- 投稿日:2019-02-28T20:19:56+09:00
softmax関数の処理を今まで勘違いしていた話
もしかしたら同じ勘違いをしている人がいるかもしれないという事で、記事にしておきます。
sofmaxと言えば、分類問題などで使われる関数であり、以下のような特徴がある。
1.総和を1にする。
2.数値の大小は変わらない。これは、深層学習を勉強した人なら、多くの人がお世話になったであろう「ゼロから作るdeep learning」の70ページ目にも書かれている。
しかしひょんな事から、その2の特徴は正確ではないという事に気が付いた。最初から総和が1の配列をsoftmaxに通してみる。
def softmax(x): if x.ndim == 2: x = x.T x = x - np.max(x, axis=0) y = np.exp(x) / np.sum(np.exp(x), axis=0) return y.T x = x - np.max(x) # オーバーフロー対策 return np.exp(x) / np.sum(np.exp(x)) x = np.array([0.7, 0.2, 0.1]) print(softmax(x))test.py[0.46396343 0.28140804 0.25462853]総和が1である配列をsoftmaxに通したら同じ値のまま返ってくるという認識だったのだがそうではなかった。
次にsoftmaxの出力を再度softmaxに通す...という処理をしてみる。
import numpy as np def softmax(x): if x.ndim == 2: x = x.T x = x - np.max(x, axis=0) y = np.exp(x) / np.sum(np.exp(x), axis=0) return y.T x = x - np.max(x) # オーバーフロー対策 return np.exp(x) / np.sum(np.exp(x)) x = np.array([0.7, 0.2, 0.1]) for _ in range(100): x = softmax(x) print(x)test.py[0.33333333 0.33333333 0.33333333]最終的には、値が均一になる事がわかった。
この事から、softmaxに通した値の大小は変わらないというのは間違いである。
- 投稿日:2019-02-28T18:58:25+09:00
metric learning を少し勉強したからまとめる
先日某社で2週間の短期インターンシップに参加してきました。
内容としては製造ラインで行われる外観検査をディープラーニングを用いて自動化することを想定して、画像から不良を検出するモデルを作成するというものでした。そこでmetric learningについて少し勉強し、"L2-constrained Softmax Loss for Discriminative Face Verification"という論文を読んだので内容をまとめたいと思います。
嘘ついてるかもしれないので気をつけて読んでもらえると助かります。metric learningとは?
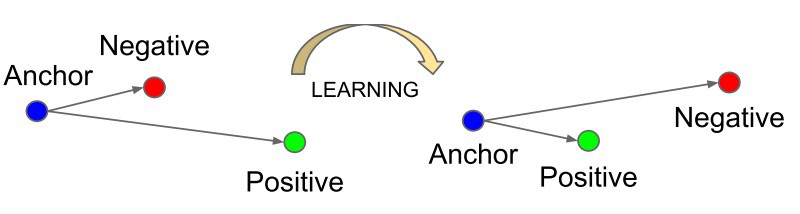
metric learningとはデータ間の関係を計量を用いて表現する特徴空間への変換を学習する手法です。図のようにニューラルネットワークを用いて同じクラスのデータは近くに、違うクラスのデータは遠くなるように特徴空間へデータの埋め込みを行います。学習によって得られたネットワークを用いてデータの変換を行い、得られた特徴ベクトル間の距離を求めることでそのデータがそのクラスに属するか、属さないか判定することができます。
異常検知では異常とされるデータ数が少なかったり、学習セットに全ての異常パターンが含まれているとは限らないといった問題があるため、metric learningを用いて正常サンプルの"正常さ"を学習し、新しい入力データと正常サンプル間の距離から適当な閾値で同一かどうか判断することで異常を検出します。
異常検知以外にも顔認識でよく用いられるみたいです。Triplet Loss
metric learningにおける代表的な損失関数としてTriplet Lossが挙げられます。
TensorFlowやPyTorchといった有名なディープラーニングフレームワークには実装されているので、簡単に使うことができます。
Triplet Lossは次式のとおりです。L(a, p, n)=\frac{1}{N}\left(\sum_{i=1}^{N} \max \left\{d\left(a_{i}, p_{i}\right)-d\left(a_{i}, n_{i}\right)+\operatorname{margin}, 0\right\}\right)\\ \text { where } d\left(x_{i}, y_{i}\right)=\left\|\mathbf{x}_{i}-\mathbf{y}_{i}\right\|_{2}^{2}\\ a\ \text{: anchor sample}\\ p\ \text{: positive sample}\\ n\ \text{: negative sample}\\ N\ \text{: minibatch size}変換後の特徴ベクトル間のユークリッド距離を組み込んだ損失関数。
計算にはanchor, positve, negativeの3つのサンプルが必要となります。
anchorは基準となるサンプル、positiveはanchorと同じクラスに属する別のサンプル、negativeはanchorと違うクラスに属するサンプルです。
このように3つサンプルを取ってくる手法をTriplet samplingといいます。
損失関数を見るとanchorとpositiveのユークリッド距離(の2乗)が小さくなり、
anchorとnegativeの距離が大きくなるように学習することがわかります。
Triplet samplingでは1回のサンプリングにつき1つのpositiveと1つのnegativeの対しか
学習できないため、学習効率が悪いという欠点があります。
そのため効率よく学習するにはなるべく寄与の大きいサンプルを選ぶなどの工夫が必要となります。
また学習効率の悪さを改善するために考案されたN-pair samplingというものもあります。Softmax Loss
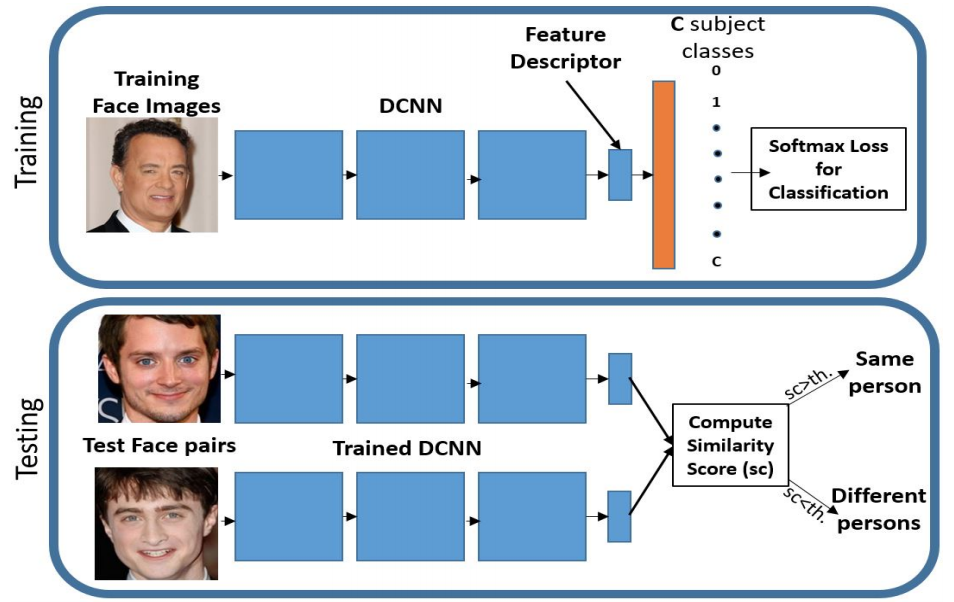
Softmax Lossはクラス分類のタスクでよく用いられるものですが、metric learningの文脈でも使われるみたいです。
Softmax Lossをmetric learningの文脈で用いる場合は、図のように学習時は通常のクラス分類のように学習を行い、評価時には最後の識別レイヤの直前の出力(feature descriptor)を変換後の特徴ベクトルとして評価を行います。
Softmax Lossを用いる場合1回の計算で1サンプルしか使わないため、Triplet Lossに比べて計算コストが小さくなります。しかしSoftmax Lossには次のような問題があります。
- 必ずしもデータ間の距離を最適化するとはかぎらない
- わかりやすい特徴にフィットしやすく、難しい特徴を無視する傾向がある
Softmax Lossを用いて学習を行うと真正面を向いている顔写真のようなわかりやすい画像では特徴ベクトルのL2ノルムが大きくなり、うつむいているわかりにくい画像ではL2ノルムが小さくなるという性質があるそうです。
そのため、わかりやすい画像の方に学習が引っ張られてしまい、難しい画像は無視される傾向があります。
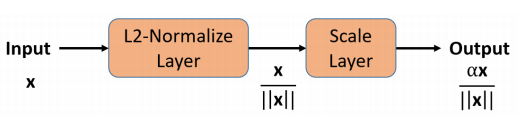
これらの問題を克服したのがL2-constrained Softmax Lossです。
L2-constrained Softmax Loss
L2-constrained Softmax Loss(以後 L2 Softmax)には
1. 同一クラスのコサイン類似度が大きく、違うクラスのコサイン類似度が小さくなるように学習する
2. すべての特徴を均一に学習することができる
3. 実装が簡単
といった特徴があります。L2 Softmax Lossの式は次のとおりです。
\text{minimize } -\frac{1}{M} \sum_{i=1}^{M} \log \frac{e^{W_{y_{i}}^{T} f\left(\mathbf{x}_{i}\right)+b_{y_{i}}}}{\sum_{j=1}^{C} e^{W_{j}^{T} f\left(\mathbf{x}_{i}\right)+b_{j}}}\\ \text { subject to } \quad\left\|f\left(\mathbf{x}_{i}\right)\right\|_{2}=\alpha, \forall i=1,2, \dots M\\L2 Softmax LossではSoftmax LossにFeature descriptorのL2ノルムがある定数$\alpha$になるように制約を加えます。これは入力データを半径$\alpha$の超球面上に埋め込んでいると解釈することができます。超球面状でSoftmax Lossをとることで、同一クラスの特徴ベクトル同士のコサイン類似度が大きくなり、違うクラスの特徴ベクトル同士のコサイン類似度が小さくなるように学習することができます。
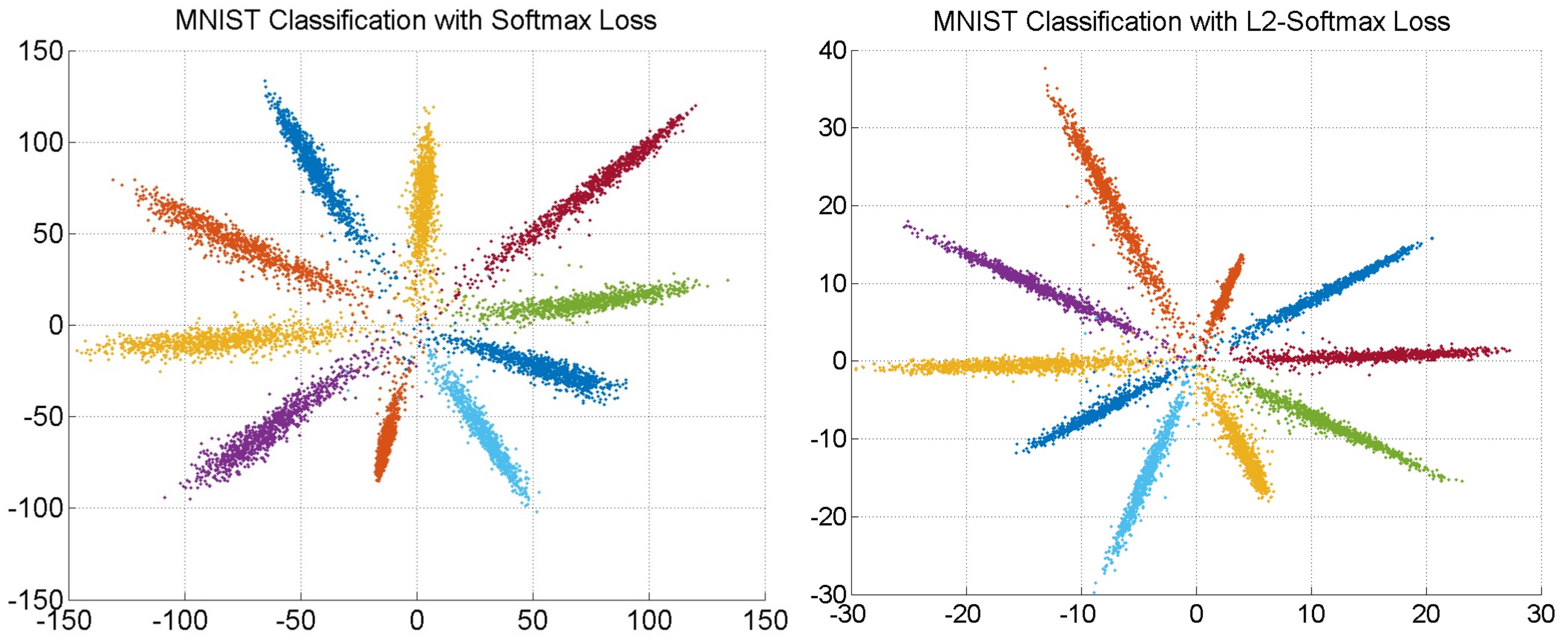
論文ではSoftmax Lossで学習したモデルとL2-constrained Softmax Lossで学習したモデルを使ってMNISTデータを2次元の特徴ベクトルに変換してプロットしたものを比較しています。
左の図がSoftmax Lossを用いて学習したもので右の図がL2 Softmaxを用いて学習したものです。
比較するとL2 Softmaxの方が角度に関するバラつきが小さくなっていることがわかります。またFeture descriptorのL2ノルムを一定にすることによって全てのデータのLossへの影響が均一になります。そのため全ての特徴を均等に学ぶことができ、よりきわどいデータも学習することができます。
L2 Softmax LossはFeature descriptorの後に正規化を行うレイヤーと定数$\alpha$でスケーリングするスケーリングレイヤーをつけてSoftmax Lossを計算するだけで実現できるため非常に簡単に実装を行うことができます。
参考文献
Rajeev Ranjan, Carlos D. Castillo, and Rama Chellappa. L2-constrained softmax loss for
discriminative face verification. CoRR, Vol. abs/1703.09507, , 2017.
deep metric learningによるcross-domain画像検索


- 投稿日:2019-02-28T10:23:13+09:00
機械学習論文読みメモ_160
機械学習論文読みメモ_160
Towards Understanding the Role of Over-Parameterization in Generalization of Neural Networks
従来のnorms, margin, sharpnessといった複雑性指標では、なぜDNNがover-parameterizationによって汎化性能が改善されるのかを説明出来てこなかった。
本論ではDNNのcapacityを測る指標を提案し、よりtightなgeneralization boundを実現する。
このboundを求めるにあたってはover-parameterizationが観測可能かつ簡単な構造として
2層のReLUを利用した。
その構造において、隠れ層の各ニューロン毎に対して複雑性を評価し、その組み合わせとして
Rademacher complexityに基づいた汎化性能のboundを導出する。
この指標を用いると、隠れ層のニューロン数を増やすに連れDNNの複雑性が低減する事が示され、
つまりover-parameterizatioによって汎化性能が改善する事が示された。Digging Into Self-Supervised Monocular Depth Estimation
depth estimationタスクにおいて、画像に対する深さ情報のコストが高いため、
最近はreconstruction errorを用いたself-supervisedな手法が注目されてきている。
こうした手法のためのネットワーク構造が多く提案してきたが、
それらのテスト性能は予想外な事がある。
例えばステレオカメラを用いたself-suprevisionの利用は、データ調達コストが高く
スケールしにくいが、スケールさせられるモノカメラベースのものより、テスト性能が安定しやすい。
このような直感に反する結果はその他のネットワーク構造、損失関数、motion handlingなどの
多方面で見受けられる。
このような観測に基づいて、本論では新たなネットワークを提案し、その他のself-supervision手法
よりも高性能を実現した。
提案ネットワークはモノカメラベースの学習を採用する。
その際depth estimatorに加えて必要となるpose estimatorがあるが、
それらの間でパラメータを共有する。To Trust Or Not To Trust A Classifier
分類器の予測が信頼に値するかどうかを知る事はsafety面で非常に重要である。
従来手法は予測機のconfidence measureを用いる事だが、本論ではそれより
性能の良い指標を提案する。
提案するtrust score指標は、分類器と修正されたkNN分類器との間の予測結果に関する同意レベル
を評価する。
従来のconfidence measureと比較するとこの指標は経験的により高い精度を持って
予測結果の信頼度を評価できる。
- 投稿日:2019-02-28T06:39:53+09:00
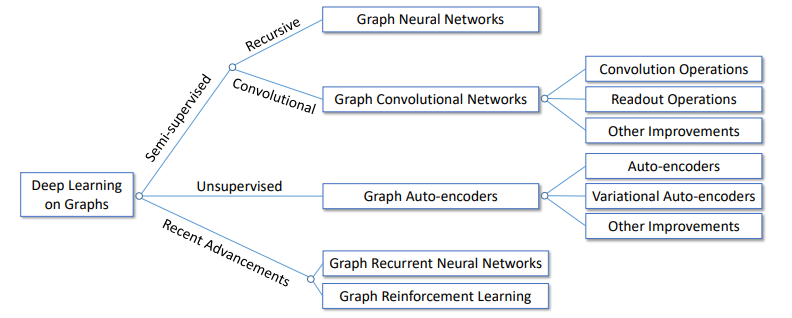
GNNまとめ(2): 様々なSpatial GCN
はじめに
本記事は3部作のうち第2部です. GCNの導入や記号の定義などは前回の記事をご参照ください.
GNNまとめ(1): GCNの導入 - Qiita前回の記事でSpatial GCNの導入までを書いたので, 今回は様々なSpatial GCNについて重要と思われるものをかいつまんで簡単に紹介します.
すべての論文を読んだわけではないので, 間違いなどがございましたら遠慮なくご指摘いただけると助かります. また, 各アルゴリズムにつき図を1枚貼っていますが, これは説明のためというより見た目で区別しやすくするためです.
[1]より引用.GCN
GCNは, CNNのようにフィルタの畳込みをグラフ上で行うことでグラフやノードの潜在ベクトルを得る方法です.
畳込みの定義の仕方にはグラフフーリエ変換を用いるアプローチとより直接的なアプローチの2種類がありますが, ここでは後者について説明します.Spatial GCN
Neural Fingerprint
Convolutional Networks on Graphs for Learning Molecular FingerprintsNeural Fingerprint (NFP) は, 分子の潜在ベクトル(molecular fingerprint)を得るためのアルゴリズムです.
原子価が5までであることを利用して, 注目しているノードの次数ごとにフィルタを用意しています.
第$l$層での計算は次のようになります. $k$は周辺ノードをどの距離まで考慮するかを表すパラメータです.\boldsymbol{h}_i^{l+1} = \rho \Biggl( \sum_{j \in \mathcal{N_k}(i)} \boldsymbol{h}_i^l \boldsymbol{\Theta}_d^l \Biggr)この式がGCN(Kipf+)と似ていることに注意してください. ラプラシアン行列を次数で正規化する代わりに, 次数によって異なるフィルタを利用しています.
PATCHY-SAN
Learning Convolutional Neural Networks for GraphsPATCHY-SANは, ノードに順番をつけることでグラフをテンソルに変換し, あとはCNNと同じように処理するという, (名前とともに)ユニークなアルゴリズムです. どなたか名前の由来を教えてください.
ノードに順番を割り振るのには, グラフ同士の類似度を測るヒューリスティクスであるWeisfeiler-Lehmanカーネルを使います(詳しくは[4]などを参照).
この順番に従って各ノードから近傍ノード$K$個を集めることで, $(N\times K \times F^V)$のテンソルを作ることができます.
テンソルができてしまえば画像と同じように扱えるので, 任意のCNNに入力することができます.
この手法のポイントは「順番付け」にあります. これによって構造的に似たノードがテンソル上で近い位置に来るようになるのですが, 全体としての性能がこのヒューリスティクスに強く依存してしまうという問題があります.DCNN
Diffusion-Convolutional Neural NetworksDCNN (diffusion-convolutional neural network) は, 長さ$K$の遷移行列のべき級数で畳み込みを定義するアルゴリズムです.
$\boldsymbol{\Theta}^l$を対角行列として, 第$l$層での計算を次のように定義します.\boldsymbol{H}^{l+1} = \rho(\boldsymbol{P}^K\boldsymbol{H}^l\boldsymbol{\Theta}^l)MPNN
Neural Message Passing for Quantum Chemistry計算の高速化と汎用性(構造の異なるグラフにも適用できる)を両立するためのフレームワークとして提案されたのがMPNN (message passing neural network) です. message passingの考え方はとても重要で, 他の手法でもしばしば登場します.
MPNNでは, 第$l$層での学習可能なメッセージ関数(message function) を$\mathcal{F}^l$, 頂点更新関数(vertex update function) を$\mathcal{G}^l$として, 次のようにノードの潜在ベクトルを更新します(message passing phase).\begin{eqnarray} \boldsymbol{m}_i^{l+1} &=& \sum_{j \in \mathcal{N}(i)} \mathcal{F}^l(\boldsymbol{h}_i^l, \boldsymbol{h}_j^l, \boldsymbol{F}_{i,j}^E)\\ \boldsymbol{h}_i^{l+1} &=& \mathcal{G}^l(\boldsymbol{h}_i^l, \boldsymbol{m}_i^{l+1}) \end{eqnarray}第1式では隣接ノードとエッジの特徴から注目ノードに向かう「メッセージ」$\boldsymbol{m}^l$の和を計算し, 第2式ではそのメッセージを使って潜在ベクトルを更新します.
グラフ全体の潜在ベクトルを得る場合は, 次の式を利用します(readout phase).\boldsymbol{\hat{y}} = \mathcal{R}([\boldsymbol{h}_i^\mathrm{T} | i \in V])MPNNをこのように定義すると, これまでに紹介したGGS-NN, Spectral GCN, GCN(Kipf+), NFPなどはMPNNの特殊な例と捉えることができます.
といってもよくわからないので, ここではGGS-NNの例を挙げます. $\mathcal{F}, \mathcal{G}$を次のように定義するとGGS-NNになるので, 前回の記事の復習も兼ねて確認してみてください.\begin{eqnarray} \mathcal{F}(\boldsymbol{h}_i, \boldsymbol{h}_j, \boldsymbol{F}_{i,j}^E) &=& \theta_{e_{ij}} \boldsymbol{h}_j\\ \boldsymbol{z}_i &=& \rho(\boldsymbol{\Theta}_z[\boldsymbol{h}_i, \boldsymbol{m}_i])\\ \boldsymbol{r}_i &=& \rho(\boldsymbol{\Theta}_r[\boldsymbol{h}_i, \boldsymbol{m}_i])\\ \boldsymbol{\tilde{h}}_i &=& \tanh{\boldsymbol{\Theta}_h[\boldsymbol{r}_i\odot \boldsymbol{h}_i, \boldsymbol{m}_i]}\\ \mathcal{G}(\boldsymbol{h}_i, \boldsymbol{m}_i) &=& (1-\boldsymbol{z}_i)\odot \boldsymbol{h}_i + \boldsymbol{z}_i \odot \boldsymbol{\tilde{h}}_i \end{eqnarray}GraphSAGE
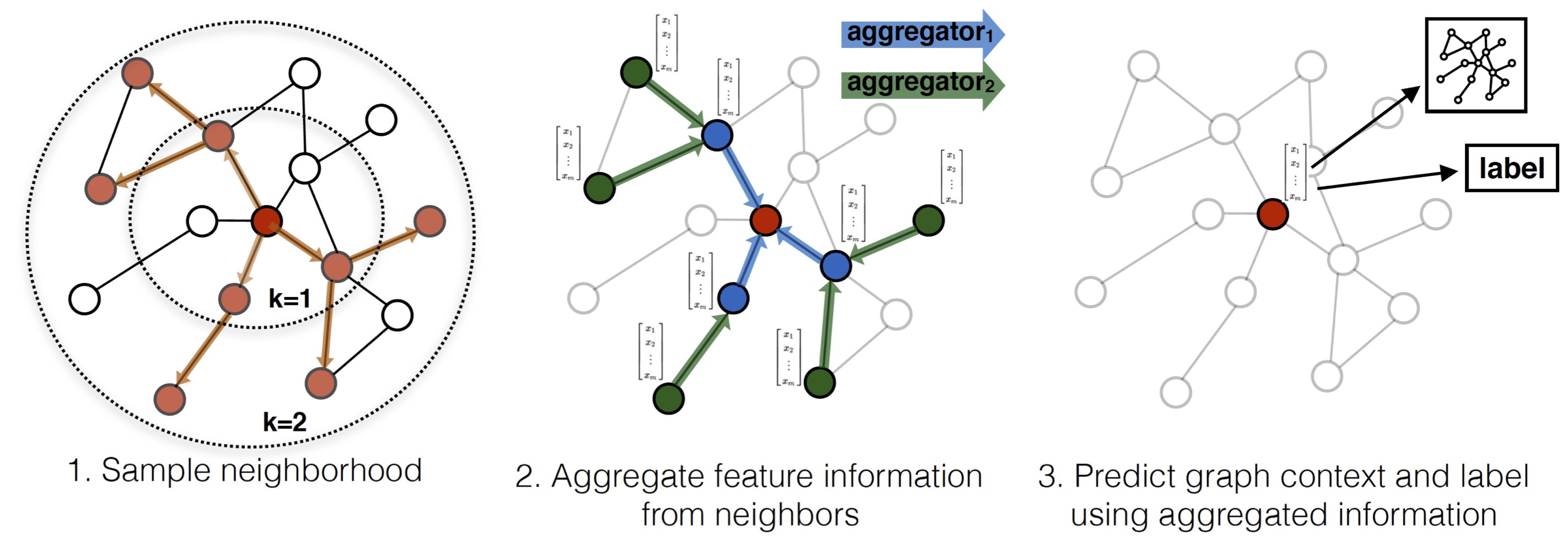
Inductive Representation Learning on Large GraphsGraphSAGE もMPNNと同様にフレームワークを提案したものです. SAGEはSAmple and aggreGatEからとったものらしいですが, わかりにくいですね.
順序不変的な集約関数$\mathrm{AGGREGATE}$を用意して, 次のように潜在ベクトルを更新します.\begin{eqnarray} \boldsymbol{m}_i^{l+1} &=& \mathrm{AGGREGATE}^l(\mathrm{\{} \boldsymbol{h}_j^l, \forall j \in \mathcal{N}(i)\mathrm{\}} )\\ \boldsymbol{h}_i^{l+1} &=& \rho(\boldsymbol{\Theta}^l[\boldsymbol{h}_i^l, \boldsymbol{m}_i^l]) \end{eqnarray}$\mathrm{AGGREGATE}$としては, element-wiseな平均, LSTM, 最大値プーリングのような関数の3種類が提案されています.
MoNet
Geometric deep learning on graphs and manifolds using mixture model CNNsMoNet (mixture model network) はグラフに擬似座標を導入し, 座標に従った重みによって畳み込みを定式化しました.
DCNNはMoNetの一例になります.GN
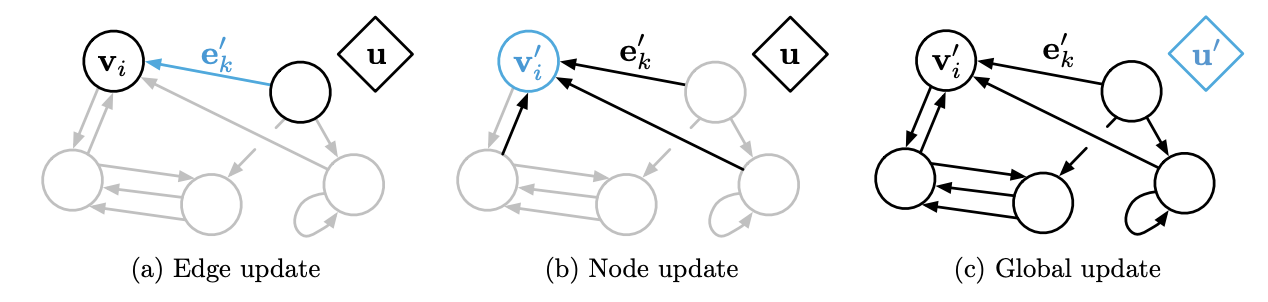
Relational inductive biases, deep learning, and graph networksGN (graph network) はGCNとGNNを一般化したフレームワークで, ノード, エッジ, グラフそれぞれの潜在ベクトル $\boldsymbol{h}_i$,
$\boldsymbol{e}_{ij}$, $\boldsymbol{z}_i$
を学習します.
具体的には, 集約($\mathcal{G}$)と更新($\mathcal{F}$)を次のように行います.\begin{eqnarray} \boldsymbol{m}_i^l &=& \mathcal{G}^{E \rightarrow V}( \mathrm{\{} \boldsymbol{h}_j^l, \forall j \in \mathcal{N}(i)\mathrm{\}} )\\ \boldsymbol{m}_V^l &=& \mathcal{G}^{V \rightarrow G}( \mathrm{\{} \boldsymbol{h}_i^l, \forall v_i \in V \mathrm{\}} )\\ \boldsymbol{m}_E^l &=& \mathcal{G}^{E \rightarrow G}( \mathrm{\{} \boldsymbol{h}_{ij}^l, \forall (v_i, v_j) \in E \mathrm{\}} )\\ \boldsymbol{h}_i^{l+1} &=& \mathcal{F}^V( \boldsymbol{m}_j^l, \boldsymbol{h}_i^l, \boldsymbol{z}^l)\\ \boldsymbol{e}_{ij}^{l+1} &=& \mathcal{F}^E( \boldsymbol{e}_{ij}^l, \boldsymbol{h}_i^l,\boldsymbol{h}_j^l, \boldsymbol{z}^l)\\ \boldsymbol{z}^{l+1} &=& \mathcal{F}^G( \boldsymbol{m}_E^l, \boldsymbol{m}_V^l, \boldsymbol{z}^l) \end{eqnarray}GAT
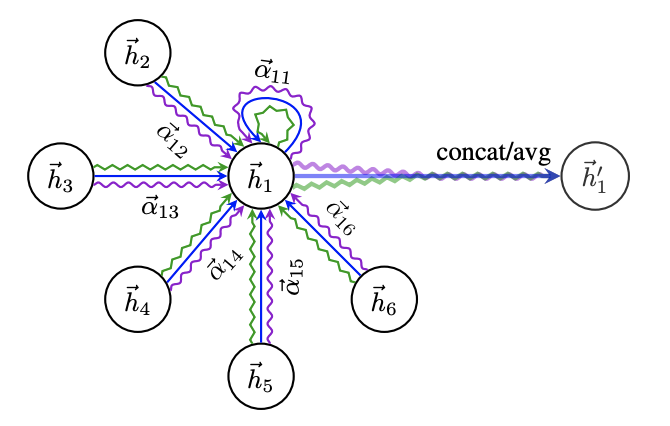
GAT (graph attention network) は, 隣接ノードを畳み込む時の重み$\alpha_{ij}^l$をAttentionで決めます.
\begin{eqnarray} \boldsymbol{h}_i^{l+1} &=& \rho \Biggl( \sum_{j\in \mathcal{N}(i)} \alpha_{ij}^l \boldsymbol{h}_i^l \boldsymbol{\Theta}^l \Biggr) \\ \alpha_{ij}^l &=& \underset{k\in \mathcal{N}(i)}{\mathrm{softmax}} ~ \mathrm{LeakyReLU}(\mathcal{F}(\boldsymbol{h}_i^l\boldsymbol{\Theta}^l, \boldsymbol{h}_j^l\boldsymbol{\Theta}^l)) \end{eqnarray}$\mathcal{F}$は小規模な全結合ニューラルネットです.
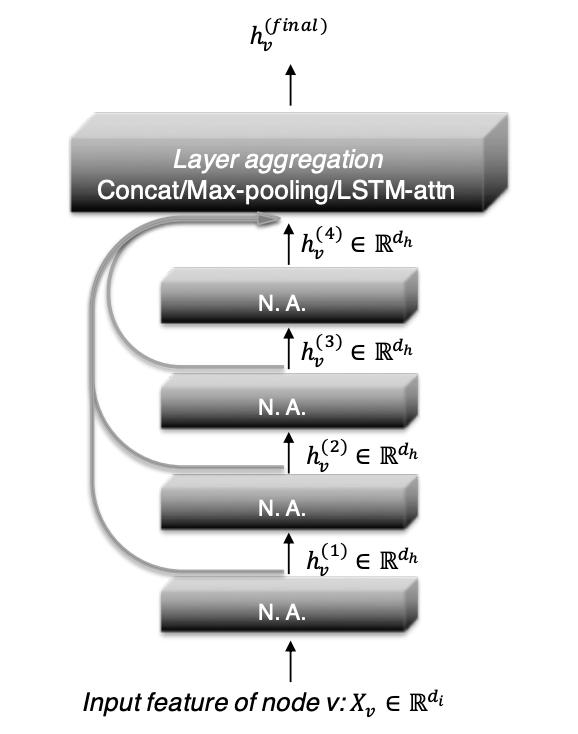
JK-Net
Representation Learning on Graphs with Jumping Knowledge NetworksJK-Net (jumping knowledge network) はResNetのような残差ブロックを利用したネットワークです. 図のように, 各層の出力$\boldsymbol{h}_i^l$を最終層の出力$\boldsymbol{h}_i^L$に連結してから集約します. これによって, タスクごとに適切な範囲で周辺ノードの特徴を取り込むことができます.
\boldsymbol{h}_i = \mathrm{AGGREGATE}(\boldsymbol{h}_i^0,...,\boldsymbol{h}_i^L)集約関数$\mathrm{AGGREGATE}$としては, concatenation, 最大値プーリング, LSTMが用いられます.
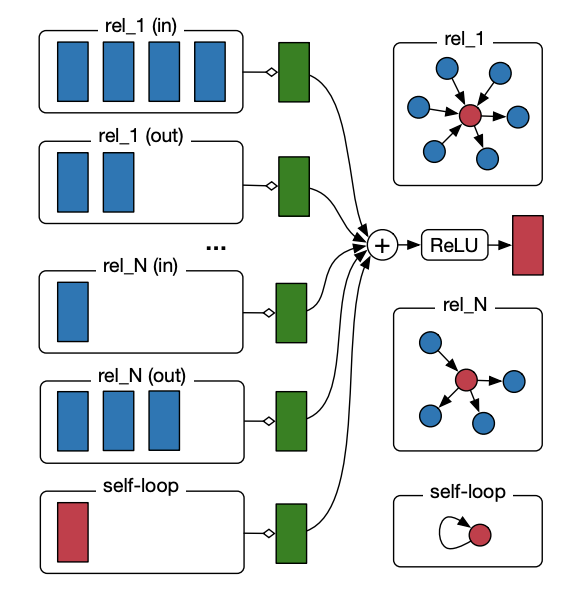
R-GCN
Modeling Relational Data with Graph Convolutional NetworksR-GCN (relational GCN) は知識ベースのように多数の種類があるエッジの特徴を利用できるアルゴリズムです.
次の式のように, エッジの種類ごとに異なる重み行列$\boldsymbol{W}^{l}_{r}$をかけてから足し合わせます.\boldsymbol{h}_i^{l+1}=\rho\Bigl(\sum_{r\in\mathcal R}\sum_{j\in\mathcal N^r(i)}\frac{1}{\mathcal c_{i,r}}\boldsymbol{W}^{l}_{r}\boldsymbol{h}_j^l+\boldsymbol{W}_0^l\boldsymbol{h}_i^l\Bigr)おわりに
今回は, 様々なSpatial GCNを紹介しました.
次回はAutoencoder, GAN, 強化学習, 動的グラフなど発展的な内容を扱います.参考文献
[1] Z. Zhang et al., Deep Learning on Graphs: A Survey, arXiv, 2018.
本記事は主にこちらの論文をベースにしています. 3本の中で一番わかりやすく感じました.[2] J. Zhou et al., Graph Neural Networks: A Review of Methods and Applications, arXiv, 2018.
[3] Z. Wu et al., A Comprehensive Survey on Graph Neural Networks, arXiv, 2019.
[4] Learning Convolutional Neural Networks for Graphs
PFN秋葉さんによるPATCHY-SANの解説スライドです. WLカーネルの解説もあります.

- 投稿日:2019-02-28T04:40:16+09:00
論文まとめ:GANomaly: Semi-Supervised Anomaly Detection via Adversarial Training
はじめに
GAN を用いた異常検知系の以下の論文
[1] S. Akcay, et. al."GANomaly: Semi-Supervised Anomaly Detection via Adversarial Training"
のまとめACCV 2018で発表された。
http://accv2018.net/wp-content/uploads/pocketprogramweb.pdfarXiv:
https://arxiv.org/abs/1805.06725著者らの GitHub コード:
https://github.com/samet-akcay/ganomaly
PyTorch 使ってます。概要
- 画像から異常検知するモデル
- GAN と auto-encoder を組み合わせたようなアーキテクチャ
- 既存の手法を上回る性能
このモデルを使った異常検出の一例は以下。
X 線を使ってバッグの中に危険物がないか判定する。左3列は正常データ(危険物なし)。この正常データでtrainingする。
右2列は推論時のもの。赤の矩形内に危険物があるが、これらを検出できている。
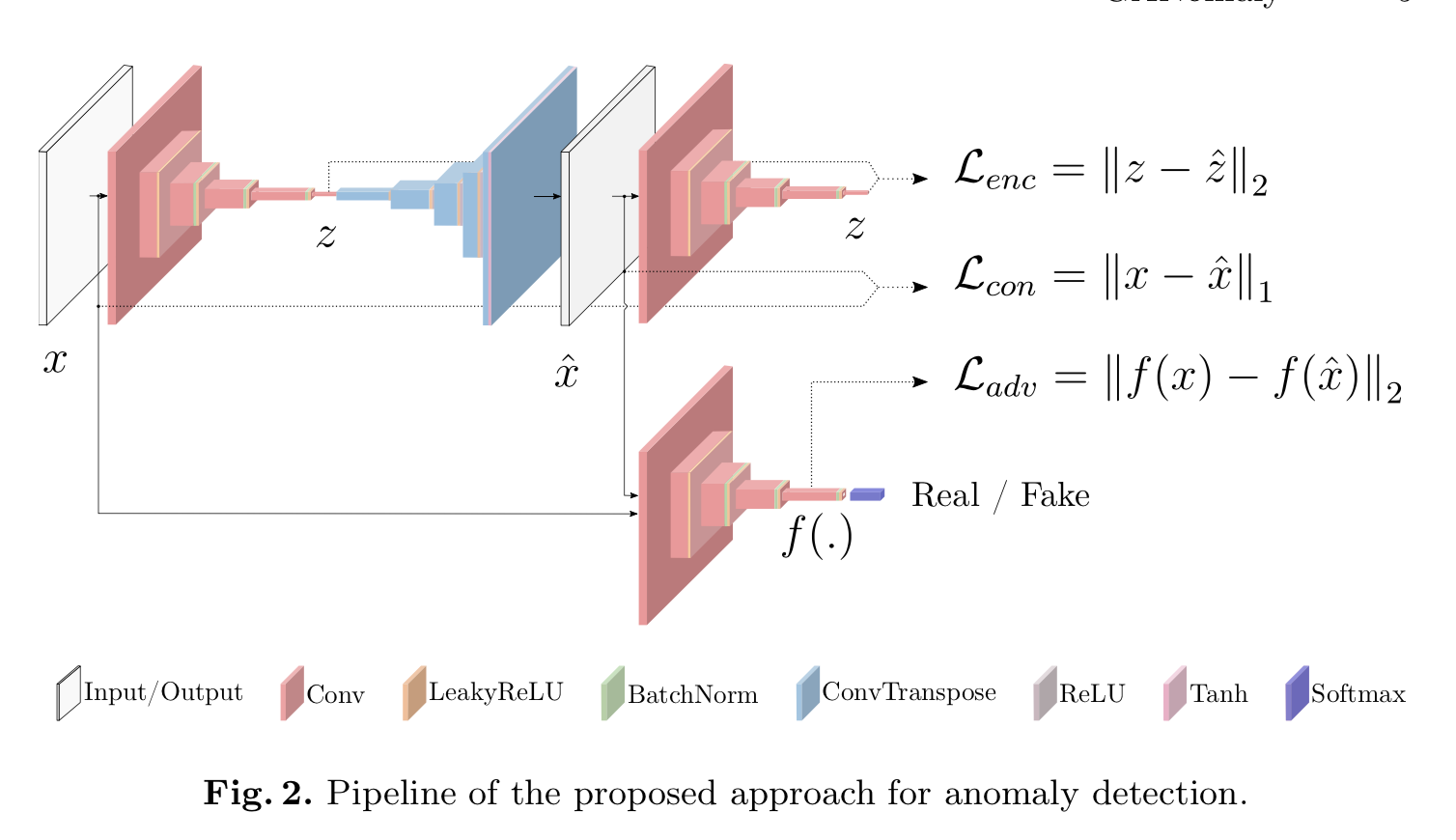
アーキテクチャ
アーキテクチャの概要
アーキテクチャの概要は以下。
左の方は auto-encoder のような構造。その右側にさらに encoder が存在する。
右下は discriminator。
アーキテクチャの詳細
まず左から元画像 $x$ を入力し、encoder して latent space の $z$ となる。
$z$ を decode して再構築画像 $\hat{x}$ となる。再構築画像 $\hat{x}$ をさらに別に用意した encoder に入力し、$\hat{z}$ を得る。
discriminator には元画像 $x$ と再構築画像 $\hat{x}$ を入力し、discriminatorはそれが real(つまり元画像)か fake (つまり再構築画像)かを識別する。
他のモデルとの比較
以下は AnoGAN、Efficient-GAN(EGBADと呼ぶ説もあり)との比較図。
左 A のAnoGANのアーキテクチャはDCGANなどのベーシックなGAN構造をしてる。
中央 B の Efficient-GAN は encoderが加わり、encoder と generator を同時に学習させる。discriminatorには1)real画像 $x$ とそのencodeした $\hat{z}$ のペア、2)$z$ とそれをgeneratorにかけて生成した画像 $\hat{x}$ とのペア、を入力し、それらを区別するよう学習する。
右 C の本モデルは更に encoder が加わっているが、discriminator に入力するのは画像と再構築画像のみ。
目的関数
トータルのロス
トータルのロスは3種類からなる。
\mathcal{L} = w_{adv} \mathcal{L}_{adv} + w_{con} \mathcal{L}_{con} + w_{enc} \mathcal{L}_{enc}$\mathcal{L}_{adv}$ : adversarial loss。
$\mathcal{L}_{con}$ : contextual loss。
$\mathcal{L}_{enc}$ : encoder loss。
adversarial loss
generator はvanilaなGAN のロスではなく、[4]のfeature matching を用いる。つまりdiscriminatorからの中間層の差から求める。discriminatorは?
contexual loss
adversarialなlossによりrealな画像が再構築されるようになるが、それが元画像っぽい保証はない。そこで元画像っぽいものを再構築するよう、両者でL1をとる。
\mathcal{L}_{con} = \mathbb{E}_{x \sim pX} \| x - G(x) \|_1encoder loss
推論時に latent 同士で比較するため、generator の encoder からの出力 $G_E(x)$ と、再構築した画像をさらにもう1つのencoderに入れた時の出力 $E(G(x))$ との L2 をとる。
\mathcal{L}_{enc} = \mathbb{E}_{x \sim pX} \| G_E(x) - E(G(x)) \|_2正常・異常の判定法
こうして学習したモデルにある推論用データ $\hat{x}$ を入力した場合、まず generatorのencoderでlatentに次元削減されるが、そのベクトル $G_E(\hat{x})$ は正常データなら学習データの分布を満たす値、異常データなら分布から外れるような値となる。
その $G_E(\hat{x})$ を generator の decoderに入力し、出てきた再構築画像 $G_D(G_E(\hat{x})) = G(\hat{x})$ は、正常画像ならかなり正確に再現するが、異常画像の場合は異常な部分が再現されず、正常画像っぽいものに変化する。
再構築画像 $G(\hat{x})$ を更にもう1つの encoder に入力すると、いずれも正常データの latentの分布に従うものとなる。
よって、以下のように
\mathcal{A}(\hat{x}) = \| G_E ( \hat{x} ) - E (G( \hat{x})) \|_1$G_E ( \hat{x} )$ と $E (G( \hat{x}))$ との差をとると、正常値は小さくなり、異常値は大きくなるだろう。
実験と結果
MNISTデータ
CIFAR10データ
UBAデータ
FFOBデータ
書きかけ
reference
[2] AnoGAN: T. Schlegl, et. al."Unsupervised Anomaly Detection with Generative Adversarial Networks to Guide Marker Discovery" IPMI 2017
[3] EGBAD:H. Zenati, et. al. "EFFICIENT GAN-BASED ANOMALY DETECTION"
[4] T. Salimans, et. al, "Improved techniques for training gans." NIPs 2016