- 投稿日:2019-12-18T23:22:34+09:00
独自VPCでEC2のAutoScalingくらい秒で組めるようになりたい
タイトルの通りです。
何回か試みてはいるのですが、毎回ヘルスチェックで壁にぶつかり、独自VPC上だとIPが発行されなかったり、、、
本記事はその辺を理解してAutoScaling構成を秒で作れるようになるための一連の手順まとめです。Contents
- Elastic Load Balancerの使い方(デフォルトVPC使用)
- Auto Scalingの使い方(デフォルトVPC使用)
- VPCの切り方
- Elastic Load Balancer/Auto Scalingの使い方(独自VPC使用)
目指す構成
よくある感じのです。Apacheを乗せたEC2にindex.html置き、ELB経由でアクセスするだけの構成から整理していきます。今回はprivateサブネットはつくりません。
Elastic Load Balancerの使い方(デフォルトVPC使用)
ロードバランサとは読んで字の如しで、load(負荷)をbalance(調整/分散)する優秀なやつです。
まずは、デフォルトのVPC配下、異なるAZ下に2つのEC2(Amazon Linux)を置いてロードバランシングします。EC2インスタンスを立てる。
ここで、詳細設定のところで、以下の「高度な詳細」欄にテキストでシェルを書きます。これは、インスタンスを立てる最初に実行したい処理をかけるスペースです。今回は使わずにインスタンスを立て、個々にsshで入ってapacheをインストールしてもいいのですが、今後、AutoScalingするときに大事になってきます。都度都度sshするわけにいかないですからね。
高度な詳細#!/bin/sh yum install httpd -y sudo service httpd start sudo chkconfig httpd on今回はインスタンス間で違いをみるため、異なるindex.htmlを配置したいので個々にsshで侵入して配置します。
index.html(1つ目)Hello I am instance1!index.html(2つ目)Hello I am instance2!ターゲットグループを作成する
ターゲットグループとは、ロードバランシングする対象のEC2をひとまとめにしたグループです。
ヘルスチェックなどの設定もここで行ないます。
- ターゲットグループ : グループの名前
- ターゲットの種類 : ロードバランシングする対象です。今回はインスタンス。
- ヘルスチェック : 定期的にインスタンスにアクセスしてちゃんと生きてるかELBが確認してくれます。
- パスはヘルスチェック対象の場所 : 後述
ヘルスチェックとは
前述の通り、ELBは、定期的に各インスタンスにアクセスしにいきます。それは私たちがwebブラウザからアクセスするように、指定したポート(上記では80)へ指定のパスへアクセスします。
このパスに/var/www/html/index.htmlを書くみたいなサイトを見た記憶がありますが、変える必要はないです。パスに何も指定しない
/のみ → ブラウザにEC2のIPを打つのと一緒 =xx.xxx.xxx.xxx
当然アクセスできます。index.htmlがお出迎えです。パスに
/var/www/html/index.htmlを書く → ブラウザにxx.xxx.xxx.xxx/var/www/html/index.htmlとしてるのと一緒。
当然、弾かれます。ロードバランサーを作成、アクセスしてみる
作成画面からALBを選択します。
ここでのインターネット向けと内部はどこからELBにアクセスするかです。今回のようにhttpでVPC外からアクセスする場合は前者を選びます。
セキュリティグループの設定や、ターゲットグループの設定を終えると終了です。(この辺は流れに沿っていくだけ)ELBがactiveになるまで数分待ったのち、発行されるDNS名にアクセスしてみましょう。
Hello I am instance1(もしくは2)と出たでしょう。アクセスする度に数字が変わると思います。
これが負荷分散です。次のAutoScalingに行く前にターゲットグループに設定したインスタンスを登録から外しましょう。インスタンスももう不要です。
Auto Scalingの使い方(デフォルトVPC使用)
起動設定を書く。
ここでは、AutoScaling(スケールアウト)が発動し、インスタンスを立てる際に元となる起動情報を記述します。
基本的にはEC2インスタンスを立てる時と変わりはないです。高度な詳細#!/bin/sh yum install httpd -y sudo service httpd start sudo chkconfig httpd on cd /var/www/html sudo touch index.html sudo echo "Hello" > index.htmlAutoScalingGroup(ASG)の作成
1 Auto Scaling グループの詳細設定
配置するAZを指定します。複数選択して可用性を向上しましょう。
今回は初期2台を選択します。
高度な詳細を開くとロードバランサ配下に置くことができます。ロードバランシングにチェックを入れ、ターゲットグループに先ほどのものを指定します。
他は特に弄らず次へ。2 スケーリングポリシーの設定
ここでは、スケーリングする条件を指定します。CPU使用率やアラームによってコントロールできますが、今回は意図的にインスタンスを落としてAutoScaleの挙動を確認するため、「このグループを初期のサイズに維持する」を選択し、次に行きます。
それ以降の設定はオプションです。通知が欲しければつけてください。
ASGを作成します。
実験
それでは、AutoScalingのテストです。事故を仮定してASGのインスタンスを1台停止してみましょう。
stoppedに変わった数秒後、新たにインスタンスが生成してきます。ロードバランサのDNSにアクセスするとちゃんと
Helloが出てきてASGに接続できていることも確認できます。
(ほんとはここもipがわかるようなhtmlを書けるといいのだが知識がたりない、、、)VPCの切り方
手順的にはこんな感じ。
1. VPCを作る。
VPCとは:仮装プライベートネットワーク・・・AWSアカウントのネットワークを論理的に分割した範囲。
EC2コンソールへ行き、サイドバーからVPCを選択して作成。
テナンシーはホストコンピュータを占有するかどうか。
(EC2の仕組みは1つのはすとコンピュータ上に複数のインスタンスが乗っており、ユーザにインスタンスを貸し出している。このホストコンピュータごと指定して占有するにはお金がかかるのだ)
2. サブネットを作る。
同じくEC2コンソールのサイドバーからサブネットを選択して作成。
VPCを論理的に分割するのでCIDERブロック
/16で区切ったVPCの中で区切る(16〜28の範囲で指定)。
一般的にはパブリックサブネットとプライベートサブネットとし、前者はインターネットと繋ぎ、後者は繋がない(VPC内からしかアクセスできない)といった使い方をします。なお、のちにEC2を立てるときに自動でパブリックIPを付与するようにするなら、サブネットを作成後にここで設定を編集します。
このままではこのVPCはインターネットと繋がっていないので、EC2を立ててもsshで入ることもできない。なので、インターネットゲートウェイを設定します。
3. インターネットゲートウェイ・ルートテーブルを設定する。
インターネットゲートウェイとは:VPCをインターネットに繋ぐためのルータのようなもの。
同じくEC2コンソールのサイドバーからインターネットゲートウェイを選択し、作成します(名前をつけるだけ)。
アクションから[VPCヘアタッチ]を選択して作成したものにアタッチ。ついで、ルートテーブルを作成する。サイドバーより選択。
名前をつけた後、アクションから[ルートの編集]を選択し、送信先0.0.0.0/0のターゲットを作成したインターネットゲートウェイに設定します。これでVPCと接続できたが、まだVPC内部のサブネットには繋がっていない状態です。
4. ルートテーブルをサブネットに紐づける。
サイドバーのサブネットを選択し、アクションから[ルートテーブルの関連付けの編集]を選択。
ルートテーブルを上で作成したものに設定する。
Elastic Load Balancer/Auto Scalingの使い方(独自VPC使用)
上記の方法で設定したVPCを使います。ただし、2つのAZにEC2を配置したいので、追加でサブネットをもう一つ作って同じようにネットワークとつないでください。
- 1つめのサブネット(AZ-a): 10.0.0.0/24 (作成済み)
- 2つめのサブネット(AZ-c): 10.0.1.0/24
ELBを設定する。
変更点のみ記します。
今回は、ロードバランサ作成時に指定するVPCをデフォルトではなく、上記で作成した物に変えます。その際、VPC関連でミスっていると以下のように警告されます。インターネット向けロードバランサーを作成中ですが、次のサブネットにはアタッチされたインターネットゲートウェイが存在しません
Auto Scalingを設定する。
変更点のみ記します。
起動設定の高度な詳細の中で、IPアドレスタイプを選択する欄があります。「パブリック IP アドレスを各インスタンスに割り当てます。」を選択。
これがないとASG作成に際して以下の警告が出ます。パブリック IP アドレスは割り当てられません
デフォルトの VPC およびサブネットで起動することを選択しなかったため、この Auto Scaling グループのどのインスタンスにもパブリック IP アドレスが割り当てられません。
デフォルト VPC のデフォルトサブネットのみを選択することにより、この設定で起動されたインスタンスにパブリック IP アドレスが割り当てられるようにすることができます。あと、少し謎だったが、起動設定を作成する流れでセキュリティグループを作成したところ、セキュリティグループのVPC IDがデフォルトのもので設定されてしまい、以下のエラーでASGが作成できない問題に遭遇しました。
セキュリティグループのコンソールからまず、VPC IDを指定して作成し、起動設定作成時に既存のものから選択という形で対応することができた。One or more security groups in the launch configuration are not linked to the VPCs configured in the Auto Scaling group
起動設定にあるセキュリティグループのVPC IDとAuto Scaling Groupで設定しようとしているVPCが違うよと怒られています。
上記を一通り終えると、同じくELBのDNS名にアクセスすると
Helloが拝めます。おしまい
まあ、ロードバランサを立てる時点で数分待たないといけないので秒で構築はできないわけなんですが、だいぶ分かってきました。
次は、AutoScalingGroupへCodeDeployからデプロイを試みます。






- 投稿日:2019-12-18T22:47:45+09:00
AWS Cloud Practitionerを受験したはなし
はじめに
はじめまして。もう何日か後には2020年になってしまうということに昨日気付いて震えている さいとうです。
今月の初めにAWSクラウドプラクティショナーを受けて合格したので、その記録です。これから受けようかなと思っている方の参考に少しでもなれば!
■ about me
- 社会人1年目(文系出身)
- AWS歴:0年
- AWS学習期間:約3か月
4月に入社して7月に配属が決まるまで、AWSの前にまずインフラ?サーバ??データベース???と分からないことだらけだったスーパー初心者です。
4〜6月はJavaなどのプログラミングの基礎を、7月〜8月はLinuxやコマンドなどのインフラの基本の部分の勉強をしていたので、本格的にAWSを勉強し始めたのは9月頃から。それまでは周りから聞こえてくる"EC2"や"CloudWatch"の意味が全く分からず「何の暗号だろう…」と思っていました。今ならちょっとわかる(はず、、、)
試験について
■ クラウドプラクティショナーって?
そもそもクラウドプラクティショナーって?という数ヶ月前の私みたいな人もいると思うので、何番煎じかわからないけれどちょっとだけ説明すると、AWS 認定クラウドプラクティショナーとは、Amazon.comが提供しているクラウドコンピューティングサービスAWS(Amazon Web Services)の初級レベルの試験のことです。クラウドの概念からAWSのサービスについてまで広く浅く出題されます。
■ 受験方法
受験のためのアカウントを作り、PSIかPearson VUE のテストセンターを選んで、試験日を決め、11,000円(+税)を払って遅刻せずに試験会場まで行けばとりあえず第1段階クリア。
試験を受けようと思ったら5分もあれば登録~支払いまでできちゃいます。試験会場によっては席が空いていれば次の日でも受験できます。
やったこと
■ 参考書
まずテキストで概要を1度理解し先輩方に分からなかったところを教えてもらいました。その後何度か読んで、サービスの違いやコストなど詳しくみていきました。1回で覚えようとせず何度も見た方が「確かあのページに書いてあったな」と記憶に残りやすかったので、繰り返し見た方がいいのかなと思います。
■ Udemy
- AWS Certified Cloud Practitioner- Updated:400+ Questions
- AWS:ゼロから実践するAmazon Web Services。手を動かしながらインフラの基礎を習得
とりあえずやってみないと分からない!と思い、模擬試験とハンズオン講座を80〜90%くらいの割引セールしているときに購入。
1つ目の模擬試験は6回分試験があったのですが、
4回目の途中で飽きてしまい最後までやってません。2つ目のハンズオンは今も現在進行形でのんびりと受講中。なので、こっちもまだ終わってません。(飽き性なのがばれてしまう。。)最後までやってもいないのに言うのはなんですが、模擬試験は雰囲気を知るのに、ハンズオンはテキストで勉強したことを実際にやってみて理解するのにちょうどよかったです。
■ AWSの公式模擬試験
試験の前の日に受けてみました。正答率だけしか分からないのでメモしながら受験。
試験と同じ画面なので、試験当日見たことのある画面でなんとなく安心して受験できました。敵は知らないと戦えないので、公式の模擬試験は雰囲気や傾向を掴むためにも受けた方がいい気がします。■ その他
- ブラックベルト
- 苦手なところをとにかくググる
- それでもわからないところは優しい先輩方に聞く。(本当にありがとうございました)
AWSの公式ドキュメントは私にとって「読めるけど理解できない外国語」だったので、とりあえずわからないけど我慢して1回眺めて、その後でもっと詳しく知りたいサービスは他のサイトや記事を見ていました。よく出てくるサービスのブラックベルトやホワイトペーパー、「よくある質問」などにできるだけ目を通そうと思ったのですが、あまり時間がとれなかったのが今回の反省点です。
試験の感想
■ テストセンター
まず、試験会場(Pearson VUE)。テストセンターによっては他の試験も同時に実施しているので、少し早めに行った方がいいかもしれません。
私は30分以上前には会場に着いたのですが、名前を書いたり写真撮ったりといった諸々の手続きに時間がかかり、PCの前に座ったのは試験開始時間ぴったりくらいでした。あと、トイレは行ける時行かないとタイミング逃します。■ 試験内容
次に試験内容。いろんなところに書いてあるように模擬試験よりも難易度が高い印象でした。AWSの基本的なサービスを理解したつもりでいたし、模擬試験でも1問しか間違えなかったので大丈夫かなと思ってましたが、見直しをしている時「あれ?これもしかしたら間違ってるかも」と何度も迷ったので、サービスの概要は詳しく覚えておいて損はないと思います。というか絶対得しかないです。
ちなみに時間は、分からないところは飛ばしながら一旦40分くらいで解いて、残りの50分たっぷり使って2回見直しました。試験内容とは直接関係ないのですが、受験前日に「遠隔試験官が〜」というブログを読んでドキドキしていましたが、私の受けた試験会場は遠隔試験管がいなかったので、特に緊張することなく受験できました。
おわりに
「awsってなに?」という初心者中の初心者の状態から約3カ月でなんとか合格できました!
まだまだたくさん知らないことがありますが、合格したらAWSに親近感が湧いてきて勉強するのが楽しくなってきたので、このままの勢いでソリューションアーキテクト-アソシエイトも合格できたらいいなあ。今回は無計画に受けちゃったから今度はちゃんと計画立てて受けよ!
- 投稿日:2019-12-18T22:46:37+09:00
ARMベースのEC2インスタンスを利用する
この記事は、ニフティグループ Advent Calendar 2019 の18日目の記事です。
昨日は @fuku710 さんのハッカソンのハックためになりましたね!
私は今月 AWS re:Invent 2019 に参加してきたのですが、同イベント中にも Hackathons and Jams というハッカソンが開催されていたので、次の機会があれば、@fuku710 さんの記事を参考にしながら参加したいですね!残念ながら、ハッカソンには参加できませんでしたが、たくさんのセッションやワークショップに参加したので、その中から ARM ベースのEC2インスタンスを利用するワークショップ CMP306 - Getting started with Arm-based Amazon EC2 instances を紹介したいと思います。
はじめに
AWS の ARM への取り組みは 2004年 Amazon Lab126 (Kindle などを作っているチーム) から始まったそうです。その後、ネットワークのオフロードや Nitro システムの構築など、カスタムシリコンの開発に情熱的に取り組んできたようです。
今年は Graviton2 を採用した次世代の ARM インスタンス(M6g/R6g/C6g)も発表されました。Graviton と比べると性能も7倍に上がったようですし、コストも20%程度は削減できるということで、是非一度使ってみたい!と思いワークショップに参加しました。
ワークショップの内容
1. arm64 で Java を動かす
Amazon Corretto を使用したアプリを A1インスタンスで動作させます。
- インスタンスの作成(AMI は Amazon Linux 2 を選択し、アーキテクチャに 64-bit Arm を選ぶこと)
- SSH でログインし Amazon Corretto 8 を
amazon-linux-extrasでインストールします- 同様に
amazon-linux-extrasでtomcat8.5もインストールし簡単のJSPを用意します- セキュリティグループで 8080 を開けて結果が表示されれば成功です!簡単ですね!
2. x86 と arm64 インスタンス混在でコンテナを動かす
- ELB のバックエンドに x86 と arm64 インスタンスを作成する(t3.small を追加)
docker buildxを実行して x86 と arm64 のコンテナを同時に作成する3.arm64 で CodeBuild を実行し BB を動かす
参考資料(※ワークショップで使ったURLなので1ヶ月程度で消えるかも)
https://arthurpt-public-ui.s3-eu-west-1.amazonaws.com/reInvent2019-cmp306-arm-instances/index.html
- 投稿日:2019-12-18T22:38:57+09:00
AWSを使ってサーバーレスにRestAPIを作ってみた。
DeNA20新卒アドベントカレンダー23日目です。
サーバーレス
サーバーレスアーキテクチャーがここ最近だいぶ浸透してきたと思います。
サーバーレスと言っても実際にはサーバーはクラウド上にあり、その上でプログラムやコンテナを走らせるのですが、
面倒な(そしてある意味楽しい)サーバーの保守から解放されて、よりアプリケーションそのものに集中できるようになったのは開発者として嬉しいポイントです。
また、他のマネージドサービスとの連携も容易で低いコストでウェブアプリケーションが作れるようになりました。
今回はAWSを使ってサーバーレスに掲示板Rest APIを作ってみました。ちなみにRestではなくGraphQLを使うのも考えましたが、学習が間に合わずに断念…
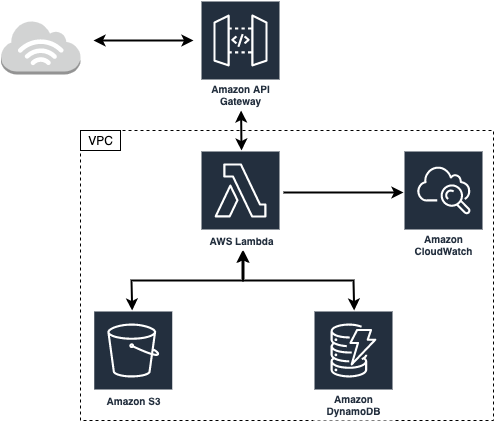
ちなみに元々掲示板のサーバーサイドだけを作って、各種APIを公開して各々のユーザーがクライアントを作ると言うコンセプトの下にAPIを作っていました。やっていくうちに色々と知見がたまったので公開すると言うのがこの記事の主旨になります。作成するAPIの構成は以下のようになります。
本当はS3を使って画像のアップロードもできるようにしたかったけど間に合いませんでした。AWS Lambda
AWS Lambdaはクラウド上でプログラムを走らせるためのサービスです。
リクエストごとに料金がかかる仕組みですが、無料分が非常に大きく並大抵のリクエスト程度ならタダで使えます。
ちなみに少し前に流行った最弱AIオセロはAWS Lambdaで動いていました。(C++のプログラムをスタティックビルドして盤面情報をコマンドライン引数としてPythonのsubprocessで動かすと言う力技)今回はバックエンドのロジックを全てLambdaを使用して実装しました。
AWS Lambdaでは現在Node.js, Python, Ruby, Java, Go, C#が使えるようですが、今回は自身の練習を兼ねてGoで実装しました。Dynamo DB
データベースにはDynamoDBを使用しています。普段MySQLばかりでNoSQLのデータベースを使ってみたいと言う理由で使いましたが、スケールが容易だったり料金が安いなどのメリットが多い一方、なかなかに癖が強く慣れるのに時間がかかりました。DynamoDBではパーティションキー、もしくはパーティションキーとレンジキーのセットがプライマリキー(=ユニーク)となるのですが、複数のデータを持ってくるような場合はただ一つのパーティションキーとレンジキーによる範囲指定が必要になります。この時、レンジキーによる範囲指定を行うと出力されるデータは自動的に降順もしくは昇順でソートされます。つまり複数のデータを取得する際は同じパーティションキーを持つデータに対して、レンジキーで範囲を指定するが、パーティションキーとレンジキーはユニークになっている必要があることになります。これらの制約のせいでテーブル設計がなかなか難しく、作り直しを何回か行う羽目になりました。
今回の掲示板APIによるデータベースの操作をまとめると以下のようになります。
- スレッド一覧の取得(スレッドの一覧は更新された時間順に100件までとする。)
- スレッドの投稿
- あるスレッドのレスポンスの取得(レスポンスの一覧は投稿順とする。)
- レスポンスの投稿(スレッドの最終更新時間を更新する。)
従ってスレッドは全て同じパーティションキー、更新時間をレンジキーとしたいのですが、パーティションキーとレンジキーのセットのユニーク性を考えると、パーティションキーが同じであればレンジキーによってのみユニーク性が担保される必要性が出てきます。しかし更新時間がユニークなのはあまり綺麗な実装とは言えない気がするので別のテーブルを考えます。ちなみにスキャンをすることで全データの摘出ができ、それらについてフィルターをかける方法もありますが、テーブルの要素が多くなることはあっても減ることはないのでできる限り避けたいところです。データ転送量で課金なことを考えるとコスト的にもなしです。
DynamoDBでは基本的にパーティションキーとレンジキーの組み合わせでデータを取得しますが、ローカルセカンダリインデックス(LSI)やグローバルセカンダリインデックス(GSI)を追加することで、同じテーブルについて異なるキーで検索をかけることができます。LSIでは同じパーティションキーについてレンジキー相当のキーの追加、GSIではパーティションキー相当のキーとレンジキー相当のキーの追加が可能ですが、内部実装的にはテーブルを複製しているらしいのでDynamoDBのコストとの相談が必要です。ここでキー相当と表現したのは、LSIについては追加したレンジキー相当のキーと既存のパーティションキーとの組み合わせがユニークでなくても良く、GSIについては追加したキー二つがユニークでなくても良いためです。ちなみにテーブルへのLSIの追加はテーブル作成時にしかできないので注意してください。
今回の要件を考えると更新時間をLSIに追加すれば更新時間によるスレッド一覧の取得が可能になります。するとレンジキーは実質スレッドをユニークにするためだけに存在するので、邪道な気もしますがこれをRDBにおけるプライマリキーと見なすことにしました。ただし、DynamoDBではRDSにおけるAuto Incrementのようなオプションは存在しない(できないことはないが別途インデックスを管理するテーブルが必要になる。)のでUUIDを使用し、このUUIDをプライマリキーとしてスレッドに対するレスポンステーブルを作成しました。
threadsテーブル
partをパーティションキー、idをレンジキー、updated_atをLSIとしています。
パーティションキーであるpartが全てのスレッドについて0で、毎回のリクエストでパーティションキーに0を入れるのは設計としてどうなんだと言う気もしますが
実際にDynamoDBのドキュメントにディスカッションフォーラムにおけるテーブル設計の例があります。
https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/SampleData.CreateTables.html
このページのthreadテーブルを見てみるとプライマリキーがフォーラム名となっています。プライマリキーをフォーラム名とかカテゴリ名として掲示板を分けていくとすれば、今回の例ではフォーラムが一つしかない場合と考えられるので、そこまで変な実装でもないのかなと言う気がします。規模が大きくなればパーティションキーを1, 2...と増やしていきパーティションキーごとに掲示板を分けていけば、負荷的にも問題ないと思われます。
responsesテーブル
responsesカラムにはDynamoDB用に変換されたjsonオブジェクトが入っています。
クエリでデータを取り出す際に取り出すカラムを指定できるので、今回の場合はスレッドのデータにそのままレスポンスのデータをくっつけるのもアリだと思いますが、上記のAWSのサンプルに則って分けました。Goの実装
LambdaでGoを使いdynamodbにアクセスするにはSDKが必要です。
必要なものだけをインストールしてもいいのですが、面倒なので下記コマンドでまとめてAWS用のGoSDKをインストールしました。
go get github.com/aws/aws-sdk-go/...LambdaでGoを使うにあたって必要なパッケージはaws-lambda-go/eventsとaws-lambda-go/lambdaになります。
前者がLambdaへの各種データの入出力を扱うパッケージ、後者がlambdaを実行するためのパッケージになっているようです。
GoでLambdaを動かす解説サイトがあまりないので割とドキュメントと睨めっこが多くなるかもしれません。https://godoc.org/github.com/aws/aws-lambda-go/lambda
https://godoc.org/github.com/aws/aws-lambda-go/eventsGoのmain関数でハンドラー関数をlambdaで実行すると言う命令を出します。
下のような定型文を書けばあとはLambdaがよしなにしてくれるので、ハンドラー関数の方で受け取ったデータを処理して返すと言うのが一連の流れです。func main() { lambda.Start(handler) }データの受け取り
データはAPI Gatewayから渡されますが、この時データがどう渡されるかによって処理の書き方が異なります。
getでデータを渡す場合、API Gatewayを通す時にURL文字列を処理する必要があります。
API Gatewayからは以下のような構造体のデータがハンドラ関数に送られます。type APIGatewayProxyRequest struct { Resource string `json:"resource"` // The resource path defined in API Gateway Path string `json:"path"` // The url path for the caller HTTPMethod string `json:"httpMethod"` Headers map[string]string `json:"headers"` MultiValueHeaders map[string][]string `json:"multiValueHeaders"` QueryStringParameters map[string]string `json:"queryStringParameters"` MultiValueQueryStringParameters map[string][]string `json:"multiValueQueryStringParameters"` PathParameters map[string]string `json:"pathParameters"` StageVariables map[string]string `json:"stageVariables"` RequestContext APIGatewayProxyRequestContext `json:"requestContext"` Body string `json:"body"` IsBase64Encoded bool `json:"isBase64Encoded,omitempty"` }この時何かしらのデータが、パスパラメータもしくはクエリ文字列として渡されていた場合
前者であればPathParameters
後者であればQueryStringParameters
にそれぞれmapで入っています。
クエリ文字列であれば単純ですが、パスパラメータの場合はAPI Gatewayの方でマッピングを行う必要です。
今回はどちらでも受け取れるようにしました。postでデータを渡す場合、jsonで渡していればそのままハンドラー関数の引数にjsonが入ってくるので、適当な構造体を用意しておけばそのままデータが使えます。
例えば以下のような構造体で表せるjsonデータを渡す場合type Request struct { ThreadID string `json:"id"` Name string `json:"name"` Content string `json:"content"` }ハンドラー関数では以下のように中身が参照できます。
func handler(request Request) { name := request.Name threadID := request.ThreadID content := request.Content }jsonでデータを受け取る際は、API Gatewayがそのままデータを渡してくれるので簡潔に受け取ることができます。
events.APIGatewayProxyRequest型で受け取ってもBodyにデータが入っていると思われますが、string型で入ってくるので別途構造体に変換する必要があります。
ちなみにlambda上でプログラムの実行テストができますが、eventsを使ったパラメータの受け取りはAPI Gatewayを介していないためエラーが発生します。
jsonによるデータの受け渡しテストを行なってからAPI Gateway用に書き換える手間が発生するので、getでもjsonでデータを渡すようにする方が楽かもしれません。データの返却
API Gatewayを通してデータを送るにはevents.APIGatewayProxyResponse型のデータを返す必要があります。
type APIGatewayProxyResponse struct { StatusCode int `json:"statusCode"` Headers map[string]string `json:"headers"` MultiValueHeaders map[string][]string `json:"multiValueHeaders"` Body string `json:"body"` IsBase64Encoded bool `json:"isBase64Encoded,omitempty"` }この中でStatusCodeとHeadersはAPI Gatewayを通してデータを返却するためには必須です。
StatusCodeはhttpパッケージのものを利用すれば大丈夫です。
HeadersはCORSを行うために'Access-Control-Allow-Originを適切に設定する必要があります。以下が実際に実装したコードです。
githubはこちら
GoでdynamoDBを操作していますが、これについて詳しく解説すると記事が丸々一本書けそうなので割愛します。
一応はAWSのドキュメントを読めばできますが、ハマるポイントも多く結構苦戦しました。質問があればコメント欄に書いてもらえればできる限り調査します。スレッド一覧の取得
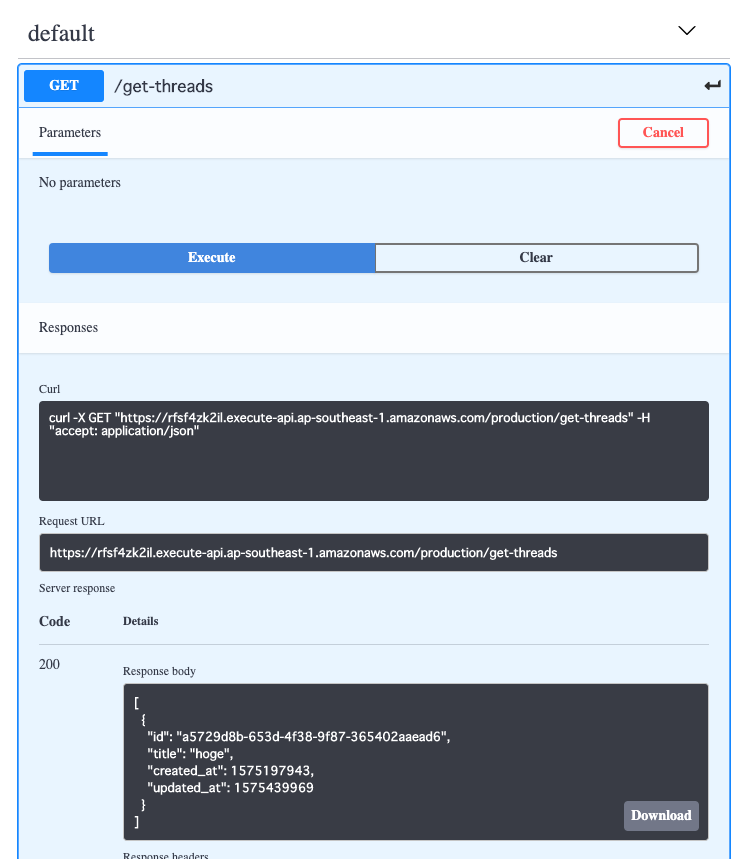
get_threads.gopackage main import ( "encoding/json" "net/http" "github.com/aws/aws-lambda-go/events" "github.com/aws/aws-lambda-go/lambda" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/dynamodb" "github.com/aws/aws-sdk-go/service/dynamodb/dynamodbattribute" ) // スレ用の構造体 type Thread struct { ID string `json:"id"` Title string `json:"title"` CreatedAt int64 `json:"created_at"` UpdatedAt int64 `json:"updated_at"` } type Threads struct { Threads []Thread } // レス用の構造体 type Response struct { Threads []Thread `json:"body"` } // 何かしらエラーが発生した場合internal server errorを返す。 func internalServerError() (events.APIGatewayProxyResponse, error) { return events.APIGatewayProxyResponse{ StatusCode: http.StatusInternalServerError, Headers: map[string]string{ "Access-Control-Allow-Origin": "*", }, }, nil } // ハンドラー関数、スレッド一覧は何も受け取らない。データベースから取得したスレッド一覧のみ返却する。 func Handler() (interface{}, error) { // awsとのsession作成、失敗すればinternal server error sess, err := session.NewSession() if err != nil { return internalServerError() } // セッションを使ってdynamoDBを利用する svc := dynamodb.New(sess) // dynamoDB用のqueryの作成 getQuery := &dynamodb.QueryInput{ // テーブル名(そのまま) TableName: aws.String("threads"), // インデックスを使用する場合はインデックス名 IndexName: aws.String("part-updated_at-index"), // カラムに別名をつける ExpressionAttributeNames: map[string]*string{ "#part": aws.String("part"), }, // カラムの値に別名をつける ExpressionAttributeValues: map[string]*dynamodb.AttributeValue{ ":part": { N: aws.String("0"), }, }, // 先ほどつけた別名を使って、プライマリキーを指定する KeyConditionExpression: aws.String("#part = :part"), // カラムのどの値を取得するかの指定 ProjectionExpression: aws.String("id, title, created_at, updated_at"), // レンジキーによるソート、昇順か降順か ScanIndexForward: aws.Bool(false), // 取得するデータ数の上限 Limit: aws.Int64(100), } // 上で定義したクエリを使って、データを取り出す。失敗すればinternal server error result, err := svc.Query(getQuery) if err != nil { return internalServerError() } // データが取り出せた場合、スレッドの一覧(=リスト)なのでそれを入れるためのThreadスライスを作成する threads := make([]Thread, 0) // 各々のスレッドは先ほどProjectionExpressionで指定したようにid, title, created_at, updated_atを持つオブジェクト // そしてそれがリストになっている(=ListOfMaps)が、この取り出したデータはDynamoDB用のフォーマットになっている。 // DynamoDBのデータフォーマットについてはhttps://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/Programming.LowLevelAPI.html // UnmarshalListOfMapsでスレッド構造体のスライスに入れられるようにデータを変換する。 if err := dynamodbattribute.UnmarshalListOfMaps(result.Items, &threads); err != nil { return internalServerError() } // json型に変換、失敗すればinternal server error jsonBody, err := json.Marshal(threads) if err != nil { return internalServerError() } // 取得したデータをjsonで返却する。 // originが異なるためAccess-Control-Allow-Originを付与 // 今回はコンセプトのために*にしているが、実際の場面では適切に設定してください。 return events.APIGatewayProxyResponse{ Body: string(jsonBody), StatusCode: http.StatusOK, Headers: map[string]string{ "Access-Control-Allow-Origin": "*", }, }, nil } // lambdaを実行 func main() { lambda.Start(Handler) }スレッドの作成
create_threads.gopackage main import ( "context" "net/http" "time" "github.com/aws/aws-lambda-go/events" "github.com/aws/aws-lambda-go/lambda" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/dynamodb" "github.com/aws/aws-sdk-go/service/dynamodb/dynamodbattribute" "github.com/google/uuid" "golang.org/x/sync/errgroup" ) type Request struct { Title string `json:"title"` Name string `json:"name"` Content string `json:"content"` } type response struct { Name string `json:"name"` CreatedAt int64 `json:"created_at"` Content string `json:"content"` } type responses struct { ThreadID string `json:"thread_id"` Responses []response `json:"responses"` } type thread struct { Part int `json:"part"` ID string `json:"id"` Title string `json:"title"` CreatedAt int64 `json:"created_at"` UpdatedAt int64 `json:"updated_at"` Name string `json:"name"` } func internalServerError() (events.APIGatewayProxyResponse, error) { return events.APIGatewayProxyResponse{ StatusCode: http.StatusInternalServerError, Headers: map[string]string{ "Access-Control-Allow-Origin": "*", }, }, nil } // データをデータベースに格納するための関数、タイムアウト処理用のcontextを受け取る。 func insertData(ctx context.Context, svc *dynamodb.DynamoDB, data interface{}, target string) error { // 格納するデータをdynamoDB用に変換 // 中身はただのmapなので手でも作れないことはない av, err := dynamodbattribute.MarshalMap(data) if err != nil { return internalServerError() } // データを格納するためのパラメータ putParams := &dynamodb.PutItemInput{ TableName: aws.String(target), Item: av, } // Timeoutになるか、データの格納が成功するまでループ for { select { case <-ctx.Done(): // タイムアウトした場合はcloudwatchにエラーログを残す return fmt.Errorf("inserting data into the table, %v failed", target) default: _, err = svc.PutItem(putParams) if err != nil { continue } return nil } } return nil } // ハンドラー関数、データをjsonで受け取るため、Request型のrequestを引数にもつ。 func handler(request Request) (events.APIGatewayProxyResponse, error) { name := request.Name title := request.Title content := request.Content sess, err := session.NewSession() if err != nil { return internalServerError() } svc := dynamodb.New(sess) // スレッドのIDをuuidv4で作成する threadID := uuid.New().String() // threadsテーブルに格納するデータの構造体 t := thread{ Part: 0, ID: threadID, Title: title, Name: name, CreatedAt: time.Now().Unix(), UpdatedAt: time.Now().Unix(), } // responsesテーブルに格納するデータの構造体 r := responses{ ThreadID: threadID, Responses: []response{ response{ Name: name, CreatedAt: time.Now().Unix(), Content: content, }, }, } // 上記二テーブルへのデータの格納はgoroutineで並列に実行 // goroutineでエラーを扱うためにerrgroupを使用 // タイムアウトしたらinternal server error eg, ctx := errgroup.WithContext(context.Background()) ctx, cancel := context.WithTimeout(ctx, 2*time.Second) defer cancel() eg.Go(func() error { return insertData(ctx, svc, t, "threads") }) eg.Go(func() error { return insertData(ctx, svc, r, "responses") }) if err := eg.Wait(); err != nil { return internalServerError() } // データの格納が完了 return events.APIGatewayProxyResponse{ StatusCode: http.StatusOK, Headers: map[string]string{ "Access-Control-Allow-Origin": "*", }, }, nil } func main() { lambda.Start(handler) }レス一覧の取得
get_responses.gopackage main import ( "encoding/json" "net/http" "github.com/aws/aws-lambda-go/events" "github.com/aws/aws-lambda-go/lambda" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/dynamodb" "github.com/aws/aws-sdk-go/service/dynamodb/dynamodbattribute" "reflect" ) type Request struct { ThreadID string `json:"id"` } type Response struct { Responses interface{} `json:"body"` } func internalServerError() (events.APIGatewayProxyResponse, error) { return events.APIGatewayProxyResponse{ StatusCode: http.StatusInternalServerError, Headers: map[string]string{ "Access-Control-Allow-Origin": "*", }, }, nil } // 取得するレスのIDをクエリパラメータもしくパスパラメータで受け取るため、events.APIGatewayProxyRequest型の引数を持つ。 func Handler(request events.APIGatewayProxyRequest) (interface{}, error) { // パスパラメータかクエリでスレのidを取得する。なければStatusBadRequest var id string if tmp, ok := request.PathParameters["id"]; ok == true { id = tmp } else if tmp, ok := request.QueryStringParameters["id"]; ok == true { id = tmp } else { return events.APIGatewayProxyResponse{ StatusCode: http.StatusBadRequest, Headers: map[string]string{ "Access-Control-Allow-Origin": "*", }, }, nil } sess, err := session.NewSession() if err != nil { return internalServerError() } svc := dynamodb.New(sess) // 今回は一つのデータを取得するのでGetItemInput型 getItemInput := &dynamodb.GetItemInput{ TableName: aws.String("responses"), // 単純なオブジェクトなので手でDynamoDBのフォーマットにする // もちろんMarshal関数を使って作ってもいい Key: map[string]*dynamodb.AttributeValue{ "thread_id": { S: aws.String(id), }, }, } result, err := svc.GetItem(getItemInput) if err != nil { return internalServerError() } // 返ってくるデータに合う構造体を作るのが面倒なのでinterface{}に入れてしまう // 今回は単一のオブジェクトなのでUnmarshalMap関数を使用する var responses interface{} if err := dynamodbattribute.UnmarshalMap(result.Item, &responses); err != nil { return internalServerError() } // 中身がjsonで、キーが何なのかもわかっているので、reflectパッケージを使って中身を取り出す rv := reflect.ValueOf(responses) res := rv.MapIndex(reflect.ValueOf("responses")).Interface() // 取り出した中身をjsonに変換する。失敗したらinternal server error jsonBody, err := json.Marshal(res) if err != nil { return internalServerError() } return events.APIGatewayProxyResponse{ Body: string(jsonBody), StatusCode: http.StatusOK, Headers: map[string]string{ "Access-Control-Allow-Origin": "*", }, }, nil } func main() { lambda.Start(Handler) }レスの追加
put_response.gopackage main import ( "context" "fmt" "net/http" "time" "github.com/aws/aws-lambda-go/events" "github.com/aws/aws-lambda-go/lambda" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/dynamodb" "github.com/aws/aws-sdk-go/service/dynamodb/dynamodbattribute" "golang.org/x/sync/errgroup" ) type Request struct { ThreadID string `json:"id"` Name string `json:"name"` Content string `json:"content"` } type Response struct { Name string `json:"name"` CreatedAt int64 `json:"created_at"` Content string `json:"content"` } type UpdatedAt struct { UpdatedAt int64 `json:"updated_at"` } func internalServerError() (events.APIGatewayProxyResponse, error) { return events.APIGatewayProxyResponse{ StatusCode: http.StatusInternalServerError, Headers: map[string]string{ "Access-Control-Allow-Origin": "*", }, }, nil } func updateData(ctx context.Context, svc *dynamodb.DynamoDB, data *dynamodb.UpdateItemInput) error { // 同じくタイムアウトまでデータの格納を試みる for { select { case <-ctx.Done(): return fmt.Errorf("Update data in the table, %v failed", aws.StringValue(data.TableName)) default: _, err := svc.UpdateItem(data) if err != nil { continue } return nil } } } func handler(req Request) (events.APIGatewayProxyResponse, error) { now := time.Now().Unix() sess, err := session.NewSession() if err != nil { return internalServerError() } svc := dynamodb.New(sess) r := []Response{Response{ Name: req.Name, CreatedAt: now, Content: req.Content, }} threadID := req.ThreadID response, err := dynamodbattribute.Marshal(r) if err != nil { return internalServerError() } // レスの追加は、データの更新にあたるのでUpdateItem rInputParams := &dynamodb.UpdateItemInput{ TableName: aws.String("responses"), Key: map[string]*dynamodb.AttributeValue{ "thread_id": {S: aws.String(threadID)}, }, // dynamoDBでのリストへの追加はlist_append関数を使う。第一引数に第二引数を追加したリストを返却するのでそれをそのままSETする UpdateExpression: aws.String("SET #ri = list_append(#ri, :vals)"), // 多分名前をつけた方がいい ExpressionAttributeNames: map[string]*string{ "#ri": aws.String("responses"), }, // 同上 ExpressionAttributeValues: map[string]*dynamodb.AttributeValue{ ":vals": response, }, } updatedAt, err := dynamodbattribute.Marshal(now) if err != nil { return internalServerError() } tInputParams := &dynamodb.UpdateItemInput{ TableName: aws.String("threads"), Key: map[string]*dynamodb.AttributeValue{ "part": {N: aws.String("0")}, "id": {S: aws.String(threadID)}, }, // 単純な値の上書きはSET a = bでできる UpdateExpression: aws.String("SET #ri = :vals"), ExpressionAttributeNames: map[string]*string{ "#ri": aws.String("updated_at"), }, ExpressionAttributeValues: map[string]*dynamodb.AttributeValue{ ":vals": updatedAt, }, } eg, ctx := errgroup.WithContext(context.Background()) ctx, cancel := context.WithTimeout(ctx, 2*time.Second) defer cancel() eg.Go(func() error { return updateData(ctx, svc, rInputParams) }) eg.Go(func() error { return updateData(ctx, svc, tInputParams) }) if err := eg.Wait(); err != nil { return internalServerError() } return events.APIGatewayProxyResponse{ StatusCode: 200, Headers: map[string]string{ "Access-Control-Allow-Origin": "*", }, }, nil } func main() { lambda.Start(handler) }AWS Lambdaでプログラムを実行するためには、実行したいファイルをzip形式でアップロード、もしくはウェブ上のエディタで直接コードを編集する必要があります。
Goに関しては前者しかできないようなので、これらのプログラムをまとめてコンパイルしてzipにするMakefileもついでに作成しました。all: get_threads.zip create_thread.zip get_responses.zip put_response.zip get_threads: get_threads.go GOOS=linux GOARCH=amd64 go build get_threads.go create_thread: create_thread.go GOOS=linux GOARCH=amd64 go build create_thread.go get_responses: get_responses.go GOOS=linux GOARCH=amd64 go build get_responses.go put_response: put_response.go GOOS=linux GOARCH=amd64 go build put_response.go get_threads.zip: get_threads zip $@ $< create_thread.zip: create_thread zip $@ $< get_responses.zip: get_responses zip $@ $< put_response.zip: put_response zip $@ $< clean: rm get_threads create_thread get_responses put_response *.zip完成した4つのバイナリのzipファイルを4つのAWS Lambdaの関数に登録すればLambda側の準備は完了です。
zipは関数コードのパネルからアップロードできます。
ハンドラには実行するファイル名を入力します。ここではget_threads.goをget_threadsにコンパイルしてget_threads.zipにしたものをアップロードしました。
API Gateway
AWS Lambdaはそのままだとhttpのリクエストをトリガーに発火できないため、リバースプロキシとしてAPI Gatewayを設置してそちらにアクセスされた場合にAWS Lambdaの特定の関数を発火させます。
また、この時パラメータをAWS Lambdaに渡すように設定する必要があります。
補足として、外部からのリクエストを受け付ける際はURLのオリジンが異なるためCORSを有効化する必要があります。現在はRest APIを作ると言う名目(=不特定多数からのアクセスを想定)のため制限はかけていませんが、実際のアプリケーションに組み込む際は適宜設定することをお勧めします。
ちなみに今回のAPIは不特定多数からのアクセスを想定してはいますが、悪戯されても嫌なのでスロットリングを有効化してレートとバーストに制限をかけています。
API Gatewayについての説明はたくさんあるので、省略気味に紹介します。
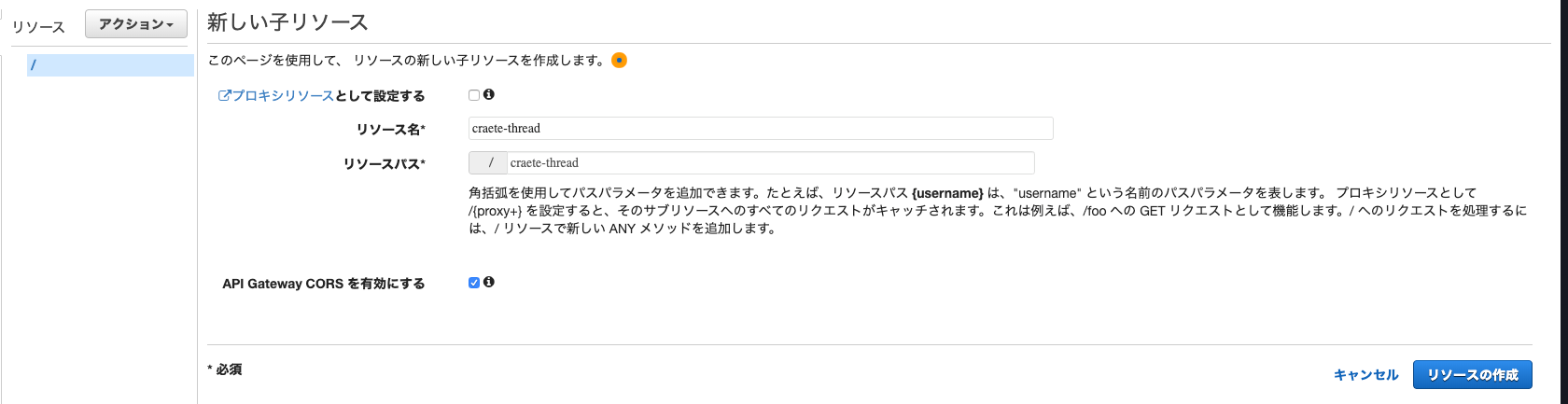
ルート直下に試しにcreate-threadのAPIを作成します。
まずリソース作成で適当なリソース名(今回はcreate-thread)を入力し、API Gateway CORS を有効にします。
これでOPTIONSメソッドが自動的に作られます。
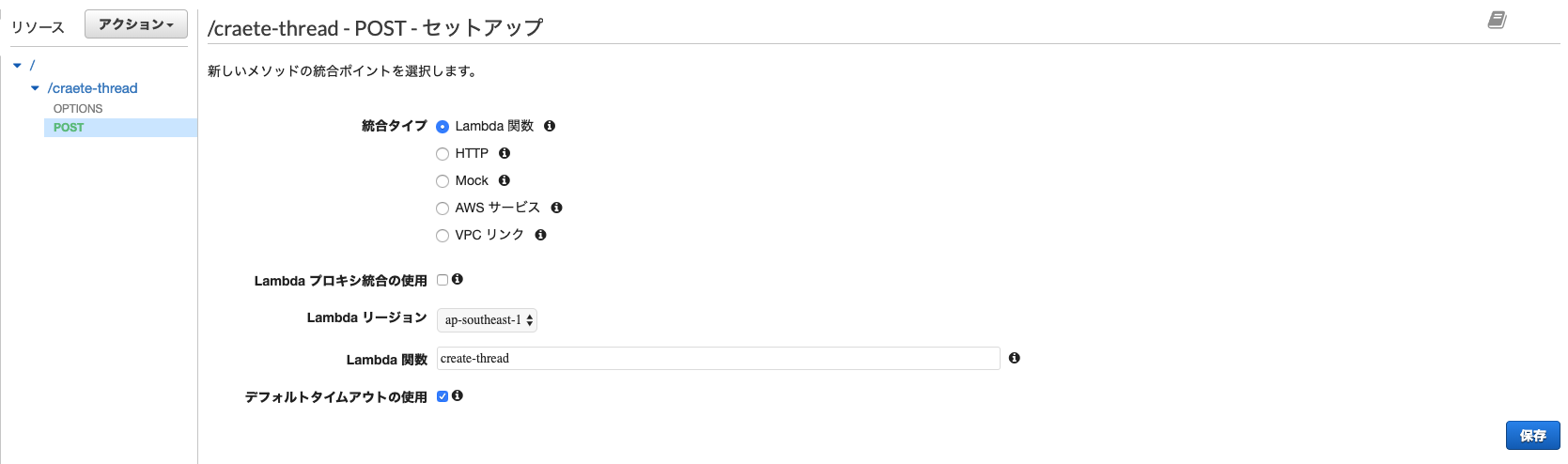
次にメソッド作成ですが、ここで使用するlambdaの関数を選択します。
ここで、Lambda プロキシ統合の使用にチェックを入れるかどうかですが、これはevents.APIGatewayProxyRequestでデータを受け渡ししたい場合はチェックを入れてください。
今回はcreate-thread, put-responseについてはjsonでデータを渡すだけでいいのでチェックせず、get-responsesについてはAPI Gatewayを通してパスパラメータを渡したいのでチェックを入れています。
get-threadsは何もデータを渡さないのでどちらでも問題ありません。
いずれにせよ全てのデータをevents.APIGatewayProxyRequestで受け取るならば全部チェックで問題ありません。
出力については、とりあえずevents.APIGatewayProxyResponse型で返せばいい感じにAPI Gatewayの方で流してくれるみたいです。各種設定を終えると以下のようになります。
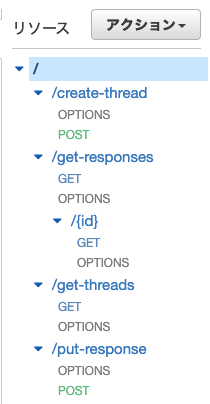
CORSを許可する設定になっていれば各種GETやPOSTなどのメソッドの下にOPTIONSメソッドが追加されます。
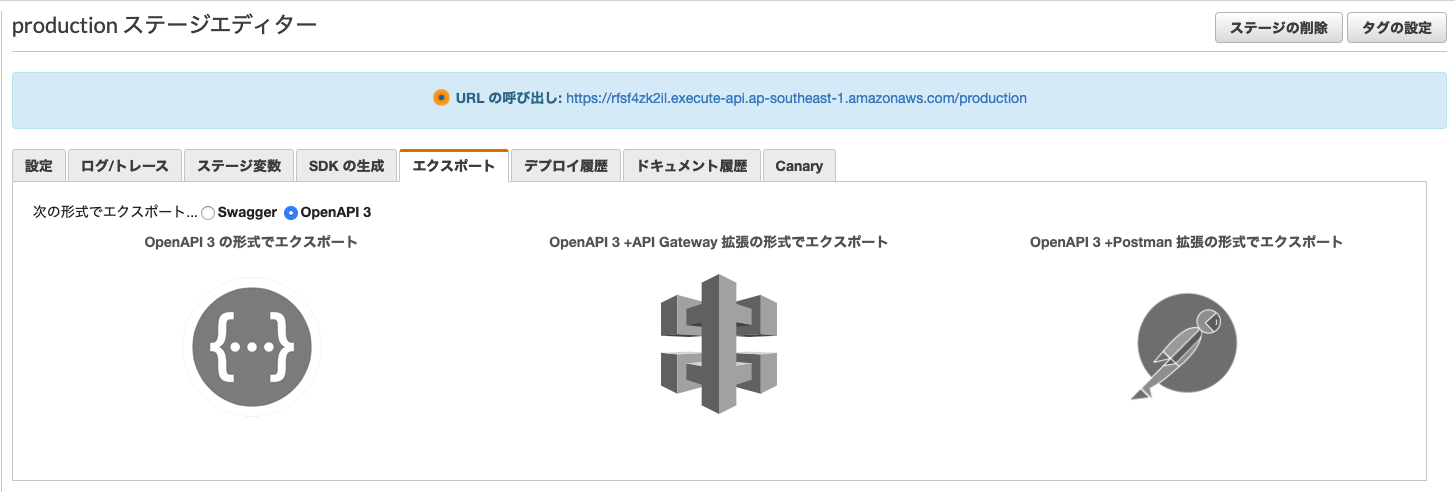
また、パスパラメータの設定ができていれば{id}のようにマッピングが表示されます。Open API
API GatewayではswaggerやOpenAPI3用のjsonやyamlをエクスポートできます。
ここでエクスポートしたファイルをswagger editorなどでインポートするとOpenAPI3でAPIの一覧が見られるようになります。
実際にOpenAPI3上でメソッドの実行もでき、レスポンスが返ってくるのが確認できます。
以上で、掲示板Rest APIが完成しました。
補足
今回はSDKを使ってGoでdynamoDBを操作しましたが、dynamoDBの癖の強さとGoの型ら辺が作用してかなりしんどいです。良い感じに面倒なところやってくれるライブラリがあるみたいなのでそっちを使った方がいいと思います。
https://github.com/guregu/dynamo終わりに
以上でバックエンドの方が完成しました。
~元々のコンセプトとしてはこれでいいのですが、正直バックエンドだけ用意してクライアントは自由に作ってねと言ったところでどうせ誰も作らないので~
ついでにReact Hooks, Redux Hooksが使いたいのもあってReactでクライアントの方も作ろうとしたのですが間に合いませんでした。(某アプリが悪い)
そのうちクライアント側も作って記事公開します。ちなみに実装は素のReactではなくReact staticを使っています。当初はgatsby.jsを使おうとしたのですが
どうもtypescriptで書くには早いかな感と、そもそもgraphQLを使ってないので止めました。
とは言え静的コンテンツとして配信するための静的化ができさえすればよく、肝心のコンテンツは動的に取得するので正直なんでもよかったのですが良い感じにシンプルそうなのでReact staticにしました。
React Hooks, Redux Hooksを使ったコンポーネントの作成やらなんやらはうまくいっているので、あとはcssがうまく書けたら公開になると思います。






- 投稿日:2019-12-18T21:52:10+09:00
ECS(Fargate)へssh接続してみた
はじめに
この記事はコンテナ勉強用として試したことまとめたものです。
ECS(Fargate)にsshログインする要件があったので実施したものをまとめました。Fargateについて
- Fargateにssh接続はできない。
- sshdをインストールして接続する必要がある。
テンプレート取得
- 以下リンクにsshd設定をしてdockerイメージ作成をしてくれるのでgit cloneする。
- https://github.com/sawanoboly/amazonlinux-sshd
git clone https://github.com/sawanoboly/amazonlinux-sshdイメージの作成
- 以下コマンドを実行してイメージを作成する。
- Dockerfileにsshdやawscliなどのインストール設定が書かれています。
docker build -t amazonlinux-sshd:latest .ECRにプッシュ
- ECRにログインする。
$(aws ecr get-login --no-include-email --region ap-northeast-1)
- タグ付けをする。
docker tag amazonlinux-sshd:latest 111111111111.dkr.ecr.ap-northeast-1.amazonaws.com/test-ecr-repo:latest
- プッシュする。
docker push 111111111111.dkr.ecr.ap-northeast-1.amazonaws.com/test-ecr-repo:latestECSデプロイの実施
サービスを設定する。
タスクを設定する。
ssh接続する
- 以下のような形でログイン確認ができる。
Last failed login: Wed Dec 18 12:44:50 UTC 2019 from kd111111111111.au-net.ne.jp on ssh:notty There was 1 failed login attempt since the last successful login. debug1: PAM: reinitializing credentials debug1: permanently_set_uid: 0/0 Environment: USER=root LOGNAME=root HOME=/root PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/opt/aws/bin MAIL=/var/mail/root SHELL=/bin/bash SSH_CLIENT=100.100.100.100 56702 22 SSH_CONNECTION=100.100.100.100 56702 101.101.101.101 22 SSH_TTY=/dev/pts/0 TERM=xterm AWS_CONTAINER_CREDENTIALS_RELATIVE_URI=/v2/credentials/1e23t01a-7a1e-3761-bc27-fa4b8473938373 AWS_EXECUTION_ENV=AWS_ECS_FARGATE AWS_DEFAULT_REGION=ap-northeast-1 AWS_REGION=ap-northeast-1 -bash-4.2#
- ロールにS3へのアクセス権限を付与すればS3からファイルをダウンロードすることもできる。
- 既存設定だとssh切断した際にコンテナが停止されてしまうので必要に応じて設定する必要あり。
まとめ
- Fargateだとsshできないかと思っていたが、やろうと思えばできる。
- sshdをインストールする必要があるのに気付けなかった。
参考


- 投稿日:2019-12-18T21:00:01+09:00
EC2インスタンスをAWS CDKとGitLab CIでCI/CDする
AWS FargateやAWS Lambdaなど、サーバレスな基盤活用が積極的に行われている昨今、EC2インスタンスがステートレスな場面で使われる機会は減ってきているのかなと思います。しかし、要件によってはEC2インスタンスを使わざるを得ない場面がまだあります。
例えばサーバレスあるいはクラウドネイティブな基盤では、IPアドレスは一時的なリソースであり、変わってしまうものであると考えるのが普通です。ところがアプリが接続する先のセキュリティ要件によって、ソースIPが固定であることを要求される場合もあるでしょう。そのようなときにはまだまだEC2インスタンスにEIPをアタッチして使う、昔ながらの構成が必要になります。
今回はそんなステートレスなワークロードであるにも関わらずEC2インスタンスを使わなくてはならないときに、dockerコンテナのようにImmutableにCI/CDする例をご紹介いたします。なお、CI/CDにはGitLab CI、プロビジョニングには皆様大好物であろうAWS CDKを使ってみたいと思います。
今回実現することの具体例
今回は対向システムがセキュリティによって特定の固定IPのみを接続許可していることを要件とします。このためECSタスクのような動的IPをもつリソースではなく、EC2インスタンス + EIPで固定IPを付与することを考えます。
上記の要件を満たしかつ、GitLab CIによってBlue/Greenデプロイメントを実現します。この際にAWS CDKを用いてEC2インスタンスのプロビジョニングを行います。
今回作ったコード
GitHubに公開しておりますので、細かいところはソースコードをご覧ください
https://github.com/bbrfkr/ec2-nginx-cdk-template簡単に解説...
CI/CD-buildステージ
まずはコードの静的解析を以下のように行います。ここではblack、flake8、mypyを実行していますね。
.gitlab-ci.ymlqualities_test: stage: build image: python:3.7 before_script: - pip3 install pipenv - cd cdk - pipenv install --system --dev script: - black . - flake8 . - mypy --config ./setup.cfg . except: - tags静的解析を通過したらdockerコンテナイメージをビルドします。EC2インスタンスをプロビジョニングしますが、nginxの起動はEC2インスタンス内部でdockerコンテナを起動することにより行いました。
トピックブランチが切られたときはコンテナイメージのビルドをし、実際にコンテナを起動してnginxのconfigが妥当なものかを確認しています。masterブランチにトピックブランチがマージされたときにはトピックブランチと同様の作業後、実際にコンテナレジストリに検証デプロイ用のイメージをpushします。タグが切られたときには既にテストを通過したコミットを利用するため、コンテナイメージのテストは省略して本番デプロイ用のイメージをビルド、レジストリにpushします。.gitlab-ci.yml.build_template: &build_template stage: build image: docker:latest variables: <<: *aws_environments TARGET_HOST: google.com RESOLVER_IP: 8.8.8.8 DOCKER_HOST: tcp://docker:2375/ DOCKER_DRIVER: overlay2 DOCKER_TLS_CERTDIR: "" services: - docker:dind dev_build: <<: *build_template before_script: - docker login -u $CI_REGISTRY_USER -p $CI_REGISTRY_PASSWORD $CI_REGISTRY script: - cd docker - docker pull $CI_REGISTRY_IMAGE:latest || true - > docker build --cache-from $CI_REGISTRY_IMAGE:latest --tag $CI_REGISTRY_IMAGE:$CI_COMMIT_SHA . - > docker run -e TARGET_HOST=$TARGET_HOST -e RESOLVER_IP=$RESOLVER_IP $CI_REGISTRY_IMAGE:$CI_COMMIT_SHA nginx -T except: - master - tags master_build: <<: *build_template before_script: - apk update && apk add python3 - pip3 install awscli - eval $(aws ecr get-login --no-include-email); - docker login -u $CI_REGISTRY_USER -p $CI_REGISTRY_PASSWORD $CI_REGISTRY script: - cd docker - docker pull $CI_REGISTRY_IMAGE:latest || true - > docker build --cache-from $CI_REGISTRY_IMAGE:latest --tag $CI_REGISTRY_IMAGE:latest --tag $ECR_REGISTRY_IMAGE:latest . - > docker run -e TARGET_HOST=$TARGET_HOST -e RESOLVER_IP=$RESOLVER_IP $CI_REGISTRY_IMAGE:latest nginx -T - docker push $CI_REGISTRY_IMAGE:latest - docker push $ECR_REGISTRY_IMAGE:latest only: - master release_build: <<: *build_template before_script: - apk update && apk add python3 - pip3 install awscli - eval $(aws ecr get-login --no-include-email); - docker login -u $CI_REGISTRY_USER -p $CI_REGISTRY_PASSWORD $CI_REGISTRY script: - cd docker - docker pull $CI_REGISTRY_IMAGE:latest || true - > docker build --cache-from $CI_REGISTRY_IMAGE:latest --tag $CI_REGISTRY_IMAGE:$CI_COMMIT_TAG --tag $ECR_REGISTRY_IMAGE:$CI_COMMIT_TAG . - docker push $CI_REGISTRY_IMAGE:$CI_COMMIT_TAG - docker push $ECR_REGISTRY_IMAGE:$CI_COMMIT_TAG only: - tagsCI/CD-provisionステージ
EC2インスタンスのプロビジョンはAWS CDKにおまかせです。デプロイ環境を環境変数
ENVIRONMENTで渡して、cdk deployコマンドを叩いて終わり! です。.gitlab-ci.yml.aws_environments: &aws_environments AWS_ACCESS_KEY_ID: $AWS_ACCESS_KEY_ID AWS_SECRET_ACCESS_KEY: $AWS_SECRET_ACCESS_KEY AWS_DEFAULT_REGION: $AWS_DEFAULT_REGION ECR_REGISTRY_IMAGE: $ECR_REGISTRY_IMAGE NGINX_STACK_PREFIX: ec2-nginx .provision_template: &provision_template stage: provision image: python:3.7 before_script: - apt update - apt install -y nodejs npm - pip3 install pipenv - cd cdk - npm install -g aws-cdk - pipenv install --system script: - cdk deploy master_provision: <<: *provision_template variables: <<: *aws_environments ENVIRONMENT: dev only: - master release_provision: <<: *provision_template variables: <<: *aws_environments ENVIRONMENT: prod only: - tagsCI/CD-deployステージ
デプロイはプロビジョニングされたEC2インスタンス上で正常にnginxが稼働していることを確認し、人間の手で承認をして行います。一度承認してしまえば新しいTarget GroupにALBの向き先とEIPのアタッチインスタンスが切り替わるようになっています。
.gitlab-ci.yml.deploy_template: &deploy_template stage: deploy image: python:3.7 before_script: - apt update - pip3 install awscli script: - > ALLOCATION_ID=$( aws ec2 describe-addresses --public-ips ${NGINX_ELASTIC_IP} --query Addresses[].AllocationId --output text ); NEW_NGINX_INSTANCE_ID=$( aws cloudformation describe-stacks --stack-name ${NEW_STACK_NAME} --query "Stacks[0].Outputs[?OutputKey=='NginxInstanceId'].OutputValue" --output text ); NEW_NGINX_TARGETGROUP_ARN=$( aws cloudformation describe-stacks --stack-name ${NEW_STACK_NAME} --query "Stacks[0].Outputs[?OutputKey=='NginxTargetGroupArn'].OutputValue" --output text ); - > aws ec2 associate-address --instance-id ${NEW_NGINX_INSTANCE_ID} --allocation-id ${ALLOCATION_ID} --allow-reassociation && aws elbv2 modify-listener --listener-arn ${NGINX_ALB_LISTENER_ARN} --default-actions Type=forward,TargetGroupArn=${NEW_NGINX_TARGETGROUP_ARN} master_deploy: <<: *deploy_template variables: <<: *aws_environments NGINX_ELASTIC_IP: $NGINX_ELASTIC_IP_DEV NGINX_ALB_LISTENER_ARN: $NGINX_ALB_LISTENER_ARN_DEV NEW_STACK_NAME: ${NGINX_STACK_PREFIX}-${CI_COMMIT_SHA} when: manual allow_failure: false only: - master release_deploy: <<: *deploy_template variables: <<: *aws_environments NGINX_ELASTIC_IP: $NGINX_ELASTIC_IP_PROD NGINX_ALB_LISTENER_ARN: $NGINX_ALB_LISTENER_ARN_PROD NEW_STACK_NAME: ${NGINX_STACK_PREFIX}-${CI_COMMIT_TAG} when: manual allow_failure: false only: - tagsCI/CD-cleanupステージ
最後が泥沼です… プロビジョニングやデプロイが途中で失敗したときを考慮して、クリーンアップ処理を自動化します。
正常にデプロイが完了した場合には、CDKが作成した古いCloudFormationスタックを消し、EIPのタグに新しいスタックの名前を付与します。このタグは次回のデプロイ時に、どのスタックが現在アクティブなのかを示す重要な役割を担います。先の「古いCloudFormationスタックを消し」といった作業ができるのも、このタグが古いスタック名を保持しているからです。
デプロイが失敗した場合は、EIPのタグから古いスタック名を参照し、古いスタック内のTarget GroupおよびEC2インスタンスにALBをEIPがそれぞれ向くように切り戻します。その後、新しく作られたスタックを削除します。.gitlab-ci.yml.cleanup_template: &cleanup_template stage: cleanup image: python:3.7 before_script: - apt update - pip3 install awscli # if deploying is succeeded, delete old stack and modify eip tag. .cleanup_old_script: &cleanup_old_script # get old stack name - > ALLOCATION_ID=$( aws ec2 describe-addresses --public-ips ${NGINX_ELASTIC_IP} --query Addresses[].AllocationId --output text ); OLD_STACK_NAME=$( aws ec2 describe-tags --filter "Name=key,Values=AssociateStackName" --query "Tags[?ResourceId=='$ALLOCATION_ID'].Value" --output text ) # delete old stack - | if [ -n "$OLD_STACK_NAME" ] ; then aws cloudformation delete-stack --stack-name ${OLD_STACK_NAME} fi # add new stack name tag to eip - > aws ec2 delete-tags --resources ${ALLOCATION_ID} --tags Key=AssociateStackName ; aws ec2 create-tags --resources ${ALLOCATION_ID} --tags Key=AssociateStackName,Value=${NEW_STACK_NAME} # if deploying is failed, recover eip direction and # listener default target group, then delete new stack. .cleanup_new_script: &cleanup_new_script # get old stack name - > ALLOCATION_ID=$( aws ec2 describe-addresses --public-ips ${NGINX_ELASTIC_IP} --query Addresses[].AllocationId --output text ); OLD_STACK_NAME=$( aws ec2 describe-tags --filter "Name=key,Values=AssociateStackName" --query "Tags[?ResourceId=='$ALLOCATION_ID'].Value" --output text ); - > OLD_NGINX_INSTANCE_ID=$( aws cloudformation describe-stacks --stack-name ${OLD_STACK_NAME} --query "Stacks[0].Outputs[?OutputKey=='NginxInstanceId'].OutputValue" --output text ); OLD_NGINX_TARGETGROUP_ARN=$( aws cloudformation describe-stacks --stack-name ${OLD_STACK_NAME} --query "Stacks[0].Outputs[?OutputKey=='NginxTargetGroupArn'].OutputValue" --output text ); - > aws ec2 associate-address --instance-id ${OLD_NGINX_INSTANCE_ID} --allocation-id ${ALLOCATION_ID} --allow-reassociation ; aws elbv2 modify-listener --listener-arn ${NGINX_ALB_LISTENER_ARN} --default-actions Type=forward,TargetGroupArn=${OLD_NGINX_TARGETGROUP_ARN} - | aws cloudformation describe-stacks --stack-name ${NEW_STACK_NAME} 2>&1 | grep "does not exist" if [ $? -eq 0 ]; then echo "cleanup target does not exist." else aws cloudformation delete-stack --stack-name ${NEW_STACK_NAME} fi master_cleanup_old: <<: *cleanup_template variables: <<: *aws_environments NGINX_ELASTIC_IP: $NGINX_ELASTIC_IP_DEV NEW_STACK_NAME: ${NGINX_STACK_PREFIX}-${CI_COMMIT_SHA} script: *cleanup_old_script when: on_success only: - master master_cleanup_new: <<: *cleanup_template variables: <<: *aws_environments NGINX_ELASTIC_IP: $NGINX_ELASTIC_IP_DEV NGINX_ALB_LISTENER_ARN: $NGINX_ALB_LISTENER_ARN_DEV NEW_STACK_NAME: ${NGINX_STACK_PREFIX}-${CI_COMMIT_SHA} script: *cleanup_new_script when: on_failure only: - master release_cleanup_old: <<: *cleanup_template variables: <<: *aws_environments NGINX_ELASTIC_IP: $NGINX_ELASTIC_IP_PROD NEW_STACK_NAME: ${NGINX_STACK_PREFIX}-${CI_COMMIT_TAG} script: *cleanup_old_script when: on_success only: - tags release_cleanup_new: <<: *cleanup_template variables: <<: *aws_environments NGINX_ELASTIC_IP: $NGINX_ELASTIC_IP_PROD NGINX_ALB_LISTENER_ARN: $NGINX_ALB_LISTENER_ARN_PROD NEW_STACK_NAME: ${NGINX_STACK_PREFIX}-${CI_COMMIT_TAG} script: *cleanup_new_script when: on_failure only: - tagsAWS CDK-app.py
次にAWS CDKのコードを見ていきましょう。pythonで書いていきます。
環境変数にENVIRONMENTをexportしてcdk deployすると、各環境にあわせたconfigを読み取ってプロビジョニングを行うようにしています。app.py... from nginx_ec2.nginx_ec2_stack import NginxEc2Stack ... with open(f"config/{os.environ.get('ENVIRONMENT')}/nginx-ec2.yaml") as f: config = yaml.safe_load(f) if os.environ.get("ENVIRONMENT") == "dev": stack_suffix = os.environ.get("CI_COMMIT_SHA", default="dev") elif os.environ.get("ENVIRONMENT") == "prod": stack_suffix = os.environ.get("CI_COMMIT_TAG", default="dev") else: stack_suffix = "dev" NginxEc2Stack(app, f"{os.environ.get('NGINX_STACK_PREFIX')}-{stack_suffix}", config) ...AWS CDK-nginx-ec2-stack.py
実際にCloudFormationスタックを作成するコードがこちらです。
UserDataのJinja2テンプレートuser_data.txt.j2を予めconfigディレクトリ内に入れておきます。Jinja2テンプレートにしているのは、configで受け取ったパラメータに応じてnginxのデプロイ方法(主にnginxコンテナに渡す環境変数)を変えたいからです。configで受け取ったその他のパラメータはスタックリソースのパラメータにそれぞれ代入していきます。nginx-ec2-stack.py... class NginxEc2Stack(core.Stack): def __init__(self, scope: core.Construct, id: str, config: dict, **kwargs) -> None: super().__init__(scope, id, **kwargs) with open(f"config/{os.environ.get('ENVIRONMENT')}/user_data.txt.j2", "r") as f: template = Template(f.read()) user_data = base64.encodestring( template.render(env=os.environ, config=config, stack=id).encode("utf8") ).decode("ascii") nginx_ec2 = CfnInstance( self, "NginxEc2", block_device_mappings=config.get("block_device_mappings"), iam_instance_profile=config.get("iam_instance_profile"), image_id=config.get("image_id"), instance_type=config.get("instance_type"), key_name=config.get("key_name"), network_interfaces=config.get("network_interfaces"), user_data=user_data, tags=config.get("tags"), ) nginx_ec2.cfn_options.creation_policy = CfnCreationPolicy( resource_signal=CfnResourceSignal(count=1, timeout="PT5M") ) nginx_targetgroup = CfnTargetGroup( self, "NginxTargetGroup", vpc_id=config.get("tg_vpc_id"), protocol=config.get("tg_protocol"), port=config.get("tg_port"), health_check_enabled=True, health_check_protocol=config.get("tg_healthcheck_protocol"), health_check_port=config.get("tg_health_check_port"), health_check_path=config.get("tg_healthcheck_path"), health_check_timeout_seconds=config.get("tg_health_check_timeout_seconds"), health_check_interval_seconds=config.get( "tg_health_check_interval_seconds" ), healthy_threshold_count=config.get("tg_healthy_threshold_count"), unhealthy_threshold_count=config.get("tg_unhealthy_threshold_count"), matcher=config.get("tg_matcher"), tags=config.get("tg_tags"), target_group_attributes=config.get("tg_target_group_attributes"), targets=[ CfnTargetGroup.TargetDescriptionProperty( id=nginx_ec2.ref, port=config.get("tg_target_port") ) ], ) ...まとめ
このようにEC2インスタンス、即ち仮想マシンでもImmutableにCI/CDすることができます。これはつまり仮想マシンでもクラウドネイティブっぽい使い方ができる良い例ではないかと思います。真にクラウドネイティブになるためには固定IPからの呪縛に打ち勝つ必要がありますが…
CDK、便利で楽しいので是非活用してみてくださいね


- 投稿日:2019-12-18T20:51:59+09:00
未経験が受託企業に入って半年経ったので、学んだスキル全部書いてみる
はじめに
今年2019年6月にエンジニアとして晴れてキャリアをスタートさせました。
それから約半年間で本当にいろいろなことを学ばせて頂いたので、私ごとですが簡単に学んだことをまとめます。もちろんマスターなんてしておらず、全てが勉強中なうえ、なんならちょっとかじっただけのものまで書いてますので悪しからず。
一概に未経験といっても、自社開発/受託企業/SES企業、大手/メガベンチャー/スタートアップ、元IT業界/全くの素人、普段からパソコン触ってた/触ってない等いろいろなキャリアの始め方があると思うので、平均的な成長度合いなのかどうかは不明ですが、ほんの一例としてご参考ください。
■簡単な経歴
・良くも悪くもない普通の大卒
パソコンスキルはitunesで音楽入れる程度
・某アパレルチェーン企業で3年ほど勤務
内2年管理職
パソコンスキルはWordで毎週報告書を書く程度
・2018/12〜 Mac購入
某オンラインスクールで勉強開始
・2019/3〜 独学開始、都内もくもく会に週1参加、Menta契約、アプリ作成等
・2019/6〜 就職
・2019/12 現在0ヶ月〜半年で学んだこと
1)プログラミング技術
Ruby/Rails
ほぼ毎日触っていました。
基本的には既存のコードや他PJのコードをマネて書くことが多いですが、必ず意味を理解しながら次へ繋げています。
ただやはりまだまだ分からないことが多く、日々痛感しています。ここでいろいろ書蹴たらいいのですがキリがなさそうなので、また別の記事で書きます。
HTML/CSS
Railsに合わせてHTMLはslimで書いていました。
特にCSSの方は奥深すぎてほんとナメてました。めちゃくちゃ難しいです。
新システム開発時にいかに大勢のユーザーに"初めから"良い印象を持ってもらえるかと考えた時に、画面作成でかなり手こずりました。SQL
本番データをよく触らせて貰える案件だったので、抽出しなければならないことが多くありました。
入社前は全く勉強できてなかったのですが、基礎的なところからサブクエリの書き方、
inner joinleft outer joinconcatあたりに触れ、
加えてlimitをつけずクエリ重すぎて本番が落ちる等も経験できたので、とても良い経験()になりました。DB
上記と同じく、よく触らせて貰えました。
案件JOIN当初、railsdbから大事なレコードをそのまま物理削除してしまい、その直後5分後くらいに先方から怒りの電話がかかってきたのは良い思い出()です。mysqlコマンドやdump、トランザクションの仕組みなど知ることができました。
Git
入社前からもちろん触っていましたが、
git mergeやgit clone等は正直あまりよく分かっていませんでした。現在でもまだそこまで幅広く扱えてないですが、
それでもgit add前にgit statusやgit diffで変更内容をちゃんと確認する習慣付けや、コンフリクト発生時の解消方法、git fetchgit stashgit reset --hard HEAD^あたりを日常的に使えるようになりました。IDE操作
cloud9で開発していました(これ言うとよく社外の方に珍しいと言われます)。
https://qiita.com/shin1kt/items/03eed49c12104002a2c7
こちらにあるような様々なショートカットを教えて頂き、いち早く見たいファイルを引っ張り出したり、直前の操作を取り消す/戻すなど、格段にスピードが速くなりました(当たり前のことかも知れませんが)。
これを通してMacのショートカットキーを覚えたりすることも多かったです。
いずれはVScodeとか使って開発したいなという思いも密かにあります。テストの書き方
Rubyでminitestを書きました。
入社前はRSpecとともに中途半端な勉強で終わっていたので、実務を通して、調べながらであればなんとか書けるようになったかなと思います。
ただ担当PJのテスト管理が少し甘そうなので、しっかりテストを書いたら実際はどうなるのかな、と気になってはいます。セキュリティ対策
新システム開発の中でセキュリティ対策をしました。
Railsガイド等を参考に、
・総当たり攻撃・辞書攻撃対策
・CSRF対策
・セッションハイジャック対策
・個人情報保護(クライアントやログ)
・SSL化
・エラー文表記修正(「入力されたユーザー名は登録されていません」のような具体的なメッセージにしない等)
・パスワード強化
・リダイレクトとファイル対策
あたりを一通りやったかなと思います(まだまだあると思いますが)。今後はAWS側でのセキュリティ対策もしたいです。
Vim
いわゆるVimmerとは程遠いのですが、
本番サーバー内でdumpファイルを探したり、落ちた原因を探るためコードを直接いじってみたりして、黒い画面に抵抗がなくなる程度にはなりました。
cdで(地道に)いろんなディレクトリに寄る旅をしたりしたので、普段全く触れないようなディレクトリやファイルがまだまだたくさんあるんだなーというのも実感できました。これで半ば強制的にLinuxの簡単な勉強にも繋がっていきました。
AWS
社内で勉強会を開催し、基礎システムの概要から掴んでみたり、PJごとにシステム構成を見ていったりしました。
ちなみに自分の案件はEC2を使わずLightsailというパッケージを使ってサーバーが構築されていたため少し特殊だったのですが、それも含め良い知見になりました。早いうちにこちらの資格取得まで結びつけたいです。。。
AWSソリューションズアーキテクトアソシエイトステージング/本番環境へのデプロイ
今でもそうですが毎週のようにリリース作業を行なっているので、抵抗がないのが怖いくらいの感覚になりました(おそらく異常なんですよね、これ)。
上記で述べたようにいろんな場面で何度もやらかして先輩方に迷惑をかけまくっているので、
今では ローカルでの確認/ステージング(テスト)環境での確認・打鍵/コマンドのテンプレ化・誤字脱字チェック 等をしっかり行なう習慣が(嫌でも)つきました。新システム作成〜システム構成〜リリース
AWSを触るということも含め、とても良い経験になりました。
DBは既存システムのものを共用したので当初「スキーマファイルはどこ??」「カラムはどうやって追加するの??」「ユーザーのパスワードが入ったかどうかってどこで確認できるの??」などパニックになったり、
まず初めにサーバーを立てようと既存サーバーのスナップショットを取ろうとしたらEC2すら使っておらず出鼻をくじかれたり、
ドメインとサブドメインの違いが分からずしばらくIPアドレスをそのまま打ち込んで画面を開いたり、
今となっては馬鹿らしいですが当時は本気で取り組んでいました。2)顧客対応
タスク/スケジュール管理
タスク量は多くマルチタスクになりがちなので、優先順位を決めたり、話が出たら漏れのないようにすぐメモしたり、不明点はすぐ聞くようにしました。
頻繁なチャットのやりとりも含め、1つのことのなかなか集中できない難しさを痛感しています。
うまくやるコツをぜひ教えて頂きたいです。工数見積もり
このタスクならだいたいこれくらいかかるだろうな、という予想を自分なりにするようにしていました。
それでもまだまだ多く工数を見積もってしまっているらしく、上司と答えあわせをするといつも大体半分くらいに修正されます泣とても難しいです。
見積書/請求書の書き方、渡し方
受託はお客様に納品して初めてお金を頂くので、書類もしっかりしたものを書く必要がありました。
渡す時期やお会いした時の渡すタイミング等にも気をつけたり、PDFでもデータ送信も行なったりしました(どこまでやるかはお客様にもよると思います)。肝心の月単位での工数計算に関しては、、、、まだまだなので、これから勉強です。
お客様を運用に乗せる気遣い/気配り
担当していた案件のお客様が、非IT/多くの部署や担当者がいる/レガシーな問題を抱えるお客様、ということも影響し、そもそも導入を嫌がっていたり、依頼したことを予定通りやってくれなかったりしました。
そのため、システムを入れるメリットや現状との具体的な比較、システムの使い方を実際に見せるなどしてお客様の抵抗を少しでも軽減できるように努めたり、食事をご一緒して少しでも親近感を持って頂けるようにしました。協力的なお客様であれば問題なかったと思うのですが、これはお会いするたびになかなか骨の折れる業務でした。
大人数に向けたシステム説明
結構大きなリリースを控えると、60名ほどのお客様の前で自分がシステムの説明をしました。
人前で説明するのはあまり緊張しない方なので助かりましたが、丁寧に説明できなかったりうまく伝えられなかった点があり、誰でも理解できる目線での話し方と内容にしないといけないと反省しました。
ただこれが、逆にベテランエンジニアだらけだった場合にどうなってたかと考えると、、、それも恐ろしいものです。
3)その他
基本的なPC操作
そもそも自分はPCに疎かったので、現役エンジニアに囲まれながら操作することでいろいろと技を盗めました。
ファイル形式の違いやデータ管理、ショートカットあたりでしょうか。タイピングスピードに関してはまだなかなかにひどいので、今後ブラインドタッチができるように頑張ります。
スプレッドシートの使い方
お客様と共有で使うものを中心に、スプレッドシートの使い方を覚えました。
ワードこそ前職で触っていましたが、エクセルは触ったことがなく今新たに使い方を覚えるのもちょっと億劫だったので、このタイミングでスプレッドシートだけでも使えるようになれて良かったです。
基本何にでも使えるので、やはり便利です。
チーム開発の流れ
Gitを中心に、ブランチをどのように管理するか、チーム全体でのコード管理はどうするか、プルリクをレビュー頂いたらどう修正して再レビュー頂くか、OKだったらどうマージするか、本番にはどのタイミングで反映させるか、ローカルの最新化はどうやるか、など一通り掴めました。
独学では単純に「コミット→プッシュ! コミット→プッシュ!」しかやってなかったので、現場で働かないとこれはなかなか掴めないですね。
分からない点の質問の仕方
初めは詰まったらすぐ質問してしまってましたが、まずは自分でひたすらググりまくって、それでもダメなら一体何がわからないのか質問内容をしっかり文章にまとめてから質問するようにしました。
質問内容をまとめているうちに、問題を俯瞰して見ることができたりググり方を変えたりすることに繋がったり、ググり方のコツを覚えるとだんだんとググり力も上がっていったりしたので、結構効果はあったと思います。
また周辺知識の定着度合いに比例して、「調べればわかりそう」と思うことも増えていきました。半年〜1年でやりたいこと
ここからはほんのメモ書き程度に、自分が今後の半年で学んでいきたいスキルをバーっと書いていきます。
先にこれ勉強すればいいのに、とかありましたら、ご指摘頂けると嬉しいです。フロント書きたい
ベタにvue.jsかreactあたり触れたいです。
、、、、の前にJSの基礎からしっかりやりたいですね。インフラを深く知る
AWSは基礎システムしかまだ触っていないので、よく聞くけどいまいち分かってないものから知見を深めていきたいです。
とりあえずセキュリティあたりが見れるようになると嬉しい。PLでチーム管理
責任を持って開発したり、スケジュール組んだりして、案件全体の流れを把握する経験がしたいです。
振られたタスクを必死でやってく、だけでは見えないところも多々あると思うので。デザイン
新システムをリリースした時に、まざまざとデザイン力のなさを感じました。
Web制作みたいなところの勉強をしたいです。
有名どころのデザインの本から数冊探して勉強してみます。IT基礎
いわゆるコンピューターリテラシーというものを全く知らないのはエンジニアとしてマズいと思うので、基礎の基礎であるITパスポートから基本情報の午前の出題範囲くらいは頭に入れておきたいです。
ググり力
マイナーな開発を調べている時に見る、英語の記事やドキュメントにまだまだ抵抗があります。
Qiita様や先人が書かれたブログ記事には日々お世話になっていますが、そろそろ幅広く読めるようになりたいです。
- 投稿日:2019-12-18T20:28:55+09:00
AWS環境構築(用語編)~EC2~
AWSの基本サービスEC2
今回はEC2についてまとめてみた。
詳細は公式ウェブサイトに譲ります。EC2とElastic Compute Cloudの略で一言で説明するなら、Amazonが提供する仮想サーバーである。
自分たちでサービスを構築する場合、まずサーバーを購入し、設置して環境を設定する必要があります。もちろん、サーバーを置く場所を適当にするわけにもいかないですし、24時間稼働する必要があります。また、その時は十分だと思っていたスペックも不足することも十分にありえます。このあたりの煩わしさをAmazonさんにお任せしてやってもらうということです。まずEC2を使用する上で頻繁に登場する単語がインスタンスという単語です。初めてその単語を聞いた時は全くなんなのか理解できませんでした。
インスタンスとは一言でいうならばOS付きの仮想サーバーです。このインスタンスを起動させるにあたり、OSの種類、インスタンスタイプを選択します。インスタンスタイプとは要はスペックです。めちゃくちゃ種類があって完璧には把握していませんが、Qiitaなどでよく見かけるt2 microというものは無料です。もちろん、それぞれの用途によって変更すべき部分です。
(インスタンスタイプ一覧)以下にEC2作成で登場する単語についてまとめます。
AMI(公式サイト)
Amazon Machine Imageの略。インスタンスを使用する時に必要となる。インスタンス起動に必要な情報が用意されている。
IOPS
Input Output per seconds の略。1秒間に何回データを出し入れできるか
パブリックアクセス
ユーザーがアクセスできるかどうか
その他の関連記事
- 投稿日:2019-12-18T18:58:46+09:00
Amazon CognitoのUser Groupを利用した権限管理について本気出して考えてみた。
Amazon CognitoのUser Groupを利用した権限管理について本気出して考えてみた。
パーソルプロセス&テクノロジー株式会社のAdvent Calendar 19日目の記事です。
Azureの記事が多い中ですが、堂々とAWSの記事を書いていこうと思います。
今回は何番煎じかわかりませんが、Amazon Cognitoを利用して役職や階級の概念を持つサービス内の権限管理を行います。
順を追って構築していくので、記事を読み終わった際に 権限管理が可能な環境が構築できる状態 になっていただければ幸いです。
あくまで『権限管理を行う』が目的です。個々の解説は適当なので、公式のドキュメントを合わせて読んでみてください。
不明点あれば質問いただければ返答します(正しい答えが返ってくるとは言っていない。)最初に
Cognitoは、認証認可、またユーザーの管理なども兼ね備えたフルマネージドなサービスです。
GoogleやFaceBookを利用したソーシャルログインも実現することもできます。今回使う機能
その他AWSサービス(今回IAMの確認にAPIを利用します。)
今回使用するIAM(かさばるので最後に明記します。)
Unauth_Role(Cognito_testUnauth_Role)
認証されていないユーザーとしてIdPool作成時に作成できます。
Auth_Role(Cognito_testauth_Role)
認証されたユーザーとしてIdPool作成時に作成できます。
God_Role(CognitoGroup_God_Role)
APIを叩く権限を与えます。設定のイメージ
どこにも認証を受けていないユーザー → Unauth_Roleを付与
Cognitoによる認証をうけたが、Groupなどには所属していないユーザー → Auth_Roleを付与
Cognitoによる認証をうけ、God_Groupに所属しているユーザー → God_Roleを付与
設定手順
順を追って設定していきます。
言及のない設定は全てデフォルトで作成します。1. API作成
Authの確認を行いたいのでMockですがIAMによる認可をかけます。
デプロイ後、発行されるURLをブラウザで叩いてみて、権限が足りないよというエラーが表示されるとAPIの設定は完了です。
2. UserPool作成
今回IdPoolとの紐付けにアプリクライアントが必要なのでクライアントIDを発行します。
3. IdPool作成
急にスペースを許容するFormに適当に名前を入力し、 認証されていないID にチェックを入れます。IdPoolの設定は後から編集が効くものばかりなので必要な項目だけ設定します。
続いて認証プロバイダーの項目を開き、 ユーザープールID・アプリクライアントID に先ほど作成したUserPoolの情報を入力しプールの作成を完了させます。Identify the IAM roles to use with your new identity pool
ここでは作成したIdPoolで付与するRoleを作成するページです。
詳細を開くとこんな感じになっています。すでに作成してあるRoleを選択することも可能ですが、今回は自動生成されたものをそのまま利用するので、許可を選択しましょう。
これでIdPoolとPoolで認証を受けたユーザーに対するRoleの作成が完了しました。
ダッシュボードを開くと認証されたユーザーの数や認証に利用しているプロバイダーの情報が表示されています。次に右上、IdPoolの編集を選択します。
認証プロバイダーの項目を開くと、 認証されたロールの選択 という項目が増えています。
ここでは認証を受けたユーザー(UserPoolでサインアップを行ったユーザー)に付与するロールを選択することができます。
今回は トークンからRoleを選択する。 を選択し、変更の保存を行います。
これでIdPoolの設定は完了です。
4. 最後にGod_Roleと付与するGroupを作成します
エンティティの種類はウェブIDを選択します。
手順に沿って作成することでIAMRoleにIDPoolとの信頼関係を持たせることができます。
作成後、ロールの詳細が以下のようになっていれば完了です。
次にUserpoolにGroupを作成しましょう。
IAMロールは上で作成したGod_Roleを設定します。
これで一通りの設定は完了しました。
動作確認
ここから動作確認をしていきます。
APIGatewayのIAM認証付きのAPIをJavascriptから叩く
Cognitoユーザープールを使ってみました
このあたりのデモアプリや手順を拝借します。1.ログインし、Credentialsを確認する
うまく情報を取得することが出来ていますね。2.APIを叩いてみる
失敗しました。
ログを確認するとこのユーザーが持っているRoleはただのAuth_Roleだからということがわかります。3.ユーザーをグループに追加し、God_Roleを付与する
$ aws cognito-idp admin-add-user-to-group \ --user-pool-id ${userPoolId} \ --username testuser \ --group-name Godユーザーをグループに追加します。
ここまでコンソールでやっていたのに、捻りを出すために急にCLIで追加してみます。4.再度APIを叩いてみる
叩けましたね。
ここでIdTokenを確認してみましょう。
公式のDocumentから読み解くと
cognito:preferred_role クレームはロール ARN です。
cognito:roles クレームは、許可されたロール ARN のセットを含むカンマ区切りの文字列です。つまり、 cognito:preferred_role の値が現在セットされているRoleというわけになります。
今回はtestuserに対してGod_Roleが付与されているかつ、IAM認可をかけたAPIをキックすることが出来たので、正しい状態であることがわかります。
詳しくは本記事の参考資料のロールベースアクセスコントロールの『トークンを使用したユーザーへのロールの割り当て』を読んでください。Token分解
Cognitoから受け取る各種TokenはBase64でデコードすることが可能です。
もし上手く権限が付与できていない、権限は付与できているけどなぜか拒否される場合は実際にデコードしてユーザーが持つ情報を確認すると、問題の解決に繋がります。echo {$IdToken} | cut -d'.' -f 2 | base64 -d最後に
少し長くなってしまいましたが、基本の設定・動作確認は以上になります。
実運用で使う際には恐らく複数グループを作成することにもなるし、一人のユーザーを複数グループに所属させるケースもあると思います。
この記事の内容でも、当然のように私も丸2,3日程度は頭を抱えつつドキュメントとにらめっこをしていました。
認証周りは難しく感じますが、コード上で管理するよりもセキュアにかつ変更も容易であることから、Cognitoで権限回りを一括管理させることが出来ると、アプリケーションの中身もスッキリするんじゃないかなと思います。実際に理解が進んでくると、意外とシンプルだなと思ったりするのでめげずにドキュメントを見渡してみてください。
以下参考資料になります。
今回使用したIAMPolicy
Cognito_testUnauth_Role(認証されていないユーザーとしてIdPool作成時に作成できます。)
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "mobileanalytics:PutEvents", "cognito-sync:*" ], "Resource": [ "*" ] } ] }Cognito_testauth_Role(認証されたユーザーとしてIdPool作成時に作成できます。)
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "mobileanalytics:PutEvents", "cognito-sync:*", "cognito-identity:*" ], "Resource": [ "*" ] } ] }CognitoGroup_God_Role(APIを叩く権限を与えます)
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "execute-api:Invoke" ], "Resource": [ "arn:aws:execute-api:ap-northeast-1:{$AWSccountID}:{$APIgatewayID}:/*" ] } ] }参考資料
Cognitoのサインイン時に取得できる、IDトークン・アクセストークン・更新トークンを理解する
APIGatewayのIAM認証付きのAPIをJavascriptから叩く
Cognitoユーザープールを使ってみました
ロールベースアクセスコントロール
Amazon Cognito グループ、およびきめ細かなロールベースのアクセス制御












- 投稿日:2019-12-18T18:35:57+09:00
AWS vs. Azure: やらかさないで!Azure ではOSからシャットダウンしてもインスタンス利用料が継続する...
課金体系について相違があるのでWindowsやLinux機を立ち上げることを主にハイレベルで差がありそうな部分を中心に整理してみました。Azureに特に気を付けないといけない注意点がある反面、Azureの方が有利となるケースもありました。
AWS
OSを停止するとstoppedになる。後述のterminatedに直接することもできる。
この状態であればインスタンス実行時間としては課金されない。
普通に考えると自然なケース。
terminatedは不要システム自体の廃止。当然課金されない。
1時間単位または1秒(1分)単位での課金でOSイメージ
(AMI)や契約形態により異なるが、
オンデマンドでWindowsを使うと1時間単位の模様。
システム停止や再起動をするとその時点で1時間使用したとみなされて課金される。
クライアントPCのような扱いで短時間、頻繁な停止・未利用時間や
再起動が伴う作業には不向き。
固定IP利用の場合、インスタンス実行中は追加請求がないが停止して割り当て解除しないと費用がかかる。
(出所)https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/ec2-instance-lifecycle.html*EC2のハイレベル価格体系(詳細はAWS公式情報を参考のこと)*
●オンデマンド:使った分だけ支払い。一番わかりやすくてオーソドックス。
●(2019年11月導入)Savings Plan:長期契約、年額コミットメントに対する割引で時間当たり単価ないしはリージョン毎に指定された特定インスタンスを使用するコミット。プランによってはEC2以外もまとめることができる対象となるサービスがある。
●スポット:問答無用で2分警告で停止される恐れがあるがリソースに空きがある場合に事前承認されれば割安利用可。
●リザーブド:キャンセル不可が前提。確定スペック、確定(予約)時間で長期契約(プランによって上位タイプへ変更可能(convertible)とするプランとできないプランがある)。Azure
OSからシャットダウンコマンドで停止しても課金が継続される(stopped / 停止済み)。
AWSになれていると勘違いしてとんでもないコスト発生危険あり。
割り当て解除という処理を踏まないといけない。1秒単位の課金で請求時合算で1分に満たないものは切り捨て。
Azure Portalから停止した場合にのみ割り当て解除になる
(Stopoped (Deallocated) 停止済み(割り当て解除済))。
固定IP利用の場合、(現代のリソースマネージャーを経由したインスタンスの作り方では)AWSと異なりインスタンスが実行されていても費用がかかる違いがある。
(出所)
https://docs.microsoft.com/ja-jp/azure/virtual-machines/windows/states-lifecycle*Virtual Machinesのハイレベル価格体系(詳細はAzure公式情報を参考のこと)*
●従量:使った分だけ支払い。一番わかりやすくてオーソドックス。
●(2019年11月から?)「Azureの予約」:年額コミットメントに対する割引。Virtual Machinesと他にいくつかまとめることができる対象となるリソースがある。
●スポット:問答無用で30秒警告で停止される恐れがあるがリソースに空きがある場合に事前承認されれば割安利用可。
●リザーブド:確定スペック、確定(予約)時間で長期契約。中途解約料支払いで中途解約ができることがある。
●Dev/Test:開発/テストでの使用に限定で個人向け、チーム向けのパッケージがある。Windows ServerかSQL ServerでSA付ライセンスを保有している場合はハイブリッド価格というもので一般向け料金より安くなることがある。


- 投稿日:2019-12-18T17:46:54+09:00
AWS container re:capのまとめ
ただの備忘録
ECS → EC2 → fargate(仮想マシンの管理) →EKS(kubernetesの管理)→ECR
WEB上の8割のコンテナはAWSで動いている。Firelens
コンテナログを容易に取り扱う為の新しい機能。
Fluentb?
ログはfirehouseに飛んでいく。ECS capacity provides
コンテナ上の仮想マシンのキャパシティを管理する。
オンデマンドとスポットにキャパを分散。ECS cluster EC2 auto scaling
キャパシティありきから、必要なキャパシティをECSが判断する。
ECSキャパシティプロバイダーがスケーリングを直接制御している。
アプリの動きに合わせてキャパシティを変更してくれるので、
今までのキャパシティありきの開発と逆の発想。コントロールプレーン
コンフリクト 対立
フルマネージド サーバー運用の全てを代行する。
アップフロント 先払いFagate→コンテナ実行のツール
ポッド
- 投稿日:2019-12-18T17:28:24+09:00
AWS MFA(2段階認証)の有効化
AWSでの2段階認証
AWSにおいて2段階認証の有効化手順を説明します。
下記のように何種類か有りますが、今回は、「仮想デバイス(スマホアプリ)」を利用します。
- 仮想MFAデバイス
スマホ等のアプリで認証する方法- U2Fセキュリティキー
コンピュータのUSBポートに接続するデバイスを用意し、認証する方法- ハードウェアMFAデバイス
専用のMFAデバイスを用意し、デバイス上のコードを入力することで認証する方法- SMSテキストメッセージベースMFA
SMSでMFA認証する方法
※まもなくサポートを終了する予定(2019年12月現在)MFA認証を設定する
設定の流れは以下の通りです。
1. 設定したいIAMユーザーでログインIAMユーザーでログイン
AWSのログインページで
アカウント(wsの番号です。分からない場合は管理者に問い合わせてください。)を入れ次へボタンを押します。
下記の画面へと遷移したら、
- ユーザー名
- パスワード
を入力し、サインインをクリックしてください。
パスワードの変更
パスワードの変更を求められなかった場合は、この手順をスキップしてください。
パスワードの更新を求められた場合は、新しいパスワードに更新してください。
仮想デバイスのインストール
スマホに仮想デバイスをインストールします。
iPhoneはこちら
AndroidはこちらMFAの有効化
AWSマネジメントコンソールが開いたら左上の
サービスボタンを押下し、検索窓でIAMと入力し、表示されたIAMを選択してください。(IAMと入力してEnterキーでもOK)
IAMの管理ページが開いたら、
左のリストからユーザーという項目を選択し、編集したいユーザーを選択してください。
自分のユーザー画面が開いたら、
認証情報のタブを開いてください。
その後、MFAデバイスの割り当ての右に有る管理ボタンを押してください。
仮想MFAデバイスを選択し、
続行ボタンを押します。
QRコードの表示を選択し、QRコードを表示してください。
スマホで「Googleの認証アプリ」を開き、右上の
+ボタンを押してください。
その後、バーコードをスキャンを押してQRコードを読み込みます。
デバイスに表示されたMFAコードを1つ目の欄に入力します。
しばらくすると、次のコードが表示されるので、2つ目の欄に入力します。
閉じるボタンを押してください。
上記の手順で仮想MFAの有効化は完了です。正しく有効化できているか確認
右上のプルダウンメニューを選択し、
サインアウトをクリックします。
右上の
コンソールにサインインを押します。
アカウント、ユーザー名とパスワードを入力し、
サインインをクリックします。正しく設定されている場合、下記のように「MFA認証」画面に遷移します。
仮想デバイス(スマホアプリ)を開いて、表示されている数字を入力し、送信をクリックします。
最後に
以上でMFA認証の設定は終了です。
アカウントのセキュリティーを担保するために、MFA認証を設定しましょう!!













- 投稿日:2019-12-18T17:08:13+09:00
CloudFormationレジストリを使ってDatadogのモニターを設定する
この記事はZOZOテクノロジーズ #3 Advent Calendar 2019 18日目の記事です。
昨日は@niba1122さんのRust+WebAssemblyでメタボールを作るでした。今年ZOZOテクノロジーズでは全部で5つのAdvent Calendarが公開されているので、
他の記事もぜひ目を通していただけると嬉しいです。ZOZOテクノロジーズ #1 Advent Calendar 2019
ZOZOテクノロジーズ #2 Advent Calendar 2019
ZOZOテクノロジーズ #4 Advent Calendar 2019
ZOZOテクノロジーズ #5 Advent Calendar 2019この記事について
先日CloudFormation レジストリが発表され、
CloudFormationでサードパーティのリソースも定義できるようになったのはご存知でしょうか、、、?CloudFormation 最新情報 – CLI + サードパーティのリソースサポート + レジストリ
今回対応したサードパーティのベンダーに弊社で採用しているDatadogも含まれていたので、
感触を確かめるべく設定を試してみました。本記事では実際に設定で使用したCloudFormationテンプレートを交えて
一連の流れや試してみてわかったこと等をご紹介します。日々修行中の身ですので、
認識が誤っている点やアドバイスいただける点があればコメントいただけると幸いです。CloudFormationレジストリとは
名前通り、CloudFormationで利用可能なリソースのリストです。
レジストリは以下の2タイプに別れており、
今回試すDatadogのリソースが登録されるのはPrivateのレジストリです。
- Public: AWSのネイティブリソースが登録されている
- Private: ユーザが作成したリソースやサードパーティベンダーから取得したリソースが登録される
同じタイミングで公開されたCloudFormationCLIを使ってスキーマやハンドラーを作成すれば
ユーザ独自のリソースも登録することができるようです。Datadog×CloudFormation レジストリで設定できること
2019/12現在は以下の設定が可能です。
- AWSとのインテグレーション
- モニターの作成、更新、削除
- モニターのダウンタイムの有効化、無効化
- ユーザ作成と管理
まだできることは少ないものの、監視するAWSリソースが多い(モニターが多い)環境では
少なからず役立つ部分もあるのではと思っています。前提
- DatadogとAWSのインテグレーションは設定済みである(DatadogのApiKeyも作成済み)
準備編
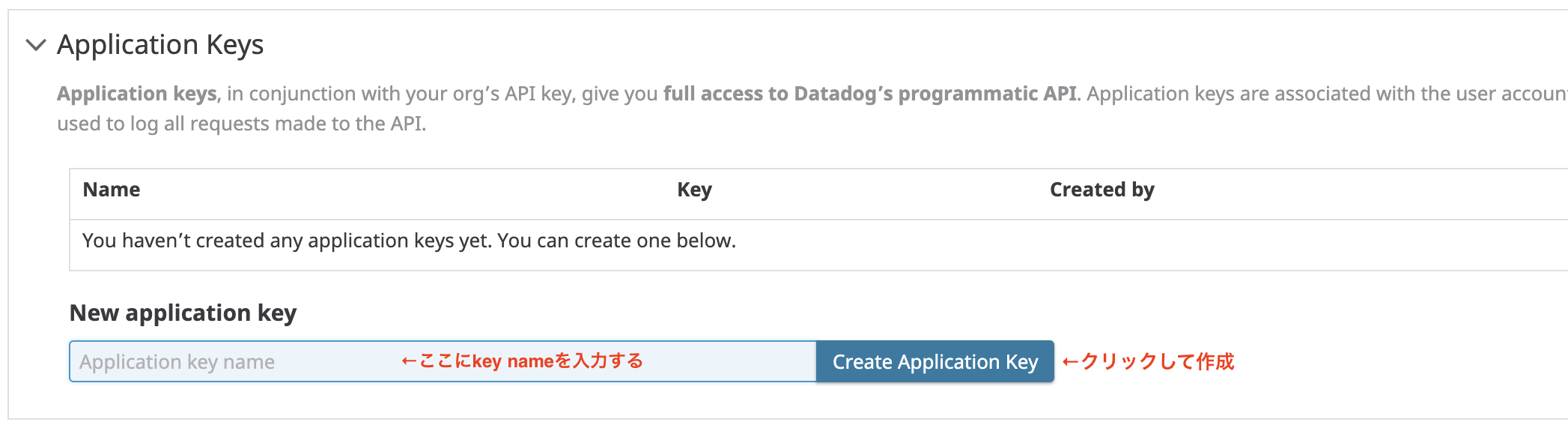
1. ApplicationKeyを作成しておく
DatadogのAPIにフルアクセスできるよう、あらかじめ上記を取得しておく必要があります。
Datadogにログインし、画面左のIntegrations > APIsを選択します。
表示された項目のうち、Application Keysから必要事項を入力して作成します。
2. AWSCLIの認証情報を設定しておく
AWSCLIを使って設定する場面があるため、IAMUserのアクセスキーとシークレットキーを取得し、
以下のような設定が必要です。~/.aws/credential[hoge] aws_access_key_id = {アクセスキー} aws_secret_access_key = {シークレットキー}~/.aws/config[profile hoge] region = {主に使用しているリージョン} output = json設定編
今回はDatadogに2つのモニターを設定します。
- healthcheckが成功しているFargateの数を監視するモニター
- FargateのCPU利用率を監視するモニター
→いずれも閾値で監視し、閾値を超えるとhogeという名前のslackチャンネルに通知が来るようにします。ここから先の作業は大きく2ステップで、Datadogの公式ドキュメントを参考にして行いました。
STEP1: CloudFormationレジストリにDatadogのリソースを登録する
AWSCLIを使って作業を行います。
まずは以下のコマンドを実行し、リソースプロバイダーとしてDatadogのMonitorを登録します。$ aws cloudformation register-type \ --type RESOURCE \ --type-name Datadog::Monitors::Monitor \ --schema-handler-package s3://datadog-cloudformation-resources/datadog-monitors-monitor/datadog-monitors-monitor-1.0.1.zip \ --profile hoge { "RegistrationToken": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxx" }RegistrationTokenが返ってくれば成功です。
type-nameやschema-handler-packageを指定していますが、値はこちらを参考にしました。
schema-handler-packageは、作成したいリソースの"RESOURCE LINK"からダウンロードしても確認した方が楽かもしれません。このようにして登録されたリソースは複数バージョン登録が可能で、どのバージョンをデフォルトで使うのかを指定する必要があります。
そのため、以下のコマンドで登録したリソースのバージョンを確認します。$ aws cloudformation list-type-versions \ --type RESOURCE \ --type-name Datadog::Monitors::Monitor \ --profile hoge { "TypeVersionSummaries": [ { "Description": "Datadog Monitor", "TimeCreated": "2019-12-09T10:15:56.394Z", "TypeName": "Datadog::Monitors::Monitor", "VersionId": "00000001", "Type": "RESOURCE", "Arn": "arn:aws:cloudformation:ap-northeast-1:123456789123:type/resource/Datadog-Monitors-Monitor/00000001" } ] }返ってきたバージョン"00000001"を指定してデフォルトに登録します。
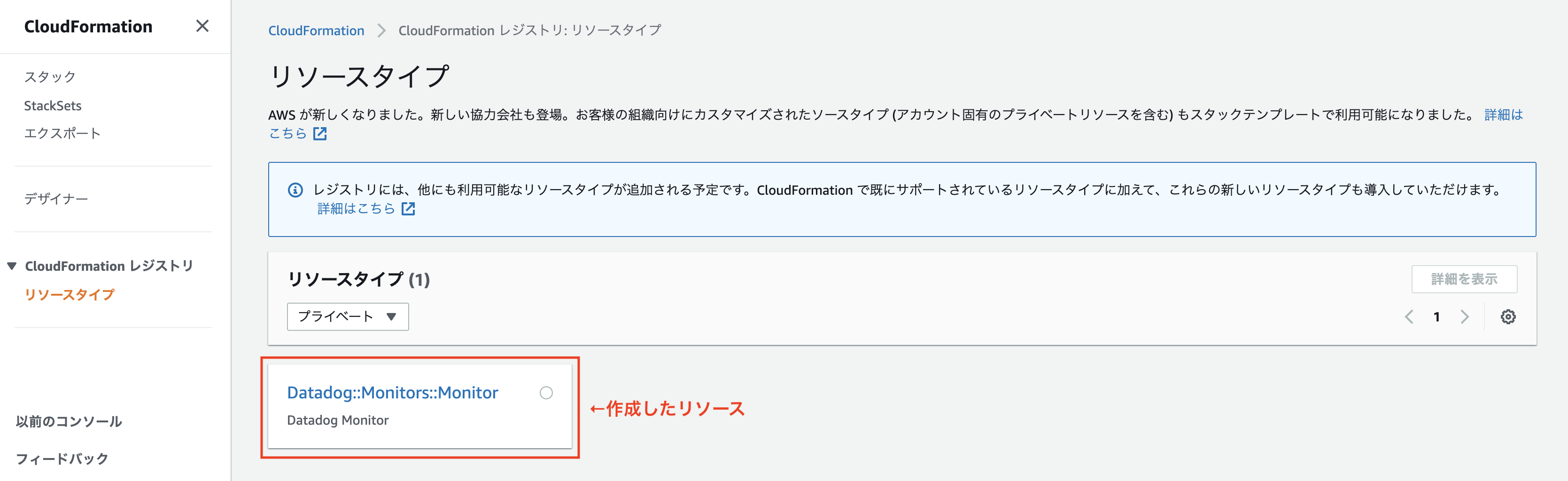
$ aws cloudformation set-type-default-version \ --type RESOURCE \ --version-id 00000001 \ --type-name Datadog::Monitors::Monitor \ --profile hogeここまで設定すると、webコンソール上からCloudFormationレジストリに作成したリソースが確認できます。
STEP2: CloudFormationスタックを作成する
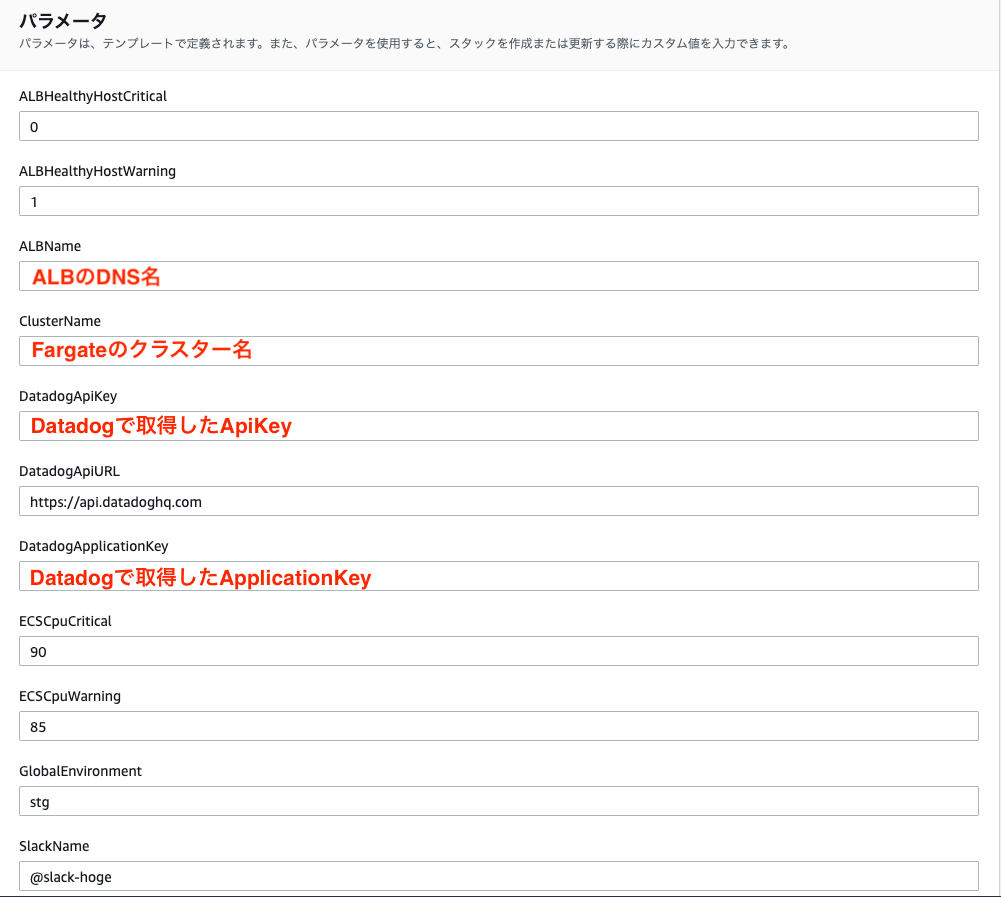
今回は以下のテンプレートを作成し、スタックの作成を行いました。
datadog-monitor.ymlAWSTemplateFormatVersion: 2010-09-09 Parameters: GlobalEnvironment: Type: 'String' Default: 'stg' ALBName: Type: 'String' Default: 'ALBのDNS名' ClusterName: Type: 'String' Default: 'ECSのクラスター名' SlackName: Type: 'String' Default: '@slack-hoge' DatadogApiURL: Type: 'String' Default: 'https://api.datadoghq.com' DatadogApiKey: Type: 'String' Default: '' NoEcho: true DatadogApplicationKey: Type: 'String' Default: '' NoEcho: true ALBHealthyHostCritical: Type: 'String' Default: '0' ALBHealthyHostWarning: Type: 'String' Default: '1' ECSCpuCritical: Type: 'String' Default: '90' ECSCpuWarning: Type: 'String' Default: '85' Resources: MonitorsMonitorALBHealthyHost: Type: 'Datadog::Monitors::Monitor' Properties: Type: 'query alert' Query: !Sub sum(last_1m):avg:aws.applicationelb.healthy_host_count{host:${ALBName}} <= ${ALBHealthyHostCritical} Name: 'ALB healthy host is low' Message: !Sub '{{#is_warning}} <!channel> ALBのhealthy host数が{{warn_threshold}}です。Fargateのステータスを確認してください。 {{/is_warning}} {{#is_alert}} <!channel> ALBのhealthy host数が{{threshold}です。Fargateのステータスを確認してください。 {{/is_alert}} {{#is_recovery}} <!channel> ALBのhealthy host数が正常に戻りました。{{/is_recovery}} Notify ${SlackName}' Tags: - !Ref GlobalEnvironment Options: Thresholds: Critical: !Ref ALBHealthyHostCritical Warning: !Ref ALBHealthyHostWarning NotifyNoData: false EvaluationDelay: '900' DatadogCredentials: ApiURL: !Ref DatadogApiURL ApiKey: !Ref DatadogApiKey ApplicationKey: !Ref DatadogApplicationKey MonitorsMonitorECSCpu: Type: 'Datadog::Monitors::Monitor' Properties: Type: 'query alert' Query: !Sub avg(last_5m):avg:ecs.fargate.cpu.percent{cluster_name:${ClusterName}} by {container_id} > ${ECSCpuCritical} Name: 'ECS cpu percent is high' Message: !Sub '{{#is_warning}} <!channel> {{ecs_task_family.name}} のCPU使用率が{{warn_threshold}}%を超えました。 {{/is_warning}} {{#is_alert}} <!channel> {{ecs_task_family.name}} のCPU使用率が{{threshold}}%を超えました。 {{/is_alert}} {{#is_recovery}} {{ecs_task_family.name}} のCPU使用率が正常値に戻りました {{/is_recovery}} Notify ${SlackName}' Tags: - !Ref GlobalEnvironment Options: Thresholds: Critical: !Ref ECSCpuCritical Warning: !Ref ECSCpuWarning NotifyNoData: false DatadogCredentials: ApiURL: !Ref DatadogApiURL ApiKey: !Ref DatadogApiKey ApplicationKey: !Ref DatadogApplicationKeyAWSCLIでもスタックの作成は可能ですが、普段通りWebコンソールから設定を行いました。
CloudFormation > スタックの作成 > 新しいリソースを使用(標準) をクリックし、
テンプレートをアップロードします。
パラメータに値が入っていない項目は値を入力し、
スタックを作成します。
スタックの更新が完了すると、作成したモニターがDatadogに表示されます。
作成直後はステータスがNO DATAになりますが、時間が経つとOKに変わります。
試してみてわかったこと
- 設定そのものにかかった時間は1時間程度でした。(スタックそのものの更新は2、3分)
- 今回のテンプレートには記載していませんが、Conditionや!IfなどのCloudFOrmationの記法を使ってモニターを設定することも可能でした。
- 更新や削除を行う際もAWSリソース同様に、ymlファイルを修正してスタック更新を行うとDatadogに反映されます。
- Datadog側で設定を変更した状態でCloudFormationを実行してもDatadog側の設定は残るようでした。
- 指定すべき値に不足や誤りがある時等はスタック更新時にエラーが出るようになっていました。
(ex.閾値を使うと定義しているのに指定していない)- サンプルコードはDatadogのGitHubのリポジトリや公式ドキュメントに記載されていますが、
それ以外で指定できるプロパティはJSONスキーマを読み込む必要がありました。今後の課題
- 繰り返し呼び出しが発生する部分の汎用化
モニターが増えるごとにほぼ同じ内容を記述するのが勿体無いので、この部分を解消したいと考えています。まとめ
CloudFormation レジストリという新しい機能を使ってDatadogのモニターを設定する流れをご紹介しました。
普段からAWSのリソース管理にCloudFormationを利用しているので、
AWSリソースを設定する時と同じ感覚・手順でDatadogのモニターを設定できるのはやはり便利だったので
今後どんどん設定できるリソースが増えていくことを期待しています。今後の課題についてはどこかのタイミングで取り組みたいと考えているので
また改善できた際は投稿したい思います。明日のZOZOテクノロジーズ #3 Advent Calendar 2019は@maaaaaaaaさんです。
ぜひそちらもご覧ください!参考サイト



- 投稿日:2019-12-18T15:42:28+09:00
EBSの高速初期化ツールを公開します
EBS 初期化を高速化するツールを作ってみましたので公開します。fio でやる場合より3倍ぐらい速く動作します。
EBS 初期化とは?
EBS は AWS の標準的な仮想ストレージです。EBS の魅力のひとつにスナップショット機能がありますが、構造上、スナップショットの利用開始直後はパフォーマンスがかなり悪くなります。これはスナップショットの実体が S3 にあり、アクセスがあったブロックから順次ダウンロードされるためです。この構造のため EBS スナップショットからボリュームを作成するとすぐに完了しますが、一度目のアクセスは非常に重いという特性があります。
この問題を回避するためには、一度 dd 等を利用して全ブロックを読み込んでしまえばオーケーです。これを「EBS の初期化」と言います。ただし dd では遅いため、ベンチマークツールの fio を利用して初期化する方法が公式ページで紹介されています。
初期化の無駄をなくすには?
EBS 初期化は全データを読み込まなくてはならたいため、大きなスナップショットだと数時間かかります。しかし、S3 のチャンクサイズはどうやら 512KiB のようであり、1ブロック中の一部でも読み込めばそのブロックの初期化は完了します。この性質を利用すると、数バイトだけ読み込んで 512KiB シークする事を繰り返し、高速に初期化が可能です。これを応用したワンライナーが、stak overflow にポストされていました。
状況にも依存するのですが、fio で初期化するより高速に動作する場合も多いです。
さらに速くするためには?
上記のワンライナーはとても優秀でお世話になったのですが、読み込み毎に dd を起動したり、
/dev/nullに出力したりしている等、シェルスクリプトであるが故の無駄が多いのも事実です。そこでこのアルゴリズムを C言語で実装したのが今回のツールです。システムコールは io_submit(2) を利用しており、シングルスレッドで高速に IO を同時発行できるようになりました。ソースファイルとライセンス
github に置きました。MIT ライセンスです。
ダウンロードとインストール
RPM パッケージを用意しましたので、以下のコマンドでダウンロード・インストールができます。
rpm -ivh https://github.com/matsumoto-sp/ebsinit/releases/download/1.0.3/ebsinit-1.0.3-Linux.rpm利用方法
コマンドラインに初期化したいデバイスを指定するだけです。以下のように利用します。
ebsinit /dev/nvme2n1その他、以下の通りいくつかのオプションがあります。
オプション 機能 -s, --silent 進捗表示を行わない -l, --syslog syslog に進捗を出力する -h, --help ヘルプメッセージを表示する -v, --version バージョン番号の表示 ベンチマーク
400GiB中、67% 程度を利用している gp2 のボリュームでテストをした所、以下のような結果になりました。
初期化方法 時間 fio 147m 上記のワンライナー 156m ebsinit 41m ストライピングとの併用でさらに高速化
LVM 等を利用してストライピングを行うとそれぞれのデバイスを同時に処理できますので、さらに速くなります。120GiB の gp2 のボリュームを8台つなげてストライピングした 950GiB のドライブ(使用率50%程度)は、わずか7分で初期化が終了しました。
なお、ストライピングドライブに適用する場合には、
/dev/mapper/以下のボリュームグループではなく、個々のボリュームそれぞれで実行して下さい。そうしないとストライプサイズの関係で特定のボリュームに偏って読み込みされてしまう場合があり、結果として初期化が正しく行えません。 ebsinit は複数のボリュームを同時に初期化する機能は今はありませんので、ボリュームの数だけ同時起動して下さい。FSR もお忘れなく!
最後になりましたが、先日公開された AWS の新機能 Fast Snapshot Restore (FSR) は、EBS スナップショットの初期化を不要にする魅力的な機能です。料金が結構掛かる事や初めて利用する時に時間がかかる等の問題がありますが、EBS 初期化の新しい方法だと思います。EBS 初期化で困っている人は、是非 FSR も検討してみて下さい。
- 投稿日:2019-12-18T15:41:39+09:00
【CloudFormation】stackerを使って複数のスタックを管理する
CloudFormation(以後CFn)で大規模なシステムを記述するときは、複数のテンプレートに分割して書いています。
分割するということは他のスタックの値を使用することがあるのですが、Cross Stack Referenceをしたくなかったので色々調べた結果Stackerにたどり着いた。他のスタックに値を渡す方法 (復習?)
Cross Stack Reference
OutputsでExportし、読み込みたいテンプレートで!ImportValueする
... Outputs: VpcId: Value: !Ref Vpc Export: Name: VpcId ... HogeFuga: Type: ... Properties: VpcId: !ImportValue VpcIdCFnの標準機能だけで実現可能
しかし、誰かがリソースをImportValueしていると、Export側のスタックが更新できない -> ボツの理由Nested Stack
他のスタックの値を親スタックから参照して、子スタックに渡す感じ。
ただ、一部スタックのみ更新ができない(関係ないスタックも処理が走ってしまう)&更新セットが子スタックは作成されないので使わなかったAWS CDK
AWS クラウド開発キット
TypeScriptなどで記述できる。
複数のスタックを利用したインフラも作成可能。
しかし、内部ではCross Stack Referenceを使っていたのでボツにShellScriptとAWS CLIで頑張る
今まではこれでやっていた。
そこそこいい感じに分割は可能。
しかし、テンプレートが増えるごとにShellScriptが増えて管理できなくなってきた。stacker
stacker GitHub
複数のStack設定をyamlで記述して、コマンド一発で展開可能なツール
Cross Stack Referenceを使用せずに、パラメータの受け渡しが可能っぽい。
テンプレート自体もtroposphereで作成したものが使えるので、ロジックが記述可能troposphereのスターが3.9kあるのに、stackerは579しかないのはなんでだろうね。。。
ディレクトリ構成
. ├── Pipfile ... Pipenv使ってるので ├── Pipfile.lock ├── blueprints ... troposphere + stacker blueprintを組み合わせたスクリプトを配置 │ ├── __init__.py │ ├── instance.py │ └── vpc.py ├── conf ... 環境ごとの設定ファイル。デプロイ時に指定可能 │ └── dev.env ├── stacker.yaml ... メインの設定ファイル └── tasks.py ... TaskRunnerにInvokeを使用しているので (べつにMakefileでもいいと思う)stacker.yaml
--- namespace: ${namespace} # CFnスタックの名前に使われる。実際の値はconf/dev.envに記載 stacker_bucket: stacker-tpl-${namespace} # CFn TemplateがUploadされるS3 Bucket名 sys_path: . stacks: - name: vpc # 実際に作成されるスタック名は「${namespace}-vpc」になります class_path: blueprints.vpc.Vpc # BluePrintのClass名までを記載 variables: CidrBlock: '10.0.0.0/16' # List表記にしたものはBlueprintでfor...inにして使う PublicSubnets: - '10.0.0.0/24' - '10.0.1.0/24' PrivateSubnets: - '10.0.128.0/24' - '10.0.129.0/24' - name: instance class_path: blueprints.instance.Instance variables: SubnetId: ${output vpc::PublicSubnet0} # 他のStackのOutputを取得する ImageId: ami-0c3fd0f5d33134a76blueprints/vpc.py
troposphere_mateはtroposphereに型定義などが追加されてIDEの入力支援が色々使えるやつです。
from stacker.blueprints.base import Blueprint from troposphere import Ref from troposphere_mate import Output import troposphere_mate.ec2 as ec2 class Vpc(Blueprint): # stacker.yamlのvariablesに記載する内容の定義 VARIABLES = { "CidrBlock": { "type": str, "description": "Vpc CidrBlock" }, "PublicSubnets": { "type": list, "description": "Public Subnet CidrBlock List" }, "PrivateSubnets": { "type": list, "description": "Private Subnet CidrBlock List" } } def create_template(self): var = self.get_variables() self.template.description = "VPC Stack" vpc = self.template.add_resource( ec2.VPC( 'Vpc', CidrBlock=var['CidrBlock'], EnableDnsHostnames=True, EnableDnsSupport=True ) ) self.template.add_output(Output('VpcId', Ref(vpc))) internet_gateway = self.template.add_resource(ec2.InternetGateway('Igw')) self.template.add_resource( ec2.VPCGatewayAttachment( 'VpcGwAttachment', VpcId=Ref(vpc), InternetGatewayId=Ref(internet_gateway) ) ) default_route_table = self.template.add_resource( ec2.RouteTable( 'DefaultRouteTable', VpcId=Ref(vpc) ) ) self.template.add_resource( ec2.Route( 'DefaultRoute', RouteTableId=Ref(default_route_table), DestinationCidrBlock='0.0.0.0/0', GatewayId=Ref(internet_gateway) ) ) # Create Public Subnet for k, v in enumerate(var['PublicSubnets']): # stacker.yamlでList表記にしていたものを使用 public_subnet = self.template.add_resource( ec2.Subnet( f'PublicSubnet{k}', CidrBlock=v, VpcId=Ref(vpc) ) ) self.template.add_output(Output(f'PublicSubnet{k}', Ref(public_subnet))) self.template.add_resource( ec2.SubnetRouteTableAssociation( f'PublicSubnetRouteTableAssociation{k}', RouteTableId=Ref(default_route_table), SubnetId=Ref(public_subnet) ) ) # Create Private Subnet for k, v in enumerate(var['PrivateSubnets']): private_subnet = self.template.add_resource( ec2.Subnet( f'PrivateSubnet{k}', CidrBlock=v, VpcId=Ref(vpc) ) ) self.template.add_output(Output(f'PrivateSubnet{k}', Ref(private_subnet)))デプロイ
$ stacker build --region ap-northeast-1 conf/dev.env stacker.yaml削除
# 削除対象を確認 $ stacker destroy --region ap-northeast-1 conf/dev.env stacker.yaml [2019-12-18T15:36:30] Using default AWS provider mode [2019-12-18T15:36:30] Plan "Destroy stacks": [2019-12-18T15:36:30] - step: 1: target: "instance", action: "_destroy_stack" [2019-12-18T15:36:30] - step: 2: target: "vpc", action: "_destroy_stack" [2019-12-18T15:36:30] To execute this plan, run with "--force" flag. # 削除実行 $ stacker destroy --region ap-northeast-1 conf/dev.env stacker.yaml --forceまとめ
複数のスタックの設定を一箇所で管理可能で、環境ごとの差分は.envとして管理ができるので非常に楽。
他スタックの値のImportがImportValueではなく、aws cliで取得した値を貼り付けているような感じなので参照先のリソースの更新も可能。
troposphereで記述できるため、開発環境だけ展開するインスタンスなども設定可能
- 投稿日:2019-12-18T15:20:04+09:00
ppa:jonathonf/python-3.6 が非公開になった
ppa:jonathonf/python-3.6 が非公開になった
ubuntu16.04などでpython3.6を入れるときに
ppa:jonathonf/python-3.6
のppaを使っていたんですが、非公開になってしまってちょっと困ったのでメモ変更前
sudo add-apt-repository ppa:jonathonf/python-3.6 sudo apt update sudo apt install python3.6apt update時のログ
W: The repository 'http://ppa.launchpad.net/jonathonf/python-3.6/ubuntu xenial Release' does not have a Release file. N: Data from such a repository can't be authenticated and is therefore potentially dangerous to use. N: See apt-secure(8) manpage for repository creation and user configuration details. E: Failed to fetch http://ppa.launchpad.net/jonathonf/python-3.6/ubuntu/dists/xenial/main/binary-amd64/Packages 403 Forbidden [IP: 91.189.95.83 80] E: Some index files failed to download. They have been ignored, or old ones used instead.ppaを以下に変更
ppa:deadsnakes/ppa変更後
sudo add-apt-repository ppa:deadsnakes/ppa sudo apt update sudo apt install python3.6こっちだと入れられる
- 投稿日:2019-12-18T14:32:50+09:00
LINEで送られてきた写真をS3に保存したい
何に使うのか
AWSのLambdaなどを用いて画像加工する時やAWS.rekognitionのリソースとして使う時に
役に立てばと思います。
今回、LINE Developperの設定などは飛ばします。同類の検索をするとSDKを使用している方が多いですが、今回は使わずにいきたいと思います。
使用技術
- LINE Messaging API
- Python 3.7
- AWS S3
- AWS Lambda
プログラム
メイン関数一部
lambda_function.pyimport requests import os import json import boto3 from io import BytesIO #Headerの生成 HEADER = { 'Content-type': 'application/json', 'Authorization': 'Bearer ' +'チャンネルアクセストークン' } #main def lambda_handler(event, context): #Json Load body = json.loads(event['body']) for event in body['events']: payload = {'replyToken': event['replyToken'], 'messages': []} # ImageMessageが来た時 if event['message']['type'] == 'image': #HEADERとmessages(pyload)を付加してpost if len(payload['messages']) > 0: response = requests.post( 'https://api.line.me/v2/bot/message/reply', headers=HEADER, data=json.dumps(payload))ImageMessageがきた時に画像を保存したいので、
lambda_function.py# ImageMessageが来た時 if event['message']['type'] == 'image':このIF文の中で処理を書いていきたいと思います。
lambda_function.pyMessageId = event['message']['id'] # メッセージID ImageFile = requests.get('https://api-data.line.me/v2/bot/message/ '+ messageId +'/content',headers=HEADER) #Imagecontent取得 Image_bin = BytesIO(ImageFile.content) Image = Image_bin.getvalue() # 画像取得コンテンツを取得する←に詳しい事が書いてあるので気になる方は読んでみてください。
lambda_function.pyS3 = boto3.client('s3') FileName = MessageId + '.jpeg' # メッセージID+jpegをファイル名 # s3へのput処理 S3.put_object(Bucket='バケット名', Body=Image, # 写真 Key=FileName) # ファイル名最後に
ここまでの処理を書いてLINEから画像送信してS3に保存されてれば大丈夫だと思います。
処理していく中で画像が毎回保存されて残っているのが気持ち悪い人は下記のコードを書けば
解決します。lambda_function.pyS3.delete_object(Bucket="バケット名", Key=FileName) # 送信画像削除
- 投稿日:2019-12-18T14:31:25+09:00
AWS SESを国内のDNSで運用するためには
AWSのSESを運用する際ドツボにハマるわけですが、なぜかというと
nameがappendされるからです。という記事で、txtだけって書いてあったんですが、
どうやら、cnameとかもごそっとだめです。
そのため、ネームサーバ毎引越ししていた時期もありました。しかし、ようやく仕掛けがわかりました。
日本のドメイン管理サーバは
【Amazon SES ✕ ムームードメイン】Domainのstatusがpending verificationから一向にverifiedにならない
にある通り、
nameで勝手に折り返すという仕様があります。つまり、AWSからは
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx._domainkey.example.com.example.jp canonical name = xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx.dkim.amazonses.com.
などのように見えるわけです。
そのため、SESが自動で払い出すレコードに記載されているものを使うと、onamae.comやムームードメインでは動きません。ですから、払い出されたものから.xxx.com等の利用ドメインを削除して記載する必要があります。
そして、xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx._domainkey.example.com canonical name = xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx.dkim.amazonses.com.
このようにAWSから見える必要があります。
国内のDNSの独自仕様も困ったものなので、今後はGoogleドメインや、それこそRoute53(っていっても、こいつも癖が相当ひどい)などのグローバル仕様を使っていった方が良いのかもしれない。
- 投稿日:2019-12-18T13:21:27+09:00
さよなら、私の100ドルクレジット… (ELBでやらかした話)
あらすじ
前提条件
- AWS Educate Starter アカウントに申し込んでいたので、100ドルのクレジット(加盟校)が付与されていました。
- AWS 超初心者で、普段はAzureしか使っていません。
事の発端
ある日、ふとBilling Management Consoleで、クレジットの残高を確認してみると...
えっ?
残高0.02ドル????? なにに使ったんだ私は...?
99.98ドルという大金を約2か月の間に使い果たしてしまっていました。まずい…なんで…?
ここで筆者の血の気が引いてきます。
なんでだ...?
12月の一か月間で引かれたクレジットを見てみると
えっ!28ドル!?!?
RDS(MySQL)を利用していたので、もしやつけっぱなしにしていてクレジットが吹っ飛んだか...?
と思い,公式ドキュメントで料金を確認してみても、db.t2.microは0.017USD/時間なので、そんなに多くはない...
(よかった...4ドルぐらいだ...。)事態が発覚
はっ!EC2だ!!
そう確信し、EC2の使用量を見てみると...
こ れ だ
でっ でも、EC2のt2.micro(無料利用枠に含まれる)を使っていたから、そんなに大きくはないはず...
目線を下のほうにやると...。
やりましたわ...これだ原因は...。起った事態をまとめると
はい。お分かりの通り,ロードバランサを実行しっぱなしにしていたので、695時間分のご請求が来ていました。
そこで、AWSの公式ドキュメントで料金を確認してみると
ん~1時間あたり0.025ドルだから、695時間で掛けると17.375ドル... これですわ。AzureのBasic Load Balancerに慣れてしまっているので、てっきり転送量の従量課金だけだろうを思い込んでいました。
対策
普段使っていないクラウドサービスを始めて使うときは、絶対の絶対に公式ドキュメントで仕様と料金を確認しましょう。
大事なことなのでもう一度言いますが、公式ドキュメントで仕様と料金を確認しましょう。
まとめ
クレジットカードに請求が来る寸前で気づいてよかったです。
偉大なる100ドルクレジット...AWSさんありがとうございます。感謝です。公式ドキュメントで仕様と料金を確認しましょう。
以上になります。読みにくい記事だったと思いますが,ここまで読んでくださりありがとうございました。







- 投稿日:2019-12-18T13:14:57+09:00
AWS 認定高度なネットワーク – 専門知識 受験メモ
先日合格したセキュリティ試験に引き続きネットワーク試験も受験したので、自分が行った受験対策を紹介します。
試験範囲
試験ガイドに記載の通りです。
「AWS 認定高度なネットワーキング – 専門知識」 (ANS-C00) 試験は、複雑なネットワーキングタスク
を実行する個人を対象としており、大規模な AWS とハイブリッド IT ネットワークアーキテクチャの設
計と実装に関する高度な技術スキルと経験を認定します。出題範囲は以下の通りです。
分野 試験における比重 分野 1: 大規模なハイブリッド IT ネットワークアーキテクチャを設計し、実装する 23% 分野 2: AWS ネットワークを設計し、実装する 29% 分野 3: AWS タスクを自動化する 8% 分野 4: アプリケーションサービスとネットワークの連携を構成する 15% 分野 5: セキュリティとコンプライアンスを設計し、実装する 12% 分野 6: ネットワークの管理、最適化、トラブルシューティングを行う 13% 試験ガイドを詳細にみていくと、「AWS Direct Connect」「Route 53」の記載もあります。
他のプロフェッショナル試験や専門知識同様、170分の試験になります。(受験料:30,000円)
受験対策
受験にあたり自分が行った対策は以下になります。
セキュリティ受験後すぐであったため、ネットワーク試験用に費やしたのは1週間ほどです。AWSのネットワーク関係のサービスのBlackbeltを読む
「AWS クラウドサービス活用資料集」の「Networking & Content Delivery」に分類されているサービスのBlackbeltに全て目を通しました。
- Elastic Load Balancing (ELB)
- Amazon VPC
- Amazon CloudFront
- Amazon CloudWatch
- Amazon Route 53
- AWS Transit Gateway
- AWS Direct Connect
YouTubeにある「VPC」「Route 53」などは通勤中に聞いていました。
ベストプラクティスを読む
以下はセキュリティのホワイトペーパーですが、ネットワークのセキュリティなども記載されていますので、再度確認しました。
https://d1.awsstatic.com/International/ja_JP/Whitepapers/AWS_Security_Best_Practices.pdfサンプル問題を解く
公式サンプル問題は10問で、回答もあります。(ただし英語です)
模擬試験が無い?
いつもの流れで模擬試験を受験しようと思ったのですが、なんと模擬試験の提供はありません。
AWS試験ではネットワークとビッグデータのみ模擬試験が提供されていないようです。
その他
この試験は受講後にスコアレポートが渡されます。通常AWSの試験の場合スコアレポートは後日WEBからになりますが、この試験の場合は現地で手渡しでした。
(受付の方に聞いたらスコアレポートを渡す試験が2つあるらしいです。)セキュリティ試験から1週間ほどの学習でネットワーク試験も突破することができました。
個人的にはDirectConnect構築を含めた案件に携わったことがあり、そこのでのアドバンテージも大きかったと思います。
- 投稿日:2019-12-18T13:13:07+09:00
AWSのアラームをAWS ChatbotでSlackに通知する
AWSのアラームをSlackに通知するにはlambdaとかを設定する必要があるのですが、AWS Chatbotを使えば簡単に設定できるようです。ということで試してみました。
前提
以下の設定はできているものとします。
- Slackでアラートを通知させたいチャンネルの作成
- Cloudwatchでのアラーム作成
- Amazon SNSの設定設定方法
AWS Chatbotを開き、Configure new clientをクリック。
Slackを選択します。
Slackが立ち上がるので許可するを選択します。
成功すればこんな画面になります。
Slack Channelは通知するチャンネルを指定します。
次にパーミッションの設定ですが、既存のIAMロールを利用するか、自動で作成されるIAMロールを利用するか選択します。
今回はテンプレートから作成を選択し、Role nameを入力します。
ポリシーはデフォルトでNotification Permissionsが選択されている状態です。特に変更はしません。
NotificationではSNSのトピックを選択します。
AWS Chatbot側の設定は以上です。
次にSlackに戻って、通知するチャンネルで/invite @awsを入力します。
問題なく連携できていれば@aws helpでヘルプが表示されます。アラームを発生させるとこんな感じで通知がきます。
以上です。

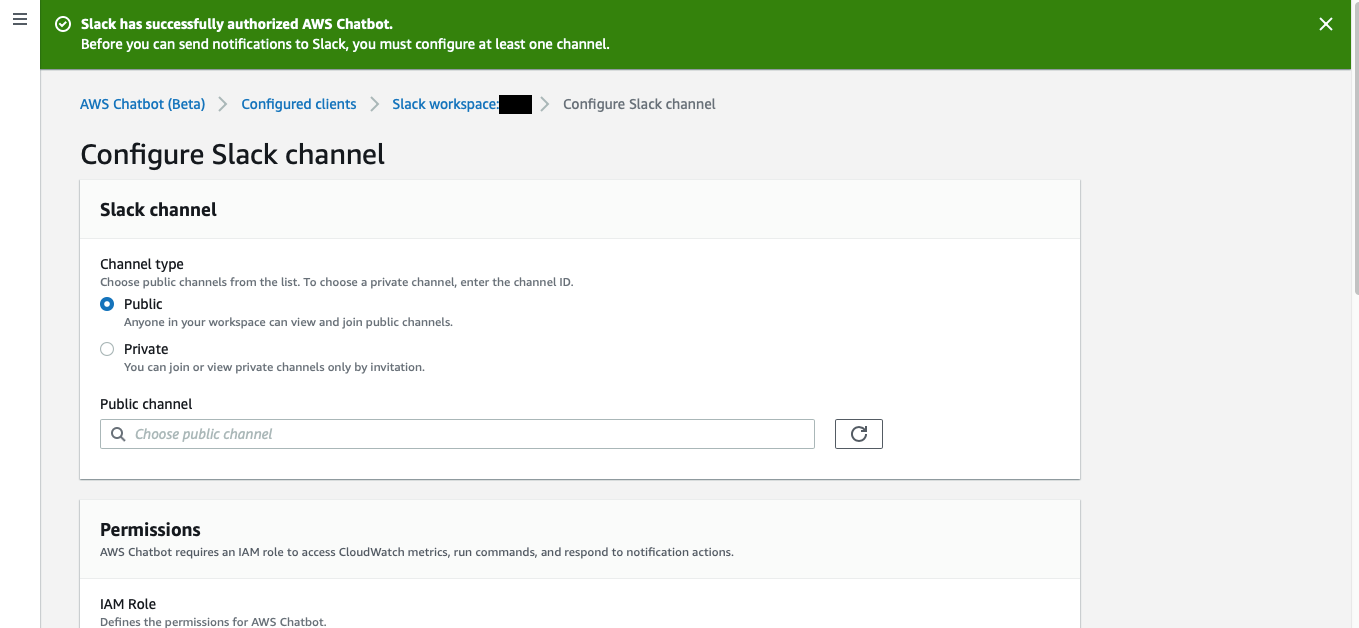

- 投稿日:2019-12-18T12:26:42+09:00
[Beanstalk] import uuidでエラーが出た時の対処法
- 投稿日:2019-12-18T11:54:42+09:00
【AWS】EC2動きっぱなしで請求きたよのお話
一度目の通達
11月中旬AWSからいきなり「もうすぐで設定していた金額超えるよ」というメールが携帯に飛んできた。
急いでAWSにログインし、確認するとEC2インスタンスの無料枠80%使用していた。
おー怖い怖いと思い、EC2インスタンス削除し安心しきっていた。二度目の通達
12月中旬またAWSから「もうすぐで設定していた金額超えるよ」というメールが携帯に飛んできた。
「ん?EC2インスタンスは止めたぞ」と思いbilldingを見に行くと、またEC2インスタンスの無料枠80%使用していた。さらには、先月分は8$請求が確定していた。
「え?」
そう思いEC2画面にいってもインスタンスはない。
EC2以外もcloud9など使用していたサービス全部を削除した。
これで安心しきっていた。次の日
次の日も念のためAWSを見に行くことに。
すると..EC2の利用時間が増えていやがる!!!!解決
どのサービスも使ってないのに...途方に暮れた私はカスタマーサポートに連絡することに。
すると「他のリージョンで使用していないですか?」とのこと
あ!!!!!!!!
そう。別のリージョンでインスタンスが立ち上がっていました。
それらすべて停止して万事休す。原因
今回の原因はリージョンの違いでしたが、なぜそのようなことが起きたのかというと
普段は東京リージョンを使っていたのですが、なにかのタイミングで北米リージョンに切り替わっていたことに気付かなかったことです。
なぜ変わったのかはわかりませんが、リージョンは常に確認しといたほうがいいかもしれません。まとめ
私と同じように「え!全サービス止めているのになんで!!!」となった方の参考になればと思います。
私はリージョンなんていじっていない!でも請求がくるという方はカスタマーサポートに連絡しましょう。無料で24時間対応してくれます。
ちなみにカスタマーサポートはできるなら電話したほうが早く対応してくれます。
- 投稿日:2019-12-18T11:42:10+09:00
【調べ方】AWS セキュリティグループに�定義している IP (CIDR) をサクッと洗い出す
経緯
会社の IP が変わるような場合、どのセキュリティグループに該当する IP が適用されているのか調べる必要がでてきます。
aws-cli と jq コマンド を使って簡単に洗い出す方法を備忘録としてメモしておきます前提
- aws-cli をセットアップ済み
- jq コマンドをセットアップ済み
実行コマンド
事前に確認したいIPを定義 (CIDR)
CIDR=8.8.8.8/32インバウンドのセキュリティグループ名確認
for region in us-east-2 us-east-1 us-west-1 us-west-2 ap-south-1 ap-northeast-2 ap-southeast-1 ap-southeast-2 ap-northeast-1 ca-central-1 eu-central-1 eu-west-1 eu-west-2 eu-west-3 eu-north-1 sa-east-1 do echo region... $region; aws --region $region ec2 describe-security-groups \ |jq -r \ '.SecurityGroups[] | select((.IpPermissions[].IpRanges[].CidrIp == "'$CIDR'") or (.IpPermissions[].IpRanges[].CidrIp == "'$CIDR'")) | .GroupName' \ |sort \ |uniq doneアウトバウンドのセキュリティグループ名確認
for region in us-east-2 us-east-1 us-west-1 us-west-2 ap-south-1 ap-northeast-2 ap-southeast-1 ap-southeast-2 ap-northeast-1 ca-central-1 eu-central-1 eu-west-1 eu-west-2 eu-west-3 eu-north-1 sa-east-1 do echo region... $region; aws --region $region ec2 describe-security-groups \ |jq -r \ '.SecurityGroups[] | select((.IpPermissionsEgress[].IpRanges[].CidrIp == "'$CIDR'") or (.IpPermissionsEgress[].IpRanges[].CidrIp == "'$CIDR'")) | .GroupName' \ |sort \ |uniq done結果サンプル
hogehoge-sgとfugafuga-sgのセキュリティグループのインバウンドで8.8.8.8/32が定義されていることがわかりました。mac48:~ s-urabe$ CIDR=8.8.8.8/32 mac48:~ s-urabe$ for region in us-east-2 us-east-1 us-west-1 us-west-2 ap-south-1 ap-northeast-2 ap-southeast-1 ap-southeast-2 ap-northeast-1 ca-central-1 eu-central-1 eu-west-1 eu-west-2 eu-west-3 eu-north-1 sa-east-1 > do > echo region... $region; > aws --region $region ec2 describe-security-groups \ > |jq -r \ > '.SecurityGroups[] | select((.IpPermissions[].IpRanges[].CidrIp == "'$CIDR'") > or (.IpPermissions[].IpRanges[].CidrIp == "'$CIDR'")) | .GroupName' \ > |sort \ > |uniq > done region... us-east-2 region... us-east-1 region... us-west-1 region... us-west-2 region... ap-south-1 region... ap-northeast-2 region... ap-southeast-1 region... ap-southeast-2 region... ap-northeast-1 hogehoge-sg fugafuga-sg region... ca-central-1 region... eu-central-1 region... eu-west-1 region... eu-west-2 region... eu-west-3 region... eu-north-1 region... sa-east-1 mac48:~ s-urabe$
- 投稿日:2019-12-18T11:40:58+09:00
terraform(やその他CLIツール・コマンド)でMFA対応する
TL:DR
- AWSではMaster AccountにIAM Userでログインし、他のアカウント(OU)へアクセスできる権限をもったRoleへSwitch/AssumeRoleして必要な作業を行うケースが多いです。
- ポリシーとしてSwitch/AssuemRoleの際に、"MFAが有効化"されていることを必須としていることも多いです。
- terraformは公式にAssumeRoleへの対応をしていますが、MFAへの対応はされていません。
- MFAまわりはaws-vaultでカバーしました。
aws-vaultでterraformをMFA対応させる
aws-vault
https://github.com/99designs/aws-vaultaws-vaultのインストール
リポジトリのREADMEにある通りに。
Macの場合brew cask install aws-vaultaws-vaultでMFAするための設定
事前に必要なもの
- terraformが利用するIAM UserのAccess KeyとSecrets(A)
- (A)に紐付いたMFAデバイスのARN(B)
- こういうやつ → arn:aws:iam::xxxxxxxxxxxx:mfa/yourIAM
aws-vaultで使うprofile追加
$ aws-vault add hoge-prov ※Access KeyとSecretsを聞かれるので(A)を登録する
- profileにmfa_deviceのARN(B)を追加登録
~/.aws/config~(snip)~ [profile hoge-prov] ← 先程追加したprofileの項 mfa_serial = arn:aws:iam::xxxxxxxxxxxx:mfa/yourIAM ←ここに(B)を登録するaws-vaultでMFAしつつterraformを実行してみる
$ aws-vault exec hoge-prov -- terraform plan -out=apply.plan -target=module.compute.aws_instance.hogefuga Enter token for arn:aws:iam::xxxxxxxxxxxx:mfa/yourIAM: ※^ MFAデバイスのTokenを入力してあげましょうterraformの処理に時間がかかりすぎてセッション切れしちゃう場合
execの下記オプションでセッションの有効期限を変更できるようなのでお試しあれ
$ aws-vault exec --help ~(snip)~ -t, --session-ttl=4h Expiration time for aws session --assume-role-ttl=15m Expiration time for aws assumed role ~(snip)~
- 投稿日:2019-12-18T10:43:32+09:00
【AWS】APサーバー用のセキュアなネットワークを作る【備忘録】
APサーバー用のセキュアなネットワークを作る
AWSでこんな感じのネットワークを作りたい。
手順書をまとめたが、途中詰まった部分があったので、勉強ついでにいろいろメモしつつまとめます。
設定項目キャプチャ撮ってたのですが、マスクするのが面倒だったので画像無しです。ネットワーク作成の流れ
- VPCの作成
- サブネットの作成
- インターネットGWの設定
- NATゲートウェイの作成
- ルートテーブルの設定
- セキュリティグループの作成(おまけ)
ネットワーク作成の手順
1.VPCの作成
- VPCダッシュボードを開く
- 「VPCの作成」ボタンを押下する
- 設定項目に下記を入力し、「作成」ボタンを押下する
名前タグ:任意のVPC名
IPv4CIDR ブロック:任意のIPアドレス
IPv6CIDR ブロック:IPv6CIDR ブロックなし
テナンシー:デフォルトメモ
- VPC=Virtual Private Cloud=論理的に分離されたクラウドネットワーク
- 自分の IP アドレス範囲の選択、サブネットの作成、ルートテーブルやネットワークゲートウェイの設定などができる
2.サブネットの作成
- VPCダッシュボード―サブネットメニューへ移動する
- 「サブネットの作成」ボタンを押下する
- 設定項目に下記を入力し、「作成」ボタンを押下する
名前タグ:任意のサブネット名
VPC:「1.VPCの作成」で作成したVPC
VPC CIDR:自動入力
アベイラビリティーゾーン:任意のアベイラビリティーゾーン
IPv4CIDR ブロック:任意のIPアドレスメモ
- 各リージョンにpublic用のサブネットとprivate用のサブネットを作成する
- ブロックの振り方等に特に決まりはないが、サブネットマスクの値は小さいほうが割り振れるIPアドレスが多い(一度、28で設定したためIPアドレスが10個しか割り振れなかった)
- AWSのIPアドレスは普通のネットワーク設定と違って、設定した時点で5個使われるらしい(普通はネットワークアドレスとブロードキャストアドレスの2個)
- アベイラビリティーゾーン=物理的に分けられたデータセンター
3.インターネットGWの設定
- VPCダッシュボード―インターネットゲートウェイメニューへ移動する
- 「インターネットゲートウェイ」の作成ボタンを押下する
設定項目に下記を入力し、「作成」ボタンを押下する
名前タグ:任意のインターネットゲートウェイ名
再度、VPCダッシュボード―インターネットゲートウェイメニューへ移動し、「アクション」タブから「VPCにアタッチ」を選択する
設定項目に下記を入力し、「アタッチ」ボタンを押下する
メモ
- インターネットゲートウェイが通信の出入り口となる
4.NATゲートウェイの作成
- VPCダッシュボード―NATゲートウェイメニューへ移動する
- 「NATゲートウェイの作成」ボタンを押下する
- 設定項目に下記を入力し、「NATゲートウェイの作成」ボタンを押下する
サブネット:public用に設定したサブネット
Elastic IP 割り当てID:新しいEIPの作成メモ
- NATゲートウェイはprivateサブネットのIPアドレスを割り振られたノードが外へ通信する際に必要
- 今回、NATゲートウェイの作成を失念していたため、ロードバランサとAPサーバ間の通信を許可していてもWebからアクセスできなかった
- 気付くのに一番時間がかかった
5.ルートテーブルの設定
- VPCダッシュボード―ルートテーブルメニューへ移動する
- 「3.インターネットGWの設定」で自動作成されたルートテーブルを選択し、「ルート」タブの「ルートの編集」ボタンを押下する
「ルートの追加」ボタンを押下し、設定項目に下記を選択する
ターゲット:Internet Gateway ▸ 「3.インターネットGWの設定」で作成したインターネットゲートウェイ
送信先:0.0.0.0/0再度、「3.インターネットGWの設定」で自動作成されたルートテーブルを選択し、「サブネットの関連付け」タブの「サブネットの関連付けの編集」ボタンを押下する
「2.サブネットの作成」で作成したサブネットを選択し、「保存」ボタンを押下する
メモ
- ルートテーブルを作成することで通信経路を登録できる
- public用のルートテーブルとprivate用のルートテーブルを作成する
- private用のターゲットはNATゲートウェイを指定する(外向きの通信を行う際にNATゲートウェイを経由するから)
6.セキュリティグループの作成(おまけ)
ネットワークはできたので、ここにAPサーバなり、DBを作成する際に必要なセキュリティグループの作成方法をEC2へのSSH接続許可を例に記載します。
1. EC2ダッシュボードのセキュリティグループメニューを開く
2. 「セキュリティグループの作成」ボタンを押下する
3. 設定項目に下記を入力し、「作成」ボタンを押下するセキュリティグループ名:任意のセキュリティグループ名
説明:任意の説明
インバウンド/タイプ:SSH
インバウンド/ソース:マイIP
インバウンド/説明:任意の説明メモ
- セキュリティグループ=ファイアウォールの設定
- インバウンド/ソースにマイIPを設定することで、自分のIPアドレスのSSH接続だけ許可することができる
まとめ
目標としていたネットワークを作成することができた。
今後は、NATインスタンスやまだ使ったことのないサービスを使用して、よりよいものを作りたい。

- 投稿日:2019-12-18T10:00:36+09:00
AWS CloudFormationでインフラを構築してみた
最近AWSに触ることが増えていろいろと学ぶことがありました。
その学んだことの中でもAWS CloudFormationが今後色々役に立ちそうなので、
備忘録的な感じで残したいと思います。AWS CloudFormationとは
AWSのリソースをモデル化およびセットアップするのに役立つサービスです。
詳しくは公式を参照ください。
https://docs.aws.amazon.com/ja_jp/AWSCloudFormation/latest/UserGuide/Welcome.AWS上で構築したインフラストラクチャをコードとして残して置くことができるだけでなく、
そのコードを元に再度環境を構築することができるため複製することや管理することが簡単になります。AWS CloudFormationを使用してインフラを構築する
インフラの環境をコードとして落とし込むにはJSONもしくはYAMLの形式のファイルを用意します。
今回はインターネットに接続することを想定した仮想サーバーの環境をYAML形式で構築してみたいと思います。
使用するリソースはEC2インスタンスになります。
はじめにVPC周りの設定を行い、最後にEC2の設定を行います。
VPC等の用語についての説明は公式を参照してください。
https://docs.aws.amazon.com/ja_jp/vpc/latest/userguide/what-is-amazon-vpc.htmlCloudFormation.yamlAWSTemplateFormatVersion: '2010-09-09' Parameters: EC2KeyName: Type: AWS::EC2::KeyPair::KeyName Description: SSH public key Default: MyKey Resources: # ------------------------- # VPC # ------------------------- VPC: Type: AWS::EC2::VPC Properties: CidrBlock: 10.100.0.0/16 EnableDnsSupport: true EnableDnsHostnames: true InstanceTenancy: default Tags: - Key: Name Value: VPC GatewayAttachment: Type: AWS::EC2::VPCGatewayAttachment Properties: InternetGatewayId: !Ref InternetGW VpcId: !Ref VPC # ------------------------- # Route # ------------------------- RouteTable: Type: AWS::EC2::RouteTable Properties: VpcId: !Ref VPC Tags: - Key: Name Value: RouteTable Route: Type: AWS::EC2::Route Properties: RouteTableId: !Ref RouteTable DestinationCidrBlock: 0.0.0.0/0 GatewayId: !Ref InternetGW # --------------------------- # RouteTable Associate # --------------------------- PubSubnetRouteTableAssociation: Type: AWS::EC2::SubnetRouteTableAssociation Properties: SubnetId: !Ref PubSubnet RouteTableId: !Ref RouteTable # --------------------------- # Security Group # --------------------------- SecGrpEC2: Type: AWS::EC2::SecurityGroup Properties: GroupDescription: Web Server Rule VpcId: !Ref VPC Tags: - Key: Name Value: EC2-Sec SecurityGroupIngress: - { IpProtocol: tcp, FromPort: 80, ToPort: 80, CidrIp: 0.0.0.0/0 } - { IpProtocol: tcp, FromPort: 22, ToPort: 22, CidrIp: 255.255.255.254/32, Description: MyIP} # --------------------------- # Subnet # --------------------------- PubSubnet: Type: AWS::EC2::Subnet Properties: CidrBlock: 10.100.1.0/24 VpcId: !Ref VPC MapPublicIpOnLaunch: True AvailabilityZone: ap-northeast-1a Tags: - Key: Name Value: PubSubnet # --------------------------- # InternetGW # --------------------------- InternetGW: Type: AWS::EC2::InternetGateway Properties: Tags: - Key: Name Value: InternetGW # --------------------------- # EC2 instance # --------------------------- EC2Instance: Type: AWS::EC2::Instance DeletionPolicy: Delete Properties: AvailabilityZone: ap-northeast-1a ImageId: ami-068a6cefc24c301d2 InstanceType: t2.micro KeyName: !Ref EC2KeyName SubnetId: !Ref PubSubnet BlockDeviceMappings: - DeviceName: /dev/sdb Ebs: VolumeSize: 20 VolumeType: gp2 SecurityGroupIds: - !Ref SecGrpEC2 UserData: Fn::Base64: |- #!/bin/bash yum -y update yum install -y httpd systemctl start httpd.service yum install -y docker service docker start usermod -a -G docker ec2-user curl -L "https://github.com/docker/compose/releases/download/1.9.0/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose chmod +x /usr/local/bin/docker-compose Tags: - Key: Name Value: EC2Instance※AMIについてはAWS側で用意されているものになります。
以上の設定でインターネットに接続可能なEC2インスタンスを構築することができました。
実際にURLから遷移するとApacheの画面が表示されています。
またCloudFormationのデザイナー機能で今回構築した環境を確認することもできます。
CloudFormationではEC2インスタンスを立てたときに実行させたいコマンドを
ユーザーデータとして設定することできます。
今回はEC2インスタンスを立てた時にDockerを入れるように設定しています。
また、DeletionPolicy: Deleteをつけることによって
CloudFormationでは構築したファイルを削除した時に使用したリソース全てを削除することができるためリソースの消し忘れによる課金を防ぐことができるという点でも便利だと感じています。


- 投稿日:2019-12-18T09:00:17+09:00
Amazon ECSのタスク定義で改行やタブを含むファイルを出力する方法
数時間ほどハマってようやくたどり着いたのでメモ。
やりたいこと
Amazon ECSのタスクでコンテナ実行時に簡単なスクリプトファイルを作成して実行したかったのです。
hoge.pyprint('hoge') if False: print('no print')みたいなPythonのファイルを作成して、
python hoge.pyするっていう。
インデントが効くか確認するためにif False:とかしてます。
docker runコマンドだとお手元の端末で
dockerコマンドが利用できる前提で。
catコマンドでファイル作成
catコマンドでヒアドキュメントを利用すると簡単にできます。
ヒアドキュメントについては下記が参考になります。知ると便利なヒアドキュメント - Qiita
https://qiita.com/kite_999/items/e77fb521fc39454244e7> docker run -it --rm --entrypoint="sh" \ python:3.7 \ -c "cat <<EOF > hoge.py # hogeって出力 print('hoge') if False: # インデントが効くか print('no print') EOF cat hoge.py;python hoge.py;" # hogeって出力 print('hoge') if False: # インデントが効くか print('no print') hogeなんとなく
docker runコマンド側のインデントに合わせたくなりますが、そうするとヒアドキュメントのルール「EOFが単独で現れると終了」から外れてしまうので、後続のコマンドが巻き込まれてしまいます。> docker run -it --rm --entrypoint="sh" \ python:3.7 \ -c "cat <<EOF > hoge.py # hogeって出力 print('hoge') if False: # インデントが効くか print('no print') EOF cat hoge.py;python hoge.py;" # 出力なし
cat <<-EOF > hoge.pyと<<を<<-に変更して行頭のタブを無視してみましたが、sh -cで実行しているのが原因なのかダメでした。またエディタを利用しているとタブ→スペース変換されたりするのでムダにハマりそうです。Pythonの実装でもムダにインデントがあると怒られるので諦めます。
> docker run -it --rm --entrypoint="sh" \ python:3.7 \ -c "cat <<EOF > hoge.py # hogeって出力 print('hoge') if False: # インデントが効くか print('no print') EOF cat hoge.py;python hoge.py;" # hogeって出力 print('hoge') if False: # インデントが効くか print('no print') File "hoge.py", line 2 print('hoge') ^ IndentationError: unexpected indent
echoコマンドでファイル作成
echoコマンドでも複数行を改行付きで出力できるので、catコマンドと同じことが実現できました。Dockerfileで複数行を改行付きでechoする際にハマったので共有しておきます | ゲンゾウ用ポストイット
https://genzouw.com/entry/2019/04/17/080500
-cのあと、コンテナ内で実行するコマンドをダブルクォーテーション(")で括り、echoコマンドで出力する文字列をエスケープ記号を付与したダブルクォーテーション(\") にして、Python実装ではシングルクォーテーション(')を利用すると説明は長ったらしいですが、多分スッキリします。
こちらもインデントに気をつける必要がありました。> docker run -it --rm --entrypoint="sh" \ python:3.7 \ -c "echo \" # hogeって出力 print('hoge') if False: # インデントが効くか print('no print') \" > hoge.py;cat hoge.py;python hoge.py;" # hogeって出力 print('hoge') if False: # インデントが効くか print('no print') hogeAmazon ECSタスク定義だと
本題ですが、下記のように定義してやると実現できました。
マネジメントコンソールとかで
- イメージ: python:3.7
- エンドポイント: ["sh", "-c"]
- コマンド: ["echo "# hogeって出力\nprint('hoge')\nif False:\n\t# インデントが効くか\n\tprint('no print')" > hoge.py;cat hoge.py;python hoge.py;"]
1行で定義しないとだめなので、改行を
\n、インデントのタブを\tに置き換える必要があります。(インデントは半角スペースでもOK)
試しに改行やタブをそのままでマネジメントコンソールのテキストボックスにコピペってみましたがダメでした(´・ω・`)
catコマンドでヒアドキュメントを利用する方法も試してみましたが、どうにも思った結果が得られず断念しました。AWS CloudFormationだと
AWS CloudFormationだとYAMLで定義できるのでおすすめです。
AWS::ECS::TaskDefinitionの詳細については下記を参考ください。AWS::ECS::TaskDefinition - AWS CloudFormation
https://docs.aws.amazon.com/ja_jp/AWSCloudFormation/latest/UserGuide/aws-resource-ecs-taskdefinition.htmlYAML中で改行を含ませる方法は下記を参考にさせてもらいました。
YAMLで値の中に改行を含ませる - 日々此妄想
https://hana-da.hatenadiary.org/entry/20081222/1229930738テンプレート抜粋Resources: (略) ECSTaskDefinitionSample: Type: AWS::ECS::TaskDefinition Properties: Family: "ECSTaskDefinitionSample" Cpu: 256 Memory: 512 TaskRoleArn: !Ref ECSTaskRole NetworkMode: awsvpc RequiresCompatibilities: - FARGATE ContainerDefinitions: - Name: test Image: python:3.7 EntryPoint: - sh - -c Command: - |- echo " # hogeって出力 print('hoge') if False: # インデントが効くか print('no print') " > hoge.py; cat hoge.py; python hoge.py; LogConfiguration: LogDriver: awslogs Options: awslogs-group: /ecs/test/ awslogs-region: !Sub "${AWS::Region}" awslogs-stream-prefix: hoge作成したAmazon ESCのタスク定義からタスク実行すると下記のようにログ出力されて思ったとおりに実行されたことがわかります。
aws logs get-log-eventsコマンドでいい感じにログを取得する方法は下記が参考になります。Amazon CloudWatch LogsのログをAWS CLIでいい感じに取得する - Qiita
https://qiita.com/kai_kou/items/60bbe314b74b9eaf7126> aws logs get-log-events \ --log-group-name <ロググループ名> \ --log-stream-name <ストリーム名> \ --query "events[].[message]" \ --output text # hogeって出力 print('hoge') if False: # インデントが効くか print('no print') hogeまとめ
せっかくのコンテナサービスなんだからDockerイメージ作れって話ではあるのですが、ほんとにちょっとしたファイルを作成したいときに使えるかなと思います。
参考
知ると便利なヒアドキュメント - Qiita
https://qiita.com/kite_999/items/e77fb521fc39454244e7Dockerfileで複数行を改行付きでechoする際にハマったので共有しておきます | ゲンゾウ用ポストイット
https://genzouw.com/entry/2019/04/17/080500AWS::ECS::TaskDefinition - AWS CloudFormation
https://docs.aws.amazon.com/ja_jp/AWSCloudFormation/latest/UserGuide/aws-resource-ecs-taskdefinition.htmlYAMLで値の中に改行を含ませる - 日々此妄想
https://hana-da.hatenadiary.org/entry/20081222/1229930738Amazon CloudWatch LogsのログをAWS CLIでいい感じに取得する - Qiita
https://qiita.com/kai_kou/items/60bbe314b74b9eaf7126
- 投稿日:2019-12-18T08:53:16+09:00
AWS初心者がCodeBuildとCodeDeployを使ってCI/CDやってみた
富士通システムズウェブテクノロジー Advent Calendar 2019 18日目の投稿です。
(お約束)記事の内容は全て個人の見解であり、執筆内容は執筆者自身の責任です。所属する組織は関係ありません。
執筆者は入社三年目なので、至らない点や誤り等あればご指摘いただけると泣いて喜びます。AWSでCI/CDやってみようと思った理由
- せっかくやるなら自動化でしょって思ったから
- クラウドを使ってCI/CDをできるってかっよくね?そう思ったから
- どうせやるなら記録に残った方がいいかな?と思ったから
・・・そうです。ただの自己満です。 どうか、わがままにお付き合い下さい。筆者のレベル
- リージョンの指定方法知らずにずっとオハイヨのリージョンで作業してたぐらいにはAWS初心者です
- CI/CDについてちょっとは分かる
- 他のクラウドに触れたことがある
- dockerは多少使える
- 得意と言えるほどでもないけどできる分野
- インフラ < ミドル < アプリの順番
前提
- AWSのアカウント発行する
- CI/CDについての説明は省略
- MVCモデルで構築したJava言語のソースコードを使用
- ビルドツールはGradleを使用(独自docker image)
- AWSのロールについての説明は無いです
- 備忘録的に書いてるだけなので悪しからず
ざっくりな全体構成
鉄板構成なんじゃないかと
かる~く使用するツールの説明
AWS CodeCommit
https://aws.amazon.com/jp/codecommit/
- gitリポジトリサービス
- Javaのソースコードを配備するのに使用しましたAWS CodeBuild
https://aws.amazon.com/jp/codebuild/
- 専用のビルドスクリプトを元にビルドやらテストやらできるやつ
- デフォルトでは8種類のビルド環境を用意してくれてる
- AWS上に構築した、独自のビルド環境(dockerイメージ)も使用できる
- ビルド + S3(後述)に成果物を格納するのに使用しましたAWS CodeDeploy
https://aws.amazon.com/jp/codedeploy/
- 専用のデプロイスクリプトを元に成果物を特定のサーバやサービスに配備したり、シェルの実行やらできるやつ
- S3(後述)に配備された成果物をEC2(後述)に構築したVMにデプロイし、成果物の展開やら実行やらをするのに使用しましたEC2
https://aws.amazon.com/jp/ec2/
- VM構築サービス
- OSは色々選べます(今回はCentOSを選びました)
- VMにtomcatをインストールしてMVCで作ったJavaのソースコードを実行できるようにしましたS3
https://aws.amazon.com/jp/s3/
- ストレージです
- バックアップファイルやアーカイブなど色々なデータを置くことができます
- 成果物(warファイル)の置き場として使用しましたECR
https://aws.amazon.com/jp/ecr/
- Container Registryです(dockerイメージ置き場だと思ってもらえれば)
- コンテナベースで作成したサービス等の配備先として使用できます
- 今回は独自のビルド環境を構築したのでそちらの配備先として使用しました
- CodeDeployに必要なagentはインストールしましたいざ実践
CodeCommitにリポジトリを作成する
入力された数値の足し算だけをして次画面に結果を返却するだけのプログラムを作って、CodeCommit上に格納しただけ
(ソースは公開してないです。需要があればソース公開します。)Codebuldeでソースコードをビルドする前に...
ECR上にビルド環境を作成する
(やった後にDockerfileで書いていないことを非常に後悔...)
Gradleプロジェクトをビルドするための環境をdockerコンテナベースで用意する
- ローカルにdockerサービスをインストール
- CentOSのdockerイメージをPull + 起動
- Java + Gradleのインストール
- dockerイメージをdocker tagコマンドでイメージ名を書き換え
- 作成したECRにイメージをPUSHこれだけでAWS上に自身が作成したdockerイメージを格納することが可能
S3に成果物を格納する領域を作成する
※ S3上に構築するバケット名は重複が認められていない為、独自の名前を指定して作成する。CodeBuile上にビルドプロジェクトを作成する
- 送信元に上記手順で作成したCodeCommitのリポジトリを指定する
- 環境に上記手順で作成したECR上のdockerイメージを指定する
- ビルドの仕様に
buildspecを使用するを選択する- アーティファクトに上記手順で作成したS3上のバケットを指定する
buildspec.ymlを作成する
CodeCommit上のリポジトリのルートディレクリに
buildspec.ymlという名前のファイルを作成しますversion: 0.2 phases: install: commands: - gradle -v build: commands: - gradle war - tar -cvf sampleJava.tar ./build ./appspec.yml ./deploy.sh artifacts: files: - ./sampleJava.tar
- phasesタグにはinstallジョブとbuildタグを指定
- installタグではgradleのバージョン確認コマンドのみ実行(もちろんなくてもいい)
- biuldタグではgradleのwarファイル作成コマンドと、成果物をtarに固めるコマンドを実行
ビルドプロジェクトを動かしてみる
成功しました
画面をスクロールしていくとログも確認することができます。
成果物がS3上に格納されたことを確認
ログには格納が成功した旨がログ出力されてる
S3上に無事格納されてました
CodeDeployで成果物をデプロイするまえに...
EC2上にVMを構築する
- OSにCentOSを使用しました
- tomcatをインストールしました
- CodeDeploy用のagentをインストールしましたappspec.ymlを作成する
CodeCommit上のリポジトリのルートディレクリに
appspec.ymlという名前のファイルを作成しますversion: 0.0 os: linux files: - source: / destination: /home/centos hooks: ApplicationStart: - location: deploy.sh runas: root
- 上記手順で作成したVMの
/home/centosディレクトリに成果物を配備します- デプロイ時に
deploy.shを実行しますdeploy.shの実行はrootユーザで行いますまた、デプロイ時に実行するコマンドをまとめたシェルを作成しました
systemctl stop tomcat rm -fr /var/lib/tomcat/webapps/sampleJava/* mkdir /var/lib/tomcat/webapps/sampleJava cp /home/centos/build/libs/sampleJava.war /var/lib/tomcat/webapps unzip /var/lib/tomcat/webapps/sampleJava.war -d /var/lib/tomcat/webapps/sampleJava systemctl start tomcat
- tomcatの停止
- 成果物の配備 + 展開
- tomcatの開始 を行うシェルです。
CodeDeploy上にデプロイアプリケーションを作成する
- デプロイグループの作成も一緒に行う
- 環境設定にEC2インスタンスを選択する
- タグの設定を行う(同様のタグ値・キーの設定をEC2のインスタンスにも行う)
デプロイアプロケーションを動かしてみる
成功しました
成功の場合はブラウザ上から成功のログを確認することはできないっぽいです
失敗の場合はちょっとだけエラー理由が表示されます
EC2に構築したVMにデプロイされたか確認する
EC2のVMのパプリックIPアドレスでブラウザからアクセス
無事ブラウザからアクセスすることができました。背景色を変更してもう一回CI/CDを実行する
よし。できた。
エラーっぽくて心臓に悪いな...AWS初心者でもCodeBuildとCodeDeployを使ってCI/CDをすることができました

今回得た学び
- なんかしらのツールでCI/CDやったことあればAWSだろうがなんだろうがなんとかCI/CDできる
- 新しいことを学んで実践してみて、成功した時のうれしみが半端ない
- 控えめに言ってめちゃめちゃ楽しかった
最後に
だらだらと書いちゃいましたが、最後まで見ていただいてありがとうございます。
今回アドカレに挑戦してみてめちゃめちゃ楽しかったです。(大事なので2回言う)
また機会があったら積極的にチャレンジしていきたいと思います!
(ネタが尽きてくるのでアドカレの場合、初週あたりに設定したほうがいいことも学んだ)おわり。
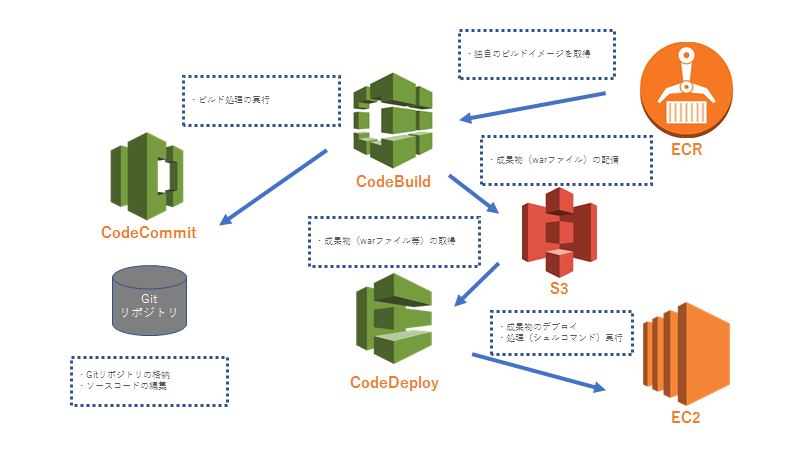


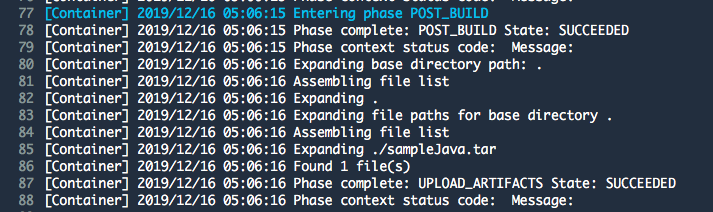
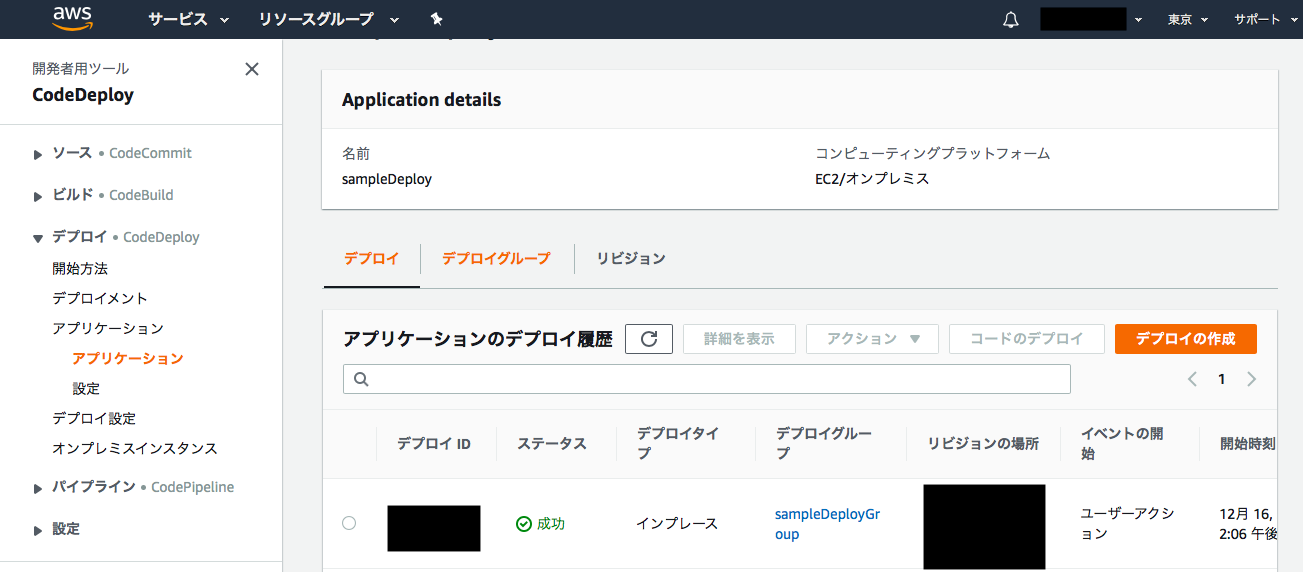
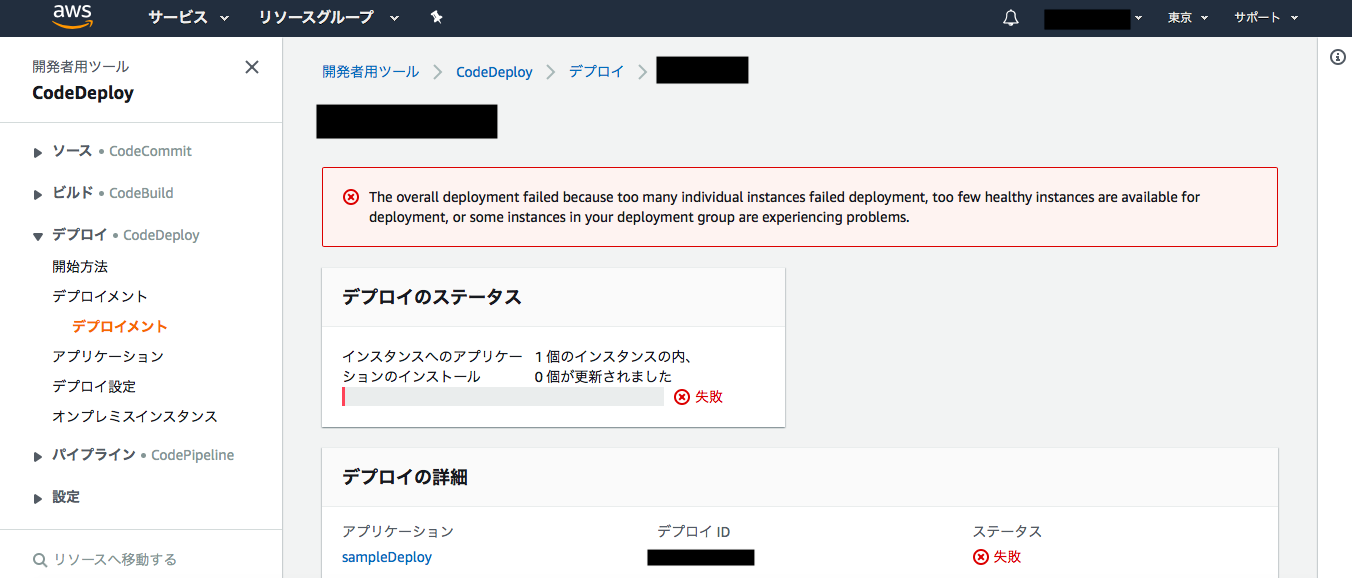

- 投稿日:2019-12-18T02:03:47+09:00
Amazon VPC CNI plugin for KubernetesのソースコードリーディングでEKSのネットワーキングについて理解を深める #3 (Last)
はじめに
この記事はAmazon EKS #2 Advent Calendar 2019 18日目の記事です。
今回は #3 になります。前回からの続きになりますので、先に以下の記事をご覧ください。
- Amazon VPC CNI plugin for KubernetesのソースコードリーディングでEKSのネットワーキングについて理解を深める #1
- Amazon VPC CNI plugin for KubernetesのソースコードリーディングでEKSのネットワーキングについて理解を深める #2
- Amazon VPC CNI plugin for KubernetesのソースコードリーディングでEKSのネットワーキングについて理解を深める #3 (イマココ)
長くなりましたが、これで終わりです。
最後にkubernetes本体(kubelet)との架け橋となる、CNIプラグインを見ていきます。Go2: aws-cni (CNIプラグイン)
CNIプラグインはコマンドラインモジュールで、kubeletからキックされます。
CNIの仕様に沿ってパラメータでPodの情報を受け取るので、L-IPAMDから割り当て可能なIPアドレスを取得後、ネットワーク設定を行ってIPアドレス情報をkubeletに返却する、といった役割となります。CNIプラグインのメインルーチンは
cni.goで、実際にネットワーク設定を行うのはdriver.goというモジュールです。cni.go
ソースはこちら。 -> amazon-vpc-cni-k8s/plugins/routed-eni/cni.go
cni.goは本家CNI(containernetworking)のスケルトンパッケージを元に作られていて、addとdelという2つのファンクションを実装しています。cni.go#L332e := skel.PluginMainWithError(cmdAdd, cmdDel, cniSpecVersion.All)package skel
https://godoc.org/github.com/containernetworking/cni/pkg/skelPackage skel provides skeleton code for a CNI plugin. In particular, it implements argument parsing and validation.
~~
PluginMainWithError is the core "main" for a plugin. It accepts callback functions for add, check, and del CNI commands and returns an error.The caller must also specify what CNI spec versions the plugin supports.
大体addとdelはおんなじだと思うので、Pod作成時に呼ばれる
cmdAddを見てみます。
流れとしては、「PodのIPを取得 -> 取得したIPでPodのネットワークを設定」というシンプルなものです。まずgRPCクライアントでL-IPAMDに対してAddNetworkRequestでIPアドレスを要求します。
cni.go#L107~conn, err := grpcClient.Dial(ipamDAddress, grpc.WithInsecure()) defer conn.Close() c := rpcClient.NewCNIBackendClient(conn) r, err := c.AddNetwork(context.Background(), &pb.AddNetworkRequest{ Netns: args.Netns, K8S_POD_NAME: string(k8sArgs.K8S_POD_NAME), K8S_POD_NAMESPACE: string(k8sArgs.K8S_POD_NAMESPACE), K8S_POD_INFRA_CONTAINER_ID: string(k8sArgs.K8S_POD_INFRA_CONTAINER_ID), IfName: args.IfName}) addr := &net.IPNet{ IP: net.ParseIP(r.IPv4Addr), Mask: net.IPv4Mask(255, 255, 255, 255), }
args.XXXはkubeletから起動時に渡されるPodの情報です。
続いて、取得したIPでネットワーク設定を行います。cni.go#L193err = driverClient.SetupNS(hostVethName, args.IfName, args.Netns, addr, int(r.DeviceNumber), r.VPCcidrs, r.UseExternalSNAT, mtu)あとは、設定したPodのIPアドレス情報をkubeletに返すだけです。
driver.go
driver.goはcni.goと同じ階層のディレクトリ driver の中にあります。
こちら -> amazon-vpc-cni-k8s/plugins/routed-eni/driver/driver.goネットワーク設定の流れは、前回引用したドキュメントの以下の通りです。
CNI Plugin Sequence
https://github.com/aws/amazon-vpc-cni-k8s/blob/master/docs/cni-proposal.md#cni-plugin-sequence
- create a veth pair and have one veth on host namespace and one veth on Pod's namespace
- Get an Secondary IP address assigned to the instance and perform following inside Pod's name space:
- Assign this IP address to Pod's eth0
- Add default gateway and default route to Pod's route table
- Add a static ARP entry for default gateway
- On host side, add host route so that incoming Pod's traffic can be routed to Pod.
ソースコードでも上記の流れで作っているのが確認でき、ソースも長いので今回一つ一つのファンクションを追っていくのは行いません。ただ、実際のネットワーク設定はほぼ外部ライブラリを利用しているので、今回はそのライブラリを紹介したいと思います。
import文をみると、ラップしているものの含めて、ネットワーク周りのライブラリは以下の5つが利用されています。
- net
- github.com/vishvananda/netlink
- github.com/coreos/go-iptables/iptables
- github.com/containernetworking/cni/pkg/ns
- github.com/containernetworking/cni/pkg/ip
前回のOperator-sdkのバージョンが古い点を指摘しましたが、CNIについてもかなり古いです。。
特に、github.com/containernetworking/cni/pkg/nsとipはすでに存在していません。
netGoの標準ライブラリですが、
net.IPでAmazon VPC CNIプラグインではIPアドレスを処理する程度しか使っていなそうです。
github.com/vishvananda/netlinkhttps://godoc.org/github.com/vishvananda/netlink
https://github.com/vishvananda/netlinkhelokuのvishvanandaという方の個人ライブラリっぽいです。スター数も多く、かなり昔にコミットされている物もあるので、Goではメジャーなライブラリなのでしょうか。
Amazon VPC CNIプラグインのveth等のPodのネットワーク設定のほぼ全てをこちらのライブラリで行っています。Linuxのipコマンドに相当する機能です。
ネットワーク設定の一番コアな部分が外部の個人ライブラリというところがOSSらしい感じですね(適当)
github.com/coreos/go-iptables/iptableshttps://godoc.org/github.com/coreos/go-iptables/iptables
https://github.com/coreos/go-iptablesこちらはcoreosのiptablesライブラリです。Godocでiptabesと検索するといくつか出てきますが、何がメジャーなのかはよくわかりません。 -> https://godoc.org/?q=iptables
ただkubernetes本体では、kube-proxyがiptablesを操作するときは、kubenrnetesのpkg/util内のk8s.io/kubernetes/pkg/util/iptablesというライブラリを利用しています。
github.com/containernetworking/cni/pkg/ns本家CNI(containernetworking)のpkgです。
ただし、go.modを見るとcni:v0.5.2を利用していることが分かりますが、これは2017年4月にリリースされたものです。
https://github.com/containernetworking/cni/releases/tag/v0.5.2現在はすでにcniのリポジトリにはなく、pluginという別リポジトリにあります(結構探しました。笑)
https://godoc.org/github.com/containernetworking/plugins/pkg/ns
https://github.com/containernetworking/plugins/blob/master/pkg/nsこちらは主にPod内のネットワーク設定をする際に、利用されています。
README.mdにGoにおけるネットワーク名前空間とスレッドについて解説がありました。Namespaces, Threads, and Go
https://github.com/containernetworking/plugins/blob/master/pkg/ns/README.md
On Linux each OS thread can have a different network namespace. Go's thread scheduling model switches goroutines between OS threads based on OS thread load and whether the goroutine would block other goroutines. This can result in a goroutine switching network namespaces without notice and lead to errors in your code.goでネットワーク名前空間を切り替えを安全に行ってくれるもののようです。
driver.goでは、Pod内のネットワーク名前空間に設定する部分はrun()というファンクションns.Do()に渡す形で実行しています。以下ネットワーク設定部分以外だいぶ端折ってますが、
run()の中身です。driver.go#84~// run defines the closure to execute within the container's namespace to create the veth pair func (createVethContext *createVethPairContext) run(hostNS ns.NetNS) error { err := createVethContext.netLink.LinkAdd(veth) // Add a connected route to a dummy next hop (169.254.1.1) // # ip route show // default via 169.254.1.1 dev eth0 // 169.254.1.1 dev eth0 gw := net.IPv4(169, 254, 1, 1) gwNet := &net.IPNet{IP: gw, Mask: net.CIDRMask(32, 32)} err = createVethContext.netLink.RouteReplace(&netlink.Route{ LinkIndex: contVeth.Attrs().Index, Scope: netlink.SCOPE_LINK, Dst: gwNet}); // Add a default route via dummy next hop(169.254.1.1). Then all outgoing traffic will be routed by this // default route via dummy next hop (169.254.1.1). err = createVethContext.ip.AddDefaultRoute(gwNet.IP, contVeth); err = createVethContext.netLink.AddrAdd(contVeth, &netlink.Addr{IPNet: createVethContext.addr}); // add static ARP entry for default gateway // we are using routed mode on the host and container need this static ARP entry to resolve its default gateway. neigh := &netlink.Neigh{ LinkIndex: contVeth.Attrs().Index, State: netlink.NUD_PERMANENT, IP: gwNet.IP, HardwareAddr: hostVeth.Attrs().HardwareAddr, } err = createVethContext.netLink.NeighAdd(neigh); // Now that the everything has been successfully set up in the container, move the "host" end of the // veth into the host namespace. err = createVethContext.netLink.LinkSetNsFd(hostVeth, int(hostNS.Fd())); }
github.com/containernetworking/cni/pkg/iphttps://godoc.org/github.com/containernetworking/plugins/pkg/ip
https://github.com/containernetworking/plugins/tree/master/pkg/ipこちらも現在は本家CNI(containernetworking)のcniではなく、pluginsというリポジトリにありますのでURLが異なります。
Amazon VPC CNIプラグインのリポジトリでは、
AddDefaultRoute()というファンクションしか利用していなそうです。 ->
https://github.com/containernetworking/plugins/blob/master/pkg/ip/route_linux.goroute_linux.gopackage ip import ( "net" "github.com/vishvananda/netlink" ) // AddDefaultRoute sets the default route on the given gateway. func AddDefaultRoute(gw net.IP, dev netlink.Link) error { _, defNet, _ := net.ParseCIDR("0.0.0.0/0") return AddRoute(defNet, gw, dev) }なんとこちらでも
github.com/vishvananda/netlinkを使っていました。笑終わりに
全体を見渡して見ると、Amazon VPC CNI pluginは利用しているライブラリが非常に古くなっており、前回紹介した通り、アーキテクチャの改善も含めた抜本的な改善に向かっていることを改めて感じました。
ただそれでも、EKSのネットワーキングやKubernetes、Goの理解を深めるには十分な収穫がありました。
普段は利用するだけのものかもしれませんが、折角のOSSなので、実際にソースコードを読んだり、自分でビルドしたりするだけでも、かなり理解が深まり、トラブルシューティング力は大きく向上すると思います。
記事的には全然まとまっていない気がしますが、個人的には記事にできてよかったです。
最後までご覧いただきありがとうございました。