- 投稿日:2019-02-28T23:46:17+09:00
【機械学習】MLflowのQuickstartやってみた(1)
MLflowのQuickstartやってみました。
環境
- macOS High Sierra
- pyenv 1.2.1
- anaconda3-5.0.1
- Python 3.6.8
MLflowとは
MLflow (currently in beta) is an open source platform to manage the ML lifecycle, including experimentation, reproducibility and deployment.
機械学習の様々なデータ(ハイパーパラメータの設定値や学習に使用したデータ、損失関数の推移やモデルパラメータなど)を管理できるオープンソースプラットフォームです。
管理だけにとどまらず、ブラウザを使った可視化や推論APIの提供などをしてくれます。
Python、R、Java用のAPIやREST APIが用意されています。
ライセンスはApache-2.0です。その他については先人の記事が大変参考になるのでご参照ください。
https://qiita.com/masa26hiro/items/574c48d523ed76e76a3bQuickstart
(前提条件)
事前にanacondaの仮想環境を作成して有効化しておきます。
conda create -n mlflow python=3.6 pyenv global anaconda3-5.0.1/envs/mlflow source ~/.pyenv/versions/anaconda3-5.0.1/bin/activate mlflowMLflowをインストール
pip install mlflowこの時点の
pip freezeは以下の通り。boto3==1.9.103 botocore==1.12.103 certifi==2018.11.29 chardet==3.0.4 Click==7.0 cloudpickle==0.8.0 configparser==3.7.3 databricks-cli==0.8.4 docutils==0.14 Flask==1.0.2 gitdb2==2.0.5 GitPython==2.1.11 gunicorn==19.9.0 idna==2.8 itsdangerous==1.1.0 Jinja2==2.10 jmespath==0.9.4 MarkupSafe==1.1.1 mleap==0.8.1 mlflow==0.8.2 nose==1.3.7 nose-exclude==0.5.0 numpy==1.16.2 pandas==0.24.1 protobuf==3.6.1 python-dateutil==2.8.0 pytz==2018.9 PyYAML==3.13 querystring-parser==1.2.3 requests==2.21.0 s3transfer==0.2.0 scikit-learn==0.20.2 scipy==1.2.1 simplejson==3.16.0 six==1.12.0 smmap2==2.0.5 tabulate==0.8.3 urllib3==1.24.1 Werkzeug==0.14.1この時点で、numpy、pandas、scikit-learn、scipyなどは勝手にインストールされています。
もちろんmlflowも入っています。Quickstart用に用意されているサンプルリポジトリのクローン
git clone https://github.com/mlflow/mlflow cd mlflow/examplesTracking APIを使ってみる
任意のエディタで以下のコードを書いて保存します。
tracking_api_sample.pyimport os from mlflow import log_metric, log_param, log_artifact if __name__ == "__main__": # Log a parameter (key-value pair) log_param("param1", 5) # Log a metric; metrics can be updated throughout the run log_metric("foo", 1) log_metric("foo", 2) log_metric("foo", 3) # Log an artifact (output file) with open("output.txt", "w") as f: f.write("Hello world!") log_artifact("output.txt")さてこのスクリプトを実行してみます。
python tracking_api_sample.pyすると同階層に
mlrunsというディレクトリが出来ているはずです。
この中に先程実行したスクリプトの結果が入っています。中身は以下のようになっていました。
mlruns/ └── 0 ├── cde43510000043a2a4af734625dc95e7 │ ├── artifacts │ │ └── output.txt │ ├── meta.yaml │ ├── metrics │ │ └── foo │ └── params │ └── param1 └── meta.yaml 5 directories, 5 files以下、生成されたファイルの中身を見ていきます。
meta.yaml$ cat mlruns/0/meta.yaml artifact_location: /Users/takeshi/daylywork/2019-02-27/mlflow/examples/mlruns/0 experiment_id: 0 lifecycle_stage: active name: Defaultおー。まだよくわかんないとこもありますが、実験結果の保存場所とか実験IDとかが書いてあるぽいです。
じゃあ次はハッシュ値(cde43510000043a2a4af734625dc95e7)の中身を見ていきます。
mlruns/0/cde43510000043a2a4af734625dc95e7/meta.yaml$ cat mlruns/0/cde43510000043a2a4af734625dc95e7/meta.yaml artifact_uri: /Users/takeshi/daylywork/2019-02-27/mlflow/examples/mlruns/0/cde43510000043a2a4af734625dc95e7/artifacts end_time: 1551278143295 entry_point_name: '' experiment_id: 0 lifecycle_stage: active name: '' run_uuid: cde43510000043a2a4af734625dc95e7 source_name: tracking_api_sample.py source_type: 4 source_version: 8ab7d382b3364ebf4fb4ddd1ebde43245c62e339 start_time: 1551278143207 status: 3 tags: [] user_id: takeshiおー。こちらはより詳細な情報が書いてある感じぽいです。
mlruns/0/cde43510000043a2a4af734625dc95e7/params/param1$ cat mlruns/0/cde43510000043a2a4af734625dc95e7/params/param1 5これはどうやら
tracking_api_sample.pyの以下の部分に該当しているぽいです。# Log a parameter (key-value pair)
log_param("param1", 5)パラメータ名そのままのファイルの中に値が直接書き込まれているという非常にわかりやすい形式ですね。
実際に使用するときは学習データのファイルパスとかハイパーパラメータの値を残しておくという感じでしょうか。
mlruns/0/cde43510000043a2a4af734625dc95e7/metrics/foo$ cat mlruns/0/cde43510000043a2a4af734625dc95e7/metrics/foo 1551278143 1 1551278143 2 1551278143 3これは
tracking_api_sample.pyの以下の部分に対応しているようです。# Log a metric; metrics can be updated throughout the run
log_metric("foo", 1)
log_metric("foo", 2)
log_metric("foo", 3)paramと同じように、metric名そのままのファイル名の中に値が直接書き込まれ...ているわけではなさそうです。
1551278143という値が何かはわかりませんが、mlruns/0/cde43510000043a2a4af734625dc95e7/meta.yamlに書かれていたstart_timeやend_timeにこの値が含まれているので、時間が関係していそうな感じです。
実際に使用するときはエポック毎の損失関数の値とかConfusionMatrixの値とかを書き留めとくみたいな感じでしょうか。
mlruns/0/cde43510000043a2a4af734625dc95e7/artifacts/output.txt$ cat mlruns/0/cde43510000043a2a4af734625dc95e7/artifacts/output.txt Hello world!こいつは
tracking_api_sample.pyのここです。(インデントできない)
# Log an artifact (output file)
with open("output.txt", "w") as f:
f.write("Hello world!")
log_artifact("output.txt")実験中に生成したものを置いとく場所って感じだと思われます。
なるほどなるほど。
なんかもうある程度のことは出来そうな気もしてきました。管理している情報をブラウザで表示する
mlflow uiこれでローカルサーバーが立ち上がっているのでブラウザで
http://localhost:5000/にアクセスします。※私はこの段階で
-bash: mlflow: command not foundエラーが発生しました。
いろいろ調べていると以下のファイルが実体のようでした。
/Users/takeshi/.local/lib/python3.6/site-packages/mlflow/cli.pycli.pyの一部@cli.command() @click.option("--file-store", metavar="PATH", default=None, help="The root of the backing file store for experiment and run data " "(default: ./mlruns).") @click.option("--host", "-h", metavar="HOST", default="127.0.0.1", help="The network address to listen on (default: 127.0.0.1). " "Use 0.0.0.0 to bind to all addresses if you want to access the UI from " "other machines.") @click.option("--port", "-p", default=5000, help="The port to listen on (default: 5000).") @click.option("--gunicorn-opts", default=None, help="Additional command line options forwarded to gunicorn processes.") def ui(file_store, host, port, gunicorn_opts): """ Launch the MLflow tracking UI. The UI will be visible at http://localhost:5000 by default. """ # TODO: We eventually want to disable the write path in this version of the server. try: _run_server(file_store, file_store, host, port, 1, None, gunicorn_opts) except ShellCommandException: print("Running the mlflow server failed. Please see the logs above for details.", file=sys.stderr) sys.exit(1)そこで以下のコマンドを実行したのですが、エラー発生してしまいました。。。
python /Users/takeshi/.local/lib/python3.6/site-packages/mlflow/cli.py uiこの問題は現在未解決です。誰かタスケテ。。。
(ちなみに別の環境(Ubuntu 16.04 LTS)ではなんの問題もなく動作したのでMacの問題かもしれません。これ以降はUbuntu上で実行した結果になります)(解決に役立つかもしれない)
https://www.cnblogs.com/sandyyeh/p/9414058.html
https://github.com/mlflow/mlflow/issues/599起動画面
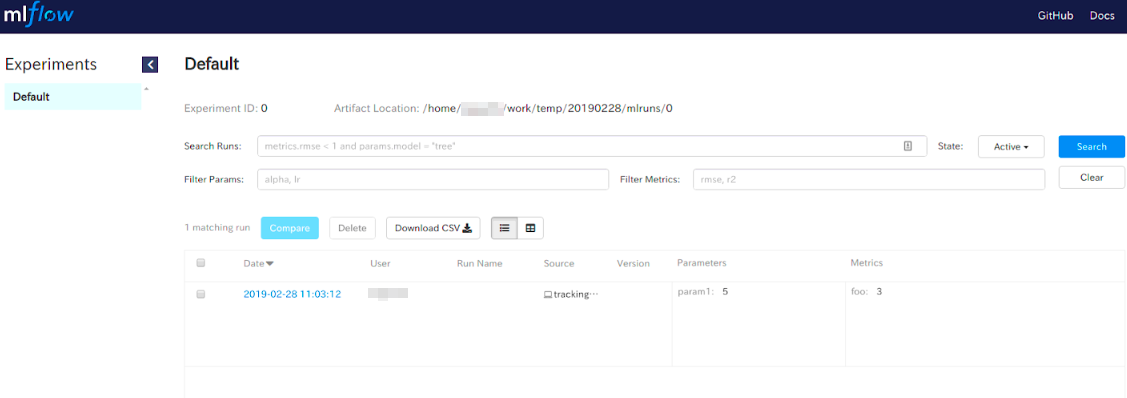
正常に起動できている場合は以下のような画面が表示されます。
なにやらいろいろ表示されていますが、実験条件などでのフィルターなども出来そうです。
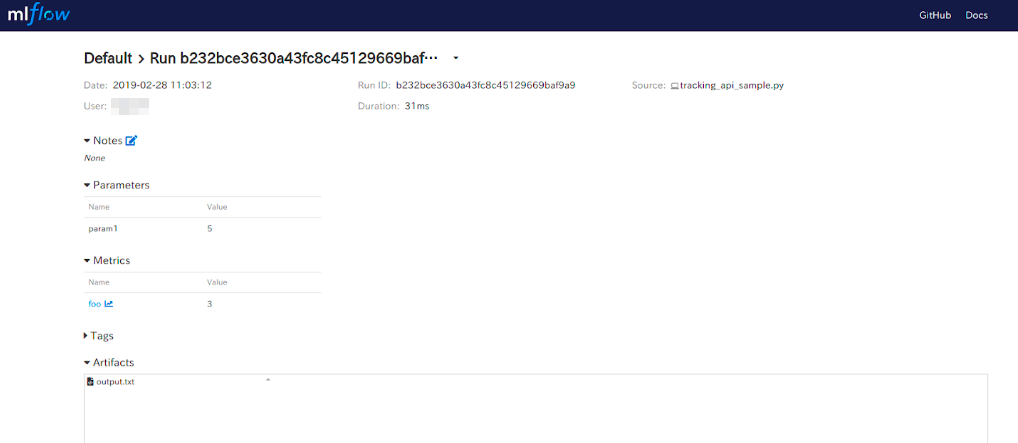
リストアップされているリンクをクリックすると以下のような詳細画面になります。詳細画面
実行日時や処理時間と共に、記録したparametersやmetrics、Artifactsが表示されています。
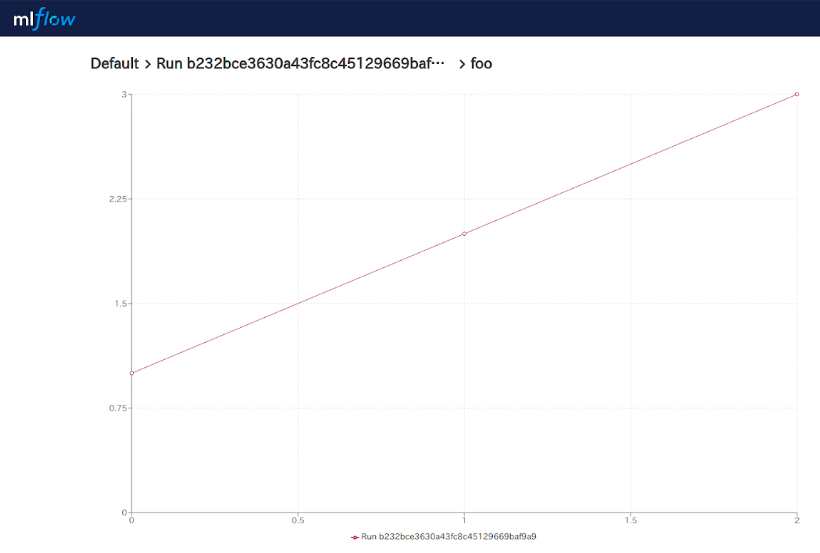
metricsのfooには値を3個保存したので、クリックしてその中身を見てみます。metrics(foo)
自動でグラフにしてくれています。これは便利ですね。
lossなどを保存しておけば自動でグラフが表示されるはずです。次はArtifactsで保存した
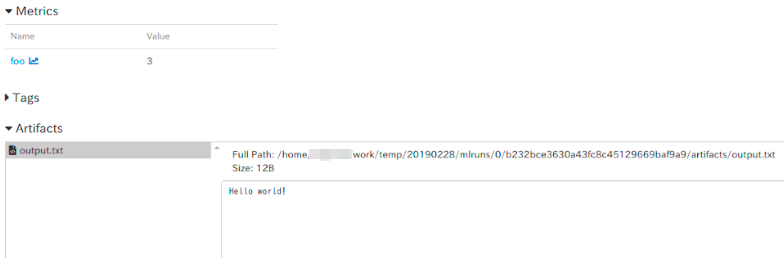
output.txtを見てみます。Artifacts(
output.txt)
うん。しっかり
Hello World!していますね。
ここ(Artifacts)には、実験中や実験後に生成されるファイル達を置いとくって感じでしょう。たぶん。
画像なんかも置けるようです。その他もTagやNotesなどを追加できるようですが、まだ使い方はわかりません。
まとめ
一気にやろうかと思ってましたが、ちょっと長くなってしまったので以下の項目については次回以降にしようかと思います。
- Running MLflow Projects
- Saving and Serving Models乞うご期待
- 投稿日:2019-02-28T23:42:49+09:00
モンテカルロ法で円の面積を近似的に計算してみる
やること
モンテカルロ法を利用することによって円の面積の近似解を得ることを目的とします。また、乱数の数が多いときと少ないときとで近似解の精度に違いが出るかを検証します。
どうやるか
実験にはpython3とMatplotlibを用いて計算します。円の半径は5とするため面積は5×5×3.14=78.5になり、この値に近いほど精度が高いといえます。例えば、座標平面上で(x,y)=(5,5)を中心とする円があるとき、0から10までの乱数を100個用意すると近似解の値はおおよそ78.0となります。
import matplotlib.pyplot as plt import pylab import random x = [] y = [] random_number = 100 #乱数の個数を指定 for i in range(random_number): #座標をランダムに指定 x.append(random.uniform(0, 10)) #x軸 y.append(random.uniform(0, 10)) #y軸 area = 0 for i in range(random_number): #乱数が円の内側にあるかを判断 if x[i]**2 + y[i]**2 <= 10**2: #三平方の定理 area += 1 area = area/((i+1)/100.0) #すべての乱数のうち円の中にある乱数の割合 print('疑似乱数による円の面積は' + area) print('計算による円の面積は' + 5*5*3.14) #グラフを作成 pylab.figure('Area of a circle') pylab.title('Area of a circle') pylab.xlabel('X axis') pylab.ylabel('Y axis') #円の作成 t = pylab.arange(1000.)/1000 #0.1刻みで配列をつくる x_en = 5*pylab.sin(2*pylab.pi*2*t) y_en = 5*pylab.cos(2*pylab.pi*2*t) pylab.plot(x_en+5, y_en+5, 'b') #円の線を青色に指定 pylab.plot(x, y, 'o', color="#ffa500")#乱数をオレンジ色に指定 pylab.show()結果と検証
始めに乱数を100個用意して実験すると、近似解は79.0となりました。
次に、乱数を10000個用意すると近似解は78.77となりました。
これだけでも近似解の精度が上がっていることが分かりますが、精度の向上を裏付けるため検証を施してみようと思います。検証では100個から4100個までの乱数を順次用意していくため、近似解を求める試行回数は4001回となります。
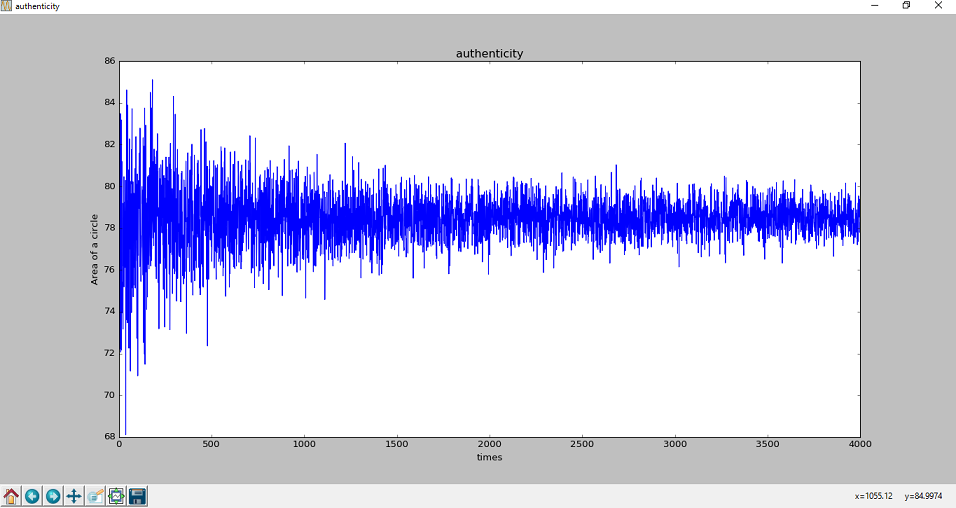
import pylab import random pseudo = [] simulation = 4000 #疑似乱数によって面積の近似解を求める試行回数 simulation = simulation + 101 for i in range(100, simulation): x = [] y = [] for j in range(i): #座標をランダムに指定 x.append(random.uniform(0, 10)) y.append(random.uniform(0, 10)) area = 0 for j in range(i): #乱数が円の内側にあるかを判断 if x[j] ** 2 + y[j] ** 2 <= 10 ** 2: #三平方の定理 area += 1 area = area / ((i + 1) / 100.0) #すべての乱数のうち円の中にある乱数の割合 pseudo.append(area) #グラフの作成 pylab.figure('authenticity') pylab.title('authenticity') pylab.xlabel('times') pylab.ylabel('Area of a circle') pylab.plot(range(0, simulation-100), pseudo) pylab.show()
作成したグラフをみると、試行回数を重ねるごとに近似解のばらつきが抑えられていき、だいたい78あたりに収束していることが分かります。
- 投稿日:2019-02-28T22:53:04+09:00
jupyter/datascience-notebookでPythonのデータ解析環境を構築する
『Software Design 2019年3月号』で「ITエンジニアのための機械学習と微分積分入門」という特集が組まれています。特集の第3章「Pythonで実践する機械学習」ではPythonのコードで簡単なデータ解析のアルゴリズムが解説されています。章の最初にPythonの環境構築の節があり、以下3種類の環境構築の方法が示されています。
- 標準のPythonを使う
- Anaocndaの利用
- Dockerを使う
3番目の「Dockerを使う」方法では、
jupyter/datascience-notebookを利用すればサンプルコードを全て実行できるとあります。本記事では、
jupyter/datascience-notebookを使って特集記事のコードを実行する環境を構築する手順をまとめました。環境構築の手順
概要
手順の概要は以下の通りです。
- Dockerをインストールする。
- Dockerイメージを取得する。
- Dockerイメージを実行する。
- データ解析環境にアクセスする。
1. Dockerをインストールする。
最初にDockerをインストールします。
以下はmacOSでHomebrewをインストール済みの場合です。
$ brew cask install docker2. Dockerイメージを取得する。
jupyter/datascience-notebookのDockerイメージを取得します。$ docker pull jupyter/datascience-notebookイメージのタグを省略すると、自動的に最新版
jupyter/datascience-notebook:latestがダウンロードされます。3. Dockerイメージを実行する。
以下のコマンドで取得したイメージを実行します。
$ docker run --rm -p 10000:8888 -e JUPYTER_ENABLE_LAB=yes -v $(pwd):/home/jovyan/work jupyter/datascience-notebook
-p 10000:8888はホストの10000ポートをコンテナの8888ポートにマッピングします。
-e JUPYTER_ENABLE_LAB=yesはコンテナ開始時にjupyter notebookの代わりにjupyter labを実行するオプションです。
-vオプションではホストのカレントディレクトリをコンテナのworkディレクトリにマウントしています。4. データ解析環境にアクセスする。
ブラウザを開いて
http://localhost:10000/?token=<token>にアクセスします。<token>の値はdocker runした時にコンソールに表示されます。JupyterLabのLauncherが表示されれば環境構築は完了です。jupyter/datascience-notebookとは
ここで実行した
jupyter/datascience-notebookは、Jupyter Docker Stacksで管理されているDockerイメージの一つです。docker runすることでJupyter NotebookまたはJupyterLabのサーバを実行します。Jupyter Docker Stacksとは
Jupyter Docker Stacksは、Jupyter公式で管理されているDockerイメージです。Jupyterのアプリケーションとその他各種ツールがあらかじめインストールされ、すぐに実行可能な状態になっています。用途ごとに複数のイメージがあり、2019年2月現在では以下のイメージが存在します。
- jupyter/base-notebook
- jupyter/minimal-notebook
- jupyter/r-notebook
- jupyter/scipy-notebook
- jupyter/tensorflow-notebook
- jupyter/datascience-notebook
- jupyter/pyspark-notebook
- jupyter/all-spark-notebook
jupyter/datascience-notebookの内容
jupyter/datascience-notebookはデータ解析のためにJulia、Python、Rのライブラリを追加したイメージです。主な機能は以下の通りです。
jupyter/scipy-notebookとjupyter/r-notebookに含まれる機能全て- Juliaのコンパイラと基本的な環境
- JuliaのコードをJupyter notebookで実行するためのIJulia
- HDF5、Gadfly、RDatasetsパッケージ
最後に
上記の手順で構築した環境で特集のサンプルコードを実際に実行できることを確認しました。環境構築にかかった時間はほぼDockerイメージのダウンロード待ちだけでした。同じ環境を自力で構築するのは結構大変だと思います。Dockerの便利さを改めて認識しました。
参考URL
- 投稿日:2019-02-28T22:16:48+09:00
Webスクレイピング
- 投稿日:2019-02-28T21:24:23+09:00
Pytorchのモデル構築、評価を補助するVisdomとtorchsummary
タイトルの通りなんですが、pytorchで地味に役立つ2つのライブラリについての説明を実際にCIFAR10の識別モデルをうごかしながら説明します。
tl;dr
VisdomはTensorboardのPytorch版だよtorchsummaryはKerasでいうところのmodel.summaryだよ- Visdomの使い方の例を実際のモデルを動かしながら説明している記事がなかったから書いたよ
モデル
下のようなモデルを使います。
model.pyclass Model(nn.Module): def __init__(self, nch=3, n_classes=10): super(Model, self).__init__() self.layers = nn.ModuleList([ nn.Sequential( nn.Conv2d(nch, 32, 3, 1, 1), nn.ReLU(inplace=True), nn.MaxPool2d(2, 2), ), # 28x28 -> 14x14 nn.Sequential( nn.Conv2d(32, 64, 3, 1, 1), nn.BatchNorm2d(64), nn.ReLU(inplace=True), nn.MaxPool2d(2, 2), ), # 14x14 -> 7x7 ]) self.classifier = nn.Sequential( nn.Linear(8*8*64, 128), nn.ReLU(128), nn.Linear(128, n_classes), ) def forward(self, x): for layer in self.layers: x = layer(x) x = x.view(x.size(0), -1) x = self.classifier(x) return xpytorch-summary
ネットワークのアーキテクチャを確認するためのライブラリです。
インストール
% pip install torchsummary使い方
from torchsummary import summary summary(your_model, input_size=(channels, H, W))具体例
使い方はすごく簡単でNNと入力する画像の形状を引数にして呼び出すだけです
from torchsummary import summary net = Model().to(device) summary(net, (3, 32, 32)) # GPUを使わない場合、引数のdeviceをcpuに変更します出力例
forwardに書かれている
viewによる形状の変化は、明示的な表示はされないことに留意してください---------------------------------------------------------------- Layer (type) Output Shape Param # ================================================================ Conv2d-1 [-1, 32, 32, 32] 896 ReLU-2 [-1, 32, 32, 32] 0 MaxPool2d-3 [-1, 32, 16, 16] 0 Conv2d-4 [-1, 64, 16, 16] 18,496 BatchNorm2d-5 [-1, 64, 16, 16] 128 ReLU-6 [-1, 64, 16, 16] 0 MaxPool2d-7 [-1, 64, 8, 8] 0 Linear-8 [-1, 128] 524,416 ReLU-9 [-1, 128] 0 Linear-10 [-1, 10] 1,290 ================================================================ Total params: 545,226 Trainable params: 545,226 Non-trainable params: 0 ---------------------------------------------------------------- Input size (MB): 0.01 Forward/backward pass size (MB): 0.97 Params size (MB): 2.08 Estimated Total Size (MB): 3.06 ----------------------------------------------------------------Visdom
データの可視化のためのツールで、TorchとNumpyをサポートしています。
今回紹介する学習過程の表示以外にも2次元、3次元プロットや画像・テキストの描画など様々な機能を備えています。
(Visdom - githubより)基本的な書き方
from visdom import Visdom viz = Visdom() viz.line() # 直線を引く viz.text() # 文章を残す viz.image() # 画像を表示するロス、正解率を順次プロットする
手順は
Visdomをインポートし、インスタンスを作成- ロス、正解率をエポックごとに
viz.line()に追加です。
from visdom import Visdom viz = Visdom() # インスタンスを作る n_epochs = 20 train_loss_list = [] train_acc_list = [] test_loss_list = [] test_acc_list = [] for epoch in range(n_epochs): train_loss = 0 train_acc = 0 test_loss = 0 test_acc = 0 net.train() # 学習モードに切り替え for i, (imgs, labels) in enumerate(trainloader): imgs = imgs.to(device) labels = labels.to(device) optimizer.zero_grad() outputs = net(imgs) loss = criterion(outputs, labels) # ロスと正解率の更新 train_loss += loss.item() train_acc += (outputs.max(1)[1] == labels).sum().item() loss.backward() # 逆伝搬 optimizer.step() avg_train_loss = train_loss / len(trainloader.dataset) avg_train_acc = train_acc / len(trainloader.dataset) # test net.eval() with torch.no_grad(): for imgs, labels in testloader: imgs = imgs.to(device) labels = labels.to(device) outputs = net(imgs) loss = criterion(outputs, labels) test_loss += loss.item() test_acc += (outputs.max(1)[1] == labels).sum().item() avg_test_loss = test_loss / len(testloader.dataset) avg_test_acc = test_acc / len(testloader.dataset) #------ここから-------# viz.line(X=np.array([epoch]), Y=np.array([avg_train_loss]), win='loss', name='avg_train_loss', update='append') viz.line(X=np.array([epoch]), Y=np.array([avg_train_acc]), win='acc', name='avg_train_acc', update='append') viz.line(X=np.array([epoch]), Y=np.array([avg_test_loss]), win='loss', name='avg_test_loss', update='append') viz.line(X=np.array([epoch]), Y=np.array([avg_test_acc]), win='acc', name='avg_test_acc', update='append') #------ここまで-------# print('epoch: {}, train_loss: {:.3f}, train_acc: {:.3f}, val_loss: {:.3f}, val_acc: {:.3f}' .format(epoch, avg_train_loss, avg_train_acc, avg_test_loss, avg_test_acc)) train_loss_list.append(avg_train_loss) train_acc_list.append(avg_train_acc) test_loss_list.append(avg_test_loss) test_acc_list.append(avg_test_acc)ちなみにリスト化された精度のプロットも簡単です
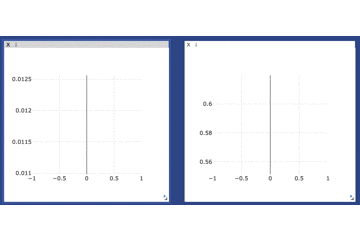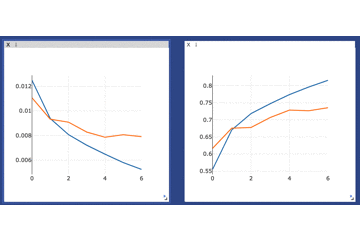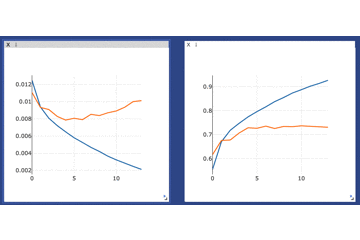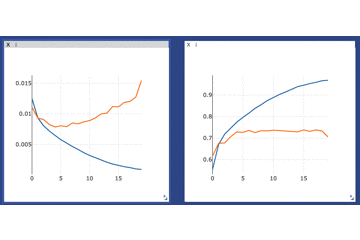
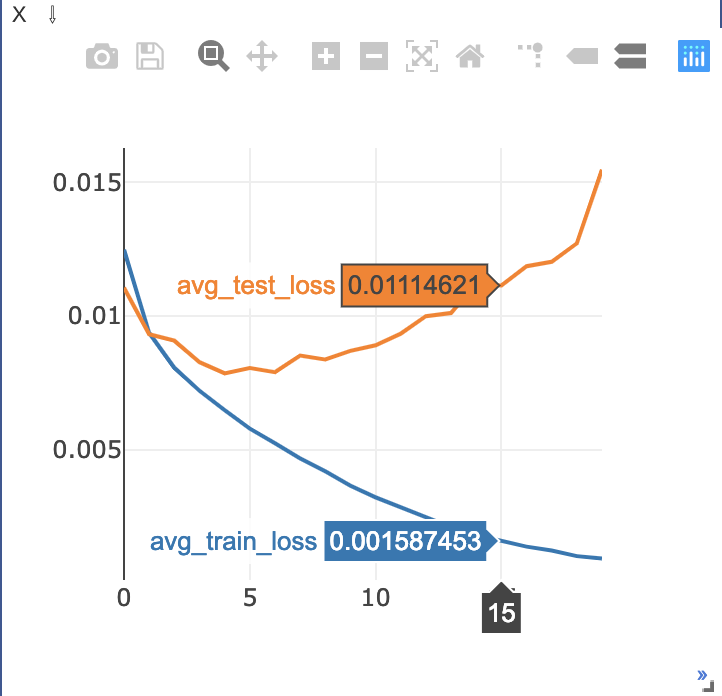
viz.line(X=np.array(range(n_epochs)), Y=np.array(train_loss_list), win='loss', name='avg_train_loss', update='append') viz.line(X=np.array(range(n_epochs)), Y=np.array(train_acc_list), win='acc', name='avg_train_acc', update='append') viz.line(X=np.array(range(n_epochs)), Y=np.array(test_loss_list), win='loss', name='avg_test_loss', update='append') viz.line(X=np.array(range(n_epochs)), Y=np.array(test_acc_list), win='acc', name='avg_test_acc', update='append')ゴリゴリに過学習してますがそれは置いておいて、カーソルを合わせることで詳細な数値などをみることもできます。
さらに、画面上部のメニューから例えば拡大などをすることでさらに細かくみることもできます(窓自体を大きくすることもできます)
カーソルを合わせた様子
ズームした様子ちなみに、カーソルを合わせなくてもラベルと色がわかるようにするには
viz.line(~, opts={'legend': ['avg_train_loss', 'avg_test_loss']})という風に書くことができます。
コード全体像
モデルのところだけ省いてます
import numpy as np import torch import torch.nn as nn import torch.optim as optim import torch.nn.functional as F from torch.autograd import Variable from torchvision import transforms, datasets from torchsummary import summary from visdom import Visdom device = torch.device("cuda" if torch.cuda.is_available() else "cpu") if torch.cuda.is_available(): torch.set_default_tensor_type('torch.cuda.FloatTensor') else: torch.set_default_tensor_type('torch.FloatTensor') transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5, ), (0.5, )) ]) trainset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) trainloader = torch.utils.data.DataLoader(trainset, batch_size=100, shuffle=True, num_workers=2) testset = datasets.CIFAR10(root='./data', train=False, download=True, transform=transform) testloader = torch.utils.data.DataLoader(testset, batch_size=100, shuffle=False, num_workers=2) class Model(nn.Module): pass # (上にあるので中略) net = Model(3).to(device) summary(net, (3, 32, 32)) criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(net.parameters()) viz = Visdom() n_epochs = 20 train_loss_list = [] train_acc_list = [] test_loss_list = [] test_acc_list = [] for epoch in range(n_epochs): train_loss = 0 train_acc = 0 test_loss = 0 test_acc = 0 net.train() # 学習モードに切り替え for i, (imgs, labels) in enumerate(trainloader): imgs = imgs.to(device) labels = labels.to(device) optimizer.zero_grad() outputs = net(imgs) loss = criterion(outputs, labels) # ロスと正解率の更新 train_loss += loss.item() train_acc += (outputs.max(1)[1] == labels).sum().item() loss.backward() # 逆伝搬 optimizer.step() avg_train_loss = train_loss / len(trainloader.dataset) avg_train_acc = train_acc / len(trainloader.dataset) # test net.eval() with torch.no_grad(): for imgs, labels in testloader: imgs = imgs.to(device) labels = labels.to(device) outputs = net(imgs) loss = criterion(outputs, labels) test_loss += loss.item() test_acc += (outputs.max(1)[1] == labels).sum().item() avg_test_loss = test_loss / len(testloader.dataset) avg_test_acc = test_acc / len(testloader.dataset) viz.line(X=np.array([epoch]), Y=np.array([avg_train_loss]), win='loss', name='avg_train_loss', update='append') viz.line(X=np.array([epoch]), Y=np.array([avg_train_acc]), win='acc', name='avg_train_acc', update='append') viz.line(X=np.array([epoch]), Y=np.array([avg_test_loss]), win='loss', name='avg_test_loss', update='append') viz.line(X=np.array([epoch]), Y=np.array([avg_test_acc]), win='acc', name='avg_test_acc', update='append') print('epoch: {}, train_loss: {:.3f}, train_acc: {:.3f}, val_loss: {:.3f}, val_acc: {:.3f}' .format(epoch, avg_train_loss, avg_train_acc, avg_test_loss, avg_test_acc)) train_loss_list.append(avg_train_loss) train_acc_list.append(avg_train_acc) test_loss_list.append(avg_test_loss) test_acc_list.append(avg_test_acc)
- 投稿日:2019-02-28T21:07:48+09:00
プログラミング~学習記録~
プログラミングスタート
これまで、IT全般に対して漠然とした興味を持っており、幅広い媒体から情報収集、また、プログラミングそのものを体験
してみる為にProgateを通じて勉強を進めています。勉強を始めた当初は、「やはり難しいなぁ?」、「言葉の意味自体がわかんねぇ。。。」という思いもありましたが、
簡単なコードを書いたりして、「自分が思った通りに動く事が単純に面白い」という感情が沸き、
本格的に勉強をスタートさせる事にしました。また、多くの先輩が、学習内容等を記録に残す事大切であると述べておりましたので、
見習って、この「Qiita」を通じてアウトプットを していこうと考えています。目標:
2019年度中にエンジニアとして就職
理想像:
フルスタックエンジニア
言語
・pytyon
・Ruby
・HTML.CSS
・Ruby on Rails
・swift.java
上記の言語を使用したエンジニアと目標を達成出来るように進めたいと思います。
学習ツール:
・Progate
・Udemy
・有料プログラミングスクール AIコース
その他学習内容:
・簿記、会計
・アフィリエイト
・読書
・英語、数学、国語
時間:
プログラミングには5時間/1日で確保しつつ、その他の学習も進める
現在の心境
勉強したいなと考えていた事を羅列した状態となっていますが、ほんの少し長いスパンで学習を進めたいと思います。
- 投稿日:2019-02-28T21:02:06+09:00
【深層学習】Pythonで、シーンから映画のタイトルを予測するモデルを作る【実装】
概要
この記事は何か?
シーンから映画のタイトルを予測するモデルを深層学習で作成するための記事
せっかくやるので、人間と人工知能に競わせます。対象読者
- 動画を分析することに興味がある初心者の方
- 深層学習?何ができるの?て方
- 人間 VS 深層学習に興味がある方
- 映画が好きな方
背景/問題提起
見たことのない映画のシーンをみて、どの映画のシーンか、あなたはすぐに答えることはできますか?
かなり難しいかもしれませんが、よほどの映画好きの方なら可能かもしれません。
しかし、その映画が長編シリーズの一つであったとしたらどうでしょうか?映画には長編シリーズになっているものがたくさんあります。
スターウォーズ、スパイキッズ、スパイダーマン、バットマン、ハリーポッター…etc
いくらでもあげることができます。
この記事では、映画の中でも特に同シリーズの作品を見分けることを目的とした
深層学習モデルをVGG16で作成します。要約
シリーズ映画三本(シーズン1~3)の冒頭50分程度を見せた後、
見ていないシーンがクイズ形式で出題されます。何番目のシリーズのシーンかどれくらいの割合で、正解できるでしょうか?
今回は、非常に小規模な人工知能VS人間の戦いなので
人気映画ターミネーターシリーズの1, 2, 3を対象に、
どの程度シリーズを正解して答えられるか(正答率:accuracy)を、深層学習と人間で競います。
(※3シリーズの訓練データ数、テストデータ数は均衡させ、同数とします。)
結果として、以下のことがわかりました。
①映画を最初の50分で止められて次のシリーズにいくのは苦痛。さらに、回答を手で回収するのが苦痛。
②人間(識別正答率:70.5%)は、深層学習モデル(識別正答率:94.1%)には勝てない。
③映画後半の方が、深層学習モデルの識別精度が上がる。
④人の顔が写っているシーンは識別されやすい。(横顔は難しい。)
⑤炎が写っていたら、ターミネーター3だと判断する。
仮説
- 深層学習モデルは、あまり上手く識別精度が出なそう。 (シーンに連関性があると思えないため)
- 人の顔が出てくると識別精度が上がるはず。
- 日本語字幕を出力した状態で、訓練とテストを行ったため 字幕が写っているシーンと写っていないシーンは一つの要因になりそう。
人間に対するクイズ
人間は、映画好きの3名(20代男性)に対して、同等画質で出力した
ターミネーター1~3の冒頭50分を見てもらった後、PCで表示した一人につき600枚の
見ていないシーンが、どのタイトルに属するかを当ててもらい、その正答率を集計した。全体結果:識別正答率(accuracy):0.705(1269/1800)
全体の識別正答率は70.5%であり、人が写っているとは限らないことを、考えるとオタクといっても過言ではない正答率が出た。2は一番有名であるためか、識別正答率が3人とも他のシリーズに比べて高かったことがあります。これは考察で触れます。
被験者A 被験者B 被験者C 識別率合計 0.69(414/) 0.740(444/) 0.685(411/) Terminator1 0.660(132/200) 0.705(141/200) 0.605(121/200) Terminator2 0.815(163/200) 0.855(171/200) 0.800(160/200) Terminator3 0.595(119/200) 0.660(132/200) 0.65(130/200) (accuracy = 0.0~1.0)
実装【深層学習】
動作環境
MacOS X 10.14.3
Google Colaboratory
- jupyter 1.0.0
- jupyter-core 4.4.0
-Ubuntu 18.04.1
keras 2.2.4
Google Drive 1.15.6430.6825参考URL:google colaboratoryの使い方
https://www.codexa.net/how-to-use-google-colaboratory/学習/モデル生成
下準備
ターミネーター1、ターミネーター2、ターミネーター3の開始46分40秒を4秒ごとに区切り、
各700枚ずつの画像を用意する。以下のパラメーターを指定し、VGG16の14層までを凍結して、15〜16層の全結合層のみを学習
train_data = 2100枚(各シリーズ700枚) :作品オープニング〜 4秒ごと×700枚
val_data = 300枚(各シリーズ100枚):〜作品後半 4秒ごと×100枚
test_data = 600枚(各シリーズ200枚):〜作品後半 4秒ごと×200枚
epoch : 100
n_categories=3
batch_size=32スクリーンショットで動画から画像を生成
# import module import pyautogui import time # change display time.sleep(2) # start screen shot for i in range(1000): s = pyautogui.screenshot() s.save('filename_{0:04d}.png'.format(i)) time.sleep(4)Jupyter notebookで上記コードを実行し、画面を映画に切り替えると、
4秒ごとに画面のスクリーンショットをとってきます。
上のような感じで、Jupyter notebookを起動した同ディレクトリ内に大量の映画の写真が保存されます。
3作品に関して、同じ処理をした後、フォルダ名でアノテーション(教師フラグづけ)するので、フォルダ名を
「Terminator1」「Terminator2」「Terminator3」とし、Google Driveに保存します。指定ディレクトリから画像を取り込み、モデルを学習する。
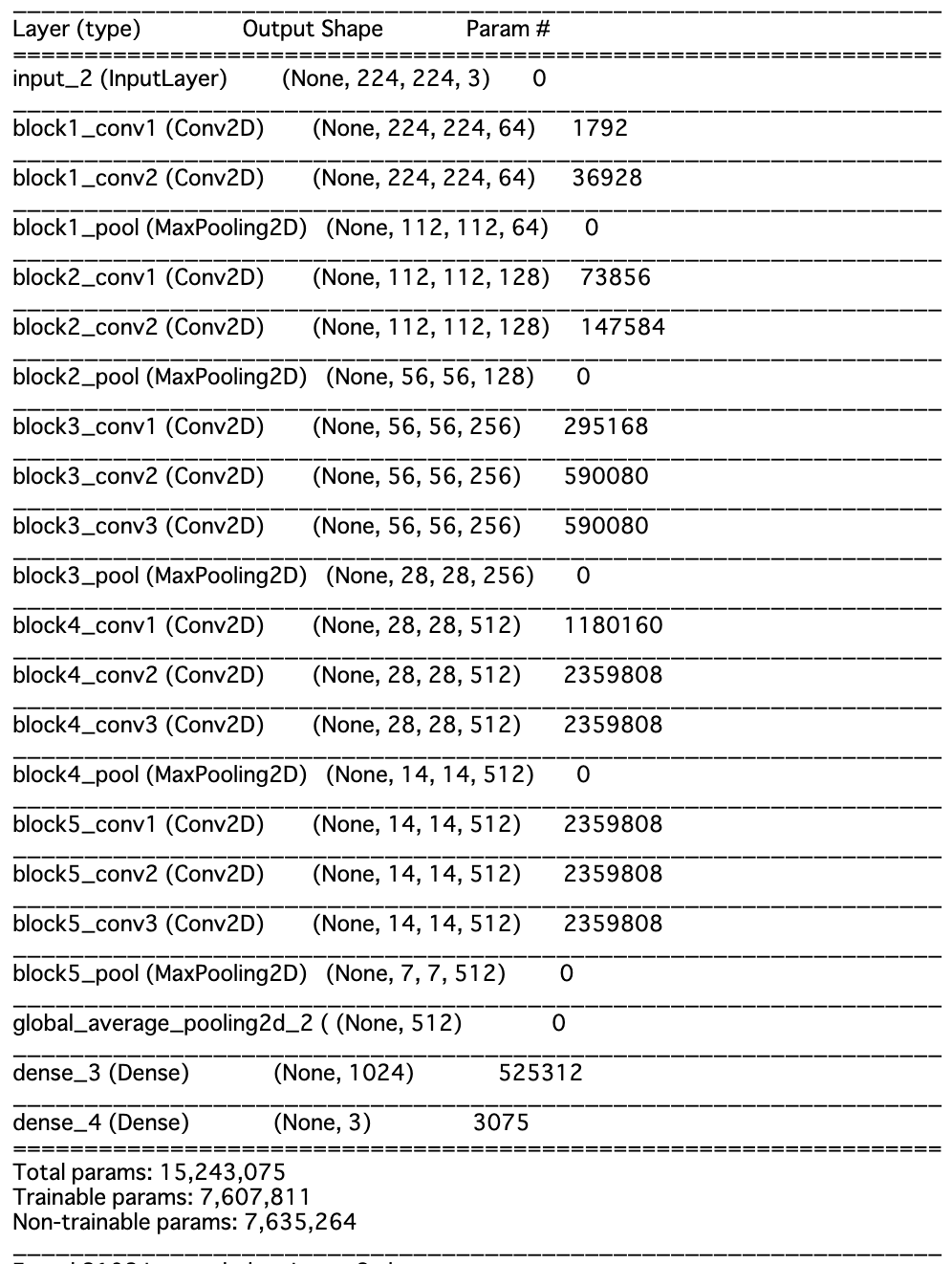
from keras.models import Model from keras.layers import Dense, GlobalAveragePooling2D,Input from keras.applications.vgg16 import VGG16 from keras.preprocessing.image import ImageDataGenerator from keras.optimizers import SGD from keras.callbacks import CSVLogger %matplotlib inline n_categories=3 batch_size=32 train_dir = 'gdrive/My Drive/Google Driveディレクトリ名/train' validation_dir = 'gdrive/My Drive/Google Driveディレクトリ名/val' file_name='vgg16_movie_fine' base_model=VGG16(weights='imagenet',include_top=False, input_tensor=Input(shape=(224,224,3))) #add new layers instead of FC networks x=base_model.output x=GlobalAveragePooling2D()(x) x=Dense(1024,activation='relu')(x) prediction=Dense(n_categories,activation='softmax')(x) model=Model(inputs=base_model.input,outputs=prediction) #fix weights before VGG16 14layers for layer in base_model.layers[:15]: layer.trainable=False model.compile(optimizer=SGD(lr=0.0001,momentum=0.9), loss='categorical_crossentropy', metrics=['accuracy']) model.summary() #save model json_string=model.to_json() open(file_name+'.json','w').write(json_string) train_datagen=ImageDataGenerator( rescale=1.0/255, shear_range=0.2, zoom_range=0.2, horizontal_flip=True) validation_datagen=ImageDataGenerator(rescale=1.0/255) train_generator=train_datagen.flow_from_directory( train_dir, target_size=(224,224), batch_size=batch_size, class_mode='categorical', shuffle=True ) validation_generator=validation_datagen.flow_from_directory( validation_dir, target_size=(224,224), batch_size=batch_size, class_mode='categorical', shuffle=True ) hist=model.fit_generator(train_generator, steps_per_epoch=10, epochs=100, verbose=1, validation_data=validation_generator, validation_steps=10, callbacks=[CSVLogger(file_name+'.csv')]) #save weights model.save(file_name+'.h5')VGG16学習
↓学習過程
....
ここまででモデルの学習をする。
テスト/タイトルを予測
指定ディレクトリから画像を取り込み、タイトルを予測して、正答率を求める。
from keras.models import model_from_json import matplotlib.pyplot as plt import numpy as np import os,random from keras.preprocessing.image import img_to_array, load_img from keras.preprocessing.image import ImageDataGenerator from keras.optimizers import SGD batch_size=32 file_name='vgg16_movie_fine' test_dir = 'gdrive/My Drive/__Google Driveディレクトリ名/test__' display_dir = 'gdrive/My Drive/__Google Driveディレクトリ名/test__' label = ['Terminator1', 'Terminator2', 'Terminator3'] #load model and weights json_string=open(file_name+'.json').read() model=model_from_json(json_string) model.load_weights(file_name+'.h5') model.compile(optimizer=SGD(lr=0.0001,momentum=0.9), loss='categorical_crossentropy', metrics=['accuracy']) #data generate test_datagen=ImageDataGenerator(rescale=1.0/255) test_generator=test_datagen.flow_from_directory( test_dir, target_size=(224,224), batch_size=batch_size, class_mode='categorical', shuffle=True ) #evaluate model score = model.evaluate_generator(test_generator, steps=10) print('\n test loss:',score[0]) print('\n test_acc:',score[1])上記までのコードを打ち込めば、後は結果を待つのみです。
結果
深層学習モデルのコールド勝ち。
深層学習-識別正答率: 0.941
人間-識別正答率: 0.705
下記で実際の結果を見ていきます。
正解ラベルが'Terminator1'のデータに関して、予測結果とシーンを出力。
display_dir = 'gdrive/My Drive/ディレクトリ名/test/Terminator1' #predict model and display images files=os.listdir(display_dir) #print("files:",files) img=random.sample(files,200) #print("img:",img) plt.figure(figsize=(17,150)) for i in range(200): temp_img=load_img(os.path.join(display_dir,img[i]),target_size=(224,224)) #print("temp_img:", temp_img) plt.subplot(40,5,i+1) plt.imshow(temp_img) #Images normalization temp_img_array=img_to_array(temp_img) temp_img_array=temp_img_array.astype('float32')/255.0 temp_img_array=temp_img_array.reshape((1,224,224,3)) #predict image img_pred=model.predict(temp_img_array) plt.title(label[np.argmax(img_pred)]) #eliminate xticks,yticks plt.xticks([]),plt.yticks([]) plt.show()上手くいくと下記のように予測ラベルと出力されます。
これを3つのラベルごとに出力し、タイトル予測を間違えた画像と正解した画像を見比べ、仮説検証した後、考察します。深層学習モデルが、誤認識したシーンを抽出
- Terminator2の識別正答率が、極端に高い。
- Terminator1が正解ラベルのとき間違えるのは、Terminator3だけであり、 Terminator3が正解ラベルのとき、間違えるのは、Terminator1だけである。
- 人が写っているショットは予測が正解しやすいが、横顔や、違うものがメインのシーン、暗いシーンなどのとき、誤認識している。
正解ラベル'Terminator1'-7シーン
強い光、炎が写っているシーンはTerminator3だと判断。
人間が勝ったのは、サラコナーが写っている一枚のみ。正解ラベル'Terminator2'-1シーン
まったくといっていいほど間違えない。
正解ラベル'Terminator2'-17シーン
上記二つの作品に比べると間違えるシーンが多くなる。暗いシーンが多い。
【仮説検証】
・深層学習モデルは、あまり上手く識別精度が出なそう。(シーン連関があると思えないため)
精度が0.941と高い結果が出ました。VGG16、低く見積もって申し訳ないです。・人の顔が出てくると識別精度が上がるはず。
必ずしもそれだけが要因ではないが、人が出てくると精度は上がった。横顔には弱い。・日本語字幕を出力した状態で、訓練とテストを行ったため、字幕が写っているシーンと写っていないシーンは一つの要因になりそう。
字幕が写っているシーンでも、そうでないシーンでも関わりなく間違えていそうなので、関係なさそう。考察
深層学習モデルの圧勝という形になりましたが、考えられることは多そうです。
名作は深層学習も見分けやすい?
ターミネーターシリーズの中でもターミネーター2は一番有名で話を覚えている人も多いです。
実際に、協力してもらった3名もターミネーター2のシーンを当てる方が正答率が高くなっています。深層学習モデルに関しても、ターミネーター2の正答率が最も高く、
正解ラベルがターミネーター1,ターミネーター3のとき、ターミネーター2であると予測したケースはありませんでした。名作は深層学習モデルも見分けやすいというのはキャッチーですが、要因を考えるのは面白そうです。
映画後半の方が機械学習モデルは判別しやすい?
次に注目したのは、訓練データよりも、テストデータの方が損失が少なく、正答率が高くなったことです。
(何度試行してみても、数値は変わるが同様の結果になリます。)
- train_loss: 0.2945 - train_acc: 0.8938
- test loss: 0.2446 - test_acc: 0.9406一般的に、テストデータで学習を行うため、テストデータの損失が少なく、正答率が高くなります。
これは、今回のデータ構成が、訓練データを作品の前半、テストデータを作品の後半としたため、
以下のようなことだと考えています。・後半に重要なシーンが集まっている(人の顔のアップなどが多くなるため)
・前半には本編と関係ない人物が登場し、風景シーンなどが多くなるため。つまり、映画を分析する際後半に焦点を当てて、分析をする方が効率が良さそうだと言えます。
今後
・名作と呼ばれる作品と駄作と呼ばれる作品を見分けるモデルはつくれるか。
・機器の出力画質を同等としたため、時代による画質は大きい要因になりそう。
・損失関数はまだ収束していなかったため、エポック回数増やしても良さそう。引用
こちらの記事をソースコードを利用させていただきました。
https://qiita.com/God_KonaBanana/items/2cf829172087d2423f58








- 投稿日:2019-02-28T21:02:06+09:00
【深層学習】Pythonで映画のタイトルを予測するモデルを作る【実装】
概要
この記事は何か?
シーンから映画のタイトルを予測するモデルを深層学習で作成するための記事
せっかくやるので、人間と人工知能に競わせます。対象読者
- 動画を分析することに興味がある初心者の方
- 深層学習?何ができるの?て方
- 人間 VS 深層学習に興味がある方
- 映画が好きな方
背景/問題提起
見たことのない映画のシーンをみて、どの映画のシーンか、あなたはすぐに答えることはできますか?
かなり難しいかもしれませんが、よほどの映画好きの方なら可能かもしれません。
しかし、その映画が長編シリーズの一つであったとしたらどうでしょうか?映画には長編シリーズになっているものがたくさんあります。
スターウォーズ、スパイキッズ、スパイダーマン、バットマン、ハリーポッター…etc
いくらでもあげることができます。
この記事では、映画の中でも特に同シリーズの作品を見分けることを目的とした
深層学習モデルをVGG16で作成します。要約
シリーズ映画三本(シーズン1~3)の冒頭50分程度を見せた後、
見ていないシーンがクイズ形式で出題されます。何番目のシリーズのシーンかどれくらいの割合で、正解できるでしょうか?
今回は、非常に小規模な人工知能VS人間の戦いなので
人気映画ターミネーターシリーズの1, 2, 3を対象に、
どの程度シリーズを正解して答えられるか(正答率:accuracy)を、深層学習と人間で競います。
(※3シリーズの訓練データ数、テストデータ数は均衡させ、同数とします。)
結果として、以下のことがわかりました。
①映画を最初の50分で止められて次のシリーズにいくのは苦痛。さらに、回答を手で回収するのが苦痛。
②人間(識別正答率:70.5%)は、深層学習モデル(識別正答率:94.1%)には勝てない。
③映画後半の方が、深層学習モデルの識別精度が上がる。
④人の顔が写っているシーンは識別されやすい。(横顔は難しい。)
⑤炎が写っていたら、ターミネーター3だと判断する。
仮説
- 深層学習モデルは、あまり上手く識別精度が出なそう。 (シーンに連関性があると思えないため)
- 人の顔が出てくると識別精度が上がるはず。
- 日本語字幕を出力した状態で、訓練とテストを行ったため 字幕が写っているシーンと写っていないシーンは一つの要因になりそう。
人間に対するクイズ
人間は、映画好きの3名(20代男性)に対して、同等画質で出力した
ターミネーター1~3の冒頭50分を見てもらった後、PCで表示した一人につき600枚の
見ていないシーンが、どのタイトルに属するかを当ててもらい、その正答率を集計した。全体結果:識別正答率(accuracy):0.705(1269/1800)
全体の識別正答率は70.5%であり、人が写っているとは限らないことを、考えるとオタクといっても過言ではない正答率が出た。2は一番有名であるためか、識別正答率が3人とも他のシリーズに比べて高かったことがあります。これは考察で触れます。
被験者A 被験者B 被験者C 識別率合計 0.69(414/) 0.740(444/) 0.685(411/) Terminator1 0.660(132/200) 0.705(141/200) 0.605(121/200) Terminator2 0.815(163/200) 0.855(171/200) 0.800(160/200) Terminator3 0.595(119/200) 0.660(132/200) 0.65(130/200) (accuracy = 0.0~1.0)
実装【深層学習】
動作環境
MacOS X 10.14.3
Google Colaboratory
- jupyter 1.0.0
- jupyter-core 4.4.0
-Ubuntu 18.04.1
keras 2.2.4
Google Drive 1.15.6430.6825参考URL:google colaboratoryの使い方
https://www.codexa.net/how-to-use-google-colaboratory/学習/モデル生成
下準備
ターミネーター1、ターミネーター2、ターミネーター3の開始46分40秒を4秒ごとに区切り、
各700枚ずつの画像を用意する。以下のパラメーターを指定し、VGG16の14層までを凍結して、15〜16層の全結合層のみを学習
train_data = 2100枚(各シリーズ700枚) :作品オープニング〜 4秒ごと×700枚
val_data = 300枚(各シリーズ100枚):〜作品後半 4秒ごと×100枚
test_data = 600枚(各シリーズ200枚):〜作品後半 4秒ごと×200枚
epoch : 100
n_categories=3
batch_size=32スクリーンショットで動画から画像を生成
# import module import pyautogui import time # change display time.sleep(2) # start screen shot for i in range(1000): s = pyautogui.screenshot() s.save('filename_{0:04d}.png'.format(i)) time.sleep(4)Jupyter notebookで上記コードを実行し、画面を映画に切り替えると、
4秒ごとに画面のスクリーンショットをとってきます。
上のような感じで、Jupyter notebookを起動した同ディレクトリ内に大量の映画の写真が保存されます。
3作品に関して、同じ処理をした後、フォルダ名でアノテーション(教師フラグづけ)するので、フォルダ名を
「Terminator1」「Terminator2」「Terminator3」とし、Google Driveに保存します。指定ディレクトリから画像を取り込み、モデルを学習する。
from keras.models import Model from keras.layers import Dense, GlobalAveragePooling2D,Input from keras.applications.vgg16 import VGG16 from keras.preprocessing.image import ImageDataGenerator from keras.optimizers import SGD from keras.callbacks import CSVLogger %matplotlib inline n_categories=3 batch_size=32 train_dir = 'gdrive/My Drive/Google Driveディレクトリ名/train' validation_dir = 'gdrive/My Drive/Google Driveディレクトリ名/val' file_name='vgg16_movie_fine' base_model=VGG16(weights='imagenet',include_top=False, input_tensor=Input(shape=(224,224,3))) #add new layers instead of FC networks x=base_model.output x=GlobalAveragePooling2D()(x) x=Dense(1024,activation='relu')(x) prediction=Dense(n_categories,activation='softmax')(x) model=Model(inputs=base_model.input,outputs=prediction) #fix weights before VGG16 14layers for layer in base_model.layers[:15]: layer.trainable=False model.compile(optimizer=SGD(lr=0.0001,momentum=0.9), loss='categorical_crossentropy', metrics=['accuracy']) model.summary() #save model json_string=model.to_json() open(file_name+'.json','w').write(json_string) train_datagen=ImageDataGenerator( rescale=1.0/255, shear_range=0.2, zoom_range=0.2, horizontal_flip=True) validation_datagen=ImageDataGenerator(rescale=1.0/255) train_generator=train_datagen.flow_from_directory( train_dir, target_size=(224,224), batch_size=batch_size, class_mode='categorical', shuffle=True ) validation_generator=validation_datagen.flow_from_directory( validation_dir, target_size=(224,224), batch_size=batch_size, class_mode='categorical', shuffle=True ) hist=model.fit_generator(train_generator, steps_per_epoch=10, epochs=100, verbose=1, validation_data=validation_generator, validation_steps=10, callbacks=[CSVLogger(file_name+'.csv')]) #save weights model.save(file_name+'.h5')VGG16学習
↓学習過程
....
ここまででモデルの学習をする。
テスト/タイトルを予測
指定ディレクトリから画像を取り込み、タイトルを予測して、正答率を求める。
from keras.models import model_from_json import matplotlib.pyplot as plt import numpy as np import os,random from keras.preprocessing.image import img_to_array, load_img from keras.preprocessing.image import ImageDataGenerator from keras.optimizers import SGD batch_size=32 file_name='vgg16_movie_fine' test_dir = 'gdrive/My Drive/__Google Driveディレクトリ名/test__' display_dir = 'gdrive/My Drive/__Google Driveディレクトリ名/test__' label = ['Terminator1', 'Terminator2', 'Terminator3'] #load model and weights json_string=open(file_name+'.json').read() model=model_from_json(json_string) model.load_weights(file_name+'.h5') model.compile(optimizer=SGD(lr=0.0001,momentum=0.9), loss='categorical_crossentropy', metrics=['accuracy']) #data generate test_datagen=ImageDataGenerator(rescale=1.0/255) test_generator=test_datagen.flow_from_directory( test_dir, target_size=(224,224), batch_size=batch_size, class_mode='categorical', shuffle=True ) #evaluate model score = model.evaluate_generator(test_generator, steps=10) print('\n test loss:',score[0]) print('\n test_acc:',score[1])上記までのコードを打ち込めば、後は結果を待つのみです。
結果
深層学習モデルのコールド勝ち。
深層学習-識別正答率: 0.941
人間-識別正答率: 0.705
下記で実際の結果を見ていきます。
正解ラベルが'Terminator1'のデータに関して、予測結果とシーンを出力。
display_dir = 'gdrive/My Drive/ディレクトリ名/test/Terminator1' #predict model and display images files=os.listdir(display_dir) #print("files:",files) img=random.sample(files,200) #print("img:",img) plt.figure(figsize=(17,150)) for i in range(200): temp_img=load_img(os.path.join(display_dir,img[i]),target_size=(224,224)) #print("temp_img:", temp_img) plt.subplot(40,5,i+1) plt.imshow(temp_img) #Images normalization temp_img_array=img_to_array(temp_img) temp_img_array=temp_img_array.astype('float32')/255.0 temp_img_array=temp_img_array.reshape((1,224,224,3)) #predict image img_pred=model.predict(temp_img_array) plt.title(label[np.argmax(img_pred)]) #eliminate xticks,yticks plt.xticks([]),plt.yticks([]) plt.show()上手くいくと下記のように予測ラベルと出力されます。
これを3つのラベルごとに出力し、タイトル予測を間違えた画像と正解した画像を見比べ、仮説検証した後、考察します。深層学習モデルが、誤認識したシーンを抽出
- Terminator2の識別正答率が、極端に高い。
- Terminator1が正解ラベルのとき間違えるのは、Terminator3だけであり、 Terminator3が正解ラベルのとき、間違えるのは、Terminator1だけである。
- 人が写っているショットは予測が正解しやすいが、横顔や、違うものがメインのシーン、暗いシーンなどのとき、誤認識している。
正解ラベル'Terminator1'-7シーン
強い光、炎が写っているシーンはTerminator3だと判断。
人間が勝ったのは、サラコナーが写っている一枚のみ。正解ラベル'Terminator2'-1シーン
まったくといっていいほど間違えない。
正解ラベル'Terminator2'-17シーン
上記二つの作品に比べると間違えるシーンが多くなる。暗いシーンが多い。
【仮説検証】
・深層学習モデルは、あまり上手く識別精度が出なそう。(シーン連関があると思えないため)
精度が0.941と高い結果が出ました。VGG16、低く見積もって申し訳ないです。・人の顔が出てくると識別精度が上がるはず。
必ずしもそれだけが要因ではないが、人が出てくると精度は上がった。横顔には弱い。・日本語字幕を出力した状態で、訓練とテストを行ったため、字幕が写っているシーンと写っていないシーンは一つの要因になりそう。
字幕が写っているシーンでも、そうでないシーンでも関わりなく間違えていそうなので、関係なさそう。考察
深層学習モデルの圧勝という形になりましたが、考えられることは多そうです。
名作は深層学習も見分けやすい?
ターミネーターシリーズの中でもターミネーター2は一番有名で話を覚えている人も多いです。
実際に、協力してもらった3名もターミネーター2のシーンを当てる方が正答率が高くなっています。深層学習モデルに関しても、ターミネーター2の正答率が最も高く、
正解ラベルがターミネーター1,ターミネーター3のとき、ターミネーター2であると予測したケースはありませんでした。名作は深層学習モデルも見分けやすいというのはキャッチーですが、要因を考えるのは面白そうです。
映画後半の方が機械学習モデルは判別しやすい?
次に注目したのは、訓練データよりも、テストデータの方が損失が少なく、正答率が高くなったことです。
(何度試行してみても、数値は変わるが同様の結果になリます。)
- train_loss: 0.2945 - train_acc: 0.8938
- test loss: 0.2446 - test_acc: 0.9406一般的に、テストデータで学習を行うため、テストデータの損失が少なく、正答率が高くなります。
これは、今回のデータ構成が、訓練データを作品の前半、テストデータを作品の後半としたため、
以下のようなことだと考えています。・後半に重要なシーンが集まっている(人の顔のアップなどが多くなるため)
・前半には本編と関係ない人物が登場し、風景シーンなどが多くなるため。つまり、映画を分析する際後半に焦点を当てて、分析をする方が効率が良さそうだと言えます。
今後
・名作と呼ばれる作品と駄作と呼ばれる作品を見分けるモデルはつくれるか。
・機器の出力画質を同等としたため、時代による画質は大きい要因になりそう。
・損失関数はまだ収束していなかったため、エポック回数増やしても良さそう。引用
こちらの記事をソースコードを利用させていただきました。
https://qiita.com/God_KonaBanana/items/2cf829172087d2423f58
- 投稿日:2019-02-28T20:54:38+09:00
Python 日時系備忘録
環境
virtualbox 5.2.26
vagrant 2.1.2
mac 10.14.2日時取得
input.pyfrom datetime import datetime now = datetime.now() print(now.year, '/', now.month, '/', now.day, ' ', now.hour, ':', now.minute, ':', now.second, sep='')output.py2019/2/26 12:00:00時刻がずれていた場合手動で設定
$ sudo date -s "2019/02/26 13:00:00"※仮想マシンを落とすと同期する設定にしてても時間がズレるため手動で設定。
Vagrantfile弄ったり、Vboxmanage,vboxadd-serviceなどのコマンド色々試したがズレる・・。
解決策探してます。。日時作成して文字列で表示
input.pyfrom datetime import datetime day = datetime(1853, 6, 3, 13, 00, 00) str_day = day.strftime('%Y年%m月%d日 %H時%M分%S秒') print(str_day)output.py1853年06月03日 13時00分00秒文字列を日時に変換
input.pyfrom datetime import datetime str_day = '1853/6/3 12:00:00' day = datetime.strptime(str_day, '%Y/%m/%d %H:%M:%S') # 指定フォーマットは同じにする。 print(day)output.py1853-06-03 12:00:00日時の差を求める
input2019 2 27input.pyfrom datetime import datetime from datetime import timedelta day = input().strip().replace(' ', '/') base = datetime.strptime(day, '%Y/%m/%d') result = base - timedelta(days=10000) # 入力された日にちから1万日前を求める。 str_result = result.strftime('%Y年%m月%d日') print(str_result)output1991年10月12日
- 投稿日:2019-02-28T20:19:56+09:00
softmax関数の処理を今まで勘違いしていた話
もしかしたら同じ勘違いをしている人がいるかもしれないという事で、記事にしておきます。
sofmaxと言えば、分類問題などで使われる関数であり、以下のような特徴がある。
1.総和を1にする。
2.数値の大小は変わらない。これは、深層学習を勉強した人なら、多くの人がお世話になったであろう「ゼロから作るdeep learning」の70ページ目にも書かれている。
しかしひょんな事から、その2の特徴は正確ではないという事に気が付いた。最初から総和が1の配列をsoftmaxに通してみる。
def softmax(x): if x.ndim == 2: x = x.T x = x - np.max(x, axis=0) y = np.exp(x) / np.sum(np.exp(x), axis=0) return y.T x = x - np.max(x) # オーバーフロー対策 return np.exp(x) / np.sum(np.exp(x)) x = np.array([0.7, 0.2, 0.1]) print(softmax(x))test.py[0.46396343 0.28140804 0.25462853]総和が1である配列をsoftmaxに通したら同じ値のまま返ってくるという認識だったのだがそうではなかった。
次にsoftmaxの出力を再度softmaxに通す...という処理をしてみる。
import numpy as np def softmax(x): if x.ndim == 2: x = x.T x = x - np.max(x, axis=0) y = np.exp(x) / np.sum(np.exp(x), axis=0) return y.T x = x - np.max(x) # オーバーフロー対策 return np.exp(x) / np.sum(np.exp(x)) x = np.array([0.7, 0.2, 0.1]) for _ in range(100): x = softmax(x) print(x)test.py[0.33333333 0.33333333 0.33333333]最終的には、値が均一になる事がわかった。
この事から、softmaxに通した値の大小は変わらないというのは間違いである。
- 投稿日:2019-02-28T19:16:07+09:00
Lesson2:Naive Bayes まとめ Intro to Machine learning@ Udacity
大分前にやったのですが、復習もかねて書いてみる。
このレッスンの概要
Naive(単純) Bayes分類器は教師あり学習の一つで、決定境界(Decision boundary)を決めるもの。
実装が簡単で計算効率がいいらしい。このレッスンの前半では、入力データを学習用データとテスト用データに分けたり、分類器の性能を図るためにsklearn.metrics.accuracy_scoreを使ったりします。
Video22からは、Naive Bayes文類器の中身を、ガン検査(Cancer Test)を使って解説してくれます。個人的にはこれが大変わかりやすかった。
前提として下記のようなガン検査があると仮定します。単純ベイズ分類器の中身説明
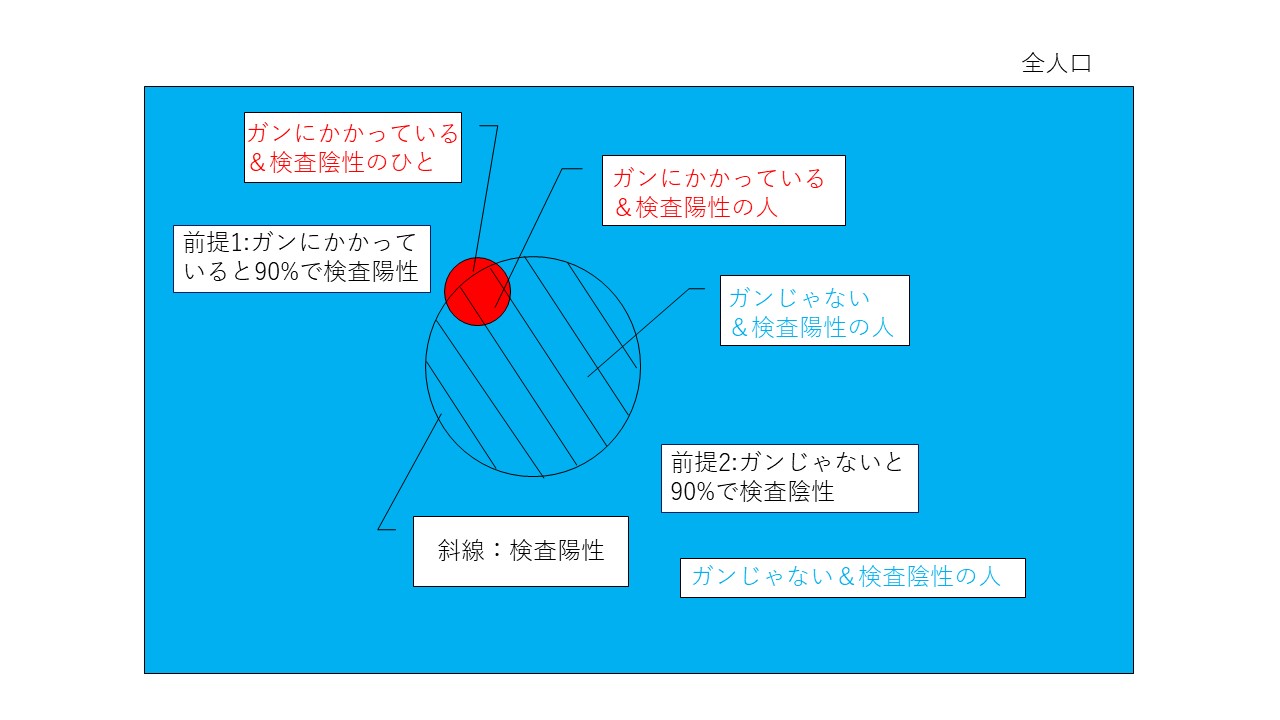
<ガン検査の前提>
前提1:ガンにかかっている人は90%陽性(Positive)
前提2:ガンにかかっていない人は90%陰性(Negative)
前提3:ガン罹患率P(c)は0.01(1%)
図にするとこんな感じ。
上の条件で自分が検査を受けて陽性だった場合の、実際に癌にかかっている率は実は8%に過ぎない。どうしてそうなるか見ていく。図の斜線のエリアが検査陽性の集団。この中で、実際に癌にかかっている集団が赤色。直感的にすごく小さいのがわかると思う。
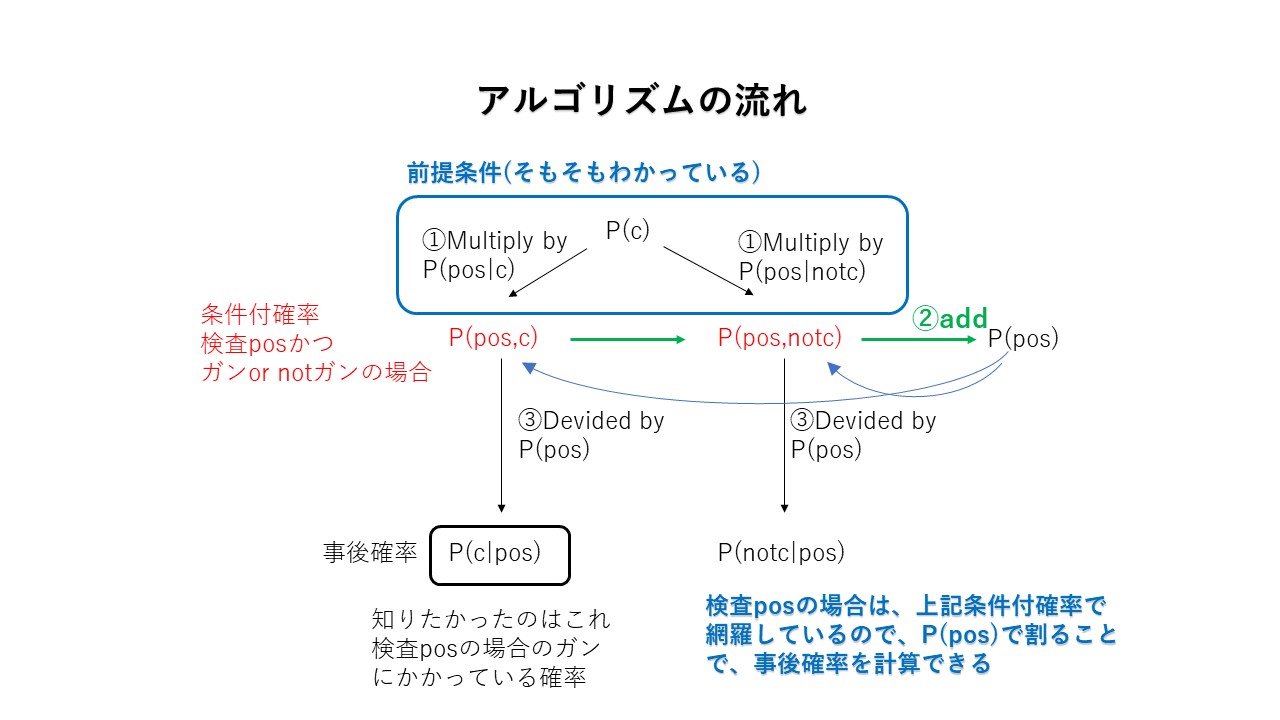
ベイズルールでは
事前確率*テストエビデンス→事後確率
となる。◆STEP1:事前準備◆
事前確率:P(c) = 0.01 1引く→ P(notc) = 0.99
P(pos|c) = 0.9 1引く→ P(neg|c) = 0.1
P(neg|notc) = 0.9 1引く→ P(pos|notc) = 0.1
※P(pos|c) はprobability of positive given c。c(ガン)の時にpositiveとなる確率という意味。縦棒の後にある事象が起こった場合の縦棒の前の現象(この場合陽性)が起こる確率という意味。◆STEP2:条件付確率の計算◆
条件付確率を計算すると。。。
P(c, pos) = P(c)P(pos|c) = 0.01*0.9 = 0.009・・・①
P(notc, pos) = P(notc)P(pos|notc) =0.99*0.1 = 0.099・・・②◆STEP3:Normalizerによる事後確率計算◆
条件付確率で、
ⅰ)検査陽性、かつ、ガンにかかっている確率
と、
ⅱ)検査陽性、かつ、ガンにかかっていない確率Normalizer : P(pos)=P(c|pos)+P(notc|pos) = 0.108・・・③
求めたいのはP(c|pos)
P(c|pos) = ①/③ = 0.0833
P(notc|pos) = ②/③ = 0.9167
上記を足すと1になる。
なぜ、Normalizerで割れるのかというと、検査陽性の場合はP(c|pos)、P(notc|pos)で網羅できているから。これで、もし検査陽性だとしても、ガンである確率は0.08(8%)であることがわかる。上記図の斜線部分をみると直感的にわかる(比率はすみません)
アルゴリズムをまとめると下記の図のようになる。
つまり、
事後確率P(c|pos) = \frac{P(pos,c)}{P(pos)} = \frac{P(c)*P(pos|c)}{P(pos)}単純ベイズ分類器の応用~texis learning~
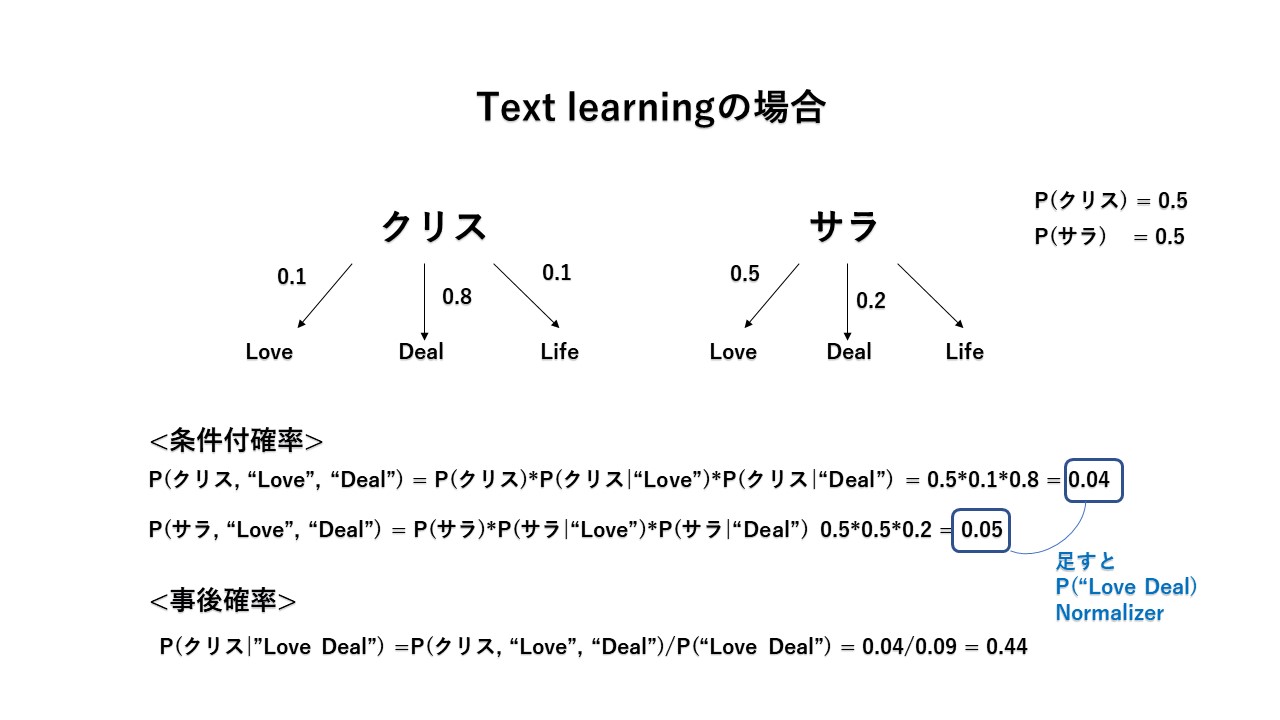
クリスとサラがいて、彼らが使うLove, Deal, Lifeの確率はそれぞれわかっている場合、"Love Deal"の文章は、クリスかサラのどちらが書いたか分類したい場合。
単純ベイズ分類器を使うと下記のようになる。
余談だが、なぜ単純(甘い)ベイズ分類器なのかは、語順を無視している為らしい。
Mini project
事前にPreprocessされたメールデータを学習して、クリスの文章か、サラの文章化に分類する。preprocessについては下記参照。
コード
nb_author_id.py######################################################### ### your code goes here ### import numpy as np from sklearn.naive_bayes import GaussianNB from sklearn.metrics import accuracy_score clf = GaussianNB() t0 = time() clf.fit(features_train, labels_train) print "training time:", round(time()-t0,3),"s" t1 = time() pred = clf.predict(features_test) print "predicting time:", round(time()-t1,3),"s" accuracy = accuracy_score(labels_test, pred) print(accuracy)<出力>
no. of Chris training emails: 7936
no. of Sara training emails: 7884
training time: 3.9 s
predicting time: 0.752 s
0.9732650739476678学習よりも分類のほうが圧倒的に早いね。
features_trainは15820行、3785列の行列。
features_testは1758行、3785列の行列。
3785列は出現した全単語の数。
行列の中身は各単語の重みづけ(重要度)が入っている(0.632とか)つまり、全email 15820+1758 = 17578のメールの中に記述された各単語が3785個あるということですね。
この辺の処理は、Lesson11: Text Learning まとめ みればどんなのがわかるかも!
ドキュメンテーション:sklearn.naive_bayes.GaussianNBはご参考
感想
Lesson2をまとめたのがLesson11をまとめた後だったので、事前処理も含めて復習になってよかった。ベイズルールも何となく釈然としないまま日々を過ごしていたけど、理解できた気がする。
- 投稿日:2019-02-28T18:59:35+09:00
自然言語処理以外でのトピックモデルによる特徴抽出
はじめに
2019年2月27日に終了したKaggleのコンペ「Elo Merchant Category Recommendation」で非文章のカテゴリ変数からトピックモデルを用いて特徴量を生成したところ、スコアが大きく伸びたので紹介したいと思います。
利用したモデル
- LDA(gensim)
- FM_FTRL(WordBatch)
コンペの上位陣が公開してくれている解法でもトピックモデルによる特徴量生成は行われており、Word2Vecを利用している人が多かったようです。
とは言え、LDAとFM_FTRLで作成した特徴量でもPrvate LBでスコアが0.012改善していました(シングルモデル)利用方法
「Elo Merchant Category Recommendation」コンペでは、カード会員の購買履歴からターゲット変数としてロイヤリティを算出するのですがカード会員を特定するcard_idに対して複数レコードの情報が紐づいています。
このような場合、card_idをグループとして何らかのカラム(単数、複数の組み合わせ)でカウントや最小値、最大値、平均を取ったり、One Hot Encodingで特徴量を生成するのがまずは考えられます。
当然、私もそのような特徴量生成から始めたのですがOne Hot Encodingの問題点であるデータのカーディナリティが高いとカラム数が爆発して手に負えなくなるという状況に陥りました。
そこでカーディナリティの高いカテゴリ変数を中心にcard_idと対象のカテゴリ変数でグループ化したカウントをスペース区切りで次々と繋げて一行の文章のようにします。
後はそれをトピックモデルに与えて分類して各トピックのスコアを特徴量として利用します。
この際にどのような順番で繋げた文章を作成するかや分類するトピックの数をいくつかにするかで精度が変わってくるので、CVをたよりに調整していきます。
実際のコードはこのような感じです。
コンペでは、merchant_id以外にもcity_id、state_id、subsector_id、merchant_category_idで同様にトピックを生成しました。def create_merchant_topic(df): global merchant_texts merchant_texts = {} merchants = df.groupby(["card_id", "merchant_id"]).size().reset_index() merchants.rename(columns={0:"size"}, inplace=True) merchants["text"] = merchants["card_id"] + "," + merchants["merchant_id"] + "," + merchants["size"].astype(str) merchants["text"].progress_apply(lambda x: create_merchant_texts(x)) df_merchant_texts = pd.DataFrame.from_dict(merchant_texts, orient='index').reset_index() df_merchant_texts.rename(columns={"index": "card_id", 0: "merchant_id_topic"}, inplace=True) return calc_topic_score(df_merchant_texts, "merchant_id").drop("merchant_id_topic", axis=1) def create_merchant_texts(x): t = x.split(",") if t[0] not in merchant_texts.keys(): merchant_texts[t[0]] = "" for i in range(int(t[2])): merchant_texts[t[0]] += " " + t[1] def calc_topic_score(df, prefix): texts = [[word for word in document.lower().split()] for document in df[prefix+"_topic"].values] dictionary = corpora.Dictionary(texts) bow_corpus = [dictionary.doc2bow(t) for t in texts] lda = models.LdaModel(bow_corpus, id2word=dictionary, num_topics=11) topics = {0: [-1]*len(df), 1: [-1]*len(df), 2: [-1]*len(df), 3: [-1]*len(df), 4: [-1]*len(df), 5: [-1]*len(df)} for i, row in enumerate(lda[bow_corpus]): for j, (topic_num, prop_topic) in enumerate(row): topics[topic_num][i] = prop_topic df[prefix+"_topic_0"] = topics[0] df[prefix+"_topic_1"] = topics[1] df[prefix+"_topic_2"] = topics[2] df[prefix+"_topic_3"] = topics[3] df[prefix+"_topic_4"] = topics[4] df[prefix+"_topic_5"] = topics[5] return df一方で、FM_FTRLでは複数のカテゴリ変数の組み合わせでカウントを繋ぎ合わせた文章として学習させて、target変数に対する予測値を特徴量として生成しました。
変数を繋げたもの A3 B3 C3 D2 E2 F2 G3 H2 I-1 A3 B3 C3 D2 E2 F2実際のコードはこのような感じです。
batchsize = 201000 D = 2 ** 20 global WB global FM_CLS WB = wordbatch.WordBatch(None, extractor=(WordHash, {"ngram_range": (1, 1), "analyzer": "word", "lowercase": False, "n_features": D, "norm": None, "binary": True}), minibatch_size=batchsize//100, procs=8, freeze=True, timeout=1800, verbose=0) FM_CLS = FM_FTRL(alpha=0.0001, beta=0.001, iters=20, L1=0.0, L2=0.0, D=D, alpha_fm=0.02, L2_fm=0.0, init_fm=0.01, weight_fm=1.0, D_fm=8, e_noise=0.0, inv_link="identity", e_clip=1.0, use_avx=1, verbose=0) def create_wordbatch_topic(df): global wordbatch_topic_texts wordbatch_topic_texts = {} df["category_2"] = df["category_2"].fillna(-1) df["category_3"] = df["category_3"].fillna("A") df["merchant_id"] = df["merchant_id"].fillna("M_ID_00a6ca8a8a") df['purchase_date'] = pd.to_datetime(df['purchase_date']) df['month_diff'] = ((RECENT_DATETIME - df['purchase_date']).dt.days)//30 df['month_diff'] += df['month_lag'] df['authorized_flag'] = df['authorized_flag'].map({'Y': 1, 'N': 0}).astype(int) df['purchase_amount'] = df['purchase_amount'].apply(lambda x: min(x, 0.8)) df['duration'] = df['purchase_amount']*df['month_diff'] df["count_1"] = df.groupby(['card_id', 'month_diff', 'state_id', 'city_id'])["card_id"].transform("count") df["count_2"] = df.groupby(['card_id', 'month_diff', 'category_1', 'category_2', 'category_3'])["card_id"].transform("count") df["count_3"] = df.groupby(['card_id', 'month_diff'])["card_id"].transform("count") df["count_4"] = df.groupby(['card_id', 'month_diff', 'merchant_id'])["card_id"].transform("count") df["count_5"] = df.groupby(['card_id', 'month_diff', 'merchant_category_id'])["card_id"].transform("count") df["count_6"] = df.groupby(['card_id', 'month_diff', 'subsector_id'])["card_id"].transform("count") df["count_7"] = df.groupby(['card_id', 'month_diff', 'installments'])["card_id"].transform("count") df["count_8"] = df.groupby(['card_id', 'month_diff'])["authorized_flag"].transform("sum") df["count_9"] = df.groupby(['card_id'])["duration"].transform("mean") df["count_1"] = df["count_1"].astype(int) df["count_2"] = df["count_2"].astype(int) df["count_3"] = df["count_3"].astype(int) df["count_4"] = df["count_4"].astype(int) df["count_5"] = df["count_5"].astype(int) df["count_6"] = df["count_6"].astype(int) df["count_7"] = df["count_7"].astype(int) df["count_8"] = df["count_8"].astype(int) df["count_9"] = df["count_9"].astype(int) df["wordbatch_topic"] = "A"+df["count_1"].astype(str) \ +" B"+df["count_2"].astype(str) \ +" C"+df["count_3"].astype(str) \ +" D"+df["count_4"].astype(str) \ +" E"+df["count_5"].astype(str) \ +" F"+df["count_6"].astype(str) \ +" G"+df["count_7"].astype(str) \ +" H"+df["count_8"].astype(str) \ +" I"+df["count_9"].astype(str) t = df.sort_values("month_diff") t["text"] = t["card_id"] + "," + t["wordbatch_topic"] t["text"].progress_apply(lambda x: create_wordbatch_topic_texts(x)) df_wordbatch_topic_texts = pd.DataFrame.from_dict(wordbatch_topic_texts, orient='index').reset_index() df_wordbatch_topic_texts.rename(columns={"index": "card_id", 0: "wordbatch_topic"}, inplace=True) return df_wordbatch_topic_texts def create_wordbatch_topic_texts(x): t = x.split(",") if t[0] not in wordbatch_topic_texts.keys(): wordbatch_topic_texts[t[0]] = t[1] else: wordbatch_topic_texts[t[0]] += " " + t[1] hist_df = pd.read_csv('../input/historical_transactions.csv') df = pd.merge(df, create_wordbatch_topic(hist_df), on='card_id', how='outer') train = df[df['target'].notnull()] test = df[df['target'].isnull()] X = WB.transform(train["wordbatch_topic"].values) FM_CLS.fit(X, train["target"].values) y = WB.transform(test["wordbatch_topic"].values) train["topic_predict"] = np.round(FM_CLS.predict(X), 5) test["topic_predict"] = np.round(FM_CLS.predict(y), 5)最後に
以上が、トピックモデルによる非文章のカテゴリ変数から特徴抽出の紹介です。
カテゴリ変数の繋げ方やハイパーパラメータのチューニングなど大いに改善の余地があるとは思いますが、
そのような状態でもかなりのスコア改善が実現できたため、今後も大いに活用していきたいと思います。
- 投稿日:2019-02-28T18:56:02+09:00
日本語訳 NEO Smart Contract Workshop (Part 1 & 2)
Dockerを使用してNEO-Pythonの環境を作るNEOのワークショップ Part1の和訳です。
NEOで開発を始めたい方々の参考になれば幸いです。0. 下準備
まず、次の環境が揃っているのか確認してみましょう。
1. Linux/Mac Operating System
2. Docker
3. Python3.6
4. leveldb次に、自分のPCにDockerを入れる際には次のコマンドをターミナルで順番に実行しましょう。
sudo apt-get install curl
sudo curl -sSL https://get.docker.com/ | sh
sudo apt-get update && apt-get upgrade
sudo service docker start最後に、自分のPCにPythonを入れる際に次のコマンドをターミナルで順番に実行しましょう。
sudo apt-get install software-properties-common python-software-properties
sudo add-apt-repository ppa:deadsnakes/ppa
sudo apt-get update
sudo apt-get upgrade
sudo apt-get install python3.6 python3.6-dev python3.6-venv libleveldb-dev libssl-dev g++1. はじめる
次にローカルのプライベート・ブロックチェーンをセットします。
下の2つの手順によってスマートコントラクトのアップロードと実行ができるようになります。
1. Dockerのコンテナをセットする
2. NEO Pythonを起動する1-1. Dockerのコンテナをセットする
次のコマンドによってDocker Hubから最新のイメージをプルしましょう。
docker pull cityofzion/neo-privatenet
もしこれが初めて行う作業であれば、少し時間がかかるのでしばらく待ちましょう。
Docker Hubからのイメージのプルが完了したら、次のコマンドでコンテナを起動しましょう。
docker run --rm -d --name neo-privatenet -p 20333-20336:20333-20336/tcp -p 30333-30336:30333-30336/tcp cityofzion/neo-privatenetそして、次のコマンドでコンテナの中に入りましょう。
docker exec -it neo-privatenet /bin/bash.(ちなみに起動したコンテナを止めるコマンドは次のようなものになります。)
docker rm -f neo-privatenet1-2. NEO Python を起動する
(もしgitをもっていない場合は、次のコマンドを実行してgitをインストールしましょう。)
sudo apt-get install gitまずNEO Pythonのリポジトリを[ https://github.com/CityOfZion/neo-python/releases/tag/v0.7.1] からダウンロードしましょう。
ダウンロードしたフォルダーをUnzipした後、次のコマンドを実行しましょう。
cd neo-python-0.7.1次にターミナルの新しいウィンドウを開いて、次のコマンドを順番に実行しましょう。
sudo python3.6 -m venv venv
source venv/bin/activateそして次のコマンドを順番に実行して、NEO Pythonをインストールしましょう。
sudo pip install -r requirements.txt
sudo pip install -eその後次のコマンドを実行してNEO Pythonを起動しましょう。
np-prompt -pおそらく次のような画面になることが多いと思います。
ここまでくれば、DockerのコンテナのセットとNEO Pythonの起動の両方は完了です!!
Part2 からは、NEO Pythonが起動している状態と前提として進めていきます!!
参考資料
NEO Smart Contract Workshop (Part 1)
https://github.com/neo-ngd/NEO-Tutorial/blob/master/neo_docs_neopython_tutorial/part1_setup.md
- 投稿日:2019-02-28T18:56:02+09:00
日本語訳 NEO Smart Contract Workshop Part 1
Dockerを使用してNEO-Pythonの環境を作るNEOのワークショップ Part1の和訳です。
NEOで開発を始めたい方々の参考になれば幸いです。0. 下準備
まず、次の環境が揃っているのか確認してみましょう。
1. Linux/Mac Operating System
2. Docker
3. Python3.6
4. leveldb次に、自分のPCにDockerを入れる際には次のコマンドをターミナルで順番に実行しましょう。
sudo apt-get install curl
sudo curl -sSL https://get.docker.com/ | sh
sudo apt-get update && apt-get upgrade
sudo service docker start最後に、自分のPCにPythonを入れる際に次のコマンドをターミナルで順番に実行しましょう。
sudo apt-get install software-properties-common python-software-properties
sudo add-apt-repository ppa:deadsnakes/ppa
sudo apt-get update
sudo apt-get upgrade
sudo apt-get install python3.6 python3.6-dev python3.6-venv libleveldb-dev libssl-dev g++1. はじめる
次にローカルのプライベート・ブロックチェーンをセットします。
下の2つの手順によってスマートコントラクトのアップロードと実行ができるようになります。
1. Dockerのコンテナをセットする
2. NEO Pythonを起動する1-1. Dockerのコンテナをセットする
次のコマンドによってDocker Hubから最新のイメージをプルしましょう。
docker pull cityofzion/neo-privatenet
もしこれが初めて行う作業であれば、少し時間がかかるのでしばらく待ちましょう。
Docker Hubからのイメージのプルが完了したら、次のコマンドでコンテナを起動しましょう。
docker run --rm -d --name neo-privatenet -p 20333-20336:20333-20336/tcp -p 30333-30336:30333-30336/tcp cityofzion/neo-privatenetそして、次のコマンドでコンテナの中に入りましょう。
docker exec -it neo-privatenet /bin/bash.(ちなみに起動したコンテナを止めるコマンドは次のようなものになります。)
docker rm -f neo-privatenet1-2. NEO Python を起動する
(もしgitをもっていない場合は、次のコマンドを実行してgitをインストールしましょう。)
sudo apt-get install gitまずNEO Pythonのリポジトリを[ https://github.com/CityOfZion/neo-python/releases/tag/v0.7.1] からダウンロードしましょう。
ダウンロードしたフォルダーをUnzipした後、ターミナルで次のコマンドを実行しましょう。
cd neo-python-0.7.1次にターミナルの新しいウィンドウを開いて、次のコマンドを順番に実行しましょう。
sudo python3.6 -m venv venv
source venv/bin/activateそして次のコマンドを順番に実行して、NEO Pythonをインストールしましょう。
sudo pip install -r requirements.txt
sudo pip install -eその後次のコマンドを実行してNEO Pythonを起動しましょう。
np-prompt -pおそらく次のような画面になることが多いと思います。
ここまでくれば、DockerのコンテナのセットとNEO Pythonの起動の両方は完了です。
Part2 からは、NEO Pythonが起動している状態を前提として進めていきます。
補足とトラブルシューティング
Python3.6、 leveldb、NEO PythonはDockerイメージに含まれるので、Dockerコンテナ内に入ってしまえばインストール不要だということが指摘されます。
Windowsで開発を行う際にローカルにNEO-Pythonをいれられない場合、コンテナ内で作業する形をとったほうがよいかもしれません。
これを踏まえてよりシンプルな環境構築を説明しているのがこちらの記事になりますのでぜひご覧ください。
neo-pythonの環境構築 (Docker使用)
参考資料
NEO Smart Contract Workshop (Part 1)
日本人技術者向けの技術書「Starting NEO」
Keymakers(NEOの日本人開発者コミュニティ)のMedium
- 投稿日:2019-02-28T18:42:48+09:00
Django + sqlite3 のテスト環境で、Database is lockedエラーでハマった話
メモ書きに近い内容で恐縮ですが、同様のエラーが発生した方は参考にしてみてください。
対象の読者
- Djangoでサーバサイドプログラミングを実施する方。
- テスト環境でデータベースにsqlite3を用いている方。
- 自動テストなどで、sqlite3に並行負荷をかける可能性のある方。
前提条件
- Python: 3.6.3
- Django: 2.1.3
- TestCafe: 0.23.3
- TestCafe Studio: 0.4.1
今回対象とする問題
OperationalError: database is locked
- 画面操作の自動テスト時に、たまにテストが失敗する。(Django側でクラッシュする)
- 用いるテストツールやタイミングによって、大丈夫な時とそうでない時がある。
- 上記のエラーメッセージが、Djangoの標準エラー出力に出力される。
結論 (忙しい人はここまで)
- Django + sqlite3の組み合わせで、設定で ATOMIC_REQUESTS = Trueを有効化している場合、ほぼ同時に更新リクエストが来た際、クラッシュする。
回避方法
- settings.pyのsqliteに、ATOMIC_REQUESTSオプションがあれば、削除する。
settings.pyDATABASES = { 'default': { 'ENGINE': 'django.db.backends.sqlite3', 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'), # 'ATOMIC_REQUESTS': True # この行を無効化 } }
- デフォルトではこのオプションは設定されていないため、設定済の方のみが今回の対象となります。
- なお、公式のドキュメントにあるタイムアウト値を大きくする対処法を実施しても効果がありませんでしたが、ATOMIC_REQUESTSが無効でこのエラーが起きている場合は、試してみる価値はありそうです。
この回避方法について
- あくまで、テスト環境向けの対処法であり、本番環境では非推奨です。
- (そもそもsqlite3を使わないので、この問題自体が発生しない可能性あり)
備考
- TestCafeのGUI版 (TestCafe Studio)で、たまたま、Javascriptが(通常のブラウザやCUI版 TestCafeと違い)多重実行されるバグ(?)に遭遇し、TestCafe Studioが管理するブラウザからDjango側にほぼ同時に2つの更新リクエストが発生していた。
- 2個目の更新リクエストがエラーになり、E2Eテストが失敗扱いになった。
原因をどう発見したか
- Djangoのエラーメッセージがトランザクションの衝突を示唆していたため、トランザクションおよびデータベースに関する設定を調べ、試行錯誤的に設定を変え発見した。
まとめ
テスト用ならsqlite3でも大丈夫と思っていると、思わぬ落とし穴にはまることがあります!
皆様もお気をつけくださいm(_ _)m
- 投稿日:2019-02-28T18:26:23+09:00
file sample to use python as batch file
save as exe.py
'''
#!/usr/bin/python
import subprocess
prg="main.run furu"
subprocess.call(prg, shell=True)
'''
- 投稿日:2019-02-28T18:25:19+09:00
pythonにおける積分とその計算速度:正規分布関数を例とした実験
はじめに
今回は正規分布関数(ガウス関数)の数値積分をpythonで試みた.
その際に3つの手法を比較したのでそちらを記す.手法は「数値積分法」,「scipy」,「monte-carlo法」の3つ.
ソースコードはこちら
今回もそうであるが,実際に積分計算を行いたい式は解析的な形の積分関数を求めることができないことが一般的であるから,今回はその典型例である正規分布関数を用いた.
手法概要
今回計算したいのは以下の式:
\int_{lower}^{upper} \frac{1}{\sqrt{2\pi}\sigma}\exp\Biggl ({-\frac{(x-\mu)^2}{2\sigma^2}}\Biggl) dxそして,引数は以下の通り:
lower(=a): 積分の下端 \\ upper(=b): 積分の上端 \\ \mu: 分布の平均値 \\ \sigma: 分布の標準偏差 \\また,scipyを除いた他の2手法に関しては積分の評価精度に関わる変数 $n$ が存在する.
数値積分法
ここでいう数値積分法とはいわゆる区分求積法のことである.Monte-Carlo法は後述する.つまり,積分値を
\frac{b-a}{n} \sum_{k=1}^{n} f\Bigl(a + \frac{b-a}{n}k\Bigl)によって,近似する方法である.$n$ の値が十分に大きい場合,この値は真の値に近づく.近似は以下のように行っている.$\Bigl(\Delta x=\frac{b-a}{n} \ll 1, a_k = a+k\Delta x\Bigl)$
\int_{a_k}^{a_{k + 1}}f(x)dx \simeq \int_{a_k}^{a_{k + 1}}f(a_k)dx = f(a_k)\Delta xただし,$\ 0 < \theta < 1$ として.$Taylor$展開を用いると,
f(a_k+\theta\Delta x)\Delta x - f(a_k)\Delta x = \theta f'(a_k)\Delta x^2 + o(\Delta x^3)この値を $\theta$ で0〜1 の積分をすると,
\int_{0}^{1}\Bigl (f(a_k+\theta\Delta x) - f(a_k)\Bigl)\Delta x d\theta = \frac{f'(a_k)}{2!} \Delta x^2 + o(\Delta x^3)という誤差が得られるから,全体としては,
\sum_{k=1}^{n}\frac{f'(a_k)}{2!} \Delta x^2 \simeq \Delta x \int_{a}^{b}\frac{f'(x)}{2}dx=\frac{f(b)-f(a)}{2}\Delta x程度の誤差が生じる.つまり,定義域をどの程度細かく区切るかによって,積分の値の精度に差が出る.もちろん,プログラム上では丸め誤差も存在するため,限界ぎりぎりの桁数では精度の逆転現象が起こる可能性がある.この誤差を減らすために矩形を台形に変更して数値積分をする方法もある(今回はそのネタではないので,一旦おいておきます).
追記
台形公式では,$a_k$ と $a_{k+1}$ の間を線形補間する方法です.そして,この手法を使用することによって,上の $\frac{f(b)-f(a)}{2}\Delta x$ の項が消えて,計算精度の桁のオーダーがワンランク上( $ \Delta x^2 $ )に上がることになる.
そのコードが下のもの.シンプルですね.
def naive_integral(lower, upper, mu, sgm, dx_div): dx = float(1 / dx_div * (upper - lower)) x = np.linspace(lower, upper, int(dx_div)) c1 = 1.0 / np.sqrt(2 * np.pi) / sgm idx = - 0.5 * ((x - mu) / sgm) ** 2 print("value:",np.sum(dx * c1 * np.exp(idx)))scipy(誤差関数)
正規分布を積分した関数系は解析的に求めることができていないが,その関数を形容する単語は存在する.それが誤差関数.
誤差関数は正規分布関数の累積分布関数を求めるときに使用され,
F(x)=\int_{-\infty}^{x} \frac{1}{\sqrt{2\pi}\sigma}\exp\Biggl(-\frac{(x'-\mu)^2}{2\sigma^2}\Biggl) dx' = \frac{1}{2}\Biggl(1+{\rm erf }\ \frac{x-\mu}{\sqrt{2}\sigma} \Biggl)という形で累積分布関数を表したときの,${\rm erf}$ が誤差関数である.scipyにはこちらの関数値を求めるライブラリが存在し,書き方は以下の通り.
def scipy_lib(lower, upper, mu, sgm, dx_div): idx_l = (lower - mu) / np.sqrt(2) / sgm idx_u = (upper - mu) / np.sqrt(2) / sgm print("value:",0.5 * ( scipy.special.erf(idx_u) - scipy.special.erf(idx_l) ) )Monte-carlo法
最後がモンテカルロ法.一番単純な考え方で例えば,サイコロの目がそれぞれ何回出るかわからないなら,サイコロ振っちゃえみたいな手法.要は実際に乱数によるサンプリングを行い,そのサンプリングのうち条件をみたすものを数え上げ,全体に対して条件を満たす確率をとったものをその事象が起こる確率として採択を行うもの.
正規分布の積分では実際に$N(\mu,\sigma^2)$ に従う乱数を $n$ 個生成し,その乱数のうち $a〜b$ の間に入ったものがどの程度の割合存在するか測定する.
こちらの測定誤差に関しては大数の法則と中心極限定理から誤差の分散は $\frac{1}{\sqrt{n}}$ のオーダーであることがわかる.
def monte_carlo(lower, upper, mu, sgm, dx_div): samples = np.random.normal( loc = mu, scale = sgm, size = int(dx_div)) print("value:",np.mean((lower <= samples) & (samples <= upper)))結果
正規分布表の参照はこちら.
そして,本題の計算速度.(以下の計算ではすべて $\mu=0,\sigma = 1$)
ちなみに,$\pm \sigma$ なら確率 0.68269,$\pm 5\sigma$ なら確率 1 - 5.74E-07.
一応,速度がどれくらい変わるか見るために広めの定義域で試しました.$a = -1, b = 1, n = 1000$
正解は0.68269function naive_integral value: 0.6824905826186739 elapsed time[s]: 0.00016736984252929688 function scipy_lib value: 0.6826894921370859 elapsed time[s]: 2.9802322387695312e-05 function monte_carlo value: 0.686 elapsed time[s]: 0.0001266002655029297$a = -1, b = 1, n = 1000000$
正解は0.68269function naive_integral value: 0.6826892933888814 elapsed time[s]: 0.03223371505737305 function scipy_lib value: 0.6826894921370859 elapsed time[s]: 4.267692565917969e-05 function monte_carlo value: 0.682288 elapsed time[s]: 0.05030488967895508$a = -5, b = 5, n = 1000$
正解は1 - 5.74E-07function naive_integral value: 0.9989994420133417 elapsed time[s]: 0.0001678466796875 function scipy_lib value: 0.9999994266968562 elapsed time[s]: 2.86102294921875e-05 function monte_carlo value: 1.0 elapsed time[s]: 0.0001285076141357422$a = -5, b = 5, n = 1000000$
正解は1 - 5.74E-07function naive_integral value: 0.9999984267122968 elapsed time[s]: 0.03359627723693848 function scipy_lib value: 0.9999994266968562 elapsed time[s]: 5.435943603515625e-05 function monte_carlo value: 0.999998 elapsed time[s]: 0.05029034614562988まとめ
測定精度に関しては上で導出したとおりのオーダーでまとまっていました.こうやって,数学とプログラミングをつなげて考えるのは面白いですね.Monte-Carlo法に関しては統計物理のような分野をマスターしてからやるともっと面白そう.
速度に関してはMonte-Carlo法ではサンプル数を1000倍にすると400倍遅くなり,数値積分法では200倍遅くなった.
scipyには精度の項目が存在していないので速度は一切変わらず.ただし,精度は完璧でかつ速度も断然早いので複雑でない限りはscipyが良さそう.複雑になってきた場合に精度を強く求めない場合は少数サンプルのMonte-Carlo法で良いかもしれないが,精度をある程度必要とする場合はMonte-Carlo法ではサンプル数の増加に対して精度の安定が数値積分よりも遅いので数値積分のほうが良いかもしれない.今回は有名なガウス関数であったため,専用のライブラリが存在したが,実際には存在しないことのほうが一般的であることを考えると,サンプル数を多めにとって精度の数値積分もしくはサンプル数少なめで良いから早く結果を求めるMonte-Carlo法,という選択を迫られることになると感じた.
- 投稿日:2019-02-28T17:25:46+09:00
ラスボス系後輩ヒロインAIチャットボットを作りたい・環境の構築〜Pythonの基礎
前哨戦・VagrantにPython環境を作る
$ vagrant init $ vi VagrantfileVagrantfile
※埋め込みもコードシンタックスもできなかったので(<<-SHELLのあたりでおかしくなる)gistのリンクだけ張っておきます。これで
vagrant up一発でpython環境ができるはずだったのですが、pyenvインストールの途中、PATH書き込みのあたりでコケてるっぽくて何だろうな……? コピペすると動くのでちょっとよくわからない。でもまあとりあえずpython作業用環境が発生しました。やったね。
少なくとも今回はフォルダ共有は使わないと思ってそのように設定しました。vbguest調子悪いし。$ python --version Python 3.6.5本戦・Python入門
昼休みに本屋に行って入門Python3買ってきたんですけど想像してた倍くらいの厚みがあってビビりました。500ページオーバー……鈍器……
四則演算
演算子 意味 例 結果 + 加算 1 + 2 3 - 減算 1 - 2 -1 * 乗算 1 * 2 2 / 浮動小数点数の除算 1 / 2 0.5 // 整数の除算(切り捨て) 1 // 2 0 % 剰余 1 % 2 1 ** 指数 1 ** 2 1 基数
基本的な基数は10であるが、2, 8, 16なども使用できる。
>>> 0b10 2 >>> 0o10 8 >>> 0x10 16この表現なんかすごく久し振りに見た気がすると思って調べ直したところ、Javaすらこの記法ではないからC言語以来じつに十年ぶりの邂逅でした(OCとかC++とか履修してないので)。ぐええ。JavaScriptもこの記法ですけど使った覚えはないな……
longは無く、intは 任意のサイズ である。10**100**2すら格納できる。強い。文字列の連結
文字列の連結は
+で行う。ただし リテラル文字列の場合は並べるだけでも連結できる 。>>> "Hello" + "World" 'HelloWorld' >>> "Hello" "World" 'HelloWorld'※シングルクォートが出力されているのはインタプリタ自動エコーのため。横着して
print()を使っていないせいです。以下同じ。さらに
*演算子によって 文字列を繰り返すことができる 。>>> "Ya"*7 'YaYaYaYaYaYaYa'何に使うんだろうこれ……
文字列のスライス
文字列からの文字の抽出はこれもRubyと同じく
[]を使用する。末尾の表現は[-1]となる。>>> str = "入門Python3" >>> str[1] '門' >>> str[-1] '3'
[start:end:step]によるスライス>>> str = "入門Python3" >>> str[1:8:2] '門yhn'
[:]は文字列の先頭から末尾まですべてを取り出す(やる意味がわからない)
[start:]はstartから文字列の末尾までを取り出す。
[:end]は文字列の先頭からend の前 までを取り出す。10と指定した場合9まで。- ステップに負の値を設定すると逆にステップしていく。
>>> str = "abcdefghijklmnopqrstuvwxyz" >>> str[-1::-1] 'zyxwvutsrqponmlkjihgfedcba' >>> str[-1:0:-1] 'zyxwvutsrqponmlkjihgfedcb'なるほどendの手前までだから逆ステップでaまで遡るにはendを省略することになるのか。
splitとjoin
このあたりはこともなし。PHPからRubyに行ったときはぎょっとしたけどRubyやってからだと違和感がない。
>>> "a,b,c".split(',') ['a', 'b', 'c'] >>> ','.join(['a','b','c']) 'a,b,c'大文字と小文字の区別、配置
>>> str = "Come, woo me, woo me, for now I am in a holiday humor." >>> str.strip('.') 'Come, woo me, woo me, for now I am in a holiday humor' >>> str.capitalize() 'Come, woo me, woo me, for now i am in a holiday humor.' >>> str.title() 'Come, Woo Me, Woo Me, For Now I Am In A Holiday Humor.' >>> str.upper() 'COME, WOO ME, WOO ME, FOR NOW I AM IN A HOLIDAY HUMOR.' >>> str.lower() 'come, woo me, woo me, for now i am in a holiday humor.' >>> str.swapcase() 'cOME, WOO ME, WOO ME, FOR NOW i AM IN A HOLIDAY HUMOR.'文章はシェイクスピア「お気に召すまま(As You Like It)」より。
ちなみに>>> str = "あいうえお" >>> str.lower() 'あいうえお'そりゃそうか。これで「ぁぃぅぇぉ」とか出されたらびっくりするところだった(そもそもそれはlowercaseとは言わない)
二章の終わりまで来たので一旦ここで区切ります。存外伸びてしまった。
四章のコード構造までは最低限行かなきゃいけないとして、あと二日くらい。ページ数にして100ページ弱なので多少コードいじって遊んでも収まるでしょう。
Udemyの講座の目次を参考に予定立ててたんですけど、あの講座、44分半で何をどこまでやるつもりだったのか……?初日感想。Pythonたのしい!好きな言語の好きなところが詰め込んである感。新鮮なのにストレスはない。すごい。手に馴染んだ書式にプラス便利なものが積んであるという感触。
入門Python3もまず読み物としてとても読みやすい、面白いです。翻訳もいいのだろうな。良きスタートになりました。
- 投稿日:2019-02-28T16:59:03+09:00
pyenv のインストールと version の切り替え
mac に ansible を入れようとしたら pip が依存している python の version に言及があった。
$ sudo pip install ansible DEPRECATION: Python 2.7 will reach the end of its life on January 1st, 2020. Please upgrade your Python as Python 2.7 won't be maintained after that date. A future version of pip will drop support for Python 2.7. The directory '/Users/<あなたのお名前>/Library/Caches/pip/http' or its parent directory is not owned by the current user and the cache has been disabled. Please check the permissions and owner of that directory. If executing pip with sudo, you may want sudo's -H flag. The directory '/Users/<あなたのお名前>/Library/Caches/pip' or its parent directory is not owned by the current user and caching wheels has been disabled. check the permissions and owner of that directory. If executing pip with sudo, you may want sudo's -H flag.バージョンを上げれば解決しそうだが、pyenv を入れたほうが良さそうである。
https://github.com/pyenv/pyenvinstall
$ brew update $ brew install pyenvお好きな python の version をインストール
$ pyenv install --list $ pyenv install 2.7.15バージョンが変わったか確認
$ pyenv global 2.7.15 system * 2.7.15 (set by /Users/<あなたのお名前>/.pyenv/version) $ python --version Python 2.7.10変わっとらんがな???
環境変数PATHを修正
$PATHに pyenv の作業ディレクトリの shims へのパスを通す必要がある。
https://github.com/pyenv/pyenv#understanding-pathUnderstanding Shims
pyenv works by inserting a directory of shims at the front of your PATH:
$(pyenv root)/shims:/usr/local/bin:/usr/bin:/binということで、
~/.config/fishconfig.fishに下記を追加。# pyenv set -x PATH (pyenv root)/shims $PATHリロード
$ source ~/.config/fish/config.fish再度確認
$ python --version Python 2.7.15 $ which python /Users/<あなたのお名前>/.pyenv/shims/pythonうぇーい???
おわり
- 投稿日:2019-02-28T16:29:33+09:00
FlickrAPIでの画像取得
はじめに
deep learningで画像識別を使用と思ったので学習用の画像をFlickrAPIを使って画像を集めるときのメモです。
使用したpythonのバージョンは3.6です。FlickrAPIライブラリのインストール
pythonでFlickrAPIを使うためのライブラリをpipを使ってインストールします。
pip install flickrapiコード
あらかじめ、APIの公開鍵と秘密鍵を入手しておいてください。
また、最後にtime.sleep()などで少し時間をおいて画像を保存するようにすると、サーバーに負荷が軽減されるのでいいです。download.pyfrom flickrapi import FlickrAPI from urllib.request import urlretrieve from pprint import pprint import os,time,sys #キーの作成 key = "公開鍵の番号" secret = "秘密鍵の番号" wait_time = 1 #コマンドラインで保存先と検索する名前を指定する AnimalName = sys.argv[1] #保存先の指定 SaveDir = "./" + AnimalName #APIキーの作成 flickrapi = FlickrAPI(key,secret,format='parsed-json') #検索する result = flickrapi.photos.search( text = AnimalName, per_page = 400, media = 'photos', sort = 'relevance', safe_search=1, extras = 'url_q,licence' ) #結果の表示 photos = result['photos'] #pprint(photos) for i ,photos in enumerate(photos['photo']): url_q = photos['url_q'] filepath = SaveDir + '/' + photos['id'] + '.jpg' if os.path.exists(filepath):continue urlretrieve(url_q,filepath) time.sleep(wait_time)このプログラムは第一引数に保存先を指定しているのでこのファイルの保存先と同じ名前のディレクトリをあらかじめ作っておく必要があります。
たとえば、牛の画像を保存するときにcowと第一引数に指定するときにディレクトリ構成は以下のようにしておく必要があります。root/ ├─download.py └─cow
- 投稿日:2019-02-28T16:16:28+09:00
PythonでDiscordボットを作る時のFAQ
PythonでDiscordボットを作る時に引っかかりやすい罠や、Discordのpythonjpでよくやり取りされる質問等をゆるくまとめていこうと思います。
初心者が対象です。
※注意
PythonやDiscordは活発に更新されていきます。情報がどんどん古くなっていきます。ここに書かれている情報が古くなっている可能性もありますので注意してください。全般
Q: ボット作成の大まかな流れを知りたいんだけど?
A: https://qiita.com/PinappleHunter/items/af4ccdbb04727437477f
A: https://qiita.com/3894eye/items/4b4d5cda958c11069229
A: 【VOICEROID解説】Python環境でDiscord Botを作る。 Part1 前準備編 discord.py rewrite 修正版
https://www.youtube.com/watch?v=31HPbI2LPc4
(discord.pyのrewrite版を使う場合、Pythonは3.7.? 以降を導入してください)
(discord.pyのasync版を使う場合、Pythonは3.6.? を導入してください)開発環境
Q: 開発環境は何をインストールしたらいいの?
A: 好きなエディタとかIDEで構いません。PyCharmとかVSCodeが多数派かな。
(☓Windowsのメモ帳はダメです。BOM付きUTF-8という形式で保存されてしまう為 → 「Windows 10 19H1」で改善の予定があります)
PyCharm:
https://www.jetbrains.com/pycharm/
VSCode:
https://code.visualstudio.com/Python
Q: Pythonの何から学べばいいの?チュートリアルないの?
A: https://docs.python.org/ja/3/tutorial/index.html
Q: python3.7でボット作ったのに動かないんだけど?
A: https://qiita.com/1ntegrale9/items/f4c47a6a69ecf23fc5db
A: http://nao-y.hatenablog.com/entry/2018/08/22/202616Q: コルーチンって何なの?
A: https://ekulabo.com/whats-coroutine#outline__2
(↑ Unityの中での説明ですが分かりやすいです)Q: asyncとかawaitって何なの?
https://qiita.com/matsui-k20xx/items/4d1c00c4eefd60ba635b
(↑ リンク先にさらにリンクがあります)
(asyncやawaitはボットを作る上で頻出しますので大事ですよー)pip
Q: 仮想環境内でpipでパッケージをインストールしたのに認識されない!
A: Pythonが複数インストールされている環境では、pipコマンドを直接使うとかならず事故が発生します。
python -m pip installを使用してください。Bot commands framework
Q: コード内にcommands.Botとか書いてあるけどこれ何なの?
A: https://starnak.hatenablog.com/#Bot-commands-framework%E3%81%A8%E3%81%AF
Discord
discord.py
Q: async版とかrewrite版って何なの?
A: https://qiita.com/1ntegrale9/items/f4c47a6a69ecf23fc5db
Heroku
Q: ボットを24時間無料で動かしたいんだけど?
A: Herokuという所で動かすことができます
・Herokuの無料プラン、クレカ登録無し → 550時間まで(一ヶ月は無理です。31日*24時間=744時間だから)
・Herokuの無料プラン、クレカ登録有り → 550時間+450時間=1000時間(一ヶ月連続稼働OK)
(条件がコロコロ変わるみたいなので公式サイトで確認してください)リンク
Discord Python.jpサーバに参加
https://www.python.jp/pages/pythonjp_discord.htmlShun Tannai (PythonでDiscordボットを作る時に大変参考になりました)
https://qiita.com/1ntegrale9Python 3.7.2 ドキュメント
https://docs.python.org/ja/3/discord.py rewrite版 API Reference
https://discordpy.readthedocs.io/en/rewrite/api.htmlheroku
https://jp.heroku.com/
- 投稿日:2019-02-28T16:02:04+09:00
DjangoとAPIを呼ぶの一歩目
環境
windows 8
Python 3.6.7
django 2.1.4インストール済みか確認
pythonがインストール済みか確認
$ python --versionDjangoがインストール済みか確認
$ python >> import djanog >> django.get_version()プロジェクトの立ち上げ
$ django-admin startproject {projectName}{projectName} = myapp
$ cd myappmyappディレクトリに移動
サーバー起動
$ python manage.py runserverアプリの作成
$ python manage.py startapp {appName}{appName} = app1
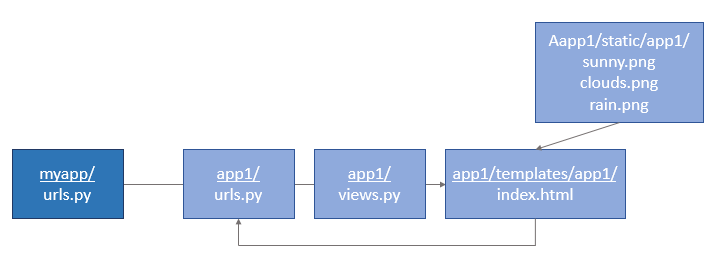
myapp ├── manage.py ├── myapp │ ├── __init__.py │ ├── __pycache__ │ │ ├── __init__.cpython-36.pyc │ │ └── settings.cpython-36.pyc │ ├── settings.py │ ├── urls.py │ └── wsgi.py └── app1 ├── __init__.py ├── admin.py ├── apps.py ├── migrations │ └── __init__.py ├── models.py ├── templates │ └── app1 │ └── index.html ├── static │ └── app1 │ ├── sunny.png │ ├── clouds.png │ └── rain.png ├── tests.py └── views.py上図のように、ディレクトリ・ファイルを作成します。
API呼んで画面に表示するまで
※今回は OpenWeatherMap のAPIを使用
myapp/settings.pyINSTALLED_APPS = [ 'app1', # 追記 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', ]アプリ名を追記する。
myapp/urls.pyfrom django.contrib import admin from django.urls import path, include urlpatterns = [ path('app1/', include('app1.urls')), path('admin/', admin.site.urls), ]http://localhost:8000/app1/ にアクセスすると
app1/urls.pyに行き...app1/urls.pyfrom django.urls import path from . import views urlpatterns = [ path("", views.weather, name="weather"), path("form", views.form, name="form"), ]
app1/viewsのweather関数を実行するapp1/views.pyfrom django.shortcuts import render # Create your views here. from django.http import HttpResponse import requests import json from .forms import cityform def weather(request): params = { 'city': '', 'msg':'How is the weather today?', 'weather': '', } return render(request,'app1/index.html', params) def form(request): if (request.POST['city']): city = request.POST['city'] # call OpenWeatherMapAPI # APIキーの指定 apikey = "{APIKey}" api = "http://api.openweathermap.org/data/2.5/weather?q={city}&APPID={key}" # 各都市の温度を取得する # APIのURLを得る url = api.format(city=city, key=apikey) # 実際にAPIにリクエストを送信して結果を取得する r = requests.get(url) # print(r) # 結果はJSON形式なのでデコードする data = json.loads(r.text) city = data["name"] weather = data["weather"][0]["description"] params = { 'city': city, 'msg': '', 'weather': weather, } else: params = { 'city': '', 'msg': 'Select City!', 'weather': '', } return render(request,'app1/index.html', params)paramsに代入した値と共に、
app1/templates/app1/index.htmlに行き...app1/templates/app1/index.html{% load static %} <!doctype html> <html lang="en"> <head> <!-- Required meta tags --> <meta charset="utf-8"> <meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no"> <!-- Bootstrap CSS --> <link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/css/bootstrap.min.css" integrity="sha384-ggOyR0iXCbMQv3Xipma34MD+dH/1fQ784/j6cY/iJTQUOhcWr7x9JvoRxT2MZw1T" crossorigin="anonymous"> <title>How is the weather today?</title> </head> <body class="bg-secondary"> <div class="text-center mb-5"> <h1 class="mt-2">{{ city }}</h1> <h1>{{ msg }}</h1> <h1>{{ weather }}</h1> {% if 'sunny' in weather %} <img src="{% static 'app1/sunny.png' %}" style="height: 60px;"/> {% elif 'clouds' in weather %} <img src="{% static 'app1/clouds.png' %}" style="height: 60px;"/> {% elif 'rain' in weather %} <img src="{% static 'app1/rain.png' %}" style="height: 60px;"/> {% elif 'haze' in weather %} <img src="{% static 'app1/haze.png' %}" style="height: 60px;"/> {% endif %} <form action = "{% url 'form' %}" method = "post" class="mt-5"> {% csrf_token %} <label for = "city" class="mr-1">Select City:</label> <!-- <input id = "city" type="text" name ="city" value="Tokyo,JP"> {{ form.city_r.label }}: {{ form.city_r }} --> <select name="city" class="custom-select" style="width:140px;"> <option value="">---</option> <option value="Tokyo,JP">Tokyo</option> <option value="London,UK">London</option> <option value="New York,US">New York</option> </select> <input type="submit" value="input" class="btn btn-outline-primary"> </form> </div> <!-- Optional JavaScript --> <!-- jQuery first, then Popper.js, then Bootstrap JS --> <script src="https://code.jquery.com/jquery-3.3.1.slim.min.js" integrity="sha384-q8i/X+965DzO0rT7abK41JStQIAqVgRVzpbzo5smXKp4YfRvH+8abtTE1Pi6jizo" crossorigin="anonymous"></script> <script src="https://cdnjs.cloudflare.com/ajax/libs/popper.js/1.14.7/umd/popper.min.js" integrity="sha384-UO2eT0CpHqdSJQ6hJty5KVphtPhzWj9WO1clHTMGa3JDZwrnQq4sF86dIHNDz0W1" crossorigin="anonymous"></script> <script src="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/js/bootstrap.min.js" integrity="sha384-JjSmVgyd0p3pXB1rRibZUAYoIIy6OrQ6VrjIEaFf/nJGzIxFDsf4x0xIM+B07jRM" crossorigin="anonymous"></script> </body> </html>※Bootstrap のStarter templateを使用
index.html<h1 class="mt-2">{{ city }}</h1> <h1>{{ msg }}</h1> <h1>{{ weather }}</h1>先ほどのparamsの値が
{ city },{ msg },{ weather }に代入されて...
上図が表示される。そして...
都市を選択して、ボタンを押すと...index.html<form action= "{% url 'form' %}" method = "post" class="mt-5"> {% csrf_token %} <label for = "city" class="mr-1">Select City:</label> <select name="city" class="custom-select" style="width:140px;"> <option value="">---</option> <option value="Tokyo,JP">Tokyo</option> <option value="London,UK">London</option> <option value="New York,US">New York</option> </select> <input type="submit" value="input" class="btn btn-outline-primary"> </form>
<form action= {% url 'form' %}へ
'form'は...app1/urls.pypath("form", views.form, name="form"),
name="form"のformであり、views.pydef form(request): if (request.POST['city']): city = request.POST['city'] # call OpenWeatherMapAPI # APIキーの指定 apikey = "{APIKey}" api = "http://api.openweathermap.org/data/2.5/weather?q={city}&APPID={key}" # 各都市の温度を取得する # APIのURLを得る url = api.format(city=city, key=apikey) # 実際にAPIにリクエストを送信して結果を取得する r = requests.get(url) # print(r) # 結果はJSON形式なのでデコードする data = json.loads(r.text) city = data["name"] weather = data["weather"][0]["description"] params = { 'city': city, 'msg': '', 'weather': weather, } else: params = { 'city': '', 'msg': 'Select City!', 'weather': '', } return render(request,'app1/index.html', params)
app1/viewsのform関数が実行され...index.html{% if 'sunny' in weather %} <img src="{% static 'app1/sunny.png' %}" style="height: 60px;"/> {% elif 'clouds' in weather %} <img src="{% static 'app1/clouds.png' %}" style="height: 60px;"/> {% elif 'rain' in weather %} <img src="{% static 'app1/rain.png' %}" style="height: 60px;"/> {% elif 'haze' in weather %} <img src="{% static 'app1/haze.png' %}" style="height: 60px;"/> {% endif %}
paramsのweather値によって分岐させ...
上図のように、今日の天気を教えてくれる。参考
【Python3】WebAPIを叩く【requests】
[Python]とにかくわかりやすく!djangoでアプリ開発!ーその1ー
【Django入門】画像などのstatic(静的)なファイルを使ってみよう
- 投稿日:2019-02-28T15:35:30+09:00
Ridgeで精度行列をもとめる
1 Disclaimer
論文が読んだ時のメモを公開するつもりで書きました.マサカリ投げていただけると有り難いです.
2 はじめに
$D$次元正規分布は平均を0にする標準化を仮定すると,精度行列$\Lambda$,$D$次元ベクトル$\boldsymbol{x}$を用いて以下のようにかけます.この記事では異常検知などの機械学習に必要な精度行列$\Lambda$の推定について書いてみます.
$$p(\boldsymbol{x} ; \Lambda)=\frac{\sqrt{\det \Lambda}}{\left(\sqrt{2 \pi}\right)^D}\exp \left( -\frac{\boldsymbol{x}^T \Lambda\boldsymbol{x}}{2} \right)$$
2.1 精度行列の最尤推定
平均0の多変量正規分布にしたがうデータから精度行列を最尤推定することを考えます.精度行列を$\Lambda$,分散共分散行列を$S$,対数尤度関数を$L(\Lambda)$とすると
\begin{align} L(\Lambda) &= \sum_{i=1}^{N} \ln p(\boldsymbol{x}_i;\Lambda)\\ &= - \frac{ND}{2} \ln 2 \pi + \frac{N}{2} \ln \det \Lambda - \frac{N}{2} \mathrm{trace}(S\Lambda) \end{align}したがって正規分布の精度行列の最尤推定は以下になります.
$$
\mathrm{maximize}\quad \ln \det \Lambda -
\mathrm{trace}(S\Lambda)
$$
これの解は偏微分を行うことで
$$\Lambda = S^{-1}$$となります.2.2 Graphical Lasso
一般に多変量になり多重共線性があると,分散共分散$S$がランク落ちもしくはランク落ちに近い状態になります.そこで,精度行列の推定にL1正則化項を加え正則にし,さらに疎な精度行列を求めることで解釈性も与える手法があります.最適化問題として書くと以下のようになります.
\begin{align} \begin{cases} \text{maximize} & \ln \det \Lambda -\mathrm{trace}(S\Lambda)-\rho \|\Lambda\|_1\\ \text{subject to} & \Lambda \succ O \end{cases}\\ \|\Lambda\|_1 = \sum_{ij}\|\Lambda_{ij}\|_1 \end{align}ここでの正則化は次のように考えられます.分散共分散行列がランク落ちに近い時.固有値に0に近いものが存在します.精度行列を計算する時に,その0に近い固有値の逆数を取るので精度行列に非常に大きな要素が存在することになります.そこで精度行列に大きな要素が存在することに罰則が加わるような正則化項を加えます.Graphical Lassoについての詳細はこの記事がわかりやすいと思います.
2.3 ROPE
Graphical LassoのRidge版が今回紹介するROPE(Ridge-type Operator for the Precision matrix Estimation)です[1].
\begin{align} \text{maximize} \ln \det \Lambda -\mathrm{trace}(S\Lambda)-\rho \|\Lambda\|_2 \tag{1} \end{align}式(1)は凸最適化問題であり,最適性条件から劣微分が,要素がすべて0の行列になるときが最適解です.つまり
$$
\Lambda^{-1} - S - 2\rho \Lambda = 0
$$
ここで右辺の0は要素がすべて0の行列を示しています.
$\Lambda$を右から掛けることで以下の式になります.
$$
D(\Lambda) = 2\rho \Lambda^2 + S\Lambda - I = 0
\tag{2}
$$
ここで式(2)の解が対称行列であることを仮定します.式(2)に\式(2)を転置したものを加えると,
$$
-S\Lambda - \Lambda S - \Lambda 4\rho I \Lambda +2I = 0
\tag{3}
$$
これは代数的Ricatti方程式の形です.3 代数的Ricatti方程式
[2]を参考にして.代数的Ricatti方程式について軽くまとめます.数式がややこしいので,この節は読み飛ばしてもらっても構いません.以下の式を代数的Ricatti方程式と呼びます,
$$
A^HX+XA-XRX+Q=0\tag{4}
$$
$R,Q$はエルミート行列,$A,R,Q, X\in \boldsymbol{C}^{n\times n}$.ここで$G$を以下のように定義します.\begin{align} G = \begin{bmatrix} A & -R\\ -Q & -A^H \end{bmatrix} \end{align}補題3.1
$\lambda$が$G$の固有値の時$\bar{\lambda}$も$G$の固有値となる.
証明は以下のようになります.\begin{align} S \equiv \begin{bmatrix} 0 & -I_n\\ I_n & 0 \end{bmatrix} \end{align}とすると,
\begin{align} SG&= \begin{bmatrix} 0 & -I_n\\ I_n & 0 \end{bmatrix} \begin{bmatrix} A & -R\\ -Q & -A^H \end{bmatrix} = \begin{bmatrix} Q&A^H\\ A &-R \end{bmatrix}\\ -G^HS&= - \begin{bmatrix} A^H & -Q^H\\ -R^H & -A \end{bmatrix} \begin{bmatrix} 0 & -I_n\\ I_n & 0 \end{bmatrix} = \begin{bmatrix} Q&A^H\\ A &-R \end{bmatrix}\\ \end{align}となるから
$$
SGS^{-1} = -G^H
$$
ここで随伴行列の行列式は、 もとの行列の行列式の複素共役であるから$p(\lambda ) = \det (\lambda I_{2n} -G) = 0$から$ \det (-\bar{\lambda} I_{2n} -G^H) = 0$
$$
p(\bar{\lambda}) = \det (\bar{\lambda} I_{2n} -G)
= \det (S) \det (\bar{\lambda} I_{2n} -G) \det(S^{-1})
= \det (\bar{\lambda} I_{2n} +G^H) = 0
$$3.2 Jordan分解
ここで.$R$と$Q$は半正定値行列であると仮定すると$G$は純虚数の固有値を持たない[3]
証明難しくて追えませんでした.よって,$G$が以下の形でJordan分解することができます.\begin{align} G = U \begin{bmatrix} J_1 & 0\\ 0 & J_2 \end{bmatrix} U^{-1} \end{align}ここで$J_1,J_2 \in \boldsymbol{C}^{n\times n}$,$\sigma(J_1) \in \Pi_-,\sigma(J_2) \in \Pi_+$,$\sigma$は固有値の集合を表し,$\Pi_-$は複素平面での左半面,$\Pi_+$は右半面を表す.
$U$は以下のように$n\times n$の行列を用いて表せます.\begin{align} U = \begin{bmatrix} U_{11}& U_{12}\\ U_{21} & U_{22}\\ \end{bmatrix} \end{align}ここで式(4)の解は以下のようになります.詳しくは[4]を参考にしてください.
$$
X = U_{21}U_{11}^{-1}
$$
試しに,$A^HX+XA-XRX+Q=0$に代入してみます.\begin{align} A^HX+XA-XRX+Q&= \begin{bmatrix} X & -I_n \end{bmatrix} \begin{bmatrix} A & -R\\ -Q & -A^H \end{bmatrix} \begin{bmatrix} I_n\\ X \end{bmatrix}\\ &= \begin{bmatrix} U_{21}U_{11}^{-1} & -I_n \end{bmatrix} G \begin{bmatrix} I_n\\ U_{21}U_{11}^{-1} \end{bmatrix}\\ &= \begin{bmatrix} U_{21}U_{11}^{-1} & -I_n \end{bmatrix} G \begin{bmatrix} U_{11}\\ U_{21} \end{bmatrix} U_{11}^{-1}\\ &= \begin{bmatrix} U_{21}U_{11}^{-1} & -I_n \end{bmatrix} \begin{bmatrix} U_{11}\\ U_{21} \end{bmatrix} J_1 U_{11}^{-1}\\ &= ( U_{21}-U_{21} ) J_1 U_{11}^{-1}\\ &= 0 \end{align}4 分散共分散行列の固有値との関連
3節で代数的Ricatti方程式の解について述べましたが,[1]によって式(3)の解が分散共分散行列$S$の固有値と固有ベクトルを用いて表せることが示されています.
こっちの形の解を導出するべきだが,線形代数力が足らなかった.$l_i$を$S$の固有値として\begin{align} \hat{\lambda_i} &= \frac{2}{l_i + \sqrt{l^2_i + 8\rho}}\\ V &= \mathrm{diag} (\hat{\lambda_1},......,\hat{\lambda_p}), \hat{\lambda_1} \geq\cdots \geq\hat{\lambda_p} \end{align}とすると
$$
\hat{\Lambda} =
M V M^T
$$と表せます.ここで$M$は$l_i$に対応する固有ベクトルを,$V$と同じ順序になるように並べて作った行列です.5 PCAとの関連
5.1 マハラノビス距離
マハラノビス距離とは正規分布に従う多変量の距離であり,ホテリング$T2$理論といった異常検知手法に用いられます.
具体的には,$\Lambda$を精度行列として,以下のように示せます.
$$
a(\boldsymbol{x}^\prime) = (\boldsymbol{x}^\prime - \hat{\boldsymbol{\mu}})^T \Lambda (\boldsymbol{x}^\prime - \hat{\boldsymbol{\mu}})
$$
多重共線性があると分散共分散行列はランク落ちしがちで,精度行列をうまく求められなくなるので,ホテリング$T2$理論と言った異常検知手法は,多重共線性があるときにうまく行きません.5.2 PCA
PCAは,分散共分散行列の固有値が大きいもの順に選び,小さいものを捨てるといった次元削減の考えで前述の問題を解決しています.以下,標準化を仮定してPCAについて軽く述べます.
データ行列を$X\in \boldsymbol{R}^{n\times p}$とするとその特異値分解は
$U \in \boldsymbol{R}^{n\times n}$,$V \in \boldsymbol{R}^{p\times p}$,$\Sigma \in \boldsymbol{R}^{n\times p}$として
$$
\frac{1}{\sqrt{n}}X = U \Sigma V^T
$$
これによって,分散共分散行列$S$の固有値分解は以下のように与えることができます.
$$
S = \frac{1}{n}X^TX= V \Sigma^2 V^T
$$
PCAを用いたマハラノビス距離のようなもの($T^2$統計量と呼ばれる)は次のように書けます.
$$
T^2 = x^T P \Sigma_a^{-2} P^T x
$$
ここで$\Sigma_a$は$\Sigma$のうち大きいものから$a$個選んだもので$P$はそれらに対応する固有ベクトルからなる行列です.これが前述の固有値が小さいものを捨てるということです.5.3 ROPE
ROPEでは,精度行列を求める時に,精度行列の固有値を純粋に分散共分散の固有値$l_i$の逆数にするのではなく$l_i$よりも大きなものの逆数をとる.つまり
$$
\frac{1}{\hat{\lambda_i}} = \frac{l_i + \sqrt{l^2_i + 8\rho}}{2}
$$
とすることで$l_i$が0に近い場合でも$\hat{\lambda_i}$が大きくなることを防ぎます.PCAは共分散行列の固有値が小さいものを捨てる一方で.ROPEは小さい固有値を大きくしていると考えることができます.6 まとめ
ROPEはPCAと似てますが,PCAは分散共分散行列の固有値が小さいものをすてる一方.ROPEは固有値を大きくするという異なったアプローチをとっています.似てるなと思い,シミュレーションデータの異常検知において,PCAとROPEを比較してみましたが,PCAの方が強かったですね.なんでだろう.
コード
w,v = np.linalg.eigh(train_covariance) def ridge(rho): lambda_hat = 2/(w+np.sqrt(w**2+8*rho)) precision = v @ np.diag(lambda_hat) @ v.T return precision参考文献
[1]M. O. Kuismin, J. T. Kemppainen, M. J.Sillanpää. Precision matrix estimation with rope.Journalof Computational and Graphical Statistics, Vol. 26, No. 3, pp. 682-694, 2017.
[2]Harry Dym.Linear Algebra in Action (Graduate Studies in Mathematics). American MathematicalSociety, 2 edition, 12 2013.
[3]Chris Paige and Charles Van Loan. A schur decomposition for hamiltonian matrices.Linear Algebraand its Applications, Vol. 41, pp. 11 - 32, 1981.
[4]Alan J. Laub. Schur method for solving algebraic riccati equations.Laboratory for Info. and DecisionSystems Report No. LIDS-R-859, 10 1978
- 投稿日:2019-02-28T15:22:36+09:00
【python】各種変調方式(QPSK, 16QAM, 64QAM)でAWGN通信を行ったときのBERの比較
過去の自分の記事をみると、MATLABで全く同じことをしていましたが、もしかしたらpythonのほうが需要があったりするのではないかと思い作った次第です。
本記事の内容としては。
https://qiita.com/Seiji_Tanaka/items/a059090ee020a5d5c648
に書いたビット→シンボルの変調用関数が入ったpythonファイル「QAM_modulation」と、https://qiita.com/Seiji_Tanaka/items/b29d8a5a3447680370ce
に書いたシンボル→ビットの復調用関数が入ったpythonファイル「QAM_demodulation」とimport numpy as np def AWGN_noise(EbNo, N, sym_num, bit_num): """ EbNo : 発生させたい雑音の強度を決める N : 受信機側アンテナの数 sym_num : 送信シンボル系列長 bit_num : 送信ビット系列長 """ #変調多値数を求める QSPK : 2, 16QAM : 4, 64QAM : 6となる値 QAM_order = int(bit_num / sym_num) SNR = QAM_order * 10 ** (EbNo / 10) No = 1 / SNR noise = np.random.normal(0, np.sqrt(No / 2), (N, sym_num)) \ + 1j * np.random.normal(0, np.sqrt(No / 2), (N, sym_num)) return noiseという3つのpythonファイルをインポートして、通信シミュレーションを行います。
import numpy as np import matplotlib.pyplot as plt # https://qiita.com/Seiji_Tanaka/items/a059090ee020a5d5c648 import QAM_modulation # https://qiita.com/Seiji_Tanaka/items/b29d8a5a3447680370ce import QAM_demodulation # Qiitaのこのページの上部に記載 import channel_generation # 送信側アンテナ数 M = 1 # 受信側アンテナ数 N = 1 # 送信ビット数 bit_num = 12 * 10 ** 5 # 計算するEbNoの範囲 freqは計測点の間隔の狭さに対応する EbNo_min = 0 EbNo_max = 20 freq = 21 power_range = np.linspace(EbNo_min, EbNo_max, freq) BER_QPSK = np.zeros((1, freq)) BER_16QAM = np.zeros((1, freq)) BER_64QAM = np.zeros((1, freq)) count = 0 for EbNo in power_range: TX_bit = np.random.randint(0, 2, (M, bit_num)) # 変調 TX_QPSK = QAM_modulation.bit_to_QPSK(TX_bit) TX_16QAM = QAM_modulation.bit_to_16QAM(TX_bit) TX_64QAM = QAM_modulation.bit_to_64QAM(TX_bit) # AWGN雑音を付加 noise = channel_generation.AWGN_noise(EbNo, N, len(TX_QPSK[0, :]), bit_num) RX_QPSK = TX_QPSK + noise noise = channel_generation.AWGN_noise(EbNo, N, len(TX_16QAM[0, :]), bit_num) RX_16QAM = TX_16QAM + noise noise = channel_generation.AWGN_noise(EbNo, N, len(TX_64QAM[0, :]), bit_num) RX_64QAM = TX_64QAM + noise # 判定・復調 RX_bit_QPSK = QAM_demodulation.QPSK_to_bit(RX_QPSK) RX_bit_16QAM = QAM_demodulation.QAM16_to_bit(RX_16QAM) RX_bit_64QAM = QAM_demodulation.QAM64_to_bit(RX_64QAM) # BERの計算 error_sum_QPSK = np.sum(np.abs(TX_bit - RX_bit_QPSK)) error_sum_16QAM = np.sum(np.abs(TX_bit - RX_bit_16QAM)) error_sum_64QAM = np.sum(np.abs(TX_bit - RX_bit_64QAM)) BER_QPSK[0, count] = error_sum_QPSK / (M * bit_num) BER_16QAM[0, count] = error_sum_16QAM / (M * bit_num) BER_64QAM[0, count] = error_sum_64QAM / (M * bit_num) count += 1 plt.semilogy(power_range, BER_QPSK[0,:], label="QPSK") plt.semilogy(power_range, BER_16QAM[0,:], label='16QAM') plt.semilogy(power_range, BER_64QAM[0,:], label="64QAM") plt.legend(bbox_to_anchor=(1, 1), loc='upper right', borderaxespad=0, fontsize=18) plt.ylim(10**(-5), 10**(-0)) plt.xlabel('Eb/N0 [dB]') plt.ylabel('BER') ax = plt.gca() ax.set_yscale('log') plt.grid(which="both") plt.show()出力結果は、
という感じで得られると思います。
もしpythonで通信系の理論シミュレーションを行おうとする方で変復調用の関数を作るのに手間取っているひとがいたらぜひ使ってください。
こういうことで悩む時間というのは本当にもったいないと思いますので。

- 投稿日:2019-02-28T14:18:01+09:00
【python】QPSK・16QAM・64QAM判定・復調用の関数
https://qiita.com/Seiji_Tanaka/items/a059090ee020a5d5c648
の続きですが、変調した信号を復調する関数も書きました。自分でも驚くほどのクソコードなので腰を抜かさないように注意してください。import numpy as np def QPSK_to_bit(RX_symbol): temp = RX_symbol.shape N = temp[0] sym_num = temp[1] bit_num = sym_num * 2 odd_bit = np.real(RX_symbol) odd_bit[odd_bit > 0] = 1 odd_bit[odd_bit < 0] = 0 even_bit = np.imag(RX_symbol) even_bit[even_bit > 0] = 1 even_bit[even_bit < 0] = 0 RX_bit = np.zeros((N, bit_num)) RX_bit[:, 0:bit_num:2] = odd_bit RX_bit[:, 1:bit_num:2] = even_bit return RX_bit def QAM16_to_bit(RX_symbol): temp = RX_symbol.shape N = temp[0] sym_num = temp[1] bit_num = sym_num * 4 # 整数に直す RX_symbol = RX_symbol * np.sqrt(10) # 複素数を一旦分離する RX_symbol_real = np.real(RX_symbol) RX_symbol_imag = np.imag(RX_symbol) # 最も近いシンボルの値に丸め込み real_copy = RX_symbol_real.copy() imag_copy = RX_symbol_imag.copy() RX_symbol_real[real_copy > 2] = 3 RX_symbol_real[2 > real_copy] = 1 RX_symbol_real[0 > real_copy] = -1 RX_symbol_real[-2 > real_copy] = -3 RX_symbol_imag[imag_copy > 2] = 3 RX_symbol_imag[2 > imag_copy] = 1 RX_symbol_imag[0 > imag_copy] = -1 RX_symbol_imag[-2 > imag_copy] = -3 # 再び結合し、もろもろの操作 temp = np.zeros((N, sym_num * 2)) temp[:, 0:sym_num*2:2] = RX_symbol_real temp[:, 1:sym_num*2:2] = RX_symbol_imag temp2 = np.zeros((N, sym_num * 2)) + 1j * np.zeros((N, sym_num * 2)) temp2[temp == 3] = 1 - 0j temp2[temp == 1] = 1 + 1j temp2[temp == -1] = - 0 + 1j temp2[temp == -3] = - 0 - 0j RX_bit = np.zeros((N, bit_num)) RX_bit[:, 0:bit_num:2] = np.real(temp2) RX_bit[:, 1:bit_num:2] = np.imag(temp2) return RX_bit def QAM64_to_bit(RX_symbol): temp = RX_symbol.shape N = temp[0] sym_num = temp[1] bit_num = sym_num * 6 # 整数に直す RX_symbol = RX_symbol * np.sqrt(42) # 複素数を一旦分離する RX_symbol_real = np.real(RX_symbol) RX_symbol_imag = np.imag(RX_symbol) # 最も近いシンボルの値に丸め込み real_copy = RX_symbol_real.copy() imag_copy = RX_symbol_imag.copy() RX_symbol_real[real_copy > 6] = 7 RX_symbol_real[6 > real_copy] = 5 RX_symbol_real[4 > real_copy] = 3 RX_symbol_real[2 > real_copy] = 1 RX_symbol_real[0 > real_copy] = -1 RX_symbol_real[-2 > real_copy] = -3 RX_symbol_real[-4 > real_copy] = -5 RX_symbol_real[-6 > real_copy] = -7 RX_symbol_imag[imag_copy > 6] = 7 RX_symbol_imag[6 > imag_copy] = 5 RX_symbol_imag[4 > imag_copy] = 3 RX_symbol_imag[2 > imag_copy] = 1 RX_symbol_imag[0 > imag_copy] = -1 RX_symbol_imag[-2 > imag_copy] = -3 RX_symbol_imag[-4 > imag_copy] = -5 RX_symbol_imag[-6 > imag_copy] = -7 # 再び結合し、もろもろの操作 temp = np.zeros((N, sym_num * 2)) temp[:, 0:sym_num*2:2] = RX_symbol_real temp[:, 1:sym_num*2:2] = RX_symbol_imag RX_bit_first = np.zeros((N, int(bit_num/3))) RX_bit_first[temp > 0] = 1 RX_bit_first[temp < 0] = 0 RX_bit_second = np.zeros((N, int(bit_num / 3))) RX_bit_second[temp == 7] = 0 RX_bit_second[temp == 5] = 0 RX_bit_second[temp == 3] = 1 RX_bit_second[temp == 1] = 1 RX_bit_second[temp == -1] = 1 RX_bit_second[temp == -3] = 1 RX_bit_second[temp == -5] = 0 RX_bit_second[temp == -7] = 0 RX_bit_third = np.zeros((N, int(bit_num / 3))) RX_bit_third[temp == 7] = 0 RX_bit_third[temp == 5] = 1 RX_bit_third[temp == 3] = 1 RX_bit_third[temp == 1] = 0 RX_bit_third[temp == -1] = 0 RX_bit_third[temp == -3] = 1 RX_bit_third[temp == -5] = 1 RX_bit_third[temp == -7] = 0 RX_bit = np.zeros((N, bit_num)) RX_bit[:, 0:bit_num:3] = RX_bit_first RX_bit[:, 1:bit_num:3] = RX_bit_second RX_bit[:, 2:bit_num:3] = RX_bit_third return RX_bit通信全体のシミュレーションはまたそのうち書きます。
- 投稿日:2019-02-28T13:47:02+09:00
分類-データの取得から分類までの流れ-
取得したデータを実際に識別器にかけて分類するまでには、かなりの下処理が必要です
「機械学習の9割は前処理」という話がよく理解できました
よい分類精度を出すためにはいろいろ考慮しないといけませんそこでデータの取得から分類までの流れを自分用にまとめています
詳細はリンクを参考にしてください1.データの取得
データといっても色々あります。
画像、音声、センサー出力、数値、文字(項目)などなど
そして、これらすべてのデータを数値、すなわちベクトル化する必要があります2.特徴量抽出
特徴量抽出とはベクトル化することです
2-1.画像のベクトル化
2-2.文字のベクトル化
3.特徴量選択
すべてのデータが有効であるかといえば、そうでもありません
必要なデータ、いらないデータの取捨選択が必要です
特徴量選択の時に使うモジュールは、from sklearn.feature_selectionにある
参考
特徴量選択について
sklearn.feature_selection による特徴量選択3-1.SelectKBest
上位K個のベストな特徴量を選択する
引数score_func_にはf_regression(回帰)やchi2(カイ二乗)の適用もできるfrom sklearn.feature_selection import SelectKBest #上位k個のベストな特徴量を選ぶ from sklearn.feature_selection import chi2 #カイ二乗基準で skb=SelectKBest(chi2, k=20)skb=selectKBest(score_func=f_regression, k=5)4.特徴量変換
4-1.主成分分析PCA
高次元データセットの可視化が可能
特徴量x1とx2に相関関係があれば、片方の特徴量はいらない = 冗長データ
処理の時間やメモリを圧迫するだけなので、特徴量の削減=次元削減がしたいpca.explained_variance_ratio_で寄与率を見ることで何次元減らせるか可視化できる
plt.plot(np.add.accumulate(pca.explained_variance_ratio_))PCAを適用する前に、データを
StandrdScalerでスケール変換し、古語の特徴量の分散が1になるようにする参考
意味がわかる主成分分析
主成分分析を Python で理解する4-2. PCA Whitening 白色化
pca=PCA(whiten=True)平均0、分散1にする
PCAによる変換後にStandardScalerをかけるのと同義4-3. ZCA Whitening
Deep-learningの画像認識によく使われる。
未勉強4-4. 非線形(多項式)変換 PolynomialFeatures
これは多項式の特徴に変換するものです。すなわち次元増大ともいえる
次数degreeを選択することで、次元を増やせるpolf=PolynomialFeatures(degree=2) #次数を2にするとき参考
Pythonでデータ分析:非線形効果を導入
scikit-learnで線形回帰5. 正規化
スケールを同じにする。めっちゃ大事
参考
【Python】数量データの正規化 ( 標準化 ) について
sklearn StandardScaler で標準化の効果を確かめる-python
Python: データセットの標準化について5-1 標準化 Standardization
from sklearn.preprocessing import StandardScaler平均0、分散1にする
5-2 スケーリング Range Scaling
from sklearn.preprocessing import MinMaxScaler mmscaler = MinMaxScaler([-1,1])最小、最大値を定義してその範囲内のものだけ選択
5-3. 正規化 Normalization
from sklearn.preprocessing import Normalizer normalizer=Normalizer().fitで学習する必要がない
ノルム(超訳:ベクトルの長さ)を1にする
うまくいかないことも多いらしく、工夫が必要6. 学習データと検証用データに分割
参考
Python: パラメータ選択を伴う機械学習モデルの交差検証について
6.1 Hold-Out
データセットを学習用と検証用に分割し、学習用データを用いて識別器を学習させ、検証用データで性能評価する
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=True, random_state=1)とか
from sklearn.model_selection import ShuffleSplit ss=ShuffleSplit(n_splits=1, test_size=0.5, train_size=0.5, random_state=0)データをランダムに分けるだけなので、データに偏りが出る恐れがあるから注意!
6.2 Cross-Validation(交差検証)
Hold-Outのデータ偏り問題を解決するための方法で、データの分割を何度も繰り返して、複数のモデルを訓練する。
K-fold cross-validation(k分割交差検証)が一般的from sklearn.model_selection import KFold ss=KFold(n_splits=10,shuffle=True) #kは基本5から10の範囲6.3 Leave-One-Out
leave-one-out cross validation は、正解データから 1 つだけ抜き出してテストデータとし、残りのデータを教師データとして、交差検証を行う方法である。これを、全ての組み合わせについて、学習と評価を繰り返す。ちょうど、k-fold cross validation のとき、k をデータ数とした場合と同じ
from sklearn.model_selection import LeaveOneOut loocv = LeaveOneOut()参考
6.4 Leave-One-Group-Out
6.5 層化Stratified
上の方法では各分割内でのクラスの比率がおかしくなることも
そこでStratify層化することでクラス内比率と全体の比率を同じにするfrom sklearn.model_selection import StratifiedKFold ss=StratifiedKFold(n_splits=10,shuffle=True)参考
モデルの汎化性を評価する「交差検証」について、Pythonで学んでみた
7. 分類評価
7.1 Confusion Matrix
7.2 classification_report
- 投稿日:2019-02-28T12:24:28+09:00
TensorFlowのsess.run()が遅かった
やりたいこと
色んな画像に対してObject Detection APIで
sess.run()したかったが、一枚5~8秒ほどかかった。# イメージ for i in range(10): tf.Session(graph=hoge) as sess: sess.run(hoge_op, feed_dict={})実際はクラス化したり、sessionがネストしてたり、
外部から呼び出されたりでもっと複雑だったが、
まぁ雰囲気はこんな感じだった。対処
要はこう。
# イメージ tf.Session(graph=hoge) as sess: for i in range(10): sess.run(hoge_op, feed_dict={})何故か。グラフとセッションの関係
この2つの概念を知っておけば、自分のような初心者でも何となくTensorflowのコードが理解出来るようになった。
- グラフ:計算グラフ
情報系の人間には見覚えのあるグラフ。
TensorFlowで書く時は↓みたいな感じ。上の画像とは関係ないです。add_graph = tf.Graph() with add_graph.as_default(): a = tf.placeholder(tf.int32, shape=[], name="a") b = tf.placeholder(tf.int32, shape=[], name="b") add_op = tf.add(a, b, name="add_op")
- セッション:
グラフを実行するために存在する。
コードによっては省略されているが、tf.Session(graph=hoge)のように、実行対象のグラフは必ず指定されている。
tf.Session()でグラフを指定したsessを作成出来て、
sess.run()でその中の一部とか全部を出力出来る(最後のoperationとかが引数)。with tf.Session(graph=add_graph) as sess: ret = sess.run(add_op, feed_dict={a:1,b:1}) print ret
- 実装の流れ:
- グラフを作成
- セッションを作成
- sess.run()
何故遅かったのか
最初の例だと、毎回セッションの作成を行ってしまうから。
セッションは作成時にメモリ確保とかを行うので、作成にはかなり時間がかかる。参考サイト
グラフとセッションの部分のコード参考:
http://docs.fabo.io/tensorflow/building_graph/tensorflow_graph_part2.html
グラフとセッションについての説明:
https://arakan-pgm-ai.hatenablog.com/entry/2017/05/04/173031感想
Chainerとかは直感的だけど、TensorFlowは結構独特で、
ごくごく軽く触る程度の身としては困っている。勉強(機械学習)のための勉強(Tensorflowへの慣れ)、
になってしまったので、
やはりChainerみたいなdefine by run系がとっつきやすいと思う。

- 投稿日:2019-02-28T11:27:33+09:00
ラスボス系後輩ヒロインAIチャットボットを作りたい・プロローグ
当記事はQrunchにクロス投稿しています。
前置き
保守対応に回されてチケット来ない日は暇なので二度とIE8案件の保守なんかにぶち込まれないで済むように勉強をはじめました(IEを口汚く罵る絵文字)
とりあえずFGOのCCCイベが楽しかった&BBちゃんが可愛かったのでラスボス系後輩ヒロインAIチャットボット制作を目標に据え置いて作業します。
何を隠そう「先輩」と呼ばれることにものすごく弱いのだ……(マシュも大好き)本編
予定の目次と、語の定義についてざっと検索してみた結果
- Pythonの基礎 with O'Reilly本
- NumPy
- matplotlib(ふたつともO'Reilly本に収録されていることを確認、ラッキィ)
- 数学の基礎
- 線形代数
- 微分
- 正規分布
- 交差エントロピーも目を通しておきたいけどKaresに入ってるっぽいからやらなくてもよい? 保留
- ニューラルネットワークの概要
- バックプロパゲーションの概要
- 仮想環境の構築
- JUMAN++入門
- シンプルなRNN(Recurrent Neural Network - 再帰的ニューラルネットワーク)の実装
- 勾配クリッピング
- シンプルなLSTM(Long Short Term Memory)の実装
- シンプルなGRU(Gated Recurrent Unit)の実装
- LSTM、GRUによる自然言語処理
目次はUdemyを参考に作りました。クレカ審査落ちたので受講はできません。調べたらPayPalが銀行口座からの支払いに対応しているようで、本人確認すればPayPal越しに行けそうな感じがあったんですけど、なんか時間かかるっぽいしめんどくさいし保留。デビットカード作ればいいんだろうか……お金周りはめんどうだねえ。
元々形態素解析はMeCabでやってたんですけど(Rubyラッパのnattoとか係り受け解析機CabochaとかMeCab周りは食べ物の名前が多い)、この記事 新形態素解析器JUMAN++を触ってみたけど思ったより高精度でMeCabから乗り換えようかと思った話 - Qiita を読んで、砕けた喋り方のチャットボットならJUMAN++の方が向きそうだなと思ったので乗り替えることに。
目下の明確な問題は 明らかに教師データが足りない ことなんですけど(FGOからBBちゃんのセリフ全部起こしても足りないだろうし、CCC持ってないし)(実家からVita持ってくればPSストアから買えるっぽい?)まあそのへんは最悪ぐだBB夢小説でも書いてなんとかしましょう(なんとかなるんだろうか?)
- 投稿日:2019-02-28T11:06:47+09:00
次の年号をゴリ押しで予測する
なにこれ
こんなのを見掛けたので、
常用漢字が2136字なので、2文字の組み合わせは約456万通り、1秒に2つずつ漏洩させていけば約27日、まだ元号の発表までに間に合う、今すぐやれ
— twinrail (@twinrail) 2019年2月26日やってみた。
常用漢字を
文化庁から取ってきて
wget http://www.bunka.go.jp/kokugo_nihongo/sisaku/joho/joho/kijun/naikaku/kanji/joyokanjisakuin/index.html案の定 sjis なので utf-8 に変換
nkf -w index.html > index.utf8.html抜き出す
そして安定のfontタグ。
xpathはこれ//*[@id="urlist"]/tbody/tr/td[1]/font[1]a.py(前半)import lxml.html contents = open("index.utf8.html").read() xpath = '//*[@id="urlist"]/tbody/tr/td[1]/font[1]' doc = lxml.html.fromstring(contents) elems = doc.xpath(xpath) kanji = [ x.text_content() for x in elems ] print(len(kanji)) print(kanji[:10])$ python a.py 2136 ['亜', '哀', '挨', '愛', '曖', '悪', '握', '圧', '扱', '宛']2文字の順列
a.py(後半)import itertools for a, b in itertools.permutations(kanji, 2): print(f"次の年号は\t{a}{b}\tかな?")結果
$ python a.py > out $ wc -l out 4560360 out $ head out 次の年号は 亜哀 かな? 次の年号は 亜挨 かな? 次の年号は 亜愛 かな? 次の年号は 亜曖 かな? 次の年号は 亜悪 かな? 次の年号は 亜握 かな? 次の年号は 亜圧 かな? 次の年号は 亜扱 かな? 次の年号は 亜宛 かな? 次の年号は 亜嵐 かな?おわり。
- 投稿日:2019-02-28T10:45:55+09:00
Pythonで複素数(実数部の取り出し)- 2019京都大学理系数学より
2019年京都大学 理系数学 問6
https://www.yomiuri.co.jp/nyushi/sokuho/k_mondaitokaitou/kyoto/mondai/mondai/1306785_5050.html
i は虚数単位とする。 (1+i)^n + (1-i)^n > 10^{10} をみたす最小の正の整数 n を求めよpythonの虚数は j で表す。
ただし、
1 + iのような値 は
1jのように表記する というポイントがある。5iが5jになるのはわかるが・・・1+jと書くと変数jが定義されていないということにハマるので注意。(ハマった)虚数を含んだ複素数の実数部の取り出し
値は
complexクラスになるので、.realで行う。(虚数部はimag)。両方共値としてはfloatで返る。解答例
2019-kyoto-06.pyn = 1 while True: s = (1+1j)**n + (1-1j)**n # s は明らかに実数 if (s.real > 10**10): print(n) break n += 1これで正解の
71を得ました。