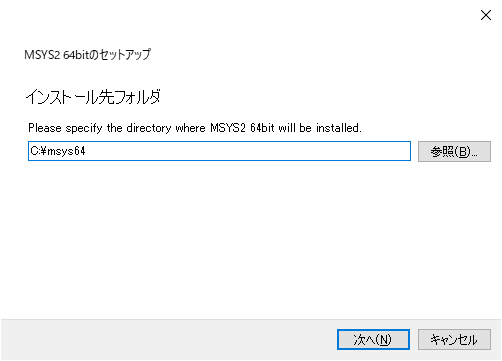
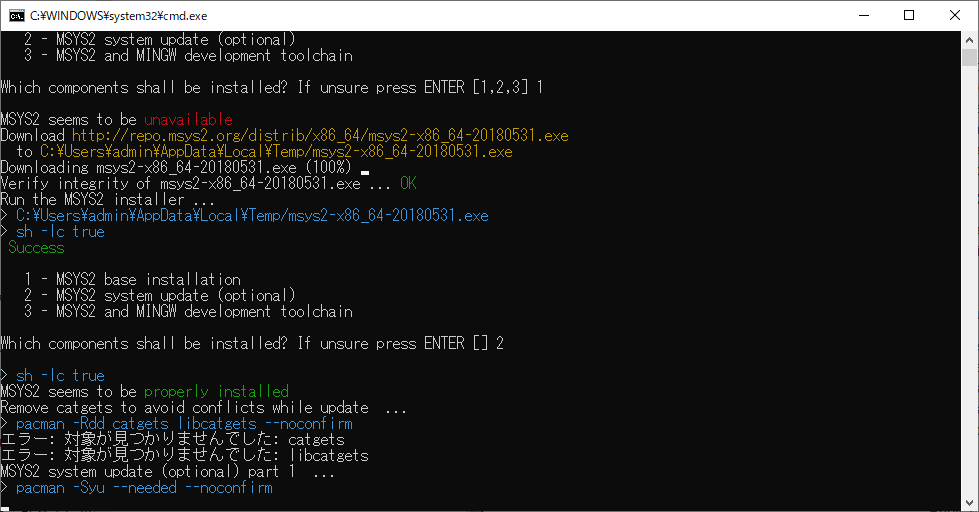
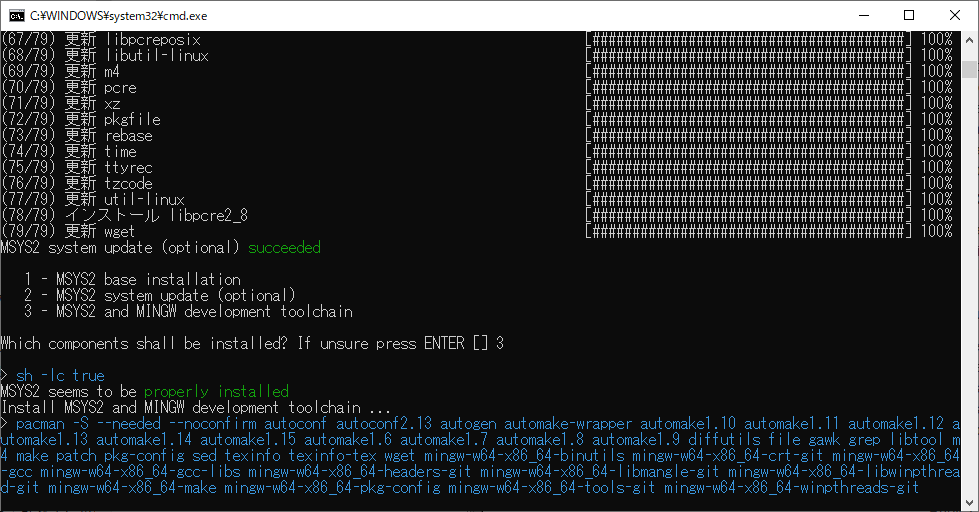
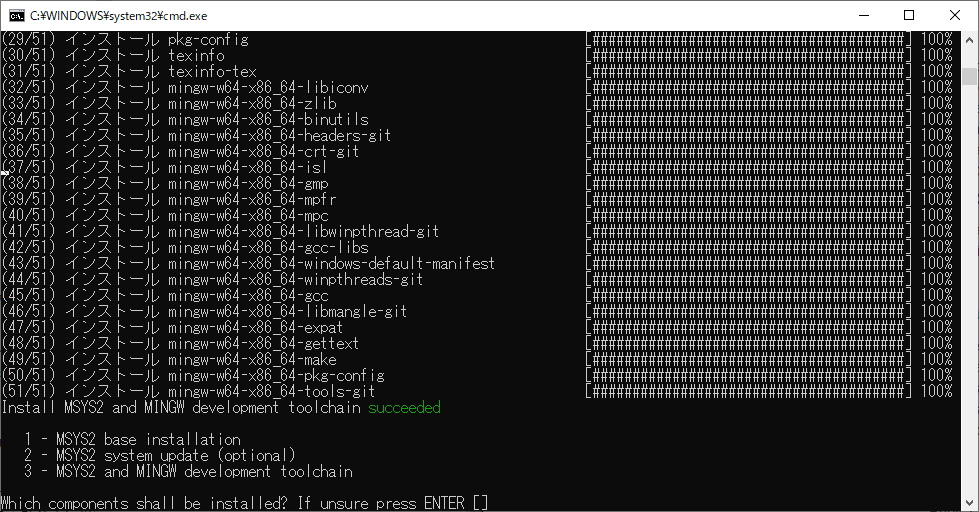
rails console
rails g controller home top
rails g model Post content:text
rake db:migrate
docker-composeコマンドの例
docker-compose exec web rails console
docker-compose exec web rails g controller home top
docker-compose exec web rails g model Post content:text
docker-compose exec web rake db:migrate
#!/usr/bin/env rubyrequire'active_support/core_ext'puts'--- DEPRECATED WARNING ---'pActiveSupport::Multibyte::Chars.consumes?('あ')puts'--- NO DEPRECATED WARNING ---'p'あ'.is_utf8?
Rails 6 では
実行すると DEPRECATION WARNING が表示されます。
$ bin/duration.rb
--- DEPRECATED WARNING ---
DEPRECATION WARNING: ActiveSupport::Multibyte::Chars.consumes? is deprecated and will be removed from Rails 6.1. Use string.is_utf8? instead. (called from <main> at bin/consumes:5)true--- NO DEPRECATED WARNING ---true
require 'method_source'
def my_important_method
# do nothing, just sleep
sleep 4
'successfuly done with my hard work!!'
end
method = method(:my_important_method)
method.source.display
すると。。。
def my_important_method
# do nothing, just sleep
sleep 4
'successfuly done with my hard work!!'
end
require'rails_helper'RSpec.feature"UsersSignups",type: :featuredofeature"valid signup information"dobeforedovisitsignup_pathfill_in"Name",with: "Example User"fill_in"Email",with: "user@example.com"fill_in"Password",with: "password"fill_in"Confirmation",with: "password"endscenario"add users count"doexpect{click_button"Create my account"expect(page).tohave_current_pathuser_path(User.last)}.tochange(User,:count).by(1)endscenario"show flash message"doclick_button"Create my account"expect(page).tohave_content"Welcome to the Sample App!"visitcurrent_pathexpect(page).to_nothave_content"Welcome to the Sample App!"endscenario"login created user"doclick_button"Create my account"expect(is_logged_in?).tobe_truthy#### ここで使用 ####endendfeature"invalid signup information"dobeforedovisitsignup_pathfill_in"Name",with: ""fill_in"Email",with: "user@invalid"fill_in"Password",with: "foo"fill_in"Confirmation",with: "bar"endscenario"no difference users count"doexpect{click_button"Create my account"expect(page).tohave_current_pathsignup_path}.to_notchange(User,:count)endscenario"is show error messages"doclick_button"Create my account"expect(page).tohave_content"Name can't be blank"expect(page).tohave_content"Email is invalid"expect(page).tohave_content"Password is too short"expect(page).tohave_content"Password confirmation doesn't match Password"endendend
するとこんなエラーが、、、
1) UsersSignups valid signup information login created user
Failure/Error: !session[:user_id].nil?
NameError:
undefined local variable or method `session' for #<RSpec::ExampleGroups::UsersSignups::ValidSignupInformation:0x00007fe38a4a3e20>
# ./spec/support/login_macros.rb:3:in `is_logged_in?'
# ./spec/features/users_signup_spec.rb:30:in `block (3 levels) in <top (required)>'
# -e:1:in `<main>'