- 投稿日:2019-03-18T22:54:51+09:00
FlappyBird で強化学習の練習 その1: DQN
— ᴉɥsᴉuɐʞɐu oɹɐʇuǝʞ (@cfiken) 2019年3月18日この記事は何
せっかく Pythonで学ぶ強化学習 をざっと読んだので、手を動かしてみる大作戦です。
FlappyBird という数年前に話題になったゲームがあり、それを強化学習を用いて学習していきたいと思います。
目標は満点である264点を安定して取ることです。
のんびり動かしてみつつ、色々やったことを記録していこうと考えています
本記事はひとまずベースラインとなるシンプルな DQN で学習をさせたものを紹介します。
以降の更新で、まずは Rainbow のそれぞれのアイディアを試しつつ、ベースラインからの改良度合いを見ていけたらと考えています。
勉強しつつ書いてるので、何か誤りなどあればコメントいただけると助かります
実装は jupyter notebook 上で行っており、 今回のコードはこちらです。
リポジトリはこちら: cfiken/flappybird-try目次
- DQN とは
- FlappyBird における問題設定
- DQN による学習結果
- 実装の紹介
- まとめ
DQN とは
DQN は Deep Q-Network の略で、強化学習における Q-Learning を、ディープラーニングを使って実現する手法のことを言います。
ここでは詳解はしません(詳しい記事は既に死ぬほどあります
発表論文は nature に掲載されています。
Deep Mind による記事Q-Learning では、ある状態と行動の価値(Q値)をTD誤差を用いて反復的に更新し、それが最大となるような行動を取りました。
\begin{align} Q\left(s_{t}, a_{t}\right) &= Q\left(s_{t}, a_{t}\right)+\eta *\left(R_{t+1}+\gamma \max _{a} Q\left(s_{t+1}, a\right)-Q\left(s_{t}, a_{t}\right)\right) \\ \pi(a|s_t) &= \mathrm{arg}\max_a Q(s_t, a) \end{align}DQN では Q-Learning に対して、TD誤差を用いて反復的にQ値を推定するのではなく、状態を入力として入れるとそれぞれの行動をとった際の価値を出力するようなニューラルネットワークに置き換えて価値を推定するモデルとなっています。
\begin{align} Q\left(s_{t}, a \right) &= f(s_t; \boldsymbol{\theta}) \,\,\,\, (f\mathrm{: neural \, network \, model})\\ \pi(a|s_t) &= \mathrm{arg}\max_a Q(s_t, a) \end{align}ここでこの$f(s_t; \boldsymbol{\theta})$は、先程の TD 誤差を最小化するようにパラメータを学習します。
特に DQN の発表論文である では、ゲーム画面という画像から CNN を使って直接価値を推定し、それを使って人間並みの能力を持つエージェントが作成できたという点でとても話題になった手法とのことでした。
また、DQN では、学習の難しい強化学習で学習を安定化させるためのノウハウがいくつか入っています。本記事の実装では Experience Replay と Fixed Target Q-Network, reward clipping などを取り入れています。
FlappyBird における問題設定
強化学習には、状態、行動、報酬のセットが必要です。FlappyBird というタスクを解くにあたって、どのようにそれぞれを定義するかについて説明します。
状態 (state)
単に状態といっても次の2通りがあります。
- gym のインターフェースから得られる生の状態
- 学習に使うために前処理を適用した後の状態
前者は、FlappyBird の gym 上のインスタンスを
envからenv.step(action)やenv.reset()で得られる状態です。
FlappyBird の場合は、(height, width, channel) = (288, 512, 3)で、それぞれ0-255の値を取る画像データが得られます。ここから、学習をしやすくするために前処理を行ったものが後者にあたります。
今回は、まずそれぞれのデータをまずグレースケールに変換し、全体を255.0で割って 0~1 の値に変換します。
それを時系列で 4 frame 並べ、 shape を(width, height, frames)としたものを学習に使用する状態としています。
コードとしては、Observerクラスのtransformメソッドにあたります。class Observer: # ... def transform(self, state): grayed = Image.fromarray(state).convert('L') # h, w, c -> h, w resized = grayed.resize((self.width, self.height)) resized = np.array(resized).astype(np.float32) resized = np.transpose(resized, (1, 0)) # h, w -> w, h normalized = resized / 255.0 if len(self._frames) == 0: for i in range(self.frame_count): self._frames.append(normalized) else: self._frames.append(normalized) feature = np.array(self._frames) feature = np.transpose(feature, (1, 2, 0)) # [f, w, h] -> [w, h, f] return feature行動 (action)
FlappyBird における行動は、何もしない (=0) か飛ぶ (=1) の二種類です。
今回の実装では、学習をしやすくするために「同じ行動を4回繰り返す」という制約を入れています。
すなわち行動は、「4step の間何もしない」か「4step の間飛び続ける」のどちらかとしました。
あくまで今回の実装ではそうしたというだけで、生の行動をそのまま扱っても問題ないかと思います。報酬 (reward)
FlappyBird のデフォルトの実装では、
- ドカンの間を一つ抜けるたびに +1
- ぶつかってしまうと -5
- それ以外は 0
という報酬が与えられます。今回は学習をしやすくするため、次のような reward shaping を加えました。
def reward_shaping(self, reward): if 0.1 > reward > -0.1: return 0.01 elif reward <= -0.1: return -1.0 else: return 1.0全体の学習を安定化させるために報酬をクリップしつつ、長生きする方が良いということを学習させる意図で、前に進むだけで少しの報酬が与えられるようにしています。
ここまでの定義は、あくまで私が識者に聞いたりしつつ現在それで試しているというだけのもので、工夫の余地があると思います。
DQN による学習結果
学習後のモデルで50回ゲームをプレイし、スコア(超えたドカンの数)の平均値を最終スコアとします。
50回実行した上での平均スコアは
42.2600でした。平均約42本のドカンを超えているようです。
とはいえまだスコアはブレが大きく、1本で死んでるプレイもあり、安定して攻略できているとは言えません。
が、人間がプレイしても40を超えるのは結構難しいので(私は結構やって人力スコア20ちょいでした...)、人間レベルに達したと言っても良さそうです。下記は、冒頭に上げたものと同じで、 episode 45 で89回成功したときの動画です。
— ᴉɥsᴉuɐʞɐu oɹɐʇuǝʞ (@cfiken) 2019年3月18日下記は50プレイ分の結果です。
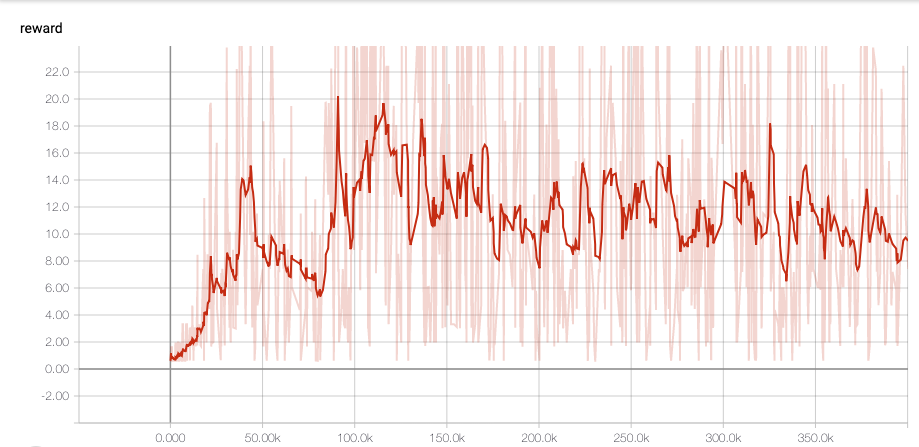
episode 0, total reward: 21.0000 episode 1, total reward: 44.0000 episode 2, total reward: 12.0000 episode 3, total reward: 29.0000 episode 4, total reward: 32.0000 episode 5, total reward: 68.0000 episode 6, total reward: 264.0000 episode 7, total reward: 50.0000 episode 8, total reward: 22.0000 episode 9, total reward: 10.0000 episode 10, total reward: 14.0000 episode 11, total reward: 1.0000 episode 12, total reward: 32.0000 episode 13, total reward: 150.0000 episode 14, total reward: 12.0000 episode 15, total reward: 16.0000 episode 16, total reward: 7.0000 episode 17, total reward: 44.0000 episode 18, total reward: 36.0000 episode 19, total reward: 58.0000 episode 20, total reward: 40.0000 episode 21, total reward: 81.0000 episode 22, total reward: 11.0000 episode 23, total reward: 32.0000 episode 24, total reward: 26.0000 episode 25, total reward: 35.0000 episode 26, total reward: 45.0000 episode 27, total reward: 1.0000 episode 28, total reward: 100.0000 episode 29, total reward: 79.0000 episode 30, total reward: 38.0000 episode 31, total reward: 23.0000 episode 32, total reward: 57.0000 episode 33, total reward: 88.0000 episode 34, total reward: 31.0000 episode 35, total reward: 5.0000 episode 36, total reward: 55.0000 episode 37, total reward: 75.0000 episode 38, total reward: 3.0000 episode 39, total reward: 7.0000 episode 40, total reward: 14.0000 episode 41, total reward: 93.0000 episode 42, total reward: 31.0000 episode 43, total reward: 22.0000 episode 44, total reward: 13.0000 episode 45, total reward: 89.0000 episode 46, total reward: 28.0000 episode 47, total reward: 35.0000 episode 48, total reward: 10.0000 episode 49, total reward: 24.0000 average reward by 50: 42.2600また、学習中の TensorBoard での reward の様子です。
100k step ほどで学習は終わっていそうですね。
実装の紹介
実行時の notebook はこちらです。
主要なところを紹介していきます。Experience クラス
まずは次のように
NamedTupleを使って Experience クラスを定義します。
学習のため、エージェントに行動をさせた結果を学習データとして Experience Reply に積みますが、その1データ分を格納するクラスを作っておきます。class Experience(NamedTuple): state: gym.spaces.Box action: int reward: float next_state: gym.spaces.Box done: boolここでの state や reward は上記で定義したもの(変換済みのもの)です。
モデル
次に、ニューラルネットによるモデルを定義します。入力を状態、出力を各行動 (0 or 1) 毎の価値を出力するようなモデルです。
今回はtf.keras.Modelのサブクラスとして作成し、後にこれを用いて keras の Functional API を使えるようなモデルに変換しました。
(keras, サブクラスでも Functional API 使えるようになってほしい)class AgentModel(tf.keras.Model): def __init__(self, is_training: bool, num_outputs: int): super(AgentModel, self).__init__() self.is_training = is_training self.num_outputs = num_outputs k_init = tf.keras.initializers.glorot_normal() relu = tf.nn.relu self.conv_01 = tf.keras.layers.Conv2D(16, kernel_size=8, strides=4, padding='same', kernel_initializer=k_init, activation=relu) self.conv_02 = tf.keras.layers.Conv2D(32, kernel_size=4, strides=4, padding='same', kernel_initializer=k_init, activation=relu) self.conv_03 = tf.keras.layers.Conv2D(64, kernel_size=3, strides=2, padding='same', kernel_initializer=k_init, activation=relu) self.flatten = tf.keras.layers.Flatten() self.dense = tf.keras.layers.Dense(256, kernel_initializer=k_init, activation=relu) self.output_layer = tf.keras.layers.Dense(num_outputs, kernel_initializer=k_init) def call(self, inputs): outputs = inputs outputs = self.conv_01(outputs) outputs = self.conv_02(outputs) outputs = self.conv_03(outputs) outputs = self.flatten(outputs) outputs = self.dense(outputs) outputs = self.output_layer(outputs) return outputsモデルの構成としては、特に工夫せずに書籍などを参考にしました。
3層の convolution レイヤのあと、flat なベクトルに変形し、dense レイヤを通して2つの値を出力します。
このように定義したモデルを、後ほど定義する Agent クラスで次のように使っています。
このようにしないと、 Keras API を使えなかったためです。tf.keras.Modelsのサブクラスでも Keras API を使う方法を知ってる方いれば教えてくださいinputs = tf.keras.Input(shape=self.input_shape) model = AgentModel(is_training=True, num_outputs=len(self.actions)) outputs = model(inputs) self.model = tf.keras.Model(inputs=inputs, outputs=outputs)Agent クラス
Agent クラスでは、次のことを行います。
- ニューラルネットによるモデルを準備する
- 状態を入力として行動を返す
- データをもとにモデルを学習する
class Agent: def __init__(self, actions, epsilon, input_shape, learning_rate=0.0001): self.actions = actions self.epsilon = epsilon self.input_shape = input_shape self.learning_rate = learning_rate self.model = None self._teacher_model = None self.initialize() def initialize(self): self.build() optimizer = tf.train.RMSPropOptimizer(self.learning_rate) self.model.compile(optimizer, loss='mse') def save(self, model_path): self.model.save_weights(model_path, overwrite=True) @classmethod def load(cls, env, model_path, epsilon=0.0001): actions = list(range(env.action_space.n)) input_shape = (env.width, env.height, env.frame_count) agent = cls(actions, epsilon, input_shape) agent.initialize() agent.model.load_weights(model_path) return agent def build(self): inputs = tf.keras.Input(shape=self.input_shape) model = AgentModel(is_training=True, num_outputs=len(self.actions)) outputs = model(inputs) self.model = tf.keras.Model(inputs=inputs, outputs=outputs) # teacher_model を更新するため、両方のモデルで一度計算し重みを取得する self._teacher_model = AgentModel(is_training=True, num_outputs=len(self.actions)) dummy = np.random.randn(1, *self.input_shape).astype(np.float32) dummy = tf.convert_to_tensor(dummy) _ = self.model.call(dummy) _ = self._teacher_model.call(dummy) self.update_teacher() def policy(self, state) -> int: ''' epsilon greedy で受け取った state をもとに行動を決定する ''' # epsilon greedy if np.random.random() < self.epsilon: return np.random.randint(len(self.actions)) else: estimates = self.estimate(state) return np.argmax(estimates) def estimate(self, state): ''' ある state の状態価値を推定する ''' state_as_batch = np.array([state]) return self.model.predict(state_as_batch)[0] def update(self, experiences, gamma): ''' 与えられた experiences をもとに学習 ''' states = np.array([e.state for e in experiences]) next_states = np.array([e.next_state for e in experiences]) estimated_values = self.model.predict(states) next_state_values = self._teacher_model.predict(next_states) # train for i, e in enumerate(experiences): reward = e.reward if not e.done: reward += gamma * np.max(next_state_values[i]) estimated_values[i][e.action] = reward loss = self.model.train_on_batch(states, estimated_values) return loss def update_teacher(self): self._teacher_model.set_weights(self.model.get_weights()) def play(self, env, episode_count: int = 2, render: bool = True): total_rewards = [] for e in range(episode_count): state = env.reset() done = False episode_reward = 0 while not done: if render: env.render() action = self.policy(state) step_reward = 0 for _ in range(4): next_state, reward, done = env.step_with_raw_reward(action) if done: break step_reward += reward episode_reward += reward state = next_state print('episode {}, total reward: {:.4f}'.format(e, episode_reward)) total_rewards.append(episode_reward) env.reset() print('average reward by {}: {:.4f}'.format(episode_count, np.mean(total_rewards)))
def policyでは、epsilon greedy によって、ランダムに選んだ行動か、与えられた状態をもとに最も価値が高くなる行動を返しています。
def updateでは、experiences (データの batch)からモデルの学習を行っています。また、ここでは Fixed Target Q-Network というテクニックを使用しています。
次のように、update内で、遷移先の状態価値の計算にはself.modelではなくself._teacher_modelを使用し、それを正解ラベルとして学習を行っています。estimated_values = self.model.predict(states) next_state_values = self._teacher_model.predict(next_states)
self.modelは各 minibatch 毎にパラメータが更新されているため、遷移先状態もself.modelを用いて推定を行ってしまうと、TD誤差も不安定になってしまいます。
これを避けるために、self._teacher_modelを用意し、定期的に更新しつつも各 minibatch では同じモデルを使えるようにしています。Trainer クラス
Trainer クラスは、名前の通りモデルの学習を行うクラスです。
agent を初期化し、行動させながらデータを溜め、そのデータを使って agent を学習させます。また、学習状況の可視化や、モデルの保存、前述したteacher_modelの更新などの処理も含まれています。
細かい実装はソースを見ていただくとして、メインの学習部分を下記に貼ります。class Trainer: # ... 略 ... def train_loop(self, env, agent, episode_count, initial_count): for episode in range(episode_count): state = env.reset() done = False step_count = 0 episode_reward = 0 while not done: action = agent.policy(state) step_reward = 0 for _ in range(4): next_state, reward, done = env.step(action) if done: break step_reward += reward e = Experience(state, action, step_reward, next_state, done) self.experiences.append(e) episode_reward += step_reward loss = self.step(episode, agent) state = next_state if not self.training and (len(self.experiences) >= self.buffer_size or episode >= initial_count): self.begin_training(agent) self.training = True self.end_episode(episode, episode_reward, loss, agent)エピソードカウント分、下記のループを回します。
- 環境を初期化する
- Agent モデルに状態を渡して行動を受け取る
- 環境に対して行動し、遷移先状態と報酬、ゲームが終わったかどうかのフラグを得る
- 得られた状態、行動、遷移先状態、報酬を experiences に追加する
- (ある程度データが溜まっていれば)モデルを1ステップ学習させる
行動選択後に少し注意点があります。
action = agent.policy(state) step_reward = 0 for _ in range(4): next_state, reward, done = env.step(action) if done: break step_reward += reward現在の状態から行動を受け取ったあと、4回連続でそれを実行しています。
これは、問題設定で書いた「同じ行動を4回繰り返す」をコードに落としたものです。
通常ではこのような処理は必要なく、得られた行動を1度だけ環境に対して実行してやれば良いと思います。まとめ
FlappyBird を強化学習で攻略する第一歩として、ベースラインとなる DQN を実装しました。
学習させた結果、人間レベルのプレイが既に出来てきました。
とはいえ、学習が難しいと言われる強化学習を取り扱うためには、問題設定や前処理がかなり重要になってくることも分かりました。
報酬や行動をどのように定義すればうまくいくかなどについても、実問題への適用の際には熟考する必要がありそうです。
- 投稿日:2019-03-18T22:42:44+09:00
FXの一分足データから五分後の上昇下落を予想する
ディープラーニングを初めて実装した
今回はディープを使ってFXの株価予想をしていきたいと思う。理由は僕がお金稼ぎに興味があるから。今まで勉強してきて金を稼ぐよりも強い動機は今までにない。
開発環境はGoogleColaboratory
言語はpython3
実装にはtensorflow/kerasを使用した使用するデータはFXの一分足データを処理して特徴量を11用意した。期間は2018/1/1~2018/10/8
期間が中途半端なのはデータを習得した日付である。許して。
時系列データなので本当はバックプロパゲーションではなくリカレントのほうがいいのだとは思うが習作なのでとりあえずはこれでいく。
上がるか下がるかのニクラス分類問題にする。
実装
from google.colab import files import pandas as pd import io dataM1 = pd.read_csv('/content/drive/My Drive/out_2018usdjpy.csv', sep = ",") import random import numpy as np import pandas as pd import tensorflow as tf from sklearn.model_selection import train_test_split from sklearn.feature_extraction import DictVectorizer from sklearn import preprocessing import time import keras #csvデータの読み取り time1 = time.time() dataM2 = dataM1.dropna() #欠損値がある行の削除 data1 = dataM2.values#numpy配列に変更 print(data1.shape) col = 11 #特徴量の数 X = data1[col:, 1:col]#特徴量行列の設定 y = data1[col:, col:]#ターゲットデータの設定 print(X.shape) hl = y#numpy配列に変更 print(hl.shape) time2= time.time() time3 = time2-time1 print(time3) sc=preprocessing.StandardScaler() sc.fit(X) X_std=sc.transform(X) #データの正規化 X_train, X_test, y_train, y_test=train_test_split(X_std,hl.reshape(-1,), test_size=0.3,random_state = 1) #テストデータとトレーニングデータを分割 print(X_train.shape[0]) print(X_train.shape[1]) print(X_train.shape) print(y_train.shape) np.random.seed(123) tf.set_random_seed(123) time4 = time.time() y_train_onehot = keras.utils.to_categorical(y_train) model = keras.models.Sequential() model.add(keras.layers.Dense(units = 300, input_dim = X_train.shape[1], kernel_initializer ="glorot_uniform", bias_initializer ='zeros', activation = "tanh" )) model.add(keras.layers.Dense(units = 300, input_dim = 300, kernel_initializer ="glorot_uniform", bias_initializer ='zeros', activation = "tanh" )) model.add(keras.layers.Dense(units = 300, input_dim = 300, kernel_initializer ="glorot_uniform", bias_initializer ='zeros', activation = "tanh" )) model.add(keras.layers.Dense(units = 300, input_dim = 300, kernel_initializer ="glorot_uniform", bias_initializer ='zeros', activation = "tanh" )) model.add(keras.layers.Dense(units = 300, input_dim = 300, kernel_initializer ="glorot_uniform", bias_initializer ='zeros', activation = "tanh" )) model.add(keras.layers.Dense(units = y_train_onehot.shape[1], input_dim = 300, kernel_initializer ="glorot_uniform", bias_initializer ='zeros', activation = "softmax" )) sgd_optimizer = keras.optimizers.SGD(lr=0.01,decay = 1e-7,momentum= .9) model.compile(optimizer= sgd_optimizer,loss='categorical_crossentropy') history = model.fit(X_train, y_train_onehot, batch_size = 64, epochs = 0, verbose= 1, validation_split = 0.1 ) y_train_pred = model.predict_classes(X_train,verbose =0) print("first 3 predictions: ",y_train_pred[:3]) correct_preds = np.sum(y_train == y_train_pred,axis = 0) time5 = time.time() print(time5-time4) train_acc = correct_preds / y_train.shape[0] print("training accuracy: %.2f%%" % (train_acc * 100)) y_test_pred = model.predict_classes(X_test,verbose =0) correct_preds2 = np.sum(y_test == y_test_pred,axis = 0) test_acc = correct_preds2 / y_test.shape[0] print("test accuracy: %.2f%%" % (test_acc * 100))結果
training accuracy: 50.15%
test accuracy: 50.09%感想
まあ儲からないよなっていう印象。流石はランダムウォークというべきか。結果を見ての通りにクラス分類で50%ってことはそういうことなんだろうと思う。
今回はとりあえず学習させてみて挙動を見たかったのでこれで良い。改善したいことはこちらの記事にまとめた。