(目次はこちら) はじめに 畳み込みニューラルネット Part1 [TensorFlowでDeep Learning 4]をtensorflow2.0で実現するためにはどうしたらいいのかを書く(tf.keras)。 コード Python: 3.6.8, Tensorflow: 2.0.0a0で動作確認済み 畳み込みニューラルネット Part1 [TensorFlowでDeep Learning 4] (mnist_fixed_cnn_simple.py)を書き換えると、 v2/mnist_fixed_cnn_simple.py v2/mnist_fixed_cnn_simple.py from helper import * IMAGE_WIDTH, IMAGE_HEIGHT = 28, 28 CATEGORY_NUM = 10 LEARNING_RATE = 0.1 FILTER_NUM = 2 EPOCHS = 15 BATCH_SIZE = 100 LOG_DIR = 'log_fixed_cnn' class Prewitt(tf.keras.layers.Layer): def build(self, input_shape): v = np.array([[ 1, 0, -1]] * 3) h = v.swapaxes(0, 1) self.kernel = tf.constant(np.dstack([v, h]).reshape((3, 3, 1, 2)), dtype = tf.float32, name='prewitt') self.built = True def call(self, x): x_ = tf.reshape(x, [-1, x.shape[1], x.shape[2], 1]) return tf.abs(tf.nn.conv2d(x_, self.kernel, strides=[1, 1, 1, 1], padding='SAME')) if __name__ == '__main__': (X_train, y_train), (X_test, y_test) = mnist_samples() model = tf.keras.models.Sequential() model.add(Prewitt((IMAGE_HEIGHT * IMAGE_WIDTH, FILTER_NUM), input_shape=(IMAGE_HEIGHT, IMAGE_WIDTH))) model.add(tf.keras.layers.Flatten()) model.add(tf.keras.layers.Dense(CATEGORY_NUM, activation='softmax')) model.compile( loss='categorical_crossentropy', optimizer=tf.keras.optimizers.SGD(LEARNING_RATE), metrics=['accuracy']) cb = [tf.keras.callbacks.TensorBoard(log_dir=LOG_DIR)] model.fit(X_train, y_train, batch_size=BATCH_SIZE, epochs=EPOCHS, callbacks=cb, validation_data=(X_test, y_test)) print(model.evaluate(X_test, y_test)) と書ける。ただ、Prewittフィルタの表現が適切かどうかが不安が残るが、動作は適切。 めでたしめでたし。(1epochで、すでに精度高い)
(目次はこちら)
畳み込みニューラルネット Part1 [TensorFlowでDeep Learning 4]をtensorflow2.0で実現するためにはどうしたらいいのかを書く(tf.keras)。
tf.keras
Python: 3.6.8, Tensorflow: 2.0.0a0で動作確認済み
畳み込みニューラルネット Part1 [TensorFlowでDeep Learning 4] (mnist_fixed_cnn_simple.py)を書き換えると、
v2/mnist_fixed_cnn_simple.py
from helper import * IMAGE_WIDTH, IMAGE_HEIGHT = 28, 28 CATEGORY_NUM = 10 LEARNING_RATE = 0.1 FILTER_NUM = 2 EPOCHS = 15 BATCH_SIZE = 100 LOG_DIR = 'log_fixed_cnn' class Prewitt(tf.keras.layers.Layer): def build(self, input_shape): v = np.array([[ 1, 0, -1]] * 3) h = v.swapaxes(0, 1) self.kernel = tf.constant(np.dstack([v, h]).reshape((3, 3, 1, 2)), dtype = tf.float32, name='prewitt') self.built = True def call(self, x): x_ = tf.reshape(x, [-1, x.shape[1], x.shape[2], 1]) return tf.abs(tf.nn.conv2d(x_, self.kernel, strides=[1, 1, 1, 1], padding='SAME')) if __name__ == '__main__': (X_train, y_train), (X_test, y_test) = mnist_samples() model = tf.keras.models.Sequential() model.add(Prewitt((IMAGE_HEIGHT * IMAGE_WIDTH, FILTER_NUM), input_shape=(IMAGE_HEIGHT, IMAGE_WIDTH))) model.add(tf.keras.layers.Flatten()) model.add(tf.keras.layers.Dense(CATEGORY_NUM, activation='softmax')) model.compile( loss='categorical_crossentropy', optimizer=tf.keras.optimizers.SGD(LEARNING_RATE), metrics=['accuracy']) cb = [tf.keras.callbacks.TensorBoard(log_dir=LOG_DIR)] model.fit(X_train, y_train, batch_size=BATCH_SIZE, epochs=EPOCHS, callbacks=cb, validation_data=(X_test, y_test)) print(model.evaluate(X_test, y_test))
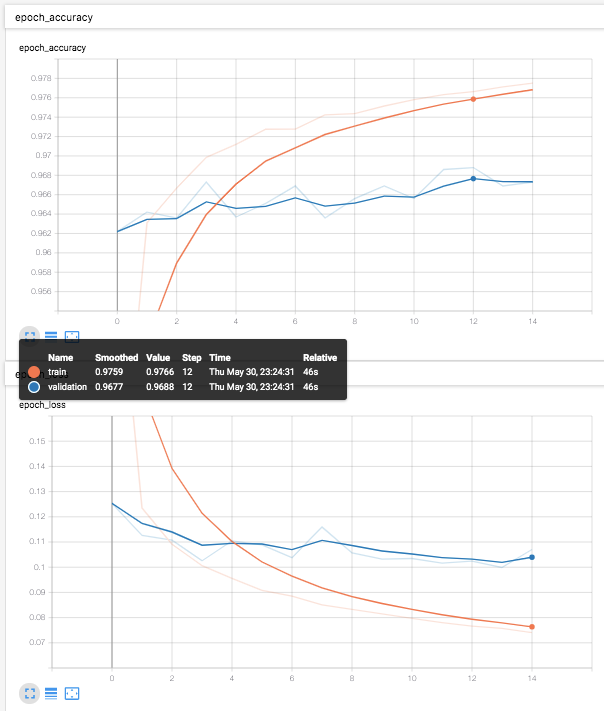
と書ける。ただ、Prewittフィルタの表現が適切かどうかが不安が残るが、動作は適切。
めでたしめでたし。(1epochで、すでに精度高い)
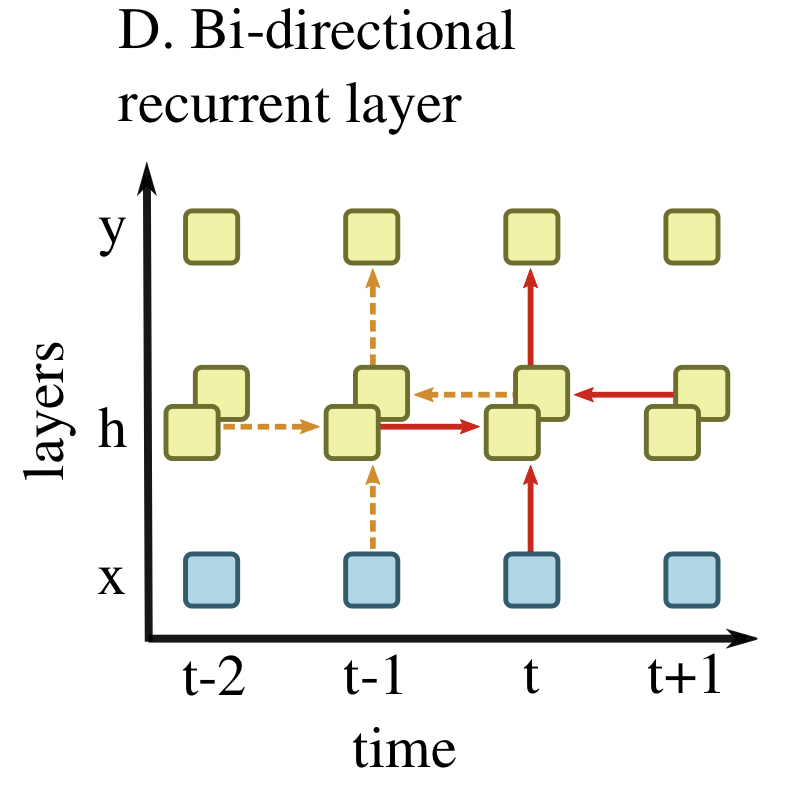
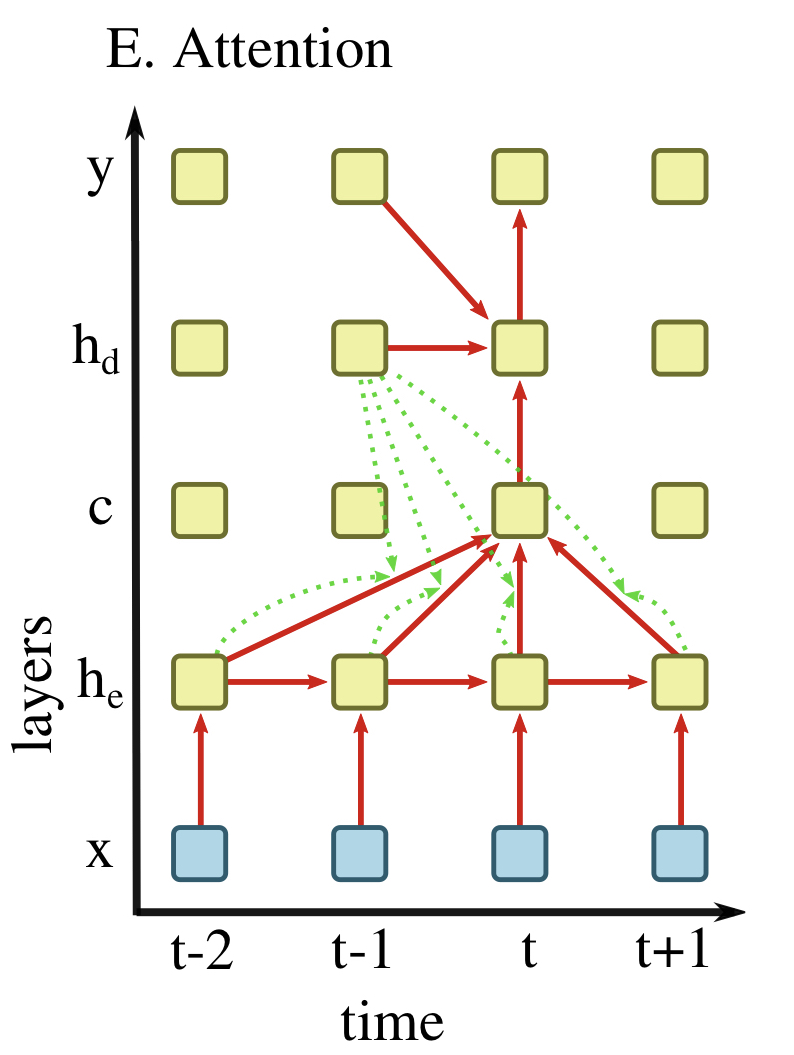
Deep Learning for Audio Signal Processingという論文でDeep Learningにおける、音声をはじめとする時系列データの処理方法がまとめられていたので紹介したいと思います。 この記事で紹介するのは 1D Convolution Dialated 1D Convolution RNN Bi-directional RNN Attention の5つです。 1D Convolution 上の図は入力時系列$x$が中間層$h$を通り、出力時系列$y$に変換される様子を表しています。 オレンジの破線は時刻$t-1$での出力$y_{t-1}$を計算する処理を表し、赤の実線は時刻$t$での出力$y_t$を表します。各ブロックは各層のセルの値を表します。 1D Convolution Layerでは各層のセルの値は前の層のセルと一次元のフィルタの畳み込みによって表されます。この図の例では3つの重みを持つフィルタを用いています。 形式的に書くと、例えば$h_t, y_t$の値は活性化関数を$\sigma$、バイアスを$b$とすると h_t = \sigma(w_1^{(1)}x_{t-1} + w_2^{(1)}x_{t} + w_3^{(1)}x_{t+1} + b)\\ y_t = \sigma(w_1^{(2)}h_{t-1} + w_2^{(2)}h_{t} + w_3^{(2)}h_{t+1} + b) のように計算できます。 Dialated 1D Convolution Dialated 1D Convolutionではdialation $k$に従って畳み込みに使うセルを決めます。 この図の例では$h$から$y$への畳込み層で$k=2$としており、3つの重みを2時刻ずらしながら畳み込んでいます。なので$y$を計算する際には$h_{t-2}, h_t, h_{t+2}$が使われています。 $x$から$h$への畳み込み層では$k=1$としています。このようにDialated 1D Convolution Layerを用いる際は、入力側から$k$を$(1, 2, 4, \dots)$と増やしていくことで、入力層での受容野をより広く確保することが出来ます。 RNN GRUやLSTMなどのRNNでは、隠れセル$h_t$は現時刻の入力$x_t$と1つ前の時刻の隠れセル$h_{t-1}$の値によって形式的に次のように計算できます。 ht = \tanh(w_h h_{t-1} + w_x x_t + b) この計算は再帰的に行われ、勾配消失も起きやすくなるため通常は普通のRNNは用いずにGRUやLSTMが使われます。 RNNのより詳しい説明はゼロから作るDeep Learning 2がとてもわかりやすいのでそちらを参照してください。 Bi-directional RNN Bi-directional RNN(双方向RNN)では過去の隠れセルの情報だけでなく未来の隠れセルの情報も加味します。 未来の情報を用いるので、オンライン学習には使えません。 Attention AttentionではEncoderとDecoderという機構を持ちます。それぞれに対応する埋め込み層$h_e$および$h_d$を持ち、コンテキスト$c$が橋渡し役として働きます。この図において、時刻$t$に対応するコンテキスト$c_t$はEncoderの埋め込み層のセル$h_{e, t-2}, h_{e, t-1}, h_{e, t}, h_{e, t+1}$の重み付け和で計算でき、その重みはDecoderの埋め込み層のセル$h_{d, t-1}$と計算に使われたEncoderの埋め込み層のセルの値から計算されます。この様子は図中の緑の点線で表されています。 最終的に$y_t$は1つ前の時刻$y_{t-1}$と1つ前の時刻のDecoderの埋め込み層のセル$h_{d, t-1}$とコンテキスト$c_t$によって計算されます。 この計算方法により、入力と出力の相関性を考慮することが出来ます。 参考 Deep Learning for Audio Signal Processing ゼロから作るDeep Learning 2
Deep Learning for Audio Signal Processingという論文でDeep Learningにおける、音声をはじめとする時系列データの処理方法がまとめられていたので紹介したいと思います。
この記事で紹介するのは
の5つです。
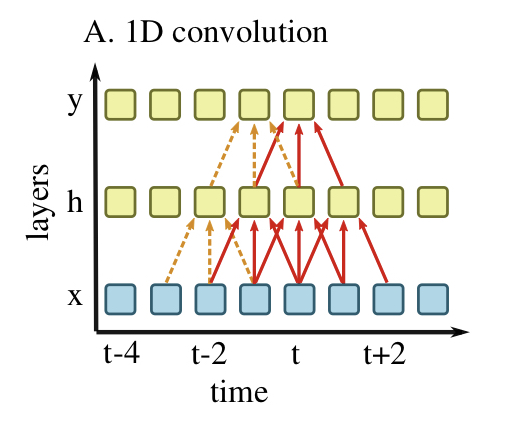
上の図は入力時系列$x$が中間層$h$を通り、出力時系列$y$に変換される様子を表しています。
オレンジの破線は時刻$t-1$での出力$y_{t-1}$を計算する処理を表し、赤の実線は時刻$t$での出力$y_t$を表します。各ブロックは各層のセルの値を表します。
1D Convolution Layerでは各層のセルの値は前の層のセルと一次元のフィルタの畳み込みによって表されます。この図の例では3つの重みを持つフィルタを用いています。
形式的に書くと、例えば$h_t, y_t$の値は活性化関数を$\sigma$、バイアスを$b$とすると
h_t = \sigma(w_1^{(1)}x_{t-1} + w_2^{(1)}x_{t} + w_3^{(1)}x_{t+1} + b)\\ y_t = \sigma(w_1^{(2)}h_{t-1} + w_2^{(2)}h_{t} + w_3^{(2)}h_{t+1} + b)
のように計算できます。
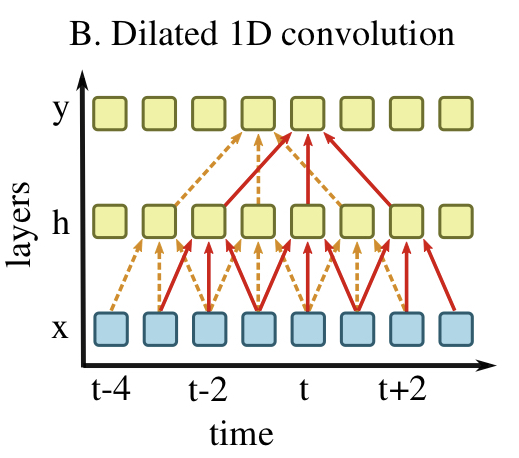
Dialated 1D Convolutionではdialation $k$に従って畳み込みに使うセルを決めます。
この図の例では$h$から$y$への畳込み層で$k=2$としており、3つの重みを2時刻ずらしながら畳み込んでいます。なので$y$を計算する際には$h_{t-2}, h_t, h_{t+2}$が使われています。
$x$から$h$への畳み込み層では$k=1$としています。このようにDialated 1D Convolution Layerを用いる際は、入力側から$k$を$(1, 2, 4, \dots)$と増やしていくことで、入力層での受容野をより広く確保することが出来ます。
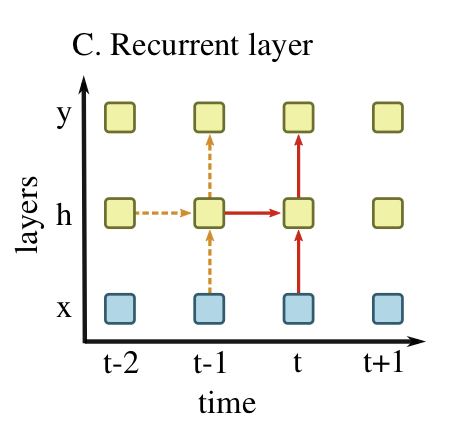
GRUやLSTMなどのRNNでは、隠れセル$h_t$は現時刻の入力$x_t$と1つ前の時刻の隠れセル$h_{t-1}$の値によって形式的に次のように計算できます。
ht = \tanh(w_h h_{t-1} + w_x x_t + b)
この計算は再帰的に行われ、勾配消失も起きやすくなるため通常は普通のRNNは用いずにGRUやLSTMが使われます。
RNNのより詳しい説明はゼロから作るDeep Learning 2がとてもわかりやすいのでそちらを参照してください。
Bi-directional RNN(双方向RNN)では過去の隠れセルの情報だけでなく未来の隠れセルの情報も加味します。
未来の情報を用いるので、オンライン学習には使えません。
AttentionではEncoderとDecoderという機構を持ちます。それぞれに対応する埋め込み層$h_e$および$h_d$を持ち、コンテキスト$c$が橋渡し役として働きます。この図において、時刻$t$に対応するコンテキスト$c_t$はEncoderの埋め込み層のセル$h_{e, t-2}, h_{e, t-1}, h_{e, t}, h_{e, t+1}$の重み付け和で計算でき、その重みはDecoderの埋め込み層のセル$h_{d, t-1}$と計算に使われたEncoderの埋め込み層のセルの値から計算されます。この様子は図中の緑の点線で表されています。
最終的に$y_t$は1つ前の時刻$y_{t-1}$と1つ前の時刻のDecoderの埋め込み層のセル$h_{d, t-1}$とコンテキスト$c_t$によって計算されます。
この計算方法により、入力と出力の相関性を考慮することが出来ます。
Deep Learning for Audio Signal Processing
ゼロから作るDeep Learning 2
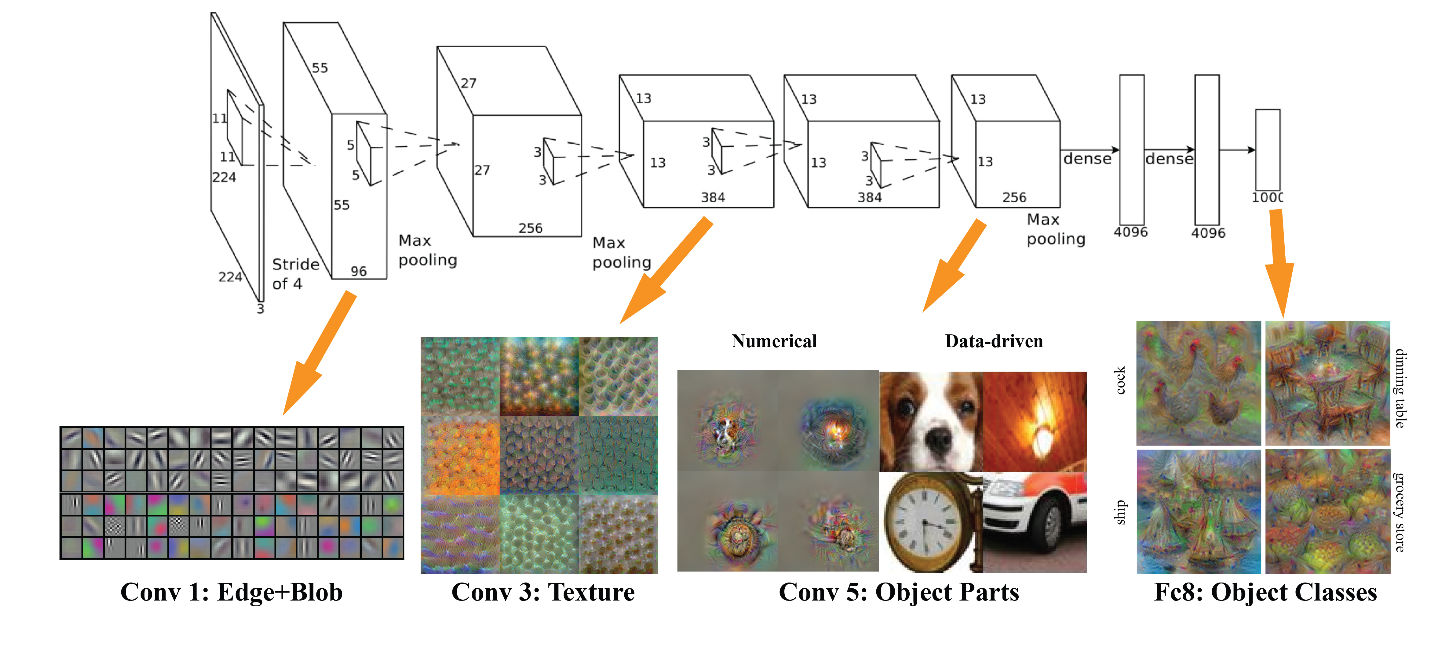
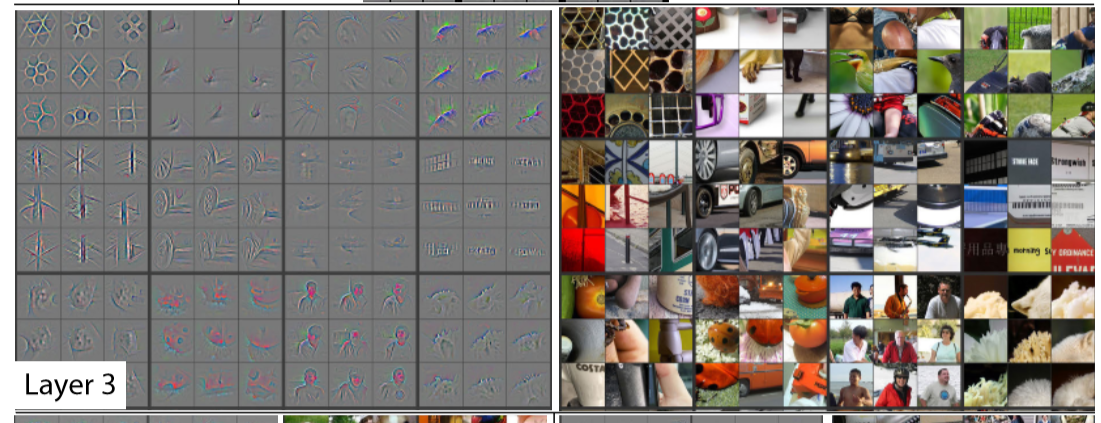
目的 畳み込みニューラルネットワークの説明をされているサイトが沢山ある。 勉強になる。 説明の仕方として、CNNの層毎の役割を説明する方法がとられていることがよくある。 色々な解説があるが、一層目ぐらいの説明(エッジとかを抽出している等)は、順調であるが、それ以降の説明がやや飛躍があると感じる。 それを示す。 ちなみに、 下記の「 [C]さらにこちらの図 」の項で引用している内容、 『何にニューロンが反応するか』についての説明を表にすると、 層 説明 1層目 エッジやブロブ 3層目 テクスチャ 5層目 物体のパーツ (最後の)全結合層 物体のクラス(犬や車など) です。あまり納得がいきません。 層毎の役割の説明とは、少し、ずれるのかもしれないが、 CNNがどこに注目しているかを示す手法?であるGrad-CAMの説明は、わりと、素直に聞ける。 →後述の「 [B]こちらの図 」参照。 特徴強度を図示する手法も、素直に聞けるが、少し、評価手法がシンプルすぎる気がする。 →後述の「 [D]もうひとつ、こちらの画 」参照。 [A]この画 この図は、非常によく見る画で、実際に、この画のとおりの情報がどこかにあるのだろうと思うが、 層に対応づけるのは、かなり、無理があると素人的には、思う。 (出典:http://web.eecs.umich.edu/~honglak/icml09-ConvolutionalDeepBeliefNetworks.pdf ) [B]こちらの画 こちらの画は、すごく、理解の助けになる。 うまくまとまっていると思う。Grad-CAMという手法。 ただ、これは、『全結合層の成果では?』と思ってしまう。 別にそうでないと記載されているわけでは、ありませんが。。。。 (出典:https://newtechnologylifestyle.net/vgg16networkvisual/ ) [C]さらにこちらの画 関連ページにも、記載しましたが、 Conv3のTextureという説明が、しっくりきません。 (出典:http://vision03.csail.mit.edu/cnn_art/index.html#v_single ) Textureという説明の元ネタは、以下の文献じゃないですかねと教えて頂きました。(コメント欄参照) Visualizing and Understanding Convolutional Networks https://arxiv.org/pdf/1311.2901.pdf Layer 3 has more complex invariances, capturing similar textures (e.g. mesh patterns (Row 1, Col 1); text (R2,C4)). [D]もうひとつ、こちらの画 特徴強度を図示している。 わかりやすいです。へーなるほどー、と思います。 尚、シンプルに特徴強度を図示しているので、、、かならずしも、網羅した説明にはならない気はします。 (出典: https://hazm.at/mox/machine-learning/computer-vision/keras/intermediate-layers-visualization/index.html ) まとめ 畳み込みニューラルネットワークの説明が、やや、うまくいっていないというか、少し、意味を付与しすぎな気がするので、それを示した。 単に、素人が、ストンと理解しようとして、理解できない不満を示しているだけであることは認識していますが。 コメントなどあれば、お願いします。 すみません、有意な情報の記載ができていません。別途、改定します。 知りたいことを整理すると、 層を重ねることによりどういう扱いやすい特徴量がどういう形式で獲得され、それが、どううまく全結合層と連携して、物体認識に至っているのか を知りたいということになると思います。旧来の技術との比較も含め。 関連(本人) 良書「ゼロから作るDeep Learning -- Pythonで学ぶディープラーニングの理論と実装」を読む
畳み込みニューラルネットワークの説明をされているサイトが沢山ある。 勉強になる。 説明の仕方として、CNNの層毎の役割を説明する方法がとられていることがよくある。 色々な解説があるが、一層目ぐらいの説明(エッジとかを抽出している等)は、順調であるが、それ以降の説明がやや飛躍があると感じる。 それを示す。
ちなみに、 下記の「 [C]さらにこちらの図 」の項で引用している内容、 『何にニューロンが反応するか』についての説明を表にすると、
です。あまり納得がいきません。
層毎の役割の説明とは、少し、ずれるのかもしれないが、 CNNがどこに注目しているかを示す手法?であるGrad-CAMの説明は、わりと、素直に聞ける。 →後述の「 [B]こちらの図 」参照。
特徴強度を図示する手法も、素直に聞けるが、少し、評価手法がシンプルすぎる気がする。 →後述の「 [D]もうひとつ、こちらの画 」参照。
この図は、非常によく見る画で、実際に、この画のとおりの情報がどこかにあるのだろうと思うが、 層に対応づけるのは、かなり、無理があると素人的には、思う。
(出典:http://web.eecs.umich.edu/~honglak/icml09-ConvolutionalDeepBeliefNetworks.pdf )
こちらの画は、すごく、理解の助けになる。 うまくまとまっていると思う。Grad-CAMという手法。
ただ、これは、『全結合層の成果では?』と思ってしまう。 別にそうでないと記載されているわけでは、ありませんが。。。。
(出典:https://newtechnologylifestyle.net/vgg16networkvisual/ )
関連ページにも、記載しましたが、 Conv3のTextureという説明が、しっくりきません。
(出典:http://vision03.csail.mit.edu/cnn_art/index.html#v_single )
Textureという説明の元ネタは、以下の文献じゃないですかねと教えて頂きました。(コメント欄参照)
Visualizing and Understanding Convolutional Networks https://arxiv.org/pdf/1311.2901.pdf
Layer 3 has more complex invariances, capturing similar textures (e.g. mesh patterns (Row 1, Col 1); text (R2,C4)).
特徴強度を図示している。 わかりやすいです。へーなるほどー、と思います。 尚、シンプルに特徴強度を図示しているので、、、かならずしも、網羅した説明にはならない気はします。
(出典: https://hazm.at/mox/machine-learning/computer-vision/keras/intermediate-layers-visualization/index.html )
畳み込みニューラルネットワークの説明が、やや、うまくいっていないというか、少し、意味を付与しすぎな気がするので、それを示した。 単に、素人が、ストンと理解しようとして、理解できない不満を示しているだけであることは認識していますが。
コメントなどあれば、お願いします。
すみません、有意な情報の記載ができていません。別途、改定します。
知りたいことを整理すると、 層を重ねることによりどういう扱いやすい特徴量がどういう形式で獲得され、それが、どううまく全結合層と連携して、物体認識に至っているのか を知りたいということになると思います。旧来の技術との比較も含め。
良書「ゼロから作るDeep Learning -- Pythonで学ぶディープラーニングの理論と実装」を読む