- 投稿日:2019-08-04T23:30:02+09:00
畳み込みニューラルネットワークは何を見ているか
1. はじめに
PyTorchの使い方にも少し慣れてきたので、arXivに公開されているディープラーニング関連の論文の実装にチャレンジをはじめました。まず今回はVisualizing and understanding convolutional networksを実装してみました。本論文はディープラーニングの可視化の文献としてよく参照されているので1、以前から興味がありました。
本論文の流れは、前半でCNNの可視化手法を中心に取り扱い、後半では構築したモデルのパフォーマンスを取り扱います。有名な論文ということもあり、Web上で日本語の解説もこちらに公開されています。
本論文の概要に関しては上記リンクの解説の通りなので、本記事では上記解説であまり触れられていない提案された可視化手法の実装に重点を置いて解説してみようと思います。
2. 本論文の概要
CNNは画像分類において高い精度を実現する一方、なぜそれが可能なのかがはっきりしていないという課題があります。本論文の前半では、中間層や分類器の動作を理解する手段として、CNNの各中間層で入力画像の最も反応している部分を可視化する方法が提案されています。
CNNでは入力画像から特徴マップが生成されますが、本論文ではその逆のプロセスとして任意の中間層の特徴マップから入力画像を復元する手法を利用します。
上記の手法では特徴マップ全体が復元対象ですが、ここではさらに工夫を加えます。復元したいCNNの各中間層の特徴マップに対して、活性度が最も高いpixelはそのままにし、それ以外の全てのpixelはすべて0となるように特徴マップを修正します。そしてこの修正された特徴マップに対して、上記手法を適用して入力画像の復元します。
この復元された入力画像は、中間層で最も反応している部分(=特徴マップにおいてもっとも大きな値を持つpixel)をもとに生成されています。つまり、これは入力画像から対象の中間層でもっとも反応した部分のみを抽出することに相当しています。本プロセスを入力層に近い中間層から順に適用していくことで、入力層側の浅い中間層から出力層側の深い中間層に進むにつれて、入力画像のどの部分に最も反応したかを確認することができます。
本論文では入力層に近い浅い中間層ほどコーナやエッジなど具体的な形状に強く反応する一方、出力層に近い深い中間層では犬やキーボードや人の顔などの抽象的な形状に反応していることが示されています。
下図Fig.2(本論文から抜粋)は、入力層に近い浅い中間層のLayer1から出力層に近い深い中間層のLayer5まで上記プロセスを行った結果です。左側の画像が復元された入力画像、右側が元の入力画像になります。深い層ほど抽象的なパターンが抽出できていることがわかります。
3. 取り組んでみたこと
次の4節では、中間層の特徴マップから入力画像を復元する提案手法で用いるMaxUnpooling処理およびDeconvolution処理の概要を記載しています。5節では本論文の提案手法を持ちいて各中間層の最も活性度が高いpixelを元に入力画像を復元してみました。どちらもPyTorchの充実したライブラリを利用することで極めて容易に実装できます。
4. MaxUnpooling処理およびDeconvolution処理
中間層の特徴マップから入力画像を復元する提案手法は、下図のFig.1に概要が記載されています。入力画像にConvolution(畳み込み)処理→ReLU関数→MaxPooling処理を適用して得た特徴マップを入力として、MaxUnPooling処理→ReLU関数→Deconvolution処理を順に適用することで入力画像を再現しています。すなわち復元処理ではConvolution処理にはDeconvolution処理を、ReLU関数には同じReLU関数を、MaxPooling処理にはMaxUnpooling処理を対応させています。
ここからは下の入力画像2を元にMaxUnpooling処理およびDeconvolution処理を見てみます。
4-1. MaxUnpooling処理
MaxUnpooling処理の概要を下図に載せました。左の3x3の入力に対して、カーネルサイズ2x2・ストライド1・パディング0としてMaxPool処理を適用すると中心の2x2の出力が得られます。これにカーネルサイズ2x2・ストライド1・パディング0のMaxUnpooling処理を適用すると、右のような3x3の出力が得られます。
MaxUnpooling処理はMaxPool処理の逆転に相当する処理です。しかし最大値以外の値は0となるため一部の情報は消失しまいます。MaxUnpoolingはPyTorchには既にMaxUnpool2dとして実装済みです。注意点としては、MaxUnpooling処理を行うには、MaxPool処理の適用時に最大値が存在したインデックスをindicesとして取得しておく必要があります。
MaxUnpooling処理の動作を確認するために、MaxPooling処理を行った画像にMaxUnpooling処理を行い元画像を復元してみました。下に処理の概要を抜粋しました。全体のソースコードはこちらにあります。
# MaxUnpooling処理の抜粋 # VGG16モデルの取得 model = models.vgg16(pretrained=True).eval() # indicesを取得するためにreturn_indicesを設定 for i, layer in enumerate(model.features): if isinstance(layer, torch.nn.MaxPool2d): layer.return_indices = True # VGG16のプーリング層の取得 maxpooling_layer = model.features[4] # MaxPooling処理の実施およびindicesの取得 maxpooling_result, indices = maxpooling_layer(input_img) # 入力画像→MaxPooling処理の可視化 visualize(maxpooling_result) # MaxUnpooling用のパラメータの取得 kernel_size = maxpooling_layer.kernel_size stride = maxpooling_layer.stride padding = maxpooling_layer.padding # MaxUnpooling層の作成 unpooling_layer = torch.nn.MaxUnpool2d(kernel_size, stride, padding) # indicesを指定してMaxUnpooling処理の実施 unpooling_result = unpooling_layer(maxpooling_result, indices) # 入力画像→MaxPooling処理→MaxUnpooling処理結果の可視化 visualize(unpooling_result)下が入力画像→MaxPooling処理を適用した結果です。MaxPooling処理の最大値のみを取得するという動作のため、全体的に画像が粗くなっているのがわかります。
下が入力画像→MaxPooling処理→MaxUnpooling処理を続けて行い、入力画像を復元した結果です。元画像の再現とならず画像に欠損が存在しています。
4-2. Deconvolution処理
Deconvolutionの説明はこちらやこちらにあります。DeconvolutionはPyTorchには既にConvTranspose2dとして実装済みです。CNNにおいて畳み込み処理(Convolution)を行うと、一般的に出力結果の画像の高さや幅は小さくなりチャネル数が増大するのですが、Deconvolution処理ではその逆になります。
特に下のように特徴マップの生成に用いたConvolution処理と同じパラメータを用いてDeconvolution処理を行うことで、特徴マップの入力画像と同じチャネル数と高さと幅を持つ画像を取得できます。
Deconvolution処理の動作を確認するために、Convlution処理を行った画像にDeconvolution処理を行い元画像を復元してみました。下に処理の概要を抜粋しました。全体のソースコードはこちらにあります。
# Deconvolution処理の抜粋 # VGG16モデルの取得 model = models.vgg16(pretrained=True).eval() # VGG16の畳み込み層の取得 conv_layer = model.features[0] # 畳み込み処理の実施 conv_result = conv_layer(input_img) # Deconvolution用のパラメータの取得 in_channels = conv_layer.out_channels out_channels = input_img.shape[1] kernel_size = conv_layer.kernel_size stride = conv_layer.stride padding = conv_layer.padding # Deconvolution層の作成 deconv_layer = torch.nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride, padding) deconv_layer.weight = conv_layer.weight # Deconvolution処理の実施 deconv_result = deconv_layer(conv_result) # 入力画像→Convolution処理→Deconvolution処理結果の可視化 visualize(deconv_result)MaxUnPooling処理と同じく、入力に対してConvolution処理→DeConvolution処理を続けた結果は、元の入力の完全な再現とならず情報の欠落が発生します。
下が入力画像→Convolution処理→Deconvolution処理を適用して入力画像を復元した結果です。全体的に画像が薄くなっているのがわかります。
5. 再現確認
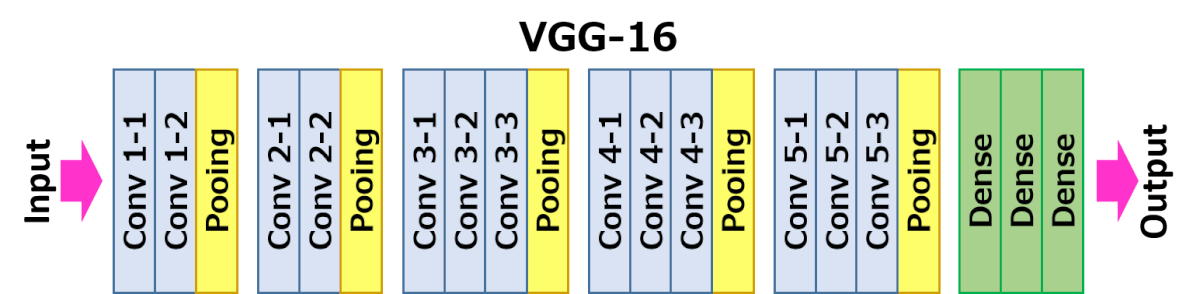
実際に本論文の提案手法を試してみました。ソースコードはこちらにあります。今回の実装ではPyTorchの学習済みモデルのVGG-16を利用しました。VGG−16には下のように全部で5つのMaxPooling層があります。各MaxPooling層経由後に特徴マップから元の入力画像を再現してみました。
入力画像は下のアメリカン・ショートヘアーの画像を利用しました。
入力画像の再現において、A.特徴マップ全体を用いた入力画像の再現と、B.特徴マップ中から値が最大となるpixelのみを用いた入力画像を再現を記載しています。以降の5-1から5-4において上の画像がAに下の画像がBに対応しています。
AとBのどちらにおいても再現する層が深くなるほど、MaxUnpooling処理やDeconvolution処理を行う回数が多くなるため再現された画像が不鮮明となっています。またCNNの各層において入力画像のどこに最も強く反応したのかを意味する下側のBに着目すると5-3.では目に、5-4.では耳に、5-5.では顔に反応しているのがわかります。
これらからCNNの層が深くなるほど、入力画像においてより複雑で抽象度の高いパターンに強く反応していることが可視化されています。
5-1. 1つめのMaxPooling層経由後
5-2. 2つめのMaxPooling層経由後
5-3. 3つめのMaxPooling層経由後
5-4. 4つめのMaxPooling層経由後
5-5. 5つめのMaxPooling層経由後


















- 投稿日:2019-08-04T23:21:53+09:00
3種類の基底関数によるベイズ線形回帰の実装
はじめに
この記事は古川研究室 Workout_calendar 20日目の記事です。
本記事はベイズ線形回帰の実装をメインに行っています。理論式の方は途中計算を省いていますので、うまく計算したら次の式になるんだな程度にお考え下さい。詳しい式の導出は 最尤推定、MAP推定を用いたパラメトリック回帰(12日目の記事)にて説明します!実装に必要なベイズ線形回帰の式
まずは、ベイズ線形回帰の予測分布の求め方を説明します。
ベイズ線形回帰は新しい観測値(測定値) $x_{new}$ を入力としたときに出力である推定値 $y_{new}$ の確率を関数のパラメータをデータセットから推定することで求めるものです。まず、正規分布 $N(x|\mu,σ^2)$ の式は以下になります。
$σ^2=$ 分散$,$ $μ=$ 平均N(x|\mu,σ^2)=\frac{\displaystyle1}{\displaystyle\sqrt{2π\sigma^2}}\exp\left\{-\frac{\displaystyle(x-μ)^2}{\displaystyle 2σ^2}\right\}以上を踏まえた上で
X=\left\{(x_{1},y_{1}),(x_{2},y_{2})....(x_{n},y_{n})\right\}$X$=データセット
$w=$ パラメータ(ベクトルです)
$φ(x)=$ 基底関数(実装では$w,φ(x)$は10次元ベクトルとしてます)このときの予測分布
$p(y_{new}|x_{new},X) =\underline{N(y_{new}|m^Tφ(x_{new}) ,β+φ(x_{new})^TSφ(x_{new}))}$
を求めていきます。$\beta$ と $φ(x)$はこちらで設定するので、事後分布の平均$m$と分散$S$を求めれば予測分布を求めることができます。
まず事後分布$p(w|X)$を求めます。事後分布$p(w|X)$はベイズの定理より$p(w|X)=\frac{\displaystyle p(y|x,w)p(w)}{\displaystyle p(y|x)}$
となります。右辺の $p(y|x,w)$ は尤度で $p(w)$は事前分布です。また、どちらともガウス関数に従うと仮定します。予めこちらでパラメータ値を設定する必要があり、設定するパラメータは平均と分散です。計算の簡略化のため平均$μ=0$としてます。
$p(w)=N(w|μ,α^{-1}I)$
パラメーターはガウス関数(平均$μ=0$,分散$=α^{-1}I$)ここでは$f(x)=w^Tφ(x)$
$p(X|w)=N(y_{n}|f(x_{n}),β^{-1})=\sqrt\frac{β}{2π}\exp\left[-\frac{β}{2}(w^Tφ(x_{n})-y_{n})^2\right]$よって事後確率は次のようになります。
$p(w|X)\propto p(X|w)p(w)$
$=\left(p(y_{1}|x_{1},w)×…×p(y_{n}|x_{n},w)\right)×p(w)=\left({\displaystyle\prod_{n=1}^{N}p(y_{n}|x_{n},w)}\right)×p(w)$
$\ln p(w|X)=\displaystyle-\frac{1}{2}w^T(\beta\Phi^T\Phi+\alpha I)w+(\beta y^T\Phi)w+const$ここで、事後確率は平均 $m$ 分散 $S$ の正規分布となるので
$p(w|X)=N(w|m,S)$
となります。対数をとると
$\ln p(w|X)=-\displaystyle\frac{1}{2}(w-m)^TS^{-1}(w-m)+const$この式を先ほど求めた$\ln p(w|X)$ と係数を比較することで事後確率の平均と分散が求まります。
$S=(\beta \Phi^T\Phi+\alpha I)^{-1}$
$m=(\Phi^T\Phi+\lambda I)^{-1}\Phi^Ty$
$\lambda=\frac{\alpha}{\beta}$以上により予測分布$\underline{N(y_{new}|m^Tφ(x_{new}) ,β+φ(x_{new})^TSφ(x_{new}))}$が求まります。
$p(y_{new}|x_{new},X) = \displaystyle\int p(y_{new}|x_{new},w)p(w|X)dw=\underline{N(y_{new}|m^Tφ(x_{new}) ,β+φ(x_{new})^TSφ(x_{new}))}$
Pythonで実装していきましょう!
ベイズ線形回帰をPythonで実装しました。実装には参考文献を大いに参考させて頂きました。
実装の流れは以下です。予測する真の関数を定義
↓
真の関数にノイズをのせて15個プロット
↓
基底関数を定義(3種類)
↓
計画行列の作製
↓
事前分布のパラメーター設定
↓
事後確率を計算
↓
グラフ化$p(y_{new}|x_{new})=\underline{N(y_{new}|m^Tφ(x_{new}) ,β+φ(x_{new})^TSφ(x_{new}))}$
目標は下線の正規分布を作って$(x_{new},y_{new})$として$x$軸の$0~1$の値と$y$軸の$-1.5~1.5$を代入することです。正規分布の分散と平均に含まれている変数は以下です。$\alpha$ と $\beta$ はハイパーパラメータなので事前にこちらで設定しておく必要があります。
$\Large平均:\large m^Tφ(x_{new})$
$φ(x):$基底関数
$m:$事後確率の平均
$m=(\Phi^T\Phi+\displaystyle\frac{α}{β}I)^{-1}\Phi y$
$α:$パラメータ $w$ の事前確率の分散の逆数
$\Phi=(φ(x_{1}),...φ(x_{n}))$$\Large分散:\large β+φ(x_{new})^TSφ(x_{new})$
$β:$尤度の分散の逆数
$φ(x):$基底関数
$S:$事後確率の分散
$S=(β\Phi^T\Phi+αI)^{-1}$これらの値を求めることで、グラフ化していきます。
今回はガウス関数,sin関数,多項式を基底関数としてそれぞれグラフ化しました。実行結果を以下に示します。ガウス関数を基底関数に選んだ時が一番うまくフィッティング出来ています。またベイズ線形回帰では予測した結果の平均、分散がわかるので予測結果にどのくらい自信があるのかが分かります。線形回帰では得られないメリットです。
ここからpythonでのプログラムを示していきます。
まずは恒例のおまじないです。import numpy as np import matplotlib.pyplot as plt import scipy.stats as stats plt.style.use("ggplot")つぎにデータ点を作成します。
真の関数は $\cos(3\pi x)$ で、15個のデータ点にはノイズを加えています。n = 15 X = np.random.uniform(0, 1, n) T = np.cos(3 * np.pi * X) + np.random.normal(0, 0.1, n)基底関数は3つ用意しました。(※$\theta$はパラメーターです。)
重みと基底はそれぞれ10個あります。ガウス関数
y=\theta_{0}\exp\left\{-\frac{\displaystyle(x-μ_{0})^2}{\displaystyle 2σ^2}\right\}+\theta_{1}\exp\left\{-\frac{\displaystyle(x-μ_{1})^2}{\displaystyle 2σ^2}\right\}+...+\theta_{n}\exp\left\{-\frac{\displaystyle(x-μ_{2})^2}{\displaystyle 2σ^2}\right\}sin関数
$y=\theta_{0}\sin(x\pi)+\theta_{1}\sin(2x\pi)+...+\theta_{n}\sin(nx\pi)$多項式
$y=\theta_{0}+\theta_{1}x+\theta_{2}x^2+...+\theta_{n}x^n$def phi(x):#基底関数:ガウス関数 h = 0.1 return np.exp(-(x - np.arange(0, 1, 0.1))**2/(2*h **2)) def phi2(x):#基底関数:sin関数 m = 10 return np.sin(x*np.pi*np.arange(0,m)) def phi3(x):#基底関数:多項式 m = 10 return x**np.arange(0,m)計画行列を作ります。($\Phi$ のことです)
基底関数が3つあるので計画行列も3つ作ります。Phi = np.array([phi(x) for x in X]) #ガウス関数の計画行列 Phi2 = np.array([phi2(x) for x in X]) #sin関数の計画行列 Phi3 = np.array([phi3(x) for x in X]) #多項式の計画行列次にハイパーパラメータを設定します。
これはグラフ化した結果を見ながら、うまくいくように値を設定すればいいです。M = 10 #基底の数 alpha = 0.01 beta = 9.0事後分布の平均と分散です。
$m=(\Phi^T\Phi+\displaystyle\frac{α}{β}I)^{-1}\Phi y$
$S=(β\Phi^T\Phi+αI)^{-1}$#平均 m = beta * S.dot(Phi.T).dot(T) #ガウス関数の平均 m2 = beta * S2.dot(Phi2.T).dot(T) #sin関数の平均 m3 = beta * S3.dot(Phi3.T).dot(T) #多項式の平均 #分散 S = np.linalg.inv(alpha * np.eye(M) + beta * Phi.T.dot(Phi)) #ガウス関数の分散 S2 = np.linalg.inv(alpha * np.eye(M) + beta * Phi2.T.dot(Phi2)) #Sin関数の分散 S3 = np.linalg.inv(alpha * np.eye(M) + beta * Phi3.T.dot(Phi3)) #多項式の分散では、予測分布を求めましょう。
$p(y_{new}|x_{new})=N(y_{new}|m^Tφ(x_{new}) ,β+φ(x_{new})^TSφ(x_{new}))$
def sigma(x): return 1.0/ beta + phi(x).dot(S).dot(phi(x)) def norm(x,y): #ガウス基底関数での予測関数 return stats.norm(m.dot(phi(x)), sigma(x)).pdf(y) def sigma2(x): return 1.0/ beta + phi2(x).dot(S2).dot(phi2(x)) def norm2(x,y): #sin基底関数での予測関数 return stats.norm(m2.dot(phi2(x)), sigma2(x)).pdf(y) def sigma3(x): return 1.0/ beta + phi3(x).dot(S3).dot(phi3(x)) def norm3(x,y): #多項式基底での予測関数 return stats.norm(m3.dot(phi3(x)), sigma3(x)).pdf(y)最後にグラフ化です。
グラフ化にはまずメッシュを作ります。x_, y_ = np.meshgrid(np.linspace(0 ,1 ,100), np.linspace(-1.5, 1.5,80))次にそれぞれの関数を出力していきます。
Z = np.vectorize(norm)(x_,y_) Z2 = np.vectorize(norm2)(x_,y_) Z3= np.vectorize(norm3)(x_,y_) y = [m.dot(phi(x__)) for x__ in x] y2 = [m2.dot(phi2(x__)) for x__ in x] y3 = [m3.dot(phi3(x__)) for x__ in x] plt.figure(figsize=(16, 10)) #ガウス基底関数 plt.subplot(2,2,1) plt.xlim(0, 1) plt.ylim(-1.5, 1.5) plt.pcolor(x_, y_, Z,cmap='jet',alpha=0.2) plt.colorbar() plt.scatter(X, T) plt.plot(np.linspace(0,1), np.cos(3 * np.pi * np.linspace(0,1)), c ="royalblue") plt.plot(x, y) plt.title("Gaussian basis function") #多項式基底関数 plt.subplot(2,2,2) plt.pcolor(x_, y_, Z3,cmap='jet',alpha=0.2) plt.colorbar() plt.xlim(0, 1) plt.ylim(-1.5, 1.5) #点のプロット plt.scatter(X, T) plt.plot(np.linspace(0,1), np.cos(3 * np.pi * np.linspace(0,1)), c ="royalblue") #予測関数のプロット plt.plot(x, y3) plt.title("Polynomial basis function") #sin基底関数 plt.subplot(2,2,3) plt.pcolor(x_, y_, Z2,cmap='jet',alpha=0.2) plt.colorbar() plt.xlim(0, 1) plt.ylim(-1.5, 1.5) #点のプロット plt.scatter(X, T) #予測関数をプロット plt.plot(x, y2) plt.title("Sine basis function") #真の関数プロット plt.plot(np.linspace(0,1), np.cos(3 * np.pi * np.linspace(0,1)), c ="royalblue") plt.show() for m_ in m_list: x = np.linspace(0,1) y = [m_.dot(phi(x__)) for x__ in x] plt.plot(x, y, c = "r") plt.plot(np.linspace(0,1), np.cos(3 * np.pi * np.linspace(0,1)), c ="g") plt.show()最後に余談ですが、
3次元にプロットするとこうなります。$\cos$関数の山脈ができます。$x,y$軸は$\cos$関数の値を示しています。z軸は分散の逆数です。
3D表示にするには以下のプログラムを加えて下さい。
from mpl_toolkits.mplot3d import Axes3D from matplotlib import cm from matplotlib.ticker import LinearLocator, FormatStrFormatter fig = plt.figure() ax = fig.gca(projection='3d') surf = ax.plot_surface(y_, x_, Z2, cmap=cm.coolwarm, linewidth=0, antialiased=False) # Customize the z axis. ax.set_zlim(0, 10) ax.zaxis.set_major_locator(LinearLocator(10)) ax.zaxis.set_major_formatter(FormatStrFormatter('%.02f')) # Add a color bar which maps values to colors. fig.colorbar(surf, shrink=0.5, aspect=5) plt.show()おわりに
本記事では実装をメインに説明してきました。なかなか理論式だけを追っかけてみても、いまいち理解できないところや、ここの値は何を意味しているのかなどの疑問を解消するのは難しいです。私がそうでした。コードをいじってみることで理解を深めていければと思います!


- 投稿日:2019-08-04T23:07:39+09:00
ABC136反省会
ABC136反省会
Cで2ミス、Dが間に合わず、終了10分後にAC
戒めの意味で公開
A
https://atcoder.jp/contests/abc136/submissions/6683489
B
https://atcoder.jp/contests/abc136/submissions/6688327
C
WA https://atcoder.jp/contests/abc136/submissions/6696185
TLE https://atcoder.jp/contests/abc136/submissions/6698030
https://atcoder.jp/contests/abc136/submissions/6698654
このタイプ毎回TLEやらかすの学んでなさすぎ馬鹿
D
https://atcoder.jp/contests/abc136/submissions/6712874
一発OKだけど実装遅すぎるし汚い
C, Dのメモ
https://drive.google.com/open?id=1_89_8WNZ7tTYV5JmBzoOt1g4-_MsyH7H
- 投稿日:2019-08-04T22:50:26+09:00
NotebookのServerlessバッチジョブ化
はじめに
Jupyter Notebookで作成したPythonコードをAWSマネージドサービスを利用してバッチジョブ化できないかと思い試してみました。
用意したもの
- AWS CLI
- Papermill(Notebookの実行に利用)
- Jupyter Notebook
- Docker
環境
- Jupyter Notebookサーバー(EC2)
- ECS
- ECR
- Step Functions
- CloudWatch
やったこと
- Notebookファイル作成
- Dockerイメージ作成
- S3へのNotebookファイル保存
- IAMロール作成
- ECSタスク作成
- StepFunctionsステートマシーン作成
※ECSクラスターやVPC,Subnetなど諸々は事前に作成していたものを利用しました。
処理フロー
- CloudWatchEventsのインプットにPapermillのパラメーターを設定
- CloudWatchEventsから10分にStepFunctionsステートマシーンを実行
- StepFunctionsステートマシーンからECSタスクを実行
- ECSタスクにてPapermillを実行
- PapermillからS3にNotebook実行結果が保存される
詳細
Notebookファイル作成
Jupyter Notebook上でパラメーター付きのNotebookファイルを作成
※nteractだとセルの右上から"Toggle Parameter Cell"の選択でパラメーター化できました。
パラメーターセルmsg = "Hello, World!"プログラムprint(msg)Dockerイメージの作成&Push
DockerfileFROM python:3 RUN pip install papermill[all] RUN pip install jupyterDokerイメージ作成&Push$(aws ecr get-login --no-include-email --region ap-northeast-1) docker build -t xxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/papermill ./ docker push xxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/papermill:latestS3 Bucket作成&Notebookファイルコピー
SAM,INPUT/OUTPUT用のBucketを作成
aws s3 mb s3://${SAM_BUCKET} aws s3 mb s3://${INPUT_NOTEBOOK} aws s3 mb s3://${OUTPUT_NOTEBOOK}S3へファイルをコピー
shell-session
aws s3 cp HelloWorld.ipynb s3://${INPUT_NOTEBOOK}/HelloWorld.ipynb
IAMロール,ECSタスク,StepFunctionsステートマシーン,CloudWatch Events作成
CloudFormationを利用したため、テンプレートファイルを作成
template.yamlAWSTemplateFormatVersion : '2010-09-09' Transform: AWS::Serverless-2016-10-31 Parameters: S3RolePolicyName: Type: String Default: hello-s3 HelloWorldTaskExecutionRoleName: Type: String Default: hello-taskexec HelloWorldECSTaskName: Type: String Default: HelloWorldTask HelloWorldInvocationRoleName: Type: String Default: HelloWorld-Invocation ImageRepoURI: Type: String Default: xxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/papermill:latest InputS3FileURI: Type: String Default: s3://xxxxxxxxx/HelloWorld.ipynb OutputS3FileURI: Type: String Default: s3://xxxxxxxxx/output.ipynb MsgParameter: Type: String Default: "Hello,Papermill" ClusterArn: Type: String Default: arn:aws:ecs:ap-northeast-1:xxxxxxxxx:cluster/xxxxxxxxx SubnetID: Type: AWS::EC2::Subnet::Id Default: subnet-xxxxxxxxx Resources: #ECSタスクからのS3アクセス用ロール作成 HelloWorldS3BucketRole: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Principal: Service: - ecs-tasks.amazonaws.com Action: - sts:AssumeRole Policies: - PolicyName: !Ref S3RolePolicyName PolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Action: - s3:PutObject - s3:GetObject - s3:ListBucket - s3:DeleteObject - s3:PutObjectAcl Resource: "*" HelloWorldTaskExecutionRole: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Principal: Service: - ecs-tasks.amazonaws.com Action: - sts:AssumeRole Policies: - PolicyName: !Ref HelloWorldTaskExecutionRoleName PolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Action: - ecr:GetAuthorizationToken - ecr:BatchCheckLayerAvailability - ecr:GetDownloadUrlForLayer - ecr:BatchGetImage - logs:CreateLogStream - logs:PutLogEvents Resource: "*" #ECSタスク作成 HelloWorldECSTask: Type: AWS::ECS::TaskDefinition Properties: ContainerDefinitions: - Name: !Ref HelloWorldECSTaskName Image: !Ref ImageRepoURI Memory: 500 Command: - "papermill" - !Ref InputS3FileURI - !Ref OutputS3FileURI Cpu: 256 Memory: 512 NetworkMode: awsvpc RequiresCompatibilities: - FARGATE TaskRoleArn: !GetAtt [ HelloWorldS3BucketRole, Arn ] ExecutionRoleArn: !GetAtt [ HelloWorldTaskExecutionRole, Arn ] #StepFunctionからのECSタスク実行用ロール作成 HelloWorldTaskExecution: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Principal: Service: - !Sub states.amazonaws.com Action: sts:AssumeRole Policies: - PolicyName: StatesExecutionPolicy PolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Action: - iam:PassRole - ecs:DescribeTasks - events:PutTargets - events:PutRule - events:DescribeRule - ecs:RunTask - ecs:StartTask - ecs:StopTask Resource: "*" #StepFunctionsステートマシーン作成 HelloWorldStateMachine: Type: AWS::StepFunctions::StateMachine Properties: DefinitionString: !Sub - |- { "Comment": "A Hello World example using an AWS ECS function", "TimeoutSeconds": 3600, "StartAt": "HelloWorld", "States": { "HelloWorld": { "Type": "Task", "Resource": "arn:aws:states:::ecs:runTask.sync", "Parameters": { "LaunchType": "FARGATE", "Cluster": "${ClusterArn}", "TaskDefinition": "${TaskArn}", "Overrides": { "ContainerOverrides": [ { "Name": "${HelloWorldECSTaskName}", "Command.$": "$.Command" } ] }, "NetworkConfiguration": { "AwsvpcConfiguration": { "Subnets": [ "${SubnetID}" ], "AssignPublicIp": "DISABLED" } } }, "End": true } } } - { TaskArn: !Ref HelloWorldECSTask } RoleArn: !GetAtt [ HelloWorldTaskExecution, Arn ] #CloudWatchからのStepFunctionsステートマシーン実行用ロール作成 HelloWorldInvocationRole: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Principal: Service: - events.amazonaws.com Action: - sts:AssumeRole Policies: - PolicyName: !Ref HelloWorldInvocationRoleName PolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Action: - states:StartExecution Resource: !Ref HelloWorldStateMachine #CloudWatch Eventsのルール作成 HelloWorldSchedule: Type: AWS::Events::Rule Properties: Description: ScheduledRule ScheduleExpression: "rate(10 minutes)" State: ENABLED Targets: - Arn: !Ref HelloWorldStateMachine Id: StepFunctionExecV1 RoleArn: !GetAtt [HelloWorldInvocationRole, Arn] #InputとしてESCタスクのコマンドを文字列として設定 #ここでPapermillのパラメーターを設定 Input: !Sub "{\"Command\": [\"papermill\",\"${InputS3FileURI}\",\"${OutputS3FileURI}\",\"-p\",\"msg\",\"${MsgParameter}\"]}"参考
Beyond Interactive: Notebook Innovation at Netflix : https://medium.com/netflix-techblog/notebook-innovation-591ee3221233

- 投稿日:2019-08-04T22:04:02+09:00
【深層強化学習】Double DQN、Dueling Networkを実装してDQNと比較してみた
Pytorchで書いた自作DQNでCartPoleを学習させた記事の続編になります。
DQNの代表的な改良手法であるDouble DQNとDueling Networkを実装し、CartPoleを画像から学習させてみました。実装にはPytorchを使用しています。
本記事では、それぞれのについて簡単に説明し、バニラのDQNの学習結果と比較します。DQN
前回ではCartPole-v0を学習させましたが、性能比較をしやすくするため、今回はCartPole-v1を学習させます。
v0とv1の違いはエピソードが終わるステップ数で、v0では200ステップ、v1では500ステップになったら成功扱いとなりエピソードが終わります。つまり、長い時間ポールを立たせる必要のあるv1の方が難易度が高いです。また、前回同様、CartPoleの直近4フレームの画像を状態として学習させています。
このような状態にした理由は、Atariの学習を模倣したかったことと、カートやポールの速度などを状態にしたら簡単に学習出来てしまうため、今回紹介する改良手法とバニラのDQNの差が出なくなることがモチベーションとしたあったからです。
前回からの変更
前回とは実装、学習、評価のやり方を以下のように変更しています。各変更の説明は割愛します。
・学習の回数をエピソード数ではなく、ネットワークの更新回数で管理する
・報酬設計(495ステップ以内にエピソードエンド→-1, それ以外→+0.01)
・2フレーム間連続して同じ行動を取るようにする
・ハイパパラメータの変更(target_update_frequency=5000, update_frequency=1)
・Experience Replayの実装方法
・動画保存などの記録部分を環境のラッパークラスで行う学習結果
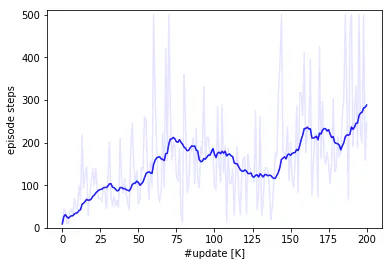
CartPole-v1の強化学習において、1000回のネットワーク更新ごとにgreedy方策によるエピソードを実行し、そのエピソードのステップ数を記録しました。全部で200,000回ネットワークを更新しています。
図の横軸の単位はK(キロ)回であり、薄い青線が記録したステップ数、濃い青線がステップ数を過去20回分の平均を計算して平滑化した値を示しています。episode stepsの値はどのくらい長くポールの直立状態を維持できているかを表しており、更新回数が増えるごとにポールを立てるのがうまくなっていることが分かります。プロット図を見る限りまだ学習が進みそうな感じですが、時間の都合上200,000回のネットワーク更新で打ち切りました。
この結果をベースラインとして、これから紹介する手法を取り入れたときの結果と比較していきます。※補足ですが、私の環境(CPU:i7-7700、RAM:16GB、GPU:GTX 1070)でここまで学習するのに2時間30分ほどかかっています。
Double DQN
Double DQNとは、DQNにおけるtarget値の計算を改良する手法です。DQNでは、行動価値を推定するネットワークのパラメータとtarget値を計算するネットワークのパラメータを別々にし、行動価値推定用のネットワークのみを学習させ、一定周期で2つのパラメータを同期させます。Double DQNでもこの考え方は同様ですが、計算方法が普通のDQNと違っており、以下その違いについて説明します。
行動価値推定用のネットワーク、target値計算用のネットワークのそれぞれのパラメータを$\theta, \theta^{-}$とし、ネットワークを$Q_{\theta}, Q_{\theta^{-}}: S \times A \rightarrow \mathbb{R}$とします。$S$は状態空間、$A$は行動空間です。
強化学習では状態$s$、行動$a$の行動価値の推定値$Q_{\theta}(s, a)$がtarget値に近づくように学習が行われますが、そのの計算方法がDQNとDouble DQNで異なります。
次の数式において、$R$は報酬、$s'$は次の状態を意味しています。・DQNでのtarget値の計算
\begin{array}{ll} {\rm target} &= R + \gamma \, max_{a \in A} Q_{\theta^{-}}(s', a) \\ &= R + \gamma \, Q_{\theta^{-}}(s', {\rm argmax}_{a \in A}Q_{\theta^{-}}(s', a)) \end{array}target用$Q_{\theta^{-}}$によって得られた行動価値の最大値を計算することで、次の状態$s'$の状態価値を推定しています。
・Double DQNでのtarget計算用のネットワーク
{\rm target} = R + \gamma \, Q_{\theta^{-}}(s', {\rm argmax}_{a \in A}Q_{\theta}(s', a))行動価値推定用ネットワーク$Q_{\theta}$で得られた最適行動の行動価値をtarget用$Q_{\theta^{-}}$によって計算することで、$s'$の状態価値を推定しています。
論文1によれば、通常のDQNの計算では行動価値の推定が過大評価になりがちなのに対し、Double DQNの計算では過大評価な推定を抑えてより正確に推定されるそうです。
人間で例えるなら、自分で選んだ行動を自分で評価すると甘めな採点になるのに対し、他人が選んだ行動を自分が評価するときはしっかりとした採点になるということでしょうか。実装
DQNクラスを継承してtarget値を計算するメソッドを書き換えるだけです。
実装(見たい方は展開してください)
DQNとDouble DQNについて、異なる部分(target値の計算)のみ掲載します。
dqn.pyimport torch class DQN(object): """ 省略 """ def _compute_target(self, reward_batch, next_state_batch, terminal_batch): with torch.no_grad(): max_next_q_value = self.target_function(next_state_batch).max(dim=1, keepdim=True)[0] target = reward_batch + self.gamma * (1 - terminal_batch) * max_next_q_value return target class DoubleDQN(DQN): def _compute_target(self, reward_batch, next_state_batch, terminal_batch): argmax_action_batch = self._compute_q_values(next_state_batch, train=False).max(dim=1, keepdim=True)[1] #勾配を残さずに行動価値を計算する with torch.no_grad(): max_next_q_value = self.target_function(next_state_batch).gather(1, argmax_action_batch) target = reward_batch + self.gamma * (1 - terminal_batch) * max_next_q_value return targetdouble_dqn.pyimport torch from .dqn import DQN class DoubleDQN(DQN): def _compute_target(self, reward_batch, next_state_batch, terminal_batch): argmax_action_batch = self._compute_q_values(next_state_batch, train=False).max(dim=1, keepdim=True)[1] with torch.no_grad(): max_next_q_value = self.target_function(next_state_batch).gather(1, argmax_action_batch) target = reward_batch + self.gamma * (1 - terminal_batch) * max_next_q_value return target
学習結果
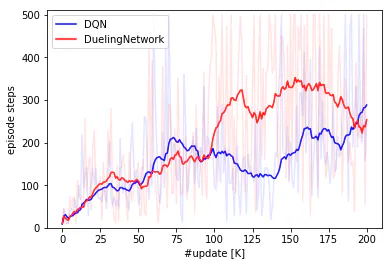
200,000回ネットワーク更新されるまで強化学習を行い、DQNでの学習結果と比較しました。
青線がDQN、赤線がDouble DQNの結果です。Double DQNの方がうまく学習しています。
Dueling Network
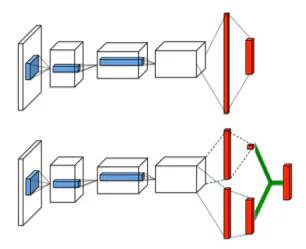
Dueling Networkとは、DQNに使用するニューラルネットワークの構造を改良する手法です。
通常のDQNでは、入力を状態、出力を各行動の行動価値とするニューラルネットワークを使用します。前回記事の構成では、入力された状態(=直近4回分の画像)が畳み込み層、全結合層を経て、行動数と同数のユニットを持つ出力層にfowardされ、それぞれのユニットが行動に対応する行動価値を出力していました。ここで、行動価値を直接推定するのではなく、状態の価値を差し引いた相対的な行動価値を推定するという発想で考えられたのがDueling Networkです。この相対的な行動価値をAdvantage値と呼びます。
Dueling Networkの構成では、畳み込み層の後にネットワークが分岐し、一方は行動数と同数のユニットで各行動に対応するAdvantage値を、もう一方は、1つのユニットで状態価値を出力します。
下図は論文2から引用した図で、上が通常の構成、下がDueling Networkの構成を表しています。
以下、Dueling NetwotkにおけるAdvantage値と行動価値について説明します。
Advantage値とは、行動価値$Q(s, a)$から状態価値$V(s)$を引いたもので、次のように定義されます。Adv(s, a) := Q(s, a) - V(s)よって、Dueling Networkから出力された$Adv(s, a)$と$V(s)$から行動価値を$Q(s, a) = V(s) + Adv(s, a)$と計算すれば良いのですが、このままでは$Adv(s, a)$と$V(s)$を一意に決めることが出来ず、学習の性能が悪くなります。
※例えば、$Q(s, a)=1.5$のとき、$V(s) = 1, Adv(s, a) = 0.5$や$V(s) = 0.5, Adv(s, a) = 1$などが考えられ、$Adv(s, a)$と$V(s)$が一意に決まりません。
そこで、実際には次の式で行動価値を計算します。
Q(s, a) = V(s) + Adv(s, a) - \frac{1}{|A|} \sum_{b \in A} Adv(s, b)この場合、$V(s), Adv(s, a)$が一意に決まるため、上記で述べたような学習性能の悪化を防ぐことが出来ます。
実装
ネットワーク構成の部分のみ掲載します。
実装(見たい方は展開してください)
class DuelingQNetwork(nn.Module): def __init__(self): super().__init__() # In shape : 4x84x84 self.conv1_layer = nn.Conv2d(4, 32, kernel_size=12, stride=4) #To 32x40x40 self.conv2_layer = nn.Conv2d(32, 64, kernel_size=6, stride=2) #To 64x18x18 self.conv3_layer = nn.Conv2d(64, 64, kernel_size=3, stride=1) #To 64x16x16 self.vstream_layer = nn.Linear(64*16*16, 512) self.vout_layer = nn.Linear(512, 1) self.astream_layer = nn.Linear(64*16*16, 512) self.aout_layer = nn.Linear(512, 2) def forward(self, x): x = x.view(-1, 4, 168, 168) h = self.conv1_layer(x) h = F.relu(h) h = self.conv2_layer(h) h = F.relu(h) h = self.conv3_layer(h) h = F.relu(h) h = h.view(-1, 64*16*16) #v_stream vh = self.vstream_layer(h) vh = F.relu(vh) v = self.vout_layer(vh) #advantage_stream ah = self.astream_layer(h) ah = F.relu(ah) a = self.aout_layer(ah) amean = a.mean(dim=1, keepdim=True) y = v + a - amean return y
学習結果
200,000回ネットワーク更新されるまで強化学習を行い、DQNでの学習結果と比較しました。
100K回更新以降、Dueling Networkでは高スコアを維持していますが、150K回あたりからスコアが悪化していき、200K回時点ではDQNに抜かれてしまいました。もっと学習を続けることで性能の優越がはっきりするのかもしれません。
おわりに
今回、Double DQNとDueling NetworkをPytorchで実装し、普通のDQNと性能を比較しました。
両者とも簡単に実装できるため、学習の性能を上げたい場合まず取り組んでみるべきものかもしれません。
次回は、Prioritized Experience Replayを実装して学習させてみたいと思います。


- 投稿日:2019-08-04T21:45:44+09:00
ラズパイ初心者がRaspberry Pi 3 Model B+とPythonを使ってLチカに挑戦してみた。
Raspberry Pi(通称ラズパイ)を始める方が、一番最初に恐る恐る挑戦するだろう「Lチカ」。
例に漏れず自分も挑戦することにしてみた。さて、ラズパイこそ初心者ではあるものの、普段電子工作を生業としているので幾分気は楽、だがどうしても最初は不安。
まずは先人の記録をパクらせて参考にさせてもらい、別なアプローチでのLチカも試してみたので学習記録として残しておく。
使用言語はPython。やりたいこと
下記先人の記録の後半にある、「LEDを点滅させる」動画のようなことをやりたい。
ラズパイでLチカをしてみる(入門編)
レッツラズパイ!〜Lチカ&Lピカをマスターしよう編〜準備した物
グーグル先生の助けを借り、必要な物としてこれらをリストアップ。
大半の方の手元にないであろう電子工作品類(②~⑤)は1000円程度で揃えられる。
No. 品名 数量 備考 ① Raspberry Pi 3 Model B+ 1 ② ブレッドボード 1 小さな物でOK ③ LED 1 安価な砲弾型 ④ 330Ω抵抗 1 小さな物でOK ⑤ ジャンパーワイヤー 2 オス~メスタイプ ⑥ マウス 1 まずはUSB対応品 ⑦ キーボード 1 まずはUSB対応品 ⑧ HDMIケーブル 1 ディスプレイ出力はHDMIのみ ⑨ HDMI対応ディスプレイ 1 ラズパイセットアップ
今回購入したのはこちら。
初心者にとっての鬼門である「SDカードへのOSインストール」が、ありがたいことにプロによって完了されている。
安心、安全をお求めの方は是非。
尚、自分はOSインストールが完了されていることに気付かず購入した。もし、OSをインストールされていない場合は下記を参考にしていただくとわかりやすい。
Raspberry PiにOSインストールする
Raspberry Pi 3 Model B+の初回セットアップ(購入から起動まで)接続
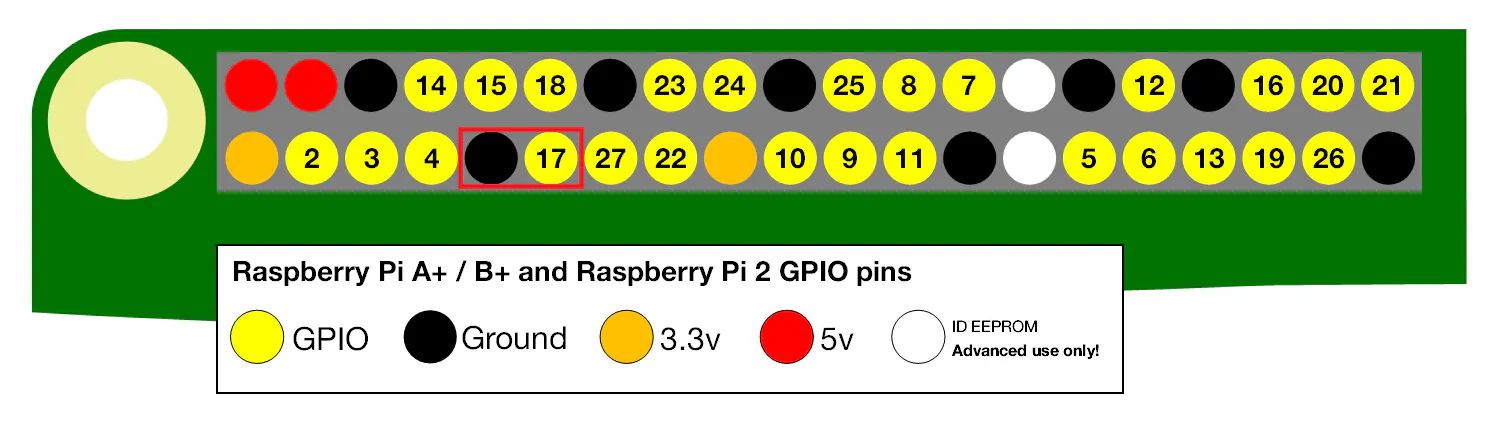
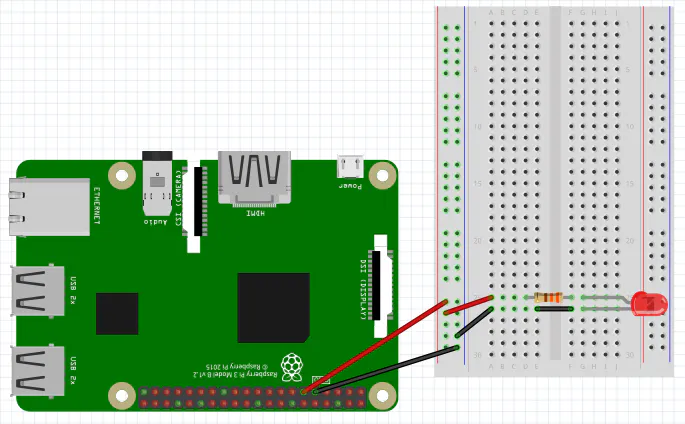
今回は赤枠内の、GPIO17と隣にあるGroundを使用する。
実際の接続はこのような感じ。(ラズパイの向きが上図と逆なので注意)
コード作成ツール
初心者用ツールとして、ラズパイにプリインストール(最初からインストール)されている「Thonny Python IDE」というツールでコードを作成していく。
コード記述
ググるとよく出てくるのがこのようなコード。
GPIO17ピンにLEDを接続すれば、コード実行後LEDが点灯し1秒後消灯する。import RPi.GPIO as GPIO import time GPIO.setmode(GPIO.BCM) GPIO.setup(17, GPIO.OUT) GPIO.output(17, GPIO.HIGH) time.sleep(1) GPIO.cleanup()これでLチカ完了である。
コピペしてしまえば確認まで1分もかからない。あっさり終わってしまうのもなんなので、他の手法がないか調べてみた結果、下記を発見。
これは1秒毎にLEDが点滅してくれるもの。from gpiozero import LED from time import sleep led = LED(17) while True: led.on() sleep(1) led.off() sleep(1)やはりこれもコピペしてしまえば確認まで1分もかからない。
消化不良なので↓ココでさらに調べてみた。
Raspberry Pi Documentation
全て英語なので慣れていないと苦痛だが、from gpiozero import LED led = LED(17) led.blink()LEDを点滅させる為に8行も記述していたのが、なんとたったの3行で済んだ。
しかも挙動は全く同じである。ちなみに、カッコの中にパラメータを追加で記述するとLEDの点滅時間、回数を調整可能だ。
led.blink( on_time=x.x, #ON時間 off_time=x.x, #OFF時間 n=x #点滅回数 )作動確認
下記のようなコードにし高速でLEDをチカチカさせることに成功。
(動画は2秒程度なのでn=100の意味がない)from gpiozero import LED led = LED(17) led.blink(on_time=0.1, off_time=0.1, n=100)
おわりに
Python学習の足掛かりとして初めて投稿しようと試みてみたが、やはり慣れない作業に大分時間がかかった。
この投稿で使い方は大体わかったので、引き続きPWMやThermal関連についての調査・学習内容をアウトプットしていきたい。

- 投稿日:2019-08-04T20:38:59+09:00
LeetCode / Balanced Binary Tree
(ブログ記事からの転載)
[https://leetcode.com/problems/balanced-binary-tree/]
Given a binary tree, determine if it is height-balanced.
For this problem, a height-balanced binary tree is defined as:
a binary tree in which the depth of the two subtrees of every node never differ by more than 1.
Example 1:
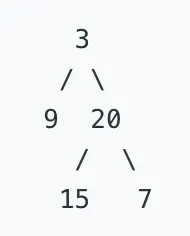
Given the following tree [3,9,20,null,null,15,7]:
Return true.Example 2:
Given the following tree [1,2,2,3,3,null,null,4,4]:
Return false.どのsubtree間の深さの違いが1以下であるtreeを、balanced binary treeと言っています。
treeがbalanced binary treeになっているか判定せよという問題です。解答・解説
解法1
subtreeの深さの違いからbalancedな状態か判定する問題なので、subtreeの深さを取得しながら、左右のsubtreeの深さの違いが1以下であるか判定する、再帰的な処理を書くこととします。
以下ではcheck関数を定義し、(subtreeの深さ, 左右のsubtree間の深さの差が1以下であるかのboolean)をtupleで返す構造とし、rootがない末端では(0, True)を返すこととして、再帰的な処理をかけます。
isBalanced関数の返り値としては、tupleの2つ目の要素を返すことになります。# Definition for a binary tree node. # class TreeNode: # def __init__(self, x): # self.val = x # self.left = None # self.right = None def check(root): if not root: return (0, True) l_depth, l_balanced = check(root.left) r_depth, r_balanced = check(root.right) return max(l_depth, r_depth) + 1, l_balanced and r_balanced and abs(l_depth - r_depth) <= 1 class Solution: def isBalanced(self, root): return check(root)[1]iterativeなコードはちょっと長くなるので、recursiveが良いと思います。
考え方は同じですが、違う書き方をすると例えば以下の通り。def check(root): if not root: return 0 l_depth = check(root.left) r_depth = check(root.right) if l_depth == -1 or r_depth == -1 or abs(l_depth - r_depth) > 1: return -1 return max(l_depth, r_depth) + 1 class Solution: def isBalanced(self, root): return check(root) != -1

- 投稿日:2019-08-04T20:08:36+09:00
Python3: str型のメソッド 分類別一覧
はじめに
公式リファレンスの組み込みメソッド一覧は基本的にアルファベット順に並んでいますよね。
それが初学者の私には少し見づらかったので、ざっくりと分類ごと(?)にまとめてみました。本記事はサンプルコードがほとんどで、細かい説明はしていません。
また、一部載せていないメソッドもあります。詳しくはリファレンスを確認してください。公式
https://docs.python.org/ja/3.6/library/stdtypes.html#str
メソッド分類
分類1:大文字小文字 系 (引数:なし)
'hello world'.capitalize() # 'Hello world' 'hello world'.title() # 'Hello World' 'hello world'.upper() # 'HELLO WORLD' 'HELLO WORLD'.lower() # 'hello world' 'HELLO world'.swapcase() # 'hello WORLD'分類2:部分文字列 系(引数:sub)
# 含まれる? 'a' in 'abc' # True 'z' in 'abc' # False # 出現回数 str.count(sub[, start[, end]]) 'aba'.count('a') # 2 'abcdef'.count('abc') # 1 # 最初に出現するインデックス str.find(sub[, start[, end]]) 'Hello, world'.find('o') # 4 'Hello, world'.find('x') # -1 str.index(sub[, start[, end]]) 'Hello, world'.index('o') # 4 'Hello, world'.index('x') # ValueError <- findとの違い # 最後に出現するインデックス str.rfind(sub[, start[, end]]) 'Hello, world'.find('o') # 8 'Hello, world'.find('x') # -1 str.rindex(sub[, start[, end]]) 'Hello, world'.index('o') # 8 'Hello, world'.index('x') # ValueError <- findとの違い # prefixで始まってる?(タプルで複数指定可) str.startswith(prefix[, start[, end]]) 'Hello, world'.startswith('H') # True 'Hello, world'.startswith(('HELLO', 'Hello', 'hello')) # True # suffixで終わってる?(タプルで複数指定可) str.endswith(suffix[, start[, end]]) 'Hello, world'.endswith('d') # True 'Hello, world'.endswith(('WORLD', 'World', 'world')) # True分類3:長さ調節? 系(引数:width)
- width が len(s) 以下なら元の文字列が返される
# 中央寄せ str.center(width[, fillchar]) 'abc'.center(5) # ' aaa ' 'abc'.center(5, '-') # '-aaa-' # 左寄せ str.ljust(width[, fillchar]) 'abc'.ljust(5, '-') # 'abc--' # 右寄せ str.rjust(width[, fillchar]) 'abc'.rjust(5, '-') # '--abc' # 0パディング str.zfill(width) "42".zfill(5) # '00042' "+42".zfill(5) # '+0042' "-42".zfill(5) # '-0042'分類4:is 系(引数:なし)
# 大文字? 小文字? str.islower() str.isupper() str.istitle() # どんな種類の文字? str.isalpha() str.isdecimal() str.isnumeric() str.isspace()分類5:除去 系(引数:chars)
- 引数charsは除去される文字集合を指定する文字列
# 左右から str.strip([chars]) ' spacious '.strip() # -> 'spacious' 'www.example.com'.strip('cmowz.') # 'example' # 左から str.lstrip([chars]) ' spacious '.lstrip() # -> 'spacious ' 'www.example.com'.lstrip('cmowz.') # 'example.com' # 右から str.rstrip([chars]) ' spacious '.rstrip() # ' spacious' 'mississippi'.rstrip('ipz') # 'mississ'分類6:分割 系(引数:sep)
# --リストに分割---------------------- # 最初の出現位置で分割 sepは消える str.split(sep=None, maxsplit=-1) '1,2,3'.split(',') # ['1', '2', '3'] '1,2,3'.split(',', maxsplit=1) # ['1', '2,3'] # 最後の出現位置で分割 sepは消える str.rsplit(sep=None, maxsplit=-1) '1,2,3'.rsplit(',') # ['1', '2', '3'] '1,2,3'.rsplit(',', maxsplit=1) # ['1,2', '3'] # 改行で分割(\n, \r, \r\n, \v, \fなど多くに対応) str.splitlines([keepends]) 'ab c\n\nde fg\rkl\r\n'.splitlines() # ['ab c', '', 'de fg', 'kl'] # --タプルに分割-------------------- # 最初の出現位置で分割 sepは消えない str.partition(sep) 'a-b-c'.partition('-') # ('a', '-', 'b-c') 'a-b-c'.partition('x') # ('a-b-c', '', '') # 最後の出現位置で分割 sepは消えない str.rpartition(sep) 'a-b-c'.rpartition('-') # ('a-b', '-', 'c') 'a-b-c'.rpartition('x') # ('a-b-c', '', '')分類7:結合 系(引数:iterable)
str.join(iterable) '-'.join(['a', 'b', 'c']) # 'a-b-c' '-'.join(('a', 'b', 'c')) # 'a-b-c' '-'.join('abc') # 'a-b-c'分類8:置換 系(引数:old, new またはtable)
# 複数(単一)文字の換字(1パターン) str.replace(old, new[, count]) 'Hi, Alice'.replace('Alice', 'Bob') # 'Hi, Bob' 'aaaaaa'.replace('a', 'A', 3) # 'AAAaaa' # 単一文字の換字(複数パターン) table = str.maketrans({ 'a': '1', 'b': None, 'c': 'three', 'd': None, 'e': 'FIVE', }) 'abcde'.translate(table) # 1threeFIVEおわりに
やっぱりアルファベット順じゃなく分類別(?)にまとめられていた方が、さらっと全体を見返すのにはいいかも。
- 投稿日:2019-08-04T19:37:26+09:00
Python 文字列系メソッド
はじめに
Pythonの文字列で利用できるメソッドのまとめメモ。
新しく学べば随時アップデートしていきます。検索系メソッド
find()メソッド
文字列の先頭から検索したい文字列を探し、最初に見つかった位置(0から始まるインデックス)を返す。
見つからなかった場合は−1を返す 。
開始インデックス/終了インデックスは、指定しなければ文字列の先頭/末尾になる。使い方#文字列sからある文字列を検索する。 s.find(検索したい文字列,開始インデックス,終了インデックス)例s = 'This is a string.' #文字列先頭から末尾までで'string'を検索 print(s.find('string')) # =>10 #文字列’is a’から'string'を検索 print(s.find('string', 5, 8)) # =>-1rfind()メソッド
findメソッドとは逆に、文字列の末尾から検索を行う。
使い方はfindメソッドと同様。使い方#文字列sからある文字列を検索する。 s.rfind(検索したい文字列,開始インデックス,終了インデックス)例s = 'This is a string.That is a string.' #文字列末尾から先頭までで'string'を検索 print(s.rfind('string')) # =>27index()メソッド
find()と同様の動作するが、見つからなかった場合「ValueError」という例外が発生する。
使い方#文字列sからある文字列を検索する。 s.index(検索したい文字列,開始インデックス,終了インデックス)例s = 'This is a string.' w = 'This is a word.' #文字列sの末尾から先頭までで'string'を検索 print(s.index('string')) # =>10 #文字列wの末尾から先頭までで'string'を検索 print(w.index('string')) # =>ValueError: substring not foundrindex()メソッド
find()に対するrfind()と同様、indexに対するrindex()。
文字列の末尾から検索を行い、見つからなかった場合「ValueError」という例外が発生する。
使い方はindexメソッドと同様なので省略。endswith()メソッド
文字列が検索したい文字列で終わっている時Trueを返す。そうでない場合、Falthを返す。
開始インデックス/終了インデックスは、指定しなければ文字列の先頭/末尾になる。使い方#文字列sがある文字列で終わっているか調べる。 s.endswith(検索したい文字列,開始インデックス,終了インデックス)例s = 'apple' #文字列sが'e'で終わっているか調べる。 print(s.endswith('e')) # =>True #文字列sが'a'で終わっているか調べる。 print(s.endswith('a')) # =>Falthstartswith()メソッド
文字列が検索したい文字列で始まっている時Trueを返す。そうでない場合、Falthを返す。
開始インデックス/終了インデックスは、指定しなければ文字列の先頭/末尾になる。使い方#文字列sがある文字列で始まっているか調べる。 s.startswith(検索したい文字列,開始インデックス,終了インデックス)例s = 'apple' #文字列sが'a'で始まっているか調べる。 print(s.startswith('e')) # =>True #文字列sが'e'で始まっているか調べる。 print(s.startswith('a')) # =>Falth文字列の分割・連結
split()メソッド
文字列を「区切り文字」で区切り、文字列のリストを作って返す。
区切り文字を指定しない場合、スペース・改行等の空白文字が区切り文字となる。使い方#文字列sを「区切り文字」で区切る。 s.split(区切り文字)例1fruits = 'apple,banana,peach' #文字列fruitsを','で区切り、リストを作成。 print(fruits.split(',')) # =>['apple', 'banana', 'peach']例2fruits = 'apple banana peach' #文字列fruitsをスペースで区切り、リストを作成。 print(fruits.split()) # =>['apple', 'banana', 'peach']例3fruits = ''' apple banana peach ''' #文字列fruitsを改行で区切り、リストを作成。 print(fruits.split()) # =>['apple', 'banana', 'peach']join()メソッド
シーケンス中の要素を連結した文字列を返す。
使い方#シーケンスを文字列sで分割し連結した文字列を返す。 s.join(シーケンス)例fruits = ['apple', 'banana', 'peach'] #リストfruitsの要素を結合する(区切り文字なし) print(''.join(fruits)) # =>applebananapeach #リストfruitsの要素を結合する(区切り文字カンマ) print(','.join(fruits)) # =>apple,banana,peach文字列の書き換え
stripメソッド
文字列の先頭および末尾から文字列を削除し、削除した文字列を返す。
「削除する文字列」を指定しない場合、スペース・タブ等の空白文字を削除する。使い方#文字列sの先頭および末尾から文字列を削除する。 s.strip(削除する文字列)例1#文字列fruitsの先頭および末尾から1を削除する。 fruits = '1apple1' print(fruits.strip('1')) # => apple複数の文字も削除可能。
例2#文字列fruitsの先頭および末尾から1を削除する。 fruits = '11111apple11111' print(fruits.strip('1')) # => appleただし、「削除する文字列」に含まれている文字なら削除してしまうことが注意。
例3#文字列fruitsの先頭および末尾からpineを削除する。 #この場合、'p','i','n''e'が削除対象となる。 fruits = 'pineapple' print(fruits.strip('pine')) # => applupper()メソッド
文字列の英字小文字を英字大文字に変換し、その結果を返す。
使い方#文字列sの小文字を大文字に変換する。 s.upper()例#文字列fruitsの英字小文字を大文字にする。 fruits = 'Apple' print(fruits.upper()) # => APPLElower()メソッド
文字列の英字大文字を英字小文字に変換し、その結果を返す。
使い方#文字列sの大文字を子文字に変換する。 s.lower()例#文字列fruitsの英字大文字を小文字にする。 fruits = 'Apple' print(fruits.upper()) # => appleljust()メソッド
文字列を幅を考慮して左寄せした結果を返す。文字列の幅が指定した値に満たない場合、指定した文字で埋める(埋め草文字)。埋め草文字を指定しない場合、スペースで埋める。
右寄せを行う場合はrjust(),中央寄せを行う場合はcenter()メソッドがある。使い方#文字列sの幅を考慮して左寄せする。 s.ljust(幅, 埋め草文字)例#埋め草文字-として文字列fruitsの幅を7にする fruits = 'apple' print(fruits.ljust(7,'-')) #=> apple--
- 投稿日:2019-08-04T19:37:26+09:00
Python 文字列メソッド
はじめに
Pythonの文字列で利用できるメソッドのまとめメモ。
新しく学べば随時アップデートしていきます。検索系メソッド
find()メソッド
文字列の先頭から検索したい文字列を探し、最初に見つかった位置(0から始まるインデックス)を返す。
見つからなかった場合は−1を返す 。
開始インデックス/終了インデックスは、指定しなければ文字列の先頭/末尾になる。使い方#文字列sからある文字列を検索する。 s.find(検索したい文字列,開始インデックス,終了インデックス)例s = 'This is a string.' #文字列先頭から末尾までで'string'を検索 print(s.find('string')) # =>10 #文字列’is a’から'string'を検索 print(s.find('string', 5, 8)) # =>-1rfind()メソッド
findメソッドとは逆に、文字列の末尾から検索を行う。
使い方はfindメソッドと同様。使い方#文字列sからある文字列を検索する。 s.rfind(検索したい文字列,開始インデックス,終了インデックス)例s = 'This is a string.That is a string.' #文字列末尾から先頭までで'string'を検索 print(s.rfind('string')) # =>27index()メソッド
find()と同様の動作するが、見つからなかった場合「ValueError」という例外が発生する。
使い方#文字列sからある文字列を検索する。 s.index(検索したい文字列,開始インデックス,終了インデックス)例s = 'This is a string.' w = 'This is a word.' #文字列sの末尾から先頭までで'string'を検索 print(s.index('string')) # =>10 #文字列wの末尾から先頭までで'string'を検索 print(w.index('string')) # =>ValueError: substring not foundrindex()メソッド
find()に対するrfind()と同様、indexに対するrindex()。
文字列の末尾から検索を行い、見つからなかった場合「ValueError」という例外が発生する。
使い方はindexメソッドと同様なので省略。endswith()メソッド
文字列が検索したい文字列で終わっている時Trueを返す。そうでない場合、Falthを返す。
開始インデックス/終了インデックスは、指定しなければ文字列の先頭/末尾になる。使い方#文字列sがある文字列で終わっているか調べる。 s.endswith(検索したい文字列,開始インデックス,終了インデックス)例s = 'apple' #文字列sが'e'で終わっているか調べる。 print(s.endswith('e')) # =>True #文字列sが'a'で終わっているか調べる。 print(s.endswith('a')) # =>Falthstartswith()メソッド
文字列が検索したい文字列で始まっている時Trueを返す。そうでない場合、Falthを返す。
開始インデックス/終了インデックスは、指定しなければ文字列の先頭/末尾になる。使い方#文字列sがある文字列で始まっているか調べる。 s.startswith(検索したい文字列,開始インデックス,終了インデックス)例s = 'apple' #文字列sが'a'で始まっているか調べる。 print(s.startswith('e')) # =>True #文字列sが'e'で始まっているか調べる。 print(s.startswith('a')) # =>Falth文字列の分割・連結
split()メソッド
文字列を「区切り文字」で区切り、文字列のリストを作って返す。
区切り文字を指定しない場合、スペース・改行等の空白文字が区切り文字となる。使い方#文字列sを「区切り文字」で区切る。 s.split(区切り文字)例1fruits = 'apple,banana,peach' #文字列fruitsを','で区切り、リストを作成。 print(fruits.split(',')) # =>['apple', 'banana', 'peach']例2fruits = 'apple banana peach' #文字列fruitsをスペースで区切り、リストを作成。 print(fruits.split()) # =>['apple', 'banana', 'peach']例3fruits = ''' apple banana peach ''' #文字列fruitsを改行で区切り、リストを作成。 print(fruits.split()) # =>['apple', 'banana', 'peach']join()メソッド
シーケンス中の要素を連結した文字列を返す。
使い方#シーケンスを文字列sで分割し連結した文字列を返す。 s.join(シーケンス)例fruits = ['apple', 'banana', 'peach'] #リストfruitsの要素を結合する(区切り文字なし) print(''.join(fruits)) # =>applebananapeach #リストfruitsの要素を結合する(区切り文字カンマ) print(','.join(fruits)) # =>apple,banana,peach文字列の書き換え
strip()メソッド
文字列の先頭および末尾から文字列を削除し、削除した文字列を返す。
「削除する文字列」を指定しない場合、スペース・タブ等の空白文字を削除する。使い方#文字列sの先頭および末尾から文字列を削除する。 s.strip(削除する文字列)例1#文字列fruitsの先頭および末尾から1を削除する。 fruits = '1apple1' print(fruits.strip('1')) # => apple複数の文字も削除可能。
例2#文字列fruitsの先頭および末尾から1を削除する。 fruits = '11111apple11111' print(fruits.strip('1')) # => appleただし、「削除する文字列」に含まれている文字なら削除してしまうことが注意。
例3#文字列fruitsの先頭および末尾からpineを削除する。 #この場合、'p','i','n''e'が削除対象となる。 fruits = 'pineapple' print(fruits.strip('pine')) # => applupper()メソッド
文字列の英字小文字を英字大文字に変換し、その結果を返す。
使い方#文字列sの小文字を大文字に変換する。 s.upper()例#文字列fruitsの英字小文字を大文字にする。 fruits = 'Apple' print(fruits.upper()) # => APPLElower()メソッド
文字列の英字大文字を英字小文字に変換し、その結果を返す。
使い方#文字列sの大文字を子文字に変換する。 s.lower()例#文字列fruitsの英字大文字を小文字にする。 fruits = 'Apple' print(fruits.upper()) # => appleljust()メソッド
文字列を幅を考慮して左寄せした結果を返す。文字列の幅が指定した値に満たない場合、指定した文字で埋める(埋め草文字)。埋め草文字を指定しない場合、スペースで埋める。
右寄せを行う場合はrjust(),中央寄せを行う場合はcenter()メソッドがある。使い方#文字列sの幅を考慮して左寄せする。 s.ljust(幅, 埋め草文字)例#埋め草文字-として文字列fruitsの幅を7にする fruits = 'apple' print(fruits.ljust(7,'-')) #=> apple--参考資料
- 投稿日:2019-08-04T19:18:53+09:00
【答え合わせ編】ゴールデンウィークの旅行者数を予測してみた。
はじめに
以前、[機械学習]ゴールデンウィークの旅行者数を予測してみた。というネタを投稿しました。
今回はその答え合わせの投稿です。
なお、技術的な事は何も書かれていません。
ポエムタグをつけておけば許されると聞きました。前回の記事について
やったこと
観光庁が公開している宿泊旅行統計調査を元に、月ごとの旅行者数を予測する。
謝ること
ライブラリのアップデートで前回の記事と予測結果に差が出てしまいました。
そのため、今回使用する予測は前回の予測数値と若干異なります。誠にごめんなさい。結果
観光庁発表
※観光庁の発表した「宿泊旅行統計調査」の平成31年5月分第2次速報を元にしています。
今年はゴールデンウィークが長かったためか、5月で調査開始以来最大の宿泊者数だったようです。予測値との比較
pd.options.display.float_format = '{:.8g}'.format vs.head()
pred real Hokkai 2896237.8 3037530 Aomori 481010.21 411970 Iwate 535289.62 535170 Miyagi 806132.11 886800 Akita 348669.11 368860 vs["diff"] = vs["pred"] - vs["real"] vs["per"] = abs(( vs["diff"] / vs["real"] ) * 100) print("誤差平均:" + str(vs["per"].mean())) # 誤差平均:9.430030930263827誤差の平均は約9.430%でした。
まあ、あまり良くない数値ですね。。。8月、9月の予測
どうせなので8月、9月の予測値を載せておきます。
8月の予測(前年比)
前年比で空く県:鳥取(-16.63%)、沖縄(-11.59%)、福島(-10.24%)
前年比で混む県:奈良(23.21%)、島根(19.92%)、栃木(18.08%)Hokkai 1.5461477 Aomori -0.12899934 Iwate 3.8532742 Miyagi -1.3618699 Akita -1.4536219 Yamagata 4.8129373 Fukushima -10.249967 Ibaragi 0.28800193 Tochigi 18.089495 Gunma 8.0097683 Saitama 5.052978 Chiba -9.8669406 Tokyo -1.5686302 Kanagawa 0.82889818 Niigata 4.7295012 Toyama 6.6432742 Ishikawa 5.152687 Fukui -7.1461065 Yamanashi 7.1176747 Nagano -0.80464436 Gifu -0.83231587 Shizuoka -4.0189035 Aichi -5.0119414 Mie -7.4170226 Siga 9.2092603 Kyoto 0.68663971 Osaka -5.3579359 Hyogo 7.255461 Nara 23.209964 Wakayama -4.1223054 Tottori -16.634197 Shimane 19.918169 Okayama 6.9212813 Hiroshima -2.0764377 Yamaguchi 11.731277 Tokushima -0.78001178 Kagawa -4.4419368 Ehime 1.98476 Kouchi -8.201771 Hukuoka 5.8027727 Saga 11.929003 Nagasaki 0.30879221 Kumamoto -5.402026 Ohita -0.31561992 Miyazagi -2.1906969 Kagoshima -7.9594635 Okinawa -11.5944599月の予想(前年比)
前年比で空く県:福井(-25.28%)、鳥取(-16.10%)、千葉(-16.09%)
前年比で混む県:北海道(29.31%)、長崎(23.54%)、佐賀(19.35%)Hokkai 29.310405 Aomori 5.7293101 Iwate 9.775667 Miyagi -12.503692 Akita 8.8918918 Yamagata -2.7769751 Fukushima 1.4730333 Ibaragi -1.9782563 Tochigi 17.633472 Gunma 5.8313744 Saitama 2.1632078 Chiba -16.094461 Tokyo -5.9573963 Kanagawa -2.0076661 Niigata 4.7053917 Toyama 15.41432 Ishikawa 14.832828 Fukui -25.283566 Yamanashi -0.88744807 Nagano -7.8685883 Gifu 10.264169 Shizuoka -6.01285 Aichi -1.7513369 Mie -8.7556244 Siga 0.72663133 Kyoto 3.4934475 Osaka 1.5981535 Hyogo 14.590287 Nara 11.561046 Wakayama 10.049818 Tottori -16.107172 Shimane 15.486279 Okayama -5.4374055 Hiroshima -2.6782992 Yamaguchi 13.577108 Tokushima 0.34449741 Kagawa 7.2651328 Ehime 6.7382174 Kouchi -3.9885319 Hukuoka 6.5202921 Saga 19.358182 Nagasaki 23.540356 Kumamoto -1.0762426 Ohita 1.4712151 Miyazagi 7.0189591 Kagoshima -12.592754 Okinawa -12.570894夏休みの旅行先は鳥取に決まり!!
自分は9月、北海道に行ってきます。使用データ
観光庁 宿泊旅行統計調査
観光庁 宿泊旅行統計調査 報道発表資料(PDF) (2019/8/2 アクセス)
観光庁 宿泊旅行統計調査 集計結果(5月)(xlsx) (2019/7/31 アクセス)
- 投稿日:2019-08-04T17:09:06+09:00
【初心者向け】python/競プロでローカルでテストしてから提出する場合のテンプレを作りました。
今日は、競プロの環境についてちょっと書いておきたいなと思います。
もう今日プロに参加しはじめて半年以上たちます。
4月5月6月は事情により参加できなかったのですが、最近少し参加しています。
レート推移はこんな感じ。
今日は、アルゴリズムがどうこうよりも、競プロのテンプレ的なメモです。
いつもみなさんはテストケースなどはどのように試していますか?
試していない猛者はおいておくとして、僕はvimでコードを書いているので、ローカルでpythonを実行して、入力を貼り付けしてテストしていました。しかし、これだいぶ効率悪いなと今更ながらに気づき、改めることとなりました。
要件としては、
1. 入力を一回貼り付けたらそれですむようにしたい
2. 外部ファイルにするのが面倒なので、ソースコード内にinputを置いておきたい
3. 提出時はスルーされるように
の3点を満たすように考えました。色々と説明する前に、一旦完成形を載せます。
import os def main(N, A): # 処理を書く return N if __name__ == '__main__': if 'LOCAL' in os.environ: # ローカル実行時のみ通る処理 # テストしたい入力を入れておく input_values = [ """3 7 6 8 3 """.strip(), """3 12 15 18 6 """.strip() ] for input_value in input_values: input_value = input_value.split('\n') N = int(input_value[0]) A = list(map(int, input_value[1].split())) ans = main(N, A) expected_value = int(input_value[2]) assert ans == expected_value, 'failed: ans: {ans}, exp: {exp}'.format(ans=ans, exp=expected_value) else: # 実際に提出したときの処理 N = 'some_input' A = 'some_input' print(main(N, A))ポイントとしては、環境変数を利用して、ローカル実行時と、提出時の処理を変えています。
LOCALという環境変数があれば、ローカル実行となります。
これは
LOCAL='なんらかの値 ' python my_code.pyのように実行すると、LOCALというキーで環境変数が設定されるので、最初のif文の中の処理を実行できます。
提出時はLOCALには値がセットされていないので、elseの中の処理が実行されます。input_valuesに入力値を貼り付けた後、リスト化、数値化などの処理は問題によりけりですが、基本的にはリストの中に入力をstringとして突っ込んで、1つ1つ取り出して上手くやるという感じです。
今回は実際にAtCoderの入力をそのまま貼り付けています
空白とか無駄なものがついてくるので、一応今回はstrip()しています。最後に、assertを利用してやることで、失敗ケースで止めるようにしました。
その際、""" """内に入力した入力値の1行下に、正解の値を入れるのが良いと思います。
お好みで。以上、ローカルでpythonで競プロに参加する場合のちょっとしたテンプレでした。
かんたんな問題では利用する必要はあまりありませんが、何回もテストしてから提出するぐらいの問題であれば使えるのかなと思います。
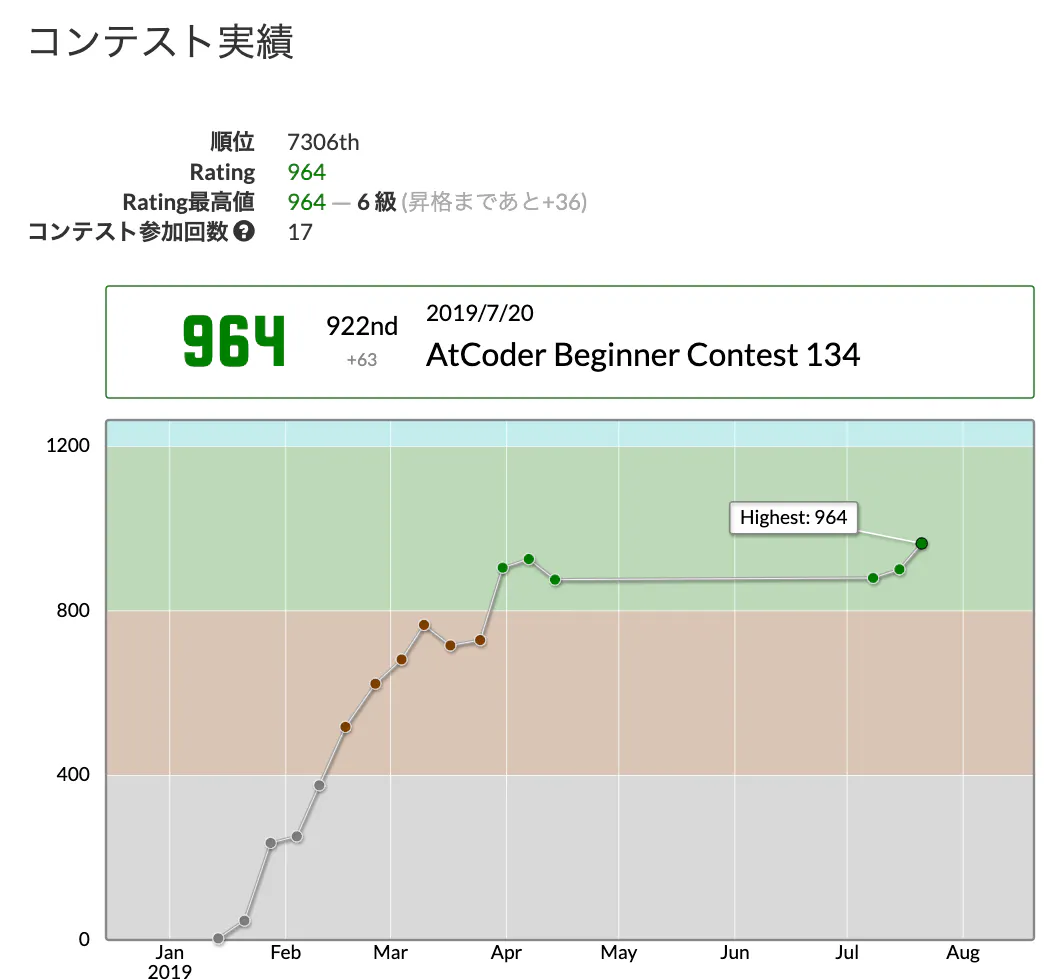
- 投稿日:2019-08-04T16:52:08+09:00
PyMC3がうまくいかない場合(numpyのモジュールがないといわれたときの解決法)
概要
ベイズ推論の考え方の説明とそれを行うことのできるPythonライブラリPyMC3を使ってみようとしたらうまいことできなかったため,その対処法を載せる.ちなみにインストール方法は以下に書いてあります
https://docs.pymc.io/各種バージョン
・OS:windows10
・anaconda環境下
・editor:jupyter notebook・numpy:1.16.4
・pandas:0.24.2
・pymc3:3.6後に記述するが
・theano:1.0.3
インストール
インストールは上記に載せたURLの通り
conda install -c conda-forge pymc3と,anaconda promptを使ってインストールした.(pipとconda混ぜるな危険,windowsユーザーはcondaで入らないときは積極的にconda-forgeを使いましょう)
今回の問題
よーし,これでベイズ推論の検証ができるぞとばかり思い,以下のコードを実行してみた
import numpy as np import scipy.stats as stats import pymc3 as pm import warnings warnings.simplefilter('ignore') # 乱数のseed固定 random_state = 0 np.random.seed(random_state) n_trials = 4 theta_real = 0.35 data = stats.bernoulli.rvs(p=theta_real, size=n_trials) data # withブロックの内側すべてが一つのモデル with pm.Model() as model: # モデリング theta = pm.Beta('θ', alpha=1., beta=1.) # 事前確率 y = pm.Bernoulli('y', p=theta, observed=data) # 尤度 # 推論 trace = pm.sample(1000, random_seed=random_state)すると,以下のエラーが出てきた.
AttributeError: module 'numpy.core.multiarray' has no attribute '_get_ndarray_c_version'pm.Model()でエラーが出た.
どうやらnumpyで関連で怒られているらしい…
調べてみると,https://github.com/pymc-devs/pymc3/issues/3340 ここで言われているようにいろんな人に起きてるみたい.読んでみると,theanoというパッケージを1.0.3から1.0.4にあげないとダメとのことで,やってみた.
conda install theano==1.0.4
これでもダメそう…結局,numpyを入れ直し,pymc3を3.6から3.7に無理やりあげるとうまくいった.また,pandasやnumpyのバージョンはこれでないといろんなところでエラーが出たので,けっこうデリケートな設計だなPyMC3って感じでした.
- 投稿日:2019-08-04T16:43:50+09:00
【物理シミュレーション】単振り子・二重振り子をシミュレーションしてみた!
概要
物理シミュレーションの第一歩ということで、単振り子(pendulum)および二重振り子(double pendulum)をつくってみました.
二重振り子については,軌跡付きでつくってみました.動作環境
- Windows10(64bit)
- Python 3.7.2
単振り子の理論
まずは,単振り子の運動方程式を導きます.
直交座標系の運動方程式を立ててから,角度のみの運動方程式に変形してもいいのですが,
ラグランジアンを使って導いた方がラクでしょう.振り子が鉛直方向となす角を$\theta$とすると,
運動エネルギー
K=\frac{1}{2}m\dot{x}^2=\frac{1}{2}m{(l\dot{\theta})}^2ポテンシャル
U=mglcos\thetaゆえにラグランジアンは
\begin{align} L & = K - U\\ & = \frac{1}{2}m{(l\dot{\theta})}^2 - mglcos\theta \end{align}オイラーラグランジュ方程式に代入して
\begin{align} \frac{d}{dt}(ml^2(\dot{\theta}^2) + mglsin\theta) = 0\\ ml^2\ddot{\theta} = -mglsin\theta\\ \ddot{\theta} = -\frac{g}{l}sin\theta \end{align}となり,$\theta$に関する二階の微分方程式を得る.
Pythonで解くときには,微分方程式は一階の微分方程式にする必要があるが,
一般に$n$階の微分方程式は$n$次の連立微分方程式に変形することができる.今の場合,以下のように$\theta$に関する二階微分方程式が$\theta$と$\omega$に関する連立一階微分方程式に変形ができる.
\begin{cases} \dot{\theta} & = \omega\\ \dot{\omega} & = -\frac{g}{l}sin\theta \end{cases}微分方程式を解く方法
Pythonで微分方程式を解くためには,scipy.integrateの中のodeintやodeがありますし,
実際この関数を使ったコードはネット上にも多く見られました.
しかし,odeintの公式ドキュメントを見てみると,微分方程式を解くための新しい関数として
scipy.integrate.solve_ivpが推奨されています.
ということで,今回は,solve_ivp()を使っていこうと思います.使い方を具体例を使って説明していきます。
- 例1
\frac{dy}{dt}=y\\ y(0)=1解:$y = exp(t)$
def func (t, y): dydt = y return dydt sol = scipy.integrate.solve_ivp(func, [0,20], [1]) t1 = sol.t y1 = sol.y.T t2 = np.linspace(0, 20, 100) plt.plot(t1, y1) plt.plot(t2, np.exp(t2)) plt.show()solve_ivp()の第1引数は微分値を返す関数です.つまり,以下の方程式で言う右辺を返り値に持つ関数です.
\frac{dy}{dt} = f(t, y)solve_ivp()第2引数は時間を,第3引数は初期値を取ります.今回は,$t=0$から$t=20$までとしました.
時間の刻み幅自動で設定されます.これはodeintなどとの違いの一つです.
もし,刻み幅を指定したい場合は例2のようにt_evalキーワードを追加します.実行結果は以下のようになります.
- 例2
\frac{d^2y}{dt^2}=-y\\ y(0)=1\\ \frac{dy}{dt}(0)=0\\解:$y = cos(t)$
例2は2階の微分方程式です.関数funcの中身は上記のようになります.
考え方としては,y = y_0\\ \frac{dy}{dt} = y_1として,以下の連立1階微分方程式に帰着させます.
\frac{d}{dt}y_0 = y_1\\ \frac{d}{dt}y_1 = -y_0def func (t, y): dydt = np.zeros_like(y) dydt[0] = y[1] dydt[1] = -y[0] return dydt t_span=[0,20] y0 = [0,1] t = np.linspace(t_span[0], t_span[1], 100) sol = scipy.integrate.solve_ivp(func, t_span, y0, t_eval=t) t1 = sol.t y1 = sol.y[1,:] t2 = np.linspace(0, 20, 100) plt.plot(t1, y1, 'o') plt.plot(t2, np.cos(t2), '--') plt.show()実行結果は以下のようになります.
単振り子の実装
それでは,単振り子のシミュレーションを行うプログラムを実装してみましょう!
from numpy import sin, cos from scipy.integrate import solve_ivp from matplotlib.animation import FuncAnimation import matplotlib.pyplot as plt import numpy as np G = 9.8 # 重力加速度 [m/s^2] L = 1.0 # 振り子の長さ [m] # 運動方程式 def derivs(t, state): dydt = np.zeros_like(state) dydt[0] = state[1] dydt[1] = -(G/L)*sin(state[0]) return dydt t_span = [0,20] # 観測時間 [s] dt = 0.05 # 間隔 [s] t = np.arange(t_span[0], t_span[1], dt) th1 = 30.0 # 初期角度 [deg] w1 = 0.0 # 初期角速度 [deg/s] state = np.radians([th1, w1]) # 初期状態 sol = solve_ivp(derivs, t_span, state, t_eval=t) theta = sol.y[0,:] print(np.shape(sol.y)) x = L * sin(theta) # x = Lsin(theta) y = -L * cos(theta) # y = -Lcos(theta) fig, ax = plt.subplots() line, = ax.plot([], [], 'o-', linewidth=2) # このlineに次々と座標を代入して描画 def animate(i): thisx = [0, x[i]] thisy = [0, y[i]] line.set_data(thisx, thisy) return line, ani = FuncAnimation(fig, animate, frames=np.arange(0, len(t)), interval=25, blit=True) ax.set_xlim(-L,L) ax.set_ylim(-L,L) ax.set_aspect('equal') ax.grid() plt.show() # ani.save('pendulum.gif', writer='pillow', fps=15)解説
- ライブラリのインポート
まずは,必要なライブラリをインポートします.
from numpy import sin, cos from scipy.integrate import solve_ivp from matplotlib.animation import FuncAnimation import matplotlib.pyplot as plt import numpy as np
- 運動方程式の記述
続いて運動方程式を記述する関数を定義します.重力加速度はG,振り子の長さはLとしています.
def derivs(t, state): dydt = np.zeros_like(state) dydt[0] = state[1] dydt[1] = -(G/L)*sin(state[0]) return dydt
- 初期条件の記述
運動方程式の初期条件を与えます.2階微分方程式なので自由度は2ですね.
th1 = 30.0 w1 = 0.0 state = np.radians([th1, w1])
- 運動方程式を解く
運動方程式の数値解を求めます.
yは(2,len(t))型の二次元配列なので,今は,1行目の角度$\theta$のみを取得します.
2行目の角速度$\omega$は今回は必要ないです.sol = solve_ivp(derivs, t_span, state, t_eval=t) theta = sol.y[0,:]
- 直交座標系に変換
求まった$\theta$から直交座標系$(x,y)$に変換します.これでデータは得られました.
あとは,これをプロットするだけです.x = L * sin(theta) y = -L * cos(theta)
- 逐次描画していく関数の定義
順次描画していくための関数を定義します.1行目のlineに次々と座標を代入して描画をしていきます.
linewidth=2はlw=2と省略することもできます.'o-'は端点と線分を表します.line, = ax.plot([], [], 'o-', linewidth=2) def animate(i): x = [0, x[i]] y = [0, y[i]] line.set_data(x, y) return line,
- アニメーションの関数
最後にアニメーションを実行します.
blitキーワードやintervalキーワードはアニメーションが滑らかになるように設定しています.なくても動きます.
あとは,レイアウトなどを整え,プロットすれば終わりです.ani = FuncAnimation(fig, animate, frames=np.arange(0, len(t)), interval=25, blit=True)実行結果
二重振り子
では,単振り子でアニメーションの方法はマスターできたと思うので,二重振り子をシミュレーションしてみましょう.
カオスが見れて面白いです!
さらに,単振り子のレベルアップということで軌跡も描画しちゃいましょう.二重振り子の理論
二重振り子の運動方程式も単振り子同様ラグランジアンを求めて,オイラーラグランジュ方程式に代入すれば求まります.
ここでは,計算が面倒なので結果だけを示します.運動方程式
(m_1+m_2)l_1\ddot{\theta_1} + m_2l_2\ddot{\theta_2}cos(\theta_1-\theta_2) + m_2l_2\dot{\theta_2}^2sin(\theta_1-\theta_2) + (m_1+m_2)gsin\theta_1 = 0\\ l_1l_2\ddot{\theta_1}cos(\theta_1-\theta_2) + l_2^2\ddot{\theta_2}-l_1l_2\dot{\theta_1}^2sin(\theta_1-\theta_2) gl_2sin{\theta_2} = 0整理して,
\frac{d\theta_1}{dt} = \omega_1\\ \frac{d\omega_1}{dt} = \frac{m_2l_1\omega_1^2sin\delta cos\delta + m_2gsin\theta_2cos\delta + m_2l_2\omega_2^2sin\delta -(m_1+m_2)gsin\theta_1}{(m_1+m_2)l_1-m_2l_1cos^2{\delta}}\\ \frac{d\theta_2}{dt} = \omega_2\\ \frac{d\omega_2}{dt} = \frac{-m_2l_2\omega_2^2sin\delta cos\delta + (m_1+m_2)gsin\theta_1cos\delta -(m_1+m_2)l_1\omega_1^2sin\delta -(m_1+m_2)gsin\theta_2}{(m_1+m_2)l_1-m_2l_1cos^2{\delta}}ただし,$\delta = \theta_2-\theta_1$.
二重振り子の実装
それでは,二重振り子のシミュレーションを行うプログラムを実装しています.
matplotlibの公式ドキュメントに二重振り子のシミュレーションプログラムがあるのでそちらを参考にしました.from numpy import sin, cos from scipy.integrate import solve_ivp from matplotlib.animation import FuncAnimation import numpy as np import matplotlib.pyplot as plt G = 9.8 # 重力加速度 [m/s^2] L1 = 1.0 # 単振り子1の長さ [m] L2 = 1.0 # 単振り子2の長さ [m] M1 = 1.0 # おもり1の質量 [kg] M2 = 1.0 # おもり2の質量 [kg] # 運動方程式 def derivs(t, state): dydx = np.zeros_like(state) dydx[0] = state[1] delta = state[2] - state[0] den1 = (M1+M2) * L1 - M2 * L1 * cos(delta) * cos(delta) dydx[1] = ((M2 * L1 * state[1] * state[1] * sin(delta) * cos(delta) + M2 * G * sin(state[2]) * cos(delta) + M2 * L2 * state[3] * state[3] * sin(delta) - (M1+M2) * G * sin(state[0])) / den1) dydx[2] = state[3] den2 = (L2/L1) * den1 dydx[3] = ((- M2 * L2 * state[3] * state[3] * sin(delta) * cos(delta) + (M1+M2) * G * sin(state[0]) * cos(delta) - (M1+M2) * L1 * state[1] * state[1] * sin(delta) - (M1+M2) * G * sin(state[2])) / den2) return dydx # 時間生成 t_span = [0,20] dt = 0.05 t = np.arange(t_span[0], t_span[1], dt) # 初期条件 th1 = 120.0 w1 = 0.0 th2 = -10.0 w2 = 0.0 state = np.radians([th1, w1, th2, w2]) # 運動方程式を解く sol = solve_ivp(derivs, t_span, state, t_eval=t) y = sol.y # ジェネレータ def gen(): for tt, th1, th2 in zip(t,y[0,:], y[2,:]): x1 = L1*sin(th1) y1 = -L1*cos(th1) x2 = L2*sin(th2) + x1 y2 = -L2*cos(th2) + y1 yield tt, x1, y1, x2, y2 fig, ax = plt.subplots() ax.set_xlim(-(L1+L2), L1+L2) ax.set_ylim(-(L1+L2), L1+L2) ax.set_aspect('equal') ax.grid() locus, = ax.plot([], [], 'r-', linewidth=2) line, = ax.plot([], [], 'o-', linewidth=2) time_template = 'time = %.1fs' time_text = ax.text(0.05, 0.9, '', transform=ax.transAxes) xlocus, ylocus = [], [] def animate(data): t, x1, y1, x2, y2 = data xlocus.append(x2) ylocus.append(y2) locus.set_data(xlocus, ylocus) line.set_data([0, x1, x2], [0, y1, y2]) time_text.set_text(time_template % (t)) ani = FuncAnimation(fig, animate, gen, interval=50, repeat=True) plt.show() # ani.save('double_pendulum.gif', writer='pillow', fps=15)解説
- 運動方程式の記述
def derivs(t, state): dydx = np.zeros_like(state) dydx[0] = state[1] delta = state[2] - state[0] den1 = (M1+M2) * L1 - M2 * L1 * cos(delta) * cos(delta) dydx[1] = ((M2 * L1 * state[1] * state[1] * sin(delta) * cos(delta) + M2 * G * sin(state[2]) * cos(delta) + M2 * L2 * state[3] * state[3] * sin(delta) - (M1+M2) * G * sin(state[0])) / den1) dydx[2] = state[3] den2 = (L2/L1) * den1 dydx[3] = ((- M2 * L2 * state[3] * state[3] * sin(delta) * cos(delta) + (M1+M2) * G * sin(state[0]) * cos(delta) - (M1+M2) * L1 * state[1] * state[1] * sin(delta) - (M1+M2) * G * sin(state[2])) / den2) return dydx
- 初期条件の記述
th1 = 100.0 w1 = 0.0 th2 = -10.0 w2 = 0.0 state = np.radians([th1, w1, th2, w2])
- 運動方程式を解く
sol = solve_ivp(derivs, t_span, state, t_eval=t) y = sol.y
- ジェネレータ関数の定義
これは単振り子と少し異なります。軌跡を描くためにジェネレータを定義します。
ジェネレータはreturnではなくyield文で返します.
また,zip()関数を使うことで,並列的に反復処理を行えます.def gen(): for tt, th1, th2 in zip(t,y[0,:], y[2,:]): x1 = L1*sin(th1) y1 = -L1*cos(th1) x2 = L2*sin(th2) + x1 y2 = -L2*cos(th2) + y1 yield tt, x1, y1, x2, y2
- アニメーション関数の定義
locusにどんどん値を追加していくことで,軌跡を描画します.
また今回はタイマーもついています.locus, = ax.plot([], [], 'r-', linewidth=2) line, = ax.plot([], [], 'o-', linewidth=2) time_template = 'time = %.1fs' time_text = ax.text(0.05, 0.9, '', transform=ax.transAxes) xlocus, ylocus = [], [] def animate(data): t, x1, y1, x2, y2 = data xlocus.append(x2) ylocus.append(y2) locus.set_data(xlocus, ylocus) line.set_data([0, x1, x2], [0, y1, y2]) time_text.set_text(time_template % (t))
- アニメーションの実行
ani = FuncAnimation(fig, animate, gen, interval=50, repeat=False)実行結果
まとめ
いかがだったでしょうか?今回は物理シミュレーションとして,単振り子と二重振り子を扱ってみました.
二重振り子のカオスが見れたときは興奮しますよね.
今回のコードに関して改善点などありましたらコメントいただけると助かります.




- 投稿日:2019-08-04T16:37:49+09:00
python×Cloud Functions×FirestoreでAPIを簡単に作ってみる Pt2 テスト編(詳細)
概要
Firestoreのデータ操作を行う関数をローカルでテストするためのあれこれをまとめます。やり方としては、Flaskのrequestオブジェクトを使ってローカルにAPIを作成します。
- 前回の記事はこちら
開発環境
- 開発環境
- MacOS
- python3.7
- pycharm
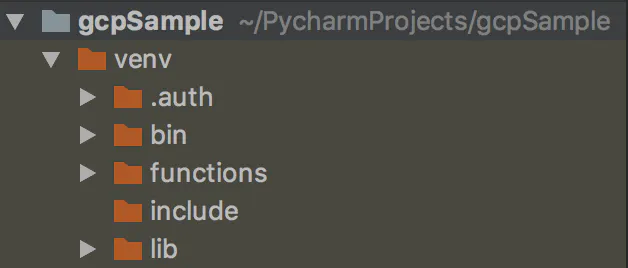
新規プロジェクトの作成
pycharmまたはpyvenvコマンドを用いて新規プロジェクトを作成します。画面イメージはpycharmですが、デフォルトで作成されるフォルダに加えて「.auth」「functions」も作成しています。また、ファイルは省略します。
関数の作成
テストする関数はPt1と同じです。functions/に置きます。
functions/getFilteredUser.pyimport json from google.cloud import firestore # ソースはPt1と同じ def get_filtered_user(request): request_json = request.get_json() if request.args and 'name' in request.args: request_name = request.args.get('name') elif request_json and 'name' in request_json: request_name = request_json['name'] else: request_name = '' db = firestore.Client() query = db.collection('user').where('name', '==', request_name) docs = query.get() users_list = [] for doc in docs: users_list.append(doc.to_dict()) return_json = json.dumps({"users": users_list}, ensure_ascii=False) return return_jsonローカルにAPIを作る
Cloud FunctionsではFlaskのrequestオブジェクトを使って、リクエスト条件が関数に受け渡しされます。なので、ローカルにFlaskを使ってAPIを作ることで、テスト可能になります。
以下のようなソースを作ります。
localServer.pyfrom flask import Flask, request, abort, render_template, send_from_directory # 作成した関数を外部ソースからimport from functions.getFilteredUser import get_filtered_user app = Flask(__name__) # methodにPOST等も明示的に指定(FlaskではデフォルトGETのみのため) # '/~'がテストするときのパス @app.route('/get-filtered-user', methods=['GET', 'POST']) def local_api(): return get_filtered_user(request) if __name__ == '__main__': app.run()これで
http://localhost:5000/get-filtered-userにリクエストを投げると、get_filtered_userが実行されるようになります。
但し、関数がローカルからFirebaseにアクセスするには、秘密鍵を環境変数に読み込ませる必要があります。秘密鍵の取得・設定
秘密鍵の取得方法は以下のいずれかのページがわかりやすいです。
Cloud FirestoreのデータをPythonで取得する
Firebase公式 - SDK の初期化取得したファイルのパスを、
GOOGLE_APPLICATION_CREDENTIALSの環境変数に設定することでローカルからのFirestoreへのアクセスが可能になります。環境変数の設定は以下のような方法があります。[方法1] pycharmの「構成の編集>環境変数」から追加
pycharmではこのやり方が使えます。ソースごとに環境変数が設定可能なので、複数のFirebaseプロジェクトを扱う場合でも、bash_profileを書き換える必要がなくなります。
この例では「.auth/firebase_auth.json」という秘密鍵ファイルを読み込ませています。
[方法2] ターミナルから環境変数を設定
MacOS$ export GOOGLE_APPLICATION_CREDENTIALS="<保存先>/<秘密鍵ファイル>.json" # .bash_profileに追記する場合 (ターミナルの再起動が必要) $ echo 'export GOOGLE_APPLICATION_CREDENTIALS="<保存先>/<秘密鍵ファイル>.json"' >> ~/.bash_profile作成したソースをターミナルから
python sample.pyと実行する場合、このやり方が一番シンプルです。[方法3] pythonのソースにベタ書き
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "<保存先>/<秘密鍵ファイル>.json"ソースの中に書きたい事情がある場合はこれでもいけると思います。
ディレクトリの最終状態
functionsと.authを含めて以下の状態になっているはず。
functions/getUser.pyはPt1のソースが残ってるだけなので無くても問題ありません。
ローカルでのテスト
環境変数を設定した状態で、localServer.pyを実行して
http://localhost:5000/get-filtered-userにリクエストを投げます。localServer.pyの実行$ python localServer.py * Serving Flask app "localServer" (lazy loading) * Environment: production WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead. * Debug mode: off * Running on http://127.0.0.1:5000/ (Press CTRL+C to quit) 127.0.0.1 - - [04/Aug/2019 14:51:35] "POST /get-filtered-user HTTP/1.1" 200 -ローカルでの関数テスト$ curl -X POST -H "Content-Type: application/json" -d '{"name": "Alice"}' http://localhost:5000/get-filtered-user {"users": [{"age": 19, "name": "Alice", "gender": "female"}]}これで、Cloud Functionsにデプロイせずともテストできるようになりました。デプロイすると2分ほど待ちますが、この方法だとすぐにテストできます。localServer.pyのコンソールにはprintの内容が出力されるのでデバッグも容易になります。
また、pycharmの場合、pythonの実行とターミナルを並べて実行すれば便利です。
もちろんPostmanを使ってもOKです。
おわりに
Cloud Functionsではいきなりデプロイするのではなく、以下のような流れでコードを作成すると、どこでバグってるかがわかりやすいので、ハマることが少なく開発できると思います。
- デプロイしたい関数だけでテスト
- ローカルにAPIを作成してテスト
- Cloud Functionsにデプロイ
1では、リクエスト条件などをベタ書きで書いてみて、関数が想定通り動くか確認します。2では、GETやPOSTでリクエストが渡された時の動きを確認できます。
今回は、この中の2のやり方を書きました。
Pt3では、3のデプロイをローカルから行う方法を書こうと思います。
参考リンク
How to develop Python Google Cloud Functions
ローカルでの関数の実行
MacでCloud Machine Learning Engineを利用してみる


- 投稿日:2019-08-04T16:11:16+09:00
Gridgedge [Aizu Competitive Programming Camp 2018 Day 2 D]
Gridgedge [Aizu Competitive Programming Camp 2018 Day 2 D]
ダイクストラ法。全ての地点に関して距離と経路数をそれぞれ記録しておく。距離テーブルをdist、経路数テーブルをpathとする
(x,y)から(nx,ny)に移動する時、
1. dist[y][x]+1 < dist[nx][ny]の時(新記録更新した場合)path[ny][nx]=path[y][x]
2. dist[y][x]+1 = dist[nx][ny]の時、(同じ経路長の場合)path[ny][nx]+=path[y][x]
3. dist[y][x]+1 < dist[nx][ny]の時、(より短い経路長ですでに到達していた場合)探索打ち切り。https://onlinejudge.u-aizu.ac.jp/beta/room.html#ACPC2018Day2/problems/D
r, c, sx, sy, gx, gy=list(map(int,raw_input.split())) dist=[[np.inf for i in range(r)] for j in range(c)] path=[[0 for i in range(r)] for j in range(c)] que=deque() que.append((sy,sx)) dist[sy][sx]=0 while que: y, x=que.popleft() for i,j in ((y,x+1),(y+1,x),(y-1,x),(y,x-1),(c-1,x),(y,r-1),(0,x),(y,0)): ny,nx=i,j if 0<=ny<c and 0<=nx<r: if dist[ny][nx]<dist[y][x]+1: continue if dist[ny][nx]>dist[y][x]+1: dist[ny][nx]=dist[y][x]+1 path[ny][nx]=1 else: path[ny][nx]+=1 que.append((ny,nx)) print(dist[gy][gx],path[gy][gx])
- 投稿日:2019-08-04T15:54:53+09:00
Ultra-fast build of Tensorflow with Bazel Remote Caching [Google Cloud Storage version]
Tensorflow-bin
Bazel_bin
1.Introduction
今回は Google Cloud Storage をキャッシング環境に使用した最もお手軽なビルド手順を試行しました。 1時間掛かる Tensorflow のビルドを 2分20秒ほどに短縮できます。 ビルド済みのバイナリとソースファイルをハッシュ化してストレージ上にキャッシュし、2回目以降のビルド時にはキャッシュ済みのハッシュ値と現ファイルから計算したハッシュ値を比較して同じであればビルドを簡略化し、ハッシュ値に差分のあるファイルのみコンパイルします。 よって、初回ビルド時はキャッシュが全く無くキャッシングの処理に余分な時間を割くため、通常のビルドよりも少しだけ遅くなります。 検証の結果、Tensorflow がバージョンアップした場合はキャッシングのベースとなっているハッシュ値が完全に異なるようで、うまくキャッシュが効きませんでした。 試行錯誤しながらビルドバラメータを頻繁に変更したり、とあるソースファイルのバグフィックスを単発で実施した場合のリビルドの場合にはかなり強力なパフォーマンスを発揮します。 複数の開発者間でビルド済みのバイナリを共有してデバッグ効率を少しだけ上げるような用途には向いていそうです。 次回は、nginxを使用した完全無料ローカルキャッシュ環境構築にトライしてみようと思います。
Build Tensorflow super fast using Bazel's Remote Caching feature. It is 24 times faster than the standard build method. However, according to the examination result of this article, it seems that the difference in the version upgrade of the repository can not be compensated. Provides a shared and incremental compilation environment for pre-built binaries among multiple developers. Next time, I would like to try the local cache procedure by nginx.
Bazel の リモートキャッシングを有効にした Tensorflow v1.14.0 のフルビルドの様子を動画にしました。 速すぎて笑えます。https://t.co/fACRf2WfKu
— PINTO0309 (@PINTO03091) August 4, 20192.Environment
- Ubuntu 16.04 x86_64
- Tensorflow v1.13.2 + Bazel 0.20.0
- Tensorflow v1.14.0 + Bazel 0.24.1
- Google Cloud Storage
3.Prepare Google Cloud Storage for Caching
You need a Google Cloud account with billing enabled.
3−1.Create storage bucket
https://docs.bazel.build/versions/master/remote-caching.html#google-cloud-storage
3−2.Create service account
https://cloud.google.com/iam/docs/creating-managing-service-accounts#creating_a_service_account
A json file with a name such as
xxxxx-xxxxxxxxxxxx.jsonwill be downloaded automatically.
3−3.Preparation for connection to Remote cache (Google Cloud Storage)
$ cd ~ $ mkdir bazel-caching $ mv ~/Downloads/xxxxx-xxxxxxxxxxxx.json ${HOME}/bazel-caching4.(First time) Building Tensorflow v1.13.2
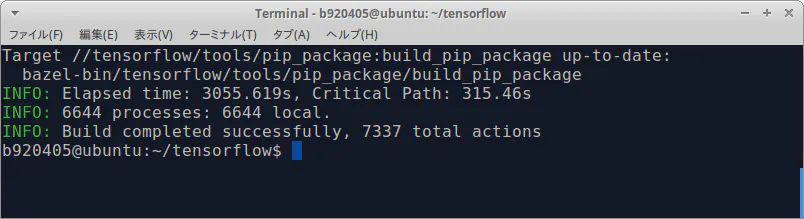
$ sudo apt-get install -y libhdf5-dev libc-ares-dev libeigen3-dev $ sudo pip3 install keras_applications==1.0.7 --no-deps $ sudo pip3 install keras_preprocessing==1.0.9 --no-deps $ sudo pip3 install h5py==2.9.0 $ sudo apt-get install -y openmpi-bin libopenmpi-dev $ sudo -H pip3 install -U --user six numpy wheel mock $ sudo apt update;sudo apt upgrade $ cd ~ $ git clone https://github.com/PINTO0309/Bazel_bin.git $ Bazel_bin/0.20.0/Ubuntu1604_x86_64/install.sh $ cd ~ $ git clone https://github.com/tensorflow/tensorflow.git $ cd tensorflow $ git branch -a * master remotes/origin/0.6.0 remotes/origin/HEAD -> origin/master remotes/origin/bananabowl-patch-1 remotes/origin/ewilderj-patch-1 remotes/origin/jvishnuvardhan-patch-1 remotes/origin/jvishnuvardhan-patch-9 remotes/origin/master remotes/origin/patch-cherry-pick-tf-data remotes/origin/r0.10 remotes/origin/r0.11 remotes/origin/r0.12 remotes/origin/r0.7 remotes/origin/r0.8 remotes/origin/r0.9 remotes/origin/r1.0 remotes/origin/r1.1 remotes/origin/r1.10 remotes/origin/r1.11 remotes/origin/r1.12 remotes/origin/r1.13 remotes/origin/r1.14 remotes/origin/r1.2 remotes/origin/r1.3 remotes/origin/r1.4 remotes/origin/r1.5 remotes/origin/r1.6 remotes/origin/r1.7 remotes/origin/r1.8 remotes/origin/r1.9 remotes/origin/r2.0 remotes/origin/release_1.14.0 remotes/origin/rthadur-patch-1 $ git checkout -b r1.13 origin/r1.13 $ sudo bazel clean $ ./configure WARNING: --batch mode is deprecated. Please instead explicitly shut down your Bazel server using the command "bazel shutdown". INFO: Invocation ID: 202dac03-9d5d-4544-ba79-90001b7b2ca9 You have bazel 0.20.0- (@non-git) installed. Please specify the location of python. [Default is /usr/bin/python]: /usr/bin/python3 Found possible Python library paths: /opt/intel/openvino_2019.2.242/python/python3 /opt/intel/openvino_2019.2.242/python/python3.5 /home/b920405/git/caffe-jacinto/python /opt/intel/openvino_2019.2.242/deployment_tools/model_optimizer . /opt/movidius/caffe/python /usr/lib/python3/dist-packages /usr/local/lib/python3.5/dist-packages /usr/local/lib Please input the desired Python library path to use. Default is [/opt/intel/openvino_2019.2.242/python/python3] /usr/local/lib/python3.5/dist-packages Do you wish to build TensorFlow with XLA JIT support? [Y/n]: n No XLA JIT support will be enabled for TensorFlow. Do you wish to build TensorFlow with OpenCL SYCL support? [y/N]: n No OpenCL SYCL support will be enabled for TensorFlow. Do you wish to build TensorFlow with ROCm support? [y/N]: n No ROCm support will be enabled for TensorFlow. Do you wish to build TensorFlow with CUDA support? [y/N]: n No CUDA support will be enabled for TensorFlow. Do you wish to download a fresh release of clang? (Experimental) [y/N]: n Clang will not be downloaded. Do you wish to build TensorFlow with MPI support? [y/N]: n No MPI support will be enabled for TensorFlow. Please specify optimization flags to use during compilation when bazel option "--config=opt" is specified [Default is -march=native -Wno-sign-compare]: Would you like to interactively configure ./WORKSPACE for Android builds? [y/N]: n Not configuring the WORKSPACE for Android builds. Preconfigured Bazel build configs. You can use any of the below by adding "--config=<>" to your build command. See .bazelrc for more details. --config=mkl # Build with MKL support. --config=monolithic # Config for mostly static monolithic build. --config=gdr # Build with GDR support. --config=verbs # Build with libverbs support. --config=ngraph # Build with Intel nGraph support. --config=dynamic_kernels # (Experimental) Build kernels into separate shared objects. Preconfigured Bazel build configs to DISABLE default on features: --config=noaws # Disable AWS S3 filesystem support. --config=nogcp # Disable GCP support. --config=nohdfs # Disable HDFS support. --config=noignite # Disable Apacha Ignite support. --config=nokafka # Disable Apache Kafka support. --config=nonccl # Disable NVIDIA NCCL support. Configuration finished $ sudo bazel build \ --config=opt \ --config=noaws \ --config=nogcp \ --config=nohdfs \ --config=noignite \ --config=nokafka \ --config=nonccl \ --copt=-ftree-vectorize \ --copt=-funsafe-math-optimizations \ --copt=-ftree-loop-vectorize \ --copt=-fomit-frame-pointer \ --remote_http_cache=https://storage.googleapis.com/bucket-bazel-tensorflow \ --google_credentials=${HOME}/bazel-caching/xxxxx-xxxxxxxxxxxx.json \ //tensorflow/tools/pip_package:build_pip_package
Action result metadata is stored under the path/ac/
Output files are stored under the path/cas/
5.(Second time) Building Tensorflow v1.14.0
$ cd ~ $ Bazel_bin/0.24.1/Ubuntu1604_x86_64/install.sh $ cd ~ $ cd tensorflow $ git checkout -b r1.14 origin/r1.14 $ sudo bazel clean $ ./configure WARNING: --batch mode is deprecated. Please instead explicitly shut down your Bazel server using the command "bazel shutdown". You have bazel 0.24.1- (@non-git) installed. Please specify the location of python. [Default is /usr/bin/python]: /usr/bin/python3 Found possible Python library paths: /opt/intel/openvino_2019.2.242/python/python3 /opt/intel/openvino_2019.2.242/python/python3.5 /home/b920405/git/caffe-jacinto/python /opt/intel/openvino_2019.2.242/deployment_tools/model_optimizer . /opt/movidius/caffe/python /usr/lib/python3/dist-packages /usr/local/lib/python3.5/dist-packages /usr/local/lib Please input the desired Python library path to use. Default is [/opt/intel/openvino_2019.2.242/python/python3] /usr/local/lib/python3.5/dist-packages Do you wish to build TensorFlow with XLA JIT support? [Y/n]: n No XLA JIT support will be enabled for TensorFlow. Do you wish to build TensorFlow with OpenCL SYCL support? [y/N]: n No OpenCL SYCL support will be enabled for TensorFlow. Do you wish to build TensorFlow with ROCm support? [y/N]: n No ROCm support will be enabled for TensorFlow. Do you wish to build TensorFlow with CUDA support? [y/N]: n No CUDA support will be enabled for TensorFlow. Do you wish to download a fresh release of clang? (Experimental) [y/N]: n Clang will not be downloaded. Do you wish to build TensorFlow with MPI support? [y/N]: n No MPI support will be enabled for TensorFlow. Please specify optimization flags to use during compilation when bazel option "--config=opt" is specified [Default is -march=native -Wno-sign-compare]: Would you like to interactively configure ./WORKSPACE for Android builds? [y/N]: n Not configuring the WORKSPACE for Android builds. Preconfigured Bazel build configs. You can use any of the below by adding "--config=<>" to your build command. See .bazelrc for more details. --config=mkl # Build with MKL support. --config=monolithic # Config for mostly static monolithic build. --config=gdr # Build with GDR support. --config=verbs # Build with libverbs support. --config=ngraph # Build with Intel nGraph support. --config=numa # Build with NUMA support. --config=dynamic_kernels # (Experimental) Build kernels into separate shared objects. Preconfigured Bazel build configs to DISABLE default on features: --config=noaws # Disable AWS S3 filesystem support. --config=nogcp # Disable GCP support. --config=nohdfs # Disable HDFS support. --config=noignite # Disable Apache Ignite support. --config=nokafka # Disable Apache Kafka support. --config=nonccl # Disable NVIDIA NCCL support. Configuration finished $ sudo bazel build \ --config=opt \ --config=noaws \ --config=nogcp \ --config=nohdfs \ --config=noignite \ --config=nokafka \ --config=nonccl \ --copt=-ftree-vectorize \ --copt=-funsafe-math-optimizations \ --copt=-ftree-loop-vectorize \ --copt=-fomit-frame-pointer \ --remote_http_cache=https://storage.googleapis.com/bucket-bazel-tensorflow \ --google_credentials=${HOME}/bazel-caching/xxxxx-xxxxxxxxxxxx.json \ //tensorflow/tools/pip_package:build_pip_packageIt seems that caching does not work well if you switch the version or branch of the OSS to be built.
6.(Third time) Building Tensorflow v1.14.0 (Fix the program and rebuild it after removing Bazel's prebuilt binaries)
tensorflow/lite/python/interpreter.py# Add the following two lines to the last line def set_num_threads(self, i): return self._interpreter.SetNumThreads(i)tensorflow/lite/python/interpreter_wrapper/interpreter_wrapper.cc// Corrected the vicinity of the last line as follows PyObject* InterpreterWrapper::ResetVariableTensors() { TFLITE_PY_ENSURE_VALID_INTERPRETER(); TFLITE_PY_CHECK(interpreter_->ResetVariableTensors()); Py_RETURN_NONE; } PyObject* InterpreterWrapper::SetNumThreads(int i) { interpreter_->SetNumThreads(i); Py_RETURN_NONE; } } // namespace interpreter_wrapper } // namespace tflitetensorflow/lite/python/interpreter_wrapper/interpreter_wrapper.h// should be the interpreter object providing the memory. PyObject* tensor(PyObject* base_object, int i); PyObject* SetNumThreads(int i); private: // Helper function to construct an `InterpreterWrapper` object. // It only returns InterpreterWrapper if it can construct an `Interpreter`.tensorflow/lite/tools/make/MakefileBUILD_WITH_NNAPI=falsetensorflow/contrib/__init__.pyfrom tensorflow.contrib import checkpoint #if os.name != "nt" and platform.machine() != "s390x": # from tensorflow.contrib import cloud from tensorflow.contrib import cluster_resolvertensorflow/contrib/__init__.pyfrom tensorflow.contrib.summary import summary if os.name != "nt" and platform.machine() != "s390x": try: from tensorflow.contrib import cloud except ImportError: pass from tensorflow.python.util.lazy_loader import LazyLoader ffmpeg = LazyLoader("ffmpeg", globals(), "tensorflow.contrib.ffmpeg")$ sudo bazel clean $ ./configure WARNING: --batch mode is deprecated. Please instead explicitly shut down your Bazel server using the command "bazel shutdown". You have bazel 0.24.1- (@non-git) installed. Please specify the location of python. [Default is /usr/bin/python]: /usr/bin/python3 Found possible Python library paths: /opt/intel/openvino_2019.2.242/python/python3 /opt/intel/openvino_2019.2.242/python/python3.5 /home/b920405/git/caffe-jacinto/python /opt/intel/openvino_2019.2.242/deployment_tools/model_optimizer . /opt/movidius/caffe/python /usr/lib/python3/dist-packages /usr/local/lib/python3.5/dist-packages /usr/local/lib Please input the desired Python library path to use. Default is [/opt/intel/openvino_2019.2.242/python/python3] /usr/local/lib/python3.5/dist-packages Do you wish to build TensorFlow with XLA JIT support? [Y/n]: n No XLA JIT support will be enabled for TensorFlow. Do you wish to build TensorFlow with OpenCL SYCL support? [y/N]: n No OpenCL SYCL support will be enabled for TensorFlow. Do you wish to build TensorFlow with ROCm support? [y/N]: n No ROCm support will be enabled for TensorFlow. Do you wish to build TensorFlow with CUDA support? [y/N]: n No CUDA support will be enabled for TensorFlow. Do you wish to download a fresh release of clang? (Experimental) [y/N]: n Clang will not be downloaded. Do you wish to build TensorFlow with MPI support? [y/N]: n No MPI support will be enabled for TensorFlow. Please specify optimization flags to use during compilation when bazel option "--config=opt" is specified [Default is -march=native -Wno-sign-compare]: Would you like to interactively configure ./WORKSPACE for Android builds? [y/N]: n Not configuring the WORKSPACE for Android builds. Preconfigured Bazel build configs. You can use any of the below by adding "--config=<>" to your build command. See .bazelrc for more details. --config=mkl # Build with MKL support. --config=monolithic # Config for mostly static monolithic build. --config=gdr # Build with GDR support. --config=verbs # Build with libverbs support. --config=ngraph # Build with Intel nGraph support. --config=numa # Build with NUMA support. --config=dynamic_kernels # (Experimental) Build kernels into separate shared objects. Preconfigured Bazel build configs to DISABLE default on features: --config=noaws # Disable AWS S3 filesystem support. --config=nogcp # Disable GCP support. --config=nohdfs # Disable HDFS support. --config=noignite # Disable Apache Ignite support. --config=nokafka # Disable Apache Kafka support. --config=nonccl # Disable NVIDIA NCCL support. Configuration finished $ sudo bazel build \ --config=opt \ --config=noaws \ --config=nogcp \ --config=nohdfs \ --config=noignite \ --config=nokafka \ --config=nonccl \ --copt=-ftree-vectorize \ --copt=-funsafe-math-optimizations \ --copt=-ftree-loop-vectorize \ --copt=-fomit-frame-pointer \ --remote_http_cache=https://storage.googleapis.com/bucket-bazel-tensorflow \ --google_credentials=${HOME}/bazel-caching/xxxxx-xxxxxxxxxxxx.json \ //tensorflow/tools/pip_package:build_pip_packageIf you just fix a bug fix or build sequence without switching the OSS version or branch to build, caching seems to work well.
7.Appendix
bucket_object_delete_gsutil_commandgsutil -m rm -r gs://bucket-bazel-tensorflow/ac gsutil -m rm -r gs://bucket-bazel-tensorflow/cas8.Reference articles
https://docs.bazel.build/versions/master/remote-caching.html

















- 投稿日:2019-08-04T15:48:36+09:00
小学生の自由研究に⁉ RaspberryPiでラジコン★☆無線マウス操作☆★
@shion21さんの『小学生でも簡単⁉RaspberryPiとScratchを使ったラジコン』を参考にして、
ラジコン操作を無線マウスで出来るようにしました。躯体はamazon The perseids 2WDロボットスマートカーシャーシを使いました。
amazon The perseids 2WDロボットスマートカーシャーシ
1.必要なもの
部品名 個数 RaspberryPi 1 microUSBケーブル 1 HDMIケーブル 1 モニター(TV) 1 無線マウス 1 キーボード 1 モバイルバッテリー 1 amazon The perseids 2WDロボットスマートカーシャーシ 1 モータードライバーTA7291P 2 抵抗器 10kΩ 2 ブレッドボード 170タイポイント 1 ジャンパーワイヤー(オス-オス) 1程度 ジャンプワイヤー(オス-メス) 10程度 単三電池 4 2.作り方
カーシャーシは先に組み立てておいてください。回路も出来上がったら、シャーシに乗っけてください。
回路は以下の通りです。
@shion21さんの『小学生でも簡単⁉RaspberryPiとScratchを使ったラジコン』を参考にして、
ちょっと配線を直してあります。
3.テスト
@shion21さんの[小学生でも簡単⁉RaspberryPiとScratchを使ったラジコン]https://qiita.com/shion21/items/714576ee10a1fe6dacdd
の『3.テスト』を参照してください。
4.プログラム
sudo vim mousebutton.py下記コマンドを張り付けてください。
pygameで黒スクリーンを作成して、スクリーン上でのマウス操作を
GPIO信号に割り当てます。from pygame.locals import * import pygame import sys import RPi.GPIO as GPIO import time GPIO.setmode (GPIO.BCM) GPIO.setup(4, GPIO.OUT) GPIO.setup(17, GPIO.OUT) GPIO.setup(9, GPIO.OUT) GPIO.setup(11, GPIO.OUT) def main(): pygame.init() screen = pygame.display.set_mode((400, 330)) pygame.display.set_caption("mouse event") while True: for event in pygame.event.get(): if event.type == QUIT: pygame.quit() sys.exit() if event.type == MOUSEBUTTONDOWN and event.button == 5: GPIO.output(4,1) GPIO.output(9,1) time.sleep(0.5) GPIO.output(4,0) GPIO.output(9,0) if event.type == MOUSEBUTTONDOWN and event.button == 4: GPIO.output(17,1) GPIO.output(11,1) time.sleep(0.5) GPIO.output(17,0) GPIO.output(11,0) if event.type == MOUSEBUTTONDOWN and event.button == 1: GPIO.output(4,1) GPIO.output(11,1) time.sleep(0.25) GPIO.output(4,0) GPIO.output(11,0) if event.type == MOUSEBUTTONDOWN and event.button == 3: GPIO.output(17,1) GPIO.output(9,1) time.sleep(0.25) GPIO.output(17,0) GPIO.output(9,0) if __name__=="__main__": main() GPIO.cleanup()スクロールアップで『前進』
スクロールダウンで『後退』
左クリックで『左旋回』
右クリックで『右旋回』です。RaspberryPiの起動時にプログラムを自動起動させるには
sudo vim /etc/rc.localファイルの最後にexit 0とあるので、その手前に起動時に実行したいプログラムを書きます。
# sudo python /home/pi/mousebutton.py exit 05.まとめ
このラジコンは、親子で楽しく電子工作をしながらプログラミングもできると思います。
小学校2年の息子を楽しく作りました。Qiitaで初めてHPを書いています。
初心者が書いているので間違いがあるかもしれません。間違っていたらコメントをください。小学校4年生の娘とはMicroBitでSPY-Watchを作製中です。アドバイスとかあったらコメントください。
6.参照リンク
@shion21さんの[小学生でも簡単⁉RaspberryPiとScratchを使ったラジコン]https://qiita.com/shion21/items/714576ee10a1fe6dacdd

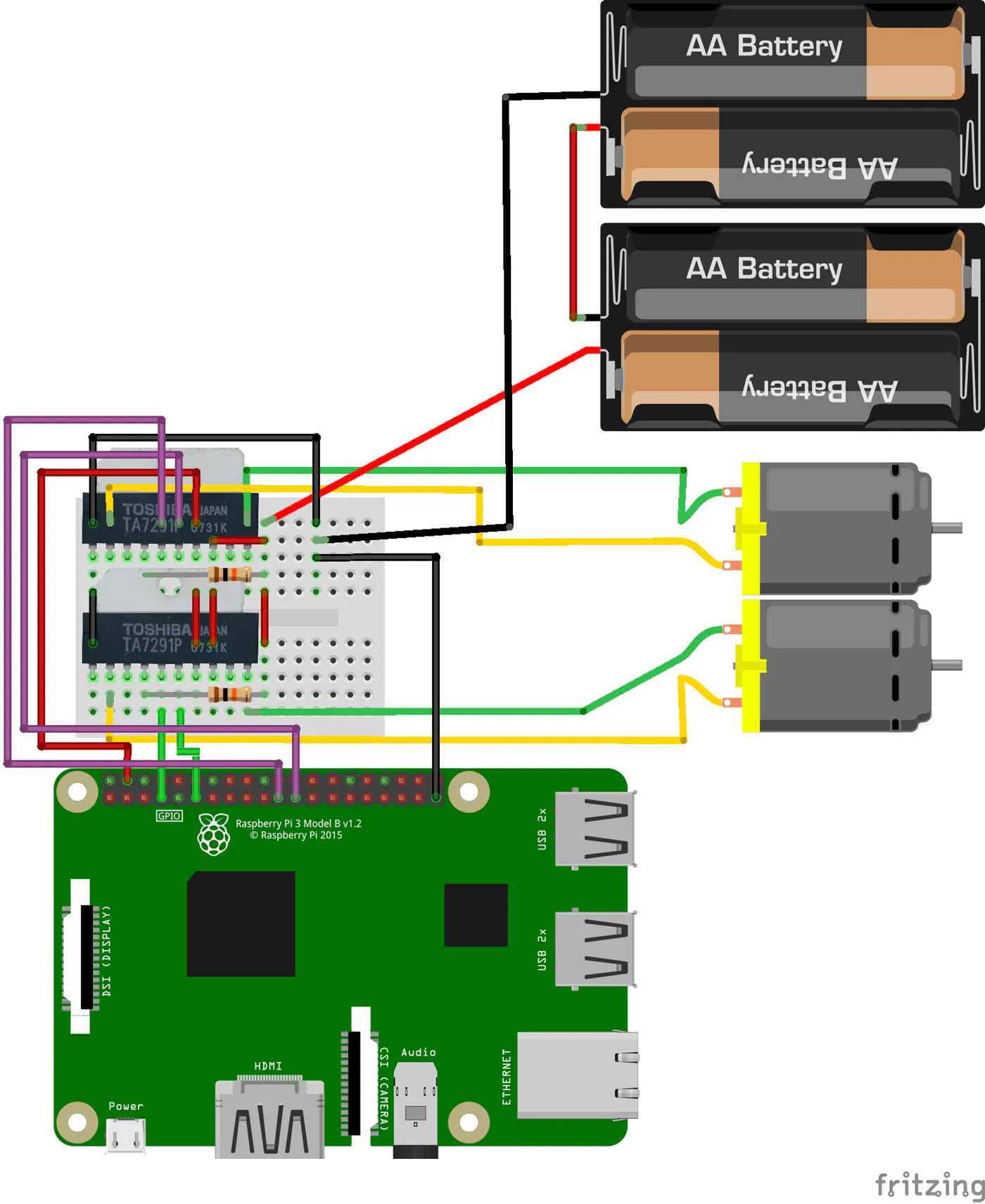


- 投稿日:2019-08-04T15:24:04+09:00
【物理シミュレーション】単振り子・二重振り子のシミュレーションをしてみた!
概要
物理シミュレーションの第一歩ということで、単振り子(pendulum)および二重振り子(double pendulum)をつくってみました.
二重振り子については,軌跡付きでつくってみました.動作環境
- Windows10(64bit)
- Python 3.7.2
単振り子の理論
まずは,単振り子の運動方程式を導きます.
直交座標系の運動方程式を立ててから,角度のみの運動方程式に変形してもいいのですが,
ラグランジアンを使って導いた方がラクでしょう.振り子が鉛直方向となす角を$\theta$とすると,
運動エネルギー
K=\frac{1}{2}m\dot{x}^2=\frac{1}{2}m{(l\dot{\theta})}^2ポテンシャル
U=mglcos\thetaゆえにラグランジアンは
\begin{align} L & = K - U\\ & = \frac{1}{2}m{(l\dot{\theta})}^2 - mglcos\theta \end{align}オイラーラグランジュ方程式に代入して
\begin{align} \frac{d}{dt}(ml^2(\dot{\theta}^2) + mglsin\theta) = 0\\ ml^2\ddot{\theta} = -mglsin\theta\\ \ddot{\theta} = -\frac{g}{l}sin\theta \end{align}となり,$\theta$に関する二階の微分方程式を得る.
Pythonで解くときには,微分方程式は一階の微分方程式にする必要があるが,
一般に$n$階の微分方程式は$n$次の連立微分方程式に変形することができる.今の場合,以下のように$\theta$に関する二階微分方程式が$\theta$と$\omega$に関する連立一階微分方程式に変形ができる.
\begin{cases} \dot{\theta} & = \omega\\ \dot{\omega} & = -\frac{g}{l}sin\theta \end{cases}微分方程式を解く方法
Pythonで微分方程式を解くためには,scipy.integrateの中のodeintやodeがありますし,
実際この関数を使ったコードはネット上にも多く見られました.
しかし,odeintの公式ドキュメントを見てみると,微分方程式を解くための新しい関数として
scipy.integrate.solve_ivpが推奨されています.
ということで,今回は,solve_ivp()を使っていこうと思います.使い方を具体例を使って説明していきます。
- 例1
\frac{dy}{dt}=y\\ y(0)=1解:$y = exp(t)$
def func (t, y): dydt = y return dydt sol = scipy.integrate.solve_ivp(func, [0,20], [1]) t1 = sol.t y1 = sol.y.T t2 = np.linspace(0, 20, 100) plt.plot(t1, y1) plt.plot(t2, np.exp(t2)) plt.show()solve_ivp()の第1引数は微分値を返す関数です.つまり,以下の方程式で言う右辺を返り値に持つ関数です.
\frac{dy}{dt} = f(t, y)solve_ivp()第2引数は時間を,第3引数は初期値を取ります.今回は,$t=0$から$t=20$までとしました.
時間の刻み幅自動で設定されます.これはodeintなどとの違いの一つです.
もし,刻み幅を指定したい場合は例2のようにt_evalキーワードを追加します.実行結果は以下のようになります.
- 例2
\frac{d^2y}{dt^2}=-y\\ y(0)=1\\ \frac{dy}{dt}(0)=0\\解:$y = cos(t)$
例2は2階の微分方程式です.関数funcの中身は上記のようになります.
考え方としては,y = y_0\\ \frac{dy}{dt} = y_1として,以下の連立1階微分方程式に帰着させます.
\frac{d}{dt}y_0 = y_1\\ \frac{d}{dt}y_1 = -y_0def func (t, y): dydt = np.zeros_like(y) dydt[0] = y[1] dydt[1] = -y[0] return dydt t_span=[0,20] y0 = [0,1] t = np.linspace(t_span[0], t_span[1], 100) sol = scipy.integrate.solve_ivp(func, t_span, y0, t_eval=t) t1 = sol.t y1 = sol.y[1,:] t2 = np.linspace(0, 20, 100) plt.plot(t1, y1, 'o') plt.plot(t2, np.cos(t2), '--') plt.show()実行結果は以下のようになります.
単振り子の実装
それでは,単振り子のシミュレーションを行うプログラムを実装してみましょう!
- ライブラリのインポート
まずは,必要なライブラリをインポートします.
from numpy import sin, cos from scipy.integrate import solve_ivp from matplotlib.animation import FuncAnimation import matplotlib.pyplot as plt import numpy as np
- 運動方程式の記述
続いて運動方程式を記述する関数を定義します.重力加速度はG,振り子の長さはLとしています.
def derivs(t, state): dydt = np.zeros_like(state) dydt[0] = state[1] dydt[1] = -(G/L)*sin(state[0]) return dydt
- 初期条件の記述
運動方程式の初期条件を与えます.2階微分方程式なので自由度は2ですね.
th1 = 30.0 w1 = 0.0 state = np.radians([th1, w1])
- 運動方程式を解く
運動方程式の数値解を求めます.
yは(2,len(t))型の二次元配列なので,今は,1行目の角度$\theta$のみを取得します.
2行目の角速度$\omega$は今回は必要ないです.sol = solve_ivp(derivs, t_span, state, t_eval=t) theta = sol.y[0,:]
- 直交座標系に変換
求まった$\theta$から直交座標系$(x,y)$に変換します.これでデータは得られました.
あとは,これをプロットするだけです.x = L * sin(theta) y = -L * cos(theta)
- 逐次描画していく関数の定義
順次描画していくための関数を定義します.1行目のlineに次々と座標を代入して描画をしていきます.
linewidth=2はlw=2と省略することもできます.'o-'は端点と線分を表します.line, = ax.plot([], [], 'o-', linewidth=2) def animate(i): x = [0, x[i]] y = [0, y[i]] line.set_data(x, y) return line,
- アニメーションの関数
最後にアニメーションを実行します.
blitキーワードやintervalキーワードはアニメーションが滑らかになるように設定しています.なくても動きます.
あとは,レイアウトなどを整え,プロットすれば終わりです.ani = FuncAnimation(fig, animate, frames=np.arange(0, len(t)), interval=25, blit=True)実行結果
二重振り子
では,単振り子でアニメーションの方法はマスターできたと思うので,二重振り子をシミュレーションしてみましょう.
カオスが見れて面白いです!
さらに,単振り子のレベルアップということで軌跡も描画しちゃいましょう.二重振り子の理論
二重振り子の運動方程式も単振り子同様ラグランジアンを求めて,オイラーラグランジュ方程式に代入すれば求まります.
ここでは,計算が面倒なので結果だけを示します.運動方程式
(m_1+m_2)l_1\ddot{\theta_1} + m_2l_2\ddot{\theta_2}cos(\theta_1-\theta_2) + m_2l_2\dot{\theta_2}^2sin(\theta_1-\theta_2) + (m_1+m_2)gsin\theta_1 = 0\\ l_1l_2\ddot{\theta_1}cos(\theta_1-\theta_2) + l_2^2\ddot{\theta_2}-l_1l_2\dot{\theta_1}^2sin(\theta_1-\theta_2) gl_2sin{\theta_2}整理して,
\frac{d\theta_1}{dt} = \omega_1\\ \frac{d\omega_1}{dt} = \frac{m_2l_1\omega_1^2sin\delta cos\delta + m_2gsin\theta_2cos\delta + m_2l_2\omega_2^2sin\delta -(m_1+m_2)gsin\theta_1}{(m_1+m_2)l_1-m_2l_1cos^2{\delta}}\\ \frac{d\theta_2}{dt} = \omega_2\\ \frac{d\omega_2}{dt} = \frac{-m_2l_2\omega_2^2sin\delta cos\delta + (m_1+m_2)gsin\theta_1cos\delta -(m_1+m_2)l_1\omega_1^2sin\delta -(m_1+m_2)gsin\theta_2}{(m_1+m_2)l_1-m_2l_1cos^2{\delta}}ただし,$\delta = \theta_2-\theta_1$.
二重振り子の実装
それでは,二重振り子のシミュレーションを行うプログラムを実装しています.
matplotlibの公式ドキュメントに二重振り子のシミュレーションプログラムがあるのでそちらを参考にしました.
- 運動方程式の記述
def derivs(t, state): dydx = np.zeros_like(state) dydx[0] = state[1] delta = state[2] - state[0] den1 = (M1+M2) * L1 - M2 * L1 * cos(delta) * cos(delta) dydx[1] = ((M2 * L1 * state[1] * state[1] * sin(delta) * cos(delta) + M2 * G * sin(state[2]) * cos(delta) + M2 * L2 * state[3] * state[3] * sin(delta) - (M1+M2) * G * sin(state[0])) / den1) dydx[2] = state[3] den2 = (L2/L1) * den1 dydx[3] = ((- M2 * L2 * state[3] * state[3] * sin(delta) * cos(delta) + (M1+M2) * G * sin(state[0]) * cos(delta) - (M1+M2) * L1 * state[1] * state[1] * sin(delta) - (M1+M2) * G * sin(state[2])) / den2) return dydx
- 初期条件の記述
th1 = 100.0 w1 = 0.0 th2 = -10.0 w2 = 0.0 state = np.radians([th1, w1, th2, w2])
- 運動方程式を解く
sol = solve_ivp(derivs, t_span, state, t_eval=t) y = sol.y
- ジェネレータ関数の定義
これは単振り子と少し異なります。軌跡を描くためにジェネレータを定義します。
ジェネレータはreturnではなくyield文で返します.
また,zip()関数を使うことで,並列的に反復処理を行えます.def gen(): for tt, th1, th2 in zip(t,y[0,:], y[2,:]): x1 = L1*sin(th1) y1 = -L1*cos(th1) x2 = L2*sin(th2) + x1 y2 = -L2*cos(th2) + y1 yield tt, x1, y1, x2, y2
- アニメーション関数の定義
locusにどんどん値を追加していくことで,軌跡を描画します.
また今回はタイマーもついています.locus, = ax.plot([], [], 'r-', linewidth=2) line, = ax.plot([], [], 'o-', linewidth=2) time_template = 'time = %.1fs' time_text = ax.text(0.05, 0.9, '', transform=ax.transAxes) xlocus, ylocus = [], [] def animate(data): t, x1, y1, x2, y2 = data xlocus.append(x2) ylocus.append(y2) locus.set_data(xlocus, ylocus) line.set_data([0, x1, x2], [0, y1, y2]) time_text.set_text(time_template % (t))
- アニメーションの実行
ani = FuncAnimation(fig, animate, gen, interval=50, repeat=False)実行結果
まとめ
いかがだったでしょうか?今回は物理シミュレーションとして,単振り子と二重振り子を扱ってみました.
二重振り子のカオスが見れたときは興奮しますよね.
今回のコードに関して改善点などありましたらコメントいただけると助かります.


- 投稿日:2019-08-04T14:03:06+09:00
PyOpenGL glGenBuffersでエラー
PythonからOpenGLを使ってとあるプログラムを開発中です。
初歩的なところですが、glGenBufferwsを実行して以下のエラーが出てはまったので対処方法を紹介します。
OpenGLのエラー
OpenGL.error.NullFunctionError: Attempt to call an undefined function glGenBuffers, check for bool(glGenBuffers) before calling
対処方法
glutInit と glutInitDisplayMode と glutCreateWindow を先に実行すること。
OpenGLの初期化が完了していないのが原因です。
- 投稿日:2019-08-04T14:01:24+09:00
【ピーナッツくん】ゆるきゃらグランプリの獲得票数と順位をスクレイピングする【がんばれ】
はじめに
8/1より、ゆるキャラグランプリがはじまりました!
10/25までネット上で投票(1日1回投票可能)が行われ、ご当地および企業キャラクターがそれぞれ得票数を競います。
得票数は定期的にネット上で公開され、推しのゆるキャラがいま何位ぐらいかがわかるようになっているみたいです。
しかし、Webサイトの情報にアクセスしにくい(個人的な感想)うえ、票数や順位の時間的な推移を確認することができません。
そこで、今回はPythonを使ったWebスクレイピングで情報を引っ張ってくることにしました。
スクレイピングの前準備
プログラムを書く前に、以下のことを確認する必要があります。
- Webページのソースコード中のどの部分に欲しい情報が書かれているか
- ページのURLがどのような構造になっているか
今回は、この過程も簡単に解説していきます。
タグの確認
まず、スクレイピングをする前にどんな情報が欲しいかを確認します。
例えば、以下のゆるキャラグランプリ企業部門の検索画面
"https://www.yurugp.jp/jp/vote/result.php?enterprise=1"
では、ゆるキャラの順位、得票数、名前、地域、そして所属が確認できます。
今回はこの情報だけで十分なので、個別ページに飛ぶ必要はなさそうです。
次に、この情報が表示されている部分のhtmlタグを確認します。
自分はChromeを使っているので、タグを見たい部分を右クリック→検証でソースが見えます。
このように、例えば順位、得票数はrankdetailクラスのdivタグで、名前、地域、所属はnameクラスのdivタグで囲まれていることが分かります。
ここまでがわかればスクレイピングには十分です。
次に、URLの確認をしていきます。URLの確認
例えば、企業のゆるキャラの検索画面のURLは以下のようになっています。
https://www.yurugp.jp/jp/vote/result.php?page=1&enterprise=1
page=nの部分がn = 2,3... となると次ページのURLとなります。
非常にわかりやすいURLなので、簡単にスクレイピングできそうです。また、nの値が大きすぎた場合、例えば
https://www.yurugp.jp/jp/vote/result.php?page=20&enterprise=1
のようなURLはどうなるのかというと、404エラーが返ってくるのではなく、空のページに飛ばされるようです。
今回はこの仕様を利用して、ぱぱっとプログラムを書いていきます。
HPの情報をスクレイピングするコード
以下は、企業ゆるキャラの情報をスクレイピングするコードです。
今回はPythonのurllibとBeautifulSoupを使いました。import urllib.request from bs4 import BeautifulSoup import numpy as np import time dataset = [] n = 1 isContinue = True while(isContinue): url_pref = "https://www.yurugp.jp/jp/vote/result.php?page="+str(int(n))+"&enterprise=1" # urllibで読み込み、BeautifulSoupでパースする nem = urllib.request.urlopen(url_pref).read() soup = BeautifulSoup(nem,"html.parser") # rankdetail, nameクラスのdivタグの部分を抽出 rank = soup.find_all("div",class_="rankdetail") name = soup.find_all("div",class_="name") # 情報を抽出してリストに保存 ranks = [[j.text.split('位')[0],j.text.split('位')[1].replace("PT",""), i.find_all("h4")[0].text.replace("(","").replace(")",""), i.find_all("span",class_="country")[0].text.replace("(","").replace(")",""), i.find_all("span",class_="biko")[0].text] for i,j in zip(name,rank)] if(len(ranks) == 0): # 空のページに行くとrankdetail, nameのdivタグの部分がないので # ranksは空のリストとなる。ここで繰り返し処理を終了する。 isContinue = False else: # ranksの長さが0より多きければdatasetに追加してnに1を足す dataset.extend(ranks) n += 1 time.sleep(1) dataset_ent = np.array(dataset)たったこれだけです、簡単ですね!
ちなみにdataset_entの中身はこんな感じになっています。array([['36', '142', 'よりぞう', '東京都', 'JAバンク(農林中央金庫)'], ['65', '75', 'でんのすけ', '香川県', '四電エナジーサービス株式会社'], ['25', '196', 'ミクちゃん', '兵庫県', '株式会社タツミコーポレーション'], ..., ['161', '16', 'えひめれっちゃくんすまいるえきちゃん', '愛媛県', 'JR四国'], ['133', '25', 'かがわれっちゃくんすまいるえきちゃん', '香川県', 'JR四国'], ['210', '8', 'こうちれっちゃくんすまいるえきちゃん', '高知県', 'JR四国']], dtype='<U35')左から順に順位、得票数、名前、地域、所属です。
データを分析して遊ぶ
目的のデータが得られたので、さっそく解析してみます!
まずは基礎データですが、現在の企業ゆるキャラの総数は362名、総票数は29162票でした。上位50名のゆるキャラとその得票数のプロットは以下になります。
ダントツの1位がバーチャルYoutuberのオシャレになりたい!ピーナッツくん、2位が株式会社宇佐美鉱油のうさっぴぃ、3位がNEXCO生日本のみちまるくん・・・と続いています。
上位の得票数が全体に占める割合が非常に多そうなので、得票率が1%以上の候補を円グラフで可視化してみましょう。
すると、上位陣が全体の票数のほとんどを独占していることがよくわかります。
中でも1位のオシャレになりたい!ピーナッツくんは一人で15%以上の得票率をたたき出しています。
Youtubeチャンネルの登録者数が8.4万人ぐらいなので、その5%程度が投票していると考えればおかしな数字ではありませんが、ゆるキャラ界(あるのか?)に大きな衝撃を与えていることでしょう。おまけ
ご当地のゆるキャラをスクレイピングするプログラムはこんな感じです。
県ごとに検索ページが分かれているのが違いですが、数が増えることはない(48個)ので、対応はそんなに難しくないです。dataset = [] search_list = np.linspace(1,48,48) for i in search_list: n = 1 isContinue = True while(isContinue): url_pref = "https://www.yurugp.jp/jp/vote/result.php?page="+str(int(n))+"&prefectures="+str(int(i)) nem = urllib.request.urlopen(url_pref).read() soup = BeautifulSoup(nem,"html.parser") rank = soup.find_all("div",class_="rankdetail") name = soup.find_all("div",class_="name") ranks = [[j.text.split('位')[0],j.text.split('位')[1].replace("PT",""), i.find_all("h4")[0].text.replace("(","").replace(")",""), i.find_all("span",class_="country")[0].text.replace("(","").replace(")",""), i.find_all("span",class_="biko")[0].text] for i,j in zip(name,rank)] if(len(ranks) == 0): isContinue = False else: dataset.extend(ranks) n += 1 time.sleep(1)最後に
この記事を書いた目的の3/4ぐらいは、技術的な内容にかこつけてバーチャルYoutuberのオシャレになりたい!ピーナッツくんと、その相方のぽんぽこさんの応援です!
(ぽんぽこさんも着ぐるみ化してエントリーしたけど落選してしまった模様)バーチャルYoutuberなのに身銭切って着ぐるみ化してゆるキャラグランプリに出るとか面白すぎでしょ。
10/25まで先は長いぞ!
一日一票! ピーナッツくんの応援よろしくね!konkon


- 投稿日:2019-08-04T13:33:21+09:00
javascriptのPromiseをpythonで実装する方法
Motive
seleniumでスマホ版でブラウザを起動しようと思った時、sp_args = "--user-agent=" sp_args_list = ["Mozilla/5.0 (iPhone; CPU iPhone OS 10_2 like Mac OS X)", "AppleWebKit/602.3.12 (KHTML, like Gecko)", "Version/10.0 Mobile/14C92 Safari/602.1"] sp_args += " ".join(sp_args_list)と設定するだけでは一部のサイトではレスポンシブになっているため対応しない場合があります。
そのため、
widthを450くらいにしてリロードをするとスマホ版の表示になるのですが、ブラウザ設定 → スマホ画面の大きさを設定 -> リロードの順に一つのプロセスが完了したことがcompleteになった状態で次のプロセスに移す実装ができないかと思ったわけです。で、 javascriptの非同期処理で使われる
Promiseと同等のものがpythonでできないかと考えたわけっす。Preparetion
pipで探すと早速パッケージが見つかりました。ふつーにpip install Promiseで良いです。
Model
参考にしたサンプルコードですが初めてのJavaScript 第3版 ――ES2015以降の最新ウェブ開発 14章 非同期プログラミングにあったロケット発射モデルを題材にしました。
元コードからブラウザに表示する編集等々でちょっと変えています。
<html> <head> <script src="https://ajax.googleapis.com/ajax/libs/jquery/3.4.1/jquery.min.js"></script> <script type="text/javascript" src="./sample.js"></script> </head> <body> <h3>apolonX</h3> <div class="box"> </div> </body> </html>$(()=>{ countdown(10) .then(()=>{ return new Promise((resolve, reject) => { setTimeout(() => { //大気圏突入 resolve(insertBox("atmosphere...")); }, 2000); }); }) .then(()=>{ //成功 insertBox("success!!"); }); }); //カウントダウン function countdown(seconds){ let dst = new Promise( (resolve, reject) => { for (let i=seconds;0 <=i;i--){ setTimeout(() => { if(i>0){ insertBox(countSign(i)); } else { resolve(insertBox(goSign())); } }, (seconds-i)*1000); } } ); return dst } function insertBox(src){ let p = $("<p>") p.text(src); $(".box").append(p); } function countSign(index){ return index + "..."; } function goSign(){ return "GO!"; }で約2秒ごとにブラウザにメッセージが表示されます。
Method
from promise import Promise import time def main(): countdown(10).then(go()).then(Promise.resolve(atmosphere())).then(success()) def countdown(seconds): def myfunc(resolve, reject): for i in reversed(range(0,seconds + 1)): if 0 < i: print( str(i) + "..." ) time.sleep(2) else : resolve() return Promise(myfunc) def go(): time.sleep(1) print("GO") def atmosphere(): time.sleep(1) print("atmosphere") def success(): print("success!!") if __name__ == '__main__': main()
countdown(10).then(go()).then(Promise.resolve(atmosphere())).then(success())でチェイン化しています。
Future
複数のAPIでデータ取得後に一括処理して文章生成するなどのケースであったら、全てのAPIのデータ取得後に一括処理する一貫性が保たれるので何かと良い。
簡易的なトランザクション処理ですかね。Reference
promise
promise:github
初めてのJavaScript 第3版 ――ES2015以降の最新ウェブ開発 14章 非同期プログラミング
Python の Promise 実装とその活用方法について / How to implement Promise by Python and how to use it


- 投稿日:2019-08-04T11:01:00+09:00
KAGGLEでどこから手を付けていいか分からず学ぶことが多すぎてまとめてみた
Googleで「KAGGLE」で検索し1ページ目(公式、Wikipedia除く)
タイトル 著者 記事日時 特徴 初心者のToDo Kaggleとは?機械学習初心者が知っておくべき3つの使い方 Codexaチーム 2017-11-22 初心者向け カーネルをやれ Kaggleを始める人に役に立つ記事 @jeayoon 2019-05-16 初心者向け - Kaggle参戦記 〜入門からExpert獲得までの半年間の記録 & お役立ち資料まとめ〜 naotaka1128 Expert 2019-01-15 詳細 *1)にまとめ KaggleでSilver取るためにどういう段階を踏んでいけばよいですか? カレーちゃん?専業kaggler(たまにSilver) 2019-01-15 初心者向け カーネルの理解、改良 Kaggle Titanic やってみた感想 mizchi 2019-02-08 Titanicの紹介 - 最近のKaggleに学ぶテーブルデータの特徴量エンジニアリング mlm_kansai 2019-03-27 特徴量エンジニアリングについて詳細 *2)にまとめ - 機械学習の勉強歴が半年の初心者が、 Kaggle で銅メダルを取得した話 株式会社トップゲートのエンジニア(Brond) 2019-02-27 詳しめ *3)にまとめ 性能の良い分類器、出力のアンサンブル 上記の方々の推奨本
- 2票(naotaka1128、カレーちゃん)[第2版]Python 機械学習プログラミング 達人データサイエンティストによる理論と実践 (impress top gear)

- 1票(naotaka1128)PythonとKerasによるディープラーニング

- 1票(naotaka1128)scikit-learnとTensorFlowによる実践機械学習

- 1票(mlm_kansai)機械学習のための特徴量エンジニアリング ―その原理とPythonによる実践 (オライリー・ジャパン)

記事の概要
Kaggle参戦記 〜入門からExpert獲得までの半年間の記録 & お役立ち資料まとめ〜 *1)
- 特徴量エンジニアリング
- 次元削減系 LDA、PCA、tSNE
- Kaggle TalkingData Fraud Detection コンペの解法まとめ(基本編)
- 「カテゴリー変数を組み合わせて特徴量を量産してLightGBMにぶち込む」
- Kaggle TalkingData Fraud Detection コンペの解法まとめ(応用編)
- もはや常識 random seed average
- 予測モデルを複数作ってそれらの平均を最終的な予測とするensembleという手法がkaggleでは常識となっています。
- お手軽な手法としてrandom seed averageといういうのがあります。それは、モデルを訓練する際にランダム性がある場合にランダムシード値を変えて複数モデルを作りそれの単純平均をとる
- Negative Down Sampling
- 判別で目的変数が不均衡な場合、多い方のデータを捨てる
- 特徴量選択
- ランダムフォレストと検定を用いた特徴量選択手法Boruta
- 特徴量選択とは
- コンペでは精度のみが重視されるがビジネス上は説明変数の特定が重要視される
- ただ、モデルの学習や推論が高速化されたり、過学習しづらくなったり、結果判別の精度が良くなったりもする
- 既存の手法の特徴
- ランダムフォレスト
- どれぐらいの特徴量重要度があったら重要だと言えるのかがイマイチ
- ランダム性から訓練するたびに特徴量重要度が変動する
- Forward selectionやBackward eliminationと言ったステップワイズな方法
- 計算量が多い
- 選んだ特徴量が過学習する
- lasso
- 選んだ特徴量が過学習する
- Boruta
- ニセの特徴量を作って重要度を比較する
- アンサンブル
- KAGGLE ENSEMBLE GUIDE アンサンブルのバイブル
- ブレンド
最近のKaggleに学ぶテーブルデータの特徴量エンジニアリング *2)
trainデータ、testデータ、Private testデータ間での乖離が大きいコンペが増えている → 単純にtrain, testで学習検証しただけではだめ → 特徴量エンジニアリング
- 特徴量エンジニアリング
- Target Encoding
- カテゴリ変数をそのカテゴリにおけるTargetの平均値で置き換える
- カテゴリ変数のレベルが多い場合に使う
- テーブル間の集約
- 集約し、sumやaverage
- トランザクション側のデータが多い場合
- 四則演算
- GBDTは差や比率を直接表現できない
- 意味が明確な連続値がある場合
- サブモデルによる特徴量
- 重要な特徴量の予測
- トランザクションレベルの予測
機械学習の勉強歴が半年の初心者が、 Kaggle で銅メダルを取得した話 *3)
- 性能の良い分類器を使う
- アンサンブル学習系
- 深層学習系
- 複数の予測値のブレンド
- 多数決、平均
- 感度解析
- 複数の予測値のブレンドだが重み付け
まとめ、気付き(つか無知の反省)
- 特徴量エンジニアリング
- 思いつく限りたくさん作ってlightGBM(が軽いので)放り込んじまえ!?
- 不均衡データ
- Negative Down Sampling
- その発想はなかった!って感じ
- 特徴量選択
- Boruta知らなんだ
- アンサンブル
- KAGGLE ENSEMBLE GUIDE アンサンブルのバイブル、知らなんだ、、、
- ブレンド
- 複数のアルゴリズムの結果で多数決、平均するのってそれも「アンサンブル」と思っていたが「ブレンド」と言うらしい
上記記事にはないが(わたしの見落としかも)関連する手法
- 不均衡データのときに目的変数の少ない側のデータを増やすもの
- データ生成
- 判別データにて、均衡したデータでもデータ生成で精度が良くなるという事例もある
- 連続値の場合もデータ生成手法がある
- 共変量シフト
- trainとtestで説明変数に偏りがある場合の対応
補足的な資料
欠測値補完
- 欠測値データを除去していたり平均値を埋めていたりではKAGGLEでは勝てない。
- 欠測データ処理: Rによる単一代入法と多重代入法 (統計学One Point)

- Rによる実例があり分かりやすい。
不均衡データ対策
- 【ML Tech RPT. 】第4回 不均衡データ学習 (Learning from Imbalanced Data) を学ぶ(1)
- 日本語で読める資料の中では一番詳しくまとまっていると思う
- 判別でのSMOTE
- 『前処理大全』

- RとPythonによりSMOTEの解説がある。SMOTEのみでなく前処理について詳しい解説があり、必須の書だと思う。
- 回帰でのSMOTERegressについての本は見つけていない
- smoteRegress: SMOTE algorithm for imbalanced regression problems
- ライブラリの解説記事程度しかなさそう






- 投稿日:2019-08-04T02:29:38+09:00
LINE Notifyを使ってLINEへメッセージを送信するpythonプログラムを作ってみる2
前回まで
LINE Notifyを使ってLINEへメッセージを送信するpythonプログラムを作ってみる
前回の続きでは、iniファイルの読み込み部分も起動するプログラムファイル内に含めているが、java屋のクセとして機能的に分割したい。
iniファイルを読み込むプログラムとメッセージ送信プログラムを区別してみる。コーディング3回目
- setting.iniは前回と同じ
- setting.iniを読み込んで設定情報にアクセスするためのクラス(Settings.py)を追加
- 起動するプログラムから2.を参照する
- 2.の単体テスト用プログラム
setting.ini[LINENotify] line_notify_token = <アクセストークン> line_notify_api = https://notify-api.line.me/api/notifySettings.pyfrom configparser import ConfigParser from pconst import const # Settting.iniを管理するクラス class Settings: # setting.ini セクション名 NOTIFY = 'LINENotify' const.SECTION_LINENotify = NOTIFY # LINENotifyセクション トークン名 NOTIFY_TOKEN = 'line_notify_token' const.LINENotify_TOKEN = NOTIFY_TOKEN # LINENotifyセクション URL NOTIFY_APIURL = 'line_notify_api' const.LINENotify_APIURL = NOTIFY_APIURL # コンストラクタ # iniファイルを読み込み def __init__(self): self.config = ConfigParser() self.config.read('setting.ini', encoding="utf-8") # ConfigParserインスタンスを生成する def getConfigParserInstance(self): return self.config # setting.iniよりアクセストークンを取得する def getLINENotify_Token(self): return self.config[const.SECTION_LINENotify][const.LINENotify_TOKEN] # setting.iniよりアクセスURLを取得する def getLINENotify_APIPath(self): return self.config[const.SECTION_LINENotify][const.LINENotify_APIURL]sendmessege.py# -*- coding: utf-8 -*- import requests import configparser from Settings import Settings def main(): # 設定ファイル読み込み config = Settings() print("LINEへ送信するメッセージを入力してください。") message = input("送信メッセージ:") print('送信メッセージ:' + message) payload = {'message': message} headers = {'Authorization': 'Bearer ' + config.getLINENotify_Token()} requests.post(config.getLINENotify_APIPath(), data=payload, headers=headers) if __name__== '__main__': main()SettingsTest.pyimport unittest from Settings import Settings # Setttingsユニットテストクラス class SettingsTest(unittest.TestCase): # # テスト準備 def setUp(self): self.config = Settings() # テストケース:コンストラクタ def test_constructor(self): self.assertIsNotNone(self.config) # テストケース:iniファイル設定値取得メソッド def test_getSettings(self): self.assertIsNotNone(self.config.getConfigParserInstance()) self.assertIsNotNone(self.config.getLINENotify_Token()) self.assertIsNotNone(self.config.getLINENotify_APIPath()) if __name__ == '__name__': unittest.main()気づき・感想
- setting.iniにはアクセストークンが記載されており、アプリケーション固有の設定情報が記載されたiniファイルはこのままGitHubへpushできない。
- 設定情報を扱うクラスを区別化したことで、変更箇所だけをテストでき保守性がアップした。
- pconstがあれば定数行を宣言できる。
コーディング4回目
- setting.iniはパラメータのみ削除する
- アプリ固有の設定情報は初期セットアップ時にsetting.iniを書き込むためのクラス(SetUpScript.py)を追加
setting.ini[LINENotify] line_notify_token = line_notify_api =SetUpScript.py""" セットアップ用スクリプト Setting.iniファイルの初期設定を行う。 """ from Settings import Settings config = Settings() cpins = config.getConfigParserInstance() print("Setting.iniの初期設定を開始します。") print() print("LINE Notify登録時のアクセストークンを入力してください。") token = input('アクセストークン:') cpins.set(config.NOTIFY, config.NOTIFY_TOKEN, token) print("アクセストークンを登録しました。") cpins.set(config.NOTIFY, config.NOTIFY_APIURL, 'https://notify-api.line.me/api/notify') print("API用URLを登録しました。") with open('setting.ini', 'w') as contextfile: cpins.write(contextfile) print() print("Setting.iniの初期設定が完了しました。")気づき・感想
- GitHubにsetting.iniを追加できた。
- アプリ固有の設定情報はローカルにて設定できるようになった。
- 投稿日:2019-08-04T02:11:25+09:00
Google Cloud Functions (Python3) を使ってみた
Google Cloud Functions で Python3 が使えるということだったので使ってみました。実際のプロダクトで使うことも考えて、環境変数の扱い、ローカルでの開発についても説明しています。
なお、この記事はタスク管理にGitHubを使う一連の記事の中の一つです。
- 情シスのタスクをGitHubのissueで管理するようにしたら捗った
- プロジェクト管理ツールとしてGitHubを"普通に"使う
- Google Cloud Functions (Python) を使ってみた ←ここ
- GitHub App を作ってPythonからAPIを叩いてみた
- Google Apps Script から Google Cloud Functions のHTTPトリガーを実行してみた
前提
以下のことが完了している前提で説明します。
- Google Cloud Platform のアカウント作成
- gcloudコマンドのインストール
- ログイン (
gcloud auth login)クイックスタート
まずは簡単に関数を作ってみます。
関数の作成
https://console.cloud.google.com/functions
設定
今回指定した設定は以下の表のとおりです。
項目 メモリ 256 MB トリガー HTTP ランタイム Python 3.7 ソースコード インライン エディタ 実行する関数 hello_world
確認
Google Cloud Platform のコンソール画面からも確認できますが、 gcloud でログインしていればローカルからのコマンドでも確認できます。
$ gcloud functions list結果
NAME STATUS TRIGGER REGION function-1 ACTIVE HTTP Trigger us-central1実行
実行のためのトリガーは以下のように複数の選択肢があります。
- HTTP
- Cloud Storage
- Cloud Pub/Sub
- Firebase
今回はHTTPのトリガーを作成したので、ブラウザや
curlコマンドで直接GETリクエストを送って確認できます。URLはコンソール画面でに表示されています。
Python3 関連ファイル
Python3で Cloud Functions を作成すると、2つのファイルができています。
- main.py
- requirements.txt
実行したい関数は main.py の中に適当な名前で実装し、「実行する関数」でその名前を指定すると実行できます。サードパーティ製の必要なライブラリがあったら requirements.txt に書いておけばデプロイしたときに自動的にインストールしてくれます。また、Pythonファイルは一つだけではなくPythonパッケージを作成して main.py から
importすることもできます。
ローカルからのデプロイ
できるならコードを毎回ブラウザ上のエディタではなくローカルで開発してGit管理するほうが望ましいと思われます。Cloud Source Repositories を使うと Google Cloud Platform 上での管理もできますが、ここではGitHubを想定します。
gcloudコマンドによるデプロイ
とりあえずコピーしてくるなり何なりして同様の環境をローカルに作り、ローカルからデプロイコマンドを実行すればデプロイできます。
$ gcloud functions deploy function-1 --trigger-http --runtime=python37少し変更を加えて先程のエンドポイントにアクセスするとローカルからのデプロイができていることがわかると思います。
不要なファイルをアップロードしないようにする
ローカルに適当なファイルを置いておけばコマンド一つでデプロイしてくれるのですが、何もしなければGit管理用のファイルなど、関係ないファイルまでアップロードしてしまいます。
そこで .gcloudignore というファイルを作成しておきます。.gitignore のように、ここにアップロードしたくないファイルやディレクトリを記載しておけば、デプロイの際にアップロードされることがありません。
なお、 .gcloudignore から他のファイルを参照することもできるので、 .gitignore を参照すると良いかもしれません。
.gcloudignore .gitignore Makefile README.md requirements_local.txt test/ venv/ #!include:.gitignoreローカルでの開発
簡単にデプロイして確認ができる Cloud Functions ですが、毎回アップロードしなければ確認できないのは不便です。そのためにローカルでエミュレートする仕組みを作ります。
仮想環境の作成 (venv)
必須ではありませんが、必要に応じて仮想環境を用意しておくと便利です。
$ python3 venv venv $ source venv/bin/activateFlaskによるエミュレート
Google Cloud Function で始めに実行される関数は、Flaskの
flask.Requestオブジェクトを受け取ります。ローカルで開発する際にはlocalhostにFlaskの開発用サーバーが立ち上がるようにすることでエミュレートできます。ライブラリのインストール
$ pip install flask実装
main.pyfrom flask import Flask, request def hello_world(request): # ... return 'HelloWorld!' if __name__ == "__main__": app = Flask(__name__) @app.route('/') def index(): return hello_world(request) app.run('127.0.0.1', 8000, debug=True)このように、 main.py が直接呼ばれた場合は開発用サーバーが立ち上がり、 localhost:8000 にアクセスすると
hello_worldが実行されます。環境変数
作成するアプリケーションによっては、他のサービスのAPIキーなど、ソースコードに書きたくない情報を含んでいる場合があります。そういった場合には環境変数を設定することができます。
設定方法
コマンドの引数を使う方法
一つの方法は、デプロイする際にコマンドの引数で指定する方法です。
$ gcloud functions deploy function-1 --trigger-http --runtime=python37 --set-env-vars FOO=bar,BAZ=boo
Yamlを使う方法
env.yamlFOO: bar BAZ: boo$ gcloud functions deploy function-1 --trigger-http --runtime=python37 --env-vars-file=./env.yaml読み込み
Google Cloud Function に設定した環境変数を使う方法は自分でサーバーを立ち上げたときなど、他の環境と同じです。
import os FOO = os.getenv('FOO') # 'bar' BAZ = os.getenv('BAZ') # 'boo'Yamlを使うときの運用方法
コマンドの引数を使う方法とYamlを使う方法がありますが、どちらかといえばファイルで管理できるYamlを使うほうが好みです。しかし、Git管理はしたくないので、そのために少し工夫を加えます。
ローカルでの確認
Yamlで環境変数を設定する場合は、ローカル環境でもそのYamlを読み込むようにすると便利です。そこで以下のようにYamlから環境変数を設定するように手を加えます。
ライブラリのインストール
$ pip install PyYAML※ ImportError にならないようにするために requirements.txt にもPyYAMLを書き加えておきます。
実装
import os import yaml try: # local with open('./env.yaml') as f: os.environ.update(yaml.load(f)) except FileNotFoundError as e: # Google Cloud Functions pass FOO = os.getenv('FOO') # 'bar' BAZ = os.getenv('BAZ') # 'boo'Google Cloud Storage を使う
Git管理をしたくないので、適当な Google Cloud Storage のバケットを作って、そこに env.yaml を保存しておき、デプロイする際にコピーしてくるようにします。 .gitignore に env.yaml を書き加えるのも忘れずに。
アップロード
$ gsutil cp ./env.yaml gs://[bucket_name]/env.yamlダウンロード
$ gsutil cp gs://[bucket_name]/env.yaml ./env.yamlちなみに
gsutilコマンドは Google Cloud SDK をインストールしたときにインストールされているかと思います。環境変数を使わない運用
公開したくない情報をGit管理しないために環境変数を使う方法もありますが、 Google Cloud Storage を直接 Google Cloud Function から読み込んで環境変数を使わない方法もあります。
IAMの設定
Google Cloud Functions から Cloud Storage の情報を取得するために、必要に応じてサービスアカウントに対して権限を付与します。ちなみにサービスアカウントとは Google Cloud Platform の各サービスが、疑似ユーザーのように振る舞う仕組みです。
Google Cloud Functions のサービスアカウント
サービスアカウントはコンソール画面から確認できます。
サービスアカウントに権限を付与
おそらくデフォルトのままでも大丈夫ですが、権限が足りない場合は「IAM と管理」から対象のサービスアカウントを編集して↓の権限を付与します。
ストレージ→ストレージ オブジェクトの閲覧者※ なお、これは「バケットレベルで権限を一様に設定(バケットポリシーのみ)」のアクセス制御モデルで作成したバケットを使用しています。
ライブラリのインストール
ここでは
google-cloud-storageを利用してみます。$ pip install google-cloud-storage実装
google-cloud-storageを利用したときの実装例です。import os import yaml from google.cloud import storage def get_data(): client = storage.Client() bucket = client.get_bucket('[bucket_name]') blob = storage.Blob('env.yaml', bucket) return yaml.load(blob.download_as_string()) os.environ.update(get_data()) FOO = os.getenv('FOO') # 'bar' BAZ = os.getenv('BAZ') # 'boo'ローカルでの開発
なお、ローカルで開発する場合は↓のようにログインする必要があります。
$ gcloud auth application-default loginサンプルコード
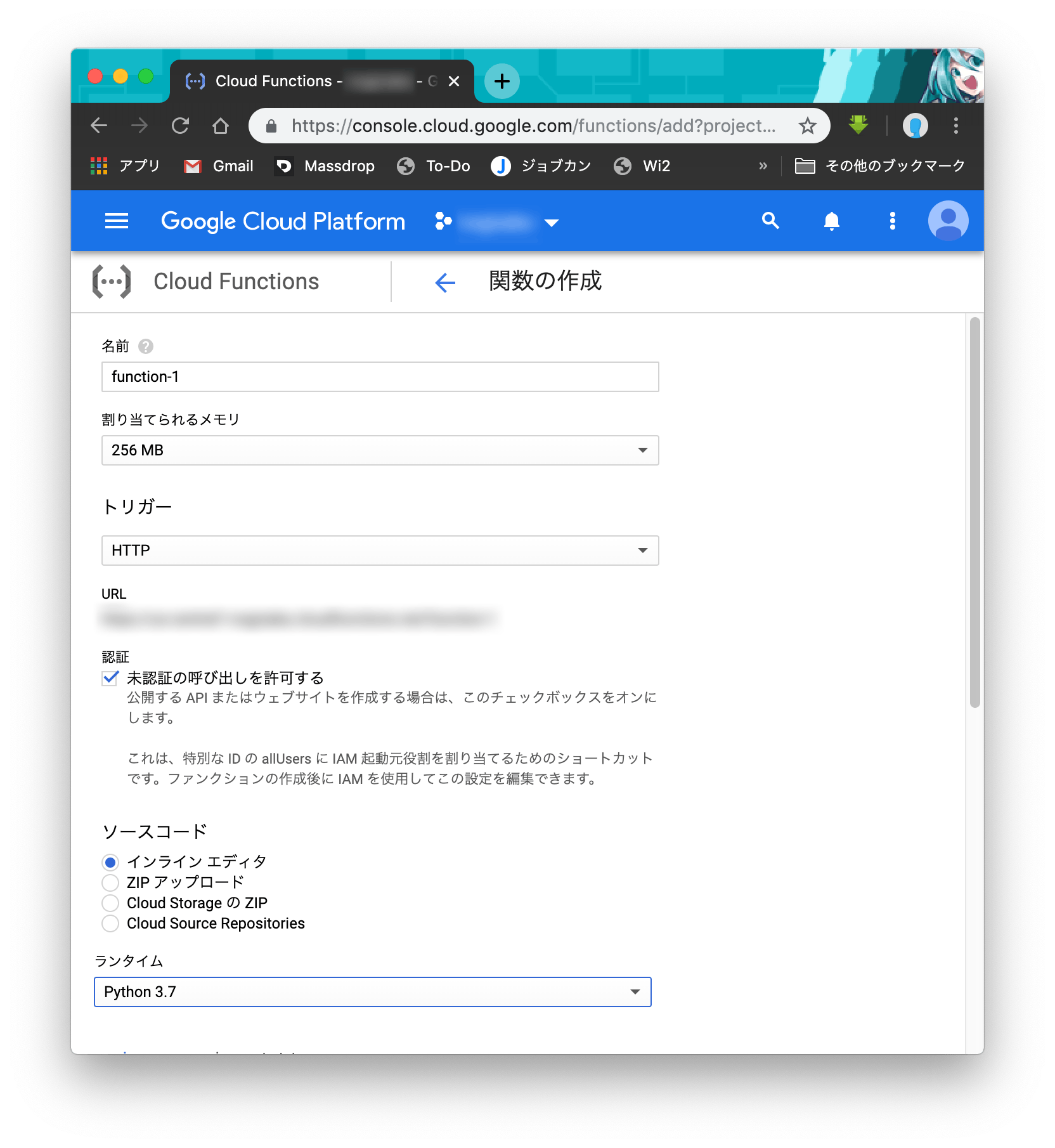

- 投稿日:2019-08-04T01:02:18+09:00
Windowsにサイクロマティック複雑度の計測ツール「lizard」入れてみた
目的
業務で簡単に品質等を確認したい
環境
OS:Windows10
Python
pip
lizard
jinja2環境作成ではまりそうなポイント
Could not install packages due to an EnvironmentError: [WinError 5] アクセスが拒否されました 。: 'c:\\program files\\python37\\lib\\site-packages\\pip-19.0.3.dist-info\\entry_points.txt' Consider using the `--user` option or check the permissions. You are using pip version 19.0.3, however version 19.2.1 is available. You should consider upgrading via the 'python -m pip install --upgrade pip' command.このようなエラーになった場合は、コマンドプロンプトを管理者権限で起動させてください。そうすることで以下のように成功します。
C:\WINDOWS\system32>python -m pip install --upgrade pip Collecting pip Using cached https://files.pythonhosted.org/packages/62/ca/94d32a6516ed197a491d17d46595ce58a83cbb2fca280414e57cd86b84dc/pip-19.2.1-py2.py3-none-any.whl Installing collected packages: pip Found existing installation: pip 19.0.3 Uninstalling pip-19.0.3: Successfully uninstalled pip-19.0.3 Successfully installed pip-19.2.1lizardのインストール
C:\WINDOWS\system32>pip install lizard Collecting lizard Using cached https://files.pythonhosted.org/packages/7e/01/650cfb0e613217003fe29d7edba549b71731122a5dc6e61fc41ad6f58fb8/lizard-1.16.3-py2.py3-none-any.whl Installing collected packages: lizard Successfully installed lizard-1.16.3操作方法
標準出力
今回はJavaのソースのCCNを計測してみます。-l オプションの値は言語に応じて変更してください。
プロジェクトのルートフォルダへ移動してlizard実行
C:\spring-boot-rest-api-sample-master\web-demo-2\spring\demo-2> lizard -l java ================================================ NLOC CCN token PARAM length location ------------------------------------------------ 43 8 307 1 48 MavenWrapperDownloader::main@55-102@.\.mvn\wrapper\MavenWrapperDownloader.java 9 1 75 2 9 MavenWrapperDownloader::downloadFileFromURL@104-112@.\.mvn\wrapper\MavenWrapperDownloader.java 5 1 37 2 5 IndexController::hello@18-22@.\src\main\java\com\web\demo\controller\IndexController.java 5 1 37 2 5 IndexController::formHoge@25-29@.\src\main\java\com\web\demo\controller\IndexController.java 5 1 37 2 5 IndexController::root@32-36@.\src\main\java\com\web\demo\controller\IndexController.java 3 1 20 1 3 WebDemo2Application::main@11-13@.\src\main\java\com\web\demo\WebDemo2Application.java 2 1 5 0 2 WebDemo2ApplicationTests::contextLoads@13-14@.\src\test\java\com\web\demo\WebDemo2ApplicationTests.java 4 file analyzed. ============================================================== NLOC Avg.NLOC AvgCCN Avg.token function_cnt file -------------------------------------------------------------- 69 26.0 4.5 191.0 2 .\.mvn\wrapper\MavenWrapperDownloader.java 28 5.0 1.0 37.0 3 .\src\main\java\com\web\demo\controller\IndexController.java 10 3.0 1.0 20.0 1 .\src\main\java\com\web\demo\WebDemo2Application.java 12 2.0 1.0 5.0 1 .\src\test\java\com\web\demo\WebDemo2ApplicationTests.java ============================================================================================= No thresholds exceeded (cyclomatic_complexity > 15 or length > 1000 or parameter_count > 100) ========================================================================================== Total nloc Avg.NLOC AvgCCN Avg.token Fun Cnt Warning cnt Fun Rt nloc Rt ------------------------------------------------------------------------------------------ 119 10.3 2.0 74.0 7 0 0.00 0.00メソッドごとのCCN→ファイルごとのCCN平均→全ファイルのCCN平均 の順で出力されます。
「メソッドごとのCCN」について、各列の意味は以下の通りです。
列 略 説明 NLOC Number Line Of Code コードの行数(コメントを除く) CCN Cyclomatic Complexity Number サイクロマティック複雑度 token - ? PARAM PARAMeter メソッドの引数の数 length - NLOCから空行を除いた行数 location - {メソッド名}@{開始行}-{終了行}@{ファイルパス} CSV出力
lizard -l java --csv > resule_lizard.csv
HTML出力
pip install jinja2 Collecting jinja2 Downloading https://files.pythonhosted.org/packages/1d/e7/fd8b501e7a6dfe492a433deb7b9d833d39ca74916fa8bc63dd1a4947a671/Jinja2-2.10.1-py2.py3-none-any.whl (124kB) |████████████████████████████████| 133kB 242kB/s Collecting MarkupSafe>=0.23 (from jinja2) Downloading https://files.pythonhosted.org/packages/65/c6/2399700d236d1dd681af8aebff1725558cddfd6e43d7a5184a675f4711f5/MarkupSafe-1.1.1-cp37-cp37m-win_amd64.whl Installing collected packages: MarkupSafe, jinja2 Successfully installed MarkupSafe-1.1.1 jinja2-2.10.1HTML形式で出力する場合、jinja2というツールが必要なためpipでインストールする
lizard -l java --html > resule_lizard.html
まとめ
今回はJavaファイルのみの検証でしたが、JSファイルの検証等もできたので
いろいろ試してみてください
参考
https://qiita.com/uhooi/items/a1a96a2d7f5e081e2049
https://qiita.com/uhooi/items/c77a53a4c7ac232a1ba1

- 投稿日:2019-08-04T00:36:03+09:00
[備忘録] OpenCVのHoughCirclesは二値化してからやるかどうか
OpenCVのハフ変換による円検出(cv2.HoughCircles)をやるとき、
普通はモノクロ画像に対して行うのが基本だけど
- 検出したい円が結構綺麗
- 二値化するといい感じ
のときはcv2.thresholdで二値化してからの方がうまく円を検出できることがある。
ただし、多くの場合param2を小さくしないと無理。
- 投稿日:2019-08-04T00:23:40+09:00
[備忘録] Pythonでディレクトリの中の条件に合うファイルを取り出す
リスト内包表記を使ってこんな風に書けば良い。
path = '任意のディレクトリ' file = [i for i in os.listdir(path) if 条件]例えば 'image' というディレクトリに入っている jpgファイルを取り出したかったら以下のようにすれば良い。
ただし jpgファイルでなくても '.jpg' という文字列が含まれていたらそのファイルも返してしまうので注意。path = 'image' jpgfile = [i for i in os.listdir(path) if '.jpg' in i]
- 投稿日:2019-08-04T00:22:25+09:00
gbkファイルから階級を取得する
最初に
gbkファイルは以下のようになっている
NC_018118.gbkLOCUS NC_018118 14932 bp DNA circular INV 13-JUL-2012 DEFINITION Elodia flavipalpis mitochondrion, complete genome. ACCESSION NC_018118 VERSION NC_018118.1 DBLINK Project: 170288 KEYWORDS RefSeq. SOURCE mitochondrion Elodia flavipalpis (parasitic fly) ORGANISM Elodia flavipalpis Eukaryota; Metazoa; Ecdysozoa; Arthropoda; Hexapoda; Insecta; Pterygota; Neoptera; Holometabola; Diptera; Brachycera; Muscomorpha; Oestroidea; Tachinidae; Exoristinae; Goniini; Elodia. REFERENCE 1 (bases 1 to 14932) AUTHORS Zhao,Z., Su,T.-J. and Zhu,C.-D. TITLE The complete mitochondrial genome of Elodia flavipalpis Aldrich (Diptera: Tachinidae) and the evolutionary timescale of tachinid flies JOURNAL Unpublished REFERENCE 2 (bases 1 to 14932) CONSRTM NCBI Genome Project TITLE Direct Submission JOURNAL Submitted (10-JUL-2012) National Center for Biotechnology Information, NIH, Bethesda, MD 20894, USA REFERENCE 3 (bases 1 to 14932) AUTHORS Zhao,Z., Su,T.-J. and Zhu,C.-D. TITLE Direct Submission JOURNAL Submitted (03-JAN-2012) Key Laboratory of Zoological Systematics and Evolution, Institute of Zoology, Chinese Academy of Sciences, 1 Beichen West Road, Chaoyang District, Beijing, Beijing 100101, P.R. China COMMENT REVIEWED REFSEQ: This record has been curated by NCBI staff. The reference sequence is identical to JQ348961. COMPLETENESS: full length. FEATURES Location/Qualifiers source 1..14932 /organism="Elodia flavipalpis" /organelle="mitochondrion" /mol_type="genomic DNA" /db_xref="taxon:1146932" /common="parasitic fly" tRNA 1..65 /product="tRNA-Ile" \\以下略例えばこのファイルを綱で分類したい時、次のようにする。
taxonomy IDを取得する
NCBI Taxonomy データベースからTaxonomy ID を取得する
from Bio import SeqIO, Entrez Entrez.email = "your mail address" def get_taxonomyID(creature_name): global Entrez.email with Entrez.esearch(db="Taxonomy", term=creature_name) as handle: record = Entrez.read(handle) taxonomyID = record["IdList"][0] return taxonomyIDここで
taxonomyID = record["IdList"][0]としているので複数ヒットした場合は最初のヒットが返される。
また、エラーが出る場合はクエリが冗長すぎる(space以下には新規IDを振らないようにしているらしい)ので別のものをクエリとするしなければいけない。例えば引数をSeqRecord.annotations["taxonomy"]にして各taxonomyに対してtaxonomyIDを取得するようにするとか。。。for taxa inSeqRecord.annotations["taxonomy"]: with Entrez.esearchd(db="Taxonomy", term=taxa) as handle: ...取得したtaxonomy IDを使って階級を取得する
さっきの関数で取得したTaxonomy IDをもう一度投げてエントリを取得する
def get_category_dictionary(taxonomyID): global Entrez.email with Entrez.efetch(db="Taxonomy", id=taxonomyID, retmode="xml") as handle: records = Entrez.read(handle) for record in records: category_dict = record["LineageEx"] yield category_dictまとめると
from Bio import SeqIO, Entrez Entrez.email = "your email address" def get_taxonomyID(creature_name): with Entrez.esearch(db="Taxonomy", term=creature_name) as handle: record = Entrez.read(handle) taxonomyID = record["IdList"][0] return taxonomyID def get_category_dictionary(taxonomyID): with Entrez.efetch(db="Taxonomy", id=taxonomyID, retmode="xml") as handle: records = Entrez.read(handle) for record in records: category_dict = record["LineageEx"] yield category_dict if __name__ == "__main__": with open("NC_018118.gbk", "r") as gbkfile: for entry in SeqIO.parse(gbkfile, "genbank"): taxonomyID = get_taxonomyID(entry.annotations["organism"]) for category_dict_list in get_category_dictionary(taxonomyID): for category_dict in category_dict_list: print(f"{category_dict['ScientificName']} : {category_dict['Rank']}")みたいな感じになります。
実行結果(長いので折りたたみ)
cellular organisms : no rank Eukaryota : superkingdom Opisthokonta : no rank Metazoa : kingdom Eumetazoa : no rank Bilateria : no rank Protostomia : no rank Ecdysozoa : no rank Panarthropoda : no rank Arthropoda : phylum Mandibulata : no rank Pancrustacea : no rank Hexapoda : subphylum Insecta : class Dicondylia : no rank Pterygota : subclass Neoptera : infraclass Holometabola : cohort Diptera : order Brachycera : suborder Muscomorpha : infraorder Eremoneura : no rank Cyclorrhapha : no rank Schizophora : no rank Calyptratae : no rank Oestroidea : superfamily Tachinidae : family Exoristinae : subfamily Goniini : tribe Elodia : genusこんな感じで出力されるので、今回のNC_018118はInsectaに分類!みたいなことができます