- 投稿日:2019-04-11T23:31:22+09:00
node.jsを触るために簡単なチャットシステムを作る(サーバー接続編)
Node.js を触ってみたいと思ったので、備忘録も兼ねて以下に記します。
よりよい方法やバグ等ございましたら、アドバイスいただけると光栄です。今回は「サーバー接続編」ということで、クライアントとサーバーの接続処理をやっていきます。
※前回 node.jsを触るために簡単なチャットシステムを作る(環境構築編) という表題で、環境構築をしていますので、環境構築がまだな方はこちらを参照ください。
サーバーを起動する
まずは、
mychatフォルダに、server.jsというファイルを作成します。$ cd mychat $ mkdir server.jsファイルが作成出来たら、
server.jsを下記のようにします。'use strict'; // モジュール const http = require('http'); const express = require('express'); const socketIO = require('socket.io'); const moment = require('moment'); // オブジェクト const app = express(); const server = http.Server(app); const io = socketIO(server); // 定数 const PORT = process.env.PORT || 3000; // サーバーの起動 server.listen( PORT, () => { console.log('server starts on port: %d', PORT); });動作を確認する
下記コマンドで実行すると動作の確認が出来ます。
$ node server server starts on port: 30003000番ポートでサーバーが立ち上がったことが分かるかと思います。
尚、起動したサーバーは、「Ctrl + C」で終了します。HTMLファイルを表示する
実際にビュー側に表示させるHTMLファイル(/public/index.html)を作成します。
$ mkdir -p public/index.htmlファイルが作成出来たら、
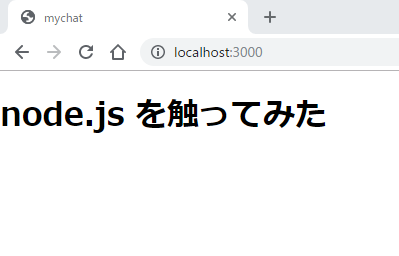
/public/index.htmlを下記のようにします。<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>mychat</title> </head> <body> <h1>node.js を触ってみた</h1> </body> </html>表示するHTMLファイルを上記の
public/index.htmlに指定する為
server.jsの「サーバーの起動」処理の前に、以下の処理を追加します。// 公開フォルダの指定 app.use(express.static(__dirname + '/public'));動作を確認する
サーバーを立ち上げた状態で、
http://localhost:3000 にアクセスすると
このように表示されれば完了です。クライアントとサーバーを接続する
サーバーへの接続要求処理、接続時の処理を記載するJSファイル(/public/client.js)を作成します。
$ mkdir public/client.jsファイルが作成出来たら、
/public/client.jsを下記のようにします。// クライアントからサーバーへの接続要求 const socket = io.connect(); // 接続時の処理 socket.on( 'connect', () => { console.log('connect'); });上記の
client.jsファイルを反映させる為
public/index.htmlの<body>の末尾に、以下の処理を追加します。<script src="/socket.io/socket.io.js"></script> <script src="https://ajax.googleapis.com/ajax/libs/jquery/3.3.1/jquery.min.js"></script> <script src="client.js"></script>
server.jsの「公開フォルダの指定」処理の前に、以下の「接続時の処理」を追加します。// 接続時の処理 io.on( 'connection', (socket) => { console.log('connection'); });
server.js全体としては、以下のようになります。'use strict'; // モジュール const http = require('http'); const express = require('express'); const socketIO = require('socket.io'); const moment = require('moment'); // オブジェクト const app = express(); const server = http.Server(app); const io = socketIO(server); // 定数 const PORT = process.env.PORT || 3000; // グローバル変数 let iCountUser = 0; // ユーザー数 // 接続時の処理 io.on( 'connection', (socket) => { console.log('connection'); }); // 公開フォルダの指定 app.use(express.static(__dirname + '/public')); // サーバーの起動 server.listen( PORT, () => { console.log('server starts on port: %d', PORT); });動作を確認する
サーバーを立ち上げた状態で、
http://localhost:3000 にアクセスします。
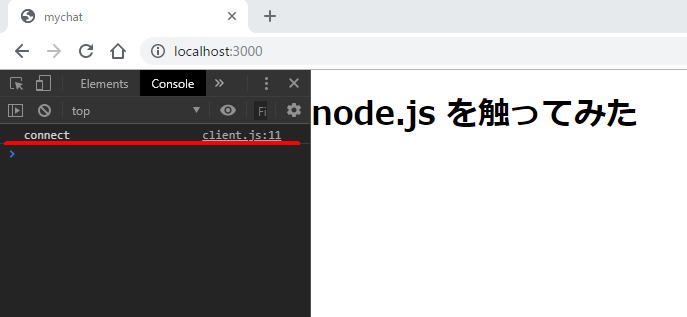
デベロッパーツールの Console に、
connectと表示(画像赤線)されます。また、サーバー側では
connectionと表示されれば完了です。$ node server server starts on port: 3000 connection以上で、クライアントとサーバーの接続に関する基本処理が完了です。
次回は実際にメッセージを送信してみます。
- 投稿日:2019-04-11T23:12:47+09:00
4/11 javascript 例外処理
- 投稿日:2019-04-11T22:38:53+09:00
インスタンスの外からメソッドを呼ぶ
初投稿です。インスタンスの外からメソッドを呼びたいときがあります。
Vue インスタンスはマウントした要素の
__vue__プロパティにセットされるそうなので、例えば次のようなコンポーネントがあったとき<template> <div id="awesome-element" /> </template> <script> export default { methods: { awesomeMethod () { // ... }, }, } </script>次のようにメソッドを呼ぶことができます。
document.querySelector('#awesome-element').__vue__.awesomeMethod()これがいつ必要になるんだという話ですが、WKWebView とか WebView とかそういう事情があります。
- 投稿日:2019-04-11T22:17:55+09:00
Node.js で Oracle DBのテーブル変更を検知する
TL;DR
データベース変更通知機能 Oracle Database Continuous Query Notification を利用して実現可能。
https://docs.oracle.com/database/121/JJDBC/dbchgnf.htm#JJDBC28815データが変わったことをプログラム側で検知する
データが変わったことを検知する方法は、大きく分けて
PullとPushの2通りが考えられます。
Pullは、クライアントプログラムで一定時間ごとにデータを取得し、データが変わっているかどうかを判定します。主にポーリングと呼ばれます。Pushは、データが変わったことをクライアントプログラムにサーバーから通知してもらう方法です。通知受付用APIやリスナーをクライアント側に用意します。それぞれの良し悪しはありますが、今回はデータ変更の検知スピードが重要視されていたので
Pushで実現方法を検討します。DBサーバーで変更を検知する(TRIGGER) -> 失敗
データの変更といえば
TRIGGERですね。
変更を検知したらクライアントプログラムにHTTPで通知します。CREATE OR REPLACE TRIGGER TRIGGER_HOGE_TABLE AFTER INSERT OR UPDATE OR DELETE ON HOGE_TABLE DECLARE vResponse VARCHAR2(100); v_errcode number; v_errmsg varchar2(100); BEGIN INSERT INTO HOGE (HOGE) VALUES ('start'); vResponse := UTL_HTTP.REQUEST('http://162.168.0.2:3000/fuga'); INSERT INTO HOGE (HOGE) VALUES (vResponse); EXCEPTION WHEN OTHERS THEN v_errcode := sqlcode; v_errmsg := substr(sqlerrm, 1, 100); INSERT INTO HOGE (HOGE) VALUES ('error'); INSERT INTO HOGE (HOGE) VALUES (TO_CHAR(v_errcode)); INSERT INTO HOGE (HOGE) VALUES (v_errmsg); END; /Oracle 11g以降で
UTL_HTTP.REQUESTを使うためには権限が必要です。ORA-29273: HTTP request failed ORA-24247: network access denied by access control list (ACL)BEGIN DBMS_NETWORK_ACL_ADMIN.CREATE_ACL ( ACL => 'NETWORK_ACL_HOGE', DESCRIPTION => 'ACL for REST', PRINCIPAL => 'スキーマ名', IS_GRANT => TRUE, PRIVILEGE => 'connect', START_DATE => NULL, END_DATE => NULL); COMMIT; END; /BEGIN DBMS_NETWORK_ACL_ADMIN.assign_acl ( acl => '/sys/acls/acl_smtp.xml', host => 'ホスト名', lower_port => 3001, upper_port => NULL); END; /BEGIN DBMS_NETWORK_ACL_ADMIN.ADD_PRIVILEGE( acl => 'NETWORK_ACL_1F858DA0B2597454E0538FF412AC543C', principal => 'スキーマ名', is_grant => TRUE, privilege => 'connect'); END; /SELECT * FROM DBA_NETWORK_ACLS; SELECT * FROM DBA_NETWORK_ACL_PRIVILEGES;なんやかんや頑張った挙句、トリガーが発動するタイミングはコミット時ではないということに気付く。
TRIGGERはデータが変わったタイミングで発動するので、その時点ではまだコミットされていない。
クライアントに通知された後でロールバックされると、ピンポンダッシュになる。コミット時にリフレッシュされるMaterialized Viewを使って、無理やり実現することはできたが、どうもにも気持ちが悪い。しかも遅い。
DBサーバーで変更を検知する(CQN) -> 本題
データベース変更通知機能 Oracle Database Continuous Query Notification を利用して実現できそうだったので、これを試してみることにした。
https://docs.oracle.com/database/121/JJDBC/dbchgnf.htm#JJDBC28815まずは権限付与。
GRANT CHANGE NOTIFICATION TO HOGE_SCHEMA;DB側の設定はこれで終わり。
クライアント側から監視対象を登録する形となる。
今回のクライアントプログラムはNode.jsだったので、node-oracledbを利用することになる。https://github.com/oracle/node-oracledb
こちらの記事を参考に…
https://blogs.oracle.com/opal/demo-oracle-database-continuous-query-notification-in-nodejs// Oracle DB const oracledb = require("oracledb"); // Return Object oracledb.outFormat = oracledb.OBJECT; oracledb.fetchAsString = [ oracledb.DATE, oracledb.NUMBER ]; // Continuous Query Notification(CQN) Event Mode oracledb.events = true; // Connection Pooling const pool = await oracledb.createPool({ "user": "HOGE_SCHEMA", "password": "PIYO", "connectString": ` (DESCRIPTION = (ADDRESS_LIST = (ADDRESS = (PROTOCOL = TCP)(HOST = 168.0.0.3)(PORT = 1234)) ) (CONNECT_DATA = (SERVICE_NAME = hogedb) ) ) `, "poolMax": 20, // 最大プール数 "poolMin": 2, // 最小プール数 "poolIncrement": 1, // 足りない場合に増やす数 "poolTimeout": 60, // プールが未使用の場合にクローズするまでの秒数[default:60] 最小プール数は維持される "queueTimeout": 60000 // 接続要求キューで待機している処理のタイムアウト ミリ秒[default:60000 ms] }); // CQN const cqn_con = await pool.getConnection(); await cqn_con.subscribe("hogesub", { "callback": async message => { // 登録解除イベントは処理しない if (!message || !message.type || message.type == oracledb.SUBSCR_EVENT_TYPE_DEREG) { return; } // HOGEのイベント通知 if (message.tables.some(val => val.name == "HOGE_SCHEMA.HOGE")) { // HOGEテーブルを取得して処理する } // FUGAのイベント通知 if (message.tables.some(val => val.name == "HOGE_SCHEMA.FUGA")) { // FUGAテーブルを取得して処理する } // PIYOのイベント通知 if (message.tables.some(val => val.name == "HOGE_SCHEMA.PIYO")) { // PIYOテーブルを取得して処理する } // HOGERAのイベント通知 if (message.tables.some(val => val.name == "HOGE_SCHEMA.HOGERA")) { // HOGERAテーブルを取得して処理する } }, "sql": "SELECT * FROM HOGE WHERE STATUS = 'Use'", "port": 3002, "groupingClass" : oracledb.SUBSCR_GROUPING_CLASS_TIME, "groupingValue" : 1, // 1秒以内の通知はまとめる "groupingType" : oracledb.SUBSCR_GROUPING_TYPE_SUMMARY }); // 監視対象2個目以降 await Promise.all([ cqn_con.subscribe("hogesub", { "sql": "SELECT * FROM FUGA" }), cqn_con.subscribe("hogesub", { "sql": "SELECT * FROM PIYO WHERE STATUS = 'Use'" }), cqn_con.subscribe("hogesub", { "sql": "SELECT ID,SCRIPT_NAME,DESCRIPTION FROM HOGERA WHERE DELETE_FLG = 0" }) ]); : : // プログラム終了時(監視終了) await cqn_con.unsubscribe("hogesub"); await cqn_con.release();これで対象のテーブルに対して変更(コミット)があった場合に通知と処理をすることが出来るようになりました。
しかもかなり早く検知してくれる。監視対象の登録は以下で確認できる。
SELECT * FROM USER_CHANGE_NOTIFICATION_REGS余談
タイムアウトまたは、初回受けたらパージするオプションを入れていない場合、DB側に登録が残り続ける。
プログラム側で解除をするのが正しいが、もし忘れた場合は上のSQLで確認したREGIDを指定して解除する。BEGIN DBMS_CQ_NOTIFICATION.DEREGISTER(21); END;解除する…。いやいや、解除できないんだけど。
ORA-29970: Specified registration id does not exist ORA-06512: at "SYS.DBMS_CHANGE_NOTIFICATION", line 3 ORA-06512: at "SYS.DBMS_CHANGE_NOTIFICATION", line 72 ORA-06512: at line 4Oracleパッチが当たっていないと解除できないらしい。
https://stackoverflow.com/questions/46831869/delete-oracle-change-notificationsREVOKE CHANGE NOTIFICATION FROM HOGE_SCHEMA;権限をはく奪すれば、無事全部消えました。セーフ。
- 投稿日:2019-04-11T22:15:10+09:00
GASでGmailをDiscordに転送できるようにした
はじめに
皆さん、Gmail、使ってますか?
結構な方が使ってると思うのですが、中にはメールチェックをさぼりがちで、ついつい重要な連絡を見過ごしてしまう、という人もいると思います。僕もその一人です。
と、言うわけでそれを解決するソリューション(言ってみたかった)として、Gmailの内容を普段使っているチャットツールに転送出来たらチェック漏れが減るのではないか、と思いGASを使って実際にやってみました。
今回は、その知見をまとめていきたいと思います。DiscordのWebhookを取得する
まず、今回はDiscordを使用したいので、メールを転送するためのDiscordサーバーをさくっと作ります。
そうしたら次に、メールを受け取るためのチャンネルを用意して、下の設定マークのボタンから設定画面に入ります。
Webhooksという項目があるのでそこをクリックして
Webhookを作成をクリックします。
僕は既にGmailという名前で作っているので一個表示されていますね。
出てくる画面で任意の名前を付けると、WebhookのURLが発行されるので保管しておきます。後で使います。
また、このURLにアクセスするとTokenが手に入るのでブラウザでアクセスして取得しておきます。
GASを書く
念のために説明をしておきますと、GASとは
Google Apps Scriptの略で、JavaScriptと似たような言語を使ってGoogleのサービスと連携したりしたツールを作れます。
Googleのサービスと連携するので、当然Gmailも呼び出すことができるわけです。
これはスプレッドシートから編集することができます。
ここのツールというボタンを押して、スクリプトエディタを選択すればスクリプトの編集画面に行きます。
基本は任意の関数を置いて、指定のトリガーでその関数を起動させるという感じです。
では実際にコードを書いていきます。まずDiscordのWebhookにメッセージをPOSTする関数を作ります。
function discord(postMsg){ const webhooks = '取得したURL' const token = '取得したToken'; const channel = 'Discordで投稿するチャンネル名'; const userName = 'Discordで表示する名前'; const parse = 'full'; const methods = 'post'; const payload = { 'token': token, 'channel': '#mails', 'content' : postMsg, 'parse': parse, }; const params = { 'method': methods, 'payload' : payload, 'muteHttpExceptions': true, }; response = UrlFetchApp.fetch(webhooks, params); }次に、Gmailの情報を一定間隔で取得してその内容をDiscord関数に渡して実行する関数を作ります。
function mails(){ var searchQuery = "Gmailで取得したい検索クエリ(例:to(me@gmail.com))"; var dt = new Date(); //メールをチェックする頻度を指定します。短すぎるとGmailの制限に引っかかります。 const checkSpanMinute = 30; dt.setMinutes(dt.getMinutes() - checkSpanMinute); var threads = GmailApp.search(searchQuery); var msgs = GmailApp.getMessagesForThreads(threads); for(var i = 0; i < msgs.length; i++) { var lastMsgDt = threads[i].getLastMessageDate(); if(lastMsgDt.getTime() < dt.getTime()) { break; } for(var j = 0; j < msgs[i].length; j++) { var msgDate = msgs[i][j].getDate(); var msgBody = msgs[i][j].getPlainBody(); var msgFrom = msgs[i][j].getFrom(); var matches = msgFrom.match(/"(.+)".*<(.+)>/) { var subject = msgs[i][j].getSubject(); //取得したデータを最終的に受け取りたいフォーマットに整えます。Discordでは[```]を引用符として使えるので前後に着けています。 var postMsg = "```" + "\n" + Utilities.formatDate(msgDate, 'Asia/Tokyo', 'yyyy/MM/dd hh:mm:ss') + "\n" + "件名:" + subject + "\n" + "[hr]" + msgBody + "```"; discord(postMsg); } } } }こんな感じのスクリプトを書いてあげます。
完成したら一度実行->関数を指定して実行、でmails関数を実行して問題ないか確かめましょう。
トリガーを設定する
編集->現在のプロジェクトのトリガーからトリガーの設定画面に入れます。
トリガーを追加から時間主導型でcheckSpanMinuteで設定したスパンでmails関数を実行するように設定します。これであとはGoogleのサーバーでスクリプトを自動的に実行してくれるようになります。
まとめ
これで、よく使うツールでGmailを取得できるようになりました。
実際に運用してからかなりメールの確認漏れが減りました。
何より、メールの連絡と普段の連絡を同じツールで管理できるというのがQOL高くていい感じです。
皆さんもGASを使って身の回りを少し便利にしてみてはいかがでしょうか?





- 投稿日:2019-04-11T22:06:48+09:00
Qiitaのサイトバグを見つけたのでコード解析 ? 原因見つけて報告 ? 一瞬で修正してくれました!【神対応】
インクリメンツし過ぎてハミ出ちゃいました、的な!
— 無職やめ太郎(本名) (@Yametaro1983) April 11, 2019バグの内容
Qiitaは通知が100件以上になると、「99+」と表示される仕様がありました。
しかし実はそのアルゴリズム、『トレンド画面』しか効いておらず、他の画面では『素の数字』が表示されていたのです。プロフィールや記事ページは100を越えて表示され、それ以外は99+となるみたいですね。 pic.twitter.com/BXVZ8gi2Ds
— std::がっちょ( ¨̮ ) (@wanotaitei) April 11, 2019
他にも、結構通知を貯金されて気づいていらっしゃる方がいたんですね。Qiitaで有名な@suin さんまで・・・
これやりたくなるの分かるw
— suin❄️PHPでオブジェクト指向 (@suin) April 10, 2019
うっかりクリックして貯めた数百が吹き飛ぶ
↓
そっとインスペクタ開く
って流れ、やったなあ… https://t.co/uT7VnWTAu7
JS の丸め処理が評価される前は、そのままの数字が出る。閾値は1000なのかな pic.twitter.com/EGRVZJh0eV
— Enjoy Hacking! (@zaru) April 10, 2019
『13954件ってなんだよ(羨望)(感動)』早速Qiitaのコードを解析してみる
【1/2】トレンド画面
【2/2】それ以外の画面
既に構造が変わっていますね。
特にglobalHeaderなるidが、トレンド画面にしか存在していないのが気になります。
多分セレクタミスをしているのでしょうね。スクリプトを調査するため、Source画面でJSファイルを掘り出してみましょう。
いっぱいありますね!
QiitaはRuby on Railsで作られているので、サーバーが絡んでたら終わりです。
rbファイルとかphpファイルはSourceで確認できないからです。とりあえず望みに賭けて、それっぽいjsファイルを目星付けてみます。
indexの隣にあったり、社名の入ったCDNの中なんかは当たりが多いですね。
qiita用のCDN・・・これが怪しいですね。早速見てみましょう。
セレクタが不明なので、「99+」で検索してみます。
い ま し た
変数名からして、こいつが99%悪さしてそうですね(99+だけに)。
中のコードはmin(最小化)されているので、beautifyして正体を顕にしてあげましょう
使うサイトはこちら⇛ https://beautifier.io/これ?を・・・
こう?します!
変換したらsyntaxの効いているエディタにコピペして、解析を始めてみましょう。
ここの部分ですね。
99<t.unreadNotificationsCount?"99+":t.unreadNotificationsCount
- unreadNotificationsCountが99より大きい場合、"99+”に書き換える。
- それ以外の場合は、unreadNotificationsCountのまま。
この処理が、トレンド画面にしか反映されていないわけです。
トレンド画面以外のページでは、「スキップしている」or「前の処理でエラーを起こしてしまっている」の2パターンが考えられますね。そしたら色々、前の方の条件式を見てみるか・・・
あ り ま し た
やっぱりglobalHeaderじゃないか!
関数の中まで追うまでもなく、このglobalHeaderが存在しないページでは以降の処理に不具合が出る事が想定されますね。
ここまでの検証はパッと5分程でした。Qiitaに報告
Qiitaのお問い合わせからバグを報告してみます。
こういうissue文が一番、プログラマーに文才を求められる瞬間ですね。
読み返すと非常に読みづらい・・・githubでこんなissue文書いたら、弾かれそうですね(笑)結果
2時間で直してくれました。
神対応すぎる、さすがQiita様!Qiita、通知バグなおってた。
— std::がっちょ( ¨̮ ) (@wanotaitei) April 11, 2019
運営さん対応がはやい。 pic.twitter.com/biaju0b1Oxまとめ
全然技術的な話が無くって申し訳ありません。
一番言いたかった事は、そう、冒頭の「Increments株式会社なのにインクリメントの表示処理バグってる(笑)」
この奇跡ともいえるギャグを広めたかっただけです・・・改めて、光速の対応をして頂いたQiita運営様、本当にありがとうございました。
(できれば99+の方ではなく、無制限表示の方が嬉しいです・・・)おまけ
99+じゃなくて、ちゃんとインクリメンツしておくんなはれや、ってことですね!
— 無職やめ太郎(本名) (@Yametaro1983) April 11, 2019
Incrementsだけに!










- 投稿日:2019-04-11T20:41:49+09:00
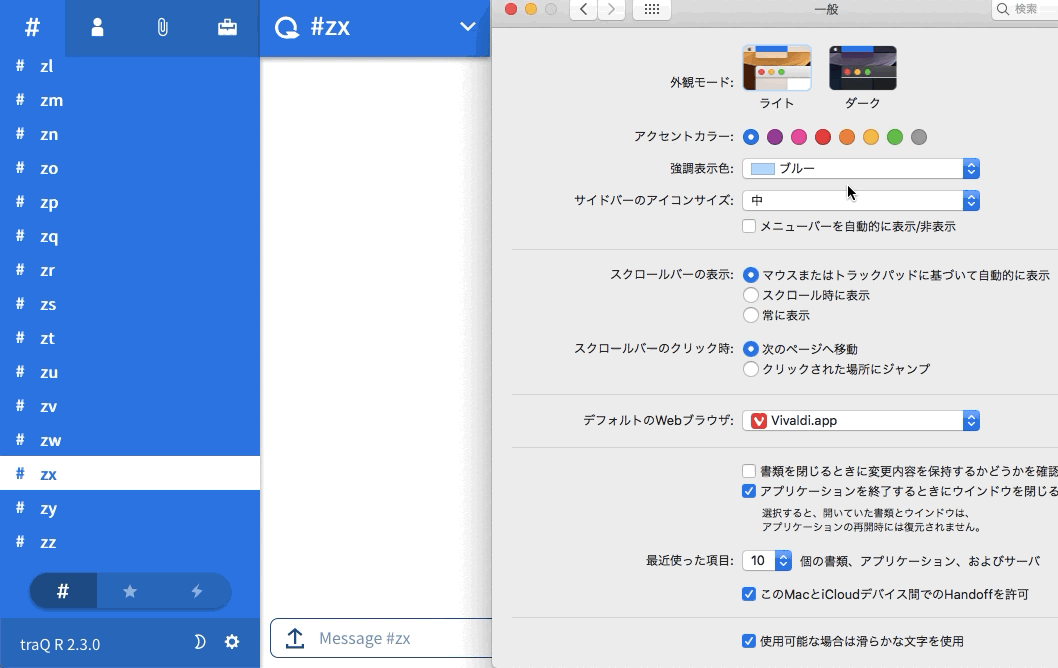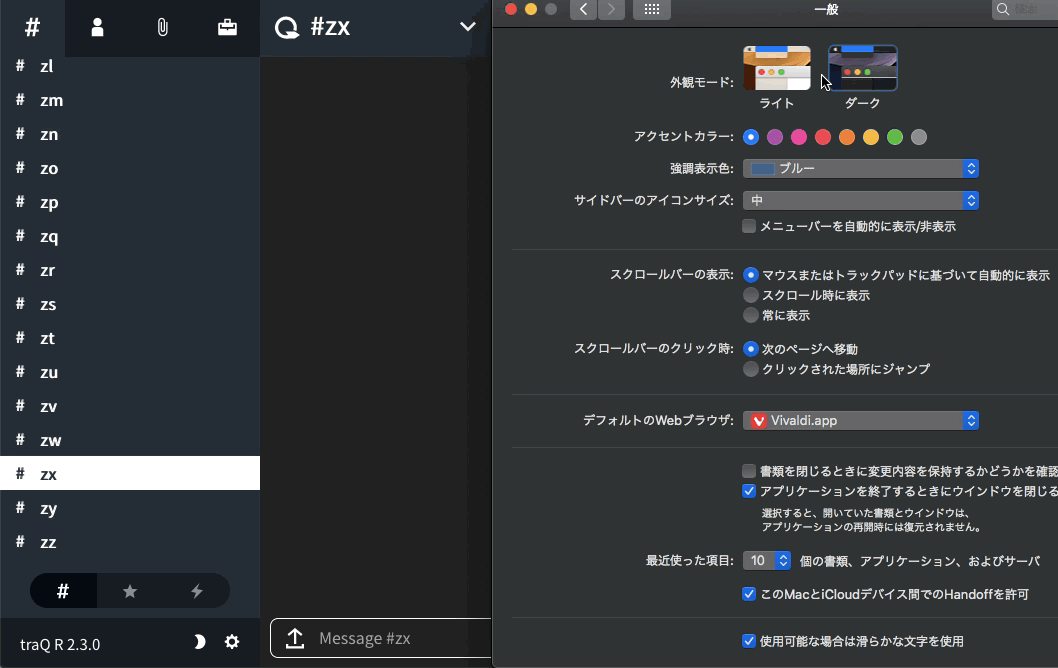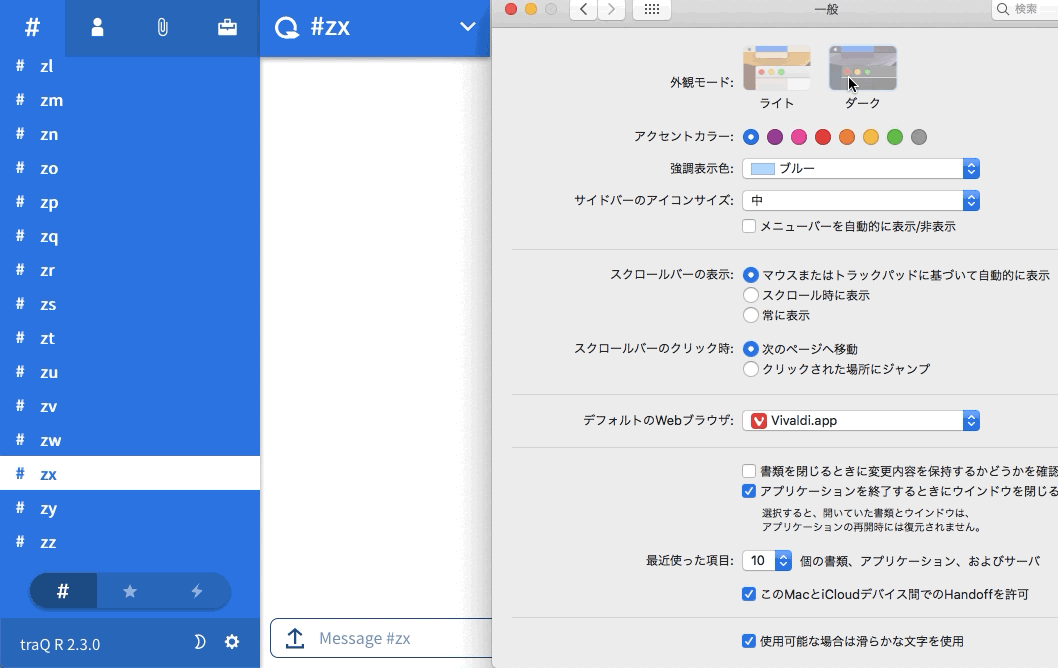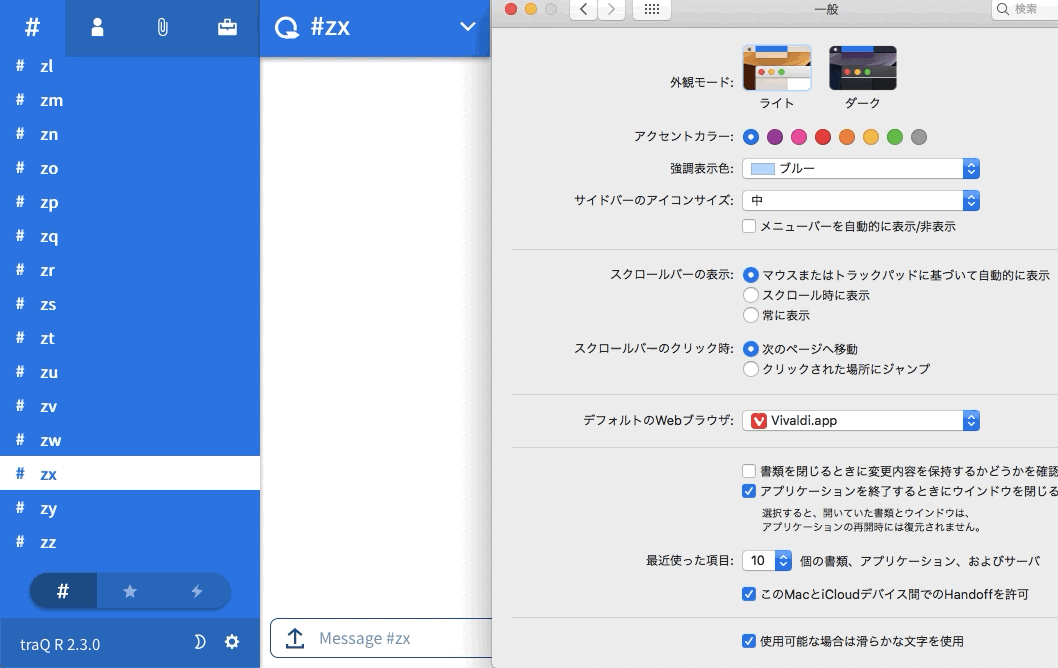
WebアプリでmacOSのテーマ切り替えを取得する方法
macOS Mojaveで画面を目に優しい黒基調にしてくれる「ダークテーマ」が導入されました。
それ以降、設定したテーマに色調を追従させるようなアプリが続々と出てますね。
こうなるとWebアプリやWebサイトもテーマに合わせたくなります。
今回、開発しているWebアプリ(テーマ切り替え機能自体は導入済み)でmacOSテーマに追従しようとして方法を調べたのでまとめます。CSS Media Queryで取得する方法
Media Queryで利用できるメディア特性として、
prefers-color-schemeというものがあります。
これはユーザーが明色か暗色のどちらを求めているかを教えてくれます。
つい先日リリースされたSafari 12.1からデフォルトで有効になっており、Firefoxは67から対応となっています。
Chromeは実装作業中のようです。実際にCSSで表示を切り替えたい場合は以下のようにすれば良いです。
@media (prefers-color-scheme: light) { body { background-color: white; color: black; } } @media (prefers-color-scheme: dark) { body { background-color: black; color: white; } }実際はこんな感じでCSS変数にまとめると各所の色を一括して変更できるのでおすすめです。
@media (prefers-color-scheme: light) { html { --primary-color: black; --background-color: white; } } @media (prefers-color-scheme: dark) { html { --primary-color: white; --background-color: black; } } html { color: var(--primary-color); background-color: var(--background-color); }JavaScriptで取得する方法
初めてテーマを導入する場合は上記のCSSによる切り替えでいいと思います。
ただJavaScriptによるテーマの切り替えと同時に実装したい場合は、現在の状態をJavaScript側で取得する必要があります。
Media Queryでスタイルを切り替えてwindow.getComputedStyleを使って状態を取得する、という方法でも良いです。
が、OSテーマの切り替え時に即座に反応するためにはポーリングしなくてはならなくなり非効率です。そこでテーマの切り替えをイベントで取得するために
window.matchMediaを使います。
window.matchMediaに通常のMedia Queryの文字列をそのまま渡すとMediaQueryListオブジェクトが手に入ります。const mql = window.matchMedia('(prefers-color-scheme: dark)')
MediaQueryListオブジェクトのmatchesプロパティがMedia Queryがマッチしたかどうかを真偽値で持っているので、if (window.matchMedia('(prefers-color-scheme: dark)').matches) { /* ダークテーマの時 */ } else { /* ライトテーマの時 */ }とりあえずこれで状態の取得が可能です。
イベントを受け取るためには次のようにします。
// ダークテーマの時にマッチするMediaQueryListオブジェクト const isDark = window.matchMedia('(prefers-color-scheme: dark)') // コールバック関数はMediaQueryListオブジェクトを受け取る function toggleTheme (mql) { if (mql.matches) { /* ダークテーマの時 */ } else { /* ライトテーマの時 */ } } // イベントリスナーを追加 isDark.addListener(toggleTheme)テーマを切り替えるたびに
toggleTheme関数が呼ばれ、マッチ状態に応じてテーマの切り替え処理を実行することができます。今回私が書いた環境のVue.js+Vuexだとこんな感じです。
export default { name: 'app', methods: { toggleTheme(mql) { if (mql.matches) { this.$store.commit('updateTheme', 'dark') } else { this.$store.commit('updateTheme', 'light') } } }, mounted() { this.$nextTick(() => { const isDark = window.matchMedia('(prefers-color-scheme: dark)') isDark.addListener(this.toggleTheme) }) } }これでどんな感じのテーマ機能が実装できるか置いておきます。
左下の月のアイコンがテーマのトグルボタンですが、JavaScript側にも状態が反映されていることがわかると思います。
- 投稿日:2019-04-11T19:18:05+09:00
Ajaxでテキストをgzipして他のパラメータと一緒にPOSTするテスト
クライアント側でgzipをした後、バイナリで送信してみた。
gzipはこちらを使用してみる
https://www.npmjs.com/package/zlibjsバイナリはファイルとして送信するといいらしい。
クライアント(javascript)let a = "クライアント側でgzipをした後、バイナリで送信してみた。"; console.log("元データ:"+encodeURIComponent(a).replace(/%../g,"x").length+"Bytes"); var gzip = new Zlib.Gzip(unicode2utf8_uint8array(a)); var compressed = gzip.compress(); console.log("圧縮:"+compressed.length+"Bytes"); let fd = new FormData(); fd.append('hoge', "aaa"); fd.append('hoge2', "bbb"); fd.append('hoge3', new Blob([compressed], {type: "application/octet-binary"})); $.ajax({url: "https://xxxx.com/hoge.php", type: "POST", contentType:false, processData: false, cache: false, data: fd, }).then(function(data, textStatus, jqXHR) { alert(data); },function(jqXHR, textStatus, errorThrown) {}); }unicode2utf8_uint8arrayは、https://qiita.com/ukyo/items/1626defd020b2157e6bfから。
ありがとうございます!送信後は、サーバーにファイルとして保存されている。
サーバー側(PHP)header('Content-Type: text/html; charset=UTF-8'); header("Access-Control-Allow-Origin: *"); echo "hoge:".$_POST["hoge"]; echo "hoge2:".$_POST["hoge2"]; var_dump($_FILES["hoge3"]); echo "[". gzdecode(file_get_contents($_FILES["hoge3"]["tmp_name"])) ."]";テスト結果元データ:82Bytes 圧縮:98Bytes hoge:aaa hoge2:bbb array(5) { ["name"]=> string(4) "blob" ["type"]=> string(24) "application/octet-binary" ["tmp_name"]=> string(14) "/tmp/phpHlyZxg" ["error"]=> int(0) ["size"]=> int(98) } [ クライアント側でgzipをした後、バイナリで送信してみた。 ]普通のパラメータとバイナリが一緒に送られていますね。
gzip後のサイズと送信後に受け取ったサイトが同じなので、そのまま送られているはず。たぶん。よく見ると圧縮後のサイズが増えとるよ…
送信前にバイト数を確認して、そのまま送るか圧縮するか判断するべきですね。
- 投稿日:2019-04-11T18:04:26+09:00
Apollo+Expressで始めるGraphQL超入門 ~ データ取得Lv1
あらすじ
1.Apollo+Expressで始めるGraphQL超入門 ~ GraphQLをざっくり理解する
はじめに
前回の続きをやっていきます。
そのため使用するソースや環境構築は あらすじ を参照してくだい。今回はデータの取得について色々書いていこうと思います。
※ 筆者はまだまだ初心者です。間違った解釈や実装などがあればご指摘お願いします。
Select
GraphQLは、必要なときに必要なものを取得することできます。
いらないデータは指定しなければ取得されません。type User { id: Int name: String age: Int created_date: String }
Userに対してidとnameがあればOKであればクエリにそう書きましょう。{ users { id name } }SQLのSELECTみたいな感じですね。
Limit
実装
app.jsconst typeDefs = gql` type User { id: Int name: String age: Int created_date: String } type Query { - users: [User] + users(limit: Int): [User] } `;
typeDefsのQueryのusersに対して引数を設定します。
limitは数字がくるように設定しました。app.jsconst resolvers = { Query: { - users: () => users + users: (parent, args) => { + let result = users; + let limit = args.limit || null; + + if (limit) { + result = result.slice(0, limit); + } + + return result + } } };
resolversのQueryに引数が渡るように設定しました。
argsに引数が代入されます。
あとは、渡されたlimitの数字に沿って処理を行うだけです。※ コードの書き足しを行ったらnodeタスクを再起動してください
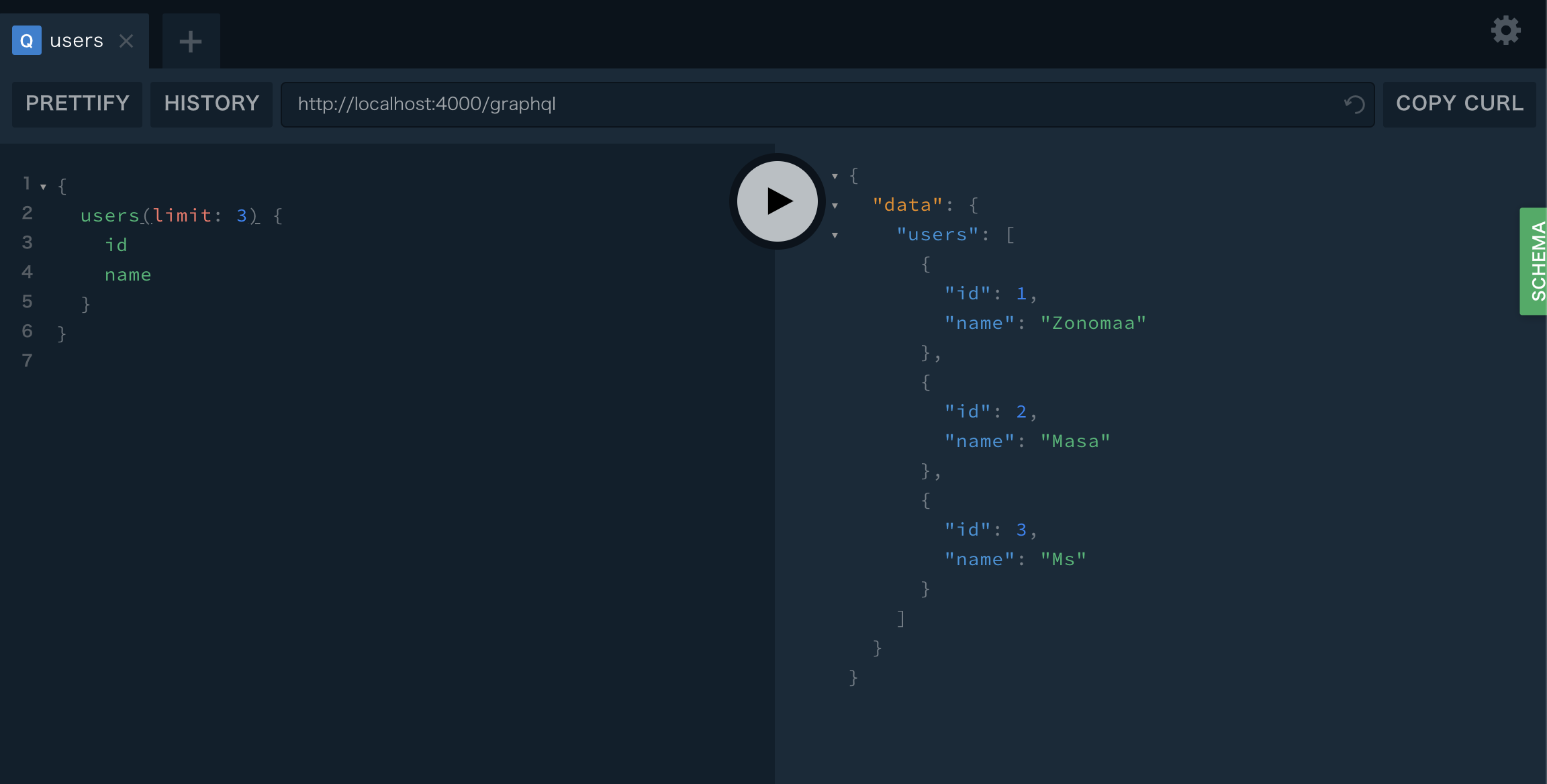
実行
{ users(limit: 3) { id name } }
Limit Done!
Sort
Usersを年齢でソートかけてみましょう。年齢の降順、昇順が行えるように設定します。
実装
app.jsconst typeDefs = gql` type User { id: Int name: String age: Int created_date: String } type Query { users: [User] - users(limit: Int): [User] + users(limit: Int, age_sort:String): [User] } `;
age_sortという引数を足しました。String型でDESCか、ASCが指定される想定です。app.jsconst resolvers = { Query: { users: () => users users: (parent, args) => { let result = users; let limit = args.limit || null; + let age_sort = args.age_sort || ""; + + if (age_sort) { + const ope = age_sort === 'ASC' ? 1 : -1; + result = users.sort((x, y) => { + if (x['age'] > y['age']) return ope; + if (x['age'] < y['age']) return -(ope); + return 0; + }) + } if (limit) { result = result.slice(0, limit); } return result } } };これで年齢ソートができるようになります。
しかし、age_sortの引数に
DESC,ASC以外の文字列が設定されたらどうでしょう。
正しく処理が行えなくなってしまいます。そこで新しい概念として
enumを使ってみましょう。enum とは TypeScriptで例えるとわかりやすいのですが
age_sort: "DESC" | "ASC";指定した文字列のみに制限することができます!
enumの場合だとこのような書き方となります。
enum SortOP { ASC DESC }指定したい文字列が決まっている場合は
enumを使ったほうが圧倒的にわかりやすくメンテしやすいコードになりますので、
こちらを使うことをおすすめします。それでは
enumで実装し直してみます。const typeDefs = gql` type User { id: Int name: String age: Int created_date: String } + enum SortOP { + ASC + DESC + } type Query { - users(limit: Int, age_sort:String): [User] + users(limit: Int, age_sort:SortOP): [User] } `;これで
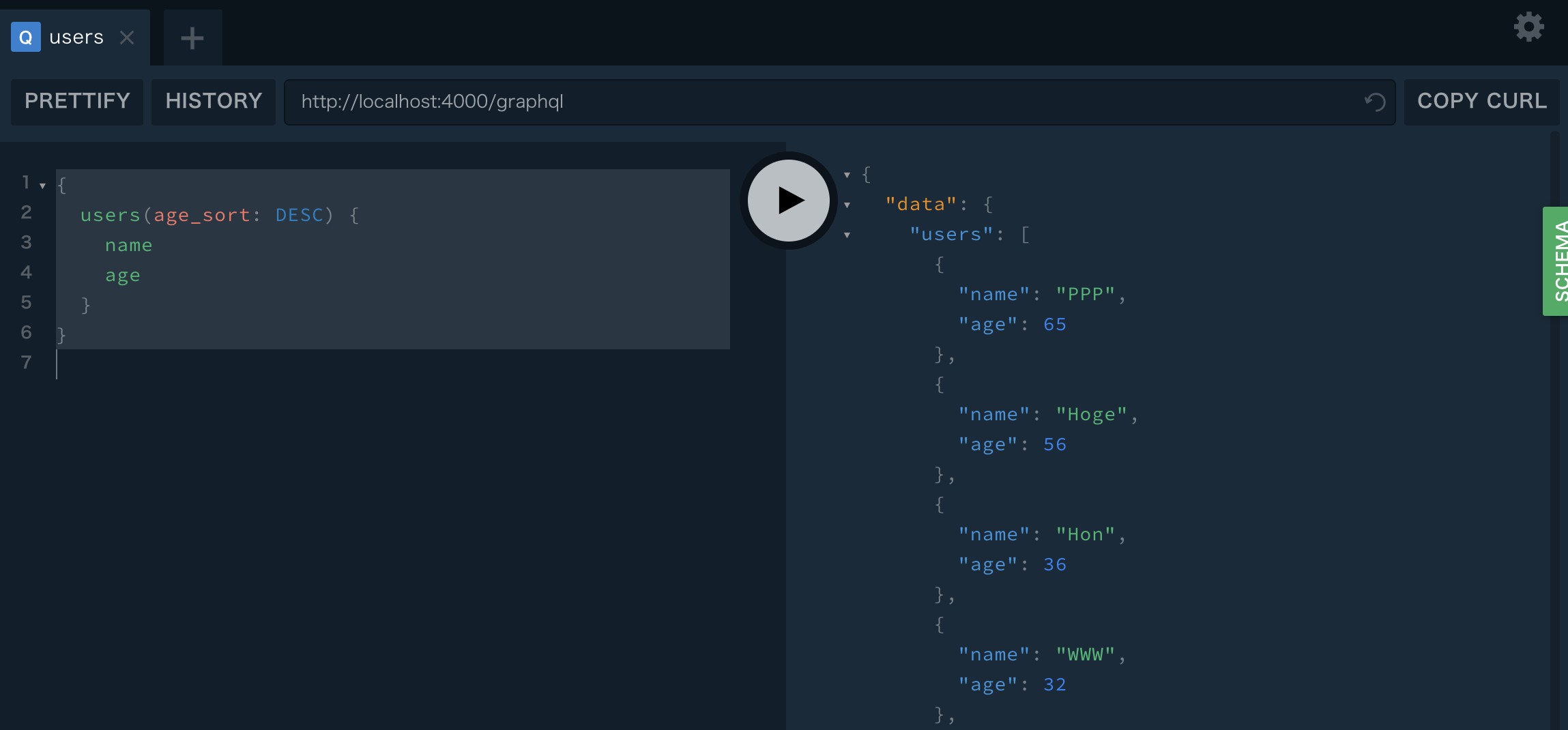
age_sortにはASC,DESCが設定されるように型定義しました。実行
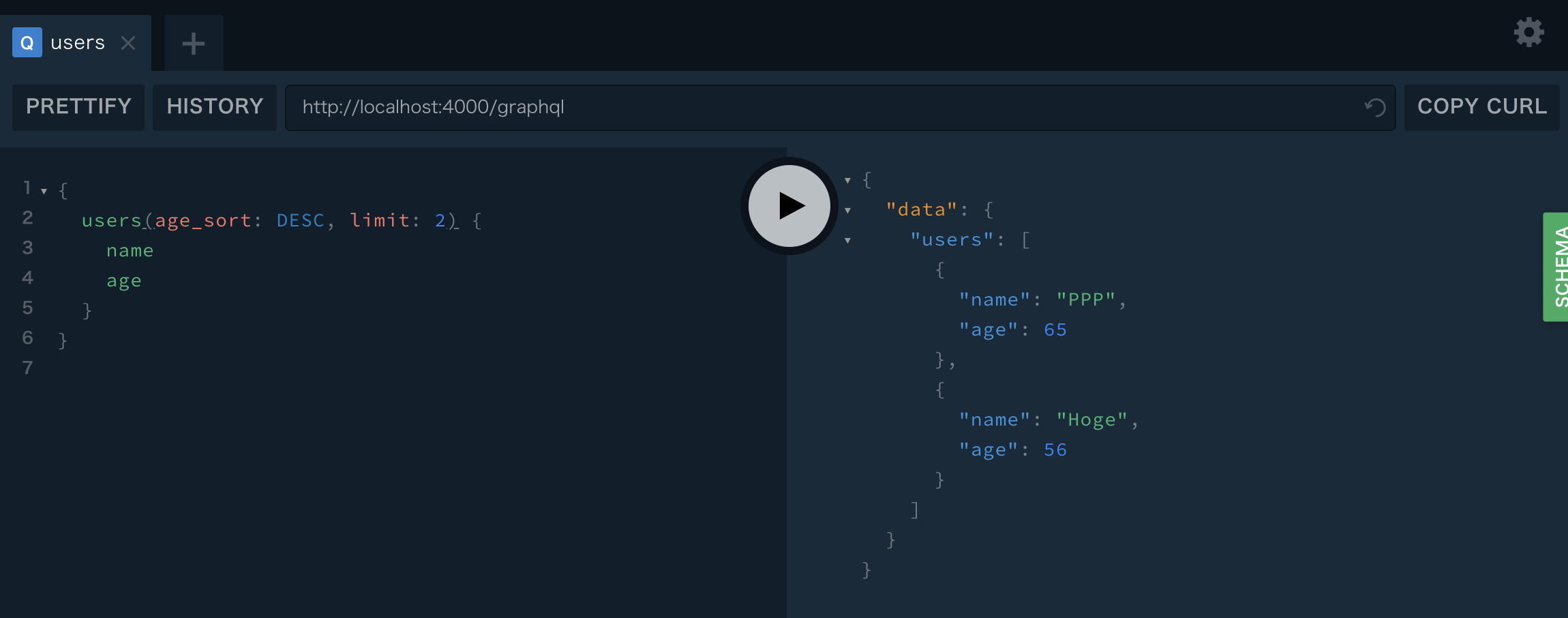
{ users(age_sort: DESC) { name age } }
ソートすることができました。
Sort & Limit
もちろん、SortとLimitを組み合わせて使うこともできます。
{ users(age_sort: DESC, limit: 2) { name age } }
まとめ
簡単な取得系処理を実装してみました。
実際にやってみると、すごく自由度が高いという感想と、処理を足していくうちにどんどん肥大化していくんじゃないか?などいろいろと思うことがありました。
その部分を解消できる方法も調べてみたいと思います。次回もう少し難易度を上げた データ取得Lv2 に続きます! (予定)
- 投稿日:2019-04-11T17:32:31+09:00
javscript の matchMediaをaddListnerで呼び出した際の挙動について
javascript (with jQuery)で下記を書き、ページをロード後リサイズすると、
addClass('className')removeClass('className')は期待通り、サイズによってクラスの追加削除ができるのですが、
hover()については、ページロード時の挙動がリサイズ後も引き継がれます。「リサイズがかかるごとに、if文を見に行っている」=「リサイズのごとに hoverの挙動もそのたび適応され直す」
のかと思ったのですが、overwriteなのですね。。。mqFunc = function(mql) { if (mql.matches) { $('body').addClass('className'); $('header .item').hover(function() { $(this).css('width', '2em') }, function() { $(this).css('width', '') }); } else { $('body').removeClass('className'); } } const mql = window.matchMedia('(max-width: 720px)'); mqFunc(mql); mql.addListener(mqFunc);
- 投稿日:2019-04-11T17:12:45+09:00
【2019年4月版】NativeScript+Angularで新時代を感じた
NativeScript でハイブリッドアプリの開発に入門してみました。
ちょっと興奮冷めやらぬ感じですが、NativeScript で Angular のサンプルを Android で動かしてみたらこれはもうもってかれた感すごかったのでご紹介いたします。(語彙力)
対象環境
- PC: Windows 10 Pro
- スマホ: Android
- IDE: VSCode
今回は Android スマホで動作確認しましたが、たぶん iOS も同様の手順で大丈夫かと思います。
また、環境構築で例によって管理者権限でコマンドプロンプトを実行する必要あります。NativeScript の環境構築
管理者権限でコマンドプロンプトを立ち上げ、以下のコマンドを叩きます。
> @powershell -NoProfile -ExecutionPolicy Bypass -Command "iex ((new-object net.webclient).DownloadString('https://www.nativescript.org/setup/win'))"インストールの確認が出るので適宜
yを指定してください。めんどくさい場合はaを指定して都度の確認をスキップできます。
最後のAVDの確認だけは別途、yが必要でした。
上記のスクリプトで事前に必要な環境はすべてインストールしてくれるはずです。(あら便利。。。)いったんコマンドプロンプトを終了し、再度、管理者権限でコマンドプロンプトを立ち上げます。
以下のコマンドで、NativeScript本体のインストールを行います。> npm i -g nativescript > tns doctor
tnsコマンドが見つからない旨のエラーが発生した場合はコマンドプロンプトを再度立ち上げなおしてみてください。
tns doctorで必要な環境が整っているかチェックしてくれます。とくに文句がないようであればVSCodeを立ち上げてさっそく開発モードに入りましょう。Angular でのサンプルプロジェクトの作成
VSCodeのターミナルを起動し、以下のコマンドでさっそく最初のNativeScrit+Angular アプリを作成しましょう!
$ tns create my-angular-app --ngプロジェクト作成時に「匿名の使用状況送信していいですか~?」って聞かれるので
nとしておきます。プロジェクトが作成し終わったら表示されるご案内の通りに以下のコマンドを入力します。
$ cd my-angular-app $ tns previewしばらくすると・・・で、でっかいQRコードが表示されました?!
マジすか?w
ただし、ご案内をよく読むと "NativeScript Playgroud アプリをインストールしてね!" ってことなので、渋々従います。(以降、私は Android 版をダウンロードして確認してますが、iOSでも同様かと思います。)
GoogleのストアからNativeScriptを検索して
NativeScript Playgroudアプリをインストール(・・・自分で検索しなきゃダメなの?)
しばらくしてダウンロードが終わり、NativeScript PlaygroudアプリからQRコードを読み込ませると、"NativeScript Preview App を入れてね!"と案内が出ます。(いや、先に言えってw)渋々従います。再び、Googleのストアから
NativeScript Previewアプリをインストールします。しばらくして、ダウンロードが終わると勝手に何かが立ち上がり・・・
ん??なんか出た?
最初は意味が分かりませんでしたが・・・
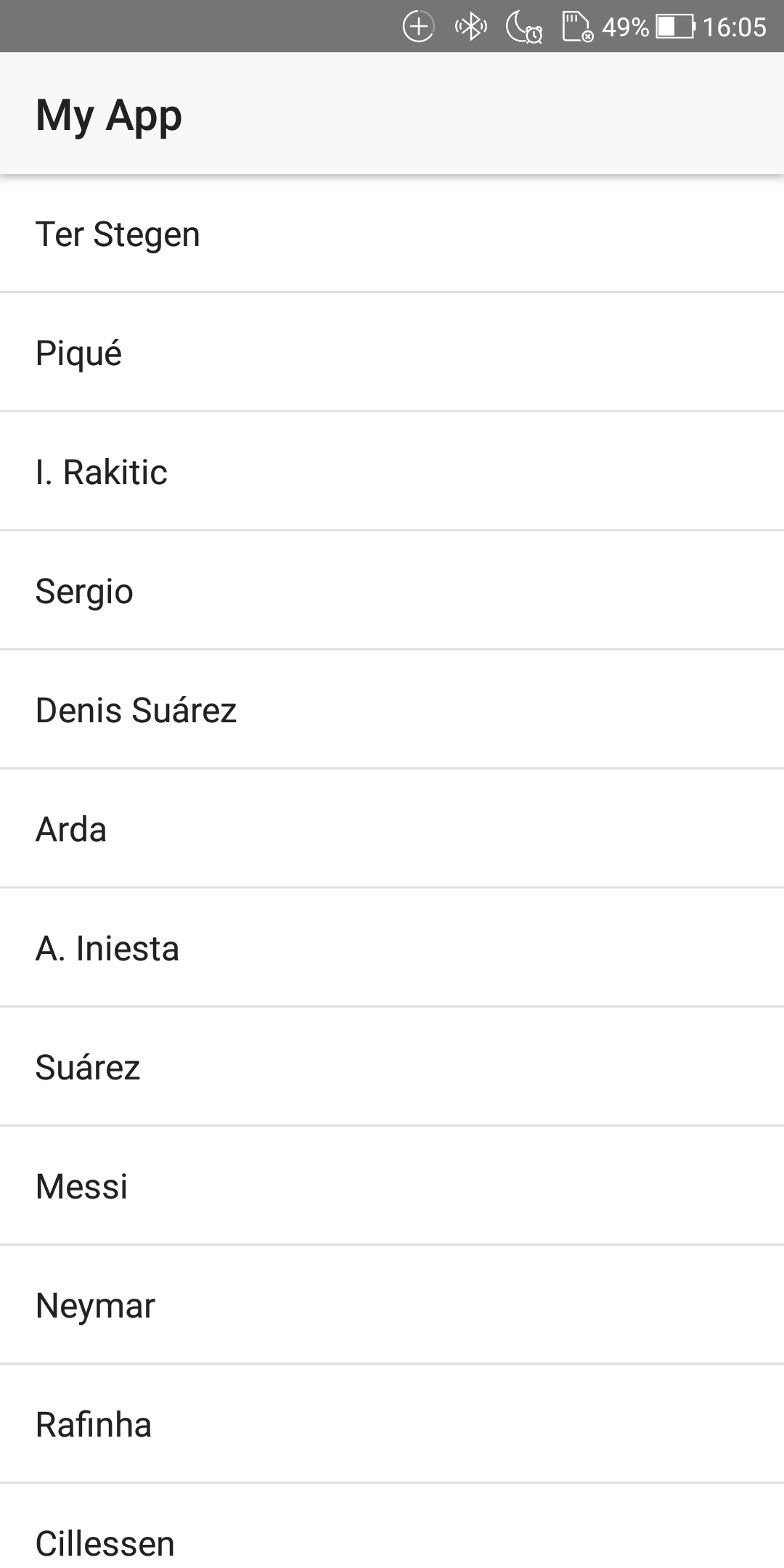
しばらくして、以下のコードを発見しました。
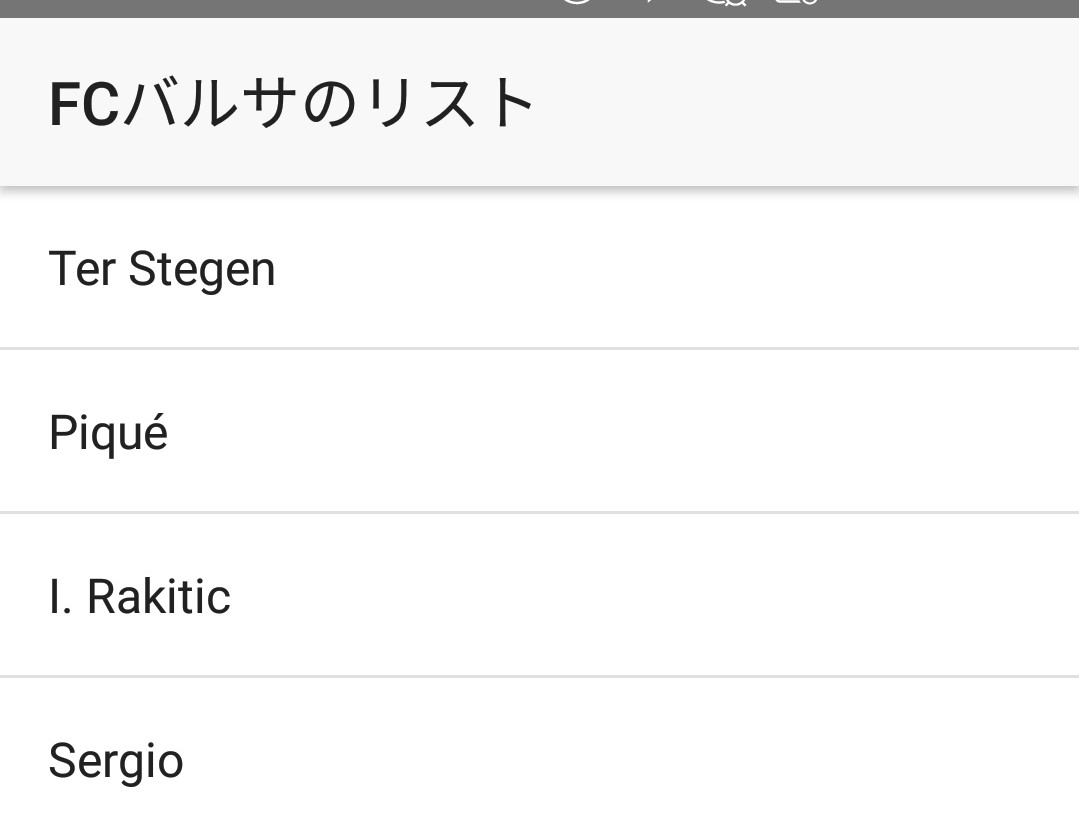
function ItemService() { this.items = new Array( { id: 1, name: 'Ter Stegen', role: 'Goalkeeper' }, { id: 3, name: 'Piqué', role: 'Defender' }, { id: 4, name: 'I. Rakitic', role: 'Midfielder' }, { id: 5, name: 'Sergio', role: 'Midfielder' }, { id: 6, name: 'Denis Suárez', role: 'Midfielder' }, { id: 7, name: 'Arda', role: 'Midfielder' }, ...え・・・ウソ。。。このリストが自分のスマホに出てる・・・?
半信半疑で以下のようにリストを変えてみます。
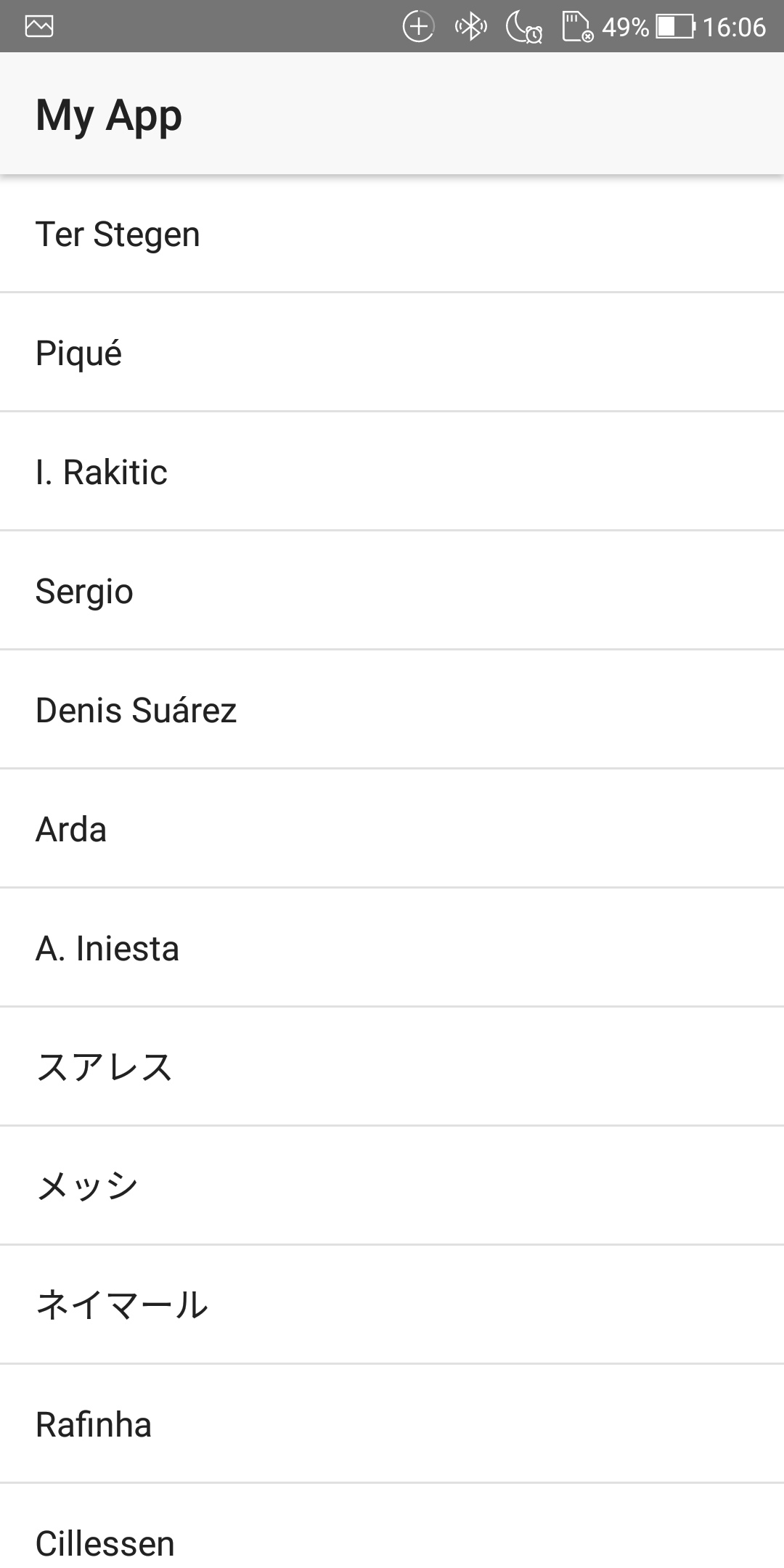
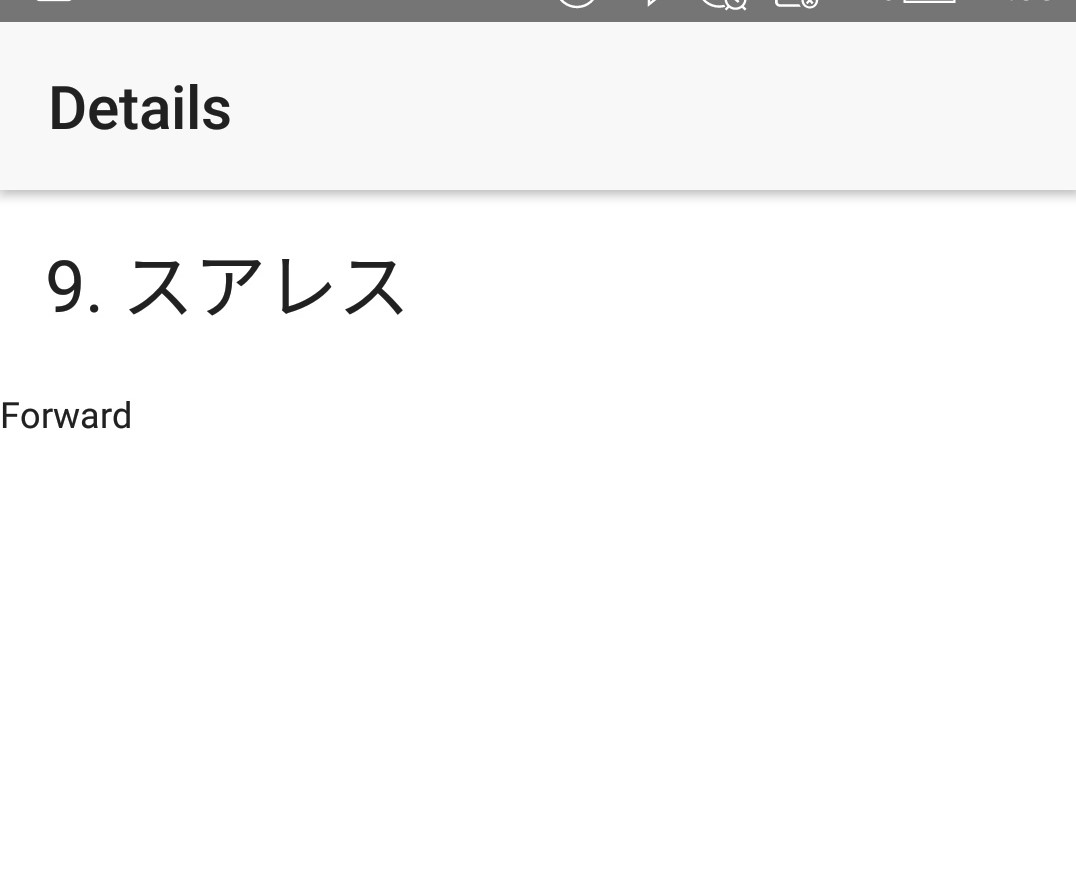
item.service.ts... { id: 7, name: 'Arda', role: 'Midfielder' }, { id: 8, name: 'A. Iniesta', role: 'Midfielder' }, { id: 9, name: 'スアレス', role: 'Forward' }, { id: 10, name: 'メッシ', role: 'Forward' }, { id: 11, name: 'ネイマール', role: 'Forward' }, { id: 12, name: 'Rafinha', role: 'Midfielder' }, { id: 13, name: 'Cillessen', role: 'Goalkeeper' }, ...
Ctrl+Sでファイルを保存すると・・・
直ちにAndroid側のPreviewアプリが勝手に再起動?し・・・
変わってるーーーーーーーーーーーーー!!!!!w
えっ?!ちょっ!?ナニコレ!?試しに
スアレスをタップしてみると・・・
しょ・・・詳細画面、出てる!!!
何回か試しましたが、PC画面でVSCodeでリストを更新し
Ctrl+Sをすると、手元のAndroidのPreviewアプリに即座に反映されます。。。ビュー側の更新も・・・
items.component.html<ActionBar title="FCバルサのリスト" class="action-bar"> </ActionBar>
Ctrl+Sで、ポンっと!
こちらはアプリの再起動なしで、表示がアップデートされてます。。。
なんか、完全に新時代来ちゃってるわ・・・よし!と、とりあえずこの興奮をQiitaにぶん投げておこう!(←イマココ)
というわけで引き続きいろいろ試してみたいと思います!!
本家サイトのセットアップ手順について
以下の本家サイトにWindowsでのセットアップ手順が書かれていましたが・・・
- https://docs.nativescript.org/angular/start/ns-setup-win最終的には、というか手順の途中で必要なsetupスクリプトが
404になっていました。
そこでgithubのsetup-scriptをリポジトリを確認してみると・・・
- https://github.com/NativeScript/setup-scripts実際のスクリプトは以下ですが、なにやら
Chocolateyやgooglechromeもインストールしています。
https://github.com/NativeScript/setup-scripts/blob/master/native-script.ps1これはセットアップ手順に書いてあった
Prerequiresそのまんまじゃないですかー。
README.md にfor Windows: @powershell -NoProfile -ExecutionPolicy Bypass -Command "iex ((new-object net.webclient).DownloadString('https://www.nativescript.org/setup/win'))"
とありますので、はい・・・これでOKよ、ということらしいです。
iOSもここにrubyのスクリプトがありますのでサクッとインストールできるかと思います。
それでは、実験に戻りたいと思います!
- 投稿日:2019-04-11T17:12:45+09:00
【2019年4月版】NativeScript+Angularで感じた新時代
NativeScript でハイブリッドアプリの開発に入門してみました。
ちょっと興奮冷めやらぬ感じですが、NativeScript で Angular のサンプルを Android で動かしてみたらこれはもうもってかれた感すごかったのでご紹介いたします。(語彙力)
対象環境
- PC: Windows 10 Pro
- スマホ: Android
- IDE: VSCode
今回は Android スマホで動作確認しましたが、たぶん iOS も同様の手順で大丈夫かと思います。
また、環境構築で例によって管理者権限でコマンドプロンプトを実行する必要あります。NativeScript の環境構築
管理者権限でコマンドプロンプトを立ち上げ、以下のコマンドを叩きます。
> @powershell -NoProfile -ExecutionPolicy Bypass -Command "iex ((new-object net.webclient).DownloadString('https://www.nativescript.org/setup/win'))"インストールの確認が出るので適宜
yを指定してください。めんどくさい場合はaを指定して都度の確認をスキップできます。
最後のAVDの確認だけは別途、yが必要でした。
上記のスクリプトで事前に必要な環境はすべてインストールしてくれるはずです。(あら便利。。。)いったんコマンドプロンプトを終了し、再度、管理者権限でコマンドプロンプトを立ち上げます。
以下のコマンドで、NativeScript本体のインストールを行います。> npm i -g nativescript > tns doctor
tnsコマンドが見つからない旨のエラーが発生した場合はコマンドプロンプトを再度立ち上げなおしてみてください。
tns doctorで必要な環境が整っているかチェックしてくれます。とくに文句がないようであればVSCodeを立ち上げてさっそく開発モードに入りましょう。Angular でのサンプルプロジェクトの作成
VSCodeのターミナルを起動し、以下のコマンドでさっそく最初のNativeScrit+Angular アプリを作成しましょう!
$ tns create my-angular-app --ngプロジェクト作成時に「匿名の使用状況送信していいですか~?」って聞かれるので
nとしておきます。プロジェクトが作成し終わったら表示されるご案内の通りに以下のコマンドを入力します。
$ cd my-angular-app $ tns previewしばらくすると・・・で、でっかいQRコードが表示されました?!
マジすか?w
ただし、ご案内をよく読むと "NativeScript Playgroud アプリをインストールしてね!" ってことなので、渋々従います。(以降、私は Android 版をダウンロードして確認してますが、iOSでも同様かと思います。)
GoogleのストアからNativeScriptを検索して
NativeScript Playgroudアプリをインストール(・・・自分で検索しなきゃダメなの?)
しばらくしてダウンロードが終わり、NativeScript PlaygroudアプリからQRコードを読み込ませると、"NativeScript Preview App を入れてね!"と案内が出ます。(いや、先に言えってw)渋々従います。再び、Googleのストアから
NativeScript Previewアプリをインストールします。しばらくして、ダウンロードが終わると勝手に何かが立ち上がり・・・
ん??なんか出た?
最初は意味が分かりませんでしたが・・・
しばらくして、以下のコードを発見しました。
function ItemService() { this.items = new Array( { id: 1, name: 'Ter Stegen', role: 'Goalkeeper' }, { id: 3, name: 'Piqué', role: 'Defender' }, { id: 4, name: 'I. Rakitic', role: 'Midfielder' }, { id: 5, name: 'Sergio', role: 'Midfielder' }, { id: 6, name: 'Denis Suárez', role: 'Midfielder' }, { id: 7, name: 'Arda', role: 'Midfielder' }, ...え・・・ウソ。。。このリストが自分のスマホに出てる・・・?
半信半疑で以下のようにリストを変えてみます。
item.service.ts... { id: 7, name: 'Arda', role: 'Midfielder' }, { id: 8, name: 'A. Iniesta', role: 'Midfielder' }, { id: 9, name: 'スアレス', role: 'Forward' }, { id: 10, name: 'メッシ', role: 'Forward' }, { id: 11, name: 'ネイマール', role: 'Forward' }, { id: 12, name: 'Rafinha', role: 'Midfielder' }, { id: 13, name: 'Cillessen', role: 'Goalkeeper' }, ...
Ctrl+Sでファイルを保存すると・・・
直ちにAndroid側のPreviewアプリが勝手に再起動?し・・・
変わってるーーーーーーーーーーーーー!!!!!w
えっ?!ちょっ!?ナニコレ!?試しに
スアレスをタップしてみると・・・
しょ・・・詳細画面、出てる!!!
何回か試しましたが、PC画面でVSCodeでリストを更新し
Ctrl+Sをすると、手元のAndroidのPreviewアプリに即座に反映されます。。。ビュー側の更新も・・・
items.component.html<ActionBar title="FCバルサのリスト" class="action-bar"> </ActionBar>
Ctrl+Sで、ポンっと!
こちらはアプリの再起動なしで、表示がアップデートされてます。。。
なんか、完全に新時代来ちゃってるわ・・・よし!と、とりあえずこの興奮をQiitaにぶん投げておこう!(←イマココ)
というわけで引き続きいろいろ試してみたいと思います!!
本家サイトのセットアップ手順について
以下の本家サイトにWindowsでのセットアップ手順が書かれていましたが・・・
- https://docs.nativescript.org/angular/start/ns-setup-win最終的には、というか手順の途中で必要なsetupスクリプトが
404になっていました。
そこでgithubのsetup-scriptをリポジトリを確認してみると・・・
- https://github.com/NativeScript/setup-scripts実際のスクリプトは以下ですが、なにやら
Chocolateyやgooglechromeもインストールしています。
https://github.com/NativeScript/setup-scripts/blob/master/native-script.ps1これはセットアップ手順に書いてあった
Prerequiresそのまんまじゃないですかー。
README.md にfor Windows: @powershell -NoProfile -ExecutionPolicy Bypass -Command "iex ((new-object net.webclient).DownloadString('https://www.nativescript.org/setup/win'))"
とありますので、はい・・・これでOKよ、ということらしいです。
iOSもここにrubyのスクリプトがありますのでサクッとインストールできるかと思います。
それでは、実験に戻りたいと思います!
ビルドの手順について追記
Playgroundアプリで遊んだだけではダメなので、ちゃんとパッケージとしてビルドしましょう。
はい、以下のコマンドです。
$ tns build androidもしくは、
$ tns build iosで、
my-angular-app\platforms\android\app\build\outputs\apk\debug\app-debug.apkが出力されます。なんか・・・いろいろ、大変だったのになぁ。。。
ここで紹介した
tnsコマンドの使い方は以下のnpmサイトに載っています。いや、ホント、進化してるのね・・・
- 投稿日:2019-04-11T15:25:31+09:00
独学でプログラミングを学んでいる僕が使っているUdemy教材
テスターやネットワークのエンジニアとしての傍ら、12月よりプログラミングの独学を始めた僕が使っている教材について書いていこうと思う。僕が使っている教材について書いてきます。
その前に、独学よりプログラミングスクール行けばいいじゃんって言う人に向けて僕が何故独学しているのかを記しておこう。(1)お金がない
色々音楽機材を買いすぎてお金がなかった(笑)今でも毎月5,6万円ほど払っています(笑)エンジニアとしてお金稼ぎます‼
(2)仮に通ってもどうせ独学しなければいけない気がした。
「ruby使ってtwitterに似たアプリ作ります!」位のレベル感で50万円近く払うのって結構自分的には嫌だったんだよね。
色々サービスがあるのに、勉強する環境を構築するのにここまでお金を支払う必要性があるのかと感じたっていう所がでかい。
何回かプログラミングスクールの説明会に行って、ここに金使うならこの分教材買って独学したら最強だなってなりましたよね。
— しげにぃ@エンジニア (@ShigenoEngineer) 2019年3月16日
+この前の日曜日プログラミングスクールの説明会に行ったんだけど、「rubyでtwitterっぽいアプリとかなら、独学でやれば良いのでは?」ってなったんだよな〜
— しげにぃ@エンジニア (@ShigenoEngineer) 2019年2月28日やってきた・やっている教材
(1)【世界で30万人が受講】フルスタック・Webエンジニア講座(2017最新版)
https://www.udemy.com/share/1000IwBEYSd1dXRng=/HTML5,CSS3,Javascript,jQuery,Bootstrap4,Wordpress,PHP,MySQL,API,モバイルアプリ,Pythonなど結構詰め込んでいる。
PCに環境を構築するためとか、プログラミングについての基本的な考え方について学ぶためには良いと思います。
文系出身の僕には関数とか何で使うかちょっと理解できない所あったけど、JS,PHP,Pythonで何回か説明されるうちに分かるようになってきたところあるし。一方で、様々な分野を取り上げている弊害と言えますが、深く学ぶ分にはおススメ出来ないです。それぞれについてのUdemy教材を買うか、書籍を買っていきましょう!(2)【JavaScript】作って覚える!未経験者が一流WEBエンジニアになる為のノウハウを完全網羅!
https://www.udemy.com/share/100ddoBEYSd1dXRng=/Javascriptについて。簡単なアプリプリ作成まで書いてあるので、初心者の方にとっては良いと思う。パーと一通り流し見して、後はオリジナルアプリ制作とか模倣みたいな感じで良いのでは。
(3)Learn to Program in Javascript: Beginner to Pro
https://www.udemy.com/share/1004oqBEYSd1dXRng=/言語Javascript。英語教材、無料で購入した覚えがある。プログラミング自体英語だし、英語の方がテンポ感あって、無駄がなくて良いよね、と感じることはまれにあります。
(4)手を動かしながら2週間で学ぶ AWS 基本から応用まで
https://www.udemy.com/share/100taiBEYSd1dXRng=/
今勉強している。(5)【最短30分でできる!】Laravel5.7入門: 初心者でも簡単! ブラウザだけでLaravelを使ったWeb開発!
https://www.udemy.com/share/100wDkBEYSd1dXRng=/
Larabelに興味あって、無料だったので、視聴。Paiza Cloud上でやっているから、別途環境構築は必要だけど、MVCを理解するのには、講座自体の時間も短いし良い気がする。(6)実践Webサイトコーディング講座 | HTML5とCSS3を使って、カフェのサイトやWebメディアサイトを作ってみよう
https://www.udemy.com/share/1005eiBEYSd1dXRng=/
HTMLとCSSについて。photoshopを適宜使ってデザインを構築しているので、Webエンジニア向けというより、Webデザイナー入門といった感じの講座。初学者の段階では良いかも。講座に関しては、繰り返し説明している所が多々あるので、冗長に感じる人もいるかもしれない。(7)ゼロからはじめる Dockerによるアプリケーション実行環境構築
https://www.udemy.com/share/100gMSBEYSd1dXRng=/(8)フロントエンドエンジニアのためのReact・Reduxアプリケーション開発入門
(9)非エンジニアでも学べるPHP入門講座
https://www.udemy.com/share/10094kBEYSd1dXRng=/(10)8 Beautiful Ruby on Rails Apps in 30 Days & TDD - Immersive
https://www.udemy.com/share/10017ABEYSd1dXRng=/(11)初めてでもできるWordPressで作る人気の出るホームページ作成
https://www.udemy.com/share/100k3ABEYSd1dXRng=/(12)よくわかるRuby on Rails入門-RubyとRailsを基礎から学びWebアプリケーションをネットに公開しよう
https://www.udemy.com/share/100AcWBEYSd1dXRng=/(13)フルスタックエンジニアが教える 即戦力Railsエンジニア養成講座
https://www.udemy.com/share/1003s4BEYSd1dXRng=/まだ書きかけなので、その適宜リライトしながら投稿していこうと思う。
下記のようになれるように頑張っていこうと思います。では。
転職無事に終わったら、スクールに(お金がなくて)入れなかったけど、転職できた話書くか〜 https://t.co/S3pg4eLjL7
— しげにぃ@エンジニア (@ShigenoEngineer) 2019年2月24日
- 投稿日:2019-04-11T15:06:32+09:00
Next.jsでつくる動的ページ
チュートリアルをもとに、Next.jsでの動的ページ作成方法を見ていきます。
チュートリアル用のリポジトリをクローンしておきましょう。
$ git clone https://github.com/zeit/next-learn-demo.git $ cd next-learn-demoインストールとルーティングの基礎はこちらからどうぞ。
クエリパラメーターで記事を表示する
サンプルのソースコードディレクトリに移動し、
npm iしておきます。$ cd 3-create-dynamic-pages $ npm i
pages/index.jsでは投稿リストを表示し、遷移先のpages/post.jsではクエリパラメーターをもとに記事タイトルを表示します。
以下のように書き換えてみてください。// pages/index.js import Layout from '../components/MyLayout.js' import Link from 'next/link' // 各記事タイトルと遷移先のコンポーネント const PostLink = props => ( <li> <Link href={`/post?title=${props.title}`}> <a>{props.title}</a> </Link> </li> ) export default function Blog() { return ( <Layout> <h1>My Blog</h1> <ul> {/* title属性がクエリパラメーターとして渡される */} <PostLink title="Hello Next.js" /> <PostLink title="Learn Next.js is awesome" /> <PostLink title="Deploy apps with Zeit" /> </ul> </Layout> ) }// pages/post.js import { withRouter } from 'next/router' import Layout from '../components/MyLayout.js' const Page = withRouter(props => ( <Layout> {/* props.router.query で ?title={hoge}を取得できます*/} <h1>{props.router.query.title}</h1> <p>This is the blog post content.</p> </Layout> )) export default Page
pages/post.jsの<Layout>の中身をコンポーネントにしたい場合は、以下のようにします。// pages/post.js import { withRouter } from 'next/router' import Layout from '../components/MyLayout.js' const Content = withRouter(props => ( <div> <h1>{props.router.query.title}</h1> <p>This is the blog post content.</p> </div> )) const Page = props => ( <Layout> <Content /> </Layout> ) export default PageルートマスキングによるクリーンなURL
Next.jsのルートマスキング機能を使うことにより、クリーンなURLを作成できます。
ディレクトリを移動して、
npm iしておきましょう。$ cd ../4-clean-urls $ npm i
pages/index.jsを以下のように書き換えます。// pages/index.js import Layout from '../components/MyLayout.js' import Link from 'next/link' // 各記事タイトルと遷移先のコンポーネント const PostLink = props => ( <li> {`/* asを使うことにより、hrefの記述をシンプルなものにすることができる */`} <Link as={`/p/${props.id}`} href={`/post?title=${props.title}`}> <a>{props.title}</a> </Link> </li> ) export default function Blog() { return ( <Layout> <h1>My Blog</h1> <ul> <PostLink id="hello-nextjs" title="Hello Next.js" /> <PostLink id="learn-nextjs" title="Learn Next.js is awesome" /> <PostLink id="deploy-nextjs" title="Deploy apps with Zeit" /> </ul> </Layout> ) }
<Link>コンポーネントのasに<PostLink>コンポーネントのidを、hrefにtitleをそれぞれ渡しています。// pages/post.jsから抜粋 const Page = withRouter(props => ( <Layout> {/* props.router.query で ?title={hoge}を取得できます*/} <h1>{props.router.query.title}</h1> <p>This is the blog post content.</p> </Layout> ))
withRouterメソッドの引数propsのprops.router.asPathをみると、pages/index.jsのasを受け取っていることがわかります。hrefで渡しているクエリーパラメーターは?title={hoge}なので、props.router.query.titleでは、{hoge}の部分が表示されます。ただし、この方法ですとクライアントサイドでのレンダリング結果なので、
/p/{hoge}ページで再読込をすると404になってしまいます。それを避けるために、カスタムサーバーAPIを使います。カスタムサーバーAPI
例によって、チュートリアルのディレクトリを移動しましょう。また、Expressを利用するので、一緒にインストールしてください。
$ cd 5-clean-urls-ssr $ npm i $ npm install --save express
server.jsを作成します。const express = require('express') const next = require('next') const dev = process.env.NODE_ENV !== 'production' const app = next({ dev }) const handle = app.getRequestHandler() app .prepare() .then(() => { const server = express() server.get('/p/:id', (req, res) => { const actualPage = '/post' const queryParams = { title: req.params.id } app.render(req, res, actualPage, queryParams) }) server.get('*', (req, res) => { return handle(req, res) }) server.listen(3000, err => { if (err) throw err console.log('> Ready on http://localhost:3000') }) }) .catch(ex => { console.error(ex.stack) process.exit(1) })また、package.jsonのnpm scriptsを以下のように書き換えます。
{ "scripts": { "dev": "node server.js", "build": "next build", "start": "NODE_ENV=production node server.js" } }今度は、
/p/{hoge}で再読込しても404にならなくなりました。しかし、pages/index.jsから遷移してきたときと表示が異なってしまっているはずです。これは、/p/{hoge}ページだけではpages/index.jsから?title={hoge}を受け取ることができないからです。外部からAPIで情報を受け取る場合は、どちらも共通のIDを利用するため、これは問題にならないかと思われます。外部APIから情報を取得する
チュートリアルではバットマンのAPIから情報を取得しているので、こちらもバットマンを呼んでみましょう。
ディレクトリを移動して、
npm iしておきましょう。また、データを取得するためにisomorphic-unfetchもインストールしておきましょう。$ cd ../6-fetching-data $ npm i $ npm install --save isomorphic-unfetch
pages/index.jsを以下のように書き換えます。// pages/index.js import Layout from '../components/MyLayout.js' import Link from 'next/link' import fetch from 'isomorphic-unfetch' const Index = props => ( <Layout> <h1>Batman TV Shows</h1> <ul> {props.shows.map(show => ( <li key={show.id}> <Link as={`/p/${show.id}`} href={`/post?id=${show.id}`}> <a>{show.name}</a> </Link> </li> ))} </ul> </Layout> ) Index.getInitialProps = async function() { const res = await fetch('https://api.tvmaze.com/search/shows?q=batman') const data = await res.json() console.log(`Show data fetched. Count: ${data.length}`) return { shows: data.map(entry => entry.show) } } export default Index
getInitialPropsメソッドは、静的な非同期関数です。初回の読み込み時、getInitialPropsはサーバーサイドで実行され、クライアント側のルーティングで遷移してきた場合はクライアントサイドで実行されます。関数内のconsole.logが、どのコンソールで表示されているかで確認できます。
pages/post.js側も対応しましょう。server.jsを以下に書き換えます。// server.js const express = require('express') const next = require('next') const dev = process.env.NODE_ENV !== 'production' const app = next({ dev }) const handle = app.getRequestHandler() app .prepare() .then(() => { const server = express() server.get('/p/:id', (req, res) => { const actualPage = '/post' const queryParams = { id: req.params.id } // title: を id: に変更 app.render(req, res, actualPage, queryParams) }) server.get('*', (req, res) => { return handle(req, res) }) server.listen(3000, err => { if (err) throw err console.log('> Ready on http://localhost:3000') }) }) .catch(ex => { console.error(ex.stack) process.exit(1) })
pages/post.jsも書き換えます。// pages/post.js import Layout from '../components/MyLayout.js' import fetch from 'isomorphic-unfetch' const Post = props => ( <Layout> <h1>{props.show.name}</h1> <p>{props.show.summary.replace(/<[/]?p>/g, '')}</p> <img src={props.show.image.medium} /> </Layout> ) Post.getInitialProps = async function(context) { const { id } = context.query const res = await fetch(`https://api.tvmaze.com/shows/${id}`) const show = await res.json() console.log(`Fetched show: ${show.name}`) return { show } } export default Post
pages/post.jsでもバットマンの情報が表示されるようになりました。前回のエントリーと合わせて、Next.jsの大枠は見えてきたかと思います。
- 投稿日:2019-04-11T14:53:55+09:00
JavaScriptで総当たり戦の表を作る
方針
かけ算九九でやったみたく、多重ループを使ってやったらいけそう。
コード
ES5まで
var member = ['悟空','ベジータ','ピッコロ','クリリン','亀仙人']; for(var cnt_a=0; cnt_a<5; cnt_a++){ for(var cnt_b=0; cnt_b<5; cnt_b++){ console.log(member[cnt_a] + ' vs ' + member[cnt_b]); } }ES2015
let member = ['悟空','ベジータ','ピッコロ','クリリン','亀仙人']; for(let player1 of member){ for(let player2 of member){ console.log(player1 + ' vs ' + player2); } }これだと、悟空 vs 悟空みたいなことが起こっているので、この辺を
if文を使って修正する。コード修正版
ES5まで
var member = ['悟空','ベジータ','ピッコロ','クリリン','亀仙人']; for(var cnt_a=0; cnt_a<5; cnt_a++){ for(var cnt_b=0; cnt_b<5; cnt_b++){ if(member[cnt_a] !== member[cnt_b]) console.log(member[cnt_a] + ' vs ' + member[cnt_b]); } }ES2015
let member = ['悟空','ベジータ','ピッコロ','クリリン','亀仙人']; for(let player1 of member){ for(let player2 of member){ if(player1 !== player2){ console.log(player1 + ' vs ' + player2); } } }ここでまた問題発生。
悟空vsベジータとベジータvs悟空は一緒じゃん。
同じ組み合わせを避けたい。コード修正版(改)
ES5まで
var member1 = ['悟空','ベジータ','ピッコロ','クリリン','亀仙人']; var member2 = ['悟空','ベジータ','ピッコロ','クリリン','亀仙人']; for(var cnt_a=0; cnt_a<5; cnt_a++){ member2.shift(); for(var cnt_b=0; cnt_b<(5-(cnt_a+1)); cnt_b++){ console.log(member1[cnt_a] + ' vs ' + member2[cnt_b]); } }ES2015
let member1 = ['悟空','ベジータ','ピッコロ','クリリン','亀仙人']; let member2 = ['悟空','ベジータ','ピッコロ','クリリン','亀仙人']; for(let m1 of member1){ member2.shift(); for(let m2 of member2){ console.log(m1 + ' vs ' + m2); } }参考
ふりがなプログラミング
- 投稿日:2019-04-11T13:09:29+09:00
webpackでPromiseを使用する(IE,Edge対策)
前提
webpackを使用している。※webpackとは
webpack使用していなくても、解決策2なら問題ない
問題
非同期通信で使用するPromiseに関して、IE,Edgeでは使用できない。
解決策1(本題)
es6-promiseをインストールし、bundle.jsに含めた形にする。
これにより、CDNを使用する必要がなくなる。npm install es6-promisewebpack.config.jsconst config = { entry:{...}, plugins: [ new webpack.ProvidePlugin({ Promise: 'es6-promise', }), ], }解決策2
手っ取り早く、HTMLにスクリプト読み込むように設定。
<!-- polyfillsを読み込むように設定 --> <script src="https://www.promisejs.org/polyfills/promise-7.0.4.min.js"></script> <script src="assets/js/bundle.js" type="text/javascript"></script>使い方
sample.jsnew Promise(function(resolve,reject){});さいごに
全てのHTMLファイルに、CDN使用するように書くと、手間だったので、改善できてよかったです。
webpack便利ですね。何か間違っている箇所があれば、ご教示よろしくお願いします。
- 投稿日:2019-04-11T11:07:00+09:00
配列の内容を繰り返し文で表示
コード
ES5まで
for文で作った連続する数値を配列のインデックス(添字)として使う。var tsuna = ['クロ','ミナミ','メバチ','キハダ','ビンナガ']; for(var cnt=0; cnt<5; cnt++){ console.log(tsuna[cnt] + 'マグロ'); }ES2015
配列に所属する要素を変数に入れていく。
for(let 変数 of 配列)let fish = ['クロ','ミナミ','メバチ','キハダ','ビンナガ']; for(let tsuna of fish){ console.log(tsuna + 'マグロ'); }参考
ふりがなプログラミング
- 投稿日:2019-04-11T09:55:24+09:00
JavaScriptで簡単かけ算九九
- 投稿日:2019-04-11T09:29:58+09:00
JavaScriptで扱えるUnicodeプロパティ一覧
JavaScriptで扱えるUnicodeプロパティ一覧
ES2018版
Binary
\p{LoneUnicodePropertyNameOrValue}形式で指定する。以下は、Binaryプロパティの名前の一覧。
Short Name Long Name Alian Description AHex ASCII_Hex_Digit ASCII Alpha Alphabetic Any Assigned Bidi_C Bidi_Control Bidi_M Bidi_Mirrored CE Composition_Exclusion 未実装 CI Case_Ignorable Cased CWCF Changes_When_Casefolded CWCM Changes_When_Casemapped CWL Changes_When_Lowercased CWKCF Changes_When_NFKC_Casefolded CWL Changes_When_Lowercased CWT Changes_When_Titlecased CWU Changes_When_Uppercased Dash DI Default_Ignorable_Code_Point Dash Dep Deprecated Dia Diacritic EComp Emoji_Component EBase Emoji_Modifier_Base EMod Emoji_Modifier EPres Emoji_Presentation Emoji Ext Extender Gr_Base Grapheme_Base Gr_Ext Grapheme_Extend Gr_Link Grapheme_Link 未実装 Hex Hex_Digit Hyphen 未実装 IDC ID_Continue IDSB IDS_Binary_Operator IDST IDS_Trinary_Operator IDC ID_Continue IDS ID_Start Ideo Ideographic Join_C Join_Control LOE Logical_Order_Exception Lower Lowercase Math NChar Noncharacter_Code_Point OAlpha Other_Alphabetic 未実装 ODI Other_Default_Ignorable_Code_Point 未実装 OGr_Ext Other_Grapheme_Extend 未実装 OIDC Other_ID_Continue 未実装 OIDS Other_ID_Start 未実装 OLower Other_Lowercase 未実装 OMath Other_Math 未実装 OUpper Other_Uppercase 未実装 PCM Prepended_Concatenation_Mark 未実装 Pat_Syn Pattern_Syntax Pat_WS Pattern_White_Space QMark Quotation_Mark Radical RI Regional_Indicator STerm Sentence_Terminal SD Soft_Dotted STerm Sentence_Terminal Term Terminal_Punctuation UIdeo Unified_Ideograph Upper Uppercase VS Variation_Selector WSpace White_Space space XIDC XID_Continue XIDS XID_Start General_Category(gc)
\p{UnicodePropertyName=UnicodePropertyValue}で指定する。
つまり
\p{General_Category=UnicodePropertyValue}
\p{gc=UnicodePropertyValue}
と指定する。
また、General_CategoryはUnicodePropertyNameと省略できるので
\p{UnicodePropertyValue}
でも指定できる。以下は、
General_Category(gc)が取れうる値の一覧。
Short Value Long Value Alian Description Cc Control cntrl Cf Format Cn Unassigned Co Private_Use Cs Surrogate C Other Cc+Cf+Cn+Co+Cs LC Cased_Letter Ll+Lt+Lu Ll Lowercase_Letter Lm Modifier_Letter Lo Other_Letter Lt Titlecase_Letter Lu Uppercase_Letter L Letter Ll+Lm+Lo+Lt+Lu Mc Spacing_Mark Me Enclosing_Mark Mn Nonspacing_Mark M Mark Combining_Mark Mc+Me+Mn Nd Decimal_Number digit Nl Letter_Number No Other_Number N Number Nd+Nl+No Pc Connector_Punctuation Pd Dash_Punctuation Pe Close_Punctuation Pf Final_Punctuation Pi Initial_Punctuation Po Other_Punctuation Ps Open_Punctuation P Punctuation punct Pc+Pd+Pe+Pf+Pi+Po+Ps Sc Currency_Symbol Sk Modifier_Symbol Sm Math_Symbol So Other_Symbol S Symbol Sc+Sk+Sm+So Zl Line_Separator Zp Paragraph_Separator Zs Space_Separator Z Separator Zl+Zp+Zs Script(sc) Script_Extensions(scx)
\p{UnicodePropertyName=UnicodePropertyValue}で指定する。
つまり
\p{Script=UnicodePropertyValue}
\p{sc=UnicodePropertyValue}
\p{Script_Extensions=UnicodePropertyValue}
\p{scx=UnicodePropertyValue}
で指定する。以下は、
Script(sc)およびScript_Extensions(scx)が取れうる値の一覧。
Short Value Long Value Alian Description Adlm Adlam Aghb Caucasian_Albanian Ahom Arab Arabic Armi Imperial_Aramaic Armn Armenian Avst Avestan Bali Balinese Bamu Bamum Bass Bassa_Vah Batk Batak Beng Bengali Bhks Bhaiksuki Bopo Bopomofo Brah Brahmi Brai Braille Bugi Buginese Buhd Buhid Cakm Chakma Cans Canadian_Aboriginal Cari Carian Cham Cher Cherokee Copt Coptic Qaac Cprt Cypriot Cyrl Cyrillic Deva Devanagari Dogr Dogra Dsrt Deseret Dupl Duployan Egyp Egyptian_Hieroglyphs Elba Elbasan Elym Elymaic 未実装 Ethi Ethiopic Geor Georgian Glag Glagolitic Gong Gunjala_Gondi Gonm Masaram_Gondi Goth Gothic Gran Grantha Grek Greek Gujr Gujarati Guru Gurmukhi Hang Hangul Hani Han 漢字 Hano Hanunoo Hatr Hatran Hebr Hebrew Hira Hiragana 平仮名 Hluw Anatolian_Hieroglyphs Hmng Pahawh_Hmong Hmnp Nyiakeng_Puachue_Hmong 未実装 Hrkt Katakana_Or_Hiragana 未実装 Hung Old_Hungarian Ital Old_Italic Java Javanese Kali Kayah_Li Kana Katakana 片仮名 Khar Kharoshthi Khmr Khmer Khoj Khojki Knda Kannada Kthi Kaithi Lana Tai_Tham Laoo Lao Latn Latin Lepc Lepcha Limb Limbu Lina Linear_A Linb Linear_B Lisu Lyci Lycian Lydi Lydian Mahj Mahajani Maka Makasar Mand Mandaic Mani Manichaean Marc Marchen Medf Medefaidrin Mend Mende_Kikakui Merc Meroitic_Cursive Mero Meroitic_Hieroglyphs Mlym Malayalam Modi Mong Mongolian Mroo Mro Mtei Meetei_Mayek Mult Multani Mymr Myanmar Nand Nandinagari 未実装 Narb Old_North_Arabian Nbat Nabataean Newa Nkoo Nko Nshu Nushu Ogam Ogham Olck Ol_Chiki Orkh Old_Turkic Orya Oriya Osge Osage Osma Osmanya Palm Palmyrene Pauc Pau_Cin_Hau Perm Old_Permic Phag Phags_Pa Phli Inscriptional_Pahlavi Phlp Psalter_Pahlavi Phnx Phoenician Plrd Miao Prti Inscriptional_Parthian Rjng Rejang Rohg Hanifi_Rohingya Runr Runic Samr Samaritan Sarb Old_South_Arabian Saur Saurashtra Sgnw SignWriting Shaw Shavian Shrd Sharada Sidd Siddham Sind Khudawadi Sinh Sinhala Sogd Sogdian Sogo Old_Sogdian Sora Sora_Sompeng Soyo Soyombo Sund Sundanese Sylo Syloti_Nagri Syrc Syriac Tagb Tagbanwa Takr Takri Tale Tai_Le Talu New_Tai_Lue Taml Tamil Tang Tangut Tavt Tai_Viet Telu Telugu Tfng Tifinagh Tglg Tagalog Thaa Thaana Thai Tibt Tibetan Tirh Tirhuta Ugar Ugaritic Vaii Vai Wara Warang_Citi Wcho Wancho 未実装 Xpeo Old_Persian Xsux Cuneiform Yiii Yi Zanb Zanabazar_Square Zinh Inherited Qaai Zyyy Common Zzzz Unknown
- 投稿日:2019-04-11T09:23:38+09:00
JavaScriptのES2018で追加された正規表現の新機能の検証
はじめに
正規表現を使ったソースの修正をしているときにexec()やmatch()の実行結果に見慣れないプロパティgroupsを見つけました。
いつの間にかJavaScriptにも名前付きグループが実装されていたようです。
そこで軽く調べてみましたら、それ以外にもES2018において色々と追加されていたようです。
何番煎じか分かりませんが、この記事では、簡単にES2018の正規表現に関する新機能の動作を検証してみたいと思います。
厳密な定義等は、ほかの記事等を見てください。正規表現の新機能
Named Capture Groups
従来は、
(pattern)
のようにpatternにマッチしたキャプチャにアクセスするには、$1などキャプチャが現れた順番に対応する数値でしかアクセスできませんでした。
ES2018以降では、
(?<name>pattern)
と書くとキャプチャに名前$<name>でアクセスできるようになります。
また、exec()やmatch()の結果にgroupsプロパティが追加されるのでそれからもアクセス出来るようになります。これは、有っても使い勝手がそれほど変わらないと思います。
分かりやすいプログラムを書くのには、重宝すると思います。JavaScriptlet str = "white dog 800, black dog 1000, white cat 1000, black cat 1200,"; let reG = /(?<color>white|black) (?<animal>cat|dog) (?<price>\d+)/g let re = /(?<color>white|black) (?<animal>cat|dog) (?<price>\d+)/ let reN = /(white|black) (cat|dog) (\d+)/ let execResultG = reG.exec(str); let execResult = re.exec(str); let matchResultG = str.match(reG); let matchResult = str.match(re); let matchResultN = str.match(reN); console.log(execResultG); console.log(execResult); console.log(matchResultG); console.log(matchResult); console.log(matchResultN); let replaceResultName = str.replace(reG, "$<color>+$<animal>+$<price>"); let replaceResult = str.replace(reG, "$1+$2+$3"); let replaceResultN = str.replace(reN, "$1+$2+$3"); console.log(replaceResultName); console.log(replaceResult); console.log(replaceResultN);execResultG, execResult, matchResultの出力例
0: "white dog 800" 1: "white" 2: "dog" 3: "800" groups: {color: "white", animal: "dog", price: "800"} index: 0 input: "white dog 800, black dog 1000, white cat 1000, black cat 1200," length: 4matchResultGの出力例
["white dog 800", "black dog 1000", "white cat 1000", "black cat 1200"]matchResultNの出力例
0: "white dog 800" 1: "white" 2: "dog" 3: "800" groups: undefined index: 0 input: "white dog 800, black dog 1000, white cat 1000, black cat 1200," length: 4replaceResultName, replaceResult, replaceResultNの出力例
white+dog+800, black+dog+1000, white+cat+1000, black+cat+1200,dotAll flag
.は、従来では改行コードなどの一部を除いた文字にマッチしていました。
改行コードを含んだ文字にマッチさせたい場合、[\s\S]や[^]などを使用する必要がありました。
ES2018以降では、/.*/sのようにsフラグを追加することで.が改行文字などすべての文字に対応するようになります。これも、有ったら便利だなという程度でしょうか。
何故いままでなかったのだろうかとも思います。JavaScriptlet str = "white dog 800\nblack dog 1000\nwhite cat 1000\nblack cat 1200\n"; let reS = /.*/s let re = /.*/ let reB = /[\s\S]*/ let reNB = /[^]*/ let matchResultS = str.match(reS); let matchResult = str.match(re); let matchResultB = str.match(reB); let matchResultNB = str.match(reNB); console.log(str); console.log(matchResultS); console.log(matchResult); console.log(matchResultB); console.log(matchResultNB);matchResultS, matchResultB, matchResultNBの出力例
0: "white dog 800↵black dog 1000↵white cat 1000↵black cat 1200↵" groups: undefined index: 0 input: "white dog 800↵black dog 1000↵white cat 1000↵black cat 1200↵" length: 1matchResultの出力例
0: "white dog 800" groups: undefined index: 0 input: "white dog 800↵black dog 1000↵white cat 1000↵black cat 1200↵" length: 1Lookbehind Assertions
ES2018以降では、戻り読み(Lookbehind)が実装されました。
特定のパターンに続くパターンにマッチさせる事が出来るようになりました。
以下のように書くと、
/(?<=prePattern)pattern/
prePatternが前にあるpatternにのみ、マッチするようになります。
逆に、特定のパターンに続かないパターンにマッチさせることも出来ます。
以下のように書くと、
/(?<!prePattern)pattern/
prePatternが前にないpatternにのみ、マッチするようになります。
厳密にいえば、(?<=prePattern)は、prePatternが前に存在する位置にマッチします。
同じように、(?<!prePattern)は、prePatternが前に存在しない位置にマッチします。
本当に使いこなそうとすると、この位置にマッチするという事を意識する必要があったりします。
あまりにも複雑な場合は、正規表現だけで解決するのを考え直した方が簡単だと思いますが。str = "white cat1, gray cat2, black cat3, red cat4, green cat5, blue cat6, cyan cat7, magenta cat8, yellow cat9"; re = /(?<=green )cat\d/g; reN = /(?<!green )cat\d/g; result = str.match(re); resultN = str.match(reN); console.log(result); console.log(resultN);
/(?<=green )cat\d/g;の出力例["cat5"]
/(?<!green )cat\d/g;の出力例["cat1", "cat2", "cat3", "cat4", "cat6", "cat7", "cat8", "cat9"]位置にマッチするという動きから、patternが含まれない行にマッチさせるという事も出来るようになります。
よく見る下の記述はよくある例です。
戻り読みが使えない状況で正規表現だけでマッチさせられるかもしれませんが、筆者は分かりません。
この場合も、JavaScriptを使えば正規表現だけで解決する必要はないのですが。/* str abc cat def dog ghi cat jkl dog mno cat 123 abc cat 789 def dog 012 ghi cat 345 jkl dog 678 mno cat //*/ str = "abc cat\ndef dog\nghi cat\njkl dog\nmno cat\n123 abc cat\n789 def dog\n012 ghi cat\n345 jkl dog\n678 mno cat\n" re = /^((?<!abc).)+$/mg; result = str.match(re); console.log(result);
/^((?<!abc).)+$/mgの出力例["def dog", "ghi cat", "jkl dog", "mno cat", "789 def dog", "012 ghi cat", "345 jkl dog", "678 mno cat"]余談ですが、数値の3桁毎にカンマを打つ正規表現はないかと考えたことがありました。
戻り読みがなくても実装できるのですが、戻り読みを使えばより分かりやすいのではないかと思います。
(どっちも分からんがな)str = "1\n12\n123\n1234\n12345\n123456\n1234567\n12345678\n123456789\nabc1def\nabc12def\nabc123def\nabc1234def\nabc12345def\nabc123456def\nabc1234567def\nabc12345678def\nabc123456789def\n 123456789 123456789 123456789"; re = /(\d)(?=(?:\d{3})+(?!\d))/g; result = str.replace(re, "$1,"); console.log(result); re = /(?<=\d)(?=(?:\d{3})+(?!\d))/g; result = str.replace(re, ","); console.log(result);
/(\d)(?=(?:\d{3})+(?!\d))/gおよび/(?<=\d)(?=(?:\d{3})+(?!\d))/gの出力例1 12 123 1,234 12,345 123,456 1,234,567 12,345,678 123,456,789 abc1def abc12def abc123def abc1,234def abc12,345def abc123,456def abc1,234,567def abc12,345,678def abc123,456,789def 123,456,789 123,456,789 123,456,789Unicode property escapes
ES2018以降では、Unicodeプロパティを指定してマッチさせることが出来るようになりました。
これはとても便利ですね。ウヒョー
と言いたいところですが、使いこなすにはUnicodeプロパティの知識が必要そうです。
迂闊に使うと想定していない文字をマッチさせてしまいそうです。
厳密に使いたいからと色々調べていくとUnicodeの闇へようこそとなります。ウヒャー基本的には、
\p{property}もしくは\P{property}と記述します。
指定したpropertyを持っている文字とマッチさせたいときは、以下のように小文字で書きます。
\p{property}
逆に、指定したpropertyを持っていない文字とマッチさせたいときは、大文字を使います。
\P{property}
正規表現の本来の定義ならば、"property"に相当する記述は、大文字小文字の区別なく扱えるようになっています。
しかし、JavaScriptで扱う場合は、大文字小文字を正確に入力しなければいけません。
またJavaScriptで扱い場合は、/\p{property}/uのようにuフラグが必須となります。
では、具体的にpropertyにはどんな記述をするか述べていきたいと思います。まず、Unicodeプロパティは、数多くありますが大きく分けるとbinary propertyとnon-binary propertyに分けられます。
Binaryプロパティ
binaryプロパティは、その属性を持っているどうかの値として、Yes/No(Y/N)もしくはTrue/False(T/F)を持ちます。
(厳密にいえば、Maybe(M)も設定できるようです。)
Binaryプロパティを指定する場合は、以下の形式で行います。
\p{LoneUnicodePropertyNameOrValue}binaryプロパティの
PropertyNameとしてES2018で扱えるものの一部をあげると以下のようなものがあります。
ASCII_Hex_DigitAHex,AlphabeticAlphaCasedDashHex_DigitHexHyphenIdeographicIdeoLowercaseLowerMathRadicalUppercaseUpperWhite_SpaceWSpace具体的な例としては、
/\p{ASCII_Hex_Digit}+/ug; /\p{Math}*/u; /[\p{Alphabetic}]/u;などになります。
non-binaryプロパティ
non-binaryプロパティは、binaryプロパティ以外のプロパティです。
non-binaryプロパティの持てる値は、プロパティごとに異なります。
ES2018で扱えるのは、次の3つです。
General_Category,gcScript,scScript_Extensions,scx
General_Category
General_Categoryは、文字を大まかに分けるとどのような分類になるかを表すものです。
具体的には、文字、記号、数字、空白などの分類です。
General_Categoryを指定する場合は、
\p{UnicodePropertyName=UnicodePropertyValue}
の形式か、Non-binaryプロパティの中で唯一UnicodePropertyName=を省略することができるので、
\p{LoneUnicodePropertyNameOrValue}
と、2つの形式が有効です。
General_Categoryの値
General_Categoryが持てる値は、以下のようなものがあります。
SurrogateLetterLowercase_LetterUppercase_LetterNumberMarkSeparatorSymbolPunctuationOther具体的には、
/\p{General_Category=Lowercase_Letter}+/ug; /\p{gc=Uppercase_Letter}/u; /[\p{Number}\p{Mark}]+/u;などと指定できます。
ScriptおよびScript_Extensions
ScriptおよびScript_Extensionsは、
\p{UnicodePropertyName=UnicodePropertyValue}
の形式のみ指定できます。
Scriptは、文字を文字体系で分けるとどのような分類になるかを表すものです。
具体的には、ラテン文字、アラビア文字、平仮名、片仮名、漢字などの分類です。
Scriptは、1文字に1つの値しか持てません。
"、"や"。"などの複数の体系に現れる文字でも、Commonなど何らかの1つの値に設定されています。
これで困るのが以下のような文章から、例えば平仮名で構成されている文字列だけを抜き出したいときです。
ねこだいすき、ふりすびー。cat love Frisbee!!!.
これをScriptのみで抜き出そうとして、
/\p{Script=Hiragana}+/ug;
を指定してみます。
結果は、
["ねこだいすき", "ふりすび"]
と句読点と長音記号が入りません。
では、
/[\p{Script=Hiragana}\p{Script=Common}]+/ug;
と指定してみます。
今度は、
["ねこだいすき、ふりすびー。", " ", " ", "!!!."]
と目的のものは手に入りましたが空白など余計なものも抜き出してしまっています。そこで、複数の文字体系に現れる文字にも対応しようというのが
Script_Extensionsです。
こちらも、ラテン文字、アラビア文字、平仮名、片仮名、漢字などの分類を表すものです。
Scriptとの違いは、1文字でも複数の値を持てるという事です。
このため"、"や"。"など複数の体系に現れる文字は、Bopo Hang Hani Hira Kana Yiiiなど複数の値を持つことになります。
(注音符号(ボポモフォ)、ハングル、漢字、平仮名、片仮名、彝文字(いもじ))
さて今度は、Script_Extensionsのみを使って上記の文章から平仮名で構成されている文字列を抜き出してみます。
/\p{Script_Extensions=Hiragana}+/ug;
とすると、
["ねこだいすき、ふりすびー。"]
と目的のものだけすっきりと抜き出すことが出来ました。
(そもそも、平仮名に長音記号を使って良いのか分かりませんが、Unicodeは一般的な使われ方を採用したようです。)
ScriptおよびScript_Extensionsの値
ScriptおよびScript_Extensionsが持てる値は、以下のようなものがあります。
Han漢字Hiragana平仮名Katakana片仮名Common一般具体的には、
/\p{Script=Hiragana}/u; /\p{Script_Extensions=Katakana}/u; /\p{Script_Extensions=Han}/u;などと指定できます。
NameとValue用語が正しいか分かりませんが、
Property NameとProperty Valueの区別をしっかり付けたほうが良さそうです。
ASCII_Hex_Digit(Binaryプロパティ)Lowercase(Binaryプロパティ)Uppercase(Binaryプロパティ)General_CategoryScriptScript_Extensionsなどは
Property Name(もしくは単にProperty)です。
一方、
Lowercase_Letter(General_Categoryの値)Uppercase_Letter(General_Categoryの値)Math_Symbol(General_Categoryの値)Punctuation(General_Categoryの値)Han(ScriptおよびScript_Extensionsの値)Hiragana(ScriptおよびScript_Extensionsの値)Katakana(ScriptおよびScript_Extensionsの値)などは、
Property Valueです。
つまり\p{UnicodePropertyName=UnicodePropertyValue}とした場合の、左辺がNameで、右辺がValueです。
Binaryプロパティは、右辺値がYes/NoだけなのでNameを調べる必要があります。
一方、Non-binaryプロパティは、左辺値がGeneral_Category,Script,Script_Extensionsと3つだけですが、取りうるValueを調べる必要があります。同じように動作する小文字を抜き出す正規表現でも以下のようにいくつか記述を変えることができます。
\p{Lowercase}(Binaryプロパティ)\p{General_Category=Lowercase_Letter}
\p{gc=Lowercase_Letter}(略記法)\p{Lowercase_Letter}(略記法)
NameやValueなど何を扱っているかしっかり把握しておかないと思わぬところでつまずきそうです。指定方法に関して
\p{property}の記述は文字クラスを表す表現なので[]で囲むのが望ましいという記述も見かけました。
それを信じるならば、/[\p{General_Category=Decimal_Number}]/u; /[\p{Script=Greek}]/u; /[\p{Script_Extensions=Han}]/u;とするのが一番お行儀が良い書き方なようです。
(そもそもこのように書かないとエラーになる言語もあるようです。)コード
長々と記述してきましたが、とりあえずどんな文字がどんなプロパティなのか全部まとめて調べてみました。
と言っても出力結果が膨大になりますので結果は省略します。
npm6.7.0
babel6.26.0
babel-core6.26.3
node.jsv11.13.0
の環境で実行させました。
表示には、
Atom Editor
Unifont
を使いました。
重いのでAtomじゃない方が良いかもしれないです。"use babel"; import fs from "fs"; const binary = [ { "name": "AHex", "regex": /\p{AHex}+/ug }, { "name": "ASCII_Hex_Digit", "regex": /\p{ASCII_Hex_Digit}+/ug }, { "name": "ASCII", "regex": /\p{ASCII}+/ug }, { "name": "Alpha", "regex": /\p{Alpha}+/ug }, { "name": "Alphabetic", "regex": /\p{Alphabetic}+/ug }, { "name": "Any", "regex": /\p{Any}+/ug }, { "name": "Assigned", "regex": /\p{Assigned}+/ug }, { "name": "Bidi_C", "regex": /\p{Bidi_C}+/ug }, { "name": "Bidi_Control", "regex": /\p{Bidi_Control}+/ug }, { "name": "Bidi_M", "regex": /\p{Bidi_M}+/ug }, { "name": "Bidi_Mirrored", "regex": /\p{Bidi_Mirrored}+/ug }, // { "name": "CE", "regex": /\p{CE}+/ug }, // { "name": "Composition_Exclusion", "regex": /\p{Composition_Exclusion}+/ug }, { "name": "CI", "regex": /\p{CI}+/ug }, { "name": "Case_Ignorable", "regex": /\p{Case_Ignorable}+/ug }, { "name": "Cased", "regex": /\p{Cased}+/ug }, { "name": "CWCF", "regex": /\p{CWCF}+/ug }, { "name": "Changes_When_Casefolded", "regex": /\p{Changes_When_Casefolded}+/ug }, { "name": "CWCM", "regex": /\p{CWCM}+/ug }, { "name": "Changes_When_Casemapped", "regex": /\p{Changes_When_Casemapped}+/ug }, { "name": "CWL", "regex": /\p{CWL}+/ug }, { "name": "Changes_When_Lowercased", "regex": /\p{Changes_When_Lowercased}+/ug }, { "name": "CWKCF", "regex": /\p{CWKCF}+/ug }, { "name": "Changes_When_NFKC_Casefolded", "regex": /\p{Changes_When_NFKC_Casefolded}+/ug }, { "name": "CWL", "regex": /\p{CWL}+/ug }, { "name": "Changes_When_Lowercased", "regex": /\p{Changes_When_Lowercased}+/ug }, { "name": "CWT", "regex": /\p{CWT}+/ug }, { "name": "Changes_When_Titlecased", "regex": /\p{Changes_When_Titlecased}+/ug }, { "name": "CWU", "regex": /\p{CWU}+/ug }, { "name": "Changes_When_Uppercased", "regex": /\p{Changes_When_Uppercased}+/ug }, { "name": "Dash", "regex": /\p{Dash}+/ug }, { "name": "DI", "regex": /\p{DI}+/ug }, { "name": "Default_Ignorable_Code_Point", "regex": /\p{Default_Ignorable_Code_Point}+/ug }, { "name": "Dash", "regex": /\p{Dash}+/ug }, { "name": "Dep", "regex": /\p{Dep}+/ug }, { "name": "Deprecated", "regex": /\p{Deprecated}+/ug }, { "name": "Dia", "regex": /\p{Dia}+/ug }, { "name": "Diacritic", "regex": /\p{Diacritic}+/ug }, { "name": "EComp", "regex": /\p{EComp}+/ug }, { "name": "Emoji_Component", "regex": /\p{Emoji_Component}+/ug }, { "name": "EBase", "regex": /\p{EBase}+/ug }, { "name": "Emoji_Modifier_Base", "regex": /\p{Emoji_Modifier_Base}+/ug }, { "name": "EMod", "regex": /\p{EMod}+/ug }, { "name": "Emoji_Modifier", "regex": /\p{Emoji_Modifier}+/ug }, { "name": "EPres", "regex": /\p{EPres}+/ug }, { "name": "Emoji_Presentation", "regex": /\p{Emoji_Presentation}+/ug }, { "name": "Emoji", "regex": /\p{Emoji}+/ug }, { "name": "Ext", "regex": /\p{Ext}+/ug }, { "name": "Extender", "regex": /\p{Extender}+/ug }, { "name": "Gr_Base", "regex": /\p{Gr_Base}+/ug }, { "name": "Grapheme_Base", "regex": /\p{Grapheme_Base}+/ug }, { "name": "Gr_Ext", "regex": /\p{Gr_Ext}+/ug }, { "name": "Grapheme_Extend", "regex": /\p{Grapheme_Extend}+/ug }, // { "name": "Gr_Link", "regex": /\p{Gr_Link}+/ug }, // { "name": "Grapheme_Link", "regex": /\p{Grapheme_Link}+/ug }, { "name": "Hex", "regex": /\p{Hex}+/ug }, { "name": "Hex_Digit", "regex": /\p{Hex_Digit}+/ug }, // { "name": "Hyphen", "regex": /\p{Hyphen}+/ug }, { "name": "IDC", "regex": /\p{IDC}+/ug }, { "name": "ID_Continue", "regex": /\p{ID_Continue}+/ug }, { "name": "IDSB", "regex": /\p{IDSB}+/ug }, { "name": "IDS_Binary_Operator", "regex": /\p{IDS_Binary_Operator}+/ug }, { "name": "IDST", "regex": /\p{IDST}+/ug }, { "name": "IDS_Trinary_Operator", "regex": /\p{IDS_Trinary_Operator}+/ug }, { "name": "IDC", "regex": /\p{IDC}+/ug }, { "name": "ID_Continue", "regex": /\p{ID_Continue}+/ug }, { "name": "IDS", "regex": /\p{IDS}+/ug }, { "name": "ID_Start", "regex": /\p{ID_Start}+/ug }, { "name": "Ideo", "regex": /\p{Ideo}+/ug }, { "name": "Ideographic", "regex": /\p{Ideographic}+/ug }, { "name": "Join_C", "regex": /\p{Join_C}+/ug }, { "name": "Join_Control", "regex": /\p{Join_Control}+/ug }, { "name": "LOE", "regex": /\p{LOE}+/ug }, { "name": "Logical_Order_Exception", "regex": /\p{Logical_Order_Exception}+/ug }, { "name": "Lower", "regex": /\p{Lower}+/ug }, { "name": "Lowercase", "regex": /\p{Lowercase}+/ug }, { "name": "Math", "regex": /\p{Math}+/ug }, { "name": "NChar", "regex": /\p{NChar}+/ug }, { "name": "Noncharacter_Code_Point", "regex": /\p{Noncharacter_Code_Point}+/ug }, // { "name": "OAlpha", "regex": /\p{OAlpha}+/ug }, // { "name": "Other_Alphabetic", "regex": /\p{Other_Alphabetic}+/ug }, // { "name": "ODI", "regex": /\p{ODI}+/ug }, // { "name": "Other_Default_Ignorable_Code_Point", "regex": /\p{Other_Default_Ignorable_Code_Point}+/ug }, // { "name": "OGr_Ext", "regex": /\p{OGr_Ext}+/ug }, // { "name": "Other_Grapheme_Extend", "regex": /\p{Other_Grapheme_Extend}+/ug }, // { "name": "OIDC", "regex": /\p{OIDC}+/ug }, // { "name": "Other_ID_Continue", "regex": /\p{Other_ID_Continue}+/ug }, // { "name": "OIDS", "regex": /\p{OIDS}+/ug }, // { "name": "Other_ID_Start", "regex": /\p{Other_ID_Start}+/ug }, // { "name": "OLower", "regex": /\p{OLower}+/ug }, // { "name": "Other_Lowercase", "regex": /\p{Other_Lowercase}+/ug }, // { "name": "OMath", "regex": /\p{OMath}+/ug }, // { "name": "Other_Math", "regex": /\p{Other_Math}+/ug }, // { "name": "OUpper", "regex": /\p{OUpper}+/ug }, // { "name": "Other_Uppercase", "regex": /\p{Other_Uppercase}+/ug }, // { "name": "PCM", "regex": /\p{PCM}+/ug }, // { "name": "Prepended_Concatenation_Mark", "regex": /\p{Prepended_Concatenation_Mark}+/ug }, { "name": "Pat_Syn", "regex": /\p{Pat_Syn}+/ug }, { "name": "Pattern_Syntax", "regex": /\p{Pattern_Syntax}+/ug }, { "name": "Pat_WS", "regex": /\p{Pat_WS}+/ug }, { "name": "Pattern_White_Space", "regex": /\p{Pattern_White_Space}+/ug }, { "name": "QMark", "regex": /\p{QMark}+/ug }, { "name": "Quotation_Mark", "regex": /\p{Quotation_Mark}+/ug }, { "name": "Radical", "regex": /\p{Radical}+/ug }, { "name": "RI", "regex": /\p{RI}+/ug }, { "name": "Regional_Indicator", "regex": /\p{Regional_Indicator}+/ug }, { "name": "STerm", "regex": /\p{STerm}+/ug }, { "name": "Sentence_Terminal", "regex": /\p{Sentence_Terminal}+/ug }, { "name": "SD", "regex": /\p{SD}+/ug }, { "name": "Soft_Dotted", "regex": /\p{Soft_Dotted}+/ug }, { "name": "STerm", "regex": /\p{STerm}+/ug }, { "name": "Sentence_Terminal", "regex": /\p{Sentence_Terminal}+/ug }, { "name": "Term", "regex": /\p{Term}+/ug }, { "name": "Terminal_Punctuation", "regex": /\p{Terminal_Punctuation}+/ug }, { "name": "UIdeo", "regex": /\p{UIdeo}+/ug }, { "name": "Unified_Ideograph", "regex": /\p{Unified_Ideograph}+/ug }, { "name": "Upper", "regex": /\p{Upper}+/ug }, { "name": "Uppercase", "regex": /\p{Uppercase}+/ug }, { "name": "VS", "regex": /\p{VS}+/ug }, { "name": "Variation_Selector", "regex": /\p{Variation_Selector}+/ug }, { "name": "WSpace", "regex": /\p{WSpace}+/ug }, { "name": "White_Space", "regex": /\p{White_Space}+/ug }, { "name": "space", "regex": /\p{space}+/ug }, { "name": "XIDC", "regex": /\p{XIDC}+/ug }, { "name": "XID_Continue", "regex": /\p{XID_Continue}+/ug }, { "name": "XIDS", "regex": /\p{XIDS}+/ug }, { "name": "XID_Start", "regex": /\p{XID_Start}+/ug }, ]; const generalCategory = [ { "name": "Cc", "regex": /\p{gc=Cc}+/ug }, { "name": "Control", "regex": /\p{gc=Control}+/ug }, { "name": "cntrl", "regex": /\p{gc=cntrl}+/ug }, { "name": "Cf", "regex": /\p{gc=Cf}+/ug }, { "name": "Format", "regex": /\p{gc=Format}+/ug }, { "name": "Cn", "regex": /\p{gc=Cn}+/ug }, { "name": "Unassigned", "regex": /\p{gc=Unassigned}+/ug }, { "name": "Co", "regex": /\p{gc=Co}+/ug }, { "name": "Private_Use", "regex": /\p{gc=Private_Use}+/ug }, { "name": "Cs", "regex": /\p{gc=Cs}+/ug }, { "name": "Surrogate", "regex": /\p{gc=Surrogate}+/ug }, { "name": "C", "regex": /\p{gc=C}+/ug }, { "name": "Other", "regex": /\p{gc=Other}+/ug }, { "name": "LC", "regex": /\p{gc=LC}+/ug }, { "name": "Cased_Letter", "regex": /\p{gc=Cased_Letter}+/ug }, { "name": "Ll", "regex": /\p{gc=Ll}+/ug }, { "name": "Lowercase_Letter", "regex": /\p{gc=Lowercase_Letter}+/ug }, { "name": "Lm", "regex": /\p{gc=Lm}+/ug }, { "name": "Modifier_Letter", "regex": /\p{gc=Modifier_Letter}+/ug }, { "name": "Lo", "regex": /\p{gc=Lo}+/ug }, { "name": "Other_Letter", "regex": /\p{gc=Other_Letter}+/ug }, { "name": "Lt", "regex": /\p{gc=Lt}+/ug }, { "name": "Titlecase_Letter", "regex": /\p{gc=Titlecase_Letter}+/ug }, { "name": "Lu", "regex": /\p{gc=Lu}+/ug }, { "name": "Uppercase_Letter", "regex": /\p{gc=Uppercase_Letter}+/ug }, { "name": "L", "regex": /\p{gc=L}+/ug }, { "name": "Letter", "regex": /\p{gc=Letter}+/ug }, { "name": "Mc", "regex": /\p{gc=Mc}+/ug }, { "name": "Spacing_Mark", "regex": /\p{gc=Spacing_Mark}+/ug }, { "name": "Me", "regex": /\p{gc=Me}+/ug }, { "name": "Enclosing_Mark", "regex": /\p{gc=Enclosing_Mark}+/ug }, { "name": "Mn", "regex": /\p{gc=Mn}+/ug }, { "name": "Nonspacing_Mark", "regex": /\p{gc=Nonspacing_Mark}+/ug }, { "name": "M", "regex": /\p{gc=M}+/ug }, { "name": "Mark", "regex": /\p{gc=Mark}+/ug }, { "name": "Combining_Mark", "regex": /\p{gc=Combining_Mark}+/ug }, { "name": "Nd", "regex": /\p{gc=Nd}+/ug }, { "name": "Decimal_Number", "regex": /\p{gc=Decimal_Number}+/ug }, { "name": "digit", "regex": /\p{gc=digit}+/ug }, { "name": "Nl", "regex": /\p{gc=Nl}+/ug }, { "name": "Letter_Number", "regex": /\p{gc=Letter_Number}+/ug }, { "name": "No", "regex": /\p{gc=No}+/ug }, { "name": "Other_Number", "regex": /\p{gc=Other_Number}+/ug }, { "name": "N", "regex": /\p{gc=N}+/ug }, { "name": "Number", "regex": /\p{gc=Number}+/ug }, { "name": "Pc", "regex": /\p{gc=Pc}+/ug }, { "name": "Connector_Punctuation", "regex": /\p{gc=Connector_Punctuation}+/ug }, { "name": "Pd", "regex": /\p{gc=Pd}+/ug }, { "name": "Dash_Punctuation", "regex": /\p{gc=Dash_Punctuation}+/ug }, { "name": "Pe", "regex": /\p{gc=Pe}+/ug }, { "name": "Close_Punctuation", "regex": /\p{gc=Close_Punctuation}+/ug }, { "name": "Pf", "regex": /\p{gc=Pf}+/ug }, { "name": "Final_Punctuation", "regex": /\p{gc=Final_Punctuation}+/ug }, { "name": "Pi", "regex": /\p{gc=Pi}+/ug }, { "name": "Initial_Punctuation", "regex": /\p{gc=Initial_Punctuation}+/ug }, { "name": "Po", "regex": /\p{gc=Po}+/ug }, { "name": "Other_Punctuation", "regex": /\p{gc=Other_Punctuation}+/ug }, { "name": "Ps", "regex": /\p{gc=Ps}+/ug }, { "name": "Open_Punctuation", "regex": /\p{gc=Open_Punctuation}+/ug }, { "name": "P", "regex": /\p{gc=P}+/ug }, { "name": "Punctuation", "regex": /\p{gc=Punctuation}+/ug }, { "name": "punct", "regex": /\p{gc=punct}+/ug }, { "name": "Sc", "regex": /\p{gc=Sc}+/ug }, { "name": "Currency_Symbol", "regex": /\p{gc=Currency_Symbol}+/ug }, { "name": "Sk", "regex": /\p{gc=Sk}+/ug }, { "name": "Modifier_Symbol", "regex": /\p{gc=Modifier_Symbol}+/ug }, { "name": "Sm", "regex": /\p{gc=Sm}+/ug }, { "name": "Math_Symbol", "regex": /\p{gc=Math_Symbol}+/ug }, { "name": "So", "regex": /\p{gc=So}+/ug }, { "name": "Other_Symbol", "regex": /\p{gc=Other_Symbol}+/ug }, { "name": "S", "regex": /\p{gc=S}+/ug }, { "name": "Symbol", "regex": /\p{gc=Symbol}+/ug }, { "name": "Zl", "regex": /\p{gc=Zl}+/ug }, { "name": "Line_Separator", "regex": /\p{gc=Line_Separator}+/ug }, { "name": "Zp", "regex": /\p{gc=Zp}+/ug }, { "name": "Paragraph_Separator", "regex": /\p{gc=Paragraph_Separator}+/ug }, { "name": "Zs", "regex": /\p{gc=Zs}+/ug }, { "name": "Space_Separator", "regex": /\p{gc=Space_Separator}+/ug }, { "name": "Z", "regex": /\p{gc=Z}+/ug }, { "name": "Separator", "regex": /\p{gc=Separator}+/ug }, ]; const script = [ { "name": "Adlm", "regex": /\p{sc=Adlm}+/ug }, { "name": "Adlam", "regex": /\p{sc=Adlam}+/ug }, { "name": "Aghb", "regex": /\p{sc=Aghb}+/ug }, { "name": "Caucasian_Albanian", "regex": /\p{sc=Caucasian_Albanian}+/ug }, { "name": "Ahom", "regex": /\p{sc=Ahom}+/ug }, { "name": "Arab", "regex": /\p{sc=Arab}+/ug }, { "name": "Arabic", "regex": /\p{sc=Arabic}+/ug }, { "name": "Armi", "regex": /\p{sc=Armi}+/ug }, { "name": "Imperial_Aramaic", "regex": /\p{sc=Imperial_Aramaic}+/ug }, { "name": "Armn", "regex": /\p{sc=Armn}+/ug }, { "name": "Armenian", "regex": /\p{sc=Armenian}+/ug }, { "name": "Avst", "regex": /\p{sc=Avst}+/ug }, { "name": "Avestan", "regex": /\p{sc=Avestan}+/ug }, { "name": "Bali", "regex": /\p{sc=Bali}+/ug }, { "name": "Balinese", "regex": /\p{sc=Balinese}+/ug }, { "name": "Bamu", "regex": /\p{sc=Bamu}+/ug }, { "name": "Bamum", "regex": /\p{sc=Bamum}+/ug }, { "name": "Bass", "regex": /\p{sc=Bass}+/ug }, { "name": "Bassa_Vah", "regex": /\p{sc=Bassa_Vah}+/ug }, { "name": "Batk", "regex": /\p{sc=Batk}+/ug }, { "name": "Batak", "regex": /\p{sc=Batak}+/ug }, { "name": "Beng", "regex": /\p{sc=Beng}+/ug }, { "name": "Bengali", "regex": /\p{sc=Bengali}+/ug }, { "name": "Bhks", "regex": /\p{sc=Bhks}+/ug }, { "name": "Bhaiksuki", "regex": /\p{sc=Bhaiksuki}+/ug }, { "name": "Bopo", "regex": /\p{sc=Bopo}+/ug }, { "name": "Bopomofo", "regex": /\p{sc=Bopomofo}+/ug }, { "name": "Brah", "regex": /\p{sc=Brah}+/ug }, { "name": "Brahmi", "regex": /\p{sc=Brahmi}+/ug }, { "name": "Brai", "regex": /\p{sc=Brai}+/ug }, { "name": "Braille", "regex": /\p{sc=Braille}+/ug }, { "name": "Bugi", "regex": /\p{sc=Bugi}+/ug }, { "name": "Buginese", "regex": /\p{sc=Buginese}+/ug }, { "name": "Buhd", "regex": /\p{sc=Buhd}+/ug }, { "name": "Buhid", "regex": /\p{sc=Buhid}+/ug }, { "name": "Cakm", "regex": /\p{sc=Cakm}+/ug }, { "name": "Chakma", "regex": /\p{sc=Chakma}+/ug }, { "name": "Cans", "regex": /\p{sc=Cans}+/ug }, { "name": "Canadian_Aboriginal", "regex": /\p{sc=Canadian_Aboriginal}+/ug }, { "name": "Cari", "regex": /\p{sc=Cari}+/ug }, { "name": "Carian", "regex": /\p{sc=Carian}+/ug }, { "name": "Cham", "regex": /\p{sc=Cham}+/ug }, { "name": "Cher", "regex": /\p{sc=Cher}+/ug }, { "name": "Cherokee", "regex": /\p{sc=Cherokee}+/ug }, { "name": "Copt", "regex": /\p{sc=Copt}+/ug }, { "name": "Coptic", "regex": /\p{sc=Coptic}+/ug }, { "name": "Qaac", "regex": /\p{sc=Qaac}+/ug }, { "name": "Cprt", "regex": /\p{sc=Cprt}+/ug }, { "name": "Cypriot", "regex": /\p{sc=Cypriot}+/ug }, { "name": "Cyrl", "regex": /\p{sc=Cyrl}+/ug }, { "name": "Cyrillic", "regex": /\p{sc=Cyrillic}+/ug }, { "name": "Deva", "regex": /\p{sc=Deva}+/ug }, { "name": "Devanagari", "regex": /\p{sc=Devanagari}+/ug }, { "name": "Dogr", "regex": /\p{sc=Dogr}+/ug }, { "name": "Dogra", "regex": /\p{sc=Dogra}+/ug }, { "name": "Dsrt", "regex": /\p{sc=Dsrt}+/ug }, { "name": "Deseret", "regex": /\p{sc=Deseret}+/ug }, { "name": "Dupl", "regex": /\p{sc=Dupl}+/ug }, { "name": "Duployan", "regex": /\p{sc=Duployan}+/ug }, { "name": "Egyp", "regex": /\p{sc=Egyp}+/ug }, { "name": "Egyptian_Hieroglyphs", "regex": /\p{sc=Egyptian_Hieroglyphs}+/ug }, { "name": "Elba", "regex": /\p{sc=Elba}+/ug }, { "name": "Elbasan", "regex": /\p{sc=Elbasan}+/ug }, // { "name": "Elym", "regex": /\p{sc=Elym}+/ug }, // { "name": "Elymaic", "regex": /\p{sc=Elymaic}+/ug }, { "name": "Ethi", "regex": /\p{sc=Ethi}+/ug }, { "name": "Ethiopic", "regex": /\p{sc=Ethiopic}+/ug }, { "name": "Geor", "regex": /\p{sc=Geor}+/ug }, { "name": "Georgian", "regex": /\p{sc=Georgian}+/ug }, { "name": "Glag", "regex": /\p{sc=Glag}+/ug }, { "name": "Glagolitic", "regex": /\p{sc=Glagolitic}+/ug }, { "name": "Gong", "regex": /\p{sc=Gong}+/ug }, { "name": "Gunjala_Gondi", "regex": /\p{sc=Gunjala_Gondi}+/ug }, { "name": "Gonm", "regex": /\p{sc=Gonm}+/ug }, { "name": "Masaram_Gondi", "regex": /\p{sc=Masaram_Gondi}+/ug }, { "name": "Goth", "regex": /\p{sc=Goth}+/ug }, { "name": "Gothic", "regex": /\p{sc=Gothic}+/ug }, { "name": "Gran", "regex": /\p{sc=Gran}+/ug }, { "name": "Grantha", "regex": /\p{sc=Grantha}+/ug }, { "name": "Grek", "regex": /\p{sc=Grek}+/ug }, { "name": "Greek", "regex": /\p{sc=Greek}+/ug }, { "name": "Gujr", "regex": /\p{sc=Gujr}+/ug }, { "name": "Gujarati", "regex": /\p{sc=Gujarati}+/ug }, { "name": "Guru", "regex": /\p{sc=Guru}+/ug }, { "name": "Gurmukhi", "regex": /\p{sc=Gurmukhi}+/ug }, { "name": "Hang", "regex": /\p{sc=Hang}+/ug }, { "name": "Hangul", "regex": /\p{sc=Hangul}+/ug }, { "name": "Hani", "regex": /\p{sc=Hani}+/ug }, { "name": "Han", "regex": /\p{sc=Han}+/ug }, { "name": "Hano", "regex": /\p{sc=Hano}+/ug }, { "name": "Hanunoo", "regex": /\p{sc=Hanunoo}+/ug }, { "name": "Hatr", "regex": /\p{sc=Hatr}+/ug }, { "name": "Hatran", "regex": /\p{sc=Hatran}+/ug }, { "name": "Hebr", "regex": /\p{sc=Hebr}+/ug }, { "name": "Hebrew", "regex": /\p{sc=Hebrew}+/ug }, { "name": "Hira", "regex": /\p{sc=Hira}+/ug }, { "name": "Hiragana", "regex": /\p{sc=Hiragana}+/ug }, { "name": "Hluw", "regex": /\p{sc=Hluw}+/ug }, { "name": "Anatolian_Hieroglyphs", "regex": /\p{sc=Anatolian_Hieroglyphs}+/ug }, { "name": "Hmng", "regex": /\p{sc=Hmng}+/ug }, { "name": "Pahawh_Hmong", "regex": /\p{sc=Pahawh_Hmong}+/ug }, // { "name": "Hmnp", "regex": /\p{sc=Hmnp}+/ug }, // { "name": "Nyiakeng_Puachue_Hmong", "regex": /\p{sc=Nyiakeng_Puachue_Hmong}+/ug }, // { "name": "Hrkt", "regex": /\p{sc=Hrkt}+/ug }, // { "name": "Katakana_Or_Hiragana", "regex": /\p{sc=Katakana_Or_Hiragana}+/ug }, { "name": "Hung", "regex": /\p{sc=Hung}+/ug }, { "name": "Old_Hungarian", "regex": /\p{sc=Old_Hungarian}+/ug }, { "name": "Ital", "regex": /\p{sc=Ital}+/ug }, { "name": "Old_Italic", "regex": /\p{sc=Old_Italic}+/ug }, { "name": "Java", "regex": /\p{sc=Java}+/ug }, { "name": "Javanese", "regex": /\p{sc=Javanese}+/ug }, { "name": "Kali", "regex": /\p{sc=Kali}+/ug }, { "name": "Kayah_Li", "regex": /\p{sc=Kayah_Li}+/ug }, { "name": "Kana", "regex": /\p{sc=Kana}+/ug }, { "name": "Katakana", "regex": /\p{sc=Katakana}+/ug }, { "name": "Khar", "regex": /\p{sc=Khar}+/ug }, { "name": "Kharoshthi", "regex": /\p{sc=Kharoshthi}+/ug }, { "name": "Khmr", "regex": /\p{sc=Khmr}+/ug }, { "name": "Khmer", "regex": /\p{sc=Khmer}+/ug }, { "name": "Khoj", "regex": /\p{sc=Khoj}+/ug }, { "name": "Khojki", "regex": /\p{sc=Khojki}+/ug }, { "name": "Knda", "regex": /\p{sc=Knda}+/ug }, { "name": "Kannada", "regex": /\p{sc=Kannada}+/ug }, { "name": "Kthi", "regex": /\p{sc=Kthi}+/ug }, { "name": "Kaithi", "regex": /\p{sc=Kaithi}+/ug }, { "name": "Lana", "regex": /\p{sc=Lana}+/ug }, { "name": "Tai_Tham", "regex": /\p{sc=Tai_Tham}+/ug }, { "name": "Laoo", "regex": /\p{sc=Laoo}+/ug }, { "name": "Lao", "regex": /\p{sc=Lao}+/ug }, { "name": "Latn", "regex": /\p{sc=Latn}+/ug }, { "name": "Latin", "regex": /\p{sc=Latin}+/ug }, { "name": "Lepc", "regex": /\p{sc=Lepc}+/ug }, { "name": "Lepcha", "regex": /\p{sc=Lepcha}+/ug }, { "name": "Limb", "regex": /\p{sc=Limb}+/ug }, { "name": "Limbu", "regex": /\p{sc=Limbu}+/ug }, { "name": "Lina", "regex": /\p{sc=Lina}+/ug }, { "name": "Linear_A", "regex": /\p{sc=Linear_A}+/ug }, { "name": "Linb", "regex": /\p{sc=Linb}+/ug }, { "name": "Linear_B", "regex": /\p{sc=Linear_B}+/ug }, { "name": "Lisu", "regex": /\p{sc=Lisu}+/ug }, { "name": "Lyci", "regex": /\p{sc=Lyci}+/ug }, { "name": "Lycian", "regex": /\p{sc=Lycian}+/ug }, { "name": "Lydi", "regex": /\p{sc=Lydi}+/ug }, { "name": "Lydian", "regex": /\p{sc=Lydian}+/ug }, { "name": "Mahj", "regex": /\p{sc=Mahj}+/ug }, { "name": "Mahajani", "regex": /\p{sc=Mahajani}+/ug }, { "name": "Maka", "regex": /\p{sc=Maka}+/ug }, { "name": "Makasar", "regex": /\p{sc=Makasar}+/ug }, { "name": "Mand", "regex": /\p{sc=Mand}+/ug }, { "name": "Mandaic", "regex": /\p{sc=Mandaic}+/ug }, { "name": "Mani", "regex": /\p{sc=Mani}+/ug }, { "name": "Manichaean", "regex": /\p{sc=Manichaean}+/ug }, { "name": "Marc", "regex": /\p{sc=Marc}+/ug }, { "name": "Marchen", "regex": /\p{sc=Marchen}+/ug }, { "name": "Medf", "regex": /\p{sc=Medf}+/ug }, { "name": "Medefaidrin", "regex": /\p{sc=Medefaidrin}+/ug }, { "name": "Mend", "regex": /\p{sc=Mend}+/ug }, { "name": "Mende_Kikakui", "regex": /\p{sc=Mende_Kikakui}+/ug }, { "name": "Merc", "regex": /\p{sc=Merc}+/ug }, { "name": "Meroitic_Cursive", "regex": /\p{sc=Meroitic_Cursive}+/ug }, { "name": "Mero", "regex": /\p{sc=Mero}+/ug }, { "name": "Meroitic_Hieroglyphs", "regex": /\p{sc=Meroitic_Hieroglyphs}+/ug }, { "name": "Mlym", "regex": /\p{sc=Mlym}+/ug }, { "name": "Malayalam", "regex": /\p{sc=Malayalam}+/ug }, { "name": "Modi", "regex": /\p{sc=Modi}+/ug }, { "name": "Mong", "regex": /\p{sc=Mong}+/ug }, { "name": "Mongolian", "regex": /\p{sc=Mongolian}+/ug }, { "name": "Mroo", "regex": /\p{sc=Mroo}+/ug }, { "name": "Mro", "regex": /\p{sc=Mro}+/ug }, { "name": "Mtei", "regex": /\p{sc=Mtei}+/ug }, { "name": "Meetei_Mayek", "regex": /\p{sc=Meetei_Mayek}+/ug }, { "name": "Mult", "regex": /\p{sc=Mult}+/ug }, { "name": "Multani", "regex": /\p{sc=Multani}+/ug }, { "name": "Mymr", "regex": /\p{sc=Mymr}+/ug }, { "name": "Myanmar", "regex": /\p{sc=Myanmar}+/ug }, // { "name": "Nand", "regex": /\p{sc=Nand}+/ug }, // { "name": "Nandinagari", "regex": /\p{sc=Nandinagari}+/ug }, { "name": "Narb", "regex": /\p{sc=Narb}+/ug }, { "name": "Old_North_Arabian", "regex": /\p{sc=Old_North_Arabian}+/ug }, { "name": "Nbat", "regex": /\p{sc=Nbat}+/ug }, { "name": "Nabataean", "regex": /\p{sc=Nabataean}+/ug }, { "name": "Newa", "regex": /\p{sc=Newa}+/ug }, { "name": "Nkoo", "regex": /\p{sc=Nkoo}+/ug }, { "name": "Nko", "regex": /\p{sc=Nko}+/ug }, { "name": "Nshu", "regex": /\p{sc=Nshu}+/ug }, { "name": "Nushu", "regex": /\p{sc=Nushu}+/ug }, { "name": "Ogam", "regex": /\p{sc=Ogam}+/ug }, { "name": "Ogham", "regex": /\p{sc=Ogham}+/ug }, { "name": "Olck", "regex": /\p{sc=Olck}+/ug }, { "name": "Ol_Chiki", "regex": /\p{sc=Ol_Chiki}+/ug }, { "name": "Orkh", "regex": /\p{sc=Orkh}+/ug }, { "name": "Old_Turkic", "regex": /\p{sc=Old_Turkic}+/ug }, { "name": "Orya", "regex": /\p{sc=Orya}+/ug }, { "name": "Oriya", "regex": /\p{sc=Oriya}+/ug }, { "name": "Osge", "regex": /\p{sc=Osge}+/ug }, { "name": "Osage", "regex": /\p{sc=Osage}+/ug }, { "name": "Osma", "regex": /\p{sc=Osma}+/ug }, { "name": "Osmanya", "regex": /\p{sc=Osmanya}+/ug }, { "name": "Palm", "regex": /\p{sc=Palm}+/ug }, { "name": "Palmyrene", "regex": /\p{sc=Palmyrene}+/ug }, { "name": "Pauc", "regex": /\p{sc=Pauc}+/ug }, { "name": "Pau_Cin_Hau", "regex": /\p{sc=Pau_Cin_Hau}+/ug }, { "name": "Perm", "regex": /\p{sc=Perm}+/ug }, { "name": "Old_Permic", "regex": /\p{sc=Old_Permic}+/ug }, { "name": "Phag", "regex": /\p{sc=Phag}+/ug }, { "name": "Phags_Pa", "regex": /\p{sc=Phags_Pa}+/ug }, { "name": "Phli", "regex": /\p{sc=Phli}+/ug }, { "name": "Inscriptional_Pahlavi", "regex": /\p{sc=Inscriptional_Pahlavi}+/ug }, { "name": "Phlp", "regex": /\p{sc=Phlp}+/ug }, { "name": "Psalter_Pahlavi", "regex": /\p{sc=Psalter_Pahlavi}+/ug }, { "name": "Phnx", "regex": /\p{sc=Phnx}+/ug }, { "name": "Phoenician", "regex": /\p{sc=Phoenician}+/ug }, { "name": "Plrd", "regex": /\p{sc=Plrd}+/ug }, { "name": "Miao", "regex": /\p{sc=Miao}+/ug }, { "name": "Prti", "regex": /\p{sc=Prti}+/ug }, { "name": "Inscriptional_Parthian", "regex": /\p{sc=Inscriptional_Parthian}+/ug }, { "name": "Rjng", "regex": /\p{sc=Rjng}+/ug }, { "name": "Rejang", "regex": /\p{sc=Rejang}+/ug }, { "name": "Rohg", "regex": /\p{sc=Rohg}+/ug }, { "name": "Hanifi_Rohingya", "regex": /\p{sc=Hanifi_Rohingya}+/ug }, { "name": "Runr", "regex": /\p{sc=Runr}+/ug }, { "name": "Runic", "regex": /\p{sc=Runic}+/ug }, { "name": "Samr", "regex": /\p{sc=Samr}+/ug }, { "name": "Samaritan", "regex": /\p{sc=Samaritan}+/ug }, { "name": "Sarb", "regex": /\p{sc=Sarb}+/ug }, { "name": "Old_South_Arabian", "regex": /\p{sc=Old_South_Arabian}+/ug }, { "name": "Saur", "regex": /\p{sc=Saur}+/ug }, { "name": "Saurashtra", "regex": /\p{sc=Saurashtra}+/ug }, { "name": "Sgnw", "regex": /\p{sc=Sgnw}+/ug }, { "name": "SignWriting", "regex": /\p{sc=SignWriting}+/ug }, { "name": "Shaw", "regex": /\p{sc=Shaw}+/ug }, { "name": "Shavian", "regex": /\p{sc=Shavian}+/ug }, { "name": "Shrd", "regex": /\p{sc=Shrd}+/ug }, { "name": "Sharada", "regex": /\p{sc=Sharada}+/ug }, { "name": "Sidd", "regex": /\p{sc=Sidd}+/ug }, { "name": "Siddham", "regex": /\p{sc=Siddham}+/ug }, { "name": "Sind", "regex": /\p{sc=Sind}+/ug }, { "name": "Khudawadi", "regex": /\p{sc=Khudawadi}+/ug }, { "name": "Sinh", "regex": /\p{sc=Sinh}+/ug }, { "name": "Sinhala", "regex": /\p{sc=Sinhala}+/ug }, { "name": "Sogd", "regex": /\p{sc=Sogd}+/ug }, { "name": "Sogdian", "regex": /\p{sc=Sogdian}+/ug }, { "name": "Sogo", "regex": /\p{sc=Sogo}+/ug }, { "name": "Old_Sogdian", "regex": /\p{sc=Old_Sogdian}+/ug }, { "name": "Sora", "regex": /\p{sc=Sora}+/ug }, { "name": "Sora_Sompeng", "regex": /\p{sc=Sora_Sompeng}+/ug }, { "name": "Soyo", "regex": /\p{sc=Soyo}+/ug }, { "name": "Soyombo", "regex": /\p{sc=Soyombo}+/ug }, { "name": "Sund", "regex": /\p{sc=Sund}+/ug }, { "name": "Sundanese", "regex": /\p{sc=Sundanese}+/ug }, { "name": "Sylo", "regex": /\p{sc=Sylo}+/ug }, { "name": "Syloti_Nagri", "regex": /\p{sc=Syloti_Nagri}+/ug }, { "name": "Syrc", "regex": /\p{sc=Syrc}+/ug }, { "name": "Syriac", "regex": /\p{sc=Syriac}+/ug }, { "name": "Tagb", "regex": /\p{sc=Tagb}+/ug }, { "name": "Tagbanwa", "regex": /\p{sc=Tagbanwa}+/ug }, { "name": "Takr", "regex": /\p{sc=Takr}+/ug }, { "name": "Takri", "regex": /\p{sc=Takri}+/ug }, { "name": "Tale", "regex": /\p{sc=Tale}+/ug }, { "name": "Tai_Le", "regex": /\p{sc=Tai_Le}+/ug }, { "name": "Talu", "regex": /\p{sc=Talu}+/ug }, { "name": "New_Tai_Lue", "regex": /\p{sc=New_Tai_Lue}+/ug }, { "name": "Taml", "regex": /\p{sc=Taml}+/ug }, { "name": "Tamil", "regex": /\p{sc=Tamil}+/ug }, { "name": "Tang", "regex": /\p{sc=Tang}+/ug }, { "name": "Tangut", "regex": /\p{sc=Tangut}+/ug }, { "name": "Tavt", "regex": /\p{sc=Tavt}+/ug }, { "name": "Tai_Viet", "regex": /\p{sc=Tai_Viet}+/ug }, { "name": "Telu", "regex": /\p{sc=Telu}+/ug }, { "name": "Telugu", "regex": /\p{sc=Telugu}+/ug }, { "name": "Tfng", "regex": /\p{sc=Tfng}+/ug }, { "name": "Tifinagh", "regex": /\p{sc=Tifinagh}+/ug }, { "name": "Tglg", "regex": /\p{sc=Tglg}+/ug }, { "name": "Tagalog", "regex": /\p{sc=Tagalog}+/ug }, { "name": "Thaa", "regex": /\p{sc=Thaa}+/ug }, { "name": "Thaana", "regex": /\p{sc=Thaana}+/ug }, { "name": "Thai", "regex": /\p{sc=Thai}+/ug }, { "name": "Tibt", "regex": /\p{sc=Tibt}+/ug }, { "name": "Tibetan", "regex": /\p{sc=Tibetan}+/ug }, { "name": "Tirh", "regex": /\p{sc=Tirh}+/ug }, { "name": "Tirhuta", "regex": /\p{sc=Tirhuta}+/ug }, { "name": "Ugar", "regex": /\p{sc=Ugar}+/ug }, { "name": "Ugaritic", "regex": /\p{sc=Ugaritic}+/ug }, { "name": "Vaii", "regex": /\p{sc=Vaii}+/ug }, { "name": "Vai", "regex": /\p{sc=Vai}+/ug }, { "name": "Wara", "regex": /\p{sc=Wara}+/ug }, { "name": "Warang_Citi", "regex": /\p{sc=Warang_Citi}+/ug }, // { "name": "Wcho", "regex": /\p{sc=Wcho}+/ug }, // { "name": "Wancho", "regex": /\p{sc=Wancho}+/ug }, { "name": "Xpeo", "regex": /\p{sc=Xpeo}+/ug }, { "name": "Old_Persian", "regex": /\p{sc=Old_Persian}+/ug }, { "name": "Xsux", "regex": /\p{sc=Xsux}+/ug }, { "name": "Cuneiform", "regex": /\p{sc=Cuneiform}+/ug }, { "name": "Yiii", "regex": /\p{sc=Yiii}+/ug }, { "name": "Yi", "regex": /\p{sc=Yi}+/ug }, { "name": "Zanb", "regex": /\p{sc=Zanb}+/ug }, { "name": "Zanabazar_Square", "regex": /\p{sc=Zanabazar_Square}+/ug }, { "name": "Zinh", "regex": /\p{sc=Zinh}+/ug }, { "name": "Inherited", "regex": /\p{sc=Inherited}+/ug }, { "name": "Qaai", "regex": /\p{sc=Qaai}+/ug }, { "name": "Zyyy", "regex": /\p{sc=Zyyy}+/ug }, { "name": "Common", "regex": /\p{sc=Common}+/ug }, { "name": "Zzzz", "regex": /\p{sc=Zzzz}+/ug }, { "name": "Unknown", "regex": /\p{sc=Unknown}+/ug }, ]; const scriptExtensions = [ { "name": "Adlm", "regex": /\p{scx=Adlm}+/ug }, { "name": "Adlam", "regex": /\p{scx=Adlam}+/ug }, { "name": "Aghb", "regex": /\p{scx=Aghb}+/ug }, { "name": "Caucasian_Albanian", "regex": /\p{scx=Caucasian_Albanian}+/ug }, { "name": "Ahom", "regex": /\p{scx=Ahom}+/ug }, { "name": "Arab", "regex": /\p{scx=Arab}+/ug }, { "name": "Arabic", "regex": /\p{scx=Arabic}+/ug }, { "name": "Armi", "regex": /\p{scx=Armi}+/ug }, { "name": "Imperial_Aramaic", "regex": /\p{scx=Imperial_Aramaic}+/ug }, { "name": "Armn", "regex": /\p{scx=Armn}+/ug }, { "name": "Armenian", "regex": /\p{scx=Armenian}+/ug }, { "name": "Avst", "regex": /\p{scx=Avst}+/ug }, { "name": "Avestan", "regex": /\p{scx=Avestan}+/ug }, { "name": "Bali", "regex": /\p{scx=Bali}+/ug }, { "name": "Balinese", "regex": /\p{scx=Balinese}+/ug }, { "name": "Bamu", "regex": /\p{scx=Bamu}+/ug }, { "name": "Bamum", "regex": /\p{scx=Bamum}+/ug }, { "name": "Bass", "regex": /\p{scx=Bass}+/ug }, { "name": "Bassa_Vah", "regex": /\p{scx=Bassa_Vah}+/ug }, { "name": "Batk", "regex": /\p{scx=Batk}+/ug }, { "name": "Batak", "regex": /\p{scx=Batak}+/ug }, { "name": "Beng", "regex": /\p{scx=Beng}+/ug }, { "name": "Bengali", "regex": /\p{scx=Bengali}+/ug }, { "name": "Bhks", "regex": /\p{scx=Bhks}+/ug }, { "name": "Bhaiksuki", "regex": /\p{scx=Bhaiksuki}+/ug }, { "name": "Bopo", "regex": /\p{scx=Bopo}+/ug }, { "name": "Bopomofo", "regex": /\p{scx=Bopomofo}+/ug }, { "name": "Brah", "regex": /\p{scx=Brah}+/ug }, { "name": "Brahmi", "regex": /\p{scx=Brahmi}+/ug }, { "name": "Brai", "regex": /\p{scx=Brai}+/ug }, { "name": "Braille", "regex": /\p{scx=Braille}+/ug }, { "name": "Bugi", "regex": /\p{scx=Bugi}+/ug }, { "name": "Buginese", "regex": /\p{scx=Buginese}+/ug }, { "name": "Buhd", "regex": /\p{scx=Buhd}+/ug }, { "name": "Buhid", "regex": /\p{scx=Buhid}+/ug }, { "name": "Cakm", "regex": /\p{scx=Cakm}+/ug }, { "name": "Chakma", "regex": /\p{scx=Chakma}+/ug }, { "name": "Cans", "regex": /\p{scx=Cans}+/ug }, { "name": "Canadian_Aboriginal", "regex": /\p{scx=Canadian_Aboriginal}+/ug }, { "name": "Cari", "regex": /\p{scx=Cari}+/ug }, { "name": "Carian", "regex": /\p{scx=Carian}+/ug }, { "name": "Cham", "regex": /\p{scx=Cham}+/ug }, { "name": "Cher", "regex": /\p{scx=Cher}+/ug }, { "name": "Cherokee", "regex": /\p{scx=Cherokee}+/ug }, { "name": "Copt", "regex": /\p{scx=Copt}+/ug }, { "name": "Coptic", "regex": /\p{scx=Coptic}+/ug }, { "name": "Qaac", "regex": /\p{scx=Qaac}+/ug }, { "name": "Cprt", "regex": /\p{scx=Cprt}+/ug }, { "name": "Cypriot", "regex": /\p{scx=Cypriot}+/ug }, { "name": "Cyrl", "regex": /\p{scx=Cyrl}+/ug }, { "name": "Cyrillic", "regex": /\p{scx=Cyrillic}+/ug }, { "name": "Deva", "regex": /\p{scx=Deva}+/ug }, { "name": "Devanagari", "regex": /\p{scx=Devanagari}+/ug }, { "name": "Dogr", "regex": /\p{scx=Dogr}+/ug }, { "name": "Dogra", "regex": /\p{scx=Dogra}+/ug }, { "name": "Dsrt", "regex": /\p{scx=Dsrt}+/ug }, { "name": "Deseret", "regex": /\p{scx=Deseret}+/ug }, { "name": "Dupl", "regex": /\p{scx=Dupl}+/ug }, { "name": "Duployan", "regex": /\p{scx=Duployan}+/ug }, { "name": "Egyp", "regex": /\p{scx=Egyp}+/ug }, { "name": "Egyptian_Hieroglyphs", "regex": /\p{scx=Egyptian_Hieroglyphs}+/ug }, { "name": "Elba", "regex": /\p{scx=Elba}+/ug }, { "name": "Elbasan", "regex": /\p{scx=Elbasan}+/ug }, // { "name": "Elym", "regex": /\p{scx=Elym}+/ug }, // { "name": "Elymaic", "regex": /\p{scx=Elymaic}+/ug }, { "name": "Ethi", "regex": /\p{scx=Ethi}+/ug }, { "name": "Ethiopic", "regex": /\p{scx=Ethiopic}+/ug }, { "name": "Geor", "regex": /\p{scx=Geor}+/ug }, { "name": "Georgian", "regex": /\p{scx=Georgian}+/ug }, { "name": "Glag", "regex": /\p{scx=Glag}+/ug }, { "name": "Glagolitic", "regex": /\p{scx=Glagolitic}+/ug }, { "name": "Gong", "regex": /\p{scx=Gong}+/ug }, { "name": "Gunjala_Gondi", "regex": /\p{scx=Gunjala_Gondi}+/ug }, { "name": "Gonm", "regex": /\p{scx=Gonm}+/ug }, { "name": "Masaram_Gondi", "regex": /\p{scx=Masaram_Gondi}+/ug }, { "name": "Goth", "regex": /\p{scx=Goth}+/ug }, { "name": "Gothic", "regex": /\p{scx=Gothic}+/ug }, { "name": "Gran", "regex": /\p{scx=Gran}+/ug }, { "name": "Grantha", "regex": /\p{scx=Grantha}+/ug }, { "name": "Grek", "regex": /\p{scx=Grek}+/ug }, { "name": "Greek", "regex": /\p{scx=Greek}+/ug }, { "name": "Gujr", "regex": /\p{scx=Gujr}+/ug }, { "name": "Gujarati", "regex": /\p{scx=Gujarati}+/ug }, { "name": "Guru", "regex": /\p{scx=Guru}+/ug }, { "name": "Gurmukhi", "regex": /\p{scx=Gurmukhi}+/ug }, { "name": "Hang", "regex": /\p{scx=Hang}+/ug }, { "name": "Hangul", "regex": /\p{scx=Hangul}+/ug }, { "name": "Hani", "regex": /\p{scx=Hani}+/ug }, { "name": "Han", "regex": /\p{scx=Han}+/ug }, { "name": "Hano", "regex": /\p{scx=Hano}+/ug }, { "name": "Hanunoo", "regex": /\p{scx=Hanunoo}+/ug }, { "name": "Hatr", "regex": /\p{scx=Hatr}+/ug }, { "name": "Hatran", "regex": /\p{scx=Hatran}+/ug }, { "name": "Hebr", "regex": /\p{scx=Hebr}+/ug }, { "name": "Hebrew", "regex": /\p{scx=Hebrew}+/ug }, { "name": "Hira", "regex": /\p{scx=Hira}+/ug }, { "name": "Hiragana", "regex": /\p{scx=Hiragana}+/ug }, { "name": "Hluw", "regex": /\p{scx=Hluw}+/ug }, { "name": "Anatolian_Hieroglyphs", "regex": /\p{scx=Anatolian_Hieroglyphs}+/ug }, { "name": "Hmng", "regex": /\p{scx=Hmng}+/ug }, { "name": "Pahawh_Hmong", "regex": /\p{scx=Pahawh_Hmong}+/ug }, // { "name": "Hmnp", "regex": /\p{scx=Hmnp}+/ug }, // { "name": "Nyiakeng_Puachue_Hmong", "regex": /\p{scx=Nyiakeng_Puachue_Hmong}+/ug }, // { "name": "Hrkt", "regex": /\p{scx=Hrkt}+/ug }, // { "name": "Katakana_Or_Hiragana", "regex": /\p{scx=Katakana_Or_Hiragana}+/ug }, { "name": "Hung", "regex": /\p{scx=Hung}+/ug }, { "name": "Old_Hungarian", "regex": /\p{scx=Old_Hungarian}+/ug }, { "name": "Ital", "regex": /\p{scx=Ital}+/ug }, { "name": "Old_Italic", "regex": /\p{scx=Old_Italic}+/ug }, { "name": "Java", "regex": /\p{scx=Java}+/ug }, { "name": "Javanese", "regex": /\p{scx=Javanese}+/ug }, { "name": "Kali", "regex": /\p{scx=Kali}+/ug }, { "name": "Kayah_Li", "regex": /\p{scx=Kayah_Li}+/ug }, { "name": "Kana", "regex": /\p{scx=Kana}+/ug }, { "name": "Katakana", "regex": /\p{scx=Katakana}+/ug }, { "name": "Khar", "regex": /\p{scx=Khar}+/ug }, { "name": "Kharoshthi", "regex": /\p{scx=Kharoshthi}+/ug }, { "name": "Khmr", "regex": /\p{scx=Khmr}+/ug }, { "name": "Khmer", "regex": /\p{scx=Khmer}+/ug }, { "name": "Khoj", "regex": /\p{scx=Khoj}+/ug }, { "name": "Khojki", "regex": /\p{scx=Khojki}+/ug }, { "name": "Knda", "regex": /\p{scx=Knda}+/ug }, { "name": "Kannada", "regex": /\p{scx=Kannada}+/ug }, { "name": "Kthi", "regex": /\p{scx=Kthi}+/ug }, { "name": "Kaithi", "regex": /\p{scx=Kaithi}+/ug }, { "name": "Lana", "regex": /\p{scx=Lana}+/ug }, { "name": "Tai_Tham", "regex": /\p{scx=Tai_Tham}+/ug }, { "name": "Laoo", "regex": /\p{scx=Laoo}+/ug }, { "name": "Lao", "regex": /\p{scx=Lao}+/ug }, { "name": "Latn", "regex": /\p{scx=Latn}+/ug }, { "name": "Latin", "regex": /\p{scx=Latin}+/ug }, { "name": "Lepc", "regex": /\p{scx=Lepc}+/ug }, { "name": "Lepcha", "regex": /\p{scx=Lepcha}+/ug }, { "name": "Limb", "regex": /\p{scx=Limb}+/ug }, { "name": "Limbu", "regex": /\p{scx=Limbu}+/ug }, { "name": "Lina", "regex": /\p{scx=Lina}+/ug }, { "name": "Linear_A", "regex": /\p{scx=Linear_A}+/ug }, { "name": "Linb", "regex": /\p{scx=Linb}+/ug }, { "name": "Linear_B", "regex": /\p{scx=Linear_B}+/ug }, { "name": "Lisu", "regex": /\p{scx=Lisu}+/ug }, { "name": "Lyci", "regex": /\p{scx=Lyci}+/ug }, { "name": "Lycian", "regex": /\p{scx=Lycian}+/ug }, { "name": "Lydi", "regex": /\p{scx=Lydi}+/ug }, { "name": "Lydian", "regex": /\p{scx=Lydian}+/ug }, { "name": "Mahj", "regex": /\p{scx=Mahj}+/ug }, { "name": "Mahajani", "regex": /\p{scx=Mahajani}+/ug }, { "name": "Maka", "regex": /\p{scx=Maka}+/ug }, { "name": "Makasar", "regex": /\p{scx=Makasar}+/ug }, { "name": "Mand", "regex": /\p{scx=Mand}+/ug }, { "name": "Mandaic", "regex": /\p{scx=Mandaic}+/ug }, { "name": "Mani", "regex": /\p{scx=Mani}+/ug }, { "name": "Manichaean", "regex": /\p{scx=Manichaean}+/ug }, { "name": "Marc", "regex": /\p{scx=Marc}+/ug }, { "name": "Marchen", "regex": /\p{scx=Marchen}+/ug }, { "name": "Medf", "regex": /\p{scx=Medf}+/ug }, { "name": "Medefaidrin", "regex": /\p{scx=Medefaidrin}+/ug }, { "name": "Mend", "regex": /\p{scx=Mend}+/ug }, { "name": "Mende_Kikakui", "regex": /\p{scx=Mende_Kikakui}+/ug }, { "name": "Merc", "regex": /\p{scx=Merc}+/ug }, { "name": "Meroitic_Cursive", "regex": /\p{scx=Meroitic_Cursive}+/ug }, { "name": "Mero", "regex": /\p{scx=Mero}+/ug }, { "name": "Meroitic_Hieroglyphs", "regex": /\p{scx=Meroitic_Hieroglyphs}+/ug }, { "name": "Mlym", "regex": /\p{scx=Mlym}+/ug }, { "name": "Malayalam", "regex": /\p{scx=Malayalam}+/ug }, { "name": "Modi", "regex": /\p{scx=Modi}+/ug }, { "name": "Mong", "regex": /\p{scx=Mong}+/ug }, { "name": "Mongolian", "regex": /\p{scx=Mongolian}+/ug }, { "name": "Mroo", "regex": /\p{scx=Mroo}+/ug }, { "name": "Mro", "regex": /\p{scx=Mro}+/ug }, { "name": "Mtei", "regex": /\p{scx=Mtei}+/ug }, { "name": "Meetei_Mayek", "regex": /\p{scx=Meetei_Mayek}+/ug }, { "name": "Mult", "regex": /\p{scx=Mult}+/ug }, { "name": "Multani", "regex": /\p{scx=Multani}+/ug }, { "name": "Mymr", "regex": /\p{scx=Mymr}+/ug }, { "name": "Myanmar", "regex": /\p{scx=Myanmar}+/ug }, // { "name": "Nand", "regex": /\p{scx=Nand}+/ug }, // { "name": "Nandinagari", "regex": /\p{scx=Nandinagari}+/ug }, { "name": "Narb", "regex": /\p{scx=Narb}+/ug }, { "name": "Old_North_Arabian", "regex": /\p{scx=Old_North_Arabian}+/ug }, { "name": "Nbat", "regex": /\p{scx=Nbat}+/ug }, { "name": "Nabataean", "regex": /\p{scx=Nabataean}+/ug }, { "name": "Newa", "regex": /\p{scx=Newa}+/ug }, { "name": "Nkoo", "regex": /\p{scx=Nkoo}+/ug }, { "name": "Nko", "regex": /\p{scx=Nko}+/ug }, { "name": "Nshu", "regex": /\p{scx=Nshu}+/ug }, { "name": "Nushu", "regex": /\p{scx=Nushu}+/ug }, { "name": "Ogam", "regex": /\p{scx=Ogam}+/ug }, { "name": "Ogham", "regex": /\p{scx=Ogham}+/ug }, { "name": "Olck", "regex": /\p{scx=Olck}+/ug }, { "name": "Ol_Chiki", "regex": /\p{scx=Ol_Chiki}+/ug }, { "name": "Orkh", "regex": /\p{scx=Orkh}+/ug }, { "name": "Old_Turkic", "regex": /\p{scx=Old_Turkic}+/ug }, { "name": "Orya", "regex": /\p{scx=Orya}+/ug }, { "name": "Oriya", "regex": /\p{scx=Oriya}+/ug }, { "name": "Osge", "regex": /\p{scx=Osge}+/ug }, { "name": "Osage", "regex": /\p{scx=Osage}+/ug }, { "name": "Osma", "regex": /\p{scx=Osma}+/ug }, { "name": "Osmanya", "regex": /\p{scx=Osmanya}+/ug }, { "name": "Palm", "regex": /\p{scx=Palm}+/ug }, { "name": "Palmyrene", "regex": /\p{scx=Palmyrene}+/ug }, { "name": "Pauc", "regex": /\p{scx=Pauc}+/ug }, { "name": "Pau_Cin_Hau", "regex": /\p{scx=Pau_Cin_Hau}+/ug }, { "name": "Perm", "regex": /\p{scx=Perm}+/ug }, { "name": "Old_Permic", "regex": /\p{scx=Old_Permic}+/ug }, { "name": "Phag", "regex": /\p{scx=Phag}+/ug }, { "name": "Phags_Pa", "regex": /\p{scx=Phags_Pa}+/ug }, { "name": "Phli", "regex": /\p{scx=Phli}+/ug }, { "name": "Inscriptional_Pahlavi", "regex": /\p{scx=Inscriptional_Pahlavi}+/ug }, { "name": "Phlp", "regex": /\p{scx=Phlp}+/ug }, { "name": "Psalter_Pahlavi", "regex": /\p{scx=Psalter_Pahlavi}+/ug }, { "name": "Phnx", "regex": /\p{scx=Phnx}+/ug }, { "name": "Phoenician", "regex": /\p{scx=Phoenician}+/ug }, { "name": "Plrd", "regex": /\p{scx=Plrd}+/ug }, { "name": "Miao", "regex": /\p{scx=Miao}+/ug }, { "name": "Prti", "regex": /\p{scx=Prti}+/ug }, { "name": "Inscriptional_Parthian", "regex": /\p{scx=Inscriptional_Parthian}+/ug }, { "name": "Rjng", "regex": /\p{scx=Rjng}+/ug }, { "name": "Rejang", "regex": /\p{scx=Rejang}+/ug }, { "name": "Rohg", "regex": /\p{scx=Rohg}+/ug }, { "name": "Hanifi_Rohingya", "regex": /\p{scx=Hanifi_Rohingya}+/ug }, { "name": "Runr", "regex": /\p{scx=Runr}+/ug }, { "name": "Runic", "regex": /\p{scx=Runic}+/ug }, { "name": "Samr", "regex": /\p{scx=Samr}+/ug }, { "name": "Samaritan", "regex": /\p{scx=Samaritan}+/ug }, { "name": "Sarb", "regex": /\p{scx=Sarb}+/ug }, { "name": "Old_South_Arabian", "regex": /\p{scx=Old_South_Arabian}+/ug }, { "name": "Saur", "regex": /\p{scx=Saur}+/ug }, { "name": "Saurashtra", "regex": /\p{scx=Saurashtra}+/ug }, { "name": "Sgnw", "regex": /\p{scx=Sgnw}+/ug }, { "name": "SignWriting", "regex": /\p{scx=SignWriting}+/ug }, { "name": "Shaw", "regex": /\p{scx=Shaw}+/ug }, { "name": "Shavian", "regex": /\p{scx=Shavian}+/ug }, { "name": "Shrd", "regex": /\p{scx=Shrd}+/ug }, { "name": "Sharada", "regex": /\p{scx=Sharada}+/ug }, { "name": "Sidd", "regex": /\p{scx=Sidd}+/ug }, { "name": "Siddham", "regex": /\p{scx=Siddham}+/ug }, { "name": "Sind", "regex": /\p{scx=Sind}+/ug }, { "name": "Khudawadi", "regex": /\p{scx=Khudawadi}+/ug }, { "name": "Sinh", "regex": /\p{scx=Sinh}+/ug }, { "name": "Sinhala", "regex": /\p{scx=Sinhala}+/ug }, { "name": "Sogd", "regex": /\p{scx=Sogd}+/ug }, { "name": "Sogdian", "regex": /\p{scx=Sogdian}+/ug }, { "name": "Sogo", "regex": /\p{scx=Sogo}+/ug }, { "name": "Old_Sogdian", "regex": /\p{scx=Old_Sogdian}+/ug }, { "name": "Sora", "regex": /\p{scx=Sora}+/ug }, { "name": "Sora_Sompeng", "regex": /\p{scx=Sora_Sompeng}+/ug }, { "name": "Soyo", "regex": /\p{scx=Soyo}+/ug }, { "name": "Soyombo", "regex": /\p{scx=Soyombo}+/ug }, { "name": "Sund", "regex": /\p{scx=Sund}+/ug }, { "name": "Sundanese", "regex": /\p{scx=Sundanese}+/ug }, { "name": "Sylo", "regex": /\p{scx=Sylo}+/ug }, { "name": "Syloti_Nagri", "regex": /\p{scx=Syloti_Nagri}+/ug }, { "name": "Syrc", "regex": /\p{scx=Syrc}+/ug }, { "name": "Syriac", "regex": /\p{scx=Syriac}+/ug }, { "name": "Tagb", "regex": /\p{scx=Tagb}+/ug }, { "name": "Tagbanwa", "regex": /\p{scx=Tagbanwa}+/ug }, { "name": "Takr", "regex": /\p{scx=Takr}+/ug }, { "name": "Takri", "regex": /\p{scx=Takri}+/ug }, { "name": "Tale", "regex": /\p{scx=Tale}+/ug }, { "name": "Tai_Le", "regex": /\p{scx=Tai_Le}+/ug }, { "name": "Talu", "regex": /\p{scx=Talu}+/ug }, { "name": "New_Tai_Lue", "regex": /\p{scx=New_Tai_Lue}+/ug }, { "name": "Taml", "regex": /\p{scx=Taml}+/ug }, { "name": "Tamil", "regex": /\p{scx=Tamil}+/ug }, { "name": "Tang", "regex": /\p{scx=Tang}+/ug }, { "name": "Tangut", "regex": /\p{scx=Tangut}+/ug }, { "name": "Tavt", "regex": /\p{scx=Tavt}+/ug }, { "name": "Tai_Viet", "regex": /\p{scx=Tai_Viet}+/ug }, { "name": "Telu", "regex": /\p{scx=Telu}+/ug }, { "name": "Telugu", "regex": /\p{scx=Telugu}+/ug }, { "name": "Tfng", "regex": /\p{scx=Tfng}+/ug }, { "name": "Tifinagh", "regex": /\p{scx=Tifinagh}+/ug }, { "name": "Tglg", "regex": /\p{scx=Tglg}+/ug }, { "name": "Tagalog", "regex": /\p{scx=Tagalog}+/ug }, { "name": "Thaa", "regex": /\p{scx=Thaa}+/ug }, { "name": "Thaana", "regex": /\p{scx=Thaana}+/ug }, { "name": "Thai", "regex": /\p{scx=Thai}+/ug }, { "name": "Tibt", "regex": /\p{scx=Tibt}+/ug }, { "name": "Tibetan", "regex": /\p{scx=Tibetan}+/ug }, { "name": "Tirh", "regex": /\p{scx=Tirh}+/ug }, { "name": "Tirhuta", "regex": /\p{scx=Tirhuta}+/ug }, { "name": "Ugar", "regex": /\p{scx=Ugar}+/ug }, { "name": "Ugaritic", "regex": /\p{scx=Ugaritic}+/ug }, { "name": "Vaii", "regex": /\p{scx=Vaii}+/ug }, { "name": "Vai", "regex": /\p{scx=Vai}+/ug }, { "name": "Wara", "regex": /\p{scx=Wara}+/ug }, { "name": "Warang_Citi", "regex": /\p{scx=Warang_Citi}+/ug }, // { "name": "Wcho", "regex": /\p{scx=Wcho}+/ug }, // { "name": "Wancho", "regex": /\p{scx=Wancho}+/ug }, { "name": "Xpeo", "regex": /\p{scx=Xpeo}+/ug }, { "name": "Old_Persian", "regex": /\p{scx=Old_Persian}+/ug }, { "name": "Xsux", "regex": /\p{scx=Xsux}+/ug }, { "name": "Cuneiform", "regex": /\p{scx=Cuneiform}+/ug }, { "name": "Yiii", "regex": /\p{scx=Yiii}+/ug }, { "name": "Yi", "regex": /\p{scx=Yi}+/ug }, { "name": "Zanb", "regex": /\p{scx=Zanb}+/ug }, { "name": "Zanabazar_Square", "regex": /\p{scx=Zanabazar_Square}+/ug }, { "name": "Zinh", "regex": /\p{scx=Zinh}+/ug }, { "name": "Inherited", "regex": /\p{scx=Inherited}+/ug }, { "name": "Qaai", "regex": /\p{scx=Qaai}+/ug }, { "name": "Zyyy", "regex": /\p{scx=Zyyy}+/ug }, { "name": "Common", "regex": /\p{scx=Common}+/ug }, { "name": "Zzzz", "regex": /\p{scx=Zzzz}+/ug }, { "name": "Unknown", "regex": /\p{scx=Unknown}+/ug }, ]; const data1 = [ { "start": 0x0000, "end": 0x007F, "name": "Basic Latin", "japaneseName": "基本ラテン文字" }, { "start": 0x0080, "end": 0x00FF, "name": "Latin-1 Supplement", "japaneseName": "ラテン1補助" }, { "start": 0x0100, "end": 0x017F, "name": "Latin Extended-A", "japaneseName": "ラテン文字拡張A" }, { "start": 0x0180, "end": 0x024F, "name": "Latin Extended-B", "japaneseName": "ラテン文字拡張B" }, { "start": 0x0250, "end": 0x02AF, "name": "IPA Extensions", "japaneseName": "IPA拡張(国際音声記号)" }, { "start": 0x02B0, "end": 0x02FF, "name": "Spacing Modifier Letters", "japaneseName": "前進を伴う修飾文字" }, { "start": 0x0300, "end": 0x036F, "name": "Combining Diacritical Marks", "japaneseName": "ダイアクリティカルマーク" }, { "start": 0x0370, "end": 0x03FF, "name": "Greek and Coptic", "japaneseName": "ギリシア文字及びコプト文字" }, { "start": 0x0400, "end": 0x04FF, "name": "Cyrillic", "japaneseName": "キリール文字" }, { "start": 0x0500, "end": 0x052F, "name": "Cyrillic Supplement", "japaneseName": "キリール文字補助" }, { "start": 0x0530, "end": 0x058F, "name": "Armenian", "japaneseName": "アルメニア文字" }, { "start": 0x0590, "end": 0x05FF, "name": "Hebrew", "japaneseName": "ヘブライ文字" }, { "start": 0x0600, "end": 0x06FF, "name": "Arabic", "japaneseName": "アラビア文字" }, { "start": 0x0700, "end": 0x074F, "name": "Syriac", "japaneseName": "シリア文字" }, { "start": 0x0750, "end": 0x077F, "name": "Arabic Supplement", "japaneseName": "アラビア文字補助" }, { "start": 0x0780, "end": 0x07BF, "name": "Thaana", "japaneseName": "ターナ文字" }, { "start": 0x07C0, "end": 0x07FF, "name": "NKo", "japaneseName": "ンコ文字" }, { "start": 0x0800, "end": 0x083F, "name": "Samaritan", "japaneseName": "サマリア文字" }, { "start": 0x0840, "end": 0x085F, "name": "Mandaic", "japaneseName": "マンダイック文字" }, { "start": 0x0900, "end": 0x097F, "name": "Devanagari", "japaneseName": "デーヴァーナーガリー文字" }, { "start": 0x0980, "end": 0x09FF, "name": "Bengali", "japaneseName": "ベンガル文字" }, { "start": 0x0A00, "end": 0x0A7F, "name": "Gurmukhi", "japaneseName": "グルムキー文字" }, { "start": 0x0A80, "end": 0x0AFF, "name": "Gujarati", "japaneseName": "グジャラート文字" }, { "start": 0x0B00, "end": 0x0B7F, "name": "Oriya", "japaneseName": "オリヤー文字" }, { "start": 0x0B80, "end": 0x0BFF, "name": "Tamil", "japaneseName": "タミル文字" }, { "start": 0x0C00, "end": 0x0C7F, "name": "Telugu", "japaneseName": "テルグ文字" }, { "start": 0x0C80, "end": 0x0CFF, "name": "Kannada", "japaneseName": "カンナダ文字" }, { "start": 0x0D00, "end": 0x0D7F, "name": "Malayalam", "japaneseName": "マラヤーラム文字" }, { "start": 0x0D80, "end": 0x0DFF, "name": "Sinhala", "japaneseName": "シンハラ文字" }, { "start": 0x0E00, "end": 0x0E7F, "name": "Thai", "japaneseName": "タイ文字" }, { "start": 0x0E80, "end": 0x0EFF, "name": "Lao", "japaneseName": "ラオス文字" }, { "start": 0x0F00, "end": 0x0FFF, "name": "Tibetan", "japaneseName": "チベット文字" }, { "start": 0x1000, "end": 0x109F, "name": "Myanmar", "japaneseName": "ミャンマー文字" }, { "start": 0x10A0, "end": 0x10FF, "name": "Georgian", "japaneseName": "グルジア文字" }, { "start": 0x1100, "end": 0x11FF, "name": "Hangul Jamo", "japaneseName": "ハングル字母" }, { "start": 0x1200, "end": 0x137F, "name": "Ethiopic", "japaneseName": "エチオピア文字" }, { "start": 0x1380, "end": 0x139F, "name": "Ethiopic Supplement", "japaneseName": "エチオピア文字補助" }, { "start": 0x13A0, "end": 0x13FF, "name": "Cherokee", "japaneseName": "チェロキー文字" }, { "start": 0x1400, "end": 0x167F, "name": "Unified Canadian Aboriginal Syllabics", "japaneseName": "統合カナダ先住民音節" }, { "start": 0x1680, "end": 0x169F, "name": "Ogham", "japaneseName": "オガム文字" }, { "start": 0x16A0, "end": 0x16FF, "name": "Runic", "japaneseName": "ルーン文字" }, { "start": 0x1700, "end": 0x171F, "name": "Tagalog", "japaneseName": "タガログ文字" }, { "start": 0x1720, "end": 0x173F, "name": "Hanunoo", "japaneseName": "ハヌノオ文字" }, { "start": 0x1740, "end": 0x175F, "name": "Buhid", "japaneseName": "ブヒッド文字" }, { "start": 0x1760, "end": 0x177F, "name": "Tagbanwa", "japaneseName": "タグバヌワ文字" }, { "start": 0x1780, "end": 0x17FF, "name": "Khmer", "japaneseName": "クメール文字" }, { "start": 0x1800, "end": 0x18AF, "name": "Mongolian", "japaneseName": "モンゴル文字" }, { "start": 0x18B0, "end": 0x18FF, "name": "Unified Canadian Aboriginal Syllabics Extended", "japaneseName": "統合カナダ先住民音節拡張" }, { "start": 0x1900, "end": 0x194F, "name": "Limbu", "japaneseName": "リンブ文字" }, { "start": 0x1950, "end": 0x197F, "name": "Tai Le", "japaneseName": "タイ・ロ文字" }, { "start": 0x1980, "end": 0x19DF, "name": "New Tai Lue", "japaneseName": "新タイ・ロ文字" }, { "start": 0x19E0, "end": 0x19FF, "name": "Khmer Symbols", "japaneseName": "クメール文字用記号" }, { "start": 0x1A00, "end": 0x1A1F, "name": "Buginese", "japaneseName": "ブギス文字" }, { "start": 0x1A20, "end": 0x1AAF, "name": "Tai Tham", "japaneseName": "ラーンナー文字" }, { "start": 0x1B00, "end": 0x1B7F, "name": "Balinese", "japaneseName": "バリ文字" }, { "start": 0x1B80, "end": 0x1BBF, "name": "Sundanese", "japaneseName": "スンダ文字" }, { "start": 0x1BC0, "end": 0x1BFF, "name": "Batak", "japaneseName": "バタク文字" }, { "start": 0x1C00, "end": 0x1C4F, "name": "Lepcha", "japaneseName": "レプチャ文字" }, { "start": 0x1C50, "end": 0x1C7F, "name": "Ol Chiki", "japaneseName": "オルチキ文字" }, { "start": 0x1CD0, "end": 0x1CFF, "name": "Vedic Extensions", "japaneseName": "ヴェーダ文字拡張" }, { "start": 0x1D00, "end": 0x1D7F, "name": "Phonetic Extensions", "japaneseName": "音声記号拡張" }, { "start": 0x1D80, "end": 0x1DBF, "name": "Phonetic Extensions Supplement", "japaneseName": "音声記号拡張補助" }, { "start": 0x1DC0, "end": 0x1DFF, "name": "Combining Diacritical Marks Supplement", "japaneseName": "ダイアクリティカルマーク補助" }, { "start": 0x1E00, "end": 0x1EFF, "name": "Latin Extended Additional", "japaneseName": "ラテン文字拡張追加" }, { "start": 0x1F00, "end": 0x1FFF, "name": "Greek Extended", "japaneseName": "ギリシア文字拡張" }, { "start": 0x2000, "end": 0x206F, "name": "General Punctuation", "japaneseName": "一般句読点" }, { "start": 0x2070, "end": 0x209F, "name": "Superscripts and Subscripts", "japaneseName": "上付き・下付き" }, { "start": 0x20A0, "end": 0x20CF, "name": "Currency Symbols", "japaneseName": "通貨記号" }, { "start": 0x20D0, "end": 0x20FF, "name": "Combining Diacritical Marks for Symbols", "japaneseName": "記号用ダイアクリティカルマーク" }, { "start": 0x2100, "end": 0x214F, "name": "Letterlike Symbols", "japaneseName": "文字様記号" }, { "start": 0x2150, "end": 0x218F, "name": "Number Forms", "japaneseName": "数字に準じるもの" }, { "start": 0x2190, "end": 0x21FF, "name": "Arrows", "japaneseName": "矢印" }, { "start": 0x2200, "end": 0x22FF, "name": "Mathematical Operators", "japaneseName": "数学記号(演算子)" }, { "start": 0x2300, "end": 0x23FF, "name": "Miscellaneous Technical", "japaneseName": "その他の技術用記号" }, { "start": 0x2400, "end": 0x243F, "name": "Control Pictures", "japaneseName": "制御機能用記号" }, { "start": 0x2440, "end": 0x245F, "name": "Optical Character Recognition", "japaneseName": "光学的文字認識" }, { "start": 0x2460, "end": 0x24FF, "name": "Enclosed Alphanumerics", "japaneseName": "囲み英数字" }, { "start": 0x2500, "end": 0x257F, "name": "Box Drawing", "japaneseName": "罫線素片" }, { "start": 0x2580, "end": 0x259F, "name": "Block Elements", "japaneseName": "ブロック要素" }, { "start": 0x25A0, "end": 0x25FF, "name": "Geometric Shapes", "japaneseName": "幾何学模様" }, { "start": 0x2600, "end": 0x26FF, "name": "Miscellaneous Symbols", "japaneseName": "その他の記号" }, { "start": 0x2700, "end": 0x27BF, "name": "Dingbats", "japaneseName": "装飾記号" }, { "start": 0x27C0, "end": 0x27EF, "name": "Miscellaneous Mathematical Symbols-A", "japaneseName": "その他の数学記号A" }, { "start": 0x27F0, "end": 0x27FF, "name": "Supplemental Arrows-A", "japaneseName": "補助矢印A" }, { "start": 0x2800, "end": 0x28FF, "name": "Braille Patterns", "japaneseName": "ブライユ点字" }, { "start": 0x2900, "end": 0x297F, "name": "Supplemental Arrows-B", "japaneseName": "補助矢印B" }, { "start": 0x2980, "end": 0x29FF, "name": "Miscellaneous Mathematical Symbols-B", "japaneseName": "その他の数学記号B" }, { "start": 0x2A00, "end": 0x2AFF, "name": "Supplemental Mathematical Operators", "japaneseName": "補助数学記号" }, { "start": 0x2B00, "end": 0x2BFF, "name": "Miscellaneous Symbols and Arrows", "japaneseName": "その他の記号及び矢印" }, { "start": 0x2C00, "end": 0x2C5F, "name": "Glagolitic", "japaneseName": "グラゴル文字" }, { "start": 0x2C60, "end": 0x2C7F, "name": "Latin Extended-C", "japaneseName": "ラテン文字拡張C" }, { "start": 0x2C80, "end": 0x2CFF, "name": "Coptic", "japaneseName": "コプト文字" }, { "start": 0x2D00, "end": 0x2D2F, "name": "Georgian Supplement", "japaneseName": "グルジア文字補助" }, { "start": 0x2D30, "end": 0x2D7F, "name": "Tifinagh", "japaneseName": "ティフナグ文字" }, { "start": 0x2D80, "end": 0x2DDF, "name": "Ethiopic Extended", "japaneseName": "エチオピア文字拡張" }, { "start": 0x2DE0, "end": 0x2DFF, "name": "Cyrillic Extended-A", "japaneseName": "キリール文字拡張A" }, { "start": 0x2E00, "end": 0x2E7F, "name": "Supplemental Punctuation", "japaneseName": "補助句読点" }, { "start": 0x2E80, "end": 0x2EFF, "name": "CJK Radicals Supplement", "japaneseName": "CJK部首補助" }, { "start": 0x2F00, "end": 0x2FDF, "name": "Kangxi Radicals", "japaneseName": "康熙部首" }, { "start": 0x2FF0, "end": 0x2FFF, "name": "Ideographic Description Characters", "japaneseName": "漢字構成記述文字" }, { "start": 0x3000, "end": 0x303F, "name": "CJK Symbols and Punctuation", "japaneseName": "CJKの記号及び句読点" }, { "start": 0x3040, "end": 0x309F, "name": "Hiragana", "japaneseName": "平仮名" }, { "start": 0x30A0, "end": 0x30FF, "name": "Katakana", "japaneseName": "片仮名" }, { "start": 0x3100, "end": 0x312F, "name": "Bopomofo", "japaneseName": "注音字母" }, { "start": 0x3130, "end": 0x318F, "name": "Hangul Compatibility Jamo", "japaneseName": "ハングル互換字母" }, { "start": 0x3190, "end": 0x319F, "name": "Kanbun", "japaneseName": "漢文用記号" }, { "start": 0x31A0, "end": 0x31BF, "name": "Bopomofo Extended", "japaneseName": "注音字母拡張" }, { "start": 0x31C0, "end": 0x31EF, "name": "CJK Strokes", "japaneseName": "CJKの筆画" }, { "start": 0x31F0, "end": 0x31FF, "name": "Katakana Phonetic Extensions", "japaneseName": "片仮名拡張" }, { "start": 0x3200, "end": 0x32FF, "name": "Enclosed CJK Letters and Months", "japaneseName": "囲みCJK文字・月" }, { "start": 0x3300, "end": 0x33FF, "name": "CJK Compatibility", "japaneseName": "CJK互換用文字" }, { "start": 0x3400, "end": 0x4DBF, "name": "CJK Unified Ideographs Extension A", "japaneseName": "CJK統合漢字拡張A" }, { "start": 0x4DC0, "end": 0x4DFF, "name": "Yijing Hexagram Symbols", "japaneseName": "易経記号(六十四卦)" }, { "start": 0x4E00, "end": 0x9FFF, "name": "CJK Unified Ideographs", "japaneseName": "CJK統合漢字" }, { "start": 0xA000, "end": 0xA48F, "name": "Yi Syllables", "japaneseName": "イ文字" }, { "start": 0xA490, "end": 0xA4CF, "name": "Yi Radicals", "japaneseName": "イ文字部首" }, { "start": 0xA4D0, "end": 0xA4FF, "name": "Lisu", "japaneseName": "リス文字" }, { "start": 0xA500, "end": 0xA63F, "name": "Vai", "japaneseName": "ヴァイ文字" }, { "start": 0xA640, "end": 0xA69F, "name": "Cyrillic Extended-B", "japaneseName": "キリール文字拡張B" }, { "start": 0xA6A0, "end": 0xA6FF, "name": "Bamum", "japaneseName": "バムン文字" }, { "start": 0xA700, "end": 0xA71F, "name": "Modifier Tone Letters", "japaneseName": "声調修飾文字" }, { "start": 0xA720, "end": 0xA7FF, "name": "Latin Extended-D", "japaneseName": "ラテン文字拡張D" }, { "start": 0xA800, "end": 0xA82F, "name": "Syloti Nagri", "japaneseName": "シロティナグリ文字" }, { "start": 0xA830, "end": 0xA83F, "name": "Common Indic Number Forms", "japaneseName": "共通インド数字に準じるもの" }, { "start": 0xA840, "end": 0xA87F, "name": "Phags-pa", "japaneseName": "パスパ文字" }, { "start": 0xA880, "end": 0xA8DF, "name": "Saurashtra", "japaneseName": "サウラーシュトラ文字" }, { "start": 0xA8E0, "end": 0xA8FF, "name": "Devanagari Extended", "japaneseName": "デーヴァーナーガリー文字拡張" }, { "start": 0xA900, "end": 0xA92F, "name": "Kayah Li", "japaneseName": "カヤー文字" }, { "start": 0xA930, "end": 0xA95F, "name": "Rejang", "japaneseName": "ルジャン文字" }, { "start": 0xA960, "end": 0xA97F, "name": "Hangul Jamo Extended-A", "japaneseName": "ハングル字母拡張A" }, { "start": 0xA980, "end": 0xA9DF, "name": "Javanese", "japaneseName": "ジャワ文字" }, { "start": 0xAA00, "end": 0xAA5F, "name": "Cham", "japaneseName": "チャム文字" }, { "start": 0xAA60, "end": 0xAA7F, "name": "Myanmar Extended-A", "japaneseName": "ミャンマー文字拡張A" }, { "start": 0xAA80, "end": 0xAADF, "name": "Tai Viet", "japaneseName": "タイ・ヴェト文字" }, { "start": 0xAB00, "end": 0xAB2F, "name": "Ethiopic Extended-A", "japaneseName": "エチオピア文字拡張A" }, { "start": 0xABC0, "end": 0xABFF, "name": "Meetei Mayek", "japaneseName": "マニプリ文字" }, { "start": 0xAC00, "end": 0xD7AF, "name": "Hangul Syllables", "japaneseName": "ハングル音節文字" }, { "start": 0xD7B0, "end": 0xD7FF, "name": "Hangul Jamo Extended-B", "japaneseName": "ハングル字母拡張B" }, { "start": 0xD800, "end": 0xDB7F, "name": "High Surrogates", "japaneseName": "上位代用符号位置" }, { "start": 0xDB80, "end": 0xDBFF, "name": "High Private Use Surrogates", "japaneseName": "上位私用代用符号位置" }, { "start": 0xDC00, "end": 0xDFFF, "name": "Low Surrogates", "japaneseName": "下位代用符号位置" }, { "start": 0xE000, "end": 0xF8FF, "name": "Private Use Area", "japaneseName": "私用領域(外字領域)" }, { "start": 0xF900, "end": 0xFAFF, "name": "CJK Compatibility Ideographs", "japaneseName": "CJK互換漢字" }, { "start": 0xFB00, "end": 0xFB4F, "name": "Alphabetic Presentation Forms", "japaneseName": "アルファベット表示形" }, { "start": 0xFB50, "end": 0xFDFF, "name": "Arabic Presentation Forms-A", "japaneseName": "アラビア表示形A" }, { "start": 0xFE00, "end": 0xFE0F, "name": "Variation Selectors", "japaneseName": "字形選択子" }, { "start": 0xFE10, "end": 0xFE1F, "name": "Vertical Forms", "japaneseName": "縦書き形" }, { "start": 0xFE20, "end": 0xFE2F, "name": "Combining Half Marks", "japaneseName": "半記号" }, { "start": 0xFE30, "end": 0xFE4F, "name": "CJK Compatibility Forms", "japaneseName": "CJK互換形" }, { "start": 0xFE50, "end": 0xFE6F, "name": "Small Form Variants", "japaneseName": "小字形" }, { "start": 0xFE70, "end": 0xFEFF, "name": "Arabic Presentation Forms-B", "japaneseName": "アラビア表示形B" }, { "start": 0xFF00, "end": 0xFFEF, "name": "Halfwidth and Fullwidth Forms", "japaneseName": "半角・全角形" }, { "start": 0xFFF0, "end": 0xFFFF, "name": "Specials", "japaneseName": "特殊用途文字" }, ]; const data2 = [ { "start": 0x10000, "end": 0x1007F, "name": "Linear B Syllabary", "japaneseName": "線文字B音節文字" }, { "start": 0x10080, "end": 0x100FF, "name": "Linear B Ideograms", "japaneseName": "線文字B表意文字" }, { "start": 0x10100, "end": 0x1013F, "name": "Aegean Numbers", "japaneseName": "エーゲ数字" }, { "start": 0x10140, "end": 0x1018F, "name": "Ancient Greek Numbers", "japaneseName": "古代ギリシア数字" }, { "start": 0x10190, "end": 0x101CF, "name": "Ancient Symbols", "japaneseName": "古代記号" }, { "start": 0x101D0, "end": 0x101FF, "name": "Phaistos Disc", "japaneseName": "ファイストスの円盤文字" }, { "start": 0x10280, "end": 0x1029F, "name": "Lycian", "japaneseName": "リュキア文字" }, { "start": 0x102A0, "end": 0x102DF, "name": "Carian", "japaneseName": "カリア文字" }, { "start": 0x102E0, "end": 0x102FF, "name": "Coptic Epact Numbers", "japaneseName": "コプト・エパクト数字" }, { "start": 0x10300, "end": 0x1032F, "name": "Old Italic", "japaneseName": "古代イタリア文字" }, { "start": 0x10330, "end": 0x1034F, "name": "Gothic", "japaneseName": "ゴート文字" }, { "start": 0x10350, "end": 0x1037F, "name": "Old Permic", "japaneseName": "古ペルム文字" }, { "start": 0x10380, "end": 0x1039F, "name": "Ugaritic", "japaneseName": "ウガリト文字" }, { "start": 0x103A0, "end": 0x103DF, "name": "Old Persian", "japaneseName": "古代ペルシャ文字" }, { "start": 0x10400, "end": 0x1044F, "name": "Deseret", "japaneseName": "デザレット文字" }, { "start": 0x10450, "end": 0x1047F, "name": "Shavian", "japaneseName": "ショー文字" }, { "start": 0x10480, "end": 0x104AF, "name": "Osmanya", "japaneseName": "オスマニア文字" }, { "start": 0x104B0, "end": 0x104FF, "name": "Osage", "japaneseName": "オセージ文字" }, { "start": 0x10500, "end": 0x1052F, "name": "Elbasan", "japaneseName": "エルバサン文字" }, { "start": 0x10530, "end": 0x1056F, "name": "Caucasian Albanian", "japaneseName": "カフカス・アルバニア文字" }, { "start": 0x10600, "end": 0x1077F, "name": "Linear A", "japaneseName": "線文字A" }, { "start": 0x10800, "end": 0x1083F, "name": "Cypriot Syllabary", "japaneseName": "キプロス音節文字" }, { "start": 0x10840, "end": 0x1085F, "name": "Imperial Aramaic", "japaneseName": "帝国アラム文字" }, { "start": 0x10860, "end": 0x1087F, "name": "Palmyrene", "japaneseName": "パルミラ文字" }, { "start": 0x10880, "end": 0x108AF, "name": "Nabataean", "japaneseName": "ナバテア文字" }, { "start": 0x108E0, "end": 0x108FF, "name": "Hatran", "japaneseName": "ハトラ文字" }, { "start": 0x10900, "end": 0x1091F, "name": "Phoenician", "japaneseName": "フェニキア文字" }, { "start": 0x10920, "end": 0x1093F, "name": "Lydian", "japaneseName": "リュディア文字" }, { "start": 0x10980, "end": 0x1099F, "name": "Meroitic Hieroglyphs", "japaneseName": "メロエ文字楷書体" }, { "start": 0x109A0, "end": 0x109FF, "name": "Meroitic Cursive", "japaneseName": "メロエ文字草書体" }, { "start": 0x10A00, "end": 0x10A5F, "name": "Kharoshthi", "japaneseName": "カローシュティー文字" }, { "start": 0x10A60, "end": 0x10A7F, "name": "Old South Arabian", "japaneseName": "古代南アラビア文字" }, { "start": 0x10A80, "end": 0x10A9F, "name": "Old North Arabian", "japaneseName": "古代北アラビア文字" }, { "start": 0x10AC0, "end": 0x10AFF, "name": "Manichaean", "japaneseName": "マニ文字" }, { "start": 0x10B00, "end": 0x10B3F, "name": "Avestan", "japaneseName": "アヴェスタ文字" }, { "start": 0x10B40, "end": 0x10B5F, "name": "Inscriptional Parthian", "japaneseName": "碑文パルティア文字" }, { "start": 0x10B60, "end": 0x10B7F, "name": "Inscriptional Pahlavi", "japaneseName": "碑文パフラヴィ文字" }, { "start": 0x10B80, "end": 0x10BAF, "name": "Psalter Pahlavi", "japaneseName": "詩編パフラヴィ文字" }, { "start": 0x10C00, "end": 0x10C4F, "name": "Old Turkic", "japaneseName": "突厥文字" }, { "start": 0x10C80, "end": 0x10CFF, "name": "Old Hungarian", "japaneseName": "古ハンガリー文字" }, { "start": 0x10E60, "end": 0x10E7F, "name": "Rumi Numeral Symbols", "japaneseName": "ルミ数字記号" }, { "start": 0x11000, "end": 0x1107F, "name": "Brahmi", "japaneseName": "ブラーフミー文字" }, { "start": 0x11080, "end": 0x110CF, "name": "Kaithi", "japaneseName": "カイティー文字" }, { "start": 0x110D0, "end": 0x110FF, "name": "Sora Sompeng", "japaneseName": "ソラングソンペング文字" }, { "start": 0x11100, "end": 0x1114F, "name": "Chakma", "japaneseName": "チャクマ文字" }, { "start": 0x11150, "end": 0x1117F, "name": "Mahajani", "japaneseName": "マハージャニー文字" }, { "start": 0x11180, "end": 0x111DF, "name": "Sharada", "japaneseName": "シャーラダー文字" }, { "start": 0x111E0, "end": 0x111FF, "name": "Sinhala Archaic Numbers", "japaneseName": "旧シンハラ数字" }, { "start": 0x11200, "end": 0x1124F, "name": "Khojki", "japaneseName": "ホジャ文字" }, { "start": 0x11280, "end": 0x112AF, "name": "Multani", "japaneseName": "ムルターニー文字" }, { "start": 0x112B0, "end": 0x112FF, "name": "Khudawadi", "japaneseName": "フダーワーディー文字" }, { "start": 0x11300, "end": 0x1137F, "name": "Grantha", "japaneseName": "グランタ文字" }, { "start": 0x11400, "end": 0x1147F, "name": "Newa", "japaneseName": "ネワ文字" }, { "start": 0x11480, "end": 0x114DF, "name": "Tirhuta", "japaneseName": "ティルフータ文字" }, { "start": 0x11580, "end": 0x115FF, "name": "Siddham", "japaneseName": "悉曇文字" }, { "start": 0x11600, "end": 0x1165F, "name": "Modi", "japaneseName": "モーディー文字" }, { "start": 0x11660, "end": 0x1167F, "name": "Mongolian Supplement", "japaneseName": "モンゴル文字補助" }, { "start": 0x11680, "end": 0x116CF, "name": "Takri", "japaneseName": "タークリー文字" }, { "start": 0x11700, "end": 0x1173F, "name": "Ahom", "japaneseName": "アーホム文字" }, { "start": 0x118A0, "end": 0x118FF, "name": "Warang Citi", "japaneseName": "ワラング・クシティ文字" }, { "start": 0x11A00, "end": 0x11A4F, "name": "Zanabazar Square", "japaneseName": "ザナバザル方形文字" }, { "start": 0x11A50, "end": 0x11AAF, "name": "Soyombo", "japaneseName": "ソヨンボ文字" }, { "start": 0x11AC0, "end": 0x11AFF, "name": "Pau Cin Hau", "japaneseName": "パウ・チン・ハウ文字" }, { "start": 0x11C00, "end": 0x11C6F, "name": "Bhaiksuki", "japaneseName": "バイクシュキー文字" }, { "start": 0x11C70, "end": 0x11CBF, "name": "Marchen", "japaneseName": "マルチェン文字" }, { "start": 0x11D00, "end": 0x11D5F, "name": "Masaram Gondi", "japaneseName": "マサラム・ゴーンディー文字" }, { "start": 0x12000, "end": 0x123FF, "name": "Cuneiform", "japaneseName": "楔形文字" }, { "start": 0x12400, "end": 0x1247F, "name": "Cuneiform Numbers and Punctuation", "japaneseName": "楔形文字の数字及び句読点" }, { "start": 0x12480, "end": 0x1254F, "name": "Early Dynastic Cuneiform", "japaneseName": "シュメール楔形文字" }, { "start": 0x13000, "end": 0x1342F, "name": "Egyptian Hieroglyphs", "japaneseName": "エジプト聖刻文字" }, { "start": 0x14400, "end": 0x1467F, "name": "Anatolian Hieroglyphs", "japaneseName": "アナトリア聖刻文字" }, { "start": 0x16800, "end": 0x16A3F, "name": "Bamum Supplement", "japaneseName": "バムン文字補助" }, { "start": 0x16A40, "end": 0x16A6F, "name": "Mro", "japaneseName": "ムロ文字" }, { "start": 0x16AD0, "end": 0x16AFF, "name": "Bassa Vah", "japaneseName": "バサ文字" }, { "start": 0x16B00, "end": 0x16B8F, "name": "Pahawh Hmong", "japaneseName": "パハウ・フモン文字" }, { "start": 0x16F00, "end": 0x16F9F, "name": "Miao", "japaneseName": "ミャオ文字" }, { "start": 0x16FE0, "end": 0x16FFF, "name": "Ideographic Symbols and Punctuation", "japaneseName": "漢字の記号及び句読点" }, { "start": 0x17000, "end": 0x187FF, "name": "Tangut", "japaneseName": "西夏文字" }, { "start": 0x18800, "end": 0x18AFF, "name": "Tangut Components", "japaneseName": "西夏文字の構成要素" }, { "start": 0x1B000, "end": 0x1B0FF, "name": "Kana Supplement", "japaneseName": "仮名補助" }, { "start": 0x1B100, "end": 0x1B12F, "name": "Kana Extended-A", "japaneseName": "仮名拡張A" }, { "start": 0x1B170, "end": 0x1B2FF, "name": "Nushu", "japaneseName": "女書" }, { "start": 0x1BC00, "end": 0x1BC9F, "name": "Duployan", "japaneseName": "デュプロワイエ式速記" }, { "start": 0x1BCA0, "end": 0x1BCAF, "name": "Shorthand Format Controls", "japaneseName": "速記書式制御記号" }, { "start": 0x1D000, "end": 0x1D0FF, "name": "Byzantine Musical Symbols", "japaneseName": "ビザンチン音楽記号" }, { "start": 0x1D100, "end": 0x1D1FF, "name": "Musical Symbols", "japaneseName": "音楽記号" }, { "start": 0x1D200, "end": 0x1D24F, "name": "Ancient Greek Musical Notation", "japaneseName": "古代ギリシア音符記号" }, { "start": 0x1D300, "end": 0x1D35F, "name": "Tai Xuan Jing Symbols", "japaneseName": "太玄経記号" }, { "start": 0x1D360, "end": 0x1D37F, "name": "Counting Rod Numerals", "japaneseName": "算木用数字" }, { "start": 0x1D400, "end": 0x1D7FF, "name": "Mathematical Alphanumeric Symbols", "japaneseName": "数学用英数字記号" }, { "start": 0x1D800, "end": 0x1DAAF, "name": "Sutton SignWriting", "japaneseName": "サットン手話表記法" }, { "start": 0x1E000, "end": 0x1E02F, "name": "Glagolitic Supplement", "japaneseName": "グラゴル文字補助" }, { "start": 0x1E800, "end": 0x1E8DF, "name": "Mende Kikakui", "japaneseName": "メンデ文字" }, { "start": 0x1E900, "end": 0x1E95F, "name": "Adlam", "japaneseName": "アドラム文字" }, { "start": 0x1EE00, "end": 0x1EEFF, "name": "Arabic Mathematical Alphabetic Symbols", "japaneseName": "アラビア数字記号" }, { "start": 0x1F000, "end": 0x1F02F, "name": "Mahjong Tiles", "japaneseName": "マージャン記号" }, { "start": 0x1F030, "end": 0x1F09F, "name": "Domino Tiles", "japaneseName": "ドミノ記号" }, { "start": 0x1F0A0, "end": 0x1F0FF, "name": "Playing Cards", "japaneseName": "トランプ記号" }, { "start": 0x1F100, "end": 0x1F1FF, "name": "Enclosed Alphanumeric Supplement", "japaneseName": "囲み英数字補助" }, { "start": 0x1F200, "end": 0x1F2FF, "name": "Enclosed Ideographic Supplement", "japaneseName": "囲み漢字補助" }, { "start": 0x1F300, "end": 0x1F5FF, "name": "Miscellaneous Symbols and Pictographs", "japaneseName": "その他の記号及び絵記号" }, { "start": 0x1F600, "end": 0x1F64F, "name": "Emoticons", "japaneseName": "顔文字" }, { "start": 0x1F650, "end": 0x1F67F, "name": "Ornamental Dingbats", "japaneseName": "装飾用絵記号" }, { "start": 0x1F680, "end": 0x1F6FF, "name": "Transport and Map Symbols", "japaneseName": "交通及び地図記号" }, { "start": 0x1F700, "end": 0x1F77F, "name": "Alchemical Symbols", "japaneseName": "錬金術記号" }, { "start": 0x1F780, "end": 0x1F7FF, "name": "Geometric Shapes Extended", "japaneseName": "幾何学模様拡張" }, { "start": 0x1F800, "end": 0x1F8FF, "name": "Supplemental Arrows-C", "japaneseName": "補助矢印C" }, { "start": 0x1F900, "end": 0x1F9FF, "name": "Supplemental Symbols and Pictographs", "japaneseName": "補助記号及び絵記号" }, { "start": 0x20000, "end": 0x2A6DF, "name": "CJK Unified Ideographs Extension B", "japaneseName": "CJK統合漢字拡張B" }, { "start": 0x2A700, "end": 0x2B73F, "name": "CJK Unified Ideographs Extension C", "japaneseName": "CJK統合漢字拡張C" }, { "start": 0x2B740, "end": 0x2B81F, "name": "CJK Unified Ideographs Extension D", "japaneseName": "CJK統合漢字拡張D" }, { "start": 0x2B820, "end": 0x2CEAF, "name": "CJK Unified Ideographs Extension E", "japaneseName": "CJK統合漢字拡張E" }, { "start": 0x2CEB0, "end": 0x2EBEF, "name": "CJK Unified Ideographs Extension F", "japaneseName": "CJK統合漢字拡張F" }, { "start": 0x2F800, "end": 0x2FA1F, "name": "CJK Compatibility Ideographs Supplement", "japaneseName": "CJK互換漢字補助" }, { "start": 0xE0000, "end": 0xE007F, "name": "Tags", "japaneseName": "タグ" }, { "start": 0xE0100, "end": 0xE01EF, "name": "Variation Selectors Supplement", "japaneseName": "字形選択子補助" }, // { "start": 0xF0000, "end": 0xFFFFF, "name": "Supplementary Private Use Area-A", "japaneseName": "補助私用領域A" }, // { "start": 0x100000, "end": 0x10FFFF, "name": "Supplementary Private Use Area-B", "japaneseName": "補助私用領域B" }, ]; /** * Unicode Blockの文字を得るためのクラス。容量が大きくなるので文字データは持たない。 */ class UnicodeBlock { /** * Blockの開始符号位置、終了符号位置、名前、日本語名を設定する * @param {Number} [start=0x0000] : 開始符号位置。0xhhh0でなければならない * @param {Number} [end=0x0000] : 終了符号位置。 0xhhhFでなければならない * @param {String} [name=""] : Block name * @param {String} [japaneseName="" }] : Block name の日本語訳 */ constructor({ start = 0x0000, end = 0x0000, name = "", japaneseName = "" }) { this.start = 0x0000; this.end = 0x0000; this.name = "Invalid"; this.japaneseName = "無効"; this.outputFormat = { "linebreak": 0, "space": false }; if ((start & 0x0) === 0 || (end & 0xF) === 0xF) { this.start = start; this.end = end; this.name = name; this.japaneseName = japaneseName; } } /** * 出力の書式を設定する * @param {Number} [linebreak=32] : 何文字ごとに改行を入れるか。0ならば入れない * @param {[type]} [space=true] : 文字と文字の間に空白を入れるかどうか。入れないと結合文字が見づらい */ setOutputFormat({ linebreak = 32, space = true }) { let lb = linebreak; if (lb % 16 !== 0) { lb = 32; } this.outputFormat = { lb, space }; } /** * Blockに割り当てられている文字列を返す * @return {String} Blockに割り当てられている文字列 */ get data() { let str = ""; for (let i = this.start; i <= this.end; ++i) { str += String.fromCodePoint(i); if (this.outputFormat.space) { str += " "; } if (i !== this.start && this.outputFormat.linebreak !== 0 && (i + 1) % this.outputFormat.linebreak === 0) { str += "\n"; } } return str; } } /** * Unicode Block全てを表示するクラス */ class UnicodeBlocks { /** * Unicode Block を定義したオブジェクトからUnicodeBlockを作って格納する。 * @param {Object[]} data : Unicode Block を定義したオブジェクトの配列 */ constructor(data) { this.data = []; for (const datum of data) { this.data.push(new UnicodeBlock(datum)); } this.lastIndex = 0; } /** * イテレータ */ *[Symbol.iterator]() { while (this.lastIndex < this.data.length) { yield this.data[this.lastIndex]; this.lastIndex += 1; } this.lastIndex = 0; } /** * 入力したデータをもとにUnicode Blockを得る * @param {string} name : 探したいUnicodeBlockのプロパティ名 * @param {integer|string} value : 探したいUnicodeBlockの値 * @return {UnicodeBlock} : 条件に合致するUnicodeBlock。見つからなかったらnullを返す。 */ getFrom(name, value) { for (const datum of this.data) { if (datum[name] === value) { return datum; } } return null; } } function insertSpace(string) { const re = /(.)/ug; return string.replace(re, "$1 "); } function insertLineBreak(string) { if(string.length <= 128) { return string; } const re = /(.{128})/ug; return string.replace(re, "$1\n"); } function countChar(string) { const re = /./ug; const result = string.match(re); if (result !== null) { return result.length; } return 0; } function output(blocks, path) { let categories = [ { "name": "Binary", "data": binary }, { "name": "GeneralCategory", "data": generalCategory }, { "name": "Script", "data": script }, { "name": "ScriptExtensions", "data": scriptExtensions }, ]; let result = null; let outputString = ""; let i = 0; const file = fs.createWriteStream(path); for (const { name, data } of categories) { for (const property of data) { i = 0; for (const block of blocks) { result = block.data.match(property.regex) if (result !== null) { i += 1; result = result.reduce((acc, val) => { return acc += val; }, ""); outputString = `${name}, ${property.name} ${i}, ${block.name} ${countChar(result)} / ${block.end - block.start + 1}\n`; result = insertLineBreak(insertSpace(result)); outputString += `<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<\n`; outputString += `${result}`; if (outputString[outputString.length - 1] !== "\n" ) { outputString += "\n"; } outputString += `>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>\n\n`; file.write(outputString); } } } } file.end(); } ///* let blocks1 = new UnicodeBlocks(data1); let blocks2 = new UnicodeBlocks(data2); output(blocks1, "output1.txt"); output(blocks2, "output2.txt"); //*/参考URLs
UNICODE CHARACTER DATABASE(http://www.unicode.org/reports/tr44/)
UNICODE REGULAR EXPRESSIONS(http://unicode.org/reports/tr18/)
UNICODE SCRIPT PROPERTY(https://www.unicode.org/reports/tr24/)
ECMAScript proposal: Unicode property escapes in regular expressions(https://github.com/tc39/proposal-regexp-unicode-property-escapes)最後に
戻り読みとUnicodeプロパティが追加されたのは、とても嬉しいです。
戻り読みが出来ずに妥協していた正規表現を作り替えたり、日本語をうまく区別できずに諦めていた機能を作ってみたくなったりしました。
新機能が増えた結果、手間が増えるような気がしますが。Atomのパッケージが作りたいのですが、本体が新機能に対応していないのにDeveloper Toolが対応しているという残念な状況のようです。
まだおあずけのようです。(´・ω・`)ヒモジイ
- 投稿日:2019-04-11T09:15:58+09:00
Gatsbyのチュートリアルのまとめ(3章-1)
1章 、2章 に引き続き、Gatsby公式サイトのチュートリアルを紹介していきます。今回は3章ですが、長いので2つの記事に分割してお送りします。
3. Creating nested layout components
Creating nested layout components | GatsbyJS
3章はプラグインの使い方とlayout componentについて学ぶ章です。今回の記事では前半であるプラグインの使い方について紹介です。軽くまとめると以下の感じです。
- Gatsbyではプラグインを利用することができる。プラグインはnpmでインストールする
- 利用するプラグインはgatsby-config.jsで記述し、それぞれ個別の設定ファイルを用意する
Gatsbyプラグイン
Gatsbyは機能を拡張するプラグインに対応しています。プラグインの一覧は公式サイトのプラグイン情報ページで確認することができます。
このチュートリアルでは、フォントのスタイルをテーマとして扱い、簡単に適用できるようにするJavaScriptライブラリTypography.jsをGatsbyで利用するプラグイン「gatsby-plugin-typography」をインストールし、使い方を学びます。
前準備
チュートリアルのため、新しいプロジェクトを作成します。
gatsby new tutorial-part-three https://github.com/gatsbyjs/gatsby-starter-hello-world cd tutorial-part-threegatsby-plugin-typographyのインストールと設定
作成したチュートリアル用プロジェクトのディレクトリで、npmによりプラグイン「gatsby-plugin-typography」をインストールします。
npm install --save gatsby-plugin-typography react-typography typography typography-theme-fairy-gatesプロジェクトのディレクトリ直下に、gatsby-config.jsを作成します。
gatsby-config.jsmodule.exports = { plugins: [ { resolve: `gatsby-plugin-typography`, options: { pathToConfigModule: `src/utils/typography`, }, }, ], }gatsby-config.jsは前章で出てきたgatsby-browser.js同様特殊なファイルで、プラグインやその他サイト設定などを記述するファイルとのことです。詳細は下記ドキュメントに記載されています。ここでは使用するプラグインとしてgatsby-plugin-typographyを設定しています。
さて、上記の設定には「PathToConfigModule」というフィールドがあります。プラグインの設定ファイルの指定なのですが、このファイルはまだ存在しません。というわけでsrc/utils下にtypography.jsを下記内容で作成します。
(utilsディレクトリはデフォルトでは存在しないので作成します)src/utils/typography.jsimport Typography from "typography" import fairyGateTheme from "typography-theme-fairy-gates" const typography = new Typography(fairyGateTheme) export const { scale, rhythm, options } = typography export default typography上記では「Fairy Gates」というテーマのスタイルを利用するよう設定しています。typography.jsのテーマがどんなものがあるか確認したい方は、typegraphy.jsの公式サイトの右側にあるメニューの「Pick theme」でいろいろなテーマを適用できるので、試してみると良いでしょう。
この状態で
gatsby developを実行し、http://127.0.0.1:8000 にアクセスしてページを確認してみます。gatsby developこの状態ではHello Worldしか表示されないので分かりにくいですが、デベロッパーツールで確認してみると「typography.js」というidのCSSスタイルが設定されていることが分かると思います。
というわけで、これでプラグイン「gatsby-plugin-typography」を適用できました。
以上が3章の前半の内容になります。
3章の後半(次回)は、各ページで共通して利用できるlayout componentについてのチュートリアルです。

- 投稿日:2019-04-11T04:31:28+09:00
Yahooニュースのコメントを一括取得(AutoPagerize)するブックマークレットを作ってみた
Yahooニュースの記事において上のように分割されているコメントを一気に読みたい。
前回、東洋経済オンラインのコメントを一括取得するブックマークレットを作ってみたが、Yahooニュース用にブックマークレットを作ってみる。
東洋経済オンラインのコメントは
fetchで取得した。Yahooニュースのコメントはfetchで取得できなかったので、iframeで取得するようにした。ブックマークレット
javascript: (() => { const start_page = 1; const page_times = 4; const comment_num = 50; const frame_height = "8000px"; const sleep_time = 1000; const insertFrame = (times, page, baseNode) => { if (times <= 0) return; const frameURL = `https://news.yahoo.co.jp/comment/plugin/v1/full/?origin=https://headlines.yahoo.co.jp&sort=${baseNode.getAttribute('data-sort')}&order=${baseNode.getAttribute('data-order')}&page=${page}&type=t&keys=${baseNode.getAttribute('data-keys')}&full_page_url=${baseNode.getAttribute('data-full-page-url')}&comment_num=${baseNode.getAttribute('data-comment-num')}`; const frameNew = `<iframe class="news-comment-plguin-iframe" scrolling="yes" frameborder="0" src="${frameURL}" style="width: 100%; height: ${frame_height}; border: none;"></iframe>`; baseNode.insertAdjacentHTML('beforeend', frameNew); setTimeout(() => { insertFrame(times - 1, page + 1, baseNode) }, sleep_time); }; const replaceFrame = () => { const iframes = document.querySelectorAll("iframe.news-comment-plguin-iframe"); const baseNode = iframes[0].parentNode; if (baseNode.getAttribute("data-page-type") !== "full") return; iframes.forEach(iframe => baseNode.removeChild(iframe)); baseNode.setAttribute("data-comment-num", comment_num); insertFrame(page_times, start_page, baseNode); }; replaceFrame(); })()使い方
Yahooニュースの記事を開いて、すべてのコメントを読むをクリックしてから、ブックマークレットを動かす。ブックマークレットの作り方は省略。
- const start_page = 1; コメントの開始ページ。
- const page_times = 4; 取得ページ数。
- const comment_num = 50; 1ページあたりのコメント数(元は10)。
- const frame_height = "8000px"; ページのコメントの高さ(固定値)。
- const sleep_time = 1000; 次のコメントを取得するまでの待機時間(ms)。
諸事情につき設定値を変更する必要がある。

- 投稿日:2019-04-11T01:26:14+09:00
これだけ覚えればできる!Three.jsのGPU Instancing
概要
WebGLには拡張機能でインスタンシングなるものがあります。GPUに一つだけ3Dモデルのデータをロードし、GPU側で繰り返しそれを描画させることで高速に大量のモデルを描画する手法です。
Three.jsにはそれをラップしたInstancedBufferGeometryがあるのでそちらの使用法を解説したいと思います。作るもの
どうやって作るの?
手順は以下のようになります。
- ベースとなるモデルのジオメトリを生成
- InstancedBufferGeometryを用意
- InstancedBufferGeometryに全てのモデルに共通のAttribute(頂点座標やノーマル、インデックスなど)を設定
- モデルごとで異なる値のAttributeを生成、InstancedBufferGeometryに設定
- シェーダーを作成。
- メッシュ(ラインなどでも)を生成
コード
let originBox = new THREE.BoxBufferGeometry(0.3,0.3,0.3); let geo = new THREE.InstancedBufferGeometry(); let vertice = originBox.attributes.position.clone(); geo.addAttribute('position', vertice); let normal = originBox.attributes.normal.clone(); geo.addAttribute('normals', normal); let uv = originBox.attributes.normal.clone(); geo.addAttribute('uv', uv); let indices = originBox.index.clone(); geo.setIndex(indices); let offsetPos = new THREE.InstancedBufferAttribute(new Float32Array(this.num * 3), 3, false, 1); let num = new THREE.InstancedBufferAttribute(new Float32Array(this.num * 1), 1, false, 1); for (let i = 0; i < this.num; i++) { let range = 5; let x = Math.random() * range - range / 2; let y = Math.random() * range - range / 2; let z = Math.random() * range - range / 2; offsetPos.setXYZ(i,x,y,z); num.setX(i,i); } geo.addAttribute('offsetPos', offsetPos); geo.addAttribute('num', num); let cUni = { time: { value: 0 } } this.uni = THREE.UniformsUtils.merge([THREE.ShaderLib.standard.uniforms,cUni]); this.uni.diffuse.value = new THREE.Vector3(1.0,1.0,1.0); this.uni.roughness.value = 0.1; let mat = new THREE.ShaderMaterial({ vertexShader: vert, fragmentShader: THREE.ShaderLib.standard.fragmentShader, uniforms: this.uni, flatShading: true, lights: true }) this.obj = new THREE.Mesh(geo, mat);コード解説
順番に解説します。
1.ベースとなるモデルのジオメトリを生成
let originBox = new THREE.BoxBufferGeometry(0.3,0.3,0.3);Three.jsのBoxBufferGeometryです
2. InstancedBufferGeometryを用意
let geo = new THREE.InstancedBufferGeometry();3. InstancedBufferGeometryに全てのモデルに共通のAttributeを設定
let vertice = originBox.attributes.position.clone(); geo.addAttribute('position', vertice); let normal = originBox.attributes.normal.clone(); geo.addAttribute('normals', normal); let uv = originBox.attributes.normal.clone(); geo.addAttribute('uv', uv); let indices = originBox.index.clone(); geo.setIndex(indices);originBoxから
position、normal、UVのattributeをコピーしてそのまま設定してます。4. モデルごとで異なる値のAttributeを生成、設定
let offsetPos = new THREE.InstancedBufferAttribute(new Float32Array(this.num * 3), 3, false, 1); let num = new THREE.InstancedBufferAttribute(new Float32Array(this.num * 1), 1, false, 1); for (let i = 0; i < this.num; i++) { let range = 5; let x = Math.random() * range - range / 2; let y = Math.random() * range - range / 2; let z = Math.random() * range - range / 2; offsetPos.setXYZ(i,x,y,z); num.setX(i,i); } geo.addAttribute('offsetPos', offsetPos); geo.addAttribute('num', num);ここが肝です。
一つのBoxごとに位置を変えたいのでワールド座標を示すoffsetPosのAttributeを生成します。
こちらは個々で別の値を入れるため,InstancedBufferAttributeを使います。
引数はよくわかんないですが、こんな感じ...かな..InstancedBufferAttribute( データ配列, データサイズ(vec3なら3みたいな, (...とりあえずfalseで), (...とりあえず1で) )5. シェーダー、マテリアルを作成
let cUni = { time: { value: 0 } } this.uni = THREE.UniformsUtils.merge([THREE.ShaderLib.standard.uniforms,cUni]); this.uni.diffuse.value = new THREE.Vector3(1.0,1.0,1.0); this.uni.roughness.value = 0.1; let mat = new THREE.ShaderMaterial({ vertexShader: vert, fragmentShader: THREE.ShaderLib.standard.fragmentShader, uniforms: this.uni, flatShading: true, lights: true })フラグメントシェーダーはThreeのStandardを使ってます。
attribute vec3 offsetPos; varying vec3 vViewPosition; uniform float time; float PI = 3.141592653589793; highp mat2 rotate(float rad){ return mat2(cos(rad),sin(rad),-sin(rad),cos(rad)); } void main() { vec3 pos = position; float s = max(0.0,sin(-time * 4.0 + length(offsetPos))); pos *= s; pos.xz *= rotate(s * 4.0); pos.xy *= rotate(s * 4.0); vec4 mvPosition = modelViewMatrix * vec4(pos + offsetPos, 1.0); gl_Position = projectionMatrix * mvPosition; vViewPosition = -mvPosition.xyz; }boxを回転してから位置を移動してます。
6. メッシュ(ラインなどでも)を生成
this.obj = new THREE.Mesh(geo, mat);できました
今回はInstancedBufferGeomtryを使ってジオメトリを効率的に使用することできました。ComputationRendererとも相性がとても良さそうですね!
