- 投稿日:2019-07-09T23:20:21+09:00
Pythonのappendをよりはやく
はじめに
はじめて記事を書きました。至らぬ点もあるかと思いますが生暖かい目で見守りください。
なんの話か
Pythonのlistのメソッドの一つであるappendの処理を最適化して実行速度を速くする話です。
Pythonを学習している中で「へーそうなんだ」と思ったので記事にしました。
もちろん私は "Hello World チョットデキル" レベルでしかないので皆さんにとっては常識かもしれません。実行環境
- Python 3.6.7
- OS : Windows 10 Home 64bit 1903
- CPU Pentium Gold G5400 (2C 4T)
- RAM 8GB
実際にやってみる
いつもの
append_test.pynumbers = [] for n in range(10 ** 8): numbers.append(n) # 15.14177393913269[sec]numbers = [] for n in range(10 ** 7): numbers.append(n) # 1.565068006515503[sec]最適化
append_test_opt.pynumbers = [] numbers_append = numbers.append for n in range(10 ** 8): numbers_append(n) # 11.622382164001465[sec]numbers = [] numbers_append = numbers.append for n in range(10 ** 7): numbers_append(n) # 1.0725383758544922[sec]結構揺らぎが大きいものの、確実にはやくなる。
なぜはやくなるのか
ご存じの方ぜひご教授頂けると嬉しいです。
- 投稿日:2019-07-09T23:15:26+09:00
AIdemyのブロックチェーン発展Ⅰで学んだこと&講義内容の補足
前提
- この記事は2019/7/9にAIdemyのブロックチェーン発展Ⅰを受講した後、学んだことと理解に時間がかかったところ(個人的ハマりポイント)の備忘録です。
- 筆者はブロックチェーン勉強始めたばかりなので誤りがあるかもしれません。気がつけばすぐに修正します。
- AIdemyのリンク先 https://aidemy.net/courses
以下、学んだこととハマりポイント
公開鍵暗号方式の概要
公開鍵暗号方式の流れは以下の通り
1. 受信者は送信者に対して公開鍵を送信する(公開する)。
2. 送信者は公開鍵を使用して暗号文を作成する。
3. 受信者に対して暗号文を送信する。
4. 受信者は秘密鍵を使用して暗号文を復号する。秘密鍵、公開鍵、ビットコインアドレスの生成
生成順は以下の通り
1. 秘密鍵を"暗号学的に安全な方法で"ランダムに生成する
秘密鍵とはランダムな数字の並びのこと
言語に用意されている乱数器ではダメ。ビットコインでは、osの乱数器を用いて人由来のランダム性を用いて初期化される
2. 公開鍵を秘密鍵から生成する
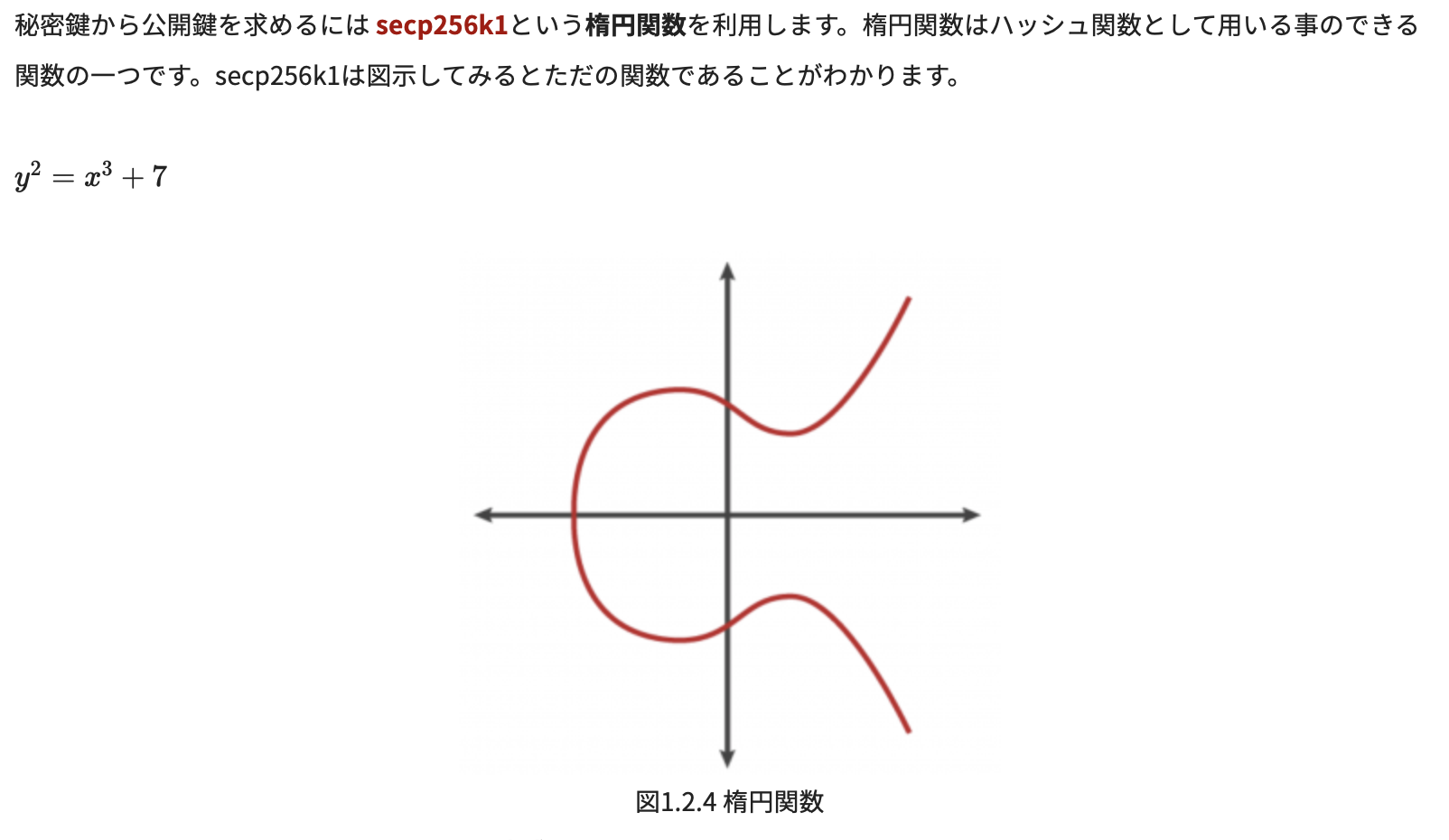
secp256k1と呼ばれる楕円曲線暗号を用いてスカラー倍算により生成する
公開鍵は楕円曲線上の、ある点の座標のことである(つまりx=??,y=??という形)
公開鍵から秘密鍵を特定することは現実的な時間では困難
ハマりポイント①
講義の中で楕円曲線の式と図が出てきて、あたかもその式が下の図を表したもののように見える(筆者には見えた)が、実は違う。
問題の箇所↓
↑数学に強い人なら式と図が対応していないことは見た瞬間違うと分かるだろうし、実際微分とかしてみれば確かめられるのだが、筆者は「なんかおかしいよなー??」という状態で30分も時間を消費してしまった。
※結局、以下のサイトの解説がとても分かり易かった↓
https://gaiax-blockchain.com/elliptic-curve-cryptography3. 公開鍵からビットコインアドレスを生成する
公開鍵から公開鍵ハッシュという20byteの数字を作り出し、次にその公開鍵ハッシュをBase58Checkと呼ばれる形にエンコードすることでビットコインアドレスが得られる
公開鍵ハッシュを生成する際は、2回ハッシュ関数にかける
2回ハッシュ関数かけることを「ダブルハッシュ」と呼び、ビットコインではあらゆる場面で用いられる
Base58Checkという方式を用いてエンコード(一定の規則に従って符号に変換)することでビットコインアドレスを作成する
ハマりポイント②
ここで、いきなり初めて聞く「RIPEMD-160」が登場し、何のために使うのか解説もなく当たり前のように使おうとするので、「何それ??」と戸惑った。
調べた結果、RIPEMD-160は「ライプエムディー160」と呼び、SHA-256と同じハッシュ関数である。SHA-256とRIPEMD-160違いは以下の通り
SHA-256 RIPEMD-160 得られるハッシュ値の長さ 64文字(256bit) 40文字(160bit) 開発元 NSA(米国標準技術局) オープンな学術コミュニティ ビットコインアドレスなどの短いハッシュ値を得たいときに、SHA-256からのRIPEMD-160というダブルハッシュが用いられる。ビットコインにおいては、その他基本的にはSHA-256を2回ともかけるダブルハッシュが用いられる。
※SHA-256とRIPEMD-160については以下のサイトでより詳しく解説されている↓
https://gaiax-blockchain.com/ripemd-160ウォレットの実装
ここからはまだ講義を受けていないので、受け次第更新する。(数日のうちに)
- 投稿日:2019-07-09T22:33:53+09:00
文字列とリストにファイルっぽくアクセスできるライブラリ「AbsStream」を作った
AbsStream
AbsStreamというライブラリを作りました。
GitHub: https://github.com/narupo/absstream
PyPi: https://pypi.org/project/absstream/インストール方法
pipでインストールできます。
$ pip install absstream特徴
文字列とリストにファイルオブジェクトっぽくアクセスできます。
データに対するアクセスは読み込みだけです。
書き込みはできません。使い方
Streamをインポートして文字列やリストをコンストラクタに渡します。
あとはメソッドからデータにアクセスできます。from absstream.stream import Stream strm = Stream('123') print(strm.get()) # '1'リストにも同じようにアクセスできます。
from absstream.stream import Stream strm = Stream(['1', '2', '3']) print(strm.get()) # '1'
getは範囲外のアクセスや、ストリームを読みつくすとStream.EOFを返します。from absstream.stream import Stream strm = Stream('123') print(strm.get()) # '1' print(strm.get()) # '2' print(strm.get()) # '3' print(strm.get()) # Stream.EOFループで回す場合は
eofメソッドでストリームがEOFに達したかチェックできます。from absstream.stream import Stream strm = Stream('123') while not strm.eof(): print(strm.get())現在の読み込み位置を変更するには
prevやnextが使えます。from absstream.stream import Stream strm = Stream('123') strm.next() strm.prev()現在の読み込み位置を起点にデータを取得したい場合は
curが使えます。from absstream.stream import Stream strm = Stream('123') print(strm.cur()) # '1' print(strm.cur(1)) # '2' print(strm.cur(2)) # '3' print(strm.cur(3)) # Stream.EOF作った背景
言語制作などをやっていて、文字列やトークン列に対して共通のインターフェースが欲しくなったので、この
AbsStreamを作って個人的に使っていました。
しかし使い心地が思いのほかよかったので、今回公開することにしました(単純にコードを使いまわすのがめんどうくさくなったのでpipでインストールできるようにした)。
- 投稿日:2019-07-09T22:33:53+09:00
「AbsStream」という文字列とリストにファイルっぽくアクセスできるライブラリを作った
AbsStream
AbsStreamというライブラリを作りました。
GitHub: https://github.com/narupo/absstream
PyPi: https://pypi.org/project/absstream/ライセンス
MIT
インストール方法
pipでインストールできます。
$ pip install absstream特徴
文字列とリストにファイルオブジェクトっぽくアクセスできます。
データに対するアクセスは読み込みだけです。
書き込みはできません。使い方
Streamをインポートして文字列やリストをコンストラクタに渡します。
あとはメソッドからデータにアクセスできます。from absstream.stream import Stream strm = Stream('123') print(strm.get()) # '1'リストにも同じようにアクセスできます。
from absstream.stream import Stream strm = Stream(['1', '2', '3']) print(strm.get()) # '1'
getは範囲外のアクセスや、ストリームを読みつくすとStream.EOFを返します。from absstream.stream import Stream strm = Stream('123') print(strm.get()) # '1' print(strm.get()) # '2' print(strm.get()) # '3' print(strm.get()) # Stream.EOFループで回す場合は
eofメソッドでストリームがEOFに達したかチェックできます。from absstream.stream import Stream strm = Stream('123') while not strm.eof(): print(strm.get())現在の読み込み位置を変更するには
prevやnextが使えます。from absstream.stream import Stream strm = Stream('123') strm.next() strm.prev()現在の読み込み位置を起点にデータを取得したい場合は
curが使えます。from absstream.stream import Stream strm = Stream('123') print(strm.cur()) # '1' print(strm.cur(1)) # '2' print(strm.cur(2)) # '3' print(strm.cur(3)) # Stream.EOF作った背景
言語制作などをやっていて、文字列やトークン列に対して共通のインターフェースが欲しくなったので、この
AbsStreamを作って個人的に使っていました。
しかし使い心地が思いのほかよかったので、今回公開することにしました(単純にコードを使いまわすのがめんどうくさくなったのでpipでインストールできるようにした)。
- 投稿日:2019-07-09T22:33:53+09:00
新ライブラリ!「AbsStream」を使えば文字列やリストのパースが簡単に
AbsStream
AbsStreamというライブラリを作りました?
GitHub: https://github.com/narupo/absstream
PyPi: https://pypi.org/project/absstream/より詳細な解説を見たい人は
をご覧ください。
ライセンス
MIT
インストール方法
pipでインストールできます。
$ pip install absstream特徴
文字列とリストにファイルオブジェクトっぽくアクセスできます。
データに対するアクセスは読み込みだけです。
書き込みはできません。使い方
Streamをインポートして文字列やリストをコンストラクタに渡します。
あとはメソッドからデータにアクセスできます。from absstream.stream import Stream strm = Stream('123') print(strm.get()) # '1'リストにも同じようにアクセスできます。
from absstream.stream import Stream strm = Stream(['1', '2', '3']) print(strm.get()) # '1'
getは範囲外のアクセスや、ストリームを読みつくすとStream.EOFを返します。from absstream.stream import Stream strm = Stream('123') print(strm.get()) # '1' print(strm.get()) # '2' print(strm.get()) # '3' print(strm.get()) # Stream.EOFループで回す場合は
eofメソッドでストリームがEOFに達したかチェックできます。from absstream.stream import Stream strm = Stream('123') while not strm.eof(): print(strm.get())現在の読み込み位置を変更するには
prevやnextが使えます。from absstream.stream import Stream strm = Stream('123') strm.next() strm.prev()現在の読み込み位置を起点にデータを取得したい場合は
curが使えます。from absstream.stream import Stream strm = Stream('123') print(strm.cur()) # '1' print(strm.cur(1)) # '2' print(strm.cur(2)) # '3' print(strm.cur(3)) # Stream.EOF作った背景
言語制作などをやっていて、文字列やトークン列に対して共通のインターフェースが欲しくなったので、この
AbsStreamを作って個人的に使っていました。
しかし使い心地が思いのほかよかったので、今回公開することにしました(単純にコードを使いまわすのがめんどうくさくなったのでpipでインストールできるようにした)。
- 投稿日:2019-07-09T22:05:32+09:00
論文arxiv1302.5843 実装その2
1. 本記事の概要
NPな色々な問題に対してIsingで定式化した論文arxiv1302.5843があります。
D-waveの勉強がてら、それを実装してみようというもの。https://arxiv.org/abs/1302.5843
2. 本記事の想定読者
- 最適化がなんとなくわかっている
- 理屈はいいから使えればいいや
- Pythonなんとなくわかる
レベルの人
3. 対象の問題
「2.2. Graph Partitioning」を対象とする。
頂点の数 $N=|V|$が偶数である無向グラフ $ G=(V,E) $ において、頂点数が同数の$N/2$ となるようグラフを分割した際に、エッジ数(辺)が最小となる分割方法は?
4. Ising式
論文を見ると2つのパーツに分かれていますね。頂点が同数となるような制限事項$H_A$と辺のCut方法$H_B$からなるようです。
すなわち、
$$ H_A = A(\sum_{n=1}^N s_i)^2 $$$$ H_B = B(\sum_{(uv) \in E} \frac{1-s_us_v}{2}) $$
だそうです。(Qiitaはきれいな数式が書けるので気持ちいですね!)
さて、グダグダ言わず、実装に移りましょう。(ほんと、Pyqubo超絶便利です。というか私、Pyquboなくしては何もできないんですが、いいのか!?)
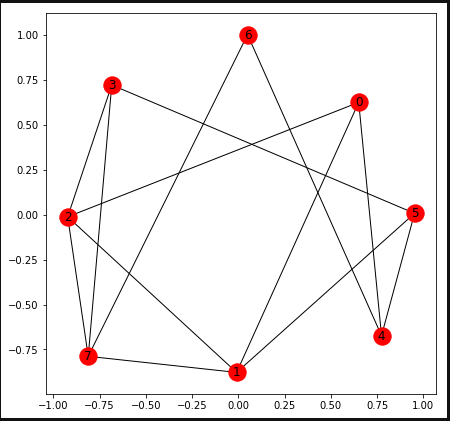
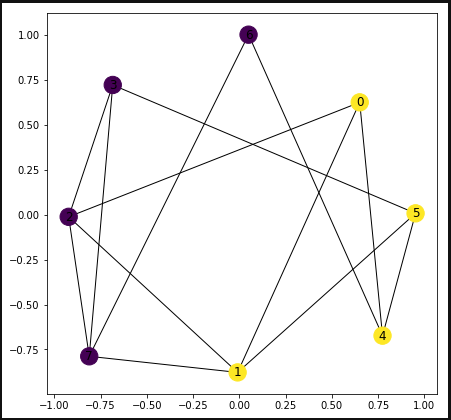
問題生成%matplotlib inline import matplotlib.pyplot as plt import networkx as nx import numpy as np import random from pyqubo import Placeholder,Array,Constraint,Sum,solve_qubo SIZE = 8 G = nx.Graph() #サイズ分のVertixを作成し、適当にEdgeをつなぐ for i in range(SIZE): G.add_node(i) if i != 0: for j in range(random.randint(1,6)): New_line = random.randint(0,i-1) if (G.get_edge_data(i,New_line) == None): G.add_edge(i,New_line,W=1) #グラフの出来具合を確認する pos = nx.spring_layout(G, k=5.,seed=0) nx.draw_networkx(G,pos) plt.rcParams['figure.figsize'] = (7.0, 7.0) plt.show()今回生成された問題は以下のようなもの。
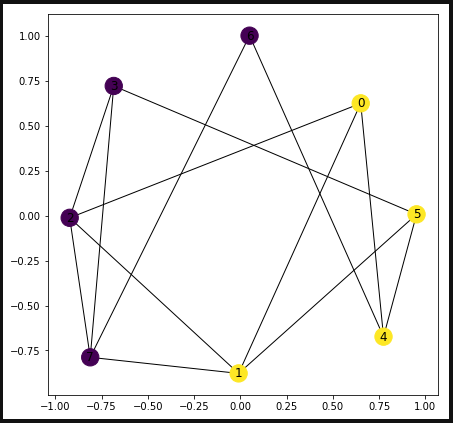
SAで解を確認#ハミルトニアンを構成 A = Placeholder("A") B = Placeholder("B") x = Array.create('x',SIZE,'SPIN') H_A = Constraint(Sum(0,SIZE, lambda i:x[i])**2,label="H_A") H_B = 0.0 for i in range(SIZE): for j in range(SIZE): if (G.get_edge_data(i,j) != None): H_B = H_B + (1.0 - x[i] * x[j]) / 2.0 H = A * H_A + B * H_B # モデルをコンパイル model = H.compile() # QUBOを作成 feed_dict = {'A': 0.2,'B':0.1} qubo, offset = model.to_qubo(feed_dict=feed_dict) #PyquboのSAで解いてみる sol = solve_qubo(qubo) #結果表示 pos = nx.spring_layout(G, k=5.,seed=0) nx.draw_networkx(G,pos,node_color=list(sol.values())) plt.rcParams['figure.figsize'] = (7.0, 7.0) plt.show()
次にD-waveで試します。
D-WAVEで実行from dwave.system.samplers import DWaveSampler from dwave.system.composites import EmbeddingComposite import dimod sampler = EmbeddingComposite(DWaveSampler(solver='DW_2000Q_VFYC_5')) response = sampler.sample_qubo(qubo, num_reads=100) result = [] result = model.decode_dimod_response(response,feed_dict=feed_dict) pos = nx.spring_layout(G, k=5.,seed=0) nx.draw_networkx(G,pos,node_color=list(result[0][0]['x'].values())) plt.rcParams['figure.figsize'] = (7.0, 7.0) plt.show()
お、無事いい感じの答えが出ました!
めでたしめでたし
- 投稿日:2019-07-09T22:01:10+09:00
CNTK 2.7 Release Notes
- 投稿日:2019-07-09T22:00:47+09:00
CNTK 2.6 Release Notes
導入
CNTK 2.6 で更新された主な特徴を紹介します。
内容
・.NET をサポート(省略)
・Group Convolution のパフォーマンス改善
・Sequential Convolution の改善
・Operators の追加と改善
・default arguments order の変更
・ONNX 関係のアップデートと変換におけるオプションをサポート(省略)
・バグ修正Group Convolution のパフォーマンス改善
Group Convolution はチャネル方向に対する畳み込みを実行します。
以下の条件で旧版と新版の性能を比較。
・Input tensor (C, H, W) = (32, 128, 128)
・Number of output channels = 32 (channel multiplier is 1)
・Groups = 32 (depth-wise convolution)
・Kernel size = (5, 5)
GPU time (msec., 1000 run avg.) CPU time (msec., 1000 run avg.) Model size (KB, CNTK format) Old implementation 9.349 41.921 38 New implementation 6.581 9.963 5 Speedup/savings Approx. 30% 65-75% 87% GPU では3割、CPU では6~7割の計算速度の改善が見られます。さらにモデルの容量も85%以上抑えられています。
Sequential Convolution の改善
Separate Sequential Convolution が実行可能になった。これは通常の畳み込みと異なり、Dynamic Axis に適用でき、filter_shape[0] がそれに対応します。CNTK 2.6 では、Sequential Axis に対するストライドが1より大きくなる場合に対応できるようになった。
例えば、画像の高さは 640 の固定で、幅が可変のカラー画像に適用するとき、(width, channel, height) とすると (*, 3, 640) になります。* は、Dynamic Axis を表します。
>>> f = SequentialConvolution((3, 3), 32, pad=True, strides=(2, 2), activation=C.relu) >>> x = C.input_variable(**Sequence[Tensor[3, 640]]) >>> x Input('Input', [#, *], [3 x 640]) >>> h = f(x) >>> h.shape (32, 320)このとき、width は任意のサイズを受け取って実行することができます。ストライドが (2, 2) なので出力の高さは半分になっています。幅は Dynamic Axis なので可変なため、この時点では表示されていません。このように、Dynamic Axis を用いることで可変サイズにも対応できます。
Operators の追加と改善
depth_to_space() と space_to_depth()
ONNX で他のライブラリと合わせるための更新で、Depth dimension と Spatial dimension の permutation を行うための演算子の追加。
tan() と atan()
tan 関数と arctan 関数の追加。
elu()
Exponential Linear Unit は以下のような性質をもつ関数。
$x \geq 0$ のとき、
y = ReLU(x)$x < 0$ のとき、
y = \alpha * (\exp(x) -1)この関数は以下の図のようになります。
Convolution()
CPU で効率的に対称 Padding をする自動 Padding アルゴリズムを更新。
最終的な畳み込みの出力値には影響なし。
MKL API でカバーできる範囲の拡張とパフォーマンスの向上。default arguments order の変更
C++ 形式から Python 形式に変更。
バグ修正
・畳み込み層の Group と Dialtion 引数の更新
・Group 畳み込みに対する入力の検証追加
・LogSoftMax を安定化
・不正確な勾配値の修正
・Python クローン代用におけるNoneの検証追加
・畳み込みにおける Padding チャネル軸の検証追加
・Numpy (version >= 1.14) に対する更新参考

- 投稿日:2019-07-09T21:56:44+09:00
医薬系データエンジニアのはじめ方、そして、稼ぎ方のイロハ。
医薬系のデータエンジニアというお仕事
近年、医薬品(製薬・創薬)関連企業や大学病院などの多くがITエンジニアを積極採用しようとしているのはご存知でしょうか?
多くの人に馴染みのある知名度の高いweb系企業とは違い、医薬系企業に注目しているエンジニアの数は少ない気がします。でも、元々がITに強い業界ではないだけに、初心者エンジニアでも採用されやすい狙い目の業界だったりするのです。私は某製薬関連企業で、データエンジニアとして働く者。元々はしがないwebエンジニア(正直、web開発者としては手が遅くダメな方だった...)。
いわゆるデータサイエンティストやAIエンジニアになりたい場合、多量のデータを持っている医薬系企業や大学病院で働くことは近道の一つなのです(もちろん、データサイエンスやAIを勉強すれば、なれるかも、ですが)。また、グローバル企業も多く、職場がホワイトで待遇も安定しているところが多いです。。
医薬品業界の給与水準については以下をご参考に:最新版】医薬品業界の年収ランキング 1位サノフィは手当充実、賞与年3回「管理職に昇格すると年収900~1000万円まで上がる」
...医薬品企業の経営に比較的余裕があるのは、近年まで、日本の多くの人々(特に年齢の高い方々)が薬好きだったことに起因するのかな?
私はエンジニアとしてはそこそこ長くやってますが、医薬系のデータエンジニアとしての経験自体は2年弱なので偉そうに書くのは少し恥ずかしいのですが、割と良い経験をさせてもらっていることに感謝しつつ、医薬系データエンジニアのはじめ方、おまけに、稼ぎ方(私見)をここに書きます。
エンジニアのの皆さん、エンジニアになりたい皆さん、医薬系の(データ)エンジニアに興味を持っていただけると幸いです。...そもそもデータエンジニアって何よっていう方は、とりありず、『いろいろなデータを扱うエンジニア』くらいに思ってもらって大丈夫です。
この投稿で業界に興味抱いた人や質問ある人は、私のtwitter等にどうぞ(twitterには別に業界のことは書いてませんが...個人情報を扱う職場ゆえ、業務上のソーシャルメディアの使用は禁止ですし...^^;)。
「で、お前の今の稼ぎは?」
やはり、気になりますよね。
このあたりを直球で言うのは技術系ブログでは下品な気もしちゃいますが(私は昭和な教育を受けたおっさんです)、
近年のqiitaのトレンドにならって、書いておきましょう。参考 「転職ドラフトで1000万円超えのオファーを2度貰ったエンジニアが「評価された理由」と「正社員で働く意味」について考えてみました。」
はい、正社員エンジニア(管理職)として1,000万円超えの年収をいただいております。
また、ありがたいことに年金・個人保険等の福利厚生も充実しています。
↑の投稿にならって ご参考までに、私の現在のスキルセット・経験も軽く羅列しておきしょう。
分野 内容 言語 Python,Scala,Java,Julia,Go,Nim,COBOL,Delphi,SQL,Perl,C/Objective-C,JavaScript,PHP,ActionScript,Ruby,Kotlin 各種フレームワーク等 Ruby on Rails,Spring-Boot,Play Framework 各種ミドルウェア等 Linux,pandas/numpy/scipy,Tomcat,apache,nginx,Docker,Terraform,ansible,Elasticsearch,kibana,Mecab,Spark,MySQL,Postgresql,Redis, kudu AWS APIGateway,Lambda,Cognito,EMRSQS,Redshift,RDS,S3,ELB,Route53,CLI 医療分野のサービス等 HPC(ハイパフォーマンスコンピューティング環境,パイプラインツール(ゲノム系、治験系、製薬系),Google DeepVariant ↑の投稿の方と比べて大したことないですね。言語の数は結構多いですが、半分くらいは私の趣味です。
そこそこの経験あるエンジニアであれば、業界に骨を埋める覚悟をした時点でそこそこのオファーを頂きやすい方だと思います(少なくとも平均給与水準+αの1000万円くらいまでは)。おっさん(私)の話はこれくらいにして、以下、若い皆さんとIT業界の経験がない方向けに書きます。
医薬系データエンジニアのはじめ方
私のおすすめの資質を三行で書きます。
- Pythonを使おう。
- TSV/CSVデータの扱いに強くなろう。
- 業界用語を知る意欲を持とう。
この3つを武器に、医薬系企業への就職・転職活動をしてみてください。
もちろん、RやJuliaなど他の言語を知ってもいいし、SQLに強いのも望ましいし、本当は、生物医学などの専門知識がある程度あった方が良いのは事実です。また、.NET限定、XML使うぞ、Excelのマクロが必要などなど、職場によって、各論的な知識はいろいろと求められるでしょう。
ですが、(そこそこ)若くてやる気が出せる皆さんがこの3つの資質をお持ちならば、多くの医薬品関連企業や病院の採用担当者がデータを扱うエンジニアとして歓迎してくれるはずです。以下、これから始める方向けに少し述べておきます。
Pythonを使おう。
Pythonの基本文法をマスターした後は、まずはpandasです。以下を索引代わりに勉強してください。
データ分析で頻出のPandas基本操作
細かいところはpython/pandas周りのTipsを安定して投稿してくださっている以下サイトに学ぶのが良いかと。
note.nkmk.me余裕があったら、numpyで行列を扱ったりしてみるのが良いでしょう(データサイエンティストになりたい人は、行列と線形代数の知識は必須でですよ)。
TSV/CSVデータの扱いに強くなろう。
pandasをマスターした時点で、当然TSV/CSVは扱えるようになっているはずですが、少し補充しておきます。
医薬系企業、大学病院、及び関連研究室では、TSV/CSVを取り扱うシステムは、しばしば「パイプライン」と呼ばれます。原油の代わりに、データを流すというわけですね。このパイプラインでは、複数のCSVを結合することが多いです。そして、ひとつひとつのCSVはかなり大きなものになったりします(例えば、全ゲノム解析に関連するTSVファイルのサイズは、ひとつあたり数百メガバイトになったりします。...
そんなのが数千個並んでいたりする。)
すなわち、上の『強い』という言葉には、大きなTSV/CSVデータの扱いに強い、という意味があるのです。ただし、ここは実際のノウハウは、大きなサイズのファイルと格闘してみなくては分からないところなので、まずは就職してから先輩に聞きながらノウハウを身に着けていくということで良いかと思います。業界用語を知る意欲を持とう。
医薬業界には、専門用語が極めて多いです。また、毎年増え続けています。なので、業界用語を学び続ける意欲が求められます。ただし、深く理解しなくとも何とかなるので、広く浅く業界用語を知る、といったスタンスでも大丈夫です。
実務に入った後には、知らない単語を聞いた時にまずはググってみて、わからないことは素直に質問するということができれば良いです(...これは、医薬業界に限らない社会人基礎力ですね)。
どんな用語が飛び足してくるかを知りたい方は、例えば、近年の業界のバズワードReal World Data(RWD)あたりからググってみてください。参考 : http://www.jpma.or.jp/medicine/shinyaku/tiken/allotment/real_world_data.html
おまけですが、業界内では、医薬IT系の人はドライ(dry)と言われたりします。試験管等で血液や水溶液を扱うウェット(wet)系の人と対比する意味で、ですね。このウェット系の方々はIT業界よりも女性の比率が高いです(臨床検査技師、薬剤師、保健師、看護師等の出身の方が多い)。
白衣のきれいなお姉さんを見て、ハァハァ...となる方はだめですが、きれいなお姉さんに素直に質問できる方は大歓迎です。
その意味で、女性ITエンジニアの皆さんにもおすすめの業界だったりします。(おまけ)白衣のきれいなお姉さんと一緒じゃないと医薬業界の用語を学べないという方
ひとまず、以下のtwitterをフォローして、呪文のような専門用語をググってみてください
https://twitter.com/souyakuchan
※ソーシャル創薬(叢薬)の申し子、創薬ちゃん:はい、きれいなお姉さんですね。つぶやきはケモインフォマティクス業界界隈らしいマニアックなものばかりで私は1/10も分かりませんが、フォローはしています。
...というのは半ば冗談として、医薬系の先生方のtwitterをフォローするのは役に立ちます。まずは創薬ちゃんがフォローしているアカウントをチェックしていくあたりから...稼ぎ方のイロハ
最後に医薬系企業、又は、医学部・大学病院などに業界に就職した方向けに。
まずは就職おめでとうございます。頑張って、職場のドメイン特化型の知識の習得に励んでくださいませ。
で、そこからもっと稼げるようになっていくにはどうしたら良いのか。
イロハといいつつ、私が言えることはただ一つ、実践的な英語知識です。
すなわち、
- ある程度、仕様を英語で理解できる。
- ある程度、医学系の論文が読める。
あたりが入口で、
- 上司に英語でホウレンソウできる。
- 部下に英語で的確な指示かできる。
あたりがゴールです。 なぜなら、医薬品業界は欧米企業(特に米国とスイス)が強いためです。
グローバル企業の待遇はきちんとしています。私は入口を少し超えたくらいですが、2年で年収が倍増しました。
これからはゴールを目指して通勤電車で日々勉強してます。どこから英語を学ぶかはそれぞれでしょうが、ひとつだけ:
若干スキャンダラスな話題ゆえにか、コメントが荒れ気味ですね。
この記事で紹介されている論文(以下)を読んでみてください。https://www.thelancet.com/journals/lancet/article/PIIS0140-6736(17)32252-3/fulltext
そして、正しく読めているかはさておき、論文で言っているであろうことと荒れ気味のコメントとの関係を考えてみるのです。
コメントの大多数は論文を読んでないものと思いますが、それが良いのです。
製薬系のグローバル企業での日本人エンジニアに求められる役割の一つは、日本人の医薬系の専門家・関係者と外国人エンジニアとの橋渡しです。(私をはじめ)多くの日本人にとって英語は鬼門なのです。でも、逆に、外国人エンジニアにとって日本語の細やかな理解は鬼門なのです。
この橋渡し役にやりがいを感じられれば、医薬系エンジニアとしての価値は高まっていきます。終わりに
偉そうに書いちゃいましたが、医薬系ITは成長産業なんですよ~、これを言いたかった。
おしまい。

- 投稿日:2019-07-09T21:56:28+09:00
EDINET APIをpythonで実行するまわりを調べてみた
EDINET APIを実行する
有報キャッチャーAPIは、証券コードを指定すると該当書類のZIPファイルが取得できるが、任意の日付にどの会社がどういう書類をEDINETに提出したかが分からない(任意の指定した日付で有報キャッチャーAPIが実行できない)ので、2019年春にEDINETのAPIがローンチしているので、そちらのAPIを試してみた。
edinet_api.pyimport json import requests import datetime def fn_getzipfile(docid): url2 = "https://disclosure.edinet-fsa.go.jp/api/v1/documents/" + docid params2 = { "type" : 1} fname = docid + ".zip" print('■'+ str(fname)) # EDINET API_2:提出書類のZIP取得 res = requests.get(url2, params=params2) # ファイルへ出力 if res.status_code == 200: with open(filename, 'wb') as f: for chunk in res.iter_content(chunk_size=1024): f.write(chunk) def fn_rtrv_edinet(ymd): url = "https://disclosure.edinet-fsa.go.jp/api/v1/documents.json" params = {"date": str(ymd), "type": 2} # EDINET API_1:提出書類の取得 res = requests.get(url, params=params) #print(res.text) #print(len(json_form["results"])) i = 0 json_form = json.loads(res.text) for jsn in json_form["results"]: if str(jsn["docDescription"]).find("有価証券報告書")>-1 : if str(jsn["docDescription"]).find("内国投資信託受益証券")==-1 : if str(jsn["docDescription"]).find("訂正")==-1 : docid = jsn["docID"] print('■' + str(docid)) i = i +1 #print(jsn) lst = ['docID','SecuritiesCode','edinetCode','secCode','filerName'] lst = lst + ['submitDateTime','periodStart','periodEnd','docDescription'] for l in lst: x= [print(jsn[l]) for j in jsn if l in j] #fn_getzipfile(docid) return i if __name__ == '__main__': # 日付 date = datetime.datetime.today().strftime("%Y-%m-%d") # date = "2018-06-28" print( date) r=fn_rtrv_edinet(date) print(r)・まず任意の日付を指定してEDINET API(documents.json)を実行すると、その日に提出された提出書類一覧が取得できる。各書類にはdocidがあるので、このdocidを引数として再度APIを実行して提出書類のZIPを取得する。
・過去の提出書類も取得可能のようである。
- 投稿日:2019-07-09T21:54:28+09:00
Pythonではじめる機械学習 復習
はじめに
Pythonではじめる機械学習の復習
Numpy配列
scikit-learnはNumpy配列でデータを受け取るため,使用するデータはNumpy配列に変換する必要がある。下記の配列がNumpy配列のコアとなる多次元配列(ndarrayクラス)である。
In[1]: import numpy as np x = np.array([[1, 2, 3], [4, 5, 6]]) print("x:\n{}".format(x)) Out[1]: x: [[1 2 3] [4 5 6]]SciPy
SciPyとはPythonで科学技術計算を行うための関数を集めたもの。scikit-learnではアルゴリズム実装の際にSciPyの関数を使用する。SciPyで最も重要な要素はscipy.sparseであり,これは疎行列(成分のほとんどが0である行列)を表現するもの。疎行列は成分のほとんどがゼロとなっている2次元配列を格納する際に用いられ,scikit-learnで使用されるもう1つのデータ表現である。
・eye
・csr_matrixIn[2]: # eye関数 import numpy as np from scipy import sparse eye = np.eye(4) # 4 x 4の単位行列(対角成分が1で,非対角成分が0の行列)を作成する print("Numpy array:\n{}".format(eye)) # Numpy配列を作成する Out[2]: Numpy array: [[1. 0. 0. 0.] [0. 1. 0. 0.] [0. 0. 1. 0.] [0. 0. 0. 1.]] In[3]: # CSR形式 sparse_matrix = sparse.csr_matrix(eye) # 上記のNumPy配列をCSR形式(NumPy配列の非ゼロ要素の座標を抽出する)に格納する print("\nSciPy sparse CSR matrix:\n{}".format(sparse_matrix)) Out[3]: SciPy sparse CSR matrix: (0, 0) 1.0 # NumPy配列の0行0列 (1, 1) 1.0 # NumPy配列の1行1列 (2, 2) 1.0 # NumPy配列の2行2列 (3, 3) 1.0 # NumPy配列の3行3列 In[4]: # COO形式 data = np.ones(4) # 1で埋められ4つの要素を持つ1次元配列を作成 row_indices = np.arange(4) col_indices = np.arange(4) eye_coo = sparse.coo_matrix((data, (row_indices, col_indices))) print("COO representation:\n{}".format(eye_coo)) Out[4]: # 上のものと同じ疎行列をCOO形式で作成する COO representation: (0, 0) 1.0 (1, 1) 1.0 (2, 2) 1.0 (3, 3) 1.0matplotlib
matplotlibはデータや解析結果を可視化するグラフ描画ライブラリである。グラフの描画にはAnacondaのJupyterNotebookを使用する。
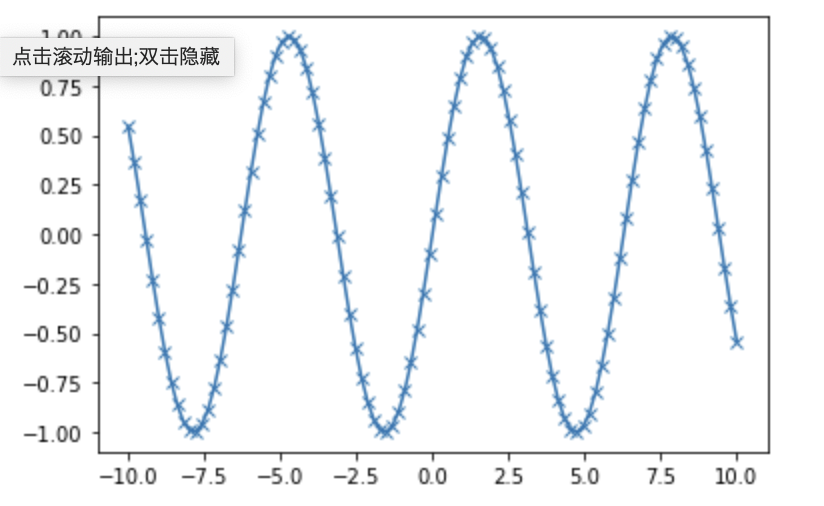
In[5]: %matplotlib inline # Jupyter Notebookへの表示に必要 %matplotlib notebookでも可 import numpy as np import matplotlib.pyplot as plt x = np.linspace(-10, 10, 100) # -10から10までを100ステップ区切った配列を作成 y = np.sin(x) # 配列xをsin関数のグラフにする plt.plot(x, y, marker="x") # plt.plot(x, y)でグラフを表示 marker="x"で100ステップのマークxを表示する↓
Out[5]:
pandas
pandasはデータ変換・解析を行い,エクセルシートのような形で結果を表示することができる(これをDataFarameという)。また様々なファイルやデータベースからデータを取り込むこともできる。
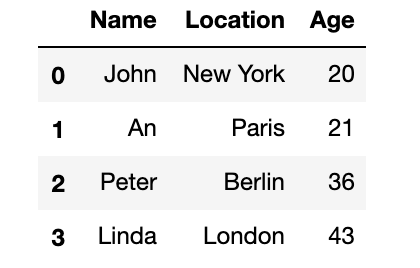
In[6]: import pandas as pd from IPython.display import display data = {'Name': ["John", "An", "Peter", "Linda"], 'Location': ["New York", "Paris", "Berlin", "London"], 'Age': ["20", "21", "36", "43"]} data_pandas = pd.DataFrame(data) display(data_pandas)Out[6]:
↓
また上記のテーブルに対して,ある条件を満たす項目のみを抽出することができる。下記の例では30歳以上のみを抽出する。display(data_pandas) ↓ display(data_pandas.Age > 30)とするとテーブルが作成されずエラーが発生した。
最後の文章を見てみると「TypeError: '>' not supported between instances of 'str' and 'int'」とある。data_pandas.Ageのstr型と30のint型を比較してるけどできません,と言われてるっぽい。よくみるとdisplay(data_pandas[data_pandas.Age > '30']) # であるべきが display(data_pandas[data_pandas.Age > 30]) # となっていた本書の誤植?いずれにせよ単純なことなので次からこういうミスは無くしたい。
おわりに
次回はアイリスのクラス分類を行う。

- 投稿日:2019-07-09T21:54:28+09:00
機械学習で扱うモジュールの基礎
はじめに
Pythonではじめる機械学習の復習を兼ねて,モジュールの基礎を扱う。
Numpy配列
scikit-learnはNumpy配列でデータを受け取るため,使用するデータはNumpy配列に変換する必要がある。下記の配列がNumpy配列のコアとなる多次元配列(ndarrayクラス)である。
In[1]: import numpy as np x = np.array([[1, 2, 3], [4, 5, 6]]) print("x:\n{}".format(x)) Out[1]: x: [[1 2 3] [4 5 6]]SciPy
SciPyとはPythonで科学技術計算を行うための関数を集めたもの。scikit-learnではアルゴリズム実装の際にSciPyの関数を使用する。SciPyで最も重要な要素はscipy.sparseであり,これは疎行列(成分のほとんどが0である行列)を表現するもの。疎行列は成分のほとんどがゼロとなっている2次元配列を格納する際に用いられ,scikit-learnで使用されるもう1つのデータ表現である。
・eye
・csr_matrixIn[2]: # eye関数 import numpy as np from scipy import sparse eye = np.eye(4) # 4 x 4の単位行列(対角成分が1で,非対角成分が0の行列)を作成する print("Numpy array:\n{}".format(eye)) # Numpy配列を作成する Out[2]: Numpy array: [[1. 0. 0. 0.] [0. 1. 0. 0.] [0. 0. 1. 0.] [0. 0. 0. 1.]] In[3]: # CSR形式 sparse_matrix = sparse.csr_matrix(eye) # 上記のNumPy配列をCSR形式(NumPy配列の非ゼロ要素の座標を抽出する)に格納する print("\nSciPy sparse CSR matrix:\n{}".format(sparse_matrix)) Out[3]: SciPy sparse CSR matrix: (0, 0) 1.0 # NumPy配列の0行0列 (1, 1) 1.0 # NumPy配列の1行1列 (2, 2) 1.0 # NumPy配列の2行2列 (3, 3) 1.0 # NumPy配列の3行3列 In[4]: # COO形式 data = np.ones(4) # 1で埋められ4つの要素を持つ1次元配列を作成 row_indices = np.arange(4) col_indices = np.arange(4) eye_coo = sparse.coo_matrix((data, (row_indices, col_indices))) print("COO representation:\n{}".format(eye_coo)) Out[4]: # 上のものと同じ疎行列をCOO形式で作成する COO representation: (0, 0) 1.0 (1, 1) 1.0 (2, 2) 1.0 (3, 3) 1.0matplotlib
matplotlibはデータや解析結果を可視化するグラフ描画ライブラリである。グラフの描画にはAnacondaのJupyterNotebookを使用する。
In[5]: %matplotlib inline # Jupyter Notebookへの表示に必要 %matplotlib notebookでも可 import numpy as np import matplotlib.pyplot as plt x = np.linspace(-10, 10, 100) # -10から10までを100ステップ区切った配列を作成 y = np.sin(x) # 配列xをsin関数のグラフにする plt.plot(x, y, marker="x") # plt.plot(x, y)でグラフを表示 marker="x"で100ステップのマークxを表示する↓
Out[5]:
pandas
pandasはデータ変換・解析を行い,エクセルシートのような形で結果を表示することができる(これをDataFarameという)。また様々なファイルやデータベースからデータを取り込むこともできる。
In[6]: import pandas as pd from IPython.display import display data = {'Name': ["John", "An", "Peter", "Linda"], 'Location': ["New York", "Paris", "Berlin", "London"], 'Age': ["20", "21", "36", "43"]} data_pandas = pd.DataFrame(data) display(data_pandas)Out[6]:
↓
また上記のテーブルに対して,ある条件を満たす項目のみを抽出することができる。下記の例では30歳以上のみを抽出する。display(data_pandas) ↓ display(data_pandas.Age > 30)とするとテーブルが作成されずエラーが発生した。
最後の文章を見てみると「TypeError: '>' not supported between instances of 'str' and 'int'」とある。data_pandas.Ageのstr型と30のint型を比較してるけどできません,と言われてるっぽい。よくみるとdisplay(data_pandas[data_pandas.Age > '30']) # であるべきが display(data_pandas[data_pandas.Age > 30]) # となっていた本書の誤植?いずれにせよ単純なことなので次からこういうミスは無くしたい。
おわりに
次回はアイリスのクラス分類を行う。
- 投稿日:2019-07-09T21:43:39+09:00
初心者が10分で実装するコメント機能
初めに
実務なんかで使えません。
フレームワークとか高尚なものは使いません。
というか使えません。めっちゃ簡単にできたので投稿
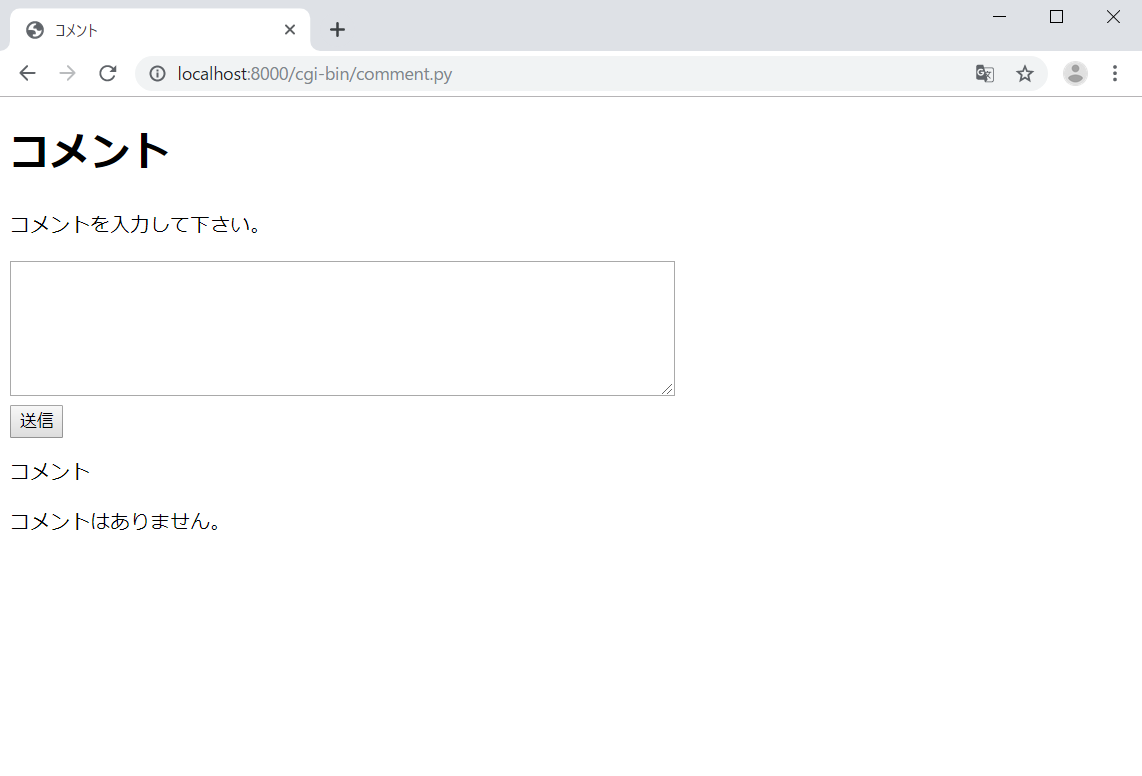
コメント機能
フォームを作り、その下にコメントを表示するだけ
コメントを入力、送信
コメントが表示される
手順
1.適当なディレクトリ(Aとする)にcgi-binディレクトリを作る。
2.その中に以下のプログラムをコピペし、comment.pyと名付ける。comment.py#! /usr/bin/env python3 import sqlite3 import csv import cgi import sys import io from datetime import datetime sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding="utf-8") db_path = "./comment.db" con = sqlite3.connect(db_path) con.row_factory = sqlite3.Row cur = con.cursor() htmlText = "" try: cur.execute( "create table if not exists commentTable(id integer primary key autoincrement, comment text, date datetime);" ) except sqlite3.Error as e: print("ERROR:", e.args[0]) form = cgi.FieldStorage() input_comment = form.getvalue("comment") try: if input_comment is not None: date = datetime.now().strftime("%Y/%m/%d %H:%M:%S") cur.execute("insert into commentTable(comment, date)values(?, ?);", (input_comment, date)) except sqlite3.Error as e: print("ERROR:", e.args[0]) def show_database(): try: cur.execute("select * from commentTable;") except sqlite3.Error as e: print("ERROR:", e.args[0]) debug = "except completed" return 0 show_database() rows = cur.fetchall() if not rows: htmlText = "コメントはありません。" else: for row in rows: if str(row["id"]): htmlText += str(row["date"]) + "<br>" + str(row["comment"])+ "</br>" con.commit() con.close() print("Content-type: text/html; charset=utf-8") print( f''' <!DOCTYPE html> <html lang="en" dir="ltr"> <head> <meta charset="utf-8"> <title>コメント</title> </head> <body> <div id="comment-div" class=""> <h1>コメント</h1> <p>コメントを入力して下さい。</p> <form name="comment-form" class="" action="comment.py" method="post"> <textarea name="comment" rows="8" cols="80"></textarea><br> <input type="submit" name="" value="送信"> </form> <p>コメント</p> {htmlText} </div> </body> </html> ''' )3.ディレクトリAで次のコマンドを実行する。
$ python -m http.server --cgiこれでローカルサーバが立つ。
やめるときはctrl-c
4.以下のurlにアクセスする。
http://localhost:8000/cgi-bin/comment.py
- 投稿日:2019-07-09T21:14:18+09:00
Python 画像の縦横幅をチェックする簡易ツール
前書き
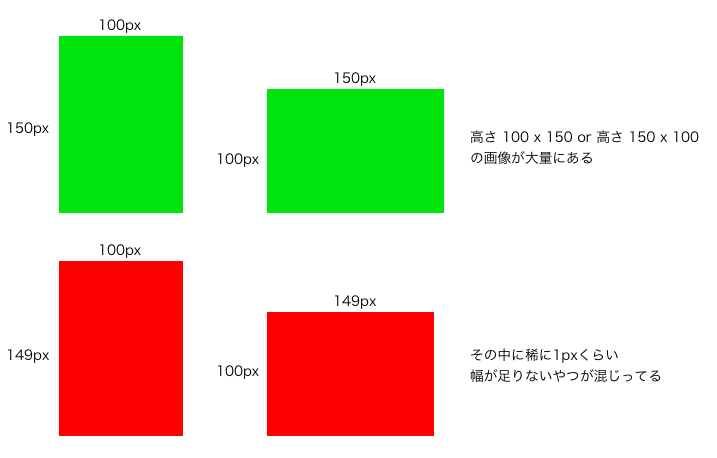
以下のような画像群がありました。
ここから画像サイズに誤りあるもの(赤い画像)を検出しないといけない。
普通にGUIで見たらこんな感じです。
赤い画像がサイズ違いの画像。
実際の画像は全て違うデザインなので、これだけでは画像の判別がつかないです。こういうのを見れるGUIツールはいくらでもありそうですが、
画像の数が多いので、GUIツールが重かったり見にくかったり。何がしたいのか
なるだけラクにチェックしたいです。
何をやるのか
簡単な処理で対処してしまおう、と思いました。
やったこと
Python で対処しました。
Pythonの画像処理ライブラリPillowを使ってます。
pip などで簡単にインストールできます。
https://pillow.readthedocs.io/en/stable/import glob from PIL import Image # 処理 def main(x, y, type_str, path, file_type): files = glob.glob(path + file_type) ng_cnt = 0 ok_cnt = 0 for file in files: sample = Image.open(file) sizestr = str(sample.size) chkstr_yoko = '(' + str(x) + ', ' + str(y) + ')' chkstr_tate = '(' + str(y) + ', ' + str(x) + ')' if sizestr != chkstr_yoko and sizestr != chkstr_tate: print('NG:' + file) ng_cnt = ng_cnt + 1 else: ok_cnt = ok_cnt + 1 # print('OK:' + file) # print(chkstr) print() print(type_str) print('Tate: W = ' + str(y) + ', H = ' + str(x) + ' / Yoko: W = ' + str(x) + ', H = ' + str(y)) print('OK:' + str(ok_cnt)) print('NG:' + str(ng_cnt)) # チェックする画像サイズを定義 x = 150 y = 100 path = '/Users/sawai/images/' file_type = '/*.png' type_str = '# Test_Image' # 処理呼び出し main(x, y, type_str, path, file_type)画像サイズやパスはロジック内に書きましたが、
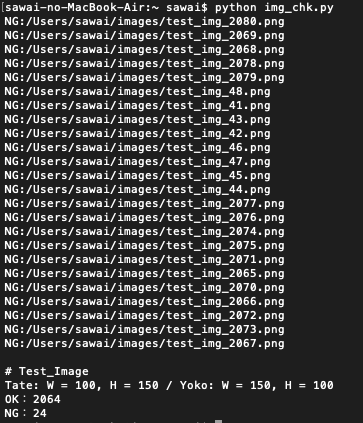
別ファイル定義やコマンドライン引数にしても良いと思います。実行結果
こんな感じでサイズが違う画像をピックアップできました。
処理速度も苦にならず、数秒で完了します。
まとめ
自身は業務上PHPを書く機会が多いのですが、
ちょっとしたタイミングで、ちょっとしたことを、ちょっと理由作って、
興味ある言語で書いてみる機会を作るのも大事かも。
(じゃないと実務で使う機会ってあまりないんですよねぇ・・・)もちろん、
他タスクのリソースを食いつぶすまで熱入れしない程度にですけども。
まぁロジック書くことは楽しいことだと思いますから(笑)

- 投稿日:2019-07-09T20:57:27+09:00
Macでyolo v3を動かして画像認識する
目的
Macでyolo v3を動かして画像認識した際の備忘録です
準備
下記サイトを参考にさせて頂きyolo v3の動作環境構築します。
YOLOv3をCPU環境でpython使ってリアルタイム画像認識を動かしてみた
Macで物体検知アルゴリズムYOLO V3を動かす
pytorch-yolo-v3下記の通りcondaを使ってYolov3用の環境を構築して試しました。
$ conda create -n yolo_v3 python=3.6 pipテスト
imgsフォルダに画像認識させたい.jpgファイルを格納してdetect.pyを実行します。
$ python detect.py --images imgs --det det
dog, bicycle.person...が認識されました
たまにdogがchair, teddy bearと認識されるのは一体なぜ..Pexelsからダウンロードした動画にvideo_demo.pyを実行します。
$ python video_demo.py --video samplemovie.mp4yolo v3 テスト pic.twitter.com/pDCnri5GhG
— st (@st17890027) July 8, 2019Error対策
$ python detect.py --images imgs --det det RuntimeError: invalid argument Sizes of tensors must match except in dimensionbatサイズの指定が誤っているようです。
下記サイトを参考に修正して動作させました。RuntimeError: invalid argument 0: Sizes of tensors must match except in dimension 0
You might add if output.size()[1] == prediction.size()[1]: condition, beforeoutput = torch.cat((output,prediction)), inside detect.py参考
YOLO: Real-Time Object Detection
YOLOv3をCPU環境でpython使ってリアルタイム画像認識を動かしてみた
Macで物体検知アルゴリズムYOLO V3を動かす
pytorch-yolo-v3YOLOv3を動かしてみる
KerasのYOLO-v3を動かしたった
YOLOとかOpenCVとかで物体検知
PexelsRuntimeError: invalid argument 0: Sizes of tensors must match except in dimension 0









- 投稿日:2019-07-09T20:47:19+09:00
辞書型データのvalueの直積を返したい
やりたいこと
pythonで、辞書が持つvalue同士の直積を、対応するkeyを変えずに辞書としてそれぞれ出力したい。
具体的には
{'A':[1,2,3], 'B':[4,5]}という辞書が存在するときに
[{'A':1, 'B':4}, {'A':1, 'B':5}, {'A':2, 'B':4}, {'A':2, 'B':5}, {'A':3, 'B':4}, {'A':3, 'B':5}]といった具合のリストが得られるようにしたい。
前提知識
itertools.product()で直積を求められます。
https://docs.python.org/ja/3/library/itertools.html#itertools.product
実装
test1.pyimport itertools test1 = {'A': [1, 2, 3], 'B': [4, 5]} product = [x for x in itertools.product(*test1.values())] result = [dict(zip(test1.keys(), r)) for r in product] for r in result: print(r)console{'A': 1, 'B': 4} {'A': 1, 'B': 5} {'A': 2, 'B': 4} {'A': 2, 'B': 5} {'A': 3, 'B': 4} {'A': 3, 'B': 5}valueの型が異なっていてもOK
test2.pyimport itertools test2 = {'A': ['TEST', 1, 2.5], 'B': [[3, 4], 5]} product = [x for x in itertools.product(*test2.values())] result = [dict(zip(test1.keys(), r)) for r in product] for r in result: print(r)console{'A': 'TEST', 'B': [3, 4]} {'A': 'TEST', 'B': 5} {'A': 1, 'B': [3, 4]} {'A': 1, 'B': 5} {'A': 2.5, 'B': [3, 4]} {'A': 2.5, 'B': 5}注意点
直積を求めたい辞書のvalueはlist型でなければなりません。
例えば以下の様な辞書を変換しようとするとエラーとなります。test3.pyimport itertools test3 = {'A': 1, 'B': [2, 3], 'C': [4, 5, 6]} product = [x for x in itertools.product(*test3.values())] result = [dict(zip(test1.keys(), r)) for r in product] for r in result: print(r)consoleTraceback (most recent call last): File "test3.py", line 5, in <module> product = [x for x in itertools.product(*test1.values())] TypeError: 'int' object is not iterableこの様な場合は一旦valueを舐めてlistでなければlistに変換してあげれば良いです。
test4.pyimport itertools test4 = {'A': 1, 'B': [2, 3], 'C': [4, 5, 6]} test4_after = dict([(key, val if type(val) is list else [val]) for key, val in test4.items()]) product = [x for x in itertools.product(*test4_after.values())] result = [dict(zip(test4_after.keys(), r)) for r in product] for r in result: print(r)console{'A': 1, 'B': 2, 'C': 4} {'A': 1, 'B': 2, 'C': 5} {'A': 1, 'B': 2, 'C': 6} {'A': 1, 'B': 3, 'C': 4} {'A': 1, 'B': 3, 'C': 5} {'A': 1, 'B': 3, 'C': 6}key値を捨てる場合
key値を捨ててvalueの直積だけ欲しい場合はzipの部分を消せばOK。
test5.pyimport itertools test5 = {'A': [1, 2], 'B': [4, 5, 6]} product = [x for x in itertools.product(*test5.values())] for r in product: print(r)console(1, 4) (1, 5) (1, 6) (2, 4) (2, 5) (2, 6)
- 投稿日:2019-07-09T20:35:03+09:00
ESP32-WROOM-32で撮影した画像をAWS(API Gateway→Lambda→S3)へ送信
概要
題名のままですが、ESP32-WROOM-32で撮影した画像をAWS(API Gateway→Lambda→S3)へ送信してみました!
カメラはOV2640を使用しています。ESP32での制御方法は以前の記事にまとめています。本記事では既に回路図作成済み前提で話を進めます。
https://qiita.com/koki-iwaizumi/items/db81c46b0d1b39b01655
S3バケット作成
画像保存先のS3のバケットを作成しておきます。バケット作成するだけなので詳細は割愛します。
lambda設定
下記を参考にlambda関数を作成します。今回はAPIキーあり、Python3.7を使用して関数を作成しました。
https://dev.classmethod.jp/cloud/aws/getting-start-api-gateway/関数作成後、その関数にS3のロールを割り当てる必要があるので下記を参考にS3を割り当てます。
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/with-s3-example.html下記がlambda_functionになります。BUCKET_NAMEはS3のバケットネームに変更してください。
処理の中身としては、json形式のデータ{"image":"base64で変換したjpeg"}を受信し、base64デーコード後、S3へランダム名で保存されるようになっています。※base64で変換できない場合などの例外処理などはしてないので、後で追加する予定です、、トリガーをAPI Gatewayに設定し、APIキーありで保存します。
lambda_function.pyimport boto3 import base64 import uuid BUCKET_NAME = '*' def lambda_handler(event, context): response = { "status": "failed", } print(event) if "image" not in event: return response s3 = boto3.resource('s3') bucket = s3.Bucket(BUCKET_NAME) bucket.put_object( Key=f'{uuid.uuid4()}.jpg', Body=base64.b64decode(event["image"]), ContentType='image/jpeg') response["status"] = "success" return responseESP-WROOM-32
下記のプログラムをESP-WROOM-32に書き込みます。全ファイルはgitに挙げています。
https://github.com/koki-iwaizumi/esp32-ov2640/tree/aws-lambdawifi接続後、OV2640で画像撮影、jpegデータをbase64に変換、postメソッドでAPI Gatewayへリクエストしています。jpegデータはVGA(640px:480px)のサイズにしています。
下記の変数はそれぞれ任意の値を入力してください。
WIFI_SSID、WIFI_PASSWORD、AWS_ENDPOINT、AWS_API_KEYapp_main.c#include <stdio.h> #include <stdlib.h> #include <string.h> #include "freertos/FreeRTOS.h" #include "freertos/task.h" #include "freertos/semphr.h" #include "freertos/event_groups.h" #include "esp_system.h" #include "esp_wifi.h" #include "esp_event_loop.h" #include "esp_http_client.h" #include "esp_log.h" #include "esp_err.h" #include "nvs_flash.h" #include "driver/i2c.h" #include "driver/gpio.h" #include "camera.h" #include "http_server.h" #include "mbedtls/base64.h" /********* config ***********/ #define WIFI_SSID "*" #define WIFI_PASSWORD "*" #define AWS_ENDPOINT "*" #define AWS_API_KEY "*" /********* i2c ***********/ #define I2C_CAMERA_TX_BUF_DISABLE 0 #define I2C_CAMERA_RX_BUF_DISABLE 0 #define I2C_CAMERA_FREQ_HZ 100000 #define I2C_CAMERA_NUM I2C_NUM_0 #define ACK_CHECK_EN 0x1 #define ACK_CHECK_DIS 0x0 #define ACK_VAL 0x0 #define NACK_VAL 0x1 #define CAMERA_SLAVE_ADDRESS_READ 0b01100001 #define CAMERA_SLAVE_ADDRESS_WRITE 0b01100000 /********* gpio ***********/ #define PIN_D0 35 #define PIN_D1 17 #define PIN_D2 34 #define PIN_D3 5 #define PIN_D4 39 #define PIN_D5 18 #define PIN_D6 36 #define PIN_D7 19 #define PIN_XCLK 27 #define PIN_PCLK 21 #define PIN_VSYNC 22 #define PIN_HREF 26 #define PIN_SDA 25 #define PIN_SCL 23 #define PIN_RESET 15 #define GPIO_OUTPUT_PIN_SEL (1 << PIN_RESET) static const char* TAG = "camera_demo app_main"; static EventGroupHandle_t s_wifi_event_group; const int CONNECTED_BIT = BIT0; static ip4_addr_t s_ip_addr; /********* camera reg ***********/ static const uint8_t default_regs[][2] = { {0xFF, 0x00}, {0x2C, 0xFF}, {0x2E, 0xDF}, {0xFF, 0x01}, {0x3C, 0x32}, {0x11, 0x80}, {0x09, 0x02}, {0x28, 0x00}, {0x13, 0xE5}, {0x14, 0x48}, {0x15, 0x00}, {0x2C, 0x0C}, {0x33, 0x78}, {0x3A, 0x33}, {0x3B, 0xFB}, {0x3E, 0x00}, {0x43, 0x11}, {0x16, 0x10}, {0x39, 0x02}, {0x35, 0x88}, {0x22, 0x0A}, {0x37, 0x40}, {0x23, 0x00}, {0x34, 0xA0}, {0x06, 0x02}, {0x06, 0x88}, {0x07, 0xC0}, {0x0D, 0xB7}, {0x0E, 0x01}, {0x4C, 0x00}, {0x4A, 0x81}, {0x21, 0x99}, {0x24, 0x40}, {0x25, 0x38}, {0x26, 0x82}, {0x48, 0x00}, {0x49, 0x00}, {0x5C, 0x00}, {0x63, 0x00}, {0x46, 0x00}, {0x47, 0x00}, {0x0C, 0x3A}, {0x5D, 0x55}, {0x5E, 0x7D}, {0x5F, 0x7D}, {0x60, 0x55}, {0x61, 0x70}, {0x62, 0x80}, {0x7C, 0x05}, {0x20, 0x80}, {0x28, 0x30}, {0x6C, 0x00}, {0x6D, 0x80}, {0x6E, 0x00}, {0x70, 0x02}, {0x71, 0x94}, {0x73, 0xC1}, {0x3D, 0x34}, {0x5A, 0x57}, {0x4F, 0xBB}, {0x50, 0x9C}, {0xFF, 0x00}, {0xE5, 0x7F}, {0xF9, 0xC0}, {0x41, 0x24}, {0xE0, 0x14}, {0x76, 0xFF}, {0x33, 0xA0}, {0x42, 0x20}, {0x43, 0x18}, {0x4C, 0x00}, {0x87, 0xD0}, {0x88, 0x3F}, {0xD7, 0x03}, {0xD9, 0x10}, {0xD3, 0x82}, {0xC8, 0x08}, {0xC9, 0x80}, {0x7C, 0x00}, {0x7D, 0x00}, {0x7C, 0x03}, {0x7D, 0x48}, {0x7D, 0x48}, {0x7C, 0x08}, {0x7D, 0x20}, {0x7D, 0x10}, {0x7D, 0x0E}, {0x90, 0x00}, {0x91, 0x0E}, {0x91, 0x1A}, {0x91, 0x31}, {0x91, 0x5A}, {0x91, 0x69}, {0x91, 0x75}, {0x91, 0x7E}, {0x91, 0x88}, {0x91, 0x8F}, {0x91, 0x96}, {0x91, 0xA3}, {0x91, 0xAF}, {0x91, 0xC4}, {0x91, 0xD7}, {0x91, 0xE8}, {0x91, 0x20}, {0x92, 0x00}, {0x93, 0x06}, {0x93, 0xE3}, {0x93, 0x03}, {0x93, 0x03}, {0x93, 0x00}, {0x93, 0x02}, {0x93, 0x00}, {0x93, 0x00}, {0x93, 0x00}, {0x93, 0x00}, {0x93, 0x00}, {0x93, 0x00}, {0x93, 0x00}, {0x96, 0x00}, {0x97, 0x08}, {0x97, 0x19}, {0x97, 0x02}, {0x97, 0x0C}, {0x97, 0x24}, {0x97, 0x30}, {0x97, 0x28}, {0x97, 0x26}, {0x97, 0x02}, {0x97, 0x98}, {0x97, 0x80}, {0x97, 0x00}, {0x97, 0x00}, {0xA4, 0x00}, {0xA8, 0x00}, {0xC5, 0x11}, {0xC6, 0x51}, {0xBF, 0x80}, {0xC7, 0x10}, {0xB6, 0x66}, {0xB8, 0xA5}, {0xB7, 0x64}, {0xB9, 0x7C}, {0xB3, 0xAF}, {0xB4, 0x97}, {0xB5, 0xFF}, {0xB0, 0xC5}, {0xB1, 0x94}, {0xB2, 0x0F}, {0xC4, 0x5C}, {0xA6, 0x00}, {0xA7, 0x20}, {0xA7, 0xD8}, {0xA7, 0x1B}, {0xA7, 0x31}, {0xA7, 0x00}, {0xA7, 0x18}, {0xA7, 0x20}, {0xA7, 0xD8}, {0xA7, 0x19}, {0xA7, 0x31}, {0xA7, 0x00}, {0xA7, 0x18}, {0xA7, 0x20}, {0xA7, 0xD8}, {0xA7, 0x19}, {0xA7, 0x31}, {0xA7, 0x00}, {0xA7, 0x18}, {0x7F, 0x00}, {0xE5, 0x1F}, {0xE1, 0x77}, {0xDD, 0x7F}, {0xC2, 0x0E}, {0x00, 0x00} }; static const uint8_t svga_regs[][2] = { {0xFF, 0x01}, {0x12, 0x40}, {0x03, 0x0F}, {0x32, 0x09}, {0x17, 0x11}, {0x18, 0x43}, {0x19, 0x00}, {0x1A, 0x4B}, {0x3D, 0x38}, {0x35, 0xDA}, {0x22, 0x1A}, {0x37, 0xC3}, {0x34, 0xC0}, {0x06, 0x88}, {0x0D, 0x87}, {0x0E, 0x41}, {0x42, 0x03}, {0xFF, 0x00}, {0x05, 0x01}, {0xE0, 0x04}, {0xC0, 0x64}, {0xC1, 0x4B}, {0x8C, 0x00}, {0x53, 0x00}, {0x54, 0x00}, {0x51, 0xC8}, {0x52, 0x96}, {0x55, 0x00}, {0x57, 0x00}, {0x86, 0x3D}, {0x50, 0x80}, {0xD3, 0x80}, {0x05, 0x00}, {0xE0, 0x00}, {0x00, 0x00} }; static const uint8_t jpeg_regs[][2] = { {0xFF, 0x00}, {0xE0, 0x04}, {0xDA, 0x18}, {0xD7, 0x03}, {0xE1, 0x77}, {0x44, 0x0C}, {0xE0, 0x00}, {0x00, 0x00} }; static const uint8_t framesize_low_regs[][2] = { {0xFF, 0x00}, {0x05, 0x01}, {0x5A, 0xA0}, {0x5B, 0x78}, {0x5C, 0x00}, {0xFF, 0x01}, {0x11, 0x83}, {0x00, 0x00} }; static const uint8_t framesize_high_regs[][2] = { {0xFF, 0x00}, {0x05, 0x00}, {0x00, 0x00} }; static const uint8_t quality_regs[][2] = { {0xFF, 0x00}, {0x44, 0x0F}, {0x00, 0x00} }; esp_err_t read_camera_config(uint8_t reg, uint8_t* data){ i2c_cmd_handle_t cmd = i2c_cmd_link_create(); i2c_master_start(cmd); i2c_master_write_byte(cmd, CAMERA_SLAVE_ADDRESS_WRITE, ACK_CHECK_EN); i2c_master_write_byte(cmd, reg, ACK_CHECK_EN); i2c_master_stop(cmd); esp_err_t err = i2c_master_cmd_begin(I2C_CAMERA_NUM, cmd, 10 / portTICK_RATE_MS); i2c_cmd_link_delete(cmd); if(err != ESP_OK){ return err; } cmd = i2c_cmd_link_create(); i2c_master_start(cmd); i2c_master_write_byte(cmd, CAMERA_SLAVE_ADDRESS_READ, ACK_CHECK_EN); i2c_master_read_byte(cmd, data, NACK_VAL); i2c_master_stop(cmd); err = i2c_master_cmd_begin(I2C_CAMERA_NUM, cmd, 10 / portTICK_RATE_MS); i2c_cmd_link_delete(cmd); if(err != ESP_OK){ return err; } return ESP_OK; } esp_err_t write_camera_config(uint8_t reg, uint8_t data){ i2c_cmd_handle_t cmd = i2c_cmd_link_create(); i2c_master_start(cmd); i2c_master_write_byte(cmd, CAMERA_SLAVE_ADDRESS_WRITE, ACK_CHECK_EN); i2c_master_write_byte(cmd, reg, ACK_CHECK_EN); i2c_master_write_byte(cmd, data, ACK_CHECK_EN); i2c_master_stop(cmd); esp_err_t err = i2c_master_cmd_begin(I2C_CAMERA_NUM, cmd, 10 / portTICK_RATE_MS); i2c_cmd_link_delete(cmd); if(err != ESP_OK){ return err; } return ESP_OK; } static esp_err_t event_handler(void *ctx, system_event_t *event){ switch(event->event_id){ case SYSTEM_EVENT_STA_START: esp_wifi_connect(); break; case SYSTEM_EVENT_STA_GOT_IP: xEventGroupSetBits(s_wifi_event_group, CONNECTED_BIT); s_ip_addr = event->event_info.got_ip.ip_info.ip; break; case SYSTEM_EVENT_STA_DISCONNECTED: esp_wifi_connect(); xEventGroupClearBits(s_wifi_event_group, CONNECTED_BIT); break; default: break; } return ESP_OK; } static void initialise_wifi(void){ tcpip_adapter_init(); s_wifi_event_group = xEventGroupCreate(); esp_event_loop_init(event_handler, NULL); wifi_init_config_t cfg = WIFI_INIT_CONFIG_DEFAULT(); esp_wifi_init(&cfg); esp_wifi_set_storage(WIFI_STORAGE_RAM); wifi_config_t wifi_config = { .sta = { .ssid = WIFI_SSID, .password = WIFI_PASSWORD, }, }; esp_wifi_set_mode(WIFI_MODE_STA); esp_wifi_set_config(WIFI_IF_STA, &wifi_config); esp_wifi_start(); esp_wifi_set_ps(WIFI_PS_NONE); ESP_LOGI(TAG, "Connecting to \"%s\"", wifi_config.sta.ssid); xEventGroupWaitBits(s_wifi_event_group, CONNECTED_BIT, false, true, portMAX_DELAY); ESP_LOGI(TAG, "Connected"); } esp_err_t init_camera_clock(camera_config_t* config){ periph_module_enable(PERIPH_LEDC_MODULE); ledc_timer_config_t timer_conf = { .duty_resolution = 1, .freq_hz = config->xclk_freq_hz, .speed_mode = LEDC_HIGH_SPEED_MODE, .timer_num = config->ledc_timer }; esp_err_t err = ledc_timer_config(&timer_conf); if(err != ESP_OK){ ESP_LOGE(TAG, "ledc_timer_config failed, err=%d", err); return err; } ledc_channel_config_t ch_conf = { .channel = config->ledc_channel, .timer_sel = config->ledc_timer, .intr_type = LEDC_INTR_DISABLE, .duty = 1, .speed_mode = LEDC_HIGH_SPEED_MODE, .gpio_num = config->pin_xclk }; err = ledc_channel_config(&ch_conf); if(err != ESP_OK){ ESP_LOGE(TAG, "ledc_channel_config failed, err=%d", err); return err; } return ESP_OK; } void init_i2c(camera_config_t* config){ int i2c_master_port = I2C_NUM_0; i2c_config_t conf; conf.mode = I2C_MODE_MASTER; conf.sda_io_num = config->pin_sscb_sda; conf.sda_pullup_en = GPIO_PULLUP_ENABLE; conf.scl_io_num = config->pin_sscb_scl; conf.scl_pullup_en = GPIO_PULLUP_ENABLE; conf.master.clk_speed = I2C_CAMERA_FREQ_HZ; i2c_param_config(i2c_master_port, &conf); i2c_driver_install(i2c_master_port, conf.mode, I2C_CAMERA_RX_BUF_DISABLE, I2C_CAMERA_TX_BUF_DISABLE, 0); } esp_err_t _http_event_handle(esp_http_client_event_t *evt){ switch(evt->event_id){ case HTTP_EVENT_ERROR: ESP_LOGI(TAG, "HTTP_EVENT_ERROR"); break; case HTTP_EVENT_ON_CONNECTED: ESP_LOGI(TAG, "HTTP_EVENT_ON_CONNECTED"); break; case HTTP_EVENT_HEADER_SENT: ESP_LOGI(TAG, "HTTP_EVENT_HEADER_SENT"); break; case HTTP_EVENT_ON_HEADER: ESP_LOGI(TAG, "HTTP_EVENT_ON_HEADER"); printf("%.*s", evt->data_len, (char*)evt->data); break; case HTTP_EVENT_ON_DATA: ESP_LOGI(TAG, "HTTP_EVENT_ON_DATA, len=%d", evt->data_len); if( ! esp_http_client_is_chunked_response(evt->client)){ printf("%.*s", evt->data_len, (char*)evt->data); } break; case HTTP_EVENT_ON_FINISH: ESP_LOGI(TAG, "HTTP_EVENT_ON_FINISH"); break; case HTTP_EVENT_DISCONNECTED: ESP_LOGI(TAG, "HTTP_EVENT_DISCONNECTED"); break; } return ESP_OK; } static void http_post_task(){ esp_http_client_config_t http_config = { .url = AWS_ENDPOINT, .event_handler = _http_event_handle, .method = HTTP_METHOD_POST, }; unsigned char image0[15000]; char image[15000]; size_t olen; mbedtls_base64_encode(image0, sizeof(image0), &olen, camera_get_fb(), camera_get_data_size()); sprintf(image, "{\"image\":\"%s\"}", image0); const char *post_data = (const char*)image; esp_http_client_handle_t client = esp_http_client_init(&http_config); esp_http_client_set_post_field(client, post_data, strlen(post_data)); esp_http_client_set_header(client, "x-api-key", AWS_API_KEY); esp_http_client_set_header(client, "Content-Type", "application/json"); esp_err_t err = esp_http_client_perform(client); if(err == ESP_OK){ ESP_LOGI(TAG, "Status = %d, content_length = %d", esp_http_client_get_status_code(client), esp_http_client_get_content_length(client)); } esp_http_client_cleanup(client); while(1); } void app_main(){ esp_log_level_set("*", ESP_LOG_VERBOSE); esp_err_t err = nvs_flash_init(); if(err != ESP_OK){ nvs_flash_erase(); nvs_flash_init(); } gpio_install_isr_service(0); camera_config_t camera_config = { .ledc_channel = LEDC_CHANNEL_0, .ledc_timer = LEDC_TIMER_0, .pin_d0 = PIN_D0, .pin_d1 = PIN_D1, .pin_d2 = PIN_D2, .pin_d3 = PIN_D3, .pin_d4 = PIN_D4, .pin_d5 = PIN_D5, .pin_d6 = PIN_D6, .pin_d7 = PIN_D7, .pin_xclk = PIN_XCLK, .pin_pclk = PIN_PCLK, .pin_vsync = PIN_VSYNC, .pin_href = PIN_HREF, .pin_sscb_sda = PIN_SDA, .pin_sscb_scl = PIN_SCL, .pin_reset = PIN_RESET, .xclk_freq_hz = 6000000, .width = 640, .height = 480, }; ESP_LOGE(TAG, "xclk_freq_hz=%d[Hz]", camera_config.xclk_freq_hz); //GPIO設定 gpio_config_t io_conf; io_conf.intr_type = GPIO_PIN_INTR_DISABLE; io_conf.mode = GPIO_MODE_OUTPUT; io_conf.pin_bit_mask = GPIO_OUTPUT_PIN_SEL; io_conf.pull_down_en = 0; io_conf.pull_up_en = 0; gpio_config(&io_conf); //CAMERA クロック出力 init_camera_clock(&camera_config); //I2C 初期化 init_i2c(&camera_config); //CAMERA リセット gpio_set_level(PIN_RESET, 0); vTaskDelay(10 / portTICK_RATE_MS); gpio_set_level(PIN_RESET, 1); vTaskDelay(10 / portTICK_RATE_MS); //CAMERA OV2640確認 uint8_t camera_pid_h; read_camera_config(0x0A, &camera_pid_h); ESP_LOGI(TAG, "camera_pid_h=0x%02X", camera_pid_h); if(camera_pid_h != 0x26){ ESP_LOGE(TAG, "failed, camera_pid_h=%02X", camera_pid_h); return; } //CAMERA システムリセット write_camera_config(0xFF, 0x01); write_camera_config(0x12, 0x80); vTaskDelay(10 / portTICK_RATE_MS); //CAMERA 設定書き込み int i = 0; while(default_regs[i][0]){ write_camera_config(default_regs[i][0], default_regs[i][1]); i++; } i = 0; while(jpeg_regs[i][0]){ write_camera_config(jpeg_regs[i][0], jpeg_regs[i][1]); i++; } i = 0; while(framesize_low_regs[i][0]){ write_camera_config(framesize_low_regs[i][0], framesize_low_regs[i][1]); i++; } i = 0; while(svga_regs[i][0]){ write_camera_config(svga_regs[i][0], svga_regs[i][1]); i++; } i = 0; while(framesize_high_regs[i][0]){ write_camera_config(framesize_high_regs[i][0], framesize_high_regs[i][1]); i++; } i = 0; while(quality_regs[i][0]){ write_camera_config(quality_regs[i][0], quality_regs[i][1]); i++; } //CAMERA その他設定 err = camera_init(&camera_config); if(err != ESP_OK){ ESP_LOGE(TAG, "Camera init failed with error 0x%x", err); return; } //CAMERA wifi設定 initialise_wifi(); //写真撮影 err = camera_run(); if(err != ESP_OK){ ESP_LOGD(TAG, "Camera capture failed with error = %d", err); return; } xTaskCreate(&http_post_task, "http_post_task", 50000, NULL, 5, NULL); vTaskDelay(10000 / portTICK_RATE_MS); }実行
ESP32を実行すると、S3に撮影した画像が保存されます。
参考まとめ
ゼロから作りながら覚えるAPI Gateway環境構築
https://dev.classmethod.jp/cloud/aws/getting-start-api-gateway/lambda (トリガー:APIGateway)
https://blog.apar.jp/web/10804/S3のロールを作成
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/with-s3-example.htmlAPIGateway + Lambdaでbase64変換された画像ファイルをS3に保存する
https://qiita.com/yumakkt/items/1a62d279e81d9f6d0c63[Python]Base64でエンコードされた画像データをデコードする。
https://qiita.com/TsubasaSato/items/908d4f5c241091ecbf9bM5Cameraから画像をPOSTする
https://qiita.com/dinosauria123/items/149535349d98f51bd876

- 投稿日:2019-07-09T20:33:01+09:00
LeafletとFlaskでシンプルなWebGISをつくった話
はじめに
オープンソースのGISにはQGISというド定番・大正義が存在しますが、インストールの手間、投影法など、若干敷居が高いです(初心者にとって)。ウェブ上で公開されている多数のオープンGISデータ(国土数値情報など)の内容をすぐに確認出来る、シンプルなWebGISがあれば便利なんじゃないかと思い開発したのがVanillaGISです。
VanillaGIS
Vanilla GIS
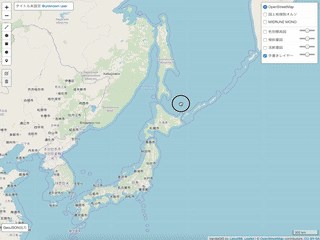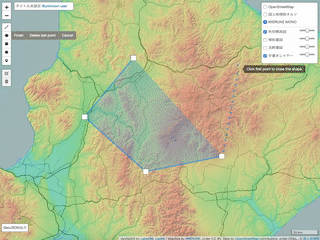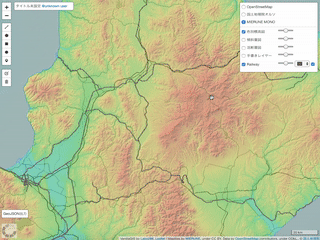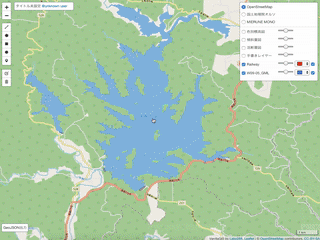
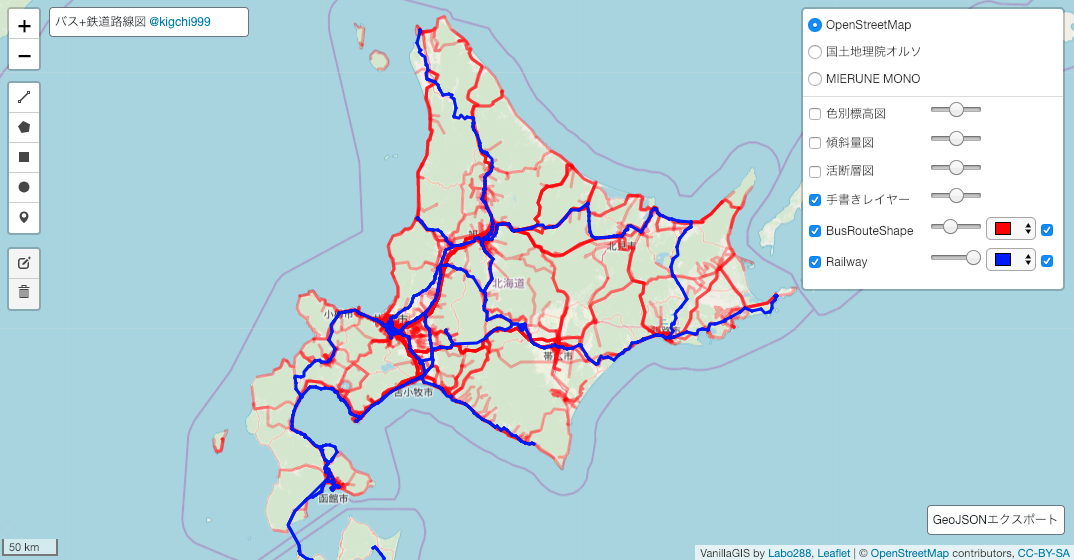
GitHub - Kanahiro/vanilla-gis使用例(北海道のバス・鉄道路線図)
技術概要
主な使用ライブラリ
- Leaflet(JavaScript)
- Flask(Python)
フロントエンド
Leafletと以下の外部プラグインを使用しています。
- Leaflet.Control.Custom
- Leaflet.Control.Draw
- Leaflet.Control.Appearance(自作プラグイン)
バックエンド
- Flask
- SQLite
- SQLAlchemy
技術詳細
バックエンド(Flask)
前提としてRESTful APIを意識し、URLはリソースを参照する形式になっています。
/(ルート)
- GET
地図画面の表示。
- POST
外部ファイル(.zip(シェープファイル), .geojson)を投げるとjsonデータを返します。
.zipファイルの中身はシェープファイル(.shp, .shx, dbf)である必要があります。
pyshpモジュールを利用し、内部的にjsonに変換しています(LeafletはGeoJSONを読み込めるため)。
オープンデータで提供されるシェープファイルの多くはShift-JISエンコーディングですが、UTF-8やその他のエンコードである場合も踏まえ、通常利用されるすべてのエンコードに対応させています。Pythonでデコードする際、エンコードが相違しているとUnicode Errorが発生します。事前に主要なエンコードをリストにしておき、デコードでエラーが発生しなくなるまで各エンコードを順番にトライします(以下の記事で紹介しています)。シェープファイルをGeoJSON形式に変換する - Qiita
/user_map/
- GET
ユーザーが作成し保存したカスタムマップの、レイヤーデータ以外を返します。
- PUT
ユーザーが作成し保存したカスタムマップの、レイヤーデータを返します。
GETで返すと、レイヤーデータが読み込むまでページ全体の読み込みが完了しないため、GETとはレスポンスを分離しています。Fetchにより非同期でレスポンスを取得します。
- POST
ユーザーが作成したカスタムマップをDBに保存します(公開されているアプリでは実装していません)。
/export
これだけnot RESTfulです。
- POST
ユーザーが作成し保存したレイヤーを投げるとjsonデータが返ってきます。
フロントでは、返ってきたデータを.geojsonとしてダウンロードさせます。FlaskとJavaScriptのFetch通信でダウンロードさせる方法 - Qiita
フロントエンド
シングルページアプリケーションで、常にindex.htmlが表示されます。
/user_map/では、index.htmlにDBから取得したデータを渡しています。
Leafletと外部プラグイン(各種Control)を組み合わせる事でGUIを実装しています。使用しているControl
- L.control.scale
純正プラグイン。地図の縮尺を表示。
- L.control.custom
外部プラグイン。htmlを記述する事でかなり自由にGUIを作成可能。
- L.control.draw
外部プラグイン。手書き図形の作図機能。
- L.control.Appearance
自作プラグイン。純正のL.control.layerと、外部プラグインのL.control.Opacityを参考に作成。
ベースマップ切り替え、オーバーレイのオンオフ、レイヤーごとの透過度設定、オーバーレイごとの色設定、オーバーレイの削除。
各レイヤーをひとつのプラグインで管理したくて作成(Chromeで動作確認済み)。
※レイヤーのプロパティにcolorを設定しないと、色設定機能は動作しないなど、まだ未完成です。GitHub - Kanahiro/Leaflet.Control.Appearance
外部ファイル読み込み
ウィンドウにドラッグドロップする事で、ファイルを読み込みます。
対応している形式は.zip(.shp, .shx, .dbfのアーカイブ)か.geojsonです。
すべてFetchでサーバーに投げて、返ってきた.jsonをLeafletマップに追加します。
- 投稿日:2019-07-09T20:14:33+09:00
FlaskとJavaScriptのFetch通信でダウンロードさせる方法
はじめに
Flaskのレスポンスによってファイルをダウンロードさせる方法は以下のリンクのとおり3つあるようです。
https://qiita.com/5zm/items/760000cf63b176be544cしかしながら、Fetch通信によるPOSTに対するresponseにはこれらの方法だけでは対応出来ませんでした。解決した方法を以下に載せておきます。
前提
①Fetch通信で、Flaskサーバに対しPOSTリクエスト
②Flaskサーバでデータを処理し、ファイルを生成、responseヘッダに添付
③Fetchでresponseを受け取って、ダウンロードしたい③で引っかかっていました。単なるinputによるPOSTとは勝手が違うようで、responseはメモリ上で受けるだけです。
解決方法
fetch("/export", { method:"POST", body:formdata //データを添付 }) .then(response => response.blob()) //blobで読み込む .then(blob => { //DOMでダウンロードファイルを添付したアンカー要素を生成 let anchor = document.createElement("a"); anchor.download = String(Date.now()) + '.geojson' anchor.href = window.URL.createObjectURL(blob); //アンカーを発火 anchor.click(); }) .catch(function(err) { console.log("err=" + err); });要はresponseをblobで読み込んでアンカーリンクを踏ませた事にするというわけですね。
- 投稿日:2019-07-09T20:11:28+09:00
シェープファイルをGeoJSON形式に変換する
前提
zip圧縮されたシェープファイル群(.shp, .shx, .dbf)を、GeoJson形式で出力する関数です。
当然、シェープファイル群のファイル名が共通している必要があります。
また、.geojsonファイルを出力するのではなく、メモリ上で処理します。
事前にpyshp(shapefile)が必要になります。コード
import shapefile, io, zipfile #zipファイルからshpファイルを探してファイル名を取得 def find_shpfile_inzip(zipped_shp): zip_infolist = zipped_shp.infolist() for info in zip_infolist: if not info.filename.startswith('__MACOSX/'): #Mac-ZIP対応 if info.filename.endswith('.shp'): return info.filenameまずこのように、zip圧縮されたshapefileのファイル名を取得する関数を定義します。
この関数を用いて#ZIP保存されたSHP群をGEOJSON形式で返す def zipped_shp_to_geojson(zipped_shp): zipped_files = zipfile.ZipFile(zipped_shp) #zipファイルからshpファイルを探してファイル名を取得 shp_name = find_shpfile_inzip(zipped_files)[:-4] #shapefile読み込みと適合判定 try: shp_file_bytes = zipped_files.read(shp_name + '.shp') shx_file_bytes = zipped_files.read(shp_name + '.shx') dbf_file_bytes = zipped_files.read(shp_name + '.dbf') except: print("Imported file was not apropriate Shape-Zip-File.") return None geojson = dict(type="FeatureCollection", features=[]) #pyshpはライブラリ内部でデコードするので、正しいエンコーディングでデコード出来るまでループ for codec in CODECS: try: reader = shapefile.Reader(shp=io.BytesIO(shp_file_bytes), shx=io.BytesIO(shx_file_bytes), dbf=io.BytesIO(dbf_file_bytes),encoding=codec) fields = reader.fields[1:] field_names = [field[0] for field in fields] for sr in reader.shapeRecords(): atr = dict(zip(field_names, sr.record)) geom = sr.shape.__geo_interface__ geojson['features'].append(dict(type="Feature", \ geometry=geom, properties=atr)) print(codec + 'encoding is correct.' ) break except UnicodeDecodeError: print(codec + 'is not suitable for this file.') continue return geojsonこれでgeojsonに変換されます。
エンコーディングについてはコメントのとおりです。pyshpではデフォルトだとUTF-8でデコードされますが、オープンデータで提供されるシェープファイルは、大半がcp932(Windows環境のShift-JIS)です。エンコーディングの指定が間違っているとUnicode errorが発生します。それならcp932を指定してデコードすれば良いのでは、と考えますが、当然ながらUTF-8等にも対応しておきたいところです。したがって、メジャーなエンコーディングのなかから適合するまでデコードし続けるようになっています(このモジュールの冒頭で、CODECS定数を定義してある)。
- 投稿日:2019-07-09T19:40:03+09:00
Pythonでパスワード付きのPDFを、パスワード無しのPDFとして別名保存するスクリプト
はじめに
パスワード付きのPDFは開くたびにパスワードの入力を求められてストレスが溜まります。そのストレスをぶつけたらスクリプトが出来ましたので紹介します。
PythonにおけるPDFの扱い
おそらくPythonでPDFを読み書きしようとすると、まずPyPDF2というライブラリを使う事になると思います。しかしながらパスワードロック解除については、限定された条件のPDFにしか対応していないため、C++のライブラリのqpdfなどとの合わせ技にせざるを得ません。
pikepdf
マイナーなライブラリでpikepdfというものがあり、MPL ライセンスなのでたぶんライセンス表記しておけば怒られないんだろうと思います。このライブラリはqpdfを内蔵?しているようなので、前述のケースとは違い、ライブラリはpikepdfだけで完結します。
pip install pikepdf でインストール可能です。完成品
https://github.com/Kanahiro/PDFUnlocker
こちらにスクリプトの完成品をアップしてあります。こきたないコードですが許してください。
zipファイルの中身はWindows32bit環境で動作する(であろう)実行ファイル一式です。Pyinstallerで作成しました。ほんとは--onefileで使いたかったんですけど、ライブラリ周りでこけたので諦めました。PDFファイル名を「(パスワードの文字列).pdf」として、.exeにドラッグドロップすると、パスワードが解除されたPDFファイルが「decrypt.pdf」として出力されます。おわりに
ライブラリは神、ライブラリを作る人は神の上か!?
ぼくもライブラリかけるようなおとなになりたいと思いました。
- 投稿日:2019-07-09T19:05:41+09:00
【日記】Pythonで上位階層のモジュールを力技によりimportさせた
Pythonは自作のスクリプトでもモジュールとして別ファイルから読み込んで使うことができます。便利ですね。
公式ドキュメント → 6. モジュール (module)基本的には(?)同階層や下位階層に存在するファイルからモジュールを読み込んで使うようです。
しかし、上位階層にあるモジュールを普通に読み込もうとするとエラーになります。
出力されるエラー内容はAttempted relative import beyond top-level packageです。
スクリプト自身が存在する階層を、最上位のルート階層としてそれぞれ解釈するという挙動をしているのが原因のようですね。こういう階層構造があるとする.txt最上位フォルダ ├ 上位フォルダ │ ├ 下位フォルダ │ │ └ C.py │ ├ A.py │ └ B.py └ D.pyA.pyfrom B import hoge # 同階層。出来る from .下位フォルダ.C import foo # 下位階層。出来る from ..D import bar # `..`は上位階層を示すらしい。なのに出来ない。出来ない。出来ない。出来ない。しかし、これは各階層がパッケージ化(?)されていれば上位階層でも読み込めるんだそうです。
階層をパッケージ化するための要件はよくわかっていないんですが、とりあえず__init__.pyという名前の空ファイルを全階層に置いておけば良いという理解で私は解決しました。全階層にinit.pyを置くことで解決させました。絶対これ間違ってるよね(でも解決したから) pic.twitter.com/lfhaPJYmOm
— あつし⛅ヒト?♀️速バラ撒きおじさん (@Anaakikutsushit) July 9, 2019つまりこういうことです.txt最上位フォルダ ├ 上位フォルダ │ ├ 下位フォルダ │ │ ├ __init__.py # 追加 │ │ └ C.py │ ├ __init__.py # 追加 │ ├ A.py │ └ B.py ├ __init__.py # 追加 └ D.pyウッソだろお前wwwwって目を疑いたくなるような光景ですが、事実これで上手くいったので、間違いということはないみたいです(明らかに最善とも思えませんが)。ビックリです。
このように__init__.pyさえ置いておけば、先ほどのA.pyの記述のままで上位階層のモジュールも読むことができるようになります。ホントは同階層か下層に配置してキレイになるようなパッケージの設計をすべきなんでしょうけど、今日のところはとりあえずこれで。
- 投稿日:2019-07-09T19:05:41+09:00
【日記】Pythonで上位階層のモジュールを力技によりimportさせたい
Pythonは自作のスクリプトでもモジュールとして別ファイルから読み込んで使うことができます。便利ですね。
公式ドキュメント → 6. モジュール (module)基本的には(?)同階層や下位階層に存在するファイルからモジュールを読み込んで使うようです。
しかし、上位階層にあるモジュールを普通に読み込もうとするとエラーになります。
出力されるエラー内容はAttempted relative import beyond top-level packageです。
スクリプト自身が存在する階層を、最上位のルート階層としてそれぞれ解釈するという挙動をしているのが原因のようですね。こういう階層構造があるとする.txt最上位フォルダ ├ 上位フォルダ │ ├ 下位フォルダ │ │ └ C.py │ ├ A.py │ └ B.py └ D.pyA.pyfrom B import hoge # 同階層。出来る from .下位フォルダ.C import foo # 下位階層。出来る from ..D import bar # `..`は上位階層を示すらしい。なのに出来ない。出来ない。出来ない。出来ない。しかし、これは各階層がパッケージ化(?)されていれば上位階層でも読み込めるんだそうです。
階層をパッケージ化するための要件はよくわかっていないんですが、とりあえず__init__.pyという名前の空ファイルを全階層に置いておけば良いという理解で私は解決しました。全階層にinit.pyを置くことで解決させました。絶対これ間違ってるよね(でも解決したから) pic.twitter.com/lfhaPJYmOm
— あつし⛅ヒト?♀️速バラ撒きおじさん (@Anaakikutsushit) July 9, 2019つまりこういうことです.txt最上位フォルダ ├ 上位フォルダ │ ├ 下位フォルダ │ │ ├ __init__.py # 追加 │ │ └ C.py │ ├ __init__.py # 追加 │ ├ A.py │ └ B.py ├ __init__.py # 追加 └ D.pyウッソだろお前wwwwって目を疑いたくなるような光景ですが、事実これで上手くいったので
……って書こうとしたらうまく行ってませんでした。とてもつらい。いや、やっぱり上手くいきました。う~~ん??????
上手くいったときは、最上位階層でターミナルを開いて、py -m スクリプト.pyの形式で実行しました。この辺り関係あるかも。とまあ、最後よく分かんなくなっちゃいましたけど、このように
__init__.pyさえ置いておけば、先ほどのA.pyの記述のままで上位階層のモジュールも読むことができるようになります。なるみたいなんです。ホントは同階層か下層に配置してキレイになるようなパッケージの設計をすべきなんでしょうけど、今日のところはとりあえずこれで。
- 投稿日:2019-07-09T18:29:54+09:00
venvを使ってLambdaをデプロイするまでの手順
手順
仮想環境をセット
venvを有効化することで、pipのインストール先が指定した環境にインストールされるようになる。
$ python -m venv /opt/ここに環境名 $ source /opt/ここに環境名/bin/activate $ cd /var/www/lambda/ここに環境名 $ pip install -r requirements.txt$ pip install requests -t ./ $ zip -r zip_file ./*aws lambda create-function \ --region ap-northeast-1 \ --function-name function-name \ --zip-file fileb://{Path}xxx.zip \ --role arn:aws:iam::XXXXX:role/XXXXX \ --handler lambda_function.lambda_handler \ --runtime python3.7 \ --profile xxxxx\ --environment Variables="{VariableA=xxxx,VariableB=xxxxx}"仮想環境を解除
$ deactivateその他
venvで有効化する前にグローバルでインストールしたライブラリは、仮想環境に切り替えたあとも共有で使える。
なので、共有で使いたいライブラリはグローバルにインストールして、共有で使いたくないものは仮想環境に切り替えてインストールする。
- 投稿日:2019-07-09T18:09:56+09:00
【機械学習】学習プラットフォーム10選!
はじめに
最新の「機械学習の学習プラットフォーム」をさっくりとまとめてみました。
新しい情報は随時更新していきます。目次(「機械学習」とAnd検索した時のヒット数順)
- Aidemy (7,430,000 件)
- AI academy (717,000 件)
- Amazon Machine Learning University (271,000 件)
- Elements of AI (141,000 件)
- Learn with Google AI (137,000 件)
- メディカルAIコース (135,000 件)
- Grow with Google (97,200 件)
- Chainerチュートリアル (65,000 件)
- Coursera (48,200 件)
- Codexa (26,100 件)
それぞれの特徴
1. Aidemy (7,430,000 件)
- 圧倒的な知名度
- 有料プランが多い(無料プランでできることは少ない)
- デザインが評価されている(Good Design Award 2018受賞)
- 「理論よりもまずは実践」スタイル
- Pythonもちゃんと教えてくれる
- 環境構築不要
2. AI academy (717,000 件)
- 教材が豊富(200種類以上のオリジナルテキストを提供)
- クイズ形式のシステムあり
- 目的別にコースがわかれている
- DjangoやJuliaや量子コンピュータなど分野が結構幅広い
3. Amazon Machine Learning University (271,000 件)
- AWSアカウントの登録が必要
- AWS認定書などのシステムあり
- 英語(一部)
4. Elements of AI (141,000 件)
- フィンランドのヘルシンキ大学発のプラットフォーム
- 英語(全て)
- 実践よりも知識ベース
- クイズあり
5. Learn with Google AI (137,000 件)
- 実践よりも知識ベース
- Google Colaboratoryとの連携あり
- 英語(全て)
6. メディカルAIコース (135,000 件)
- 医療で人工知能技術を使う際に最低限必要な知識や実践方法を学ぶことができる(らしい)
- ソースコード配布あり (.ipynb形式)
- 前提知識が必要(PythonやGoogle Colaboratory)
- MRI画像のセグメンテーションや血液の顕微鏡画像からの細胞検出などの実践的な内容あり
7. Grow with Google (97,200 件)
- 目的別に分かれている (個人向け / ビジネス向け / 学生・教育者向け / スタートアップ向け / デベロッパー向け)
- 機械学習に留まらず、様々なスキルについて扱っている
8. Chainerチュートリアル (65,000 件)
- Chainerだけではなく、機械学習全体のチュートリアル
- 数学をしっかりと扱っている
- Google Colaboratoryとの連携あり
9. Coursera (48,200 件)
- ビデオ講義あり
- テストのシステムあり
- 修了書のシステムあり
- コースが豊富
- 英語(ほぼ全て)
10. Codexa (26,100 件)
- 無料プランで手軽にできる(有料プランもあり)
- 初学者向け
その他(Pythonプラットフォーム)
理論抜きにして、まずPythonを使えるようになりたい方は、以下のサイトもおすすめかもです。
Progate Python学習コース
- おそらく一番易しいPythonの教材
- スライド形式
- 機械学習についてはそこまで深く掘っていない
ドットインストール Python3入門
- 老舗のプラットフォーム
- 動画形式
- Pythonのプログラミングについては結構深く扱っている
Paiza Learning
- 動画形式
- jupyter notebookで進行
その他(東大発プラットフォーム)
DL4US
- 東大の松尾豊さんがgithubに公開
- エンジニア対象の深層学習の入門教材
- Kerasを使用
終わりに
コンテンツの紹介は以上です。
もしもこれら以外に「こんなコンテンツもあるよ」という情報などがもしありましたら、ぜひコメントしてくださると嬉しいです。





- 投稿日:2019-07-09T17:56:12+09:00
__pycache__とはいったいなんなのか?
__pycache__とはいったいなんなのか?
開発中に幾度となく目にします。
知らぬ間に追加されていて、消してよいのか悪いのかわからず放って置くものの、目障りでしょうがない。一体誰なんだお前は!
そもそも読み方わからない問題
pycache?なんだそれ?
pyはわかるけどせめてぱっと見で意味が通る名前にしてくれよ~しかし私はただの馬鹿だったようです。
キャッシュ
よく使うデータへのアクセスを速くするために、より高速な記憶装置に一時的に保存する仕組み。
ASCII.jpデジタル用語辞典より
プログラマなら当然知っているべき単語でした。
今まで「パイケイク」と読んでいましたが「パイキャッシュ」が正解であるようですね…
__pycache__が何してるかわからない問題
もうgoogle翻訳にかけた時点でほとんどわかっているのですが、続けましょう。
pythonファイルを実行したとき、コンパイルされたモジュールが__pycache__の中pycファイルにキャッシュされます。
これを残しておけばコンパイルを経ずにプログラムを実行することができるので実行が速くなります。
プログラムを変更するたびに書き換えられます。
消しても問題ありませんが、実行が少し遅くなります。__pycache__君、帰っていいよ
頑張ってくれてはいるんだけどね。
たまにおせっかいだなぁ…なんて。どうしても邪魔だと思う方へ
__pycache__を消す方法1(コマンドで指定)
$ python -hを実行すると方法を教えてくれます。
-B : don't write .py[co] files on import; also PYTHONDONTWRITEBYTECODE=x例えば、hoge.pyを実行するときにキャッシュを作られたくなければ
$ python -B hoge.pyこのように-Bを付けることで解決します。
__pycache__を消す方法2(環境変数)
環境変数の変数名をPYTHONDONTWRITEBYTECODEに、値を適当に設定することでキャッシュを作るのをやめるようです。
値は1が無難でしょう。実際にやったことはない。
__pycache__を消す方法3(プログラムで指定する)
import sys sys.dont_write_bytecode = Trueこのように書けばキャッシュを作らなくなります。
- 投稿日:2019-07-09T16:15:51+09:00
Pandasによる欠損値の出し方
Pandasによる欠損値の出し方
PandasでCSVファイルを読み取り、欠損値の合計を出して、結果を保存する方法
pandas_to_missing#pandasのインポート import pandas as pd #pandasデータフレームに読み込む。注意点はエクセル2010はutf-8では、保存できなくて、shift-jisなので、encoding="SHIFT-JIS"を入れること。 data = pd.read_csv("dataset_****.csv",encoding="SHIFT-JIS") #データ構造のプリント print(data.shape) #欠損値のある行の数をカウントする print(data.isnull().sum()) #カウントしたデータを、リストに入れる data_insul_sum = data.isnull().sum() #リストをpandasデータフレームに入れる data_missing = pd.DataFrame(data=data_insul_sum) #データフレームを保存する data_missing.to_csv("missing_****.csv")
- 投稿日:2019-07-09T16:08:37+09:00
QuantXアルゴリズム作成者に向けて
はじめに
QuantXではアルゴ開発者に向けて様々なコードと解説を用意しています。
アルゴリズムに使える指標、利用できるデータセットはQuantXのドキュメントに記載されています。ドキュメントには、サンプルコードとそれについての解説もあります。
また、まずはテンプレートの値を動かして、色々触ってみたい人に対しては、アルゴリズム作成の時に出てくる、テンプレートコードとそのノートを参考にすることが出来ます。
さらに、実際作っていく上で、ヘルプからいくつかの代表的なサンプルコードを参考にすることもできます。QuantXが用意しているコードと解説について、詳しくはこちらをご覧ください。
python初心者に向けて
QuantXはpythonを使用してアルゴリズムを作成します。そのため、pythonとデータ分析によく用いられるpandasやtalibを勉強することで、株売買のアルゴリズムを作ることが出来ます。
以下の記事はpandasについての解説記事です。これを読むことでも、QuantXでよく使用するpandasを学ぶことが出来ます。
・QuantX Factory、pandasチュートリアル1
・QuantX Factory、pandasチュートリアル2
・QuantX Factory、pandasチュートリアル3QuantX Factoryを初めて使う人に向けて
QuantXはpythonを使用して、株売買のアルゴリズムを作成することが出来ますが、pythonとは異なるいくつかの注意点があります。
また、2019年5月末に0.0.1から0.0.5へエンジンの改装が行われました。0.0.5エンジンは0.0.1からいくつか改変が行われているので、注意が必要です。(本記事のQiitaリンクの中には0.0.5エンジンに対応していないものがいくつかあります。今後編集予定ですが、注意をよろしくお願いいたします。)特殊ルールまとめ
・【QuantX】売買注文order関数の種類
・QuantXでこの変数なんだよって思ったものリスト
・QuantXでのデバッグについて
・QuantXでNaNをカウント
・QuantX SDK チョットワカル になりたいQunatX0.0.5エンジンについて
・QuantX maron0.0.5 に移行する
・QuantXで指値注文基本的なアルゴリズム
移動平均、BBANDS、AROONOSC、HILBERT TRANSFER についてはヘルプにサンプルコードとノートに解説がありますが、より、詳しいものやこれらを発展させたものは、以下のQiita記事にあります。これらを参考にすることも出来ます。
・ブル・ベアファンド自動裁定 〜はじめの一歩〜
・QuantX FactoryでMACDのアルゴリズムを作ってみよう。
・RSIっていう指標、長期短期で使ってみたもっと詳しく知りたい方へ
Smart Trade社では、インターン生が日々学んだことをQiitaにまとめています。これらの記事はこちらとこちらにまとめてありますので、より詳しく知りたい方はご覧ください。
勉強会のお知らせ
Smart Trade社では、水曜日に勉強会を開催しています。詳しい日程、勉強会の内容についてはconnpassをご覧ください。
- 投稿日:2019-07-09T16:06:39+09:00
[Blender2.8]blender.orgのBMesh Operators (bmesh.ops)のサンプルを試す。
ドキュメントへのリンク
2019年7月時点でのblender.orgドキュメントのサンプルを読んでいく。
https://docs.blender.org/api/blender2.8/bmesh.ops.htmlコードから生成されるのは下記。
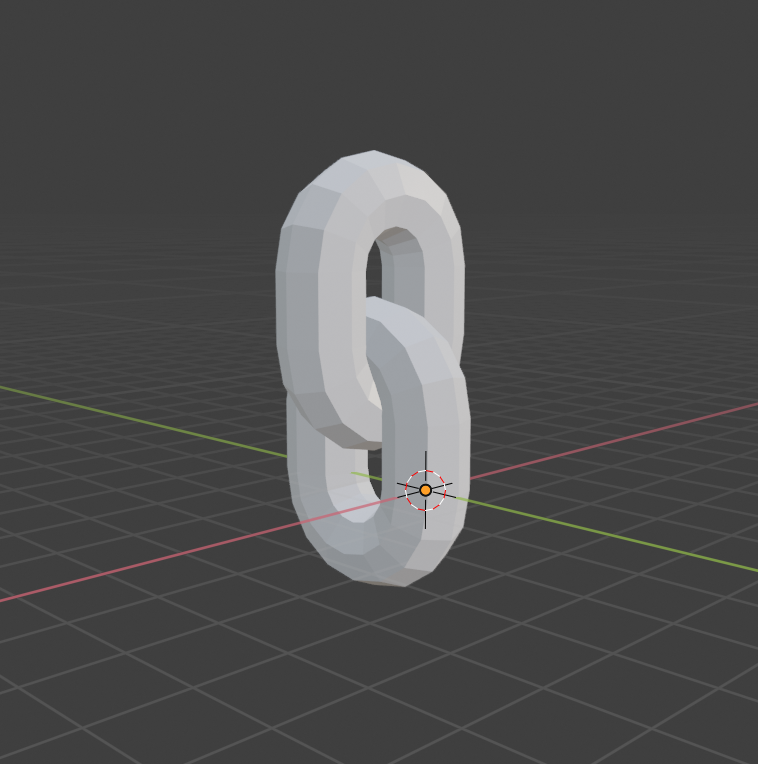
コード全体
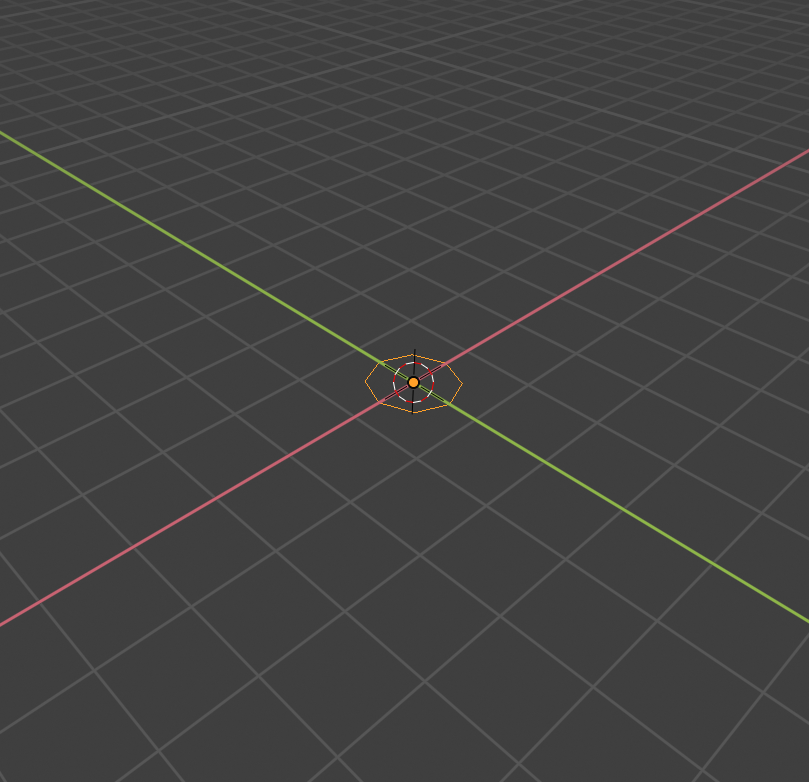
# This script uses bmesh operators to make 2 links of a chain. import bpy import bmesh import math import mathutils # Make a new BMesh bm = bmesh.new() # Add a circle XXX, should return all geometry created, not just verts. bmesh.ops.create_circle( bm, cap_ends=False, radius=0.2, segments=8) # Spin and deal with geometry on side 'a' edges_start_a = bm.edges[:] geom_start_a = bm.verts[:] + edges_start_a ret = bmesh.ops.spin( bm, geom=geom_start_a, angle=math.radians(180.0), steps=8, axis=(1.0, 0.0, 0.0), cent=(0.0, 1.0, 0.0)) edges_end_a = [ele for ele in ret["geom_last"] if isinstance(ele, bmesh.types.BMEdge)] del ret # Extrude and create geometry on side 'b' ret = bmesh.ops.extrude_edge_only( bm, edges=edges_start_a) geom_extrude_mid = ret["geom"] del ret # Collect the edges to spin XXX, 'extrude_edge_only' could return this. verts_extrude_b = [ele for ele in geom_extrude_mid if isinstance(ele, bmesh.types.BMVert)] edges_extrude_b = [ele for ele in geom_extrude_mid if isinstance(ele, bmesh.types.BMEdge) and ele.is_boundary] bmesh.ops.translate( bm, verts=verts_extrude_b, vec=(0.0, 0.0, 1.0)) # Create the circle on side 'b' ret = bmesh.ops.spin( bm, geom=verts_extrude_b + edges_extrude_b, angle=-math.radians(180.0), steps=8, axis=(1.0, 0.0, 0.0), cent=(0.0, 1.0, 1.0)) edges_end_b = [ele for ele in ret["geom_last"] if isinstance(ele, bmesh.types.BMEdge)] del ret # Bridge the resulting edge loops of both spins 'a & b' bmesh.ops.bridge_loops( bm, edges=edges_end_a + edges_end_b) # Now we have made a links of the chain, make a copy and rotate it # (so this looks something like a chain) ret = bmesh.ops.duplicate( bm, geom=bm.verts[:] + bm.edges[:] + bm.faces[:]) geom_dupe = ret["geom"] verts_dupe = [ele for ele in geom_dupe if isinstance(ele, bmesh.types.BMVert)] del ret # position the new link bmesh.ops.translate( bm, verts=verts_dupe, vec=(0.0, 0.0, 2.0)) bmesh.ops.rotate( bm, verts=verts_dupe, cent=(0.0, 1.0, 0.0), matrix=mathutils.Matrix.Rotation(math.radians(90.0), 3, 'Z')) # Done with creating the mesh, simply link it into the scene so we can see it # Finish up, write the bmesh into a new mesh me = bpy.data.meshes.new("Mesh") bm.to_mesh(me) bm.free() # Add the mesh to the scene obj = bpy.data.objects.new("Object", me) bpy.context.collection.objects.link(obj) # Select and make active bpy.context.view_layer.objects.active = obj obj.select_set(True)円の生成
# Make a new BMesh bm = bmesh.new() # Add a circle XXX, should return all geometry created, not just verts. bmesh.ops.create_circle( bm, cap_ends=False, radius=0.2, segments=8)ops.xxxに、生成したBMesh(ここではbm)を渡して、BMeshを更新していくのが基本。上記の画像では円が実際に画面に表示されているが、ObjectとMeshを生成して、それをシーンにリンクする必要がある。コードの最後の方の処理。
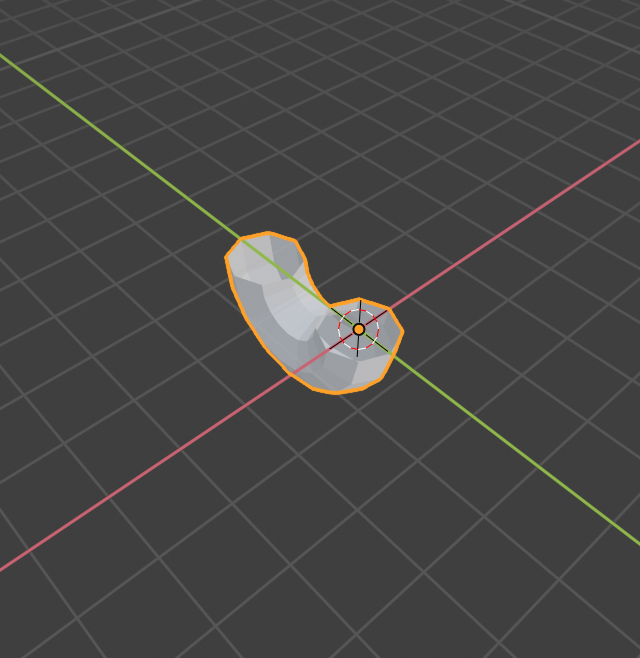
円からチューブの生成
# Spin and deal with geometry on side 'a' edges_start_a = bm.edges[:] geom_start_a = bm.verts[:] + edges_start_a ret = bmesh.ops.spin( bm, geom=geom_start_a, angle=math.radians(180.0), steps=8, axis=(1.0, 0.0, 0.0), cent=(0.0, 1.0, 0.0)) edges_end_a = [ele for ele in ret["geom_last"] if isinstance(ele, bmesh.types.BMEdge)] del ret円を回転して、半周のチューブを生成。頂点の配列と、エッジの配列をひとつの配列につなげて、それをジオメトリのデータとして渡すという特徴的な処理があるが、エッジの配列だけをgeomに渡しても頂点とエッジが生成され、エラーも特に出てこない。bmesh.ops.spinから返ってくるのは、geom_lastのみをキーに持つdictionary。
最初に作ったサークルを引き伸ばす
Blenderで、最初に作ったサークルを選択して、E > G する処理。# Extrude and create geometry on side 'b' ret = bmesh.ops.extrude_edge_only( bm, edges=edges_start_a) geom_extrude_mid = ret["geom"] del ret伸ばす処理。Blenderで、頂点を選択してEを押した直後の状態。
# Collect the edges to spin XXX, 'extrude_edge_only' could return this. verts_extrude_b = [ele for ele in geom_extrude_mid if isinstance(ele, bmesh.types.BMVert)] edges_extrude_b = [ele for ele in geom_extrude_mid if isinstance(ele, bmesh.types.BMEdge) and ele.is_boundary] bmesh.ops.translate( bm, verts=verts_extrude_b, vec=(0.0, 0.0, 1.0))引き伸ばした頂点を実際にZ軸方向に1.0移動する。
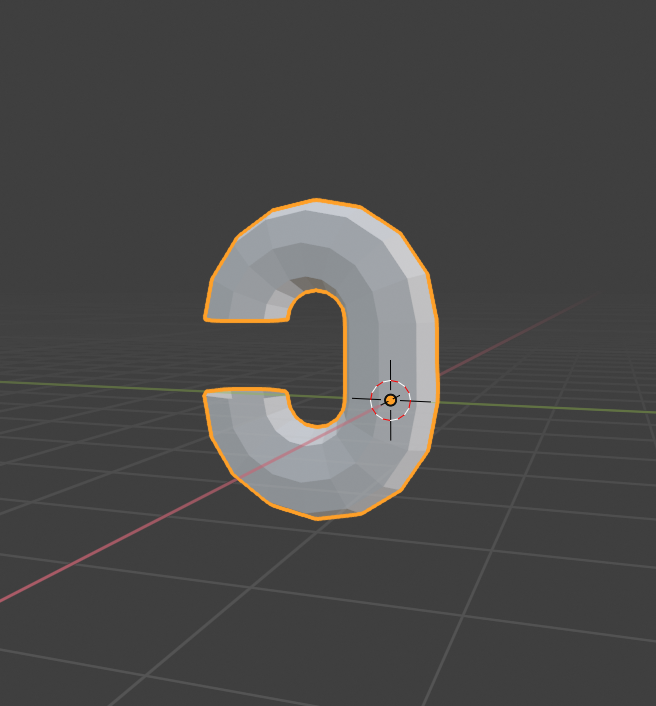
反対側にチューブを半周させる
# Create the circle on side 'b' ret = bmesh.ops.spin( bm, geom=verts_extrude_b + edges_extrude_b, angle=-math.radians(180.0), steps=8, axis=(1.0, 0.0, 0.0), cent=(0.0, 1.0, 1.0)) edges_end_b = [ele for ele in ret["geom_last"] if isinstance(ele, bmesh.types.BMEdge)] del ret伸ばした先のエッジからスピン。
くっつける
# Bridge the resulting edge loops of both spins 'a & b' bmesh.ops.bridge_loops( bm, edges=edges_end_a + edges_end_b)edges_end_aは、下の半周チューブを生成したときに格納している。これで1つ目が完成。
輪っかを複製する
# Now we have made a links of the chain, make a copy and rotate it # (so this looks something like a chain) ret = bmesh.ops.duplicate( bm, geom=bm.verts[:] + bm.edges[:] + bm.faces[:]) geom_dupe = ret["geom"] verts_dupe = [ele for ele in geom_dupe if isinstance(ele, bmesh.types.BMVert)] del ret輪っかを複製して、verts_dupeに、複製された頂点群を格納。
複製したメッシュを移動
# position the new link bmesh.ops.translate( bm, verts=verts_dupe, vec=(0.0, 0.0, 2.0)) bmesh.ops.rotate( bm, verts=verts_dupe, cent=(0.0, 1.0, 0.0), matrix=mathutils.Matrix.Rotation(math.radians(90.0), 3, 'Z'))オブジェクトとメッシュを生成し、シーンに追加して表示する
me = bpy.data.meshes.new("Mesh") bm.to_mesh(me) bm.free() # Add the mesh to the scene obj = bpy.data.objects.new("Object", me) bpy.context.collection.objects.link(obj) # Select and make active bpy.context.view_layer.objects.active = obj obj.select_set(True)これまでに制作したBMeshからMeshを作り出し、そのMeshを持つオブジェクトを生成する。
最後の2行は、オブジェクトを選択する処理。感想
BMeshそのものは参照渡しで更新。返り値で、端っこの部分・複製されたものだけのように都合が良いものを返してくれるのが素敵。