- 投稿日:2019-03-18T22:42:44+09:00
FXの一分足データから五分後の上昇下落を予想する
ディープラーニングを初めて実装した
今回はディープを使ってFXの株価予想をしていきたいと思う。理由は僕がお金稼ぎに興味があるから。今まで勉強してきて金を稼ぐよりも強い動機は今までにない。
開発環境はGoogleColaboratory
言語はpython3
実装にはtensorflow/kerasを使用した使用するデータはFXの一分足データを処理して特徴量を11用意した。期間は2018/1/1~2018/10/8
期間が中途半端なのはデータを習得した日付である。許して。
時系列データなので本当はバックプロパゲーションではなくリカレントのほうがいいのだとは思うが習作なのでとりあえずはこれでいく。
上がるか下がるかのニクラス分類問題にする。
実装
from google.colab import files import pandas as pd import io dataM1 = pd.read_csv('/content/drive/My Drive/out_2018usdjpy.csv', sep = ",") import random import numpy as np import pandas as pd import tensorflow as tf from sklearn.model_selection import train_test_split from sklearn.feature_extraction import DictVectorizer from sklearn import preprocessing import time import keras #csvデータの読み取り time1 = time.time() dataM2 = dataM1.dropna() #欠損値がある行の削除 data1 = dataM2.values#numpy配列に変更 print(data1.shape) col = 11 #特徴量の数 X = data1[col:, 1:col]#特徴量行列の設定 y = data1[col:, col:]#ターゲットデータの設定 print(X.shape) hl = y#numpy配列に変更 print(hl.shape) time2= time.time() time3 = time2-time1 print(time3) sc=preprocessing.StandardScaler() sc.fit(X) X_std=sc.transform(X) #データの正規化 X_train, X_test, y_train, y_test=train_test_split(X_std,hl.reshape(-1,), test_size=0.3,random_state = 1) #テストデータとトレーニングデータを分割 print(X_train.shape[0]) print(X_train.shape[1]) print(X_train.shape) print(y_train.shape) np.random.seed(123) tf.set_random_seed(123) time4 = time.time() y_train_onehot = keras.utils.to_categorical(y_train) model = keras.models.Sequential() model.add(keras.layers.Dense(units = 300, input_dim = X_train.shape[1], kernel_initializer ="glorot_uniform", bias_initializer ='zeros', activation = "tanh" )) model.add(keras.layers.Dense(units = 300, input_dim = 300, kernel_initializer ="glorot_uniform", bias_initializer ='zeros', activation = "tanh" )) model.add(keras.layers.Dense(units = 300, input_dim = 300, kernel_initializer ="glorot_uniform", bias_initializer ='zeros', activation = "tanh" )) model.add(keras.layers.Dense(units = 300, input_dim = 300, kernel_initializer ="glorot_uniform", bias_initializer ='zeros', activation = "tanh" )) model.add(keras.layers.Dense(units = 300, input_dim = 300, kernel_initializer ="glorot_uniform", bias_initializer ='zeros', activation = "tanh" )) model.add(keras.layers.Dense(units = y_train_onehot.shape[1], input_dim = 300, kernel_initializer ="glorot_uniform", bias_initializer ='zeros', activation = "softmax" )) sgd_optimizer = keras.optimizers.SGD(lr=0.01,decay = 1e-7,momentum= .9) model.compile(optimizer= sgd_optimizer,loss='categorical_crossentropy') history = model.fit(X_train, y_train_onehot, batch_size = 64, epochs = 0, verbose= 1, validation_split = 0.1 ) y_train_pred = model.predict_classes(X_train,verbose =0) print("first 3 predictions: ",y_train_pred[:3]) correct_preds = np.sum(y_train == y_train_pred,axis = 0) time5 = time.time() print(time5-time4) train_acc = correct_preds / y_train.shape[0] print("training accuracy: %.2f%%" % (train_acc * 100)) y_test_pred = model.predict_classes(X_test,verbose =0) correct_preds2 = np.sum(y_test == y_test_pred,axis = 0) test_acc = correct_preds2 / y_test.shape[0] print("test accuracy: %.2f%%" % (test_acc * 100))結果
training accuracy: 50.15%
test accuracy: 50.09%感想
まあ儲からないよなっていう印象。流石はランダムウォークというべきか。結果を見ての通りにクラス分類で50%ってことはそういうことなんだろうと思う。
今回はとりあえず学習させてみて挙動を見たかったのでこれで良い。改善したいことはこちらの記事にまとめた。
- 投稿日:2019-03-18T19:41:46+09:00
Learning Pytorch with examples
Learning Pytorch with examples
TL;DR
PytorchのLearning Pytorch with examplesのまとめ
Pytorchで二層のネットワークを愚直に書いてみる
GPUを扱えるようにPyTorchを使いましたが、numpyでも簡単に再現できる二層のニューラルネットワークを作成しました。これをうまくPytorchっぽく書き直していこうと思います。
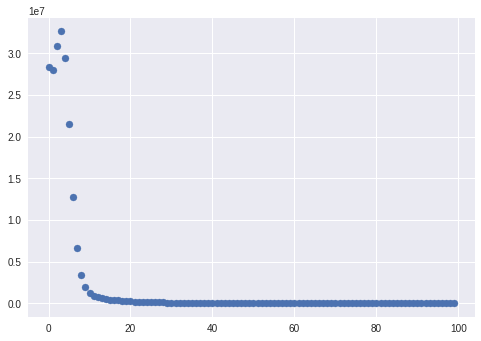
import torch import numpy as np import matplotlib.pyplot as plt #device, dtypeの定義 dtype = torch.float device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") #入力と出力、レイヤーごとの重みの定義 N, D_in, H, D_out = 64, 1000, 100, 10 x = torch.randn(N, D_in, device=device, dtype=dtype) y = torch.randn(N, D_out, device=device, dtype=dtype) w1 = torch.randn(D_in, H, device=device, dtype=dtype) w2 = torch.randn(H, D_out, device=device, dtype=dtype) #学習率などの定義 learning_rate = 1e-6 #plotのための準備 t_list=np.arange(0,100) loss_list=[] for t in range(100): #forward h = x.mm(w1) h_relu = h.clamp(min=0) y_pred = h_relu.mm(w2) # lossの計算 loss = (y_pred - y).pow(2).sum().item() loss_list.append(loss) #backward grad_y_pred = 2.0 * (y_pred - y) grad_w2 = h_relu.t().mm(grad_y_pred) grad_h_relu = grad_y_pred.mm(w2.t()) grad_h = grad_h_relu.clone() grad_h[h < 0] = 0 grad_w1 = x.t().mm(grad_h) # 重み行列の更新 w1 -= learning_rate * grad_w1 w2 -= learning_rate * grad_w2 plt.scatter(t_list, loss_list)出力
classやnnモジュールを使ってより抽象的に書く
1. Classとnnモジュールを使って二層のニューラルネットワークの構造と順伝播を定義する
愚直に書いたやつ
基本的に非常に単純で、クラスで表すと実は長くなるけど、ネットワークを重ねるごとにクラスを使うメリットが出てくる。
#forward h = x.mm(w1) h_relu = h.clamp(min=0) y_pred = h_relu.mm(w2)Classとnnモジュールを使って書いたやつ
nn.Liner:FC層を作るF.relu:relu関数import torch.nn as nn import torch.nn.functional as F #torch.nn.Moduleを継承してクラスを作る class TwoLayerNet(torch.nn.Module): def __init__(self, D_in, H, D_out): #TwoLayerNetの継承 super(TwoLayerNet, self).__init__() self.fc1=nn.Linear(D_in, H) self.fc2=nn.Linear(H, D_out) def forward(self, x): #順伝播の時に起こる処理を書く h=F.relu(self.fc1(x)) y=self.fc2(h) return y2. 損失関数を定義
# 愚直に書いたやつ loss = (y_pred - y).pow(2).sum().item() # nnモジュールを使ったやつ criterion=nn.MSELoss(reduction='sum') loss=criterion(y_pred, y)3. 自動微分
これは非常に短くなる。loss関数を微分していくのはこのくらいならかけるけど大きくなると大変になるが、nnモジュールを使えば一行でかける。
愚直に書いたやつ
grad_y_pred = 2.0 * (y_pred - y) grad_w2 = h_relu.t().mm(grad_y_pred) grad_h_relu = grad_y_pred.mm(w2.t()) grad_h = grad_h_relu.clone() grad_h[h < 0] = 0 grad_w1 = x.t().mm(grad_h)nnモジュールを使った場合
loss.backward()4. optimizerの定義
MomentumSGDやAdamなんかが気軽に使える。複雑なモデルになってもこれで一瞬。
愚直に書いたやつ
w1 -= learning_rate * grad_w1 w2 -= learning_rate * grad_w2optimizerを作成する場合
ここでモデルを作ったのが効いてくる。愚直に書くと重み行列の量だけ更新する必要があるが、optimizerをすれば複雑なモデルでもやってくれる。
lr=learning rateはSGDなので低め。momentum=0.9などとすることでMomentumSGDになるし、optimizer=torch.optim.Adam(model.parameters()とかすればAdamが使える。optimizer=torch.optim.SGD(model.parameters(), lr=1e-4)5. model verで学習させる。
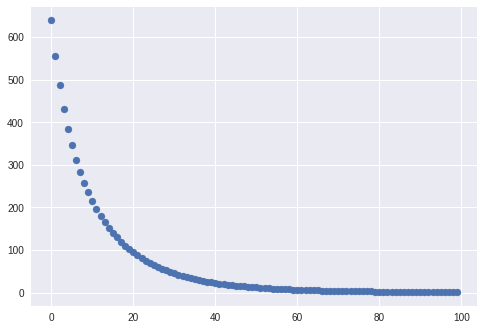
最後にこれまでのをまとめると以下のようなコードになる。構造がわかりやすくなっていると思う。
import torch.nn as nn import torch.nn.functional as F #modelの作成 class TwoLayerNet(torch.nn.Module): def __init__(self, D_in, H, D_out): super(TwoLayerNet, self).__init__() self.fc1=nn.Linear(D_in, H) self.fc2=nn.Linear(H, D_out) def forward(self, x): h=F.relu(self.fc1(x)) y=self.fc2(h) return y model=TwoLayerNet(D_in, H, D_out) model=model.to(device) #modelをGPUへ送る #損失関数とoptimizerの定義 criterion=nn.MSELoss(reduction='sum') optimizer=torch.optim.SGD(model.parameters(), lr=1e-4) #データ作成 x = torch.randn(N, D_in, device=device, dtype=dtype) y = torch.randn(N, D_out, device=device, dtype=dtype) t_list=np.arange(0,100) loss_list=[] #学習 for t in range(100): #順伝播 y_pred=model(x) #損失関数の計算 loss=criterion(y_pred, y) loss_list.append(loss.cpu().detach().numpy()) # variableかつGPUなのでCPUに移してnumpyに変換できるようにする #optimzeされてTensorを初期化する optimizer.zero_grad() #自動微分 loss.backward() #optimizerによる重みの更新 optimizer.step() plt.scatter(t_list,loss_list)
結論
とりあえずどの部分がどの部分に当たるのかはなんとなくわかった。次は転移学習しましょう。
- 投稿日:2019-03-18T18:04:03+09:00
DockerでDeep Learningなどの環境をドカドカ構築
はじめに
やぁみんな!最近はAI人材になれば新卒でも年収1000万円も手が届くとかで,みんなDeep Learningに興味津々だね!
えっ?環境構築が難しくて手が出せない?確かにGPUが絡んだ途端に周りのライブラリの整備とか無限に面倒だし,右も左もわからない人には環境構築がまず敷居が高くて手が出せないし,
そもそもネットに落ちてるサンプルとかはフレームワークそのものが違ったり,フレームワークのバージョンが違うのがいくつもあって,フレームワークの切り替えが大変で使いこなすのが難しいよね...でも大丈夫!今時のDeep Learningフレームワークは公式でDocker Imageを配っていたり,GitHubでDockerfileを配っているのがほとんどだから,それをちょっと改変するだけで,あっという間に環境構築が出来るんだ!
最初の設定は,慣れてない人にはちょっと手こずるかもしれないけど,一度設定すればあらゆる環境をすぐに切り替えて動かすことが出来るよ!
必要な物(物理)
- Nvidia GPUが入ったLinuxマシン
- ストレージ(仮想環境をドカドカ立てるのであれば,自由に使える容量が100GBは欲しい)
環境構築手順
以下Ubuntuを前提にして話を進めます
GPUドライバーインストール
公式ページからダウンロード出来るので,それに実行権限を付けて実行しましょう.
通常以下のコマンドで大丈夫なはずです.chmod +x (ダウンロードしたファイル) sudo ./(ダウンロードしたファイル)です.
インストール中は色々聞かれますが,適宜対処してください.dockerインストール
aptでインストール...と言いたいところですが,aptで通常インストール出来る奴はバージョンが古かったりしてあまり推奨されてないので,公式に従ってインストールしましょう.
なお,デフォルトではdockerはsudoを付けないと動作しませんが,それが嫌って人は,自分のアカウントをdockerが所属するグループに紐づけましょう.nvidia-dockerインストール
公式GitHubのQuickstartの所を実行してください.
なお,上記の方法でdockerをインストールした場合は最初から最新のdockerが入ってるはずなので,二番目のリポジトリを追加するところから始めて大丈夫です.Docker Imageの用意
公式が配布するDocker Imageを入手する
メジャーなフレームワークだったら,Docker Imageが配布されている場合があるので,DockerfileをBuildする手間が省けます.
ただし環境をカスタマイズしたいなら,後述のようにDockerfileからビルドした方が良いです.Tensorflowの例
- TensorflowのDockerHub にアクセスして,Tagsから欲しいバージョンのimageを見つけます.
- 次のコマンドを入力してdocker imageを落としてきます
docker pull tensorflow/(欲しいTagの名前)(Docker Imageが無い場合)公式のGitHubのページにいってcloneする
だいたいのメジャーなDeepLearningフレームワークはGitHubのページがあるので,それをcloneしましょう
Pytorchの例
- PytorchのGitHubにアクセスして,git cloneします.
- docker/pytorchディレクトリに移って,Dockerfileを確認します.するとこのような中身があるはずです.
FROM nvidia/cuda:10.0-cudnn7-devel-ubuntu16.04 ARG PYTHON_VERSION=3.6 RUN apt-get update && apt-get install -y --no-install-recommends \ build-essential \ cmake \ git \ curl \ vim \ ca-certificates \ libjpeg-dev \ libpng-dev &&\ rm -rf /var/lib/apt/lists/* RUN curl -o ~/miniconda.sh -O https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh && \ chmod +x ~/miniconda.sh && \ ~/miniconda.sh -b -p /opt/conda && \ rm ~/miniconda.sh && \ /opt/conda/bin/conda install -y python=$PYTHON_VERSION numpy pyyaml scipy ipython mkl mkl-include cython typing && \ /opt/conda/bin/conda install -y -c pytorch magma-cuda100 && \ /opt/conda/bin/conda clean -ya ENV PATH /opt/conda/bin:$PATH RUN pip install ninja # This must be done before pip so that requirements.txt is available WORKDIR /opt/pytorch COPY . . RUN git submodule update --init RUN TORCH_CUDA_ARCH_LIST="3.5 5.2 6.0 6.1 7.0+PTX" TORCH_NVCC_FLAGS="-Xfatbin -compress-all" \ CMAKE_PREFIX_PATH="$(dirname $(which conda))/../" \ pip install -v . RUN git clone https://github.com/pytorch/vision.git && cd vision && pip install -v . WORKDIR /workspace RUN chmod -R a+w /workspace中を見れば大体何やってるかわかると思いますが,ここではapt-getで最小限の環境をそろえて,ビルド環境を整えて,condaをインストールしてからそこにpytorchをビルドしてインストールしてます.
あとは自分が欲しいものに応じてDockerfileを編集してください.
- Dockerfileを以下のコマンドでbuildします.
docker build -t (tagの名前) .Dockerfileがあるディレクトリでビルドすることに気を付けてください.
大抵のDeepLearningフレームワークでは,Dockerfileが存在するディレクトリでビルドすることが想定されています(それ以外でビルドしたらエラーが起こった)docker-compose.ymlの記述
ビルド出来たらいよいよコンテナを起動して使う...前にdocker-composeでコンテナを簡単に扱いやすくしましょう.
以下がtensorflowのdocker-composeの例です.docker-compose.ymlversion: '2.3' services: tensorflow: container_name: tensorflow_1 image: tensorflow/tensorflow:latest-gpu-py3-jupyter volumes: - /path/to/data:/mnt runtime: nvidia tty: true command: /bin/bash ports: - 8889:8889詳しい解説は他の物に譲りますが,ここで設定しているのは以下のようになります.
- version: docker-composeのバージョン.古いとnvidia-dockerが動かないので,2.3を指定しています.
- services:tensorflow: サービスの名称を決めます.ここ被ると他のdocker-composeで操作されるので被らないようにしましょう
- container_name:コンテナ名を決める.docker psなどで確認したりする際に重要
- image:DockerHubから取ってきたりビルドしたりしたimageファイルを指定
- volumes:Dockerホストとのデータをやり取りする場所を指定.大体の環境では/mntがあるので,自分はいつも,Dockerホストの共有したいフォルダを/mntにマウントしてます
- runtime: nvidia-dockerを動かすために必要なおまじない
- tty: true :ここfalseだと,dockerが起動即終了するので,立ち上げてすぐプログラムを走らせて終了,みたいな使い方じゃなければ,trueにして,あとからexecコマンドで動作させましょう.
- command: 起動した際に走らせるコマンドです.
- ports:Dockerホストとつなげたいポートです.
起動&実行
以上までで環境構築及びdocker-compose.ymlの記述が終わったら,ymlファイルがあるところに移動して次のコマンドでコンテナを起動してください.
docker-compose up -dするとコンテナが起動するので,psコマンドで以下のように出るはずです.
docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 89a5fb55012c tensorflow/tensorflow:latest-gpu-py3-jupyter "/bin/bash" 3 days ago Up 3 days 8888/tcp, 0.0.0.0:8889->8889/tcp tensorflow_1このコンテナに対してtensowflowを行う場合は,以下のexecコマンドでコンテナの中でbashを起動します
docker exec -it 89a5 /bin/bashここでは,IDが89a5fb55012cなので,-itの後に89a5とこのIDを特定できる文字列を渡せばそのコンテナの中に入れます.
あとは,中にtensowflowの環境が用意されているので,思いっきりDeepLearningをするだけです!DockerHubにimageがある著名なDeepLearningフレームワーク例
著名なDeepLearningフレームワークにはDockerHubにimageが転がってきて,しかも大体最新のバージョンのimageが直ぐに配布されるので,その中から使いたいものを使いましょう
GitHubにDockerfileがあるフレームワーク(DeepLearningとは限らない)例
DockerHubに公式のものが無い場合は,GitHubに転がってるDockerfileを使うのがオススメです.
他人が作ったImageもあることにはありますが,公式で配布されているものを使った方が確実だったり,自分好みの環境を整えたりと考えると自前でbuildした方が良い気がします
-WebDNN
ブラウザ上でDeepLearningが出来るようになるフレームワーク.使うためにはサーバーの設定とかややこしい設定がいくつかありますが,Dockerでなら一発で出来ます
-LightGBM
DeepLearningではないですが,Kaggleなどのコンペで用いられる決定木ベースのアンサンブル学習の実装です.GPU周りの設定などもこのDockerfileを使えば一発でわかります.終わりに
いかがでしたでしょうか.機械学習関係は時代が進むにつれてどんどん新しいものが出てくるため,一つの環境に色々と混在させているとやっかいなことになりがちですが,Dockerを使えば様々な環境を同時に便利に扱うことが出来ます.Dockerはもはや機械学習関係のことを行うのに必須な環境と言ってよいでしょう.みなさんの健闘をお祈りします.
- 投稿日:2019-03-18T16:53:25+09:00
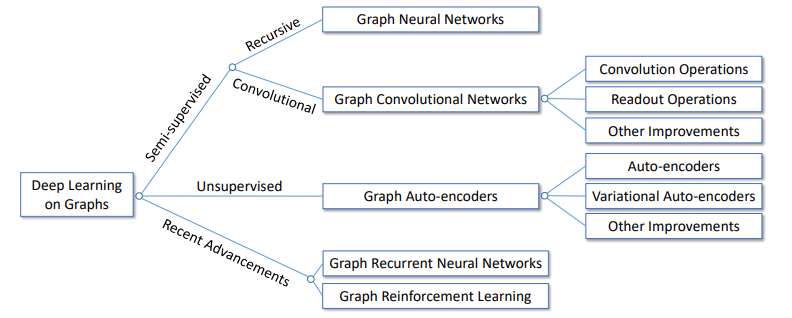
GNNまとめ(3): 発展編とこれから
はじめに
本記事は3部作の最終回です. 記号の定義などは第1回の記事をご参照ください.
GNNまとめ(1): GCNの導入 - Qiita
種々のGCNを紹介した第2回の記事はこちら.
GNNまとめ(2): 様々なSpatial GCN - Qiita今回はautoencodersによるグラフ埋め込みの獲得やGAN, 時間発展のあるグラフなど発展的な事項を扱います.
[1]より引用.その他
第1部, 第2部の小見出しを受けて「その他」という名目でまとめます.
AE/VAE
前回までグラフの埋め込みを得るための畳込みについて考えてきましたが, 画像において行われているように, autoencoderやVAEを用いて教師なしの表現学習をしたいと思うのは自然な流れです. しかし, 畳込みの逆演算としてのdecodeの方法は自明ではありません.
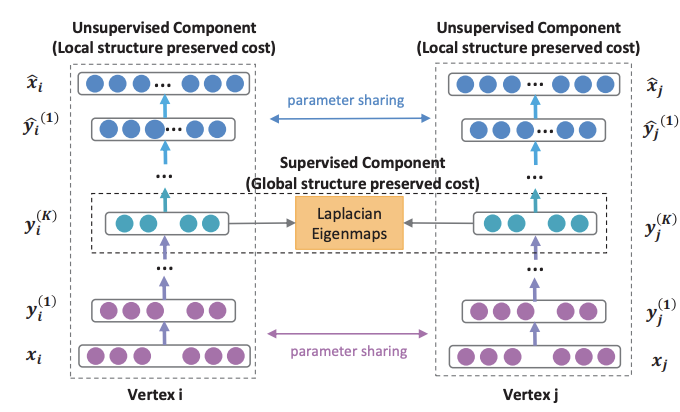
本記事では, ニューラルネットを使わずにdecodeする方法と, 全結合のニューラルネットでdecodeする方法の2通りを紹介します.GAE/VGAE
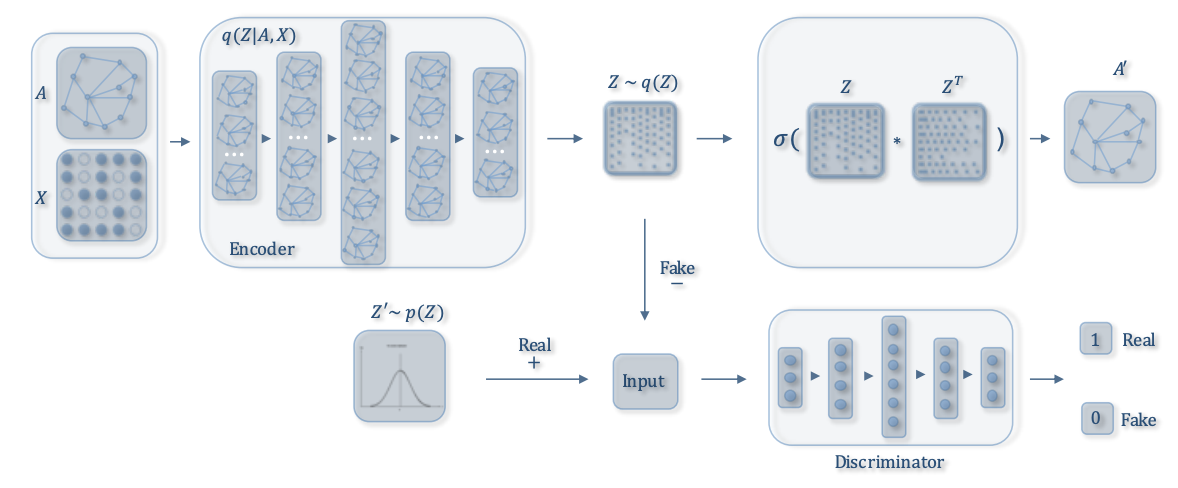
グラフ界の重鎮であるKipfとWellingが提案したグラフを扱うAutoencoderとVAEの元祖です. 元祖なので詳しく説明します.
隣接行列を入出力とし, encoderをGCN (Kipf+)で, decoderを内積とシグモイド関数のみで構成します.
入力にノード特徴を含めることもできます.
GAE (graph autoencoder) の式はこのようになります.\boldsymbol{H} = GCN(\boldsymbol{F}^V,\boldsymbol{A})\\ \hat{\boldsymbol{A}} = sigmoid(\boldsymbol{HH}^{\mathrm{T}})VGAE (variational graph autoencoder) の場合はreparametrization trickの平均と標準偏差をそれぞれ$\boldsymbol{\mu}, \boldsymbol{\sigma}$として, それぞれを2層のGCNで求めます. これがencoderに当たります.
\boldsymbol{\mu} = GCN_{\boldsymbol{\mu}}(\boldsymbol{F}^V,\boldsymbol{A})\\ \log\boldsymbol{\sigma} = GCN_{\boldsymbol{\sigma}}(\boldsymbol{F}^V,\boldsymbol{A})ノード$i$の潜在ベクトル$\boldsymbol{h}_i$は$\boldsymbol{\mu}, \boldsymbol{\sigma}$でパラメトライズされた正規分布に従うとして,
q(\boldsymbol{h}_i|\boldsymbol{F}^V,\boldsymbol{A}) = \mathcal{Norm}(\boldsymbol{h}_i|\boldsymbol{\mu}_i, \boldsymbol{\sigma_i})からサンプリングされます. decoderは次のように確率分布の形で書けます.
p(A_{i,j}=1|\boldsymbol{h}_i, \boldsymbol{h}_j) = sigmoid(\boldsymbol{h}_i^{\mathrm{T}}\boldsymbol{h}_j)全ノードについてまとめた分布は単純な積で表せます.
q(\boldsymbol{H}|\boldsymbol{F}^V,\boldsymbol{A}) = \prod_{i=1}^N q(\boldsymbol{h}_i|\boldsymbol{F}^V,\boldsymbol{A})\\ p(\boldsymbol{A}|\boldsymbol{H}) = \prod_{i=1}^N \prod_{j=1}^N p(A_{ij}=1|\boldsymbol{h}_i, \boldsymbol{h}_j)それから, 変分下限を次のように定めて最大化することでモデルを学習させます.
ELBO = \mathbb{E}_{q(\boldsymbol{H}|\boldsymbol{F}^V,\boldsymbol{A})}[\log p(\boldsymbol{A}|\boldsymbol{H}) ] - D_{KL}[q(\boldsymbol{H}|\boldsymbol{F}^V,\boldsymbol{A})||p(\boldsymbol{H})]*VGAEを取り上げている[1]と[3]では両方とも「変分下限を最小化」と書いてありましたが, おそらく間違っているので「最大化」と直してあります. 原著論文でも"optimize"としか書いていなかったので紛らわしいですね. [1]は特に, 転置するベクトルを取り違えていたりもしていて, ここに限らず間違いが散見されます.

Variational Graph Auto-EncodersSDNE
SDNE (structural deep network embedding) は次のように損失関数の改良を提案したものです.
Loss = \sum_{i=1}^N||(\hat{\boldsymbol{A}}_i-\boldsymbol{A}_i)\odot\boldsymbol{b}_i||_2^2 + \alpha\sum_{i=1}^N\sum_{j=1}^N A_{i,j}||\boldsymbol{h}_i-\boldsymbol{h}_j||_2^2第1項は通常の再構成誤差に$\boldsymbol{b}_i$というハイパーパラメータを加えたものです.
b_{i,j} = \begin{cases} 1 &A_{i,j}=0\\ \beta (>1) &\text{otherwise}\\ \end{cases}非ゼロ成分のときに誤差を大きくすることで疎な隣接行列をうまく扱えるそうです.
第2項はLaplacian Eigenmapsにと対応する項と書かれていますが, 私には難しくてよくわかりません.
Structural Deep Network EmbeddingDNGR
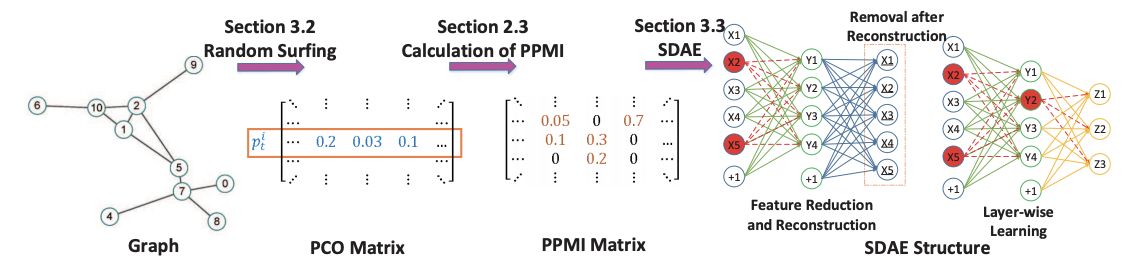
DNGR (deep neural networks for graph representations) は隣接行列や遷移行列ではなくPPMI(positive pointwise mutual information)行列を再構成するアプローチです. これによって, グラフ上をランダムウォークしたときに各ノードを訪れる確率が特徴として取り込まれます.
Deep Neural Networks for Learning Graph RepresentationsDRNE
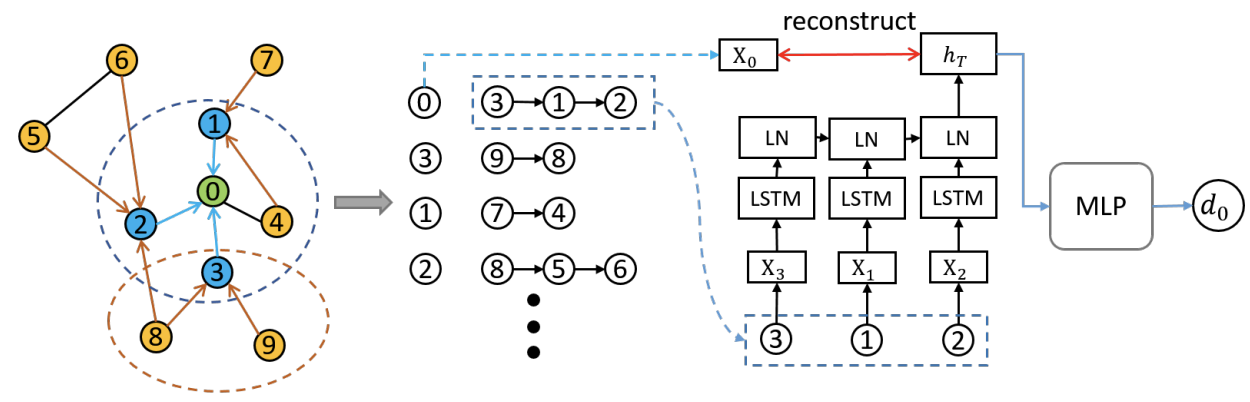
DRNE (deep recursive network embedding) はノードの潜在ベクトルを再構成するという特殊なautoencoderです(原著ではautoencoderとは呼ばれていません).
具体的には, 参照ノードの潜在ベクトルを隣接ノードの集約によって再構成するというアプローチです. 集約関数にはLSTMが用いられます.
次の損失関数の最小化でLSTMを学習させます.Loss = \sum_{i=1}^N ||\boldsymbol{h}_i-\mathrm{LSTM}(\{ \boldsymbol{h}_j|j \in \mathcal{N(i)} \})||_2^2
Deep Recursive Network Embedding with Regular EquivalenceARGA/ARVGA
adversarial trainingを利用したAE/VAEもあります.
ARGA (adversarially regularized graph autoencoder) とARVGA (adversarially regularized variational graph autoencoder) は, 隣接行列$\boldsymbol{A}$とノード特徴$\boldsymbol{F}^V$を潜在ベクトルの系列$\boldsymbol{H}$にencodeし, $\boldsymbol{H}$から$\hat{\boldsymbol{A}}$をdecodeするという枠組みはGAE/VGAEと同じですが, $\boldsymbol{H}$に関して真贋判定を行う識別器を用意しているところが特徴です. 識別器を潜在ベクトルに対して作用させるのは画像のGANでも見たことがありません.
識別器は, $\boldsymbol{H}$が事前分布(一様分布や正規分布)からサンプルされたもの(real)かグラフをGCNでencodeして得られたもの(fake)かを判定します.
これによりadversarial lossが計算され, recontruction lossと合わせた損失関数を最小化することで, $\boldsymbol{H}$は事前分布に近くかつグラフの特徴を保存した表現になります.
GAE, VGAEに対応するものがそれぞれARGA, ARVGAです.
Learning Graph Embedding with Adversarial Training MethodsGraphVAE
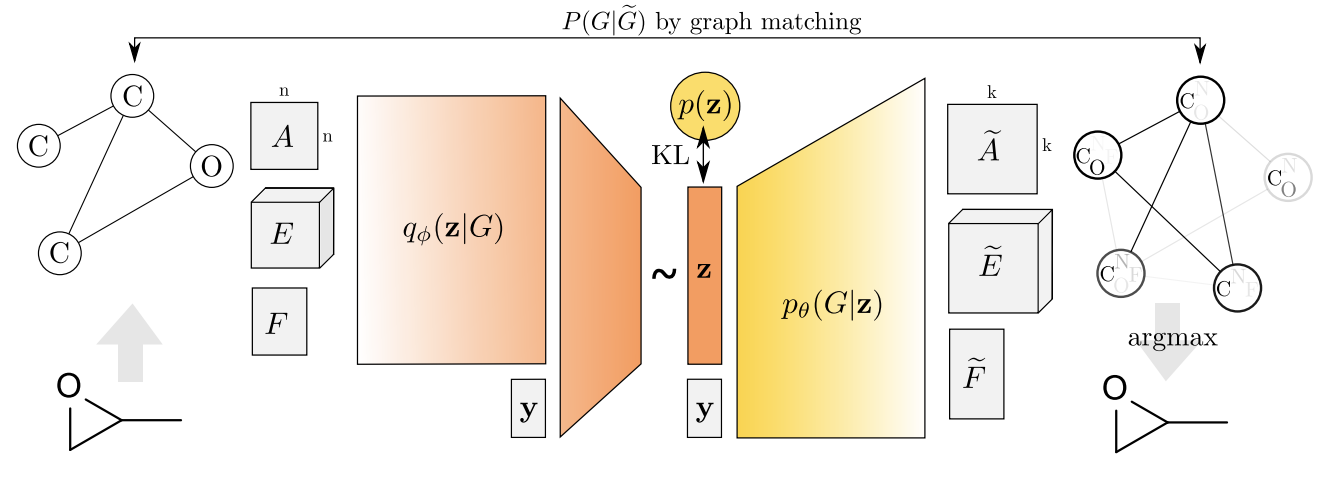
GraphVAE は, これまでに紹介したVAEとは異なり, 全結合のネットワークで$\boldsymbol{h}$から隣接行列$\hat{\boldsymbol{A}}$, エッジ特徴のテンソル$\hat{\boldsymbol{F}^E}$, ノード特徴$\hat{\boldsymbol{F}^V}$を再構成します.
グラフには最大のノード数$k$を設定します. また, エッジのクラス数を$C_E$, ノードのクラス数を$C_V$とします.
再構成する$\hat{\boldsymbol{A}} \in \mathbb{R}^{k \times k}, \hat{\boldsymbol{F}^E} \in \mathbb{R}^{k \times k \times C_E}, \hat{\boldsymbol{F}^V} \in \mathbb{R}^{k \times C_V}$はそれぞれ, エッジの確率分布, エッジのクラスに関する確率分布, ノードのクラスに関する確率分布を想定しています. 存在しないノードについてはゼロ埋めで対処することで, 異なるノード数のグラフを全結合ネットワークで扱えるようになります.
再構成誤差の計算にも工夫があります. 詳細は割愛しますが, MPM(max-pooling matching; 最大値プーリングマッチング)という2つのグラフのノード同士を対応付けるアルゴリズムを使って損失を定義します. しかし, ここの計算量が$O(N^4)$なので, 小さいグラフ(論文では$k=38$)にしか適用できない点が課題です.
GraphVAE: Towards Generation of Small Graphs Using Variational AutoencodersJT-VAE
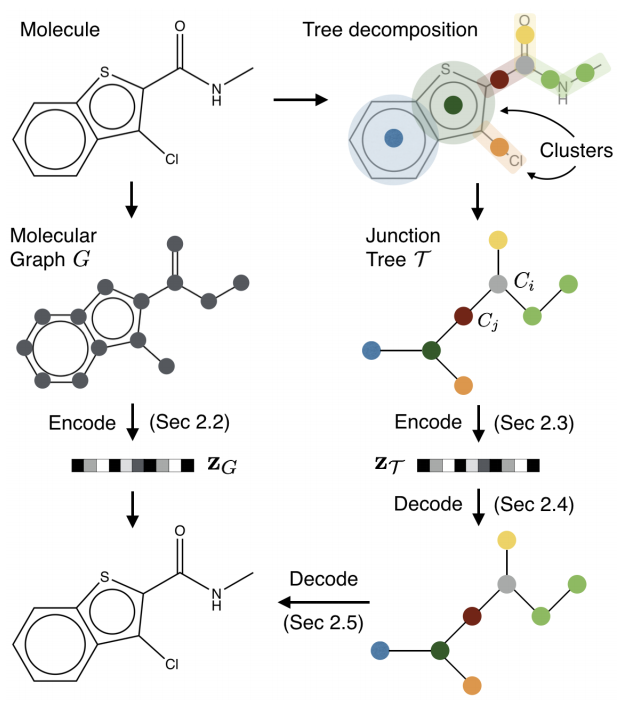
サーベイ論文には載っていませんでしたが, グラフを木に簡約化してGRUなどでencode/decodeするJT-VAE (junction tree VAE) というアプローチもあります.
GCNから話が逸れてしまうので詳しくは論文を参照していただきたいと思いますが, 図のように, 分子グラフを環構造をまとめて1つのノードに置き換えることで閉路のない木に変換することができます(木分解).
Junction Tree Variational Autoencoder for Molecular Graph GenerationGAN+強化学習
VAEがあるならGANもあります. グラフ一般ではなく, 小分子のグラフを生成する研究がほとんどのようです.
また, 分子の特性の最適化のために強化学習の枠組みを取り入れているものが多いです.MolGAN
MolGAN (molecular GAN) は, 生成器を多層パーセプトロン, 識別器をR-GCNとGGS-NNで構成したWasserstein GANです. 隣接行列$\hat{\boldsymbol{A}}$とノード特徴$\hat{\boldsymbol{F}^V}$を生成・識別します.
この論文は所望の特性を持つ分子の生成を目的としているので, ただの分子を生成するのでは意味がありません.
そこで, 強化学習の報酬の考え方を取り入れて, 生成された分子の「実用の観点から見た」評価を行います. 識別器と同じ構造を持つ報酬ネットワークを用意し, DDPGで分子の特性を学習させます.
生成器の損失関数はWGANの損失と報酬ネットワークから得られるスコアの損失の線形和で定義します.
MolGAN: An implicit generative model for small molecular graphsGCPN
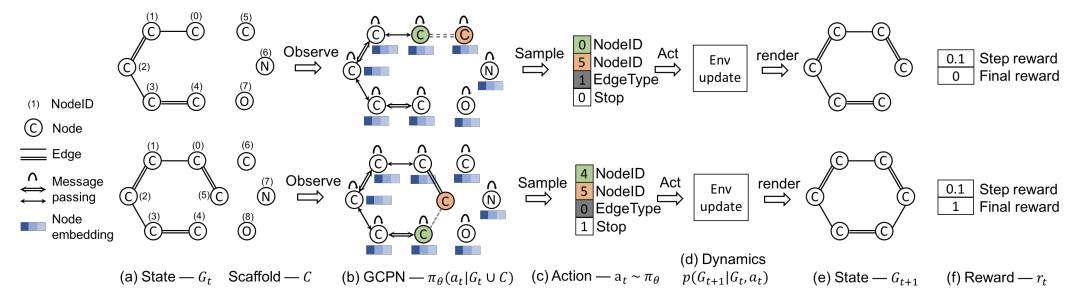
GCPN (graph convolutional policy network) は強化学習をもっと活用したアルゴリズムで, 分子グラフの生成過程をマルコフ決定過程として捉えます.
状態は生成途中の分子グラフ, 行動は次に繋ぐ原子と結合次数の選択です. 報酬は, 原子価ルールを守れているかのスコア(step reward), 分子の特性(LogPやQED)に関するスコア(final reward), 教師データの分布に近づけるためのadversarial rewardの合計で与えます.
強化学習のアルゴリズムはPPOを使います.
方策関数と識別器はGCN(Kipf+)をベースに設計します. エッジのクラス数を$C_E$として, クラスごとに畳み込んでから集約します.\boldsymbol{H}^{l+1} = \mathrm{AGGREGATE}( \mathrm{ReLU} (\{\boldsymbol{\tilde{D}}_i^{- \frac{1}{2}}\boldsymbol{\tilde{A}}_i\boldsymbol{\tilde{D}}_i^{- \frac{1}{2}}\boldsymbol{H}^l\boldsymbol{\Theta}_i^l, ~\forall i\in(1,...,C_E)\} ) )集約関数の候補には平均, 最大値, 和, 結合がありますが, 和の場合が最もよく機能するそうです. 集約関数の話は[5]が詳しいです.
Graph Convolutional Policy Network for Goal-Directed Molecular Graph GenerationRNN
グラフの時間発展を扱うために, RNNを組み込んだGNNもあります. まだ勉強中なので, 簡単な紹介に留めさせてください.
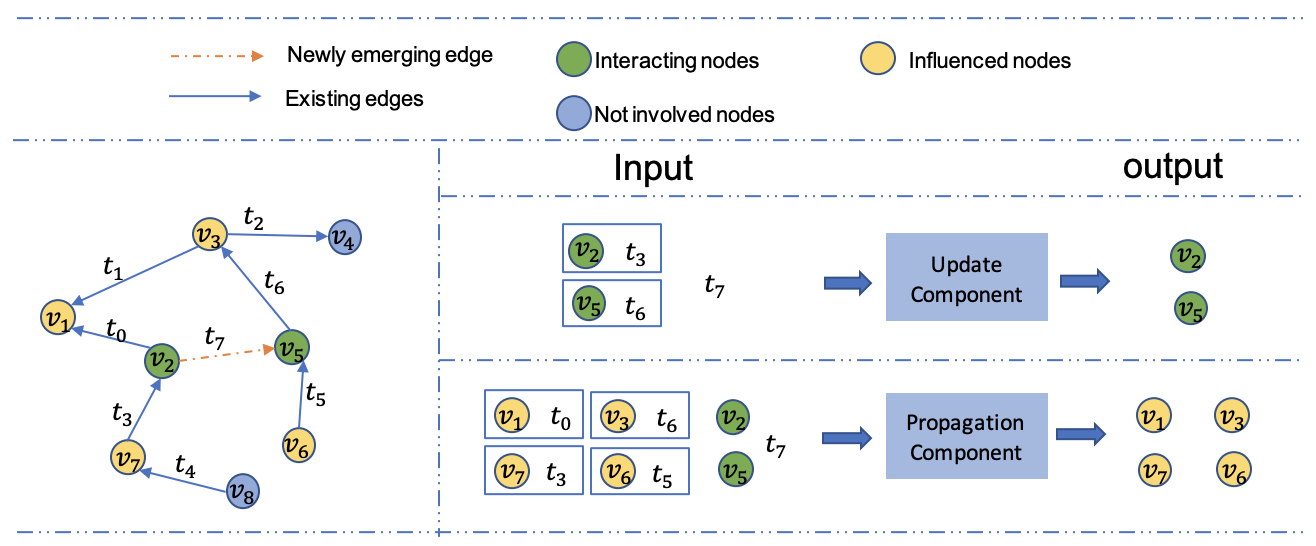
DGNN
DGNN (dynamic GNN) は, 新たなノードやエッジの出現に対応して各ノードやグラフの潜在ベクトルを更新するためにLSTMを利用しています.
Streaming Graph Neural NetworksDGCN
DGCN (dynamic GCN) はGCNとLSTMを組み合わせたものです.
Dynamic Graph Convolutional Networks今後の課題
今後の研究の方向性として, 以下のような視点が挙げられています.
- 多様なグラフ
無向/有向, 重み付き/なし, ラベル付き/なし, 大規模/小規模…といった様々なグラフに対して汎用に使えるアルゴリズムがあると便利ですよね.- 動的グラフ
参考文献でも本記事でもあまり大きく扱われませんでしたが, 動的グラフは今でもうまく扱えていないようです. 一方で, 交通網やwebやSNSなどグラフが時間的に変化する実例はとても多いので, 今後のGNNについて最も期待されている部分だと思います.- 多層化
GNNは2, 3層程度のものが多く, 152層のResNetのように深いネットワークでの学習はまだ成功していません. ただし, 理論的には畳込みを繰り返すとすべてのノードの潜在ベクトルが1点に収束するらしく, そもそも深いネットワークでの学習が有効なのかもわかっていません.- スケーラビリティ
第1部の冒頭でも同じことを書いています. これまでいろいろなモデルを見てきましたが, 特にGANはスケーラビリティが大きな課題となっていますね.おわりに
深層学習のグラフへの適用は比較的新しい分野で教科書などもないので, なかなか手を出しづらいという方が(私も含め)多かったのではないでしょうか. この記事を書いてとても勉強になりました.
最近Twitterでグラフの話題を見かけることが多く, 流行の兆しを感じているので, これを機にこの分野がもっと盛り上がっていったらおもしろいなと思っています.
偉そうにいろいろと書いてしまいましたが, 私もよくわかっていないことが多いです. まだ手を動かせていないので, そろそろ実際にコードを書いたりして理解をより深めていきたいと思います.
最後までお読みいただきありがとうございました!参考文献
[1] Z. Zhang et al., Deep Learning on Graphs: A Survey, arXiv, 2018.
本記事は主にこちらの論文をベースにしています. 3本の中で一番わかりやすく感じました.[2] J. Zhou et al., Graph Neural Networks: A Review of Methods and Applications, arXiv, 2018.
[3] Z. Wu et al., A Comprehensive Survey on Graph Neural Networks, arXiv, 2019.
[4] 論文紹介: "MolGAN: An implicit generative model for small molecular graphs"
創薬の背景についても紹介されていておもしろいです.[5] K. Xu et al., How Powerful are Graph Neural Networks?, ICLR, 2019.


- 投稿日:2019-03-18T15:16:48+09:00
Pytorch Tensorについて
Pytorch Turtorial
TL;DR
PytorchのTensorについての自分なりのまとめです。追記していくかもしれません。
Tensor
TensorはGPUで動くように作成されたPytorchでの行列のデータ型です。Tensorはnumpy likeの動きをし、numpyと違ってGPUで動かすことができます。基本的にnumpy likeの操作が可能です。(インデックスとかスライスとかそのまま使えます)
Tensorとnumpy
import numpy as np import torch # Tensor用にdtypeとdeviceを定義 dtype = torch.float device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") print("device:", device) # 10*10行列の作成 np_arr=np.random.randn(10,10) tensor=torch.randn(10,10,device=device,dtype=dtype) # データ型の確認 print("np_arr:", type(np_arr)) print("tensor:", type(tensor)) # データの形状確認 print("np_arr shape:", np_arr.shape) print("tensor shape:", tensor.size()) #tensor.shapeもできるけどこっちが推奨っぽい # データの色々確認 print("np_arr dtype:", np_arr.dtype) print("tensor device:", tensor.device) print("tensor dtype:", tensor_dtype)#device device: cuda:0 #データ型 np_arr: <class 'numpy.ndarray'> tensor: <class 'torch.Tensor'> #データの形状 np_arr shape: (10, 10) tensor shape: torch.Size([10, 10]) #データの詳細 np_arr dtype: float64 tensor device: cuda:0 tensor dtype: torch.float32numpyとTensorの相互変換
Tensorがどのdeviceに乗っているかの注意が必要です。numpyに変換するときはcpuに乗ってないとエラーが起こります。また、
torch.from_numpy()でTensorに変換するとdeviceはCPUになりdtypeはtorch.float64になるので注意が必要です。GPUかCPUはis cudaを使っても確認できます。CPU, GPUの移動はto()メソッドで実装できます。new_np_arr=tensor.cpu().numpy() new_tensor=torch.from_numpy(np_arr) # データ型の確認 print("new_np_arr:", type(new_np_arr)) print("new_tensor:", type(new_tensor)) # データの形状確認 print("new_np_arr shape:", new_np_arr.shape) print("new_tensor shape:", new_tensor.size()) # データの色々確認 print("new_np_arr dtype:", new_np_arr.dtype) print("new_tensor device:", new_tensor.device) print("new_tensor dtype:", new_tensor.dtype) # TensorをGPUに飛ばし、dytpeをfloat32に変換 new_tensor=new_tensor.to(device) new_tensor=new_tensor.to(dtype) print("new_tensor device:", new_tensor.device) print("new_tensor dtype:", new_tensor.dtype)# 変換後のデータ型の確認 new_np_arr: <class 'numpy.ndarray'> new_tensor: <class 'torch.Tensor'> # 変換後のデータの形状 new_np_arr shape: (10, 10) new_tensor shape: torch.Size([10, 10]) # 変換後のデータの情報 new_np_arr dtype: float32 new_tensor device: cpu new_tensor dtype: torch.float64 # 変換後のデータをGPU、torch.float32になっているかの確認 new_tensor device: cuda:0 new_tensor dtype: torch.float32Tensorの生成
大体numpyと同じです。numpyからの変換もこれでいいんじゃないのか?
最悪numpyで作ってTensorに変換すればいい説。
基本的に元のデータのコピーからTensorを生成します。データをTensorに置き換えたいならrequires_grad=Trueするとできます。(defaultはFalse)# リストから生成 tensor=torch.tensor([[1,2,3],[4,5,6]], device=device, dtype=dtype) print("liset:\n", tensor,"\n") #numpyから生成 np_tensor=torch.tensor(np.array([[1, 2, 3], [4, 5, 6]]) , device=device, dtype=dtype) print("np:\n",np_tensor,"\n") #ゼロ行列の作成 zero_tensor=torch.zeros([2,2], device=device, dtype=dtype) print("zero:\n",zero_tensor,"\n") #一行列? one_tensor=torch.ones([2,2], device=device, dtype=dtype) print("one:\n",one_tensor,"\n") #空行列 empty_tensor=torch.empty([2,2] , device=device, dtype=dtype) print("empty:\n",empty_tensor,"\n") #ランダム(正規分布) randn_tensor=torch.randn([2,2], device=device, dtype=dtype) print("randn:\n",randn_tensor,"\n") #ランダム(一様分布) rand_tensor=torch.rand([2,2], device=device, dtype=dtype) print("rand:\n",rand_tensor,"\n") #arange arange_tensor=torch.arange(4, device=device, dtype=dtype) print("arange:\n",arange_tensor,"\n") #reshape reshape_tensor=torch.reshape(arange_tensor, (2,2)) print("rehape:\n",reshape_tensor,"\n")list: tensor([[1., 2., 3.], [4., 5., 6.]], device='cuda:0') np: tensor([[1., 2., 3.], [4., 5., 6.]], device='cuda:0') zero: tensor([[0., 0.], [0., 0.]], device='cuda:0') one: tensor([[1., 1.], [1., 1.]], device='cuda:0') empty: tensor([[1., 1.], [1., 1.]], device='cuda:0') randn: tensor([[-0.4707, 0.2586], [-2.1400, -0.7504]], device='cuda:0') rand: tensor([[0.6047, 0.8802], [0.5218, 0.9891]], device='cuda:0') arange: tensor([0., 1., 2., 3.], device='cuda:0') rehape: tensor([[0., 1.], [2., 3.]], device='cuda:0')Tensorの演算
よく使いそうなものを
methods torch.abs() 絶対値 torch.mean() 平均値 torch.std() 偏差値 Tensor.t() Tensorの転置行列 torch.cat((x1,x2),dim=1) dim=1でx1,x2を結合 Tensor.transpose() numpyのtransposeと同じ dot vectorの内積 mv matrixとvectorの積 mm matrixの積 matmul matrixとvectorをいい感じに計算 gesv LU分解による連立方程式の解 eig 固有値分解 symeig 対称行列の時の固有値分解 svd 特異値分解 x.backward() 自動微分 結論
大体numpyって思っとけば使えそう, cpuとgpuたまにエラー吐く原因になるので注意するかdeviceを毎回ちゃんと指定しておくと良さそう。
- 投稿日:2019-03-18T08:38:54+09:00
[最新論文/cGANs]モード崩壊を解決するかもしれない正則化項
論文紹介・画像引用
2019.3.13提出
https://arxiv.org/pdf/1903.05628v1.pdf本研究の成果
・モード崩壊に対処するための正則化項(本研究提案・後述)を目的関数に追加することで、
conditional GANs(cGANs)での多様な画像生成を可能にした・正則化項は潜在変数間の距離に対する生成画像間の距離の比率を最大化することを目的としたもの
(「Mode collapseとMode seeking」の章の図と「Mode Seeking GANs」の章の図を見れば直感的な理解ができるはず)・正則化項は様々なcGANに適用できる
・カテゴリ生成・image-to-image・text-to-imageの3つの条件付き画像生成を行ったが、
どのタスクでも画像の質を落とすことなく多様性の向上を実現したこれまでのconditional GANの問題点と改善
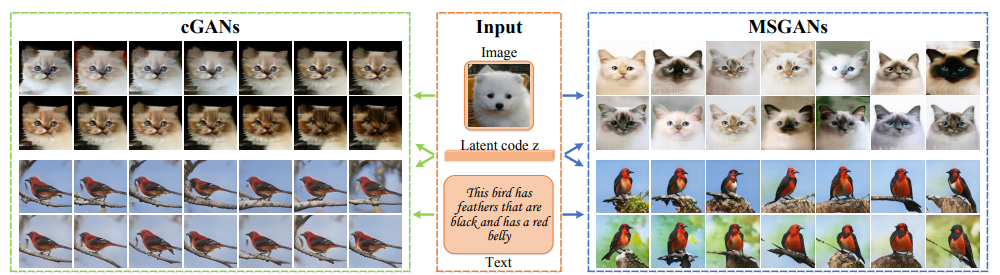
(左図:cGANs)
これまでのcGANsはcondition情報(ラベル・画像・テキスト)を重視する一方で、多様性を出す役割のある潜在変数z(ノイズベクトル)を無視していたため、同じような画像を生成してしまう傾向があったcondition情報は出力画像に関しての構造的な事前情報が多く、潜在変数よりも高次元のため重視されやすい
(右図:MSGANs(Mode-Seeking GANs))
これまでのcGANsに本研究提案の正則化項を目的関数に追加したものをMSGANsと呼ぶ
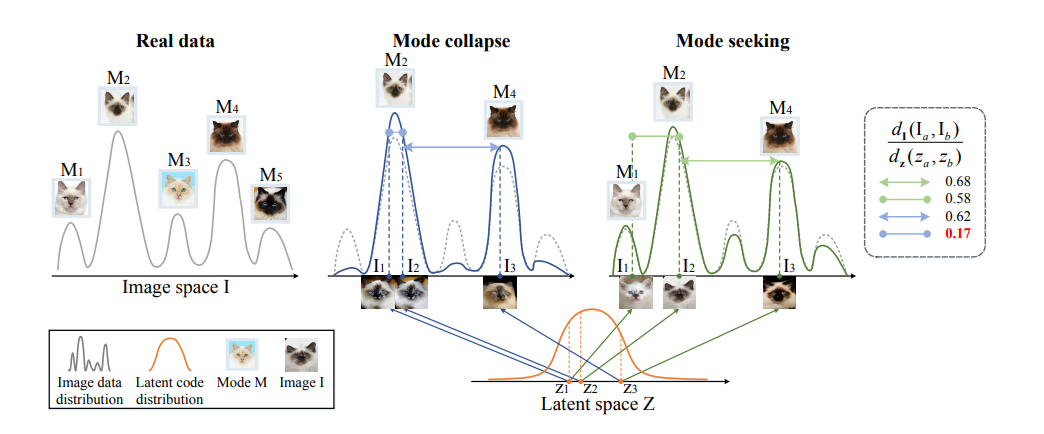
多様な画像を生成することができているMode collapseとMode seeking
画像の分布(左1:Real data)には多様な画像(モード)があるが、モード崩壊(左2:Mode collapse)が起こるとGeneratorは多様性のない生成をしてしまう
Mode collapse
z1とz2という近いけれど異なる潜在変数を使っているにも関わらず、生成される画像は同じモード(似た画像)になってしまっている
Mode seeking
z1とz2という近いけれど異なる潜在変数を使っていることを上手く反映しているため、異なるモードの画像を生成できている
=潜在変数の変化に対応して生成画像も変化している多様性評価のための比率
$$\frac{d_I(I_a,I_b)}{d_z(z_a,z_b)}$$
上図の1番右にある分数について
$d_I(I_a,I_b)$:生成画像$I_a$と生成画像$I_b$の間の距離
$d_z(z_a,z_b)$:潜在変数$z_a$と潜在変数$z_b$の間の距離距離の比率を計算することによって
潜在変数の距離の変化が生成画像のモードの変化に対応しているかがわかる・Mode collapse(青線)は低い値になっている(0.17)
これは潜在変数を変化させても画像のモードが変化していないことを意味している
潜在変数間の距離に対して画像のモードが変化していない=画像間の距離が近い=上記の分子が小さい値になる・Mode Seeking(緑線)は青線よりも大きい値になっている(0.58)
潜在変数間の距離に対して画像のモードが変化している=画像間の距離が遠い=上記の分子が大きい値になるMode Seeking GANs
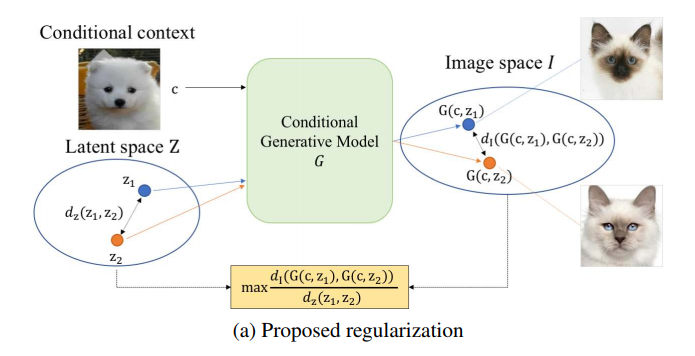
モード崩壊を軽減するために以下のmode seeking正則化項をこれまで通りのcGANsの目的関数に加える
$$L_{ms}=\max_G(\frac{d_I(G(c,z_1),G(c,z_2))}{d_z(z_1,z_2)})$$
潜在変数間の距離に対する生成画像間の距離の比率を最大化することを目的としている
「Mode collapseとMode seeking」の章で紹介した分数よりも文字が多くなっているが、内容は全く同じ分子:生成画像①(condition情報$c$と潜在変数$z_1$から生成)と生成画像②(condition情報$c$と潜在変数$z_2$から生成)の距離
分母:潜在変数$z_1$と潜在変数$z_2$の距離
MSGANsの目的関数
$$L_{new}=L_{ori}+\lambda_{ms}L_{ms}$$
MSGANsの目的関数は上記のようになる
$L_{ori}$:元々cGANsで使っていた目的関数(下記詳細)
$\lambda_{ms}$:項のバランスをとるためのもの・どれほど正則化を強くするかを調整する
$L_{ms}$:上述したもの①カテゴリ情報を条件にした画像生成の場合
例)犬の画像を生成
$$L_{ori}=E_{c,y}[\log{D(c,y)}]+E_{c,z}[\log{(1-D(c,G(c,z)))}]$$
$C$:クラスラベル
$y$:本物画像
$z$:潜在変数第1項
本物画像を正しく本物と識別できるか
第2項
クラスラベルと潜在変数からできた生成画像を正しく偽物と識別できるか
②image-to-imageの場合
例)グレイスケール→カラーの画像変換(ペア画像がある場合)
$$L_{ori}=L_{GAN}+E_{x,y,z}[||y-G(x,z)||_1]$$
$x$:入力画像
$y$:目的ドメインの画像
$z$:潜在変数第1項
$L_{GAN}$:普通のGANの目的関数
・discriminatorは本物は本物、偽物は偽物として識別できればいい
・生成された画像が本物っぽい画像として成り立っているかを評価$L_{GAN}=E_{x,y}[\log{D(x,y)}]+E_{x,z}[\log{(1-D(x,G(x,z)))}]$
第2項
・生成された画像が目的通りに変換されているかを評価
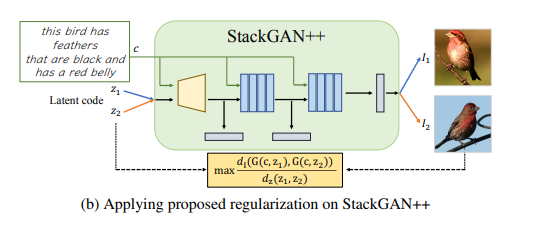
正則化項の適用
・どんなcGANsにも適用することができる
・text-to-imageで使われるStackGAN++のような木構造があるモデルに対しても適用できる上図が示すように、モデルの構造が変わっているだけで
潜在変数間の距離に対する生成画像間の距離の比率を最大化することを目的としていることは変わらない正則化項の効果を検証
距離の指標($d_I,d_z$)として$L_1$ノームを使う
$\lambda_{ms}=1$に設定評価指標
FID
・生成画像の質を評価
・生成画像分布と本物画像分布の距離を計測
・小さい値=高品質画像LPIPS
・生成画像の多様性を評価
・生成画像間の平均特徴距離を計測
・大きい値=生成画像に多様性があるNDB・JSD
・生成画像分布と本物画像分布の類似性を計測
・生成モデルが多様な画像を生成しているかを評価する指標①本物画像(訓練画像)に対してK-meansをすることで、本物画像の分布をビンとして表す
②生成画像を同じようなモードを表している本物画像のビンに割り当てる
③本物画像と生成画像のビン比率を計算して、生成画像と本物画像の分布の違いを評価するNDBとJSDが小さい値=多様なモードを生成できているため、生成画像分布が本物画像分布に近い
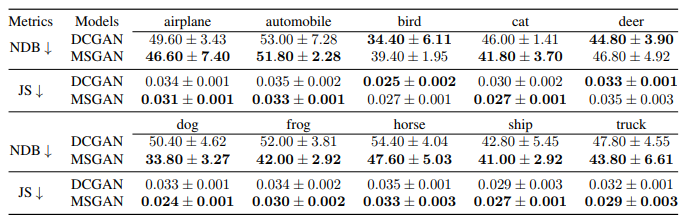
カテゴリ生成
・クラスラベルを条件として様々なカテゴリの画像を生成する
・CIFAR-10データセット
・正則化項をDCGANに適用・MSGANは画像の質を落とすことなく(FIDが小さくなっている)ほとんどのクラスでモード崩壊を軽減することができている(NDBとJSが小さくなっている)
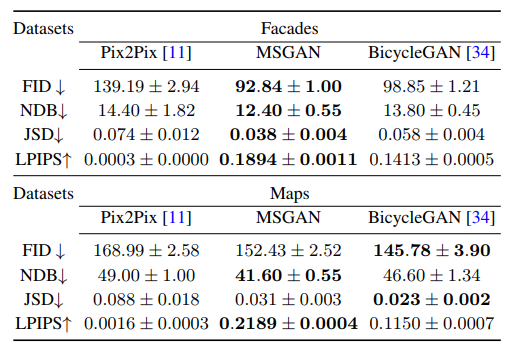
image-to-image
・ある画像を他のドメインの画像に転換する
例)犬→猫 冬→夏・これまでは1対1の変換(ある犬を変換しても限られたモードの猫のみ)になっていたがMSGANを使うことで1つの画像に対して多様な変換ができるかがポイント
ペア画像があるとき
Pix2Pixをベースラインに、BicycleGANを比較対象とする
generatorとdiscriminatorのアーキテクチャはBicycleGANのものを使う正則化項を加えたこと(MSGAN)で多様な画像が生成できている
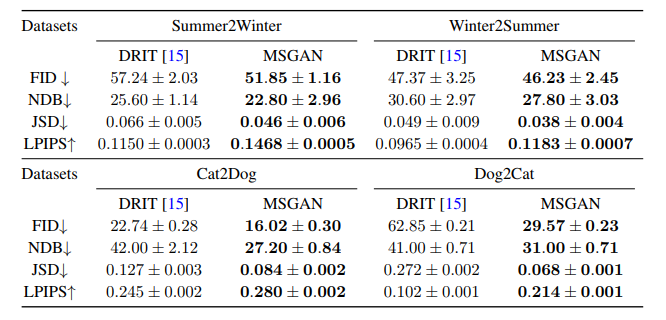
ペア画像がないとき
多様な画像を生成できるDRITをベースラインとする
形状保存が求められる季節変化のデータセットと形状変化が求められる犬猫のデータセットを使う
・どちらのデータセットでもすべての指標でDRITを上回ることができている
・特に犬猫の変換では、MSGANが多様性を大きく改善していることが数値からわかる
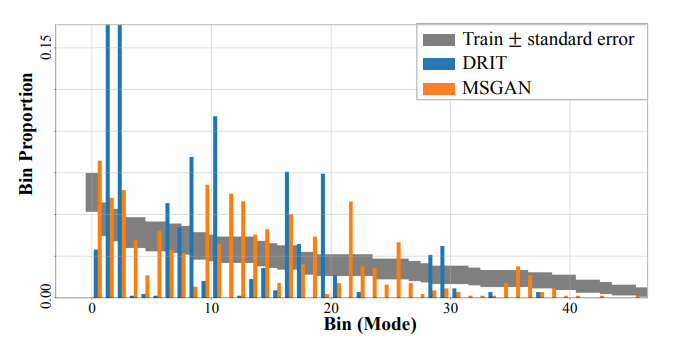
・上図は犬から猫への変換のビン比率を可視化したもの
・DRITは限られたモード(1・2・8・10・16・19)の比率が大きいが、MSGANは様々なモードを生成することができている
=MSGANの方が本物画像の分布に上手く近似した生成
MSGANは画像の質を落とすことなく多様な画像を生成することができていることが上図からわかる
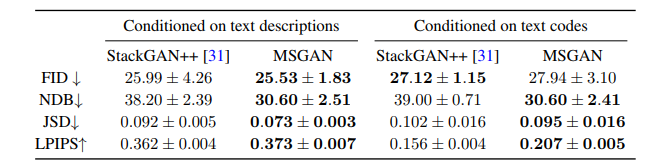
text-to-image
・文章を入力として条件付けて、その文章を表す画像を生成する
・StackGAN++に正則化項を加える
2つの状況でStackGAN++とMSGANを比較する①Conditioned on text descriptions
テキストを表すテキストコードを固定しないで生成する
この場合、テキストコードも出力画像の多様性に影響を与える②Conditioned on text codes
テキストコードを固定して生成する
この場合、テキストコードによる出力画像への影響はなくなる・MSGANは画像の質を保ちながら多様性を向上させることができている
・Conditioned on text codesではテキストコードの影響がないため、数値の向上は潜在変数がちゃんと生成に使われていることを意味している
StackGAN++では文章に対して同じような画像を生成しているが
MSGANでは潜在変数が上手く使われているため、鳥の見た目・向き・背景が多様に表現されているMSGANの潜在空間でinterpolation
ある2つの潜在変数間でinterpolationをして、それに対応する画像を生成した結果
生成モデルがちゃんと潜在変数を画像生成に使えているかを確認することができる
潜在変数を動かしても同じモードの画像が生成されていたらモード崩壊と考えられる上図のように、MSGANでは潜在変数の変化とともに画像も徐々に変化している
まとめ
・cGANsでのモード崩壊に対処するためのmode seeking正則化項を提案
・generatorが多様なモードを生成できるようにするために、潜在変数間の距離に対する生成画像間の距離の比率を最大化することを目的とした正則化項を加える
・正則化はネットワーク構造を変えたりすることなく簡単に既存のcGANsに適用することができる
・既存のcGANsに正則化項を加えることで、すべてのタスク(カテゴリ生成・image-to-image・text-to-image)において画像の質を落とすことなく多様性を向上させることができる
参考・関連論文
conditional GAN
https://www.foldl.me/uploads/2015/conditional-gans-face-generation/paper.pdf
image-to-image, pix2pix
https://arxiv.org/pdf/1611.07004v3.pdf
BicycleGAN
https://arxiv.org/pdf/1711.11586.pdf
DRIT
https://arxiv.org/pdf/1808.00948.pdf
StackGAN++
https://arxiv.org/pdf/1710.10916v3.pdf






- 投稿日:2019-03-18T08:38:54+09:00
[最新論文/cGANs]この正則化項を付け足すだけで、バラエティに富んだ画像を生成できるかもしれない。
論文紹介・画像引用
2019.3.13提出
https://arxiv.org/pdf/1903.05628v1.pdf本研究の成果
・モード崩壊に対処するための正則化項(本研究提案・後述)を目的関数に追加することで、
conditional GANs(cGANs)での多様な画像生成を可能にした・正則化項は潜在変数間の距離に対する生成画像間の距離の比率を最大化することを目的としたもの
(「Mode collapseとMode seeking」の章の図と「Mode Seeking GANs」の章の図を見れば直感的な理解ができるはず)・正則化項は様々なcGANに適用できる
・カテゴリ生成・image-to-image・text-to-imageの3つの条件付き画像生成を行ったが、
どのタスクでも画像の質を落とすことなく多様性の向上を実現したこれまでのconditional GANの問題点と改善
(左図:cGANs)
これまでのcGANsはcondition情報(ラベル・画像・テキスト)を重視する一方で、多様性を出す役割のある潜在変数z(ノイズベクトル)を無視していたため、同じような画像を生成してしまう傾向があったcondition情報は出力画像に関しての構造的な事前情報が多く、潜在変数よりも高次元のため重視されやすい
(右図:MSGANs(Mode-Seeking GANs))
これまでのcGANsに本研究提案の正則化項を目的関数に追加したものをMSGANsと呼ぶ
多様な画像を生成することができているMode collapseとMode seeking
画像の分布(左1:Real data)には多様な画像(モード)があるが、モード崩壊(左2:Mode collapse)が起こるとGeneratorは多様性のない生成をしてしまう
Mode collapse
z1とz2という近いけれど異なる潜在変数を使っているにも関わらず、生成される画像は同じモード(似た画像)になってしまっている
Mode seeking
z1とz2という近いけれど異なる潜在変数を使っていることを上手く反映しているため、異なるモードの画像を生成できている
=潜在変数の変化に対応して生成画像も変化している多様性評価のための比率
$$\frac{d_I(I_a,I_b)}{d_z(z_a,z_b)}$$
上図の1番右にある分数について
$d_I(I_a,I_b)$:生成画像$I_a$と生成画像$I_b$の間の距離
$d_z(z_a,z_b)$:潜在変数$z_a$と潜在変数$z_b$の間の距離距離の比率を計算することによって
潜在変数の距離の変化が生成画像のモードの変化に対応しているかがわかる・Mode collapse(青線)は低い値になっている(0.17)
これは潜在変数を変化させても画像のモードが変化していないことを意味している
潜在変数間の距離に対して画像のモードが変化していない=画像間の距離が近い=上記の分子が小さい値になる・Mode Seeking(緑線)は青線よりも大きい値になっている(0.58)
潜在変数間の距離に対して画像のモードが変化している=画像間の距離が遠い=上記の分子が大きい値になるMode Seeking GANs
モード崩壊を軽減するために以下のmode seeking正則化項をこれまで通りのcGANsの目的関数に加える
$$L_{ms}=\max_G(\frac{d_I(G(c,z_1),G(c,z_2))}{d_z(z_1,z_2)})$$
潜在変数間の距離に対する生成画像間の距離の比率を最大化することを目的としている
「Mode collapseとMode seeking」の章で紹介した分数よりも文字が多くなっているが、内容は全く同じ分子:生成画像①(condition情報$c$と潜在変数$z_1$から生成)と生成画像②(condition情報$c$と潜在変数$z_2$から生成)の距離
分母:潜在変数$z_1$と潜在変数$z_2$の距離
MSGANsの目的関数
$$L_{new}=L_{ori}+\lambda_{ms}L_{ms}$$
MSGANsの目的関数は上記のようになる
$L_{ori}$:元々cGANsで使っていた目的関数(下記詳細)
$\lambda_{ms}$:項のバランスをとるためのもの・どれほど正則化を強くするかを調整する
$L_{ms}$:上述したもの①カテゴリ情報を条件にした画像生成の場合
例)犬の画像を生成
$$L_{ori}=E_{c,y}[\log{D(c,y)}]+E_{c,z}[\log{(1-D(c,G(c,z)))}]$$
$C$:クラスラベル
$y$:本物画像
$z$:潜在変数第1項
本物画像を正しく本物と識別できるか
第2項
クラスラベルと潜在変数からできた生成画像を正しく偽物と識別できるか
②image-to-imageの場合
例)グレイスケール→カラーの画像変換(ペア画像がある場合)
$$L_{ori}=L_{GAN}+E_{x,y,z}[||y-G(x,z)||_1]$$
$x$:入力画像
$y$:目的ドメインの画像
$z$:潜在変数第1項
$L_{GAN}$:普通のGANの目的関数
・discriminatorは本物は本物、偽物は偽物として識別できればいい
・生成された画像が本物っぽい画像として成り立っているかを評価$L_{GAN}=E_{x,y}[\log{D(x,y)}]+E_{x,z}[\log{(1-D(x,G(x,z)))}]$
第2項
・生成された画像が目的通りに変換されているかを評価
正則化項の適用
・どんなcGANsにも適用することができる
・text-to-imageで使われるStackGAN++のような木構造があるモデルに対しても適用できる上図が示すように、モデルの構造が変わっているだけで
潜在変数間の距離に対する生成画像間の距離の比率を最大化することを目的としていることは変わらない正則化項の効果を検証
距離の指標($d_I,d_z$)として$L_1$ノームを使う
$\lambda_{ms}=1$に設定評価指標
FID
・生成画像の質を評価
・生成画像分布と本物画像分布の距離を計測
・小さい値=高品質画像LPIPS
・生成画像の多様性を評価
・生成画像間の平均特徴距離を計測
・大きい値=生成画像に多様性があるNDB・JSD
・生成画像分布と本物画像分布の類似性を計測
・生成モデルが多様な画像を生成しているかを評価する指標①本物画像(訓練画像)に対してK-meansをすることで、本物画像の分布をビンとして表す
②生成画像を同じようなモードを表している本物画像のビンに割り当てる
③本物画像と生成画像のビン比率を計算して、生成画像と本物画像の分布の違いを評価するNDBとJSDが小さい値=多様なモードを生成できているため、生成画像分布が本物画像分布に近い
カテゴリ生成
・クラスラベルを条件として様々なカテゴリの画像を生成する
・CIFAR-10データセット
・正則化項をDCGANに適用・MSGANは画像の質を落とすことなく(FIDが小さくなっている)ほとんどのクラスでモード崩壊を軽減することができている(NDBとJSが小さくなっている)
image-to-image
・ある画像を他のドメインの画像に転換する
例)犬→猫 冬→夏・これまでは1対1の変換(ある犬を変換しても限られたモードの猫のみ)になっていたがMSGANを使うことで1つの画像に対して多様な変換ができるかがポイント
ペア画像があるとき
Pix2Pixをベースラインに、BicycleGANを比較対象とする
generatorとdiscriminatorのアーキテクチャはBicycleGANのものを使う正則化項を加えたこと(MSGAN)で多様な画像が生成できている
ペア画像がないとき
多様な画像を生成できるDRITをベースラインとする
形状保存が求められる季節変化のデータセットと形状変化が求められる犬猫のデータセットを使う
・どちらのデータセットでもすべての指標でDRITを上回ることができている
・特に犬猫の変換では、MSGANが多様性を大きく改善していることが数値からわかる
・上図は犬から猫への変換のビン比率を可視化したもの
・DRITは限られたモード(1・2・8・10・16・19)の比率が大きいが、MSGANは様々なモードを生成することができている
=MSGANの方が本物画像の分布に上手く近似した生成
MSGANは画像の質を落とすことなく多様な画像を生成することができていることが上図からわかる
text-to-image
・文章を入力として条件付けて、その文章を表す画像を生成する
・StackGAN++に正則化項を加える
2つの状況でStackGAN++とMSGANを比較する①Conditioned on text descriptions
テキストを表すテキストコードを固定しないで生成する
この場合、テキストコードも出力画像の多様性に影響を与える②Conditioned on text codes
テキストコードを固定して生成する
この場合、テキストコードによる出力画像への影響はなくなる・MSGANは画像の質を保ちながら多様性を向上させることができている
・Conditioned on text codesではテキストコードの影響がないため、数値の向上は潜在変数がちゃんと生成に使われていることを意味している
StackGAN++では文章に対して同じような画像を生成しているが
MSGANでは潜在変数が上手く使われているため、鳥の見た目・向き・背景が多様に表現されているMSGANの潜在空間でinterpolation
ある2つの潜在変数間でinterpolationをして、それに対応する画像を生成した結果
生成モデルがちゃんと潜在変数を画像生成に使えているかを確認することができる
潜在変数を動かしても同じモードの画像が生成されていたらモード崩壊と考えられる上図のように、MSGANでは潜在変数の変化とともに画像も徐々に変化している
まとめ
・cGANsでのモード崩壊に対処するためのmode seeking正則化項を提案
・generatorが多様なモードを生成できるようにするために、潜在変数間の距離に対する生成画像間の距離の比率を最大化することを目的とした正則化項を加える
・正則化はネットワーク構造を変えたりすることなく簡単に既存のcGANsに適用することができる
・既存のcGANsに正則化項を加えることで、すべてのタスク(カテゴリ生成・image-to-image・text-to-image)において画像の質を落とすことなく多様性を向上させることができる
参考・関連論文
conditional GAN
https://www.foldl.me/uploads/2015/conditional-gans-face-generation/paper.pdf
image-to-image, pix2pix
https://arxiv.org/pdf/1611.07004v3.pdf
BicycleGAN
https://arxiv.org/pdf/1711.11586.pdf
DRIT
https://arxiv.org/pdf/1808.00948.pdf
StackGAN++
https://arxiv.org/pdf/1710.10916v3.pdf