- 投稿日:2019-03-05T23:55:34+09:00
Pythonで親階層のモジュールをimportする
python 3.7でのみ動作検証しました。
以下のような構成があったとします。
sample/ ├── sample1.py ├── main │ ├── main1.py │ └── src1 │ ├── main2.py │ └── src2 │ ├── main3.py │ └── main4.py └── sub └── sub1.pymain4.pyから
- main3.py
- main2.py
- main1.py
- sample1.py
- sub1.py
を呼び出したいときのメモです。
Pythonでimportを記述した場合、ライブラリを探すディレクトリが決まっています。しかしそこには、実行ファイルを含むディレクトリとそのサブディレクトリ群しか含まれません。
実行ファイル親階層にあるファイルをimportする場合、探索範囲に指定ディレクトリを追加する必要があります(パスが通っている状態にする)。
なお、
main4.py以外のファイルでは、以下の内容で実装されてるとします。def hello(): print(os.path.basename(__file__)) # 該当のファイル名を出力とりあえず動く
main4.pyimport main3 import sys sys.path.append('../') import main2 sys.path.append('../../') import main1 sys.path.append('../../../') import sample1 sys.path.append('../../../sub') import sub1 main3.hello() main2.hello() main1.hello() sample1.hello() sub1.hello()参考
- 投稿日:2019-03-05T23:29:24+09:00
pythonメモ 噛み砕いて覚えるos.pathの一部
特定のファイルを他のディレクトリから参照したい場合に衝突した
pathの取得の分かった部分だけ (最初いがいprint()は割愛していますmain.pyimport os print(__file__) # これで実行中の.pyの絶対パスが分かる os.path.abspath('test.txt') # 実行中の.pyと同じディレクトリならばこれでパスを調べれる os.path.dirname(__file__) # これで実行している.pyが存在するディレクトリのパスがわかる os.path.dirname(os.path.dirname(__file__)) # どうやら上位のディレクトリにどんどんいけそうだ dir_path = os.path.dirname(os.path.dirname(__file__)) new_path = os.path.join(dir_path, 'hello.txt') # これでパスを繋げることができるのでディレクトリを探したりもできそうだ結果.pyC:\User\mpec\python\main.py C:\User\mpec\python\test.txt C:\User\mpec\python C:\User\mpec C:\User\mpec\hello.txtまとめ
pathlibの方が良いみたいだな。。。
- Python3.4以降ならos.pathはさっさと捨ててpathlibを使うべきまた、お気づきの点がありましたら遠慮なくご指摘お願いいたします。
- 投稿日:2019-03-05T23:12:42+09:00
pubmedからスクレイピングしたデータをcsv形式で保存する
はじめに
初投稿です。
今回はpubmedで検索してきたデータをcsvとして保存するコードを書きました。
seleniumのchrome driverを使っています。環境設定
seleniumのchrome driverを使用するにはPATHを設定する必要があります。
環境設定の方法は省略します。環境設定で参考にしたサイト
Python + Selenium で Chrome の自動操作を一通りライブラリ
import time from selenium import webdriver import chromedriver_binary import pandas as pdChrome Driverを動かす
任意のキーワードに対して、検索を行います。
find_element_by_idでページ数を取得して、
そのページ数分の情報をスクレイピングしています。
ページ数が1ページの場合、pagenoが存在しなくてエラーが出るので、
try exceptを使っていますが、もっと上手いやり方があるような気がします。def get_pubmed_info(keyword): driver = webdriver.Chrome() url = "https://www.ncbi.nlm.nih.gov/pubmed/?term="+keyword.replace(' ','+') driver.get(url) driver.implicitly_wait = 1 data = [] try: page_num = int(driver.find_element_by_id('pageno').get_attribute('last')) except: page_num = 1 for i in range(page_num): driver.find_element_by_name('Display').click() [tag for tag in driver.find_elements_by_tag_name('input') if (tag.get_attribute('value') == 'abstract')][1].click() source = driver.page_source.split('\n\n\n') for paper in source: block = paper.split('\n\n') if(len(block) >= 6): data.append(block) driver.back() time.sleep(1) if (i < page_num - 1): driver.find_element_by_css_selector('a.active.page_link.next').click() print(i) time.sleep(1) return dataCSVとして出力
pandasのto_csvを使って出力しています!
保存先のPATHは適当に設定してください。def get_dataframe(data, keyword): csv_data = pd.concat([ pd.DataFrame([data[i][1] for i in range(len(data))], columns=["title"]), pd.DataFrame([data[i][2] for i in range(len(data))], columns=["authors"]), pd.DataFrame([data[i][4] for i in range(len(data))], columns=["abstract"])], axis=1) keyword = keyword.replace(" ", "_") csv_data.to_csv(f"../desktop/{keyword}.csv")全文
import time from selenium import webdriver import chromedriver_binary import pandas as pd def main(): keyword = "yamanaka shinya" data = get_pubmed_info(keyword) get_dataframe(data, keyword) def get_pubmed_info(keyword): driver = webdriver.Chrome() url = "https://www.ncbi.nlm.nih.gov/pubmed/?term="+keyword.replace(' ','+') driver.get(url) driver.implicitly_wait = 1 data = [] try: page_num = int(driver.find_element_by_id('pageno').get_attribute('last')) except: page_num = 1 for i in range(page_num): driver.find_element_by_name('Display').click() [tag for tag in driver.find_elements_by_tag_name('input') if (tag.get_attribute('value') == 'abstract')][1].click() source = driver.page_source.split('\n\n\n') for paper in source: block = paper.split('\n\n') if(len(block) >= 6): data.append(block) driver.back() time.sleep(1) if (i < page_num - 1): driver.find_element_by_css_selector('a.active.page_link.next').click() print(i) time.sleep(1) return data def get_dataframe(data, keyword): csv_data = pd.concat([ pd.DataFrame([data[i][1] for i in range(len(data))], columns=["title"]), pd.DataFrame([data[i][2] for i in range(len(data))], columns=["authors"]), pd.DataFrame([data[i][4] for i in range(len(data))], columns=["abstract"])], axis=1) keyword = keyword.replace(" ", "_") csv_data.to_csv(f"../desktop/{keyword}.csv")最後に
初投稿ということで、あまり難しくない内容をテーマに選びましたが、
今後は少しずつレベルを上げていきます(ネタ探ししなきゃ。。)
- 投稿日:2019-03-05T23:01:21+09:00
Python seleniumでわからないことを解決する記事
概要
Seleniumを使用していてわからなかったところを、誰かの役に立てばよいということから書きます。
WebScraypingは著作権違法などに気を付けて行ってください(詳しくは@nezuqさんが書かれた記事を参考にしてください。)Seleniumの良記事紹介
すばらしい記事にて導入の仕方と、簡単なチュートリアルが書かれています。勘が良い方はこれだけをみてわかると思いますが、具体的にどうすればよいかわからないことがあったので、補完する意味合いの記事です。
スクレイピング画像保存
requestsを使ってください。Bit単位でファイルに保存してます。
import requests src = driver.find_element_by_id("A").get_attribute("src") imagename = src.split("/")[-1] with open("img/"+imagename, "wb") as f: re = requests.get(src) f.write(re.content)Tableの詳細一覧を個別に取得したい
for分を使ってループ処理します。下コードは場所を特定したかったのでenumerateを使ってindexも取得しています。
scroll = driver.find_element_by_id("A") table = scroll.find_element_by_tag_name("table") thead = table.find_element_by_tag_name("thead").find_element_by_tag_name("tr").find_elements_by_tag_name("th") for i, th in enumerate(thead): explain += "<th>"+ th.text+ "</th>" tbody = table.find_element_by_tag_name("tbody").find_element_by_tag_name("tr").find_elements_by_tag_name("th") for i, th in enumerate(tbody): explain += "<th>"+ th.text+ "</th>"ID_Aの下のtagBの中のtagCの中のhrefがほしい
Xpathを使って素直に書くこともできますが、こういう書き方もあるよとご参考になれば
href = driver.find_element_by_id("A").find_element_by_tag_name("B").find_element_by_tag_name("C").get_attribute("href")指定されたIDがあるかチェックしたい
find_elements_by_idでlistで取得して、サイズを確認して個別処理を走らせる
if(len(driver.find_elements_by_id("A")) > 0): a = hogehoge(driver)
- 投稿日:2019-03-05T22:28:05+09:00
【Python】切り捨て除算演算子を使った切り上げ【算数】
pythonで切り上げはいつも次のようにmathをimportして求めていた。
import math n = 2 / 3 # 0.6666666666666666 math.ceil(n) # 1次のような書き方もできるが何しているのか良く分からなかったのでメモ。
x, y = 2, 3 -(-x // y) # 1//が割り算の整数部分を返す演算子という事は分かる。
でもマイナスつけたら何で切り上げになるんだ。
細かく実行してみた。x, y = 2, 3 # 1. 普通の割り算 x / y # 0.6666666666666666 # 2. 1の小数部分を切り捨て x // y # 0 # 3. 1の負数版 -x / y # -0.6666666666666666 # 4. 3を切り捨てて-1側になる -x // y # -1 # 5. 4の符号を反転させると切上げの結果と等しくなる -(-x // y) # 1切り捨てて数字が大きくなるのは確かにおかしい。
ここまで動かして、負数の切り捨てが小さい方へ倒れるからだと理解。こういう問題めっちゃ苦手なんですが、克服する方法ってないんでしょうかね...
- 投稿日:2019-03-05T22:09:16+09:00
python, ruby, php, node のループの速さ
今日も楽しいマイクロベンチマーク。
某所で python の for ループが遅いという話を聞いたので、そうなの? と思って他の言語と比べてみた。
ソース
python3
python3import sys r=0 for i in range(int(sys.argv[1])): r+=1 print(r)PHP
<?php $len = (int)$argv[1]; $r=0; for( $i=0 ; $i<$len ; ++$i ){ ++$r; } echo($r);node.js
node.jsconst len = process.argv[2]|0; let r=0; for( let i=0 ; i<len ; ++i ){ ++r; } console.log(r);ruby
ruby2.6n=ARGV[0].to_i r=0 n.times do r+=1 end p r測る人
測る人はわりとやる気ない感じで、
Benchmark.realtimeを使っている。bench.rbrequire "benchmark" require "pp" COMMANDS = [ [ "php for.php", "php" ], [ "node for_pp.js", "node" ], [ "python3 for_range.py", "python3" ], [ "ruby times.rb", "ruby" ], ] COUNTS = (10..27).map{ |e| 2**e } File.open( "result.csv", "w" ) do |f| f.puts( (["tick"]+COMMANDS.map{ |cmd| cmd[1] }).join(",") ) COUNTS.each do |count| s=([count]+COMMANDS.map{ |cmd| Benchmark.realtime{ %x(#{cmd[0]} #{count}) } }).join(",") f.puts(s) puts(s) end end各言語のファイル名がいい加減なのがバレるね。
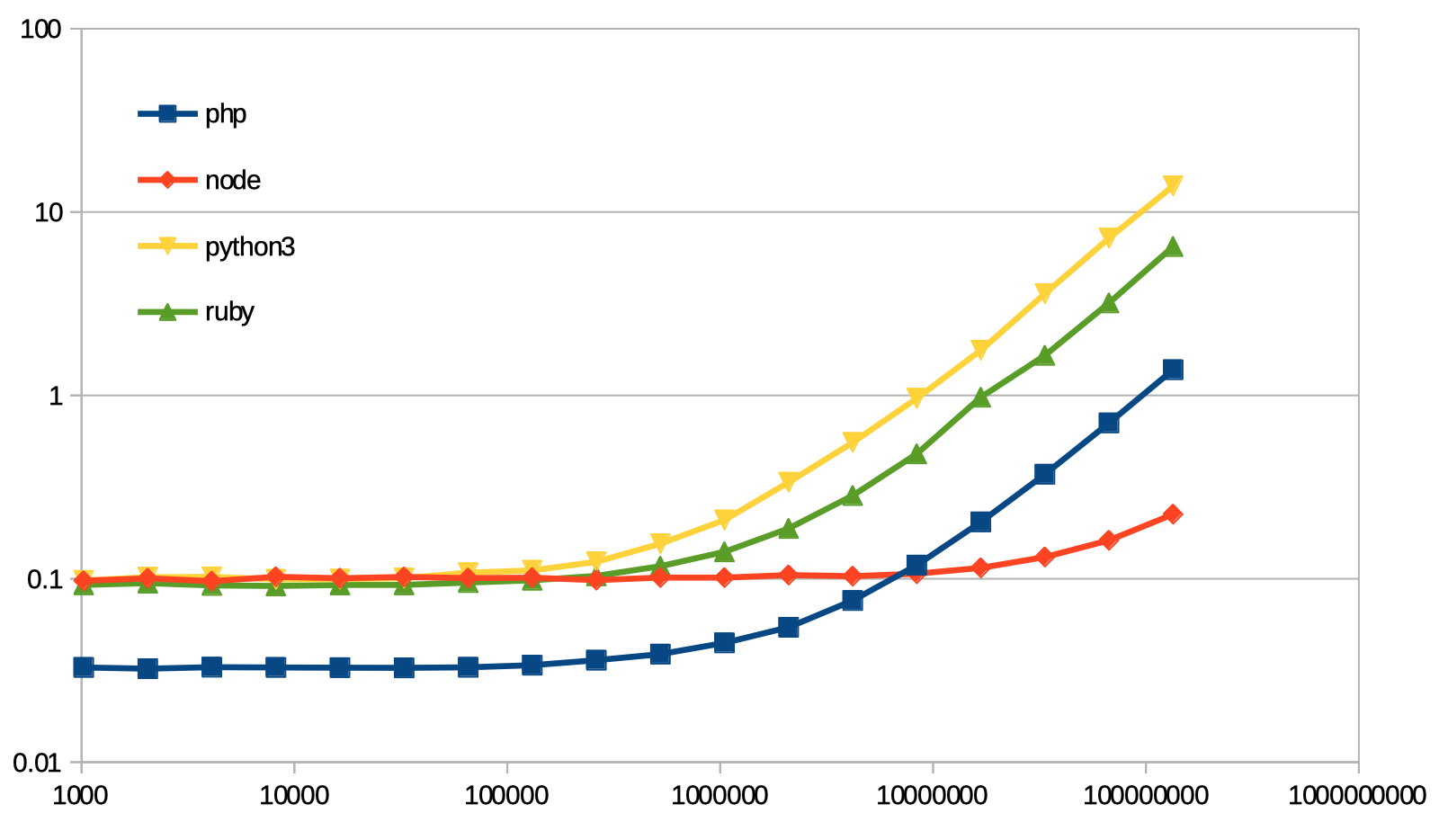
結果
結果は下記グラフの通り。
両対数グラフ注意。
測る人のソースコードを見ると分かる通り、プログラムの起動時間を含んでいる。
10万回ぐらい回しても、起動時間の影に隠れて殆ど見えないということがわかる。1.34億回回すのに要する時間を、node.js を 1.00 として表にすると:
php node python3 ruby Benchmark.realtime そのまま 6.13 1.00 61.72 28.83 起動時間らしきものを減算 10.56 1.00 108.11 50.13 「起動時間らしきものを減算」は、1.34億回の結果から 1024回の結果を減じたもの。
こんな感じ。node 速いね。
そして噂のとおり、python3 は遅いのであった。あと。PHP だけ起動が速いらしい。そういうものか。
- 投稿日:2019-03-05T22:05:43+09:00
Pythonでseleniumを用いたスクレイピング
pythonにてseleniumを使う機会があったので、メモ。
chromedriverのダウンロード
以下のURLからchromedriverをダウンロード
http://chromedriver.chromium.org/downloads
firefoxdriverもあるらしい。ライブラリの追加
➜ pip install selenium無事インストールできたらOK
スクリプトでseleniumとchrome driverを読み込む
from selenium import webdriver driver = webdriver.Chrome(executable_path="./chromedriver")chromedriverへのパスは注意。上記コードは同じディレクトリに配置想定。
所定のURLのページを開く
url = "https://www.google.co.jp/"; driver.get(url)要素を取得する
以下の2つのメソッドを使用した。
find_elements_by_xpath
- リストなど、複数あるものを取得。
- ループを回してリストに繰り返し処理をかけて処理を効率化することができる。
find_element_by_xpath
- 特定の要素を狙って取得
なお、
xpath以外にも、
- id名
- class名
- その他
などの要素取得方法がある。
参考今回は
xpathを使用した。xapthはデベロッパーツールから確認できる。
macのショートカットは、command+option+iデベロッパーツールにて、HTML要素を右クリックするとメニューが出てくるので、
Copy > Copy XPath の順で選択。
要素の中の属性を取得したい場合
要素(HTMLタグ)の中の属性(attribute)を取得したい場合は
get_attribute("属性名")を使う。例
driver.find_element_by_xpath("//div[@class='hoge']/div[1]/a/img").get_attribute("src")例では
src属性の値を取得している。取りたい要素にidやclassが割り振られておらず、同じタグが子要素として並んでいる場合
以下のような場合に
bを取得するにはどうしたらいいか?<div id="hoge"> <div>a</div> <div>b</div> <div>c</div> </div?>以下のようにする。
driver.find_element_by_xpath("//div[@id='hoge']/div[2]").text2番目に格納されているdivと明示的に示せば、
bが取得できる。
参考

- 投稿日:2019-03-05T21:56:04+09:00
機械学習用にプロ野球の球団マスコット画像を集めるスクリプトを作ってみた
機械学習用(画像判定のデータ収集用)のデータ集め用に、google画像検索から画像ファイルを集めるスクリプトを書いてみたので、ここに残しておこうかと思います。
ちなみにseleniumを使用するための環境構築は以下のリンクなんかを参考にしています。
https://tanuhack.com/python/selenium/from selenium import webdriver from selenium.webdriver.common.keys import Keys import os import json import urllib import sys import time import io from PIL import Image text = [ "ドアラ","スラィリー","トラッキー","ジャビット", "つば九郎","スターマン" ] download_path = ["doara/","sllighly/","toracky/","jabitto/","tubakuro/","starman/"] headers = {} headers['User-Agent'] = "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36" extensions = {"jpg", "jpeg", "png", "gif"} img_count = 0 downloaded_img_count = 0 img_skip = 0 dPath_index = 0 #画像を取得 for index in text: # ディレクトリを作成 try: os.mkdir(download_path[dPath_index]) except OSError: print("file exist") # Firefoxを起動 browser = webdriver.Firefox() # Webブラウザを表示 url = "https://www.google.co.in/search?q={}&source=lnms&tbm=isch".format(index) browser.get(url) # 画像を全て表示させる for __ in range(10): # スクロール browser.execute_script("window.scrollBy(0, 1000000)") time.sleep(0.2) try: # 「結果をもっと表示」があればクリック browser.find_element_by_xpath("//input[@value='結果をもっと表示']").click() time.sleep(2.5) except Exception as e: print("not found:"+ str(e)) imges = browser.find_elements_by_xpath('//div[contains(@class,"rg_meta")]') print("Total images:"+ str(len(imges)) + "\n") for img in imges: # Get image img_count += 1 img_url = json.loads(img.get_attribute('innerHTML'))["ou"] img_type = json.loads(img.get_attribute('innerHTML'))["ity"] print("Downloading image "+ str(img_count) + ": "+ img_url) try: if img_type not in extensions: img_type = "jpg" # Download image and save it raw_img = io.BytesIO(urllib.urlopen(img_url).read()) img = Image.open(raw_img) img.save( download_path[dPath_index]+'img{}.jpg'.format(img_count)) time.sleep(0.2) downloaded_img_count += 1 except Exception as e: print("Download failed:"+ str(e)) finally: print("") # Webブラウザを一旦閉じる img_count = 0 browser.close() dPath_index+= 1参考文献
- 以下のgitHubと記事を参考に作らせていただきました。
https://github.com/penseeartificielle/google-image-scrapping/blob/master/google-image-scraping.py
- 投稿日:2019-03-05T19:03:15+09:00
Terobosan Terbaru situs judi online rajasenangqq
Terobosan terbaru dari situs judi poker domino online terpercaya rajasenangqq
Rajasenangqq mempermudah para member untuk melakukan deposit dengan mudah tanpa harus ribet yaitu dengan system deposit menggunakan pulsa.
Jadi anda tidak perlu harus ke ATM untuk transfer dana deposit.Untuk anda para pecinta domino QQ, Kini hadir situs domino QQ :
- TERBAIK (Dalam hal PELAYANAN)
- TERPERCAYA (GAMPANG MENANG)
- TERCEPAT (Proses DEPO-WD).
Kami menyediakan 8 permainan dalam 1ID :
- POKER
- BANDAR POKER
- ADU Q
- BANDAR Q
- DOMINO 99
- CAPSA SUSUN
- SAKONG
- BANDAR 66MIN. DEPO HANYA RP. 10.000
DAPATKAN BONUS {TO - 0.5%, REFERAL - 10%, TRIK}
KLIK LINK :
http://bit.ly/RJ53nang
Whatsapp : http://bit.ly/w4hpRJQQ

- 投稿日:2019-03-05T18:38:24+09:00
Flaskでツイートからおススメの「いらすとや」の画像を表示するアプリつくった
こんにちは、Takaです。
今回は、簡単な自然言語処理を使って、ツイートから「いらすとや」さんの画像を表示させるアプリを作りました。仕組みとしては
1.ツイートを収集
2.ツイートを形態素解析する
3.最も多かった単語で検索をする
4.検索した項目の一番初めの画像を表示する
感じです。完成したアプリはこのようになります
0.環境
Windows10
python 3.7.2
jupyter notebook 1.0.0
atom(Flask用エディター)
janome 0.3.7(自然言語処理用ライブラリ)
Flask 0.12.2 (アプリ作成)1.ツイート収集
Twitterの情報を扱うにはTwitterAPIの認証をしなければいけません。
また、APIを扱うには以下の4つが必要になります。・Consumer API key
・API Secret key
・Access token
・Access token secret詳しい認証方法は以下のサイトを参照にしてください。
【2019年1月最新版】新しくなったTwitterのAPIの登録方法と使い方。Developer登録をしてAPI keyを取得するまでの手順を公開!RailsもPythonも対応可能!
(APIの取得方法は不定期で変わるので最新版を調べることをお勧めします)また、パラメータ(コード上ではparams)の引数を変えることで、取得するツイートの数、ユーザーの指定など細かい設定を行うことが可能です。
詳しくはこちらを参照してください。
Twitter 開発者 ドキュメント日本語訳以下のコードで最新20件のツイートを取得します。
def_tweet.pyfrom requests_oauthlib import OAuth1Session import json #TwitterAPIの認証情報 consumer_key = "" consumer_secret = "" access_token = "" access_token_secret = "" #APIの認証 twitter = OAuth1Session(consumer_key, consumer_secret, access_token, access_token_secret) #最新のタイムラインを取得する url = "https://api.twitter.com/1.1/statuses/user_timeline.json" #取得するツイートの数:20,Rtは除く params = {"screen_name":"適用するユーザーのID","count":20,"include_rts":False} req = twitter.get(url, params=params) if req.status_code == 200: timeline = json.loads(req.text) #格納用リスト tweets = [] for tweet in timeline: #リストに追加 tweets.append(tweet["text"]) else: print("ERROR: %d" % req.status_code)2.前処理
自然言語処理をするにあたって前処理が必要です。
ツイートにはノイズ(URL,記号,etc...)が存在します。これらは形態素解析する際に邪魔になるので削除したいです。また、ストップワード(頻繁に出てくる言葉)も削除したいです。今回は名詞のみを取り出すコードにしたので、助詞などのストップワードは含まれないつもりでした。しかし、出力結果を見ると助詞らしきものが名詞と判断されているものもあったので、ここでは見つけたものを自分でリストにして削除しました。
そして、ツイートはカジュアルなものが多いのです。例えば、
後期フル単
やったーーーーーーーーー!!
わーーーーーーーーーい!!?2019年2月28日
「ー」を使って喜びを表しているつもりかもしれませんが、形態素解析をする上では邪魔以外の何物でもありません。
そこで、NEologdnライブラリを用います。このライブラリは文字の正規化を行ってくれます。
上のツイートで試してみましょう。neologd.pyimport neologdn tweet = neologdn.normalize("後期フル単\nやったーーーーーーーーー!!\nわーーーーーーーーーい!!?") print(tweet)後期フル単
やったー!!
わーい!!?こんな感じになります。喜びがさっきより感じられなくなりましたね。
以上を踏まえて、前処理をする関数は以下のようにしました。
format_text.pyimport re import neologdn def format_text(text): text=re.sub(r'https?://[\w/:%#\$&\?\(\)~\.=\+\-…]+', "", text)#URL text=re.sub(r'[!-~]', "", text)#半角記号,数字,英字 text=re.sub(r'[︰-@]', "", text)#全角記号 #文字を正規化 text = neologdn.normalize(text) #大文字を小文字に変換 text = text.lower() #ひらがなのストップワードリスト hira_stop = ["の","こと","ん","さ","そ","これ","こ","ろ"] for x in hira_stop: text = re.sub(x,"",text) return text3.形態素解析
いよいよ自然言語処理に入ります。使ったライブラリはjanomeです。
まず、先ほど取り出したツイートを1つの文字列データにし、前処理を行います。
後に、janomeに備わっているCount機能を使い、名詞だけを取り出してトップ5まで取り出すことにします。
janomeのCount機能に関しては開発者さんが詳しく説明しているので以下のURLを参照にしてみてください。
[janome 開発日誌] 速くなってワードカウント機能が追加された janome 0.3.5 をリリースしましたdef_nlp.pyfrom janome.tokenizer import Tokenizer from janome.analyzer import Analyzer from janome.tokenfilter import * string = "\n".join(tweets) #1つの文字列データにする #前処理実行 normalized_string = format_text(string) #POSKeepFilter - 引数に指定した品詞を取り出す #tokenCountFiletr - トークンの出現回数をカウントする token_filters = [POSKeepFilter('名詞'), TokenCountFilter()] #Analyzerオブジェクトを生成 a = Analyzer(token_filters=token_filters) #カウントを実行 words = list(a.analyze(normalized_string)) #top5を取り出す top_pair = sorted(words, key = lambda x:x[1], reverse=True)[:5] #dict #名詞のみ取り出す top_words = list(map(lambda x:x[0], top_pairs))4.スクレイピング
次に取り出した名詞を使って「いらすとや」の検索をかけ、一番上にあるリンクの画像を表示させます。
このコードを作るにあたってこちらの記事を大変参考にさせていただきました。
ありがとうございます
「いらすとや」の画像をスクレイピングで自動収集してみたdef_scraping.pyfrom bs4 import BeautifulSoup import requests #出現頻度が最も高い単語 top_word = top_words[0] linkData = [] url = "https://www.irasutoya.com/search?q=" #top_wordで検索 response = requests.get(url+top_word) soup = BeautifulSoup(response.text, "lxml") links = soup.select("a") for link in links: #aタグにある全てのhref href = link.get("href") #取得したリンクが画像リンクかどうか if re.search('irasutoya.*blog-post.*html$',href): #取得したリンクがlinkData[]にないか確認 if not href in linkData: linkData.append(href) #画像リンクを取得 imageLinks = [] for link in linkData: res = requests.get(link) soup = BeautifulSoup(res.text, "lxml") links = soup.select(".separator > a") for a in links: imageLink = a.get('href') imageLinks.append(imageLink) #一番初めの画像を取り出す img_1 = imageLinks[0]5.Flaskで書く
以上のコードをFlaskを使って実行できるように修正します。
今までのコードはJupyter Notebookを使っていたのですが、Flaskを使うと正常に作動しなかったため、ここではテキストエディタのAtomを使いました。
FlaskについてはAI AcademyさんのサイトとDaiさんのNoteを参考にしました。
・AI Academy:Webアプリケーション開発編
・Flaskチュートリアル - Pythonでツイッターの分析ツールを作ってディプロイしよう!(動画つき!)-初めに、Flask用にFlask_appというディレクトリを作り、そこにファイルを保存していくことにします。
最終的なディレクトリはこのようになっています。dir_treeflask_app ├ main.py ├ config.py └ templates └ index.htmlconfig.pyはAPIのKeyを保存したものです。
config.pyCONFIG = { "CONSUMER_KEY":"", "CONSUMER_SECRET":"", "ACCESS_TOKEN":"", "ACCESS_TOKEN_SECRET":"" }次に、templatesディレクトリですが、ここにはhtmlファイルを保存します。
Flaskのrender_template関数を使うとtemplatesディレクトリに入っているhtmlファイルをアプリとして表示させ、またそのファイルに値を入れることができます。ここで重要なのはrender_templateはtemplatesという名前のディレクトリでないとエラーになることです。あと、templatesのsを忘れないようにしてください!
templatesディレクトリのidex.htmlはこのようになっています。
※HTMLは勉強不足なのでかなり適当です※index.html<!DOCTYPE html> <html lang="ja"> <head> <title>おススメや</title> <meta charset="utf-8"> <style type="text/css"> body{background-color:#CCFF16; height: 200px; } .container{ text-align: center; padding: 5px, 15px; background-color: #fff; margin: 0 auto; width: 410px; } .btn{ margin:5px; display: inline-block; padding: 7px 20px; border-radius: 25px; text-decoration: none; color: #FFF; background-image: linear-gradient(45deg, #FFC107 0%, #ff8b5f 100%); transition: .4s; } .btn:hover{ background-image: linear-gradient(45deg, #FFC107 0%, #f76a35 100%); } .image{ text-align: center; } .image h2{ background-color: #FFFACD; padding: 5px, 15px; } </style> </head> <html> <body> <div class = "container"> <div class="row"> <div class=col-md-12> <h1>おススメや</h1> <p>ツイッターのIDを入れると、おススメの「いらすとや」の画像が表示されます。</p> <form class="form-inline" method="post"> <div class="form-group"> <span class="input-group-addon">@</span> <input id="user_id" name="user_id" placeholder="ここにツイッターIDを入力してください" type=text class="form-control"> {% if message %} <p>{{message}}</p> {% endif %} </div> </div> <button type="submit" class="btn">試す</button> </form> {% if top_1 %} <p>{{user_id}}が最近多くつぶやいているのは「{{top_1}}」です</p> {% endif %} {% if imageLink %} <p>あなたにおすすめの画像はこれです↓</p> {% endif %} </div> </div> </div> <div class=image> {% if imageLink %} <h2>{{title}}</h2> <img src="{{imageLink}}"></img> {% endif %} </div> </body> </html>次にFlaskの基本的な書き方ですが、先ほど述べた参考サイトに載っているので今回は省略します。
それでは、main.pyのコードをお見せします。
main.py#Flaskのライブラリ from flask import Flask, render_template, request #API情報があるフォルダのimport from config import CONFIG #自然言語処理用のライブラリ from janome.tokenizer import Tokenizer from janome.analyzer import Analyzer from janome.tokenfilter import * from requests_oauthlib import OAuth1Session import json import re import neologdn #スクレイピング用のライブラリ from bs4 import BeautifulSoup import requests consumer_key = CONFIG["CONSUMER_KEY"] consumer_secret = CONFIG["CONSUMER_SECRET"] access_token = CONFIG["ACCESS_TOKEN"] access_token_secret = CONFIG["ACCESS_TOKEN_SECRET"] twitter = OAuth1Session(consumer_key, consumer_secret, access_token, access_token_secret) url = "https://api.twitter.com/1.1/statuses/user_timeline.json" #インスタンス作成 app = Flask(__name__) #ルーティング @app.route("/", methods=["GET", "POST"]) def index(): mg=[] if request.method=="POST": user_id = request.form["user_id"] print("user_id: ",user_id) twts = tweet(user_id) #存在しないアカウント if twts == 404: message = "このアカウントは存在しません" return render_template("index.html",message=message) #鍵垢 elif twts == 401: message = "アカウントの鍵を外してから試してください" return render_template("index.html",message=message) #IDの入れ忘れ elif not user_id or " " in user_id : message = "IDが入力されていません" return render_template("index.html",message=message) else: t_words = nlp(twts) n = 0 most_word = t_words[n] lnkData = scraping(most_word) imglnk = img(lnkData) ttl = title(lnkData) while len(imglnk) == 7: n += 1 most_word = t_words[n] lnkData = scraping(most_word) imglnk = img(lnkData) ttl = title(lnkData) message = "" return render_template("index.html",imageLink=imglnk[0],top_1=most_word,message=message,user_id=user_id,title=ttl[0]) else: mg.append("入力内容が間違っています") return render_template("index.html") #user_idを取得しツイートを取得 def tweet(user_id): tweets=[] params = {"screen_name":user_id,"count":30,"include_rts":False} req = twitter.get(url, params=params) if tweets: tweets = [] else: tweets = [] if req.status_code == 200: timeline = json.loads(req.text) for tweet in timeline: tweets.append(tweet["text"]) return tweets else: print("ERROR: %d" % req.status_code) return req.status_code #自然言語処理 def nlp(tweets): string = "\n".join(tweets) def format_text(text): text=re.sub(r'https?://[\w/:%#\$&\?\(\)~\.=\+\-…]+', "", text) text=re.sub(r'[!-~]', "", text) text=re.sub(r'[︰-@]', "", text) text = neologdn.normalize(text) text = text.lower() hira_stop = ["の","こと","ん","さ","そ","これ","こ","ろ"] for x in hira_stop: text = re.sub(x,"",text) return text normalized_string = format_text(string) token_filters = [POSKeepFilter('名詞'), TokenCountFilter()] a = Analyzer(token_filters=token_filters) words = list(a.analyze(normalized_string)) top_pairs = sorted(words,key=lambda x:x[1], reverse=True)[:5] top_words = list(map(lambda x:x[0], top_pairs)) return top_words #tp_wordを受け取りサイトのリンクデータを格納する関数 def scraping(tp_word): linkData = [] url = "https://www.irasutoya.com/search?q=" response = requests.get(url+tp_word) soup = BeautifulSoup(response.text, "lxml") links = soup.select("a") for link in links: href = link.get("href") if re.search('irasutoya.*blog-post.*html$',href): if not href in linkData: linkData.append(href) return linkData #画像のリンクをリストで返す def img(linkData): imageLinks = [] for link in linkData: res = requests.get(link) soup = BeautifulSoup(res.text, "lxml") links = soup.select(".separator > a") for a in links: imageLink = a.get('href') imageLinks.append(imageLink) return imageLinks #画像のタイトルをリストで返す def title(linkData): titles = [] for link in linkData: res = requests.get(link) soup = BeautifulSoup(res.text, "lxml") h2_links = soup.select("#post > div.title > h2") for link in h2_links: title = link.text title = re.sub("\n", "", title) titles.append(title) return titles app.run(port=12344, debug=False)一つ一つの関数の内容自体に大きな変化はないのですが、細かいところをFlaskで作動させるために変えています。
まず、tweet関数ですが、HTML上で入力されたuser_idを受け取って、そのユーザーのツイートリスト(tweets)、またはステータスーコードを返します。
def_tweet#@use_idのツイートをリストで返す def tweet(user_id): tweets=[] params = {"screen_name":user_id,"count":30,"include_rts":False} req = twitter.get(url, params=params) #1 if tweets: tweets = [] else: tweets = [] if req.status_code == 200: timeline = json.loads(req.text) for tweet in timeline: tweets.append(tweet["text"]) return tweets #2 else: print("ERROR: %d" % req.status_code) return req.status_code#1の部分ですが、ここではtweetsを初期化しています。これによって2回目にuser_idを入力した際にtweetsが空リストに更新されます。
#2の部分でステータスーコードを返しているのは、次に説明する関数でステータスーコードごとに表示させるメッセージを変えるためです。
次にindex関数をみてみましょう。
def_index.pydef index(): title=[] if request.method=="POST": user_id = request.form["user_id"] #1 twts = tweet(user_id) #2 if twts == 404: message = "このアカウントは存在しません" return render_template("index.html",message=message) elif twts == 401: message = "アカウントの鍵を外してから試してください" return render_template("index.html",message=message) elif not user_id or " " in user_id: message = "IDが入力されていません" return render_template("index.html",message=message) #3 else: t_words = nlp(twts) n = 0 most_word = t_words[n] lnkData = scraping(most_word) imglnk = img(lnkData) ttl = title(lnkData) while len(lnkData) == 7: n += 1 most_word = t_words[n] lnkData = scraping(most_word) imglnk = img(lnkData) ttl = title(lnkData) message = "" return render_template("index.html",imageLink=lnkData[0],top_1=most_word,message=message,title=ttl[0]) else: title.append("入力内容が間違っています") return render_template("index.html")#1では、HTMLファイル上のform内にあるname=user_idを取得しています。
これによってHTMLファイル上でユーザーが入力された値を、Flask上で扱うことができます。#2では、先ほどのtweet関数で返されたステータスコードごとにエラーメッセージを表示させるようにしています。また、user_idに何も入力されなかった場合の処理もしました。
#3は上から順に説明していきます。
関数nlp()は、先ほど 3.形態素解析 で説明したものを関数化したものです。
この関数ではツイートを形態素解析した後、その中のトップ5をリストにして返します。t_words = nlp(twts)次に、一番多かった単語をリストから取り出し、scraping関数に渡します。
scraping関数は 4.スクレイピング で説明したものの一部で、画像が表示されるサイトのリンクをリストで返します。
次にimg関数はそのサイトから画像リンクをリストで返し、title関数はその画像のタイトルを返します。n = 0 most_word = t_words[n] lnkData = scraping(most_word) imglnk = img(lnkData) ttl = title(lnkData)最後に、検索した画像が「いらすとや」さんになかった時の処理を行います。
今回、その場合には次に多い単語で検索をするようにしました。
検索した画像が存在しないとき、必ず同じ画像リンクが7個リストの中に入っていることが分かったので、それを利用してwhileで処理しました。while len(imglnk) == 7: n += 1 most_word = t_words[n] lnkData = scraping(most_word) imglnk = img(lnkData) ttl = title(lnkData) message = "" return render_template("index.html",imageLink=imglnk[0],top_1=most_word,message=message,user_id=user_id,title=ttl[0])他の関数は、前述したものと全く同じなので説明は省きます。
まとめ
今回初めてローカルではありますが、アプリケーションを作成できました
次はherokuなどでデプロイまでできたらいいなと思います!その他参考文献
Pythonでサクッと簡単にTwitterAPIを叩いてみる
Pythonで画像スクレイピングをしよう
いらすとや
--書籍--
Pythonによるテキストマイニング入門
Pythonではじめる機械学習 ―scikit-learnで学ぶ特徴量エンジニアリングと機械学習の基礎

- 投稿日:2019-03-05T18:37:10+09:00
C#でむりやりOpenCVを使った話。
C#でOpenCVを頑張って使います。
結論から言うと、PythonでOpenCVを動かし、その結果をTCP通信を介してC#に送るというかなりクソ面白い設計になってしまったので参考になるかはわかりません。前書き
こんにちは。
この記事は高専カンファレンス×学生LT in 東京で話した内容に少し加えた内容です。
初めてのQiita記事&初めてのMarkdownなので間違い等ありましたらご連絡ください。C#でOpenCVが使えないのだが...
長々と話してもしょうがないのでさっさと本題に移りましょう。
私の場合、NuGetパッケージからOpenCVのライブラリをダウンロードしてきて使用するという方法をとったとき、謎のエラーが連発しNuGetからOpenCVを使う気が失せてしまったので仕方なく別の方法をとる必要がありました。
そこでできるやつ(Python)に任せてC#はその結果だけを受け取るという方法を取り、そして実際に試したことを書いていきます。Pythonを使ってOpenCVを使おう
1.IronPythonを使う
IronPythonとは何か。
IronPythonとは、.NET FrameworkおよびMono上で動作するPythonの実装である。(引用:Wikipedia)
らしいです(適当)。もっとかみ砕くとC#とかで簡単に動かせることのできるPythonだよ。ってことです。
しかしこのIronPythonでOpenCVを動かそうとしたときOpenCVのライブラリがうまく読み込ませませんでした。詳しい原因は不明ですが、おそらくPythonとIronPythonが本質的に別のものだからだと思います(誰か詳しい人教えてください)。2.Pythonファイルの外部ファイルとしてC#から起動する
Proceess.Start(@"FileName.py");こうするだけでファイルの起動はでき、返り値も簡単に取得できます(詳しくは別の記事を参照してください)。
が、これにも問題があります。それは遅延の問題です。OpenCVをPythonで使用するときの初期化処理には1秒ほど時間がかかり、いちいち起動し直していては実用性がありません。3.TCP通信を使用する
結論としてこの方法をとりました。なんでこんな仕様にしたんだというお叱りあると思いますが設計したのが朝の三時なので仕方ないですね()。
さて、実装ですがC#側でもPython側でも大したことはしていませんので参考にしたリンクだけ貼っておきます。TCPクライアント・サーバープログラムを作成する
少しだけ付け足すと、クライアントからはデータを受け取る必要がないので送信する部分は全部カットでき、何回もデータを受け取る必要があるのですべてをwhile(true)でくくってください。
一応使用したコードを這っておきます(変数の宣言やusingディレクディブについては書いていないので適当に補完しながら見てください)while (true) { listener.Start(); //開始 TcpClient client = null; try { client = await listener.AcceptTcpClientAsync(); } //受け取り catch (Exception) { return; } if (client == null) return; NetworkStream ns = client.GetStream(); //クライアントからストリーム情報を取得 ns.ReadTimeout = 10000; ns.WriteTimeout = 10000; MemoryStream ms = new MemoryStream(); byte[] resBytes = new byte[256]; int resSize = 0; do { //データの一部を受信する resSize = ns.Read(resBytes, 0, resBytes.Length); //Readが0を返した時はクライアントが切断したと判断 if (resSize == 0) break; //受信したデータを蓄積する ms.Write(resBytes, 0, resSize); //まだ読み取れるデータがあるか、データの最後が\nでない時は受信を続ける } while (ns.DataAvailable || resBytes[resSize - 1] != '\n'); //受信したデータを文字列に変換 string resMsg = Encoding.UTF8.GetString(ms.GetBuffer(), 0, (int)ms.Length); ms.Close(); //末尾の\nを削除 resMsg = resMsg.TrimEnd('\n'); //Console.WriteLine(resMsg); CheckMessage(resMsg); //Pythonから送られてくる座標データを解析して適切に処理するすごーい関数。 }次にPython部分の実装です。といってもsocketの機能が強いのであまりコードは書いていません。
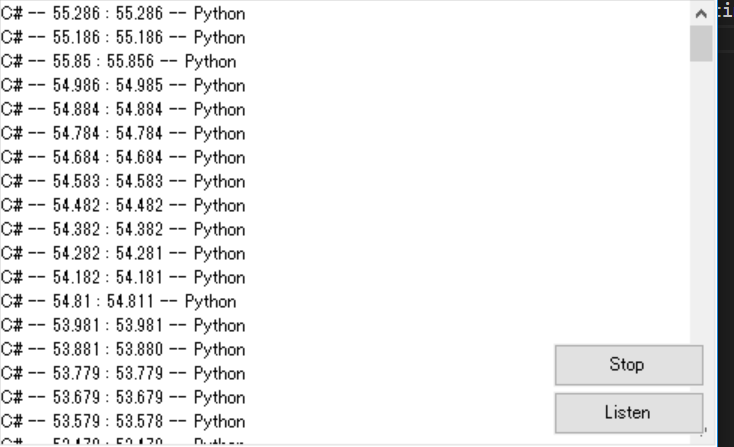
def Send(msg): client = socket.socket(socket.AF_INET,socket.SOCK_STREAM) host = "127.0.0.1" port = 51018 client.connect((host,port)) client.send(str(msg).encode()) Send("this is Message")これだけです。そして、実際に動かし遅延を調べた結果がこちら。
左側がC#、右側がPythonになっていて、数字は時間を表しています。御覧の通りそれぞれで時間の差があまりないことがわかると思います。
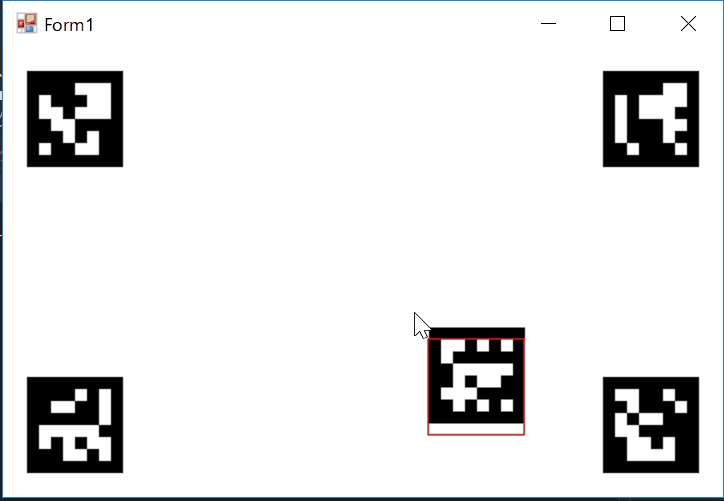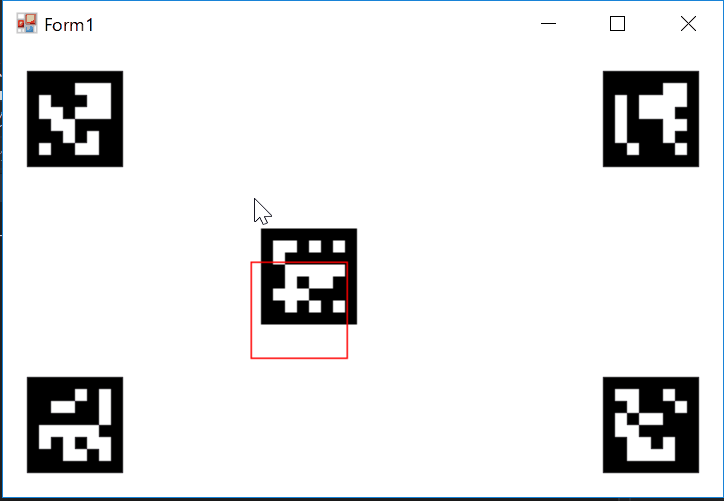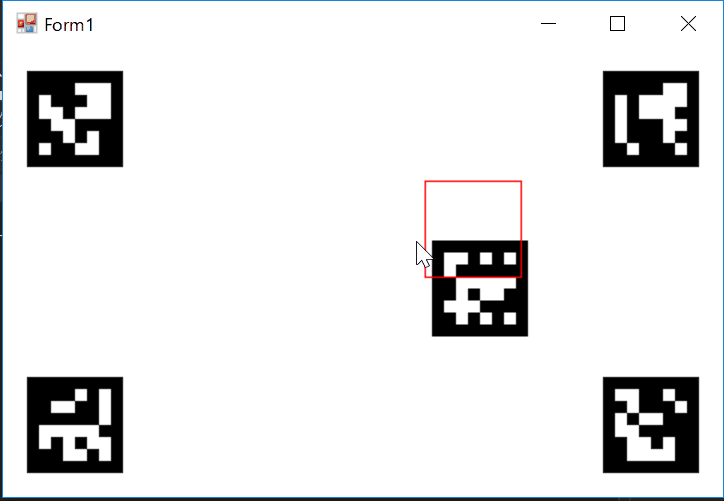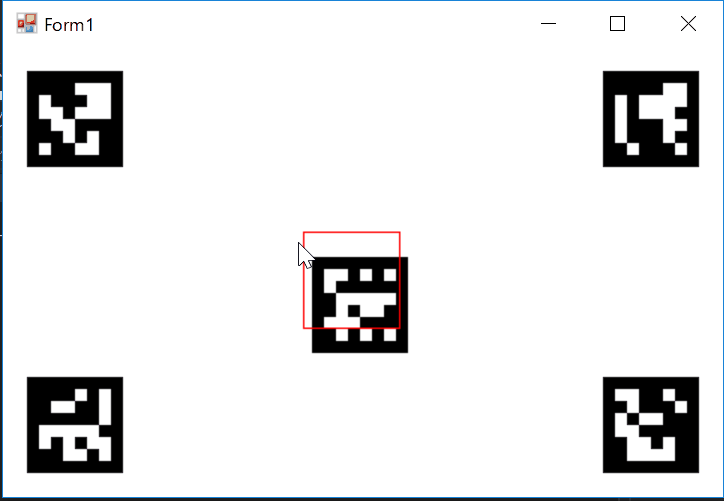
そして、OpenCVのマーカー検出ライブラリArUcoを使用して得た情報をformに送って表示した結果がこちら
赤いのがカメラからの情報を座標変換してもう一度表示したものです。あまり誤差がないのがわかると思います。
まとめ
本当はC#だけでOpenCVを使えるまで頑張ったほうがいいのですが、Pythonの練習とネットワークの勉強も兼ねてTCP通信を使用してみました。
余談ですが、PythonからC#に送る情報は文字列なので、座標の情報や、idを送る際にすこし工夫が必要だと思います。私の場合は特定の文字列で区切り、正規表現を活用して情報を取り出しました。以上です。ありがとうございました。
参考
IronPython https://ja.wikipedia.org/wiki/IronPython
サーバのコード https://dobon.net/vb/dotnet/internet/tcpclientserver.html
- 投稿日:2019-03-05T16:24:31+09:00
Pythonでオブジェクト指向プログラミング
Introduction
Pythonでは「全てがオブジェクト」というのは広く知られていますが、それを自分でも理解できていませんでした。ということで、この記事ではオブジェクト指向とはどのようなものか、その概要をPythonを使って解説します(と、見栄を張ってはみましたが、もし間違いなどありましたら、どしどしコメントください)。
よくある車の例ではさっぱり理解できない...
昔からある、古典的なオブジェクト指向プログラミングの説明書きを掲載します。
普通車を例にしましょう。普通やの動作原理を知らなくても、運転の仕方さえわかっていれば、走る。普通車の設計書さえ持っていれば、スポーツカーやトラックなどを開発するときにも、ゼロから構築せずに、普通車の設計書を元に組み立てることができる。それがオブジェクト指向プログラミング。
...正直に申し上げると、この一文だけでは自分は理解ができませんでした。
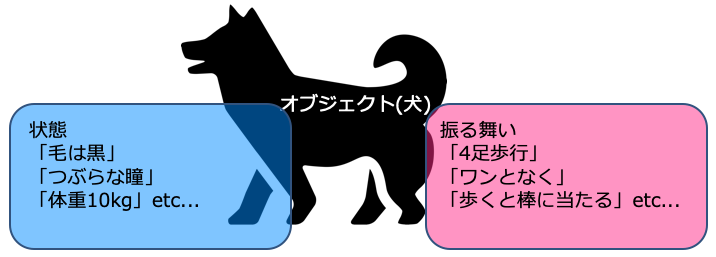
そもそもオブジェクトとは?
今度は上図のように犬を例にしてみましょう。
この犬は「黒い毛」「つぶらな瞳」「~歳で体重10kg」などの状態を持っています。この状態をデータと呼びます。
犬はある規則に従って行動します。それが「4足歩行」「ワンとなく」「歩くと棒に当たる」などの振る舞いです。この振る舞いを処理と呼びます。
この状態(データ)と振る舞い(処理)の2つをまとめたものがオブジェクトと呼ばれるものです。ではクラスやインスタンスとかいう専門用語は?
クラス
クラスは犬を作るための設計書、生物学でいうところのDNAに相当します。
プロパティ
このDNAには「犬はこのような状態で生まれ成長する」という、データを司る部分が刻み込まれています。これをプロパティと呼びます。
メソッド
さらにこのDNAには「犬はこのような振る舞いをする動物である」という処理を司る部分が刻み込まれています。これをメソッドと呼びます。
インスタンス
プロパティ・メソッドの2つが刻み込まれたDNAという設計書通りに作られた「犬本体」をインスタンスと呼びます。
オブジェクト指向の利点
コードの中身を知らなくても、使い方さえ知っていれば、スクリプトを動かすことができるところが大きな点です。上述の犬の例で言えば、犬のDNA構造を知ってさえいれば、ゴールデン・レトリーバやシェトランド・シープドッグなど、様々な種類の犬を作ることができるのです。
実感がわかないので、具体的なコード例を見てみよう
dog.py''' dog.py ''' class Dog: def __init__(self): print('I am a dog.') def legs(self): print('The number of legs is 4.') def bark(self): print('BowWow!')スクリプトの詳細はさておき、一度、このような犬のDNAを作ってしまえば、例えばゴールデン・レトリーバがほしいときには
golden_retriever = Dog()の一行だけで、「私は犬です」「4本足です」「ワンワン!」の3つのデータ・処理を行うゴールデン・レトリーバが作れます。シェトランド・シープドッグがほしければ
shetland_sheepdog = Dog()とするだけで、同様のものを得ることができます。
実はオブジェクト指向害悪説も...
ここまでで、オブジェクト指向の良さやその例を掲載してきましたが、デメリットも当然あるようです。
私自身、完全理解にはほど遠い身。ですが、なんとなくの概念を整理したくて、この記事を書きました。

- 投稿日:2019-03-05T16:18:13+09:00
Jupyter notebookで遊んでいたら「Connecting kernel」のままkernelが起動しなかったので解決方法をメモ
症状
pipenv install jupyter pipenv run jupyter notebookとやると、Jupyter Notebookは起動するが、
Notebookを作成してみると、左上に"Connecting kernel"と出たまま実行できない。(pipでjupyterを最新版にupdateした場合もおそらく同様)
解決方法
ググっていたら下記にぶち当たったのでこれで解決した。
juipiter notebook server "connecting to kernel" problem #2664tornado をダウングレードすれば解決。
pipenv uninstall tornado pipenv install tornado==5.1.1pipenvじゃなくてpipを使っている場合は
pip uninstall tornado pip install tornado==5.1.1原因
4日前くらいにjupyterの依存ライブラリのtornadoにアップデートがあった模様。
What’s new in Tornado 6.0
おそらくこれが原因?
- 投稿日:2019-03-05T16:05:15+09:00
Googleドライブ上のファイル�名をPython経由で変更する
Googleドライブ上のファイルを自動で一括変更したかったので少し調べてやってみました。
実行環境
- macOS Mojave
- Python 3.7.2
まず,Googleドライブのファイルを操作するためのAPIですが,Googleの公式のAPI「Google Drive API」を使います。
QuickStartを参考にインストールします。(執筆時点でのAPIのバージョンは3です。)
QuickStartではcredentials.jsonがワークディレクトリにある想定になっています。ダウンロードして配置します。スコープについて
Googleドライブのファイル名を変更するには,デフォルトの「
https://www.googleapis.com/auth/drive.metadata.readonly」
では権限が足りないのでここを参考にして「https://www.googleapis.com/auth/drive」に変更します。ファイル名の変更
QuickStartにはファイル名の変更に関する情報がなかったので,Drive API v2を使ってやっているサイトとDrive APIのページを参考にしました。
以下,QuickStartの一部を改変したコードを示します。from __future__ import print_function import pickle import os.path from googleapiclient.discovery import build from google_auth_oauthlib.flow import InstalledAppFlow from google.auth.transport.requests import Request # If modifying these scopes, delete the file token.pickle. SCOPES = ['https://www.googleapis.com/auth/drive'] def main(): """Shows basic usage of the Drive v3 API. Prints the names and ids of the first 10 files the user has access to. """ creds = None # The file token.pickle stores the user's access and refresh tokens, and is # created automatically when the authorization flow completes for the first # time. if os.path.exists('token.pickle'): with open('token.pickle', 'rb') as token: creds = pickle.load(token) # If there are no (valid) credentials available, let the user log in. if not creds or not creds.valid: if creds and creds.expired and creds.refresh_token: creds.refresh(Request()) else: flow = InstalledAppFlow.from_client_secrets_file( 'credentials.json', SCOPES) creds = flow.run_local_server() # Save the credentials for the next run with open('token.pickle', 'wb') as token: pickle.dump(creds, token) service = build('drive', 'v3', credentials=creds) # Call the Drive v3 API results = service.files().list( pageSize=10, fields="nextPageToken, files(id, name)", q="name contains 'ファイル名'").execute() #q=で指定したファイル名のファイルを検索できます。 items = results.get('files', []) if not items: print('No files found.') else: print('Files:') for item in items: #このまま実行するとitems内のファイルが全て変更されるので注意 new_name = '変更後の名前' file = {'name': new_name} service.files().update( fileId=item['id'], body=file).execute() if __name__ == '__main__': main()ファイル名を変更しているのは
service.files().update()の部分です。
fileIdにはもともとのファイルのfileIdをbodyには変更後のファイル名を入れた辞書型のオブジェクトを渡します。
とりあえずこれで動きましたがやり方があってるかは不明です。
- 投稿日:2019-03-05T15:33:07+09:00
pyenv環境でpip install --upgrade pipがSSLエラーしたときの簡潔な対処法
THE結論
$ curl https://bootstrap.pypa.io/get-pip.py | pythonを実行で解決
以下顛末
pyenvとvirtualenvで新しく環境を作り、必要なパッケージをインストールしようとしたら
Could not find a version that satisfies the requirement。
pipバージョンの問題だとおもうのでいつものpip install --upgrade pipすると$ pip install --upgrade pip Could not fetch URL https://pypi.python.org/simple/pip/: There was a problem confirming the ssl certificate: [SSL: TLSV1_ALERT_PROTOCOL_VERSION] tlsv1 alert protocol version (_ssl.c:590) - skipping Requirement already up-to-date: pip in ./lib/python2.7/site-packagesとなりSSLエラー発生。
OpenSSLの再設定、trusted-hostをホワイトリスト形式で設定、などの手があるようだけど未検証。
- 投稿日:2019-03-05T15:13:03+09:00
今まで勘違いしていたPythonのrange関数
range関数
恥ずかしながら、今までrange関数はリストを返すものだと勘違いしていました。
Python 2系
私が開発環境として準備したPython 2.7でrange関数を使って、様々試してみました。以下にそれを示します。
>>> a = range(0, 10) >>> a [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] >>> type(a) <type 'list'>このようにPython 2系では、range関数はlist型を返してきます。これがPython 3系でも同様に成り立っていると勘違いしていました。
Python 3系
では私がメインの開発環境として使用しているPython 3.7で同様のことを実行してみましょう。
>>> a = range(0, 10) >>> a range(0, 10) >>> type(a) <class 'range'>このようにPython 3系ではrange関数はrange型という、イテラブルなオブジェクトを返します。[0, 1, ..., 9]のような戻り値をどうしても取り出したい場合は、forループで取り出すか、リストなどのシーケンスに変換する必要があります。
>>> list(a) [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] >>> tuple(a) (0, 1, 2, 3, 4, 5, 6, 7, 8, 9)当たり前のようにforループで使っていましたが、まさかこんな落とし穴があったとは...まだまだ勉強の余地がたくさんありそうです。
- 投稿日:2019-03-05T15:13:03+09:00
今まで勘違いしていたPythonのrange()
range()
恥ずかしながら、今までrange()はリストを返すものだと勘違いしていました。
Python 2系
私が開発環境として準備したPython 2.7でrange()を試してみました。以下にそれを示します。
>>> a = range(0, 10) >>> a [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] >>> type(a) <type 'list'>このようにPython 2系では、range()はlist型を返してきます。これがPython 3系でも同様に成り立っていると勘違いしていました。
Python 3系
では私がメインの開発環境として使用しているPython 3.7で同様のことを実行してみましょう。
>>> a = range(0, 10) >>> a range(0, 10) >>> type(a) <class 'range'>このようにPython 3系ではrange()はrange型という、イテラブルなオブジェクトを返します。[0, 1, ..., 9]のような戻り値をどうしても取り出したい場合は、forループで取り出すか、リストなどのシーケンスに変換する必要があります。
>>> list(a) [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] >>> tuple(a) (0, 1, 2, 3, 4, 5, 6, 7, 8, 9)勘違いの原因: len()
len()は引数にリスト型などのシーケンスをとると思っていたのです。ところが
>>> a = range(0, 10) >>> len(a) 10のようにrangeオブジェクトの長さも平気で計算して返してきます。しかし、よくよく調べてみれば(というよりもすでに私自身、意識せずとも使っていたのですが)、len()は様々なオブジェクトのサイズを返すことができる万能な関数だったのです。
当たり前のようにforループで使っていましたが、まさかこんな落とし穴があったとは...まだまだPythonの奥深さを勉強していく必要がありそうです。
- 投稿日:2019-03-05T14:59:27+09:00
Pythonで相関係数を計算する[4パターン]
PythonでPearsonの相関係数を計算する方法を、パターンごとにまとめてみた
- 2つのリストを比較 -> pd.Series.corr()
- 1つのDataFrameに含まれるデータの総当たり -> pd.DataFrame.corr()
- 2つの対応のあるDataFrameで、対応しているデータ同士を比較 -> pd.DataFrame.corrwith()
- 2つの対応のないDataFrameを総当たりで比較 -> scipyのcdist
2つのリストを比較 -> pandasのcorr()を使用
list_corr.py#!/usr/bin/env python3 import pandas as pd import numpy as np # テスト用のリストを作る l1=list(np.random.randint(0, 10, 10)) l2=list(np.random.randint(0, 10, 10)) # 作ったlist print(l1) [4, 6, 0, 8, 6, 2, 0, 3, 3, 5] print(l2) [4, 6, 3, 7, 8, 4, 6, 9, 0, 0] # リストをps.Seriesに変換 s1=pd.Series(l1) s2=pd.Series(l2) # pandasを使用してPearson's rを計算 res=s1.corr(s2) # numpy.float64 に格納される # 結果 print(res) 0.23385611715924406補足
s1.corr(s2) は s1.corr(s2, method='pearson') と同じ
他にも以下などが使える
s1.corr(s2, method='spearman')
s1.corr(s2, method='kendall')1つのDataFrameに含まれるデータの総当たり -> pandasのcorr()を使用する
df_corr.py#!/usr/bin/env python3 import pandas as pd import numpy as np # テスト用のDataFrameを作る df=pd.DataFrame(index=['idx'+str(i) for i in range(10)]) for i in range(3): df['col'+str(i)]=np.random.rand(10) # 作ったdata frame print(df) col0 col1 col2 idx0 0.490571 0.338749 0.683458 idx1 0.815814 0.959449 0.463660 idx2 0.396800 0.317452 0.170291 idx3 0.962362 0.662069 0.811776 idx4 0.474287 0.479441 0.307625 idx5 0.162198 0.680460 0.694463 idx6 0.551089 0.202127 0.615898 idx7 0.799246 0.155890 0.906621 idx8 0.279273 0.152200 0.879839 idx9 0.430898 0.267056 0.430798 # pandasを使用してPearson's rを計算 res=df.corr() # pandasのDataFrameに格納される # 結果 print(res) col0 col1 col2 col0 1.000000 0.300315 0.210017 col1 0.300315 1.000000 -0.185880 col2 0.210017 -0.185880 1.000000補足
df.corr() は df.corr(method='pearson') と同じ
他にも以下などが使える
df.corr(method='spearman')
df.corr(method='kendall')2つの対応のあるDataFrameで、対応しているデータ同士を比較 -> pandasのcorrwith()を使用する
pd_corrwith.py#!/usr/bin/env python3 import pandas as pd import numpy as np # テスト用のDataFrameを作る df1=pd.DataFrame(index=['idx'+str(i) for i in range(10)]) for i in range(3): df1['col'+str(i)]=np.random.rand(10) df2=pd.DataFrame(index=['idx'+str(i) for i in range(10)]) for i in range(4): df2['col'+str(i)]=np.random.rand(10) # 作ったdata frame # indexの名前がdf1とdf2で一致している必要あり print(df1) col0 col1 col2 idx0 0.470484 0.529014 0.200872 idx1 0.036357 0.999937 0.949096 idx2 0.097277 0.152169 0.568015 idx3 0.640013 0.253285 0.365569 idx4 0.738058 0.496349 0.597689 idx5 0.230077 0.979614 0.820738 idx6 0.026953 0.301144 0.739461 idx7 0.472698 0.062897 0.833863 idx8 0.081538 0.250960 0.038582 idx9 0.196873 0.683337 0.062061 print(df2) col0 col1 col2 col3 idx0 0.873917 0.404390 0.427867 0.135733 idx1 0.156623 0.332094 0.779584 0.971294 idx2 0.672574 0.085956 0.030390 0.017714 idx3 0.920469 0.951883 0.484358 0.013711 idx4 0.820394 0.041568 0.070731 0.911695 idx5 0.575050 0.754205 0.146625 0.787360 idx6 0.994348 0.156208 0.040534 0.908418 idx7 0.108996 0.002158 0.609719 0.829356 idx8 0.953230 0.215288 0.296275 0.954589 idx9 0.907425 0.165094 0.756403 0.742972 # pandasを使用してPearson's rを計算 res=df1.corrwith(df2) # pandasのSeriesに格納される # 結果 # df1とdf2で、同じ名前のカラム同士が比較される # df2のcol3のように、同じ名前のカラムがdf1に存在しない場合は比較されない print(res) col0 0.073014 col1 0.331766 col2 -0.121577 col3 NaN dtype: float64補足
df1.corrwith(df2) は df1.corrwith(df2, method='pearson') と同じ
他にも以下などが使える
df.corrwith(df2, method='spearman')
df.corrwith(df2, method='kendall')2つの対応のないDataFrameを総当たりで比較 -> scipyのcdistを使用する
scipy_cdist.py#!/usr/bin/env python3 import pandas as pd import numpy as np from scipy.spatial.distance import cdist # テスト用のDataFrameを作る df1=pd.DataFrame(index=['df1idx'+str(i) for i in range(10)]) for i in range(2): df1['df1col'+str(i)]=np.random.rand(10) df2=pd.DataFrame(index=['df2idx'+str(i) for i in range(10)]) for i in range(3): df2['df2col'+str(i)]=np.random.rand(10) # 作ったdata frame # indexやcolumnの名前が異なっていても大丈夫 # 当然、indexの長さはdf1とdf2で同じである必要がある print(df1) df1col0 df1col1 df1idx0 0.024177 0.665551 df1idx1 0.658245 0.551047 df1idx2 0.273205 0.457382 df1idx3 0.379643 0.219442 df1idx4 0.148248 0.925876 df1idx5 0.384743 0.606885 df1idx6 0.191794 0.667464 df1idx7 0.413076 0.453384 df1idx8 0.135606 0.461234 df1idx9 0.211061 0.369848 print(df2) df2col0 df2col1 df2col2 df2idx0 0.887360 0.589831 0.472463 df2idx1 0.215978 0.236339 0.215376 df2idx2 0.134346 0.366870 0.866473 df2idx3 0.712904 0.679260 0.110819 df2idx4 0.810794 0.514622 0.359084 df2idx5 0.597531 0.080000 0.327408 df2idx6 0.753117 0.935979 0.943992 df2idx7 0.961404 0.585718 0.477759 df2idx8 0.599601 0.046453 0.908469 df2idx9 0.509900 0.457647 0.964165 # pd.DataFrameをnumpy.ndarrayに変換 ndf1=df1.T.values ndf2=df2.T.values # cdistを使用してPearson's rを計算 # cdistは (1から相関係数を引いた値) を返す # つまり、相関係数は (1 - cdistの結果) となる res=(1 - cdist(ndf1, ndf2, metric='correlation')) # numpy.ndarrayに格納される # 結果 print(res) [[-0.43182966 -0.23828196 -0.51695954] [ 0.25207449 0.06124553 -0.05151853]] # (オプション) 結果をpd.DataFrameに変換する res=pd.DataFrame(res, index=df1.columns, columns=df2.columns) print(res) df2col0 df2col1 df2col2 df1col0 -0.431830 -0.238282 -0.516960 df1col1 0.252074 0.061246 -0.051519環境
Ubuntu 18.04
Python 3.7.2
pandas 0.24.1
numpy 1.15.4
scipy 1.1.0
- 投稿日:2019-03-05T14:42:25+09:00
人の画像が送られたら送信者に役職を付与するDiscordのbot
ソースコード
import discord import requests import cv2 def create_given_rolls(url): response = requests.get(url, allow_redirects=False, timeout=10) if response.status_code != 200: e = Exception('HTTP status: ' + response.status_code) raise e content_type = response.headers['content-type'] if 'image' not in content_type: e = Exception('Content-Type: ' + content_type) raise e filename = 'tmp.' + url,split('.')[-1] with open(filename, 'wb') as fout: fout.write(response.content) rolls = ['face', 'eye',] cascades = {'face': ['haarcascade_frontalface_default.xml'], 'eye': ['haarcascade_eye.xml']} img = cv2.imread('tmp.png', 0) gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) for roll, cascades in cascades.items(): for cascade in cascades: cascade = cv2.CascadeClassifier(cascade) if cascade.detectMultiScale(gray) == []: rolls.remove(roll) return rolls client = discord.Client() @client.event async def on_ready(): print('Logged in as') print(client.user.name) print(client.user.id) print('------') @client.event async def on_message(message): if client.user != message.author: url = message.attachments['url'] given_rolls = create_given_rolls(url) client.add_roles(message.author, given_rolls) send_message = message.author + 'さんに' + str(given_rolls) + 'を付与しました!' await client.send_message(message.channel, send_message) client.run(os.environ['discord_mike'])
- 投稿日:2019-03-05T13:59:34+09:00
Linuxを触りたての頃に知っておきたかったよ〜ってことのまとめ
B4になって研究室配属され、一年たって
なんで早く教えてくれなかったのってことが多数あるから
後輩のためにも記録を残そうと思う。ターミナル系
そもそもログインシェルは
bashなんて使わなくてよく、
おすすめはzshである。
bashからzshに移行する方法は お前らのターミナルはダサいが非常によく参考になる。(さらbash)シェルの機能系
>,>>,|,&&について
>: 標準出力に表示されるものを指定ファイルに上書きする。ちょっとしたファイルを作成するときに使える。example$ echo mou_kenkyu_sitakunai > test.dat $ cat test.dat mou_kenkyu_sitakunai仮に、指定ファイルと同名のものがあると上書きされるため注意が必要。
>>: 標準出力に表示されるものを指定ファイルの下に書き足す。こちらは2つに分かれているプロットしたいデータを連結したり、
トポロジーファイルの合体に使えたりと、よく使う。example$ cat test.dat ohayo $ echo konnichiha > test.dat $ cat test.dat ohayo konnichiha
|: パイプといい、左側の出力結果を右のコマンドに引数として渡せる。例で説明すると、
example$ ls #ディレクトリの中身の表示 aaa.mp3 aaa.png aaa.dat aaa.txt bbb.png ccc.png ddd.dat $ ls | grep png #ディレクトリの中身から[png]がついてるものだけを表示 aaa.png bbb.png ccc.pngこのように、ディレクトリの中のファイル数が多くなって見づらい時とかに使える。
また長いファイルから特定の文字が含まれる行だけを抜き出すこともできるため、example$ cat test.dat #ファイルの中身の表示 hogehoge 0 hogehoge 8 aaaaaaa 1 bbbbbbb 7 ccccccc 6 tip3p 10 hogehoge 20 hogehoge 38 aaaaaaa 16 bbbbbbb 76 ccccccc 67 tip3p 18 : $ cat test.dat | grep tip3p #ファイルの中身から[tip3p]がついてる行だけを表示 tip3p 10 tip3p 18などの用途がある。
&&左のコマンドが終わったら右のコマンドを実行簡単な例としては。新規ディレクトリを作りそこに移動とか?
example#従来法 $ mkdir testdir $ cd testdir ##こっちが楽 $ mkdir testdir $$ cd testdir他にも、グラフをgnuplotでプロットしたあと画像ファイルに変換とかできる。
conv.sh#!/bin/bash pict_name=`ls -t | head -n1 | head -c-4` #pict_name is "test." echo " #################################################################" echo "" echo " " `ls -t | head -n1` " -->> ${pict_name}png" echo "" echo " #################################################################" convert -density 1000 `ls -t | head -n1` ${pict_name}png display -resize 1680x1050 ${pict_name}pngこのシェルスクリプトは、今いるデイレクトリで一番新しく生成された画像を
pngに変換するものである。
これをホームディレクトリに保存し、
gnuplot aaa.plt && ~/conv.sh
で画像の生成まで一発である。ブレース展開
連番でループしたいときに便利。
いちいちシェルスクリプトを書く必要もない。example$ echo {1..10} 1 2 3 4 5 6 7 8 9 10 $ echo {A..Z} A B C D E F G H I J K L M N O P Q R S T U V W X Y Z $ echo test{1..30..2} test1 test3 test5 test7 test9 test11 test13 test15 test17 test19 test21 test23 test25 test27 test29このように、文字でもループできるし、インクリメント数も変更できる。
例ではechoを上げたが、当然すべてのコマンドで使える。コマンド系
cd誰もが知っているディテクトリ移動のコマンドだが、一つ前にいたディレクトリに戻りたいとき、
$ cd -とすると戻れる。
example$ pwd test1/ $ cd test2 $ pwd test1/test2/ $ cd - $ pwd test1/エディター系(Vi,Vim)
Vi(Vim)ははじめは使いにくいと思うかもしれないが、慣れたりカスタマイズするとすごく便利
カスタマイズする
~/.vimrcに設定を書いておくと様々な設定を起動時に読み込んでくれる。
自分の使ってるものは、予測変換がついたり何かと高機能だがデフォルトのVimでは
一部機能が有効にならないので以下を参考に新しいVimをインストールすべし。
(centos vim lua 有効)とかでググる。インストールの後、以下の内容を
~/.vimrcに記述~/.vimrcset encoding=utf-8 scriptencoding utf-8 " ↑1行目は読み込み時の文字コードの設定 " ↑2行目はVim Script内でマルチバイトを使う場合の設定 " Vim scriptにvimrcも含まれるので、日本語でコメントを書く場合は先頭にこの設定が必要になる "---------------------------------------------------------- " NeoBundle "---------------------------------------------------------- if has('vim_starting') " 初回起動時のみruntimepathにNeoBundleのパスを指定する set runtimepath+=~/.vim/bundle/neobundle.vim/ " NeoBundleが未インストールであればgit cloneする if !isdirectory(expand("~/.vim/bundle/neobundle.vim/")) echo "install NeoBundle..." :call system("git clone git://github.com/Shougo/neobundle.vim ~/.vim/bundle/neobundle.vim") endif endif call neobundle#begin(expand('~/.vim/bundle/')) " インストールするVimプラグインを以下に記述 " NeoBundle自身を管理 NeoBundleFetch 'Shougo/neobundle.vim' " カラースキームmolokai NeoBundle 'tomasr/molokai' "カラースキームiceberg NeoBundle 'cocopon/iceberg.vim' "カラースキームjellybeans NeoBundle 'nanotech/jellybeans.vim' "カラースキームhybrid NeoBundle 'w0ng/vim-hybrid' " ステータスラインの表示内容強化 NeoBundle 'itchyny/lightline.vim' " インデントの可視化 NeoBundle 'Yggdroot/indentLine' " 末尾の全角半角空白文字を赤くハイライト NeoBundle 'bronson/vim-trailing-whitespace' " 構文エラーチェック NeoBundle 'scrooloose/syntastic' " 多機能セレクタ NeoBundle 'ctrlpvim/ctrlp.vim' " CtrlPの拡張プラグイン. 関数検索 NeoBundle 'tacahiroy/ctrlp-funky' " CtrlPの拡張プラグイン. コマンド履歴検索 NeoBundle 'suy/vim-ctrlp-commandline' " CtrlPの検索にagを使う NeoBundle 'rking/ag.vim' " プロジェクトに入ってるESLintを読み込む NeoBundle 'pmsorhaindo/syntastic-local-eslint.vim' "カッコの補完 NeoBundle 'cohama/lexima.vim' "ブロックのendを自動で挿入 NeoBundle 'tpope/vim-endwise' "ツリー型のファイル表示 NeoBundle 'scrooloose/nerdtree' "autocmd vimenter * NERDTree let g:NERDTreeDirArrows = 1 let g:NERDTreeDirArrowExpandable = '▶' let g:NERDTreeDirArrowCollapsible = '▼' "NeoBundle 'Shougo/neocomplete.vim' "NeoBundle 'Shougo/vimproc.vim', { " \ 'build' : { " \ 'windows' : 'make -f make_mingw32.mak', " \ 'cygwin' : 'make -f make_cygwin.mak', " \ 'mac' : 'make -f make_mac.mak', " \ 'unix' : 'make -f make_unix.mak', " \ }, " \ } "NeoBundle 'justmao945/vim-clang' "NeoBundle 'Shougo/neoinclude.vim' " "" 'Shougo/neocomplete.vim' {{{ "let g:neocomplete#enable_at_startup = 1 "if !exists('g:neocomplete#force_omni_input_patterns') " let g:neocomplete#force_omni_input_patterns = {} "endif "let g:neocomplete#force_overwrite_completefunc = 1 "let g:neocomplete#force_omni_input_patterns.c = '[^.[:digit:] *\t]\%(\.\|->\)' "let g:neocomplete#force_omni_input_patterns.cpp = '[^.[:digit:] *\t]\%(\.\|->\)\|\h\w*::' """"}}} " "" 'justmao945/vim-clang' {{{ " "" disable auto completion for vim-clanG "let g:clang_auto = 0 "let g:clang_complete_auto = 0 "let g:clang_auto_select = 0 "let g:clang_use_library = 1 " "" default 'longest' can not work with neocomplete "let g:clang_c_completeopt = 'menuone' "let g:clang_cpp_completeopt = 'menuone' " "if executable('clang-3.6') " let g:clang_exec = 'clang-3.6' "elseif executable('clang-3.5') " let g:clang_exec = 'clang-3.5' "elseif executable('clang-3.4') " let g:clang_exec = 'clang-3.4' "else " let g:clang_exec = 'clang' "endif " "if executable('clang-format-3.6') " let g:clang_format_exec = 'clang-format-3.6' "elseif executable('clang-format-3.5') " let g:clang_format_exec = 'clang-format-3.5' "elseif executable('clang-format-3.4') " let g:clang_format_exec = 'clang-format-3.4' "else " let g:clang_exec = 'clang-format' "endif " "let g:clang_c_options = '-std=c11' "let g:clang_cpp_options = '-std=c++11 -stdlib=libc++' " "" }}} " "コメントアウト NeoBundle 'tomtom/tcomment_vim' " vimのlua機能が使える時だけ以下のVimプラグインをインストールする if has('lua') " コードの自動補完 NeoBundle 'Shougo/neocomplete.vim' " スニペットの補完機能 NeoBundle "Shougo/neosnippet" " スニペット集 NeoBundle 'Shougo/neosnippet-snippets' endif call neobundle#end() " ファイルタイプ別のVimプラグイン/インデントを有効にする filetype plugin indent on " 未インストールのVimプラグインがある場合、インストールするかどうかを尋ねてくれるようにする設定 NeoBundleCheck "---------------------------------------------------------- " カラースキーム "---------------------------------------------------------- "if neobundle#is_installed('molokai') " colorscheme molokai " カラースキームにmolokaiを設定する " endif colorscheme iceberg " カラースキームにicebergを設定する " colorscheme jellybeans " カラースキームにjellybeansを設定する " colorscheme hybrid" カラースキームにhybrid(in white background)を設定する set t_Co=256 " iTerm2など既に256色環境なら無くても良い syntax enable " 構文に色を付ける "---------------------------------------------------------- " 文字 "---------------------------------------------------------- set fileencoding=utf-8 " 保存時の文字コード set fileencodings=ucs-boms,utf-8,euc-jp,cp932 " 読み込み時の文字コードの自動判別. 左側が優先される set fileformats=unix,dos,mac " 改行コードの自動判別. 左側が優先される set ambiwidth=double " □や○文字が崩れる問題を解決 "---------------------------------------------------------- " ステータスライン "---------------------------------------------------------- set laststatus=2 " ステータスラインを常に表示 set showmode " 現在のモードを表示 set showcmd " 打ったコマンドをステータスラインの下に表示 set ruler " ステータスラインの右側にカーソルの位置を表示する "---------------------------------------------------------- " コマンドモード "---------------------------------------------------------- set wildmenu " コマンドモードの補完 set history=5000 " 保存するコマンド履歴の数 "---------------------------------------------------------- " タブ・インデント "---------------------------------------------------------- set expandtab " タブ入力を複数の空白入力に置き換える set tabstop=4 " 画面上でタブ文字が占める幅 set softtabstop=4 " 連続した空白に対してタブキーやバックスペースキーでカーソルが動く幅 set autoindent " 改行時に前の行のインデントを継続する set smartindent " 改行時に前の行の構文をチェックし次の行のインデントを増減する set shiftwidth=4 " smartindentで増減する幅 "---------------------------------------------------------- " 文字列検索 "---------------------------------------------------------- set incsearch " インクリメンタルサーチ. 1文字入力毎に検索を行う set ignorecase " 検索パターンに大文字小文字を区別しない set smartcase " 検索パターンに大文字を含んでいたら大文字小文字を区別する set hlsearch " 検索結果をハイライト " ESCキー2度押しでハイライトの切り替え nnoremap <silent><Esc><Esc> :<C-u>set nohlsearch!<CR> "---------------------------------------------------------- " カーソル "---------------------------------------------------------- set whichwrap=b,s,h,l,<,>,[,],~ " カーソルの左右移動で行末から次の行の行頭への移動が可能になる set number " 行番号を表示 set cursorline " カーソルラインをハイライト " 行が折り返し表示されていた場合、行単位ではなく表示行単位でカーソルを移動する nnoremap j gj nnoremap k gk nnoremap <down> gj nnoremap <up> gk " バックスペースキーの有効化 set backspace=indent,eol,start "カーソルの最終編集位置へ augroup vimrcEx au BufRead * if line("'\"") > 0 && line("'\"") <= line("$") | \ exe "normal g`\"" | endif augroup END "---------------------------------------------------------- " カッコ・タグの対応 "---------------------------------------------------------- set showmatch " 括弧の対応関係を一瞬表示する set matchtime=1 " 0.1秒だけ "let loaded_matchparen=1 止めるとき source $VIMRUNTIME/macros/matchit.vim " Vimの「%」を拡張する "hi MatchParen ctermbg=1" "hi MatchParen term=standout ctermbg=Black ctermfg=LightGrey guibg=Black guifg=LightGrey "---------------------------------------------------------- " マウスでカーソル移動とスクロール "---------------------------------------------------------- if has('mouse') set mouse=a if has('mouse_sgr') set ttymouse=sgr elseif v:version > 703 || v:version is 703 && has('patch632') set ttymouse=sgr else set ttymouse=xterm2 endif endif "---------------------------------------------------------- " クリップボードからのペースト "---------------------------------------------------------- " 挿入モードでクリップボードからペーストする時に自動でインデントさせないようにする if &term =~ "xterm" let &t_SI .= "\e[?2004h" let &t_EI .= "\e[?2004l" let &pastetoggle = "\e[201~" function XTermPasteBegin(ret) set paste return a:ret endfunction inoremap <special> <expr> <Esc>[200~ XTermPasteBegin("") endif "---------------------------------------------------------- " height of menu "---------------------------------------------------------- set pumheight=10 "if value is 0 , show menu all "---------------------------------------------------------- " スペルチェック(試験) "---------------------------------------------------------- set spelllang=en,cjk fun! s:SpellConf() redir! => syntax silent syntax redir END set spell hi clear SpellBad hi SpellBad cterm=underline hi clear SpellCap hi SpellCap cterm=underline,bold if syntax =~? '/<comment\>' syntax spell default syntax match SpellMaybeCode /\<\h\l*[_A-Z]\h\{-}\>/ contains=@NoSpell transparent containedin=Comment contained else syntax spell toplevel syntax match SpellMaybeCode /\<\h\l*[_A-Z]\h\{-}\>/ contains=@NoSpell transparent endif syntax cluster Spell add=SpellNotAscii,SpellMaybeCode endfunc augroup spell_check autocmd! autocmd BufReadPost,BufNewFile,Syntax * call s:SpellConf() augroup END "---------------------------------------------------------- " neocomplete・neosnippetの設定 "---------------------------------------------------------- if neobundle#is_installed('neocomplete.vim') " Vim起動時にneocompleteを有効にする let g:neocomplete#enable_at_startup = 1 " smartcase有効化. 大文字が入力されるまで大文字小文字の区別を無視する let g:neocomplete#enable_smart_case = 1 " 3文字以上の単語に対して補完を有効にする let g:neocomplete#min_keyword_length = 3 " 区切り文字まで補完する let g:neocomplete#enable_auto_delimiter = 1 " 1文字目の入力から補完のポッ"プアップを表示 let g:neocomplete#auto_completion_start_length = 1 " バックスペースで補完のポップアップを閉じる inoremap <expr><BS> neocomplete#smart_close_popup()."<C-h>" " エンターキーで補完候補の確定. スニペットの展開もエンターキーで確定 imap <expr><CR> neosnippet#expandable() ? "<Plug>(neosnippet_expand_or_jump)" : pumvisible() ? "<C-y>" : "<CR>" " タブキーで補完候補の選択. スニペット内のジャンプもタブキーでジャンプ imap <expr><TAB> pumvisible() ? "<C-n>" : neosnippet#jumpable() ? "<Plug>(neosnippet_expand_or_jump)" : "<TAB>" endif "---------------------------------------------------------- " Syntastic "---------------------------------------------------------- " 構文エラー行に「>>」を表示 let g:syntastic_enable_signs = 1 " 他のVimプラグインと競合するのを防ぐ let g:syntastic_always_populate_loc_list = 1 " 構文エラーリストを非表示 let g:syntastic_auto_loc_list = 0 " ファイルを開いた時に構文エラーチェックを実行する let g:syntastic_check_on_open = 1 " 「:wq」で終了する時も構文エラーチェックする let g:syntastic_check_on_wq = 1 " python setting let g:syntastic_python_checkers = ['flake8'] "" Javascript用. 構文エラーチェックにESLintを使用 "let g:syntastic_javascript_checkers=['eslint'] "" Javascript以外は構文エラーチェックをしない "let g:syntastic_mode_map = { 'mode': 'passive', " \ 'active_filetypes': ['javascript'], " \ 'passive_filetypes': [] } " "---------------------------------------------------------- " CtrlP "---------------------------------------------------------- let g:ctrlp_match_window = 'order:ttb,min:20,max:20,results:100' " マッチウインドウの設定. 「下部に表示, 大きさ20行で固定, 検索結果100件」 let g:ctrlp_show_hidden = 1 " .(ドット)から始まるファイルも検索対象にする let g:ctrlp_types = ['fil'] "ファイル検索のみ使用 let g:ctrlp_extensions = ['funky', 'commandline'] " CtrlPの拡張として「funky」と「commandline」を使用 " CtrlPCommandLineの有効化 command! CtrlPCommandLine call ctrlp#init(ctrlp#commandline#id()) " CtrlPFunkyの絞り込み検索設定 let g:ctrlp_funky_matchtype = 'path' if executable('ag') let g:ctrlp_use_caching=0 " CtrlPのキャッシュを使わない let g:ctrlp_user_command='ag %s -i --hidden -g ""' " 「ag」の検索設定 endif "--------------------------------------------------------- " CtrlP "---------------------------------------------------------- let g:lightline = { \ 'colorscheme': 'wombat', \ 'mode_map': {'c': 'NORMAL'}, \ 'active': { \ 'left': [ [ 'mode', 'paste' ], [ 'fugitive', 'filename' ] ] \ }, \ 'component_function': { \ 'modified': 'LightlineModified', \ 'readonly': 'LightlineReadonly', \ 'fugitive': 'LightlineFugitive', \ 'filename': 'LightlineFilename', \ 'fileformat': 'LightlineFileformat', \ 'filetype': 'LightlineFiletype', \ 'fileencoding': 'LightlineFileencoding', \ 'mode': 'LightlineMode' \ } \ } function! LightlineModified() return &ft =~ 'help\|vimfiler\|gundo' ? '' : &modified ? '+' : &modifiable ? '' : '-' endfunction function! LightlineReadonly() return &ft !~? 'help\|vimfiler\|gundo' && &readonly ? 'x' : '' endfunction function! LightlineFilename() return ('' != LightlineReadonly() ? LightlineReadonly() . ' ' : '') . \ (&ft == 'vimfiler' ? vimfiler#get_status_string() : \ &ft == 'unite' ? unite#get_status_string() : \ &ft == 'vimshell' ? vimshell#get_status_string() : \ '' != expand('%:t') ? expand('%:t') : '[No Name]') . \ ('' != LightlineModified() ? ' ' . LightlineModified() : '') endfunction function! LightlineFugitive() if &ft !~? 'vimfiler\|gundo' && exists('*fugitive#head') return fugitive#head() else return '' endif endfunction function! LightlineFileformat() return winwidth(0) > 70 ? &fileformat : '' endfunction function! LightlineFiletype() return winwidth(0) > 70 ? (&filetype !=# '' ? &filetype : 'no ft') : '' endfunction function! LightlineFileencoding() return winwidth(0) > 70 ? (&fenc !=# '' ? &fenc : &enc) : '' endfunction function! LightlineMode() return winwidth(0) > 60 ? lightline#mode() : '' endfunction我ながら凄まじい量だと思うが、すべてを使う必要もないと思う。
幸いコメントが書いてあるので、使わない部分は消してもらって構わない。
ここからはVimの挿入・ヴィジュアルモードくらいは理解しているものとして説明する。Vimの便利な機能
一括置換
:%s/置換したい文字/置換後の文字/g文章中のすべての置換したい文字を置き換えてくれる。
また%sを92sとかにすると92行目だけ置換が行われる。文字列検索
/検索したい文字一致する文字を検索し、表示してくれる。また
nキーを押すことで次に一致する部分までジャンプ。
検索を辞めたければ」escキーを連打すればいい。
また先ほどの.vimrcを記述していれば
小文字で検索をかければ大文字も検索でき、
大文字で検索をすると大文字しかヒットしません。一括挿入
①ctrl + vでヴィジュアルブロックモードに入る
②挿入したい範囲を選ぶ
③shift + iで挿入モードへ
④挿入する語句を打ち込む
⑤エスケープキーを押すと挿入される。一括切り取り
上とおんなじ理屈で文字を切り取ることもできる。
コメントアウトした部分を一気に戻すのに便利。①ctrl + vでヴィジュアルブロックモードに入る
②切り取りたい範囲を選ぶ
③xで切り取る日本語入力系
かな漢字を選べば、日本語入力は一応できるが、超絶使いにくいのでMozcのインストールを推奨。
Centos7でMozc(Google日本語入力)を使う方法
を、参考にしてほしい(宣伝)。MD系
VMDでのスナップショットの保存の仕方
VMD(Visual Molecular Dynamics)でMDシミュレーションの綺麗なスナップショットを作る
を、参考にしてほしい(宣伝)。Pythonによる解析ツール
輪講で習うFortranなんて捨てたほうがいい。
今流行りのPythonを勉強して、便利な解析ツールを使おう!
MDの計算結果を解析できるPythonライブラリ:MDAnalysisのチュートリアルを日本語化する#1
を、参考にしてほしい(宣伝)。
- 投稿日:2019-03-05T12:33:14+09:00
brew install python で checking size of size_t... configure: error: in `/private/tmp/python-20190305-41841-p17rug/Python-3.7.2':
なぜ
MacBookPro の引っ越しをしたら brew の環境が盛大にぶっ壊れた
vim
$ brew install vim ==> Installing dependencies for vim: python and ruby ==> Installing vim dependency: python Warning: Building python from source: The bottle needs the Apple Command Line Tools to be installed. You can install them, if desired, with: xcode-select --install ==> Downloading https://www.python.org/ftp/python/3.7.2/Python-3.7.2.tgz Already downloaded: /Users/ishii/Library/Caches/Homebrew/downloads/c0a14628b5078ca696f1e18227df67d9c5fbe04462c041d9252709c120ea3e1a--Python-3.7.2.tgz ==> ./configure --prefix=/usr/local/Cellar/python/3.7.2_2 --enable-ipv6 --datarootdir=/usr/local/Cellar/python/3.7.2_2/share --datadir=/usr/local/Cellar/python/3.7.2_2/share --enable-framework=/usr/local/Cellar/python/3.7.2_2/Frameworks - Last 15 lines from /Users/ishii/Library/Logs/Homebrew/python/01.configure: checking for size_t... yes checking for uid_t in sys/types.h... yes checking for ssize_t... yes checking for __uint128_t... yes checking size of int... 0 checking size of long... 0 checking size of long long... 0 checking size of void *... 0 checking size of short... 0 checking size of float... 0 checking size of double... 0 checking size of fpos_t... 0 checking size of size_t... configure: error: in `/private/tmp/python-20190305-37442-u0c38a/Python-3.7.2':どうやら pythonでエラー
python
$ brew install python Warning: Building python from source: The bottle needs the Apple Command Line Tools to be installed. You can install them, if desired, with: xcode-select --install ==> Downloading https://www.python.org/ftp/python/3.7.2/Python-3.7.2.tgz Already downloaded: /Users/ishii/Library/Caches/Homebrew/downloads/c0a14628b5078ca696f1e18227df67d9c5fbe04462c041d9252709c120ea3e1a--Python-3.7.2.tgz ==> ./configure --prefix=/usr/local/Cellar/python/3.7.2_2 --enable-ipv6 --datarootdir=/usr/local/Cellar/python/3.7.2_2/share --datadir=/usr/local/Cellar/python/3.7.2_2/share --enable-framework=/usr/local/Cellar/python/3.7.2_2/Frameworks - Last 15 lines from /Users/ishii/Library/Logs/Homebrew/python/01.configure: checking for size_t... yes checking for uid_t in sys/types.h... yes checking for ssize_t... yes checking for __uint128_t... yes checking size of int... 0 checking size of long... 0 checking size of long long... 0 checking size of void *... 0 checking size of short... 0 checking size of float... 0 checking size of double... 0 checking size of fpos_t... 0 checking size of size_t... configure: error: in `/private/tmp/python-20190305-41841-p17rug/Python-3.7.2': configure: error: cannot compute sizeof (size_t)Oops
解決
xcode-select --installxcode のコマンドラインツールを入れたら治りましたとさ
- 投稿日:2019-03-05T12:00:42+09:00
Word2Vecを使って類似検索キーワードを発見する
はじめに
Word2Vecを使って、VALUESの保有するWeb行動ログデータから類似の検索キーワードを発見する
というサービスを作ってみました。Word2Vecって何?という方はこちらを一読いただくとよいかと思います。
・絵で理解するWord2vecの仕組み
・word2vec(Skip-Gram Model)の仕組みを恐らく日本一簡潔にまとめてみたつもりWord2Vecのモデル作成
コーパスの用意
元データとして、VALUESのWeb行動ログデータから検索キーワードを抽出します。
最小単位の文章として成立するように、スペースを含んだ複合キーワードのみを用います。
例えば下記のようなデータとなります。keyword.txtダイエット 炭水化物 ダイエット レシピ もずく ダイエット ダイエット 腹 締め付け 効果 :※上記は「ダイエット」の部分一致で例を示していますが、実際は一定のデータ期間中に発生した
すべての検索キーワードを対象のデータとしています。モデルの作成
gensimというPythonのライブラリを使用します。
train.py#!/usr/bin/env python3 # -*- coding: utf-8 -*- from gensim.models import word2vec import logging logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO) sentences = word2vec.LineSentence('keyword.txt') model = word2vec.Word2Vec(sentences, sg=1, size=200, min_count=10, sample=0) model.save('keyword.model')類似キーワードの確認
作成したモデルを使って、次のようなコードで類似キーワードを確認できます。
most_similar.py#!/usr/bin/env python3 # -*- coding: utf-8 -*- from gensim.models import word2vec model = word2vec.Word2Vec.load('keyword.model') results = model.most_similar(positive=['ダイエット'], topn=10) for result in results: print(result[0] + "\t" + "%.3f" % result[1])※上記例では「ダイエット」の類似キーワードを出力しています。
結果は、下記のようになりました。
$python3 most_similar.py 痩せる 0.850 ダイエット方法 0.824 やせる 0.754 減量 0.748 糖質制限 0.699 太る 0.692 脂肪燃焼 0.689 だいえっと 0.686 ダイエツト 0.681 痩せ 0.679※入力した「ダイエット」と類似度が高いキーワードが出力されています。
サービスの起動
作成したモデルのファイルサイズが大きい場合、1リクエストごとにモデルファイルを読み込んでいると
オーバーヘッドが大きくなります。
今回、Pythonの比較的簡易なWebフレームワークであるBottleを使ってWebサービス化し、
モデルは起動時に読み込むことで高速にレスポンスを返すことにしました。
サンプルのコードは下記の通りです。keyword_daemon.py#!/usr/bin/env python3 # -*- coding: utf-8 -*- from bottledaemon import daemon_run from bottle import route, HTTPResponse @route("/keyword/") @route("/keyword/<target_word>") def keyword(target_word=None): out = {'success': True, 'errcode': 0, 'errmessage': '', 'result': {'similar_list': []}} tartget_list = target_word.split(' ') results = model.most_similar(positive=tartget_list, topn=100) similar_list = [] for result in results: record = {'keyword': result[0], 'score': '%.3f' % result[1]} similar_list.append(record) out['result']['similar_list'] = similar_list jsonstr = json.dumps(out, ensure_ascii=False) response = HTTPResponse(status=200, body=jsonstr) response.set_header("Content-Type", "application/json") return response if __name__ == "__main__": import sys if sys.argv[1] == 'start': import json from gensim.models import word2vec model = word2vec.Word2Vec.load('keyword.model') daemon_run(host='0.0.0.0', port=5000)Wikipediaをコーパスとした時の違い
Wikipedia
・文字通り辞書・事典としての意味合いが強くワードの網羅性と文章量が豊富で
ある程度のデータ量を必要とするWord2Vecにおいては使い勝手が非常によい。
(既にダンプ化されたものが用意されているのも魅力)
・文章として登録されているものなので、MeCabなど形態素による分かち書きが必要になる。
(形態素のやり方によっては意図通りに単語が分かれないこともたまにある)検索キーワード
・検索キーワードは、人が何かしらの意図を持って(調べたい商品、悩み、事柄など)
入力しているワードのため、人の行動を知る分野(特にマーケティング分野)と相性が良い。
・複合キーワードの場合、入力時に人が意味を理解してスペースで分けていることが大半なため、
形態素で分かち書きをする必要がない。
・肌感に合う結果を得るためには、膨大な検索キーワードデータが必要になる。何に使える?
SEO・リスティングのワード拡充に使える
・新たなユーザーニーズを発見し、SEOやリスティングのワードに活用
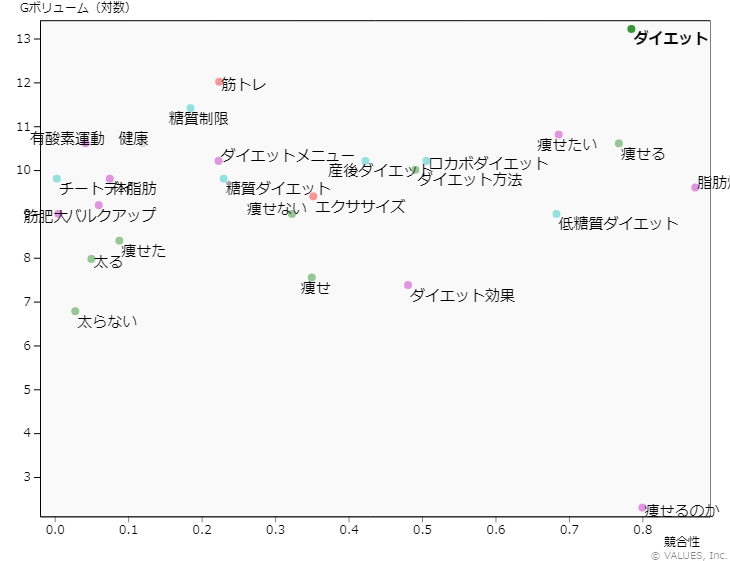
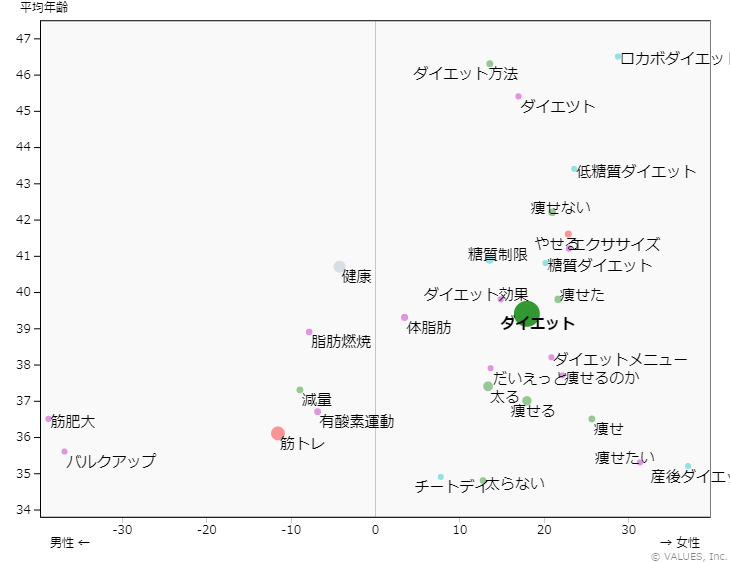
・人では想起しづらい専門用語系の類似ワードにも有効例えば「ダイエット」の類似キーワードを抽出し、それぞれのワードの検索ボリュームと
リスティングの競合性をGoogleのキーワードプランナーで調べて
縦軸に検索ボリューム、横軸に競合性をプロットすると下記のようになります。
ここから理解できることは、
「ダイエット」はメジャーキーワードであり検索ボリュームはあるが競合性も高く買いづらい...
が、類似ワードで見ると「筋トレ」「糖質制限」「有酸素運動」などがボリュームがあって
比較的競合性が低く買いワードである、と考えることができます。※キーワードプランナーとの連携はこちらで紹介しています。
AdWords APIでキーワードプランナーの検索ボリューム・CPC・競合性を取得するコンテンツマーケティングに使える
・コンテンツ企画のアイデア出しに
・LPやクリエイティブのワード選定に
・サイトコンテンツの運用、ターゲティング広告に例えば「ダイエット」の類似キーワードを抽出し、それぞれのワード検索者の性別年代を調べて
縦軸に平均年齢、横軸の男女をプロットすると下記のようになります。
ここから理解できることは、
(当然ながら)「ダイエット」系のワードは女性に多い。
ただ、「バルクアップ」「筋トレ」など男性向きなワードも存在する。
女性の中でも若い人は「産後ダイエット」などでも検索している。
など、どのターゲットに合わせてどのような類似ワードを使えば有用そうか
を俯瞰してみることができます。検索での競合ブランドがわかる
・ブランド名を指定すると検索から見た類似ブランドがわかる
・新規参入カテゴリの市場調査に活用例えば「シチュー」の類似キーワードを調べると、下記のようなキーワードが抽出できます。
ビーフシチュー 0.838 ハヤシライス 0.819 ポトフ 0.811 ハッシュドビーフ 0.804 グラタン 0.791 クリームシチュー 0.789 ホワイトシチュー 0.777 キーマカレー 0.773 ラタトゥイユ 0.77 ミネストローネ 0.768例えがあまりよくないかもしれませんが、、、
シチューの類似が「ビーフシチュー」「クリームシチュー」などは想像できますが
「ハヤシライス」「ポトフ」「グラタン」などが競合にあがるとはちょっと想像の範囲を越えますよね。参考にしたサイト
・絵で理解するWord2vecの仕組み
・word2vec(Skip-Gram Model)の仕組みを恐らく日本一簡潔にまとめてみたつもり
・「OK word2vec ! "マジ卍"の意味を教えて」 Pythonでword2vec実践してみた
・【Python】Word2Vecの使い方おわりに
Word2Vecの魅力を知ってから、これを何か形にしてみたい!という思いがようやく一つの
サービスになりました。
今はまだ社内ツールの位置付けですが、近い将来主力サービスの中にも組み込んでいきたい
と思っています。
まずは今回わかりやすい検索キーワードを元データに取り組んでみましたが、特に言葉でなくとも
閲覧サイトであったり閲覧商品であったり、類似を調べたいニーズはたくさんありそうなので、
今後もWord2Vecを使った面白そうなサービスを開発していきたいと思います。
- 投稿日:2019-03-05T10:41:30+09:00
Ruby と Python は似ているというけれど、設計思想レベルで見るとめちゃめちゃ違う
RubyもPythonもスクリプト言語ですし、確かに似ている部分はあります。
しかし、"設計思想"レベルで見てみると大きく違っています。
その違いがとてもおもしろいので紹介したいと思います。
Rubyは自由を好み、Pythonは統一を好む
簡単に言ってしまえば、Rubyは自由を好み、Pythonは統一を好みます。
Pythonはインデントによるdefなどの範囲指定が特徴的ですが、Rubyにはそのような制約はありません。
というのも、
Rubyは「書きたいように書く」というような自由な設計思想があるからです。それに対し、
Pythonは「誰が書いても同じようなコードになる」というような、統一感を好む設計思想になっています。
このような設計思想を知っていれば各言語の細々とした違いも理解しやすくなります。
他の言語も調べてみると面白いかもしれないですね。
- 投稿日:2019-03-05T10:16:52+09:00
逆引き DataFrameのデータ抽出(選択)処理
DataFrameのデータ抽出処理のまとめ。こういうのでいいんだよ的なものなので、細かい内容は他の方の記事を参考にしてください。
逆引き用の分類
これを書きたかったがための記事です。何(インデックスor列名or値)を対象にどうやって(抽出条件)データを抽出したいのかにマッチする方法が何かを整理しています。おすすめの選択方法を赤字にしました。df[bools]が何かは後述しますが、初心者には敷居が高いと感じます。
抽出条件 インデックス(ラベル) 列名 dfの値 = 値
isin 複数の値df.loc
df.reindex
df.filter
df.query
df[bools]df[]
df.loc
df.reindex
df.filter
(df.T.query.T)
df[bools]df.query
df[bools]!= 値
not isin 複数の値df.drop
df.query
df[bools]df.drop
(df.T.query.T)
df[bools]df.query
df[bools]スライス df.loc <,≤,>,≥ 値 df.query
df[bools](df.T.query.T)
df[bools]df.query
df[bools]like 値 df.filter
df.query
df[bools]df.filter
(df.T.query.T)
df[bools]df.query
df[bools]正規表現 df.filter
df.query
df[bools]df.filter
(df.T.query.T)
df[bools]df.query
df[bools]関数 上記組み合わせ(and,or,not) df.query
df[bools](df.T.query.T)
df[booleans]df.query
df[bools]正規表現については以下を参照。
https://qiita.com/luohao0404/items/7135b2b96f9b0b196bf3以下のデータを対象に、次のセクション以降で具体的なデータ抽出方法を説明します。
df = pd.DataFrame({'都道府県':['千葉県','三重県','北海道','神奈川県'], 'まいわし':[10,20,100,np.nan], 'かたくちいわし':[20,30,60,60], 'あじ':[np.nan,np.nan,100,30]} ).set_index('都道府県')
都道府県 まいわし かたくちいわし あじ 千葉県 10 20 NaN 三重県 20.0 30 NaN 北海道 100.0 60 100.0 神奈川県 NaN 60 30.0 注)上の表の数字に意味はありません。神奈川でまいわしが獲れない訳でも、千葉・三重であじが獲れない訳でもありません。気分を悪くされた方がいたら申し訳ありません。私は神奈川のいわしも、千葉、三重のあじもおいしいと思っています。
DataFrame[]
https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#slicing-ranges
https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#attribute-access列名 == 値
df['まいわし'] # Seriesになる # 都道府県 # 千葉県 10.0 # 三重県 20.0 # 北海道 100.0 # 神奈川県 NaN # Name: まいわし, dtype: float64 df[['まいわし']] # DataFrameになる # 都道府県 まいわし # 千葉県 10.0 # 三重県 20.0 # 北海道 100.0 # 神奈川県 NaN列名 isin 複数の値
df[['まいわし','かたくちいわし']] # 都道府県 まいわし かたくちいわし # 千葉県 10.0 20 # 三重県 20.0 30 # 北海道 100.0 60 # 神奈川県 NaN 60DataFrame.loc
インデックス == 値
df.loc['千葉県'] #Seriesになる # まいわし 10.0 # かたくちいわし 20.0 # あじ NaN # Name: 千葉県, dtype: float64 df.loc['千葉県'] #DataFrameになる # 都道府県 まいわし かたくちいわし あじ # 千葉県 10.0 20 NaNインデックス isin 複数の値
df.loc[['三重県','神奈川県'],:] # 都道府県 まいわし かたくちいわし あじ # 三重県 20.0 30 NaN # 神奈川県 NaN 60 30.0列名 == 値
df.loc[:,'まいわし'] # Seriesになる # 都道府県 # 千葉県 10.0 # 三重県 20.0 # 北海道 100.0 # 神奈川県 NaN # Name: まいわし, dtype: float64 df.loc[:,['まいわし']] # DataFrameになる # 都道府県 まいわし # 千葉県 10.0 # 三重県 20.0 # 北海道 100.0 # 神奈川県 NaN列名 isin 複数の値
df.loc[:,['まいわし','かたくちいわし']] # 都道府県 まいわし かたくちいわし # 千葉県 10.0 20 # 三重県 20.0 30 # 北海道 100.0 60 # 神奈川県 NaN 60DataFrame.reindex
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.html
インデックス isin 複数の値
df.reindex(index=['三重県','神奈川県']) # 都道府県 まいわし かたくちいわし あじ # 三重県 20.0 30 NaN # 神奈川県 NaN 60 30.0列名 isin 複数の値
df.reindex(columns=['まいわし','かたくちいわし']) # 都道府県 まいわし かたくちいわし # 千葉県 10.0 20 # 三重県 20.0 30 # 北海道 100.0 60 # 神奈川県 NaN 60DataFrame.drop
インデックス not isin 複数の値
df.drop(index=['千葉県','北海道']) # 都道府県 まいわし かたくちいわし あじ # 三重県 20.0 30 NaN # 神奈川県 NaN 60 30.0列名 not isin 複数の値
df.drop(columns=['あじ']) # 都道府県 まいわし かたくちいわし # 千葉県 10.0 20 # 三重県 20.0 30 # 北海道 100.0 60 # 神奈川県 NaN 60DataFrame.filter
インデックス isin 複数の値
df.filter(items=['三重県','神奈川県'],axis=0) # df.loc[['三重県','神奈川県']]と同じ # 都道府県 まいわし かたくちいわし あじ # 三重県 20.0 30 NaN # 神奈川県 NaN 60 30.0列名 isin 複数の値
df.filter(items=['まいわし','かたくちいわし']) # df[['まいわし','かたくちいわし']]と同じ # 都道府県 まいわし かたくちいわし # 千葉県 10.0 20 # 三重県 20.0 30 # 北海道 100.0 60 # 神奈川県 NaN 60インデックス like 値
df.filter(like='県',axis=0) # 都道府県 まいわし かたくちいわし あじ # 千葉県 10.0 20 NaN # 三重県 20.0 30 NaN # 神奈川県 NaN 60 30.0列名 like 値
df.filter(like='いわし',axis=1) # 都道府県 まいわし かたくちいわし # 千葉県 10.0 20 # 三重県 20.0 30 # 北海道 100.0 60 # 神奈川県 NaN 60正規表現 search インデックス
df.filter(regex='^..県',axis=0) # 都道府県 まいわし かたくちいわし あじ # 千葉県 10.0 20 NaN # 三重県 20.0 30 NaN正規表現 search 列名
df.filter(regex='.*いわ',axis=1) # 都道府県 まいわし かたくちいわし # 千葉県 10.0 20 # 三重県 20.0 30 # 北海道 100.0 60 # 神奈川県 NaN 60DataFrame.quety
- https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.query.html#pandas.DataFrame.query
- https://note.nkmk.me/python-pandas-query/
インデックス(or dfの値) == 値
df.query('都道府県=="千葉県"') # df.query('index=="千葉県")でもOK # 都道府県 まいわし かたくちいわし あじ # 千葉県 10.0 20 NaNインデックス(or dfの値) isin 複数の値
df.query('都道府県 in ["三重県","神奈川県"]') #df.query('都道府県==[...])でもOK # 都道府県 まいわし かたくちいわし あじ # 三重県 20.0 30 NaN # 神奈川県 NaN 60 30.0インデックス(or dfの値) != 値
hokkaido = '北海道' df.query('都道府県!=@hokkaido') #@で変数使用可 # 都道府県 まいわし かたくちいわし あじ # 千葉県 10.0 20 NaN # 三重県 20.0 30 NaN # 神奈川県 NaN 60 30.0インデックス(or dfの値) not isin 複数の値
chi_hok = ['千葉県','北海道'] df.query('都道府県 not in @chi_hok') # 都道府県 まいわし かたくちいわし あじ # 三重県 20.0 30 NaN # 神奈川県 NaN 60 30.0インデックス(or dfの値) <,≤,>,≥ 値
df.query('まいわし>0') # 都道府県 まいわし かたくちいわし あじ # 千葉県 10.0 20 NaN # 三重県 20.0 30 NaN # 北海道 100.0 60 100.0インデックス(or dfの値) like 値
df.query('index.str.contains("道")', engine='python') # 都道府県 まいわし かたくちいわし あじ # 北海道 100.0 60 100.0正規表現 match インデックス(or dfの値)
df.query('index.str.match("^..県")', engine='python') # 都道府県 まいわし かたくちいわし あじ # 千葉県 10.0 20 NaN # 三重県 20.0 30 NaNインデックス(or dfの値) の条件組み合わせ
df.query('まいわし>0 and あじ > 0') # 都道府県 まいわし かたくちいわし あじ # 北海道 100.0 60 100.0 df.query('not まいわし>0') # 都道府県 まいわし かたくちいわし あじ # 神奈川県 NaN 60 30.0DataFrame[bools]
DataFrame[bools]は私の勝手な表現です。df[]やdf.loc[]にboolのリストを渡すと、Trueのものだけが抽出されるので、そのように書いています。詳しくは以下を参照してください。
Python pandas データ選択処理をちょっと詳しく <中編>インデックス == 値
df[df.index=='千葉県'] # df.loc[df.index=='千葉県']でもOK # 都道府県 まいわし かたくちいわし あじ # 千葉県 10.0 20 NaNインデックス isin 複数の値
df[df.index.isin(['三重県','神奈川県'])] #df.loc[df.index.isin(['三重県','神奈川県'])]でもOK # 都道府県 まいわし かたくちいわし あじ # 三重県 20.0 30 NaN # 神奈川県 NaN 60 30.0列名 == 値
df.loc[:,df.columns=='あじ'] #df[['あじ']]と同じ # 都道府県 あじ # 千葉県 NaN # 三重県 NaN # 北海道 100.0 # 神奈川県 30.0列名 isin 複数の値
df.loc[:,df.columns.isin(['まいわし','かたくちいわし'])] #df[['まいわし','かたくちいわし']]と同じ # 都道府県 まいわし かたくちいわし # 千葉県 10.0 20 # 三重県 20.0 30 # 北海道 100.0 60 # 神奈川県 NaN 60dfの値 == 値
df[df['あじ']==30] # df.loc[df['あじ']==30]でもOK # 都道府県 まいわし かたくちいわし あじ # 神奈川県 NaN 60 30.0dfの値 isin 複数の値
df[df['かたくちいわし'].isin([20,30])] # df.loc[df['かたくちいわし'].isin([20,30])]でもOK # 都道府県 まいわし かたくちいわし あじ # 千葉県 10.0 20 NaN # 三重県 20.0 30 NaNインデックス != 値
df[df.index !='北海道'] # []内は、~(df.index='北海道')でもnp.logical_not(df.index='北海道')でもOK。というかdropを使おう。 # 都道府県 まいわし かたくちいわし あじ # 千葉県 10.0 20 NaN # 三重県 20.0 30 NaN # 神奈川県 NaN 60 30.0インデックス not isin 複数の値
df[~(df.index.isin(['千葉県','北海道']))] # dropを使おう。 # 都道府県 まいわし かたくちいわし あじ # 三重県 20.0 30 NaN # 神奈川県 NaN 60 30.0列名 != 値
df.loc[:,df.columns !='あじ'] # []内は、~(df.clumns='あじ')でもnp.logical_not(df.index='あじ')でもOK。というかdropを使おう。 # 都道府県 まいわし かたくちいわし # 千葉県 10.0 20 # 三重県 20.0 30 # 北海道 100.0 60 # 神奈川県 NaN 60列名 not isin 複数の値
df.loc[:,~(df.columns.isin(['まいわし','かたくちいわし']))] # dropを使おう # 都道府県 あじ # 千葉県 NaN # 三重県 NaN # 北海道 100.0 # 神奈川県 30.0dfの値 != 値
df[df['あじ'] != 30] # 都道府県 まいわし かたくちいわし あじ # 千葉県 10.0 20 NaN # 三重県 20.0 30 NaN # 北海道 100.0 60 100.0dfの値 not isin 複数の値
df[~(df['あじ'].isin([30,100]))] # 都道府県 まいわし かたくちいわし あじ # 千葉県 10.0 20 NaN # 三重県 20.0 30 NaNインデックス(or 列名、dfの値) <,≤,>,≥ 値
df[df['まいわし']>0] #dfの値の場合。インデックスの場合はdf.index、列名の場合はdf.columnで条件判定。 # 都道府県 まいわし かたくちいわし あじ # 千葉県 10.0 20 NaN # 三重県 20.0 30 NaN # 北海道 100.0 60 100.0インデックス(or 列名、dfの値) like 値
df[df.index.str.contains('道')] #インデックスの場合。列名の場合はdf.column、dfの値の場合はdf[列名]に.str.containsをつなげる。 # 都道府県 まいわし かたくちいわし あじ # 北海道 100.0 60 100.0正規表現 match インデックス(or 列名、dfの値)
df[df.index.str.match('^..県')] #インデックスの場合。列名の場合はdf.column、dfの値の場合はdf[列名]に.str.matchをつなげる。 # 都道府県 まいわし かたくちいわし あじ # 千葉県 10.0 20 NaN # 三重県 20.0 30 NaNインデックス(or 列名、dfの値) の条件組み合わせ
df[(df['まいわし']>0) & (df['あじ']>0)] # df.query('まいわし>0 and あじ > 0')と同じ # 都道府県 まいわし かたくちいわし あじ # 北海道 100.0 60 100.0 df[~(df['まいわし']>0)] # 都道府県 まいわし かたくちいわし あじ # 神奈川県 NaN 60 30.0 df.loc[df['まいわし']>0,df.columns.str.contains('いわし')] #インデックスとdfの値のboolsは&や|でつなげても良いが、列名のboolsとその他はつなげられない。locの別の引数として設定する。 # 都道府県 まいわし かたくちいわし # 千葉県 10.0 20 # 三重県 20.0 30 # 北海道 100.0 60DataFrame.xs
参考
- 投稿日:2019-03-05T10:16:52+09:00
DataFrameのデータ抽出(選択)処理 (under constraction...)
DataFrameのデータ抽出処理のまとめ。こういうのでいいんだよ的なものなので、細かい内容は他の方の記事を参考にしてください。
逆引き用の分類
これを書きたかったがための記事です。何(インデックスor列名or値)を対象にどうやって(抽出条件)データを抽出したいのかにマッチする方法が何かを整理しています。おすすめの選択方法を赤字にしました。df[bools]が何かは後述しますが、初心者には敷居が高いと感じます。
抽出条件 インデックス(ラベル) 列名 dfの値 = 値
isin 複数の値df.loc
df.reindex
df.filter
df.query
df[bools]df[]
df.loc
df.reindex
df.filter
(df.T.query.T)
df[bools]df.query
df[bools]!= 値
not isin 複数の値df.drop
df.query
df[bools]df.drop
(df.T.query.T)
df[bools]df.query
df[bools]スライス df.loc <,≤,>,≥ 値 df.query
df[bools](df.T.query.T)
df[bools]df.query
df[bools]like 値 df.filter
df.query
df[bools]df.filter
(df.T.query.T)
df[bools]df.query
df[bools]正規表現 df.filter
df.query
df[bools]df.filter
(df.T.query.T)
df[bools]df.query
df[bools]関数 上記組み合わせ(and,or,not) df.query
df[bools](df.T.query.T)
df[booleans]df.query
df[bools]正規表現については以下を参照。
https://qiita.com/luohao0404/items/7135b2b96f9b0b196bf3以下のデータを対象に、次のセクション以降で具体的なデータ抽出方法を説明します。
df = pd.DataFrame({'都道府県':['千葉県','三重県','北海道','神奈川県'], 'まいわし':[10,20,100,np.nan], 'かたくちいわし':[20,30,60,60], 'あじ':[np.nan,np.nan,100,30]} ).set_index('都道府県')
都道府県 まいわし かたくちいわし あじ 千葉県 10 20 NaN 三重県 20.0 30 NaN 北海道 100.0 60 100.0 神奈川県 NaN 60 30.0 注)上の表の数字に意味はありません。神奈川でまいわしが獲れない訳でも、千葉・三重であじが獲れない訳でもありません。気分を悪くされた方がいたら申し訳ありません。私は神奈川のいわしも、千葉、三重のあじもおいしいと思っています。
DataFrame[]
https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#slicing-ranges
https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#attribute-access列名 == 値
df['まいわし'] # Seriesになる # 都道府県 # 千葉県 10.0 # 三重県 20.0 # 北海道 100.0 # 神奈川県 NaN # Name: まいわし, dtype: float64 df[['まいわし']] # DataFrameになる # 都道府県 まいわし # 千葉県 10.0 # 三重県 20.0 # 北海道 100.0 # 神奈川県 NaN列名 isin 複数の値
df[['まいわし','かたくちいわし']] # 都道府県 まいわし かたくちいわし # 千葉県 10.0 20 # 三重県 20.0 30 # 北海道 100.0 60 # 神奈川県 NaN 60DataFrame.loc
インデックス == 値
df.loc['千葉県'] #Seriesになる # まいわし 10.0 # かたくちいわし 20.0 # あじ NaN # Name: 千葉県, dtype: float64 df.loc['千葉県'] #DataFrameになる # 都道府県 まいわし かたくちいわし あじ # 千葉県 10.0 20 NaNインデックス isin 複数の値
df.loc[['三重県','神奈川県'],:] # 都道府県 まいわし かたくちいわし あじ # 三重県 20.0 30 NaN # 神奈川県 NaN 60 30.0列名 == 値
df.loc[:,'まいわし'] # Seriesになる # 都道府県 # 千葉県 10.0 # 三重県 20.0 # 北海道 100.0 # 神奈川県 NaN # Name: まいわし, dtype: float64 df.loc[:,['まいわし']] # DataFrameになる # 都道府県 まいわし # 千葉県 10.0 # 三重県 20.0 # 北海道 100.0 # 神奈川県 NaN列名 isin 複数の値
df.loc[:,['まいわし','かたくちいわし']] # 都道府県 まいわし かたくちいわし # 千葉県 10.0 20 # 三重県 20.0 30 # 北海道 100.0 60 # 神奈川県 NaN 60DataFrame.reindex
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.html
インデックス isin 複数の値
df.reindex(index=['三重県','神奈川県']) # 都道府県 まいわし かたくちいわし あじ # 三重県 20.0 30 NaN # 神奈川県 NaN 60 30.0列名 isin 複数の値
df.reindex(columns=['まいわし','かたくちいわし']) # 都道府県 まいわし かたくちいわし # 千葉県 10.0 20 # 三重県 20.0 30 # 北海道 100.0 60 # 神奈川県 NaN 60DataFrame.drop
インデックス not isin 複数の値
df.drop(index=['千葉県','北海道']) # 都道府県 まいわし かたくちいわし あじ # 三重県 20.0 30 NaN # 神奈川県 NaN 60 30.0列名 not isin 複数の値
df.drop(columns=['あじ']) # 都道府県 まいわし かたくちいわし # 千葉県 10.0 20 # 三重県 20.0 30 # 北海道 100.0 60 # 神奈川県 NaN 60DataFrame.filter
インデックス isin 複数の値
df.filter(items=['三重県','神奈川県'],axis=0) # df.loc[['三重県','神奈川県']]と同じ # 都道府県 まいわし かたくちいわし あじ # 三重県 20.0 30 NaN # 神奈川県 NaN 60 30.0列名 isin 複数の値
df.filter(items=['まいわし','かたくちいわし']) # df[['まいわし','かたくちいわし']]と同じ # 都道府県 まいわし かたくちいわし # 千葉県 10.0 20 # 三重県 20.0 30 # 北海道 100.0 60 # 神奈川県 NaN 60インデックス like 値
df.filter(like='県',axis=0) # 都道府県 まいわし かたくちいわし あじ # 千葉県 10.0 20 NaN # 三重県 20.0 30 NaN # 神奈川県 NaN 60 30.0列名 like 値
df.filter(like='いわし',axis=1) # 都道府県 まいわし かたくちいわし # 千葉県 10.0 20 # 三重県 20.0 30 # 北海道 100.0 60 # 神奈川県 NaN 60正規表現 search インデックス
df.filter(regex='^..県',axis=0) # 都道府県 まいわし かたくちいわし あじ # 千葉県 10.0 20 NaN # 三重県 20.0 30 NaN正規表現 search 列名
df.filter(regex='.*いわ',axis=1) # 都道府県 まいわし かたくちいわし # 千葉県 10.0 20 # 三重県 20.0 30 # 北海道 100.0 60 # 神奈川県 NaN 60DataFrame.quety
- https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.query.html#pandas.DataFrame.query
- https://note.nkmk.me/python-pandas-query/
インデックス(or dfの値) == 値
df.query('都道府県=="千葉県"') # df.query('index=="千葉県")でもOK # 都道府県 まいわし かたくちいわし あじ # 千葉県 10.0 20 NaNインデックス(or dfの値) isin 複数の値
df.query('都道府県 in ["三重県","神奈川県"]') #df.query('都道府県==[...])でもOK # 都道府県 まいわし かたくちいわし あじ # 三重県 20.0 30 NaN # 神奈川県 NaN 60 30.0インデックス(or dfの値) != 値
hokkaido = '北海道' df.query('都道府県!=@hokkaido') #@で変数使用可 # 都道府県 まいわし かたくちいわし あじ # 千葉県 10.0 20 NaN # 三重県 20.0 30 NaN # 神奈川県 NaN 60 30.0インデックス(or dfの値) not isin 複数の値
chi_hok = ['千葉県','北海道'] df.query('都道府県 not in @chi_hok') # 都道府県 まいわし かたくちいわし あじ # 三重県 20.0 30 NaN # 神奈川県 NaN 60 30.0インデックス(or dfの値) <,≤,>,≥ 値
df.query('まいわし>0') # 都道府県 まいわし かたくちいわし あじ # 千葉県 10.0 20 NaN # 三重県 20.0 30 NaN # 北海道 100.0 60 100.0インデックス(or dfの値) like 値
df.query('index.str.contains("道")', engine='python') # 都道府県 まいわし かたくちいわし あじ # 北海道 100.0 60 100.0正規表現 match インデックス(or dfの値)
df.query('index.str.match("^..県")', engine='python') # 都道府県 まいわし かたくちいわし あじ # 千葉県 10.0 20 NaN # 三重県 20.0 30 NaNインデックス(or dfの値) の条件組み合わせ
df.query('まいわし>0 and あじ > 0') # 都道府県 まいわし かたくちいわし あじ # 北海道 100.0 60 100.0 df.query('not まいわし>0') # 都道府県 まいわし かたくちいわし あじ # 神奈川県 NaN 60 30.0DataFrame[bools]
DataFrame[bools]は私の勝手な表現です。df[]やdf.loc[]にboolのリストを渡すと、Trueのものだけが抽出されるので、そのように書いています。詳しくは以下を参照してください。
Python pandas データ選択処理をちょっと詳しく <中編>インデックス == 値
df[df.index=='千葉県'] # df.loc[df.index=='千葉県']でもOK # 都道府県 まいわし かたくちいわし あじ # 千葉県 10.0 20 NaNインデックス isin 複数の値
df[df.index.isin(['三重県','神奈川県'])] #df.loc[df.index.isin(['三重県','神奈川県'])]でもOK # 都道府県 まいわし かたくちいわし あじ # 三重県 20.0 30 NaN # 神奈川県 NaN 60 30.0列名 == 値
df.loc[:,df.columns=='あじ'] #df[['あじ']]と同じ # 都道府県 あじ # 千葉県 NaN # 三重県 NaN # 北海道 100.0 # 神奈川県 30.0列名 isin 複数の値
df.loc[:,df.columns.isin(['まいわし','かたくちいわし'])] #df[['まいわし','かたくちいわし']]と同じ # 都道府県 まいわし かたくちいわし # 千葉県 10.0 20 # 三重県 20.0 30 # 北海道 100.0 60 # 神奈川県 NaN 60dfの値 == 値
df[df['あじ']==30] # df.loc[df['あじ']==30]でもOK # 都道府県 まいわし かたくちいわし あじ # 神奈川県 NaN 60 30.0dfの値 isin 複数の値
df[df['かたくちいわし'].isin([20,30])] # df.loc[df['かたくちいわし'].isin([20,30])]でもOK # 都道府県 まいわし かたくちいわし あじ # 千葉県 10.0 20 NaN # 三重県 20.0 30 NaNインデックス != 値
df[df.index !='北海道'] # []内は、~(df.index='北海道')でもnp.logical_not(df.index='北海道')でもOK。というかdropを使おう。 # 都道府県 まいわし かたくちいわし あじ # 千葉県 10.0 20 NaN # 三重県 20.0 30 NaN # 神奈川県 NaN 60 30.0インデックス not isin 複数の値
df[~(df.index.isin(['千葉県','北海道']))] # dropを使おう。 # 都道府県 まいわし かたくちいわし あじ # 三重県 20.0 30 NaN # 神奈川県 NaN 60 30.0列名 != 値
df.loc[:,df.columns !='あじ'] # []内は、~(df.clumns='あじ')でもnp.logical_not(df.index='あじ')でもOK。というかdropを使おう。 # 都道府県 まいわし かたくちいわし # 千葉県 10.0 20 # 三重県 20.0 30 # 北海道 100.0 60 # 神奈川県 NaN 60列名 not isin 複数の値
df.loc[:,~(df.columns.isin(['まいわし','かたくちいわし']))] # dropを使おう # 都道府県 あじ # 千葉県 NaN # 三重県 NaN # 北海道 100.0 # 神奈川県 30.0dfの値 != 値
df[df['あじ'] != 30] # 都道府県 まいわし かたくちいわし あじ # 千葉県 10.0 20 NaN # 三重県 20.0 30 NaN # 北海道 100.0 60 100.0dfの値 not isin 複数の値
df[~(df['あじ'].isin([30,100]))] # 都道府県 まいわし かたくちいわし あじ # 千葉県 10.0 20 NaN # 三重県 20.0 30 NaNインデックス(or 列名、dfの値) <,≤,>,≥ 値
df[df['まいわし']>0] #dfの値の場合。インデックスの場合はdf.index、列名の場合はdf.columnで条件判定。 # 都道府県 まいわし かたくちいわし あじ # 千葉県 10.0 20 NaN # 三重県 20.0 30 NaN # 北海道 100.0 60 100.0インデックス(or 列名、dfの値) like 値
df[df.index.str.contains('道')] #インデックスの場合。列名の場合はdf.column、dfの値の場合はdf[列名]に.str.containsをつなげる。 # 都道府県 まいわし かたくちいわし あじ # 北海道 100.0 60 100.0正規表現 match インデックス(or 列名、dfの値)
df[df.index.str.match('^..県')] #インデックスの場合。列名の場合はdf.column、dfの値の場合はdf[列名]に.str.matchをつなげる。 # 都道府県 まいわし かたくちいわし あじ # 千葉県 10.0 20 NaN # 三重県 20.0 30 NaNインデックス(or 列名、dfの値) の条件組み合わせ
df[(df['まいわし']>0) & (df['あじ']>0)] # df.query('まいわし>0 and あじ > 0')と同じ # 都道府県 まいわし かたくちいわし あじ # 北海道 100.0 60 100.0 df[~(df['まいわし']>0)] # 都道府県 まいわし かたくちいわし あじ # 神奈川県 NaN 60 30.0 df.loc[df['まいわし']>0,df.columns.str.contains('いわし')] #インデックスとdfの値のboolsは&や|でつなげても良いが、列名のboolsとその他はつなげられない。locの別の引数として設定する。 # 都道府県 まいわし かたくちいわし # 千葉県 10.0 20 # 三重県 20.0 30 # 北海道 100.0 60DataFrame.xs
参考
- 投稿日:2019-03-05T10:14:32+09:00
Pandasでデータを操る。重複した行のみを残したい編
Introduction
ここに以下のような実験データ(test.tsv)があります。
このデータをよく見てみると、POS列に同じ値が入っている箇所がいくつかあることがわかりました。今後はこれに注目してデータ処理を行いたいと思ったため、POS列で重複した箇所だけを抽出するスクリプトがほしい、というのが今回のお題です。この例ではPOSの値が865545, 874671, 874826が重複しているので、その部分さえぬき出せればよいということになります。
.duplicated()
ズバリ、今回の願いを叶えるスクリプトは以下のようになります。
test.py''' test.py ''' import pandas as pd # read data data = pd.read_csv('test.tsv', delimiter='\t', index_col=0) # delete non-overlapping row data2 = data[data.duplicated(subset='POS', keep=False)] # write to excel data2.to_excel('test.xlsx')そして結果は以下のようになります。
subset 引数
.duplicated()の引数subsetに重複を判定したい列名を指定しています。試しに以下のコマンドを実行してみましょう。
print(data.duplicated(subset='POS', keep=False))結果は以下のようになります。
#CHROM chr1 False chr1 False chr1 True chr1 True chr1 False chr1 False chr1 False chr1 True chr1 True chr1 False chr1 False chr1 False chr1 False chr1 True chr1 True dtype: boolPOS列で重複している行全てがTrue, それ以外がFalseとなっていることがわかります。もし、POS列だけでなくREF列の重複も判定したい場合は
data2 = data[data.duplicated(subset=['POS', 'REF'], keep=False)]のようにsubsetに列名のリストを渡してあげます。
keep引数
では.duplicated()のもう一つの引数であるkeepはどのように使うのでしょうか。
今度は試しにprint(data.duplicated(subset='POS', keep='first'))としてみます。すると結果は
#CHROM chr1 False chr1 False chr1 False chr1 True chr1 False chr1 False chr1 False chr1 False chr1 True chr1 False chr1 False chr1 False chr1 False chr1 False chr1 True dtype: boolとなります。keep='first'とすると、重複した行の中でも最初に見つけた行がFalseとなります。keep='last'とすれば、逆に重複した行の中でも最後に見つけた行がFalseとなり、
#CHROM chr1 False chr1 False chr1 True chr1 False chr1 False chr1 False chr1 False chr1 True chr1 False chr1 False chr1 False chr1 False chr1 False chr1 True chr1 False dtype: boolとなります。今回の場合、keep=Falseを指定することで、重複した行全てをTrueとして残しています。
- 投稿日:2019-03-05T09:26:20+09:00
いまさらながら、Pyhton3.7をCentOS/RHEL 7に導入する。
事前準備
下記コマンドを実行して、各パッケージを導入する
yum install gcc openssl-devel bzip2-devel libffi-devellibffi-develは、7.3.1以降でインストール時に必要なパッケージ
インストールするソースコード
本来であれば、Pythonの公式から拾ってくる。
Pyhton.org:https://www.python.org/ftp/python/3.7.1/Python-3.7.1.tgzソースコードを展開
ここでは、次の場所に展開します。
ソースコード:/usr/local/src/Python-3.7.x
インストール先:/usr/local/Python3.7/default
※今後バージョンを変更することを考えてシンボリックリンク経由でインストールする
保存先:/usr/local/Python-3.7.1展開~インストールまで
ファイルを解凍し回答先へ移動
mkdir /usr/local/src/Python-3.7.1 tar xzf Python-3.7.1.tgz -C /usr/local/src/Python-3.7.1 cd /usr/local/src/Python-3.7.1バージョン変更を容易にするためのシンボリックファイル作成
mkdir /usr/local/Python3.7/Python-3.7.2rc1 ln -s /usr/local/Python3.7/Python-3.7.2rc1 /usr/local/Python3.7/latest ln -s /usr/local/Python3.7/latest /usr/local/Python3.7/defaultインストール
command./configure --enable-optimizations --prefix=/usr/local/Python3.7/default make -j4 make altinstall※ make の-jオプションはコンパイル時のCPUの数を指定できる、複数あるなら複数個指定、無いなら-jを付与しないで実行
pipを使えるようにする
Pythonのモジュールを管理するツールにpipがあり、ほぼ必須といえる。3.4系以降のpythonを導入した場合は、pipが自動でインストールされるが、今回の方法だとパスが通らないので、次の手順を実施する。
echo "export PATH="/usr/local/Python3.7/default/bin:$PATH"" >> /etc/profile ln -s /usr/local/Python3.7/default/bin/pip3.7 /usr/local/Python3.7/default/bin/pip以下のコマンドを実行して、バージョンが出力されるか確認する
# pip -V pip 10.0.1 from /usr/local/Python/lib/python3.7/site-packages/pip (python 3.7)pythonのバージョンを確認する。
# su - # python --version Python 3.7.1
- Python 2.7.x と表示された場合 その環境には、別なpythonが導入されているため、そっちにパスが通っています。 ので、python3用のパスを通します。下記コマンドを実行してください。
ln -s /usr/local/Python3.7/default/bin/python3.7 /usr/local/Python3.7/default/bin/python ln -s /usr/local/Python3.7/default/bin/python /usr/local/bin/python ln -s /usr/local/Python3.7/default/bin/python /usr/local/bin/python3
- 使用可能なモジュールを確認しつつ、インストールが出来たか確認 下記を記述して実行する。
# cat help_modules.py # -*- coding: utf-8 -*- # prints a list of existing modules print(help('modules'))実行する。現在使用可能なモジュール一覧がでてくればインストール成功
# python help_modules.py Please wait a moment while I gather a list of all available modules... /usr/lib64/python2.7/site-packages/gobject/constants.py:24: Warning: g_boxed_type_register_static: assertion 'g_type_from_name (name) == 0' failed import gobject._gobject BaseHTTPServer cProfile inspect rpmUtils Bastion cStringIO io runpy CDROM calendar ipaddress sched CGIHTTPServer cgi itertools schedutils ConfigParser cgitb json select Cookie chunk keyword selinux DLFCN cmath lib2to3 sets DocXMLRPCServer cmd liblzma setuptools :(以下略)
- 投稿日:2019-03-05T07:42:37+09:00
[OR-Tools] Cryptarithmetic Puzzles using CP-SAT Solver
OR-Toolsは便利?
検証中.
ものによって言語別サンプルが無いので,補間.''' OR-Toolsのサイトには,CP-SAT SolverでのCryptarithmetricが無かったので自作''' # S E N D # + ) M O R E # ----------- # M O N E Y # # ANSWER:FISIBLE (最適かは不明) # 9 5 6 7 # + ) 1 0 8 5 # ----------- # 1 0 6 5 2 # # 魔法のコトバ from __future__ import absolute_import from __future__ import division from __future__ import print_function from ortools.sat.python import cp_model def SendMoreMoney(): # 問題モデルの宣言 model = cp_model.CpModel() # 変数の宣言 limit = 9 s = model.NewIntVar(1, limit, 'S') e = model.NewIntVar(0, limit, 'E') n = model.NewIntVar(0, limit, 'N') d = model.NewIntVar(0, limit, 'D') m = model.NewIntVar(1, limit, 'M') o = model.NewIntVar(0, limit, 'O') r = model.NewIntVar(0, limit, 'R') # e # m # o # n # e y = model.NewIntVar(0, limit, 'Y') # 全ての英語に割り当たる数字が異なるという制約を造るために変数のグループを作る letters = [s, e, n, d, m, o, r, y] # 各位を表すのに必要 kBase = 10 # Verify that we have enough digits assert kBase >= len(letters) # ソルバに全ての数字が異なるという制約を追加 model.AddAllDifferent(letters) # 足し算の制約を追加 # SEND + MORE = MONEY model.Add(s * kBase * kBase * kBase + e * kBase * kBase + n * kBase + d + m * kBase * kBase * kBase + o * kBase * kBase + r * kBase + e == m * kBase * kBase * kBase * kBase + o * kBase * kBase * kBase + n * kBase * kBase + e * kBase + y) # Solverの宣言 solver = cp_model.CpSolver() status = solver.Solve(model) print(solver.StatusName(status)) print('s = %i' % solver.Value(s)) print('e = %i' % solver.Value(e)) print('n = %i' % solver.Value(n)) print('d = %i' % solver.Value(d)) print('m = %i' % solver.Value(m)) print('o = %i' % solver.Value(o)) print('r = %i' % solver.Value(r)) print('y = %i' % solver.Value(y)) SendMoreMoney()
- 投稿日:2019-03-05T06:48:39+09:00
PythonとRの制御構造
RとPythonの制御構造(for)
いろいろなスクリプトを書いているとこの処理系はどういう制御構造だったかな?と迷うことがあります。まずはforループについて記述してみました。
Python等のループは機能豊富で描ききれていないところも多くあります。今後少しづつ書き込んでいきたいと考えます。
ループ(for) Python
for i in range(10): print(i)Pythonの特徴として、字下げで一つのブロックを表すことです。他の処理系出身者が間違えやすいのが
for i in 10: print(i)と記述してしまうことです。
その理由は考え方の違いです。Pythonの考え方
range(10):の意味は、0〜9の配列(リスト)を作りなさいという意味です。1〜10出ないことに注意してください。
そのため、次のようなこともできます。
char1 = 'test' for char2 in char1: print(char2) char3 = ['test1','test2','test3'] for char4 in char3: print(char4)t e s t test1 test2 test3ループ(for) R
for(i in 1:10){ print(i) }RもPythonと同じような考え方です。明示的に1〜10を指定します。
forの対象となるのは{}の内部です。見やすくなるようにインテンドしていますが、Pythonと異なり、インデントに意味はありません。PythonとRに共通するのは、最初に配列を作ってから、それに対してループを行うことです。
- 投稿日:2019-03-05T06:48:39+09:00
PythonとRの制御構造(for)
RとPythonの制御構造(for)
いろいろなスクリプトを書いているとこの処理系はどういう制御構造だったかな?と迷うことがあります。まずはforループについて記述してみました。
Python等のループは機能豊富で描ききれていないところも多くあります。今後少しづつ書き込んでいきたいと考えます。
ループ(for) Python
for i in range(10): print(i)Pythonの特徴として、字下げで一つのブロックを表すことです。他の処理系出身者が間違えやすいのが
for i in 10: print(i)と記述してしまうことです。
その理由は考え方の違いです。Pythonの考え方
range(10):の意味は、0〜9の配列(リスト)を作りなさいという意味です。1〜10出ないことに注意してください。
そのため、次のようなこともできます。
char1 = 'test' for char2 in char1: print(char2) char3 = ['test1','test2','test3'] for char4 in char3: print(char4)t e s t test1 test2 test3ループ(for) R
for(i in 1:10){ print(i) }RもPythonと同じような考え方です。明示的に1〜10を指定します。
forの対象となるのは{}の内部です。見やすくなるようにインテンドしていますが、Pythonと異なり、インデントに意味はありません。PythonとRに共通するのは、最初に配列を作ってから、それに対してループを行うことです。