- 投稿日:2019-12-22T23:59:58+09:00
OpenCVを用いてアムステルダム駅を通る人を認識するのはびっくりするほど簡単だった。
最終目的
僕はマーケティングが好きなのでこのような人体認識を機械にさせるところから始まり、最終的にはマーケティングなどに使えるツールを自作できるようにしたいなと考えている第一歩として、OpenCVを触ってみた。
この一歩目が正しいかはわからないが...
Jupyter Notebook上でコードは回した。
この記事の内容
OpenCVを使って、動画解析をするというのは非常に簡単ではあるが、初心者として詰まったところなどを紹介していきながら執筆していこうと思う。
実際の動画
アムステルダム駅で人体認識をOpenCVを用いて実行してみた。
コード
detect.ipybimport cv2 import os #setting cascade file f_cascade = cv2.CascadeClassifier('./haarcascade_fullbody.xml') #Capture the target movie cap = cv2.VideoCapture('./amsterdam.mp4') #catch the details of the movie width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)) height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) fps = cap.get(cv2.CAP_PROP_FPS) #set data format to save movie fourcc = cv2.VideoWriter_fourcc(*'H264') writer = cv2.VideoWriter("amsterdam_detected_1.avi", fourcc, fps, (width, height)) while(True): #catch every frames. ret indicates wether reading is succeeded, return must be True or False ret, frame = cap.read() print(ret) #detect body facerect = f_cascade.detectMultiScale(frame, scaleFactor=1.2, minNeighbors=2, minSize=(1, 1)) if ret: #make rectangles around detected body for rect in facerect: cv2.rectangle(frame, tuple(rect[0:2]), tuple(rect[0:2] + rect[2:4]), (255,255,255), thickness=2) text = 'Detected' font = cv2.FONT_HERSHEY_PLAIN cv2.putText(frame, text ,(rect[0],rect[1]-10),font, 2, (255, 255, 255), 2, cv2.LINE_AA) #save frames to movie writer.write(frame) cv2.imshow("Show Result", frame) k = cv2.waitKey(1) if k == ord('q'): break writer.release() cap.release() cv2.destroyAllWindows()構成
コードが短いように構成は非常にシンプルでした。
まずすでに用意されているカスケード学習器であるhaarcascade_fullbody.xmlを用意します。
この中にフレーム内にあるBodyを検出するための学習済み特徴が入っています。そしてその後、OpenCVを用いて動画を用意します。動画パスを渡します。その上で、fpsや動画の高さ、幅なども用意しておくと動画を保存する時に楽です。
f_cascade = cv2.CascadeClassifier('./haarcascade_fullbody.xml') #Capture the target movie cap = cv2.VideoCapture('./amsterdam.mp4') #catch the details of the movie width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)) height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) fps = cap.get(cv2.CAP_PROP_FPS)今回は動画を保存したかったのでOpenCVを用いて動画を書き込むということもしました。出力は.aviファイルで行いました。fourccというのは出力フォーマットを指定するための4つの記号というような認識でしょうか。ここで先ほど入手したwidth height fpsなどを使います。出力の際の詳細情報を書き込む必要があるからです。
fourcc = cv2.VideoWriter_fourcc(*'H264') writer = cv2.VideoWriter("amsterdam_detected_1.avi", fourcc, fps, (width, height))その後、発見したBodyに対して長方形の白い囲みとDetected
for rect in facerect: cv2.rectangle(frame, tuple(rect[0:2]), tuple(rect[0:2] + rect[2:4]), (255,255,255), thickness=2) text = 'Detected' font = cv2.FONT_HERSHEY_PLAIN cv2.putText(frame, text ,(rect[0],rect[1]-10),font, 2, (255, 255, 255), 2, cv2.LINE_AA)まあ後はやめる処理です。qを押したら処理を終了しようという処理は真似させていただきました。waitKeyの中のintとかはきをつけてください
k = cv2.waitKey(1) if k == ord('q'): break手こずったところ・手こずっているところ
実は4点いまだに解決していないところがあるので,もし読んでくれた方でわかる人がいたら教えていただきたいです。
1.認識精度を向上させるには
認識精度をここから向上させる方法がイマイチつかめません。カスケード学習器を自作して認識精度をあげるのがいいのでしょうか?
それとも今回は少し手ブレが動画に入ってしまっているのでしっかい固定したりすれば駅の塔を誤認したりしなくなるのでしょうか?
次の改善ステップを聞きたいです。2.動画を最後まで処理できない
お気付きの方もいるかもしれませんが、今回print(ret)で動画の読み込みがしっかりできているかoutputで確認しています。が、途中(10秒)くらい目のframeまで行くとあとは全部Falseになっちゃうんですよ。なぜかわからない
3.MP4で出力ができなかった
もともと.aviファイルで出力したくなくて、書き込み設定もmp4でできるようにfourccもMP4Vを試したりだとかしたんですけど、書き込んだ後の.mp4ファイルは正常に書き込めていないのかなぜか開いても動画を再生できなかったんですよね。これも謎でした。
4.qでやめる処理をしたけど、実際に画面止まったりしなかった
qを押したらbreakして処理終わって、画面とか全部閉じるようにコーディングしたと思ったのですが実際にはPython No reponseみたいになってしまっていっつも出力動画を強制終了させていました。
以上のことが手こずった点です。誰か助けてぇ〜〜〜

- 投稿日:2019-12-22T23:58:49+09:00
Spotifyの関連アーティストからネットワーク図を作って次に聞く曲の決定支援
この記事は、NTTコミュニケーションズ Advent Calendar 2019の22日目の記事です。
昨日は @kanatakita さんの記事、アプリケーションのリリースに必要な会議を倒したい話 でした。はじめに
こんにちは、NTTコミュニケーションズのSkyWayチームに所属しているyuki uchidaです。
本記事は、BERTを理解しながら自分のツイートを可視化してみるハンズオンに続いて『可視化したい』シリーズ第二弾です。プライベートでSpotifyのAPIを叩いていたところ、個人的な興味範囲であるリコメンドシステムに絡めて面白そうな可視化ができそうだと思ったため、この記事を書いています。
何をする記事?
Spotifyは業界最高峰のリコメンドシステムを提供していますが、そのリコメンド結果に疑問を持つことも多くあります。
今回、この記事では納得感のあるリコメンドを行うため、Spotifyの関連アーティストからネットワーク図を作って次に聞く曲の決定支援をします。(リコメンドの一種と言えるかもしれません)
pythonのコードも合わせて乗っけているため、自分でやってみたいと感じた方はぜひ試してみてください!!Spotifyのリコメンドシステム
Spotifyでは、既に非常に精度の良いリコメンドシステムが実装されています。曲のテンポやジャンルなど、非常に多くの情報を使った上でリコメンドがなされています。
どれだけ多くの情報を使っているかはSpotify APIで取得できる情報を調べてみるとよくわかります。Spotifyの76,000曲の属性データを分析した結果、J-RockはRockというよりむしろPunkだった
Spotifyのレコメンドロジックについて語り尽くすSpotifyでは、以下のようにプレイリストからオススメの曲をリコメンドしてくれたり、好きそうなアーティストをプレイリストにしてくれたりします。
Spotifyは本当に素晴らしいリコメンドシステムを有しており、私はSpotifyのおかげで音楽が好きになりました。
オススメされる曲の多くが自分の感性に非常にマッチしていて、Spotifyがオススメしてくれる曲で一日過ごせるくらいにはSpotifyが好きです。一生課金します。リコメンドシステムの精度指標
確かにSpotifyのリコメンドは優秀です。しかし、『どうしてこの曲をオススメしてきたか?』という疑問に答えられるようなシステムになっているわけではありません。そのため、Spotifyに限った話ではなく、今ある多くのリコメンドシステムは、『どうしてこの曲なのかはわからないけど結果的に好きな曲だった』となりがちなのです。
リコメンドシステムにおける議論
多くのリコメンドシステムにおいて、精度指標として、
accuracyが使われることが多いです。
しかし、accuracyのみを精度指標とすることには議論が必要です。
Charu C Aggarwaは『リコメンデーションシステム』で、「accuracy(精度)だけでなく、diversity(多様性)、serendipity(意外性)、Novelty(新規性)などの指標からも評価するべき」と述べています。リコメンドシステムにおいては、
accracyのみを精度指標にしてしまうと、リコメンドするものが有名なものに限られてしまって面白みに欠けるという問題が産まれてしまいます。そのため、他の指標を使うことも重要です。リコメンドシステムの最近の流れ
最近では、accuracyではなくupliftを精度指標とすることでリコメンドの精度を高めたという論文も発表されました。
リコメンドの精度指標は数多くあり、非常に興味深い議論が多くなされています。
以下の記事ではUplift-based Evaluation and Optimization of Recommendersという論文をわかりやすく解説しているので、ぜひ参考にしてください。(こちらのメディアでもたまに記事を書いています)
そのリコメンド、本当に効果ありますか?accuracyではなくupliftで学習することでリコメンドは進化する。現在Spotifyで提供されているリコメンドシステムは、どのような精度指標が用いられているかわからないため、今回は、アーティストの関連度から、多様性を求めてリコメンドをしてもらうか、好きなタイプのアーティストを深掘りしていくか自身で決定できるようにしたいと思います。
アーティストの関連度をネットワーク図として表現し、自身が聴いてる曲をプロットする
アーティストの関連度から、多様性を求めてリコメンドをしてもらうか、好きなタイプのアーティストを深掘りしていくか自身で決定できるようにするため、ネットワーク図と自身の聴いているアーティストをプロットしたものを用意します。
SpotifyAPIを使って関連アーティストをdigってネットワーク図を構築する
まずは必要なライブラリのimportを行います。
test.pyimport pandas as pd import spotipy from spotipy.oauth2 import SpotifyClientCredentials import json import networkx as nx import matplotlib.pyplot as plt次に、SpotifyAPIに接続するためのインスタンスを生成し、
spotifyという変数に格納します。test.pyclient_id = 'XXXXXXXXXXXXXXX' client_secret = 'XXXXXXXXXXXXXXX' client_credentials_manager = spotipy.oauth2.SpotifyClientCredentials(client_id, client_secret) spotify = spotipy.Spotify(client_credentials_manager=client_credentials_manager)以下のSpotifyのトップチャートから、人気な邦楽リストをcsvとしてダウンロードしてきましょう!
https://spotifycharts.com/regional/jp/weekly/latest
そしてそのcsvを読み込みます。test.pytop_records = pd.read_csv("regional-jp-weekly-latest.csv", header=1) top_artists = top_records["Artist"].unique()ここからはpandasのDataFrame整形のための処理のため、流して読んでください
test.pyartist_info_list = [] for artist in top_artists: artist_info_list.append(spotify.search(q='artist:' + artist, type='artist')) artist_info_list = [artist_info['artists']['items'] for artist_info in artist_info_list] artist_info_list = [artist_info[0] for artist_info in artist_info_list if len(artist_info) > 0] ## 情報がないものはスキップ artist_info_df = pd.DataFrame(artist_info_list) artist_info_df = artist_info_df[['genres','id','name','popularity','type']] followers = [artist_info_record['followers']['total'] for artist_info_record in artist_info_list] artist_info_df['followers'] = followers artist_info_dfcsvを読み込んで整形した後、SpotifyAPIを用いて、関連アーティストをdigって行きます。再帰関数として実装して、何回digるかを決定します。今回は5回digります。これでもデータ量としては万を軽く越えるため、ご注意ください。
test.pyrelated_artist_info = [] digged_artist_ids = [] def dig(parent_id,parent_name,limit,i): digged_artist_ids.append(parent_id) # print(parent_name) if len(related_artist_info) % 1000 == 0: print(len(related_artist_info)) related_artists = spotify.artist_related_artists(parent_id) for artist_info in related_artists['artists']: artist_info['parent_id'] = parent_id artist_info['parent_name'] = parent_name related_artist_info.append(artist_info) if i < limit: if artist_info['id'] in digged_artist_ids: pass else: dig(artist_info['id'],artist_info['name'],limit,i+1) for parent_id,parent_name in zip(artist_info_df['id'],artist_info_df['name']): dig(parent_id,parent_name,limit=6,i=1) related_artist_df = pd.DataFrame(related_artist_info) related_artist_df = related_artist_df[['genres','id','name','popularity','type','parent_id','parent_name']] followers = [artist_info_record['followers']['total'] for artist_info_record in related_artist_info] related_artist_df['followers'] = followers related_artist_df ## 親アーティストのparent_idをnullに artist_info_df['parent_id'] = None artist_info_df['parent_name'] = None merge_df = pd.concat([artist_info_df,related_artist_df],sort=False)ここで、ネットワーク図を作るために、関連アーティストとして出てきたアーティストのペアを作成しておきます。
test.pygraph_tuple = [] for network in merge_df[['name','parent_name']].values: graph_tuple.append(tuple(network))では次に、自身が聴いているアーティスト群を用意しましょう。
Spotifyと接続するためのインスタンスに、usernameとplaylist_idを与えてあげます。test.pyimport sys import pprint import spotipy import spotify_token as st client_id = 'XXXXXXXXXXXx' client_secret = 'XXXXXXXXXXX' client_credentials_manager = spotipy.oauth2.SpotifyClientCredentials(client_id, client_secret) spotify = spotipy.Spotify(client_credentials_manager=client_credentials_manager) username = "XXXXXXXXX" playlist_name = "XXXXXXXXXXXX" my_tracks = spotify.user_playlist(username, playlist_id=playlist_name, fields=None) my_track_list = [track['track'] for track in my_tracks['tracks']['items'] ] my_track_df1 = pd.DataFrame(my_track_list) my_track_df1['artists'] = [artists[0]['name'] for artists in my_track_df1['artists']]ここから、ネットワーク図を作るために、
networkxというライブラリを用いて行きます。
おそらく、現在graph_tupleに格納されている関連アーティストのペアは、非常にデータ数が多く、まともに表示できないと思われるので、関連アーティストが少ないアーティストに関しては枝切りしていきます。また、その中で自身が聴いているアーティストに関しては枝切りしないようにしておきましょう。ここは実行にかなり時間がかかるため、数分ほど待ちましょうtest.pyG = nx.Graph() G.add_nodes_from(merge_df['name'].unique()) G.add_edges_from(tuple(graph_tuple)) like_artists_name = set(track_df['artists'].unique()) for i in range(3,1,-1): remove_nodes = G.degree() if i == 1: print(remove_nodes) remove_node_names = [node[0] for node in remove_nodes if node[1] < 15*i] ## 自分のプレイリストに入ってるアーティストは消さない remove_node_names = set(remove_node_names) - like_artists_name G.remove_nodes_from(remove_node_names)test.py# グラフの構築 # G = nx.karate_club_graph() G = nx.Graph() G.add_nodes_from(merge_df['name'].unique()) G.add_edges_from(tuple(graph_tuple)) like_artists_name = set(track_df['artists'].unique()) for i in range(3,1,-1): remove_nodes = G.degree() if i == 1: print(remove_nodes) remove_node_names = [node[0] for node in remove_nodes if node[1] < 10*i] ## 自分のプレイリストに入ってるアーティストは消さない remove_node_names = set(remove_node_names) - like_artists_name G.remove_nodes_from(remove_node_names) ## 1以下のやつは中心から離れ過ぎてしまっている可能性が高いので削除 remove_nodes = G.degree() remove_node_names = [node[0] for node in remove_nodes if node[1] <= 3] G.remove_nodes_from(remove_node_names) # レイアウトの取得 pos = nx.spring_layout(G) pr = nx.pagerank(G) # 可視化 plt.figure(figsize=(100, 100)) # nx.draw_networkx_edges(G, pos) nx.draw_networkx_nodes(G, pos, node_size=[75000*v for v in pr.values()], node_color=list(pr.values()), cmap=plt.cm.Reds) # nx.convert_node_labels_to_integers(G, first_label=0, ordering='default', label_attribute=None) add_artists_nodes = G.degree() add_artists_names = [node[0] for node in add_artists_nodes] like_artists_nodes = set(add_artists_names) & like_artists_name nx.draw_networkx_nodes(G,pos, nodelist=like_artists_nodes, node_color='b', node_size=1500, label=like_artists_nodes, alpha=0.5) labels = {} for node in G.degree(): labels[node[0]] = node[0] nx.draw_networkx_labels(G, pos,font_size=10) # nx.draw_networkx_labels(G, pos, labels, font_size=8) plt.savefig('figure.png',format = 'png', dpi=300) plt.show()プロット結果を使って次に聴く曲の決定
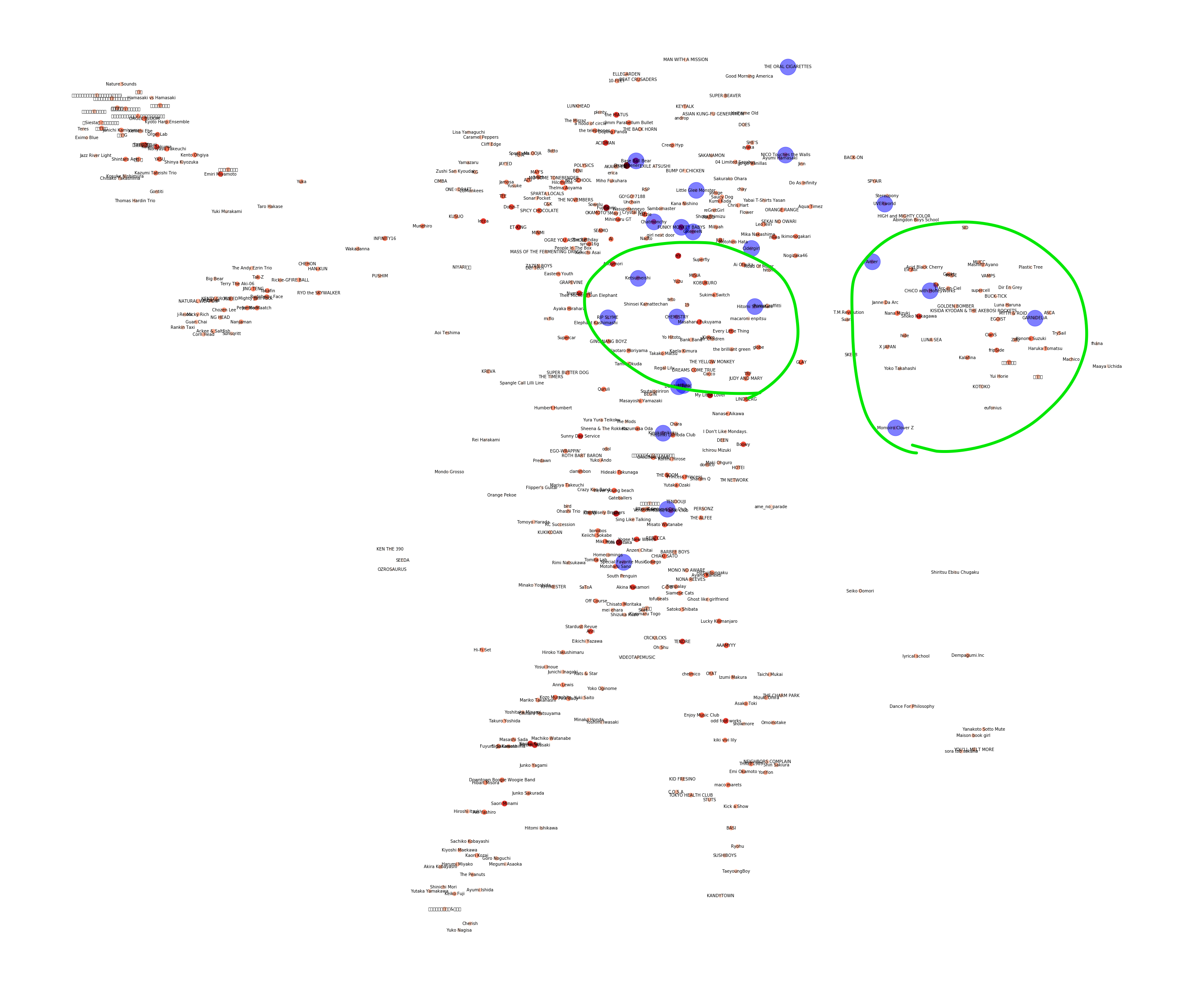
今回、トップチャートからdigったアーティストのネットワーク図と、自身のプレイリストをプロットしたものは以下のようになりました。この図をみると、どのようなアーティストが同じような場所にあり、自分がどのアーティストを聴いているかがよくわかりますね!!!!
私は基本的にSpotifyがオススメした曲を聴いてプレイリストに追加するという流れが多いため、この図から、右上の方に位置しているアーティストをよく聴いていることがわかります。
その中から、わかりやすいアーティスト群をピックアップして見てみましょう。
今回、『わかりやすくて面白いなー』と感じた二つの領域(アーティスト群)を紹介します。
まず、左のアーティスト群はこのように表示されています。
ゆずやコブクロ、ケツメイシが同じような場所にあるのはすごく納得感がありますね。僕はこの辺りのアーティストが好きなことはプロット結果からわかっているので、この辺りのアーティストを埋めるようにオススメするのがいちばん分かりやすいリコメンドだと思います。
また、右側のアーティスト群はこのようになっています。
この辺りは女性アーティストが集まっているように見えますね。
また、その中でもアニソン系が集まっていそうです。(Craris/EGOIST/fripsideなど)
僕はこの辺りのアーティストを少しだけ聴いているため、周辺のアーティストをオススメすると良いかもしれません。まとめ
このように、アーティスト群をネットワーク図として表示することで、自身がどのようなタイプのアーティストが好きなのかよく分かります。
また、ネットワーク図を参照することで次どのようなアーティストを聞くかの決断を支援することができます。
ネットワーク図では、左側の領域や下の領域は一切聴いていない未開拓領域です。自分が好きなタイプのアーティストを深掘りしていくのも面白いですが、このように多様性を求めて全く聴いていないアーティストを聴いてみるのも楽しいですね。
とりあえず、自分の好きなアーティストに近く、未開拓領域の方向に位置しているアーティスト として、今回はtofubeatsさんを聴いてみようかと思います。
個人的に実装したいもの
リコメンドでは、『自身がどのようなアーティストを聞きたいか』ではなく、『自身が好きそうなアーティスト』をオススメされるため、受動的なシステムになっていることが多いです。
しかし、このようにネットワーク図を用いたリコメンドでは、『多様性を求めて未開拓領域に進むのか』『好きなタイプのアーティスト深掘りしていくのか』ということを自分で決められます。
こういった、アシスト寄りのリコメンドシステムがあっても良いのではないかと思いました。次は、このネットワーク図を用いて実際にリコメンドシステムを提供できるようにシステム構築を頑張ってみます。(Chrome拡張か、webアプリで)
完成したらぜひご利用ください!!それではこの辺りで僕の記事は終わりにします。
明日は、 @__kaname__ さんの記事です。お楽しみに!






- 投稿日:2019-12-22T23:51:21+09:00
【AWS SAM】 DynamoDB+Lambda+APIGatewayでAPIを作る
内容
DynamoDBのデータを取ってくるAPIを、AWS SAMで構築してみる
要するに、こんな感じのテーブルから、、、
group(Hash) name(Range) group1 name1 group1 name2 group2 name3 こんな感じに取ってこれるようにしたい。
curl https://hogehoge/Prod/dynamo-api/v1/?group=group1&name=name1 { "result": [ { "name": "group1", "group": "name1" } ] }環境
- macOS Mojave -10.14
- python3.7.4
- sam 0.38.0
目次
- アプリケーションの環境構築
- template.yamlを書く
- 実行スクリプトを書く
- デプロイ
- 検証
1. アプリケーションの環境構築
構築は前回の【AWS SAM】Python版入門 を参考にしてください。
(Pipenvを使ったAWS SAMアプリケーションの初期化手順です。)2. template.yamlを書く
リソース
今回作成するリソースは以下です
- Table(DynamoDB)
- Lambda用Role(IAM)
- Lambda
リソース定義
では、上記リソースを作成するtemplate.yamlを書いていきましょう。
template.yamlAWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31 Description: > dynamo-api Sample SAM Template for dynamo-api # Lambdaのタイムアウト設定 Globals: Function: Timeout: 60 # テーブル名、関数名などの定義 Parameters: DynamoAPIFunctionName: Type: String Default: dynamo-api DynamoTableName: Type: String Default: DynamoApiTable # リソースの定義 Resources DynamoTable: Type: AWS::DynamoDB::Table Properties: TableName: !Ref DynamoTableName # HashキーとRangeキーの定義(カラム名と型) AttributeDefinitions: - AttributeName: group AttributeType: S - AttributeName: name AttributeType: S KeySchema: - AttributeName: group KeyType: HASH - AttributeName: name KeyType: RANGE # 料金モード指定(PAY_PER_REQUESTは従量課金) BillingMode: PAY_PER_REQUEST DynamoAPIFunctionRole: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Principal: Service: - 'lambda.amazonaws.com' Action: - 'sts:AssumeRole' ManagedPolicyArns: - 'arn:aws:iam::aws:policy/CloudWatchLogsFullAccess' # DynamoDBテーブルへの読み取り許可(こうすると、今回作成するテーブルの読み取りのみを許可できます) Policies: - PolicyName: 'DynamoApiTablePolicy' PolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Action: - dynamodb:Get* - dynamodb:Query Resource: !GetAtt DynamoTable.Arn DynamoAPIFunction: Type: AWS::Serverless::Function Properties: FunctionName: !Ref DynamoAPIFunctionName Role: !GetAtt DynamoAPIFunctionRole.Arn # app.pyがあるディレクトリパス CodeUri: dynamo-api/ # ハンドラーのパス(むやみに変更するとミスしやすい、、、そっとしておくのが吉) Handler: app.lambda_handler Runtime: python3.7 # APIGatewayの設定(SAM独特の記述) Events: DynamoApi: Type: Api Properties: Path: /dynamo-api/v1/ Method: get # Outputsに指定したパラメータは、他のtemplateへデータを渡したりするのが本来の役目ですが # 今回はデプロイ完了時にAPIのエンドポイントを出力するために使っています。 Outputs: DynamoApi: Description: "API Gateway endpoint URL for Prod stage for Dynamo API function" Value: !Sub "https://${ServerlessRestApi}.execute-api.${AWS::Region}.amazonaws.com/Prod/dynamo-api/v1/"LambdaやAPIGatewayの設定なんかは、ほとんど雛形と同じなので楽に書けます。
3. 実行スクリプトを書く
ライブラリのインストール
まずは、必要なライブラリをインストールします。
$ pipenv install requests boto3APIの処理を書く
次に、実際にDynamoテーブルからデータを取ってくる処理を作っていきます。
GETパラメータに指定されたgroupとnameでDynamoテーブルを検索、その値を返す
という単純な仕組みです。
nameは前方一ができるようにしてみました。app.pyimport json import json import boto3 from boto3.dynamodb.conditions import Key from http import HTTPStatus as status DYNAMODB_TABLE_NAME = 'DynamoApiTable' def lambda_handler(event, context): table = boto3.resource('dynamodb').Table(DYNAMODB_TABLE_NAME) params = event.get('queryStringParameters') results = dynamo_search(table, params) if results is None: return { "statusCode": status.BAD_REQUEST, "body": json.dumps({ "error": "Bad Request" }, ensure_ascii=False), } return { "statusCode": status.OK, "body": json.dumps({ "results": results }, ensure_ascii=False), } def dynamo_search(table, params): if params.get('group'): keyConditionExpression = Key('group').eq(params.get('group')) if params.get('name'): keyConditionExpression &= Key('name').begins_with(params.get('name')) return table.query( KeyConditionExpression=keyConditionExpression).get('Items', []) return None4. デプロイ
(余談) Pipfile to requirements.txt
Pipfileからrequirements.txtに変換したい、、、
そんな時はこのコマンドで変換可能です。
(boto3もLambdaに最初から用意されてるし、あまり使い所ないかも。。)
$ pipenv lock -r > requirements.txt今回は、デフォルトの
requirements.txtのままで大丈夫ですビルド
$ sam buildBuilding resource 'DynamoAPIFunction' Running PythonPipBuilder:ResolveDependencies Running PythonPipBuilder:CopySource Build Succeeded Built Artifacts : .aws-sam/build Built Template : .aws-sam/build/template.yaml Commands you can use next ========================= [*] Invoke Function: sam local invoke [*] Deploy: sam deploy --guidedデプロイ
~/.aws/credentialsで設定を分けている方は、--profile オプションを付けてください。
--guidedオプションは初回のみでOKです。(samconfig.tomlに設定が保存されるので)$ sam deploy --guidedStack dynamo-api-stack outputs: ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- OutputKey-Description OutputValue ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- DynamoApi - API Gateway endpoint URL for Prod stage for Dynamo API function https://hogehoge/Prod/dynamo-api/v1/ -----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------エンドポイントもちゃんと出力されてますね〜
5.検証
Dynamoにデータを登録
今回は(も)、推しのグループ名と名前を登録しました。
group(Hash) name(Range) ハニーストラップ 周防パトラ ハニーストラップ 堰代ミコ ホロライブ 白上フブキ ... ... APIを叩いてみる
出力されたエンドポイントにリクエストを送ってみます。見にくいので
jqで整形しましょう。
(curl面倒だよって人はブラウザで)
まずは
group(Hashキー)指定です。$ curl https://hogehoge/Prod/dynamo-api/v1/ \ --get \ --data-urlencode 'group=ハニーストラップ' | jq{ "results": [ { "name": "周防パトラ", "group": "ハニーストラップ" }, { "name": "堰代ミコ", "group": "ハニーストラップ" }, { "name": "島村シャルロット", "group": "ハニーストラップ" }, { "name": "西園寺メアリ", "group": "ハニーストラップ" } ] }取れました
もちろん、前方一致で
name(Rangeキー)も検索できます。$ curl https://hogehoge/Prod/dynamo-api/v1/ \ --get \ --data-urlencode 'group=ハニーストラップ' \ --data-urlencode 'name=周防' | jq{ "results": [ { "name": "周防パトラ", "group": "ハニーストラップ" } ] }取れました!完璧です!
終わりに
今回は、単純なAPIを作ってみました。次回は
pytestでテストをしてみようと思います。
最後まで読んでいただきありがとうございました!前回
- 投稿日:2019-12-22T23:37:27+09:00
Python基礎 if文
Python基礎①
アウトプット用にメモ
if文
number = 40 if number > 30: print "hello world!" print "Hello World!"比較演算子 > < >= <= == != 論理演算子 and or not
if number > 50 and number < 70: print "hello world!" print "Hello World!" if 50 < number <70 print print "hello world!" print "Hello World!"` number = 60 if number > 50: print "hello world!" elif number > 30: print "Hello World!" else: print "HELLO WORLD" print "yes" if number > 60 else "no"
- 投稿日:2019-12-22T23:25:09+09:00
Tkinterを使ってサンタになりきる
令和元年が早くも終わりそうになってます。今年は芸能人の結婚ラッシュが目立ちましたね。
私も先日親友からいきなり結婚を報告されました。ついこの前まで六花ちゃんの足太くて良いよねとか言ってたじゃん…Twitterで愚痴ったら知らない外国人が慰めてくれました。さっそく留学経験が生きて良かったです。そして世間はクリスマス。数多くのお父さんお母さん達がサンタになることでしょう。今年結婚した方々も将来子供が生まれればサンタになるはずです。
しかし人生1度きりの子育て、多くの新婚夫婦がどうサンタになればいいか悩んでいるのではないでしょうか。
そんな方々のためにサンタの予行演習が出来るゲームを作りました。ということでMake IT AdventCalendar2019、22日目の記事を書かせていただきます。
はじめに
今回ゲーム制作にあたって利用したのはTkinterになります。
基本的なコードは12歳からはじめるゼロからのPythonゲームプログラミング教室に載っていますので、追加した要素を主に記述していこうかと思います。この本の良いところとして、理解に詰まったときに「自分が12歳以下である」ことを実感できる点があります。若いって良いね。タイトル画面
タイトルに他意はありません。デトロイトに住む一人の男がサンタになるまでの物語です。今年のFrostbiteも楽しみですね。
Santagame.py# タイトル作成 frame = tkinter.Frame(width=960, height=640) frame.place(x=10, y=10) title = tkinter.Canvas(frame, width=960, height=640) title.place(x=0, y=0) title.create_rectangle(0, 0, 960, 640, fill="black") title_label_up = tkinter.Label(frame, width=0, height=0, text=" ", font=("Arial Black", 70), fg="white", bg="black") title_label_down = tkinter.Label(frame, width=0, height=0, text=" ", font=("Arial", 20), fg="white", bg="black") press_any_key = tkinter.Label(frame, width=0, height=0, text=" ", font=("Arial", 25), fg="white", bg="black") title_label_up["text"] = "DETROIT" title_label_down["text"] = "B E C O M E S A N T A" press_any_key["text"] = "- Press any key to start -" title_label_up.place(x=240, y=220) title_label_down.place(x=230, y=340) press_any_key.place(x=280, y=480) # タイトル消去 def forget_title(event): frame.destroy() # title消去 root.bind("<Any-KeyPress>", forget_title)コードに関してはFrameとCanvasとLabelをつくる、基本的な形になっています。
キーバインドを使い、いずれかのキーを押すことで消えます。プレイ画面
矢印キーでサンタを操作します。
基本的なルールとして、おもちゃと斧を手に入れて家を目指します。斧もしくはお金を持っておもちゃ屋に行くことでおもちゃを手に入れることが出来ます。斧のみしか持っていない場合、強盗扱いとなり一部の敵の攻撃力が上がるので注意を。しかし斧を持つと自分自身の攻撃力も上がります。
雪上で斧を振り回す姿はさながら竃門炭治郎。生殺与奪の権を相手に渡してはいけません。殺られる前に殺る、そんな社会の厳しさを子供に教えることもできるゲームに仕上がりました。
戦闘画面
暴力と狂気が渦巻くデトロイト(偏見)、敵は国家権力と反社会勢力です。
主人公もサンタになる前はただの赤い服を着た不審者です。職務質問されても仕方ないでしょう。
無料素材に拘るばかりに世界観が崩れてしまいました。でも異世界転生って多分こんな感じ。陰キャの天敵ヤクザはお金を持っていたらカツアゲしてきます。やられる前に殺りましょう。
強盗した後だと警察官は発砲してきます。殺られる前に殺りましょう。斧を持っていた場合は戦闘後に血痕が残ります。
戦闘で負けると洋・和の2種類のbad end画面がランダムで出てきます。
実装出来なかった機能
サンタ画像のgifアニメ表示
Tkinterでそのままgifを使うと1フレーム目しか表示されないので、ループさせたりafter()使ったり試行錯誤するも撃沈。
妥協案として歩くたびに画像が変わる仕組みに。SantaGame.pyglobal santa_i canvas.create_image(santa_x * 64 + 31, santa_y * 64 + 31, image=santaImages[santa_direction][santa_i], tag="santa") santa_i += 1 if santa_i > 3: santa_i = 0Tkinterのウィンドウ内での動画の再生
こちらもafter()なり使うも撃沈。
妥協案で別ウィンドウで再生し、終了後ウィンドウを閉じる仕組みに。SantaGame.pyfps = 250 if cap.isOpened() == False: print("Error!") while cap.isOpened(): ret, ending = cap.read() if ret == True: time.sleep(1/fps) cv2.imshow('ending', ending) if cv2.waitKey(1) & 0xFF == ord('q'): break else: break cap.release() cv2.destroyAllWindows()戦闘時のキーのunbind
サンタの移動について、当初は矢印ボタンをクリックすることで動かしていましたが、あまりにもダサいのでキーバインドすることに。
しかし戦闘時にunbindしてしまうと戦闘終了後までに再びbindするタイミングが見つからず…。スタイリッシュ(仮)を取るか機能性をとるか悩んだ結果、バグと共存することを選びました。言うなればこのバグは禰豆子みたいなものです。
善良なバグと悪いバグの区別もつかないならエンジニアなんてやめてしまえ
なのでみなさん戦闘中は矢印キー押さないで下さいね。おわりに
遊びたい方はこちらからダウンロード後、SantaGame.pyを起動してください。
明日は@fumihumiが担当します。

- 投稿日:2019-12-22T23:07:32+09:00
AtCoder Beginner Contest 148 参戦記
AtCoder Beginner Contest 148 参戦記
A - Round One
2分半で突破. 簡単なんだけど、なんかシンプルに書こうと思うと難しいなあと思った.
A = int(input()) B = int(input()) print(*(set([1, 2, 3]) - set([A, B])))B - Strings with the Same Length
1分半で突破. 書くだけ. zip かなあと思いつつ使わなかった.
N = int(input()) S, T = input().split() print(''.join(S[i] + T[i] for i in range(N)))C - Snack
3分で突破. 最小公倍数が答えだけど、どう解けばいいんだっけ、最大公約数が分かれば分かる?と思いつつ、Google に「最小公倍数 Python」ってググったら
lcm(a, b) = a * b / gcd(a, b)って出てきたので書いて終わり.from fractions import gcd A, B = map(int, input().split()) print(A * B // gcd(A, B))E - Double Factorial
20分くらい?で突破. WA1. Dをちょっと考えたけど難しかったので、飛ばしてこっちをやってみた. とりあえずナイーブに f(n) を実装して、動かしてみた. N が奇数のときは常に0はすぐ分かった.
N // 10で入力例3を流すとだいぶズレたので、n 増やして試してみたところ、f(50) で数字がずれて、50には5が含まれるからカーとなる.N // 10 + N // 50でも入力例3とは合わず、脳内で次は250カーとなってようやくからくりが分かって実装.while t <= N:をwhile t < N:と書いて WA を食らったが無事AC.from sys import exit N = int(input()) if N % 2 == 1: print(0) exit() result = 0 t = 10 while t <= N: result += N // t t *= 5 print(result)D - Brick Break
27分くらい?で突破. 右から処理することばっかり考えてて、難しいなと飛ばしてEからやって戻ってきたんだけど、順位表の状況から明らかに簡単なので、多分考えすぎてると左から処理することを考えたら簡単だった orz.
N = int(input()) a = [int(s) - 1 for s in input().split()] result = 0 for i in range(N): if a[i] != (i - result): result += 1 if result == N: print(-1) else: print(result)F - Playing Tag on Tree
突破できず. ミニマックス法なのは分かったけど、過去問であたったのは一回だけで、幅優先だとどうなるんだろうと考えているうちに終わった. 精進不足.
- 投稿日:2019-12-22T23:06:20+09:00
pythonのseleniumで`arguments[0].scrollIntoView();`が失敗するときの対応
概要
pythonのseleniumでarguments[0].scrollIntoView(); を使って画面の表示位置を調整していたスクリプトを久しぶりに動かしたときにエラーで落ちてしまったのでその対応方法
対処方法
self.driver.execute_script("arguments[0].scrollIntoView();", inputLabel)から
inputLabel.location_once_scrolled_into_viewに変更しました。
inputLabelはwebdriverのfind_element_by_XXX のメソッドで取得した要素になります。状況
- seleniumの処理中画面の範囲外の要素を操作しようとすると
MoveTargetOutOfBoundsExceptionが発生してしまうので、対処としてarguments[0].scrollIntoView();を使って画面をスクロールしてから動かすようにしていました。- そのスクリプトはしばらく動かしていなかったのですが、最近使うかもということで動作確認をしたところ
javascript error: arguments[0].scrollIntoView is not a functionとエラーが・・・- いろいろしらべたところstackoverflowの状況のようなのでこちらの方法を採用
- 公式ドキュメントでは勝手に変更するかも?とあったのでださいですがtry,exceptで失敗したときのみ動作するようにしました。
- 投稿日:2019-12-22T22:53:44+09:00
猫ももう飽きてるゆるふわ深層学習めも
TL; DR
- 教師あり機械学習の文脈で深層学習を簡単に説明します(厳密性は皆無)
- 勉強会の題材として使用する予定なので、今後加筆修正される可能性があります
深層学習とは?
- 英語でDeep Learning
- 機械学習手法のうちの1つ
- 神経回路を模した機械学習手法のニューラルネットワーク(NN)を多層化したもの
- NN自体は50年以上の歴史があり、いくつかの冬の時代(ダメな子扱いされてた)時代を経て、2012年に画像認識コンテスト ILSVRCにおいて圧倒的な精度で優勝してDeep Learningという名前で蘇った
- 色んな構造のモデルがあり、画像認識ではConvolutional Neural Network(CNN)、画像生成ではGenerative Adversarial Network(GAN)、自然言語処理ではLong Short Term Memory(LSTM)がよく使用される
教師あり機械学習としての深層学習
深層学習はNNを多層化したものと説明しましたが、実際は単純な多層化ではなく畳み込み演算や再帰計算、自己注意計算など複雑な構成を取ることが現在では一般的になっているため、まずは教師あり学習の文脈で機械学習を簡単に説明し、その後にどのコンポーネントが深層学習にあたるのか説明して行きたいと思います。
教師あり学習
教師あり機械学習とは以下の式で表されるように、ある入力 $\boldsymbol{x}$ からパラメータ $\boldsymbol{w}$ を持つ写像関数 $f$ を通して出力された $\boldsymbol{y}$ と真の答えである $\boldsymbol{t}$ との間の誤差関数 $E$ の出力値 を最小化するパラメータ$\boldsymbol{w'}$を推定する問題であると定式化することができます。
\boldsymbol{y} = f(\boldsymbol{w},\boldsymbol{x}) \\ E(\boldsymbol{y}, \boldsymbol{t}) ← こいつを最小化するパラメータ\boldsymbol{w'}を求めたいデータとして入力値 $\boldsymbol{x}$と、 目的出力値 $\boldsymbol{t}$はニンゲンが用意してあげないといけないものです1。手書き文字(0~9)画像からその画像に写っている数字を識別する教師あり機械学習タスクを想定した場合、$\boldsymbol{x}$は手書き文字画像のピクセルごとに入った輝度値をベクトル化したもの、$\boldsymbol{t}$はその画像に写る数字+1のインデックスのみ1、残りは0が入ってるベクトルだとイメージしてもらえれば良いかと思います。
例) 手書き文字画像に写ってる数字が5だった場合の入力値 $\boldsymbol{x}$ 、目的出力値 $\boldsymbol{t}$
\boldsymbol{x} = \begin{bmatrix} 0.5 \\ 0.3 \\ 0.2 \\ 0.5 \\ ... \end{bmatrix} ←ピクセル数だけの次元を持つ, \, \boldsymbol{t} = \begin{bmatrix} 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 1 \\ 0 \\ 0 \\ 0 \\ 0 \\ \end{bmatrix} ←インデックス6番目だけ1が立つパラメータ$\boldsymbol{w'}$はどうやって求めるのでしょうか。様々な最適化手法がありますが、深層学習の文脈では一般的に(確率的)勾配降下法(かその亜種)が用いられます。勾配降下法は、誤差関数 $E$ をパラメータ $\boldsymbol{w}^{(t)}$ で微分し、そこから得られる傾きの方向にパラメータ $\boldsymbol{w}$ を調整してあげるといったステップを繰り返すことで、誤差を最小化するパラメータを求めます。
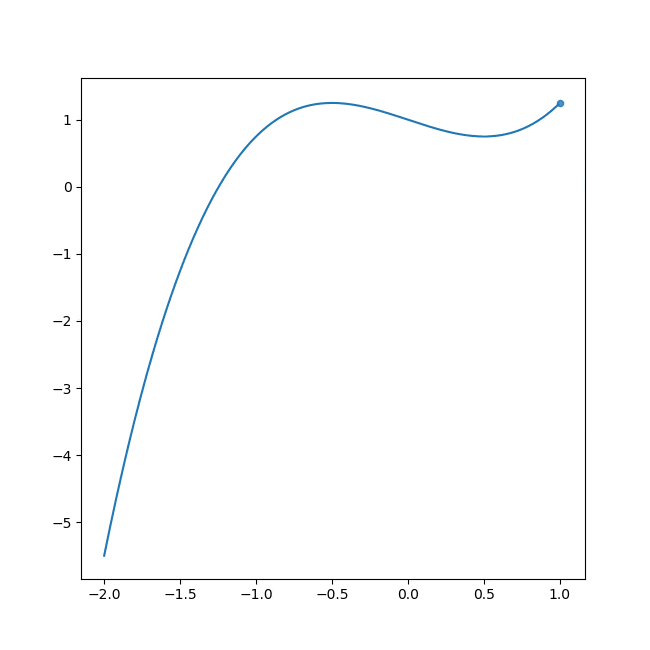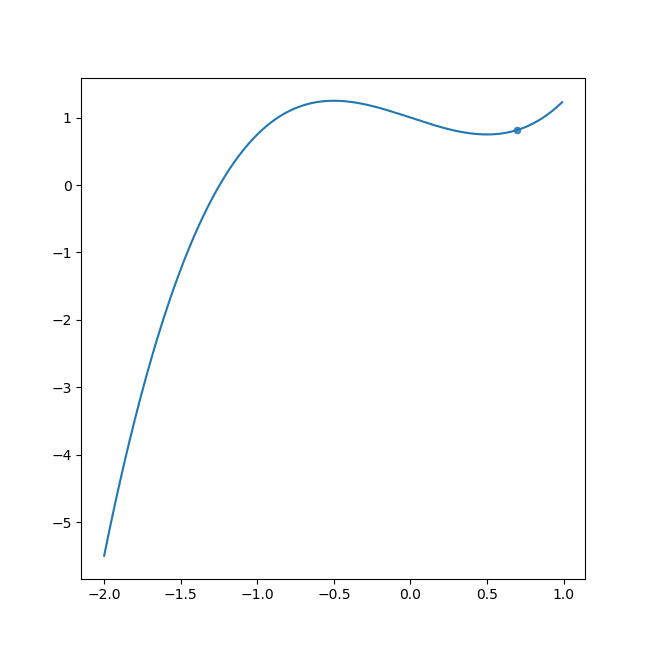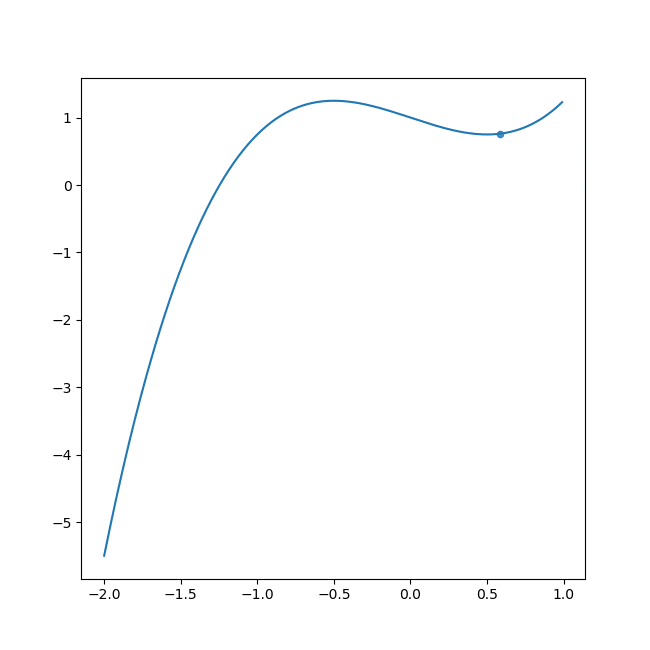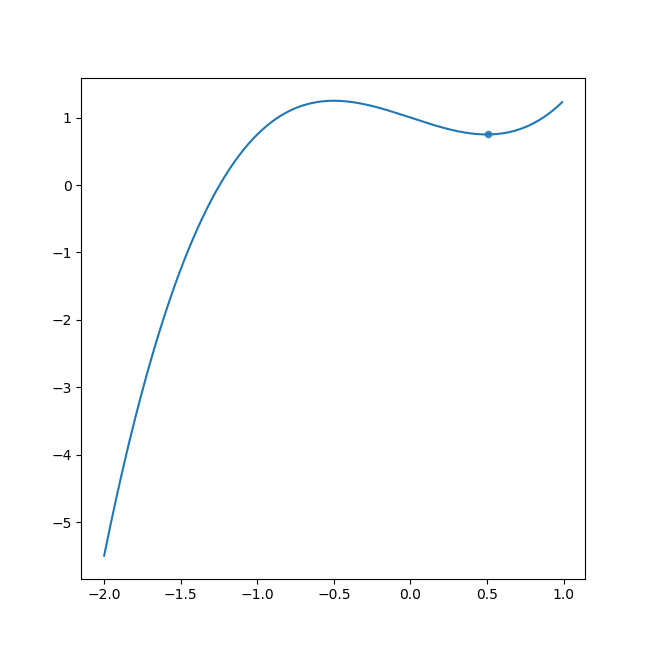
\boldsymbol{w}^{(t+1)} = \boldsymbol{w}^{(t)} - \epsilon \frac{\partial E(\boldsymbol{y}, \boldsymbol{t})}{\partial \boldsymbol{w}^{(t)}}, \,\epsilon: 学習率, \, t:ステップ数これがどういったことを行っているかイメージを持ってもらうために誤差関数 $E$ を2次関数、3次関数とした場合に、最終的にパラメータ $w$ (初期値:1.0)がどのような値に収束するか見てもらいたいと思います。
例) 2次関数($y=x^2$)の場合(縦軸: $E(w)$、横軸: $w$、 $w^{(0)}$: 1.0、 ステップ数: 25000)
例) 3次関数($y=x^3-0.75x+1$)の場合(縦軸: $E(w)$、横軸: $w$、 $w^{(0)}$: 1.0、 ステップ数: 25000)
2次関数の例は最小値0付近で収束してるのに対して、3次関数の例ではもっと左側にいけばより最小値に向かっていけるはずなのに、中途半端なクボみ2で収束してしまっていますね。これは勾配降下法の名の通り、勾配をもとに $w^{(t+1)} $の値を決めるのでクボみでは傾きが0で、$w^{(t+1)} = w^{(t)} + 0$となってしまうことに起因しています。
\frac{\partial E(w^{(t)})}{\partial w^{(t)}} ←こいつが0これを避ける方法としてモーメンタム法や学習スピードを高速化3する方法としてAdam、AdaGradなど様々な手法があります(が、ここら辺は気になったらググってみてください)。誤差を最小にするパラメータ $\boldsymbol{w'}$ を求める(学習する)ということは、目的出力 $\boldsymbol{t}$ に近い出力 $\boldsymbol{y} = f(\boldsymbol{w'}, \boldsymbol{x})$ を得るということと同義です。
深層学習
ところで、深層学習どこやねんという話ですよね、はい。深層学習は $f$ (深層学習である必要はないですが)です。つまり入力 $\boldsymbol{x}$ を出力 $\boldsymbol{y}$ にマッピング(写像)する関数です。え、じゃあ2次関数、3次関数も深層学習なんですか?と思った熱心な読者のみなさん、それは違います。何が違うのかというと関数構造が違います。深層学習はネストにネストを重ねた合成関数4であり、かつそれぞれのネストされた関数の出力に掛け算する形で莫大な数のパラメータ $\boldsymbol{W}^{(1)},...,\boldsymbol{W}^{(n)}$ を持ちます。また、ネストされた関数 $\boldsymbol{a}^{(1)},...,\boldsymbol{a}^{(n)}$ の中では、Relu、sigmoid、tanh5といった微分可能な非線形関数が用いられます。6
\boldsymbol{y} = f(\boldsymbol{x}) = \boldsymbol{W}^{(n)} a^{(n)}(\boldsymbol{W}^{(n-1)}a^{(n-1)}(・・・(\boldsymbol{W}^{(1)} a^{(1)})・・・))なんでこんな構造を持つ深層学習が他の機械学習手法と比べて精度がいいのかと疑問を持つかと思いますが、実はこれは数学的に厳密に証明はされていません7。但し、十分な深さ(3層以上のネスト)を持ちかつ非線形関数をかました深層学習手法は局所最適解が大域最適解とほぼ同等であるという論文が出ています8。これが意味するところは、パラメータの初期値がなんであっても学習ループ回して収束すればその収束値は大域最適解とほぼ同等の精度を持ってるよ!と言うことです。とても嬉しいですね。深層学習、サイコー!!!
3層ニューラルネットワークでMNIST
ここまで厳密性のない数式を用いた説明で飽き飽きしてる皆さんに朗報です。次に厳密性のないコードの説明をします。下に貼り付けたコードは3層ニューラルネットワークを用いてMNISTと呼ばれる手書き文字データセットの学習そして検証を行うものです。細かい説明はコードを見てください。ポイントとしては日本製DNNフレームワークChainer9を使っているところで、普通フルスクラッチで書こうと思うと意識が朦朧とするニューラルネットですが、Chainerを使うとあら不思議、100行未満で簡単にコードが書けちゃいます。(TensorFlow、Pytorchでも同様のことが実現できます)。これがコモディティ化ってやつ。
環境
- macOS Catalina 10.15.1
- Chaner 7.0.0
- Python 3.7.0
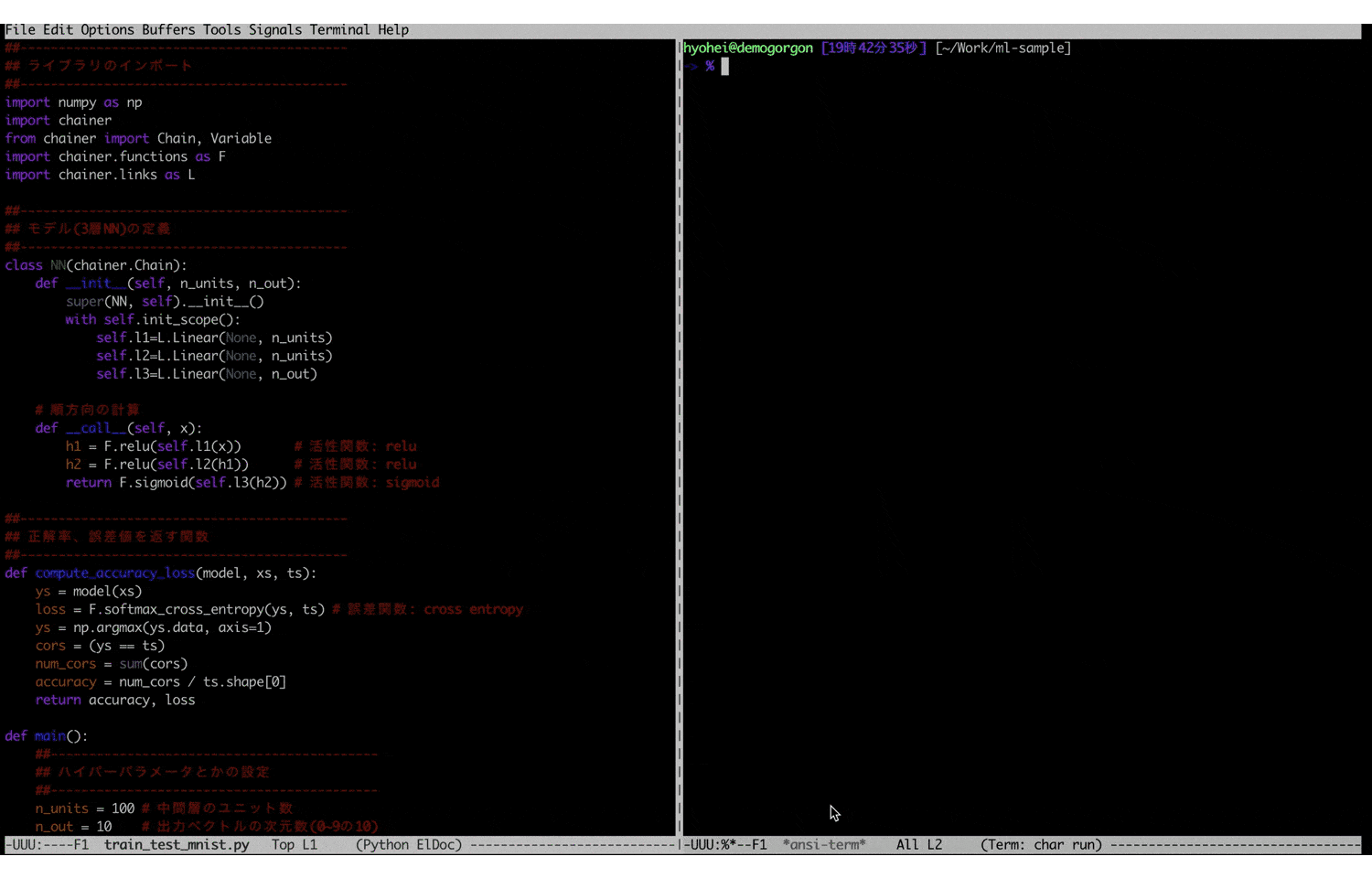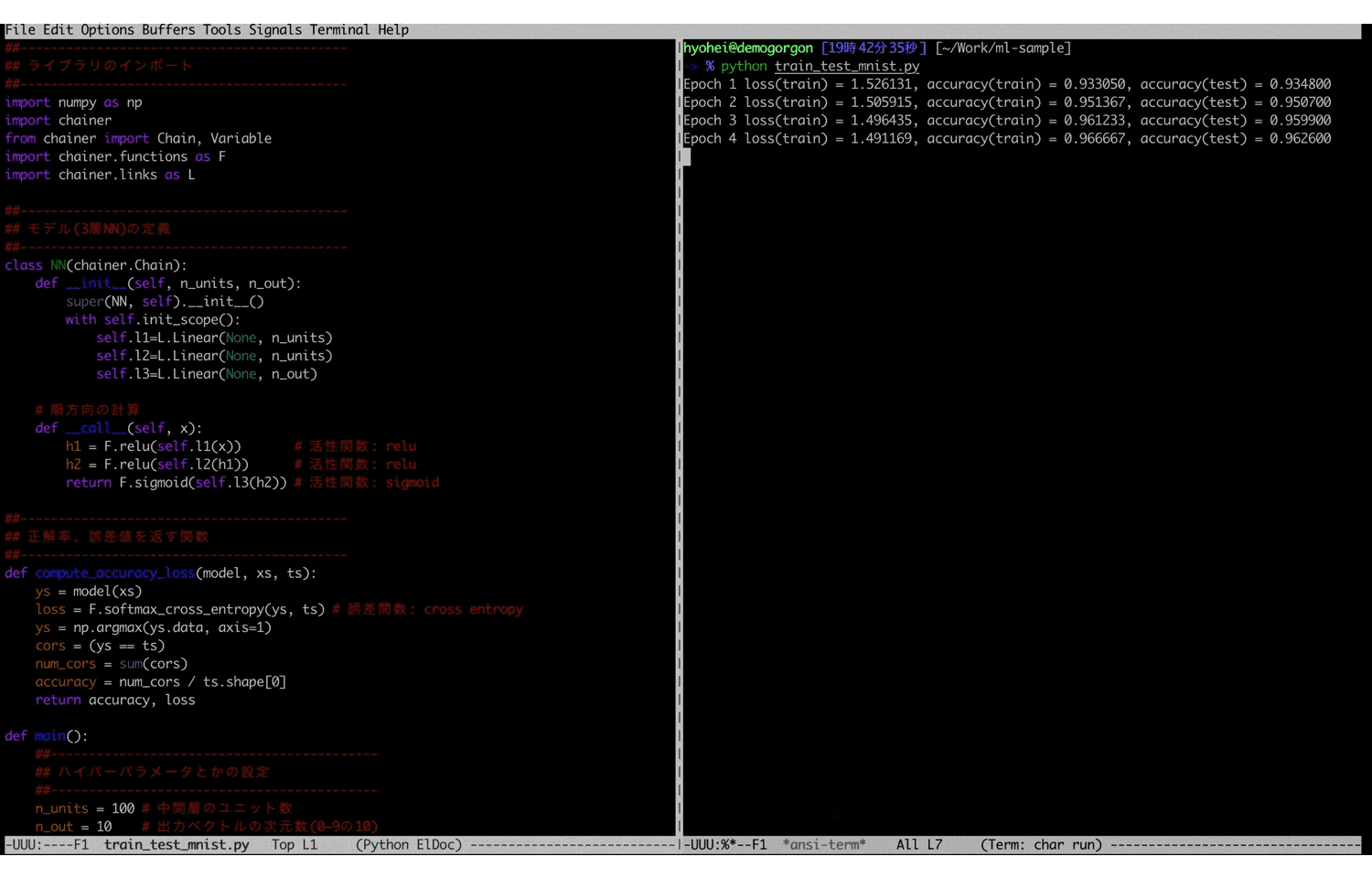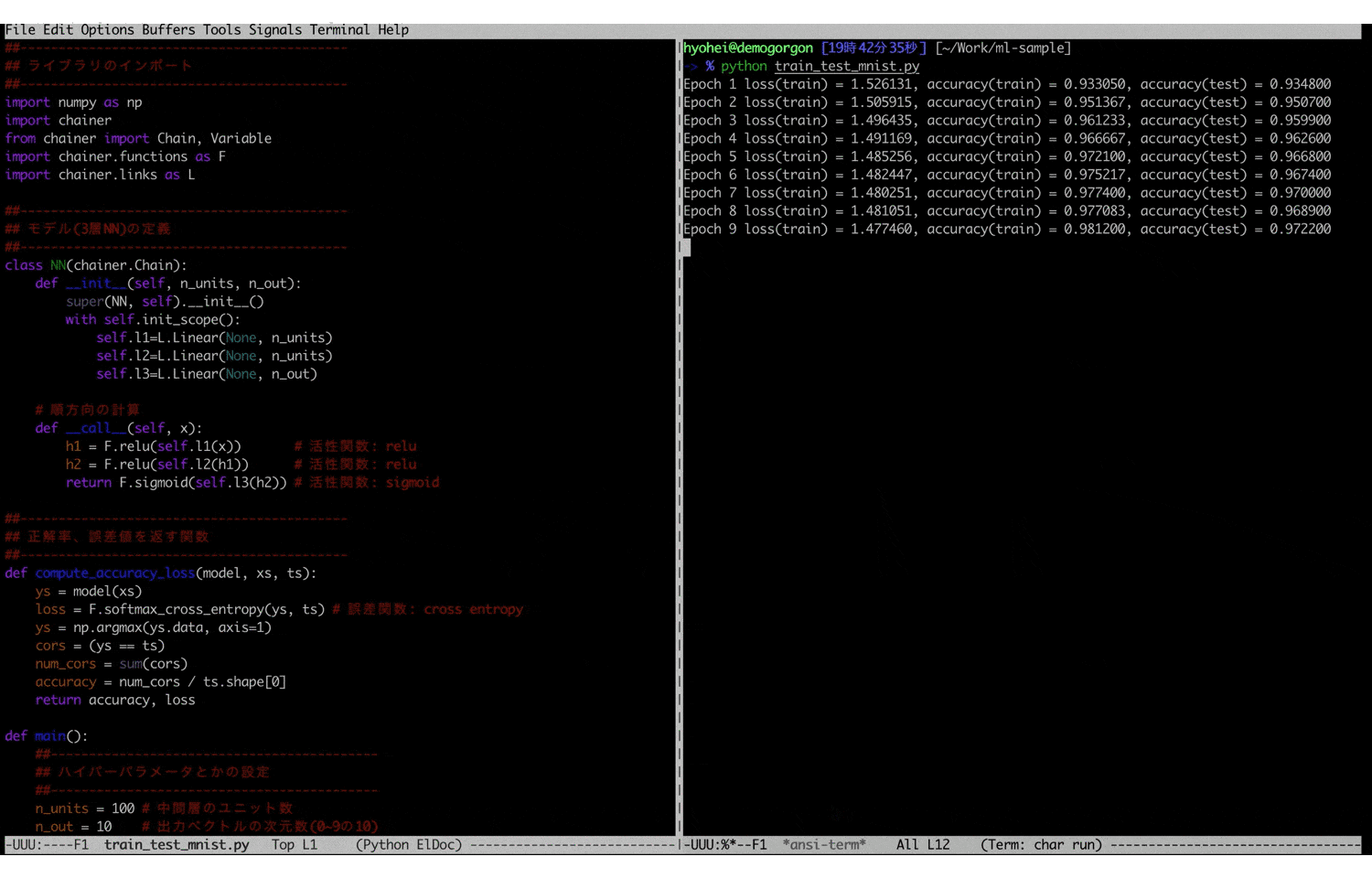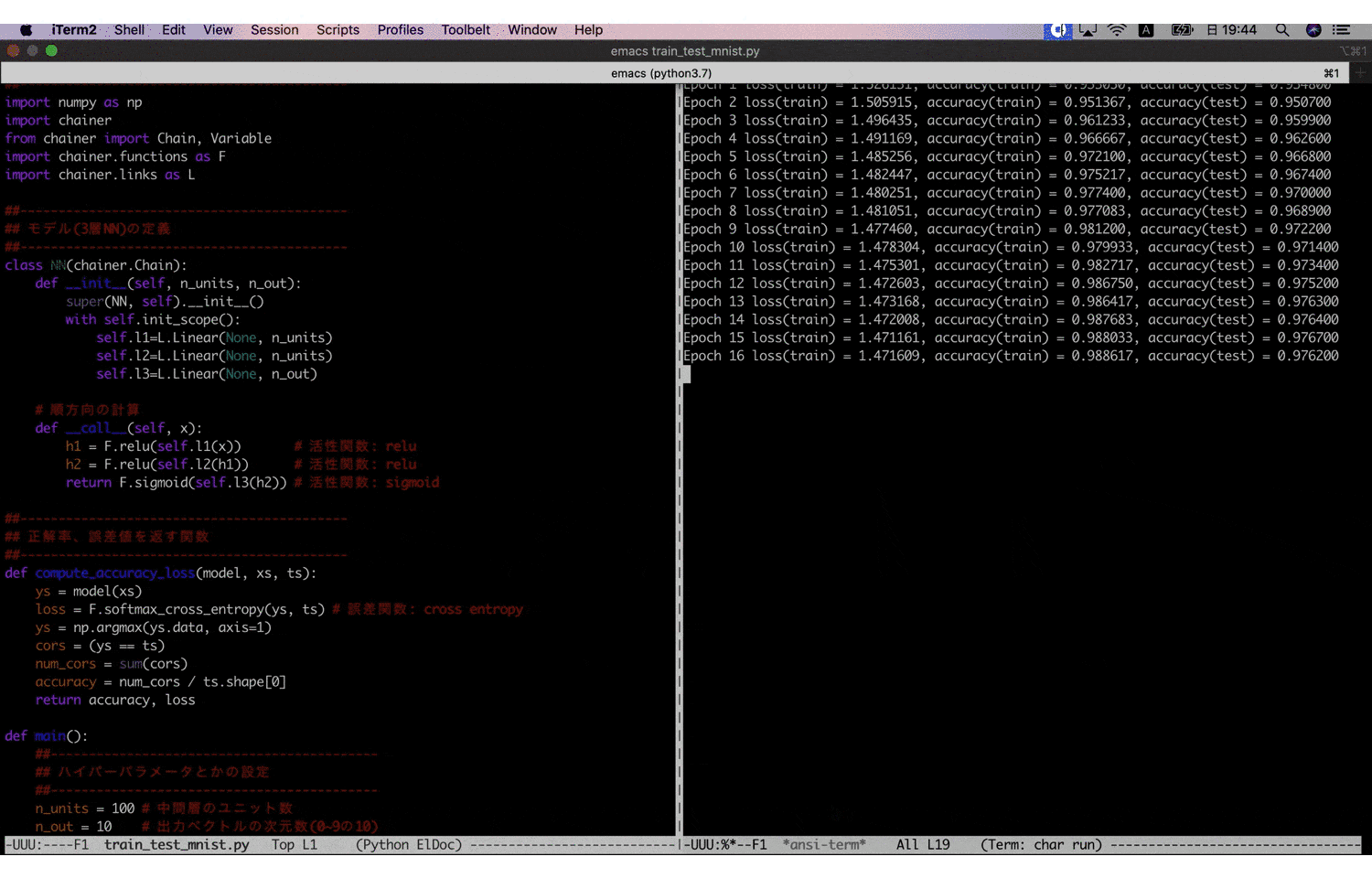
train_test_mnist.py##------------------------------------------- ## ライブラリのインポート ##------------------------------------------- import numpy as np import chainer from chainer import Chain, Variable import chainer.functions as F import chainer.links as L ##------------------------------------------- ## モデル(3層NN)の定義 ##------------------------------------------- class NN(chainer.Chain): def __init__(self, n_units, n_out): super(NN, self).__init__() with self.init_scope(): self.l1=L.Linear(None, n_units) self.l2=L.Linear(None, n_units) self.l3=L.Linear(None, n_out) # 順方向の計算 def __call__(self, x): h1 = F.relu(self.l1(x)) # 活性関数: relu h2 = F.relu(self.l2(h1)) # 活性関数: relu return F.sigmoid(self.l3(h2)) # 活性関数: sigmoid ##------------------------------------------- ## 正解率、誤差値を返す関数 ##------------------------------------------- def compute_accuracy_loss(model, xs, ts): ys = model(xs) loss = F.softmax_cross_entropy(ys, ts) # 誤差関数: cross entropy ys = np.argmax(ys.data, axis=1) cors = (ys == ts) num_cors = sum(cors) accuracy = num_cors / ts.shape[0] return accuracy, loss def main(): ##------------------------------------------- ## ハイパーパラメータとかの設定 ##------------------------------------------- n_units = 100 # 中間層のユニット数 n_out = 10 # 出力ベクトルの次元数(0~9の10) n_batch = 100 # バッチサイズ n_epoch = 100 # 学習回数 ##------------------------------------------- ## モデルの設定 ##------------------------------------------- model = NN(n_units, n_out) opt = chainer.optimizers.Adam() # 最適化手法: Adam opt.setup(model) ##------------------------------------------- ## データの準備 ##------------------------------------------- train, test = chainer.datasets.get_mnist() xs, ts = train._datasets # 学習データ txs, tts = test._datasets # テストデータ ##------------------------------------------- ## 学習 ##------------------------------------------- for i in range(n_epoch): for j in range(600): model.zerograds() x = xs[(j * n_batch):((j + 1) * n_batch)] t = ts[(j * n_batch):((j + 1) * n_batch)] t = Variable(np.array(t, "i")) y = model(x) loss = F.softmax_cross_entropy(y, t) # 誤差の計算 loss.backward() # 勾配の計算 opt.update() # パラメータの更新 ##------------------------------------------- ## テスト ##------------------------------------------- acc_train, loss_train = compute_accuracy_loss(model, xs, ts) acc_test, _ = compute_accuracy_loss(model, txs, tts) print("Epoch %d loss(train) = %f, accuracy(train) = %f, accuracy(test) = %f" % (i + 1, loss_train.data, acc_train, acc_test)) if __name__ == '__main__': main()このコードを僕の貧弱なローカル環境10で実行すると、以下のような学習結果が得られます。
学習回数100まで到達すると、ほぼ100%に近くまで行きます。
最後に
ここまで読んでいただき、誠にありがとうございます。上でちょいと触れたように世の中で持て囃されている深層学習はもはや要素技術であり、コモディティ化が進んでいます(なんなら枯れてきてる)。これからはいかに深層学習と他のCS・Webの技術を組み合わせて新しいサービス・事業を生み出せるかが鍵となっています。僕個人としては、Webの世界も好きなので今後この深層学習を使ったWebサービスを作りたいと思っています。同じような興味をお持ちの方がいたら基本ぼっちの僕と一緒にやりましょう!募集しています!!

- 投稿日:2019-12-22T22:43:39+09:00
pythonでテキストファイルから条件に一致した行を抽出
概要
複数の条件を使ってに前方一致、後方一致、部分一致、完全一致のいずれかを使ってテキストを抽出する処理をpythonで作ってみました。
もとはとあるテキストから特定の文言が含まれているものを抽出して除去する処理をpythonで作りましたが、抽出する処理だけでも有効かと考えその部分を一部変更できるようにして作り直してみました。必要なもの
- python 3.7.2
- pandas
- numpy
今回はexeもあるので動かすだけならpythonなど不要です。
公開場所
- githubで公開しています。
処理内容
resources/検索データ.xlsxに定義された文言をもとにresources/appConfig.iniに設定した定義に応じて前方一致、後方一致、部分一致、完全一致の条件で抽出を行います。- 処理する対象は
dataディレクトリの中に格納されているファイルをすべて処理します。- 結果は
outputディレクトリの下に出力します。ソース説明
以下の処理が検索するための条件を作成しています。
* 検索データ.xlsxから検索用の文字列を取得します。
* ソート条件に応じて文字列の長さでソートを行います。
* 前方一致、後方一致などの条件に応じて.*を付与して条件を|でつなげています。def createReg(self): searchItems=pd.read_excel('resources/検索データ.xlsx') sortTypeCode=iniFile.get('info','sortType') searchItemArray=np.asarray(searchItems['検索語']) sortType=SORT_ENUM(sortTypeCode) if sortType==SORT_ENUM.SORT_LENGTH_ASC or sortType==SORT_ENUM.SORT_LENGTH_DESC: searchItemIndex=[] for item in searchItemArray: searchItemIndex.append(len(item)) searchSeries=pd.Series(searchItemIndex) serchItemDataFrame=pd.concat([searchItems['検索語'],searchSeries],axis=1) if sortType==SORT_ENUM.SORT_LENGTH_ASC: sortItems=serchItemDataFrame.sort_values(0,ascending=True) else: sortItems=serchItemDataFrame.sort_values(0,ascending=False) searchItemArray=np.asarray(sortItems['検索語']) regTypeCode=iniFile.get('info','regType') regType=REG_ENUM(regTypeCode) regStr='' for item in searchItemArray: if regStr!='': regStr=regStr+'|' sItem=item if REG_ENUM.REG_TYPE_CONTAIN==regType: sItem='.*'+item+'.*' elif REG_ENUM.REG_TYPE_FRONT==regType: sItem=item+'.*' elif REG_ENUM.REG_TYPE_BACKWARD==regType: sItem='*.'+item elif REG_ENUM.REG_TYPE_EXACT_MATCH==regType: sItem=item regStr=regStr+sItem return re.compile(regStr)以下の処理で前述の処理で作成した条件をもとに抽出しています。
*with openを使ってファイルを読み込み一行ずつ一致するかを確認します。
* 一致したものを配列に格納します。
* 最後にテキストファイルとして出力しています。def extract(self): reg=self.createReg() paths=glob.glob('data/*.csv') fileDict={} for pathName in paths: extractList=[] with open(pathName,encoding=iniFile.get('info','encoding')) as f: # targetStrs=f.read() for targetStr in f: extractStr=reg.search(targetStr) if extractStr: extractList.append(targetStr) fileDict[os.path.basename(pathName)]=extractList outputPath=iniFile.get('info','outputPath') for key,data in fileDict.items(): outputFile=outputPath+'extract_'+key+'.txt' with open(outputFile,encoding='utf-8',mode='w') as f: for d in data: f.write(d)使い方
- githubのreadme参照
- 動かしてみたいだけなら
dataに処理したいファイルを格納resources/検索データ.xlsxに抽出したい文言を設定regExtract.exeを実行する。活用方法
- 連携ようのファイルに時含まれているか確認したいものが複数あるときなど
- 処理を修正して特定の文言を変換できるようにするなど
- 投稿日:2019-12-22T22:34:32+09:00
mong続報 - Dockerの名前生成ツールは2年前にPythonに移植されていた-
mong - Dockerのコンテナ名をランダム生成するコードをPythonに移植してみた -の続きです.
TL;DR
- namesgenerator というパッケージが見つかりました.mongは見事に車輪の再発明でした.
- 一方
namesgeneratorは2017年12月からアップデートされていないので辞書が古く,生成できるパターンが本家やmongより少ないです.mongでインスタンス生成が必須なのは使いにくかったのでnamesgeneratorを見習ってmong.get_random_name()を追加してみましたnamesgenerator
Google, pypiで検索していて Dockerの名前生成ツールのPython版はないなぁと思っていました.しかしGitHubのコード検索をしてみたら,一瞬で下記が見つかりました.GitHubすごい.
https://github.com/shamrin/namesgenerator
上記のレポジトリにはPython版のほか,JavaScript/TypeScript版も含まれています.
pypiにも登録してあったので,インストールも一瞬です.
pypiの統計を見ると,月間1,000ダウンロードあるので,それなりに需要もあるようです.もう,これを使えばいいじゃん,と思ったのですが,反省も兼ねてコードリーディングしてみました
namesgenerator と mong の違い
大きく下記の4点が違います
1. 辞書の持ち方
2. 関数 or クラス
3.boring_wozniakのときの再生成の方法
4.get_random_nameの引数辞書の持ち方
mongは辞書を別ファイルにしているのに対して,namesgeneratorはpythonコード中にべた書きしています.べた書きすると,データ読み込み処理が不要で楽なのですが,メンテがつらそうです.
namesgeneratorは2年前に更新がとまっているので,それから本家に追加された語もあるかと思い,辞書のエントリ数で比べてみました:
-namesgeneratorの辞書は形容詞が93語で人名が160語
-mongの辞書(現在のmobyと同じはず)は形容詞が108語, 人名が235語
mongの方が形容詞で15語,人名で75語多いです.追加された語を調べる際に,べた書き方式だとGoのコードとPythonのコードを比較する必要があります.単純なdiffはできません.一方で
mongではmong/create_dict.pyを実行してGoコードからJSON形式の辞書を抜き出します.1行1単語にしてあるので,diffで差分が確認できます.もっとも,Goコードのフォーマットが大きく変わると辞書を抜き出すコードの修正が必要になるわけですが,mobyはそれなりに枯れているっぽいので大丈夫だと思います(思いたい).以上から,メンテは
mongの方が楽かもしれません.関数 or クラス
namesgeneratorは名前生成を関数get_random_nameで提供していて,mongはNameGeneratorクラスのget_random_nameで提供しています.クラスだといったんインスタンスを生成しないといけないので面倒です.mongを作り始めたときに,辞書を変更可能に,とか乱数シードの管理を別にできた方がよいのでは,などと考えてクラスにしましたが,一晩頭を冷やしてみるとそんなことはありませんでした.namesgeneratorの方式が良いです.
boring_wozniakのときの再生成の方法
namesgeneratorはwhileループで生成ロジックを回している一方でmongはget_random_nameメソッドを再帰呼び出しています.boring_wozniakが生成される確率は1/25,380なので,どちらでもいいかなと思います.
get_random_nameの引数
namesgeneratorはretry関係のロジックがありません.ここ2年で追加されたのでしょうか.また,その代わりに形容詞と名詞をつなぐsepを変更できます.これも仕様変更でしょうか?mongへの反映と今後の方針
いやー,見事に車輪の再発明をしてしまいました.
ただ,
namesgeneratorの実装と比較することで良い点,悪い点の答え合わせができましたので,経験値が溜まってよかったかなと思います.また,良いところは見習おう,ということで関数方式を取り入れてmong.get_random_nameを追加しました.つまり,今は下記のように書けるようになりました.
import mong mong.get_random_name() # 'trusting_engelbart' mong.get_random_name() # 'thirsty_brahmagupta'今後ですが,
namesgeneratorはメンテされていないので,mongをメンテしていくとそれなりに需要あるのかもと思います.参考文献
- 投稿日:2019-12-22T22:33:49+09:00
Janus gatewayのAdmin APIを使ってみる
概要
Janus gatewayというWebRTCメディアサーバーについての記事は多数ありますが、
用意されているAPIの使い方については公式以外ほとんどありません。
調べるのに苦労しましたので、ここにまとめておきたいと思います。参考になるサイト
APIの種類
Janusで用意されているAPIには大きく分けると二つの種類があります。
- Admin API
Janusを管理、モニターするためのAPIです。
この記事にて使ってみます。
- プラグイン API
Janusにはビデオ通話やストリーミング、SIP関連などの多数のプラグインが用意されています。
そのプラグインを操作するためのAPIです。
次回記事にて使ってみるつもりです。Websocketを介してAdmin APIを使ってみる
Janusのコンフィグを設定する
Admin APIを呼び出す際に使うパスワードを設定します。
/usr/local/etc/janus/janus.cfg[general] admin_secret = password
Websocketを介して使えるように設定します。
今回はwsの設定していますが、暗号化が必要な場合はwssの設定および証明書の準備をしましょう。
また、ここで指定したポートはFW等でブロックされないようにしておきます。/usr/local/etc/janus/janus.transport.websockets.cfg[admin] admin_ws = yes admin_ws_port = 7188Pythonでコードを書く
Pythonのバージョンは2.7です。
今回はJanusにアクセスしてきたユーザの情報をモニターしてみます。まずは、アクセスしているセッションのリストを取得します。
import websocket import json import random import string # Janusのエンドポイント janus_admin_url = 'ws://10.0.0.1:7188/janus' # 管理用パスワード janus_admin_secret = 'password' # ランダム文字生成 def random_string(length, seq=string.digits): sr = random.SystemRandom() return ''.join([sr.choice(seq) for i in range(length)]) # 8文字のランダム文字 transaction = random_string(8) # list_sessionsメソッド呼び出すJsonを作る data = {"janus":'list_sessions', "admin_secret": janus_admin_secret, "transaction": transaction} # Websocketのコネクションを作成 websock = websocket.create_connection(janus_admin_url,subprotocols=["janus-admin-protocol"]) # 送信 websock.send(json.dumps(data)) # 受信 rejson = websock.recv() # 受信結果を表示 print rejson{ "janus": "success", "transaction": "73677159", "sessions": [ 311091039069809 ] }次に、そのセッションがハンドルしているリストを取得します。
複数のプラグインが使われている場合などは、ハンドルが複数返されます。sessions_list = json.loads(rejson).get('sessions',[]) # list_handlesメソッド呼び出すJsonを作る data = {"janus":'list_handles', "admin_secret": janus_admin_secret, "transaction": transaction, "session_id": sessions_list[0]} websock.send(json.dumps(data)) rejson = websock.recv() print rejson{ "janus": "success", "transaction": "73677159", "session_id": 311091039069809, "handles": [ 1721128026873430 ] }最後に、そのハンドルの情報を取得します。
handles_list = json.loads(rejson).get('handles',[]) # handle_infoメソッド呼び出すJsonを作る data = {"janus":'handle_info', "admin_secret": janus_admin_secret, "transaction": transaction, "session_id": sessions_list[0], "handle_id": handles_list[0]} websock.send(json.dumps(data)) rejson = websock.recv() print rejson{ "janus": "success", "transaction": "73677159", "session_id": 311091039069809, "handle_id": 1721128026873430, "info": { "session_id": 311091039069809, "session_last_activity": 1367674698, "session_transport": "janus.transport.http", "handle_id": 1721128026873430, "opaque_id": "videoroomtest-L4YiOtywt1nm", "created": 464048923, "send_thread_created": true, "current_time": 1368713443, "plugin": "janus.plugin.videoroom", "plugin_specific": { "type": "publisher", "room": 1234, "id": 4565592288551424, "private_id": 3477273478, "display": "You", "media": { "audio": true, "audio_codec": "opus", "video": true, "video_codec": "h264", "data": false }, "bitrate": 128000, "audio-level-dBov": 0, "talking": false, "destroyed": 0 }, ・・・ (省略) ・・・ } }上記の情報を説明します。
infoのpluginが「janus.plugin.videoroom」となっていることから、
このユーザはvideoroomにアクセスしていることがわかります。
またpluginの詳細はplugin_specificにあり、
room番号が「1234」、名前が「You」ということがわかります。
その他にもコーデックやビットレート、SDP等の情報も取得することができます。最後に
今回はAdmin APIの基本的な使い方を説明しました。
この他にもAdmin APIには多数のメソッドが用意されています。
公式サイトを確認してみてください。
次回はプラグインAPIについても記事を書きたいと思います。余談
今回が自分のQiita初記事でした。
間違っている箇所等あれば、ぜひご指摘ください。
- 投稿日:2019-12-22T22:14:03+09:00
Python2の引退に向けて
はじめに
今年もあと10日ほどになりました。2010年代が終わるという節目であると同時に、Pythonの世界でも一つの時代が終わることになります。長らくサポートされてきたPython2.7が2020年1月1日にサポート終了(EOL: End of Life)となります。つまりそれ以降はバグが見つかっても修正バージョンが出ない。Python2.7が2シリーズの最後となり、Python2は引退することになります。
Python2.7の最初のバージョンが出たのが2010年7月3日だったので9年半に渡って現役を続けました。その頃のPython3はVersion 3.1。そこからバージョンを重ねて3.8まで来ていて、マイナーバージョン数ではPython2を越えました。
Python2の約20年の歴史の中で2.7がその半分を占めるという異常な状態になったのもPython3がPython2と互換性がなく以降に時間がかかったからでした。PEP-404で宣言されていたようにPython2.8は出ないことになっていたので、Python2.7のまま引っ張り続けました。実は最初の引退予定は2015年でしたが、2014年なっても全然移行が進んでおらず「こりゃダメだ」ってことでEOLを5年間先延ばししたのでした。
Python3は当初は性能的な問題も有り、私も長らくPython2に留まっていた人の一人です。時間をかけて徐々にそういった問題も解決し、有名どころのライブラリがPython3対応をするようになってようやく人々が移行を始めました。10年かけて引退までこぎ着けた人たちの苦労は想像に難くないですが、例え良いものであっても移行によって得られるベネフィットが移行に伴うコストを越えない限り人々は動かないということを思い知らされます。
Python2のサポートが終了してもすぐに使えなくなるわけではありません。一方でバグやセキュリティ問題があってもアップデートされないソフトウエアを商用で使うわけにも行かないですし、非商用であっても被害を被る可能性があるのは同じなのでPython3への切り替えは待ったなしかと思います。
自分で使うPythonはもうVersion 3にしているよ、という方も多いと思いますが、一つ見落としがちなのが間接的に使っている場合。多くのツールがPythonに依存していて、それらを例えばパッケージマネージャ経由でインストールしている場合、Python2を引っ張ってきてしまう場合があります。例えば、一見関係なさそうなnode.jsとかvimとかもpythonを使っていたりします。そのため、各パッケージマネージャの管理者の人たちはPython2に依存しているパッケージをPython3依存に移行しようと頑張っています。その状況をHomebrewとDebianに関して調べたので書いてみたいと思います。
Homebrew
Homebrewでは、
pythonというパッケージはpython3を指していて、python2はpython@2というパッケージ名で提供されています。このpython@2パッケージは年明け早々に消去されるべくこんな Pull Requestも既に出ていたりします。ただまだこれに依存しているパッケージもあって、それを先に解消しなければならない。その為のIssueがこちらにあるのですが、それを見るとまだ幾つかのパッケージが未対応になっています。その状況を手元で確認するとこのようになります。
$ brew uses python@2 git-remote-hg ipython@5 mysql-utilities pwntools terminator headphones mkvtomp4 offlineimap pygobject volatility hg-flow molecule ooniprobe redo vteこの中で自分がインストールしているものが含まれているかどうかを知りたければ、
brew uses --installed python@2をやってみるとわかります。私はmysql-utilitiesがインストールされていました。どうやらアップデートはもうなく、ここの案内によると MySQL Shellへの移行が促されているようなのでそうしてみようかと思います。なお、MacOS標準のpythonは最新のCatalinaでも 2.7のようです。ただし、起動すると「Python2.7を使うのはオススメしないよ!」というメッセージがでてきます。将来的には消されるとのことだけど、次のバージョンが出るまではこのままなのかな。
Debian
Debianの方でもPython2を削除しようとしています。ただし、Debianは歴史も長くパッケージ数が多いこともあって事態はもっと複雑です。Python2削除によって影響を受けるパッケージはDebianのバグ管理システムに登録されていて
py2removalというタグが付いていますが(Bugs tagged py2removal)、総数は3,443。そのうち解決済みとなっているのが1,960。残りの1,483パッケージがまだ未解決となっています。利用数が少ないものやアップストリーム(開発元)でメンテナンスがされていないものはバシバシ消去対象になっていて、既に消されているものも多数あります。なので、残っている1,500ほどのパッケージはそこそこ重要なものが含まれています。特に、「serious」(最も深刻)とされているものが600以上あって、これらが解決しないとたぶんpython2は消せない。いつまでかかるのか動向を見守るしかないですね。
未解決のリストをざっと眺めてみると幾つか見知った名前があります。例えば
trac。これはチケット管理ツールでいわばPython版redmine。だいぶ前に使っていたことがありましたが久しぶりに名前を聞きました。アップストリームをみると今年の8月に新しいバージョン(1.4)が出ていますが、まだpython3対応していない。ロードマップを見ると次の1.6で対応する予定みたいですが全然間に合ってないですね。Tracの開発自体をTrac https://trac.edgewall.org/wiki でやっていますが、やはり古い感じが否めない。Githubでやったらもっと楽なのにと思ったけど、そうするとそもそもこのTracの存在意義がなくなっちゃう(笑)。やはりソフトウエアにも寿命があるんだなと思い知らされます。あと、それぞれのパッケージメンテナーとのやり取りがバグチケットに載っているのですが、結構激しくバトっていたりします。例えば Calibreというパッケージのチケット だと「おまえら全然何もやってねえじゃないか」とか「そういう嘘やFUD(恐怖、不安、疑念)を撒き散らすのはやめろ」とか、結構強い言葉が並んでいたりします。Python2がそのまま使い続けられればすることのない無駄な作業なのでわからないでもないですが、Python2をPython3と並行して長い間残したことの功罪相半ばという感じですね。
Python2.7の今後
Python2.7は1月以降どうなるのか。なんと実はPEP-373にはこの先のリリース予定が載ってます。
- 2.7.18 コードフリーズ … 2020年1月
- 2.7.18 リリース候補 … 2020年4月初旬
- 2.7.18 正式リリース … 2020年4月中旬
あれ、1月で打ち止めじゃなかったっけ⁉と思ったのですが、最後のメンテナンスリリースがもう一度だけあるみたいです。Homebrewとかはもう Python@2をドロップしてしまうので次の 2.7.18 は幻のバージョンになるのかも。
まとめ
Python2引退に伴うHomebrewとDebianの準備状況を調べてみました。実際にこの後どうなっているのか、見守ってみたいと思います。
なお、引退までのカウントダウンは https://pythonclock.org/ でみることができます。
- 投稿日:2019-12-22T21:55:48+09:00
試験の電子採点を画像認識でサポートした話
ゆるゆる新卒1年生 Advent Calendar 2019、23日目へようこそ。
ゆるいにも程がある新卒1年生、 @NamedPython です今日は僕の隠し特技である OpenCVによる画像認識 についてです。
画像認識について書くことはあらかじめ決めていましたが、新しく何かネタを見つけるのもきつかったので、学校の授業で
頑張って書いたのにどこにも供養してなかった回答用紙の領域抽出 をした記録をここに残します何を作ろうとしたのさ
授業と言いましたが、授業名は プログラミング応用 で、普段授業で学んでいること・学生の持つ技術を絡めて、ソフトウェア開発による問題解決をチームで取り組んでみましょうねというものです。
じゃあ、問題解決のテーマは何かというと、
先生が行なっている試験の電子採点を楽にしてくれ
というものでした。そもそも電子採点している時点でかなりナウでヤングなんですが要件をまとめると
- 学生の試験回答をスキャンしてiPadに取り込んでいる(ナウい)
- 回答用紙は解答欄を用意しているわけではなく、自由記述
- 上記のこともあり回答の位置が生徒によってバラバラ
- なので、取り込んだ画像の回答の領域をApple Pencilで色分けして囲んでいる(ナウい)
- 同じ問題(同じ色分け)を一気に採点したい
- 君たち、なんとかしてくれ

って感じでした。
チーム
実はこの授業の一年前に、
- バックエンドAPI、Webフロントの @NamedPython
- iOSの @Taillook
- Androidの @youta1119
- PythonとRasPi制御、自然言語処理の @Kyoskk
というそこそこ最強のチームを組んで大批判を浴びました。その影響で、チームを組むメンツに制限がかかりました

それでも、先述の @Taillook と、もう一人仲の良いクラスメイトを引っ張って3人のチームを組みました。
ソリューション
先述のチーム組みで、iOS書けるやつを引っ張ってきました。
せっかくなので、何から何までiOSに乗っける以下のような構成のシステムを提案しました(最終発表のプレゼンから抽出)。 iOS周りの実装をありがとう、@Taillook。
この図はKeynoteでゴリゴリ頑張りました。フォントはM+と、筑紫B丸ゴシック。
認識概要
- 色分けする運用が既にあるので、彩度のある部分のみを抽出すれば良さそう
BGR空間からHSV空間に変換して、S(彩度のチャネル)のみ抽出- 二値化
- Sチャネル抽出の時点でそこそこ二値化されているため、単純な
判別分析法でOK- 領域をそれぞれ切り出す
findContoursによる辺検出- 様々な辺が検出されるため、
cv2.RETR_TREEによる辺の構造化
- 内側にさらに辺があるもの
OR面積が一定以下 をスキップ- その領域がどの色で塗られているかを判別する
- 抽出された辺の斜め左上(
x - 1,y - 1)のピクセルの色を20点ほど抽出- 平均をとって、その辺の色とする
対象画像
当時は動作検証用の実物の回答用紙をもらいましたが、ここで持ってくるには権利周りがグレーな予感がしたので、Pages職人 の力を使ってサンプルを生成しました。
実装
さて、もうそろそろ退屈なのでドーンとソースコードを。
FROM jjanzic/docker-python3-opencvなDockerfileを用意してどこでも開発できるように用意しました。最終的に画像認識部分は僕がフルで開発したのでオーバーキルでしたが。Dockerの中身は以下。
- Python 3.7.0
- OpenCV 3.4.1
source.pyimport os import cv2 import numpy as np DIR = os.path.dirname(os.path.abspath(__file__)) image = cv2.imread(f'{DIR}/image/sample_answer_sheet.png') if image is None: print("File not found.") exit() def write_out(img, name): cv2.imwrite(f'{DIR}/image/result/{name}.png', img) def extract_inside(contours, hierarchy, debug=False): extracted = [] contours_drawed = image.copy() if debug: print(f'len: {len(contours)}') print(hierarchy) for index in range(len(contours)): if hierarchy[0, index, 2] != -1 or cv2.contourArea(contours[index]) < 8000: continue extracted.append(contours[index]) if debug: cv2.drawContours(contours_drawed, contours, index, (255, 0, 255), 10) print(f'{index} : {cv2.contourArea(contours[index])}') if debug: write_out(contours_drawed, 'out_contours') return extracted width, height = image.shape[:2] extracted = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)[:, :, 1] write_out(extracted, 'after_cvt') ret, thrshld_ex = cv2.threshold(extracted, 0, 255, cv2.THRESH_OTSU) write_out(thrshld_ex, 'thrshld') kernel = np.ones((3, 1), np.uint8) thrshld_ex = cv2.morphologyEx(thrshld_ex, cv2.MORPH_OPEN, kernel) write_out(thrshld_ex, 'thrshld_ex') _, contours, hierarchy = cv2.findContours(thrshld_ex, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE) inside_contours = extract_inside(contours, hierarchy, True) print(f'extracted {len(inside_contours)} countours') clr_img_cp = image.copy() for circle in inside_contours: colors = [] av_color = 0 M = cv2.moments(circle) center_of_circle = (int(M['m10']/M['m00']), int(M['m01']/M['m00'])) cnt = 0 for approx in circle: if cnt == 20: break cv2.circle(clr_img_cp, (approx[0, 0] - 1, approx[0, 1] - 1), 1, (255, 0, 255), 1) colors.append(image[approx[0, 1] - 1, approx[0, 0] - 1]) cnt += 1 cav = np.mean(colors, axis=0) cv2.circle(clr_img_cp, center_of_circle, 100, cav, 20) write_out(clr_img_cp, 'out')先ほどの認識概要に書いていたものをソースコードに落とすとこんな感じです。こんな感じで
PythonでプロトタイピングしてからObjective-Cに移植して @Taillook にSwiftとブリッヂしてもらいました。結果
HSV色空間への変換をしてSのみ抽出判別分析法による二値化- 辺検出
- 辺の色を抽出
の4工程それぞれの結果を載せます。
HSV色空間への変換をしてSのみ抽出extract_s_of_hsv.pycv2.cvtColor(image, cv2.COLOR_BGR2HSV)[:, :, 1] # 0: H, 1: S, 2: V
もうこの時点でほぼ二値化なんですよね。すぎょい。
判別分析法による二値化
cv2.THRESH_OTSUを指定するだけ。イージー。thresold_with_otsu.pycv2.threshold(extracted, 0, 255, cv2.THRESH_OTSU)
少しノイズが入る場合は、このあと
morphologyEXをかけてノイズ除去をするとよきです。辺検出
もうもはやOpenCVがすごい。
findContoursがすごい。論文を一応読んだんですが、辺の構造情報まで認識するとか変態的すぎる。find_contours_with_structure.py_, contours, hierarchy = cv2.findContours(thrshld_ex, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
hierarchyに、contours内のどのindexの辺がのindexの辺の横にあるとか、内包してるとかを格納しています。すぎょい。
辺を点の集合で表し、紫色で描画しています。
辺の色を抽出 + 描画
ここはゴリ押しです。色の平均をこんなにも簡単に取れる
numpyに感謝。sampling_color_and_averaging_and_plotting.pyclr_img_cp = image.copy() for circle in inside_contours: colors = [] av_color = 0 M = cv2.moments(circle) center_of_circle = (int(M['m10']/M['m00']), int(M['m01']/M['m00'])) cnt = 0 for approx in circle: if cnt == 20: break cv2.circle(clr_img_cp, (approx[0, 0] - 1, approx[0, 1] - 1), 1, (255, 0, 255), 1) colors.append(image[approx[0, 1] - 1, approx[0, 0] - 1]) cnt += 1 cav = np.mean(colors, axis=0) cv2.circle(clr_img_cp, center_of_circle, 100, cav, 20)
図形の中心を割り出し、そこに平均をとった色で円を描画しています。
(実はこの画像よく見ると、20サンプルの対象ピクセルに紫色がついています。)
だいたい辺と同じ色で良い感じ。まとめ
ということで、学生時代に組んだ画像処理のプログラムをここで供養しました
僕からすれば振り返りだったのですが、これを読んで
Python+OpenCVの可能性を感じていただければ幸いです。ただ一つ注意点として、
OpenCVは理論を知っていなくても多くの事例から学んで使えてしまいますが、やはり問題解決に対する手段適用の最短経路を導くには理論が先決な気がしているので、情報工学は大事です。僕は軽くすっぽかしたためぎりぎりの理論しかありません。ただ以下は確実に言えるでしょう。
OpenCVはすごいPython+OpenCVはやりやすい
numpyとの相性がいいということです。実はこの記事を書く前に
RustによるOpenCVを試したりもしたんですが、Python+OpenCVの使い心地と比べてしまうとイマイチでした。まぁRustの実装に慣れていない僕が言うので参考にはならないかもしれませんが
Pythonだし遅いんでしょー?って話もありそうですが、描画を除くとなんと 0.3 [sec] ほど。
ただのC-bindingだしね。すげえや。
僕が開発に携わっている自転車通販サイト cyma -サイマ-でも、なんだか画像認識をやる気運が上がってきたので、力を発揮していきたい。@shimura_atsushi が Ateam cyma Advent Calendar 2019 で2記事書いているので興味がある方はどうぞ。
おわりに
ゆるゆる新卒1年生 Advent Calendar 2019、23日目いかがでしたか?
24日目は、バックエンドもわかるつよつよフロントエンドエンジニア @cheez921 のターンです。デュエル、スタンバイ!
よいクリスマス、よい年末、よい年始、よい画像認識を。




- 投稿日:2019-12-22T21:33:08+09:00
DEAPに学ぶdeepなPython
はじめに
DEAPという進化計算フレームワークをご存じでしょうか。
え?DEAP以前に進化計算何それという状態ですか?
まあ進化計算の前提知識はこの記事ではあまり関係ありません。この記事の主目的は進化計算を実装するためにDEAPがどれだけPythonをうまく使っているかを説明し、Python力向上の助けになればいいなということですので。進化計算特に遺伝的アルゴリズムについて
前提知識がなくてもOKと言ってもこの後に出てくる単語がわからないといけないので進化計算、特に説明に使用する遺伝的アルゴリズム(Genetic Algorithm : GA)について簡単に説明します。
GAは「遺伝的」とあるように、生物の進化をヒントに考えられたアルゴリズムです。
今いる生物が生き残っているのは何故か?いろいろな理由はありますがGAでは以下の3つが主要な要素になります。
- 選択(selection)
- 弱い生物は死に、強い生物は生き残ります。強い弱いとはどういうことかということについてはこの後で説明します。
- 交叉(crossover)
- 生き残った生物は子孫を残すために交配します。子供には両親の遺伝子が受け継がれます。
- 突然変異(mutation)
- 今いる生物はもちろん地球ができたころからいるわけではありません。徐々に進化していったわけですがそれには親からの性質を受け継ぐ以外にちょっと違う部分を持つ子が必要になります。それが積もり積もると全く違う生物にもなるわけです。
さて、選択で強い生物が生き残ると書きましたが「強い」とは「適合度(fitness)が高い」という意味です。次に「じゃあ適合度って何?」となりますが、GAにおいては「解きたい目的関数の値」となります。$f(\vec{x})$です。お次は$\vec{x}$の話。
遺伝子表現と操作
やっと遺伝的アルゴリズムの「遺伝」のところに来ました。「遺伝」とは遺伝子のことです。この遺伝子が数式的に書いた場合の$\vec{x}$です。
遺伝子の表現は大きく分けて二つ、0/1のバイナリ列で表し$f(\vec{x})$を計算するときは0/1から目的関数の定義域に変換して計算する方法、数値をそのまま「遺伝子」として使う実数値GAと呼ばれる方法です。交叉では両親の遺伝子が受け継がれると書きましたが、以下のように遺伝子を切り貼りして子供を作ります。どこで切るかは通常乱数で決めます。
父 :01101101 母 :11000011 真ん中で切って貼り付け(子1は父の左半分+母の右半分、子1は母の左半分+父の右半分) 子1:01100011 子2:11001101突然変異は一定確率でビットを反転させます。
交叉後、子1突然変異(左端が0→1になった) 子1:11100011このようにしてできた子が生き残れるかは子の適合度(目的関数値)によります。これが選択です。
この選択、交叉、突然変異をぐるぐる回します。するとそのうち適合度の高い(目的関数値の高い)個体が生き残っており求めたい$\vec{x}$(設計変数値)が得られているというのがGAの発想です。どのように交叉させる(交叉手法を用いる)か、突然変異させるか、選択するのがよいかは対象問題の性質にもよります。もちろん対象問題の性質は既知でないことの方が多いため、「いろいろ試してみる」ということになります。
さて簡単にと言いつつだいぶ長くなってしまいましたが、そろそろDEAPの萌えポイントについて説明することにしましょう。
DEAPでの個体表現
Overviewに沿って見ていきましょう。まずは個体表現です。
「個体表現」という場合に考慮が必要なのは「遺伝子をどう実装するか」と「適合度をどう実装するか」です。適合度(Fitness)の実装
DEAPでは先に適合度を表すクラスを定義します。ここからすでにおもしろい。
from deap import base, creator creator.create("FitnessMin", base.Fitness, weights=(-1.0,))Overviewには「これでFitnessMinクラスが作られます」と書かれています。
いや待て「クラスが作成される」ってどういうことだよ関数呼び出しじゃねえのかよこれと思いませんか。次にcreator.createのリファレンスを見てみましょう(リンク先は英語です)deap.creator.create(name, base[, attribute[, ...]])
creatorモジュールにbaseを継承したnameという名前のクラスを作成します。そのクラスには第3引数以降のキーワード引数で指定された属性を定義できます。引数がクラスの場合、作成するクラスのオブジェクトを作るときに引数で渡されたクラスのオブジェクトが作られ属性に設定されます。引数がクラスでない場合は、作成クラスの静的属性として設定されます。リファレンスではFooクラスについて
creator.createを書いたものと等価なクラス定義が示されていますが先のcreator.create("FitnessMin", base.Fitness, weights=(-1.0,))を同じように当てはめてみると以下となります。creatorモジュール内で実行されることになるclass FitnessMin(base.Fitness): weights = (-1.0,)どう動くかはわかった。だがどうやってるんだ?というところで出てくるのがPythonではクラスも第一級オブジェクト1という概念です。WIkipediaの第一級オブジェクトの項でその性質が挙げられていますがその中で今特に重要なのはこちら。
実行時に構築可能である。
そうPythonは実行時にクラスを定義できるのです。
普通にプログラム作るときは必要なことはまずありませんが、フレームワーク作るときにはこれができると便利です。次にPythonリファレンスのtype関数を見てみましょう。class type(name, bases, dict)
引数が 3 つの場合、新しい型オブジェクトを返します。本質的には class 文の動的な形式です。 name 文字列はクラス名で、 name 属性になります。 bases タプルは基底クラスの羅列で、 bases 属性になります。 dict 辞書はクラス本体の定義を含む名前空間で、標準の辞書にコピーされて dict 属性になります。
creator.createはこのtype関数を利用し、クラスの動的定義を行っています。なお、globals関数は「モジュール内のグローバル変数」の辞書を返します。これを利用し、代入することでクラスが定義されます(type関数で作成するだけではまだ他から参照することはできません)
普通にクラス定義させればいいのでは?とか、提供モジュール内にクラスができるのどうなん?とかいろいろ突っ込みたくもなりますが、おもしろいのでOK(笑)なお継承元のbase.Fitnessもおもしろいことをしていますがそれについてはもう少し後で萌えポイントを説明します。
個体(Individual)の実装
Overviewでは次に個体クラスを定義しています。
creator.create("Individual", list, fitness=creator.FitnessMin)上で説明した
creator.createの動作により以下のクラスがcreatorモジュールに定義されることになります。class Individual(list): def __init__(self): self.fitness = FitnessMin()ここで大事なのは「個体はリストである2。リストに何を入れるかはこの時点では決まっていない」という点です。
個体の初期化
GAでは選択、交叉、突然変異のループの開始点となる初期個体を通常ランダムに発生させます。それに該当する定義を行っているのが以下の部分です。なお正確にはこの時点では定義だけで実際の個体は生成されていません。
import random from deap import tools IND_SIZE = 10 toolbox = base.Toolbox() toolbox.register("attribute", random.random) toolbox.register("individual", tools.initRepeat, creator.Individual, toolbox.attribute, n=IND_SIZE) toolbox.register("population", tools.initRepeat, list, toolbox.individual)新しい要素が出てきました。Toolboxクラスです。道具箱の名の通りこれに登録を行うようです。とりあえずToolbox.registerのリファレンスを見てみましょう。
register(alias, method[, argument[, ...]])
関数(method引数)をaliasという名前で登録する。登録される関数に渡すデフォルト引数を設定できる。関数呼び出し時に上書きも可能である。
individualという名前で登録しているコードを改めて確認します。toolbox.register("individual", tools.initRepeat, creator.Individual, toolbox.attribute, n=IND_SIZE)これが何をしているのかを確認するにはtools.initRepeatのリファレンスを見る必要があります。
deap.tools.initRepeat(container, func, n)
funcの関数をn回呼び出して、それを引数にcontainerの関数を呼び出す。
containerの位置に対応するのはIndividualです。これはリスト(を継承したクラス)でした。
funcはtoolbox.attribute。これはただのrandom.randomの別名です。
このことから、Toolbox.register("individual", tools.initRepeat, creator.Individual, toolbox.attribute, n=IND_SIZE)の呼び出しで以下のようなメソッドが定義されることになります。def individual(): return tools.initRepeat(creator.Individual, random.random, n=IND_SIZE) """ initRepeatの処理をさらに展開すると以下のようになる return Individual([random.random() for _ in range(IND_SIZE)]) """つまり、
individual()と呼び出すことで[0, 1)の乱数を10個発生させ個体に詰め込むメソッドを定義するということを行っています。
これで、先ほど書いた「リストに何を入れるかはこの時点では決まっていない」に対応して「リストに入れる要素は何か」が定義されてたことになります。バイナリ遺伝子のGAを行うか、実数値GAを行うかで結構プログラム構造に影響を与えるのですが、DEAPでは比較的気軽に「リストに実際入るもの」を定義できるのも萌えポイントの一つです。部分適用
さておもしろいのはここからです。
Toolbox.registerでは「渡された関数にデフォルト引数を設定して別名を付ける」ということが行われますが何故このようなことができるのでしょうか。ここで出てくるのが部分適用という考え方です。とりあえずToolbox.registerのコードを見てみましょう。大事なところだけ抜き出したものを貼ります。deap/pydef register(self, alias, function, *args, **kargs): pfunc = partial(function, *args, **kargs) setattr(self, alias, pfunc)partialはfunctoolsモジュールで提供されている関数です。
functools.partial(func, /, *args, **keywords)
新しい partial オブジェクト を返します。このオブジェクトは呼び出されると位置引数 args とキーワード引数 keywords 付きで呼び出された func のように振る舞います。部分適用の何が楽しいかを説明するために個体群を生成する
populationの定義を見てみましょう。比較のためにindividualの定義も再掲します。toolbox.register("individual", tools.initRepeat, creator.Individual, toolbox.attribute, n=IND_SIZE) toolbox.register("population", tools.initRepeat, list, toolbox.individual)
individualではinitRepeatの「全引数を指定しています」が、populationでは「nを指定していません」。そのため、populationを呼び出す際にはnを指定する必要があります。pop = toolbox.population(n=50)GAで問題を解く場合、対象問題に対する遺伝子の表現(遺伝子長)を決めればそれは普通変えません。一方、個体数は少ない場合、多い場合、その中間と「色々変えてみるパラメータ」となります。そのため、nは都度指定するものなります。部分適用があることにより、汎用の関数を用いてより特化した関数を作成、それを使って処理が記述できるということになります。
DEAPでの手法の設定
ここまでの説明でOverviewの残りの部分も何をやっているのかわかるようになったと思いますが一応説明します。
GAでは選択、交叉、突然変異の手法を色々試してみると説明しました。各手法には手法特有のパラメータというものがあります。
一方、交叉であれば「2匹の個体を引数に取り、2匹の子個体を返す」、突然変異であれば「1匹の個体を引数に取り、1匹の突然変異した個体を返す」、選択であれば「個体群と生き残らせる数を引数に取り、生存個体を返す」のような、「操作の一般的な入出力」というものが決まっています。
これらについても部分適用を利用し、用意されている各手法に対して手法独自のパラメータを部分適用しておいたメソッドを作り出します。def evaluate(individual): return sum(individual), toolbox.register("mate", tools.cxTwoPoint) toolbox.register("mutate", tools.mutGaussian, mu=0, sigma=1, indpb=0.1) toolbox.register("select", tools.selTournament, tournsize=3) toolbox.register("evaluate", evaluate)この際、mate, mutate, select, evaluateという名前を付けるのは「GAを回す全体のアルゴリズム」を使う際に重要です。「全体のアルゴリズム」の一つであるeaSimpleには以下のように書かれています。
deap.algorithms.eaSimple(population, toolbox, cxpb, mutpb, ngen[, stats, halloffame, verbose])
この関数はtoolboxにmate, mutate, select, evaluateが登録されていることを想定している。枠組み(フレームワーク)側が想定する名前を付けておくことで適切に呼び出される、ということです。
再計算の抑止
長々と書いてしまい自分でも忘れかけていましたが最後にbase.Fitnessの萌えポイントです。Tutorials: Part 2を見るとおもしろいことが書いてあります。
ind1.fitness.values = evaluate(ind1) print ind1.fitness.valid # True何故valuesに代入するとvalidがTrueになるのでしょうか。これはプロパティで実現されています。
さらにvalues自体も実はプロパティです。こちらは代入が行われると初めに定義したweightsが掛けられたものが保持されるというカラクリになっています。3何故このようにvalidというものがあるのか。
それは交叉や突然変異ではそれぞれ交叉率、突然変異率というものが設定され、実際には「交叉も突然変異も起こらなかった遺伝子できる」ことがあるためです。同じ遺伝子なので当然目的関数値も同じになります。その場合に再計算をするのは無駄でありそれを回避するためです4。まとめ
以上、DEAPのdeepな裏側について見てきました。普段あまりお目にかからない、知ってるとどこかで使えるかもしれないPython奥義としては以下のものがありました。
- type関数を用いたクラスの動的定義
- functiontools.partialを用いた部分適用
私は言語の機能を使い倒しているフレームワークが大好きなのですが、DEAPもまさにPythonを駆使しているといった感じでいいですね。
- 投稿日:2019-12-22T21:25:59+09:00
分類の代表的な指標
こんにちは。
今回はちょっと気合を入れて分類精度について述べようと思います指標って何?
指標とは、データのクラスをどの程度正確に当てられたかを測る基準的なものです。
このモデルが正しい!!!だから採用してください!!と言われても誰も納得しませんよね。周りの生活での具体的な例としては、偏差値。
偏差値は勉強に対するある基準の役割を持っています。
偏差値が全てとは全然思いませんが、ある程度の基準は必要になります。
なぜなら、基準がなければ判断は不公平な決断が生まれる可能性があるからです。
また学業の世界では、通知表、履歴書など基準は色々な方法が存在します。またそれぞれの基準は違う軸を持っています。これは分類の世界でも同じです。
機械学習を用いて構築したモデルの良し悪しを評価する為の指標が沢山存在します。
今回紹介したいのは4つです。
- 適合率 (precision)
- 再現率 (recall)
- F値 (F-Value)
- 正解率 (accuracy)これらを紹介する前に混同行列という存在を説明したいと思います。
混合行列
結論から言うと、混合行列とは分類の結果をまとめた行列です。
はぁ?って思った人もいると思いますが、今から説明するので安心してください。正例と負例
分類の世界には、「興味がある」と「興味がない」と言う考え方があります。
また
「興味がある」を正例といい、
「興味がない」を負例をいいます。例えば、送られてきたメールがスパムであることを予測する場合、
どのメールがスパムであることに興味があるので、
正例はスパム、負例は通常のメールです。
大体正例と負例のイメージがつかめましたか?これを頭に入れた上で以下の画像をみてください。
混合行列の説明
混合行列は4種類に分かれています。
真陽性(左上)・・・実際のデータが正例で、機械学習自体も正例と分類した場合。(正解)
偽陰性(右上)・・・実際のデータは正例だが、機械学習は負例と分類した場合。(不正解)
偽陽性(左下)・・・実際のデータは負例だが、機械学習も正例と分類した場合。(不正解)
真陰性(右下)・・・実際のデータが負例で、機械学習自体も負例と分類した場合。(正解)数学的にもこの4種類しかあり得ません。
なぜなら場合の数により、2(実際のデータは2種類(正例OR負例)) * 2(予測も2種類) = 4混合行列の説明はこの辺にして、
この図を元に指標の4つを見ていこうと思います。適合率
適合率・・・機械学習モデルが正例であると予測した内の何%が当たっていたか(正例であったか)を示す。
上記の図の記号を使って計算式で書くと、適合率 = \frac{tp}{tp + fp}と書けます。
つまり適合率が高いとは、正例と予測して実際に正例であったデータの割合が高いことを示す。再現率
再現率・・・実際の正例のデータのうち、正例と予測したものの割合を示す。
これは適合率ととても似ているがある関係になっている。それは後々説明するとしよう。
先に再現率を数式で書くと、再現率 = \frac{tp}{tp + fn}つまり再現率が高いとは、正例のデータに対して正例だと予測できたデータの割合が高いことを示します。
適合率と再現率の関係
この二つの評価指標はトレードオフの関係にあります。
言い換えるのであれば、再現率を高くしようとすると適合率が低くなり、逆も然りです。想像が付きにくい人は下記の例を読んでみてください。とてもわかりやすかったです。
再現りつと適合率の関係F値
F値・・・適合率と再現率の調和平均
即ち、F値 = \frac{2}{\frac{1}{適合率} + \frac{1}{再現率}} = \frac{2 \times 適合率 \times 再現率}{適合率 + 再現率}F値は適合率と再現率の調和平均を取ることにより、両方の指標がバランスの良い値になることを目指す時に重視する指標。
正解率
正解率・・・正例か負例かを問わず、予測と実績が一致したデータの割合を示す。
即ち、正解率 = \frac{tp + tn}{tp + fp + fn + tn}予測結果全体と、答えがどれぐらい一致しているかを判断する指標。
まとめ
いかがだったでしょうか?
機械学習のモデルが良いか悪いかを判断するには様々な観点があります。
自分自身がどんなモデルを欲しているかを課題全体を通して見抜く必要がありそうですね。
今回まとめたのは,
- 適合率
- 再現率
- F値
- 正解率
でした。
この世の中には指標は沢山あります。
指標を覚える必要はないと思いますが、知っておく事は大切ですよね。
ありがとうございました。参考文献

- 投稿日:2019-12-22T20:42:51+09:00
[Blender] テキストエディタでBlenderのPython APIを補完する
Blender Advent Calendar 2019 の23日目の記事です。
Blenderのスクリプトやアドオンを作るとき、テキストエディタを使ってソースコードを編集することが多いと思います。
テキストエディタを利用するメリットの1つとして、コード補完機能による開発の効率化がありますが、Blenderが提供するPython APIの一部はPythonのソースコードではなく、バイナリデータとして提供されるため、そのままではコードを補完できません。
このような問題を解決するため、Blenderが提供するPython APIのインタフェース部分のみを記述した疑似モジュール「fake-bpy-module」を開発しました。「fake-bpy-module」を利用することで、基本的にコード補完機能を持つすべてのエディタで、BlenderのPython APIに関してコード補完できます。
本記事では、「fake-bpy-module」を使って、Visual Studio CodeとPyCharm上でコード補完する方法を紹介します。前提条件
本記事で対象とするBlenderのバージョンは 2.80 とします。
「fake-bpy-module」がサポートするバージョンは、GitHubの README を参考にしてください。
「fake-bpy-module」は、Windows/Mac/Linuxのいずれの環境でも動作しますが、Type Hint機能が導入された Python 3.6 以上のPythonでなければ、補完機能が利用できないことに注意してください。将来的には、Blender 2.81以降のバージョンに対応したモジュールを提供予定です。
「fake-bpy-module」の提供形態
「fake-bpy-module」は、以下の3つの方式で提供しています。
- PyPIパッケージ
- GitHubで公開中のモジュール
- モジュールの自作
本記事ではそれぞれについて、具体的なコード補完の手順を説明します。
方法1:PyPIパッケージ
1. pipコマンドを用いてパッケージをインストール
pipコマンドを利用することで、PyPIに登録されている「fake-bpy-module」をインストールできます。
次に示すコマンドを実行して、「fake-bpy-module」をインストールしてください。$ pip install fake-bpy-module-<version>ここで
<version>には、Blenderのバージョンを指定します。
Blender 2.8に対応する「fake-bpy-module」をインストール場合は、次のコマンドを実行します。$ pip install fake-bpy-module-2.80pipを利用できる環境であれば、pipを利用して「fake-bpy-module」をインストールするのが簡単で確実ですが、pipを利用できない環境の場合は、別の方法を試みてください。
2. エディタでコード補完を確認する
pipコマンドを用いてパッケージをインストールした場合、コード補完するための各エディタの設定は不要です。
Visual Studio CodeとPyCharmそれぞれについて、コード補完の例を示します。Visual Studio Code
PyCharm
方法2:GitHubで公開中のモジュール
1. GitHubからモジュールをダウンロードする
「fake-bpy-module」は、GitHubでも公開 しています。
モジュール一式をまとめたファイルは、fake_bpy_modules_<Blenderのバージョン>-<モジュールを作成した年月日>.zipとして公開しているため、環境にあわせて必要なモジュールをダウンロードします。
ここでは、2019/10/8に作成したBlender 2.80向けのモジュール であるfake_bpy_modules_2.80-20191008.zipをダウンロードします。
ダウンロードが完了したら、ファイルを解凍します。2. エディタにモジュールのパスを伝える
エディタにモジュールのパスを伝え、コード補完できるようにします。
モジュールのパスを伝える方法は、エディタによって異なります。Visual Studio Code
Visual Studio Codeでコード補完するためには、次の手順に従います。
- Pythonの Visual Studio Code Extention をダウンロードします
- [File] > [Preferences] > [Settings] をクリックします
settings.jsonが開いたら、python.autoComplete.extraPathsにモジュールのパスを設定します{ "python.autoComplete.extraPaths": [ "<path-to-generated-modules>" ] }
<path-to-generated-modules>には、モジュールの絶対パスを指定してください。PyCharm
PyCharmでコード補完するためには、次の手順に従います。
- Windowsの場合は [File] > [Settings] をクリックして [Settings] ウィンドウを、macOSの場合は [Pycharm Menu] > [Preferences] をクリックして [Preferences] ウィンドウを開きます
- [Project:] > [Project Interpreter] を選択します
- [Project Interpreter:] の右隣にあるギアのアイコンをクリックします
- 表示されたポップアップメニューから [Show All...] をクリックします
- [Project Interpreters] ウィンドウにおいて、[Show paths for the selected Interpreter] のアイコンをクリックし、[Interpreter Paths] ウィンドウを表示します
- [+] アイコンをクリックすると、ファイルブラウザが立ちあがります
- モジュールが配置されたディレクトリを指定し、[OK] をクリックします
- Windowsの場合は [Settings] ウィンドウ、macOSの場合は [Preferences] ウィンドウが閉じるまで、[OK] を複数回クリックします
3. エディタでコード補完を確認する
方法1の方式でモジュールをインストールした場合と同様、それぞれのエディタでコード補完できるようになります。
方法3:モジュールの自作
1. Blenderのバイナリをダウンロードする
公式のBlenderのダウンロードサイト から、対象となるBlenderのバイナリをダウンロードします。
Blender 2.80のバイナリは、https://download.blender.org/release/Blender2.80/ で公開されています。2. Blenderのソースコードをcloneする
次に示すコマンドを実行し、Blenderのソースコードをダウンロードします。
$ git clone git://git.blender.org/blender.git3. GitHubのfake-bpy-moduleプロジェクトをcloneする
次に示すコマンドを実行し、GitHubに公開されているfake-bpy-moduleプロジェクトをcloneします。
$ git clone https://github.com/nutti/fake-bpy-module.git4. 「fake-bpy-module」を生成する
次に示すコマンドを実行し、「fake-bpy-module」を生成します。
$ cd fake-bpy-module/src $ sh gen_module.sh <source-dir> <blender-dir> <branch/tag/commit> <output-dir> <mod-version>
<source-dir>:Blenderのソースコードのルートディレクトリ<blender-dir>:Blenderのバイナリが配置されたディレクトリ<branch/tag/commit>:生成するモジュールに対応する、Blenderのソースコードのブランチ<output-dir>:モジュールの生成先ディレクトリ<mod_version>:指定したバージョンについて、modsディレクトリに配置したパッチを使ってAPIを修正する仮に2から連続してコマンドを実行してきた場合は、次のようにコマンドを実行します。
$ cd fake-bpy-module/src $ sh gen_module.sh ../../blender <1でダウンロードしたBlenderのバイナリが配置されたディレクトリ> v2.80 out 2.805. エディタにモジュールのパスを伝える
方法2の方式に従い、モジュールのパスをエディタに伝えます。
6. エディタでコード補完を確認する
方法1や方法2の方式と同様、それぞれのエディタでコード補完できるようになります。
まとめ
「fake-bpy-module」を使って、BlenderのPython APIを、Visual Studio CodeとPyCharm上でコード補完する方法を紹介しました。
コード補完を利用することで、Blenderのスクリプトやアドオン開発の効率がよくなるため、ぜひ活用してみてください。
本記事では紹介していませんが、PyPIパッケージを利用しない場合でも、Visual Studio CodeやPyCharmに限らず、すべてのエディタでコード補完するための方法を、GitHubのプロジェクトページにて ドキュメント を公開しています。
こちらもぜひ参考にしてみてください。なお、「fake-bpy-module」はOSSとして公開していますので、バグ報告 や プルリク などのContributionは大歓迎です!
それでは、ぜひ楽しいBlenderのアドオン開発ライフを!

- 投稿日:2019-12-22T20:39:48+09:00
Codeforces Round #609 (Div. 2)(まだBまで)
Div2A. Equation
差が $n$ であるような2数を答える。差が $n$ のもので順番に素因数分解していこうかと一瞬思いましたが,よく考えるとギャグでした。$9n$ と $8n$ を答えてやれば差が $n$ でいずれも合成数になってくれます。
pythonn = int(input()) print(9*n,8*n)C++#include<bits/stdc++.h> int main(){ int n; std::cin >> n; std::cout << 9*n << " " << 8*n << std::endl; }Div2B. Modulo Equality
まず問題文が分かりづらいです。置換 $p_n$ を用いてどうこう……と書いてありますが,要するに
数列 ${a_i}$ と ${b_i}$ が与えられる。数列 ${a_i + x\ (\mathrm{mod}\ m)}$ が ${b_i}$ を 適当に並び替えたもの と一致するような最小の $x$ を答えよ。
という問題です。
さて,まず脳死で思いつくこととして $x$ を全探索したいという気持ちになるでしょう。$\mathrm{mod}\ m$を考えるので $x$ として $m$ を越える分は同一視できます。しかしながらそれでも $m$ の範囲が$1\leq m \leq 10^9$なので,この範囲内をすべて探索するのは時間的に不可能です。
他の制約として,$1\leq n\leq 2000$ すなわち数列 $a$ と $b$ のサイズが2000までというものがあります。じつはこれが大切で,$x$ をすべて探索するという方針はそのままに調べる範囲を少なくすることができます。
aに x 加算したものとbを適当に並び替えたものが一致するためには,a[i]+xの要素の少なくとも1つはb[0]と一致しなければいけません。そこで,
aのどれがb[0]と対応するかを全探索して,そのうち条件を満たす最小のものを出力してあげましょう。具体的には下のコードを参考にしてください。Pythonimport sys input = sys.stdin.readline def main(): n, m = map(int, input().split()) a = list(map(int, input().split())) b = list(map(int, input().split())) b.sort() answer = [] for i in range(n): x = (b[0] - a[i]) % m # b[0]とa[i]が一致するようにxを決める tmp = list(map(lambda num: (num + x) % m, a)) tmp.sort() if tmp == b: answer.append(x) print(min(answer)) return if __name__ == '__main__': main()C++#include <bits/stdc++.h> using i64 = int_fast64_t; #define repeat(i, a, b) for(int i = (a); (i) < (b); ++(i)) #define rep(i, n) repeat(i, 0, n) void solve() { int n, m; scanf("%d %d", &n, &m); std::vector<int> a(n), b(n); rep(i, n) scanf("%d", &a[i]); rep(i, n) scanf("%d", &b[i]); std::sort(begin(b), end(b)); std::vector<int> ans; rep(i, n) { int x = (b[0] - a[i] + m) % m; std::vector<int> tmp(n); std::transform(begin(a), end(a), begin(tmp), [&](int num) { return (num + x) % m; }); std::sort(begin(tmp), end(tmp)); if(tmp == b) { ans.emplace_back(x); } } std::sort(begin(ans), end(ans)); printf("%d\n", ans[0]); } int main() { solve(); return 0; }
- 投稿日:2019-12-22T20:28:03+09:00
numbaでざっくりPython高速化
numbaというライブラリを使うと、Pythonのコードを比較的簡単に高速化できます。
うまくいけば、from numba import jitを書いて、高速化したい関数の前の行に@jitを書くだけで高速化できます。仕組みとしては、numbaはPythonの仮想マシンコードを取得し、LLVM IRにコンパイルし、LLVMを使ってネイティブコードにするようです。
初回実行時は、コンパイル処理が走るので、若干遅くなりますが、重い処理だと、コンパイル時間を考えてもnumbaの方が速いこともあります。利点と欠点
先に述べておきます。
利点
- 場合によっては、コード自体は改造せずに手軽に高速化できる
- コードの改造があったとしても、軽微な改造で済むことも多い
- 別ファイルに分けてビルドする、みたいな手間なことが必要なく、手軽に
.pyファイルの中で使える欠点
- すべてのPython機能がサポートされているわけではないらしく、場合によっては
@jitをつけるだけでは済まない
- 型の扱いが厳格になるので、今まで「なぁなぁ」で動いていた部分がエラーになったりするようになります。また、numbaにうまく型推論してもらうよう工夫が必要になる場合があります。
- 当然だが、動かすのにnumbaが必要になる。環境によっては、numbaのインストールに苦労する
- conda環境だと簡単なようです。pipで入る環境も結構あります。私の使っているArch Linuxでは、今現在、Python 3.8、LLVM 9.0になっており、どちらも現時点ではnumbaが対応していないため、ビルドするのは諦めてDockerでconda環境を使ってます
- コンパイルに時間がかかるので、闇雲につけたら逆効果になる
例
とてもうまくいく事例を紹介します。
なんかしらんけど、とっても遅い関数があります。import sys sys.setrecursionlimit(100000) def ack(m, n): if m == 0: return n + 1 if n == 0: return ack(m - 1, 1) return ack(m - 1, ack(m, n - 1))ちょっと時間測ってみますね。
import time from contextlib import contextmanager @contextmanager def timer(): t = time.perf_counter() yield None print('Elapsed:', time.perf_counter() - t) with timer(): print(ack(3, 10))8189
Elapsed: 10.27042054200137510秒もかかっちゃいました。
数字を大きくするともっと時間かかりますが、本当に時間がかかるのでおすすめしません。
特に、3を4に増やすと、多分、死ぬまでかかっても終わらないので、全くおすすめしません。
この関数はアッカーマン関数として知られています。これをnumbaで速くしてみます。
from numba import jit @jit def ack(m, n): if m == 0: return n + 1 if n == 0: return ack(m - 1, 1) return ack(m - 1, ack(m, n - 1)) # 1回目 with timer(): print(ack(3, 10)) # 2回目 with timer(): print(ack(3, 10)) # 3回目 with timer(): print(ack(3, 10))8189
Elapsed: 0.7036043469997821
8189
Elapsed: 0.4371343919992796
8189
Elapsed: 0.4372558859977289なんと、10秒かかっていたものが、初回0.7秒、2回目以降0.4秒にまで縮みました。
1行付け足すだけでこうなるなら、本当にお得ですね。思ったより速くない場合は
Objectモードが使われている可能性があります。
numbaには、No PythonモードとObjectモードがあり、一旦No Pythonモードでコンパイルされますが、失敗したらObjectモードでコンパイルされます。
(ただし、この仕様は将来なくなり、デフォルトでNo Pythonモードのみ、Objectモードはオプションになるようです)前者は、型が全部直接扱われるのに対し、後者は、PythonのオブジェクトをPython C APIから叩き、前者のほうがより高速です。
さらに、後者だと、ループを効率よくネイティブコードに書き換えられない場合がありますが、前者だとループが効率化されます。(loop-jitting)No Pythonモードを強制するためには
@jit(nopython=True)または@njitと書きますが、こうすると「型が分からない」といった類のエラーがよく発生するようになります。基本的には、
- ひとつの変数には、ひとつの型のみを入れる
returnが複数ある場合、どのreturnでも同じ型を返すようにする- No Pythonモードの関数で呼び出している関数もNo Pythonモードにする
などの方法で、型を明確にすることができます。
比較的簡単にNo Pythonモードに対応させるには
- 計算が重い部分だけを別関数に切り出してnumbaに対応させる
- 切り出した中でも、型をごちゃごちゃいじったり、オブジェクトにあれこれ代入したりしている部分は、外に出すことを考える
- numba対応する部分の前処理あるいは後処理の形で、なんとかnumbaでやらずに済ませることを考える
などがおすすめです。
Pythonが得意なことはPythonでやる、Pythonが苦手なことはnumbaでやる、を意識します。並列化してみる
@jit(parallel=True)とすると、forループでrangeの代わりにprangeが使えます(from numba import prangeが必要)。
prangeで書いたループは、並列化されます。コンパイル結果のキャッシュ
@jit(cache=True)で、コンパイル結果をキャッシュファイルに書き出し、毎回コンパイルする手間を避けることができます。
fastmathを使う
@jit(fastmath=True)で使えます。
gccやclangにもあるfastmathを有効にします。やや危なっかしい最適化でfloatの計算を早くするやつです。CUDAを使う
あまりお手軽ではありませんが、一応、CUDAも使えます。
CUDA使ったことある人なら、以下のコードでなんとなく分かるかと思います。個人的には、これだったらcupyでいいかなぁ、と思いました。
import numpy as np from numba import cuda @cuda.jit def add(a, b, n): idx = cuda.threadIdx.x + cuda.blockIdx.x * cuda.blockDim.x if idx < n: a[idx] += b[idx] N = 1000000 a_host = np.array(np.ones(N)) b_host = np.array(np.ones(N)) a_dev = cuda.to_device(a_host) b_dev = cuda.to_device(b_host) n_thread = 64 n_block = N // n_thread + 1 add[n_block, n_thread](a_dev, b_dev, N) a_dev.copy_to_host(a_host) print(a_host) # Expect: [2, 2, ..., 2]もし
libNVVMがない、などと怒られたら、CUDAをインストールしていない(conda install cudatoolkitなどでインストールできます)か、環境変数の設定が必要です。Google Colabなどでの設定例:
import os os.environ['NUMBAPRO_LIBDEVICE'] = "/usr/local/cuda-10.0/nvvm/libdevice" os.environ['NUMBAPRO_NVVM'] = "/usr/local/cuda-10.0/nvvm/lib64/libnvvm.so"まとめ
numbaを使うと、ざっくりとPythonコードを高速化できます。
簡単な使い方を見ていきました。参考になれば幸いです。
参考文献
公式ドキュメントは、必要なところだけ読めば、さほど長くなく、非常に参考になります。
特にPerformance Tipsは役立ちます。CUDAを使う際のの環境変数設定については、
https://colab.research.google.com/github/cbernet/maldives/blob/master/numba/numba_cuda.ipynb
を参考にしました。
- 投稿日:2019-12-22T20:12:14+09:00
kafka-pythonでconsumerのオフセットを他にコピーする
Kafka consumerを実装するときはJavaやScalaなどの言語を使うことが多いのですが、そこまで複雑でなければ軽く実装できるPythonを使いたいですね。
今回はPython向けのApache Kafkaライブラリのkafka-pythonを使って、あるconsumerのオフセットを他のconsumerに移すメンテナンス処理を書いて見たいと思います。コンシューマーのオフセット取得
今回はKafkaAdminClientを使用します。KafkaConsumerから取得することもできるのですが、consumerを購読したりpollしたりと煩雑なのでこちらのクライアントを使うのがおすすめです。
from kafka import KafkaAdminClient # consumer01はtopic01を購読中という想定 target_consumer_name = "consumer01" # KafkaAdminClientを取得 cluster_admin = KafkaAdminClient(bootstrap_servers=bootstrap_servers) # オフセットを取得 offsets = cluster_admin.list_consumer_group_offsets(target_consumer_name)参考までにこんな感じのものが返却されてきます。
TopicPartitionクラスをキーとしたオフセットの情報です。{TopicPartition(topic='topic01', partition=0): OffsetAndMetadata(offset=14475, metadata='aa6c00e6-ffbf-41a3-b011-6997549f6166a'), TopicPartition(topic='topic01', partition=1): OffsetAndMetadata(offset=14494, metadata='8fcc736c-1cb0-41b5-b111-6d55d67b3096a')}別のコンシューマーにオフセットを書き込み
consumerの書き変えを行うにはKafkaConsumerを使用します。
先程取得したオフセット情報をconsumer02に書き込みます。
consumerが存在ない場合は自動で作成が行われます。from kafka import KafkaConsumer consumer_group_name = 'consumer02' consumer = KafkaConsumer( group_id=consumer_group_name, bootstrap_servers=bootstrap_servers, enable_auto_commit=False) # offsetの情報を書き込み(consumerが存在しない場合作成される) consumer.commit(offsets)これでconsumer02にはconsumer01と同じtopicのオフセット情報が書き込まれました。
consumer02を使用して購読を開始すると、オフセット取得時のconsumer01と同じオフセットから購読を開始するはずです。購読の例
consumer_group_name='consumer02' # consumerを取得 consumer = KafkaConsumer( group_id=consumer_group_name, bootstrap_servers=bootstrap_servers) # topic01を購読する設定に変更 consumer.subscribe(topics=['topic01']) # topic01 consumer02に実際に参加 consumer.poll() # 受信できたメッセージをprintし続ける for msg in consumer: print(msg)参考
https://kafka-python.readthedocs.io/en/master/apidoc/KafkaConsumer.html
https://kafka-python.readthedocs.io/en/master/apidoc/KafkaAdminClient.html
- 投稿日:2019-12-22T19:28:26+09:00
ROSパッケージ(gx_sound_player)を使ってUSBスピーカーから音楽再生する
目的
ROSパッケージ(gx_sound_player)を使ってUSBスピーカーから音楽再生しました。
再生するまでに何点か詰まった箇所がありましたので、実際に実施した確認手順とともに本記事にまとめさせて頂きます。尚、本記事の内容は以下の記事をベースにしております。
準備
USBスピーカー :例えばこちら
Ubuntu16.04 + ROS kinetic環境
テスト用音楽ファイル(.wav) :例えばこちらからダウンロードさせて頂くstep1. USBスピーカーから音楽再生できることを確認
1.USBスピーカーをPCに接続する 2.サウンドデバイスがみえることをチェック $ ls -l /dev/snd/* ⇒ pcmC1D0p などがみえるはず (以降、pcmC1D0p がUSBスピーカーのデバイスファイルであることを前提) 3.aplayでWAVファイルを再生 $ aplay -D hw:1,0 musicbox.wav ⇒ USBスピーカーから音楽再生できればOKUSBスピーカーから音楽再生できなければ手順を見直します。
step2. gx-soundパッケージでWAVファイル再生できることをテスト
gx-soundパッケージをインストールする。
$ sudo apt install ros-kinetic-gx-sound1.roscore起動 $ source ~/catkin_ws/devel/setup.sh $ roscore 2.gx-soundノード起動 $ roslaunch gx_sound_player sound_player.launch device_name:="hw:1,0" 3.WAV再生 $ rosrun rulo sound-test.py ⇒ USBスピーカーから音楽再生できればOK 音楽ファイルを/home/ubuntu/Downloads/musicbox.wavに格納しておくsound-test.py#! /usr/bin/env python # -*- coding: utf-8 -*- import actionlib import os import rospy from gx_sound_msgs.msg import SoundRequestAction, SoundRequestGoal def main(): rospy.init_node('sound_request_client_node') client = actionlib.SimpleActionClient('/gx_sound_player/sound_player/sound_request', SoundRequestAction) client.wait_for_server() rospy.loginfo("connected to actionlib server") now = rospy.Time.now() # 0秒後に audio3.wav を再生 # 音楽ファイルを/home/ubuntu/Downloads/musicbox.wavに格納しておく goal1 = SoundRequestGoal(stamp=now + rospy.Duration(0.0), file="/home/ubuntu/Downloads/musicbox.wav") rospy.loginfo("send request") client.send_goal(goal1) rospy.loginfo("send complete") #client.wait_for_result(rospy.Duration.from_sec(5.0)) if __name__ == '__main__': main()音声停止方法
無音ファイルをsendすればOK
無音ファイルはこちらからダウンロードさせて頂きます。Error対策
gx-soundパッケージが見つからない状況になった場合
gx-soundパッケージインストール $ sudo apt install ros-kinetic-gx-sound ros-kinetic-gx-sound not found以下の通りパッケージリストを更新して解決しました。
sudo sh -c 'echo "deb http://packages.ros.org/ros/ubuntu $(lsb_release -sc) main" > /etc/apt/sources.list.d/ros-latest.list' sudo apt-get update--
音声フォーマットエラーになった場合
ffpmegでフォーマット変換すれば解決しました。
音声ファイルを48000Hz, 16bit LittleEndian, stereoに変換する方法 $ sudo apt-get install ffmpeg $ ffmpeg -i input.wav -ar 48000 -format S16_LE -channel 2 output.wav参考
- 投稿日:2019-12-22T19:11:19+09:00
FlaskでIP制限する
あったけれどマスクでかける。
from flask import Flask, request, abort import ipaddress app = Flask(__name__) @app.route('/') def hello_world(): return 'Hello World!' ALLOW_NETWORKS = ["10.0.0.0/8", "172.16.0.0/12", "192.168.0.0/16", "127.0.0.1"] @app.before_request def before_request(): remote_addr = ipaddress.ip_address(request.remote_addr) app.logger.info(remote_addr) for allow_network in ALLOW_NETWORKS: ip_network = ipaddress.ip_network(allow_network) if remote_addr in ip_network: app.logger.info(ip_network) return return abort(403, 'access denied from your IP address') if __name__ == '__main__': app.run()
- 投稿日:2019-12-22T19:04:06+09:00
Python3のvirtualenvでrospyを使う
はじめに
ROS Advent Calendar 2019 23日目の記事です。
Python2のEOLまで残すところあと8日になりましたが、皆様Python3への以降はお済みでしょうか。
今回、ROS1のrospyをPython3のvirtualenvで実行できるようにしてみたので紹介したいと思います。公式なROS1の
rospyを使うためには、以下のような環境の制約があります。
1. Ubuntuを使う
2. ROSをインストールする
3. システムにインストールされたPython2/ライブラリを使うこれは
a. 既存のpipを使ったPythonプロジェクト(Python3)とROS1を共存させたい
b. MacOSでrospyをちょっと試したいのような場合には不便です。
解決方法として、roslibpyもありますが、rosbridgeで一度通信をwebsocketでブリッジするため、通信のオーバヘッドがかなりかかります。そこで
rospy関係のROSのコードは、Pythonのみで書かれている事を利用し、純粋なPythonのパッケージとしてrospyをインストールできるPyPI(Python Package Index)を用意することで、Python3でもrospyを使えるようにしてみました。使い方
以下の環境で確認しています。
- OS: Ubuntu 18.04
- Python: Python3.6.7
virtualenvを使う方法をサンプルで示します。ROSのインストールは不要です。
(pipenv等でも基本同じです)virtualenv -p python3 venv . ./venv/bin/activate pip install --extra-index-url https://rospypi.github.io/simple rospy-allTF2やcv_bridgeを使いたい場合は、さらに追加で
pip install --extra-index-url https://rospypi.github.io/simple cv_bridge tf2_rosとするとできます。
以下のサンプルを用意し、
talker.pyimport rospy import std_msgs.msg rospy.init_node("talker") pub = rospy.Publisher("chat", std_msgs.msg.String, queue_size=1) rate = rospy.Rate(2) while not rospy.is_shutdown(): pub.publish("hello") rate.sleep()listner.pyimport rospy import std_msgs.msg def callback(msg): print(msg.data) rospy.init_node("listener") rospy.Subscriber("chat", std_msgs.msg.String, callback) rospy.spin()rosmasterを追加でインストールします
pip install --extra-index-url https://rospypi.github.io/simple rosmaster defusedxml3つの端末からそれぞれ
まず、rosmasterを起動します。
. ./venv/bin/activate rosmaster --rcore次に、talkerノードを起動します。
. ./venv/bin/activate export ROS_MASTER_URI=http://localhost:11311 python talker.py最後に、listnerノードを起動します。
. ./venv/bin/activate export ROS_MASTER_URI=http://localhost:11311 python listener.py最後のlistnerノードで以下の用にSubscirbeしたトピックが表示できたら成功です。
$ python listener.py WARNING: cannot load logging configuration file, logging is disabled hello hello hello hello helloこれでROSをインストールすることなく、Python3のみでROSのノードを書けるようになりました。
MacOSでも同じ事ができることを確認済みです。中身について
- PyPIは静的ファイルさえホストできれば作れる(PEP53)
- tf2_py、PyKDL、cv_bridge等のパッケージははc++のビルドが必要なPythonパッケージだがちょっと頑張ればROSのruntimeに依存せずに実行できる
ような事をしています。
おわりに
今回用意したPyPIは個人で趣味的に作ってみたもので、どこまでサポートできるかわからないですが、ちょっと使って見るには便利だと思うので是非試してみてください。
https://github.com/rospypi/simple公式でだせるようにしていきたい・・・
Let's enjoy robot programming!
- 投稿日:2019-12-22T18:50:38+09:00
【python】flaskを使ってローカルサーバーを動かしてみた
はじめに
Progateでしかpythonを触ったことのない筆者が、pythonを使ってローカルサーバーを立てて、任意のアドレス対して動作をさせるまでの備忘録。
開発環境
Windows 10 64bit
Python 3.7.3
pip 19.3.1
flask 1.1.1環境構築
pythonをインストールしていない人はまずはインストールをします!
詳しい方法はこちらからインストールした記憶がないけどあるかも...と思う方はコマンドプロンプトを開いて、
python -Vで確認してみましょう!$ python --version Python 3.7.3 $ python -V Python 3.7.3インストール済みであれば以上のように表示されます!
インストールが完了したら、Pythonのパッケージ管理ツールであるpipをインストールしていきます!
インストール済みか確認したい方はpython -m pip -Vで確認できます!
インストールされていなかった人は詳しいインストール方法はこちら以下のコマンドを叩いてインストールしていきます!
py -m pip install pypdf2インストールができたら、今回使うpythonの軽量フレームワークであるflaskのインストールを行っていきます!
flask使ったことのある人はこの記事を読まないであろうと想定して、インストールの仕方から!pip install Flask確認したいときは
$ python >> import flask >> flask.__version__(\$マークはコピペしないでね。てかこの\$って何なんでしょう?)
ここまで出来たらとりあえずの環境構築は終了です。
おつかれさまでした。さっそく実装
今回は前々回の記事で作成したreact-appでボタンをクリックしたときに指定したデータを返すような実装をしていきます。
前々回の記事→【React】はじめてReact触ってみた!~create-react-app編~
よかったらいいねしてください()それはさておき、コードを書いていきます。
前回作ったもののフォルダとの相関関係はこんな感じです!Sample └ resource └ react-test └ node_modules └ public └ src └ App.js ・ ・ ・ └ flask-test └ run.pyまずは、いろいろなサイトを参考にpython側のコードを作成しました。
run.pyimport json # Flask などの必要なライブラリをインポートする from flask import Flask from flask_cors import CORS from flask import request, make_response, jsonify # 自身の名称を app という名前でインスタンス化する app = Flask(__name__) # CORS (Cross-Origin Resource Sharing) CORS(app) # ここからウェブアプリケーション用のルーティングを記述 # index にアクセスしたときの処理 @app.route('/', methods=['GET']) def show_user(): response = {'user': {'name': 'index', 'age': 'hoge', 'job': 'web'}} return make_response(jsonify(response)) # /user にアクセスしたときの処理 @app.route('/user', methods=['GET']) def show_user2(): response = {'user': {'name': 'user', 'age': 'fuga', 'job': 'free'}} return make_response(jsonify(response)) if __name__ == '__main__': app.run()↓ 参考にした記事の数々はこちら ↓
・ウェブアプリケーションフレームワーク Flask を使ってみる
・PythonのFlaskを使用してWebアプリ作成してみよう(1)こんにちは世界
・Flaskのユーザーガイド続いて、以前create-react-appを使って作成したアプリを改造していきます!
react-test > App.js を開き、以下のようにした。App.jsimport React from 'react'; import logo from './logo.svg'; import './App.css'; import Axios from 'axios'; function App() { function click(){ Axios.get('http://127.0.0.1:5000/').then(function(res){ console.log(res); alert(res.data.user.age); }).catch(function(e){ alert(e); }) } return ( <div className="App"> <header className="App-header"> <img src={logo} className="App-logo" alt="logo" /> <p> Edit <code>src/App.js</code> and save to reload. </p> <a className="App-link" href="https://reactjs.org" target="_blank" rel="noopener noreferrer" > Learn React <br/> </a> <button onClick={() => {click()}}>click</button> </header> </div> ); } export default App;やっとこさ実行
ここまで来たらあとはコマンドプロンプトで動かすだけ!
早速コマンドプロンプトを開いて、cd C:\Users\{user}\Documents\Sample\flask-testで、指定ディレクトリに移動します。
ここで、python run.pyを起動!
C:\Users\{user}\Documents\Sample\flask-test>python run.py * Serving Flask app "run" (lazy loading) * Environment: production WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead. * Debug mode: off * Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)となれば成功!!
続いて、コマンドプロンプトを別ウィンドウでも開き、
cd C:\Users\{user}\Documents\Sample\react-testでcreate-react-appのディレクトリに移動します。
そして前々回と同様にC:\Users\{user}\Documents\Sample\react-test>npm startで起動!これでうご...かない!?
Module not found: Can't resolve 'axios' ・・・axiosのモジュールがないとか...
たしかに、インポートするaxiosのモジュールインストールした記憶ない...ってことで早速以下のコマンドを叩いてインストールします!C:\Users\{user}\Documents\Sample\react-test>npm install axiosこんどこそいけるはず!ってことでもう一度
C:\Users\{user}\Documents\Sample\react-test>npm start...
C:\Users\{user}\Documents\Sample\react-test>npm start npm WARN lifecycle The node binary used for scripts is C:\Program Files (x86)\Nodist\bin\node.exe but npm is using C:\Program Files (x86)\Nodist\v-x64\10.15.3\node.exe itself. Use the `--scripts-prepend-node-path` option to include the path for the node binary npm was executed with. > test@0.1.0 start C:\Users\sleep\Documents\React-Tutorial\test > react-scripts start Setting NODE_PATH to resolve modules absolutely has been deprecated in favor of setting baseUrl in jsconfig.json (or tsconfig.json if you are using TypeScript) and will be removed in a future major release of create-react-app. Starting the development server... Compiled successfully! You can now view test in the browser. Local: http://localhost:3000/ On Your Network: http://192.168.10.101:3000/ Note that the development build is not optimized. To create a production build, use npm run build.
きた~~~~~~~~!
これでclickボタンを押すと...
hogeが返ってきた!!成功!!
次にclickしたときに飛ぶアドレスを変える!
App.jsfunction click(){ Axios.get('http://127.0.0.1:5000/').then(function(res){ console.log(res); alert(res.data.user.age); }).catch(function(e){ alert(e); }) }これを
App.jsfunction click(){ Axios.get('http://127.0.0.1:5000/user').then(function(res){ console.log(res); alert(res.data.user.age); }).catch(function(e){ alert(e); }) }こうして(アドレスの末尾にuserを追加)クリックボタンを押すと、
fugaに変わった!!!とりあえず想定通り動かせました、よかった~。
ちょっと躓くところもありましたが、環境構築さえできてしまえば何とかなりそうです!おわりに
最後まで見てくださった方がいましたら、本当にありがとうございます。
初歩の初歩らしいところからやってみましたが、動かせるだけでめちゃくちゃうれしいものですね。
もっと改良してまたまとめていきたいと思います!



- 投稿日:2019-12-22T18:43:17+09:00
twitter+機械学習で胸の大きさ推定して返すbot作ってみた
はじめに
せっかく機械学習勉強してきたんで面白いことをやりたいなと思い、胸の大きさを推定してみようと思いました。
・胸の大きさを予測する機械学習のモデルを作る
・twitterのAPIを用いて送られてきた写真に対して自動返信を行う
という流れで説明していきたいと思います。実際に使用したいという方やアプリの説明を見たい方は
youtubeでの説明や
https://www.youtube.com/watch?v=zrO1R2xq2wkこのツイッターアカウントにメッセージを送って使ってみて下さい
https://twitter.com/breast_pred_aiファイル構成
構成は以下のようになっています。
config.py
twitterアカウントのトークンとか、各自取得してね
make_models.py
tuning.pyのパラメータを利用してモデル作る
これをlocalで定期実行にすることでサービスが動く
tuning.py
modelの層の数とかのtuning
model_timely_reply.py
実際に使う返信するやつ
use_model.py
この中身をmodel_timely_reply.pyから呼び出してる機械学習のモデルの作り方
流れとしては、
・前処理
・モデルのチューニング
・モデルを使った予測という流れでやっていきます
前処理
ここでやることとしては、
・画像をロード
・画像サイズを統一
という二つです。使用した画像
ABCDEFGH以上の8カテゴリで20枚ずつ収集した画像、合計160枚を使用します。ここで気をつけたこととしては、
・横を向かない
・切り取りがあるのである程度中央に収まるもののみ使用する
という二つのことです。
画像については手動で集めました、結構大変でした笑まず使うライブラリのimportをします。
tuning.py
import numpy as np import pandas as pd import os import cv2 from sklearn.model_selection import train_test_split from keras.applications.vgg19 import VGG19 from keras.optimizers import * from keras.preprocessing.image import ImageDataGenerator from keras.models import Sequential, Model from keras.layers import Input, Activation, Dropout, Flatten, Dense, GlobalAveragePooling2D from keras.preprocessing.image import ImageDataGenerator from keras import optimizers from keras.callbacks import EarlyStopping, ModelCheckpoint from sklearn.metrics import mean_absolute_error from statistics import mean import optuna from sklearn.model_selection import KFoldデータの読み込みを行います。ここでは読み込むだけではなくラベル付けも同時に行います。今回は回帰分類を行うために
A→0,B→1,C→2というようにラベル付けしていきます。tuning.py
#数値に変換 def trans_from_cup_to_int(name_value): name_array = ["A","B","C","D","E","F","G","H以上"] return name_array.index(name_value) #データの読み込み def load_data(): print("start loading...") path = "data" name_list = [i for i in os.listdir(path) if i != '.DS_Store'] x_data = [] y_label_data = [] for name in name_list: label_value = trans_from_cup_to_int(name) pic_folder_path = path + "/" + name pic_list = [i for i in os.listdir(pic_folder_path) if i != '.DS_Store'] for pic_name in pic_list: pic_path = pic_folder_path+"/"+pic_name img = cv2.imread(pic_path) x_data.append(img) y_label_data.append(label_value) x_data = np.array(x_data) y_label_data = np.array(y_label_data).astype('int8') print("loading has finished!") return x_data, y_label_dataこのメソッド化したものを以下のコードで読み込みます。ここまでで前処理は終了です。
tuning.py
X, Y = load_data()モデルのチューニング
ここからの流れとしては、
・モデルを作成
・最適化
という流れでやっていきます。モデルの作成
今回使うのはVGG19という、CNNを用いた学習済みモデルです。これを転移学習させる形でやっていきます。このモデルお使ったのは、単純に記事をみていてVGG16が多く、コードコピペできるなと思った部分が多いからです。Classification系ならResnet、またSegmentation系を使ってみてももっと精度は高くなる気がしています。また、optunaというライブラリを用いて最適化していきます。また、今回は転移学習やoptunaについての詳しい説明は省きます。
optunaのドキュメンテーション
https://optuna.readthedocs.io/en/latest/ということでモデルを作っていきます。
以下の記事を参考にしながら、15層目までは学習させないようにして、アウトプットの層にさらに新しく層を追加する方式を取っています。また、今回チューニングするパラメータは、
・層の数(0から3)
・ドロップアウトの割合(最初の2層のみ)
・3つの層のニューロンの数
という3つについて学習させます。https://intellectual-curiosity.tokyo/2019/07/09/kerasで転移学習を行う方法/
tuning.py
def build_model(structure_params): base_model=VGG19(weights='imagenet',include_top=False, input_tensor=Input(shape=(100,100,3))) for layer in base_model.layers[:15]: layer.trainable=False model = Sequential() model.add(base_model) model.add(Flatten()) if structure_params["num_layers"] >= 1: model.add(Dense(structure_params["first_param_num"])) model.add(Activation('relu')) model.add(Dropout(structure_params["first_dropout_rate"])) if structure_params["num_layers"] >= 2: model.add(Dense(structure_params["second_param_num"])) model.add(Activation('relu')) model.add(Dropout(structure_params["second_dropout_rate"])) if structure_params["num_layers"] >= 3: model.add(Dense(structure_params["third_param_num"])) model.add(Activation('relu')) model.add(Dense(1)) model.compile(optimizer=Adam(lr=0.001), loss="mean_absolute_error") return modelここまででモデルを作り切ったので、モデルを最適化します。
モデルを評価する方法としては、kfoldで5つに分割しています。ここではStratifiedKFoldを使うべきだったなと後から後悔してます。ニューラルネットはモデルによるスコアの精度のブレが大きいので、hold out法は断念しています。また、maeを使用した理由としては、mseより予想値が中央に集まることを避けられると考えたからです。
画像のかさましやearly stoppingなどもやってあります。
ちなみにむちゃくちゃ重いので50回は回すことができず、数回を何度もやりながらパラメータを変更することをやりました。ローカルのパソコンでは時間かかりすぎてできなかったので、CPU使うとかは絶対オススメしません。tuning.py
def objective(trial): num_layers = trial.suggest_int('num_layers', 0, 3) first_dropout_rate = trial.suggest_uniform('first_dropout_rate', 0.0, 0.5) second_dropout_rate = trial.suggest_uniform('second_dropout_rate', 0.0, 0.5) first_param_num = trial.suggest_categorical("first_param_num", [256,512]) second_param_num = trial.suggest_categorical("second_param_num", [32,64,128]) third_param_num = trial.suggest_categorical("third_param_num", [16,32,64]) structure_params = { # "optimizer": optimizer, "num_layers": num_layers, "first_dropout_rate": first_dropout_rate, "second_dropout_rate": second_dropout_rate, "first_param_num": first_param_num, "second_param_num": second_param_num, "third_param_num": third_param_num } kfold = KFold(5, random_state = 0, shuffle = True) scores = [] print(structure_params) for k_fold, (tr_inds, val_inds) in enumerate(kfold.split(X)): X_train,Y_train = X[tr_inds],Y[tr_inds] X_val,Y_val = X[val_inds],Y[val_inds] model = build_model(structure_params) score = use_model(model,X_train,Y_train,X_val,Y_val) scores.append(score) print("score→ "+str(mean(scores))) params_and_scores.append([structure_params,mean(scores)]) return mean(scores) def use_model(model, X_train, Y_train, X_val, Y_val): batch_size=16 epochs = 20 #とりあえずぼかし以外 datagen = ImageDataGenerator( rotation_range=30, width_shift_range=0.2, height_shift_range=0.2, zoom_range=0.3, horizontal_flip=True ) early_stopping = EarlyStopping(monitor='val_loss', patience=3 , verbose=0) history = model.fit_generator( datagen.flow(X_train, Y_train, batch_size=batch_size), epochs = epochs, validation_data=(X_val,Y_val), callbacks=[early_stopping] ) return history.history["val_loss"][-1] study = optuna.create_study() study.optimize(objective, n_trials=50)モデルを使った予測
ここまででできたパラメータを利用してモデルを作り、その保存まで行います。
load_dataとresize_pictureの関数はtuningのところのやつをそのまま流用します。importも省略してます。make_models.py
def build_model(): base_model=VGG19(weights='imagenet',include_top=False, input_tensor=Input(shape=(100,100,3))) for layer in base_model.layers[:15]: layer.trainable=False model = Sequential() model.add(base_model) model.add(Flatten()) model.add(Dense(512)) model.add(Activation('relu')) model.add(Dense(128)) model.add(Activation('relu')) model.add(Dense(64)) model.add(Activation('relu')) model.add(Dense(1)) model.compile(Adam(lr=1e-4,clipnorm=1), loss="mean_absolute_error") print("Build model!") return model def fit_model(model, X_train, Y_train, X_val, Y_val): batch_size=16 epochs = 20 #とりあえずぼかし以外 datagen = ImageDataGenerator( rotation_range=30, width_shift_range=0.2, height_shift_range=0.2, zoom_range=0.3, horizontal_flip=True ) #ここから下はこれを参照https://lp-tech.net/articles/Y56uo early_stopping = EarlyStopping(monitor='val_loss', patience=1 , verbose=1) model.fit_generator( datagen.flow(X_train, Y_train, batch_size=batch_size), epochs = epochs, validation_data=(X_val,Y_val), callbacks=[early_stopping] ) return model def make_model(): skf = StratifiedKFold(5, random_state = 0, shuffle = True) scores = [] i = 0 for k_fold, (tr_inds, val_inds) in enumerate(skf.split(X,Y)): X_train,Y_train = X[tr_inds],Y[tr_inds] X_val,Y_val = X[val_inds],Y[val_inds] model = build_model() model = fit_model(model,X_train,Y_train,X_val,Y_val) model.save('use_models/model'+str(i)+'.h5') i += 1 del model def make_dir() if not os.path.exists('use_models'): os.mkdir("use_models") make_dir() X, Y = load_data() X = resize_picture(X) make_model()モデルについての変更点
本当はこのままモデルを使用したかったのですが、試してみたところCかDが大半という結果となりました。理由としてはおそらくある程度全部真ん中で予測するのがいいスコアが出るからだと思われます。これだと面白くないのである程度予測に振れ幅が出るように設定しました。
(本当にちゃんと予測するものだったら絶対やってはいけないです、今回はあくまでもエンタメのためこのようなことをやっています)use_models.py
from keras.models import load_model import numpy as np from keras.preprocessing.image import img_to_array, load_img from statistics import mean import cv2 def resize_picture(image): image = cv2.resize(image, dsize=(100, 100)).astype('int8') image = np.reshape(image, (1, 100, 100, 3)) return image def load_models(): models = [] for i in range(5): models.append(load_model('use_models/model'+str(i)+'.h5')) return models def predict(models,image): preds = [] for model in models: pred = model.predict(image, batch_size=1, verbose=0)[0][0] preds.append(pred) return mean(preds) def comment_content(pred): if pred<=1.8: content = "真っ平らのAカップじゃ" elif pred<=2.2: content = "Bカップか、平均くらいだのう" elif pred<=2.5: content = "Cカップ、ちょうどいいサイズじゃな" elif pred<=2.8: content = "Dカップとはかなり大きめの部類じゃな" elif pred<=3.1: content = "Eカップとはとても大きいのう、、、" elif pred<=3.4: content = "Fカップ!とても大きい胸じゃのう、、、、" elif pred<=3.6: content = "Gカップじゃと、、、こんな大きいのみたことないぞい、、、" else: content = "Hカップ以上、、、これは幻覚か、天国が広がってるぞい、、、" return content def use_this_file(models, file_name): image = cv2.imread(file_name) image = resize_picture(image) pred = predict(models,image)ということでここまでで機械学習の実装が完了しました。ここからはtwitterのapiを実装していきます。
twitterによる自動返信
ここからは実際にアプリに載せていきましょう。
実装の流れとしては、
リプライを送るべきツイートの取得→リプライ
という流れになります。前準備
twitterのapi用のトークンの取得をします。
この辺を参考にしてみてやってみました、正直めんどくさいです笑
https://qiita.com/kngsym2018/items/2524d21455aac111cdeeここで書いたものをconfig.pyに入れます(今は空白になっていますが、実際は中身を入れてみて下さい)
config.py
CONSUMER_KEY = '' # Consumer Key CONSUMER_SECRET = '' # Consumer Secret ACCESS_TOKEN = '' # Access Token ACCESS_TOKEN_SECRET = '' # Accesss Token Secertリプライを送るべきツイートの取得
取得方法としては、今の時刻を取得してそこから10時間以内に行われたツイートを取得します。
ツイッターは検索するところで「since: 日時」というように検索ワードの後につけることで最近のツイートを取得できるので、この方法で検索してみます。また、この方法だと前回すでにリプライしたメッセージにもリプライしてしまうので、リプライのタイミングでいいねを押して、一度いいねされたものにはメッセージを送らないようにします。
ちなみにここで10時間になっているのはパソコンでローカルから定期実行するようになっているからです。クラウドに上げて定期実行するとお金がかかりそうだったので諦めました(herokuは試してみたが、お金がかかりそうだった)、実際に使う人が多そうだったらGCP上でやるなどこの辺はもうちょっと考えようかなと思っています。
写真を取得して機械学習に入れられる形に変換するところが一番苦労しました。model_timely_reply.py
import json, config from requests_oauthlib import OAuth1Session from urllib import request import numpy as np from PIL import Image import schedule import datetime from datetime import timedelta from use_model import resize_picture, load_models, predict, comment_content import time import cv2 import io from matplotlib import pylab as plt import tweepy dt_past = datetime.datetime.now() - timedelta(hours=10) CK = config.CONSUMER_KEY CS = config.CONSUMER_SECRET AT = config.ACCESS_TOKEN ATS = config.ACCESS_TOKEN_SECRET twitter = OAuth1Session(CK, CS, AT, ATS) auth = tweepy.OAuthHandler(CK, CS) auth.set_access_token(AT, ATS) api = tweepy.API(auth) search_url = "https://api.twitter.com/1.1/search/tweets.json" create_url = "https://api.twitter.com/1.1/statuses/update.json" dt_past_date = str(dt_past).split(" ")[0] dt_past_hm = dt_past.strftime("%H:%M") keyword = "@breast_pred_ai since:" + dt_past_date + "_"+ str(dt_past_hm)+"_JST" params = {'q' : keyword, 'count' : 50} req = twitter.get(search_url, params = params) if req.status_code == 200: models = load_models() tweet_ids = [] search_result = json.loads(req.text) for tweet in search_result['statuses']: print(tweet) tweet_id = tweet['id'] screen_name = tweet["user"]['screen_name'] try: api.create_favorite(tweet_id) if list(tweet.keys()).count('extended_entities')==1: img = tweet['extended_entities']["media"][0]["media_url"] img = request.urlopen(img).read() img = np.asarray(bytearray(img),dtype="uint8") img = cv2.imdecode(img, cv2.IMREAD_COLOR) img = resize_picture(img) pred = predict(models,img) content = comment_content(pred) # content += "という結果が出ました"+str(pred) else: content = "写真が入ってないぞい" params = {"status": "@"+screen_name+ " "+content,'in_reply_to_status_id': tweet_id} # params = {"status": "@"+screen_name+ " "+content} twitter = OAuth1Session(CK, CS, AT, ATS) twitter.post(create_url, params = params) except: print("もういいねされてます") continue else: print("ERROR: %d" % req.status_code)というところで実装は以上になります。あとはローカルのパソコンから定期実行します。
改善できるところ
まず絶対的なデータ数が足りない
160枚じゃ水増ししましたが足りないです、本気で予想するならこの数倍くらデータあった方がいい気がします。
モデルについて
今回はVGG19を利用していますが、大きさを測るものなのでSegmentation系のモデルの方が精度が良くなるかもなと考えています。
- 投稿日:2019-12-22T18:13:48+09:00
lmfitでモデルフィッティング
はじめに
この記事は株式会社ACCESSのAdvent Calendar 2019の21日目の記事です。
弊社のとある案件で、非線形最小二乗法フィッティングをすることになるはずなので、その予習の為に、以前使ったことのある
lmfitによる非線形最小二乗法フィッティングを復習してここにまとめます。lmfit
lmfitとは、"Non-Linear Least-Squares Minimization and Curve-Fitting for Python"と公式のサブタイトルがある通り非線形最小二乗法を用いたモデルフィットのためのライブラリで、scipy.optimizeの多くの最適化方法を基にして拡張し、開発されている。
特長
以下特長が挙げられている。
- Parameter クラスオブジェクトの導入。これにより、モデルのパラメータの扱いが容易になる。
- モデルフィッティングのアルゴリズムの変更のしやすさ。
- パラメータの信頼区間推定の改善。scipy.optimize.leastsqのものに比べて、簡潔に信頼区間推定ができるようになっている。
- Modelクラスオブジェクトを使用することで、カーブフィットが改善されている。この
Modelクラスオブジェクトは、scipy.optimize.curve_fitの機能を拡張している。- 一般的な線形の多くのビルドインモデルが用意されていて、すぐに使用できる。
(主観的に)便利だと思うところ
モデルとモデルのパラメータの扱いやすさ
- 自分で定義したモデルフィッティングで使いたい関数を簡単に導入できる。
- モデルのパラメータへのアクセスがPythonのdictinaryの機能で容易にできる。
- パラメータの境界/固定の設定が容易にできる。
フィッティングするときにパラメータの最適値を探す範囲の設定や、パラメータの値を固定にする(フリーパラメータでなくす)ことが容易にできる。- 目的関数を変更することなく、パラメータを修正できる。
- パラメータに代数的に制約を与えられる。 他のパラメータとの関係を制限できる。
lmfitでモデルフィッティング
データは、この記事用に作成したもので、プロットすると以下のようになっています。
ぱっと見てわかるように、このデータには2つの構造があって、6.0 と7.5 あたりに、正規分布ような構造が見える。
このデータをフィッティングして見る。モデル
上でも述べたように、2つの正規分布ような構造があるので、これらを表すモデルを導入する必要がある。また、0ではない一定なオフセットがあるように見えるので、これを再現する成分もモデルに組み込む必要がある。式に表すと以下のとおり。
f\left( x \right) = G_1 \left( x \right) + G_2 \left( x \right) + Cこれを
lmfit.modelsクラスオブジェクトを用いて表すと以下のようになる。import lmfit as lf import lmfit.models as lfm # モデルの定義 model = lfm.ConstantModel() + lfm.GaussianModel(prefix='gauss1_') + lfm.GaussianModel(prefix='gauss2_')
prefixを指定することで、同じモデル関数を用いていても、パラメータの区別がつけられるので便利。自前のモデルを導入する場合
Modelクラスオブジェクトに定義した関数を渡せば一発で、導入可能。
def constant(x, const): return const model = lf.Model(constant) + lfm.GaussianModel(prefix='gauss1_') + lfm.GaussianModel(prefix='gauss2_')パラメータ
Modelクラスオブジェクトを宣言しても、そのModelクラスオブジェクトに対する、Parametersクラスオブジェクトは宣言されないので、まずはその宣言からする。# 各パラメータの初期値等を設定 par_val = { 'c' : 20, 'const' : 20, 'gauss1_center' : 6.0, 'gauss1_sigma' : 1.0, 'gauss1_amplitude' : 400, 'gauss2_center' : 7.5, 'gauss2_sigma' : 1.0, 'gauss2_amplitude' : 150 } par_min = { 'c' : 0, 'const' : 0, 'gauss1_center' : 0, 'gauss1_sigma' : 0, 'gauss1_amplitude' : 0, 'gauss2_center' : 0, 'gauss2_sigma' : 0, 'gauss2_amplitude' : 0 } par_max = { 'c' : 100, 'const' : 100, 'gauss1_center' : 10, 'gauss1_sigma' : 10, 'gauss1_amplitude' : 1000, 'gauss2_center' : 10, 'gauss2_sigma' : 10, 'gauss2_amplitude' : 1000 } par_vary = { 'c' : True, 'const' : True, 'gauss1_center' : True, 'gauss1_sigma' : True, 'gauss1_amplitude' : True, 'gauss2_center' : True, 'gauss2_sigma' : True, 'gauss2_amplitude' : True } # 定義したモデル用のParameters クラスオブジェクトの宣言 params = model.make_params() for name in model.param_names: params[name].set( value=par_val[name], # 初期値 min=par_min[name], # 下限値 max=par_max[name], # 上限値 vary=par_vary[name] # パラメータを動かすかどうか )以下のようにして、パラメータ同士の関係を代数的に制約を与えられる。
params['gauss2_center'].set(expr='gauss1_center*1.25')フィッティング
result = model.fit(x=df.x, data=df.y, weights=df.dy**(-1.0), params=params, method='leastsq')注意: データは
pandasのDataFrameオブジェクトで与えている。フィッティング結果の確認
summary
print(result.fit_report())以下のように、フィッティング結果のまとめを見ることができる。
[[Model]] ((Model(constant) + Model(gaussian, prefix='gauss1_')) + Model(gaussian, prefix='gauss2_')) [[Fit Statistics]] # fitting method = leastsq # function evals = 383 # data points = 50 # variables = 6 chi-square = 29.2390839 reduced chi-square = 0.66452463 Akaike info crit = -14.8258350 Bayesian info crit = -3.35369698 [[Variables]] const: 21.4200227 +/- 1.47331527 (6.88%) (init = 20) gauss1_amplitude: 88.4566498 +/- 1.39004141 (1.57%) (init = 400) gauss1_center: 5.99651706 +/- 0.00136123 (0.02%) (init = 6) gauss1_sigma: 0.09691089 +/- 0.00153157 (1.58%) (init = 1) gauss2_amplitude: 31.6555368 +/- 1.39743186 (4.41%) (init = 150) gauss2_center: 7.49564632 +/- 0.00170154 (0.02%) == 'gauss1_center*1.25' gauss2_sigma: 0.09911853 +/- 0.00446584 (4.51%) (init = 1) gauss1_fwhm: 0.22820770 +/- 0.00360656 (1.58%) == '2.3548200*gauss1_sigma' gauss1_height: 364.139673 +/- 4.89553113 (1.34%) == '0.3989423*gauss1_amplitude/max(2.220446049250313e-16, gauss1_sigma)' gauss2_fwhm: 0.23340629 +/- 0.01051624 (4.51%) == '2.3548200*gauss2_sigma' gauss2_height: 127.410415 +/- 4.77590041 (3.75%) == '0.3989423*gauss2_amplitude/max(2.220446049250313e-16, gauss2_sigma)' [[Correlations]] (unreported correlations are < 0.100) C(gauss2_amplitude, gauss2_sigma) = 0.647 C(gauss1_amplitude, gauss1_sigma) = 0.636 C(const, gauss2_amplitude) = -0.555 C(const, gauss1_amplitude) = -0.552 C(const, gauss1_sigma) = -0.367 C(const, gauss2_sigma) = -0.359 C(gauss1_amplitude, gauss2_amplitude) = 0.306 C(gauss1_sigma, gauss2_amplitude) = 0.203 C(gauss1_amplitude, gauss2_sigma) = 0.198 C(gauss1_sigma, gauss2_sigma) = 0.131confidence interval
print('[[Confidence Intervals]]') print(result.ci_report())[[Confidence Intervals]] 99.73% 95.45% 68.27% _BEST_ 68.27% 95.45% 99.73% const : -4.72534 -3.05035 -1.49522 21.42002 +1.48820 +3.02111 +4.65531 gauss1_amplitude: -4.37979 -2.84434 -1.40305 88.45665 +1.41243 +2.88513 +4.47133 gauss1_center : -0.00435 -0.00278 -0.00131 5.99652 +0.00131 +0.00278 +0.00436 gauss1_sigma : -0.00479 -0.00312 -0.00154 0.09691 +0.00156 +0.00321 +0.00499 gauss2_amplitude: -4.31612 -2.82491 -1.40294 31.65554 +1.43259 +2.94767 +4.61057 gauss2_sigma : -0.01344 -0.00889 -0.00446 0.09912 +0.00466 +0.00971 +0.01540フィッティング結果のプロット
fig, gridspec = result.plot(data_kws={'markersize': 5})以下のようなグラフが自動で生成される。
フィッティング結果
最適値の値等は以下のプロパティが持っているので、あとはご自由にどうぞ。result.chisqr # カイ自乗値 esult.nfree # 自由度 result.redchi # 換算カイ自乗値 result.aic # aic result.bic # bic result.best_fit # best-fit modelの値 (フィッティング結果のオレンジ色のプロットの値) result.residual # (best-fit model)-(data)の値 (フィッティング結果の上側のパネルの値) result.best_values # 各パラメータの最適値: dict型 result.result.params['const'].value # パラメータの最適値 result.result.params['const'].stderr # パラメータの標準誤差以上。引き続き、22日目の、@rheza_hの記事をお楽しみください。

- 投稿日:2019-12-22T17:14:01+09:00
学習記録 その9(13日目)
学習記録(13日目)
勉強開始:12/7(土)〜
教材等:
・大重美幸『詳細! Python3 入門ノート』(ソーテック社、2017年):12/19(木)読了
・Progate Python講座(全5コース):12/21(土)終了
・Andreas C. Müller、Sarah Guido『(邦題)Pythonではじめる機械学習』(オライリージャパン、2017年):12月21日(土)〜第1章 はじめに
・機械学習モデルを新たなデータに適用するためにはうまく汎化(generalize)しなければならない。
・テストセットに割り当てるデータは25%程度が一般的
・機械学習を用いる必要性、及び必要なデータが含まれているかを確認するために、まず最初にデータをよく観察すること。
・観察はpandasのscattermatrixによるペアプロット等を作成して実施する方法がある。第2章 教師あり学習(Supervised Learning)
・クラス分類(classification)と回帰(regression)の2つに大別できる。連続性があれば後者といえる。
・適合不足と過剰適合のトレードオフにおける最良の汎化性能を示すスイートスポットを模索する。K-最近傍法(KNeighborsClassifier)
・訓練データセットから一番近い点を見つける。
・小さいデータに関しては良いベースライン
・多くの場合、あまり調整しなくても十分に高い性能を示す。より高度な技術を利用する前のベースラインとして使用するとよい。
・ただし多数の特徴量(数百以上)を持つデータセットではうまく機能せず、ほとんどの特徴量が多くの場合0となるような疎なデータセットでは性能が悪くなってしまう。線形モデル(linear model)
・入力特徴量の線形関数(linear function)を用いて予測する。
(それぞれのデータに対し、一番近くなるように線を引くイメージ)
・多数の特徴量を持つ場合に非常に有効。まず試してみるべきアルゴリズム
・訓練セットとテストセットで性能が大きく異なる場合は過剰適合の兆候
逆に近すぎる場合は適合不足の兆候
・ridge:線形モデルによる回帰の一つ。制約が強く、過剰適合の危険が少ない。汎化性能が高い。
・lasso:特徴量を自動的に選択するようなイメージ。特徴量が多いが柔道度の高いものがわずかしかないと予想される場合など。
・scikit-learnには上記の2つを組み合わせたElasticNetクラスもある。
・ロジスティック回帰(logisticRegression):クラス分類のための線形モデル
・線形サポートベクターマシン(linearSVM):同上ナイーブベイズクラス分類器
・線形モデルによく似たクラス分類器の1種。訓練が高速なのが特徴。クラス分類にしか使えない。
・線形モデルですら時間がかかるような大規模なデータセットに対するベースラインモデルとして有用。決定木(Decision Tree)
・クラス分類と回帰タスクに広く用いられている。
・Yes/Noで答えられる質問で構成された階層的構造を学習する。
(特徴量aはbよりも大きいか?など。アキネイターみたいな感じ?)
・可視化が可能で説明しやすい。非常に高速。
・決定木の深さに制約を与えないといくらでも深く複雑になるため、過剰適合を誘発、汎化性能も低くなる傾向がある。
・treeモジュールのexport_graphvizで木を可視化できる。
・特徴量の重要度(feature importance)などから挙動の特性値を推測
ただし、使われていない特徴量でも、単にその決定木で採用されなかっただけというケースもある。決定木のアンサンブル法(Ensembles)
・複数の機械学習モデルを組み合わせてより協力なモデルを構築する手法
ランダムフォレスト(Random Forest)
・訓練データに対し過剰適合する決定木の抱える問題に対応する方法の1つ。
・回帰でもクラス分類でも、最も多く使われている機械学習手法
・高次元の疎なデータには適さない。
・それぞれ異なった方向に過剰適合した決定木をたくさん作り、その平均を取ることで過剰適合の度合いを減らすことができる。
・ブートストラップサンプリング(bootstrap sample):データポイントをランダムに復元抽出する。
完成した新しいデータセットで決定木を作る。特徴量サブセットをmax_feartureで制御しつつ選択する。勾配ブースティング回帰木(Gradient Boosting)
・1つ前の決定木の誤りを次の決定木が修正するようにして、順番に作っていく。
・弱学習器(weak learner)を多数組み合わせて構成する。
・パラメータさえ正しく設定すれば、ランダムフォレストより性能はよい。訓練に時間はかかる。
・ランダムフォレスト同様、文章のような高次元で疎なデータに対してはあまりうまく機能しない。
・learning_rate(学習率)、n_estimator、max_depthというパラメータが重要
・まず試すべきはランダムフォレスト(より頑健であるため。)
予測時間が非常に重要な場合や、最後の1%まで性能を絞り出したい場合はこちらを試すとよい。
・大きい問題に適用する場合は、xgboostパッケージとpythonインターフェースを参照すること。カーネル法を用いたサポートベクタマシン
・より複雑なモデルを可能にするため、線形SVMを拡張したもの。
・同じような意味を持つ特徴量からなる中規模データセットに対しては強力。パラメータに敏感。
・低次元における線形モデルは直線や超平面が柔軟性を制限するため、非常に制約が強い。
より柔軟にするために、入力特徴量の交互作用(積)や多項式項を用いる。
・ガウシアンカーネル:元の特徴量の特定の次数までの全ての多項式を計算する。
多項式カーネル(polynomial kernel)
放射基底関数(radial basis function:RBF)
・2つのクラスの境界に位置する特定の訓練データだけが決定境界を決定する。これらのデータポイントをサポートベクタ(support vector)と呼ぶ。(名前の由来)
・特徴量の細部の違いがSVMでは破壊的な影響をもたらす。これを解決する方法として、全てがだいたい同じスケールになるように変換する方法の1つとして Min-Max Scalerというものがある。(0〜1の間になるように収める)
・データにわずかな特徴量しかない場合でも複雑な決定境界を生成できるのが強み。
・問題点はデータの前処理及びパラメータ調整を注意深く行う必要がある。多くのアプリで勾配ブースティングなどの決定木ベースモデルが用いられているのはこのため。また、ある予測がされた理由を検証・理解することが難しく、専門家以外に説明するのも大変。
・ただし、カメラのピクセルのような特徴量が似た測定器の結果に対してはSVMwo試す価値がある。
・gamma(ガウシアンカーネルの幅の逆数)、C(正則化パラメータ)というパラメータが重要ニューラルネットワーク(ディープラーニング)
・多層パーセプトロン(multilayer perceptron:MLP)について以下記載
・特に大きなデータセットに有効。パラメータに敏感。訓練に時間がかかる。
・MLPでは出力に対する入力の重み付けが重要
・入力から出力に至る途中に、重み付き和の計算を行う中間処理ステップ(隠れ層:hidden units)があり、ここで算出された値に対して更に重み付き和が行われて結果が出力される。
・ここまでの過程のみでは数学的に1つの重み付き和を計算することと同じなため、このモデルを線形より強力にするために、結果に対して非線形関数を適用する。
多くの場合、relu(rectified unit:正規化線形関数)やtanh(hyperbolic tangent:双曲正接関数)を用いる。
・デフォルトではMLPは100の隠れ層を用いるが、データセットの規模に応じて変更する必要がある。
・SVMと同様、データスケールを変換する必要がある。StandardScalerというものを書面上用いている。ConvergenceWarning: #収束警告: Stochastic Optimizer: Maximum iterations reached and the optimization hasn't converged yet. #確率的最適化器:繰り返し回数が上限に達したが、最適化が収束していない・上記はモデル学習に使っているadamアルゴリズムの機能。学習繰り返しの回数を増やすべきという意味。alphaパラメータを変更することで重みに対する正則化を強化することで汎化性能が上がる可能性もある。
・より柔軟で大きなモデルを扱うのであればkerasやlasgana、tensor-flowを用いるとよい。
・十分な計算時間、データをかけ、慎重にパラメータを調整すれば他の機械学習アルゴリズムに勝てることも多い。が、これは欠点でもあり、大きくて強力なものは非常に時間がかかる。また、パラメータのチューニングはそれ自体が1つの技芸となっている。
・同質ではなく、さまざまな種類の特徴量を持つデータに関しては決定木モデルの方が性能がよい。
・隠れ層の数や層あたりの隠れユニットの数が最も重要なパラメータ。
【第2章 教師あり学習(p.126)】 まで終了
- 投稿日:2019-12-22T16:41:42+09:00
⛅️小説「天気の子」を丸ごと一冊、感情分析してみた☔️
1.簡単な概要
この記事では、小説「天気の子」の文章を自然言語処理して、感情分析をするやり方を解説していきます!
一般的に 感情分析 とは、文章中に含まれる 「感情」 を発見し数値化し、その文章の意見を判断することを指します。
自社の製品やサービスに対するユーザーの意見を機械的に分類することができるため、現在注目されている分野です。
「レビューや口コミ以外にも感情分析が活用できるのでは?」と思い、本記事では、巷でほとんどやられていない小説を題材にした感情分析にチャレンジすることにしました。小説を感情分析すれば、「物語のおおまかな展開や登場人物の性格を推察できるのでは?」、というのが今回の趣旨です。
例えば物語の中で、
・感情値の浮き沈みが激しければ、非常にドラマチックな展開である
・感情値によりポジティブからネガティブへの転換点を見つかれば、物語の起承転結を客観的に発見することができる
といった具合です。そして、今回選んだ題材は、天気の子です!
前作の 「君の名は。」 に引き続き大ヒットした作品で、映画をご覧になった方も多いのではないでしょうか。まだ、記憶に新しい
(さすがにもう忘れてるか)と思いますので、劇場へ行かれた方は映画のシーンを思い出しながら見ていただけると楽しめるのと思います。映画と小説の違い
- 小説は、登場人物の視点(一人称)が入れ替わりながら物語が進行する。
- 視点は主人公の帆高の視点がメインだが、陽菜や夏美が視点の章もある。
- ストーリーは基本的に同じ。小説の方が説明が詳しい。
個人的な感想ですが、映画とは少し違った視点から物語を楽しめます。
2.感情分析のやり方
今回は最もシンプルな感情分析である「ポジネガ分析」を行いました。
「ポジネガ分析」とは、文章がポジティブな意見なのか、ネガティブな意見なのか、それともニュートラルなのかを、一連の単語から判断する分類手法です。
まず、感情分析のおおまかな流れを、簡単な例をあげながら説明していきます。
最初に、文章を形態素解析して、以下のように形態素(単語)ごとに分解します。『はいっと夏美さんが元気に手を上げ、須賀さんはそれを無視する。』
↓
['はいっ', 'と', '夏美', 'さん', 'が', '元気', 'に', '手', 'を', '上げ', '、', '須賀', 'さん', 'は', 'それ', 'を', '無視', 'する']
そして単語ごとにポジティブかネガティブかを判定し、それぞれに感情値を付与します。
['はいっ', 0],['と', 0],['夏美', 0], ['さん', 0], ['が', 0], ['元気', 1],['に', 0], ['手', 0], ['を', 0],['上げる', 0],['、', 0],['須賀', 0],['さん', 0],['は', 0],['それ', 0],['を', 0],['無視', -1],['する', 0]
この文では、感情極性値のある元気と無視に、
元気:+1
無視:-1
の感情値が付与されました。最後に、文章感情値を算出するために合計値を出します。上記の文の場合だと、1+(-1)で感情値は0ということになりますね。このようにして、一文ごとに感情値を出していきます。
単語のポジネガ度を判定するためには、感情辞書というものを使います。
感情辞書とは、以下のようにどの単語がポジティブかネガティブなのかがあらかじめ記されている辞書のことです。
この辞書でいうと、ネガ(評価)と入っている単語がくれば感情値に-1をし、ポジ(評価)がくれば+1をする、といった具合です。この辞書を基準として感情値を出していきます。
また、下記のように複数語によるポジネガ判定もできる仕様にしております。
[口角+上がる,+1][声+弾ける,+1][元気+ない,-1][途方+暮れる,-1]3.コーパスの作成
まず、元となるコーパスを作成します。
私は友人に協力してもらい、このような感じで自作しました。↓
※著作権の都合上、コーパスは公開できないため一部のみの紹介となります友人でありコーパス作成者のSさんより一言
今回、「よくわからないけど間違いなく面白いやつだ」という直感で文字起こしを引き受けました。
Kindleの『メモとハイライト』を使い、数文ずつコピペして分割する作業に丸々一週間。正直非常に大変でした。
ページや天気は文章をドラッグしながらコピペして入力できますが、コピペ作業で疲弊している状態でこれをやったら、なんだかラリホーな感じになりました。
納品時に「コーパスありがとう!」と言われましたが、『コーパス』がわからなくてこっそりググっていたことを今ここに告白します。4.感情辞書を準備
前述の通り、感情分析を準備します。
今回は、東北大の乾・岡崎研究室が公開されている「日本語評価極性辞書」を天気の子の内容に合うように一部改編し、使用することにします。
先ほど紹介しました[口角+上がる,+1]のような複数語によるポジネガ判定のための「複数語辞書」については、マンパワーで自作しました。5.一文ごとに感情値を出す
感情辞書をインポートさせ、一文ごとに感情値を出していきます。
コードは本記事の最後に記載しますが、手っ取り早く日本語の感情分析をされたい方は、「oseti」 というライブラリが非常に便利です。私も参考にさせていただきました。日本語評価極性辞書を利用したPython用Sentiment Analysisライブラリ oseti を公開しました
テキストを入力すると返り値として感情値が返ってくるスクリプトを作成し、下記のようにコーパスのdataframeに感情値を付与しました。
カラムの説明
total_word_score_pair_list_abs1:感情極性値がある形態素とその感情値のリスト
sum_positive_srore:ポジティブ値の合計
sum_pegative_srore:ネガティブ値の合計
new_srore_sum:ポジティブ値とネガティブ値を加算した値6.感情値の推移をグラフ化・小説の内容と比較
可視化ライブラリのseabornを使って、感情値をグラフにしてみます。
1ページごとの感情値を合計し、時系列で推移を見ていきます。
x軸がページ数、y軸が感情値です。
※ここからネタバレを多分に含みます。ご注意下さい。ページ単位の感情値の推移import matplotlib.pyplot as plt from statistics import mean, median from matplotlib import pyplot as plt import seaborn as sns; sns.set() import re %matplotlib inline page_sum_df = df_tenki2.groupby("page_num").new_score_sum.sum().reset_index() sns.lineplot(x="page_num", y="new_score_sum", data=page_sum_df)結果がこちら!
感情の起伏がかなり激しいですね!ポジティブとネガティブが交互に現れています。
このグラフから読み取れること
- ページごとにポジティブとネガティブが起伏として明確に現れている
- ポジティブ値、ネガティブ値が極端に高いページがある
- 物語と展開によって感情値の推移している(かもしれない)
しかし、グラフでは起伏が非常に細かく、特徴がちょっとわかりづらいですね...もう少しざっくりとした特徴を掴むために、x軸のページ単位から章単位に置き換えて合計して出してみます。
章単位の感情値の推移chapter_sum_df = df_tenki2.groupby("chapter_flag").new_score_sum.sum().reset_index() sns.lineplot(x="chapter_flag", y="new_score_sum", data=chapter_sum_df)
グラフから読み取れること
- ページ単位よりも章単位の方が大局的に特徴を掴むことができる
- 章ごとに感情値の起伏が大きく、感情値が下降した直後の章では感情値が大きくポジティブ振れる傾向がある。
- 章単位でみると感情値がネガティブとなっている章がない
感情の起伏がさっきよりもわかりやすく解釈しやすくなりましたね!
が、しかし...
グラフのy軸の値に注目して見てみてください。
ネガティブな値がほとんどありません。
映画や小説を見た人は、違和感を感じたのではないでしょうか?「天気の子ってこんな平和ボケした作品でしたっけ...?」
ということで,もう一歩踏み込んで分析してみましょう。
次は、感情値を合計値ではなく、ポジティブ値とネガティブ値の2つに分けてグラフを描画します。chapter_sum_df = df_tenki2.groupby("chapter_flag").sum_positive_scores.sum().reset_index() sns.lineplot(x="chapter_flag", y="sum_positive_scores", data=chapter_sum_df,color="red") chapter_sum_df2 = df_tenki2.groupby("chapter_flag").sum_negative_scores.sum().reset_index() sns.lineplot(x="chapter_flag", y="sum_negative_scores", data=chapter_sum_df2,color="blue")赤いグラフがポジティブ値、青がネガティブ値の推移です。
ポジ度とネガ度の両方の特徴がはっきりと見えるようになりました!
先程のように、ポジ値とネガ値を合計して一つのグラフで表現した場合、
「ポジ値とネガ値が両方大きい値を示していたときに、値が相殺されて特徴が見えづらくなっていた」
ようです。さて、ここからは小説の内容も交えて簡単に考察をしていきましょう。
全体感を見ると、物語の最初と後半、感情値の振れ幅が大きくなっていますね。
chapter2とchapter8以降の章は、ポジティブ値、ネガティブ値共にかなり高く推移しています。
起承転結で言うところの「起」の部分と「転」の部分でしょうか。続いて、値の大きさについても見てみましょう。
このグラフからchapter8とchapter10のポジティブ値が一番大きくchapter2が一番ネガティブであることが読み取れます。
chapter8
chapter8は、比較的平和な場面です。
みんなで公園で遊んだり、「帆高」が「陽菜」に告白するために、陽菜の弟の「凪」に相談したり指輪を買いに行ったりするところです。ポジティブ値が高くなっている理由もうなずけますね。chapter10
chapter10は、物語のクライマックスです。
「陽菜」を助けようとして、「帆高」が奮闘する場面です。ポジティブ値だけでなくネガティブ値も高くなっているので、「帆高」の感情が激しくなっていることが想像できます。chapter2
chapter2は、物語の序盤の場面です。
家出をした「帆高」が東京に来て、バイトを探そうとするも都会の波に揉まれ、最後に「須賀」の事務所を訪ねて働いていく場面です。都会の波に揉まれたり「須賀」に叱られたりしているところがネガティブ値に現れたのでしょうか。7.登場人物ごとに感情値を比較
ここからは登場人物ごとに感情値を比較してみます。
各キャラのセリフ一文あたりの感情値の平均を出してみます。平均値の算出方法
各キャラのセリフの感情値の合計 / 各キャラのセリフ数
今回は主要人物の「帆高」、「陽菜」、「須賀」、「夏美」の4人で比較してみます。
df_tenki3=df_tenki2.groupby(['speaker_name'])['new_score_sum'].mean().reset_index() df_tenki4 = df_tenki3.sort_values('new_score_sum', ascending=False) df_tenki_person = df_tenki4[(df_tenki4["speaker_name"] == "suga") | (df_tenki4["speaker_name"] == "hodaka") | (df_tenki4["speaker_name"] == "natsumi") | (df_tenki4["speaker_name"] == "hina")] sns.catplot(x="speaker_name", y="new_score_sum", data=df_tenki_person,height=6,kind="bar",palette="muted")
男女でポジネガがはっきりと分かれましたね。
女性陣はめっちゃポジティブです!
逆に男性陣2人はかなりネガティブです。2人ともかなり近い値を示していますね。
実際に、小説内でも主人公の穂高と須賀は、「この二人はよく似ている」
と、周囲から言われる描写がありますが、感情値という点から見ても似ていることがわかります。
ポジティブ値とネガティブ値についても見てみましょう。
df_tenki3=df_tenki2.groupby(['speaker_name'])['sum_positive_scores','sum_negative_scores'].mean().reset_index() df_tenki4 = df_tenki3.sort_values('sum_positive_scores', ascending=False).reset_index() df_tenki_person2 = df_tenki4[(df_tenki4["speaker_name"] == "suga") | (df_tenki4["speaker_name"] == "hodaka") | (df_tenki4["speaker_name"] == "natsumi") | (df_tenki4["speaker_name"] == "hina")] sns.catplot(x="speaker_name", y="sum_positive_scores", data=df_tenki_person2,kind="bar",palette="muted") sns.catplot(x="speaker_name", y="sum_negative_scores", data=df_tenki_person2,kind="bar",palette="muted")
「陽菜」は3人に比べてネガティブな言葉をほとんどしゃべっていないようです。なんて強い女の子なんだ...
「夏美」はポジティブ値はトップですが、ネガティブ値もそこそこ高いです。
「夏美」は普段はかなり明るいほうではありますが、就活に悩んで自己嫌悪したり須賀に文句を垂れたりと色々とネガティブな言葉もしゃべっている印象があります。
そして「帆高」のポジティブ値がかなり低くなっています。確かに明るい印象はあまりないですよね...
でも「陽菜」のポジティブさが引っ張っていってくれるなら、この2人はいいコンビなのかもしれないですね(?)8.天気と感情値に関連性はあるのか
最後に、この物語の鍵になる「天気」と感情値の関係を調べてみます。
やり方は、登場人物のときと同様、それぞれの天気の場面ごとで平均値を算出します。
天気の種類は、コーパス作成時に描写から判断し下記6分類としました。
「晴れ(sunny)」「雨(rain)」「小雨(light_rain)」「豪雨(heavy_rain)」「快晴(clear)」「雪(snow)」
雨の強さは3種類あるため、雨の強さと感情値の関連を見ることができます。
ちなみに、物語の設定上、ヒロインの「陽菜」が晴れを願ったときと、あることが起こったとき以外は基本的に物語の舞台(東京)は「雨」の状態です。
毎日雨が降っている状況のため、街の人々はみんな晴れることを望んでいるわけです。仮説
仮説として、晴れのシーンは大きくポジティブになり、雨が強くなればなる程ネガティブになるのでは?
と予想してみました。
では、結果を見てみましょう!sns.catplot(x="weather_flag", y="new_score_sum", data=df_tenki2_edited,height=6,kind="bar",palette="muted")
やはり晴れが一番ポジティブになっていますね!予想的中です!
雨の強さについてはあまり関連はなさそうですね。
しかし、「晴れ」は非常にポジティブであるにも関わらず、「快晴(clear)」はあまりポジティブな方に推移していません。なぜでしょうか...?
前述したように、天気が晴れるのは陽菜が晴れを願ったときとあることが起こったときだけなのですが、そのあることとは.....
そう、$\huge{"陽菜が消えてしまった"}$
陽菜が消えてしまったことにより、今まで雨ばかり降っていた街は一気に快晴になります。
しかし、「陽菜」が犠牲になったことなど知らない一般の人々は、晴れたことに素直に喜んでいます。
ただ、主人公の「帆高」だけはそのことを知っていて、非常に悲しむわけです。物語の中で一番いい天気のはずなのですが、ここでは「帆高」の感情は世間とは真逆にいくんですね。なので晴れているにもかかわらずあまりポジティブにはならないんですね。最後に雪についてですが、ここが一番ネガティブになっています。ここは映画を観たことがある人であれば、しっくりくるのではないでしょうか。
ここは、クライマックスで、「帆高」と「陽菜」が警察から逃げてラブホテルへ逃げ込むシーンですね。
8月なのに雪が降るという超異常気象に、世間も帆高たちも大混乱していて、非常にネガティブな表現が多いシーンです。9.結論
小説を感情分析をしてわかったこと
- 物語の大まかな展開や起承転結の転換点の読み取りができる
- 登場人物の性格をポジネガ値からざっくり判断ができる
- 時系列ごとの感情値の変遷は、章単位でかつ、ポジティブ値とネガティブ値に分けると解釈が容易になる
そして、今回は一番わかりやすい天気と感情値との関連性を調べてみましたが、他の要素との関連性も調べてみると面白い結果が出てきそうです。
「こんな分析したらおもしろそう!」みたいなアイディアがありましたらコメントいただけますと幸いです。10.課題
小説の表現の幅の広さ
当然覚悟はしていましたが、予想以上に小説の表現の幅が広く、単語単位でポジネガを付与するのが難しい描写がありました。
最後のシーンで「帆高」が「天気なんて狂ったままでいいんだ」と叫ぶセリフがありますが、物語の中で一番力強くポジティブなシーンですが、言葉通りに受け取るとネガティブになります。
単語の単位で感情値を付与するだけでは限界があり、このあたりは非常に難しいところです。11.コード
#感情極性辞書をインポートする関数 def _make_dict(): import pandas as pd df_word_dict = pd.read_csv('./dict/edited_target_pair_list_word_out.csv')#名詞 df_wago_dict = pd.read_csv('./dict/edited_target_pair_list_wago_out.csv')#用言 df_one_gram_dict = pd.read_csv('./dict/one_gram_dict_out.csv')#複数語 word_dict = {} for pair_list in df_word_dict[['word','count']].values.tolist(): if pair_list[1] !='0': word_dict[pair_list[0]] = pair_list[1] wago_dict = {} for pair_list in df_wago_dict[['word','count']].values.tolist(): if pair_list[1] !='0': wago_dict[pair_list[0]] = pair_list[1] one_gram_dict = {} for pair_list in df_one_gram_dict[['word1','word2','score']].values.tolist(): one_gram_dict[(str(pair_list[0]),str(pair_list[1]))] = pair_list[2] return word_dict,wago_dict,one_gram_dict #テキストを1文ごとにスプリットする関数 def _split_per_sentence(text): import re re_delimiter = re.compile("[。,.!\?!?]") for sentence in re_delimiter.split(text): if sentence and not re_delimiter.match(sentence): yield sentence def _sorted_second_list(polarities_and_lemmanum): from operator import itemgetter sorted_polarities_and_lemmanum=sorted(polarities_and_lemmanum, key=itemgetter(1)) return [i[0] for i in sorted_polarities_and_lemmanum] def _calc_sentiment_polarity(sentence): import MeCab word_dict,wago_dict,one_gram_dict = _make_dict() NEGATION = ('ない', 'ず', 'ぬ','ん') tagger = MeCab.Tagger('-Owakati -d /usr/local/lib/mecab/dic/mecab-ipadic-neologd') tagger.parse('') # for avoiding bug word_polarities = [] # word_dict に対応する感情値のリスト wago_polarities = [] # wago_dict に対応する感情値のリスト polarities_and_lemmanum = [] # 最終的な感情値とlemmanumのリスト lemmas = [] # 見出し語, 辞書に載っている形式の単語 word_polarity_apeared = False wago_polarity_apeared = False word_nutoral_polarity_apeared = False wago_nutoral_polarity_apeared = False word_out_polarity_apeared = False wago_out_polarity_apeared = False word_polarity_word = '' #エラー処理のため暫定 wago_polarity_word = '' #エラー処理のため暫定 word_nutoral_word = '' wago_nutoral_word = '' word_out_polarity_word = '' wago_out_polarity_word = '' last_hinsi = '' last_word = '' node = tagger.parseToNode(sentence) word_score_pair_list = [] lemma_num = 0#単語の順番をメモる用 lemma_dict = {} while node: if 'BOS/EOS' not in node.feature: surface = node.surface feature = node.feature.split(',') lemma = feature[6] if feature[6] != '*' else node.surface lemma_num += 1 lemma_dict[lemma] = lemma_num #分かち書きした単語の辞書に載っている形式の単語になおしたlemmaの処理 #その単語がword_dictにあった場合の処理 if word_polarity_apeared and (feature[0] not in ['助動詞','助詞'] and last_hinsi not in ['助動詞','助詞'] and last_word not in ['ある','おる','する']) and last_word not in word_dict: word_polarity_apeared = False elif wago_polarity_apeared and (feature[0] not in ['助動詞','助詞'] and last_hinsi not in ['助動詞','助詞'] and last_word not in ['ある','おる','する']) and last_word not in wago_dict: wago_polarity_apeared = False elif word_nutoral_polarity_apeared and (feature[0] not in ['助動詞','助詞'] and last_hinsi not in ['助動詞','助詞'] and last_word not in ['ある','おる','する']) and last_word not in word_dict: word_nutoral_polarity_apeared = False elif wago_nutoral_polarity_apeared and (feature[0] not in ['助動詞','助詞'] and last_hinsi not in ['助動詞','助詞'] and last_word not in ['ある','おる','する']) and last_word not in wago_dict: wago_nutoral_polarity_apeared = False try: if word_dict[lemma] in ['p','n']: polarity = 1 if word_dict[lemma] == 'p' else -1 word_polarities.append([polarity,lemma_dict[lemma]]) word_polarity_apeared = True word_polarity_word = lemma elif word_dict[lemma] == 'f': word_polarities.append([0,lemma_dict[lemma]]) word_nutoral_polarity_apeared = True word_nutoral_word = lemma polarity = 0 #word_dict で0は事前に消去しているためelseの処理は不要だが、可読性を考慮して残しておく else: polarity = 0 #word_dict に 単語がないとき except: #wago_dictに単語があるとき try: if wago_dict[lemma] in ['ポジ(経験)','ネガ(経験)','ポジ(評価)','ネガ(評価)']: polarity = 1 if wago_dict[lemma] in ['ポジ(経験)','ポジ(評価)'] else -1 # print(polarity) wago_polarities.append([polarity,lemma_dict[lemma]]) wago_polarity_apeared = True wago_polarity_word = lemma elif wago_dict[lemma] == 'ニュートラル': wago_polarities.append([0,lemma_dict[lemma]]) wago_nutoral_polarity_apeared = True wago_nutoral_word = lemma polarity = 0 else: polarity = 0 #word_dict にも wago_dictにも単語がないときの処理 except: if word_polarity_apeared and surface in NEGATION and wago_nutoral_polarity_apeared is False: if last_hinsi in ['名詞','助詞','助動詞','動詞','形容詞']: word_polarities[-1][0] *= -1 try: reverse_num = -1*([i for i in reversed(word_score_pair_list)].index([word_polarity_word,1])+1) except: reverse_num = -1*([i for i in reversed(word_score_pair_list)].index([word_polarity_word,-1])+1) finally: word_score_pair_list[reverse_num]=[word_polarity_word+'+'+lemma,word_polarities[-1][0]] word_polarity_apeared = False word_polarity_word = '' polarity = 0 else: polarity = 0 #「直してください」「改善してください」を-1にする処理 elif lemma in ['くださる','ほしい','願う']: try: if word_polarity_word or word_nutoral_word !='': last_polarities_word = [i for i in [word_polarity_word,word_nutoral_word] if i !=''][0] try: reverse_num = -1*([i for i in reversed(word_score_pair_list)].index([last_polarities_word,word_polarities[-1][0]])+1) except: reverse_num = -1*([i for i in reversed(word_score_pair_list)].index([last_polarities_word,word_polarities[-1][0]])+1) finally: word_score_pair_list[reverse_num]=[last_polarities_word+'+'+surface,-1]#感情値-1を付与 word_polarity_apeared = False word_polarity_word = '' word_polarities[-1][0] = -1 polarity = 0 elif wago_polarity_word or wago_nutoral_word !='': last_polarities_word = [i for i in [wago_polarity_word,wago_nutoral_word] if i !=''][0] try: reverse_num = -1*([i for i in reversed(word_score_pair_list)].index([last_polarities_word,wago_polarities[-1][0]])+1) except: reverse_num = -1*([i for i in reversed(word_score_pair_list)].index([last_polarities_word,wago_polarities[-1][0]])+1) finally: word_score_pair_list[reverse_num]=[last_polarities_word+'+'+surface,-1]#感情値-1を付与 wago_polarity_apeared = False wago_polarity_word = '' wago_polarities[-1][0] = -1 polarity = 0 except: polarity = 0 #文末に「か」があったとき-1にする処理 elif last_hinsi in ['助動詞','助詞'] and lemma == 'か': try: if word_polarity_word or word_nutoral_word !='': last_polarities_word = [i for i in [word_polarity_word,word_nutoral_word] if i !=''][0] try: reverse_num = -1*([i for i in reversed(word_score_pair_list)].index([last_polarities_word,word_polarities[-1][0]])+1) except: reverse_num = -1*([i for i in reversed(word_score_pair_list)].index([last_polarities_word,word_polarities[-1][0]])+1) finally: word_score_pair_list[reverse_num]=[last_polarities_word+'+'+surface,-1]#感情値-1を付与 word_polarity_apeared = False word_polarity_word = '' word_polarities[-1][0] = -1 polarity = 0 elif wago_polarity_word or wago_nutoral_word !='': last_polarities_word = [i for i in [wago_polarity_word,wago_nutoral_word] if i !=''][0] try: reverse_num = -1*([i for i in reversed(word_score_pair_list)].index([last_polarities_word,wago_polarities[-1][0]])+1) except: reverse_num = -1*([i for i in reversed(word_score_pair_list)].index([last_polarities_word,wago_polarities[-1][0]])+1) finally: word_score_pair_list[reverse_num]=[last_polarities_word+'+'+surface,-1]#感情値-1を付与 wago_polarity_apeared = False wago_polarity_word = '' wago_polarities[-1][0] = -1 polarity = 0 except: polarity = 0 elif word_nutoral_polarity_apeared: if last_hinsi in ['名詞','助詞','助動詞','動詞'] and lemma in NEGATION: lemma_type = '否定' try: word_polarities[-1][0] += one_gram_dict[(word_nutoral_word,lemma_type)] reverse_num = -1*([i for i in reversed(word_score_pair_list)].index([word_nutoral_word,0])+1) word_score_pair_list[reverse_num]=[word_nutoral_word+'+'+lemma,one_gram_dict[(word_nutoral_word,lemma)]] word_nutoral_polarity_apeared = False word_nutoral_word = '' except: polarity = 0 elif last_hinsi in ['名詞','助詞','助動詞','動詞'] and lemma not in NEGATION: try: word_polarities[-1][0] += one_gram_dict[(word_nutoral_word,lemma)] reverse_num = -1*([i for i in reversed(word_score_pair_list)].index([word_nutoral_word,0])+1) word_score_pair_list[reverse_num]=[word_nutoral_word+'+'+lemma,one_gram_dict[(word_nutoral_word,lemma)]] word_nutoral_polarity_apeared = False word_nutoral_word = '' except: polarity = 0 #その単語がword_dictになかった場合の処理 else: #単語が,ない', 'ず', 'ぬ'だった場合はその前の単語の極性を逆にする if wago_polarity_apeared and surface in NEGATION and wago_nutoral_polarity_apeared is False\ and word_polarity_apeared is False and word_nutoral_polarity_apeared is False: if last_hinsi in ['名詞','形容詞','助動詞']: wago_polarities[-1][0] *= -1 reverse_num = -1*([i for i in reversed(word_score_pair_list)].index([wago_polarity_word,wago_polarities[-1][0]*(-1)])+1) word_score_pair_list[reverse_num]=[wago_polarity_word+'+'+lemma,wago_polarities[-1][0]] wago_polarity_apeared = False word_polarity_word = '' polarity = 0 else: polarity = 0 elif wago_nutoral_polarity_apeared: #ニュートラル+否定の処理 if last_hinsi in ['動詞','助詞','助動詞'] and lemma in NEGATION: lemma_type = '否定' try: lemma_type = '否定' wago_polarities[-1][0] += one_gram_dict[(wago_nutoral_word,lemma_type)] #リストを逆からたどるための処理 reverse_num = -1*([i for i in reversed(word_score_pair_list)].index([wago_nutoral_word,0])+1) word_score_pair_list[reverse_num]=[wago_nutoral_word+'+'+lemma,one_gram_dict[(wago_nutoral_word,lemma_type)]] wago_nutoral_polarity_apeared = False wago_nutoral_word = '' except: polarity = 0 #ニュートラル+否定以外の処理 elif last_hinsi in ['名詞','動詞','形容詞','助詞','助動詞'] : try: wago_polarities[-1][0] += one_gram_dict[(wago_nutoral_word,lemma)] #リストを逆からたどるための処理 reverse_num = -1*([i for i in reversed(word_score_pair_list)].index([wago_nutoral_word,0])+1) word_score_pair_list[reverse_num]=[wago_nutoral_word+'+'+lemma,one_gram_dict[(wago_nutoral_word,lemma)]] wago_nutoral_polarity_apeared = False wago_nutoral_word = '' except: polarity = 0 else: polarity = 0 else: polarity = 0 word_score_pair = [lemma,polarity] word_score_pair_list.append(word_score_pair) last_hinsi = node.feature.split(',')[0] last_word = lemma node = node.next if word_polarities: polarities_and_lemmanum.extend(word_polarities) if wago_polarities: polarities_and_lemmanum.extend(wago_polarities) #lemma_numで昇順ソート try: polarities = _sorted_second_list(polarities_and_lemmanum) #0以外の極性値だけにする。0が残ると後の処理でエラーになるため。 polarities = [i for i in polarities if i !=0] except: polarities = [] try: if sum(polarities) / len(polarities) ==0: score = float(polarities[-1]) # print('=================================================') print(sentence+'→→文末の感情値を優先') # print('=================================================') else: score = sum(polarities) / len(polarities) except: score = 0 if not polarities: return 0,0,0,word_score_pair_list return score,sum(i for i in polarities if i > 0),sum(i for i in polarities if i < 0),word_score_pair_list def _analyze(text): scores,total_word_score_pair_list,positive_word_cnt_list,negative_word_cnt_list = [],[],[],[] for sentence in _split_per_sentence(text): #感情分析用に文章を置換 例:ありません→ないです replaced_sentence = _emotion_replace_text(sentence) score,positive_word_cnt,negative_word_cnt,word_score_pair_list = _calc_sentiment_polarity(replaced_sentence) scores.append(score) positive_word_cnt_list.append(positive_word_cnt) negative_word_cnt_list.append(negative_word_cnt) total_word_score_pair_list.append(word_score_pair_list) return scores,positive_word_cnt_list,negative_word_cnt_list,total_word_score_pair_list def _flatten_abs1(x): #2重のリストをフラットにして感情値が付与されてるペアだけのリストにする関数 return [e for inner_list in x for e in inner_list if e[1] !=0] def score_sum_get(x): #_flatten_abs1で出た感情値を合計する関数 emo_list=[] for inner_list in x: for e in inner_list: if e[1] !=0: emo_list.append(e[1]) return sum(emo_list) from datetime import datetime as dt from datetime import date #学習データの読み込み import pandas as pd path='./data/tenkinoko.csv' df_tenki = pd.read_csv(path,encoding="SHIFT-JIS") df_tenki["chapter_flag"] = df_tenki.chapter.apply(chapter_flag) add_col_name=['scores','positive_word_cnt_list','negative_word_cnt_list','total_word_score_pair_list'] for i in range(len(add_col_name)): col_name=add_col_name[i] df_tenki2[col_name]=df_tenki2['text'].apply(lambda x:_analyze(x)[i]) df_tenki2['score_sum']=df_tenki2['scores'].apply(lambda x:sum(x)) #単語単位のポジ数をカウント df_tenki2['sum_positive_scores']=df_tenki2['positive_word_cnt_list'].apply(lambda x:sum(x)) #単語単位のネガ数をカウント df_tenki2['sum_negative_scores']=df_tenki2['negative_word_cnt_list'].apply(lambda x:sum(x)) #感情極性単語のある[形態素,感情値]のペアのみにする処理 df_tenki2['total_word_score_pair_list_abs1']=df_tenki2['total_word_score_pair_list'].apply(lambda x:_flatten_abs1(x)) # 感情値の合計を出す df_tenki2['new_score_sum']=df_tenki2['total_word_score_pair_list'].apply(lambda x:score_sum_get(x))







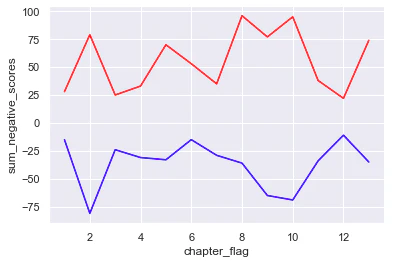


- 投稿日:2019-12-22T16:34:57+09:00
pythonでslackの特定チャンネル内にいるactiveメンバーを表示させるBotを作成した話
はじめに
pythonでslackの特定チャンネル内にいるactiveメンバーをslackのAPIを用いて、slackbotに特定のメンションを飛ばして表示させます。
実行結果
こんな感じです。個人情報含まれているので一部隠してます。
それではやっていきましょう!!ディレクトリ構成
├───.gitignore ├───.env ├───requirements.txt ├───Procfile │───plugins │ └───my_mention.py #このファイルを主に使用します。 │ └───__init__.py │───run.py │───settings.py │───slackbot_settings.py └───README.mdコード
my_mention.py
from slackbot.bot import respond_to import requests import random import sys sys.path.append('..') import settings CHANNEL_ID = settings.CHANNEL_ID SLACK_API_TOKEN = settings.SLACK_API_TOKEN @respond_to('') def main(message): url = 'https://slack.com/api/channels.info?token={0}&channel={1}&pretty=1'.format(SLACK_API_TOKEN, CHANNEL_ID) response = requests.get(url).json() channel_info = response["channel"] member_id = channel_info["members"] member_id_list = [id for id in member_id] name_active_dict = member(member_id_list) active_member = [] for key, value in name_active_dict.items(): if value == 'active': active_member.append(key) active_member = random.sample(active_member, len(active_member)) member_text = '' for i, active_name in enumerate(active_member): member_text = member_text + '{} : {}\n'.format(i+1, active_name) message.reply(member_text) def member(member_id_list): member_dict = {} user_list = [] is_active_list = [] for name_id in member_id_list: user_url = 'https://slack.com/api/users.info?token={0}&user={1}&pretty=1'.format(SLACK_API_TOKEN, name_id) active_user_url = 'https://slack.com/api/users.getPresence?token={0}&user={1}&pretty=1'.format(SLACK_API_TOKEN, name_id) user_response = requests.get(user_url).json() active_user_response = requests.get(active_user_url).json() user_list.append(user_name(user_response)) is_active_list.append(is_active_user(active_user_response)) for user, active in zip(user_list, is_active_list): member_dict[user] = active return member_dict def user_name(user_response_json): user = user_response_json["user"] user_profile = user["profile"] name = user_profile["real_name"] return name def is_active_user(active_user_response_json): is_active = active_user_response_json["presence"] return is_activeslackbot_settings.py
import settings API_TOKEN = settings.API_TOKEN DEFAULT_REPLY = 'メンバーを決めよう!' PLUGINS = ['plugins']settings.py
import os from os.path import join, dirname from dotenv import load_dotenv dotenv_path = join(dirname(__file__), '.env') load_dotenv(dotenv_path) SLACK_API_TOKEN = os.environ.get("SLACK_API_TOKEN") API_TOKEN = os.environ.get('API_TOKEN') CHANNEL_ID = os.environ.get('CHANNEL_ID')run.py
from slackbot.bot import Bot def main(): bot = Bot() bot.run() if __name__ == '__main__': main()Procfile
worker: python run.pyruntime.txt
python-3.6.0requirements.txt
slackbot==0.5.3まとめ
結構簡単にできますね。皆さんもslackbot有効活用していきましょう!!

- 投稿日:2019-12-22T16:25:58+09:00
【Python】tkinterでファイル&フォルダパス指定画面を作成する
tkinterで、添付ファイル指定とフォルダ指定の画面を作成しました。様々なツールを作るうえでファイルやフォルダをGUIで指定できると便利なので重宝してます。
tkinterとは
tkinterはPythonをインストールした際にデフォルトで入っている標準モジュールです。非常にシンプルなコードでGUI画面を作成することができます。個人でGUIツールを作成する際は便利なモジュールです。
基本的な使い方等は下記のサイトが分かりやすいです。
Tkinter による GUI プログラミングファイル&フォルダ参照
tkinterでファイルorフォルダを参照する機能は、filedialogを使うと実装可能です。コード上の呼び出し方は以下の通りです。
from tkinter import filedialog今回はfiledialogの以下を使って2つの機能を実装しました。
1、askdirectory
ディレクトリを指定する機能です。本機能によって以下画像の画面が開き、フォルダパスを指定することが可能です。
2、askopenfilename
フォイルを指定する機能です。本機能によって以下画像の画面が開き、ファイルパスを指定することが可能です。
実装
今回は以下のようなGUI画面を作成しました。フォルダパスとファイルパスを指定し、実行ボタンを押せばmessagebox機能で指定されたパスを返却します。
トップ画面イメージ図
実行結果(messagebox)
コードは以下の通りです。tkinter_sample.pyimport os,sys from tkinter import * from tkinter import ttk from tkinter import messagebox from tkinter import filedialog # フォルダ指定の関数 def dirdialog_clicked(): iDir = os.path.abspath(os.path.dirname(__file__)) iDirPath = filedialog.askdirectory(initialdir = iDir) entry1.set(iDirPath) # ファイル指定の関数 def filedialog_clicked(): fTyp = [("", "*")] iFile = os.path.abspath(os.path.dirname(__file__)) iFilePath = filedialog.askopenfilename(filetype = fTyp, initialdir = iFile) entry2.set(iFilePath) # 実行ボタン押下時の実行関数 def conductMain(): text = "" dirPath = entry1.get() filePath = entry2.get() if dirPath: text += "フォルダパス:" + dirPath + "\n" if filePath: text += "ファイルパス:" + filePath if text: messagebox.showinfo("info", text) else: messagebox.showerror("error", "パスの指定がありません。") if __name__ == "__main__": # rootの作成 root = Tk() root.title("サンプル") # Frame1の作成 frame1 = ttk.Frame(root, padding=10) frame1.grid(row=0, column=1, sticky=E) # 「フォルダ参照」ラベルの作成 IDirLabel = ttk.Label(frame1, text="フォルダ参照>>", padding=(5, 2)) IDirLabel.pack(side=LEFT) # 「フォルダ参照」エントリーの作成 entry1 = StringVar() IDirEntry = ttk.Entry(frame1, textvariable=entry1, width=30) IDirEntry.pack(side=LEFT) # 「フォルダ参照」ボタンの作成 IDirButton = ttk.Button(frame1, text="参照", command=dirdialog_clicked) IDirButton.pack(side=LEFT) # Frame2の作成 frame2 = ttk.Frame(root, padding=10) frame2.grid(row=2, column=1, sticky=E) # 「ファイル参照」ラベルの作成 IFileLabel = ttk.Label(frame2, text="ファイル参照>>", padding=(5, 2)) IFileLabel.pack(side=LEFT) # 「ファイル参照」エントリーの作成 entry2 = StringVar() IFileEntry = ttk.Entry(frame2, textvariable=entry2, width=30) IFileEntry.pack(side=LEFT) # 「ファイル参照」ボタンの作成 IFileButton = ttk.Button(frame2, text="参照", command=filedialog_clicked) IFileButton.pack(side=LEFT) # Frame3の作成 frame3 = ttk.Frame(root, padding=10) frame3.grid(row=5,column=1,sticky=W) # 実行ボタンの設置 button1 = ttk.Button(frame3, text="実行", command=conductMain) button1.pack(fill = "x", padx=30, side = "left") # キャンセルボタンの設置 button2 = ttk.Button(frame3, text=("閉じる"), command=quit) button2.pack(fill = "x", padx=30, side = "left") root.mainloop()まとめ
tkinterのfiledialog機能によってフォルダとファイルのパスを指定する機能をご紹介しました。このモジュールに処理モジュールを繋げれば、任意のフォルダorファイルを処理することが可能となります。



- 投稿日:2019-12-22T16:17:55+09:00
Livedoorブログの記事更新をPythonとseleniumで自動化してみた。
皆さん、こんにちは。中川です。かなり久しぶりの投稿です。普段は会社でJavaを使った業務用のWebアプリケーションを作っていますが、一般生活ではPythonでスクレイピングをしていることが多いです。特にブログの自動更新やsnsなどの自動フォローなどにはまっています。そこで今回、Pythonとseleniumを使って簡単なブログ更新を行ってみました。
環境
Python 3.7.0
selenium 78コード
qiita.pyfrom selenium import webdriver from time import sleep from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions from selenium.webdriver.common.by import By from selenium.common.exceptions import TimeoutException class LivedoorAuto: def __init__(self): options = webdriver.ChromeOptions() options.add_argument("user-data-dir=/home/nakagawa/.config/google-chrome/Default") #executable_pathには、chromedriverのパスを記入 self.bot = webdriver.Chrome(executable_path="", chrome_options=options) def livedoor(self): bot = self.bot #ブログ投稿ページのurl bot.get("") wait = WebDriverWait(bot,60) entry_title = wait.until(expected_conditions.visibility_of_element_located((By.ID,"entry_title"))) entry_title.send_keys("Hello") while True: try: entry_body = wait.until(expected_conditions.visibility_of_element_located((By.ID,"editor_1_f"))) entry_body.send_keys("Hello Everyone") break except TimeoutException: print("timeout") continue sleep(2) bot.find_element_by_class_name("quickSocialMessage").send_keys("Hello") ed = LivedoorAuto() ed.livedoor()タイトルをhello、記事内容にhelloという文字を記入するようなコードです。
最初にurlにアクセスする際に、ログインページに飛ばされますが、何度もログインを繰り返すとスパム扱いされることがあるため、最初からログイン情報をセッションに保持するようにしています。
seleniumで、ログイン情報を保持する方法は、以下のページに詳しく説明されています。
Seleniumで次の実行時にもサイトのログイン状態を維持したい場合あまり難しくはないのですが、案外ネットでこのような情報が少なかったので、書いてみました。何かの参考になると幸いです。