- 投稿日:2019-12-22T23:58:46+09:00
トランザクションとロックと二重課金
この記事は、 CAMエンジニア Advent Calendar 2019 23日目の記事です。
昨日は @cotsupa さんのShell Scriptで検索コマンドを作ってみましたでした。はじめに
こんにちは、@takehziです。
業務で二重課金を防止するタスクをやったので、その備忘録になります。背景としては、ユーザーが決済ボタンをポチポチっと二回押してしまった際、
決済処理が二回走ってしまうという状態だったので、その改修をしました。
(フロントの方でも制御する処理は実装されています)トランザクションとは
トランザクションについてふわっとした理解しかなかったので、まずそこから調べて見ました。
簡単に言うと、トランザクションとは連続したDB操作(1つ以上のsql操作)をひとまとまりとして扱う作業単位のことです。DBはsqlを実行するだけで、どこからどこまでがワンセットの処理なのかはわかりません。
なのでこちら側から(DBに対して)トランザクションを設定することで、DB側はここからここまでがワンセットなんだなと認識でき、それらを1つの処理(グループ)として扱います。トランザクションの結果は
・コミット(commit)
・ロールバック(rollback)
の2つしかありません。トランザクション内のすべての処理が成功したら、commitを発行して関連するすべてのテーブルへの変更を有効にしてトランザクションを終了し、
もし処理のどれかが失敗したら、rollbackを発行して関連するすべてのテーブルへの変更を無効にし(トランザクション処理に入る前の状態にして)トランザクションを終了します。
ロック
二重課金の防止策として、DB対してロック制御を行う必要がありますが、
今回は「SELECT...FOR UPDATE」を用いて、占有ロック(悲観ロック)を行うことにしました。また、二重課金が行われている最中に別のユーザーが決済を行う可能性は十分にあるので、
行ロックがかかるようにします。行ロックをかけるにはインデックスを貼る必要があるので(あるいはプライマリーキーを条件に入れる)、
あらかじめインデックスを貼っておく必要もあります。試しにSELECT...FOR UPDATEを使ってみます。
mysql> select * from user; +----+--------------+------+ | id | name | age | +----+--------------+------+ | 1 | takehzi | 25 | | 2 | komatsunana | 23 | | 3 | yoshiokariho | 26 | +----+--------------+------+ 3 rows in set (0.00 sec)このテーブルに対してSELECT...FOR UPDATEを使い、takehziのageを25から20に変更します。
A) ================================== //トランザクション開始 mysql> begin; Query OK, 0 rows affected (0.00 sec) //id=1のレコードを取得する際に行ロックをかける。 mysql> select * from user where id=1 for update; +----+---------+------+ | id | name | age | +----+---------+------+ | 1 | takehzi | 25 | +----+---------+------+ 1 row in set (0.00 sec) =================================== B) mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> select * from user where id=1 for update; //...待機中Aで行ロックがかかっているため、Bは待機中になります。
そして、Aでレコードを更新してコミットすると、ロックが解除されBのselect文が走ります。================================ A) //ageを25から20に変更 mysql> update user set age="20" where id=1; Query OK, 1 row affected (0.01 sec) Rows matched: 1 Changed: 1 Warnings: 0 //トランザクション終了 mysql> commit; Query OK, 0 rows affected (0.00 sec) ============================== B) mysql> select * from user where id=1 for update; +----+---------+------+ | id | name | age | +----+---------+------+ | 1 | takehzi | 20 | +----+---------+------+ 1 row in set (9.26 sec)AでcommitしたタイミングでBのsqlが実行されます。
Bで取得した値ですが、25ではなく、ちゃんと20になっていますね。このSELECT...FOR UPDATEを利用して二重課金を制御しました。
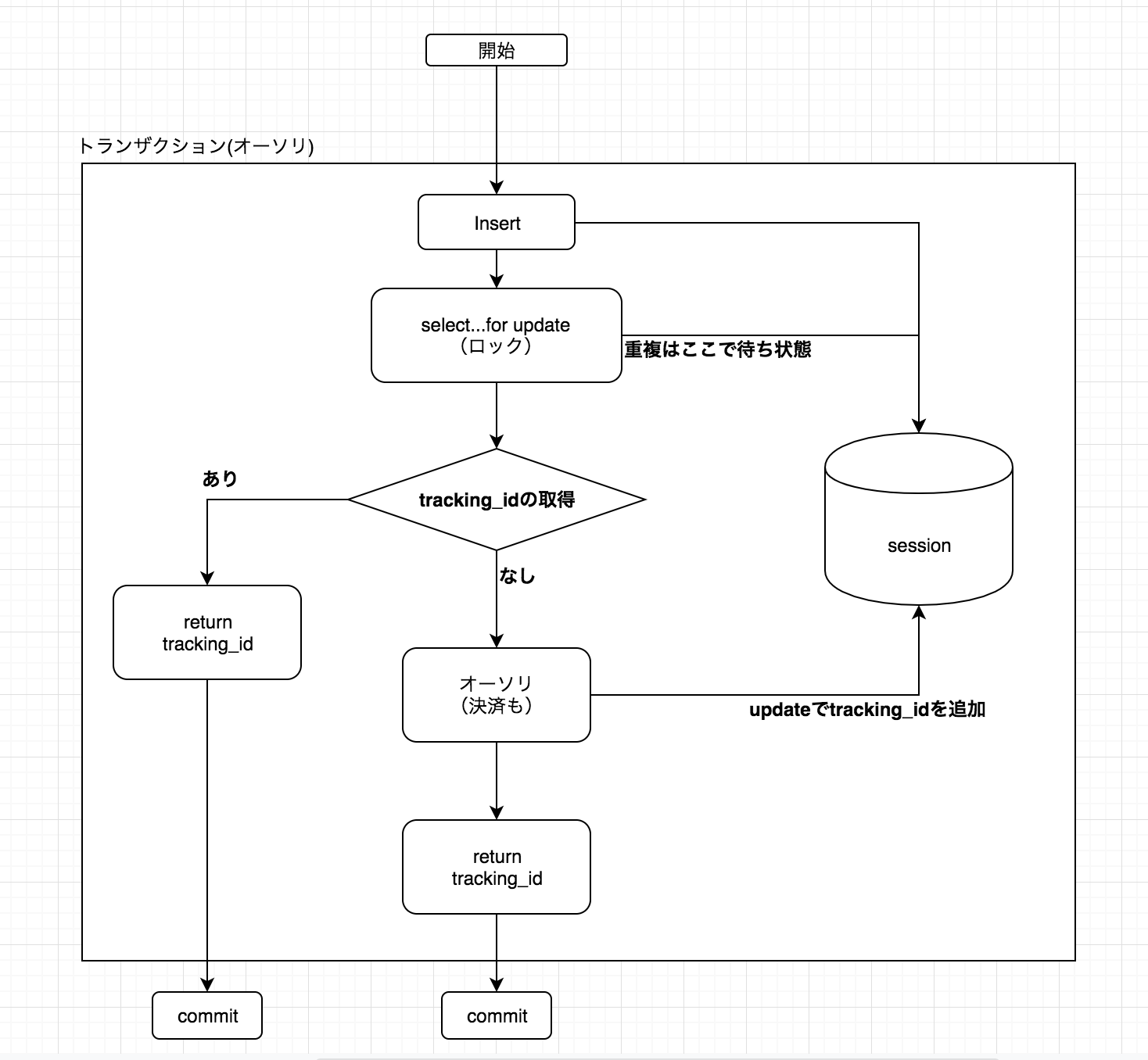
二重課金問題と対応策
前提条件
・決済が完了したらtrackingIdが発行される。
・authorization(決済を行うメソッド)の処理は結果的にtrackingIdを返す。これらの条件を踏まえた上でsessionテーブルを設けて二重課金の制御を行うことにしました。
trackingIdがあるかどうかで制御しています。
アーキテクチャ図は以下になります。
実際のコードです。
public void tempInsert(String serviceName, AmazonPayChargeParam param){ assert StringUtils.isNoneBlank(serviceName); assert StringUtils.isNoneBlank(param.getReferenceId()); assert StringUtils.isNoneBlank(param.getCustCode()); assert StringUtils.isNoneBlank(param.getItemId()); try{ AmazonPaySession session = new AmazonPaySession(); session.setReferenceId(param.getReferenceId()); session.setCustCode(param.getCustCode()); session.setItemId(param.getItemId()); session.setServiceName(serviceName); amazonPaySessionRepository.insert(session); }catch (DuplicateKeyException dke){ //重複insertによる一位制約エラーを制御。 auditLogHelper.loggingParam(dke.getMessage()); } }まず仮データとしてsessionテーブルにinsertを処理を行います。(この時点でtrackingIdはnull)
public String authorization(Long apiAuthId, String serviceName, AmazonPayChargeParam param) { ChargeRequest chargeRequest = getChargeRequest(param); String trackingId = chargeRequest.getChargeReferenceId(); AuthorizationDetails authDetails = null; switch(chargeRequest.getType()) { //...略 case BILLING_AGREEMENT_ID: //ここで行ロックをかける.重複側はtrackingIdが取得できる。 AmazonPaySession sessionData = amazonPaySessionRepository.tempSelectForUpdate(serviceName, param.getReferenceId(), param.getCustCode(), param.getItemId()); //重複側はtracking_idを取得して早期リターン。 if(Objects.nonNull(sessionData.getTrackingId())){ return sessionData.getTrackingId(); } //課金処理 authDetails = execBillingAgreement(serviceName, param, chargeRequest, apiAuthId, authDetails, trackingId, sessionData); //...略 //最終的にtrackingIdを返す return trackingId; }ここで、trackingIdの有無を判断し、
trackingIdがあれば(重複側)そのままそのtrackingIdを早期リターンします。「trackingIdが無い=まだ決済が行われていない」ので、そのまま決済処理が行われ、
発行されたtrackingIdをsessionテーブルに追加するようにします。このようにして、SELECT...FOR UPDATEを用いて重複課金を制御しました。
終わりに
かなり雑に書いてしまいましたが(後回しにしすぎて時間がなかった...)、
実際はもっと考慮すべき点があります。・トランザクションの分離レベルはどうするのか(リード現象をどこまで許容するか)
・今回はREPEATABLE-READでファントムリードを許容しています。
・ACID特性を担保できているか(独立性は作る物によって落とし所が違うかと思います)
・ちゃんと行ロックになっているか。
・デッドロックが起きないか。などなど、他にもシステムレベルやコードレベルで見た場合の考慮すべき点はまだまだありますが、
今回の改修における認識をざっとまとめて見ました。正直まだまだ理解が曖昧なところがあるので、引き続き学習を頑張っていきたいと思います!
また、今回こうやって記事を書こうとした際に、思ったよりも認識が甘かったということに気づいたので、
こういったアウトプットを今後もっと積極的に行っていきたいと思います!
- 投稿日:2019-12-22T23:03:53+09:00
java 条件分岐
今日は条件分岐について書きます。
条件分岐とは
条件を満たした場合と満たさなかった場合の処理を行う
コードのことif文
最も基本的な条件分岐式
基本形はこのような形です。
if()の中に条件式(a=1,a>2など)を設定し
成立した場合最初の{}の中の処理を行い
成立しなかった場合else後の{}の中の処理を行います。※else以降のコードがなくても動作しますが
何も出力されないだけなので。原則設定します。if文基本構文if(条件){ //条件と合致した場合の処理 }else{ //条件と合致しなかった場合の処理 }例文はこちら
numberを1と設定してるので
正解と出力
1以外の場合が設定されると
不正解
さらに不正解と出力されます。if文public class Main { public static void main(String[] args) { int number = 1; if(number == 1){ System.out.println("正解"); }else{ System.out.println("不正解"); System.out.println("さらに不正解"); } } }else if文 (条件の追加)
さらに細かい条件分岐をしたい場合はelseif文を間に書きます。
if()を条件1とし
else if()を条件2とします。
さらに続けてelse if()を書けば
条件3
同上
条件4
と増やして行けます。if文基本構文if(条件1){ //条件1と合致した場合の処理 }else if(条件2){ //条件2と合致した場合の処理 }else{ //条件1,2どちらとも合致しなかった場合の処理 }例文はこちら
numberを1と設定してるので
スキ!と出力
numberが2と設定されたら
❓と出力
1以外の場合が設定されると
キライと出力されます。if文public class Main { public static void main(String[] args) { int number = 1; if (number == 1) { System.out.println("スキ!"); // 条件1が成立した場合の処理 }else if(number ==2){ System.out.println("❓") ; //条件2が成立した場合の処理 }else { System.out.println("キライ"); // 条件式が成立しなかったときの処理 } } }比較演算子
条件という単語がでてきていますが。
その中で数値を扱う場合の処理を紹介します。ざっくりいうと下のように書きます。
==で同じ
!=でそれ以外など
珍しい形が多いので注目すべきです。比較演算子if(例==1)//等しい場合 if(例>1)//1を超える場合 if(例>=1)//1以上の場合 if(例!=1)//1以外の場合一覧を作ったので参考までに見て下さい。
比較演算子 条件成立する時 a==b aとb等しい a>b aがbを超える場合 a<b aがb未満の場合 a>=b aがb以上の場合 a<=b aがb以下の場合 a!=b aがb以外の場合
- 投稿日:2019-12-22T22:37:24+09:00
Java8 リスト変換を Stream map で
リスト変換について、for 文を使う場合と Stream map を使う場合で比較していきます。
以下のリストを使います。stream-map.javafinal List<String> months = Arrays.asList("January", "February", "March", "April", "May", "June", "July", "Augast", "September", "October", "November", "December");それぞれの要素の一文字目だけで構成されるリストを作ります。
1. for 文を使う
一文字目を格納する空のリストを宣言し、for ループ内で一文字ずつ格納しています。
for.javafinal List<String> firstChars = new ArrayList<>(); for (String c : months) { firstChars.add(c.substring(0,1)); } for (String fc : firstChars) { System.out.print(fc); }以下のように出力されます。
JFMAMJJASOND2. forEach 文を使う
関数型に書き換えたものの、空のリストをプログラマ側で用意する必要があります。
forEach.javafinal List<String> firstChars = new ArrayList<>(); months.forEach(c -> firstChars.add(c.substring(0,1))); firstChars.forEach(System.out::print);3. Stream map() を使う
空のリストを用意するステップはなく、リストから最初の一文字ずつ取り出した結果が、そのまま新しいリストに格納されるように見えます。
Stream の map() メソッドは連続した入力を連続した出力に変換します。stream-map.javafinal List<String> firstChars = months.stream().map(c -> c.substring(0,1)).collect(Collectors.toList()); firstChars3.forEach(System.out::print);map() メソッドは、入力のリストと出力のリストの要素数が同じになることを保証しますが、データ型については同じになるとは限りません。
もし、各要素の文字数を取得したい場合、文字列型から数値型に変換されて出力されます。以下は変換後のリストは用意せずに、forEach で要素の内容を直接出力しています。
その程度であれば、1行で記述が可能となります。stream-map2.javamonths.stream().map(c -> c.length()).forEach(cnt -> System.out.print(cnt + " ")); // 7 8 5 5 3 4 4 6 9 7 8 8 と出力される
- 投稿日:2019-12-22T22:27:47+09:00
OutsystemsでCSVの読み込みと出力をしてみた
はじめに
会社のITメンバーで参加している2019年のアドベントカレンダーに、自身2つ目の記事を投稿します!
自己紹介も兼ねて、前回書いた記事はこちらになります。
https://qiita.com/tom-k7/items/d8ef19dccb42891a0698今回もOutsystemsについて書きます。
今はちょうどOutsystemsでCSV変換ツール(Webアプリ)を開発しているので、
OutsystemsでCSVの読み込み・出力の実装方法、あとは開発中にぶち当たった壁について共有させていただきます。やりたいこと
今開発しているツールでやりたいこととしては、
いろんな他社さんのサイトからダウンロードしたCSVファイルを
社内で使ってるシステムにインポートできるフォーマットのCSVファイルに変換したい。
なので、ダウンロードしたCSVファイルを読み込んで、
ごにょごにょ変換して新たなCSVファイルを出力するということをOutsystemsで実現します。Forge
CSVファイルの読み込み・出力にはCSVUtilのForgeコンポーネントを使います。
https://www.outsystems.com/forge/component-overview/636/csvutilこちらをダウンロードし、ServiceStudioにインストールしてDependencyに追加してください。
画面の開発
CSV処理をやる前に画面を作っちゃいます。
CSVファイルのアップロード
まずは読み込む対象のCSVファイルをアップロードする必要があります。
方法は2つあります。
①Uploadを使う
②RichWidgets\Popup_Uploadを使う
今回は①のほうが良いということになったので、Uploadを使います。
※ちなみにUploadウィジェットは、ListRecordsのようなリストの中では動かないのでご注意ください。変換処理を行うサーバアクションを呼ぶためのボタンを配置
ConvertボタンのDestinationに変換処理を行うConvertサーバアクションを指定し、
そのサーバアクション内で変換処理を行います。
CSV読み込み処理の実装
さて、ここからは本題のCSVの処理です。
まずはCSVファイルの読み込みを実装します。LoadConfigの設定
CSV読み込み時の設定をするためのCSVLoadConfig型のローカル変数を定義し、Assignで設定します。
主な設定内容は以下の通り。
- Encode:CSVファイルの文字コード。utf-8やshift-jisなどを設定。
- IsSkipHeader:CSVファイルにヘッダー行がある場合はTrue、ない場合はFalse。
- IsIgnoreColumnChange:カラム数が合わない場合にエラーとする場合はFalse、エラーとしない場合はTrue。
- FieldDelimiter:カラムの間の区切り文字。複数文字入れられるが、先頭の1文字しか適用されない。
- IsDisableDoubleQuote:カラムがダブルクオーテーションで囲われてる場合はFalse、そうでない場合はTrue。
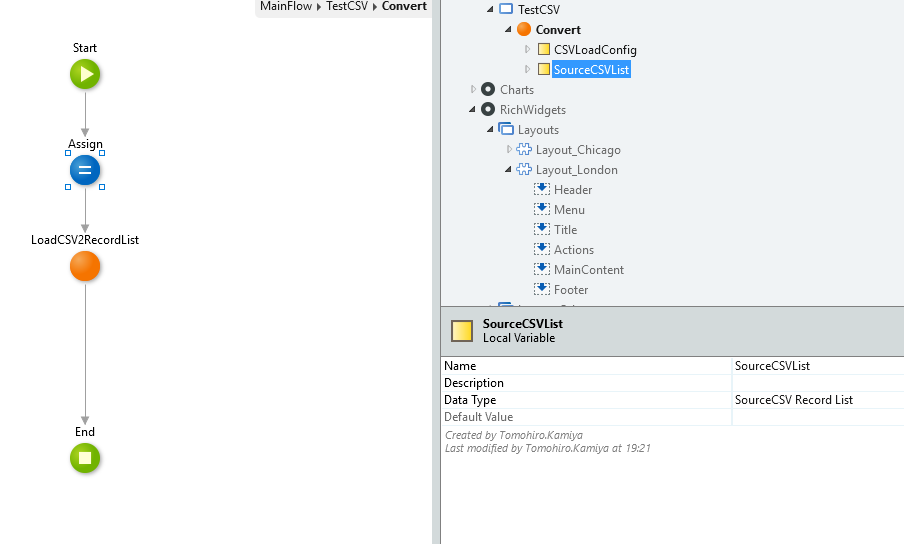
読み込み用RecordListを定義
CSVを読み込んだ結果を格納するEntity/StructureのRecordのリストを、ローカル変数で定義します。
今回は自作のSourceCSVというStructureのRecordListにしています。
※StructureのListでなく、StructureのRecordのListにしないとうまくいきません。Extension処理の呼出し
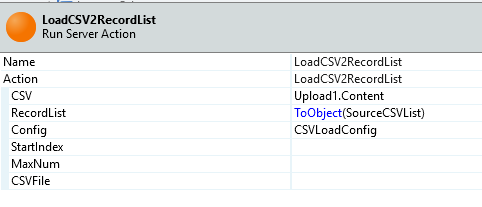
ForgeのCSVUtilで定義されているLoadCSVRecordListサーバアクションを呼び出し、
引数には画面で作ったUploadのContentと、CSVLoadConfigのローカル変数、
Entity/StructureのRecordListをToObject()で変換した結果をそれぞれ設定します。
これで読み込みは完了です。CSV出力処理の実装
続いて、CSV出力のほうも実装していきます。
ExportConfigの設定
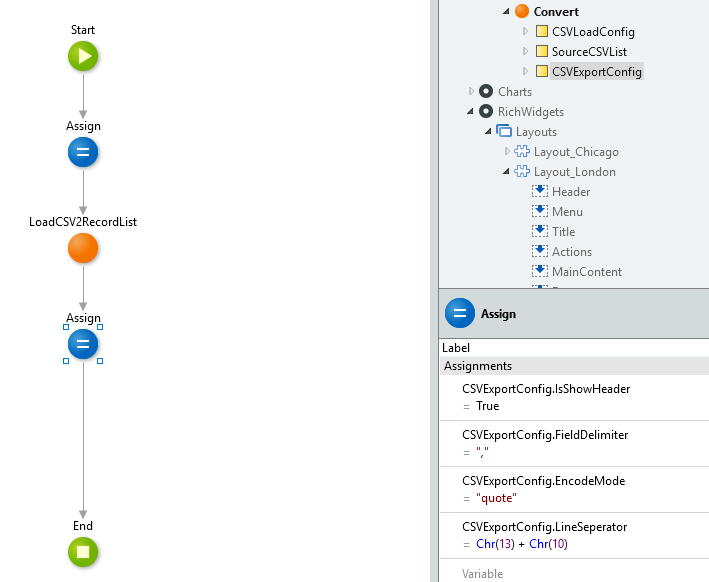
CSV出力時の設定をするためのCSVExportConfig型のローカル変数を定義し、Assignで設定します。
主な設定内容は以下の通り。
- IsShowHeader:CSVファイルにヘッダー行を入れる場合はTrue、入れない場合はFalse。
- FieldDelimiter:カラムの間の区切り文字。複数文字入れられるが、先頭の1文字しか適用されない。
- EncodeMode:カラムをダブルクオーテーションで囲うか否か。auto/quote/noquote/noquote_nocheckのいずれかを文字列で設定。
- LineSeparator:改行コード。CRだとChr(13)、LFだとChr(10)、CRLFはChr(13) + Chr(10)と設定。
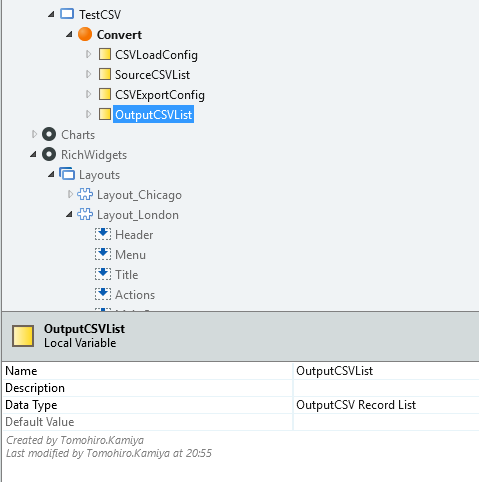
出力用RecordListを定義
出力するCSVのデータを格納するためのEntity/StructureのRecordのリストを、ローカル変数で定義します。
画像は自作のOutputCSVというStructureのRecordListにしています。
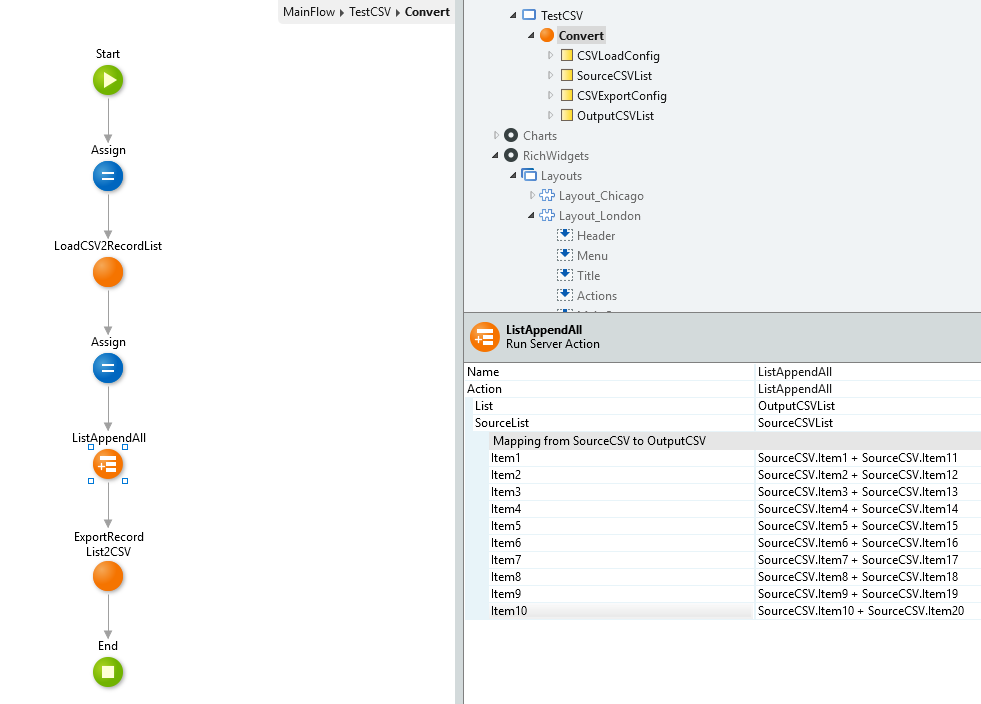
出力用RecordListに読み込んだデータを変換して設定
↑で定義した出力用RecordListに対して、Loadしたデータが入っているRecordListの全件を設定します。
その際に値を変換したり、結合したり、不要なものは捨てたりして出力用に設定すれば変換ができますね。
画像ではListAppendAllで単純に項目の結合だけしてますが、実際にはここでいろんな変換をします。
かなり複雑なことをやる場合はForEachでループするケースもあると思います。Extension処理の呼出し
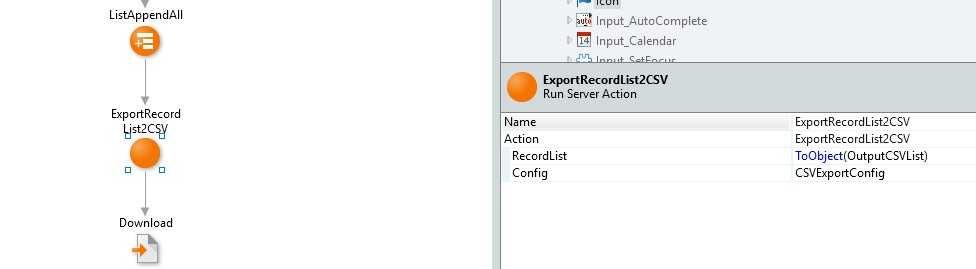
CSVUtilで定義されているExportRecordList2CSVサーバアクションを呼び出し、
引数にはEntity/StructureのRecordListをToObject()で変換した結果とCSVExportConfigのローカル変数をそれぞれ設定します。
変換後CSVファイルの出力(ダウンロード)
最後にExportRecordList2CSVで作成されたCSVデータをDownloadウィジェットに渡して終了です。
開発中に引っかかった罠
以上が実装方法になりますが、その他CSVUtilを使っててぶち当たった壁について共有したいと思います。
出力時にダブルクオーテーションで囲う方法がわかりづらい
「ExportConfigの設定」でダブルクオーテーションで囲う方法はすでに記載済みですが、
そこにたどり着くまでに結構かかりました。
だって、その項目の名前EncodeModeて。。
文字コードのことかと思うやん。わからんて。。
ていう愚痴でしたwwちなみにCSVExportConfig.EncodeModeに"quote"を指定するとダブルクオーテーションで囲ってくれます!
Export処理でNullReferenceException
CSVUtilのExportRecordList2CSVサーバアクションを呼び出した際にこんなエラーが出ました。
Object reference not set to an instance of an object.
NullReferenceExceptionです。Javaでいうヌルポですね。
CSVの項目としては基本型しか使ってないので、Outsystemsで基本型でNullってあるんだっけ?って感じでした。それでこのエラーはこれ以上詳細にはログに出ないので、いろいろ試してもうまくいかず途方に暮れた結果、
Extensionの中見るしかないな!ってなりました。
でExtensionダウンロードして、VisualStudioでsln開いてソース追っても原因わからず。
じゃあってことで、実際に渡してたデータをC#上で作って実行してみました!(^^)!(これが地味にめんどかった)やってみた結果、渡したデータのカラムが1個足りてないせいでNullReferenceExceptionになっていたことが判明。
そのカラム何だろうと思ってたら、データ変換するときに特殊なことをしているカラムでした。説明が意味不明だったらすいません
例えば読み込んだデータの値が"1"なら、変換後は"大学院"とするみたいなものをJSONファイルにKeyとValueのペアとして定義し、
JSONファイルをResourcesとしてモジュールにインポート。
そのJSONファイルをJSONDeserializeで読み込み、ForgeのHashTableを使ってKeyとValueのペアとしてメモリに格納しておき、
変換時はそのHashTableからgetした値を設定するという処理にしていました。ForgeのHashable:https://www.outsystems.com/forge/component-overview/21/hashtable
それが、JSONで定義したKeyにはないデータ(↑のJSONだと"5"とか空文字とか)が読み込むCSVに入っていたため、getの結果がNullとなり、
それをExportRecordList2CSVに渡したためにNullReferenceExceptionとなったということでした。Outsystemsで普通に実装してたらText型にNullは入らないのですが、
Extensionを介すとNullが入るんだなって知り、勉強になったなと思いました。最後に
OutsystemsでのCSV読み込み・出力について説明しました。
これからCSVUtilを使う方、同じ壁にぶつかった方の一助になればと思っています。





- 投稿日:2019-12-22T21:22:12+09:00
Javaのswitch文
Javaを使った条件分岐
if文を用いると
class Main { public static void main(String[] args) { int number = 12; if(number % 3 == 0){ System.out.println("3で割り切れます"); else if(number % 3 == 1){ System.out.println("3で割ると1余ります"); else System.out.println("3で割ると2余ります"); } } }swich文を用いると
※ 各caseの最後に、break;をつけるのを忘れずに!
忘れると、合致したcaseの処理を行った後、その次のcaseの処理も実行してしまう。class Main { public static void main(String[] args) { int number = 12; switch(number % 3){ case 0: System.out.println("3で割り切れます"); break; case 1: System.out.println("3で割ると1余ります"); break; case 2: System.out.println("3で割ると2余ります"); break; } } }
- 投稿日:2019-12-22T20:37:31+09:00
OCJP Silver SE 11を無事取得できたのでそのまとめ
はじめに
Javaの知識を体系的に取得したかったので、OCJP Silver SE11を受けてみた。
OCJP Silver SE 11のレベル感
オラクルのサイトには以下のように記載されていました。
上級者の指導のもと開発作業ができる開発初心者1
受けた人のレベル
実務経験3年未満。Java歴は1年経つか経たないかくらい。実務経験3年未満だけど実年齢はそんな若くない。JavaのBronzeとかITパスポートとかCCENTとかは持っている。そんなレベル。
結果
受験日を引き伸ばした結果
pass
受けてみて
資格を受けてみてよかった
曖昧な部分が明瞭になったり、11の機能などを知る事ができたので。
自分の場合は資格取得を目標に知識を積み上げていくのが性に合うかも学習期間
真剣に取り組んだのは2週間くらい。
資格取得に向けてやったこと
1.黒本を購入。
2.1章〜11章を読む。
3.総仕上げ問題を解く。このとき、以下の3点に気をつけて勉強した。(つもりでいる)
- 知識があいまいだったり自信がない箇所は、Javaの本を読んでから黒本に取り掛かった。(スッキリわかるJavaとか独習Javaとか。自分に合う本を読めばいいかと)
- 解説をよく読んだ。
- 実際に問題のプログラムを書いて動作を確認。(すべてではないが)
気になるところ
自己投資とはいえ受験料がお高い。
まとめ
受かってよかった…
次はOracle MasterのBronzeかな。

- 投稿日:2019-12-22T19:55:04+09:00
PHP を JVM 言語にするには?
はじめに
みなさんは JVM を知っていますか?そして JVM を実装したことがありますか?さらに、 JVM 言語そのものを実装したことがありますか?
このアドベントカレンダーは PHP アドベントカレンダー並びに言語実装のアドベントカレンダー 25 日目になっており、記事の内容は PHP を JVM 言語そのものにするといった内容になっています。
Java は JDK 9 から構成されるバイナリが大きく変わっており書籍に載せたいくらいの規模になるので、今回については JDK 8 として書かせていただきます。そもそもなんで JVM なのか?
JVM は Java Virtual Machine の略で、 Oracle から公式に Java Virtual Machine Specification という名前のドキュメントが出ています。
そのため、書いてあることがどのような方法でも理解できれば、誰もが作りやすい物といっても過言ではないかと思います。
関連する登壇
過去に PHP と JVM を絡めた登壇をいくつかしているので、興味のある方は見てみてください。
プロジェクトについて
100% PHP で JVM の実装及び PHP そのものを JVM 言語化する実装を php-java というリポジトリで行っています。
こちらも興味がある方は見てみてください。そして、コントリビュートしてくれるとうれしいです⭐PHP そのものを JVM 言語にしてく
さて本題に入り PHP を JVM 言語にしていきます。
PHP のコードを AST (Abstract Syntax Tree, 抽象構文木) に変換する
AST (Abstract Syntax Tree) とは抽象構文木のことを指しますが、正直初見で AST や抽象構文木この単語を見ても何を言っているんだ?となるので、どういうものかを軽く説明します。
Wikipedia によると
抽象構文木(英: abstract syntax tree、AST)は、通常の構文木(具象構文木あるいは解析木とも言う)から、 言語の意味に関係ない情報を取り除き、意味に関係ある情報のみを取り出した(抽象した)木構造の木である。と書いてありますが、よくわからない。これをとてつもなく簡単に言い換えると、PHP 限定で言えば スペース だとか ブレース ({, }) とかを取り除いて、ノード上、つまりそのステートメントを階層とオブジェクトで表現したものです。
例えば
<?php namespace A; class SomethingClass { }というコードがあったときに、これを下記のようにツリー状にしたものを AST とだと思えば大丈夫です。
+ Namespace + Name + A + Statements + Class + Name + SomethingClass + Statements + ...上記のような状態にしたもので、PHP 言語をパースする方法としては
nikic/php-parserを使います。ちなみに余談ですが
nikic/php-parserは PHP そのものの静的解析などに有用です。
nikic/php-parserを composer でインストールします。$ composer require nikic/php-parserそして、
Hello World!を AST にしてみましょうHelloWorld.php<?php echo "Hello World!";ast.php<?php require __DIR__ . '/vendor/autoload.php'; use PhpParser\ParserFactory; var_dump( (new ParserFactory()) ->create( ParserFactory::PREFER_PHP7 ) ->parse( file_get_contents( __DIR__ . '/HelloWorld.php' ) ) );
ast.phpを実行すると下記のように出力されます。array(1) { [0]=> object(PhpParser\Node\Stmt\Echo_)#1100 (2) { ["exprs"]=> array(1) { [0]=> object(PhpParser\Node\Scalar\String_)#1099 (2) { ["value"]=> string(12) "Hello World!" ["attributes":protected]=> array(3) { ["startLine"]=> int(2) ["endLine"]=> int(2) ["kind"]=> int(2) } } } ["attributes":protected]=> array(2) { ["startLine"]=> int(2) ["endLine"]=> int(2) } } }これが AST になります。 exprs は expressions, つまり式の複数形です。式を 1 つしか受け取れないものは expr になります。
そして、またここでも余談ですが echo が exprs である理由は echo はカンマ区切りで複数の式を受け取ることができるのです。そのため複数の式を受け取る形になっています。 print は echo とは違い複数の式ではなく一つの式のみしか受け取れず、また常に 1 を返す仕様です。
なお、どちらも言語構造ですが AST に分解した際に echo はステートメントとして扱われ、 print は式として扱われます。構成するクラスファイルのバイナリを理解する
バイナリファイルにコンパイルする際に AST と同様で重要なのが JVM のクラスファイルの仕様そのものです。
JVM におけるクラスファイルの仕様は Java Virtual Machine Specification のChapter 4. The class File Formatにかかれています。さて、上記に書かれているクラスファイルの仕様は下記のとおりです。
ClassFile { u4 magic; u2 minor_version; u2 major_version; u2 constant_pool_count; cp_info constant_pool[constant_pool_count-1]; u2 access_flags; u2 this_class; u2 super_class; u2 interfaces_count; u2 interfaces[interfaces_count]; u2 fields_count; field_info fields[fields_count]; u2 methods_count; method_info methods[methods_count]; u2 attributes_count; attribute_info attributes[attributes_count]; }これらの意味そのものについては PHP または JavaScript での実装方法を Qiita にまとめているので詳しく知りたい方は読んでみてください。
- PHP で Java の中間コードの class ファイルを生成して、 java コマンドで Hello World を出力する
- JavaScript で JVM (Java Virtual Machine) を実装する (Hello World 出力編)
- JavaのバイトコードをPHPで見よう(とりあえずメソッドだけ拾ってみる)
AST を上記のフォーマットに則りバイナリファイルに書き出していく必要があります。
構成される Constant Pool を理解する
Constant Pool は文字列やメソッドなどのシンボルテーブルのような役割を担っているとても重要なものです。この Constant Pool からメソッド名やクラス名、出力する文字列などを探し出す必要があります。
今回の出力は HelloWorld を中心にしていきたいと思います。クラスファイルの仕様も踏まえて、Hello World で必要な Constant Pool のエントリは下記になります。
親のクラス名
- java.lang.Object
現在のクラス名
- ここでは HelloWorld としておきます。
System.out.print
- echo を Java に置き換えると
System.out.printが適任であるため。java.io.PrintStream
- System.out は java.io.PrintStream であるため。
Hello World!
- 出力される文字列
main
- エントリーポイントになるため
<init>,<clinit>
- あってもなくてもどっちでも動く。動的、静的コンストラクタの役割を担っている。今回は使わない。
Code
- Code Attribute を識別するための文字列
これ以外にも Constant Pool はそのメソッドと対になる引数の情報や返り値の情報が入っているディスクリプタ(Descriptor)と呼ばれるエントリも必要です。これによりメソッド・フィールドの引数の型を理解することができます。
そしてそれを紐付けるために NameAndType と呼ばれるエントリも必要になります。Code Attribute において生成されるべきオペコードとそれに付随するオペランドを理解する
そもそも、 Code Attribute とは何か?というところですが、Code Attribute はメソッドに付随する属性の一つで、そのメソッドのオペレーションコードが書かれています。
Hello World を出力するにあたり、オペレーションコードの理解をする必要があります。オペレーションコードとは何か?というと 命令 のことを指します。略されてオペコードとも呼ばれたりします。一般的なオペレーションコードはアセンブリでもそうですが、1 バイトの数字で表されることが多いです。命令はそれぞれ異なる動きをし、引数を持つものもあります。その引数のことを オペランド といいます。
そして、これらを人間に見やすい形にしたものを総じて ニーモニック と呼びます。例えば、JVM の命令の一つとして、 invokevirtual などがありますが、これはニーモニックです。そして、 invokevirtual は indexbyte1, indexbyte2 の 2 つのオペランドを必要とします。
また、invokevirtual のオペレーションコードは 0xB6 です。そして、 JVM にはもう一つ重要な単語としてオペランドスタックというものがあります。これは何かというと、オペレーションコードを実行したにあたって、オペレーションコードにより返された値を保持する場所と認識していただければ大丈夫です。一般的にはプッシュと言います。また、返り値は積まれていく一方でそれを使用することもあります。それをポップといいます。
さて、 本題ですが Hello World を出力するにあたって、必要なオペレーションコードは何か?というと、JVM においては概ね下記のようになります。
- System.out をロードする(オペランドスタックに積む)
- static なフィールドから値をロードするには
getstaticを使用する- Hello World をロードする(オペランドスタックに積む)
- 定数文字列を Constant Pool からロードするには
ldcやldc_wを使用する- print をコールする (PHP の echo は終端に改行コードが入らないため)
- 通常のメソッドの呼び出しには
invokevirtualを使用する。- return (オペレーションの終了として)
これをオペコードで表すと下記です
getstatic #indexbyte1 #indexbyte2 // System.out の Constant Pool の位置 ldc #index // Hello World! の Constant Pool の位置 invokevirtual #indexbyte1 #indexbyte2 // NameAndType のもの returnバイナリファイルを構成する
前菜は終わり、ここからが本題です。とても長くなります。
PHP でバイナリを書くには?
PHP でバイナリを書くには、
packを使用するのがベターです。特に JVM だと符号付き、符号なしの場合や、 2 byte 整数値、 4 byte 整数値などを使用することが多々あります。
pack関数を使用することにより、 PHP の数値リテラルから整数値を割り出すひと手間を省く事が可能です。例えば
1234という数値リテラルがあった場合、 ビッグエンディアンの 2 バイトになおす場合、<?php $integerLiteral = 1234; echo chr(($integerLiteral >> 8) & 0xff) . chr($integerLiteral & 0xff)
($integerLiteral >> 8) & 0xffは何をしているのかというと、数値リテラルを2進数に直したときに8ビット分右にシフトさせていて、 0xff, つまり 255 の範囲内で数値が収まるようにマスクをしています。
1234 を 2 進数に治すと下記です。0100 1101 0010これを右に 8bit シフトさせます。
01000100, つまり
4となります。そして、これに 0xff をマスクさせています。0000 0000 0000 0100 & 1111 1111 1111 1111 ---------------------- 0000 0000 0000 0100なぜマスクをする必要があるのかというと 4 という数字が 255 を超えていた場合、値がオーバーフローすることになります。
それを防ぐためです。なぜ防げるのかというと、&オペレータは左右のオペランド(両辺)のビットが立っていない場合は 0 となるからです。つまり、 255 以上の値は必然的に 0 になるので、その値を超えることはないのです。話に戻りますが、4バイトである場合は下記のようになるでしょう。
<?php $integerLiteral = 1234; echo chr(($integerLiteral >> 32) & 0xff) . chr(($integerLiteral >> 16) & 0xff) . chr(($integerLiteral >> 8) & 0xff) . chr(($integerLiteral) & 0xff)そして、こんな面倒くさいことを関数一つ叩けばしてくれるのが pack です。
例えば 2 バイトのビッグエンディアンである場合は下記のようになります。<?php echo pack('n', 1234);4 バイトの場合は
nがNになります。メタ情報を書き込む
PHP でバイナリを書く方法を説明しました。では、実際にどういう値を書いていけばいいのでしょうか。
ずばり ClassFile Structure の通りに書いていきます。ClassFile { u4 magic; u2 minor_version; u2 major_version; u2 constant_pool_count; cp_info constant_pool[constant_pool_count-1]; u2 access_flags; u2 this_class; u2 super_class; u2 interfaces_count; u2 interfaces[interfaces_count]; u2 fields_count; field_info fields[fields_count]; u2 methods_count; method_info methods[methods_count]; u2 attributes_count; attribute_info attributes[attributes_count]; }まず、 magic, minor_version, major_version のメタデータを書き込んでいきます。
magic はファイルを識別するためのマジックバイトのことで、 Java のクラスファイルの場合は0xCAFEBABEとなります。minor_version および major_version は JDK 8 である場合、下記の表より、 minor_version は 0, major_version は 52 となります。
Java SE class file format version range 1.0.2 45.0 ≤ v ≤ 45.3 1.1 45.0 ≤ v ≤ 45.65535 1.2 45.0 ≤ v ≤ 46.0 1.3 45.0 ≤ v ≤ 47.0 1.4 45.0 ≤ v ≤ 48.0 5.0 45.0 ≤ v ≤ 49.0 6 45.0 ≤ v ≤ 50.0 7 45.0 ≤ v ≤ 51.0 8 45.0 ≤ v ≤ 52.0 9 45.0 ≤ v ≤ 53.0 10 45.0 ≤ v ≤ 54.0 11 45.0 ≤ v ≤ 55.0 この対応表、 SE 8 のページではなく SE 11 のページに載っています。
<?php $className = 'HelloWorld'; $handle = fopen($className . '.class', 'w+'); // unsigned short, unsigned int で書き込むための関数を用意する function writeUnsignedByte(int $number) { global $handle; fwrite($handle, pack('C', $number)); } function writeUnsignedShort(int $number) { global $handle; fwrite($handle, pack('n', $number)); } function writeUnsignedInt(int $number) { global $handle; fwrite($handle, pack('N', $number)); } // magic writeUnsignedInt(0xCAFEBABE); // minor_version writeUnsignedShort(0); // major_version writeUnsignedShort(52);AST にした PHP を解釈して Constant Pool を書き込む
次に constant_pool_count, constant_pool の書き込みを行います。
Constant Pool にはエントリを識別するためのタグがあり、JDK 8 である場合、下記のとおりとなります。
Constant Type Value CONSTANT_Class 7 CONSTANT_Fieldref 9 CONSTANT_Methodref 10 CONSTANT_InterfaceMethodref 11 CONSTANT_String 8 CONSTANT_Integer 3 CONSTANT_Float 4 CONSTANT_Long 5 CONSTANT_Double 6 CONSTANT_NameAndType 12 CONSTANT_Utf8 1 CONSTANT_MethodHandle 15 CONSTANT_MethodType 16 CONSTANT_InvokeDynamic 18 今回使うのは Class, Fieldref, Methodref, String, NameAndType, Utf8 の 6 つとなります。
ConstantPool のエントリ番号は 0 からではなく 1 からスタートする仕様であるため、基本的に 0 から採番されないように 0 番目の配列の要素には null を入れておくと良いです。これらを書きやすくするため予めルーチン化しておきます。
function writeConstantPoolEntry(int $tag, $value): int { global $constantPool; $constantPool[] = [$tag, $value]; return count($constantPool); } function writeConstantPoolClass($value): int { return writeConstantPoolEntry(7, $value); } function writeConstantPoolFieldref($value): int { return writeConstantPoolEntry(9, $value); } function writeConstantPoolMethodref($value): int { return writeConstantPoolEntry(10, $value); } function writeConstantPoolString($value): int { return writeConstantPoolEntry(8, $value); } function writeConstantPoolNameAndType($value): int { return writeConstantPoolEntry(12, $value); } function writeConstantPoolUtf8($value): int { return writeConstantPoolEntry(1, $value); }また、 Constant Pool は以後、検索してエントリの番号を知る必要があるため、検索を簡易に行えるようこれについても予めルーチン化しておきます。
function findEntryIndex(int $tag, $value) { global $constantPool; foreach ($constantPool as $index => $element) { if ($element === null) { continue; } [$entryTag, $entryValue] = $element; if ($tag === $entryTag && $value === $entryValue) { return $index; } } throw new RuntimeException( 'Could not found on the ConstantPool' ); }そして、上の方で説明した Constant Pool の値を書き込んでいきます。
親のクラス名
- java.lang.Object
現在のクラス名
- ここでは HelloWorld としておきます。
System.out.print
- echo を Java に置き換えると
System.out.printが適任であるため。java.io.PrintStream
- System.out は java.io.PrintStream であるため。
Hello World!
- 出力される文字列
main
- エントリーポイントになるため
<init>,<clinit>
- あってもなくてもどっちでも動く。動的、静的コンストラクタの役割を担っている。今回は使わない。
Code
- Code Attribute を識別するための文字列
上記から、書き込む文字列は下記のとおりになります。
// 親クラス名を書き込む writeConstantPoolUtf8('java/lang/Object'); // クラス名を書き込む writeConstantPoolUtf8($className); // java/lang/System を書き込む writeConstantPoolUtf8('java/lang/System'); // out を書き込む writeConstantPoolUtf8('out'); // print を書き込む writeConstantPoolUtf8('print'); // java/io/PrintStream を書き込む writeConstantPoolUtf8('java/io/PrintStream'); // print の引数 writeConstantPoolUtf8('(Ljava/lang/String;)V'); // main メソッドの名称を書き込む writeConstantPoolUtf8('main'); // main の引数 writeConstantPoolUtf8('([Ljava/lang/String;)V'); // Code Attribute の識別子である Code を書き込む writeConstantPoolUtf8('Code');Java における名前空間はコード上では
.で表現されますが、 Constant Pool では/になります。これはディレクトリであることを示しているからなのだと勝手に推測しています(要出典)そして、メソッドに対する引数の情報を書き込む必要があるため、少し解説をします。
JVM の引数は基本的には 1 文字の識別子からその種類が何であるかを示します。例えばIであれば Integer です。また、オブジェクトは少し少々特殊でLのあとに;が現れるまでの間の文字列をオブジェクト名として認識します。例えばLjava/lang/String;です。そして、配列は[の文字数で次元数を表します。これらの組み合わせも Constant Pool に書く必要があります。最終的な書式については
([Ljava/lang/String;)Vのようになります。(から)の間が引数であり、その後ろのシグネチャが返り値となります。したがって、下記を書き込む必要があります。
// main における引数を書き込む writeConstantPoolUtf8('([Ljava/lang/String;)V');さらに、これらをエントリの採番から紐付ける必要があります。例えばクラスであることを示すために Class を使用したり、メソッド名と引数を紐付けるために NameAndType を使用したりします。
今回のケースで必要なのは親クラス, カレントクラス, java.lang.System, main, System.out.print です。
まず、親クラスとカレントクラスを書き込みます。// カレントクラス $currentClassEntryIndex = writeConstantPoolClass(findEntryIndex(1, $className)); // 親クラス $parentClassEntryIndex = writeConstantPoolClass(findEntryIndex(1, 'java/lang/Object')); // java.lang.System $javaLangSystemClassEntryIndex = writeConstantPoolClass(findEntryIndex(1, 'java/lang/System')); // print を包括するクラス $printStreamClassEntryIndex = writeConstantPoolClass(writeConstantPoolUtf8('java/io/PrintStream'));そして、 main と引数の情報が対になったものを書き込みます。対であることを示すのは NameAndTypeです。さらに、そのメソッドがどこのクラスのものであるかを示す必要があり、 Methodref を使用する必要があります。
コードで表すと下記のようになります。
// main と引数を対にする $mainAndArgumentsEntryIndex = writeConstantPoolNameAndType([ findEntryIndex(1, 'main'), findEntryIndex(1, '([Ljava/lang/String;)V'), ]); // Methodref を書き込む $mainMethodrefEntryIndex = writeConstantPoolMethodref([ $currentClassEntryIndex, $mainAndArgumentsEntryIndex ]);次に System.out フィールドの参照を書き込みます。フィールドは引数はなく返り値のみなので、
()を省略して、書き込みます。writeConstantPoolUtf8('Ljava/io/PrintStream;');そして、これを out に紐付け、更にその値を java.lang.System に紐付けます。
// System.out を書き込む $outAndPrintStreamEntryIndex = writeConstantPoolNameAndType([ findEntryIndex(1, 'out'), findEntryIndex(1, 'Ljava/io/PrintStream;'), ]); // java.lang.System に紐付ける $systemFieldrefEntryIndex = writeConstantPoolFieldref([ $javaLangSystemClassEntryIndex, $outAndPrintStreamEntryIndex, ]);そして、 print 自体の情報を ConstantPool に登録する必要があるため、下記を書き込みます。
// print を紐付ける $printmethodNameAndTypeEntryIndex = writeConstantPoolNameAndType([ findEntryIndex(1, 'print'), findEntryIndex(1, '(Ljava/lang/String;)V'), ]); $printMethodrefEntryIndex = writeConstantPoolMethodref([ $currentClassEntryIndex, $printmethodNameAndTypeEntryIndex ]);print を使えるようにクラスに ConstantPool を登録しておきます。
$printMethodrefEntryIndex = writeConstantPoolMethodref([ $printStreamClassEntryIndex, $printmethodNameAndTypeEntryIndex, ]);さらに予め PHP の AST から文字列を抜き出し Constant Pool に追加する処理を行います。
私が行っている php-java というプロジェクトでは動的に追加 (Constant Pool に入れる必要のある文字列が出現したタイミングで追加)をするようにしていますが、ここでは話の流れとして、追加するようにしています。function registerConstantsRecursive(\PhpParser\Node ...$nodes): void { foreach ($nodes as $node) { if (property_exists($node, 'exprs')) { registerConstantsRecursive(...$node->exprs); continue; } if (property_exists($node, 'expr')) { registerConstantsRecursive(...[$node->expr]); continue; } if (property_exists($node, 'value')) { $utf8Index = writeConstantPoolUtf8($node->value); writeConstantPoolString($utf8Index); } } } registerConstantsRecursive(...$ast);(アドベントカレンダーということもあり、だいぶ雑実装ですが、 php-java だともっとまともに書いています。)
最後に、
$constantPoolへ追加された値をバイナリへ書き込んでいきます。foreach ($constantPool as $element) { if ($element === null) { continue; } [$tag, $value] = $element; writeUnsignedByte($tag); switch ($tag) { case 7: // Class case 8: // String writeUnsignedShort($value); break; case 9: // Fieldref case 10: // Methodref case 12: // NameAndType writeUnsignedShort($value[0]); writeUnsignedShort($value[1]); break; case 1: // Utf8 fwrite($handle, $value); break; default: throw new RuntimeException( 'The kind tag is not implemented.' ); } }access_flags を書き込む
access_flags は、
finalであったりpublicのようなアクセス権限を設定できます。
今回の例だと、コード上においては継承していない(が、実態は java.lang.Object を継承している)ため、publicとsuperを設定します。access_flags は下記に従って設定します。
Flag Name Value Interpretation ACC_PUBLIC 0x0001 Declared public; may be accessed from outside its package. ACC_FINAL 0x0010 Declared final; no subclasses allowed. ACC_SUPER 0x0020 Treat superclass methods specially when invoked by the invokespecial instruction. ACC_INTERFACE 0x0200 Is an interface, not a class. ACC_ABSTRACT 0x0400 Declared abstract; must not be instantiated. ACC_SYNTHETIC 0x1000 Declared synthetic; not present in the source code. ACC_ANNOTATION 0x2000 Declared as an annotation type. ACC_ENUM 0x4000 Declared as an enum type.
ACC_PUBLIC及びACC_SUPERが該当します。この値を unsigned short で書き込みます。writeUnsignedShort(0x0001 | 0x0020);this_class, super_class を書き込む
次に this_class と super_class を書き込みます。
これは予め ConstantPool に書き込んだである Class を使用し、それらを unsigned short で書き込みます。writeUnsignedShort($currentClassEntryIndex); writeUnsignedShort($parentClassEntryIndex);field_count, interface_count を書き込む
HelloWorldクラスにはフィールド及びインタフェースは存在しないため、 2 つとも0と書き込みます。writeUnsignedShort(0); writeUnsignedShort(0);AST にした PHP を解釈してメソッドを書き込む
今回のアドベントカレンダーの趣旨の話をします。 しかし残念ながら、AST にふれるのはここだけで、あっという間に終わってしまいます。まるで、作るのは手間暇がかかるけど、食べるのは一瞬である北京ダックのようです。ちなみに北京ダックは好きです。
まず、メソッドの数を書き込みます。本来は
<init>も必要ですが、省略しても動くので省略します。
つまり必要なメソッド数は 1 つです。ということで 1 を書き込みます。writeUnsignedShort(1);次に、PHP で AST された値を再度確認してみます。
array(1) { [0]=> object(PhpParser\Node\Stmt\Echo_)#1100 (2) { ["exprs"]=> array(1) { [0]=> object(PhpParser\Node\Scalar\String_)#1099 (2) { ["value"]=> string(12) "Hello World!" ["attributes":protected]=> array(3) { ["startLine"]=> int(2) ["endLine"]=> int(2) ["kind"]=> int(2) } } } ["attributes":protected]=> array(2) { ["startLine"]=> int(2) ["endLine"]=> int(2) } } }通常トップレベルなものは配列であるので、配列を回しつつ処理を分けていく形になります。
余談ですが、php-java は下記のように分けています。今回の場合下記のようなコードになるでしょう。
$operations = ''; foreach ($ast as $stmt) { switch ($type = get_class($stmt)) { case \PhpParser\Node\Stmt\Echo_::class: // echo は PHP だとカンマで区切って複数出力できるため複数形の exprs になっているが、 // 出力は一つのみとして考慮する。 $expr = $stmt->exprs[0]; $reference = null; switch ($expressionType = get_class($expr)) { case \PhpParser\Node\Scalar\String_::class: /** * @var \PhpParser\Node\Scalar\String_ $expr */ $reference = findEntryIndex(8, $expr->value); break; // ... default: throw new RuntimeException( $expressionType . 'is not implemented yet.' ); // ここの解説をします。 } break; // ... default: throw new RuntimeException( $type . 'is not implemented yet.' ); } }このように取得した Node ごとに処理をの役割を分離していく必要があります。
// ...と書かれている箇所に分岐処理が大量に入ってきます。楽しいね!さて、
// ここの解説をします。の部分について解説をします。ここにはずばり PHP における echo そのものの実装が入り、それらをすべてオペレーションコードで表す必要があります。では、一体必要なオペレーションコードは何かを考えたときに、上記でも説明した通りのものになります。
- System.out をロードする(オペランドスタックに積む)
- static なフィールドから値をロードするには
getstaticを使用する- Hello World をロードする(オペランドスタックに積む)
- 定数文字列を Constant Pool からロードするには
ldcやldc_wを使用する- print をコールする (PHP の echo は終端に改行コードが入らないため)
- 通常のメソッドの呼び出しには
invokevirtualを使用する。- return (オペレーションの終了として)
上記はニーモニックですから、オペレーションコードが必要になります。それぞれのペアは JVM Specification にも書かれていますが、下記のとおりです。
ニーモニック オペコード getstatic 0xb2 ldc 0x12 invokevirtual 0xb6 return 0xb1 これらを
$operationsに書いていきます。// getstatic $operations .= pack('Cn', 0xb2, $systemFieldrefEntryIndex); // ldc $operations .= pack('CC', 0x12, $reference); // invokevirtual $operations .= pack('Cn', 0xb6, $printMethodrefEntryIndex); // return $operations .= pack('C', 0xb1);上記が実行するオペレーションコードになります。そしてこれは Code Attribute という属性に分類され、これを紐付ける先であるメソッドのエントリを構築します。
メソッドのエントリは JVM Specification より下記です。
method_info { u2 access_flags; u2 name_index; u2 descriptor_index; u2 attributes_count; attribute_info attributes[attributes_count]; }書き込むエントリはずばり main メソッドです。まず
access_flagsを書き込みます。
access_flagsは クラスとちょっと異なります。
Flag Name Value Interpretation ACC_PUBLIC 0x0001 Declared public; may be accessed from outside its package. ACC_PRIVATE 0x0002 Declared private; accessible only within the defining class. ACC_PROTECTED 0x0004 Declared protected; may be accessed within subclasses. ACC_STATIC 0x0008 Declared static. ACC_FINAL 0x0010 Declared final; must not be overridden (§5.4.5). ACC_SYNCHRONIZED 0x0020 Declared synchronized; invocation is wrapped by a monitor use. ACC_BRIDGE 0x0040 A bridge method, generated by the compiler. ACC_VARARGS 0x0080 Declared with variable number of arguments. ACC_NATIVE 0x0100 Declared native; implemented in a language other than Java. ACC_ABSTRACT 0x0400 Declared abstract; no implementation is provided. ACC_STRICT 0x0800 Declared strictfp; floating-point mode is FP-strict. ACC_SYNTHETIC 0x1000 Declared synthetic; not present in the source code. 上記になります。そして main メソッドは
publicとstaticを使用します。writeUnsignedShort(0x0001 | 0x0008);次に、
name_indexおよびdescriptor_indexですが、これはメソッド名と引数・返り値情報の文字列のエントリー番号になります。writeUnsignedShort(findEntryIndex(1, 'main')); writeUnsignedShort(findEntryIndex(1, '([Ljava/lang/String;)V'));上記のようになります。次に
attribute_countですが、 CodeAttribute が入ってくるため1となります。writeUnsignedShort(1);次に Code Attribute を書き込んでいきます。 Code Attribute は JVM Specification により下記です。
Code_attribute { u2 attribute_name_index; u4 attribute_length; u2 max_stack; u2 max_locals; u4 code_length; u1 code[code_length]; u2 exception_table_length; { u2 start_pc; u2 end_pc; u2 handler_pc; u2 catch_type; } exception_table[exception_table_length]; u2 attributes_count; attribute_info attributes[attributes_count]; }まず、
attribute_name_indexは何の属性であるかを示したものが入ります。今回の場合はCodeになります。次にattribute_lengthは属性自体の長さです。この値は予め、それ以外の値及び長さを知っている必要があります。
max_stack及びmax_localsはオペランドスタックに積まれる最大のスタック数及び、パラメータの数を含めたローカル変数の最大値となります。ぶっちゃけ、足りなくならなければ何でもいいので、両方とも 10 とか雑な値で大丈夫です。php-java はオペレーションコードを見て、サイズを見るようにしています。これには実際にエミュレート的な仕様が必要で、オペレーションコードが走って初めてオペランドスタックの最大の大きさがわかったりするのですが、だいぶ面倒くさいということもあり、説明を省略します。
ちなみに、話が脱線しますが、 if 文の実装にも実はこのエミュレートっぽい処理は必要(もしかしたら別手段はあるかもしれない)、 StackMap テーブルと呼ばれる if 文のブランチ先を定義するものが必要になります。そして、
code_lengthはすべてのオペレーションコード及びオペランドのサイズが入ります。
次に、codeにはそのまま code が入ります。
exception_table_length及びexception_tableは例外処理を適用するオペレーションコードの範囲を定義するものですが、今回に至っては例外処理はないのでexception_table_lengthは 0 になります。最後に
attributes_count及びattributesは存在しないため、attribute_lengthは 0 になります。それを踏まえると下記のようなコードになります。$attribute = ''; // max_stack $attribute .= pack('n', 10); // max_locals $attribute .= pack('n', 10); // code_length $attribute .= pack('N', strlen($operations)); // code $attribute .= $operations; // exception_table_length $attribute .= pack('n', 0); // attributes_count $attribute .= pack('n', 0); // 書き込む writeUnsignedShort(findEntryIndex(1, 'Code')); writeUnsignedInt(strlen($attribute)); fwrite($handle, $attribute);あと処理
そして、最後にクラスファイル自体の
attributes_countを書き込みます。特に付ける必要はないので0です。writeUnsignedShort(0);少し長くなってしまいましたが、以上で JVM 言語の開発ができるようになりました。めでたい?
実際に動かしてみる
java HelloWorld上記を実行し
Hello World!が出れば成功です。コードのまとめ
バイナリはどうなっているかというと、下記みたいな形になります。
00000000: CA FE BA BE 00 00 00 34 00 19 01 00 10 6A 61 76 .......4.....jav 00000010: 61 2F 6C 61 6E 67 2F 4F 62 6A 65 63 74 01 00 0A a/lang/Object... 00000020: 48 65 6C 6C 6F 57 6F 72 6C 64 01 00 10 6A 61 76 HelloWorld...jav 00000030: 61 2F 6C 61 6E 67 2F 53 79 73 74 65 6D 01 00 04 a/lang/System... 00000040: 6D 61 69 6E 01 00 04 43 6F 64 65 01 00 16 28 5B main...Code...([ 00000050: 4C 6A 61 76 61 2F 6C 61 6E 67 2F 53 74 72 69 6E Ljava/lang/Strin 00000060: 67 3B 29 56 01 00 15 28 4C 6A 61 76 61 2F 6C 61 g;)V...(Ljava/la 00000070: 6E 67 2F 53 74 72 69 6E 67 3B 29 56 01 00 15 4C ng/String;)V...L 00000080: 6A 61 76 61 2F 69 6F 2F 50 72 69 6E 74 53 74 72 java/io/PrintStr 00000090: 65 61 6D 3B 01 00 03 6F 75 74 01 00 05 70 72 69 eam;...out...pri 000000a0: 6E 74 01 00 13 6A 61 76 61 2F 69 6F 2F 50 72 69 nt...java/io/Pri 000000b0: 6E 74 53 74 72 65 61 6D 07 00 02 07 00 01 07 00 ntStream........ 000000c0: 03 01 00 13 6A 61 76 61 2F 69 6F 2F 50 72 69 6E ....java/io/Prin 000000d0: 74 53 74 72 65 61 6D 07 00 0F 0C 00 04 00 06 0A tStream......... 000000e0: 00 0C 00 11 0C 00 09 00 08 0C 00 0A 00 07 0A 00 ................ 000000f0: 10 00 14 09 00 0E 00 13 01 00 0C 48 65 6C 6C 6F ...........Hello 00000100: 20 57 6F 72 6C 64 21 08 00 17 00 21 00 0C 00 0D World!....!.... 00000110: 00 00 00 00 00 01 00 09 00 04 00 06 00 01 00 05 ................ 00000120: 00 00 00 15 00 0A 00 0A 00 00 00 09 B2 00 16 12 ................ 00000130: 18 B6 00 15 B1 00 00 00 00 00 00 ...........このバイナリは普通に Hello World! と書かれた Java ファイルを javac でコンパイルしたクラスファイルより余分な情報がないので、短い形で済み、かつ
javaコマンドを使用しても動きます。<?php require __DIR__ . '/../../vendor/autoload.php'; use PhpParser\ParserFactory; $className = 'HelloWorld3'; $handle = fopen($className . '.class', 'w+'); // unsigned short, unsigned int で書き込むための関数を用意する function writeUnsignedByte(int $number) { global $handle; fwrite($handle, pack('C', $number)); } function writeUnsignedShort(int $number) { global $handle; fwrite($handle, pack('n', $number)); } function writeUnsignedInt(int $number) { global $handle; fwrite($handle, pack('N', $number)); } // magic writeUnsignedInt(0xCAFEBABE); // minor_version writeUnsignedShort(0); // major_version writeUnsignedShort(52); $constantPool = [null]; function writeConstantPoolEntry(int $tag, $value): int { global $constantPool; $constantPool[] = [$tag, $value]; return count($constantPool) - 1; } function writeConstantPoolClass($value): int { return writeConstantPoolEntry(7, $value); } function writeConstantPoolFieldref($value): int { return writeConstantPoolEntry(9, $value); } function writeConstantPoolMethodref($value): int { return writeConstantPoolEntry(10, $value); } function writeConstantPoolString($value): int { return writeConstantPoolEntry(8, $value); } function writeConstantPoolNameAndType($value): int { return writeConstantPoolEntry(12, $value); } function writeConstantPoolUtf8($value): int { return writeConstantPoolEntry(1, $value); } function findEntryIndex(int $tag, $value) { global $constantPool; foreach ($constantPool as $index => $element) { if ($element === null) { continue; } [$entryTag, $entryValue] = $element; if ($tag === $entryTag && $value === $entryValue) { return $index; } } throw new RuntimeException( 'Could not found on the ConstantPool' ); } // 親クラス名を書き込む writeConstantPoolUtf8('java/lang/Object'); // クラス名を書き込む writeConstantPoolUtf8($className); // java/lang/System を書き込む writeConstantPoolUtf8('java/lang/System'); // main メソッドの名称を書き込む writeConstantPoolUtf8('main'); // Code Attribute の識別子である Code を書き込む writeConstantPoolUtf8('Code'); // main における引数を書き込む writeConstantPoolUtf8('([Ljava/lang/String;)V'); writeConstantPoolUtf8('(Ljava/lang/String;)V'); writeConstantPoolUtf8('Ljava/io/PrintStream;'); writeConstantPoolUtf8('out'); writeConstantPoolUtf8('print'); // java/io/PrintStream を書き込む writeConstantPoolUtf8('java/io/PrintStream'); // 親クラス $currentClassEntryIndex = writeConstantPoolClass(findEntryIndex(1, $className)); // カレントクラス $parentClassEntryIndex = writeConstantPoolClass(findEntryIndex(1, 'java/lang/Object')); $javaLangSystemClassEntryIndex = writeConstantPoolClass(findEntryIndex(1, 'java/lang/System')); $printStreamClassEntryIndex = writeConstantPoolClass(writeConstantPoolUtf8('java/io/PrintStream')); // main と引数を対にする $mainAndArgumentsEntryIndex = writeConstantPoolNameAndType([ findEntryIndex(1, 'main'), findEntryIndex(1, '([Ljava/lang/String;)V'), ]); // Methodref を書き込む $mainMethodrefEntryIndex = writeConstantPoolMethodref([ $currentClassEntryIndex, $mainAndArgumentsEntryIndex, ]); // System.out を書き込む $outAndPrintStreamEntryIndex = writeConstantPoolNameAndType([ findEntryIndex(1, 'out'), findEntryIndex(1, 'Ljava/io/PrintStream;'), ]); // print を紐付ける $printmethodNameAndTypeEntryIndex = writeConstantPoolNameAndType([ findEntryIndex(1, 'print'), findEntryIndex(1, '(Ljava/lang/String;)V'), ]); $printMethodrefEntryIndex = writeConstantPoolMethodref([ $printStreamClassEntryIndex, $printmethodNameAndTypeEntryIndex, ]); $systemFieldrefEntryIndex = writeConstantPoolFieldref([ $javaLangSystemClassEntryIndex, $outAndPrintStreamEntryIndex, ]); $ast = (new ParserFactory()) ->create( ParserFactory::PREFER_PHP7 ) ->parse( file_get_contents( __DIR__ . '/test.php' ) ); function registerConstantsRecursive(\PhpParser\Node ...$nodes): void { foreach ($nodes as $node) { if (property_exists($node, 'exprs')) { registerConstantsRecursive(...$node->exprs); continue; } if (property_exists($node, 'expr')) { registerConstantsRecursive(...[$node->expr]); continue; } if (property_exists($node, 'value')) { $utf8Index = writeConstantPoolUtf8($node->value); writeConstantPoolString($utf8Index); } } } registerConstantsRecursive(...$ast); writeUnsignedShort(count($constantPool)); foreach ($constantPool as $element) { if ($element === null) { continue; } [$tag, $value] = $element; writeUnsignedByte($tag); switch ($tag) { case 7: // Class case 8: // String writeUnsignedShort($value); break; case 9: // Fieldref case 10: // Methodref case 12: // NameAndType writeUnsignedShort($value[0]); writeUnsignedShort($value[1]); break; case 1: // Utf8 writeUnsignedShort(strlen($value)); fwrite($handle, $value); break; default: throw new RuntimeException( 'The kind tag is not implemented.' ); } } writeUnsignedShort(0x0001 | 0x0020); writeUnsignedShort($currentClassEntryIndex); writeUnsignedShort($parentClassEntryIndex); writeUnsignedShort(0); writeUnsignedShort(0); $operations = ''; foreach ($ast as $stmt) { switch ($type = get_class($stmt)) { case \PhpParser\Node\Stmt\Echo_::class: // echo は PHP だとカンマで区切って複数出力できるため複数形の exprs になっているが、 // 出力は一つのみとして考慮する。 $expr = $stmt->exprs[0]; $reference = null; switch ($expressionType = get_class($expr)) { case \PhpParser\Node\Scalar\String_::class: /** * @var \PhpParser\Node\Scalar\String_ $expr */ $utf8pos = findEntryIndex(1, $expr->value); $reference = findEntryIndex(8, $utf8pos); break; // ... default: throw new RuntimeException( $expressionType . 'is not implemented yet.' ); } // getstatic $operations .= pack('Cn', 0xb2, $systemFieldrefEntryIndex); // ldc $operations .= pack('CC', 0x12, $reference); // invokevirtual $operations .= pack('Cn', 0xb6, $printMethodrefEntryIndex); // return $operations .= pack('C', 0xb1); break; // ... default: throw new RuntimeException( $type . 'is not implemented yet.' ); } } writeUnsignedShort(1); writeUnsignedShort(0x0001 | 0x0008); writeUnsignedShort(findEntryIndex(1, 'main')); writeUnsignedShort(findEntryIndex(1, '([Ljava/lang/String;)V')); writeUnsignedShort(1); $attribute = ''; // max_stack $attribute .= pack('n', 10); // max_locals $attribute .= pack('n', 10); // code_length $attribute .= pack('N', strlen($operations)); // code $attribute .= $operations; // exception_table_length $attribute .= pack('n', 0); // attributes_count $attribute .= pack('n', 0); writeUnsignedShort(findEntryIndex(1, 'Code')); writeUnsignedInt(strlen($attribute)); fwrite($handle, $attribute); // attributes_count writeUnsignedShort(0);※ 上記は本アドベントカレンダーを解説するために作った雑コードであるため、一部説明している手順と異なっている可能性があります?
おわりに
PHP で JVM を作るのは、 JVM Specification に則れば作ることが可能であることがわかりました。
本アドベントカレンダーでは JVM を題材にしていますが、 AST にすることにより別言語を作ることも可能であり、アセンブリに直し、実行ファイルを生成することもぶっちゃけ可能です。
さらに PHP で説明をしていますが、こういった処理ができるのであればどんな言語でも実装可能なのです。夢が広がりますよね。日頃のプロダクションコードとは少し離れて、プログラムと戯れるのもまたありだと思います。ぜひお試しください。そして、 JVM 言語の実装ではなく、 PHP で JVM を実装する方法を以前何回か登壇しています。 JVM の実装そのものに興味があるかたはぜひ見てみてください。
そして、最後になりますが、本を書いていたりするので買ってね。
- 投稿日:2019-12-22T17:46:03+09:00
Spring Fest 2019 スライド一覧
概要
Spring Fest 2019に参加してきました。
その際の、登壇スライドのまとめとなります。
Spring Boot アプリの運用が楽になる? Pivotal と Microsoft が共同開発した専用 PaaS「Azure Spring Cloud」のご紹介 !!
Spring Boot爆速開発超絶技巧
入社1年目のプログラミング初心者がSpringを学ぶための手引き
LINE公式アカウントのチャットシステムにおけるSpringおよびWebFluxの活用事例
徹底解剖Spring MVCアーキテクチャー -DispatcherServletの中身を覗いてきました-
NissanConnectの舞台裏で動くSpring Boot/Spring Cloud 〜Microserviceの実運用の事例〜
無茶振りMicrometerの話
システム間連携を担うSpring Integrationのエンタープライズ開発での活用
RSocket徹底入門 ~Spring 5.2の目玉機能であるRSocket対応とは~
Quarkus による超音速な Spring アプリケーション開発
JSP/JSF から Spring Web + Thymeleaf への移行
Spring Social でソーシャルログインを実装する
Springアプリケーションのテスト道具 使いどころ、使わないどころ
Spring with React for Enterprise Application
- 投稿日:2019-12-22T17:15:43+09:00
【StreamAPI】max(またはmin)で空Optionalが返るシチュエーション
maxの返り値はOptional型
Streamのメソッドに
max(以下、minも同様)というものがある。一見、Streamの最大値をそのまま返すように見えるが、返り値の型は以下の例の通りOptionalである。コード
List<Integer> integerList = Arrays.asList(1, 2, 3); Optional<Integer> maxIntegerOpt = integerList .stream() .max(Integer::compareTo); System.out.println("maxIntegerOpt = " + maxIntegerOpt);実行結果
maxIntegerOpt = Optional[3]ということは最大値が見つからない場合もあるということである。
色んな値のStreamで試してみた
「え、最大値が見つからないことってあるの?」と疑問に思ったので、色んな値のStreamで試してみた。
重複する値がある場合は見つかる
ははーん、きっと値が重複してたら最大値が一意に定まらないから最大値なしとなるんだな!
コードList<Integer> integerList = Arrays.asList(1, 2, 3, 3); Optional<Integer> maxIntegerOpt = integerList .stream() .max(Integer::compareTo); System.out.println("maxIntegerOpt = " + maxIntegerOpt);実行結果
maxIntegerOpt = Optional[3]げぇー!重複してるのは一つの値としてまとめて判定している!地味にこれは新たな発見。
Streamが空の場合は見つからない
正解はこちら。
コードList<Integer> integerList = Collections.emptyList(); Optional<Integer> maxIntegerOpt = integerList .stream() .max(Integer::compareTo); System.out.println("maxIntegerOpt = " + maxIntegerOpt);実行結果
maxIntegerOpt = Optional.emptyまあ要素が無ければ最大値も調べようがないですよね。てか公式に書いてました。マニュアル読めって話。
Streamが空になるシチュエーション
※コメントを受けて追記しました。
空Streamに対して最大値を取りに行くシチュエーションある?と思っていましたが、間にfilterなどを噛ます場合は途中でStreamが空になります。
例えば以下のような、100以下の値でfilterをかけて最大値を取りに行く場合は途中でStreamが空になり、空Optionalが返ります。コード
List<Integer> integerList = Arrays.asList(101, 104); Optional<Integer> maxIntegerOpt = integerList .stream() .filter(integer -> integer <= 100) .max(Integer::compareTo)この場合、結果が空Optionalということは
filterに該当する要素がなかったということなので、結果を利用する側でその場合の処理を書く必要があります(そのためのOptional)。
空Optionalを返すのってどうよ?
要するにmaxはStreamが空でもエラーとせず、空Optionalを返してくれます。
しかし直感的にその動作がわかるでしょうか?最大値を調べようがなく、自分はてっきり何か例外が返ってくるものだと思っていましたので、空Optionalが返ってくることに違和感を感じていました。※ご指摘いただき、
Optionalで返すことで、空Streamでも例外とならないことが明らかだと判断しました。
- 投稿日:2019-12-22T17:15:43+09:00
【StreamAPI】空Streamではmax(またはmin)の呼び出しを避ける
maxの返り値はOptional型
Streamのメソッドに
max(以下、minも同様)というものがある。一見、Streamの最大値をそのまま返すように見えるが、返り値の型は以下の例の通りOptionalである。コード
List<Integer> integerList = Arrays.asList(1, 2, 3); Optional<Integer> maxIntegerOpt = integerList .stream() .max(Integer::compareTo); System.out.println("maxIntegerOpt = " + maxIntegerOpt);実行結果
maxIntegerOpt = Optional[3]ということは最大値が見つからない場合もあるということである。
色んな値のStreamで試してみた
「え、最大値が見つからないことってあるの?」と疑問に思ったので、色んな値のStreamで試してみた。
重複する値がある場合は見つかる
ははーん、きっと値が重複してたら最大値が一意に定まらないから最大値なしとなるんだな!
コードList<Integer> integerList = Arrays.asList(1, 2, 3, 3); Optional<Integer> maxIntegerOpt = integerList .stream() .max(Integer::compareTo); System.out.println("maxIntegerOpt = " + maxIntegerOpt);実行結果
maxIntegerOpt = Optional[3]げぇー!重複してるのは一つの値としてまとめて判定している!地味にこれは新たな発見。
Streamが空の場合は見つからない
正解はこちら。
コードList<Integer> integerList = Collections.emptyList(); Optional<Integer> maxIntegerOpt = integerList .stream() .max(Integer::compareTo); System.out.println("maxIntegerOpt = " + maxIntegerOpt);実行結果
maxIntegerOpt = Optional.emptyまあ要素が無ければ最大値も調べようがないですよね。てか公式に書いてました。マニュアル読めって話。
空Optionalを返すのってどうよ?
要するに
maxはStreamが空でもエラーとせず、空Optionalを返してくれます。
しかし直感的にその動作がわかるでしょうか?最大値を調べようがなく、自分はてっきり何か例外が返ってくるものだと思っていましたので、空Optionalが返ってくることに違和感を感じていました。動作が予想し辛いコードは可読性を落とします。そもそも空Streamの
maxが呼び出されないようなコードを書けば、その時の動きを調べる必要もなくなります。以下の二つのコードを見比べてください。
事前にリストの空チェックを実施したコード
// integerListは何かしらの処理で事前に取得されているものとする if (CollectionUtils.isEmpty(integerList)) { // 〜リストが空の時の処理 } else { int maxInteger = integerList .stream() .max(Integer::compareTo) .orElseThrow(() -> new IllegalStateException("最大値抽出対象のリストが空です。")); // 最大値を使った処理 }こちらは事前にリストの空チェックをすることで空Streamの
maxが呼ばれることを未然に防いでいます。また、orElseThrowでIllegalStateExceptionを出すことで、空リストに対し最大値を取ろうとすることを想定していないことを明示しています。リストの空チェックをせずmaxの返り値で処理を分岐させているコード
// integerListは何かしらの処理で事前に取得されているものとする Optional<Integer> maxIntegerOpt = integerList .stream() .max(Integer::compareTo); if (maxIntegerOpt.isPresent()) { int maxInteger = maxIntegerOpt.get(); // 最大値を使った処理 } else { // リストが空の時の処理 }一方こちらはリストの空チェックを事前に実施せず、
maxの結果からリストが空であるかを判断しています。空Stream時のmax処理を調べる必要がありますし、リストが空の場合の処理をmaxの結果に頼り切っているので、maxの実装が変わると影響を受ける恐れがあります。まとめ
- Streamの
maxは、Streamが空の時に空Optionalを返す。- 直感的に動作が予想し辛いので、空Streamの
maxがそもそも呼ばれないよう事前にコレクションの空チェックをしよう。
- 投稿日:2019-12-22T17:01:00+09:00
gradleとmavenの人気の動向
調査を始めたきっかけ
Mac版のVSCodeにJava Extension Packを入れることにしました。
これは、VSCodeでJavaを扱うために必要な単語補完やデバッガーなどの拡張機能をまとめてインストールできる拡張機能です。この拡張機能にはmavenが入っていますが、gradleが入っていません。
最近では、androidの影響もあり、mavenよりもgradleの方が勢いがあり、流行っていると考えていたため、違和感を覚え、調査を始めたのがきっかけです。人気の動向
日本の直近12ヶ月の動向を、Google Trendで調べてみます。
ほとんど差はありませんが、若干mavenの方が上のようです。
私はgradleの方が流行っていると考えていたので、少々驚きました。次に、世界の直近12ヶ月の動向を、Google Grendで調べてみます。
mavenの方がずっと上ですね。最後に、地域別のキーワード比較をしてみます。
真っ赤ですね。
どの地域でもmavenの方が上みたいです。
日本ではGradleがかなり善戦しているようですが、それでもこの状況です。もしかして、期間を5年で見たら変わるのではないかと考えて調べてみましたが、ほとんど変わりませんでした。
mavenの方はアパレル関係や人名で、「maven」を冠するものがあるのかと思い、流行りのキーワードを調べて「maven -fortnite」(ゲームのキャラらしい)のように無関係と思わしきキーワードを除外してみましたが、それでも結果はほとんど変わりませんでした。ビルド・プロジェクト管理ツールの選定で悩んでいる方々のお役に立てれば幸いです。



- 投稿日:2019-12-22T11:54:39+09:00
RustでJavaのClassファイルを読んでみた
この記事はZYYX Advent Calendar 2019の22日目の記事です。
今回はRustでJavaのClassファイルを読むプログラムを作成したので(まだすべてのパターンに対応したわけではありませんが)そのプログラムの紹介をします。(N番煎じ感半端ないですが、自分のアウトプットの練習、めもなどもかねて記事としました)
実行環境
この記事では以下の環境で動作確認しています。
- OS: MacOS (Catalina 10.15.2)
- Java: adoptOpenJdk(11.0.5+10)
- Rust: rustc 1.39.0 (4560ea788 2019-11-04)
Classファイルリーディング
JavaのClassファイル
一般的に知られているように、Javaはコンパイラによってソースコードを中間言語に変換し、それをJava VMと呼ばれる仮想マシン上で実行することで実行されます。この中間言語はバイトコードなどと呼ばれており、javaの拡張子のソースコードをjavacでコンパイルし生成されたclassの拡張子のファイルのことを指します。
Classファイルの生成
まずは実装するにあたってテスト的に読んでいくClassファイルを用意します。
class Test { public static void main(String [] args) { int a = 0; int b = 3; int c = a + b; } }なんてことはない変数に一時的に保存した値を足し算するプログラムです。上記のコードでコンパイルして生成されたファイルを読んでいく対象とします。上記のコードをTest.javaというファイルで保存し、以下のコマンドを実行します。
$ javac Test.java上記のコマンドが成功すると同じディレクトリにTest.classが生成されます。Macのターミナルで
xxd Test.classと叩くと以下のように出力されるかと思います。00000000: cafe babe 0000 0037 000f 0a00 0300 0c07 .......7........ 00000010: 000d 0700 0e01 0006 3c69 6e69 743e 0100 ........<init>.. 00000020: 0328 2956 0100 0443 6f64 6501 000f 4c69 .()V...Code...Li 00000030: 6e65 4e75 6d62 6572 5461 626c 6501 0004 neNumberTable... 00000040: 6d61 696e 0100 1628 5b4c 6a61 7661 2f6c main...([Ljava/l 00000050: 616e 672f 5374 7269 6e67 3b29 5601 000a ang/String;)V... 00000060: 536f 7572 6365 4669 6c65 0100 0954 6573 SourceFile...Tes 00000070: 742e 6a61 7661 0c00 0400 0501 0004 5465 t.java........Te 00000080: 7374 0100 106a 6176 612f 6c61 6e67 2f4f st...java/lang/O 00000090: 626a 6563 7400 2000 0200 0300 0000 0000 bject. ......... 000000a0: 0200 0000 0400 0500 0100 0600 0000 1d00 ................ 000000b0: 0100 0100 0000 052a b700 01b1 0000 0001 .......*........ 000000c0: 0007 0000 0006 0001 0000 0001 0009 0008 ................ 000000d0: 0009 0001 0006 0000 002d 0002 0004 0000 .........-...... 000000e0: 0009 033c 063d 1b1c 603e b100 0000 0100 ...<.=..`>...... 000000f0: 0700 0000 1200 0400 0000 0300 0200 0400 ................ 00000100: 0400 0600 0800 0700 0100 0a00 0000 0200 ................ 00000110: 0b .Java Specification
Javaのバイトコードを読むにあたって避けて通れないのはJava Specificationの存在でしょう。(英語苦手マンの私にはとてもつらい所業です)これはJava VMなどのJavaに関わる仕様を取りまとめたドキュメントになっており、Java VMなどを実装するにあたってこの仕様を準拠する必要があります。
今回はJava 11のバイトコードを読んでいくので、The Java® Virtual Machine Specification Java SE 11 EditionのChapter 4. The class File Formatを見ていきます。まず 4.1. The ClassFile Structure にclassファイルの構造の説明があります。
ClassFile { u4 magic; u2 minor_version; u2 major_version; u2 constant_pool_count; cp_info constant_pool[constant_pool_count-1]; u2 access_flags; u2 this_class; u2 super_class; u2 interfaces_count; u2 interfaces[interfaces_count]; u2 fields_count; field_info fields[fields_count]; u2 methods_count; method_info methods[methods_count]; u2 attributes_count; attribute_info attributes[attributes_count]; }u4, u2はunsignedの4bit, 2byteのことです。先頭4byteがmagic, 次2byteにminor_version, major_version, constant_pool_countが続く構造となっているようです。
magic
ドキュメントのmagicの項目を見ると
0xCAFEBABEの固定の数値が来るようです。Classファイルか判別するためのマジックナンバーなのでしょう。実際にxxdした結果の先頭4byteがcafe babeになってています。minor_version, major_version
次のminor_version, major_versionはClassファイル自体のバージョン番号を示すようです。Java VMのバージョンによって実行できるclassファイルのバージョンが決まっているので、ここで判定しているようです。ちなみに対応表はドキュメントのTable 4.1-Aにあります。
xxdした結果を見ると、0x00000x0037がそれに当たります。minor_versionが0, major_versionが55となってます。constant_pool_count
名前の通り後述するconstant_poolの数を表します。
xxdした結果だと、0x000fで、10進の15です。constant_pool
この辺りから英語を読むのが辛くなってきたのでだいぶ曖昧理解になります。constant_poolはStringの定数やclass, interface, fieldの名前などを持ちます。この定義はドキュメントの4.4(cp_info)にあります。先頭のtagの1byteによってcp_infoの構造が変わりますが共通した構造として、以下の形になっています。infoの部分がtagの値によって構造が変わりイメージです。
cp_info { u1 tag; u1 info[]; }xxdした結果をベースに説明していきます。
まず0x0aは10進で10、Table 4.4-Aの表によるとCONSTANT_Methodrefで、構造は以下です。CONSTANT_Methodref_info { u1 tag; u2 class_index; u2 name_and_type_index; }これはクラスのメソッドの情報で、class_indexにこのメソッドが属するクラスのconstant_poolでの場所を指すindexが、name_and_type_indexにこのメソッドの名前を保持するconstant_poolの場所を指すindexを持ちます。
xxdした結果だと0x0a00 0300 0cの部分に当たります。class_indexが0x0003(10進で3), name_and_type_indexが0x000c(10進で12)となります。
次のtagの値は
0x07です。同じくTable 4.4-Aの表によるとCONSTANT_Class_infoで、構造は以下のとおりです。CONSTANT_Class_info { u1 tag; u2 name_index; }こちらはクラスの情報で、name_indexにクラス名のconstant_poolでの場所を指すindexです。
xxdした結果だと0x0700 0dの部分に当たります。
name_indexが0x000d(10進で13)です。後ほどconstant_poolの表を示しますのでそのときにまとめて確認してみましょう。
次のtagも
0x07なので、同じくCONSTANT_Class_infoです。
xxdした結果の0x0700 0eの部分です。
name_indexが0x000e(10進で14)です。
次のtagは
0x01です。CONSTANT_Utf8_infoで、これはUtf8の文字列を持ちます。
定義は以下です。CONSTANT_Utf8_info { u1 tag; u2 length; u1 bytes[length]; }lengthにそのUtf8のbyte数を、bytesはlengthの値だけbyte数を持ちます。
xxdした結果だと0x01 0006 3c69 6e69 743eの部分です。
lengthは0x0006なのでここから6byte分の0x3c69 6e69 743eがbytesの値になります。
ちなみにこれは<init>になります。
以降はCONSTANT_Utf8が続くので、16進の値とそれぞれの対応表を以下に示します。
16進 length bytes デコード結果 0x0100 0328 29563 03282956()V 0x0100 0443 6f64 654 436f6465Code 0x0100 0f4c 696e 654e 756d 6265 7254 6162 6c6515 4c696e654e756d6265725461626c65LineNumberTable 0x0100 046d 6169 6e4 6d61696emain 0x0100 1628 5b4c 6a61 7661 2f6c 616e 672f 5374 7269 6e67 3b29 5622 285b4c6a6176612f6c616e672f537472696e673b2956([Ljava/lang/String;)V 0x0100 0a53 6f75 7263 6546 696c 6510 536f7572636546696c65SourceFile 0x0100 0954 6573 742e 6a61 76619 546573742e6a617661Test.java 0x0100 0454 6573 744 54657374Test 0x0100 106a 6176 612f 6c61 6e67 2f4f 626a 6563 7416 6a6176612f6c616e672f4f626a656374java/lang/Object 途中でUtf8以外のtagがあったのでそれを説明します。以下の画像の部分です。tagが
0x0cなので、CONSTANT_NameAndType_infoです。これは以下の構造で、メソッド、もしくはフィールドを表すために使用され、各値がconstant_poolの場所を指します。
name_indexはメソッド名のconstnat_poolの場所を指します。descriptor_indexはGoogle翻訳さんによるとフィールド記述子§4.3.2または、メソッド記述子§4.3.3のようです。CONSTANT_NameAndType_info { u1 tag; u2 name_index; u2 descriptor_index; }xxdの結果の部分だと、name_indexが
0x0004、descriptor_indexが0x0005です。
これでconstant_poolの値が出揃ったので一通り確認してみましょう。
index constant_pool 1 Methodref_info {class_index: 3, name_and_type_index: 12 } 2 Class_info {name_index: 13 } 3 Class_info {name_index: 14 } 4 Utf8 {bytes: '<init>'} 5 Utf8 {bytes: '()V'} 6 Utf8 {bytes: 'Code'} 7 Utf8 {bytes: 'LineNumberTable'} 8 Utf8 {bytes: 'main'} 9 Utf8 {byets: '([Ljava/lang/String;)V'} 10 Utf8 {bytes: 'SourceFile'} 11 Utf8 {bytes: 'Test.java'} 12 NameAndType {name_index: 4, descriptor_index: 5} 13 Utf8 {bytes: 'Test'} 14 utf8 {bytes: 'java/lang/Object'} 2のClass_infoのname_indexは13なので"Test"、3のClass_infoはname_indexが14なので"java/lang/Object"です。
1のMethodrefはclass_indexが3なので、先のjava/lang/Objectに属するメソッドということがわかります。name_and_type_indexが12なので、12のNameAndTypeを見ます。これのname_indexは4なので、<init>, descriptor_indexは5なので()Vです。
これは引数無しで返り値がVoidのメソッドということを示してます。access_flags
constant_poolが終わったので、クラス定義に戻って次はaccess_flagsを見てみます。access_flagsはclassもしくはinterfaceのアクセス修飾子などを表します。Table 4.1-Bの値となっており,各値の組み合わせで表現します。
例えば
abstract public class Testがあった場合、各値はabstractが0x0400、publicが0x0001でなのでその総和の0x0401になります。今回で言えば、
0x0020が設定されています。
this_class
この値は自身のクラスの情報のconstant_poolのindexを指します。
0x00 02なので、constant_poolの2番目のClass_info(Test)ということがわかります。
super_class
super_classは自身のクラスの親クラスを指すconstant_poolのindexの値です。
0x00 03なので、constant_poolの3番目のClass_info(java/lang/Object)が親クラスということがわかります。
interfaces_count
こちらも名前の通り、interfacesの数を指します。今回はinterfaceを定義していなかったので、0になっています。
fields_count
こちらも名前の通り、fieldsの数を指します。Testクラスにfieldを定義していなかったので、こちらも0になっています。
methods_count
同じく、methodsの数を指します。今回は2になっています。methodsは後述します。
methods
methodsの定義は以下です。
method_info { u2 access_flags; u2 name_index; u2 descriptor_index; u2 attributes_count; attribute_info attributes[attributes_count]; }access_flagsはメソッドのアクセス修飾子などを表します。
クラスのaccess_flagsの値と同じように、こちらの表Table 4.6-Aにある該当する値の総和がaccess_flagsになります。
name_indexはメソッド名のconstant_poolの場所を指します。
descriptor_indexはメソッドの記述子を示す文字列のconstant_poolの場所を指します。
attributes_countは次のattributes_infoの数です。
attributesは後述しますが、定数の値やメソッドのコードなど、様々な値を表します。このClassファイルでは、1つ目のmethodsは以下の画像の赤枠で囲った部分。
method_info {
access_flags: 0,
name_index: 4,
descriptor_index: 5,
attributes_count: 1,
attribute_info: [
'0x0006 0000 001d 0001 0001 0000 0005 2AB7 0001 B100 0000 0100 0700 0000 0600 0100 0000 01'
]
}
access_flagsは0なので修飾子は特になにもついていない。name_indexは4なので、constant_poolの4番目の'<init>'となります。descriptor_indexは5なので、constant_poolの5番目の'()V'です。attributes_countは1なので、attributeの個数は1ということがわかります。
2つ目のmethodsは以下の画像の赤枠で囲った部分です。
method_info { access_flags: 9, name_index: 8, descriptor_index: 9, attribute_count: 1, attribute_info: [ "0x0006 0000 002d 0002 0004 0000 0009 033C 063D 1B1C 603E B100 0000 0100 0700 0000 1200 0400 0000 0300 0200 0400 0400 0600 0800 07" ] }access_flagsは9なので、
ACC_PUBLIC: 0x0001とACC_STATIC: 0x0008の値の和になってますので、public, staticの修飾子がついていることがわかります。
name_indexは8なのでconstant_poolの8番目の値の'main'です。
descriptor_indexは9なので、constant_poolの9番目の'([Ljava/lang/String;)V'です。
これは引数がjava/lang/String、返り値がvoidということです。
attribute_countは1なので、attributeの個数は1ということです。
attributes_count
こちらも名前の通り、attributesの個数を表します。
attributes
こちらの定義はまだ未実装なので、今回は説明を省きます。
実装
上記で見てきたことを実装に落とし込みます。ソースコードの全体はgithubのリポジトリにありますので、そちらをご確認ください。
基本的にやっていることは、各定義の構造体を用意しファイルを上から順に読んでいっています。
例えばmethod_infoだと、以下の構造体を用意しています。173 #[derive(PartialEq, Debug)] 174 struct MethodInfo { 175 access_flags: u16, 176 name_index: u16, 177 descriptor_index: u16, 178 attributes_count: u16, 179 attributes: Vec<AttributeInfo> 180 }access_flagsや、name_index, descriptor_index, attributes_countはu2の2byteなので、u16型で定義します。
ファイルを読んでmethodsの構造体を作っているのが以下のコードになります。275 let methods = (0..methods_count).map(|_| { 276 let access_flags = reader.read_u16::<BigEndian>().unwrap(); 277 let name_index = reader.read_u16::<BigEndian>().unwrap(); 278 let descriptor_index = reader.read_u16::<BigEndian>().unwrap(); 279 let attributes_count = reader.read_u16::<BigEndian>().unwrap(); 280 281 let attributes = (0..attributes_count).map(|_| { 282 let attribute_name_index = reader.read_u16::<BigEndian>().unwrap(); 283 let attribute_length = reader.read_u32::<BigEndian>().unwrap(); 284 285 let info = (0..attribute_length).map(|_| { 286 reader.read_u8().unwrap() 287 }).collect(); 288 289 AttributeInfo::new(&cp_info_vec, attribute_name_index, attribute_length, info) 290 }).collect();readerは以下のようにBufReaderでClassファイルをオープンしています。
193 let mut reader = BufReader::new(File::open("res/Test.class")?);そのreaderを使って、read_u16などで指定のbyte数ずつ値を読み取っていきます。read_u16やread_u32などは
byteorderというcrateで提供される関数です。これがあるbyte数ずつ値を読み取り、指定の型に変換してくれるので今回の実装でとても使いました。また、関数を呼ぶ際にendinanの指定が必要なのですが、ClassファイルはBigEndianで書かれているので、BigEndianを指定しています。次はconstant_poolの読み込みのコードを見ていきましょう。
28 #[derive(PartialEq, Debug, Clone)] 29 enum Info { 30 Offset, 31 Class {name_index: u16}, 32 Methodref {class_index: u16, name_and_type_index: u16}, 33 Utf8 {length: u16, bytes: Vec<u8>}, 34 NameAndType {name_index: u16, descriptor_index: u16} 35 } 36 37 #[derive(PartialEq, Debug, Clone)] 38 struct CpInfo { 39 tag: u8, 40 info: Info 41 } ============================================ 203 let mut cp_info_vec = Vec::new(); 204 cp_info_vec.push(CpInfo {tag: 0, info: Info::Offset}); 205 for _ in 0..(constant_pool_count - 1) { 206 let tag = reader.read_u8()?; 207 match tag { 208 1 => { 209 let length = reader.read_u16::<BigEndian>()?; 210 let vec = reader.read_limit(length as u32); 211 cp_info_vec.push(CpInfo {tag, info: Info::Utf8 {length, bytes: vec}}) 212 } 213 7 => { 214 let name_index = reader.read_u16::<BigEndian>()?; 215 cp_info_vec.push(CpInfo {tag, info: Info::Class {name_index}}) 216 } 217 10 => { 218 let class_index = reader.read_u16::<BigEndian>()?; 219 let name_and_type_index = reader.read_u16::<BigEndian>()?; 220 cp_info_vec.push(CpInfo {tag, info: Info::Methodref {class_index, name_and_type_index}}); 221 } 222 12 => { 223 let name_index = reader.read_u16::<BigEndian>()?; 224 let descriptor_index = reader.read_u16::<BigEndian>()?; 225 226 cp_info_vec.push(CpInfo {tag, info: Info::NameAndType {name_index, descriptor_index}}) 227 } 228 n => { 229 println!("{}: unimplmeneted!", n); 230 break; 231 } 232 } 233 }constant_poolはまず結果を格納するVec(cp_info_vec)にOffsetを入れます。これはconstant_poolを指すindexの値が1から始まっているため、0番目を埋めるために入れています。あとはconstant_pool_count - 1の数だけループで回し、最初のタグの値によって読み取り方法を変えている実装になっています。
まだ、1(CONSTANT_Utf8), 7(CONSTANT_Class), 10(CONSTANT_Methodref), 12(CONSTANT_NameAndType)にしか対応していないので、それ以外が来た場合は、unimplementedと表示してループを中断しています。(今回の読む対象としたClassファイルにはそれ以外が登場してこなかったので読み取れるはずです。)まとめ
今回はJavaのバイトコードであるClassファイルの仕様を見ていき、その使用をRustのプログラムコードに落とし込んでいくところを紹介しました。
Classファイルを読むこと自体はそこまで難しくなく、淡々と仕様どおりに実装していくことができるので(内容を理解することはまた別問題ですが…)、楽しかったです。今後は、まだ実装していない部分を実装し、最終的にオレオレJVMを作りたいと考えています。進捗があれば、Qiitaの記事で投稿したいと思っています。
今回の記事で誤りなどあればコメントをお願いいたします。また、まだまだRustの初心者なので、コードの方でもっと効率のよい方法などあればgithubのissueなどでご指摘いただければ幸いです。














- 投稿日:2019-12-22T11:41:28+09:00
SpringのAutowiredはコンストラクタに書く
概要
SpringでDIをする時使うAutowiredのアノテーションは使いやすいし便利ですよね!
しかし、使い方が複数あり、どの使い方がいいのか迷うところではあります。
私はよくコンストラクタで使うのですが、そうなった経緯を整理したいと思います。Autowiredを設定できる方法
ざっくりと復習。Autowiredの設定方法は三種類あります。
フィールドインジェクション
フィールドに直接書くタイプの宣言方法です。
public class A { @Autowired private B b; }コンストラクタインジェクション
コンストラクタに書くタイプの宣言方法です。
public class A { private final B b; @Autowired public A(B b) { this.b = b; } }セッターインジェクション
セッターに書くタイプの宣言方法です。
public class A { private B b; @Autowired public void setB(B b) { this.b = b; } }なぜコンストラクタインジェクションを選ぶのか。
フィールドにfinalを使用することができて、不変性を担保できる。この理由が大きいですね。
こうすることで、処理の途中で書き換えられることがないので安全ですよね。
(保守で訳わからない人でもfinal書き換える時にコンパイルエラーになるから、わかる。本当に)
また、テストでnewしできるのが大きいですね。
テストでDIするか単なるnewで済ますのかを選択できるようになるのは、個人的に嬉しい。逆にフィールドインジェクションを使用しているのはダメ
そもそも公式が非推奨としているものです。(たしか)
それを、わざわざ使用する意味はないでしょう。サンプルソースとかでもフィールドインジェクションを使用しているのは信用しないようにしています。
そのぐらいダメだと個人的に思ってます。(すごく楽だけど)まとめ
どんなソースでもめんどくさがらずにコンストラクタインジェクションを使用しましょうね。
- 投稿日:2019-12-22T10:36:17+09:00
【IT専門学生の就活】僕がこれからやること
自己紹介
僕はIT系の専門学生1年で、現在はWeb系の企業を目指して学習を進めています。今回この記事を書こうと思った理由は、就活が迫ってきたのですが学校にはWeb系企業の求人がなく、ポートフォリオを作成し、技術を証明する必要があると考えたからです。
今までやったこと
僕がWeb開発を始めたのは大学受験に落ちた日からです。もちろん最初は Progateさんから始めました:)
そしていつの間にかIT系の専門学校に
独学
- ポートフォリオページ作成(HTML&CSS)
- Ruby
- Ruby on Rails
- AWS(EC2)
- adobeXD
- PaizaスキルチェックBランク(Java,Ruby)
学校
- MySQL
- CentOS
- GUI電卓作成(JavaFX)
- GUIポーカー作成(JavaFX)
- シューティングゲーム作成(JavaFX)
- 基本情報技術者試験合格
- 成績全てA(1年前期)
書き途中に気付いたのですが、自主学習時間の割に形になっているものが少ないなと思ったので、作成物や資格合格を目標として取り組むことにします。
これからやること
自分でやることで何をすればよいかを整理するために書くので、学校のみで勉強するものは省いています。
就活までにやること(専門1年)
先頭の番号は優先順位です
- Webアプリ作成(Rails&HTML&CSS&BT) [独学]
- PaizaスキルチェックAランク(Python) [独学]
- ポートフォリオサイト作成(HTML&CSS&BS) [独学]
- 成績全てA [自宅+学校]
- 応用情報技術者試験合格 [自宅+学校]
プラスしてやること(専門2年)
まだ具体的に定まっていないため優先順位はつけられないのでつけません。
- Webアプリ作成(Laravel)
- Webアプリ作成(Java Spring Framework)
- TOEIC600点?(受けたことないからわからない)
ここからは趣味でやりたいことかもしれません。余裕があればやります
- 高校数学復習+大学数学
- 機械学習・人工知能
- Pythonでいろんな分野で遊ぶ
タスクに分解
やることを明確にするため、目標をタスクに分解していきます。
1.Webアプリ作成(Rails)
- Ruby
- Rails
- HTML・CSS
- Git
主役はRailsですがもちろん基礎文法としてRuby、デザインとしてHTML・CSS、バージョン管理としてGitをやる必要があります。デプロイはHerokuで行います(デプロイについてはRailsチュートリアルで学習できます↓)
タスク
【Ruby】
・[完了]Progate Rubyコース
・[完了]Paiza Rubyコース
・[完了]プロを目指す人のためのRuby【Rails】
・[完了]Progate Railsコース
・Railsチュートリアル【HTML・CSS】
・[完了]Progate HTML&CSS【Git】
・Udemy Git:はじめてのGitとGitHub2.PaizaスキルチェックAランク
- Python
- アルゴリズム
Pythonは応用情報と組み合わさった良い講座があったのでそれを見ることにします。アルゴリズムは演習もやりながらできるものがQiitaにたくさんあったのでそれをやることにします。
タスク
【Python】
・基本情報技術者試験+応用情報技術者試験+Python+SQL【アルゴリズム】
・AtCoder に登録したら次にやること 過去問精選10問
・AtCoder 版!蟻本 (初級編)3.ポートフォリオサイト作成(HTML&CSS&BS)
サーバーサイドを見せるためのポートフォリオ程度のHTML・CSSで新たに学習することはないので適当に調べながらやることにします。
4.成績全てA
テスト範囲が発表されてから考えます
5.応用情報技術者試験合格
基本情報で基本的なことは覚えたのでやるべきことは過去問演習だけです
タスク
・過去問演習
おわりに
応用情報合格したいな...?
- 投稿日:2019-12-22T05:17:04+09:00
アルゴリズム体操8
Find Maximum Single Sell Profit (Similar to Max-Subarray)
説明
毎日の株価(簡単にするための整数)を要素とした配列が渡されて、最大の利益を得るために売買価格を返すアルゴリズムを実装しましょう。
前提条件として、買うと行為が売る行為よりも必ず先に来ることにします。
つまり、もし株価が最小の要素が配列の最後にあるとしても売る価格がその後にないので、その要素は買う価格としては認められません。
単一の売買利益を最大化する必要があります。利益を上げることができない配列が渡された場合は、損失を最小限に抑えようとします。 以下の例では、最大の利益を上げるための売買の価格が黄色と緑で強調されています。二番目の例は損失を最小限にしています。
Hint 『 Kadane's algorithm 』
Solution
Runtime Complexity O(n)
Memory Complexity O(1)
解説
配列の値は、毎日の株価を表します。 1日に一度だけ株式を売買できるので、一定の期間にわたって利益が最大化される
または損失が最小化される、最高の売買価格を見つける必要があります。力づく解決策はO(n^2)で、各要素とそれに続く要素間の最大利益を見つけることです。
ただ、この問題を実行時間O(n)で片付けることができます。
それは、現在の購入価格(これまでに見られた最小数)、現在の利益(売る価格 - 現在の購入価格)、最大利益を
維持する必要があります。 各反復で、現在の利益をグローバルな利益と比較し、それに応じてグローバルな利益を更新します。
グローバル利益 = 売る価格(反復の中で一番大きい株価) - 買う価格(反復の中で一番小さい株価)具体例
では具体的な例で実際に見ていきましょう。
まず、初期設定をcurrent_profitを-∞として、buying_priceを配列の最初の要素12、global_sellが配列の二番目の要素5、
そして、gobal_profitがglobal_sell からbuying_priceを引いた数の-7となります。
buying_priceは12より小さいので5に更新され、current_profitはINT_MINより大きいので-7に更新されます
current_profitは4になり、global_profitはglobal_sellと同様に更新されます。 buying_priceは前回の5よりも9の方が大きいので、同じままであることに注意してください。
current_profitは14になり、global_profitはglobal_sellと同様に更新されます。 buying_priceは同じままであることに注意してください。 19を売値として、5(19-14)を買値として返します。
このアルゴリズムのポイントはループでどの変数を毎回更新していくかを決める点。
ループの中で今までの最適な買う価格を保持しつつ、一つ一つの要素を売る価格と見なして現在の利益を更新している。
そして、更新された現在の利益が今までの利益よりも低いか高いかを比較して高ければグローバル利益として更新している。実装
StockPrice.javapublic class StockPrices { public Tuple find_buy_sell_stock_prices (int[] stock_prices) { if (stock_prices == null || stock_prices.length < 2) { return null; } int current_profit = Integer.MIN_VALUE; int global_sell = stock_prices[1]; int buying_price = stock_prices[0]; int global_profit = global_sell - buying_price; for (int i = 1; i < stock_prices.length; i++) { current_profit = stock_prices[i] - buying_price; // if true, stock_prices[i] is smaller than global_sell if (current_profit > global_profit) { global_profit = current_profit; global_sell = stock_prices[i]; } if (stock_prices[i] < buying_price){ buying_price = stock_prices[i]; } } Tuple<Integer, Integer> result = new Tuple(global_sell - global_profit, global_sell); return result; } }Tuple.javaclass Tuple<X, Y> { public X buy; public Y sell; public Tuple(X x, Y y) { this.buy = x; this.sell = y; } }Main.javapublic class Main { public static void main(String[] args) { // write your code here StockPrices algorithm = new StockPrices(); int[] array = {100, 113, 110, 85, 102, 86, 63, 81, 101, 94, 106, 101, 79, 94, 90, 97}; Tuple result = null; result = algorithm.find_buy_sell_stock_prices(array); System.out.println(String.format("Buy Price: %d Sell Price: %d", result.buy, result.sell)); int[] array2 = {12,5,9,19,8}; result = algorithm.find_buy_sell_stock_prices(array2); System.out.println(String.format("Buy Price: %d Sell Price: %d", result.buy, result.sell)); } }OUTPUT
テストの一つ目の配列についてのイメージ図







- 投稿日:2019-12-22T02:04:03+09:00
protocol buffeer migration from 2.x to 3.x
- 投稿日:2019-12-22T01:24:44+09:00
[Java] Stream API 入門
Stream API #とは
こちらの記事の続きみたいなものです.
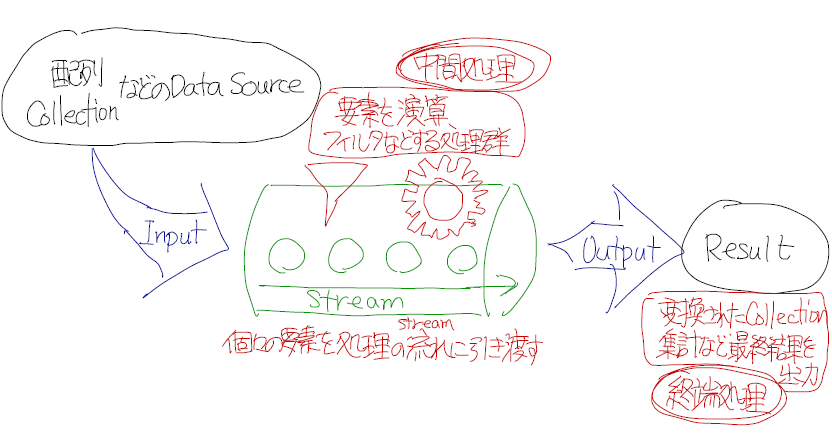
Stream API はDataをPipeLine形式で処理するためのAPIです.
Collection,配列,ファイルなどデータの集合体(Data Source)から,個々の要素を取り出して
これを「処理の流れ」(Stream)に引き渡すための仕組みを提供します.Streamに対して関数操作を行った結果をStreamで返す「中間操作」と
処理結果をDataとして返す「終端操作」があります.中間操作も終端操作もメソッド引数は関数型インターフェースを取るものが多いため,
ここでラムダ式の知識が利用していくとスマートということになります.
Stream…?I/O Streamとは違う?
Javaにはjava.ioパッケージにI/O Streamが提供されていますが,
こちらのStreamの意味は入出力をStreamになぞらえた概念ですが,
Stream APIのStreamはDataのPipeLine処理をStreamに見立てた概念です.Stream API の基本
import java.util.ArrayList; import java.util.Arrays; public class Main { public static void main(String[] args) { // ①Data Sourceを準備する var list = new ArrayList<String>( Arrays.asList("tokyo", "nagoya", "osaka", "fukuoka", "hokkaido", "okinawa")); // ②ストリームを作る list.stream(). filter(s -> s.length() > 5). // ③中間処理を行う map(String::toUpperCase). forEach(System.out::println); // ④終端処理を行う // 結果:NAGOYA FUKUOKA HOKKAIDO OKINAWA } }Stream APIの処理は以下で構成されます.
①Data Source準備する→②Stream生成→③抽出/加工などの中間処理→④出力/集計などの終端処理上の例でいえば,
①まずArrayListのData Sourceを作る②Streamを生成する.ここではArrayList<String>をもとにしているため,
Streamメソッドも,Stream<String>オブジェクトを返します.※与えられるData Sourceの型によって型引数は変動することと,
Streamの途中で値が加工されることで,型が変化していく場合もある.③filterメソッドで「文字数が5より大きい値だけを取り出す」
mapメソッドで「大文字に変換する」
中間処理は複数あってもよし.省略してもよし.④forEachメソッドで,得られた値をSystem.out::printlnメソッドで出力
終端処理は省略できません.
中間処理の戻り値はいずれもStream<T>です.
Stream APIでは,Streamの生成から中間処理/終端処理までを「.」演算子で
ひとまとめに連結でき,スマートな記述ができます.
(メソッドの連鎖という意味でメソッドチェーンと呼ばれる)Streamの一連の処理が実行されるのは,終端処理のタイミングです.
中間で抽出/加工などの演算が呼び出されていても,それは一旦ストックされて,
その場では実行されず,終端処理まで処理の実施を待ちます.これを遅延処理といいます.Stream の作り方
Collection/配列から生成
Collectionから
Collection.stream()
配列から
Arrays.stream(T[])
Mapから
Map.entrySet().stream()stream()メソッドの並列版として,parallelStream()メソッドもあります.
streamをparallelStreamに置換するだけで,並列処理が可能になります.(強い…)
扱う要素数が多い場合,並列処理を有効にすることで,効率的に処理できる場合があります.
(勿論並列化のオーバーヘッドがあるため,必ずしも高速にはなりません.)
既存のStreamを並列化,あるいは直列化することもできます.StreamクラスからStream生成
Streamクラスでは,Stream生成するためのFactory Methodがあります.
最も基本的なのは,指定された可変数引数をStreamに変換するofメソッドです.var stream = Stream.of("tokyo","osaka","nagoya"); stream.forEach(System.out::println); // tokyo, osaka, nagoya他にもgenerate(),builder(),concat(),iterator()があります.ここでは割愛します.
プリミティブ型のStream生成
IntStream
intで特殊化されたストリーム
LongStream
longで特殊化されたストリーム
DoubleStream
doubleで特殊化されたストリームIntStream.range(int start, int endExclusive) [第2引数は範囲外:開空間]
IntStream.rangeClosed(int start,int endInclusive) [第2引数は範囲内:閉空間]IntStreamを使った繰り返し処理の例は以下のようになります.
for文を使った場合と比較します.ちょっとオサレですね.for文を使った繰り返しfor(int i = 1; i <= 5 ; i++){ System.out.println(i); }IntStreamを使った繰り返しIntStream.rangeClosed(1, 5).forEach(System.out::println);Javaのジェネリクスの型引数では,プリミティブ型は使えないため,
Stream<int>のような書き方はエラーになります.中間処理
Streamに流れる値を抽出/加工する役割を持ちます.
中間処理が実行されるのは,あくまで終端処理が呼び出されたタイミングであり,
呼び出しのたびに実行されるわけではないです.filter
指定された条件で値を抽出します.
Stream.of("tokyo", "nagoya", "osaka").filter(s -> s.startsWith("t")).forEach(System.out::println); //tokyomap
与えられた値を加工します.
Stream.of("tokyo", "nagoya", "osaka").map(s -> s.length)).forEach(System.out::println); //5, 6, 5生成直後はStream<String>だったのが,mapメソッドの後はStream<Integer>になってることに注意.
sorted
要素を並べ替えます.
Stream.of("tokyo", "nagoya", "osaka").sorted().forEach(System.out::println); // nagoya, osaka, tokyo Stream.of(2,1,3).sorted().forEach(System.out::println); // 1, 2, 3デフォルトの動作は自然順序によるソートです.文字列ではれば辞書順,数値であれば大小でのソートです.
独自のソート規則を指定したい場合は,ソート規則をラムダ式で設定しましょう.
sorted()の引数はComparatorインターフェイスです.Stream.of("tokyo", "nagoya", "osaka"). sorted((str1, str2) -> str1.length() - str2.length()).forEach(System.out::println); // tokyo, osaka, nagoyaskip/limit
skip: m番目までの要素を切り捨てる
limit: n+1番目以降の要素を切り捨てるIntStream.range(1, 10).skip(3).limit(5).forEach(System.out::println); // 4, 5, 6, 7, 8skipメソッドで最初の4要素をスキップし,
limitメソッドでそこから5個分の要素を取り出しています.
limitメソッドではすでに先頭が切り捨てたStreamを操作するため,引数に注意しましょう.peek
Streamの途中状態を確認します.
peekメソッドそのものはStreamに影響を与えないため,主にデバッグ用に使われます.Stream.of("tokyo", "nagoya", "osaka").peek(System.out::println).sorted().forEach(System.out::println); //ソート前の結果:tokyo, nagoya, osaka ← peekのprintln //ソート後の結果:nagoya, osaka, tokyo ← forEachのprintlndistinct
値の重複を除去します.
Stream.of("tokyo", "nagoya", "osaka", "osaka", "nagoya", "tokyo").distinct().forEach(System.out::println); // tokyo, nagoya, osaka終端処理
Streamに流れる値を最終的に出力/集計する役割を持ちます.
Streamは終端処理の呼び出しをトリガーにして最終的にまとめて処理されるため,
中間処理と異なり,終端処理は省略できません.終端処理したStreamを再利用することはできないため,
再度Stream処理を行いたい場合は,StreamそのものをData Sourceから再生成する必要があります.forEach
個々の要素を順に処理します.
Stream.of("tokyo", "nagoya", "osaka").forEach(v -> System.out.println(v)); // tokyo, nagoya, osaka Stream.of("tokyo", "nagoya", "osaka").forEach(System.out::println); // tokyo, nagoya, osakafindFirst
最初の値を取得します.
System.out.println(Stream.of("tokyo", "nagoya", "osaka").filter(s -> s.startsWith("t")).findFirst().orElse("empty")); // tokyo空Streamの場合があるため,findFirstメソッドの戻り値はOptional型です.
空の場合System.out.println(Stream.of("tokyo", "nagoya", "osaka").filter(s -> s.startsWith("a")).findFirst().orElse("empty")); // emptyanyMatch/allMatch/noneMatch
値が特定の条件を満たすか判定します.
順に「条件式がtrueになる要素が存在するか」,「条件式がすべてtrueになるか」,
「条件式がすべてtrueにならないか」になります.System.out.println(Stream.of("tokyo", "nagoya", "osaka").anyMatch(v -> v.length() == 5)); // true System.out.println(Stream.of("tokyo", "nagoya", "osaka").allMatch(v -> v.length() == 5)); // false System.out.println(Stream.of("tokyo", "nagoya", "osaka").noneMatch(v -> v.length() == 5)); // falsetoArray
Stream処理の結果を文字列配列として変換します.
var list = Stream.of("tokyo", "nagoya", "osaka").filter(s -> s.startsWith("t")).toArray();collect(コレクション変換)
Stream処理の結果をCollectionとして変換します.
collectメソッドにはCollectorsクラスで提供されている変換メソッドを渡します.
Listへの変換はtoList,Setへの変換はtoSet,マップへの変換はtoMapを使います.var list = Stream.of("tokyo", "nagoya", "osaka").filter(s -> s.startsWith("t")).collect(Collectors.toList());collectメソッドはコレクション変換専用のメソッドというより,
リダクション処理を行うメソッドでもあります.リダクション処理の場合は後述します.min/max
最小値/最大値をもとめます.引数には比較規則(Comparator)を指定する必要があります.
戻り値がOptional型であるため,orElse経由になります.(ここではないことを意味する-1としています.)System.out.println(Stream.of(1, 3, 2).min((int1, int2) -> int1 - int2).orElse(-1)); // 1 System.out.println(Stream.of(1, 3, 2).min((int1, int2) -> int2 - int1).orElse(-1)); // 3 System.out.println(Stream.of(8, 7, 9).max((int1, int2) -> int1 - int2).orElse(-1)); // 9 System.out.println(Stream.of(8, 7, 9).max((int1, int2) -> int2 - int1).orElse(-1)); // 7count
要素の個数を求めます.
System.out.println(Stream.of("tokyo", "nagoya", "osaka").filter(s -> s.length() > 5).count()); // 1reduce
Streamの値を一つにまとめます(Reduction).
reduceメソッドは3種類のオーバーロードを提供しています.引数1個の場合
Optional reduce(BinaryOperator accumulator);
戻り値がOptional型であるため,orElse経由になります.引数は演算結果を格納するための変数result,個々の要素を受け取るための変数strがあります.
引数1個の場合System.out.println( Stream.of("tokyo", "nagoya", "osaka").sorted() .reduce((result, str) -> { return result + "," + str;}).orElse("")); // nagoya,osaka,tokyo引数2個の場合
T reduce(T identity, BinaryOperator accumulator);
第一引数で初期値を受け取ることができます.
結果は非nullであることが明らかなため,非Optional型になります.OrElse経由は不要です.引数2個の場合System.out.println( Stream.of("tokyo", "nagoya", "osaka").sorted() .reduce("hokkaido", (result, str) -> { return result + "," + str;})); //hokkaido,nagoya,osaka,tokyo引数3個の場合
U reduce(U identity, BiFunction accumulator, BinaryOperator combiner);
少々難しいかもしれません.Streamの要素型と,最終的な要素型が異なる場合に使います.ここでは例を割愛します.
詳細を知りたい方はこちらの記事を見るといいかもしれません.collect(リダクション操作)
Stream内の要素をCollectionなどにまとめます.
reduceがStream内の要素をint,Stringのような単一値にリダクション処理するのに対し,
collectはCollection/StringBuilderのような可変な入れ物に対して値を蓄積してから返します(可変リダクション).こちらは少々難解なため,後程更新します….
終わりに
自分は3月までにJava Gold SE 11を取得するつもりです.
(そもそも前提としてJava Silver SE 11を受けないといけませんが….)
Goldではラムダ式/Stream APIの出題率がとても高いため,整理しました.Java SE 11 は半年前(2019/06下旬)くらいにできたばかりの資格で,
今まではSE 8 が最新版でした.Silver SE 11の参考書はすでに出ていますが,
Gold SE 11は現時点(2019/12)まだ参考書は出てないです.
SE 11 の試験ではSE 8の試験と違いラムダ式/Stream APIの使い方は
SE 11ベースになると思いますので,受験する方はご注意を.
- 投稿日:2019-12-22T00:58:50+09:00
java 繰り返し処理
今日はjavaの繰り返し処理について書きます。
繰り返し文とは
一定の指示を与えた命令を繰り返す処理のこと
実行結果をこう出す場合
[1]
[2]
[3]
[4]
[5]通常だと
通常処理public class PrintFiveStars { | public static void main (String[] args){ | System.out.println("[1]"); System.out.println("[2]"); System.out.println("[3]"); System.out.println("[4]"); System.out.println("[5]"); } }繰り返し構文を使用した場合
5行ほどで済みます。
これを応用すれば、100でも1000行でも
編集するだけで処理を行うことができます。繰り返し処理public class Print100Stars { public static void main (String[] args) { int sum = 0; for (int i = 1; i <= 5; i++){ sum += 1; System.out.println(sum); } } }
- 投稿日:2019-12-22T00:43:31+09:00
Python Javaでどうやったらマネタイズできるか戦略
Python Javaでどうやったらお金になるか?
フレームワークではなくて言語から勉強する。
PythonならPython JavaならJava
プログラム作成の仕事を探す。
実務しながらの方がやはり伸びると思う。
テストではなくてプログラミングがある仕事を探す。
どっちが偉いってことはないけど違う仕事だと思う。Javaでマネタイズ
フレームワーク(Spring)やフロントエンド的な勉強やSQLなど(Linuxもあります)
周辺知識が多くて辛いがやればお金にはなると思うので心を込めてやろうと思う。
→ Springを中心にやってあとは深めていくみたいなやり方がいいかも。Pythonは
Flaskの公式見たり、ソース見たり
Flask + chabot
勉強
既存の物を使って研究してみるとか
→ IBM Watson等Flask + APIとか
フレームワークも改造できたりするところまでいけたらと思うね。