- 投稿日:2019-03-23T23:27:19+09:00
AWS Certified Security Specialtyの模試を受けてみる
この前一つ受かったのでプラクティスのタダ券がGETできました。
アソシエイトとプロを制覇したわけですが、ここ最近いろいろ増えてきています。
とりあえずどれか受けてみようと思います。ただし、クラウドプラクテショナーは費用対効果薄いので除外。専門知識系のどれか。クラウドプラクティショナー
アソシエイトレベルの下のレベルで、入門という位置づけ。とりあえず受けたら?みたいな。
特に特定のカテゴリではなさそう。https://aws.amazon.com/jp/certification/certified-cloud-practitioner/
AWS 認定クラウドプラクティショナー試験は、AWS クラウドの知識とスキルを身に付け、全体的な理解を効果的に説明できる個人が対象です。他の AWS 認定 (AWS 認定ソリューションアーキテクト – アソシエイト、AWS 認定デベロッパー – アソシエイト、AWS 認定 SysOps アドミニストレーター – アソシエイトなど) で扱われる特定の技術的役割からは独立しています。
AWS 認定セキュリティ – 専門知識
セキュリティの専門知識を問う認定試験。レベル的にはアソシエイトとプロの間の位置づけらしいが、一部の知識はプロ以上のものが求められると思う。ただ、この試験はこれまでと被る所が多そうで他の専門知識に比べると専門性は薄く感じる。
AWS プラットフォームのセキュリティ強化における技術的な専門知識を認定します。経験豊かなセキュリティ担当者が対象です。
AWS 認定ビッグデータ – 専門知識
awsでbig dataというとredshiftだとかそういう感じ?サンプル問題を見た感じだとそんなにビックデータビックデータしてなかった。なんとなく解けそうな気がしなくもない。
データから価値を引き出すために AWS のサービスを設計および実装するのに必要となる技術的な専門知識を認定します。複雑なビッグデータ分析に携わる方が対象です。
AWS 認定高度なネットワーク – 専門知識
ネットワークに特化してる認定試験。これまでの試験の延長線上にあるような気もする。vpnだとかそのあたりが出てくるのかな。苦手じゃないかもしれない。
AWS、および大規模なハイブリッド IT アーキテクチャの設計および実装における技術的な専門知識を認定します。複雑なネットワーク業務に携わる方が対象です。
AWS 認定 機械学習 – スペシャリティ
SageMakerとか出てくるんだと思う。サンプル問題みてみても専門性高いですね。これはちゃんと学ばないときついかという感じ。
AWS クラウドを使用して機械学習 (ML) モデルを構築、トレーニング、チューニングおよびデプロイするのに必要となる技術的な専門知識を認定します。開発およびデータサイエンスの業務に携わる方が対象です。
そんなわけで、セキュリティスペシャリストを受けてみることにしました。
ネットワークを受けてみようと思ったんだけど・・なぜか選んでみようと思ってpsiのサイト開くと一覧にない。。専門系はMLとセキュリティしかないんですもの。
消去法でセキュリティです。あんまり自信ないです。4割取れたらいい方なんじゃないかな。AWS認定アカウントのサイトにログインして、
特典のページを開きます。
受かった試験があれば、AWS Free Practice Exam Voucherというのが有効になっているので、特典を有効にするをクリック。コードが表示されるのでこれを模試の支払いの時に使います。そしたら支払金額が0に。試験時間は60分。20問くらいかな。
それでは行ってきます!・・・・・
ただいま。
そんなわけでお試しで受けてみましたよ。
深く考えずテンポよく答えてみました。20問で30分くらい。
- Trasted Advisor
- Cloud Trail
- KMS, CMK
- Inspector
のあたりが多かったです。あとはiamやらセキュリティグループやらの基本的な部分。
CMKのあたりはあまりよくわからんかった。キーマテリアルのインポートとかぜんぜん馴染みないし。
ただ、正直、そんなに答えにくい問題はなかった。もしかしたらそこそこ取れてるんじゃ?とか思ってる。悪くなかったらそう遠くない内に本試験も受けてみよう。しかし、模試なんてすぐ結果くるかと思ったら、10分経っても来ないですね。
なんか新しい試験ほど通知が遅いのかな。気長に待つか。結果きたら追記します。追記がない場合は結果が死ぬほど悪かったと思ってください。追記
15~20分くらいで結果届きました。
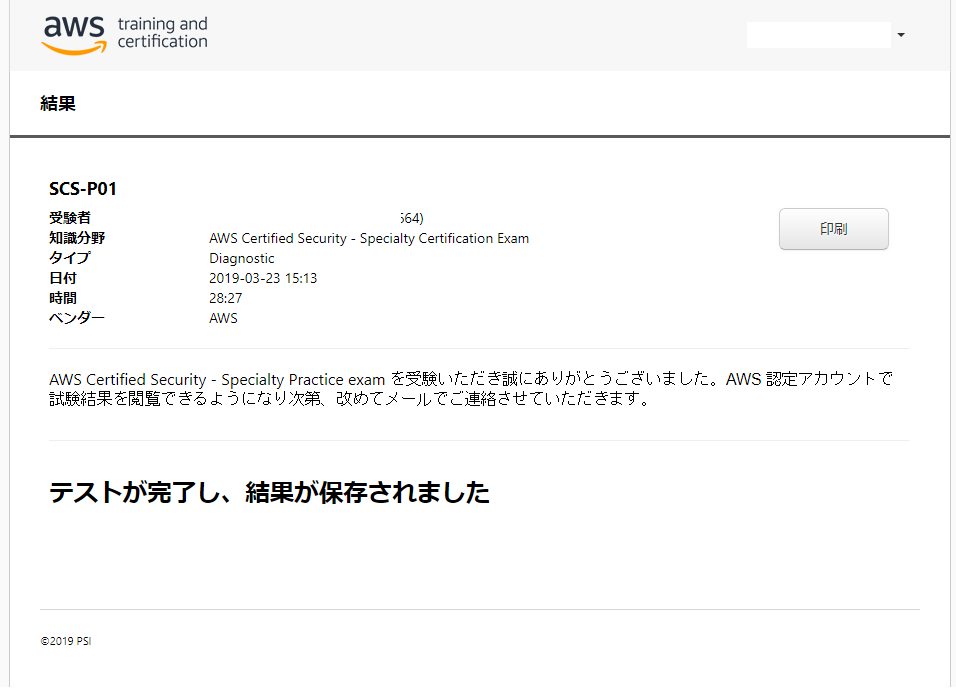
総合スコア: 50% トピックレベルスコア: 1.0 Incident Response: 0% 2.0 Logging and Monitoring: 75% 3.0 Infrastructure Security: 50% 4.0 Identity and Access Management: 75% 5.0 Data Protection: 33%ん~、微妙だ。
でもちゃんとサンプル問題を勉強したり、キャプチャしといた模試の問題を振り返ればいけるぐらいかもしれない。
次受けるのはこれかプラクティショナーにしよう。
- 投稿日:2019-03-23T19:27:46+09:00
Amazon SQS
■Amazon SQSとは
処理の間にQueueを噛ませることで、非同期処理にすることができる。
例えば全ての処理を同期処理してしまうと時間がかかってしまうので、Queueだけ登録してレスポンスを返してしまう。
■機能
- 1度に複数件のメッセージを登録、削除し、バルク処理をすることもできる。
- Long Polling:キューが空の場合、タイムアウトするまで待ち続ける時間。
- Dead Letter Queue:いつまでも残るメッセージを別のキューに移動する。
- Delay Queue:新しいメッセージを指定した時間見えなくする。
■注意点
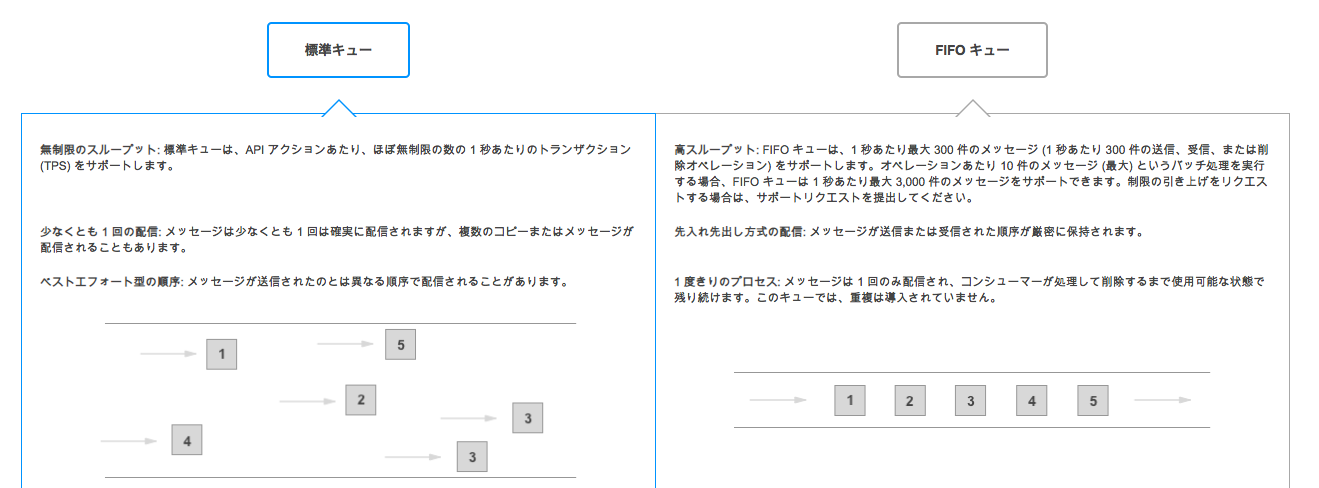
- 順序は保証されない
- なんだかのタイミングで同じメッセージを複数回受信する場合がある。→FIFOキューを検討する。
1.キューを作成する
[キュー名]だけ入力し、パラメータはデフォルトで作成する。
(標準キーで作成する)
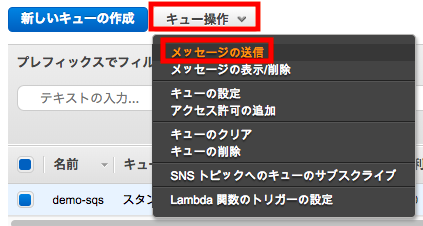
2.マネージメントコンソールからメッセージを送受信する
[キュー操作]から[メッセージの送信]
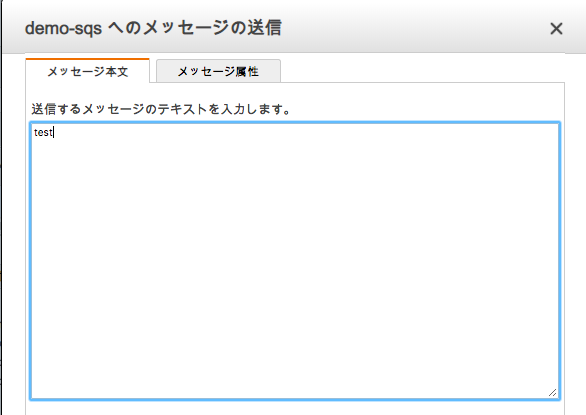
2つメッセージを作成してみます。
メッセージ本文:test
メッセージ本文:test2
メッセージ属性:名前(key), タイプ(String),値(value)
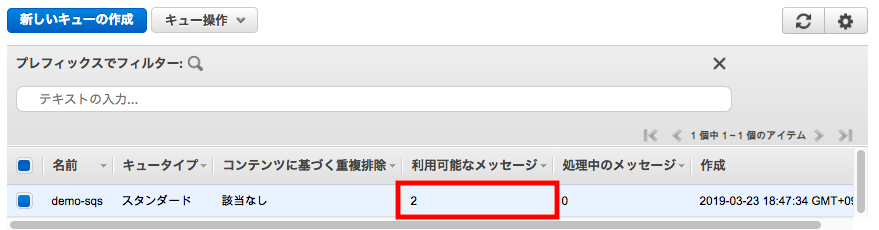
キューに2つあることがわかります。
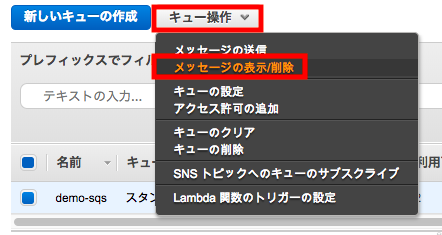
[キュー操作]から[メッセージの表示/削除]
[メッセージのボーリングを開始]を押すと先ほど作成した2
つのメッセージが受信されていることがわかる。
ただし、マネージメントコンソールからの操作はキューを詰め込むことはあっても受信するという操作はあまりない。
3.SDK for PHP でメッセージを送受信する
SendQueue.phpSendQueue.php <?php require '../vendor/autoload.php'; use Aws\Sqs\SqsClient; use Aws\Exception\AwsException; date_default_timezone_set('Asia/Tokyo'); $client = new SqsClient([ 'region' => 'ap-northeast-1', 'version' => '2012-11-05' ]); $params = [ 'MessageAttributes' => [ "Sender" => [ 'DataType' => "String", 'StringValue' => "ketancho" ] ], 'MessageBody' => date('YmdHis'), //TODO: Queue の URL を記載する 'QueueUrl' => '***' ]; try { $result = $client->sendMessage($params); var_dump($result); } catch (AwsException $e) { error_log($e->getMessage()); }php SendQueue.php を実行してみる。
vim php SendQueue.php object(Aws\Result)#142 (2) { ["data":"Aws\Result":private]=> array(4) { ["MD5OfMessageBody"]=> string(32) "88fcc276b82edad126cc8d8a71adb831" ["MD5OfMessageAttributes"]=> string(32) "cb369c99da64119aab2384a948af506c" ["MessageId"]=> string(36) "6a4a6716-a2ea-4cb2-8b4a-2aa4340a72e0" ["@metadata"]=> array(4) { ["statusCode"]=> int(200) ["effectiveUri"]=> string(62) "https://sqs.ap-northeast-1.amazonaws.com/268546037544/demo-sqs" ["headers"]=> array(4) { ["x-amzn-requestid"]=> string(36) "d6f69a23-fad5-5bb6-82af-cf33f262a6f6" ["date"]=> string(29) "Sat, 23 Mar 2019 10:12:07 GMT" ["content-type"]=> string(8) "text/xml" ["content-length"]=> string(3) "459" } ["transferStats"]=> array(1) { ["http"]=> array(1) { [0]=> array(0) { } } } } } ["monitoringEvents":"Aws\Result":private]=> array(0) { } }ReceiveQueue.phpvim ReceiveQueue.php <?php require '../vendor/autoload.php'; use Aws\Sqs\SqsClient; use Aws\Exception\AwsException; //TODO: Queue の URL を記載する $queueUrl = "***"; $client = new SqsClient([ 'region' => 'ap-northeast-1', 'version' => '2012-11-05' ]); try { $result = $client->receiveMessage(array( 'AttributeNames' => ['SentTimestamp'], 'MaxNumberOfMessages' => 1, 'MessageAttributeNames' => ['All'], 'QueueUrl' => $queueUrl, // REQUIRED 'WaitTimeSeconds' => 0, )); if (count($result->get('Messages')) > 0) { var_dump($result->get('Messages')[0]); $result = $client->deleteMessage([ 'QueueUrl' => $queueUrl, // REQUIRED 'ReceiptHandle' => $result->get('Messages')[0]['ReceiptHandle'] // REQUIRED ]); } else { echo "No messages in queue. \n"; } } catch (AwsException $e) { // output error message if fails error_log($e->getMessage()); }php ReceiveQueue.php を実行する
php ReceiveQueue.php array(7) { ["MessageId"]=> string(36) "6a4a6716-a2ea-4cb2-8b4a-2aa4340a72e0" ["ReceiptHandle"]=> string(412) "AQEBWpLLVfMBwxeVBxkn+I4rTIIqCuLXR+G1rYoWqCrmyiIY1lI3kWwsPd7F1Ai12IYUInDomtw09Z+EQFVE+nsogXOooadkdN8NDQ8B2wHjLZ/X8DaBDCuKGCsUQ9TwZ5/Kjq2rM9vfrboq8KBgkdV+I+ZXVAvmPOoLk+YSMhohw07vZjnwMmB1beenTV8O+/yXXGIaCwwc0lRmcM8eRCmaYz1++jTn2SIEbIL9L9tkAqBtU07UOkBSTUUyeHd+/Nap/QlA4+dnLEhW+ygUS9aN6ppPnK5Gk53vVrQyRs386oDR7gJ6Xa8DKALKPpReq5jED6yL3x0WJc5ljgeVvgyyN9ILWkXvZikF1JWIvD8ne1rWRWEAeurxnOYrMP0fKQSkM21vOLZ2P7VUWHUrLoKncQ==" ["MD5OfBody"]=> string(32) "88fcc276b82edad126cc8d8a71adb831" ["Body"]=> string(14) "20190323191207" ["Attributes"]=> array(1) { ["SentTimestamp"]=> string(13) "1553335927345" } ["MD5OfMessageAttributes"]=> string(32) "cb369c99da64119aab2384a948af506c" ["MessageAttributes"]=> array(1) { ["Sender"]=> array(2) { ["StringValue"]=> string(8) "ketancho" ["DataType"]=> string(6) "String" } } }


- 投稿日:2019-03-23T18:50:50+09:00
[aws]autoscaling構成でのログ集約を簡単にやりたい
fluentdやらkinesis firehoseやらELKやらathenaやら、いろいろ考えてるとややこしくなってきました。
例えば、新規にaws上にサービスを構築するとして、あまり作りこむこともなく、お金をかけることもなく、って場合にどれがいいのやら。そういうのを考えながらやってみるエントリでございます。
前提
- elb配下でec2がauto scaling構成で稼働している
- ec2はステートレス
- ec2上でapacheが稼働している
要件
- apacheのログを自動で集約したい
- ログはDLせずにクラウド上で調査したい
- 導入は1~2時間くらいで
- コストは最小限
- 拡張性もほしい
- ログが複数行にわたる場合にも対応したい
構成検討
構成としてはec2に何らかのエージェントを入れて、そこからpushする方式とします。
エージェントとして検討するのは、
- fluentd
- kinesis agent
- CloudWatch Logs agent
- logstash
の4つのエージェントとしました。
fluentdはトレジャーデータ社が開発したデータ収集ミドルウェアでプラグインも豊富で拡張性もある。
logstashはelastic社が開発したデータ収集ミドルウェアで、elastic search、kibanaを合わせて使う構成がELKと呼ばれていて一般的だったりする。
上記二つはどちらもrubyにスクリプトです。
kinesis agent、CloudWatch Logs agentはawsのツールで、前者はjava、後者はpythonみたいです。次に検討したいものとしてはデータの保存方法。これによってエージェントも絞れそうです。
- (とりあえず)S3
- Elastic search
- redshift
他にも考えれるとは思いますがとりあえず。
ただ、コストはなるべく抑えるという要件がありまして、そうなるとec2インスタンスやらDBインスタンスやらを用いるようなサーバータイプのものは消したいです。
つまり(とりあえず)S3にしたいです。
S3に入れておけばAthenaで調査ができたりQuickSightで可視化ができるかなと思います。
Athenaだとクエリーで課金なのは少し気になりますが、S3のライフサイクルポリシー設定や、ログの圧縮、glueを使って形式変換(json -> parquet)とかやるとほぼ気にならない程度になるのではないでしょうか。そんなわけでagentに戻ります。
kinesis firehoseとかを使う事も考えてたんだけど、これは使わなくても良さそうかな。
kinesis agent外しときましょう。極力、シンプルにする。
CloudWatchLogsは、cloudwatchに出力した後にs3にエクスポートという事はできそうなのですが、基本的にはcloudwatchに出力するためのツールでしょうか。これはこれで便利だと思うけど、ちょっと方向性が違うので外しましょう。
fluentdかlogstashか。
jsonに変換できてS3に保存できればどちらでもよいのだけど、elastic searchに流すのが本筋なlogstashに比べて、多用途に作られてるfluentdの方が扱いやすそうには思える。fluent/fluent-plugin-s3:
https://github.com/fluent/fluent-plugin-s3
S3 output plugin:
https://www.elastic.co/guide/en/logstash/current/plugins-outputs-s3.htmlというわけで、
fluentd + S3 + aws Athenaにしようと思います。fluentd インストール
https://docs.fluentd.org/v1.0/articles/before-install
/etc/security/limits.confとか編集しますそして下記のAmazon Linux 2の部分を参考にしてインストール
https://docs.fluentd.org/v1.0/articles/install-by-rpm$ sudo curl -L https://toolbelt.treasuredata.com/sh/install-amazon2-td-agent3.sh | sh $ sudo systemctl start td-agent.service $ /opt/td-agent/usr/sbin/td-agent --version td-agent 1.3.3あっさりと起動しました。
あとはapacheのログを拾ってjsonとしてS3に投げるconfigを作る。
ここにだいたい書かれてます
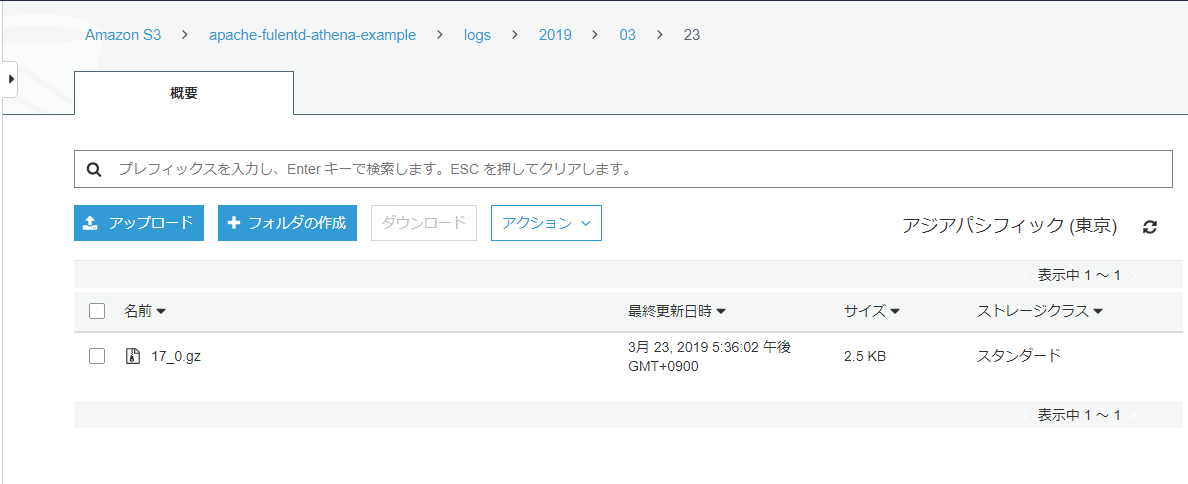
https://docs.fluentd.org/v0.12/articles/apache-to-s3$ sudo /opt/td-agent/usr/sbin/td-agent-gem install fluent-plugin-s3/etc/td-agent/td-agent.conf<source> @type tail format apache2 keep_time_key true time_format %d/%b/%Y:%H:%M:%S %z path /var/log/httpd/access_log pos_file /var/log/td-agent/apache2.access_log.pos tag s3.apache.access </source> <match s3.*.*> @type s3 s3_bucket apache-fluentd-athena-example time_slice_format "%Y/%m/%d/%H" path logs/%Y/%m/%d/ s3_object_key_format %{path}%{time_slice}_%{index}.%{file_extension} <buffer time> @type file path /var/log/fluent/s3 timekey 60 timekey_wait 1m timekey_use_utc false timekey_zone Asia/Tokyo </buffer> <format> @type json </format> </match>S3bucketはapache-fluentd-athena-exampleと名付けました。
インスタンスはiamロール割り当ててるので設定がシンプルです。検証なので掃き出し間隔も短め。
config書いたらtd-agent.serviceをリスタートします。
その後、ab -c 10 -n 100000 http://localhost/とかやってログを増し増しします。
なお、td-agentユーザーだとaccess.log読めなかったので/lib/systemd/system/td-agent.serviceのUserとGroupはrootにしました。
データは3日で消えるようにしました。
ログも保存できてるようです。aws glue
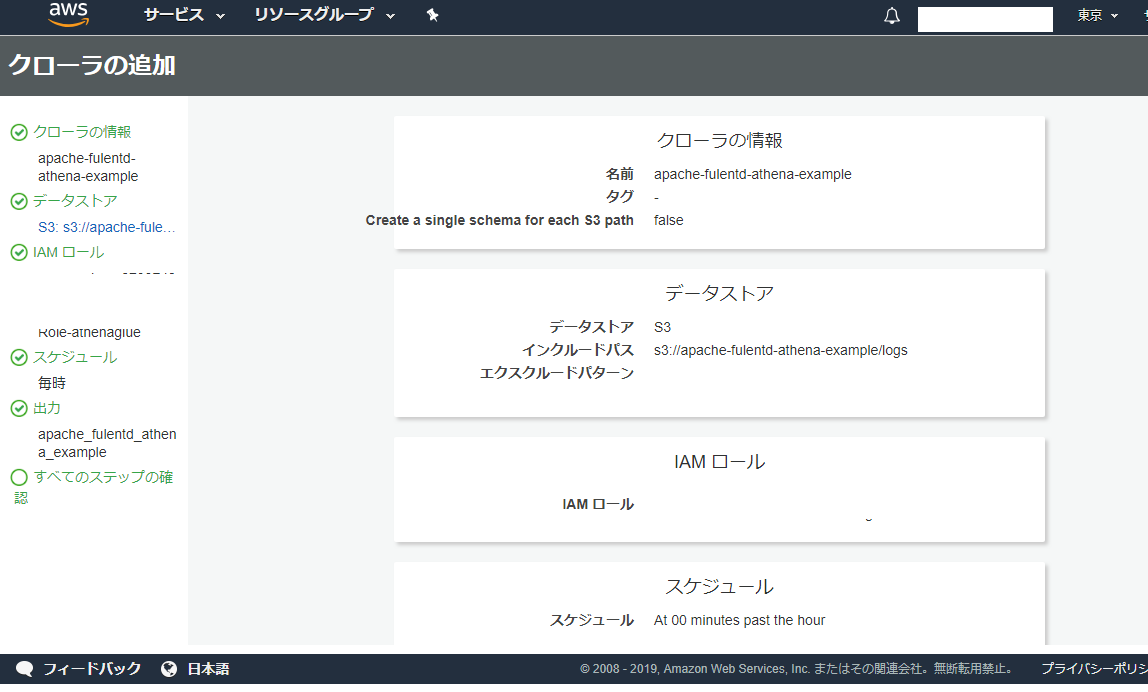
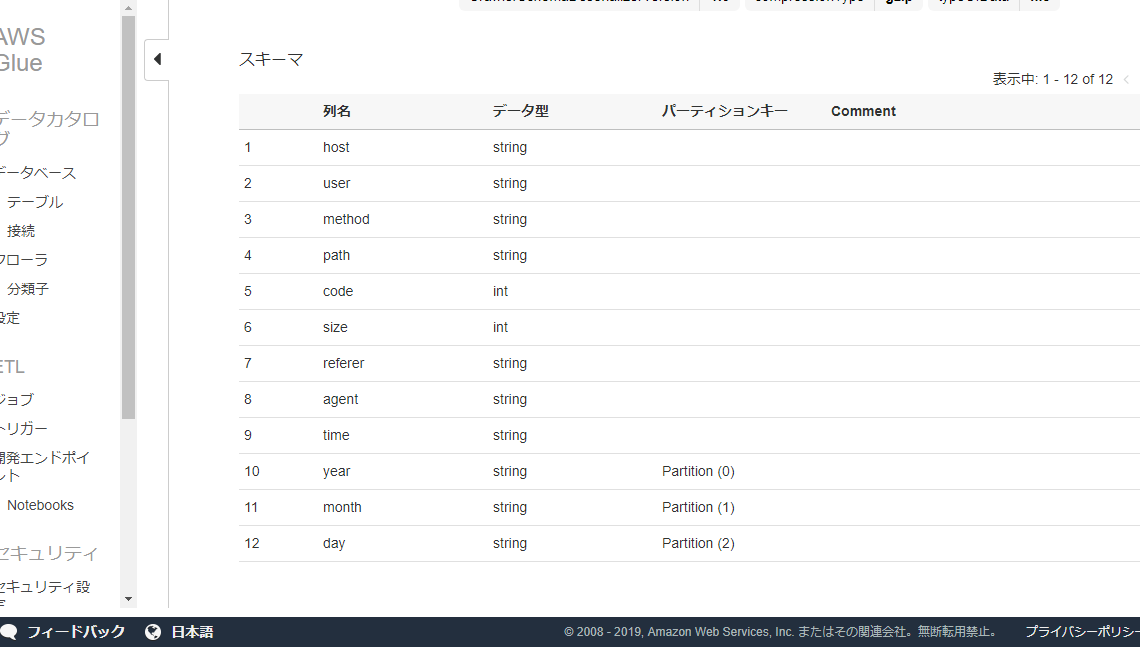
クロールするとathenaのschemaを勝手に作ってくれるみたいなので、glueを使ってみます。
良い感じに解析してくれました。
partitionのとこはpartition1みたいな名前になってたので編集してyearとかmonthに変えておきました。athena
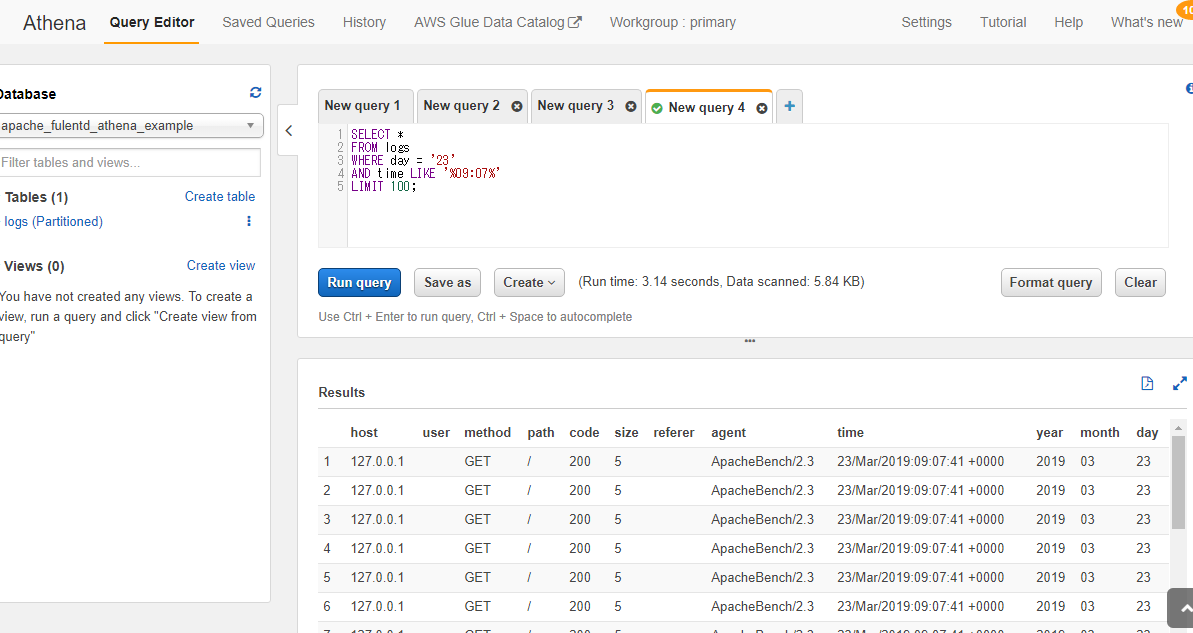
ではathenaでquery投げてみます。
ほぼ、ただのSQLですね。
https://docs.aws.amazon.com/ja_jp/athena/latest/ug/select.html
ちょっとデータが適当すぎてつまらないけど一応できました。
ちなみにAthenaは1TBをスキャン(の対象に)した場合に5USDらしいです。
ついうっかりどでかいデータにフルスキャンとかしちゃった日には無事死亡できますね。
圧縮とかパーティショニングとか怠らないようにしましょう。
- 投稿日:2019-03-23T18:50:50+09:00
[aws]auto scaling構成でのログ集約を簡単にやりたい
fluentdやらkinesis firehoseやらELKやらathenaやら、いろいろ考えてるとややこしくなってきました。
例えば、新規にaws上にサービスを構築するとして、あまり作りこむこともなく、お金をかけることもなく、って場合にどれがいいのやら。そういうのを考えながらやってみるエントリでございます。
前提
- elb配下でec2がauto scaling構成で稼働している
- ec2はステートレス
- ec2上でapacheが稼働している
要件
- apacheのログを自動で集約したい
- ログはDLせずにクラウド上で調査したい
- 導入は1~2時間くらいで
- コストは最小限
- 拡張性もほしい
- ログが複数行にわたる場合にも対応したい
構成検討
構成としてはec2に何らかのエージェントを入れて、そこからpushする方式とします。
エージェントとして検討するのは、
- fluentd
- kinesis agent
- CloudWatch Logs agent
- logstash
の4つのエージェントとしました。
fluentdはトレジャーデータ社が開発したデータ収集ミドルウェアでプラグインも豊富で拡張性もある。
logstashはelastic社が開発したデータ収集ミドルウェアで、elastic search、kibanaを合わせて使う構成がELKと呼ばれていて一般的だったりする。
上記二つはどちらもrubyにスクリプトです。
kinesis agent、CloudWatch Logs agentはawsのツールで、前者はjava、後者はpythonみたいです。次に検討したいものとしてはデータの保存方法。これによってエージェントも絞れそうです。
- (とりあえず)S3
- Elastic search
- redshift
他にも考えれるとは思いますがとりあえず。
ただ、コストはなるべく抑えるという要件がありまして、そうなるとec2インスタンスやらDBインスタンスやらを用いるようなサーバータイプのものは消したいです。
つまり(とりあえず)S3にしたいです。
S3に入れておけばAthenaで調査ができたりQuickSightで可視化ができるかなと思います。
Athenaだとクエリーで課金なのは少し気になりますが、S3のライフサイクルポリシー設定や、ログの圧縮、glueを使って形式変換(json -> parquet)とかやるとほぼ気にならない程度になるのではないでしょうか。そんなわけでagentに戻ります。
kinesis firehoseとかを使う事も考えてたんだけど、これは使わなくても良さそうかな。
kinesis agent外しときましょう。極力、シンプルにする。
CloudWatchLogsは、cloudwatchに出力した後にs3にエクスポートという事はできそうなのですが、基本的にはcloudwatchに出力するためのツールでしょうか。これはこれで便利だと思うけど、ちょっと方向性が違うので外しましょう。
fluentdかlogstashか。
jsonに変換できてS3に保存できればどちらでもよいのだけど、elastic searchに流すのが本筋なlogstashに比べて、多用途に作られてるfluentdの方が扱いやすそうには思える。fluent/fluent-plugin-s3:
https://github.com/fluent/fluent-plugin-s3
S3 output plugin:
https://www.elastic.co/guide/en/logstash/current/plugins-outputs-s3.htmlというわけで、
fluentd + S3 + aws Athenaにしようと思います。fluentd インストール
https://docs.fluentd.org/v1.0/articles/before-install
/etc/security/limits.confとか編集しますそして下記のAmazon Linux 2の部分を参考にしてインストール
https://docs.fluentd.org/v1.0/articles/install-by-rpm$ sudo curl -L https://toolbelt.treasuredata.com/sh/install-amazon2-td-agent3.sh | sh $ sudo systemctl start td-agent.service $ /opt/td-agent/usr/sbin/td-agent --version td-agent 1.3.3あっさりと起動しました。
あとはapacheのログを拾ってjsonとしてS3に投げるconfigを作る。
ここにだいたい書かれてます
https://docs.fluentd.org/v0.12/articles/apache-to-s3$ sudo /opt/td-agent/usr/sbin/td-agent-gem install fluent-plugin-s3/etc/td-agent/td-agent.conf<source> @type tail format apache2 keep_time_key true time_format %d/%b/%Y:%H:%M:%S %z path /var/log/httpd/access_log pos_file /var/log/td-agent/apache2.access_log.pos tag s3.apache.access </source> <match s3.*.*> @type s3 s3_bucket apache-fluentd-athena-example time_slice_format "%Y/%m/%d/%H" path logs/%Y/%m/%d/ s3_object_key_format %{path}%{time_slice}_%{index}.%{file_extension} <buffer time> @type file path /var/log/fluent/s3 timekey 60 timekey_wait 1m timekey_use_utc false timekey_zone Asia/Tokyo </buffer> <format> @type json </format> </match>S3bucketはapache-fluentd-athena-exampleと名付けました。
インスタンスはiamロール割り当ててるので設定がシンプルです。検証なので掃き出し間隔も短め。
config書いたらtd-agent.serviceをリスタートします。
その後、ab -c 10 -n 100000 http://localhost/とかやってログを増し増しします。
なお、td-agentユーザーだとaccess.log読めなかったので/lib/systemd/system/td-agent.serviceのUserとGroupはrootにしました。
データは3日で消えるようにしました。
ログも保存できてるようです。aws glue
クロールするとathenaのschemaを勝手に作ってくれるみたいなので、glueを使ってみます。
良い感じに解析してくれました。
partitionのとこはpartition1みたいな名前になってたので編集してyearとかmonthに変えておきました。athena
ではathenaでquery投げてみます。
ほぼ、ただのSQLですね。
https://docs.aws.amazon.com/ja_jp/athena/latest/ug/select.html
ちょっとデータが適当すぎてつまらないけど一応できました。
ちなみにAthenaは1TBをスキャン(の対象に)した場合に5USDらしいです。
ついうっかりどでかいデータにフルスキャンとかしちゃった日には無事死亡できますね。
圧縮とかパーティショニングとか怠らないようにしましょう。
- 投稿日:2019-03-23T18:23:40+09:00
Amazon SES
■特徴
送信 受信 AWS SDK経由でプログラムからメール送信を行うことが可能
独自ドメインからメールを遅れる
バウンス(送信エラー)の対応が必要独自ドメインを設定可能
受信メールをS3に保存したり、受信をトリガに後続の処理を実施可能バウンス処理
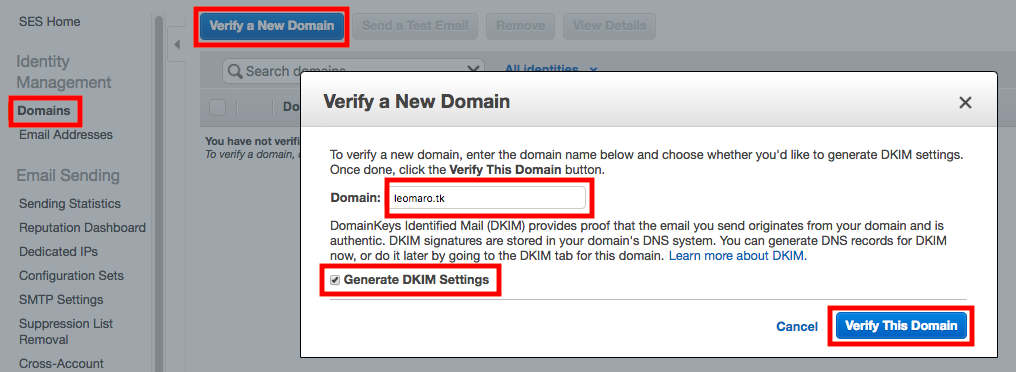
もし、メールが正しく送信されなかった場合や、苦情を受けてしまった場合、そのメールアドレスに対してメールを送らないように実装する必要がある。1.SESにドメインを登録し、Route53に紐付ける
※Route53にドメインを登録済みであるものと過程する。
[Domains]-[Verify a New Domain]
[Domain]をに入力し、「Generate DKIM Settings」にチェック。
次の画面はそれぞれ、
[Use Route53]
[Create Record Sets]
をクリック。Route53を開くと、TXTとCNAMEレコードが作成されているはず。
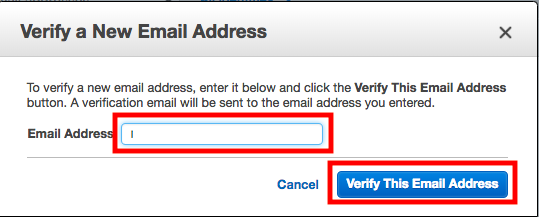
2.メールアドレスの事前登録
[Email Addresses]-[Verify a Email Address]
メールアドレスを入力し、[Verify This Email Address]
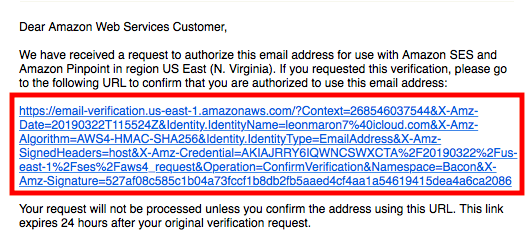
登録したメールアドレスに届いたリンクをクリック。
このように認証される。
参考:利用暖和申請
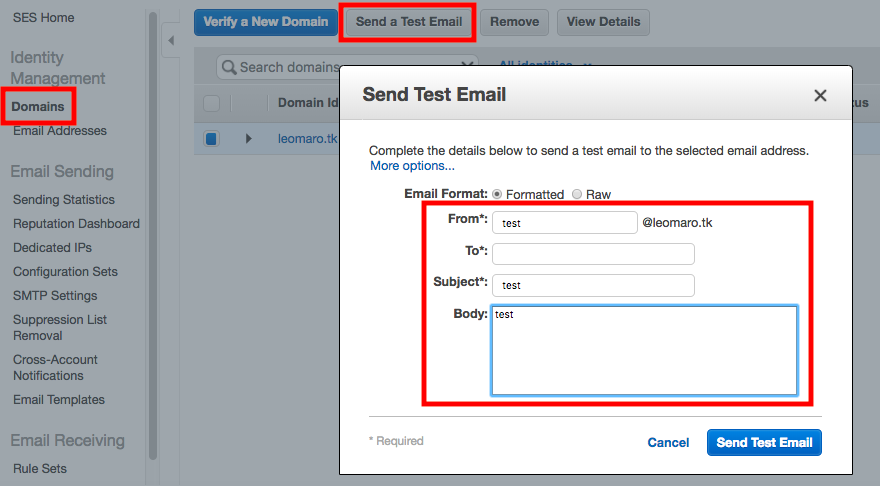
サポートに問い合わせることで、事前登録していないメールアドレスへの送信が可能になります。3.マネージメントコンソロールからテスト送信する
[Domains]の「Send a Test Email」をクリック。
必要な項目を入力し、「Send Test Email」
メールが届いているか確認してみましょう。
4.SDK for PHP でメッセージを送信する
SendEmail.phpvim SendEmail.php <?php require '../vendor/autoload.php'; use Aws\Ses\SesClient; // バージニア北部リージョン以外を利用している場合は、region を変更すること $ses = SesClient::factory(array( 'version'=> 'latest', 'region' => 'us-east-1', )); try { $result = $ses->sendEmail([ // TODO: 送信元メールアドレスの入力 'Source' => '***@***.***', 'Destination' => [ 'ToAddresses' => [ // TODO: 送信先メールアドレスの入力 '***@***.***', ], ], 'Message' => [ 'Subject' => [ 'Charset' => 'UTF-8', 'Data' => 'Hello SES World!!', ], 'Body' => [ 'Text' => [ 'Charset' => 'UTF-8', 'Data' => 'AWS SDK for PHP を使った SES 送信テストです。', ], ], ], ]); $messageId = $result->get('MessageId'); echo("Email sent! Message ID: $messageId"."\n"); } catch (SesException $error) { echo("The email was not sent. Error message: ".$error->getAwsErrorMessage()."\n"); }メールを送信し、届いているか確認する。
php SendEmail.php Email sent! Message ID: 01000169a9d810aa-c6dc4afc-b2a6-46a0-b084-a678918f5a88-000000


- 投稿日:2019-03-23T16:04:19+09:00
Laradock + Nuxt(SSRモード)をAWS Fargateで実行する
前提
同一リポジトリでLaradock + Nuxt(SSRモード)の環境構築
上記のサイトでLaradock+Nuxtで環境構築できていること参考サイト
nginxプロキシ設定
nuxt.js(フロント)とLaravel(API)を同一リポジトリ/サーバで動かす時
laradockをdocker-composeをproductionで使用したい場合
DockerfileのCMDコマンドを複数実行したい場合
Dockerfileでは、CMDコマンドを複数実行できない
そのためstartup.shでコマンドを記載して実行してもらうNuxtをバックグラウンドで起動したい
実行したら、npm run startでコマンドが止まってしまい
nginxコマンドが実行されずにWebサーバが起動できてなかったそのためバックグラウンドでnpm run startを実行するために
foreverモジュールを入れるNuxt.jsのアプリケーションをinitd-foreverを使ってデーモン化、自動起動する
githubのプライベートリポジトリからクローンできるように準備する
Dockerfileのbuildで簡単にGithubのプライベートリポジトリをクローンする方法
nginxサーバをプロキシとしてNuxtとLaravel APIと切り替える
Laradockでは、nginxの設定を下記のパスで設定を行えるため
そこでnginxに対してリクエストが来た際に振り分けを行うようにする/laradock/nginx/sites/default.conf
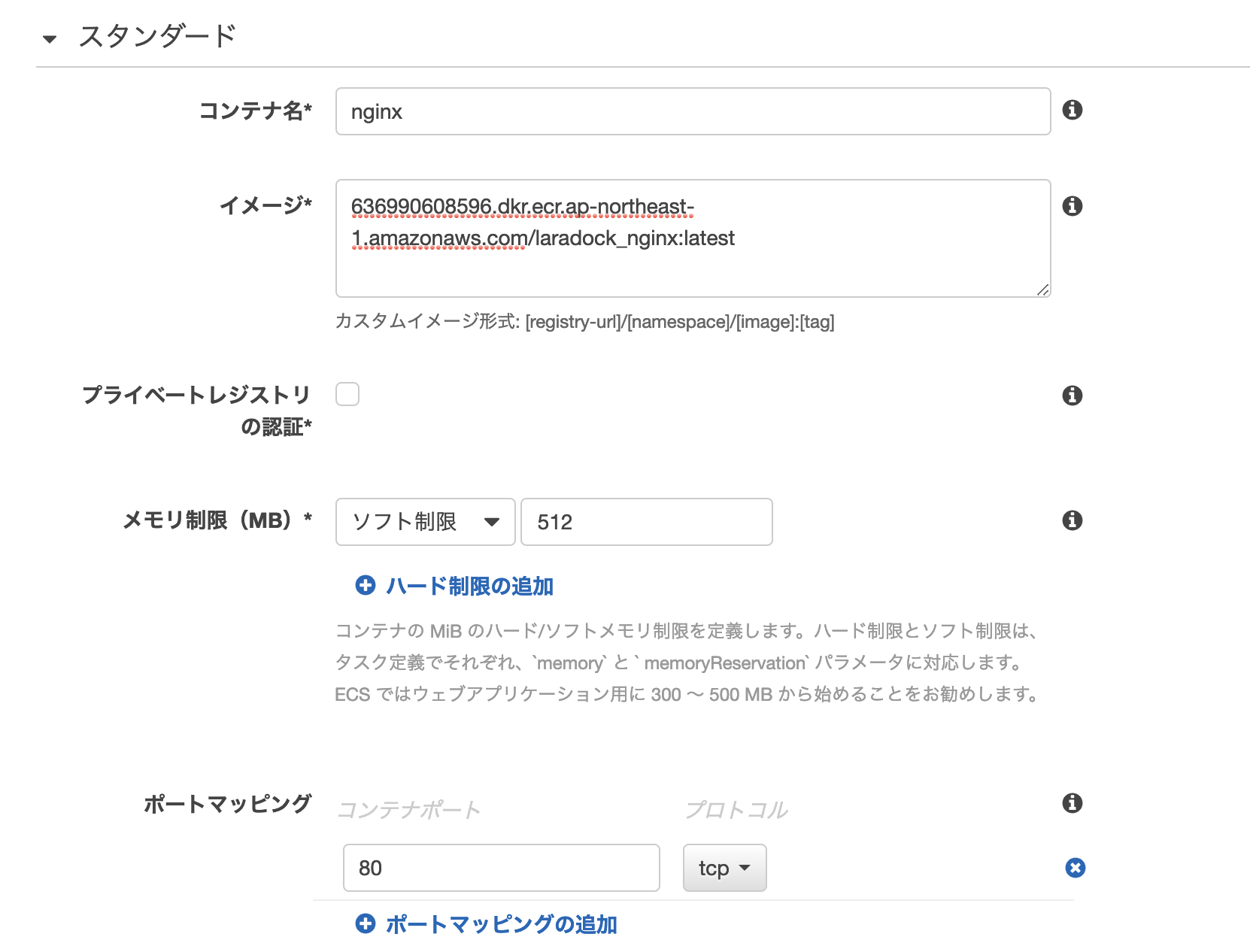
server { listen 80 default_server; listen [::]:80 default_server ipv6only=on; # For https # listen 443 ssl default_server; # listen [::]:443 ssl default_server ipv6only=on; # ssl_certificate /etc/nginx/ssl/default.crt; # ssl_certificate_key /etc/nginx/ssl/default.key; server_name localhost; root /var/www/public; index index.php index.html index.htm; # 基本はすべてLaravelのpublicにアクセスがいくが、/api 以降のパスだけLaravelとする # location / { # try_files $uri $uri/ /index.php$is_args$args; # } # 基本は3000ポートのNuxtサーバに転送を行う location / { proxy_pass http://localhost:3000; proxy_http_version 1.1; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection 'upgrade'; proxy_set_header Host $host; } # Laravel API用にnginxをプロキシサーバとして転送させる location /api { try_files $uri $uri/ /index.php$is_args$args; } location ~ \.php$ { try_files $uri /index.php =404; fastcgi_pass php-upstream; fastcgi_index index.php; fastcgi_buffers 16 16k; fastcgi_buffer_size 32k; fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name; #fixes timeouts fastcgi_read_timeout 600; include fastcgi_params; } location ~ /\.ht { deny all; } location /.well-known/acme-challenge/ { root /var/www/letsencrypt/; log_not_found off; } }nuxtプロキシの転送先のポートを変更する
/{ProjectName}/nuxt.config.jsproxy:{ '/api' : "http://localhost:8000" }Fargateに乗せる用のProduction用Dockerイメージを作成する
Production環境では、下記の順番で実行するコマンドをDockerfileに入れる必要がある
nginxコンテナ
- githubから/var/wwwにcloneを実行する
- node/npmをインストールする
- npm installを実行する
- コンテナ起動時にnpm run build / npm run startでNuxtサーバを立ち上げる
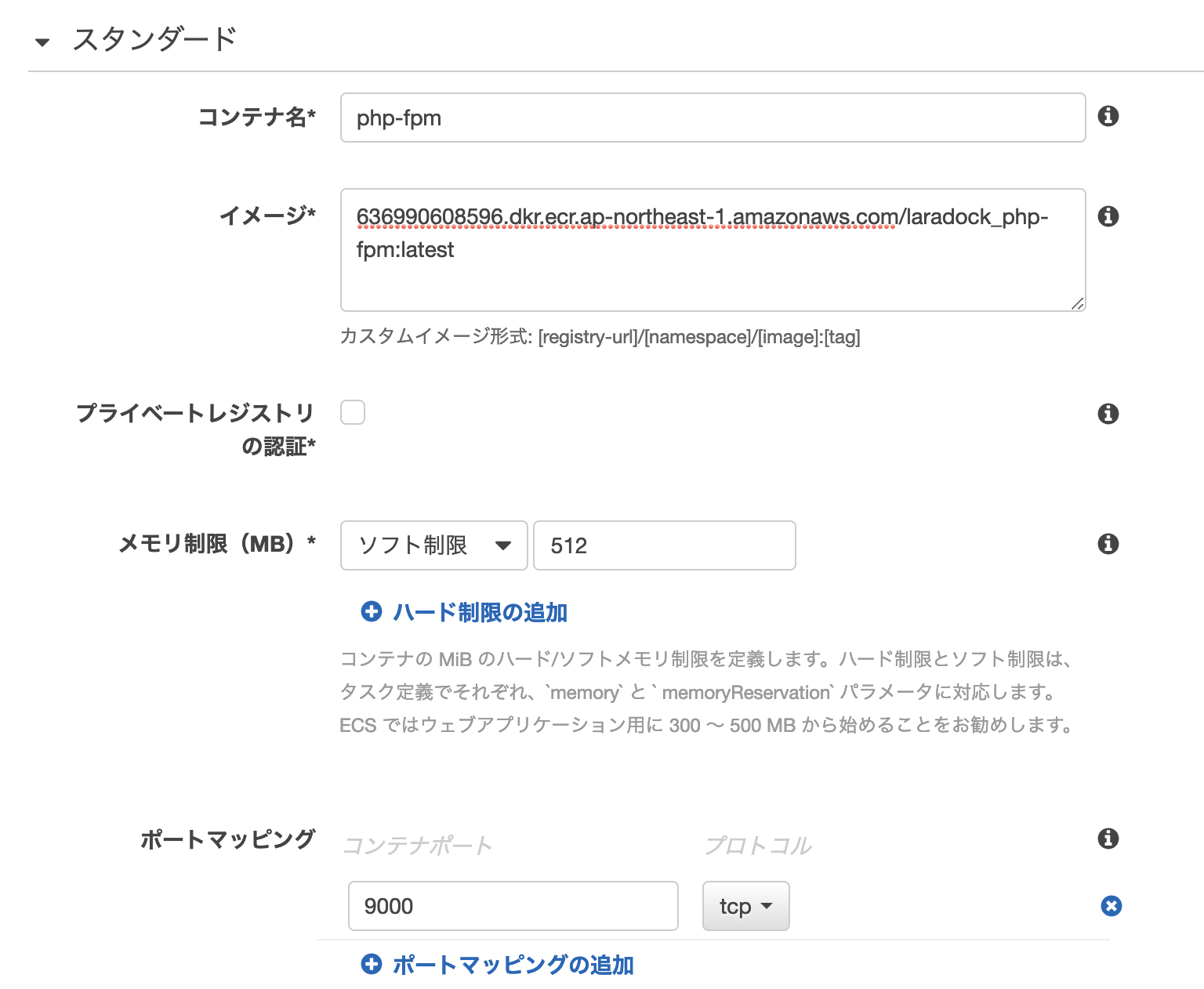
php-fpmコンテナ
- githubから/var/wwwにcloneを実行する
- composerをインストールする
- composer install/php artisan key:generateを実行する
production用のDockerfile-productionとdocker-compose.ymlを作成する
/laradock/nginx/Dockerfile-production
FROM nginx:alpine LABEL maintainer="Mahmoud Zalt <mahmoud@zalt.me>" # nginxの設定ファイルをコンテナ内に配置する COPY nginx.conf /etc/nginx/ COPY sites/ /etc/nginx/sites-available/ COPY ssl/ /etc/nginx/ssl/ COPY sites/default.conf /etc/nginx/conf.d/ # If you're in China, or you need to change sources, will be set CHANGE_SOURCE to true in .env. ARG CHANGE_SOURCE=false RUN if [ ${CHANGE_SOURCE} = true ]; then \ # Change application source from dl-cdn.alpinelinux.org to aliyun source sed -i 's/dl-cdn.alpinelinux.org/mirrors.aliyun.com/' /etc/apk/repositories \ ;fi RUN apk update \ && apk upgrade \ && apk add --no-cache openssl \ && apk add --no-cache bash \ # gitをダウンロード && apk add --no-cache git \ && adduser -D -H -u 1000 -s /bin/bash www-data # AWS fargateではdepends_onやlinkでのコンテナ通信を行えないため、コンテナ名(php-fpm)では接続できない # そのため127.0.0.1で通信を行う ARG PHP_UPSTREAM_CONTAINER=127.0.0.1 #ARG PHP_UPSTREAM_CONTAINER=php-fpm ARG PHP_UPSTREAM_PORT=9000 # Set upstream conf and remove the default conf RUN echo "upstream php-upstream { server ${PHP_UPSTREAM_CONTAINER}:${PHP_UPSTREAM_PORT}; }" > /etc/nginx/conf.d/upstream.conf \ && rm /etc/nginx/conf.d/default.conf # nginxコンテナ内でNuxtをSSRモードで立ち上げるためにnpmをインストールする RUN apk add --update nodejs nodejs-npm # ワーキングディレクトリの指定 WORKDIR /var/www # githubからソースをcloneして配置する # githubOAuthで作成したKeyを元にcloneする RUN git clone https://918e37d82bcbcbd0455ffe52e192d8ba0ec67825:x-oauth-basic@github.com/hajime1103/laravel-nuxt-aws-fargate.git . # Nuxtをビルドする準備をする RUN npm install # foreverモジュールを入れて、Nuxtサーバをバックグラウンドで起動できるようにする RUN npm install -g -y forever ADD ./startup.sh /opt/startup.sh RUN sed -i 's/\r//g' /opt/startup.sh CMD ["/bin/bash", "/opt/startup.sh"] EXPOSE 80 443/laradock/nginx/startup.sh
#!/bin/bash if [ ! -f /etc/nginx/ssl/default.crt ]; then openssl genrsa -out "/etc/nginx/ssl/default.key" 2048 openssl req -new -key "/etc/nginx/ssl/default.key" -out "/etc/nginx/ssl/default.csr" -subj "/CN=default/O=default/C=UK" openssl x509 -req -days 365 -in "/etc/nginx/ssl/default.csr" -signkey "/etc/nginx/ssl/default.key" -out "/etc/nginx/ssl/default.crt" fi # Nuxt server lunch npm run build forever start -c "npm run start" ./ # nginx sever lunch nginx/laradcok/php-fpm/Dockerfile-production
# #-------------------------------------------------------------------------- # Image Setup #-------------------------------------------------------------------------- # # To edit the 'php-fpm' base Image, visit its repository on Github # https://github.com/Laradock/php-fpm # # To change its version, see the available Tags on the Docker Hub: # https://hub.docker.com/r/laradock/php-fpm/tags/ # # Note: Base Image name format {image-tag}-{php-version} # ARG LARADOCK_PHP_VERSION=7.2 # FROM laradock/php-fpm:2.2-${LARADOCK_PHP_VERSION} FROM letsdockerize/laradock-php-fpm:2.4-${LARADOCK_PHP_VERSION} LABEL maintainer="Mahmoud Zalt <mahmoud@zalt.me>" ARG LARADOCK_PHP_VERSION # Set Environment Variables ENV DEBIAN_FRONTEND noninteractive # always run apt update when start and after add new source list, then clean up at end. RUN set -xe; \ apt-get update -yqq && \ pecl channel-update pecl.php.net && \ apt-get install -yqq \ apt-utils \ # #-------------------------------------------------------------------------- # Mandatory Software's Installation #-------------------------------------------------------------------------- # # Mandatory Software's such as ("mcrypt", "pdo_mysql", "libssl-dev", ....) # are installed on the base image 'laradock/php-fpm' image. If you want # to add more Software's or remove existing one, you need to edit the # base image (https://github.com/Laradock/php-fpm). # # next lines are here becase there is no auto build on dockerhub see https://github.com/laradock/laradock/pull/1903#issuecomment-463142846 libzip-dev zip unzip && \ docker-php-ext-configure zip --with-libzip && \ # Install the zip extension docker-php-ext-install zip && \ php -m | grep -q 'zip' # #-------------------------------------------------------------------------- # Final Touch #-------------------------------------------------------------------------- # COPY ./laravel.ini /usr/local/etc/php/conf.d COPY ./xlaravel.pool.conf /usr/local/etc/php-fpm.d/ USER root # Clean up RUN apt-get clean && \ rm -rf /var/lib/apt/lists/* /tmp/* /var/tmp/* && \ rm /var/log/lastlog /var/log/faillog RUN usermod -u 1000 www-data # Adding the faketime library to the preload file needs to be done last # otherwise it will preload it for all commands that follow in this file RUN if [ ${INSTALL_FAKETIME} = true ]; then \ echo "/usr/lib/x86_64-linux-gnu/faketime/libfaketime.so.1" > /etc/ld.so.preload \ ;fi WORKDIR /var/www # php.iniをコンテナに配置する COPY ./php7.2.ini /usr/local/etc/php/php.ini # Laravelプロジェクト入れるためにgitをインストールする #RUN apt-get install git RUN apt-get update && apt-get install -y git # ゴミが残っているとgitのcloneが行えないため消していおく RUN rm -r html # githubからソースをcloneして配置する # githubOAuthで作成したKeyを元にcloneする RUN git clone https://918e37d82bcbcbd0455ffe52e192d8ba0ec67825:x-oauth-basic@github.com/hajime1103/laravel-nuxt-aws-fargate.git . # .envファイルを作成する RUN cp .env.example .env # Laravelを動作させるための準備をする # composerをインストールしPHPの依存モジュールをインストールする # /storage/logs/に対してアクセス権を変更する RUN curl -sS https://getcomposer.org/installer | php && \ mv composer.phar /usr/local/bin/composer && \ composer install && \ php artisan key:generate && \ chown -R www-data:www-data /var/www CMD ["php-fpm"] # 宣言的な意味で実際にポートを開いてる場合ではない EXPOSE 9000/laradock/docker-compose.production.yml
version: '3' services: ### PHP-FPM ############################################## php-fpm: build: context: ./php-fpm dockerfile: Dockerfile-production args: - LARADOCK_PHP_VERSION=${PHP_VERSION} - LARADOCK_PHALCON_VERSION=${PHALCON_VERSION} expose: - "9000" ### NGINX Server ######################################### nginx: build: context: ./nginx dockerfile: Dockerfile-production ports: - "${NGINX_HOST_HTTP_PORT}:80" - "${NGINX_HOST_HTTPS_PORT}:443" depends_on: - php-fpmdocker-composeでビルドを行う
docker-compose -f docker-compose.production.yml build --no-cache nginx php-fpmdocker-compose無しで起動する
※Fargateではlink機能は使用できないため
Fargateでの方法を検討するdocker run -d --name php-fpm laradock_php-fpm docker run -d --link php-fpm:php-fpm -p 80:80 laradock_nginxLaravel+NuxtプロジェクトをFargateに乗せる
ECRにDockerイメージをプッシュする
php-fpmをpushする
$(aws ecr get-login --no-include-email --region ap-northeast-1) docker tag laradock_php-fpm:latest 636990608596.dkr.ecr.ap-northeast-1.amazonaws.com/laradock_php-fpm:latest docker push 636990608596.dkr.ecr.ap-northeast-1.amazonaws.com/laradock_php-fpm:latestnginxコンテナをpushする
$(aws ecr get-login --no-include-email --region ap-northeast-1) docker tag laradock_nginx:latest 636990608596.dkr.ecr.ap-northeast-1.amazonaws.com/laradock_nginx:latest docker push 636990608596.dkr.ecr.ap-northeast-1.amazonaws.com/laradock_nginx:latestFargateクラスターの作成
AWSでのECSサービスを起動する。
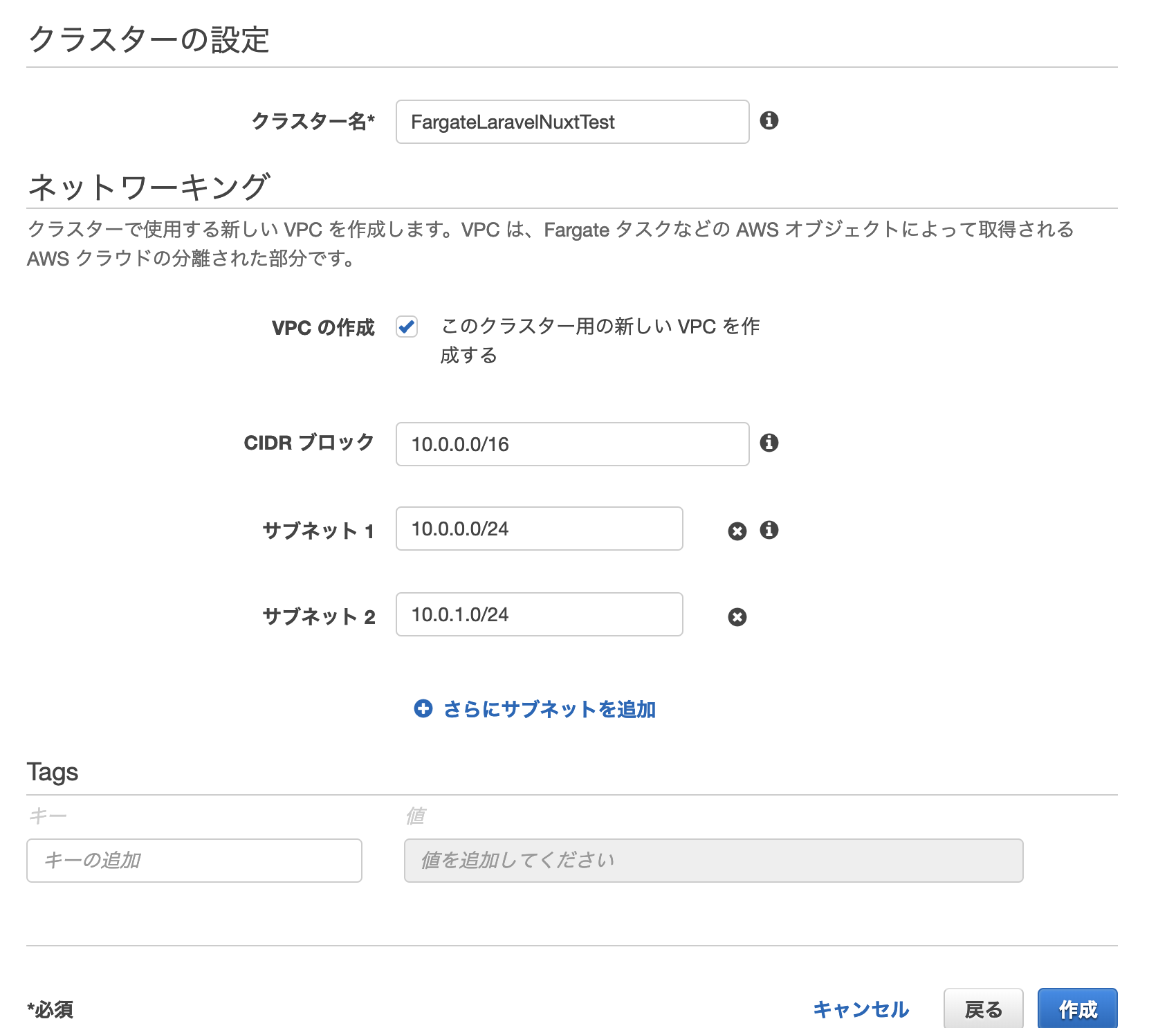
クラスター>クラスターの作成クラスターテンプレートを「ネットワーキングのみ」を選択肢して「次のステップへ」
クラスタに名前を付け、このクラスタ用の新しいVPCの作成を有効にします。CIDRブロックとサブネットをデフォルトのままにして[作成]をクリックします。
正常にクラスターが作成されたことを確認する
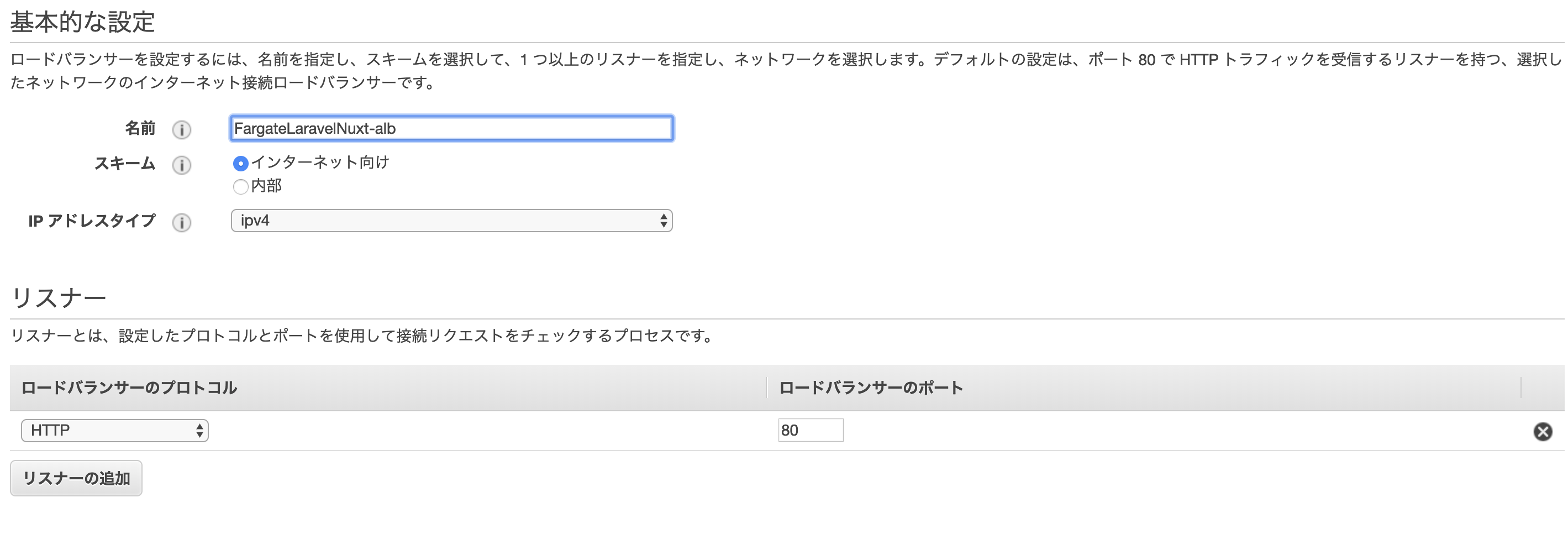
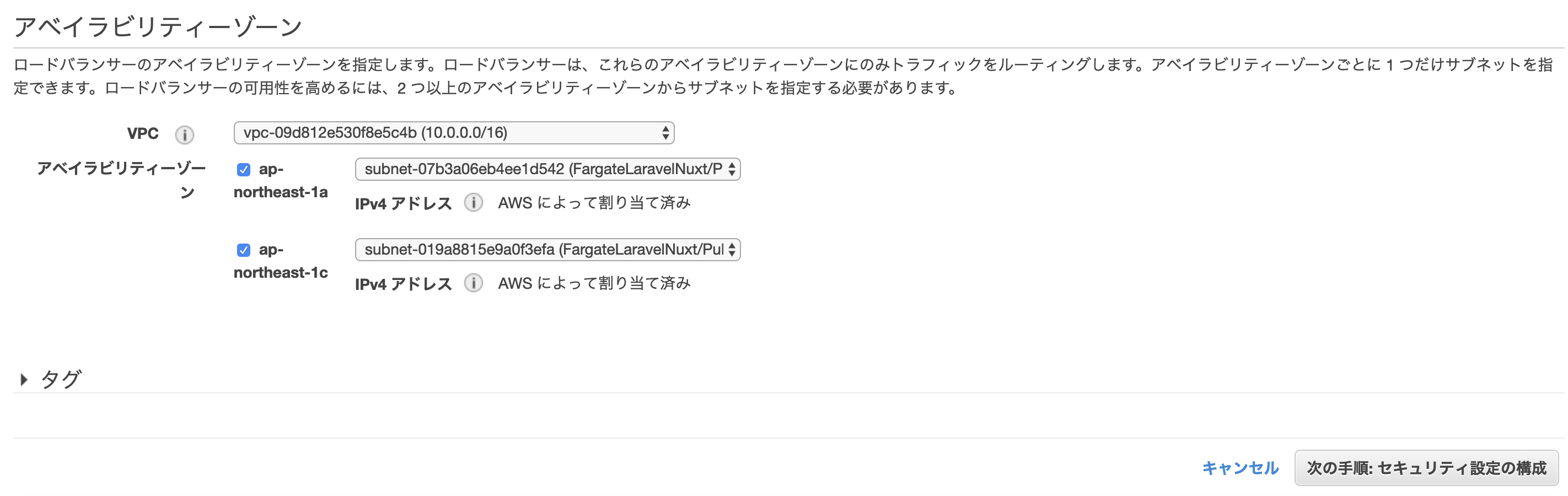
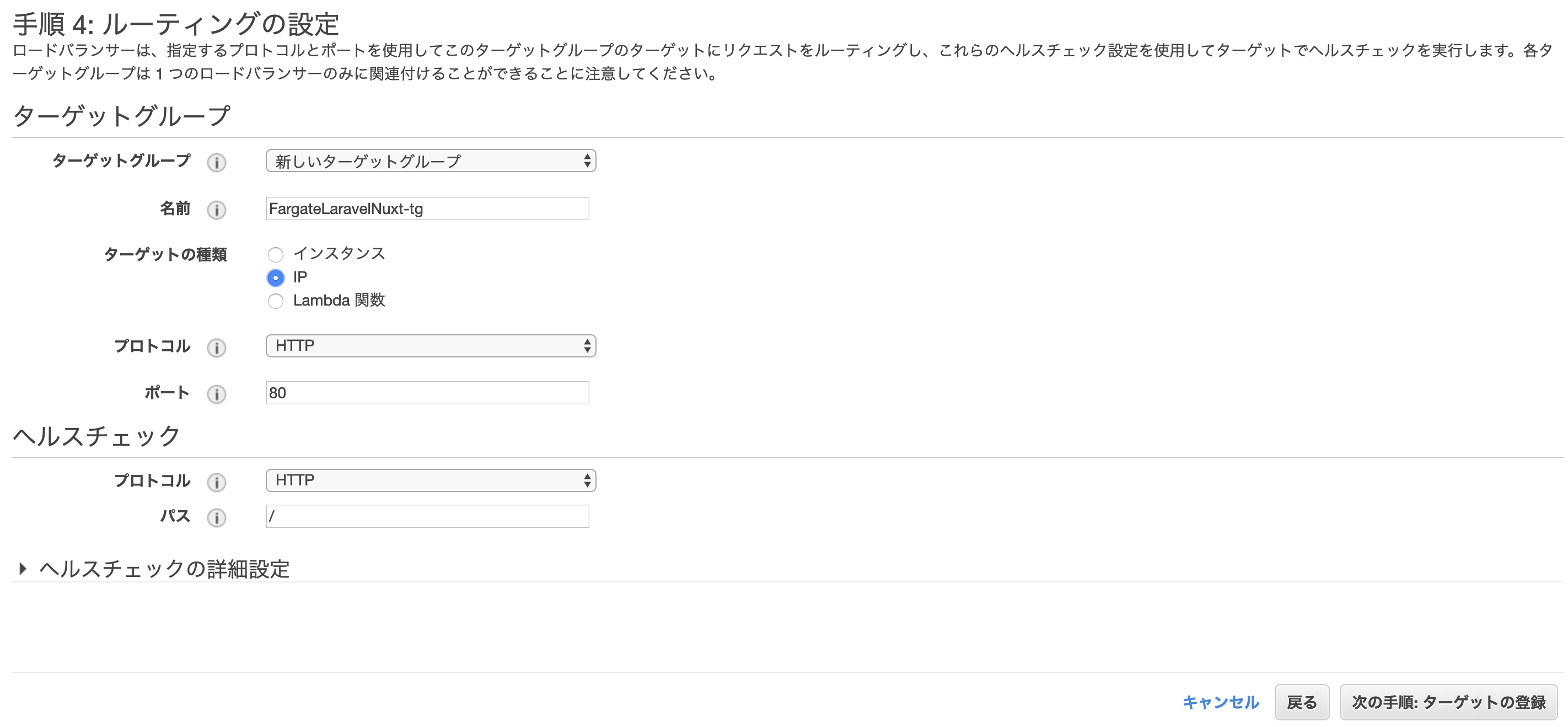
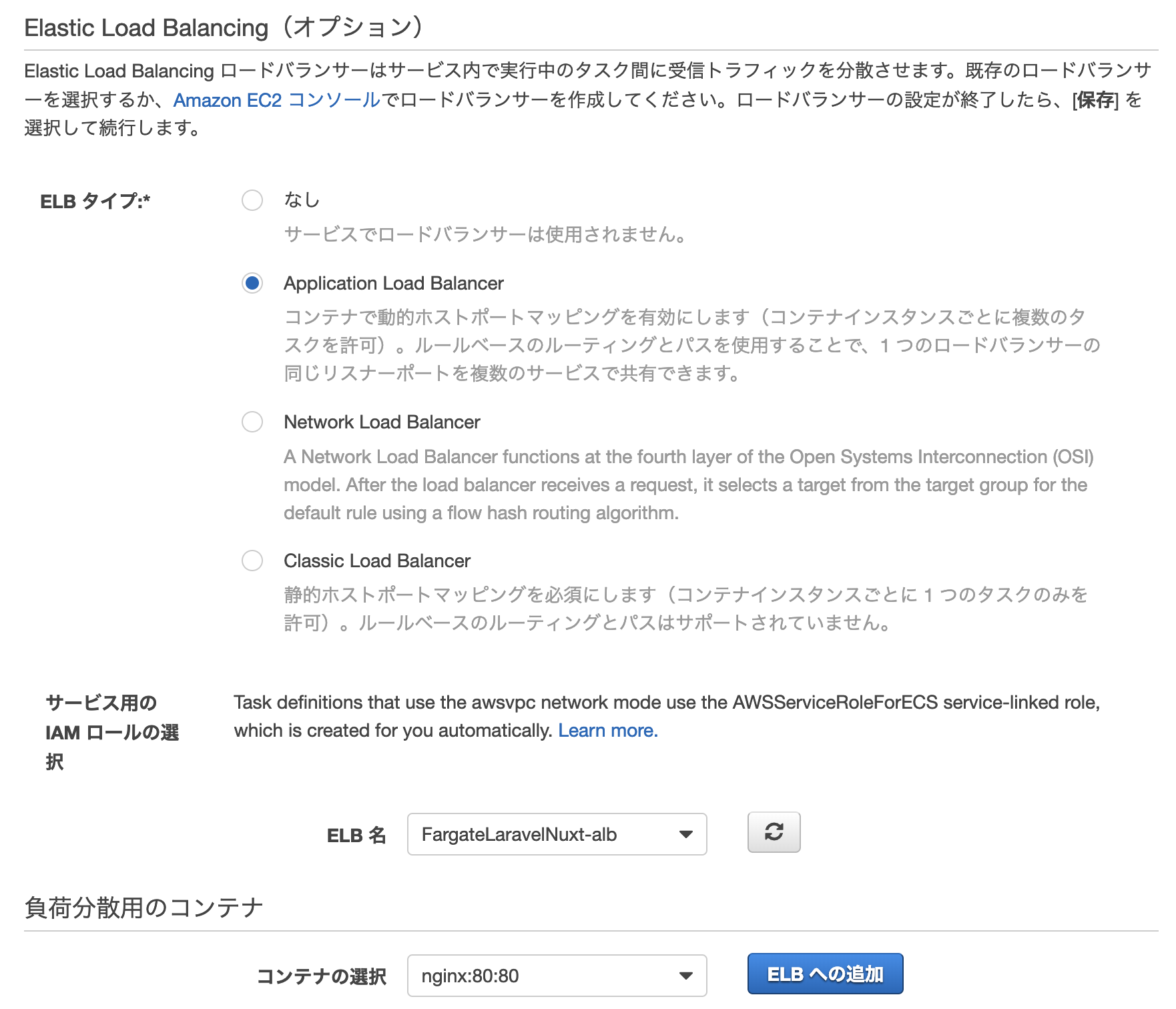
Application Load balancerの作成
- EC2サービス>ロードバランサー>ロードバランサーの作成をクリック
- Application Load Balancerの作成ボタンをクリック
下記のように設定を行い次の手順へ進む
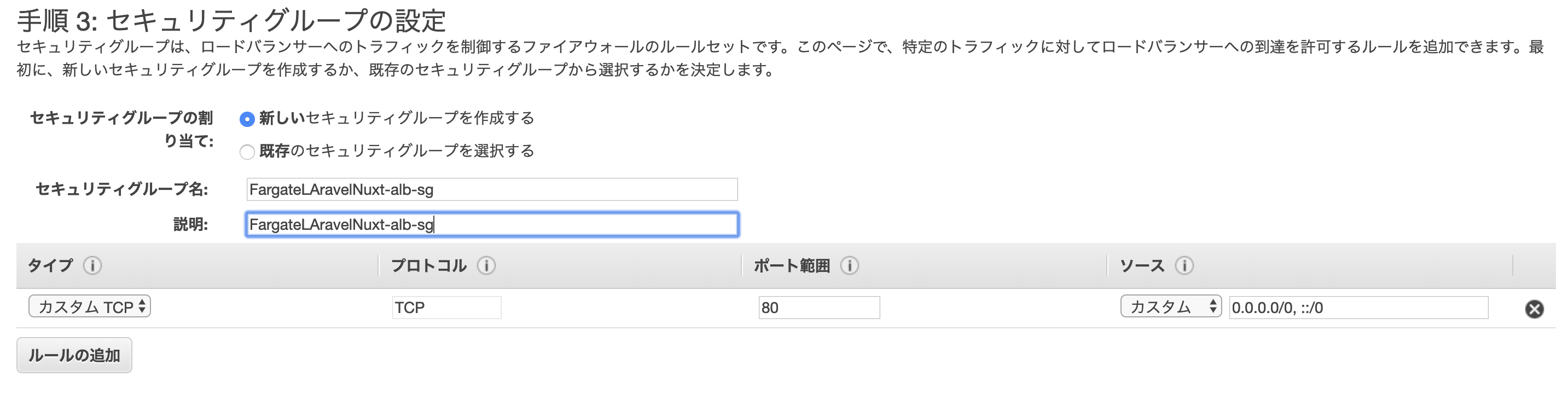
ALB用の新しいセキュリティグループを作成します
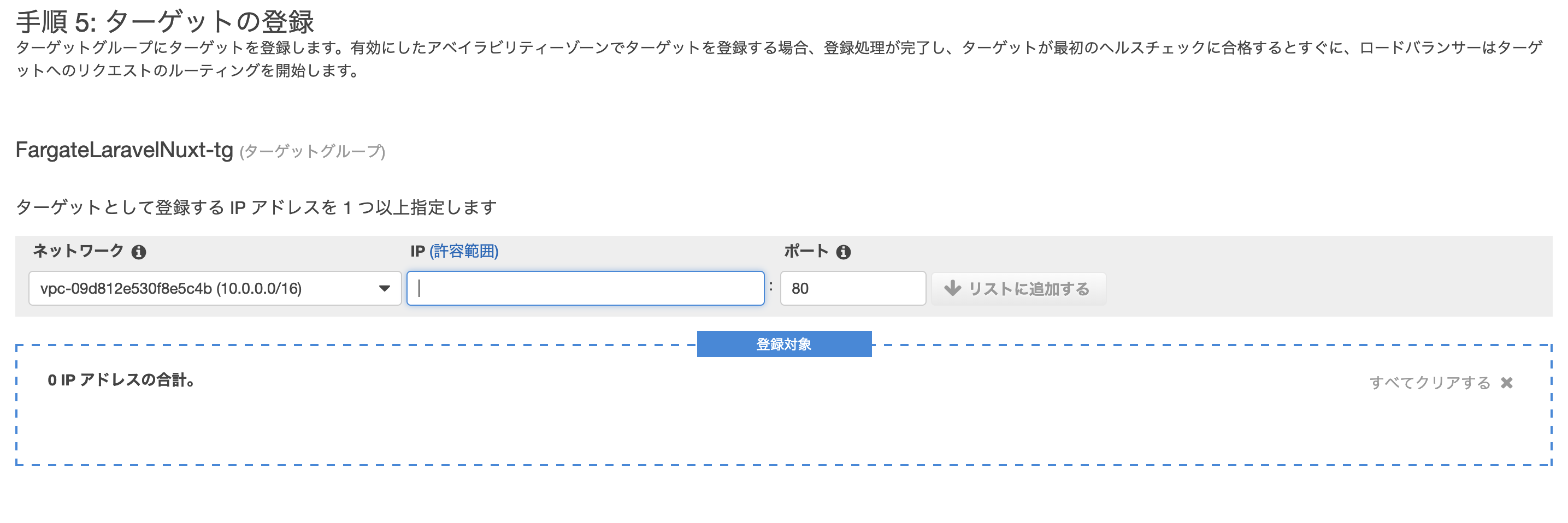
ターゲットグループに名前を付け、残りのパラメータに次のように設定します。
ターゲットタイプは、ECSタスクレベルロードバランシングのIPアドレスとして選択する必要があります。
作成完了されたことを確認する
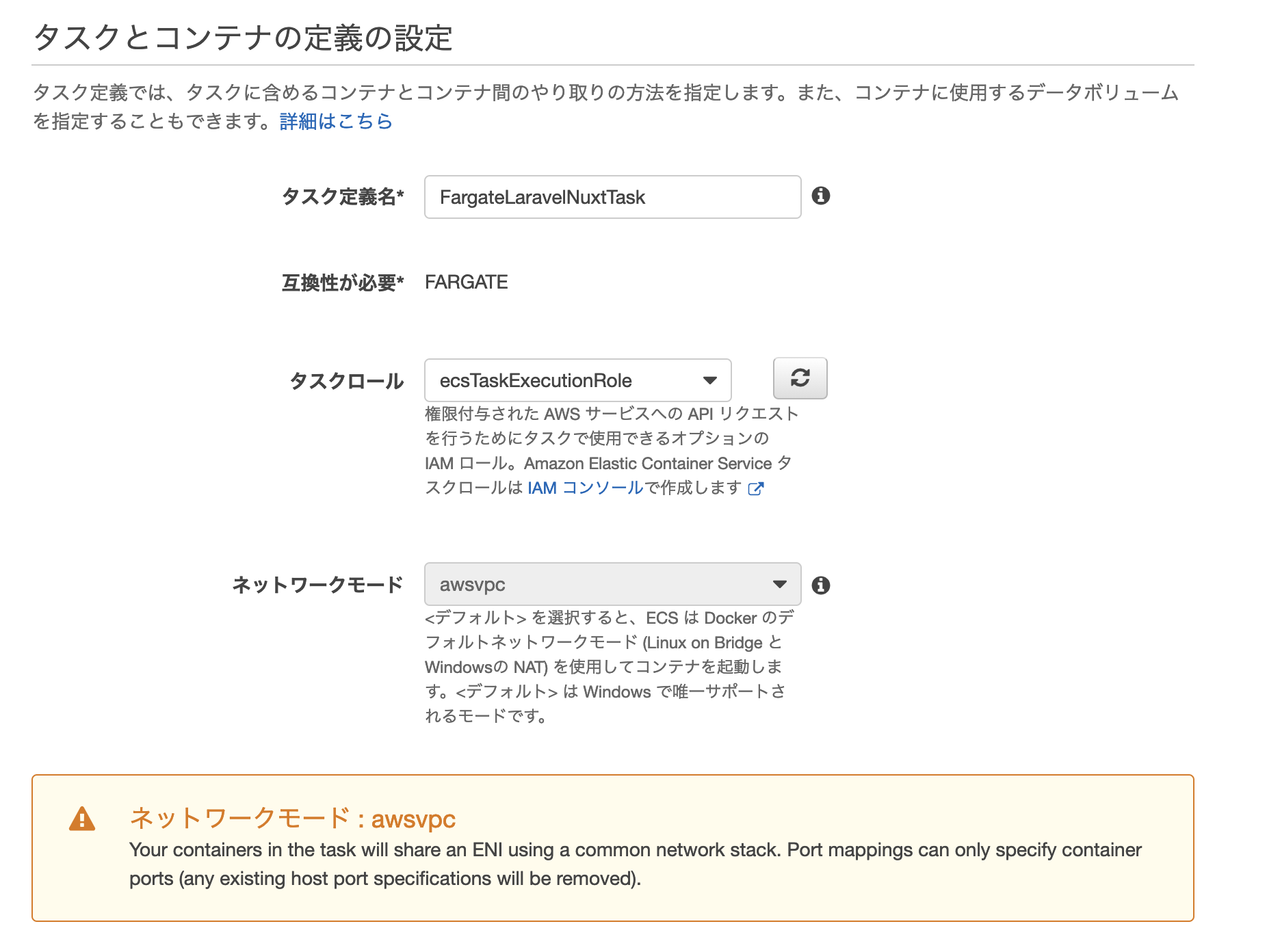
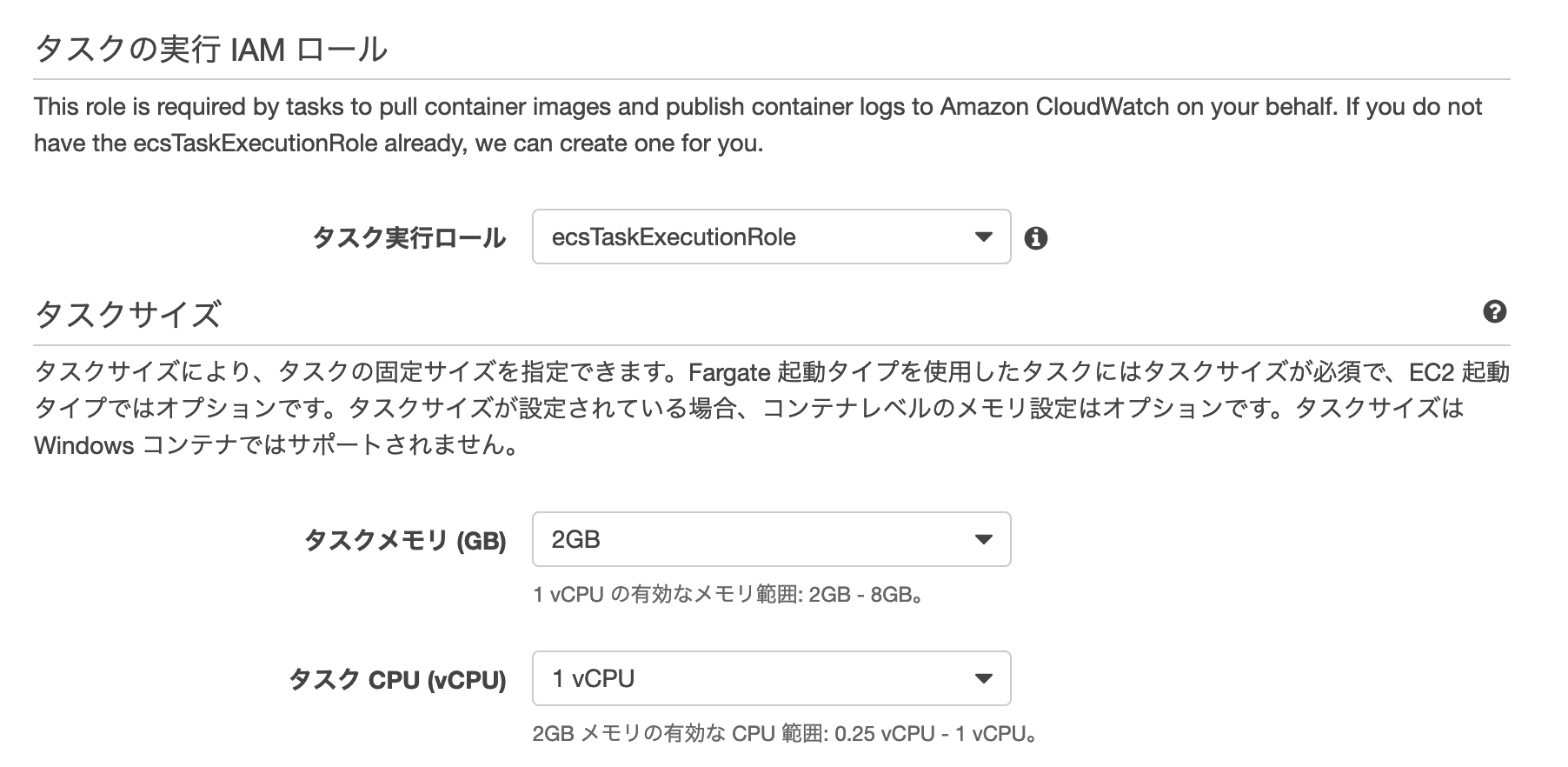
ECS Fargateタスクを作成する
ECSサービス>タスク定義>新しいタスク定義の作成
Fargateを選択する
タスクとコンテナの定義
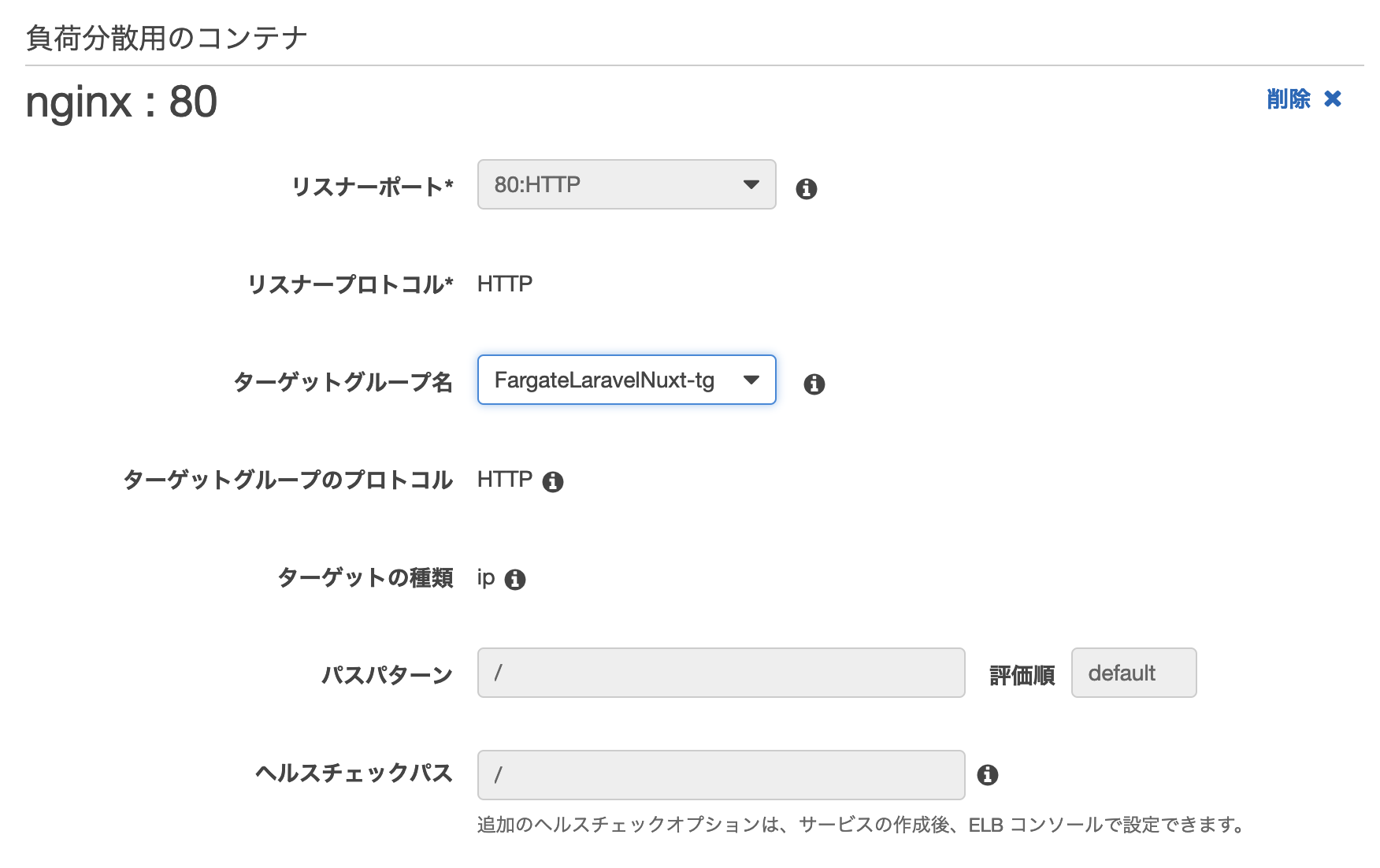
nginxコンテナの設定
php-fpmコンテナの設定
作成を実施する
ECS Fargateサービスを作成する
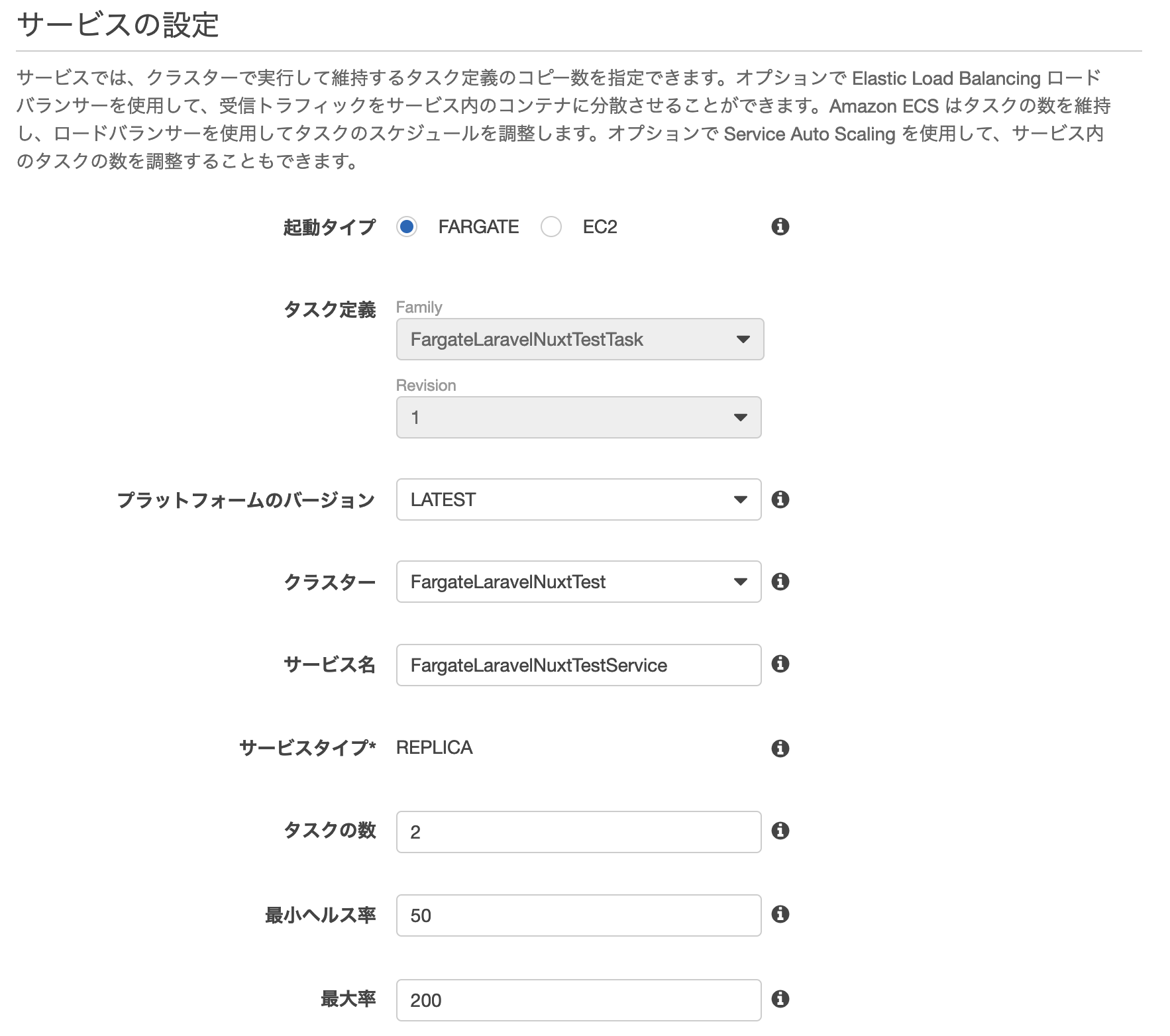
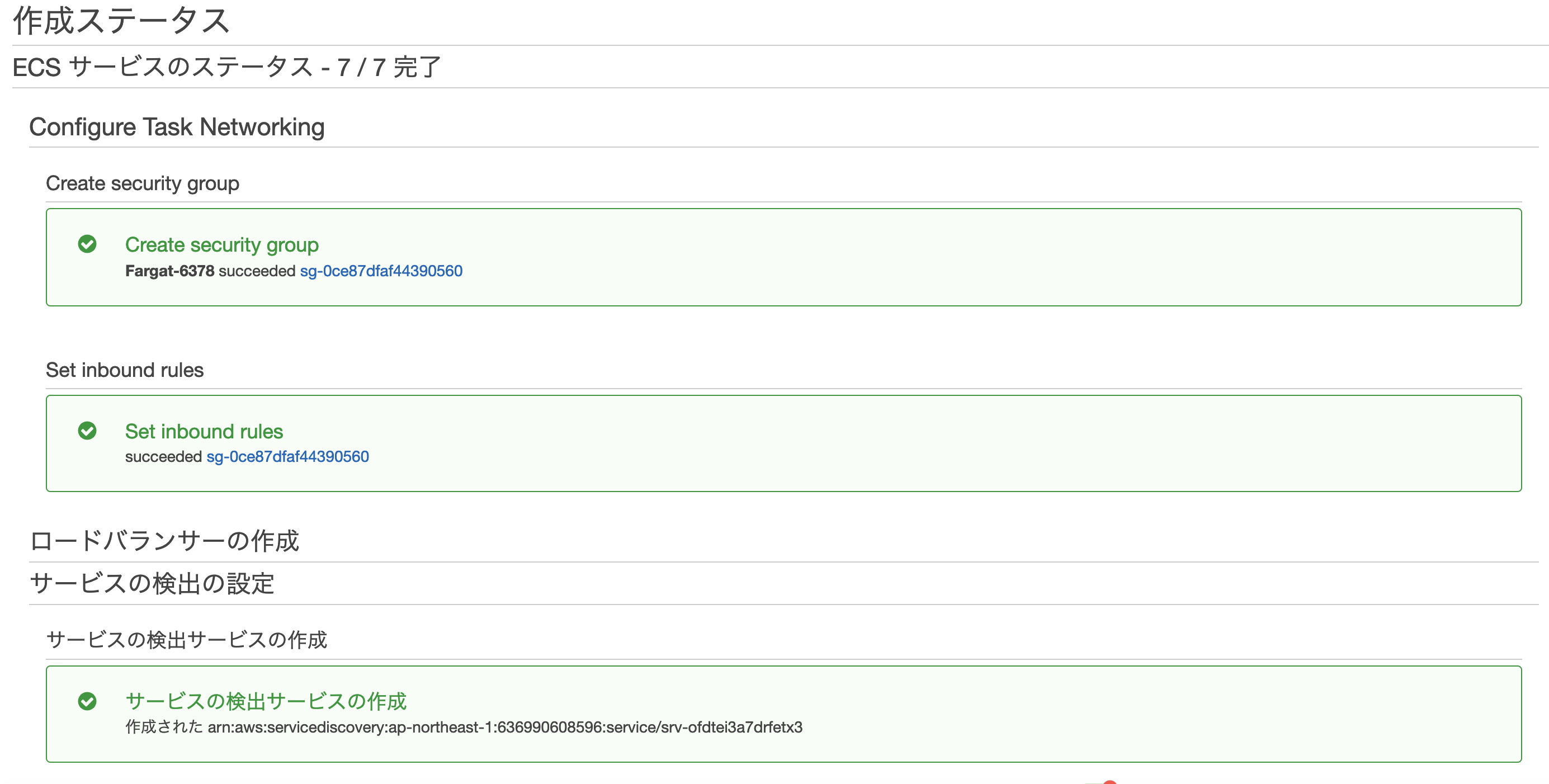
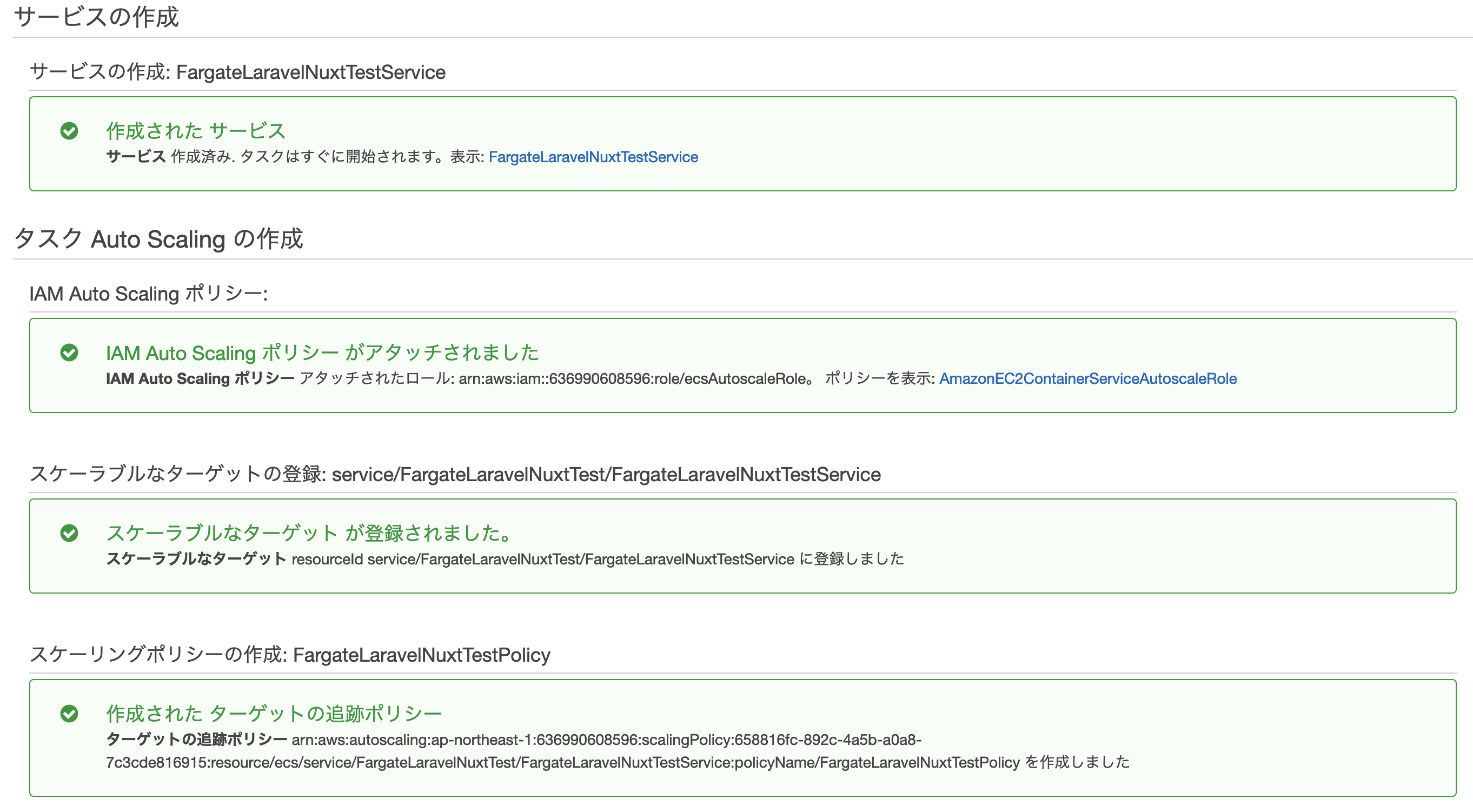
ECSサービス>タスク定義>FargateLaravelNuxtTestTask>サービスの作成
サービスの設定を行う
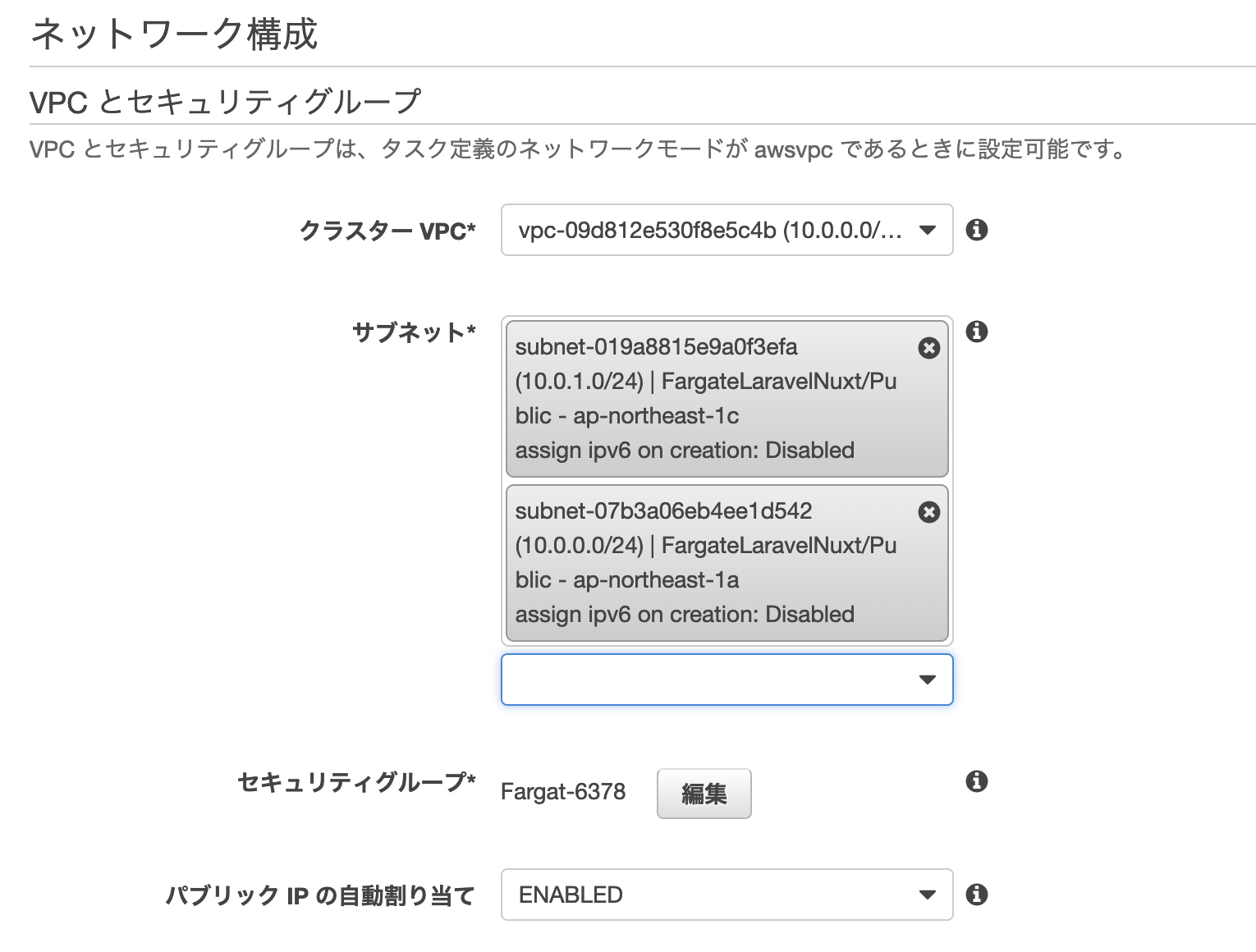
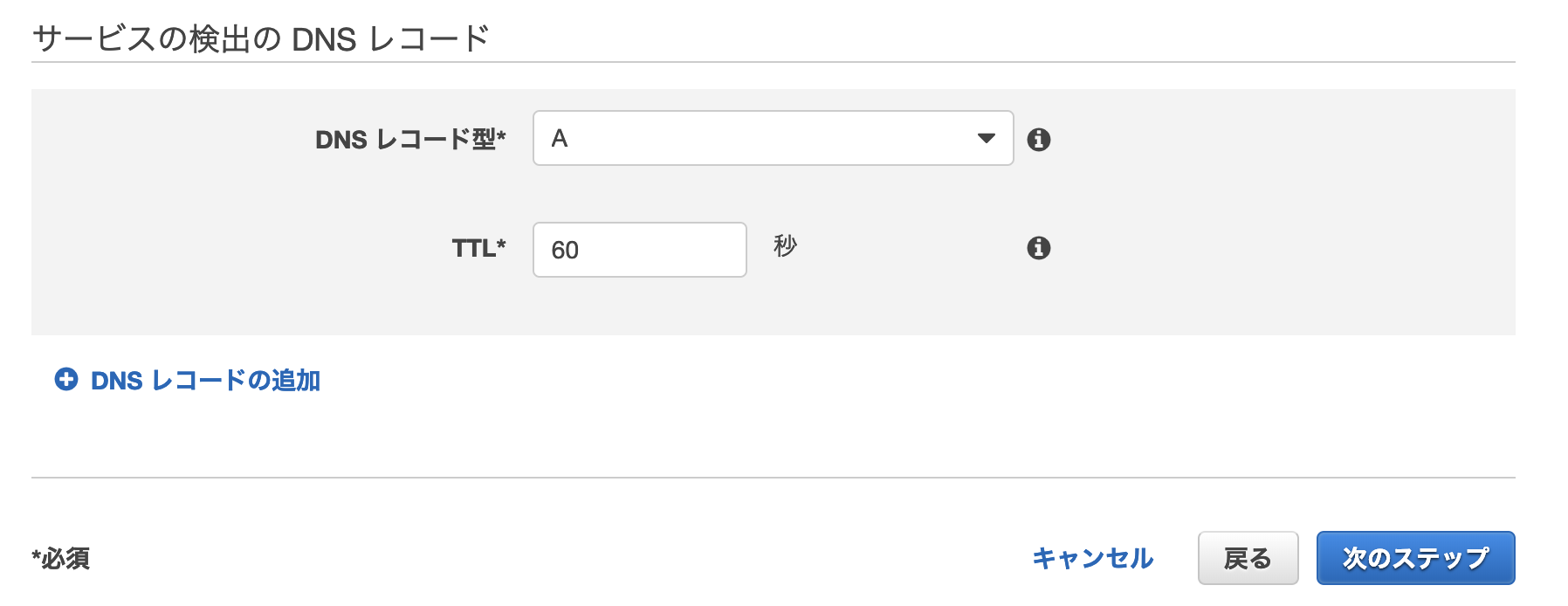
ネットワーク構成
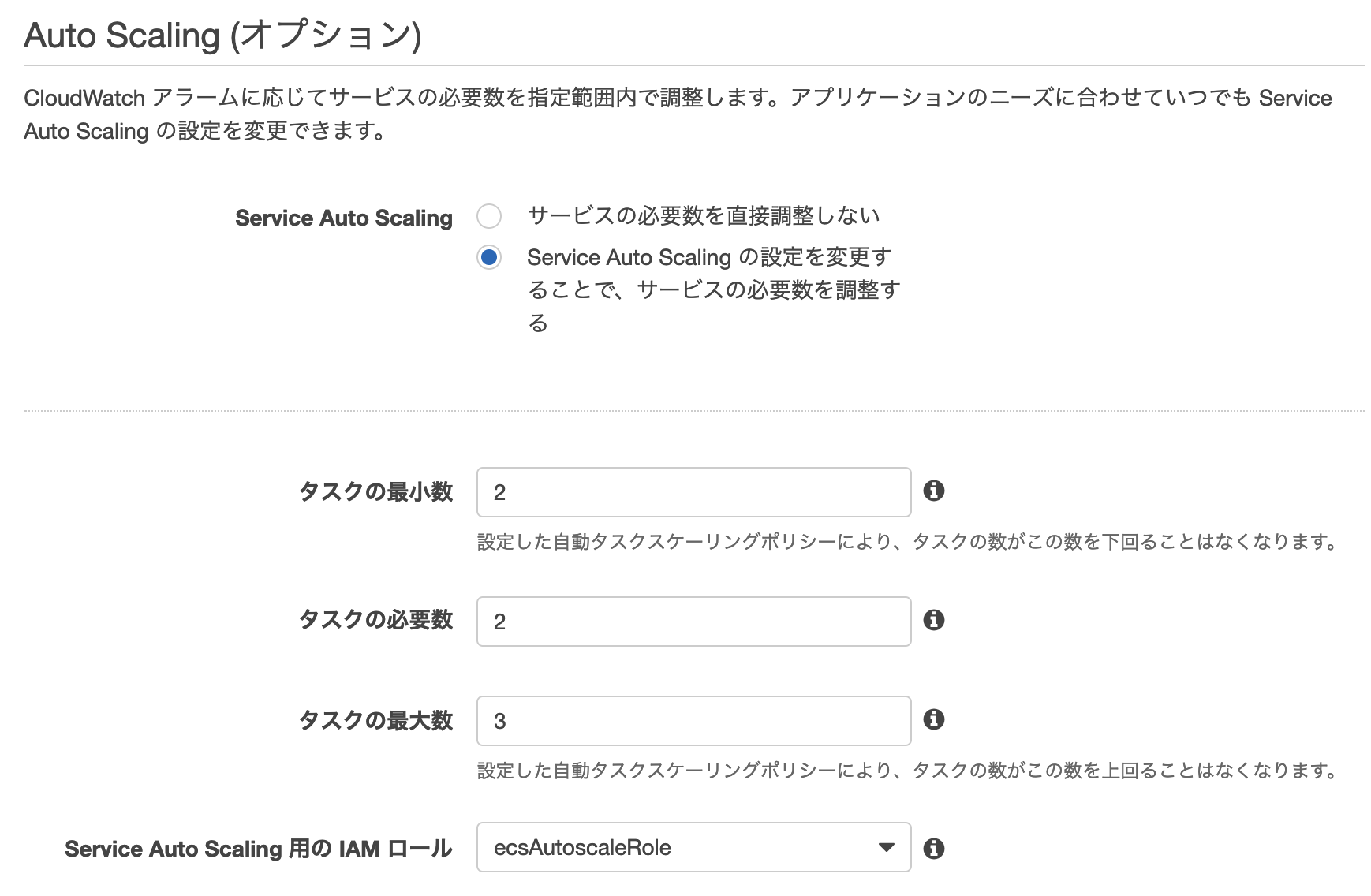
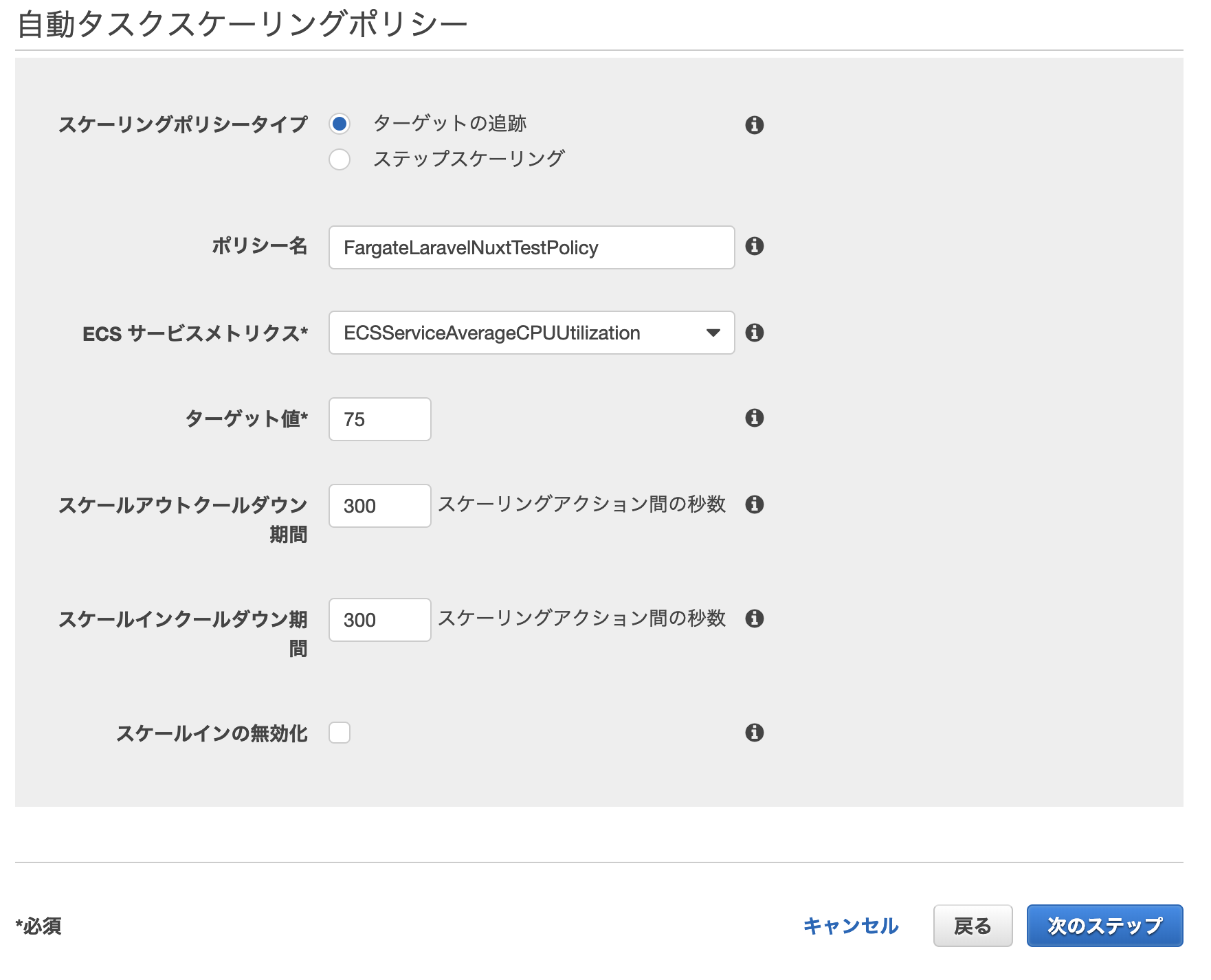
AutoScalingの設定
作成する
動作を確認する
作成したロードバランサーのDNSからアクセスする



- 投稿日:2019-03-23T15:51:13+09:00
AWS CLI を利用してIAMロールを引き受ける
概要
背景
よく、「◯◯の操作をする前に、
export AWS_PROFILE=some-developerする」みたいな操作をAWSに関するコマンドラインからの作業の際にするのですが、これが何をやっているのか手を動かしながら理解を深めていきました。ここでは、AWS IAM のロール、AWS STS に関しての概要と、あるプリンシパルエンティティ(ユーザー、グループ、ロール)から別のロールに切り替えるにはどうしたらいいのかを確認します。
やったこと
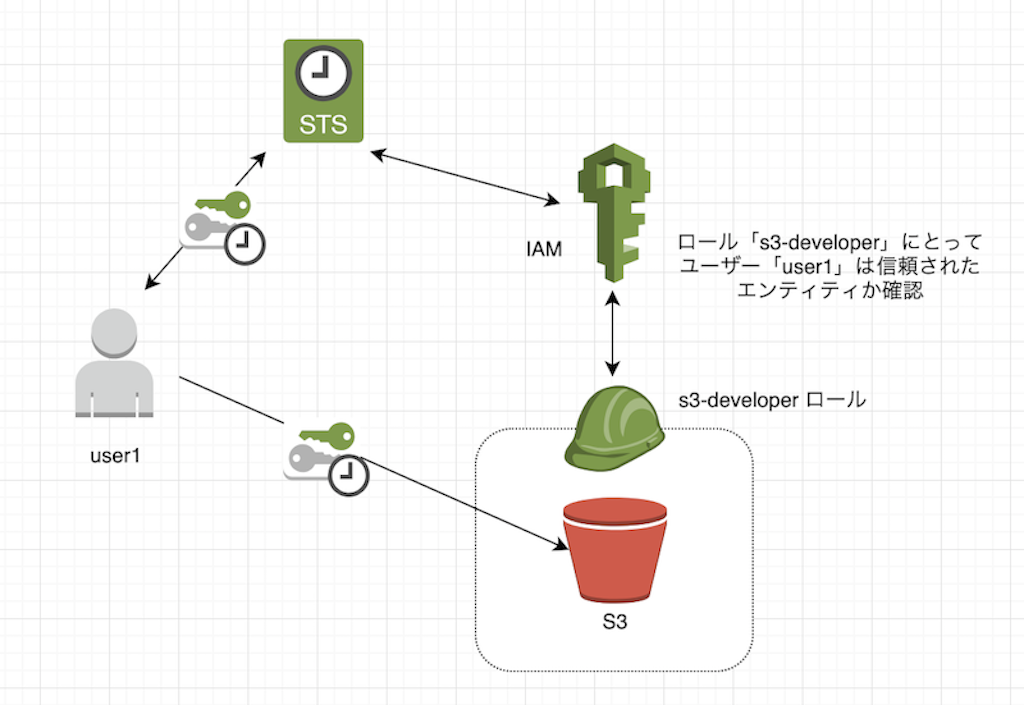
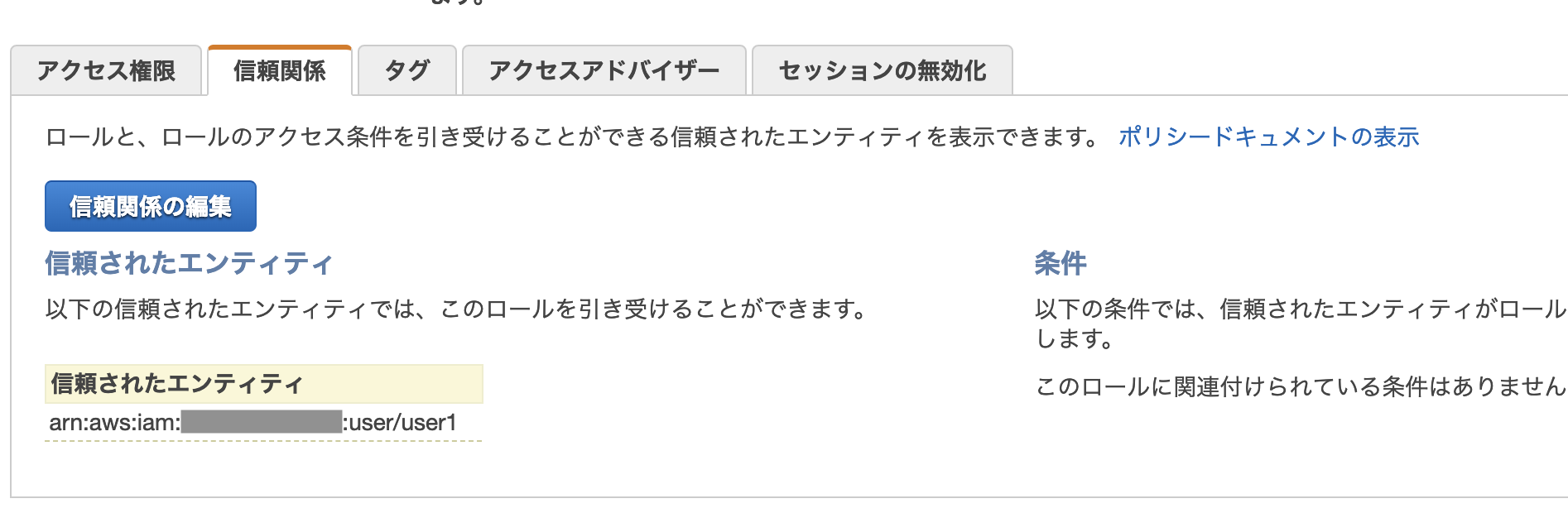
あらかじめs3-developerロールに、信頼されたプリンシパルエンティティとして、user1を登録しておきます。また、s3-developerロールにS3へアクセスできるポリシーを付与しておきます。
その上で、以下の図のように AWS STS を利用して、そのロールの一時的な認証情報を取得して、user1が、s3-developerとして(AssumeRoleして)でS3へアクセスできるようにしています。
前提の確認
基本的な用語
まず、用語の意味を確認します。細かいことはここでは説明する必要がないのでざっくりとした説明に留めておきます。
(IAM)ポリシー
どのサービスに対して、どのような操作を許可、拒否できるかというルール。要するにAWSサービスへの権限のこと。(IAM)ユーザー
AWSを利用するための認証情報のことで、AWSのアカウント作成者(ルートユーザー)ではなく、AWSのサービスにアクセスする人。コマンドラインツールからアクセスするには、アクセスキーとシークレットアクセスキーのペアが必要。(IAM)グループ
ユーザーの集まりで、グループ単位にポリシーを付与することもできる。認証自体はユーザーが行う。ロールの構成要素と役割
(IAM)ロール
ユーザーやAWSリソース(EC2とかLambdaとか)が一時的に利用できる権限セットのことです。
これを利用することで、AWSリソースへアクセス権のないユーザー、サービスにアクセス権を委譲することができます。c.f https://docs.aws.amazon.com/ja_jp/IAM/latest/UserGuide/id_roles.html
IAM ロールは、特定のアクセス権限を持ち、アカウントで作成できる IAM アイデンティティです。IAM ロールは、 AWSで許可/禁止する操作を決めるアクセス権限ポリシーが関連付けられている AWS アイデンティティであるという点で、IAM ユーザーと似ています。ただし、ユーザーは 1 人の特定の人に一意に関連付けられますが、ロールはそれを必要とする任意の人が引き受けるようになっています。また、ロールには標準の長期認証情報 (パスワードやアクセスキーなど) も関連付けられません。代わりに、ロールを引き受けると、ロールセッション用の一時的なセキュリティ認証情報が提供されます。
要するに、以下の特徴があります。
- 複数のPolicyを持つことができる
- 複数のプリンシパルエンティティが利用できる
- 信頼関係にあるプリンシパルエンティティに一時的な認証情報を提供できる
ロールの構成要素
以上のような役割を実現するために、ロールは主に二つの構成要素からなります。
- ポリシー
- 信頼ポリシー
最初のポリシーは、ロールに対するAWSリソースへのアクセス権限を表すポリシーです。
二つ目の信頼ポリシーとは、どのプリンシパルエンティティから利用できるのか、つまり権限を委譲できるのかを表すポリシーになります。例えば以下は、一つのAWSアカウント(ID: 111122223333)のルートユーザーと、もう一つのAWSアカウント(ID: 444455556666)のuser1という名前のユーザーがロールを引き受けることを示しています。
{ "Principal": { "AWS": [ "arn:aws:iam::111122223333:root", "arn:aws:iam::444455556666:user/user1", ] }, }こうすることで、どのプリンシパルエンティティにロールを引き受けさせるかを制限することができます。
c.f https://docs.aws.amazon.com/ja_jp/IAM/latest/UserGuide/id_roles_manage_modify.html
AWS Security Token Service (AWS STS)
AWSリソースにアクセスするための一時的セキュリティ認証情報を取得することができます。
c.f https://docs.aws.amazon.com/ja_jp/IAM/latest/UserGuide/id_credentials_temp.htmlそして、信頼されたプリンシパルエンティティからロールの権限セットを引き受ける(AssumeRoleする)際は、STSへAPI呼び出しをしています。そうすることで、STSが要求されたロールに要求したプリンシパルエンティティが信頼されているかどうかを確認し、信頼されている場合はセキュリティ認証情報を発行します。
CLIからの操作
それでは実際にAWS CLIを使って、AssumeRoleを実現します。
全体の流れ
- S3の準備
- バケットの作成
- 適当なファイルをアップロードする
- ユーザーの作成
- デフォルトのユーザーにはポリシーは付与されていないので何もできない状態
- ロールを作成
- 作成したユーザーを Trust Relationship として持つ
- S3への読み取りが可能なポリシーを持つ
S3の準備
まず、ルートユーザー相当の権限を持つユーザーとして、S3のバケットと、それへのファイルのアップロードを済まします。
$ aws s3api create-bucket --bucket assume-role-bucket --region ap-northeast-1 --create-bucket-configuration LocationConstraint=ap-northeast-1 { "Location": "http://assume-role-bucket.s3.amazonaws.com/" } $ $ cat << EOF > sample.html <html> <head> <title>タイトル</title> </head> <body> aws cli の練習 </body> </html> EOF $ aws s3 cp sample.html s3://assume-role-bucket upload: ./sample.html to s3://assume-role-bucket/sample.htmlユーザーの作成
user1という名前のユーザーを作成します。
$ aws iam create-user --user-name user1 { "User": { "Path": "/", "UserName": "user1", "UserId": "AAAAAAAAAAAAAA", "Arn": "arn:aws:iam::123456789:user/user1", "CreateDate": "2019-03-22T10:29:46Z" } }AWSのコマンドラインツールを利用するには、AccessKeyIDとSecretAccessKeyのペアが必要なので、user1のペアを作成します。(もちろん適当な文字列に置き換えています。)
$ aws iam create-access-key --user-name user1 { "AccessKey": { "UserName": "user1", "AccessKeyId": "ACCESSKEYID", "Status": "Active", "SecretAccessKey": "SECRETACCESSKEY", "CreateDate": "2019-03-22T10:30:15Z" } }後にuser1として、S3にコマンドラインからアクセスするため、ここで返ってきたキーのペアをCLIが読み取るパスのファイルに格納します。
# .aws/credentials [user1] aws_access_key_id = ACCESSKEYID aws_secret_access_key = SECRETACCESSKEYロールの作成
まず、作成したユーザー(user1)がAssumeRoleできるように、信頼ポリシーの定義をしたJSONファイルを作成します。先ほど作成したuser1のARNが指定されていることが確認できるかと思います。
$ cat << EOF > s3-developer-policy.json { "Version": "2012-10-17", "Statement": { "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::123456789:user/user1" }, "Action": "sts:AssumeRole" } } EOF次に、先ほど作った信頼ポリシーの定義のファイルを指定して、s3-developerというロールを作成します。
$ aws iam create-role --role-name s3-developer --assume-role-policy-document file://s3-developer-policy.json { "Role": { "Path": "/", "RoleName": "s3-developer", "RoleId": "ABAAAAAAAAAAAAAAA", "Arn": "arn:aws:iam::123456789:role/s3-developer", "CreateDate": "2019-03-22T11:23:54Z", "AssumeRolePolicyDocument": { "Version": "2012-10-17", "Statement": { "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::123456789:user/user1" }, "Action": "sts:AssumeRole" } } } }これで、s3-developerロールにuser1からAssumeRoleすることができるようになりました。
実際にマネジメントコンソールを確認するとIAMのs3-developerロールにuser1が信頼されたエンティティとして登録されていることが確認できます。
そして、コマンドラインからAssumeRoleを実現できるように以下のように設定ファイルを編集します。
これは、source_profileにuser1を指定することで、s3-developerロールとしてAWSにCLIからアクセスすると、STSがuser1は信頼関係にあるかどうかを自動的に検索し、一時的な認証情報を取得することができるようになるためです。c.f https://docs.aws.amazon.com/ja_jp/cli/latest/userguide/cli-configure-role.html
AWS CLI コマンドでのプロファイル marketingadmin の使用を指定すると、CLI はリンクされた user1 プロファイルの認証情報を自動的に検索し、その認証情報を使用して、指定された IAM ロールの一時的な認証情報を要求します。これらの一時的な認証情報は、次に CLI コマンドを実行するために使用されます。
# .aws/credentials [user1] aws_access_key_id = ACCESSKEYID aws_secret_access_key = SECRETACCESSKEY [s3-developer] role_arn = arn:aws:iam::123456789:role/s3-developer source_profile = user1ただ、これだけでは、s3-developerは何もポリシーを付与されていないので、S3への読み取りポリシーを付与します。
$ aws iam attach-role-policy --role-name s3-developer --policy-arn "arn:aws:iam::aws:policy/AmazonS3ReadOnlyAccess" $ aws iam list-attached-role-policies --role-name s3-developer { "AttachedPolicies": [ { "PolicyName": "AmazonS3ReadOnlyAccess", "PolicyArn": "arn:aws:iam::aws:policy/AmazonS3ReadOnlyAccess" } ] }実際に試してみる
必要な準備が整ったので、実際にS3にアクセスできるか確認してみます。
まず、user1として、S3のバケットの内容を確認しようとしてみます。環境変数に先ほど接続設定ファイルに指定したプロファイル名を渡して、そのユーザーの認証情報でアクセスします。
$ export AWS_PROFILE=user1 $ aws sts get-caller-identity { "UserId": "AAAAAAAAAAAAAA", "Account": "123456789", "Arn": "arn:aws:iam::123456789:user/user1" }user1だとAccessDeniedになりました。
$ aws s3 ls s3://assume-role-bucket/sample.html An error occurred (AccessDenied) when calling the ListObjectsV2 operation: Access Denied次にs3-developerにAssumeRoleします。
$ export AWS_PROFILE=s3-developer $ aws sts get-caller-identity { "UserId": "ABAAAAAAAAAAAAAAA:botocore-session-1553254029", "Account": "123456789", "Arn": "arn:aws:sts::123456789:assumed-role/s3-developer/botocore-session-1553254029" }確かに最初にアップロードしたファイルを確認することができました!
$ aws s3 ls s3://assue-role-bucket/sample.html 2019-03-22 20:06:52 107 sample.html
- 投稿日:2019-03-23T14:54:22+09:00
いつでもどこでもLambdaを呼ぼう(Web版DashボタンのLambda版を作りました)
無性にLambdaを呼びたいことありますよね?
そんなあなたに「Virtaul LambdashButton」https://moritalous.github.io/VLambdashButtonTmp/
使い方の説明も必要ないと思いますが、
- SettingからAWSのアクセスキー/シークレットアクセスキー/リージョンを入力します。
- Addから使いたいLambdaを追加
- Homeに戻りポチる
Lambdaにわたすパラメータは
{}固定です。JavaScriptのAWS SDKを使ってLambdaの一覧取得
lambda.listFunctions()とLambdaの実行lambda.invoke()をしてるだけです。設定情報はlocalStorageに保存してます。

- 投稿日:2019-03-23T11:00:05+09:00
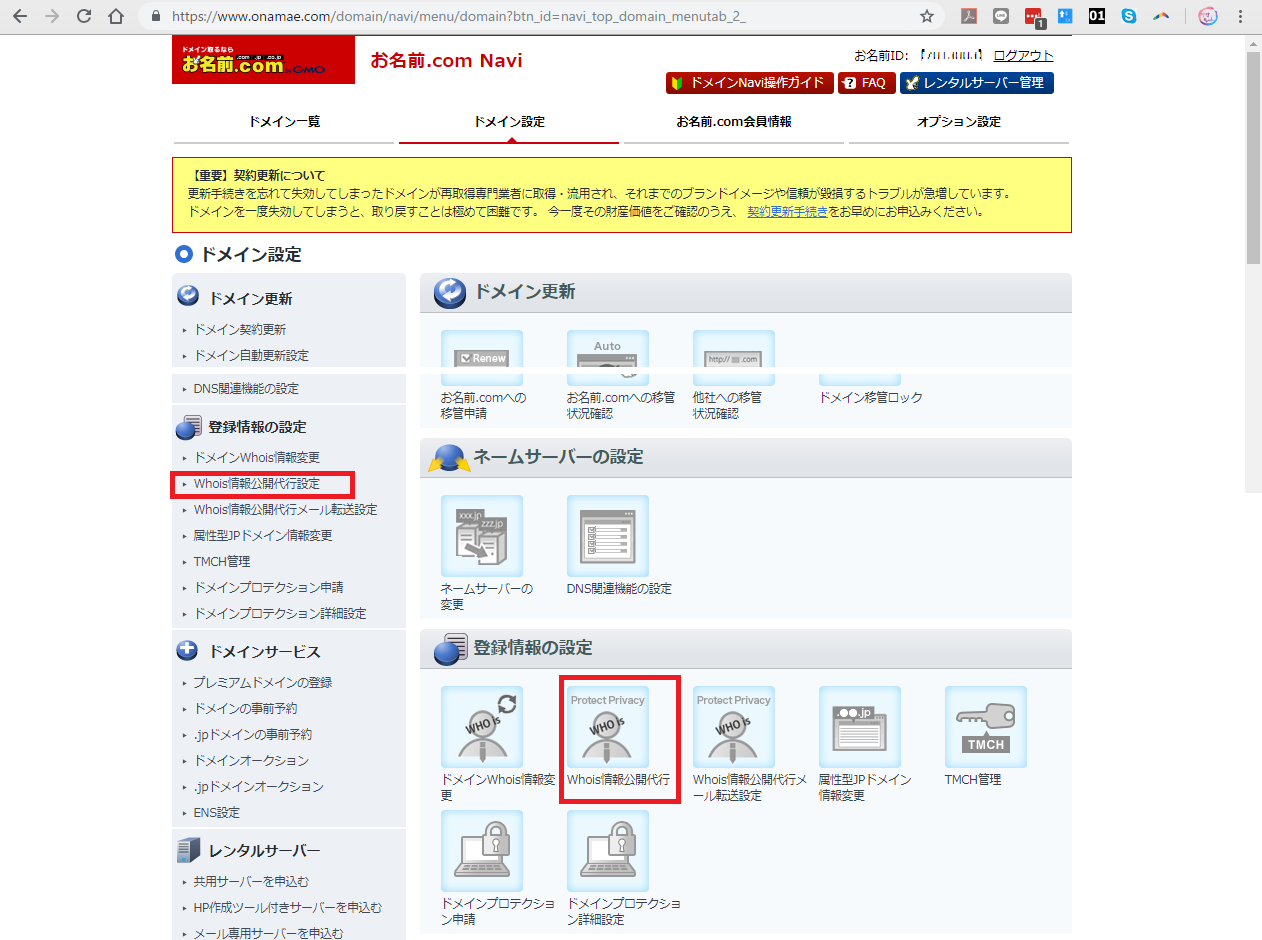
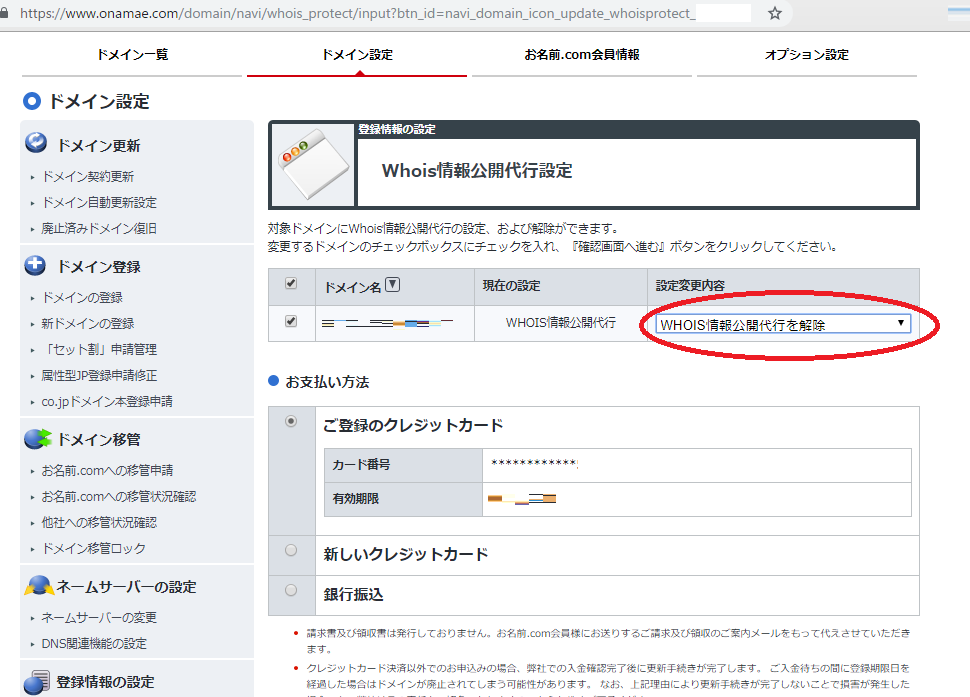
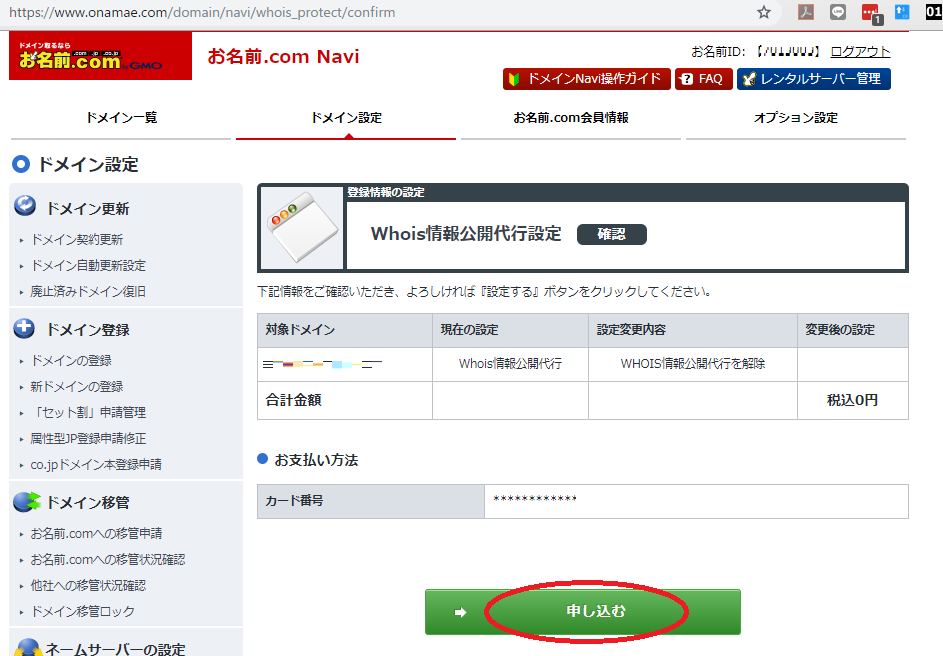
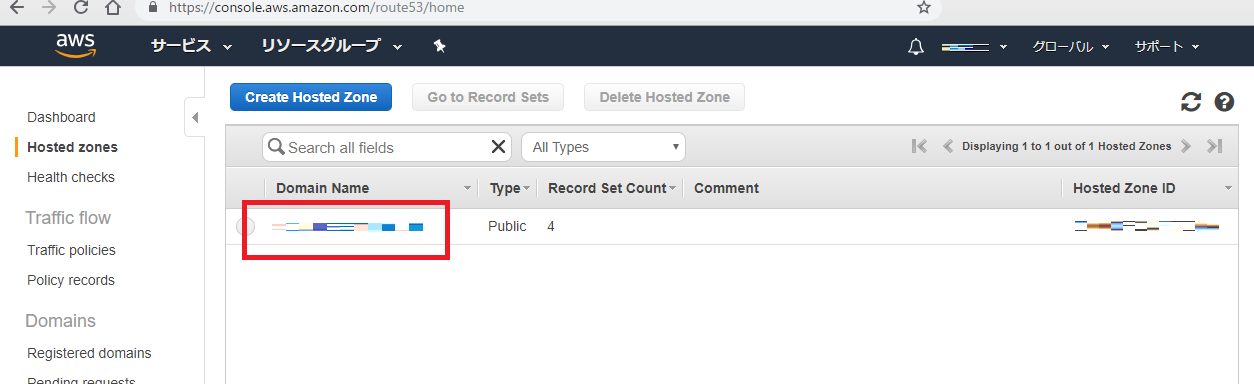
お名前.com から Amazon Route53 へドメインを移管する
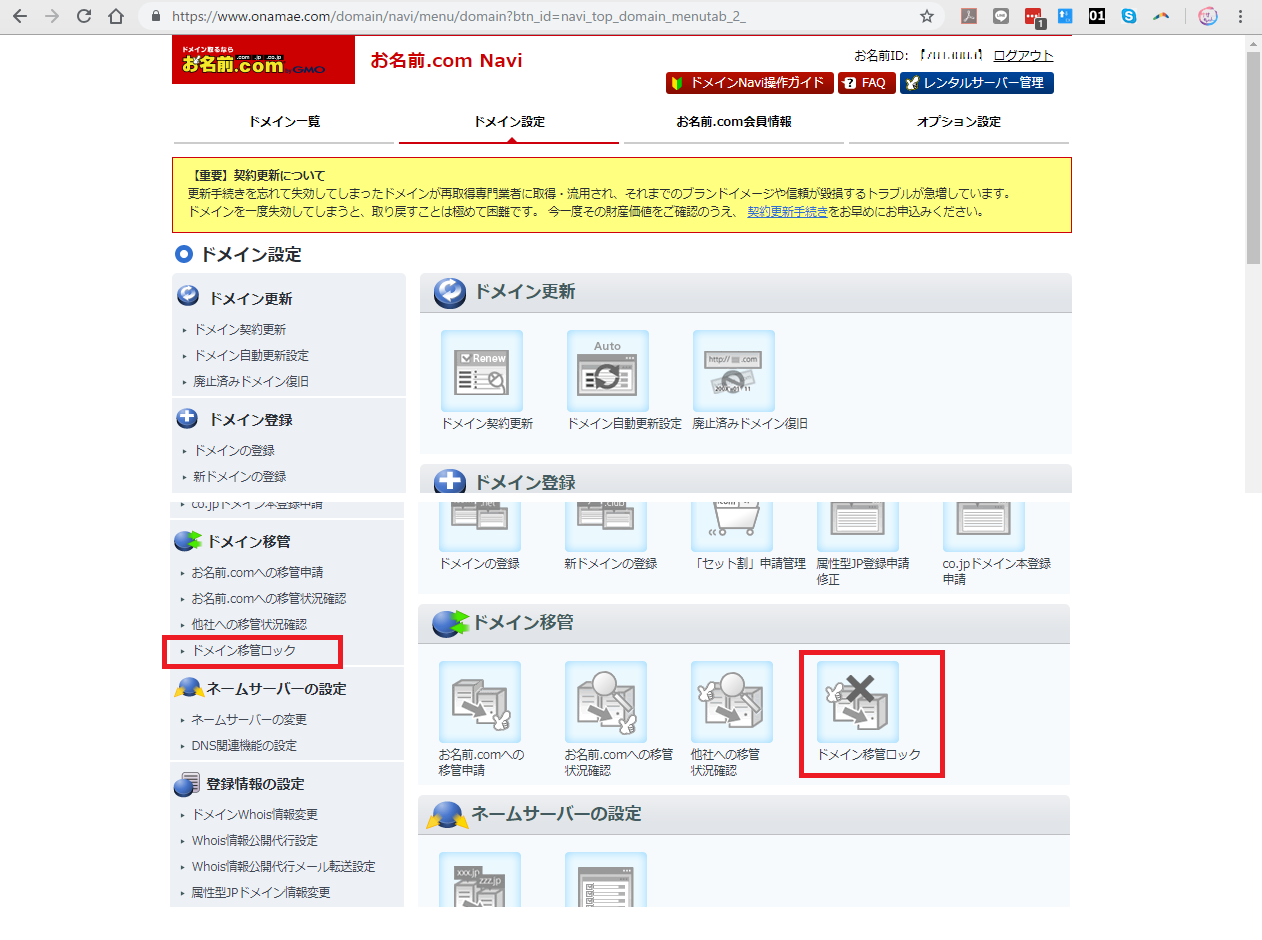
ステップ2.移行対象ドメイン(お名前.com)に対して規定の手順を実行する
現在のドメインレジストラが提示する手順に則って、次の作業を行います
- ドメインを移行できるようにアンロックします
- ドメインのプライバシー保護を無効にします
- ドメインの登録Email アドレスが更新されていることを確認します
- authorization code (認証コード) を取得します
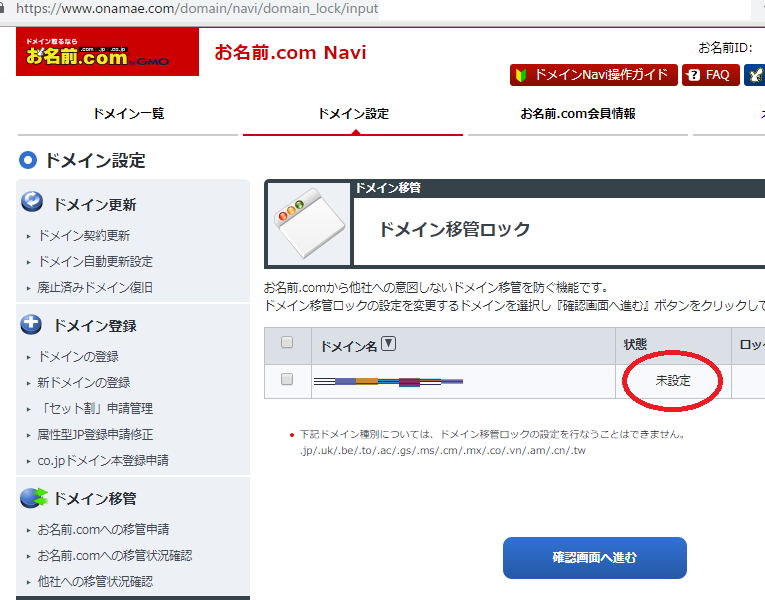
2.1 ドメインを移行できるようにアンロックします
未設定でした
2.2 ドメインのプライバシー保護を無効にします
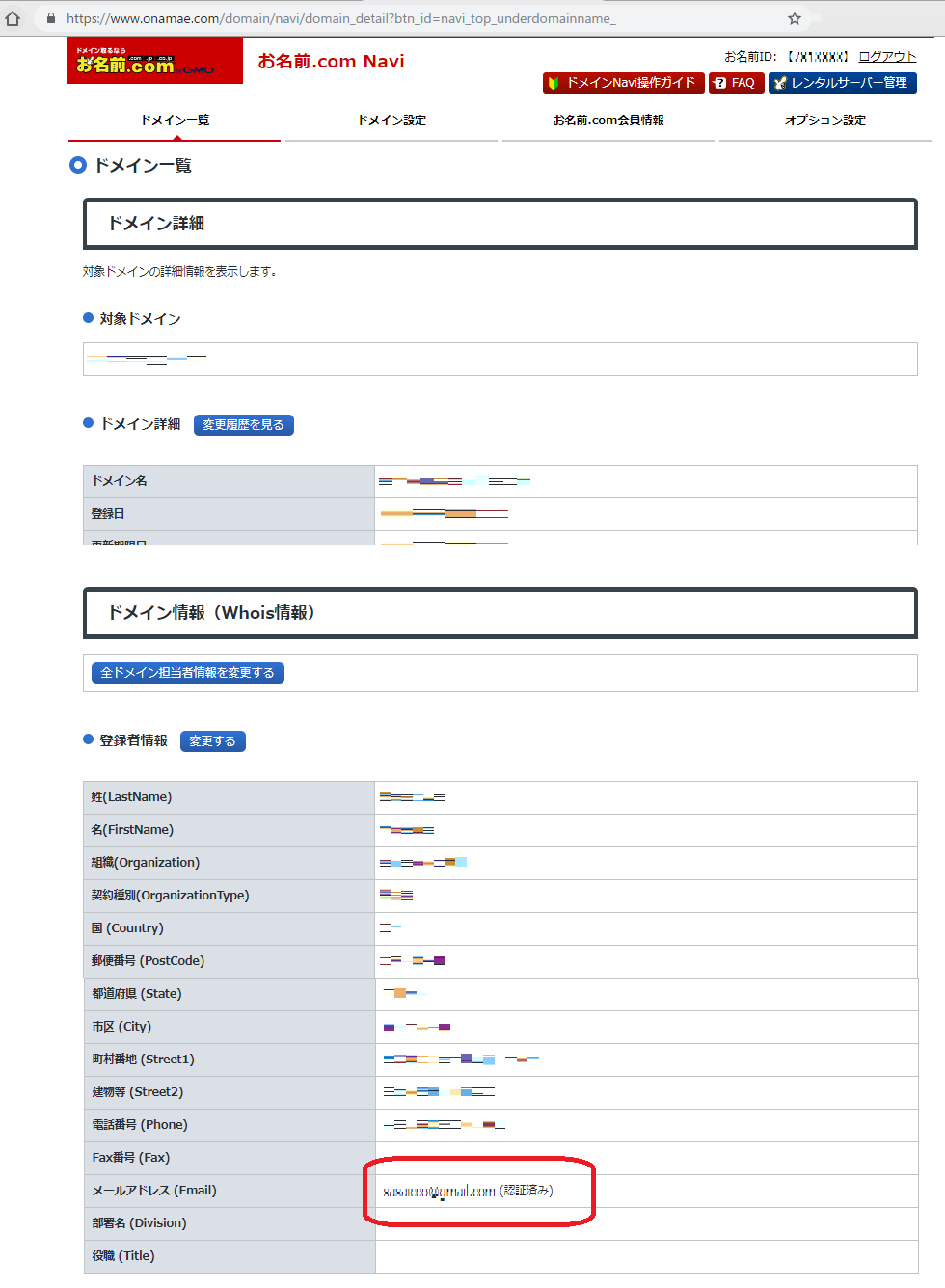
2.3 ドメインの登録Email アドレスが更新されていることを確認します
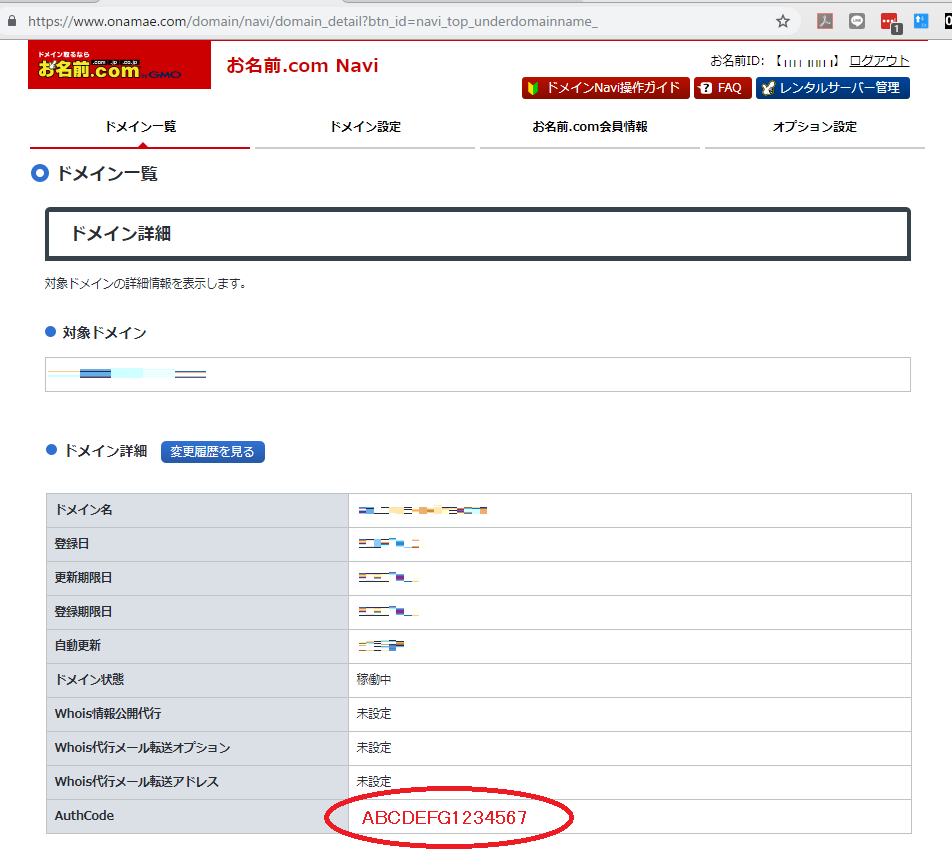
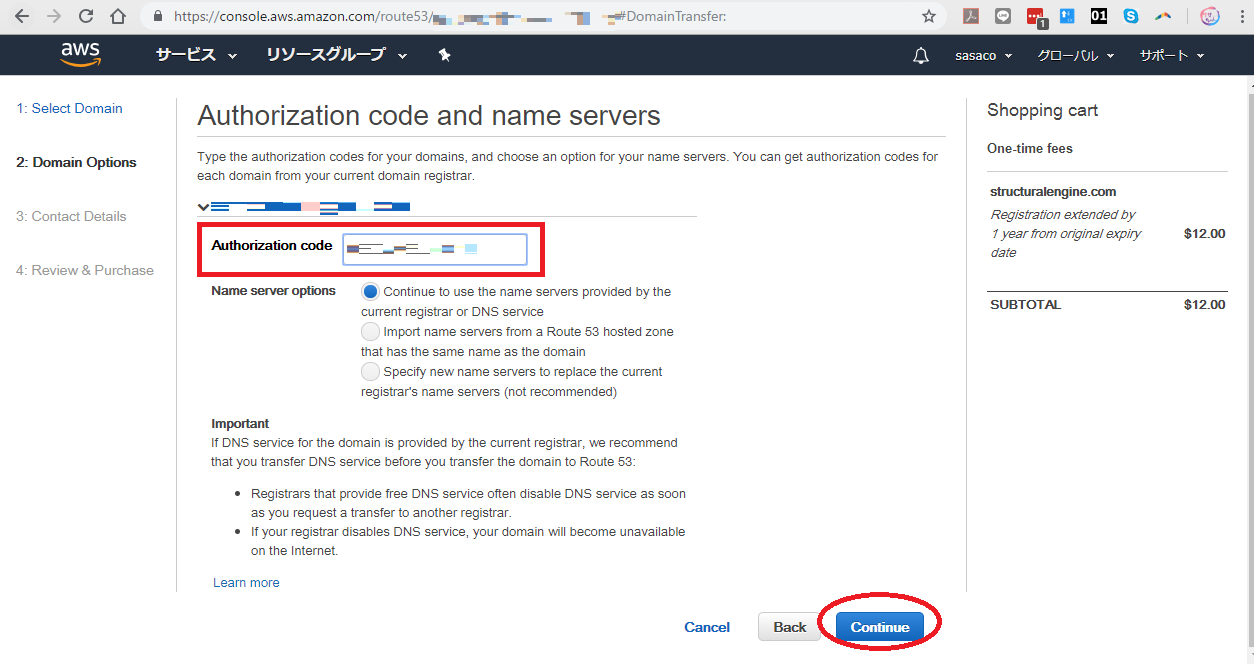
2.4 authorization code (認証コード) を取得します
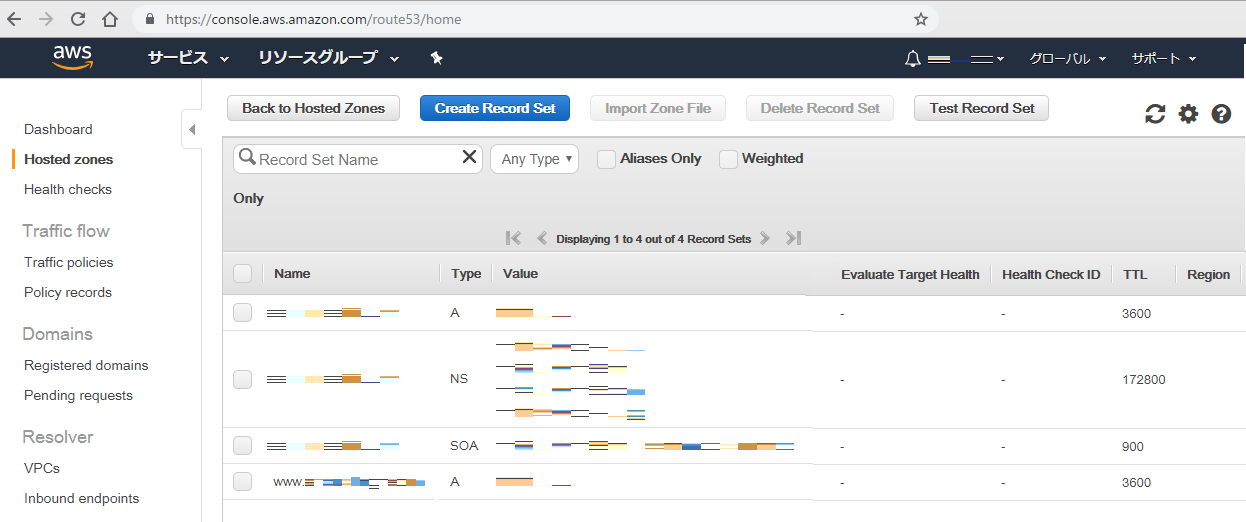
ステップ3.ネームサーバー情報の取得
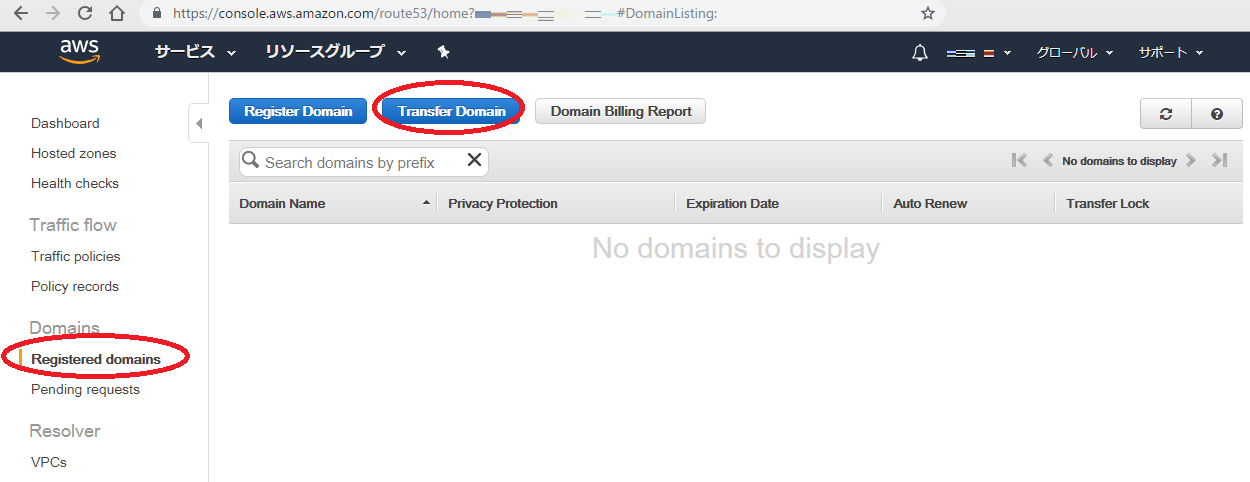
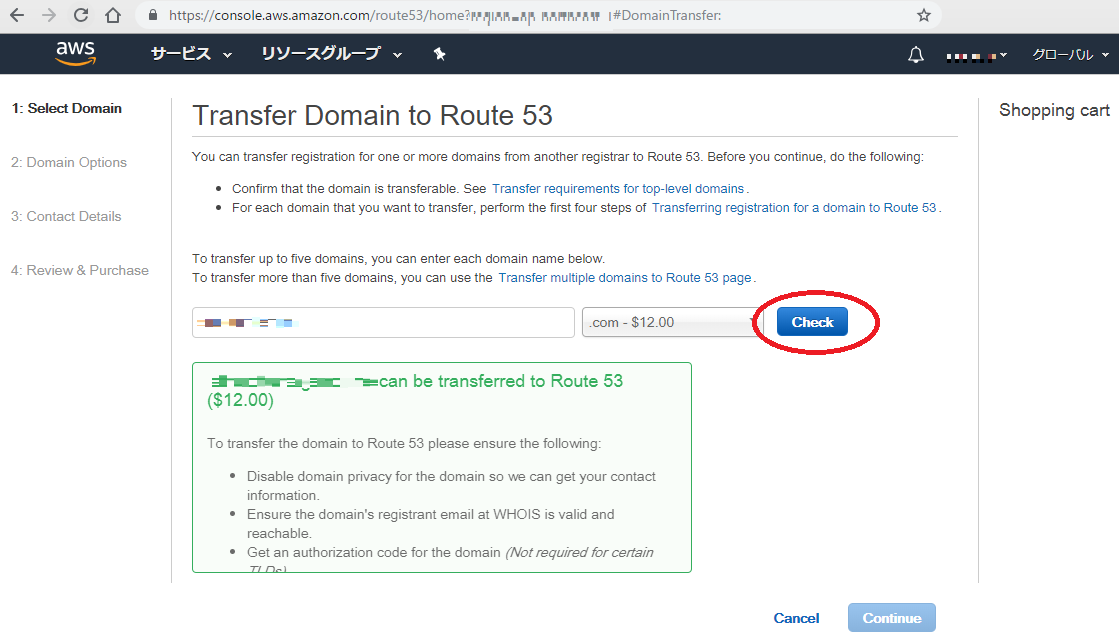
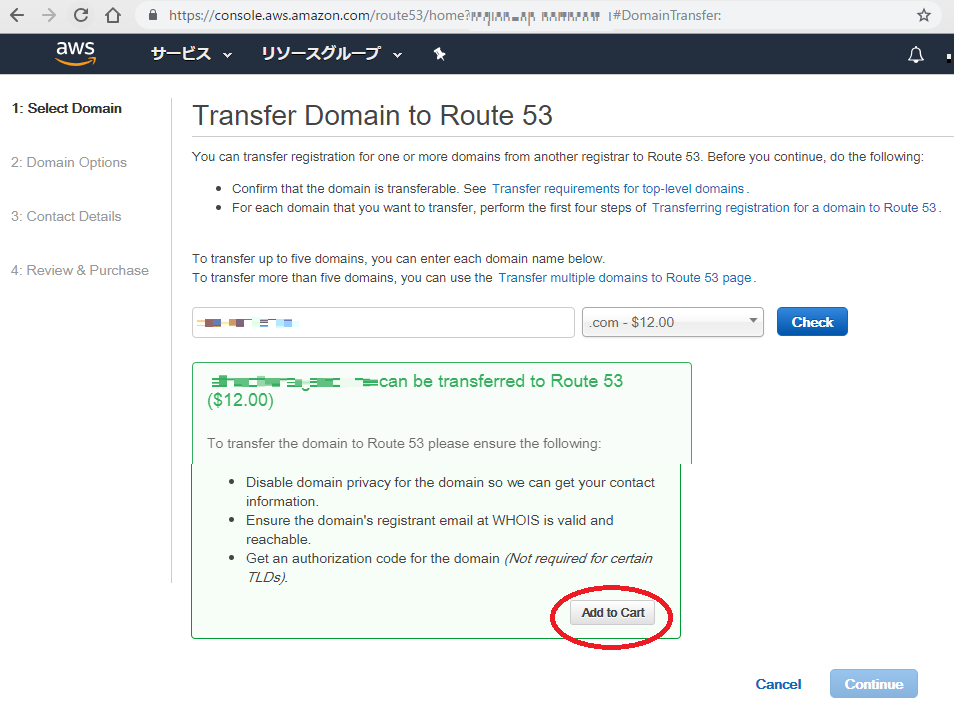
ステップ4.ドメイン移管
移管したいドメインを入力し check ボタンを押す
チェック結果を確認して、ドメインをカートに追加する
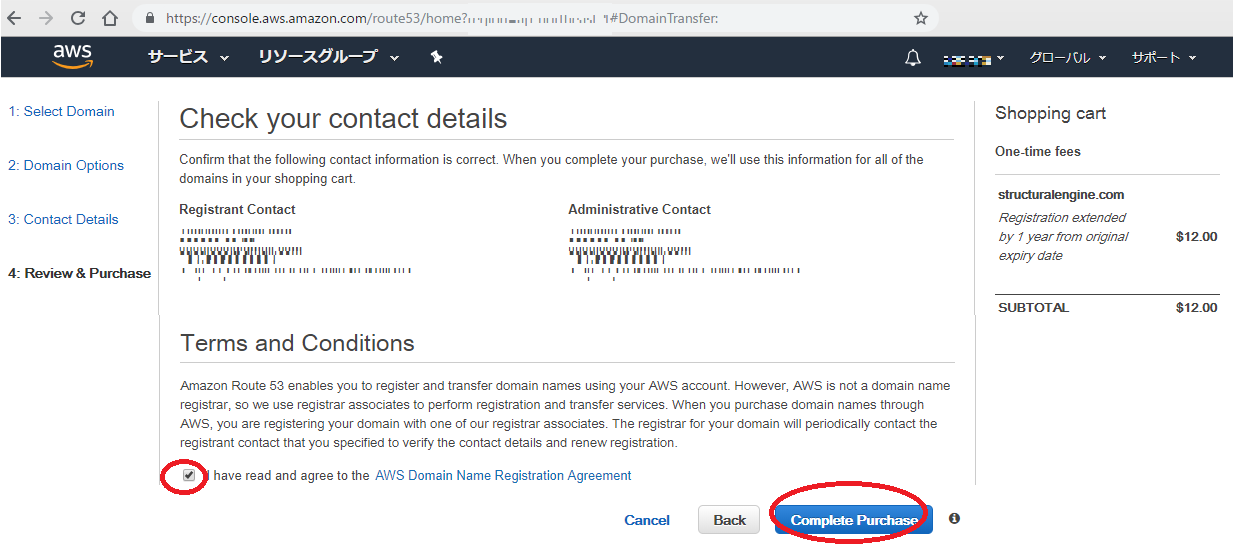
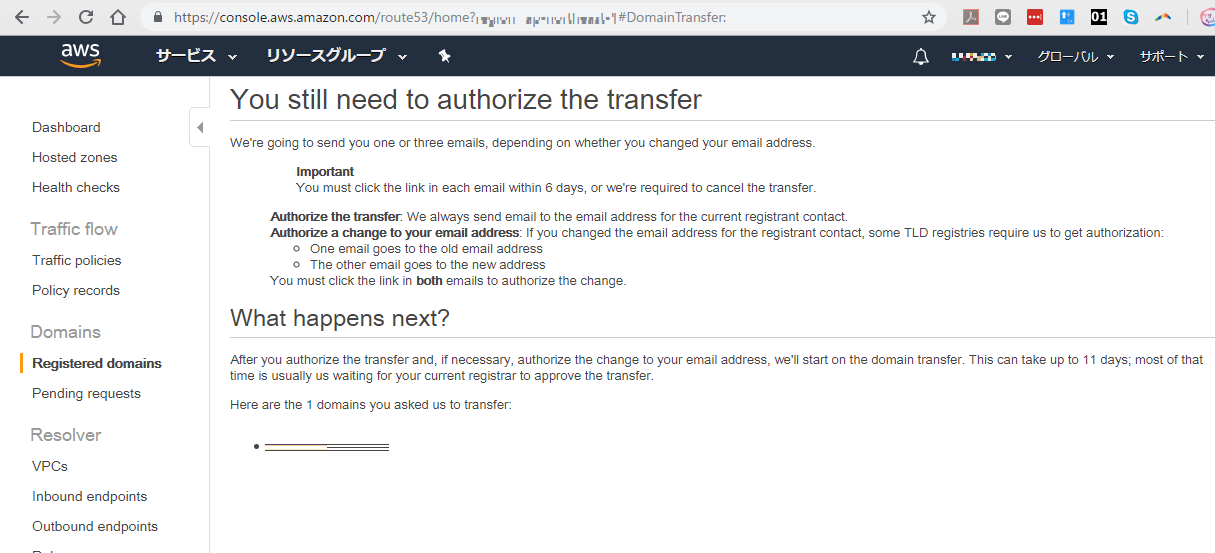
次は何が起こる?
転送を承認し、必要に応じて自分の電子メールアドレスの変更を承認したら、ドメイン転送を開始します。これには最大11日かかることがあります。その時間の大部分は通常あなたの現在のレジストラが移管を承認するのを待っています。
これはあなたが私達に移管するように頼んだ1つのドメインです:
ステップ5.お名前.com からメールが届いた
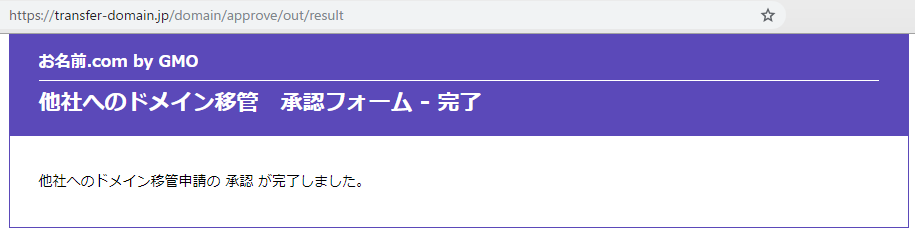
重要】トランスファー申請に関する確認のご連絡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ ■ お名前.com by GMO ■ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ An English version of this message is contained below. ─────────────────────────────────── ■重要■トランスファー申請に関する確認のご連絡 ─────────────────────────────────── 〇〇〇〇 様 ドメイン名:〇〇〇〇〇〇〇〇〇〇.〇〇 お名前.com by GMOは、上記ドメインについて に他社 レジストラへのトランスファー申請を承りました。 トランスファー手続きにつきまして、他社レジストラへ移管をご希望の場合は 期日までに以下URLから承認のお手続きをお願いいたします。 https://transfer-domain.jp/domain/approve/out?requestId=〇〇〇〇〇〇〇 【対応期日】 各種JPドメイン:本メール送信日時から168時間(7日)後まで JPドメイン以外:本メール送信日時から96時間(4日)後まで 【お手続き方法】 1.下記URLへアクセスしてください。 https://transfer-domain.jp/domain/approve/out?requestId=〇〇〇〇〇〇〇〇 2.ドメイン名をご確認の上、トランスファーを承認する場合は「承認する」、 拒否する場合は「拒否する」をクリックしてください。 3.確認画面が表示されますので内容を確認し、間違いなければ「完了」をク リックしてください。 期日までにご対応が確認できない場合は、トランスファー申請を一旦拒否 させていただきます。 ●その他注意事項●────────────────────────── ・JPドメインにつきまして、複数年のご契約を頂いている場合は、レジストリ でありますJPRSにおいては1年単位での更新となっているため、残登録期間が 1年未満にならない状態で他レジストラへ移行すると、弊社にて行なわれた 複数年分のご契約は無効となりますので、ご注意ください。 ・JPドメイン以外のドメインは、トランスファーが行われますと、トランス ファー完了日から60日間は他のレジストラへのトランスファーを行うことが 出来ません(トランスファー完了前・後のレジストラ双方の合意の基に行わ れる前レジストラへのトランスファー、もしくは紛争処理における裁定の 結果の場合は除く)。
トランスファー申請承認のご連絡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ ■ お名前.com by GMO ■ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ ■トランスファー申請承認処理完了のご連絡■ ─────────────────────────────────── sasaco.co.ltd 様 ドメイン名 :structuralengine.com 上記ドメインにつきまして、トランスファー申請の承認処理が完了 いたしました。 お名前.com by GMO をご利用いただきありがとうございました。 ※以後上記ドメインに関する情報変更等はお名前.com by GMO からは一切できません。ステップ6.Amazon からメールが届いた
Verify_your_email_address_or_your_domain_〇〇〇〇〇〇〇〇〇〇.〇〇_will_be_suspendedHello, You must verify your email address or your 〇〇〇〇〇〇〇〇〇〇.〇〇 domain will be suspended on Sun, 〇 Apr 2019 〇:〇:〇 GMT. If your domain is suspended, it will be unavailable on the Internet. Click the following link to verify your email address: https://registrar.amazon.com/email-verification?code=〇〇〇〇〇〇〇〇〇〇 If you use this link, we won’t need to ask you for a password. Why is this required? ICANN, the organization that manages the domain name system, requires registrants of domains to verify their contact information after registering, transferring, or updating registration data for a domain. Sincerely, The Amazon Registrar teamYour_email_address_has_been_successfully_verifiedHi, Your email address 〇〇〇@〇〇〇.com has been successfully verified. No further action is required on your part. Sincerely, Amazon RegistrarTransferring_the_domain_〇〇〇〇〇〇〇〇〇〇.〇〇_to_Route53_succeededHi, We have finished transferring your domain registration for the domain 〇〇〇〇〇〇〇〇〇〇.〇〇 from your previous registrar to Amazon Route 53. If you requested this transfer, you can now create a hosted zone and resource record sets for your domain. For more information, see the Amazon Route 53 Developer Guide. If you did not request this change, please contact Amazon Web Services Customer Support immediately. Amazon Route 53



- 投稿日:2019-03-23T10:34:25+09:00
Circle CIを用いてGoアプリをAWS Elastic Beanstalkへ自動Deployする
はじめに
本記事では、Elastic Beanstalk DockerベースのGoプラットフォームを利用しているアプリを、Circle CIを用いてデプロイする方法を記載します。
初期環境の構築
AWSのチュートリアルを参考に初期構築を行い、ローカルからElastic Beanstalk (以下、EB)へデプロイする。
これを行うことで、アプリ配置ディレクトリ配下に elasticbeanstalk/config.ymlが作成される。
ローカルからデプロイを実施する際はこのままconfig.ymlを活用できるが、circle CIからデプロイするため、yamlファイルの
profile: eb-cliを削除Circle CIの設定
管理コンソール上での設定
対象プロジェクトのBUILD SETTING -> Enviroment Variablesにて以下の項目を設定
- AWS_ACCESS_KEY_ID
- AWS_SECRET_ACCESS_KEYcircleci/config.yamlの追加
「アプリケーションソースバンドルを作成する」を参考にyamlファイルを作成
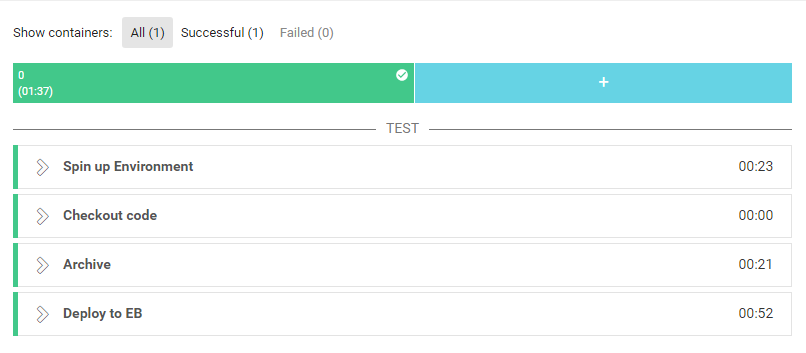
config.yamlversion: 2 jobs: build: machine: true working_directory: ~/project/{{ORG_NAME}}/{{REPO_NAME}} steps: - checkout - run: name: Archive command: | pip install awsebcli --upgrade mv ./eb-go-sample/Dockerfile ./eb-go-sample/Dockerfile.local zip ./eb-go-sample/go-sample.zip ./eb-go-sample/* - deploy: name: Deploy to EB command: cd ~/project/{{ORG_NAME}}/{{REPO_NAME}}/eb-go-sample/ && eb deploy最終的なディレクトリ構成は以下の通りとなる
C:. ├─.circleci │ config.yml │ └─eb-go-sample │ .gitignore │ Dockerfile │ server.go │ └─.elasticbeanstalk config.yml上記内容でGitHubへPush!
実行結果
その他参考にしたサイト
https://blog.guildworks.jp/2015/12/15/circleci-beanstalk/
https://qiita.com/hardreggaecafe/items/995ad9a278e80c903e42
- 投稿日:2019-03-23T08:05:10+09:00
AWS IAMポリシーのJSONに入ってるVersionって何なの?
結論
Versionはユーザーがポリシーを変更した日時ではなく、IAMポリシーの構文ルールのバージョンを示すものである。この Version JSON ポリシー要素はポリシーバージョンとは異なります。Version ポリシーエレメントは、ポリシー内で使用され、ポリシー言語のバージョンを定義します。
Versionというキー名が話をややこしくしていますが、要はJavaが8なのか11なのか、PHPが5系なのか7系なのかを示すのと同じものだということですね。Versionはいくつあるの?
現時点では
2012-10-17と2008-10-17の2種類のみが定義されています。2012-10-17これはポリシー言語の現行バージョンであり、常に Version 要素を含め、2012-10-17 に設定する必要があります。このようにしない場合、このバージョンで導入されたポリシー変数などの機能は使用できません。
2008-10-17これはポリシー言語の旧バージョンです。既存のポリシーで古めのものでは、このバージョンが表示される場合があります。新規ポリシーを作成するときや既存ポリシーを更新するときは、この旧バージョンを使用しないでください。参考
- 投稿日:2019-03-23T00:51:12+09:00
Webサービスの企画、開発、公開まで全部ひとりでやってみた話
先日、ひとり旅のための宿検索サイト「ソロ旅ねっと」というサービスを公開しました。
ソロ旅ねっとは、複数地域、複数の宿泊予定日を自由に組み合わせて、一人宿泊が可能な旅館、ホテルを検索できるサービスです。
「どこかの金曜日に有給を取って北の方の温泉地に泊りで行きたい」、みたいな条件で、旅館、ホテルを簡単に検索できるようなサービスを目指しています。このサービスをまじめに考えだしたのは2018年の12月初旬で、ソースを書き始めたのは同年12月の下旬頃です。
ソースコードの最初のコミットから3か月、最初のリリースからも約2か月が経ったので、これまでを振り返りつつ、宣伝もかねて、今回は、サービスを作ろうと思った経緯、サービスの中身の話などを、サービスの紹介と合わせてお話ししたいと思います。なぜ作ろうと思ったか
僕は割と一人での旅行(特に温泉地)が好きで、年に数回、どこかの温泉地に赴き、1~2泊で、ひたすらダラダラするのを生きがいの一つとしております。
泊りで行くので宿泊場所は事前に取らなきゃアカンのですが、既存の宿泊施設検索サイトで宿探しをするのはとてもとても使いづらい&面倒くさいのです。
そこで、僕が使いやすいサービスを作ってみようと思ったのがきっかけです。僕の使い方だと、今ある宿検索サイト全部がとてもとても使いづらい&宿探しが面倒くさい
「来週か再来週あたりの金曜日に、北の方の温泉地に行ってみたい」という条件で、宿泊施設を探そうとすると、既存の宿検索サイトはとんでもなく使いづらいです。
宿泊施設検索サイトは、楽天トラベル、じゃらん、JTB、など、いくつもありますが、どのサイトも目的地をきちんと入力しないと検索できないようになっております。
しかも、「北の方にある温泉地」などという曖昧な表現ではだめで、○○県××市、だとか ○○温泉、などという感じで目的地をかなり正確に限定する必要があります。なぜ、こういう仕様なのか
僕は旅館・ホテル検索サービスを運営しているようなところで働いた経験がないので完全な憶測になりますが、そのようなサイト設計になっている原因はいくつか推測できます。
そういう需要はそもそも無い
検索サービスに入ってくる人の大半は、観光で行きたい場所などの目的地は完全に決まっている。
この場合、わざわざ広範囲での宿泊施設検索を用意する必要はありません。システム設計の都合
内部管理している宿泊施設データが、地域をキーとして検索されることを前提として設計されている。
複数地域をまたいだ検索を実装した場合、クエリーが複雑になったり、サーバに負荷がかかったり、十分な応答性能が出せない可能性があり、簡単に実装することができない。
サービス公開後のシステム設計の変更ってとんでもなく大変なのです。いい感じのUI/UXが思いつかない、もしくは実現が難しい
大雑把な地域でも細かい地域でも検索できる、見栄えが良く、使い勝手の良いUI/UXを提供するのは確かに難しいと思います。
複数の地域を色々選べるようにしても、エンドユーザさんが使いこなせなかったり、条件指定がめんどくさくて離脱してしまっては元も子もありません。地域ごとに設定されている広告枠や検索結果上位表示枠の都合
宿泊施設から掲載料とは別にお金をもらって、地域ページのサイドバーに「おすすめの宿泊施設」として特定の施設を常時表示させたり(広告)、お金をたくさん支払ってくれた宿泊施設を検索結果の上位に表示させたりといった施策がとられていることもあると思います。
しかし、それゆえに複数地域をまたいだ検索コンテンツは提供しづらい(サイドバーのおすすめに何を出すか、表示順位をどうするかなどの問題)。SEOがらみの都合
この辺あまり詳しくないのですが、サイトトップ > 都道府県 > 市区町村 > ホテル一覧 みたいなきれいな構造になっていた方がSEO上有利、なのかもしれません。
ただ、エンドユーザさんの使い勝手を犠牲にしてでも、検索エンジンには気を使うという設計方針が選ばれているんだとしたら少し残念と感じます。自分の望む形のものがないならば・・・
いよいよ年末の2018年の12月初旬、お正月明けの温泉旅行プランを妄想しつつ、使いづらいと思いながらも楽天トラベルで宿検索をしておりました。その時に、作れそうなら、自分が使いやすいと思うサービスを作ってみてもいいかな、と思い、調査を始めました。
実現手段を考える
楽天が、開発者向けに楽天市場の商品検索APIを公開しているのは知っていたので、楽天トラベルの情報もとれるのではないかと思い、調べてみました。
楽天Webサービス:API一覧
ドキュメントを確認したところ、楽天トラベルの施設検索、空室検索もAPIとして提供されていました。
そこで、今回はこちらを利用させていただいて、一人旅専用の旅館、ホテルの検索サービスを作ってみることにしました。
なお、あとで知ったのですが、同様のサービスがじゃらんからも提供されているようです。要件定義
サイトにどんな機能を盛り込むか
楽天が提供しているAPIを利用させていただくため、楽天が提供していない機能、規約違反になってしまうような機能は提供できません。
それを踏まえたうえで、APIドキュメントを読みつつ、どれくらいのことができそうかを決めていきます。できそうなこと
- 複数地域をまたいだ一人で泊まれる旅館・ホテルの検索
- 1回のAPI呼び出しで取得できるのは、1つの地域の宿泊施設の結果のみ。
- 事前に全施設の情報を取得して、ソロ旅ねっと管理のデータベースに蓄積。
- エンドユーザさんが検索したら、楽天にクエリーを投げるのではなく、 ソロ旅ねっとのデータベースに問い合わせを行う。
- 駅近く、温泉宿などでの絞り込み条件
- 温泉付き施設、朝食付きプランあり、夕食付プランあり、禁煙部屋の有り無し、といった絞り込み条件は APIで提供されています。
- また、鉄道駅が近くにあるか、という情報は、緯度経度付きの駅データを別途用意できれば実現可能
- 楽天トラベルの宿泊施設情報には、緯度経度データも付与されている
- 旅館、ホテルが提供しているプラン、価格を表示
- APIで、宿泊プラン(最大3件)、プランごとの価格情報は取得できるようになっている。
- ただ、最大3件までしか取得できないため、全プラン&それぞれの価格を提示することは不可能。
- 同じプランでも土日祝日などは少し高めの値段を設定している宿泊施設もそれなりにあるのですが、その情報をちゃんと取得できるようになっている。えらい。
- 当日から数えて1か月程度の空室状況の確認
- API単発の呼び出しでは、〇月〇日に大人1人で宿泊可能な、○○(地域、緯度経度半径xキロ以内 など)に存在する宿泊施設を検索ということしかできない
- 複数の宿泊日での検索を行うためには、APIで事前にクロール&データ取得しておく必要がある。
- 空室状況のデータは生ものなので、ある程度の頻度で常に更新しないといけない。
- 検索結果ページからの楽天トラベルの宿泊施設ページへのアフィリエイトリンク
- こちらは、APIで容易に取得できるようになっている
実現できそうにないこと
- 宿泊人数を自由に指定して検索できるようにする
- APIとして提供されている機能の制限、時間当たりに呼び出せるAPIの回数などの制限のため難しい
- 楽天が提供しているすべての絞り込み条件に対応する
- APIの検索条件としては利用できるのですが、API戻り値の仕様や、時間当たりに呼び出せるAPIの回数などの制限のため難しい
- 僕が絶対はずしたくなかった、夕食付プラン、温泉付き施設の2つと、別途用意した駅データを利用した駅近くの施設、の3つの絞り込み条件に対応することにした
- 駅近くの宿泊施設の場合、最寄り駅の時刻表サイトや、路線検索サイトへのリンクを張る
- APIの利用規約に、「APIを利用したページから楽天以外のサイトにリンクしてはならない」という利用規約があるため不可能。
- おそらく、楽天以外の予約サイトに飛ばしたり、amazonなどの競合他社サイトへの流出を抑制したいという意図があるのだと思いますが、ここは非常に残念なところ。
- そのため、アドセンス広告なども貼れない。悲しい。
- 施設周辺の地図を出したい
- google map APIの利用が有料化され、しかも結構なお値段がするので断念。
「できそうなこと」でも書いていますが、このサービスを実現するには、宿泊施設の情報、空室状況を、常に更新していく必要があります。そして、それを実現するには結構な回数のAPIコールが必要です。
例えば、空室状況の更新を10日に1回とした場合、データ取得&検索タイミングによっては、すでに予約でいっぱいな施設だらけになってしまうかもしれません。最終的には、
- どれくらい先までの空室状況を取得したいか
- 空室状況の鮮度はどれくらいにするか
- 検索条件として指定できるオプションで外したくないものはどれか
- DBに保存するデータ量はどのくらいになるか
- 現実的なAPI呼び出し回数で実現可能か
- 運用費用(サーバ費用)はどんなもんになるか
などを考えつつ、システム仕様に落とし込んでいきます。
ちなみに、ソロ旅ねっとでは、28日後までの空室状況を1日~1日半程度の時間をかけて取得、更新をしています。
本当は、30日分の宿泊可能な施設情報を1日以内に取得したかったのですが、性能的に一歩及ばず、今後の課題になっています。なお、楽天トラベルに登録されている一人宿泊が可能な宿泊施設は1万~2万ほどです(事前に1回クロールして調べた)
これを踏まえると、各施設に設定されているプランの空室状況を表すテーブルのレコード数は100万以上になる可能性があります。
宿泊施設データ(約1万~2万)はともかく、空室状況データの100万レコードを1つのテーブルに格納するのは多少サーバにお金をかけないと厳しいかもと思ったので、空室状況テーブルのデータはパーティショニングした方がよさそうです。開発言語、利用技術のの選定
要件が固まってきたので、言語は何にするか、DBはどうするかということの検討に移ります。
- DBの選定
- MySQLは嫌いなので候補から除外
- ElasticSearchは、低スぺサーバーでアプリと一緒に動かすのは多分無謀すぎるのでこれも除外
- 割と消去法ですが、DBはpostgreSQLに決定
- バージョンは9.6か10系にする予定でしたが、上で少し書いた通り、hashパーティショニングの機能が欲しかったため11に決定
- PostgreSQL11の難点が1つ。Windowsから安定してつながるクライアントアプリがない。
- pgAdmin3が完全サポート外(一応つながるけど、エラーがバンバン出る)。
- 今は、VisualStudio codeのプラグイン[ms-ossdata.vscode-postgresql] を利用。
- テーブル一覧などの機能はないが、クエリー投げて結果をテーブル表示する程度の用途であれば使いやすい。
- 開発言語の選定
- Java
- JVMってメモリー食いそう
- 前々職の天才中国人エンジニアが作ったasta4dというフレームワークを使おうかとも思ったけど、割とキャッシュ前提のつくりなので、低スぺサーバーで動かすにはちょっと不安
- PHP
- 現職で使ってるけど、とにかく楽。
- 人をダメにする開発言語なんじゃないかって思うくらいとにかく楽。
- よく言えば、アルゴリズム以外で詰まることが何もない。
- Ruby
- 昔は好きだったけどRailsで嫌いになった。
- 書いていてあんま楽しくなかったため。
- でも slim(テンプレートエンジン)は好き。
- 書いてて楽しくないフレームワークをわざわざ選択する気はない。
- Goとか、Rustとか
- 勉強しながら作るのも楽しいのですが、今回はそれよりも早く作ってサービス公開したい
- お作法などがわかってきたらPHPから乗り換えるかも
- 最終的にはPHPを選択
- 実装開始から公開まで最短で進めたかったため
どれだけのお金がかかるか
利用規約に、「一般に公開されていないサイトでの利用は不可」との記述があるため、僕専用サービスとして、ずっとlocalhostで動かし続けるわけにはいきません。
また、収益化できているというのも、開発モチベーションとしてはとても大事なことです。現状の収益化手段は、楽天アフィリエイトプログラムです。
運よく利用者が現れて、サイト経由で予約が成立すれば、楽天アフィリエイトプログラムにより収益が発生するようになっています。
が、現状では、需要があるか、人が来るか等、まったくわからないため、コストはできる限り抑えたいです。
とはいえ、ある程度のレスポンス速度はやっぱり必要なので、その辺のバランスを考えて、ソロ旅ねっとは以下のような構成で運用しています。
- ドメイン管理
- お名前.com
- 年間1000円程度
- サーバー
- AWS
- ec2 instance
- 米国バージニア州 t3-micro 3年物Reserved instance
- 日本から接続した場合、東京リージョンよりも若干レスポンスに時間がかかるという欠点はありますが、東京リージョンよりも安いです。
- ubuntu 18.04
- 利用したいミドルウェア(Postgres11)のパッケージが用意されていなかったため、amazon linuxは候補から除外。
- Webはnginx/php7.2
- DBはpostgresql 11(RDSを立てるということはせず、1つのインスタンスにWebとDBを共存させています。理由はもちろん費用を抑えるため)
- この構成で3年間で140ドルほど
- ec2-instance の費用が3年間で110ドル。ほかにebsの費用が1日3セントほど。データ転送の費用は別途。
サービス運営に直接かかった費用だけを考えれば、損益分岐点は3年で1万5千円~1万8千円程度となります。
予約1件あたりの収益を100円(楽天アフィリエイトの収益は、予約金額の1%)程度で計算しても、少なくとも送客数150人から180人は必要です。
過疎ったら確実に達成できない。過疎らなくても難易度は割とハードな気がします。
少なくとも、確定申告が必要になるくらい稼ぐのは難しそう。
自分が欲しいからという動機づけがなければ、この時点で計画倒れとなっていたと思います。サイト名をどうするか
gitリポジトリ名をどうするか、という問題もあったため、サイト名は最初に決めました。
名前を決めるために考えたことは以下の4つです。
- 言いやすく、覚えやすいこと
- ドメインが取られていないこと
- 同名のサービスが存在しないこと
- 商標登録されていないこと
特に商標は、権利者がいた場合とんでもなく面倒くさいことになりそうな気もしますし、事前に確認するのは大事だと思います。
実装開始から公開まで
gitリポジトリへの最初のcommitが2018年の12月20日、1stリリースが2019年1月27日なので、開発期間は1か月ちょっとでした。開発は、会社の昼休み、平日帰宅後にすこし、休日予定がなかった時に進めていました。
業務時間中も、どんな感じで実装していこうかっていう妄想くらいはしていたかも。サーバ側の実装に関して
サーバ側の実装に関しては、今更困るようなことは特にありませんでした。
slim(フレームワーク)を使おうかとも思ったけど、完全に理解しているわけでもないし、ハマった時の調査とか面倒くさかったので、お手製のMVCフレームワークもどきを作成&使用しています。
なお、外部のライブラリ、モジュールを全く使っていないわけではなく、例えば、template engine として twig を利用しております。
DB接続まわりについては、PDOを直接利用することにしました。Lalavel等を組み入れてもよかったのですが、slimと同様の理由で使用していません。画面デザイン
デザインセンスがあるわけでもなく、cssにさほど詳しいわけでもなかったため、ここはかなり試行錯誤で進めていました。
- 最低限の見た目は担保
- 初回リリースは、いかにもbootstrapで作りました的なサイト。
- 12分割グリッドは使いやすいようで細かい制御はやりずらい、等、様々な理由により、初回リリース後の機能拡張、デザイン変更、などのフェーズで徐々に依存度は下がってます。
- 旧式ブラウザ対応で苦労はしたくない
- cssであまりトリッキーなこととか難しいことはやりたくない
- Firefoxとchromeで意図通りに見られて、Edge最新版でもとりあえずは不自由なく見られればOKとしました。
- 最初のリリースでは、IE11でもとりあえず見られる形にはなっていたんだけど、現在公開されているバージョンでは表示が乱れまくっています。
- 旧世代IEでの表示確認は1度もやってません
- flexboxが神過ぎる。
- flexboxが存在しなかった時代、デザイナーはどうやって横並びのコンテンツをきれいに配置していたのか全く分からない
- float: left なんですかそれ、いまだにさっぱりわからないし、特に覚える気もないです
- 画面レイアウト、デザイン設計は基本だけは押さえる
- サイトのデザインは以下の5点だけ気を付けました
- 色を使いすぎない
- 最初のリリース時は結構ごてごてしてたけど今は3色+白+黒に抑えています。
- メインカラー(緑系)+アクセントカラー(メインカラーの反対色)+補助色(青)
- メインカラーの緑はなんとなく決めた
- カレンダー表示で、土曜日(青)、日曜日(赤)を使っていたので、それををそのままアクセントカラー、補助色として採用
- アクセントカラーとして赤色、リンクなどで利用する色として青を割り当て
- 色コードは、最初はマテリアルデザインの標準カラーを適当に選んで使用していましたが、現在は日本の伝統色 和色大辞典というサイトに載っている色から、自分の気に入った色を選んで使用しています。
- 余白を適切にとる
- これは特に説明の必要ないかもしれませんが、適切に行間を設けるだとか、各コンテンツ間に適切な余白を入れる等のことです。
- 余白の大きさは統一する
- 例えば「3つ横並びのコンテンツ」があったとき1つ目と2つ目の隙間は15px、2つ目と3つ目の隙間は18px のようなことはせず、ページ全体を通して、余白のサイズはなるべくそろえています。
- テキストの開始位置(右詰めの場合は終了位置)をそろえる
- タイトル+リード文みたいなリストがあったとき、リード文部分は16px下げる、みたいなことを僕もよくやっていたのですが、端をそろえた方が、安定した感じになり、見た目も綺麗になります。
- borderを使いすぎない。その代わり、コンテンツの境目は色の違いで表現する。
- 現在のデザインでもカレンダー部分や一部のボタンでborder を使っていますが、ごちゃごちゃしてしまうので、極力使わないようにしています。
- デザインについては、前々職のデザイン社内勉強会で聞いた「見た目最低のパワポプレゼンをいい感じに改善する手法」のという話がとても参考になっています。
- 大体同様の内容が、やってはいけないデザイン という書籍にとても丁寧に書かれています(勉強会の人と本の著者は全然別の人です。念のため)。
- まじめな遊び心ということで、他のサイトではあまり見かけないデザインも取り入れてみる
- せっかくのオレオレサービスなので、少し変わったこともやってみました。
- ページネーション、検索結果ヘッダ部分(〇ページ目/〇件の結果中)の部分は、画面をスクロールさせても常に表示されるようにしています。
- あまり深い意図があったわけではなく、なんとなく、他のサイトと差別化したかったから。
- 圧迫感が出ないような調整をするのは結構大変でした。
- 課題
- スマホで見ると文字が小さい。タップ領域も小さいので操作性も悪い。
- サーチコンソールにも指摘されている。
そしてサービス公開
サービスを公開したのは、金曜日深夜(土曜日早朝近く)、仕事では絶対に選びたくない曜日&時間でした。
割とぎりぎりまでコードを書いていて、公開直前に、awsのインスタンスの購入やドメイン取得&設定を行いました。
この時点まで、Linux環境で全く動かしていなかった(Windowsのローカル環境使ってました)ため、ハマったらその日の公開はとりあえず諦めるつもりでいましたが、特にトラブルもなく、無事に公開までこぎつけることができました。公開からこれまで
サービスの公開以降は、ユーザさんの反応やGAなどを確認しつつ、改善していくのがセオリーだと思うのですが、PVが全然ないし、自分が作りたいと思ったこともまだまだできていないので、現在は、その辺の実装もやりつつ、最低限の環境整備的なことをやっています。
機能追加、性能改善以外では、以下のようなことをやっていました。
テスト環境の準備
さすがにテスト環境も必要だと思い、本公開後に準備しました。
といっても、テスト時だけ立ち上がるinstanceなどを用意したわけではなく、本番環境のport8080がテスト環境になっています。
会社で同じことやったら、方々からアホといわれること間違いなしです。デプロイ手順の簡略化
初回リリース直後は、毎回WinSCPを立ち上げてファイルのコピーというとても残念な運用をしていました。
さすがにそれはやめましたが、今でも割と残念な運用をしています。
CI使って、テストにpassしたらデプロイするとかの仕組みを作るのが割と当たり前なんでしょうけど、個人で作ったオレオレサービスだし、いろいろ設定するのも面倒くさい、とはいえ scpで毎回アップロードするのも面倒くさいので、rsyncするだけのスクリプトを組んで、リリース時はそれを流しています。deploy.sh#!/bin/bash cp .key/solotabiproduction.pem ~/ chmod 0600 ~/solotabiproduction.pem composer update rsync -arvz --exclude 'composer.*' --exclude='.*' --exclude '*.bat' --exclude='environment' --exclude '*.sh' --exclude 'cache' --delete --partial --progress -e "ssh -i ~/solotabiproduction.pem" ./ ubuntu@ec2-**-**-**-**.compute-1.amazonaws.com:~/webroot/ rm ~/solotabiproduction.pem開発環境はWindowsなので、別途以下のような deploy.batを用意し、実際のリリース時にはこちらのバッチをたたいています
deploy.batwsl bash ./deploy.shお手軽ですが、このやり方ではリリース中にサーバのソースファイルが中途半端な状態になり、更新中にサイトが500になる可能性が非常に高いです。
instanceをRoute53にぶら下げて、リリース時に向き先のインスタンスを切り替えるとか、サーバの別ディレクトリに全ファイルをアップロードし、サーバ側でリネームする、などで、ダウンタイムをなくす or 減らすことはできますが、そういうのは人がたくさん来るようになったら考えることにしています。なお、stage.batというバッチファイルもあり、これを使えば(以下略
今やってること
- 都道府県よりももう少し細かい範囲での地域検索
- UIをどうするかで悩み中
- Aタグで検索結果ページに遷移する導線が全くないので、一応それくらいは用意しようかと(SEO)
総括
- 技術的な裏付けができていて、細かい部分にあまり神経質にならなければ、サービス開発&リリースは意外と簡単
- ただし、収益的に成功する可能性のあるサービスを企画するのは大変
力尽きたので、この辺で終了です。
もうちょい内部の話とか、PHP製のなんちゃってMVCフレームワークの話とか、気が向いたら書くかもしれません。
それでは、ごきげんよう。