- 投稿日:2019-03-10T22:27:01+09:00
【fast.ai】 text API解説
概要
本記事はfast.aiのwikiのTextページの要約となります。
筆者の理解した範囲内で記載します。Text モデル、データ、トレーニング
fast.aiライブラリのText モジュールは、DatasetをNLP (Natural Language Processing)目的へ最適化するための関数を多数備えています。具体的には:
- text.transform にてデータの前処理実施し、テキストをidへと変換する
- text.data にて TextDataBunch を用いてNLPに必要なDatasetのクラスを規定する
- text.learner にて素早くlanguage model や RNN classifierを作成できる
上のリンクを辿って各モジュールのAPIを参考にしてみて下さい。
早速やってみる: ULMFiTIでimdbの感情modelを鍛える
早速fast.ai textモジュールを使ってみましょう。以下の例では名の知れたimdbデータを用いて、感情分類モデルを4ステップで鍛えていきます。
1) Imdbデータを読み込み俯瞰する
2) データをモデルに最適化する
3) language modelをfine-tuneする
4) 分類モデルを作成する1) Imdbデータを読み込み俯瞰する
text に必要なパッケージを読み込みましょう。
from fastai.text import *画像認識とは異なり、テキストは直接モデルに読み込むことができません。従って、最初にデータを前処理してテキストをトークンへと変換して(tokenization)それを数字へと変換する(numericalization)必要があります。これらの数字 embedding layer へと引き渡されることで浮動小数点の配列へと変換されます。
これらトークンを浮動小数点へと変換するWord Embeddingsはweb上で掲載されています。これらのWord Embeddingsはwikipediaなどの膨大なサイズのcorpusで鍛えられたものです。ULMFiTの手法を用いて、fast.aiライブラリはpre-trained Language Modelsを用いて、fine-tuneすることに焦点を絞っています。Word embeddingsとは、具体的に300から400の小数点を異なる単語を表すために鍛えられたもので、pre-trained language model はこれらの特性を備えているだけではなく、文や文章を表現する性質も備わっております。
注記: ライブラリは以下の3ステップで構成されています。
- データを最小限のコードで前処理を済ませる
- pre-trained された language model をベースに、データセットを用いてfine-tuneする
- 分類器などのモデルをlanguage modelの上に載せる。
1000レビューに抽出されたIMDBデータセットを用いる(陽性または陰性)
path = untar_data(URLs.IMDB_SAMPLE) pathPosixPath('/home/ubuntu/.fastai/data/imdb_sample')
データセットをテキストから作成するには以下の方法がベストです
- ImageNet スタイルにフォルダへ整理されている
- csv ファイルへラベルの欄とテキスト欄へ整理されている
こちらの例ではimdbをtexts.csvファイルから読み込んで以下のようになっております。
df = pd.read_csv(path/'texts.csv') df.head()
label text is_valid 0 negative Un-bleeping-believable! Meg Ryan doesn't even ... 1 positive This is a extremely well-made film. The acting... 2 negative Every once in a long while a movie will come a... 3 positive Name just says it all. I watched this movie wi... 4 negative This movie succeeds at being one of the most u... 2) データをモデルに最適化する
DataBunchを準備するためには、複数のfactory methodsがデータの構成に応じて存在します。詳細はtext.data。こちらでは
from_csvメソッドを用いてTextLMDataBunch(Language Modelのためのデータ処理)とTextClasDataBunch(Text Classifierのためのデータ処理)クラスを用います。# Language model データ処理 data_lm = TextLMDataBunch.from_csv(path, 'texts.csv') # Classifier model データ処理 data_clas = TextClasDataBunch.from_csv(path, 'texts.csv', vocab=data_lm.train_ds.vocab, bs=32)これで必要なデータの前処理がなされます。分類器には、vocabulary(wordからidを引き渡す役目)を引き渡すことによって、data_clasがdata_lmと同じdictionaryを用いる点は注意して下さい。
この処理は時間がかかるため、結果を保存するために以下のコードを実行しましょう。
data_lm.save('data_lm_export.pkl') data_clas.save('data_clas_export.pkl')これで全ての結果を保存するための
tmpdirectoryが作成されます。ロードするためには以下のコードを実行しましょう。data_lm = load_data(path, fname='data_lm_export.pkl') data_clas = load_data(path, fname='data_clas_export.pkl', bs=16)注記:
DataBunchのパラメータを設定できます。(batch size,bptt,...)3) language modelをfine-tuneする
data_lmを用いてlanguage modelをfine-tuneしましょう。fast.ai は、AWD-LSTM architectureの英語モデルを用意してるので、それとpretrained weightsをダウンロードし、fine-tuneするためのlearnerオブジェクトを作成しましょうlearn = language_model_learner(data_lm, AWD_LSTM, drop_mult=0.5) learn.fit_one_cycle(1, 1e-2)Total time:00:13
epoch train_loss valid_loss accuracy 1 4.514897 3.974741 0.282455 画像認識モデルと同様に、モデルを
unfreezeすることでさらにfine-tuneすることができます。learn.unfreeze() learn.fit_one_cycle(1, 1e-3)Total time: 00:17
epoch train_loss valid_loss accuracy 1 4.159299 3.886238 0.289092 モデルを評価するために、以下の
Learner.predictを実行することで、単語とその数を指定し予測させることができます。learn.predict("This is a review about", n_words=10)'This is a review about dog - twist credited , and that , along with'
あまり意味は通じませんが(小さいvocabularyのため)ここでは基本的な文法をmodelが習得していることは驚愕すべきことです。(pretrained modelが可能にしたもの)
最後にencoderを保存して分類モデルに用いるようにできるようにしましょう。
learn.save_encoder('ft_enc')4) 分類モデルを作成する
ここでは、先述して作成した
data_clasオブジェクトを用いて、分類器をencoderを用いて新たに作成します。learnerオブジェクト自体はたった一行のコードで作成できます。learn = text_classifier_learner(data_clas, AWD_LSTM, drop_mult=0.5) learn.load_encoder('ft_enc')data_clas.show_batch()
text target xxbos xxmaj raising xxmaj victor xxmaj vargas : a xxmaj review \n \n xxmaj you know , xxmaj raising xxmaj victor xxmaj vargas is like sticking your hands into a big , xxunk bowl of xxunk . xxmaj it 's warm and gooey , but you 're not sure if it feels right . xxmaj try as i might , no matter how warm and gooey xxmaj raising xxmaj negative xxbos xxmaj now that xxmaj che(2008 ) has finished its relatively short xxmaj australian cinema run ( extremely limited xxunk screen in xxmaj xxunk , after xxunk ) , i can xxunk join both xxunk of " xxmaj at xxmaj the xxmaj movies " in taking xxmaj steven xxmaj soderbergh to task . \n \n xxmaj it 's usually satisfying to watch a film director change his style / negative xxbos i really wanted to love this show . i truly , honestly did . \n \n xxmaj for the first time , gay viewers get their own version of the " xxmaj the xxmaj xxunk " . xxmaj with the help of his obligatory " hag " xxmaj xxunk , xxmaj james , a good looking , well - to - do thirty - something has the chance negative xxbos xxmaj to review this movie , i without any doubt would have to quote that memorable scene in xxmaj tarantino 's " xxmaj pulp xxmaj fiction " ( xxunk ) when xxmaj jules and xxmaj vincent are talking about xxmaj mia xxmaj wallace and what she does for a living . xxmaj jules tells xxmaj vincent that the " xxmaj only thing she did worthwhile was pilot " . negative xxbos xxmaj how viewers react to this new " adaption " of xxmaj shirley xxmaj jackson 's book , which was promoted as xxup not being a remake of the original 1963 movie ( true enough ) , will be based , i suspect , on the following : those who were big fans of either the book or original movie are not going to think much of this one negative learn.fit_one_cycle(1, 1e-2)Total time: 00:33
epoch train_loss valid_loss accuracy 1 0.650518 0.599687 0.691542 再度modelをunfreezeしてfine-tuneしましょう。
learn.freeze_to(-2) learn.fit_one_cycle(1, slice(5e-3/2., 5e-3))Total time: 00:38
epoch train_loss valid_loss accuracy 1 0.628320 0.563579 0.716418 learn.unfreeze() learn.fit_one_cycle(1, slice(2e-3/100, 2e-3))Total time: 00:56
epoch train_loss valid_loss accuracy 1 0.533411 0.539693 0.721393 そして、
Learner.predictを用いてテキストを予測してみましょう。learn.predict("This was a great movie!")(Category positive, tensor(1), tensor([0.0118, 0.9882]))
- 投稿日:2019-03-10T19:13:26+09:00
[深層学習]webカメラで顔認識して、linebotで報告するシステムをつくった。
はじめに
私が所属しているサークルでは、部屋の出入りをいちいちLINEとslackで報告しなくてはならず、これがめんどい。。。。
ならば、監視カメラ的な物をつくってLINEbotとslackbotに代わりに報告してもらおう!というのがコレを作った動機です。流れは、
1.webカメラを起動する
2.カメラで顔を認識したら、顔の部分だけをトリミングして保存
3.保存した画像を学習済みモデルに通して分類する
4.分類結果をLINE,slackbotからメッセージとして送信する
という感じです。サークルメンバー10人の顔を見分けたい!!
目次
1.環境
2.画像収集
3.画像の水増し
3.転移学習
4.webカメラの起動・LINE,slackとの連携
5.終わりに環境
・python 3.6.5
・opencv-python 3.4.4.19
・Keras 2.2.4
・Flask 1.0.2
・line-bot-sdk 1.8.0
・slackbot 0.5.3画像収集
画像はLINEグループのアルバムから丸ごともってきました。
学習データ用に、これらの画像から顔だけを切り出していきます!
学習済みの検出器をこちらから持ってきて、face_cut.pyと同じ階層においておきました。face_cut.pyimport cv2 import glob import numpy as np model = "./models/haarcascade_frontalface_alt.xml" faceCascade = cv2.CascadeClassifier(model)#顔検出器を生成 PHOTOS_PATH = "./input_done" SAVE_PATH = "./detected_faces" files = glob.glob(PHOTOS_PATH + "/*.jpg") detect_count= 0 undetect_count= 0 read_count = 0 for i,file in enumerate(files): img = cv2.imread(file)#第二引数に0指定しろよ img = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY) h, w = img.shape[:2] img = cv2.resize(img, (w,h))#結局リサイズしてない。 face = faceCascade.detectMultiScale(img)#顔として認識した正方形の左上の座標がx,yに、横、縦幅がw,hに格納されている read_count += 1 if len(face)>0:#顔を認識したら、 for rect in face:#認識したすべての顔を切り出す cv2.imwrite(SAVE_PATH + "/" +str(read_count) + "_" + str(detect_count) +".jpg", img[rect[1]:rect[1] + rect[3], rect[0]:rect[0] + rect[2]]) detect_count += 1 print("detect!",detect_count) else: undetect_count += 1 print("undetect...", undetect_count) print("detect_count", detect_count) print("undetect_count", undetect_count)
PHOTOS_PATHで指定したフォルダの画像を読み込み、切り出した画像はSAVE_PATHで指定したフォルダに保存します。この後、画像を使いやすいようにクラス(人物)ごとにフォルダに分類しました。この作業で6時間くらいかかった。。。
......さあ、各クラス150枚準備できました!
画像の水増し
さっそく学習!...といきたいのですが、これだけでは足りないのでトレーニングデータを水増ししていきます!
トレーニングデータには120枚をあてました。それぞれの画像に対して左右反転、コントラスト調整、平滑化、γ変換をして2^4倍に増やします。
この際、水増しをするのはトレーニングデータのみにします。face_aug.pyimport cv2 import os,glob import numpy as np from sklearn import model_selection #クラスごとのフォルダ名をリストにまとめる classes = ["member1","menber2","member3","member4","member5","member6","member7","member8","member9","member10","others"] num_classes = len(classes) image_size = 50 X_train = [] X_test = [] y_train = [] y_test = [] #----------------------------------------------------------- #~水増しする関数のみなさん~ #左右反転 def flip(img): #第二引数を正でy軸対象 flip_images = cv2.flip(img, 1) return flip_images #コントラスト def cont(img): #ルックアップテーブルの生成 min_table=50 max_table=205 diff_table=max_table - min_table LUT_HC = np.arange(256, dtype = "uint8") #ハイコントラストLUT作成 for i in range(0, min_table): LUT_HC[i] = 0 for i in range(min_table, max_table): LUT_HC[i] = 255 * (i - min_table) / diff_table for i in range(max_table, 255): LUT_HC[i] = 255 #変換 #cv2.LUTで適用 high_cont_imgs = cv2.LUT(img, LUT_HC) return high_cont_imgs #ぼかし def blur(img): blur_images = cv2.GaussianBlur(img, (5, 5), 0) return blur_images #γ変換 def gamma(img): # ガンマ変換ルックアップテーブル gamma1 = 0.75 LUT_G1 = np.arange(256, dtype="uint8") for i in range(256): LUT_G1[i] = 255 * pow(float(i) / 255, 1.0 / gamma1) #変換 gamma1_images = cv2.LUT(img, LUT_G1) return gamma1_images #----------------------------------------------------------------- for index, classlabel in enumerate(classes): photos_dir = "./" + classlabel files = glob.glob(photos_dir + "/*.jpg") for i,file in enumerate(files): if i >= 150: #ラベルごとの画像の枚数をそろえる break img = cv2.imread(file) img = cv2.resize(img, (image_size,image_size)) if i < 30: #この番号以下の写真のデータはテスト用になる data = np.asarray(img) X_test.append(data) y_test.append(index) else: #それ以外はトレーニング用になる #1枚の画像ずつ処理する images = [img] images.extend(list(map(flip, images)))#倍倍に増えていく~ images.extend(list(map(cont, images))) images.extend(list(map(blur, images))) images.extend(list(map(gamma, images))) for _ in range(len(images)):#imagesの枚数分だけ正解ラベルを作成 y_train.append(index) #処理した全ての画像を格納する X_train.extend(images) print(classlabel , "done!") X_train = np.array(X_train)#nparrayに変換する X_test = np.array(X_test) y_train = np.array(y_train) y_test = np.array(y_test) xy = (X_train,X_test,y_train,y_test)#これらをxyにまとめ、 np.save("./face_aug.npy", xy)#画像データを保存する #ちゃんとデータができているか確認した X_train, X_test, y_train, y_test = np.load("face_aug.npy") print(len(X_train),len(X_test),len(y_train),len(y_test)) for i in range(len(classes)): count = 0 for j in range(len(y_train)): if y_train[j] == i: count += 1 print(count)各クラス約2000枚のデータがそろったので、いよいよ転移学習させていきましょう?
VGG16で転移学習させる
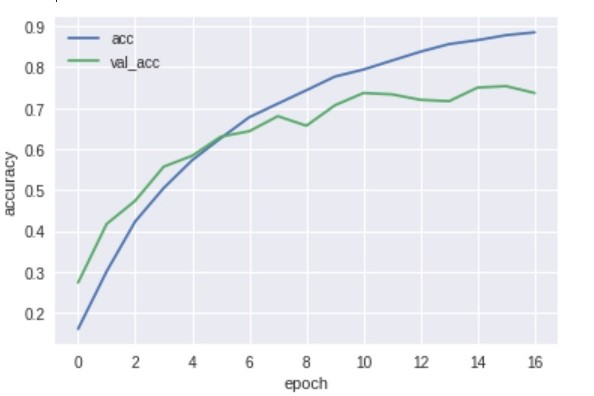
vgg16.pyfrom keras import optimizers from keras.applications.vgg16 import VGG16 from keras.datasets import cifar10 from keras.layers import Dense, Dropout, Flatten, Input, BatchNormalization, Activation from keras.models import Model, Sequential from keras.callbacks import EarlyStopping from keras.utils import plot_model, np_utils import matplotlib.pyplot as plt import numpy as np %matplotlib inline classes = ["member1","menber2","member3","member4","member5","member6","member7","member8","member9","member10","others"] num_classes = len(classes) epochs=20 batch_size=64 X_train, X_test, y_train, y_test = np.load("face_aug.npy") X_train = X_train.astype("float") / 255 #X_trainの各チャンネルの値は0~255だがそれを255で割ることですべての値を0~1にする(正規化) X_test = X_test.astype("float") / 255 y_train = np_utils.to_categorical(y_train, num_classes) #one_hotベクトルに変換 y_test = np_utils.to_categorical(y_test, num_classes) input_tensor = Input(shape=(50, 50, 1)) vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor) top_model = Sequential() top_model.add(Flatten(input_shape=vgg16.output_shape[1:])) #top_model.add(Dense(128)) #top_model.add(BatchNormalization()) #top_model.add(Activation('sigmoid')) #top_model.add(Dropout(0.5)) #top_model.add(Dense(64)) #top_model.add(BatchNormalization()) #top_model.add(Activation('sigmoid')) #top_model.add(Dropout(0.5)) top_model.add(Dense(32)) #top_model.add(BatchNormalization()) top_model.add(Activation('sigmoid')) #top_model.add(Dropout(0.5)) top_model.add(Dense(num_classes, activation="softmax")) model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output)) for layer in model.layers[:6]:#VGGの層の重みの固定を調整する layer.trainable = False model.compile(optimizer=optimizers.SGD (lr=1e-4, momentum=0.9),loss='categorical_crossentropy', metrics=['accuracy']) es = EarlyStopping(monitor='val_loss', patience=0, verbose=0, mode='min')#バリデーションデータ(テストデータ)の損失関数の値が大きくなると早期終了する history = model.fit(X_train, y_train, validation_data=(X_test, y_test), batch_size=batch_size, epochs=epochs, callbacks=[es]) model.save("faces.h5") #モデルの評価 scores = model.evaluate(X_test, y_test, verbose=1) print('Test loss: ', scores[0]) print('Test accuracy: ', scores[1]) print() #学習曲線の表示 plt.plot(history.history['acc'], label='acc', ls='-') plt.plot(history.history['val_acc'], label='val_acc', ls='-') plt.ylabel('accuracy') plt.xlabel('epoch') plt.legend(loc='best') plt.show()結果は75%くらい。
グラフ見た感じもっと精度あげられそう。
実用化するなら95%くらい欲しいけど、妥協しました。。
いろんなサイズのモデルで学習させてみましたが、1番精度が良かったのはごく小さなモデルでした。
考察してみた
・今回は50x50にリサイズしたが、元画像がそれよりも小さい画像があった。そのため、かなりぼやけてしまい上手く学習できなかったのではないか。
・今回はサークルメンバー以外の人も分類できるように、othersクラスを設けた。このクラスだけ異なる多数の人の顔で学習させたので、上手く重みの調整ができなかったのかもしれない。
・重みを固定するVGGの層を減らした方が精度がよかった。初期の層でよりプリミティブな特徴を捉え、残りの層で今回扱ったデータ特有の特徴を捉えたためだろう。こういう結果が出たのは、imagenetが人の顔を含んでいないためだろうか。
webカメラの起動・LINEとslackとの連携
いよいよ、先ほど作成したモデルと、LINEとslackとの連携部分を書いていきます!
長々とディープラーニングについて書いてきましたが、メインはこれからですね!
came.pyでwebカメラを起動して、顔を認識したらdetect_pushモジュールを呼び出してLINEbotとslackbotからメッセージを送っています。(以前は
subprocess.check_call()を使っていました。モジュール化すると見やすいですね。)came.pyimport cv2 import numpy as np from keras.models import load_model from detect_push import detectFace, pushToLine, pushToSlack import time SAVE_PATH = "./input/face.jpg" model = load_model('faces.h5') face_cascade = cv2.CascadeClassifier('./models/haarcascade_frontalface_default.xml') cap = cv2.VideoCapture(0)#webカメラをキャプチャーする while True: ret, img = cap.read() img = cv2.flip(img, 1)#反転 gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)#グレースケール化 cv2.imshow("img",img) faces = face_cascade.detectMultiScale(gray, 1.9, 5) if len(face)>0: for rect in face: cv2.imwrite(SAVE_PATH, img[rect[1]:rect[1] + rect[3], rect[0]:rect[0] + rect[2]]) print("recognize face !!") member = detectFace(SAVE_PATH, model)#上で保存した画像を読み込み、モデルでの予測結果をmemberに代入 pushToLine(member)#予測結果を受け取り、LINEbotから送信 pushToSlack(member)#予測結果を受け取り、slackbotから送信 time.sleep(10) if cv2.waitKey(30) == 27:#Escキーを押すとbreak break # キャプチャをリリースして、ウィンドウをすべて閉じる cap.release() cv2.destroyAllWindows()detect_push.pyimport os import tensorflow as tf import cv2 import numpy as np from linebot import LineBotApi from linebot.models import TextSendMessage, ImageSendMessage from linebot.exceptions import LineBotApiError from slackbot.slackclient import SlackClient def detectFace(filepath, model):#指定されたパスの画像を読み込んで,予測結果を返す image = cv2.imread(filepath) image = cv2.resize(image,(50,50)) data = np.expand_dims(image, axis=0) result = model.predict(data) predicted = result.argmax() members = ["member1","member2","member3","member4","member5","member6","member7","member8","member9","member10","others"] return members[predicted] def pushToLine(member):#LINEbotからメッセージを送信する channel_access_token = os.getenv('LINE_CHANNEL_ACCESS_TOKEN', None)#環境変数に設定したchannel_access_tokenを取得 line_bot_api = LineBotApi(channel_access_token) try: line_bot_api.push_message("メッセージを送信したいトークルームのid", TextSendMessage(text = member + "が開けました")) except LineBotApiError as e: # error handle ... def pushToSlack(member):#slackbotからメッセージを送信する #slackclientのインスタンスを作成 bot = SlackClient("slackbotのid") bot.send_message("メッセージを送信したいチャンネル名", member + "が開けました")これだけの記述でbotからメッセージが送れる!!!
各アカウント登録は最後にリンクを張っておくので、そのサイトを参考にしてみてください。
公式ドキュメントを見た感じ、LINEbotでもっといろんなことができそうですね...!まとめ
kerasでめちゃめちゃ簡単にモデルが作れて、転移学習であまり考えずにそこそこの精度がでる。
ただ学習データの準備がものすごく大変です。。。
LINEbotもslackbotも簡単に作れたので、他に面白いbotを作ったら紹介したいですね!
参考にしたサイト
Kerasでアニメ 「けいおん!」を画像認識させてみた
openCVで複数画像ファイルから顔検出をして切り出し保存
Messaging APIを利用するには-LINE Developers
Pythonを使ったSlackBotの作成方法
- 投稿日:2019-03-10T19:13:26+09:00
[深層学習]webカメラで顔認識して、LINEbotで報告するシステムをつくった。
はじめに
私が所属しているサークルでは、部屋の出入りをいちいちLINEとslackで報告しなくてはならず、これがめんどい。。。。
ならば、監視カメラ的な物をつくってLINEbotとslackbotに代わりに報告してもらおう!というのがコレを作った動機です。流れは、
1.webカメラを起動する
2.カメラで顔を認識したら、顔の部分だけをトリミングして保存
3.保存した画像を学習済みモデルに通して分類する
4.分類結果をLINE,slackbotからメッセージとして送信する
という感じです。サークルメンバー10人の顔を見分けたい!!
目次
1.環境
2.画像収集
3.画像の水増し
3.転移学習
4.webカメラの起動・LINE,slackとの連携
5.終わりに環境
・python 3.6.5
・opencv-python 3.4.4.19
・Keras 2.2.4
・Flask 1.0.2
・line-bot-sdk 1.8.0
・slackbot 0.5.3画像収集
画像はLINEグループのアルバムから丸ごともってきました。
学習データ用に、これらの画像から顔だけを切り出していきます!
学習済みの検出器をこちらから持ってきて、face_cut.pyと同じ階層においておきました。face_cut.pyimport cv2 import glob import numpy as np model = "./models/haarcascade_frontalface_alt.xml" faceCascade = cv2.CascadeClassifier(model)#顔検出器を生成 PHOTOS_PATH = "./input_done" SAVE_PATH = "./detected_faces" files = glob.glob(PHOTOS_PATH + "/*.jpg") detect_count= 0 undetect_count= 0 read_count = 0 for i,file in enumerate(files): img = cv2.imread(file)#第二引数に0指定しろよ img = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY) h, w = img.shape[:2] img = cv2.resize(img, (w,h))#結局リサイズしてない。 face = faceCascade.detectMultiScale(img)#顔として認識した正方形の左上の座標がx,yに、横、縦幅がw,hに格納されている read_count += 1 if len(face)>0:#顔を認識したら、 for rect in face:#認識したすべての顔を切り出す cv2.imwrite(SAVE_PATH + "/" +str(read_count) + "_" + str(detect_count) +".jpg", img[rect[1]:rect[1] + rect[3], rect[0]:rect[0] + rect[2]]) detect_count += 1 print("detect!",detect_count) else: undetect_count += 1 print("undetect...", undetect_count) print("detect_count", detect_count) print("undetect_count", undetect_count)
PHOTOS_PATHで指定したフォルダの画像を読み込み、切り出した画像はSAVE_PATHで指定したフォルダに保存します。この後、画像を使いやすいようにクラス(人物)ごとにフォルダに分類しました。この作業で6時間くらいかかった。。。
......さあ、各クラス150枚準備できました!
画像の水増し
さっそく学習!...といきたいのですが、これだけでは足りないのでトレーニングデータを水増ししていきます!
トレーニングデータには120枚をあてました。それぞれの画像に対して左右反転、コントラスト調整、平滑化、γ変換をして2^4倍に増やします。
この際、水増しをするのはトレーニングデータのみにします。face_aug.pyimport cv2 import os,glob import numpy as np from sklearn import model_selection #クラスごとのフォルダ名をリストにまとめる classes = ["member1","menber2","member3","member4","member5","member6","member7","member8","member9","member10","others"] num_classes = len(classes) image_size = 50 X_train = [] X_test = [] y_train = [] y_test = [] #----------------------------------------------------------- #~水増しする関数のみなさん~ #左右反転 def flip(img): #第二引数を正でy軸対象 flip_images = cv2.flip(img, 1) return flip_images #コントラスト def cont(img): #ルックアップテーブルの生成 min_table=50 max_table=205 diff_table=max_table - min_table LUT_HC = np.arange(256, dtype = "uint8") #ハイコントラストLUT作成 for i in range(0, min_table): LUT_HC[i] = 0 for i in range(min_table, max_table): LUT_HC[i] = 255 * (i - min_table) / diff_table for i in range(max_table, 255): LUT_HC[i] = 255 #変換 #cv2.LUTで適用 high_cont_imgs = cv2.LUT(img, LUT_HC) return high_cont_imgs #ぼかし def blur(img): blur_images = cv2.GaussianBlur(img, (5, 5), 0) return blur_images #γ変換 def gamma(img): # ガンマ変換ルックアップテーブル gamma1 = 0.75 LUT_G1 = np.arange(256, dtype="uint8") for i in range(256): LUT_G1[i] = 255 * pow(float(i) / 255, 1.0 / gamma1) #変換 gamma1_images = cv2.LUT(img, LUT_G1) return gamma1_images #----------------------------------------------------------------- for index, classlabel in enumerate(classes): photos_dir = "./" + classlabel files = glob.glob(photos_dir + "/*.jpg") for i,file in enumerate(files): if i >= 150: #ラベルごとの画像の枚数をそろえる break img = cv2.imread(file) img = cv2.resize(img, (image_size,image_size)) if i < 30: #この番号以下の写真のデータはテスト用になる data = np.asarray(img) X_test.append(data) y_test.append(index) else: #それ以外はトレーニング用になる #1枚の画像ずつ処理する images = [img] images.extend(list(map(flip, images)))#倍倍に増えていく~ images.extend(list(map(cont, images))) images.extend(list(map(blur, images))) images.extend(list(map(gamma, images))) for _ in range(len(images)):#imagesの枚数分だけ正解ラベルを作成 y_train.append(index) #処理した全ての画像を格納する X_train.extend(images) print(classlabel , "done!") X_train = np.array(X_train)#nparrayに変換する X_test = np.array(X_test) y_train = np.array(y_train) y_test = np.array(y_test) xy = (X_train,X_test,y_train,y_test)#これらをxyにまとめ、 np.save("./face_aug.npy", xy)#画像データを保存する #ちゃんとデータができているか確認した X_train, X_test, y_train, y_test = np.load("face_aug.npy") print(len(X_train),len(X_test),len(y_train),len(y_test)) for i in range(len(classes)): count = 0 for j in range(len(y_train)): if y_train[j] == i: count += 1 print(count)各クラス約2000枚のデータがそろったので、いよいよ転移学習させていきましょう?
VGG16で転移学習させる
vgg16.pyfrom keras import optimizers from keras.applications.vgg16 import VGG16 from keras.datasets import cifar10 from keras.layers import Dense, Dropout, Flatten, Input, BatchNormalization, Activation from keras.models import Model, Sequential from keras.callbacks import EarlyStopping from keras.utils import plot_model, np_utils import matplotlib.pyplot as plt import numpy as np %matplotlib inline classes = ["member1","menber2","member3","member4","member5","member6","member7","member8","member9","member10","others"] num_classes = len(classes) epochs=20 batch_size=64 X_train, X_test, y_train, y_test = np.load("face_aug.npy") X_train = X_train.astype("float") / 255 #X_trainの各チャンネルの値は0~255だがそれを255で割ることですべての値を0~1にする(正規化) X_test = X_test.astype("float") / 255 y_train = np_utils.to_categorical(y_train, num_classes) #one_hotベクトルに変換 y_test = np_utils.to_categorical(y_test, num_classes) input_tensor = Input(shape=(50, 50, 1)) vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor) top_model = Sequential() top_model.add(Flatten(input_shape=vgg16.output_shape[1:])) #top_model.add(Dense(128)) #top_model.add(BatchNormalization()) #top_model.add(Activation('sigmoid')) #top_model.add(Dropout(0.5)) #top_model.add(Dense(64)) #top_model.add(BatchNormalization()) #top_model.add(Activation('sigmoid')) #top_model.add(Dropout(0.5)) top_model.add(Dense(32)) #top_model.add(BatchNormalization()) top_model.add(Activation('sigmoid')) #top_model.add(Dropout(0.5)) top_model.add(Dense(num_classes, activation="softmax")) model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output)) for layer in model.layers[:6]:#VGGの層の重みの固定を調整する layer.trainable = False model.compile(optimizer=optimizers.SGD (lr=1e-4, momentum=0.9),loss='categorical_crossentropy', metrics=['accuracy']) es = EarlyStopping(monitor='val_loss', patience=0, verbose=0, mode='min')#バリデーションデータ(テストデータ)の損失関数の値が大きくなると早期終了する history = model.fit(X_train, y_train, validation_data=(X_test, y_test), batch_size=batch_size, epochs=epochs, callbacks=[es]) model.save("faces.h5") #モデルの評価 scores = model.evaluate(X_test, y_test, verbose=1) print('Test loss: ', scores[0]) print('Test accuracy: ', scores[1]) print() #学習曲線の表示 plt.plot(history.history['acc'], label='acc', ls='-') plt.plot(history.history['val_acc'], label='val_acc', ls='-') plt.ylabel('accuracy') plt.xlabel('epoch') plt.legend(loc='best') plt.show()結果は75%くらい。
グラフ見た感じもっと精度あげられそう。
実用化するなら95%くらい欲しいけど、妥協しました。。
いろんなサイズのモデルで学習させてみましたが、1番精度が良かったのはごく小さなモデルでした。
考察してみた
・今回は50x50にリサイズしたが、元画像がそれよりも小さい画像があった。そのため、かなりぼやけてしまい上手く学習できなかったのではないか。
・今回はサークルメンバー以外の人も分類できるように、othersクラスを設けた。このクラスだけ異なる多数の人の顔で学習させたので、上手く重みの調整ができなかったのかもしれない。
・重みを固定するVGGの層を減らした方が精度がよかった。初期の層でよりプリミティブな特徴を捉え、残りの層で今回扱ったデータ特有の特徴を捉えたためだろう。こういう結果が出たのは、imagenetが人の顔を含んでいないためだろうか。
webカメラの起動・LINEとslackとの連携
いよいよ、先ほど作成したモデルと、LINEとslackとの連携部分を書いていきます!
長々とディープラーニングについて書いてきましたが、メインはこれからですね!
came.pyでwebカメラを起動して、顔を認識したらdetect_pushモジュールを呼び出してLINEbotとslackbotからメッセージを送っています。(以前は
subprocess.check_call()を使っていました。モジュール化すると見やすいですね。)came.pyimport cv2 import numpy as np from keras.models import load_model from detect_push import detectFace, pushToLine, pushToSlack import time SAVE_PATH = "./input/face.jpg" model = load_model('faces.h5') face_cascade = cv2.CascadeClassifier('./models/haarcascade_frontalface_default.xml') cap = cv2.VideoCapture(0)#webカメラをキャプチャーする while True: ret, img = cap.read() img = cv2.flip(img, 1)#反転 gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)#グレースケール化 cv2.imshow("img",img) faces = face_cascade.detectMultiScale(gray, 1.9, 5) if len(face)>0: for rect in face: cv2.imwrite(SAVE_PATH, img[rect[1]:rect[1] + rect[3], rect[0]:rect[0] + rect[2]]) print("recognize face !!") member = detectFace(SAVE_PATH, model)#上で保存した画像を読み込み、モデルでの予測結果をmemberに代入 pushToLine(member)#予測結果を受け取り、LINEbotから送信 pushToSlack(member)#予測結果を受け取り、slackbotから送信 time.sleep(10) if cv2.waitKey(30) == 27:#Escキーを押すとbreak break # キャプチャをリリースして、ウィンドウをすべて閉じる cap.release() cv2.destroyAllWindows()detect_push.pyimport os import tensorflow as tf import cv2 import numpy as np from linebot import LineBotApi from linebot.models import TextSendMessage, ImageSendMessage from linebot.exceptions import LineBotApiError from slackbot.slackclient import SlackClient def detectFace(filepath, model):#指定されたパスの画像を読み込んで,予測結果を返す image = cv2.imread(filepath) image = cv2.resize(image,(50,50)) data = np.expand_dims(image, axis=0) result = model.predict(data) predicted = result.argmax() members = ["member1","member2","member3","member4","member5","member6","member7","member8","member9","member10","others"] return members[predicted] def pushToLine(member):#LINEbotからメッセージを送信する channel_access_token = os.getenv('LINE_CHANNEL_ACCESS_TOKEN', None)#環境変数に設定したchannel_access_tokenを取得 line_bot_api = LineBotApi(channel_access_token) try: line_bot_api.push_message("メッセージを送信したいトークルームのid", TextSendMessage(text = member + "が開けました")) except LineBotApiError as e: # error handle ... def pushToSlack(member):#slackbotからメッセージを送信する #slackclientのインスタンスを作成 bot = SlackClient("slackbotのid") bot.send_message("メッセージを送信したいチャンネル名", member + "が開けました")これだけの記述でbotからメッセージが送れる!!!
各アカウント登録は最後にリンクを張っておくので、そのサイトを参考にしてみてください。
公式ドキュメントを見た感じ、LINEbotでもっといろんなことができそうですね...!まとめ
kerasでめちゃめちゃ簡単にモデルが作れて、転移学習であまり考えずにそこそこの精度がでる。
ただ学習データの準備がものすごく大変です。。。
LINEbotもslackbotも簡単に作れたので、他に面白いbotを作ったら紹介したいですね!
参考にしたサイト
Kerasでアニメ 「けいおん!」を画像認識させてみた
openCVで複数画像ファイルから顔検出をして切り出し保存
Messaging APIを利用するには-LINE Developers
Pythonを使ったSlackBotの作成方法
- 投稿日:2019-03-10T17:39:22+09:00
【ひらけごま】STFT,VGG16-like,そしてPyaudioで「エッジ音声認識アプリ」を作ってみた♬垂れ流し改善編
昨夜のアプリ、どんどん垂れ流しアプリなので、今後の利用のために少し改善して待てるようにしました。
つまり、ファイルの格納ディレクトリから一度だけ読み込むように、
①ファイルの存在チェックを実施
②読込んだらファイル消去
というのを追加して、新規に声を取得したら反応するように改善しました。
合わせて流れを変更して読込初期の揺らぎを改善しました。やったこと
・ファイル存在チェックの追加
・読み込んだらファイル消去
・コード解説・ファイル存在チェックの追加
【参考】
・pythonでファイルの存在を確認する
参考のとおりに以下で実施できます。import os path = "./out_test/figure.jpg" os.path.exists(path)これで./out_test/にfigure.jpgが存在するかどうかの判定ができます。
Trueで存在、Falseで存在しない。
ということで、存在を確認してから読み込むというシーケンスが作成できます。・読み込んだらファイル消去
上記と対の機能がファイルを読み込んだら、二度目は読み込まないように消去しておきたいところです。
ということで、以下の参考が役に立ちます。
【参考】
・ファイルやフォルダーを削除する
つまり、参考のとおり、以下で実施できました。import os path = "./out_test/figure.jpg" os.remove(path)ちなみに、参考ではディレクトリの削除やディレクトリツリーごと削除も掲載されています。
・コード解説
上記二つの機能を盛り込んで以下のように変更しました。
学習などは変わらないので昨夜の記事を見てください。
import osを追記しています。
昨夜のコード
hirakegoma / out_onsei.py
hirakegoma / pyaudio_realtime_last.pyout_onsei_improve.py#-*- cording: utf-8 -*- import numpy as np #np.random.seed(1337) # for reproducibility import wave import pyaudio from vgg16_like import model_family_cnn from keras.preprocessing import image import matplotlib.pyplot as plt import keras from keras.preprocessing import image import ospredictionに変更はありません。
out_onsei_improve.pydef prediction(imgSrc): img = np.array(imgSrc) img = img.reshape(1, img_rows,img_cols,3) img = img.astype('float32') img /= 255 t0=time.time() y_pred = model.predict(img) return y_predwhile前に
path = "./out_test/figure.jpg"
を定義しました。out_onsei_improve.pynum_classes = 2 img_rows,img_cols=128, 128 input_shape = (img_rows,img_cols,3) #224, 224, 3) model = model_family_cnn(input_shape, num_classes = num_classes) # load the weights from the last epoch model.load_weights('params_hirakegoma-61.hdf5', by_name=True) print('Model loaded.') path = "./out_test/figure.jpg"while True:の中で最初に
if os.path.exists(path)==True:
として、存在すれば以下を実行するように変更しました。
また、音声を新たに入力してpathに格納するとき、タイミングを計るために
for i in range(100000): i += 1
を入れました。
また、最後のところでファイルの削除を実施しています。if input==b'': os.remove(path) breakそれ以外は変更していません。
out_onsei_improve.pywhile True: imgSrc=[] if os.path.exists(path)==True: for i in range(100000): i += 1 imgSrc = image.load_img("./out_test/figure.jpg", target_size=(img_rows,img_cols)) plt.imshow(imgSrc) plt.pause(1) plt.close() pred = prediction(imgSrc) print(pred[0]) if pred[0][0]>=0.5: filename = "ohayo.wav" print("ohayo") else: filename = "hirakegoma.wav" print("hirakegoma") # チャンク数を指定 CHUNK = 1024 #filename = "hirakegoma.wav" wf = wave.open(filename, "rb") # PyAudioのインスタンスを生成 p = pyaudio.PyAudio() # Streamを生成 stream = p.open(format=p.get_format_from_width(wf.getsampwidth()), channels=wf.getnchannels(), rate=wf.getframerate(), output=True) # データを1度に1024個読み取る input = wf.readframes(CHUNK) # 実行 while stream.is_active(): output = stream.write(input) input = wf.readframes(CHUNK) #print(input) if input==b'': os.remove(path) break # ファイルが終わったら終了処理 stream.stop_stream() stream.close() p.terminate()また、音声録音側のアプリは以下のように変更しました。
実は、前回のコードだと測定開始時にミスって、変なデータを格納してから正しいデータを格納していました。
そこで、start_measure():の変数にp1のように1をつけました。
※これ最終的には不要でした
ということで、基本的に最初の部分は変更なしです。pyaudio_realtime.py# -*- coding:utf-8 -*- import pyaudio import time import matplotlib.pyplot as plt import numpy as np import wave from scipy.fftpack import fft, ifft from scipy import signal import os def start_measure(): CHUNK=1024 RATE=44100 #11025 #22050 #44100 p1=pyaudio.PyAudio() input1 = [] stream1=p1.open(format = pyaudio.paInt16, channels = 1, rate = RATE, frames_per_buffer = CHUNK, input = True) input1 =stream1.read(CHUNK) sig1 = np.frombuffer(input1, dtype="int16")/32768.0 while True: if max(sig1) > 0.001: break input1 =stream1.read(CHUNK) sig1 = np.frombuffer(input1, dtype="int16")/32768.0 stream1.stop_stream() stream1.close() p1.terminate() return以下のコードも基本はあまり変更なく、
以下の設定を毎回初期化するようにfor s in range(0,900,1):
の中に入れました。これで最初に変な録音が入るバグが解消しました。
※昨夜のバージョンだと垂れ流しで変な録音が入ってもファイル取得前に上書きされてノイズが見えていませんでしたが、今回は一個一個取得ー消去をするのでより鮮明になってバグが発見できましたstream=p.open(format = pyaudio.paInt16, channels = 1, rate = RATE, frames_per_buffer = CHUNK, input = True)したがって、以下のパラメータ部分のみ外だししています。
pyaudio_realtime.pyfig = plt.figure(figsize=(6, 5)) ax2 = fig.add_subplot(111) N=50 CHUNK=1024*N RATE=44100 #11025 #22050 #44100 p=pyaudio.PyAudio() fr = RATE fn=51200*N/50 fs=fn/fr for s in range(0,900,1): print(s) start_measure() stream=p.open(format = pyaudio.paInt16, channels = 1, rate = RATE, frames_per_buffer = CHUNK, input = True) input = [] start_time=time.time() input = stream.read(CHUNK) stop_time=time.time() sig =[] sig = np.frombuffer(input, dtype="int16") /32768.0 nperseg = 1024 f, t, Zxx = signal.stft(sig, fs=fn, nperseg=nperseg) ax2.pcolormesh(fs*t, f/fs/2, np.abs(Zxx), cmap='hsv') ax2.set_xlim(0,fs) ax2.set_ylim(20,20000) ax2.set_yscale('log') ax2.set_axis_off() plt.pause(0.01) plt.savefig('out_test/figure.jpg') #output = stream.write(input) stream.stop_stream() stream.close() p.terminate() print( "Stop Streaming")結果
こうして以下のとおり、録音と読込の記録の数が一致するようになりました。
>python pyaudio_realtime.py 0 1 2 3 4 5 6 7 8ちょっと1より小さい数字が出ているところは「おはー」とか録音している部分です。
※0は録音前に表示されているので、以下の方が一個少ないですModel loaded. 2019-03-10 17:07:16.052326: W ... [ 2.01997850e-07 9.99999762e-01] hirakegoma [ 1.00000000e+00 8.13874673e-33] ohayo [ 0.00337285 0.99662721] hirakegoma [ 1.00000000e+00 1.21284272e-29] ohayo [ 1.00000000e+00 1.55338318e-34] ohayo [ 1.00000000e+00 6.55481190e-15] ohayo [ 4.60651776e-25 1.00000000e+00] hirakegoma [ 1.00000000e+00 1.52230811e-10] ohayo forrtl: error (200): program aborting due to control-C eventまとめ
・録音データ(スペクトログラム)の保存ー消去を実施したので、余裕をもって一つずつ処理ができるようになった
・読み込むデータの時間軸の初期値が安定した・少し長めの文章に挑戦したいと思う
- 投稿日:2019-03-10T13:27:52+09:00
Convert Models from Darknet to Caffe
Memo
Darknet/Yoloのモデルや重みデータを、prototxt、caffemodelに変換したいので調べてみた。
Tsingjinyunの説明をそのまま以下に。Darknet configuration file .cfg to the .prototxt definition in Caffe, a tool to convert the weight file .weights to .caffemodel in Caffe and a detection demo to test the converted networks.
CaffeとDarknet
ググってざっと見つけたのは
Tsingjinyun
変換、まだ試していない・・・
Convert_the_configuration_file_withpython create_yolo_prototxt.py tiny-yolo.cfg yolo_tinyTo_convert_weights_to_caffemodelpython create_yolo_caffemodel.py yolo_tiny_deploy.prototxt tiny-yolo.weights \ yolo_tiny.caffemodelPushyami
CaffeでYolov3を・・・
How to implement a YOLOv3 from scratch in PyTorch Part1
How to implement a YOLOv3 from scratch in PyTorch Part2
How to implement a YOLOv3 from scratch in PyTorch Part3Jasonlovescoding
CaffeでYolov3を・・・
prototxtとcaffemodelが、中国のサイトにUpされている、GoogleDriveからもダウンロードできるが、ちょっと怖いな。
ChenYingpeng
こちらはBaidouに、prototxt/caffemodel、cfg/weightsがUpされている。
exeファイルでダウンロードされるが、これもちょっと怖い。Marvis
Pytorch、Caffe、DarknetのConvert
Pytorch ⇒ Caffe ⇒ Darknet
Pytorch ⇒ Darknet ⇒ Caffe
Darknet ⇒ CaffeYsh329
darknet2inferx
InferXって何、あらゆる推論ってこと?
Xingwangsfu
This is a caffe implementation of the YOLO
prototxtとcaffemodel
ネットワークモデルの定義、重みファイルについて・・・
Caffeの実装理解のために
Ubuntu16.04にDockerをインストール
環境を壊したくないので、Docker Container上でいろいろ試せるようにする。
準備中
Ubuntu16.04のDockerにCaffeをインストール
準備中
2019/03/11 更新
- 投稿日:2019-03-10T02:32:41+09:00
[Python]機械学習で作ったストライク判定機で、好みの女性との素敵な出会いを実現する[Tinder]
はじめに
こんにちは。Qiita初投稿・エンジニア転職を目指し勉強中の営業マン(@kuro_bkk)です。
学習のアウトプット発信の一環として本記事を投稿します。未熟者故、至らぬ点やつっこみ所が満載かと存じますが、暖かくご指摘・コメントいただければ幸いです。目的
マッチングアプリTinderで好みのタイプにだけ自動的にいいねをつけて素敵な出会いを実現する。
Tinderとは
Tinder(ティンダー)は、Facebookを利用し、位置情報を使った出会い系サービスを提供するアプリケーションソフトウェア、「デートアプリ」で、相互に関心をもったユーザー同士の間でコミュニケーションをとることを可能にし、マッチしたユーザーの間でチャットすることができるようにするもの。
Tinderは世界中で流行しているマッチングアプリです。
なんと世界190以上の国で利用されており、1日あたり2600万組のマッチが成立しているそうです。(2015年時点)本記事の内容に関わるのでざっくりとした使い方を説明します。
- 自身の近くにいるTinderユーザーがあるアルゴリズムに基づいて表示される。
- 写真をみて、気に入ったらLIKE(いいね)、気に入らなければNOPEに振り分ける。
- 相互にいいねを送りあうと「マッチ」が成立し、Tinderを通してチャットができる。
他にも追加機能があるようですが、基本となるのはこの流れです。
※Tinderを利用できる年齢は18歳以上です。
やったこと
- 写真を収集
- 写真から顔部分だけを抽出、好みのタイプ(ストライク)か否か分類
- 機械学習で自分の好みを判定するストライク判定機を作成
- ストライク判定機を用いてTinderで好みのタイプのみを自動でいいねする
言語はPython、環境はGoogle Colaboratoryを使用しました。
Tinderから写真を収集
判定機を作るために顔写真をできるだけたくさん集め、あらかじめストライクorボールに分類する(ラベルをつける)必要があります。
まず思いついたのは画像検索を用いて芸能人の顔写真を大量にスクレイピングする方法です。
しかし、同じ人物の画像を大量に集める場合においてこの方法は効果的ですが、今回のように異なる人物の顔写真をたくさん集める場合はひと工夫必要になります。
また、集める顔写真に偏りがあってもいけません。顔立ちが整った芸能人ばかりを収集してしまうと判定が厳しくなりすぎる可能性もあります。バッティングセンターでど真ん中直球だけを練習してもしょうがない、実戦の生きた球で練習(学習)することが大事と考え、結局顔写真もTinderから集めました。
Pynderというライブラリを利用することでTinderを操作できます。通常使用では位置情報を自由に更新できないそうですが、Pynder経由であれば位置情報も設定できるようです。
準備するものはFacebookで認証済のTinderアカウントだけでOKです。
Pynderの設定など、これらの記事を参考にさせていただきました。ありがとうございます
- 【Python】TinderのAPIを使って、青山大学周辺で遠隔ナンパする - Qiita
- TinderAPIで女の子の顔写真を集めて、加工アリorナシを自動で判定してみた | Aidemy Blog
- [Python] Tinder APIでPythonを使って自動マッチングマシンを作ってみた - 筋肉エンジニアの備忘録
- PythonでTinder APIを使ってネトストとサイバーナンパ師やってみた|Review of My Life
試しに渋谷駅付近にいるユーザーの名前、年齢、写真のURLを表示してみましょう。
緯度・経度はこちらのサイトから調べることができます。
クリックしてコード展開
import pynder #facebookのアクセストークン入力 session = pynder.Session('your facebook access token') #緯度と経度を入力 LAT = 35.658034 LON = 139.701636 #位置情報を更新 session.update_location(LAT, LON) #ユーザーを取得 users = session.nearby_users() for user in users: print(user.name) print(str(user.age)+'歳') photos = user.photos for photo in photos: #形式が場合によってwebpとjpgになるのでjpgにする if photo.endswith(".webp"): photo = photo.replace(".webp",".jpg") print(photo)
結果はこちら。
一度に情報を取得できる人数の上限がわからないのですが、Tinder側の制限なのか、表示させている途中に不規則にエラーが出て勝手に止まりました。エラーを調べるとライブラリ側のバグ?という可能性もあるようで、細かい仕様はわかりませんでした。エラーを避けるには必要に応じてカウンターを設けて少な目の人数でストップさせてください。
実はこの時、海外にいたのですがきちんと日本人の名前が表示されたので(モザイクしていますが)位置情報の更新を含め問題はなさそうです。
短時間に連続してアクセスすると制限がかかるようなので、取得できない場合は時間を置いてみましょう。顔を含む写真だけをピックアップする
顔が写っていない写真は判定機作成の上で必要ないので、写真を保存する前に顔の有無を判定します。
顔認識といえばOpenCVが手軽に利用できますが、顔でない部分に反応したりと精度があまりよろしくなかったのでMicrosoftのFace APIを使用しました。
もちろん、工夫次第でOpenCVでも精度をあげられるとは思いますがFace APIが非常に便利で使いやすかったです。(後の工程である顔部分の抽出についてはOpenCVを使用しました。)
顔写真抽出についてはこちらの記事が大変参考になりました。ありがとうございます
取得したURLをFace APIに渡します。1つ以上の顔が認識されるとその位置情報を返してくれます。たとえば4人が同一画像に写っていても、きちんと4人分の顔の位置情報を返してくれる優れものです。この顔認識をさきほど取得したTinderのプロフィール画像で試してみます。
クリックしてコード展開
import pynder import requests import json def detectFace(imageUrl): result = requests.post( 'https:// your endpoint /detect', headers = { 'Ocp-Apim-Subscription-Key': 'your subscription key' }, json = { 'url': imageUrl } ) return json.loads(result.text) for user in users: print('-----------') print(user.name) print(str(user.age)+'歳') photos = user.photos for photo in photos: if photo.endswith(".webp"): photo = photo.replace(".webp",".jpg") #顔を検出 faces = detectFace(photo) if len(faces) > 0: print(str(len(faces)) + '個の顔を検出') for face in faces: print(face['faceRectangle']) else: print('顔が写っていません')
結果はこちら。
無事に認識できており、顔の位置情報が得られました。
驚いたことに、顔(正面)が写っている写真をアップしている人が少ないことがわかりました。
体感では顔が写っている写真は取得総数の半分以下でした。後ろ姿や、顔が認識できない横顔だけの写真。そのほかにもおしゃれレストランでのランチ(食べ物だけの)写真や風景だけの写真など、マッチング目的と考えると大切な情報が抜け落ちた写真が多かったです。そのため、顔写真取得にかなりの時間を要してしまいましたが根気強く何度も繰り返して合計500人分ほどのデータを準備しました。
写真から顔部分を抽出して保存
1つ以上の顔を認識できた写真に対して顔部分のみを抽出して保存します。
Face APIから返ってくる生データを使うと本当に顔面部分だけが切り取られてしまい、分類が困難だった(顔の輪郭も判断材料である)ため生データの範囲を上下左右20%広げ、さらに正方形になるように抽出しました。
クリックしてコード展開
import pynder import requests import json import cv2 from PIL import Image import io import numpy as np def face_position(face): x = face['faceRectangle']['left'] y = face['faceRectangle']['top'] h = face['faceRectangle']['height'] w = face['faceRectangle']['width'] #幅、高さのうち、長い辺で正方形にする l = h if h > w else w #顔の輪郭も含めるため範囲を20%拡大 x = int(x - (0.1 * l)) y = int(y - (0.1 * l)) l = int(1.2 * l) return x,y,l def crop_face(imageUrl,x,y,l): #pillowによる画像の読み込み file =io.BytesIO(urlopen(imageUrl).read()) img = Image.open(file) #openCVで加工するためnumpy配列に変換 imgArray = np.asarray(img) #openCVでトリミング imgArrayCropped = imgArray[y:y+l, x:x+l] #RGBへ変換 imgArrayCropped = cv2.cvtColor(imgArrayCropped, cv2.COLOR_BGR2RGB) return imgArrayCropped for user in users: photos = user.photos for photo in photos: if photo.endswith(".webp"): photo = photo.replace(".webp",".jpg") faces = detectFace(photo) if len(faces) > 0: print(str(len(faces))+'個の顔を検出') for face in faces: #顔の位置を取得 left, top, length = face_position(face) #切り取る cropped_face = crop_face(photo,left,top,length) #保存 cv2.imwrite('your file name' + '.jpg', cropped_face) else: print('顔が写っていません')
緯度、経度を変更して大都市を周遊しながら何度も実行した結果がこちら。(保存先のフォルダのスクショです)
アバターやイラストといった非人間の顔を誤認識してしまいますが、分類時に削除します。
私が実行した範囲では全く顔でない部分(背景など)を顔と認識したものはありませんでした。
逆に、顔の大部分が隠れていたり、見切れている顔なども認識していてFace APIの精度の高さに驚きました。ストライクorボールに分類(ラベル付け)
収集した顔写真を自分の好みかどうかで分類していきます。一人一人の顔を見ながら手動で該当するフォルダへ移動していきます。
はたから見たら夜な夜な大量の顔写真をフォルダ分けする怪しい人になってしまいましたが勉強のためです。後ほど説明するKerasのImageDataGeneratorで扱いやすいよう下記のようなフォルダ構成にしておきます。
face_images // train // strike // train_strike_1.jpg,... // ball // train_ball_1.jpg,... // test // strike // test_strike_1.jpg,... // ball // test_ball_1.jpg,...学習データとテストデータは8:2の割合でランダムに分けました。
ストライク判定機の作成
データ拡張
学習データ(写真の枚数)が少ないのでデータ拡張が必要です。
KerasのImageDataGeneratorを使うことで指定した範囲でランダムに写真を加工してくれ、データを無限に水増しできます。
今回は回転、左右反転、水平移動、垂直移動、拡大縮小の5種類の加工をしました。flow_from_directoryというメソッドを使うことでデータ拡張と同時にサブディレクトリ名(strike/ball)から自動的にラベルをつけてくれます。
クリックしてコード展開
from keras.preprocessing.image import ImageDataGenerator train_datagen = ImageDataGenerator( rescale=1./255, shear_range=0.1, zoom_range=0.1, rotation_range=10, height_shift_range=0.1, width_shift_range=0.1) test_datagen = ImageDataGenerator(rescale=1./255) train_generator = train_datagen.flow_from_directory( '/face_images/train', target_size=(64,64), batch_size=16, class_mode='categorical') validation_generator = test_datagen.flow_from_directory( '/face_images/test', target_size=(64,64), batch_size=16, class_mode='categorical')
target_sizeとbatch_sizeはデータサイズによって調整が必要です。
今回は2クラス分類なのでclass_modeはbinaryでもよいですが、3クラス以上の識別を後ほど試してみようと思ってcategoricalのままにしてしまっていました。特に深い意味はありません。
Kerasの公式ドキュメントが参考になります。転移学習で判定機作成
転移学習とは偉大なる先人たちが構築した学習モデルを応用するという方法です。
今回はVGG16という学習モデルをベースに、畳み込み層をちょこっとくっつけてオリジナルの判定機を作成しました。全結合層を再学習させます。
(追記)
@peaceiris さんからコメントいただき、表現が不適切だったので一部変更しました。もちろん、試行錯誤しながらパラメータのチューニングを実施しています。
クリックしてコード展開
from keras import optimizers from keras.applications.vgg16 import VGG16 from keras.layers import Dense, Dropout, Flatten, Input, Activation from keras.models import Model, Sequential from keras.callbacks import CSVLogger input_tensor = Input(shape=(64,64, 3)) vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor) top_model = Sequential() top_model.add(Flatten(input_shape=vgg16.output_shape[1:])) top_model.add(Dense(128)) top_model.add(Activation('relu')) top_model.add(Dropout(0.5)) top_model.add(Dense(128)) top_model.add(Activation('relu')) top_model.add(Dropout(0.5)) top_model.add(Dense(128)) top_model.add(Activation('relu')) top_model.add(Dropout(0.5)) top_model.add(Dense(2)) top_model.add(Activation('softmax')) model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output)) for layer in model.layers[:15]: layer.trainable = False model.compile(loss='categorical_crossentropy', optimizer=optimizers.Adam(lr=1e-5), metrics=['accuracy']) csv_logger = CSVLogger('your file name' + '.csv') history = model.fit_generator( train_generator, steps_per_epoch=16, epochs=100, validation_data=validation_generator, validation_steps=16, callbacks=[csv_logger]) model.save('your file name' + '.h5')
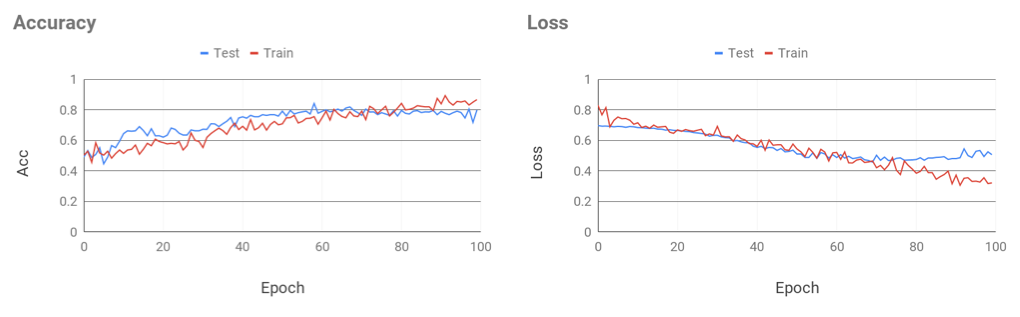
エポック数は100回に設定して、処理時間はおよそ1時間でした。
学習結果はこちら。
(実際はMatplotlibで出力しながら作業していましたが、投稿用に見やすく加工するのが面倒だったのでSpread sheetでグラフを作りました
)
Epoch数がすすむにつれ正答率が徐々に上がり、損失も下がっているので、学習そのものはできていそう。
しかし70Epochあたりから損失が上昇して、正答率も若干下がってきているのでこのあたりから過学習していそう。
途中で学習を打ち切るEarlyStopping機能がKerasにあるので、それを使えばよかったかもしれないが、今回はこのままいきます
最終的な正答率はおよそ75から80%になりました。これはすなわち用意したデータに関しては、ストライクゾーンに飛んできた球をきちんとストライクと判定できた確率が75から80%ということ。
ためしに何人かの有名人をこのモデルで判定してみました。
クリックしてコード展開
from keras.models import load_model #保存したモデルを読み込む model = load_model('your file name' + '.h5') imageUrl = 'your image URL' faces = detectFace(imageUrl) if len(faces) > 0: for face in faces: #顔部分を切り取る left, top, length = face_position(face) imgArray = crop_face(imageUrl,left,top,length) imgArray = cv2.cvtColor(imgArray, cv2.COLOR_BGR2RGB) #PIL形式にしてリサイズ img = array_to_img(imgArray) img_resized = img.resize((64,64)) #再びArrayに戻して正規化 x = img_to_array(img_resized) / 255 x = np.expand_dims(x, axis=0) pred = model.predict(x) #判定結果 percent = int(round(pred[0][1]*100)) print('ストライクの確率 : ' + str(percent) + '%') else: print('顔が写っていません')
結果
- 広瀬すずさんのストライク確率 99%

- 広瀬アリスさんのストライク確率 64%

- 女芸人Aさんのストライク確率 2%

- 安倍首相のストライク確率 1%

もしTinderで広瀬姉妹があらわれても逃さないということで最低限の仕事はできているようなので良しとします。
他にもいろんな人の写真を試しましたが、大きな問題はなさそう?好みのタイプという直感を数値化しているのでいまいち評価の仕方がわかりません。
同一人物でも写真の写り方で大きくストライク確率が変化してしまいました。しかし確認した範囲では、写り具合で95%が30%になったりと判定が覆るほどの変化はなかったように思えます。
無事に(?)判定機が作成できたので次はいよいよ判定に基づいて自動いいねをしていきます。
好みのタイプを自動でいいねする
画像取集のパートですでに基本となるTinderの操作は実施済みです。
その時のコードほとんどそのままで判定部分とLIKEをする部分を追加します。
ストライクの確率が50%を超えるといいねをするように設定してみました。
クリックしてコード展開
session = pynder.Session('your facebook access token') #緯度と経度を入力 LAT = 'your location' LON = 'your location' #位置情報を更新 session.update_location(LAT, LON) #ユーザーを取得 users = session.nearby_users() #モデルを読み込む model = load_model('your file name' + '.h5') for user in users: print('-----------') print(user.name) print(str(user.age)+'歳') photos = user.photos for photo in photos: if photo.endswith(".webp"): photo = photo.replace(".webp",".jpg") #顔を検出 faces = detectFace(photo) if len(faces) > 0: for face in faces: left, top, length = face_position(face) imgArray = crop_face(photo,left,top,length) imgArrayRGB = cv2.cvtColor(imgArray, cv2.COLOR_BGR2RGB) img = array_to_img(imgArrayRGB) img_resized = img.resize((64,64)) x = img_to_array(img_resized) / 255 pitch = np.expand_dims(x, axis=0) pred = model.predict(pitch) strike_percent = int(round(pred[0][1]*100)) if strike_percent > 50: print('ストライク!!!') #いいねして画像保存 user.like() cv2.imwrite('your file name', imgArray) else: print('ボール') else: print('顔が写っていません')実際にやってみた
場所は東京の繁華街をいくつか指定、とりあえず3人ストライク判定が出るまでやってみました。
ストライク判定1人目
ストライク判定2人目
ストライク判定3人目
ストライク判定になった方はみなさんかわいくて素敵な方です!感動!!!
ただ自身の好みかどうかと言われるとよくわからない...
さらに大きな問題があり、今の設定ではボール判定の数が非常に多いです。
ストライクの確率が50%を上回ったらいいねをする設定にしましたが、いいねした数は検出された顔のうち、10%以下でした。前述したように、そもそもアップされている顔写真も少ないので、この状態ではかなり辛口な気がします。出会いの質を取るか量を取るか、難しい問題ですね。
実際の野球でも、ボール球をどんどん振って良い成績を残す選手もいますし、選球眼が売りの選手もいます。
自身の置かれている状況を考え、程よい値を設定することが鍵となりそうです。時間の経過とともに閾値が下がっていってもおもしろそうですね。
これにて目的達成です。あとは向こうからのアプローチを待つのみです。
さいごに
長々とお付き合いいただきありがとうございました。
機械学習はデータ集めや前処理が大切で、作業の中でいちばん時間を割くなんて言葉を聞いたことがあります。その言葉通り、顔写真の収集が大変でした。効率が悪いと感じたので改善の余地ありですね。フリーで使える日本人の顔データセットってあるのでしょうか。
学習データが少なすぎたのでなんちゃって機械学習になってしまった感があります。とはいえ、書籍を読みながら学習を進めるよりよっぽど考えながら、かつ楽しみながら手を動かせたのはよかったです。
恥ずかしくてなかなか異性へ積極的にアプローチができないかたも多くいらっしゃると思います。「判定機がストライクをだした」という事実があれば精神的にも楽に行動できるかもしれません。
出会いをお求めのエンジニアのみなさま、ぜひ試してみてください。
みなさまに素敵な出会いがありますように☆
おわり





- 投稿日:2019-03-10T01:53:23+09:00
ディープラーニングを使って5等分の花嫁の将来の嫁を予測する
今話題の5等分の花嫁の将来のお嫁さんが誰なのかいろいろ憶測あって、気になったので予測しようとおもいました
ディープラーニングの物体検出のstate-of-the-artたち、YOLO v3とFaster R-CNNにまかせてみました
見る人によってはネタバレとかになると思うので注意して下さい
学習データ
Kindleで1巻を開いて、スクショをひたすらとって、アノテーション付けました
YOLO v3
YOLOはKeras実装を使いました
https://github.com/qqwweee/keras-yolo3
こっちの画像の結果は
Itsuki 0.36 (220, 93) (273, 153)
Nino 0.24 (220, 93) (273, 153)
ということで、二乃か五月らしいです。だけど、五月の方が確率が高いので五月なのかも。。ちゃんと書き分けできてるんだなーと
あとディープラーニングもしっかり書き分けを学習できてるんだなーと
こっちの結果は
Itsuki 0.11 (157, 121) (246, 208)
Nino 0.11 (157, 121) (246, 208)
ということで、やっぱ五月か二乃らしいっす。Faster R-CNN
pytorch実装を使いましたー
https://github.com/jwyang/faster-rcnn.pytorch
Ichika 0.7306731343269348
Nino 0.11791589856147766
Yotsuba 0.07815735787153244
Itsuki 0.8343716859817505
ということで五月!
Ichika 0.9910896420478821
ということで、一花!総合的に見ると五月!!
結論
五月なのかなー だれが嫁でもかわいい!




- 投稿日:2019-03-10T01:53:23+09:00
ディープラーニングを使って五等分の花嫁の将来の嫁を予測する
今話題の五等分の花嫁の将来のお嫁さんが誰なのかいろいろ憶測あって、気になったので予測しようとおもいました
ディープラーニングの物体検出のstate-of-the-artたち、YOLO v3とFaster R-CNNにまかせてみました
見る人によってはネタバレとかになると思うので、そう思ったらすぐこのページを閉じて下さい
これはあくまでテクログです。ネタバレとかがしたいのではなく、ただディープラーニングを使ったあそびとして捉えて下さい
学習データ
Kindleで1巻を開いて、スクショをひたすらとって、アノテーション付けました
YOLO v3
YOLOはKeras実装を使いました
https://github.com/qqwweee/keras-yolo3
こっちの画像の結果は
Itsuki 0.36 (220, 93) (273, 153)
Nino 0.24 (220, 93) (273, 153)
ということで、二乃か五月らしいです。だけど、五月の方が確率が高いので五月なのかも。。ちゃんと書き分けできてるんだなー??と
あとディープラーニングもしっかり書き分けを学習できてるんだなーと
こっちの結果は
Itsuki 0.11 (157, 121) (246, 208)
Nino 0.11 (157, 121) (246, 208)
ということで、やっぱ五月か二乃らしいっす。Faster R-CNN
pytorch実装を使いましたー
https://github.com/jwyang/faster-rcnn.pytorch
Ichika 0.7306731343269348
Nino 0.11791589856147766
Yotsuba 0.07815735787153244
Itsuki 0.8343716859817505
ということで五月!
Ichika 0.9910896420478821
ということで、一花!そう言われると一花っぽい感じもする
とりあえず断定はできないけど総合的に見ると五月らしい!!
結論
五月なのかなー だれが嫁でもかわいい!
- 投稿日:2019-03-10T00:12:49+09:00
【ひらけごま】STFT,VGG16-like,そしてPyaudioで「ひらけごま」を作ってみた♬
「ひらけごま」できた!
作ろうと思ったが、なんとなく時が過ぎてしまった。
そして最近、アレクサ使い始めてそれなりな(拒否が多い)ので、「ひらけごま」作ってみた。
今となっては、簡単そうだが、それでもそれなりに実現するのは難しい。
※エッジアプリの音声認識やエッジ利用のシーンもそれなりに有効だと考えられるやったこと
順序はやった順番ではないが、わかりやすいと思うので、以下の順に記載していこうと思う。
・「ひらけごま」と「おはよう」の識別をやってみた
・「ひらけごま」と「おはよう」をVGG16-likeモデルで学習
・Pyaudioで学習データを集めること
・「ひらけごまアプリ」の説明コードは以下に置きました
・「ひらけごま」と「おはよう」の識別をやってみた
識別といっても、マイクに話すと「ひらけごま」と「おはよう」を拾って、異なる反応をするというだけのもので、今回は単に同じ「ひらけごま」なら予め録音しておいたhirakegoma.wavを再生し、「おはよう」ならohayo.wavを再生する。一応、音は消えちゃうので履歴として標準出力に予測結果とhirakegomaとohayoと記載した。
動きは以下のとおりである。① マイク;ひらけごま ↓ ② 音声が閾値を超えると、Pyaudioで音声を拾う ↓ ③ STFTして画像ファイルfigure.jpgを./out_test/に出力 ↓ ④ 1秒ごとにfigure.jpgを読み込んで、VGG16-like cnnで推論 ↓ ⑤ 予測結果に応じてwavファイルで音を出力する 画面に予測結果を出力 ↓ ⑥ ①に戻る上記のフローから分かるように、今回は垂れ流しである。
・「ひらけごま」と「おはよう」をVGG16-likeモデルで学習
学習用コード
hirakegoma/VGG16_originalData.py
データ取得コード
hirakegoma/getDataSet.py
まず、肝心な識別は以下のように実施した。工夫点は以下のとおり ・学習用データはPyaudioで録音しつつSTFTして結果を図(スペクトログラム)で蓄積するが、座標等は一切表示しないこととした ・当初は、Augumentationによって900個に増やしたが、単に時間軸の移動と音の周波数の変換を実施したがうまくいかなかった。 そこで、「ひらけごま」と「おはよう」を何度も録音して、それぞれ実データを218個ずつ取得して180個を学習データ、38個を検証用データにした ※なお、学習データのバリエーションは、ほぼ綺麗に録音できたものをセレクトした つまり、「ゴマ」とか「ひらけ」とか「お」や「は」のみの録音データは入れていない ・VGG16-likeモデルは、深ければよいという感じではなく、今回はマシンのメモリーと収束性の関係で、入力サイズを(none,128,128,3)とし、 block3までを使った。 ・メモリーの関係で、学習はbatch-size=32で実行した。 ・BatchNormalizationとdropout(0.5)は収束性と汎化性能のために残した ※なお、収束はぎりぎりな状況である ・つまり、全結合部分は、パラメータ数はdense(2*num_classes)位が少なくて済むが、dense(10*num_classes)位でないと収束しない。 block5まで利用した方が、パラメータ的(数的にも特徴量的)には有利であるが、(学習データが少なくかつデータ間の相関が高いため) 収束性とメモリーの関係でblock3までを利用した。・Pyaudioで学習データを集めること
学習コードは以下のコードで収集した。
pyaudio_realtime_last.py# -*- coding:utf-8 -*- import pyaudio import time import matplotlib.pyplot as plt import numpy as np import wave from scipy.fftpack import fft, ifft from scipy import signal以下の関数で音声が一定の閾値を超えると測定開始する。
pyaudio_realtime_last.pydef start_measure(): CHUNK=1024 RATE=44100 #11025 #22050 #44100 p=pyaudio.PyAudio() input = [] stream=p.open(format = pyaudio.paInt16, channels = 1, rate = RATE, frames_per_buffer = CHUNK, input = True) input =stream.read(CHUNK) sig1 = np.frombuffer(input, dtype="int16")/32768.0 while True: if max(sig1) > 0.001: break input =stream.read(CHUNK) sig1 = np.frombuffer(input, dtype="int16")/32768.0 stream.stop_stream() stream.close() p.terminate() returnpyaudioの設定をして、測定に入る。
pyaudio_realtime_last.pyN=50 CHUNK=1024*N RATE=44100 #11025 #22050 #44100 p=pyaudio.PyAudio() stream=p.open(format = pyaudio.paInt16, channels = 1, rate = RATE, frames_per_buffer = CHUNK, input = True) fig = plt.figure(figsize=(6, 5)) ax2 = fig.add_subplot(111) #ax2.set_ylabel('Freq[Hz]') #ax2.set_xlabel('Time [sec]') start=time.time() stop_time=time.time() stp=stop_time fr = RATE fn=51200*N/50 #*RATE/44100 fs1=4.6439909297052155*N/50*11025/RATE fs=fn/fr print(fn,fs,fs1)繰り返しは、for文で有限回数としている。
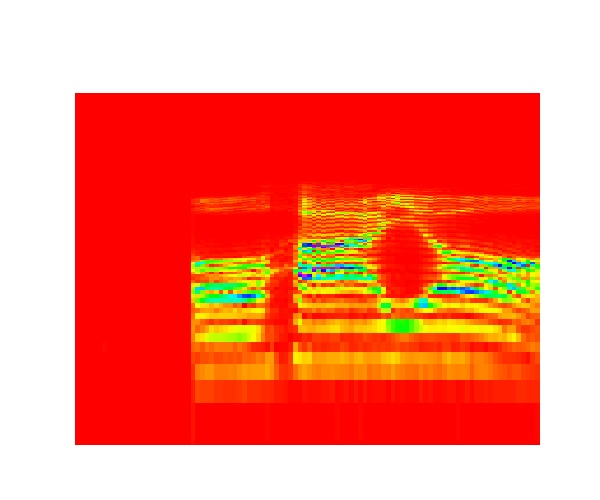
このスタートのsの値でファイル蓄積の最初のファイル名を変更している。pyaudio_realtime_last.pyfor s in range(0,900,1): start_measure() input = [] start_time=time.time() input = stream.read(CHUNK) stop_time=time.time() print(stop_time-start_time) sig = np.frombuffer(input, dtype="int16") /32768.0 nperseg = 1024 f, t, Zxx = signal.stft(sig, fs=fn, nperseg=nperseg) ax2.pcolormesh(fs*t, f/fs/2, np.abs(Zxx), cmap='hsv') ax2.set_xlim(0,fs) ax2.set_ylim(20,20000) ax2.set_yscale('log') ax2.set_axis_off() #軸見出しなどを非表示 plt.pause(0.01) plt.savefig('train_images/0/figure' +str(s)+'.jpg') #0;ohayo 1;hirakegoma stream.stop_stream() stream.close() p.terminate() print( "Stop Streaming")ということで、学習データの例
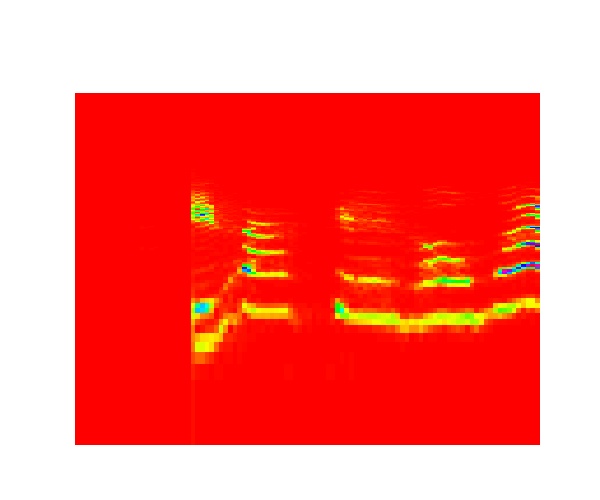
「おはよう」
「ひらけごま」
推論中は上記のコードの保存先を以下に変更するだけである。plt.savefig('out_test/figure.jpg')・「ひらけごまアプリ」の説明
ここまでくれば、あとは簡単である。
・hirakegoma/out_onsei.py
最初の部分でnp.random.seed(1337)が入っているが、当初安定性が悪かったのでこの初期値依存の可能性を排除するために入れていたが、以下の最終版では必要ないことが判明している。ただし、これを入れるとバグっているときの推論の予測結果のふらつきは無くなり原因特定に役立った。out_onsei.py#-*- cording: utf-8 -*- import numpy as np #np.random.seed(1337) # for reproducibility import wave import pyaudio from vgg16_like import model_family_cnn from keras.preprocessing import image import matplotlib.pyplot as plt import keras import timeprediction関数で予測している。なお、modelは呼び出し元で上記のmodel_family_cnnを利用している。
実は、以下ではimgのデータ処理を実施しているが、データ処理前には予測結果が無茶苦茶であった。
※学習を以下の処理後にやっているのでそのために必要であるdef prediction(imgSrc): #np.random.seed(1337) # for reproducibility img = np.array(imgSrc) img = img.reshape(1, img_rows,img_cols,3) img = img.astype('float32') img /= 255 t0=time.time() y_pred = model.predict(img) return y_pred num_classes = 2 img_rows,img_cols=128, 128 input_shape = (img_rows,img_cols,3) #224, 224, 3) model = model_family_cnn(input_shape, num_classes = num_classes) # load the weights from the last epoch model.load_weights('params_hirakegoma-900.hdf5', by_name=True) #params_hirakegoma-61.hdf5 print('Model loaded.') while True: #np.random.seed(1337) # for reproducibility img_rows,img_cols=128,128 imgSrc=[] imgSrc = image.load_img("./out_test/figure.jpg", target_size=(img_rows,img_cols)) plt.imshow(imgSrc) plt.pause(1) plt.close() pred = prediction(imgSrc) print(pred[0]) if pred[0][0]>=0.5: #二択なので、一応0.5以上で選択とした filename = "ohayo.wav" print("ohayo") else: #おはよう以外は全てhirakegoma。追加してAlexaみたいに「わかりません」とかもありだが失敗しないので。。 filename = "hirakegoma.wav" print("hirakegoma") # チャンク数を指定 CHUNK = 1024 #filename = "hirakegoma.wav" #デバッグ用;マイク不調でreal timeで取得できない場合に利用 wf = wave.open(filename, "rb") # PyAudioのインスタンスを生成 p = pyaudio.PyAudio() # Streamを生成 stream = p.open(format=p.get_format_from_width(wf.getsampwidth()), channels=wf.getnchannels(), rate=wf.getframerate(), output=True) # データを1度に1024個読み取る input = wf.readframes(CHUNK) # 実行 while stream.is_active(): output = stream.write(input) input = wf.readframes(CHUNK) if input==b'': #dataがなくなると、''ではなく、b''が返ってくる break # ファイルが終わったら終了処理 stream.stop_stream() stream.close() p.terminate()【ウワンの駄文的妄想】 このシーケンスで一番悩むのは、計測時間と計測間隔(トリガー)かもしれません。 それなりに長いセンテンスを一連として判断する場合は、もう少し長い計測時間が必要で、 今回は一定の閾値で動き始めますが、商用を考えると出だしは「Alexa」が必要なのが理解できます。 そして肝心なのはそのあとの待ち時間や会話終了判断等がある意味営業秘密になると思われます。 ※Alexaも少し長文の質問だと結構混乱するので、たぶん短文ベースで変換⇒意味解釈⇒回答や検索や動作⇒出力 をほとんどはCacheベースでやっているようです結果
今回のアプリを動かしてちょっと驚いたことは、「ひらけごま」と「おはよう」しか学習していないが、この二択だと「ひらけ」とか「らけごま」とか、「おはー」や「よう」くらいの短い単語でも数値的にほぼ100%の予測結果を返している。これは二択だと当たり前なのかもだけど、そんな感じに見えないので、もう少しカテゴリを増やして同様な事象となるか実験したいと思う。
上にしめしたような通常の周波数の音声しか入れていないが、以下のようにとっても高周波の「おはよう」や「ひらけごま」も認識する。つまり汎化性能は高そうだ。
「おはよう」
「ひらけごま」
まとめ
・「ひらけごま」と「おはよう」に反応するアプリを作成した
・今回はVGG16-likeなモデルで識別した
・Pyaudioの音声をリアルタイムなSTFT変換して識別に利用した・機械学習でどこまで行けるかや100個くらいの文章まで拡張したいと思う
・このアプリ利用なTello制御もやってみたいと思う
・Unity連携もできそうである
・今回の結果は終始一貫ウワンの音声でやっているので一般化されたときの精度はどの程度なのかは試してみたい
⇒一応、Githubに学習済データを置いたので試したら教えてくださいm(__)mおまけ
出力例
[ 1.61695224e-19 1.00000000e+00] hirakegoma [ 1.61695224e-19 1.00000000e+00] hirakegoma [ 2.75610277e-04 9.99724329e-01] hirakegoma [ 9.99943733e-01 5.63181093e-05] ohayo [ 9.99943733e-01 5.63181093e-05] ohayo [ 9.99943733e-01 5.63181093e-05] ohayo [ 9.99824941e-01 1.75072724e-04] ohayo [ 9.99824941e-01 1.75072724e-04] ohayo [ 9.99824941e-01 1.75072724e-04] ohayo [ 0.99702293 0.00297703] ohayo [ 0.99702293 0.00297703] ohayo [ 2.03095806e-05 9.99979734e-01] hirakegoma [ 2.03095806e-05 9.99979734e-01] hirakegoma [ 1.00000000e+00 1.99542429e-23] ohayoVGG16-likeモデル
Model loaded. _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) (None, 128, 128, 3) 0 _________________________________________________________________ conv1_1 (Conv2D) (None, 128, 128, 32) 896 _________________________________________________________________ conv1_2 (Conv2D) (None, 128, 128, 32) 9248 _________________________________________________________________ batch_normalization_1 (Batch (None, 128, 128, 32) 128 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 64, 64, 32) 0 _________________________________________________________________ dropout_1 (Dropout) (None, 64, 64, 32) 0 _________________________________________________________________ conv2_1 (Conv2D) (None, 64, 64, 64) 18496 _________________________________________________________________ conv2_2 (Conv2D) (None, 64, 64, 64) 36928 _________________________________________________________________ batch_normalization_2 (Batch (None, 64, 64, 64) 256 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 32, 32, 64) 0 _________________________________________________________________ dropout_2 (Dropout) (None, 32, 32, 64) 0 _________________________________________________________________ conv3_1 (Conv2D) (None, 32, 32, 256) 147712 _________________________________________________________________ conv3_2 (Conv2D) (None, 32, 32, 256) 590080 _________________________________________________________________ conv3_3 (Conv2D) (None, 32, 32, 256) 590080 _________________________________________________________________ conv3_4 (Conv2D) (None, 32, 32, 256) 590080 _________________________________________________________________ batch_normalization_3 (Batch (None, 32, 32, 256) 1024 _________________________________________________________________ max_pooling2d_3 (MaxPooling2 (None, 16, 16, 256) 0 _________________________________________________________________ dropout_3 (Dropout) (None, 16, 16, 256) 0 _________________________________________________________________ flatten_1 (Flatten) (None, 65536) 0 _________________________________________________________________ dense_1 (Dense) (None, 40) 2621480 _________________________________________________________________ activation_1 (Activation) (None, 40) 0 _________________________________________________________________ dropout_6 (Dropout) (None, 40) 0 _________________________________________________________________ dense_2 (Dense) (None, 2) 82 _________________________________________________________________ activation_2 (Activation) (None, 2) 0 ================================================================= Total params: 4,606,490 Trainable params: 4,605,786 Non-trainable params: 704 _________________________________________________________________ WARNING:tensorflow:Variable *= will be deprecated. Use variable.assign_mul if you want assignment to the variable value or 'x = x * y' if you want a new python Tensor object. Train on 360 samples, validate on 76 samples


- 投稿日:2019-03-10T00:12:49+09:00
【ひらけごま】STFT,VGG16-like,そしてPyaudioで「エッジ音声認識アプリ」を作ってみた♬
「ひらけごま」できた!
作ろうと思ったが、なんとなく時が過ぎてしまった。
そして最近、アレクサ使い始めてそれなりな(拒否が多い)ので、「ひらけごま」作ってみた。
今となっては、簡単そうだが、それでもそれなりに実現するのは難しい。
※エッジアプリの音声認識やエッジ利用のシーンもそれなりに有効だと考えられるやったこと
順序はやった順番ではないが、わかりやすいと思うので、以下の順に記載していこうと思う。
・「ひらけごま」と「おはよう」の識別をやってみた
・「ひらけごま」と「おはよう」をVGG16-likeモデルで学習
・Pyaudioで学習データを集めること
・「ひらけごまアプリ」の説明コードは以下に置きました
・「ひらけごま」と「おはよう」の識別をやってみた
識別といっても、マイクに話すと「ひらけごま」と「おはよう」を拾って、異なる反応をするというだけのもので、今回は単に同じ「ひらけごま」なら予め録音しておいたhirakegoma.wavを再生し、「おはよう」ならohayo.wavを再生する。一応、音は消えちゃうので履歴として標準出力に予測結果とhirakegomaとohayoと記載した。
動きは以下のとおりである。① マイク;ひらけごま ↓ ② 音声が閾値を超えると、Pyaudioで音声を拾う ↓ ③ STFTして画像ファイルfigure.jpgを./out_test/に出力 ↓ ④ 1秒ごとにfigure.jpgを読み込んで、VGG16-like cnnで推論 ↓ ⑤ 予測結果に応じてwavファイルで音を出力する 画面に予測結果を出力 ↓ ⑥ ①に戻る上記のフローから分かるように、今回は垂れ流しである。
・「ひらけごま」と「おはよう」をVGG16-likeモデルで学習
学習用コード
hirakegoma/VGG16_originalData.py
データ取得コード
hirakegoma/getDataSet.py
まず、肝心な識別は以下のように実施した。工夫点は以下のとおり ・学習用データはPyaudioで録音しつつSTFTして結果を図(スペクトログラム)で蓄積するが、座標等は一切表示しないこととした ・当初は、Augumentationによって900個に増やしたが、単に時間軸の移動と音の周波数の変換を実施したがうまくいかなかった。 そこで、「ひらけごま」と「おはよう」を何度も録音して、それぞれ実データを218個ずつ取得して180個を学習データ、38個を検証用データにした ※なお、学習データのバリエーションは、ほぼ綺麗に録音できたものをセレクトした つまり、「ゴマ」とか「ひらけ」とか「お」や「は」のみの録音データは入れていない ・VGG16-likeモデルは、深ければよいという感じではなく、今回はマシンのメモリーと収束性の関係で、入力サイズを(none,128,128,3)とし、 block3までを使った。 ・メモリーの関係で、学習はbatch-size=32で実行した。 ・BatchNormalizationとdropout(0.5)は収束性と汎化性能のために残した ※なお、収束はぎりぎりな状況である ・つまり、全結合部分は、パラメータ数はdense(2*num_classes)位が少なくて済むが、dense(10*num_classes)位でないと収束しない。 block5まで利用した方が、パラメータ的(数的にも特徴量的)には有利であるが、(学習データが少なくかつデータ間の相関が高いため) 収束性とメモリーの関係でblock3までを利用した。・Pyaudioで学習データを集めること
学習コードは以下のコードで収集した。
pyaudio_realtime_last.py# -*- coding:utf-8 -*- import pyaudio import time import matplotlib.pyplot as plt import numpy as np import wave from scipy.fftpack import fft, ifft from scipy import signal以下の関数で音声が一定の閾値を超えると測定開始する。
pyaudio_realtime_last.pydef start_measure(): CHUNK=1024 RATE=44100 #11025 #22050 #44100 p=pyaudio.PyAudio() input = [] stream=p.open(format = pyaudio.paInt16, channels = 1, rate = RATE, frames_per_buffer = CHUNK, input = True) input =stream.read(CHUNK) sig1 = np.frombuffer(input, dtype="int16")/32768.0 while True: if max(sig1) > 0.001: break input =stream.read(CHUNK) sig1 = np.frombuffer(input, dtype="int16")/32768.0 stream.stop_stream() stream.close() p.terminate() returnpyaudioの設定をして、測定に入る。
pyaudio_realtime_last.pyN=50 CHUNK=1024*N RATE=44100 #11025 #22050 #44100 p=pyaudio.PyAudio() stream=p.open(format = pyaudio.paInt16, channels = 1, rate = RATE, frames_per_buffer = CHUNK, input = True) fig = plt.figure(figsize=(6, 5)) ax2 = fig.add_subplot(111) #ax2.set_ylabel('Freq[Hz]') #ax2.set_xlabel('Time [sec]') start=time.time() stop_time=time.time() stp=stop_time fr = RATE fn=51200*N/50 #*RATE/44100 fs1=4.6439909297052155*N/50*11025/RATE fs=fn/fr print(fn,fs,fs1)繰り返しは、for文で有限回数としている。
このスタートのsの値でファイル蓄積の最初のファイル名を変更している。pyaudio_realtime_last.pyfor s in range(0,900,1): start_measure() input = [] start_time=time.time() input = stream.read(CHUNK) stop_time=time.time() print(stop_time-start_time) sig = np.frombuffer(input, dtype="int16") /32768.0 nperseg = 1024 f, t, Zxx = signal.stft(sig, fs=fn, nperseg=nperseg) ax2.pcolormesh(fs*t, f/fs/2, np.abs(Zxx), cmap='hsv') ax2.set_xlim(0,fs) ax2.set_ylim(20,20000) ax2.set_yscale('log') ax2.set_axis_off() #軸見出しなどを非表示 plt.pause(0.01) plt.savefig('train_images/0/figure' +str(s)+'.jpg') #0;ohayo 1;hirakegoma stream.stop_stream() stream.close() p.terminate() print( "Stop Streaming")ということで、学習データの例
「おはよう」
「ひらけごま」
推論中は上記のコードの保存先を以下に変更するだけである。plt.savefig('out_test/figure.jpg')・「ひらけごまアプリ」の説明
ここまでくれば、あとは簡単である。
・hirakegoma/out_onsei.py
最初の部分でnp.random.seed(1337)が入っているが、当初安定性が悪かったのでこの初期値依存の可能性を排除するために入れていたが、以下の最終版では必要ないことが判明している。ただし、これを入れるとバグっているときの推論の予測結果のふらつきは無くなり原因特定に役立った。
【参考】
・Each time I run the Keras, I get different result. #2743out_onsei.py#-*- cording: utf-8 -*- import numpy as np #np.random.seed(1337) # for reproducibility import wave import pyaudio from vgg16_like import model_family_cnn from keras.preprocessing import image import matplotlib.pyplot as plt import keras import timeprediction関数で予測している。なお、modelは呼び出し元で上記のmodel_family_cnnを利用している。
実は、以下ではimgのデータ処理を実施しているが、データ処理前には予測結果が無茶苦茶であった。
※学習を以下の処理後にやっているのでそのために必要であるdef prediction(imgSrc): #np.random.seed(1337) # for reproducibility img = np.array(imgSrc) img = img.reshape(1, img_rows,img_cols,3) img = img.astype('float32') img /= 255 t0=time.time() y_pred = model.predict(img) return y_pred num_classes = 2 img_rows,img_cols=128, 128 input_shape = (img_rows,img_cols,3) #224, 224, 3) model = model_family_cnn(input_shape, num_classes = num_classes) # load the weights from the last epoch model.load_weights('params_hirakegoma-900.hdf5', by_name=True) #params_hirakegoma-61.hdf5 print('Model loaded.') while True: #np.random.seed(1337) # for reproducibility img_rows,img_cols=128,128 imgSrc=[] imgSrc = image.load_img("./out_test/figure.jpg", target_size=(img_rows,img_cols)) plt.imshow(imgSrc) plt.pause(1) plt.close() pred = prediction(imgSrc) print(pred[0]) if pred[0][0]>=0.5: #二択なので、一応0.5以上で選択とした filename = "ohayo.wav" print("ohayo") else: #おはよう以外は全てhirakegoma。追加してAlexaみたいに「わかりません」とかもありだが失敗しないので。。 filename = "hirakegoma.wav" print("hirakegoma") # チャンク数を指定 CHUNK = 1024 #filename = "hirakegoma.wav" #デバッグ用;マイク不調でreal timeで取得できない場合に利用 wf = wave.open(filename, "rb") # PyAudioのインスタンスを生成 p = pyaudio.PyAudio() # Streamを生成 stream = p.open(format=p.get_format_from_width(wf.getsampwidth()), channels=wf.getnchannels(), rate=wf.getframerate(), output=True) # データを1度に1024個読み取る input = wf.readframes(CHUNK) # 実行 while stream.is_active(): output = stream.write(input) input = wf.readframes(CHUNK) if input==b'': #dataがなくなると、''ではなく、b''が返ってくる break # ファイルが終わったら終了処理 stream.stop_stream() stream.close() p.terminate()【ウワンの駄文的妄想】 このシーケンスで一番悩むのは、計測時間と計測間隔(トリガー)かもしれません。 それなりに長いセンテンスを一連として判断する場合は、もう少し長い計測時間が必要で、 今回は一定の閾値で動き始めますが、商用を考えると出だしは「Alexa」が必要なのが理解できます。 そして肝心なのはそのあとの待ち時間や会話終了判断等がある意味営業秘密になると思われます。 ※Alexaも少し長文の質問だと結構混乱するので、たぶん短文ベースで変換⇒意味解釈⇒回答や検索や動作⇒出力 をほとんどはCacheベースでやっているようです結果
今回のアプリを動かしてちょっと驚いたことは、「ひらけごま」と「おはよう」しか学習していないが、この二択だと「ひらけ」とか「らけごま」とか、「おはー」や「よう」くらいの短い単語でも数値的にほぼ100%の予測結果を返している。これは二択だと当たり前なのかもだけど、そんな感じに見えないので、もう少しカテゴリを増やして同様な事象となるか実験したいと思う。
上にしめしたような通常の周波数の音声しか入れていないが、以下のようにとっても高周波の「おはよう」や「ひらけごま」も認識する。つまり汎化性能は高そうだ。
「おはよう」
「ひらけごま」
まとめ
・「ひらけごま」と「おはよう」に反応するアプリを作成した
・今回はVGG16-likeなモデルで識別した
・Pyaudioの音声をリアルタイムなSTFT変換して識別に利用した・機械学習でどこまで行けるかや100個くらいの文章まで拡張したいと思う
・このアプリ利用なTello制御もやってみたいと思う
・Unity連携もできそうである
・今回の結果は終始一貫ウワンの音声でやっているので一般化されたときの精度はどの程度なのかは試してみたい
⇒一応、Githubに学習済データを置いたので試したら教えてくださいm(__)mおまけ
出力例
[ 1.61695224e-19 1.00000000e+00] hirakegoma [ 1.61695224e-19 1.00000000e+00] hirakegoma [ 2.75610277e-04 9.99724329e-01] hirakegoma [ 9.99943733e-01 5.63181093e-05] ohayo [ 9.99943733e-01 5.63181093e-05] ohayo [ 9.99943733e-01 5.63181093e-05] ohayo [ 9.99824941e-01 1.75072724e-04] ohayo [ 9.99824941e-01 1.75072724e-04] ohayo [ 9.99824941e-01 1.75072724e-04] ohayo [ 0.99702293 0.00297703] ohayo [ 0.99702293 0.00297703] ohayo [ 2.03095806e-05 9.99979734e-01] hirakegoma [ 2.03095806e-05 9.99979734e-01] hirakegoma [ 1.00000000e+00 1.99542429e-23] ohayoVGG16-likeモデル
Model loaded. _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) (None, 128, 128, 3) 0 _________________________________________________________________ conv1_1 (Conv2D) (None, 128, 128, 32) 896 _________________________________________________________________ conv1_2 (Conv2D) (None, 128, 128, 32) 9248 _________________________________________________________________ batch_normalization_1 (Batch (None, 128, 128, 32) 128 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 64, 64, 32) 0 _________________________________________________________________ dropout_1 (Dropout) (None, 64, 64, 32) 0 _________________________________________________________________ conv2_1 (Conv2D) (None, 64, 64, 64) 18496 _________________________________________________________________ conv2_2 (Conv2D) (None, 64, 64, 64) 36928 _________________________________________________________________ batch_normalization_2 (Batch (None, 64, 64, 64) 256 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 32, 32, 64) 0 _________________________________________________________________ dropout_2 (Dropout) (None, 32, 32, 64) 0 _________________________________________________________________ conv3_1 (Conv2D) (None, 32, 32, 256) 147712 _________________________________________________________________ conv3_2 (Conv2D) (None, 32, 32, 256) 590080 _________________________________________________________________ conv3_3 (Conv2D) (None, 32, 32, 256) 590080 _________________________________________________________________ conv3_4 (Conv2D) (None, 32, 32, 256) 590080 _________________________________________________________________ batch_normalization_3 (Batch (None, 32, 32, 256) 1024 _________________________________________________________________ max_pooling2d_3 (MaxPooling2 (None, 16, 16, 256) 0 _________________________________________________________________ dropout_3 (Dropout) (None, 16, 16, 256) 0 _________________________________________________________________ flatten_1 (Flatten) (None, 65536) 0 _________________________________________________________________ dense_1 (Dense) (None, 40) 2621480 _________________________________________________________________ activation_1 (Activation) (None, 40) 0 _________________________________________________________________ dropout_6 (Dropout) (None, 40) 0 _________________________________________________________________ dense_2 (Dense) (None, 2) 82 _________________________________________________________________ activation_2 (Activation) (None, 2) 0 ================================================================= Total params: 4,606,490 Trainable params: 4,605,786 Non-trainable params: 704 _________________________________________________________________ WARNING:tensorflow:Variable *= will be deprecated. Use variable.assign_mul if you want assignment to the variable value or 'x = x * y' if you want a new python Tensor object. Train on 360 samples, validate on 76 samples