆さんにつきましては適時読み替えて頂きますようにお願いします。
- AWSアカウントの作成&AWSマネージメントコンソールへのログイン成功
- GitHubアカウントの作成とSSH接続
- こちらのSSH接続についてわからない方は、GitHubでssh接続する手順~公開鍵・秘密鍵の生成から~ をご覧ください!
- Dockerがローカル環境で利用できる状態であること
目次
本ハンズオンでは下記のような流れでWebアプリケーションの公開〜自動デプロイの構築までを行っていきます。
0. 事前準備
1. VPCを構築しよう!
2. EC2インスタンスを起動しよう!
3. Webアプリをデプロイしよう!0. 事前準備
本ハンズオンでは私が事前に作っておいたアプリケーションを使用します。
下記の手順に従ってアプリケーションをダウンロード&動作確認してみましょう!GitHubリポジトリをforkしてこよう!
下記のGitHubリポジトリから自分のリポジトリへforkしてきましょう!
▼まずはアクセス▼
https://github.com/Takumaron/AWS_tutorial
フォーク先を指定して、きちんとフォークできていれば下記のような画面になります。(Qiita-test-aws-tutorialの部分は皆さんのGitHubアカウント名になります。)
続いて、Forkしてきたリポジトリを自分のPCにクローンしてきます。
ターミナルを開いて下記のコマンドを入力してください。
git clone [コピーしたURL]下記のような出力結果が得られれば正常にクローンできています。
$ git clone git@github.com:Qiita-test-aws-tutorial/AWS_tutorial.git Cloning into 'AWS_tutorial'... remote: Enumerating objects: 55, done. remote: Counting objects: 100% (55/55), done. remote: Compressing objects: 100% (45/45), done. remote: Total 55 (delta 9), reused 49 (delta 5), pack-reused 0 Receiving objects: 100% (55/55), 155.68 KiB | 484.00 KiB/s, done. Resolving deltas: 100% (9/9), done.アプリケーションが正常に動作するかチェックしよう!
クローンまでできたら、自分の環境で正しく動作するか検証しましょう。
下記のコマンドを入力してください。$ cd AWS_tutorial $ make start docker-compose up -d Building api_server Step 1/4 : FROM golang:1.12.4-alpine ---> b97a72b8e97d Step 2/4 : COPY ./ /go/aws_tutorial ---> 4fda45b3bf59 Step 3/4 : WORKDIR /go/aws_tutorial ---> Running in 421be46cf16b Removing intermediate container 421be46cf16b ---> 032f324638b8 Step 4/4 : RUN apk update && apk add --no-c ---- 中略(少し時間がかかります。少々お待ちください。) ----- Creating aws_tutorial_api_server_1 ... done Creating aws_tutorial_client_1 ... doneDockerコンテナが正常に立ち上がったら、お好みのWebブラウザを開いて http://localhost:3000/hello へアクセスしてください。
下記のような画面が表示されていれば、OKです!お疲れ様でした。
1. VPCを構築しよう!
さっそく、先ほどローカル上で動作確認したアプリケーションをAWSに乗せていきます!
まずはVPCというサービスを使って、グローバルなWebの世界に自分の領域を作っていきます。下記の手順に従って一緒に設定していきましょう!
まずは、AWSマネジメントコンソールへサインインします。
https://console.aws.amazon.com/console/home?region=us-east-1
サインインが完了したら、左上の「サービス」をクリックして下記の画像のようにVPCを検索します。
このような画面は開けましたか?
今回構築するVPCの全体像
出た!訳のわからない図!!って言って諦めないでくださいw
システム構成図も理解できればそんなに大したものではありません。まず押さえていただきたいポイントは、VPCのなかにパブリックサブネットっていう奴があって、その中にEC2っていうものが動いているというざっくりしたイメージです。
分かりやすい例えがないかなと一生懸命考えて思いついた「家の例え」でこの構成を説明していきます。
まずはこの対応表を頭にいれてください。
サービス名 家に例えると? VPC ? 家 インターネットゲートウェイ ? 玄関 サブネット ? 部屋 EC2 ?? 住人 イメージとしては、
家(VPC)に外部から人がやってきたときには、玄関(インターネットゲートウェイ)を通して家に入ります。そして、部屋(サブネット)へ案内をして、住人(EC2)がおもてなしします。という一連の流れで理解するとそれぞれの役割が明確になるのではないでしょうか?
それぞれのサービスの役割が理解できたところでハンズオンに戻っていきましょう!
VPCを作成する
サブネットを作成する
インターネットゲートウェイを作成する
ルートテーブルを編集する
サブネット(部屋)やインターネットゲートウェイ(玄関)がバラバラに存在している状態なので、それぞれの対応づけをしていきます。
VPCの構築はここまでで完了となります!お疲れ様でした!
次は、VPCの中で動作するEC2インスタンスを作成していきます。2. EC2インスタンスを起動しよう!
Webアプリケーションを動かすための場所作りは1. VPCを構築しよう!にて完了したので、実際に作ったWebアプリケーションを動かしてくれるマシーンを構築していきましょう!
【補足】
EC2インスタンスとは、仮想サーバーのようなものです。
AWSが事前に用意しているOSや独自で作成したOSイメージを使ってサーバを立てることができます。
今回は無料枠で利用できるAmazon Linux 2 AMIを利用します。
【変更点】のみ入力内容を修正して「次のステップ」へ
キーペアは後ほどEC2にローカルからつなぎに行くときに必要になるファイルですので、ダウンロード後も無くさないようにしてくださいね!ダウンロードが完了したら、「インスタンスの作成」をクリックすればEC2インスタンスの作成が始まります。(約2分ほど待てば下記のようにインスタンスの状態が「running」に切り替わると思います。)
お疲れ様でした!
ここまででVPCの構築と、EC2インスタンスの起動まで終わりました!あとは、EC2インスタンス上でWebアプリケーションを動かすだけです。もうちょっとなので一緒に頑張りましょう?
3. Webアプリをデプロイしよう!
さぁ、あとは自作したWebアプリケーションをEC2上で動かすだけですね!
Webアプリのデプロイは下記のような手順で行なっていきます。
- EC2インスタンスにssh接続する
- GitコマンドとDocker・Docker-composeコマンドが使用できるようにパッケージをインストール
- GitHubからプロジェクトをクローンしてくる
- アプリケーションを立ち上げる
それでは、さっそく始めましょう〜!
EC2インスタンスにSSH接続しよう!
まずは、作成したEC2インスタンスにSSHで接続しましょう!
自分のEC2インスタンスのIPアドレスを知っておく必要があるので、下記の画像を参考にして、IPアドレスをコピーしておきます。
それが完了したら、ターミナルを起動して下記のようなコマンドを打ちます。
# ダウンロードしたaws-tutorial.pemがあるディレクトリへ移動 $ cd ~/Downloads # pemファイルを~/.sshへ移動 $ mv aws-tutorial.pem ~/.ssh # pemファイルにアクセス権限を付与しておく $ chmod 400 ~/.ssh/aws-tutorial.pem # ssh接続 $ ssh -i "~/.ssh/aws-tutorial.pem" ec2-user@[自分のIPアドレス(ペースト)] Are you sure you want to continue connecting (yes/no)? yes # ←初回起動時には`yes`と入力ssh接続が完了すると、下記のようなコマンドプロンプトに切り替わります。
__| __|_ ) _| ( / Amazon Linux 2 AMI ___|\___|___| https://aws.amazon.com/amazon-linux-2/ 8 package(s) needed for security, out of 17 available Run "sudo yum update" to apply all updates. [ec2-user@ip-10-0-10-151 ~]$これでSSH接続は完了です!
ちなみに、SSH接続を切断する場合は、下記のコマンドを打ちます。$ exitGitとDockerを動かせるようにしよう!
SSH接続が完了したら、GitとDockerを使えるようにセットアップしていきましょう!
# yumをアップデート $ sudo yum update -y # Gitのインストール $ sudo yum install git -y # Dockerのインストール $ sudo yum install -y docker # Dockerの起動 $ sudo service docker start $ sudo systemctl enable docker.service $ sudo service docker status # 下記のような出力結果が得られればOK ● docker.service - Docker Application Container Engine Loaded: loaded (/usr/lib/systemd/system/docker.service; enabled; vendor preset: disabled) Active: active (running) since 日 2019-12-22 03:26:02 UTC; 10s ago Docs: https://docs.docker.com Main PID: 12952 (dockerd) CGroup: /system.slice/docker.service └─12952 /usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.... # dockerコマンドを使用可能にする $ sudo usermod -a -G docker ec2-user # 一度exit $ exitここまででDockerとGitが動くようになりました。
SSHで再接続して、Docker-composeも入れていきましょう!# スーパーユーザに切り替える $ sudo -i # 必要なファイルをダウンロード curl -L "https://github.com/docker/compose/releases/download/1.22.0/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose # 権限を与える chmod +x /usr/local/bin/docker-compose # 通常ユーザに戻る exit # 確認 $ docker-compose --versionGitHubからプロジェクトをクローンしてこよう!
DockerとGitが使えるようになったので、GitHubからアプリケーションをダウンロードしてきましょう!
https://github.com/[あなたのGitHubID]/AWS_tutorial へ遷移しましょう。
「Clone with HTTPS」モードでクローンURLをコピーします。
コピーしたクローンURLを使ってEC2上にクローンしてきましょう!
$ git clone [ペースト] # AWS_tutorialが存在するか確認 $ ls AWS_tutorialアプリケーションを立ち上げよう!
ここまでこれば準備万端!あとは立ち上げるだけですね?
プロジェクトフォルダに移動して、アプリケーションを立ち上げましょう!
# プロジェクトフォルダへ移動 $ cd AWS_tutorial # アプリケーションを立ち上げる $ make start ... Creating aws_tutorial_api_server_1 ... done Creating aws_tutorial_client_1 ... done立ち上がりました!
Webブラウザからアクセスをして動作チェックをしてみましょう!動いているみたいですね!
バックエンドとの連携もできているでしょうか?http://EC2インスタンスのIPアドレス:3000/hello
できているみたいですね!!
バックエンドAPIに対してブラウザからはアクセスできないことも確認しておきましょう。
http://EC2インスタンスのIPアドレス:8080/ping
成功です!!お疲れ様でした
ハンズオンはここまでとなります。【発展】
バックエンド側(:8080)にアクセスできない理由は分かりますか?
余裕のある方は、発展としてなぜアクセスできないのか考えてみてください!(ヒントは、セキュリティグループです!)
いかがだったでしょうか?
かなり長いハンズオンになってしまいましたが、ここまで読んでいただきましてありがとうございました!今回はVPCとEC2を使って簡単なWebアプリケーションをデプロイしました。
次はRDSというサービスを使ってDB機能を持たせたり、Code Buildというサービスを使って自動デプロイを実現できるようなハンズオンを作りたいと思います!
明日のCA Tech Dojo/Challenge/JOB Advent Calendar 2019は@hmarfさんが担当です!引き続きお楽しみください!!
▼こちらも要チェック!!
?サイバーエージェント 2021エンジニア採用本選考開始?
— ゴッティ@サイバーエージェントエンジニア採用 (@masagotty) December 5, 2019
今年のテーマは『Make Your Chance』。
Chanceという単語には本来「偶然性」の意味合いもありますが、
それも含め自分から声を上げ動き、チャンスを作り出してほしいという思いを込めています。
挑戦、待ってます!https://t.co/zpnxztQOpl

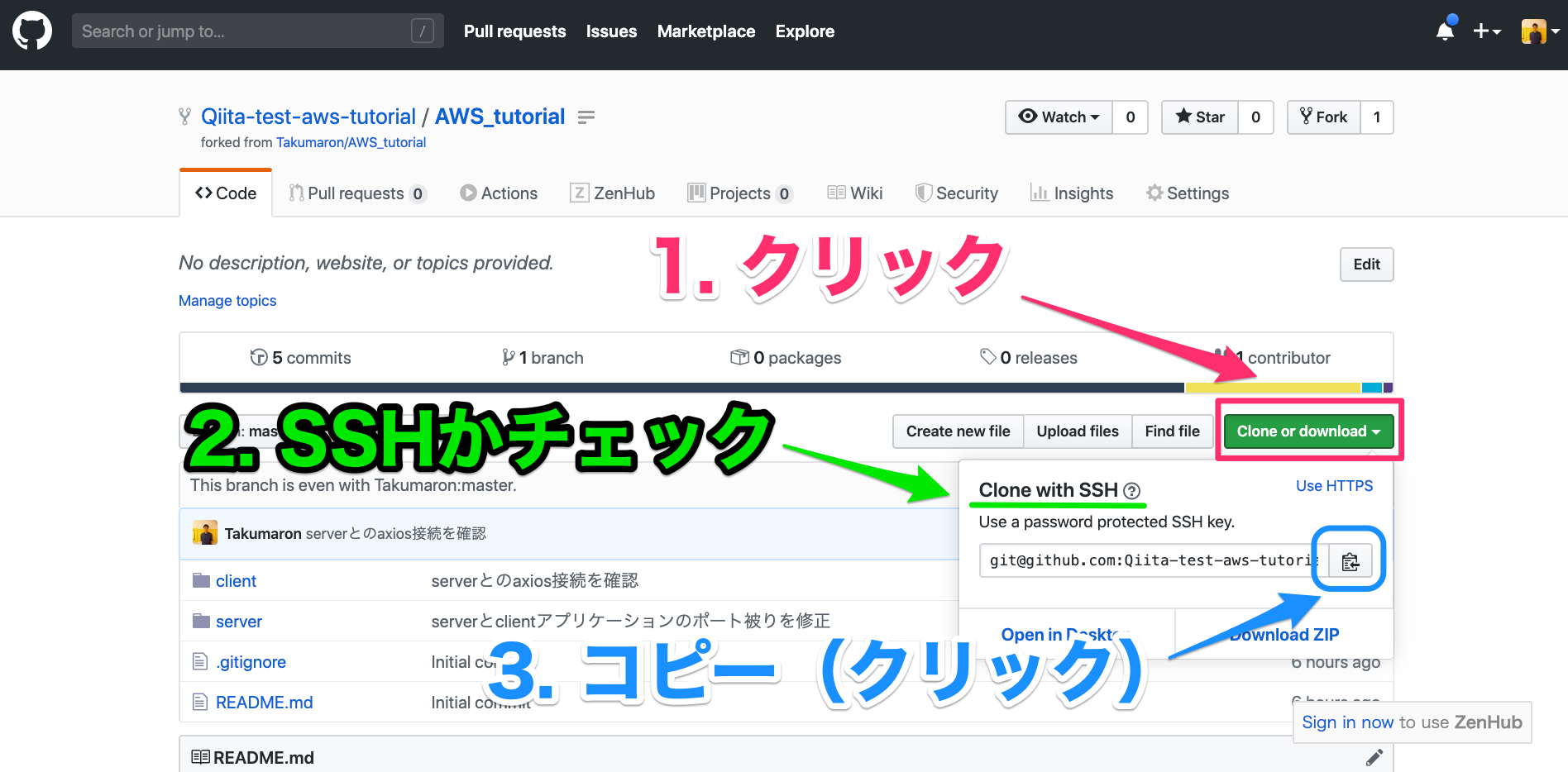
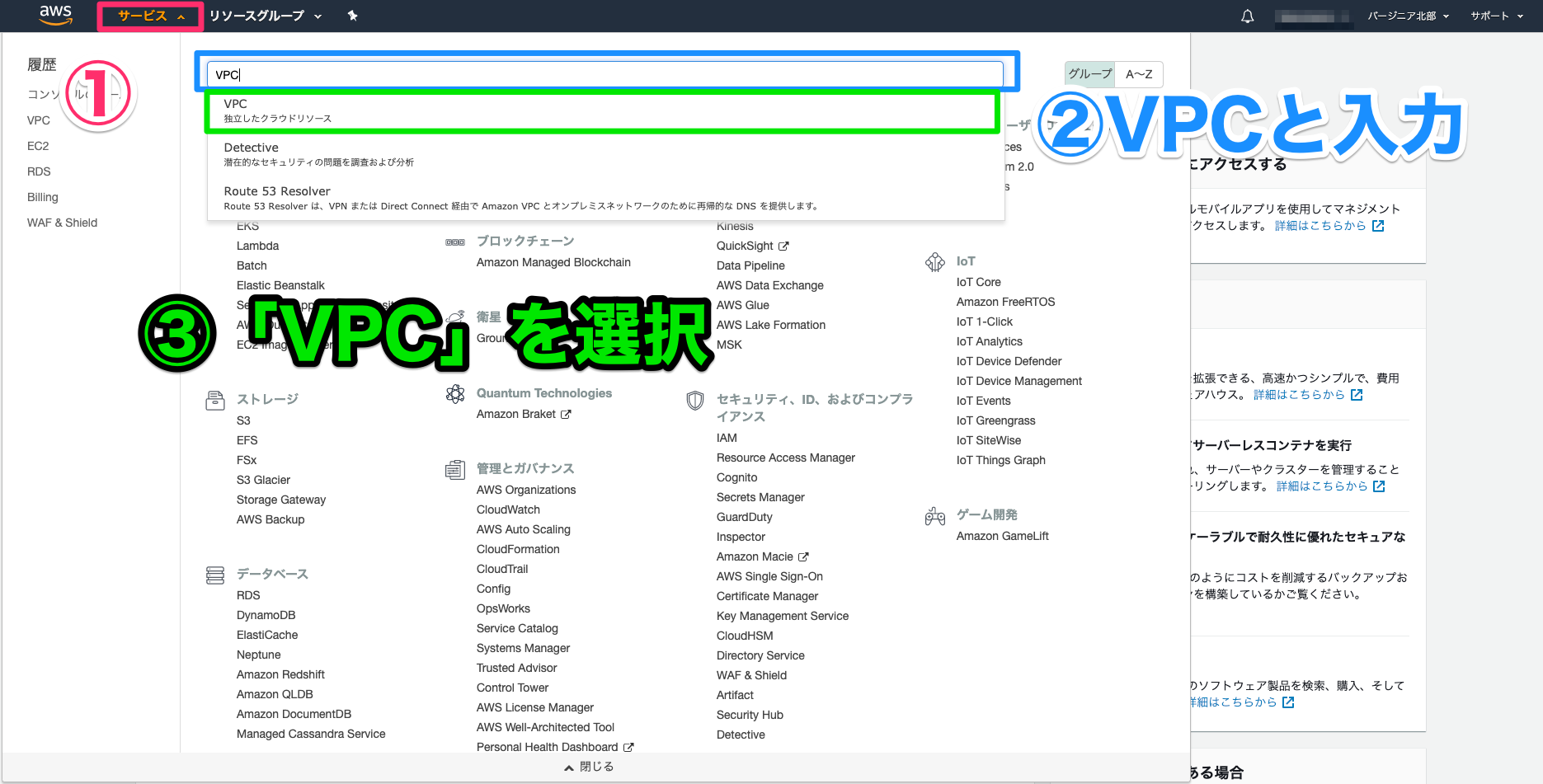

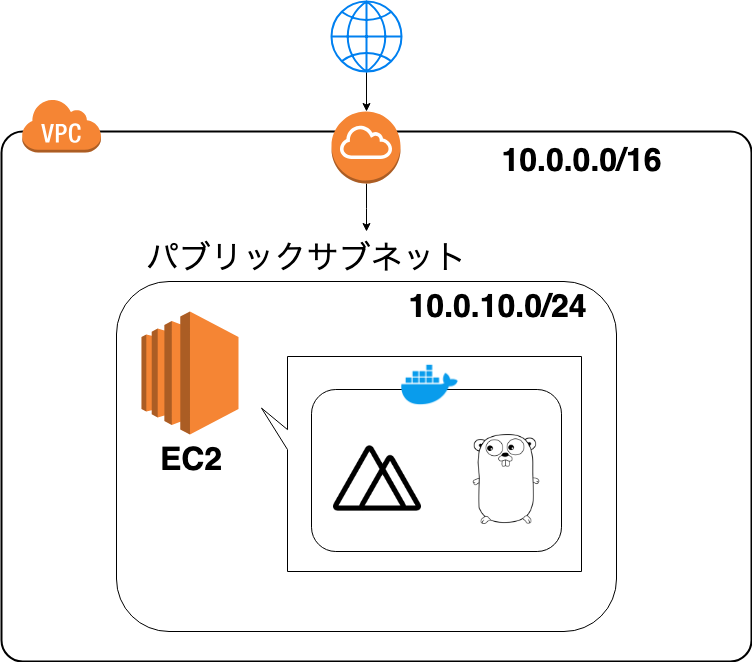



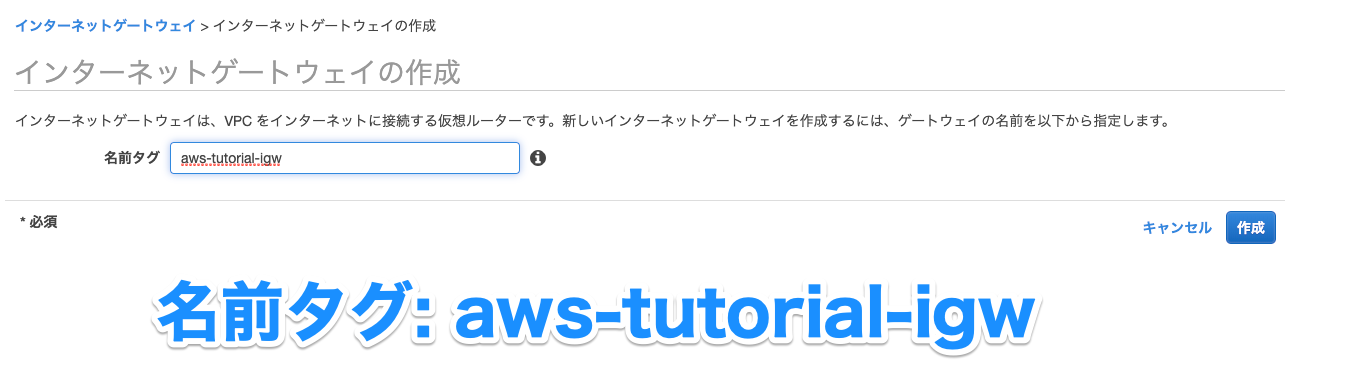
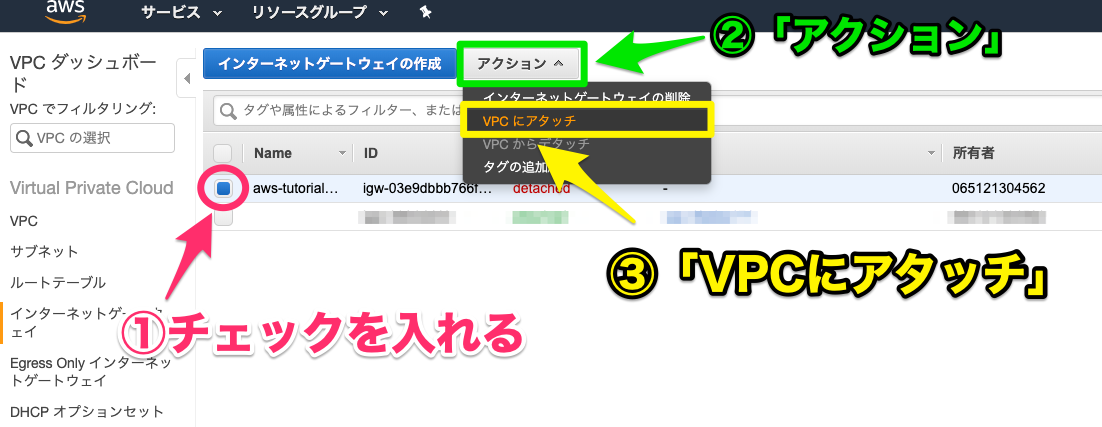
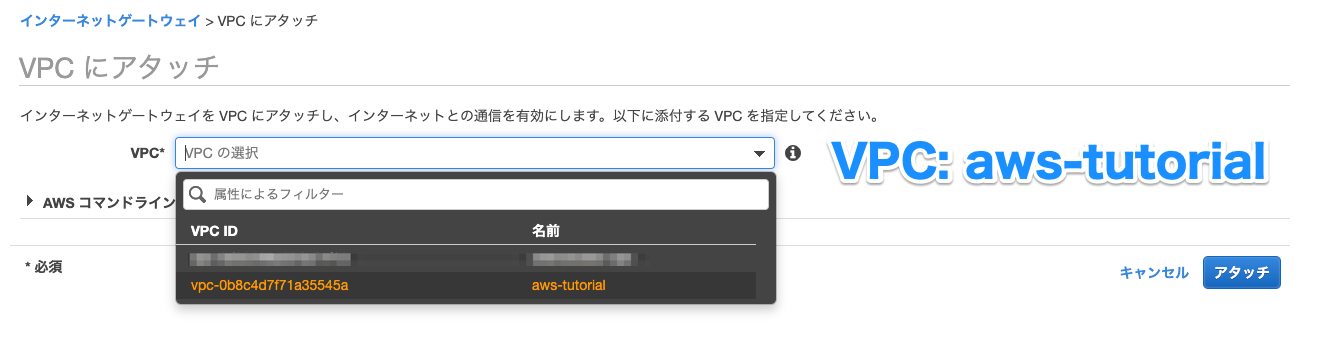
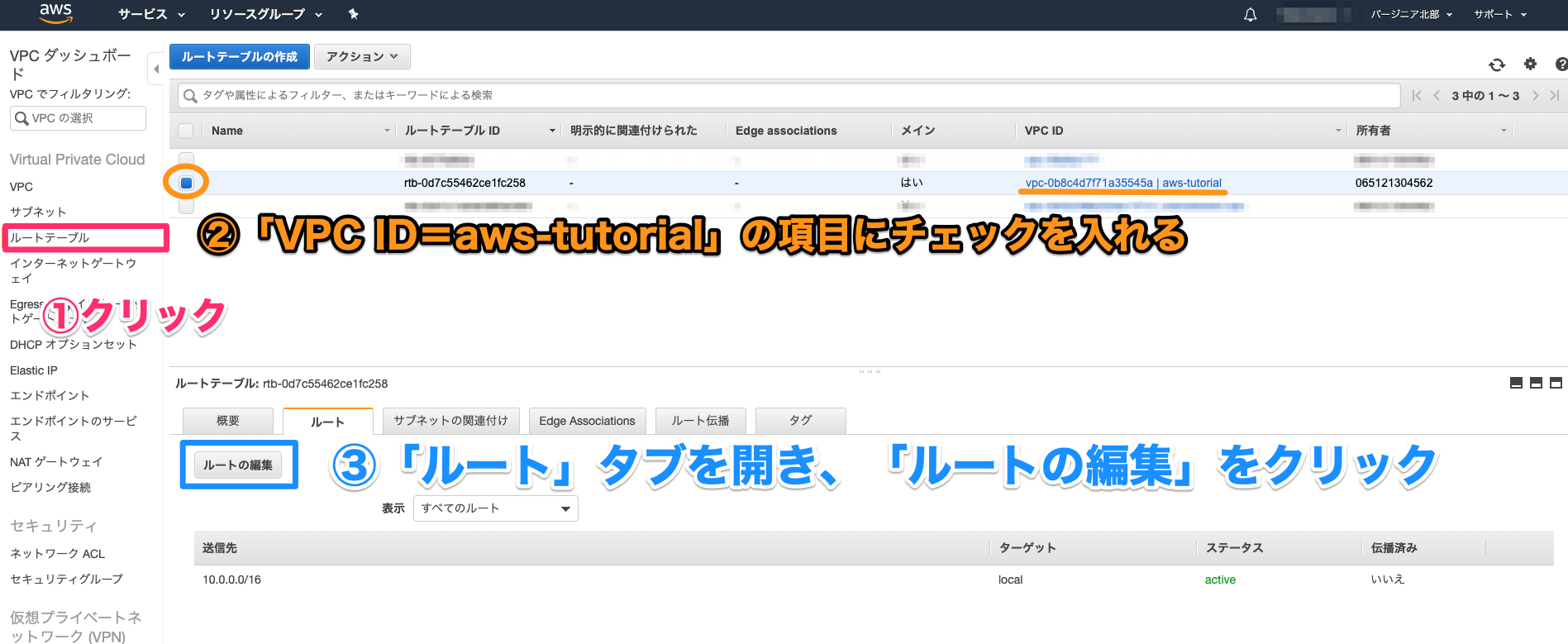

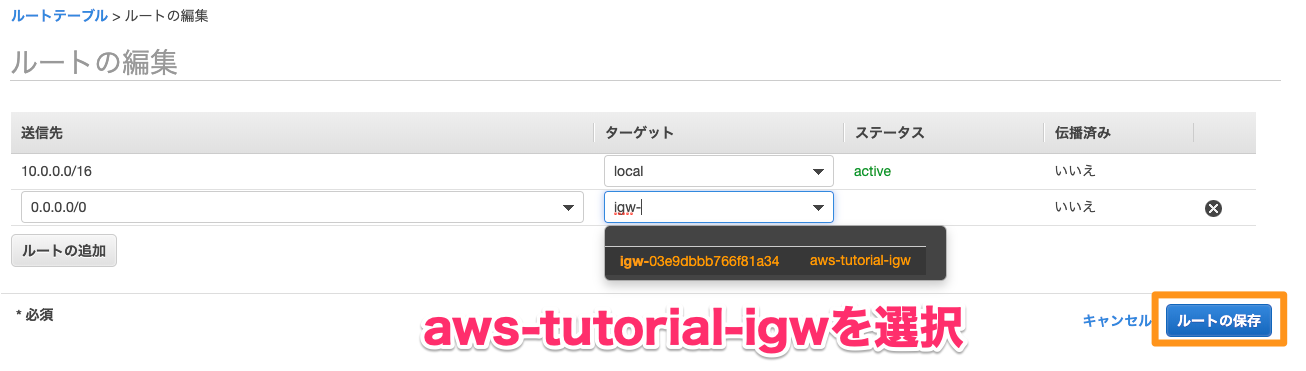
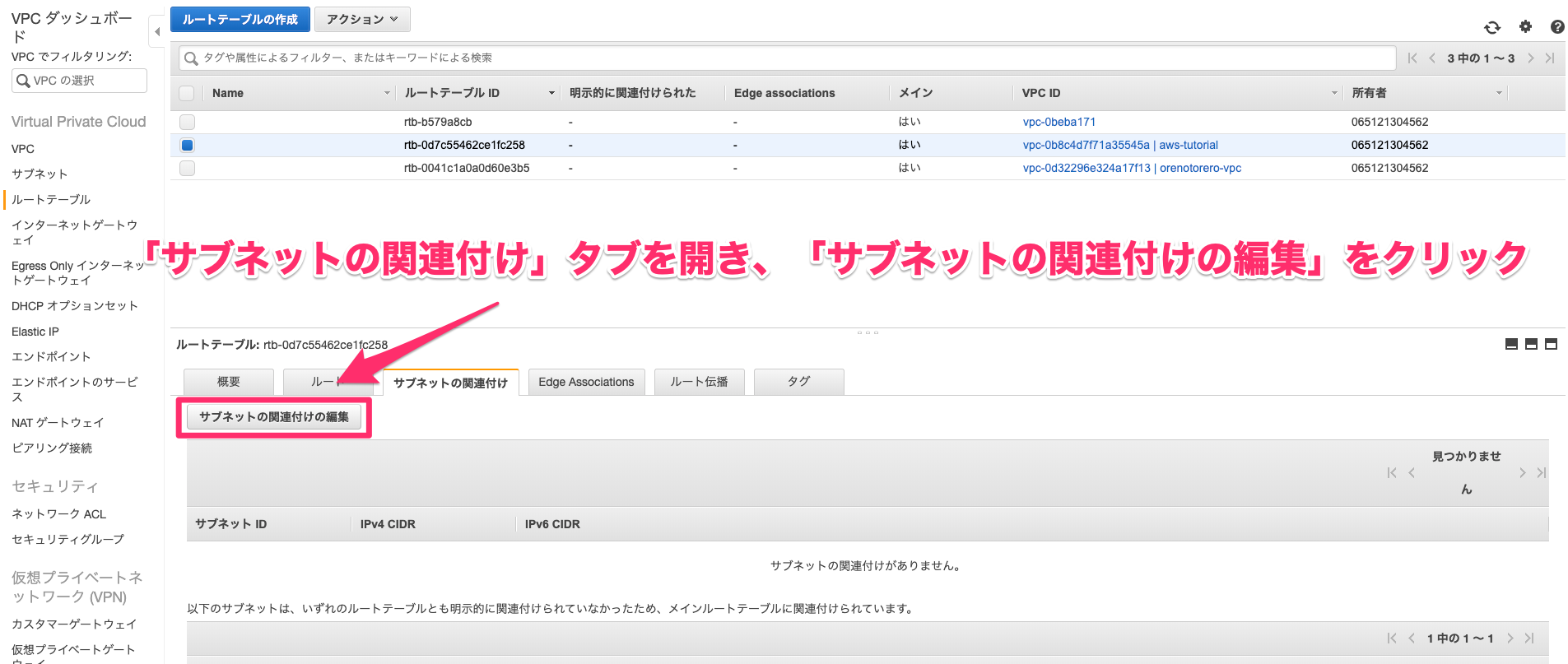

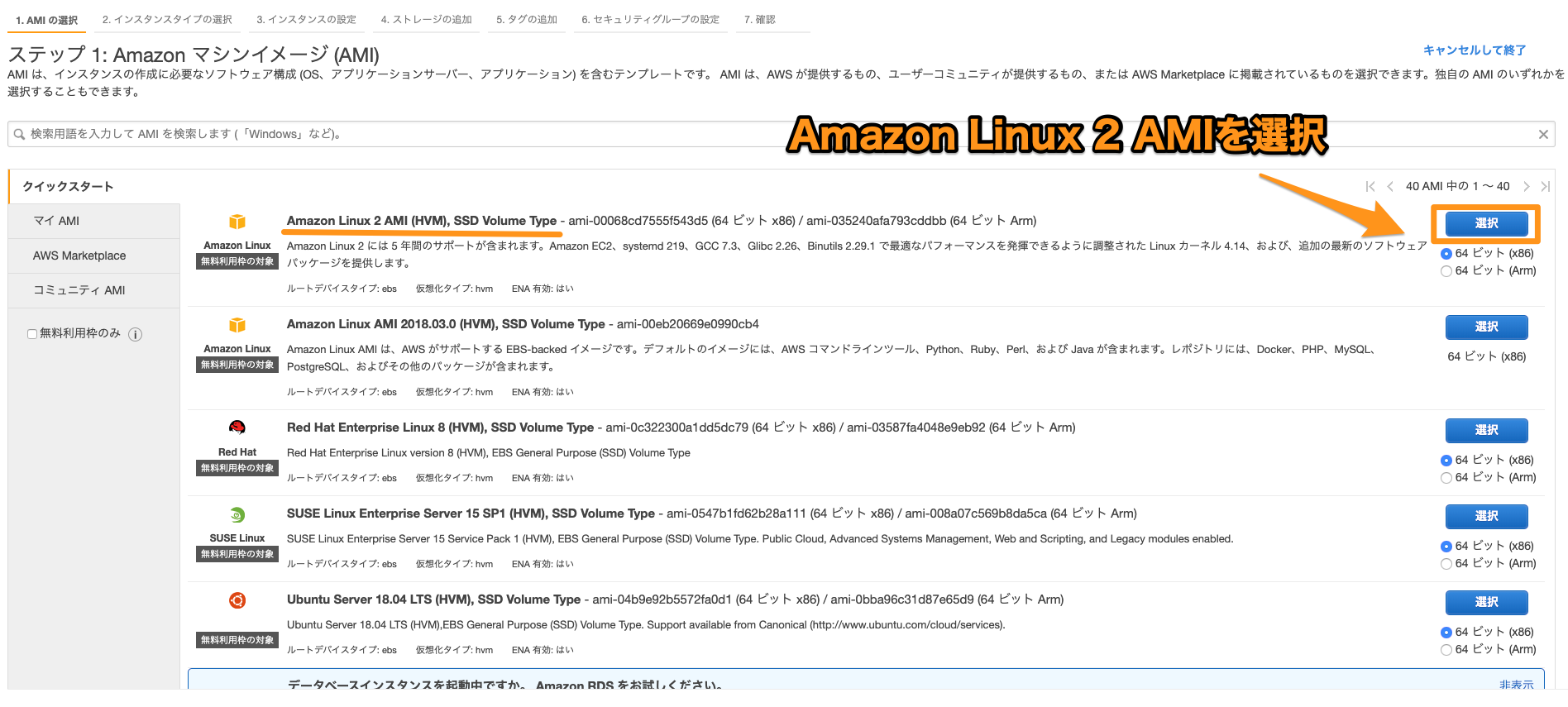

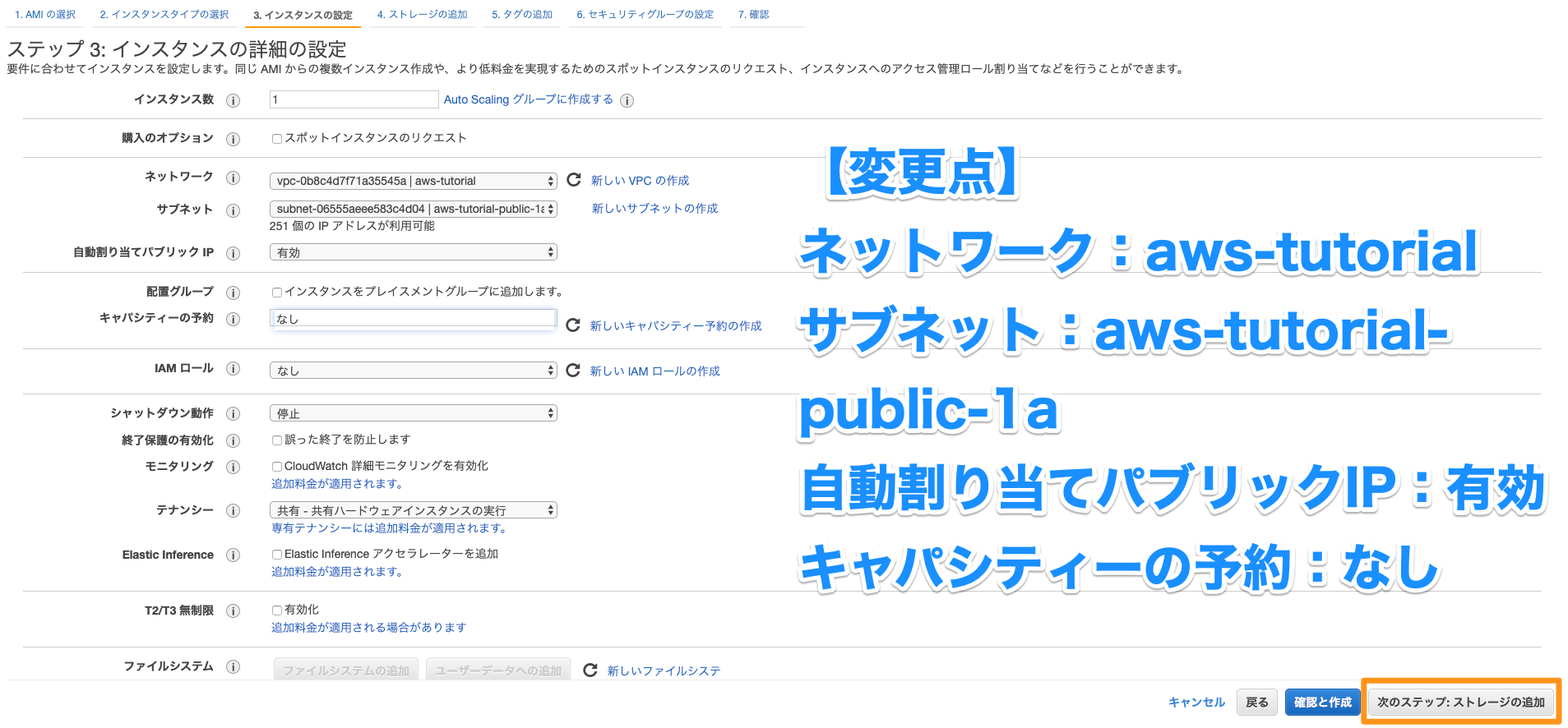

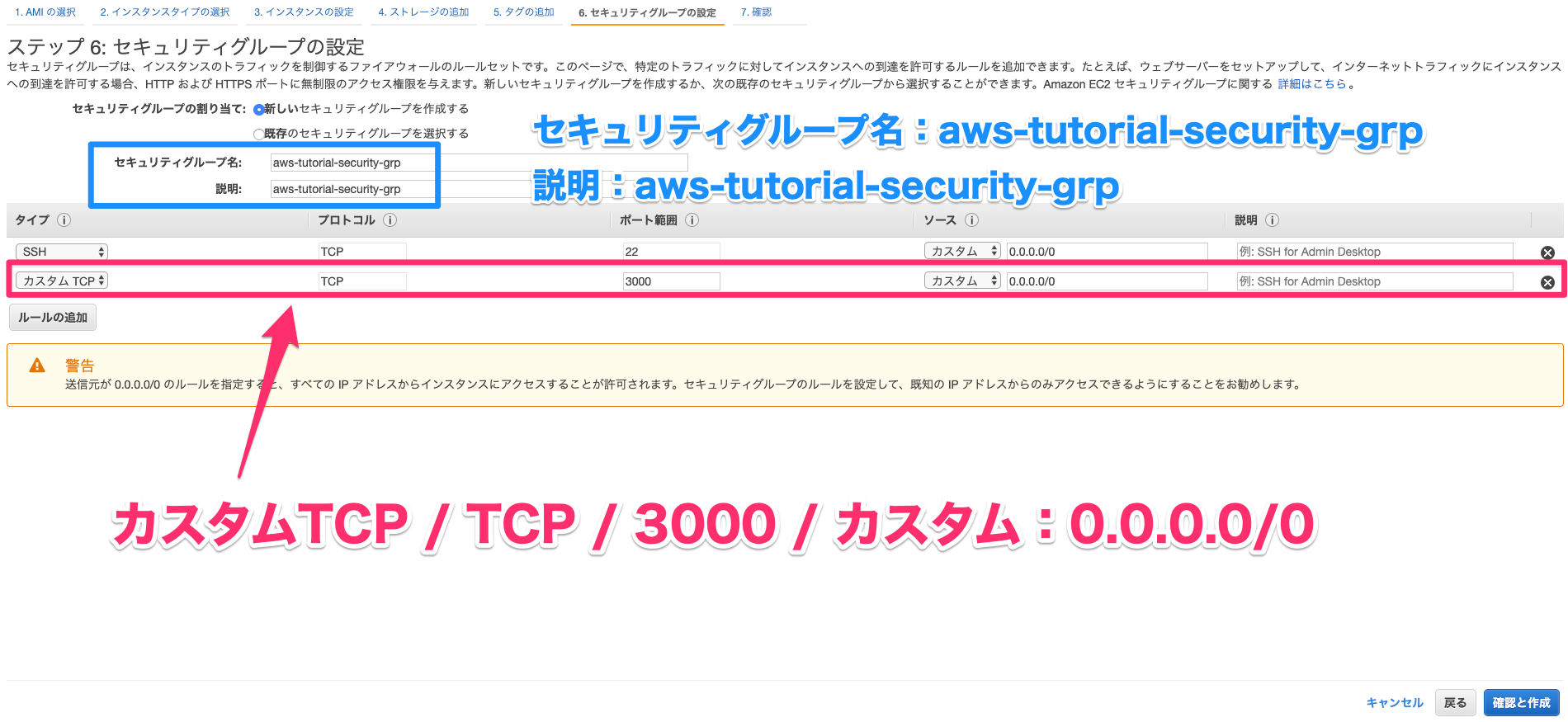
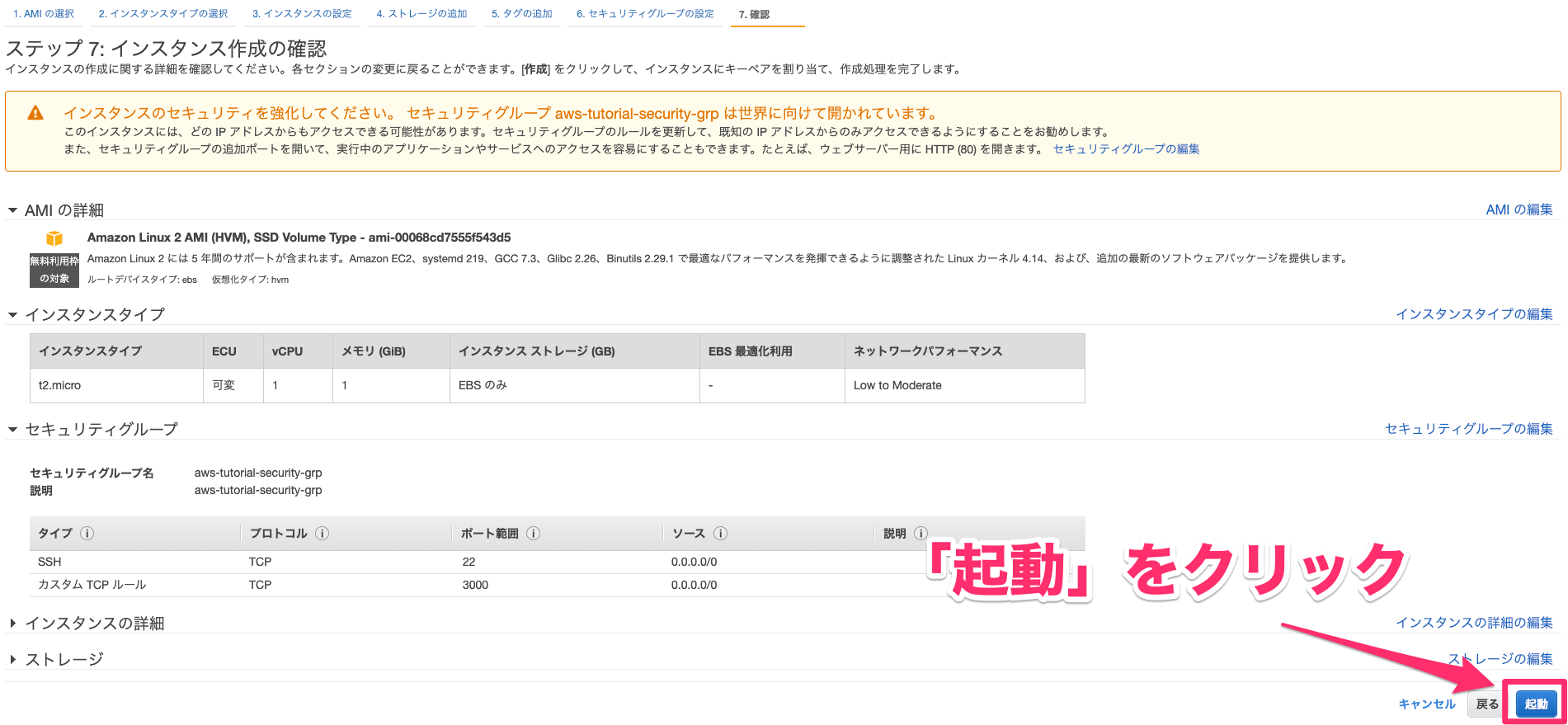
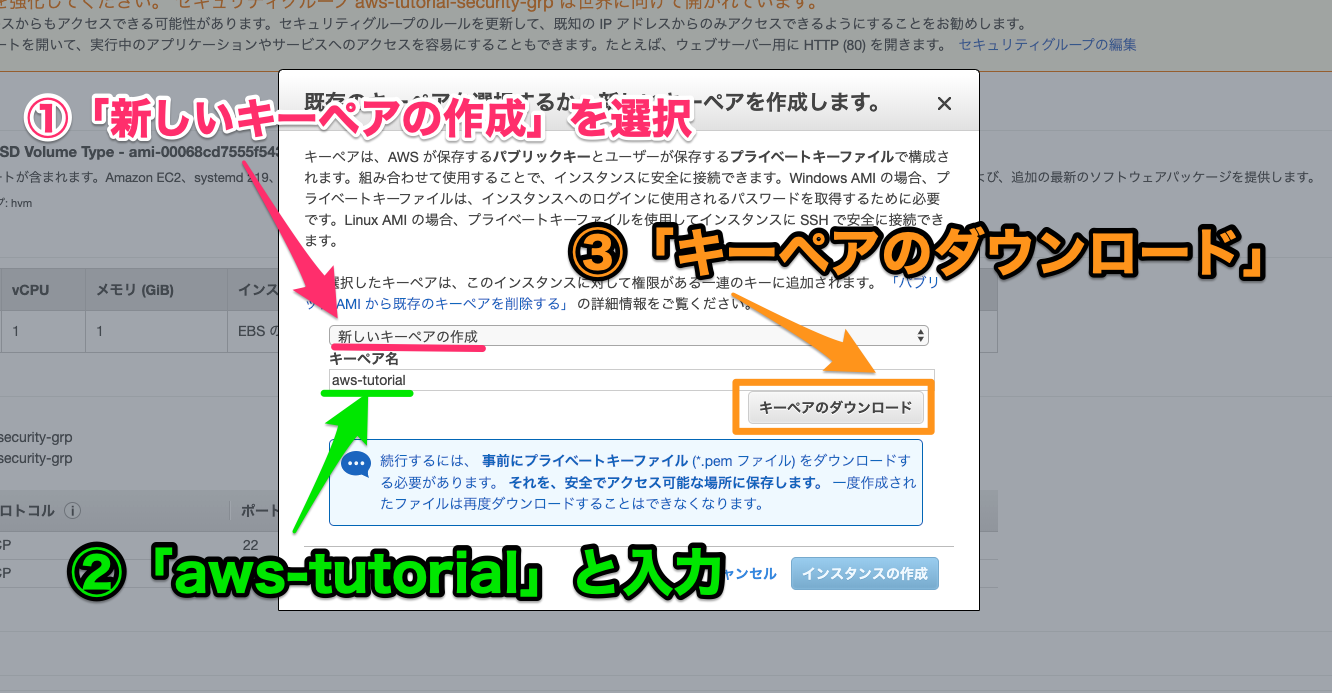
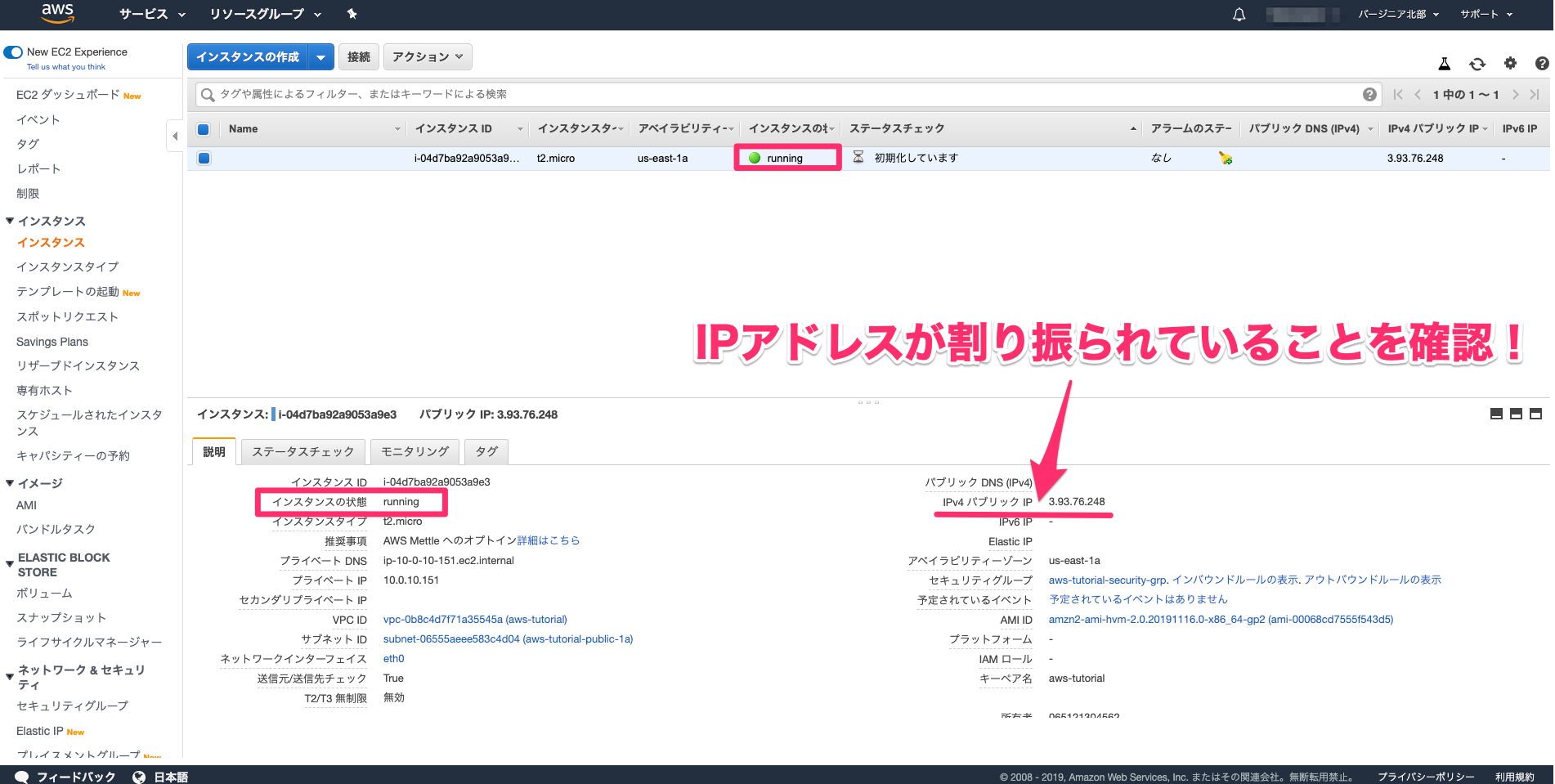
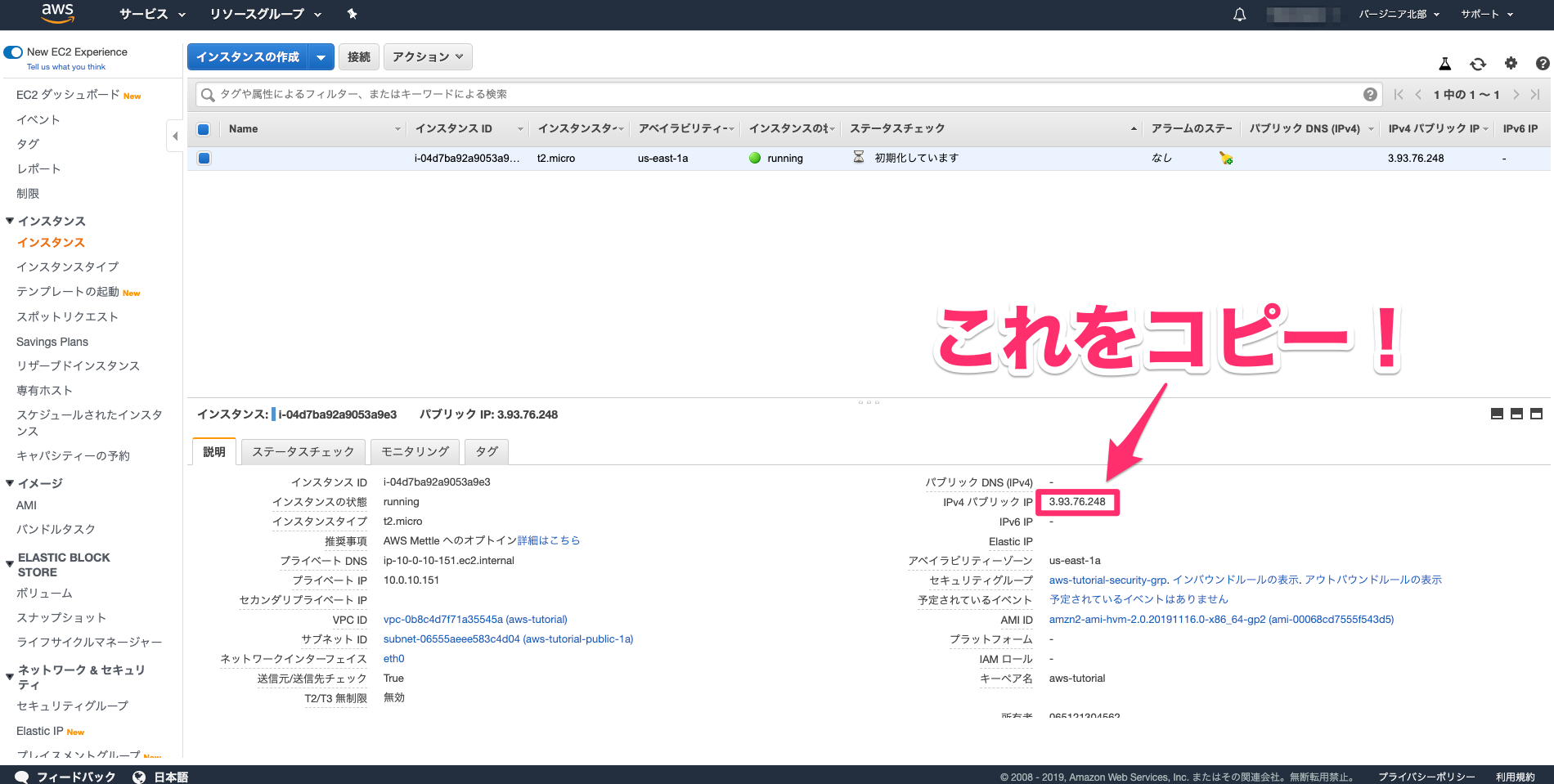

- 投稿日:2019-12-22T13:07:36+09:00
Serverless Framework で Step Functions を設定する
はじめに
今回は Serverless Framework を使用して、Step Functions のステートマシンを作成する方法をご紹介します。
今回ご紹介する方法は、Serverless Framework を Docker コンテナ上で実行する形にしています。
今回のサンプルプログラムは以下に置いてあります。
https://github.com/memememomo/sls-step-functions-sampleプロジェクトディレクトリの作成
まずは、プロジェクト用のディレクトリを作成します。
プロジェクトディレクトリを作成$ mkdir sls-step-functions-sample $ cd sls-step-functions-sampleDocker の設定ファイル作成と初期化
Serverless Framework を Docker で実行するための設定ファイルを作成します。
docker-compose.ymlversion: '3' services: sls: build: context: ./ dockerfile: Dockerfile volumes: - .:/opt/app env_file: - aws-credentialsDockerfileFROM amaysim/serverless:1.60.0 WORKDIR /opt/app COPY . /opt/app/設定ファイルを作成したら、 docker-compose コマンドでビルドします。
ServerlessFrameworkの初期化$ docker-compose buildServerlessFramework の初期化
Docker コンテナ上で、ServerlessFramework の初期化コマンドを実行します。
ServerlessFrameworkの初期化$ docker-compose run sls sls create -t aws-nodejs $ docker-compose run sls npm init -yServerlessFramework のプラグインインストール
Step Functions の設定をするために、プラグインをインストールする必要があります。以下のように、必要なプラグインをインストールします。
必要なプラグインをインストール$ docker-compose run sls npm install -D serverless-pseudo-parameters $ docker-compose run sls npm install -D serverless-step-functionsStep Functions プラグインの他に、疑似パラメータを使用できるようになるプラグインもインストールしています。このプラグインにより、
#{AWS::AccountId}や#{AWS::Region}などのパラメータが設定ファイル上で使用できるようになります。これらのプラグインを有効にするため、Serverless Framework の設定ファイルに追記します。
serverless.ymlplugins: - serverless-step-functions - serverless-pseudo-parametersサンプル用のプログラムを作成
以下のように、
helloとworldをそれぞれ返す関数を定義します。handler.js'use strict'; module.exports.hello = async event => { return { statusCode: 200, body: JSON.stringify( { message: 'Hello', }, null, 2 ), }; }; module.exports.world = async event => { return { statusCode: 200, body: JSON.stringify( { message: 'World', }, null, 2 ), } };これらの Lambda 関数を作成するために、Serverless Framework の設定ファイルに追記します。
serverless.ymlfunctions: hello: name: hello handler: handler.hello world: name: world handler: handler.worldStep Functions のステートマシンの設定
Step Functions のステートマシンは正式には JSON で定義するのですが、Serverless Framework の設定ファイルでは YAML で以下のように定義します。
serverless.ymlstepFunctions: stateMachines: HelloWorld: name: hello-world definition: StartAt: Hello States: Hello: Type: Task Resource: arn:aws:lambda:#{AWS::Region}:#{AWS::AccountId}:function:hello Next: World World: Type: Task Resource: arn:aws:lambda:#{AWS::Region}:#{AWS::AccountId}:function:world End: truehello と world を順番に実行するステートマシンを定義しています。
デプロイと実行
以上で、一通りの設定が終わったので、以下のコマンドでデプロイします。
デプロイ$ docker-compose run sls sls deployコマンドの実行が終わると、AWS 上の Step Functions のステートマシンが作成されます。「実行の開始」ボタンを押して実行すると、ステートマシンが正常に実行されることが確認できます。
以上が、Step Functions の設定の流れとなります。
おわりに
Serverless Framework で、Step Functions の設定を行う方法をご紹介しました。とっかかりとして、参考にしていただければ幸いです。


- 投稿日:2019-12-22T12:32:04+09:00
expoのスマホアプリビルドをCodePipelineで自動化する!
お手軽になったスマホアプリ開発
React NativeでiOSもAndroidも対応!
40を越えた中年のおじさんである僕は、スマホアプリ開発といえば
JavaとかObjective-Cを使って地道に画面を作りこんでいくイメージがあったのですが(嗚呼…)
昨今は JavaScript(React Native・Vue Native) を使用すると
簡単にどちらにも対応するアプリが作れるようになりつつあります。React Native+Expoでジオフェンシングを使ったリマインドアプリを作って忘れっぽい自分を救う!
こちらの記事にもある通りで、React Nativeは沢山のサンプル・ライブラリが揃ってきていて、
スマホアプリ開発をJavaScriptで実現していくことが出来ます。スタイルシート、タグ共にWebに慣れている人にとっては若干差異がありますが、
JavaScriptを書き慣れている人にとってはネイティブ言語よりも遥かにとっつきやすいでしょう。動作確認もexpo-cliで簡単に!
React Nativeで書かれたプログラムを動かす方法の中で、expoを使用するとお手軽です。
expoのコマンドを起動するとブラウザが立ち上がって、
シミュレーターにアプリをリリース出来ます。コマンドは簡単!expo start androidwindowsマシンでシミュレーターを予め起動して(あるいは実機をつなげて)おいて、
上記コマンドを実行するとアプリが起動してテストが出来ます。expo start iosmacマシンでコマンドを実行するとシミュレーターが自動で起動します。
予めxcodeをインストールしておく必要があります。コードを書きながらアプリをシミュレーターで動かして動作確認をしていくことが出来るので、
iOS/Androidの双方に対応するアプリを完成させることの敷居は随分下がりました。
手間がかかるスマホアプリの公開…
アプリを書いたら公開してみたくなるのがエンジニアの常だと思いますが、
実の所、公開はそんなに簡単ではありません。
今回の記事はその公開までの手順を一部自動化しようという試みで記載しています。公開の準備
早速、以下の記事を読んで事前準備をお済ませください。
さほど難しくはないのですが手間と時間(とお金…)がかかりますので、ゆとりを持ってご準備ください。
expo.ioに登録する(IDとパスワードは後述の手順で使用します)
expo.ioGoogle Play Storeに登録する
Google Play Storeにアプリを公開するApple Store Connectに登録する(AppleIDとパスワード、TeamIDは後述の手順で使用します)
【2019年版】iOSアプリをApp Storeに公開するための全手順まとめexpo-cliとCodePipelineでビルドを自動化する!
準備が整ったらビルドを自動化していきます。
今回はaws CodeCommit + CodeBuildを使用して、それらをaws Code Pipelineでつないで自動化します。
Github/Gitlabを使用している方も、
設定ファイルの記述方法を随時読み替えていただければ対応出来ます。まず、CodeCommitにリポジトリを作ってコードを格納します。
CodeCommitはawsの中にgitリポジトリを置く事が出来るサービスです。
.gitignoreはこんな感じに設定します。node_modules/**/* .expo/* .expo-shared/* *.jks *.p8 *.p12 *.key *.mobileprovision *.orig.* npm-debug.* web-build/ web-report/ .DS_Storeモジュール一式が格納出来たら、ビルド用の設定ファイル(buildspec.yml)を作成します。
buildspec.ymlversion: 0.2 env: variables: EXPO_USERNAME: [expo.ioのusername] EXPO_PASSWORD: [expo.ioのpassword] EXPO_APPLE_ID: [AppleId] EXPO_APPLE_PASSWORD: [AppleIdのパスワード(アプリパスワードではなく普通のパスワード)] APPLE_TEAM_ID: [初期設定時に発行されるTeamId] phases: install: runtime-versions: docker: 18 nodejs: 10 commands: - npm install -g expo-cli - npm install build: commands: - expo start --minify -m --tunnel --no-dev & - sleep 10 - expo login -u $EXPO_USERNAME -p $EXPO_PASSWORD - expo build:android --no-wait - expo build:ios --no-wait --apple-id $EXPO_APPLE_ID --team-id $APPLE_TEAM_ID残りは、この設定ファイルが読まれるようにCodeBuildを設定していきます。
CodeCommit/CodeBuildが完成したら、CodePipelineでつないでテストします。
設定が上手くいくと、gitにモジュールをpushすると自動でCodePipelineが動いて
数十分後にexpo.ioに以下のようにipa(iOS向け)/apk(Android向け)アプリがビルドされます。
緑色のアイコンが表示されていたらビルド成功です。
ダウンロードしてそれぞれのストアにアップロードしましょう。
(ストアにアップロードするところも自動化出来る記事を時々見かけますので、
この先時間があれば挑戦していきたいです)なお、Androidはブラウザ経由でapkファイルを簡単にアップロードできますが、
iOSはTransporterというアプリを使用するなどしてmacマシンよりipaファイルをアップロードします。まとめ
という訳で、gitにコードをpushしたら自動でiOS/Androidアプリがビルドされる環境を整えました。
いつもコマンドで実行していてビルドが手間…という方がいらしたら、ぜひお試しください!年の瀬になりました。
本年もお世話になりました、どうぞよいお年をお迎えください。



- 投稿日:2019-12-22T11:33:07+09:00
AWS Certified SAA を受けてみた
概要
AWS Certified Solution Architect Associate(SAA)を受験し、合格しました。以下はその記録です。
経緯
会社の偉い人に「お金出すから受けてみたら?」と言われたので業務で使うことになっていきそうだったからです(その時点では未経験でした)。前半
8月くらいに受験を考え始め、Udemyでそれっぽいハンズオンのコースを受講しました。それに満足し試験を受けるのをすっかり忘れていました。
12月になり、今年中にとっておこうと思い立って試験を予約、受験することにしました。試験の予約が難しかったです。日程や立地の都合が良かった銀座の歌舞伎座タワー5階のテストセンターを選びました。
情報収集を始め、いわゆる黒本を買い読み始めました。SAAはQiitaにもたくさん記事があり助かりました。先人の知恵は偉大です。そういうわけでこの記事では、試験の概要などの説明は割愛します。
後半
会社の先輩に、whizlabsという練習問題を体験できるサイトを教えてもらい、適当に進めました。理解が不足している箇所をあぶり出すのに有効でした。いわゆる赤本も貸してもらったのですが、思いの外よく、個人的には黒本よりも網羅的に学習するのには向いているなと感じました。個人の感想です。
当日
14:30に試験開始でした。演習問題で間違えたものを見直し、試験会場に行きました。
待機中に他の受験者を観察していたのですが、黒本を使っている人が多かったですね。あとはスマホアプリで勉強している(もしくは遊んでいる?)人も結構いました。
簡単に説明を受けて会場に入り、指定された座席のPCを操作して試験を受けます。ぱっとみ初見の問題が多くどきっとしました。日本語が怪しい箇所は時々英語で読み直したりしながら解きました。
一周解き終えて60分くらい。見直しながら回答を修正していき30分。途中退室しました。早々に解き終えている人も何人かいてすごいなあと思いました。試験を終えるボタンを押すと簡単なアンケートを答えさせられ、その後、試験終了の画面に遷移します。文中にさりげなく「合格しました」と書いてあるのを確認し、一息つきました。
まとめ
情報は古くなる
他の記事などでも多く言及されているのですが、AWSは現在進行系で機能が追加され続けているサービスです。故に情報はすぐに陳腐化します。例えば「VPC内ではLambdaの起動が遅い」と本などには書かれていますが、ちょっと前に改善されたなどがあります。
ある程度網羅的に学習したあとは、1次情報であるAWS公式の資料を見て最新の情報をキャッチアップする必要がありそうです。とはいえ、本質的な設計思想はそこまで変わらないため、そういう問題を取りこぼしたとしても合格はできる気がします。入門にはよい
どのような方法で学習するにせよ、この試験を受験して合格することができたならば、AWSに入門できたといえるでしょう。
もちろん合格しただけで使いこなせるわけではないのですが、受験で得た知識を利用して自分でサービスを組むきっかけにはなりますし、その中でわからないところが出てきたら改めて調べつつ理解を深めていけるようになっている気がします。情報が陳腐化することを理解した受験生は今後も1次情報を参照するようになりますし、そういう教育的な目的もあるのかもしれません。
- 投稿日:2019-12-22T09:53:38+09:00
AWS Amplifyを使ってCognito User PoolsログインするSwiftUIのサンプル
はじめに
最近Amplifyを利用し始めたのですが、Amplify CLIでちょっとコマンドを実行するだけで、アプリからAWSのリソースを利用できるようになり、すごく便利に感じています。
ここでは、Amplifyを使って、Cognito User Poolsログインする処理をSwiftUIで行う方法を説明します。
ドキュメントには、ログインやログアウトなど一つ一つの例はあるのですが、具体的にアプリにどのように組み込むかまでは記載されていません。そこで、このサンプルが具体的にアプリにどう組み込むか悩んでいる方に役に立つのではないかと思い、書きました。
前提
バージョンは次の通りです。
- Xcode 11.2.1
- Amplify iOS SDK 2.0
また、この記事では、サインインの処理を具体的にどう組み込むかのみを説明します。
CocoaPodsに依存関係を設定して、
$ amplify add authして、...のような基本的な手順は割愛します。基本的な利用手順については、以下のドキュメントをざっと読んでいただければと思います。
https://aws-amplify.github.io/docs/sdk/ios/authenticationイメージ
アプリを起動して、ユーザーがログイン済で出ない場合、ログイン画面を開きます。
ログインしたら、ホーム画面に遷移します。
Podfile
target 'MyApp' do use_frameworks! pod 'AWSMobileClient', '~> 2.12.0' target 'MyAppTests' do inherit! :search_paths end target 'MyAppUITests' do end endSceneDelegate
ポイントは以下の2つです。
AWSMobileClient.initialize(completionHandler:)でAWSMoblieClientを初期化し、結果に応じてホーム画面またはログイン画面を開くAWSMobileClient.addStateListener(object:callback:)でuserStateをobserveし、userStateの変化に応じてホーム画面またはログイン画面を開くSceneDelegate.swiftimport UIKit import SwiftUI import AWSAppSync import AWSMobileClient class SceneDelegate: UIResponder, UIWindowSceneDelegate { var window: UIWindow? func scene(_ scene: UIScene, willConnectTo session: UISceneSession, options connectionOptions: UIScene.ConnectionOptions) { if let windowScene = scene as? UIWindowScene { let window = UIWindow(windowScene: windowScene) AWSMobileClient.default().initialize { [weak self, window] (userState, error) in guard let self = self else { return } if let error = error { print("### AWSMobileClient.initialize.error", error.localizedDescription) return } if let userState = userState { switch (userState) { case .signedIn: self.showHomeView(in: window) // ホームを開く case .signedOut: self.showSignInView(in: window) // ログインページを開く default: AWSMobileClient.default().signOut() self.showSignInView(in: window) // ログインページを開く } } } AWSMobileClient.default().addUserStateListener(self) { [weak self, window] (userState, info) in guard let self = self else { return } switch (userState) { case .signedIn: self.showHomeView(in: window) // ホームを開く case .signedOut, .signedOutUserPoolsTokenInvalid: self.showSignInView(in: window) // ログインページを開く default: AWSMobileClient.default().signOut() self.showSignInView(in: window) // ログインページを開く } } } } private func showHomeView(in window: UIWindow) { DispatchQueue.main.async { window.rootViewController = UIHostingController(rootView: HomeView()) self.window = window window.makeKeyAndVisible() } } private func showSignInView(in window: UIWindow) { DispatchQueue.main.async { window.rootViewController = UIHostingController(rootView: SignInView(viewModel: SignInViewModel())) self.window = window window.makeKeyAndVisible() } } }SignInView
パスワードの初期化とサインアップは割愛させていただきます。
SignInView.swiftimport SwiftUI struct SignInView: View { @ObservedObject var viewModel: SignInViewModel var body: some View { VStack(spacing: 20) { Spacer() Text("MyApp") .bold() .font(.title) Spacer() TextField("Username", text: $viewModel.userName) .autocapitalization(.none) .padding() .overlay( RoundedRectangle(cornerRadius: 6) .stroke(Color.gray, lineWidth: 1) ) SecureField("Password", text: $viewModel.password) .padding() .overlay( RoundedRectangle(cornerRadius: 6) .stroke(Color.gray, lineWidth: 1) ) Button(action: { print("### signinButton did tap") self.viewModel.signIn() }) { HStack { Spacer() Text("Sign in") Spacer() } .padding() } .accentColor(.white) .background(Color.green) .cornerRadius(6) .alert(isPresented: $viewModel.showAlert) { Alert(title: Text("Sign in error"), message: Text(viewModel.errorMessage)) } HStack { Spacer() Button(action: { fatalError("forget password hasn't be implemented.") // 省略 }) { Text("Forget password?") } } Spacer() HStack { Spacer() Text("Don't have an account?") Button(action: { fatalError("sign up hasn't be implemented.") // 省略 }) { Text("Sign up") } Spacer() } Spacer() } .padding(EdgeInsets(top: 15, leading: 15, bottom: 15, trailing: 15)) } } struct SignInView_Previews: PreviewProvider { static var previews: some View { SignInView(viewModel: SignInViewModel()) } }SignInViewModel
SignInViewModel.swiftimport Foundation import AWSMobileClient class SignInViewModel: ObservableObject { @Published var userName: String = "" @Published var password: String = "" @Published var showAlert = false @Published var errorMessage: String = "" func signIn() { AWSMobileClient.default().signIn(username: userName, password: password) { (result, error) in if let error = error { print("### signin error:", error.localizedDescription) self.showAlert = true self.errorMessage = error.localizedDescription } print("### Signin success") } } }HomeView
HomeView.swiftimport SwiftUI struct HomeView: View { var body: some View { Text("Home") .font(.title) } } struct HomeView_Previews: PreviewProvider { static var previews: some View { HomeView() } }以上です。

- 投稿日:2019-12-22T08:39:44+09:00
AWS Lambdaのランタイムサポートポリシーについて、および、廃止が迫った場合の対処法
TL;DR
知っているようで知らないAWS Lambdaのランタイムポリシー、そして、これまで使っていたランタイムが使えなくなったらどうしよう?
そんな疑問にお答えします。
背景
AWS Lambdaは2019/12/22現在、サポートランタイムが12個あり、それらは以下のとおり。これはマネージメントコンソールからいつでも確認できます。
re:Inventで新しいランタイムのサポートがアナウンスされました。
- AWS Lambda now supports Node.js 12
- AWS Lambda now supports Java 11
- AWS Lambda now supports Python 3.8
新しいランタイムが増えるのは開発者としては嬉しいですよね。
でも、来る者あれば、去る者あり、、、
こんなメールが来てたりします?
「AWS Lambda: Node.js 8.10 is EOL, please migrate your functions to a newer runtime version」というタイトルで開くと、、
Hello, We are contacting you as we have identified that your AWS Account currently has one or more Lambda functions using Node.js 8.10, which will reach its EOL at the end of 2019. > What’s happening? The Node community has decided to end support for Node.js 8.x on December 31, 2019 [1]. From this date forward, Node.js 8.x will stop receiving bug fixes, security updates, and/or performance improvements. To ensure that your new and existing functions run on a supported and secure runtime, language runtimes that have reached their EOL are deprecated in AWS [2]. For Node.js 8.x, there will be 2 stages to the runtime deprecation process: 1. Disable Function Create – Beginning January 6, 2020, customers will no longer be able to create functions using Node.js 8.10 2. Disable Function Update – Beginning February 3, 2020, customers will no longer be able to update functions using Node.js 8.10 After this period, both function creation and updates will be disabled permanently. However, existing Node 8.x functions will still be available to process invocation events. > What do I need to do? We encourage you to update all of your Node.js 8.10 functions to the newer available runtime version, Node.js 10.x[3] or Node.js 12.x[4]. You should test your functions for compatibility with either the Node.js 10.x or Node.js 12.x language version before applying changes to your production functions. > What if I have issues/What if I need help? Please contact us through AWS Support [5] or the AWS Developer Forums [6] should you have any questions or concerns. [1] https://github.com/nodejs/Release [2] https://docs.aws.amazon.com/lambda/latest/dg/runtime-support-policy.html [3] https://aws.amazon.com/about-aws/whats-new/2019/05/aws_lambda_adds_support_for_node_js_v10/ [4] https://aws.amazon.com/about-aws/whats-new/2019/11/aws-lambda-supports-node-js-12/ [5] https://aws.amazon.com/support [6] https://forums.aws.amazon.com/forum.jspa?forumID=186 Sincerely, Amazon Web Servicesこれって、端的に言うとランタイムの廃止予定の連絡なんですよね。
今回は、Node.js 8.xについてですが、他のランタイムもEOLのアナウンスが来ることでしょう。これが来るとドキドキしますよね。
ちなみに、ランタイム自体のLTSを決めているのは、そのランタイムごとの運営管理母体があり、AWSではありません。ですので足の速いランタイムや長く使えるランタイムなどの個性がでます。
古いランタイムってどうなるの?
ランタイムサポートポリシーを理解する
過去のメールを見逃してないか、公式サイトも見ておきましょう。
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/runtime-support-policy.htmlAWSの公式サイトにいくと、ランタイムの廃止スケージュールが書かれているのですが、よく見ると「End of Life」以外にいろいろな項目があるのがわかります。廃止 (作成) 、廃止 (更新)と書かれているのですよね。
End of Lifeがアナウンスがアナウンスされると、この廃止 (作成) 、廃止 (更新)のスケジュールが重要になります。
廃止 (作成)の意味は、End of Lifeアナウンス対象のランタイムのLambda関数が、この日以降作成できなくなるという意味です。作成済みであれば、更新は可能です。廃止 (更新)の意味は、作成済みであれば、この日まで更新は可能ですが、この日以降は更新もできなくなるという意味です。ここまでは、おそらく直感的に理解できると思います。
さて、疑問なのは更新もできなくなった関数がいつまで
実行できるかです。公式サイトの表にも記載がありません。
実行については数ヶ月間の期間をおいて、停止されますがそのスケジュールがこの表に明記されることはありません。逆に言えば廃止(更新)後もしばらくは実行できるということですね。しばらく実行できるとは言っても、EOLアナウンスがされたLambda関数の管理者は、すみやかな対処をした方が良いでしょう。
対処法
プロダクト、サービスのワークロードに応じて様々な対処法が考えられると思います。ここに挙げている対処がすべてではありませんので、ご自身の管理されているワークロードに応じて決定してください。
- ランタイムのversion upがstraight forwardな方法です。ただし、syntaxの修正や依存ライブラリの解決など個別対応が必要となる場合があります。
- カスタムランタイムの使用もできます。これは現行ランタイムのversionを維持する方法ですが、この場合には、カスタム実装したランタイムはAWSサポート対象外になりますし、カスタムランタイムの構築もユーザー側で行う必要があります。
- 比較的、小さなコードブロックの場合、別の言語へのポーティングも考えられます。例えば足の速いNodejsから比較的長期で使えるPythonへのコードポーティングなどもできるでしょう。顧客に利益にならない裏側の実装のことで時間やコストがかかるのは嬉しくないでしょうし、あくまでも運用上利用している小さな関数の場合という感じでしょうか。
- 3rd Partyのランタイムで良いのであれば、 出来合いのカスタムランタイムをユーザーの責任で使用することもできます。
プロジェクトの人的、時間的リソースが割り当てられる場合、1の対処法を選ぶ場合が多いでしょう。しかし様々な理由から古いランタイムを維持することを選ばざるを得ないケースもあることでしょう。
ここからは、そういったケースのお話しになります。
カスタムランタイムの実装
カスタムランタイムの実装によるサポート対象外となってしまったランタイムの維持ができます。
カスタム AWS Lambda ランタイムここに、書かれているようにカスタムランタイムをつかえば古いバージョンの実行も可能になります。
問題点としては、
- AWSのサポートが受けられないこと。つまり何かランタイムの挙動についてサポートを使いたいとしてもAWSサポートはの守備範囲外になってしまいます。
- カスタムランタイムにおけるセキュリティ的な脆弱性が発見された場合にも、ユーザー側でパッチを当てるなどの対処が必要になります。またランタイムを利用している全ての関数に対して行う必要が出て来ます。
- そもそもカスタムランタイムを実装するのにコストと時間をかけなければならない。
AWSサポートが使えないというのは、しょうがないとしても、少なくともカスタムランタイムを実装するのにかかるコストと時間をなんとか軽減できないでしょうか?
Lambda Layers
そこで、本日ご紹介するのがawesome-layersです。
Layersの欄にNode.js v8があります。この3rd party Runtimeが使えるのであれば、これをワークアラウンドとして採用することもできます。もちろんユーザーの責任範囲でこの対処方法を選択してください。
2019/12/22時点でawesome-layersの内容
Name ARN / Link Compatible Runtimes C++ (official) Link: awslabs/aws-lambda-cpp providedRust (official) Link: awslabs/aws-lambda-rust-runtime providedBash ARN: arn:aws:lambda:<region>:744348701589:layer:bash:<version>
Link:gkrizek/bash-lambda-layerprovidedBallerina Link: ballerina.io/deployment/aws-lambda providedCrystal Link: lambci/crambda providedNim Link: lambci/awslambda.nim providedNode.js v8 - N\ Solid ARN: arn:aws:lambda:<region>:800406105498:layer:nsolid-node-8:<version>
Link: accounts.nodesource.com/downloads/nsolid-lambdaNode.js v10 ARN: arn:aws:lambda:<region>:553035198032:layer:nodejs10:<version>
Link:lambci/node-custom-lambdaprovidedNode.js v10 - N\ Solid ARN: arn:aws:lambda:<region>:800406105498:layer:nsolid-node-10:<version>
Link: accounts.nodesource.com/downloads/nsolid-lambdaNode.js v12 ARN: arn:aws:lambda:<region>:553035198032:layer:nodejs12:<version>
Link:lambci/node-custom-lambdaprovidedPerl 5.3.0 ARN: arn:aws:lambda:<region>:445285296882:layer:perl-5-30-runtime:4
Link:shogo82148/p5-aws-lambda- see links to other version and Paws builds in repoprovidedPHP 7.1 & 7.3 ARN: arn:aws:lambda:<region>:887080169480:layer:php71:3
Link:stackery/php-lambda-layerprovidedPHP 7.2 & 7.3
cli & fpmARN: arn:aws:lambda:<region>:209497400698:layer:php-73:<version>
Link:brefphp/brefprovidedPypy 3.5 ARN: arn:aws:lambda:<region>:146318645305:layer:pypy35:<version>
Link: IOpipe Pypy Layerpypy3.5Brainfuck ARN: arn:aws:lambda:<region>:444134189787:layer:brainfuck:1
Built for fun, will not process events!providedLOLCODE ARN: arn:aws:lambda:<region>:444134189787:layer:lolcode:1
Built for fun, will not process events!providedJava 11 Link: andthearchitect/aws-lambda-java-runtime providedHaskell ARN: arn:aws:lambda:<YOUR REGION>:785355572843:layer:aws-haskell-runtime:2
Link: Getting Started with the Haskell AWS Lambda Runtimeprovidedこのように、かなり豊富なランタイムの種類が列挙されています。中には3rd Party企業のサポートを受けれるものもありますので、そういう場合は直接その企業にコンタクトを取って見るのも良いでしょう。
さらに、ついでに紹介しておくと、awesome-layersはランタイムだけでなく、PandocやparamikoといったUtilitiesや、DatadogやEpsagonといったMonitoringのLayersも列挙してくれています。
これら3rd Party Layersを使うことで、ランタイムの維持だけでなく、新しい価値を生み出すLayerを取り込むことでビジネスの速度を上げていただければと思います!


- 投稿日:2019-12-22T03:40:10+09:00
Serverless FrameworkでAmazon API Gatewayのベースパスマッピングを作ろうとした時の話
この記事は ハンズラボ Advent Calendar 2019 22日目の記事です。
昨日は、@jnuankさんの「来月退職します」から始めるモブプログラミング でした。はじめまして、今年4月に中途入社し、毎日AWSをがっつり触れて楽しい日々を送る@t-nmrです。
Advent Calendarに参加するの初めてなので何書こうか…?と悩みましたが、
業務でよく触れる機会のあるServerlessで、最近遭遇した内容について書こうと思います。何があったのか
タイトルにもある通り、ServerlessでAPI Gatewayとそのカスタムドメインを作ろうとしたところ、
ベースパスマッピングが上手く作成出来ず、ちょっとハマってしまう事がありました。何故かというと、ベースパスマッピングはパスと一緒に対象のステージを指定しなければいけないから。
つまり、初回sls deployの時点ではベースパスマッピング作成のタイミングで
まだメソッドがステージに一度もデプロイされておらず、ステージ自体が無い。API Gatewayと一緒にfunctionsでAPIのメソッドとなるLambdaを作成していたため、
「自動的にServerlessがデプロイやってくれるんだから、そいつをDependsOnで参照してやればいい」
そんな風に考えて何回か試してみたところ、対象リソースの論理IDの名前がコロコロ変わって予測出来ない。1
(論理IDの名前は「ApiGatewayDeploymentXXXXXXXX」といった感じで毎回名前が異なる)これじゃDependsOnで参照出来ない。凄く困る。
色々考えた結果
先にAPI GatewayとLambda作ってから2回に分けてリソース構築するとか、
別途スクリプトあたりで作るとかも考えましたが、やっぱりsls deployコマンド一発で作りたいですよね。という事で、シンプルにserverless.yml中でステージへのデプロイを別途明示的に行い、
その完了をDependsOnで待つ事にしました。ソースコード
こんな感じになりました (一部記載は簡略化しています)
また余談ですが、Deploymentの際にDependsOnで見ているApiGatewayMethodApiV1TestGetも、
Serverlessが自動的に作ってくれるリソースになります。しかし、このリソースの論理IDは名前の予測が可能 かつ 普通にDependsOnで指定可能です。
(「ApiGatewayMethod + {APIパスのupper camel case} + {HTTPメソッド} 」 という形式で作成されます。
慣れてる人には常識かと思いますが、初心者だとこういう部分も知らないと地味にハマりかけたりする…)functions: test: handler: lambda.handler timeout: 15 tracing: true events: - http: path: /api/v1/test method: get cors: true integration: lambda-proxy resources: Resources: ApiGatewayRestApi: Type: AWS::ApiGateway::RestApi Properties: Name: test-api ApiKeySourceType: HEADER EndpointConfiguration: Types: - REGIONAL ApiGatewayDomainName: Type: AWS::ApiGateway::DomainName Properties: DomainName: ${self:custom.domain_name} EndpointConfiguration: Types: - REGIONAL RegionalCertificateArn: ${self:custom.acm_arn_regional} # BasePathMappingの依存解決(stage作成)のために、デプロイを個別に実行する ApiGatewayDeploy: Type: AWS::ApiGateway::Deployment DependsOn: ApiGatewayMethodApiV1TestGet Properties: RestApiId: Ref: ApiGatewayRestApi StageName: ${self:provider.stage} ApiGatewayBasePathMapping: Type: AWS::ApiGateway::BasePathMapping DependsOn: ApiGatewayDeploy # ここで個別に実行したステージへのデプロイ完了を待つ Properties: BasePath: "" DomainName: ${self:custom.domain_name} RestApiId: Ref: ApiGatewayRestApi Stage: ${self:provider.stage}めでたしめでたし。
とでも思っていたのか?
はい、ここまで書いておいて全てをひっくり返します。
「デプロイの論理IDの名前がコロコロ変わって予測出来ない」と上で書きましたが違いました。
普通に記述出来る方法がありました。この記事を書いている最中(Advent Calendar投稿当日)に、念のためServerless Framworkの公式ドキュメントを再調査していたらこんな記載がありました。
あのランダムだと思っていた数字列はInstanceIdとやらで、${sls:instanceId}って感じで参照出来ますと。
つまり、結論としてはAWS::ApiGateway::Deploymentを書く必要は無く、
「ApiGatewayDeployment${sls:instanceId}」というリソースを
ベースパスマッピング作成時にDependsOnで見てやればオッケー。……… よし、週明けにserverless.ymlを書き直そう!
おわり
公式ドキュメントはちゃんと読もう。おじさんとの約束だ。
明日は@o2346さんです。
そう思っていた時期が私にもありました。 ↩
- 投稿日:2019-12-22T02:53:17+09:00
LogstashとFilebeatでIISログをあれこれしてみた話
この記事はElastic Stack (Elasticsearch) Advent Calendar 2019の22日目の記事です。
21日目は@yukata_unoさんによる「Elastic Machine Learningの歴史を振り返る」でした。はじめに
先日、知人より下記のご相談を頂きまして、この機会に技術検証してみることにしました^^
AWS環境上のIISサーバのアクセスログを使って
リアルタイムログ監視をやりたいけど、Elasticsearchで宜しくやれないの!?ということで、、
IISサーバのアクセスログをLogstashとFilebeatを使って、どんな構成が最適か追求してみました。余談ですが、LogstashとFilebeatは「どちらが良いの?」という質問をよく頂きます。
この記事を通して、vsモードではなく、補完関係にあることもお伝えできればと思います!!利用環境
product version Filebeat 6.5.4 logstash 6.5.4 Elasticsearch 6.5.4 kibana 6.5.4 Java 1.8.0 IIS 10.0.14293.0 EC2 (IIS) Windows Server 2016 (t3.medium) AMI ID (IIS) ami-03efee33577540873 EC2 (ES) Amazon Linux 2 (t3.large) AMI ID (ES) ami-00068cd7555f543d5 AWS Region us-east-1 ※ Elastic Stackのバージョンは少し古いです。(持ち合わせていたAmazon ESのバージョンが6.5.4であったため)
※ AWSのリージョンは料金の安いバージニアで構築しています。構成図
- IISサーバをEC2で構築し、ALB配下に配置しています。(ログ監視にX-Forwarded-forヘッダを利用するため)
- IISのアクセスログをAmazon ESに転送するため、LogstashとFilebeatを両方とも導入しています。
- Amazon ESのAlerting機能を用いて、Slack経由でシステム管理者に通知が行くようにしています。
- EC2で構築したElastic Stackサーバは構築途中で切り分けに利用した環境となっています。

前提として
- 本記事ではIISサーバやElastic Stackのインストール手順は省力しています。
【参考】
・IISのインストール
・Logstashインストール方法(Linux版)
・Logstashインストール方法(Windows版)
・Filebeatインストール方法
・Elasticsearchインストール方法
・Kibanaインストール方法検証内容
- Elastic Stackの構成を決める上で、以下の内容について今回検証しました。
1. IISアクセスログのパース処理 (LogstashとFilebeat module)
2. LogstashとFilebeatのWindowsサーバに与えるCPU負荷
3. End-to-Endでのデータパイプラインの構築実施手順
- 以下の手順で検証を実施します。
1. IISサーバのログ出力設定
2. Logstashのログ取得設定とその結果
3. Filebeat Moduleによるログ取得設定とその結果
4. FilebeatからLogstash経由でAmazon ESに格納1. IISサーバのログ出力設定
- Windowsサーバで
IISマネージャーを起動し、[ホーム画面] > [IIS] >ログ記録で機能を開きます。
- ログの形式は
W3C、ログファイルの保存先ディレクトリはデフォルトのままとします。
上記画面で
フィールドの選択を開くとこの画面が開きます。
ここでアクセスログに出力するフィールドを指定します。
以下、IISアクセスログに関するログ情報一覧になります。(設定値は今回の検証における設定になります)
# フィールド名(論理) フィールド名(物理) デフォルト値 設定値 種別 データ型 1 日付 date 有効 有効 標準 Date 2 時間 time 有効 有効 標準 Date 3 クライアントIPアドレス c-ip 有効 有効 標準 IP 4 ユーザー名 cs-username 有効 有効 標準 Keyword 5 サービス名 s-sitename 無効 有効 標準 Keyword 6 サーバー名 s-computename 無効 有効 標準 Keyword 7 サーバーIPアドレス s-ip 有効 有効 標準 IP 8 サーバーポート s-port 有効 有効 標準 Keyword 9 メソッド cs-method 有効 有効 標準 Keyword 10 URIステム cs-uri-stem 有効 有効 標準 Keyword 11 URIクエリ cs-uri-query 有効 有効 標準 Keyword 12 プロトコルの状態 sc-status 有効 有効 標準 Keyword 13 プロトコルの副状態 sc-substatus 有効 有効 標準 Keyword 14 Win32の状態 sc-win32-status 有効 有効 標準 Keyword 15 送信バイト数 sc-bytes 無効 有効 標準 Float 16 受信バイト数 cs-bytes 無効 有効 標準 Float 17 所要時間 time-taken 有効 有効 標準 Float 18 プロトコルバージョン cs-version 無効 有効 標準 Keyword 19 ホスト cs-host 無効 有効 標準 Keyword 20 ユーザーエージェント cs(User-Agent) 有効 有効 標準 Keyword 21 Cookie cs(Cookie) 無効 有効 標準 Keyword 22 参照者 cs(Referer) 有効 有効 標準 Keyword 23 X-Forwared-For X-Forwared-For 無効 有効 カスタム IP
- 今回は全てのフィールドをログに利用するように設定します。
またカスタムフィールドとしてX-Forwarded-Forを出力設定します。※ 1行1件のログを出力します。以下のフィールド順で各フィールド間はスペース区切りのTSV形式になります。
ログのフォーマットdate time s-sitename s-computername s-ip cs-method cs-uri-stem cs-uri-query s-port cs-username c-ip cs-version cs(User-Agent) cs(Cookie) cs(Referer) cs-host sc-status sc-substatus sc-win32-status sc-bytes cs-bytes time-taken X-Forwarded-Forサンプルログ2019-11-10 14:48:35 W3SVC1 EC2AMAZ-1D0KC7E 172.31.90.5 GET /favicon.ico - 80 - 172.31.6.170 HTTP/1.1 Mozilla/5.0+(Windows+NT+10.0;+Win64;+x64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/78.0.3904.87+Safari/537.36 - http://iis-212063043.us-east-1.elb.amazonaws.com/ iis-212063043.us-east-1.elb.amazonaws.com 404 0 2 1383 583 0 17.7.42.220【参考】
・X-Forwarded-Forフィールド追加方法2. Logstashのログ取得設定とその結果
- 公式HPからZIPダウンロード後、解凍した
Logstash-6.5.4フォルダを以下のディレクトリに配置します。(コンフィグファイルは、iislog.cfgというファイルとしています。)
※
C:\Program Files配下にフォルダを配置したら、エラーが出たため、C:直下に配置してます。
logstash.conf(今回はiislog.cfgという名前)の内容は以下のように設定します。iislog.cfginput { # input from iis accesslog file{ path=> ["C:/inetpub/logs/LogFiles/W3SVC1/*"] start_position => "beginning" } } filter { # skip header if "^#" in [message] { drop {} } dissect { # log format is TSV mapping => { "message" => "%{ts} %{+ts} %{s-sitename} %{s-computername} %{s-ip} %{cs-method} %{cs-uri-stem} %{cs-uri-query} %{s-port} %{cs-username} %{c-ip} %{cs-version} %{cs(User-Agent)} %{cs(Cookie)} %{cs(Referer)} %{cs-host} %{sc-status} %{sc-substatus} %{sc-win32-status} %{sc-bytes} %{cs-bytes} %{time-taken} %{X-Forwarded-For}" } } # skip ELB-HealthCheck if "ELB-HealthChecker/2.0" in [cs(User-Agent)] { drop {} } date { match => ["ts", "YYYY-MM-dd HH:mm:ss"] timezone => "UTC" } ruby { code => "event.set('[@metadata][local_time]',event.get('[@timestamp]').time.localtime.strftime('%Y-%m-%d'))" } mutate { convert => { "sc-bytes" => "integer" "cs-bytes" => "integer" "time-taken" => "integer" } remove_field => "message" } } output { # output to Amazon Elasticsearch Service elasticsearch { hosts => ["https://search-test-iislogs-************************.us-east-1.es.amazonaws.com:443"] index => "iislog-%{[@metadata][local_time]}" } }【補足】
※ grok filterではなく、処理負荷が低く記述が簡単なdissect filterでパース処理しています。
※ ファイルの冒頭4行に#(コメント)があるため、drop filterで削除しています。
※ LBのヘルスチェックがログ記録されるため、同様にdrop filterで削除しています。
※ 時刻が-18時間ズレてしまったため、date filterでtime zoneをUTC指定しています。
- Windowsコマンドプロンプトを起動し、上記コンフィグを読み込むようにLogstashをバッチ起動します。
Logstash起動C:\>logstash-6.5.4\bin\logstash.bat -f \logstash-6.5.4\iislog.cfgLogstashパース結果{ "_index": "iislog-2019.11.12", "_type": "doc", "_id": "cVM7X24BErkrDIwplkLo", "_version": 1, "_score": null, "_source": { "s-computername": "EC2AMAZ-1D0KC7E", "s-ip": "172.31.90.5", "cs(User-Agent)": "Mozilla/5.0+(Windows+NT+10.0;+Win64;+x64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/78.0.3904.87+Safari/537.36", "path": "C:/inetpub/logs/LogFiles/W3SVC1/u_ex191112_x.log", "cs-username": "-", "host": "EC2AMAZ-1D0KC7E", "time-taken": 0, "cs-method": "GET", "sc-status": "304", "cs-host": "iis-212063043.us-east-1.elb.amazonaws.com", "@version": "1", "c-ip": "172.31.15.135", "cs-uri-stem": "/", "ts": "2019-11-12 10:49:01", "@timestamp": "2019-11-12T10:49:01.000Z", "s-port": "80", "sc-win32-status": "0", "X-Forwarded-For": "126.xxx.248.xxx", "cs-version": "HTTP/1.1", "cs(Cookie)": "-", "sc-bytes": 143, "sc-substatus": "0", "cs(Referer)": "-", "cs-uri-query": "-", "s-sitename": "W3SVC1", "cs-bytes": 685 }, "fields": { "@timestamp": [ "2019-11-12T10:49:01.000Z" ] }, "sort": [ 1573555741000 ] }無事きれいにログをAmazon ESに取り込めました。
しかし、LogstashはJVMヒープ上で起動し、CPUとメモリリソースを消費します。
(以下は15MB程度のログをまとめて取り始めた時のCPU負荷)
3. Filebeat Moduleによるログ取得設定とその結果
WindowsサーバにLogstashを導入してフィルタ処理をすると
それなりの負荷がかかる可能性があるため、軽量なFilebeatを試してみます。
Filebeatには決まったログフォーマットをパース処理してくれるFilebeat moduleがあります。
今回、IIS Moduleを使ってみます。(フィールドは、IIS Fieldsの通りにパースされます)
- 公式HPからZIPダウンロード後、解凍した
FilebeatフォルダをC:\Program Files配下に配置します。- WindowsでPowerShellを管理者権限で起動し、以下の手順でIIS Moduleをセットアップします。
IIS_ModuleのセットアップWindows PowerShell Copyright (C) 2016 Microsoft Corporation. All rights reserved. PS C:\> cd '.\Program Files\Filebeat\' PS C:\Program Files\Filebeat> dir ディレクトリ: C:\Program Files\Filebeat Mode LastWriteTime Length Name ---- ------------- ------ ---- d----- 2019/12/19 8:17 kibana d----- 2019/12/19 8:17 module d----- 2019/12/19 8:17 modules.d -a---- 2018/12/17 20:24 41 .build_hash.txt -a---- 2018/12/17 20:21 83009 fields.yml -a---- 2018/12/17 20:22 37665280 filebeat.exe -a---- 2018/12/17 20:21 67865 filebeat.reference.yml -a---- 2019/12/19 13:45 7686 filebeat.yml -a---- 2018/12/17 20:24 566 install-service-filebeat.ps1 -a---- 2018/12/17 20:17 11358 LICENSE.txt -a---- 2018/12/17 20:18 163067 NOTICE.txt -a---- 2018/12/17 20:24 802 README.md -a---- 2018/12/17 20:24 250 uninstall-service-filebeat.ps1 PS C:\Program Files\Filebeat> .\filebeat.exe modules enable iis Enabled iis PS C:\Program Files\Filebeat> .\filebeat.exe modules list Enabled: iis Disabled: apache2 auditd elasticsearch haproxy icinga kafka kibana logstash mongodb mysql nginx osquery postgresql redis system traefik PS C:\Program Files\Filebeat> .\filebeat.exe setup -e
C:\Program Files\Filebeat配下にあるfilebeat.ymlにAmazon ESのURLを指定します。filebeat.ymlの抜粋#-------------------------- Elasticsearch output ------------------------------ output.elasticsearch: # Array of hosts to connect to. hosts: ["https://search-test-iislogs-************************.us-east-1.es.amazonaws.com:443"]
- Filebeatをサービス起動しますが、ログは転送されてきません。
Filebeat起動PS C:\Program Files\Filebeat> Start-Service filebeat理由は、Amazon ESに必要なプラグインが足りていないからになります。
ingest-geoipとingest-user-agentが必要ですが、Amazon ESにingest-geoipが入りません。【参考】
・必要なElasticsearchプラグイン
・Amazon ESでサポートされるプラグイン※ 切り分けのため、EC2でElastic Stackを構築し、必要なプラグインを入れ、IIS Moduleの動作を確認しました。
※ IIS ModuleではカスタムフィールドのX-Forwarded-Forが処理できませんでした。
※ IIS Moduleだと不要なログの除外ができないため、ALBヘルスチェックもログに記録されてしまいました。IIS_Moduleパース結果{ "_index": "filebeat-6.5.4-2019.12.19", "_type": "doc", "_id": "88QcHm8BmhZ_RuQ5BSok", "_version": 1, "_score": null, "_source": { "offset": 100308, "prospector": { "type": "log" }, "read_timestamp": "2019-12-19T12:22:11.963Z", "source": "C:\\inetpub\\logs\\LogFiles\\W3SVC1\\u_ex191219_x.log", "fileset": { "module": "iis", "name": "access" }, "input": { "type": "log" }, "iis": { "access": { "server_name": "EC2AMAZ-1D0KC7E", "response_code": "200", "cookie": "-", "method": "GET", "sub_status": "0", "user_name": "-", "http_version": "1.1", "url": "/", "site_name": "W3SVC1", "referrer": "-", "body_received": { "bytes": "126" }, "hostname": "172.31.90.5", "remote_ip": "172.31.15.196", "port": "80", "server_ip": "172.31.90.5", "body_sent": { "bytes": "947" }, "win32_status": "0", "request_time_ms": "0", "query_string": "-", "user_agent": { "original": "ELB-HealthChecker/2.0", "os": "Other", "name": "Other", "os_name": "Other", "device": "Other" } } }, "@timestamp": "2019-12-19T12:21:59.000Z", "host": { "os": { "build": "14393.3274", "family": "windows", "version": "10.0", "platform": "windows" }, "name": "EC2AMAZ-1D0KC7E", "id": "0f6315cb-94f6-4f67-a538-ffb397bb4b12", "architecture": "x86_64" }, "beat": { "hostname": "EC2AMAZ-1D0KC7E", "name": "EC2AMAZ-1D0KC7E", "version": "6.5.4" } }, "fields": { "@timestamp": [ "2019-12-19T12:21:59.000Z" ] }, "sort": [ 1576758119000 ] }4. FilebeatからLogstash経由でAmazon ESに格納
ということで、最終形態として以下のような構成になりました。普通に推奨構成ですね(笑)
- 以下、FilebeatとLogstashの設定内容になります。
filebeat.yml抜粋#=========================== Filebeat inputs ============================= filebeat.inputs: # Each - is an input. Most options can be set at the input level, so # you can use different inputs for various configurations. # Below are the input specific configurations. - type: log # Change to true to enable this input configuration. enabled: true # Paths that should be crawled and fetched. Glob based paths. paths: #- /var/log/*.log - C:\inetpub\logs\LogFiles\W3SVC1\*.log # Exclude lines. A list of regular expressions to match. It drops the lines that are # matching any regular expression from the list. #exclude_lines: ['^DBG'] exclude_lines: ['^#','HealthChecker'] #----------------------------- Logstash output -------------------------------- output.logstash: # The Logstash hosts hosts: ["172.31.89.243:5044"]iislog.cfginput { # input from Filebeat beats { port => 5044 } } filter { dissect { # log format is TSV mapping => { "message" => "%{ts} %{+ts} %{s-sitename} %{s-computername} %{s-ip} %{cs-method} %{cs-uri-stem} %{cs-uri-query} %{s-port} %{cs-username} %{c-ip} %{cs-version} %{cs(User-Agent)} %{cs(Cookie)} %{cs(Referer)} %{cs-host} %{sc-status} %{sc-substatus} %{sc-win32-status} %{sc-bytes} %{cs-bytes} %{time-taken} %{X-Forwarded-For}" } } date { match => ["ts", "YYYY-MM-dd HH:mm:ss"] timezone => "UTC" } ruby { code => "event.set('[@metadata][local_time]',event.get('[@timestamp]').time.localtime.strftime('%Y-%m-%d'))" } mutate { convert => { "sc-bytes" => "integer" "cs-bytes" => "integer" "time-taken" => "integer" } remove_field => "message" } } output { # output to Amazon Elasticsearch Service elasticsearch { hosts => ["https://search-test-iislogs-************************.us-east-1.es.amazonaws.com:443"] index => "iislog-%{[@metadata][local_time]}" } }【参考】
・Filebeat output logstash
- Amazon ESに格納されたログは以下の通りです。
Elasticsearch格納結果{ "_index": "iislog-2019.12.20", "_type": "doc", "_id": "pixjIm8BSanoT0aR-wUf", "_version": 1, "_score": null, "_source": { "sc-win32-status": "0", "prospector": { "type": "log" }, "cs-method": "GET", "cs-uri-stem": "/", "cs-version": "HTTP/1.1", "tags": [ "beats_input_codec_plain_applied" ], "cs(Cookie)": "-", "s-port": "80", "cs-username": "-", "ts": "2019-12-20 08:13:47", "sc-bytes": 143, "cs(User-Agent)": "Mozilla/5.0+(Windows+NT+10.0;+Win64;+x64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/79.0.3945.79+Safari/537.36", "time-taken": 1, "offset": 169190, "input": { "type": "log" }, "host": { "id": "0f6315cb-94f6-4f67-a538-ffb397bb4b12", "os": { "family": "windows", "platform": "windows", "build": "14393.3274", "version": "10.0" }, "name": "EC2AMAZ-1D0KC7E", "architecture": "x86_64" }, "s-ip": "172.31.90.5", "cs(Referer)": "-", "@timestamp": "2019-12-20T08:13:47.000Z", "cs-bytes": 691, "@version": "1", "cs-uri-query": "-", "c-ip": "172.31.8.185", "source": "C:\\inetpub\\logs\\LogFiles\\W3SVC1\\u_ex191220_x.log", "s-computername": "EC2AMAZ-1D0KC7E", "cs-host": "iis-212063043.us-east-1.elb.amazonaws.com", "sc-substatus": "0", "beat": { "hostname": "EC2AMAZ-1D0KC7E", "name": "EC2AMAZ-1D0KC7E", "version": "6.5.4" }, "s-sitename": "W3SVC1", "X-Forwarded-For": "126.182.xxx.xxx", "sc-status": "304" }, "fields": { "@timestamp": [ "2019-12-20T08:13:47.000Z" ] }, "sort": [ 1576829627000 ] }WindowsサーバにLogstashを導入して取り込んだ時と同様に
15MB程度のログをまとめて取り始めた時のCPU負荷は以下のようになりました。
瞬発的に50%くらいまで上がっていますが、取り込みもすぐ落ち着き
その後は1~2%程度を推移するくらいでCPUもメモリも負荷は圧倒的に低かったです。
- 取り込んだログを用いて、Amazon ESのAlerting機能を設定すれば
閾値監視も簡単に出来そうでした。(今回、設定方法は割愛しています。)まとめ
さて、いかがでしたでしょうか?
IISアクセスログの取り込みだけでも色々な方法がありましたが、今回要件を満たせた構成は推奨構成でした。
Filebeat Moduleもセットアップは非常に簡単で良かったですが、痒いところに手が届かない結果となりました。
FilebeatとLogstashを組み合わせることで、Windowsサーバへのサービス影響を極力抑えることができました。
しかしながら、Logstash用にEC2を別途立てて管理する必要があるところは頭を抱えてしまいますね。。これまでLogstashとFilebeat Moduleをちゃんと使い分けたり、技術検証まではしたことはなかったので
この機会に自分なりに突き詰めてみました。皆様にとって何かの参考になれば幸いです^^/長文になってしまいましたが、お付き合いいただき、ありがとうございましたー!!
明日は残念ながら不在のようですが、24日の@tetsuyasodoさんに期待しましょう!!