- 投稿日:2019-04-11T23:52:45+09:00
DjangoのテンプレートにVue.jsを導入してaxiosでAjaxしてみた話(後編)
はじめに
前編では,Ajax通信でサーバ側(のDjango)からクライアント側(のVue.js)にデータをもってくることができた.後編では,逆にクライアント側(のVue.js)からサーバ側(のDjango)にデータを送って必要に応じてデータベースを更新することを試みる.
全体のコードはまとめてGitHubに置いた.
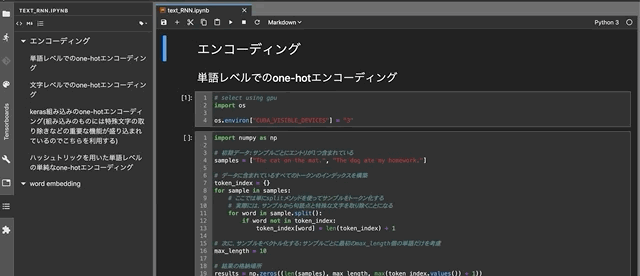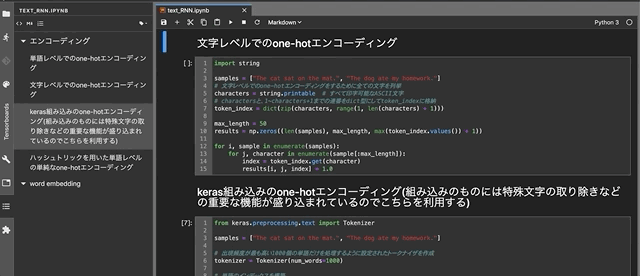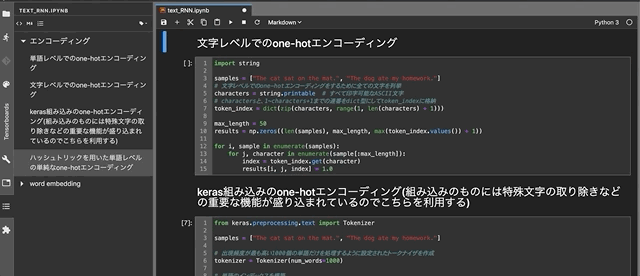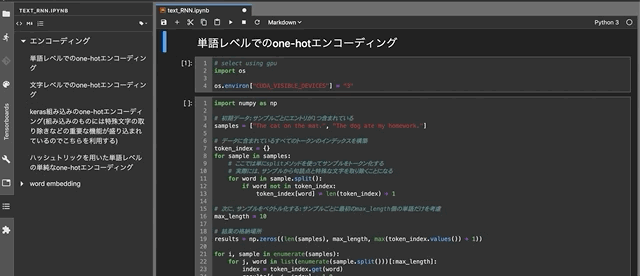
DjangoのFormによる新規タスクの追加
最初に,Ajaxを使わずに,クライント側からDjangoのFormでデータを取得する方法を振り返っておこう.そのために,新規タスクを追加することを考える.新規タスクはすべて未完了だと仮定して,次のようなFormを用意した(新たにFormを定義せず,ModelFormを利用する手もあるが).
from django import forms import datetime from . import models class TodoForm(forms.Form): task = forms.CharField(max_length=255) due = forms.DateTimeField( widget=forms.DateTimeInput(format="%Y-%m-%d"), initial = datetime.date.today() ) def save(self): new_task = self.cleaned_data["task"] its_due = self.cleaned_data["due"] if models.Todo.objects.filter(task=new_task).count() == 0: todo = models.Todo(task=new_task, due=its_due, done=False); todo.save()続いて,このFormを扱うview関数
def add_todo(request): if request.method == "POST": form = forms.TodoForm(request.POST) if form.is_valid(): form.save() return redirect("which_url_to_be_redirected_to") else: form = forms.TodoForm() todos = models.Todo.objects.all().order_by("due") my_context = { "form":form, "todos":todos, } return render(request, "name_of_your_template", my_context)とFormを埋め込むテンプレート
<html> <head><title>Todo</title></head> <body> <h1>My Todo List</h1> <div> <ul> {% for item in todos %} <li> {% if item.done %} <span style="text-decoration: line-through; color: red"> {{ item.task }} ({{ item.due|date:"n" }}/{{ item.due|date:"j" }}) </span> {% else %} <span> {{ item.task }} ({{ item.due|date:"n" }}/{{ item.due|date:"j" }}) </span> {% endif %} </li> {% endfor %} </ul> <hr> <form method="post" action="{% url 'of_this_page_itself' %}">{% csrf_token %} {{ form }} <button type="submit" >Add</button> </form> </div> </body> </html>を作成した.これで,既存タクスのリストの下に新規タスクを追加するための入力フォームと登録ボタンが表示されるようになった.Formを利用したデータの取得は定石的な流れなので,比較的簡単に実装できるようになっている.
ポイントは,フォーム要素(
<form></form>)の中に埋め込んだ{% csrf_token %}である.これを埋め込んでおくだけでDjango側でcsrfの対策が講じられる.逆に,これを埋め込むのを忘れると,DjangoにPOST通信を受け付けてもらえない.Vue.jsでの新規タスクの追加
次に,Vue.jsで新規タスクを追加できるようにしてみよう.そのために,前編の最後のテンプレートを下記のように少し拡張する.
<html> <head><title>Todo</title></head> <body> <h1>My Todo List</h1> <div id="app"> <ul v-cloak v-for="item in todos"> <li v-on:click="changeStatus(item)"> <span style="text-decoration: line-through; color: red" v-if="item.done"> [[ item.task ]] ([[ item.due.getMonth()+1 ]]/[[ item.due.getDate() ]]) </span> <span v-else> [[ item.task ]] ([[ item.due.getMonth()+1 ]]/[[ item.due.getDate() ]]) </span> </li> </ul> <hr> <form v-on:submit.prevent="addTask"> <label for="task">Task:</label> <input type="text" id="task" v-model="new_task"> <label for="due">Due:</label> <input type="date" id="due" v-model="its_due"> <button type="submit" >Add</button> </form> </div> <script src="https://unpkg.com/vue"></script> <script src="https://unpkg.com/axios/dist/axios.min.js"></script> <script> var vm = new Vue({ delimiters: ['[[', ']]'], el: '#app', data: { todos: [], new_task: "", its_due: "" }, mounted: function() { axios.get('{% url "for_view_function_get_todo()" %}') .then(function (response) { for(var d in response.data) { var item = response.data[d]; item.due = new Date(item.due); vm.todos.push(item); } }) .catch(function (error) { console.log(error); }) .then(function () { }); }, methods: { changeStatus: function(item) { item.done = !item.done; }, addTask: function() { if(this.new_task && this.its_due){ this.todos.push({ "task":this.new_task, "due": new Date(this.its_due), "done":false }); } this.new_task = ""; this.its_due = ""; } } }) </script> </body> </html>上部のhtmlの部分を見てみると,DjangoのFormを利用した場合と同じ箇所にフォーム要素(
<form></form>)が挿入され,サブミットイベントを処理するディレクティブが追加されていることがわかる.この際に呼び出されるのがaddTaskメソッドである.この
addTaskメソッドの本体は,下部のVue.jsのスクリプトの中に追加されている.具体的には,new_taskとits_dueに情報が入っていることを確認し,それらの情報をもとに新しいtodoのオブジェクトを生成した上で,それをtodosに追加し,最後にnew_taskとits_dueを空に戻している.なお,
new_taskとits_dueはVueインスタンスのdataの中に追加されており,それらはv-modelディレクティブでフォームに入力されたデータと紐付けてある.これで,Vue.jsの方でも(ページ上で)新規タスクを追加できるようになった.Ajax通信(その2,POST編)
ただし,まだデータベースは更新していないので,このままではページをリロードすると新しく追加したタスクは消えてしまう.そこで,前編とは逆に,Vue.js側からDjango側にAjax通信でJSON形式の情報を送り込んで,データベースを更新することを試みよう.ここからが後編の本題である.
このAjaxリクエストを処理するview関数から始めよう.これは次のように構成した.
def post_todo(request): if request.method == 'POST' and request.body: json_dict = json.loads(request.body) task = json_dict['task'] due = json_dict['due'] done = json_dict['done'] todos = models.Todo.objects.filter(task=task) if not todos: models.Todo.objects.create(task=task, due=due, done=done); else: todos[0].due=due todos[0].done=done todos[0].save() return JsonResponse(json_dict) else: return HttpResponseServerError()POST通信のリクエストから必要なJSONデータを抽出し,pythonの辞書に変換するには,
request.bodyをjson.loads()に渡せばいいらしい.そして,得られた辞書からタスク(
task),納期(due),完了済みかどうか(done)の情報を取り出し,同じ名称のタスクがなければ,それを新しいタスクとして生成しデータベースに格納している.すでに同じ名称のタスクがあった場合は,そのタスクの情報を上書きしている.一方,Vue.js側のメソッドは,GET通信の場合と同様に考えると,例えば次のようになる.
updateDB: function(item) { data = { "task":item.task, "due": new Date(item.due), "done":item.done }; axios.post('{% url "for_view_function_post_todo()" %}') .then(function (response) { console.log(response); }) .catch(function (error) { console.log(error); }); }しかし残念ながら,このままではDjangoはこのリクエストを受け付けてくれない.これは,後編の最初に書いたcsrf対策のためである.Ajax通信の場合は
{% csrf_token %}を埋め込むことはできないので,これに変わる方法が必要となる.詳細はDjangoの公式ドキュメントのここを参照してほしいが,要するに,Cookieから必要な情報(csrfトークン)を抽出してそれを
X-CSRFTokenという名称でPOST通信のリクエストのヘッダに書き込めばいいということらしい.公式ドキュメントにはcsrfトークンを抽出するためのjQueryのコードも紹介されているが,ここでもそのためだけにjQueryをロードするのは避けたいので,もうひとつの手段として紹介されているJavaScriptクッキーライブラリを利用することにする.これも次のタグでCDNからロードしておこう.
<script src="https://cdn.jsdelivr.net/npm/js-cookie@2/src/js.cookie.min.js"></script>これを用いて,上の
updateDBメソッドを次のように拡張すると無事動くようになった.updateDB: function(item) { csrftoken = Cookies.get('csrftoken'); headers = {'X-CSRFToken': csrftoken}; data = { "task":item.task, "due": new Date(item.due), "done":item.done }; axios.post('{% url "todo:post_todo" %}', data, {headers: headers}) .then(function (response) { console.log(response); }) .catch(function (error) { console.log(error); }); }他の部分も含めたテンプレートの全体は次の通りである.
<html> <head><title>Todo</title></head> <body> <h1>My Todo List</h1> <div id="app"> <ul v-cloak v-for="item in todos"> <li v-on:click="changeStatus(item)"> <span style="text-decoration: line-through; color: red" v-if="item.done"> [[ item.task ]] ([[ item.due.getMonth()+1 ]]/[[ item.due.getDate() ]]) </span> <span v-else> [[ item.task ]] ([[ item.due.getMonth()+1 ]]/[[ item.due.getDate() ]]) </span> </li> </ul> <hr> <form v-on:submit.prevent="addTask"> <label for="task">Task:</label> <input type="text" id="task" v-model="new_task"> <label for="due">Due:</label> <input type="date" id="due" v-model="its_due"> <button type="submit" >Add</button> </form> </div> <script src="https://unpkg.com/vue"></script> <script src="https://unpkg.com/axios/dist/axios.min.js"></script> <script src="https://cdn.jsdelivr.net/npm/js-cookie@2/src/js.cookie.min.js"></script> <script> var vm = new Vue({ delimiters: ['[[', ']]'], el: '#app', data: { todos: [], new_task: "", its_due: "" }, mounted: function() { axios.get('{% url "todo:get_todo" %}') .then(function (response) { for(var d in response.data) { var item = response.data[d]; item.due = new Date(item.due); vm.todos.push(item); } }) .catch(function (error) { console.log(error); }) .then(function () { }); }, methods: { changeStatus: function(item) { item.done = !item.done; this.updateDB(item); }, addTask: function() { if(this.new_task && this.its_due){ item = { "task":this.new_task, "due": new Date(this.its_due), "done":false }; this.todos.push(item); this.updateDB(item); } this.task = ""; this.due = ""; }, updateDB: function(item) { csrftoken = Cookies.get('csrftoken'); headers = {'X-CSRFToken': csrftoken}; data = { "task":item.task, "due": new Date(item.due), "done":item.done }; axios.post('{% url "todo:post_todo" %}', data, {headers: headers}) .then(function (response) { console.log(response); }) .catch(function (error) { console.log(error); }); } } }) </script> </body> </html>よく見るとツッコミどころはたくさんありそうだけど,ひとまず目標は達成できたのでよしとする.
まとめ
前編,後編を通して,DjangoのテンプレートにVue.jsを導入してちょこっと使ってみるための基礎はできたと思う.Vue.js自体の機能はまだほんの触りしか使っていないので,これからいろいろ試してみたい.
ここまで読んでくださった方に感謝. m(__)m
- 投稿日:2019-04-11T23:48:17+09:00
Python Cloud functions をローカル環境で実行する
最近cloud functionsを使っていてローカルでデバッグしたかったので。
自分用覚え書きpipenv使ってる人はflaskインストールします
環境変数使ってる方はpyyamlもpipenv install --dev flask, pyyamlついでにpipfileにscriptsも追加します
Pipfile[scripts] dev = "python main.py"こんな感じで追加
main.pyif __name__ == "__main__": from flask import Flask, request import yaml app = Flask(__name__) # 環境変数読み込み with open('.env.yaml', 'r') as f: ENV = yaml.load(f) MY_TOKEN = ENV.get('MY_TOKEN') @app.route('/', methods=['OPTIONS', 'POST', 'GET]) def index(): return my_function(request) app.run('127.0.0.1', 8000, debug=True)サーバー起動して簡単に確認できちゃいます
pipenv run devdeployもこんな感じでbashスクリプト作っておけば簡単
deploy.shGCF_NAME="my-func-name" PROJECT_ID="my-project-id" GCF_REGION="asia-northeast1" gcloud functions deploy $GCF_NAME \ --runtime python37 \ --region $GCF_REGION \ --trigger-http \ --env-vars-file .env.yamlもっと楽ちんな方法あったら誰か教えてくださ〜い
- 投稿日:2019-04-11T23:37:22+09:00
python requestsを使ってログインする
問題
Webサイトへのログイン/ログアウトを自動化したいが、
訳あってSeleniumが使えない。
Robobrowserやmechanicalsoupだとログアウトのリンクが選択できない。
さて、困った。
その時の備忘録。ググってみると、requestsモジュールを使用して
必要なフォームパラメータをpostしてやるとログインできるぜ!
っといった記事を多く目にした。
よし!参考になる!以前自作したWebアプリで実験。まずは対象のログインフォームのソースを確認。
login.html<form action="/login" accept-charset="UTF-8" method="post"> <input name="utf8" type="hidden" value="✓"> <input type="hidden" name="authenticity_token" value="SmPba8H6cRcKKH/hK5DAyyONn/LGWD7vPIMM4eJDQH3FIzu55qhYsJXOnub0xQaVguMH4O4qI5a0hAtyHSkZUg=="> <div class="form-group"> <label for="session_email">メールアドレス</label> <input class="form-control" type="email" name="session[email]" id="session_email"> </div> <div class="form-group"> <label for="session_password">パスワード</label> <input class="form-control" type="password" name="session[password]" id="session_password"> </div> <input type="submit" name="commit" value="ログイン" class="btn btn-primary btn-block" data-disable-with="ログイン"> </form>pythonのソースはこんな感じ。
login.pyimport requests session = requests.Session() session.get(url) data = { 'UTF-8': '✓', 'session[email]': メールアドレス, 'session[password]': パスワード, } login = session.post(login url, data=data) print(login.text)ムム、ログイン出来ない。
ん?フォームにはauthenticity_tokenというのがある。
これも必要かな?
ただ、これはサイトアクセス毎にランダムで変わるね。
さてどうやって取得しようか?試した環境など
・Python 3.6.7
・CentOS7requests以外に入れたモジュール
・BeautifulSoup
以下の様してみた。
login.pyimport requests from bs4 import BeautifulSoup session = requests.Session() response = session.get(url) # BeautifulSoupオブジェクト作成(token取得の為) bs = BeautifulSoup(response.text, 'html.parser') data = { 'UTF-8': '✓', 'session[email]': メールアドレス, 'session[password]': パスワード, } # tokenの取得 authenticity_token = bs.find(attrs={'name':'authenticity_token'}).get('value') # 取得したtokenをpostするパラメータに追加 data["authenticity_token"] = authenticity_token login = session.post(login url, data=data) print(login.text)ダメでした。。
じゃあ、Cookieを取得してpostしてみよう。login.pyimport requests from bs4 import BeautifulSoup session = requests.Session() response = session.get(url) bs = BeautifulSoup(response.text, 'html.parser') data = { 'UTF-8': '✓', 'session[email]': メールアドレス, 'session[password]': パスワード, } authenticity_token = bs.find(attrs={'name':'authenticity_token'}).get('value') data["authenticity_token"] = authenticity_token # cookieの取得 response_cookie = response.cookies # post時にcookieを追加 login = session.post(login url, data=data, cookies=response_cookie) print(login.text)ログイン出来た。
ログアウトについては後日追記する。
- 投稿日:2019-04-11T23:36:24+09:00
DjangoのテンプレートにVue.jsを導入してaxiosでAjaxしてみた話(前編)
はじめに
Vue.jsが便利そうなのでDjangoと組み合わせて使ってみようと試してみた.使ってみたいといっても,大それたことしたいわけではなく,まずはDjangoのテンプレートの中にVue.jsのスクリプトを埋め込んでクライアント側でちょこっとした機能を実現できるようになるあたりまでが目標だ.
架空のTodoアプリを具体例として話を進めていくが,これはあくまで例示のためで,アプリ自体は実用には程遠いので悪しからず...
全体のコードはまとめてGitHubに置いた.
Django側での雛形の作成
最初に,Todoアプリに登録したいタスクのモデルを設計しておく.具体的には,次のように,タスクの名称(task),納期(due),完了済みかどうか(done)の3つのフィールドをもつデータモデル(Todo)を定義した.
class Todo(models.Model): task = models.CharField(max_length=255, unique=True) due = models.DateTimeField() done = models.BooleanField() def __str__(self): return self.task後で利用するために,このデータモデルをadminサイトに登録し,adminサイトから架空のタスクをいくつか追加しておこう.
続いて,データベース内のタスクをすべて取得して納期順に並べて表示するページの雛形をつくる.具体的には,次のようなview関数
def show_todo(request): todos = models.Todo.objects.all().order_by("due") my_context = { "todos":todos, } return render(request, "name_of_your_template", my_context)とテンプレート
<html> <head><title>Todo</title></head> <body> <h1>My Todo List</h1> <div> <ul> {% for item in todos %} <li> {% if item.done %} <span style="text-decoration: line-through; color: red"> {{ item.task }} ({{ item.due|date:"n" }}/{{ item.due|date:"j" }}) </span> {% else %} <span> {{ item.task }} ({{ item.due|date:"n" }}/{{ item.due|date:"j" }}) </span> {% endif %} </li> {% endfor %} </ul> </div> </body> </html>を用意した.urlルーティングを適切に設定してページが表示されれば準備OKだ.
テンプレートへのVue.jsの導入
土台となる雛形ができたので,このテンプレートにVue.jsを導入していこう.簡単に試してみるには,次のように,CDNからロードするのが手っ取り早い.
<script src="https://unpkg.com/vue"></script>今回はお試しなので,Vue.jsの具体的なスクリプトもこのテンプレートの中に直接書き込んでいくことにする.Vueのインスタンスを作成し,タスクの情報をリアクティブにするためにdata内のプロパティに取り込み,簡単な機能をまずひとつ実装してみた.
<html> <head><title>Todo</title></head> <body> <h1>My Todo List</h1> <div id="app"> <ul v-cloak v-for="item in todos"> <li v-on:click="changeStatus(item)"> <span style="text-decoration: line-through; color: red" v-if="item.done"> [[ item.task ]] ([[ item.due.getMonth()+1 ]]/[[ item.due.getDate() ]]) </span> <span v-else> [[ item.task ]] ([[ item.due.getMonth()+1 ]]/[[ item.due.getDate() ]]) </span> </li> </ul> </div> <script src="https://unpkg.com/vue"></script> <script> var vm = new Vue({ delimiters: ['[[', ']]'], el: '#app', data: { todos: [] }, mounted: function() { {% for item in todos %} this.todos.push({ "task": "{{ item.task }}", "due": new Date({{ item.due|date:'U' }} * 1000), "done": {{ item.done|lower }}, }) {% endfor %} }, methods: { changeStatus: function(item) { item.done = !item.done; } } }) </script> </body> </html>DjangoのテンプレートにVue.jsを導入する際には
{{}}の扱いに注意する必要がある.デフォルトのままだと,双方でこの表記を使うことになるのでぶつかってしまう.これを回避するために個人的に気にいっている方法は,Vue.js側で{{}}を,例えば,[[]]に変更してしまうことだ.これは,上の例にもあるように,Vueインスタンスを生成する際に次のように指定すればよい.
delimiters: ['[[', ']]']次に,
mounted:の項目を見てほしい.まだAjax通信を実装していないので,苦肉の策として,Djangoからcontextとして渡されたtodosからタスクの情報をforループで取り出し,JavaScriptのオブジェクトに変換してからVue.js側のtodosに順に追加していっている.ひとまずこれで動いた.この部分は,後でAjax通信に変更する.なお,考えてみれば当然だが,Vue.jsのスクリプトの中でDjangoのテンプレートタグが使えていることが確認できる.
html側のリスト表示(
<ul></ul>)が,Djangoのcontextではなく,Vue.jsのdataからタスクの情報を引き出す形に変更されていることにも注意する.また,リスト要素(<li></li>)にクリックイベントを処理するディレクティブも追加してある.これによって,リスト要素をクリックすると,
methods:の項目で定義されているchangeStatusが呼び出され,対応するタスクのdoneのブール値が裏返る.Ajax通信(その1,GET編)
続いて,Ajax通信を実装していこう.Vue.js自体にはAjax通信の機能は用意されていないらしいので,まずどういう策を取るかを決めなければならない.Vue.jsを導入していけはjQueryを使う機会は減っていくだろうから,Ajax通信のためだけにjQueryをロードするのは気が引ける.そういう場合にはaxiosがおすすめらしい(ので.それに従うことにする).
まず,Vue.jsの場合と同じように,axiosもCDNからロードしておく.
<script src="https://unpkg.com/axios/dist/axios.min.js"></script>その上で,テンプレート内のVue.jsのスクリプトを下記のように更新する.
var vm = new Vue({ delimiters: ['[[', ']]'], el: '#app', data: { todos: [] }, mounted: function() { axios.get('{% url "for_view_function_get_todo()" %}') .then(function (response) { for(var d in response.data) { var item = response.data[d]; item.due = new Date(item.due); vm.todos.push(item); } }) .catch(function (error) { console.log(error); }) .then(function () { }); }, methods: { changeStatus: function(item) { item.done = !item.done; } } })
mounted:の項目の中身がaxiosを利用したAjaxのGET通信に置き換わっている.中身を見ると,JSON形式で取得したタスクのリストをresponse.dataからforループで取り出し,順にtodosに追加していっていることがわかる.また,この際に,納期(due)は,JavaScriptのDateオブジェクトに変換している.テンプレートの側はこれでOKだ.ただし,このAjaxリクエストに対して,Django側がレスポンスを返してくれないと話にならない.続いて,Django側の設定を行おう.
まずこのリクエストを処理するために,下記のようなview関数を用意する,
import json from django.http import JsonResponse from . import models def get_todo(request): todos = models.Todo.objects.all().order_by("due").values() todolist = list(todos) return JsonResponse(todolist, safe=False)そして,上の
axios.get()で,このview関数が呼ばれるようにurlルーティングを設定する.実は,ここで詰まってかなりの時間を浪費した.ポイントは,クエリセットの末尾に
.values()を追加すること,それをlist()でリストに変換してから返すこと,そしてJsonResponse()にsafe=Falseを指定することである(このページに助けられた,感謝).なお,テンプレートの中ではもうDjango側の
todosは使わなくなったので,ページ全体の方のview関数でそれを作成してcontextに含める処理は不要になる.したがって,こちらのview関数は,例えば次のように簡略化してしまえる.from django.views import generic class ShowTodoView(generic.TemplateView): template_name = "todo/show_todo.html"まとめ
前編では,Vue.jsをDjangoのテンプレートに導入し,Django側からAjaxでとってきたJSON形式の情報をVue.js側で取得して処理するところまでできた.話は後編に続く.後編では,逆に,Vue.js側の情報をDjango側に送ってデータベースを更新することを試す.
- 投稿日:2019-04-11T22:51:01+09:00
RNA-seq 発現変動遺伝子解析:salmonとTCC-GUIを使って
概要
salmonを用いることにより、alighnerを使用せず、転写物配列のインデックスを利用して、readsをカウントする。
TCC-GUIを用いて、PCA分析、クラスタリング、シルエット分析、これらの可視化、発現変動遺伝子(DEG)抽出を行う。
どの程度、コンピュータ資源と解析時間を節約して、DEG抽出が可能かを確認する。環境
MacBook Pro 13-inch (Touch Bar) 2018 16GB RAM Core-i5 (4core, 8 threads)
内蔵用SSD 500GB を USB3.1 Gen2 接続で外付けとして利用macOS 10.14.4
anaconda3-2018.12
Python 3.7.1
R version 3.5.2
RStudio ver1.1.463準備
1. Salmonのインストール
conda create -n salmon salmon -c bioconda今回ダウンロードされたパッケージのバージョン
package build jemalloc-5.1.0 h6de7cb9_1001 1.6 MB conda-forge libboost-1.67.0 hebc422b_4 18.8 MB salmon-0.13.1 heb0d2e1_0 13.5 MB bioconda tbb-2019.4 h04f5b5a_0 156 KB conda-forge 起動
source activate salmon2. 転写物の配列データの取得
1)Ensembleの場合
①マウス:Genome assembly: GRCm38.p6 (GCA_000001635.8)
mkdir -p Volumes/Samsung500_J/mouse_salmon
cd /Volumes/Samsung500_J/mouse_salmon
wget ftp://ftp.ensembl.org/pub/release-95/fasta/mus_musculus/cdna/
gunzip Mus_musculus.GRCm38.cdna.all.fa.gz
grep ">" Mus_musculus.GRCm38.cdna.all.fa | cut -d' ' -f 1 | wc
116067 116067 2561207と出力されて、転写物:116,067個 であることがわかる。
②ヒト:Genome assembly: GRCh38.p12 (GCA_000001405.27)
mkdir -p /Volumes/Samsung500_J/human_salmon
cd /Volumes/Samsung500_J/human_salmon
wget ftp://ftp.ensembl.org/pub/release-95/fasta/homo_sapiens/cdna/Homo_sapiens.GRCh38.cdna.all.fa.gz
gunzip Homo_sapiens.GRCh38.cdna.all.fa.gz
grep ">" Homo_sapiens.GRCh38.cdna.all.fa | cut -d' ' -f 1 | wc
187626 187626 3568377と出力されて、転写物が 187,626個 であることがわかる。
2) GENCODEの場合
①マウス: gencode.vM20.transcripts.fa
mkdir -p /Volumes/Samsung500_J/mouse_GENCODE/salmon/
cd /Volumes/Samsung500_J/mouse_GENCODE/salmon/
wget ftp://ftp.ebi.ac.uk/pub/databases/gencode/Gencode_mouse/release_M20/gencode.vM20.transcripts.fa.gz
gunzip gencode.vM20.transcripts.fa.gz
grep ">" gencode.vM20.transcripts.fa | cut -d' ' -f 1 | wc
138835 138835 16998089転写物:138,835個 (Ensemble 116,067個 より多い)
②ヒト
mkdir -p /Volumes/Samsung500_J/human_GENCODE/salmon
cd /Volumes/Samsung500_J/human_GENCODE/salmon
wget ftp://ftp.ebi.ac.uk/pub/databases/gencode/Gencode_human/release_29/gencode.v29.transcripts.fa.gz
gunzip gencode.v29.transcripts.fa.gz
grep ">" gencode.v29.transcripts.fa | cut -d' ' -f 1 | wc
206694 206694 24332877転写物:206,694個 (Ensemble 187,626個 より多い)
3. salmon indexの作成
構文
salmon index -t /path/to/hoge.cdna.all.fa -i hoge_salmon_index -k 31https://salmon.readthedocs.io/en/latest/salmon.html#quantifying-in-alignment-based-mode
によれば、We find that a k of 31 seems to work well for reads of 75bp or longer, but you might consider a smaller k if you plan to deal with shorter reads. Also, a shoter value of k may improve sensitivity even more when using the –validateMappings flag. So, if you are seeing a smaller mapping rate than you might expect, consider building the index with a slightly smaller k.
ただし、salmon index -hで確認すると 31 がデフォルト値なので、現状のリード長なら省略で可。
実行時間は以下のようにそれほどかからない。1) Emsemble の場合
①マウス
cd /Volumes/Samsung500_J/mouse_salmon
salmon index -t Mus_musculus.GRCm38.cdna.all.fa -i Mus_musculus.GRCm38_salmon_index -k 31② ヒト
cd /Volumes/Samsung500_J/human_salmon
time salmon index -t Homo_sapiens.GRCh38.cdna.all.fa -i Homo_sapiens.GRCh38_salmon_index -k 31real 3m6.119s
user 2m54.204s
sys 0m8.833s2)GENCODE の場合
① マウス
cd /Volumes/Samsung500_J/mouse_GENCODE/salmon/
time salmon index -t gencode.vM20.transcripts.fa -i gencode.vM20_salmon_index -k 31real 2m47.658s
user 2m39.345s
sys 0m7.678s②ヒト
cd /Volumes/Samsung500_J/human_GENCODE/salmon
time salmon index -t gencode.v29.transcripts.fa -i gencode.v29_salmon_index -k 31real 3m31.654s
user 3m17.814s
sys 0m13.055s4. mapping-based modeでのカウント
alighnerを用いずに直接定量することを売り物としているが、実際にはsalmonはBAMを利用することもできる。
ここでは、starとの比較のためfastqからの直接定量の方法を示す。構文 (PE/unstranded reads の場合)
./bin/salmon quant -i transcripts_index -l "LIBTYPE" -1 reads1.fq -2 reads2.fq --validateMappings -o transcripts_quant
- 注1:anacondaでインストールした場合、./bin/ は省略
- 注2: -l -1 -2 ( -r :SEの場合)の順番が守られていないといけない。
Order of command-line parameters
The library type -l should be specified on the command line before the read files (i.e. the parameters to -1 and -2, or -r). This is because the contents of the library type flag is used to determine how the reads should be interpreted.また、"LIBTYPE"の指定も重要。readが各ストランド上にどのような向きで張り付くかを考慮してカウントするので、ライブラリー調整法に合わせて設定する必要がある。今回はIU (an unstranded paired-end library where the reads face each other)を選択。
- 注3:-0 で指定されたoutput dirを作成し結果を保存する
実行 (例:マウスGENCODE と hoge_1.fastq/hoge_2.fastq)
mkdir -p /Volumes/Samsung500_J/salmon_hoge
cd /Volumes/Samsung500_J/salmon_hoge
salmon quant -i /Volumes/Samsung500_J/mouse_GENCODE/salmon/gencode.vM20_salmon_index \
-l IU \
-1 /Volumes/Samsung500_J/fastq/hoge_1.fastq \
-2 /Volumes/Samsung500_J/fastq/hoge_2.fastq \
--validateMappings \
-o /Volumes/Samsung500_J/salmon_hoge/hoge_fastq_salmon_quant結果 所要時間:約3分 (star-RSEMの10倍以上の速さ)
- 出力されたカウントデータのファイルは、quant.sf である。以下、作成されたファイルとサブディレクトリです。
(salmon) $ ls -lh /Volumes/Samsung500_J/salmon_hoge/hoge_fastq_salmon_quant
total 40576
drwxr-xr-x 0 piyo staff 0B 4 1 16:49 aux_info
-rw-r--r-- 1 piyo staff 397B 4 1 16:48 cmd_info.json
drwxr-xr-x 0 piyo staff 0B 4 1 16:49 libParams
-rw-r--r-- 1 piyo staff 648B 4 1 16:49 lib_format_counts.json
drwxr-xr-x 0 piyo staff 0B 4 1 16:46 logs
-rw-r--r-- 1 piyo staff 20M 4 1 16:49 quant.sf
(salmon)$ ls -lh /Volumes/Samsung500_J/salmon_hoge/hoge_fastq_salmon_quant/aux_info/
total 2048
-rw-r--r-- 1 piyo staff 695K 4 1 16:49 ambig_info.tsv
-rw-r--r-- 1 piyo staff 89B 4 1 16:49 expected_bias.gz
-rw-r--r-- 1 piyo staff 498B 4 1 16:49 fld.gz
-rw-r--r-- 1 piyo staff 1.4K 4 1 16:49 meta_info.json
-rw-r--r-- 1 piyo staff 54B 4 1 16:49 observed_bias.gz
-rw-r--r-- 1 piyo staff 54B 4 1 16:49 observed_bias_3p.gz
(salmon) $ ls -lh /Volumes/Samsung500_J/salmon_hoge/hoge_fastq_salmon_quant/logs
total 128
-rw-r--r-- 1 piyo staff 3.6K 4 1 16:49 salmon_quant.log
(salmon) $ ls -lh /Volumes/Samsung500_J/salmon_hoge/hoge_fastq_salmon_quant/libParams/
total 128
-rw-r--r-- 1 piyo staff 11K 4 1 16:49 flenDist.txt一括処理 < bash スクリプトで全fastqファイルをまとめて処理>
①configファイルの作成
list_sample.txt にサンプル名に相当するprefixのリストを記す
pwd
/Volumes/Samsung500_J/salmon_hoge
touch list_sample.txtnanoで以下をlist_sample.txt に記入して保存する
hoge
hoge2
hoge3
fuga
fuga2
fuga3② script ファイルの作成
touch salmon_count.shnanoで以下をsalmon_count.shに記入して保存する
#!/bin/bash
for sample in `cat ./list_sample.txt`
do
salmon quant -i /Volumes/Samsung500_J/mouse_GENCODE/salmon/gencode.vM20_salmon_index -l IU -1 /Volumes/Samsung500_J/fastq/\${sample}_1.fastq -2 /Volumes/Samsung500_J/fastq/\${sample}_2.fastq --validateMappings -o /Volumes/Samsung500_J/salmon_hoge/${sample}.fastq_salmon_quant
doneその後、実行可能にするために、
chmod +x salmon_count.sh③ シェルスクリプトの実行
pwd
/Volumes/Samsung500_J/salmon_hoge
sh ./salmon_count.sh5. 発現量の群間比較 ー quant.sf をtximport でファイル整形し、TCC-GUI へ流し込む
①準備 RStudioでの環境設定
定量したデータ(quant.sf ファイル)を使って、edgeR や DESeq2 などで発現量の群間比較を行うことができる。この際に、Bioconductor の tximport パッケージ(Soneson et al, 2015)を利用することで、salmon の定量結果を edgeR/DESEq2 に取り込める形式にする。
ここでは、edgeR/DESeq2を内包するTCC-GUI へ流し込み、クラスター分析、averaded shilluete score の算出、DEGの抽出、PCA分析等を行う。raw count dataが必要になることに注意。
R-3.5.2 であることを確認しておく。依存バッケージの一部に3.5.2で作成されたものがあった。
私は3.5.1から 3.5.2へ切り替えました
以下のコマンドで一旦Rをアンインストール
sudo rm -rf /Library/Frameworks/R.framework /Applications/R.app \> /usr/local/bin/R /usr/local/bin/RscriptR-3.5.2のMac用インストーラーでインストール
jsonlite, readrをCRANでインストール
② RStudioでの環境設定
RStudioの起動してコンソールで以下を実行していく
> getwd()
[1] "/Volumes/Samsung500_J/salmon_hoge"tximportをインストール
ただしCRANではインストールできない。Bioconductor で検索しインストールコマンドを確認,以下をコピペし実行
if (!requireNamespace("BiocManager", quietly = TRUE))
install.packages("BiocManager")
BiocManager::install("tximport", version = "3.8")③ tximportでquant.sf を整形
1)directoryの構造を確認
(salmon) $ ls -lh
total 168
drwxr-xr-x 0 chao staff 0B 4 1 17:33 fuga.fastq_salmon_quant
drwxr-xr-x 0 chao staff 0B 4 1 16:49 fuga2.fastq_salmon_quant
drwxr-xr-x 0 chao staff 4.0K 4 1 17:24 fuga3.fastq_salmon_quant
drwxr-xr-x 0 chao staff 4.0K 4 1 17:26 hoge.fastq_salmon_quant
drwxr-xr-x 0 chao staff 4.0K 4 1 17:29 hoge2.fastq_salmon_quant
drwxr-xr-x 0 chao staff 4.0K 4 1 18:08 hoge3.fastq_salmon_quant
-rw-r--r-- 1 chao staff 68B 4 1 17:14 list_sample.txt
-rwxr-xr-x 1 chao staff 343B 4 1 17:22 salmon_count.sh2)実行 コマンドライン directoryのPrefix を参照して以下。
library(tximport)
library(jsonlite)
library(readr)salmon.files <- file.path(list.files('.', pattern = 'fastq_salmon_quant'), 'quant.sf')
names(salmon.files) <- c('hoge', 'hoge2', 'hoge3', 'fuga', 'fuga2', 'fuga3')
tx.exp <- tximport(salmon.files, type = "salmon", txOut = TRUE)# txname|expでのcount tabelをgene id | expに変換
salmonForTCC.gene.exp <- summarizeToGene(tx.exp, tx2gene)3) 実行結果
salmonForTCC.gene.exp <- summarizeToGene(tx.exp, tx2gene
summarizing abundance
summarizing counts
summarizing length
head(salmonForTCC.gene.exp$counts)
hoge hoge2 hoge3 fuga fuga2 fuga3
ENSMUST00000000001 832.000 722.000 764.000 719.000 1057.000 621.000
ENSMUST00000000003 0.000 0.000 0.000 0.000 0.000 0.000
ENSMUST00000000010 0.000 0.000 0.000 0.000 0.000 0.000
ENSMUST00000000028 36.918 13.449 33.598 17.705 41.000 21.000
ENSMUST00000000033 2081.155 1911.423 1889.926 1683.395 2561.719 1521.427
ENSMUST00000000049 2.000 3.000 7.000 6.000 3.000 4.000salmonForTCC.gene.exp$counts をTCC-GUIへの入力とすれば良い。この段階がstar-RSEMでの出力結果に相当する。
ここで
head(salmonForTCC.gene.exp)とすると、他にどんなデータがobjectに格納されているか確認できる、
$abundance
hoge hoge2 hoge3 fuga fuga2 fuga3
ENSMUST00000000001 19.429877 18.611211 19.115514 17.293916 20.951762 16.330796
ENSMUST00000000003 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000
ENSMUST00000000010 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000
・
・
・
[ reached getOption("max.print") -- 137105 行を無視しました ]$counts
hoge hoge2 hoge3 fuga fuga2 fuga3
ENSMUST00000000001 832.000 722.000 764.000 719.000 1057.000 621.000
ENSMUST00000000003 0.000 0.000 0.000 0.000 0.000 0.000
ENSMUST00000000010 0.000 0.000 0.000 0.000 0.000 0.000
・
・
・
[ reached getOption("max.print") -- 137105 行を無視しました ]$length
hoge hoge2 hoge3 fuga fuga2 fuga3
ENSMUST00000000001 3.084807e+03 3.086667e+03 3.069008e+03 3.071679e+03 3.086726e+03 3.070576e+03
ENSMUST00000000003 7.182677e+02 7.182677e+02 7.182677e+02 7.182677e+02 7.182677e+02 7.182677e+02
ENSMUST00000000010 2.390244e+03 2.390244e+03 2.390244e+03 2.390244e+03 2.390244e+03 2.390244e+03
・
・
・
[ reached getOption("max.print") -- 137105 行を無視しました ]
\$countsFromAbundance
[1] "no"TCC-GUIに用いるのは salmonForTCC.gene.exp$counts
③ TCC-GUIへの入力のためにファイルへ書き出す
1) as.data.frame()関数を用いる
書き出す内容: salmonForTCC.gene.exp$countstable <- as.data.frame(salmonForTCC.gene.exp$counts)
write.table(table, file = "salmonForTCC.gene.txt", col.names = T, row.names = T, sep = "\t")2)実行:
getwd()
table <- as.data.frame(salmonForTCC.gene.exp$counts)
write.table(table, file = "salmonForTCC.gene.txt", col.names = T, row.names = T, sep = "\t")3)結果:
$ ls -lh
total 78528
-rw-r--r--@ 1 chao staff 10M 4 2 14:51 190402_salmon_edgeR_result.xlsx
drwxr-xr-x 0 chao staff 0B 4 1 17:33 hoge.fastq_salmon_quant
drwxr-xr-x 0 chao staff 0B 4 1 16:49 hoge2.fastq_salmon_quant
drwxr-xr-x 0 chao staff 4.0K 4 1 17:24 hoge3.fastq_salmon_quant
drwxr-xr-x 0 chao staff 4.0K 4 1 17:26 fuga.fastq_salmon_quant
drwxr-xr-x 0 chao staff 4.0K 4 1 17:29 fuga2.fastq_salmon_quant
drwxr-xr-x 0 chao staff 4.0K 4 1 18:08 fuga3.fastq_salmon_quant
-rw-r--r-- 1 chao staff 68B 4 1 17:14 list_sample.txt
-rw-r--r-- 1 chao staff 6.0M 4 2 15:47 salmonForTCC.gene.txt # <= 作成された6MBのdata
-rw-r--r-- 1 chao staff 205B 4 2 13:30 salmon_count.Rproj
-rwxr-xr-x 1 chao staff 343B 4 1 17:22 salmon_count.sh
-rw-r--r--@ 1 chao staff 22M 4 2 14:12 salmon_edgeR_result.txt4)内容確認
$ wc -l salmonForTCC.gene.txt
137272 salmonForTCC.gene.txt$ head salmonForTCC.gene.txt
"hoge" "hoge2" "hoge3" "fuga" "fuga2" "fuga3"
"ENSMUST00000000001" 832 722 764 719 1057 621
"ENSMUST00000000003" 0 0 0 0 0 0
"ENSMUST00000000010" 0 0 0 0 0 0
"ENSMUST00000000028" 36.918 13.449 33.598 17.705 41 21
"ENSMUST00000000033" 2081.155 1911.423 1889.926 1683.395 2561.719 1521.427
"ENSMUST00000000049" 2 3 7 6 3 4
"ENSMUST00000000058" 831.867 789 703.472 609.765 983.875 630.786
"ENSMUST00000000080" 1209.643 1207.307 988.747 848.888 1328.56 1063.687
"ENSMUST00000000087" 571.847 697.089 685.971 383.457 714.186 335.9815)TCC-GUI用にヘッダー行の修正
ヘッダー行がいきなり、サンプル名で始まっている。
これはTCC-GUIでは読み込みエラーとなる。行頭にタブを打ち込んで保存。6)現在のprojectは salmon_count なので一旦終了
④ TCC-GUI で解析
詳細は以下を参照
https://github.com/swsoyee/TCC-GUIRStudioを起動してインストール
# Check "BiocManager"
if (!requireNamespace("BiocManager", quietly = TRUE))
install.packages("BiocManager")
# Package list
libs <- c("shiny", "shinydashboard", "shinyWidgets", "plotly", "dplyr", "DT", "heatmaply", "tidyr","utils","rmarkdown","data.table","RColorBrewer", "knitr", "cluster", "shinycssloaders", "shinyBS", "MASS", "TCC")起動
# Install packages if missing
for (i in libs){
if( !is.element(i, .packages(all.available = TRUE)) ) {
BiocManager::install(i)
}
}
shiny::runGitHub("TCC-GUI", "swsoyee", subdir = "TCC-GUI", launch.browser = TRUE)ブラウザで起動
salmonForTCC.gene.txtを入力解析後、htmlで保存
- 投稿日:2019-04-11T22:26:13+09:00
はじめてのDjango (7) 画像データの管理やページへの表示,アップロードの方法などについて知ろう
はじめに
このドキュメントは,もともとはラボの新メンバー向けの入門テキストとして作成したもので,はじめてDjangoにふれる人にざっとその全体像をつかんでもらうことを狙っています.Djangoの日本語での参考資料も充実してきたので今さらという気がしないでもないですが,見直しを機にQiitaに移すことにしました.万が一でもどなたかの参考になれば幸いです.
Djangoのバージョンは2.0以降を想定しています.説明のための具体例として,Djangoのオフィシャルチュートリアルにある投票アプリをとりあげています(が,説明上の都合で少しコードを追加,変更しているところもあります).素人の独学がベースで,特に前半は公式チュートリアルをやってみた感想のような記事です(今回は全7回中の最終回).
全体のコードはまとめてGitHubに置きました.
画像の表示とアップロード
今回は,画像ファイルをデータベースで管理し,ページに表示する方法や,ユーザに画像ファイルをアップロードしてもらう方法をみていきます.
なお,Djangoで画像ファイルを扱うためにはPillowという画像処理ライブラリが必要になるので,まだインストールしていない場合は,下記のコマンドであらかじめインストールしておきましょう.
$ pip install pillow最初に,mysiteのプロジェクト内に,pollsとは別に,albumというアプリケーションを作成します.
$ python manage.py startapp album外側のmysiteのディレクトリで上記のコマンドを打ち込むと,その中にalbumというディレクトリが新たに作成されます(ここで忘れずに,settings.pyの
INSTALLED_APPSのリストにこのアプリケーションを追加しておきましょう).続いて,画像を扱う簡単なモデルを作成します.具体的には,albumディレクトリ内のmodels.py(album/models.py)の中に下記の内容を書き足します.
from django.db import models class Image(models.Model): picture = models.ImageField(upload_to='images/') title = models.CharField(max_length=200) def __str__(self): return self.titleこれは,画像ファイルを表す
pictureとその表題を表すtitleという2つのfieldをもった,Imageクラスの定義になっています(なお,このmodels.ImageField()を使うためにPillowが必要になるわけです).画像ファイルの実体はデータベース内に格納されるわけではなく,あるディレクトリにアップロードされることになります.
models.ImageField()の引数に指定されているupload_toでこのディレクトリを指定しています.上の例では,
upload_toにimages/というディレクトリが指定されていますが,これはMEDIA_ROOTを起点とした相対パス指定になります.また,MEDIA_ROOT内の画像ファイルをurlで参照する際に起点となるアドレスをMEDIA_URLとして指定しておく必要があります.今回は,外側のmysiteディレクトリ内にmediaというディレクトリを作成し,それを
MEDIA_ROOTに指定しましょう.また,MEDIA_URLもわかりやすくmediaという名称にしておきます.具体的には,settings.pyの中に下記のように指定しておくことにします.BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) MEDIA_ROOT = os.path.join(BASE_DIR, 'media') MEDIA_URL = '/media/'
BASE_DIRはデフォルトのままですが,具体的には外側のmysiteディレクトリを指すことになります.MEDIA_ROOTはその中のmediaディレクトリという意味にります.また,MEDIA_URLをこのように設定すると,開発用サーバを用いている場合,が画像ファイルのurlの起点となります.
次に,このモデルをadminサイトに登録して,adminサイトでImageクラスの画像ファイルを操作できるようにしましょう.まず,album/admin.pyに次の内容を書き込みます.
from django.contrib import admin from .models import Image admin.site.register(Image)makemigrationsとmigrateでデータベースの構成を更新してから,開発用サーバを立ち上げ,adminサイトにアクセスしてみましょう.追加したImageクラスが現れているはずです.
これでadminサイトを通じて,画像ファイルをデータベースにアップロードしたり,データベースから削除したりできるようになりました.実際に画像ファイルをいくつかアップロードしてみましょう.
続いて,画像ファイルを表示するページを作成します.このためにまず,album/views.pyの中に次のような簡単なview関数を用意しましょう.
from django.shortcuts import render from .models import Image def showall(request): images = Image.objects.all() context = {'images':images} return render(request, 'album/showall.html', context)データベース内にあるすべてのImageクラスのオブジェクトを取得して,それを
imagesという名称でtemplateに渡していることがわかります.次に,templateを用意します.具体的には,album/templates/album/showall.htmlというファイルを作成し,下記の内容を書き込みます.
<h1>Your Album</h1> {% for image in images %} <img src='{{ MEDIA_URL }}{{image.picture}}' width=200> <h2>{{ image.title }}</h2> {% endfor %}albumアプリケーションに関するurlルーティングは,album/urls.pyというファイルを作成し,その中に指定するようにします.ここでは,ひとまず次のように指定しておけばよいでしょう.
from django.urls import path from . import views app_name = 'album' urlpatterns = [ path('showall/', views.showall, name='showall'), ]また,あわせてmysite/urls.pyの方を次のように更新しておきます.
from django.contrib import admin from django.urls import include, path from django.views.generic import base from django.conf import settings from django.conf.urls.static import static urlpatterns = [ path('polls/', include('polls.urls')), path('album/', include('album.urls')), path('admin/', admin.site.urls), path('accounts/login/', base.RedirectView.as_view(pattern_name="polls:login")), path('accounts/profile/', base.RedirectView.as_view(pattern_name="polls:index")), ] + static(settings.MEDIA_URL, document_root=settings.MEDIA_ROOT)
urlpatternsの2行目の項目で,album/以降のルーティングを,上で作成したalbum/urls.pyに引き継ぐように指定していることがわかります.なお,最後に追加されている
static()は,開発用サーバが,MEDIA_ROOT以下のディレクトリに格納されているファイルをMEDIA_URLを起点としたurlで供給できるようにするための設定です(詳しくはここを参照).これでOKといいたいところですが,もう1つだけ準備が必要です.settings.pyの
TEMPLATESの中のcontext_processorsに次の項目を追加しておきます(そうでないとtemplate内でMEDIA_URLの値が参照できないそうです).TEMPLATES = [ { ... 'OPTIONS': { 'context_processors': [ ... 'django.template.context_processors.media', # これを追加する ], }, }, ]以上で準備は整ったはずです.下記のページにアクセスして画像が表示されることを確認してみましょう.
http://localhost:8000/album/showall/
最後にユーザが画像ファイルをアップロードするためのページを作成しておきましょう.まず,Imageクラスのデータ(画像ファイルとそのタイトル)を取得するためのフォームを作成します.album/models.pyに次の内容を書き込みます.
from django import forms from .models import Image class ImageForm(forms.ModelForm): class Meta: model = Image fields = ['picture', 'title']今回は
ModelFormという仕組みを利用しました.これは,あるモデルに対応した形式でデータを取得したい場合に,モデルの定義を利用してフォームを簡単に定義する仕組みです(詳細はここを参照).class Metaの中をみると,これはImageクラスに対応しており,pictureとtitleのデータを取得するためのフォームであることがわかります.続いて,album/views.pyの中にアップロード用のview関数
upload()を用意します.from django.shortcuts import render, redirect from .models import Image from .forms import ImageForm def upload(request): if request.method == "POST": form = ImageForm(request.POST, request.FILES) if form.is_valid(): form.save() return redirect('album:showall') else: form = ImageForm() context = {'form':form} return render(request, 'album/upload.html', context)これは,フォームを利用してユーザからデータを取得する場合の典型的なパターンになっていますが,2点だけ補足しておきます.
まず,POSTのリクエストを受けた際に
ImageForm()にrequest.POSTだけではなく,request.FILESも渡している点です.これはPOSTで画像(に限らず他の種類であっても)ファイルを取得する際に必要になるので頭の片隅においておきましょう.2点目は,
form.save()です.上のImageFormクラスでは特にsave()メソッドは定義していませんが,form.ModelFormを継承しているので,デフォルトのsave()メソッドが機能します.具体的には,モデルのインスタンスを渡した場合はそれが取得データで上書きされ,今回のように,インスタンスを渡さなかった場合は新しいインスタンスが生成,保存されることになります(詳しくはここを参照).
簡単なtemplateも用意しておきましょう.album/templates/album/upload.htmlのファイルを作成し,次の内容を書き込みます.
<h1>Please Upload</h1> <form enctype="multipart/form-data" action="{% url 'album:upload' %}" method="post"> {% csrf_token %} {{form.as_p}} <input type="submit" value="Upload"> </form>ここでのポイントは,
<form>タグの属性としてenctype="multipart/form-data"を指定しておくことです.この指定がないとファイルをDjangoに渡せません.最後にurlルーティングの情報をalbum/urls.pyに追加します.具体的には,
urlpatternsの中に下の記述を追加します.path('upload/', views.upload, name='upload'),ついでに,showallのページからuploadのページにリンクを張っておきましょう.album/templates/album/showall.htmlの末尾に次の1行を追加します.
<h2><a href="{% url 'album:upload' %}">Upload more</a></h2>以上で準備が整ったので,開発サーバを立ち上げて,下のページにアクセスすると画像のアップロードができるはずです.
http://localhost:8000/album/upload/
おわりに
以上で最終回まで終了です. m(__)m
- 投稿日:2019-04-11T21:51:20+09:00
fastTextをpipインストールしてはいけない話(2019/4/11現在、pyenv環境)
これは何?
自然言語処理で使用する、facebookのエンジニアの開発した打倒word2vecかもしれない、単語ベクトルを得るためのライブラリのFastTextの話です。
Pythonを利用するときpipはよく使うと思います。fastTextもpipに登録されているので後述の通りインストールできるのですが、インストールしてもプログラムからimportできないという症状が出ました。次のサイトにたどり着いて解決しました。
https://github.com/facebookresearch/fastText/issues/474一か月前にも全く同じ症状で苦しんでいたのですが、歳とは恐ろしいもので、そのことをすっかり忘れて前回と同じサイトで解決した自分にあきれて投稿します。備忘録って大切ですね!
2019年4月11日現在の内容です。
近いうちに改善されると思います。
影響があるか未調査ですがpyenv環境での話です。fastTextについてはこのへんを参照
https://qiita.com/icoxfog417/items/42a95b279c0b7ad26589【解決策】Githubからソースをダウンロードして手動で入れよう!
このように
git clone https://github.com/facebookresearch/fastText.git cd fastText pip install .以上
【失敗例】普通にpip installでインストールしても、import できない
普通にpipに存在するので、pip installでインストールで行けそうな気がします。依存等のエラーがでますが、簡単そうなので逆にのりのりでトラブルシュートしてしまいます。
pip install fastText怒られる
ModuleNotFoundError: No module named 'Cython'Cython直してもう一度
pip install --upgrade cython pip install fastTextまた怒られる
gcc: error trying to exec 'cc1plus': execvp: No such file or directorygcc-c++ をインストールしてもう一度
yum install gcc-c++ pip install fastTextすると、ちゃんとインストールされる。やった!
けれど、プログラムを走らせると、、、$ python app.py ModuleNotFoundError: No module named 'fastText'インストール成功と出て、site-packagesにもちゃんとフォルダがあるのに、なぜかimportされない病
小一時間pythonpathなど弄るも解決しない、、、
- 投稿日:2019-04-11T21:47:37+09:00
はじめてのDjango (6) サイトにユーザ登録とログイン・ログアウトの機能を組み込もう
はじめに
このドキュメントは,もともとはラボの新メンバー向けの入門テキストとして作成したもので,はじめてDjangoにふれる人にざっとその全体像をつかんでもらうことを狙っています.Djangoの日本語での参考資料も充実してきたので今さらという気がしないでもないですが,見直しを機にQiitaに移すことにしました.万が一でもどなたかの参考になれば幸いです.
Djangoのバージョンは2.0以降を想定しています.説明のための具体例として,Djangoのオフィシャルチュートリアルにある投票アプリをとりあげています(が,説明上の都合で少しコードを追加,変更しているところもあります).素人の独学がベースで,特に前半は公式チュートリアルをやってみた感想のような記事です(今回は全7回中の6回目).
全体のコードはまとめてGitHubに置きました.
ユーザ登録とログイン・ログアウト
ここまでは,urlさえ指定すれば誰でも閲覧できるページを作成してきました.続いて,ログインしないと閲覧できないページや,ログインしたユーザに応じてチューニングした内容が表示されるページを作成する方法をみていきましょう.
このためには,まずユーザという概念を導入する必要があります.
実は,Djangoにはユーザを扱う枠組みが標準装備されています.データベースを初期化した際に,管理者を登録したのを思い出しましょう.あれがユーザの例です.adminサイトのUsersのページをみると,その管理者のデータが格納されているはずです.
最初にユーザ登録用のページ(signupページ)を作成しましょう.希望するusernameとpasswordを取得するためのフォームを下記のように作成し,forms.pyに書き込みます.
from django.contrib.auth.models import User class SignUpForm(forms.Form): username = forms.CharField(widget=forms.TextInput) enter_password = forms.CharField(widget=forms.PasswordInput) retype_password = forms.CharField(widget=forms.PasswordInput) def clean_username(self): username = self.cleaned_data.get('username') if User.objects.filter(username=username).exists(): raise forms.ValidationError('The username has been already taken.') return username def clean_enter_password(self): password = self.cleaned_data.get('enter_password') if len(password) < 5: raise forms.ValidationError('Password must contain 5 or more characters.') return password def clean(self): super(SignUpForm, self).clean() password = self.cleaned_data.get('enter_password') retyped = self.cleaned_data.get('retype_password') if password and retyped and (password != retyped): self.add_error('retype_password', 'This does not match with the above.') def save(self): username = self.cleaned_data.get('username') password = self.cleaned_data.get('enter_password') new_user = User.objects.create_user(username = username) new_user.set_password(password) new_user.save()文字列のfieldが3つ定義されていますが,それらのうち,
enter_passwordとretype_passwordの2つにパスワード入力用のwidgetが指定してあります.これによって,キー入力の内容が画面に表示されないようになります.また,
clean()の中では,エラーをraiseするのではなく,add_error()というメソッドを呼んでいます.これによって,エラーを特定のfieldに対応付けることができます.
save()メソッドをみると,Userクラスのインスタンスの生成方法やpasswordの設定方法が確認できます.続いて,このフォームを処理するview関数
signup()を作成しましょう.views.pyに下記の内容を書き込みます.def signup(request): if request.method == 'POST': form = SignUpForm(request.POST) if form.is_valid(): form.save() return redirect('polls:index') else: form = SignUpForm() context = {'form':form} return render(request, 'polls/signup.html', context)これは,view関数でフォームを処理するための典型的なパターンに沿ったものになっています.対応するtemplate(signup.html)は,例えば次のように作成すればいいでしょう.
<h1>Please Sign Up to Polls App.</h1> <form action="{% url 'polls:signup' %}" method="post"> {% csrf_token %} {{ form.as_p }} <input type="submit" value="Sign Up"> </form> <p>or <a href= "{% url 'polls:login' %}">Login</a></p>最後に,urlルーティングの情報を更新します.まず,polls/urls.pyを下記のように書き換えます.
from django.contrib.auth import views as auth_views from django.urls import path from . import views app_name = 'polls' urlpatterns = [ path('', views.index, name='index'), path('<int:question_id>/', views.detail, name='detail'), path('<int:question_id>/results/', views.results, name='results'), path('signup/', views.signup, name='signup'), path('login/', auth_views.LoginView.as_view(template_name="polls/login.html"), name='login'), path('logout/', auth_views.LogoutView.as_view(next_page="polls:index"), name='logout'), ]ユーザ登録用のsignupページの指定が追加されており,上で作成したview関数
signup()に対応付けられていることがわかります.これで,http://localhost:8000/polls/signup/
にアクセスするとユーザ登録用のページが表示されるはずなので,実際に登録できるか確認してみましょう.
すでに登録済みのユーザに対してはloginのページを用意しましょう.
ユーザ登録と同様にフォームとview関数を自作することもできますが,ここではDjangoに用意されている標準viewを利用してみることにします.また,あわせてlogoutの機能も実装しておきましょう.
上のpolls/urls.pyをよくみると,loginとlogoutのページの指定も追加されていることがわかります.
auth_views.LoginView.as_view()とauth_views.LogoutView.as_view()で標準view(関数ではなくクラス)を呼び出しています.まずloginページの方からみていきます.この標準viewを用いると,view関数を自作する必要はなくなります.標準viewに引数としてtemplateを渡していることからわかるように,templateは用意しなければなりません.下記はその一例です.
<h1>Please Login to Polls App.</h1> <form action="{% url 'polls:login' %}" method="post"> {% csrf_token %} {{ form.as_p }} <input type="submit" value="Login"> </form> <p>or <a href= "{% url 'polls:signup' %}">Sign Up</a></p>なお,この標準viewのデフォルトのurlはaccounts/login/なので,そのアドレスが指定された場合にpolls/loginにリダイレクトされるように仕組んでおきましょう.また,loginに成功した場合,標準ではaccounts/profile/にリダイレクトされるので,このアドレスはpolls/indexに再リダイレクトすることにしましょう.
これらの設定は,リダイレクトのための標準view(のクラス
base.RedirectView.as_view())を用いて,mysite/urls.pyの中に下記のように書くことができます.from django.contrib import admin from django.urls import include, path from django.views.generic import base urlpatterns = [ path('polls/', include('polls.urls')), path('admin/', admin.site.urls), path('accounts/login/', base.RedirectView.as_view(pattern_name="polls:login")), path('accounts/profile/', base.RedirectView.as_view(pattern_name="polls:index")), ]一方,logoutの方は,特にそれ専用のページは用意せず,このアドレスがリクエストされるとlogout処理を行って,それが終わったらindexページにリダイレクトするように指定してあります(この機能の呼び出し方は下で考えることにします).
続いて,detailページを,loginしているユーザしか利用できないように変更してみます.これは,
@login_requiredというデコレータを利用すれば簡単に実装できます.view関数detail()を次のように書き換えましょう.from django.contrib.auth.decorators import login_required @login_required def detail(request, question_id): user = request.user question = get_object_or_404(Question, pk=question_id) if request.method == 'POST': form = VoteForm(request.POST, question=question) if form.is_valid(): form.save() return redirect('polls:results', question_id=question.id) else: form = VoteForm(question=question) context = {'user':user, 'question':question, 'form':form} return render(request, "polls/detail.html", context)
detail()がデコレータ@login_requiredで修飾されているのがわかります.この結果,もしloginしていないユーザがこのページにアクセスしようとした場合は,detailページは表示されず,accounts/login/にリダイレクトされるようになります(accounts/login/はさらにpolls/login/にリダイレクトされるので,上で作成したloginページが表示されます).
また,
request.user(loginしているユーザのUserインスタンス)を取得してuserというキーでcontextの中に含めてrender()を呼んでいることもみてとれます.せっかくなので,この
userの情報をtemplateの中で利用してみよう.具体的には,detail.htmlを次のように更新します.<h1>Hi {{ user|title }}! {{ question.question_text }}</h1> {{ form.non_field_errors }} <form action="{% url 'polls:detail' question.id %}" method="post"> {% csrf_token %} <p> {{ form.your_choice.label }}<br> {{ form.your_choice }} </p> <p> {{ form.new_option.label }}<br> {{ form.new_option }} </p> <input type="submit" value="Vote"> </form> <p>or <a href= "{% url 'polls:logout' %}">Logout</a></p>最初にloginしているユーザ名を表示するようにしました.
titleは,与えられた文字列の先頭だけを大文字にするフィルタです.また,最後にlogoutを呼ぶリンクも追加してある.このリンクを踏むとlogoutの処理が走り,indexページにリダイレクトされるはずです.
おわりに
以上で6回目は終了です.最終回に続きます.
- 投稿日:2019-04-11T21:18:26+09:00
はじめてのDjango (5) フォームを用いたユーザからのデータの取得とデータベースへの格納
はじめに
このドキュメントは,もともとはラボの新メンバー向けの入門テキストとして作成したもので,はじめてDjangoにふれる人にざっとその全体像をつかんでもらうことを狙っています.Djangoの日本語での参考資料も充実してきたので今さらという気がしないでもないですが,見直しを機にQiitaに移すことにしました.万が一でもどなたかの参考になれば幸いです.
Djangoのバージョンは2.0以降を想定しています.説明のための具体例として,Djangoのオフィシャルチュートリアルにある投票アプリをとりあげています(が,説明上の都合で少しコードを追加,変更しているところもあります).素人の独学がベースで,特に前半は公式チュートリアルをやってみた感想のような記事です(今回は全7回中の5回目).
全体のコードはまとめてGitHubに置きました.
フォームを用いたユーザからのデータの取得とデータベースへの格納
ここまでは,adminサイトから管理者があらじめデータベースに格納しておいたデータをview関数で利用する方法をみてきました.続いて,view関数自体でユーザからデータを取得し,(必要に応じてなんらかの処理を加えた上で)データベースに格納したり,データベースに格納されていたデータを書き換えたりする方法をみていきます.
データベースに格納したいデータのまとまりをデータモデルとしてmodels.pyの中に定義したのを思い出しましょう.それと同じように,ユーザから取得したいデータのまとまりもあらかじめ定義しておくとわかりやすくなります.
このユーザから取得したいデータの構成をフォームと呼び,forms.pyに記述していきます.外側のmysiteディレクトリの中にあるpollsディレクトリの中にforms.pyというファイルを作成し,その中に次の内容を書き込みましょう.
from django import forms from .models import Question, Choice class VoteForm(forms.Form): CHOICES = [(ch.id, ch.choice_text) for ch in Choice.objects.all()] your_choice = forms.ChoiceField(choices = CHOICES) def save(self): choice_id = self.cleaned_data.get('your_choice') selected_choice = Choice.objects.get(pk=choice_id) selected_choice.votes += 1 selected_choice.save()これは,回答の選択肢(
CHOICES)の中からどれかを選ぶかを表す選択データのフォームを定義したものです.フォームにも,データモデルのときと同じように,取得したいデータ項目のfield(
forms.****Field()のように指定される)を列挙していきます.この例では,選択データを表すyour_choiceというfieldのみが定義されています.フォームで利用可能なfieldはここに整理されています.
save()というメソッドが追加されていますが,これについては後で説明することにして,ひとまず先に進みます.このフォームを利用してユーザからデータを取得できるように,view関数detail()を次のように書き換えます.from .forms import * def detail(request, question_id): question = get_object_or_404(Question, pk=question_id) if request.method == 'POST': form = VoteForm(request.POST) if form.is_valid(): form.save() return redirect('polls:results', question_id=question.id) else: form = VoteForm() context = {'question':question, 'form':form} return render(request, "polls/detail.html", context)最初に外側のif文以外の部分をみてみると,
questionとformをcontextに加えてrender()を呼び,detailのページを表示していることがわかります.ここに,formとはforms.pyで作成したフォームのインスタンスであり,外側のif文の中で作成されています.外側のif文では,ユーザからのリクエストがPOSTかどうかを判定しています(フォームにまつわるリクエストの方式にはGETとPOSTの2つがありますが,セキュリティの面でPOSTの方が好ましいため,そちらでないと受け付けないようにしています).
POSTの場合は,受け取ったデータ(
request.POST)をVoteForm()に渡してフォームのインスタンス(form)を作成しています.さらに,内側のif文でそのデータの妥当性をチェックし(is_valid()メソッド),この妥当性チェックにもパスした場合は,save()メソッドを呼んでから,resultsのページにリダイレクトしています.一方,POSTでなかった場合(最初にページを開き,まだデータを送信していないときなど)は,空のフォームのインスタンス(
form)を作成しています.そして,途中でリダイレクトされずに外側のif文から出てくると,detailのページが表示されるようになっています.
これが,フォームを利用するview関数の典型的な流れになります.特に,POSTデータの処理に成功したときは常に
redirect()を返すことが推奨されていますので,それに従うようにしましょう.ここで,
save()メソッド中身を,forms.pyの方で確認しておきましょう.ユーザが入力したデータをそのまま扱うのは危険が伴うので,Djangoが前処理を行ってくれます.この前処理後のデータには,
self.cleaned_data.get('field名')でアクセスすることができます.
save()の中では,まずyour_choiceの前処理後のデータをchoice_idという変数に代入しています.そして,そのidのChoiceデータをget()で取り出して,そのvotesの値に1を加えてから,データベースにセーブし直しています.ここでわかるように,データモデルクラスのインスタンスの
save()メソッドを呼ぶことでそのインスタンスをデータベースにセーブすることができます(このセーブ処理によって初めてデータベース内の値が更新されます).template(detail.html)の方も,ここまでの内容にあわせて更新しておきましょう.
<h1>{{ question.question_text }}</h1> <form action="{% url 'polls:detail' question.id %}" method="post"> {% csrf_token|title %} {{ form.as_p }} <input type="submit" value="Vote"> </form>
{% csrf_token %}は,フォームを使ってユーザとデータをやり取りする際にクロスサイトリクエストフォージェリ(csrf)という攻撃を受けるのを防ぐためにDjangoが用意してくれている仕組みです(ので,フォームを使うときにはtemplateに忘れずにこれを記載しておきましょう).
contextを通じて渡されたフォーム(form)は{{ form.as_p }}のところに挿入されます(.as_pをつけると,フォームが<p></p>タグで囲まれ,段落として扱われます).それでは,開発用サーバを立ち上げて,detailのページがどのように更新されたかをみてみましょう. 回答の選択肢をプルダウンで選んで投票できるようになっています.そして,投票するとresultsのページに飛び,実際に票数に増えていることも確認できます.
これで投票の機能まで実装することができました.ただし,いくつか不満な点もあります.1つ目は,プルダウンでは投票しにくいということです.
これについては,forms.pyの中で,下記のように,
your_choiceの引数にwidgetの指定を書き足すと,簡単にラジオボタンに変更することができます(これは好みの問題なので,プルダウンの方が好きという人はもとのままでもいいです).your_choice = forms.ChoiceField(choices = CHOICES, widget=forms.RadioSelect())2つ目は,回答の選択肢として,この質問項目に関係のないものまで出てきてしまうことです.続いて,これに対する対策を考えていきましょう.具体的には,フォームを作成するときの初期化処理(
__init__()メソッド)をオーバーライドしていきます.まず,この原因は,VoteFormクラスの1行目にある,
CHOICESの定義の仕方にあることを確認しておきます.Choice.objects.all()でクエリセットを作っているので,データベースの中のすべてのChoiceインスタンスが抜き出されてくるわけです.これにさえ気づけば,質問項目を
questionとおいて,クエリセットをquestion.choice_set.all()に変更すれば解決されることがわかります.ただし,質問項目はその都度異なるので,CHOICESをそのときのquestionに応じて動的に生成できるように工夫する必要があります.そこで目をつけるのが初期化処理です.質問項目(
question)を初期化処理に引数として渡し,それに対応する選択肢のリストをCHOICESとして定義した上で,your_choiceのfieldをフォームに追加するという手順を考えてみましょう.これは,フォームの
fieldを動的に構成するときの常套手段です.具体的には,VoteFormクラスの定義を次のように書き換えます.class VoteForm(forms.Form): def __init__(self, *args, **kwargs): self.question = kwargs.pop('question') super(VoteForm, self).__init__(*args, **kwargs) CHOICES = [(ch.id, ch.choice_text) for ch in self.question.choice_set.all()] self.fields['your_choice'] = forms.ChoiceField(choices = CHOICES, widget=forms.RadioSelect()) def save(self): choice_id = self.cleaned_data.get('your_choice') selected_choice = Choice.objects.get(pk=choice_id) selected_choice.votes += 1 selected_choice.save()VoteFormインスタンスの初期化処理を担当するのが,上の
__init__()メソッドです.これを実行する際には,__init__()ではなく(Javaのコンストラクタのように)VoteForm()と書くことになります(が,厳密には,__init__()メソッドはコンストラクタとは言わないらしいです).引数のうち,
selfは自分自身を指すもので,初期化処理を呼び出す際には明示する必要はありません.上のview関数では,VoteForm()とVoteForm(request.POST)という2通りの方法で初期化処理を呼び出していたことを思い出しましょう.引数に質問項目(
question)を加えるためにこれらをそれぞれ,VoteForm(question=question)とVoteForm(request.POST, question=question)のように書き換えます.def detail(request, question_id): question = get_object_or_404(Question, pk=question_id) if request.method == 'POST': form = VoteForm(request.POST, question=question) if form.is_valid(): form.save() return redirect('polls:results', question_id=question.id) else: form = VoteForm(question=question) context = {'question':question, 'form':form} return render(request, "polls/detail.html", context)これで該当する質問項目に対応する回答の選択肢だけが表示されるようになったはずです.開発用サーバを立ち上げて確認しておきましょう.
続いて,このページにもう少し機能を追加してみます.具体的には,回答したい項目が選択肢に含まれていなかった場合に,このページからそれを追加できるようにします.まずフォームを次のように書き換えます.
class VoteForm(forms.Form): new_option = forms.CharField(max_length=200, required=False) def __init__(self, *args, **kwargs): self.question = kwargs.pop('question') super(VoteForm, self).__init__(*args, **kwargs) CHOICES = [(ch.id, ch.choice_text) for ch in self.question.choice_set.all()] CHOICES.append((-1, 'other option (please specify in the box below)')) self.fields['your_choice'] = forms.ChoiceField(choices = CHOICES, widget=forms.RadioSelect()) def clean_your_choice(self): your_choice = self.cleaned_data.get('your_choice') return int(your_choice) def clean(self): cleaned_data = super(VoteForm, self).clean() choice_id = self.cleaned_data.get('your_choice') new_option = self.cleaned_data.get('new_option') if choice_id < 0: if not new_option: raise forms.ValidationError( 'Please specify a new option (or choose an existing one)!' ) else: if new_option: raise forms.ValidationError( 'Do not specify a new option with also choosing an existing one!' ) def save(self): choice_id = self.cleaned_data.get('your_choice') if choice_id < 0: new_option = Choice( question=self.question, choice_text=self.cleaned_data.get('new_option'), votes=0 ) new_option.save() else: selected_choice = Choice.objects.get(pk=choice_id) selected_choice.votes += 1 selected_choice.save()まず,
new_optionという文字列のfieldが追加されていることを確認しましょう.required=Falseが指定されているので,空欄のままデータ送信してもエラーにはなりません(これを省くと,空欄チェックが働くようになります).これまでと同じく,初期化処理の中で選択データのfieldを動的に生成しており,最後に
other optionという選択肢を新たに追加しています(idには仮の値として-1を入れています).
save()メソッドをみてみると,idの値が負の場合(すなわち,この新しく追加したother optionが選択された場合),Choiceクラスのインスタンスを生成してそれをデータベースにセーブしていることがみてとれます.このように,
Model名()でデータモデルの新しいインスタンスを生成し,そのfieldに適切な値を代入した後,そのインスタンスのsave()メソッドを呼ぶことで,新しいデータをデータベースの中に格納することができます.なお,この例のように,オブジェクトの生成とセーブとの間で他の処理を行う必要がない場合は,
Model名.objects.create()で同じ流れ(インスタンスの生成とセーブ)をまとめて書くことができます.次に,新しく追加されている2つのメソッドについてみていきます.これらはユーザが入力したデータの前処理のためのメソッドです.
clean_field名()は対応するfield固有のチェック処理,clean()はフォーム全体に対するチェック処理をそれぞれ担当するもので,(is_valid()メソッドの中で)この順番に自動的に呼ばれます.
clean()メソッドは,Djangoが標準で用意している処理をオーバーライドすることになるので,最初に標準処理(super().clean())を呼ぶことを忘れないようにしましょう.
clean_your_choice()メソッドでは,標準処理ではidの番号が文字列で返されるので,それを整数に変換しています.
clean()メソッドでは,other optionが選択されたときのみnew optionへの入力が必要で,そうでないときはnew optionは空欄でないといけないという条件を確認しています(この条件に反するとエラーメッセージが表示されることを確認してみましょう).このままtemplate(detail.html)を変更しなくてもページは表示されますが,New optionがYour choiceよりも上に表示されてしまうので「下のボックスに記入してください」というメッセージと整合していません.これを修正するには,templateを次のように書き換えればいいでしょう.
<h1>{{ question.question_text }}</h1> {{ form.non_field_errors }} <form action="{% url 'polls:detail' question.id %}" method="post"> {% csrf_token %} <p> {{ form.your_choice.label }}<br> {{ form.your_choice }} </p> <p> {{ form.new_option.label }}<br> {{ form.new_option }} </p> <input type="submit" value="Vote"> </form>この例のように,フォームの表示の仕方はtemplateの中でfield別に指定することができます(し,
labelでfield名を取り出すこともできます).おわりに
以上で5回目は終了です.第6回に続きます.
- 投稿日:2019-04-11T21:07:49+09:00
JupyterLabのおすすめ拡張機能7選
はじめに
Jupyter notebookの進化形、Jupyter Lab。見た目が綺麗で使いやすいです。
今回は2019年4月現在で使用できる便利な拡張機能をご紹介します。※JupyterLab,Node.jsが既にインストールされていることが前提です。以下バージョンで動作を確認しています。
JupyterLab : v0.35.4
Node.js : v11.13.0これからJupyterLab,Node.jsを導入する人は以下を実行してください。
# Jupyterlabの導入(anacondaを入れている人は既に入っている可能性があります。) $ pip install jupyterlab # Node.jsの導入(バージョンは適宜修正してください) $ curl -sL https://deb.nodesource.com/setup_11.x | bash - $ apt-get install -y --no-install-recommends nodejs1.Variable Inspector
変数名や型、内容を常に横に表示しておけるようになります。
いちいちprint文を打つ手間が省けます。
導入手順
以下コマンドを実行
$ jupyter labextension install @lckr/jupyterlab_variableinspector2.Table of Contents
Markdown記法で書いた見出しが一覧で表示され、目的の見出しにワンクリックで飛べるようになります。
導入手順
以下コマンドを実行
$ jupyter labextension install @jupyterlab/toc3.コード自動整形
Pythonの自動整形ツールであるBlack,YAPF,Autopep8を使用してコード整形を行えるようにする拡張です。
ショートカットを登録すれば任意のキーを押すことで整形させられるようになります。導入手順
1.使用したい自動整形ツールをインストール
pip install (black or yapf or autopep8)2.拡張機能の導入、有効化
pip install jupyterlab_code_formatter jupyter labextension install @ryantam626/jupyterlab_code_formatter jupyter serverextension enable --py jupyterlab_code_formatter3.ショートカットキーの登録
settings→Advanced Settings Editor→Keyboard Shortcutsを開き、
User Overridesに以下を記入。"Ctrl K","Ctrl M"を変更することで任意のショートカットを作成できる。
{"jupyterlab_code_formatter:black":{ "command": "jupyterlab_code_formatter:black", "keys": [ "Ctrl K", "Ctrl M" ], "selector": ".jp-Notebook.jp-mod-editMode"} }4.Vim風キーバインド
vimライクなカーソル移動やコマンドが打てるようになります。
導入手順
以下コマンドを実行
$ jupyter labextension install jupyterlab_vim5.TensorBoard管理
JupyterLabのファイルディレクトリからTensorBoardが起動できたり、起動中のTensorBoardを一覧化できます。
導入手順
以下コマンドを実行
$ pip install tensorflow-gpu #tensorflow(-gpu)がv1.3以上でないと動作しない $ pip install tensorboard $ pip install jupyter-tensorboard $ jupyter labextension install jupyterlab_tensorboard $ jupyter serverextension enable --py jupyterlab_tensorboard6.git連携
JupyterLabのGUI上からcommit,push,pull,ブランチ切り替えができるようになります。
導入手順
以下コマンドを実行
$ jupyter labextension install @jupyterlab/git $ pip install jupyterlab-git $ jupyter serverextension enable --py jupyterlab_git7.ipywidgets使用
導入手順
以下コマンドを実行
$ pip install ipywidgets $ jupyter labextension install @jupyter-widgets/jupyterlab-manager $ jupyter nbextension enable --py --sys-prefix widgetsnbextension動作未確認だけど役立ちそうな拡張
私の環境ではうまく動かなかったり試していなかったりで動作未確認ですが、今後対応される可能性もあるので一応紹介しておきます。
・jupyterlab-flake8
flake8のコードチェック機能が使えるようになる
・jupyterlab_voyager
csvをきれいなグラフで可視化してくれるhttps://medium.com/@subpath/jupyter-lab-extensions-for-data-scientist-e0d97d529fc1
可視化関連の拡張機能がいくつか紹介されています。最後に
そのままでも結構便利に使えるJupyterLabですが、拡張機能を入れることで自分好みにカスタマイズできます。
気になる拡張があったらぜひ入れてみてください。





- 投稿日:2019-04-11T19:55:07+09:00
pandas のSeries・DataFrameの間違ったイメージ
Pandas の入門記事には、大抵こんなことが書かれています。
Seriesは一次元配列です。組み込み型のlistに対応します。DataFrameは二次元配列です。私も「ふーん、なるほど」と理解したつもりになって Pandas を使い始めたのですが、あとでとんでもない思い違いをしていたの気づきました。
Series はリストではないし、DataFrame は二次元配列ではないのです。
Series・DataFrameの間違ったイメージ
私の間違ったイメージはこうでした:
SeriesやDataFrameは配列のようなものだ、だから
s[i],df[i]で i+1 番目の値・行にアクセスできる。図で書くとこんな感じです:
まぁ、このイメージでも、使い始めてしばらくは何とかなりました。
しかしインデックスが現れると、私の間違ったイメージは破綻しました。
s = Series(['val0', 'val1', 'val2', 'val3', 'val4'], index=('a', 'b', 'c', 'd', 'e']) # `[]`の中が数値ではないのに、要素にアクセスできる!? s['c'] # => 'val2'Series・DataFrameの正しいイメージ
私の誤解は、「
s[i],df[i]は i+1 番目の値・行にアクセスしている」ということでした。
実際にはs[i]のiは添字(位置)ではなくインデックスの値なのです。s[i]にアクセスするのに、添字は関係ないのです1。図で表すとこうです:
SeriesやDataFrameで明示的にインデックスを指定しないと、添字と同じ連番が使われるので、たまたま「Seriesはlistのようなもの」と思ってもうまく行きました。しかし、本来インデックス≠添字なので、インデックスに連番数値以外のものも指定できるのです。
インデックスあれこれ
一見、非直感的な「インデックス≠添字」ですが、Pandasはインデックスの存在が前提の作りになっていて、それにより効率的なデータ操作ができるようになっています。
以下では、(昔の私のように)「インデックスは添字のこと」という理解だと、思っていたのと違う動作になってしまったり、無駄な書き方をしてしまうような例を紹介します。
DataFrame を作ると、Series のインデックスが自動的に使われる
DataFrameを作る時、各列のSeriesのインデックスが同じものであれば、
index=を指定しなくても、DataFrameに同じインデックスが使われます。from pandas import * s1 = Series(['val1', 'val2', 'val3'], index=['a', 'b', 'c']) s2 = Series(['val10', 'val20', 'val30'], index=['a', 'b', 'c']) df = DataFrame({'Col1': s1, 'Col2': s2}) # df = DataFrame({'Col1': s1, 'Col2': s2}, index=['a', 'b', 'c']) # インデックスを明示しなくても同じ print(df) # 添字(0, 1, 2) ではなく、'a', 'b', 'c' がインデックスになる # Col1 Col2 # a val1 val10 # b val2 val20 # c val3 val30異なるインデックスの Series から DataFrame を作ると、インデックスがマージされる
各列のSeriesが違うインデックスを持っているときは、マージされた新しいインデックスが作られます。このとき、インデックスに対応する値が無い部分は na になります。
from pandas import * s1 = Series(['val1', 'val2', 'val3'], index=['a', 'b', 'c']) s2 = Series(['val10', 'val20', 'val30'], index=['b', 'c', 'd']) df = DataFrame({ 'Col1': s1, 'Col2': s2, }) print(df) # Col1 Col2 # a val1 NaN # b val2 NaN # c val3 val10 # d NaN val20 # e NaN val30インデックスに異なる型が混じっていてもエラーにはならない
listやSeriesと同様に、インデックスには文字列と数値のような異なる型を混在させられます。そのため、DataFrameを作る時に、各列のSeriesのインデックスの型が異なっていてもエラーにはなりません。from pandas import * s1 = Series(['val1', 'val2', 'val3'], index=['a', 'b', 'c']) s2 = Series(['val10', 'val20', 'val30'], index=[1, 2, 3]) df = DataFrame({ 'Col1': s1, 'Col2': s2, }) print(df) # Col1 Col2 # a val1 NaN # b val2 NaN # c val3 NaN # 1 NaN val10 # 2 NaN val20 # 3 NaN val30DataFrame の特定の列を、インデックスにできる
インデックスは、添字ではなく「特別な列」のようなものです。そのため、後からインデックスを変更したり、特定の列をインデックスに切り替えたりできます。
from pandas import * df = DataFrame({ 'amount': [1000, 2000, 10000], 'name': ['北里', '津田', '渋沢'], 'birthyear': [1853, 1864, 1840], }) print(df.loc[0]) # デフォルトでは連番がインデックスになる # amount 1000 # name 北里 # birthyear 1853 # Name: 0, dtype: object df = df.set_index('amount') # 特定の列をインデックスに変えられる print(df.loc[1000]) # name 北里 # birthyear 1853 # Name: 1000, dtype: objectインデックスには重複があってもよい
インデックスは特殊な列に過ぎないので、値が重複することも可能です。
from pandas import * # インデックスに重複値があってもよい s = Series(['val1', 'val2', 'val3', 'val4', 'val5'], index=['a', 'b', 'b', 'c', 'b']) print(s['a']) # 重複していないインデックス値ではそのまま取り出せる # val1 print(type(s['b'])) # 重複したインデックス値では、戻り値がSeriesになる # <class 'pandas.core.series.Series'> print(s['b']) # b val2 # b val3 # b val5 # dtype: objectただし、DataFrameを作るためにインデックスのマージが起きるときには、重複値があるとエラーになります。
from pandas import * # インデックスに重複値があってもよい s1 = Series(['val1', 'val2', 'val3', 'val4', 'val5'], index=['a', 'b', 'b', 'c', 'b']) s2 = Series(['valA', 'valB', 'valC', 'valD', 'valE'], index=['a', 'b', 'b', 'c', 'b']) s3 = Series(['val10', 'val20', 'val30'], index=['a', 'b', 'c']) # 同じインデックス同士なら、重複値があってもエラーにならない df = DataFrame({ 'Col1': s1, 'Col2': s2, }) print(df) # Col1 Col2 # a val1 valA # b val2 valB # b val3 valC # c val4 valD # b val5 valE # 異なるインデックス同時だと、重複値があるとエラーになる df = DataFrame({ 'Col1': s1, 'Col3': s3, }) # => ValueError: cannot reindex from a duplicate axisインデックスを無視して添字でアクセスできる
時にはインデックスを無視して添字(位置)でアクセスしたくなることもありますが、Series・DataFrameともに、
.ilocで添字アクセス可能です。from pandas import * s = Series(['val1', 'val2', 'val3'], index=['a', 'b', 'c']) print(s.iloc[1]) # 添字(位置)でアクセスできる df = DataFrame({ 'index': ['a', 'b', 'c'], 'Col1': Series(['val1', 'val2', 'val3']), 'Col2': Series(['valA', 'valB', 'valC']), }).set_index('index') print(df.iloc[2]) # 添字(位置)でアクセスできる # Col1 val3 # Col2 valC # Name: c, dtype: object良心的な入門記事の見分け方
さて、冒頭で取り上げた、Series・DataFrameの間違った説明ですが、
Seriesは一次元配列です。組み込み型のlistに対応します。DataFrameは二次元配列です。入門者にとりあえずイメージを掴んでもらう目的なら、そんなに的外れな説明でもありません。インデックスが添字である間は正しい説明です。
でも、良心的な入門記事なら、上記の説明のあとにこんな但し書きをするはずです。
ただし、連番以外の「インデックス」を持つことができるなど、リストや二次元配列より高機能です。インデックスについては第2章で説明します。
まとめ
Series はリストではない!DataFrame は二次元配列ではない!
内部的にはインデックス値→添字の変換をしていると思いますが、外からは添字を意識しなくてもよい作りになっています。 ↩



- 投稿日:2019-04-11T19:50:25+09:00
windowsでPythonを使ってローカルサーバーを立ち上げる
こんにちは
未来電子テクノロジー
でインターンをしているodattiです。Pythonを勉強を始めたところです。
ローカルサーバーを立ち上げることは初心者にはとても難しく、そもそも「何が分からないのかが分からない」という方も多いのではないでしょうか。そこで、ローカルサーバーを立ち上げる方法について、復習がてら書いておきます。
使用しているパソコンは、windows10、64bitのレッツノートです。準備
Pythonをダウンロードします。
ご自身が使っているパソコンの種類に合わせて適切なものをダウンロードしましょう。
(Pythonのセットアップに関しては省略させていただきます)Powershellを立ち上げる
windowsにはpowershellが入っていると思います。
パソコンで検索して、起動しましょう。
ちなみにpowershellとは、簡単に言うとパソコンに命令を送るツールです。Pythonが入っていることの確認
ここからはpowershellを使っていきます。
Pythonが正しくインストールされているかの確認を行います。
(Pythonを起動してprint(~)を実行する方法とは別)python -V上のように打って実行し、ダウンロードしたPythonのバージョンが表示されればOK!
(ちなみに、Vはversionの略)以下のコマンドを入力
次のようにコマンドを入力します。
mkdir
mkdirmkdirとはmake directoryの略です。
ディレクトリ(パソコン上のファイルや管理情報のこと)
を作りなさいっていうコマンドです。cd
cd webchange directoryの略。
ディレクトリを移動しなさいという意味。最後に
python -m ~~.serverこのコードの解釈がわかりません。。
例えば~~の部分にhttpを入れればhttpサーバーを起動するということだと思います。
(ほかの例がわからないので、教えていただけると嬉しいです。)これでローカルホストのサーバーを立ち上げられたかと思います。
終わりに
間違っている部分や表現も多々あるかと思います。
ご指摘をいただけると嬉しいです。
すぐに修正します。
- 投稿日:2019-04-11T19:35:31+09:00
時間が文字列になっているときに2つの時系列データをPython/Pandasで統合させる方法
サッカーのデータを取得するツールを使って、出力したデータをいざ分析しようと思ったときに、
- 前半後半が別々のファイル形跡(.csvと.xlsx)で保存されていた → 同じように扱いたい
- 時間が文字列として出力されていた → 数字として扱いたい
- 時間が 時間:分:秒:センチ秒 という形式になっていた → 秒に変換したい
- 前半と後半が別々のファイル → 統合して一つの.xslxファイルに入れたい
などの問題がありました。
Pandasとdatetimeのライブラリを使うことで大体解決できました。
import pandas as pd import datetime as dt from IPython.display import display.csvと.xlsxをDataFrameに読み込む
df1 = pd.read_csv('splyza_data/firsthalf.csv') df2 = pd.read_excel('splyza_data/secondhalf.xlsx') display(df1.head()) display(df2.head())
時間 default セットプレー 選手名 攻撃 守備 反則 0 0:00:48:96 NaN キックオフ NaN NaN NaN NaN 1 0:00:54:88 NaN NaN スコット NaN クリア NaN 2 0:01:01:68 NaN NaN スコット NaN ブロック NaN 3 0:01:13:80 NaN GK スコット NaN NaN NaN 4 0:01:18:08 NaN NaN スコット パス NaN NaN
時間 default セットプレー 選手名 攻撃 守備 反則 0 0:00:21:48 NaN キックオフ NaN NaN NaN NaN 1 0:00:25:20 NaN NaN スコット パス NaN NaN 2 0:00:41:40 NaN スローイン NaN NaN NaN NaN 3 0:00:44:52 NaN NaN スコット パス NaN NaN 4 0:00:47:52 NaN NaN スコット ボールロスト NaN NaN strptimeで文字列の時間情報を読み込む
t = df1['時間'][0] print(type(t)) #ここがポイント! _t = dt.datetime.strptime(t,'%H:%M:%S:%f') print(type(_t)) print(_t) z = dt.datetime.strptime('','') print(z) d = _t - z d.total_seconds()<class 'str'> <class 'datetime.datetime'> 1900-01-01 00:00:48.960000 1900-01-01 00:00:00DataFrameにapplyを使って、文字列形式の時間を全て秒に変換する
def f(t, offset=Non 48.96 ```python #オフセットは病に時間を変換した後に、任意の秒数ずらすための引数 #サッカーだとキックオフ時間を0秒に合わせたいので作った def f(t, offset=None): _t = dt.datetime.strptime(t,'%H:%M:%S:%f') z = dt.datetime.strptime('','') d = _t - z d = d.total_seconds() if offset is not None: d+=offset return d df1['時間'] = df1['時間'].apply(lambda x: f(x,-48.96)) df2['時間'] = df2['時間'].apply(lambda x: f(x,df1['時間'].iloc[-1]-21.48)) display(df1.head()) display(df2.tail())
時間 default セットプレー 選手名 攻撃 守備 反則 0 0.00 NaN キックオフ NaN NaN NaN NaN 1 5.92 NaN NaN スコット NaN クリア NaN 2 12.72 NaN NaN スコット NaN ブロック NaN 3 24.84 NaN GK スコット NaN NaN NaN 4 29.12 NaN NaN スコット パス NaN NaN
時間 default セットプレー 選手名 攻撃 守備 反則 421 5412.04 NaN GK スコット ボールロスト NaN NaN 422 5441.40 NaN NaN スコット パス NaN NaN 423 5441.40 NaN NaN NaN ボールロスト NaN NaN 424 5446.40 NaN NaN スコット NaN カット NaN 425 5483.56 NaN GK スコット NaN NaN NaN concatで一つのデータフレームにまとめる
df = pd.concat([df1,df2]) display(df.head()) display(df.tail())
時間 default セットプレー 選手名 攻撃 守備 反則 0 0.00 NaN キックオフ NaN NaN NaN NaN 1 5.92 NaN NaN スコット NaN クリア NaN 2 12.72 NaN NaN スコット NaN ブロック NaN 3 24.84 NaN GK スコット NaN NaN NaN 4 29.12 NaN NaN スコット パス NaN NaN
時間 default セットプレー 選手名 攻撃 守備 反則 421 5412.04 NaN GK スコット ボールロスト NaN NaN 422 5441.40 NaN NaN スコット パス NaN NaN 423 5441.40 NaN NaN NaN ボールロスト NaN NaN 424 5446.40 NaN NaN スコット NaN カット NaN 425 5483.56 NaN GK スコット NaN NaN NaN to_excelで.xlsxに保存する
df.to_excel('splyza_data/20190406.xlsx',encoding='shift-jis')
- 投稿日:2019-04-11T18:38:29+09:00
Python Web スクレイピング
スクレイピングを今後勉強していこうと思うので、記事を書いていきたいと思います。
基本的に学習記録です。
こちらの本を参考にさせていただきました。スクレイピング(Scraping)とは
スクレイピングとは、webサイトから任意の情報を抽出する技術です。
スクレイピングすることにより、web上で情報を自動収集できます。つまり、効率的に情報を収集できる技術です。
スクレイピングを調べていると、クローリングという言葉がよく出てきます。
では、クローリングとは何か以下にまとめます。クローリングとは
クローリングとは、プログラムがwebサイトを定期的に巡回して、
情報をダウンロードする技術のことです。定期的に巡回することによって、最新情報を検索することが可能です。
データのダウンロード
web上の情報を取得する方法
Pythonでは、urllibライブラリを使います。このライブラリを使用すると、HTTPやFTPを利用してデータをダウンロードできます。その中でも、urllib.requestモジュールは、Webサイトにあるデータにアクセスする機能を提供します。
Webサイトからファイルをダウンロードする方法
download_sample.pyimport urllib.request ulr = "(URL)" savename = "sample.png" urllib.request.urlretrieve(url,savename) print("save the image")*urlretrieve func : 直接ファイルをダウンロードできる。
クライアントの接続情報を表示してみる
download.pyimport urllib.request url = "(URL)" res = urllib.request.urlopen(url) data = res.read() #convert binary to string text = data.decode("utf-8")簡単ですが、今回はこのぐらいで
随時、勉強したことをアップしていきます。
- 投稿日:2019-04-11T18:31:47+09:00
初心者Pythonistの日記 Day1
ども
かつてのプログラマー兼研究者
しかし、ここ15年は、経営コンサルだったり、事業開発で買収交渉したり、海外いたり、スタートアップを経営したり、飲食店やったり、プログラムから離れてました。昔はこんな感じのスペックです
C, C++, Java, html, css, perl, Pascal, VHDL, csh などをいじりつつ、IT系論文を5本ほど執筆
unix, linux, free bsd, mule, emacs
GUI系経験ゼロそこから浦島太郎状態で、いまから、Python, javascript, swiftをちょっとやろうと思ってます。現在43歳。
これはそんなおじさんの復活の物語(になるか?)
ということで、まずは、Pythonから。
友人の天才プログラマーに、まずは、これからということで教えてもらったFlask
https://a2c.bitbucket.io/flask/index.htmlまずはこれを動かしてみようと。
前提、Pythonいじるのが、今日が初日。
まずは、環境構築・・・だが、当然ながら、いろいろと、コマンドがインストールされない
進んでいくが、まずつまったのが、Python3.6が、BUILDされない~ $ pyenv install 3.6.6 python-build: use openssl from homebrew python-build: use readline from homebrew Downloading Python-3.6.6.tar.xz... -> https://www.python.org/ftp/python/3.6.6/Python-3.6.6.tar.xz Installing Python-3.6.6... python-build: use readline from homebrew BUILD FAILED (OS X 10.14 using python-build 20180424) Inspect or clean up the working tree at /var/folders/d4/2z2crny959n4sbybccx45jhm0000gn/T/python-build.20181001145113.76758 Results logged to /var/folders/d4/2z2crny959n4sbybccx45jhm0000gn/T/python-build.20181001145113.76758.log Last 10 log lines: File "/private/var/folders/d4/2z2crny959n4sbybccx45jhm0000gn/T/python-build.20181001145113.76758/Python-3.6.6/Lib/ensurepip/__main__.py", line 5, in <module> sys.exit(ensurepip._main()) File "/private/var/folders/d4/2z2crny959n4sbybccx45jhm0000gn/T/python-build.20181001145113.76758/Python-3.6.6/Lib/ensurepip/__init__.py", line 204, in _main default_pip=args.default_pip, File "/private/var/folders/d4/2z2crny959n4sbybccx45jhm0000gn/T/python-build.20181001145113.76758/Python-3.6.6/Lib/ensurepip/__init__.py", line 117, in _bootstrap return _run_pip(args + [p[0] for p in _PROJECTS], additional_paths) File "/private/var/folders/d4/2z2crny959n4sbybccx45jhm0000gn/T/python-build.20181001145113.76758/Python-3.6.6/Lib/ensurepip/__init__.py", line 27, in _run_pip import pip._internal zipimport.ZipImportError: can't decompress data; zlib not available make: *** [install] Error 1BUILD FAILURE
むむ、ということで、そこで気づいたのが、そもそもXcodeなどないもしてなかった・・・
それをインストール。待つこと30分。(ファイル、大きいね、Xcode)それでも動かない・・・
xcode-select --installこれをしても動かない・・・
と思っていたら、また別の天才プログラマーの友人から、これをやってみたら?と。
https://medium.com/@digitalnauts/pyenv-install-error-mac-dcbd28fdc9dbCFLAGS="-I$(brew --prefix readline)/include -I$(brew --prefix openssl)/include -I$(xcrun --show-sdk-path)/usr/include" \ LDFLAGS="-L$(brew --prefix readline)/lib -L$(brew --prefix openssl)/lib" \ PYTHON_CONFIGURE_OPTS=--enable-unicode=ucs2 \ pyenv install -v 3.6.6こちらのコマンド。な、長い・・・
コピペで、Enter!
できました。
とりあえず、初心者Pythonist、環境構築できました。
localでうごくところまで行きました。
https://gyazo.com/c62c80bd84459e8d1c45e4b76857a468/初日はこれにて終了。
Python環境構築
インストールで、BUILD FAILURE
その対策
でした。2時間
- 投稿日:2019-04-11T18:13:58+09:00
データベースプラットフォームD-Oceanを使ってみた
こんにちは
初投稿です。まっつんと言います。東京大学工学部システム創成学科システムデザインアンドマネジメントコースに在籍してます。
この記事では、今学科でやっている基礎プロジェクト(大規模データ分析)という授業で学んだことを書いていきます。データベースとは
データベースについては、僕自身詳しくはわかっていませんが、こちらの記事などに詳しく書いてあります。
D-0cean
D-OceanはGoogleが作ったデータベース、BigQueryを操作するためのプラットフォームです。2019年2月に出来たばかりのようです。
D-Oceanのページ↓
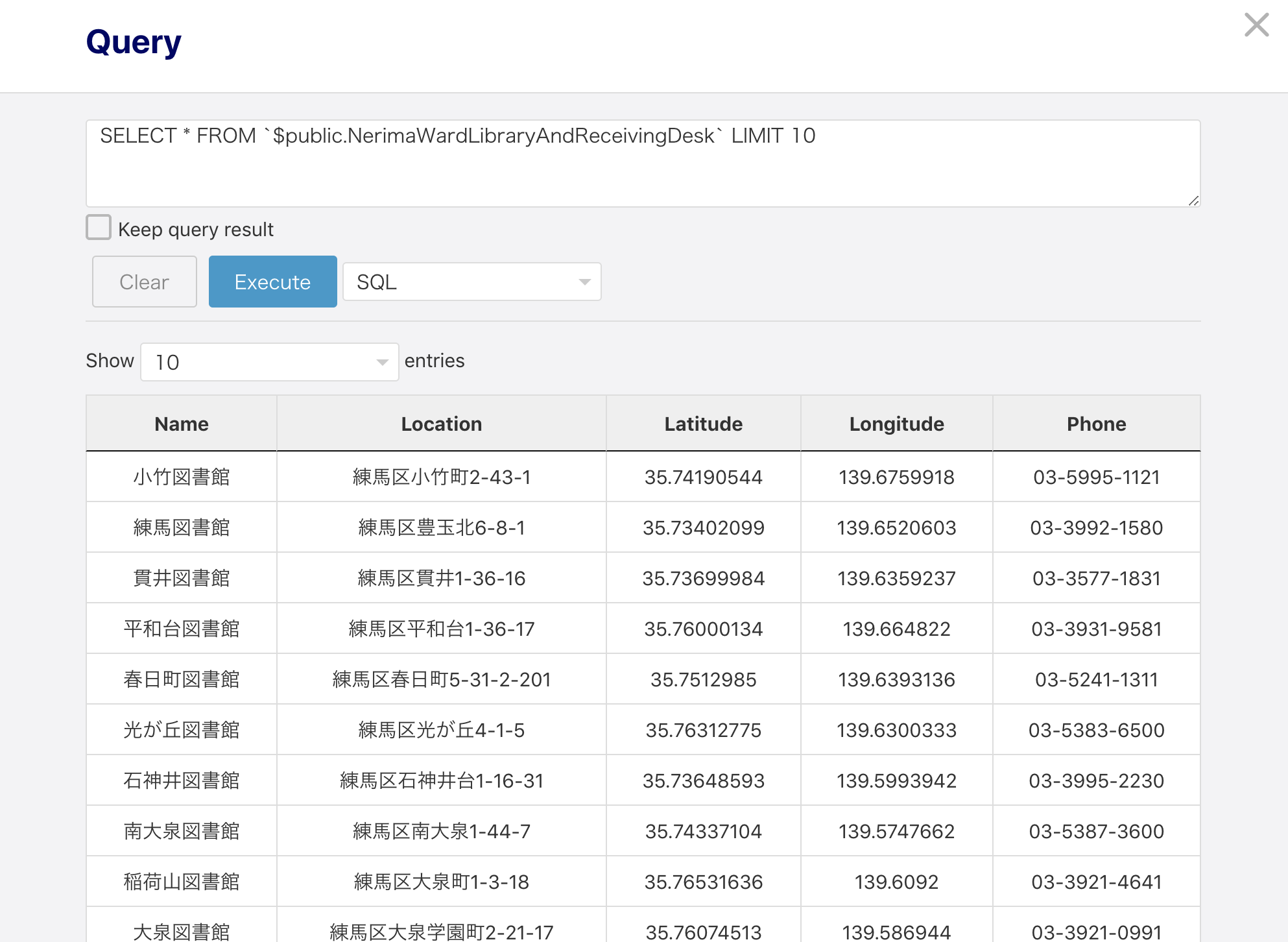
どれかのデータをクリックすると、SQLを入れるボックスが出てきます。SQLはデータベースの操作をするための言語です。後々、SQLのメモ記事もあげる予定です。
実際にSQLを入れてクエリを投げた結果↓
出来たばかりということと、僕が他のデータベースプラットフォームを使ったことがないというのもあり、D-Oceanが使いやすいのかはわかりませんが、見た目はかっこいいと思います。機会があったら積極的に使っていこうと思います。
- 投稿日:2019-04-11T18:06:55+09:00
Python で 1次元的 2次元リストを 1次元化[スニペット的備忘録的に]
CSV から 1次元リストを読み込んだと思ったらなぜか 2次元だった:
[[1, 2, 3, 4, 5]]これを 1次元化したい:
[1, 2, 3, 4, 5]とりあえず,最小コーディング労力で 1次元化したかった自分的に最良の方法は「元リストの第一要素を新変数に格納する」:
ls = [[1, 2, 3, 4, 5]] ls_new = ls[0] print(ls_new) # [1, 2, 3, 4, 5]こんなコードを記事にするのは申し訳ないと思うのですが,作業中は心理的盲点?をつかれたのか,若干ハマってしまったので,備忘録的に書き残します
ハマってしまった一因は,
[[1, 2, 3], [4, 5]]のような「普通の」2次元リストを 1次元化する無数の方法の中から,最小コーディング労力のものを探そうとしてしまったことでした.教訓があるとすれば「ググるだけでなく自分でも考えよう」でしょうか
ちなみに上記のような「普通の」2次元リストの場合,最小コーディング労力という観点から,
「元 2次元リストで 2重に iterate し,要素を新 1次元リストに順次格納する」
というコンセプトのコードを,某 overflow あたりで見た記憶があるのですが,再発掘できなかったので,これも自分への備忘として残しておきますls = [[1, 2, 3], [4, 5]] ls_new = [] print(ls) for i in ls: for x in range(len(i)): ls_new.append(i[x]) print(ls_new) # [1, 2, 3, 4, 5]
- 投稿日:2019-04-11T18:05:04+09:00
Google ColabでGiNZAを使う
Google ColabでGiNZAを使おうとしたら引っかかった
GoogleColabでGiNZAを使うときにちょっと引っかかったのでめも
結論
!pip uninstall spacy !pip install "https://github.com/megagonlabs/ginza/releases/download/v1.0.2/ja_ginza_nopn-1.0.2.tgz"GiNZAとは?
https://www.recruit.co.jp/newsroom/2019/0402_18331.html
ここから引用「GiNZA」は、ワンステップでの導入、高速・高精度な解析処理、単語依存構造解析レベルの国際化対応などの特長を備えた日本語自然言語処理オープンソースライブラリです。
使い方
サンプルコードです
import spacy nlp = spacy.load('ja_ginza_nopn') doc = nlp('依存構造解析の実験を行っています。') for sent in doc.sents: for token in sent: print(token.i, token.orth_, token.lemma_, token.pos_, token.dep_, token.head.i) print('EOS')このように解析されました。
0 依存 依存 NOUN compound 2
1 構造 構造 NOUN compound 2
2 解析 解析 NOUN nmod 4
3 の の ADP case 2
4 実験 実験 NOUN obj 6
5 を を ADP case 4
6 行っ 行う VERB root 6
7 て て SCONJ mark 6
8 い 居る AUX aux 6
9 ます ます AUX aux 6
10 。 。 PUNCT punct 6
EOS使い方はこちらの記事のほうがわかりやすいと思います
https://qiita.com/kannkyo/items/2472cf3d82a61fb8584e
- 投稿日:2019-04-11T16:58:01+09:00
D-Oceanで取得したデータをpythonで料理する!
ここではD-Oceanを使ってデータを取得し、pythonのpandasを使って処理することを考えます。
目次
・D-Oceanのログインから
・BigQueryとは何か
・BigQueryにおけるSQL文
・csvデータの読み込みと分析D-Oceanのログインから
D-Oceanはデータプラットフォームであり、いろいろな種類のデータを使うことができる。データ処理の練習したい人にはおすすめかも。右上のログインボタンを押して、Google アカウントなどでログインしよう。
ログインするとこんな感じのページにくる。
【注意】
授業などでGROUPでデータが共有されることもある。
GROUP内のデータを使う場合、GROUP をそのまま押してはいけない。
GROUPを押してプルダウンメニューが出たグループをクリックしないと、グループ内に共有されたデータは見ることができない。
なんというシステムでしょう。。。これでグループ内で共有されたデータは見れるはずなので、ひとつクリックしてみよう。
クリックすると以下のようなウィンドウになる
下にcomment、queryがあるので、queryを押してみよう!
ここからはqueryでsql文を書くことになる。BigQueryとは何か
BigQueryに興味がある人は以下のリンクからみてみるのが一番早いと思われる。
https://thinkit.co.jp/story/2015/08/27/6346BigQueryにおけるSQL文
SQL文はあんまり詳しくないので、以下の基本的な文法構造だけのせておきます。
SELECT column FROM table_nameが基本構造で、*はすべての列、LIMITは何行か指定して選ぶことができる。
SQLはムズイです!csvデータの読み込みと分析
csvのデータはQueryからcsvをプルダウンで選んだ後、ダウンロードできる。
今回は1000行だけダウンロードする。
csvファイルをダウンロードしたらここからはpythonの出番。
このcsvファイルをダウンロードしたら、テキストエディタをなにか開いてpythonファイルをつくろう。import.pyimport pandas as pd import matplotlib.pyplot as plt data = pd.read_csv('downloads/data/file_name.csv') data.tail() #下から5行取得可能pandasはpythonで使えるめっちゃはやいエクセル、だと勝手に考えている。
pd.read_csv()という関数でcsvファイルをpandasのdataframe(エクセルの表みたいな)に落とし込むことができる。
これでdataを料理する準備はできました!ちなみに上から5行抽出したい場合は以下のhead()を使って確認することができる。
head.pydata.head()
Name_ location latitude longitude phone 0 関子ども家庭支援センター 練馬区関町北1-21-15 35.726719 139.578657 1 練馬子ども家庭支援センター(児童福祉担当係石神井) 練馬区石神井町3-30-26 石神井庁舎4階 35.743405 139.602759 2 練馬子ども家庭支援センター練馬駅南分室 練馬区豊玉北5-18-12 35.737083 139.654433 3 光が丘子ども家庭支援センター 練馬区光が丘2-9-6 光が丘区民センター6階 35.759233 139.629303 4 練馬子ども家庭支援センター 練馬区豊玉北6-12-1 東庁舎4階 35.735650 139.652422
- 投稿日:2019-04-11T16:12:16+09:00
QuantXを使ってみた
自己紹介
理系大学で情報学を専攻しています。現在2年生で、先月からSmartTrade社の方でインターンを始めました。
QuantXとは
QuantXは株式や仮想通貨などの売買ルール(アルゴリズムと呼んでいます)の作成、販売ができるシステムトレードプラットフォームです。Python Codingを利用した自由度の高い方法と、Visual Codingを利用したプログラミングの知識がなくてもアルゴリズムを作成できる環境をご用意しています。(※Visual Codingは今後提供予定)作成されたアルゴリズムは実際の過去のデータでシミュレーションして成績を確認できます。開発したアルゴリズムはご自身のトレードに、またはQuantX Storeで販売できます。(公式Q&Aから引用)
もっと詳しく知りたい方はこちらからどうぞ^^
今回作るのは
ボリンジャーバンドテクニカル指標を用いて売買するアルゴリズムを書いていきます。
ボリンジャーバンドについてはこちらを参照して下さい。売買シグナルの出し方については、
「+2σを越えたら上昇し過ぎなので売り、-2σを越えたら下落し過ぎなので買い」
として、まずは利益確定/損切りは行わずに実装していきます。扱う銘柄はTopixCore30です。(銘柄選定わからない・・・)
完成コード
自分で書いたのは売買シグナルを生成する関数部分だけです。
import pandas as pd import talib as ta import numpy as np def initialize(ctx): # 設定 ctx.logger.debug("initialize() called") ctx.configure( channels={ # 利用チャンネル "jp.stock": { "symbols": [ "jp.stock.2914", #JT(日本たばこ産業) "jp.stock.8766", #東京海上ホールディングス "jp.stock.8031", #三井物産 "jp.stock.8316", #三井住友フィナンシャルグループ "jp.stock.8411", #みずほフィナンシャルグループ "jp.stock.9437", #NTTドコモ "jp.stock.4502", #武田薬品工業 "jp.stock.8058", #三菱商事 "jp.stock.9433", #KDDI "jp.stock.9432", #日本電信電話 "jp.stock.7267", #ホンダ(本田技研工業) "jp.stock.8306", #三菱UFJフィナンシャル・グループ "jp.stock.4503", #アステラス製薬 "jp.stock.4063", #信越化学工業 "jp.stock.7974", #任天堂 "jp.stock.6981", #村田製作所 "jp.stock.3382", #セブン&アイ・ホールディングス "jp.stock.9020", #東日本旅客鉄道 "jp.stock.8802", #三菱地所 "jp.stock.9022", #東海旅客鉄道 "jp.stock.9984", #ソフトバンクグループ "jp.stock.6861", #キーエンス "jp.stock.6501", #日立製作所 "jp.stock.6752", #パナソニック "jp.stock.6758", #ソニー "jp.stock.6954", #ファナック "jp.stock.7203", #トヨタ自動車 "jp.stock.7751", #キヤノン "jp.stock.4452", #花王 "jp.stock.6098", #リクルートホールディングス ], "columns": [ "close_price", # 終値 "close_price_adj", # 終値(株式分割調整後) ] } } ) #売買シグナル生成する関数の定義 def _my_signal(data): #終値取得、欠損データ補完 cp = data["close_price_adj"].fillna(method="ffill") #データを格納するための空箱を作っておく upperband=pd.DataFrame(data=0, columns=[], index=cp.index) lowerband=pd.DataFrame(data=0, columns=[], index=cp.index) middleband=pd.DataFrame(data=0, columns=[], index=cp.index) buy_sig = pd.DataFrame(data=0, columns=[], index=cp.index) sell_sig = pd.DataFrame(data=0, columns=[], index=cp.index) #uband = pd.DataFrame(data=0, columns=[], index=cp.index) #lband = pd.DataFrame(data=0, columns=[], index=cp.index) for (sym,val) in cp.items(): #ボリンジャーバンドの生成 upperband[sym], middleband[sym], lowerband[sym] = ta.BBANDS(cp[sym].values.astype(np.double), timeperiod=21, nbdevup=2.0, nbdevdn=2.0) buy_sig[sym] = lowerband[sym]/ cp[sym] sell_sig[sym] = cp[sym]/ upperband[sym] return { "upperband":upperband, "lowerband":lowerband, "buy:sig":(buy_sig>=1.001), "sell:sig":(sell_sig>=1.001) } # シグナル登録 ctx.regist_signal("my_signal", _my_signal) def handle_signals(ctx, date, current): ''' current: pd.DataFrame ''' done_syms = set([]) #利益確定/損切り for (sym,val) in ctx.portfolio.positions.items(): returns = val["returns"] if returns < -0.03: sec = ctx.getSecurity(sym) #sec.order(-val["amount"], comment="損切り(%f)" % returns) done_syms.add(sym) elif returns > 0.05: sec = ctx.getSecurity(sym) #sec.order(-val["amount"], comment="利益確定売(%f)" % returns) done_syms.add(sym) buy = current["buy:sig"].dropna() for (sym,val) in buy.items(): if sym in done_syms: continue sec = ctx.getSecurity(sym) sec.order(sec.unit() * 1, comment="SIGNAL BUY") #ctx.logger.debug("BUY: %s, %f" % (sec.code(), val)) pass sell = current["sell:sig"].dropna() for (sym,val) in sell.items(): if sym in done_syms: continue sec = ctx.getSecurity(sym) sec.order(sec.unit() * -1, comment="SIGNAL SELL") #ctx.logger.debug("SELL: %s, %f" % (sec.code(), val)) passバックテスト結果
損しているし、なんでこんなにシグナル回数がでるの?
2σのバンドってそんなに超えていくの?データの約95%はバンド内に収まるんじゃなかったの?利益確定と損切りを導入してみる
利益確定と損切りを導入するとどんな変化が起きるのか試してみます。
handle_signals()の中にある、sec.order()のコメントを外します。
ほぼ変わらない、というかもっと悪い結果になった・・・
残念ながら今の自分の知識ではなんでそうなったのかがわかりません。いろんな数字を変えてみる
・同じ期間内で移動平均の日数やバンド幅、シグナルの条件を弱めたり強めたりしてみたがあまり結果は変わらなかった。
・テスト期間を変えるとプラスになることもあった。
(こういった局面で何が違うのかを比較してみるのかもいいかも。)最後に
気になった点
・移動平均は正規分布しているのか
約95%のデータが2σバンドに収まるということは、2σバンドを超えるものは5%ほどしかないということ。
それにもかかわらず、5000回以上のシグナルが1年間で出ることはおかしいと思った。
日経平均をはじめいくつかのデータをピックアップしてほんとに移動平均が正規分布しているのかを実際に確認してみようと思う。・売買の方法が単純すぎる
たとえばトレンドの発生前後で売買の方法を変えたりなど、あらゆる局面に対応できるアルゴリズムを開発するべきだと思った。
そういえば、オフィスで行われたアルゴリズムレビュー会でもそのような指摘があった。この2つの点に着目して、またボリンジャーバンドを改良してみるのも面白いかもしれない。
今後の課題
やることが山積みで全然定まってないのが正直辛みなところです。
・金融に関する知識
・QuantXの仕様に慣れる、メソッドとかを使いこなす
・Pythonコーディングスキルの向上
・ファンダメンタルズ分析
など、上げたらキリがないです。まずは今後の方針をもっと明確に決めていきたいです。
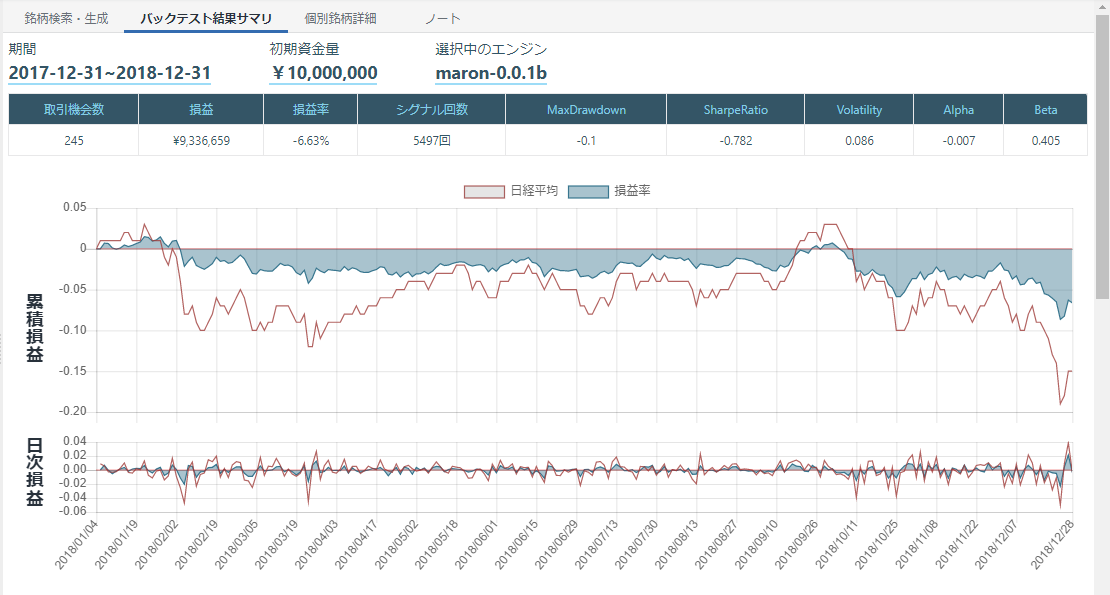
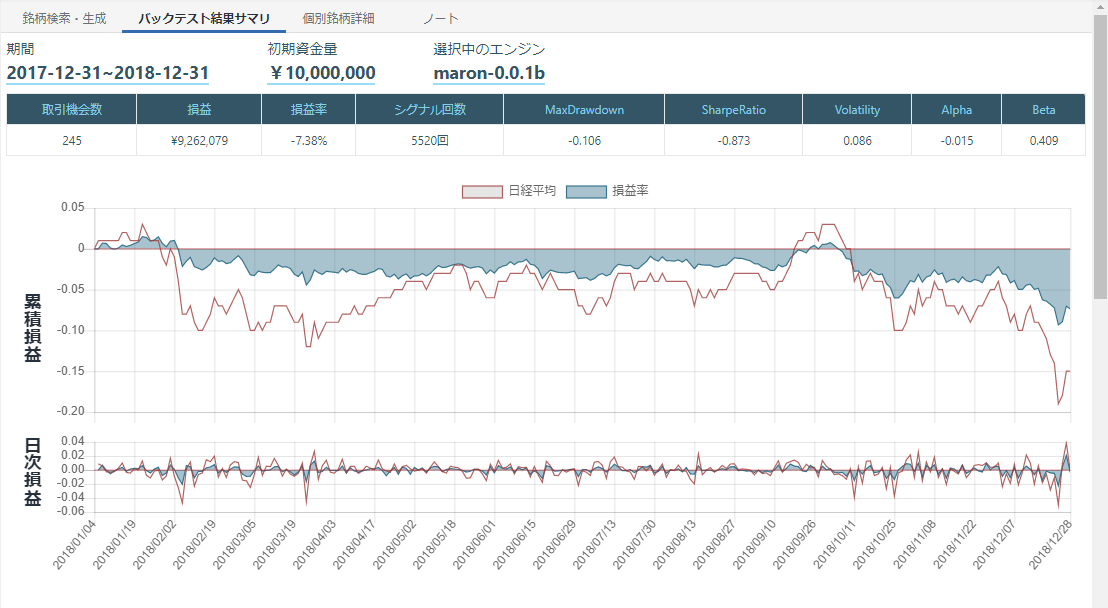
- 投稿日:2019-04-11T16:02:58+09:00
DjangoのtemplateとLaravelのbladeの構文をちょっと比較してみた
まとめ
両者非常に似通っていて、同じ感覚で使用できる
Laravelでは親の
@yieldに子の@sectionが展開されるが、Djangoでは親子ともにblockで表現するLaravelでは、
@extendsにlayouts/app.blade.phpを使用する際に、layouts.appと指定する(layouts/appではない)のが少し戸惑ったDjangoの場合
親のテンプレート
templates/base.html<!DOCTYPE html> <html> <head> ... </head> <body> <header> ... </header> <main> {% block content %} {% endblock %} </main> <footer> ... </footer> </body>子のテンプレート
templates/hoge/fuga.html{% extends 'base.html' %} {% block content %} <div> {% if items %} <ul> {% for item in items %} <li>{{ item }}</li> {% endfor %} </ul> {% endif %} </div> {% endblock %}Laravelの場合
親のテンプレート
resources/views/layouts/app.blade.php<!DOCTYPE html> <html> <head> ... </head> <body> <header> ... </header> <main> @yield('content') </main> <footer> ... </footer> </body>子のテンプレート
resources/views/hoge.blade.php@extends('layouts.app') @section('content') <div> @if (count($items)) > 0) <ul> @foreach( $items->all() as $item) <li>{{ $item }}</li> @endforeach </ul> @endif </div> @endsection
- 投稿日:2019-04-11T15:50:42+09:00
はじめてのDjango (4) view関数からデータベースを参照してページに情報を送り込もう
はじめに
このドキュメントは,もともとは研究室の新メンバー向けの入門テキストとして作成したもので,はじめてDjangoにふれる人にざっとその全体像をつかんでもらうことを狙っています.Djangoの日本語での参考資料も充実してきたので今さらという気がしないでもないですが,見直しを気にQiitaに移すことにしました.万が一でもどなたかの参考になれば幸いです.
Djangoのバージョンは2.0以降を想定しています.説明のための具体例として,Djangoのオフィシャルチュートリアルにある投票アプリをとりあげています(が,説明上の都合で少しコードを追加,変更しているところもあります).素人の独学がベースで,特に前半は公式チュートリアルをやってみた感想のような記事です(今回は全7回中の4回目).
全体のコードはまとめてGitHubに置きました.
view関数からのデータベースの参照
ここでは,データベースに格納されているデータにアクセスしてそれをview関数の中で利用する方法を紹介します.
例えば,データベースに格納されているQestionクラスのデータ(インスタンス)をすべて取得したいときには,次のようにします(データモデルのクラス名の後ろに.
objects.all()をつける).questions = Question.objects.all()データベースに対するクエリ処理はDjangoが面倒をみてくれるので,view関数の中では,
questionsを単にQuestionクラスのリストのように扱うことができます(厳密には,リストではなくクエリセットというデータ構造みたいです).したがって,このあとquestions[0]やquestions[0:5]といった表現が使えます.何らかのfieldの値でクエリセットをソートしたいときは次のようにします.
questions = Question.objects.all().order_by(field名)ある条件を満たすものだけを抜き出したいときや,逆に,ある条件を満たすものを除外して抜き出したいときには,次のように書くことができます.
questions = Question.objects.filter(条件) questions = Question.objects.exclude(条件)また,条件に合うものが1つだけであることがわかっているときには,
question = Question.objects.get(条件)とすることもできます(この場合は,クエリセットではなく1つのインスタンスが得られます).
Choiceも同じように扱うことができますが,Questionとの関係を利用して,ある
questionというQuestionインスタンスに関連するものだけを抜き出す,といったこともできます.choices = question.choice_set.all() choices = question.choice_set.filter(条件) choices = question.choice_set.exclude(条件)クエリセットを取得する方法の詳しい説明はここを参照してください.
続いて,これらを用いた具体的なview関数の例をみていきましょう.まず,views.pyにQuestionとChoiceをimportしてから,
index()を次のように書き換えてみます.from .models import Question, Choice def index(request): latest_question_list = Question.objects.all().order_by('-pub_date')[:5] context = {'latest_question_list': latest_question_list} return render(request, 'polls/index.html', context)Questionクラスのインスタンスをすべて抜き出したあと,
pub_dataフィールドの逆順(新しいものから古いものへ)にソートし,最後にスライスで前から5個のみを取り出してlatest_question_listに代入していることがみてとれます.そして,それをcontextに含めてrender()を呼んでいます.対応するtemplate(index.html)も忘れずに作成しておきましょう.
<h1>Welcome to Polls App.</h1> {% if latest_question_list %} <ul> {% for question in latest_question_list %} <li> <a href="{% url 'polls:detail' question.id %}"> {{ question.question_text }} </a> </li> {% endfor %} </ul> {% else %} <p>No polls are available.</p> {% endif %}この例で,templateの中でif文やforループを使用する方法が示されています.
また,
idはデータモデル作成の際に自動的に追加された行番号のようなもので,これによって同じデータモデルクラスのインスタンスを個々に区別することができます(このようにデータモデルのインスタンスを区別するための目印をprimary_keyといいます.id以外のfieldを自分でprimary_keyに指定することもできますが,その場合は異なるインスタンスのそのfieldには同じ値は入れられません.また,pkという名前でprimary_keyを指し示すことができ,デフォルトのままprimary_keyにidを使用している場合はpk=idとなります).次に,
detail()を書き換えます.このview関数は,指定された質問項目の詳細を表示するためのものであり,もし指定された質問項目が存在しなかった場合には404エラーページを表示させています.from django.http import Http404 def detail(request, question_id): try: question = Question.objects.get(pk=question_id) except Question.DoesNotExist: raise Http404("Question does not exist") choice_list = question.choice_set.all() context = {'question': question, 'choice_list':choice_list} return render(request, 'polls/detail.html', context)最初に
importしているHttp404は,404エラーページを表示させるためのものです.
tryで指定されたpk(=id)のQuestionインスタンスの取得を試みています.もしそれが存在しなかった場合は例外(DoesNotExist)が発生するので,それをexceptで捕捉して404エラーページを表示させていることがみてとれます.うまく行った場合は,choice_listを作成し,それをcontextに含めてrender()を呼んでいます.なお,
get_object_or_404というショートカットを用いると,これを同じ処理が次のように簡単に書けるようです.from django.shortcuts import get_object_or_404 def detail(request, question_id): question = get_object_or_404(Question, pk=question_id) choice_list = question.choice_set.all() context = {'question': question, 'choice_list':choice_list} return render(request, 'polls/detail.html', context)対応するtemplate(detail.html)もこれにあわせて次のように更新しておきましょう.
<h1>{{ question.question_text }}</h1> <ul> {% for choice in choice_list %} <li>{{ choice.choice_text }}</li> {% endfor %} </ul>実は,
question.choice_set.all()で関連するChoiceインスタンスを抜き出してくるメソッドはtemplateの中で実行することもできます.その場合は,次のように書きます.<h1>{{ question.question_text }}</h1> <ul> {% for choice in question.choice_set.all %} <li>{{ choice.choice_text }}</li> {% endfor %} </ul>templateの中でメソッドを呼ぶ場合は
()が不要になることに注意しましょう(上の例では,all()がallになっています).なお,こちらの方法を用いる場合は,view関数のcontextにchoice_listを含める必要はありません.最後に,
results()も同じように更新しておきましょう.def results(request, question_id): question = get_object_or_404(Question, pk=question_id) return render(request, 'polls/results.html', {'question': question})対応するtemplateも以下のように書き換えます.
<h1>{{ question.question_text }}</h1> <ul> {% for choice in question.choice_set.all %} <li> {{ choice.choice_text }} -- {{ choice.votes }} vote{{ choice.votes|pluralize }} </li> {% endfor %} </ul> <p> <a href="{% url 'polls:detail' question.id %}">Vote again</a> or <a href="{% url 'polls:index' %}">go back to top page</a>? </p>ここに,forループの中の
<li>タグの中で出てくるpluralizeはフィルタの一種であり,choice.votesの値が2以上の場合に名詞を複数形にするためのsを出力してくれます.おわりに
以上で4回目は終了です.第5回に続きます.
- 投稿日:2019-04-11T15:48:24+09:00
Jupyter Notebook: pandasのSeriesをnumpyのndarrayに変換する方法

- 投稿日:2019-04-11T15:28:57+09:00
Jupyter Notebook: pandas.DataFrameから指定した列の値リストを抜き出したい
次のようなテーブルデータを持ったpandasの
DataFrameから、b列の値だけを抜き出す方法です。
a b 1 10 2 20 3 30 こういうリストがほしい:
[10, 20, 30]まず、
DataFrameの定義:df = pandas.DataFrame([ {'a': 1, 'b': 10}, {'a': 2, 'b': 20}, {'a': 3, 'b': 30} ])
df[取り出したい列名]で指定する:df['b']なお、このとき
df['b']のデータ型はpandas.core.series.Series型になる。Jupyter Notebookでの実行例:

- 投稿日:2019-04-11T15:13:08+09:00
#python で #ruby の Hash#merge 的なことをやる ( 複数のディクショナリをマージする )
- 投稿日:2019-04-11T15:01:54+09:00
Pythonで開発するならKiteを導入して爆速開発
Kiteとは?
Kite integrates with your IDE and uses machine learning to give you useful code completions for Python.
AIがコード補完やってくれる便利なツール。ドキュメントもすぐ見れる。
Atom、VSCode、Vim、NeoVIm、PyCharmなど主要なエディタ・IDEで簡単に導入ができる。導入手順
1. 公式サイトからアプリをダウンロードしてインストール
2. Kiteアプリを立ち上げてアカウントを登録する
3. 設定から使ってるエディタ・IDEに対応したものをインストール
実際の動作
Vim(MacVim) + Kiteでやってみました。Kite以外に他のPython用のVimプラグインは入れてないです。



- 投稿日:2019-04-11T14:14:58+09:00
Anaconda3 コマンドまとめ
はじめに
便利なAnaconda3のコマンドをまとめた記事です。
コマンドリスト
- conda info -e
- 仮想環境の一覧表示
- conda create --name myenv python=3.6
- 仮想環境作成 (仮想環境名をmyenv、使用Python versionを3.6にする場合)
- activate [仮想環境名] - 仮想環境を切り替える
- deactivate
- 仮想環境を終了する
- conda list
- インストールされているパッケージの一覧を表示
- conda install <パッケージ>
- パッケージのインストール
- conda install <パッケージ>=バージョン指定
- バージョンを固定してパッケージをインストールする
- 例[
conda install tensorflow-gpu==1.8.0]- conda uninstall <パッケージ名>
- パッケージのアンインストール
- conda list --export > package-list.txt
- 環境再現のためのリストを出力
- conda create -n myenv --file package-list.txt
- 出力したファイルに基づいて再構築(新規に環境をつくる場合)
パッケージの検索
- conda search <パッケージ名>
特定のチャンネル内に存在するパッケージの検索
- conda search -c <チャンネル名> <パッケージ名>
全てのチャンネル内でパッケージの検索
- anaconda search -t conda <パッケージ名> ## 補足
仮想環境の一覧表示
conda info -eコマンドを使用すれば、Anaconda Prompt上で、仮想環境の一覧の表示と仮想環境の切り替えが可能です。conda info -e WARNING: The conda.compat module is deprecated and will be removed in a future release. # conda environments: # base * C:\Users\<ユーザー名>\Anaconda3 tensorflow-gpu C:\Users\<ユーザー名>\Anaconda3\envs\tensorflow-gpu仮想環境の作成方法
conda createコマンドで作成可能です。pythonの3.7のバージョンを設定したい場合は、以下のようにします。conda create --name myenv python=3.7仮想環境の切り替え方法
activateコマンドで切り替え可能です。conda info -eと合わせて使うことが多いです。activate tensorflow-gpu conda info -e # conda environments: # base C:\Users\<ユーザー名>\Anaconda3 tensorflow-gpu * C:\Users\<ユーザー名>\Anaconda3\envs\tensorflow-gpuconda listでパッケージ一覧表示
抽出してリスト表示することも可能です。
conda list gpu # packages in environment at <あなたの仮想環境パス> # # Name Version Build Channel keras-gpu 2.1.6 py36_0 tensorflow-gpu 1.8.0 h21ff451_0 tensorflow-gpu-base 1.8.0 py36h376609f_0モジュール動作確認方法
インストールしたモジュールが正しく使用できるか、Anaconda Command Prompt上で確認する方法です。
python -c "import tensorflow as tf; print( tf.__version__ )"python -c "import tensorflow as tf; print( tf.__version__ )" 1.13.1Anacondaのアップデート方法
conda update -n base conda参考
Conda コマンド
anaconda のコマンドリストメモ
- 投稿日:2019-04-11T14:13:56+09:00
docker-compose から docker network を少しだけ理解したい
docker-compose での疑問
docker公式っぽいやつの docker-compose の例 : https://docs.docker.com/compose/gettingstarted/
ここでの
app.pyのredisのhostが以下のように指定されています。cache = redis.Redis(host='redis', port=6379)なぜ
host='redis'で別のコンテナのredisにつなぐことが出来るんだい?上記の公式サイトには以下のように解説されています。
In this example, redis is the hostname of the redis container on the application’s network. We use the default port for Redis, 6379.
はぇ〜
application’s network ってなに
ここでいう
application’s networkとはdocker containerにおけるネットワークのことっぽい?
docker-compose up等で起動されたコンテナ群は、すべて同一のネットワークに所属することになるようです。参考にさせていただいた記事 : https://qiita.com/roba4coding/items/efd3a38db08eb476d412
つまりどういうことだってばよ
docker inspectコマンドを使うことでふわっと概要がわかります。
inspectするためにまず コンテナのIDを調べます。$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES aa690f2ae5d4 example_docker_compose_web "python app-server/s…" 2 minutes ago Up 2 minutes 0.0.0.0:5000->5000/tcp example_docker_compose_web_1 4f39c7c9cc47 redis:alpine "docker-entrypoint.s…" 2 minutes ago Up 2 minutes 6379/tcp example_docker_compose_redis_1
inspectします。$ docker inspect 4f39c7c9cc47 ... "Networks": { "example_docker_compose_default": { "IPAMConfig": null, "Links": null, "Aliases": [ "4f39c7c9cc47", "redis" ], ... } } ...コンテナのID :
4f39c7c9cc47がredisというエイリアスで登録されているのですね。このエイリアスを使うことが出来るのが、同一
docker networkに所属するものだけだということですね。上記でいうと コンテナ
aa690f2ae5d4が エイリアスを使うことが出来るということですね。docker network ってなに
docker network lsで現在存在するdocker networkの一覧を見ることができます。$ docker network ls NETWORK ID NAME DRIVER SCOPE ac27f0096628 bridge bridge local e72136cdac25 example_docker_compose_default bridge local d2b0552308a8 host host localここで 最初の
docker-composeのexampleで作られたであろうexample_docker_compose_defaultのdocker networkの詳細を見てみましょう。コマンドは
docker network inspectです。$ docker network inspect example_docker_compose_default [ { "Name": "example_docker_compose_default", "Id": "e72136cdac25de9dbc9875467aacd59e916ba8b7122cbede91f81387a2a18715", ... "Containers": { "4f39c7c9cc478dc30aca3bd21c6dc1eda2bb189c0b5264a325f98b38ad8cd7c6": { "Name": "example_docker_compose_redis_1", ... }, "aa690f2ae5d483c0c2cf213d9929a3d49025859464abe095f861c05bbb66ee32": { "Name": "example_docker_compose_web_1", ... } }, ... ]
Containersに 先ほどdocker-composeで作られたコンテナ達がありますね。コンテナIDも一致しているようです。参考にさせていただいた記事 : https://qiita.com/TsutomuNakamura/items/ed046ee21caca4a2ffd9
docker-compose を使わずにやってみよう
今回は別の例として
mysqlが起動しているコンテナ に対してpythonが起動したコンテナからアクセスしたいと思います。docker networkを知らなかった時
まず
mysqlのコンテナをたてます。$ docker run -e MYSQL_ROOT_PASSWORD=root -d -p 3307:3306 --name test-mysql mysql:5.6 4f7475ea1ac4db5d4aad630cbe585faf2dca39db61d7e405e14e9554414bd486
pythonが起動しているコンテナからmysqlのコンテナにアクセスするためには、そのコンテナのアドレスを知る必要があります。$ docker exec test-mysql cat /etc/hosts 127.0.0.1 localhost .. 172.17.0.2 4f7475ea1ac4こうすることでようやく接続することができました。(もっといいやり方あったら教えてください..)
>>> import mysql.connector >>> conn = mysql.connector.connect(host="172.17.0.2",user="root",password="root",port=3306,database="mysql") >>> conn.is_connected() Truedocker networkを使った場合
まず、コンテナが所属するための
docker networkを作ります。
docker networkに関して参考にさせていただいたブログ : https://www.sambaiz.net/article/7/$ docker network create -d bridge test-network 25d355cf117def0e6ce801341e1b535320cd688435a436ce063dc49bbb3c9c0e $ docker network ls NETWORK ID NAME DRIVER SCOPE ac27f0096628 bridge bridge local e72136cdac25 example_docker_compose_default bridge local d2b0552308a8 host host local 07263a6d0de1 test-network bridge localコンテナが作成される時に、作ったネットワークに所属してもらうようにするには、
--netオプションを使うようです。$ docker run -e MYSQL_ROOT_PASSWORD=root -d -p 3307:3306 --name test-mysql --net=test-network --net-alias mysql mysql:5.6 0f901dbda634c3d05cce10d2bf91fb0ef82d39fbd1b1046f284db522bc8387f8こうすることで、
docker-composeで起動したコンテナと同様にエイリアスが登録されます。$ docker inspect 0f901dbda634 ... "Networks": { "test-network": { ... "Aliases": [ "mysql", "0f901dbda634" ] ... } ...そして python が起動するコンテナも同一
docker network上にたててあげれば、$ docker run -it --net=test-network test-python >>> import mysql.connector >>> conn = mysql.connector.connect(host='mysql',user='root',password='root',port=3306,database='mysql') >>> conn.is_connected() True無事、コンテナを名前解決できるようになり、
host='mysql'で接続できているのがわかると思います。
--linkの場合$ docker run -e MYSQL_ROOT_PASSWORD=root -d -p 3307:3306 --name test-mysql --net=test-network mysql:5.6 2d96784fb9ae77cec276558d3439e3b455782bb4bac4291b76b65a27d5c27480 $ docker run -it --net=test-network --link test-mysql:mysql test-python Python 3.7.3 (default, Mar 27 2019, 23:48:15) [GCC 8.2.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import mysql.connector >>> conn = mysql.connector.connect(host='mysql',user='root',password='root',port=3306,database='mysql') >>> conn.is_connected() True同様に繋ぐことが出来ました。
linkの場合AliasesではなくLinksに名前解決するための情報が書かれていました。... "Networks": { "test-network": { ... "Links": [ "test-mysql:mysql" ], "Aliases": [ "d0d2ed057334" ], ... } } ...
--net-aliasと--linkの使い分けに関してはまだ知識が浅いのでいつか調べたいと思います。まとめ
docker-compose を使おう!
- 投稿日:2019-04-11T13:55:56+09:00
UTF-8ってそもそもどういう仕組み?
はじめに
UTF-8が結局どういう仕組みか、曖昧なままにしていたので調べてみました。
文字符号化方式と符号化文字集合
この2つは全く別物で、
符号化文字集合はユニコードなどの、ある文字に対してある数字やコードが当てられたリストのようなもの
文字符号化方式はUTF-8やshift-jisなどの、ビット列と符号化文字集合とを橋渡しをするものです。アルファベットや数字のみを扱う時にはASCIIだけ事足りるので、この2つはの違いが意識しづらいようです。
UTF-8の規則
ビット列の先頭のパターン
1バイトの文字や4バイトの文字が混在していても大丈夫なように、UTF-8ではそれぞれのバイトの先頭のビット列が決まったパターンをとるようにしています。
1バイトの文字
先頭を
0とする。2バイトの文字
1バイト目の先頭を
110、2バイト目の先頭を10とする。3バイトの文字
1バイト目の先頭を
1110、2バイト目と3バイト目の先頭を10とする。文字の始まりを探そうと思えば、先頭が
10でないバイト列を探せばいいわけです。先頭より後
前頭よりも後の部分は有効ビットと呼ばれ、文字を特定する役割があります。
例えば、「あ」の実態は
111000111000000110000010
ですが、先頭のビットパターンを除くと、
0011000001000010
が現れます。
この有効ビットを16進数にすると、そのままユニコードの符号位置となります。UTF-8でエンコードした例
「オロナミンC」をPythonでエンコードしてみます。
>>> 'オロナミンC'.encode() b'\xe3\x82\xaa\xe3\x83\xad\xe3\x83\x8a\xe3\x83\x9f\xe3\x83\xb3C'Pythonのバイト型では、16進数の前に
\xと付くようです。最後の「C」はそのままです。ですから、「オロナミンC」をUTF-8でエンコードすると、実際には16進数で
E382AAE383ADE3838AE3839FE383B343となると思います。(最後の「C」はASCIIで43なのでUTF-8でも43となります。)
2進数(ビット列)に直してみます
11100011100000101010101011100011100000111010110111100011100000111000101011100011100000111001111111100011100000111011001101000011これを8ビット毎に区切っていくと、先頭のビットパターンの規則により、文字の区切れがわかります。
すると、最初の文字を表す二進数は
111000111000001010101010だとわかります。ここから有効ビットの部分を取り出すと、
0011000010101010です。そして16進数に戻すと、
30AAとなり、これは「オ」のユニコード U+30AA に対応しています。まとめ
UTF-8でエンコードしたビット列は16進数で表記されることが多いです。
そこから文字を読み取るには、2進数に変換して文字の区切れを見つけ、有効ビットを抽出する必要があります。
- 投稿日:2019-04-11T13:00:39+09:00
pandasをpipでインストールする
pip install pandasもしも、ModuleNotFoundError: No module named 'pandas'となる場合はpip3でインストールする必要があるかもしれない。