- 投稿日:2019-10-12T23:55:43+09:00
PythonでOP/COMPを制御する
TouchDesignerはノードベースのプログラミング言語ですが、Pythonでも書けます。
『どこに書くか?』についてはsatoruhigaさんが、Pythonの基本的な書き方はいろんなひとが書いているので今回は『TouchDesignerの機能を具体的にPythonで制御するには?』について書きたいと思います。TouchDesignerで主に扱う3つのClass
TouchDesignerをPythonで扱う場合、主に4つのクラスを扱います。
COMP Class, OP Class, Par Class、Connector Classです。
COMP ClassはBase COMPなどのCOMPを扱うときのクラス、OP ClassはTOPやSOPなどを扱うクラス、そしてOPやCOMPが持つ各種の値、例えばtx, ty, tzやbuttonのw(width), h(height)などがPar Classとなっています。また、細かく言えばOP Classは各OPごとにOP Classを継承して作られています。
今回は個別のメソッドには触れず、全体に共通した処理を紹介していきます。
CHOP Class, TOP Class, SOP Class, MAT Class, DAT Classです。Python上での変数名の確認方法
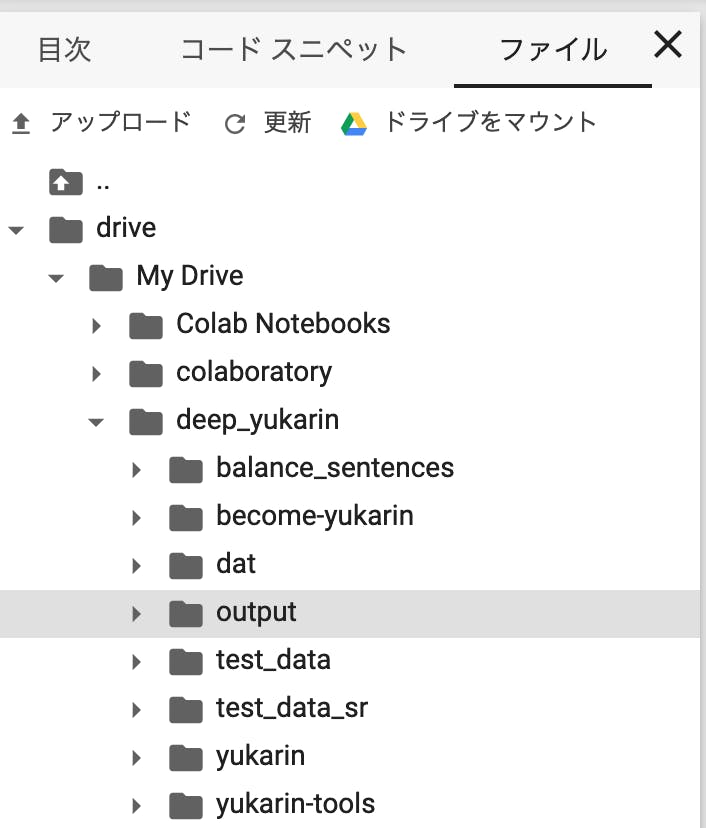
マウスカーソルを知りたいパラメータの名前の上にロールオーバーすれば名称が表示されます。
"Width"のPython上の変数名は"w"のようです。
よく書くやついくつか
よく書く処理を挙げておきます。チートシート替わりにどうぞ。
Constantの値を変更する
直接値の読み書きができます。
op('circle1').par.radiusx.val = 0.5expressionのパスを変更する
パスを文字列として書き込みます。
op('circle1').par.radiusx.expr = 'absTime.seconds'モードを変更する
Expressionモードにするには、
op('circle1').par.radiusx.mode = ParMode.EXPRESSIONConstantモードにするには、
op('circle1').par.radiusx.mode = ParMode.CONSTANTConnector Classの例1. OP同士をつなぐ
コネクタが一個しかないものは、
op('circle1').onputConnectors[0].connect(op('level1'))コネクタが複数あるのものは、
op('circle1').onputConnectors[0].connect(op('comp1').inputConnectors[0])ちなみにconnectメソッドはインプットコネクタからも叩けます。
op('level1').inputConnectors[0].connect(op('circle1').outputConnectors[0])COMP同士をつなぐ
基本OPのコネクタと一緒で、名称がinputCOMPConnector/outputCOMPConnectorになってるだけです。
op('button1').outputCOMPConnectors[0].connect(op('container1').inputConnectors[0])Inputの数を数える
len(op('circle1').inputConnectors) len(op('button1').inputCOMPConnectors)コネクションを解除する
op('circle1').inputConnectors[0].disconnect() op('button1').inputCOMPConnectors[0].disconnect()OPやCOMPの位置を移動する
op('circle1').nodeY = op('circle1').nodex + 10 op('button1').nodeY = op('button1').nodeY + 10
- 投稿日:2019-10-12T23:33:34+09:00
BeautifulSoup+Pythonで、マルウェア動的解析サイトからWebスクレイピング
はじめに
JoeSandboxというマルウェアを解析してレポートを出力してくれるサイトがあります。
https://www.joesandbox.comJoeSandboxには色々バージョンがありますが、Cloud Basicというバージョンであれば無料でマルウェア解析ができます。
さらにCloud Basicで解析されたレポートは公開されますので、他の人の分析結果レポートを見ることもできます。今回はマルウェアの分析結果レポートをBeautifulSoup+PythonでWebスクレイピングし、プロセス情報を取得してみたいと思います。
ちなみにCloud Basic以外のバージョンですとWeb APIが利用できますが、Cloud Basicでは利用できないようです。JoeSandboxについて
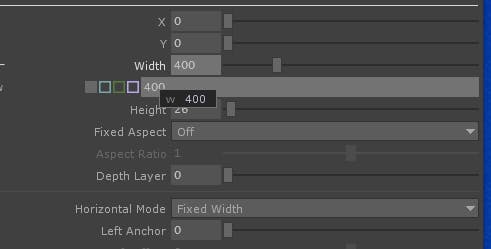
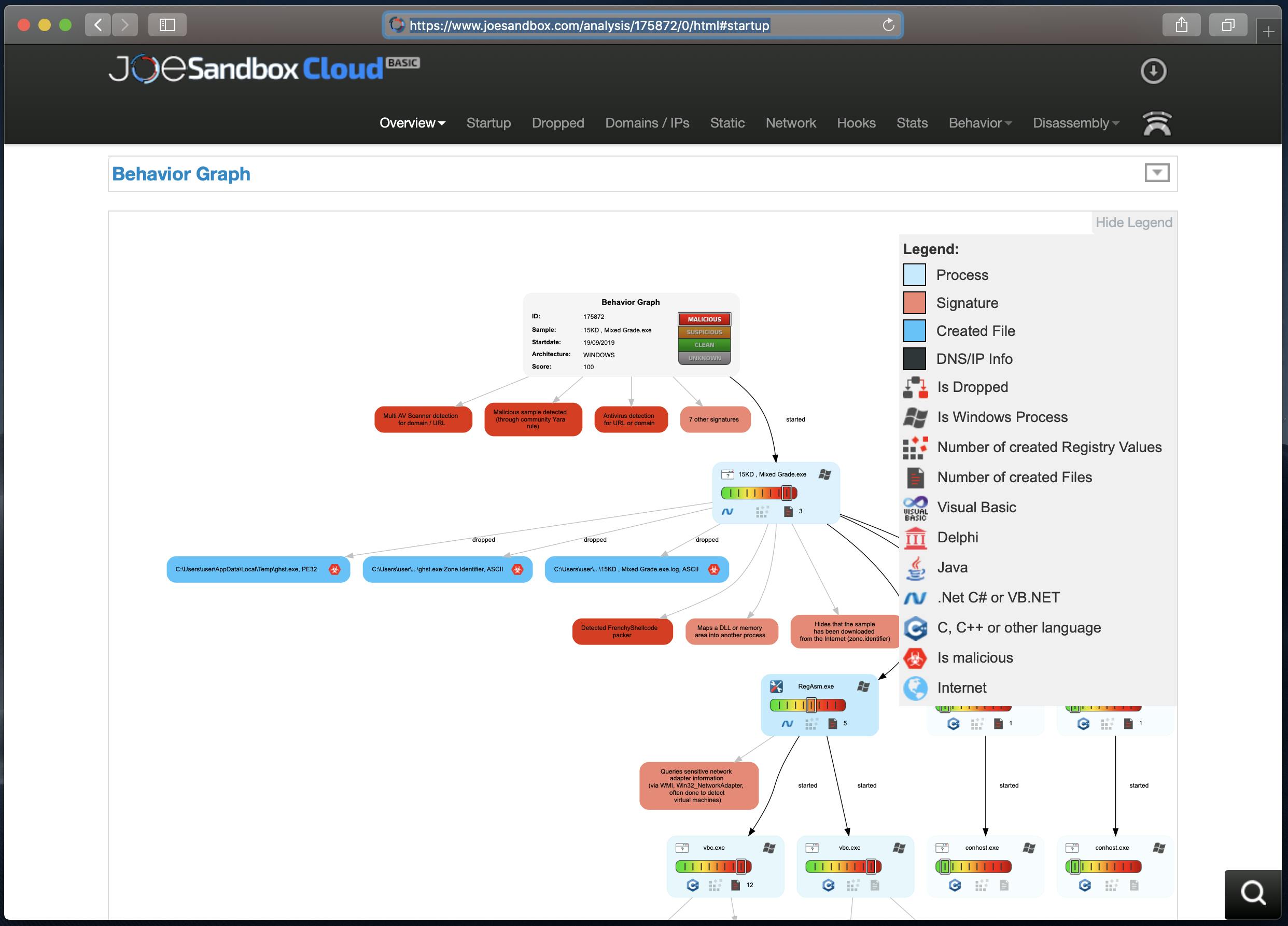
分析画面です。この画面でマルウェアを指定し、色々なオプションなどを設定したのちに分析を行います。
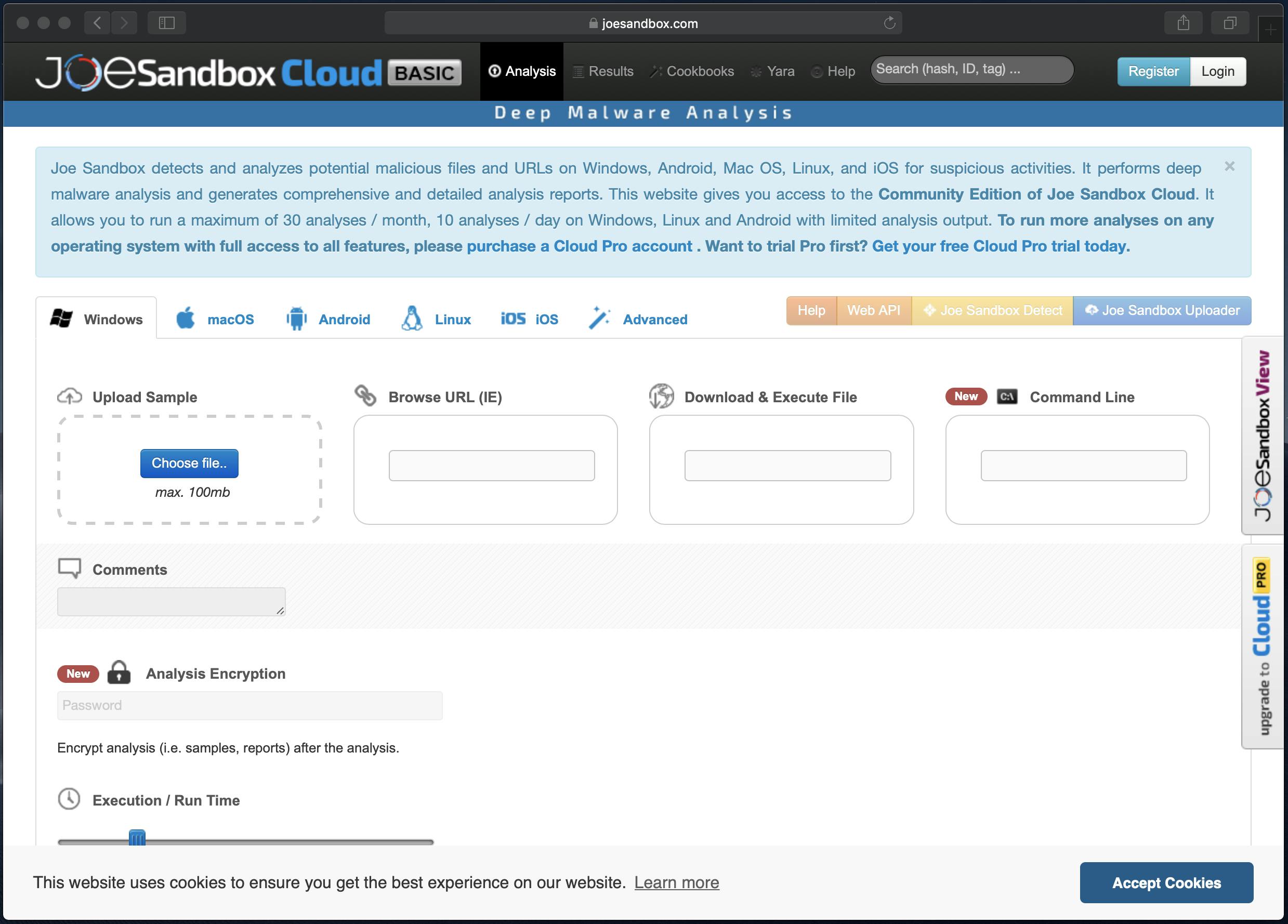
分析結果の一覧画面です。
分析結果の詳細画面です。色々な分析結果が出力されていますので、分析結果の一部分の画面キャプチャです。
https://www.joesandbox.com/analysis/175872/0/html#startup
今回やりたいこと
今回は分析結果の詳細画面から、マルウェアのプロセスの一連の流れを抽出したいと思います。
具体的には以下の部分の情報を抽出します。
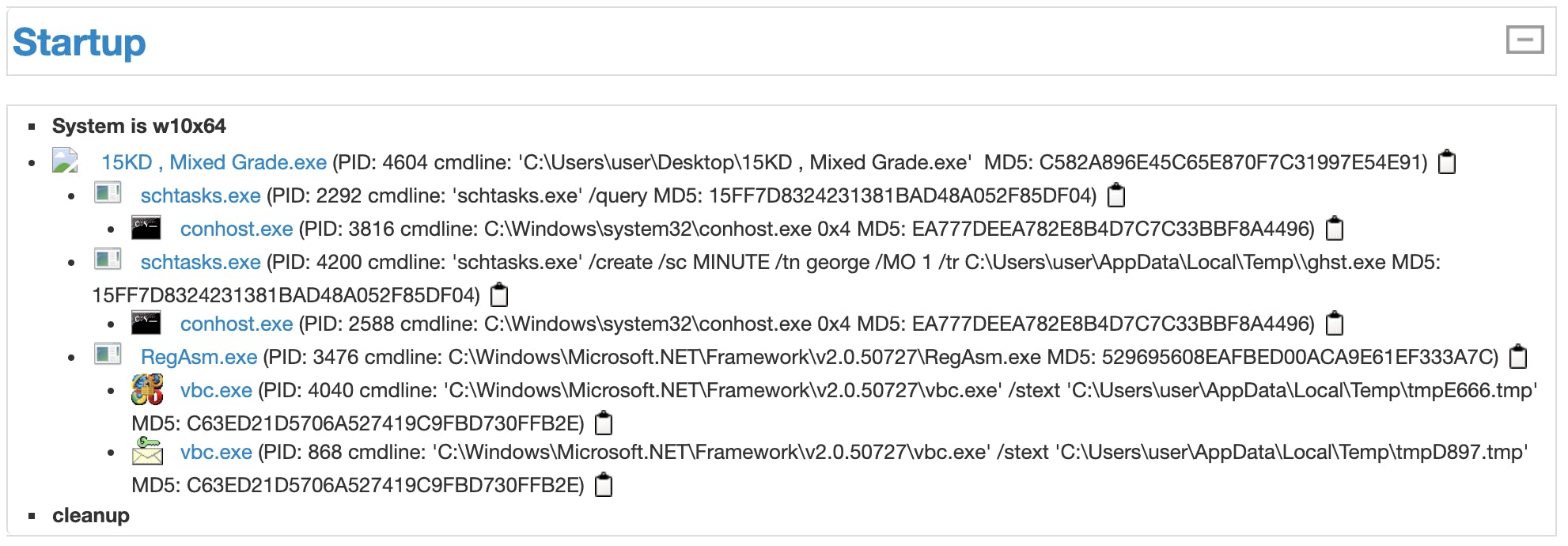
出力結果は以下のようにしようと思います。プロセスの親子関係がわかるようにインデントをつけた状態で出力しようと思います。
レポート番号:xxxxx 実行日時 15KD , Mixed Grade.exe schtasks.exe conhost.exe schtasks.exe conhost.exe RegAsm.exe vbc.exe vbc.exeコード
以下に記載の内容を繋げたら動くようにしています。
必要なライブラリをインポート
BeautifulSoup以外にrequests, os, datetime, pytz もインポートします。
import requests from bs4 import BeautifulSoup import os import datetime, pytz抽出するレポート番号の指定
複数のレポートから情報を抽出するため、fromとtoを入力するように準備します。ここではテスト用に1つだけ指定しています。
report_num_from = 175872 report_num_to = 175872指定されたページのクロール
レポートのURLは以下のようになっています。この「175872」の部分がレポート番号のようですので、この番号をループするようにしたいと思います。
https://www.joesandbox.com/analysis/175872/0/htmldef find_process_name(report_num_from, report_num_to): for i in range(report_num_from, report_num_to + 1): try: process_names = [] process_names.append('\n[report number]:{} {}'.format(i, datetime.datetime.now(pytz.timezone('Asia/Tokyo')))) target_url = 'https://www.joesandbox.com/analysis/' + str(i) + '/0/html' response = requests.get(target_url) soup = BeautifulSoup(response.text, 'lxml')JoeSandboxの状態の確認
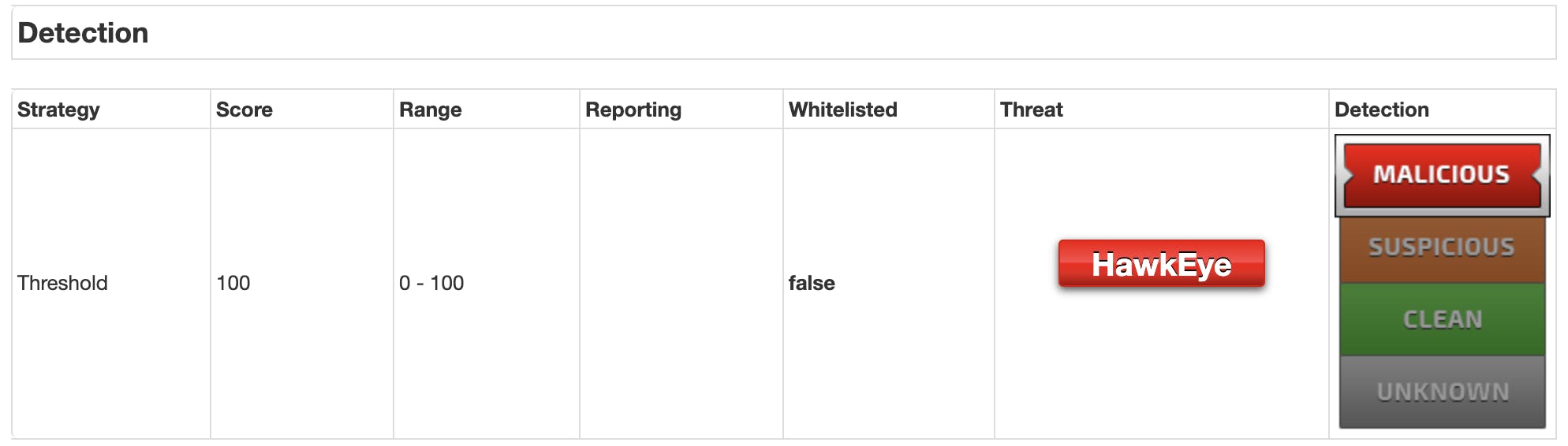
JoeSandboxはマルウェアの分析結果により、malicious, suspicious, clean, unknownと分けられているようです。
マルウェアのプロセス情報を取得したいので、ここではmaliciousのみ抽出しようと思います。以下はmaliciousの画面例です。
上記のmaliciousの情報を情報を取得してみようと思います。
該当のコードは以下でした。
imgでidがanalysisDetectionStatusのaltに情報が指定されるようです。
この情報を取得するにはsoup.find('img', id='analysisDetectionStatus').get('alt')と記載すれば良いので、それを組み込みます。detection = soup.find('img', id='analysisDetectionStatus').get('alt')プロセス情報の取得
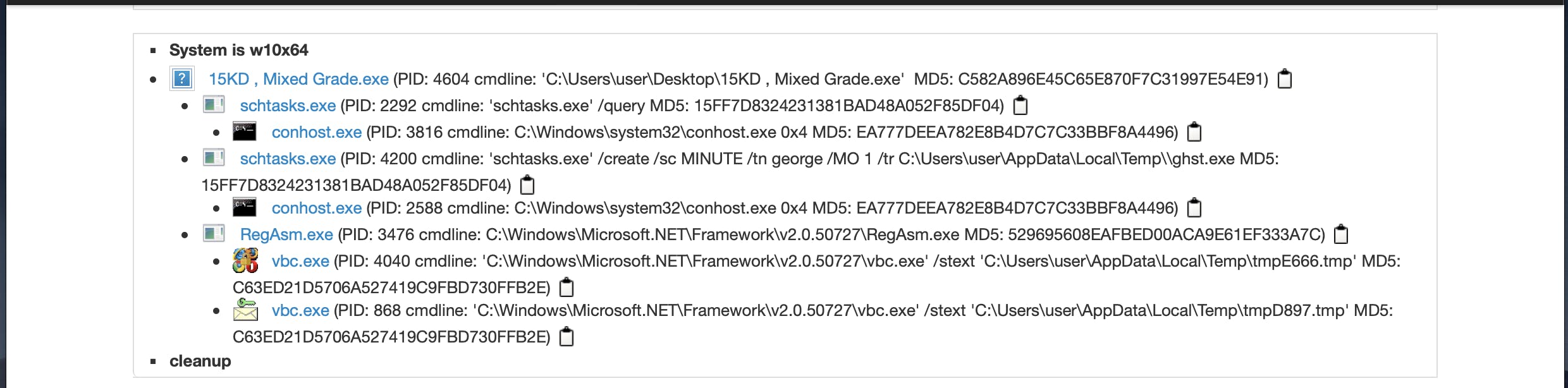
以下はプロセス情報の画面例です。
このプロセス情報を取得してみようと思います。
該当のコードは以下でした。
中身を確認してみます。
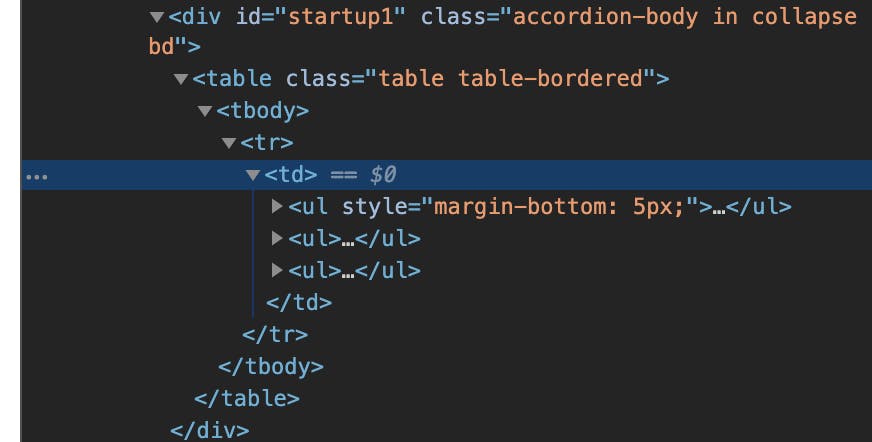
どうやらプロセス情報はテーブルに格納されているようです。
divのidがstartup1の中身を配列に格納して、その中でプロセス情報を取得しようと思います。
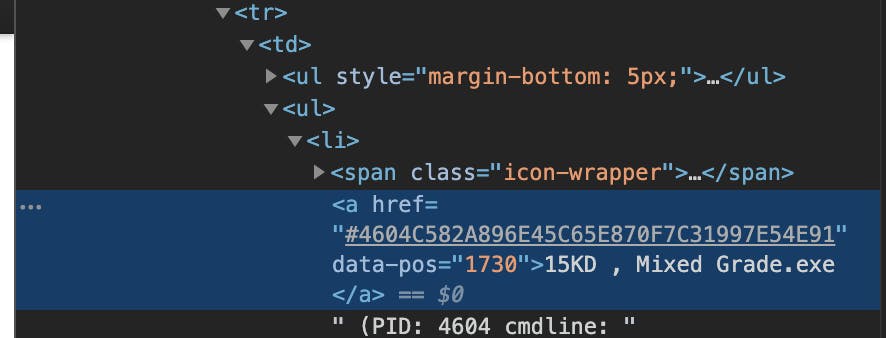
ちなみにプロセス情報は<a hrefの次に格納されていましたので、以下のようにしました。
もっとスマートなやり方がありそうですが・・・。if detection == 'malicious': startup = soup.find('div', id='startup1') flag = False for line in startup.prettify().split('\n'): if flag == True: process_names.append(line) flag = False if '<a href' in line: flag = True else: process_names.append('not malicious')例外処理
例外処理の部分も忘れずに記載します。
処理の最後にsave_file関数(この後記載)を呼び出します。# Report number does not exist except IndexError as e: process_names.append('ERROR:{}'.format(e)) except Exception as e: process_names.append('ERROR:{}'.format(e)) finally: save_file(process_names)ファイル書き込み
ファイルに書き込む処理です。
別に関数にしなくても良いですが今後ファイル書き出し以外の処理に変更しようと思うので、書き換えやすいように関数にしました。
同じフォルダにoutput.txtを作成して書き込みます。def save_file(process_names): with open('./output.txt', 'a') as f: for x in process_names: f.write(str(x) + "\n")処理の実行
関数を実行します。
これで完了です。find_process_name(report_num_from, report_num_to)完成したコード
今までのコードをつなげて、コメントを追加しました。
当たり前のことですがfromとtoで指定する範囲はほどほどにしてください。# Extract process name from JoeSandbox analysis result. # # How to use: # 1. Enter the first and last report number you want to analyze. # -> report_num_from and report_num_to # 2. Result is saved as output.txt in the same folder. import requests from bs4 import BeautifulSoup import os import datetime, pytz report_num_from = 175872 report_num_to = 175874 def find_process_name(report_num_from, report_num_to): """ Extract process name from JoeSandbox analysis result. Parameters ---------- report_num_from : int First report number to analyze report_num_to : int Last report number to analyze """ for i in range(report_num_from, report_num_to + 1): try: process_names = [] process_names.append('\n[report number]:{} {}'.format(i, datetime.datetime.now(pytz.timezone('Asia/Tokyo')))) target_url = 'https://www.joesandbox.com/analysis/' + str(i) + '/0/html' response = requests.get(target_url) soup = BeautifulSoup(response.text, 'lxml') # check JoeSandbox Detection (malicious, suspicious, clean, unknown) detection = soup.find('img', id='analysisDetectionStatus').get('alt') if detection == 'malicious': # 'startup1' is a table with process names startup = soup.find('div', id='startup1') # process name is next to '<a href' flag = False for line in startup.prettify().split('\n'): if flag == True: process_names.append(line) flag = False if '<a href' in line: flag = True else: process_names.append('not malicious') # Report number does not exist except IndexError as e: process_names.append('ERROR:{}'.format(e)) except Exception as e: process_names.append('ERROR:{}'.format(e)) finally: save_file(process_names) def save_file(process_names): """ Save the extraction results to a file. File I/O is a function because it may change. Parameters ---------- process_names : list of str List containing process names. """ with open('./output.txt', 'a') as f: for x in process_names: f.write(str(x) + "\n") find_process_name(report_num_from, report_num_to)実行結果
上記のコードを実行すると以下のような結果が得られます。
[report number]:175872 2019-10-12 22:14:58.066360+09:00 15KD , Mixed Grade.exe schtasks.exe conhost.exe schtasks.exe conhost.exe RegAsm.exe vbc.exe vbc.exe [report number]:175873 2019-10-12 22:15:04.034550+09:00 not malicious [report number]:175874 2019-10-12 22:15:11.023350+09:00 EXCEL.EXE

- 投稿日:2019-10-12T23:03:26+09:00
楽天競馬に自動入金/精算することでハッピープログラム取引件数を稼ぐ
はじめに
突然ですが、皆さんは楽天の「ハッピープログラム」を知っていますでしょうか?
楽天銀行には、「ハッピープログラム」というランクシステムがあり、月間の楽天銀行の取引件数や残高に応じてランクが決定されます。
このランクが上がれば、つまり取引件数を増やすことによって楽天ポイントの倍率が上がるというわけです。
https://www.rakuten-bank.co.jp/happyprogram/今回は楽天競馬に100円だけ入金/即100円出金を毎日繰り返し、無料で楽天銀行の取引件数を増やしてこのランクを上げる方法を紹介します。
前提
- 楽天銀行、楽天競馬のアカウントをあらかじめ作成しておいてください。
- ハッピープログラムに登録しておいてください。
参考サイト:
https://nameaji.com/rakuten_bank_vip_how/環境
- Amazon Linux 2
- python 2.7.16
- Selenium 3.141.0
- Chrome 77.0.3865.120
- Chrome Driver 77.0.3865.40
AWS EC2にpythonスクリプトをcron登録し、その前後でEC2を起動/停止させます。
構築手順
ブラウザのインストール
- Chrome用リポジトリ作成
/etc/yum.repos.d/google.chrome.repo[google-chrome] name=google-chrome baseurl=http://dl.google.com/linux/chrome/rpm/stable/$basearch enabled=1 gpgcheck=1 gpgkey=https://dl-ssl.google.com/linux/linux_signing_key.pub
- Chromeのインストールと日本語フォントのインストール
# yum update # yum -y install google-chrome-stable # google-chrome --version Google Chrome 77.0.3865.120 # yum -y install ipa-gothic-fonts ipa-mincho-fonts ipa-pgothic-fonts ipa-pmincho-fonts
- Chromeのバージョンが77.0なので、driverもそれに合わせたバージョンをダウンロードする。 https://sites.google.com/a/chromium.org/chromedriver/downloads
# cd /usr/local/bin # wget https://chromedriver.storage.googleapis.com/77.0.3865.40/chromedriver_linux64.zip # unzip chromedriver_linux64.zip # chmod 755 chromedriver # rm chromedriver_linux64.zipSeleniumのインストール
- インストール実行
# pip install selenium自動入出金スクリプト作成
- お好みのディレクトリに以下スクリプトを配置。ログイン用IDやパスワードは自身の情報を入力してください。
※ パスワード情報をスクリプトに直打ちしているので、取扱には注意してください。
rakuten.py# coding:utf-8 from selenium import webdriver from selenium.webdriver.chrome.options import Options import time # ブラウザーを起動 options = webdriver.ChromeOptions() # headlessで起動 options.add_argument('--headless') options.add_argument('--disable-gpu') options.add_argument('--no-sandbox') driver = webdriver.Chrome(executable_path="/usr/local/bin/chromedriver", options=options) # Google検索画面にアクセス driver.get('https://keiba.rakuten.co.jp/') # 入金をクリック driver.find_element_by_id('noBalanceStatus').click() # ウィンドウハンドルを取得する handle_array = driver.window_handles # seleniumで操作可能なdriverを切り替える driver.switch_to.window(handle_array[1]) # ログイン driver.find_element_by_id('loginInner_u').send_keys("楽天ログイン用ID") driver.find_element_by_id('loginInner_p').send_keys("楽天ログイン用パスワード") driver.find_element_by_class_name('loginButton').click() ### 入金処理 ### # 入金 driver.find_element_by_class_name('definedNumber').send_keys("100") # [確認する]クリック driver.find_element_by_class_name('confirm').click() # 暗証番号入力 driver.find_element_by_class_name('tealeaf_masking').send_keys("楽天競馬用パスワード") # [入金する]クリック driver.find_element_by_class_name('credit').click() ################ ### Sleep 60 ### time.sleep(60) ### 精算処理 ### # [精算]クリック driver.find_element_by_xpath('//*[@id="menuBar"]/div/div[2]/ul/li[2]').click() # [確認する]クリック driver.find_element_by_class_name('confirm').click() # 暗証番号入力 driver.find_element_by_class_name('tealeaf_masking').send_keys("楽天競馬用パスワード") # [精算する]クリック driver.find_element_by_class_name('inquire').click() ################ # ブラウザーを終了 driver.quit()※2019/10/13 追記
入金してから精算するまで60秒のSleepを入れるようにしました。
これは入金処理が反映される前に精算するのを防ぐためです。Cronスケジュール登録
- まずはサーバ上でcron登録します。12:00 JSTに起動するようにしています。(サーバ上はUTC)
※楽天競馬は入出金可能な時間帯が決められています。適宜最新の情報を確認するようにしてください。
# crontab -e 0 3 * * * python /root/rakuten.pyAWS EC2インスタンス起動スケジュール
- 次にAWSのCloudWatchにてEC2を自動起動させるようスケジュールします。
1) IAMロールを新規作成する。
ここでは AWS 管理ポリシーの AmazonSSMAutomationRole をアタッチします。
EC2 起動停止するために必要な権限以外も含まれますので、必要に応じてカスタムポリシーを作成してください。
作成後、信頼関係から信頼されたエンティティに events.amazonaws.com を追加します。{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": [ "events.amazonaws.com" ] }, "Action": "sts:AssumeRole" } ] }2) CloudWatch の ルールを新規作成する。
3) スケジュールのCron式で起動時間を設定する。11:30 JSTに起動させます。
30 2 * * ? *
4) ターゲットを追加し「SSM Automation」を選択する。
5) Documentで「AWS-StartEC2Instance」を選択する。
6) 定数のInstanceIdに起動したいEC2インスタンスのIDを設定する。
7) 既存のロールの使用: 作成したIAM ロールを指定する。AWS EC2インスタンス停止スケジュール
- 今度は停止スケジュールです。起動と違いIAMロールの必要はありません。
1) CloudWatch の ルールを新規作成する。
2) スケジュールのCron式で停止時間を設定する。14:00 JSTに停止させます。
0 4 * * ? *
3) ターゲットを追加し「EC2 StopInstances API 呼び出し」を選択する。
4) 停止したいEC2インスタンスのIDを設定する。これで自動で毎日楽天競馬にログインし、入出金してくれることでしょう!
まとめ
本スクリプトを単発実行でテストしたところ問題なく稼働したのですが、現時点でスケジュール実行実績がないためどうなることやら…少し様子見してNGだったら追記して修正します。
また、今回AWSのEC2を利用しているので、なるべく無料枠で実施すべく面倒なスケジューリングを登録していますが、本来は自宅のRaspberry Piで稼働させる予定でした。
しかし購入したRaspberry Pi Zero WHだとCPUスペックが足りないようで、どうも失敗してしまったため回避策として上記手順を載せています。参考にさせていただいたサイト
EC2インスタンスのスケジュール起動がお手軽に実現できるようになっていた!
- 投稿日:2019-10-12T22:32:54+09:00
Spotify APIでアーティストを指定して楽曲一覧をPythonで取得する
嵐さんがサブスクリプション解禁したため、Spotify APIを使って楽曲情報を取得しました。
こちらの記事を一部参考にしています。
Spotify APIで楽曲情報やアーティスト情報を取得してみたSpotify APIに登録
API利用のためにClient IDとSeclet Clientが必要なので取得する。
Spotifyのアカウントを取得していない場合はサイトから取得。
その後、Spotify for developersにてSpotifyアカウントでログイン。Dashboardに移動し、「CREARE A CLIENT ID」より
・App or Hardware Name:アプリケーション名
・App or Hardware Description:説明文
・What are you building?:利用用途?
を入力すると、Client IDとSeclet Clientが取得できる。アーティストIDを取得する
今回は直接アーティストIDを指定する。
Spotifyよりアーティストを検索。
詳細からアーティストリンクをコピー。artistの後ろ22桁の英数字がID。楽曲情報を取得する
取得したClient ID、Seclet Client、アーティストIDを利用し、情報を取得する。
はじめにSpotify APIのライブラリspotipyをインストール。
pip install spotipy一覧を取得します。
今回はタイトルと発売日と楽曲IDを取得する。artist_songs.pyimport spotipy from spotipy.oauth2 import SpotifyClientCredentials import sys import pprint client_id = '取得したClient ID' client_secret = '取得したClient Secret' artist_id = '取得したいアーティストID' # 認証を行う client_credentials_manager = spotipy.oauth2.SpotifyClientCredentials(client_id, client_secret) spotify = spotipy.Spotify(client_credentials_manager=client_credentials_manager) # アーティストに紐づく楽曲一覧を取得する # album_type:‘album’, ‘single’, ‘appears_on’, ‘compilation’から選択可能 # country:発売国 # limit:取得する楽曲数 results = spotify.artist_albums(artist_id, album_type='single', country='JP', limit=20) # ほしい情報を配列で取得する artist_songs = [] for song in results['items'][:len(results)]: data = [ '曲名:'+ song['name'], '発売日:'+ song['release_date'], 'id:'+ song['id']] artist_songs.append(data) pprint.pprint(artist_songs)実行すると下記の通り。
[['曲名:Monster', '発売日:2010-05-19', 'id:0rDRRzBNKrzfgBa64kg0iF'], ['曲名:truth', '発売日:2008-08-20', 'id:3uVtXUio0J76jVElcXYHbP'], ['曲名:Happiness', '発売日:2007-09-05', 'id:5ydLlz0lePqmscLjd0Kw9I'], ['曲名:Love so sweet', '発売日:2007-02-21', 'id:5Vc35N1lqdE7xzwpEtwrBz'], ['曲名:A・RA・SHI', '発売日:1999-11-03', 'id:39X0fGQUhTkwg43DcSzZs7']]今回の例は現在5曲のみ解禁されている嵐さんなので、limitの設定しなくてもいいかもしれません。
楽曲ごとのIDを取得できたので次は楽曲情報を取得していろいろ遊ぼうと思います。
- 投稿日:2019-10-12T22:30:07+09:00
DjangoでHello world (初学者がどこまで理解できるか(1))
Djangoで"Hello world"までやってみよう
Djangoのインストールは実施済として記載していきます。
HTML, CSS, Javascriptとの連携までやっていきます。その第1回目。
参考:https://docs.djangoproject.com/ja/2.2/intro/tutorial01/Djangoが使用できる環境を用意
$ django-admin startproject practice $ cd practice ; tree ./ . ├── manage.py └── practice ├── __init__.py ├── settings.py ├── urls.py $ mv practice/ config/・
practiceという、Djangoが使用できる環境(フォルダ)を作りました。
その配下には、manage.pyファイルと、practiceフォルダがあります。
practiceフォルダが2つあるとややこしいので、配下のフォルダを変更します。
(practiceフォルダをconfigに)・
manage.py:Djangoで実行する際に使用するコマンド(スクリプト)です。configフォルダ配下には、以下4つのファイルが自動で作成されます。
・__init__.py:pythonのパッケージだよと、教える空っぽのファイル。
・settings.py:設定を管理するファイル。
・urls.py:作ったアプリケーションの、URLへのパスを管理するファイル。
・wsgi.py:webサーバーとの接続口
*WSGI = Web Server Gateway Interfaceの略#### practice/manage.py **** def main(): #第二引数を'config.settings'に変更 os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'config.settings') ****#### practice/config/wsgi.py **** def main(): #第二引数を'config.settings'に変更 os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'config.settings') ****#### practice/config/settings.py **** def main(): #'config.urls'に変更 ROOT_URLCONF = 'config.urls' **** #'config.wsgi.application'に変更 WSGI_APPLICATION = 'config.wsgi.application' ****アプリケーションを作る
$ python manage.py startapp myapplication $ tree ./myapplication/ myapplication/ ├── __init__.py ├── admin.py ├── apps.py ├── migrations │ └── __init__.py ├── models.py ├── tests.py └── views.py・
admin.py:「ブラウザで編集できる管理ページ」、に関するファイル。
・apps.py:アプリケーションとDjango環境の接続口。
・models.py:アプリケーションとデータベースの接続口。
・tests.py:テストを書く場所。
・views.py:ビュー(画面への出力)への挙動。アプリケーションのビューを設定
#### practice/myapplication/views.py from django.http import HttpResponse #index関数にHTTPリクエストがあったら、"Hello, world."のHTTPレスポンスを返す def index(request): return HttpResponse("Hello, world.")アプリケーションのURLをDjango環境に設定
#アプリケーションのフォルダに、"urls.py"を作成 $ touch ./myapplication/urls.py ; cd ./myapplication ; tree . ├── __init__.py ├── admin.py ├── apps.py ├── migrations │ └── __init__.py ├── models.py ├── tests.py ├── urls.py └── views.py#### practice/myapplication/urls.py #path関数を呼び出し from django.urls import path from . import views #URLに、「myapplication/」の後に何も指定しなければ、views.pyに記載の、index関数が呼び出される #このURLパターンには、indexという名前をつける urlpatterns = [ path('', views.index, name='index'), ]#### practice/config/urls.py from django.contrib import admin from django.urls import include, path urlpatterns = [ #URLで、myapplication/へのアクセス依頼があれば、myapplication/のurls.pyを呼び出す path('myapplication/', include('myapplication.urls')), path('admin/', admin.site.urls), ]これにより、URLで「http://****/apps/」アクセスがあれば、
practice/config/urls.py->practice/myapplication/urls.py->
practice/myapplication/views.pyの順で、HTTPリクエストが届く仕組みができた。さいごに
#### practice/ $ python manage.py runserver ***** ***** Starting development server at http://127.0.0.1:8000/ Quit the server with CONTROL-C.開発環境用サーバーを起動させ、ブラウザで
http://127.0.0.1:8000/myapplicationを検索。
"Hello, world."と表記があればOKです。
- 投稿日:2019-10-12T22:30:07+09:00
Django初学者がどこまで理解できるか(1)
Djangoで"Hello world"までやってみよう
Djangoのインストールは実施済として記載していきます。
HTML, CSS, Javascriptとの連携までやっていきます。その第1回目。
参考:https://docs.djangoproject.com/ja/2.2/intro/tutorial01/Djangoが使用できる環境を用意
$ django-admin startproject practice $ cd practice ; tree ./ . ├── manage.py └── practice ├── __init__.py ├── settings.py ├── urls.py $ mv practice/ config/・
practiceという、Djangoが使用できる環境(フォルダ)を作りました。
その配下には、manage.pyファイルと、practiceフォルダがあります。
practiceフォルダが2つあるとややこしいので、配下のフォルダを変更します。
(practiceフォルダをconfigに)・
manage.py:Djangoで実行する際に使用するコマンド(スクリプト)です。configフォルダ配下には、以下4つのファイルが自動で作成されます。
・__init__.py:pythonのパッケージだよと、教える空っぽのファイル。
・settings.py:設定を管理するファイル。
・urls.py:作ったアプリケーションの、URLへのパスを管理するファイル。
・wsgi.py:webサーバーとの接続口
*WSGI = Web Server Gateway Interfaceの略#### practice/manage.py **** def main(): #第二引数を'config.settings'に変更 os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'config.settings') ****#### practice/config/wsgi.py **** def main(): #第二引数を'config.settings'に変更 os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'config.settings') ****#### practice/config/settings.py **** def main(): #'config.urls'に変更 ROOT_URLCONF = 'config.urls' **** #'config.wsgi.application'に変更 WSGI_APPLICATION = 'config.wsgi.application' ****アプリケーションを作る
$ python manage.py startapp myapplication $ tree ./myapplication/ myapplication/ ├── __init__.py ├── admin.py ├── apps.py ├── migrations │ └── __init__.py ├── models.py ├── tests.py └── views.py・
admin.py:「ブラウザで編集できる管理ページ」、に関するファイル。
・apps.py:アプリケーションとDjango環境の接続口。
・models.py:アプリケーションとデータベースの接続口。
・tests.py:テストを書く場所。
・views.py:ビュー(画面への出力)への挙動。アプリケーションのビューを設定
#### practice/myapplication/views.py from django.http import HttpResponse #index関数にHTTPリクエストがあったら、"Hello, world."のHTTPレスポンスを返す def index(request): return HttpResponse("Hello, world.")アプリケーションのURLをDjango環境に設定
#アプリケーションのフォルダに、"urls.py"を作成 $ touch ./myapplication/urls.py ; cd ./myapplication ; tree . ├── __init__.py ├── admin.py ├── apps.py ├── migrations │ └── __init__.py ├── models.py ├── tests.py ├── urls.py └── views.py#### practice/myapplication/urls.py #path関数を呼び出し from django.urls import path from . import views #URLに、「apps/」の後に何も指定しなければ、views.pyに記載の、index関数が呼び出される #このURLパターンには、indexという名前をつける urlpatterns = [ path('', views.index, name='index'), ]#### practice/config/urls.py from django.contrib import admin from django.urls import include, path urlpatterns = [ #URLで、myapplication/へのアクセス依頼があれば、myapplication/のurls.pyを呼び出す path('myapplication/', include('myapplication.urls')), path('admin/', admin.site.urls), ]これにより、URLで「http://****/apps/」アクセスがあれば、
practice/config/urls.py->practice/myapplication/urls.py->
practice/myapplication/views.pyの順で、HTTPリクエストが届く仕組みができた。さいごに
#### practice/ $ python manage.py runserver ***** ***** Starting development server at http://127.0.0.1:8000/ Quit the server with CONTROL-C.開発環境用サーバーを起動させ、ブラウザで
http://127.0.0.1:8000/myapplicationを検索。
"Hello, world."と表記があればOKです。
- 投稿日:2019-10-12T22:21:16+09:00
FX予測 : PyTorchのBERTで経済ニュース解析
こんにちは @THERE2 です。
現在自然言語処理においては、BERTというディープラーニングのモデルの評価が高いようです。
そこで、BERTを使ってロイターの経済ニュース(英語)を解析し、そのニュースによってFX(USD/JPY)が上がるか下がるかという予測をするモデルを実装してみました。実装にあたっては、先日購入した「Pytorchによる発展ディープラーニング」を参考にしました。
この本はある程度ディープラーニングの知識、経験がある人にとっては非常にうまくまとまっていてかなりの良書です。ゼロから作るシリーズを読んだ後に取り組むのがオススメです。
BERTについて
BERTは事前学習済みのモデルを転用できるのが大きなメリットのようです。自然言語や画像のようなデータを一から学習させていくのは大変ですが、大きなデータセットですでに学習済みのモデルをベースにできれば、学習時間を短縮して最初から高い精度を見込めます。
また、BERTは文書解析のコアのモデルの後にレイヤを追加することで文書生成や単語の予測、各単語に対するクラス分類、文書全体に対するクラス分類と様々なタスクを行えます。今回のモデルでは、コアのモデルでニュース文章を解析し、ニュース毎にFXが上がるか下がるかを予測させるという
BertForSequenceClassificationを利用します。実装にあたって以下のソースコードも参考にしました。
Transformers: State-of-the-art Natural Language Processing for TensorFlow 2.0 and PyTorch.
BERT Fine-Tuning Tutorial with PyTorch
利用データについて
BERTでFX予測をするにあたり、次のようなモデルとしました。
英語版のロイターの経済ニュースのタイトルを利用します。本当は本文を利用したかったのですが、本文を使うとデータの前処理でもBERTのトレーニングでも時間がかかりすぎるので諦めました。ただ、タイトルだけでも最大255文字あり、主要なキーワードが含まれているので、FXの予測に使うだけであればタイトルだけでも十分かと考えています。
おそらくFXで売買する人達もニュースの本文は目を通さずヘッドラインだけで反応している人が多いと思いますので、それもタイトルだけで十分かと思った理由です。
また、ロイターニュースは英語にしていますが、USD/JPYの為替の予測であれば英語のニュースが必要な情報の大半をカバーしているのと、自然言語処理のモデルは英語での解析が一番進んでいるためです。
学習用のニュースデータは、kaggleで公開されている以下のデータを使いました。
2018年1月から5月までのBloomberg.com, CNBC.com, reuters.com, wsj.com, fortune.comの英語でのfinancial data(経済データ)となります。
この中から、reuters.comのデータを抜出して利用します。https://www.kaggle.com/jeet2016/us-financial-news-articles
News APIというサービスを使えば、リアルタイムに近い(フリー版は15分のディレイ有り)ニュースデータを取得する事ができます。
しかし、このサービスは残念ながら過去1ヶ月分のデータしか取得できず、学習用としては不十分です。
そのため、今回学習用としてはkaggleのデータを利用する事にしました。※449ドル払って商用利用にすれば、過去1年分のデータをディレイ無しで利用できるようです。流石に約5万円の出費は厳しいですね。
FXの価格データ
FXの価格データは、上記のニュースと同期間(2018年1月から5月)の時間足データとしました。
次の時間のClose価格を利用して予測をしていきます。
- ニュースが公開された時間の次の時間足のclose価格
- その時間足の6時間後(6足後)の時間足のclose価格
2の価格が1の価格より高ければ価格アップ(ラベル:1)、2の価格が1の価格より低ければ価格ダウン(ラベル:0)としてラベルデータを用意しました。
これを各ニュース毎にラベルとして付与してニュースタイトルと一緒にBERTに学習させる事とします。では実装していきましょう。
PyTorchによるBERTの実装
ソースコードの全体は以下のgistに格納しておきました。
https://gist.github.com/THERE2/4518239e7c099e95b3a78432a01eeab9追加パッケージのインストール
PyTorchではBERTの実装済みのモデルはインストールして利用できます。
「Pytorchによる発展ディープラーニング」では一から実装して説明していますが、ここではパッケージでインストールしたものをそのまま使わせていただきます。
インストールは
pipから次のコマンドで可能です。BERTのモデルとBERT用のtokenizerが入ってます。このインストール自体はすぐに終わります。
ただ、最初にBERTのモデルをロードする時に学習済みのモデルをダウンロードするのですが、そのダウンロードがかなり時間かかります。1時間以上かかったでしょうか。根気強く待ちましょう。一度ダウンロードしておけば次からのモデルのロードはすぐに終わります。
公式ドキュメントへのリンクを貼っておきます。
https://huggingface.co/pytorch-transformers/index.htmlpip install pytorch-transformersまた、テキストデータを変換したりミニバッチで取り出したりするのに、
torchtextというライブラリを利用しますので、これもインストールしておきます。
同じくpipでインストールします。pip install torchtextその他
pytorch、pandas、numpy等必要になります。ニュースデータの取得
kaggleから取得したデータをdataフォルダに展開しました。月ごとのフォルダに1記事毎に一つのJSONファイルとして格納されていますので、これらをまとめて
pandasのDataFrameに格納します。
- data以下にあるファイルは、blogとnewsの両方があるのですが、今回はnewsしか使わないので、ファイル名をnews_*.jsonで指定して取り込みました。
- JSONファイルを一つづつ開いて
DataFrameに格納していきます。日付型はISO形式からpandasのdatetime型に変換しました。タイムゾーンは価格データと合わせるためUTCとしています。- テキストは本文は数千文字と長すぎるのでタイトルのみを使う事にしました。タイトルだけでも最大255文字有り、重要な情報がコンパクトにまとまっているため、タイトルだけでも十分効果的だと思ったためです。
DataFrameは後から取り出しやすいようにpickle形式で保存しました。- ニュース数は全部で30万件弱となります。
import json import glob import pandas as pd # blogは対象外にするので、newsから始まるjsonファイルのみを取り出す。 # 必要な項目のみlistに格納していく。 json_news_files = glob.glob('./data/*/news_*.json') data = [] for json_file in json_news_files: json_data = json.load(open(json_file, 'r')) data.append([ json_data['uuid'], pd.to_datetime(json_data['published'], utc=True), #datetime型に変換してutc時間に設定。 json_data['language'], json_data['thread']['country'], json_data['thread']['site'], json_data['title'], json_data['text'], ]) # pandasのデータフレームに変換して、カラム名を設定。uuidをindexとする。 df = pd.DataFrame(data) df.columns = ['uuid', 'published', 'language', 'country', 'site', 'title', 'text'] df = df.set_index('uuid') df.to_pickle('./pickle/all_news_df.pkl')FXの価格データの取得
OANDA APIから価格データを取得する方法については、以前に投稿した記事を参照ください。
機械学習でFX:Oanda APIを使ってPythonから自動売買する
今回は、ニュースデータの期間と合わせて、2017年12月〜2018年5月末までの時間足データを取得して
PandasのDataFrameに格納しpickleで塩漬けしました。from oandapyV20 import API from oandapyV20.exceptions import V20Error from oandapyV20.endpoints.pricing import PricingStream import oandapyV20.endpoints.orders as orders import oandapyV20.endpoints.instruments as instruments import json import datetime import pandas as pd # accountID, access_tokenは各自のコードで書き換えてください。 accountID = my_accountID access_token = my_access_token api = API(access_token=access_token, environment="practice") # Oandaからcandleデータを取得する。 def getCandleDataFromOanda(instrument, api, date_from, date_to, granularity): params = { "from": date_from.isoformat(), "to": date_to.isoformat(), "granularity": granularity, } r = instruments.InstrumentsCandles(instrument=instrument, params=params) return api.request(r) # Oandaからのresponse(JSON形式)をpython list形式に変換する。 def oandaJsonToPythonList(JSONRes): data = [] for res in JSONRes['candles']: data.append( [ datetime.datetime.fromisoformat(res['time'][:19]), res['volume'], res['mid']['o'], res['mid']['h'], res['mid']['l'], res['mid']['c'], ]) return data all_data = [] date_from = datetime.datetime(2017, 12, 1) date_to = datetime.datetime(2018, 6, 1) ret = getCandleDataFromOanda("USD_JPY", api, date_from, date_to, "H1") all_data = oandaJsonToPythonList(ret) # pandas DataFrameへ変換 df = pd.DataFrame(all_data) df.columns = ['Datetime', 'Volume', 'Open', 'High', 'Low', 'Close'] df = df.set_index('Datetime') # pickleファイルへの出力 df.to_pickle('./pickle/USD_JPY_201712_201805.pkl')前処理の実施
続いて取得したニュースデータと価格データを結合してラベルを設定します。
- ラベルとしては、各ニュースデータ毎に次の時間足での価格と、その6時間後の価格を比較して、上がっていれば1、下がっていれば0をセットするようにしました。
- データ件数が多いとBERTのトレーニングに時間がかかるので、対象データをreuters.comに限定し、さらにそのうち30%のみをサンプリングする事にしました。BERTは事前トレーニング済みのモデルのため、データ総数自体はそこまで多くなくてもいいのではないかと思っています。ただ、各月によってニュースの内容も異なるでしょうから、月ごとのバリエーションは必要だと思います。
- 最後に
DataFrameをトレーニング用、バリデーション用、テスト用に60%, 20%, 20%の割合で分割してtsvファイル形式で保存しました。この後使うtorchtextがテキストファイル読み込みを想定しており、DataFrameのままだと面倒そうだったので、いったんテキストファイルで保存しておくことにしました。import re import torchtext import pandas as pd import numpy as np # read text data news_df = pd.read_pickle('./pickle/all_news_df.pkl') # read candle data candle_df = pd.read_pickle('./pickle/USD_JPY_201712_201805.pkl') ################## labelの設定 ################### # labelとして6時間後の価格が上がっているかどうかとするため、6時間後のclose値とのdiffを取る。 # 上がっていればプラス、下がって入ればマイナス値となる。 candle_df['diff_6hours'] = - candle_df['Close'].astype('float64').diff(-6) candle_df['label'] = 0 # labelに6時間後の価格が上がっているか下がっているかをセット candle_df.loc[candle_df['diff_6hours']>0, 'label'] = 1 # newsのtimestampから次の時間足のラベルを取得する。 # 例) 2017-12-04 19:35:51のタイムスタンプのニュースであれば、2017-12-04 20:00:00の時間足のclose値に対して6時間後の時間足の価格が上がっているかどうかがラベルとなる。 def get_label_from_candle(x): tmp_idx = candle_df.loc[candle_df.index > x.tz_localize(None)].index.min() return candle_df.loc[tmp_idx, 'label'] # 各ニュースへのラベル設定。件数が多いので数分かかる。 news_df['label'] = news_df['published'].map(get_label_from_candle) # BERTでトレーニングするにはボリュームが有りすぎるので、ロイターニュースの30%に絞る news_df = news_df[news_df.site == 'reuters.com'] news_df = news_df.sample(frac=0.3) # 学習用、バリデーション用、テスト用の配分 train_size = 0.6 validation_size = 0.2 test_size = 1 - train_size - validation_size total_num = news_df.shape[0] train_df = news_df.iloc[:int(total_num*(1-validation_size-test_size))][['title', 'label']] val_df = news_df.iloc[int(total_num*train_size):int(total_num*(train_size+validation_size))][['title', 'label']] test_df = news_df.iloc[int(total_num*(train_size+validation_size)):][['title', 'label']] # torchtextのdatasetとして取り込むのに、csvファイル形式に保存。 # ※他にいい方法があると思うが、参考にしている本がCSVファイル形式での記載だったため。 train_df.to_csv('data/dataset_for_torchtext_train.tsv', index=False, sep='\t') val_df.to_csv('data/dataset_for_torchtext_val.tsv', index=False, sep='\t') test_df.to_csv('data/dataset_for_torchtext_test.tsv', index=False, sep='\t')DataLoaderの実装
続いてテキストデータをトークンに分割してミニバッチ毎に取り出す
DataLoaderを実装します。ここはtorchtextを利用しています。torchtextの使い方は発展ディープラーニング本に詳しく書いてありました。
- テキストをトークンに分割するために、インストールした
BertTokenizerを利用します。- BERTの事前学習済みモデルとして、
bert-base-uncasedを利用します。BertTokenizerにテキストの前処理として、改行コードの削除、記号のスペースへの変換、小文字への変換を加えたものをtokenizer_with_preprocessingとして実装しました。torchtextのDataLoaderで、tokenizerを実装したものを指定すると共に、init_token、eos_token、pad_token、unk_tokenを指定しています。これにより、torchtextがテキストを読み込む時に文書にそれぞれ適切なtokenを追加してくれます。torchtextのTabularDataset.splitでファイルを読み込んでDataSetを生成します。- TEXTオブジェクトにwordを数値に変換する単語リストを登録します。
BertTokenizerのvocab属性がその単語のOrderedDictとなっていますのでそれを設定してあげます。ただ、いきなりTEXTオブジェクトに指定するとエラーになってしまうので一旦回避策としてダミーのボキャブラリを作成TEXT.build_vocab(train_ds, min_freq=1)して上書きしています。- 最後に
torchtextのIteraterでDataSetからDataLoaderを生成します。この時、バッチサイズを指定します。import pandas as pd import torchtext import pickle import string import re from torchtext.vocab import Vectors from pytorch_transformers import BertTokenizer pre_trained_weights = 'bert-base-uncased' tokenizer_bert = BertTokenizer.from_pretrained(pre_trained_weights) def tokenizer_with_preprocessing(text, tokenizer=tokenizer_bert.tokenize): #改行の削除 text = re.sub('\r', '', text) text = re.sub('\n', '', text) #数字文字の一律0化 text = re.sub(r'[0-9]', '0', text) #カンマ、ピリオド以外の記号をスペースに置換 for p in string.punctuation: if (p == '.') or (p == ","): continue else: text = text.replace(p, " ") #ピリオド等の前後にはスペースを入れておく text = text.replace("."," . ") text = text.replace(","," , ") #トークンに分割して返す return tokenizer(text.lower()) def get_DataLoaders_and_TEXT(max_length, batch_size): #テキストの前処理 TEXT = torchtext.data.Field(sequential=True, tokenize=tokenizer_with_preprocessing, use_vocab=True, include_lengths=True, batch_first=True, fix_length=max_length, init_token='[CLS]', eos_token='[SEP]', pad_token='[PAD]', unk_token='[UNK]', ) LABEL = torchtext.data.Field(sequential=False, use_vocab=False) #data setの取得 train_ds, val_ds, test_ds = torchtext.data.TabularDataset.splits( path='./data/', train='dataset_for_torchtext_train.tsv', validation='dataset_for_torchtext_val.tsv', test='dataset_for_torchtext_test.tsv', format='tsv', skip_header=True, fields=[('title', TEXT), ('label', LABEL)] ) # ボキャブラリーの作成 # エラー回避のため一旦仮で作成し、bertのvocabで上書き TEXT.build_vocab(train_ds, min_freq=1) TEXT.vocab.stoi = tokenizer_bert.vocab # Data loaderの作成 train_dl = torchtext.data.Iterator(train_ds, batch_size=batch_size, train=True) val_dl = torchtext.data.Iterator(val_ds, batch_size=batch_size, train=False, sort=False) test_dl = torchtext.data.Iterator(test_ds, batch_size=batch_size, train=False, sort=False) return train_dl, val_dl, test_dl, TEXTトレーニング用コードの実装
ここまでで準備が整ったので、トレーニング用のコードを実装していきます。
ちょっと長いのでソースコードのコメントの番号に沿って簡単に解説します。#1. パッケージのインポート、定数定義
- BERTのテキストから分類問題を解くための専用のクラスがありますので、それを利用します。これはBERTのモデルの後に
Dropout層とLinear層を付けて、CrossEntropyでlossを計算してそのlossとlogitsを返してくれます。コンストラクタの引数で分類クラス数も指定できます。2値分類であればクラス数を2にしてlogitsに対してmaxのindexを取れば推定できます。- random seedは42で固定しています。42が望ましい理由があるようなのですが、調べてもよくわかりませんでした。
- batch sizeは私のGTX1050だと64ではメモリ不足となってしまうので、32としました。
#2. DataLoaderの取得
- 事前に定義したメソッド
get_DataLoaders_and_TEXTを使ってDataLoaderを取得します。- 取得した
DataLoaderをdataloaders_dictにまとめておきます。#3. Bertモデルの読み込み
- BERTの事前学習済みモデルを読み込みます。分類クラス数を2で指定しています。
- BERTは
Encoder層が12層あるのですが、全部再学習すると時間がかかりすぎるので、1〜11層までは固定param.requires_grad = Falseで学習対象外としています。 ※デフォルトは全ての層が学習対象です。- いったん全て学習対象外
param.requires_grad = Falseとした上で、Encoder層の12層目とLinearのClassification層を学習対象param.requires_grad = Trueで更新するようにしました。#4. Optimizerの設定
- Optimizerは
Adamにしています。インストールしたBERTのパッケージにBertAdamというのが含まれているようなのですが、よく分からなかったので使っていません。- 重み減衰(weight decay)は入れた方が良いようなのですが、実装がややこしくなるので入れていません。
- lossファンクションを定義していませんが、これは読み込んでいる
BertForSequenceClassificationの中で定義しているためです。モデルの中ではCrossEntropyLossが利用されています。# 5. BERTモデルでの予測とlossの計算、backpropの実行
BertForSequenceClassificationのforwardには、inputデータとlabelデータの両方を渡します。labelデータを渡す事で、BertForSequenceClassificationがCrossEntropyLossでlossを計算して返してくれます。token_type_idsは、1文が複数のセンテンスに分かれているわけではなければ不要なのでNoneです。attention_maskも、学習済みモデルを利用し、1〜11層まで固定しているため特に必要無いと重いNoneとしています。- 戻り値はリストとなっており、1つ目が
loss、2つ目がlogitsです。後は設定に応じてhidden stateやattentionsなどが帰ってきます。_, preds = torch.max(logits, 1)でlogitsの最大値とそのインデックスが取得できます。ここではindexのみが必要なので、そのindexをpredsに格納しています。- あとは
lossとpredsを使ってbackpropしてAccuracyを計算してログ出力しています。# 6. testデータでの検証
- メインループではepoch毎にトレーニングデータとバリデーションデータを交互に処理して学習させていきました。
- 最後学習が終わった後に、学習済みモデルを使ってテストデータで精度を確認します。
# 7. torchモデルを保存しておく
- 学習済みモデルを再利用できるように、保存しておきます。
torch.save(net_trained.state_dict(), 'weights/bert_net_trainded.model')# 1. パッケージのインポート、定数定義 import random import math import numpy as np import json import torch import torch.nn as nn import torch.optim as optim import torch.utils.data as data import torch.nn.functional as F from dataloader import get_DataLoaders_and_TEXT from pytorch_transformers import BertForSequenceClassification torch.manual_seed(42) np.random.seed(42) random.seed(42) device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu') max_length=256 batch_size=32 pre_trained_weights = 'bert-base-uncased' # 2. data loaderの取得 train_dl, val_dl, test_dl, TEXT = get_DataLoaders_and_TEXT( max_length=max_length, batch_size=batch_size ) dataloaders_dict = {"train":train_dl, "val": val_dl} # 3. Bertモデルの読み込み net = BertForSequenceClassification.from_pretrained(pre_trained_weights, num_labels=2) net.to(device) # Bertの1〜11段目は更新せず、12段目とSequenceClassificationのLayerのみトレーニングする。 # 一旦全部のパラメータのrequires_gradをFalseで更新 for name, param in net.named_parameters(): param.requires_grad = False # Bert encoderの最終レイヤのrequires_gradをTrueで更新 for name, param in net.bert.encoder.layer[-1].named_parameters(): param.requires_grad = True # 最後のclassificationレイヤのrequires_gradをTrueで更新 for name, param in net.classifier.named_parameters(): param.requires_grad = True # 4. Optimizerの設定 optimizer = optim.Adam([ {'params': net.bert.encoder.layer[-1].parameters(), 'lr': 5e-5}, {'params': net.classifier.parameters(), 'lr': 5e-5}], betas=(0.9, 0.999)) def train_model(net, dataloaders_dict, optimizer, num_epochs): net.to(device) torch.backends.cudnn.benchmark = True for epoch in range(num_epochs): for phase in ['train', 'val']: if phase == 'train': net.train() else: net.eval() epoch_loss = 0.0 epoch_corrects = 0 batch_processed_num = 0 # データローダーからミニバッチを取り出す for batch in (dataloaders_dict[phase]): inputs = batch.title[0].to(device) labels = batch.label.to(device) # optimizerの初期化 optimizer.zero_grad() with torch.set_grad_enabled(phase=='train'): # 5. BERTモデルでの予測とlossの計算、backpropの実行 outputs = net(inputs, token_type_ids=None, attention_mask=None, labels=labels) # loss and accuracy loss, logits = outputs[:2] _, preds = torch.max(logits, 1) if phase =='train': loss.backward() optimizer.step() curr_loss = loss.item() * inputs.size(0) epoch_loss += curr_loss curr_corrects = (torch.sum(preds==labels.data)).to('cpu').numpy() / inputs.size(0) epoch_corrects += torch.sum(preds==labels.data) batch_processed_num += 1 if batch_processed_num % 10 == 0 and batch_processed_num != 0: print('Processed : ', batch_processed_num * batch_size, ' Loss : ', curr_loss, ' Accuracy : ', curr_corrects) # loss and corrects per epoch epoch_loss = epoch_loss / len(dataloaders_dict[phase].dataset) epoch_acc = epoch_corrects.double() / len(dataloaders_dict[phase].dataset) print('Epoch {}/{} | {:^5} | Loss:{:.4f} Acc:{:.4f}'.format(epoch+1, num_epochs, phase, epoch_loss, epoch_acc)) return net # trainingの実施 num_epochs = 3 net_trained = train_model(net, dataloaders_dict, optimizer, num_epochs=num_epochs) # 6. testデータでの検証 net_trained.eval() net_trained.to(device) epoch_corrects = 0 for batch in (test_dl): inputs = batch.title[0].to(device) labels = batch.label.to(device) with torch.set_grad_enabled(False): # input to BertForSequenceClassifier outputs = net_trained(inputs, token_type_ids=None, attention_mask=None, labels=labels) # loss and accuracy loss, logits = outputs[:2] _, preds = torch.max(logits, 1) epoch_corrects += torch.sum(preds == labels.data) epoch_acc = epoch_corrects.double() / len(test_dl.dataset) print('Correct rate {} records : {:.4f}'.format(len(test_dl.dataset), epoch_acc)) # 7. torchモデルを保存しておく torch.save(net_trained.state_dict(), 'weights/bert_net_trainded.model')実行結果の確認
かなり時間がかかりますが、3 epoch回してみました。
Validation結果では、Lossがわずかに下がっていますが、Accuracyはいったん下がった後に上がっています。51.4%のAccuracyは悪くないですが、このままトレーニングを続けていくと精度があがっていくでしょうか。
※validationの結果のみ抜粋 Epoch 1/3 | val | Loss:0.6932 Acc:0.4959 Epoch 2/3 | val | Loss:0.6939 Acc:0.4859 Epoch 3/3 | val | Loss:0.6928 Acc:0.5141テストデータでの検証結果は以下のようになりました。12万件弱で50.46%。完全にランダムよりは若干良さそうですが誤差の範囲内かもしれません。
Correct rate 11779 records : 0.5046もっと時間をかけて学習させてみたり、学習用データを増やしたり、予測を6時間後から前後させてみたりと工夫する事で精度があがっていく可能性はあると思います。
また、このニュース解析だけではなく、通常の価格データやテクニカル指標と組み合わせる事で精度を上げていくことが出来るかも知れませんね。
次の記事では機械学習の最強モデルという評判のLightGBMでFX予測に取り組んでみたいと思います。

- 投稿日:2019-10-12T21:59:24+09:00
大容量のtsvデータを分割する。
とある事情より25GBもの容量のデータを処理しなくてはならず、それを処理しようと色々やってみたお話。
まずは素直に、、、これをやってみた。
import pandas as pd data=pd.read_csv( 'ファイル名.tsv', delimiter='\t' )無限に終わらん、、、、待ってるのつらい、、、
次にやってみたこと
DASKというのを使うと早くなるとの噂をきき使ってみる。import dask.dataframe as ddf import dask.multiprocessing df_dask = ddf.read_csv( 'ファイル名.tsv',parse_dates=True) df_dask = df_dask.compute() display(df_dask.tail()) print(df_dask.info())変わらなくね????遅くね???
次にチャンクで区切ってみる。
reader = pd.read_csv('ファイル名.tsv', skiprows=[0, 1], chunksize=10000000) df = pd.concat((r for r in reader), ignore_index=True)pd.concatにめっちゃ時間がかかり、耐えられなくなる。
そうだまずはデータの行数を調べようと思って、ターミナルで下を入れてみたところ、
wc -l ファイル名.tsv
1億行を超えてることがわかった。
最終的に選んだ手法
データ分割しちゃおっと!
split -l 1000000 ファイル名.tsv [お好みの名前]
こうした後に、たくさんできたファイルの名前の後ろに.tsvをつけて、、、分割に成功。
- 投稿日:2019-10-12T21:57:30+09:00
ナイーブベイズ分類器でニュース記事を分類する(自力実装編)
はじめに
ナイーブベイズ分類器によるテキスト分類について理論を勉強した内容を以前の記事(ナイーブベイズ分類器(Naive bayes classifier)を用いたテキスト分類を理解する(理論編))でまとめました。今回はそのアルゴリズムを用いてニュース記事分類タスクをやってみます。また可能な限りライブラリを用いず、自力で実装することを目指します。
参考
ナイーブベイズの理解と実装に当たって下記を参考にさせていただきました。
- 言語処理のための機械学習入門 (自然言語処理シリーズ) 高村 大也 (著), 奥村 学 (監修) 出版社; コロナ社
- ナイーブベイズを用いたテキスト分類
- sklearnのナイーブベイズについてのドキュメント
- ニュース記事の分類を機械学習で予測する
ナイーブベイズを自力実装する
今回使用するデータ
データセットは「livedoor ニュースコーパス」を使用させていただきます。データのフォーマットは各記事ごとに下記のようになっており、テキストデータとしてダウンロードして使用できます。
1行目:記事のURL
2行目:記事の日付
3行目:記事のタイトル
4行目以降:記事の本文
今回は各記事がどのニュースサイトの記事であるのか分類するタスクに挑戦したいと思います。まずサイトからフォルダをダウンロードして解凍します。
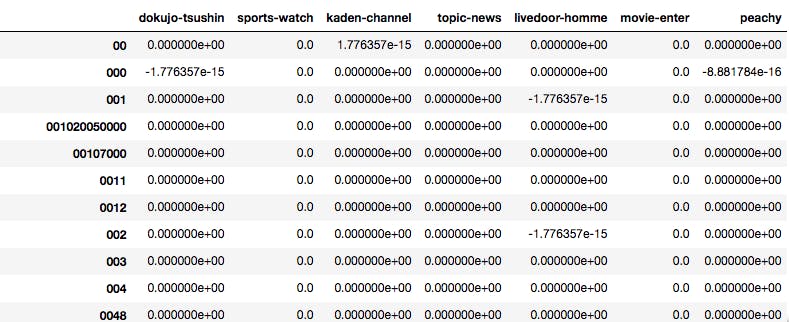
そのフォルダがカレントディレクトリに存在するとして、下記を実行してデータフレームに落とし込みます。import pandas as pd import numpy as np import os import pathlib import glob import re p_temp = pathlib.Path('text') article_list = [] #フォルダ内のテキストファイルを全てサーチ for p in p_temp.glob('**/*.txt'): #第二階層フォルダ名がニュースサイトの名前になっているので、それを取得 media = str(p).split('/')[1] #テキストファイルを読み込む with open(p, 'r') as f: #テキストファイルの中身を一行ずつ読み込み、リスト形式で格納 article = f.readlines() #不要な改行等を置換処理 article = [re.sub(r'[\n \u3000]', '', i) for i in article] #ニュースサイト名・記事URL・日付・記事タイトル・本文の並びでリスト化 article_list.append([media, article[0], article[1], article[2], ''.join(article[3:])]) df = pd.DataFrame(article_list) df.head()するとこのような形で出力されます。
こちらのデータを利用してテキスト分類を行います。
理論編の復習
ナイーブベイズ分類器を利用するに当たって最終的に求めるのは下記でした。
\newcommand{\argmax}{\mathop{\rm arg~max}\limits} \newcommand{\argmin}{\mathop{\rm arg~min}\limits} \argmax_{cat} \Bigl( \log P(cat) + \displaystyle \sum_i \log p_{word_i,cat}^{n_{word_i,doc}} \Bigr)
- $ \log P(cat)$はその文書がカテゴリ$cat$である確率の対数を取ったもの
- $\displaystyle \sum_i \log p_{word_i,cat}^{n_{word_i,doc}} $は単語$word$がカテゴリ$cat$である時に$n$回出現する確率の対数を取り、各単語に関してそれを計算して全て足し合わせたもの。
詳細な解説は前回の投稿に記載しています。
それでは、上記を計算するプログラムを組んでいきます。ナイーブベイズの実装
データの前処理
データをナイーブベイズ分類器にかけるに当たって、まずデータの前処理を行います。
前処理自体はsklearnのナイーブベイズ分類器を使用する際も同様に必要となります。from datetime import datetime #ニュース記事の本文を分かち書きする l = [] for i, row in df.iterrows(): text = ' '.join(tkn.tokenize(row[4], wakati = True)) l.append([i, row[0], row[2], text]) df_wakati = pd.DataFrame(l) #日付で条件を絞るためにdatetime型に変換する df_wakati[2] = pd.to_datetime(df_wakati[2]) #2011年のニュース記事のみ抽出する df_2011 = df_wakati[(df_wakati[2] >= datetime(2011, 1, 1)) & (df_wakati[2] < datetime(2012, 1, 1))]自力実装
下記がナイーブベイズ分類器を自力実装した結果です。
sklearnのナイーブベイズに比べてかなり遅いのと、完全に同様の構造は再現できませんでした...
勉強したものをそのままコードに落とし込んだ勉強メモ程度のものになっていますが、ご了承ください。class NB: def __init__(self): self.wordcount = None self.category_count = None self.wordlog_df = None self.log_proba = None self.result = None def fit(self, x, y): #単語数をカウントしてベクトル化する工程だけsklearnを使用 from sklearn.feature_extraction.text import CountVectorizer vectorizer = CountVectorizer() X = vectorizer.fit_transform(x) #ベクトル化した単語をデータフレームの形式に落とし込む df_words = pd.DataFrame(X.toarray(), columns = vectorizer.get_feature_names()) self.wordcount = pd.concat([df_words, pd.Series(y.reset_index(drop = True), name = 'カテゴリ分類')], axis = 1) #分類する各カテゴリにどれくらいのデータ数があるのかをカウントする category_count = pd.DataFrame(pd.Series(y, name = 'カテゴリ分類').value_counts()) #各カテゴリ数の割合を対数にとる category_count['log'] = np.log(category_count['カテゴリ分類']/category_count['カテゴリ分類'].sum()) self.category_count = category_count #各カテゴリにそれぞれの単語が何回出現するのかをデータフレームに落とし込む x = [] for i in category_count.index: all_words_count = self.wordcount[self.wordcount['カテゴリ分類']==i].sum().drop('カテゴリ分類').sum() x.append([i ,all_words_count]) self.category_count = category_count.join(pd.DataFrame(x).set_index(0)).rename(columns = {1:'全単語数'}) import math ddf = pd.DataFrame() for i in self.category_count.index: #各カテゴリのそれぞれの単語数をseries形式で表し、全ての単語数に1を足す。 df_temp = self.wordcount[self.wordcount['カテゴリ分類']==i].sum().drop('カテゴリ分類')+1 #各カテゴリのそれぞれの単語数+1をその総計で割り、対数を取る temp = (df_temp/df_temp.sum()).apply(lambda x: math.log(x)) temp.name = i ddf = pd.concat([ddf, temp], axis = 1) self.wordlog_df = ddf def predict(self, X): dic_all = {} X = X.reset_index(drop = True) #予測したいそれぞれの文書がどのカテゴリに当たるのか、教師データを基に計算していく。 for x in range(len(X)): dic = {} for cate in nb.category_count.index: x_list = re.findall(r'\b\w+\b', X.iloc[x]) try: score = ddf[cate].loc[x_list].sum() except: score = 0 dic[cate] = score if (x % 100) == 0: print(x) dic_all[x]=dic self.log_proba = pd.DataFrame(dic_all).sort_index() .T + nb.category_count['log'].sort_index() self.result = self.log_proba.T.idxmax() def score(self, y): #このアルゴリズムの精度を算出 self.score = (self.result == y).sum() / len((nb.result == y))検証
上記の自力実装のモデルと、sklearnの結果が一致しているか検証します。
自力実装の結果
今回は「livedoor ニュースコーパス」の2011年度記事を教師データとし、2012年6月以降ニュース記事分類を行おうと思います。
nb = NB() nb.fit(df_2011[3], df_2011[1]) df_other = df_wakati[df_wakati[2] >= datetime(2012, 6, 1)].reset_index(drop = True) nb.fit(df_2011[3], df_2011[1]) nb.score(df_other[3], df_other[1]) print(nb.socre_)するとこのように出力されます。
0.30748519116855144正解率30%程度ということですね。精度自体は非常に微妙です。。。
sklearnの結果
sklearnのライブラリを用いて、ナイーブベイズ分類器を実装してみます。
from sklearn.feature_extraction.text import CountVectorizer #単語を出現回数でベクトル化するまでは一緒 vectorizer = CountVectorizer() X = vectorizer.fit_transform(df_2011[3]) rom sklearn.naive_bayes import MultinomialNB clf = MultinomialNB() #2011年度の記事データを教師データとして投入 clf.fit(X, df_2011[1]) test_X = vectorizer.transform(df_other[3]) #正解率スコアを算出 print(clf.score(test_X, df_other[1]))出力結果はこちら。
0.31394722670974690.4%ほど自力実装の結果と異なります。。
なぜ異なる結果が出るのか確認するため、計算過程の値を比較してみました。#各単語の各毎での出現確率を対数取ったもの(自力実装の方) self_df = nb.wordlog_df.T.sort_values(by = '00').T #各単語の各毎での出現確率を対数取ったもの(sklearnの方) sk_df = pd.DataFrame(clf.feature_log_prob_, columns = vectorizer.get_feature_names()).sort_values(by = '00').T sk_df-self_dfデータフレームを出力するとこんな感じです。
差がある値もありますが、小数点第15位レベルの差で丸め誤差かなと思います。
ちなみにこんな感じで入力しても。
print((abs(sk_df-self_df) > 0.0000000000001).sum())出力はこんな感じです。
dokujo-tsushin 0 sports-watch 0 kaden-channel 0 topic-news 0 livedoor-homme 0 movie-enter 0 peachy 0 dtype: int64Next
ほぼ、skelarnの処理を再現することができました。文書分類系のアルゴリムに興味があるので、他も色々勉強していこうと思います。

- 投稿日:2019-10-12T21:38:15+09:00
バブルソート(Bubble Sort)
概要
バブルソートはソートアルゴリズムの一種で、隣り合う要素で大小が逆になっているものを交換していく手法です。下図のように列の末尾から要素の交換を行っていく場合、列の先頭から順にソートされていくイメージです。バブルソートで整列するのに必要となる要素の交換回数は反転数(転倒数)と呼ばれ、列の乱れ具合を表す数値として用いられます。平均計算時間、最悪計算時間はともにO($n^2$)で、安定(stable)なソートアルゴリズムです。
実装例
※上の図とは逆に、列の先頭から末尾に向かって要素の交換を行なっていきます
# 要素数2以上の配列aを昇順にソートする def bubble_sort(a): # (要素数−1)回繰り返す for i in range(len(a) - 1): # 列の先頭2要素を最初の比較対象に選ぶ l = 0 r = 1 # rが末尾に達するまで、隣り合う要素の大小を比較する while r < len(a): # 隣り合う要素の大小が逆であれば交換する if a[l] > a[r]: a[l], a[r] = a[r], a[l] # 比較対象のindexをインクリメントする l += 1 r += 1参考
https://ja.wikipedia.org/wiki/バブルソート
http://judge.u-aizu.ac.jp/onlinejudge/description.jsp?id=ALDS1_2_A
- 投稿日:2019-10-12T21:08:07+09:00
自分メモ2「Pythonについて調べた」
Pythonとは
コードがシンプルでわかりやすく初心者にも扱いやすい言語である。
Pythonの歴史
Pythonは1991年にオランダ人のグイド・ヴァンロッサムが開発した。名前の由来はイギリスのテレビ番組「空飛ぶモンティ・パイソン」である。
Pythonの特徴
オフサイドルール
if文などのブロックを字下げによって表す。これにより誰が書いても同じコードになって読みやすい。
スクリプト言語
動的型付け言語
Pythonは動的型付け言語なので、オブジェクト指向、命令型、手続き型、関数型などの形式でプログラムを書くことができる。
Pythonのメリット・デメリット
Pythonのメリット
ライブラリが豊富なこと、特に機械学習のライブラリは充実していて機械学習を扱うエンジニアにとっては必須の言語であると言える。
Pythonのデメリット
Pythonはインタプリタで実行することを前提としているため、インタプリタの短所がそのままPythonの短所となる。例えば実行速度の遅さだ、インタプリタではループの部分の構文を毎回毎回解釈する必要があるのでループが多いプログラムでは必然的に実行速度が遅くなる。
Pythonまとめ
Pythonはわかりやすく、ライブラリも充実している。
- 投稿日:2019-10-12T20:20:48+09:00
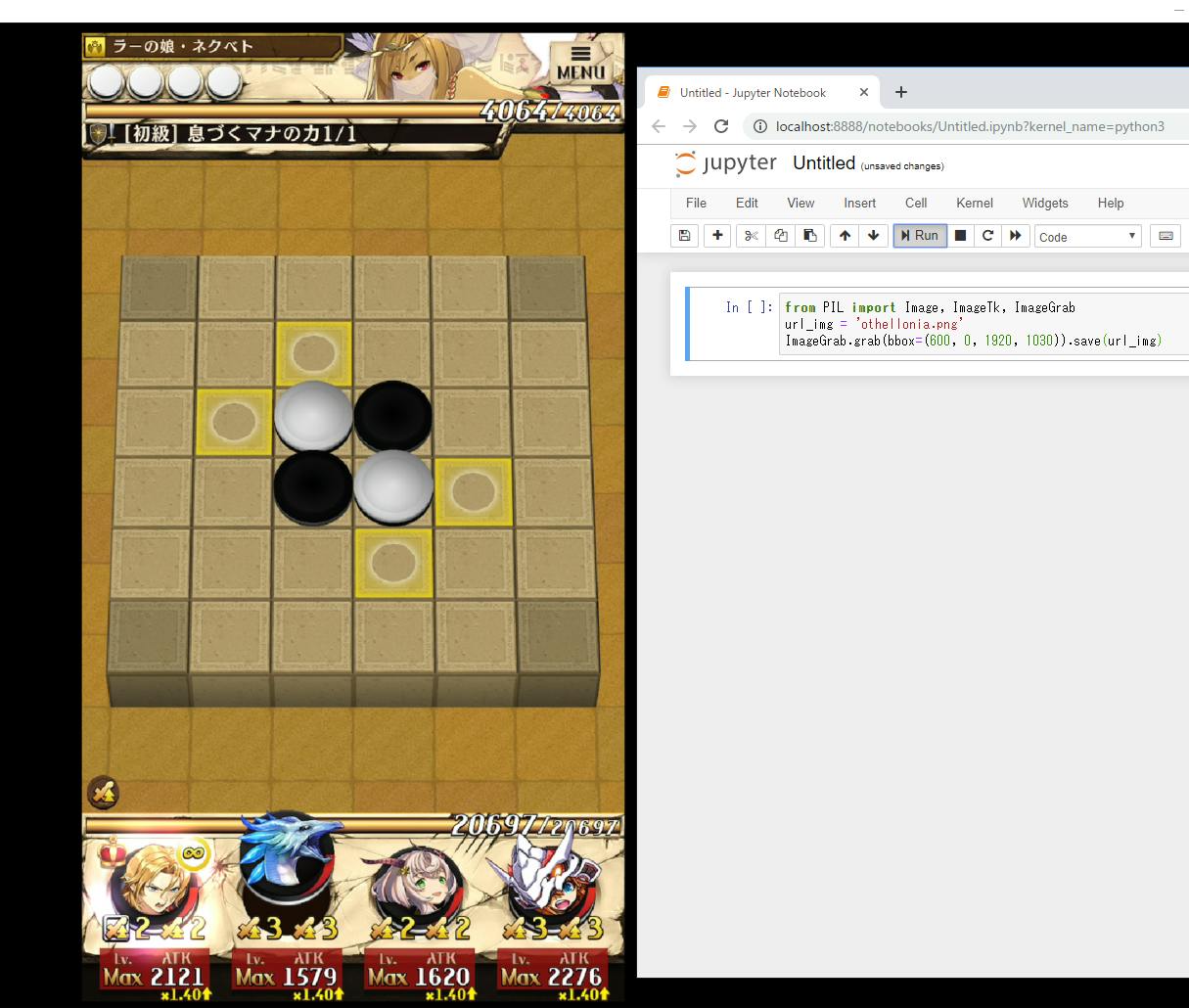
スマホゲームアプリ「逆転オセロニア」を画像解析して自動でダメージ計算
逆転オセロニア画面を解析して自動でダメージ計算
逆転オセロニアとはオセロのルールで駒を置いていき、スキルやコンボを駆使して相手のHPを削ったら勝ちという対戦型のスマホゲームアプリになります。
そのためダメージ計算はかなり重要な部分になってきます。
詳しくは
で確認してみてください。
その逆転オセロニアのダメージ計算を自動で行うためのプログラムを1年ほど前に作成していましたが、
その時の作業手順を思い出しながら少しだけ解説していこうと思います。
オセロニアの画面を解析してダメージ計算できるプログラムを作ってみました(●´ω`●)
— とよとよ (@toyotoyo_) October 25, 2018
端数の計算が間違ってるなど、まだまだ問題だらけです(@_@;) pic.twitter.com/WL7FaiBmz3
オセロニアで画像解析を行いましたが、他のスマホアプリにも応用が利くと思います。
今回はiPhoneに表示されている画面を、Windows10でキャプチャするまでで、画像解析の前までになります。
※ プログラムの完全公開は今のところ考えていません。
オセロニアをパソコンで表示
オセロニアのダメージ計算を自動でできないか?
というのを考えた結果、
オセロニアに映っているATKの数値をパソコンで読み取ることは可能か?
というのをまず考えてみました。
私はiPhone7とWindows10を使っているので
LonelyScreen
というソフトを入れて、とりあえずパソコンにiPhoneの画面を映し出すことにしました。
※ 他にもパソコンに映し出すソフトはありますLonelyScreen のインストール
LonelyScreen公式
https://www.lonelyscreen.com/download.html
「Download for Windows」
ボタン押下
インストーラーがダウンロードされるので実行
インストール完了後起動してみると確認ダイアログが出ます。
今回は無料版で使うので
「Maybe Later」
ボタンを押下
iPhone側で下からスワイプしコントロールセンターを開き
「画面ミラーリング」
を押下します
画面ミラーリングで
「LonelyScreen」
を押下するとPC画面にiPhone画面が表示されます。
オセロニアを起動すると
のようにパソコン画面でオセロニアを確認できるようになります。
オセロニア画面をスクリーンキャプチャ準備
続いてその画面をキャプチャし、ATKの数値を読み取るため
画像処理ならPython!と安易な考えでAnaconda
を入れてPython実行環境を作りました。
Anaconda のインストール
Anaconda公式のダウンロードページ
https://www.anaconda.com/download
Python 3.7 versionの
「64-Bit Graphical Installer (486 MB)」
を選択
インストーラーがダウンロードされるので実行
インストール完了後スタートメニューから
「Jupyter Notebook (Anaconda3)」
を実行するとJupyter Notebookの画面が立ち上がります。
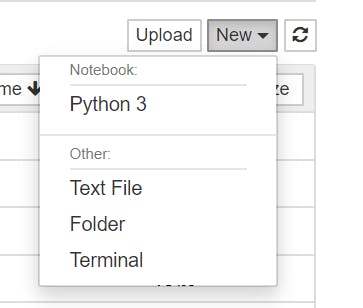
右上にある
New
を選択するとコンテキストが出るので
Python3
を選択
これでPythonの実行環境は完了です。
スクリーンキャプチャ実行
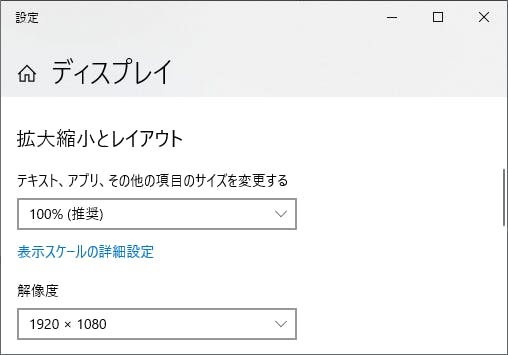
スクリーンキャプチャをとるのに座標が必要なので解像度を合わせます。
ディスレイ設定を開き
拡大縮小とレイアウト
100%解像度
1920×1080
に変更して進めてみます。
LonelyScreen画面を最大表示にし
Jupyter Notebookがオセロニアの右側に来るように配置します。
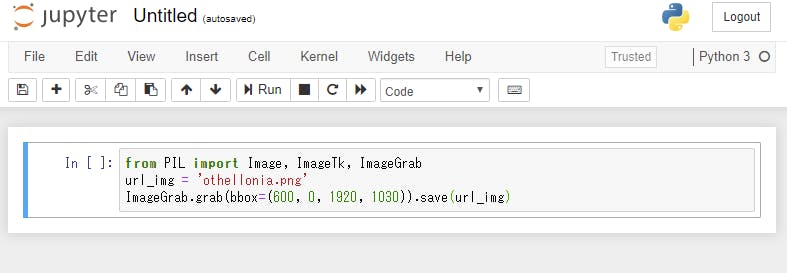
スクリーンキャプチャには PIL を使用しています。
In [ ]: と書いている右の枠部分にスクリーンキャプチャ用のプログラムを書きます。
from PIL import Image, ImageTk, ImageGrab url_img = 'othellonia.png' ImageGrab.grab(bbox=(600, 0, 1920, 1030)).save(url_img)
を入力後
Run
ボタンを押下
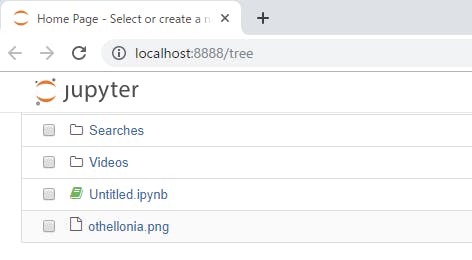
Jupyter Notebookの最初のページに戻ると
othellonia.png
ができていると思います。
othellonia.png
を確認してみると
スクリーンキャプチャが取得できています。
このように座標指定でキャプチャ出来るのでLonelyScreenを最大化しておけば、ATKの座標が固定で取れますね!
今回はここまでです。
気力があれば続きも書いていきたいと思います。

- 投稿日:2019-10-12T19:54:54+09:00
watson SpeechToText をpythonで実行 2019年10月
導入
watson の SpeechToText を python のライブラリを使って実行できます。ライブラリの使い方が分からなくて困った方の参考になれたら幸いです。
[Python]WatsonのSpeech To Textを使うお話 という良記事があったのですが、以下の二つの点でアップデートが必要なことが分かりました。
- SpeechToTextV1 のコンストラクタに与える情報を、username と password から、api_key に変える。
- sst の返り値がjsonではなくwatson独自クラスのインスタンスであるため、jsonだと思って操作するとエラーが起こる。それを意識してコードを書く。
また自分は長時間のmp3ファイルを扱った関係で、mp3を分割するコードも仕込んであります。api_key の取得
以下のサイトを参考にAPI鍵を取得する。 https://blog.apar.jp/web/9036/
環境構築
Windows10, Anaconda で検証
$ conda create -n sst python=3.7 anaconda $ conda activate sst $ pip install watson_developer_cloud (以下はmp3分割用ライブラリなので任意) $ conda install -c conda-forge pydubまた、ファイル分割関係でエラーが起こった場合は、以下のサイトを参考にしてください。
https://algorithm.joho.info/programming/python/pydub-install/音声データの分割
2時間の音声ファイルを15分刻みに分割して送っていたが、エラーになるデータがありました。10分刻みに変更したらエラーが出なくなりました。
コード
導入で書いたことは、主に 関数 sst() と split_data() のコードが対応しています。
from watson_developer_cloud import SpeechToTextV1 from pydub import AudioSegment # 音声分割用ライブラリ import math import json import glob import traceback def split_data(path): sound = AudioSegment.from_file(path, format='mp3') # 10分刻みで分割 unit = 1000*60*10 for i in range(math.ceil((len(sound)/unit))): print(i) sound_tmp = sound[i*unit:(i+1)*unit] sound_tmp.export(f"split_{i}.mp3", format='mp3') def sst(): api_key = 'your api key' cont_type = "audio/mp3" lang = "ja-JP_BroadbandModel" audio_files = glob.glob('split_*.mp3') for i, audio_file_name in enumerate(audio_files): try: # watson connection print(audio_file_name) audio_file = open(audio_file_name, "rb") # ここが変わったその1 stt = SpeechToTextV1(iam_apikey=api_key) print('start') result_json = stt.recognize(audio=audio_file, content_type=cont_type, model=lang) print('end') # ここが変わったその2 # result_json.result とするのがjsonを取り出すミソ # json file save result = json.dumps(result_json.result, indent=2) f = open(f"sst_{i}.json", "w") f.write(result) f.close() # print results = result_json.result["results"] for res in results: print(res["alternatives"][0]["transcript"], end='\n') except Exception as e: traceback.print_exc() def json2strings(watson_json): docs = [] for trans in watson_json['results']: doc = trans["alternatives"][0]["transcript"] print(doc) docs += [doc] return docs def strings2md(docs): f = open('result.md', 'w', encoding='utf-8') for x in docs: f.write(str(x) + "\n") f.close() def json2md(): strings = [] json_files = glob.glob('stt_*.json') for json_file in json_files: with open(json_file, 'r') as f: d = json.load(f) docs += json2strings(d) strings2md(docs) if __name__=='__main__': split_data('sound_data.mp3') sst() json2md()最後に
- 必要なところだけ選んで使ってください。
- 翻訳の精度は大体の意味は通じるレベルだと思います。
- ここまで調べないと使えないのは面倒ですね。
- 投稿日:2019-10-12T19:54:54+09:00
watson SpeechToText をpythonで実行 2019年10月秋
導入
watson の SpeechToText を python のライブラリを使って実行できます。ライブラリの使い方が分からなくて困った方の参考になれたら幸いです。
[Python]WatsonのSpeech To Textを使うお話 という良記事があったのですが、以下の二つの点でアップデートが必要なことが分かりました。
- SpeechToTextV1 のコンストラクタに与える情報を、username と password から、api_key に変える。
- SpeechToTextV1 インスタンスの返り値がjsonではなくwatson独自クラスのインスタンスであるため、jsonだと思って操作するとエラーが起こる。それを意識してコードを書く。
また自分は長時間のmp3ファイルを扱った関係で、mp3を分割するコードも仕込んであります。api_key の取得
以下のサイトを参考にAPI鍵を取得する。 https://blog.apar.jp/web/9036/
環境構築
Windows10, Anaconda で検証
$ conda create -n stt python=3.7 anaconda $ conda activate stt $ pip install watson_developer_cloud (以下はmp3分割用ライブラリなので任意) $ conda install -c conda-forge pydubまた、ファイル分割関係でエラーが起こった場合は、以下のサイトを参考にしてください。
https://algorithm.joho.info/programming/python/pydub-install/音声データの分割
2時間の音声ファイルを15分刻みに分割して送っていたが、エラーになるデータがありました。10分刻みに変更したらエラーが出なくなりました。
コード
導入で書いたことは、主に 関数 stt() と split_data() のコードが対応しています。
from watson_developer_cloud import SpeechToTextV1 from pydub import AudioSegment # 音声分割用ライブラリ import math import json import glob import traceback def split_data(path): sound = AudioSegment.from_file(path, format='mp3') # 10分刻みで分割 unit = 1000*60*10 for i in range(math.ceil((len(sound)/unit))): print(i) sound_tmp = sound[i*unit:(i+1)*unit] sound_tmp.export(f"split_{i}.mp3", format='mp3') def stt(): api_key = 'your api key' cont_type = "audio/mp3" lang = "ja-JP_BroadbandModel" audio_files = glob.glob('split_*.mp3') for i, audio_file_name in enumerate(audio_files): try: # watson connection print(audio_file_name) audio_file = open(audio_file_name, "rb") # ここが変わったその1 stt = SpeechToTextV1(iam_apikey=api_key) print('start') result_json = stt.recognize(audio=audio_file, content_type=cont_type, model=lang) print('end') # ここが変わったその2 # result_json.result とするのがjsonを取り出すミソ # json file save result = json.dumps(result_json.result, indent=2) f = open(f"stt_{i}.json", "w") f.write(result) f.close() # print results = result_json.result["results"] for res in results: print(res["alternatives"][0]["transcript"], end='\n') except Exception as e: traceback.print_exc() def json2strings(watson_json): docs = [] for trans in watson_json['results']: doc = trans["alternatives"][0]["transcript"] print(doc) docs += [doc] return docs def strings2md(docs): f = open('result.md', 'w', encoding='utf-8') for x in docs: f.write(str(x) + "\n") f.close() def json2md(): strings = [] json_files = glob.glob('stt_*.json') for json_file in json_files: with open(json_file, 'r') as f: d = json.load(f) docs += json2strings(d) strings2md(docs) if __name__=='__main__': split_data('sound_data.mp3') stt() json2md()最後に
- 必要なところだけ選んで使ってください。
- 翻訳の精度は大体の意味は通じるレベルだと思います。
- ドキュメントはあまり整備されていない印象を受けます。
- 投稿日:2019-10-12T19:33:34+09:00
[初心者・文系必見]ディープランニングの起源 ~パーセプトロン~ を分かりやすく解説してみた
はじめに
この記事は現在自分が勉強をしている技術書、ゼロから作るディープランニング 3章パーセプトロンを自分なりに理解してアウトプットしたものです。
文系の自分でも理解することができたので、難しく考えずに楽にみていただけたら幸いです。
さらに、本書を進めるにあたって参考にしていただけたら嬉しいです。パーセプトロンとは
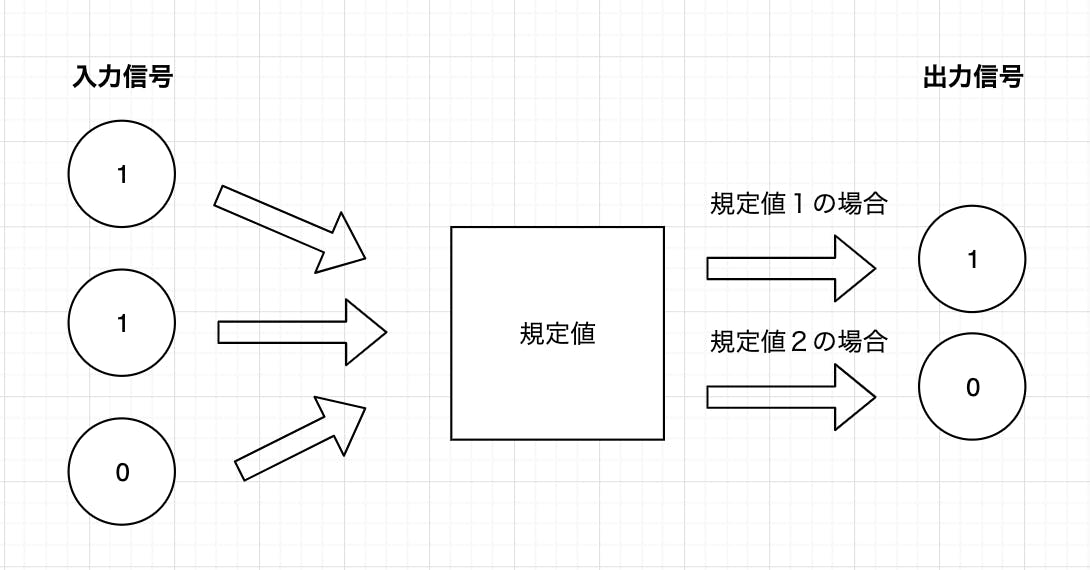
パーセプトロンとは、複数の0または1の入力信号を受け取り、その合計がある規定値を超えた場合に1を出力してそれ以外の場合は0を出力するアルゴリズムです。
規定値を設定して入力信号を受け取り出力信号に変換する上の四角い箱をニューロンと言います。さらに規定値のことを闘値と言います。
次は今の内容を少し詳細にして解説しようと思います。
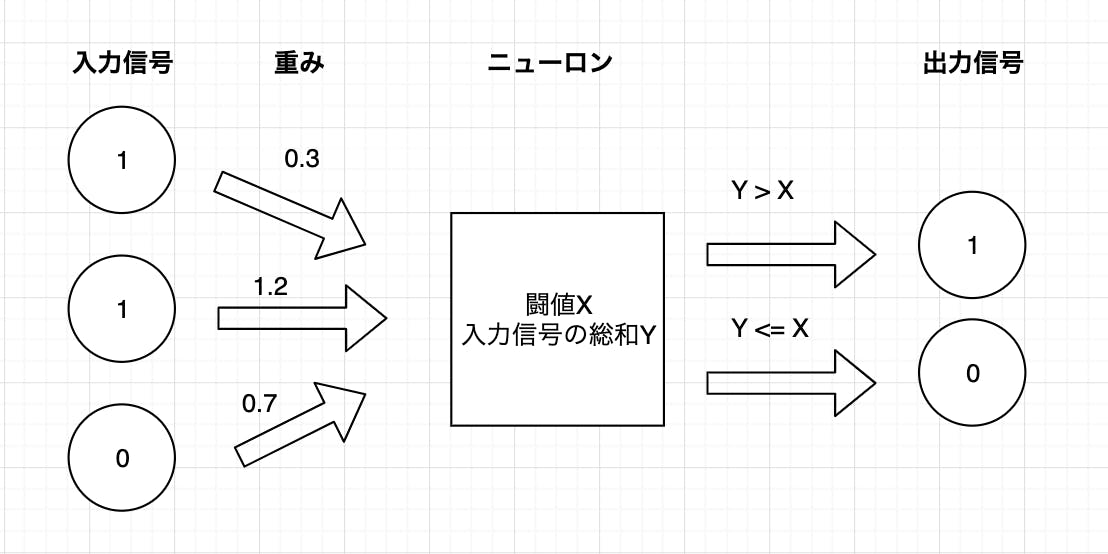
各入力信号はニューロンに向かう途中に各自に設定された重みがかけられます。重みや闘値をパーセプトロンのパラメータと言い、このパラメータがパーセプトロンにとって一番重要な値になります。
重みがかけられた入力信号たちがニューロンに集まり総和(合計)され、その総和が設定した闘値を超えたら1出力して超えられなければ0を出力します。
これをPythonコードで表すと下のようになります。
import numpy as np def perceptron(X): x = np.array([0,1,1,0,1]) #入力信号 w = np.array([0.3,0.7,1.4,0.5,0.3])#重み xw = x*w Y = x.sum() #ニューロンの役割 if Y > X: return 1 elif Y <= X: return 0 print(perceptron(2)) #闘値が2の場合 1 print(perceptron(3)) #闘値が3の場合 0少し詳細に解説しましたが、プログラミングを勉強したことがある人なら理解することは簡単だと思います。
今回はパーセプトロンを解説してみました。このパーセプトロンがなぜディープランニングの起源と呼ばれているかなどは次回以降に解説しようと思います。
- 投稿日:2019-10-12T19:33:34+09:00
[初心者・文系必見]ディープラーニングの起源 ~パーセプトロン~ を分かりやすく解説してみた
はじめに
この記事は現在自分が勉強をしている技術書、ゼロから作るディープラーニング 3章パーセプトロンを自分なりに理解してアウトプットしたものです。
文系の自分でも理解することができたので、難しく考えずに楽にみていただけたら幸いです。
さらに、本書を進めるにあたって参考にしていただけたら嬉しいです。パーセプトロンとは
パーセプトロンとは、複数の0または1の入力信号を受け取り、その合計がある規定値を超えた場合に1を出力してそれ以外の場合は0を出力するアルゴリズムです。
規定値を設定して入力信号を受け取り出力信号に変換する上の四角い箱をニューロンと言います。さらに規定値のことを闘値と言います。
次は今の内容を少し詳細にして解説しようと思います。
各入力信号はニューロンに向かう途中に各自に設定された重みがかけられます。重みや闘値をパーセプトロンのパラメータと言い、このパラメータがパーセプトロンにとって一番重要な値になります。
重みがかけられた入力信号たちがニューロンに集まり総和(合計)され、その総和が設定した闘値を超えたら1出力して超えられなければ0を出力します。
これをPythonコードで表すと下のようになります。
import numpy as np def perceptron(X): x = np.array([0,1,1,0,1]) #入力信号 w = np.array([0.3,0.7,1.4,0.5,0.3])#重み xw = x*w Y = x.sum() #ニューロンの役割 if Y > X: return 1 elif Y <= X: return 0 print(perceptron(2)) #闘値が2の場合 1 print(perceptron(3)) #闘値が3の場合 0少し詳細に解説しましたが、プログラミングを勉強したことがある人なら理解することは簡単だと思います。
今回はパーセプトロンを解説してみました。このパーセプトロンがなぜディープラーニングの起源と呼ばれているかなどは次回以降に解説しようと思います。
- 投稿日:2019-10-12T19:19:47+09:00
[python]numpyの使い方まとめ
はじめに
NumPyとは、数値計算を効率的に行うための拡張モジュールである。NumPyの内部はC言語 (およびFortran)によって実装されているため非常に高速に動作する。
※純粋にPythonのみを使って数値計算を行うと、ほとんどの場合C言語やJavaなどの静的型付き言語で書いたコードに比べて大幅に計算時間がかかる。
NumPy - Wikipedia導入など
・インポート
下のようにインポートすることでnumpyのライブラリを使うことが出来るようになる。import numpy as np線形代数系機能
・ベクトル
ベクトルと行列は異なるものとされている。ベクトルには列、行どちらの方向かの区別がない。x = np.array([1,2,3])・行列
A = np.array([[1,2],[3,4],[5,6]])・ベクトル(行列型)
行ベクトル、列ベクトルのどちらか明示的に指定できることが利点。x1 = np.array([[1,2,3]]) x2 = np.array([[1],[2],[3]])・行列の積
A = np.array([[1,2],[3,4],[5,6],[7,8]]) B = np.array([[1,2,3],[4,5,6]]) C = np.dot(B,C)#D=BC・行列の各成分に対して四則演算
乗算のことはアダマール積という。
行列をA=(aij),B=(bij),C=(cij)とすると、加減乗除の計算はそれぞれ以下の計算に対応する。
(cij)=(aij+bij)
(cij)=(aij-bij)
(cij)=(aij*bij)
(cij)=(aij/bij)A = np.array([[1,2],[3,4]]) B = np.array([[5,6],[7,8]]) #加算 C = np.add(A,B) # C=A+B でも可 #減算 C = np.subtract(A,B) # C=A-B でも可 #乗算(通常の行列の積の意味で使わないように注意) C = np.multiply(A,B) # C=A*B でも可 #除算 C = np.divide(A,B) # C=A/B でも可・剰余
md = np.mod(13,3) # md = 10 % 3 でも可 # 1が出力(12/3 = 4あまり1)・行列の転置
(aij)が転置後は(aji)となっている。A = np.array([[1,2],[3,4],[5,6]]) t_A = A.transpose()・ベクトルの内積
内積はドット積とも言われる。numpyではnp.dotを使うv1 = np.array([1,2]) v2 = np.array([3,4]) ip = np.dot(v1,v2)・ベクトル(行列型)の内積
v1,v2が縦ベクトルならこれらの内積をとる時、内積は(v1の転置)v2という行列の積で表せる。v1 = np.array([[1],[2]]) v2 = np.array([[3],[4]]) ip= np.dot(v1.transpose(),v2)・クロス積(2ベクトルに直交するベクトルを生成する:外積)
v1 = np.array([1,2,3]) v2 = np.array([1,3,5]) v3 = np.cross(v1,v2)・テンソル積
要素をすべての組み合わせで掛け合わせたもの(戻り値は行列)v1 = np.array([1,2,3]) v2 = np.array([1,3,5]) # 行ベクトル(行列)でも可 v3 = np.outer(v1,v2)・ブロック行列の作成
行列をnp.arrayと同じような記述でくっつけることが出来ます。
列ベクトルを三つ並べて[v1,v2,v3]みたいにやりたいと思ってこれを見つけたときは心が躍りました。A = np.array([[0.71,0.71],[-0.71,0.71]]) o = np.array([[0],[0]]) t_o= o.transpose() i = 1 #[ A,o] #[t_o,i]のような行列を作りたい M = np.block([[A,o],[t_o,i]])・行列式
A = np.array([[1,2],[3,4]]) d = np.linalg.det(A)・逆行列
A = np.array([[1,2],[3,4]]) inv_A = np.linalg.inv(A)・行列の累乗
A = np.array([[1,2],[3,4]]) A5 = np.linalg.matrix_power(A,5)・固有値、固有ベクトル
A = np.array([[1,2],[3,4]]) (eig_val,eig_vec) = numpy.linalg.eig(A)定数
・円周率
PI = np.pi・ネイピア数(自然対数の底)
E = np.e初等関数
・累乗
x = 2; l = 2 p = np.power(x,l) # x**lでも可・平方根
x = 2 s = np.sqrt(x) # x**(1/2)でも可・正弦関数sin()
x = np.pi s = np.sin(x) # s = 0・余弦関数cos()
x = np.pi c = np.cos(x) # c = 1・正接関数tan()
x = np.pi t = np.tan(x) # t = 0・指数関数exp()
x = 1 e = np.exp(x) # e:ネイピア数・対数関数log()
x = np.e l = np.log(x) # l = 1・逆正弦関数arcsin(),逆余弦関数arccos(),逆正接関数arctan()
x = np.pi as = np.arcsin(x) # 逆正弦関数 as = np.arccos(x) # 逆余弦関数 as = np.arctan(x) # 逆正接関数
- 投稿日:2019-10-12T18:26:21+09:00
挿入ソート(Insertion sort)
概要
挿入ソートはソートアルゴリズムの一種で、手に持ったトランプの並べ替え方に例えられる手法です。配列をソート済みの部分と未ソートの部分に分けて考え、未ソート部分の要素をソート部分の然るべき位置に挿入していくイメージです。平均計算時間・最悪計算時間はともにO($n^2$)です。
実装例
# 配列aを挿入ソートで昇順に並べ替える def insertion_sort(a): for i in range(len(a) - 1): # a[i]の一つ右の要素: a[j]をソート対象に定める j = i + 1 # a[j]がソート済みの位置に収まるまで繰り返す while i >= 0: # a[j]を一つ左の要素と比較し、a[j]の方が小さければ交換する if a[j] < a[i]: a[i], a[j] = a[j], a[i] # 比較対象が左に移動しているので、indexを1ずつ減らす i -= 1 j -= 1 else: break参考
http://judge.u-aizu.ac.jp/onlinejudge/description.jsp?id=ALDS1_1_A
https://ja.wikipedia.org/wiki/挿入ソート
- 投稿日:2019-10-12T18:26:21+09:00
挿入ソート(Insertion Sort)
概要
挿入ソートはソートアルゴリズムの一種で、手に持ったトランプの並べ替え方に例えられる手法です。配列をソート済みの部分と未ソートの部分に分けて考え、未ソート部分の要素をソート部分の然るべき位置に挿入していくイメージです。平均計算時間・最悪計算時間はともにO($n^2$)ですが、ある程度整列されたデータに対しては高速に動作します。挿入ソートは安定(stable)なソートアルゴリズムです。
実装例
# 配列aを挿入ソートで昇順に並べ替える def insertion_sort(a): for i in range(len(a) - 1): # a[i]の一つ右の要素: a[j]をソート対象に定める j = i + 1 # a[j]がソート済みの位置に収まるまで繰り返す while i >= 0: # a[j]を一つ左の要素と比較し、a[j]の方が小さければ交換する if a[j] < a[i]: a[i], a[j] = a[j], a[i] # 比較対象が左に移動しているので、indexを1ずつ減らす i -= 1 j -= 1 else: break参考
http://judge.u-aizu.ac.jp/onlinejudge/description.jsp?id=ALDS1_1_A
https://ja.wikipedia.org/wiki/挿入ソート
- 投稿日:2019-10-12T17:52:08+09:00
【Python】 交互方向乗数法 (ADMM) を用いた制約付き LASSO 回帰
制約付き LASSO 回帰の論文1中で紹介されていた手法から,交互方向乗数法 (Alternating Direction Method of Multipliers: ADMM) を用いた手法を紹介する.
扱う問題
$X\in\mathbb{R}^{n\times p}, y\in\mathbb{R}^p$ を入力データとする.次の線形制約付き LASSO 回帰問題を考える.
\begin{align} \mathop{\text{minimize}}_\beta\quad &\frac{1}{2}\|y-X\beta\|_2^2 + \rho \|\beta\|_1 \quad\\ \text{subject to}\quad &A\beta = b\ \text{and}\ G\beta\leq h \end{align}ADMM
線形等式制約付き最適化問題
\begin{align} \mathop{\text{minimize}}_{\beta,z}\quad &f(\beta) + g(z) \quad\\ \text{subject to}\quad &M\beta + Fz = c \end{align}を扱う手法として,交互方向乗数法 (ADMM) が知られている.ADMM では,拡張ラグランジュ関数
\mathcal{L}_\tau (\beta,z,\nu) = f(\beta) + g(z) + \nu^T(M\beta + Fz - c) + \frac{\tau}{2}\|M\beta + Fz - c\|_2^2を $\beta,z$ について交互に最小化するように変数を更新する.
\newcommand{\argmin}{\mathop{\rm arg\,min}\limits} \begin{align} \beta^{(t+1)} &\leftarrow \argmin_\beta \mathcal{L}_\tau (\beta, z^{(t)}, \nu^{(t)})\\ z^{(t+1)} &\leftarrow \argmin_z \mathcal{L}_\tau (\beta^{(t+1)}, z, \nu^{(t)})\\ \nu^{(t+1)} &\leftarrow \nu^{(t)} + \tau(M\beta^{(t+1)}+Fz^{(t+1)}-c) \end{align}ここで,$u=\nu/\tau$ とすると,$\mathcal{L}_\tau(\beta, z, \nu)$ は
\mathcal{L}_\tau (x,z,\nu) = f(x) + g(z) + \frac{\tau}{2}\|Mx + Fz - c + u\|_2^2 - \frac{\tau}{2}\|u\|_2^2と書けるので,更新式を
\newcommand{\argmin}{\mathop{\rm arg\,min}\limits} \begin{align} \beta^{(t+1)} &\leftarrow \argmin_\beta \left\{f(\beta) + \frac{\tau}{2}\left\|M\beta + Fz^{(t)} - c + u^{(t)}\right\|_2^2\right\}\\ z^{(t+1)} &\leftarrow \argmin_z \left\{g(z) + \frac{\tau}{2}\left\|M\beta^{(t+1)} + Fz - c + u^{(t)}\right\|_2^2\right\}\\ u^{(t+1)} &\leftarrow u^{(t)} + M\beta^{(t+1)}+Fz^{(t+1)}-c \end{align}と書き換えられる.
ADMM の制約付き LASSO 回帰への適用
制約集合を
\mathcal{C} = \left\{\beta\in\mathbb{R}^p \mid A\beta=b,\ G\beta\leq h\right\}と定義し,ADMM 内の $f,g,M,F,c$ をそれぞれ
f(\beta) = \frac{1}{2}\|y-X\beta\|_2^2 + \rho \|\beta\|_1,\quad g(z) = \begin{cases} \infty & z\notin\mathcal{C}\\ 0 & z\in\mathcal{C} \end{cases},\\ M = I,\quad F = -I,\quad c = 0とすることで,制約付き LASSO 回帰問題に対する次の更新式を得る.
\begin{align} \beta^{(t+1)} &\leftarrow \argmin_\beta \left\{\frac{1}{2}\|y-X\beta\|_2^2 + \frac{\tau}{2}\left\|\beta - z^{(t)} + u^{(t)}\right\|_2^2 + \rho \|\beta\|_1\right\}\\ z^{(t+1)} &\leftarrow \text{proj}_\mathcal{C}(\beta^{(t+1)} + u^{(t)})\\ u^{(t+1)} &\leftarrow u^{(t)} + \beta^{(t+1)}-z^{(t+1)} \end{align}β の更新
\begin{align} & \frac{1}{2}\|y-X\beta\|_2^2 + \frac{\tau}{2}\left\|\beta - z^{(t)} + u^{(t)}\right\|_2^2 + \rho \|\beta\|_1\\ =& \frac{1}{2}\left\|\left( \begin{matrix} y\\ \sqrt{\tau}(z^{(t)} - u^{(t)}) \end{matrix} \right)-\left( \begin{matrix} X\\ \sqrt{\tau}I_p \end{matrix} \right)\beta\right\|_2^2 + \rho \|\beta\|_1 \end{align}と変形することにより,制約なし LASSO 回帰問題となる.
z の更新
\newcommand{\argmin}{\mathop{\rm arg\,min}\limits} \text{proj}_\mathcal{C}(\beta^{(t+1)} + u^{(t)}) = \argmin_{z\in\mathcal{C}}\left\{\frac{1}{2}\left\|z-(\beta^{(t+1)} + u^{(t)})\right\|_2^2\right\}より,2 次計画問題
\begin{align} \mathop{\text{minimize}}_z\quad &\frac{1}{2}\left\|z-(\beta^{(t+1)} + u^{(t)})\right\|_2^2 \quad\\ \text{subject to}\quad &Az= b\ \text{and}\ Gz\leq h \end{align}を解けば良い.
変数の初期化
\begin{align} \mathop{\text{minimize}}_\beta\quad &\|\beta\|_1 \quad\\ \text{subject to}\quad &A\beta= b\ \text{and}\ G\beta\leq h \end{align}を解くことで制約条件を満たす $\beta^{(0)}$ を得る.
この問題は,新たな変数 $\gamma$ を導入することで線形計画問題とみなすことができる.\begin{align} \mathop{\text{minimize}}_{\beta,\gamma}\quad &\sum_{i=1}^p \gamma_i \quad\\ \text{subject to}\quad &A\beta= b,\ G\beta\leq h,\\ &\ \gamma\geq0,\ \gamma\geq\beta,\ \gamma\geq-\beta \end{align}ソースコード
Python で実装.
$\beta$ の更新時の LASSO は sklearn を,$z$ の更新時の 2 次計画問題は cvxopt を,$\beta$ の初期化時の線形計画問題は scipy を用いた.from cvxopt import matrix from cvxopt.solvers import qp import numpy as np from scipy.optimize import linprog from sklearn.linear_model import Lasso class ConstrainedLasso: """ Problem: minimize 0.5 * ||Xβ-y||^2 + ρ||β||_1 subject to Aβ = b, Gβ ≤ h Algorithm: Alternating Direction Method of Multipliers (ADMM) """ def __init__( self, A: np.ndarray = None, b: np.ndarray = None, G: np.ndarray = None, h: np.ndarray = None, rho: float = 1.0, tau: float = None, max_iter: int = 300, extended_output: bool = False ): """ Parameters ---------- A : np.ndarray, optional (default=None) The equality constraint matrix. b : np.ndarray, optional (default=None) The equality constraint vector. G : np.ndarray, optional (default=None) The inequality constraint matrix. h : np.ndarray, optional (default=None) The inequality constraint vector. rho : float, optional (default=1.0) Constant that multiplies the L1 term. tau : float, optional (default=None) Constant that used in augmented Lagrangian function. max_iter : int, optional (default=300) The maximum number of iterations. extended_output : bool, optional (default=False) If set to True, objective function value will be saved in `self.f`. """ if (A is None or b is None) and (G is None or h is None): raise ValueError('Invalid input for __init__: (A, b) or (G, h) must not be None!') if A is None or b is None: self.A = None self.b = None self.G = matrix(G) self.h = matrix(h) elif G is None or h is None: self.A = matrix(A) self.b = matrix(b) self.G = None self.h = None else: self.A = matrix(A) self.b = matrix(b) self.G = matrix(G) self.h = matrix(h) self.rho = rho self.tau = None if tau is None else tau self.max_iter = max_iter self.extended_output = extended_output # Lasso self.clf = Lasso(alpha=rho, fit_intercept=False) self.f = list() def _linear_programming(self, n_features: int) -> np.ndarray: """ Solve following problem. Problem: minimize ||β||_1 subject to Aβ=b, Gβ≤h Solver: scipy.optimize.linprog Parameters ---------- n_features : int The dimension of decision variables Returns ---------- : np.ndarray, shape = (n_features, ) The values of the decision variables that minimizes the objective function while satisfying the constraints. """ # equality constraint matrix and vector c = np.hstack((np.zeros(n_features), np.ones(n_features))) A_eq = None b_eq = None if self.A is not None and self.b is not None: A, b = np.array(self.A), np.array(self.b).flatten() A_eq = np.hstack((A, np.zeros_like(A))) b_eq = b # inequality constraint matrix and vector eye = np.eye(n_features) A_ub = np.vstack(( np.hstack((eye, -eye)), np.hstack((-eye, -eye)), np.hstack((np.zeros((n_features, n_features)), -eye)) )) b_ub = np.zeros(n_features * 3) if self.G is not None and self.h is not None: G = np.array(self.G) h = np.array(self.h).flatten() A_ub = np.vstack((np.hstack((G, np.zeros_like(G))), A_ub)) b_ub = np.hstack((h, b_ub)) return linprog(c=c, A_ub=A_ub, b_ub=b_ub, A_eq=A_eq, b_eq=b_eq)['x'][:n_features] def _projection(self, P: np.ndarray, q: np.ndarray) -> np.ndarray: """ Projection into constraint set Problem: minimize ||x - q||^2 subject to Ax = b, Gx ≤ h Solver: cvxopt.solvers.qp Parameters ---------- P : np.ndarray, shape = (n_features, n_features) Coefficient matrix. q: np.ndarray, shape = (n_features, ) Coefficient vector. Returns ---------- : np.ndarray, shape = (n_features, ) """ sol = qp(P=matrix(P), q=matrix(-q), G=self.G, h=self.h, A=self.A, b=self.b) return np.array(sol['x']).flatten() def fit(self, X: np.ndarray, y: np.ndarray) -> None: """ Parameters ---------- X : np.ndarray, shape = (n_samples, n_features) Data. y : np.ndarray, shape = (n_samples, ) Target. """ n_samples, n_features = X.shape # initialize tau if necessary if self.tau is None: self.tau = 1 / n_samples tau = np.sqrt(self.tau) # initialize constants n_samples_sqrt = np.sqrt(n_samples) Q = np.vstack((X, np.eye(n_features) * tau)) * n_samples_sqrt p = y * n_samples_sqrt P = np.eye(n_features, dtype=np.float) # initialize variables beta = self._linear_programming(n_features) z = np.copy(beta) u = np.zeros_like(beta) # save objective function value if necessary if self.extended_output: self.f.append(0.5 * np.linalg.norm(y - X.dot(beta)) ** 2 + np.sum(np.abs(beta)) * self.rho) # main loop for _ in range(self.max_iter): w = np.hstack((p, (z - u) * tau * n_samples_sqrt)) self.clf.fit(Q, w) beta = self.clf.coef_ z = self._projection(P=P, q=beta+u) u = u + beta - z # save objective function value if necessary if self.extended_output: self.f.append(0.5 * np.linalg.norm(y - X.dot(beta)) ** 2 + np.sum(np.abs(beta)) * self.rho) # save result self.coef_ = z
- 投稿日:2019-10-12T17:37:44+09:00
mysql.connector.errors.DatabaseError: 1366 (HY000): Incorrect string valueが出る
様々な事をしてきましたが、「mysql.connector.errors.DatabaseError: 1366 (HY000): Incorrect string value: '\xE7\xA6\x8F\xE5\xB2\xA1...' for column 'title' at row 1」とエラーが出て、直りませんでした。でも、めちゃくちゃ単純なことで直りました(笑)
結論から言うと、データベースを新しく作り直したらエラーが出なくなりました。原因としては、utf-8に変更してからテーブルしか作り直してませんでした。なのでデータベースに反映されてなかったのかと。
やったこと
エラーが出てからやっていった事を簡単に書きます。
まずは文字コードの変更
mysql> show variables like "chara%"; +--------------------------+----------------------------+ | Variable_name | Value | +--------------------------+----------------------------+ | character_set_client | utf8 | | character_set_connection | utf8 | | character_set_database | utf8 | | character_set_filesystem | binary | | character_set_results | utf8 | | character_set_server | utf8 | | character_set_system | utf8 | | character_sets_dir | /usr/share/mysql/charsets/ | +--------------------------+----------------------------+utf8mb4にもしましたが、エラーは変わらず。
設定が反映されてないのかと思い、もう一度mysqlの再起動、そしてサーバーの再起動するも変わらず。
pythonのコードで「charset='utf-8'」指定するも変わらず。connect = mysql.connector.connect( host='localhost', port='3306', user='root', password='パスワード', database='DB名', charset='utf-8' )mysql-connector-pythonを使っていたので、pythonのコードがおかしいのかと思い、ネットで使い方を紹介されている方のをやってみるとエラーがでなくなりました。なので私のプログラムをもう一度見直すもおかしいところはありませんでした。まあ、その方のを試すとき新しくデータベース作ってやっているので、エラーが出なくなって当然ですよねwww(今思うと)
でもその時は深夜まで何時間も粘って原因を探していたので、頭には何でエラーがなくったのかはてなマークでいっぱいでした。その日の解決は諦め、一度寝ました。朝起きてから、データベースから作り直すかと思い、やってみるとエラーがでなくなり解決。まとめ
今思うとなんでデータベースから作り直さなかったと思いましたが、あの時はまったく頭になかったですね(笑)計6時間くらいは悩んでたと思います。まあmysql触り始めたばかりなので、様々なこと調べたりしていい勉強になりました。
- 投稿日:2019-10-12T17:27:13+09:00
RとPythonで匿名化
はじめに
今回の勉強会のテーマは「匿名化」
経済産業省で作成されている、事業者が匿名加工情報の具体的な作成方法を検討するにあたっての参考資料を参照しながら、対象データの匿名化処理を実施しましたhttps://www.meti.go.jp/press/2016/08/20160808002/20160808002.html
https://www.meti.go.jp/press/2016/08/20160808002/20160808002-1.pdf目的は、Rの講習会の内容をpythonではどうやって書くの?を復習かねて記録することです
環境
windows10 Pro 64bit
R :3.6.1
RStudio :1.2.1335Google Colaboratoryを使用
Python :3.6.8なにするの
①データの暗号化処理
②データの匿名化処理今回は匿名化の必要性についての座学が多かったため処理は少なめでした
暗号化
可逆可能な方法でデータを符号化すること(かな?)
データの再利用が必要な場合に利用
共通鍵暗号方式:RC4,DES、AES 等
公開鍵暗号方式:DH,DH,RSA,ECC など匿名化
データの特定化を避けることが目的のため、可逆性は問わない。むしろいらない。
パスワードなどは、データそのものに意味がなく匿名化されたデータ同士が同じであれば使用用途を満たせる。
ハッシュ関数などで符号化を行う。
データベースの場合は、識別子(個人を特定できるデータ)を匿名化してもその他のデータの組み合わせで特定可能な場合がある。どの程度特定化が困難か?はk-匿名化で示される。ハッシュ化のアルゴは色々あります
['sha1', 'sha224', 'sha256', 'sha384', 'sha3_224', 'sha3_256', 'sha3_384', 'sha3_512', 'sha512', 'shake_128', 'shake_256']Rのコード
①データの暗号化処理
Rではsaferを用いて暗号化ができます
が、、この暗号化アルゴは何なんでしょう?
ドキュメントをさっと見たんですが分かりませんでした、、
https://cran.r-project.org/web/packages/safer/safer.pdf#search='R+safer'#packageのインストール install.packages("digest") install.packages("safer") library(safer) library(digest) install.packages("tidyverse") library(tidyverse) # abcde を key を secret として暗号化 str <- "abcde" str %>% safer::encrypt_string(key="secret") -> enc_res #str %>% encrypt_string(key="secret") -> enc_res enc_res > enc_res [1] "Np2yuAUVDyLK6WKFSHyhVqxWbHTG" # key を間違えると複合化できません enc_res %>% safer::decrypt_string(key="secre") Error in safer::decrypt_string(., key = "secre") : Unable to decrypt. Ensure that the input was generated by 'encrypt_string'.②データの匿名化処理
Rではdigestを用いてハッシュ関数を使用できます
https://cran.r-project.org/web/packages/digest/digest.pdf#search='R+digest'#暗号化で用いたstr 'abcde'をハッシュ化します algo_list <- c("md5", "sha1", "crc32", "sha256", "sha512", "xxhash32", "xxhash64", "murmur32", "spookyhash") for(i in 1:9){ res <- str %>% digest::digest(algo = algo_list[[i]]) %>% print() } [1] "7ab53e2465ca2aebc97740ee54bdee23" [1] "e2bec62fc7f686f4cc9f4e4a2be15d3132b79251" [1] "1ed3d69b" [1] "f7107ae8895bafe851d7c392138b849074fc0cd15d527dc979a712739d732c3f" [1] "91727d0e21cd6991a13eaf8f4882ac0710b57d6221c95e767d29963b562da45757a709caf80073d9b5979b73938ca9bacf8313bc7f30b86a82e4a3aeac95ada4" [1] "5e828f4f" [1] "44a5ade049cd23e2" [1] "f07b8be8" [1] "3e4e2953dd0812f83a0eb4708ecccfe7"digestはベクトル化されていない関数のため、dataframeなどで使用するとうまく動作しない問題があるそうです。
(Rだとしばしば問題になるようです、、pythonでは聞いたことないのですがどうなんでしょう?)
「匿名加工情報作成マニュアル」P5 にあるようなデータを想定してデータを匿名化
そのままではすべて同じ値になってしまう# csvファイルを読み込み customer01 <- read.csv("xxx.csv") #hash カラムを作成し契約者IDをハッシュ化してみる customer01 <- customer01 %>% mutate(hash = digest(契約者ID)) customer01 #結果はすべて同じ値になってしまう hash 1 1c6e3b479dbd166e11f85907196de69a 2 1c6e3b479dbd166e11f85907196de69a 3 1c6e3b479dbd166e11f85907196de69a 4 1c6e3b479dbd166e11f85907196de69a 5 1c6e3b479dbd166e11f85907196de69a 6 1c6e3b479dbd166e11f85907196de69a 7 1c6e3b479dbd166e11f85907196de69a 8 1c6e3b479dbd166e11f85907196de69a 9 1c6e3b479dbd166e11f85907196de69a 10 1c6e3b479dbd166e11f85907196de69asapply関数を使うことで、digestにベクトルデータを入力できる(でいいのかな?)
customer01$hash <- sapply(customer01$契約者ID, digest) customer01 #hash カラムが正常にハッシュ化されている hash 1 99730c015b03d5b64967e51a69fb2a0e 2 ac1b66f3dd4dd5471abcb6877e8f0eed 3 d7bc915ef4ce356c836b956ed69be4d1 4 eb67463847fd6f9deca7524cd38b9a15 5 350ad2498e32998191ca0a3127a2e9eb 6 0d046e6a38b56b72d1d2532a5034442b 7 dd3c3167624b05477813e0c936112897 8 1228a56be1f3ecbc99814f6fa8f0e8c7 9 99152d2c3e276f967140ea4c52ac3445 10 88706daa36af8945e125950d0d80d25fPythonのコード
①データの暗号化処理
ライブラリー pycrypto で、AESの暗号化を行えます
keyは、16,24,32バイト長にする必要あり
元データは、16バイトの倍数にする必要あり#ライブラリーをインポート pip install pycrypto #AED をインポート from Crypto.Cipher import AES #keyと入力データを設定 secret_key = 'secretsecretsecd' message = 'abcdefghijklopqr' crypto = AES.new(secret_key) cipher_data = crypto.encrypt(message) cipher_data b'\xf2Le\xeas\xfea\\\xc1\xb0Ug\x99\x04B\x94'②データの匿名化処理
ライブラリー hashlib でハッシュ化できますimport hashlib str='abcde' hs = hashlib.md5(str.encode('utf-8')).hexdigest() print(hs) ab56b4d92b40713acc5af89985d4b786 #hashlibで使用できる関数 print(dir(hashlib)) ['__all__', '__builtin_constructor_cache', '__builtins__', '__cached__', '__doc__', '__file__', '__get_builtin_constructor', '__loader__', '__name__', '__package__', '__spec__', '_hashlib', 'algorithms_available', 'algorithms_guaranteed', 'blake2b', 'blake2s', 'md5', 'new', 'pbkdf2_hmac', 'scrypt', 'sha1', 'sha224', 'sha256', 'sha384', 'sha3_224', 'sha3_256', 'sha3_384', 'sha3_512', 'sha512', 'shake_128', 'shake_256']dataframeに対して使用する場合は、関数化してapplyすれば可能です
import pandas as pd #csvをdataframeとして読み込み customer = pd.read_csv('xxx.csv',encoding='shift-jis') #関数定義 def hash_tf(x): return hashlib.md5(x.encode('utf-8')).hexdigest() #dataframeに適用 customer['hash_ID'] = customer['契約者ID'].astype(str).apply(hash_tf) customer['hash_ID'] 0 62f249ecf0c6b67132facb2d09f6fc22fd5012da 1 f6b3bf35a478c62ee83e25f684099de2cc5d40d3 2 b9a2972621ddd5d155b37010c92e9b2fdebb6f79 3 7788648e3e62072021824b26c43323f7dc88b3c3 4 290f5053d8fee1cf06d00a2f3c0495393acf5639 5 df90bf5ca5ace2c2f77138fb5920cd23bef0d1f0 6 620d2b6aedec60b1c2442180d3ee34aa41a83986 7 eedc474694ba572ca312e2412b1e5a506bacc16e 8 39f7787b563b793dbd698d84dbfa5d9e462e7447 9 60aee79bd0c98a0d5408106b389ad62395e008d8 10 4ee7760595b71cdbe88af93cfe8545caf6e895a5
- 投稿日:2019-10-12T16:22:43+09:00
ユークリッドの互除法による最大公約数の求め方
概要
ユークリッドの互除法とは、2つの自然数の最大公約数(Gratest Common Divisor)を求める手法の一つです。一方をもう一方で割って剰余を求め、その剰余を使ってさらに除算を繰り返すことで、最終的に剰余が0になった時点で最大公約数を見つけることができます。最古のアルゴリズムとしても知られ、紀元前300年頃に編纂されたユークリッドの『原論』にその記述があります。
実装例
def gcd(a, b): # 大きい方を被除数、小さい方を除数とする dividend = max(a, b) divider = min(a, b) if divider == 0: return dividend # 最大公約数を見つけるまで繰り返す while dividend % divider != 0: # 除算を行い、その除数を次回の被除数、剰余を次回の除数として処理を繰り返す r = dividend % divider dividend = divider divider = r # 一方がもう一方を割り切れた時点で、その除数を最大公約数とみなせる return divider注意点
厳密には被除数と除数の大小関係は関係ない(被除数の方が小さい場合、被除数がそのまま剰余となり、次回の処理で除数と入れ替わる)のですが、本記事では直感的にわかりやすくするため最初の除算で大きい方を小さい方で割るようにしています。
参考
http://judge.u-aizu.ac.jp/onlinejudge/description.jsp?id=ALDS1_1_B
https://ja.wikipedia.org/wiki/ユークリッドの互除法
- 投稿日:2019-10-12T16:17:38+09:00
Djangoで使用しているSqlite3に登録しているテーブルを削除する。
Djangoで使用しているSqlite3に登録しているテーブルを削除する。
なぜ必要になったのか?
Django で使用していたDBのテーブルやフィールドを変更したかったのだが、migration時に変更前のDB情報が残っているためにうまくmigrateできない自体が発生したため。
手順
・環境変数の設定
・コマンドプロンプトでdbshellにアクセス
・実際に編集を行う。の3つの手順で進めていきます。
環境変数の設定
sqlite3ダウンロード
sqlite3をDLした後に環境変数の設定を行う必要があります。
以下のページから「Precompiled Binaries for Windows」の「sqlite-tools-win32-x86-3300100.zip(1.72 MiB)」をダウンロードしてください。
sqlite DLページダウンロードしたフォルダを回答し任意のディレクトリに移動しておいてください。
windows環境での環境変数の設定
・エクスプローラを開き、PCのプロパティをクリック
・システムの詳細設定をクリック
・一番下にある環境変数をクリック
・次の画面に進んだら「システム環境変数」の「Path」を選択し「編集」をクリック(保守の都合上写真割愛させていただきます。)
・「新規」をクリック、sqlite3を格納しているフォルダのパスを追加する。
以上で環境変数の設定は終了です。ここで一度コマンドプロンプトを再起動しておいてください。
コマンドプロンプトでdbshellにアクセス
自身のプロジェクトのmanage.pyファイルがあるディレクトリまで移動。
以下のコードを実行します。python manage.py dbshell適切にPathが設定されていればsqlite3が立ち上がります。
SQLite version 3.30.0 2019-10-04 15:03:17 Enter ".help" for usage hints. sqlite>実際に編集を行う
まず、登録されているテーブルを確認するには
sqlite>.tableと入力します。
必要のないテーブルが確認できたら次のように入力し、テーブルを削除します。(登録されているデータが跡形もなく消えるので十分に操作は注意してください。)sqlite>drop table hogehoge;hogehogeの部分に任意の削除したいテーブル名を入力してください。
これで、既存の必要のないDBデータをDjangoを介さずに削除することができます。
- 投稿日:2019-10-12T16:11:14+09:00
DynamoDBにCSVをインポートしたりエクスポートしたいだけ
本当にただタイトル通りにやりたいだけですが、これが意外と面倒。
まず CSV のエクスポートですが、AWS マネジメントコンソールにログイン後、GUI で実行できる機能があるにはあります。
が、こちらの機能、画面上に一度に表示できる数(最大100?)が限界のようで、大量データを全量となるとぽちぽちページ送りをして何回も CSV をダウンロードする羽目になりそうです。めんどくさいですね。
また、インポートに関してはそもそもそういった機能はなさそう。どうしましょ。。調べてみると、大きく2通りの解決方法がありそうです。
1. AWS Data Pipeline を使う
2. ツール(有償)を使うData Pileline は入出力先として s3 が必要なうえ、JSON ⇔ CSV の変換はやってあげないといけないみたいですね。
ツールのほうは良さそうなのがありますが、このためだけにお金をかけるのはちょっと・・・。と、前置きが長くなりましたが、それならば実装しちゃいましょう!
前提
以下の環境で実装していきます。
- Google Colaboratory
- DynamoDBの読み書き権限のあるユーザーのアクセスキーとシークレットキーがある
- DynamoDB のチュートリアル「NoSQL テーブルを作成してクエリを実行する」のステップ2の状態のテーブルがある(↓こんな感じ)
このテーブルのデータを CSV でローカルに保存すること、およびローカルにある CSV 形式のデータをこのテーブルに追加することを目指します。
データの確認
まずは今あるデータを colaboratory で確認してみます。
認証情報をセットしておきましょう。
リージョンは東京だと ap-northeast-1 となります。dynamo_tabla_scan.ipynb# 認証情報 aws_access_key_id='XXXXXXXXXXXXXXXXXXX' aws_secret_access_key='XXXXXXXXXXXXXXXXXXX' # テーブル名 table_name = 'Music' # リージョン region_name = 'XXXXXXXXXXXXXXXXXXX'AWS に接続するので、以下のインポートが必要ですね。
dynamo_tabla_scan.ipynb# インポート from boto3.session import Session以下を実行して colaboratory に出力してみます。
dynamo_tabla_scan.ipynb# テーブルを取得する関数 def get_dynamo_table(key_id, access_key, table_name, region_name): session = Session( aws_access_key_id=key_id, aws_secret_access_key=access_key, region_name=region_name ) dynamodb = session.resource('dynamodb') dynamo_table = dynamodb.Table(table_name) return dynamo_table # データ確認 dynamo_table = get_dynamo_table(aws_access_key_id, aws_secret_access_key, table_name, region_name) dynamo_table.scan()以下のような結果になればOKです!
{'Count': 5, 'Items': [{'Artist': 'No One You Know', 'SongTitle': 'Call Me Today'}, {'Artist': 'No One You Know', 'SongTitle': 'My Dog Spot'}, {'Artist': 'No One You Know', 'SongTitle': 'Somewhere Down The Road'}, {'Artist': 'The Acme Band', 'SongTitle': 'Look Out, World'}, {'Artist': 'The Acme Band', 'SongTitle': 'Still in Love'}], 'ResponseMetadata': {'HTTPHeaders': {'connection': 'keep-alive', 'content-length': '389', 'content-type': 'application/x-amz-json-1.0', 'date': 'Sat, 12 Oct 2019 04:23:31 GMT', 'server': 'Server', 'x-amz-crc32': '272980438', 'x-amzn-requestid': 'ABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890'}, 'HTTPStatusCode': 200, 'RequestId': 'ABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890', 'RetryAttempts': 0}, 'ScannedCount': 5}CSV をインポート
先ほどのテーブルに以下のデータを追加してみましょう。
Artist SongTitle 評価 Blue Day Majority 4 Quuun We Will Knock You BAAB Dancing King 3 Balloon5 Read Only Memories 4 Hotplay Fax You スパッツ 海も泳げるはず 5 クイーンアンドプリンセス シンデレラボーイ 4 大阪事件 黄色日和 米酢玄人 カボス 3 いろは坂44 こないでリンス こんな感じの表をエクセルで作って CSV として保存したファイルを使います。
また、先ほど確認したデータにはない「評価」というフィールドが入っていますね。このように元のテーブルにないフィールドが来ても対応できるような実装をしていきます。データを確認したものとは別のノートブック(ipynb)に実装していくので、まずは先ほどと同様の認証情報をセットし、以下をインポートしておきます。
dynamo_import_csv.ipynb# インポート from boto3.session import Session from google.colab import files import pandas as pd import csv続いて以下を実行してファイルをアップロードしましょう。
dynamo_import_csv.ipynb# ファイルアップロード uploaded_file = files.upload()中身を pandas の read_csv で確認してみます。
dynamo_import_csv.ipynb# データ確認(pandas) key = [x for x in uploaded_file.keys()] data = pd.read_csv(key[0]) data以下のような結果になります。
「評価」の列がいくつかNaNになっていることが分かりますね!
今度は cvs モジュールの DictReader で読み込んでみましょう。
ちなみに encoding が utf-8-sig なのは、CSV ファイルに BOM がついているからです。dynamo_import_csv.ipynb# データ確認(csv) with open(key[0], 'r', encoding = 'utf-8-sig') as f: for line in csv.DictReader(f): print(line)結果↓
OrderedDict([('Artist', 'Blue Day'), ('SongTitle', 'Majority'), ('評価', '4')]) OrderedDict([('Artist', 'Quuun'), ('SongTitle', 'We Will Knock You'), ('評価', '')]) OrderedDict([('Artist', 'BAAB'), ('SongTitle', 'Dancing King'), ('評価', '3')]) OrderedDict([('Artist', 'Balloon5'), ('SongTitle', 'Read Only Memories'), ('評価', '4')]) OrderedDict([('Artist', 'Hotplay'), ('SongTitle', 'Fax You'), ('評価', '')]) OrderedDict([('Artist', 'スパッツ'), ('SongTitle', '海も泳げるはず'), ('評価', '5')]) OrderedDict([('Artist', 'クイーンアンドプリンセス'), ('SongTitle', 'シンデレラボーイ'), ('評価', '4')]) OrderedDict([('Artist', '大阪事件'), ('SongTitle', '黄色日和'), ('評価', '')]) OrderedDict([('Artist', '米酢玄人'), ('SongTitle', 'カボス'), ('評価', '3')]) OrderedDict([('Artist', 'いろは坂44'), ('SongTitle', 'こないでリンス'), ('評価', '')])1行1行を OrderedDict の形式で読み込むことができます。
値が空の部分でもキーはちゃんと入るんですね~
これなら boto3 の table.batch_writer() で行けそうな気がします!
というわけで早速以下を試してみると・・・dynamo_import_csv.ipynb# テーブル取得 def get_dynamo_table(key_id, access_key, table_name, region_name): session = Session( aws_access_key_id=key_id, aws_secret_access_key=access_key, region_name=region_name ) dynamodb = session.resource('dynamodb') dynamo_table = dynamodb.Table(table_name) return dynamo_table dynamo_table = get_dynamo_table(aws_access_key_id, aws_secret_access_key, table_name, region_name) # データ登録 with open(key[0], 'r', encoding = 'utf-8-sig') as f: with dynamo_table.batch_writer() as batch: for line in csv.DictReader(f): for d in [x for x in line.keys() if line[x]=='']: del line[d] batch.put_item(line) print(line)結果(一部)↓
/usr/local/lib/python3.6/dist-packages/botocore/client.py in _make_api_call(self, operation_name, api_params) 659 error_code = parsed_response.get("Error", {}).get("Code") 660 error_class = self.exceptions.from_code(error_code) --> 661 raise error_class(parsed_response, operation_name) 662 else: 663 return parsed_response ClientError: An error occurred (ValidationException) when calling the BatchWriteItem operation: One or more parameter values were invalid: An AttributeValue may not contain an empty stringエラーになってしまいました。。。
どうやら value が空で key だけっていうのはダメみたいですね。しかたないので value が空の要素を削除します!
dynamo_import_csv.ipynb# 辞書から空の要素を削除 with open(key[0], 'r', encoding = 'utf-8-sig') as f: for line in csv.DictReader(f): for d in [x for x in line.keys() if line[x]=='']: del line[d] print(line)結果↓
OrderedDict([('Artist', 'Blue Day'), ('SongTitle', 'Majority'), ('評価', '4')]) OrderedDict([('Artist', 'Quuun'), ('SongTitle', 'We Will Knock You')]) OrderedDict([('Artist', 'BAAB'), ('SongTitle', 'Dancing King'), ('評価', '3')]) OrderedDict([('Artist', 'Balloon5'), ('SongTitle', 'Read Only Memories'), ('評価', '4')]) OrderedDict([('Artist', 'Hotplay'), ('SongTitle', 'Fax You')]) OrderedDict([('Artist', 'スパッツ'), ('SongTitle', '海も泳げるはず'), ('評価', '5')]) OrderedDict([('Artist', 'クイーンアンドプリンセス'), ('SongTitle', 'シンデレラボーイ'), ('評価', '4')]) OrderedDict([('Artist', '大阪事件'), ('SongTitle', '黄色日和')]) OrderedDict([('Artist', '米酢玄人'), ('SongTitle', 'カボス'), ('評価', '3')]) OrderedDict([('Artist', 'いろは坂44'), ('SongTitle', 'こないでリンス')])これで行けるはず!!
以下を実行してみます。dynamo_import_csv.ipynb# テーブル取得 def get_dynamo_table(key_id, access_key, table_name, region_name): session = Session( aws_access_key_id=key_id, aws_secret_access_key=access_key, region_name=region_name ) dynamodb = session.resource('dynamodb') dynamo_table = dynamodb.Table(table_name) return dynamo_table dynamo_table = get_dynamo_table(aws_access_key_id, aws_secret_access_key, table_name, region_name) # データ登録 with open(key[0], 'r', encoding = 'utf-8-sig') as f: with dynamo_table.batch_writer() as batch: for line in csv.DictReader(f): for d in [x for x in line.keys() if line[x]=='']: del line[d] batch.put_item(line) print(line)エラーっぽいのが出てなければOKですね~
テーブルを確認してみましょう。
「評価」フィールドも含め、無事にインポートできたようです!CSV にエクスポート
また別のノートブックでやっていきますので、認証情報のセットと以下のインポートを実行しておきます。
dynamo_export_csv.ipynb# インポート from boto3.session import Session from google.colab import files import pandas as pd先ほど DynamoDB の画面でテーブルは確認していますが、あらためて colaboratory でも以下を実行して確認しておきます。
dynamo_export_csv.ipynb# データ確認 def get_dynamo_table(key_id, access_key, table_name, region_name): session = Session( aws_access_key_id=key_id, aws_secret_access_key=access_key, region_name=region_name ) dynamodb = session.resource('dynamodb') dynamo_table = dynamodb.Table(table_name) return dynamo_table dynamo_table = get_dynamo_table(aws_access_key_id, aws_secret_access_key, table_name, region_name) dynamo_table.scan()結果↓
{'Count': 15, 'Items': [{'Artist': '大阪事件', 'SongTitle': '黄色日和'}, {'Artist': 'Blue Day', 'SongTitle': 'Majority', '評価': '4'}, {'Artist': 'Balloon5', 'SongTitle': 'Read Only Memories', '評価': '4'}, {'Artist': 'No One You Know', 'SongTitle': 'Call Me Today'}, {'Artist': 'No One You Know', 'SongTitle': 'My Dog Spot'}, {'Artist': 'No One You Know', 'SongTitle': 'Somewhere Down The Road'}, {'Artist': 'クイーンアンドプリンセス', 'SongTitle': 'シンデレラボーイ', '評価': '4'}, {'Artist': 'BAAB', 'SongTitle': 'Dancing King', '評価': '3'}, {'Artist': 'Hotplay', 'SongTitle': 'Fax You'}, {'Artist': 'The Acme Band', 'SongTitle': 'Look Out, World'}, {'Artist': 'The Acme Band', 'SongTitle': 'Still in Love'}, {'Artist': '米酢玄人', 'SongTitle': 'カボス', '評価': '3'}, {'Artist': 'いろは坂44', 'SongTitle': 'こないでリンス'}, {'Artist': 'Quuun', 'SongTitle': 'We Will Knock You'}, {'Artist': 'スパッツ', 'SongTitle': '海も泳げるはず', '評価': '5'}], 'ResponseMetadata': {'HTTPHeaders': {'connection': 'keep-alive', 'content-length': '1182', 'content-type': 'application/x-amz-json-1.0', 'date': 'Sat, 12 Oct 2019 06:31:58 GMT', 'server': 'Server', 'x-amz-crc32': '4044681601', 'x-amzn-requestid': 'ABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890'}, 'HTTPStatusCode': 200, 'RequestId': 'ABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890', 'RetryAttempts': 0}, 'ScannedCount': 15}これらを pandas のデータフレームにして、最後は CSV にしていきます!
まずデータフレームのカラムを取得していきます。「Artist」などのキーがカラムになる部分ですね!
以下を実行して、重複がないようにリストを作ります。ついでにソートもしておきます。dynamo_export_csv.ipynb# fields取得 data_to_dump = dynamo_table.scan() fields_list = [] for record in data_to_dump['Items']: for key in record.keys(): if key not in fields_list: fields_list.append(key) fields_list.sort() fields_list結果↓
['Artist', 'SongTitle', '評価']これをカラムとして、空のデータフレームを作っておきましょう。
dynamo_export_csv.ipynb# 空のデータフレーム作成 export_df = pd.DataFrame(columns=fields_list)作ったデータフレームにデータを入れていきましょう。
dynamo_export_csv.ipynb# export用データフレーム作成 export_df = pd.DataFrame(columns=fields_list) for d in data_to_dump['Items']: export_df = export_df.append(pd.Series([d[x] if x in d else "" for x in fields_list], index=export_df.columns), ignore_index=True) export_df結果↓
無事にできました!あとは以下を実行してローカルにダウンロードしましょう!
dynamo_export_csv.ipynb# csv作成 export_df.to_csv('export.csv', index=False)dynamo_export_csv.ipynb# ローカルに保存 files.download('export.csv')
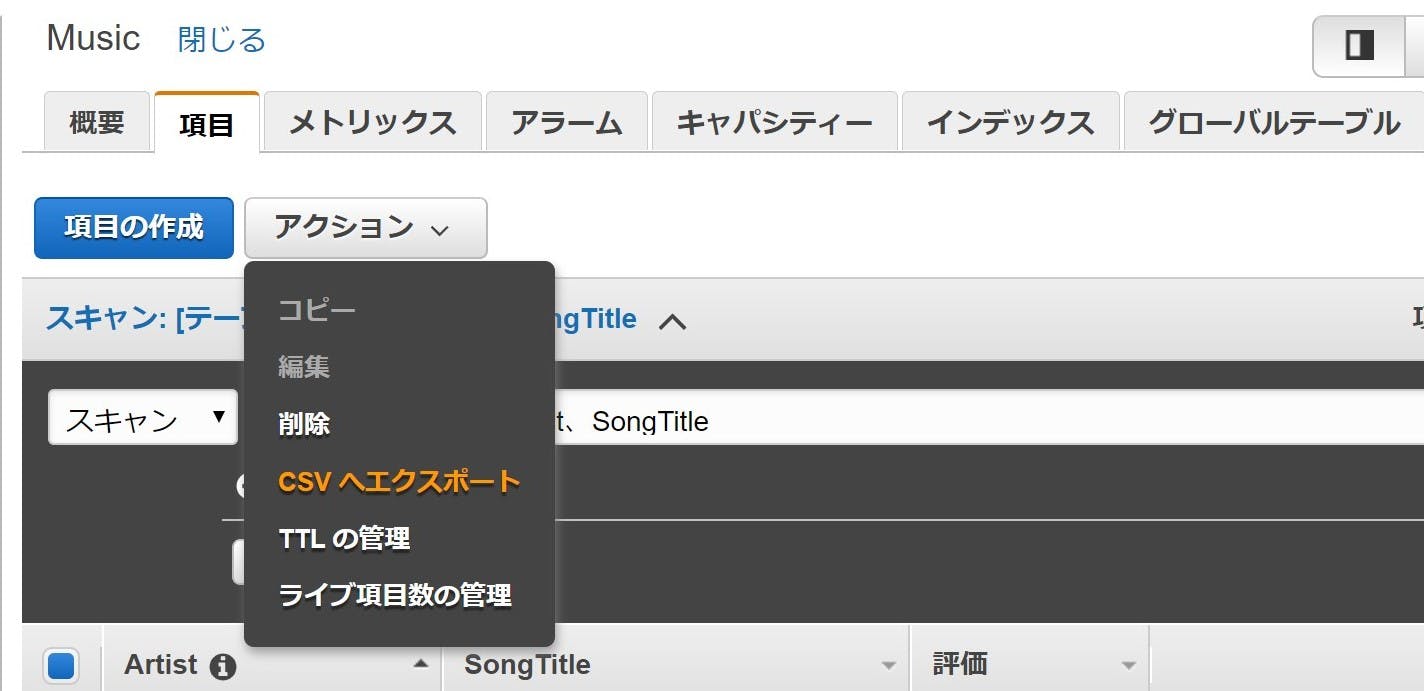
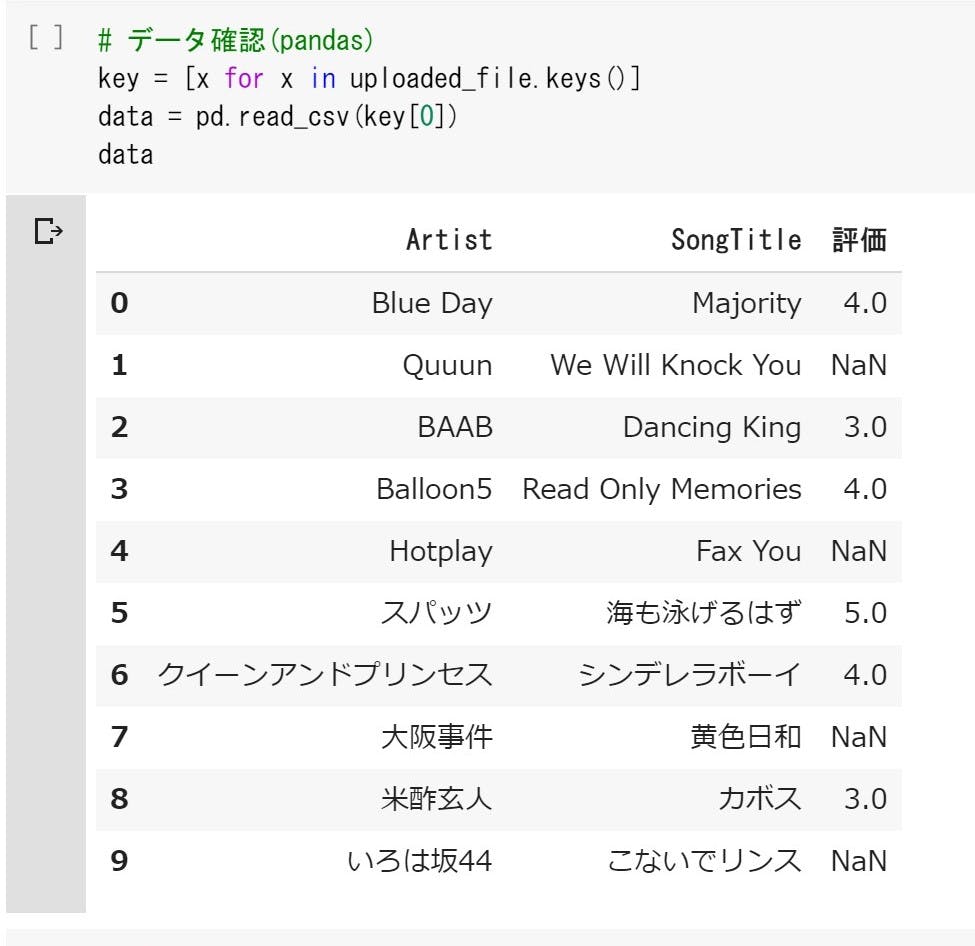
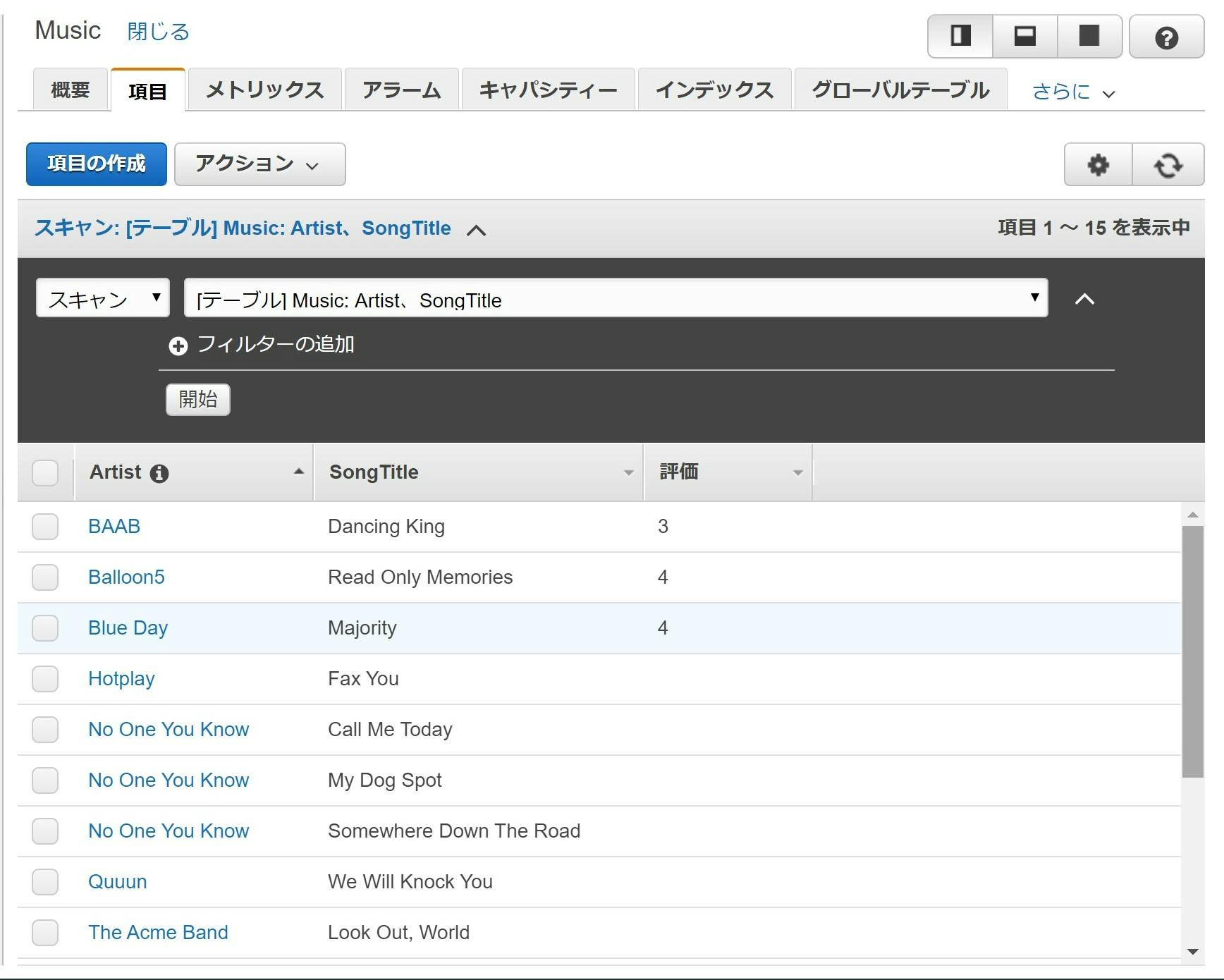
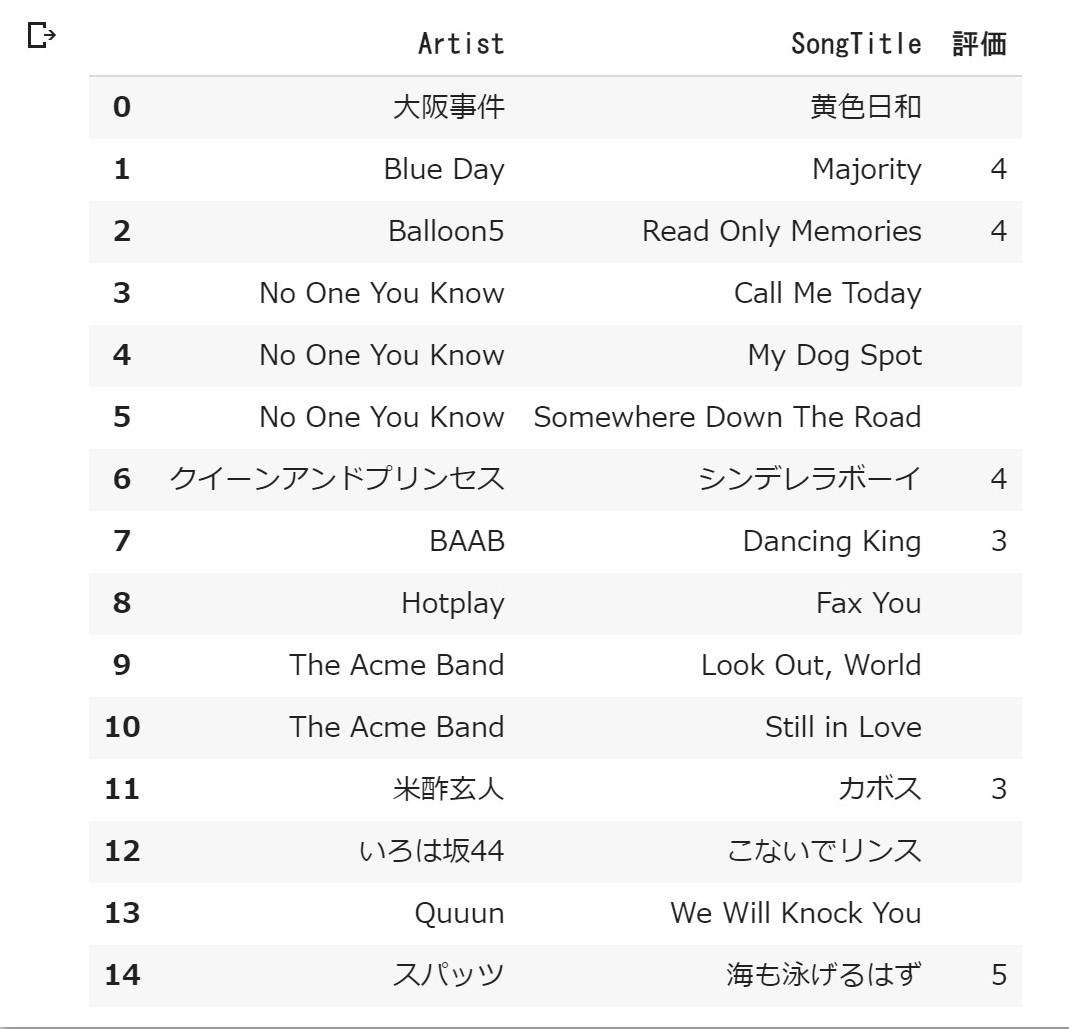
- 投稿日:2019-10-12T16:10:36+09:00
IntelliJ + Docker + Pythonの環境構築
はじめに
Macbookを買い換えたのでPythonの開発環境を作り直すことになるのですが、ローカルに直接Pythonをインストールすると、ついうっかりglobalにパッケージをインストールしてしまったり、venvを使っていても環境を作り直したいときに一手間が面倒だったり、ということが嫌だったのでDockerを使って構築することにしました。
前提
- IntelliJを使う
- Pythonを使う(バージョンは任意)
IntelliJにPluginインストール
IntelliJにDocker Pluginが入っていない場合は
Preferences > Pluginsからインストールします。
Pythonプロジェクトの作成
次にIntelliJを立ち上げてPythonプロジェクトを作成します。
Dockerの必要なイメージはこの後作るので、ここではとりあえず適当なProject SDKを選んでおきます。(ここではPython2.7(venv)になっています)
それ以外はデフォルトのままで良くて、プロジェクトを作成します。
IntelliJ上でDockerfileを作成してイメージをビルドする
今回はPythonQiitaというプロジェクト名にしました。最初にPython環境をDockerイメージにしておく必要があるので、プロジェクトフォルダの直下に
Dockerfileを作成します。(場所はどこでも良い)
Dockerfileにはベースとなるイメージファイル、初期設定コマンドなどを書いておきます。
今回はpython:3イメージを使います。パッケージにpandasnumpyを入れておきます。
作成したDockerfileを右クリックして、メニューから
Create Dockerfileを選択します。
Configurationウィンドウが表示されるので
Image tagを入力します。このタグ名は後で使います。ここではpython_qiitaとしました。
Run built imageのチェックは外しておきます。これをオンにしておくと、イメージをビルドした後、コンテナとして起動してくれます。Container nameを入力すると、そのコンテナ名で起動するようになっています。
下記の
から作成したDockerfile設定を起動すればイメージがビルドされます。Deploy Logに
'python_qiita Dockerfile: Dockerfile' has been deployed successfully.と出て完了したことが分かります。
イメージが作成されるとServicesビューにイメージ名が表示され、ビルドが成功したことが分かります。
ビルドしたイメージをProject SDKとして設定する
Dockerイメージがビルドできると、プロジェクトで利用するSDKとして利用できるようになります。コンテナはSDKにはならないので注意が必要です。
FIle > Project Structureを開き、Project項目にあるNewボタンを押し、ポップアップにあるPython SDKを選択します。
Python Interpreterを選択するウィンドウが表示されるので、左メニューにある
Dockerを選びます。すると、Image nameに先ほどビルドしたDockerイメージのタグ名が選択できるようになっていることを確認してOKボタンを押します。
Project StructureのSDKs項目に
Remote Python 3.7.4 Docker...が表示されており、packagesにDockerfileに書いたパッケージがインストールされていることが分かります。venvなどの環境では、ここでパッケージの追加・削除ができますが、DockerイメージのPythonだと追加・削除はできません。パッケージの構成が変わるたびにイメージをビルドしなおす必要があります。
Pythonの実行とデバッグ
ここまでくれば後は通常通りPythonファイルを作成して実行するだけですが、、、
設定を完了した直後だと、IntelliJがPythonの構成を適切に読み込めていないらしく、一度プロジェクトを閉じて開きなおす必要があります。さらに、画面下に下記のような更新中のインジケータが完了するまで待たないといけません。ここだけが難点です。仕組みはわかりませんが、改善されることに期待したいですね。
ここまで出来ればPythonのコード補完や実行、デバッグがIntelliJ上でできるようになっています。下記はpandasをインポートして実行した状態。
不便なこと
環境はDockerで構築できるのでポータブルになるし、気軽に作り直せることは実行環境面で非常に便利に感じます。一方で、いくつか不便に思うことがあるので書いておきます。
Dockerイメージをビルドしなおすと構成読み込みに時間がかかる
上述のSDKを設定した直後と同様に、イメージをビルドし直してPythonパッケージの構成を変えたとしても、すぐに反映されません。プロジェクトを再起動するなどして、IntelliJが再認識するのを待つ必要があります(数分)。
構成見直しが不要になってくると気になりませんが、プロジェクトの初期フェーズでは煩わしいです。matplotlibなどの
show()的なことができない当たり前ですが、Docker上で実行するので
show()のようなウィンドウを立ち上げることができません。諦めてファイルに保存して確認するしかないです。まとめ
紹介したような不便なところもありますが、環境も汚れないしポータブルであることは便利だと感じています。今までだと、パッケージの再構築が面倒だったり、requirements.txtのようなものに書きださなければならなかった環境が、Dockerfileにまとまるし、必要ならイメージをレポジトリで保存しておく事もできるのは良い感じだなと。
venvとどちらが楽か、と聞かれるとvenvだと思いますが、新しい環境で色々とやってみる方が今の自分の好みに合っているので、暫くはDockerで進めてみようと思います。
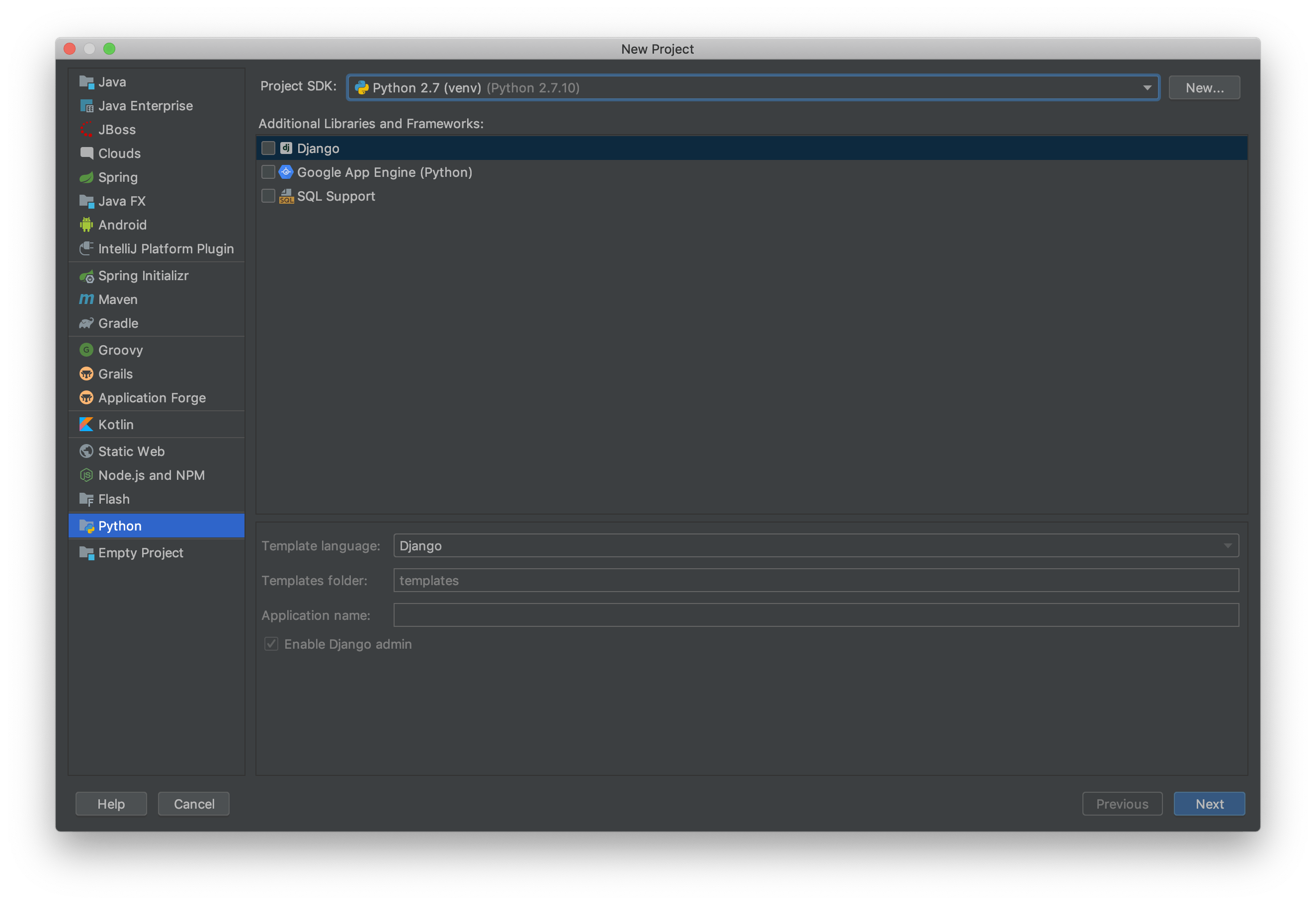
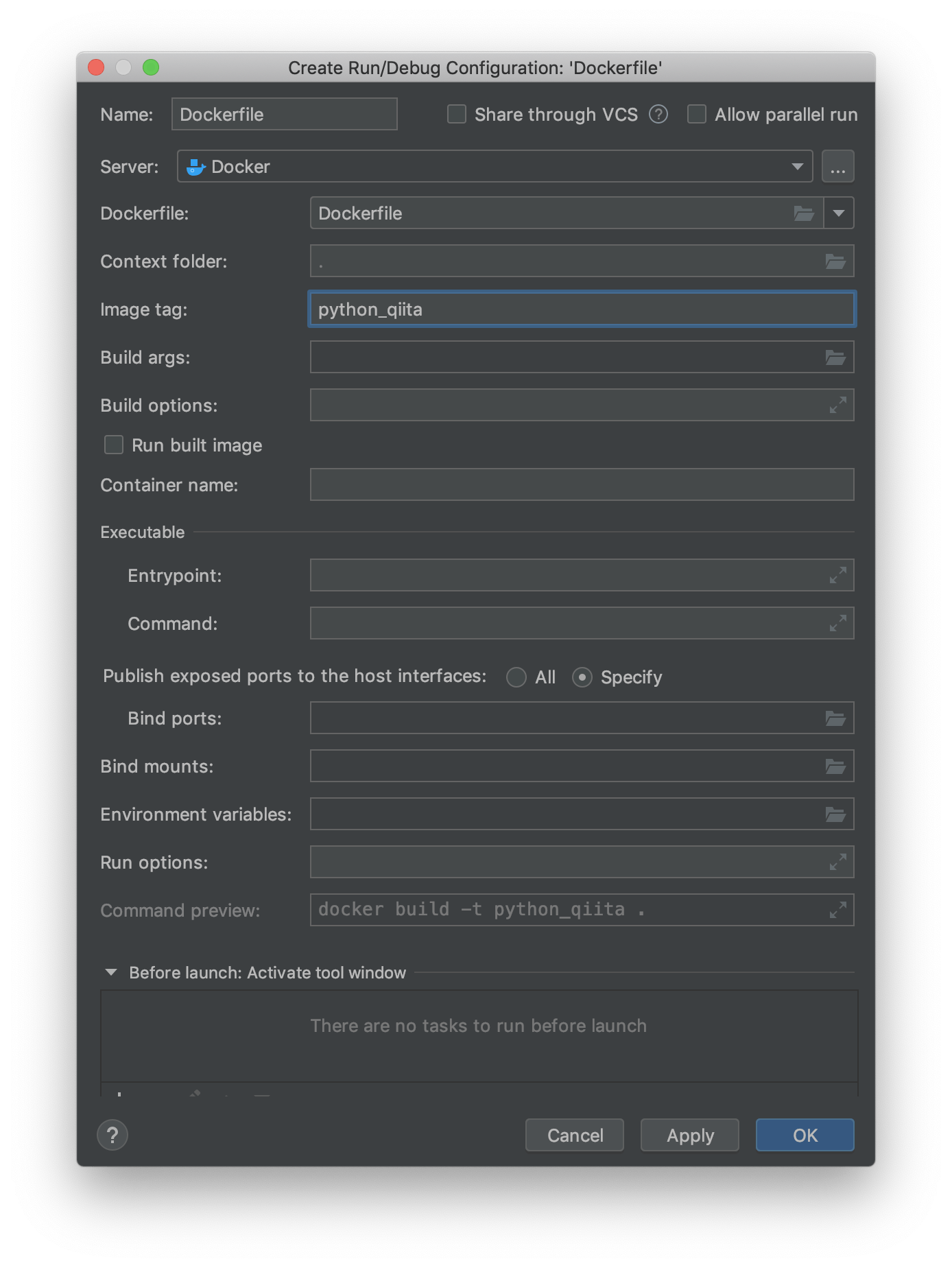
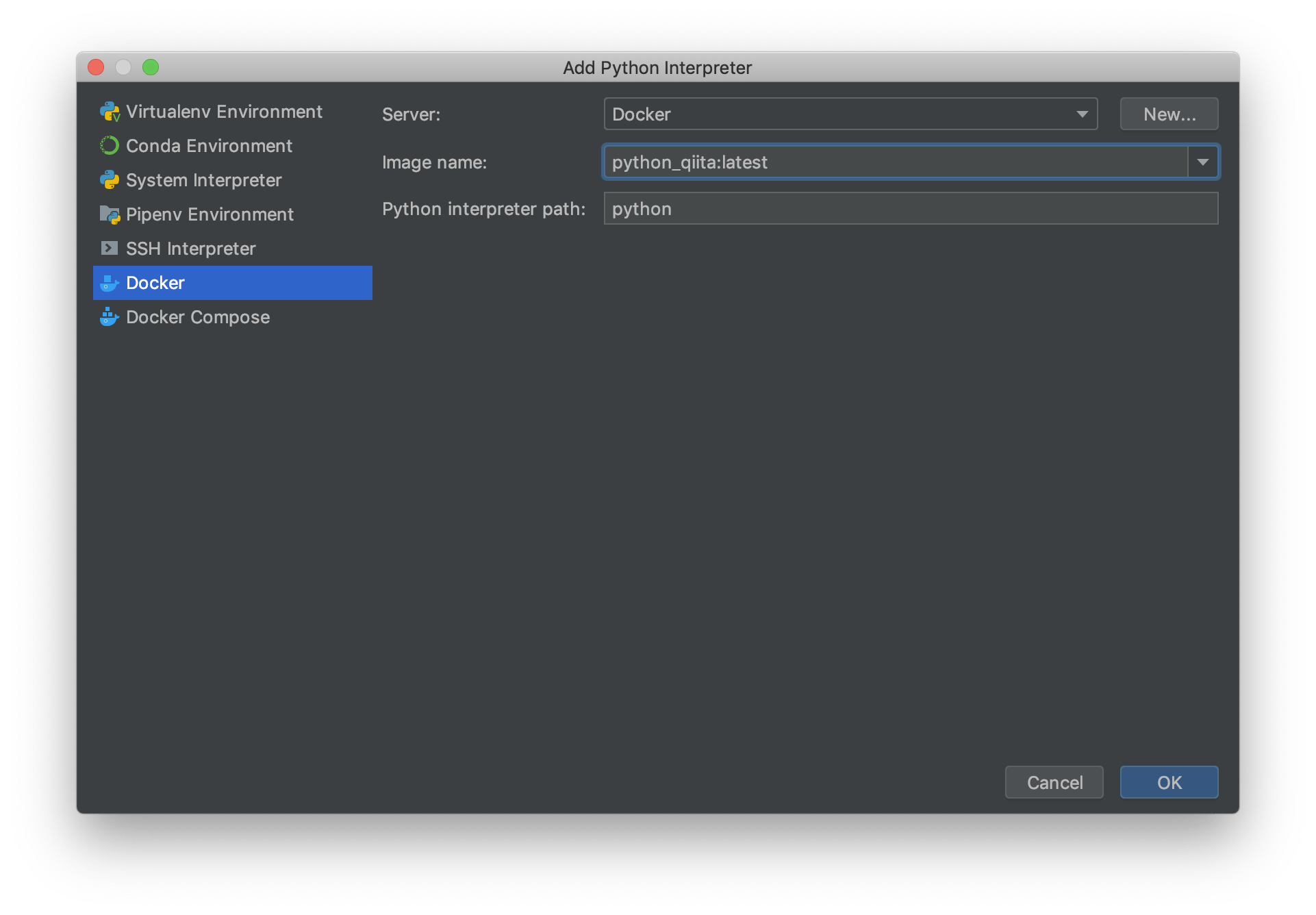
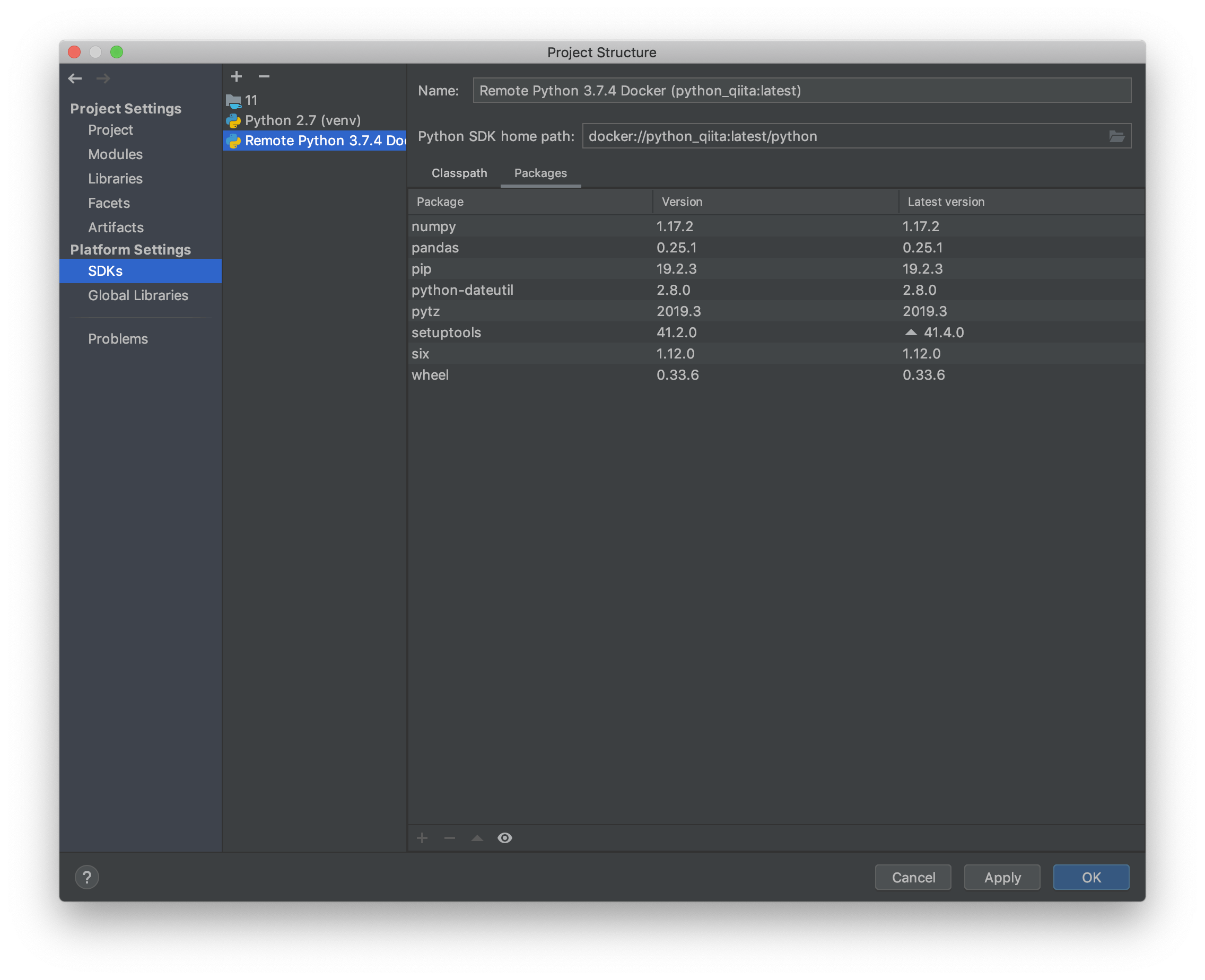

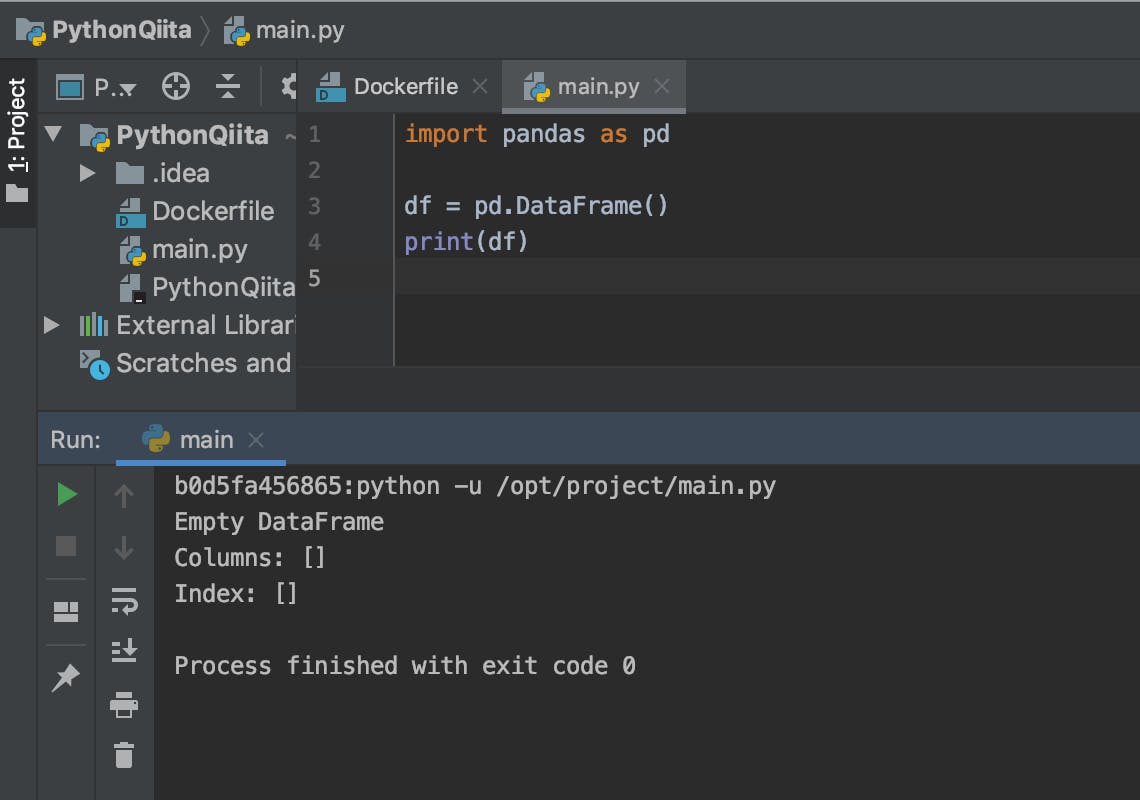
- 投稿日:2019-10-12T15:11:18+09:00
PythonでGoogle Cloud Storage(GCS)、BigQueryへpandas DataFrameをcsv保存するclass
やること
PythonでデータをGCSへ保存する、BigQueryへ保存&BigQueryからデータを取得するクラスを使って、
データを保存したり、取得したりする。目的
pandas dataframeの形から、そのままGCSへ直接フリーキックする日本語の記事がなかったため、
記事を書いた。
オブジェクト指向がなんやらとか、クラスの使い方とかようわからんが、
このクラスを継承し、よく遊んでるので、参考になるやもしれぬ。迷える子羊達よ。神の加護をあらんことを。
コード実行の前提条件
- 自ら機会を作り出し、機会によって自らを変えている
- この世で一匹光通信の営業マンである
- GCP credential.jsonファイルをダウンロードしている
ということでざっくり説明しますが、細かいところは自分で調べてちょ。
クラス
sample_class.pyfrom datetime import datetime from google.cloud import storage from google.cloud import bigquery import pandas as pd import os import re # gcp credentailファイルの読み込み os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "/Users/USERNAME/GOOGLE_CREDENTIAL.json" class UpDownLoad: # BQクライアント初期化 bq_client = bigquery.Client() # ファイルタイプ一覧の辞書 content_dict = { "csv": "text/csv", "txt": "text/plain", "jpeg|jpg": "image/jpeg", "png": "image/png", "pdf": "application/pdf", "zip": "application/zip" } def data2gcs(self, data, bucket_name, folder_name, file_name): try: # GCSクライアント初期化 client = storage.Client() # バケットオブジェクト取得 bucket = client.get_bucket(bucket_name) # 保存先フォルダとファイル名作成 blob = bucket.blob(os.path.join(folder_name, file_name)) # コンテントタイプ判定 for k, v in self.content_dict.items(): if re.search(rf"\.{k}$", file_name): content_type = v # 保存 if content_type == 'text/csv': blob.upload_from_string(data=data.to_csv(sep=",", index=False), content_type=content_type) else: blob.upload_from_string(data=data, content_type=content_type) return "success" except Exception as e: return str(e) def make_bq(self, df, table_name): try: # _TABLE_SUFFIX作成のためのdate date = datetime.today().strftime("%Y%m%d") dataset, new_table = table_name.split(".") dataset_ref = self.bq_client.dataset(dataset) table_ref = dataset_ref.table(f'{new_table}_{date}') self.bq_client.load_table_from_dataframe(df.astype("str"), table_ref).result() return "success" except Exception as e: return str(e) def read_bq(self, query): return self.bq_client.query(query).to_dataframe()pandas dataframeをGCSへCSVとして保存するコード
gcs.py# 初期化 load = UpDownLoad() # データフレーム作成 data = pd.DataFrame([i for i in range(100)], columns=["test_col"]) date = datetime.today().strftime("%Y%m%d%H%M%S") bucket_name = "qiita_test" folder_name = "test" file_name = f"{date}_{folder_name}.csv" # データをGCSへアップロードする res = load.data2gcs(data, bucket_name, folder_name, file_name) print(res)pandas dataframeをBigQueryへ保存&取得するコード
bq.py# 初期化 load = UpDownLoad() # データをBigQueryへアップロードする table_name = "test.qiita_test" res_bq = load.make_bq(data, table_name) print(res_bq) # BigQueryへアップロードしたデータをデータフレームとして取得 project_id = "自分のPROJECT_ID" bq_tb = f"`{project_id}.{table_name}_*`" query = f"select * from {bq_tb}" bq_df = load.read_bq(query)注意点
data2gcsに関して、csv以外のデータを保存する際は、引数としてdataを与える前に、
事前に加工しとくべし。
こんな感じ。jpgとかはImageとか使いなや。read.pywith open("./txt.txt") as f: data = f.read()GCSへ保存する際には、事前にbucketを作成しておく必要がある。
また、BigQueryへ保存するもデータセットは先に作成しておく必要がある(うろ覚え)。参考URL
GoogleのPython clientドキュメント見てたが、探すのがちと面倒なので、記載なし。
- 投稿日:2019-10-12T15:06:29+09:00
Djangoで簡単なWebサイトを作ってみよう!
はじめに
未来電子テクノロジーでインターンをしているsajoです!
プログラミング初心者であるため、内容に誤りがあるかもしれません。
もし、誤りがあれば修正するのでどんどん指摘してください!今回はDjangoについてまとめていきます。
プロジェクトとアプリケーションの作成
terminal# [django-app]というプロジェクト名のディレクトリを生成 # 仮想環境下でコマンドを実行 $ django-admin startproject django_app # [hello]というアプリケーションを生成 # プロジェクト内でコマンドを実行 $ python manage.py startapp hellourls.pyの編集
ここでは「アプリのアドレス管理は、各アプリ内で行わせる」ようにします。
こうすることでアプリを編集した際に、わざわざプロジェクトまで気にする必要がなくなるのです。django_app/hello/urls.pyfrom django.urls import path from . import views urlpatterns = [ path('', views.index, name='index'), ]django_app/django_app/urls.pyfrom django.contrib import admin from django.urls import path, include urlpatterns = [ path('admin/', admin.site.urls), paht('hello/', include('hello.urls')), ]views.pyの編集
ここでは http://localhost:8000/hello/ にアクセスした時に、テンプレートフォルダに格納してある hello/index.html というHTMLファイルを表示させるように、views.pyを編集します。
HTMLファイルで使用する変数を、paramsに辞書形式で定義し、render関数の第3引数で返しています。django_app/hello/views.pyfrom django.shortcuts import render from django.http import HttpResponse def index(request): params = { 'title':'Hello/Index', 'msg':'これは、サンプルで作ったページです。', } return render(request, 'hello/index.html', params)index.htmlの編集
vies.pyのindex関数で定義したparams辞書は、HTMLファイル内で{{キー}}のように指定すると画面に表示することができます。
index.html<!doctype html> <html lang='ja'> <head> <meta charset='utf-8'> <title>{{title}}</title> </head> <body> <h1>{{title}}</h1> <p>{{msg}}</p> </body> </html>まとめ
この記事では、Djangoの基本中の基本事項をまとめてみました。
最後までご覧いただきありがとうございました!
- 投稿日:2019-10-12T14:51:07+09:00
文系大学生がアプリ開発よりも機械学習の方が自学自走しやすいと考える理由について
はじめに
最近の風潮として、アプリの開発を一人で自学自走は頑張れば可能と言う考えが蔓延っていて、機械学習はなんか難しそうみたいな考え方があるように見受けられます。確かにアプリの開発を一人で自学自走する人はとてもすごいと思いますが、自分はアプリ開発を一人でやりきるのはとても難しく、また機械学習の自学自走はそれに比べると難しくないと考えています。
自分の感覚で言うと
・アプリ開発自走→天才じゃないと無理ゲー
・機械学習自走→頑張れば可能
という感じです(これは自分の感覚なので、個人差はあると思います)。その理由について述べていきたいと思います。
自分のそれぞれの経験について
まずその前に自分の(お前の経歴なんか興味ねえよって人はすっ飛ばして見て下さい)
アプリ開発
・実際に去年の3月にtechcampさんの方に通って勉強→3ヶ月ほどやるもそこで挫折
・今年の3月にpreogate→railsチュートリアルの流れで勉強をするも、railsチュートリアルで挫折機械学習
・去年の末から初めて今のところ挫折なし
詳しくは以下を参照
https://qiita.com/HayatoYamaguchi/items/1c20595c5e6dac4530dcこんな感じでやっています。確かに機械学習の方が本腰を入れて行なっていたという面だったり実際に一度アプリ開発でプログラミングを学んだ後だからというものもあるかもしれませんが、それを加味しても自分は機械学習の方が自学自走しやすいと考える理由をいかに述べたいと思います。
1、参照するページが多く、さらに自分がどこまで反映させたのかがわかりにくい
プログラミング初心者あるあるとして、まずは写生をしますがこの写生内容は往々にして「,」と「.」のミスなどの文字やスペルミスや、括弧やendの位置などのミスが起こりやすいです。その中でエラーメッセージを見てみると、そのメッセージが起きたサイトに言ってもエラーの根本的な原因はそのページではないなどのことが往々に発生します(例えばビューファイルのエラーなのに実際はコントローラーの中の変数の受け取りに問題があるなど)。そのためエラーの発掘が自分では困難になり、挫折しやすいです。一方機械学習の場合は最初はクラス分けを行わなければjupyter notebookなどの一つのファイルで完結します。そのため、エラーの行を見ればその行や周辺を直せば大体のエラーは解決します。
2、アプリ開発には必要な言語や概念が多すぎる
機械学習においてプログラミング面で必要なのはpythonやそれに付随する各種ライブラリ(numpy,pandas,sklearnなど)のみです。
しかし、アプリ開発を学ぼうとすると、例えばrailsだったらrailsチュートリアルを完遂して自分でポートフォリオを作ろうとすると、・htmlcss
・ruby
・javascript
・SQL
・Gitなどが必要で、データベースとの連携方法やさらにテストの実装についても理解も必要なことがあります。そのため何もやったことがない初心者が始めようとすると、「なんかごちゃごちゃしてるけど今は何をやればいいんだっけ、、、」という状態になりやすいです。
ここまで見ると機械学習の方がはるかに簡単そう、、、って思いそうなので、一応機械学習の方が難しい点も述べたいと思います。
機械学習の方が難しい点について
ある程度の数学や統計が必要である
アプリ開発にはほぼ一切数学の知識は求められません。
一方機械学習ではそうはいかず、ある程度アルゴリズムの中身を理解するとなると、大学基礎レベルの数学は必要になります。そのため数学アレルギーの人には厳しいです。論理的な式がより求められる
機械学習ではモデルを作る前にデータの変形などをする必要があります。そのため、「この条件の時にここを変形する」などの少し論理的なコードを書く力が必要です。例えばこれは自分の昔の記事から引っ張ってきたものですが、条件を指定して削除するなどの少し複雑なものになっています。これは簡単な例ですが、論理的な式を求められることが多いです。」
Xmat = Xmat.drop(Xmat[(Xmat['TotalSF']>5) & (Xmat['SalePrice']<12.5)].index)終わりに
これはあくまでもサンプル数1の考え方ですが、実際にこのような考え方を投稿している人がいなかったので投稿させてもらいました。何をやるかを考えている人には参考にしてもらえると嬉しいです。
- 投稿日:2019-10-12T13:38:03+09:00
「GPU・Linuxがなくても、Google Colaboratoryで『Yukarinライブラリ』を使いたい」
概要
「Google Colaboratory」で、『Yukarinライブラリ』become-yukarin, yukarin コマンド解説を実行する方法を紹介します。
音声の収録以外であれば、ほぼ全て Google Colaboratoryで実行できます。一般に、機械学習には GPU付きのLinux マシンを用意する必要があり、環境設定だけでも一苦労します。しかし、Google Colaboratoryを利用すれば、ブラウザだけで『Yukarinライブラリ』を使用できます。
このアイデアは @BURI55 様がくださいました。本記事は『GPUがなくても、Google Colaboratory で Yukarinライブラリを使いたい』をリファインした記事になります。
Googleドライブの課金が必要になる場合があります
Googleドライブの無料容量は15Gのみなので、音声データを増やしていくと容量が足りなくなります。その際、有料になりますがGoogleドライブの容量を増やして対応してください。(GPUマシンの電気代がかからないと考えると、安いと思います)Linux環境はなくていいの?
本格的に学習をやりたい場合は、Linux環境をオススメします。
Google Colaboratoryは簡単に利用できますが、"処理速度が遅め"・"利用時間の上限がある"などの面で本格利用には向きません。不明点・ご質問
Yukarinライブラリ Discord サーバ 招待リンクで、ご質問いただくのが、一番早くお返事できると思います。
もちろん、本記事にコメントいただければお返事いたします。Google Colaboratory とは?
ブラウザで Python を利用できるサービスです。GPUも利用できるため機械学習の入門には最適です。イメージ的には、Google のスプレットシートのような、ブラウザで動くアプリケーションのようなものです。
Google アカウントでログインしてから「Colaboratory へようこそ」の動画をみてもらうのが一番わかりやすいと思います。
英語で話していますが、設定で日本語字幕を出せるので、心配いりません!連続実行は 12時間までで、長時間の学習はできませんが、『ちょっと試してみる』程度であれば十分な学習ができます。
Colaboratory Notebook
Google Colaboratory で動作確認を行った ノートブックはyukarin_library.ipynb です。
ノートブックはリンクを開いて、『マイドライブに追加』ボタンで自分のGoogle Driveにコピーしてください参考記事
- 【秒速で無料GPUを使う】深層学習実践Tips on Colaboratory
- Colaboratoryを使う際のGoogle Driveマウント方法など取り扱いかた色々
- Jupyterの magic command
- Google Compute Engine(GEC) 上に Google Colaboratory の ローカルランタイムを作成する
1. 事前処理(Z. become-yukarin, yukarin共通の事前作業)
『Yukarinライブラリ』become-yukarin, yukarin コマンド解説にある、Z.1〜Z.4は Google Colaboratoryを利用した場合でも必要な処理となります
Z.1, Z.2, Z.3 は、ローカルPCで実行してください。
Z.4はノートブックで実行します。
Z.1
ディレクトリ作成コマンドは、Windowsの"Power Shell"で実行可能です。
deep_yukarinディレクトリは、Googleドライブアプリをインストールして、同期ディレクトリ"Google ドライブ"に配置してください。
ブラウザ経由でアップロードしても問題ありませんが、ディレクトリ同期する方が楽だと思います。Z.2
Windowsでgitコマンドを使う場合は、別途インストールが必要です。面倒な場合は git/bitbucketのサイトからダウンロードしてください。
それ以外は、Windowsの"Power Shell"で実行可能です。Z.3
記事の通り、音声収録してください。Z.4
Z.4に対応するコマンドはノートブックに記載してあるので、そちらで実行してください。2. Google Colaboratory で『Yukarinライブラリ』を実行(元記事の A, B)
Google Colaboraory でノートブック yukarin_library.ipynb 公開しているので、それを参照・実行してください。
基本的に上から実行すればいいように書いてあります。各コマンドで何をしているかは 『Yukarinライブラリ』become-yukarin, yukarin コマンド解説の記事を参照してください。
だいたい雰囲気でわかるかと思いますが、あまり詳しく書いてないのでわかりにくいところなど指摘いただければ追記します。
3. Google Colaboratory の補足
3.1 Google Colaboratoryの予備知識
- Google Colaboraory は Pythonの対話モードが、ブラウザで動いているようなもの
- ディレクトリ移動は
cp [dir]の代わりに%cp [dir]を使う- コマンド実行するときは先頭に "!" をつける(例 :
!echo "コマンドテスト",!ls -lなど)- ブラウザを閉じる or 12時間使い切る と、全てやり直し(これをランタイムのリセットと言う)
- 学習中はブラウザを閉じないように! (90分以内に開き直さないとランタイムリセットされて学習は中断します)
- 挙動がおかしい場合は、メニューの『ランタイム』-> 『全てのランタイムのリセット』で最初からやり直す
- ランタイムがリセットされても、生成したファイルはGoogle Driveに残る
3.2 学習を止めると、以後Pythonが実行できなくなる
学習処理(A.3, A.5, B.4)を手動で終了する必要がありますが、それ以降Pythonを実行すると下記のエラーが発生して動かなくなってしまいます。
ERROR:root:Internal Python error in the inspect module. Below is the traceback from this internal error. ...理由はいまいちよくわかりませんが、学習処理を止めたあとは、
- ランタイムリセット
- Y.1 〜 Y.3を再実行
を行なってから、続きの処理を行ってください。
3.2 補足 Google Drive のマウント
ノートブックにも書いてありますが、Google Drive をマウントする際には下記のコマンドを実行します。
from google.colab import drive drive.mount("/content/drive/")すると、下記画像のような結果が表示され、認証コードの入力が必要になります。
下記の手順で認証コードを入力
1. 上記の実行結果に書いてある URLをクリック
2. 『Google Drive File Stream が Google アカウントへのアクセスをリクエストしています』を許可する
3. 認証コードが表示されるの、上記画像の入力欄にを貼り付けるうまくいけば、ノートブックの左のパネルに、Google ドライブの Myドライブが表示されます。
以上です。
ご質問等あればDiscordサーバやコメントでお問い合わせください。
それでは、皆さんでゆかりんになりましょう!