- 投稿日:2019-05-30T20:53:47+09:00
SQL/RDB のことを全然わかっていなかった 1 年前の自分に教えてあげたいこと
はじめに
『SQL 実践入門 高速でわかりやすいクエリの書き方』を読んだので、学んだことの整理・備忘のために個人的に「これもっと早く知っておきたかった」と思ったことをまとめました。1年前の私のような人の目に止まって、SQL/RDB について学ぶきっかけにもなれば幸いです。
(2019/5/31 現在、書きかけ項目多数)
1. 統計情報は大事
- SQL において、どこにあるデータをどのように探すかという手続き (データアクセスの方法) は一切現れない
- クエリ評価エンジン (の中のオプティマイザ) が、以下のような 統計情報 をもとに、最適なデータアクセスの方法(実行計画)を決める
- 各テーブルのレコード数
- 各テーブルの列数と列のサイズ
- 列内の一意な値の個数(カーディナリティ)
- 列内の値のヒストグラム
- 列内にある
NULLの数- インデックス情報
- この実行計画が、SQL のパフォーマンスを決める
Note:
実行計画は、実際のテーブルの内容ではなく、統計情報にもとづいて作成 される。
よって、テーブルに対してデータの挿入/更新/削除がおこなわれたのに、統計情報が更新されていないと、オプティマイザは古い情報をもとに実行計画を作ろうとしてしまう。適切な実行計画が作成されるようにするには?
テーブルのデータが大きく更新されたら、統計情報もセットで更新する。
(WIP) 2. 結合のアルゴリズム
- Nested Loops
- Hash
- Sort Merge
3. メモリ領域の種類
DBMS は、パフォーマンス向上のため (ディスクへの I/O を回避するため)、データの一部をメモリに乗せている。
データキャッシュ
ディスクにあるデータの一部を保持するためのメモリ領域。もし、 SELECT したいデータがすべてこの中に収まっていれば非常に高速なレスポンスを期待できる。
ログバッファ
SQL の実行と実際のディスクへの更新処理とを非同期におこなうために、更新情報を溜めておく領域。
ワーキングメモリ
ソートやハッシュなどの処理に利用する作業領域。ワーキングメモリが溢れると、ディスク上の一時領域が使用されることになり、レスポンスは悪くなる。
Note:
「データがメモリ内に収まっているときは非常に高速なのに、メモリから溢れた瞬間に一気に遅くなる」という極端な劣化が突然起きてしまうところが厄介。(WIP) 4. 「困難の分割」は必ずしも正義ではない
- サブクエリは困難を分割できる便利な道具だが、結合を増やしパフォーマンスを悪化させることもある
- サブクエリ + 結合 → ウインドウ関数で代替
(WIP) 5. SQL の主役は「文」ではなく「式」
SELECT,FROM,WHERE,GROUP BY,HAVING,ODER BY,... に記載するのは、すべて 式。
列名だけ:たまたま演算子がない式、定数だけ:たまたま変数も演算子もない式参考文献
- 投稿日:2019-05-30T20:53:47+09:00
SQL/DBMS のことを全然わかっていなかった 1 年前の自分に教えてあげたいこと
はじめに
『SQL 実践入門 高速でわかりやすいクエリの書き方』を読んだので、学んだことの整理・備忘のために個人的に「これもっと早く知っておきたかった」と思ったことをまとめました。1年前の私のような人の目に止まって、SQL/DBMS について学ぶきっかけにもなれば幸いです。
1. 統計情報は大事
- SQL において、どこにあるデータをどのように探すかという手続き (データアクセスの方法) は一切現れない
- クエリ評価エンジン (の中のオプティマイザ) が、以下のような 統計情報 をもとに、最適なデータアクセスの方法(実行計画)を決める
- 各テーブルのレコード数
- 各テーブルの列数と列のサイズ
- 列内の一意な値の個数(カーディナリティ)
- 列内の値のヒストグラム
- 列内にある
NULLの数- インデックス情報
- この実行計画が、SQL のパフォーマンスを決める
Note:
実行計画は、実際のテーブルの内容ではなく、統計情報にもとづいて作成 される。
よって、テーブルに対してデータの挿入/更新/削除がおこなわれたのに、統計情報が更新されていないと、オプティマイザは古い情報をもとに実行計画を作ろうとしてしまう。適切な実行計画が作成されるようにするには?
テーブルのデータが大きく更新されたら、統計情報もセットで更新する。
2. 結合のアルゴリズム
オプティマイザが選択可能な結合アルゴリズムは大きく以下の 3 つ。 (順に頻繁に選択される)
- Nested Loops
- 利点
- 「小さな駆動表」 + 「内部表のインデックス」の条件下で高速
- メモリやディスクの消費が少なく、OLTP (Online Transaction Processing) に適している
- 非等値結合でも使用できる
- 欠点
- 大規模テーブル同士の結合に不向き
- 内部表のインデックスが使えなかったり、内部表の選択率が高かったりすると低速
- Hash
- 利点
- 大規模テーブル同士の結合に適している
- 欠点
- メモリ消費が大きく、 OLTP に不向き
- メモリ不足の場合は TEMP 落ちが発生する
- 等値結合のみ で使用できる
- Sort Merge
- 利点
- 大規模テーブル同士の結合に適している
- 非等値結合でも使用できる
- 欠点
- メモリ消費が大きく、 OLTP に不向き
- メモリ不足の場合は TEMP 落ちが発生する
- データが ソート済でなければ あまり効率的でない
結合アルゴリズムの選択方針
- 小テーブル - 小テーブル: 何を選んでも大差ない
- 小テーブル - 大テーブル: Nested Loops
- 小テーブルを駆動表
- 大テーブル (内部表) にインデックス
- 内部表の対象行が多い場合は、駆動表とひっくり返すか Hash を検討する
- 大テーブル - 大テーブル: まずは Hash 。 結合キーがソート済なら Sort Merge
結合アルゴリズム (実行計画) の制御方法
そもそも結合アルゴリズムの選択はオプティマイザがおこなうのでは?
→ ヒント句 でユーザが制御できる (どこまで制御できるかは DBMS による)実行計画をユーザが制御することによるリスク
データ量やカーディナリティは運用を続けていく中で変化するため、ある時点において最適な実行計画が、別の時点においてはそうでなくなることがある。
3. メモリ領域の種類
DBMS は、パフォーマンス向上のため (ディスクへの I/O を回避するため)、データの一部をメモリに乗せている。
データキャッシュ
ディスクにあるデータの一部を保持するためのメモリ領域。もし、 SELECT したいデータがすべてこの中に収まっていれば非常に高速なレスポンスを期待できる。
ログバッファ
SQL の実行と実際のディスクへの更新処理とを非同期におこなうために、更新情報を溜めておく領域。
ワーキングメモリ
ソートやハッシュなどの処理に利用する作業領域。ワーキングメモリが溢れると、ディスク上の一時領域が使用されることになり、レスポンスは悪くなる。
Note:
「データがメモリ内に収まっているときは非常に高速なのに、メモリから溢れた瞬間に一気に遅くなる」という極端な劣化が突然起きてしまうところが厄介。4. 「困難の分割」は必ずしも正義ではない
- サブクエリは困難を分割できる便利な道具だが、パフォーマンスを悪化させることもある
- サブクエリ + 結合 → ウインドウ関数で代替
そもそもテーブル/ビュー/サブクエリの違いとは
- テーブル: 永続的かつデータを保持する
- ビュー: 永続的だがデータは保持しないため、アクセスのたびに SELECT 文が実行される
- サブクエリ: 非永続的なのでスコープが SQL の実行中に限られる
サブクエリの問題点
サブクエリの問題点は、サブクエリが実体的なデータを持っていないことに起因する。
- サブクエリの計算コストが上乗せされる (テーブルと比べて)
- データの I/O コストがかかる
- 計算したデータがメモリ上に収まればこのオーバーヘッドは小さい
- メモリに収まらなければ、ファイルに書き出す (TEMP 落ち)
- 最適化を受けられない
- 制約インデックスなどのメタ情報が一切ないため、オプティマイザがクエリを解析するために必要な情報が、サブクエリからは得られない
(例題)サブクエリ + 結合をウインドウ関数で代替
- 顧客の購入明細を記録する、以下のような購入明細テーブルがあるとする
seq列は、顧客の古い購入ほど小さな値が振られている- 顧客ごとに最小の
seqの金額を求める (= 一番古い購入履歴を見つける)
customer_id seq price A 1 500 A 2 1000 A 3 700 B 5 100 B 6 5000 B 7 300 B 9 200 B 12 1000 C 10 600 C 20 100 C 45 200 C 70 50 D 3 2000 サブクエリを使った場合
顧客ごとに最小の
seqの値を保持するサブクエリ (R2) を作り、それと本体とを結合する。sub_querySELECT R1.customer_id, R1.seq, R1.price FROM Receipts R1 INNER JOIN ( SELECT customer_id, MIN(seq) AS min_seq FROM Receipts GROUP BY customer_id ) R2 ON R1.customer_id = R2.customer_id AND R1.seq = R2.min_seqパフォーマンス上の欠点
- サブクエリは多くの場合、(メモリにせよディスクにせよ)一時的な領域に確保されるため、オーバーヘッドが生じる
- サブクエリはインデックスや制約の情報を持っていないので、最適化が受けられない
- 結合を必要とするためコストが高く、かつ実行計画変動のリスクが発生する
- Receipts テーブルへのスキャンが 2 回必要となる
ウインドウ関数を使った場合
ROW_NUMBER()で行に通番を振り、常に最小値を 1 にすることで、seq列の最小値が不確定という問題に対処。window_functionSELECT customer_id, seq, price FROM (SELECT customer_id, seq, price, ROW_NUMBER() OVER (PARTITION BY customer_id ORDER BY seq) AS row_seq FROM Receipts) WORK WHERE WORK.row_seq = 15. SQL の主役は「文」ではなく「式」
SELECT,FROM,WHERE,GROUP BY,HAVING,ODER BY,... に記載するのは、すべて 式。
列名だけ:たまたま演算子がない式、定数だけ:たまたま変数も演算子もない式たとえば、 WHERE 句に CASE 式 を与えることもできる。
case_expressionSELECT ... FROM ... WHERE CASE WHEN a = 1 THEN value1 WHEN a = 2 THEN value2 WHEN a = 3 THEN value3 ELSE NULL = 'VALUE'6. スカラサブクエリ
- 戻り値が単一の値になるクエリのこと
- 戻り値が単一なので、 SELECT 句や CASE 式の引数、 UPDATE 文の SET の右辺などに記述できる
SELECT E.emp_id, E.emp_name, E.dept_id, (SELECT D.dept_name FROM Departments D WHERE E.dept_id = D.dept_id) AS dept_name FROM Employees E参考文献
- 投稿日:2019-05-30T18:52:00+09:00
SQLだけで√nの小数部100桁まで算出する(nは自然数)
やりたいこと
√2(1.41421356...)のような小数部を100桁までSQLだけを使って算出する。
動機
複雑なSQLを書いたり読んだりする際のスピードを上げたく、
いい感じのアルゴリズム問題を探していたら開平法の存在を知り、実装してみたくなった次第。あと、SQLはプログラミング言語ではない(だって、順次・分岐・反復の処理ができないから)と主張する層に
このくらいまではできるぞと示せる記事があってもいいんじゃないかという気持ち。※業務用ではないです。
動作環境
PostgreSQL(
PostgreSQL 10.5, compiled by Visual C++ build 1800, 64-bit)を使用。
※基本的に標準SQLにある程度対応しているDBであれば多少記述の仕方が違うだけで実装は可能です。
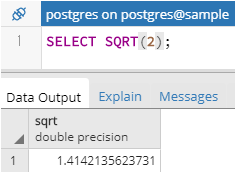
※MySQL5.7以下だとWITH句がないですが、ユーザ定義変数を上手いこと使えば実装できると思います。ちなみに、標準で用意されているSQRT関数だと結果が
double precision型になるので、小数部は13桁までしか表示されないようです。
開平法について
√2を小数表現に変換する計算方法として開平法があるので、今回はそちらのアルゴリズムをそのままSQLに変換していきます。
開平法については 開平法のやり方と原理 | 高校数学の美しい物語 に既にわかりやすい説明があるのでそちらをご参照ください。
実装したクエリ
以下、実装したクエリです。
SQLですがテーブル作成はせずに1回のクエリ実行で算出できるようにしました。※なお、√1.44などのパターンは気力の問題で対応してません。
※eosr.digit > -100の部分を10000にすれば1万桁まで算出できました。自分の環境では30秒程度かかるようです。
SQLによる開平法の実装
WITH RECURSIVE -- 引数関連 ---------------------------------------------- -- 開平対象となる数値を指定 args(input_val) AS ( VALUES (2), (144), (9801) ), -- 以降の算出処理用に引数を変換 formatted_args(input_val, val_char, val_len) AS ( SELECT input_val, input_val::VARCHAR, CHAR_LENGTH(input_val::VARCHAR) FROM args ), -- 開平対象値を右から2桁区切りで分割 two_digits_unordered(input_val, splitted_args_val, digit, val_char, val_len) AS ( SELECT input_val, SUBSTRING(val_char FROM val_len - 1 FOR 2), 2, val_char, val_len FROM formatted_args UNION ALL SELECT input_val, SUBSTRING(val_char FROM val_len - digit - 1 FOR 2), digit + 2, val_char, val_len FROM two_digits_unordered WHERE digit < val_len ), two_digits(input_val, splitted_args_val, digit) AS ( SELECT input_val, splitted_args_val, digit / 2 FROM two_digits_unordered ORDER BY input_val, digit DESC ), -- 定数テーブル ---------------------------------------------- -- 数値(0~9)を定義 numbers(val) AS ( VALUES (0), (1), (2), (3), (4), (5), (6), (7), (8), (9) ), -- 1以上100未満の平方を定義 squares_lt_100(root, square) AS ( SELECT 1, POWER(1, 2)::INTEGER UNION ALL SELECT root + 1, POWER(root + 1, 2)::INTEGER FROM squares_lt_100 WHERE POWER(root + 1, 2) < 100 ), -- 開平法ロジック -------------------------------------------- extraction_of_square_root(input_val, ans, digit, summation, difference) AS ( SELECT td.input_val, s1.root::VARCHAR, (CHAR_LENGTH(td.input_val::VARCHAR) - 1) / 2, (s1.root + s1.root)::NUMERIC, ( (td.splitted_args_val::INTEGER - POWER(s1.root, 2))::VARCHAR || COALESCE(( SELECT splitted_args_val FROM two_digits AS td3 WHERE td.input_val = td3.input_val AND td3.digit = td.digit - 1 ), '00') )::NUMERIC FROM ( SELECT td1.input_val, td1.splitted_args_val::INTEGER, td1.digit FROM two_digits AS td1 WHERE td1.digit = ( SELECT MAX(td2.digit) FROM two_digits AS td2 WHERE td1.input_val = td2.input_val ) ) AS td JOIN squares_lt_100 AS s1 ON s1.square <= td.splitted_args_val AND s1.root = ( SELECT MAX(root) FROM squares_lt_100 AS s2 WHERE s2.square <= td.splitted_args_val ) UNION ALL SELECT eosr.input_val, num1.val::VARCHAR, eosr.digit - 1, (eosr.summation::VARCHAR || num1.val::VARCHAR)::NUMERIC + num1.val, ( (eosr.difference - (eosr.summation::VARCHAR || num1.val::VARCHAR)::NUMERIC * num1.val)::VARCHAR || COALESCE(( SELECT td.splitted_args_val FROM two_digits AS td WHERE eosr.input_val = td.input_val AND td.digit = eosr.digit - 1 ), '00') )::NUMERIC FROM extraction_of_square_root AS eosr JOIN numbers AS num1 ON (eosr.summation::VARCHAR || num1.val::VARCHAR)::NUMERIC * num1.val <= eosr.difference AND num1.val = ( SELECT MAX(num2.val) FROM numbers AS num2 WHERE (eosr.summation::VARCHAR || num2.val::VARCHAR)::NUMERIC * num2.val <= eosr.difference ) WHERE eosr.difference <> 0 AND eosr.digit > -100 ), -- 数字の整形処理 ------------------------------------------------------- plus_ans(input_val, val) AS ( SELECT input_val, ARRAY_TO_STRING(ARRAY_AGG(plus.ans ORDER BY plus.digit DESC), '') FROM extraction_of_square_root AS plus WHERE plus.digit >= 0 GROUP BY input_val ), minus_ans(input_val, val) AS ( SELECT input_val, '.' || ARRAY_TO_STRING(ARRAY_AGG(minus.ans ORDER BY minus.digit DESC), '') FROM extraction_of_square_root AS minus WHERE minus.digit < 0 GROUP BY input_val ) -- 開平値を出力 ------------------------------------------------------------- SELECT input_val AS square, plus.val || COALESCE(minus.val, '') AS square_root FROM plus_ans AS plus LEFT JOIN minus_ans AS minus USING (input_val) ;解説
以降、上記のクエリの解説を簡単に書いておきます。
WITH句の使い方について
今回のように一回のクエリ実行で値を算出したい場合、WITH句でLinuxのパイプのように処理を繋げて書いていくと
いい感じでクエリが分割できるため便利です。WITH句で作成する一時的なテーブルの書き方を共通テーブル式といいますが、
今回、大きく2通りの使い方をしています。WITH句の使い方1:再帰WITH句によるループ処理
再帰クエリあまり書く機会ないと最初は読みづらいですが、以下のように解釈すると入りやすいのではないかと思ってます。
WITH RECURSIVE -- ループ処理を実装したい場合 `共通テーブル式名`('列名1', ...) AS ( ['初期化処理'] -- 最初だけ実行 UNION ALL -- 他の集合演算子でも可能ですが、ループ処理したい場合はだいたいこれ ['ループ処理'] -- WHERE句の条件がFALSEになるまで実行。(FALSEになった最初の行は結果として含まれる点に注意!) )WITH句の使い方2:共通テーブル式で定数を定義
今回のよううに0~9の数値を単純に定数として持っておきたい場合、
共通テーブル式で定義しておくと以降のクエリがよりシンプルになりやすいです。共通テーブル式で定義した値は定義した後で変更することができないので、文字通り定数扱いになります。
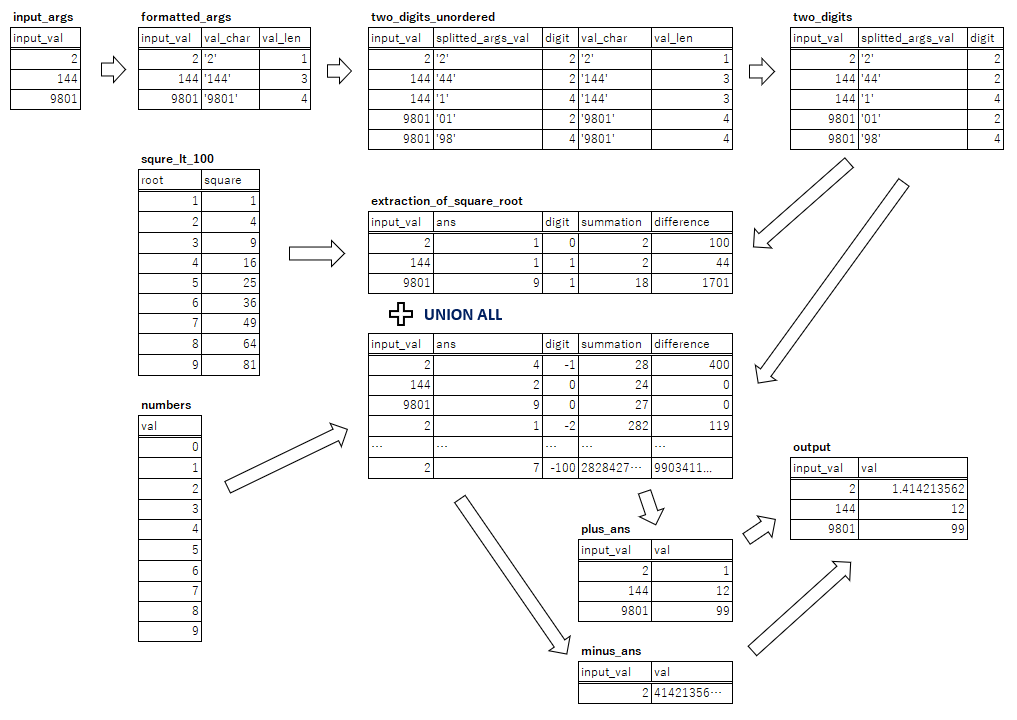
WITH `共通テーブル式名`('列名1', ...) AS ( ['定数テーブル'] )各共通テーブル式の依存関係と処理の流れ
今回定義した共通テーブル式は全部で9つあるわけですが、
それぞれの依存関係は図にすると以下のようになっています。
こう見ると100行以上のSQLの概要が掴めやすいですね。
WITH句の共通テーブル式でLinuxのパイプみたいに前の処理結果を受けてを繰り返して処理していく場合、
いくつ書いてもこの図のような閉路のない依存関係を構成するようになります。
- 投稿日:2019-05-30T09:02:47+09:00
【BigQuery】正規表現関数を使ってテキストマッチングをしてみた
概要
便利な正規表現関数を利用してテキストマッチングを行ってみたいと思います。
記事は下記の流れとなっています。
1. 正規表現とは
2. データ紹介
3. 正規表現関数を使った実践
4. BigQueryで使える正規表現関数について※BigQueryのSQL言語設定は、標準です。
正規表現とは
以下Wikipediaからの抜粋です。
https://ja.wikipedia.org/wiki/%E6%AD%A3%E8%A6%8F%E8%A1%A8%E7%8F%BE正規表現(せいきひょうげん、英: regular expression)とは、文字列の集合を一つの文字列で表現する方法の一つである。
ここで言うところの"文字列の集合"を不特定多数の人のメールアドレスと読みかえて、"一つの文字列で表現"をドメインと読みかえてみるとわかりやすいかもしれません。メールアドレスの構成は
[アカウント名] @ [ドメイン名] となっていますよね。例えば携帯会社A(ドメイン名:a.com)を利用している人だけを集計の対象としたい場合に、「@の前はなんでもよくて、ドメイン名はa.comの人 」なんていうざっくりした指定表現をできるのが正規表現です。よく使う正規表現を下記に記載します。
集計対象に応じて、これらの正規表現を組み合わせて使います。
正規表現 意味 . 改行文字以外の任意の1文字 * 直前の1文字の0回以上の繰り返しに一致 ^ 行頭 $ 行末 + 直前の文字の1個以上の連続 ? 直前の文字の0または1文字にマッチ \d 0~9の数字 pattern1|pattern2 pattern1あるいはpattern2のいずれかにマッチ \ .や*をリテラルで扱いたいとき (例: \. \*) これらの記号を適切に組み合わせて、目的の正規表現を作るには、練習を要すると思われます。
簡単なWITH文を書いて、挙動を確認するのがおすすめです。データ紹介
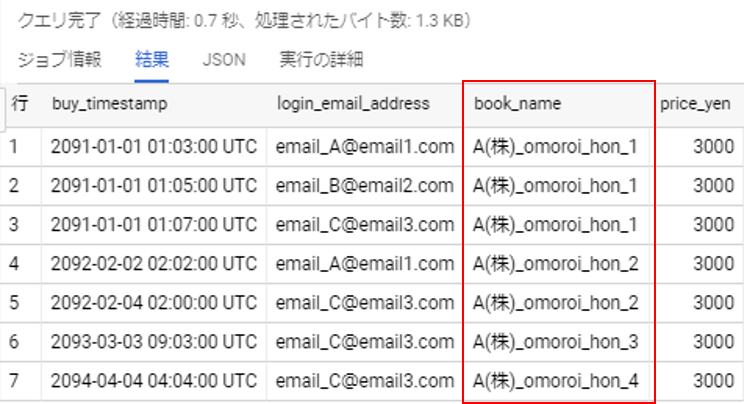
テーブル:book_app.book_buy_log
buy_timestamp login_email_address book_name price_yen 2091/1/1 1:03 email_A@email1.com A(株)_omoroi_hon_1 3000 2092/2/2 2:02 email_A@email1.com A(株)_omoroi_hon_2 3000 2092/2/2 2:12 email_A@email1.com COGRAPH(株)_tanosii_hon_1 2000 2093/3/3 3:30 email_A@email1.com COGRAPH(株)_tanosii_hon_2 2000 2093/3/3 4:00 email_A@email1.com (有)A_tumaranai_hon_1 9999 2091/1/1 1:04 email_B@email2.com B(株)_kawaii_hon 55000 2091/1/1 1:05 email_B@email2.com A(株)_omoroi_hon_1 3000 2092/1/1 1:05 email_B@email2.com (有)A_tumaranai_hon_1 9999 2091/1/1 1:07 email_C@email3.com A(株)_omoroi_hon_1 3000 2092/2/4 2:00 email_C@email3.com A(株)_omoroi_hon_2 3000 2093/3/3 9:03 email_C@email3.com A(株)_omoroi_hon_3 3000 2094/4/4 4:04 email_C@email3.com A(株)_omoroi_hon_4 3000 2091/1/1 1:17 email_C@email3.com COGRAPH(株)_tanosii_hon_1 2000 2092/2/2 2:05 email_C@email3.com COGRAPH(株)_tanosii_hon_2 2000 2093/3/3 3:33 email_C@email3.com COGRAPH(株)_tanosii_hon_3 2000 2094/4/4 4:14 email_C@email3.com COGRAPH(株)_tanosii_hon_4 2000 2091/9/1 1:27 email_D@email4.com (有)A_tumaranai_hon_1 9999 2092/8/2 2:02 email_C@email3.com (株)A_tumaranai_hon_98 99999 2091/10/1 1:17 email_C@email3.com B(株)_kawaii_hon 55000 2092/2/2 2:02 email_D@email4.com (有)A_tumaranai_hon_1 9999 2093/3/3 3:03 email_E@email5.com (有)A_tumaranai_hon_1 9999 スキーマ詳細は以下の通りです。
正規表現関数を使った実践
早速ですが、正規表現関数を使って集計をしてみましょう。
ここで使うのはREGEXP_REPLACE関数です。REGEXP_REPLACE(value, regex, replacement)
正規表現 regex と一致する value のすべての部分文字列が replacement で置き換えられて、STRING が返されます。集計内容
メールアドレスからユーザー特定し、本のタイトル毎に購入金額を集計します。
すこし曖昧な指示になっているので、下記に例を示します、、、テーブル:例
buy_timestamp login_email_address book_name price_yen 2091/1/1 1:03 email_A@email1.com A(株)_omoroi_hon_1 3000 2092/2/2 2:02 email_A@email1.com A(株)_omoroi_hon_2 3000 上の場合は、アカウント名がemail_Aで一致していて、本のタイトルがomoroi_honで一致しているので合計は6000円。といったように集計するものとします。タイトルの前についている社名と、後ろについている数字は、無視するものとします。例えば、結果は下の通りとなります。
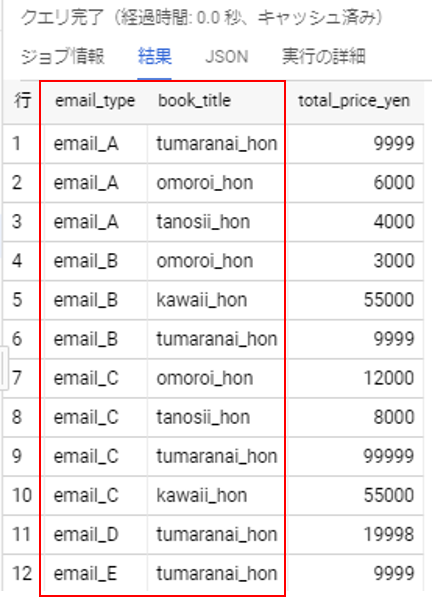
出力テーブル:例
email_type book_title total_price_yen email_A omoroi_hon 6000 上記の集計内容を、正規表現関数を利用して集計してみましょう。
BigQuery 正規表現関数を使って集計するWITH with_1 AS ( SELECT REGEXP_REPLACE(login_email_address, '@.+', '') AS email_type , REGEXP_REPLACE(book_name, r'_\d*$', '') AS book_title , price_yen FROM book_app.book_buy_log ) ( SELECT email_type , REGEXP_REPLACE(book_title, '^.+?_', '') AS book_title , SUM(price_yen) AS total_price_yen FROM with_1 GROUP BY email_type , REGEXP_REPLACE(book_title, '^.+?_', '') ) ORDER BY email_type;出力は以下の通りです。
結果
しっかりと結果が返ってきました。
ここでは、REGEXP_REPLACE関数を使って集計しました。
なお正規表現関数を使わず、ごり押しで集計した場合のクエリは以下の通りです。BigQuery ごり押しで集計するWITH with_1 AS ( SELECT buy_timestamp , login_email_address , SUBSTR( login_email_address , 1 , LENGTH(login_email_address) - 11 ) AS email_type , book_name , CASE WHEN SUBSTR(book_name, 5, 1) = '_' THEN SUBSTR(book_name, 6, LENGTH(book_name)) ELSE SUBSTR(book_name, 12, LENGTH(book_name) - 11) END AS book_title , price_yen FROM book_app.book_buy_log ) , with_2 AS ( SELECT buy_timestamp , login_email_address , email_type , book_name , CASE WHEN SUBSTR(book_title, LENGTH(book_title) - 2, 3) = 'hon' THEN book_title WHEN SUBSTR(book_title, LENGTH(book_title) - 4, 3) = 'hon' THEN SUBSTR(book_title, 1, LENGTH(book_title) - 2) ELSE SUBSTR(book_title, 1, LENGTH(book_title) - 3) END AS book_title , price_yen FROM with_1 ) SELECT email_type , book_title , SUM(price_yen) AS total_price_yen FROM with_2 GROUP BY email_type , book_title ORDER BY email_type;冗長で、汎用性が低いコードになってしまいました、、、
コードを書くのも大変ですし、メールアドレスや本のタイトル名の構成が変わると、正しい集計結果が出なくなる可能性があります。BigQueryで使える正規表現関数
実践から、REGEXP_REPLACE関数がとても便利な関数であることが分かったと思います。
BigQueryで使うことができる正規表現関数には、他にREGEXP_CONTAINS、REGEXP_EXTRACT、REGEXP_EXTRACT_ALLが用意されているようです。こちらについても説明をしたいと思います。REGEXP_CONTAINS関数使用例
REGEXP_CONTAINS(value, regex)
value が正規表現 regex に対して部分一致である場合、TRUE を返します。上の説明を読んだ感じ、WHERE句内でLIKEの代わりに使用できる関数といったところでしょうか。
A(株)から出版されているものに絞って抽出します。実行するコードは次の通りです。BigQuery REGEXP_CONTAINSを使って集計するSELECT * FROM book_app.book_buy_log WHERE REGEXP_CONTAINS(book_name, '^A\\(株\\).*');正規表現でA(株)から始まるものを表現しています。
正規表現にマッチしたものが抽出できていますね。
REGEXP_EXTRACT関数使用例
REGEXP_EXTRACT(value, regex)
正規表現 regex と一致する value 内の最初の部分文字列を返します。
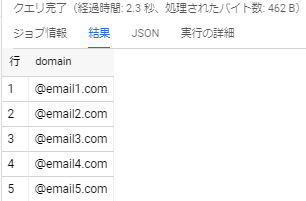
一致がない場合、NULL を返します。今度は、正規表現に一致した箇所を抜き出してくる感じですね。
例えば、メールアドレスのドメインの種類が知りたいとします。その際のコードは以下の通りです。BigQuery REGEXP_EXTRACTを使って集計するSELECT DISTINCT REGEXP_EXTRACT(login_email_address, '@.*') AS domain FROM book_app.book_buy_log ORDER BY domain;問題なく結果が出力されました。
REGEXP_EXTRACT_ALL関数使用例
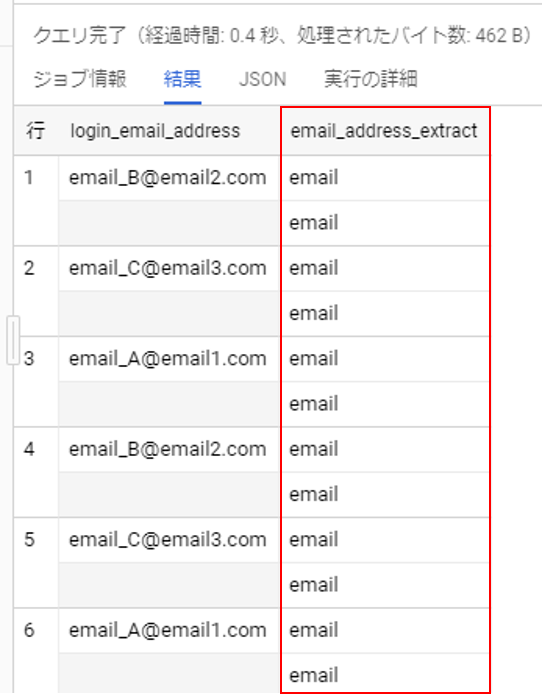
REGEXP_EXTRACT_ALL(value, regex)
正規表現 value と一致する regex のすべての部分文字列の配列を返します。REGEXP_EXTRACTと似た関数ですが、異なる点としては、正規表現に一致した箇所をすべて抜き出してくる点です。こちらも実際に使ってみましょう。
BigQuery REGEXP_EXTRACT_ALLを使って集計するSELECT login_email_address , REGEXP_EXTRACT_ALL(login_email_address, 'email') AS email_address_extract FROM book_app.book_buy_log;結果の抜粋はこちらです。
一つの行に対して、emailが二つずつ一致し、それらが抽出されました。
このような形で表現されるのですね。まとめ
以上、BigQueryにて正規表現関数を使いテキストマッチングを行いました。
SUBSTRやCASE文を使って、がちゃがちゃとコードを書くのに比較して、コード量が減り、シンプルになるだけでなく、汎用性が高くなりましたね。便利な関数をしっかり使っていきましょう。参考サイト
https://ja.wikipedia.org/wiki/%E6%AD%A3%E8%A6%8F%E8%A1%A8%E7%8F%BE
https://cloud.google.com/bigquery/docs/reference/standard-sql/functions-and-operators?hl=ja#regexp_contains
https://github.com/google/re2/wiki/Syntax