- 投稿日:2019-02-28T20:56:52+09:00
RailsでDBをMySQLに変更する方法(Ubuntu)
MySQLの設定
MySQLのインストール
以下のコマンドを順に実行。
$ sudo apt update $ sudo apt install mysql-server mysql-clientこれでMySQLのインストールが完了しました。
Railsで使うユーザーの設定
以下を実行しRailsで使うMySQLのユーザー名(user)とパスワード(password)を設定する。Railsには開発環境(development)、テスト環境(test)、本番環境(production)がある。それぞれに対してDBが割り当てられるので3つのユーザーを作るほうが管理が楽だと思う(以下のコマンドでは1人のユーザーを作っている)。
$ sudo mysql -u root -p # パスワードを要求されるが「Enter」をおせばよい mysql> CREATE USER 'user'@'localhost' IDENTIFIED BY 'password';RailsがMySQLにアクセスできるように権限を与える。特定のDBにだけ権限を絞ることができるが、この段階ではDBが生成されていないので制限をかけるのが難しいので、強めの権限を与えることにする。後にRails側の設定が終わってDBが作ってから変更することを推奨する。
GRANT ALL ON *.* TO 'user'@'localhost';Railsの設定
プロジェクトの作成とデーターベースの設定ファイルの編集
Railsのインストールができていない方はこちら。
Rails new -d mysql --skip-bundleを実行することでDBをMySQLに指定してプロジェクトを作ることができる。上記のコマンドを実行したら、以下のようにファイルを編集しよう。config/database.yml# MySQL. Versions 5.1.10 and up are supported. # # Install the MySQL driver # gem install mysql2 # # Ensure the MySQL gem is defined in your Gemfile # gem 'mysql2' # # And be sure to use new-style password hashing: # https://dev.mysql.com/doc/refman/5.7/en/password-hashing.html # default: &default adapter: mysql2 encoding: utf8 pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> username: MySQLで設定したuser password: MySQLで設定したpassword socket: /var/run/mysqld/mysqld.sock host: localhost development: <<: *default database: Math-Dictionary_development # Warning: The database defined as "test" will be erased and # re-generated from your development database when you run "rake". # Do not set this db to the same as development or production. test: <<: *default database: Math-Dictionary_test # As with config/secrets.yml, you never want to store sensitive information, # like your database password, in your source code. If your source code is # ever seen by anyone, they now have access to your database. # # Instead, provide the password as a unix environment variable when you boot # the app. Read http://guides.rubyonrails.org/configuring.html#configuring-a-database # for a full rundown on how to provide these environment variables in a # production deployment. # # On Heroku and other platform providers, you may have a full connection URL # available as an environment variable. For example: # # DATABASE_URL="mysql2://myuser:mypass@localhost/somedatabase" # # You can use this database configuration with: # # production: # url: <%= ENV['DATABASE_URL'] %> # production: <<: *default database: Math-Dictionary_production password: <%= ENV['MATH-DICTIONARY_DATABASE_PASSWORD'] %>※もし、MySQLの設定で3つのユーザーを設定している場合は、それぞれの環境の設定のところに上書きして更新することができる。
bundle install のエラー対処法
次に
bundle installを実行する。ここでAn error occurred while installing mysql2 (0.3.16), and Bundler cannot continue. Make sure that `gem install mysql2 -v '0.3.16' --source 'https://rubygems.org/'` succeeds before bundling.このようなエラーが出る場合はこのエラーメッセージ通り
gem install mysql2 -v '0.3.16'を実行しよう。さらに、これでもエラーが出る場合は、そのエラーメッセージの上部にインストールするべきものがないかを確認しよう。私の場合は、sudo apt-get install libmysqlclient-devを実行せよとなっていた。これでgem install mysql2 -v '0.3.16'が実行できて、無事bundle installすることができた。他にも、bundle config --local build.mysql2 "--with-ldflags=-L/usr/local/opt/openssl/lib --with-cppflags=-I/usr/local/opt/openssl/include"を実行するといける場合もあるらしい(ググって出てきただけ)。実際にデーターベースを作成する
rake db:createこれでDBがMySQLになりました。
- 投稿日:2019-02-28T19:55:34+09:00
ソートしたクエリ同士をUnionしたくて泥沼だった話
条件1でソートしたものと、条件2でソートしたものをユニオンで結合しようとしたらソートが効かずにどっぷりハマりました。
結論から書きますが、ユニオンは内部でソートしても効きません
しかし裏技がありました。
まずは想定ですが、人気の野球選手ベスト三位と、人気のサッカー選手ベスト三位をくっつけたテーブルを取得したいとします。
まずダメな例から書きます.
(select * from baseball_player order by vote DESC limit 3) union (select * from soccer_player order by vote DESC limit 3)まんまとハマったやつです。
上のクエリも下のクエリも独立でなら正しい結果を吐きますが、ユニオン内部だとソートが効かないので、無意味です。そこで裏技!!
結構よくあることなのですが、””テーブルに包む””とうまく行ったりします。
何を言ってるのかわからないと思うが俺にも(ryselect * from ((select * from baseball_player order by vote DESC limit 3)) tbl1 union select * from ((select * from soccer_player order by vote DESC limit 3)) tbl2なぜかこうするとユニオン内にも関わらずソートが効きます。
おそらく、テーブルに直すことで先にその中のクエリを作ってくれるんだと思います。
4 - 2 * 5 = -6
を
(4 - 2) * 5 = 10
に直すようなイメージで、ときどきこうしてテーブルに直すことがあります。SQLの不具合基準ってよくわからないものが多いですよね。
- 投稿日:2019-02-28T19:04:35+09:00
Rails で Web API 開発(Part. 3 DB 関連)
はじめに
本記事は、自身が今までの Ruby on Rails で開発してきた知識 / 知見の総まとめをおこなったものです。
「ここは、もっとこうしたほうがいいよ!こういうものがあるよ!」というようなことがあれば、随時おしらせください!
最終的なプロダクトは、 Rails API Sample に置いておきます。各記事
- Rails で Web API 開発(Part. 1 概要)
- Rails で Web API 開発(Part. 2 Docker 関連)
- Rails で Web API 開発(Part. 3 DB 関連)
- Rails で Web API 開発(Part. 4 CORS 関連)
- Rails で Web API 開発(Part. 5 R(CRUD) の実装)
記事の構成
前回の記事
前回は、Docker 上で開発をするうえでの下準備を行いました。
今回の記事
今回は、前回開発した Docker 上で DB の設定を行い、実際に
curl コマンドが通るところまで行います。次回の記事
次回は、API を実装するうえでかかせない CORS の設定をおこなっていきたいと思います。
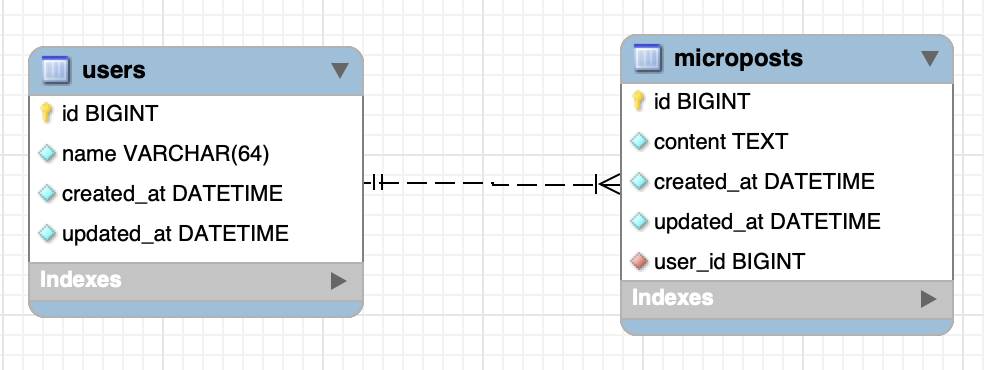
ER 図の作成
MySQL Workbench
ER 図を作成するために、今回は MySQL Workbench を使用します。今回は、使用方法については控えますが(ごにょごにょして)以下のような ER 図を作成しました。(今後、設計図等はリポジトリの docs 配下 に置いておくことにします。)
- DB 名: rails_api_sample
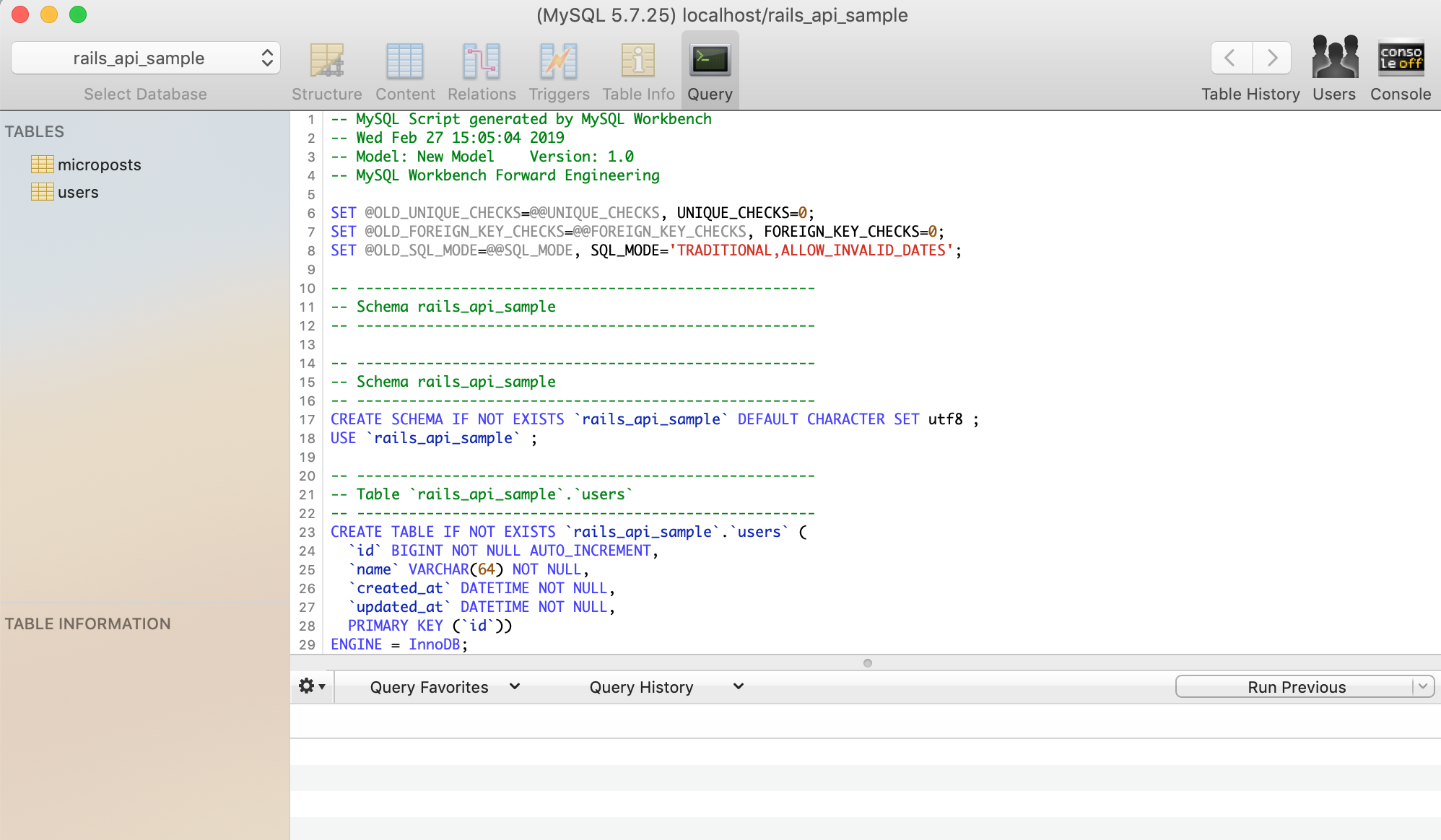
また、MySQL Workbench の機能を利用して、以下のような SQL 文を作成しました。
-- MySQL Script generated by MySQL Workbench -- Wed Feb 27 15:05:04 2019 -- Model: New Model Version: 1.0 -- MySQL Workbench Forward Engineering SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0; SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0; SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='TRADITIONAL,ALLOW_INVALID_DATES'; -- ----------------------------------------------------- -- Schema rails_api_sample -- ----------------------------------------------------- -- ----------------------------------------------------- -- Schema rails_api_sample -- ----------------------------------------------------- CREATE SCHEMA IF NOT EXISTS `rails_api_sample` DEFAULT CHARACTER SET utf8 ; USE `rails_api_sample` ; -- ----------------------------------------------------- -- Table `rails_api_sample`.`users` -- ----------------------------------------------------- CREATE TABLE IF NOT EXISTS `rails_api_sample`.`users` ( `id` BIGINT NOT NULL AUTO_INCREMENT, `name` VARCHAR(64) NOT NULL, `created_at` DATETIME NOT NULL, `updated_at` DATETIME NOT NULL, PRIMARY KEY (`id`)) ENGINE = InnoDB; -- ----------------------------------------------------- -- Table `rails_api_sample`.`microposts` -- ----------------------------------------------------- CREATE TABLE IF NOT EXISTS `rails_api_sample`.`microposts` ( `id` BIGINT NOT NULL AUTO_INCREMENT, `content` TEXT NOT NULL, `created_at` DATETIME NOT NULL, `updated_at` DATETIME NOT NULL, `user_id` BIGINT NOT NULL, PRIMARY KEY (`id`), INDEX `fk_microposts_users_idx` (`user_id` ASC), CONSTRAINT `fk_microposts_users` FOREIGN KEY (`user_id`) REFERENCES `rails_api_sample`.`users` (`id`) ON DELETE NO ACTION ON UPDATE NO ACTION) ENGINE = InnoDB; SET SQL_MODE=@OLD_SQL_MODE; SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS; SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS;テーブルの作成
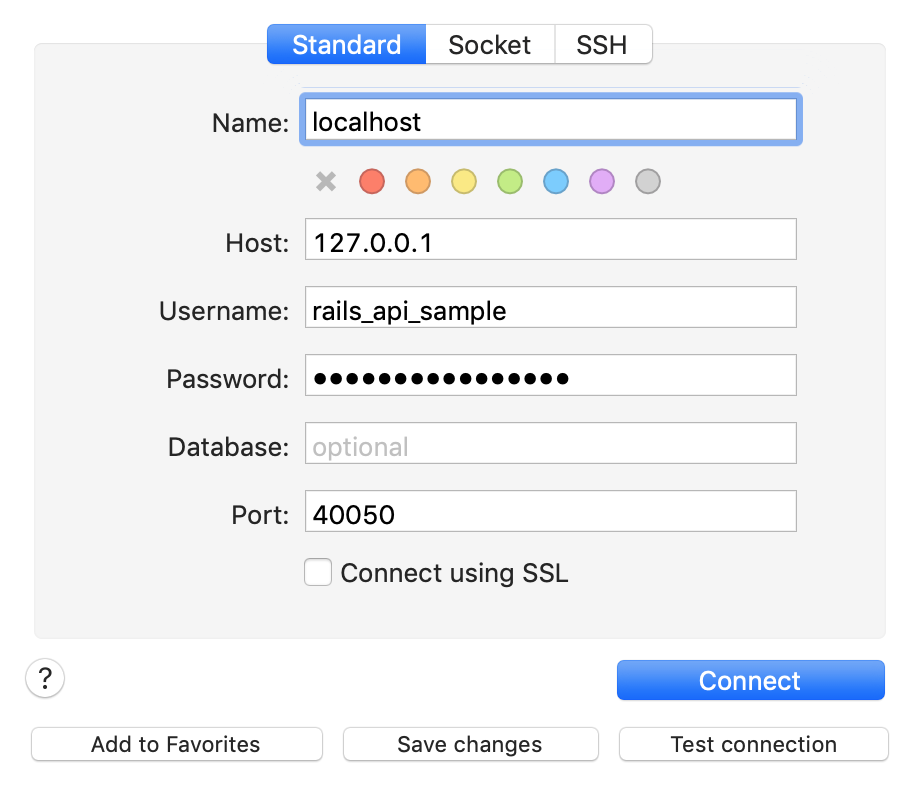
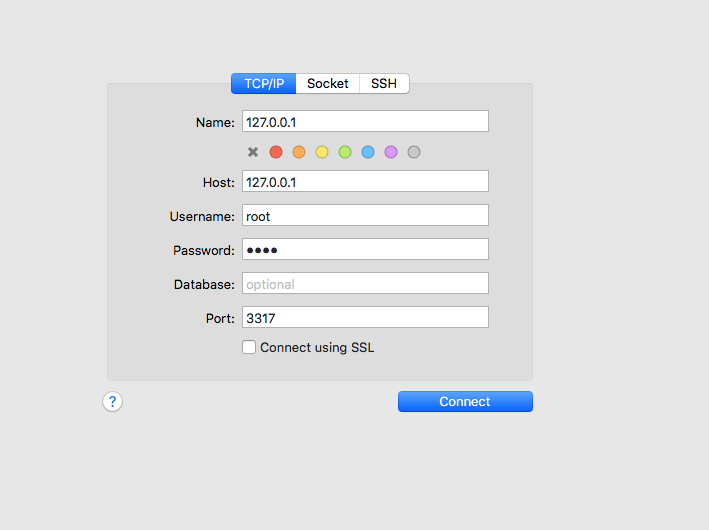
実際に、Docker 上の DB に接続しテーブルを作成していきましょう。今回は、 Sequel Pro という MySQL の可視化ツールを用いたいと思います。
前回の作業をおこなっていれば、以下のような設定で疎通が確認できるはずです。
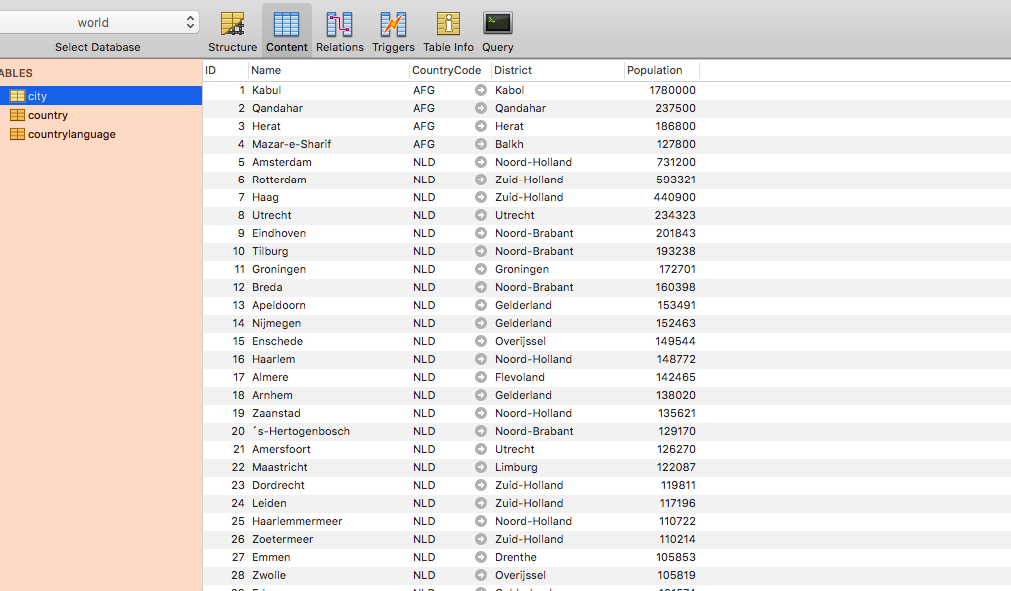
先ほど作成した SQL 文を(Sequel Pro 上で)実際に入力することでテーブルが作成できることが確認できます。
以下は、 SQL 文 入力をし、実行をおこなった後の画面になります。
database.yml の編集
Docker Compose 上で環境変数を流しているために、以下のような設定を行うことで疎通が行えるはずです。
記述した後に、再度$ docker-compose down; docker-compose upを行えば、$ curl localhost:40000で疎通確認が行えるはずです。default: &default adapter: mysql2 encoding: utf8 pool: 5 host: <%= ENV['MYSQL_HOST'] %> username: <%= ENV['MYSQL_USER'] %> password: <%= ENV['MYSQL_PASSWORD'] %> port: <%= ENV['MYSQL_PORT'] %> database: rails_api_sample development: <<: *default test: <<: *default database: rails_api_sample_test production: <<: *defaultMigration の管理
DB というものは、実装をしていくうえでよく変わりうるものです。上記の ER図 を用いて運用上でうまい感じにやっていくというのもできないこともないですが、ちょっと面倒です。
今回、Migration の管理を行うために、 Ridgepole という gem を扱います。最初の Gemfile に記述済みですので、今回新しくインストールのために何かやる必要はないです。Ridgepole タスクの作成
Ridgepole を扱うための Rake タスクを作成してきましょう。今回は、以下のようなファイルを作成します。
若干コメント文にもありますが 既存の DB から Schemafile を作成することと、またその逆ができるようになります。# (lib/tasks/ridgepole.rake) # Schema -> DB # ./bin/bundle exec rails ridgepole:apply "env" # # ex) ./bin/bundle exec rails ridgepole:apply RAILS_ENV=development # # DB -> Schema # ./bin/bundle exec rails ridgepole:export "env" # # ex) ./bin/bundle exec rails ridgepole:export RAILS_ENV=development namespace :ridgepole do task export: :environment do options = [ '--export', '--split', "--output #{schemafile_path}" ] exec_ridgepole(options) end task apply: :environment do options = [ '--apply', "--file #{schemafile_path}" ] exec_ridgepole(options) end def exec_ridgepole(options) yml_file_path = Rails.root.join('config', 'database.yml') default_options = [ "--env #{Rails.env}", "--config #{yml_file_path}" ] sh("bundle exec ridgepole #{default_options.join(' ')} #{options.join(' ')}") end def schemafile_path Rails.root.join('db', 'schemas', 'Schemafile') end end既存の DB から Schemafile を作成 / 更新
以下のコマンドを実行することで、DB の作成 / 更新を行えるようになっているはずです。作成された Schemafile は、 db/schemas に保存されているはずです。
$ docker-compose run --rm app ./bin/bundle exec rails ridgepole:export RAILS_ENV=development既存の Schemafile から テーブル を作成 / 更新
以下のコマンドを実行することで、テーブルの作成 / 更新を行えるようになっているはずです。
$ docker-compose run --rm app ./bin/bundle exec rails ridgepole:apply RAILS_ENV=developmentおわりに
今回は、DB 周りのことに関してお話しました。次回は、Rails で Web API 開発(Part. 4 CORS 関連)を行います。
- 投稿日:2019-02-28T19:04:13+09:00
Rails で Web API 開発(Part. 2 Docker 関連)
はじめに
本記事は、自身が今までの Ruby on Rails で開発してきた知識 / 知見の総まとめをおこなったものです。
「ここは、もっとこうしたほうがいいよ!こういうものがあるよ!」というようなことがあれば、随時おしらせください!
最終的なプロダクトは、 Rails API Sample に置いておきます。各記事
- Rails で Web API 開発(Part. 1 概要)
- Rails で Web API 開発(Part. 2 Docker 関連)
- Rails で Web API 開発(Part. 3 DB 関連)
- Rails で Web API 開発(Part. 4 CORS 関連)
- Rails で Web API 開発(Part. 5 R(CRUD) の実装)
記事の構成
前回の記事
前回は、Mac 上でとりあえず
$ rails serverが動くところまでやりました。今回の記事
今回は、Docker Container 上で
$ rails serverが動くようにします。次回の記事
次回は、しっかりと DB 部分の実装をおこなっていきます。
各種 Docker ファイルの作成
docker-compose.yaml の作成
以下のような docker-compose.yaml を作成します。
version: '3' services: db: image: mysql:5.7 volumes: - db_data:/var/lib/mysql ports: - "40050:3306" restart: always # 環境変数は、Docker 上から流すことにします。 environment: TZ: "Asia/Tokyo" MYSQL_ROOT_PASSWORD: rails_api_sample MYSQL_DATABASE: rails_api_sample MYSQL_USER: rails_api_sample MYSQL_PASSWORD: rails_api_sample app: build: . volumes: - .:/rails_api_sample depends_on: - db ports: - "40000:3000" tty: true stdin_open: true # 環境変数は、Docker 上から流すことにします。 environment: TZ: "Asia/Tokyo" MYSQL_HOST: db MYSQL_DB: rails_api_sample MYSQL_PORT: 3306 MYSQL_USER: rails_api_sample MYSQL_PASSWORD: rails_api_sample volumes: db_data: {}Dockerfile の作成
以下のような Dockerfile を作成します。
FROM ruby:2.6.1 RUN mkdir -p /rails_api_sample WORKDIR /rails_api_sample RUN apt-get update -qq && \ apt-get install -y build-essential mysql-client nodejs tzdata COPY Gemfile* /rails_api_sample/ RUN mkdir -p /rails_api_sample/bin COPY bin/* /rails_api_sample/bin/ RUN ./bin/bundle install --path vendor/bundle COPY . /rails_api_sample # Add a script to be executed every time the container starts. COPY entrypoint.sh /usr/bin/ RUN chmod +x /usr/bin/entrypoint.sh ENTRYPOINT ["entrypoint.sh"] EXPOSE 3000 CMD ["./bin/bundle", "exec", "rails", "server", "-p", "3000", "-b", "0.0.0.0", "-e", "development"]Docker 上で rails server
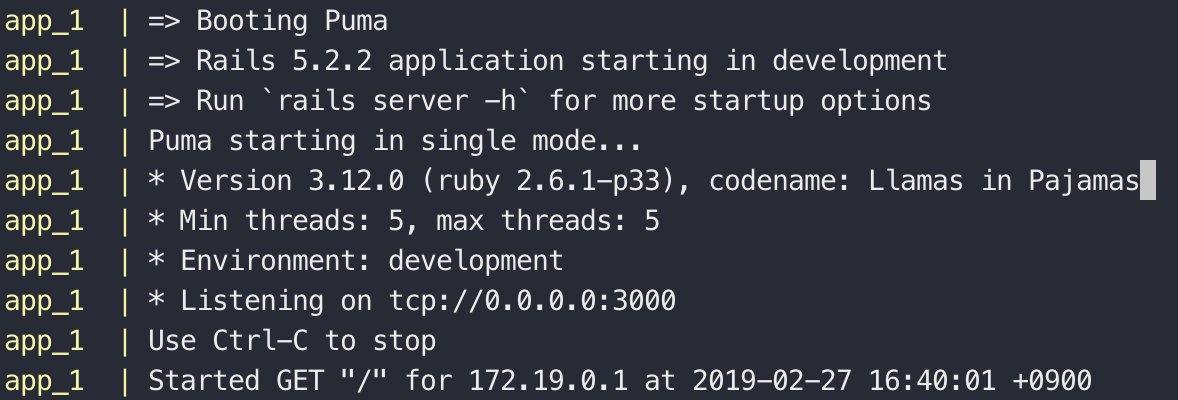
docker-compose up
以下のコマンドを実行します。
$ docker-compose build次に、以下のコマンドを実行します。
$ docker-compose run --rm app ./bin/bundle install --path vendor/bundle最後に、以下のコマンドを実行します。
$ docker-compose up以下のようになったら、とりあえず完了です!( curl コマンド 等で確認してもおそらく DB 周りの設定ができていないのでちゃんとはかえってこないです…。)
各種コマンド
覚えておいたほうがよいコマンドに関して少しだけ記述しておきます。
$ docker-compose up: docker-compose を起動します。
$ docker-compose down: docker-compose を停止します。
$ docker-compose run --rm ${SERVICE_NAME} ${COMMAND}: ${SERVICE_NAME} 内で、指定のコマンドを実行します。 ex)$ docker-compose run --rm app bash
$ docker attach ${CONTAINER_NAME}: ${CONTAINER_NAME} 内に、入れます。次の例では、binding.pry等を実行する際によく使います。 ex)$ docker attach rails_api_sample_appおわりに
まだまだ DB 関連が整っていないです…。次回は、Rails で Web API 開発(Part. 3 DB 関連)を行います。
- 投稿日:2019-02-28T19:03:46+09:00
Rails で Web API 開発(Part. 1 概要)
はじめに
現在、執筆中です。
本記事は、自身が今までの Ruby on Rails で開発してきた知識 / 知見の総まとめをおこなったものです。
「ここは、もっとこうしたほうがいいよ!こういうものがあるよ!」というようなことがあれば、随時おしらせください!
最終的なプロダクトは、 Rails API Sample に置いておきます。対象
- Mac での開発者
- ある程度 Rails / Docker の知識があるとよいかな…。と
各記事
- Rails で Web API 開発(Part. 1 概要)
- Rails で Web API 開発(Part. 2 Docker 関連)
- Rails で Web API 開発(Part. 3 DB 関連)
- Rails で Web API 開発(Part. 4 CORS 関連)
- Rails で Web API 開発(Part. 5 R(CRUD) の実装)
記事の構成
今回の記事
今回は、全体の記事について記述します。また、とりあえずローカルで
$ rails serverコマンドが動くところまで記述します。次回の記事
Docker を用いた開発を行う上での下準備をおこなっていきます。
主に扱うもの
- Ruby(ver. 2.6.1) + Ruby on Rails(ver. 5.2.2)
- Docker + Docker-Compose(コンテナ 関連)
- MySQL + MySQL Workbench + Sequel Pro + Ridgepole (DB 関連)
- Rspec + Factory Girl + Shoulda Matcher(テスト 関連)
Rails プロジェクトの作成
Version
先述のとおり、Ruby / Ruby on Rails の各 Version は、以下の通りです。
rails new
以下のコマンドを実行しましょう。( DBには、MySQL を使用し 、 API モードで 、 Minitest は使わない ようにするオプション。)
$ rails new rails_api_sample --database=mysql --api -T
$ cd rails_api_sampleGemfile の編集
今回扱う Gemfile は、以下のようにしています。
source 'https://rubygems.org' git_source(:github) { |repo| "https://github.com/#{repo}.git" } ruby '2.6.1' gem 'rails', '5.2.2' # DB(MySQL) の設定に必要な gem gem 'mysql2' # JSON の管理に必要な gem gem 'jbuilder' # 'rails server' 起動時に必要な gem gem 'bootsnap', require: false gem 'puma' # CORS の設定に必要な gem gem 'rack-cors' # Migration の管理に必要な gem gem 'ridgepole' # Trailblazer を扱うのに必要な gem gem 'reform-rails' gem 'trailblazer-loader' gem 'trailblazer-rails' group :development, :test do # 便利コマンド 'binding.pry' を使用するのに必要な gem gem 'pry-byebug' gem 'pry-doc' gem 'pry-rails' # ソースコードが綺麗かどうか Check する gem gem 'rubocop' end group :development do # ファイルの変更を監視する gem gem 'listen' # 起動を早くするために必要な gem gem 'spring' gem 'spring-watcher-listen' end group :test do # TEST 用 DB の管理をする gem gem 'database_rewinder' # TEST 用 データの管理をする gem gem 'factory_bot_rails' gem 'faker' # Rspec で TEST をするために必要な gem gem 'rspec-json_matcher' gem 'rspec-rails' gem 'rspec_junit_formatter' # モデルの関連を TEST するために必要な gem gem 'shoulda-matchers' endbundle install
以下のコマンドを実行しましょう。( vendor/bundle 配下にインストール するオプション。)
$ bundle install --path vendor/bundlerails server
以下のコマンドを実行しましょう。( $ rails s は $ rails server の省略コマンド。 -p はポート指定。-b はIP Address指定。-e は環境指定。)
$ bundle exec rails s -p 3000 -b '127.0.0.1' -e 'development'以下のようになったら、とりあえず完了です!( curl コマンド 等で確認してもおそらく DB 周りの設定ができていないのでちゃんとはかえってこないです…。)
おわりに
今回は、とりあえず
$ rails serverコマンドまでを行いました。次回は、Rails で Web API 開発(Part. 2 Docker 関連)を行います。

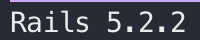
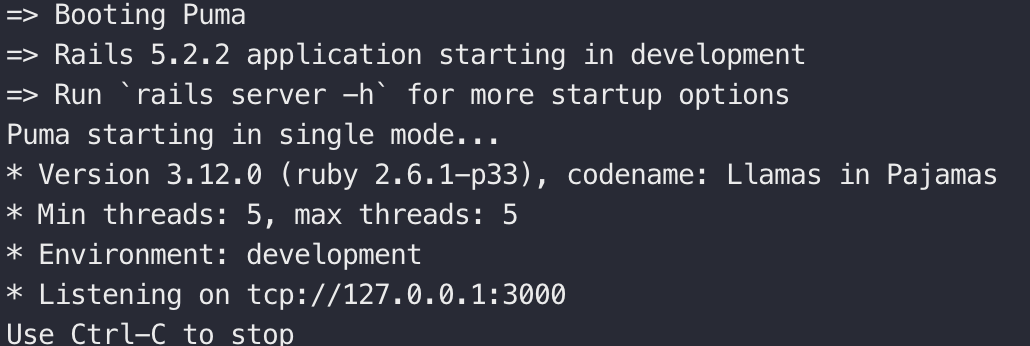
- 投稿日:2019-02-28T10:04:14+09:00
Laravel で外部キー制約の onDelete / onUpdate をマイグレーション後に設定する + 論理削除でハマったこと
やりたいこと
CompanyとEmployeeのように親子関係にあるテーブルを作成employeeテーブルにcompany_idという外部キーを設定- その後、
onDeleteonUpdateに対する挙動を設定し忘れたことに気づいたので後から設定をしたいマイグレーションファイル
- companies
timestamp_create_companies_table.phpclass CreateCompanyTable extends Migration { /** * Run the migrations. * * @return void */ public function up() { Schema::create('companies', function (Blueprint $table) { $table->increments('id'); $table->string('name'); $table->timestamps(); $table->softDeletes(); }); } /** * Reverse the migrations. * * @return void */ public function down() { Schema::dropIfExists('company'); } }
- employee
timestamp_create_employee_table.phpclass CreateEmployeeTable extends Migration { /** * Run the migrations. * * @return void */ public function up() { Schema::create('employee', function (Blueprint $table) { $table->increments('id'); $table->string('name')->nullable(); $table->integer('company_id')->unsigned(); $table->foreign('company_id')->references('id')->on('companies'); $table->timestamps(); $table->softDeletes(); }); } /** * Reverse the migrations. * * @return void */ public function down() { Schema::dropIfExists('employee'); } }マイグレーションは問題なくて、その後も色々なテーブルを追加していった後、onDelete / onUpdate の設定ができていないことに気づいて、「全部ロールバックするのも気が重いし、一部分だけ弄れないかな…」と逡巡して以下の方法を取った。
やったこと
あまりお行儀がよくないかもしれないが、
employeeテーブルのcompany_idだけを drop するマイグレーションファイルを作り、php artisan migrateを実行。
その後外部キー制約を再設定するマイグレーションファイルを作って、同様にphp artisan migrate。
- 外部キーを一旦Drop
timestamp_drop_foreign_key_from_employee.phpclass DropForeignKeyFromEmployee extends Migration { /** * Run the migrations. * * @return void */ public function up() { //外部キー制約を引き剥がす時は dropForeign('テーブル名'_'外部キー名'_foreign); Schema::table('employee', function (Blueprint $table) { $table->dropForeign('employee_company_id_foreign'); }); } }timestamp_reset_foreign_key_to_employee.phppublic function up() { //子テーブルに対象レコードがある場合、親テーブルのレコード削除を禁止 ->onDelete('restrict'); //親テーブルのレコード更新は許可 ->onUpdate('cascade'); Schema::table('employee', function (Blueprint $table) { $table->index('company_id'); $table->foreign('company_id')->references('id')->on('companies') ->onDelete('restrict') ->onUpdate('cascade'); }); } /** * Reverse the migrations. * * @return void */ public function down() { Schema::table('employee', function (Blueprint $table) { $table->dropForeign('employee_company_id_foreign'); }); }問題点
このやり方だとロールバックした時に
DropForeignKeyFromEmployeeエラーで怒られる。なので、最初からなるべくテーブル作成時に onDelete / onUpdate の条件は慎重に考えて設定した方がいい。うまく後付けで設定できる方法があればコメントで教えていただきたいです。個人的に思いつくのがMySQLのコマンドで直接テーブルを書き換える手段だけなので…その他ハマったこと
onDelete('restrict')を設定したあと、Laravel アプリケーションからCompany::destroyで実際に削除を試してみたところ、なんと制約に引っかからず普通に削除できてしまった…
どうやらuse SoftDeleteで論理削除をさせている場合、物理削除と違ってdeleted_atにタイムスタンプを書き込むだけなので制約をすり抜けてしまうらしい…。早めに知っておきたかった。
- 投稿日:2019-02-28T02:42:35+09:00
CentOS7にMySQLをインストール
▼記事を書いた経緯
1.ConoHA VPSを借りてブログを作りたい。
2.ConoHA VPSのSSHセキュリティ設定は完了した。
3.ブログ記事のデータ保存の為にMySQLをCentOSに設定したい。3のCentOSにMySQLを設定する際に少し躓いたので、同じく悩んだ方がスムーズに進めるように残しました。
書いている私も至らない点が多いと思いますので、誤記がありましたらご指摘いただけると幸いです。▼参考サイト
https://support.conoha.jp/v/setupmysql/
https://qiita.com/ritukiii/items/f4e2fbae5d6e7b1aa5f91.MySQLのインストール
CentOSには標準のMariaDBが入っていて、そのままSQLをインストールすると競合する
▼MariaDBとデータフォルダを削除しておく
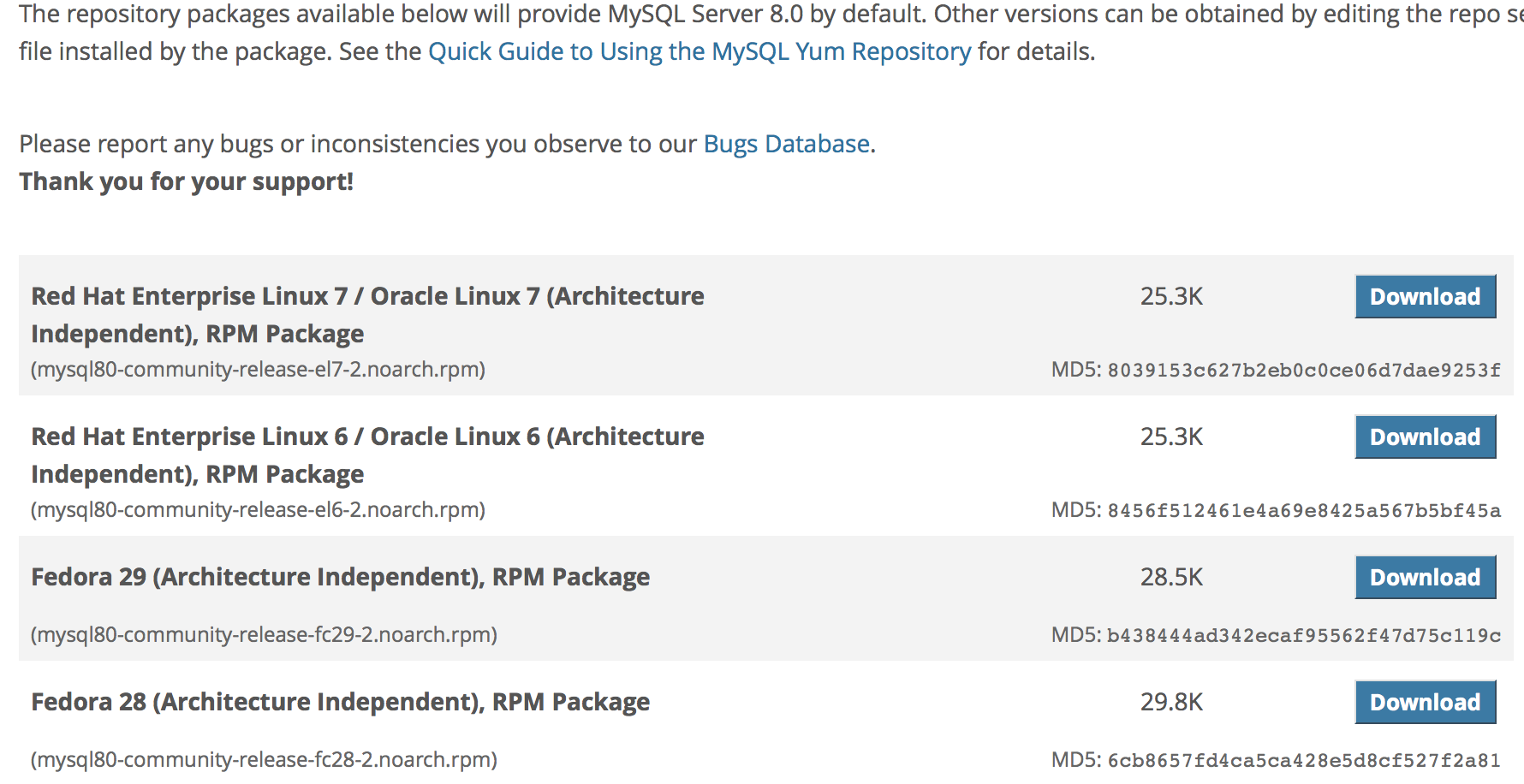
$ sudo yum remove mariadb-libs $ sudo rm -rf /var/lib/mysqlMySQLのダウンロードページを開いてOSのバージョンが同じものをダウンロード
▼CentOSのバージョンの確認は以下で
$ cat /etc/redhat-release CentOS Linux release 7.6.1810 (Core)▼'No thanks,just start my download.'を右クリックしリンクをコピー選択
$ yum install https://dev.mysql.com/get/mysql80-community-release-el7-2.noarch.rpm最後に
Complete!と出ればMySQLインストール完了MySQLの追加が完了すると
mysql-community-serverというパッケージを追加することが出来る$ yum -y install mysql-community-server最後に
Complete!と出ればパッケージの追加も完了▼MySQLの自動起動
#OSの起動時にMySQLも起動することが出来ます $ systemctl enable mysqld.service #今回限りMySQLをスタートさせる為に使います。(次回からは不要) $ systemctl start mysqld.serviceコンソール上は何も表示されませんがこれで自動起動設定完了です
まとめ
・CentOSには標準にMariaDBが付いているため、別のDBを入れる際は削除する(競合してしまうため)
・CentOS7からは起動処理の仕組みが違うためsystemctlを使う。
- 投稿日:2019-02-28T01:46:00+09:00
MySQL8でMySQL10本ノックを解いてみる!
はじめに
皆さん、どうもです。k.s.ロジャースのやすもんです。
前回の記事 MySQL10本ノック作ってみた! が想像以上に好評だったので、その続きでmysql8版を書いてみます!
docker使って動かすところからおこない
前回の MySQL10本ノック作ってみた! からMySQL8で記述方式が変わる設問を参照し、参考回答を記述していこうと思いますDockerでMySQL8環境構築
Dockerのインストールなどは割愛します
適当にworkフォルダ作成して準備します$ mkdir sand_box $ cd sand_box $ mkdir mysql8 $ cd mysql8 $ mkdir volumesdocker-compose.ymlを作成します
version: '2' services: db: image: mysql:latest container_name: mysql8 command: --default-authentication-plugin=mysql_native_password restart: always environment: MYSQL_ROOT_PASSWORD: hoge ports: - "3317:3306" volumes: - $PWD/volumes:/var/lib/mysqldocker-composeでたち上げます
$ docker compose up -d $ docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES cc448a369afb mysql:latest "docker-entrypoint.s…" 11 hours ago Up 11 hours 33060/tcp, 0.0.0.0:3317->3306/tcp mysql8SequelProをMySQL8に対応させる
アプリケーションの中にあるSequelProを適当にリネーム
以下のコマンドでSequelProのnightlyバージョンをインストール
$ brew cask install homebrew/cask-versions/sequel-pro-nightly
nightlyバージョンのSequelProを起動して、先程dockerで立ち上げたMySQL8に接続
前回の 事前準備 を元にサンプルデータをダウンロードし、DBにimportする
※不安定?なのか調べていたらSequelProのnightlyバージョンでもMySQL8動かないという記事もチラホラあったので、これで動かない場合はコメント下さい!(解決できるかはわかりませんが。。。)
問題
前回の問題 1~4本はMySQL8でも記述方式変わらないので、飛ばします
5本目
cityテーブルにてCountryCodeごとにPopulationの平均値を算出し、countryテーブルと結合、国名・大陸・平均Populationを表示せよ
また、上記の内容をwith句を用いて実現せよ6本目
cityテーブルにてCountryCodeごとにPopulationの平均値を算出した結果と、countryテーブルにてGNPとGNPOldを比較し、大きい値の方をGNP_bigとしてカラムに格納した結果を結合し、国名・大陸・平均Population・GNPBigを表示せよ
また、上記の内容をwith句を用いて実現せよ7本目
6本目の結果に対して、continent_nameで集約を行いavg_populationの最大値が10万以上、GNP_bigの平均値が10万以上の結果を抽出して表示せよ
また、上記の内容をwith句を用いて実現せよ8本目
countryテーブルにidを振りcoutry_with_idテーブルを作成
その後、cityとcoutrylanguageのテーブルのCountryCodeカラムを↑で付与したidに更新せよ
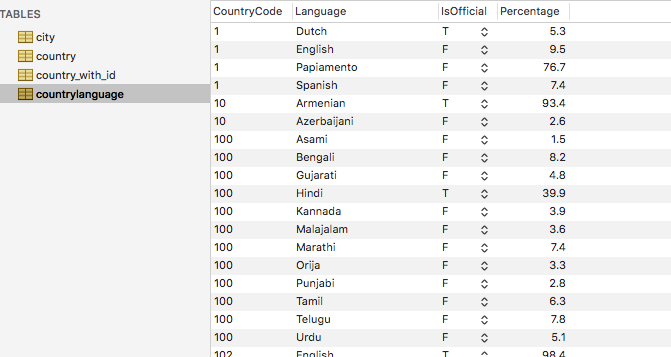
また、idははwindow関数を用いて付与せよ9本目
countrylanguageテーブルにてPercentageにランキングを付与せよ
また、上記のランキングをwindow関数を用いて付与せよ10本目
9本目のSQLを参考にして
countrylanguageテーブルにてCountryCode単位で最もPercentageが高い言語をcountry_with_idテーブルに結合し
cityテーブルにてCountryCode単位で最もPopulationが高いシティをcountry_with_idテーブルに結合
その後、PercentageとPopulationをキーに降順でソートせよ
また、上記のランキングをwindow関数を用いて付与し、with句を用いて実現せよ正解
前回の問題 1~4本はMySQL8でも記述方式変わらないので、飛ばします
5本目
問題
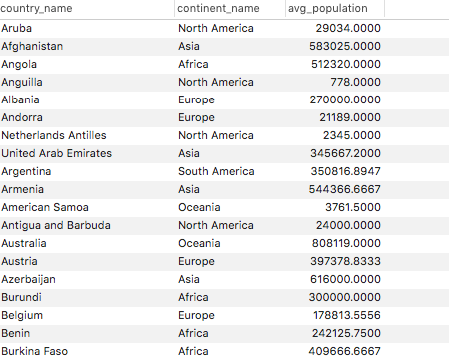
cityテーブルにてCountryCodeごとにPopulationの平均値を算出し、countryテーブルと結合、国名・大陸・平均Populationを表示せよ
また、上記の内容をwith句を用いて実現せよ解説
MySQL8の新機能のひとつwith句です!
HQLやBigQueryなどでは当然のように使えるこの機能ですが、MySQLでは最近まで使えませんでした。。。
挙動的にはWITHで書かれた部分が最初に実行されテンポラリテーブルとしてメモリに保存され、別のfrom句で利用できるという形です
良い点としては、viewでwith句を使う場合はメモリに結果を保持するので、再度クエリを回したときにDBへの問い合わせが発生しないです。副問合せの場合は毎回問い合わせする感じですね。そして、何より可読性が高い!
悪い点としては、メモリリソースを消費するので、めちゃくちゃでかいデータを処理する場合にはメモリ枯渇に気をつけないといけません。ということもあり、Hadoopなどは副問合せを使われることが多いですね。前回の回答例
select country.name as country_name , country.Continent as continent_name , city_calc.avg_population as avg_population from ( select CountryCode, avg(Population) as avg_population from city group by CountryCode ) as city_calc left join country on city_calc.CountryCode = country.Code ;今回の回答例
WITH city_calc (CountryCode, avg_population) AS ( select CountryCode, avg(Population) as avg_population from city group by CountryCode ) select country.name as country_name , country.Continent as continent_name , city_calc.avg_population as avg_population from city_calc left join country on city_calc.CountryCode = country.Code ;結果
6本目
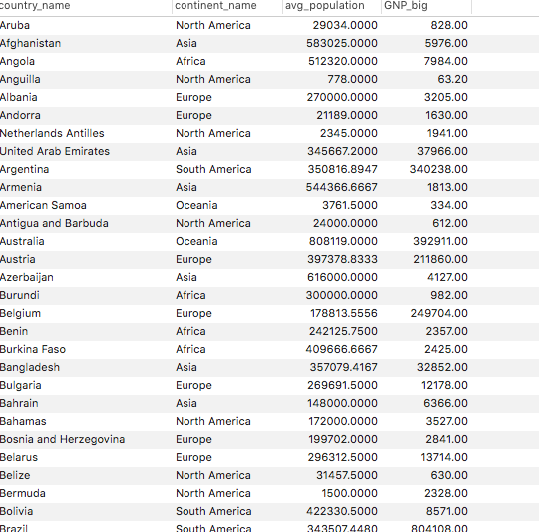
問題
cityテーブルにてCountryCodeごとにPopulationの平均値を算出した結果と、countryテーブルにてGNPとGNPOldを比較し、大きい値の方をGNP_bigとしてカラムに格納した結果を結合し、国名・大陸・平均Population・GNPBigを表示せよ
また、上記の内容をwith句を用いて実現せよ解説
5本目と同様にwith句を使い、わかりやすく記述します
with句が複数あってもカンマでつなげるだけです。めちゃめちゃ簡単!前回の回答例
select country_calc.name as country_name , country_calc.Continent as continent_name , city_calc.avg_population as avg_population , country_calc.GNP_big as GNP_big from ( select CountryCode, avg(Population) as avg_population from city group by CountryCode ) as city_calc left join ( select Code , Name , Continent , case when GNP >= GNPOld then GNP when GNP < GNPOld then GNPOld when GNPOld is null then GNP else null end as GNP_big from country ) as country_calc on city_calc.CountryCode = country_calc.Code ;今回の回答例
WITH city_calc (CountryCode, avg_population) AS ( select CountryCode, avg(Population) as avg_population from city group by CountryCode ), country_calc (Code, Name, Continent, GNP_big) AS ( select Code , Name , Continent , case when GNP >= GNPOld then GNP when GNP < GNPOld then GNPOld when GNPOld is null then GNP else null end as GNP_big from country ) select country_calc.name as country_name , country_calc.Continent as continent_name , city_calc.avg_population as avg_population , country_calc.GNP_big as GNP_big from city_calc left join country_calc on city_calc.CountryCode = country_calc.Code ;結果
7本目
問題
6本目の結果に対して、continent_nameで集約を行いavg_populationの最大値が10万以上、GNP_bigの平均値が10万以上の結果を抽出して表示せよ
また、上記の内容をwith句を用いて実現せよ解説
6本目とほぼ同じです
ちなみに、with句の実行順序も通常のSQLと同じです
from→join→where→group by→sumなど→having→select→order by→limit前回の回答例
select country_calc.Continent as continent_name , max(city_calc.avg_population) as max_avg_population , avg(country_calc.GNP_big) as avg_GNP_big from ( select CountryCode, avg(Population) as avg_population from city group by CountryCode ) as city_calc left join ( select Code , Name , Continent , case when GNP >= GNPOld then GNP when GNP < GNPOld then GNPOld when GNPOld is null then GNP else null end as GNP_big from country ) as country_calc on city_calc.CountryCode = country_calc.Code group by country_calc.Continent having max_avg_population >= 100000 and avg_GNP_big >= 100000 ;今回の回答例
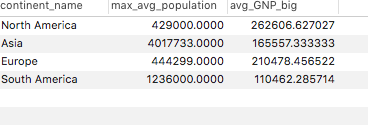
WITH city_calc (CountryCode, avg_population) AS ( select CountryCode, avg(Population) as avg_population from city group by CountryCode ), country_calc (Code, Name, Continent, GNP_big) AS ( select Code , Name , Continent , case when GNP >= GNPOld then GNP when GNP < GNPOld then GNPOld when GNPOld is null then GNP else null end as GNP_big from country ) select country_calc.Continent as continent_name , max(city_calc.avg_population) as max_avg_population , avg(country_calc.GNP_big) as avg_GNP_big from city_calc left join country_calc on city_calc.CountryCode = country_calc.Code group by country_calc.Continent having max_avg_population >= 100000 and avg_GNP_big >= 100000 ;結果
8本目
問題
countryテーブルにidを振りcoutry_with_idテーブルを作成
その後、cityとcoutrylanguageのテーブルのCountryCodeカラムを↑で付与したidに更新せよ
また、idははwindow関数を用いて付与せよ解説
MySQLの新機能window関数です!
こちらも、HQLやBigQueryなどでは当然のように使える関数ですが、MySQLでは最近まで使えませんでした。。。
以前、書いたrow_numberをふるSQLが1行でかけちゃいます。感激!前回の回答例
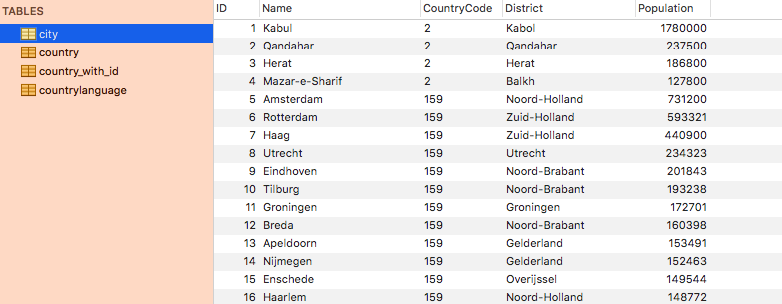
set @id:=0; create table country_with_id as ( select *, @id:=@id+1 as id from country ); update country_with_id as t1, city as t2 set t2.CountryCode = t1.id where t1.Code = t2.CountryCode ; update country_with_id as t1, countrylanguage as t2 set t2.CountryCode = t1.id where t1.Code = t2.CountryCode ;今回の回答例
create table country_with_id as ( select * , row_number() over () as id from country ); update country_with_id as t1, city as t2 set t2.CountryCode = t1.id where t1.Code = t2.CountryCode ; update country_with_id as t1, countrylanguage as t2 set t2.CountryCode = t1.id where t1.Code = t2.CountryCode ;結果
9本目
問題
countrylanguageテーブルにてPercentageにランキングを付与せよ
また、上記のランキングをwindow関数を用いて付与せよ解説
こちらも、window関数の
rank()を用いることで、鬼のように簡単に書くことができます
ちなみに、window関数一覧は以下のような感じです
rank、lag、lead、fist_value、row_numberはよく使いますね
- CUME_DIST():累積分布値
- DENSE_RANK():そのパーティション内の現在の行のランク(順位が飛ばされない)
- FIRST_VALUE():ウィンドウフレームの最初の値を取得
- LAG():パーティション内の現在の行の次の値
- LAST_VALUE():ウィンドウフレームの最後の値を取得
- LEAD():パーティション内の現在の行の前の値
- NTH_VALUE():ウィンドウ枠のN番目の行の値を取得
- NTILE():パーティション内でバケット分割を行う
- PERCENT_RANK():パーセントランクを計算して表示
- RANK():パーティション内の現在の行のランクを取得
- ROW_NUMBER():パーティション内の現在の行の数を取得
partition byはいわゆるgroup byみたいなものですね
order byはwindow内の並び順を意味しています前回の回答例
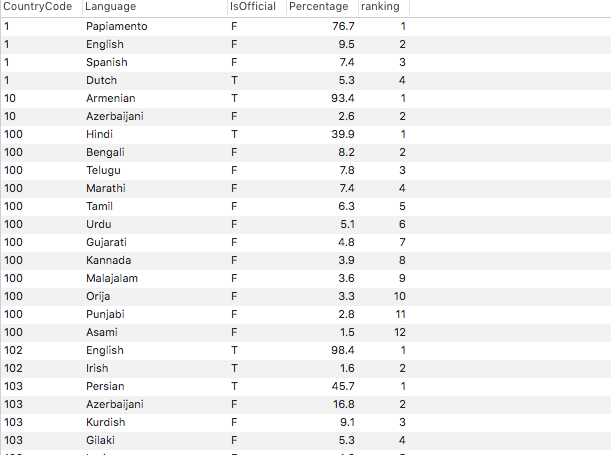
set @no:=0; set @groupid:=null; select * , if(@groupid <> CountryCode, @no:=1, @no:=@no+1) as rank , @groupid:=CountryCode from countrylanguage order by CountryCode, Percentage DESC ;今回の回答例
select * , rank() over (partition by CountryCode order by CountryCode, Percentage desc) as ranking from countrylanguage結果
10本目
問題
9本目のSQLを参考にして
countrylanguageテーブルにてCountryCode単位で最もPercentageが高い言語をcountry_with_idテーブルに結合し
cityテーブルにてCountryCode単位で最もPopulationが高いシティをcountry_with_idテーブルに結合
その後、PercentageとPopulationをキーに降順でソートせよ
また、上記のランキングをwindow関数を用いて付与し、with句を用いて実現せよ解説
もちろん、with句の中で別のwith句で実行した内容をfrom句で呼び出せます
前回のSQLよりとても可読性が上がってると思います前回の回答例
set @city_no:=0; set @city_groupid:=null; set @language_no:=0; set @language_groupid:=null; select Code, Name, Continent, Language as popular_language, city_name as popular_city from country_with_id left join ( select CountryCode, Language, Percentage from ( select * , if(@language_groupid <> CountryCode, @language_no:=1, @language_no:=@language_no+1) as rank , @language_groupid:=CountryCode from countrylanguage order by CountryCode, Percentage DESC ) as lang_calc where rank = 1 ) as lang_rank1 on lang_rank1.CountryCode = country_with_id.id left join ( select CountryCode, Name as city_name, Population from ( select * , if(@city_groupid <> CountryCode, @city_no:=1, @city_no:=@city_no+1) as rank , @city_groupid:=CountryCode from city order by CountryCode, Population DESC ) as city_calc where rank = 1 ) as city_rank1 on city_rank1.CountryCode = country_with_id.id ;今回の回答例
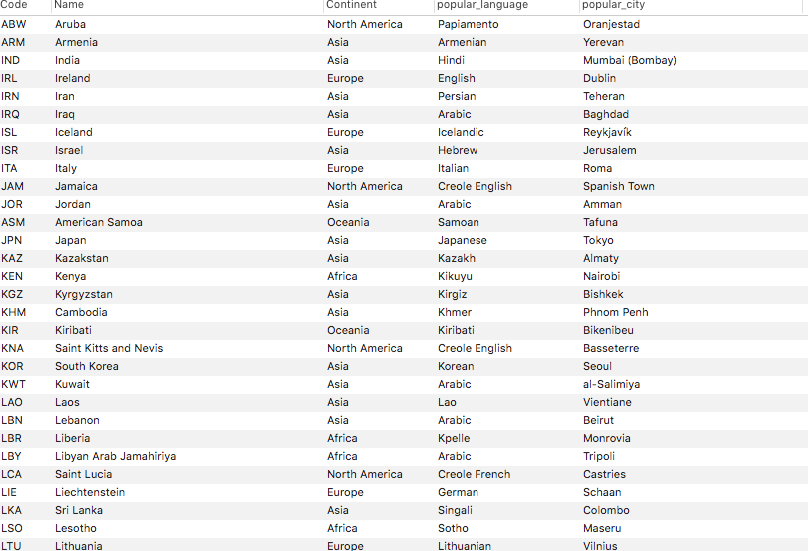
WITH lang_calc AS ( select * , rank() over (partition by CountryCode order by CountryCode, Percentage desc) as ranking from countrylanguage ), lang_rank1 AS ( select CountryCode, Language, Percentage from lang_calc where ranking = 1 ), city_calc AS ( select * , rank() over (partition by CountryCode order by CountryCode, Population desc) as ranking from city ), city_rank1 AS ( select CountryCode, Name as city_name, Population from city_calc where ranking = 1 ) select Code, Name, Continent, Language as popular_language, city_name as popular_city from country_with_id left join lang_rank1 on lang_rank1.CountryCode = country_with_id.id left join city_rank1 on city_rank1.CountryCode = country_with_id.id結果
さいごに
いかがでしたでしょうか、前回の MySQL10本ノック作ってみた! では、MySQL5.7だったのもありrow_numberを無理やりふっていましたが、今回MySQL8になって専用の関数が用意されたことでとても簡単にrow_numberなどが扱えるようになりました。with句もとてもありがたいです!
window関数が難しそうだな。。。と感じてる人もこれを機に挑戦してみてはいかがでしょうか!使いこなせたらとても便利ですよ!
また、SQLの回答例ですが、あくまで例です。もちろん、今回記述した内容以外の書き方もありますので、ご了承くださいmmWantedlyでもブログ投稿してます
Techブログに加えて会社ブログなどもやっているので、気になった方はぜひ覗いてみてください。
https://www.wantedly.com/companies/ks-rogers


- 投稿日:2019-02-28T01:46:00+09:00
MySQL8をDockerで動かし、window関数を使って自作のMySQL10本ノックを解いてみる!
はじめに
皆さん、どうもです。k.s.ロジャースのやすもんです。
前回の記事 MySQL10本ノック作ってみた! が想像以上に好評だったので、その続きでmysql8版を書いてみます!
docker使って動かすところからおこない
前回の MySQL10本ノック作ってみた! からMySQL8で記述方式が変わる設問を参照し、参考回答を記述していこうと思いますDockerでMySQL8環境構築
Dockerのインストールなどは割愛します
適当にworkフォルダ作成して準備します$ mkdir sand_box $ cd sand_box $ mkdir mysql8 $ cd mysql8 $ mkdir volumesdocker-compose.ymlを作成します
version: '2' services: db: image: mysql:latest container_name: mysql8 command: --default-authentication-plugin=mysql_native_password restart: always environment: MYSQL_ROOT_PASSWORD: hoge ports: - "3317:3306" volumes: - $PWD/volumes:/var/lib/mysqldocker-composeでたち上げます
$ docker compose up -d $ docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES cc448a369afb mysql:latest "docker-entrypoint.s…" 11 hours ago Up 11 hours 33060/tcp, 0.0.0.0:3317->3306/tcp mysql8SequelProをMySQL8に対応させる
アプリケーションの中にあるSequelProを適当にリネーム
以下のコマンドでSequelProのnightlyバージョンをインストール
$ brew cask install homebrew/cask-versions/sequel-pro-nightly
nightlyバージョンのSequelProを起動して、先程dockerで立ち上げたMySQL8に接続
前回の 事前準備 を元にサンプルデータをダウンロードし、DBにimportする
※不安定?なのか調べていたらSequelProのnightlyバージョンでもMySQL8動かないという記事もチラホラあったので、これで動かない場合はコメント下さい!(解決できるかはわかりませんが。。。)
問題
前回の問題 1~4本はMySQL8でも記述方式変わらないので、飛ばします
5本目
cityテーブルにてCountryCodeごとにPopulationの平均値を算出し、countryテーブルと結合、国名・大陸・平均Populationを表示せよ
また、上記の内容をwith句を用いて実現せよ6本目
cityテーブルにてCountryCodeごとにPopulationの平均値を算出した結果と、countryテーブルにてGNPとGNPOldを比較し、大きい値の方をGNP_bigとしてカラムに格納した結果を結合し、国名・大陸・平均Population・GNPBigを表示せよ
また、上記の内容をwith句を用いて実現せよ7本目
6本目の結果に対して、continent_nameで集約を行いavg_populationの最大値が10万以上、GNP_bigの平均値が10万以上の結果を抽出して表示せよ
また、上記の内容をwith句を用いて実現せよ8本目
countryテーブルにidを振りcoutry_with_idテーブルを作成
その後、cityとcoutrylanguageのテーブルのCountryCodeカラムを↑で付与したidに更新せよ
また、idははwindow関数を用いて付与せよ9本目
countrylanguageテーブルにてPercentageにランキングを付与せよ
また、上記のランキングをwindow関数を用いて付与せよ10本目
9本目のSQLを参考にして
countrylanguageテーブルにてCountryCode単位で最もPercentageが高い言語をcountry_with_idテーブルに結合し
cityテーブルにてCountryCode単位で最もPopulationが高いシティをcountry_with_idテーブルに結合
その後、PercentageとPopulationをキーに降順でソートせよ
また、上記のランキングをwindow関数を用いて付与し、with句を用いて実現せよ正解
前回の問題 1~4本はMySQL8でも記述方式変わらないので、飛ばします
5本目
問題
cityテーブルにてCountryCodeごとにPopulationの平均値を算出し、countryテーブルと結合、国名・大陸・平均Populationを表示せよ
また、上記の内容をwith句を用いて実現せよ解説
MySQL8の新機能のひとつwith句です!
HQLやBigQueryなどでは当然のように使えるこの機能ですが、MySQLでは最近まで使えませんでした。。。
挙動的にはWITHで書かれた部分が最初に実行されテンポラリテーブルとしてメモリに保存され、別のfrom句で利用できるという形です
良い点としては、viewでwith句を使う場合はメモリに結果を保持するので、再度クエリを回したときにDBへの問い合わせが発生しないです。副問合せの場合は毎回問い合わせする感じですね。そして、何より可読性が高い!
悪い点としては、メモリリソースを消費するので、めちゃくちゃでかいデータを処理する場合にはメモリ枯渇に気をつけないといけません。ということもあり、Hadoopなどは副問合せを使われることが多いですね。前回の回答例
select country.name as country_name , country.Continent as continent_name , city_calc.avg_population as avg_population from ( select CountryCode, avg(Population) as avg_population from city group by CountryCode ) as city_calc left join country on city_calc.CountryCode = country.Code ;今回の回答例
WITH city_calc (CountryCode, avg_population) AS ( select CountryCode, avg(Population) as avg_population from city group by CountryCode ) select country.name as country_name , country.Continent as continent_name , city_calc.avg_population as avg_population from city_calc left join country on city_calc.CountryCode = country.Code ;結果
6本目
問題
cityテーブルにてCountryCodeごとにPopulationの平均値を算出した結果と、countryテーブルにてGNPとGNPOldを比較し、大きい値の方をGNP_bigとしてカラムに格納した結果を結合し、国名・大陸・平均Population・GNPBigを表示せよ
また、上記の内容をwith句を用いて実現せよ解説
5本目と同様にwith句を使い、わかりやすく記述します
with句が複数あってもカンマでつなげるだけです。めちゃめちゃ簡単!前回の回答例
select country_calc.name as country_name , country_calc.Continent as continent_name , city_calc.avg_population as avg_population , country_calc.GNP_big as GNP_big from ( select CountryCode, avg(Population) as avg_population from city group by CountryCode ) as city_calc left join ( select Code , Name , Continent , case when GNP >= GNPOld then GNP when GNP < GNPOld then GNPOld when GNPOld is null then GNP else null end as GNP_big from country ) as country_calc on city_calc.CountryCode = country_calc.Code ;今回の回答例
WITH city_calc (CountryCode, avg_population) AS ( select CountryCode, avg(Population) as avg_population from city group by CountryCode ), country_calc (Code, Name, Continent, GNP_big) AS ( select Code , Name , Continent , case when GNP >= GNPOld then GNP when GNP < GNPOld then GNPOld when GNPOld is null then GNP else null end as GNP_big from country ) select country_calc.name as country_name , country_calc.Continent as continent_name , city_calc.avg_population as avg_population , country_calc.GNP_big as GNP_big from city_calc left join country_calc on city_calc.CountryCode = country_calc.Code ;結果
7本目
問題
6本目の結果に対して、continent_nameで集約を行いavg_populationの最大値が10万以上、GNP_bigの平均値が10万以上の結果を抽出して表示せよ
また、上記の内容をwith句を用いて実現せよ解説
6本目とほぼ同じです
ちなみに、with句の実行順序も通常のSQLと同じです
from→join→where→group by→sumなど→having→select→order by→limit前回の回答例
select country_calc.Continent as continent_name , max(city_calc.avg_population) as max_avg_population , avg(country_calc.GNP_big) as avg_GNP_big from ( select CountryCode, avg(Population) as avg_population from city group by CountryCode ) as city_calc left join ( select Code , Name , Continent , case when GNP >= GNPOld then GNP when GNP < GNPOld then GNPOld when GNPOld is null then GNP else null end as GNP_big from country ) as country_calc on city_calc.CountryCode = country_calc.Code group by country_calc.Continent having max_avg_population >= 100000 and avg_GNP_big >= 100000 ;今回の回答例
WITH city_calc (CountryCode, avg_population) AS ( select CountryCode, avg(Population) as avg_population from city group by CountryCode ), country_calc (Code, Name, Continent, GNP_big) AS ( select Code , Name , Continent , case when GNP >= GNPOld then GNP when GNP < GNPOld then GNPOld when GNPOld is null then GNP else null end as GNP_big from country ) select country_calc.Continent as continent_name , max(city_calc.avg_population) as max_avg_population , avg(country_calc.GNP_big) as avg_GNP_big from city_calc left join country_calc on city_calc.CountryCode = country_calc.Code group by country_calc.Continent having max_avg_population >= 100000 and avg_GNP_big >= 100000 ;結果
8本目
問題
countryテーブルにidを振りcoutry_with_idテーブルを作成
その後、cityとcoutrylanguageのテーブルのCountryCodeカラムを↑で付与したidに更新せよ
また、idははwindow関数を用いて付与せよ解説
MySQLの新機能window関数です!
こちらも、HQLやBigQueryなどでは当然のように使える関数ですが、MySQLでは最近まで使えませんでした。。。
以前、書いたrow_numberをふるSQLが1行でかけちゃいます。感激!前回の回答例
set @id:=0; create table country_with_id as ( select *, @id:=@id+1 as id from country ); update country_with_id as t1, city as t2 set t2.CountryCode = t1.id where t1.Code = t2.CountryCode ; update country_with_id as t1, countrylanguage as t2 set t2.CountryCode = t1.id where t1.Code = t2.CountryCode ;今回の回答例
create table country_with_id as ( select * , row_number() over () as id from country ); update country_with_id as t1, city as t2 set t2.CountryCode = t1.id where t1.Code = t2.CountryCode ; update country_with_id as t1, countrylanguage as t2 set t2.CountryCode = t1.id where t1.Code = t2.CountryCode ;結果
9本目
問題
countrylanguageテーブルにてPercentageにランキングを付与せよ
また、上記のランキングをwindow関数を用いて付与せよ解説
こちらも、window関数の
rank()を用いることで、鬼のように簡単に書くことができます
ちなみに、window関数一覧は以下のような感じです
rank、lag、lead、fist_value、row_numberはよく使いますね
- CUME_DIST():累積分布値
- DENSE_RANK():そのパーティション内の現在の行のランク(順位が飛ばされない)
- FIRST_VALUE():ウィンドウフレームの最初の値を取得
- LAG():パーティション内の現在の行の次の値
- LAST_VALUE():ウィンドウフレームの最後の値を取得
- LEAD():パーティション内の現在の行の前の値
- NTH_VALUE():ウィンドウ枠のN番目の行の値を取得
- NTILE():パーティション内でバケット分割を行う
- PERCENT_RANK():パーセントランクを計算して表示
- RANK():パーティション内の現在の行のランクを取得
- ROW_NUMBER():パーティション内の現在の行の数を取得
partition byはいわゆるgroup byみたいなものですね
order byはwindow内の並び順を意味しています前回の回答例
set @no:=0; set @groupid:=null; select * , if(@groupid <> CountryCode, @no:=1, @no:=@no+1) as rank , @groupid:=CountryCode from countrylanguage order by CountryCode, Percentage DESC ;今回の回答例
select * , rank() over (partition by CountryCode order by CountryCode, Percentage desc) as ranking from countrylanguage結果
10本目
問題
9本目のSQLを参考にして
countrylanguageテーブルにてCountryCode単位で最もPercentageが高い言語をcountry_with_idテーブルに結合し
cityテーブルにてCountryCode単位で最もPopulationが高いシティをcountry_with_idテーブルに結合
その後、PercentageとPopulationをキーに降順でソートせよ
また、上記のランキングをwindow関数を用いて付与し、with句を用いて実現せよ解説
もちろん、with句の中で別のwith句で実行した内容をfrom句で呼び出せます
前回のSQLよりとても可読性が上がってると思います前回の回答例
set @city_no:=0; set @city_groupid:=null; set @language_no:=0; set @language_groupid:=null; select Code, Name, Continent, Language as popular_language, city_name as popular_city from country_with_id left join ( select CountryCode, Language, Percentage from ( select * , if(@language_groupid <> CountryCode, @language_no:=1, @language_no:=@language_no+1) as rank , @language_groupid:=CountryCode from countrylanguage order by CountryCode, Percentage DESC ) as lang_calc where rank = 1 ) as lang_rank1 on lang_rank1.CountryCode = country_with_id.id left join ( select CountryCode, Name as city_name, Population from ( select * , if(@city_groupid <> CountryCode, @city_no:=1, @city_no:=@city_no+1) as rank , @city_groupid:=CountryCode from city order by CountryCode, Population DESC ) as city_calc where rank = 1 ) as city_rank1 on city_rank1.CountryCode = country_with_id.id ;今回の回答例
WITH lang_calc AS ( select * , rank() over (partition by CountryCode order by CountryCode, Percentage desc) as ranking from countrylanguage ), lang_rank1 AS ( select CountryCode, Language, Percentage from lang_calc where ranking = 1 ), city_calc AS ( select * , rank() over (partition by CountryCode order by CountryCode, Population desc) as ranking from city ), city_rank1 AS ( select CountryCode, Name as city_name, Population from city_calc where ranking = 1 ) select Code, Name, Continent, Language as popular_language, city_name as popular_city from country_with_id left join lang_rank1 on lang_rank1.CountryCode = country_with_id.id left join city_rank1 on city_rank1.CountryCode = country_with_id.id結果
さいごに
いかがでしたでしょうか、前回の MySQL10本ノック作ってみた! では、MySQL5.7だったのもありrow_numberを無理やりふっていましたが、今回MySQL8になって専用の関数が用意されたことでとても簡単にrow_numberなどが扱えるようになりました。with句もとてもありがたいです!
window関数が難しそうだな。。。と感じてる人もこれを機に挑戦してみてはいかがでしょうか!使いこなせたらとても便利ですよ!
また、SQLの回答例ですが、あくまで例です。もちろん、今回記述した内容以外の書き方もありますので、ご了承くださいmmWantedlyでもブログ投稿してます
Techブログに加えて会社ブログなどもやっているので、気になった方はぜひ覗いてみてください。
https://www.wantedly.com/companies/ks-rogers