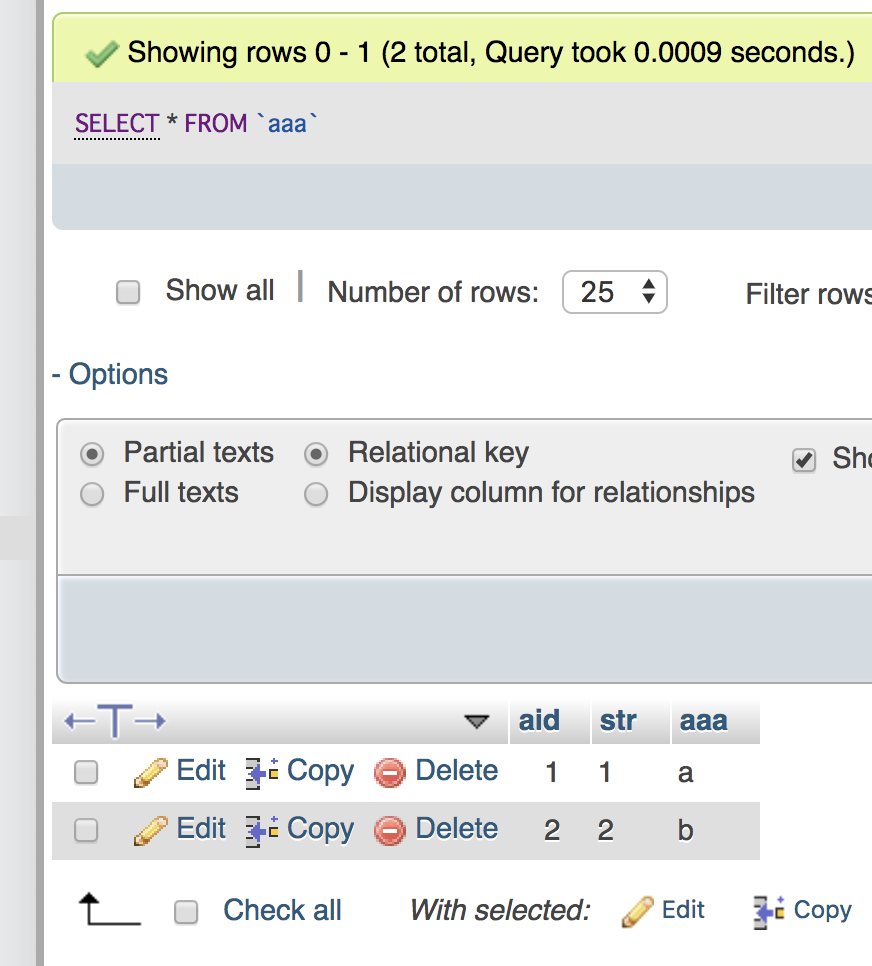
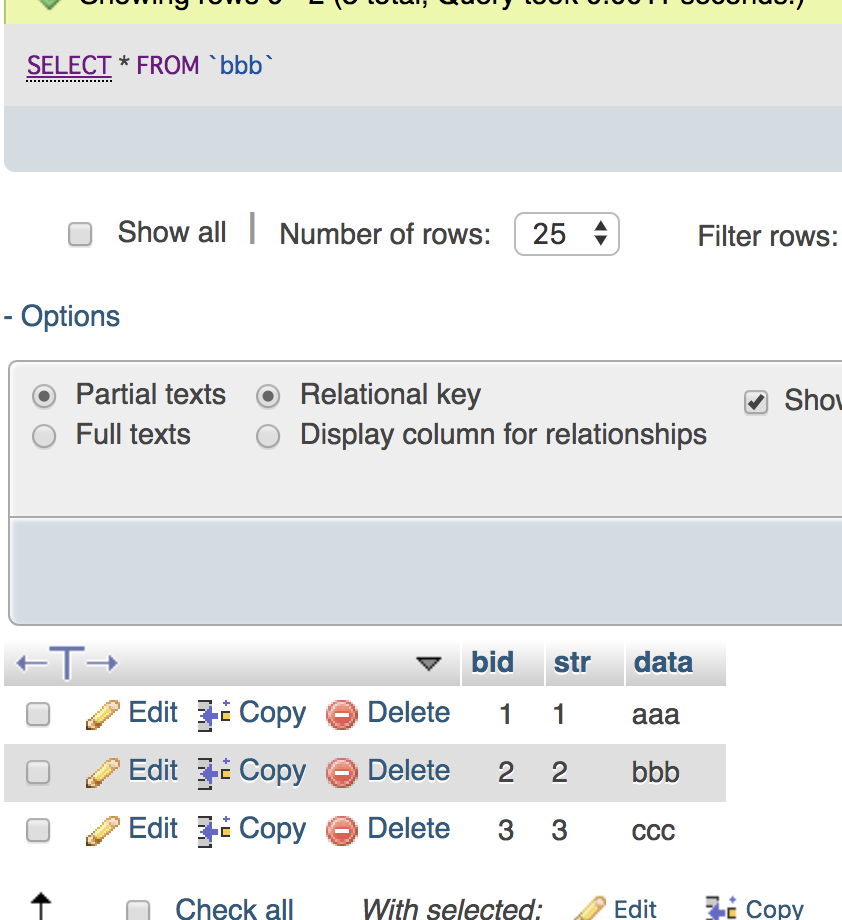
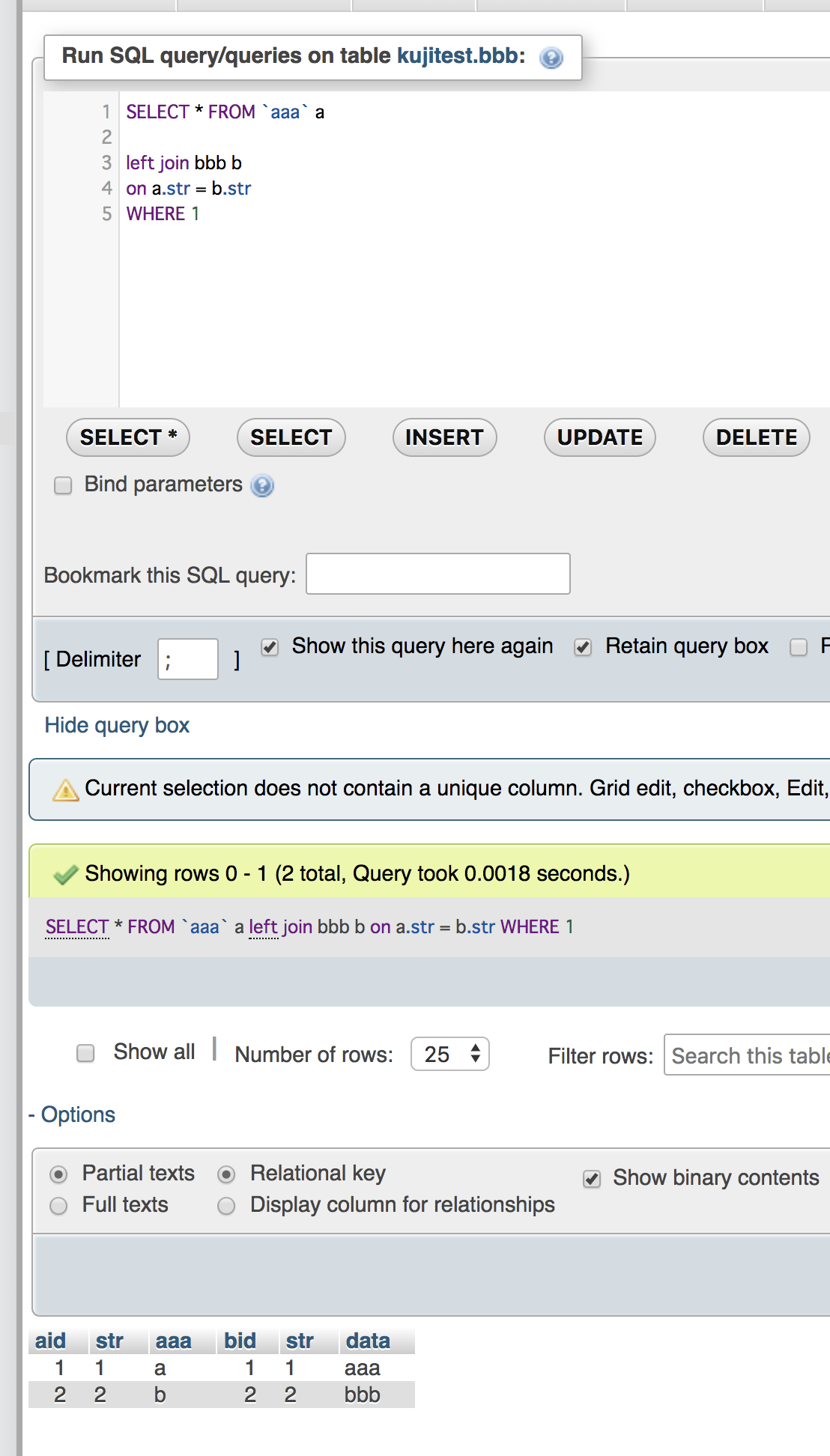
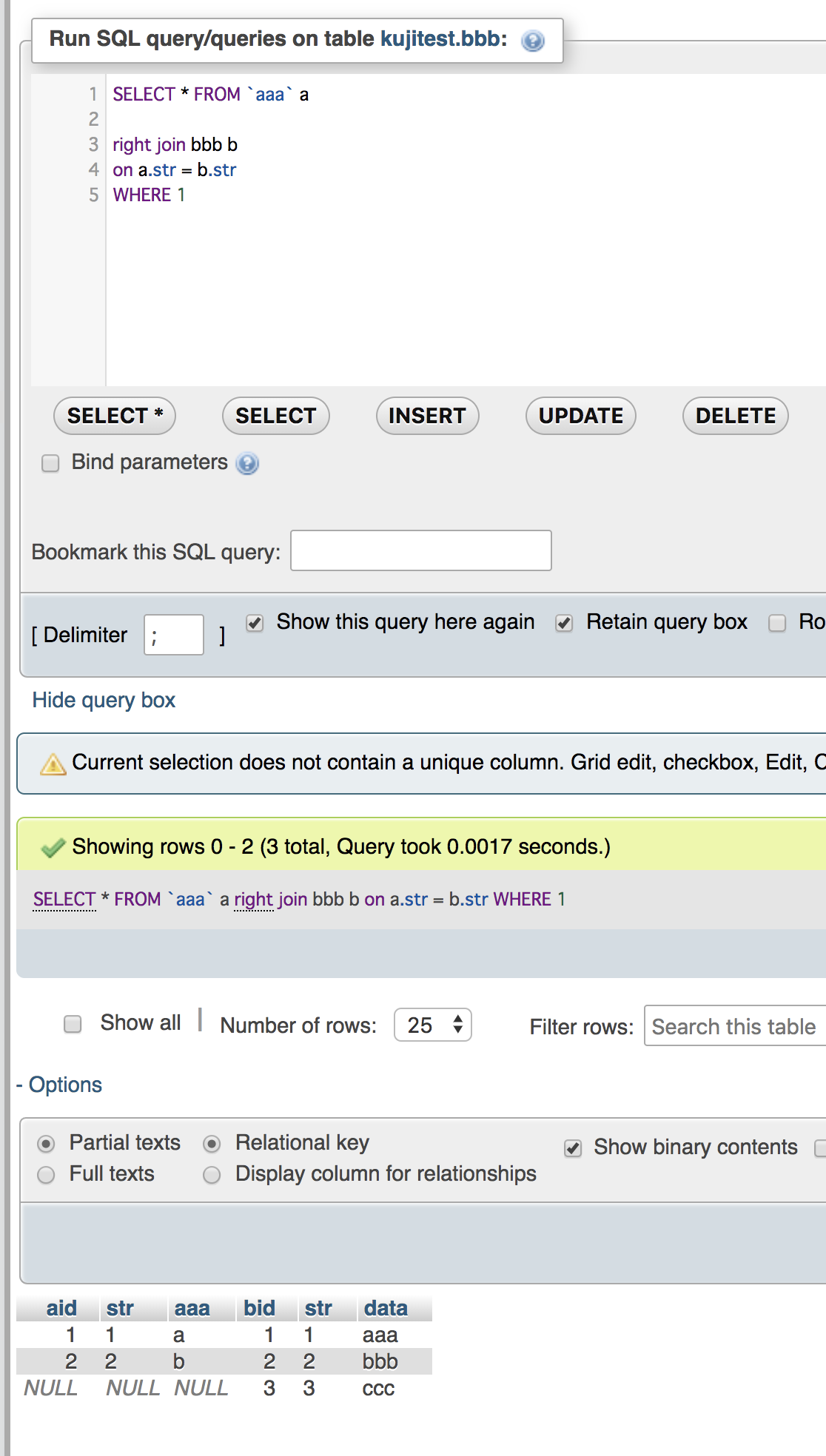
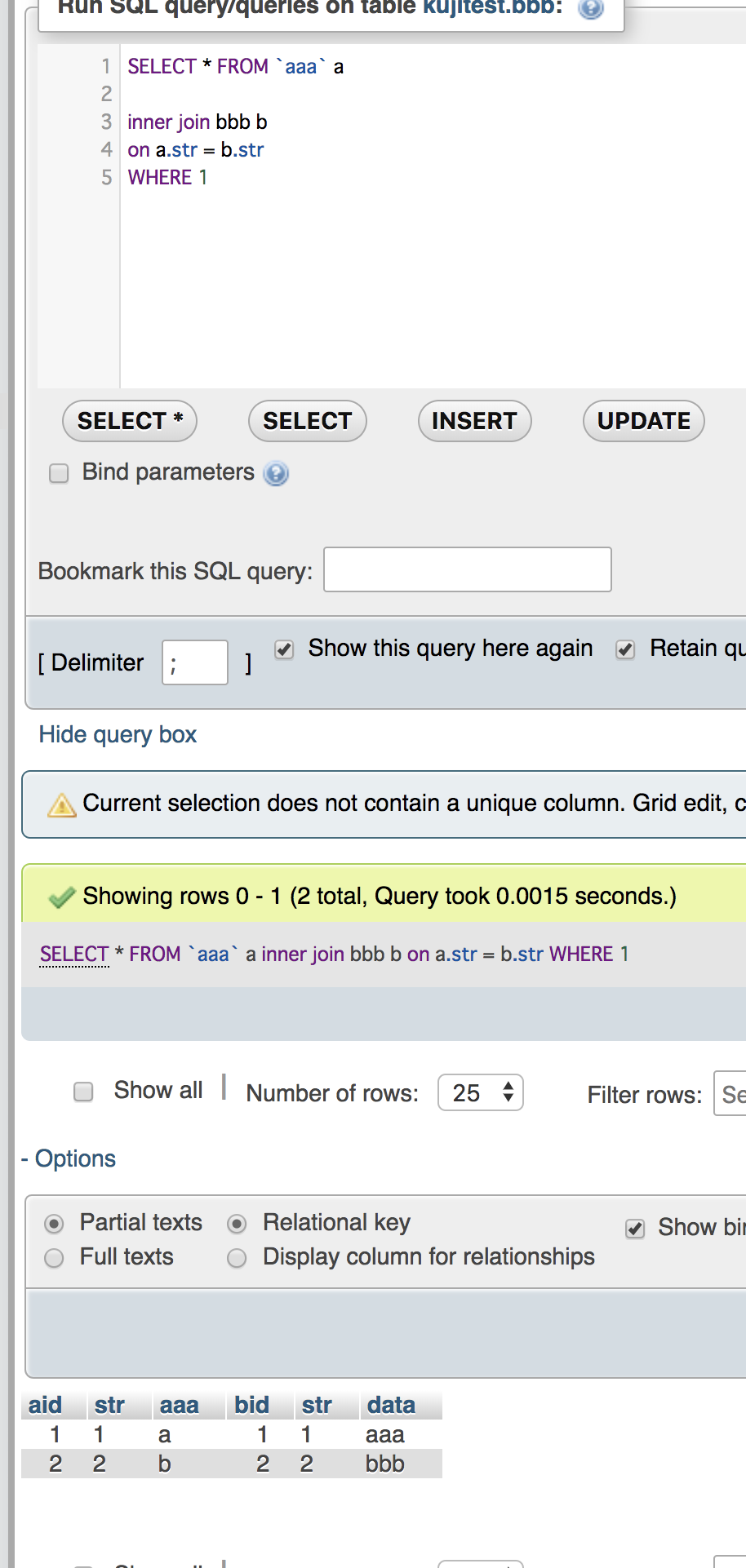
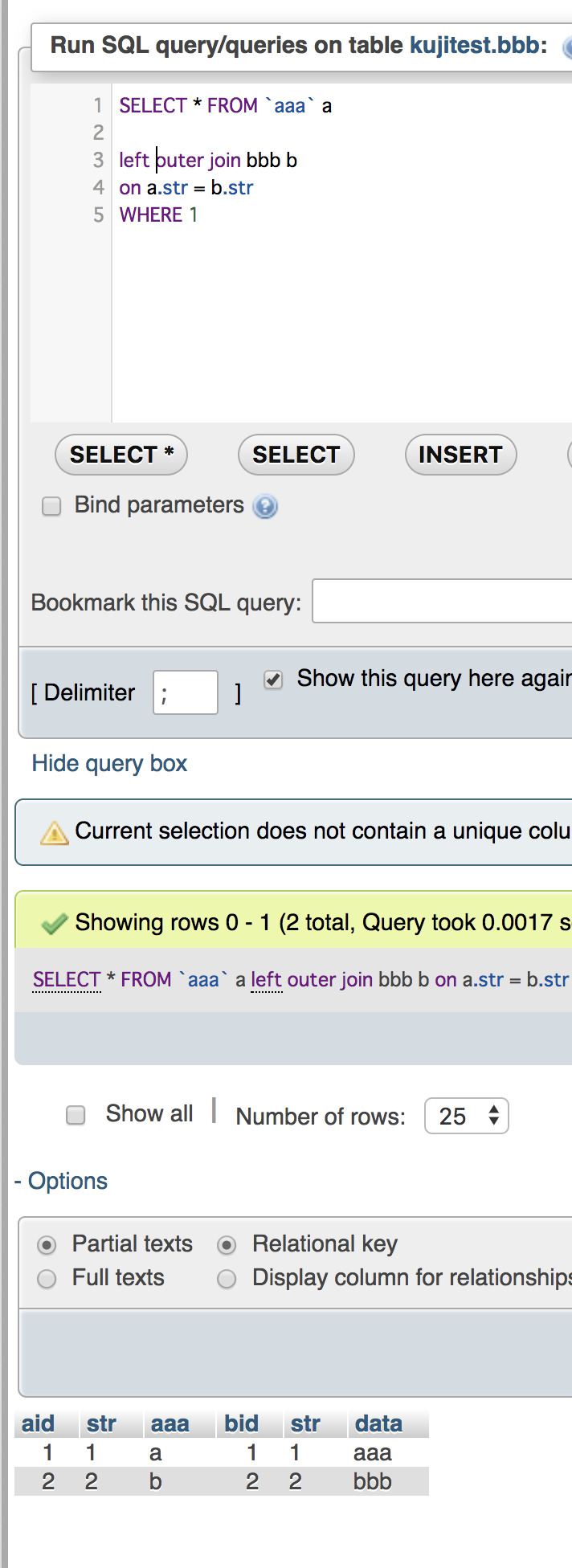
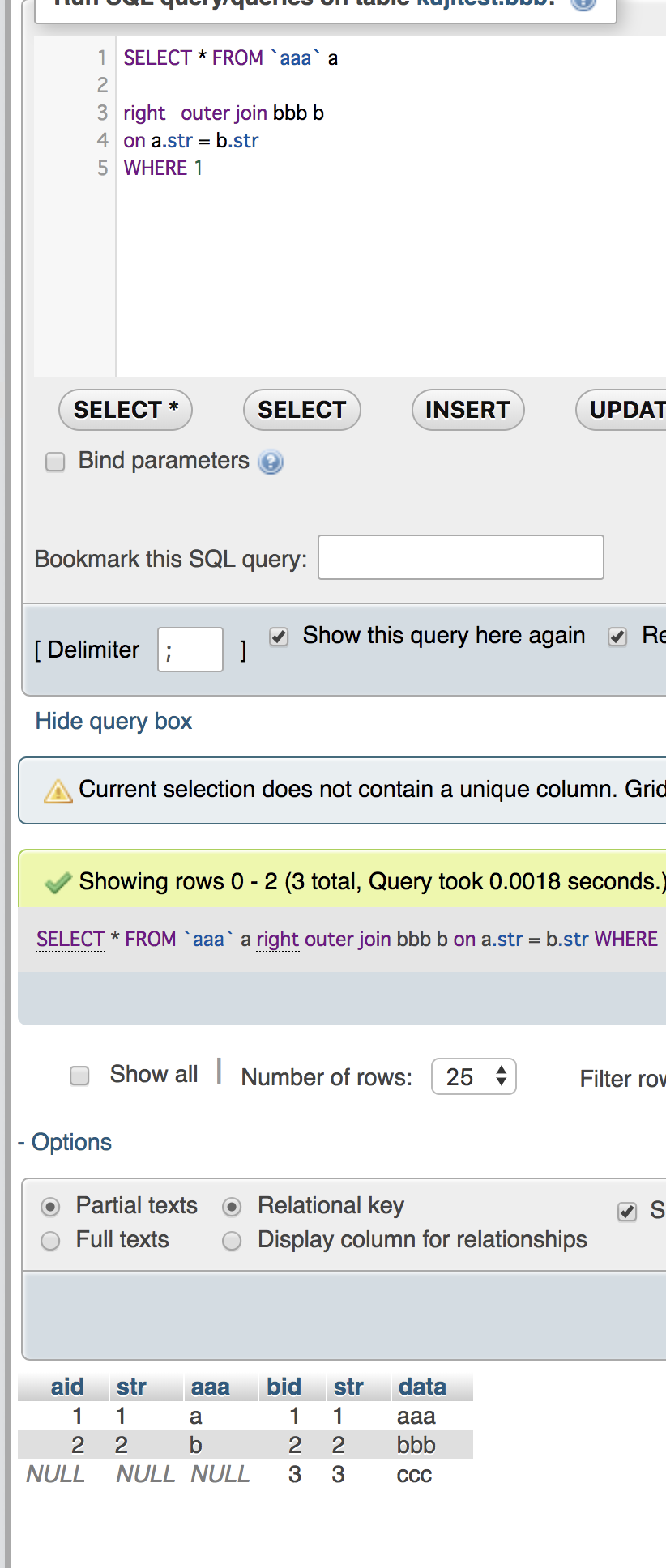
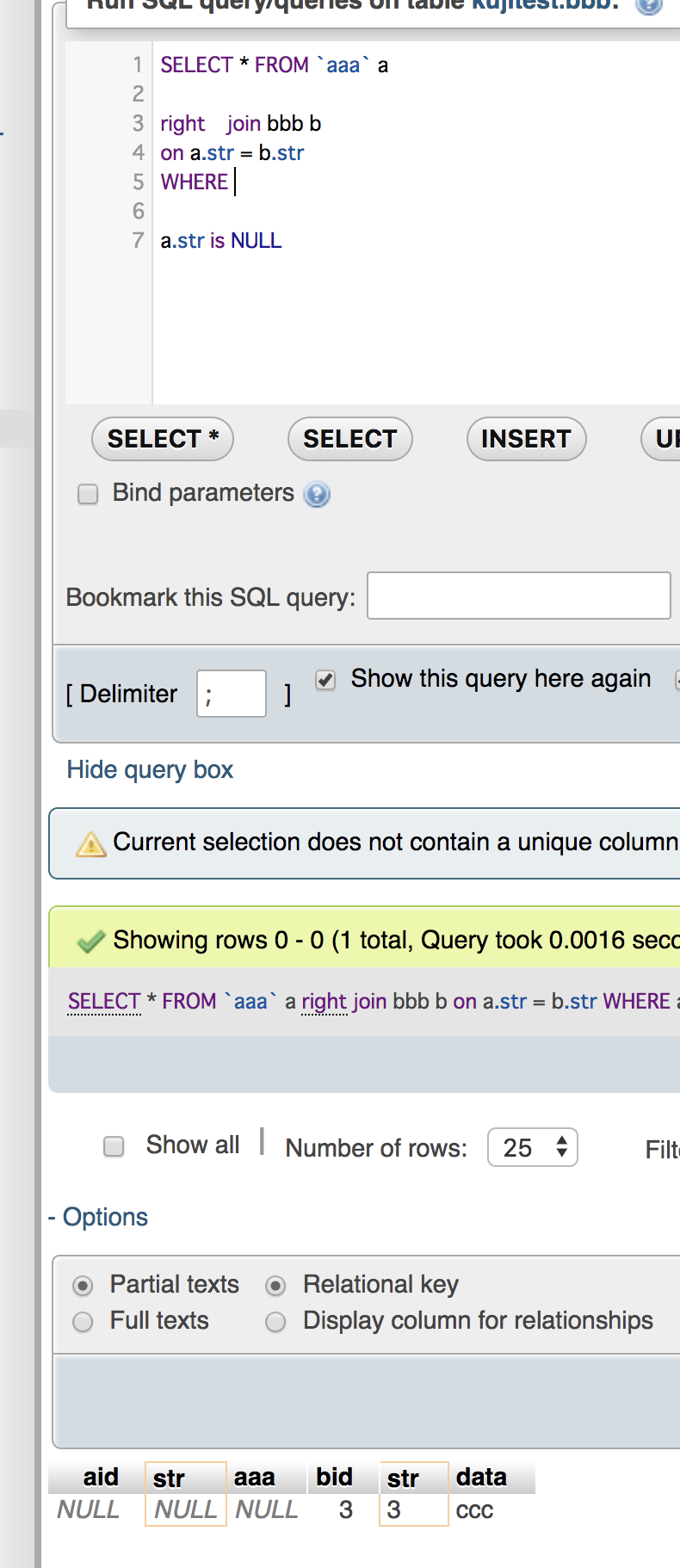
select t13_c1,UNIX_TIMESTAMP(t13_c4),UNIX_TIMESTAMP(t13_c5) from ${dbname}.${tblname} where t13_c4 > now() and t13_c5 < now();
select UNIX_TIMESTAMP(now());で出るのをdateで出したいときに。 date +%s
特定の日付をunixtimeにしたいならdate --date '2012/12/1' +%sなど。
通知対象の抽出は残り日のdatediffのbetweenで最初に0いれると過去の日付でない。
select t13_c1 as enrolle_num,t13_c2 as company,t13_c5 as current_end,t13_c4 as final_end,datediff(t13_c5,now()) 'valid days' from ${dbname}.${tblname} where datediff(t13_c5,now()) between 0 and 60;