- 投稿日:2019-12-22T23:37:38+09:00
初学者向け「Deviseの導入の仕方」
deviseの導入で、一番最初にやる手順の紹介です。
deviseとは
Rubyのgemのひとつ。
新規登録機能やログイン機能の実装をとても簡単にしてしまうgem。まずはGemfile&インストール
Gemfilegem 'devise'追記したら、bundle install実行
$bundle installdeviseを使うためのコマンド
$rails g devise:installターミナルに以下の表示が出ればOKです
create config/initializers/devise.rb create config/locales/devise.en.yml =============================================================================== Some setup you must do manually if you haven't yet: 1. Ensure you have defined default url options in your environments files. Here is an example of default_url_options appropriate for a development environment in config/environments/development.rb: config.action_mailer.default_url_options = { host: 'localhost', port: 3000 } In production, :host should be set to the actual host of your application. 2. Ensure you have defined root_url to *something* in your config/routes.rb. For example: root to: "home#index" 3. Ensure you have flash messages in app/views/layouts/application.html.erb. For example: <p class="notice"><%= notice %></p> <p class="alert"><%= alert %></p> 4. You can copy Devise views (for customization) to your app by running: rails g devise:views ===============================================================================簡単にまとめると、
1.デフォルトURLの設定
config/environment/development.rbにURLを記載してください。
※アクションメーラーを使う時に必要になります。2.rootURLの設定
config/routes.rbにroot URLを記載してください。
※deviseではデフォルトの挙動としてroot_urlにリダイレクトされるようになっているため、設定が必要になります。3.flashメッセージの設定
登録時やログイン時のflashメッセージを表示させるためには、views/layouts/application.rbに<p class="notice"><%= notice %></p> <p class="alert"><%= alert %></p>と記載すると、表示されるようになります。
4.viewsのカスタマイズ
deviseではデフォルトでviewsが用意されていますが、それらを変えるには以下のコマンドを実行。$rails g devise:views以上、4つの内容が表示されています。
userモデルの生成
まずは、userモデルを生成する
$rails g devise usersmigrationファイルを見てみると、
db/migrate/create_devise_users.rb# frozen_string_literal: true class DeviseCreateUsers < ActiveRecord::Migration[5.2] def change create_table :users do |t| ## Database authenticatable t.string :email, null: false, default: "" t.string :encrypted_password, null: false, default: "" ## Recoverable t.string :reset_password_token t.datetime :reset_password_sent_at ## Rememberable t.datetime :remember_created_at ## Trackable # t.integer :sign_in_count, default: 0, null: false # t.datetime :current_sign_in_at # t.datetime :last_sign_in_at # t.string :current_sign_in_ip # t.string :last_sign_in_ip ## Confirmable # t.string :confirmation_token # t.datetime :confirmed_at # t.datetime :confirmation_sent_at # t.string :unconfirmed_email # Only if using reconfirmable ## Lockable # t.integer :failed_attempts, default: 0, null: false # Only if lock strategy is :failed_attempts # t.string :unlock_token # Only if unlock strategy is :email or :both # t.datetime :locked_at t.timestamps null: false end add_index :users, :email, unique: true add_index :users, :reset_password_token, unique: true # add_index :users, :confirmation_token, unique: true # add_index :users, :unlock_token, unique: true end endこういったファイルが生成され、自動でemailやpasswordなど、登録やログインに必要なカラムは追加されます。
追加で、nameなど必要なカラムがある場合は追記する。$rails db:migrateマイグレーションファイルを実行。
この時点で、routes.rbに
devise_for :usersが自動追加され、
http://localhost:3000/users/sign_in
http://localhost:3000/users/sign_up
にアクセスすれば、デフォルトのviewが見れるようになる。userビューの生成
デフォルトのviewはかなり質素なものなので、viewのカスタマイズしたい場合は、
$rails g devise:views usersここで、viewsが生成されますが、
rails routesでルーティングを確認すると、Prefix Verb URI Pattern Controller#Action new_user_session GET /users/sign_in(.:format) devise/sessions#new user_session POST /users/sign_in(.:format) devise/sessions#create destroy_user_session DELETE /users/sign_out(.:format) devise/sessions#destroy new_user_password GET /users/password/new(.:format) devise/passwords#new edit_user_password GET /users/password/edit(.:format) devise/passwords#edit user_password PATCH /users/password(.:format) devise/passwords#update PUT /users/password(.:format) devise/passwords#update POST /users/password(.:format) devise/passwords#create cancel_user_registration GET /users/cancel(.:format) devise/registrations#cancel new_user_registration GET /users/sign_up(.:format) devise/registrations#new edit_user_registration GET /users/edit(.:format) devise/registrations#edit user_registration PATCH /users(.:format) devise/registrations#update PUT /users(.:format) devise/registrations#update DELETE /users(.:format) devise/registrations#destroy POST /users(.:format) devise/registrations#createとなっているため、コントローラーがdeviseになっているため、viewの中身を編集しても、反映されません。
viewのコードを反映させるためには、route.rbに
routes.rbdevise_for :users, controllers: { registrations: 'users/registrations', sessions: 'users/sessions', passwords: 'users/passwords' }を追記する。
rails routesで確認。Prefix Verb URI Pattern Controller#Action new_user_session GET /users/sign_in(.:format) users/sessions#new user_session POST /users/sign_in(.:format) users/sessions#create destroy_user_session DELETE /users/sign_out(.:format) users/sessions#destroy new_user_password GET /users/password/new(.:format) users/passwords#new edit_user_password GET /users/password/edit(.:format) users/passwords#edit user_password PATCH /users/password(.:format) users/passwords#update PUT /users/password(.:format) users/passwords#update POST /users/password(.:format) users/passwords#create cancel_user_registration GET /users/cancel(.:format) users/registrations#cancel new_user_registration GET /users/sign_up(.:format) users/registrations#new edit_user_registration GET /users/edit(.:format) users/registrations#edit user_registration PATCH /users(.:format) users/registrations#update PUT /users(.:format) users/registrations#update DELETE /users(.:format) users/registrations#destroy POST /users(.:format) users/registrations#create無事、usersコントローラーになりました。
userコントローラーの生成
最後に、
$rails devise:controllers users各コントローラーが生成されます。
今回は、以上です。
deviseでは、デフォルトで様々なメソッド等が用意されているので、挙動をよく理解しつつ、使っていくことが大切ですね。
最後に
今回、Qiita初投稿です。
誤り等ありましたら、ご指摘ください。プログラミングを始めたての頃、deviseの挙動が全然分からず、苦い想い出があって、、、
まずは、deviseの記事を書いてみようと思いました。
- 投稿日:2019-12-22T22:36:55+09:00
#Rails の ActionMailer で利用するテンプレートのパス・ファイルをデフォルト以外で指定する ( ActionView::MissingTemplate: ))
app/view/path/to/directory/file.text.erbを使いたい場合template_path にディレクトリを
template_name に拡張子を除くファイルを指定すれば良いらしいわかりにくいな
mail( to: email, subject: subject, template_path: 'path/to/directory', template_name: 'file' )Ref
Action Mailer Basics — Ruby on Rails Guides
https://guides.rubyonrails.org/action_mailer_basics.htmlOriginal by Github issue
- 投稿日:2019-12-22T22:24:01+09:00
#Ruby で gem install や #Rails で bundle install すると Could not find xxx in any of the sources とエラーが出る場合は gem 名をタイポしてない?
どんな時のエラー?
gem が見つからなかった時のエラー。
例
"Could not find gem 'email-spec' in any of the gem sources listed in your Gemfile."
解決
例えばこのgem
例えばgithub での レポジトリ名がハイフン区切りだというからと言って安心してはいけない。
https://github.com/email-spec/email-specgem名はアンダースコア区切りだ。
名前を間違っていたらinstallできるはずないよね。
Ref
"Could not find gem 'email-spec' in any of the gem sources listed in your Gemfile."
Original by Github issue

- 投稿日:2019-12-22T21:52:44+09:00
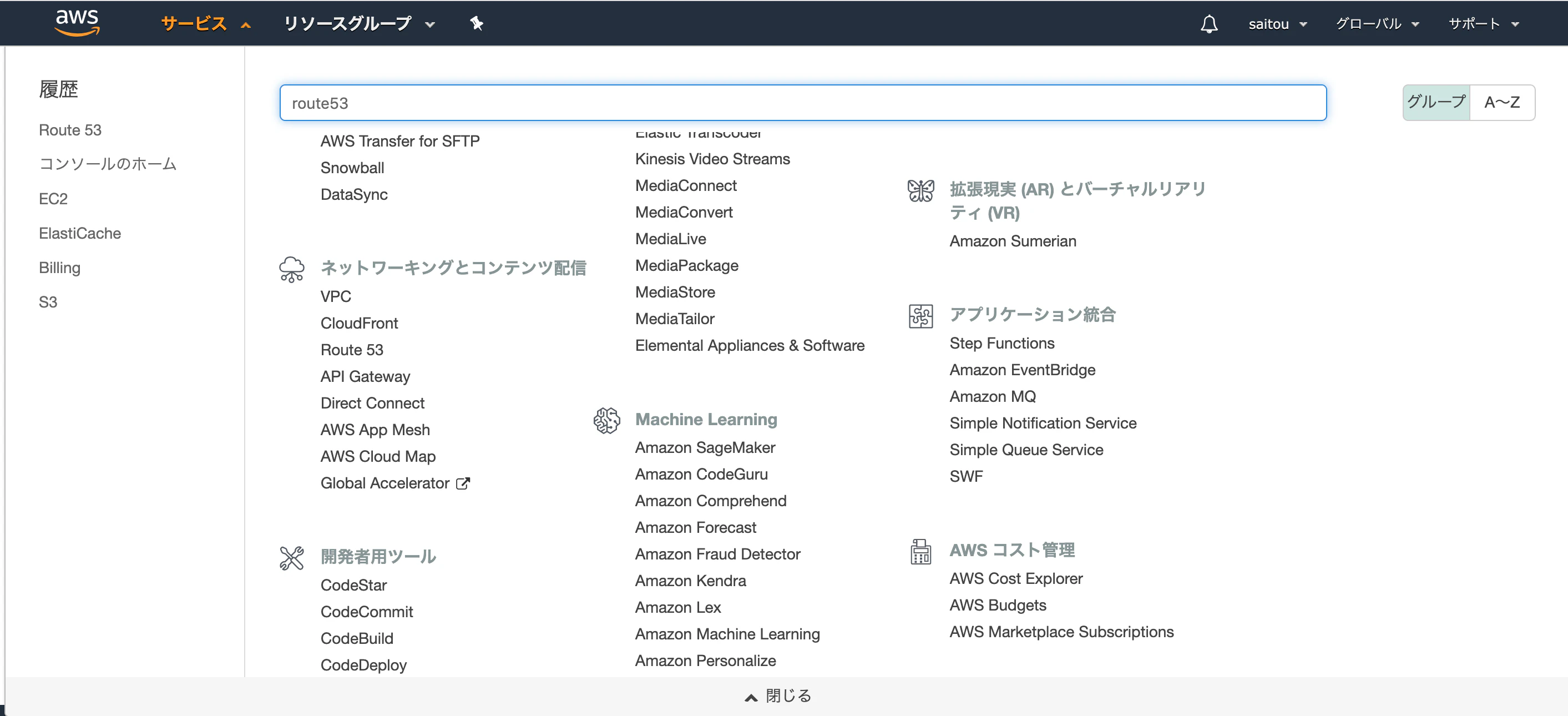
【AWS】Route53で取得したドメインをElastic IPとひもづける方法。
Route53を使用して取得したドメインを、ElasticIPと紐付けてアクセスできるようにする方法を記事にしました。
前提条件
・AWSでアカウントを登録済み。
・ElasticIPを使用してデプロイがすんでいる。
・Route53をドメインを取得するが、課金に抵抗がない(例えば.comのドメインの場合、年間12$かかります)無料でドメインを取得する方法もあるそうですが、エラーにはまる可能性があると聞いたので、今回はRoute53を使用して取得したドメインをElasticIPとひもづけることでAWS上で完結させます。
ドメインを取得するメリットをこちらの通りです。
・Twitterの自己紹介にURLを載せることができる(ElasticIPだと入力がはじかれました)
・番号よりドメインの方が見栄えがよい。
・アドレスを利用者に覚えてもらいやすくなる。まずはAWSのコンソールにアクセスします。
1.Route53のダッシュボードに移動
Route53をのページにアクセスします。
2.ドメインの取得画面へ移動します。
記事にしたのは登録後の為、便宜上私の登録済みのドメインが画面に表示されていますが、ご了承ください。ドメインの登録は初めてかと思うので、左上のドメインの登録ボタンを押します。
3.ドメイン名の選択
自分の好きなドメイン名を入力してチェックボタンを押します。
使用が不可能の場合は下の写真のように使用不可のボタンが出ますが、まだ使用済みのドメインでなければ利用可能と出ます。ドメインは.comを選ぶのが一般的なようなので、特に理由がなければ.comのドメインを選択しておきましょう。少しでも安く済ませたければ.netのドメインでも大丈夫です。
4.購入する
入力したドメインが取得可能であれば、右側のカートを入れるボタンが押せるようになるので、そちらを押しましょう。
カートに入れるボタンを押すと、右側に小計が表示されます。
金額と取得するドメイン名に間違いないかを確認したら、下にスクロールして続行ボタンを押します。
5.連絡先の詳細を記入。
連絡先の詳細を上から順番に記入します。
登録後に記事にしたため、画面による説明がないことをご了承ください。
不安な場合は、こちらのサイトをご参照ください。
https://qiita.com/ymzk-jp/items/ae115ed6d0fd2d383cec6.確認と購入。
購入内容を確認します。
よければ同意するにチェックを押して、購入を確定させます。7.ドメインの登録に成功できたかを確認。
ドメインの登録に成功すると、ステータスのところにドメインの登録に成功と出ます。
自分の場合ですが、ドメインの登録が成功と出るまで半日ほどかかりました。
また、メールアドレスに購入確認の通知がくるかと思うので、確認しておきましょう。
DNSに登録
お疲れ様でした!
登録しただけでは、ElasitcIPとひもづけができないので、今度は紐付けをします。1.ホストゾーン
左側のホストゾーンをクリックして選びましょう。
取得したドメインのホストゾーンは既に作成済みになっているかと思いますので、水色の文字で表示されている自分のドメイン名をクリックしましょう。
2.レコードセットの作成。
レコードセットの作成の青いボタンを押すと右側にタブが表示されます。
名前は空欄。タイプはそのままA-IPv4アドレスのままで大丈夫です。
値の入力欄にElasticIPを入れてください。画面の下にある例が参考になります。
うまく行かない場合はこちらの記事が参考になるかもしれません。
https://qiita.com/ymzk-jp/items/ae115ed6d0fd2d383cec独自ドメインにアクセスできるようにする
取得したドメインをアクセスするとこのような画面がおそらく出るかと思います。
この画面が出ていればAWS上での登録はうまくいっているかと思うので、nginxの設定が
できればうまくいくかと思います。あともう少しです。
ここから先は我流になりますので、うまくいかない可能性もあるかと思いますがご了承ください。
アプリのフォルダを開いて
config/deploy/production.rbを選択する。server '11.111.111.111'
このようにElasticIPのアドレスが設定されているかと思いますが、先ほど取得したドメインに書き換えます。続いてnginxの設定。
まずは. ssh/に移動してEC2のサーバーを立ち上げます。|[ec2-user@ip-111-11-11-111 ~]$ sudo vim /etc/nginx/conf.d/rails.conf|
このようにコマンドを打ち込んで、設定を変更します。
server {
# このプログラムが接続を受け付けるポート番号
listen 80;
# 接続を受け付けるリクエストURL ここに書いていないURLではアクセスできない
server_name 11.111.111.111;画面上でiボタンを押して、server_nameの右側の横に
server_name 11.111.111.111 取得したドメイン;
といった形で空欄を一つ開けてドメイン名をうちます。
打ち込み終わったら、ESCボタンを押した後、:wqとして設定を終了させます。忘れずにnginxの設定を反映させましょう。
[ec2-user@ip-111-11-11-111 ~]$ cd /var/lib
[ec2-user@ip-111-11-11-111 lib]$ sudo chmod -R 775 nginxnginxを再起動して設定ファイルを読み込ませます。
[ec2-user@ip-172-31-25-189 lib]$ cd ~
[ec2-user@ip-172-31-25-189 ~]$ sudo service nginx restartこれで設定が完了したかと思います。
ドメインとElasticIPの両方でアクセスできるか確認してみましょう。
取得したドメイン及びIPアドレスでアクセスできれば無事成功です。
お疲れ様でした。これでTwitterの自己紹介にもURLを載せれるようになりました。
ドメイン取得はお金がかかりますが、アドレスを覚えてもらいやすくなるなどメリットが大きいので、
チャレンジしてみる価値はあるかと思います。無料でドメインを取得してAWSのIPと紐付けする方法もあります。
参考になる記事もいくつかありますので、気になるようでしたら
チャレンジしてみるのもありかもしれません。








- 投稿日:2019-12-22T21:02:46+09:00
超初心者がrailsで躓いた基礎的コード5選
はじめに
プログラミング超初心者だった私(ビズサイドでIT業界に関わった経験もなし)ですが、プログラミングを身につけ、IT業界に飛び込んでいくために、今年の9月からrailsをメインで扱っているRUNTEQというプログラミングスクールに通い始めました。
RUNTEQは、ツイッターなどで最近流行りの未経験者向けのプログラミングスクールとは一味違ったスクールで、通学者の方の多くは、もともと違う言語などで実務を経験していたり、実務未経験でも何かしら別の教室でプログラミングを触った経験があったり、独学でチュートリアルをやっていたりする人も多く、そういった方向けのカリキュラムになっています。
そんなことで、私自身も「入学する前に、チュートリアルは最低限やっといて!」って、講師の方に言われていたにも関わらず、時間が足りず、プロゲートを一周しかせず(gemすら使ったことない)、突撃していってしまった私の贖罪も込めて、これからプログラミングを学びたいと思っている誰かのためになればと筆を取りました!
そんな基本的なコードにしか触れていない初心者が、現役エンジニアからコードレビューなどを受ける中で、詰まった(理解に苦しんだ)コードを、徒然なるままに、備忘録的に記録する目的も兼ねて、紹介していきたいと思います!
※カリキュラムのネタバレにならないように書いていますが、不都合あれば修正します!
1、form_with
初学者の自分にとって一番ブラックボックスに感じたのはform_withでした。RANTEQの課題にも頻繁に出てきますし、避けては通れません。
「なんで、この書き方でちゃんとデータがDBに登録されるの?」
「何も書いてないのに、新規投稿の時と、編集の時で出力先がきちんと区別されてる!」
「入力項目にないboard_id(外部キー)をURLへ載せてDBに送りたいときはどうするの?」
...etc
私が躓いたポイントを紐解いていきます!
form_withの第一引数 model: @○○
最初は見よう見まねで実装していましたが、「いきなり@userって出てきたけど、どういうこと!?」ってなりました。
form_withの性質として、データーベースに保存する場合、form_withの引数にはモデルクラスのインスタンスを指定するとなっているようです。
モデルクラスのインスタンスとは保存したいテーブルのクラスのインスタンスのことです。
で!!!ここからがミソなんですが、例えば、掲示板アプリの場合は、form_withを使って入力画面を作る時、「掲示板を作成する」、「掲示板を編集する」の2パターン出てきます。この時の入力フォームはどうなるのかというと、なんと「全く同じ書き方」です!
出力先も違うし、編集する場合は編集前のデータを入力欄に表示しておいたりしなければいけないと思いますが、これをform_withは良しなにやってくれるようです。
以下、事例です。①usersテーブルに新たにレコードを作成。
controllerは以下になります。
users_controller.rbdef new @user = User.new endこの「@user」をform_withの引数に指定するわけです。
viewの書き方は、
<%= form_with model: @user do |form| %> <%= form.text_field :name %> <%= form.submit %> <% end %>新規作成の場合は、コントローラーで作成したインスタンスがnewメソッドで新たに作成されて何も情報を持っていないので、自動的にcreateアクションへ送られます!pathの指定も必要ありません。
ブラウザで見るともちろん入力フォームは空欄になっています。すごく便利ですね!
②usersテーブルのレコードを編集する場合
controllerは以下になります。
def edit @user = User.find(params[:id]) endviewの書き方は新規投稿の時と全く同じ。
<%= form_with model: @user do |form| %> <%= form.text_field :name %> <%= form.submit %> <% end %>findメソッドなどで作成され、すでに情報を持っている場合はupdateアクションへ自動的に振り分けてくれます。
そして、ブラウザで見ると、入力項目には、編集前の記載内容がデフォルトで入った状態で表示され、そこから編集をして投稿できる仕様になっています。
最初、ここの部分があまりよく理解できていませんでした。
ちなみに、さらっと書きますが、ルーティングでネストしている時の書き方は、model: [@board, @comment]みたいな感じになります!さらっと書いてますが、ここもハマるポイントかもです!
urlを指定する場合
form_withはpathを指定しなくても良いと書きましたが、ルーティングがうまくいかない時などは直接、pathを指定することもできます。方法は2通りです。
ルーティングのpathをそのまま指定する、コントローラー名とアクション名を書く方法です。
以下はルーティングのpathをそのまま指定する方法です。<%= form_with @user, url: login_path do |form| %> <%= form.text_field :name %> <%= form.submit %> <% end %>form_withで入力項目にないboard_idとか、user_idを送る方法
form_withのinput部分の話です。
通常、form_withは、入力項目に入力した情報をHTTPリクエストのbody要素に格納してDBへ送信するイメージを持っていたのですが、外部キーを設定しているDBへ、データを送る場合は、入力項目の情報だけを送信しようとして、「user_idがありません」みたいなエラーが出ました。
この場合に、何とかしてパラメーターに外部キーのidを送りたいって時に出てきたのが、
<%= form.hidden_field :カラム名, value: "値" %>って書き方です!
例えばユーザーidに現在ログインしているユーザーのidを入れたい場合は下記のように記述します。
<%= form.hidden_field :user_id, value: current_user.id %>ただ、課題では、ストロングパラメーターを使って書く方法を学んだので、課題ではこの書き方は使っていません!
2、renderの引数
部分テンプレートを呼び出す時にrenderを使うと思いますが、ここも引数の渡し方が色々あり、よく詰まりました。知って入れば、何の事は無いのですが、知らないと結構詰まりました。
部分テンプレート内でローカル変数を使うための引数の指定
部分テンプレートは、汎用性を上げるために、部分テンプレート内では、インスタンス変数をなるべく使わないようにしなければならないということをコードレビューの中で学びました。
最初は「ん??」って、感じでしたが、こう理解しました。
例えば、以下のような検索フォームの部分テンプレートを作る場合、ローカル変数のみで書くと、以下のようになります。
_search_form.html.erb<%= search_form_for search do |f| %> <div class='input-group mb-3'> <%= f.search_field :title_or_body_cont, placeholder: "検索ワード", class: 'form-control' %> <div class='input-group-append'> <%= f.submit value: "検索", class: 'btn btn-primary' %> </div> </div> <% end %>serachというローカル変数は、@searchというインスタンス変数でも書けますが、あえてローカル変数で書きます。
この場合、呼び出し元でのrenderの書き方はどうなるかというと
view<%= render 'search_form', search: @search %>こんな感じになります。
オプションをきちんと書くなら、
render partial: 'search_form', locals: { search: @search }
です。
ここの、「locals: { search: @search }」の部分は、私は言葉でこういう風に宣言しているものと理解しています。
「部分テンプレート内にあるsearchは@searchとして扱いますのでよろしく!」
要は、@searchを部分テンプレート内に引き渡しますよと。部分テンプレート内にpathを引き渡す
部分テンプレート内にpathを引き渡さなければならない場合はどのように書けばいいのか一瞬詰まりました。
これもローカル変数引き渡しの時と同様の考えで解決できます。
例えば、以下の部分テンプレートにboards_pathを引き渡したいとします
_search_form.html.erb<%= search_form_for search url: url do |f| %> <div class='input-group mb-3'> <%= f.search_field :title_or_body_cont, placeholder: "検索ワード", class: 'form-control' %> <div class='input-group-append'> <%= f.submit value: "検索", class: 'btn btn-primary' %> </div> </div> <% end %>呼び出し元では、
view<%= render 'search_form', url: boards_path, search: @search %>こうすることで、「部分テンプレート内にあるurlを、boards_pathとして扱います。」
要は、部分テンプレート内にboards_pathを引き渡しています。で、部分テンプレート側では、urlで、pathを受け入れています。
こうすることで、pathを部分テンプレート内にいちいち書かなくても、呼び出し元で自由に調整でき、部分テンプレートは一つで済みます。
3、Userモデルのバリデーション
Userモデルのバリデーションの中で、この辺のとこが意味プー(死語)になってました。
validates :password, length: { minimum: 3 }, if: -> { new_record? || changes[:crypted_password] } validates :password, confirmation: true, if: -> { new_record? || changes[:crypted_password] } validates :password_confirmation, presence: true, if: -> { new_record? || changes[:crypted_password] }if: -> { new_record? || changes[:crypted_password] } ってなんやねん!?
こう理解しました。
例えば、ユーザーの名前を変えたいが、パスワードはそのままにしたいって場合を想定します。
この場合、if: -> { new_record? || changes[:crypted_password] } の記述がないと、毎回以下の余計なバリデーションが実行されることになっちゃいます!
validates :passwordについては、
→length: { minimum: 3 }, presence: true, confirmation: truevalidates :password_confirmation,については、
→presence: trueユーザーの名前しか変更しないのに、新規ユーザーを作ると勘違いして、パスワードのバリデーションが実行されてしまうので、「同じパスワードが存在する」と誤検知して、エラーが起きます。
これを解消するには、
if: -> { new_record? || changes[:crypted_password] }のnew_record?の部分で、新しいパスワードが発行されているかを判断し、changes[:crypted_password]の部分で
、フォームから送られてきたパスワードと、usersテーブルに保存されているパスワードに変更があるかどうかを比較しています。もし、変更があるなら、パスワードのバリーデーションが実行されるし、新しいパスワードが発行されておらず、パスワードの変更が無い場合は、Userモデルのパスワード部分のバリデーションは実行されないので、名前だけ変更してもエラーにならないようになります!
4、sorceryで良しなにやってくれてるけど、current_userって何?
ここを詳しく厳密に考えると、ややこしくなりそうなんで、もし、gemを使わず、login機能を実装したらどうなるのか簡単に調べてみました。
current_user自体は以下のように定義します。application_controller.rbdef current_user @current_user = User.find_by(id: session[:user_id]) endsession[:user_id]は、ページを移動してもユーザー情報を保持し続けるために、sessionという特殊な変数を使うようrailsに実装されているようです。
sessionに値を代入すると、ページを移動してもブラウザに残り続けて、ブラウザはそれ以降のアクセスでsessionの値をRailsに送信します。このsessionが、ページが遷移してもユーザー情報を保持し続けることができるキーマンのようですね!ついでに、この先にも簡単に触れると、色々省略してますが、受けるcontrollerはこうなります。
user_sessions_controller.rbclass User_SessionsController < ApplicationController skip_before_action :current_user, only: [:login] def login @user = User.find_by(name: params[:name], email: params[:email]) if @user session[:user_id] = @user.id redirect_to user_path(session[:user_id]) else render 〜 色々省略 end end endログインすることでsessionに値が入るので、定義した@current_userが使えるようになるわけですね!
5、sorceryのrequire_login
これもgemを想定せずに実装してみると、こうなります。
application_controller.rbdef authenticate_user if @current_user == nil redirect_to login_path end endすごく単純なんですが、gemを使っているとこの辺色々省略されているので、ちゃんと考えることも重要かもしれません。
6、他人の掲示板の編集や削除ができなくする場合の書き方
ここでの話は、viewで、分岐を使って、ログインユーザー自身が作成した掲示板にしか編集ボタン、削除ボタンを表示させない実装はやった上で、直接、URLからアクセスすることもできないようにする方法です。
普通に書くと、
@board = Board.new( title: board_params[:title], body: board_params[:body], user_id: current_user.id )って感じの実装になると思うのですが、ここでもっとスマートにかけます。ストロングパラメーターとも組み合わせて、
@board = current_user.boards.new(board_params)こんなにシンプルになります。
こんな書き方があるのは知らなかった・・・実はこの感じの書き方が、エンジニアの実務している方々は普通に書いているみたいなのですが、プロゲートでは全く触れらていないし、深いなーと思いました。
最後に
他にも色々と詰まりまくってますが、力尽きたので、この辺にしておきます。
今後も頑張っていきましょう!!
- 投稿日:2019-12-22T20:11:37+09:00
Amazon Linux 2 初期設定 & Rails5.2 + Capistrano3.11で自動デプロイ
はじめに
EC2にRails環境を構築、Capistranoで自動デプロイするための初期設定を紹介していきます。
主に個人開発やテスト環境で扱う最低限の設定のみ記載します。
コピペで大体できるはず、、!環境
OS : Amazon Linux 2
Webサーバー : Nginx
アプリケーションサーバー : puma
メールサーバー : postfix
DB : RDS(MySQL)前提
macOS
AWSにてEC2、RDSを構築済みEC2に接続
ローカルPCのターミナル."sudo ssh -i [keyペアファイル] ec2-user@[パブリックIP]" #確認が出るので "yes" #PCのパスワードを要求されるので、入力。初期設定
- yumをアップデート
SSH接続したEC2インスタンス内.yumをまとめてアップデート $ sudo yum update -y $ sudo yum install -y yum-cron EPELを有効化 # sudo amazon-linux-extras install epel セキュリティのみ自動でパッチがあたるようにcronの設定ファイルを変更します。 $ vi /etc/yum/yum-cron.conf 変更点 update_cmd = security apply_updates = yes email_to = [任意] 設定したら起動及び再起動自動の自動実行を設定 $ systemctl start yum-cron $ systemctl enable yum-cron
- タイムゾーンを日本時間に変更します。
タイムゾーンをJSTに設定 $ sudo ln -sf /usr/share/zoneinfo/Asia/Tokyo /etc/localtime タイムゾーンがJSTに変更されたか確認 $date /etc/sysconfig/clockの設定変更を変更 $ sudo vi /etc/sysconfig/clock/etc/sysconfig/clock.以下の内容を変更 ZONE="Asia/Tokyo" UTC= true
- EC2インスタンスを再起動し、全てのプロセスが新しいタイムゾーンを設定を利用するようにします。
SSH接続したEC2インスタンス内.$ sudo rebootユーザー追加
セキュリティ強化のため、ec2-userのアカウント名をそのまま使うのではなく、
ec2-userを停止にして、新しいユーザでログインできるようにします。SSH接続したEC2インスタンス内.新規ユーザー作成 $ sudo adduser my-user wheelグループに追加 $ sudo usermod -G wheel my-user sudo権限を付与 $ sudo visudoviが開くので、行末に「my-user ALL=(ALL) NOPASSWD: ALL」を追加
visudo.my-user ALL=(ALL) NOPASSWD: ALL:wqで保存
ec2-userのauthorized_keysをmy-userの.sshディレクトリにコピーし、適切なパーミッションを設定します。
SSH接続したEC2インスタンス内.$ sudo rsync -a ~/.ssh/authorized_keys ~my-user/.ssh/ $ sudo chown -R my-user:my-user ~my-user/.ssh $ sudo chmod 700 ~my-user/.ssh/ $ sudo chmod 600 ~my-user/.ssh/**SSH接続設定
EC2のシークレットキーをローカルPCの以下に配置
/Users/[ユーザー]/.ssh/***.pemローカルPCのターミナル..sshディレクトリに移動 cd .ssh シークレットキーを持っている他のユーザーもログインできるように権限を変更 $ chmod 600 ***.pem 権限が変更されているか確認 $ ls -al -rw------- になっていればOK configに接続設定を記載 $ vi configローカルにショートカットを作成
/.ssh/config.Host [ホスト名] HostName [パブリックIP] Port 22 User my-user IdentityFile ~/.ssh/***.pem:wqで保存
my-userで接続できるか確認します。
ローカルPCのターミナル.$ ssh [ホスト名]接続できたら、rootになれるか確認
SSH接続したEC2インスタンス内.$ sudo su -SSHのセキュリティ設定
rootとec2-userでのSSHを禁止する
SSH接続したEC2インスタンス内.$ sudo vi /etc/ssh/sshd_config/etc/ssh/sshd_config.以下を追加 #ec2-userでのログインを禁止 DenyUsers ec2-user #暗号化アルゴリズムの指定 Ciphers aes128-ctr,aes192-ctr,aes256-ctr #鍵付きハッシュのアルゴリズム MACs hmac-sha2-256,hmac-sha2-512 以下を変更 AuthorizedKeysFile .ssh/authorized_keys PermitRootLogin no:wqで保存
SSH接続したEC2インスタンス内.設定を反映 $ service sshd reloadRVMとRubyをインストール
SSH接続したEC2インスタンス内.Rootに変更 $ sudo su - RVMをインストール # gpg --keyserver hkp://keys.gnupg.net --recv-keys 409B6B1796C275462A1703113804BB82D39DC0E3 # curl -sSL https://get.rvm.io | bash Rubyのインストールに必要なライブラリをインストール # yum install -y gcc-c++ patch readline readline-devel zlib zlib-devel libyaml-devel libffi-devel openssl-devel make bzip2 autoconf automake libtool bison iconv-devel wget libxml2 libxml2-devel libxslt libxslt-devel # yum install -y bzip2-devel lcms-devel libjpeg-devel libX11-devel libXt-devel libtiff-devel ghostscript-devel libXext-devel libpng-devel ImageMagickを使うのでインストール(任意) # yum install -y ImageMagick ImageMagick-devel RVMを有効にするために一旦ログアウトし、もう一度SSH接続してrootになります。 Rubyをインストール 今回は2.3.8を使用 # rvm install 2.3 # rvm use 2.3.8 # ruby -v bundllerをcapistranoが使うのでインストール # gem install bundlerMySQLをインストール
SSH接続したEC2インスタンス内.mariaDB削除 $ sudo yum remove mariadb-libs $ sudo rm -rf /var/lib/mysql mysqlインストール $ sudo yum install mysql Amazon RDSヘ接続 $ mysql -h {ENDPOINT} -P 3306 -u {Username} –p パスワードが要求されるので、RDSで設定したパスワードを入力posfixのインストール
SSH接続したEC2インスタンス内.# yum install postfix 設定ファイルを変更 # vi /etc/postfix/main.cf 適宜各要素を以下のように変更 inet_interfaces = all mydestination = $myhostname, localhost.$mydomain, localhost, $mydomain home_mailbox = Maildir/ smtpd_banner = $myhostname ESMTP unknown allow_min_user = yes 自動起動設定 # systemctl enable postfix # systemctl start postfixNginxをインストール
SSH接続したEC2インスタンス内.# yum -y install nginx NginxでSSL通信する場合は鍵を配置 # vi /etc/nginx/conf.d/server.key サーバー証明書、中間証明書を配置 # vi /etc/nginx/conf.d/server_geotrustca.crt 自動起動設定 # systemctl start nginx # systemctl enable nginx 設定ファイルの文法チェック # nginx -tredisのインストール
SSH接続したEC2インスタンス内.$ rpm -ivh http://rpms.famillecollet.com/enterprise/remi-release-7.rpm $ yum install --enablerepo=epel,remi redis $ systemctl enable redis $ systemctl start redisRailsディレクトリとShared内ファイルの作成
Capistranoのディレクトリ構成に合わせます。
SSH接続したEC2インスタンス内.sharedディレクトリを作成 mkdir -p /usr/local/rails/[デプロイするアプリ名]/shared/ mkdir -p /usr/local/rails/[デプロイするアプリ名]/shared/public/assets/ mkdir -p /usr/local/rails/[デプロイするアプリ名]/shared/config ※Webpackerを使う場合、アセットパイプラインでエラーが出る場合は空ファイルを配置 touch /usr/local/rails/[デプロイするアプリ名]/shared/public/assets/.manifest.json touch /usr/local/rails/[デプロイするアプリ名]/shared/public/assets/.sprockets-manifest.json secret_key_baseを.envで管理(デモ環境なのでmaster.keyは使わない) vi /usr/local/rails/[デプロイするアプリ名]/shared/.envRuntimeErrorになるので、rake secretで生成した文字列を貼り付けます。
bundle exec rake secret ff9906beb21fd77ca11aa433d42b7caa720f37641a27bf1617e67894a4fca2c64526af874d1ef1cfac4372cabdf18127110b31bb766c46ef35dbab62736b04e3shared/.envSECRET_KEY_BASE: ff9906beb21fd77ca11aa433d42b7caa720f37641a27bf1617e67894a4fca2c64526af874d1ef1cfac4372cabdf18127110b31bb766c46ef35dbab62736b04e3SSH接続したEC2インスタンス内.ファイルの所有者を変更 chown -R my-user:my-user /usr/local/rails※AWS認証情報を扱う場合は参考にしてください(CLI設定がおすすめ)
https://dev.classmethod.jp/cloud/aws/how-to-configure-aws-cli/node.jsとyarnを使う場合はインストール
SSH接続したEC2インスタンス内.node.jsのインストール $ curl --silent --location https://rpm.nodesource.com/setup_8.x | sudo bash - sudo yum install nodejs yarnのインストール $ curl --silent --location https://dl.yarnpkg.com/rpm/yarn.repo | sudo tee /etc/yum.repos.d/yarn.repo $ sudo rpm --import https://dl.yarnpkg.com/rpm/pubkey.gpg $ sudo yum install yarnCapistranoでのデプロイ
参考にさせていただきました。
https://qiita.com/ea54595/items/12ab7b3a8213b35cca10pumaの設定のみ追記しました。
config/deploy.rb#Capistranoのバージョンを固定 lock '3.11.0' #アプリケーション名 set :application, "[アプリ名]" #レポジトリURL set :repo_url, "ssh://git@github.com:****/[アプリ名].git" #gitでバージョン管理方法 set :scm, :git #対象ブランチ masterに固定 set :branch, 'master' #デプロイ先ディレクトリ フルパスで指定 set :deploy_to, "/usr/local/rails/[アプリ名]" #sharedに入るものを指定 set :linked_dirs, %w{bin log tmp/pids tmp/cache tmp/sockets bundle public/system public/assets public/uploads} #rvmのパス set :default_env, { rvm_bin_path: '~/.rvm/bin' } # sudo に必要 set :pty, true #5回分のreleasesを保持する set :keep_releases, 5 #puma設定 set :puma_threds, [4, 16] set :puma_workers, 0 set :puma_bind, "unix://#{shared_path}/tmp/sockets/#{fetch(:application)}-puma.sock" set :puma_state, "#{shared_path}/tmp/pids/puma.state" set :puma_pid, "#{shared_path}/tmp/pids/puma.pid" set :puma_access_log, "#{release_path}/log/puma.error.log" set :puma_error_log, "#{release_path}/log/puma.access.log" set :puma_preload_app, true set :puma_worker_timeout, nil set :puma_init_active_record, true SSHKit.config.command_map[:rake] = 'bundle exec rake' namespace :deploy do #puma再起動タスク desc "Restart Application" task :restart do on roles(:app), in: :sequence, wait: 5 do invoke 'puma:restart' end end after :finishing, 'deploy:cleanup' endおまけ logのローテーション
SSH接続したEC2インスタンス内.$ sudo vi /etc/logrotate.d/[アプリ名]/etc/logrotate.d/[アプリ名]/usr/local/rails/[アプリ名]/shared/log/*.log { daily #ログを毎日ローテーションする missingok #ログファイルが存在しなくてもエラーを出さずに処理を続行 rotate 10 #10世代分古いログを残す dateext #日次ローテート+日付文字列 compress #ローテーションしたログをgzipで圧縮 sharedscripts #複数指定したログファイルに対し、postrotateで記述したコマンドを実行 su my-user my-user #rotateするユーザを指定 postrotate puma_pid=/usr/local/rails/[アプリ名]/shared/tmp/pids/puma.pid test -e $puma_pid && kill -USR2 $(cat $puma_pid) || true endscript }SSH接続したEC2インスタンス内.エラーが出ていないか確認 $ logrotate -d /etc/logrotate.d/[アプリ名]
- 投稿日:2019-12-22T19:56:20+09:00
【Linux】複数あるファイルの中から特定の文字列を検索したいとき
はじめに
Railsでカラム名を変更した際、各ファイルに書いていた、変更前のカラム名を探して、変更後のカラム名に治すのがめんどくさかったので今回この記事を書きます。
コマンド
$ find ./ -type f -print | xargs grep 'hoge'上記のコマンドの説明
find
find の次で指定したディレクトリ以下のファイルを検索する。
ファイル検索の構文は「find [path] [検索条件] [アクション]」
./
今いるディレクトリ以下が検索対象。「~/」とするとホームディレクトリ以下が検索対象となる。
./ の代わりにフルパスでも可。この場合も指定したディレクトリ以下が検索対象になる。
検索結果を標準出力する。このとき結果をフルパスで表示する
-type f
指定したファイルタイプを検索する。fが通常ファイルを,cまたはdとするとディレクトリを,lとするとシンボリック・リンクを検索します。
xargs
標準入力からコマンドラインを作成し、それを実行する
grep
ファイルから文字列を検索する。grep の後に検索したい文字列を指定する。参考
- 投稿日:2019-12-22T19:03:51+09:00
hamlインストールエラー
実行したい内容
bundleしてhtmlをhamlにしたい。起こっている現象
Gemfile最下部に
gem "haml-rails", "~> 2.0"と記述しbundleを行うがエラーとなるエラー内容
ターミナルMacBook-Air:a PC$ bundle The dependency tzinfo-data (>= 0) will be unused by any of the platforms Bundler is installing for. Bundler is installing for ruby but the dependency is only for (--中省略--) Fetching mysql2 0.5.3 Installing mysql2 0.5.3 with native extensions Gem::Ext::BuildError: ERROR: Failed to build gem native extension. (--中省略--) ----- checking for mysql.h... yes checking for errmsg.h... yes checking for SSL_MODE_DISABLED in mysql.h... no checking for MYSQL_OPT_SSL_ENFORCE in mysql.h... no checking for MYSQL.net.vio in mysql.h... yes checking for MYSQL.net.pvio in mysql.h... no checking for MYSQL_ENABLE_CLEARTEXT_PLUGIN in mysql.h... yes checking for SERVER_QUERY_NO_GOOD_INDEX_USED in mysql.h... yes checking for SERVER_QUERY_NO_INDEX_USED in mysql.h... yes checking for SERVER_QUERY_WAS_SLOW in mysql.h... yes checking for MYSQL_OPTION_MULTI_STATEMENTS_ON in mysql.h... yes checking for MYSQL_OPTION_MULTI_STATEMENTS_OFF in mysql.h... yes checking for my_bool in mysql.h... yes ----- Don't know how to set rpath on your system, if MySQL libraries are not in path mysql2 may not load ----- ----- Setting libpath to /usr/local/opt/mysql@5.6/lib ----- creating Makefile current directory: /Users/itsumi/.rbenv/versions/2.5.1/lib/ruby/gems/2.5.0/gems/mysql2-0.5.3/ext/mysql2 make "DESTDIR=" clean current directory: /Users/itsumi/.rbenv/versions/2.5.1/lib/ruby/gems/2.5.0/gems/mysql2-0.5.3/ext/mysql2 make "DESTDIR=" compiling client.c compiling infile.c compiling mysql2_ext.c compiling result.c compiling statement.c linking shared-object mysql2/mysql2.bundle ld: library not found for -lssl clang: error: linker command failed with exit code 1 (use -v to see invocation) make: *** [mysql2.bundle] Error 1 make failed, exit code 2 Gem files will remain installed in /Users/itsumi/.rbenv/versions/2.5.1/lib/ruby/gems/2.5.0/gems/mysql2-0.5.3 for inspection. Results logged to /Users/itsumi/.rbenv/versions/2.5.1/lib/ruby/gems/2.5.0/extensions/x86_64-darwin-18/2.5.0-static/mysql2-0.5.3/gem_make.out An error occurred while installing mysql2 (0.5.3), and Bundler cannot continue. Make sure that `gem install mysql2 -v '0.5.3' --source 'https://rubygems.org/'` succeeds before bundling. In Gemfile: mysql2この部分がエラー内容で重要そう
``gem install mysql2 -v '0.5.3' --source 'https://rubygems.org/'` succeeds before bundling.
An error occurred while installing mysql2 (0.5.3), and Bundler cannot continue.
Make sure thatIn Gemfile:
mysql2
```色々サイト検索を行い、下記にたどり着く
打ち込む
ターミナル$ brew info openssl出てきた内容
ターミナルexport LDFLAGS="-L/usr/local/opt/openssl@1.1/lib" export CPPFLAGS="-I/usr/local/opt/openssl@1.1/include"再び打ち込む
ターミナル$gem install mysql2 -v '0.5.3' --source 'https://rubygems.org/' -- --with-cppflags=-I/usr/local/opt/openssl@1.1/include --with-ldflags=-L/usr/local/opt/openssl@1.1/lib出てきた内容
ターミナル1 gem installed再び試す
ターミナル$bundleエラーなし!!
通常通りターミナルで
$ rails haml:erb2haml実行ターミナルWould you like to delete the original .erb files? (This is not recommended unless you are under version control.) (y/n) #yを入力してエンターhaml変換成功!
お世話になったページたち
mysql2 gemインストール時のトラブルシュート
【Rails】MySQL2がbundle installできない時の対応方法
RailsプロジェクトでMySQLがbundle installできなかった
bundle install 時、mysql2でエラー終わりに
チーム開発スタート初っ端の出来事。
いきなりのエラーです。自分一人じゃないから適当にできない。。。
最初のうちに経験できてよかった(が、エラーはまだまだ続く予感。笑)
完璧ではなくていいから完成させるように頑張ります!
(bundle exec installも試してみればよかったと今更ながら思う←)
- 投稿日:2019-12-22T18:45:33+09:00
【Rails】リアルタイムDM機能作成
開発環境
rails5.1.7
ruby2.4.0
devise導入済作成する
gem 'jquery-rails'app/assets/javascripts/application.js... // //= require rails-ujs //= require activestorage //= require turbolinks //= require jquery ←追加 //= require jquery_ujs ←追加 //= require_tree . ...$ bundleモデル作成
roomモデル、entryモデル、direct_messageモデルを作成
$ rails g model room name:string $ rails g model entry user:references room:references $ rails g model DirectMessage user:references room:references name:string $ rails db:migrateモデル編集
app/models/user.rb... has_many :entries has_many :direct_messages has_many :room, through: :entries ...app/models/room.rb... has_many :entries has_many :direct_messages has_many :users, through: :entries ...コントローラ作成
$ rails g controllers Rooms showルーティングの設定
config/routes.rbroot 'users#index' devise_for :users resources :users resources :roomsこれで
rails sしてサーバーをたちあげ、http://localhost:3000
へアクセスしてみる。
成功したらおkUsersコントローラを編集
app/controllers/users_controller.rbclass UsersController < ApplicationController before_action :authenticate_user! def index @users = User.all end def show @user = User.find(params[:id]) @currentUserEntry = Entry.where(user_id: current_user.id) unless @user.id == current_user.id @currentUserEntry.each do |cu| @userEntry.each do |u| if cu.room_id == u.room_id then @isRoom = true @roomId = cu.room_id end end end unless @isRoom @room = Room.new @entry = Entry.new end end end endusers/index/html.erbの作成
app/views/users/index.html.erb<h3>ユーザー一覧</h3> <h2><%= @user.name %></h2> <% unless @user.id == current_user.id %> <% if @isRoom == true %> <%= link_to "チャットをする", room_path(@roomId) %> <% else %> <%= form_for @room do |f| %> <%= fields_for @entry do |e| %> <%= e.hidden_field :user_id, :value => @user.id %> <% end %> <%= f.submit 'チャットを始める' %> <% end %> <% end %> <% end %>Roomsコントローラ編集
app/controllers/rooms_controller.rbclass RoomsController < ApplicationController before_action :authenticate_user! def show @room = Room.find(params[:id]) # present?の戻り値はboolean, よってtrueの場合、 if Entry.where(:user_id => current_user.id, :room_id => @room.id).present? @direct_messages = @room.direct_messages @entries = @room.entries else redirect_back(fallback_location: root_path) end end def create @room = Room.create(:name => "DM") @entry1 = Entry.create(:room_id => @room.id, :user_id => current_user.id) @entry2 = Entry.create(params.require(:entry).permit(:user.id, :room_id).merge redirect_to room_path(@room_id) end end ### rooms/show.html.erbの作成 erb:app/views/rooms/show.html.erb <h1><%= @room.name %></h1> <h4>参加者</h4> <% @entries.each do |e| %> <%= link_to e.user.name, user_path(e.user_id) %> <br /> <% end %> <h1>Chat room</h1> <form> <label> Say somethig:</label><br /> <input type="text" id="chat-input" data-behavior="room_speaker> </form> <div id="direct_messages" data-room_id="<%= @room.id %>"> <%= render @direct_messages %> </div>?memo
<%= render @direct_messages %>とは
<% render partial: 'direct_messages/direct_message', collection: @direct_messages %>の略
この記述をすると、部分テンプレートで繰り返し処理ができるdirect_messageを表示する
app/views/direct_messages/_direct_message.html.erb<%= direct_message.content %> <br /> ### roomチャンネルの作成 speakメソッドを持っているroomチャンネルを作成 ```terminal $ rails g channel room speakapp/assets/javascripts/channels/room.coffeedocument.addEventListener 'turbolinks:load', -> App.room = App.cable.subscriptions.create {channel: "RoomChannel", room: $('#direct_messages').data('room_id')}, connected: -> disconnected: -> received: (data) -> $('#direct_messages').append data['direct_message'] speak: (direct_message) -> @perform 'speak', direct_message: direct_message $('#chat-input').on 'keypress',(event) -> if event.ketcode is 13 #enter App.room.speak event.target.value event.target.value = '' event.preventDefault()app/channels/room_channel.rbclass RoomChannel < ApplicationCable::Channel def subscribed stream_from "room_channel_#{params['room']}" end def unsubscribed end def speak(data) DirectMessage.create! message: data['direct_message'],user_id: current_user.id, room_id: params['room'] end endjobの作成
$ rails g job DirectMessageBroadcastjob編集
class DirectMessageBroadcastJob < ApplicationJob
queue_as :defaultdef perform(direct_message)
ActionCable.server.broadcast "room_channel_#{direct_message.room_id}", direct_message: render_direct_message(direct_message)
endprivate
def render_direct_message(direct_message)
ApplicationController.renderer.render partial: 'direct_messages/direct_message', locals:{ direct_message: direct_message}
end
endapp/models/direct_message.rb... after_create_commit{DirectMessageBroadcastJob.perform_later self}current_userの情報を取得する
app/channels/application_cable/connection.rbmodule ApplicationCable class Connection < ActionCable::Connection:Base identified_by :current_user def connect self.current_user = find_verified_user end protected def find_verified_user verified_user = User.find_by(id: env['warden'].user.id) return reject_unauthorized_connection unless verified_user verified_user end end end ### 終わり 誤字、間違いありましたらご連絡いただけばと思います
- 投稿日:2019-12-22T17:43:38+09:00
【Rails serve】Rails サーバーを起動できない場合
rails server でサーバーが起動できない場合
以下のようなエラーが出る時、
Traceback (most recent call last):
68: from bin/rails:4:in `<main>'
67: from /Users/yu/.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/activesupport-6.0.2.1/lib/active_support/dependencies.rb:325:in `require’
66: from /Users/yu/.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/activesupport-6.0.2.1/lib/active_support/dependencies.rb:291:in `load_dependency’
65: from /Users/yu/.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/activesupport-6.0.2.1/lib/active_support/dependencies.rb:325:in `block in require’
64: from /Users/yu/.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/bootsnap-1.4.5/lib/bootsnap/load_path_cache/core_ext/kernel_require.rb:30:in `require’
63: from /Users/yu/.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/bootsnap-1.4.5/lib/bootsnap/load_path_cache/core_ext/kernel_require.rb:21:in `require_with_bootsnap_lfi’
62: from /Users/yu/.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/bootsnap-1.4.5/lib/bootsnap/load_path_cache/loaded_features_index.rb:92:in `register’
61: from /Users/yu/.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/bootsnap-1.4.5/lib/bootsnap/load_path_cache/core_ext/kernel_require.rb:22:in `block in require_with_bootsnap_lfi’
この後もエラー文が長々と続きますが、何やらWebpackerというパッケージがインストールできていないようなので
rails webpacker:install
と、アプリディレクションで入力して、再度Rails サーバーを起動すれば、エラー文が解消され、無事、Railsサーバーを起動することができました!!!✨エラー文は最後までしっかり読みましょう!
何かしらのヒントがそこに必ずあります!?補足
webpackerというのは、2015年に登場した、CSS、Javascript、画像などをまとめるモジュールバンドラー(require で表現された依存関係を解決してゆき、 コンパイルする際にそれらを全て内包したファイルを作ってくれるのが一般的なモジュールバンドラー)で、Node.jsのモジュールの一つらしいです
参考:
Webpackerとは
https://www.sejuku.net/blog/68146モジュールバンドラーとは
https://blog.mach3.jp/2016/10/01/module-bundler.html
- 投稿日:2019-12-22T17:43:02+09:00
Amazon ElastiCache Rails設定
AWS側の設定
https://qiita.com/leomaro7/items/f031cfdd7d12d5d5ccc5
https://lab.sonicmoov.com/development/aws/elasticache/Rails側の設定
config/environments/staging.rbconfig.session_store :redis_store, { servers: { host: '[プライマリエンドポイント]', port: 6379, db: 0, namespace: 'sessions' }, expire_after: 60.minutes }config/initializers/sidekiq.rbSidekiq.configure_server do |config| case Rails.env when 'staging' then redis_conn = proc { Redis.new(host: 'プライマリエンドポイント', port: 6379, db: 2) } config.redis = ConnectionPool.new(size: 27, &redis_conn) else config.redis = { url: 'redis://127.0.0.1:6379' } end end Sidekiq.configure_client do |config| case Rails.env when 'staging' then redis_conn = proc { Redis.new(host: 'プライマリエンドポイント', port: 6379, db: 2) } config.redis = ConnectionPool.new(size: 27, &redis_conn) else config.redis = { url: 'redis://127.0.0.1:6379' } end end
- 投稿日:2019-12-22T17:43:02+09:00
【Amazon ElastiCache】 Rails設定
AWS側の設定
参考
https://qiita.com/leomaro7/items/f031cfdd7d12d5d5ccc5
https://lab.sonicmoov.com/development/aws/elasticache/Rails側の設定
config/environments/staging.rbconfig.session_store :redis_store, { servers: { host: '[プライマリエンドポイント]', port: 6379, db: 0, namespace: 'sessions' }, expire_after: 60.minutes }config/initializers/sidekiq.rbSidekiq.configure_server do |config| case Rails.env when 'staging' then redis_conn = proc { Redis.new(host: 'プライマリエンドポイント', port: 6379, db: 2) } config.redis = ConnectionPool.new(size: 27, &redis_conn) else config.redis = { url: 'redis://127.0.0.1:6379' } end end Sidekiq.configure_client do |config| case Rails.env when 'staging' then redis_conn = proc { Redis.new(host: 'プライマリエンドポイント', port: 6379, db: 2) } config.redis = ConnectionPool.new(size: 27, &redis_conn) else config.redis = { url: 'redis://127.0.0.1:6379' } end end
- 投稿日:2019-12-22T17:29:18+09:00
ruby on rails�をcircle ciでテストする
CircleCiの設定ファイル
circleci/config.yml# Ruby CircleCI 2.0 configuration file # # Check https://circleci.com/docs/2.0/language-ruby/ for more details # version: 2 jobs: build: docker: # specify the version you desire here - image: circleci/ruby:2.6.5-node-browsers environment: BUNDLER_VERSION: 2.0.1 # Specify service dependencies here if necessary # CircleCI maintains a library of pre-built images # documented at https://circleci.com/docs/2.0/circleci-images/ # - image: circleci/postgres:9.4 working_directory: ~/repo steps: - checkout - run: name: setup bundler command: | sudo gem update --system sudo gem uninstall bundler sudo rm /usr/local/bin/bundle sudo rm /usr/local/bin/bundler sudo gem install bundler # Download and cache dependencies - restore_cache: keys: - v1-dependencies-{{ checksum "Gemfile.lock" }} # fallback to using the latest cache if no exact match is found - v1-dependencies- - run: name: install dependencies command: | yarn install --check-files bundle install --jobs=4 --retry=3 --path vendor/bundle - save_cache: paths: - ./vendor/bundle key: v1-dependencies-{{ checksum "Gemfile.lock" }} # Database setup - run: bundle exec rake db:create - run: bundle exec rake db:schema:load # run tests! - run: name: run tests command: | mkdir /tmp/test-results TEST_FILES="$(circleci tests glob "spec/**/*_spec.rb" | \ circleci tests split --split-by=timings)" sudo gem install bundler sudo gem install rspec sudo gem install rspec-core bundle exec rspec \ --format progress \ --format RspecJunitFormatter \ --out /tmp/test-results/rspec.xml \ --format progress \ $TEST_FILES # collect reports - store_test_results: path: /tmp/test-results - store_artifacts: path: /tmp/test-results destination: test-resultsGemFileの設定
group :development, :test do # Call 'byebug' anywhere in the code to stop execution and get a debugger console gem 'byebug', platforms: [:mri, :mingw, :x64_mingw] gem 'sqlite3', '~> 1.4' gem 'rspec' gem 'rspec-core' gem 'rspec_junit_formatter' endbundle installする
bundle install --without productionすべてコミットしてPUSH
git add . git push origin master
- 投稿日:2019-12-22T16:55:33+09:00
【AWS S3 + EC2 + CarrierWave + Fog】RailsからS3へ画像アップロード手順
はじめに
Ruby on Rails 5.2からAWS S3へ画像をアップロードをするため、CarrierWave+fogを使って実装を進めました。
対象
EC2構築、デプロイ経験のある方
EC2へ画像をアップロードしていた方
はじめてS3を利用する方AWSの設定
S3作成
S3 バケットを作成する方法
https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/user-guide/create-bucket.html
- 東京リージョン
- バージョニング有効
- Static website hosting有効
- パブリックアクセスをすべてブロック
バケットポリシー{ "Statement": [ { "Effect": "Allow", "Principal": "*", "Action": "s3:*", "Resource": [ "arn:aws:s3:::[バケット名]", "arn:aws:s3:::[バケット名]/*" ], "Condition": { "StringEquals": { "aws:SourceIp": "[EC2のパブリックIP]" } } } ] }VPCエンドポイントの設定
EC2とS3の間でファイルの転送を行います。
VPCのダッシュボードを開き、 エンドポイント の作成ボタンをクリックします。
宛先の選択をします。 AWS services と com.amazonaws.ap-northeast-1.s3 にチェックを入れます。
通信したいEC2インスタンスが置かれているVPC と そのサブネットに当てられているルートテーブル を選択します。
カスタムポリシーの設定
カスタムポリシーの例{ "Statement": [ { "Effect": "Allow", "Principal": "*", "Action": "s3:*", "Resource": [ "arn:aws:s3:::[バケット名]", "arn:aws:s3:::[バケット名]/*" ] } ] }作成が完了すると、ダッシュボードにエンドポイントが表示されます。
紐付けたサブネットのルートテーブルを確認すると、エンドポイントを介したS3への経路が追加されています。AWS CLIを使ってS3へデータを送信テスト
EC2へ接続 $ ssh -i [keyペアファイル] ec2-user@[パブリックIP] テストファイルを転送 $ touch test.txt $ aws s3 mv test.txt s3://YOUR_S3_BUCKET/uploads s3バケットが閲覧できるか確認 $ aws s3 ls s3://YOUR_S3_BUCKET/ --recursiveAmazon Linux 2の設定
ImageMagickを導入
$ yum install -y ImageMagick ImageMagick-develアクセスキーとシークレットアクセスキーの設定
aws configure コマンドが、AWS CLI のインストールをセットアップするための最も簡単な方法です。
詳しくは
https://docs.aws.amazon.com/ja_jp/cli/latest/userguide/cli-chap-configure.html
https://dev.classmethod.jp/cloud/aws/how-to-configure-aws-cli/$ aws configure AWS Access Key ID [None]: AKIAXXXXXXXXXXXXXXXX AWS Secret Access Key [None]: 5my9xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx Default region name [None]: ap-northeast-1 Default output format [None]:設定の確認
$ aws configure listRailsの設定
Gemの設定
Gemfilegem 'carrierwave' gem 'rmagick' gem 'fog-aws'ImageUploaderの設定
$ rails g uploader Image/uploaders/image_uploader.rbclass ImageUploader < CarrierWave::Uploader::Base # 画像サイズを取得するためにRMagick使用 include CarrierWave::RMagick # developmentとtest以外はS3を使用 if Rails.env.development? || Rails.env.test? storage :file else storage :fog end # 画像ごとに保存するディレクトリを変える def store_dir "uploads/#{model.class.to_s.underscore}/#{model.id}/#{mounted_as}" end # 許可する画像の拡張子 def extension_whitelist %w(jpg jpeg gif png) end # ファイル名を書き換える def filename "#{Time.zone.now.strftime('%Y%m%d%H%M%S')}.#{file.extension}" if original_filename end endCarrierWaveの設定
/config/initializers/carrierwave.rb# CarrierWaveの設定呼び出し require 'carrierwave/storage/abstract' require 'carrierwave/storage/file' require 'carrierwave/storage/fog' # 画像名に日本語が使えるようにする CarrierWave::SanitizedFile.sanitize_regexp = /[^[:word:]\.\-\+]/ # 保存先の分岐 CarrierWave.configure do |config| # 本番環境はS3に保存 if Rails.env.production? config.storage = :fog config.fog_provider = 'fog/aws' config.fog_directory = '[S3のバケット名]' config.asset_host = 'https://s3-ap-northeast-1.amazonaws.com/[S3のバケット名]' # iam_profile config.fog_credentials = { provider: 'AWS', # credentialsで管理する場合 aws_access_key_id: Rails.application.credentials.aws[:access_key_id], aws_secret_access_key: Rails.application.credentials.aws[:secret_access_key], # 環境変数で管理する場合 # aws_access_key_id: ENV["AWS_ACCESS_KEY_ID"], # aws_secret_access_key: ENV["AWS_SECRET_ACCESS_KEY"], region: 'ap-northeast-1' #東京リージョン } # キャッシュをS3に保存 # config.cache_storage = :fog else # 開発環境はlocalに保存 config.storage :file config.enable_processing = false if Rails.env.test? #test:処理をスキップ end endアップローダーの使い方
作成したUploaderをModelに紐付けます。Userモデルのimageカラムに紐付ける例
User.rbclass User < ApplicationRecord mount_uploader :image, ImageUploader end



- 投稿日:2019-12-22T16:32:02+09:00
Bootstrapが動かない?
もう同じ件でハマらないようメモる
navbarのハンバーガータブが動かないって時に思い切って全ページコピペしても動かなかった人向けapp/asset/javascripts/application.js//= require rails-ujs //= require jquery //= require bootstrap //= require turbolinks //= require_tree .↑これを追加するだけ!※順番も超重要
要するにStarter templateっていう導入部分が上手く読めてなかっただけ<script src="https://code.jquery.com/jquery-3.4.1.slim.min.js" integrity="sha384-J6qa4849blE2+poT4WnyKhv5vZF5SrPo0iEjwBvKU7imGFAV0wwj1yYfoRSJoZ+n" crossorigin="anonymous"></script> <script src="https://cdn.jsdelivr.net/npm/popper.js@1.16.0/dist/umd/popper.min.js" integrity="sha384-Q6E9RHvbIyZFJoft+2mJbHaEWldlvI9IOYy5n3zV9zzTtmI3UksdQRVvoxMfooAo" crossorigin="anonymous"></script> <script src="https://stackpath.bootstrapcdn.com/bootstrap/4.4.1/js/bootstrap.min.js" integrity="sha384-wfSDF2E50Y2D1uUdj0O3uMBJnjuUD4Ih7YwaYd1iqfktj0Uod8GCExl3Og8ifwB6" crossorigin="anonymous"></script>↑をbodyの一番下に入れてからと初学者なら習ったことあるはず
ハマった人が少しでも救われますように
- 投稿日:2019-12-22T13:56:51+09:00
Railsで制御結合、スタンプ結合、データ結合、メッセージ結合
# 制御結合 # @param [User] user # @param [Bool] active_flg # @return [Hash] def shape_user_info(user, active_flg) # @type [Hash] user_info if active_flg user_info = user_info(user) else user_info = default_user_info end user_info end # スタンプ結合 # @param [User] user # @return [Hash] def user_info(user) # @type [String] first_name = user.first_name # @type [String] last_name = user.last_name # @type [String] fullname = fullname(first_name, last_name) # @type [Integer] age = user.age # @type [String] mail = user.mail { fullname: fullname, age: age, mail: mail } end # データ結合 # @param [String] first_name # @param [String] last_name # @return [String] def fullname(first_name, last_name) first_name + last_name end # メッセージ結合 # @return [Hash] def default_user_info { fullname: "fullname", age: 30, mail: "mail" } end間違ってたらごめんなさい?
- 投稿日:2019-12-22T12:51:03+09:00
#Rails で カラム名変更の migration ファイルの例
あーマイグレーションファイルを書くのが死ぬほど面倒だ
rails generate migration ChangeColumnNameUserFirstNameToGivenNameclass ChangeColumnNameUserFirstNameToGivenName < ActiveRecord::Migration[5.2] def change # テーブル名は複数形で書く # 2番目に変更前のカラム名、3番目に変更後のカラム名を書く rename_column :users, :first_name, :given_name end endrails db:migrateOriginal by Github issue
- 投稿日:2019-12-22T10:36:17+09:00
【IT専門学生の就活】僕がこれからやること
自己紹介
僕はIT系の専門学生1年で、現在はWeb系の企業を目指して学習を進めています。今回この記事を書こうと思った理由は、就活が迫ってきたのですが学校にはWeb系企業の求人がなく、ポートフォリオを作成し、技術を証明する必要があると考えたからです。
今までやったこと
僕がWeb開発を始めたのは大学受験に落ちた日からです。もちろん最初は Progateさんから始めました:)
そしていつの間にかIT系の専門学校に
独学
- ポートフォリオページ作成(HTML&CSS)
- Ruby
- Ruby on Rails
- AWS(EC2)
- adobeXD
- PaizaスキルチェックBランク(Java,Ruby)
学校
- MySQL
- CentOS
- GUI電卓作成(JavaFX)
- GUIポーカー作成(JavaFX)
- シューティングゲーム作成(JavaFX)
- 基本情報技術者試験合格
- 成績全てA(1年前期)
書き途中に気付いたのですが、自主学習時間の割に形になっているものが少ないなと思ったので、作成物や資格合格を目標として取り組むことにします。
これからやること
自分でやることで何をすればよいかを整理するために書くので、学校のみで勉強するものは省いています。
就活までにやること(専門1年)
先頭の番号は優先順位です
- Webアプリ作成(Rails&HTML&CSS&BT) [独学]
- PaizaスキルチェックAランク(Python) [独学]
- ポートフォリオサイト作成(HTML&CSS&BS) [独学]
- 成績全てA [自宅+学校]
- 応用情報技術者試験合格 [自宅+学校]
プラスしてやること(専門2年)
まだ具体的に定まっていないため優先順位はつけられないのでつけません。
- Webアプリ作成(Laravel)
- Webアプリ作成(Java Spring Framework)
- TOEIC600点?(受けたことないからわからない)
ここからは趣味でやりたいことかもしれません。余裕があればやります
- 高校数学復習+大学数学
- 機械学習・人工知能
- Pythonでいろんな分野で遊ぶ
タスクに分解
やることを明確にするため、目標をタスクに分解していきます。
1.Webアプリ作成(Rails)
- Ruby
- Rails
- HTML・CSS
- Git
主役はRailsですがもちろん基礎文法としてRuby、デザインとしてHTML・CSS、バージョン管理としてGitをやる必要があります。デプロイはHerokuで行います(デプロイについてはRailsチュートリアルで学習できます↓)
タスク
【Ruby】
・[完了]Progate Rubyコース
・[完了]Paiza Rubyコース
・[完了]プロを目指す人のためのRuby【Rails】
・[完了]Progate Railsコース
・Railsチュートリアル【HTML・CSS】
・[完了]Progate HTML&CSS【Git】
・Udemy Git:はじめてのGitとGitHub2.PaizaスキルチェックAランク
- Python
- アルゴリズム
Pythonは応用情報と組み合わさった良い講座があったのでそれを見ることにします。アルゴリズムは演習もやりながらできるものがQiitaにたくさんあったのでそれをやることにします。
タスク
【Python】
・基本情報技術者試験+応用情報技術者試験+Python+SQL【アルゴリズム】
・AtCoder に登録したら次にやること 過去問精選10問
・AtCoder 版!蟻本 (初級編)3.ポートフォリオサイト作成(HTML&CSS&BS)
サーバーサイドを見せるためのポートフォリオ程度のHTML・CSSで新たに学習することはないので適当に調べながらやることにします。
4.成績全てA
テスト範囲が発表されてから考えます
5.応用情報技術者試験合格
基本情報で基本的なことは覚えたのでやるべきことは過去問演習だけです
タスク
・過去問演習
おわりに
応用情報合格したいな...?
- 投稿日:2019-12-22T09:54:52+09:00
Railsエンジニアのための実践!テストことはじめ
最近、会社の後輩や、業務としてRails未経験の友人から、テストの書き方について質問されることがありました。プロダクトコードは実際に実現したいことがあるのでそれを実現するために実装すれば良いため、イメージしやすいのですが、テストコードは最初はイメージしにくいのでしょう。
そこで、これまでの経験を踏まえ、テストを書き始めるための基本的に知っておくべきことについて記述したいと思います。
以下では、テストのフレームワークとしてRSpecを利用する前提で書きます。
また、モデルを生成には、FactoryBotというライブラリを利用します。FactoryBotはRailsではモデル生成で広く利用されているライブラリです。FactoryBotの導入は他の記事に任せます。テストを書きつづけるための準備
これから、Railsにおけるテストについてのことはじめを述べていきますが、その前に、テストを書き続けるための準備をしておきましょう。テストは書いて終わりではありません。ソースコードを書いてクラウド上(GitHubやGitLab、Bitbucketなど)にpushしたら、自動的にこれまで書いたテストが回る様にしてそれをエンジニアが気づく仕組みを作る必要があります。そのためのツールを紹介します。
まずは、継続的インテグレーション(CI)サービスです。有名なのはCircleCI、TravisCIなどです。自前で立ち上げる場合はJenkinsなどのオープンソースもあります。チームメンバーと相談して、どのサービスを利用するかを確認しましょう。ちなみに私は自前で立ち上げる手間を省くため、CircleCIやTravisCIを利用することが多いです。
継続的にテストを回す仕組みができたのであれば、テストのカバレッジも継続的に測定してあげる必要があります。Railsであれば、simplecovというgemを利用することが多いでしょう。そして、カバレッジを可視化するためにCodeCovやCode Climateといったサービスを利用するとよいでしょう。この時、CircleCIを使っている場合はconfigファイルの追記などが必要になりますが、その辺りは公式のドキュメントやその他の解説サイトに委ねます。テストを書く範囲
全てのコードに対してテストを書くことができればそれに越したことはありません。しかし、それは事実上不可能です。テストカバレッジが100%とすることのコストに見合うほどのメリットはないと言って良いでしょう。そこで、どういうところからテストを書き始めれば良いのかということについて考えてみます。
ビューがある場合
ビューがある場合のRailsのアーキテクチャを大まかにレイヤーに分けると以下のようになります。
ビュー コントローラー モデル 基本的な考え方は、この中で、一番下のレイヤー(モデル)と一番上のレイヤー(ビュー)を中心にテストを書くということとです。
その中でも、真っ先に書かなければいけないのがモデルに対するテストです。ここではモデルという言葉はActiveRecordないし、プレーンなRubyオブジェクト等とします。Railsにおけるモデルには、業務ロジックが記載されます。例えば、請求書を作る時にBillというモデルがあって、そこでは、注文履歴から、請求明細を作るという業務ロジックが書かれます。このロジックは、実際の業務のソースコードの焼き写しですから、複雑になりがちです。また、この場合、ユーザーに対して請求を行うわけですから、絶対に間違ってはいけません。コードの中でも重要度は高い部分と言えるでしょう。こういうところは絶対にテストを十分に書くべきです。経験上、テストを十分に書いたと思ったとしても、実際には考慮漏れはあることでしょう。そしてその修正をしたと思ったら既存の挙動が壊れてしまう。テストがあれば壊れたことに気づけますが、テストがなければ気づくことができません。
一方で、一気通貫的な振る舞いをテストも書くべきです。例えば何かを購入するサイトであれば、商品を検索し、商品を選んでもらい、カートに保存、決済に進み、完了するまでの一連の流れです。Railsでは、SystemSpec(以前はFeatureSpec)に該当するものです。この一連んお流れをきちんと書いておくことができれば、コントローラーの実装も担保できますし、モデルのロジックも全部ではないとはいえ、担保できます。ただ、SystemSpecでありとあらゆるパターンを網羅するのは必ずしも得策ではない場合があります。SystemSpecはモデルのテストよりも実行時間がかかるのが一般的ですし、細かなパターンの違いはモデル側のテストで吸収するのも一つの方法です。一方で、SystemTestのいいところはホワイトボックス的にテストをかけることです。内部実装を知らない人でも、業務に精通していればシナリオを洗い出せます。テストにかける余裕がある場合は業務に詳しいQAエンジニアにSystemSpecを書いてもらって、実装者に実装漏れを気づかせることもできます。APIを提供する場合
APIの場合は、ビューが無くなりますが、代わりにJSONやXMLなどの形式で値を返すことになるでしょう。
JSON等 コントローラー モデル この場合、SystemSpecは書けませんので、RequestSpecをかくことになります。しかし、考え方は同じで、ロジックが書かれているモデルのテストはきちんと書き、APIのインターフェースもきちんとテストを書くということです。
まとめますと、業務ロジックがコテコテに書かれているモデルに関しては面倒臭がらずにきちんとテストを書き、大きな挙動・流れの確認はSystemSpec(APIの場合はRequestSpec)で書くことで、下のレイヤーと上のレイヤーの挙動を担保し、全体としての挙動を担保すると考えれば良いでしょう。
逆に、ControllerやControllerのconcernのテストを書かなければと思った場合は、設計が間違っていると思ったほうがいいでしょう。controllerに業務ロジックは書く必要はないし、そのような場合は、既存のモデルが持つべきロジックであればそちらに実装すべきですし、そうでなければプレーンなRubyのクラスとして実装することも検討したほうが良いでしょう。このようにして、テストを書くという観点からシステム全体を見直すと、設計が良くないということに気づくことができます。これもテストを書くことの一つの利点です。モデルのテスト
それでは、モデルのテストについてはどういう観点でテストを書けば良いのでしょうか。
私は、モデルのテストの観点は大きく分けて2つあると考えています。一つめはバリデーションのテスト、二つ目はモデルの外で使用される可能性のあるメソッド(publicメソッド)のテストです。モデルの外で利用される可能性があれば、インスタンスメソッドであれ、クラスメソッドであれ、テストを書くべきでしょう。ActiveRecordのscopeもクラスメソッドに含まれるので、テストを書きます。以下の例では、次のようなActiveRecordのモデルで説明をします。
バリデーションのテスト
例えば、次の様なバリデーションがあったとしましょう。OrderItemモデルには、
family_name(苗字)とgiven_name(名前)の属性を持っており、その両方を合わせたもの(フルネーム)の長さの制限を20文字とするバリデーションです。
机上で構いませんので、モデルのテストを書いてみましょう。class OrderItem < ApplicationRecord validates :full_name, length: { maximum: 20, message: :too_long_sum } def full_name "#{family_name}#{given_name}" end endリスト1. OrderItemにfull_nameのバリデーションを追加
今回は、full_nameのバリデーションのテストを以下の様に実装してみました。
RSpec.describe OrderItem, type: :model do describe '#valid?' do let(:order_item) { FactoryBot.build(:order_item, attributes) } let(:attributes) { {} } subject { order_item } describe 'full_name' do context '20文字の場合' do let(:attributes) { { family_name: 'あ' * 10, given_name: 'い' * 10 } } it { is_expected.to be_valid } end context '21文字の場合' do let(:attributes) { { family_name: 'あ' * 10, given_name: 'い' * 11 } } it { is_expected.to be_invalid expect(subject.errors.keys).to contain_exactly(:full_name) expect(subject.errors.full_messages).to contain_exactly( 'お名前は合計20文字以内で入力してください。' ) } end end end endリスト2. OrderItemにfull_nameのバリデーションのテストの実装例
バリデーションのテストの時のポイントは、テストしたいバリデーションにフォーカスをあてるということです。モデルのデフォルト値は
FactoryBotの定義されますが、このとき基本的にはvalidな値で定義しておきます。その上で、FactoryBot.buildする際にテストしたい属性のみ値を変更させ、バリデーションを実行させます。リスト2では、family_nameとgiven_nameの値を変更しています。
次に、validな場合のテストですが、こちらは簡単でvalidな値をattributesに定義してあげ、itブロックのかでbe_validを呼んであげるだけです。RSpecのsubjectを利用するかどうかは流派によりますが、次の様にしても良いでしょう。it { expect(order_item).to be_valid }リスト3.
subjectを利用しない場合の実装例そして、ポイントは、invalidな場合のテストです。invalidであることをテストしたいので
be_invalidを確認するのは問題ないでしょう。大事なのは、ここで終わらせてはいけないということです。まず、注目している属性のみにエラーが入っていることを確認する必要があります。今回の場合、一つの属性だけのテストなので、他の属性のエラーが入ることはありませんが、複雑なバリデーションを実装すると、ある属性がinvalidになると、他の属性もinvalidになることがあります。例えば、full_nameの最大文字数は20字だが、family_name単体での文字数は15字である場合を考えます。この時、family_nameがinvalidな場合は、まずはfamily_nameのエラーをユーザーに解消してもらいたいためにfull_nameのvalidationは行わないという様にしたいとします。実装はリスト4の様にします。validates :family_name length: { maximum: 15 } validates :full_name, length: { maximum: 20, message: :too_long_sum }リスト4.
family_nameにバリデーションを追加この時、
family_nameがinvalidな場合はfull_nameのバリデーションエラーは出したくないので、テストはリスト5のようになります。context '苗字が16文字の場合' do let(:attributes) { { family_name: 'あ' * 16, given_name: 'い' * 10 } } it { is_expected.to be_invalid expect(subject.errors.keys).to contain_exactly(:family_name) expect(subject.errors.full_messages).to contain_exactly( '苗字は15文字以内で入力してください。' ) } endリスト5.
family_nameにバリデーションを追加した時のテストの例しかし、リスト4の実装では、
full_nameのバリデーションも実行されてしまい、このテストはfailします。この様に、ある属性のバリデーションを追加したことで、他のバリデーションにも引っかかってしまい、期待しない挙動となってしまうことがあります。そのために、expect(subject.errors.keys).to contain_exactly(:family_name)として、errros.keyが:family_nameのみであることを明確にしています。ここでexpect(subject.errors.keys).to include(:family_name)としている方を見かけますが、これでは、errors.keysの配列に:family_nameが含まれていることしかテストできておらず、:family_name以外が存在しないということができていません。contain_exaclyを使うことで他の属性にエラーがないということを担保できます。今回は、errors.keysの要素の順序は気にしなくても良いため、contain_exactlyを使いましたが、順序も重要な場合はmatchマッチャ等を使い、順序性も担保してあげましょう。
ちなみに、family_nameがinvalidな場合にfull_nameのバリデーションを実行させないためには、例えば以下の様な実装になります。ちょっと汚いので、もう少し良い実装方法があるかもしれません。validates :family_name, length: { maximum: 15 } validates :full_name, length: { maximum: 20, message: :too_long_sum }, if: -> { !errors.include?(:family_name) }リスト6. ifを利用して、family_nameがvalidな場合のみfull_nameのバリデーションを実行させる例
モデルのバリデーションの最後のテストは、エラーメッセージです。特に日本人向けのサービスの場合、i18nを利用してエラーメッセージを日本語化することがほとんどでしょう。モデルのバリデーションエラーののテストでは、エラーメッセージもテストするべきです。
前述のfamily_nameが15文字以下であることのバリデーションでは、length: { maximum: 15 }としました。一方、full_nameが20文字以下であることのバリデーションでは、length: { maximum: 20, message: :too_long_sum }のようにmessageを追加しています。これは、family_nameとfull_nameそれぞれでエラーメッセージを出し分けたいためです。family_nameは一つの属性であるため、苗字は15文字以内で入力してください。というメッセージで良いのに対し、full_nameは二つの属性であるため、お名前は合計20文字以内で入力してください。のように合計という言葉を追加したいわけです。
詳細な内部の仕様は追っていませんが、messageを追加しないとja.activerecord.errors.models.order_item.attributes.family_name.too_longが呼ばれ、messageにtoo_long_sumを追加すると、ja.activerecord.errors.models.order_item.attributes.full_name.too_long_sumが呼ばれる様になります。
この辺りの挙動は、個人的にはやってみないとわからない様な気がしています。どのバリデーションエラー時にymlで指定したどのキーが使われるのかというのは、毎回調べるよりも実際に実行してみて確認する方が早いからです。そのためにもテストで確認しておくと実装が非常にスピードアップします。i18nが正しく設定されているかどうかを確認するという意味も込めて、エラーメッセージもきちんとチェックしておきましょう。そして、ここでも他の属性にエラーがないことを担保するためにcontain_exactlyを用いています。以上が、モデルのバリデーションのテストについての簡単な説明です。今回は、最大桁数が20文字というところだけを注目して、
full_nameが20文字および21文字の場合のみのテストを書きました。しかし、実際には、例えば、
・nilのときはどうなのだろう。
・空文字のときは?
・最小値は1文字でよいのだろうか?
・family_nameが許容する文字は全てなのだろうか?髙や?といったJISの第1水準、第2水準以外の文字も許容されるのだろうか?
などといった仕様が存在するはずです。もし仕様が明示的でない場合でも、テストを書くことで、仕様が明示的になっていないことに気づくことができます。テストはきちんと場合分けをして書く必要があるため、自然と頭の中が整理されるからです。1そのためにもテストを書くことは非常に大事なことなのです。モデルの外で使用される可能性のあるメソッド(publicメソッド)のテスト
これまでの例で、インスタンスメソッド
full_nameのテストを書いてみましょう。ただし、単純にfamily_nameとgiven_nameを連結させただけではあまり面白みがないので、少しメソッドを拡張します。def full_name(space: '') "#{family_name}#{space}#{given_name}" endリスト7. full_nameメソッドに引数を追加し拡張
リスト7の様に
spaceというキーワード引数を追加します。インスタンスメソッドfull_nameは変数spaceの値でfamily_nameとgiven_nameが連結された値を解します。引数がなければデフォルト値が空文字となります。この場合のテストを書いてみましょう。開発者が書くモデルのテストは、ホワイトボックステストと呼ばれます。ホワイトボックステストとは、内部の論理構造を把握した上で、このメソッドの場合、if文はありませんが、例えば引数の有無でデフォルト値を使うかどうかが変わってくるので、その辺りを考慮すると、full_nameメソッドのテストは例えば以下の様になります。2describe '#full_name' do context '引数がない場合' do subject { order_item.full_name } it { is_expected.to eq 'てすと太郎' } end context '引数がある場合' do subject { order_item.full_name(space: space) } context 'spaceが全角スペースの場合' do let(:space) { ' ' } it { is_expected.to eq 'てすと 太郎' } end context 'spaceが半角スペースの場合' do let(:space) { ' ' } it { is_expected.to eq 'てすと 太郎' } end context 'spaceがnilの場合' do let(:space) { nil } it { is_expected.to eq 'てすと太郎' } end end endリスト8. full_nameメソッドのテスト
今回の例では、
subjectにテストしたいメソッドをセットしています。
インスタンスメソッド以外にも、クラスメソッドなども同様にテストしていきます。3SystemSpec
SystemSpecは、モデルのスペックと違って、ブラックボックス的な意味合いが強くなります。Capybaraを使ってブラウザ上での操作を模擬するため、モデルの関数名などの内部実装を知る必要はありません。したがって、ある一面では非常に簡単にテストを書くことができます。実際のブラウザのHTMLコードを確認しながらタグやname属性をみてspecを書いていけばいいからです。
ここで「ある一面では」と書いたのは、SystemSpecを書き始めるための下準備が非常に大変であるからです。ここの準備ができていれば、テストを書き始めることは非常に簡単ですが、ここの準備が大変なのです。画面を表示させるためには、多くの場合、事前にレコードを準備していく必要があります。そしてそのレコードは一つや二つですまない場合もあります。specを書くためにそのページを書く上での前提条件を把握していないといけないわけです。そのほかにも、テストしたい画面に行くまでが大変であることもあります。例えば、事前にログイン処理をしてページを数枚挟まないといけなかったり、検索機能がある場合は、ElasticSearchなどの外部サービスへAPIを叩く必要があったりします。テスト用のElasticSearchを準備するのか、はたまたモックで対応するのかなどといった追加の作業が発生します。しかし、ここさえクリアできれば、SystemSpecはレグレッションテストとして強力な武器になります。最初は準備するのは大変かもしれませんが、あとで幸せになるためにシステムが小さいうちに苦労をしておきましょう。レコードの保存や更新まで確認するべきか
さて、SystemSpecではどこまでテストをすれば良いのでしょうか。最低限は、画面の挙動として、次のページに進めて正しく表示されることを確認します。このとき、ユーザーの一連の流れを考えてテストを書いていきます。つまりはシナリオテストです。SystemSpecの場合、モデルのspecでは
itを使っていた箇所をscenarioと書くようになります。これは、SystemSpecがシナリオテストであるということの表れです。すなわち、ユーザーがどのような振る舞いをするかをテストするということです。そうして書かれたSystemSpecでは、大抵の場合、何かしらのレコードが保存されたり、更新されたりします。このレコードの保存や更新はSystemSpecにおいて確認するべき項目となるの
レコードの保存や更新まで確認すべきではないという見解の方もいます。SystemSpecでは、画面の振る舞いをテストするべきで、レコードが正しく保存されたかどうかはSystemSpecの範疇ではないという意見です。前述の様に私は、SystemSpecでもレコードの保存まで確認するべきだという立場です。理由としては、昨今のフロントエンドの挙動は年々複雑になっており、意図した値がサーバサイドに渡ってきているかどうかが分かりにくくなっているからです。
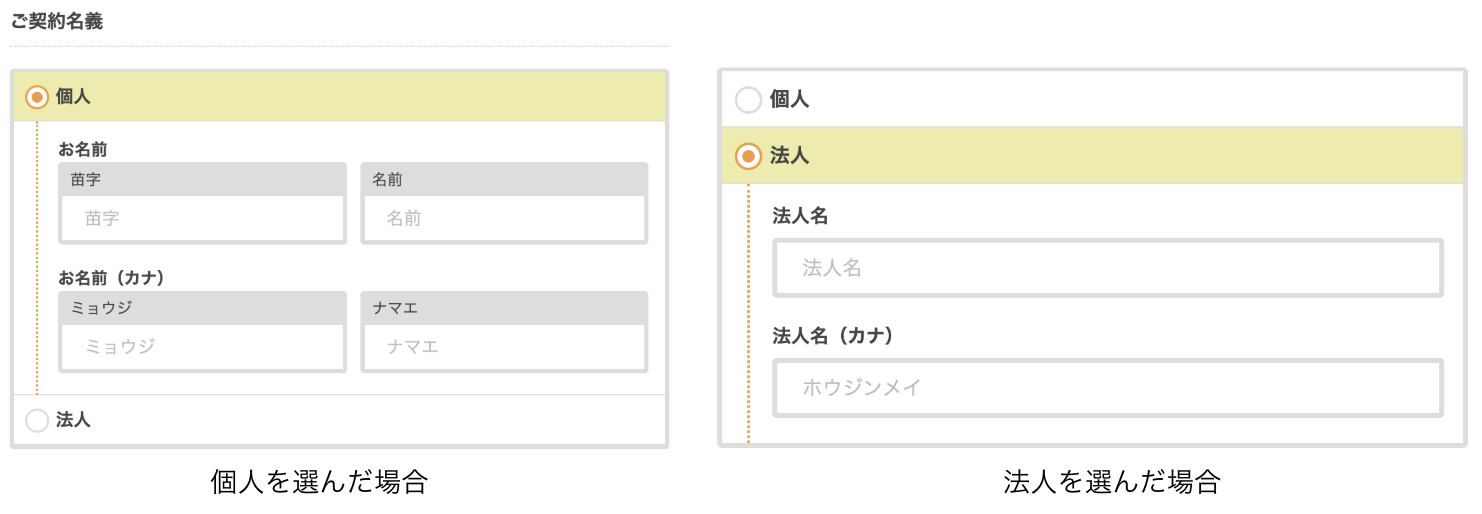
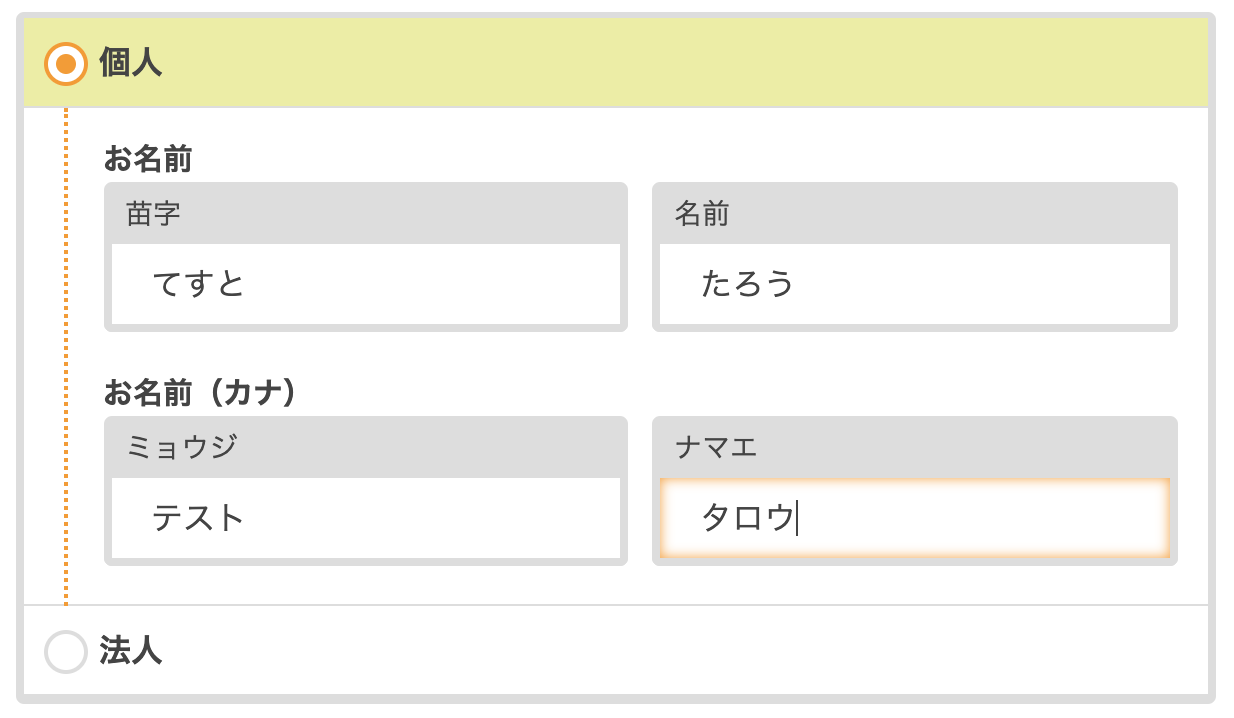
例えば、図1のように、個人名義と法人名義でフォームの形式が異なる場合を考えてみましょう。そして、OrderItemには、個人名義を保存する属性としてfamily_name、given_name、family_name_kana、given_name_kanaがあり、法人名義を保存する属性としてcorporate_name、corporate_name_kanaがあるとします。
図1. 契約名義で個人名義と法人名義でフォームの形式が異なる場合
このフォームのHTMLをみてみると次のようになっています。<%# 個人が選択された場合 %> <input name="order_item[family_name]" placeholder="苗字"> <input name="order_item[given_name]" placeholder="名前"> <input name="order_item[family_name_kana]" placeholder="ミョウジ"> <input name="order_item[given_name_kana]" placeholder="ナマエ"> <%# 法人が選択された場合 %> <input name="order_item[corporate_name]" placeholder="法人名"> <input name="order_item[corporate_name_kana]" placeholder="ホウジンメイ">リスト9. 名義入力フォームのHTML
Railsでは、inputタグのname属性によって、フォームがモデルのどの属性に対応されるかを判別するので、name属性は非常に大事です。個人名義か法人名義かによって保存するモデルの属性もかわってくるので、name属性も変わってきます。この挙動の実装としては、例えば、個人が選択されたら、JavaScriptを用いて
order_item[family_name]〜order_item[given_name_kana]のフィールドを表示にして、order_item[corporate_name]とorder_item[corporate_name_kana]のフィールドが表示されている場合は、非表示にするという制御を行います。今回は、Vue.jsを用いてこの挙動を実装しました。具体的には、v-showやv-ifを用いて表示の制御を行います。
では、図2のように、個人が選択された場合のフィールドに値が入力された時、サーバーサイドにはどのような値が送られてくるかわかりますでしょうか。
図2. 個人のフィールドに値を入力した場合当然ですが、family_name, given_name, family_name_kana, given_name_kanaは送られてきます。ログで確認するとリスト10の様になります。
Parameters: {"order_item"=>{"family_name"=>"てすと", "given_name"=>"太郎", "family_name_kana"=>"テスト", "given_name_kan"=>"タロウ"}}リスト10 図2の状態でサブミットしたときのParameters(一部省略)
では、
corporate_nameやcorporate_name_kanaはどうでしょうか。サーバーサイドに値は渡ってくるでしょうか。
答えは、Vue.js側の実装によります。v-ifで実装されている場合は渡ってきませんし、v-showで実装されている場合は値が渡ってきます。(未入力の場合は空文字("")で渡ってきます)したがって、v-showで実装した場合、個人名義なのにcorporate_nameやcorporate_name_kanaが保存されてしまうことがあるわけです。この様な挙動のテストは画面上だけのテストでは担保することができません。これを担保するにはレコードの保存状態まで確認する必要があると私は考えています。テストケースはどの様に洗い出せばいいか
モデルのテストの場合、ホワイトボックステストとして、実装の中身がわかっているという前提でテストを書けばいいので、言ってしまえばソースコードをみて分岐を確認し、C0網羅、C1網羅、C2網羅など4を考慮してテストを書いていけば良いです。では、SytemSpecの場合、どうすれば良いでしょうか。
ここでは、ユーザーは申し込み画面で必要事項を入力したあと、確認画面へ進み、確認画面後は、ユーザーの入力した値に応じて画面の遷移が変わる場合を考えてみましょう。そして、このお申し込みには、付帯サービスなるものが存在し、離島でない場合は付帯サービスの説明を確認画面で表示し、離島の時は表示しません。また、申込者が本人または配偶者の場合のみ付帯サービスの説明を表示しますが、本人・配偶者以外の場合は表示しないという制御が必要だとします。
また、付帯サービスの説明表示とは別に、申し込み画面ではポイントカード登録をするかどうかを聞く項目があり、ポイントカード登録をするを選んだ場合は、確認画面後にポイントカードを登録する画面へ遷移するものとします。これをまとめたものが表1になります。rspec対象と書かれたカラムは後ほど説明します。表1. パターンを網羅したもの
さて、この12パターンのうち、どのくらいまでテストをする必要があるでしょうか。もちろん、12パターン全てテストをするに越したことはありません。しかし、今回は3項目でそれぞれ2つまたは3つの値しか取らないので、2 x 3 x 2 = 12パターンしかありませんが、項目数や取りうる値が増えた場合、この数は文字通り指数関数的に増えていきます。全てをテストすることはたとえ自動テストであっても事実上不可能です。そこで適度に間引いたテストケースを作る必要があります。その間引き方の考え方が組み合わせテストという考え方になります。組み合わせテストでは、2因子間網羅をすれば、妥当なテストケースが作成されていると見做すことが多いです。「因子」とは、前述した表1の例であれば、「契約場所」「申込者」「ポイントカード登録」の3つの項目を指します。2因子間網羅とは、3因子のうち2つの因子の組み合わせを網羅できているということです。具体的には、「契約場所」「申込者」の2因子では、「離島でない、本人」「離島でない、配偶者」「離島でない、本人・配偶者以外」「離島、本人」「離島、配偶者」「離島、本人・配偶者以外」の6つを網羅しているということです。
表1の場合、2因子間網羅となるように間引いてテストケースとして選んだのがrspec対象と書かれたカラムに◯をつけたパターンになります。この様にしてテストケースを作成していきます。組み合わせテストの技法については、組み合わせテストの用語「2因子間網羅」「直交表」「All-Pairs法」に詳しく書かれています。なぜ、2因子間網羅で妥当なテストといえるのかということについての言及もあります。ふるまいのテストとテストコードの共通化
これまで述べてきた様に、SystemSpecではユーザーのリアルに近い挙動をテストすることができます。ユーザーは、例えば申し込み画面があれば最初からなんの迷いもなくスムーズに申し込むとは限りません。入力する値を間違えてしまったり、カナを入れる箇所に漢字を入れてしまったりということがあります。SystemSpecではこうした挙動も確認できるのが非常に強みです。そして、忘れがちなのが、実装していない挙動に対するテストです。たとえば、ブラウザバック。ブラウザの戻るボタンを押された時に挙動がおかしくならないか。あるいは、リロード。例えばリロードすると入力していた文字が消えてしまっていたり、postとgetで挙動が変わってきたりすることも確認が必要です。私が過去にみてきたソースコードでは、完了画面にてリロードをするとレコードが次々と挿入される実装になっていたり、同じ内容で何度もAPIコールされているといった実装がありました。5こうした挙動も忘れずに確認しておきましょう。リロードするとレコードが増えていないかというのも、レコードの保存まで確認しておけばテストすることが可能です。加えて、自分たちで実装しておきながらテストし忘れるのが、戻るボタンです。例えば入力項目を入力した後の確認画面で、一つ前のページに戻って修正できるようにした画面上のボタン。この挙動も忘れがちです。ここもpostでの実装なのか、getでの実装なのか、ケースによると思いますが、悩みどころの一つだと思います。申し込みフォームが複数ページにまたがる場合、前からの遷移の時は問題なく動いていても、戻ってきた場合は挙動がおかしいということもありえます。しっかりと確認しましょう。
そして、こうしたふるまいのテストを行う場合、全てのケースにおいてリロードだったり、ブラウザバックだったりのテストを書く必要は必ずしもありません。どこか1ケースでこうした挙動を紛れ込ませれば十分です。そこでしばしば問題となってくるのがテストコードが共通化されている場合です。例えばSharedExampleやメソッド化して切り出すなどしてテストコードが共通化されていると、このテストコードの場合だけこの挙動を差し込みたいと言ったことが難しくなります。無理やり行なった結果、SharedExampleやメソッドの引数を増やして対応し、共通化したコードの方は分岐がたくさんといったことになってしまいます。こうなると、テストコードの可読性が極端に低下します。テストコードの良さは、ユーザーの行動が上から読み下すことができるという点にあります。テストコードに複雑な分岐が入っていないということで、読み手は自信をもって実装の意図や使用を理解することができます。特にSystemSpecにおいてはテストコードの過度な共通化は避けたほうが無難です。逆に、共通化をしようと思うエンジニアは、前述の様なユーザーのふるまいに対して鈍感なエンジニアと言えるかもしれません。SystemSpecは現実の複雑な仕様を反映させたものです。共通化するということは実装者がその複雑な仕様を理解しているということです。そして、それを確実にあとから参画したエンジニアにも伝える自信が必要です。我々はそこまで仕様を理解しているのでしょうか。今後変化していく仕様に対して追従できる柔軟なテストコードになっているでしょうか。テストコードはプロダクションコードとは明確に役割が違います。テストコードは簡潔でわかりやすく書くことが最優先です。テストコードを過度に共通化して満足しているのは一人のエンジニアのエゴと言えるかもしれません。テストは愛
ここまで、モデルのテスト、SystemSpecについて、Railsでテストを書くにあたっての考え方、注意点を記載してきました。最後に伝えたいこと。テストを書くということは愛であるということです。プロダクションコードは実装したその瞬間は完璧に理解しているかもしれません。しかし、半年後、1年後の自分がそのコードの意味を理解できていると言えるでしょうか。半年後、1年後に修正しなければならくなったときに、求められている仕様を間違えずに修正できるでしょうか。テストコードを書くということは、半年後、1年後への自分への愛です。そして、それは同時にそのコードを触る他のメンバーへの愛でもあります。例えば、リリースしてから実際にバグがおきてしまったとしましょう。バグが起きればそれは修正されます。そのときにバグが起きるケースをテストで書き残しておくのです。こうすることで、一度自分が通ったバグを他のメンバーが踏まないようにすることができます。他のメンバーが同じバグを生み出さない様に。これはすなわち愛です。
また、テストコードは非エンジニアのためにも重要です。1年前に意図して実装したコードがあり、その意図をディレクターやデザイナーなどの非エンジニアも忘れているかもしれません。仕様書に書かれていたからと言ってそれを記憶しているとは限りません。その仕様書の存在すら忘れ去られていることもあります。テストコードはまさしく実際に動くコードにて、記憶を記録するためのものであると言えます。人はどんどん忘れていく生き物です。それが人間の性です。忘れていくことで新しいことを記憶することができます。そして新たな価値を生み出すことができるのです。なので、過去のことは記録してどんどん忘れていってよいのです。テストコードを書くことで記録していきましょう。
自動テストは愛なのです。
ここの整理がきちんとできているエンジニアは意外と多くはありません。例えば高校数学で二次関数の最大最小を求める時に場合分けをした経験はありますでしょうか。あの場合分けを思い出してください。状況によって、二つの場合分けでよかったり、三つだったりしたと思います。実際の仕様ではもっと複雑になります。この複雑な場合分けを着実にかつ素早くできることがエンジニアの力量の一つの指標であると私は思います。 ↩
ホワイトボックステストについては、多くの文献がありますので、説明はそちらに譲ります。例えばQiitaの記事ではこちらの記事がわかりやすかったです。 ↩
describeには、多くの場合、テスト対象のメソッド名を記述しますが、Rubyでは、インスタンスメソッドには
#を、クラスメソッドには.を付ける文化があります。 ↩40台のベテランエンジニアの書いたコードでした。ベテランエンジニアですら、こうした実装ミスを犯すということは私のような新米エンジニアはもっと実装をミスしているということを肝に命じておかなければなりません。 ↩


- 投稿日:2019-12-22T04:11:25+09:00
No route matches [GET] 〜 について
学習初期段階のこういったエラーは見るだけでやる気無くなりますよね...
というわけでこれまで筆者が経験で見つけたエラー原因を羅列します!
(筆者のようにあまり他人に聞けない性格の初学者の方に向けて記載しています。そんなの当たり前だなどのツッコミはご遠慮ください。)
①~/railsのファイル名/config/routes.rb
このファイルの中のroot to:'posts#index'が書かれていなかった
→下記のテンプレートを使ってください
Rails.application.routes.draw do
root to: 'posts#index'
end②~/railsのファイル名/assets/viwes/posts/index.html
このファイルがないまたは内容がないょ..ゴホンゴホン
→ファイルを右クリックで作りましょう。(エディター上でもいいしファインダーからファイルの箇所に潜ってもよいです。)名前をつけるときはフォルダ名が①の#より前、ファイル名が①の#より後とぴったり同じようになるようにしてくださいあと内容の例は下記の通りです
<div class="contents row">
<% @tweets.each do |tweet| %>
<div class="content_post" style="background-image: url(<%= tweet.image %>);">
<div class="more">
<span><%= image_tag 'arrow_top.png' %></span>
<ul class="more_list">
<li>
<%= link_to '詳細', "/tweets/#{tweet.id}", method: :get %>
</li>
<% if user_signed_in? && current_user.id == tweet.user_id %>
<li>
<%= link_to '編集', "/tweets/#{tweet.id}/edit", method: :get %>
</li>
<li>
<%= link_to '削除', "/tweets/#{tweet.id}", method: :delete %>
</li>
<% end %>
</ul>
</div>
<%= simple_format(tweet.text) %>
<span class="name">
<a href="/users/<%= tweet.user.id %>">
<span>投稿者</span><%= tweet.user.nickname %>
</a>
</span>
</div>
<% end %>
</div>③誘導式の教材(問題)を解いていた時に、localhost3000につなげれば正常に接続できる(問題が解けている)状態だったのに、localhost3000/postsで接続してしまったためエラーが起きてしまっていた。
https://localhost:3000 でlocalserver(公開していない自分のパソコン内のウェブページ)に接続できるのですが、筆者はそのURLがわからず、教材のちょっと前に使ったURLをそのまま打ち込んでいたためこういった間違いを犯しました。
教材が想定していたミスの箇所ではないミスであると気づけなければ永遠に彷徨えます。なのでこういったミスを犯すこともあると知っておこうというお話です。エラー発見問題では芋づる式になっていることが多いため、接続先を間違えるとその問いを解くことができず、そのことによりその先の問題が全て解けなくなってしまうことがよく起きます。(これで筆者は丸3日間悩んでました。笑)
とりあえずこの記事は③を一番主張したくて書きました
何かの参考になればと思います


- 投稿日:2019-12-22T00:29:47+09:00
simple_nested_form_for の子 & 孫関係で動的にフォームを追加する
simple_nested_form_for で一括登録、削除をする場合、子はできるけど、孫はできるの?
多分いけます。。
現在、実装してるとこなので、実装でき次第修正してあげます。Cocoonでの記事はあるのですが、nested_form_forで記事を探してもない。
https://qiita.com/obmshk/items/0e942177d8a44091bf09
今回はこちらの記事を参考に書いています。モデリング
app/models/user.rbclass User < ApplicationRecord has_many :articles, :dependent => :destroy accepts_nested_attributes_for :articles, allow_destroy: true endapp/models/article.rbbelongs_to :user has_many :cmments, :dependent => :destroy accepts_nested_attributes_for :comments, allow_destroy: trueapp/models/comment.rbbelongs_to :article
articleをまとめて設定する為には、親要素のUserに対して、accepts_nested_attributes_forを記述。commentをまとめて設定する為には、親要素のArticleに対して、accepts_nested_attributes_forを記述。こうすることで、孫要素までnested_formを使うことが可能。
- allow_destroy: true としていないと子項目の削除ができないようになっています。controller
users_controoler.rbdef new @user = User.new @article = @user.articles.build @comment = @article.comments.build end private def user_params params.requrie(:user).permit(:name, :email, articles_attributes: [:id, :description, :_destroy, comments_attributes: [:id, :comment, :_destroy]]) end
- 合わせてストロングパラメーターの _destroy も入れておく必要がある(入れないと削除できない)
- 子要素は親要素のストロングパラメーターに含めて記述できる(孫要素もこちらにまとめて記述する)
- 基本的に、newのページ以外でも必ずbuildして、インスタンス変数を作成しておく必要がある。
new.html.haml= simple_nested_form_for @user, url: ~~~~path do |f| = f.simple_fields_for :comments do |f| = f.text_field :comments = f.link_to_remove '削除'` = f.link_to_add '追加', :shift_patterns = f.submit '保存'こんな感じで書いてやれば、ちゃんと動くはず。
あとは、createのアクションもusers_controller.rbに追加してやれば動くはず。application.js//= require jquery //= require jquery_ujs //= require jquery-ui //= require jquery-ui/i18n/datepicker-ja //= require remodal.min //= require activestorage //= require serviceworker-companion //= require jquery_nested_form ←
//= require jquery_nested_form
require jqureyのあとに入れてやらないと動かないので注意!!最後に
- 普通なら、jquery などで、追加や削除の記述をしないといけない。
- updateとcreateを同時に実行するとき調べると、かなりややこしいことをしないといけなさそうだった。
- そんなときにめちゃくちゃ便利でした。記述も簡単なので実際に使ってみるとすごい楽なので是非つかってください。
- 投稿日:2019-12-22T00:22:25+09:00
Railsで生SQLを使用してDB情報を取得する:execute, select_all, find_by_sqlの使い方
Railsで使用する生SQL
Railsにおいて、ActiveRecordのwhere等では表現できない複雑なクエリを使用してDBのデータを取得する場合、生でSQLを書く必要が出てくると思います。
しかし、AcitiveRecordで生sqlを実行するメソッドは数多くあり、用途によってどれを使用すべきか分からないという方もいるのではないでしょうか。
そこで今回はよく使用されるであろう、execute/select_all/find_by_sqlについて、どのように呼び出すのか、戻り値はなにか、どのような用途で使用すべきかについて説明します。
先に結論を書いておくと
execute -> クエリの実行
select_all -> セレクト文の結果取得
find_by_sql -> ActiveRecordオブジェクトの取得となります。詳しくは以下ご覧ください
環境
Rails 5.2.3
Ruby 2.6.0SQL
今回は全てのメソッドで同じSQLを実行します。
StatusテーブルとAccountテーブルをJOINして、それぞれのデータを取得するselect文です。
select s.text, a.username, a.updated_at from statuses s inner join accounts a on a.id = s.account_id where a.id =1では1つずつ確認します。
execute
概要
executeは、SQLの実行を行うメソッドです。(https://api.rubyonrails.org/v5.2.3/classes/ActiveRecord/ConnectionAdapters/DatabaseStatements.html#method-i-execute)
実行
ActiveRecord::Base.connection.execute(sql)のようにして実行します。res = ActiveRecord::Base.connection.execute('select s.text, a.username, a.updated_at from statuses s inner join accounts a on a.id = s.account_id where a.id = 1') (0.6ms) select s.text, a.username, a.updated_at from statuses s inner join accounts a on a.id = s.account_id where a.id = 1 => #<PG::Result:0x00007f89f93da560 status=PGRES_TUPLES_OK ntuples=5 nfields=3 cmd_tuples=5>このように
PG::Resultのインスタンスが返ってきました。このインスタンスは使用するDBによって異なりますが、中身としては実行後のstatus情報が入っています。用途
この返り値から見ても、executeはその名の通り、クエリの実行を目的としており、取得を目的としているものではありません。
そのため、insertやupdate等のクエリを直接実行したい場合に使用するメソッドと言えます。
似たような実行を目的としたメソッドに、create(レコードの作成)やtransaction(トランザクションの実行)などがあります。
(https://api.rubyonrails.org/v5.2.3/files/activerecord/lib/active_record/connection_adapters/abstract/database_statements_rb.html)select_all
概要
select_allは、実行したSelect文のレコードを取得するメソッドです。
https://api.rubyonrails.org/v5.2.3/classes/ActiveRecord/ConnectionAdapters/DatabaseStatements.html#method-i-select_all実行
実行する場合は、
ActiveRecord::Base.connection.execute(sql)というように、sqlを引数に渡して実行します。res = ActiveRecord::Base.connection.select_all('select s.text, a.username, a.updated_at from statuses s inner join accounts a on a.id = s.account_id where a.id = 1') (0.7ms) select s.text, a.username, a.updated_at from statuses s inner join accounts a on a.id = s.account_id where a.id = 1 => #<ActiveRecord::Result:0x00007f89f93fa310 @column_types= {"text"=>#<ActiveRecord::Type::Text:0x00007f89f6fa8e80 @limit=nil, @precision=nil, @scale=nil>, "username"=>#<ActiveModel::Type::String:0x00007f89f6d5ce88 @limit=nil, @precision=nil, @scale=nil>, "updated_at"=>#<ActiveRecord::ConnectionAdapters::PostgreSQL::OID::DateTime:0x00007f89f6d5c3e8 @limit=nil, @precision=nil, @scale=nil>}, @columns=["text", "username", "updated_at"], @hash_rows=nil, @rows= [["今日から始めるドン", "sobameshi0901", "2019-12-21 11:32:44.065979"], ["何しているドン", "sobameshi0901", "2019-12-21 11:32:44.065979"], ["マストドン!", "sobameshi0901", "2019-12-21 11:32:44.065979"],ActiveRecord::Result(https://api.rubyonrails.org/classes/ActiveRecord/Result.html
)のインスタンスが返ってきました。アトリビュートとして、columnsにはsqlのselectで指定したカラムの一覧を配列が、rowsにはレコードの配列が入っています。
また、カラム名をkey、値をvalueとしたハッシュを1件のレコードとした配列を取得することができるto_aメソッドが用意されていたり、Enumerableがincludeされているので、eachやmapなどのメソッドを使用することもできます。
res.to_a => [{"text"=>"今日から始めるドン", "username"=>"sobameshi0901", "updated_at"=>"2019-12-21 11:32:44.065979"}, {"text"=>"何しているドン", "username"=>"sobameshi0901", "updated_at"=>"2019-12-21 11:32:44.065979"}, {"text"=>"マストドン!", "username"=>"sobameshi0901", "updated_at"=>"2019-12-21 11:32:44.065979"} res.each{|a|puts "#{a['username']}:#{a['text']}"} sobameshi0901:今日から始めるドン sobameshi0901:何しているドン sobameshi0901:マストドン!用途
このように、select文の結果のレコードを扱いやすい形にして返してくれるのがこのselect_allメソッドです。
selectクエリを実行した状態(ActiveRecordを継承した1モデルではなく、様々なテーブルを組み合わせた結果)をそのまま扱いやすい形で欲しいという場合にはこのメソッドが使用できるでしょう。
関連するメソッドにはselect_one(1件だけ取得する)、select_values(selectの最初のカラムのレコードのみを取得する)などがあります。
(https://api.rubyonrails.org/v5.2.3/files/activerecord/lib/active_record/connection_adapters/abstract/database_statements_rb.html)find_by_sql
概要
find_by_sqlは、ActiveRecordを継承したモデルのインスタンス一覧を取得するメソッドです。
https://api.rubyonrails.org/v5.2.3/classes/ActiveRecord/Querying.html#method-i-find_by_sql実行
Status.find_by_sql('select s.text, a.username, a.updated_at from statuses s inner join accounts a on a.id = s.account_id where a.id = 1')のように、ActiveRecordモデルから実行します。res = Status.find_by_sql('select s.text, a.username, a.updated_at from statuses s inner join accounts a on a.id = s.account_id where a.id = 1') Status Load (0.9ms) select s.text, a.username, a.updated_at from statuses s inner join accounts a on a.id = s.account_id where a.id = 1 => [#<Status:0x00007f89f2f1b160 id: nil, text: "今日から始めるドン", updated_at: Sat, 21 Dec 2019 11:32:44 UTC +00:00>, #<Status:0x00007f89f2f1afa8 id: nil, text: "何しているドン", updated_at: Sat, 21 Dec 2019 11:32:44 UTC +00:00>, #<Status:0x00007f89f2f1a5a8 id: nil, text: "マストドン!", updated_at: Sat, 21 Dec 2019 11:32:44 UTC +00:00>,]このように、一覧にStatusインスタンスの一覧が配列になって返ってきます。
返ってきたStatusインスタンスは、selectで選択されたカラム(今回はtextとupdated_at)をアトリビュートとして持っています。selectに入っているカラムでも、Statusモデルのアトリビュートにもともと存在しないものは無視されます。
また、カラム名で判断されるため、今回のようにselectでaccountsテーブルのupdated_at(a.updated_at)を選択していた場合でも、Statusインスタンスのアトリビュートとなってしまうので注意してください。用途
whereなどでは表現できない/しづらい複雑なクエリで検索した上で、ActiveRecord継承モデルの一覧を取得したい場合に使用するのがよいでしょう。
ちなみに、このメソッド、定義元を見ると、select_allを使用していることが分かります。
その結果をモデルのcolumnに存在するアトリビュートのみを抽出して、インスタンスを生成していました。def find_by_sql(sql, binds = [], preparable: nil, &block) result_set = connection.select_all(sanitize_sql(sql), "#{name} Load", binds, preparable: preparable) column_types = result_set.column_types.dup attribute_types.each_key { |k| column_types.delete k } message_bus = ActiveSupport::Notifications.instrumenter payload = { record_count: result_set.length, class_name: name } message_bus.instrument("instantiation.active_record", payload) do result_set.map { |record| instantiate(record, column_types, &block) } end end終わりに
生SQLの実行メソッドはまだまだたくさんありますが、単純に実行するもの、セレクト結果をそのまま取得するもの、ActiveRecord継承モデルのインスタンスを取得するものと、基本的な使い方がわかったのではないでしょうか。
また頻繁に使用するメソッドなどがあれば追加していきます。
- 投稿日:2019-12-22T00:22:25+09:00
Railsの生SQL概要:execute, select_all, find_by_sqlの使い方を覚える
Railsで使用する生SQL
Railsにおいて、ActiveRecordのwhere等では表現できない複雑なクエリを使用してDBのデータを取得する場合、生でSQLを書く必要が出てくると思います。
しかし、AcitiveRecordで生sqlを実行するメソッドは数多くあり、用途によってどれを使用すべきか分からないという方もいるのではないでしょうか。
そこで今回はよく使用されるであろう、execute/select_all/find_by_sqlについて、どのように呼び出すのか、戻り値はなにか、どのような用途で使用すべきかについて説明します。
先に結論を書いておくと
execute -> クエリの実行
select_all -> セレクト文の結果取得
find_by_sql -> ActiveRecordオブジェクトの取得となります。詳しくは以下ご覧ください
環境
Rails 5.2.3
Ruby 2.6.0SQL
今回は全てのメソッドで同じSQLを実行します。
StatusテーブルとAccountテーブルをJOINして、それぞれのデータを取得するselect文です。
select s.text, a.username, a.updated_at from statuses s inner join accounts a on a.id = s.account_id where a.id =1では1つずつ確認します。
execute
概要
executeは、SQLの実行を行うメソッドです。(https://api.rubyonrails.org/v5.2.3/classes/ActiveRecord/ConnectionAdapters/DatabaseStatements.html#method-i-execute)
実行
ActiveRecord::Base.connection.execute(sql)のようにして実行します。res = ActiveRecord::Base.connection.execute('select s.text, a.username, a.updated_at from statuses s inner join accounts a on a.id = s.account_id where a.id = 1') (0.6ms) select s.text, a.username, a.updated_at from statuses s inner join accounts a on a.id = s.account_id where a.id = 1 => #<PG::Result:0x00007f89f93da560 status=PGRES_TUPLES_OK ntuples=5 nfields=3 cmd_tuples=5>このように
PG::Resultのインスタンスが返ってきました。このインスタンスは使用するDBによって異なりますが、中身としては実行後のstatus情報が入っています。用途
この返り値から見ても、executeはその名の通り、クエリの実行を目的としており、取得を目的としているものではありません。
そのため、insertやupdate等のクエリを直接実行したい場合に使用するメソッドと言えます。
似たような実行を目的としたメソッドに、create(レコードの作成)やtransaction(トランザクションの実行)などがあります。
(https://api.rubyonrails.org/v5.2.3/files/activerecord/lib/active_record/connection_adapters/abstract/database_statements_rb.html)select_all
概要
select_allは、実行したSelect文のレコードを取得するメソッドです。
https://api.rubyonrails.org/v5.2.3/classes/ActiveRecord/ConnectionAdapters/DatabaseStatements.html#method-i-select_all実行
実行する場合は、
ActiveRecord::Base.connection.execute(sql)というように、sqlを引数に渡して実行します。res = ActiveRecord::Base.connection.select_all('select s.text, a.username, a.updated_at from statuses s inner join accounts a on a.id = s.account_id where a.id = 1') (0.7ms) select s.text, a.username, a.updated_at from statuses s inner join accounts a on a.id = s.account_id where a.id = 1 => #<ActiveRecord::Result:0x00007f89f93fa310 @column_types= {"text"=>#<ActiveRecord::Type::Text:0x00007f89f6fa8e80 @limit=nil, @precision=nil, @scale=nil>, "username"=>#<ActiveModel::Type::String:0x00007f89f6d5ce88 @limit=nil, @precision=nil, @scale=nil>, "updated_at"=>#<ActiveRecord::ConnectionAdapters::PostgreSQL::OID::DateTime:0x00007f89f6d5c3e8 @limit=nil, @precision=nil, @scale=nil>}, @columns=["text", "username", "updated_at"], @hash_rows=nil, @rows= [["今日から始めるドン", "sobameshi0901", "2019-12-21 11:32:44.065979"], ["何しているドン", "sobameshi0901", "2019-12-21 11:32:44.065979"], ["マストドン!", "sobameshi0901", "2019-12-21 11:32:44.065979"],ActiveRecord::Result(https://api.rubyonrails.org/classes/ActiveRecord/Result.html
)のインスタンスが返ってきました。アトリビュートとして、columnsにはsqlのselectで指定したカラムの一覧を配列が、rowsにはレコードの配列が入っています。
また、カラム名をkey、値をvalueとしたハッシュを1件のレコードとした配列を取得することができるto_aメソッドが用意されていたり、Enumerableがincludeされているので、eachやmapなどのメソッドを使用することもできます。
res.to_a => [{"text"=>"今日から始めるドン", "username"=>"sobameshi0901", "updated_at"=>"2019-12-21 11:32:44.065979"}, {"text"=>"何しているドン", "username"=>"sobameshi0901", "updated_at"=>"2019-12-21 11:32:44.065979"}, {"text"=>"マストドン!", "username"=>"sobameshi0901", "updated_at"=>"2019-12-21 11:32:44.065979"} res.each{|a|puts "#{a['username']}:#{a['text']}"} sobameshi0901:今日から始めるドン sobameshi0901:何しているドン sobameshi0901:マストドン!用途
このように、select文の結果のレコードを扱いやすい形にして返してくれるのがこのselect_allメソッドです。
selectクエリを実行した状態(ActiveRecordを継承した1モデルではなく、様々なテーブルを組み合わせた結果)をそのまま扱いやすい形で欲しいという場合にはこのメソッドが使用できるでしょう。
関連するメソッドにはselect_one(1件だけ取得する)、select_values(selectの最初のカラムのレコードのみを取得する)などがあります。
(https://api.rubyonrails.org/v5.2.3/files/activerecord/lib/active_record/connection_adapters/abstract/database_statements_rb.html)find_by_sql
概要
find_by_sqlは、ActiveRecordを継承したモデルのインスタンス一覧を取得するメソッドです。
https://api.rubyonrails.org/v5.2.3/classes/ActiveRecord/Querying.html#method-i-find_by_sql実行
Status.find_by_sql('select s.text, a.username, a.updated_at from statuses s inner join accounts a on a.id = s.account_id where a.id = 1')のように、ActiveRecordモデルから実行します。res = Status.find_by_sql('select s.text, a.username, a.updated_at from statuses s inner join accounts a on a.id = s.account_id where a.id = 1') Status Load (0.9ms) select s.text, a.username, a.updated_at from statuses s inner join accounts a on a.id = s.account_id where a.id = 1 => [#<Status:0x00007f89f2f1b160 id: nil, text: "今日から始めるドン", updated_at: Sat, 21 Dec 2019 11:32:44 UTC +00:00>, #<Status:0x00007f89f2f1afa8 id: nil, text: "何しているドン", updated_at: Sat, 21 Dec 2019 11:32:44 UTC +00:00>, #<Status:0x00007f89f2f1a5a8 id: nil, text: "マストドン!", updated_at: Sat, 21 Dec 2019 11:32:44 UTC +00:00>,]このように、一覧にStatusインスタンスの一覧が配列になって返ってきます。
返ってきたStatusインスタンスは、selectで選択されたカラム(今回はtextとupdated_at)をアトリビュートとして持っています。selectに入っているカラムでも、Statusモデルのアトリビュートにもともと存在しないものは無視されます。
また、カラム名で判断されるため、今回のようにselectでaccountsテーブルのupdated_at(a.updated_at)を選択していた場合でも、Statusインスタンスのアトリビュートとなってしまうので注意してください。用途
whereなどでは表現できない/しづらい複雑なクエリで検索した上で、ActiveRecord継承モデルの一覧を取得したい場合に使用するのがよいでしょう。
ちなみに、このメソッド、定義元を見ると、select_allを使用していることが分かります。
その結果をモデルのcolumnに存在するアトリビュートのみを抽出して、インスタンスを生成していました。def find_by_sql(sql, binds = [], preparable: nil, &block) result_set = connection.select_all(sanitize_sql(sql), "#{name} Load", binds, preparable: preparable) column_types = result_set.column_types.dup attribute_types.each_key { |k| column_types.delete k } message_bus = ActiveSupport::Notifications.instrumenter payload = { record_count: result_set.length, class_name: name } message_bus.instrument("instantiation.active_record", payload) do result_set.map { |record| instantiate(record, column_types, &block) } end end終わりに
生SQLの実行メソッドはまだまだたくさんありますが、単純に実行するもの、セレクト結果をそのまま取得するもの、ActiveRecord継承モデルのインスタンスを取得するものと、基本的な使い方がわかったのではないでしょうか。
また頻繁に使用するメソッドなどがあれば追加していきます。
- 投稿日:2019-12-22T00:13:36+09:00
heroku run rails db:migrate:status のコマンドの意味
目的
- 表題のコマンドをあまり理解せず実行していたのでまとめる。
- コミュニティやtwitterで教えていただいた内容を忘れないようにまとめる。
heroku run rails db:migrate:statusとは
- herokuサーバでのマイグレーションステータスを出力するコマンドである。
- ちなみにherokuサーバへのマイグレーションを行うコマンドは
$ heroku run rails db:migrateである。結論
コマンドを分解してみる
heroku runの意味を下記に記す。
- run a one-off process inside a Heroku dyno→「 Heroku dyno内で1回限りのプロセスを実行する。」(コマンド
$ heroku --helpで調べた。)- dynoはアプリを実行するためのコンテナのことらしい、「そのコンテナ内で後述するプロセスを実行するよ〜」って感じ。
rails db:migrate:statusの意味を下記に記す。
- 「マイグレーションのステータス(upまたはdown)を表示する。」(こちらのリンク先に記載があったhttps://railsguides.jp/active_record_migrations.html)
ちなみに
- Rails5以降は
railsコマンドを実行すればrakeコマンドを探して実行してくれるらしい。- なので下記コマンドは同じ挙動をする。
$ heroku run rails db:migrate:status $ heroku run rake db:migrate:statusだけど
railsコマンドを実行するとrakeまでコマンドを探しに行って実行してくれる。rakeコマンドを実行してもrailsコマンドを探しに行ってくれない。参考にしたリンクを載せる
rails db:migrate:statusコマンドの説明
Rakeコマンドの実行
dynoの説明
謝辞
- 本投稿内容はTwitter、コミュニティのslack、キャリアアドバイザーさんからいただいた知識です。
- 毎度知恵をおお貸しいただき本当にありがとうございます。