- 投稿日:2019-03-23T23:34:16+09:00
Java(SpringBoot)を始めるための環境構築
はじめに
4月からエンジニアに転職し、Spring Bootを使ったシステム開発に携わることになったのでJavaの環境構築についてまとめておきます。
開発環境
macOS Mojave バージョン 10.14.2
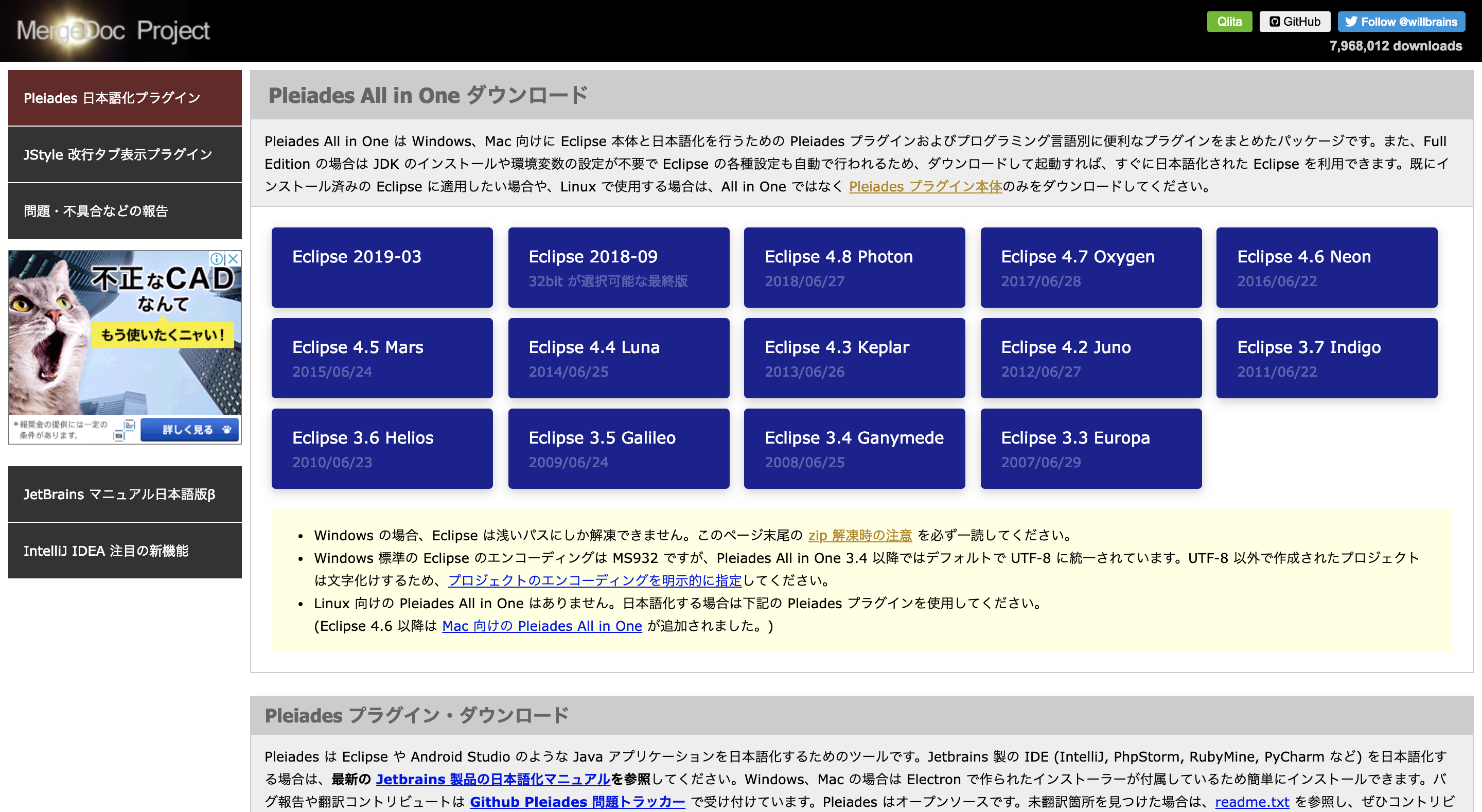
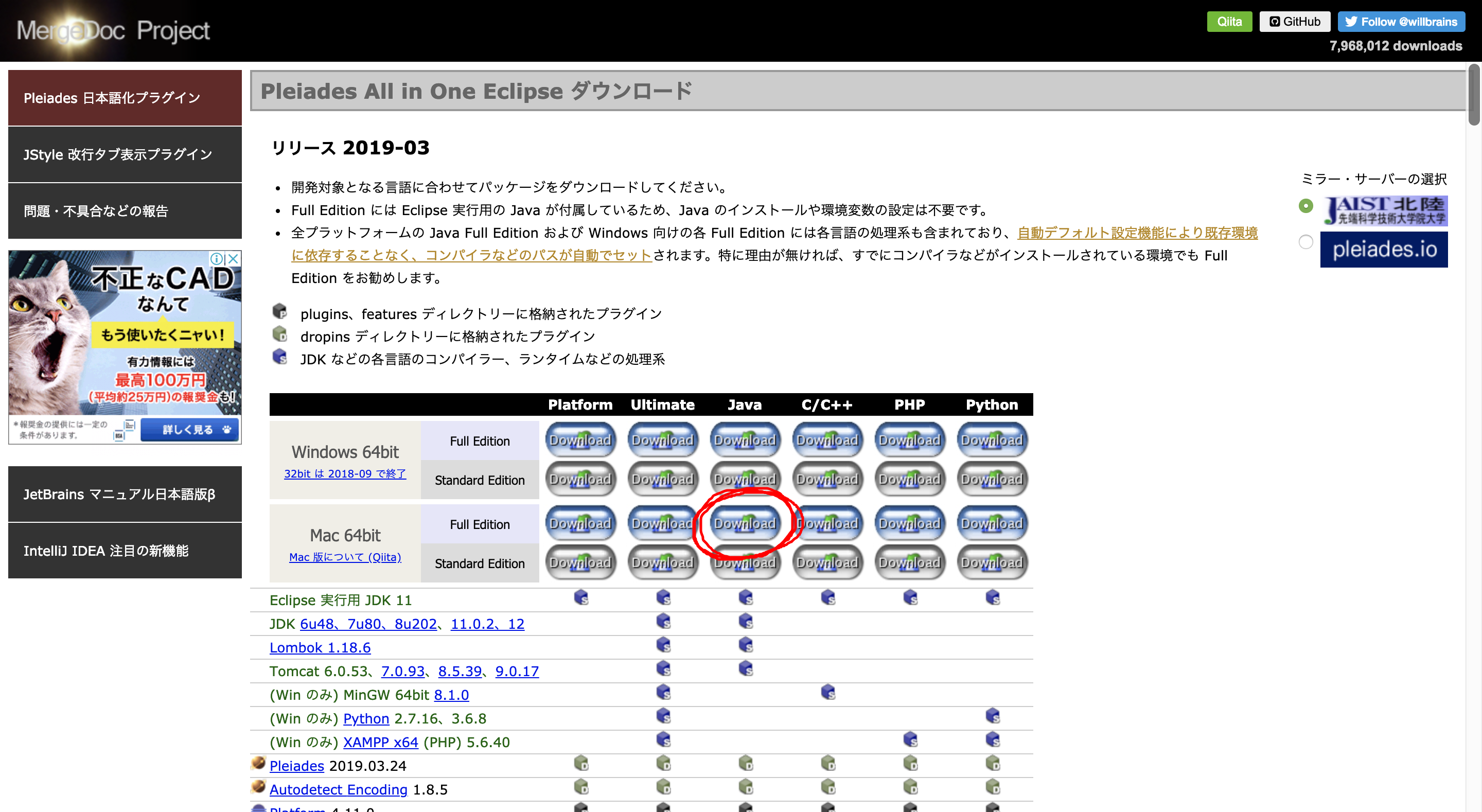
Pleiadesのインストール
Javaの総合開発環境(IDE)であるEclipseを利用するため
日本語化されたパッケージであるPleiadesをインストールします。以下のURLにアクセスして、最新版をインストール!
http://mergedoc.osdn.jp/#pleiades.html
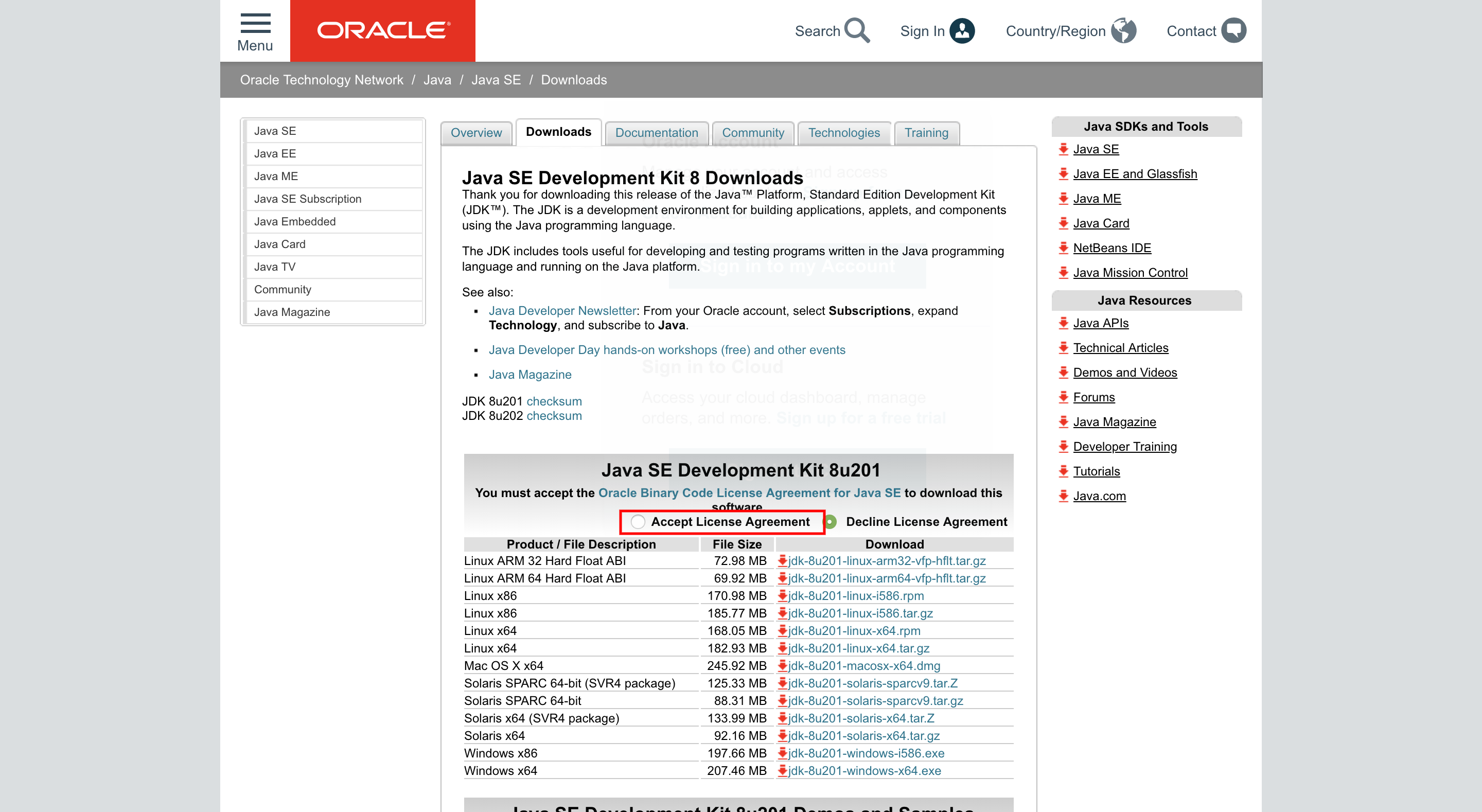
JDK(Java Development Kit)のインストール
このあと導入するSTS(Spring Tool Suite)を利用する際に必要なJDKをインストールします。
『Spring Boot 2 プログラミング入門』に沿って学習しているため、Java8を使います。以下のURLにアクセスし、Accept License Agreementにチェックを入れて
Java SE Development Kit 8u202をインストール!
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
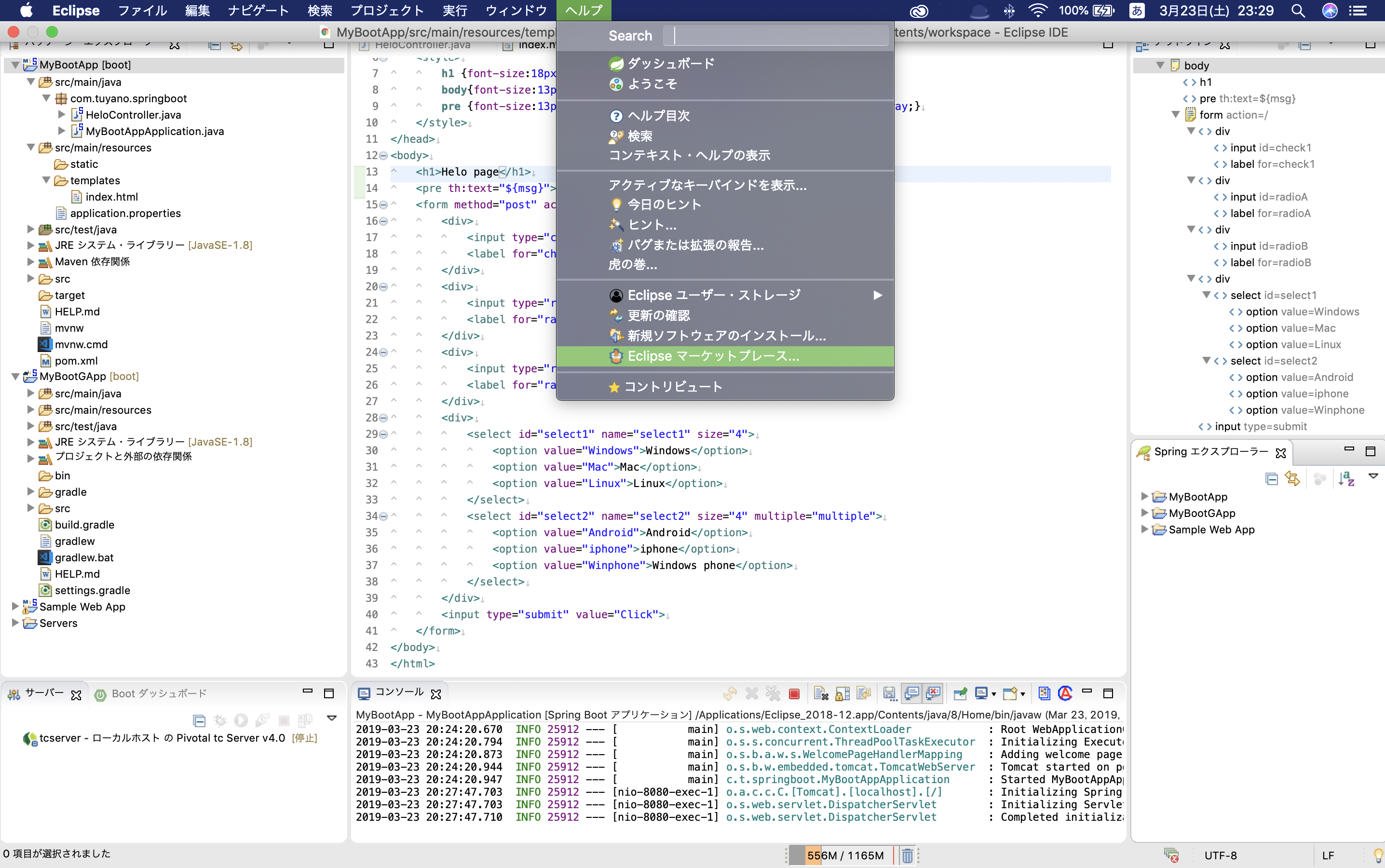
EclipseへのSTS(Spring Tool Suite)のインストール
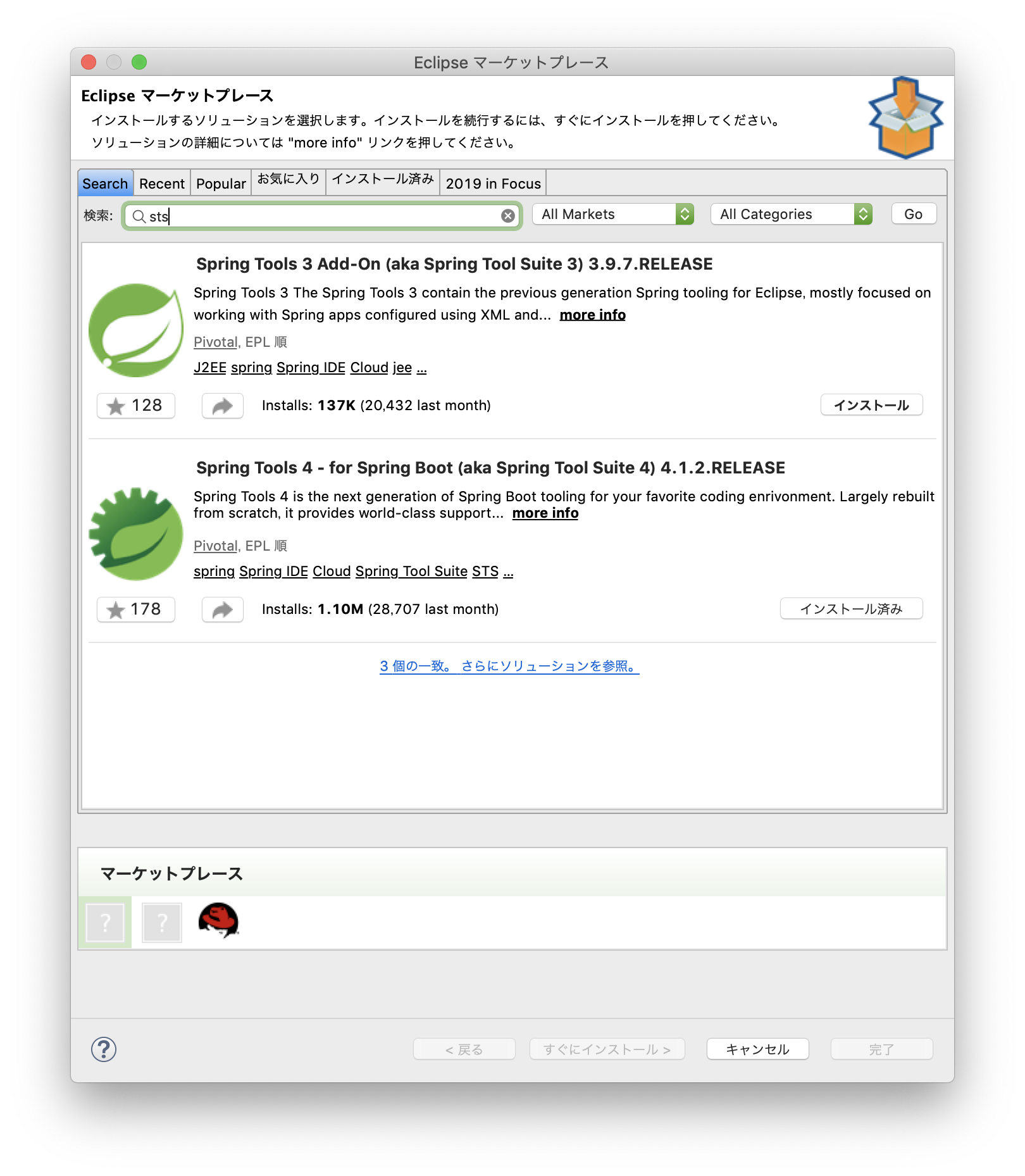
Eclipseを開いて、ヘルプ ➡︎ Eclipseマーケットプレースを選択
「sts」と検索して、検索結果から最新版をインストール
参考
- IT入門書籍 スッキリシリーズ Pleiades(Java環境)インストール手順
- Spring Boot 2 プログラミング入門 | 掌田津耶乃
- 投稿日:2019-03-23T22:51:39+09:00
Javaの配列
配列とは
・配列(array)とは、同一種類の複数データを並び順で格納するデータ構造。
・配列は中に要素(element)を複数格納しており、要素には添字(index)が0から順に付いている。
・配列も変数と同様でデータ型を指定する。java要素のデータ型[] 配列変数名; #例えば int[] score; #これでscoreをint型の配列変数として宣言している。 score = new int[5]; #配列変数scoreにnew演算子で生成したint型の要素を5つ、代入している。 int[] score = {10,20,30,40,50}; #宣言と初期化を同時に行う。 #配列変数の宣言と代入を同時に行うこともできる。 int[] score = new int[5]; #配列の中の要素を取り出す方法 score[0]; #配列変数scoreのなかの1番目の要素を取得できる。 #配列内の要素を書き換える。 score[0] = 30; #配列変数scoreのなかの1番目の要素に30という値を代入することができる。 #lengthメソッド使用 score.length; #配列変数にlengthというメソッドを使用すると配列内の要素の数を取得できる。 #lengthメソッドは文字列にも使用できる。String型変数名.length()という形になる。配列をforループで回す。
java#従来のfor文 for (int i = 0; i < 配列変数名.length; i++) { 処理.... } #配列の中の要素数をlengthで取得し、その数の分だけループを回している。 #拡張for文 for (要素の型 任意の変数名:配列変数名) { 処理... } #拡張for文で書くと従来のものよりシンプルに記述できる。 #例えば for (int value : score) { 処理... }メモリと変数と配列
コンピューターは使用するデータをメモリに記録する。メモリの中は基盤の目のように区画整備されており、各区画には住所(アドレス)が振られている。そして変数を宣言すると、空いている区画(どこが選ばれるかわからない)を変数のために確保する(変数の殻によって何区画を使用するかは異なる)。変数に値を代入するとは、確保しておいた区画に値を記録すること。
配列変数には一番最初の要素の一番最初のアドレスが代入されていることになる。つまり配列変数に要素が入っているわけではなく、配列変数のアドレスを参照してその配列変数に所属している要素を取得することができるということになる。ガベージコレクション
Javaの仕組みの一つ。メモリ上のゴミを排除してくれる。
使用されない変数や配列はメモリを無駄に消費し圧迫してしまう。このメモリのゴミは本来プログラマーが後片付けをしないといけないが、ガベージコレクションという仕組みが常に働いているためメモリのゴミを自動的に片付けてくれる。NULL
何もないという意味。
使わなくなった配列変数などにNULLを代入することでその配列変数は要素を参照しなくなり、ガベージコレクションの対象になる。
参照型変数には使用できるが基本型変数には使用できない。javaint[] score = {10,20,30}; #配列変数の要素に値を代入する。 int[] score = null; #配列変数にNULLを代入。 score[0]; #配列変数にはNULLが入っており、参照できなくなっている。2次元配列
↓2次元配列とは表のような配列のこと(わかりにくかったらごめんなさいw)
[0][0] [0][1] [0][2] [0][3] [1][0] [1][0] [1][2] [1][3] [2][0] [2][1] [2][2] [2][3] java#2次元配列の宣言 要素の型[][] 配列変数名 = new 要素の型[行数][列数] #2次元配列の要素の取得 配列変数名[行の添字][列の添字]
- 投稿日:2019-03-23T21:40:01+09:00
SpringDataJpa/集計関数等使用時に、新しいJavaBeansを作成するのではなく既存Entityを流用して実装してみた。
SpringDataJpa/集計処理使用時には、既存Entityではなく専用JavaBeansを作成して結果を格納するように推奨されているが(TERASOLUNA 6.3.3.2. Entity以外のオブジェクトにQueryの取得結果を格納する方法)、新しいクラスを都度作成するのも煩わしいので、既存のEntityで代替できないかを試してみた。結果はOKだった。
対策)
①EntityをSeirializableにする(JavaBeans化)。
②Entityに集計結果格納用フィールドを作成して、@Transient(永続化対象外フィールド指定)を付加する。
③Entityに集計結果格納用コンストラクタを追加する。Customer.javapackage hello; import java.io.Serializable; import javax.persistence.Entity; import javax.persistence.GeneratedValue; import javax.persistence.GenerationType; import javax.persistence.Id; import org.springframework.data.annotation.Transient; import lombok.NoArgsConstructor; import lombok.AllArgsConstructor; import lombok.Getter; @Getter @NoArgsConstructor @Entity public class Customer implements Serializable { private static final long serialVersionUID = 6631793395389093746L; @Id @GeneratedValue(strategy=GenerationType.AUTO) private Long id; private String firstName; private String lastName; @Transient private long count; public Customer(String firstName, String lastName) { this.firstName = firstName; this.lastName = lastName; } public Customer(String lastName, long count) { this.lastName = lastName; this.count = count; } @Override public String toString() { return String.format( "Customer[id=%d, firstName='%s', lastName='%s, count=%d']", id, firstName, lastName, count); } }CustomerRepository.javapackage hello; import java.util.List; import org.springframework.data.jpa.repository.Query; import org.springframework.data.repository.CrudRepository; public interface CustomerRepository extends CrudRepository<Customer, Long> { List<Customer> findByLastName(String lastName); @Query(value ="SELECT NEW hello.Customer(cu.lastName, Count(cu.id)) FROM Customer cu GROUP BY cu.lastName") List<Customer> GroupByLastName(); }Application.javapackage hello; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.boot.CommandLineRunner; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.context.annotation.Bean; @SpringBootApplication public class Application { private static final Logger log = LoggerFactory.getLogger(Application.class); public static void main(String[] args) { SpringApplication.run(Application.class); } @Bean public CommandLineRunner demo(CustomerRepository repository) { return (args) -> { // save a couple of customers repository.save(new Customer("Jack", "Bauer")); repository.save(new Customer("Chloe", "O'Brian")); repository.save(new Customer("Kim", "Bauer")); repository.save(new Customer("David", "Palmer")); repository.save(new Customer("Michelle", "Dessler")); // fetch all customers log.info("Customers found with findAll():"); log.info("-------------------------------"); for (Customer customer : repository.findAll()) { log.info(customer.toString()); } log.info(""); // fetch an individual customer by ID repository.findById(1L) .ifPresent(customer -> { log.info("Customer found with findById(1L):"); log.info("--------------------------------"); log.info(customer.toString()); log.info(""); }); // fetch customers by last name log.info("Customer found with findByLastName('Bauer'):"); log.info("--------------------------------------------"); repository.findByLastName("Bauer").forEach(bauer -> { log.info(bauer.toString()); }); log.info(""); // Customers'Count GroupByLastName log.info("Customers'Count GroupByLastName with GroupByLastName():"); log.info("--------------------------------------------"); repository.GroupByLastName().forEach(lastName -> { log.info(lastName.toString()); }); log.info(""); }; } }excution.loginfo : Customers found with findAll(): info : ------------------------------- info : Customer[id=1, firstName='Jack', lastName='Bauer, count=0'] info : Customer[id=2, firstName='Chloe', lastName='O'Brian, count=0'] info : Customer[id=3, firstName='Kim', lastName='Bauer, count=0'] info : Customer[id=4, firstName='David', lastName='Palmer, count=0'] info : Customer[id=5, firstName='Michelle', lastName='Dessler, count=0'] info : info : Customer found with findById(1L): info : -------------------------------- info : Customer[id=1, firstName='Jack', lastName='Bauer, count=0'] info : info : Customer found with findByLastName('Bauer'): info : -------------------------------------------- info : Customer[id=1, firstName='Jack', lastName='Bauer, count=0'] info : Customer[id=3, firstName='Kim', lastName='Bauer, count=0'] info : info : Customers'Count GroupByLastName with GroupByLastName(): info : -------------------------------------------- info : Customer[id=null, firstName='null', lastName='Bauer, count=2'] info : Customer[id=null, firstName='null', lastName='O'Brian, count=1'] info : Customer[id=null, firstName='null', lastName='Palmer, count=1'] info : Customer[id=null, firstName='null', lastName='Dessler, count=1']併せて、こちらも参照ください。
「SpringDataJpa/集計関数等使用時に、new xxxClass()を使用しない方法を試してみた。」
- 投稿日:2019-03-23T21:40:01+09:00
SpringDataJpa/集計関数等使用時に、新しいJavaBeansを作成するのではなく既存Entityを流用して実装してみた
SpringDataJpa/集計処理使用時には、既存Entityではなく専用JavaBeansを作成して結果を格納するように推奨されているが(*1 TERASOLUNA参照)、新しいクラスを都度作成するのも煩わしいので、既存のEntityで代替できないかを試してみた。結果はOKだった。
*1 http://terasolunaorg.github.io/guideline/5.4.1.RELEASE/ja/ArchitectureInDetail/DataAccessDetail/DataAccessJpa.html#entityquery対策)
①EntityをSeirializableにする(JavaBeans化)。
②Entityに集計結果格納用フィールドを作成して、@Transient(永続化対象外フィールド指定)を付加する。
③Entityに集計結果格納用コンストラクタを追加する。Customer.javapackage hello; import java.io.Serializable; import javax.persistence.Entity; import javax.persistence.GeneratedValue; import javax.persistence.GenerationType; import javax.persistence.Id; import org.springframework.data.annotation.Transient; import lombok.NoArgsConstructor; import lombok.AllArgsConstructor; import lombok.Getter; @Getter @NoArgsConstructor @Entity public class Customer implements Serializable { private static final long serialVersionUID = 6631793395389093746L; @Id @GeneratedValue(strategy=GenerationType.AUTO) private Long id; private String firstName; private String lastName; @Transient private long count; public Customer(String firstName, String lastName) { this.firstName = firstName; this.lastName = lastName; } public Customer(String lastName, long count) { this.lastName = lastName; this.count = count; } @Override public String toString() { return String.format( "Customer[id=%d, firstName='%s', lastName='%s, count=%d']", id, firstName, lastName, count); } }CustomerRepository.javapackage hello; import java.util.List; import org.springframework.data.jpa.repository.Query; import org.springframework.data.repository.CrudRepository; public interface CustomerRepository extends CrudRepository<Customer, Long> { List<Customer> findByLastName(String lastName); @Query(value ="SELECT NEW hello.Customer(cu.lastName, Count(cu.id)) FROM Customer cu GROUP BY cu.lastName") List<Customer> GroupByLastName(); }Application.javapackage hello; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.boot.CommandLineRunner; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.context.annotation.Bean; @SpringBootApplication public class Application { private static final Logger log = LoggerFactory.getLogger(Application.class); public static void main(String[] args) { SpringApplication.run(Application.class); } @Bean public CommandLineRunner demo(CustomerRepository repository) { return (args) -> { // save a couple of customers repository.save(new Customer("Jack", "Bauer")); repository.save(new Customer("Chloe", "O'Brian")); repository.save(new Customer("Kim", "Bauer")); repository.save(new Customer("David", "Palmer")); repository.save(new Customer("Michelle", "Dessler")); // fetch all customers log.info("Customers found with findAll():"); log.info("-------------------------------"); for (Customer customer : repository.findAll()) { log.info(customer.toString()); } log.info(""); // fetch an individual customer by ID repository.findById(1L) .ifPresent(customer -> { log.info("Customer found with findById(1L):"); log.info("--------------------------------"); log.info(customer.toString()); log.info(""); }); // fetch customers by last name log.info("Customer found with findByLastName('Bauer'):"); log.info("--------------------------------------------"); repository.findByLastName("Bauer").forEach(bauer -> { log.info(bauer.toString()); }); log.info(""); // Customers'Count GroupByLastName log.info("Customers'Count GroupByLastName with GroupByLastName():"); log.info("--------------------------------------------"); repository.GroupByLastName().forEach(lastName -> { log.info(lastName.toString()); }); log.info(""); }; } }excution.log. ____ _ __ _ _ /\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \ ( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \ \\/ ___)| |_)| | | | | || (_| | ) ) ) ) ' |____| .__|_| |_|_| |_\__, | / / / / =========|_|==============|___/=/_/_/_/ :: Spring Boot :: (v2.0.5.RELEASE) 2019-03-23 20:49:24.922 INFO 10688 --- [ main] hello.Application : Customers found with findAll(): 2019-03-23 20:49:24.922 INFO 10688 --- [ main] hello.Application : ------------------------------- 2019-03-23 20:49:24.968 INFO 10688 --- [ main] hello.Application : Customer[id=1, firstName='Jack', lastName='Bauer, count=0'] 2019-03-23 20:49:24.968 INFO 10688 --- [ main] hello.Application : Customer[id=2, firstName='Chloe', lastName='O'Brian, count=0'] 2019-03-23 20:49:24.968 INFO 10688 --- [ main] hello.Application : Customer[id=3, firstName='Kim', lastName='Bauer, count=0'] 2019-03-23 20:49:24.968 INFO 10688 --- [ main] hello.Application : Customer[id=4, firstName='David', lastName='Palmer, count=0'] 2019-03-23 20:49:24.968 INFO 10688 --- [ main] hello.Application : Customer[id=5, firstName='Michelle', lastName='Dessler, count=0'] 2019-03-23 20:49:24.968 INFO 10688 --- [ main] hello.Application : 2019-03-23 20:49:24.968 INFO 10688 --- [ main] hello.Application : Customer found with findById(1L): 2019-03-23 20:49:24.968 INFO 10688 --- [ main] hello.Application : -------------------------------- 2019-03-23 20:49:24.968 INFO 10688 --- [ main] hello.Application : Customer[id=1, firstName='Jack', lastName='Bauer, count=0'] 2019-03-23 20:49:24.968 INFO 10688 --- [ main] hello.Application : 2019-03-23 20:49:24.968 INFO 10688 --- [ main] hello.Application : Customer found with findByLastName('Bauer'): 2019-03-23 20:49:24.968 INFO 10688 --- [ main] hello.Application : -------------------------------------------- 2019-03-23 20:49:25.015 INFO 10688 --- [ main] hello.Application : Customer[id=1, firstName='Jack', lastName='Bauer, count=0'] 2019-03-23 20:49:25.015 INFO 10688 --- [ main] hello.Application : Customer[id=3, firstName='Kim', lastName='Bauer, count=0'] 2019-03-23 20:49:25.015 INFO 10688 --- [ main] hello.Application : 2019-03-23 20:49:33.015 INFO 10688 --- [ main] hello.Application : Customers'Count GroupByLastName with GroupByLastName(): 2019-03-23 20:49:33.030 INFO 10688 --- [ main] hello.Application : -------------------------------------------- 2019-03-23 20:49:33.048 INFO 10688 --- [ main] hello.Application : Customer[id=null, firstName='null', lastName='Bauer, count=2'] 2019-03-23 20:49:33.048 INFO 10688 --- [ main] hello.Application : Customer[id=null, firstName='null', lastName='O'Brian, count=1'] 2019-03-23 20:49:33.048 INFO 10688 --- [ main] hello.Application : Customer[id=null, firstName='null', lastName='Palmer, count=1'] 2019-03-23 20:49:33.048 INFO 10688 --- [ main] hello.Application : Customer[id=null, firstName='null', lastName='Dessler, count=1'] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Shutdown completed.
- 投稿日:2019-03-23T21:08:09+09:00
Java New FileIOを使ってみよう!(入門, 初心者向け)
きっかけ
学校でJavaを教えているのでその時の資料から作ってみました。
語句の説明
とりあえず、語句の説明を。
FileIOってなんだよ?
ファイルシステム(file system)のI (Input / 入力) と O (Output / 出力) を行えるよ!
ファイルシステムってなんやねん!!
ファイルシステムとは、OSにおいてデータを保管するファイル(File)とそれをまとめ上げて管理するディレクトリー(Directory/Folder)で作られる世界のこと。
はじめに
FileIOで何ができるん?
ファイルとディレクトリーに対して、delete(削除), create(作成), exist(存在確認),…,write(書き込み), read(読み込み)などいろいろ、私達がOSで行うこと(たぶん)すべてができる!
じゃぁJavaでそれを行うにはどうすればいいの?
→NewIOというJavaの標準ライブラリがおすすめですよ!
旧来はFile(java.io系)というクラスを中心として構成されていたが、現在では便利で最適化されているなどの様々な利点からNew I/O(java.nio系)というパッケージを用いて行うのがこれからの主流となっています(させます)。
NewIOを使ってみよう
NewIOを始めるにあたって
NewIOでは一般的に次の2つ(3つ)のクラスが基礎的な役割を持ちます。
Path: Stringを変換してファイルのパスを表すようにしたクラス Paths: Pathを作るためのクラス Files: 実際にファイル操作をするクラス※FileクラスはNewIOではなく、古のもの(NewIOでないOldなIO系)のため注意すべし。
Pathの取得
Pathの取得(例) … ファイルの場所!
Path path = Paths.get(“C:\\”, “a”);※Pathはnewでは作れません!
※Pathsのgetメソッドはstaticメソッドです!
※getメソッドの引数は、可変長引数で、引数ごとで、ファイルの階層を表すことができます。
※パス(普通に文字列)の取得は、ファイルを選択して、Shift+右クリックで「パスのコピー」を行うと楽。
※パスは、エスケープシークエンスとダブルクオーテーションに気をつける。Filesの利用例
Filesの利用の例 … ファイル/ディレクトリーに対する操作を行う。
Files.exsit(path);※戻り値はbooleanなのでこれをif文で使うことができる!
ファイルへの読み書き
基本的に次の2つのクラスを使うと良い。(ほかのクラスは基本的に古のものが多いが、他人のプログラムでは古でも使われることが多いので注意?してください)
BufferedWriter: バッファを用いて効率的に、ファイルに書き込みを行うクラス BufferedReader: バッファを用いて効率的に、ファイルに読み込みを行うクラスBuffer(バッファ)って?
メモリ空間上に一時的に置かれたデータのこと。tmp/temp(テンプ)ともいいます。
BufferedWriter/BufferedReaderの(インスタンスの)生成
古の方法
たぶん、(NewIOでは)あんまり使わないです。
BufferedWriter bw = new BufferedWriter(Writer); BufferedReader br = new BufferedReader(Reader);NewIOを用いた、BufferedWriter/BufferedReaderの生成
BufferedWriter bw = Files.newBufferedWriter(path);BufferedWriter/BufferedReaderの利用
bw.write(String); String line = br.readLine();※bw, brはそれぞれclose()メソッドを呼び出さないと行けない。
(why -> bwでclose()を呼び出さないと出力されない, flush()の呼び出し)try { BufferedWriter bw = Files.newBufferedWriter(path); bw.write(“A”); bw.close(); } catch (IOException ex) { ex.printStackTrace(); }また、closeで例外が発生する恐れがあり、closeに対する例外処理必要が必要でもある。
よって以下のようにする必要がある。try { BufferedWriter bw = Files.newBufferedWriter(path); bw.write(“A”); } catch (IOException ex) { ex.printStackTrace(); } finally { try { bw.close(); } catch (IOException ex) { ex.printStackTrace(); } }クソ長い
BufferedWriter/BufferedReaderの利用(改良) ~ try-catch-resouce!
先程のように書くと凄く長い。そこでJava7からtry-catch-resouce構文が追加され、以下のように簡潔に書けるようになった。
try (BufferedWriter bw = Files.newBufferedWriter(path)) { bw.write(“A”); }めっちゃいい。
参考: https://qiita.com/Takmiy/items/a0f65c58b407dbc0ca99改行をするには?(write()の利用)
br.write(text)を呼び出しただけでは、改行されず、
br.write("AA"); br.write("BB");↓
AABBみたいなことになってしまう。
改行するには、行の文字列の最後に改行文字をつければ良い。
bw.write(text + System.lineSeparator());※System.lineSeparator();はOS毎に正しい改行文字を返してくれるメソッド。
CRLF(\r\n), LF(\n)とかの差異に気をつけなくて良い!(改行文字については調べよう)課題
1.ファイルに文字列を書き込む
2.「1.」の複数行version (Listを用いて)
3.ファイルの読み込み
4.「3.」の複数行version (Listを用いて行の表現), なお全ての行でも良いし、任意の範囲の行でも良い。コラム
私達が今まで使ってきたいつもの構文について…
System.out.println(“Hello world!”);これをFileIOを理解した上でみるとなんだかFileIOっぽいなぁと思いますよね。
どういうこと?ってなりますけど。
実は、System.out (のout)は、OutputStreamなのである!ということ。(つまり出力用)
一応、StreamというのはFileIOを抽象化したものです。(たぶん)
同様に、System.in というものもありますが、これはInputStreamです。(つまり入力用)しかしながら、これは考えれば自然で、コンソールに文字を書くことって、実際はファイルに文字を書くこととあまり変わりないですよね(自分はこういう共通化するという所が面白いなーと思いました)。
参考/Reference
・Oracleの公式解説ページ群
・java.io.File のコードを java.nio.Path と java.nio.Files を使って書き直す
・Javaのファイル入出力関係のクラス/インタフェースについて整理する
- 投稿日:2019-03-23T18:49:58+09:00
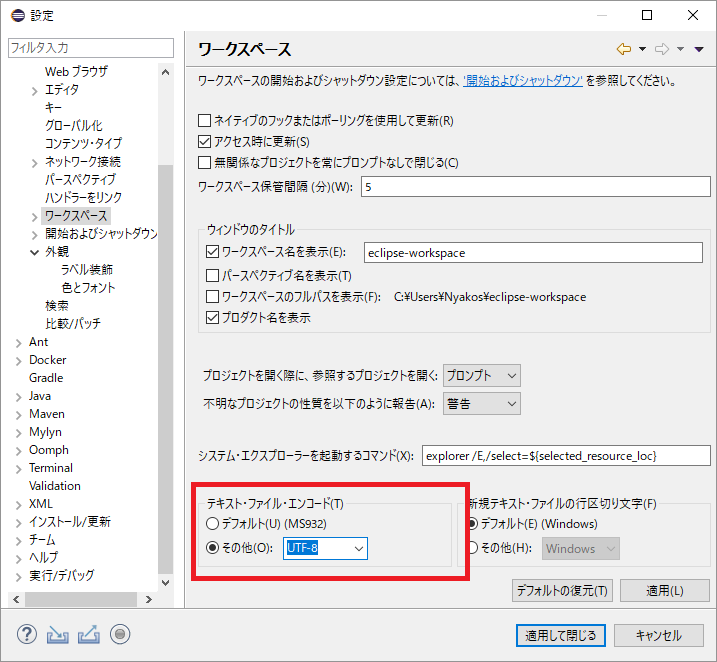
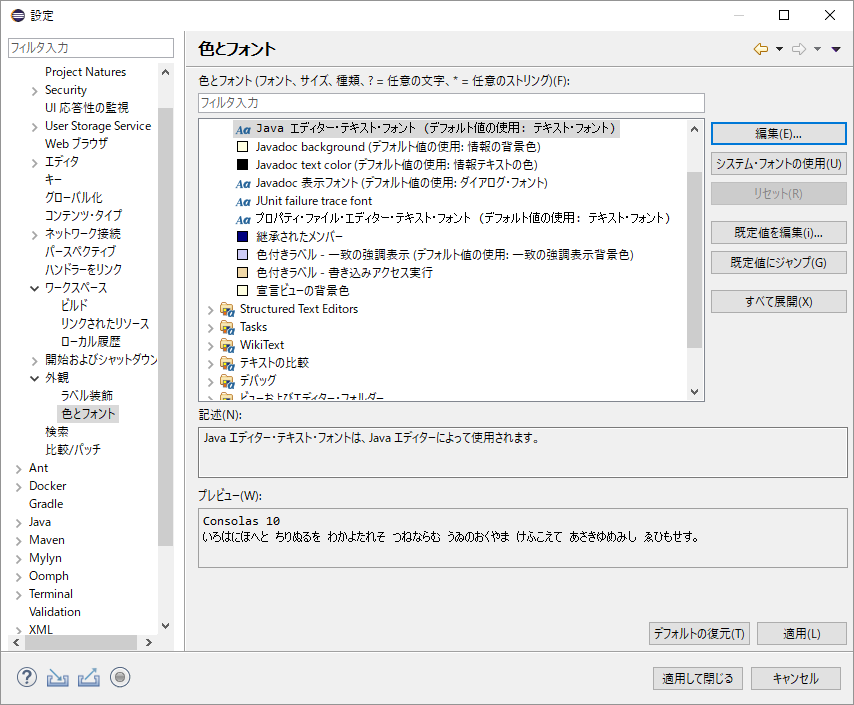
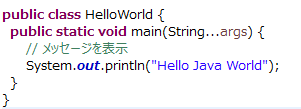
Eclipseの日本語化

- 投稿日:2019-03-23T16:06:48+09:00
Java コンテナ化ツール「Jib」はどのくらい Docker のベストプラクティスを満たしているのか
はじめに
Java アプリケーションをコンテナ化するツールに jib があります。
GitHub の README には、Docker のベストプラクティスを知らなくても最適な Docker イメージを作ってくれると書かれています。
Jib builds optimized Docker and OCI images for your Java applications without a Docker daemon - and without deep mastery of Docker best-practices.
そんな Jib がどのくらい Docker イメージのベストプラクティスを満たしているのか調査してみました。
準備
検証には、Spring Initializr で作成した Maven プロジェクトを使います。
jib-maven-plugin の README の通り、pom.xml に以下の記述を追加します。
<plugin> <groupId>com.google.cloud.tools</groupId> <artifactId>jib-maven-plugin</artifactId> <version>1.0.2</version> <configuration> <to> <image>myimage</image> </to> </configuration> </plugin>ビルドしてみます。
$ ./mvnw compile jib:dockerBuild : : : [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------ [INFO] Total time: 18.444 s [INFO] Finished at: 2019-03-23T13:59:31+09:00 [INFO] ------------------------------------------------------------------------Docker イメージを確認すると ...
$ docker image ls REPOSITORY TAG IMAGE ID CREATED SIZE myimage latest 8ef0bcee6c5d 49 years ago 141MBDockerfile を一切書かず、イメージができました !
起動も通常通り成功しました。
$ docker run --rm myimage . ____ _ __ _ _ /\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \ ( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \ \\/ ___)| |_)| | | | | || (_| | ) ) ) ) ' |____| .__|_| |_|_| |_\__, | / / / / =========|_|==============|___/=/_/_/_/ :: Spring Boot :: (v2.1.3.RELEASE) 2019-03-23 05:01:06.902 INFO 1 --- [ main] s.SpringDockerExampleApplication : Starting SpringDockerExampleApplication on 072b9539cd19 with PID 1 (/app/classes started by root in /) : : :ここまでハマる点は一切なく、想像以上に簡単でした。
ベストプラクティスへの対応の調査
コンテナイメージをビルドするには、7 best practices for building containers のようなベストプラクティスがあります。
今回は、Jib で作成したイメージが以下のプラクティスを満たしているのか調査します。
- PID 1 で起動
- ビルドキャッシュの最適化
- 不要なツールの削除
- イメージの最小化
- レイヤー数の削減
- 一般ユーザで実行
PID 1 で起動
コンテナ停止時はコンテナ内の PID 1 のプロセスにシグナルが送られるため、PID 1 でアプリケーションを起動することが推奨されています。
Spring Boot 起動時のログを見ると ...
2019-03-23 05:01:06.902 INFO 1 --- [ main] s.SpringDockerExampleApplication : Starting SpringDockerExampleApplication on 072b9539cd19 with PID 1 (/app/classes started by root in /)
Starting SpringDockerExampleApplication on 072b9539cd19 with PID 1と出力されており、PID 1 で起動していることが分かります。ビルドキャッシュの最適化
Jib の README にビルドキャッシュの最適化を目指していることが書かれています。
Fast - Deploy your changes fast. Jib separates your application into multiple layers, splitting dependencies from classes. Now you don’t have to wait for Docker to rebuild your entire Java application - just deploy the layers that changed.
詳細は調べていませんが、これを自作の Dockerfile で再現するには、ある程度 Docker の知識が必要になってきそうです。
不要なツールの削除
コンテナには何が入っているのか調べるため docker exec で sh を実行しようとすると、以下のようにエラーとなりました。
$ docker exec -it $(docker container ls | grep myimage | awk '{print $1}') sh OCI runtime exec failed: exec failed: container_linux.go:344: starting container process caused "exec: \"sh\": executable file not found in $PATH": unknownFAQ の where is bash によると ...
By default, Jib uses distroless/java as the base image. Distroless images contain only runtime dependencies. They do not contain package managers, shells or any other programs you would expect to find in a standard Linux distribution. Check out the distroless project for more information about distroless images.
If you would like to include a shell for debugging, set the base image to gcr.io/distroless/java:debug instead. The shell will be located at /busybox/sh. Note that :debug images are not recommended for production use.
実行に必要な依存関係しか入っておらず、デバッグ用にシェルがほしいならベースイメージを変更するようにとのことです。
ここまで不要なツールを削除した Java のイメージを自作するのは結構大変だと思います。ちなみに、Java についても、java コマンドは入っていましたが、javac コマンドは入っていませんでした。
$ docker run --rm --entrypoint java myimage -version openjdk version "1.8.0_181" OpenJDK Runtime Environment (build 1.8.0_181-8u181-b13-2~deb9u1-b13) OpenJDK 64-Bit Server VM (build 25.181-b13, mixed mode) $ docker run --rm --entrypoint javac myimage -version docker: Error response from daemon: OCI runtime create failed: container_linux.go:344: starting container process caused "exec: \"javac\": executable file not found in $PATH": unknown. ~/Documents/src/os1ma/spring-docker-example (master) $イメージの最小化
イメージサイズを自作の Dockerfile からビルドした場合と比較します。
Dockerfile は以下の通りです。1
FROM openjdk:8u181-jre-alpine3.8 RUN addgroup -S -g 1000 app \ && adduser -D -H -S -G app -u 1000 app USER app WORKDIR /app COPY target/*.jar . # *.jar を展開するために sh -c を実行し、 # さらに PID 1 で java プロセスを起動するため exec を使用 CMD ["sh", "-c", "exec java -jar *.jar"]JAR と Docker イメージをビルドします。
$ ./mvnw clean package $ docker build -t myimage-openjdk .イメージサイズを比較すると ...
$ docker image ls REPOSITORY TAG IMAGE ID CREATED SIZE myimage-openjdk latest 262fd5db197f 9 seconds ago 99.8MB myimage latest 8ef0bcee6c5d 49 years ago 141MBopenjdk:8u181-jre-alpine3.8 をベースに自作した方が小さくなりました。
とはいえ、Alpine ベースで提供されていない2 Amazon Correto を利用した場合よりは小さくなっています。
REPOSITORY TAG IMAGE ID CREATED SIZE myimage-amazon latest dd6500aa12d0 4 minutes ago 542MBなお、Amazon Correto を使った場合の Dockerfile は以下です。
FROM amazoncorretto:8u202 RUN groupadd -r -g 1000 app \ && useradd -M -r -g app -u 1000 app USER app WORKDIR /app COPY target/*.jar . # *.jar を展開するために sh -c を実行し、 # さらに PID 1 で java プロセスを起動するため exec を使用 CMD ["sh", "-c", "exec java -jar *.jar"]レイヤー数の削減
Jib で作成したイメージと Dockerfile から作成したイメージのレイヤ数を比較すると ...
$ docker image inspect myimage | jq '.[0].RootFS.Layers' [ "sha256:44873b569cf340a616026da244ebee1bbd7d3f2bb7a0dbf7a6526c4416dea61a", "sha256:87c747af6dc3478b57493f1f3a2e0821696f8d56b86b1fef1128d1d74881cf7c", "sha256:6189abe095d53c1c9f2bfc8f50128ee876b9a5d10f9eda1564e5f5357d6ffe61", "sha256:cdfa1ce6eb7e772884aeab7a2560bee6988f7bba47addeedb636842d72a23702", "sha256:5e1ddec1ac755324b4489ba4030512f5f461ace13be7f9617982b0a12dcaec16", "sha256:edb7e86863542fc9cfaee3eb48af4678560b396dd5dcc18ee89e089aee23abf4", "sha256:769f5c896c76f8bf79881949a0d55cbd768405580f1ae87b4519b16da83d2387" ] $ docker image inspect myimage-openjdk | jq '.[0].RootFS.Layers' [ "sha256:7bff100f35cb359a368537bb07829b055fe8e0b1cb01085a3a628ae9c187c7b8", "sha256:dbc783c89851d29114fb01fd509a84363e2040134e45181354051058494d2453", "sha256:178e89c683ce4b8f572eb7d89c48a70e39f740b2c81274a58092e02a764732d6", "sha256:9f4e44fd5bdc31d8dbe3074d8db6b5ccc13504f65cc3e3bfac580f2f1710840b", "sha256:f5892329ace5f98e26db46cf436780fa28747a95303a2e283a9ae41be0246551", "sha256:426afce096026f233072c74b991ceec088b7278166096d364bf4db9f214cb238" ]自作した方が 1 つレイヤーが少なくなっています。
Jib ではビルド時にレイヤキャッシュを利用していることが関係しているのかもしれません。一般ユーザで実行
コンテナ内で root ユーザを使わないよう、Dockerfile で一般ユーザを作成するというプラクティスがあります。
しかし、Jib で作成したイメージを起動した際のログには
(/app/classes started by root in /)と書かれており、root ユーザで実行されていました。2019-03-23 05:01:06.902 INFO 1 --- [ main] s.SpringDockerExampleApplication : Starting SpringDockerExampleApplication on 072b9539cd19 with PID 1 (/app/classes started by root in /)一般ユーザで起動するイメージを作成するには、pom.xml に追記が必要でした。
<plugin> <groupId>com.google.cloud.tools</groupId> <artifactId>jib-maven-plugin</artifactId> <version>1.0.2</version> <configuration> <to> <image>myimage</image> </to> <container> <user>1000:1000</user> </container> </configuration> </plugin>これで起動してみると ...
$ ./mvnw compile jib:dockerBuild $ docker run --rm myimage . ____ _ __ _ _ /\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \ ( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \ \\/ ___)| |_)| | | | | || (_| | ) ) ) ) ' |____| .__|_| |_|_| |_\__, | / / / / =========|_|==============|___/=/_/_/_/ :: Spring Boot :: (v2.1.3.RELEASE) 2019-03-23 06:24:42.445 INFO 1 --- [ main] s.SpringDockerExampleApplication : Starting SpringDockerExampleApplication on c864fdbdb6a7 with PID 1 (/app/classes started by ? in /)
(/app/classes started by ? in /)と表示されており、たしかに root ユーザでなくなりました。ちなみに、コンテナのユーザは以下のように起動時に設定することも可能です。
$ docker run --rm -u 1000:1000 myimageまとめ
Jib のセットアップは非常に簡単で、たしかに結構良いイメージを作ってくれました。
また、Jib はコンテナレジストリへのプッシュや Slaffold との連携も可能とのことなので、CI / CD の中で使うと面白そうです。
Java を Native バイナリとして動かす Quarkus にも対応してくれると嬉しいです。
マルチステージビルドでは .m2 のキャッシュが効かずビルドに時間がかかるため、マルチステージビルドは使っていません。マルチステージビルドで .m2 のキャッシュを利用する方法は「Buildkitを使ってMulti-stage BuildでMavenのキャッシュを効かせる」の通りです。 ↩
- 投稿日:2019-03-23T15:35:56+09:00
[JPA] 個人メモ Paging処理はPageableを使うとすごい便利
public Response<List<Some>> getXXX(Integer page, Integer pageSize) { Pageable paging = PageRequest.of(page, pageSize); List<SomeClass> test = xxxRepo.findByXXXX(100, paging);これでいける
- 投稿日:2019-03-23T13:43:49+09:00
【学習メモ】Thread勉強
関連パッケージ集
一覧
https://docs.oracle.com/javase/jp/8/docs/api/index.html?java/util/concurrent/package-summary.html
- java.lang
- java.util
- java.util.concurrent (j2SE)
- java.util.concurrent.atomic
- java.util.concurrent.locks
中身
java.lang
- java.lang
- インターフェース
- Runnable
- クラス
- Thread
- ThreadGroup
- ThreadLocal
- 列挙型
- Thread.State
- 例外
- Exception
- IllegalMonitorStateException
- IllegalThreadStateException
- InterruptedException
- RuntimeException
- SecurityException
- エラー
- Error
- ThreadDeath
- 注釈型
- Deprecated
- Override
java.util
- java.util
- インターフェース
- Collection
- Deque
- Iterator
- List
- Map
- Observer
- Queue
- Set
- クラス
- AbstractQueue
- ArrayDeque
- Collections
- LinkedList
- Objects
- Observable
- Properties
- 列挙型
- 関連なし
- 例外
- 関連なし
- エラー
- 関連なし
java.util.concurrent
- java.util.concurrent (j2SE)
- インターフェース
- BlockingDeque
- BlockingQueue
- Callable
- CompletableFuture.AsynchronousCompletionTask
- CompletionService
- Executor
- ExecutorService
- Future
- RunnableFuture
- RunnableScheduledFuture
- ScheduledExecutorService
- ScheduledFuture
- ThreadFactory
- TransferQueue
- クラス
- AbstractExecutorService
- ArrayBlockingQueue
- CompletableFuture
- Executors
- FutureTask
- LinkedBlockingDeque
- LinkedBlockingQueue
- LinkedTransferQueue
- ScheduledThreadPoolExecutor
- Semaphore
- SynchronousQueue
- ThreadPoolExecutor
- ThreadPoolExecutor.AbortPolicy
- ThreadPoolExecutor.CallerRunsPolicy
- ThreadPoolExecutor.DiscardOldestPolicy
- ThreadPoolExecutor.DiscardPolicy
- 列挙型
- TimeUnit
- 例外
- ExecutionException
- TimeoutException
- エラー
- なし
- 注釈型
- なし
java.util.concurrent.atomic
- java.util.concurrent.atomic
- インターフェース
- なし
- クラス
- AtomicBoolean
- AtomicInteger
- AtomicIntegerArray
- AtomicIntegerFieldUpdater
- AtomicLong
- AtomicLongArray
- AtomicLongFieldUpdater
- AtomicMarkableReference
- AtomicReference
- AtomicReferenceArray
- AtomicReferenceFieldUpdater
- AtomicStampedReference
- DoubleAccumulator
- DoubleAdder
- LongAccumulator
- LongAdder
java.util.concurrent.locks
- 投稿日:2019-03-23T10:31:39+09:00
Homebrewで入れたcorrettoがアップデートしたら消えたので修正した
brew update, brew upgradleすると、correttoが8から11にアップデートした上で消えた。何回かbrew cask reinstallしても同じ。
stackoverflowで、同様に「correttoインストールしたのに出てこない」って問題が報告されてる。まだ解決してない。
いろいろ調べたところ、8から11になるにあたってバグがあったらしい。2019-03-14に一旦リリースされてから修正版が2019-03-19に再度リリースされてる。
https://docs.aws.amazon.com/ja_jp/corretto/latest/corretto-11-ug/change-log.html
brew caskのスクリプトはまだ直ってない...。githubのissueを見ながら、とりあえず手動で対応してみる。
https://github.com/corretto/corretto-11/issues/12
現状。
$ /usr/libexec/java_home -V Matching Java Virtual Machines (1): 1.8.0_92, x86_64: "Java SE 8" /Library/Java/JavaVirtualMachines/jdk1.8.0_92.jdk/Contents/Home /Library/Java/JavaVirtualMachines/jdk1.8.0_92.jdk/Contents/Home $ java -version java version "1.8.0_92" Java(TM) SE Runtime Environment (build 1.8.0_92-b14) Java HotSpot(TM) 64-Bit Server VM (build 25.92-b14, mixed mode)直す。
$ sudo ln -sf ../Home/lib/jli/libjli.dylib /Library/Java/JavaVirtualMachines/amazon-corretto-11.jdk/Contents/MacOS/libjli.dylib $ /usr/libexec/java_home -V Matching Java Virtual Machines (2): 11.0.2, x86_64: "Amazon Corretto 11" /Library/Java/JavaVirtualMachines/amazon-corretto-11.jdk/Contents/Home 1.8.0_92, x86_64: "Java SE 8" /Library/Java/JavaVirtualMachines/jdk1.8.0_92.jdk/Contents/Home /Library/Java/JavaVirtualMachines/amazon-corretto-11.jdk/Contents/Home $ java -version openjdk version "11.0.2" 2019-01-15 LTS OpenJDK Runtime Environment Corretto-11.0.2.9.3 (build 11.0.2+9-LTS) OpenJDK 64-Bit Server VM Corretto-11.0.2.9.3 (build 11.0.2+9-LTS, mixed mode)直った。リンク張るだけで直るんですね。
まあでも、きっといつか誰かが気づいてbrew caskのスクリプトも修正されると思うんですよ。
- 投稿日:2019-03-23T05:37:27+09:00
Javadocで稀によく見る(オプションの操作)の謎
1.はじめに
Javadocを眺めていると目にすることのある
修飾子と型 メソッドと説明 〇〇 hoge(○○ ××)
~~~~~~(オプションの操作)。例:List(Java Platform SE8), Set(Java Platform SE8)
この意味について気にはなっていたもののググっても解説が見当たらなかった。
(もしかして常識過ぎて誰も解説してないのか。。。?)2.規約
単刀直入に言うと以下のものが規約として存在する。
・インタフェースの実装においてオプションであるメソッドは、実装されない場合にUnsupportedOperationExceptionをスローします。どのメソッドがオプションであるかは、メソッドの説明の最後に「(オプション)」と示すことで、随時示していきます。
以上
「プログラミング言語Java 第四版」東京電機大学出版局,ケン・アーノルド ジェームズ・ゴスリン デビッド・ホームズ著,柴田芳樹訳,第四版1刷発行,502p
からの引用3.Listインターフェースの例
ListインターフェースのJavadocには以下の10個のメソッドの説明に(オプションの操作)と書かれている。
修飾子と型 メソッドと説明 boolean add(E e)
指定された要素をこのリストの最後に追加します(オプションの操作)。void add(int index, E element)
このリスト内の指定された位置に、指定された要素を挿入します(オプションの操作)。boolean addAll(Collection<? extends E> c)指定されたコレクション内のすべての要素を、指定されたコレクションのイテレータによって返される順序で、このリストの最後に追加します(オプションの操作)。 boolean addAll(int index, Collection<? extends E> c)
指定されたコレクション内のすべての要素を、このリストの指定された位置に挿入します(オプションの操作)。void clear()
すべての要素をこのリストから削除します(オプションの操作)。E remove(int index)
このリスト内の指定された位置にある要素を削除します(オプションの操作)。boolean remove(Object o)
指定された要素がこのリストにあれば、その最初のものをリストから削除します(オプションの操作)。boolean removeAll(Collection<?> c)
このリストから、指定されたコレクションに含まれる要素をすべて削除します(オプションの操作)。boolean retainAll(Collection<?> c)
このリスト内で、指定されたコレクションに含まれている要素だけを保持します(オプションの操作)。E set(int index, E element)
このリスト内の指定された位置にある要素を、指定された要素に置き換えます(オプションの操作)。規約によるとこれらのメソッドをListを実装したクラスのインスタンスに使った場合、「コンパイルは通るが実行時に例外が起きる」という可能性がある。
例えば、たびたび初心者が引っかかることになる
Arrays.asList(T...)や修正不可能なリストを返すCollections.unmodifiableList(list)で返されるリストがそれにあたる。4.Arrays.asList(T...)
散々ネット上で書かれてことではあるがArrays.asList(T...)で返されるリストにはaddやremoveができない。
参考:
Java - Arrays.asList の注意点,
Arrays.asList() は単なる配列のラッパを返すだけなので、要素の追加も削除もできませんこのメソッドで返されるのはListを実装した(より正確にはListを実装したAbstractListを継承した)java.util.Arrays内staticクラスのArrayListである。(java.util.ArrayListとは別物)
public static void main(String... args){ List<String list=Arrays.asList("aaa","bbb"); System.out.println(list.getClass()); //->class java.util.Arrays$ArrayList }ソースコード
Github:jdk8/java/util/Arrays.java読んでわかる通りadd()やremove()のメソッドがOverrideされていない。
よって親クラスのメソッドが呼ばれるが、そこにはこう書かれているので無事UnsupportOperationExceptionがスローされる。AbstractList.javapublic void add(int index, E element) { throw new UnsupportedOperationException(); }ただし(オプションの操作)と記載されているメソッドのうちset()は正しく動くようにOverrideされているのでこのメソッドは例外を起こさずに使うことができる。
5.Collections.unmodifiableList(List)
これはjava.util.Collections内のstaticクラスであるUnmodifiableListかUnmodifiableRandomAccessListを返している。
Github:jdk8/java/util/Collections.java
見てわかるとおり、このクラスはオプションの操作のどのメソッドもUnsupportOperationExceptionが投げられる。
6.まとめ
まあ謎の記述が理解できてよかったねって話なんですけど、、、
static内部クラスはJavadocに出ないのでオプションの操作のうちどの操作が許される操作(Arras.asListのset()など)なのかがソース見ないと分からないのは辛くないんですかね...?
- 投稿日:2019-03-23T02:01:31+09:00
Eclipse2019-03(4.11)はJava12対応してないからな?
デフォルトでは。
Java12が使いたいならMarketplaceから拡張をインストールしてpreview featuresをアンロックしよう。