- 投稿日:2019-12-18T22:52:17+09:00
GoのSpannerクライアントについて ReadOnlyTransaction編
QualiArts Advent Calendar 2019、20日目担当のs9iです。
弊社の新規タイトルでは、バックエンドのプログラミング言語にGo、データベースにCloud Spannerを採用しています。今回はGoでSpannerを使用する際に使う、公式クライアントライブラリの使い方について書いていきます。
Cloud Spannerとは
2017年にGoogleから公開されたフルマネージドのデータベースです。
詳細な説明はここでは割愛しますが、
- リージョンを跨いだ水平スケール
- RDBとしての特性(スキーマ、トランザクション、SQL ...)
- ノード数を増やすほどスループット向上
といった特徴があります。弊社でも、RDBの特性と自動で行われる水平スケールに特に魅力を感じ、採用に至りました。
Spannerのトランザクション
Spannerには2種類のトランザクションがあります。
- ReadOnlyTransaction
- ReadWriteTransaction
この2種類を処理に応じて使い分けることで、より効率の良いデータベース操作が可能となります。本記事では、主にReadOnlyTransactionの使用方法を記します。
トランザクションの詳細についてはこちらの記事が非常に参考になります。詳解 google-cloud-go/spanner — トランザクション編
Spannerクライアントの使用方法
本記事では、
- go 1.13
- cloud.google.com/go/spanner 1.1.0
を使用しています。
スキーマ定義
今回説明に使用するテーブルとして、以下のItemテーブルを定義します。
(本来、Spannerではプライマリキーに基づいてデータのシャーディングが行われるので、連続値等の偏りがある値をプライマリキーに指定するべきではありません。その他についても突っ込みどころは多々ありますが、説明用のテーブルということでご了承ください。)CREATE TABLE Item( ItemID INT64 NOT NULL, ItemType STRING(MAX) NOT NULL, Name STRING(MAX) NOT NULL, Effect INT64 NOT NULL, Description STRING(MAX), ) PRIMARY KEY(ItemID, ItemType); CREATE INDEX IdxItemName ON Item(Name);こちらのテーブルに以下のデータを入れておきます。
ItemID ItemType Name Effect Description 1 Type1 アイテム1 10 説明1-1 1 Type2 アイテム2 20 説明1-2 1 Type3 アイテム3 30 説明1-3 1 Type4 アイテム4 40 説明1-4 2 Type1 アイテム5 50 説明2-1 2 Type2 アイテム6 60 説明2-2 2 Type3 アイテム7 70 説明2-3 3 Type1 アイテム8 80 説明3-1 3 Type2 アイテム9 90 説明3-2 4 Type1 アイテム10 100 NULL Spannerクライアントの生成
cloud.google.com/go/spannerパッケージのNewClient()でクライアントを生成します。
セッションの設定や認証情報等を指定する場合は、NewClientWithConfig()を使用します。import "cloud.google.com/go/spanner" // projectID:GCPプロジェクトのID // instance:Spannerのインスタンス名 // db:Spannerのデータベース名 func NewClient(ctx context.Context, projectID, instance, db string) (*spanner.Client, error) { dbPath := fmt.Sprintf("projects/%s/instances/%s/databases/%s", projectID, instance, db) client, err := spanner.NewClient(ctx, dbPath) if err != nil { return nil, errors.New("Failed to Create Spanner Client.") } return client, nil }Read
SpannerクライアントのReadOnlyTransaction()を用いて読み取り専用トランザクションを開始します。直後にdeferでクローズ処理を登録しておきましょう。
取得したトランザクションのRead()で検索処理が実行できます。こちらも忘れずにdeferでイテレータのStop()を実行しましょう。func ReadOnlyTxRead(ctx context.Context, client *spanner.Client) error { rtx := client.ReadOnlyTransaction() defer rtx.Close() // コンテキスト, テーブル名, キー, カラムの順で指定 iter := rtx.Read(ctx, "Item", spanner.AllKeys(), []string{"ItemID", "ItemType", "Name"}) defer iter.Stop() for { row, err := iter.Next() if err == iterator.Done { break } if err != nil { return err } var itemID int64 var itemType, name string // Read()で指定したカラム順で取得できる if err := row.Columns(&itemID, &itemType, &name); err != nil { return err } fmt.Printf("%d %s %s\n", itemID, itemType, name) } return nil }# 出力結果 1 Type1 アイテム1 1 Type2 アイテム2 1 Type3 アイテム3 1 Type4 アイテム4 2 Type1 アイテム5 2 Type2 アイテム6 2 Type3 アイテム7 3 Type1 アイテム8 3 Type2 アイテム9 4 Type1 アイテム10今回の例ではrow.Columns()を用いて値をバインドしていますが、構造体に一括でバインドするrow.ToStruct()や、カラム名を指定してバインドするrow.ColumnByName()も使用できます。
Read(カラムがNullを含む場合)
指定したカラムがNullを含む場合は、NullXxx型で値を取得した後、フィールドのValidで値の有無を判定します。
func ReadOnlyTxRead(ctx context.Context, client *spanner.Client) error { rtx := client.ReadOnlyTransaction() defer rtx.Close() iter := rtx.Read(ctx, "Item", spanner.AllKeys(), []string{"ItemID", "ItemType", "Name", "Description"}) defer iter.Stop() for { row, err := iter.Next() if err == iterator.Done { break } if err != nil { return err } var itemID int64 var itemType, name string var uncheckedDescription spanner.NullString if err := row.Columns(&itemID, &itemType, &name, &uncheckedDescription); err != nil { return err } var description string if uncheckedDescription.Valid { description = uncheckedDescription.String() } fmt.Printf("%d %s %s %s\n", itemID, itemType, name, description) } return nil }# 出力結果 1 Type1 アイテム1 説明1-1 1 Type2 アイテム2 説明1-2 1 Type3 アイテム3 説明1-3 1 Type4 アイテム4 説明1-4 2 Type1 アイテム5 説明2-1 2 Type2 アイテム6 説明2-2 2 Type3 アイテム7 説明2-3 3 Type1 アイテム8 説明3-1 3 Type2 アイテム9 説明3-2 4 Type1 アイテム10Read(特定のキーを指定する場合)
上記の例で使用していたspanner.AllKeys()はすべてのキーを指定するものでした。特定のキーを指定したい場合は、spanner.Keyでキーの順序に合わせて値を指定してあげます。
func ReadOnlyTxRead(ctx context.Context, client *spanner.Client) error { rtx := client.ReadOnlyTransaction() defer rtx.Close() keySet := spanner.KeySets(spanner.Key{1, "Type4"}, spanner.Key{3, "Type2"}) iter := rtx.Read(ctx, "Item", keySet, []string{"ItemID", "ItemType", "Name"}) defer iter.Stop() for { row, err := iter.Next() if err == iterator.Done { break } if err != nil { return err } var itemID int64 var itemType, name string if err := row.Columns(&itemID, &itemType, &name); err != nil { return err } fmt.Printf("%d %s %s\n", itemID, itemType, name) } return nil }# 出力結果 1 Type4 アイテム4 3 Type2 アイテム9Read(キー範囲を指定する場合)
キーの範囲を指定する場合はspanner.KeyRangeを使用します。
Start, Endでキーの境界を指定し、Kindで境界値を含むかどうかを指定できます。func ReadOnlyTxRead(ctx context.Context, client *spanner.Client) error { rtx := client.ReadOnlyTransaction() defer rtx.Close() keyRange := spanner.KeyRange{ Start: spanner.Key{1, "Type4"}, End: spanner.Key{3, "Type2"}, Kind: spanner.OpenOpen, } iter := rtx.Read(ctx, "Item", keyRange, []string{"ItemID", "ItemType", "Name"}) defer iter.Stop() for { row, err := iter.Next() if err == iterator.Done { break } if err != nil { return err } var itemID int64 var itemType, name string if err := row.Columns(&itemID, &itemType, &name); err != nil { return err } fmt.Printf("%d %s %s\n", itemID, itemType, name) } return nil }# 出力結果 2 Type1 アイテム5 2 Type2 アイテム6 2 Type3 アイテム7 3 Type1 アイテム8ReadUsingIndex
セカンダリインデックスを指定して検索を行う場合は、ReadUsingIndex()を使用します。
Spannerのセカンダリインデックスは、1つのテーブルとして扱われ、そのインデックステーブルに含まれるのは以下のカラムだけです。
- プライマリキー
- インデックスとして指定したカラム
- Storing句で指定したカラム
そのため、ReadUsingIndexにおいては上記のカラム以外を取得することはできません。(後述のQuery()を使用することで上記以外のカラムも取得できますが、これは元テーブルとのJoinが実行されているのでパフォーマンス面の考慮が必要です。)
func ReadOnlyTxReadUsingIndex(ctx context.Context, client *spanner.Client) error { rtx := client.ReadOnlyTransaction() defer rtx.Close() // PKとインデックス以外のカラム(Effect, Description)は取得できない iter := rtx.ReadUsingIndex(ctx, "Item", "IdxItemName", spanner.AllKeys(), []string{"ItemID", "ItemType", "Name"}) defer iter.Stop() for { row, err := iter.Next() if err == iterator.Done { break } if err != nil { return err } var itemID int64 var itemType, name string if err := row.Columns(&itemID, &itemType, &name); err != nil { return err } fmt.Printf("%d %s %s\n", itemID, itemType, name) } return nil }# 出力結果 1 Type1 アイテム1 4 Type1 アイテム10 1 Type2 アイテム2 1 Type3 アイテム3 1 Type4 アイテム4 2 Type1 アイテム5 2 Type2 アイテム6 2 Type3 アイテム7 3 Type1 アイテム8 3 Type2 アイテム9ReadRow
1行だけを読み取る場合にはReadRow()が使用できます。
イテレータから読み取る処理が内部で行われています。func ReadOnlyTxReadRow(ctx context.Context, client *spanner.Client) error { rtx := client.ReadOnlyTransaction() defer rtx.Close() row, err := rtx.ReadRow(ctx, "Item", spanner.Key{"2", "Type1"}, []string{"ItemID", "ItemType", "Name"}) if err != nil { return err } var itemID int64 var itemType, name string if err := row.Columns(&itemID, &itemType, &name); err != nil { return err } fmt.Printf("%d %s %s\n", itemID, itemType, name) return nil }# 出力結果 2 Type1 アイテム5ReadWithOptions
ReadWithOptions()はspanner.ReadOptionsを引数に取り、使用するインデックスと取得件数を指定して検索処理を行います。
func ReadOnlyTxReadWithOptions(ctx context.Context, client *spanner.Client) error { rtx := client.ReadOnlyTransaction() defer rtx.Close() opts := &spanner.ReadOptions{ Index: "IdxItemName", Limit: 2, } iter := rtx.ReadWithOptions(ctx, "Item", spanner.AllKeys(), []string{"ItemID", "ItemType", "Name"}, opts) defer iter.Stop() for { row, err := iter.Next() if err == iterator.Done { break } if err != nil { return err } var itemID int64 var itemType, name string if err := row.Columns(&itemID, &itemType, &name); err != nil { return err } fmt.Printf("%d %s %s\n", itemID, itemType, name) } return nil }# 出力結果 1 Type1 アイテム1 4 Type1 アイテム10Query
Query()を用いると任意の検索クエリを組み立てることができます。
キーバリューの形式でParamsを指定することで、プレースホルダーも使用できます。func ReadOnlyTxQuery(ctx context.Context, client *spanner.Client) error { rtx := client.ReadOnlyTransaction() defer rtx.Close() sql := `SELECT ItemID, ItemType, Name FROM Item WHERE ItemID = @ItemID` params := map[string]interface{}{"ItemID": 2} iter := rtx.Query(ctx, spanner.Statement{SQL: sql, Params: params}) defer iter.Stop() for { row, err := iter.Next() if err == iterator.Done { break } if err != nil { return err } var itemID int64 var itemType, name string if err := row.Columns(&itemID, &itemType, &name); err != nil { return err } fmt.Printf("%d %s %s\n", itemID, itemType, name) } return nil }# 出力結果 2 Type1 アイテム5 2 Type2 アイテム6 2 Type3 アイテム7AnalyzeQuery
クエリの実行計画を取得したい場合は、AnalyzeQuery()を使用します。
func ReadOnlyTxAnalyzeQuery(ctx context.Context, client *spanner.Client) error { rtx := client.ReadOnlyTransaction() defer rtx.Close() sql := `SELECT ItemID, ItemType, Name FROM Item WHERE ItemID = @ItemID AND ItemType = @ItemType` params := map[string]interface{}{ "ItemID": 2, "ItemType": "Type3", } plan, err := rtx.AnalyzeQuery(ctx, spanner.Statement{SQL: sql, Params: params}) if err != nil { return err } for _, node := range plan.GetPlanNodes() { fmt.Printf("%v\n", node) } return nil }# 出力結果 kind:RELATIONAL display_name:"Distributed Union" child_links:<child_index:1 > child_links:<child_index:18 type:"Split Range" > metadata:<fields:<key:"subquery_cluster_node" value:<string_value:"1" > > > index:1 kind:RELATIONAL display_name:"Distributed Union" child_links:<child_index:2 > metadata:<fields:<key:"call_type" value:<string_value:"Local" > > fields:<key:"subquery_cluster_node" value:<string_value:"2" > > > index:2 kind:RELATIONAL display_name:"Serialize Result" child_links:<child_index:3 > child_links:<child_index:15 > child_links:<child_index:16 > child_links:<child_index:17 > index:3 kind:RELATIONAL display_name:"FilterScan" child_links:<child_index:4 > child_links:<child_index:14 type:"Seek Condition" > index:4 kind:RELATIONAL display_name:"Scan" child_links:<child_index:5 variable:"ItemID" > child_links:<child_index:6 variable:"ItemType" > child_links:<child_index:7 variable:"Name" > metadata:<fields:<key:"scan_target" value:<string_value:"Item" > > fields:<key:"scan_type" value:<string_value:"TableScan" > > > index:5 kind:SCALAR display_name:"Reference" short_representation:<description:"ItemID" > index:6 kind:SCALAR display_name:"Reference" short_representation:<description:"ItemType" > index:7 kind:SCALAR display_name:"Reference" short_representation:<description:"Name" > index:8 kind:SCALAR display_name:"Function" child_links:<child_index:9 > child_links:<child_index:10 > short_representation:<description:"($ItemID = @itemid)" > index:9 kind:SCALAR display_name:"Reference" short_representation:<description:"$ItemID" > index:10 kind:SCALAR display_name:"Parameter" short_representation:<description:"@itemid" > metadata:<fields:<key:"name" value:<string_value:"itemid" > > fields:<key:"type" value:<string_value:"scalar" > > > index:11 kind:SCALAR display_name:"Function" child_links:<child_index:12 > child_links:<child_index:13 > short_representation:<description:"($ItemType = @itemtype)" > index:12 kind:SCALAR display_name:"Reference" short_representation:<description:"$ItemType" > index:13 kind:SCALAR display_name:"Parameter" short_representation:<description:"@itemtype" > metadata:<fields:<key:"name" value:<string_value:"itemtype" > > fields:<key:"type" value:<string_value:"scalar" > > > index:14 kind:SCALAR display_name:"Function" child_links:<child_index:8 > child_links:<child_index:11 > short_representation:<description:"($ItemID = @itemid) AND ($ItemType = @itemtype)" > index:15 kind:SCALAR display_name:"Parameter" short_representation:<description:"@itemid" > metadata:<fields:<key:"name" value:<string_value:"itemid" > > fields:<key:"type" value:<string_value:"scalar" > > > index:16 kind:SCALAR display_name:"Parameter" short_representation:<description:"@itemtype" > metadata:<fields:<key:"name" value:<string_value:"itemtype" > > fields:<key:"type" value:<string_value:"scalar" > > > index:17 kind:SCALAR display_name:"Reference" short_representation:<description:"$Name" > index:18 kind:SCALAR display_name:"Function" child_links:<child_index:19 > child_links:<child_index:22 > short_representation:<description:"(($ItemID = @itemid) AND ($ItemType = @itemtype))" > index:19 kind:SCALAR display_name:"Function" child_links:<child_index:20 > child_links:<child_index:21 > short_representation:<description:"($ItemID = @itemid)" > index:20 kind:SCALAR display_name:"Reference" short_representation:<description:"$ItemID" > index:21 kind:SCALAR display_name:"Parameter" short_representation:<description:"@itemid" > metadata:<fields:<key:"name" value:<string_value:"itemid" > > fields:<key:"type" value:<string_value:"scalar" > > > index:22 kind:SCALAR display_name:"Function" child_links:<child_index:23 > child_links:<child_index:24 > short_representation:<description:"($ItemType = @itemtype)" > index:23 kind:SCALAR display_name:"Reference" short_representation:<description:"$ItemType" > index:24 kind:SCALAR display_name:"Parameter" short_representation:<description:"@itemtype" > metadata:<fields:<key:"name" value:<string_value:"itemtype" > > fields:<key:"type" value:<string_value:"scalar" > > >QueryWithStats
QueryWithStats()を使用することで、クエリの実行統計を取得できます。(RowIteratorのNext()がDoneを返した後に使用できます。)また、AnalyzeQuery()同様にQueryPlanフィールドで実行計画も取得できます。
func ReadOnlyTxQueryWithStats(ctx context.Context, client *spanner.Client) error { rtx := client.ReadOnlyTransaction() defer rtx.Close() sql := `SELECT ItemID, ItemType, Name FROM Item WHERE ItemID = @ItemID AND ItemType = @ItemType` params := map[string]interface{}{ "ItemID": 2, "ItemType": "Type3", } iter := rtx.QueryWithStats(ctx, spanner.Statement{SQL: sql, Params: params}) defer iter.Stop() for { row, err := iter.Next() if err == iterator.Done { break } if err != nil { return err } var itemID int64 var itemType, name string if err := row.Columns(&itemID, &itemType, &name); err != nil { return err } fmt.Printf("%d %s %s\n", itemID, itemType, name) } // クエリの実行統計 for k, v := range iter.QueryStats { fmt.Printf("%s: %v\n", k, v) } // 実行計画も取得できる(省略) // fmt.Printf("QueryPlan: %v\n", iter.QueryPlan) return nil }# 出力結果 2 Type3 アイテム7 elapsed_time: 4.25 msecs data_bytes_read: 0 query_text: SELECT ItemID, ItemType, Name FROM Item WHERE ItemID = @ItemID AND ItemType = @ItemType rows_returned: 1 filesystem_delay_seconds: 0 msecs query_plan_creation_time: 2.34 msecs deleted_rows_scanned: 0 bytes_returned: 30 cpu_time: 2.34 msecs remote_server_calls: 0/0 rows_scanned: 1 runtime_creation_time: 0 msecsSingle
Single()を使用することで明示的にReadOnlyTransaction()を実行せずとも、テンポラリなトランザクション上でクエリを実行できます。単一の検索クエリを投げるだけであればこちらの方が簡単に使用できます。
func ReadOnlyTxSingleQuery(ctx context.Context, client *spanner.Client) error { sql := `SELECT ItemID, ItemType, Name FROM Item WHERE ItemID = @ItemID AND ItemType = @ItemType` params := map[string]interface{}{ "ItemID": 2, "ItemType": "Type3", } iter := client.Single().Query(ctx, spanner.Statement{SQL: sql, Params: params}) defer iter.Stop() for { row, err := iter.Next() if err == iterator.Done { break } if err != nil { fmt.Println(err) return err } var itemID int64 var itemType, name string if err := row.Columns(&itemID, &itemType, &name); err != nil { return err } fmt.Printf("%d %s %s\n", itemID, itemType, name) } return nil }# 出力結果 2 Type3 アイテム7WithTimestampBound
Spannerの読み取り時に使用するタイムスタンプには、次の3つのモードが存在します。(デフォルトはStrong reads)
- Strong reads(最新データを読み取り)
- Exact staleness(指定タイムスタンプより古くないデータを読み取り)
- Bounded staleness(指定タイムスタンプと一致するデータを読み取り)
WithTimestampBound()を用いて、トランザクション内での読み取りモードを指定することができます。(この指定は主に、マルチリージョンで効果を発揮します。)
func ReadOnlyTxQueryWithTimestampBound(ctx context.Context, client *spanner.Client) error { rtx := client.ReadOnlyTransaction() defer rtx.Close() sql := `SELECT ItemID, ItemType, Name FROM Item WHERE ItemID = @ItemID AND ItemType = @ItemType` params := map[string]interface{}{ "ItemID": 2, "ItemType": "Type3", } iter := rtx.WithTimestampBound(spanner.ExactStaleness(15*time.Second)).Query(ctx, spanner.Statement{SQL: sql, Params: params}) defer iter.Stop() for { row, err := iter.Next() if err == iterator.Done { break } if err != nil { return err } var itemID int64 var itemType, name string if err := row.Columns(&itemID, &itemType, &name); err != nil { return err } fmt.Printf("%d %s %s\n", itemID, itemType, name) } return nil }# 出力結果 2 Type3 アイテム7Timestamp
Timestamp()を実行すると、トランザクションにおけるタイムスタンプを取得できます。
タイムスタンプはクエリの実行後に取得可能です。func ReadOnlyTxTimestamp(ctx context.Context, client *spanner.Client) error { rtx := client.ReadOnlyTransaction() defer rtx.Close() t, _ := rtx.Timestamp() fmt.Println("Timestamp: ", t) sql := `SELECT ItemID, ItemType, Name FROM Item WHERE ItemID = @ItemID AND ItemType = @ItemType` params := map[string]interface{}{ "ItemID": 2, "ItemType": "Type3", } iter := rtx.Query(ctx, spanner.Statement{SQL: sql, Params: params}) defer iter.Stop() for { row, err := iter.Next() if err == iterator.Done { break } if err != nil { return err } var itemID int64 var itemType, name string if err := row.Columns(&itemID, &itemType, &name); err != nil { return err } fmt.Printf("%d %s %s\n", itemID, itemType, name) } iter = rtx.WithTimestampBound(spanner.ExactStaleness(15*time.Second)).Query(ctx, spanner.Statement{SQL: sql, Params: params}) t, _ = rtx.Timestamp() fmt.Println("Timestamp: ", t) return nil }# 出力結果 Timestamp: 0001-01-01 00:00:00 +0000 UTC 2 Type3 アイテム7 Timestamp: 2019-12-19 20:57:24.615294 +0900 JSTまとめ
今回はGoのSpannerクライアントでReadOnlyTransactionを扱う方法をまとめました。
ReadWriteTransactionの読み取り処理も、ReadOnlyTransactionを埋め込んで実装されているので、今回のポイントを抑えておけば問題なく使用できると思います。また機会があれば、ReadWriteTransactionの書き込み処理についても触れたいと思います。
最後までお付き合いいただきありがとうございました。
- 投稿日:2019-12-18T22:38:57+09:00
AWSを使ってサーバーレスにRestAPIを作ってみた。
DeNA20新卒アドベントカレンダー23日目です。
サーバーレス
サーバーレスアーキテクチャーがここ最近だいぶ浸透してきたと思います。
サーバーレスと言っても実際にはサーバーはクラウド上にあり、その上でプログラムやコンテナを走らせるのですが、
面倒な(そしてある意味楽しい)サーバーの保守から解放されて、よりアプリケーションそのものに集中できるようになったのは開発者として嬉しいポイントです。
また、他のマネージドサービスとの連携も容易で低いコストでウェブアプリケーションが作れるようになりました。
今回はAWSを使ってサーバーレスに掲示板Rest APIを作ってみました。ちなみにRestではなくGraphQLを使うのも考えましたが、学習が間に合わずに断念…
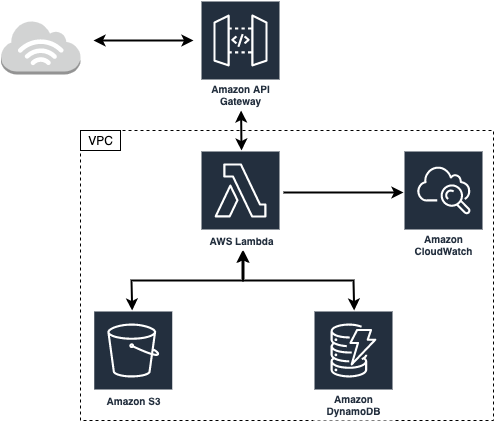
ちなみに元々掲示板のサーバーサイドだけを作って、各種APIを公開して各々のユーザーがクライアントを作ると言うコンセプトの下にAPIを作っていました。やっていくうちに色々と知見がたまったので公開すると言うのがこの記事の主旨になります。作成するAPIの構成は以下のようになります。
本当はS3を使って画像のアップロードもできるようにしたかったけど間に合いませんでした。AWS Lambda
AWS Lambdaはクラウド上でプログラムを走らせるためのサービスです。
リクエストごとに料金がかかる仕組みですが、無料分が非常に大きく並大抵のリクエスト程度ならタダで使えます。
ちなみに少し前に流行った最弱AIオセロはAWS Lambdaで動いていました。(C++のプログラムをスタティックビルドして盤面情報をコマンドライン引数としてPythonのsubprocessで動かすと言う力技)今回はバックエンドのロジックを全てLambdaを使用して実装しました。
AWS Lambdaでは現在Node.js, Python, Ruby, Java, Go, C#が使えるようですが、今回は自身の練習を兼ねてGoで実装しました。Dynamo DB
データベースにはDynamoDBを使用しています。普段MySQLばかりでNoSQLのデータベースを使ってみたいと言う理由で使いましたが、スケールが容易だったり料金が安いなどのメリットが多い一方、なかなかに癖が強く慣れるのに時間がかかりました。DynamoDBではパーティションキー、もしくはパーティションキーとレンジキーのセットがプライマリキー(=ユニーク)となるのですが、複数のデータを持ってくるような場合はただ一つのパーティションキーとレンジキーによる範囲指定が必要になります。この時、レンジキーによる範囲指定を行うと出力されるデータは自動的に降順もしくは昇順でソートされます。つまり複数のデータを取得する際は同じパーティションキーを持つデータに対して、レンジキーで範囲を指定するが、パーティションキーとレンジキーはユニークになっている必要があることになります。これらの制約のせいでテーブル設計がなかなか難しく、作り直しを何回か行う羽目になりました。
今回の掲示板APIによるデータベースの操作をまとめると以下のようになります。
- スレッド一覧の取得(スレッドの一覧は更新された時間順に100件までとする。)
- スレッドの投稿
- あるスレッドのレスポンスの取得(レスポンスの一覧は投稿順とする。)
- レスポンスの投稿(スレッドの最終更新時間を更新する。)
従ってスレッドは全て同じパーティションキー、更新時間をレンジキーとしたいのですが、パーティションキーとレンジキーのセットのユニーク性を考えると、パーティションキーが同じであればレンジキーによってのみユニーク性が担保される必要性が出てきます。しかし更新時間がユニークなのはあまり綺麗な実装とは言えない気がするので別のテーブルを考えます。ちなみにスキャンをすることで全データの摘出ができ、それらについてフィルターをかける方法もありますが、テーブルの要素が多くなることはあっても減ることはないのでできる限り避けたいところです。データ転送量で課金なことを考えるとコスト的にもなしです。
DynamoDBでは基本的にパーティションキーとレンジキーの組み合わせでデータを取得しますが、ローカルセカンダリインデックス(LSI)やグローバルセカンダリインデックス(GSI)を追加することで、同じテーブルについて異なるキーで検索をかけることができます。LSIでは同じパーティションキーについてレンジキー相当のキーの追加、GSIではパーティションキー相当のキーとレンジキー相当のキーの追加が可能ですが、内部実装的にはテーブルを複製しているらしいのでDynamoDBのコストとの相談が必要です。ここでキー相当と表現したのは、LSIについては追加したレンジキー相当のキーと既存のパーティションキーとの組み合わせがユニークでなくても良く、GSIについては追加したキー二つがユニークでなくても良いためです。ちなみにテーブルへのLSIの追加はテーブル作成時にしかできないので注意してください。
今回の要件を考えると更新時間をLSIに追加すれば更新時間によるスレッド一覧の取得が可能になります。するとレンジキーは実質スレッドをユニークにするためだけに存在するので、邪道な気もしますがこれをRDBにおけるプライマリキーと見なすことにしました。ただし、DynamoDBではRDSにおけるAuto Incrementのようなオプションは存在しない(できないことはないが別途インデックスを管理するテーブルが必要になる。)のでUUIDを使用し、このUUIDをプライマリキーとしてスレッドに対するレスポンステーブルを作成しました。
threadsテーブル
partをパーティションキー、idをレンジキー、updated_atをLSIとしています。
パーティションキーであるpartが全てのスレッドについて0で、毎回のリクエストでパーティションキーに0を入れるのは設計としてどうなんだと言う気もしますが
実際にDynamoDBのドキュメントにディスカッションフォーラムにおけるテーブル設計の例があります。
https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/SampleData.CreateTables.html
このページのthreadテーブルを見てみるとプライマリキーがフォーラム名となっています。プライマリキーをフォーラム名とかカテゴリ名として掲示板を分けていくとすれば、今回の例ではフォーラムが一つしかない場合と考えられるので、そこまで変な実装でもないのかなと言う気がします。規模が大きくなればパーティションキーを1, 2...と増やしていきパーティションキーごとに掲示板を分けていけば、負荷的にも問題ないと思われます。
responsesテーブル
responsesカラムにはDynamoDB用に変換されたjsonオブジェクトが入っています。
クエリでデータを取り出す際に取り出すカラムを指定できるので、今回の場合はスレッドのデータにそのままレスポンスのデータをくっつけるのもアリだと思いますが、上記のAWSのサンプルに則って分けました。Goの実装
LambdaでGoを使いdynamodbにアクセスするにはSDKが必要です。
必要なものだけをインストールしてもいいのですが、面倒なので下記コマンドでまとめてAWS用のGoSDKをインストールしました。
go get github.com/aws/aws-sdk-go/...LambdaでGoを使うにあたって必要なパッケージはaws-lambda-go/eventsとaws-lambda-go/lambdaになります。
前者がLambdaへの各種データの入出力を扱うパッケージ、後者がlambdaを実行するためのパッケージになっているようです。
GoでLambdaを動かす解説サイトがあまりないので割とドキュメントと睨めっこが多くなるかもしれません。https://godoc.org/github.com/aws/aws-lambda-go/lambda
https://godoc.org/github.com/aws/aws-lambda-go/eventsGoのmain関数でハンドラー関数をlambdaで実行すると言う命令を出します。
下のような定型文を書けばあとはLambdaがよしなにしてくれるので、ハンドラー関数の方で受け取ったデータを処理して返すと言うのが一連の流れです。func main() { lambda.Start(handler) }データの受け取り
データはAPI Gatewayから渡されますが、この時データがどう渡されるかによって処理の書き方が異なります。
getでデータを渡す場合、API Gatewayを通す時にURL文字列を処理する必要があります。
API Gatewayからは以下のような構造体のデータがハンドラ関数に送られます。type APIGatewayProxyRequest struct { Resource string `json:"resource"` // The resource path defined in API Gateway Path string `json:"path"` // The url path for the caller HTTPMethod string `json:"httpMethod"` Headers map[string]string `json:"headers"` MultiValueHeaders map[string][]string `json:"multiValueHeaders"` QueryStringParameters map[string]string `json:"queryStringParameters"` MultiValueQueryStringParameters map[string][]string `json:"multiValueQueryStringParameters"` PathParameters map[string]string `json:"pathParameters"` StageVariables map[string]string `json:"stageVariables"` RequestContext APIGatewayProxyRequestContext `json:"requestContext"` Body string `json:"body"` IsBase64Encoded bool `json:"isBase64Encoded,omitempty"` }この時何かしらのデータが、パスパラメータもしくはクエリ文字列として渡されていた場合
前者であればPathParameters
後者であればQueryStringParameters
にそれぞれmapで入っています。
クエリ文字列であれば単純ですが、パスパラメータの場合はAPI Gatewayの方でマッピングを行う必要です。
今回はどちらでも受け取れるようにしました。postでデータを渡す場合、jsonで渡していればそのままハンドラー関数の引数にjsonが入ってくるので、適当な構造体を用意しておけばそのままデータが使えます。
例えば以下のような構造体で表せるjsonデータを渡す場合type Request struct { ThreadID string `json:"id"` Name string `json:"name"` Content string `json:"content"` }ハンドラー関数では以下のように中身が参照できます。
func handler(request Request) { name := request.Name threadID := request.ThreadID content := request.Content }jsonでデータを受け取る際は、API Gatewayがそのままデータを渡してくれるので簡潔に受け取ることができます。
events.APIGatewayProxyRequest型で受け取ってもBodyにデータが入っていると思われますが、string型で入ってくるので別途構造体に変換する必要があります。
ちなみにlambda上でプログラムの実行テストができますが、eventsを使ったパラメータの受け取りはAPI Gatewayを介していないためエラーが発生します。
jsonによるデータの受け渡しテストを行なってからAPI Gateway用に書き換える手間が発生するので、getでもjsonでデータを渡すようにする方が楽かもしれません。データの返却
API Gatewayを通してデータを送るにはevents.APIGatewayProxyResponse型のデータを返す必要があります。
type APIGatewayProxyResponse struct { StatusCode int `json:"statusCode"` Headers map[string]string `json:"headers"` MultiValueHeaders map[string][]string `json:"multiValueHeaders"` Body string `json:"body"` IsBase64Encoded bool `json:"isBase64Encoded,omitempty"` }この中でStatusCodeとHeadersはAPI Gatewayを通してデータを返却するためには必須です。
StatusCodeはhttpパッケージのものを利用すれば大丈夫です。
HeadersはCORSを行うために'Access-Control-Allow-Originを適切に設定する必要があります。以下が実際に実装したコードです。
githubはこちら
GoでdynamoDBを操作していますが、これについて詳しく解説すると記事が丸々一本書けそうなので割愛します。
一応はAWSのドキュメントを読めばできますが、ハマるポイントも多く結構苦戦しました。質問があればコメント欄に書いてもらえればできる限り調査します。スレッド一覧の取得
get_threads.gopackage main import ( "encoding/json" "net/http" "github.com/aws/aws-lambda-go/events" "github.com/aws/aws-lambda-go/lambda" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/dynamodb" "github.com/aws/aws-sdk-go/service/dynamodb/dynamodbattribute" ) // スレ用の構造体 type Thread struct { ID string `json:"id"` Title string `json:"title"` CreatedAt int64 `json:"created_at"` UpdatedAt int64 `json:"updated_at"` } type Threads struct { Threads []Thread } // レス用の構造体 type Response struct { Threads []Thread `json:"body"` } // 何かしらエラーが発生した場合internal server errorを返す。 func internalServerError() (events.APIGatewayProxyResponse, error) { return events.APIGatewayProxyResponse{ StatusCode: http.StatusInternalServerError, Headers: map[string]string{ "Access-Control-Allow-Origin": "*", }, }, nil } // ハンドラー関数、スレッド一覧は何も受け取らない。データベースから取得したスレッド一覧のみ返却する。 func Handler() (interface{}, error) { // awsとのsession作成、失敗すればinternal server error sess, err := session.NewSession() if err != nil { return internalServerError() } // セッションを使ってdynamoDBを利用する svc := dynamodb.New(sess) // dynamoDB用のqueryの作成 getQuery := &dynamodb.QueryInput{ // テーブル名(そのまま) TableName: aws.String("threads"), // インデックスを使用する場合はインデックス名 IndexName: aws.String("part-updated_at-index"), // カラムに別名をつける ExpressionAttributeNames: map[string]*string{ "#part": aws.String("part"), }, // カラムの値に別名をつける ExpressionAttributeValues: map[string]*dynamodb.AttributeValue{ ":part": { N: aws.String("0"), }, }, // 先ほどつけた別名を使って、プライマリキーを指定する KeyConditionExpression: aws.String("#part = :part"), // カラムのどの値を取得するかの指定 ProjectionExpression: aws.String("id, title, created_at, updated_at"), // レンジキーによるソート、昇順か降順か ScanIndexForward: aws.Bool(false), // 取得するデータ数の上限 Limit: aws.Int64(100), } // 上で定義したクエリを使って、データを取り出す。失敗すればinternal server error result, err := svc.Query(getQuery) if err != nil { return internalServerError() } // データが取り出せた場合、スレッドの一覧(=リスト)なのでそれを入れるためのThreadスライスを作成する threads := make([]Thread, 0) // 各々のスレッドは先ほどProjectionExpressionで指定したようにid, title, created_at, updated_atを持つオブジェクト // そしてそれがリストになっている(=ListOfMaps)が、この取り出したデータはDynamoDB用のフォーマットになっている。 // DynamoDBのデータフォーマットについてはhttps://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/Programming.LowLevelAPI.html // UnmarshalListOfMapsでスレッド構造体のスライスに入れられるようにデータを変換する。 if err := dynamodbattribute.UnmarshalListOfMaps(result.Items, &threads); err != nil { return internalServerError() } // json型に変換、失敗すればinternal server error jsonBody, err := json.Marshal(threads) if err != nil { return internalServerError() } // 取得したデータをjsonで返却する。 // originが異なるためAccess-Control-Allow-Originを付与 // 今回はコンセプトのために*にしているが、実際の場面では適切に設定してください。 return events.APIGatewayProxyResponse{ Body: string(jsonBody), StatusCode: http.StatusOK, Headers: map[string]string{ "Access-Control-Allow-Origin": "*", }, }, nil } // lambdaを実行 func main() { lambda.Start(Handler) }スレッドの作成
create_threads.gopackage main import ( "context" "net/http" "time" "github.com/aws/aws-lambda-go/events" "github.com/aws/aws-lambda-go/lambda" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/dynamodb" "github.com/aws/aws-sdk-go/service/dynamodb/dynamodbattribute" "github.com/google/uuid" "golang.org/x/sync/errgroup" ) type Request struct { Title string `json:"title"` Name string `json:"name"` Content string `json:"content"` } type response struct { Name string `json:"name"` CreatedAt int64 `json:"created_at"` Content string `json:"content"` } type responses struct { ThreadID string `json:"thread_id"` Responses []response `json:"responses"` } type thread struct { Part int `json:"part"` ID string `json:"id"` Title string `json:"title"` CreatedAt int64 `json:"created_at"` UpdatedAt int64 `json:"updated_at"` Name string `json:"name"` } func internalServerError() (events.APIGatewayProxyResponse, error) { return events.APIGatewayProxyResponse{ StatusCode: http.StatusInternalServerError, Headers: map[string]string{ "Access-Control-Allow-Origin": "*", }, }, nil } // データをデータベースに格納するための関数、タイムアウト処理用のcontextを受け取る。 func insertData(ctx context.Context, svc *dynamodb.DynamoDB, data interface{}, target string) error { // 格納するデータをdynamoDB用に変換 // 中身はただのmapなので手でも作れないことはない av, err := dynamodbattribute.MarshalMap(data) if err != nil { return internalServerError() } // データを格納するためのパラメータ putParams := &dynamodb.PutItemInput{ TableName: aws.String(target), Item: av, } // Timeoutになるか、データの格納が成功するまでループ for { select { case <-ctx.Done(): // タイムアウトした場合はcloudwatchにエラーログを残す return fmt.Errorf("inserting data into the table, %v failed", target) default: _, err = svc.PutItem(putParams) if err != nil { continue } return nil } } return nil } // ハンドラー関数、データをjsonで受け取るため、Request型のrequestを引数にもつ。 func handler(request Request) (events.APIGatewayProxyResponse, error) { name := request.Name title := request.Title content := request.Content sess, err := session.NewSession() if err != nil { return internalServerError() } svc := dynamodb.New(sess) // スレッドのIDをuuidv4で作成する threadID := uuid.New().String() // threadsテーブルに格納するデータの構造体 t := thread{ Part: 0, ID: threadID, Title: title, Name: name, CreatedAt: time.Now().Unix(), UpdatedAt: time.Now().Unix(), } // responsesテーブルに格納するデータの構造体 r := responses{ ThreadID: threadID, Responses: []response{ response{ Name: name, CreatedAt: time.Now().Unix(), Content: content, }, }, } // 上記二テーブルへのデータの格納はgoroutineで並列に実行 // goroutineでエラーを扱うためにerrgroupを使用 // タイムアウトしたらinternal server error eg, ctx := errgroup.WithContext(context.Background()) ctx, cancel := context.WithTimeout(ctx, 2*time.Second) defer cancel() eg.Go(func() error { return insertData(ctx, svc, t, "threads") }) eg.Go(func() error { return insertData(ctx, svc, r, "responses") }) if err := eg.Wait(); err != nil { return internalServerError() } // データの格納が完了 return events.APIGatewayProxyResponse{ StatusCode: http.StatusOK, Headers: map[string]string{ "Access-Control-Allow-Origin": "*", }, }, nil } func main() { lambda.Start(handler) }レス一覧の取得
get_responses.gopackage main import ( "encoding/json" "net/http" "github.com/aws/aws-lambda-go/events" "github.com/aws/aws-lambda-go/lambda" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/dynamodb" "github.com/aws/aws-sdk-go/service/dynamodb/dynamodbattribute" "reflect" ) type Request struct { ThreadID string `json:"id"` } type Response struct { Responses interface{} `json:"body"` } func internalServerError() (events.APIGatewayProxyResponse, error) { return events.APIGatewayProxyResponse{ StatusCode: http.StatusInternalServerError, Headers: map[string]string{ "Access-Control-Allow-Origin": "*", }, }, nil } // 取得するレスのIDをクエリパラメータもしくパスパラメータで受け取るため、events.APIGatewayProxyRequest型の引数を持つ。 func Handler(request events.APIGatewayProxyRequest) (interface{}, error) { // パスパラメータかクエリでスレのidを取得する。なければStatusBadRequest var id string if tmp, ok := request.PathParameters["id"]; ok == true { id = tmp } else if tmp, ok := request.QueryStringParameters["id"]; ok == true { id = tmp } else { return events.APIGatewayProxyResponse{ StatusCode: http.StatusBadRequest, Headers: map[string]string{ "Access-Control-Allow-Origin": "*", }, }, nil } sess, err := session.NewSession() if err != nil { return internalServerError() } svc := dynamodb.New(sess) // 今回は一つのデータを取得するのでGetItemInput型 getItemInput := &dynamodb.GetItemInput{ TableName: aws.String("responses"), // 単純なオブジェクトなので手でDynamoDBのフォーマットにする // もちろんMarshal関数を使って作ってもいい Key: map[string]*dynamodb.AttributeValue{ "thread_id": { S: aws.String(id), }, }, } result, err := svc.GetItem(getItemInput) if err != nil { return internalServerError() } // 返ってくるデータに合う構造体を作るのが面倒なのでinterface{}に入れてしまう // 今回は単一のオブジェクトなのでUnmarshalMap関数を使用する var responses interface{} if err := dynamodbattribute.UnmarshalMap(result.Item, &responses); err != nil { return internalServerError() } // 中身がjsonで、キーが何なのかもわかっているので、reflectパッケージを使って中身を取り出す rv := reflect.ValueOf(responses) res := rv.MapIndex(reflect.ValueOf("responses")).Interface() // 取り出した中身をjsonに変換する。失敗したらinternal server error jsonBody, err := json.Marshal(res) if err != nil { return internalServerError() } return events.APIGatewayProxyResponse{ Body: string(jsonBody), StatusCode: http.StatusOK, Headers: map[string]string{ "Access-Control-Allow-Origin": "*", }, }, nil } func main() { lambda.Start(Handler) }レスの追加
put_response.gopackage main import ( "context" "fmt" "net/http" "time" "github.com/aws/aws-lambda-go/events" "github.com/aws/aws-lambda-go/lambda" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/dynamodb" "github.com/aws/aws-sdk-go/service/dynamodb/dynamodbattribute" "golang.org/x/sync/errgroup" ) type Request struct { ThreadID string `json:"id"` Name string `json:"name"` Content string `json:"content"` } type Response struct { Name string `json:"name"` CreatedAt int64 `json:"created_at"` Content string `json:"content"` } type UpdatedAt struct { UpdatedAt int64 `json:"updated_at"` } func internalServerError() (events.APIGatewayProxyResponse, error) { return events.APIGatewayProxyResponse{ StatusCode: http.StatusInternalServerError, Headers: map[string]string{ "Access-Control-Allow-Origin": "*", }, }, nil } func updateData(ctx context.Context, svc *dynamodb.DynamoDB, data *dynamodb.UpdateItemInput) error { // 同じくタイムアウトまでデータの格納を試みる for { select { case <-ctx.Done(): return fmt.Errorf("Update data in the table, %v failed", aws.StringValue(data.TableName)) default: _, err := svc.UpdateItem(data) if err != nil { continue } return nil } } } func handler(req Request) (events.APIGatewayProxyResponse, error) { now := time.Now().Unix() sess, err := session.NewSession() if err != nil { return internalServerError() } svc := dynamodb.New(sess) r := []Response{Response{ Name: req.Name, CreatedAt: now, Content: req.Content, }} threadID := req.ThreadID response, err := dynamodbattribute.Marshal(r) if err != nil { return internalServerError() } // レスの追加は、データの更新にあたるのでUpdateItem rInputParams := &dynamodb.UpdateItemInput{ TableName: aws.String("responses"), Key: map[string]*dynamodb.AttributeValue{ "thread_id": {S: aws.String(threadID)}, }, // dynamoDBでのリストへの追加はlist_append関数を使う。第一引数に第二引数を追加したリストを返却するのでそれをそのままSETする UpdateExpression: aws.String("SET #ri = list_append(#ri, :vals)"), // 多分名前をつけた方がいい ExpressionAttributeNames: map[string]*string{ "#ri": aws.String("responses"), }, // 同上 ExpressionAttributeValues: map[string]*dynamodb.AttributeValue{ ":vals": response, }, } updatedAt, err := dynamodbattribute.Marshal(now) if err != nil { return internalServerError() } tInputParams := &dynamodb.UpdateItemInput{ TableName: aws.String("threads"), Key: map[string]*dynamodb.AttributeValue{ "part": {N: aws.String("0")}, "id": {S: aws.String(threadID)}, }, // 単純な値の上書きはSET a = bでできる UpdateExpression: aws.String("SET #ri = :vals"), ExpressionAttributeNames: map[string]*string{ "#ri": aws.String("updated_at"), }, ExpressionAttributeValues: map[string]*dynamodb.AttributeValue{ ":vals": updatedAt, }, } eg, ctx := errgroup.WithContext(context.Background()) ctx, cancel := context.WithTimeout(ctx, 2*time.Second) defer cancel() eg.Go(func() error { return updateData(ctx, svc, rInputParams) }) eg.Go(func() error { return updateData(ctx, svc, tInputParams) }) if err := eg.Wait(); err != nil { return internalServerError() } return events.APIGatewayProxyResponse{ StatusCode: 200, Headers: map[string]string{ "Access-Control-Allow-Origin": "*", }, }, nil } func main() { lambda.Start(handler) }AWS Lambdaでプログラムを実行するためには、実行したいファイルをzip形式でアップロード、もしくはウェブ上のエディタで直接コードを編集する必要があります。
Goに関しては前者しかできないようなので、これらのプログラムをまとめてコンパイルしてzipにするMakefileもついでに作成しました。all: get_threads.zip create_thread.zip get_responses.zip put_response.zip get_threads: get_threads.go GOOS=linux GOARCH=amd64 go build get_threads.go create_thread: create_thread.go GOOS=linux GOARCH=amd64 go build create_thread.go get_responses: get_responses.go GOOS=linux GOARCH=amd64 go build get_responses.go put_response: put_response.go GOOS=linux GOARCH=amd64 go build put_response.go get_threads.zip: get_threads zip $@ $< create_thread.zip: create_thread zip $@ $< get_responses.zip: get_responses zip $@ $< put_response.zip: put_response zip $@ $< clean: rm get_threads create_thread get_responses put_response *.zip完成した4つのバイナリのzipファイルを4つのAWS Lambdaの関数に登録すればLambda側の準備は完了です。
zipは関数コードのパネルからアップロードできます。
ハンドラには実行するファイル名を入力します。ここではget_threads.goをget_threadsにコンパイルしてget_threads.zipにしたものをアップロードしました。
API Gateway
AWS Lambdaはそのままだとhttpのリクエストをトリガーに発火できないため、リバースプロキシとしてAPI Gatewayを設置してそちらにアクセスされた場合にAWS Lambdaの特定の関数を発火させます。
また、この時パラメータをAWS Lambdaに渡すように設定する必要があります。
補足として、外部からのリクエストを受け付ける際はURLのオリジンが異なるためCORSを有効化する必要があります。現在はRest APIを作ると言う名目(=不特定多数からのアクセスを想定)のため制限はかけていませんが、実際のアプリケーションに組み込む際は適宜設定することをお勧めします。
ちなみに今回のAPIは不特定多数からのアクセスを想定してはいますが、悪戯されても嫌なのでスロットリングを有効化してレートとバーストに制限をかけています。
API Gatewayについての説明はたくさんあるので、省略気味に紹介します。
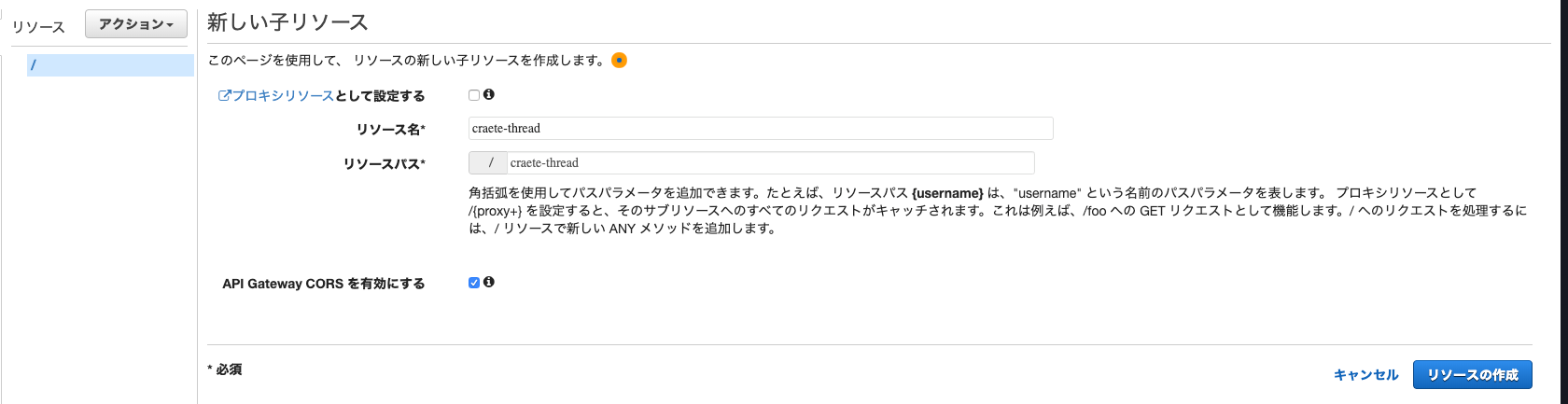
ルート直下に試しにcreate-threadのAPIを作成します。
まずリソース作成で適当なリソース名(今回はcreate-thread)を入力し、API Gateway CORS を有効にします。
これでOPTIONSメソッドが自動的に作られます。
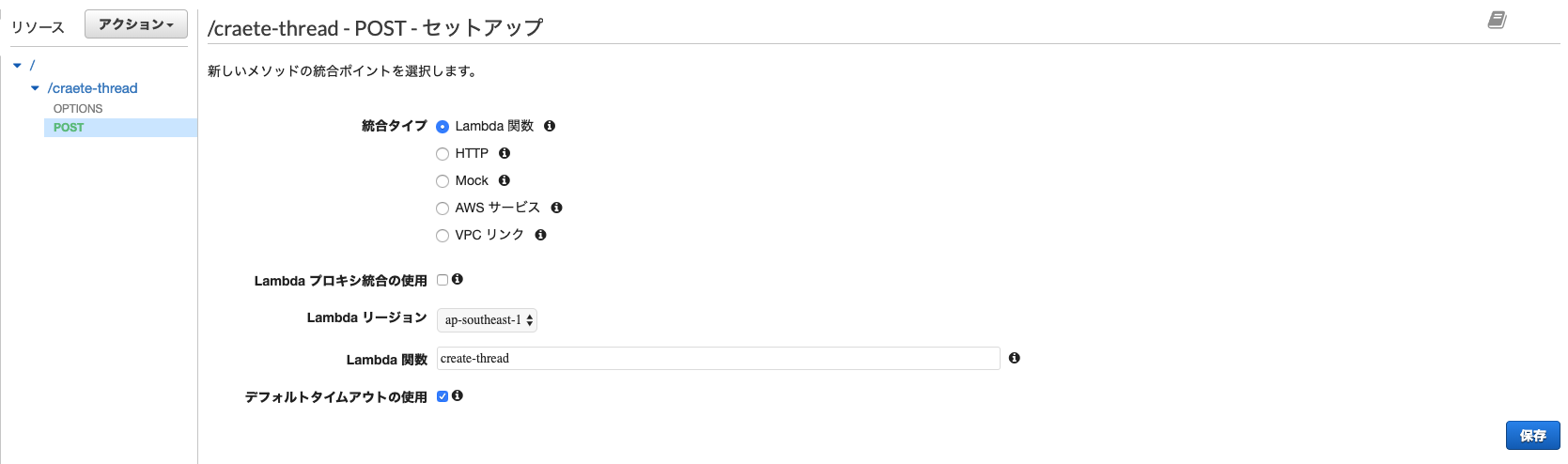
次にメソッド作成ですが、ここで使用するlambdaの関数を選択します。
ここで、Lambda プロキシ統合の使用にチェックを入れるかどうかですが、これはevents.APIGatewayProxyRequestでデータを受け渡ししたい場合はチェックを入れてください。
今回はcreate-thread, put-responseについてはjsonでデータを渡すだけでいいのでチェックせず、get-responsesについてはAPI Gatewayを通してパスパラメータを渡したいのでチェックを入れています。
get-threadsは何もデータを渡さないのでどちらでも問題ありません。
いずれにせよ全てのデータをevents.APIGatewayProxyRequestで受け取るならば全部チェックで問題ありません。
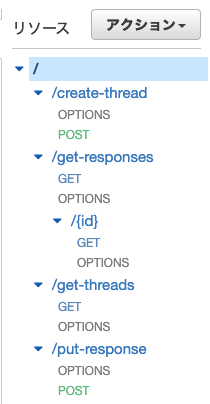
出力については、とりあえずevents.APIGatewayProxyResponse型で返せばいい感じにAPI Gatewayの方で流してくれるみたいです。各種設定を終えると以下のようになります。
CORSを許可する設定になっていれば各種GETやPOSTなどのメソッドの下にOPTIONSメソッドが追加されます。
また、パスパラメータの設定ができていれば{id}のようにマッピングが表示されます。Open API
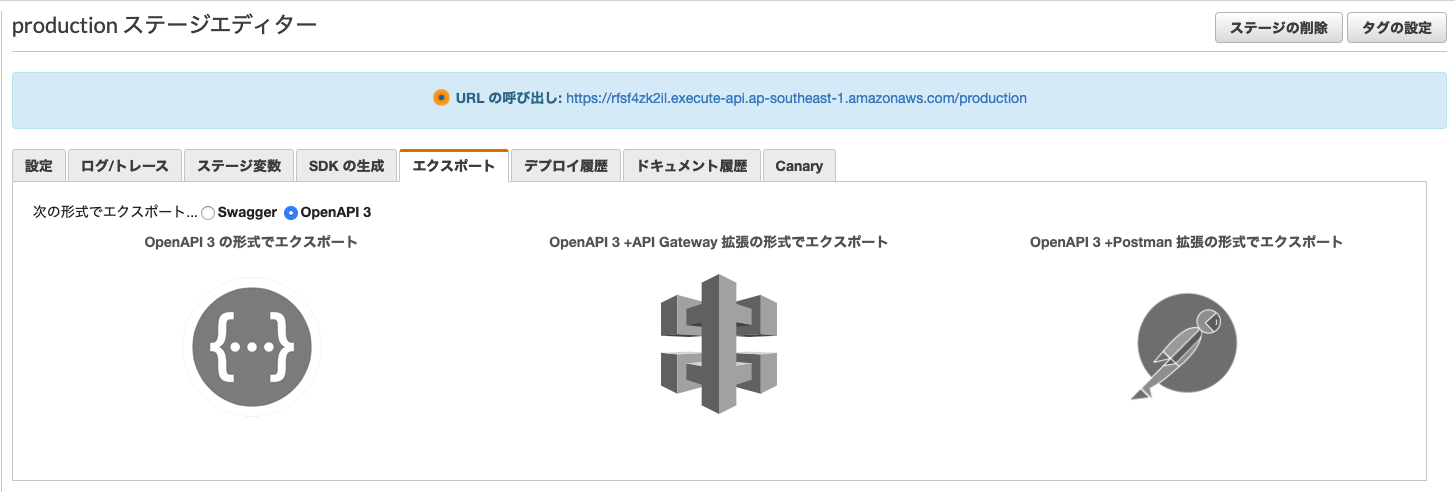
API GatewayではswaggerやOpenAPI3用のjsonやyamlをエクスポートできます。
ここでエクスポートしたファイルをswagger editorなどでインポートするとOpenAPI3でAPIの一覧が見られるようになります。
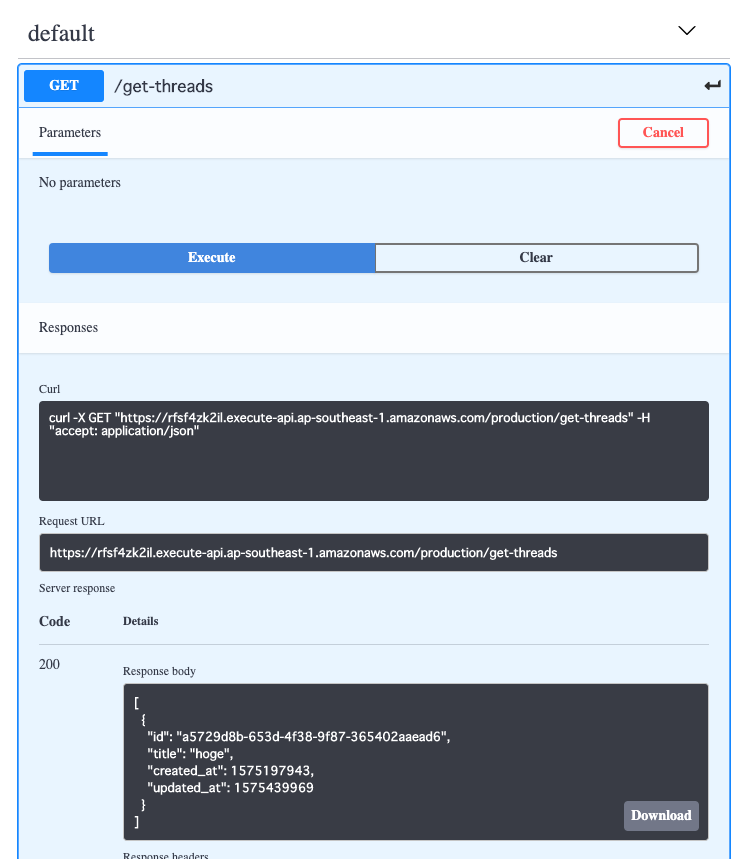
実際にOpenAPI3上でメソッドの実行もでき、レスポンスが返ってくるのが確認できます。
以上で、掲示板Rest APIが完成しました。
補足
今回はSDKを使ってGoでdynamoDBを操作しましたが、dynamoDBの癖の強さとGoの型ら辺が作用してかなりしんどいです。良い感じに面倒なところやってくれるライブラリがあるみたいなのでそっちを使った方がいいと思います。
https://github.com/guregu/dynamo終わりに
以上でバックエンドの方が完成しました。
~元々のコンセプトとしてはこれでいいのですが、正直バックエンドだけ用意してクライアントは自由に作ってねと言ったところでどうせ誰も作らないので~
ついでにReact Hooks, Redux Hooksが使いたいのもあってReactでクライアントの方も作ろうとしたのですが間に合いませんでした。(某アプリが悪い)
そのうちクライアント側も作って記事公開します。ちなみに実装は素のReactではなくReact staticを使っています。当初はgatsby.jsを使おうとしたのですが
どうもtypescriptで書くには早いかな感と、そもそもgraphQLを使ってないので止めました。
とは言え静的コンテンツとして配信するための静的化ができさえすればよく、肝心のコンテンツは動的に取得するので正直なんでもよかったのですが良い感じにシンプルそうなのでReact staticにしました。
React Hooks, Redux Hooksを使ったコンポーネントの作成やらなんやらはうまくいっているので、あとはcssがうまく書けたら公開になると思います。






- 投稿日:2019-12-18T21:58:53+09:00
GKE中のGolangアプリケーションからCloud Pub/Subを使ってデータ連携を行う
GKEの中に稼働されるアプリケーションからどうやってGCPサービスにアクセスしたり、データ連携したりするか?という疑問がある方々に回答する記事をまとめました。
Pub/Subサービスを使って、サンプルとして作成しました。手順まとめ
- サービスアカウント作成&アクセス用のaccount.jsonファイル発行
- Pub/SubのTopic&Subscription作成
- Pub/SubをSubscriptionアプリケーションの準備
- ローカルで稼働確認
- Cloudbuildでアプリケーションのイメージビルド
- GKEのCluster準備
- GKEにアプリケーションをデプロイ
- 稼働検証
フォルダ構成
accesspubsub ├── README.md ├── app │ ├── handler │ │ └── sample_handler.go │ └── sample_app.go ├── cloudbuild.sampleapp.yaml ├── deployment.sampleapp.yaml ├── go.mod ├── go.sum ├── sampleapp.Dockerfile ├── secret │ └── account.json └── tool └── publish_to_topic.go1. サービスアカウント作成&アクセス用のaccount.jsonファイル発行
サービスアカウント作成
# set work project gcloud config set project [PROJECT_ID] # create service account gcloud iam service-accounts create service-account \ --display-name "Account using to call GCP service"account.jsonファイル発行
# create service account's credential file gcloud iam service-accounts keys create {{path_to_save/account.json}} \ --iam-account service-account@[PROJECT_ID].iam.gserviceaccount.comサービスアカウント権限付与
本記事は簡単とするため、editorロールを付与します。
# ロールをサービスアカウトに付与。下記のコマンドを実施するため、オーナー権限必要 # editor権限付与 gcloud projects add-iam-policy-binding [PROJECT_ID] \ --member serviceAccount:service-account@[PROJECT_ID].iam.gserviceaccount.com \ --role roles/editorサービスアカウント権限付与について、他の付与方法はこの記事をご参考
GCPのサービスを利用権限のまとめ2. Pub/SubのTopic&Subscription作成
データ連携用のPub/SubのTopicとSubscriptionを作成する。
# Topic作成 gcloud pubsub topics create [TOPIC_NAME] # 例 gcloud pubsub topics create sample-app-topic # Topicのsubscription作成 gcloud pubsub subscriptions create [SUB_NAME] --topic=[TOPIC_NAME] # 例 gcloud pubsub topics create sample-app-topic-sub3. Pub/SubをSubscriptionアプリケーションの準備
sample_app.gopackage main import ( "log" "os" "github.com/itdevsamurai/gke/accesspubsub/app/handler" ) func main() { log.Println("Application Started.") // projectID is identifier of project projectID := os.Getenv("PROJECT_ID") // pubsubSubscriptionName use to hear the comming request pubsubSubscriptionName := os.Getenv("PUBSUB_SUBSCRIPTION_NAME") err := handler.SampleHandler{}.StartWaitMessageOn(projectID, pubsubSubscriptionName) if err != nil { log.Println("Got Error.") } log.Println("Application Finished.") }sample_handler.gopackage handler import ( "context" "fmt" "log" "cloud.google.com/go/pubsub" ) type SampleHandler struct { } // StartWaitMessageOn // projectID := "my-project-id" // subName := projectID + "-example-sub" func (h SampleHandler) StartWaitMessageOn(projectID, subName string) error { log.Println(fmt.Sprintf("StartWaitMessageOn [Project: %s, Subscription Name: %s]", projectID, subName)) ctx := context.Background() client, err := pubsub.NewClient(ctx, projectID) if err != nil { return err } sub := client.Subscription(subName) err = sub.Receive(ctx, processMessage) if err != nil { return err } return nil } // processMessage implement callback function to process received message data var processMessage = func(ctx context.Context, m *pubsub.Message) { log.Println(fmt.Sprintf("Message ID: %s\n", m.ID)) log.Println(fmt.Sprintf("Message Time: %s\n", m.PublishTime.String())) log.Println(fmt.Sprintf("Message Attributes:\n %v\n", m.Attributes)) log.Println(fmt.Sprintf("Message Data:\n %s\n", m.Data)) m.Ack() }このアプリケーションはPub/Subの指定Subscriptionをヒアリングして、メッセージがきたら、処理を行います。
処理はメッセージの内容を印刷するだけのシンプル処理となります。4. ローカルで稼働確認
稼働を検証するため、Pub/SubにメッセージをPublishするツールを準備します。
tool/publish_to_topic.gopackage main import ( "context" "encoding/json" "flag" "fmt" "log" "cloud.google.com/go/pubsub" ) var ( topicID = flag.String("topic-id", "sample-topic", "Specify topic to publish message") projectID = flag.String("project-id", "sample-project", "Specify GCP project you want to work on") ) func main() { flag.Parse() err := publishMsg(*projectID, *topicID, map[string]string{ "user": "Hashimoto", "message": "more than happy", "status": "bonus day!", }, nil) if err != nil { log.Fatalf("Failed to create client: %v", err) } } func publishMsg(projectID, topicID string, attr map[string]string, msg map[string]string) error { // projectID := "my-project-id" // topicID := "my-topic" // msg := message data publish to topic // attr := attribute of message ctx := context.Background() client, err := pubsub.NewClient(ctx, projectID) if err != nil { return fmt.Errorf("pubsub.NewClient: %v", err) } bMsg, err := json.Marshal(msg) if err != nil { return fmt.Errorf("Input msg error : %v", err) } t := client.Topic(topicID) result := t.Publish(ctx, &pubsub.Message{ Data: bMsg, Attributes: attr, }) // ID is returned for the published message. id, err := result.Get(ctx) if err != nil { return fmt.Errorf("Get: %v", err) } fmt.Printf("Published message with custom attributes; msg ID: %v\n", id) return nil }ローカルで稼働検証
# GCPサービスにアクセスためのアカウントJSONファイルを環境変数に設定 # Windowsを使う方は環境変数の設定画面から行ってください。 export GOOGLE_APPLICATION_CREDENTIALS="/path/to/account.json" # アップリケーションを実行 export PROJECT_ID="project-abc123" && \ export PUBSUB_SUBSCRIPTION_NAME="sample-app-topic" && \ go run ./app/sample_app.go # 別のターミナルを開いて、テストツールを実行 # テストのメッセージをTopicにPublishする go run tool/publish_to_topic.go --project-id=project-abc123 --topic-id=sample-app-topicローカル稼働のコンソールログ
5. Cloudbuildでアプリケーションのイメージビルド
Dockerfile作成
sampleapp.DockerfileFROM alpine:latest RUN apk --no-cache add ca-certificates WORKDIR /app COPY ./sample_app /app ENTRYPOINT ["./sample_app"]Pub/Subにアクセスするため、サービスアカウントのJSONファイルで認証します。
「alpine」イメージのみはライブラリーが足りなくて、認証仕組みはエラーとなります。
「ca-certificates」ライブラリーを追加する必要です。これは注意点となります。cloudbuild.sampleapp.yamloptions: env: - GO111MODULE=on volumes: - name: go-modules path: /go steps: # go test - name: golang:1.12 dir: . args: ['go', 'test', './...'] # go build - name: golang:1.12 dir: . args: ['go', 'build', '-o', 'sample_app', 'app/sample_app.go'] env: ["CGO_ENABLED=0"] # docker build - name: 'gcr.io/cloud-builders/docker' dir: . args: [ 'build', '-t', '${_GCR_REGION}/${_GCR_PROJECT}/${_GCR_IMAGE_NAME}:${_GCR_TAG}', '-f', 'sampleapp.Dockerfile', '--cache-from', '${_GCR_REGION}/${_GCR_PROJECT}/${_GCR_IMAGE_NAME}:${_GCR_TAG}', '.' ] # push image to Container Registry - name: 'gcr.io/cloud-builders/docker' args: ["push", '${_GCR_REGION}/${_GCR_PROJECT}/${_GCR_IMAGE_NAME}'] substitutions: # # Project ID _GCR_PROJECT: project-abc123 # # GCR region name to push image _GCR_REGION: asia.gcr.io # # Image name _GCR_IMAGE_NAME: sample-pubsub-usage-app # # Image tag _GCR_TAG: latestアプリケーションのイメージビルド。
gcloud builds submit --config cloudbuild.sampleapp.yamlビルド完了となったらContainer Registryで確認する。
Cloudbuildについてさらに確認したい場合、この記事にご参考(CloudbuildでDockerイメージビルドとContainer Registryに登録)
6. GKEのCluster準備
# クラスタ作成 gcloud container clusters create ds-gke-small-cluster \ --project ds-project \ --zone asia-northeast1-b \ --machine-type n1-standard-1 \ --num-nodes 1 \ --enable-stackdriver-kubernetes # k8sコントロールツールをインストール gcloud components install kubectl kubectl version # GKEのクラスタにアクセスするため、credentialsを設定 gcloud container clusters get-credentials --zone asia-northeast1-b ds-gke-small-cluster7. GKEにアプリケーションをデプロイ
アカウントJSONファイルを「secret generic」ボリュームとしてクラスタに登録します。
kubectl create secret generic service-account-credential \ --from-file=./secret/account.json
デプロイ定義ファイルの準備
deployment.sampleapp.yamlapiVersion: extensions/v1beta1 kind: Deployment metadata: name: sample-pubsub-usage-app spec: replicas: 1 template: metadata: labels: app: sample-pubsub-usage-app spec: volumes: - name: service-account-credential secret: secretName: service-account-credential containers: - name: sample-pubsub-usage-app-container image: asia.gcr.io/project-abc123/sample-pubsub-usage-app:latest # environment variables for the Pod env: - name: PROJECT_ID value: "project-abc123" - name: PUBSUB_SUBSCRIPTION_NAME value: "sample-app-topic-sub" - name: GOOGLE_APPLICATION_CREDENTIALS value: /app/secret/account.json volumeMounts: - mountPath: /app/secret name: service-account-credential readOnly: true【デプロイ定義の説明】
作成できた「secret generic」ボリュームをデプロイ定義にMount設定して、account.jsonファイルパスを環境変数に渡す。
「GOOGLE_APPLICATION_CREDENTIALS」の環境変数はPub/Subにアクセスするためプログラムは使います。この設定はポイントとなります。アプリケーションをGKEにデプロイします。
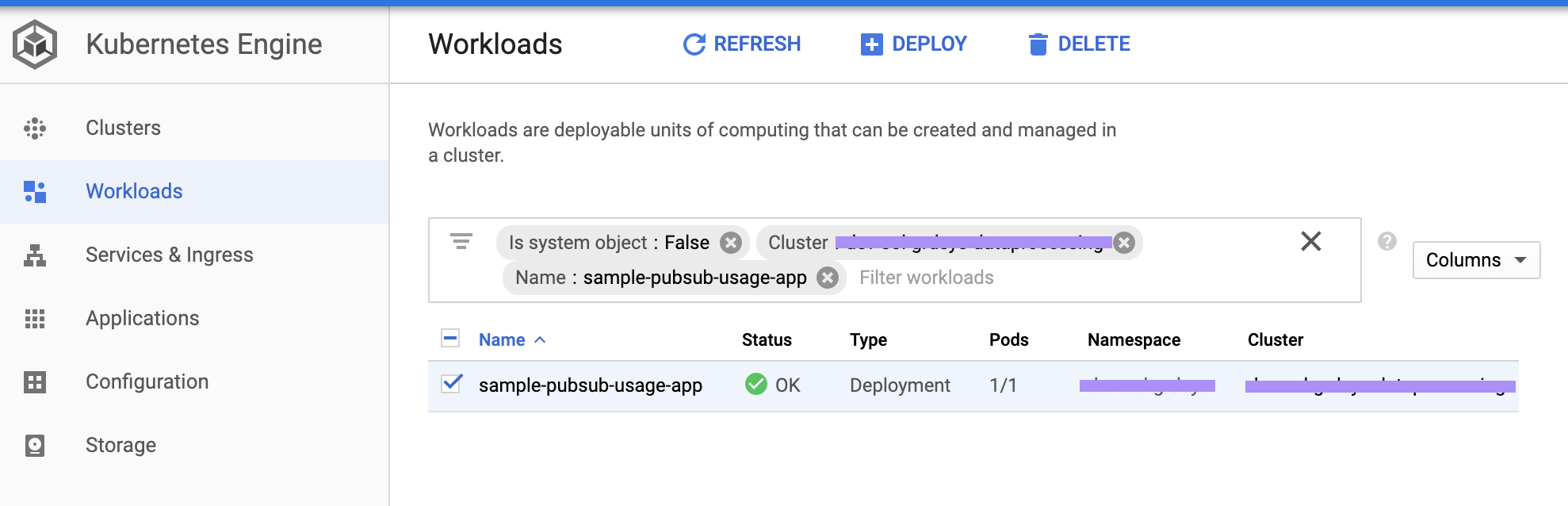
kubectl apply -f deployment.sampleapp.yamlGKE上のデプロイできたアプリケーションを確認
8. 稼働検証
TopicにメッセージのPublishを行います。
go run tools/publish_to_topic.go --project-id=project-abc123 --topic-id=sample-app-topicGKE中のアプリケーションの稼働ログを確認
本記事で利用したソースコードはこちら
https://github.com/itdevsamurai/gke/tree/master/accesspubsub
最後まで読んで頂き、どうも有難う御座います!
DevSamurai 橋本



- 投稿日:2019-12-18T21:39:04+09:00
エラーハンドリングについて考えてみた
はじめに
今回は、外部APIからデータを取得して表示する際のエラーハンドリングについて考えてみます。
方法1
ERROR HANDLING WITH ANGULAR`S ASYNC PIPE でも紹介されている方法です。
エラーを通知する先としてSubjectを用意してそれをビューテンプレートで表示します。Service
テスト用のモックを作成します。(実際に外部APIと通信は行いません。)
get(id: number): Observable<User> { return new Observable((subscriber) => { setTimeout(() => { if (!id) { subscriber.error('id is required'); return } subscriber.next(new User(id, "hello")) subscriber.complete(); }, 1000); }) }Component
user$: Observable<User> | null = null; error$ = new Subject<Error>(); get(id: number) { this.error$.next() this.user$ = this.userService.get(id).pipe( catchError(err => { this.error$.next(err); return throwError(err); }) ); }View
asyncでuserオブジェクトを取得できない場合は、ローディング中もしくは、エラーが発生している可能性があります。
その場合は loadingOrErrorTemp を表示して、その中で、エラーが出ている場合とローディング中の場合を、error$の値を参照して判定します。<ng-container *ngIf="user$"> <div *ngIf="user$ | async as user; else loadingOrErrorTemp">{{user | json}}</div> </ng-container> <ng-template #loadingOrErrorTemp> <div *ngIf="error$ | async as err; else loadingTemp">{{err}}</div> <ng-template #loadingTemp>loading</ng-template> </ng-template>方法2
次の方法は、Go言語のエラーハンドリングからヒントを得た方法です。
Goでは、以下のように、メソッドの戻り値として、エラーを受け取りハンドリングを行います。value, err := get(id) if err != nil { log.Println(err) return }これをAngularのエラーハンドリングに適応すると以下のようになります。
Object
userオブジェクトをラップして、エラーの値もサービスから返すようにします。
export class UserResponse { user?: User; errorMsg?: string; }Service
userResponseオブジェクトを返すサービスを作成します。
getUserResponse(id: number): Observable<UserResponse> { return new Observable((subscriber) => { setTimeout(() => { const userResponse = new UserResponse(); if (!id) { const errMsg = 'id is required'; userResponse.errorMsg = errMsg subscriber.next(userResponse); subscriber.complete(); return } userResponse.user = new User(id, "hello"); subscriber.next(userResponse); subscriber.complete(); }, 1000); }) }Component
getUserResponse(id: number) :Observable<UserResponse>{ this.userResponse$ = this.userService.getUserResponse(id); }Template
前回の方法と異なり、asyncで値を取得できていない状態はローディングの時のみとなります。
<ng-container *ngIf="userResponse$"> <div *ngIf="userResponse$ | async as userResponse; else loadingTemp"> <ng-container *ngIf="userResponse.errorMsg as err">{{err}}</ng-container> <ng-container *ngIf="userResponse.user as user">{{user?.id}}</ng-container> </div> <ng-template #loadingTemp>loading</ng-template> </ng-container>まとめ
どちらの方法が良いかは好みかと思いますが、個人的には方法2の方が直感的でコードの見通しも良いのではと思いました。
- 投稿日:2019-12-18T21:28:25+09:00
Goのミドルウェアのテスト
概要
GoでWebアプリケーションを作るにあたり、gRPCとgrpc-gatewayを利用して作っています。
ここで何か全APIに共通の処理を書きたい場合、grpc-gatewayにミドルウェアを作成し、そこで処理をしてしまうことが多いです。今回はそのミドルウェアのテストを書くやり方をまとめます。
なおミドルウェアはgrpc-gatewayやgRPCに依存しているものではなく、net/httpを使っているミドルウェアであれば同様にテストが書けるはずです。業務のロジックが含まれていて割愛している所も多く、また同様の事をしている例も多々あるかと思いますが、
実際に使われているものに近いミドルウェアとそのテストとして、何かしら参考になれば幸いです。テストするミドルウェア
以下はアプリバージョンを渡してもらい、最低アプリバージョン以下だとエラーを返すというミドルウェアです。
実際のアプリケーションでは強制アップデートをかけるために利用しています。appVersion.gopackage gateway import ( "fmt" "net/http" "strconv" "github.com/andfactory/xxx-webapp/domain/model" "github.com/andfactory/xxx-webapp/domain/errors/code" "github.com/andfactory/xxx-webapp/domain/errors" "github.com/andfactory/xxx-webapp/library/env" ) const ( slackTitleAppVersionInvalid = "appVersion-invalid" headerKeyAppVersion = "App-Version" ) var minimumAppVersionIos int var minimumAppVersionAndroid int func init() { minimumAppVersionIos = env.GetMinimumAppVersionIos() minimumAppVersionAndroid = env.GetMinimumAppVersionAndroid() } // getAppVersionHeader クライアントのアプリバージョンチェックを実施するミドルウェアを取得する func getAppVersionHeader(h http.Handler) http.Handler { return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) { //不要なログ出力を避けるため、healthCheckとドキュメントルートではこのチェックをおこなわない if r.RequestURI == "/health_check" || r.RequestURI == "/" { h.ServeHTTP(w, r) return } deviceTypeStr := r.Header.Get(headerKeyDeviceType) deviceType, err := model.ConvertStringToDeviceType(deviceTypeStr) if err != nil { err := errors.WrapApplicationError(err, code.InvalidDevice, fmt.Sprintf("invalid device type: '%v'", deviceTypeStr)) setUnencryptedErrorResponse(w, slackTitleAppVersionInvalid, http.StatusBadRequest, err) return } appVersionStr := r.Header.Get(headerKeyAppVersion) appVersion, err := strconv.Atoi(appVersionStr) if err != nil { err := errors.WrapApplicationError(err, code.InvalidAppVersion, fmt.Sprintf("invalid application version: '%v'", appVersionStr)) setUnencryptedErrorResponse(w, slackTitleAppVersionInvalid, http.StatusBadRequest, err) return } var minimumAppVersion int switch deviceType { case model.DeviceTypeIOS: minimumAppVersion = minimumAppVersionIos case model.DeviceTypeAndroid: minimumAppVersion = minimumAppVersionAndroid } if appVersion < minimumAppVersion { err := errors.NewApplicationError(code.NeedUpdateApplication, fmt.Sprintf("%s Application version too low. got %d want %d", deviceType, appVersion, minimumAppVersion)) setUnencryptedErrorResponse(w, slackTitleAppVersionInvalid, http.StatusBadRequest, err) return } h.ServeHTTP(w, r) }) }テストコード
上記のミドルウェアに対しては、以下のようにテストを書くことができます。
appVersion_test.gopackage gateway_test import ( "bytes" "encoding/json" "io/ioutil" "net/http" "net/http/httptest" "testing" "github.com/andfactory/xxx-webapp/adapter/grpc/presenter" "github.com/andfactory/xxx-webapp/domain/errors/code" "github.com/andfactory/xxx-webapp/infra/grpc/gateway" ) //TestAppVersionSkip 特定のpassで処理をスキップする部分のテスト func TestAppVersionSkip(t *testing.T) { ts := httptest.NewServer(gateway.GetAppVersionHeader(GetTestHandler())) defer ts.Close() tests := []struct { name string pass string isError bool expectedCode code.ErrorCode }{ { name: "ルート", pass: "/", isError: false, }, { name: "ヘルスチェック", pass: "/health_check", isError: false, }, { name: "通常", pass: "/test", isError: true, }, } for _, tt := range tests { t.Run(tt.name, func(t *testing.T) { var u bytes.Buffer u.WriteString(string(ts.URL)) u.WriteString(tt.pass) req, _ := http.NewRequest("GET", u.String(), nil) req.Header.Set(gateway.GetHeaderKeyDeviceType(), "invalidDeviceType") req.Header.Set(gateway.GetHeaderKeyAppVersion(), "0") res, err := gateway.Client.Do(req) if err != nil { t.Fatalf("request faiulure %v", err) } if res != nil { defer res.Body.Close() } if tt.isError { var d presenter.ErrorResponse if err := json.NewDecoder(res.Body).Decode(&d); err != nil { t.Fatalf("request faiulure %v", err) } if d.Body.ErrorCode != code.InvalidDevice { t.Fatalf("return want to be %v but returned %v", tt.expectedCode, d.Body.ErrorCode) } } else { b, err := ioutil.ReadAll(res.Body) if err != nil { t.Fatalf("request faiulure %v", err) } if string(b) != "OK" { t.Fatalf("return want to be OK but returned %v", string(b)) } } }) } } //TestAppVersion appVersionでチェックする処理全般のテスト func TestAppVersion(t *testing.T) { ts := httptest.NewServer(gateway.GetAppVersionHeader(GetTestHandler())) defer ts.Close() var u bytes.Buffer u.WriteString(string(ts.URL)) u.WriteString("/test") gateway.SetMinimumAppVersionIos(50) gateway.SetMinimumAppVersionAndroid(150) tests := []struct { name string deviceType string appVersion string isError bool expectedCode code.ErrorCode }{ { name: "不正なデバイス", deviceType: "", appVersion: "50", isError: true, expectedCode: code.InvalidDevice, }, { name: "不正なデバイス", deviceType: "iOS", appVersion: "50", isError: true, expectedCode: code.InvalidDevice, }, { name: "不正なデバイス", deviceType: "3", appVersion: "50", isError: true, expectedCode: code.InvalidDevice, }, { name: "iOS不正なバージョン", deviceType: "1", appVersion: "", isError: true, expectedCode: code.InvalidAppVersion, }, { name: "iOS不正なバージョン", deviceType: "1", appVersion: "1.1.1", isError: true, expectedCode: code.InvalidAppVersion, }, { name: "iOS強制アップデート", deviceType: "1", appVersion: "49", isError: true, expectedCode: code.NeedUpdateApplication, }, { name: "iOSミニマム", deviceType: "1", appVersion: "50", isError: false, }, { name: "iOSミニマムより大きい", deviceType: "1", appVersion: "51", isError: false, }, { name: "android不正なバージョン", deviceType: "2", appVersion: "", isError: true, expectedCode: code.InvalidAppVersion, }, { name: "android不正なバージョン", deviceType: "2", appVersion: "1.1.1", isError: true, expectedCode: code.InvalidAppVersion, }, { name: "android強制アップデート", deviceType: "2", appVersion: "149", isError: true, expectedCode: code.NeedUpdateApplication, }, { name: "androidミニマム", deviceType: "2", appVersion: "150", isError: false, }, { name: "androidミニマムより大きい", deviceType: "2", appVersion: "151", isError: false, }, } for _, tt := range tests { t.Run(tt.name, func(t *testing.T) { req, _ := http.NewRequest("GET", u.String(), nil) req.Header.Set(gateway.GetHeaderKeyDeviceType(), tt.deviceType) req.Header.Set(gateway.GetHeaderKeyAppVersion(), tt.appVersion) res, err := gateway.Client.Do(req) if err != nil { t.Fatalf("request faiulure %v", err) } if res != nil { defer res.Body.Close() } if tt.isError { var d presenter.ErrorResponse if err := json.NewDecoder(res.Body).Decode(&d); err != nil { t.Fatalf("request faiulure %v", err) } if d.Body.ErrorCode != tt.expectedCode { t.Fatalf("return want to be %v but returned %v", tt.expectedCode, d.Body.ErrorCode) } } else { b, err := ioutil.ReadAll(res.Body) if err != nil { t.Fatalf("request faiulure %v", err.Error()) } if string(b) != "OK" { t.Fatalf("return want to be OK but returned %v", string(b)) } } }) } } func GetTestHandler() http.HandlerFunc { fn := func(rw http.ResponseWriter, req *http.Request) { rw.Write([]byte("OK")) return } return http.HandlerFunc(fn) }privateな情報にテストからアクセスできるようにexport_test.goを作成します。
export_test.gopackage gateway import ( "net/http" ) var Client = new(http.Client) var GetAppVersionHeader = getAppVersionHeader func SetApplicationAppVersionIos(i int) { applicationAppVersionIos = i } func SetApplicationAppVersionAndroid(i int) { applicationAppVersionAndroid = i } func GetHeaderKeyDeviceType() string { return headerKeyDeviceType } func GetHeaderKeyAppVersion() string { return headerKeyAppVersion }解説
ミドルウェアのテストをするには、テストしたいミドルウェアのみを実行するサーバを作れば実現できます。
以下のようにエラーがなかった時用のハンドラを用意し、
func GetTestHandler() http.HandlerFunc { fn := func(rw http.ResponseWriter, req *http.Request) { rw.Write([]byte("OK")) return } return http.HandlerFunc(fn) }テストしたミドルウェアを通してサーバを立ててあげます。
ts := httptest.NewServer(gateway.GetAppVersionHeader(GetTestHandler())) defer ts.Close()urlの設定は以下のようにすれば実現できます
var u bytes.Buffer u.WriteString(string(ts.URL)) u.WriteString(tt.pass) req, _ := http.NewRequest("GET", u.String(), nil)gRPCとgrpc-getewayを使うときは共通のパラメータを送るときはhttpHeaderに設定し、gRPC飲めたデータとして処理しています。headerへの設定は以下のようにします。
req.Header.Set(gateway.GetHeaderKeyDeviceType(), tt.deviceType) req.Header.Set(gateway.GetHeaderKeyAppVersion(), tt.appVersion)これで、APIにアクセスします。なおクライアントはexport_test.goで作成して使いまわしています。appVersion_test.goで作っても良いのですが、他のミドルウェアのテストでも活用したいのでこのようになってます。
res, err := gateway.Client.Do(req) if err != nil { t.Fatalf("request faiulure %v", err) } if res != nil { defer res.Body.Close() }あとはレスポンスの内容をチェックしてあげればOKです。
エラーの場合は特定の型のレスポンスを返すようにしてあるので、それをパースしてコードが意図したものになっていればOK。エラーでない場合はOKが返ってくれば正常です。if tt.isError { var d presenter.ErrorResponse if err := json.NewDecoder(res.Body).Decode(&d); err != nil { t.Fatalf("request faiulure %v", err) } if d.Body.ErrorCode != tt.expectedCode { t.Fatalf("return want to be %v but returned %v", tt.expectedCode, d.Body.ErrorCode) } } else { b, err := ioutil.ReadAll(res.Body) if err != nil { t.Fatalf("request faiulure %v", err.Error()) } if string(b) != "OK" { t.Fatalf("return want to be OK but returned %v", string(b)) } }参考
export_test.goを作って非公開の変数や関数を扱うやり方は以下で詳しく解説されてます。
非公開(unexported)な機能を使ったテスト以下の記事でも同様の事が書かれています。
Unit Testing Golang HTTP Middleware
- 投稿日:2019-12-18T19:48:30+09:00
Go言語でつくるインタプリタをやってみた
tl;dr
ただの『Go言語でつくるインタプリタ』紹介記事です。
動機
私はいつも自分の開発や日々の細かい作業をツールとしてより効率化をすることを考えています。
その結果としていくつかのCLIコマンドやVimプラグインを書いたりしているわけなのですが。
その中で今まで知らないことを盛り込むことで都度新しい知識を仕入れることを心がけています。最近Language Server Protocol(LSP)周りにご執心なのですが、
ふと自分でLanguage Server(LS)をつくりたいなと思ったのですが、そのための知識が足りないことに気が付きました。
そうLSをつくる上で対象となる言語の解析への理解は欠かせないのです。そこで私は一回インタプリタを作ったら一通りの流れを理解できるのでは?
と考えて以前から気になっていた『Go言語でつくるインタプリタ』を注文したのです。似たような話でDQNEOさんのGoコンパイラをゼロから作った話がありますが、
このような壮大は話に比べるといささか小規模ではありますね。『Go言語でつくるインタプリタ』のよいところ
結論から述べましょう。『Go言語でつくるインタプリタ』は本当に素晴らしい本です。
著者であるThorsten Ball氏。そしてこの素晴らしい内容を余すことなく日本語で伝えてくれた設樂 洋爾氏には本当に感謝の気持ちでいっぱいです。言語を自分でつくるというのは、プログラマであれば一度はやってみたいことではないでしょうか?
しかしその反面どのように作ればよいのか、いまいちイメージ出来ないものでもあります。
やってみようと調べるとすると以下のようないかにも難しい本が出てきて、ぐぬぬとなること請け合いなわけです。私もいつかは読んでみたいなと思いつつも二の足を踏み続けていましたし、
やっぱり言語をつくるなんて一部の人間のみに許された神の諸行なのではと思ってしまっていたわけです。『Go言語でつくるインタプリタ』のよいところはその難しい要素をうまく噛み砕き、
躓きそうな要素を慎重に配置して、一つ一つ確実につなげてゆき、読者に確かな達成感を与えることに成功しています。
それらの要素を軽快な語り口で次はどうなるんだと常に楽しみにさせるところも注目です。適切な流れ
『Go言語でつくるインタプリタ』の基本的な流れは、
インタプリタの主要要素である以下の3つを順番に構築していくようになっています。
- 字句解析器(Lexer)
- 構文解析器(Parser)
- 評価器(Evaluator)
字句解析器でソースコードをトークン列に変換し、
構文解析器でトークン列をAST(抽象構文木)に変換し、
最後に評価器でプログラムに意味を与えます。それぞれのフェーズで完全にデータ型などをすべて作り込むことはせずに、まずはインタプリタとして通して動作するところまでを作成するのが秀逸です。
一旦インタプリタとして完全に動作する段階に行くと君はすごい偉業を成し遂げたと褒めちぎってくれます。
その後に文字列や配列, ハッシュマップなどを追加実装していくのですが。一連の流れはすでに抑えているので、だいたいどこを触るべきなのかが予測できるようになるはずです。幾多に張り巡らされた伏線(コード)が徐々に解き明かされる様は、さながら出来の良いミステリを見ているような感覚です。
テストコード
この手の写経(ソースコードを教科書から書き写す行為)は、ソースの間違えによるバグに引っかかって、結局バグが解消出来ずに途中で止まってしまうのが一番の難関ではないかと思います。
特にこの本は200ページ以上に渡り、一つのプロジェクトを触り続けていくわけで、その間に一つでもミスがあればインタプリタは期待した動きにはなりません。その問題に対応するために、この本はTDD(テスト駆動開発)を採用し、関数の仕様を全て記載した上で、実装に移るスタイルをとっています。
それらのテストコードは長大な説明文章よりも、はるかに雄弁にソースの振る舞いを語ります。なるほどこういうケースに対応するために実装がこうなっているのだなと納得しながら実装することが出来ます。最悪テストコードを記載することが面倒であれば、公開されているテストコードをペタペタ貼ってゆけばよいのです。
テストコードの内容自体もところどころで検証をするためのヘルパー関数を作って、冗長性なく快適にテストコードを書けるようにするような工夫が随所に見られます。
SubTestの未対応バージョンのGoをベースに作っているので、最新の形式でかけるわけではないですが。それでもどういうテストをするべきなのかを知るという点においても非常に勉強になります。Go標準ライブラリのみ
このおかげでGoのみインストールすれば始められます。
またコード中に出てくるものはほとんど基本的な記述のみになるので、内容も非常に簡素になるわけです。最後に
もしプログラミング言語を作ることに少しでも興味でもあれば是非一度見てほしい一冊です。
- 投稿日:2019-12-18T17:47:11+09:00
Go Lang Hello world 超簡単言語(GOlang)
ちっとお試しあれ
<<みんなでGO>>
main.gopackage main import ( "net/http" "fmt" ) func world(w http.ResponseWriter, r *http.Request) { fmt.Fprintf(w, "<a href='/japan'><h1>Hello World</h1></a>") } func japan(w http.ResponseWriter, r *http.Request) { fmt.Fprintf(w, "<a href='/'><h1>Hello Japan</h1></a>") } func main() { http.HandleFunc("/", world) http.HandleFunc("/japan", japan) http.ListenAndServe("192.168.1.10:8080", nil) }



- 投稿日:2019-12-18T16:10:13+09:00
Goで一通りのsql操作をやってみる
この記事はtomowarkar ひとりAdvent Calendar 2019の18日目の記事です。
はじめに
Goでのmysql操作を備忘録としてまとめてみた
コード全文
コード全文
package main import ( "database/sql" "fmt" "log" _ "github.com/go-sql-driver/mysql" ) const appname = "gopherbot" func run() (*sql.DB, error) { dbDriver := "mysql" dbUser := "root" dbPass := "password" dbName := "" db, err := sql.Open(dbDriver, dbUser+":"+dbPass+"@/"+dbName) if err != nil { return nil, err } defer db.Close() res, _ := db.Query("SHOW DATABASES") var database string for res.Next() { res.Scan(&database) fmt.Println(database) } fmt.Println() _, err = db.Exec("CREATE DATABASE IF NOT EXISTS " + appname) if err != nil { return nil, err } res, _ = db.Query("SHOW DATABASES") for res.Next() { res.Scan(&database) fmt.Println(database) } fmt.Println() _, err = db.Exec("USE " + appname) if err != nil { return nil, err } res, _ = db.Query("SHOW TABLES") var table string for res.Next() { res.Scan(&table) fmt.Println(table) } fmt.Println() _, err = db.Exec("CREATE TABLE IF NOT EXISTS example ( id integer, name varchar(32) )") if err != nil { return nil, err } ins, err := db.Prepare("INSERT INTO example(id,name) VALUES(?,?)") if err != nil { return nil, err } ins.Exec(1, "hoge") ins.Exec(3, "huga") res, _ = db.Query("SELECT * FROM example") for res.Next() { var id int var name string res.Scan(&id, &name) fmt.Println(id, name) } fmt.Println() _, err = db.Exec("DROP DATABASE " + appname) if err != nil { return nil, err } return db, nil } func main() { _, err := run() if err != nil { log.Fatal(err) } }outputmysql gopherbot mysql 1 hoge 3 hugaデータベース接続, 切断
dbDriver := "mysql" dbUser := "root" dbPass := "password" dbName := "" db, err := sql.Open(dbDriver, dbUser+":"+dbPass+"@/"+dbName) if err != nil { log.Fatal(err) } defer db.Close()データベース表示(SHOW DATABASES)
res, _ := db.Query("SHOW DATABASES") var database string for res.Next() { res.Scan(&database) fmt.Println(database) }データベース作成(CREATE DATABASE)
_, err = db.Exec("CREATE DATABASE IF NOT EXISTS " + yourDatabsase) if err != nil { log.Fatal(err) }データベース選択(USE)
_, err = db.Exec("USE " + yourDatabsase) if err != nil { log.Fatal(err) }テーブル表示(SHOW TABLES)
res, _ = db.Query("SHOW TABLES") var table string for res.Next() { res.Scan(&table) fmt.Println(table) }テーブル作成(CREATE TABLE)
_, err = db.Exec("CREATE TABLE IF NOT EXISTS " + yourTable + " ( id integer, name varchar(32) )") if err != nil { log.Fatal(err) }データ挿入(INSERT)
ins, err := db.Prepare("INSERT INTO " + yourTable + "(id,name) VALUES(?,?)") if err != nil { log.Fatal(err) } ins.Exec(1, "hoge") ins.Exec(3, "huga")データ表示(SELECT)
res, _ = db.Query("SELECT * FROM " + yourTable) for res.Next() { var id int var name string res.Scan(&id, &name) fmt.Println(id, name) }データベース削除(DROP DATABASE)
_, err = db.Exec("DROP DATABASE " + yourDatabsase) if err != nil { log.Fatal(err) }おわりに
以上明日も頑張ります!!
tomowarkar ひとりAdvent Calendar Advent Calendar 2019参考
https://qiita.com/merrill/items/967884c02e10bd8f32f5
https://medium.com/@udayakumarvdm/create-mysql-database-using-golang-b28c08e54660
https://flaviocopes.com/golang-sql-database/
- 投稿日:2019-12-18T15:58:17+09:00
Gobotを使ってトイレ混雑問題と真剣に向き合ってみた
この記事はGo3 Advent Calendar 2019の19日目です。
はじめに
人類はこれまで幾度となく文明を進化させてきましたが、今だに解決仕切れていない問題があります。
そう、それは「トイレ混雑問題」。人間として生きていくためには避けて通れない問題です。最近ではこの問題を危惧した様々な企業さん達が、こぞって記事を出しています。
『駅の空いてるトイレが分かる』アプリケーションを開発。「これを待っていた!」とSNSで話題に
弊社もオフィスによっては個室の数が少なく、空いているかいないかのチェックに苦労している人もいるそうです。
その為、この問題をIoTで簡単に解決できないかと考え、「ラズパイ×Gobot」でトイレの混雑検知の仕組みを試作してみました!!!
構成
この辺りの記事を参考に構成を組んでいます。
【Raspberry Pi】自作人感センサーの使い方と活用法
ソースコード
人感センサで人を感知した後に、人の背後に置いた超音波センサで人が席を離れたどうかを判定します。
超音波センサの判定距離はデモ用に作っているので、適当に設定しています。
slackへの通知はincoming-webhookを使い、このために作った専用のチャンネルに送信しています。import ( "gobot.io/x/gobot/drivers/gpio" "gobot.io/x/gobot/platforms/raspi" "time" "encoding/json" "fmt" "io/ioutil" "net/http" "net/url" "gobot.io/x/gobot" ) const ( SensorValueDetect = 1 SensorValueUndetect = 0 ) func main() { err := motion() if err != nil { println(err) } } func motion() error { r := raspi.NewAdaptor() f := false trigPin := gpio.NewDirectPinDriver(r, "11") echoPin := gpio.NewDirectPinDriver(r, "13") work := func() { gobot.Every(3*time.Second, func() { // 7番ピンから直接センサーの値を読み取る v, _ := r.DigitalRead("7") if v == SensorValueDetect { if f == false { slack.SlackPostIn("誰かが来た様です。") f = true } println("Starting probing ") err := trigPin.DigitalWrite(byte(0)) if err != nil { println(err) return } time.Sleep(2 * time.Microsecond) err = trigPin.DigitalWrite(byte(1)) if err != nil { println(err) return } start := time.Now() end := time.Now() for { val, err := echoPin.DigitalRead() start = time.Now() if err != nil { println(err) break } if val == 0 { continue } break } for { val, err := echoPin.DigitalRead() end = time.Now() if err != nil { break } if val == 1 { continue } break } duration := end.Sub(start) distance := duration.Seconds() * 34300 distance = distance / 2 println(distance) if distance > 1000 { println(distance) slackPostOut("部屋が空きました。") f = false } } }) } robot := gobot.NewRobot("blinkBot", []gobot.Connection{r}, []gobot.Device{trigPin, echoPin}, work, ) robot.Start() return nil } var IncomingURL string = "incoming-webhookで取得したURL" // jsonの情報 type Slack struct { Text string `json:"text"` Username string `json:"username"` IconEmoji string `json:"icon_emoji"` IconURL string `json:"icon_url"` Channel string `json:"channel"` } func slackPostIn(text string) { arg := text params := Slack{ Text: fmt.Sprintf("%s", arg), Username: "Close Push", IconEmoji: ":cold_sweat:", IconURL: "", Channel: "", } jsonparams, _ := json.Marshal(params) resp, _ := http.PostForm( IncomingURL, url.Values{"payload": {string(jsonparams)}}, ) body, _ := ioutil.ReadAll(resp.Body) defer resp.Body.Close() println(string(body)) } func SlackPostOut(text string) { arg := text params := Slack{ Text: fmt.Sprintf("%s", arg), Username: "Open Push", IconEmoji: ":relaxed:", IconURL: "", Channel: "", } jsonparams, _ := json.Marshal(params) resp, _ := http.PostForm( IncomingURL, url.Values{"payload": {string(jsonparams)}}, ) body, _ := ioutil.ReadAll(resp.Body) defer resp.Body.Close() println(string(body)) }結果
...なんか
鬱陶しいメンヘラチックですね。さいごに
これ実は弊社の開発合宿で作った成果物でした!下記はその時の内容が書かれているテックブログです。
【チェックリスト付き】開発合宿 運営マニュアル 〜計画から実施までの流れ〜かなり短い時間で開発を行ったのですが、Gobotでの実装がかなり楽ですぐ作ることができました。シビアな実行環境でなければ、組み込みの軽いプロトタイプを作る際におすすめです!
本記事で紹介したソースコードは
とても汚い試作要素が強いので、実行環境によってステータスとかいじって使ってみてください!トイレにはハードルが高い...という方は普通にGobotの一例として参考にしていただければと思います。



- 投稿日:2019-12-18T10:39:08+09:00
Datadogでハマった3つのこと
これは何か
Kyash Advent Calender 2019 の20日目の記事です。
Kyashには2019/5/20にサーバサイドエンジニアとして入社し、本日12/20でちょうど7か月となります。普段はWalletチーム(Kyashアプリを開発しているチーム)のサーバサイドを担当しています。
すでに導入してあるDatadogとNewRelicをDatadog一本にすることになり、その際の移行のついでにちゃんとやれてない部分や新しいマイクロサービスへの導入を行った時に想定外に大ハマりしたのでその共有を3つに絞ってしたいと思います。
テーマからして万人ウケするタイプではないですが、世の中にDatadog関連の情報が少ないこともあり、これから導入しようとしている人に参考になればと思います。
そもそもDatadogとはを簡単に
Datadogとは何?
というのを簡単に説明しとこうと思います。
一言で表現するのは難しいのですが、「サーバ、アプリケーション等システム全体の状態をモニタリングするプラットフォーム」と言えると思います。
- サービスをまたがってアプリケーションのパフォーマンスを分析するAPM(トレース)
- サーバーから送られてくるCPU使用率などのほか、ユーザが自由に送ることもできるMetrics
- それらのDashboard
- メトリクスなどからメール、SNSなどに通知するMonitor
- ログを収集するLog Collector
等があり、かつそれらがお互いに協調してます。例えばAPMを使うと自動的にそのspanに応じたメトリクスが作成され、そのメトリクスをダッシュボードにして視覚化しつつ、メトリクスの値を元に閾値をMonitorに登録しSNSに通知できるようにするといった具合です。さらに、ちょっとした工夫(traceID等を出力する)をするだけでAPMの画面上でtraceに紐づくログが確認できたりもします。
特に、Kyashでは10以上のマイクロサービスが動いており、高負荷時の調査などの場合にどのマイクロサービスのどの処理が遅延していて、そのときのホストの状態はどうだったのかがAPMで見ると大変わかりやすく視覚化でき、感動しました。やっぱりグラフが綺麗ですよね!
参考までに以下は実際のAPMのトレースの一つをスクリーンショットです。
それぞれの区間(spanという)は親子関係を持つことができ、なおかつサービスをまたがって保持することができます。
ではハマったことを次章から紹介していきます
Traceできなくてハマった
元々検証できる環境がなかったため、ローカルのdocker環境で検証できる様にしたのですが、全くtraceが表示されず、これだけで半日つぶしました。
原因はわかってしまえば単純なのですが、APMではデフォルトだとサンプリングされ、全てtraceされるわけではなかったのでした。本番環境等ではリクエストが多いので気づきませんでしたが、検証するときには必ずtraceできるようにして欲しいですよね。
サンプリングの挙動はこちらのドキュメントにもちゃんと説明されてますが、目立たないところにあり気づかなかった方もいるのでは。
簡単にまとめると
- リクエスト数、エラー数、レイテンシなどの統計値はサンプリングに関係なく、保持される
client->trace agent->Datadog server-> と3箇所でサンプリングされる- デフォルトだとサンプリングされるが、100%保持 or 削除するように設定可能
- サンプリングされたものは6時間は閲覧可能だが、次の日には25%、1週間後には10%しか残らない
のようです。
今回は、ローカル環境でのみ
span.SetTag(ext.ManualKeep, true)により必ずtraceするようにすることで解決しました。また、確証はないですが、自分の観測範囲では以下でした。
- デフォルトのサンプリングでは1割ほどしかtraceされない
span.SetTag(ext.ManualKeep, true)によりspanの子孫のコントロールはできるが、先祖についてはコントロールできないリクエストにクエリがひもづかなくてハマった
元々クエリ単体のtraceはできていたのですが、それにリクエストが紐づいておらず、一連の処理の中でどのSQLにどのくらい時間がかかっているかわからない状態でした。
Walletチーム(Kyashアプリを開発しているチーム)ではORMライブラリにGORMを利用しているのですが、GORMのtraceのドキュメントにある例を参考にしてもよくわかりません。
困っていて調べていたところ、現在は他社で活躍している入社時のメンターの記事をたまたま発見し、こちらを参考に以下のように解決することができました。記事ではリクエストにクエリが紐づき、それとは別にクエリのみが紐づく問題の対処方法でしたが、そもそもクエリをリクエストに紐づける場合には
gormtrace.WithContextを呼ぶ必要があります。GORM以外のライブラリもだいたい同じようなライブラリを呼ぶことになると思います。
// 一度だけ呼びます func newConnection() (db *gorm.DB) { // WithCallbacks registers callbacks to the gorm.DB for tracing. // It should be called once, after opening the db. // The callbacks are triggered by Create, Update, Delete, // Query and RowQuery operations. db, _ := gorm.Open("postgres", connStr) db = gormtrace.WithCallbacks(db) return db } // リクエストのコンテキストを引数に渡し、dbと紐付けます func DBWithContext(ctx context.Context) *gorm.DB { db := database.Connection() // WithContext attaches the specified context to the given db. The context will // be used as a basis for creating new spans. An example use case is providing // a context which contains a span to be used as a parent. return gormtrace.WithContext(ctx, db) }メモリリークしまくってハマった
二つグラフをあげますが、なんのグラフでしょうか。
ローカルで動作確認できたし、次はstaging環境で確認するだけだ!
とおもったら最後にまたハマりました。一つめはメモリ使用量のグラフです。(ホスト二つを別に表示してます) 笑ってしまうくらい綺麗に増加してますね。。
あるタイミングで急激に減ってるのはOOM Killerが走っているためです。二つ目のグラフはGoルーチンの数のグラフです。今回ランタイムメトリクスを有効にしたのでせっかくだし載せてみました。
この二つから明らかにGoルーチンが回収されずにメモリがリークしているのがわかります。
複数のライブラリのバージョンを最新にしたり、色々な設定変更を行ったりを同時にしているため、何が原因なのかすぐにはわからず、しばらく単調増加/減少しているグラフを見ると拒否感を覚える日々が続きました。
が、様々な状況証拠からメトリクスを送ることができるライブラリ
https://github.com/DataDog/datadog-go
が怪しそうだと思ったので、ソースをじっくり読むことにしましたが、2000行もないくらいの量でしたので数時間でリークしている箇所を発見しました。よし、PR送るぞ! と意気込んだ矢先、三日前に他の人がPRを送っており、先にソース読む前にPRを確認しろよと若干自分に苛立ちましたが、ライブラリの設計は参考になりそうなところも多く勉強になったのでいいことにします。
また、ソースを読んでみて気づいたのですが、アーキテクチャからしてリクエストのたびに
openするような設計ではなく、openしてからcloseされるまで最低4MBのメモリと3つのGoルーチンが消費されることに気づきました。なので、この機会にアプリ起動時のみ
openするようにしました。
ちなみにそれであれば今回のバグは踏まないはずです。自分が確認する限りはアーキテクチャが一新され、パフォーマンスが劇的によくなった
https://github.com/DataDog/datadog-go/pull/91
の変更で混入したバグだったのでバグが発見され修正されるまで1か月半ほどかかったことになります。スター数180なのでそこまでメジャーとは言えないライブラリなのでそういう場合は最新ではなくちょっと古いバージョンを選んだほうがいいのかなとか思ったりしましたが、難しいですね。。最新のbugfixを入れ込みたいですし。
最後に参考までに、どのようなバグだったのか極限まで簡潔にしたものを以下に載せておきます。
極限まで簡潔に書くとこんな感じのソース
type Client struct { stop chan struct{} // 処理不要であることを通知するためのチャネル } func (c *Client) watch() { ticker := time.NewTicker(c.flushTime) for { select { case <-ticker.C: // dosomething(4MB以上のメモリを辿れる) case <-c.stop: ticker.Stop() return } } } func (c *Client) watch2() { ticker := time.NewTicker(c.flushTime) for { select { case <-ticker.C: // dosomething(4MB以上のメモリを辿れる) case <-c.stop: ticker.Stop() return } } } //アプリケーションからcloseされるときに呼ばれる func (c *Client) Close() error { select { case c.stop <- struct{}{}: default: } }c:=client {} c.stop=make(chan struct{}, 1) go c.watch() go c.watch2()アプリケーションがcloseしても、goルーチンが一つ生き残ったままなので、確保したメモリがgcされておりません。
この簡単なケースでは、case c.stop <- struct{}{}:のところをclose(c.stop)にすればいいはずです。最後に
今回datadogをいい感じにしようとしたところ、知識ゼロの状態から取り組んだため、想定外に時間がかかってしまいましたが、Kyash Advent Calender 2019 4日目の記事にある「日頃の開発ではできないことを行うクォーター中に1週間の期間」でこの課題に取り組むことができたため、腰をすえて取り組むことができました。通常のプロジェクトと並行してでは難しかったでしょう。
なお、プロジェクトでは、先日発表された新しいカードに初期から関わっており、このあたりの話を来年春あたりにKyash Meetupなどで話せたらなと思っているので興味ある人は是非!!



- 投稿日:2019-12-18T10:28:03+09:00
クローリングのベンチマーク取ってみました。
はじめに
agouti を使ってクローリングを行い、ベンチマークを測定してみました。
クローリング対象ページ
今回クローリング対象のページは、goのtemplateパッケージを使用してローカルに生成したものを利用しました。以下では9つのページを生成しています。
func createPages() { createPage("/1", []string{"/2", "/3"}) createPage("/2", []string{"/4", "/5"}) createPage("/3", []string{"/6", "/7"}) createPage("/4", []string{"/8", "/9"}) createPage("/5", nil) createPage("/6", nil) createPage("/7", nil) createPage("/8", nil) createPage("/9", nil) http.ListenAndServe(":8080", nil) } func createPage(url string, links []string) { handler := newHandler(links) http.HandleFunc(url, handler) } func newHandler(links []string) func(w http.ResponseWriter, r *http.Request) { return func(w http.ResponseWriter, r *http.Request) { temp := "template.html.tmpl" t := template.Must(template.New(temp).ParseFiles(temp)) if err := t.Execute(w, links); err != nil { log.Fatal(err) } } }template.html.tmpl
<!DOCTYPE html> <html> <body> <div> {{range .}} <p><a href="{{.}}">{{.}}</a></p> {{end}} </div> </body> </html>クローラー
再起的にクローリングを行いページ内のリンクを取得するクローラーを作成しました。
// maxConcurrent = クローリング最大平行数 // maxCrawlCount = クローリングするページの最大数 func Crawls(link string, maxConcurrent int, maxCrawlCount int) ([]string, error) { errCh := make(chan error) go func() { worklinks <- link }() for i := 0; i < maxConcurrent; i++ { go func() { for link := range unseen { links, err := crawl(link) if err != nil { errCh <- err return } for _, l := range links { l := l go func() { worklinks <- l }() } } }() } for link := range worklinks { if !seen[link] { seen[link] = true unseen <- link } if len(seen) >= maxCrawlCount { links := make([]string, 0, len(seen)) for k := range seen { links = append(links, k) } return links, nil } } return nil, nil } // ページ内のリンクを検索 func crawl(link string) ([]string, error) { driver := agouti.ChromeDriver( agouti.ChromeOptions("args", []string{ "--headless", }), ) if err := driver.Start(); err != nil { return nil, errors.Wrap(err, "Failed to start driver") } defer driver.Stop() p, err := driver.NewPage() if err != nil { return nil, err } err = p.Navigate(link) if err != nil { return nil, err } t := p.All("a") length, err := t.Count() if err != nil { return nil, err } links := []string{} for i := 0; i < length; i++ { link, err := t.At(i).Attribute("href") if err != nil { return nil, err } links = append(links, link) } return links, nil }Benchmark測定
最大平行数を変えてベンチマークを測定してみました。現在の実装だと平行数を単純に増やせばその分早くなるというわけではないことがわかりました。。今後改善していきたいと思います。
平行数 処理時間(ns) 1 16479309835 2 10561147824 3 8914031897 4 8981436252 5 7767930345 10 6496013517 50 8146189396 func BenchmarkCrawl1(b *testing.B) { benchmark(b, 1) } func BenchmarkCrawl2(b *testing.B) { benchmark(b, 2) } func BenchmarkCrawl3(b *testing.B) { benchmark(b, 3) } func BenchmarkCrawl4(b *testing.B) { benchmark(b, 4) } func BenchmarkCrawl5(b *testing.B) { benchmark(b, 5) } func BenchmarkCrawl10(b *testing.B) { benchmark(b, 10) } func BenchmarkCrawl10(b *testing.B) { benchmark(b, 50) } func benchmark(b *testing.B, maxConcurrent int) { go func() { createPages() }() for i := 0; i < b.N; i++ { links, err := Crawls("http://localhost:8080/1", maxConcurrent, 9) b.Logf("links: %v", links) if err != nil { b.Error(err) return } } }
- 投稿日:2019-12-18T10:28:03+09:00
クローリングのベンチマークを取ってみました。
はじめに
agouti を使ってクローリングを行い、ベンチマークを測定してみました。
クローリング対象ページ
今回クローリング対象のページは、goのtemplateパッケージを使用してローカルに生成したものを利用しました。以下では9つのページを生成しています。
func createPages() { createPage("/1", []string{"/2", "/3"}) createPage("/2", []string{"/4", "/5"}) createPage("/3", []string{"/6", "/7"}) createPage("/4", []string{"/8", "/9"}) createPage("/5", nil) createPage("/6", nil) createPage("/7", nil) createPage("/8", nil) createPage("/9", nil) http.ListenAndServe(":8080", nil) } func createPage(url string, links []string) { handler := newHandler(links) http.HandleFunc(url, handler) } func newHandler(links []string) func(w http.ResponseWriter, r *http.Request) { return func(w http.ResponseWriter, r *http.Request) { temp := "template.html.tmpl" t := template.Must(template.New(temp).ParseFiles(temp)) if err := t.Execute(w, links); err != nil { log.Fatal(err) } } }template.html.tmpl
<!DOCTYPE html> <html> <body> <div> {{range .}} <p><a href="{{.}}">{{.}}</a></p> {{end}} </div> </body> </html>クローラー
再帰的にクローリングを行いページ内のリンクを取得するクローラーを作成しました。
// クローリング済のリンク一覧 var seen = make(map[string]bool) // クローリング対象のリンク一覧 var worklinks = make(chan string) // maxConcurrent = クローリング最大平行数 // maxCrawlCount = クローリングするページの最大数 func Crawls(link string, maxConcurrent int, maxCrawlCount int) ([]string, error) { errCh := make(chan error) go func() { worklinks <- link }() for i := 0; i < maxConcurrent; i++ { go func() { for link := range unseen { links, err := crawl(link) if err != nil { errCh <- err return } for _, l := range links { l := l go func() { worklinks <- l }() } } }() } for { select { case link := <-worklinks: if !seen[link] { seen[link] = true unseen <- link } if len(seen) >= maxCrawlCount { links := make([]string, 0, len(seen)) for k := range seen { links = append(links, k) } return links, nil } case err := <-errCh: return nil, err } } } // ページ内のリンクを検索 func crawl(link string) ([]string, error) { driver := agouti.ChromeDriver( agouti.ChromeOptions("args", []string{ "--headless", }), ) if err := driver.Start(); err != nil { return nil, errors.Wrap(err, "Failed to start driver") } defer driver.Stop() p, err := driver.NewPage() if err != nil { return nil, err } err = p.Navigate(link) if err != nil { return nil, err } t := p.All("a") length, err := t.Count() if err != nil { return nil, err } links := []string{} for i := 0; i < length; i++ { link, err := t.At(i).Attribute("href") if err != nil { return nil, err } links = append(links, link) } return links, nil }Benchmark測定
最大並行数を変えてベンチマークを測定してみました。現在の実装だと並行数を単純に増やせばその分早くなるというわけではないことがわかりました。。今後改善していきたいと思います。
並行数 処理時間(ns) 1 16479309835 2 10561147824 3 8914031897 4 8981436252 5 7767930345 10 6496013517 50 8146189396 func BenchmarkCrawl1(b *testing.B) { benchmark(b, 1) } func BenchmarkCrawl2(b *testing.B) { benchmark(b, 2) } func BenchmarkCrawl3(b *testing.B) { benchmark(b, 3) } func BenchmarkCrawl4(b *testing.B) { benchmark(b, 4) } func BenchmarkCrawl5(b *testing.B) { benchmark(b, 5) } func BenchmarkCrawl10(b *testing.B) { benchmark(b, 10) } func BenchmarkCrawl10(b *testing.B) { benchmark(b, 50) } func benchmark(b *testing.B, maxConcurrent int) { go func() { createPages() }() for i := 0; i < b.N; i++ { links, err := Crawls("http://localhost:8080/1", maxConcurrent, 9) b.Logf("links: %v", links) if err != nil { b.Error(err) return } } }
- 投稿日:2019-12-18T09:40:36+09:00
Knative Serving in Production
概要
Knative Serving は、ステートレスなアプリケーションを対象に、HTTP リクエスト駆動で自動スケールする仕組みを提供します。Kubernetes (K8s) と Ingress (Istio or Gloo, Ambassader) を程よく抽象化し、開発者が複雑な知識を必要とせずに、アプリケーションを外部に公開することが出来ます。Knative Serving のオートスケールの仕組みは、Zero Scale Abstraction in Knative Serving にまとめていますが、一部情報が古くなっているので、注意して下さい。
本記事では、Knative Serving on EKS を本番導入するにあたって、注意するべき点をまとめます。
Why Knative?
本題に入る前に Knative を採用した理由を整理します。
- K8s のネットワークを含めた実用的な抽象化
- アプリケーションのデプロイだけなら、K8s リソースの深い知識は不要
- サービスの公開に必要な Ingress リソースを裏で生成してくれる
- アプリケーションを Immutable な Revision (環境) に閉じ込めてくれる
- 切り戻しはトラフィックの向き先を変えるだけで良い
- Revision GC
- トラフィックの向いていていない Revision は、指定した時間経過した後に自動的に削除される
- Service にタグ付けすることで、テスト用のエンドポイントが楽に生成できる
- スケールの制御
- HTTP リクエストの同時処理数や RPS をベースにアプリケーションをスケールできる
- アプリケーションの同時処理数を制限することができる
- 同時に 1 つのリクエストしか処理しないとか
- YAML 地獄からの脱却
- YAML の記述量が大幅に減り、Helm や kustomize をゴリゴリ使う必要がなくなる
- ゼロスケール出来ることの意義
- ノード障害でアプリケーションが全滅しても、リクエストキュー (Activator) が生きていればリクエストを取りこぼさない可能性がある
- HPA に比べてスケールが早いため、突発的なリクエストの増加に対応できる可能性がある
- Portability の向上
- K8s 上なら基本的にどこでもデプロイ可能
- Knative の拡張
- ライブラリ (knative/pkg) やテンプレート (knative/sample-controller)を使って、Knative (K8s) を拡張するコントローラや Webhook を作成できる
- Binding Pattern (@knative-user に参加する必要あり) に従うことで、Mutating Webhook が簡単に作れる
- 例えば、Google CloudSQL Proxy をサイドカーとして追加してくれる Webhook の例が mattmoor/bindings にある
- Binding Pattern で提供しているライブラリは、Knative に限らず K8s でも利用できる
ステートレスなアプリケーションのコンテナ化を進める上で、どのプラットフォームを利用するかは難しい選択です。チームの規模や温度感による部分もあるので、正解はないと思います。AWS の場合、ECS を利用しているプロダクトが多いと思います。今回、ECS を利用しなかった理由として、ECS にも学習コストがあること、ECS だとネットワークレイヤーを自分で設定する必要があること、K8s の拡張性に魅力を感じたことがあげられます。
学習コストについては、EKSは本当にECSより難しいのか? にまとまっているので、省略します。ネットワークレイヤーに関しては、サービスが内部通信に gRPC を採用していることもあり、ALB だけではリクエストが偏ってしまいます。アプリケーション側に負荷分散のロジックを組み込むのもありですが、開発側に押し付けるよりは、Envoy などのプロキシに任せる方が無難だと判断しました。ECS で、Envoy をサイドカーで構築するとなると Envoy を自前で設定する必要があります。App Mesh を使うのもありですが、結局 Istio でいうところの Virtual Service などを定義する必要があるようです。ネットワークレイヤーも含めて抽象化したプロダクトって意外とないんですよね。拡張性については、K8s コントローラや Webhook を自作することができます。今のところ、SSM ParameterStore から機密情報をフェッチして K8s Secret として登録してくれる toVersus/aws-ssm-operator を簡単に作ったくらいですが、先述の Binding Pattern を使って、ConfigMap のライフサイクル管理やタイムゾーンなどの環境変数やアノテーションを Mutating Webhook で挟み込めるようにしたいです。他にもイメージを全ノードにプリフェッチしてくれる奴とか...。
良い点ばかりを挙げていますが、当然 Knative Serving が銀の弾丸な訳ではありません。Knative Serving を使う場合、ネットワークレイヤーが完全に抽象化されてしまうので、内部実装を深く理解する人間が必要です。今は、私がその役目を担っていますが、徐々に Knative を運用できる人を増やさないとかなり辛いです。Knative Serving を採用するかは正直悩みましたし、今でも悩んでいます。ただ、K8s を利用してみたいと開発側から話を持ちかけてくれたこともあって、これまでの (開発と運用を完全に分業してきた) 組織文化を変えるきっかけになればと思い進めています。K8s の知識に加え、ネットワークレイヤーも含めて開発側に押し付けるのは酷なので、段階的に K8s に慣れていけるレールを敷いてあげるのがインフラの役目と考えました。
Target Workload
現状、Knative Service は処理の短いワークロードに適しています。
- API/Web サーバ
- Serverless Function (別途 Runtime が必要)
HTTP リクエストをトリガーにバッチ処理を実行したくても、数十分から数時間かかる処理には適しません。最近、機械学習モデルのデプロイ先として Knative を利用するケースを見ます。kfserving といったプロジェクトがあるくらいです。ただ、Knative Service のスケールダウン時に停止する Pod は、その Pod がリクエストを処理中かどうかに関わらずランダムに決定されます。これは、スケールダウン時に Deployment のレプリカ数を -1 しているだけだからです。どの Pod を削除するかは、ReplicaSet コントローラの判断に委ねられ、選ばれた Pod が無慈悲に Termination Grace Period 経過後に停止されます。リクエストを処理し終わった後に、安全に停止させたいなら、Termination Grace Period を数十分に設定する必要があり、これは現実的ではないです。(Terminating の Pod が大量に存在することになり、ノードのリソースを食い潰すか、IP アドレスが枯渇するかになると思います。)
余談ですが、Knative では、Termination Grace Period をクラスターレベルでしか設定することができません。Deployment 経由で Pod に指定できるフィールドはマスクされています。
私の担当サービスでは、ネイティブアプリのバックエンドの API サーバと Web スクレイピングのジョブを Knative Service 上にデプロイする予定です。長時間掛かるバッチ処理は対象にしていません。
現在、Selective Pod Destruction という機能の設計が進められています。この機能が実装されると、Knative で取得している HTTP リクエストのメトリクスをベースに削除する Pod を選択するようになります。すなわち、ReplicaSet コントローラに任せるのはやめるということです。
余談ですが、Knative v1 以降は、K8s の中でサーバーレスの特性に合わない部分を Knative のコンポーネントで置き換えようとする流れがあります。上記の例もそうですが、Node Local Scheduling (@knative-user に参加する必要あり) という Proposal があります。Autoscaler がスケジューリングを担当し、DaemonSet で立てた Activator が実際にスケールさせる形になるはずです。今の Activator の役割がリクエストバッファとリバースプロキシだけなので、Activator という名前がやっと意味のあるものになります。古いデザインドキュメントを更新するところから動くはずなので、まだ先になりそうです。
Ingress
Knative Serving は、現状 4 つの Ingress に対応しています。 @toshi0607 さんが、それぞれの Ingress の違いについて、次回の技術書店で執筆するらしいので、期待しましょう。この記事では、簡単に触れます。
- Istio
- 複雑な Service Mesh を構築し、ネットワークの可視化やセキュリティポリシーの指定など様々な機能を利用できます。
- Knative が発表された当初から対応しており、多くの E2E テストが Istio ベースで実行されています。Istio への対応は基本的に Knative のコアチームが担当しています。
- Gloo
- > Glooは2019年2月,Kubernetes Knativeサービスのために,Istioに代わるものとしてローンチされた。Solo.ioの開発によるGlooは,Knativeアプリケーション用のKubernetesイングレスコントローラ(Ingress Controller)として実装されたAPIゲートウェイである。
- 今は、Knative に関係なく軽量な API Gateway としての地位を確立しているように思います。
- 先日 v1.0.0 がリリースされました。
- Ambassador
- Yet Another Envoy based lightweight API Gateway
- Kourier
- Red Hat 主導で開発が進められている Knative のための Ingress で、Istio Ingress の置き換えを目的としています。
- Knative がサポートする機能を提供できるミニマムなリファレンス実装を目指しています。
- まだまだ開発中のため、本番利用は推奨されていません。
Ingress の選択も難しい問題です。Knative のコアチームが実装を担当していることもあり、Istio が最も安定した Ingress です。Knative Serving v0.11.0 で ClusterIngress と呼ばれる Knative 内部のリソースが Deprecate されました。v0.8.0 からの長い deprecate のプロセスでしたが、この変更に対する Ambassador の対応が遅れたため、Knative Serving v0.11.0 で Ambassador が動作しない状態となっています。Gloo も v0.11.0 に対する E2E テストが壊れています。Gloo のリリースが落ち着いた段階で、サポート対象の Gloo のバージョンを上げつつ、対応する予定のようです。
では、Istio が良いかと言うと、そうとも言えない状況です。Service Mesh は、少人数のチームにとって機能過多で運用の負荷が重くなるだけだからです。私も、Knative の情報は追っているものの、Istio の情報までは追えていないので、Service Mesh によるネットワークの抽象化で問題が発生した時に切り分けられる自信がありませんでした。
いろいろと迷走した結果、Istio の Service Mesh の機能は有効にせず、Istio IngressGateway と Pilot (Envoy の動的な設定) だけを利用することにしました。Knative では、"Istio Lean" と呼ばれている方式です。Service Mesh と併せて E2E テストのカバー率が高く、flaky なテストの少ない安定した方式となります。以前の発表では、Istio with Service Mesh を使うしかないと言っていましたが、Prefer Pod IPs to ClusterIPs when possible #5820 がマージされ、他にもいくつか Activator によるロードバランサの機能が改善されたため、ゼロスケール時や急激なトラフィックの増加で Activator (中央集権的なキュー) にリクエストが送られても、gRPC (HTTP/2) の負荷分散が機能するようになってきました。mTLS やネットワークポリシーなどの Service Mesh の機能を、最初から使おうとは思っていないので、運用の負荷やチームの規模を天秤に掛けて最終的に判断しました。
ただ、注意点として、Istio Lean の場合は、Istio IngressGateway を istio-ingressgateway と cluster-localgateway の 2 台立てる必要があります。Knative では、
serving.knative.dev/visibility: cluster-localラベルを付与することで、そのサービスをクラスター内からしかアクセスできないようにできます。プライベートなサービスは、全て cluster-localgateway に紐付けられます。余談ですが、トラフィック分割に関して、ヘッダーベースで振り分ける Proposal (@knative-user に参加する必要あり) が出ており、そろそろ議論が始まる予定です。
Istio のインストールは、Knative の開発で使っている スクリプト を流用させてもらって、公式の Helm Chart から生成しています。今後、Istio 公式提供の Helm Chart が廃止になるようで、istioctl で生成するように変更する必要があります。
Cloud Load Balancer
クラスター外部から各ノード上の Istio IngressGateway にリクエストを振り分ける L4 のパススルーロードバランサーとして、Network Load Balancer (NLB) を利用することにしました。K8s v1.14 の時点で、アルファの機能であるため、採用するか迷いましたが、EKS のアップグレードをクラスターレベルの Blue/Green デプロイで行うために、
Global Accelerator を利用したいので([2019/12/20 追記] Global Accelerator の配下に NLB を置く場合は、ソース IP を保持できないことを知り、Route53 のルーティングポリシーを使うことにしたので、NLB は必須ではなくなりました。)強行しました。K8s v1.15 でベータになるので、早くリリースされることを祈っています。また、NLB で ソース IP を保持するために、.spec.externalTrafficPolicy を
Localに設定しています。EKS v1.14 時点では、kubernetes/kubernetes#61486 を参考に kube-proxy にパッチを適用しています。これにより、NLB からノードに対するヘルスチェックが通るようになります。外部からのリクエストは NLB で負荷分散されてノードに割り振られ、そのノード上の Istio IngressGateway にルーティングされるようになります。By setting .spec.externalTrafficPolicy to Local, the client IP addresses is propagated to the end Pods, but this could result in uneven distribution of traffic.
上記に書かれているように、このままでは、Istio IngressGateway へのリクエストが偏ってしまう可能性があります。そのため、Istio IngressGateway を DaemonSet として起動します。Istio が公式提供している Helm Chart には、DaemonSet でデプロイするオプションがないので、以下のようなパッチを適用しています。
--- istio-copy.yaml 2019-11-17 20:31:57.000000000 +0900 +++ istio.yaml 2019-11-17 20:32:18.000000000 +0900 @@ -1838,7 +1838,7 @@ spec: - "s390x" --- apiVersion: apps/v1 -kind: Deployment +kind: DaemonSet metadata: name: istio-ingressgateway namespace: istio-system @@ -1853,9 +1853,8 @@ spec: matchLabels: app: istio-ingressgateway istio: ingressgateway - strategy: + updateStrategy: rollingUpdate: - maxSurge: 100% maxUnavailable: 25% template: metadata:
externalTrafficPolicy: Localの場合、Cloud Load Balancer から Service のバックエンドに対するリクエストが最悪セカンドホップしてしまうことを防ぐことができます。TLS Termination
NLB は、DSR ロードバランサーではないらしい (レスポンスは必ず NLB を経由してクライアントに返る) し、mTLS を利用する予定がないので、NLB で TLS 終端しちゃっても良いかなと思っていました。ただ、v1.14 では、Service type LoadBalancer の annotation で、NLB に TLS 証明書を紐付けることができません。ですので、現在 TLS 終端は後段の Istio IngressGateway (L7) で行っています。こちらの機能も v1.15 で利用できるようになるので、待ち遠しいです。
Access Logging
Istio IngressGateway (Front Envory) と Local ClusterGateway (Internal Envoy) のアクセスログはそれぞれ global.proxy.accessLogFormat で指定可能です。Knative のコンポーネントである、queue-proxy と Activator が出力するアクセスログは、config-observability で変更可能です。Knative Service 名や Pod 名、ネームスペースなどをアクセスログとして吐け、デバッグがし易くなるのでオススメです。
logging.request-log-template: '{"httpRequest": {"requestMethod": "{{.Request.Method}}", "requestUrl": "{{js .Request.RequestURI}}", "requestSize": "{{.Request.ContentLength}}", "status": "{{.Response.Code}}", "responseSize": "{{.Response.Size}}", "userAgent": "{{js .Request.UserAgent}}", "remoteIp": "{{js .Request.RemoteAddr}}", "serverIp": "{{.Revision.PodIP}}", "referer": "{{js .Request.Referer}}", "latency": "{{.Response.Latency}}", "protocol": "{{.Request.Proto}}"}, "traceId": "{{index .Request.Header "X-B3-Traceid"}}", "revision": "{{.Revision.Name}}", "namespace": "{{.Revision.Namespace}}", "podname": "{{.Revision.PodName}}", "podip": "{{.Revision.PodIP}}"}'Domain Template
パブリックもしくはプライベートなエンドポイントのドメイン名を config-domain で変更することができます。セレクターベースで利用するドメインを変更することができるため、複数のドメインを一つの Istio IngressGateway に紐付けることができます。
サブドメインの生成テンプレートも config-network で変更しておきましょう。デフォルトだと、
"{{.Name}}.{{.Namespace}}.{{.Domain}}"という形で、サブドメインが割り振られます。ネームスペースが間に入っているのは、ネームスペース間でサービス名が衝突しないようにするためです。私の担当サービスでは、外部公開するエンドポイントが少ないため、このテンプレートを"{{.Name}}.{{.Domain}}"に変更しています。HPA-based Autoscaler
Knative では、デフォルトで HTTP リクエストベースでスケールしますが、通常の HPA を使ったリソース使用率でのスケールもサポートしています。HPA ベースを選択する場合は、現状ゼロスケールには対応していません。対応予定ではいます。
KPA (HTTP リクエストベース) のオートスケーラーと HPA (CPU/メモリ使用率ベース) のオートスケーラーは、別々のコントローラーとして動作しています。HPA ベースの利用がない場合は、コントローラー自体を停止してしまいましょう。Knative Serving が提供するマニフェストでは、デフォルトで有効になっているので、kustomize でレプリカ数をゼロに変更しています。
- op: replace path: /spec/replicas value: 0Metrics
Knative のコンポーネントは、貴重なメトリクスを Prometheus 形式で公開してくれています。Activator と Autoscaler、queue-proxy のメトリクスを最低限押さえておけば良いと思います。
私の担当サービスでは、Datadog を利用しているので、kustomize で Autoscaler の Deployment に以下のパッチを適用しています。
- op: add path: /spec/template/metadata/annotations/ad.datadoghq.com~1autoscaler.check_names value: '["openmetrics"]' - op: add path: /spec/template/metadata/annotations/ad.datadoghq.com~1autoscaler.init_configs value: '[{}]' - op: add path: /spec/template/metadata/annotations/ad.datadoghq.com~1autoscaler.instances value: '[{"prometheus_url": "http://%%host%%:9090/metrics","namespace": "knative-serving","metrics": ["*"], "send_distribution_buckets": true}]'Activator の Deployment も同様です。
- op: add path: /spec/template/metadata/annotations/ad.datadoghq.com~1activator.check_names value: '["openmetrics"]' - op: add path: /spec/template/metadata/annotations/ad.datadoghq.com~1activator.init_configs value: '[{}]' - op: add path: /spec/template/metadata/annotations/ad.datadoghq.com~1activator.instances value: '[{"prometheus_url": "http://%%host%%:9090/metrics","namespace": "knative-serving","metrics": ["*"], "send_distribution_buckets": true}]'queue-proxy の場合は、Knative Service に以下の annotation を付与しています。1 つ目が queue-proxy の、2 つ目がアプリケーションで公開している Prometheus 形式のメトリクスを収集するためのものです。
spec: template: metadata: annotations: ad.datadoghq.com/queue-proxy.check_names: '["openmetrics"]' ad.datadoghq.com/queue-proxy.init_configs: '[{}]' ad.datadoghq.com/queue-proxy.instances: '[{"prometheus_url": "http://%%host%%:9090/metrics","namespace": "default","metrics": ["*"]}]' ad.datadoghq.com/user-container.check_names: '["openmetrics"]' ad.datadoghq.com/user-container.init_configs: '[{}]' ad.datadoghq.com/user-container.instances: '[{"prometheus_url": "http://%%host%%:9091/metrics","namespace": "default","metrics": ["*"], "send_distribution_buckets": true}]'Readiness Probe
Knative Serving では、可能な限り早く Pod が Ready 状態になるように、ユーザーが定義した Probe をいじっています。これは、K8s の Readiness Probe のパラメータが秒単位でしか指定できないからです。ユーザーが定義した TCP および HTTPGet Probe は、ユーザーのコンテナ定義から削除され、サイドカーとしてデプロイされる queue-proxy の Readiness Probe にコピーされます。queue-proxy の Readiness Probe は、次のように指定されています。
readinessProbe: exec: command: - /ko-app/queue - -probe-period - "0" failureThreshold: 3 periodSeconds: 1 successThreshold: 1 timeoutSeconds: 10queueu-proxy は、ヘルスチェック用のシングルバイナリとして動作するようになっています。
// If this is set, we run as a standalone binary to probe the queue-proxy. if *readinessProbeTimeout >= 0 { if err := probeQueueHealthPath(env.QueueServingPort, *readinessProbeTimeout); err != nil { // used instead of the logger to produce a concise event message fmt.Fprintln(os.Stderr, err) os.Exit(1) } os.Exit(0) }この probeQueueHealthPath の中で、
readinessProbe.timeoutSecondsの間、より細かい粒度のポーリング間隔 (25 ms) で、ヘルスチェックをループさせています。では、readinessProbe として Exec Probe を指定した場合は、どうなるのでしょうか?gRPC サービスのヘルスチェックは、grpc-ecosystem/grpc-health-probe をイメージ内に同梱して Exec Probe で実行するのが一般的ですよね。Exec Probe の場合、ユーザー定義のコンテナから Exec Probe は削除されず、queue-proxy のヘルスチェックはコンテナのポートに対する TCP Probe に置き換えられます。そのため、Pod が Ready 状態になるのは、Pod 内の全てのコンテナのステータスが Ready になってからなので、この細かい粒度での Readiness Probe は余り意味をなさなくなります。
つい最近まで、Knative Service で Exec Probe を指定した時にエラーになっていたので、knative/serving#5712 のパッチを適用する必要がありましたが、ついにマージされたので v0.12.0 から不要になる予定です。
Graceful Shutdown
Knative Serving は、Mutating Webhook を使って PodSpec を色々といじっています。その最たる例が、Lifecycle Hook です。Knative Serving は、ユーザーコンテナに以下の Lifecycle Hook を忍ばせています。
lifecycle: preStop: httpGet: path: /wait-for-drain port: 8022 scheme: HTTP8022 番ポートは、queue-proxy のポートです。queue-proxy が提供する
/wait-for-drainのエンドポイントは、queue-proxy が停止するまでレスポンスを返さないようにします。これにより、queue-proxy が停止した後に、SIGTERM がユーザーコンテナに届きます。preStop フックを自身で定義する必要はありません。queue-proxy 自体は、SIGTERM を受けると 20 秒スリープしてから、Golang 標準の Shutdown で安全に停止します。ですので、何も考えずに アプリケーション側で Graceful Shutdown のみ実装してあげれば良いです。Private Image Registry
Knative Serving には、Revision という概念があります。Revision は、アプリケーションのコードと設定を封じ込める不変の環境です。
これを実現するため、tag to digest という機能がデフォルトで有効になっています。イメージタグが不変ではないため、Revision 作成時にイメージタグからイメージダイジェストに変換して、イメージを固定します。この tag to digest の機能は、Knative コントローラで実行されるため、Knative コントローラは、Private Registry に対する読み取り権限が必要です。Knative Serving は、Image Registry からタグをダイジェストに変換する際に、google/go-containerregistry のライブラリを利用しています。このライブラリは、k8s.io/kubernetes の credentialprovider に依存しており、バージョンが古いため、ECR で正しく動作しません。 (google/go-containerregistry で Please stop importing k8s.io/kuberneretes が上がっているので、そもそも外部で使われる前提のライブラリではないようです。Credential provider extraction という KEP もあるので、最終的にこちらに寄せるのかなと思っています。)
ですので、ECR を利用する場合は、gist にあるパッチを当てる必要があります。このパッチのおかげで、ワーカーノードの EC2 インスタンスに紐付いたポリシーを使って、tag to digest の変換が行われるようになります。以前は、このパッチが upstream に組み込まれていたのですが、v0.10.0 からこのパッチが適用されなくなりました。knative/serving#4549 で、パッチが適用されなくなった問題の状況がトラックされています。
Burst Capacity
Knative Serving におけるアプリケーション (Pod) のスケールについては、公式ドキュメントの Configuring autoscaling と Autoscale Sample App - Go にまとまっているので、省略します。
Knative Serving v0.8.0 から Burst Capacity (@knative-user に参加する必要あり) と呼ばれる機能が入りました。Burst Capacity は、急激なリクエスト数の増加に対応するために実装された機能で、ある閾値を越えると Activator (中央集権的なリクエストバッファ) がリクエストパスに入ってくれます。これにより、突発的なリクエストの増加時に Pod がスケールし終わるまで、Activator でリクエストをバッファすることができます。ベストエフォートの実装なので、特定の条件で上手くいかないことがあります。
Burst Capacity は、クラスターレベルもしくは Pod 単位で設定することができます。クラスターレベルの場合、config-autoscaler の target-burst-capacity で設定し、Pod 単位の場合は、
autoscaling.knative.dev/targetBurstCapacityを PodSpec のアノテーションで定義します。v0.11.0 時点で、クラスター全体でのデフォルト値が200に設定されています。Burst Capacity の機能では、Excess Burst Capacity というメトリクスが重要です。このメトリクスは以下の式で計算されます。
[Excess Burst Capacity] = [Total Capacity] - [Current # of Request In Flight] - [Target Burst Capacity ]Total Capacity は、Pod が同時処理できるリクエスト数 (containerConcurrency か container-concurrency-target-default の値) と Ready 状態な Pod の数で計算されます。Current # of Request In Flight は、Revision が現在処理中のリクエスト数です。Excess Burst Capacity が負の値の場合に、Activator がリクエストパスに入ります。(ServerlessService が Proxy モードにスイッチします。)
Activator を常にリクエストパスに置きたくない場合は、サービスが定常的に受けるベースのリクエスト数と突発的に受けるリクエスト数のメトリクスを事前に確かめ、
autoscaling.knative.dev/targetBurstCapacityの設定値を調整するようにして下さい。Wrapped Up
- Knative Serving を利用するワークロードと利用しないワークロードを判断する
- Ingress の選択は安定性も考慮して、慎重に行う
- Cloud Load Balancer の特性に注意して、L4/L7 のロードバランサーを適切に選択する
- アクセスログやメトリクスは正しく収集して役立てる
- Knative Serving の Readiness Probe の仕組みは少し変わっているので注意が必要
- ECR を使いたい場合は、Knative Serving にパッチを提供する必要がある
- Burst Capacity が意外と厄介な機能なので、理解してから利用する
Knative Serving の公式ドキュメントは、GA リリースに向けて絶賛改修中です。よりコンパクトにまとまった非公式の Tips もあります。

- 投稿日:2019-12-18T08:37:06+09:00
nil について調べ始めた話
はじめに
この記事は Go7 Advent Calendar 2019 の 18 日目の記事です。
Go さん nil さんの気持ちをもうちょっと理解してみようと思ったところを発端にソースコードを読み始めた記録です。
見返してみたらとても当たり前なことしか述べておりませんでした (´·ω·`)本記事は
go 1.13を前提にしています。TL;DR
- nil 周りのソースコード読んでみた
- nil って何?という話と nil っぽい何かが 2 つ見つかったけど何?という話
- 目新しい話はありません(´·ω·`)
nil の登場
nil らしきものの姿は src/go/types/universe.go にて見つけることができます。https://golang.org/ref/spec#Blocks にも記載のある
universe blockがスコープになっています。
ただ、その近辺でもnilが使われていたりしてよくわかりません。もう少し追ってみると、このあたり(builtin パッケージ) で下記のように定義されています。
var nil Type // Type must be a pointer, channel, func, interface, map, or slice type ... type Type intこれは、
/* Package builtin provides documentation for Go's predeclared identifiers. The items documented here are not actually in package builtin but their descriptions here allow godoc to present documentation for the language's special identifiers. */とある通り、ドキュメンテーションであってどこからも参照されていません。
これをそのまま受け取ると、nil は Type 型の初期値というように理解できます。
なんとなく外れていなさそうな雰囲気です。初期値とは
では
Type 型の初期値とは一体どなた様でしょうか。ふんいきしかわからない。
コンパイラ側のソースコードを読んでみると、こちらのコードに辿り着きました。// zeroVal returns the zero value for type t. func (s *state) zeroVal(t *types.Type) *ssa.Value { switch { ... case t.IsPtrShaped(): return s.constNil(t) case t.IsBoolean(): return s.constBool(false) case t.IsInterface(): return s.constInterface(t) case t.IsSlice(): return s.constSlice(t) case t.IsStruct(): n := t.NumFields() v := s.entryNewValue0(ssa.StructMakeOp(t.NumFields()), t) for i := 0; i < n; i++ { v.AddArg(s.zeroVal(t.FieldType(i))) } return v ...前述の
builtinパッケージには、var nil Type // Type must be a pointer, channel, func, interface, map, or slice typeとありますので、これを素直に受け取るとcase t.IsPtrShaped(): return s.constNil(t)で、
s.constNil(t)が正体のように見えます。二つの nil
話は nil らしきものの姿 src/go/types/universe.go に戻ります。こちら、見てみると
var Typ = []*Basic{ ... UntypedNil: {UntypedNil, IsUntyped, "untyped nil"}, ... } ... func defPredeclaredTypes() { for _, t := range Typ { def(NewTypeName(token.NoPos, nil, t.name, t)) } ...と、
func defPredeclaredNil() { def(&Nil{object{name: "nil", typ: Typ[UntypedNil], color_: black}}) }の、nil っぽい何かが 2 つあるようです。
これらの違いは、値か型か、ということがコードからわかります。
func (check *Checker) ident(x *operand, e *ast.Ident, def *Named, wantType bool) { ... switch obj := obj.(type) { ... case *TypeName: x.mode = typexpr ... case *Nil: x.mode = value ...
UntypedNilは、例えば、var x = nil // use of untyped nilとすると会うことができます。
他にも、下記のようにしても会えます。
var x interface{} x = nil // <- untyped nil の代入interface だけ ok なのは、このあたりのコード に記述されています。
case *Interface: if !x.isNil() && !t.Empty() /* empty interfaces are ok */ { goto Error } // Update operand types to the default type rather then // the target (interface) type: values must have concrete // dynamic types. If the value is nil, keep it untyped // (this is important for tools such as go vet which need // the dynamic type for argument checking of say, print // functions) if x.isNil() { target = Typ[UntypedNil] } else { // cannot assign untyped values to non-empty interfaces if !t.Empty() { goto Error } target = Default(x.typ) }おわりに
その他、いろいろ読んでみて、あ!これ前にXXでやったやつだ!みたいな発見も結構あったのですがただでさえまとまっていない内容がさらにまとまらなくなるので割愛します。
今までよりほんのちょっとだけ Go さん nil さんの気持ちがわかったような気がしました。
- 投稿日:2019-12-18T05:37:43+09:00
GoとDynamoDBを使って速度検証してみた結果
パーソンリンクアドベントカレンダー18日目の投稿です。
こんにちは桑原です。一週間ぶりの投稿です。
前回のkinesisのアンチパターンの後続処理でGoとDynamoDBを使ってみようと思いサンプルコードを書いてみました。
両方とも触り始めて数時間の状態なので自分への備忘録です。やりたいこと
kinesisからのデータが1時間で最大数憶レコードに上るシステムなため、分析用に中間データを作成しようとしています。
中間データフォーマットとしては
1時間ごとにuser_idとsegment_id単位でsession_time(滞在時間)、count(接触回数)を集計する
になります。DynamoDB
テーブル作成
AWSコンソールからテーブル作成します。
テーブル設計
下記で実装していきます。
primary_key : user_id_segment_id_yyyy-MM-dd HHss
user_id : ユーザーID
segment_id : セグメントID
start_date : 初回アクセス日時
last_date : 最終アクセス日時
session_time : 滞在時間
count : 接触回数ソースコード
指定したuser_id、segmet_idに対してループ毎にlast_date(最終アクセス日時)に+1秒したデータで集計を行っています。
sample.gopackage main import ( "fmt" "time" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/aws/credentials" "github.com/guregu/dynamo" ) type User struct { WAW string `dynamo:"w_a_w"` UserId string `dynamo:"user_id"` StartDate string `dynamo:"start_date"` LastDate string `dynamo:"last_date"` SegmentID string `dynamo:"segment_id"` SessionTime int `dynamo:"session_time"` Count int `dynamo:"count"` } /** * dbへselectし最新データの最終アクセス日時を比較、 * 滞在時間と接触回数を加算 */ func main(){ start := time.Now(); loop := 1000 //1000回処理する cred := credentials.NewStaticCredentials("*******", "*******", "") db := dynamo.New(session.New(), &aws.Config{ Credentials: cred, Region: aws.String("ap-northeast-1"), }) table := db.Table("test") user_id := "73nSpnPJ" segment_id := "11111111111111" s_date := time.Date(2019, time.December, 18, 12, 00, 00, 00, time.UTC) start_date := s_date.Format("2006-01-02 15:04:05") primary_key := user_id+"_"+segment_id+"_"+start_date for i := 0; i < loop; i++ { var users []User err := table.Get("primary_key" ,primary_key).All(&users) l_date := s_date.Add(time.Duration(i) * time.Second) last_date := l_date.Format("2006-01-02 15:04:05") if err != nil { fmt.Println("err") panic(err.Error()) } //tableにデータがなければinsertする if len(users) == 0 { u := User{WAW: primary_key, UserId: user_id, StartDate: start_date, LastDate: last_date, SegmentID:segment_id, SessionTime:0, Count:0} //fmt.Println(u) if err := table.Put(u).Run(); err != nil { fmt.Println("err") panic(err.Error()) } } else { layout := "2006-01-02 15:04:05" t, _ := time.Parse(layout, users[0].LastDate) time_diff_second := l_date.Sub(t) //前回のログと比較し差分を接触時間とする diff_second := int(time_diff_second/time.Second) session_time := users[0].SessionTime + diff_second count := users[0].Count + 1 //前回の接触回数+1 u := User{WAW: primary_key, UserId: user_id, StartDate: start_date, LastDate: last_date, SegmentID:segment_id, SessionTime:int(session_time), Count:count} if err := table.Put(u).Run(); err != nil { fmt.Println("err") panic(err.Error()) } } } end := time.Now(); fmt.Printf("%f秒\n",(end.Sub(start)).Seconds()) }実行環境
実行環境はAWS workspecesのAmazon Linux2で
物理 CPU の数
grep physical.id /proc/cpuinfo | sort -u | wc -l
1CPU ごとのコアの数
grep cpu.cores /proc/cpuinfo | sort -u
cpu cores : 4論理プロセッサーの数
grep processor /proc/cpuinfo | wc -l
4
となっています。コードの実行
go run sample.go とターミナルで入力します。
1000回DBへの書き込みと値のチェックを行うだけですので爆速を期待していました。結果
47.547127秒
遅い。。。ターミナルに出力したログも明らかに途中で停止しています。
調べてみるとコンソールにアラートが。
消費された書き込みキャパシティー 5 分間 >= 4
デフォルトキャパシティの5だったためDynamoDBへの書き込みがsample.goの処理速度に追いついていないようです。キャパシティは秒間の処理数とざっくり理解したのでいくつか設定し処理時間のログを比較してみました。
キャパシティ 10 10 キャパシティ 30 30 キャパシティ 50 30 キャパシティ 100 100 キャパシティ 150 200 43.037734秒 22.560107秒50 22.201688秒 14.260555秒
12.466228秒
19.781125秒14.321412秒
オンデマンド 14.515797秒
14.591887秒という結果でした同じキャパシティでも誤差がかなりあることが気になりますが、おおよそ14秒くらいが現在の実行環境の限界かなというところです。
EC2の高スペックなサーバやLambdaでどれくらい速度が向上するのか、ほかの言語ではどうなかを引き続き調査を行っていきます。
- 投稿日:2019-12-18T02:21:54+09:00
IoTボタンを使ってGoogleカレンダーに猫のトイレ回数や時間を記録する
この記事は KLab Engineer Advent Calendar 2019 の18日目の記事です。
はじめに
今年の2月から猫を飼い始めました。
出会ったときは手のひらに収まりそうなくらい小さかったですが、今では立派な成猫に。
つい先日、1歳を迎えたばかりの男の子です。
猫って本当にかわいいですね。
世の中にこんなにもかわいい生き物がいるものか、いや、いる!と昂ぶってしまうくらいのかわいさです。閑話休題
さて、猫は種々の動物たちの例に漏れず、体調が悪くてもそれを隠そうとします。
ですので、普段から様子をよく観察し、ご飯の食いつきが悪くなった、目ヤニが出るようになった、耳や体をよく掻く、といったささいな変化でも確実にキャッチすることが大事です。その一環として、トイレの回数や時間の記録をつけているのですが、
今回は、その作業をもっと楽にできないかと取り組んでみました。全体の構成
理想は猫がトイレをしたときに自動で記録されるといいのですが、重量センサーや赤外線センサーを使って判別するのは精度を出すのが難しそうなので、今回はシンプルに
「猫がトイレをしたのを確認したら、IoTボタンを押してGoogleカレンダーにイベントを作成する」
という形にしました。
在宅時にしか使えませんが、最初はこんなものでいいでしょう。
[IoTボタン]->[Raspberry Pi]->[Googleカレンダー]
というシンプルな構成です。IoTボタン
最初はAmazon Dash Buttonを使おうと考えていたのですが、Dash Buttonの販売は今年の2月末で終了したそうです。
代わりにAWS IoT エンタープライズボタンというものがありますが、価格は2500円とDash Buttonの5倍ほどするので、少し躊躇われます。そんな中、こちらの記事を読んでダイソーにBluetooth接続できるボタンがあることを知り、今回はこれを使ってみることにしました。
参考:IOTボタン対決 Amazon Dash ボタン VS ダイソーBLE300円ボタンダイソーのBluetoothリモートシャッター
100円ショップのダイソーで買うことができます。価格は300円です。Amazon Dash Buttonよりも安価ですね。
技適も取得しているので、技術ブログでも安心して取り上げることができます。
本体は側面の電源スイッチと、iOS用/Android用のボタンがあるだけのシンプルな作りです。
仕組みとしては、Bluetooth接続したスマホにVolumeUpの信号を送ることで、カメラのシャッターを切っているようです。ラズパイとの接続
参考:わずか300円でIoTボタンを作る方法
こちらの通りにやるだけで、ものの数分でラズパイとリモートシャッターを接続することができました。
ところが………。イベントが取得できない
bluetoothctlコマンドでペアリングするところまでは何も問題がなかったのですが、その後、bluebuttonコマンドでイベントを取得しようとしてもイベントが飛んできません。
bluebuttonのコードをいじってログを吐かせてみてもやっぱり飛んでこないので、「[Linux] /dev/input からマウスイベントを取得する」を参考に$ sudo hexdump /dev/input/event0を確認すると、そもそもここにも何もイベントが来ていません。
bluetoothのon/off、ラズパイの再起動、初期不良を疑ってリモートシャッターをもう1個買ってきて確認してもやはりダメ。
これは困った………。どう解決したか
半分あきらめかけていたのですが、「100均Bluetoothボタンをラズパイに活用」という記事内でこのような記述を発見
うまくいかない場合
ペアリング&接続は出来ているけど、ボリューム制御ができない場合があります。クラゲも何度かその状態を経験しています。その場合は、切断や削除などを行い、何度かペアリング&接続を試してみて下さいそんなバカな、と思いつつ、10回ほど接続→切断を繰り返してみると、突然イベントが届くようになりました。そんなバカな………。
Googleカレンダーにイベントを作る
ここまでいけばもう勝ったも同然です。
bluebuttonはボタンを押した/離した際にconfigファイルに記述したコマンドを実行できるので、そこでGoogleClendarAPIを叩きます。
その前に、まずは猫のトイレを記録する用のカレンダーを作成しておきます。
Googleカレンダー右上の[設定]->[カレンダーを追加]->[新しいカレンダーを作成]で記録用のカレンダーを作成します。
その後、マイカレンダーに作ったカレンダーが追加されるので、カレンダーIDをメモっておきましょう。イベントの作成
イベントの作成は何でやっても良いのですが、今回は昨年と同じGoでやりました。
公式のリファレンスにほぼそのまま使えるサンプルがあるのでこれを流用します。
認証まわり:Go Quickstart
イベントの作成:Create Eventsquickstart.got := time.Now().Format(time.RFC3339) event := &calendar.Event{ Summary: "猫のトイレ", Start: &calendar.EventDateTime{ DateTime: t, TimeZone: "Asia/Tokyo", }, End: &calendar.EventDateTime{ DateTime: t, TimeZone: "Asia/Tokyo", }, } calendarId := "ここにカレンダーIDを記載" event, err = srv.Events.Insert(calendarId, event).Do() if err != nil { log.Fatalf("Unable to create event. %v\n", err) } fmt.Printf("Event created: %s\n", event.HtmlLink)あとはビルドした実行ファイルをbluebuttonのconfigファイルから呼んでやれば完成です。
bluebuttonkeyup=echo UP keydown=~/quickstart longup=echo LONG UP longdown=echo LONG DOWNリモートシャッターをIoTボタン化して、Googleカレンダーにイベントを登録することができました。
課題
とりあえず最低要件は達成できましたが、いくつか改善すべき点があります。
大と小
ご存知の通り、トイレには大と小があり、それは猫でも同じです。
今回使用したダイソーのBluetoothリモートシャッターにはボタンが2つあり、偶然にも大きいボタンと小さいボタンなので直感的に使い分けることが可能なのですが、どちらのボタンを押しても同じ内容のイベントが飛んでくるため、区別することができませんでした。
先述した「100均Bluetoothボタンをラズパイに活用」によると、Android用のボタンはKEY_ENTERが追加で飛んでくるはずなのですが。仕様が変わった?スリープ状態からの復帰
ダイソーのリモートシャッターは、最後に通信が行われてから90秒経過するとスリープしてペアリングが解除される仕様になっています。
スリープ状態の時にリモートシャッター側のボタンを押すと、数秒で再度ペアリングできるのですが、ボタンイベントを飛ばすためにはペアリング完了後に再びボタンを押さないといけないため、少々面倒です。
keepaliveするなり、ペアリングイベント自体をフックにするなりして解決したいポイントです。終わりに
当初はあまり期待してなかったのですが、ダイソーのBluetoothリモートシャッターは安価な上に接続も簡単で、ボタンの使い分けやスリープ問題が解決すれば便利なIoTボタンとして自宅や会社などいたるところで使えそうです。
これからも、人と猫との生活のQoLを上げられるよう、色々と便利なモノを作っていきたいです。ねこはいます。






- 投稿日:2019-12-18T02:21:54+09:00
猫のトイレ回数や時間をIoTボタンを使ってGoogleカレンダーに記録する
この記事は KLab Engineer Advent Calendar 2019 の18日目の記事です。
はじめに
今年の2月から猫を飼い始めました。
出会ったときは手のひらに収まりそうなくらい小さかったですが、今では立派な成猫に。
つい先日、1歳を迎えたばかりの男の子です。
猫って本当にかわいいですね。
世の中にこんなにもかわいい生き物がいるものか、いや、いる!と昂ぶってしまうくらいのかわいさです。閑話休題
さて、猫は種々の動物たちの例に漏れず、体調が悪くてもそれを隠そうとします。
ですので、普段から様子をよく観察し、ご飯の食いつきが悪くなった、目ヤニが出るようになった、耳や体をよく掻く、といったささいな変化でも確実にキャッチすることが大事です。その一環として、トイレの回数や時間の記録をつけているのですが、
今回は、その作業をもっと楽にできないかと取り組んでみました。全体の構成
理想は猫がトイレをしたときに自動で記録されるといいのですが、重量センサーや赤外線センサーを使って判別するのは精度を出すのが難しそうなので、今回はシンプルに
「猫がトイレをしたのを確認したら、IoTボタンを押してGoogleカレンダーにイベントを作成する」
という形にしました。
在宅時にしか使えませんが、最初はこんなものでいいでしょう。
[IoTボタン]->[Raspberry Pi]->[Googleカレンダー]
というシンプルな構成です。IoTボタン
最初はAmazon Dash Buttonを使おうと考えていたのですが、Dash Buttonの販売は今年の2月末で終了したそうです。
代わりにAWS IoT エンタープライズボタンというものがありますが、価格は2500円とDash Buttonの5倍ほどするので、少し躊躇われます。そんな中、こちらの記事を読んでダイソーにBluetooth接続できるボタンがあることを知り、今回はこれを使ってみることにしました。
参考:IOTボタン対決 Amazon Dash ボタン VS ダイソーBLE300円ボタンダイソーのBluetoothリモートシャッター
100円ショップのダイソーで買うことができます。価格は300円です。Amazon Dash Buttonよりも安価ですね。
技適も取得しているので、技術ブログでも安心して取り上げることができます。
本体は側面の電源スイッチと、iOS用/Android用のボタンがあるだけのシンプルな作りです。
仕組みとしては、Bluetooth接続したスマホにVolumeUpの信号を送ることで、カメラのシャッターを切っているようです。ラズパイとの接続
参考:わずか300円でIoTボタンを作る方法
こちらの通りにやるだけで、ものの数分でラズパイとリモートシャッターを接続することができました。
ところが………。イベントが取得できない
bluetoothctlコマンドでペアリングするところまでは何も問題がなかったのですが、その後、bluebuttonコマンドでイベントを取得しようとしてもイベントが飛んできません。
bluebuttonのコードをいじってログを吐かせてみてもやっぱり飛んでこないので、「[Linux] /dev/input からマウスイベントを取得する」を参考に$ sudo hexdump /dev/input/event0を確認すると、そもそもここにも何もイベントが来ていません。
bluetoothのon/off、ラズパイの再起動、初期不良を疑ってリモートシャッターをもう1個買ってきて確認してもやはりダメ。
これは困った………。どう解決したか
半分あきらめかけていたのですが、「100均Bluetoothボタンをラズパイに活用」という記事内でこのような記述を発見
うまくいかない場合
ペアリング&接続は出来ているけど、ボリューム制御ができない場合があります。クラゲも何度かその状態を経験しています。その場合は、切断や削除などを行い、何度かペアリング&接続を試してみて下さいそんなバカな、と思いつつ、10回ほど接続→切断を繰り返してみると、突然イベントが届くようになりました。そんなバカな………。
Googleカレンダーにイベントを作る
ここまでいけばもう勝ったも同然です。
bluebuttonはボタンを押した/離した際にconfigファイルに記述したコマンドを実行できるので、そこでGoogleClendarAPIを叩きます。
その前に、まずは猫のトイレを記録する用のカレンダーを作成しておきます。
Googleカレンダー右上の[設定]->[カレンダーを追加]->[新しいカレンダーを作成]で記録用のカレンダーを作成します。
その後、マイカレンダーに作ったカレンダーが追加されるので、カレンダーIDをメモっておきましょう。イベントの作成
イベントの作成は何でやっても良いのですが、今回は昨年と同じGoでやりました。
公式のリファレンスにほぼそのまま使えるサンプルがあるのでこれを流用します。
認証まわり:Go Quickstart
イベントの作成:Create Eventsquickstart.got := time.Now().Format(time.RFC3339) event := &calendar.Event{ Summary: "猫のトイレ", Start: &calendar.EventDateTime{ DateTime: t, TimeZone: "Asia/Tokyo", }, End: &calendar.EventDateTime{ DateTime: t, TimeZone: "Asia/Tokyo", }, } calendarId := "ここにカレンダーIDを記載" event, err = srv.Events.Insert(calendarId, event).Do() if err != nil { log.Fatalf("Unable to create event. %v\n", err) } fmt.Printf("Event created: %s\n", event.HtmlLink)あとはビルドした実行ファイルをbluebuttonのconfigファイルから呼んでやれば完成です。
bluebuttonkeyup=echo UP keydown=~/quickstart longup=echo LONG UP longdown=echo LONG DOWNリモートシャッターをIoTボタン化して、Googleカレンダーにイベントを登録することができました。
課題
とりあえず最低要件は達成できましたが、いくつか改善すべき点があります。
大と小
ご存知の通り、トイレには大と小があり、それは猫でも同じです。
今回使用したダイソーのBluetoothリモートシャッターにはボタンが2つあり、偶然にも大きいボタンと小さいボタンなので直感的に使い分けることが可能なのですが、どちらのボタンを押しても同じ内容のイベントが飛んでくるため、区別することができませんでした。
先述した「100均Bluetoothボタンをラズパイに活用」によると、Android用のボタンはKEY_ENTERが追加で飛んでくるはずなのですが。仕様が変わった?スリープ状態からの復帰
ダイソーのリモートシャッターは、最後に通信が行われてから90秒経過するとスリープしてペアリングが解除される仕様になっています。
スリープ状態の時にリモートシャッター側のボタンを押すと、数秒で再度ペアリングできるのですが、ボタンイベントを飛ばすためにはペアリング完了後に再びボタンを押さないといけないため、少々面倒です。
keepaliveするなり、ペアリングイベント自体をフックにするなりして解決したいポイントです。終わりに
当初はあまり期待してなかったのですが、ダイソーのBluetoothリモートシャッターは安価な上に接続も簡単で、ボタンの使い分けやスリープ問題が解決すれば便利なIoTボタンとして自宅や会社などいたるところで使えそうです。
これからも、人と猫との生活のQoLを上げられるよう、色々と便利なモノを作っていきたいです。ねこはいます。
- 投稿日:2019-12-18T01:50:09+09:00
goroutineのよさを理解するための低レイヤの話
goroutineについて調べたところ、その良さについてしっかりと理解するためには、低レイヤの知識がないと理解できないなと思ったので、ネットや本を読んでのインプットと並行してこの記事にアウトプットとして調べたことを基礎的な内容になりますがまとめました。「goroutineとは何か」から入り、そこから掘り下げます。
goroutineとは?
goroutineとは、他のメソッドや関数と並行処理されるメソッドや関数のこと。Goのランタイムに管理される軽量なスレッドとも言うことができ、goroutineを作成するコストはスレッドに比べてずっと小さい。
ここで、スレッドってなんだっけ、と思って調べると、プロセス・仮想アドレス空間・ヒープ・スタック・・・と聞いたことはあるけどよく知らない言葉がたくさん出てきて深みにハマり混乱しました。
整理できたので、順番に解説します。
スレッドって?
CPUは一つ一つの命令を順番に読み込み、解釈しながら実行する。メモリ内で、CPUに実行される命令の列をスレッドという。CPU利用の単位。
プロセスには最低一つのスレッドがあり、CPUはそのスレッドを追い続けながら命令を実行していく。
プロセスに比べて、プログラムを実行するときのコンテキスト情報が最小で済むので切り替えが速くなる。プロセス内に作られる並列動作可能な「処理の単位」。マルチスレッド
プロセスはスレッドに含まれます。プロセスに複数のスレッドを持たせることもでき、これをマルチスレッドと言います。
複数のスレッドがあるということからも想像できる通り、すべてのスレッドにはスレッド優先順位が割り当てられ、スレッドの実行は優先順位に基づいてスケジュールされます。スケジュールされるということは、スレッドのスイッチングが発生するということです。このスレッドのスイッチングはプロセスと比べるとずっと早いものの、goroutineよりは時間がかかります。後述しますが、goroutineはスイッチングコストが非常に少ないので、これはgoroutineのスレッドに対する優位性の一つです。プロセスとは?
プログラムの実行単位をプロセスと呼ぶ。プロセスには必ず、プロセスごとにユニークなプロセスIDがある。これがプロセスの識別子として使われる。
メモ帳アプリでメモを取ったり、表計算アプリでの計算などPCで行える全ての処理はいずれもコンピュータへの命令が実行されて実現しており、そのような実行中のプログラム(コンピュータへの命令の実行手順)一つ一つがプロセスである。一つのアプリでも、複数のプロセスで動くことがある。プロセスは、OSによる「リソース」割り当ての単位でもある。例えばメモリーは、プロセスごとに管理される。つまり、プロセスはそれぞれに専用のメモリ領域を割り当てられる。そのメモリ領域を仮想アドレス空間という。仮想アドレス空間の内部構造は図で後ほど示します。
子プロセス
プロセスからは、さらにプロセスを起動できる。あるプロセスから起動されたプロセスは子プロセスと呼び、起動した側を「親プロセス」と呼ぶ。プロセスにはこのような親子関係があり、セキュリティーの設定や管理などに利用されている。しかし親子関係のあるプロセス同士の場合でも、お互いに別の仮想アドレス空間を使う。また、実行のタイミングもそれぞれ違っている。
ほとんどのプロセスはすでに存在している別のプロセスから作成された子プロセスとなっている。Go言語で、プロセスIDと親プロセスのIDを知るためのメソッドがosパッケージで用意されている。
package main import ( "fmt" "os" ) func main() { fmt.Printf("プロセスID: %d\n", os.Getpid()) fmt.Printf("親プロセスID: %d\n", os.Getppid()) }コンテキストスイッチ
CPUは瞬間的に1つの処理しかできないため、同時に複数の処理をしているように見せるために実行するプログラムを超高速で切り替えている。プロセスを切り替えることをコンテキストスイッチと呼ぶ。
コンテキストスイッチでは、その時点でのCPU内部の状態(レジスタやフラッグの値)を保存して、別のプログラムを実行していたときのCPUの状態に戻すということが行われる。このコンテキストスイッチは時間がかかる高コストな作業。1このコストをなんとかするべくスレッドが発達した。同プロセス内のスレッドアドレス空間を共有するので、プロセスよりはスケジュールコストが低い。しかし、スレッドのスイッチングも無視できないコストがかかるため、スイッチングコストが非常に低いgoroutineが有用。
プロセス>>>スレッド>>>>>>>>>>...>>>>>>>>>goroutine(>の数はイメージです)プロセスのコンテキストスイッチングについての詳しい説明はこちらの記事をお読みください。
仮想アドレス空間とは?
仮想アドレス空間は,プロセスごとに割り当てられた論理的なメモリー領域で,実行しているプロセスごとに独立して複数存在する。仮想アドレス空間は「ユーザー空間」と「カーネル空間」の2つに分けられる。2つに分けられている理由は、アプリケーションの誤作動によりシステム全体がダウンしてしまうことを防ぐため。
*ちなみに、論理的というのは「見かけ上の」とか、「(実物/ハードウェアとは異なる具合に)ソフトウェア的に解釈した」と読み替えてしまって問題ありません。ユーザー空間
ユーザー空間は,ユーザー・アプリケーションのプロセスが動作する際に利用されるメモリー領域。
カーネル空間
一方,カーネル空間はシステム全体を制御する際に利用されるメモリー領域。カーネル空間には,さまざまな制御情報,各種キャッシュや共有メモリーなどの各プロセスが共有する情報,カーネル自身が格納される。
プロセスのアドレス空間
ここで、後述するといったプロセス一つ一つに割り当てられる仮想アドレス空間の内部構造について説明します。
これがプログラムがメモリにロードされた時のアドレス空間になります。スレッドは図中のテキストセグメントと呼ばれる部分にあります。上が0番地、下がFFFFFFFF番地です。
データセグメント
データセグメントはデータを格納する領域で、さらに3つの領域に分けらる。
1. 定数領域
2. 静的変数領域
3. ヒープ定数領域、静的変数領域はそのままなので説明な特に不要かと思います。ヒープは、プログラムの実行中に動的に確保される領域です。例えばC言語のmalloc関数やJavaなどの言語では
newでインスタンス化したものがここに収められます。不要になったオブジェクトは言語によってはdelete関数で削除されたり、ガーベージコレクションがある言語ではそれによって適切に廃棄され、ヒープを解放して枯渇するのを防ぎます。テキストセグメント
CPUは機械語で書かれたプログラムをメモリから読み込んで実行していく。スレッドはCPUに実行される命令の列。テキストセグメントはプログラムがロードされる領域。すなわちテキストセグメントは命令の列、スレッドが格納される領域である。図にあるように、スレッドはアドレス空間を共有することができ、その分スレッドはプロセスよりもスケジュールのコストが低い。
スタックセグメント
- テキストセグメントと違い、スタックセグメントはスレッドの数だけ用意される(複数スレッドで共有することができない)
- プログラムの実行時に、一時的に記憶しておくデータを格納するために動的に使用される(引数やリターンアドレスなど)
- FILO(First In Last Out)方式でデータの格納と取り出しが行われる
Goでのデータの割り当て
Goではヒープやスタックの扱いなどがどうなっているのか気になりますね。Goにもガベージコレクションがあります。丁度そこらへんについて記述してある記事がトレンド入りしていましたので、引用させていただきました。
Goでは変数や関数をメモリに割り当てる際に、コンパイラがスタック領域かヒープ領域への割り当てを決定します。
スタック領域への割り当てと解放は軽い処理ですが、ヒープ領域への割り当てと解放は重い処理です。
スタック領域はそれぞれCPUへの命令のみで可能なのに対して、ヒープ領域はmalloc関数(割り当て)とGC(解放)を定期的に実行する必要があるからです。
したがって、コンパイラはまずはスタック領域への割り当てが可能かを検討し、無理であればヒープ領域への割り当てを実施します。GoのGCを10分で学ぼうより引用
goroutineとスレッドの違い
goroutineはスレッドに対して以下のような利点を持ちます。
- スタックサイズが少なく済むため、メモリ消費量が少ないだけでなく、スタックサイズを柔軟に変更することも可能(プログラマからは隠蔽されている)
- スイッチングに要する時間が少ない
- OSにリソースのリクエストをする必要がないため、その分生成と破棄にかかる時間が少ない
メモリ消費量
先ほど述べたスタックセグメントですが、Linux/x86-32では2MB、Windowsでは1MB、Macでは512kbがデフォルトとなっているようです。
環境 デフォルトサイズ Linux 2MB Windows 1MB Mac 512kb goroutine 大体2~5?kb つまり、Linuxサーバ上でスレッドを1000個生成したらそれだけで2GBメモリを使うことになります。
それに対し、goroutineを使うとこのスタックセグメントが数キロバイトで済むのが利点となっています。そのため、一つのアドレス空間に数十万ものgoroutineを作ることもできます。もしこれをスレッドで実現しようとしたら数十万に到達するよりずっと早くシステムリソースが枯渇してしまいます。https://golang.org/doc/faq#goroutines よりスタックセグメントはスレッドの数に合わせてスレッドのために用意されるものです。goroutineを使うと、このスタックセグメントの容量を数百分の一にまで小さく抑えることができます。
それに加え、スレッドの場合はスタックのサイズを事前に指定する必要があり、その後は変更することができないのに対し、goroutineは必要に応じて自動で適切なサイズにスタックサイズを調節することができます。生成と破棄
また、スレッドはOSにリクエストを投げてレスポンスが返ってくるまで待つので生成と破棄に時間がかかる一方、goroutineの生成と破棄はランタイムによってなされますが、非常に低コストです。
goroutineとスレッドの違いについての詳細はこのページとこのページを参照してください。
最後に
ここまででgoroutineについての理解を深めるため、低レイヤ周りについて書いてきました。この記事に書いたのはごく基礎的な内容でこれ以外にも知らなければいけないことはたくさんありますが、ここら辺が頭に入っていればgoroutineに関する記事の説明もよりすっと頭に入ってくるのではないかと思います。
例えば、goroutineはメモリ消費量がスレッドと比べてずっと少ないと書きましたが、なぜgoroutineではそれほどメモリ消費量を抑えることができるのかという部分については以下の記事にその説明があります。記事内のスタックマネジメントという部分です。本記事で書いてある知識があればすんなりと理解できるのではないかと思います。
https://postd.cc/performance-without-the-event-loop/今回goroutineをきっかけに本記事にまとめたようなことについて調べた結果、システムプログラミングなどを通して言語の違いによって左右されないプログラミングの根底にある部分についての理解を深めようという気持ちが強くなりました。低レイヤはちゃんと勉強して、知識がついたらまた記事にしようと思います。
最後までお読みいただき、ありがとうございました。
参考
基礎からわかるTCP/IPネットワークコンピューティング入門 松山公保[著]
https://tech.nikkeibp.co.jp/it/article/Keyword/20070207/261211/
https://tech.nikkeibp.co.jp/it/article/lecture/20070824/280260/
https://qiita.com/Kohei909Otsuka/items/26be74de803d195b37bd
https://christina04.hatenablog.com/entry/why-goroutine-is-good
http://sairoutine.hatenablog.com/entry/2017/12/02/182827#f-f0f467e9
https://golangbot.com/goroutines/
https://gihyo.jp/dev/serial/01/jvm-arc/0002
https://codeburst.io/why-goroutines-are-not-lightweight-threads-7c460c1f155f
https://medium.com/eureka-engineering/goroutine-3c92f566dcc5?
プロセスが異なるとアドレス空間が異なる。プロセスを切り替えるためには論理アドレスと物理アドレスのアドレス変換テーブルを入れ替える必要があるため、プロセスを切り替えるコンテキストスイッチは時間がかかる。 ↩

- 投稿日:2019-12-18T00:15:30+09:00
リーダブルアーキテクチャ - usecaseにおける時間軸と副作用の制御と抽象度の統一
はじめに
Clean Architectureやレイヤードアーキテクチャでは、どのようにレイヤーを定義するかついては言及されています。
そのような中usecase(レイヤードアーキテクチャではApplication層)をどのように実装するべきかについての議論は少ないです。
しかし私はリーダブルなアーキテクチャを実現するために、一番大切なことはusecaseを適切に実装することであると考えています。そこでusecaseを実装する上で起こりがちな抽象度の問題を例に、リーダブルなアーキテクチャを考えいていきたいと思います。
サンプル
1:1のチャットアプリでUserとWorkerが存在して会話ができるアプリを例にあげます。
以下の図では青い背景はinfraの関数実行、緑色の背景はdomainの関数実行、赤い背景はusecaseの関数実行を示しています。
usecaseのCreateChat関数が以下のように存在しています。
しかしMessageの送信だけをしたいというユースケースがでたので関数を分離します。
しかしメンバーの参加だけをしたいというユースケースがでたので関数を分離します。
このような変更はよく起こると思いますが、問題はないでしょうか?
問題点
問題点1
問題点2
問題点3
解決策
- 素直にべた書きをする
- Usecaseの中で時間軸を制御するレイヤーと機能を定義するレイヤーを分割する
1. 素直にべた書きをする
usecase内での関数化を諦めて素直にべた書きをします。
こうすることでusecaseはdomainとinfraを実行するレイヤーとして抽象度が揃います。適切にドメインやインフラを実装できていれば、usecaseにはロジックは登場せずほとんどがドメインとインフラの関数呼び出しをするだけになるはずです。
べた書きでusecaseの実装が複雑になるのであれば、そもそもその責務分割が間違っている可能性が高いので、まずはそちらを直せないかを検討するべきです。
2. usecaseの中で時間軸を制御するレイヤーと機能を定義するレイヤーを分割する
usecaseの中で時間制御レイヤーと機能定義レイヤーを分割して、同じレイヤー間の実行を禁止します。
時間制御レイヤーから機能定義レイヤーを実行することだけが許されます。
これによりusecaseの抽象度が揃います。複数のレイヤーの関数に時間軸の横断がなくなり、時間制御レイヤーを読むだけでどのような機能が時間軸上で実現されているかを把握することが可能となります。また機能を関数化も可能となりDRYになります。
考察
domain、infraとusecaseの違い FunctionとFlow
doaminとPresentation(infra)を分割して、domainがPresentationに依存しないというPresentation Domain Separationはよく語られる話だと思います。
しかし今回はPDSだけでは捉えることができない点を、domainとinfraを機能を実現する同じ分類とし、usecaseを時間軸と副作用を制御する層として注目します。
ソフトウェア開発で大切なことの1つは副作用を制御することです。
バックエンド開発における副作用を大きく2種類存在しており、domainを操作することでのオンメモリ上での副作用とinfraを操作することでの永続化の副作用です。
domainとinfraは副作用を起こしますが、純粋な機能であり時間軸を持ちません。usecaseでは、時間軸が存在しており、その時間軸の上でdomainとinfraを利用して副作用を制御する責務を持っています。
このときusecaseにdomainとinfraの機能が漏れ出してはいけません。そうするとusecaseに機能と副作用の制御の責務が混在することなります。
domainとinfraをfunction(機能)と捉え、usecaseをFlow(時間軸)としてFunction Flow Separationという認識がとても大切ではないかと考えています。
usecaseがusecaseを呼び出すことの問題点
usecaseがusecaseを呼び出すということは、関数を深く潜って実装を読んでいかないと副作用がどのように完了するかを理解することができません。
このようなコードは、メソッド化されているにもかかわらず適切なレイヤー化が行われていないため、とても読みにくいコードとなります。
副作用が一目瞭然であるためには、1つのusecaseの関数にすべての副作用が表現されていることが大切です。
しかしこれでは同じ処理を関数化できないという問題が発生します。そのような場合はusecaseの中に機能を実現するレイヤーを定義して、そのレイヤーをUsecaseの時間軸を制御するレイヤーから実行するようにします。
このようにすると機能を実現するレイヤーの実装を読まずとも、時間軸を制御するレイヤーさえ読めば機能的に何を実現しているかがわかります。先ほどの悪い例ではJoinChatの中でメッセージを送信するという副作用を起こしていることは、JoinChatの実装を読まなければわかりませんが、良い例ではJoinChatとSendJoinMessageをUsecaseから呼び出しているためJoinChatの実装を読まずともメッセージを送信しているということがわかります。
また今回は言及していませんが、domain serviceでinfraを実行する場合も同様の問題が発生します。
私はこのようなdomain serviceはdomain serviceではなくusecaseであると考えています。domain serviceは永続化に関する処理はするべきではありません。まとめ
usecaseを実装する際に陥りがちな問題について説明しました。
コードを読む際に1つのレイヤーの抽象度が揃っているということはとても大切なことです。 SLAP(Single Level of Abstraction Principle)という原則も存在しています。
しかしDRYを突き詰めるあまりにそれが破綻してしまうことがあります。そのDRYのための関数化は本当に必要なのかを考え、まずはusecaseの実装を適切にドメインやインフラに委譲できないかを考えます。それでも難しい場合は、時間軸の制御が必要なレイヤーとそうでないレイヤーを明確に責務を分けることで解決します。
usecaseを実装する際には以下を考えて実装するとよいでしょう。
- usecaseにdomainとinfraの機能が漏れ出してはいけない
- 1つのusecaseの関数にすべての副作用が表現されている
- usecaseの抽象度が揃っている








- 投稿日:2019-12-18T00:15:30+09:00
リーダブルアーキテクチャ - usecaseにおける時間軸と抽象度の統一
はじめに
Clean Architectureやレイヤードアーキテクチャでは、どのようにレイヤーを定義するかついては言及されています。
そのような中usecase(レイヤードアーキテクチャではApplication層)をどのように実装するべきかについての議論は少ないです。
しかし私はリーダブルなアーキテクチャを実現するために、一番大切なことはusecaseを適切に実装することであると考えています。そこでusecaseを実装する上で起こりがちな抽象度の問題を例に、リーダブルなアーキテクチャを考えいていきたいと思います。
サンプル
1:1のチャットアプリでUserとWorkerが存在して会話ができるアプリを例にあげます。
以下の図では青い背景はinfraの関数実行、緑色の背景はdomainの関数実行、赤い背景はusecaseの関数実行を示しています。
usecaseのCreateChat関数が以下のように存在しています。
しかしMessageの送信だけをしたいというユースケースがでたので関数を分離します。
さらにメンバーの参加だけをしたいというユースケースがでたので関数を分離します。
このような変更はよく起こると思いますが、問題はないでしょうか?
問題点
問題点1
問題点2
問題点3
問題点4
解決策
- 素直にべた書きをする
- Usecaseの中で時間軸を制御するレイヤーと機能を定義するレイヤーを分割する
解決策1. 素直にべた書きをする
usecase内での関数化を諦めて素直にべた書きをします。
こうすることでusecaseはdomainとinfraを実行するレイヤーとして抽象度が揃います。複数のレイヤーの関数に時間軸の横断がなくなり、usecaseを読むだけでどのような機能が時間軸上で実現されているかを把握することが可能となりました。
すべての実装を読まなければ理解できなかったユースケースを、1つの関数内の関数実行だけを読めば理解できるようになりました。
適切にドメインやインフラを実装できていれば、usecaseにはロジックは登場せずほとんどがドメインとインフラの関数呼び出しをするだけになるはずです。
べた書きでusecaseの実装が複雑になるのであれば、そもそもその責務分割が間違っている可能性が高いので、安易にusecaseの関数に括り出すことはせず、まずはそちらを直せないかを検討するべきです。
解決策2. usecaseの中で時間軸を制御するレイヤーと機能を定義するレイヤーを分割する
どうしても解決策1を取りたくないというときには、usecaseの中で時間制御レイヤーと機能定義レイヤーを分割して、同じレイヤー間の実行を禁止します。
時間制御レイヤーから機能定義レイヤーを実行することだけが許されます。これによりusecaseの抽象度が揃います。複数のレイヤーの関数に時間軸の横断がなくなり、時間制御レイヤーを読むだけでどのような機能が時間軸上で実現されているかを把握することが可能となります。また機能を関数化も可能となりDRYになります。
すべての実装を読まなければ理解できなかったユースケースを、1つの関数内の関数実行だけを読めば理解できるようになりました。
とはいえ、おすすめの解決策は圧倒的に解決策1です。
妥協案くらいに思ってもらえると良いと思います。
考察
domain、infraとusecaseの違い FunctionとFlow
doaminとPresentation(infra)を分割して、domainがPresentationに依存しないというPresentation Domain Separationはよく語られる話だと思います。
しかし今回はPDSだけでは捉えることができない点を、domainとinfraを機能を実現する同じ分類とし、usecaseを時間軸と副作用を制御する層として注目します。
ソフトウェア開発で大切なことの1つは副作用を制御することです。
バックエンド開発における副作用は大きく2種類存在しており、domainを操作することでのオンメモリ上での副作用とinfraを操作することでの永続化の副作用です。
domainとinfraは副作用を起こしますが、純粋な機能であり時間軸を持ちません。usecaseでは、時間軸が存在しており、その時間軸の上でdomainとinfraを利用して副作用を制御する責務を持っています。
このときusecaseにdomainとinfraの機能が漏れ出してはいけません。そうするとusecaseに機能と副作用の制御の責務が混在することなります。
domainとinfraをfunction(機能)と捉え、usecaseをFlow(時間軸)としてFunction Flow Separationという認識がとても大切ではないかと考えています。
usecaseがusecaseを呼び出すことの問題点
usecaseがusecaseを呼び出すということは、関数を深く潜って実装を読んでいかないと副作用がどのように完了するかを理解することができません。
このようなコードは適切なレイヤー化が行われていないため、とても読みにくいコードとなります。
副作用が一目瞭然であるためには、1つのusecaseの関数にすべての副作用が表現されていることが大切です。
domain service
「usecaseからusecaseを実行する代わりにdomain serviceを実行しているから大丈夫」と思っている方がいるかもしれません。
しかしusecaseからdomain serviceを実行しているからOKとはなりません。もしdomain serviceがinfraを実行しているのであれば、それは名前がusecaseからdomain serviceに変わっただけで同様の問題を抱えています。また私はそもそもdomain serviceでinfraを実行するべきではないと考えています。もしdomain serviceでinfraを実行しているのであれば、それはdomain serviceではなくusecaseです。domain serviceは永続化に関する処理をするべきではありません。
まとめ
usecaseを実装する際に陥りがちな問題について説明しました。
コードを読む際に1つのレイヤーの抽象度が揃っているということはとても大切なことです。 SLAP(Single Level of Abstraction Principle)という原則も存在しています。
しかしDRYを突き詰めるあまりにそれが破綻してしまうことがあります。そのDRYのための関数化は本当に必要なのかを考え、まずはusecaseの実装を適切にドメインやインフラに委譲できないかを考えます。どうしても関数かする必要に迫られたら時間軸と副作用の制御が必要なレイヤーとそうでないレイヤーを明確に責務を分けることで解決します。
最後にusecaseを実装する際の注意事項をまとめます。
- usecaseにdomainとinfraの機能の実装が漏れ出してはいけない
- 1つのusecaseの関数にすべての副作用が表現されている
- usecaseの抽象度が揃っている
- domain serviceでinfraを実行しない




- 投稿日:2019-12-18T00:15:30+09:00
リーダブルアーキテクチャ - Usecaseにおける時間軸と副作用の制御
はじめに
Clean Architectureやレイヤードアーキテクチャでは、どのようにレイヤーを定義するかついては言及されています。
そのような中usecase(レイヤードアーキテクチャではApplication層)をどのように実装するべきかについての議論は少ないです。
しかし私はリーダブルなアーキテクチャを実現するために、一番大切なことはusecaseを適切に実装することであると考えています。そこでusecaseを実装する上で起こりがちな問題を例に、リーダブルなアーキテクチャを考えいていきたいと思います。
サンプル
1:1のチャットアプリでUserとWorkerが存在して会話ができるアプリを例にあげます。
以下の図では青い背景はinfraの関数実行、緑色の背景はdomainの関数実行、赤い背景はusecaseの関数実行を示しています。
usecaseのCreateChat関数が以下のように存在しています。
しかしMessageの送信だけをしたいというユースケースがでたので関数を分離します。
しかしメンバーの参加だけをしたいというユースケースがでたので関数を分離します。
このような変更はよく起こると思いますが、問題はないでしょうか?
問題点
問題点1
問題点2
問題点3
解決策
- 素直にべた書きをする
- Usecaseの中で時間軸を制御するレイヤーと機能を定義するレイヤーを分割する
1. 素直にべた書きをする
usecase内での関数化を諦めて素直にべた書きをします。
適切にドメインやインフラを実装できていれば、usecaseにはロジックは登場せずほとんどがドメインとインフラの関数呼び出しをするだけになるはずです。
べた書きでusecaseの実装が複雑になるのであれば、そもそもその責務分割が間違っている可能性が高いので、まずはそちらを直せないかを検討するべきです。
2. usecaseの中で時間軸を制御するレイヤーと機能を定義するレイヤーを分割する
usecaseの中で時間制御レイヤーと機能定義レイヤーを分割して、同じレイヤー間の実行を禁止します。
時間制御レイヤーから機能定義レイヤーを実行することだけが許されます。このようにすることで複数のレイヤーの関数に時間軸の横断がなくなり、時間制御レイヤーを読むだけでどのような機能が時間軸上で実現されているかを把握することが可能となります。また機能を関数化も可能となりDRYになります。
考察
domain、infraとusecaseの違い FunctionとFlow
doaminとPresentation(infra)を分割して、domainがPresentationに依存しないというPresentation Domain Separationはよく語られる話だと思います。
しかし今回はPDSだけでは捉えることができない点を、domainとinfraを機能を実現する同じ分類とし、usecaseを時間軸と副作用を制御する層として注目します。
ソフトウェア開発で大切なことの1つは副作用を制御することです。
バックエンド開発における副作用を大きく2種類存在しており、domainを操作することでのオンメモリ上での副作用とinfraを操作することでの永続化の副作用です。
domainとinfraは副作用を起こしますが、純粋な機能であり時間軸を持ちません。usecaseでは、時間軸が存在しており、その時間軸の上でdomainとinfraを利用して副作用を制御する責務を持っています。
このときusecaseにdomainとinfraの機能が漏れ出してはいけません。そうするとusecaseに機能と副作用の制御の責務が混在することなります。
domainとinfraをfunction(機能)と捉え、usecaseをFlow(時間軸)としてFunction Flow Separationという認識がとても大切ではないかと考えています。
usecaseがusecaseを呼び出すことの問題点
usecaseがusecaseを呼び出すということは、関数を深く潜って実装を読んでいかないと副作用がどのように完了するかを理解することができません。
このようなコードは、メソッド化されているにもかかわらず適切なレイヤー化が行われていないため、とても読みにくいコードとなります。
副作用が一目瞭然であるためには、1つのusecaseの関数にすべての副作用が表現されていることが大切です。
しかしこれでは同じ処理を関数化できないという問題が発生します。そのような場合はusecaseの中に機能を実現するレイヤーを定義して、そのレイヤーをUsecaseの時間軸を制御するレイヤーから実行するようにします。
このようにすると機能を実現するレイヤーの実装を読まずとも、時間軸を制御するレイヤーさえ読めば機能的に何を実現しているかがわかります。先ほどの悪い例ではJoinChatの中でメッセージを送信するという副作用を起こしていることは、JoinChatの実装を読まなければわかりませんが、良い例ではJoinChatとSendJoinMessageをUsecaseから呼び出しているためJoinChatの実装を読まずともメッセージを送信しているということがわかります。
また今回は言及していませんが、domain serviceでinfraを実行する場合も同様の問題が発生します。
私はこのようなdomain serviceはdomain serviceではなくusecaseであると考えています。domain serviceは永続化に関する処理はするべきではありません。まとめ
usecaseを実装する際に陥りがちな問題について説明しました。
コードを読む際に1つのレイヤーの抽象度が揃っているということはとても大切なことです。 SLAP(Single Level of Abstraction Principle)という原則も存在しています。
しかしDRYを突き詰めるあまりにそれが破綻してしまうことがあります。そのDRYのための関数化は本当に必要なのかを考え、まずはusecaseの実装を適切にドメインやインフラに委譲できないかを考えます。それでも難しい場合は、時間軸の制御が必要なレイヤーとそうでないレイヤーを明確に責務を分けることで解決します。
usecaseを実装する際には以下を考えて実装するとよいでしょう。
- usecaseにdomainとinfraの機能が漏れ出してはいけない
- 1つのusecaseの関数にすべての副作用が表現されている
- usecaseの抽象度が揃っている
- 投稿日:2019-12-18T00:14:22+09:00
Go言語で扱えるデータフレーム厳選4つ
はじめに
データサイエンティストでなかったとしても、数値データを使って様々な解析をする際には CSV ファイル等ファイルを読み込み、数値の配列としてメモリに保持して、それらをループ等で利用して解析を行っておられると思います。
その際、配列は1次元目に行、2次元目に列、を格納するのが一般的です。多くのケースではこの方法で事足りるのですが、解析を行ううちに「列としてデータの固まりを扱いたい」「ラベル付けされた列を扱いたい」と感じる事が出てくると思います。
これを簡単にしてくれるのが「データフレーム」です。
データフレーム4種
本記事では Go 言語から扱えるデータフレームを4つご紹介します。
QFrame
QFrame は、フィルタリング、集計、およびデータ操作をサポートするイミュータブルなデータフレームです。 QFrame での操作は、それ自身が新しい QFrame となり元の QFrame は変更されません。データの多くがこの2つのフレーム間で共有されるためかなり効率的に実行できます。
QFrame は色々なケースで扱えるとても便利なライブラリです。CSV、SQL、JSON が扱え、しかも透過的に処理する事ができます。
例えばこんな JSON を扱う事も多いと思います。
[ {"id": 1, "name": "bob", "comment": "I like sushi", "age": 23}, {"id": 2, "name": "mike", "comment": "Raspberry Pi is good", "age": 47}, {"id": 3, "name": "john", "comment": "My mobile phone is Android", "age": 19}, {"id": 4, "name": "elvis", "comment": "I push the commit to GitHub", "age": 31} ]この JSON を読み込み、不必要な
commentとidのカラムを消し、ageとnameのカラムだけを残してageでソートされた CSV を出力する場合、皆さんだとどの様に処理するでしょうか。QFrame であればとても簡単です。package main import ( "bytes" "fmt" "log" "strings" "github.com/tobgu/qframe" ) const s = ` [ {"id": 1, "name": "bob", "comment": "I like sushi", "age": 23}, {"id": 2, "name": "mike", "comment": "Raspberry Pi is good", "age": 47}, {"id": 3, "name": "john", "comment": "My mobile phone is Android", "age": 19}, {"id": 4, "name": "elvis", "comment": "I push the commit to GitHub", "age": 31} ] ` func main() { newQf := qframe.ReadJSON(strings.NewReader(s)) var buf bytes.Buffer err := newQf.Drop("comment", "id").Sort(qframe.Order{Column: "age"}).ToCSV(&buf) if err != nil { log.Fatal(err) } fmt.Println(buf.String()) }とても直感的ですね。例えば
ToCSVをToJSONに変更すると以下の様に出力されます。[ { "age": 19, "name": "john" }, { "age": 23, "name": "bob" }, { "age": 31, "name": "elvis" }, { "age": 47, "name": "mike" } ]※整形しています
この様に、与えられた入力に対してとても直感的な操作が QFrame のウリです。
Apache Arrow & bullseye
Apache Arrow はマルチプラットフォームで動作するメモリ内データ向けのライブラリです。ハードウェア上で効率的な分析操作を行える様に設計されており、メモリが断片化しないよう工夫されています。現在サポートされている言語には、C、C ++、C#、Go、Java、JavaScript、MATLAB、Python、R、Ruby、および Rust が含まれています。
要はデータをカラムで持ち(カラム指向またはカラムナーと言います。えっ言わない?ちょっとした事で絡むな~)、データを扱いやすくしている訳です。さらにサイズを固定化してフラットにする事で、オフセットによる瞬時なアクセスを可能にしています。
bullseye は Apache Arrow で構築されたメモリを扱う為のデータフレームです。
Apache Arrow はデータの型をとても意識したライブラリです。データを投入するにはまずスキーマを定義する必要があります。例えば iris のデータセットであれば以下の定義になります。
schema := arrow.NewSchema([]arrow.Field{ { Name: "sepal_length", Type: arrow.PrimitiveTypes.Float32, Nullable: false, }, { Name: "sepal_width", Type: arrow.PrimitiveTypes.Float32, Nullable: false, }, { Name: "petal_length", Type: arrow.PrimitiveTypes.Float32, Nullable: false, }, { Name: "petal_width", Type: arrow.PrimitiveTypes.Float32, Nullable: false, }, { Name: "species", Type: arrow.BinaryTypes.String, Nullable: false, }, }, nil)データを投入する際はメモリプールを生成して読み込みます。iris のデータを読み込み、種別を一覧するコードは以下の様になります。
package main import ( "fmt" "log" "os" "github.com/apache/arrow/go/arrow" "github.com/apache/arrow/go/arrow/csv" "github.com/apache/arrow/go/arrow/memory" "github.com/go-bullseye/bullseye/dataframe" "github.com/go-bullseye/bullseye/iterator" ) func main() { schema := arrow.NewSchema([]arrow.Field{ { Name: "sepal_length", Type: arrow.PrimitiveTypes.Float32, Nullable: false, }, { Name: "sepal_width", Type: arrow.PrimitiveTypes.Float32, Nullable: false, }, { Name: "petal_length", Type: arrow.PrimitiveTypes.Float32, Nullable: false, }, { Name: "petal_width", Type: arrow.PrimitiveTypes.Float32, Nullable: false, }, { Name: "species", Type: arrow.BinaryTypes.String, Nullable: false, }, }, nil) f, err := os.Open("iris.csv") if err != nil { log.Fatal(err) } defer f.Close() r := csv.NewReader( f, schema, csv.WithComment('#'), csv.WithComma(','), csv.WithHeader(), csv.WithChunk(-1), ) defer r.Release() r.Next() pool := memory.NewGoAllocator() df, err := dataframe.NewDataFrame(pool, schema, r.Record().Columns()) if err != nil { log.Fatal(err) } iter := iterator.NewStringValueIterator(&df.SelectColumns("species")[0]) m := map[string]int{} for iter.Next() { s := iter.ValueInterface().(string) if _, ok := m[s]; !ok { m[s] = len(m) + 1 } } fmt.Println(m) }ちょっと冗長な感じがしますが、例えば不正なデータが投入されるかもしれない入力データを扱うには便利です。また Apache Arrow はメモリブロックを必要な単位で切り出してフレームを構成しているので、断片化が起きにくく処理速度も高速です。大量のデータを扱うのであれば Apache Arrow と bullseye を使うのが良いと思います。ただし癖が強いので慣れるまでが大変です。
dataframe-go
https://github.com/rocketlaunchr/dataframe-go
dataframe-go も直感的な操作を売りにしています。まだ安定版ではないとの事ですが、以下の特徴があります。
- CSV, JSONL, MySQL, PostgreSQL からのインポート
- CSV, JSONL, MySQL, PostgreSQL へのエクスポート
- 開発しやすさ
- カスタムシリーズを作れるなどのフレキシブルさ
- パフォーマンス優先
- gonum との相互運用性
API は Select が無いなど、幾分物足りない感がありますが、RDBMS や gonum との連携がウリの様なので今後に期待したい所です。
package main import ( "bytes" "context" "fmt" "log" "strings" "github.com/rocketlaunchr/dataframe-go" "github.com/rocketlaunchr/dataframe-go/exports" "github.com/rocketlaunchr/dataframe-go/imports" ) const s = ` {"id": 1, "name": "bob", "comment": "I like sushi", "age": 23} {"id": 2, "name": "mike", "comment": "Raspberry Pi is good", "age": 47} {"id": 3, "name": "john", "comment": "My mobile phone is Android", "age": 19} {"id": 4, "name": "elvis", "comment": "I push the commit to GitHub", "age": 31} ` func main() { df, err := imports.LoadFromJSON(context.Background(), strings.NewReader(s)) if err != nil { log.Fatal(err) } var buf bytes.Buffer err = df.RemoveSeries("comment") if err != nil { log.Fatal(err) } err = df.RemoveSeries("id") if err != nil { log.Fatal(err) } df.Sort([]dataframe.SortKey{{Key: "age"}}) exports.ExportToCSV(context.Background(), &buf, df) fmt.Println(buf.String()) }dataframe はそのまま
fmt.Printlnすると綺麗な表になってくれます。+-----+--------+--------+--------+-----------------------------+ | | AGE | ID | NAME | COMMENT | +-----+--------+--------+--------+-----------------------------+ | 0: | 23 | 1 | bob | I like sushi | | 1: | 47 | 2 | mike | Raspberry Pi is good | | 2: | 19 | 3 | john | My mobile phone is Android | | 3: | 31 | 4 | elvis | I push the commit to GitHub | +-----+--------+--------+--------+-----------------------------+ | 4X4 | STRING | STRING | STRING | STRING | +-----+--------+--------+--------+-----------------------------+※ Gota や qframe も同様です
Gota
Gota は DataFrames、Series および data wrangling (マッピング等の加工)メソッド群の実装です。とても分かりやすく直感的で、これら4つの中では一番 Go らしいライブラリだと思います。Gota の操作については、@thimi0412 さんが分かりやすく解説してくれた記事があります。
https://qiita.com/thimi0412/items/05cff32279973b0d5599
ただし記事の中で登場する Gota のリポジトリは現在
github.com/kniren/gotaからgithub.com/go-gota/gotaに変更になっているのでご注意下さい。僕はこれまで Gota をよく使ってきました。JSON や CSV を読み込む機能は他のデータフレームにもありますが、特に struct binding が便利なので、既存のコードにデータフレームを使った処理を追加する際に Gota は威力を発揮します。例えば User struct の配列から欲しいフィールドだけを集めて JSON にするのであれば以下の様になります。
package main import ( "bytes" "fmt" "log" "github.com/go-gota/gota/dataframe" ) type User struct { Name string Age int Accuracy float64 ignored bool // ignored since unexported } func main() { users := []User{ {"Aram", 17, 0.2, true}, {"Juan", 18, 0.8, true}, {"Ana", 22, 0.5, true}, } df := dataframe.LoadStructs(users) var buf bytes.Buffer err := df.Select([]string{"Age", "Name"}).WriteJSON(&buf) if err != nil { log.Fatal(err) } fmt.Println(buf.String()) }また iris の CSV を読み込んで種別を数値化(Bug of words)するのであれば以下の様になります。
package main import ( "fmt" "log" "os" "github.com/go-gota/gota/dataframe" "github.com/go-gota/gota/series" ) func main() { f, err := os.Open("iris.csv") if err != nil { log.Fatal(err) } defer f.Close() df := dataframe.ReadCSV(f) yDF := df.Select("species").Capply(func(s series.Series) series.Series { records := s.Records() floats := make([]float64, len(records)) m := map[string]int{} for i, r := range records { if _, ok := m[r]; !ok { m[r] = len(m) } floats[i] = float64(m[r]) } return series.Floats(floats) }) fmt.Println(yDF.String()) }ベンチマーク
上記のデータフレームライブラリの内、QFrame と Gota でベンチマークを取ってみました。Apache Arrow および bullseye は CSV を読み込む機能こそ用意されていますが、作ったレコードを再度 CSV に出力する為の機能が備わっておらず、自らレコードを作り直さないといけなかった為、このベンチマークからは除外しました。
package df_test import ( "bytes" "context" "io/ioutil" "testing" "github.com/go-gota/gota/dataframe" "github.com/rocketlaunchr/dataframe-go/exports" "github.com/rocketlaunchr/dataframe-go/imports" "github.com/tobgu/qframe" ) func BenchmarkQFrame(b *testing.B) { bs, err := ioutil.ReadFile("iris.csv") if err != nil { b.Fatal(err) } b.ReportAllocs() b.ResetTimer() for i := 0; i < b.N; i++ { var out bytes.Buffer qf := qframe.ReadCSV(bytes.NewReader(bs)) qf = qf.Select("sepal_length", "species") err = qf.ToCSV(&out) if err != nil { b.Fatal(err) } } } func BenchmarkGota(b *testing.B) { bs, err := ioutil.ReadFile("iris.csv") if err != nil { b.Fatal(err) } b.ReportAllocs() b.ResetTimer() for i := 0; i < b.N; i++ { var out bytes.Buffer df := dataframe.ReadCSV(bytes.NewReader(bs)) df = df.Select([]string{"sepal_length", "species"}) err = df.WriteCSV(&out, dataframe.WriteHeader(true)) if err != nil { b.Fatal(err) } } } func BenchmarkDataframeGo(b *testing.B) { bs, err := ioutil.ReadFile("iris.csv") if err != nil { b.Fatal(err) } b.ReportAllocs() b.ResetTimer() for i := 0; i < b.N; i++ { var out bytes.Buffer df, err := imports.LoadFromCSV(context.Background(), bytes.NewReader(bs)) if err != nil { b.Fatal(err) } df.RemoveSeries("sepal_width") df.RemoveSeries("petal_length") df.RemoveSeries("petal_width") err = exports.ExportToCSV(context.Background(), &out, df) if err != nil { b.Fatal(err) } } }goos: windows goarch: amd64 pkg: github.com/mattn/misc/df-benchmark BenchmarkQFrame-4 9998 120531 ns/op 59520 B/op 426 allocs/op BenchmarkGota-4 3636 374609 ns/op 150064 B/op 2401 allocs/op BenchmarkDataframeGo-4 3529 339492 ns/op 131101 B/op 4561 allocs/op PASS ok github.com/mattn/misc/df-benchmark 5.067s結果は Gota や dataframe-go よりも QFrame が2~3倍ほど速い結果になりました。この要因として、QFrame が出力する CSV の形式が
2.3,setosaの様な数値の形式であるのに比べ Gota は
2.300000,setosaの様な若干冗長な形式になっているのも起因してる様です。dataframe-go が遅いのはソースを見たところ RemoveSeries でのコピー量が多い様です。
pairplot
https://github.com/mattn/go-pairplot
これはデータフレームではありませんが、Python の seaboan.pairplot をGo言語に移植した go-pairplot というライブラリがあり、先日これを Gota を使う様に変更しました。以前までは扱える型を float64 に限定していた為、精度の必要ないデータや文字列を扱うデータでは使いどころが難しかったのですが、データフレームを使う様に変更した事でとても便利になりました。
package main import ( "log" "os" "github.com/go-gota/gota/dataframe" "github.com/mattn/go-pairplot" "gonum.org/v1/plot" "gonum.org/v1/plot/vg" ) func main() { p, err := plot.New() if err != nil { log.Fatal(err) } f, err := os.Open("iris.csv") if err != nil { log.Fatal(err) } defer f.Close() df := dataframe.ReadCSV(f) pp, err := pairplot.NewPairPlotDataFrame(df) if err != nil { log.Fatal(err) } pp.SetHue("Name") p.HideAxes() p.Add(pp) p.Save(8*vg.Inch, 8*vg.Inch, "example.png") }
もちろん Jupyter Notebook からGo言語を扱える gophernotes からでもこの go-pairplot は扱える様にしてあります。
また go-plotlib を使うと Jupyter Notebook 上で CSV を簡単に表示できます。
https://github.com/mattn/go-plotlib
Go言語でデータサイエンスをする際はお役立て下さい。
まとめ
Go言語で扱えるデータフレームライブラリを4つご紹介しました。それぞれに特色があり、やりたい処理によって選ぶ必要があります。小規模から中規模のデータで、カラムを自在に操りたい場合は QFrame または Gota、巨大なデータを高速に扱いたいのであれば Apache Arrow と bullseye の組み合わせという選択になると思います。
中規模までのデータに関しては、パフォーマンスを求めるのであれば QFrame が良いです。Gota は Go の struct binding もサポートしていますし、おそらく皆さんがやりたいと思うであろう機能が一通りそろっているので、データフレームがどんな物か触ってみたいという方はまず Gota を触ってみるのをオススメします。


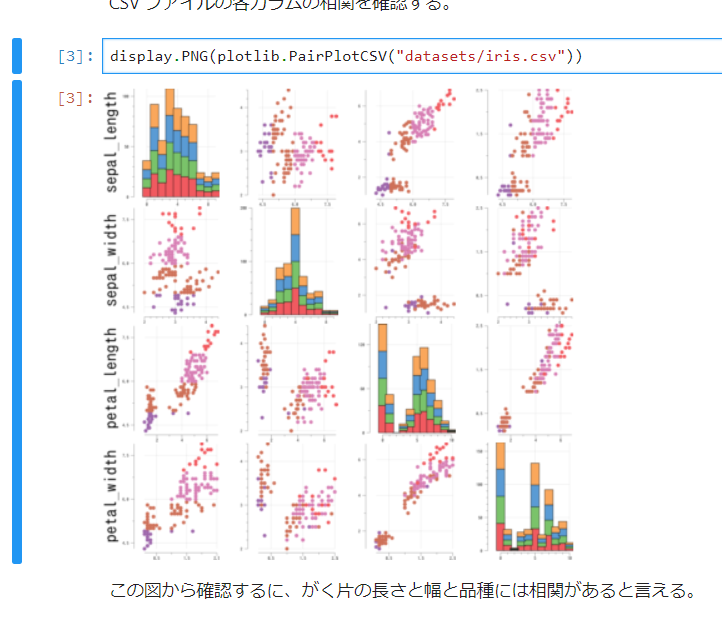
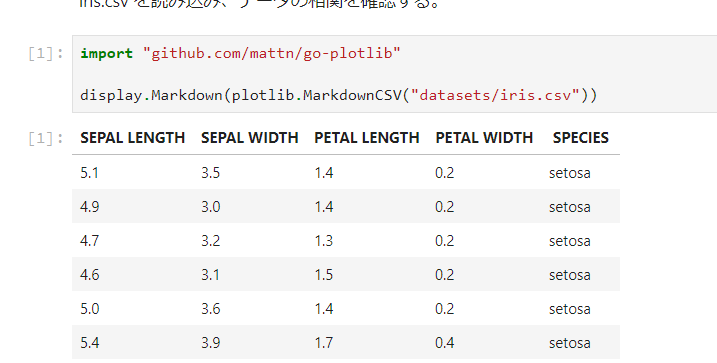
- 投稿日:2019-12-18T00:01:26+09:00
gRPCでKafkaにアクセス
ある日こう思ったとします。
「あ、Kafka飽きた。NATS使お。」ところがもしKafkaに他のチームからのアクセスがあった場合、彼らに変更をお願いする必要があります。
彼らは大体忙しいでしょう。そう簡単にNATSに変更することはできなくなります。そんなとき、Kafkaに直接アクセスする代わりに、メッセージシステムを抽象化したインターフェイスを通してアクセスしてもらうことで内部の実装を隠蔽してしまうと便利です。
今回紹介するのはまたもや弊社謹製の uw-labs/proximo というライブラリ(とGoのサーバー実装)です。
このライブラリでは以下のように、メッセージングシステムのインターフェイスをprotocol bufferの形で定義しています。proximo.protosyntax = "proto3"; package proximo; message Message { bytes data = 1; string id = 2; } // Consumer types service MessageSource { rpc Consume(stream ConsumerRequest) returns (stream Message) { } } message ConsumerRequest { // expected if this is a start request StartConsumeRequest startRequest = 2; // expected if this is a confirmation Confirmation confirmation = 3; } message StartConsumeRequest { string topic = 1; string consumer = 2; Offset initial_offset = 3; } enum Offset { OFFSET_DEFAULT = 0; OFFSET_NEWEST = 1; OFFSET_OLDEST = 2; } message Confirmation { string msgID = 1; } // Producer types service MessageSink { rpc Publish(stream PublisherRequest) returns (stream Confirmation) { } } message PublisherRequest { // expected if this is a start request StartPublishRequest startRequest = 2; // expected if this is a message Message msg = 3; } message StartPublishRequest { string topic = 1; }送信・受信ともに双方向ストリームRPCを使用しているのにご注目ください。
このインターフェイスを実装するgRPCサーバーを用意することで、Kafkaを使っていることをユーザーから隠すことができます。
レポジトリにはGoによるサーバー実装およびパブリックなDockerイメージが用意されているため、これを使います。Proximoのデプロイ
以下のマニフェストファイルでKafkaをバックエンドとして使用するproximoをデプロイします。
kubernetes/proximo.yaml--- apiVersion: v1 kind: Service metadata: annotations: prometheus.io/scrape: 'true' prometheus.io/path: /__/metrics prometheus.io/port: '8080' name: &app proximo namespace: &ns qiita labels: app: *app spec: ports: - name: app port: 6868 protocol: TCP targetPort: 6868 - name: http port: 80 protocol: TCP targetPort: 8080 selector: app: *app --- apiVersion: apps/v1 kind: Deployment metadata: labels: app: &app proximo name: *app namespace: &ns qiita spec: replicas: 1 selector: matchLabels: app: *app template: metadata: labels: app: *app namespace: *ns spec: containers: - name: *app image: quay.io/utilitywarehouse/proximo:latest args: - /proximo-server - kafka env: - name: PROXIMO_KAFKA_VERSION valueFrom: configMapKeyRef: name: kafka-brokers key: internal.kafka.broker.version - name: PROXIMO_KAFKA_BROKERS valueFrom: configMapKeyRef: name: kafka-brokers key: internal.kafka.brokers - name: PROXIMO_PROBE_PORT value: "8080" - name: PROXIMO_PORT value: "6868" imagePullPolicy: Always livenessProbe: failureThreshold: 3 httpGet: path: /__/ready port: 8080 scheme: HTTP initialDelaySeconds: 15 periodSeconds: 10 successThreshold: 1 timeoutSeconds: 10 ports: - containerPort: 6868 name: proximo protocol: TCP - containerPort: 8080 name: proximo-probe protocol: TCP readinessProbe: failureThreshold: 3 httpGet: path: /__/ready port: 8080 scheme: HTTP initialDelaySeconds: 15 periodSeconds: 10 successThreshold: 1 timeoutSeconds: 10 resources: limits: memory: 512Mi ---このマニフェストをもとにデプロイします。
$ kubectl apply -f kubernetes/proximo.yaml service/proximo created deployment.apps/proximo created $ kubectl -n qiita get pods proximo-684b45f898-9vvvr NAME READY STATUS RESTARTS AGE proximo-684b45f898-9vvvr 1/1 Running 0 36sProximo経由のメッセージ受信
ユースケースとしては別ネームスペースからの使用を想定していますが、今回は前回実装したアプリ内での受信をProximoに変更したいと思います。
どのようにProximoにアクセスするかですが、ここでもsubstrateライブラリが役に立ちます。
substrate/proximoパッケージを使い、initialiseProximoSource()関数を以下のように定義します。main.gofunc initialiseProximoSource(addr, consumerID, topic *string, offsetOldest *bool) (substrate.SynchronousMessageSource, error) { var proximoOffset proximo.Offset if *offsetOldest { proximoOffset = proximo.OffsetOldest } else { proximoOffset = proximo.OffsetNewest } source, err := proximo.NewAsyncMessageSource(proximo.AsyncMessageSourceConfig{ ConsumerGroup: *consumerID, Topic: *topic, Broker: *addr, Offset: proximoOffset, Insecure: true, }) if err != nil { return nil, err } return substrate.NewSynchronousMessageSource(source), nil }呼び出し側は以下のように変更します。
main.goproximoAddr := app.String(cli.StringOpt{ Desc: "proximo endpoint", Name: "proximo-addr", EnvVar: "PROXIMO_ADDR", Value: "proximo:6868", }) proximoOffsetOldest := app.Bool(cli.BoolOpt{ Name: "proximo-offset-oldest", Desc: "If set to true, will start consuming from the oldest available messages", EnvVar: "PROXIMO_OFFSET_OLDEST", Value: true, }) ... actionSource, err := initialiseProximoSource(proximoAddr, consumerID, actionTopic, proximoOffsetOldest) if err != nil { log.WithError(err).Fatalln("init action event kafka source") } defer actionSource.Close()以上の部分にはKafkaへの依存は含まれておらず、バックエンドシステムがなんであるか気をせず実装できています。
デプロイしたらデバッグしてみましょう。
gRPCは無事成功、新たなTodoのIDを返しました。
ではDBを覗いてみます。$ kubectl -n qiita exec -ti cockroachdb-0 -- /cockroach/cockroach sql --url postgresql://root@localhost:26257/qiita_advent_calendar_2019_db?sslmode=disable ... root@localhost:26257/qiita_advent_calendar_2019_db> select * from todo where id = '71face5d-404e-4cf3-b831-dd33da5147a2'; id | title | description +--------------------------------------+-----------+-----------------------------------------------+ 71face5d-404e-4cf3-b831-dd33da5147a2 | Holidays! | Pack your items and prepare for the holidays! (1 row) Time: 1.328365msDBへの保存も無事できています:)
というわけで、ここまでマイクロサービスの立ち上げからgRPC、DBと辿りKafkaを使った非同期コミュニーケーションとみてきました。
アドベントカレンダーはまだ残り日数ありますが、一番紹介したかったことはここまでなのでひとまず本編これにて終了としたいと思います。他にもいくつか触れたいトピックはあるのであとはマイペースに更新していきたいと思います。
ここまで読んでくださりありがとうございました:)それではみなさまメリークリスマス&よいお年を!

- 投稿日:2019-12-18T00:01:11+09:00
負荷ツール vegita の息子 trunks を作ったお話(keep-aliveについて)
はじめに
Go6 Advent Calendar 2019 の18日目はhmarfが書かせていただきます。インターンを通じて負荷対策に興味を持ち、簡単な負荷ツールを作ろうと思い作成しました。その過程で得た知識を書いていきます。vegeta がいるなら trunks がいてもいいじゃないか!!と思い命名しました。
とりあえず、keep-alive について書きます。時間をとれたら追記していきます。
Keep-Alive
Goの
net/httpはデフォルトでkeep-aliveが有効になっているが、コネクションの数が制限されます。コネクションの数が制限されると同時に送ることのできるリクエストの数が制限され不便です。そのためこのコネクションの数を変化させる必要があります。
・MaxIdeleConns: デフォルト値 100
・MaxIdeleConnsPerHost: デフォルト値 2
この二つの値を変化させることでコネクションの数を変えることができます。transport := &http.Transport{ TLSClientConfig: &tls.Config{ InsecureSkipVerify: true, }, MaxIdleConns: 0, // 0にすると無制限にコネクションを張れます MaxIdleConnsPerHost: 1000, }ただこれだけではコネクションを再利用することができません。他の条件として
・ response body を close する
・ response body を読み切る
があり、この二つを終えるとアイドル状態になり、コネクションの再利用が可能になります。defer resp.Body.Close() _, err = ioutil.ReadAll(resp.Body)これで大量のリクエストを送信することができます。
検証
(1)
net/httpのデフォルト値を使用 & bodyをcloseし、bodyを読み切った結果(=>コネクションを再利用できるがそもそも多くのコネクションを張れない)Concurrency Level: 10 Total Requests: 100000 Succeeded requests: 100000 Failed requests: 0 Requests/sec: 0 Total data received: 1200000 bytes Status code: [200] 100000 responses Latency: total: 23.008464472s max: 2.663676644s min: 166.74µs ave: 2.226824ms(2)
net/httpの値を変化 & bodyはcloseするが、bodyを読みきらない場合(=>コネクションを再利用しない)Concurrency Level: 10 Total Requests: 100000 Succeeded requests: 100000 Failed requests: 0 Requests/sec: 0 Total data received: 1200000 bytes Status code: [200] 100000 responses Latency: total: 4m5.269726967s max: 40.354151237s min: 659.368µs ave: 22.360515ms(3)
net/httpの値を変化 & bodyをcloseし、bodyを読み切った場合(=>理想型)Concurrency Level: 10 Total Requests: 100000 Succeeded requests: 100000 Failed requests: 0 Requests/sec: 0 Total data received: 1200000 bytes Status code: [200] 100000 responses Latency: total: 9.326267386s max: 88.113282ms min: 157.372µs ave: 921.916µs
Total time (1) コネクションを再利用 & connection数2 23.008464472s (2) コネクションを再利用しない 4m5.269726967s (3) コネクション数を制御 & 再利用 9.326267386s まとめ & 感想
trunks はテストコードも書いてないし、動け!!と思って作ったものなので、ゴミコードです。リファクタしていきます。
もし、時間のある人はpull request投げてください!!もしくは、レクチャーしてください!!(メール待ってます)
クリスマスは予定なく暇なので、pull request来てたら嬉しいな...
- 投稿日:2019-12-18T00:00:11+09:00
Goのテンプレートをちゃんと使ってみる
はじめに
Goのテンプレートのpackageをちゃんと使ってみたいという気持ちになったので調べました。
参考
text/templateパッケージのドキュメント
テンプレートの文法についてはこっちに書いてあります。
html/templateパッケージのドキュメント
packageのインタフェースはtext/templateと同じですが、セキュリティ上の問題を引き起こさないためには出力がHTMLの場合にはこちらを使うべきと書いてあります。Effective Go - The Go Programming Language # A web server
formに文字列を入力すると、GoogleのAPIを使ってQRコードの画像を生成して表示するサーバのサンプルコードがあります。html/templateも登場します。Writing Web Applications - The Go Programming Language
簡易的なWikiを作ってWebアプリの作り方を学べるチュートリアルです。重複を排除するようにリファクタしつつ進んでいくので教材としていい感じです。これも同じく、html/templateも登場します。テンプレートの文法
文字列の中に
{{Action}}の形式でデータや制御構造を埋め込める。Action
データの評価または制御構造を表す。
- コメント
{{/* a comment */}}の形式で出力されないコメントを書ける- pipelineの値そのもの
{{pipeline}}if{{if pipeline}} T1 {{end}}
- pipelineの値がempty(
false,0,nilのポインタかinterface,len(x) == 0の配列、スライス、map、文字列の場合)でなければT1、emptyなら何も出力されないif-else{{if pipeline}} T1 {{else}} T0 {{end}}
- pipelineの値がemptyでなければT1、emptyならT0
if-else-if{{if pipeline}} T1 {{else if pipeline}} T0 {{end}}
elseに別のifを入れこむことができる- これと同じ結果になる
{{if pipeline}} T1 {{else}}{{if pipeline}} T0 {{end}}{{end}}with{{with pipeline}} T1 {{end}}
- ifと同じだが、pipelineの値がemptyでない場合、dot(テンプレートに渡したデータ中の現在の参照位置を示す)がpipelineの値になる
with-else{{with pipeline}} T1 {{else}} T0 {{end}}
- pipelineの値がemptyでなければ
withと同じ、emptyならdotは変わらないrange{{range pipeline}} T1 {{end}}
- pipelineの値が配列、スライス、map、channelのいずれかである必要がある
- pipelineの値がempty(
len(x) == 0)なら何も出力されない- emptyでない場合、要素の数だけループする
- ループ中、dotは現在の要素を示す
range-else{{range pipeline}} T1 {{else}} T0 {{end}}
rangeと同じだが、pipelineの値がemptyの場合T0が実行されるArgument
単なる値を表す。ポインタでも自動的に値を見にいってくれる
- 表記:値
- Goの定数:untyped constantになる
nil:untyped nil.:そのときのdotの値$alphanumの形式の変数名$も有効- 構造体のフィールド名:フィールドの値
.Fieldの形式.Field1.Field2ネストしていても参照できる$x.Field1.Field2で変数のフィールドにもアクセスできる- mapのキー名:キーの値
.Keyの形式$x.key変数に対しても同じことができる- 引数を持たないメソッド名:メソッドの呼び出し結果
- この形式で使えるメソッドは返り値を2つまでしか持てない
- 2つの場合は、2つ目はerrorでないといけない
- nilではないerrorが返った場合は、テンプレートの実行は止まりExecute()からそのerrorが返却される
- 引数を持たない関数名:関数の呼び出し結果
- 返り値についての振る舞いはメソッドの場合と同じ
Pipeline
1つ以上のcommand(単なる値あるいは関数かメソッドの呼び出し)を
|で繋いだもの関数
定義済みの関数
and引数のうち最初に見つかったemptyの引数を返す。emptyのものが1つもなかった場合は最後の引数を返す。
or引数のうち最初に見つかったemptyではない引数を返す。すべてemptyだった場合は最後の引数を返す。
not引数がemptyなら
true、そうでなければfalseを返す。
call最初の引数(関数じゃないといけない)に残りの引数を渡して実行した結果を返す。
https://play.golang.org/p/B7oAqxsBKaT
package main import ( "math" "os" "text/template" ) type Point struct { X float64 Y float64 } func Distance(a, b Point) float64 { return math.Sqrt((a.X-b.X)*(a.X-b.X) + (a.Y-b.Y)*(a.Y-b.Y)) } const tmplStr = ` p1: {{printf "%#v" .p1}} p2: {{printf "%#v" .p2}} {{/* {{.distance .p1 .p2}} はダメ */}} distance: {{call .distance .p1 .p2}} ` var tmpl = template.Must(template.New("call").Parse(tmplStr)) func main() { data := map[string]interface{}{ "p1": Point{X: 3.0, Y: 0.0}, "p2": Point{X: 0.0, Y: 4.0}, "distance": Distance, } if err := tmpl.Execute(os.Stdout, data); err != nil { panic(err) } }p1: main.Point{X:3, Y:0} p2: main.Point{X:0, Y:4} distance: 5
printf,printlnそれぞれ
fmt.Sprint,fmt.Sprintf,fmt.Sprintlnの働きをする。
html,js,urlquery引数をそれぞれHTML,JavaScript,クエリストリングとしてエスケープする。
https://play.golang.org/p/JU9sPOW42NT
package main import ( "os" "text/template" ) const tmplStr = ` and: {{and 0 0}} {{and 1 0}} {{and 0 1}} {{and 1 1}} or: {{or 0 0}} {{or 1 0}} {{or 0 1}} {{or 1 1}} not: {{not "ok"}} {{0 | not}} html: {{html "<a href=\"https://golang.org/\">Go</a>"}} js: {{js "<script>alert('XSS');</script>"}} urlquery: {{urlquery "http://example.com/path?key=val"}} slice: {{slice "golang" 1 4}} eq: {{eq "?" "?"}} {{eq "?" "?"}} {{eq "?" "?"}} ne: {{ne "?" "?"}} {{ne "?" "?"}} {{ne "?" "?"}} lt: {{lt "?" "?"}} {{lt "?" "?"}} {{lt "?" "?"}} le: {{le "?" "?"}} {{le "?" "?"}} {{le "?" "?"}} gt: {{gt "?" "?"}} {{gt "?" "?"}} {{gt "?" "?"}} ge: {{ge "?" "?"}} {{ge "?" "?"}} {{ge "?" "?"}} ` var tmpl = template.Must(template.New("functions").Parse(tmplStr)) func main() { if err := tmpl.Execute(os.Stdout, nil); err != nil { panic(err) } }and: 0 0 0 1 or: 0 1 1 1 not: false true html: <a href="https://golang.org/">Go</a> js: \x3Cscript\x3Ealert(\'XSS\');\x3C/script\x3E urlquery: http%3A%2F%2Fexample.com%2Fpath%3Fkey%3Dval slice: ola eq: true false false ne: false true true lt: false true false le: true true false gt: false false true ge: true false true自分で定義した関数を使う
(*Template) Funcs()でtemplate.FuncMap(map[string]interface{})を渡すと自分で定義した関数を使える。Funcs()はParse()より前に呼ぶ必要がある。https://play.golang.org/p/7jJOVbGBqPk
package main import ( "math" "os" "text/template" ) const tmplStr = ` multiply: {{multiply 2 3}} average: {{average 2 3 5}} round: {{round 3.14}} average|round: {{average 2 3 5 | round}} reverse: {{reverse "reverse"}} sushi|beer: {{"" | sushi | beer | sushi | beer}} ` var ( funcMap = map[string]interface{}{ "multiply": func(a, b int) int { return a * b }, "average": func(nums ...int) float64 { sum := 0 for _, n := range nums { sum += n } return float64(sum) / float64(len(nums)) }, "round": func(num float64) int { return int(math.Round(num)) }, "reverse": func(s string) string { r := []rune(s) for i, j := 0, len(r)-1; i < len(r)/2; i, j = i+1, j-1 { r[i], r[j] = r[j], r[i] } return string(r) }, "sushi": func(s string) string { return s + "?" }, "beer": func(s string) string { return s + "?" }, } tmpl = template.Must(template.New("funcmap").Funcs(funcMap).Parse(tmplStr)) ) func main() { if err := tmpl.Execute(os.Stdout, nil); err != nil { panic(err) } }multiply: 6 average: 3.3333333333333335 round: 3 average|round: 3 reverse: esrever sushi|beer: ????