- 投稿日:2019-08-04T22:35:39+09:00
【JavaScript】nodebrew経由でNode.jsとnpmをアップデートする
以前にnodebrew経由でNode.jsをインストールしていたのですが、それをアップデートしました。
以下、昔書いた記事です。
Homebrew
最初にnodebrewを管理しているHomebrewをアップデートします。
$ brew updateNode.js
現在のバージョンを確認します。
$ nodebrew list v10.1.0 current: v10.1.0アップデートします。
$ nodebrew install-binary stable再度確認すると、現在nodebrewで管理されているNode.jsのバージョンが増えました。
$ nodebrew list v10.1.0 v12.7.0 current: v10.1.0安定版を使います。
$ nodebrew use stable use v12.7.0バージョンの切り替えが確認できました。
$ node -v v12.7.0npm
現在のバージョンを確認します。
$ npm -v 5.6.0アップデートします。
$ npm update -g npmバージョンの切り替えが確認できました。
$ npm -v 6.10.2参考記事
Node.jsのアップデートはこちらの記事を参考にしました。
nodebrewでNode.jsをアップデートするこちらの記事で紹介されているNode.jsのバージョン管理ツールは
nというツールです。
今回はnpmのアップデート部分のみ参考にさせていただきました。
Node.jsとnpmをアップデートする方法各ツールの繋がりがとっても分かりやすく説明されています。
npm とか bower とか一体何なんだよ!Javascript 界隈の文脈を理解しよう
- 投稿日:2019-08-04T20:43:52+09:00
動的サイトを全力でcheerioでスクレイピングしてみた
はじめに
「なんかWebスクレイピングでPuppeteerばかり注目されてる気がするけどcheerioも使えるんだからな」
ということを伝えたくて今回は動的サイトをあえてPuppeteerやSeleniumを使わずにWebスクレイピングしてみた。ただ結論から言えば今回のサイトのような場合はpuppeteerを使った方が圧倒的に簡単で確実である。
また、本投稿で登場するサイトはあくまで例として実際にスクレイピングを行なったサイトの構成を元に作成しております。
本プログラムをコピペしても動作しませんのでご注意ください。今回のチャレンジ
今回は以下のようなニュースサイトでWebスクレイピングを挑戦してみた。
ゴール
ゴールは本記事の趣旨を簡単に理解できるようにするため「2019年に出稿された記事全てを取得する」とする
事前調査
分析したところ、サイトの仕様は以下のようになっていることがわかった。
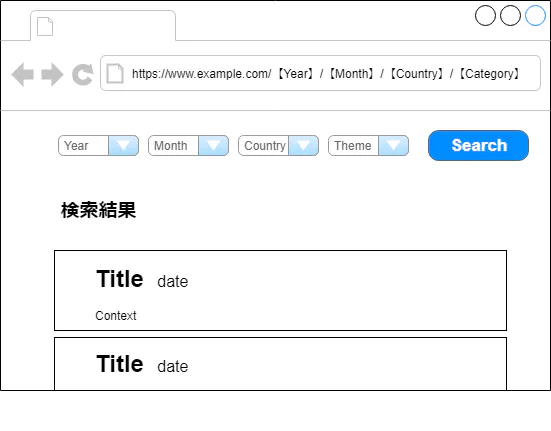
- トップページhttps://www.newsexample.comより検索を行うことができる
- 各セレクタがURLのパラメータとなり、Searchボタンを押すとhttps://www.newsexample.com/【Year】/【Month】/【Country】/【Category】といった感じでリクエストが送信される
- 条件に合致するニュースが検索結果に表示される。検索結果が0件の場合は「検索結果が見つかりませんでした」と表示される。今回はタイトル,日付,本文をここで取得する
- 各セレクタ内のデータはajax通信により選択肢が動的に変化する。また、ニュースが存在しない条件は選択肢に表示されない。例えばYearを2019に指定した際、12月のニュースが存在していなければMonthを12に指定することはできない。ポイント:検索条件をどのように取得するか
検索結果を表示するページ自体は簡単にスクレイピングできそうだが、問題はその前のプロセスである。
どのようにして動的に変化する検索条件を取得するかである。というのも
cheerioはHTML形式でページを取得してjQueryのように要素を指定することができるライブラリであって、ページ上のDOM操作をすることはできない。
もしセレクタ内のアイテムが静的であればDOM要素を分析するだけで検索条件を取得することができたが、今回のサイトは左のセレクタから選択していくことでajax通信が発生し、次のセレクタ内のアイテムが決定される。また、国やテーマにおいては実際に通信しないとどのような選択肢があるのか検討つかないので検索条件を推測することもできない。
つまり何らかの方法で選択肢のデータを取得しなければならない。
アプローチ
ざっくりまとめるとこんな感じ
scraping.jsconst year = 2019 // Monthの選択肢を取得 const months = getMonths(year); for(let month of months) { // Countryの選択肢を取得 const countries = getCountries(year, month); for(let country of countries) { // Categoryの選択肢を取得 const categories = getCategories(year, month, country); for(let category of categories) { // 検索結果(タイトル, 日付, 本文)を取得 const result = getResults(year, month, country, category) console.log(result.title, result.date, result.body) } } }多重ループを繰り返して選択肢を取得し、実行結果をひとつずつ出力してやるといった感じ。
あとはそれぞれの関数を実装してやればいけるだろう。
そのためにまずは実際に行われているAjax通信を解析してやらねばならない。手順1 : Ajax通信を解析する
まずは実際に行われる通信を解析して必要な情報を割り出す必要がある。
私は実際に以下の手順で行った。Google Developer Toolsを使ってajax通信のリクエストを解析
まずはGoogle Developer Toolsの
Networkを開く。すると、通信履歴が表示される。
履歴をクリアしておき、ajax通信を発生させると、図のようにNetwork内にあらたに履歴が表示され、通信が行われたことがわかる。
今回はセレクタを開いて選択肢を選択することで発生する。
はじめはYearセレクタを選択してMonthが取得されるまでの通信を確認する。
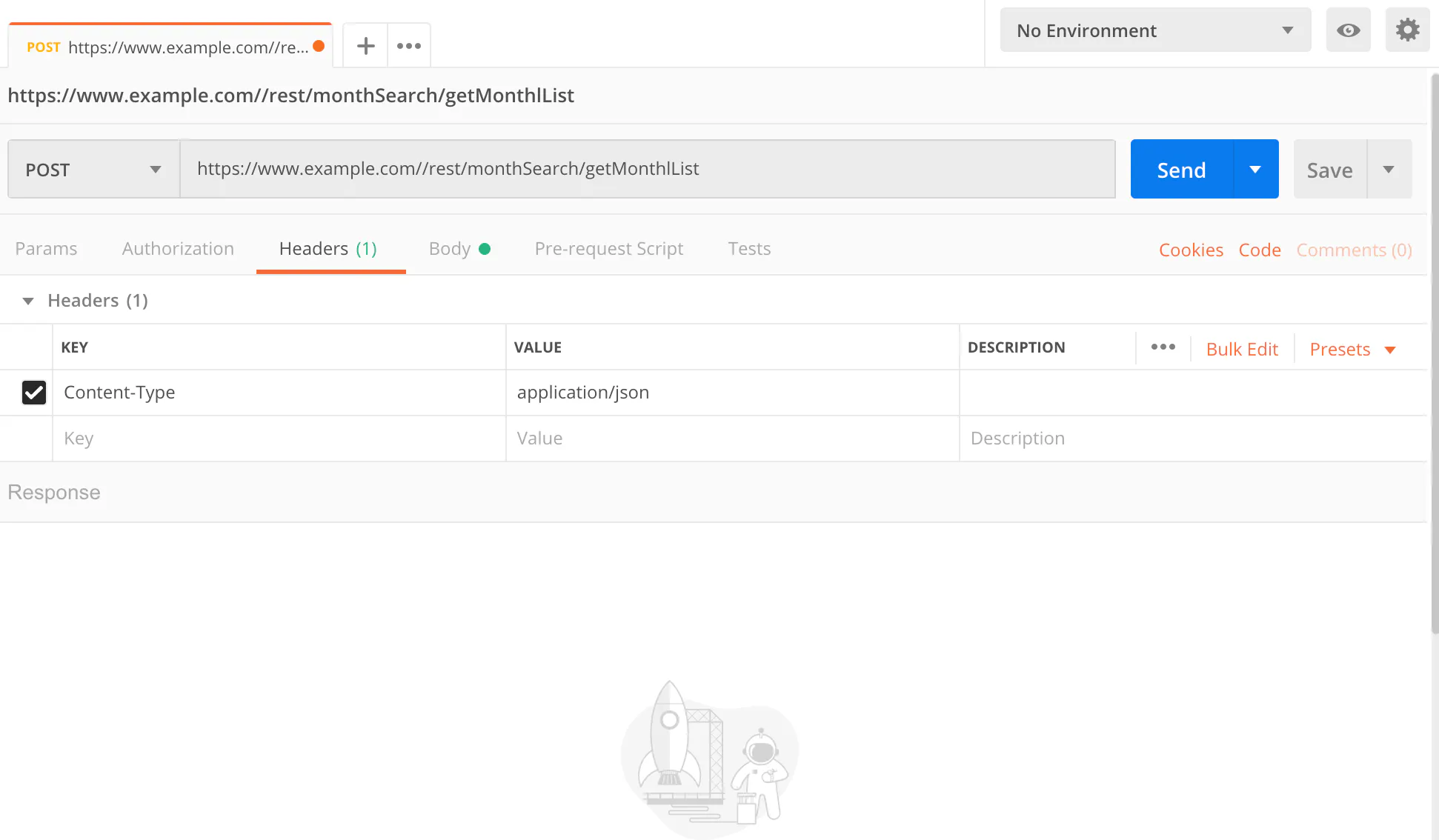
getMonthListをクリックしてHeader情報を開くと図のような情報が表示される。
…なるほど、POSTで通信しているのか。
他にもRequest URLやcookie情報、Request Payloadより送信したパラメータなどがわかる。Postmanを使ってリクエスト送信に必要な情報を確認
手順1で得られた情報をもとに
Postmanを使って通信に必要なパラメータを確認していく。
公式サイト https://www.getpostman.com/ よりダウンロードしたらpostmanを起動。今回はPOSTで通信しているのでPOSTにする。
HeadersをクリックしてそこにContent-Type : application/jsonを追加。
BodyにはRequest Payloadの内容をそのままペーストすればいいのかな?
とりあえずこれでSendをクリックしてみる。
すると以下の実行結果が出力された。
[ "January", "February", "March", "April", "May", "June", "July", ]ひとまずこれでデータは取得できることが分かった。
パラメーター"field": "news_number"の意味がよくわかっていないが、固有パラメーターなのだろうと推測。
さすがにAPI側で定められている条件などはわからないので、具体的に何を意味しているのかまで把握することは難しい...
"field": "year"はセレクタより選択した年が代入されているので、このパラメータを変更すれば任意の年の情報が取得できる。手順2: 同様に国、カテゴリーに対しても解析する
Monthを解析したときと同様の手順でCountry、Categoryの取得に必要なパラメータを確認していく。手順3:
request-promiseを用いて実装解析した情報をもとにそれぞれ
getMonths(year),getCountries(year, month),getCategories(year, month, country)を実装する。
実装は以下のようになる。scraping.jsconst rp = require('request-promise'); const filterByNewsNumber = { filters: [{ field: "news_number", value: 5,400, condition_type: "eq" }] }; let filterByYear = []; let filterByMonth = []; let filterByCountry = []; // Monthセレクタの選択肢を取得する async function getMonths(year) { fileterByYear = { filters: [{ field: "year", value: year, condition_type: "eq" }] }; const filterGroups = [].concat(filterByNewsNumber, fileterByYear); // Request Payloadと同じパラメータになるようにする let newRequest = { "searchCriteria": { "filterGroups": filterGroups } }; let option = { uri: baseUrl + "/rest/monthSearch/getMonthList", method : "post", body : newRequest, json : true } // Monthリストを返す return rp(option).catch( () => console.log("取得できませんでした")) } // Countryセレクタの選択肢を取得 async function getCountries(year, month) { fileterByMonth = { filters: [{ field: "month", value: month, condition_type: "eq" }] }; const filterGroups = [].concat(filterByNewsNumber, fileterByYear, fileterByMonth); // Request Payloadと同じパラメータになるようにする let newRequest = { "searchCriteria": { "filterGroups": filterGroups } }; let option = { uri: baseUrl + "/rest/countrySearch/getCountryList", method : "post", body : newRequest, json : true } // Countryリストを返す return rp(option).catch( () => console.log("取得できませんでした")) } // Categoryセレクタの選択肢を取得 async function getCategories(year, month, country) { fileterByCountry = { filters: [{ field: "country", value: country, condition_type: "eq" }] }; const filterGroups = [].concat(filterByNewsNumber, fileterByYear, fileterByMonth, filterByCountry); // Request Payloadと同じパラメータになるようにする let newRequest = { "searchCriteria": { "filterGroups": filterGroups } }; let option = { uri: baseUrl + "/rest/countrySearch/getCountryList", method : "post", body : newRequest, json : true } // Categoryリストを返す return rp(option).catch( () => console.log("取得できませんでした")) }手順4 : URLを生成して
cheerioでスクレイピングこれであとはURLを生成してcheerioを使って検索結果の画面を取得しに行けばいいだけ。
そのためにgetResultsを実装する。scraping.jsconst cheerio = require('cheerio'); async function getResult(year, month, country, category) { const url = `https://www.newsexample.com/$(year)/$(Month)/$(Country)/$(Category)`; // 記事一覧画面のHTMLを取得する html = await rp(url); $ = cheerio.load(html); // 情報を取得するためにそれぞれのhtml要素を指定する const title = $('#title'); const date = $('#date'); const context = $('#context'); const data = { "title" : title, "date" : date, "body" : context, } return data; }手順5 : 逐次的に実行されるように修正する
ここまでスクレイピングに必要な処理を記載してきたが、このまま実行しようとするとそれぞれの処理が非同期で行われてしまうため、エラーが発生する。
全ての処理が逐次的に行われるように以下のように修正してまとめる。scraping.jsconst cheerio = require('cheerio'); const rp = require('request-promise'); const filterByNewsNumber = { filters: [{ field: "news_number", value: 5,400, condition_type: "eq" }] }; let filterByYear = []; let filterByMonth = []; let filterByCountry = []; const year = 2019; async function main(){ // Monthの選択肢を取得 const months = getMonths(year); for(let month of months) { // Countryの選択肢を取得 const countries = await getCountries(year, month); for(let country of countries) { // Categoryの選択肢を取得 const categories = await getCategories(year, month, country); for(let category of categories) { // 検索結果(タイトル, 日付, 本文)を取得 const result = await getResults(year, month, country, category) console.log(result.title, result.date, result.body) } } } } // Monthセレクタの選択肢を取得する async function getMonths(year) { fileterByYear = { filters: [{ field: "year", value: year, condition_type: "eq" }] }; const filterGroups = [].concat(filterByNewsNumber, fileterByYear); // Request Payloadと同じパラメータになるようにする let newRequest = { "searchCriteria": { "filterGroups": filterGroups } }; let option = { uri: baseUrl + "/rest/monthSearch/getMonthList", method : "post", body : newRequest, json : true } // Monthリストを返す return rp(option).catch( () => console.log("取得できませんでした")) } // Countryセレクタの選択肢を取得 async function getCountries(year, month) { fileterByMonth = { filters: [{ field: "month", value: month, condition_type: "eq" }] }; const filterGroups = [].concat(filterByNewsNumber, fileterByYear, fileterByMonth); // Request Payloadと同じパラメータになるようにする let newRequest = { "searchCriteria": { "filterGroups": filterGroups } }; let option = { uri: baseUrl + "/rest/countrySearch/getCountryList", method : "post", body : newRequest, json : true } // Countryリストを返す return rp(option).catch( () => console.log("取得できませんでした")) } // Categoryセレクタの選択肢を取得 async function getCategories(year, month, country) { fileterByCountry = { filters: [{ field: "country", value: country, condition_type: "eq" }] }; const filterGroups = [].concat(filterByNewsNumber, fileterByYear, fileterByMonth, filterByCountry); // Request Payloadと同じパラメータになるようにする let newRequest = { "searchCriteria": { "filterGroups": filterGroups } }; let option = { uri: baseUrl + "/rest/countrySearch/getCountryList", method : "post", body : newRequest, json : true } // Categoryリストを返す return rp(option).catch( () => console.log("取得できませんでした")) } async function getResult(year, month, country, category) { const url = `https://www.newsexample.com/$(year)/$(Month)/$(Country)/$(Category)`; // 記事一覧画面のHTMLを取得する html = await rp(url); $ = cheerio.load(html); // 情報を取得するためにそれぞれのhtml要素を指定する const title = $('#title'); const date = $('#date'); const context = $('#context'); const data = { "title" : title, "date" : date, "body" : context, } return data; }Asyncで
main関数を作成し、AwaitでgetMonths,getCountries,getCategories,getResultを順番に処理させることで正しく動作する。まとめ
かなり荒技ではあったが動的サイトでも
puppeteerを使わずに、Networkからajaxを解析してWebスクレイピングすることができた。
また、HTTP通信を解析することにもなり非常に面白かった。
とはいえ非常に手間がかかるし、何より今回のようにPostリクエスト内に含まれているパラメータの意味がわからないということもあるので特に理由がなければ今後動的サイトをスクレイピングする際はpupeteerを採用しようと思う。


- 投稿日:2019-08-04T17:11:40+09:00
Alexa APL, 第5回 ヘッダーの追加
はじめに
Alexaを搭載した画面付きデバイスの画面レイアウトを作成します。
今回はAmazonが準備するヘッダーを追加します。
ヘッダーは、画面上部にスキルのタイトルなどを表示します。
もうひとつフッターは、画面下部に何かヒントを記載するために使用するようですが、今回は割愛します。今回実施する内容
Echo Spot、Echo Show 5、Echo Show用に「ヘッダー」を追加する。
中型デバイス(Echo Show用)
小型デバイス(Echo Spot用)
環境
OS:Windows 10 JP
Alexaスキル言語:Node.js
Editor:Visual Studio Code
APLバージョン:1.0, 1.1参考
・Alexa ハローAPL、Alexaスキルの画面への対応
第1回のAlexa APLの記事です。タイトル通り、ハローAPLを表示させるだけのAPLです。・Alexa Headerレイアウト
Alexa APLのドキュメント上のHeaderレイアウトの説明です。用語
APL
Alexa Presentation Language
amazonの画面つきのAlexaの画面表示用の言語。
JSONを使用した記載方法です。
インターネットのホームページはHTMLとCSSで作成しますが、AlexaはAPLで作成するということです。APLオーサリングツール
APL作成を視覚的に見ながらAPLのJSONファイルを作成するツール。
サンプルテンプレートも準備されており、その中から選択していくだけで、だいたいの画面は作成できる。前提条件
前提条件はとくにないといえばないですが、本まとめを読むにあたり、以下がわかっていることが前提です。
・alexa developer consoleのアカウントがある
・Alexaスキルを開発したことがある
・JSONの記載方法を知っている
・「Alexa ハローAPL、Alexaスキルの画面への対応」と「Alexa APL, 第4回 デバイスごとの画面表示対応」の記事をみているヘッダーの追加(マルチデバイス非対応)
ここでは、簡単化のため「Viewportプロファイルパッケージ」は読み込まず、デバイス共通のAPLを作成します。
レイアウトは以下のようなイメージです。
「alexa-layouts」パッケージの読み込み
ヘッダーを追加するには、「alexa-layouts」パッケージを読み込む必要があります。
まずはAPLオーサリングツールを起動し、「最初から作成」を選択する。
APLオーサリングツールでは、「Document」ボタンを押すと、JSONが表示されますが、「"import"」は空です。そこに以下を書き込みます。... "import": [ { "name": "alexa-layouts", "version" : "1.0.0" } ], ...これを記載するだで、「Container」、「Text」などと同じようにAPLオーサリングツールで、ヘッダー(AlexaHeader)、フッター(AlexaFooterのコンポーネントを使えるようになります。
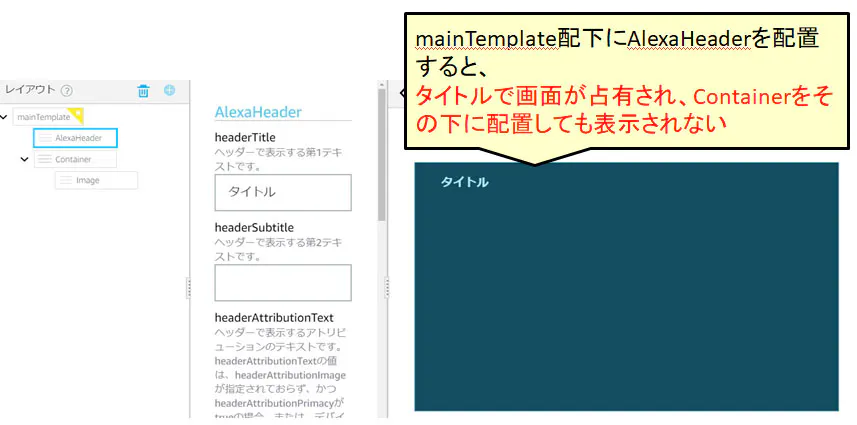
なお、「AlexaHeader」、「AlexaFooter」は、他のコンポーネントと違い、「APLコンポーネント」を継承しないため、「when」とか「width」など使えないようです。
従って、「AlexaHeader」、「AlexaFooter」を使う場合は、その上位に「Container」を配置して、マルチデバイスの対応や画面サイズ調整など行うほうが望ましいと思います。
試しに、「mainTemplate」の直下に「AlexaHeader」を配置してみたところ、「AlexaHeader」で画面が占有され、その後に「Container」、「Image」を配置して「position」を「absolute」にしても「Image」は表示されませんでした。
全体レイアウトの作成
以下のようなレイアウトにします。
- 「レイアウト画面」の「mainTemplete」を選択し、「Container」を追加する。
- 「レイアウト画面」の「Container」を選択し、「AlexaHeader」を追加する。
- 「レイアウト画面」の「Container」を選択し、「Container」を追加する。
上部にヘッダーを配置して、その下にメインで記載したいレイアウトを置くということです。
これで全体レイアウトは完成です。
ヘッダー、フッターといっても、ただのコンポーネントであり、自分で自由な位置におけるということですね。ヘッダーの追加
次はヘッダーの中身を書いていきます。
ヘッダーにはいくつか、プロパティがあるので、それを設定してみます。
初めてプロパティと書きましたが、「Container」や「Text」などのコンポーネントの「詳細設定画面」で「AlignItems」や「width」など設定できますがこれがプロパティです。
「レイアウト画面」の「AlexaHeader」を選択し、「詳細設定画面」で以下をそれぞれ設定する。
・ headerTitle:タイトル
・ headerSubtitle:サブタイトル
・ headerAttributionText:ヘッダアトリビューションテキスト
・ headerAttributionImage:coffee_265x265.png(アイコンの画像)
・ headerAttributionPrimacy:false
・ headerBackButton:true
・ headerBackgroundColor:blue今回設定していないプロパティは、以下です。
・headerNavigationAction
・headerBackButtonCommandヘッダ-の補足説明
いくつかのプロパティはそのまま画面に表れているため、上に載せたイメージ図でイメージできます。
一部について補足します。headerAttributionText
Alexa Headerレイアウトによると以下が説明されています。
Headerで表示するアトリビューションのテキストです。headerAttributionTextの値は、headerAttributionImageが指定されておらず、かつ、headerAttributionPrimacyがtrueの場合、または、デバイスがタイトル/サブタイトルとアトリビューションの両方を表示する場合のみ表示されます。
今回は、「headerAttributionImage」を設定しているため、ここで設定した値は画面に表示されません。
「headerAttributionImage」を削除して、「headerAttributionPrimacy」を「true」に設定すると以下のようになります(赤枠のところ)。中型デバイス(Echo Show)
小型デバイス(Echo Spot)
headerAttributionImage
中型デバイスで表示するアイコンです。
スキルのアイコンが設定されているため自分でつくってみました。
Alexaロゴの中にコーヒーを入れてみたのですが、これを作成するためのツールが提供されているわけではなく、Alexaのサイトからロゴをもってきて作りました。
AVS UXブランドガイドラインにマークの作り方のガイドラインが記載されているため、Alexaスキル開発でこの部分を作成することは、著作権とか肖像権などには問題にならないとは考えていますが、指摘を受けた場合削除します。
なお、ガイドラインによると、マークは白抜きが要求されるようです。
また、マークの外側は透過できるように「png」ファイルで透過設定にしました。AVS用のデザインガイドは、Echoなどにも適用されると思います。(APLを使わないDisplayテンプレートだと自動でこのガイドラインどおりのアイコンが入るようですので)
できれば、アイコン設定したら自動でマークになるようにしてほしいなと思います。headerAttributionPrimacy
今回falseに設定しましたが、「true」に設定すると、小型デバイス(Echo Spot)では、タイトルの代わりに「headerAttributionText」か「headerAttributionImage」が設定されるようになります。
「headerAttributionImage」が設定されていれば、こちらが優先です。
小型デバイスで、「headerTitle」や「headerSubtitle」の表示を優先するか、「headerAttributionText」、「headerAttributionImage」を優先するかは、開発者判断かなと思います。
headerBackButton
中型デバイスのタイトルの左にある「<」なんですが、Alexa Headerレイアウトによると以下が説明されています。
切り替えてHeaderに戻るボタンを表示します。デフォルトはfalseです。
今回試していない「headerNavigationAction」、「headerBackButtonCommand」と一緒に合わせて使うようなものかなと思いますが、まだ試せていません。まだ、画面タッチしての操作についても試していませんが、そのあたりになると思いますので、今後試していきたいと思います。
APLソースコード
今回試したソースコードを載せます。実際にスキルで表示を試す場合は、Alexa ハローAPL、Alexaスキルの画面への対応を参考しましょう。
{ "document": { "type": "APL", "version": "1.1", "settings": {}, "theme": "dark", "import": [ { "name": "alexa-layouts", "version": "1.0.0" } ], "resources": [], "styles": {}, "onMount": [], "graphics": {}, "commands": {}, "layouts": {}, "mainTemplate": { "parameters": [ "payload" ], "items": [ { "type": "Container", "items": [ { "headerTitle": "タイトル", "headerSubtitle": "サブタイトル", "headerAttributionText": "ヘッダアトリビューションテキスト", "headerAttributionImage": "https://coffee_265x265.png", "headerAttributionPrimacy": false, "headerBackButton": true, "headerBackgroundColor": "blue", "type": "AlexaHeader" }, { "type": "Container", "items": [ { "type": "Text", "text": "テキスト" } ] } ] } ] } }, "datasources": {} }注意事項
「AlexaHeader」を利用する上での注意事項を記載します。一部、「AlexaHeader」関係ない部分もありますけどね。
- 「AlexaHeader」の上位には、「Container」を配置する。
- 「AlexaHeader」は「APLコンポーネント」を継承しないため。
- 背景画像を置くならば、最初の「Container」の配下に「Image」を置く。
- 「AlexaHeader」と「Image」のどちらが先なのか?と思いましたが、APLは上から順に重ねてレイアウトをしていくため、まずは背景をつけて、それから「AlexaHeader」を置くのがよいです。
- マルチデバイス対応するならば、最上位の「Container」で対応する。
- 階層化された2段目以降の子の「Container」で「when」に値を設定しても、子のContainerごとに「when」を設定する必要があり面倒なため。
おわりに
今回は、APLにヘッダーを追加しました。





- 投稿日:2019-08-04T16:05:18+09:00
Node.js + Express でPOSTデータを取得後、WebAPIへ問い合わせる
とある Web APIを触っていたところ
- CORS設定により、ブラウザからのAPIリクエストが許可されていない。
- しかし、ブラウザからの入力値を受け取り、WebAPIへリクエストを送りたい。
- できればJavaScript(Node.js)で構築したい
というユースケースがあり、ちょっと試してみました。
やること
- Webフォームからデータを入力
- Node.jsのサーバーへPOSTで送信
- Node.js サーバーからWebAPIへリクエストを送り、返り値をWebフォームへ送る
実装
- Node.jsでPOST値を受け取るため、Expressでサーバーを立ち上げる
- POSTで送られたデータをrequest モジュールでAPIへ送信
- 返り値をPromiseで待受け、ブラウザへ返す
という流れで実装しました。
「Webフォームから入力した書籍名を、Google Books APIへ問い合わせし、返り値を返す」というシナリオで実装します。
(※Google Books API はブラウザからもリクエストを受け付けますが、参考実装ということで)
開発環境は以下のとおりです。
- OS
- Ubuntu Linux (Windows Subsystem for Linux)
- Node
- v10.16.0
- npm
- 6.9.0
Express とbody-parser のインストールとサーバー起動
最初に Express と body-parser のインストールを行う。インストールはnpmを利用
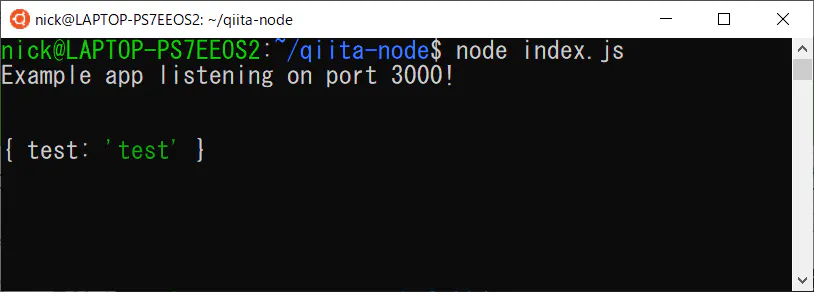
npm install express --save npm install body-parser --saveインストール後、Expressの起動スクリプトを記述。ポート番号を3000で待ち受け。「http://127.0.0.1:3000/auth/」 のエンドポイントで、POSTリクエストを待ち受ける。
POSTで送られてきたbodyデータを、console.logで出力。index.js
const express = require('express') const app = express() const bodyParser = require('body-parser') const port = 3000 app.use(bodyParser.urlencoded({ extended: true })); app.use(bodyParser.json()); app.post('/auth/', (req, res) => { console.log(req.body); res.send("Received POST Data!"); }); app.listen(port, () => console.log(`Example app listening on port ${port}!`))Expressサーバーを起動後、エンドポンイト「auth」にPOSTを送ると、POSTの値が表示される。
curl でPOST送信
curl -X POST -H "Content-Type: application/json" -d '{"test":"test"}' 127.0.0.1:3000/authExpress サーバーのコンソールに、POSTで送信されたJSON {"test": "test"} が表示されているのがわかる。
POST送信したクライアントには、「Received POST DATA!」という値が返される
requestのインストールとWebAPIへのリクエスト
次に、request を利用した Web APIへのリクエストを実装する。
最初にrequestをインストール。npm install request --save次に、requestを利用して、Google Books API へ問い合わせるためのコードを記述。
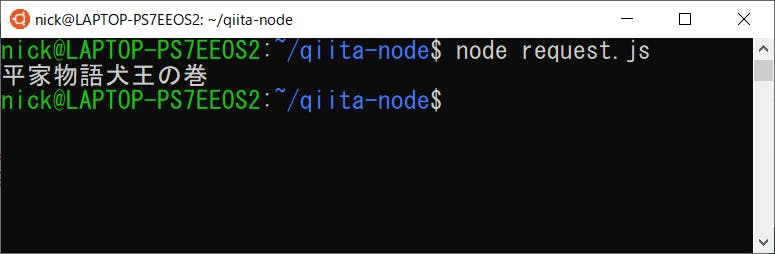
Google Books API へ、ISBNコードを送信。レスポンスのJSONから、タイトルを表示する。
サンプルデータは、小説家・古川日出男さんの著書「平家物語 犬王の巻」にしてみた。ISBNコードは
4309025447
となる。request.js
const request = require('request') const options = { method: 'GET', json: true, url: "https://www.googleapis.com/books/v1/volumes?q=isbn:4309025447", } request(options, function(error, response, body) { console.log(body.items[0].volumeInfo.title); });上記のコードを実行すると、Google Books API の返り値からタイトルを取得し、コンソールへ表示を行う。
フォームも含めた実装
上記の2つのコードを統合し、htmlの入力フォームを実装する。
- フォームからISBNコードを入力して、Express サーバーへPOST送信
- Express サーバーがPOSTデータをパースし、Google Books API へリクエスト送信
- Google Books API からのレスポンスからBodyを抽出し、JSONデータとしてhtmlフォームへ返却
- htmlフォーム側の console.log に書籍のタイトルを表示
という流れで実装しました。
Express で静的ファイルをホスティングする
Express では、「express.static」の指定を行うことで、静的ファイルのホスティングパスの指定ができる 。
Express と request のコードをまとめて実装。
index.jsは以下の通り。
「public」ディレクトリを静的ファイルの公開パスと設定。
「/public/index.html」 に保存したhtmlはで表示されます。
const express = require('express') const app = express() const bodyParser = require('body-parser') const request = require('request') const port = 3000 app.use('/', express.static('public')); app.use(bodyParser.urlencoded({ extended: true })); app.use(bodyParser.json()); app.post('/auth/', (req, res) => { const options = { method: 'GET', url: "https://www.googleapis.com/books/v1/volumes?q=isbn:" + req.body.number, json: true, }; request(options, function(error, response, body) { console.log(body.items[0].volumeInfo.title); res.send(body); }); }); app.listen(port, () => console.log(`Example app listening on port ${port}!`))index.html。index.jsで指定した「auth」エンドポイントへ、POSTデータを送信。
<!DOCTYPE html> <html lang="ja"> <head> <meta charset="utf-8"> <title>Node.js サンプルモック</title> </head> <body> <div> <h2>ISBNコード送信</h2> <div> <input id="isbn" placeholder="isbn" type="text"> </div> <div> <button id="send">送信</button> </div> </div> <script> document.getElementById("send").onclick = function() { const isbn = document.getElementById("isbn").value; const json = {"number" : isbn}; fetch('http://127.0.0.1:3000/auth/', { method: 'POST', headers: { 'content-type': 'application/json', }, body: JSON.stringify(json), }).then(response => { return response.json(); }).then(res => { console.log(res.items[0].volumeInfo.title); }).catch(error => { console.log(error); }); }; </script> </body> </html>Node.js で公開されたindex.htmlに対して、ISBNコード「4309025447」を入力後、送信すると、index.js側でGoogle Books APIに書籍情報を問い合わせ、Express サーバー、index.htmlのコンソールにそれぞれ書籍名が表示されます。
参照情報


- 投稿日:2019-08-04T15:33:02+09:00
Node.jsをバージョン管理しながらインストールするまでの道
はじめに
Node.jsをUbuntu18.04にインストールするための手順を記していきます。必要なものは以下の4つです。実際、バージョン管理をせずにただNode.jsをインストールするならanyenvやnodenvは必要ありません。ただ、今後扱っていく上で便利なので、このような手順を追っていった方が良さそう。
- Node.js
- anyenv
- nodenv
- yarn
Node.jsとは
Node.jsとは、サーバサイド側でもjavascriptが動作可能な環境。フロントエンド側で動くための言語であるjavascriptがNode.jsを使えば、サーバサイド側でも動くことができるというものらしい。これにより、別言語でサーバサイド側の処理を書かなくてもいいと言うメリットがある。
anyenv
**envと呼ばれる言語のバージョン管理ツールをインストールするためのツール。今回はnodenvをインストールするために扱う。今後、他のenv系も簡単にインストールでき、それらを一括で管理できたりして扱いやすい。
anyenvのインストール
anyenvをホームディレクトリの .anyenvにクローンする。
$ git clone https://github.com/anyenv/anyenv ~/.anyenv.bashrcに下記の部分を追加する。
anyenvにパスを通して、設定をする。.bashrcexport PATH="$HOME/.anyenv/bin:$PATH" eval "$(anyenv init -)"その後、反映させるためにシェルを再起動。
$ exec $SHELL -lanyenvでnodenvをインストール
anyenvを使い、nodenvをインストールします。その後、シェルを再起動。
$ anyenv install ---init $ anyenv install nodenv $ exec $SHELL -lnodenvとは
Node.jsのバージョン管理ツール。同様なバージョン管理ツールにnvmやnodebrew等がある。これを利用することで別のプロジェクトごとに違うバージョンのNode.jsを扱うことが可能。
nodenvでnode.jsをインストール
下記のコマンドでグローバル環境に好きなバージョンを入れることができる。
$ nodenv install 12.7.0 $ nodenv global 12.7.0以下のように表示が出れば、ok。同時に、npmもインストールされてることがわかる。
$ node -v v12.7.0 $ npm -v 6.10.0もし、プロジェクトごとに別のバージョンのnode.jsを入れたいならば、プロジェクトのフォルダの中で下記のコマンドを打てばよい。
$ nodenv install 11.12.0 $ cd hoge $ nodenv local 11.12.0Yarn
npmと同様にnode.jsのモジュールパッケージの追加や削除をするためのツール。パッケージ間の依存関係もどうにかしてくれるらしい。npmよりもパッケージのインストール時間が短い。私はパッケージのインストールにyarnを使っているが、もちろんnpmを使っても問題はない。
Yarnのインストール
$ npm install -g yarnこれで必要なものは終了。それぞれの扱い方などは下の参考サイトなどを見てください。
参考サイト
- 投稿日:2019-08-04T11:49:19+09:00
Groovy-IoTをNode.jsから操ってみた:もう少しArduinoっぽいAPI
前回の記事 Groovy-IoTをNode.jsから操ってみた で、Groovy-IoTをNode.jsから扱えるようにしたのですが、Node.js向けのAPIがまだArduinoっぽくなかったので、今回はもう少しArduinoに近づけます。
例えば、
Serial.println()
とするべきところを、
Serial_println()
となっていました。これを直します。これで、Arduinoにより近づいたので、いくつかのGroveのドライバを移植しました。試したのは以下の4つです。すべてマルツ秋葉原本店( https://www.marutsu.co.jp/GoodsListNavi.jsp?path=1100020003 )で購入しました。
- Grove - LED Bar
- Grove - PIR Motion Sensor
- Grove - Digital Light Sensor
- Grove - Light Sensor(P)
(2つLight Sensorがあるのですが、前者がI2C接続、後者がアナログGPIO接続です)
(ちなみに、Grove - Temperature, Humidity, Pressure and Gas Sensor(BME680)も買ったのですが、C言語すぎて移植を中断中)ソースコードもろもろはGithubに上げてあります。
https://github.com/poruruba/node-groovy-iotArduinoっぽいAPI
ネイティブ拡張モジュールの実装では、すべてのAPIは横並びでした。
たとえば、Serial_printlnだったりWire_beginTransmissionしました。
一方、Arduinoでは、Serial.println となっていて、「.」で表現しています。これは、世にいうオブジェクト指向のClass/Objectに相当します。
Node.jsにもあるので、横並びのAPIを呼び出すNode.jsのクラスを実装しようと思います。さっそくソースコードです。
mcp2221lib.jsconst mcp2221 = require('mcp2221native'); var mcp2221_initialized = false; function mcp2221_initialize(){ var ret = mcp2221.initialize(); if( ret != 0 ) throw 'mcp2221.Serial_initialize error'; mcp2221_initialized = true; } class Serial{ initialize(sport){ if( !mcp2221_initialized ) mcp2221_initialize(); var ret = mcp2221.Serial_initialize(sport); if( ret != 0 ) throw 'mcp2221.Serial_initialize error'; this.DEC = -1; this.BIN = -2; this.OCT = -3; this.HEX = -4; } begin(speed){ return mcp2221.Serial_begin(speed); } end(){ mcp2221.Serial_end(); } available(){ return mcp2221.Serial_available(); } read(){ return mcp2221.Serial_read(); } peek(){ return mcp2221.Serial_peek(); } flush(){ mcp2221.Serial_flush(); } write(param, len){ if( len === undefined) return mcp2221.Serial_write(param); else return mcp2221.Serial_write(param, len); } write(buf, len){ } convert(data, format){ var str; if( typeof data == 'string'){ str = data; }else{ if( format >= 0 ){ str = data.toFixed(format); }else{ switch(format){ case this.BIN: str = data.toString(2); break; case this.OCT: str = data.toString(8); break; case this.HEX: str = data.toString(16); break; default: str = data.toString(10); break; } } } return str; } print(data, format){ var str = this.convert(data, format); return mcp2221.Serial_print(str); } println(data, format){ var str = this.convert(data, format); return mcp2221.Serial_println(str); } } class GPIO{ initialize(){ if( !mcp2221_initialized ) mcp2221_initialize(); var ret = mcp2221.GPIO_initialize(); if( ret != 0 ) throw 'mcp2221.GPIO_initialize error'; this.INPUT = 0; this.OUTPUT = 1; this.LOW = 0; this.HIGH = 1; this.DEFAULT = 0; } pinMode(pin, mode){ mcp2221.GPIO_pinMode(pin, mode); } digitalWrite(pin, value){ mcp2221.GPIO_digitalWrite(pin, value); } digitalRead(pin){ return mcp2221.GPIO_digitalRead(pin); } analogRead(pin){ return mcp2221.GPIO_analogRead(pin); } analogWrite(pin, value){ mcp2221.GPIO_analogWrite(pin, value); } analogReference(type){ mcp2221.GPIO_analogReference(type); } analogReadResolution(bits){ mcp2221.GPIO_analogReadResolution(bits); } analogWriteResolution(bits){ mcp2221.GPIO_analogWriteResolution(bits); } } class Wire{ initialize(){ if( !mcp2221_initialized ) mcp2221_initialize(); var ret = mcp2221.Wire_initialize(); if( ret != 0 ) throw 'mcp2221.Wire_initialize error'; } beginTransmission(address){ mcp2221.Wire_beginTransmission(address); } endTransmission(){ mcp2221.Wire_endTransmission(); } requestFrom(address, count){ return mcp2221.Wire_requestFrom(address, count); } available(){ return mcp2221.Wire_available(); } read(){ return mcp2221.Wire_read(); } write(param, len){ if( len === undefined ) return mcp2221.Wire_write(param); else return mcp2221.Wire_write(param, len); } } var gpio = new GPIO(); module.exports = { initialize : mcp2221_initialize, Serial : new Serial(), GPIO: gpio, Wire: new Wire(), pinMode : gpio.pinMode, digitalWrite: gpio.digitalWrite, digitalRead: gpio.digitalRead, analogRead: gpio.analogRead, analogWrite: gpio.analogWrite, analogReference: gpio.analogReference, analogReadResolution: gpio.analogReadResolution, analogWriteResolution: gpio.analogWriteResolution }使い方
まずは、先ほど作成したNode.jsのソースコードをrequireします。
const { Serial, GPIO, Wire, pinMode, digitalRead, analogRead } = require('./mcp2221lib');ここで、利用したいクラスと、利用したいGPIO関係の関数を指定します。
次に、初期化します。Serial.initialize(0); GPIO.initialize(); Wire.initialize();Serial.initializeに指定している数字は/dev/ttyACM0 の数字です。複数の仮想COMポートを持ったデバイスをマイコンに接続していると、Groovy-IoTに割り当たる数字が変わってきますので、確認して指定してください。
あとは、Arduinoでよく見るAPI呼び出しができるようになります。Serial.printlnやWire.beginTransactionなど。
以下を参考にさせていただいて真似ました。Arduino 日本語リファレンス
http://www.musashinodenpa.com/arduino/ref/ドライバの移植
ドライバが必要なのは、以下の2つです。
- Grove - LED Bar
- Grove - Digital Light Sensor
それぞれ、Grove_LED_Bar.js、Digital_Light_TSL2561.js というファイル名で作成しました。
Arduinoにライブラリインストールされたcまたはcpp言語ファイルを移植したものです。
ソースコードは、GitHubを参照してください。以下の2つは、Digital InputとAnalog Inputですので、ドライバは不要です。
- Grove - PIR Motion Sensor
- Grove - Light Sensor(P)
使い方はこんな感じです。
index.jsconst { Serial, GPIO, Wire, pinMode, digitalRead, analogRead } = require('./mcp2221lib'); const ledbar = require('./Grove_LED_Bar'); const TSL2561 = require('./Digital_Light_TSL2561'); async function test(){ Serial.initialize(0); GPIO.initialize(); Wire.initialize(); /* UART */ /* Serial.begin(9600); var ret = Serial.println("Hello World"); console.log(ret); */ /* Grove - PIR Motion Sensor */ /* pinMode(2, GPIO.INPUT); while(true){ if( digitalRead(2) ) console.log("Hi, people is comming"); } */ /* Grove - Digital Light Sensor */ /* TSL2561.init(); console.log(await TSL2561.readVisibleLux()); */ /* Grove - LED Bar */ /* var Grove_LED_Bar = new ledbar(1, 0, 0, 10); Grove_LED_Bar.setLevel(3); */ /* Grove - Light Sensor(P) */ /* console.log( analogRead(2) ); */ return; } test();ちょっと、補足すると、digitalReadやanalogReadで指定している番号は、PIN番号になります。
どのPIN番号が、Groovy-IoTのどのポートに割り当たっているかは、以下の方のページが非常に参考になります。Groovy-IoT + kikori (2. 標準ハードウェア)
結局、以下の通りです。
・GPIO1(GPIO/ADC/CLKR)
Pin1:GP0 ★これがPIN番号0
Pin2:GP1/ADC1/CLKR ★これがPIN番号1・GPIO2(GPIO/ADC/DAC)
Pin1:GP2/ADC2/DAC1 ★これがPIN番号2
Pin2:GP3/ADC3/DAC2 ★これがPIN番号3digitalRead(2) や analogRead(2) では2を指定しているので、GPIO2のGrove端子のPin1に対応します。(GPIO1のPin1も使いたかったのですが、DACやADCとしては使えないようです。)
以上
- 投稿日:2019-08-04T10:58:14+09:00
Node.jsで大規模演算を並列化する
はじめに
大規模なシステムを作成していると、大規模な演算を必要とすることがあると思います。そのとき、Node.jsではどのように作っていくのが良いのか、気になったため調べ始め、この記事を書くに至りました。
大規模な演算を必要なときにNode.jsを使うなよなどなどあるかもしれませんが、チームの特性上など色々あるかと思うので、ご容赦願います。
素数を求める処理を直列と並列の2パターンで行い、それぞれの実行時間の計測を行います。計測に用いた実コードと計測結果から、並列化を行うかどうかの今後の判断にお使い頂ければと思います。
並列化の手段
並列化の手段として、Node.jsで用意されているのは、『Cluster』と『Worker Threads』です。
Node is designed to build scalable network applications.
Node.jsはWebアプリケーションを作るためにあります。そして、そのWebアプリケーションをスケーラブルにするための機能を担っているのが『Cluster』です。
では、Webアプリケーション以外を並列処理するためにはどうすれば良いでしょうか?
そのための方法こそが『Worker Threads』になります。Workers are useful for performing CPU-intensive JavaScript operations
公式ドキュメント中で、このようにCPUを使う処理で有効な操作であると説明されています。
この記事では、大規模な演算というところに絞りたいため、『Worker Threads』のみ計測を行います。注)『Worker Threads』の機能は、試験的機能です。安定版として提供されている機能でない点にはご注意ください。突如仕様が変更されるなどの危険性があります。
計測
計測コード
実際に作成したコードは以下のGitHubリポジトリに上げています。
walk8243/NodeJS-Worker素数判定の方法が雑ですが、演算量が多い単純な処理をさせたかっただけですので、気にしないで頂けると幸いです。
並列処理
thread.tsimport { Worker } from "worker_threads"; import Main from "./thread/Main"; const loop = 4; const workerData = { maxNumber: 100000, }; const main = new Main(loop); for(let i=0; i<loop; i++) { const worker = new Worker(require.resolve('./thread/worker'), { workerData: workerData }); worker.on('message', (message) => { main.emit('result', worker.threadId, message.result); }); }thread/Main.tsimport { EventEmitter } from "events"; export default class Main extends EventEmitter { public obj: { id: number, result: number[] }[] = []; private counter: number = 0; constructor(private finish = 4) { super(); this.on('result', (threadId: number, result: number[]) => { this.obj.push({ id: threadId, result: result }); }); this.on('result', () => { if(++this.counter == this.finish) { console.log(this.obj.map((value) => value.result.length)); } }); } }thread/worker.tsimport { threadId, parentPort, workerData } from "worker_threads"; console.log('worker thread', threadId); const naturalNumber = []; const maxNumber = workerData.maxNumber || 10000; target: for(let i=2; i<maxNumber; i++) { check: for(let j=2; j<i; j++) { if(i % j == 0) { continue target; } } naturalNumber.push(i); } const data = { result: naturalNumber }; parentPort ? parentPort.postMessage(data) : console.log(data);# 実行方法 # 実行時 --experimental-worker が必須です yarn run tsc node --experimental-worker thread.js直列処理
normal.tsconst data = []; const loop = 4; const maxNumber = 100000; for(let i=0; i<loop; i++) { const naturalNumber = []; target: for(let i=2; i<maxNumber; i++) { check: for(let j=2; j<i; j++) { if(i % j == 0) { continue target; } } naturalNumber.push(i); } data.push({ result: naturalNumber }); } // console.log(data); console.log(data.map((value) => value.result.length));結果
計測は以下の環境で行った。
項目 値 CPU Intel(R) Core(TM) i7-7Y75 CPU @ 1.30GHz 1.60GHz コア数 2 スレッド数 4 OS Windows 10 Home 17134.885 パターン1[10万までの素数,4回演算]
直列 並列 1回目 7.168s 3.836s 2回目 7.466s 3.904s 3回目 8.084s 3.849s 4回目 8.654s 3.963s 5回目 7.698s 3.961s 6回目 7.590s 4.072s 7回目 7.767s 4.040s 8回目 7.839s 4.078s 9回目 7.592s 4.072s 10回目 7.655s 3.830s 平均値 7.751s 3.961s パターン2[10万までの素数,2回演算]
直列 並列 1回目 3.859s 2.617s 2回目 3.949s 2.518s 3回目 3.920s 2.671s 4回目 3.871s 2.637s 5回目 4.039s 2.706s 6回目 3.950s 2.655s 7回目 3.987s 2.608s 8回目 3.938s 2.566s 9回目 4.090s 2.742s 10回目 3.824s 2.656s 平均値 3.943s 2.638s パターン3[10万までの素数,1回演算]
直列 並列 1回目 1.983s 1.963s 2回目 2.305s 1.955s 3回目 1.919s 1.984s 4回目 2.066s 1.910s 5回目 1.960s 1.947s 6回目 1.821s 2.116s 7回目 1.881s 2.042s 8回目 1.960s 1.989s 9回目 1.883s 1.997s 10回目 1.870s 2.128s 平均値 1.965s 2.003s パターン4[5万までの素数,4回演算]
直列 並列 1回目 2.330s 1.155s 2回目 2.072s 1.163s 3回目 2.044s 1.183s 4回目 2.048s 1.179s 5回目 1.987s 1.165s 6回目 1.963s 1.128s 7回目 2.567s 1.144s 8回目 2.521s 1.185s 9回目 2.800s 1.147s 10回目 2.531s 1.164s 平均値 2.286s 1.161s パターン5[5万までの素数,2回演算]
直列 並列 1回目 1.154s 0.842s 2回目 1.149s 0.871s 3回目 1.107s 0.797s 4回目 1.101s 0.779s 5回目 1.128s 0.874s 6回目 1.123s 0.877s 7回目 1.049s 0.764s 8回目 1.123s 0.852s 9回目 1.118s 0.833s 10回目 1.078s 0.870s 平均値 1.113s 0.836s パターン6[1万までの素数,4回演算]
直列 並列 1回目 0.243s 0.304s 2回目 0.213s 0.280s 3回目 0.227s 0.297s 4回目 0.219s 0.326s 5回目 0.219s 0.306s 6回目 0.208s 0.311s 7回目 0.226s 0.297s 8回目 0.240s 0.294s 9回目 0.216s 0.322s 10回目 0.202s 0.301s 平均値 0.221s 0.304s パターン7[1万までの素数,2回演算]
直列 並列 1回目 0.174s 0.230s 2回目 0.185s 0.254s 3回目 0.176s 0.246s 4回目 0.185s 0.223s 5回目 0.164s 0.219s 6回目 0.172s 0.255s 7回目 0.212s 0.249s 8回目 0.172s 0.230s 9回目 0.206s 0.243s 10回目 0.163s 0.281s 平均値 0.181s 0.243s パターン8[10万までの素数,8回演算]
CPUのスレッド数を超えるケースとして、追加計測しました。
直列 並列 1回目 15.382s 8.289s 2回目 14.982s 8.294s 3回目 15.264s 8.277s 4回目 16.475s 7.940s 5回目 15.564s 7.822s 平均値 15.533s 8.124s さいごに
総括すると、『Worker Threads』を使うことで、有意義なレベルで実行時間の短縮ができました。
演算量の多い場合に関しては、直列でも並列でも実行時間に差はほとんどありませんでした。
一方で、演算量の少ない場合は、実行回数を上げても直列の方が早い結果となりました。『Worker Threads』で並列処理を行い、演算結果をメインスレッドに返したい場合、Workerの管理が必要となってきます。手間がかかる部分なので、実行時間のことも踏まえて、全てを並列処理にするように考えるのではなく、演算量と相談をして決める必要があります。
シングルスレッドを言い訳にNodeが遅いなんて言わせない世界を目指しましょう!
- 投稿日:2019-08-04T10:18:56+09:00
Node.jsでコンソールの表示を上書きする
ダメな方法
まずはダメな方法です。こういうスクリプトを実行すると、表示が追いつかずガタガタになります。
test.jsconst main = function (f) { f() } const printAbcde = function () { process.stdout.write("aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa\n"); process.stdout.write("bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb\n"); process.stdout.write("cccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccc\n"); process.stdout.write("dddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddd\n"); process.stdout.write("eeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeee\n"); } const mainLoop = function () { for (;;) { console.clear(); printAbcde(); } } main(mainLoop);毎回、console.clear関数で画面を上に流していることが原因です。
良い方法
console.clear関数を呼び出すのは最初の1回だけでいいです。あとは毎回、上書き前のタイミングでcursorTo関数を呼び出しカーソル位置を左上(x:0, y:0)へ戻します。
mainLoop関数を以下のように書き換えます。
test.jsconst mainLoop = function () { console.clear(); for (;;) { require('readline').cursorTo(process.stdout, 0, 0); printAbcde(); } }一部を上書きする
mainLoop関数を以下のように書き換えます。
test.jsconst mainLoop = function () { console.clear(); printAbcde(); printAbcde(); printAbcde(); require('readline').cursorTo(process.stdout, 10, 4); process.stdout.write(" !!!!! UPDATE TEXT !!!!! "); require('readline').cursorTo(process.stdout, 40, 11); process.stdout.write(" !!!!! UPDATE TEXT !!!!! "); for (;;); }4行10列と11行40列のテキストが上書きされます。
参考ページ
https://nodejs.org/api/readline.html#readline_readline_cursorto_stream_x_y_callback