- 投稿日:2019-05-30T23:51:29+09:00
pandas複合検索
はじめに:
pandasにおける,複数単語+&複合検索,該当行抽出.
・メモ代わり.
・ざっと検索したが,類似の良い関数は見当たらなかった.
・わかりやすさ優先,例外処理最低限.
・分割し重ねれば複雑にもできる.
・問題がある点は認める.コード:
def searchplsund(de,pls,pcol,und,ucol): flag = 0 t = [] for i in de.index: for lc in pcol: for pw in pls: if str(de[lc][i]).find(str(pw))>-1: print(i,lc,pw) flag = 1 if flag == 1: t.append(True) else: t.append(False) flag = 0 u = [] for i in de[t].index: if ucol==[''] or und==['']: pass else: for lc in ucol: for uw in und: if str(de[lc][i]).find(str(uw))>-1: print(i,lc,uw) flag = 1 if flag == 1: u.append(True) else: u.append(False) flag = 0 if u==[]: return de[t] else: return de[t][u] import pandas as pd de = pd.DataFrame([ [1,1,'male',80.0,30.0,'S'], [1,2,'female',4.0,39.0,'S'], [0,2,'female',24.0,13.0,'S'], [0,2,'male',37.0,26.0,'S'], [0,3,'female',11.0,31.275,'S'], [1,3,'female',13.0,7.2292,'C'], [0,3,'male',22.0,7.25,'S']], columns = ['Survived','Pclass','Sex','Age','Fare','Embarked'] ) pls = [4,3] pcol = ['Age', 'Pclass'] und = ['S'] ucol = ['Embarked'] #df,+検索単語リストと列名リスト,&検索単語リストと列名リスト searchplsund(de, pls,pcol, und,ucol)元:
Survived Pclass Sex Age Fare Embarked
0 1 1 male 80.0 30.0000 S
1 1 2 female 4.0 39.0000 S
2 0 2 female 24.0 13.0000 S
3 0 2 male 37.0 26.0000 S
4 0 3 female 11.0 31.2750 S
5 1 3 female 13.0 7.2292 C
6 0 3 male 22.0 7.2500 S過程:
+検索
1 Age 4
2 Age 4
3 Age 3
4 Pclass 3
5 Age 3
5 Pclass 3
6 Pclass 3&+検索
1 Embarked S
2 Embarked S
3 Embarked S
4 Embarked S
6 Embarked S結果:
Survived Pclass Sex Age Fare Embarked
1 1 2 female 4.0 39.000 S
2 0 2 female 24.0 13.000 S
3 0 2 male 37.0 26.000 S
4 0 3 female 11.0 31.275 S
6 0 3 male 22.0 7.250 S*前投稿の母集団内からの特許抽出などに.
*.str.containsを使うと短くできる.*pandasの出力をMarkdown形式できれいに表示するにはどうすれば良いのだろう?
- 投稿日:2019-05-30T23:46:16+09:00
scratch assay2
画像読み込みから面積算出までの関数を定義
scratch.pyimport cv2 import math import numpy as np import os def analyze (path, image): #入力画像(カラー)の読み込み img_src = cv2.imread(path + "/" +image, 1) #エッジ検出、canny法 img_dst = cv2.Canny(img_src, 30, 100) #出力画像 = cv2.Canny(img_src, 閾値1, 閾値2) #平滑化 i=0 while i < 13: img_dst2 = cv2.GaussianBlur(img_dst, (11, 11), 1) i = i + 1 #膨張収縮処理 #一回膨張処理 img_dst3 = cv2.dilate(img_dst2, element8, iterations = 1) #5回収縮処理 i = 0 while i < 5: img_dst3 = cv2.erode(img_dst3, element8, iterations = 1) i = i + 1 #5回膨張処理 i=0 while i < 5: img_dst3 = cv2.dilate(img_dst3, element8, iterations = 1) i = i + 1 #2値化 thresh = 60 ret, img_dst4 = cv2.threshold(img_dst3, thresh, 255, cv2.THRESH_BINARY) #出力画像 = cv2.thresh(img_src, 閾値, 最大値、閾値処理の種類) #処理の種類(THRESH_BINARY_INV、THRESH_TRUNC、THRESH_TOZERO、THRESH_TOZERO_INV) #反転 img_dst5 = 255 - img_dst4 #面積を取得 whitearea = cv2.countNonZero(img_dst5) return whitearea #輪郭座標取得 contours = cv2.findContours(img_dst5, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)[1] #取得した輪郭を描く analyzed_img = cv2.drawContours(img_src, contours, -1, (0,255,0), 3) cv2.imwrite(path2 + "/" + "analyzed_" + image , analyzed_img)バッチ処理
フォルダの中の画像を解析して、エクセルにまとめます。
batch.py#ファイル名取得 () path = "/Users/hoge" #hoge:画像が入っているフォルダ path2 = "/Users/hogehoge" #hogehoge:輪郭を合成した画像、および面積集計エクセルファイルを保存するフォルダ files = os.listdir(path) #面積取得 areas = [] for i in files: areas.append(analyze(path, i)) #処理した画像の名前(.jpgの前)取得 samples = [] for i in files: samples.append(i.replace('.jpg', '')) #エクセルに出力 import pandas as pd import openpyxl df = pd.DataFrame(areas, index=samples, columns=["Area"]) df.to_excel(path2 + "/" + "Result.xlsx")最後に
改良したいけど、もうrdkitとかdeepchemの方に心が移ってしまいました。
NGSの解析のためにR言語も学ばねば!いろいろ勉強する時間が欲しいですね。
- 投稿日:2019-05-30T23:24:39+09:00
scratch assay1
スクラッチアッセイの画像の解析をpythonでしました。
jupyter上で作業しました。
各ステップで処理された結果の画像は以下のコマンドで表示しながら進めました。画像の表示コードについて
以下のコードを各処理後に実行して、都度画像の確認を行いました。
scratch.py#データ解読 (hoge:各処理で返されるオブジェクト) decoded_bytes = cv2.imencode(".png", hoge)[1].tobytes() #Image関数 Image(decoded_bytes)①ライブラリのインポート
scratch.pyimport cv2 import math import numpy as np②画像の読み込み
scratch.py(hoge:画像が入ってるフォルダ名) img_src = cv2.imread("C:/Users/hoge/image.jpg", 1) #入力画像(カラー)の読み込み #img_src = cv2.imread("C:/Users/hoge/image.jpg", 0) #入力画像(白黒)の読み込み
③エッジを検出 (canny法)
scratch.pyimg_dst = cv2.Canny(img_src, 30, 100) #出力画像 = cv2.Canny(img_src, 閾値1, 閾値2)
④画像をぼかす (平滑化、blur)
とりあえず13回繰り返します
scratch.pyi=0 while i < 13: img_dst2 = cv2.GaussianBlur(img_dst, (11, 11), 1) i = i + 1
⑤収縮処理 (erode) と膨張処理 (dilate)
scratch.py#8近傍指定の行列を作成 element8 = np.array([[1, 1, 1], [1, 1, 1], [1, 1, 1]], np.uint8) #一回膨張処理 img_dst3 = cv2.dilate(img_dst2, element8, iterations = 1) #5回収縮処理 i = 0 while i < 5: img_dst3 = cv2.erode(img_dst3, element8, iterations = 1) i = i + 1 #5回膨張処理 i=0 while i < 5: img_dst3 = cv2.dilate(img_dst3, element8, iterations = 1) i = i + 1
⑥2値化
scratch.pythresh = 60 ret, img_dst4 = cv2.threshold(img_dst3, thresh, 255, cv2.THRESH_BINARY) #出力画像 = cv2.thresh(img_src, 閾値, 最大値、閾値処理の種類) #処理の種類(THRESH_BINARY_INV、THRESH_TRUNC、THRESH_TOZERO、THRESH_TOZERO_INV)
⑦白黒反転
img_dst5 = 255 - img_dst4
⑧面積算出パターン1
白い部分のピクセルをカウントするパターン
scratch.pycv2.countNonZero(img_dst5)結果
9895⑨面積算出パターン2
輪郭を検出して、囲まれた部分の面積を全部計算して (すべてのエリアのラベルもされる) 合計または最大部分の面積を返すパターン
scratch.py#findContours(入力画像、輪郭抽出モード、輪郭の近似手法) #輪郭抽出モード (RETR_EXTERNAL, RETR_LIST, RETR_CCOMP, RETR_TREE) #輪郭の近似手法 (CHAIN_APPROX_NONE, CHAIN_APPROX_SIMPLE) contours = cv2.findContours(img_dst5, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)[0] #算出された全部の面積の数字をリストに放り込んで最大値(max)、または合計(sum)を返す area = [] for i in contours: area.append(cv2.contourArea(i)) #sum(area) max(area)結果
9625.5⑩面積算出パターン2で検出した輪郭をオリジナルの読み込み画像に合成
面積の算出対象エリアが正しいか確認したかった。
scratch.pyanalyzed_img = cv2.drawContours(img_src, contours, -1, (0,255,0), 3)
最後に
スクラッチされたエリアに細胞が島を形成したとき(囲いの中に囲いができたとき)、今回の面積算出法では対処できないので、何かしら対応しなければいけないかと思います。もう考えるの疲れたのでこの辺で終わります。
次回、フォルダ内に入った画像全部を処理するバッチ処理のコードを書きます。







- 投稿日:2019-05-30T22:03:47+09:00
Pythonで簡単なShellを実行するだけの関数
- 投稿日:2019-05-30T21:17:38+09:00
キチンとEMアルゴリズム
tl;dr
- EMアルゴリズムの知ったかぶり期間も長くなってしまったのでキチンとまとめたかった.
- 実装もさることながら, 数学的な理解をちゃんとしたかった.
- 混合正規分布の最尤推定問題で実装を行なった.
EMアルゴリズムを使うモチベーション
一般に観測データから混合分布に含まれる未知パラメタを推定する問題の基本的な解法は最尤推定である.
しかし, 式が複雑な形をしている場合, 解析的な (偏微分して0とおく) 方法で解を求めるのは困難である. そのような場合, 反復過程で尤度を減少させていく手法 (教師なし学習) をとる.EMアルゴリズムは教師なし学習のひとつである.EMアルゴリズムの振舞い
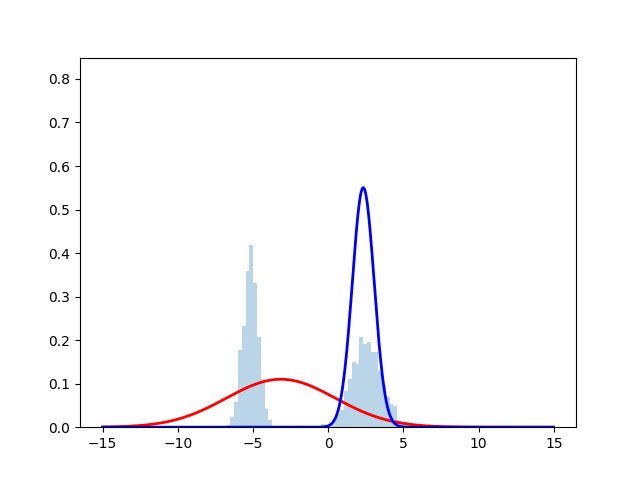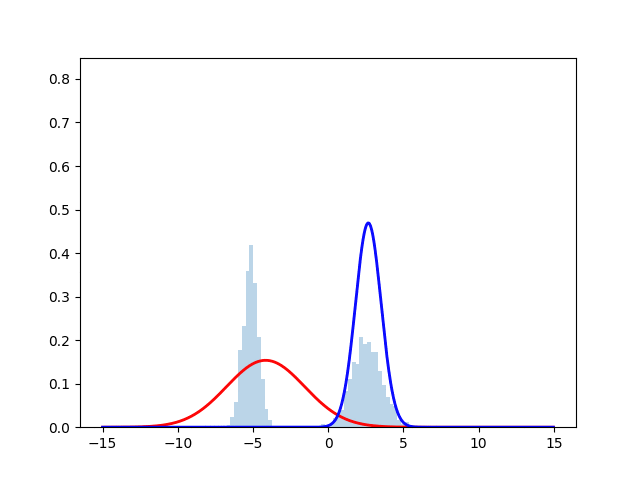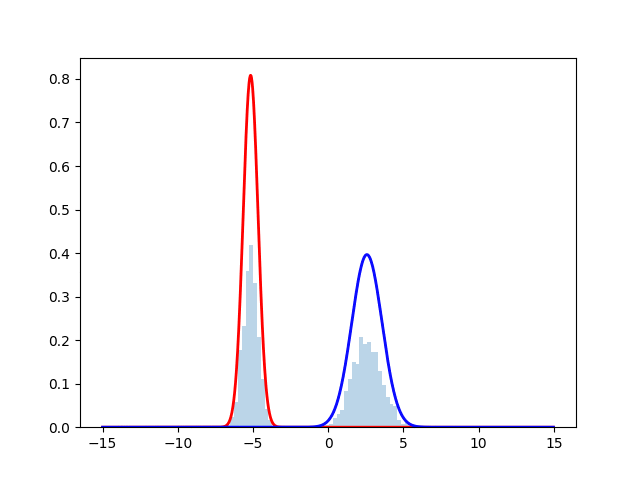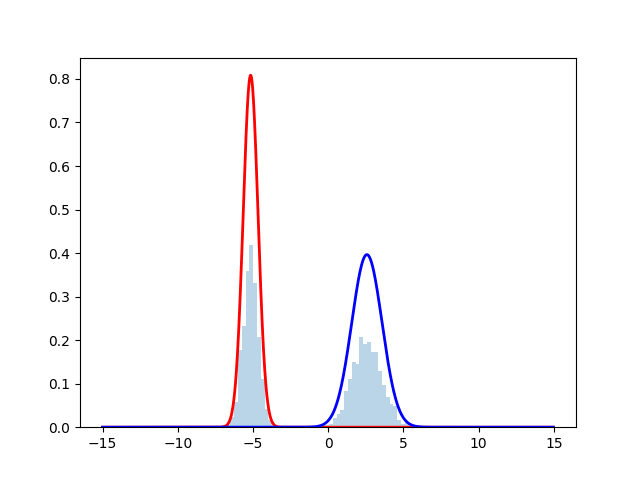
ヒストグラムが正規分布からサンプリングしたデータを表しており, 赤線と青線が最尤推定を行なった際の推定確率分布となっている. 時刻とともにサンプルにフィッティングしていく様子が見える.実際のコードは下に掲載する.
アルゴリズムアウトライン
- 未知パラメタ$\theta$の初期値$\theta^{(0)}$を与え, $K=0$とする.
- 次の関数を計算する (Eステップ) $$ Q_K(\theta) = E_{y|x,\theta(K)} [\log p(x, y|\theta)] $$
- $Q_K(\theta)$を最大にする$\theta$を$\theta(K+1)$とする (Mステップ)
- $K←K+1$としてステップ2に戻り, これを収束するまで反復する.
クラス判別問題
仮に各データ$x_{\alpha}$がどのクラスに属するか既知であるとし,
\overline{w}_{\alpha}^{(k)} = \begin{cases}1 & \text{$x_{\alpha}が$クラス$k$に属する時} \\ 0 & \text{otherwise} \end{cases} \tag{1}の$KN$個の値 $\overline{w}_{\alpha}^{(k)}$ が指定されているとする. このときデータ${ {x_{\alpha}} }$の尤度は次のように書ける.
L = \prod_{\alpha=1}^N \frac{N_k(\alpha)}{N} p_{k(\alpha)}(x_\alpha | \theta_{k(\alpha)}) \tag{2}ただし,
$k(\alpha)$:データ$x_{\alpha}$の属するクラス
$p_{k(\alpha)}(x_\alpha | \theta_{k(\alpha)}) $:そのクラスのデータ発生の確率密度
$\theta_{k(\alpha)}$:そのクラスの確率密度の (未知) パラメタ
とする.尤度の対数をとると以下のようになる.
\log L = \sum_{\alpha=1}^{N}(\log N_{k(\alpha)} + \log p_{k(\alpha)}(x_{\alpha|\theta_{k}})) - N \log N \tag{3}ここで, $x_{\alpha}$が属していないクラスでは$\overline{w}_{\alpha}^{(k)} = 0$であることを考慮すると
\log L = \sum_{\alpha=1}^{N}\overline{w}_{\alpha}^{(k)}(\log N_{k(\alpha)} + \log p_{k(\alpha)}(x_{\alpha|\theta_{k}})) - N \log N \tag{4}と書き直せる.
ところが${\overline{w}_{\alpha}^{(k)}}$は未知である. そこで, これを欠損データとみなして, 式(4)をその期待値で置き換える. (Eステップ)
Q(\{N_k\}, \{\theta_k\}) = E[\log L] = \sum_{\alpha=1}^{N} \sum_{k=1}^K E[\overline{w}_{\alpha}^{(k)}](\log N_{k(\alpha)} + \log p_{k(\alpha)}(x_{\alpha|\theta_{k}})) - N \log N \tag{5}いま, 確率変数が二項分布$B(n,p)$に従う時, 期待値$E(X)$が
E(X) = npで表されることから, 0,1をとる離散変数の期待値は, それが1となる確率に等しい. ($n=1$の場合に相当)
したがって, $E[\overline{w}_{\alpha}^{(k)}]$はデータ$x_{\alpha}$がクラス$k$に属する確率に等しい.
E[\overline{w}_{\alpha}^{(k)}] = w_{\alpha}^{(k)} \tag{6}そして, この確率は仮定した値を用いて計算した事後確率を用いることにする.
ベイズの定理より, この事後確率は次のように与えられる.
w_{\alpha}^{(k)} = \frac{\pi_k p_{k}(x_{\alpha}|\theta_k)}{\sum_{l=1}^K \pi_l p_{l}(x_{\alpha} | \theta_k)}, \qquad \pi_k = \frac{N_k}{N} \tag{7}(実装上は, この事後確率を求める計算をEステップとして処理している.)
したがって, $Q({N_k}, {\theta_k})$は
Q(\{N_k\}, \{\theta_k\}) = \sum_{\alpha=1}^{N} \sum_{k=1}^K w_{\alpha}^{(k)}\left(\log N_{k(\alpha)} + \log p_{k(\alpha)}(x_{\alpha}|\theta_{k})\right) - N \log N \tag{8}で与えられ, $Q$を未知数${N_k}, {\theta_k} (k = 1,2,...,K)$に関して最大化すればよい. (Mステップ)
▶︎ $Q({N_k}, {\theta_k})$の$N_k$での最大化$Q({N_k}, {\theta_k})$
$\theta_k$は固定して考えるので, 式(8)より $Q({N_k}, {\theta_k})$ を最大にするには, $\sum_{k=1}^K N_{k(\alpha)} = N$ という制約条件のもとで, $\sum_{\alpha=1}^{N} \sum_{k=1}^K w_{\alpha}^{(k)}\log N_{k(\alpha)}$を最大化すれば良い. すなわち以下のように定式化される.
\begin{aligned} & {\text{maximize}} && \sum_{\alpha=1}^{N} \sum_{k=1}^K w_{\alpha}^{(k)}\log N_{k(\alpha)} &\text{s.t.} && \sum_{k=1}^K N_{k(\alpha)} = N \end{aligned} \tag{9}そこで, ラグランジュの未定乗数を導入して
F = \sum_{\alpha=1}^{N} \sum_{k=1}^K w_{\alpha}^{(k)}\log N_{k(\alpha)} - \lambda \left(\sum_{k=1}^K N_{k(\alpha)} - N\right) \tag{10}これを$N_{k(\alpha)}$で偏微分して0とおくことで
N_k = \frac{1}{\lambda} \sum_{\alpha = 1}^N w_{\alpha}^{(k)} \tag{11}定義式(1)より $\sum_{k=1}^K \overline{w}_{\alpha}^{(k)} = 1$ であるから, その期待値も$E\left[\sum_{k=1}^K \overline{w}_{\alpha}^{(k)}\right] = \sum_{k=1}^K w_{\alpha}^{(k)}=1$
ゆえに,
\sum_{k=1}^K N_k = \frac{1}{\lambda} \sum_{\alpha = 1}^N \sum_{k=1}^K w_{\alpha}^{(k)} = \frac{N}{\lambda} \tag{12}制約条件$\sum_{k=1}^K N_{k(\alpha)} = N$から$\lambda = 1$となる. ゆえに次式が得られる.
N_k = \sum_{\alpha = 1}^N w_{\alpha}^{(k)} \tag{13}▶︎ $Q({N_k}, {\theta_k})$の$\theta_k$での最大化
式(8)より
\sum_{\alpha=1}^{N} \sum_{k=1}^K w_{\alpha}^{(k)}\log p_{k(\alpha)}(x_{\alpha}|\theta_{k}) = \sum_{\alpha=1}^{N} \log \sum_{k=1}^K p_{k(\alpha)}(x_{\alpha}|\theta_{k})^{w_{\alpha}^{(k)}} \tag{14}この式の右辺は各クラス$k$ごとに異なるパラメタ$\theta_k$を含む項の和であるから, それぞれのクラスごとに
\log L = \log \prod_{{\alpha}=1}^N p_{k(\alpha)}(x_{\alpha}|\theta_{k})^{w_{\alpha}^{(k)}} \tag{15}を最大にするパラメタ$\theta_k$を求めれば良い. これは各クラス$k$ごとにデータ$x_1, x_2, …, x_N$がそれぞれ$w_1^{(k)}, w_2^{(k)}, … ,w_N^{(k)} $個あるときのパラメタ$\theta_k$の最尤推定と等価となる.
▶︎ 正規分布のパラメタ$\mu, \sigma$の最尤推定値
今回は, 混合正規分布を扱うことから, $p_{k(\alpha)}(x_\alpha | \theta_{k(\alpha)}) = \mathcal{N}(x_{\alpha}|\mu_k, \Sigma_k) = \frac{\exp(- w_{\alpha}^{(k)}(x_{\alpha} - \mu_k)/2 \Sigma_k)}{\sqrt{2 \pi \Sigma_k}}$とする.
式(15)より, 負の対数尤度が以下のように書ける.
\begin{eqnarray*} J&=&- \log L\\ &=& - \log \prod_{\alpha = 1}^N \left(\frac{\exp(- (x_{\alpha} - \mu_k)/2 \Sigma_k)}{\sqrt{2 \pi \Sigma_k}}\right)^{w_{\alpha}}\\ &=& - \log \prod_{\alpha = 1}^N \frac{\exp(- w_{\alpha}^{(k)}(x_{\alpha} - \mu_k)/2 \Sigma_k)}{\left(\sqrt{2 \pi \Sigma_k}\right)^{w_{\alpha}}}\\ &=& - \log \frac{\exp \left(- \sum_{\alpha=1}^N (w_{\alpha}^{(k)}(x_{\alpha} - \mu_k)/2 \Sigma_k)\right)}{\left(\sqrt{2 \pi \Sigma_k}\right)^{N w_{\alpha}}}\\ &=& \frac{1}{2 \Sigma} \sum_{\alpha=1}^N w_{\alpha}^{(k)}(x_{\alpha} - \mu_k)^2 + \frac{N w_{\alpha}^{(k)}}{2} \log 2\pi \Sigma \\ \tag{16} \end{eqnarray*}この負の対数尤度$J$を最小にする$\mu_k$と$\Sigma_k$が正規分布のパラメタ最尤推定値となる.
すなわち, $J$を$\mu_k$, $\Sigma_k$で偏微分して$0$と置けばよい.
\begin{eqnarray*} \frac{\partial J}{\partial \mu_k} & = & 0 \\ \iff&& - \frac{1}{\Sigma} \sum_{\alpha=1}^{N} w_{\alpha}^{(k)} (x_{\alpha} - \mu_k) = 0 \\ \iff&& \sum_{\alpha=1}^N w_{\alpha} x_{\alpha} - \mu_k \sum_{\alpha=1}^N w_{\alpha} = 0 \\ \iff&& \mu_k = \frac{\sum_{\alpha=1}^N w_{\alpha} x_{\alpha}}{\sum_{\alpha=1}^N w_{\alpha}} \\ \iff&& \mu_k = \frac{1}{N_k} \sum_{\alpha=1}^N w_{\alpha} x_{\alpha} &&\left(\because \sum_{\alpha=1}^N w_{\alpha} = N_k\right )\\ \tag{17} \end{eqnarray*}\begin{eqnarray*} \frac{\partial J}{\partial \Sigma_k} & = & 0 \\ \iff&& - \frac{1}{2\Sigma^2} \sum_{\alpha=1}^{N} w_{\alpha}^{(k)} (x_{\alpha} - \mu_k)^2 + \frac{N w_{\alpha}}{2} \cdot \frac{1}{2 \pi \Sigma_k} \cdot 2 \pi = 0 \\ \iff&& - \frac{1}{\Sigma_k}\sum_{\alpha=1}^N w_{\alpha} (x_{\alpha} - \mu_k)^2 + N w_{\alpha} = 0 \\ \iff&& \sum_{\alpha=1}^N w_{\alpha} \left( 1 - \frac{(x_{\alpha} - \mu_k)^2}{\Sigma_k} \right) = 0 \\ \iff&& \sum_{\alpha=1}^N w_{\alpha} =\sum_{\alpha=1}^N w_{\alpha} (x_{\alpha} - \mu_k)^2 \cdot \frac{1}{\Sigma_k} \\ \iff&&\Sigma_k = \frac{1}{N_k}\sum_{\alpha=1}^N w_{\alpha} (x_{\alpha} - \mu_k)^2 &&\left(\because \sum_{\alpha=1}^N w_{\alpha} = N_k\right )\\ \tag{18} \end{eqnarray*}以上より, モデルパラメタの推定値を整理すると以下のようになる. (コードで実装する式はこの部分になる.)
\begin{eqnarray*} w_{\alpha}^{(k)} &=& \frac{\pi_k p_{k}(x_{\alpha}|\theta_k)}{\sum_{l=1}^K \pi_l p_{l}(x_{\alpha} | \theta_k)}\tag{19} \\ \pi_k &=& \frac{N_k}{N} \tag{20} \\ N_k &=& \sum_{\alpha = 1}^N w_{\alpha}^{(k)}\tag{21} \\ \hat{\mu} &=& \frac{1}{N_k}\sum_{\alpha = 1}^N w_{\alpha}^{(k)}x_{\alpha}\tag{22} \\ \hat{\sigma}^2 &=& \frac{1}{N_k}\sum_{\alpha=1}^N w_{\alpha}^{(k)}(x_{\alpha} - \mu_{\alpha})^2\tag{23} \\ \end{eqnarray*}実装
実装は, こちらの記事を参考にさせていただきました. 事後確率の算出コードだけ少し改変してあります.
以下のコードを実行すればgifアニメーションまで出ます.import numpy as np from matplotlib import pyplot import matplotlib.animation as animation import sys def create_data(N, K): X, mu_list, sigma_list = [], [], [] for i in range(K): loc = (np.random.rand() - 0.7) * 10.0 # 平均 scale = np.random.rand() * 2.0 # 標準偏差 X = np.append(X, np.random.normal( loc = loc, scale = scale, size = int(N / K) #出力配列のサイズ )) mu_list = np.append(mu_list, loc) sigma_list = np.append(sigma_list, scale) return (X, mu_list, sigma_list) def gaussian(mu, sigma): def f(x): return np.exp(-0.5 * (x - mu) ** 2 / sigma) / np.sqrt(2 * np.pi * sigma) return f # Eステップにおいて事後確率を計算する def estimate_posterior_probability(X, pi, gf): l = np.zeros((X.size, pi.size)) for (i, x) in enumerate(X): l[i, :] = gf(x) numerator = pi * l denominator = np.vectorize(lambda y: y)((l*pi).sum(axis=1).reshape(-1, 1)) return numerator / denominator # MステップにおいてQ関数を最大化するパラメタ mu, sigma, pi を計算する def maximize_parameters(X, post_pro): N = post_pro.sum(axis=0) mu = (post_pro * X.reshape((-1, 1))).sum(axis=0) / N sigma = (post_pro * (X.reshape(-1, 1) - mu) ** 2).sum(axis=0) / N pi = N / X.size return (mu, sigma, pi) # Q関数を計算する def calc_Q(X, mu, sigma, pi, post_pro): Q = (post_pro * (np.log(pi * (2 * np.pi * sigma) ** (-0.5)))).sum() for (i, x) in enumerate(X): Q += (post_pro[i, :] * (-0.5 * (x - mu) ** 2 / sigma)).sum() return Q if __name__ == '__main__': # data K = 2 N = 1500 * K X, mu_list, sigma_list = create_data(N, K) colors = ['r', 'b', 'g'] # 収束条件 epsilon = 1e-20 # 未知パラメタを初期化する pi = np.random.rand(K) mu = np.random.randn(K) sigma = np.abs(np.random.randn(K)) Q = -sys.float_info.max delta = None ims = [] fig = pyplot.figure() n, bins, _ = pyplot.hist(X, 50, normed=1, alpha=0.3) seq = np.arange(-15, 15, 0.02) # EMアルゴリズム while delta == None or delta >= epsilon: gf = gaussian(mu, sigma) # Eステップ: post_pro = estimate_posterior_probability(X, pi, gf) # Mステップ: Q関数を最大化するパラメタ mu, sigma, pi を求める mu, sigma, pi = maximize_parameters(X, post_pro) # plot data tmp = [] for i in range(K): im = pyplot.plot(seq, gaussian(mu[i], sigma[i])(seq), linewidth=2.0, color=colors[i]) tmp.append(im[0]) ims.append(tmp) # Q関数の計算 Q_new = calc_Q(X, mu, sigma, pi, post_pro) delta = Q_new - Q Q = Q_new # plot ani = animation.ArtistAnimation(fig, ims, interval=300) ani.save('test1.gif', writer="imagemagick") pyplot.show()以上です.
統計的機械学習のクラシックな手法は数学があざやかなものが多くて楽しいですね!
参考
- これなら分かる最適化数学―基礎原理から計算手法まで / 金谷 健一
- pythonで混合正規分布実装 (https://qiita.com/ta-ka/items/3e8b127620ac92a32864)
- 投稿日:2019-05-30T21:07:40+09:00
リスト内包表記 #3 (加工)
- 投稿日:2019-05-30T19:01:31+09:00
PythonによるAtCoder Beginners Selection - 優秀コードとの比較
最近AtCoderを始めました。
今はAtCoder Beginners Selectionという、優良な過去問10題をまとめた初心者向けの問題をやっています。この記事では自分が書いた下手コードと、実行時間が短かったりなるほどと思うような素敵コードを比べてみました。
※前から3問 ABC086A - Product, ABC081A - Placing Marbles, ABC081B - Shift onlyについてはすみません、いずれ追加します。
ABC087B - Coins
自分のコード
A = int(input()) B = int(input()) C = int(input()) X = int(input()) out = 0 for a in range(A+1): for b in range(B+1): for c in range(C+1): out = out+1 if 500*a+100*b+50*c==X else out print(out)素敵なコード
A,B,C,X = [int(input()) for i in range(4)] X //= 50 ans = 0 for i in range(A + 1): if 10*i > X: break rem = X - 10*i for j in range(B + 1): if 2*j > rem: break if rem - 2*j <= C: ans += 1 print(ans)比較
実行時間 コード長 メモリ 自分のコード 59 ms 214 Byte 3060 KB 素敵なコード 17 ms 250 Byte 2940 KB まず標準入力から違いますね。forで回して行を減らす、うーんスマート。
続いて2行目X //= 50。Xが50の倍数という問題設定を利用して値を小さくしています。これも速度向上の効果があるのでしょうか。
特筆すべきはforループが自分のコードより1個少ない!確かに500円と100円の個数が決定した時点で、50円の個数も決定しますね…3倍速度差があるのはここが一番効いてそうです。ABC083B - Some Sums
自分のコード
まず初めに思いつくだろうというのをそのまま書いた感じですね。1~Nまで確認して、条件満たしてたらtotalに加算しています。
数値の各桁の和は10で割って余りを足して…を繰り返しています。N,A,B = map(int,input().split()) total = 0 for i in range(N): j=i+1 lst = [] while j>0: lst.append(j%10) j //= 10 total = total+i+1 if A<=sum(lst)<=B else total print(total)速いコード
1の各桁の和は1, 11は2, 21は3,…のような数字の規則性に目をつけて、予めN=0~10^4までの答えを用意する作戦ですね。自分も思い付きはしたもののどう実装すべきか分からなかった…
後述しますがかなり実行時間が短縮されてます。dig1 = list(range(10)) dig2 = [] print(dig1) for i in range(10): dig2 += [j+i for j in dig1] print(dig2) dig3 = [] for i in range(10): dig3 += [j+i for j in dig2] print(dig3) dig4 = [] for i in range(10): dig4 += [j+i for j in dig3] print(dig4) dig4.append(1) def sumup(n, a, b): return sum([i for i, dig in enumerate(dig4[:n+1]) if a <= dig <= b]) n, a, b = [int(x) for x in input().split()] print(sumup(n, a, b))短いコード
最もコード長の短いプログラムで、たった2行!発想は私のコードと同じなのに…
凄いのはsum(map(int,str(i)))こんなに短く各桁の和が求まるんですね。
それからi*(A<=sum(map(int,str(i)))<=B)この部分は数値にbool型を掛けており、i*True=i、i*False=0という性質を利用しています。
これぞ競プロって感じですよね。N,A,B=map(int,input().split()) print(sum(i*(A<=sum(map(int,str(i)))<=B)for i in range(N+1)))比較
実行時間 コード長 メモリ 自分のコード 31 ms 217 Byte 3060KB 速いコード 19 ms 442 Byte 3572 KB 短いコード 28 ms 93 Byte 3064 KB こう見るとそれぞれ一長一短、いや自分のは"短いコード"の下位互換ですが…
メモリ効率は少し勝ってるABC088B - Card Game for Two
自分のコード
AとB交互に、値が大きい要素をpopしています。
N = input() A = 0 B = 0 Cards = list(map(int,input().split())) for i in range(-(-len(Cards)//2)): A += Cards.pop(Cards.index(max(Cards))) B = B+Cards.pop(Cards.index(max(Cards))) if len(Cards)!=0 else B print(A-B)短いコード
まずsorted()でソートし、そのリストを1個飛ばしでスライシング。
input();a=sorted(map(int,input().split())) print(sum(a[::-2])-sum(a[-2::-2]))比較
実行時間 コード長 メモリ 自分のコード 17 ms 228 Byte 3060 KB 短いコード 18 ms 78 Byte 2940 KB 短いコードが1ms遅いのは一度ソートしてるからでしょうか。
ABC085B - Kagami Mochi
要素の重複を除いたリストを作るだけって感じの問題で、pythonでは集合型を使えばいいので簡単でした。
自分のコード
一度リスト[ ]を作ってから集合型に変換しているので非効率です。
N = int(input()) print(len(set([int(input()) for _ in range(N)])))短いコード
こちらのコードは初めから集合型{}に格納していってます。
print(len({input()for _ in[0]*int(input())}))比較
実行時間 コード長 メモリ 自分のコード 17 ms 67 Byte 2940 KB 短いコード 17 ms 45 Byte 2940 KB 意外にも実行時間は同じでした。
ABC085C - Otoshidama
自分のコード(1)Reject
まずN枚全て1000円札にして、金額が足りなければ5000円と交換、まだ足りなければ10000円と交換、という風に両替していくアイデア。
半分くらいのケースでRejectされた(恐らくタイムアウト)。def getTotal(a,b,c): return 10*a+5*b+c N,otoshi=map(int,input().split()) otoshi /= 1000 a,b,c = 0,0,N while otoshi-4>=getTotal(a,b,c) and c>0: b+=1;c-=1 otoshi_d = list(map(int,str(int(otoshi)))) ttl_d = list(map(int,str(getTotal(a,b,c)))) while otoshi_d[len(otoshi_d)-1] != ttl_d[len(ttl_d)-1]: b-=1;c+=1 ttl_d = list(map(int,str(getTotal(a,b,c)))) for i in range(b+1): if getTotal(a,b,c)==otoshi: print("{} {} {}".format(a,b,c)) break if otoshi-5>=getTotal(a,b,c) and b>0: a+=1;b-=1 else: print("-1 -1 -1")自分のコード(2)Accept
普通にループ回せば出来るやん!と気づいて書いたコード。
10000円を一番外側にした3重…ではなく2重ループ。10000円と50000円の枚数から1000円札の数も分かるため。
恐らく何も考えず3重ループで回したらタイムアウトするようになっており、これがC問題かと思わされました。N,otoshi=map(int,input().split()) otoshi /= 1000 for a in range(N+1): for b in range(N+1): c = N - (a+b) if c<0: break if 10*a+5*b+c==otoshi: print("{} {} {}".format(a,b,c)) exit() print("-1 -1 -1")速いコード
\begin{cases} n = a + b + c \\ y = 10*a + 5*b + c \end{cases}の連立方程式を解いて書いているのだと思われる。
n, y = list(map(int, input().split())) y = int(y/1000) a = y%5 for i in range(n+1): if a == i%5: b = int((y-i)/5) c = n-i if b <= 2*c and b >= c: print(b-c, 2*c-b, i) exit() print(-1, -1, -1)比較
実行時間 コード長 メモリ 自分のコード(2) 925 ms 272 Byte 3188 KB 速いコード 17 ms 253 Byte 3064 KB 自分のコードおっそいなあ…
- 投稿日:2019-05-30T18:58:21+09:00
Grad-CAMの実装コードを読んでみた
Grad-CAMって何だろうと思ってKeras実装コードを調べてみました。
論文も読んでないし、数式も全く理解してませんが一応動作は追えたかなと思います。Grad-CAM のコード
https://github.com/eclique/keras-gradcam
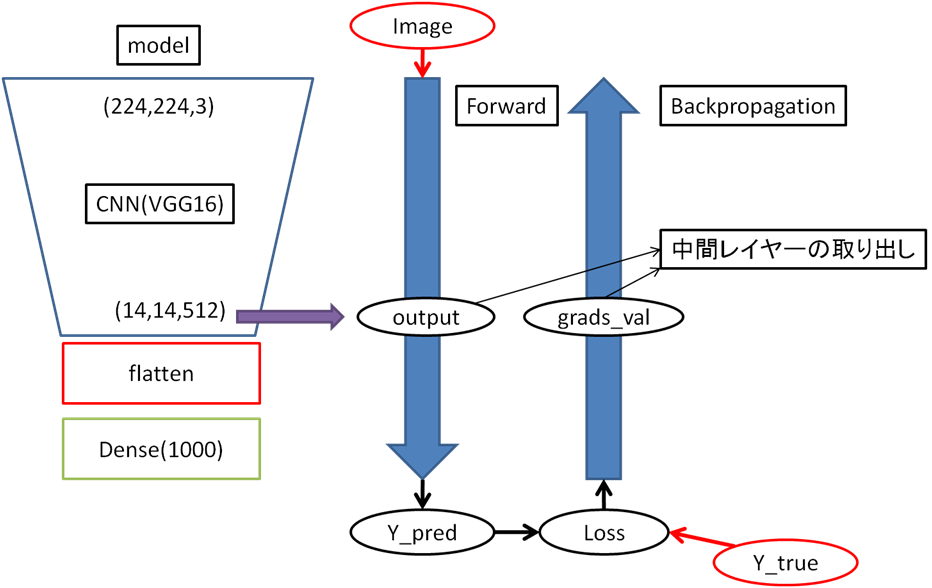
Grad-CAMの核心部分は下記です。今回の場合layer_name='block5_conv3'です。
途中にprint文を挟んでnp.arrayの形を確認しました。gradcam.pydef grad_cam(input_model, image, cls, layer_name): y_c = input_model.output[0, cls] conv_output = input_model.get_layer(layer_name).output grads = K.gradients(y_c, conv_output)[0] output, grads_val = K.function([input_model.input], [conv_output, grads])([image]) print('output.shape=', output.shape) print('grads_val.shape=', grads_val.shape) output, grads_val = output[0, :], grads_val[0, :, :, :] weights = np.mean(grads_val, axis=(0, 1)) print('weights.shape=', weights.shape) cam = np.dot(output, weights) print('cam.shape=', cam.shape) # Process CAM cam = cv2.resize(cam, (W, H), cv2.INTER_LINEAR) print('cam_new.shape=', cam.shape) cam = np.maximum(cam, 0) cam = cam / cam.max() return camshapeの出力結果は以下のようになりました。
なるほど、modelからoutputとgrads_valを取り出して、grads_valをチャンネル毎に平均化してweightを求め(正解ラベル選択時の各チャンネルの寄与度)、それにoutputを掛けるだけ。追ってみるとそんなに難しくないですね。output.shape= (1, 14, 14, 512) grads_val.shape= (1, 14, 14, 512) weights.shape= (512,) cam.shape= (14, 14) cam_new.shape= (224, 224)model.summary() #modelはVGG16 -------------------------------------------------- _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) (None, 224, 224, 3) 0 _________________________________________________________________ block1_conv1 (Conv2D) (None, 224, 224, 64) 1792 _________________________________________________________________ : _________________________________________________________________ block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ : _________________________________________________________________ fc2 (Dense) (None, 4096) 16781312 _________________________________________________________________ predictions (Dense) (None, 1000) 4097000 ================================================================= Total params: 138,357,544 Trainable params: 138,357,544 Non-trainable params: 0 _________________________________________________________________Grad-CAMイメージ:
言葉だけで説明しても伝わりにくいと思いますのでイメージ図を書いてみます。
誤差逆伝搬の理解があやふやですが、勾配レイヤーの取り出しは多分こういうイメージかと思います。
勾配自体は学習時におけるモデル重みの更新量っていう理解です。
なぜgrads_valの平均がチャンネルの正解寄与度を求めれるのかは自分には分かっていません。
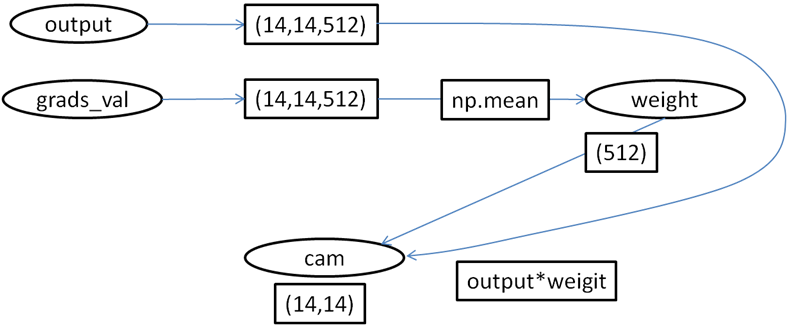
図1:中間レイヤーの取り出し
図2:中間レイヤーからcamの計算grads_valの最大値の場合
grads_valのチャンネル毎平均って結局CNN層のglobal_average_pooling層ってことですよね。
もしそうなら、別にglobal_max_pooling層相当で計算しても計算できるんでしょうか。gradcam.py#weights = np.mean(grads_val, axis=(0, 1)) weights = np.max(grads_val, axis=(0, 1))(14,14)の縦横行列の内、チャンネル毎の最大値を取り出しました。
若干範囲が広がりますが、別にこれでも大丈夫そう。

:左(mean)、右(max)
最大値チャンネルのみ表示させた場合:
outputのチャンネルとweightチャンネルの掛け算を計算させますが、weightの最も大きいチャンネルのみ表示させても問題ないのでは?と思った結果。
gradcam.py#cam = np.dot(output, weights) cam = output[:,:,np.argmax(weights)]weightsの最も大きいチャンネル結果を表示してます。従来結果よりは範囲が狭まった気がします。
もしかしたら犬の何らかの局所的な位置に反応している可能性はありますけれど、camの解像度が低いのでよく分かりません。
:左(dot)、右(argmax)
camの解像度
ところでGrad-CAMの解像度って今回VGG16の場合(14,14)で、入力画像サイズ(224,224)に比べ割と低い印象を持ちました。(こんなものでしょうか?)
試しにlayer_name='block5_conv3'をlayer_name='block4_conv3'にした場合、camの解像度自体は(28,28)に上がりましたが、特徴量の場所表示は上手く行かないようです。
:左('block5_conv3')、右('block4_conv3')
XceptionやResnetなんかは入力画像サイズ(224,224)で全結合前が(7,7)なので解像度はさらに悪くなります。かと言ってモデルのpooling層を減らせば、分類精度が下がるでしょうし。どうすればいいんでしょう。ReLUはどこに消えた?
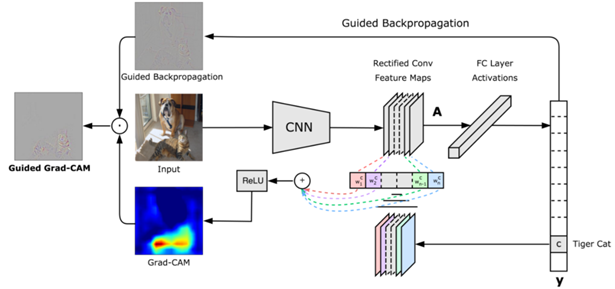
論文の図を見るとcamマップの出力前にReLUが入ってます。
(14,14)のcamデータには当然マイナスの値も含んでいますが、どこに行ったんでしょうか。
調べたら実装コードのnp.maximumがReLU相当でした。これでcamのマイナスの値には代わりにゼロが入るようになります。
なお、試しにnp.maximumとcv2.resizeの順番を入れ替えてみましたが、特に違いはないようです。
(ReLU=>resizeの順の方がcamのマイナス値の影響を除けるので良いのでは?と思いますが)gradcam.pycam = np.maximum(cam, 0) cam = cv2.resize(cam, (W, H), cv2.INTER_LINEAR)
:左(resize=>ReLU)、右(ReLU=>resize)
わざと1点だけ大きなマイナスを入れた場合、resize=>ReLUだと回りの点も影響を受けてしまいました。gradcam.pycam[2,6] = -1000 cam = np.maximum(cam, 0) cam = cv2.resize(cam, (W, H), cv2.INTER_LINEAR)

:左(resize=>ReLU)、右(ReLU=>resize)







- 投稿日:2019-05-30T17:47:57+09:00
MacでPythonからC/C++を呼ぶ
初投稿です。最近要望があってPython触ってみたけど、遅い。でもPythonで書かなきゃいけないときに「C呼んでしまえばよくね!?」ってなっていろいろ調べてみた。でも他の人が書いた記事の通りにやってもうまくいかなかった。参照か何かが間違ってたのかなぁって感じだったが、強引に動かしたら動いたのでメモ。
概要
Boost.Pythonというやつを使えばいいらしい。ライブラリを参照するのがうまくいかなかったので、一つのディレクトリ内に全部入れて動かした。
環境
macOS 10.13.6
Python 3.7
BoostPython 1.68.0必要なものを用意する
このプログラムを実行するディレクトリを用意した。どこでもいいと思うが、僕は
~/Python/BoostPythonTest/にした。ここに以下のものを用意する。
- libboost_python37.dylib
- libpython3.7.dylib
- C/C++ソース
- Pythonソース
libboost_python37.dylib
以下でBoost.Pythonをインストールする。1
% brew install boost-python3インストールしたら
/usr/local/Cellar/boost-python3/1.68.0/lib/libboost_python37.dylibがあるはずなので、これを実行するディレクトリにコピーする。libpython3.7.dylib
Pythonをインストールしておく。1
% brew install python3
/usr/local/Cellar/python/3.7.2/Frameworks/Python.framework/Versions/3.7/Pythonを実行するディレクトリにコピーして、libpython3.7.dylibという名前に変更する。C/C++ソース
テスト用に
hello.cppっていうソースを用意した。hello.cpp#include <boost/python.hpp> #include <stdio.h> char greet(int x){ printf("printHELLO!!\n"); return '0' + x + 1; } char const* fine(){ return "How are you?"; } BOOST_PYTHON_MODULE(hello){ using namespace boost::python; def("greet", greet); def("fine", fine); }Pythonソース
テスト用に
test.pyっていうソースを用意した。test.pyimport hello x = hello.greet(2) print(x) y = hello.file() print(y)コンパイル
以下でコンパイルできるはず。実行するディレクトリ内のファイルを参照するだけ。
% g++ -fPIC -Wall -O2 -shared -o hello.so hello.cpp libboost_python37.dylib libpython3.7.dylib
hello.soが実行するディレクトリに作られる。実行
実行してみる。
% python3 test.py printHELLO!! 3 How are you?ちゃんとできてそう。
まとめ
一つのディレクトリに全部ぶっ込んで動かすっていうちょっと強引な方法でしたが、とりあえず動いたのでよしとしよう。
Ubuntuでも動かそうとしたけどできなかった。
dylib使ってるからMacじゃないとダメみたい。参考
[1]c/c++をラップしてpythonで使えるように
https://www.quark.kj.yamagata-u.ac.jp/~hiroki/python/?id=19[2]boost インストールから実行(boost::python)まで。
http://nonbiri-tereka.hatenablog.com/entry/2014/02/01/004547
brewを使うときにパーミッションエラーがでたら、sudo brew ...ってやる。 ↩
- 投稿日:2019-05-30T17:32:18+09:00
[Django]デプロイしたサイトのレイアウトが壊れた(静的ファイルが読み込めない)時の対処法[CentOS7][Apache2.4]
環境
- Django 2.1
- CentOS 7
- Python 3.6
- Apache 2.4
- mod_wsgi 4.6.5
対処法
静的ファイルをApacheで配信する設定に変更する
1. Apacheの設定ファイルを開く(設定ファイルの場所)
下記のファイルは自分で作成するファイルです。
おそらくこの記事を読んでいる人の大半は既に作成していると思いますが、無い人は作成しましょう。vi /etc/httpd/conf.d/xxx.conf2. Apacheの設定ファイルを編集する
設定ファイルの基本的な書き方は他の記事に委ねます。
ここでは、静的ファイルをApacheに配信させる設定のみに焦点を当てています。また、
mysite/settings.pyを下記のように設定していることを前提とします。STATIC_URL = '/static/'1. adminと自作のmyappの静的ファイルを同じ場所に格納している場合(もしくは一方のみの場合)
Alias /static /var/www/mysite/static <Directory /var/www/mysite/static> Require all granted </Directory>2. adminと自作のmyappの静的ファイルを別場所に格納している場合
Alias /static/admin /var/www/mysite/static/admin <Directory /var/www/mysite/static/admin> Require all granted </Directory> Alias /static/myapp /var/www/mysite/myapp/static/myapp <Directory /var/www/mysite/myapp/static/myapp> Require all granted </Directory>
- 投稿日:2019-05-30T17:24:51+09:00
astropy.ioでfitsファイルの情報を取得する
更新履歴: 2019 May 31, twitterにて間違い指摘と有益情報をもたらしてくださった有志の方に感謝。
概要
以前の記事「PythonでHEALPixを描画する」で、.fitsファイルからI_StokesやQ_Stokesを描画してみました。今回はそのファイルの描画ではなく、詳細な情報を見てみましょう。
astropy.io
以下のように必要なモジュール、今回の場合はfitsをimportします。
from astropy.io import fits as ftfits
Planck衛星のデータをダウンロードして、それを読み込んでみましょう。
# read Planck data planck_map = ft.open('./LFI_SkyMap_030_1024_R2.01_full.fits')情報を見る
header
この
planck_map変数の情報を見てみましょう。以下のようにして情報を見ることができます。print(repr(planck_map[0].header))出力を見てみましょう。
SIMPLE = T / file does conform to FITS standard BITPIX = 16 / number of bits per data pixel NAXIS = 0 / number of data axes EXTEND = T / FITS dataset may contain extensions COMMENT FITS (Flexible Image Transport System) format is defined in 'Astronomy COMMENT and Astrophysics', volume 376, page 359; bibcode: 2001A&A...376..359H
repr関数は対話モードのように表示するためだけに使用しているため、あってもなくても構いません。
次に以下のようにしてみます。print(repr(planck_map[1].header))すると出力は以下のようになります。
SIMPLE = T / file does conform to FITS standard BITPIX = 16 / number of bits per data pixel NAXIS = 0 / number of data axes EXTEND = T / FITS dataset may contain extensions COMMENT FITS (Flexible Image Transport System) format is defined in 'Astronomy COMMENT and Astrophysics', volume 376, page 359; bibcode: 2001A&A...376..359H >>> print(repr(planck_map[1].header)) XTENSION= 'BINTABLE' / binary table extension BITPIX = 8 / 8-bit bytes NAXIS = 2 / 2-dimensional binary table NAXIS1 = 40 / width of table in bytes NAXIS2 = 12582912 / number of rows in table PCOUNT = 0 / size of special data area GCOUNT = 1 / one data group (required keyword) TFIELDS = 10 / number of fields in each row TTYPE1 = 'I_Stokes' / label for field 1 TFORM1 = 'E ' / data format of field: 4-byte REAL TUNIT1 = 'K_CMB ' / physical unit of field TTYPE2 = 'Q_Stokes' / label for field 2 TFORM2 = 'E ' / data format of field: 4-byte REAL TUNIT2 = 'K_CMB ' / physical unit of field TTYPE3 = 'U_Stokes' / label for field 3 TFORM3 = 'E ' / data format of field: 4-byte REAL TUNIT3 = 'K_CMB ' / physical unit of field TTYPE4 = 'Hits ' / label for field 4 TFORM4 = 'J ' / data format of field: 4-byte INTEGER TUNIT4 = 'none ' / physical unit of field TTYPE5 = 'II_cov ' / label for field 5 TFORM5 = 'E ' / data format of field: 4-byte REAL TUNIT5 = '(K_CMB)^2' / physical unit of field TTYPE6 = 'IQ_cov ' / label for field 6 TFORM6 = 'E ' / data format of field: 4-byte REAL TUNIT6 = '(K_CMB)^2' / physical unit of field TTYPE7 = 'IU_cov ' / label for field 7 TFORM7 = 'E ' / data format of field: 4-byte REAL TUNIT7 = '(K_CMB)^2' / physical unit of field TTYPE8 = 'QQ_cov ' / label for field 8 TFORM8 = 'E ' / data format of field: 4-byte REAL TUNIT8 = '(K_CMB)^2' / physical unit of field TTYPE9 = 'QU_cov ' / label for field 9 TFORM9 = 'E ' / data format of field: 4-byte REAL TUNIT9 = '(K_CMB)^2' / physical unit of field TTYPE10 = 'UU_cov ' / label for field 10 TFORM10 = 'E ' / data format of field: 4-byte REAL TUNIT10 = '(K_CMB)^2' / physical unit of field EXTNAME = 'FREQ-MAP' DATE = '2015-01-20T12:35:13' / file creation date (YYYY-MM-DDThh:mm:ss UT) COMMENT COMMENT *** Planck params *** COMMENT PIXTYPE = 'HEALPIX ' / HEALPIX pixelisation ORDERING= 'NESTED ' / Pixel ordering scheme, either RING or NESTED NSIDE = 1024 / Resolution parameter for HEALPIX FIRSTPIX= 0 / First pixel # (0 based) LASTPIX = 12582911 / Last pixel # (0 based) INDXSCHM= 'IMPLICIT' / Indexing: IMPLICIT or EXPLICIT EXTVER = 2 PROCVER = 'DX11D ' BAD_DATA= -1.6375E+30 FREQ = 30 COORDSYS= 'GALACTIC' POLCCONV= 'COSMO ' / Coord. convention for polarization (COSMO/IAU) FILENAME= 'LFI_SkyMap_030_1024_R2.01_full.fits' COMMENT --------------------------------------------------------------------- COMMENT LFI RIMO 12.1 COMMENT Madam version 3.7.4 COMMENT Added monopole offset 8.34887355761e-05 to column I_Stokes COMMENT LFI-DMC object: COMMENT TOODI%ACCTOODI%%madam_IQUmap_LFI_calib_30GHz_DX11D_full_025_sec:0% COMMENT TOODI%ACCTOODI%%madam_hit_LFI_calib_30GHz_DX11D_full_025_sec:0% COMMENT TOODI%ACCTOODI%%madam_cov_LFI_calib_30GHz_DX11D_full_025_sec:0% COMMENT --------------------------------------------------------------------- CHECKSUM= 'Ec3CFc1BEc1BEc1B' / HDU checksum updated 2015-01-20T12:35:18 DATASUM = '706919705' / data unit checksum updated 2015-01-20T12:35:18すると
TTYPE1のように書かれた項目にI_StokesやQ_Stokesがあることがわかります。header['TTYPE3']
試しに以下を実行してみましょう。
print(planck_map[1].header['TTYPE3'])すると実行結果は以下のようになります。
U_Stokes
TTYPE3にはストークスパラメータのUのデータが入っていることがわかりました。header['NSIDE']
次はこの.fitsファイルの
n_sideを見てみます。print(planck_map[1].header['NSIDE'])すると
1024のように、この.fitsファイルが何pixelなのかを求めるために必要な情報を得ることができます。
header['ORDERING']
次にこの.fitsファイルのオーダーを見てみましょう。ここでのオーダーとはpixelのナンバリングのルールを意味します。
RING
NESTEDそれではオーダーを調べてみましょう。
print(planck_map[1].header['ORDERING'])すると
NESTEDであることがわかります。
結言
このメソッドを用いることで、いちいち.fitsをダウンロードしてきたウェブサイトで情報を調べなくても「この.fitsファイルが何のデータなのか、どのようなデータ構造なのか」をローカル環境で確認することができます。
- 投稿日:2019-05-30T15:33:37+09:00
AtCoderのランキングをpythonでスクレイピングしてみる。
レート分布として水以上が強いのはわかるけどあんま参加してない灰色がめちゃくちゃ多いから実際のところどーなのよってのをスクレイピングして参加回数5回以上の参加者のレートを抜き出します。ランキングの表示形式とかが変わったら動かなくなるだろうけどサポートはしません。2019年5月30日現在、このコードは動きます。jyupyter想定です。
import urllib.request l=[] for r in range(1,311): print(r) d=urllib.request.urlopen("https://atcoder.jp/ranking?desc=true&orderBy=competitions&page="+str(r)).read().decode('utf-8').replace(" ","").split("\n") for i in range(len(d)): tmp=[] if d[i]=="<tr>": tmp.append(int(d[i+1].replace(r'<td class="no-break">',"").replace("</td>",""))) tmp.append(d[i+2].replace("</span></a>","")[-18:].split(">")[-1]) tmp.append(int(d[i+5].replace("<td><b>","").replace("</b></td>",""))) tmp.append(int(d[i+6].replace("<td><b>","").replace("</b></td>",""))) tmp.append(int(d[i+7].replace("<td>","").replace("</td>",""))) l.append(tmp)lにランキング、ユーザー名、現在のレート、最高レート、参加回数を入れます。
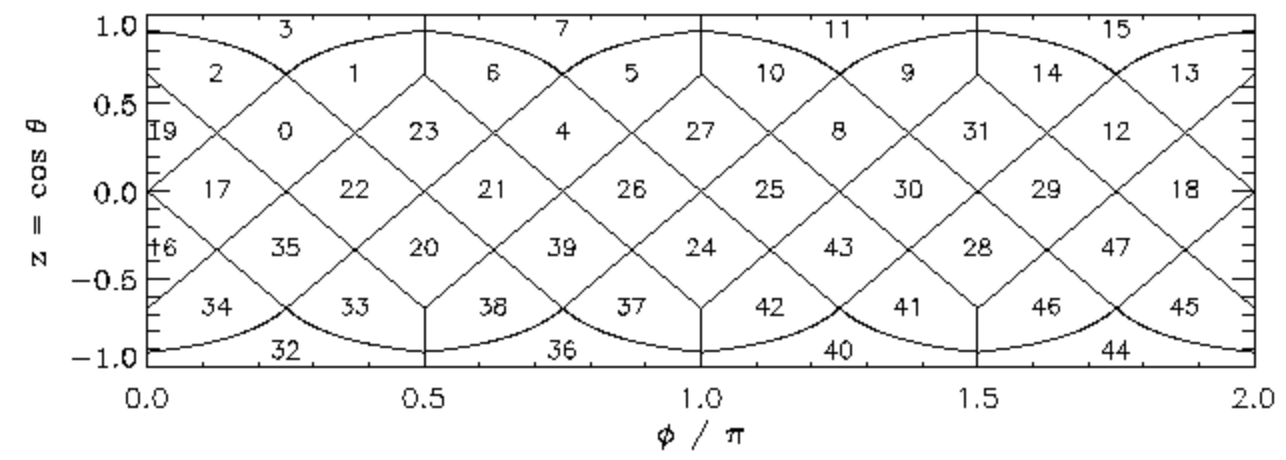
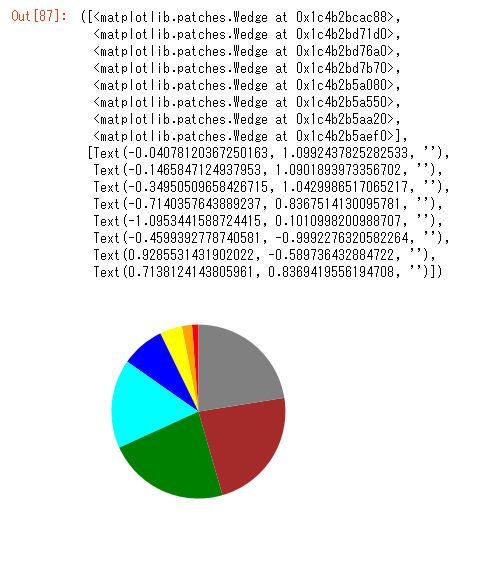
%matplotlib inline from numpy import* df=array(l) df=df[df[:,-1]>=5] x=[float("inf"),2800,2400,2000,1600,1200,800,400,0] current=[] high=[] for i in range(len(x)-1): current.append(len(df[:,2][ (x[i]> df[:,2]) & (df[:,2] >=x[i+1]) ])) high.append(len(df[:,3][ (x[i]> df[:,3]) & (df[:,3] >=x[i+1]) ])) print(current,high)レートで振り分けてcurrentとhighに入れます。
赤色から順に
[139, 223, 488, 948, 1947, 2669, 2715, 2647]人
[150, 255, 488, 998, 2028, 2680, 2660, 2517]人
であることが分かりました。from matplotlib.pyplot import* pie(current, startangle=90,colors = ["red","orange","yellow","blue","cyan","green","brown","gray"])
灰、茶、緑、水色で同じような割合で存在するようです。pie(high, startangle=90,colors = ["red","orange","yellow","blue","cyan","green","brown","gray"])
highでもあんまり変わりませんでした。おしまい。
- 投稿日:2019-05-30T15:31:15+09:00
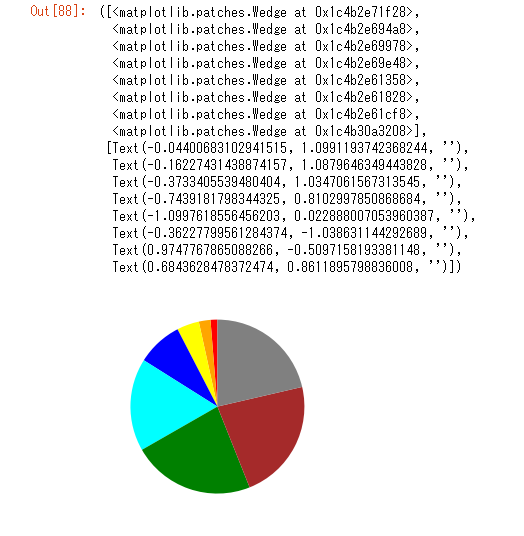
CloudWatch Events から Lambda (Python スクリプト) 経由で S3 から請求情報を取得して、SNS でメールを送ってみる
0.はじめに
コスト配分タグ毎の AWS の毎月のコストレポートが欲しくて、試してみました。
大枠の流れは、以下。
1.請求情報のコスト配分タグを付与して、S3 へ出力する。
基本的に、以下のページの手順に従って設定します。
- S3 を作成します。設定は、以下。
- バケット名 : ※任意
- バケットポリシー : ※以下参考。
{ "Version": "2008-10-17", "Id": "Policy0000000000000", "Statement": [ { "Sid": "Stmt0000000000000", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::0000000000000:root" }, "Action": [ "s3:GetBucketAcl", "s3:GetBucketPolicy" ], "Resource": "arn:aws:s3:::****-billing" }, { "Sid": "Stmt0000000000000", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::0000000000000:root" }, "Action": "s3:PutObject", "Resource": "arn:aws:s3:::****-billing/*" } ] }- ※参考
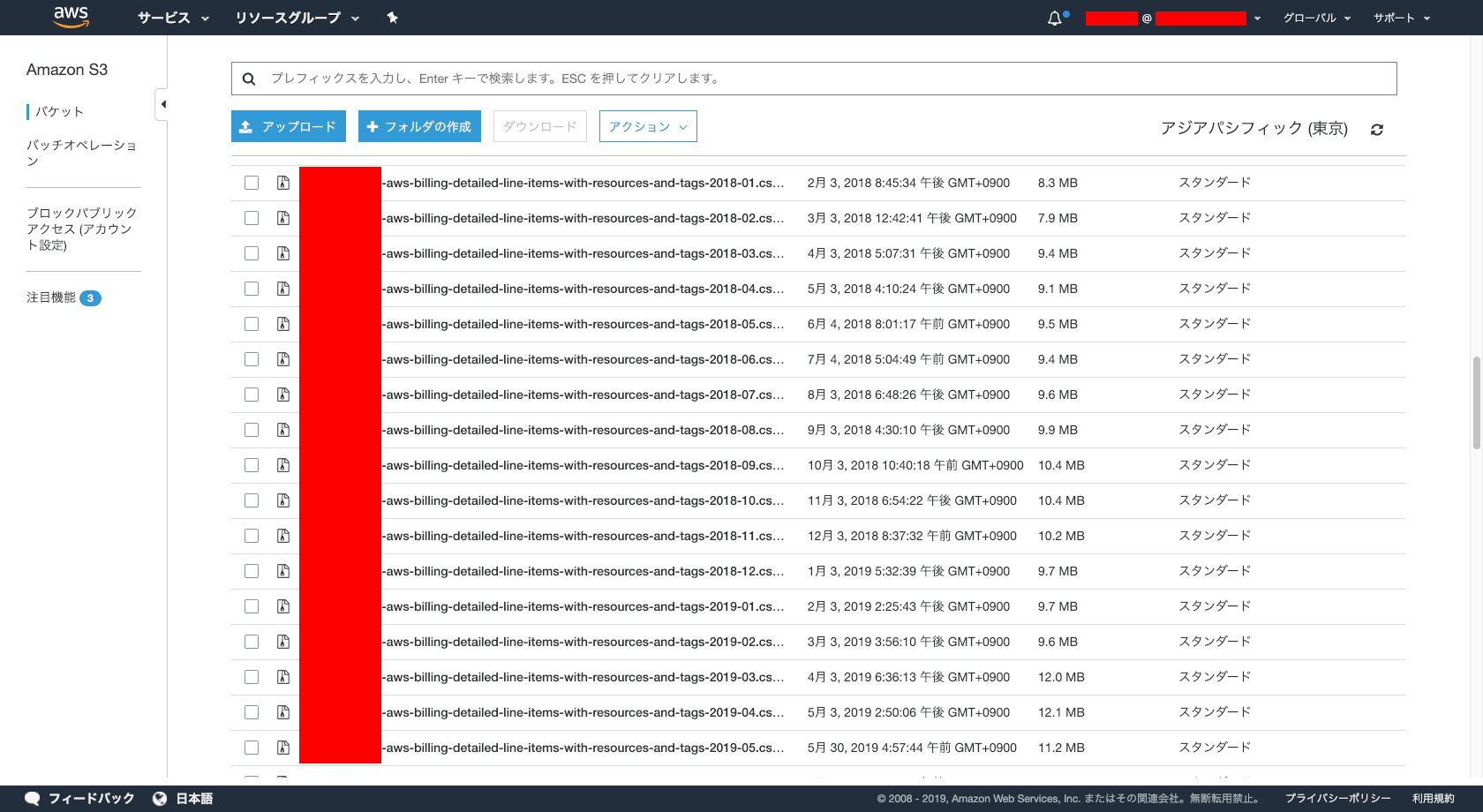
- 作成した S3 へ、コスト配分タグを付与した請求データを出力します。設定は、以下。
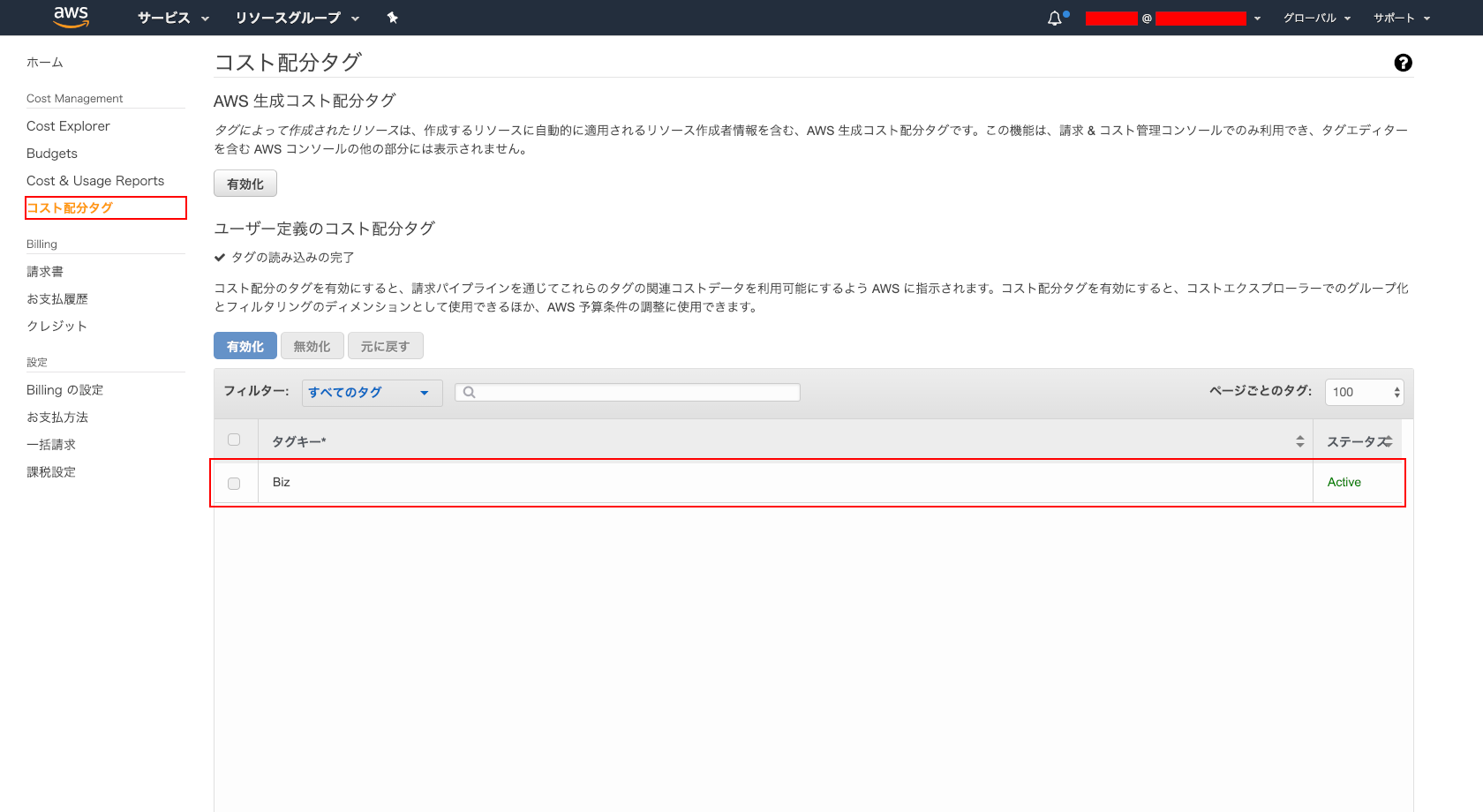
- コスト配分タグ
- ユーザー定義のコスト配分タグ : ※任意のタグをコスト配分タグとして、有効化。
- ※ここでは、Biz をコスト配分タグとして設定しました。
- ※参考
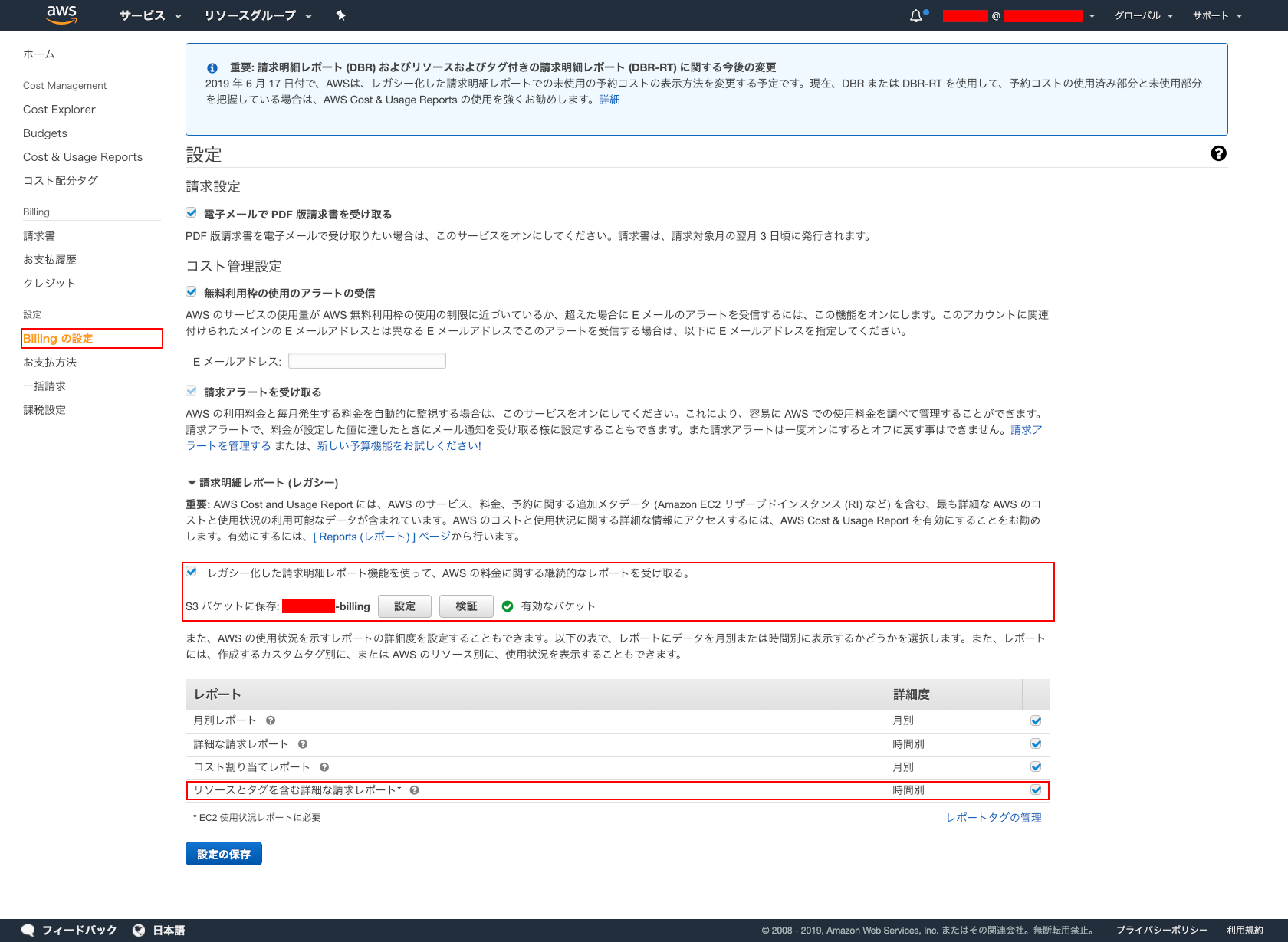
- Billing の設定
- レガシー化した請求明細レポート機能を使って、AWS の料金に関する継続的なレポートを受け取る。 : ☑︎
- S3 バケットに保存 : 作成した S3 バケット
- リソースとタグを含む詳細な請求レポート : ☑︎

- 作成した S3 へ、コスト配分タグを付与した請求データが出力されているか確認します。
2.SNS のトピックを作成し、所定のメールアドレスを登録する。
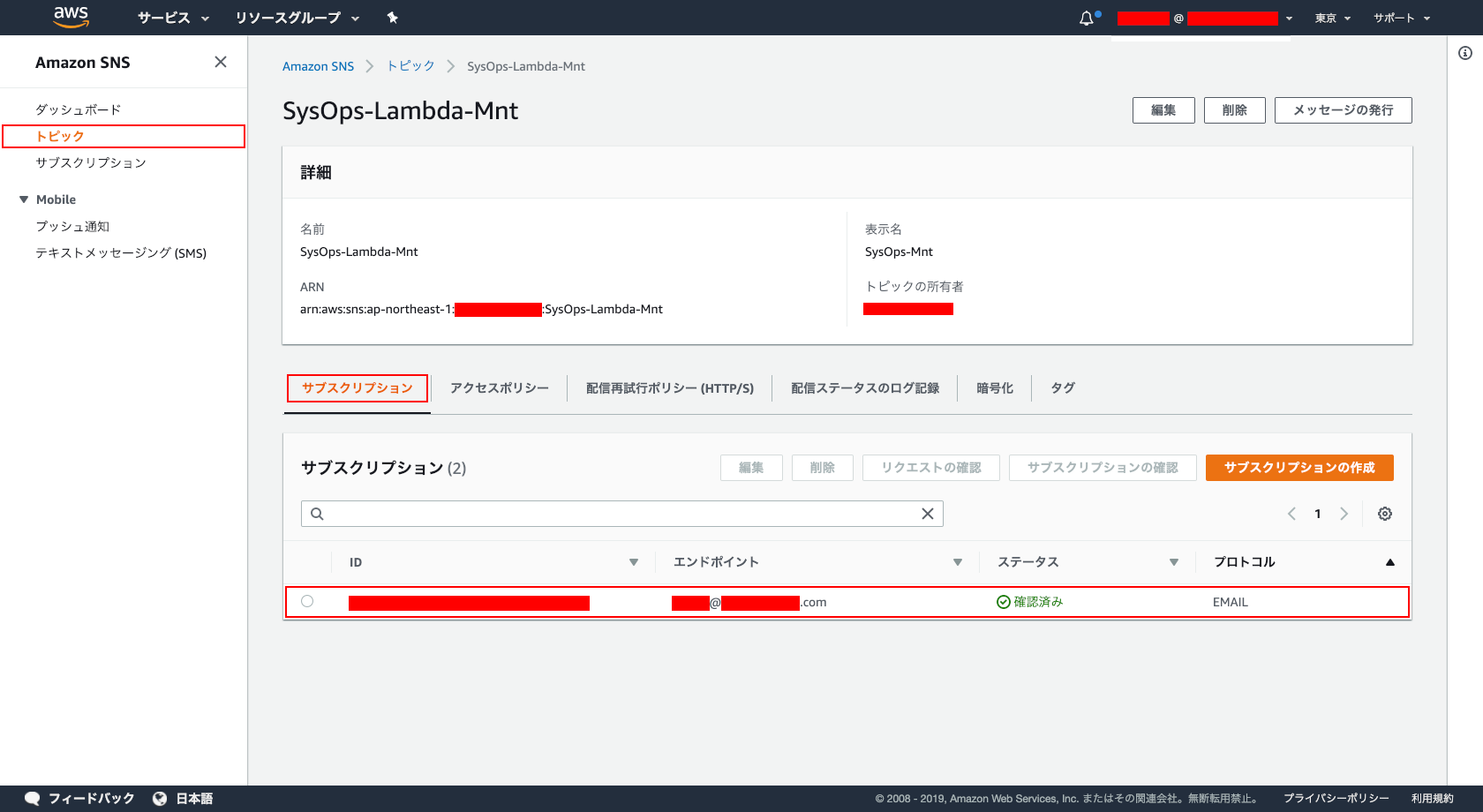
基本的に、以下のページの手順に従って設定します。
- SNS のトピックを作成します。設定は、以下。
- トピック名 : ※任意
- アクセスポリシー : ※以下参考。
{ "Version": "2008-10-17", "Id": "default_policy_ID", "Statement": [ { "Sid": "default_statement_ID", "Effect": "Allow", "Principal": { "AWS": "*" }, "Action": [ "SNS:GetTopicAttributes", "SNS:SetTopicAttributes", "SNS:AddPermission", "SNS:RemovePermission", "SNS:DeleteTopic", "SNS:Subscribe", "SNS:ListSubscriptionsByTopic", "SNS:Publish", "SNS:Receive" ], "Resource": "arn:aws:sns:ap-northeast-1:XXXXXXXXXXXX:SysOps-Lambda-Mnt", "Condition": { "StringEquals": { "AWS:SourceOwner": "XXXXXXXXXXXX" } } } ] }
- 作成した SNS のトピックへ、所定のメールアドレスをサブスクリプションとして登録する。

- 登録後、作成した SNS のトピックへ、パブリッシュして SNS トピックが正常に設定されているか、確認する。
3.Lambda ファンクションを作成する。
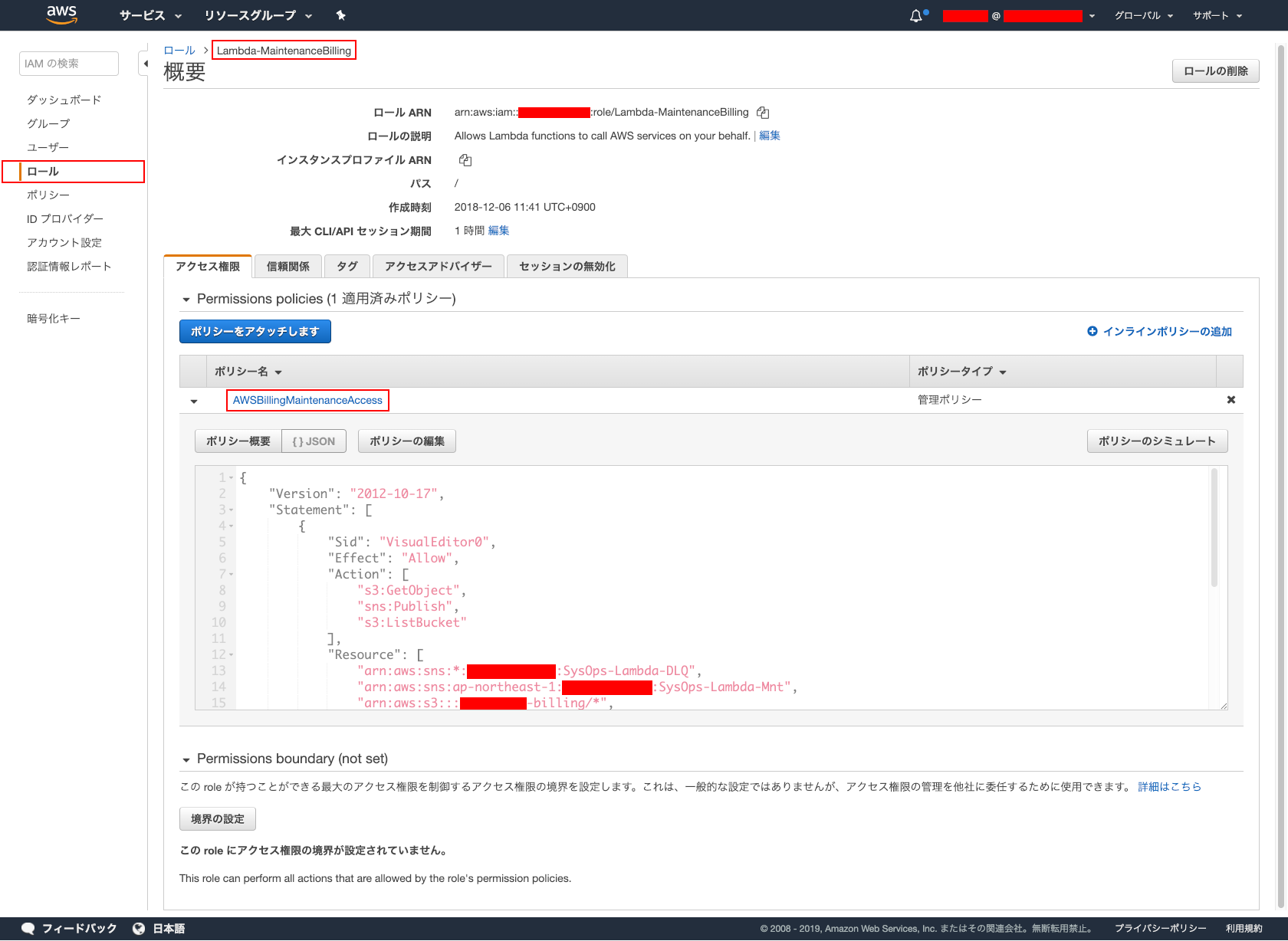
- IAM ロールを作成します。設定は、以下。
- ロール名 : ※任意
- ポリシー名 : ※任意
- ポリシー : ※以下参考。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "s3:GetObject", "sns:Publish", "s3:ListBucket" ], "Resource": [ "arn:aws:sns:*:XXXXXXXXXXXX:SysOps-Lambda-DLQ", "arn:aws:sns:ap-northeast-1:XXXXXXXXXXXX:SysOps-Lambda-Mnt", "arn:aws:s3:::gs-sysops-billing/*", "arn:aws:s3:::gs-sysops-billing" ] }, { "Sid": "VisualEditor1", "Effect": "Allow", "Action": [ "logs:CreateLogStream", "logs:CreateLogGroup", "logs:PutLogEvents" ], "Resource": "*" } ] }
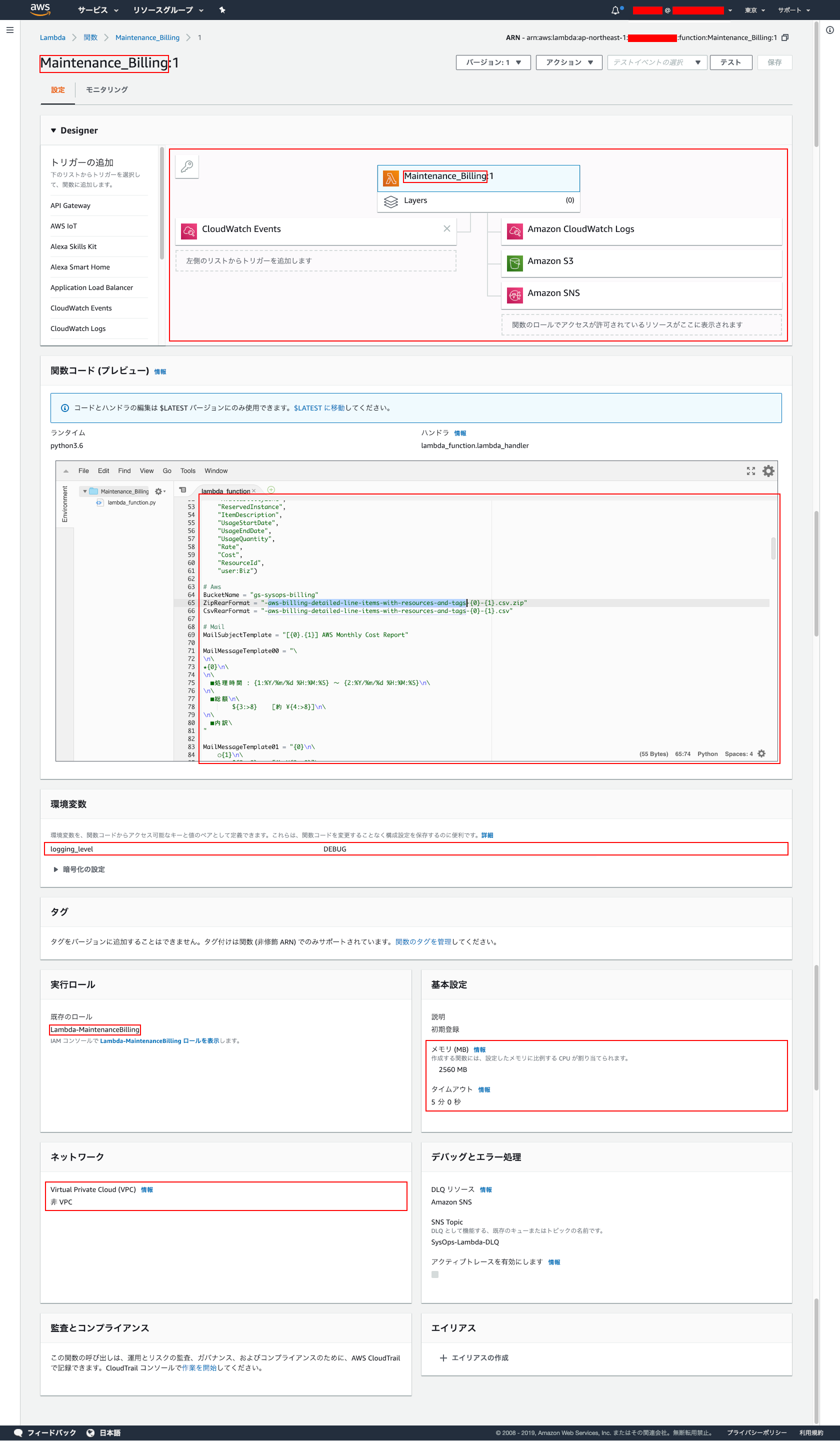
- Lambda ファンクションを作成します。設定は、以下。
- ファンクション名 : ※任意
- 実行ロール : ※作成した IAM ロール
- コード : ※以下参考。
#!/usr/bin/env python # -*- coding: utf-8-unix; -*- """AWS Lambda Function - Maintenance EC2 Images """ from __future__ import print_function import logging import boto3 import os import csv import zipfile import locale # 「python - aws lambda Unable to import module 'lambda_function': No module named 'requests' - Stack Overflow」 # https://stackoverflow.com/questions/48912253/aws-lambda-unable-to-import-module-lambda-function-no-module-named-requests from botocore.vendored import requests # 「Pythonで翌日や翌月みたいな日付の計算をする - Qiita」 # https://qiita.com/dkugi/items/8c32cc481b365c277ec2 from dateutil.relativedelta import relativedelta # 「Python 3 で少しだけ便利になった datetime の新機能 - Qiita」 # <https://qiita.com/methane/items/d7ac3c9af5a2c659bc51> from datetime import datetime, timezone, timedelta TimeZone = timezone(timedelta(hours=+9), 'JST') # 「Lambdaの本番業務利用を考える① - ログ出力とエラーハンドリング | ナレコムAWSレシピ」 # <https://recipe.kc-cloud.jp/archives/9968> logger = logging.getLogger() logLevelTable={'DEBUG':logging.DEBUG,'INFO':logging.INFO,'WARNING':logging.WARNING,'ERROR':logging.ERROR,'CRITICAL':logging.CRITICAL} if os.environ.get('logging_level') in logLevelTable : logger.setLevel(logLevelTable[os.environ['logging_level']]) else: logger.setLevel(logging.WARNING) # StartDateTime = datetime.now(TimeZone) # Csv BillingFieldNames = ( "InvoiceID", "PayerAccountId", "LinkedAccountId", "RecordType", "RecordId", "ProductName", "RateId", "SubscriptionId", "PricingPlanId", "UsageType", "Operation", "AvailabilityZone", "ReservedInstance", "ItemDescription", "UsageStartDate", "UsageEndDate", "UsageQuantity", "Rate", "Cost", "ResourceId", "user:Biz") # Aws BucketName = "\*\*\*\*-billing" ZipRearFormat = "-aws-billing-detailed-line-items-with-resources-and-tags-{0}-{1}.csv.zip" CsvRearFormat = "-aws-billing-detailed-line-items-with-resources-and-tags-{0}-{1}.csv" # Mail MailSubjectTemplate = "[{0}.{1}] AWS Monthly Cost Report" MailMessageTemplate00 = "\ \n\ ★{0}\n\ \n\ ■処理時間 : {1:%Y/%m/%d %H:%M:%S} ~ {2:%Y/%m/%d %H:%M:%S}\n\ \n\ ■総額\n\ ${3:>8} [約 ¥{4:>8}]\n\ \n\ ■内訳\ " MailMessageTemplate01 = "{0}\n\ ○{1}\n\ ${2:>8} [約 ¥{3:>8}]\ " MailMessageTemplate02 = "{0}\n\ \n\ ----\n\ " MailMessageTemplate03 = "{0}\n\ ■{1:<10} : ${2:>8} [約 ¥{3:>8}]\ " MailMessageTemplate04 = "{0}\n\ \n\ ----\n\ \n\ ※ $1 = ¥{1:>6}\n\ ※\n\ \n\ " # ------------------------------------------------------------------------------ # Billing Data Get # ------------------------------------------------------------------------------ def BillingDataGet(prmYear, prmMonth, prmBillingList): logging.info("prmYear:[%s]", prmYear) logging.info("prmMonth:[%s]", prmMonth) result = 0 try: s3 = boto3.resource('s3') bucket = s3.Bucket(BucketName) # Object Key key = None for object in bucket.objects.all(): if ZipRearFormat.format(prmYear, prmMonth) != object.key[-72:]: continue key = object.key break logging.info("key:[%s]", key) if key is None: raise Exception("No such key was found. key={}".format(key)) tmpZipPath = "/tmp/_tmp.zip" tmpCsvPath = "/tmp/_tmp.csv" # Download logging.info("tmpZipPath:[%s]", tmpZipPath) s3.Object(BucketName, key).download_file(tmpZipPath) # UnZip logging.info("UnZip") zf = zipfile.ZipFile(tmpZipPath, 'r') for f in zf.namelist(): if CsvRearFormat.format(prmYear, prmMonth) != f[-68:]: continue uzf = open(tmpCsvPath, 'wb') uzf.write(zf.read(f)) uzf.close() break zf.close() # Csv with open(tmpCsvPath) as csvfile: for row in csv.DictReader(csvfile, BillingFieldNames): if row["LinkedAccountId"] == "LinkedAccountId": continue prmBillingList.append(row) except Exception as e: logger.exception('Error dosomething: %s', e) result = 1 raise else: pass finally: pass return result # 「[小ネタ]為替レートを簡単に取得する - Qiita」 # <https://qiita.com/chromabox/items/a1323225bae146c80bec> def RateGet(): result = -1 try: Url = "https://www.gaitameonline.com/rateaj/getrate" r = requests.get(Url) r_quotes = r.json()["quotes"] for i in range(len(r_quotes)): if r_quotes[i].get("currencyPairCode") == "USDJPY": result = float(r_quotes[i].get("open")) break except Exception as e: logger.exception('Error dosomething: %s', e) result = -1 raise else: pass finally: pass return result # 「【Python】Lambdaからメールを送信 | ハックノート」 # https://hacknote.jp/archives/35679/ def MailSend(prmSubject, prmMessage): result = -1 try: sns = boto3.client('sns') response = sns.publish( TopicArn = 'arn:aws:sns:ap-northeast-1:454930157265:SysOps-Lambda-Mnt', Message = prmMessage, Subject = prmSubject ) except Exception as e: logger.exception('Error dosomething: %s', e) result = -1 raise else: pass finally: pass return result def lambda_handler(event, context): try: global StartDateTime StartDateTime = datetime.now(TimeZone) logger.info("StartDateTime:[%s]", StartDateTime) # logger.info("event:[%s]", event) logger.info("context:[%s]", context) # try: yyyymm = event.get("YYYYMM", "") tdatetime = datetime.strptime( yyyymm[0:4] + "-" + yyyymm[4:6] + "-01 01:00:00", '%Y-%m-%d %H:%M:%S') except ValueError: tdatetime = StartDateTime - relativedelta(months=1) logger.info("tdatetime:[%s]", tdatetime) yyyy = tdatetime.year mm = "{0:0>2}".format(tdatetime.month) logger.info("yyyy:[%s] mm:[%s]", yyyy, mm) # Billing Data Get tmpBliingList = [] BillingDataGet(yyyy, mm, tmpBliingList) # Rate Get rate = RateGet() logging.info("Rate:[%f]", rate) # ---------------------------------------------------------------------- # Summary # ---------------------------------------------------------------------- # Summary ProductName dicSummary = {} dicSummarySub = {} for i in range(len(tmpBliingList)): if "Sign up charge for subscription:" in tmpBliingList[i]["ItemDescription"]: logging.info("Sign up charge for subscription - tmpBliingList:[%s]", tmpBliingList[i]) dicSummarySub[tmpBliingList[i]["InvoiceID"]] = { "InvoiceID": tmpBliingList[i]["InvoiceID"], "ProductName": tmpBliingList[i]["ProductName"], "UsageType": tmpBliingList[i]["UsageType"], "UsageQuantity": tmpBliingList[i]["UsageQuantity"], tmpBliingList[i]["ItemDescription"] : { "RecordType": tmpBliingList[i]["RecordType"], "Cost": tmpBliingList[i]["Cost"], }, } continue if "Tax of type CT" in tmpBliingList[i]["ItemDescription"]: logging.info("Tax of type CT - tmpBliingList:[%s]", tmpBliingList[i]) if tmpBliingList[i]["InvoiceID"] in dicSummarySub: dicSummarySub[tmpBliingList[i]["InvoiceID"]][tmpBliingList[i]["ItemDescription"]] = { "RecordType": tmpBliingList[i]["RecordType"], "Cost": tmpBliingList[i]["Cost"], } continue if "Total amount for invoice" in tmpBliingList[i]["ItemDescription"]: if tmpBliingList[i]["InvoiceID"] in dicSummarySub: dicSummarySub[tmpBliingList[i]["InvoiceID"]][tmpBliingList[i]["ItemDescription"]] = { "RecordType": tmpBliingList[i]["RecordType"], "Cost": tmpBliingList[i]["Cost"], } continue # tmpDict = dicSummary tmpKey = tmpBliingList[i]["RecordType"] if not tmpKey in tmpDict: tmpDict[tmpKey] = {} # tmpDict = tmpDict[tmpKey] tmpKey = tmpBliingList[i]["ProductName"] if not tmpKey: tmpKey = tmpBliingList[i]["ItemDescription"] elif tmpKey == "Amazon Elastic Compute Cloud": if "EBS" in tmpBliingList[i]["UsageType"]: tmpKey = tmpKey + " - EBS" if not tmpKey in tmpDict: tmpDict[tmpKey] = {} tmpDict[tmpKey]["SumCost"] = 0.0 # tmpDict = tmpDict[tmpKey] tmpKey = tmpBliingList[i]["user:Biz"] if not tmpKey in tmpDict: tmpDict[tmpKey] = {} # tmpCost = float(tmpBliingList[i]["Cost"]) if tmpBliingList[i]["Cost"] else 0.0 if not "Cost" in tmpDict[tmpKey]: #tmpDict[tmpKey]["Count"] = 1 tmpDict[tmpKey]["Cost"] = tmpCost else: #tmpDict[tmpKey]["Count"] += 1 tmpDict[tmpKey]["Cost"] += tmpCost tmpDict["SumCost"] += tmpCost # Summary Biz tmpSumCostAllToRedistribute = 0.0 tmpSumCostAllNotToRedistribute = 0.0 dicSummaryBiz = {} for k1 in sorted(dicSummary["LineItem"]): for k2 in sorted(dicSummary["LineItem"][k1]): if not isinstance(dicSummary["LineItem"][k1][k2], dict): continue if not k2 in dicSummaryBiz: dicSummaryBiz[k2] = {} dicSummaryBiz[k2]["SumCost"] = 0.0 dicSummaryBiz[k2]["SumCostRedistributed"] = 0.0 if not k1 in dicSummaryBiz[k2]: dicSummaryBiz[k2][k1] = {} dicSummaryBiz[k2][k1]["Cost"] = dicSummary["LineItem"][k1][k2]["Cost"] dicSummaryBiz[k2]["SumCost"] += dicSummary["LineItem"][k1][k2]["Cost"] if not k2: tmpSumCostAllToRedistribute += dicSummary["LineItem"][k1][k2]["Cost"] continue if k2 == "Share": tmpSumCostAllToRedistribute += dicSummary["LineItem"][k1][k2]["Cost"] continue tmpSumCostAllNotToRedistribute += dicSummary["LineItem"][k1][k2]["Cost"] for k1 in sorted(dicSummaryBiz): if not k1: continue if k1 == "Share": continue dicSummaryBiz[k1]["SumCostRedistributed"] = dicSummaryBiz[k1]["SumCost"] + ( tmpSumCostAllToRedistribute * dicSummaryBiz[k1]["SumCost"]) / tmpSumCostAllNotToRedistribute logging.info("dicSummaryBiz:[%s]", dicSummaryBiz) # ---------------------------------- # Mail Create Message # ---------------------------------- locale.setlocale(locale.LC_NUMERIC, 'ja_JP') # Subject tmpSubject = MailSubjectTemplate.format(yyyy, mm) # Message tmpCost = list(dicSummary["InvoiceTotal"].values())[0][""]["Cost"] tmpMessage = MailMessageTemplate00.format(tmpSubject, StartDateTime, datetime.now(TimeZone) , locale.format('%.2f', tmpCost, True), locale.format('%.0f', tmpCost*rate, True)) for k1 in sorted(dicSummary["LineItem"]): tmpCost = dicSummary["LineItem"][k1]["SumCost"] if tmpCost == 0: continue tmpMessage = MailMessageTemplate01.format(tmpMessage, k1 , locale.format('%.2f', tmpCost, True), locale.format('%.0f', tmpCost*rate, True)) tmpMessage = MailMessageTemplate02.format(tmpMessage) for k1 in sorted(dicSummaryBiz): if not k1: continue if k1 == "Share": continue tmpCost = dicSummaryBiz[k1]["SumCostRedistributed"] tmpMessage = MailMessageTemplate03.format(tmpMessage, k1 , locale.format('%.2f', tmpCost, True), locale.format('%.0f', tmpCost*rate, True)) tmpMessage = MailMessageTemplate04.format(tmpMessage, locale.format('%.2f', rate, True)) # Mail Send logging.info("tmpSubject:[%s]", tmpSubject) logging.info("tmpMessage:[%s]", tmpMessage) MailSend(tmpSubject, tmpMessage) except Exception as e: logger.exception('Error dosomething: %s', e) else: pass finally: pass # return "normal end"
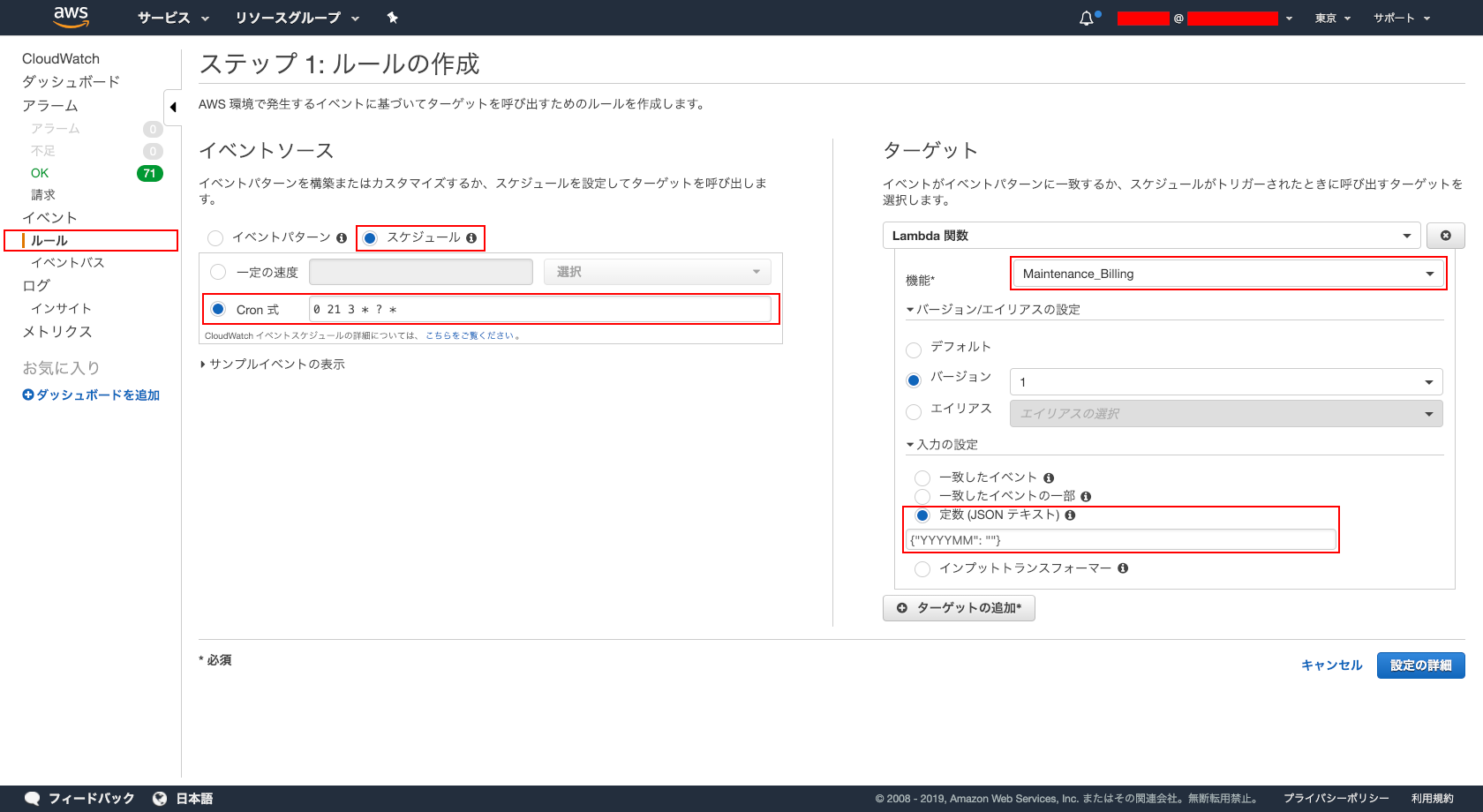
4.CloudWatch Events のルールを作成する。
- CloudWatch Events のルールを作成します。設定は、以下。
- イベントソース : ※今回は、毎月のコストレポートなので以下。
- スケジュール : ☑︎
- Cron 式 : 0 21 3 * ? *
- ターゲット
- Lambda 関数
- ※作成した Lambda ファンクション
- バージョンのエイリアス
- ※任意
- 入力の設定
- 定数 (JSON テキスト) : {"YYYYMM", ""}
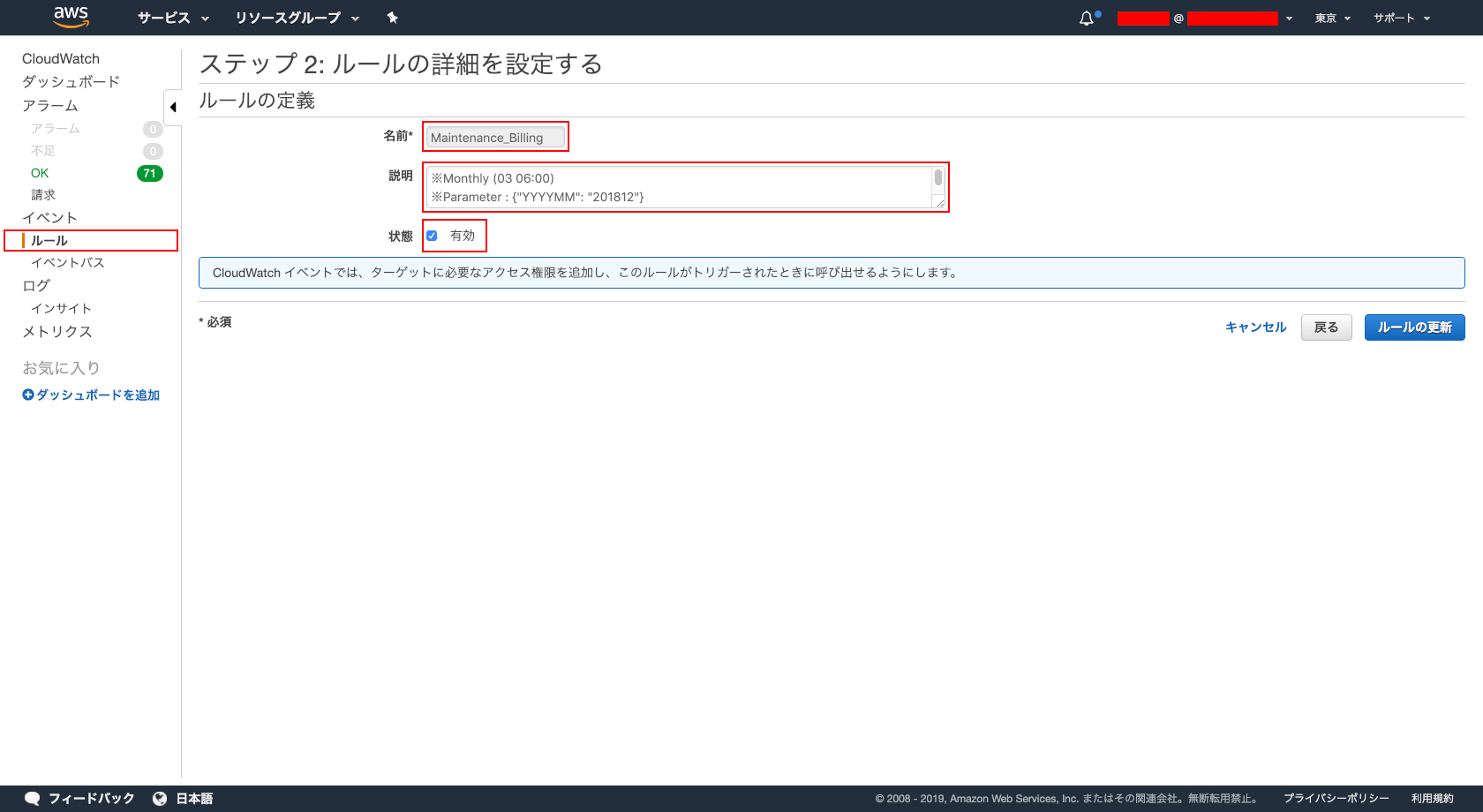
- ルールの定義
- 名前 : ※任意
- 説明 : ※任意
- 状態 : ☑︎ 有効「」
99.ハマりポイント
- うーん…。随分前に作成したので、覚えてない…。
XX.まとめ
今回、とりあえず残しておこうかなぁ、と思って記事書いたんですが、
こういう注意事項が表示されて…、
今後は、「AWS Cost and Usage Report」を使わないといけないのかなぁ。
うーん、また新しいやり方を考えなないといけないのだろうか…。



- 投稿日:2019-05-30T12:27:43+09:00
[Python3.6]サーバで作成してダウンロードしたCSVをExcelで開くと日本語が文字化けする時の対処法
- 投稿日:2019-05-30T12:13:05+09:00
[Django][CentOS7][Python3.6]ディレクトリアクセス時に発生するPermission denied 13
環境
- Django 2.1
- CentOS 7
- Python 3.6
- Apache 2.4
- mod_wsgi 4.6.5
問題
ルートディレクトリから対象ディレクトリまでの全てのディレクトリのオーナーをapache:apacheに、権限をdrwxrwxrwxに変更したが
Permission deniedとなる。原因
SELinuxが有効になっていた。
解決策
SELinuxを無効化する。
[参考]https://qiita.com/hanaita0102/items/5d3675e4dc1530b255ba
- 投稿日:2019-05-30T12:13:05+09:00
[Django][CentOS7][Python3.6]ディレクトリアクセス時に発生するPermission denied 13の対処法
環境
- Django 2.1
- CentOS 7
- Python 3.6
- Apache 2.4
- mod_wsgi 4.6.5
問題
ルートディレクトリから対象ディレクトリまでの全てのディレクトリのオーナーをapache:apacheに、権限をdrwxrwxrwxに変更したが
Permission deniedとなる。原因
SELinuxが有効になっていた。
解決策
SELinuxを無効化する。
[参考]https://qiita.com/hanaita0102/items/5d3675e4dc1530b255ba
- 投稿日:2019-05-30T11:46:53+09:00
Visual Studio CodeでPythonコードをデバッグする
Cプログラマに送るPythonコード攻略
C言語でIDEを使っていると当たり前のように使うデバッガー。ひょんなことからPythonを使わなければいけなくなり、Visual Code Studioにたどり着き、print文ではないデバッグ方法が使えて便利だったので、そのメモを書いておきます。
一番簡単な方法は、Visual Studio Codeを使います。
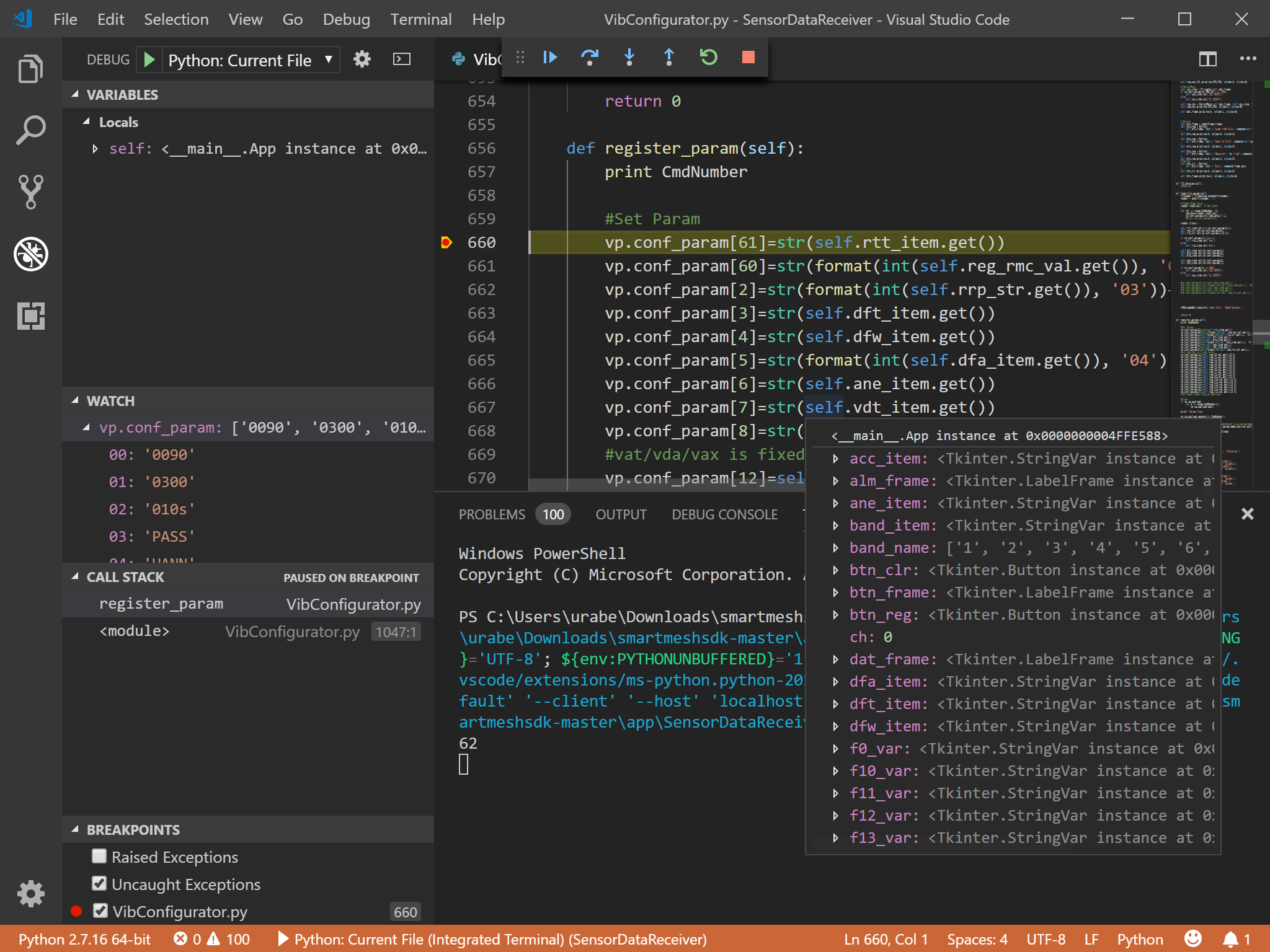
Visual Studio Codeを使用すると、pythonのコードにブレークポイントを設定でき、
該当箇所で止まった時に変数の中身を調べることができます(図1)。
図1図中のカーソルが止まっている箇所をダブルクリックするだけで、ブレークポイントを設定できます。
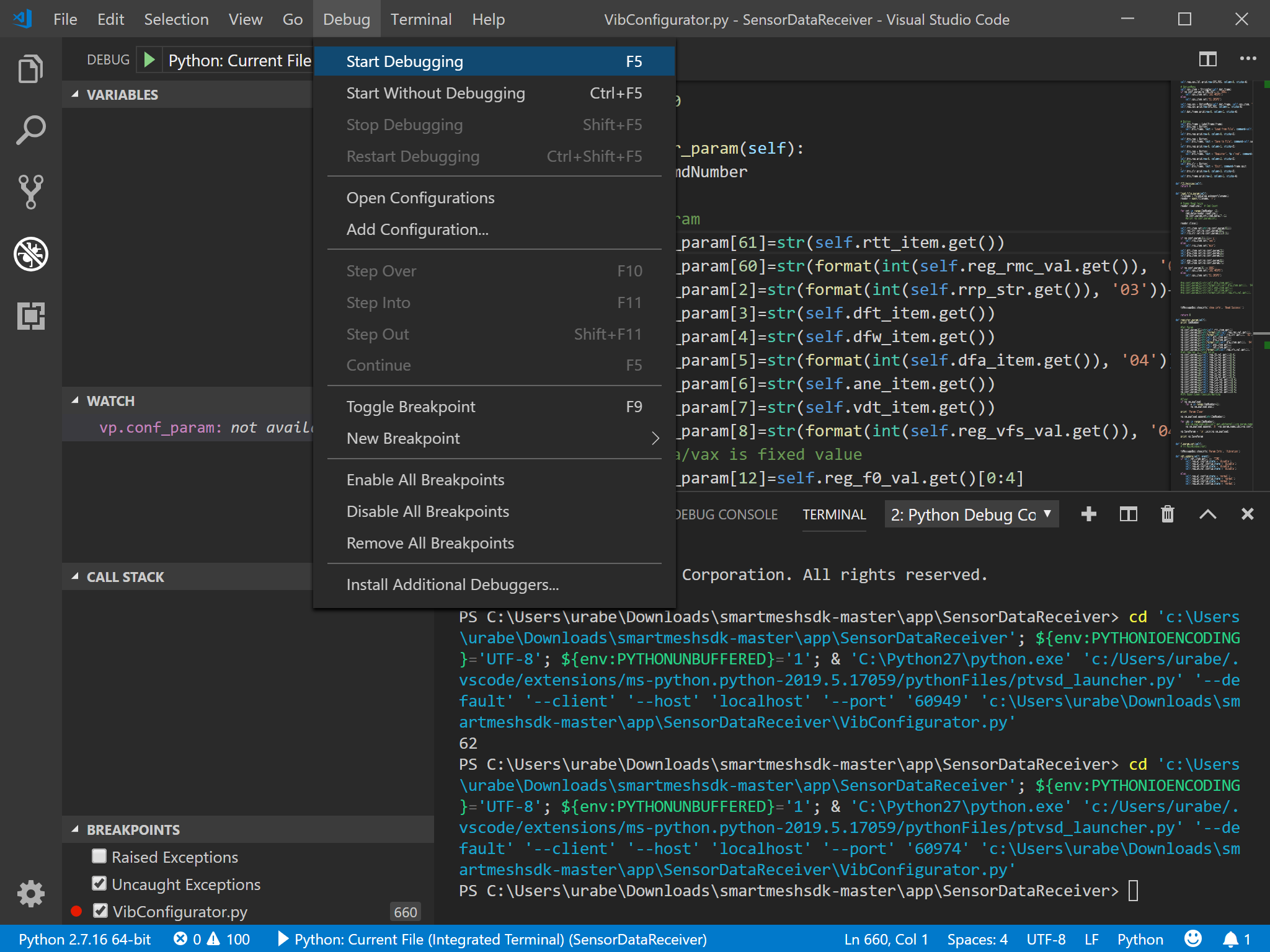
図2デバッグモードで、動かすには、「Debug」メニューから「Start Debugging」を選択します(図3)。
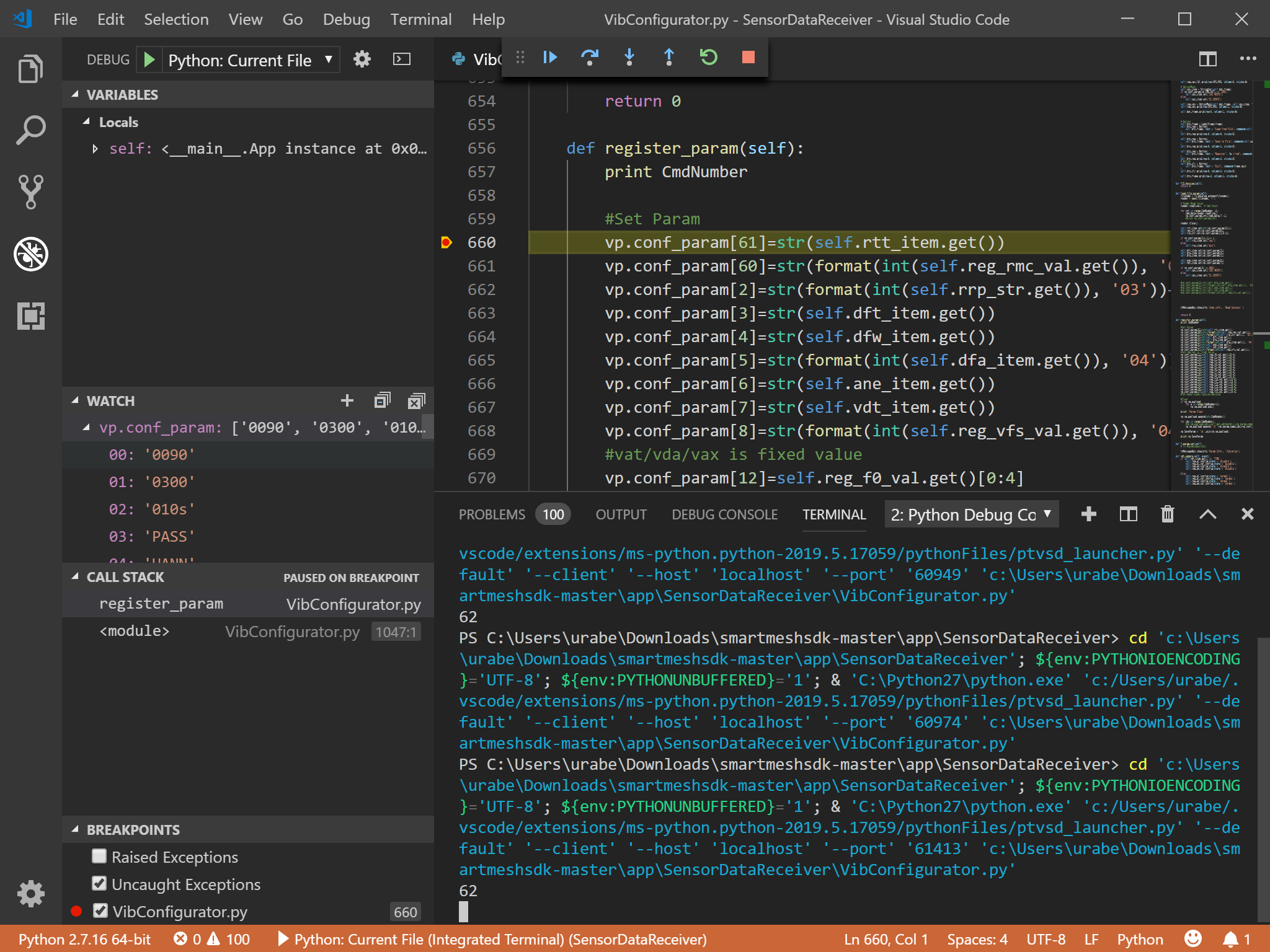
図3該当箇所に来ると、プログラムが停止し、変数やリストの中身を見ることができます(図4)。
図4このように、不慣れな言語を扱うときに、覚えておくと効率的に進めることができます。
まとめ
Pythonを使うときは、Visual Code Studioのデバッガーを最大限活用しましょう。
- 投稿日:2019-05-30T10:18:15+09:00
【Python】新卒入社して2ヶ月経ったのでKaggleのTitanicにチャレンジする【KNN】
概要
新卒2ヶ月目です(自己紹介)。
まだ色々と勉強中ですが,早いものでデータ分析会社に入ってから2ヶ月が経過し,Python歴も1ヶ月を超えました。
そこで,今回はPythonによる機械学習の練習として,KaggleのTitanic生存予測にチャレンジしていこうと思います。公式ページはこちら→https://www.kaggle.com/c/titanic
TrainデータとTestデータをダウンロードして,Trainデータを処理して予測モデルを構築してTestデータの予測をして提出,スコア確認,という流れになります。日本広しといえど,未経験からKaggleに挑戦する新卒2ヶ月目というのは,中々自分以外にはいないんじゃないかと思いますので,この記事を見た未来の新卒の人などは,ぜひ参考にしてください。
また,この記事をみたデータ分析やプログラマの諸先輩方におかれましては,拙い部分もあるかと思いますが,ぜひ,アドバイス等いただければ幸いです。
それではやっていきます。
今回のやること一覧
1.データ概観,前処理,EDA
2.KNNによる予測モデル構築
3.テストセットの生存予測,結果環境
- Windows10
- Anaconda
- Python 3.6.5
- JupyterNotebook
1.データ概観,前処理,EDA
まずは使うデータの内容を確認していきます。今回Kaggleが提供してくれるデータは以下12列,891行のデータ(今回の記事では簡単のためNameとTicketは使いません,あしからず)。
使用データ:train.csv(全12列,891行)
カラム 内容 説明 PassengerId 搭乗者番号 Survival 生死 0なら死亡,1なら生存 Pclass チケットの等級 1 = 1st,2 = 2nd,3 = 3rd Name 名前 今回は使わない Sex 性別 maleかfemale Age 年齢 1歳未満の場合は少数表記,推定した年齢なら「~.5」の表記 SibSp 同乗してた兄弟姉妹,配偶者の人数 Parch 同乗してた両親,子供の人数 Ticket チケット番号 今回は使わない Fare 運賃 Cabin 客室番号 Embarked 搭乗した港 C = Cherbourg,Q = Queenstown,S = Southampton train_csvはひとまず「df_train_raw」でDataFrame化して,行数や欠損数と,データの先頭5行を確認します。
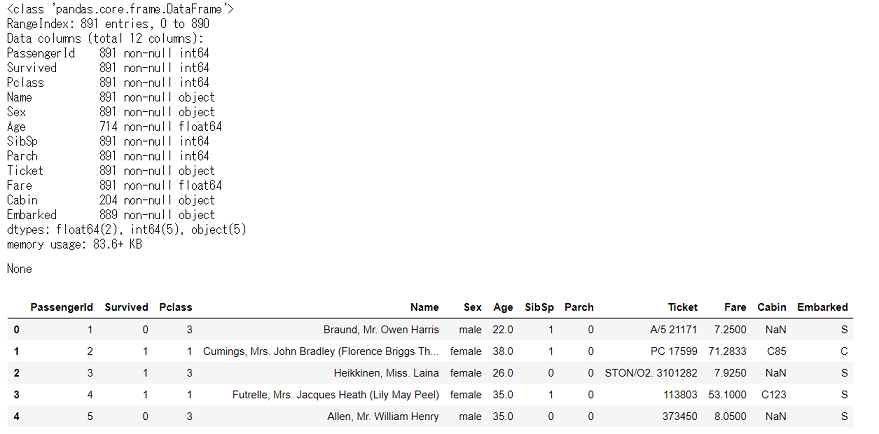
データ概観import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline df_train_raw = pd.read_csv('C:/~hoge~/train.csv') display(df_train_raw.info(), df_train_raw.head())
全体は891行,欠損値が含まれてるのはAge,Cabin,Embarkedですが,Cabinは8割くらい欠損しています。どうやらCabinが欠損している人は客室がなかった,という事のようです。このまま欠損値を除外するには数が多すぎるので,取り敢えずCabinは「あったかなかったか」の0,1にしておきましょう。
CabinのNullを補完→Cabin有:1,Cabin無:0にするfor index, values in enumerate(df_train_raw['Cabin']): try: if np.isnan(values) == True: df_train_raw.loc[index, 'Cabin'] = 0 except TypeError: df_train_raw.loc[index, 'Cabin'] = 1Ageの欠損値には平均値を入れて,Embarkedの欠損は2件なのでひとまず除外して,今回使う9行だけにして,処理後のData Frame「df_train」を作成。
Ageの欠損値にはAgeの平均値を,Embarkedの欠損した行は除外するdf_train_raw['Age'] = df_train_raw['Age'].fillna(df_train_raw['Age'].mean()) df_train = df_train_raw[['Survived', 'Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Cabin', 'Embarked']].dropna() df_train.info()
3列と2行落ちて,全部で889行になりました。
それでは,df_trainをもとに,各変数とSurvivedとの関係を簡単に見ていきます。
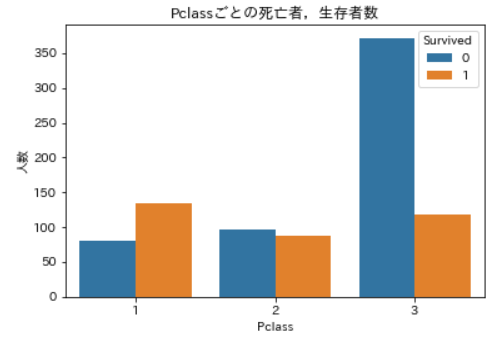
まずはPclass。Pclassごとの死亡者,生存者数の可視化ax = plt.axes() sns.countplot(x='Pclass', data=df_train, hue='Survived', ax=ax) ax.set_title('Pclassごとの死亡者,生存者数') ax.set_ylabel('人数') plt.show()
青が死亡者,橙が生存者です。
Pclassの等級が下がると死亡者数は増え,生存者数が減っているのが分かりますね。この変数は生死に大いに関係ありそうです。次はCabin。
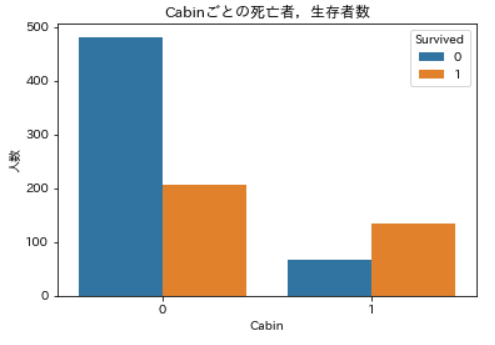
Cabinごとの死亡者,生存者数の可視化ax = plt.axes() sns.countplot(x='Cabin', data=df_train, hue='Survived', ax=ax) ax.set_title('Cabinごとの死亡者,生存者数') ax.set_ylabel('人数') plt.show()
Cabinがない場合には生存者の2倍以上の死亡者が出ていますが,Cabinがあるとちょうどその逆で,生存者数が死亡者数を2倍近く上回っていますね。
これも生存予測に役立ちそうです。次はSex。これも,あとで分類しやすいように,maleだったら0,femaleだったら1に置換しておきます。
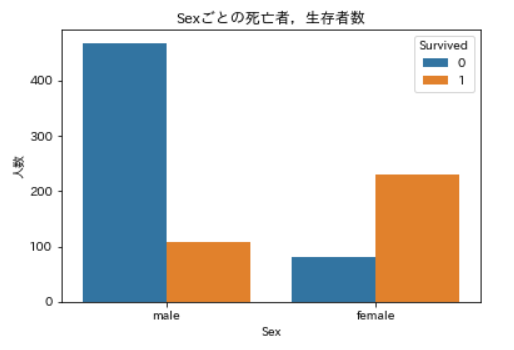
Sexごとの死亡者,生存者数の可視化 male:0,Female:1に置換するax = plt.axes() sns.countplot(x='Sex', data=df_train, hue='Survived', ax=ax) ax.set_title('Sexごとの死亡者,生存者数') ax.set_ylabel('人数') plt.show() for index, values in enumerate(df_train['Sex']): if values == 'male': df_train.loc[index, 'Sex'] = 0 else: df_train.loc[index, 'Sex'] = 1
男性の場合は生存者数の3倍以上の死亡者が出ていますが,女性の場合には死亡者数の4倍近い生存者が出ています。
性別がどっちだったかも,生存予測に役立つでしょう。次はSibSp,Parchですが,これも取り敢えず全部合計して,搭乗時に何人でいたかで分類できるようにします。
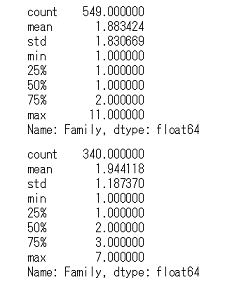
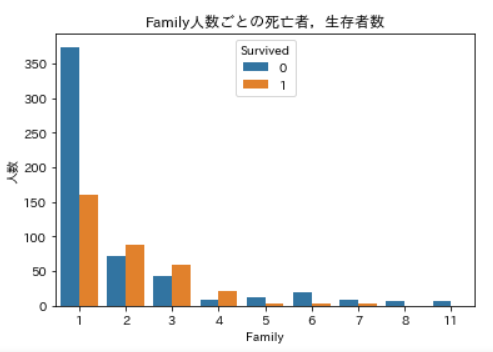
家族人数で分類するカラムを追加した新しいData Frameを作成し,そのカラムについての死亡者,生存者数の要約統計量と,それぞれの度数分布を作成していきます(以降はこのData Frameを使います)。Familyカラムを追加した新たなDFの作成,Familyごとの死亡者,生存者数の可視化## index振り直し df_train = df_train.reset_index(drop = True) ## 'SibSp'と'Parch'と自分を足した家族人数のSeriesを作成 family_series = pd.Series(df_train['SibSp'] + df_train['Parch'] + 1) ## family_seriesを追加した新たなData Frameを作成,新カラム名は'Family' df_train_with_family = pd.concat([df_train, family_series], axis=1).rename(columns={0:'Family'}) ## 死亡者,生存者ごとのFamilyの要約統計量 display(df_train_with_family.query('Survived == 0')['Family'].describe(), df_train_with_family.query('Survived == 1')['Family'].describe()) ## 死亡者,生存者数ごとのFamilyの度数分布 ax = plt.axes() sns.countplot(x='Family', data=df_train_with_family, hue='Survived', ax=ax) ax.set_title('Family人数ごとの死亡者,生存者数') ax.set_ylabel('人数') plt.show() )
上が死亡者,下が生存者です。平均値などそんなに違いはなさそうですね。
分布はこんな感じです。
一人で搭乗した人の死亡率は高いですが,複数人だと生存者数の方が高くなっていますね。
搭乗時に一人だったか,それとも誰かと一緒だったかも,生存予測に役立ちそうです。次はFareです。まずは死亡者と生存者で,それぞれの支払った運賃に関する要約統計量を見ていきます。
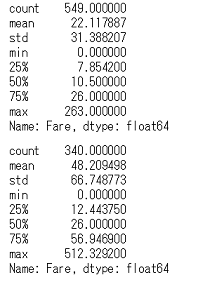
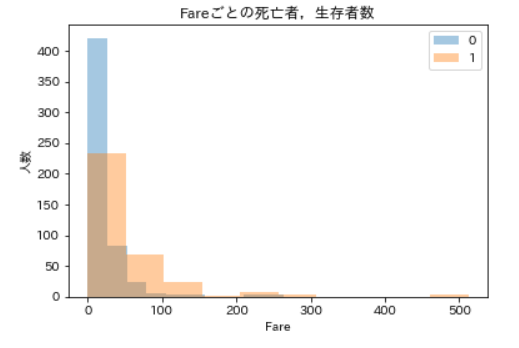
死亡者,生存者ごとのFareの要約統計量display(df_train_with_family.query('Survived == 0')['Fare'].describe(), df_train_with_family.query('Survived == 1')['Fare'].describe())
上が死亡者,下が生存者です。
パッと見ると生存者の方が払った運賃は高いようですね。ただ,どちらについても平均値の10倍ほどある最大値が気になります。分布も確認すると
死亡者,生存者ごとのFareの度数分布ax = plt.axes(ylabel='人数') sns.distplot(df_train_with_family.query('Survived == 0')['Fare'], kde=False, bins=10, ax=ax) sns.distplot(df_train_with_family.query('Survived == 1')['Fare'], kde=False, bins=10, ax=ax) ax.set_title('Fareごとの死亡者,生存者数') ax.legend(df_train_with_family['Survived']) plt.show()
青が死亡者,橙が生存者ですが,やっぱり範囲が広すぎますね。Fareが100以上の人のデータは少なすぎて全然見えません。
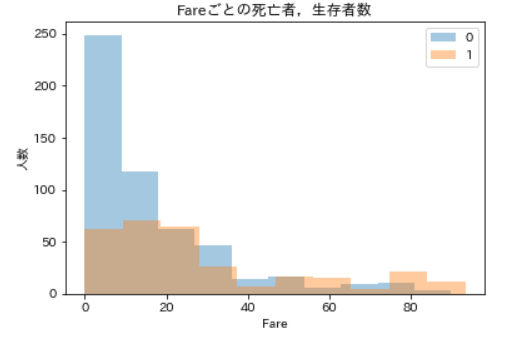
しかし100より下の方では何か面白いことが起きていそうですので,Fareを100未満に絞って分布をみてみます。Fareが100未満の死亡者,生存者数の可視化ax = plt.axes(ylabel='人数') sns.distplot(df_train_with_family.query('Survived == 0 and Fare < 100')['Fare'], kde=False, bins=10) sns.distplot(df_train_with_family.query('Survived == 1 and Fare < 100')['Fare'], kde=False, bins=10) ax.set_title('Fareごとの死亡者,生存者数') ax.legend(df_train_with_family['Survived']) plt.show()今度は見やすくなりました。
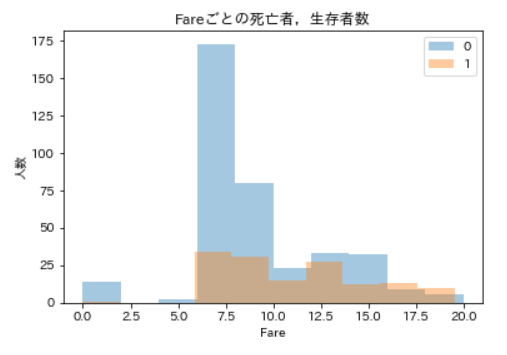
Fareが20より下のあたりで死亡者数がグンと減っていますね。もう少し詳しく見るために,今度はFareを20未満に絞って分布をみてみます。Fareが20未満の死亡者,生存者数の可視化ax = plt.axes(ylabel='人数') sns.distplot(df_train_with_family.query('Survived == 0 and Fare < 20')['Fare'], kde=False, bins=10) sns.distplot(df_train_with_family.query('Survived == 1 and Fare < 20')['Fare'], kde=False, bins=10) ax.set_title('Fareごとの死亡者,生存者数') ax.legend(df_train_with_family['Survived']) plt.show()
もっと見やすくなりました。生存者数はそこまで変化していませんが,Fareが7.5より大きくなるあたりで,死亡者数が大きく減っているのが分かります。
次はEmbarked。
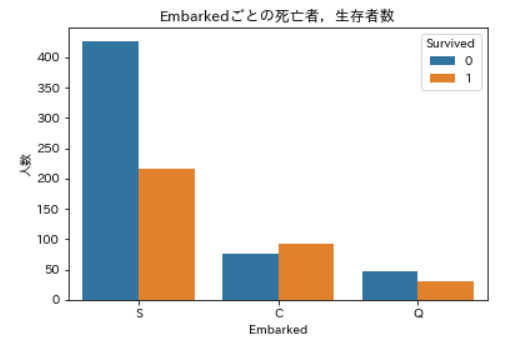
Embarkedごとの死亡者,生存者数の可視化ax = plt.axes() sns.countplot(x='Embarked', data=df_train_with_family, hue='Survived', ax=ax) ax.set_title('Embarkedごとの死亡者,生存者数') ax.set_ylabel('人数') plt.show()
EmbarkedがS,Qの場合では生存者より死亡者の方が多いですが,Cだけは生存者の方が多くなっていますね。最後はAgeです。まずは死亡者,生存者それぞれについての年齢の要約統計量を確認します。
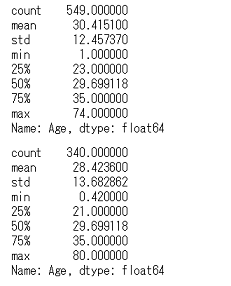
死亡者,生存者ごとのAgeの要約統計量display(df_train_with_family.query('Survived == 0')['Age'].describe(), df_train_with_family.query('Survived == 1')['Age'].describe())
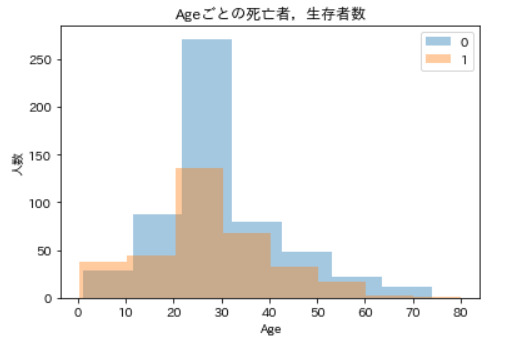
要約統計量は両方とも同じくらい,という感じですが,それぞれの年齢の度数分布も確認します。死亡者,生存者ごとのAgeの度数分布ax = plt.axes(ylabel='人数') sns.distplot(df_train_with_family.query('Survived == 0')['Age'], kde=False, bins=7) sns.distplot(df_train_with_family.query('Survived == 1')['Age'], kde=False, bins=8) ax.set_title('Ageごとの死亡者,生存者数') ax.legend(df_train_with_family['Survived']) plt.show()
青が死亡者,橙が生存者です。どちらも30代あたりが最も多くそれ以外は段々に減っていく,という感じですが,0歳代~10歳代の区間では,生存者数の方が死亡者数を上回っているようです。
それでは,各変数とSurvivedとの関係を一通り確認できましたので,これらの変数を使って生存予測のためのモデルを作っていきましょう。
2.KNNによる予測モデル構築
実際に予測モデルを作っていきます。今回は,機械学習アルゴリズムの1つであるKNN(K-Nearest Neighbor)を使います。
KNNによるモデル作成に関してはPythonではじめる機械学習とPython機械学習プログラミングを参考にしました。また,詳しい仕組みについては,
K近傍法(多クラス分類)
こちらの記事を参考にさせていただきました。KNNはその仕組みがとても分かりやすく,取り敢えず機械学習やってみたい!という方にはおススメです。
それではやっていきましょう。
KNNを用いて予測モデルの構築from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier from sklearn.preprocessing import StandardScaler df_train_with_family.loc[:, 'Cabin'] = df_train_with_family.loc[:,'Cabin'].astype(np.int64) df_train_with_family.loc[:, 'Sex'] = df_train_with_family.loc[:, 'Sex'].astype(np.int64) ## カテゴリ変数(今回はEmbarked)をダミー変数化したData Frameを新たに作成する df_train_knn_x = pd.get_dummies(df_train_with_family[['Pclass', 'Sex', 'Age', 'Fare', 'Cabin', 'Embarked', 'Family']]) ## 使用する変数の標準化 scaler = StandardScaler() df_train_knn_std_x = scaler.fit_transform(df_train_knn_x) df_train_knn_y = df_train_with_family['Survived'] ## Data Frameをtrainデータとtestデータに分割 X_train, X_test, y_train, y_test = train_test_split(df_train_knn_std_x, df_train_knn_y, random_state=1) list_kn = [] list_testscore = [] ## Kの数を1から41で試してみる for k in range(1, 41): knn = KNeighborsClassifier(n_neighbors=k) knn.fit(X_train, y_train) knn_predict = knn.predict(X_test) knn_score = round(knn.score(X_test, y_test), 5) list_kn.append(k) list_testscore.append(knn_score) ## テストセットに対する最も高い精度とその場合のKを表示 print(max(list_testscore), list_testscore.index(max(list_testscore)))結果は
こんな感じです。K=10(インデックスは0から始まってるので,ややこしいですが9番目はKが10個の時です)で,0.84でした。
それでは,このモデルを用いて,実際にテストセットの予測をやってみましょう。
3.テストセットの生存予測,結果
前項で作成したモデルをもとに,今度はKaggle公式からダウンロードした2つ目のデータ,Test.csvのSurvivedを予測していきます。Test.csvは,11列,418行で,当然ながらSurvivedのカラムはありません。それ以外のカラムの情報はTrain.csvと同じですが,行数や欠損値の数が少し違います。
まずはTrain.csv同様,データの確認から始めます。
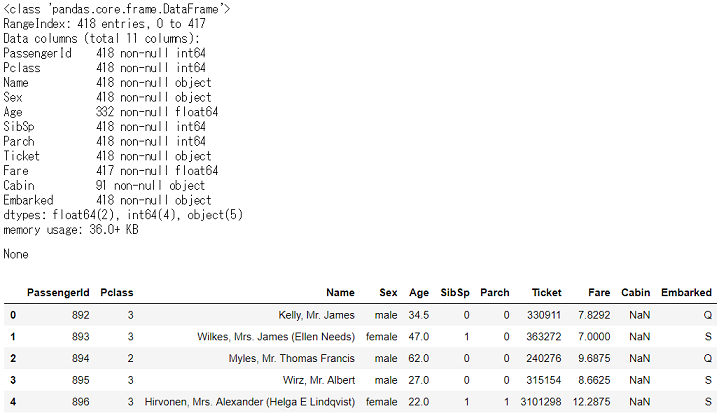
データ概観df_test_raw = pd.read_csv('C:/~hoge~/test.csv') display(df_test_raw.info(), df_test_raw.head())
全体は418行,欠損値が含まれてるのはAge,Cabin,Fareでした。
Trainデータと同様に,Ageの欠損値にはAgeの平均値を入れます。Fareの欠損値にも同様に平均値を入れておきましょう。それ以外の変数も,先ほどと同じになるように処理していきます。データ前処理df_test = df_test_raw[['Pclass', 'Age', 'Sex', 'SibSp', 'Parch', 'Fare', 'Cabin', 'Embarked']] for index, values in enumerate(df_test['Cabin']): try: if np.isnan(values) == True: df_test.loc[index, 'Cabin'] = 0 except TypeError: df_test.loc[index, 'Cabin'] = 1 for index, values in enumerate(df_test['Sex']): if values == 'male': df_test.loc[index, 'Sex'] = 0 else: df_test.loc[index, 'Sex'] = 1 df_test['Age'] = df_test['Age'].fillna(df_test['Age'].mean()) df_test['Fare'] = df_test['Fare'].fillna(df_test['Fare'].mean()) family_series = pd.Series(df_test['SibSp'] + df_test['Parch'] + 1) df_test_with_family = pd.concat([df_test, family_series], axis=1).rename(columns={0:'Family'}) df_test_with_family.loc[:, 'Cabin'] = df_test_with_family.loc[:,'Cabin'].astype(np.int64) df_test_with_family.loc[:, 'Sex'] = df_test_with_family.loc[:, 'Sex'].astype(np.int64)これで,Trainデータと同様に処理が出来ましたので,予測して,Kaggleに提出するCSVファイルを作成していきます。
KNNを用いたテストデータの生存予測,submitファイル作成df_test_knn_x = pd.get_dummies(df_test_with_family[['Pclass', 'Sex', 'Age', 'Fare', 'Cabin', 'Embarked', 'Family']]) df_test_knn_std_x = scaler.fit_transform(df_test_knn_x) knn = KNeighborsClassifier(n_neighbors=10) knn.fit(X_train, y_train) knn_predict = knn.predict(df_test_knn_std_x) ## 提出するファイルを作成 CSV出力 knn_predict = pd.Series(knn_predict) submit = pd.concat([df_test_raw['PassengerId'], knn_predict], axis = 1).rename(columns = {0:'Survived'}) submit.to_csv('gender_submission.csv')出来ました。
スコアはこんな感じ。
0.76でした。あんまり高くないですが,取り敢えず満足です。まとめ
今回は機械学習の練習として,KNNを用いてTitanic生存予測にチャレンジしました。
前述したように,KNNはどうやって分類してるのか,という仕組みを理解しやすいので,取り敢えず機械学習やってみたい!という方にはおススメですね。今後は,今回使わなかったName,Ticketの活用,また,SibSpやParchの処理,各欠損値に対するアプローチなどを工夫して,より正確な予測が出来るようにしていきたいです。
参考サイト,文献
https://www.kaggle.com/c/titanic
Pythonではじめる機械学習
Python機械学習プログラミング
https://qiita.com/yshi12/items/26771139672d40a0be32
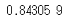
- 投稿日:2019-05-30T10:04:01+09:00
matplotlibでカラーバーの範囲を思い通りにする
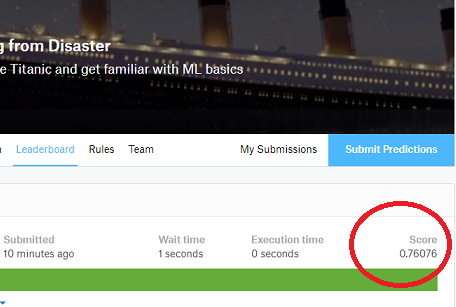
この記事を読むとできるようになること
matplotlibで,データ値の範囲によらず,カラーバーの表示範囲を決められる2次元カラーマップを書いていて,カラーバーの範囲が思うように出なくて困りました.
こんな図が欲しいのに,
描画するデータ値に引きづられて,カラーバーがこんなふうになってしまう!
表示されるカラーバーの範囲が,描画するデータ値の範囲に合わせて自動的に変わってしまいました.
これだと,複数の図を作るときにカラーバーが全部違ってしまうので美しくないですね.
- 環境
- macOS mojave 10.14.4
- Python 3.7.3
表示するカラーバーの範囲を[-4:4]にしたいとします.
なにも考えずに2次元カラーマップを描くとこうなります.colormap1#!/usr/bin/env python # -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt fig = plt.figure() ax1 = fig.add_subplot(111) #…(省略)… mappable0 = ax1.pcolormesh(X,Y,z, cmap='coolwarm') pp = fig.colorbar(mappable0, ax=ax1, orientation="vertical") pp.set_clim(-4,4) pp.set_label(“color bar“, fontname="Arial", fontsize=10)
[-4:4]からはみ出すデータの範囲までカラーバーが負の方向に伸びている&存在しないデータ範囲のカラーバーは表示されなくなっています.
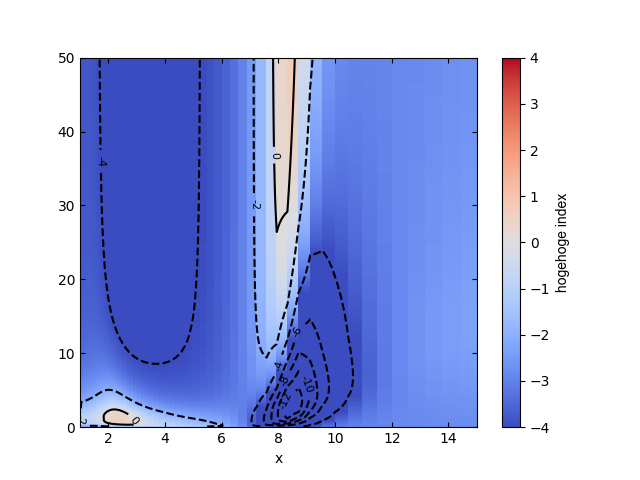
解決するには
Normalizeを使うと良いようです.colormap2#!/usr/bin/env python # -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt from matplotlib.colors import Normalize # Normalizeをimport fig = plt.figure() ax1 = fig.add_subplot(111) #…(省略)… mappable0 = ax1.pcolormesh(X,Y,z, cmap='coolwarm', norm=Normalize(vmin=-4, vmax=4)) # ここがポイント! pp = fig.colorbar(mappable0, ax=ax1, orientation="vertical") pp.set_clim(-4,4) pp.set_label(“color bar“, fontname="Arial", fontsize=10)
これでカラーバーの範囲が思い通りになりました.
pp.set_clim(min, max)
では,カラースケールのグラデーションの端点を指定するだけで,
実際に表示されるカラーバーの範囲を決めているのではないみたいです.カラーバーを対数スケールにするには,
LogNormを使います.colormap3#!/usr/bin/env python # -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt from matplotlib.colors import LogNorm # LogNormをimport fig = plt.figure() ax1 = fig.add_subplot(111) #…(省略)… mappable0 = ax1.pcolormesh(X,Y,z, cmap='coolwarm', norm=LogNorm(vmin=1e1, vmax=1e3)) # ここがポイント! pp = fig.colorbar(mappable0, ax=ax1, orientation="vertical") pp.set_clim(1e1,1e3) pp.set_label(“color bar“, fontname="Arial", fontsize=10)
この場合,グラデーションが対数目盛で描かれます.
(グラデーションの中央が,5e2ではなく1e2になるということ.
この方が見やすいです)


- 投稿日:2019-05-30T02:17:01+09:00
PythonでLINEにメッセージを送る
はじめに
何番煎じかわかりませんが,Python x LINE NotifyでLINEにメッセージを送れるボットを作ったので,その備忘録です。
深層学習モデルの学習など,時間がかかる処理を回しているときに,その場を離れても進捗状況を知りたい!というときに重宝しています。
できること
LINEのグループや自分自身にメッセージ・画像・スタンプを送る
※こちらからのメッセージには反応できない
LINE Notifyについて
Webサービスからの通知をLINEで受信
Webサービスと連携すると、LINEが提供する公式アカウント"LINE Notify"から通知が届きます。
複数のサービスと連携でき、グループでも通知を受信することが可能です。
動作環境
僕の環境は下の通りです。
が,Pythonでimport requestsできれば動くと思います。
- Windows10 (64bit)
- Python3.6
準備
LINE Notifyと友達になる
まずはLINE Notifyを友達に追加します。
自分に送るだけならこれで大丈夫です。
グループに送りたいときは,そのグループにLINE Notifyを招待しておきます。
このLINE Notifyからメッセージが送られてきます。アクセストークンの発行
次に,アクセストークンを発行します。
- LINE Notify公式にアクセス
- 右上からログイン
- ログインと同じところをクリックし,マイページへ
- ページ下部の「トークンを発行」をクリック
- トークン名を指定し,グループを選択して発行
- 発行されたトークンをコピーしてどこかに保存
- 解除したいときは「解除」をクリック
実装
ライブラリ
必要なのはrequestsだけなので,
import requests準備
LINE NotifyのAPIのURLと,アクセストークンを含んだヘッダが必要になります。
url = "https://notify-api.line.me/api/notify" access_token = 'Your Access Token' headers = {'Authorization': 'Bearer ' + access_token}メッセージを送る
3行でメッセージを送ることができます。
なお,空文字は送れません。message = 'Write Your Message' payload = {'message': message} r = requests.post(url, headers=headers, params=payload,)画像を送る
画像を送るときは,
requests.postにfilesも渡します。
なお,空文字でないメッセージと一緒でないと送れません。
このとき,エラーは出ないので注意が必要です。message = 'Write Your Message' image = 'test.png' # png or jpg payload = {'message': message} files = {'imageFile': open(image, 'rb')} r = requests.post(url, headers=headers, params=payload, files=files,)スタンプを送る
スタンプを送るときは,
payloadにstickerPackageIdとstickerIdを追加します。
これらのIDはここから探してきて指定します。
こちらも画像と同様,空文字でないメッセージと一緒じゃないと送れず,送れなかったときにはエラーも出ません。
また,存在しないIDを指定した場合はメッセージも送られないので,注意が必要です。message = 'Write Your Message' payload = { 'message': message, 'stickerPackageId': 1, 'stickerId': 13, } r = requests.post(url, headers=headers, params=payload,)まとめる
以上をまとめてクラスにしてしまうと,次のようになります。
line_notify_bot.pyimport requests class LINENotifyBot: API_URL = 'https://notify-api.line.me/api/notify' def __init__(self, access_token): self.__headers = {'Authorization': 'Bearer ' + access_token} def send( self, message, image=None, sticker_package_id=None, sticker_id=None, ): payload = { 'message': message, 'stickerPackageId': sticker_package_id, 'stickerId': sticker_id, } files = {} if image != None: files = {'imageFile': open(image, 'rb')} r = requests.post( LINENotifyBot.API_URL, headers=self.__headers, data=payload, files=files, )実行は次のようになります。
from line_notify_bot import LINENotifyBot bot = LINENotifyBot(access_token='Your Access Token') bot.send( message='Write Your Message', image='test.png', # png or jpg sticker_package_id=1, sticker_id=13, )こちらはGitHubに公開しているので,使えればOKという方はcloneして頂ければすぐ使えます。
git clone https://github.com/moritagit/LINENotifyBot.gitまとめ
自分が使いやすいように作ってみましたが,かなり簡単に使える割になかなか便利です。
とりあえず深層学習モデルの学習中にlossの値や学習曲線を送ったりしてみてます(tensorboardを使いましょう)。
スタンプを自動で送りたい場面にはまだ出会ってないので,早く出会いたいところ。
- 投稿日:2019-05-30T00:23:37+09:00
Pythonインストール時のエラーとその解決のために取ったこと
MacbookのターミナルからPythonをインストールする際、何度かエラーが出てしまった。
その際に取った解決策をここに記す。動作環境
MacBook Air (macOS Mojave 10.14.4)
Pythonインストール手順
1.Xcodeのインストール
2.Homebrewのインストール
3.Homebrewでpyenvのインストール
4.pyenvでPythonのインストール本題
2.Homebrewのインストール にて
ターミナル$ /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"以上のコードを実行し、Homebrewをインストールした。
エラー
ターミナルbrew updating...上の状態から動かない。すでにインストールされているみたいなのだが...
解決策
アンインストールしてもう一度インストール
以下のコードでアンインストール。ターミナル$ ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/uninstall)"そして、もう一度、インストールしよう。
ターミナル$ /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"エラー
また途中で止まってしまった。
解決策
問題箇所をチェックしてくれる
brew doctorコマンドを使ってみた。ターミナル$ brew doctorすると、、、
ターミナル==> Tapping homebrew/core Cloning into '/usr/local/Homebrew/Library/Taps/homebrew/homebrew-core'... remote: Enumerating objects: 4986, done. remote: Counting objects: 100% (4986/4986), done. remote: Compressing objects: 100% (4778/4778), done. remote: Total 4986 (delta 52), reused 822 (delta 17), pack-reused 0 Receiving objects: 100% (4986/4986), 4.00 MiB | 234.00 KiB/s, done. Resolving deltas: 100% (52/52), done. Checking out files: 100% (5003/5003), done. Tapped 2 commands and 4771 formulae (5,028 files, 12.4MB). Your system is ready to brew.できたみたい。
試しに、brew -vコマンドで、バージョン確認してみる。ターミナル$ brew -v Homebrew 2.1.3 Homebrew/homebrew-core (git revision 034e; last commit 2019-05-20)無事、インストールできていた。
4.pyenvでPythonのインストール にて
今回はPython 3.6.5をインストール。以下のコマンドを実行。
ターミナル$ pyenv install 3.6.5エラー
ターミナルpython-build: use openssl from homebrew python-build: use readline from homebrew Downloading Python-3.6.5.tar.xz... -> https://www.python.org/ftp/python/3.6.5/Python-3.6.5.tar.xz Installing Python-3.6.5... python-build: use readline from homebrew BUILD FAILED (OS X 10.14.4 using python-build 20180424) Inspect or clean up the working tree at /var/folders/y8/cn2cvksx0m98bcj0llww28pr0000gn/T/python-build.20190521011235.40941 Results logged to /var/folders/y8/cn2cvksx0m98bcj0llww28pr0000gn/T/python-build.20190521011235.40941.log Last 10 log lines: File "/private/var/folders/y8/cn2cvksx0m98bcj0llww28pr0000gn/T/python-build.20190521011235.40941/Python-3.6.5/Lib/ensurepip/__main__.py", line 5, in <module> sys.exit(ensurepip._main()) File "/private/var/folders/y8/cn2cvksx0m98bcj0llww28pr0000gn/T/python-build.20190521011235.40941/Python-3.6.5/Lib/ensurepip/__init__.py", line 204, in _main default_pip=args.default_pip, File "/private/var/folders/y8/cn2cvksx0m98bcj0llww28pr0000gn/T/python-build.20190521011235.40941/Python-3.6.5/Lib/ensurepip/__init__.py", line 117, in _bootstrap return _run_pip(args + [p[0] for p in _PROJECTS], additional_paths) File "/private/var/folders/y8/cn2cvksx0m98bcj0llww28pr0000gn/T/python-build.20190521011235.40941/Python-3.6.5/Lib/ensurepip/__init__.py", line 27, in _run_pip import pip zipimport.ZipImportError: can't decompress data; zlib not available make: *** [install] Error 1
zlib not available
どうやら、zlibというものが利用できないらしい。解決策
zlibを用いてインストール
まず、以下のコードで、zlibを入れるのに必要なファイルを入れる。ターミナル$ sudo installer -pkg /Library/Developer/CommandLineTools/Packages/macOS_SDK_headers_for_macOS_10.14.pkg -target /ターミナルPassword: installer: Package name is macOS_SDK_headers_for_macOS_10.14 installer: Installing at base path / installer: The install was successful.途中パスワードを要求されるがインストールできた。
次に、以下のコードで、zlibを使ってPythonをインストール。ターミナル$ env CPPFLAGS="-I/usr/local/opt/zlib/include" LDFLAGS="-L/usr/local/opt/zlib/lib" pyenv install 3.6.5ターミナルpython-build: use openssl from homebrew python-build: use readline from homebrew Downloading Python-3.6.5.tar.xz... -> https://www.python.org/ftp/python/3.6.5/Python-3.6.5.tar.xz Installing Python-3.6.5... python-build: use readline from homebrew Installed Python-3.6.5 to /Users/Keiichi/.pyenv/versions/3.6.5できたみたい。
バージョンを確認してみると、ターミナル$ python --version Python 3.6.5完了。