- 投稿日:2019-04-11T18:57:49+09:00
AWS DeepRacerを理論的に考えてみた
はじめに
AWS DeepRacerを始めるにあたり、Reward関数をどのように変更すればいいのか考えてみました。
理論先行型であるため、動作は保証しておりません。waypointとyaw
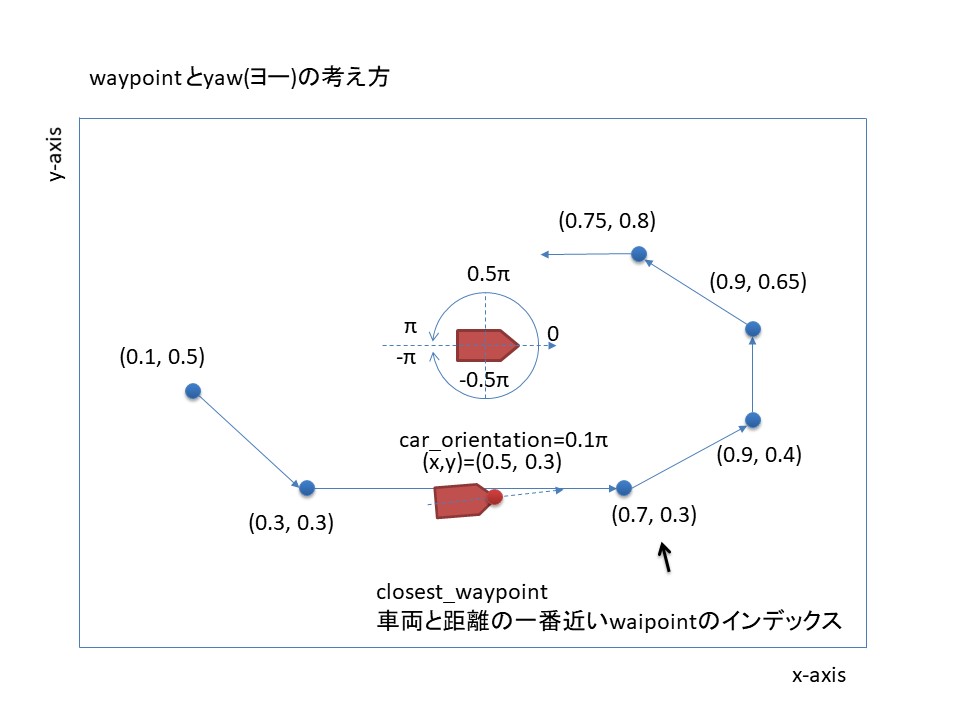
deepracer_env.py内の報酬関数の入力パラメータにwaypoints、closest_waypoints、car_orientationがあります。
waypointsはトラックの中心点の座標であり、closest_waypointsは車両に一番近いwaypointsとなっています。
car_orientationは車両のヨーイングとなっています。
そこで、次に向かうwaypointと車両のヨーイングがわかれば最短距離でコースを走れるのではないかと考えました。車両がどのwaypointsを目指すか
closest_waypointsは車両に対する直線の距離で一番近いwaypointsとなっています。
そのため、車両の後方にclosest_waypointsが存在する可能性があります。
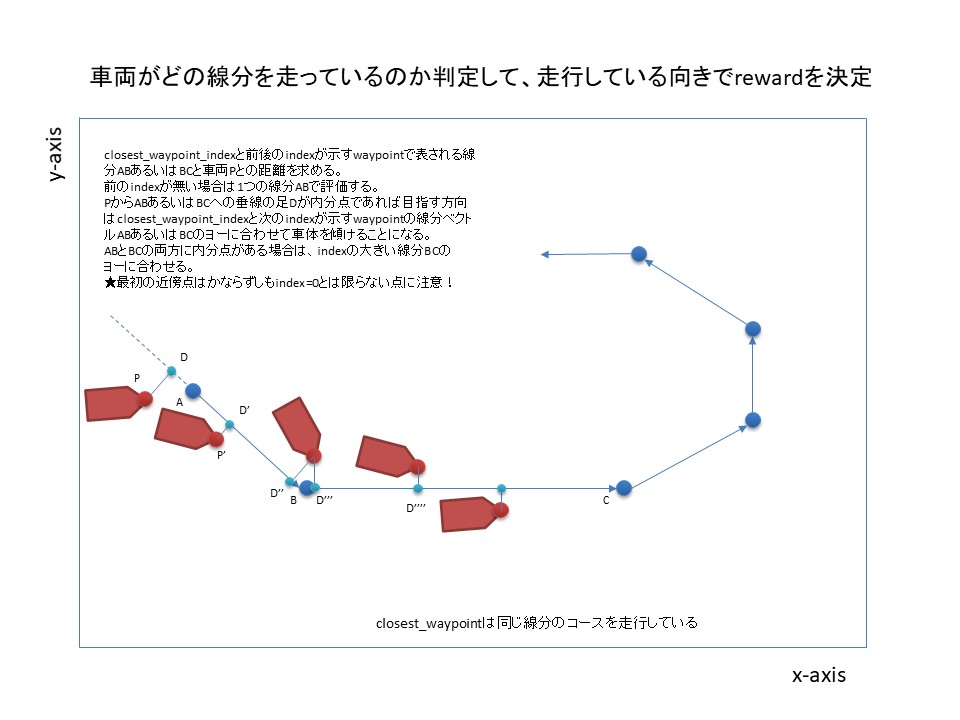
そこで、closest_waypointsとその前後のwaypointsの線分の間に車両が存在するかどうかを判定し、closest_waypointsを更新する必要があります。
closest_waypointsとその前後のwaypointsの線分の間に車両が存在するかどうかの判定は、点と線分との距離の公式から判定することができます。
公式についてはこちらを参考にさせていただきました。簡単にいうと、2点間を通る直線に対して離れた点Pから垂線を下ろし、交点(内分点)が存在すれば、2点間の間に点Pが存在するというものです。
closest_waypointsをBと置き、その前後のwaypointsをそれぞれA,Cと置きます。
線分AB、線分BCとの間に上記の公式を使い、車両から垂線を下ろした交点が存在するかどうかを判定します。
- 線分ABとの間に交点が存在し、線分BCにはない場合は線分ABの間に車両は存在するため、closest_waypointsをBとする。
- 線分ABとの間に交点が存在せず、線分BCに交点が存在する場合は、線分BC間に車両が存在するため、closest_waypointsをCとする。
- 線分AB、線分BCそれぞれに交点が存在する場合にはclosest_waypointsをCとする。
これにより、車両が目指すべきclosest_waypointsを指定することができます。
車両のヨーイングとx軸に対する線分との角度の差から報酬を決定
diff_yaw = waypoint_yaw - car_orientation if diff_yaw == math.radians(0): reward += 10.0 elif (abs(diff_yaw) < math.radians(5) and diff_yaw * steering > 0): reward += 8.0 elif (abs(diff_yaw) < math.radians(10) and diff_yaw * steering > 0): reward += 5.0 elif (abs(diff_yaw) < math.radians(15) and diff_yaw * steering > 0): reward += 3.0 elif (abs(diff_yaw) < math.radians(20) and diff_yaw * steering > 0): reward += 1.0 else: reward = 1.0e-3目指すべきwaypointを求めることができたので、次は車両のヨーイングと交点が存在する線分のヨーイングとの角度の差を求めます。
その差が小さいほどReward値を高く設定しました。まとめ
defaultの5時間の学習をした結果1周38秒という結果でした。
waypointと車両のヨーイングから報酬を決定し理論的に考えてみましたが、そこまで速くなっている感じは見受けられませんでした。
また、closest_waypointにしても車両と全waypointに対して直線の距離を求めているため、車両の前後ではなく、想定していない箇所のwaypointを参照することがあります。
そこは注意が必要です。
- 投稿日:2019-04-11T16:57:54+09:00
クロスリージョンレプリケーション - S3
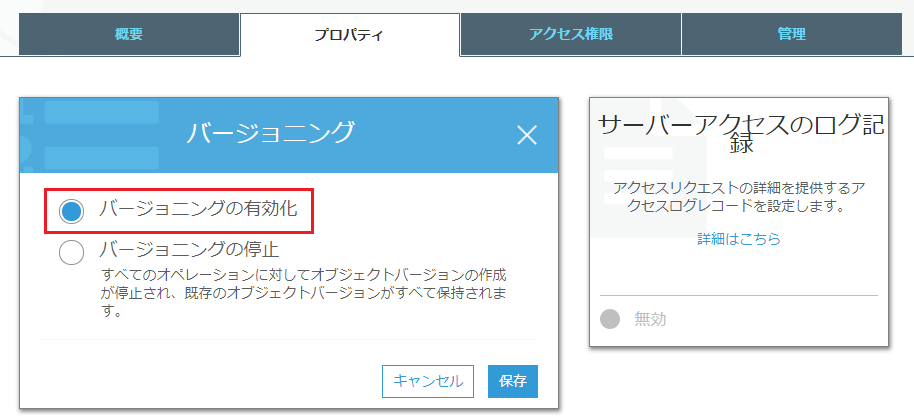
レプリケート元とレプリケート先の両方のバケットで、バージョニングを有効にする。
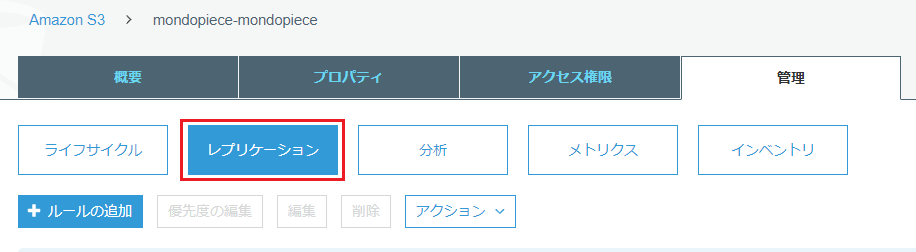
レプリケーションでルールを作成します。
レプリケーションルール
1.ソースの設定:検証なので、すべてのコンテンツにしておく。
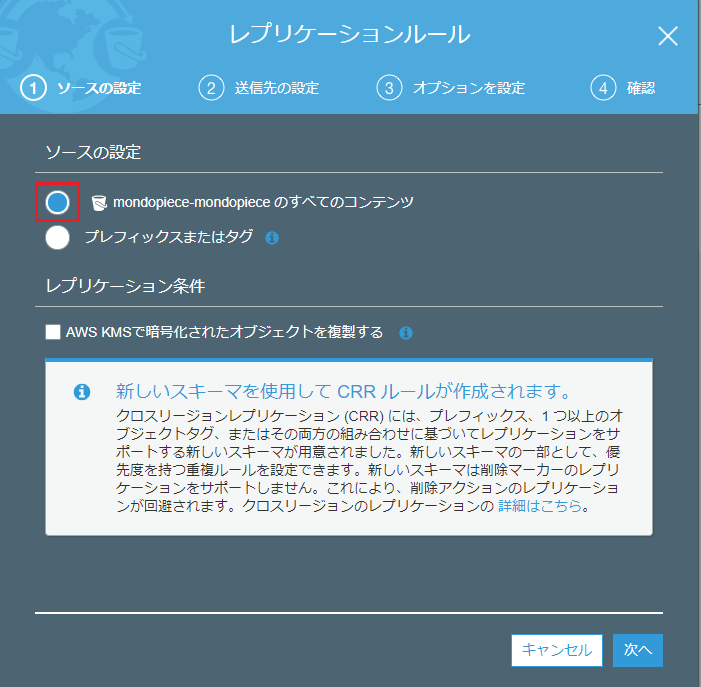
2.送信先の設定:送信先バケットを指定する。
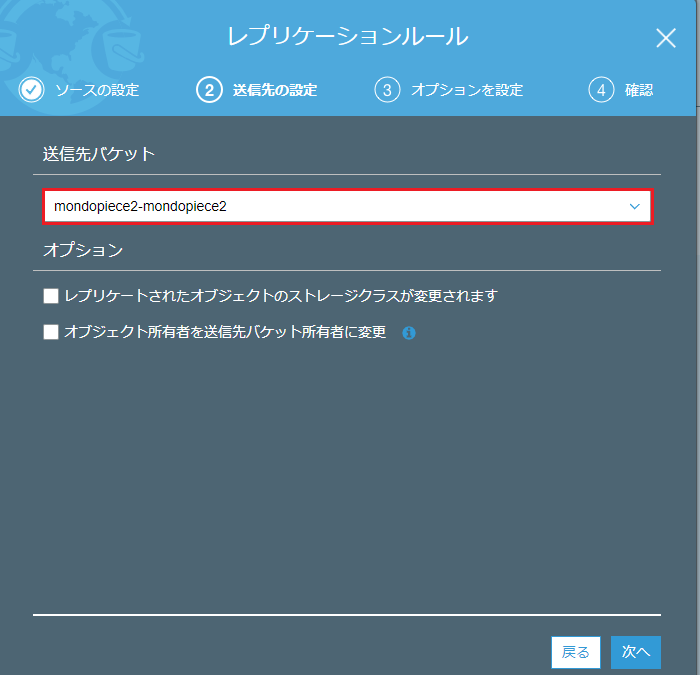
3.オプションを設定:新しいロールの作成にしておく。
IAMロールの内容は↓な感じです。
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "s3:Get*", "s3:ListBucket" ], "Effect": "Allow", "Resource": [ "arn:aws:s3:::mondopiece-mondopiece", "arn:aws:s3:::mondopiece-mondopiece/*" ] }, { "Action": [ "s3:ReplicateObject", "s3:ReplicateDelete", "s3:ReplicateTags", "s3:GetObjectVersionTagging" ], "Effect": "Allow", "Resource": "arn:aws:s3:::mondopiece2-mondopiece2/*" } ] }4.確認:保存をクリック。
Aリージョンにファイルをアップロードして動作を確認し、↓のようにBにも表示されるか確認してみましょう。
- 投稿日:2019-04-11T16:22:38+09:00
AWSのAppSyncをブランチごとに独立して自動デプロイする
AppSyncをチーム開発に向けて自動デプロイを行いました。
ブランチごとに独立したデプロイになるとPRの際に動作確認を行いやすいです。特にServerlessフレームワークでのAppSyncはDynamoDBなどもすべてセットでデプロイされるため、データ構造、データを含めて独立して完結したデプロイとなります。便利!ワークフローサイクルとして
- サーバサイドのコードに変更を入れる
- ブランチにコミットプッシュする
- PR作成
- 他のメンバーがPRでのデプロイに対して動作レビューとコードレビュー
ということを行えるようになります。
Serverlessの準備
Serverlessの準備を行います。serverlessパッケージと
serverless-appsync-pluginをインストールしておきます。$ npm init -y $ npm install --only=dev serverless serverless-appsync-plugin
serverless.ymlを作成します。(コードのほとんどを @reimenさんからもらいました)
serverless.ymlservice: my-first-app # NOTE: update this with your service name plugins: - serverless-appsync-plugin provider: name: aws runtime: nodejs8.10 stage: ${opt:stage, self:custom.defaultStage} region: ap-northeast-1 timeout: 30 stackTags: Project: ${self:service} deploymentBucket: name: serverless-deployment environment: TZ: Asia/Tokyo SERVICE: ${self:service} STAGE: ${self:provider.stage} custom: defaultStage: develop accountId: xxxxxxxxxxxxxx appSync: name: ${self:service}-${self:provider.stage} authenticationType: API_KEY mappingTemplatesLocation: mapping-templates mappingTemplates: - dataSource: Lambda type: Query field: users request: "users-request-mapping-template.vtl" response: "users-response-mapping-template.vtl" schema: schema.graphql dataSources: - type: AMAZON_DYNAMODB name: Main description: 'Main Table' config: tableName: '${self:service}-${self:provider.stage}-main' serviceRoleArn: { Fn::GetAtt: [AppSyncDynamoDBServiceRole, Arn] } - type: AWS_LAMBDA name: Lambda description: 'Lambda Function' config: functionName: graphql lambdaFunctionArn: { Fn::GetAtt: [GraphqlLambdaFunction, Arn] } serviceRoleArn: { Fn::GetAtt: [AppSyncLambdaServiceRole, Arn] } functions: graphql: handler: handler.graphqlHandler resources: Resources: MainTable: Type: 'AWS::DynamoDB::Table' Properties: TableName: '${self:service}-${self:provider.stage}-main' AttributeDefinitions: - AttributeName: pk AttributeType: S - AttributeName: sk AttributeType: S KeySchema: - AttributeName: pk KeyType: HASH - AttributeName: sk KeyType: RANGE BillingMode: PAY_PER_REQUEST AppSyncDynamoDBServiceRole: Type: "AWS::IAM::Role" Properties: RoleName: "Dynamo-${self:service}-${self:provider.stage}" AssumeRolePolicyDocument: Version: "2012-10-17" Statement: - Effect: "Allow" Principal: Service: - "appsync.amazonaws.com" Action: - "sts:AssumeRole" Policies: - PolicyName: "Dynamo-${self:service}-${self:provider.stage}-Policy" PolicyDocument: Version: "2012-10-17" Statement: - Effect: "Allow" Action: - "dynamodb:Query" - "dynamodb:BatchWriteItem" - "dynamodb:GetItem" - "dynamodb:DeleteItem" - "dynamodb:PutItem" - "dynamodb:Scan" - "dynamodb:UpdateItem" Resource: - "arn:aws:dynamodb:ap-northeast-1:${self:custom.accountId}:table/${self:service}-${self:provider.stage}-*" AppSyncLambdaServiceRole: Type: "AWS::IAM::Role" Properties: RoleName: "Lambda-${self:service}-${self:provider.stage}" AssumeRolePolicyDocument: Version: "2012-10-17" Statement: - Effect: "Allow" Principal: Service: - "appsync.amazonaws.com" Action: - "sts:AssumeRole" Policies: - PolicyName: "Lambda-${self:service}-${self:provider.stage}-Policy" PolicyDocument: Version: "2012-10-17" Statement: - Effect: "Allow" Action: - "lambda:invokeFunction" Resource: - "arn:aws:lambda:ap-northeast-1:${self:custom.accountId}:function:${self:service}-${self:provider.stage}-*"S3バケットの作成
サーバレスを置くためのバケットを作成しておきます。
$ aws s3api create-bucket --bucket serverless-deployment-yousan --create-bucket-configuration LocationConstraint=ap-northeast-1 { "Location": "http://serverless-deployment-yousan.s3.amazonaws.com/" }参考: https://docs.aws.amazon.com/cli/latest/reference/s3api/create-bucket.html
ローカルでのデプロイ
ローカルでデプロイのテストを行います。
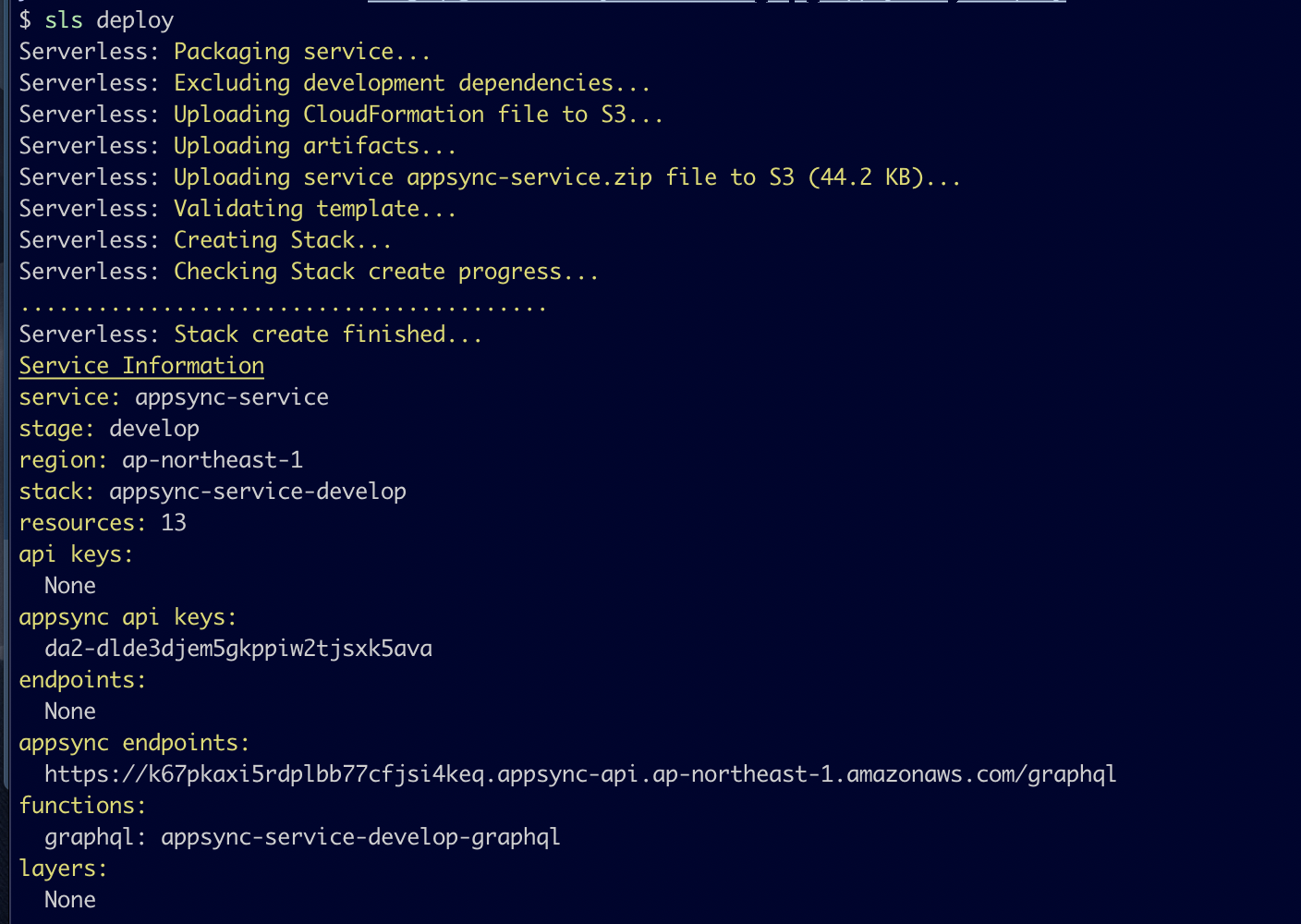
$ $(npm bin)/sls deploy Serverless: Packaging service... Serverless: Excluding development dependencies... Serverless: Uploading CloudFormation file to S3... Serverless: Uploading artifacts... Serverless: Uploading service appsync-service.zip file to S3 (44.2 KB)... Serverless: Validating template... Serverless: Creating Stack... ...
デプロイ完了しました。(上記に出ているスタックは削除済みです)
GraphQLに接続して確認できるか試しておきます。
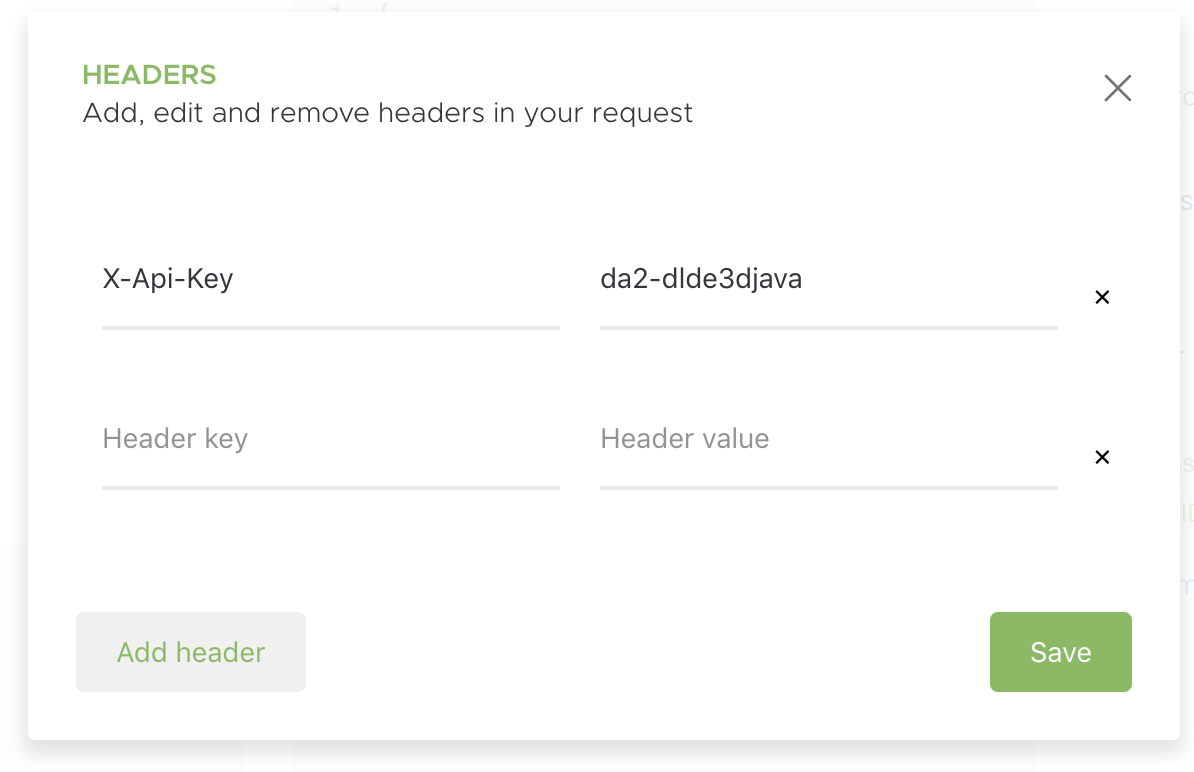
接続に必要な
api keysとappsync endpointsは控えておきます。
api keyはX-Api-Keyとして設定しておきます。
上記はAltair GraphQL Clinentです。
ブランチごとに独立したデプロイにする
ブランチごとに独立したServerlessのデプロイとなるようにします。
Serverlessの場合にはステージという概念があるので、ブランチごとに個別のステージを割り当てるようにします。GitのワークフローはGitFlow+プルリクエストでマージ方式を採用しています。そのためよく使うブランチは下記の三種類です。
- master (とreleaseブランチ) => 本番環境用
- develop => 開発用
- feature/xxx => 機能開発用。それぞれのPRが送られる単位。
このうち
featureブランチを独立してデプロイさせます。
AWSのServerlessフレームワークで使われるCloudFormationでは、名前に64文字までという制限があります。またブランチ名にスラッシュがあるとそのままではステージ名に使えません。
そこで現在のブランチ名からハッシュ値に変換するようにしました。branch.sh# 現在のブランチ名を取得する BRANCH=`git rev-parse --abbrev-ref HEAD` if type "md5" > /dev/null 2>&1; then BRANCH_HASH=$(echo ${BRANCH} | md5 | cut -c 1-6) # ブランチ名からのハッシュ値を取得。スタック名に使用する。 else # CircleCIのubuntuはmd5sumコマンドを使う(本当はelseifしたい) BRANCH_HASH=$(echo ${BRANCH} | md5sum | cut -c 1-6) # ブランチ名からのハッシュ値を取得。スタック名に使用する。 fi上記のコードで
${BRANCH_HASH}を使うと、現在位置のブランチから一意なハッシュが作成されます。このハッシュを元にステージを決定してデプロイを行います。
また後ほどCircleCI(のnode用コンテナ、Ubuntu)で自動化を行う場合、md5コマンドが見つからないと言われるためにMac環境とUbuntuで動くようにmd5sumを切り替えしています。$ $(npm bin)/sls deploy --region ap-northeast-1 --stage ${BRANCH_HASH}deploy_branch.sh#!/usr/bin/env bash # ブランチにコミットがあった場合にCFnでデプロイを行います。 set -xe # ファイルがある場所に移動 cd -- "$(dirname "$BASH_SOURCE")" # 現在のブランチ名を取得する BRANCH=`git rev-parse --abbrev-ref HEAD` # DEPLOY_BASE='/home/' # DEPLOY_PATH=${DEPLOY_BASE}${BRANCH} # ファイルを設置する場所 e.g. feature/201904/yousan/deploy-scripts if type "md5" > /dev/null 2>&1; then BRANCH_HASH=$(echo ${BRANCH} | md5 | cut -c 1-6) # ブランチ名からのハッシュ値を取得。スタック名に使用する。 else # CircleCIのubuntuはmd5sumコマンドを使う(本当はelseifしたい) BRANCH_HASH=$(echo ${BRANCH} | md5sum | cut -c 1-6) # ブランチ名からのハッシュ値を取得。スタック名に使用する。 fi cd ../ # デプロイしつつ、Slackに通知するためにファイルにも出力する ./node_modules/.bin/sls deploy --region ap-northeast-1 --stage ${BRANCH_HASH} | tee bin/output.txtこれで手元からデプロイを行います。
$ ./bin/deploy_branch.shCircleCIで自動デプロイセットアップ
GitHubに連携してCircleCIでデプロイされるようにします。
注意点としてCircleCIの
Nodeのデフォルトのイメージでは動きませんでした。
デフォルトのnode 6.10ではバージョンが低いため、新しいイメージを指定する必要があります。
今回は9.11.2を使っています。
公式イメージのバージョンを確認することができます。config.yml# Javascript Node CircleCI 2.0 configuration file # # Check https://circleci.com/docs/2.0/language-javascript/ for more details # version: 2 jobs: build: docker: # specify the version you desire here - image: circleci/node:9.11.2 # Specify service dependencies here if necessary # CircleCI maintains a library of pre-built images # documented at https://circleci.com/docs/2.0/circleci-images/ # - image: circleci/mongo:3.4.4 working_directory: ~/repo steps: - checkout # Download and cache dependencies - restore_cache: keys: - v1-dependencies-{{ checksum "package.json" }} # fallback to using the latest cache if no exact match is found - v1-dependencies- - run: yarn install - save_cache: paths: - node_modules key: v1-dependencies-{{ checksum "package.json" }} # run tests! - run: yarn test - run: ./bin/deploy_branch.sh重要なのは最後の方にある
./bin/deploy_branch.shです。これでデプロイされるようになります。CircleCIで動かすための手順
上記でCircleCIでセットアップを行いましたがうまく動きませんでした。
aws-cliの認証が通らないためです。
IAMユーザーを作成しておきます。
CloudFormationからもIAMユーザーを作成する必要があるため、ポリシーの設定で作成の許可を行います。{ "Version": "2012-10-17", "Statement": [ { "Sid": "EditSpecificServiceRole", "Effect": "Allow", "Action": [ "iam:*" ], "Resource": "*" } ] }ユーザー作成時にアクセスキーができたらCircleCIに保存しておきます。
CicleCIの設定からEnvironmentとして設定します。
以前はAWS専用の環境変数が用意されていたのですが、2019年4月現在は共通の環境変数として登録すれば良くなったようです。
CircleCI 1.0 の AWS Permissions で設定した AWS Credentials をローテーションする
https://blog.manabusakai.com/2019/04/change-aws-credentials-on-circleci/Slackへの通知
CircleCIで自動デプロイされるので、エンドポイントやキーを割り当てる必要があります。
CircleCIのデプロイ結果を確認すればよいのですがそれだと面倒なので、必要な情報をSlackで通知するようにします。
deploy_branch.shの結果が扱いにくいため(値を見やすくするため、改行で区切られている。)、teeでファイル(output.txt)に書き出し、別のスクリプトで読み込ませます。deploy_branch.sh...(前略)... ./node_modules/.bin/sls deploy --region ap-northeast-1 --stage ${BRANCH_HASH} | tee bin/output.txt ./slack.shその結果を読み込んでSlackで通知させます。
slack.sh#!/usr/bin/env bash # デプロイされたURLをSlackに通知するスクリプト # 使い方は # $ ./slack_deployed.sh https://example.com # のように、通知したいURLを後ろにつけて呼び出す set -xe # ファイルがある場所に移動 cd -- "$(dirname "$BASH_SOURCE")" # 引数を変数に格納 #API_KEYS=${1:-not_set} #ENDPOINT_URL=${2:-endpoint} #OUTPUT=${1:-notset} SLACK_URL=https://hooks.slack.com/services/T0HQ9xxJQKU/xxxx/K32b1xxxxxxxxxxxxxxxxxxxx # Slackに出力したいServerlessのレスポンスを加工 # Slackで出力するときに複数行だとcurlで送れないので、すべてセミコロンでくっつける OUTPUT=`cat output.txt | grep -A2 appsync | grep -v "\-\-" | tr '\n' ' : '` set +xe # デバッグ出力をオフにする echo -e "\n\n" printf '?\e[34m Success! \e[m?\n' #printf '\e[34m The deployed URL: \e[m '${ENDPOINT_URL}"\n" # デプロイ結果をSlackに通知 curl -X POST -H 'Content-type: application/json' \ --data '{"text": "Thank you for your commit! Your change makes us strong.\n'"${OUTPUT}"'", "username": "Deploy bot", "channel": "#graphql-notify", "icon_emoji": ":tada:", }' \ ${SLACK_URL}以上でGitでコミットプッシュすれば自動でデプロイされます。
その他まだやりたいこと
- masterブランチとdevelopブランチ、releaseブランチもそれぞれ作るようにしたい
- ハッシュじゃなくて記号をハイフンとかでサニタイズと文字数制限いれたものでも良さそう
- Slack通知をslsコマンドの出力フォーマットを変えて整形したい
- GraphQLのエンドポイント名をハッシュじゃなくてわかりやすすいものにできないかな
- ブランチのマージ時に古いデプロイを消したい(CFnは200個までの制限あり)
- 投稿日:2019-04-11T15:00:48+09:00
AWSセキュリティ入門
インフラとは
・目に見えるツール
・電波
・スピーカー など
何かしらで使っているものすべてはインフラがあるからこそ(水道や道路などもインフラ)インフラの変遷は1つのPCハードウェアに依存する形から、仮想化、コンテナ化と進んでいる(よくわかっていない)
オンプレとクラウド
・オンプレ
目に見えるデータセンターの管理
自社サーバー
自分で管理メリット・デメリット
・重要度の高いデータなどは自社でサーバーを建てて管理する方が良い
・サーバー管理にお金がかかる・クラウド
外部依存管理
ベンダーの仕様に依存
各種バージョン管理メリット・デメリット
・制限をなくしやすい
・課金によりサービスが拡大できる
・データの所在がわからない
・契約終了時にデータが完全消去されたかわからないリスク
・テクニカルリスク
巨大なインフラを管理するための技術が必要なこと・リーガルリスク
データ保護など・バーチャライズゼーションリスク
ゲストOSからハイパーバイザーに不正にアクセスされる・スペシフィックテクニカルリスク
クラウド事業者の内外部からの不正アクセス、データ漏洩、最終的な責任はクラウド利用者にあるなど責任共有モデル
責任の管理を分けている
・利用者がセキュリティ対策の実施と運用の責任(データ、アプリケーション、プログラミング言語、OS、仮想マシンなど)・提供者がインフラ環境のセキュリティの責任(ハイパーバイザ、ストレージ、ネットワーク、物理施設/データセンター)
最低限知っておくべきサービス
・AWS Shield
外部からの脅威検知(デフォルト)
ネットワークだけでなくアプリケーション層までカバー(有料)・Amazon GuardDuty
外部からの脅威検知(一部有料)・IAM
アクセス権限や暗号化キーを管理
サービスに対して権限を付与・AWS Trusted Advisor
アカウント管理(デフォルト)・AWS CloudTrail
証跡をとっておくサービス
データログをS3に保存・AWS Config
サービスの構成変更の履歴保存・通知(有料)参考
・サポーターズ勉強会 #spzcolab

- 投稿日:2019-04-11T14:53:55+09:00
NotPrincipal を使ったポリシーを書こうとして諦めた話
やりたかったこと
- KMSの鍵利用を一部のユーザのみに許可したい
- 同一アカウント内のEC2インスタンス内で利用する
- 対向AWSアカウント内のEC2インスタンス内でも利用する
- 許可されたユーザ以外の鍵の利用は拒否したい
NotPrincipal で除外設定を書いてみる
KMSのCMKにはリソースポリシー(キーポリシー)が設定できるので、
"Effect: "Deny"のポリシー内で"NotPrincipal"を使って一部ユーザ/ロール以外の利用を弾こうと思った。書いたポリシーはこんな感じ:KeyPolicy抜粋{ "Sid": "Deny use of the key without specific role/user", "Effect": "Deny", "NotPrincipal": { "AWS": [ "arn:aws:iam::111122223333:root", "arn:aws:iam::111122223333:role/role-a", "arn:aws:sts::111122223333:assumed-role/role-a/i-123456789012345678" "arn:aws:iam::111122223333:user/user-b", "arn:aws:iam::444455556666:root", "arn:aws:iam::444455556666:role/role-c", "arn:aws:sts::444455556666:assumed-role/role-c/i-987654321098765432" ] }, "Action": [ "kms:Encrypt", "kms:Decrypt", "kms:ReEncrypt*", "kms:GenerateDataKey*" ], "Resource": "*" },ポイントは次の2点。
- 除外対象のロール/ユーザを指定するのははもちろん、そのユーザが所属するアカウントも除外対象に含める必要がある
- ロールを除外するときには、AssumeRoleしたロールユーザも除外設定に含める必要がある
- ここではEC2インスタンスプロファイルがAssumeRoleするときを想定して、EC2インスタンスIDを指定している
もちろん、上記のDenyポリシーに加えて、Allowポリシーを作成する必要がある。(AllowポリシーはKMS CMKを作るときにデフォルトで設定されるので省略)
何が辛いか
ポリシーを見ればわかるが、IAM ロールを除外をするためにAssumeRoleしたロールユーザも指定する必要がある点が非常に辛い。
今回のようにEC2にアタッチしたIAMロールの場合、キーポリシーにはARN内でEC2インスタンスIDを指定する必要がある。したがって、EC2インスタンスが増えたりインスタンスを作り直したりした場合はいちいちキーポリシーを見直す必要が生じる。当然ながらAutoScaling環境ではこの方法は採用できない。
また、管理外のアカウントにあるIAMロールを除外する場合、そちらの変更を追いかけなければならず、対向の管理者とのコミュニケーションコストが高くなってしまう。
というわけで、今回はこの方法は不採用とした。
結局どうしたか
仕方ないので、いわゆるパワーユーザー的なIAMユーザとロールを洗い出して、Denyポリシーを付与することに……
これはこれで非常に辛いが、管理対象のAWSアカウントで閉じるのでまだまし。
どういうときにNotPrincipalは使えるか
こちら に書いてあった。S3バケットへのアクセスを特定のLambdaに絞るのには使えそう。
- 投稿日:2019-04-11T14:29:11+09:00
AWS ECRにdockerイメージを登録
ECRとは
Amazon Elastic Container Registry (ECR) は、完全マネージド型の Docker コンテナレジストリです。このレジストリを使うと、開発者は Docker コンテナイメージを簡単に保存、管理、デプロイできます。
ECRにレポジトリを作成
以下のコマンドでECRにレポジトリを作成します。
$ aws ecr create-repository --repository-name sample-aws-batch-repoECRにログイン
以下のコマンドを実行すると、ECRにログインします。
$ aws ecr get-login --no-include-email --region ap-northeast-1 --profile ExampleProfile作成したdocker imageに、以下のようにしてtagを付けます。
$ docker tag sample-aws-batch:latest xxxxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/sample-aws-batch-repo:latestECRにpushします。
$ docker push xxxxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/sample-aws-batch-repo:latest参考:AWSのECR
- 投稿日:2019-04-11T14:04:27+09:00
AWS LightsailのWordPressにBasic認証を設定する
AWS LightsailでWordPressを運用しているのですが、特定のディレクトリにBasic認証を設定する方法がわからずハマったので、一通りの手順をメモしておきます。
WordPressと言えば
.htaccessでルーティングの起点となるファイルにアクセスさせているので確認してみるとお決まりの設定がありました。/home/bitnami/apps/wordpress/htdocs/.htaccess# BEGIN WordPress <IfModule mod_rewrite.c> RewriteEngine On RewriteBase / RewriteRule ^index\.php$ - [L] RewriteCond %{REQUEST_FILENAME} !-f RewriteCond %{REQUEST_FILENAME} !-d RewriteRule . /index.php [L] </IfModule> # END WordPressこのファイルにBasic認証の設定すればイケるかなって思いやってみましたが、このファイル自体効いてませんでした。
※/home/bitnami/apps/wordpress/htdocs/.htaccessに設定しても意味がないなのでapacheのconfigファイルで設定することにしました。
まずは
.htpasswdを任意のディレクトリに作成します。$ htpasswd -c -b ~/apps/.htpasswd [user] [password]configファイルに設定を追記します。
$ vim ~/apps/wordpress/conf/httpd-app.conf~/apps/wordpress/conf/httpd-app.conf# ↓を追記 <Directory "/opt/bitnami/apps/wordpress/htdocs/[特定のディレクトリ]/"> AuthUserFile /home/bitnami/apps/.htpasswd # 作成した.htpasswdをフルパスで指定 AuthGroupFile /dev/null AuthName "Basic Auth" AuthType Basic Require valid-user </Directory>基本的なBasic認証の設定と変わらないので、指定するディレクトリだけ注意してもらえば大丈夫かと。
appsにシンボリックリンクが張ってあるので、実体は/opt/bitnami/apps/wordpress/htdocs/になります。$ ls -l apps -> /opt/bitnami/apps最後にapacheを再起動すれば完了です。
$ sudo /etc/init.d/bitnami restart apacheお疲れ様でした?
- 投稿日:2019-04-11T11:36:27+09:00
Auroraの性能検証(EC2との比較,データ量と計算時間の関係)
TL;DR
下記の観点で,AWS Auroraの性能検証を行いました.
- AWS Auroraと,EC2上に構成したMariaDBで性能比較しました
- RDBベンチマークTPC-Hによる計算時間の計測
- BI(Business Intelligence)向けの処理で,比較的大きな複数のテーブルからなるDBに対してクエリを発行するものです.
- 意思決定(Decision Making)などで使用される傾向がある処理です
- どちらかというと,Webサービスで使用される際の性能ではなく,バッチ処理での性能評価をしています
データ量と処理時間の関係
- 対象データ量ごとにAWS Auroraでの性能評価を行います
この記事は,下記の記事の続編です.この記事から読み始めることもできます
実験設定
TPC-Hは,使用するテーブルサイズを指定する(SF: Scale Factor)ことができるので,
SF=1, 4, 8でベンチマークするテーブルを用意しました.Aurora
以下の表のパラメータでAuroraを設定します.
設定名 パラメータ エディション MySQL 5.6 との互換性 DBエンジン Aurora(MySQL)-5.6.10a インスタンスタイプ db.r5.large 2vCPU, 16GiB RAM マルチAZ なし MariaDB
- t2.smallを作成
- MariaDBインストール,自動起動の設定
sudo yum -y update sudo yum -y install mariadb mariadb-server sudo systemctl start mariadb sudo systemctl enable mariadb
- 初期設定(ルートパスワードなどの設定)
sudo mysql_secure_installationその他は,auroraと同じように,テーブルの作成,データの登録,インデックスの作成を行います.
実験手順
- Query1からQuery22まで,順番に実行し,
- クエリの実行ごとに
RESET QUERY CACHE;を実行し,キャッシュクリアしてパフォーマンスを正しい計測を行いますfor i in `seq 1 22`; do (time mysql -u [ユーザ名] -h [DBMSエンドポイント] -D [データベース名] -p[パスワード] < ${i}.sql) >> log.txt 2>&1; mysql -u [ユーザ名] -h [DBMSエンドポイント] -p[パスワード] -e 'RESET QUERY CACHE;' done計測結果
TPC-Hで使用するテーブルおよびクエリの詳細は,ドキュメント(tpc-h_v2.18.0.pdf)を参照してください.
AuroraとEC2の比較
計算結果
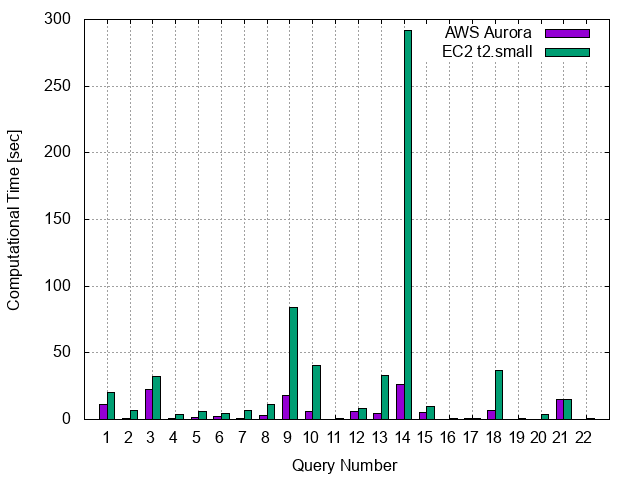
- AWS auroraと,EC2(t2.small)で,SF=1 (1GiB)のデータを対象にしたベンチマーク結果を示します
考察:フルマネージドRDBサービスauroraの利点
- インスタンスタイプに応じた性能が得られているように見えます
- auroraはec2に比べて計算時間上の利点が示されています
- インスタンスタイプの差以上に,EC2よりも良い性能を示すクエリもあります(Query9, 10, 13, 14, 18)
- 大きなテーブル(lineitem)の結合処理を含むクエリ(Query 9, 10, 14, 18)
- likeを含むクエリ(Query 13, 14)
- これらの,重たい処理を含む場合に,auroraの利点が得られるようです
Auroraの結果の比較
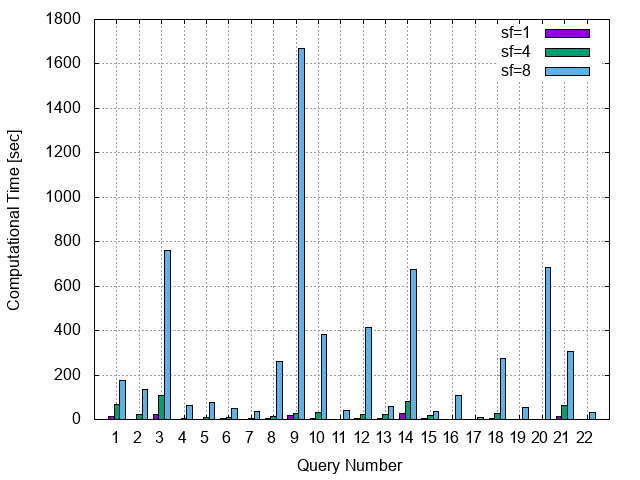
計算結果
- AWS auroraで, SF=1, 4, 8 を対象にした計算結果を示します
考察: RDBのスケーラビリティ問題
- データ量に応じて,計算時間を要します
- 結合処理を含む場合(Query1以外)は,データの量に対して, $O(n^2)$ の計算時間を要します
- MySQLの結合処理はNested-loop joinであることから,苦手な処理です
- 大きなテーブル(lineitem)の結合を含むクエリで,極端に計算時間が大きくなるものもあります(Query3, 8, 9, 10, 12, 14, 16, 18, 20, 21)
- メモリ不足で計算時間が増大したようにも見えます
まとめ
- Auroraは,フルマネージドなRDBとして,一定程度のBI(Bussiness Intelligence)処理に効果が得られることが示されました
- EC2上に自分でDBを作るよりも,性能が出そうです
- とは言え,テーブルサイズが大きくなると,(EC2はもちろんauroraでも)計算時間が激増してしまいます
- そもそもRDBで実施するクエリではないとも言えるので,巨大データの結合を含むような処理は,別の方法を考えたほうが良いかもしれません
参考
- 投稿日:2019-04-11T10:50:39+09:00
Lambda Custom Runtime を使って分かった事のまとめ。
Lambdaのカスタムランタイムを少しだけ使ったためその際に分かった事を覚えておくためにまとめたい。
Lambdaとは
サーバーを管理する必要なくコードを実行できるAWSサービス。
また、スケーリング等も自動で行ってくれるため関数のコードを書くだけで実行ができる。実態はおそらくAmazon Linux上で動いている。
Lambda 関数とは
Lambdaでコードを実行する一塊。実態は以下に展開され
通常ハンドラで設定されたコードが実行される。/var/task/
(環境変数 $LAMBDA_TASK_ROOT)
Lambda layer とは
利用可能なライブラリやカスタムランタイム(後述)をLayerとして登録することで
複数の関数で共通的に利用できる仕組み。zipでLambdaにあげ関数実行時に以下の場所に展開される。
/opt/
Lambda Custom Runtime とは
Lambda layerの一種。Lambdaでサポートされていない言語も、
Custom Runtimeを使うことで使用することができるようになる。実際は以下の場所をエンドポイントとしてそのファイルを実行する。
そのためbootstrap内にその環境でやりたいことをすべて書いていおかなくてはならない。/opt/bootstrap
bootstrapの例(公式抜粋)
#!/bin/sh
cd $LAMBDA_TASK_ROOT
./node-v11.1.0-linux-x64/bin/node runtime.jsTODO 続きを書く
参考
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/welcome.html
- 投稿日:2019-04-11T01:51:34+09:00
AWS認定ソリューションアーキテクトアソシエイトへの道 その3
tl;dr
現在Webエンジニアをやっているが下記の理由のためにAWSソリューションアーキテクトアソシエイト取得を目指す。
- スキルアップ
- 業務の幅を広げる
- 知的好奇心
現在のAWSスキル
- テスト用にEC2を作成したことはある(LAMP環境を構築)
- ネットワーク用語はある程度わかる(マスタリングTCP/IP 入門編は名著だと思う)
学習方法
- 対策本を読むことを考えたが、手を動かしながら学んだほうが身につくと考え、Udemyの動画教材を購入
- AWS INNOVATE(Amazonが主催するAWSを学ぶためのONLINE CONFERENCE) → 開催中だったために登録
- 参考書も購入
購入した教材はこちら
AWS認定ソリューションアーキテクト – アソシエイト試験突破講座
購入した本はこちら
合格対策 AWS認定ソリューションアーキテクト - アソシエイト
本日の課題
- AWSの仕組み
- AWSの操作
- アソシエイト試験概要
- AWSの全体像
- IAMの概要
- IAM設計
- IAMグループへのポリシー適用(ハンズオン) ポリシー、グループ、ロール
課題メモ
- AWSリージョン 日本には東京と大阪がある
- リージョン-アベイラビリティゾーン(AZ)
- AZとはデータセンターのこと
- 1つのリージョンに2つのAZのシステム構成を取るのがおすすめ
- IAMユーザを使うのかIAMグループを使うのか
IAMケーススタディ:自社組織に必要な権限設定
- IT管理者:フルアクセス+MFA:管理ポリシーAdministrator
- 運用管理者:運用ツール全般+開発環境(DevOps):ツール ELB/EC2/RDS/S3/Auto-Scaling/VPC Config/CloudTrail/CloudWathch
- アプリ開発者:担当しているアプリの開発範囲のみ:ツール ELB/EC2/RDS/S3/Auto-Scaling/VPC
EC2からバッチでS3にデータ保存
- S3のみへアクセスできるポリシーを作成
- EC2にそのポリシーを割り当てる