- 投稿日:2019-08-04T23:14:32+09:00
RDSスナップショットを、テスト用にマスクする、CodeBuildとdbtestdataで
本番RDSスナップショットをそのままテスト用に使うわけにいかない。個人情報とか業務上の機密とか。マスクします。みなさんどうやってるんですかね。
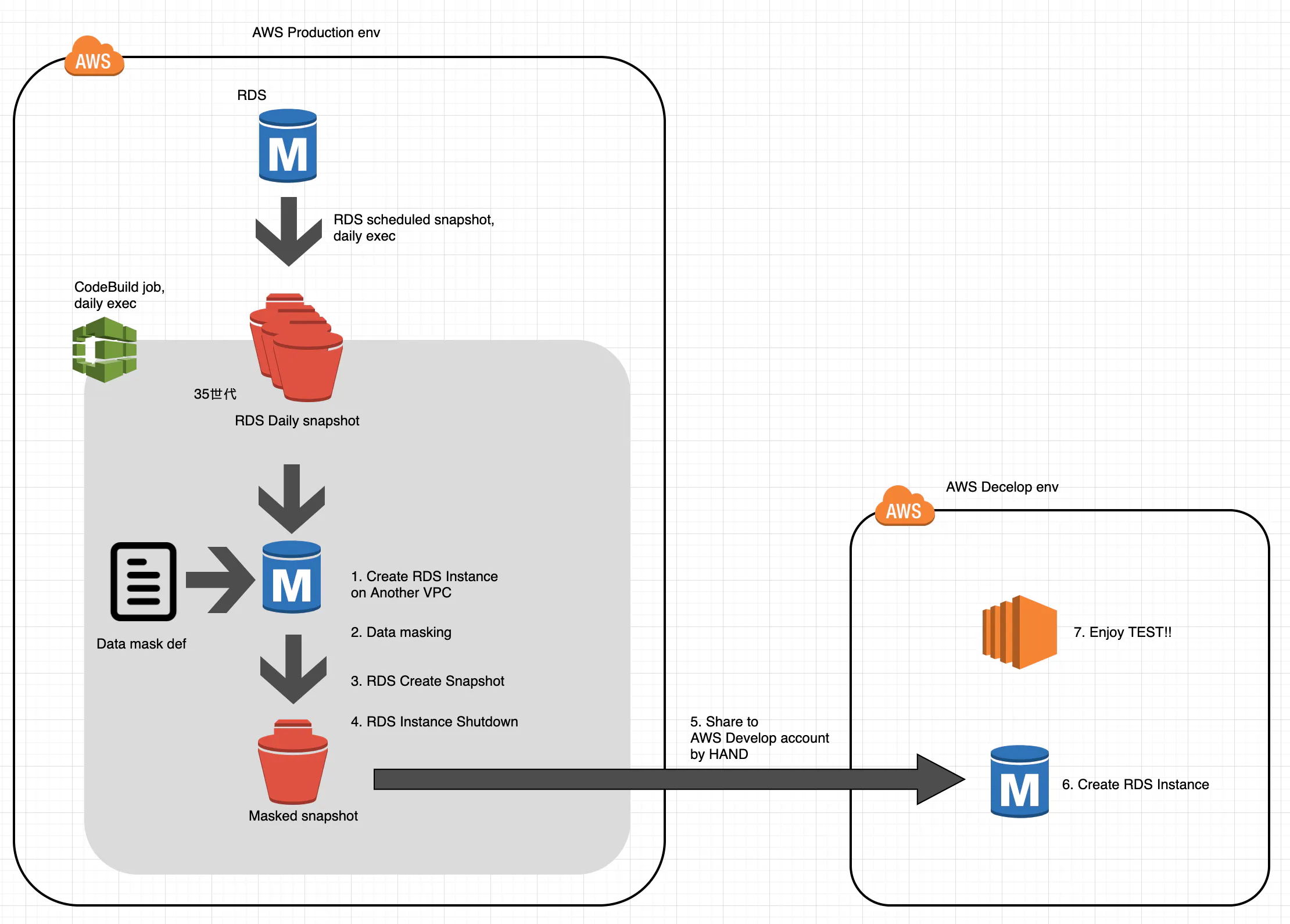
全体像
こんな流れで作ります。
- create RDS Instance
- Data masking
- RDS create snapshot
- RDS instance shutdown
この記事では 2. のところを扱います。ほかは手作業。そのうちawscliとCodeBuildで自動化する。
マスク設定ファイルをつくるのに必要な情報を用意する
- information_schema.tables, columnsを漁る
- テーブルそのものの要否をふりわける
- 必要なテーブルについて、マスクすべきカラムを選別する
- カラムごとに、どんなデータパターンでマスクするか決める
マスク設定ファイルをつくる
マスクツールは dbtestdata を使います。dbtestdata用のマスク設定ファイルを作ります。dbtestdataがMySQLしか対応してないので、MySQLかAurora(MySQL互換)にしか使えないのがツラい。
DBマイグレーションを管理しているgitリポジトリに、
dbmask/dbtestdata.update.${TABLE_NAME}.confと作っていくことにします。テーブルごとに1ファイル作ります。このように。package sample; use strict; use warnings; use data::VariableDataGenerator; use sql::VariableSQLGenerator; use utf8; return { name => __PACKAGE__, update => { users => { primary => "id", clazz => { name => RANDOM_JA_NAME_KAN, email => RANDOM_EMAIL, address => RANDOM_JA_PREF, tel => RANDOM_JA_TEL, } } } };カラムごとに、どのようにマスクするかをチクチク書いていきます。なにがどうなってるのかは、 GitHub - dino-tools/dbtestdata: database testdata generator を漁ってください。
DBマイグレのgitリポジトリに入れておきたいのは、DBマイグレによるスキーマ変更と同調して、マスク設定もアップデートしていきたいからです。テーブルごとにしたいのは、gitでコンフリクトを少なくしたいのと、CodeBuildで並列実行させたいからです。
RDSインスタンスを立てる
RDSスナップショットから、RDSインスタンスを立てます。本番環境とは別のVPCにするのが事故防止のためにも良いでしょう。手作業でチクチク立てます。CodeBuildから接続できるよう、RDSインスタンス側のセキュリティグループを調整しておきます。
CodeBuildビルドプロジェクトをつくる
buildspec.ymlはこんな。 envの部分は、よしなに置き換えて使ってください。RDSに接続するので、このCodeBuildはVPC内で動かします。Dockerイメージは、惰性で ansible/ausible-runner を利用してます。wgetとか要るのか、、、なんか要らない気がしてきた。
version: 0.2 env: variables: RDS_ENDPOINT: "hoge" RDS_USER: "hoge" CONF_FILE: "hoge" parameter-store: RDS_PASSWD: /CodeBuild/RDS_PASSWD phases: install: commands: - env | sort - yum install -y -q wget which unzip jq perl-DBI perl-DBD-MySQ mariadb-server - git clone https://github.com/dino-tools/dbtestdata.git /usr/local/dbtestdata build: commands: - | cd /usr/local/dbtestdata echo ${RDS_PASSWD} \ | perl dbtestdata.pl update \ --hostname=${RDS_ENDPOINT} \ --database=production_asp \ --username=${RDS_USER} \ --password \ --conf=${CODEBUILD_SRC_DIR}/dbmask/${CONF_FILE}ちなみにCodeBuildは実行時間が8時間までの制限があるので、クソデカいテーブルには制限時間オーバーで駄目になります。ラッキーなことに、8時間以内に終わるテーブルだけだったので、今後そのうち考えます。たぶんFargateとかでやると思います。いやどうだろう、わからない。
マスクする
こんなかんじに。とりあえず今は手元で実行してます。たぶんCodeBuildにやらせます。テーブル数が多い場合は、同時実行数を絞ったり、RDBのグレードを上げたりの工夫が必要になるかと思います。
ls dbmask/dbtestdata.update.*.conf \ | sort \ | while read CONF_FILE; do aws codebuild start-build \ --project-name dbtestdata-runner \ --environment-variables-override name="CONF_FILE",value="${CONF_FILE}",type="PLAINTEXT" doneRDSスナップショットを作って、開発アカウントに共有し、RDSを立てる
他のアカウントに共有するにはこのように。
aws rds modify-db-snapshot-attribute \ --db-snapshot-identifier masked-snapshot \ --attribute-name restore \ --values-to-add '["xxxxxxxxxxxxxxxxx"]'DBマイグレーションに並走する
ほっとくとマスク定義が古くなっていきます。テーブルの追加削除もあります。カラムの追加削除もあります。アプリケーションチームと、DBマイグレの都度、マスク定義ファイルのアップデートもしていくよう、ルール作りを忘れずに。
- 投稿日:2019-08-04T22:56:36+09:00
AWS Client VPN でインターネットに出れるVPNを作る
いまさらEC2でOpenVPNサーバーなんて立てたくないんじゃ!という思いから調べたら作れました。こいつ、できるぞ....!!
AWS Clinet VPNとは
AWS謹製のフルマネージドのVPNサービスです。OpenVPNです。
VPC 内に入る Client VPN エンドポイントを作る
作例が多々あるので割愛。こんな感じで。普通に作るとこうなります。
- [AWS]踏み台をワンチャンなくせる!?VPC接続にClient VPNを使ってみよう | DevelopersIO
- AWS Clinet VPNを分かりやすく解説してみる – サーバーワークスエンジニアブログ
VPC 内からインターネットに出る Client VPN エンドポイントを作る
Client VPNからインターネットに出るには
- Client VPNに、インターネットに出れるようにしたサブネットを関連付ける
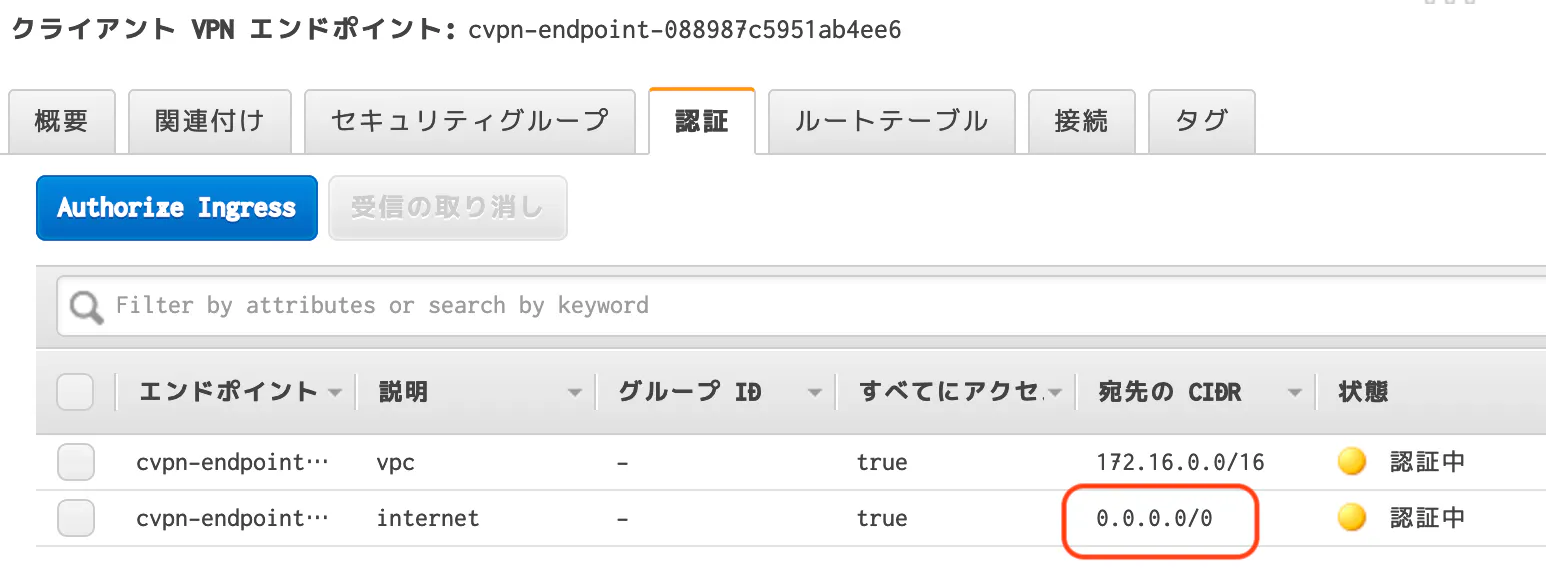
- Client VPNに付けるセキュリティグループを、インバウンド/アウトバウンドの両方0.0.0.0/0に開放したものにする
- Client VPNにの認証ルールを作る
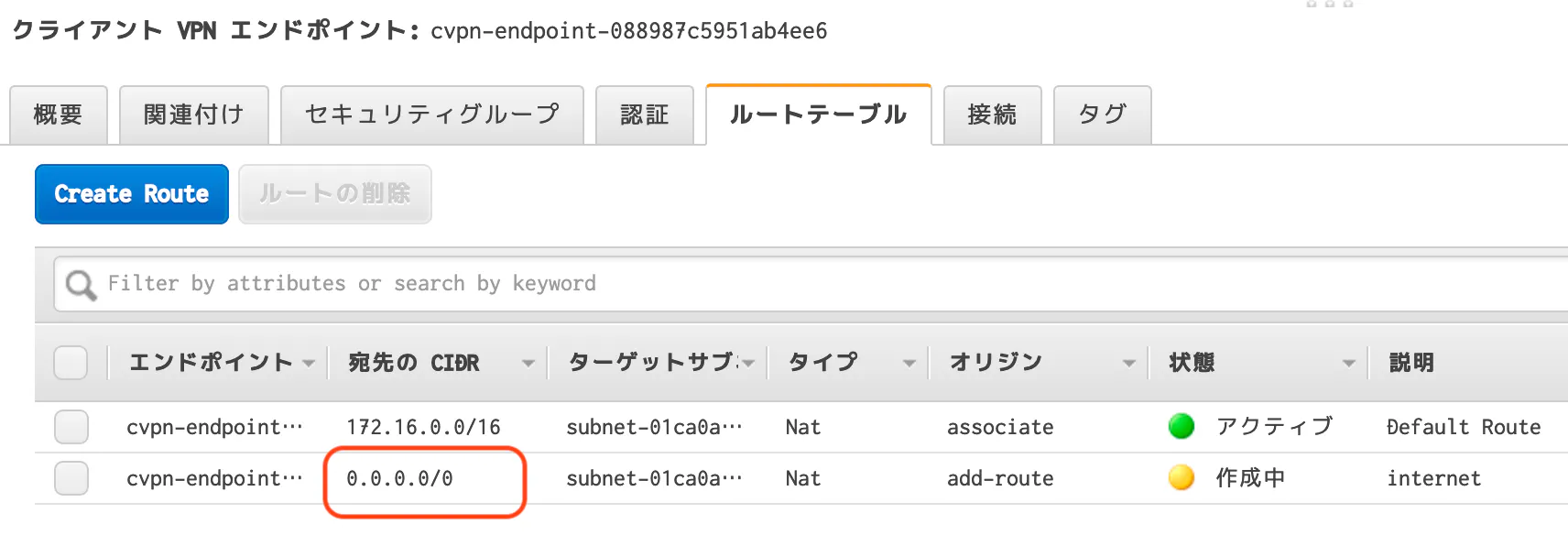
- Client VPNのルートテーブルに、宛先CIDR 0.0.0.0/0、関連付けたサブネット経由、のルートを作る
1,2は、VPCをいじってれば書くほどの話ではないと思います。
3,4が意味不なので補足します。
Client VPNにの認証ルールを作る
これは自動では作られないので、VPC向けと、インターネット向けを作ってあげます。
Client VPNのルートテーブルに、宛先CIDR 0.0.0.0/0、関連付けたサブネット経由、のルートを作る
Client VPNにサブネットを関連付けると、Client VPNのルートテーブルには、VPCのCIDRへのルートが作られます。ここに加えて、宛先CIDRを0.0.0.0/0、経由サブネットをそれぞれとした、ルートを追加します。
他、ハマりどころ
「クライアント設定のダウンロード」したファイルには、クライアント証明書のパスが書いてない
SoftetherVPNの感じだと、なんか諸々含まれたファイルを期待しちゃうでしょう。Tunnelblickのログを眺めても、まーわからなかった。
クライアント証明書はひとつしか設定できない
差し替えは可能です。とはいえ、ひとつのみということは、退職者や紛失があると、利用者全員に差し替えてもらう必要があります。チームで利用してるなら、クライアント証明書ではなく、ActiveDirectoryで認証するのが、現実的な使い方だと思いました。
Client VPNは、利用者ごとにつくるものではない
Client VPNの制限から、利用者ひとりにつきClient VPNを一個つくって、クライアント証明書で認証させていたら、一瞬で5個を使い果たしてしまいます。VPCにひとつ作り、ADで接続可能なサブネットを区切っていくのが、現実的な使い方だと思いました。
- 投稿日:2019-08-04T22:50:26+09:00
NotebookのServerlessバッチジョブ化
はじめに
Jupyter Notebookで作成したPythonコードをAWSマネージドサービスを利用してバッチジョブ化できないかと思い試してみました。
用意したもの
- AWS CLI
- Papermill(Notebookの実行に利用)
- Jupyter Notebook
- Docker
環境
- Jupyter Notebookサーバー(EC2)
- ECS
- ECR
- Step Functions
- CloudWatch
やったこと
- Notebookファイル作成
- Dockerイメージ作成
- S3へのNotebookファイル保存
- IAMロール作成
- ECSタスク作成
- StepFunctionsステートマシーン作成
※ECSクラスターやVPC,Subnetなど諸々は事前に作成していたものを利用しました。
処理フロー
- CloudWatchEventsのインプットにPapermillのパラメーターを設定
- CloudWatchEventsから10分にStepFunctionsステートマシーンを実行
- StepFunctionsステートマシーンからECSタスクを実行
- ECSタスクにてPapermillを実行
- PapermillからS3にNotebook実行結果が保存される
詳細
Notebookファイル作成
Jupyter Notebook上でパラメーター付きのNotebookファイルを作成
※nteractだとセルの右上から"Toggle Parameter Cell"の選択でパラメーター化できました。
パラメーターセルmsg = "Hello, World!"プログラムprint(msg)Dockerイメージの作成&Push
DockerfileFROM python:3 RUN pip install papermill[all] RUN pip install jupyterDokerイメージ作成&Push$(aws ecr get-login --no-include-email --region ap-northeast-1) docker build -t xxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/papermill ./ docker push xxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/papermill:latestS3 Bucket作成&Notebookファイルコピー
SAM,INPUT/OUTPUT用のBucketを作成
aws s3 mb s3://${SAM_BUCKET} aws s3 mb s3://${INPUT_NOTEBOOK} aws s3 mb s3://${OUTPUT_NOTEBOOK}S3へファイルをコピー
shell-session
aws s3 cp HelloWorld.ipynb s3://${INPUT_NOTEBOOK}/HelloWorld.ipynb
IAMロール,ECSタスク,StepFunctionsステートマシーン,CloudWatch Events作成
CloudFormationを利用したため、テンプレートファイルを作成
template.yamlAWSTemplateFormatVersion : '2010-09-09' Transform: AWS::Serverless-2016-10-31 Parameters: S3RolePolicyName: Type: String Default: hello-s3 HelloWorldTaskExecutionRoleName: Type: String Default: hello-taskexec HelloWorldECSTaskName: Type: String Default: HelloWorldTask HelloWorldInvocationRoleName: Type: String Default: HelloWorld-Invocation ImageRepoURI: Type: String Default: xxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/papermill:latest InputS3FileURI: Type: String Default: s3://xxxxxxxxx/HelloWorld.ipynb OutputS3FileURI: Type: String Default: s3://xxxxxxxxx/output.ipynb MsgParameter: Type: String Default: "Hello,Papermill" ClusterArn: Type: String Default: arn:aws:ecs:ap-northeast-1:xxxxxxxxx:cluster/xxxxxxxxx SubnetID: Type: AWS::EC2::Subnet::Id Default: subnet-xxxxxxxxx Resources: #ECSタスクからのS3アクセス用ロール作成 HelloWorldS3BucketRole: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Principal: Service: - ecs-tasks.amazonaws.com Action: - sts:AssumeRole Policies: - PolicyName: !Ref S3RolePolicyName PolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Action: - s3:PutObject - s3:GetObject - s3:ListBucket - s3:DeleteObject - s3:PutObjectAcl Resource: "*" HelloWorldTaskExecutionRole: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Principal: Service: - ecs-tasks.amazonaws.com Action: - sts:AssumeRole Policies: - PolicyName: !Ref HelloWorldTaskExecutionRoleName PolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Action: - ecr:GetAuthorizationToken - ecr:BatchCheckLayerAvailability - ecr:GetDownloadUrlForLayer - ecr:BatchGetImage - logs:CreateLogStream - logs:PutLogEvents Resource: "*" #ECSタスク作成 HelloWorldECSTask: Type: AWS::ECS::TaskDefinition Properties: ContainerDefinitions: - Name: !Ref HelloWorldECSTaskName Image: !Ref ImageRepoURI Memory: 500 Command: - "papermill" - !Ref InputS3FileURI - !Ref OutputS3FileURI Cpu: 256 Memory: 512 NetworkMode: awsvpc RequiresCompatibilities: - FARGATE TaskRoleArn: !GetAtt [ HelloWorldS3BucketRole, Arn ] ExecutionRoleArn: !GetAtt [ HelloWorldTaskExecutionRole, Arn ] #StepFunctionからのECSタスク実行用ロール作成 HelloWorldTaskExecution: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Principal: Service: - !Sub states.amazonaws.com Action: sts:AssumeRole Policies: - PolicyName: StatesExecutionPolicy PolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Action: - iam:PassRole - ecs:DescribeTasks - events:PutTargets - events:PutRule - events:DescribeRule - ecs:RunTask - ecs:StartTask - ecs:StopTask Resource: "*" #StepFunctionsステートマシーン作成 HelloWorldStateMachine: Type: AWS::StepFunctions::StateMachine Properties: DefinitionString: !Sub - |- { "Comment": "A Hello World example using an AWS ECS function", "TimeoutSeconds": 3600, "StartAt": "HelloWorld", "States": { "HelloWorld": { "Type": "Task", "Resource": "arn:aws:states:::ecs:runTask.sync", "Parameters": { "LaunchType": "FARGATE", "Cluster": "${ClusterArn}", "TaskDefinition": "${TaskArn}", "Overrides": { "ContainerOverrides": [ { "Name": "${HelloWorldECSTaskName}", "Command.$": "$.Command" } ] }, "NetworkConfiguration": { "AwsvpcConfiguration": { "Subnets": [ "${SubnetID}" ], "AssignPublicIp": "DISABLED" } } }, "End": true } } } - { TaskArn: !Ref HelloWorldECSTask } RoleArn: !GetAtt [ HelloWorldTaskExecution, Arn ] #CloudWatchからのStepFunctionsステートマシーン実行用ロール作成 HelloWorldInvocationRole: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Principal: Service: - events.amazonaws.com Action: - sts:AssumeRole Policies: - PolicyName: !Ref HelloWorldInvocationRoleName PolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Action: - states:StartExecution Resource: !Ref HelloWorldStateMachine #CloudWatch Eventsのルール作成 HelloWorldSchedule: Type: AWS::Events::Rule Properties: Description: ScheduledRule ScheduleExpression: "rate(10 minutes)" State: ENABLED Targets: - Arn: !Ref HelloWorldStateMachine Id: StepFunctionExecV1 RoleArn: !GetAtt [HelloWorldInvocationRole, Arn] #InputとしてESCタスクのコマンドを文字列として設定 #ここでPapermillのパラメーターを設定 Input: !Sub "{\"Command\": [\"papermill\",\"${InputS3FileURI}\",\"${OutputS3FileURI}\",\"-p\",\"msg\",\"${MsgParameter}\"]}"参考
Beyond Interactive: Notebook Innovation at Netflix : https://medium.com/netflix-techblog/notebook-innovation-591ee3221233

- 投稿日:2019-08-04T22:43:13+09:00
Python+AWS Cloud9で自動スクレイピング→LINEに更新通知でMENSAの入会テストに申し込んだ話
はじめに
MENSA (https://mensa.jp/)は、人工上位2%の知能指数(IQ)を有する者の交流を主たる目的とした非営利団体である。高IQ団体としては、最も長い歴史を持つ。会員数は全世界で約12万人。支部は世界40か国。イギリス・リンカンシャーにあるケイソープ(英語版)に、本部(メンサ・インターナショナル)を持つ。
Wikipediaより抜粋テレビのクイズ番組などでもたまーに目にするこのMENSA、独自のテストを通過すると入会資格が得られ、入会するとMENSA会員のみの交流会などに参加できるそうです。
ネットのIQテストや海外のMENSA支部が提供している模擬テスト(?)を解いてみるとギリギリ入会できそうだったのでテストを受けてみることにしました。
最大の障壁
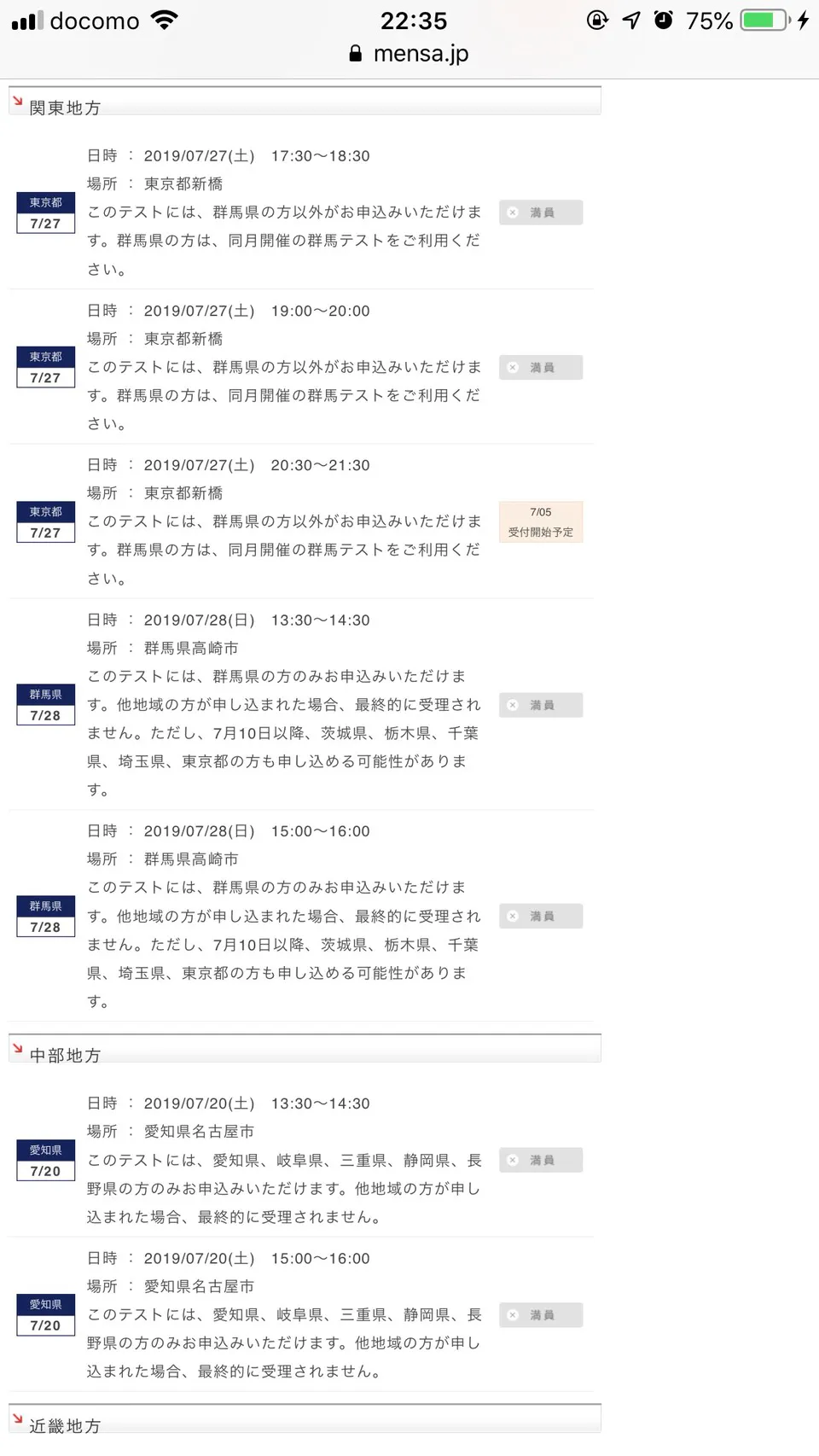
入会テスト受験を決意してから現在まで半年以上経過しました。何故かというと・・・
ご覧のように満席満席満席・・・
定期的にテストは開催されるのですが、どうも一回あたりの定員が多くないらしく、募集が開始されるとすぐに枠が埋まってしまいテストが受けられませんでした。このままでは埒が明かないのでPython3とAWSのCloud9でこの入会テスト情報のページを一定間隔でスクレイピングし、任意の箇所が更新されたらLineに通知がいくようにしてみました。ターゲットは7/5受付開始予定のテスト!ただし受付開始時間は不明です
自動でスクレイピングを行うために
いつページの更新が行われても対応できるように24時間コードが動いている状態を維持しなければなりません。
ですので今回はAWSのCloud9という総合開発環境(IDE)使用しました。この開発環境にEC2インスタンス(仮想サーバー)を用いることで、自分が使っているPCが起動していない時にも健気に稼働し続けてくれます。AWSは登録すると1年間の無料体験枠が付いてきます。1つのEC2インスタンスだけであれば、24時間稼働させても無料範囲内で収まるので安心です。
それでは始めてみましょう。AWSの登録~Cloud9で開発環境の構築
AWS アカウント作成の流れ(公式)を参照して登録を行ってください。登録が終わりましたら
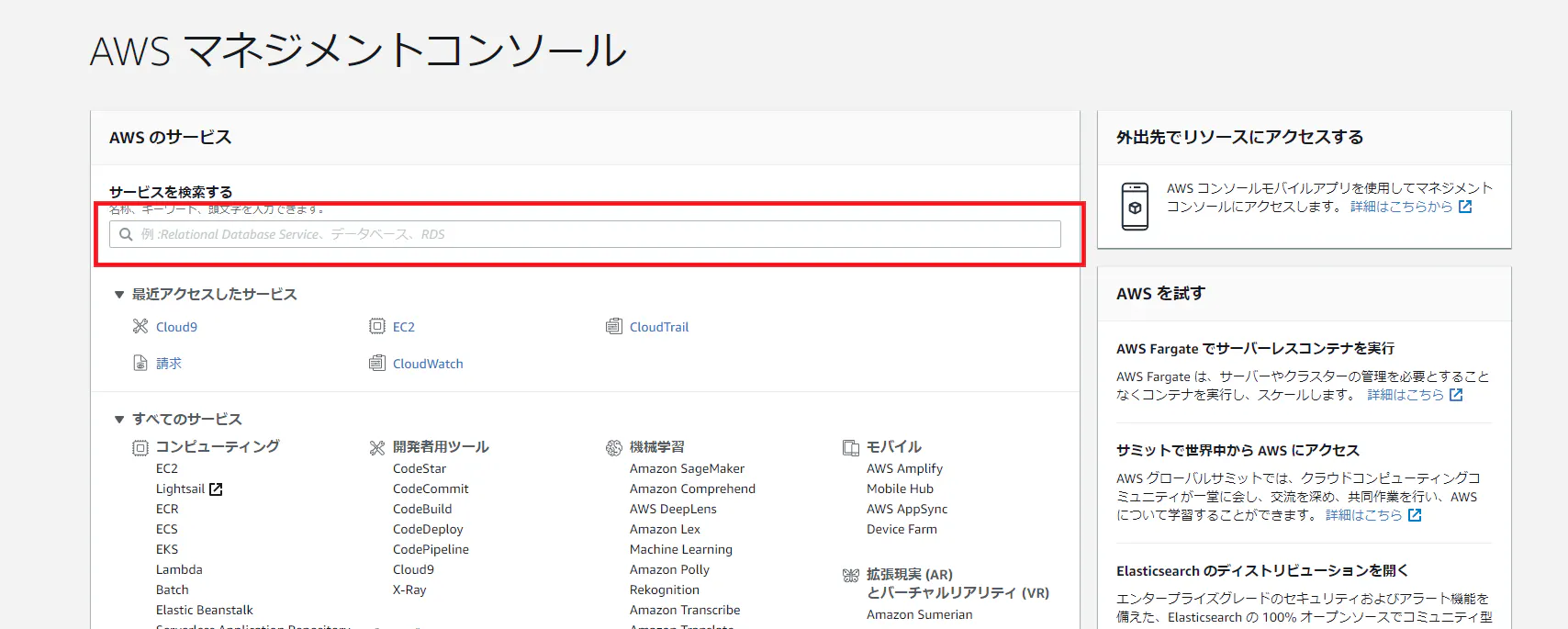
AWSアカウントを取得したら速攻でやっておくべき初期設定まとめ を一通り済ませてください。セキュリティの観点からIAMユーザーの作成は必須と言ってもいいと思います。一通りの作業が済みましたら、AWSマネジメントコンソールの検索欄(画像赤枠内)に
Cloud9と入力し、表示されるCloud9をクリックして移動してください。
Cloud9のページに移動したら
Create environmentをクリックしてください。
ここでは開発環境の名前と説明を入力します。Name欄に適当な名前を入力してください。説明を入力するDescription欄は必須ではないので入力しなくてもOKです。入力が完了したら
Next stepをクリックして次に進みます。
次に環境の設定を行います。
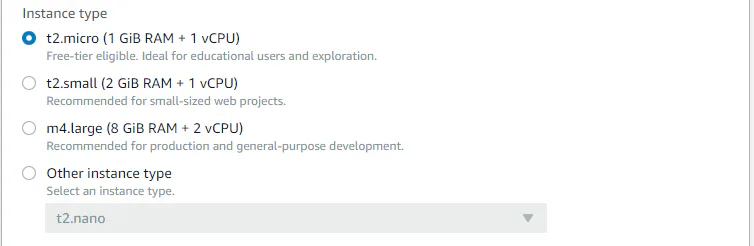
まずは開発環境をどこに置くかを設定します。上のCreate a new instance for environment(EC2)を選択しましょう。自前のサーバーを持っている人は下を選択しても良いですがここでは割愛します。
次にインスタンスの性能を選択します。ただ選択肢はなく、一番上以外は無料範囲外なので一番上の
t2macro(i GiB RAM + 1vCPU)を選択しましょう。今回行う内容ではこれで十分です。
インスタンスのOSを選択します。ここではAmazon Linuxを選択します。
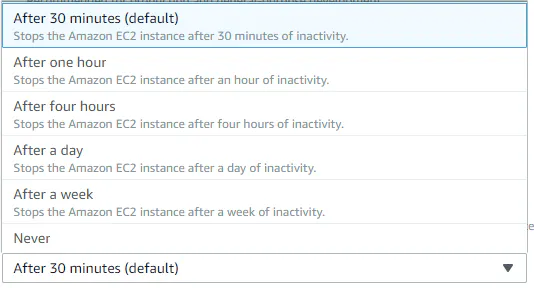
次にインスタンスの自動停止に関する設定(Cost-saving setting)です。これはブラウザを閉じてからどれぐらいの時間でインスタンスを自動停止するかを設定します。上から30分、1時間、4時間、1日、1週間、最後は停止しない です。後から設定する事も可能ですがここで選択してしましましょう。今回は一番下の
Neverつまり自動停止を行わない設定にします。
すべての項目が設定できましたら
Next stepをクリックして確認画面に移ります。表示されている内容に問題がなければCreate environmentで環境構築を実行しましょう。構築には数分間掛かります。
この画面が表示されれば開発環境の構築が完了です。それでは早速コードを書いていきましょう。
今回は3つのモジュールを作成します。それぞれ
・line_notify.py (Lineに通知する)
・mensa_scrape.py (スクレイピングを実行する)
・main.py (上記2つを一定間隔で実行する)となります。
それでは画面左のディレクトリ欄を右クリックしてNew Fileをクリックして新規ファイルを作成してください。
Lineに通知する
Lineに通知を行うためにはアクセストークンの発行が必要です。
たったの2ステップでLINEにメッセージを通知する方法【python】
に記載されている手順に従ってアクセストークンを発行してください。トークン名は自由に設定してOKです(私は「Mensaアラート」にしました)
また、発行されたアクセストークンは必ずコピーしてください。これが無いと通知を送れません。アクセストークンの発行が完了したらCloud9に戻ります。先程作成した新規ファイルを右クリックし
Renameを選択してファイル名をline_notice.pyに変更しましょう。内容は以下のようになりますline_notice.pyimport requests token = "発行したアクセストークン" def line_notify(message): line_notify_token = token line_notify_api = 'https://notify-api.line.me/api/notify' payload = {'message': message} headers = {'Authorization': 'Bearer ' + line_notify_token} requests.post(line_notify_api, data=payload, headers=headers) def main(): # 上の通知を実行する関数を呼び出します。引数は通知の際に送られるメッセージです。 line_notify("TEST") if __name__=="__main__": main()これに関しては殆ど定型文みたいなところがあるので説明は割愛します。
def main()とif __name=="main__"はこのモジュール単体でのテストを行うために追加しているコードなので厳密には不要です。
それでは保存が完了したら画面上部にあるRunをクリックしてモジュールを実行してみてください。
Line Notifyさんから[トークン名]+メッセージ で通知が送られていると思います。これでLineの通知モジュールの完成です。かなり簡単に出来たので私も最初驚きました。スクレイピングを実行する
次にスクレイピングを実行するモジュールを作成します。先程と同じ手順で新規ファイルを作成し、名前を
mensa_scrape.pyで保存してください。コード全文は以下になります。コメントを各所に入れているので参考にしてください大まかな流れとしては
スクレイピングを実行してHTMLを取得
↓
取得したHTMLをcurrent.csvに保存
↓
前回取得したHTMLが保存されているprevious.csvと比較
↓
内容が同じ場合は特になし、内容が異なる(=更新された)場合はLineに通知する。その後今回取得したHTMLをprevious.csvに保存、次回取得時の比較対象にする。
です。mensa_scrape.pyimport requests import csv import os.path import time import line_notice as ln # 先程作成したモジュールをインポートします import datetime as dt def mensa_scrape(): # urlに、スクレイピングを行いたいwebページのURLを定義します。 url = "https://mensa.jp/exam/" # 次にLineに通知を行う際に入れるメッセージをmessageに定義します。私は通知を受け取った際にすぐに移動できるように # urlを追加しています。ここは個人の好みなので何でもいいです。 message = "Mensa 検知" + url # request.get(url)で指定したURLのリクエストを取得します。 r = requests.get(url) # この行でエンコードを指定します。この行がないと取得したが文字化けする可能性があります。 r.encoding = r.apparent_encoding # 取得したリクエストのHTML部分を文字列型でhtml_textに格納します。 html_text = r.text # 更新の判定を行う箇所を絞るために、HTMLの部分を切り出しています。私は関東在住なので関東地方の部分のみ抽出しています。 extract_st = html_text.find('<h3 class="area_title">関東地方</h3>') extract_ed = html_text.find('<h3 class="area_title">中部地方</h3>') extracted_text = html_text[extract_st:extract_ed] # 今のままではテキスト内にスペースが大量に入っているので、スペースを削除してカンマ区切りに変えます html_list = extracted_text.split() # このif文はスクレイピングが成功した場合True、失敗した場合Falseです。 if str(r) == "<Response [200]>": # current.csvに今回取得したHTMLを保存します(current.csvが存在しない場合は作成して保存します) with open ("current.csv", mode="w", encoding="utf-8") as f: writer = csv.writer(f) writer.writerow(html_list) # previous.csvが存在する場合、current.csvとprevious.csvの内容をそれぞれ読み込みます if os.path.exists("previous.csv"): with open("previous.csv") as f: previous_csv = f.read() with open("current.csv") as g: current_csv = g.read() # current.csvとprevious.csvが同じ(更新がない)場合、Sameの文字と実行時の時間をコンソールに表示します if current_csv == previous_csv: print("Same: " + str(dt.datetime.now())) # current.csvとprevious.csvが異なる(更新がある)場合、Lineに通知した後previous.csvに今回のHTMLを保存します else: ln.line_notify(message) with open("previous.csv", mode="w") as f: writer = csv.writer(f) writer.writerow(html_list) # previous.csvがない場合(=今回が1回目の実行の場合)今回の内容をprevious.csvに保存して終了します。 else: with open("previous.csv", mode="w") as f: writer = csv.writer(f) writer.writerow(html_list) if __name__=="__main__": mensa_scrape()抽出するHTMLの箇所は実際にスクレイピングを行いたいページに移動し、右クリック→ページのソースを表示(Chromeの場合)を行うことでHTMLを見ることが出来るので、そこからコピペで引っ張ってきましょう。
これで必要なモジュールは揃いました。あとこれらを実行するmainモジュールを作成します。一定間隔でスクレイピングを実行する
これまでに作成したモジュールを一定間隔で実行させるmainモジ
ュールを作成します。これまでと同じ手順でmain.pyを作成してください。
内容はかなりシンプルです。While Trueで無限ループを作り、その中に先程のスクレイピングのモジュールと、間隔を開けるためのtime.sleep(120)を入れるだけです。この状態だとスクレイピングが終了すると2分待機して再度スクレイピング~ をひたすら続ける内容となっています。
※間隔の調整は自由ですが、あまり間隔を短くしすぎるとアクセス先のサーバーに負担が掛かるためある程度は開けたほうがいいです。main.pyimport mensa_scrape as ms import time def main(): while True: ms.mensa_scrape() time.sleep(120) if __name__=="__main__": main()これで自動スクレイピングのシステムが出来上がりました。
main.pyを開いた状態でRunをクリックしましょう。初回のループではスクレイピングを実行してprevious.csvとcurrent.csvを作成するだけで終了すると思います。画面左側のディレクトリ欄に2つのCSVが生成されていれば成功です。
本当に更新を検知できているかどうかは、適当なニュースサイトなど更新頻度の高いサイトをスクレイピングしてみれば確認できるかと思います。運命の日・・・
というわけで本番です。各種テストを済ませ、受付開始予定の7/5を迎えました。何時に開始されるか分からないため、普段は切っている通知音も最大に設定し準備は万全です。
そしてそのときは唐突に訪れました。
来た!!!!
メッセージに添えられているURLからアクセスしてみると・・・
ありました!!
すかさず入って各種情報を入力し・・・
成功です。ありがとうございました
おわりに
投稿時点で既にテストは終了していますが、結果は当分先にならないと分からないみたいです。
合格したときにはもしかしたらここで報告するかもしれません。以上です。最後までお付き合いいただきありがとうございました。










- 投稿日:2019-08-04T21:19:52+09:00
SSMと起動テンプレートを使って最速でお砂場EC2を用意する
「面白そうなプロダクト出てるな。ちょっとEC2用意して遊んでみるか。」
そう思ったとき、何も考えずにEC2にsshするところまで辿り着くための下準備設定を用意してみました。
方針
起動テンプレートを使うことで諸々の設定をすっ飛ばします。
またSessionManagerのsshを使うことでアクセス元IP制限や秘密鍵の手間を減らします。※インスタントなお砂場想定のため、長期安定性やちゃんとしたセキュリティはあえてそれ相応です。
SessionManager
セッションマネージャを使えば、awscliによるIAM認証でsshすることができます。
インスタンスに対する秘密鍵の管理の必要がなくなり、またセキュリティグループで22ポートを開ける必要がないため自宅のグローバルIPがころころ変わる場合でも使いやすいです。
このセッションマネージャによるsshの導入については詳細はこれらの記事を見るのがオススメです:
SSH不要時代がくるか!?AWS Systems Manager セッションマネージャーがリリースされました! | DevelopersIO
AWS Systems Manager セッションマネージャーでSSH・SCPできるようになりました | DevelopersIO本記事では詳細な説明は省略しますが、あらかじめ準備しておくことは以下となります。
- awscliの設定を済ませておく
AmazonEC2RoleforSSMが付与されたIAM roleの作成- (クライアントマシンで)セッションマネージャプラグインのインストール
- 下記ssh configの追記
host i-* ProxyCommand aws ssm start-session --target %h --document-name AWS-StartSSHSession --parameters 'portNumber=%p'その他サーバ側の設定は起動テンプレート側に記述します。
起動テンプレート
起動テンプレートには自分のお好みの設定+SSMのsshに必要な設定を埋めていきます。
ポイントとなるのは以下です:
- AMI ID: AmazonLinux2のもの1
- インスタンスタイプ: お好みで入力しておく
- キーペア・セキュリティグループ: SSMするので不要
- セキュリティグループ: SSMするので不要
- IAMインスタンスプロフィール: 事前に準備した
AmazonEC2RoleforSSMのものを指定- ユーザデータ: 以下で入力
ユーザーデータ#!/bin/bash yum install -y https://s3.amazonaws.com/ec2-downloads-windows/SSMAgent/latest/linux_amd64/amazon-ssm-agent.rpm passwd -d ec2-user sed -i /etc/ssh/sshd_config -e 's/^#PermitEmptyPasswords.*$/PermitEmptyPasswords yes/g' sed -i /etc/ssh/sshd_config -e 's/^PasswordAuthentication no$/#PasswordAuthentication no/g' sed -i /etc/ssh/sshd_config -e 's/^UsePAM yes$/#UsePAM yes/g' systemctl reload sshd記事執筆時のAmazonLinux2 AMIではSSMエージェントのアップデートが必要だったためyumコマンドでインストールしています。
ssh設定については
ec2-userを認証なしログインできるようにしています。
22ポートを開けない・認証はawscliで行うことを前提とした方針です。また起動テンプレートにはお好みでスポットインスタンスのリクエストを入れておくとリーズナブルになります。
実際に動かす
準備ができたのでインスタンスを作成してsshします。
実際に行うことは
- 起動テンプレートからインスタンスを起動する画面に遷移
- ソーステンプレートのバージョンを選択して起動ボタンを押します。
- インスタンス一覧の画面に戻り、インスタンスIDをコピーしておく
以上です。設定ダイアログをポチポチ進めたり秘密鍵を探したりセキュリティグループを追加したりする必要はありません。
あとは少し待ってインスタンスが起動したらssh ec2-user@i-XXXXXXXXするだけで見慣れたshell画面が登場します。簡単ですね。
まとめ
地味に面倒なEC2作成作業ですが、起動テンプレートとSSMを活用して楽にできました。
また実際の作成もawscliを使ってスクリプト化してより最速を目指すのもよいと思います。
SSMエージェントが入れられればなんでもよいはず ↩
- 投稿日:2019-08-04T19:56:39+09:00
インフラ知識0から始めるAWS学習 1日目
自宅PC環境
・Windows10 Home
個人学習を始めようとおもった経緯
化石言語を扱うアプリ開発プロジェクトからAWSを扱うインフラプロジェクトに異動になった
アプリ畑で生きてきた人間にインフラはまじで意味が分からない
かと言って勉強をしなかったら仕事が終わらずに帰宅が遅くなる
あとは個人でWebアプリ作って公開とかやってみたいよね!!!とりあえず基本のEC2
AWSをやるといってもサービスの種類が多すぎるまじでわからん。
# どこから手をつければええねんこんなん…
先輩社員のアドバイスでとりあえずEC2を作ってみることに
# 作成手順中の図はどうせAWSの改変で変わるので省略します** VPC **
デフォルトで用意されているVPCを敢えて使わずに構築してみたいので作成
** サブネット **
EC2はサブネット上に配置するのでサブネットを作成
** セキュリティグループ **
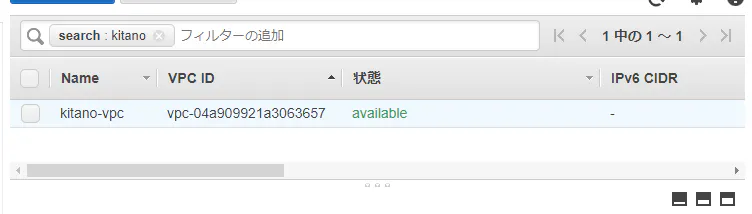
先ほど作成したkitano-vpcと紐づけてSG作成!
SGのインバウンドが未設定なので追加するのを忘れずに (1敗)
** EC2 **
AMIは適当にAmazon Linux
インスタンスタイプ、ストレージサイズは無料枠
VPC、サブネット、セキュリティグループは上で作ったもの
タグに私の名前を入れて完成!
接続してみよう
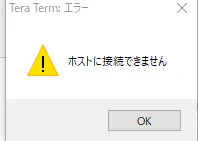
TeraTermを起動していざ接続…
デデドン!
えっ・・・・・・・?
原因は何かと調べたらいい感じに見つかりました
https://xn--o9j8h1c9hb5756dt0ua226amc1a.com/?p=3583この中に 0.0.0.0/0 : igw-xxxxxx のような設定があれば OK です。
設定がない場合は、外部と通信できないネットワークになっていますあっ。
インターネットゲートウェイを付与してリトライ
つながった!!!
本日のまとめ
- EC2接続までにすること
- EC2を配置用のサブネットを作成
- サブネットにはインターネットゲートウェイを付与
- セキュリティグループのインバウンドを追加
初日は大勢が書いてるようなテンプレ記事になりましたが、頑張って続けれるようにしていきます。





- 投稿日:2019-08-04T19:39:13+09:00
Nuxtで作ったプロジェクトをS3にデプロイする。ついでにパイプラインも作成
前回はgolangでの適当helloworldをFargateにパイプラインでデプロイしました。
Fargateすら必要ない。静的コンテンツを載せるだけでOKという場合があると思います。特に最近ではNuxtが使いやすくなってきて、genすればdistにindex.htmlが作られるという。。。
なので、今回はNuxtをS3にデプロイする方法をまとめました。
もちろんCloudFrontを使ってサブドメインでHTTPSにします。bucket作成
- 何も考えずにぽちぽち作る
- プロパティタグから「 Static website hosting」を設定する このバケットを使用してウェブサイトをホストする:ON インデックスドキュメント:index.html
参考
AWS S3で静的Webページをホスティングする - Qiita
CloudFront 経由で S3 のファイルにアクセスする - Qiita
CloudFrontよりDistributionsを作成する
- webで「Get Started」する
Origin Domain Name:対象のバケットを選択
Restrict Bucket Access:YES
Origin Access Identity:Create a New Identity
Grant Read Permissions on :Yes, Update Bucket Policy
Alternate Domain Names:ドメインを入れる
SSL Certificate:Custom SSL Certificate (example.com)
Default Root Objec:index.htmlRoute53の設定
Aレコード、エイリアスは上で作ったCloudFrontのディストリビューションを選択
ポリシーの編集(確認)
{ "Version": "2008-10-17", "Id": "PolicyForCloudFrontPrivateContent", "Statement": [ { "Sid":"PublicReadForGetBucketObjects", "Effect":"Allow", "Principal": "*", "Action":["s3:GetObject"], "Resource":["arn:aws:s3:::<BUCKET_NAME>/*" ] }, { "Sid": "1", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::cloudfront:user/CloudFront Origin Access Identity E21H4PD9QM10NM" }, "Action": "s3:GetObject", "Resource": "arn:aws:s3:::<BUCKET_NAME>/*" } ] }ソースプロジェクトに追加するもの
buildspec.yml
version: 0.2 phases: install: commands: - apt-get update -qq && apt-get install -y apt-transport-https - curl -sS https://dl.yarnpkg.com/debian/pubkey.gpg | apt-key add - - echo "deb https://dl.yarnpkg.com/debian/ stable main" | tee /etc/apt/sources.list.d/yarn.list - apt-get update && apt-get install yarn pre_build: commands: - echo 'Start pre_build phase' - yarn build: commands: - echo 'Start build phase' - yarn build post_build: commands: - echo 'Start post_build phase' - cat ./node_modules/.bin/gulp - echo '------' - ./node_modules/.bin/gulp deploy # - ./deploy.shdeploy.sh
#!/bin/bash # nvm (node version manager) のロード、node のインストール (バージョン指定は .nvmrc ファイルにある)、 npm パッケージのインストール [ -s "$HOME/.nvm/nvm.sh" ] && source "$HOME/.nvm/nvm.sh" && nvm use # 既にインストールされていなければ、 npm をインストールする [ ! -d "node_modules" ] && npm install npm run generate AWS_ACCESS_KEY_ID="<AWS_ACCESS_KEY_ID>" AWS_SECRET_ACCESS_KEY="<AWS_SECRET_ACCESS_KEY>" AWS_BUCKET_NAME="<AWS_BUCKET_NAME>" AWS_CLOUDFRONT="<AWS_CLOUDFRONT>" ./node_modules/.bin/gulp deploy
- パーミッション与える
chmod +x deploy.shgulpfile.js
var gulp = require('gulp') var awspublish = require('gulp-awspublish') var cloudfront = require('gulp-cloudfront-invalidate-aws-publish') var parallelize = require('concurrent-transform') // https://docs.aws.amazon.com/cli/latest/userguide/cli-environment.html var config = { // 必須 params: { Bucket: process.env.AWS_BUCKET_NAME }, accessKeyId: process.env.AWS_ACCESS_KEY_ID, secretAccessKey: process.env.AWS_SECRET_ACCESS_KEY, // 任意 deleteOldVersions: false, // PRODUCTION で使用しない distribution: process.env.AWS_CLOUDFRONT, // Cloudfront distribution ID region: process.env.AWS_DEFAULT_REGION, headers: { /*'Cache-Control': 'max-age=315360000, no-transform, public',*/ }, // 適切なデフォルト値 - これらのファイル及びディレクトリは gitignore されている distDir: 'dist', indexRootPath: true, cacheFileName: '.awspublish', concurrentUploads: 10, wait: true // Cloudfront のキャッシュ削除が完了するまでの時間 (約30〜60秒) } gulp.task('deploy', function() { // S3 オプションを使用して新しい publisher を作成する // http://docs.aws.amazon.com/AWSJavaScriptSDK/latest/AWS/S3.html#constructor-property var publisher = awspublish.create(config, config) var g = gulp.src('./' + config.distDir + '/**') // publisher は、上記で指定した Content-Length、Content-Type、および他のヘッダーを追加する // 指定されていない場合、 x-amz-acl はデフォルトで public-read に設定される g = g.pipe( parallelize(publisher.publish(config.headers), config.concurrentUploads) ) // CDN のキャッシュを削除する if (config.distribution) { console.log('Configured with Cloudfront distribution') g = g.pipe(cloudfront(config)) } else { console.log( 'No Cloudfront distribution configured - skipping CDN invalidation' ) } // 削除したファイルを同期する if (config.deleteOldVersions) g = g.pipe(publisher.sync()) // 連続したアップロードを高速化するために、キャッシュファイルを作成する g = g.pipe(publisher.cache()) // アップロードの更新をコンソールに出力する g = g.pipe(awspublish.reporter()) return g })gulpを追加
npm install --save-dev gulp gulp-awspublish gulp-cloudfront-invalidate-aws-publish concurrent-transform npm install -g gulpCodeDeployからデプロイプロジェクトを作る
特に難しいところはない。
特権を付与することを忘れずに環境変数
AWS_CLOUDFRONT <AWS_CLOUDFRONTのID> AWS_SECRET_ACCESS_KEY <AWS_SECRET_ACCESS_KEY> AWS_BUCKET_NAME <AWS_BUCKET_NAME> AWS_DEFAULT_REGION ap-northeast-1 AWS_ACCESS_KEY_ID <AWS_ACCESS_KEY_ID>fontsとiconsがデプロイされなかったので、手動であげる。
pipelineを作る
- ノリでいける
- 投稿日:2019-08-04T18:15:26+09:00
MacでAWS CLIのインストールからS3への接続までやってみた
目次
- 1. ゴール設定
- 2. 前提
- 3. AWS CLIのインストール
- 4. IAM 管理者のユーザーおよびグループの作成
- 5. IAM 管理者のユーザーのアクセスキーを作成
- 6. AWS CLIからS3への接続設定
- 7. AWS CLIからS3へ接続
- 8. まとめ
1. ゴール設定
AWS CLIを使用して、自分で作成したS3バケットに接続すること。
2. 前提
- 実施環境
- 実施日:2019/8/4
- 端末:Mac Book Pro(2019/7/10購入)
- OS:MacOS Mojave バージョン10.14.6
- ルートユーザーでS3バケットを作成済み
3. AWS CLIのインストール
macOS に AWS CLI をインストールするの手順を元に実施。
$ python --version $ curl "https://s3.amazonaws.com/aws-cli/awscli-bundle.zip" -o "awscli-bundle.zip" $ unzip awscli-bundle.zip $ sudo ./awscli-bundle/install -i /usr/local/aws -b /usr/local/bin/aws $ aws --version4. IAM 管理者のユーザーおよびグループの作成
私の場合、IAMのユーザーを作成していなかったので、本手順が必要でした。。。
すでにIAMユーザー作成されている方は、本手順はスキップしてください。管理者 IAM ユーザーおよびグループの作成 (コンソール)に従ってIAM 管理者のユーザーおよびグループの作成を行う。
↓ユーザーとグループを作成確認画面
↓作成完了画面
※ ユーザーの認証情報を「csvダウンロード」もしくは「Eメール送信」で控えておきましょう。
控えておかないと作成したユーザーでログインできないので、要注意。。。
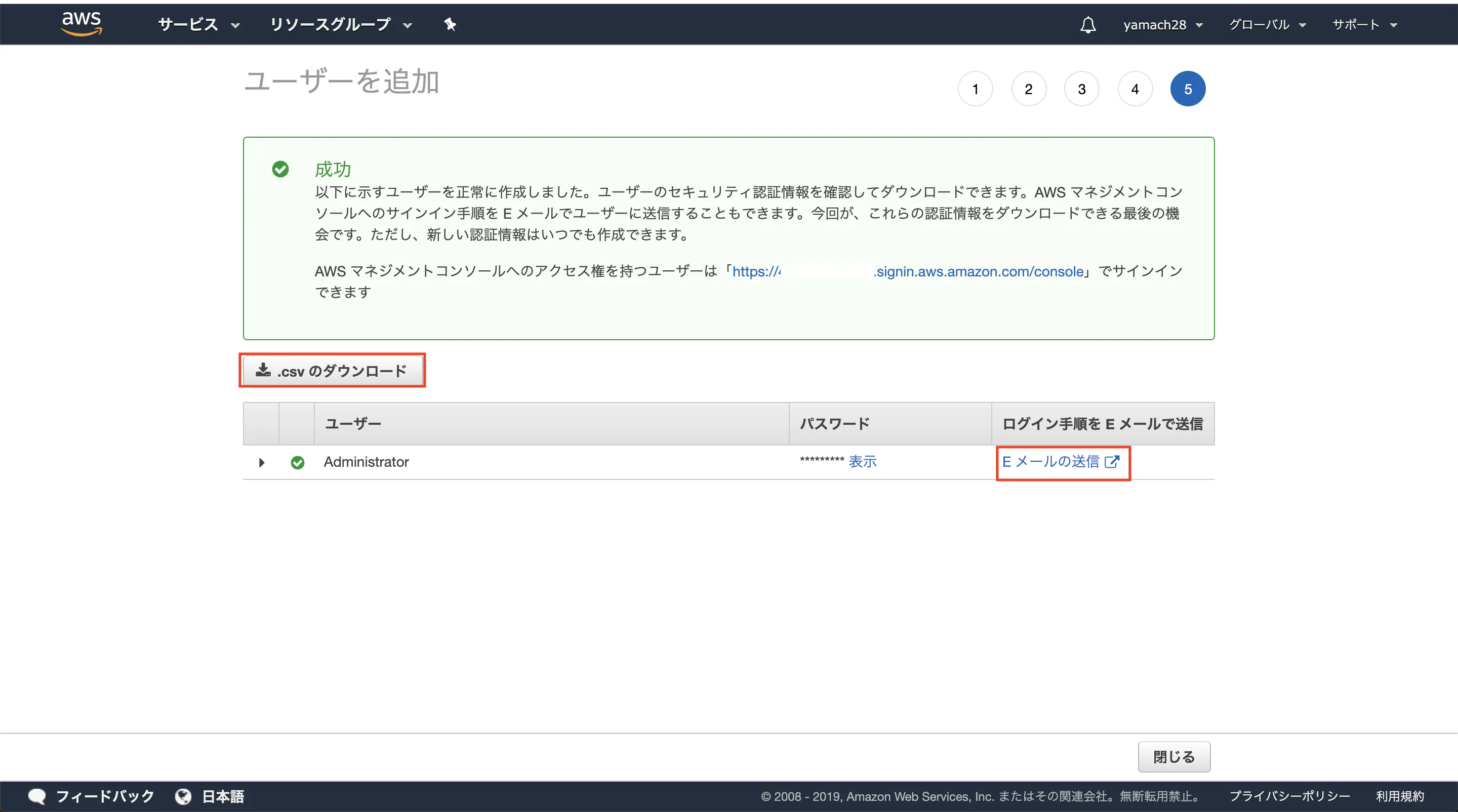
5. IAM 管理者のユーザーのアクセスキーを作成
- 先の手順で作成したユーザー(AWS CLIで使用するユーザー)でAWSコンソールにサインインし直す。
- アクセスキーを、IAM ユーザーのアクセスキーを作成するにはの手順を元に作成。
※ 作成されたアクセスキーは、必ずcsvダウンロードして控えておきましょう。
6. AWS CLIからS3への接続設定
AWS CLI のかんたん設定の手順を元に実施。
※ デフォルトの接続先リージョンは、東京リージョンにしています。$ aws configure AWS Access Key ID [None]: {{先に取得した「アクセスキーID」をここに入力}} AWS Secret Access Key [None]: {{先に取得した「シークレットアクセスキー」をここに入力}} Default region name [None]: ap-northeast-1 Default output format [None]: json7. AWS CLIからS3へ接続
いよいよ、S3へ接続です。
以下のように、S3に作成したバケット名が表示されれば接続成功です。$ aws s3 ls 2019-08-04 15:41:26 xxxxx8. まとめ
いかがでしたでしょうか?
AWSの公式ドキュメントに丁寧に記載されているので、特に迷うことなく進めることができました。今回はロール周りをあまり意識せず管理者ユーザーで設定しましたが、
開発で本格的に使うときは開発者毎にユーザーを分けて、適切なロールを割り当てることが必須だと感じました。今後は、AWS CLIを駆使して開発効率化や自動化をいきたいなーと思っています。
では!

- 投稿日:2019-08-04T16:31:34+09:00
AWS Session Managerを用いたsshレスオペレーションを、ユーザーデータでのブートストラッピングで実現する
はじめに
こんにちわ。Wano株式会社エンジニアのnariと申します。
突然ですが、どんなec2インスタンスでもsshレスにオペレーションしたい。。
今回は、 オペレーションサーバーの場合と、ec2コンテナインスタンスの場合でのユーザーデータの設定を備忘録として記録しておきます。前提知識
SSM エージェント は、デフォルトでは、2017 年 9 月以降の Amazon Linux 基本 AMI にインストールされます。SSM エージェント は、デフォルトで、Amazon Linux 2 AMI にもインストールされます。
Amazon ECS 対応の AMI のようにベースイメージではないその他のバージョンの Linux では、手動で SSM エージェント をインストールする必要があります。
(Amazon EC2 Linux インスタンスに SSM エージェント を手動でインストールする - AWS Systems Managerより抜粋)オペレーションサーバーの場合
- AMIをAmazon Linux 基本 AMIかAmazon Linux 2 AMIにすれば、ssmエージェントをインストールを記述する必要はない(前提より)
- よって、ユーザーデータでは、dockerをinstallし、起動することでECSで使用しているimageなどを動かし検証できるようにするだけでok
ユーザーデータの設定
user_data.sh#!/bin/sh amazon-linux-extras install -y docker systemctl start docker systemctl enable dockerecsコンテナインスタンスの場合
- Amazon ECS 対応の AMIはssmエージェントをインストールする記述を書く必要がある(前提より)
ユーザーデータの設定
user_data.sh#!/bin/bash echo "ECS_CLUSTER=${cluster_name}" > /etc/ecs/ecs.config //以下の記述で、ssmエージェントをインストールする # Get the current region from the instance metadata region=$(curl -s http://169.254.169.254/latest/dynamic/instance-identity/document | jq -r .region) # Install the SSM agent RPM yum install -y https://amazon-ssm-$region.s3.amazonaws.com/latest/linux_amd64/amazon-ssm-agent.rpm

- 投稿日:2019-08-04T16:07:48+09:00
本番環境でCarrierWaveでS3にアップロードした画像が表示されない時の対処
簡単なチャットアプリケーションを開発する学習で
Rails、Heroku、CarriaWave 、S3を使用して画像をアップロードした際に
以下のようになり、画像が正しく表示されませんでした
対処した時のことを忘れないように、記事を投稿したいと思います。原因を探ってみる
まずは、そもそも画像がAmazon S3の管理画面にアップロードできているのかを確認
問題なくアップロードされていました。
ファイルの記述方法は間違っていないかを確認
carrierwave.rbrequire 'carrierwave/storage/abstract' require 'carrierwave/storage/file' require 'carrierwave/storage/fog' CarrierWave.configure do |config| config.storage = :fog config.fog_provider = 'fog/aws' config.fog_credentials = { provider: 'AWS', aws_access_key_id: Rails.application.secrets.aws_access_key_id, aws_secret_access_key: Rails.application.secrets.aws_secret_access_key, region: 'ap-northeast-1' } config.fog_directory = 'バケット名' config.asset_host = 'https://s3-ap-northeast1.amazonaws.com/バケット名' endんー、カリキュラムの指示通りかけてるな
どこが悪いのかさっぱり!
解決方法
キーワードを変えながら検索をしていると同じような問題を書いてあるページを発見しました。
読んでみると、
「原因はconfig/initializers/carrierwave.rb内の、urlの指定が間違っていたからでした。以下のように asset_hostのurlの指定を修正すると、無事にストレージから画像を取得できました。」
(https://remonote.jp/rails-production-carrierwave-s3-error より引用)carrierwave.rbの書き方ミスとのこと
カリキュラムの書き方を信じるのもよくないですな
以下のようにコードを修正しましたcarrierwave.rbrequire 'carrierwave/storage/abstract' require 'carrierwave/storage/file' require 'carrierwave/storage/fog' CarrierWave.configure do |config| config.storage = :fog config.fog_provider = 'fog/aws' config.fog_credentials = { provider: 'AWS', aws_access_key_id: Rails.application.secrets.aws_access_key_id, aws_secret_access_key: Rails.application.secrets.aws_secret_access_key, region: 'ap-northeast-1' } config.fog_directory = 'バケット名' config.asset_host = 'https://s3-ap-northeast1.amazonaws.com/バケット名' #url間違い config.asset_host = 'https://バケット名.s3.amazonaws.com' #このように修正すると、画像を投稿した際に表示されるようになりました。
ふぅ・・なんとかなりました
最後に
いかがでしたでしょうか?
初投稿なので読みづらかったり分かりづらい点もあるかと思います。
コードの書き方は変わっていくので常に追っていかないといけないなと改めて思いました
同じエラーで悩んでいる人の助けになれたらいいなと思います参考元
「本番環境でCarrierWaveでS3にアップロードした画像が表示されない問題」の対処
https://remonote.jp/rails-production-carrierwave-s3-error


- 投稿日:2019-08-04T15:35:56+09:00
AWSアカウントが停止されてしまった時にした対応
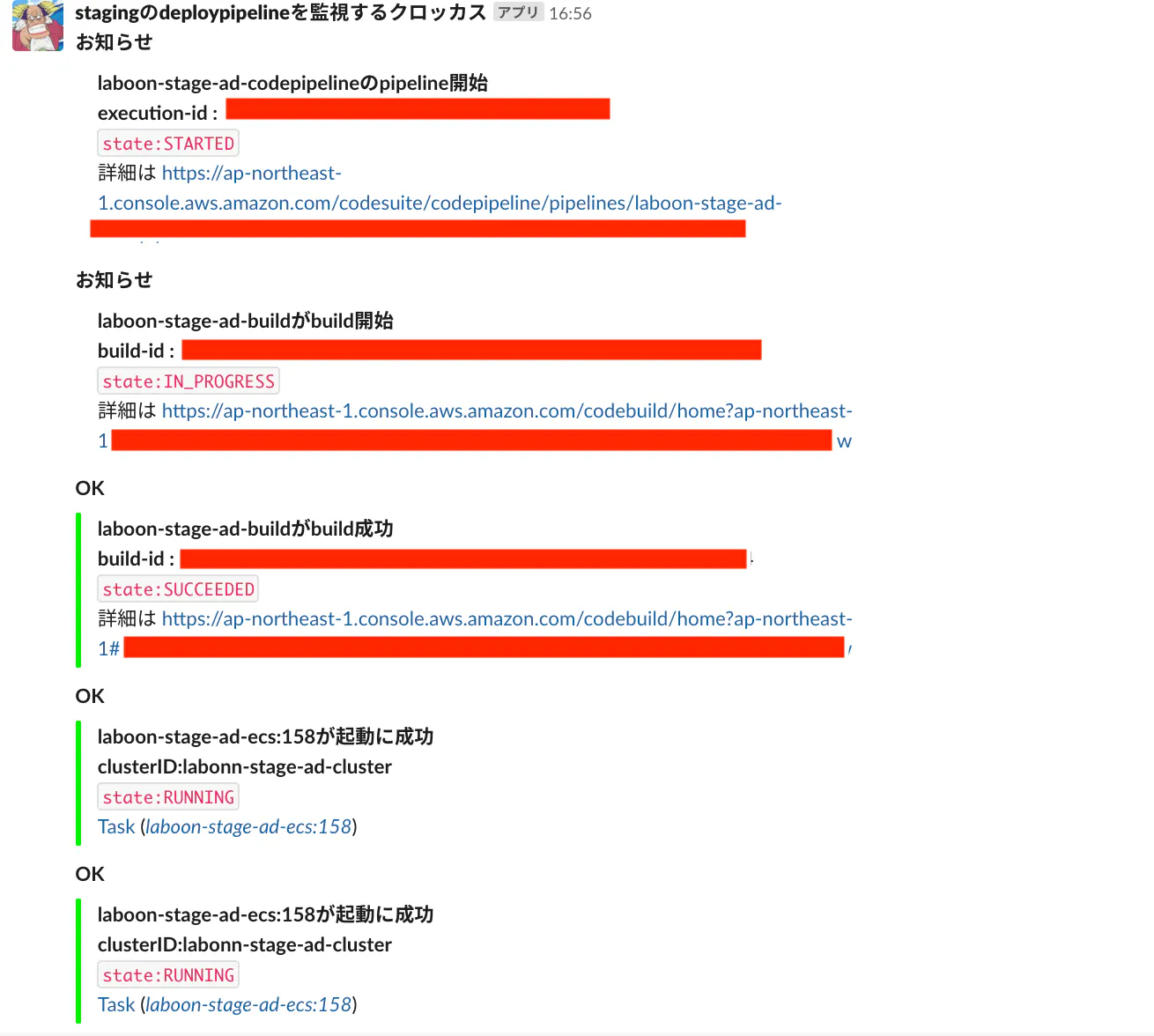
ここ最近全くエラーを吐かなかったJenkinsのジョブが突然エラーを吐き出した。
fatal error: An error occurred (InvalidAccessKeyId) when calling the ListObjectsV2 operation: The AWS Access Key Id you provided does not exist in our records.アクセスキーがダメになったのか、調べるためにサインインしようとすると、
ん?アカウントが停止中?
おかしい。ちゃんとクレジットは登録しているはずなのに。。。しかも支払履歴を確認しても、
アカウントはBasicで使っているだけなので、もちろん請求履歴もなかった
ここ1年くらい使っていたので、今更問題が発生するのもおかしいと思いながら、
再度クレジットカードを登録し直してみると、AWSからメールが届いた。Greetings from Amazon Web Services, We received an error while confirming the payment method associated with your Amazon Web Services account. To use some Amazon Web Services, you must provide a valid payment method. Please update your payment method information at the following page: https://console.aws.amazon.com/billing/home#/paymentmethods Some common reasons why an authorization might fail are: * Amazon is not set up to accept the CVV2 security code associated with credit cards. Your bank may be able to temporarily lift this requirement. * The authorization is for a low dollar amount ($1.00), which your bank may decline. * If you signed up for multiple AWS services, a $1.00 authorization may be performed for each service. Your bank may approve the first authorization and decline subsequent ones depending on their security policies. * Some banks have restrictions on Internet transactions. You may want to check with your credit card company to see if they have such a restriction. We recommend you contact your bank to determine the exact reason for the decline, or to ask them to take steps on their end to approve the authorization. Once your bank is ready to approve the authorization, please contact us back and we will retry this authorization for you. https://aws-portal.amazon.com/gp/aws/html-forms-controller/contactus/aws-account-and-billing You can contact AWS Customer Service via the Support Center: https://aws.amazon.com/support If you feel you have received this e-mail in error, please include these details in your case. Thank you for using Amazon Web Services. Sincerely, Amazon Web Servicesまあ要約すると、
お前の登録している支払方法を確認してみたら使えなかったよ。
カード会社にちょっと連絡してみてくれるかな。とのこと。
試しに登録している楽天カードに問い合わせてみると、
110円くらいの請求が来ていて、それがどうもロックされて上手く支払ができていないとのことだった。さらによくよくAWSからのメールを確認してみると
* Amazon is not set up to accept the CVV2 security code associated with credit cards. Your bank may be able to temporarily lift this requirement.ということでおそらくこれが原因で1$の請求ができなかった模様。
楽天カードにロックされている請求のロックを解除してもらって、
AWSに再度請求を送ってもらうように問い合わせした。でもなんで支払履歴に何も情報がないんだろう。。。
利用停止中だから支払履歴から支払してね。
みたいなこと言っているけど、これじゃどうしようもないじゃん

- 投稿日:2019-08-04T15:11:01+09:00
[WIP]terraformのdynamic blocksを用いたresourceの記述例と参考リンク
概要
dynamic blocksを用いたresourceの記述例と参考リンク
terraform初心者の自分為のdynamic blocksの書き方メモ
時間がある際に追記します開発環境
- OSX Mojave 10.14.4
- terraform 0.12.5
dynamic blocks参考資料リンク
記述例
- aws_autoscaling_policyのstep_adjustment
variable "asg_steps" { type = list(map(string)) default = [ { scaling_adjustment = 1 metric_interval_lower_bound = 1 metric_interval_upper_bound = 1000 }, { scaling_adjustment = 2 metric_interval_lower_bound = 1000 metric_interval_upper_bound = 2000 }, { scaling_adjustment = 3 metric_interval_lower_bound = 2000 metric_interval_upper_bound = null }, ] } resource "aws_autoscaling_policy" "asg_policy" { name = "auto scaling grouop policy" adjustment_type = "ExactCapacity" autoscaling_group_name = aws_autoscaling_group.ecs_asg.name policy_type = "StepScaling" dynamic "step_adjustment" { for_each = var.asg_steps content { scaling_adjustment = step_adjustment.value["scaling_adjustment"] metric_interval_lower_bound = step_adjustment.value["metric_interval_lower_bound"] metric_interval_upper_bound = step_adjustment.value["metric_interval_upper_bound"] } } }スキップする項目(metric_interval_upper_bound)は代入値を'null'にすることで書式を合わせてます
- 投稿日:2019-08-04T14:40:51+09:00
ApexとTerraformとGoでAWS上に構築したCD Pipelineのステータスをslackに通知
はじめに
こんにちわ。Wano株式会社エンジニアのnariと申します。
Terraform記事第三弾ということで、今回はAWS上のPipelineのモニタリング機構に関して記事にしたいと思います。何を作ったか
- AWS CodePipeline,ECS,CodeBuildのステータスが変化すると、slackに投げてくれる仕組みをApex、Terraform)GoでIaC化して作った
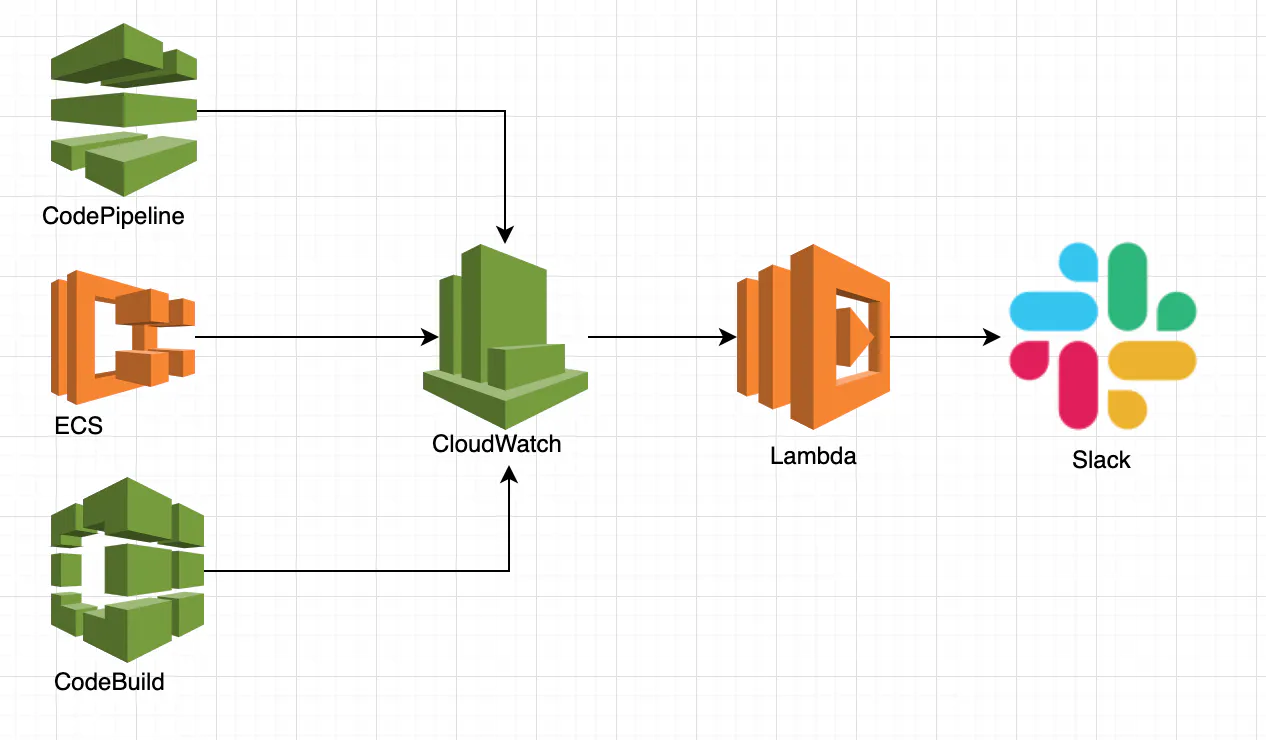
全体構成
- CodePipeline/Codebuild/ECSのステータスをCloudWatchで監視
- Statusの変更があった場合に、Lambdaを起動
- Lambda関数でステータスを、Slackへ通知
何故作ったか
- Codepipelineの進捗や結果を確認しに行くのにコンソールまで行くのが面倒くさい
- buildやdeploy失敗を見逃さないアラートの仕組みが欲しかった
何故Apexなのか
- モニタリングリソースが増えるたびにCloudWatchEventsを手動で設定するのが面倒くさい
- かといって、lambda関連のリソースをterraformだけで管理するのは辛い(バイナリ化してzip、バージョン管理etc)
- Apexならapex infraというterraformコマンドをラップした便利コマンドを使用できる(関数名などをvariableに設定するだけでよしなに補填してくれる)
開発環境
Apex 1.0.0-rc2
Terraform 0.12.0
Provider(aws) 2.12.0
Go 1.12.4ディレクトリ構成
monitoring/ ├ functions/ | └ pipeline_notice/ | ├ function.json | └ main.go ├ infrastructure/ | ├ main.tf | ├ outputs.tf | ├ variables.tf | └ event_pattern/ | ├ codepipeline.json | ├ codebuild.json | └ ecs.json └ project.jsonそれぞれのコードのご紹介
Apex
- project.json にproject全体の設定
project.json{ "name": "hogehoge", "description": "hogehoge", "nameTemplate": "{{.Project.Name}}_{{.Function.Name}}" }
- functions.jsonにそれぞれの関数の設定を
function.json{ "name": "hogehoge", "description": "hogehoge", "runtime": "go1.x", "role": "arn:aws:iam::xxxxxxxxxxxxx:role/xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx", "environment": { "webHookUrl": "https://hooks.slack.com/services/xxxxxxx/xxxxxxxxx/xxxxxxxxxxxxxxx", "slackChannel": "xxxxxxxxxxxxxxxxx" }, "memory": 1024, "timeout": 120, "handler": "main", "hooks": { "build": "go get -v -t -d ./... && GOOS=linux GOARCH=amd64 go build -o main main.go", "clean": "rm -f main" } }Go(lambda function)
main.gopackage main import ( "context" "encoding/json" "fmt" "github.com/aws/aws-lambda-go/events" "github.com/aws/aws-lambda-go/lambda" "os" "strings" ... ) type CodePipelineStatus struct { Pipeline string `json:"pipeline"` ExecutionID string `json:"execution-id"` State string `json:"state"` Version int `json:"version"` } type CodeBuildStatus struct { BuildStatus string `json:"build-status"` ProjectName string `json:"project-name"` BuildID string `json:"build-id"` } type EcsStatus struct { ClusterArn string `json:"clusterArn"` TaskArn string `json:"taskArn"` TaskDefinitionArn string `json:"taskDefinitionArn"` DesiredStatus string `json:"desiredStatus"` LastStatus string `json:"lastStatus"` } type CODEPIPELINE_STATE string const ( CODEPIPELINE_STARTED_STATE CODEPIPELINE_STATE = "STARTED" CODEPIPELINE_SUCCEEDED_STATE CODEPIPELINE_STATE = "SUCCEEDED" CODEPIPELINE_RESUMED_STATE CODEPIPELINE_STATE = "RESUMED" CODEPIPELINE_FAILED_STATE CODEPIPELINE_STATE = "FAILED" CODEPIPELINE_CANCELED_STATE CODEPIPELINE_STATE = "CANCELED" ) type CODEBUILD_STATE string const ( CODEBUILD_STOPPED_STATE CODEBUILD_STATE = "STOPPED" CODEBUILD_SUCCEEDED_STATE CODEBUILD_STATE = "SUCCEEDED" CODEBUILD_IN_PROGRESS_STATE CODEBUILD_STATE = "IN_PROGRESS" CODEBUILD_FAILED_STATE CODEBUILD_STATE = "FAILED" ) type ECS_STATE string const ( ECS_RUNNING_STATE ECS_STATE = "RUNNING" ECS_STOPPED_STATE ECS_STATE = "STOPPED" ) const ( SLACK_ICON = ":crocus:" SLACK_NAME = "stagingのdeploypipelineを監視するクロッカス" ) func main() { lambda.Start(noticeHandler) } func noticeHandler(context context.Context, event events.CloudWatchEvent) (e error) { webhookURL := os.Getenv("webHookUrl") channel := os.Getenv("slackChannel") //event.Sourceで処理を分岐 switch event.Source { case "aws.codepipeline": if err := notifyCodePipelineStatus(event, webhookURL, channel); err != nil { log.Error(err) return err } return nil case "aws.codebuild": if err := notifyCodeBuildStatus(event, webhookURL, channel); err != nil { log.Error(err) return err } return nil case "aws.ecs": if err := notifyEcsStatus(event, webhookURL, channel); err != nil { log.Error(err) return err } return nil default: log.Info("想定するリソースのイベントではない") return nil } } func notifyCodePipelineStatus(event events.CloudWatchEvent, webhookURL string, channel string) (e error) { //eventをCodePipelineStatusにunmarshal status := &CodePipelineStatus{} json.Unmarshal([]byte(event.Detail), status) pipelineURL := fmt.Sprintf("https://%v.console.aws.amazon.com/codesuite/codepipeline/pipelines/%v/executions/%v", event.Region, status.Pipeline, status.ExecutionID) text := fmt.Sprintf("*execution-id : %v*\n `state:%v` \n 詳細は %v", status.ExecutionID, status.State, pipelineURL) var messsageLevel slack_reporter.SLACK_MESSAGE_LEVEL var title string switch CODEPIPELINE_STATE(status.State) { case CODEPIPELINE_STARTED_STATE: title = fmt.Sprintf("*%vのpipeline開始*", status.Pipeline) messsageLevel = slack_reporter.SLACK_MESSAGE_LEVEL_NOTIFY case CODEPIPELINE_CANCELED_STATE, CODEPIPELINE_RESUMED_STATE: title = fmt.Sprintf("*%vが%v*", status.Pipeline, status.State) messsageLevel = slack_reporter.SLACK_MESSAGE_LEVEL_NOTIFY case CODEPIPELINE_FAILED_STATE: title = fmt.Sprintf("*%vのpipeline失敗。。。*", status.Pipeline) messsageLevel = slack_reporter.SLACK_MESSAGE_LEVEL_ALART case CODEPIPELINE_SUCCEEDED_STATE: title = fmt.Sprintf("*%vのpipeline成功!!*", status.Pipeline) messsageLevel = slack_reporter.SLACK_MESSAGE_LEVEL_OK default: messsageLevel = slack_reporter.SLACK_MESSAGE_LEVEL_NOTIFY } err := slack_reporter.ReportToLaboonSlack(webhookURL, channel, SLACK_NAME, SLACK_ICON, title, text, messsageLevel) if err != nil { log.Error(err) return err } return nil } func notifyCodeBuildStatus(event events.CloudWatchEvent, webhookURL string, channel string) (e error) { //eventをCodeBuildStatusにunmarshal status := &CodeBuildStatus{} json.Unmarshal([]byte(event.Detail), status) buildID := strings.Split(status.BuildID, "/")[1] //test-ciのbuildは無視 if status.ProjectName == "hoge-auto-test" { return nil } codebuildURL := fmt.Sprintf("https://%v.console.aws.amazon.com/codebuild/home?%v#/builds/%v/view/new", event.Region, event.Region, buildID) text := fmt.Sprintf("*build-id : %v*\n `state:%v` \n 詳細は %v", buildID, status.BuildStatus, codebuildURL) var title string var messsageLevel slack_reporter.SLACK_MESSAGE_LEVEL switch CODEBUILD_STATE(status.BuildStatus) { case CODEBUILD_IN_PROGRESS_STATE: title = fmt.Sprintf("*%vがbuild開始*", status.ProjectName) messsageLevel = slack_reporter.SLACK_MESSAGE_LEVEL_NOTIFY case CODEBUILD_FAILED_STATE, CODEBUILD_STOPPED_STATE: title = fmt.Sprintf("*%vがbuild失敗か停止した。。。*", status.ProjectName) messsageLevel = slack_reporter.SLACK_MESSAGE_LEVEL_ALART case CODEBUILD_SUCCEEDED_STATE: title = fmt.Sprintf("*%vがbuild成功*", status.ProjectName) messsageLevel = slack_reporter.SLACK_MESSAGE_LEVEL_OK default: messsageLevel = slack_reporter.SLACK_MESSAGE_LEVEL_NOTIFY } err := slack_reporter.ReportToLaboonSlack(webhookURL, channel, SLACK_NAME, SLACK_ICON, title, text, messsageLevel) if err != nil { log.Error(err) return err } return nil } func notifyEcsStatus(event events.CloudWatchEvent, webhookURL string, channel string) (e error) { //eventをEcsStatusにunmarshal status := &EcsStatus{} json.Unmarshal([]byte(event.Detail), status) // 期待するステートになるまでの過程は通知しない(予期せぬSTOPPEDを除いて) if status.LastStatus != status.DesiredStatus && status.LastStatus != string(ECS_STOPPED_STATE) { return nil } clusterID := strings.Split(status.ClusterArn, "/")[1] taskID := strings.Split(status.TaskArn, "/")[1] taskDefinitionID := strings.Split(status.TaskDefinitionArn, "/")[1] taskURL := fmt.Sprintf("https://%v.console.aws.amazon.com/ecs/home?region=%v#/clusters/%v/tasks/%v/details", event.Region, event.Region, clusterID, taskID) taskDefinitionURL := fmt.Sprintf("https://%v.console.aws.amazon.com/ecs/home?region=%v#/taskDefinitions/%v", event.Region, event.Region, strings.Replace(taskDefinitionID, ":", "/", 1)) text := fmt.Sprintf("*clusterID:%v* \n `state:%v` \n <%v|Task> (_<%v|%v>_)", clusterID, status.LastStatus, taskURL, taskDefinitionURL, taskDefinitionID) var title string var messsageLevel slack_reporter.SLACK_MESSAGE_LEVEL switch ECS_STATE(status.LastStatus) { case ECS_RUNNING_STATE: title = fmt.Sprintf("*%vが起動に成功*", taskDefinitionID) messsageLevel = slack_reporter.SLACK_MESSAGE_LEVEL_OK case ECS_STOPPED_STATE: //もし期待された停止であるならば、OK if status.DesiredStatus == string(ECS_STOPPED_STATE) { title = fmt.Sprintf("*%vが停止に成功*", taskDefinitionID) messsageLevel = slack_reporter.SLACK_MESSAGE_LEVEL_OK break } //そうでないならアラート title = fmt.Sprintf("*%vが予期せぬ停止*", taskDefinitionID) messsageLevel = slack_reporter.SLACK_MESSAGE_LEVEL_ALART default: messsageLevel = slack_reporter.SLACK_MESSAGE_LEVEL_NOTIFY } err := slack_reporter.ReportToLaboonSlack(webhookURL, channel, SLACK_NAME, SLACK_ICON, title, text, messsageLevel) if err != nil { log.Error(err) return err } return nil }ポイント
- event.Sourceで処理を分岐し、events.CloudWatchEvent(json.RawMessage型)をそれぞれのstatusにunmarshalして扱う(そうすることで、監視するリソース毎に関数を分けない)
Terraform
monitoring module(今回のdirectory構成の外部にあります 詳細はこちら
main.tf/* monitoring */ resource "aws_cloudwatch_event_rule" "default" { count = length(var.cloud_watch_event_objs) name = var.cloud_watch_event_objs[count.index]["cloud_watch_event_rule_name"] description = var.cloud_watch_event_objs[count.index]["cloud_watch_event_rule_description"] event_pattern = var.cloud_watch_event_objs[count.index]["event_pattern"] } resource "aws_cloudwatch_event_target" "default" { count = length(aws_cloudwatch_event_rule.default) rule = aws_cloudwatch_event_rule.default[count.index].name target_id = var.cloud_watch_event_objs[count.index]["aws_cloudwatch_event_target_id"] arn = var.cloud_watch_event_objs[count.index]["function_arn"] } resource "aws_lambda_permission" "default" { count = length(aws_cloudwatch_event_target.default) statement_id = var.cloud_watch_event_objs[count.index]["statement_id"] action = "lambda:InvokeFunction" function_name = aws_cloudwatch_event_target.default[count.index].arn principal = "events.amazonaws.com" source_arn = aws_cloudwatch_event_rule.default[count.index].arn }variables.tf/* required */ variable "cloud_watch_event_objs" { //map(string)でもいいんだけどparameterとしてフィールドが見えてる方がわかりやすいかなと type = list(object({ statement_id = string cloud_watch_event_rule_name = string cloud_watch_event_rule_description = string event_pattern = string aws_cloudwatch_event_target_id = string function_arn = string }) ) description = "watchしたいリソースとイベントパターンとlambda関数を打ち込む" }moduleを使う側(main.tf variables.tf)
main.tf... /* monitoring */ module "laboon_monitoring" { source = "../../../../modules/common/monitoring" cloud_watch_event_objs = local.cloud_watch_event_objs } /* locals */ locals { /* monitoring required */ cloud_watch_event_objs = [ //この配列に監視したいリソースとイベントパターンと発火したい関数の入ったobjを追加する //codepipeline { statement_id = "AllowExecutionFromCloudWatchForCodePipeline" cloud_watch_event_rule_name = "ad-pipeline-notice" cloud_watch_event_rule_description = "ad-pipeline-notice" event_pattern = file("./event_pattern/codepipeline.json") aws_cloudwatch_event_target_id = "ad-pipeline-notice" function_arn = var.apex_function_pipeline_notice }, //codebuild { statement_id = "AllowExecutionFromCloudWatchForCodeBuild" cloud_watch_event_rule_name = "ad-codebuild-notice" cloud_watch_event_rule_description = "ad-codebuild-notice" event_pattern = file("./event_pattern/codebuild.json") aws_cloudwatch_event_target_id = "ad-codebuild-notice" function_arn = var.apex_function_pipeline_notice }, //ecs { statement_id = "AllowExecutionFromCloudWatchForECS" cloud_watch_event_rule_name = "ad-ecs-notice" cloud_watch_event_rule_description = "ad-ecs-notice" event_pattern = file("./event_pattern/ecs.json") aws_cloudwatch_event_target_id = "ad-ecs-notice" function_arn = var.apex_function_pipeline_notice } ] }variables.tfvariable "apex_function_pipeline_notice" {} variable "apex_function_pipeline_notice_name" {} variable "apex_function_names" {} variable "apex_function_role" {} variable "aws_region" {} variable "apex_environment" {} variable "apex_function_arns" {}event_pattern/codebuild.json{ "source": [ "aws.codebuild" ], "detail-type": [ "CodeBuild Build State Change" ] }event_pattern/codepipeline.json{ "source": [ "aws.codepipeline" ], "detail-type": [ "CodePipeline Pipeline Execution State Change" ], "detail": { "state": [ "RESUMED", "CANCELED", "STARTED", "FAILED", "SUCCEEDED" ] } }event_pattern/ecs.json{ "source": [ "aws.ecs" ], "detail-type": [ "ECS Task State Change" ] }ポイント
- list(object)型を用いることで、簡単に監視リソースを増やせるモジュールに
参考文献

- 投稿日:2019-08-04T14:40:51+09:00
ApexとTerraformとGoでAWS上に構築したPipelineのステータスをslackに通知
はじめに
こんにちわ。Wano株式会社エンジニアのnariと申します。
Terraform記事第三弾ということで、今回はAWS上のPipelineのモニタリング機構に関して記事にしたいと思います。何を作ったか
- AWS CodePipeline,ECS,CodeBuildのステータスが変化すると、slackに投げてくれる仕組みをApex、Terraform)GoでIaC化して作った
全体構成
- CodePipeline/Codebuild/ECSのステータスをCloudWatchで監視
- Statusの変更があった場合に、Lambdaを起動
- Lambda関数でステータスを、Slackへ通知
何故作ったか
- Codepipelineの進捗や結果を確認しに行くのにコンソールまで行くのが面倒くさい
- buildやdeploy失敗を見逃さないアラートの仕組みが欲しかった
何故Apexなのか
- モニタリングリソースが増えるたびにCloudWatchEventsを手動で設定するのが面倒くさい
- かといって、lambda関連のリソースをterraformだけで管理するのは辛い(バイナリ化してzip、バージョン管理etc)
- Apexならapex infraというterraformコマンドをラップした便利コマンドを使用できる(関数名などをvariableに設定するだけでよしなに補填してくれる)
開発環境
Apex 1.0.0-rc2
Terraform 0.12.0
Provider(aws) 2.12.0
Go 1.12.4ディレクトリ構成
monitoring/ ├ functions/ | └ pipeline_notice/ | ├ function.json | └ main.go ├ infrastructure/ | ├ main.tf | ├ outputs.tf | ├ variables.tf | └ event_pattern/ | ├ codepipeline.json | ├ codebuild.json | └ ecs.json └ project.jsonそれぞれのコードのご紹介
Apex
- project.json にproject全体の設定
project.json{ "name": "hogehoge", "description": "hogehoge", "nameTemplate": "{{.Project.Name}}_{{.Function.Name}}" }
- functions.jsonにそれぞれの関数の設定を
function.json{ "name": "hogehoge", "description": "hogehoge", "runtime": "go1.x", "role": "arn:aws:iam::xxxxxxxxxxxxx:role/xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx", "environment": { "webHookUrl": "https://hooks.slack.com/services/xxxxxxx/xxxxxxxxx/xxxxxxxxxxxxxxx", "slackChannel": "xxxxxxxxxxxxxxxxx" }, "memory": 1024, "timeout": 120, "handler": "main", "hooks": { "build": "go get -v -t -d ./... && GOOS=linux GOARCH=amd64 go build -o main main.go", "clean": "rm -f main" } }Go(lambda function)
main.gopackage main import ( "context" "encoding/json" "fmt" "github.com/aws/aws-lambda-go/events" "github.com/aws/aws-lambda-go/lambda" "os" "strings" ... ) type CodePipelineStatus struct { Pipeline string `json:"pipeline"` ExecutionID string `json:"execution-id"` State string `json:"state"` Version int `json:"version"` } type CodeBuildStatus struct { BuildStatus string `json:"build-status"` ProjectName string `json:"project-name"` BuildID string `json:"build-id"` } type EcsStatus struct { ClusterArn string `json:"clusterArn"` TaskArn string `json:"taskArn"` TaskDefinitionArn string `json:"taskDefinitionArn"` DesiredStatus string `json:"desiredStatus"` LastStatus string `json:"lastStatus"` } type CODEPIPELINE_STATE string const ( CODEPIPELINE_STARTED_STATE CODEPIPELINE_STATE = "STARTED" CODEPIPELINE_SUCCEEDED_STATE CODEPIPELINE_STATE = "SUCCEEDED" CODEPIPELINE_RESUMED_STATE CODEPIPELINE_STATE = "RESUMED" CODEPIPELINE_FAILED_STATE CODEPIPELINE_STATE = "FAILED" CODEPIPELINE_CANCELED_STATE CODEPIPELINE_STATE = "CANCELED" ) type CODEBUILD_STATE string const ( CODEBUILD_STOPPED_STATE CODEBUILD_STATE = "STOPPED" CODEBUILD_SUCCEEDED_STATE CODEBUILD_STATE = "SUCCEEDED" CODEBUILD_IN_PROGRESS_STATE CODEBUILD_STATE = "IN_PROGRESS" CODEBUILD_FAILED_STATE CODEBUILD_STATE = "FAILED" ) type ECS_STATE string const ( ECS_RUNNING_STATE ECS_STATE = "RUNNING" ECS_STOPPED_STATE ECS_STATE = "STOPPED" ) const ( SLACK_ICON = ":crocus:" SLACK_NAME = "stagingのdeploypipelineを監視するクロッカス" ) func main() { lambda.Start(noticeHandler) } func noticeHandler(context context.Context, event events.CloudWatchEvent) (e error) { webhookURL := os.Getenv("webHookUrl") channel := os.Getenv("slackChannel") //event.Sourceで処理を分岐 switch event.Source { case "aws.codepipeline": if err := notifyCodePipelineStatus(event, webhookURL, channel); err != nil { log.Error(err) return err } return nil case "aws.codebuild": if err := notifyCodeBuildStatus(event, webhookURL, channel); err != nil { log.Error(err) return err } return nil case "aws.ecs": if err := notifyEcsStatus(event, webhookURL, channel); err != nil { log.Error(err) return err } return nil default: log.Info("想定するリソースのイベントではない") return nil } } func notifyCodePipelineStatus(event events.CloudWatchEvent, webhookURL string, channel string) (e error) { //eventをCodePipelineStatusにunmarshal status := &CodePipelineStatus{} json.Unmarshal([]byte(event.Detail), status) pipelineURL := fmt.Sprintf("https://%v.console.aws.amazon.com/codesuite/codepipeline/pipelines/%v/executions/%v", event.Region, status.Pipeline, status.ExecutionID) text := fmt.Sprintf("*execution-id : %v*\n `state:%v` \n 詳細は %v", status.ExecutionID, status.State, pipelineURL) var messsageLevel slack_reporter.SLACK_MESSAGE_LEVEL var title string switch CODEPIPELINE_STATE(status.State) { case CODEPIPELINE_STARTED_STATE: title = fmt.Sprintf("*%vのpipeline開始*", status.Pipeline) messsageLevel = slack_reporter.SLACK_MESSAGE_LEVEL_NOTIFY case CODEPIPELINE_CANCELED_STATE, CODEPIPELINE_RESUMED_STATE: title = fmt.Sprintf("*%vが%v*", status.Pipeline, status.State) messsageLevel = slack_reporter.SLACK_MESSAGE_LEVEL_NOTIFY case CODEPIPELINE_FAILED_STATE: title = fmt.Sprintf("*%vのpipeline失敗。。。*", status.Pipeline) messsageLevel = slack_reporter.SLACK_MESSAGE_LEVEL_ALART case CODEPIPELINE_SUCCEEDED_STATE: title = fmt.Sprintf("*%vのpipeline成功!!*", status.Pipeline) messsageLevel = slack_reporter.SLACK_MESSAGE_LEVEL_OK default: messsageLevel = slack_reporter.SLACK_MESSAGE_LEVEL_NOTIFY } err := slack_reporter.ReportToLaboonSlack(webhookURL, channel, SLACK_NAME, SLACK_ICON, title, text, messsageLevel) if err != nil { log.Error(err) return err } return nil } func notifyCodeBuildStatus(event events.CloudWatchEvent, webhookURL string, channel string) (e error) { //eventをCodeBuildStatusにunmarshal status := &CodeBuildStatus{} json.Unmarshal([]byte(event.Detail), status) buildID := strings.Split(status.BuildID, "/")[1] //test-ciのbuildは無視 if status.ProjectName == "hoge-auto-test" { return nil } codebuildURL := fmt.Sprintf("https://%v.console.aws.amazon.com/codebuild/home?%v#/builds/%v/view/new", event.Region, event.Region, buildID) text := fmt.Sprintf("*build-id : %v*\n `state:%v` \n 詳細は %v", buildID, status.BuildStatus, codebuildURL) var title string var messsageLevel slack_reporter.SLACK_MESSAGE_LEVEL switch CODEBUILD_STATE(status.BuildStatus) { case CODEBUILD_IN_PROGRESS_STATE: title = fmt.Sprintf("*%vがbuild開始*", status.ProjectName) messsageLevel = slack_reporter.SLACK_MESSAGE_LEVEL_NOTIFY case CODEBUILD_FAILED_STATE, CODEBUILD_STOPPED_STATE: title = fmt.Sprintf("*%vがbuild失敗か停止した。。。*", status.ProjectName) messsageLevel = slack_reporter.SLACK_MESSAGE_LEVEL_ALART case CODEBUILD_SUCCEEDED_STATE: title = fmt.Sprintf("*%vがbuild成功*", status.ProjectName) messsageLevel = slack_reporter.SLACK_MESSAGE_LEVEL_OK default: messsageLevel = slack_reporter.SLACK_MESSAGE_LEVEL_NOTIFY } err := slack_reporter.ReportToLaboonSlack(webhookURL, channel, SLACK_NAME, SLACK_ICON, title, text, messsageLevel) if err != nil { log.Error(err) return err } return nil } func notifyEcsStatus(event events.CloudWatchEvent, webhookURL string, channel string) (e error) { //eventをEcsStatusにunmarshal status := &EcsStatus{} json.Unmarshal([]byte(event.Detail), status) // 期待するステートになるまでの過程は通知しない(予期せぬSTOPPEDを除いて) if status.LastStatus != status.DesiredStatus && status.LastStatus != string(ECS_STOPPED_STATE) { return nil } clusterID := strings.Split(status.ClusterArn, "/")[1] taskID := strings.Split(status.TaskArn, "/")[1] taskDefinitionID := strings.Split(status.TaskDefinitionArn, "/")[1] taskURL := fmt.Sprintf("https://%v.console.aws.amazon.com/ecs/home?region=%v#/clusters/%v/tasks/%v/details", event.Region, event.Region, clusterID, taskID) taskDefinitionURL := fmt.Sprintf("https://%v.console.aws.amazon.com/ecs/home?region=%v#/taskDefinitions/%v", event.Region, event.Region, strings.Replace(taskDefinitionID, ":", "/", 1)) text := fmt.Sprintf("*clusterID:%v* \n `state:%v` \n <%v|Task> (_<%v|%v>_)", clusterID, status.LastStatus, taskURL, taskDefinitionURL, taskDefinitionID) var title string var messsageLevel slack_reporter.SLACK_MESSAGE_LEVEL switch ECS_STATE(status.LastStatus) { case ECS_RUNNING_STATE: title = fmt.Sprintf("*%vが起動に成功*", taskDefinitionID) messsageLevel = slack_reporter.SLACK_MESSAGE_LEVEL_OK case ECS_STOPPED_STATE: //もし期待された停止であるならば、OK if status.DesiredStatus == string(ECS_STOPPED_STATE) { title = fmt.Sprintf("*%vが停止に成功*", taskDefinitionID) messsageLevel = slack_reporter.SLACK_MESSAGE_LEVEL_OK break } //そうでないならアラート title = fmt.Sprintf("*%vが予期せぬ停止*", taskDefinitionID) messsageLevel = slack_reporter.SLACK_MESSAGE_LEVEL_ALART default: messsageLevel = slack_reporter.SLACK_MESSAGE_LEVEL_NOTIFY } err := slack_reporter.ReportToLaboonSlack(webhookURL, channel, SLACK_NAME, SLACK_ICON, title, text, messsageLevel) if err != nil { log.Error(err) return err } return nil }ポイント
- event.Sourceで処理を分岐し、events.CloudWatchEvent(json.RawMessage型)をそれぞれのstatusにunmarshalして扱う(そうすることで、監視するリソース毎に関数を分けない)
Terraform
monitoring module(今回のdirectory構成の外部にあります 詳細はこちら
main.tf/* monitoring */ resource "aws_cloudwatch_event_rule" "default" { count = length(var.cloud_watch_event_objs) name = var.cloud_watch_event_objs[count.index]["cloud_watch_event_rule_name"] description = var.cloud_watch_event_objs[count.index]["cloud_watch_event_rule_description"] event_pattern = var.cloud_watch_event_objs[count.index]["event_pattern"] } resource "aws_cloudwatch_event_target" "default" { count = length(aws_cloudwatch_event_rule.default) rule = aws_cloudwatch_event_rule.default[count.index].name target_id = var.cloud_watch_event_objs[count.index]["aws_cloudwatch_event_target_id"] arn = var.cloud_watch_event_objs[count.index]["function_arn"] } resource "aws_lambda_permission" "default" { count = length(aws_cloudwatch_event_target.default) statement_id = var.cloud_watch_event_objs[count.index]["statement_id"] action = "lambda:InvokeFunction" function_name = aws_cloudwatch_event_target.default[count.index].arn principal = "events.amazonaws.com" source_arn = aws_cloudwatch_event_rule.default[count.index].arn }variables.tf/* required */ variable "cloud_watch_event_objs" { //map(string)でもいいんだけどparameterとしてフィールドが見えてる方がわかりやすいかなと type = list(object({ statement_id = string cloud_watch_event_rule_name = string cloud_watch_event_rule_description = string event_pattern = string aws_cloudwatch_event_target_id = string function_arn = string }) ) description = "watchしたいリソースとイベントパターンとlambda関数を打ち込む" }moduleを使う側(main.tf variables.tf)
main.tf... /* monitoring */ module "laboon_monitoring" { source = "../../../../modules/common/monitoring" cloud_watch_event_objs = local.cloud_watch_event_objs } /* locals */ locals { /* monitoring required */ cloud_watch_event_objs = [ //この配列に監視したいリソースとイベントパターンと発火したい関数の入ったobjを追加する //codepipeline { statement_id = "AllowExecutionFromCloudWatchForCodePipeline" cloud_watch_event_rule_name = "ad-pipeline-notice" cloud_watch_event_rule_description = "ad-pipeline-notice" event_pattern = file("./event_pattern/codepipeline.json") aws_cloudwatch_event_target_id = "ad-pipeline-notice" function_arn = var.apex_function_pipeline_notice }, //codebuild { statement_id = "AllowExecutionFromCloudWatchForCodeBuild" cloud_watch_event_rule_name = "ad-codebuild-notice" cloud_watch_event_rule_description = "ad-codebuild-notice" event_pattern = file("./event_pattern/codebuild.json") aws_cloudwatch_event_target_id = "ad-codebuild-notice" function_arn = var.apex_function_pipeline_notice }, //ecs { statement_id = "AllowExecutionFromCloudWatchForECS" cloud_watch_event_rule_name = "ad-ecs-notice" cloud_watch_event_rule_description = "ad-ecs-notice" event_pattern = file("./event_pattern/ecs.json") aws_cloudwatch_event_target_id = "ad-ecs-notice" function_arn = var.apex_function_pipeline_notice } ] }variables.tfvariable "apex_function_pipeline_notice" {} variable "apex_function_pipeline_notice_name" {} variable "apex_function_names" {} variable "apex_function_role" {} variable "aws_region" {} variable "apex_environment" {} variable "apex_function_arns" {}event_pattern/codebuild.json{ "source": [ "aws.codebuild" ], "detail-type": [ "CodeBuild Build State Change" ] }event_pattern/codepipeline.json{ "source": [ "aws.codepipeline" ], "detail-type": [ "CodePipeline Pipeline Execution State Change" ], "detail": { "state": [ "RESUMED", "CANCELED", "STARTED", "FAILED", "SUCCEEDED" ] } }event_pattern/ecs.json{ "source": [ "aws.ecs" ], "detail-type": [ "ECS Task State Change" ] }ポイント
- list(object)型を用いることで、簡単に監視リソースを増やせるモジュールに
参考文献
- 投稿日:2019-08-04T11:24:23+09:00
AWS認定ソリューションアーキテクト – アソシエイトを20時間で取得
はじめに
普段は主にネットワーク技術支援やインフラ構築のプロジェクトに携わっており、2か月前までAWSの経験なし。最近自社のウェブサービスをAWS上に展開することとなり、何故かいきなり構成検討~設計を主幹で担当することになった。
そのついでにSAAを取得したので、本試験の感想と勉強方法を書いておく。本試験の感想
受験日 :2019/8/3
受験費用:16,200円
受験時間:130分
問題数 :65問
スコア :804/1000
結果 :合格40分程余らせて試験を終えた。文量は1問あたり平均2~3行。日本語への翻訳が微妙な問題もあったが、ちゃんと勉強した上で試験に臨めば「意味が分からない」なんてことにはならないと思う。
選択肢の中から最適な設計を選択させられる問題の割合が多かった。ベンダー試験でありがちな細かいパラメータ(例えばOSコマンドの引数とかオプションとか)を問われるような、いわば暗記勝負の問題が少ないという点は個人的に良かった。勉強方法
めんどくさがりなのでオーバーワークしないことが最優先事項。とは言え、今後も実務でAWSを使っていく手前、興味が湧いたトピックは余計に調べたりもした。なお、タイトルにもある「20時間」というのは机上の勉強時間の合計時間。並行して実務で何十時間も触ったり、技術調査したりしているので、そういう環境にいない人にとってこの時間は参考にならないかもしれない。
ざっくりした勉強の流れは以下の通り。(1)黒本を読む(4時間)
⇒内容の70%を理解する、くらいの気持ちでとにかくさっさと読む。4時間くらいで1周した。「4時間で読むこと」よりも「70%理解すること」が大事。(2)定番のWEB問題集を半周する(15時間)
⇒有料だがこのWEB問題集を解く学習方法が最も効率的。ただこのWEB問題集はチート問題集ではないということを理解して活用すること。問題がそのまま本試験に出るとかはなく(類似問題はある)、あくまで効率的な学習を目的としている。問題を解きながら理解が浅いと感じたトピックについては公式の資料と動画等で確認しながら進める。
ちなみに自分はWEB問題集を半周したくらいで「もういいかな」という感覚になったが、これは経験値によって変わるはずので鵜呑みにしないこと。インフラ設計の経験や知識が少ない方ならば繰り返し問いたりして、本質的な理解を深める工夫が必要になると思う。(3)公式模擬試験を受験(30分)
⇒とりあえず8割取れていたので勝手に安心して本試験の申込みをした。ただ多くの方が仰る通り、模擬試験は本試験に比べてかなり簡単なのでここでギリギリだった場合はもう少し勉強した方がいいかもしれない。次の目標
せっかくなのでSAP取得。その前に秋の情報処理でネスペ。
- 投稿日:2019-08-04T06:13:54+09:00
AWS EC2, Cloud9 composer create-project でメモリ足りない問題の対策
AWS EC2 や Cloud9 で
composer create-projectコマンドでLaravelをインストールする際メモリ不足で失敗する場合があります。環境
- OS: CentOS7.6
Linuxであれば同様の手順でSwapを設定できると思います。
エラー
$ composer create-project --prefer-dist "laravel/laravel=5.8.*" . The following exception is caused by a lack of memory or swap, or not having swap configured Check https://getcomposer.org/doc/articles/troubleshooting.md#proc-open-fork-failed-errors for detailsSwapがないことの確認
Swapを確認する方法は3つあります。(他にもあったら教えてください)
free コマンド
$ free -m total used free shared buff/cache available Mem: 989 71 633 12 284 718 Swap: 0 0 0Swap が 0 になっていること
/proc/meminfo
$ cat /proc/meminfo (一部省略) MemTotal: 1013196 kB MemFree: 648760 kB MemAvailable: 735956 kB Buffers: 0 kB Cached: 208092 kB SwapCached: 0 kB SwapTotal: 0 kB SwapFree: 0 kBSwapTotal と SwapFree が 0 になっていること
/proc/swaps
$ cat /proc/swaps Filename Type Size Used PrioritySwapが結果に出てこないこと
swapファイル領域を確保
$ sudo /bin/dd if=/dev/zero of=/swap bs=1M count=1024 1024+0 レコード入力 1024+0 レコード出力 1073741824 バイト (1.1 GB) コピーされました、 12.9409 秒、 83.0 MB/秒$ ls -lh /swap -rw-r--r--. 1 root root 1.0G 8月 4 05:52 /swap1G分の領域が確保されました。
パーミッションを変更
$ sudo chmod 600 /swap $ ls -lh /swap -rw-------. 1 root root 1.0G 8月 4 05:52 /swaprootユーザーのみ読み書きできるようにします。
swapの作成(ファイルシステムをswapにする)
$ sudo mkswap /swap スワップ空間バージョン1を設定します、サイズ = 1048572 KiB ラベルはありません, UUID=8bf61268-456b-4bd4-a9ac-9adf03415098swapの有効化
$ sudo swapon /swapSwapがあることの確認
$ free -m total used free shared buff/cache available Mem: 989 68 80 12 840 718 Swap: 1023 0 1023/proc/meminfo
$ cat /proc/meminfo | grep Swap (一部省略) MemTotal: 1013196 kB MemFree: 82220 kB MemAvailable: 735656 kB Buffers: 0 kB Cached: 768612 kB SwapCached: 0 kB SwapTotal: 1048572 kB SwapFree: 1048572 kB/proc/swaps
$ cat /proc/swaps Filename Type Size Used Priority /swap file 1048572 0 -2Laravelのインストールを再実行する
$ composer create-project --prefer-dist "laravel/laravel=5.8.*" .問題なくインストールできればokです。
Swap領域の無効化
$ sudo swapoff /swap $ sudo rm /swapSwap領域を残しておくとそれだけディスク容量を使ってしまうので、今度はディスク足りない問題が発生するかもしれません。(デフォルト8GBだったと思うので)
今回はSwap領域を無効化、Swapファイルの削除をしておきましょう。
補足
swapの永続化
システムを再起動した場合、swap領域が無効化されてしまいます。
永続化するためには、viなどで/etc/fstabを開き下記の1行を追記する必要があります。/swap swap swap defaults 0 0今回は
composer create-projectコマンド実行時にエラーとなったので、インストールできたらswapは不要になるので永続化の必要ありません。参考記事
- 投稿日:2019-08-04T01:15:51+09:00
Terraformのコンポーネント分割について検討する
はじめに
こんにちわ。Wano株式会社エンジニアのnariと申します。
前回のmoduleの記事に引き続き、terraformの話を記事にしたいと思います。
今回はtfstateをどの単位で分割し管理するか、というコンポーネント分割問題に関して書いていきます。ただし、今回の記事の構成はプロジェクトの一旦の落とし所であって、ベストな構成とは限らないのでご了承ください。
対象読者
- モノシリックなtfstateの管理が辛い方
- コンポーネント分割の粒度に同じく悩んでいる方
前提
- 筆者のプロジェクトのサービスはAWS上で構築しているため、providerはAWS
何故コンポーネントを分割するのか
- terraformの結果ファイル(tfstate)をモノシリックにするのは怖い
- 変更の影響範囲が読めない
- ファイル自体の可読性が終わる
- かといってawsサービスごとに分けると、細かくなりすぎて運用がかなり煩雑になる(makefileやterragruntなどのツールでカバーしても)
分割する際の視点
- 安定度
- ステートフル
- 影響範囲
- 組織のライフサイクル
- 関心ごとの分離
- 依存関係の制御
(Pragrmatic Terraform on AWS 17章より)
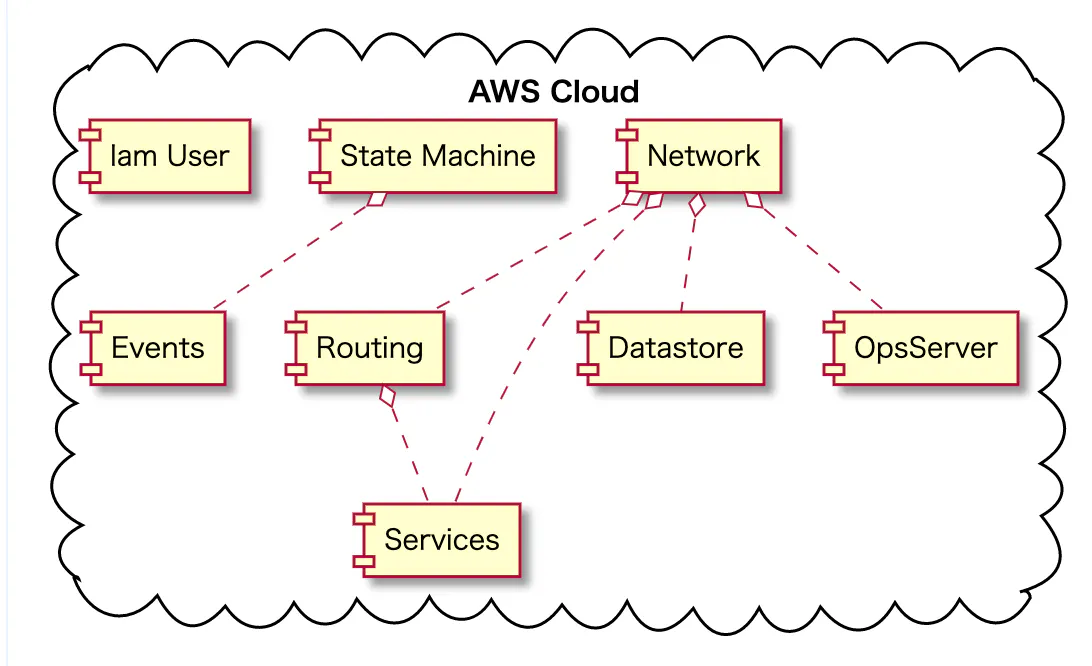
コンポーネント分割の全体像
どのように上記の分割に行き着いたか
分割する際の視点を利用し、現実的に分割粒度を検討していった
- 安定度 高
- network(vpc,subnet周辺)
- 安定度 低
- routing(route53,alb,acm)
- 関心ごとの分離
- services ecsのサービス単位(ecs cluster,taskdifinition,service,それに付随するec2系リソース ecr pipeline系)
- opsserver(session manager,ec2)
- events やりたい処理単位(lambda cloudwatchEvents ここはApex+Terraform)
- モニタリングとかもここに
- state machine(step function)
- ステートフル
- storage(s3)
- 依存関係を制御できる自信がない+複数の関心ごとの対象となるストレージが出てこなさそうなので、backend以外全て他のコンポーネントに寄せることとする(今回はコンポーネントとして登場させない)
- datastore(elasticache,RDS)
- elasticache,RDSを別々に管理する(それぞれクラスターごとに)
組織のライフサイクル
- iam user
依存関係の制御
- コンポーネント図を起こし、terragrunt.hclのdependenciesでしっかり管理する
terragrunt.hcldependencies { paths = ["../../network","../../routing"] }課題
- iam roleやpolicyの管理をそれぞれのコンポーネントに寄せてしまっているので、同じようなpolicyが量産されてしまう
- ストレージはステートフルとは言え、それぞれ独立したコンポーネントで管理すると、今度は依存関係の管理でかなり疲弊することになるので、個別管理できていない
- そもそもここまで厳密にコンポーネントを分割して運用している例を見ない(メルカリさんなどの例でも、マイクロサービス毎くらいにしか管理していないぽい)
その他
Q.こんなに分割するとデプロイの運用がめんどくさいのでは?
A.そこまで面倒臭くはない。
- terragruntというツールを使うと、それぞれのサブディレクトリでplanやapplyを打ってくれるplan-allやapply-allが使えるようになるので、コマンド一発の運用に集約できる
- 前述したterragrunt.hclという設定ファイルでコンポーネント間の依存関係も管理できる
- CIでもterragrunt plan-allをdindで唱えて差分チェックをしている(sampleのdockerfileはこちら)
- codebuildでのdindの設定に関してはこちらの記事参照
終わりに
皆さんのプロジェクトでのコンポーネント分割粒度についても教えていただけると大変嬉しいです。
よろしくお願いいたします。参考文献
terraformはどの単位で分割すべきか - Qiita
オレオレterraformディレクトリ構成ベストプラクティス - Qiita
Terraformにおけるディレクトリ構造のベストプラクティス | DevelopersIO
Terraform Best Practices in 2017 - Qiita
Terraform 運用ベストプラクティス 2019 ~workspace をやめてみた等諸々~ - 長生村本郷Engineers'Blog