- 投稿日:2019-07-09T21:47:47+09:00
デプロイ後、差分をアップデートする方法
- 投稿日:2019-07-09T20:37:58+09:00
CloudFormationでDynamoDB streamを設定する
前回の投稿【初心者向け】CFnでAPI Gateway+LambdaなAPI作成をまとめてみた
に引き続きCloudFormationネタですCFnでDynamoDB stream trigger eventを設定します
環境は
dev% aws --version aws-cli/1.16.180 Python/3.7.3 Darwin/18.2.0 botocore/1.12.170 AWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31ストリームを設定するlambda
template.yamlHogeFunction: Type: AWS::Serverless::Function Properties: Timeout: 10 CodeUri: xxxxxxxxxx Handler: app.lambdaHandler Runtime: nodejs10.x Role: !GetAtt LambdaRole.Arn Events: Stream: Type: DynamoDB Properties: Stream: !GetAtt DataTable.StreamArn BatchSize: 100 StartingPosition: LATEST LambdaRole: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Principal: Service: - lambda.amazonaws.com Action: - sts:AssumeRole Path: "/" Policies: - PolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Action: - dynamodb:DescribeStream - dynamodb:GetShardIterator - dynamodb:GetRecords - dynamodb:ListStreams Resource: "*" - Effect: Action: - logs:CreateLogGroup - logs:CreateLogStream - logs:PutLogEvents Resource: arn:aws:logs:*:*:*これでcloudformationコマンドを実行するだけ。素敵
- 投稿日:2019-07-09T20:27:20+09:00
AWS S3バケット名からCloufFrontのキャッシュをクリア(CreateInvalidation)するAPIをコールする
はじめに
以前、CloudFrontの配信元のファイル(S3)が更新されたら自動的にキャッシュをクリアする仕組みを作るという記事を作成しました。
その対応の中で「CloufFrontのキャッシュをクリア(CreateInvalidation)するAPIをコールするLambdaFunction」が必要です。
当記事では具体的な実装方法を紹介します。
実装の概要
- 配信元となるS3バケット名からCloudFrontのIDを取得する
- CloudFrontのIDをキーにしてCloufFrontのキャッシュをクリア(CreateInvalidation)する
CloudFrontのIDはAWSのマネコンから確認できるので
「配信元となるS3バケット名からCloudFrontのIDを取得する」の処理はマストではありません。
しかし、バケット名からCloufFrontのキャッシュをクリアできた方が汎用性が高くなる為、CloudFrontの一覧を取得し、バケット名からCloudFrontのIDを取得する処理も実装します。実装
CreateInvalidation.go//cloudfrontのクライアントを作成 svc := cloudfront.New(session.New()) //cloudfrontの一覧の情報を取得する為のインプットを作成 ListDistributionsInput := &cloudfront.ListDistributionsInput{} //cloudfrontの一覧の情報を取得 ListDistributions, _ := svc.ListDistributions(ListDistributionsInput) S3Domain := "s3.amazonaws.com" S3Buket := "cloudfrontの配信元のバケット名" + "." + S3Domain for _, DLItems := range ListDistributions.DistributionList.Items { for _, OriginsItems := range DLItems.Origins.Items { //cloudfrontの一覧からcloudfrontの配信元のバケット名の一致を判定 if S3Buket == *OriginsItems.DomainName { //キャッシュ削除(CreateInvalidation)コール用のIDを取得 callerReference := time.Now().Format("200601021504") //cloudfrontのキャッシュを削除するパスを指定 Path := "/*" PathItems := []*string{&Path} //キャッシュ削除用(CreateInvalidation)のクライアントを作成 CreateInvalidationInput := &cloudfront.CreateInvalidationInput{ DistributionId: aws.String(*DLItems.Id), InvalidationBatch: &cloudfront.InvalidationBatch{ CallerReference: &callerReference, Paths: &cloudfront.Paths{ Quantity: aws.Int64(1), Items: PathItems, }, }, } //キャッシュ削除(CreateInvalidation)を実行 result, _ := svc.CreateInvalidation(CreateInvalidationInput) } } }終わりに
目的のバケット名がcloudfront一覧の奥の方の構造体に入り込んでいた為、
取得するのに2重にループする必要があり、思ったより面倒でした。
改良の余地としては、cloudfrontのキャッシュを削除するパスが指定可能である為、オブジェクト名で検索をかけて対象のオブジェクトだけキャッシュクリアする方法もありますね。
追加のオブジェクトはキャッシュクリアの必要はない為、更新されたオブジェクトだけクリアしてあげてもいいですね。
- 投稿日:2019-07-09T15:54:36+09:00
AmazonRDSにおけるStorageAutoScalingに潜む罠
今回、RDS Storage Auto Scalingを実施したので、注意点も含め記事にしたいと思います。
https://aws.amazon.com/about-aws/whats-new/2019/06/rds-storage-auto-scaling/?nc1=h_ls:embed:cite・今までRDSにアタッチしているEBSはある程度の重要予測とIOPSを考慮しサイズを決めるオンプレミスライクな仕様でしたが、任意の容量を設定しておくだけで、適宜自動スケールするサービスが開始されました。設定の有効化は非同期処理されてI/O中断も発生しないので、メリットしかないですね。ただし、認識しておきたい箇所があります。
- 一度に大きなデータが取り込まれるときはスケールに時間がかかるので機能低下が発生する可能性がある
- スケール後、6時間あるいはDBインスタンスステータスが [Storage-optimization] の間のいずれか長い方の間はスケールしない
- 2017年11月からストレージ構成に修正を加えていない場合には、割り当てるストレージを増加するためにDBインスタンスを編集するときに数分間の短い停止が発生することがある
・1と2は検証が必要だし発生確率は低く、運用でカバーできますが、3が怖いですね...これ何を言ってるかというと対象のRDSがElasticVolumeでなかった場合はI/O中断することがあるやん?ってことです。
しかも不便なのがElasticVolumeなのかどうかをCLIやGUIでは参照できないという...
なので、2017年11月以前から起動しているRDSは必ず確認して実行しないとI/O中断する可能性があります。ちゃんとドキュメント読んで確認しないとダメージを受けてしまいます。
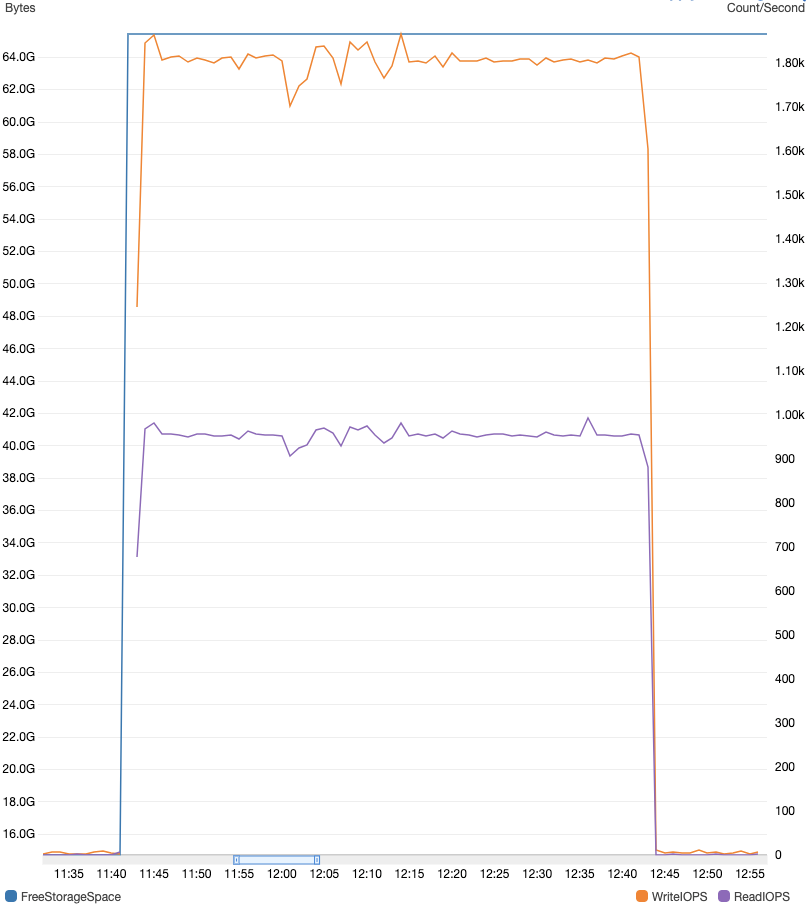
https://aws.amazon.com/jp/about-aws/whats-new/2017/11/amazon-rds-now-supports-database-storage-size-up-to-16tb-and-faster-scaling-for-mysql-mariadb-oracle-and-postgresql-engines/:embed:cite・今回、Created timeがThu Jun 02 2016 10:32:42 GMT+0900 (日本標準時)というRDSに対してStorage Auto Scalingを有効化してみました。
結果として、I/O中断は発生しませんでしたが、スケーリング時にボリューム間でのデータの移行が発生しWriteIOPSとReadIOPSがスパイクしました。
・当該RDSインスタンスは理論上ベースラインパフォーマンスは1200IOPS(gp2のバーストは最大3000IOPS)なので、クレジットが枯渇したとしてもサービス影響はないのですが、アラートが発火するので精神的にネガティブニュースです。結局、400GiBのElasticVolumeへの移行は65分ほど要しました。
・最新のアップデートは過去の複数のアップデートが絡んでいるので、注意深く見ることが必要だと再認識しました。焚き火して精神をスケールさせたいです...
- 投稿日:2019-07-09T15:10:09+09:00
AmazonLinux2でLaravelの開発環境構築
AWSでLaravelの開発環境を構築して行きたいと思います。
前提条件として、
すでにAWSでアカウントは作成済みとしています。
また、簡単なWEBアプリケーションは作成したことがある方を対象としていますEC2の起動
まずは、AWSのコンソールからEC2を起動します。
「インスタンスの作成」をクリックすると、Amazon マシンイメージ(AMI)の選択画面になるので、Amazon Linux 2 AMI (HVM),SSD Volume Type を「選択」します。次にインスタンスタイプの選択画面になるので、好きなインスタンスタイプを選択します。t2.microが無料利用枠の対象なので、利用できる方はこちらのタイプが良いかと思います。
私は開発環境での利用なので、今回 t3.nano を選択しました。インスタンスの詳細の設定については、基本的には自由に設定できますが、よくわからなければ一旦全てデフォルトのままでも問題ないかと思います。
私は、そこまで頻繁に利用しない開発環境ということもあるので、スポットインスタンスのリクエストにチェックを入れて、費用を安く抑えています。スポットインスタンスは、費用を安く抑えられる反面、連続稼働を保証していないので、本番環境ではお勧めできませんので注意ください。ストレージの追加も任意ですが、ルートの8GiBのみで進みます。
セキュリティグループの設定は、一旦最小限のセキュリティグループを作成します。
タイプ プロトコル ポート範囲 ソース SSH TCP 22 マイIP (ご自身の接続IP) HTTP TCP 80 カスタム 0.0.0.0/0,::/0 ターミナルへのログインのために、SSHのポートをご自身のIPで設定。
HTTPは、どこからでも閲覧可能なように設定。自分しか確認できないようにしたい場合は、HTTPのソースについてもマイIPを設定してください。最後に、ログイン用のキーを生成して終了です。
EC2の初期設定
EC2が起動したら、ec2-userとしてログインしてみましょう。
作成したキーを .ssh/ 以下に配置しておきます。ssh ec2-user@ec2-**-**-**-***.ap-northeast-1.compute.amazonaws.com -i ./.ssh/(秘密キー)Laravelをセットアップする前に、ざっとEC2の設定を行います。
とりあえず、パッケージを最新に更新
$ sudo yum update -yec2-userのままでも良いですが、実際に利用するユーザーを作成
ユーザー名をいつも利用しているユーザー名を利用してください。説明では munakata として進めます。$ sudo su - # useradd munakata # passwd munakata # usermod -G wheel munakatamunakata に sudo権限を付与します。
# visudoroot以下に追加
visudo## Allow root to run any commands anywhere root ALL=(ALL) ALL munakata ALL=(ALL) ALLmunakataのホームディレクトリ(/home/munakata) 以下の
.ssh/authorized_keys に公開鍵をセット。すでにご自身の公開鍵はお持ちかと思いますが、まだない方は作成してください。
SSHキー等で検索すれば、いくつか情報が出てくるかと思います。一応、権限を記載しておきます。
権限 パス 700 ~/.ssh 600 ~/.ssh/authorized_keys これで、munakataユーザーでログインする準備は完了です。
一度ログアウトして、実際に新しいユーザーでログインしてみましょう。ssh munakata@ec2-**-**-**-***.ap-northeast-1.compute.amazonaws.com -i ./.ssh/(munakataの秘密キー)ローカライズ設定を行います。
タイムゾーンを日本時間にセット
/etc/sysconfig/clock$sudo vim /etc/sysconfig/clock ZONE="Asia/Tokyo" UTC=false反映には再起動が必要なので、とりあえず日本時間にセット
$ sudo cp /usr/share/zoneinfo/Japan /etc/localtime日本語設定
/etc/sysconfig/i18n$ sudo vim /etc/sysconfig/i18n LANG=ja_JP.UTF-8ここまでで、ざっとEC2の初期設定が完了です。
必要なパッケージのインストール
ここからは、AmazonLinux2でLaravelを構築するために必要なパッケージをインストールしていきます。
なるべく特殊なことはせず、ある程度AWSで用意された標準的なもので構築したいと思います。WEBサーバーとして、apache2.4 、PHPのバージョンは、PHP7.3 を使用します。
いきなりですが、AmazonLinux2で、yumを利用してPHPをインストールするとPHP5になってしまいます。
AmazonLinuxでは、yum install php72 でPHP7.2をインストールできたのですが、AmazonLinux2には用意されていません。
その代わりに、Extra Library が用意されているようです。
Extra Library は、amazon-linux-extras で利用可能です。php7.3をインストールしてみます。
$ sudo amazon-linux-extras php7.3一緒に必要なパッケージもインストールされます
php-cli.x86_64 7.3.6-1.amzn2.0.1 @amzn2extra-php7.3 php-common.x86_64 7.3.6-1.amzn2.0.1 @amzn2extra-php7.3 php-fpm.x86_64 7.3.6-1.amzn2.0.1 @amzn2extra-php7.3 php-json.x86_64 7.3.6-1.amzn2.0.1 @amzn2extra-php7.3 php-mysqlnd.x86_64 7.3.6-1.amzn2.0.1 @amzn2extra-php7.3 php-pdo.x86_64 7.3.6-1.amzn2.0.1 @amzn2extra-php7.3確認してみましょう。
$ php -vamazon-linux-extras でパッケージをインストールすると、拡張モジュールに関しては、yumを使って適切なパッケージをインストールしてくれるようになります。便利ですね!
実際にインストール可能な拡張モジュールを確認してみましょう。
$ sudo yum list php* | grep php7.3必要な拡張モジュールをインストールしていきます。必要に応じて各自検討ください。
php-xmlは、Laravelインストール時に、phpunitのインストールに必要になるようなので、事前にインストールしておきましょう。$sudo yum install php-mbstring php-pecl-memcached php-gd php-apcu php-xml次に、apache2.4をインストールします。
AmazonLinuxの場合は、2.4系を入れる場合は、 httpd24 でしたが、AmazonLinux2の場合は、httpd で、2.4系になるようです。
$ sudo yum install httpd起動します。
$ sudo systemctl start httpdコンソール上には何も出力されないので、実際に動いているか確認します。
下記のコマンドで、active (running) とか表示されているはずです。$ sudo systemctl status httpd実際にWEBブラウザから確認してみます。
起動したEC2に、パブリックDNSが割り振られているかと思うので、そのURLで確認すると、Apacche2.4のTestPageが表示されるかと思います。
IPv4 パブリックIPでも確認可能です。
ElasticIPを紐付けた方は、そちらのIP、もしくはRoute53で設定したドメインで確認してください。
PHPの設定
この時点で、Laravelのインストール自体は可能なのですが、PHP、Apacheの細かい設定もしていきましょう。
PHPの設定は、 /etc/php.ini で行います。設定した値を確認できるように、phpinfoの表示ページを作成しておきましょう。
設定内容は、各自調整してください。
私がよく変更する箇所は、この辺です。php.ini# HTTPヘッダにPHPのバージョンを記載しない(一応セキュリティ的にOffにしておいたほうが良い) # expose_php = On expose_php = Off # メモリ上限を引き上げる(結構デフォルトのメモリは少なめなので増やしておくことが多い) # memory_limit = 128M memory_limit = 256M # POST送信の許容サイズを引き上げる # post_max_size = 8M post_max_size = 16M # アップロードファイルの許容サイズを引き上げる(スマホの写真のサイズが大きくなっているので、2Mだとほぼ画像投稿できないので増やす) # upload_max_filesize = 2M upload_max_filesize = 16M # timezoneの設定 # date.timezone = date.timezone = Asia/Tokyo設定を反映します。
モジュール版のPHPの場合、通常httpdを再起動すると、php.iniの内容が反映されるのですが、AmazonLinux2で、PHP7.3とhttpd2.4を構築した場合、デフォルトでSever APIが FPM/FastCGI となるため、httpdでは、php.iniの設定が反映されず、php-fpmの再起動が必要となります。
php-fpmについて詳しく知りたい方は、「php-fpm」等のキーワードでお調べください。
$ sudo systemctl restart php-fpmLaravelインストール
DocumentRootにLaravelを配置することも可能なのですが、開発環境として構築するので、今回はVirtualHostの機能を利用して、ホームディレクトリに、htmlディレクトリを作成して、その配下にLaravelプロジェクトを配置します。
まずは、Composerをインストール
curl -sS https://getcomposer.org/installer | phpcomposer.phar がダウンロードされるので、composer のコマンドで実行できるように、PATHが通っている場所へ移動させます。
sudo mv composer.phar /usr/local/bin/composerこれで composer が利用できるようになったので、Laravelをインストールします。
$ cd ~/html/ $ composer create-project --prefer-dist laravel/laravel blogこれで、blogというLaravelプロジェクトが構築されます。
ただし、今回利用している t3.nano などのインスタンスタイプだと、メモリが足らずにインストールの途中に下記のエラーが出てしまいます。mmap() failed: [12] Cannot allocate memoryそこで、ハードディスクにswap領域を作成して、メモリ不足を補います。
最初に、現状確認
$ free total used free shared buff/cache available Mem: 470512 145504 118000 104 207008 290656とりあえず、1G程度用意すればLaravelのインストールは可能なのでswapを作成します。
$ sudo dd if=/dev/zero of=/swapfile bs=1M count=1024 $ sudo chmod 600 /swapfile $ sudo mkswap /swapfile $ sudo swapon /swapfile再度、freeコマンドでSwapが追加されていれば、OKです。
$ free total used free shared buff/cache available Mem: 470512 145504 118000 104 207008 290656 Swap: 1048572 27904 1020668これで、やっと準備が整ったので、再度
$ composer create-project --prefer-dist laravel/laravel blogあとは、Laravelのドキュメントに記載がある通りに設定をしていきます。
$ cd ~/html/blog $ composer update $ chmod -R 777 bootstrap/cache $ chmod -R 777 storage $ php artisan key:generate基本的には、設定ファイルは、.envになりますが、開発環境専用にする場合は、下記のようにリネームします。
$ mv .env .env.developmentApache VirtualHost 設定
最後に、ApacheのVirtualHost設定を行います。
Virtual Hostの記述は、自動で設定が読み込まれる /etc/httpd/conf.d 配下にファイルを作成して記述します。
ファイル名は任意ですが、vhost.confで作成します。$ sudo su - # cd /etc/httpd/conf.d # vim vhost.conf一旦必要な記述を記載しますが、Virtual Hostの詳しい記述方法については、他で調べてみてください。
アクセス予定のドメインは、blog.munakata.net を仮定しています。適宜変更ください。vhost.conf<VirtualHost *:80> DocumentRoot /home/munakata/html/blog/public ServerName blog.munakata.net ServerAlias blog.munakata.net <Directory "/home/munakata/html/blog/public"> #.htaccessを利用可能にする AllowOverride All # Laravelで利用する環境変数を development に設定 SetEnv APP_ENV development #アクセス許可 Require all granted </Directory> </VirtualHost>httpd再起動
$ sudo systemctl restart httpdRoute53で、設定したドメインを紐付けるか、ご自身のマシンのhostsを設定して、ブラウザでアクセスしてみてください。
Laravelのトップページが表示されていれば、一旦完了です。
- 投稿日:2019-07-09T10:52:57+09:00
awscliのprofile名をすべて取得する方法
profile名だけ取得する
複数の環境を使っている人向け。
このコマンドでdefault以外のprofile名が取得できる。
$(cat ~/.aws/config | grep \\\[profile | sed -e "s/\[profile //g" -e "s/]//g")profile名つけないでコマンド叩いちゃったときが怖いので、自分はdefaultのcredentialsは
[default] aws_access_key_id = xxxxxxxxxx aws_secret_access_key = xxxxxxxxxという感じで無効化しているので、defaultはあえて取得していない。
応用
こんな感じにシェルスクリプトを書くとすべての環境に一括でなんやかんやできる。
#!/bin/bash profiles=($(cat ~/.aws/config | grep \\\[profile | sed -e "s/\[profile //g" -e "s/]//g")) for profile in ${profiles[@]}; do export AWS_PROFILE=$profile #ここにaws-cliコマンドを書く done
- 投稿日:2019-07-09T09:20:15+09:00
AWS認定 SysOps アドミニストレーター – アソシエイト合格体験記
はじめに
AWS 認定 SysOps アドミニストレーター – アソシエイトに合格したので、やってきたことをまとめます。
筆者のスペック
- セキュリティエンジニア
- AWS歴
- 業務経験なし
- プライベートで半年強
- クラウド関連は興味あり、資格あり
- Certified Kubernetes Administrator
- Certified Kubernetes Application Developer
- Cloud Foundry Certified Developer
受験履歴
試験日 試験 種別 スコア 合格体験記 2019/03/15 クラウドプラクティショナー(CLF) 本番 964 こちら 2019/03/15 SysOps アドミニストレーター – アソシエイト(SOA) 模擬 55% 2019/04/01 ソリューションアーキテクト - アソシエイト(SAA) 本番 865 こちら 2019/04/26 デベロッパー – アソシエイト(DVA) 本番 906 こちら 2019/07/07 SysOps アドミニストレーター – アソシエイト(SOA) 本番 813 本記事 試験対策
試験対策としてやったことをまとめます。
試験ガイド
まずは概要をつかむために試験ガイドに目を通しました。
模擬試験
苦手分野を明らかにするため早々に公式の模擬試験を受けました。SAA(84%)、DVA(85%)と同日に受験しましたが、突出してスコアが低かったです。
- 総合スコア: 55%
- トピックレベルスコア:
- 1.0 Monitoring and Reporting: 80%
- 2.0 High Availability: 50%
- 3.0 Deployment and Provisioning: 100%
- 4.0 Storage and Data Management: 50%
- 5.0 Security and Compliance: 25%
- 6.0 Networking: 33%
- 7.0 Automation and Optimization: 50%
Udemy
ハンズオンを求めてUdemyの対策コースを受講しました。DVAと同じ講師のものです。
Ultimate AWS Certified SysOps Administrator Associate 2019Practice Testは6/29に受けて73%の出来でした。
Black Belt セミナー
AWS サービス別資料のBlack Belt Online Seminarを視聴しました。
- Amazon Relational Database Service (RDS)
- Amazon Aurora with MySQL Compatibility
- Amazon Virtual Private Cloud (VPC) Basic
- Amazon Virtual Private Cloud (VPC) Advanced
- AWS CloudFormation
- AWS Config
- AWS Systems Manager
- Amazon GuardDuty
- Amazon Simple Notification Service (SNS)
AWS re:Invent Deep Dive
re:InventのDeep Diveセッションもサービスの理解を深めるのによいと見かけたので、UdemyのPractice Testを終えた頃から視聴しました。
- AWS re:Invent 2018: [REPEAT 1] Elastic Load Balancing: Deep Dive and Best Practices (NET404-R1)
- AWS re:Invent 2018: [Repeat] Deep Dive on Amazon S3 Security and Management (STG303-R1)
- AWS re:Invent 2017: Deep Dive on AWS CloudFormation (DEV317)
本試験
激ムズで、自信を持って回答できる設問はほとんどありませんでした。130分の試験ではありますが、45分で解答完了しました。手応えはなく、見直してもたいして変わらないと考えてそのまま試験終了しました。合格の文字を目にしたときはただただ驚きでした。
スコアレポートを見ると「分野 7: 自動化と最適化」は再学習の必要ありとなっていました。
まとめ
アソシエイト3冠を達成しました。難易度はSAA < DVA << SOAという印象です。「SAA合格できるならSOAも大丈夫、というのは改定前の話」と目にしましたが、その通りだと感じました。SOAでは今まで聞いたこともなかったサービスを使うことが多くて大変でした。
- 投稿日:2019-07-09T09:11:34+09:00
AWS CloudFormation Master Class を受けてみた⑦「 Advanced Concepts」
はじめに
Udemy にて Stephane Maarek 氏 が提供している「 AWS CloudFormation Master Class 」コースについて紹介していきます。最後の内容は「 Drift 」や「 Nested Stacks 」など CloudFormation のその他のサービスについて紹介していきます。
- これまでの AWS CloudFormation Master Class の記事
CloudFormation Drift
CloudFormation はインフラを構築してくれますが、update などで変更が起きた際の乖離(ドリフト)に対する サポートはCloudFormation にはありません。
このような問題に対応してくれるのが、CloudFormation drift です。この機能でドリフトを検出することで、スタックの設定がテンプレートの設定と異なっているかを確認できます。
※ただし、全てのリソースに対してはまだ対応できてないです。Nested Stacks
Nested Stacks とは
Nested Stacks とは、他の stacks の一部として作成された stack のことです。
以下のような特徴があります。
- 繰り返しパターンや、一般的な構成スタックを個別に作成し、他スタックからの呼び出しが可能
- nested stack のアップデートには root stack のアップデートが必要
- nested stack に対して nested stack を用意することも可能
Nested Stacks update and delete
Nested Stacks のアップデートと削除の際には、以下の点にそれぞれ注意する必要があります。
- Nested Stacks Update
- アップデートされた nested stacks は 最初に S3 にアップロードする必要がある
- その後、root stack もアップロードする
- Nested Stacks delete
- 子 stack に対して削除や変更の設定を直接行ってはいけない
- 常に、上層にある stack から変更させる必要がある
Troposphere
Troposphere を利用することで CloudFormation のテンプレートを Python で作成することができます。
メリット
- テンプレートの type から始めることができる
- 複雑な環境でも生成が可能
デメリット
- Python、JSON、そしてアップロードといった手順が必要
- Python について理解しておく必要がある
Deletion Policy
Deletion Policy を利用することで、リソースを削除から保護したり、削除前にバックアップを取ったりすることができます。
Deletion Policy の種類とそれぞれの特徴は以下となります。
- Delete:AWS CloudFormation の全リソースとコンテンツの削除を実行
- Retain:スタックの削除が実行された際、リソースやコンテンツは保持する
- Snapshot:リソースの削除前に snapshot を作成する
その他
その他にも、以下のような機能が用意されています。
- Custom resource
- テンプレートにカスタムのプロビジョニングロジックを記述し、ユーザーがスタックの作成、アップデート、そして削除を実行する度に AWS CloudFormation がそれを実行
- Lambda 関数を使うことで、プロビジョニングすることが可能
おわりに
AWS CloudFormation Master Class についての主な説明は以上となります。全体を通して、CloudFormation の機能とその使い方について説明してまいりました。日々の業務で活用し、そして実践することで、より本サービスについての理解を深めて参りましょう。





- 投稿日:2019-07-09T00:37:54+09:00
Docker で Amazon S3 に定期的に差分バックアップをとる
Docker Volume やディレクトリを Amazon S3 に定期的に差分バックアップをとるための hoto17296/backup-s3 という Docker Image を作ったので、その紹介。
やりたいこと
Docker で運用しているサーバに関するデータを Docker Volume に保存しているとして、その中身を定期的にバックアップをとりたい。1
バックアップを保存する場所としては Amazon S3 が無難で、Amazon S3 にバックアップをとるときによく使われるツールとして AWS CLI の S3 Sync がある。
sync — AWS CLI Command Reference
S3 Sync には様々なオプションがあってバックアップの方法を柔軟に指定できるのだけど、それは他の記事を見てもらえればいいとして、問題は「定期的に」バックアップする部分にある。
AWS CLI とそれを動かすための Python を入れて、バックアップ対象の Volume を Amazon S3 に Sync するシェルスクリプトを書いて、あとはそれを cron で定期実行するように設定して・・・で出来るかと思いきや OS ごとに cron の癖があってハマるのでググりながら修正して・・・と、思ったよりも面倒だったりする。
ていうか Docker が入ってるなら Docker で解決すれば良さそう。
作ったもの
Docker コンテナの中で crond と AWS CLI が動くので、ホスト OS に Python を入れる必要がないし OS ごとの cron の挙動の違いを意識する必要もない。いくつか必要な設定をしてコンテナを起動するだけでいい。
使い方は簡単で、
- いくつか環境変数を指定する
SCHEDULEバックアップをとるスケジュールを crontab フォーマットで指定するS3_URLバックアップ先の S3 バケットを指定するAWS_*コンテナ内から S3 バケットにアクセスするための認証情報を指定する/srcにバックアップ対象のディレクトリもしくは Docker Volume をマウントするこれだけ設定して、コンテナを起動する。
その他にも、タイムゾーンを指定できたり、S3 Sync のオプション (
--deleteとか) を追加できたり、除外設定--excludeをまとめて設定できたり、いくつかのオプションがある。詳しくは README を参照。Docker Compose の例
Jupyter Notebook を Docker で動かしており、その Notebook を
notebooksという Docker Volume に保存している場合の例。docker-compose.ymlversion: '3' services: backup-s3: image: hoto17296/backup-s3 environment: TZ: Asia/Tokyo SCHEDULE: '0 21 * * *' AWS_ACCESS_KEY_ID: XXXXXXXXXXXXXXXXXXXX AWS_SECRET_ACCESS_KEY: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx S3_URL: s3://backup/notebooks SYNC_OPTIONS: --delete EXCLUDE_FILES: '*.git/*, *.ipynb_checkpoints/*' volumes: - notebooks:/src上記の指定をすると、
notebooksVolume の中身を日本時間 21 時にs3://backup/notebooksにバックアップをとってくれる。追加で
--deleteオプションも指定しているので、削除されたファイルは自動的に S3 バケットからも削除される。参考
ちゃんとした Web サービスなどを運用するなら、そもそも「状態」は外部 DB に切り出せという話はある ↩
- 投稿日:2019-07-09T00:31:11+09:00
AWS summit Tokyo 2019 に行った話
はじめに
6/13(木)に仕事を休んでAWS summit Tokyo 2019に行った話を書きます。
私の個人的な興味と、参加した日の毛色と、最近のトレンドがデータ分析や機械学習関係なので、
主にそこらへんのことを書きました。
EC2とかERBとか基本的なアーキテクチャの話は出てきません。ご了承ください。
S3はちょっと出てきます。AWS summitとは
毎年5-6月にかけて行われるAWSのお祭り。
今年は6/12(水)~6/14(金)にかけて千葉の幕張メッセで開催されていました。
AWSに関するセッションが聞ける他、AWSのブースで最新機能の説明を聞いたり遊んだりできます。
また、企業ブースは商談の場だったりします。
セッションに興味があったのと、せっかく関東に来たし行ってみるかーのテンションで行ってきました。服装
寝坊したのですごく部屋着みたいな格好で行ったら、スーツ着た人がたくさんいて失敗したなと思いました。
持ち物
MacとiPad miniを持って行きました。
取り出しやすく、かつメモもしやすいため、iPad miniはとても有能でした。
Apple Pencilがあればより良いかもしれません。セッション
私が聞いたセッションは以下の3つです。
1. IoT/ML Deep Dive on AWS
2. 【初級】AWS の機械学習サービス入門
3. 【初級】AWSでのデータ収集、分析、そして機械学習IoT/ML Deep Dive on AWS
IoTからのML(マシンラーニング 機械学習)を行うためのAWSのサービスを紹介するセッションでした。
※途中から参加したので抜けてる部分もあると思います。主なサービス
Amazon SageMaker
- 機械学習のワークフローをカバーするマネージドサービス
- アマゾンのアルゴリズムを活用し、探索、ハイパーパラメータを自動的に選定
- クラウドにあげればモデルをすぐにAPIとして活用できる
- インフラを考える必要なし
Amazon SageMaker NEO
- 機械語にコンパイルしているので、高速にモデルを実行できる
- 同じランタイムで実行できる
- ハードウェアリソースの制限があるところでも活用できる
Amazon SageMaker Ground Truth
- 教師データのラベリングをしてくれるサービス
- 機械と人力のハイブリッド?
AWS IoT Greengrass
- エッジデバイスで推論可能
- インターネットが繋がってない現場で学習ができる
AWS IoT Analytics
- 時系列データのフルマネージドサービス
- クレンジングはアマゾンのアルゴリズムかラムダ
- BIツールで可視化できる
- データアナリストが分析しやすくなる
IoT Analytics Continuous Analisys
- いいモデルができたらワンクリックでコンテナ化
- モデルを定期実行できる
- 開発から運用までスムーズにできる
デザインパターン
高頻度なデータをリアルタイムに推論する場合
- エッジで推論
- Greengrass→Analytics→SageMaker
長期間の時系列データを詳細に推論したい場合、複数拠点にデータがまたがる場合
- クラウドで推論
- 学習データはバルクでクラウドにアップ
- Analyticsで必要なデータを抽出
- いいモデルができたらコンテナ化してAnalisysにアップロード
画像データの場合
- ラベルング⇨Ground Truth
- 学習⇨SageMaker
- ハードウェアのアーキテクチャにあわせてコンパイル⇨SageMaker NEO
- デプロイ⇨Greengrass
- 推論結果のみクラウドにアップ
DeepLens
- GreengrassとSageMaker NEOが搭載されている
- 簡単に画像データの機械学習が試せる
- 最近国内で注文ができるようになった
【初級】AWS の機械学習サービス入門
AWSの機械学習サービスはどんなのがあるのか気になったのと、入門という言葉に惹かれて聞いてみました。
AWSの機械学習サービスの紹介のあと、実際に活用するために何をしたらいいのかの話を聞きました。
AWSのAIサービスの紹介はググったら出てくるやつなので省略します。活用するためにやればいいのか?
ループ作る
- ビジネスにつながるかを絶えず考える
- 機械学習サービスありきではなく、出発点は必ずビジネス課題から
- 機械学習は選択肢の一つでしかない
データの管理
- セキュアなデータ管理をする
組織を作る
- 誰がやるのかを決める
- 1,2を回すための組織づくり
- どうやったらいい?
- awsの事例をwebサイトに公開している
- オフィスで事例を公開するイベントも開催してる
【初級】AWSでのデータ収集、分析、そして機械学習
データ活用の流れ データ分析と機械学習
- データ分析
- 過去を蓄積→現在理解(BIツール)→意思決定
- 機械学習
- 過去を蓄積→未来予測→意思決定
- データ分析も機械学習も、必ずビジネス課題からスタート!!!
意思決定に必要なこと
- 十分な質量のデータ
- データ分析や機械学習を行う仕組み
- 評価指標決める
データレイクとは
- データ収集、データ蓄積、データ変換
- データはできるだけ細かい単位で集める
- S3使ってデータレイクする
- S3はAPIとして呼び出していろんなサービスと連携できる
データ活用フローをつくってみる
- S3→可視化→意思決定と評価
- サーバーレスを使ってみよう
- サーバレスのメリット
- サーバーレスは利用者はアプリケーションの開発のみでいい(インフラを考える必要がない)
- プロビジョニング、管理対象のサーバーを持たない
- 処理した分のみにコストがかかる
- 利用量に応じて自動でスケール
- 可用性や耐障害性はビルドインに含まれる
それぞれのフェーズで使えるAWSのサービス
- SQL
- 標準的なSQL分析→Athena
- 高度なSQL分析→Redshift
- Hadoop→EMR
下に行くほど高度な技術が必要、人的リソースと運用コストがかかる
BI画面
- QuickSight
- サーバレスなBIサービス
- 機能をブラウザのみで使用できる
QuickSightとAthenaで大規模なデータ活用できる
ETL
- S3に集めたデータの変換を行う
- XML等の構造化データをSQLに変換
- 小規模→Lambda
- 中規模→Glue
- 大規模→Glue Spark
データ活用フローまとめ
- S3に保存
- GlueやLambdaで変換
- S3に保存
- Athena、QuickSightで可視化
まとめ
- 機械学習
- 過去のデータから未来予測
- 未知なものから予測
- 機械学習を活用する意味を考える
- 常にビジネス課題からスタート
- 機械学習でとける、解けそうな問題を理解する
- 注力する領域を決める
- 機械学習の全てを自社でやる必要はない
ブース
AWSのブースでは、AWS DeepRacerのリーグが盛り上がっていました!
DeepRacerとは、強化学習で走行コースを学習していく小型のレーシングカーです。
自分で強化学習のモデルを作ってトレーニングさせ、速さを競います。
ハイパーパラメータを調整し、どれほど最適化されたモデルが作れるかがカギになるところが、
次世代の娯楽感があって面白かったです。
人が多かったのでレースには参加はしませんでしたが、いつかやってみたいなと思いました。余談ですが、AWSのブースのガチャで1等を当て、ステンレスボトルを貰いました。
感想
誰でも比較的簡単にデータ分析や機械学習を使って課題解決ができる時代になってきているんだなという印象でした。
セッションの講演者の方も何度もおっしゃっていましたが、
データ分析や機械学習はあくまで課題解決の一手段であるため、
手段が目的になり代わらないように、都度起点に立ち返って当初の目的を考える必要があると思います。
それと同時に、課題解決のための手段としてこれらの技術を選択肢に入れられるように、
常に新しい技術、サービス、ツールのキャッチアップも欠かさず必要だなと感じました。こういう大きなイベントは初めてで、当日まで、行っていいのかなという気がしていましたが、
トレンドを把握でき、自分の中の選択肢を増やすことができたので、行ってみてよかったと思います。読んでくださりありがとうございました!