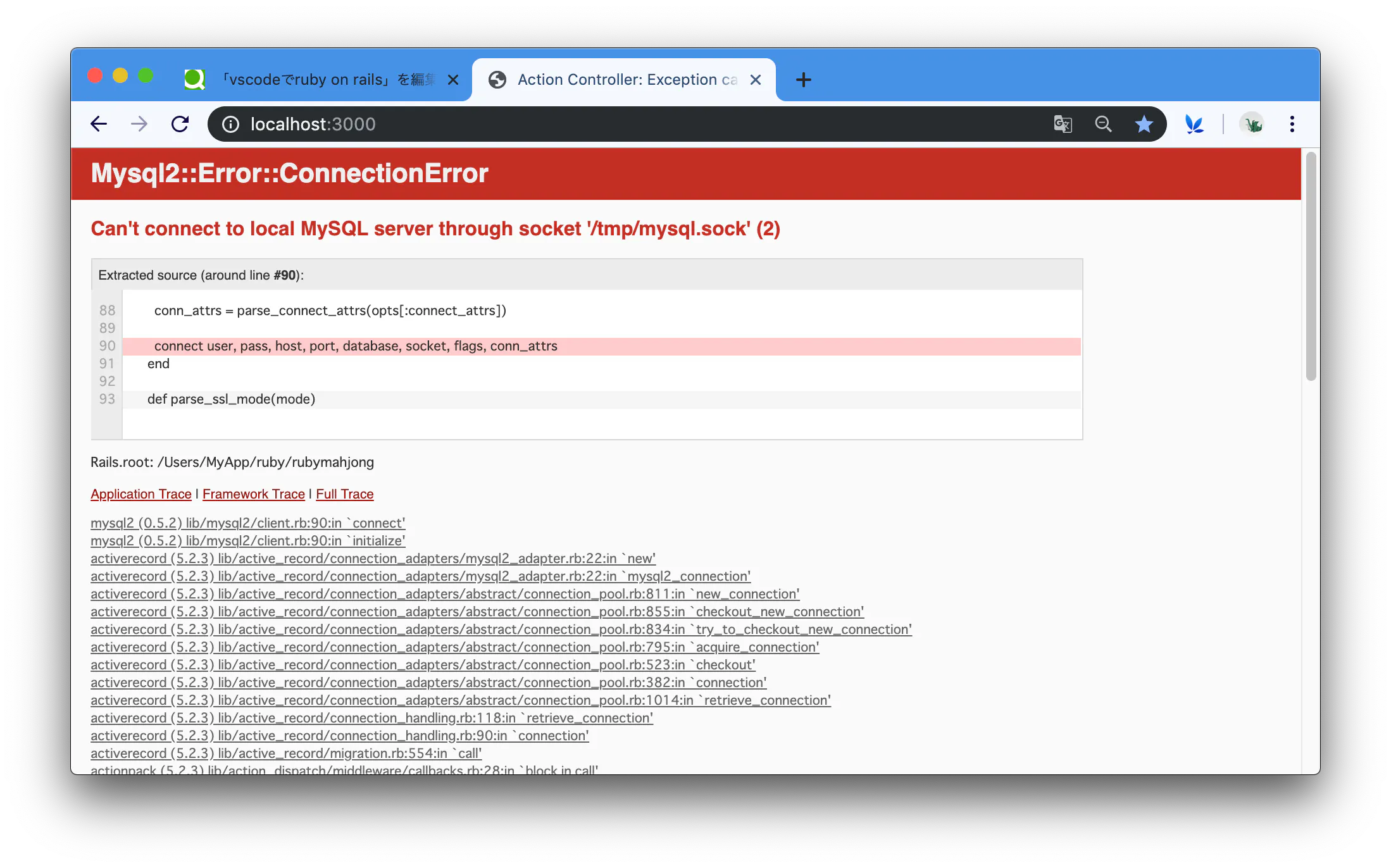
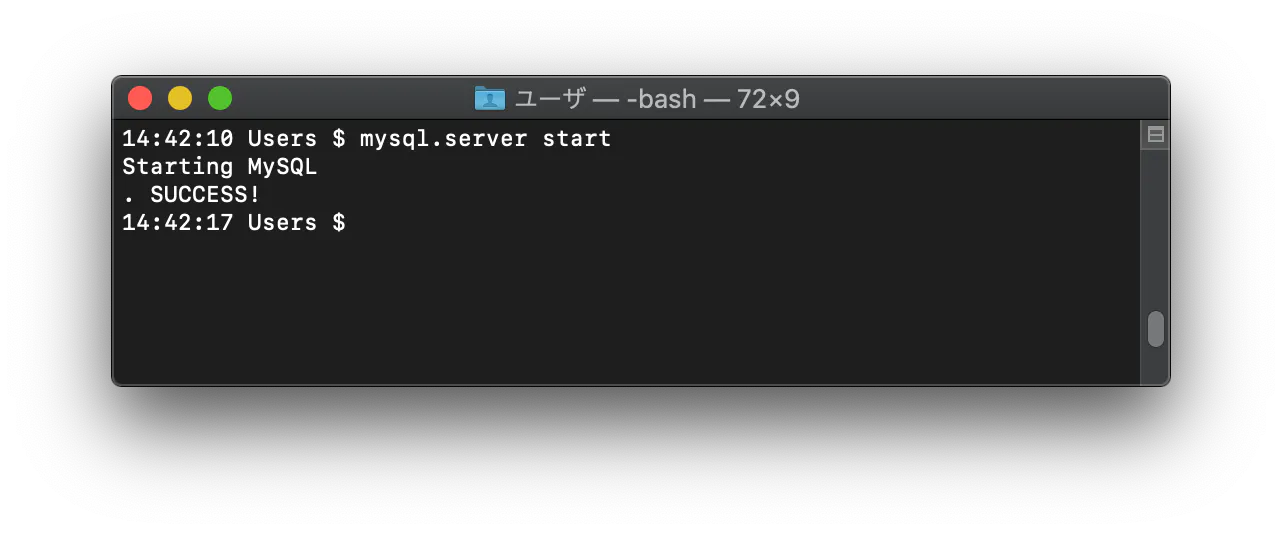
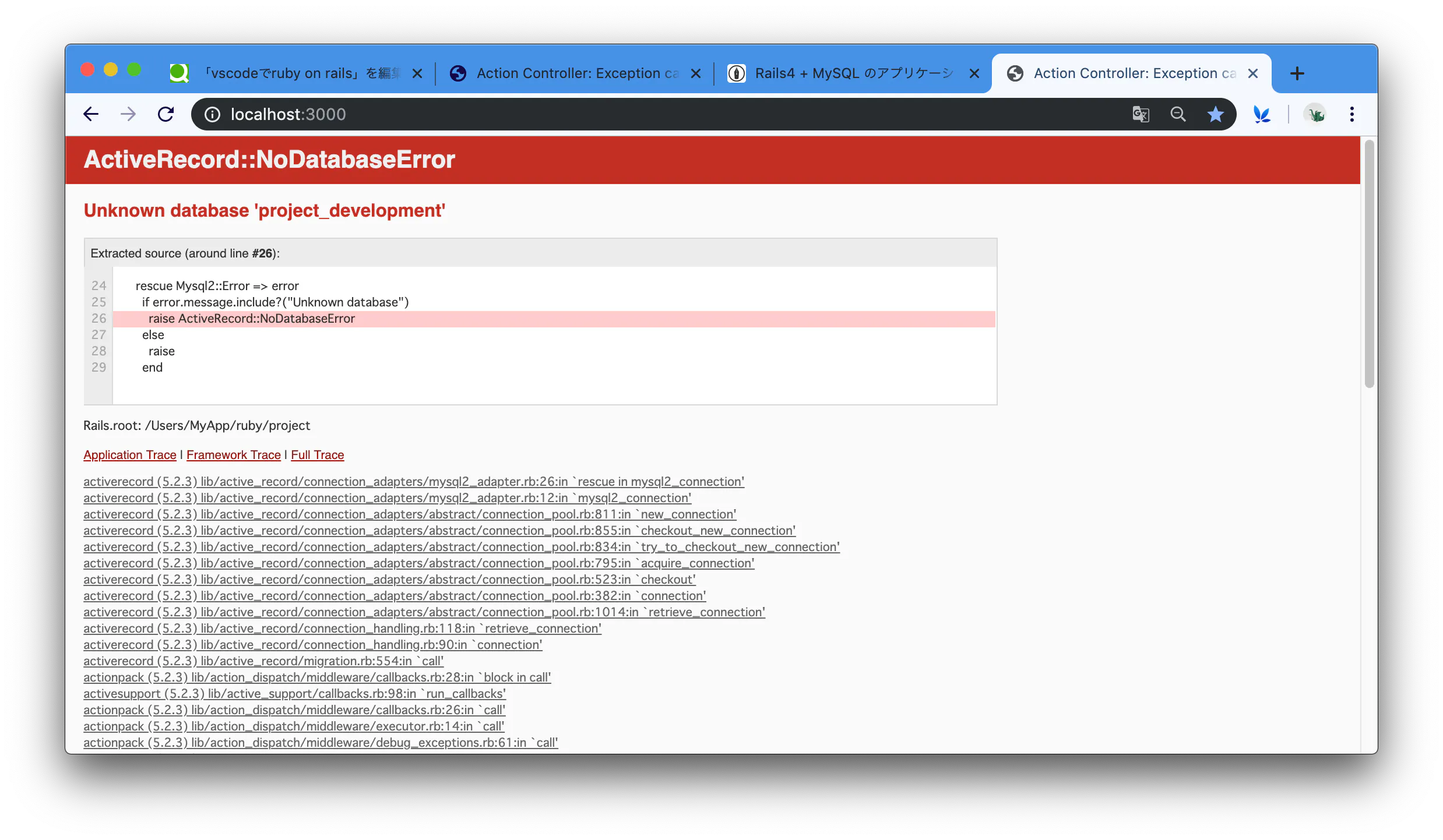
基本的にはRails Girls ガイドの通りに作業を進めればいいんですが、
Homebrewのインストールがうまく行きませんでした。
brew doctor を実行してエラーがないか確認したところ
11:05:46 Users $ brew doctor
Please note that these warnings are just used to help the Homebrew maintainers
with debugging if you file an issue. If everything you use Homebrew for is
working fine: please don't worry or file an issue; just ignore this. Thanks!
Warning: "config" scripts exist outside your system or Homebrew directories.
`./configure` scripts often look for *-config scripts to determine if
software packages are installed, and which additional flags to use when
compiling and linking.
Having additional scripts in your path can confuse software installed via
Homebrew if the config script overrides a system or Homebrew-provided
script of the same name. We found the following "config" scripts:
/Library/Frameworks/Python.framework/Versions/3.7/bin/python3.7-config
/Library/Frameworks/Python.framework/Versions/3.7/bin/python3.7m-config
/Library/Frameworks/Python.framework/Versions/3.7/bin/python3-config
11:05:52 Users $
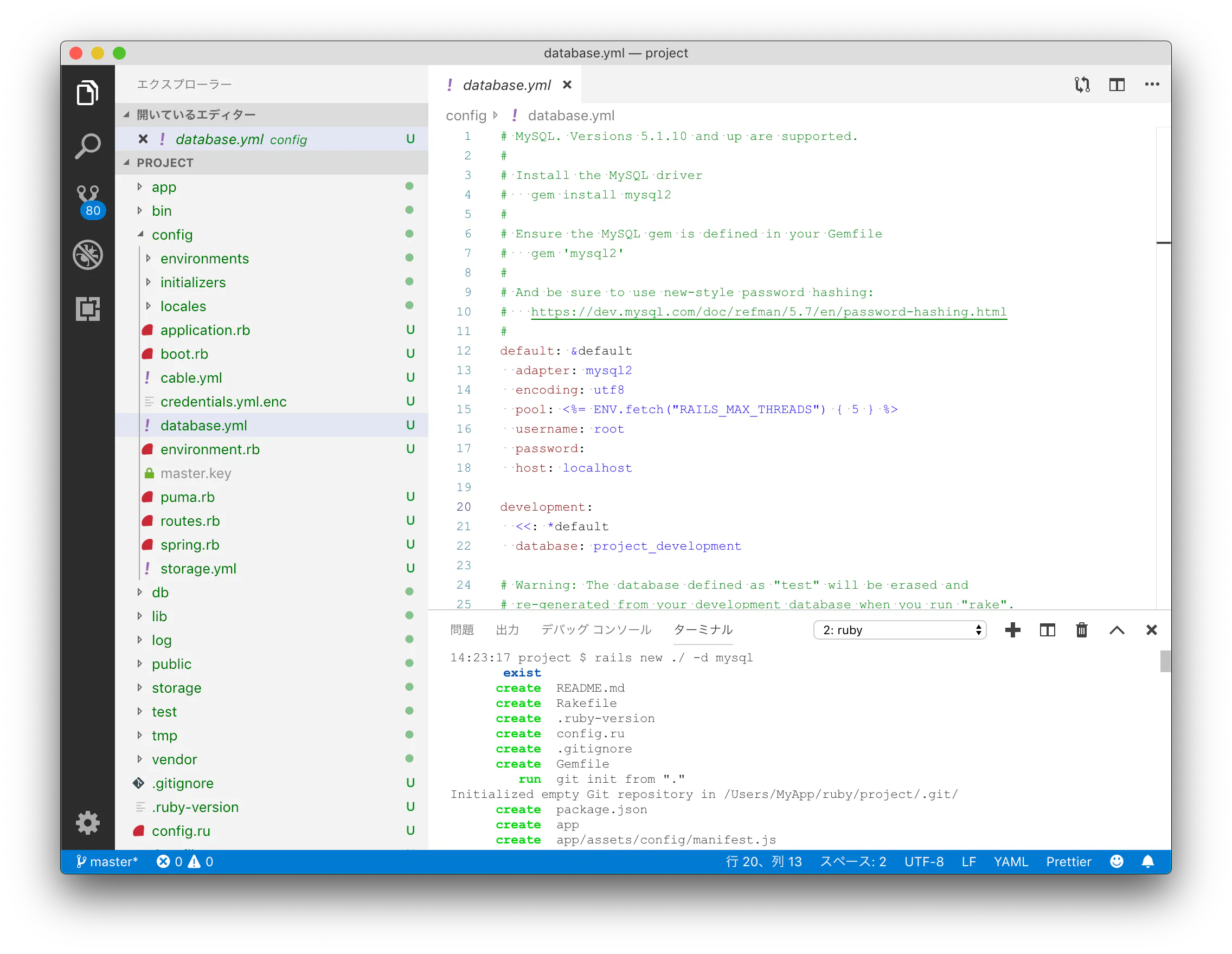
# lib/tasks/db_pull.rake
namespace :db do
desc 'Pull production db to development'
task :pull => [:dump, :restore]
task :dump do
dumpfile = "#{Rails.root}/tmp/latest.dump"
production = Rails.application.config.database_configuration['production']
puts 'mysqldump on production database...'
system "ssh user@server.tld 'mysqldump -u #{production['username']} --password=#{production['password']} -h #{production['host']} --add-drop-table --skip-lock-tables --verbose #{production['database']}' > #{dumpfile}"
puts 'Done!'
end
task :restore do
dev = Rails.application.config.database_configuration['development']
abort 'Live db is not mysql' unless dev['adapter'] =~ /mysql/
abort 'Missing live db config' if dev.blank?
dumpfile = "#{Rails.root}/tmp/latest.dump"
puts 'importing production database to development database...'
system "mysql -h #{dev['host']} -u root #{dev['database']} < #{dumpfile}"
puts 'Done!'
end
end
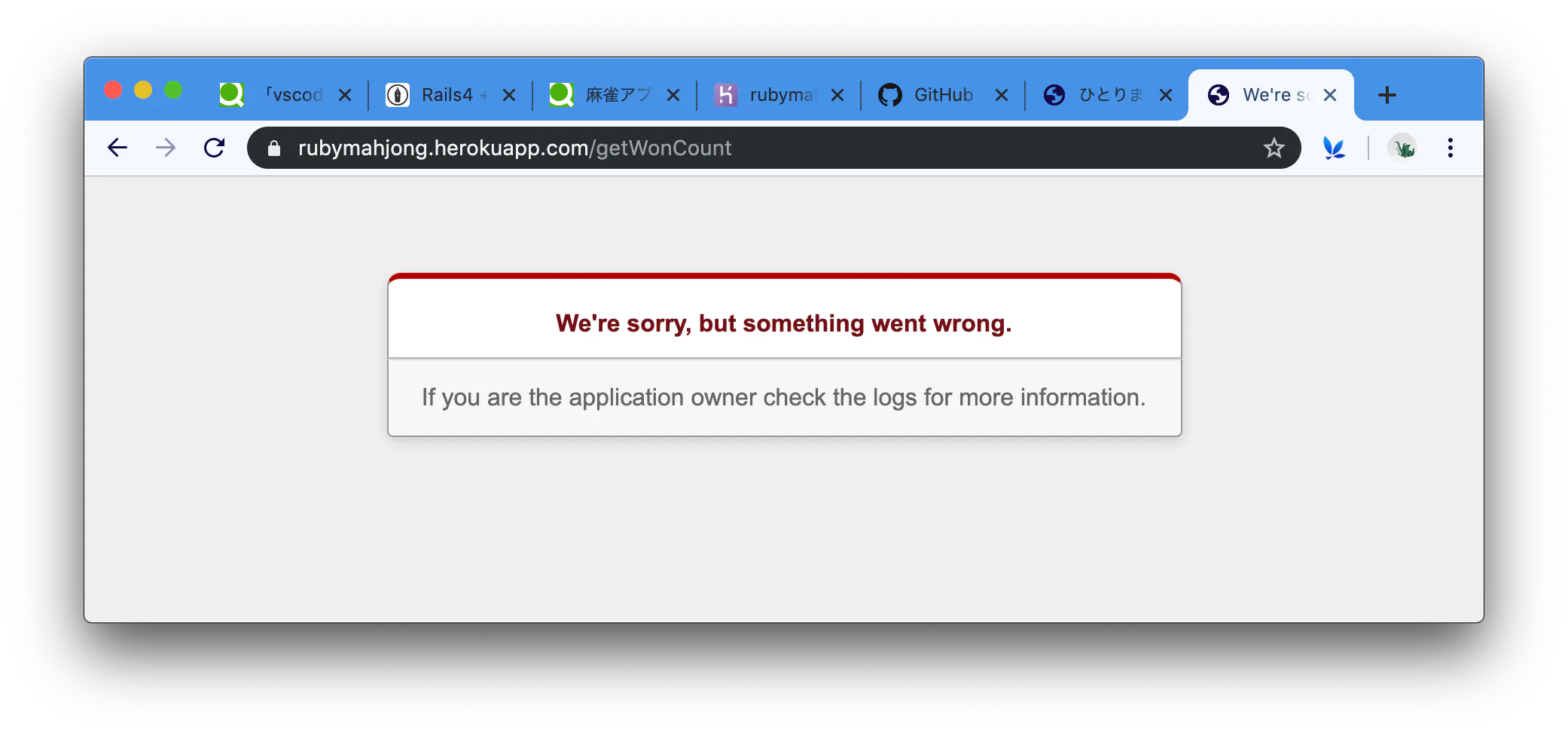
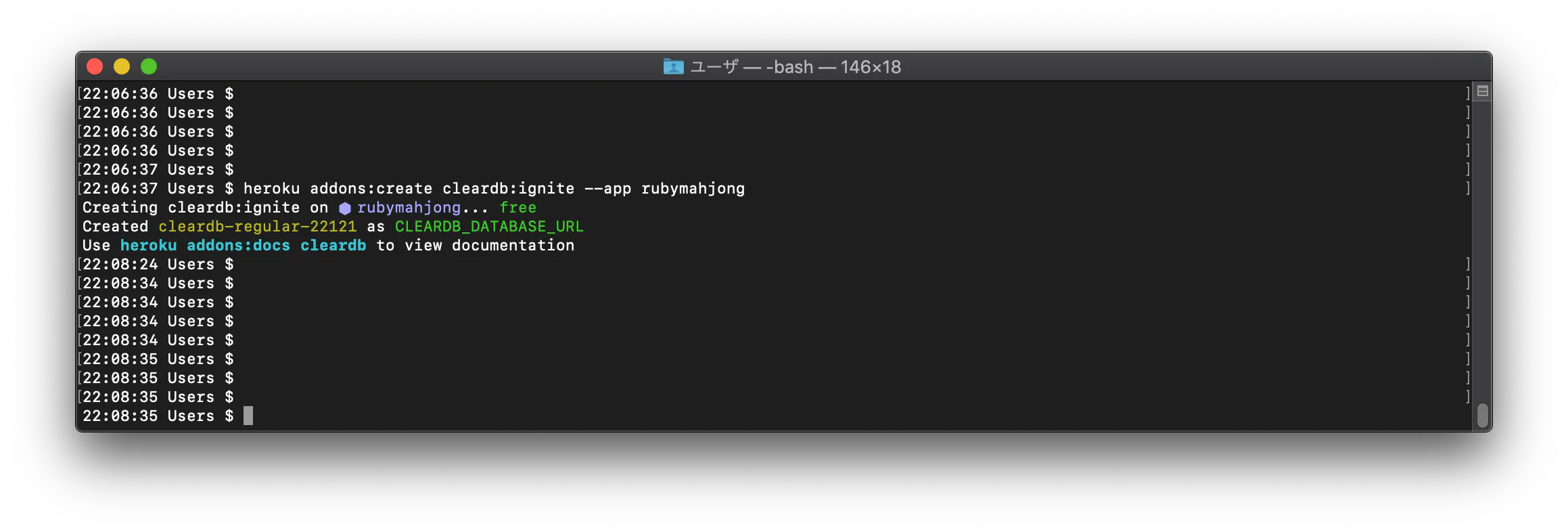
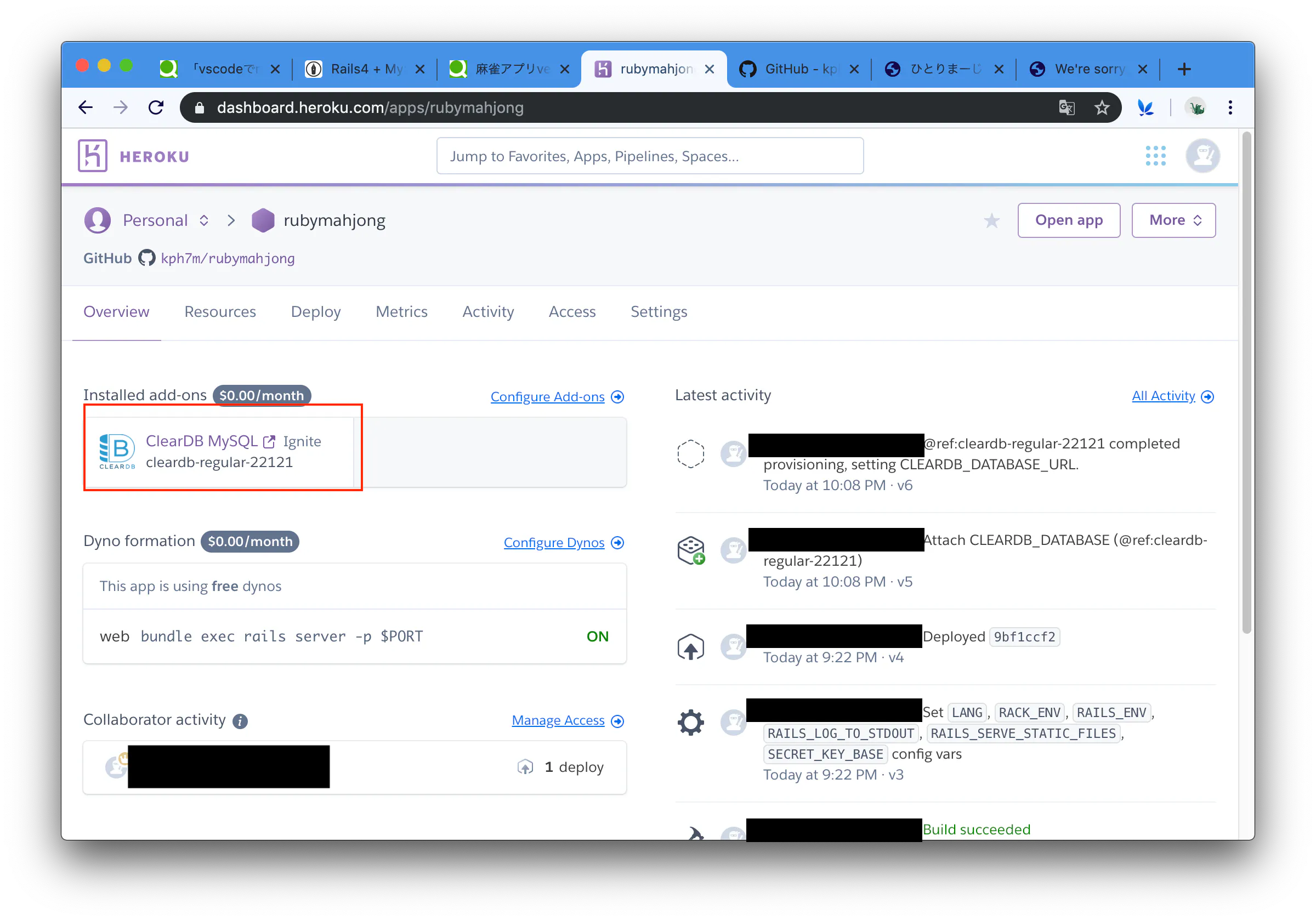
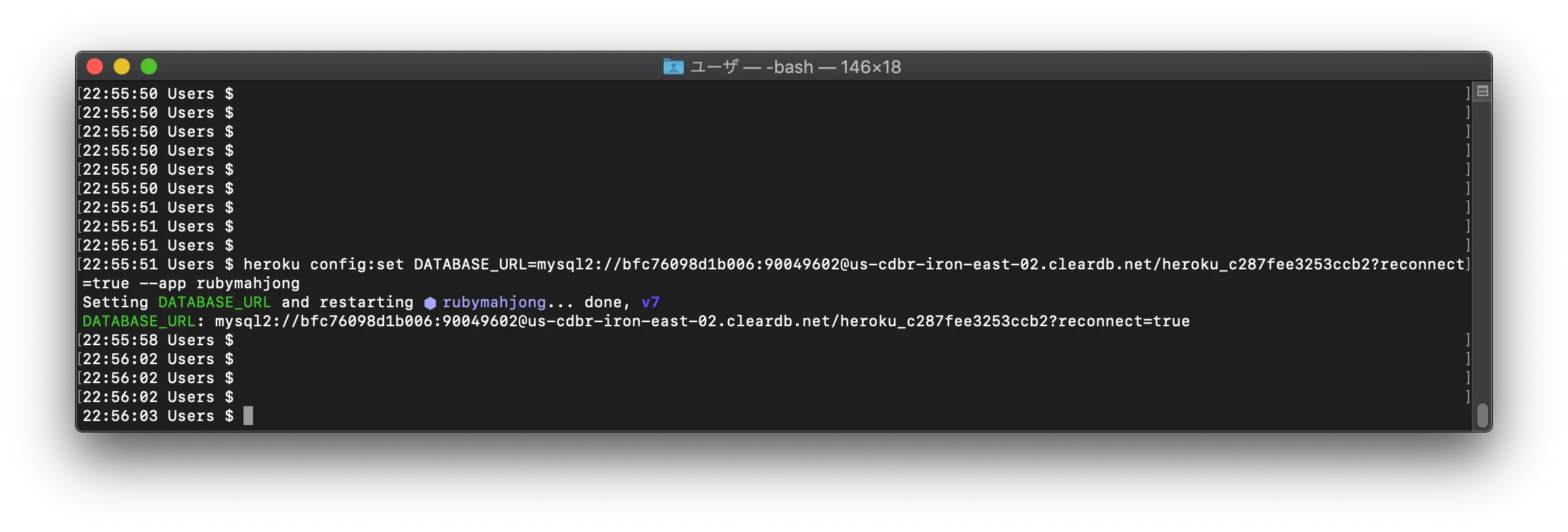
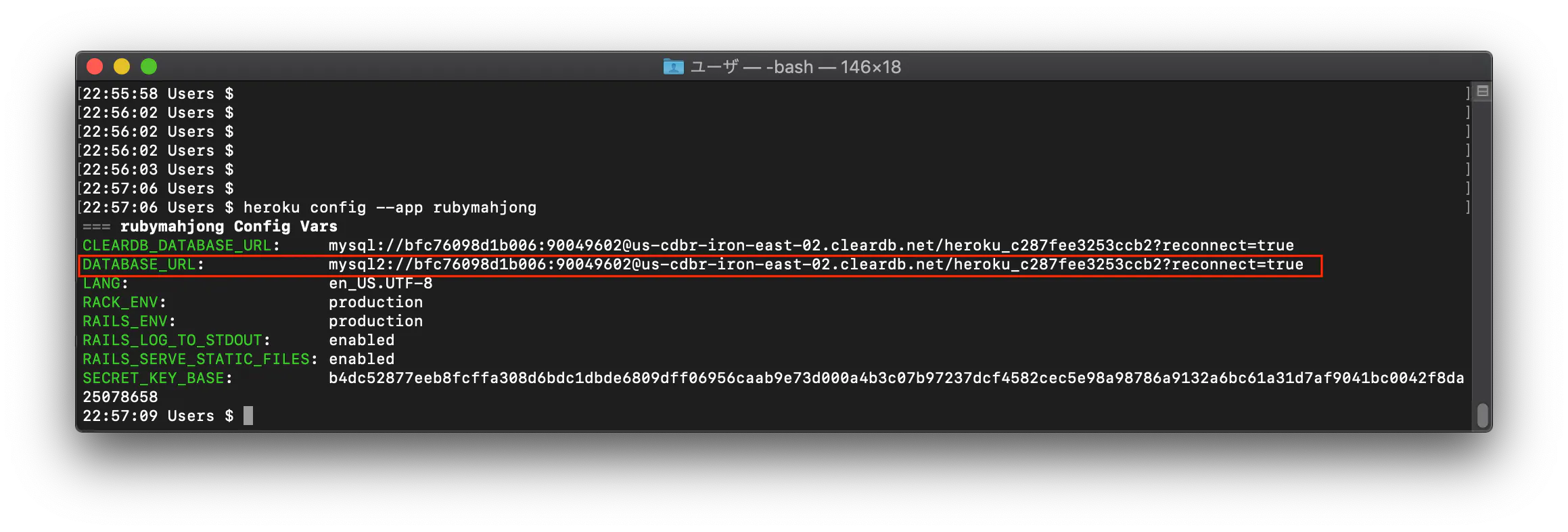
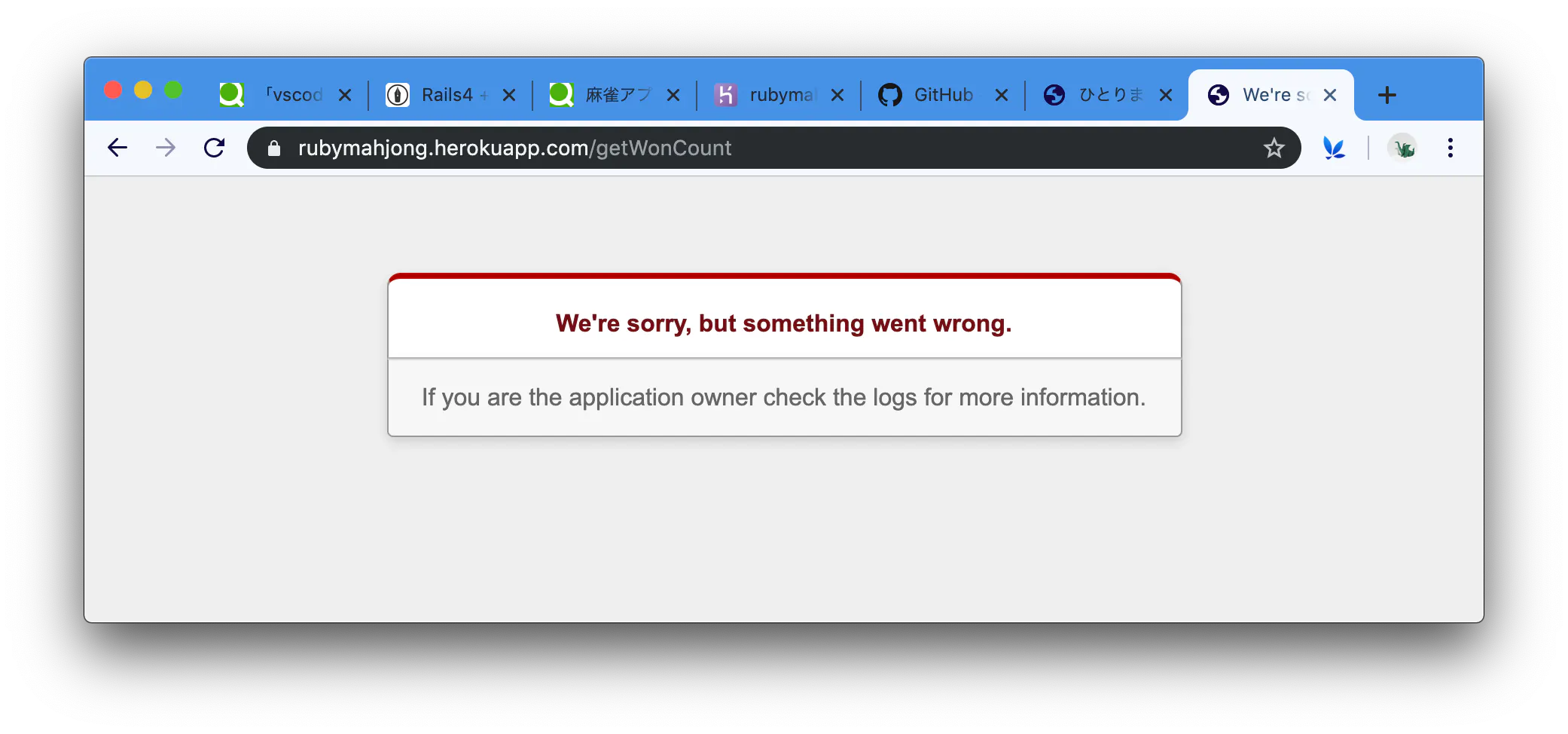
Herokuでアプリをデプロイしたら「”We're sorry, but something went wrong.”」のエラーが出た 【Rails】
Herokuでアプリをデプロイしようとしたら、「”We're sorry, but something went wrong.”」というエラーが出た
1 ググるとlogフォルダ内のdevelopment.logに表示された原因が書かれているとの事だったので、調べるが特に問題が見当たらず。
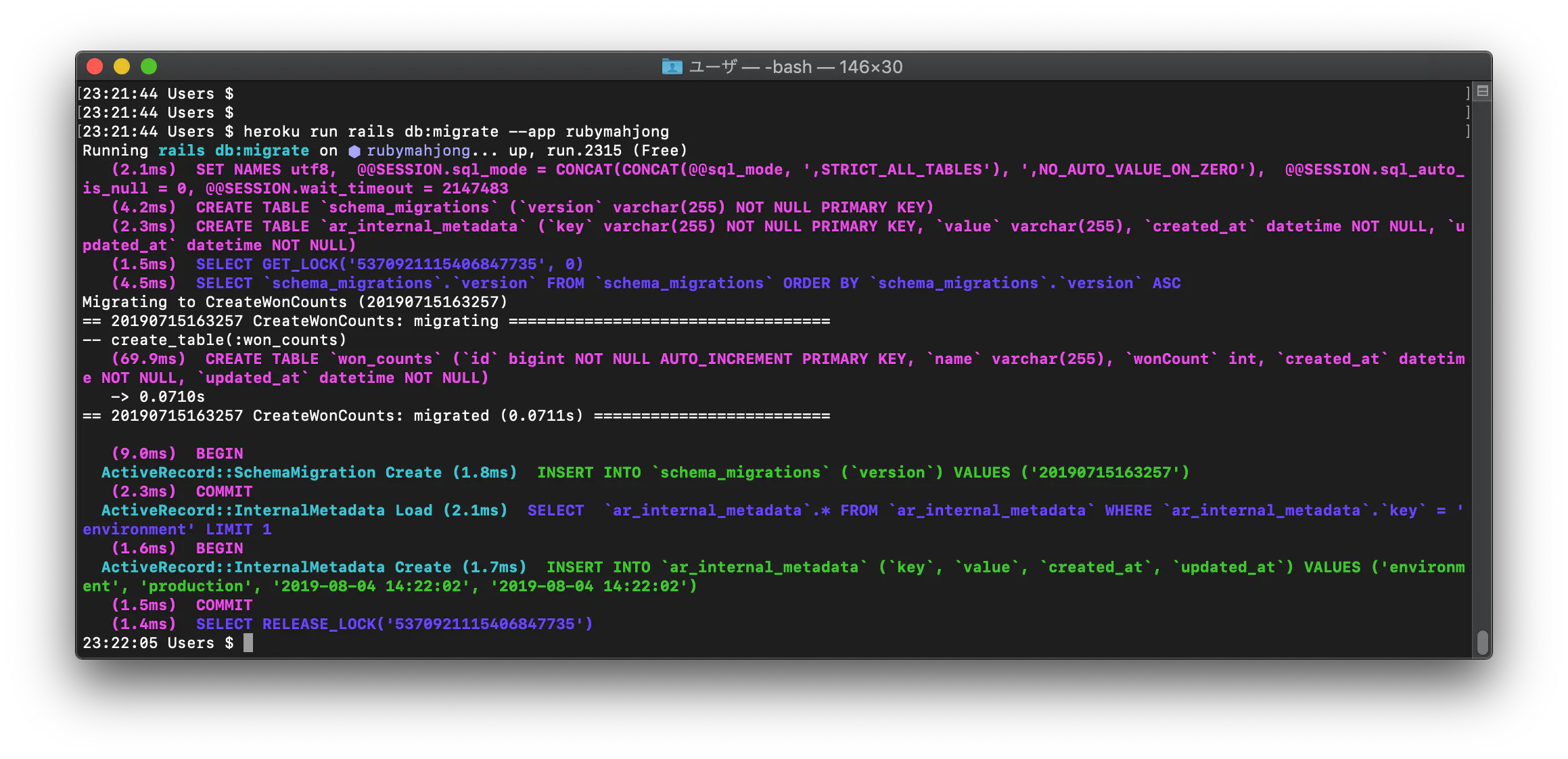
2 次にheroku デプロイ We're sorry, but something went wrong. としてヒットした記事を参考にheroku run rails db:migrateをターミナルで実行すると解決した。